
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.71k
18.9k
| golden_diff
stringlengths 145
5.13k
| verification_info
stringlengths 465
23.6k
| num_tokens_prompt
int64 556
4.1k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_4176
|
rasdani/github-patches
|
git_diff
|
pallets__click-1081
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add newlines between options in help text
In case of multi-line help messages for options the list of options ``cmd --help`` gets difficult to read. It would be great to have an option to toggle extra newlines after multi-line help messages / in general between option help messages.
</issue>
<code>
[start of click/formatting.py]
1 from contextlib import contextmanager
2 from .termui import get_terminal_size
3 from .parser import split_opt
4 from ._compat import term_len
5
6
7 # Can force a width. This is used by the test system
8 FORCED_WIDTH = None
9
10
11 def measure_table(rows):
12 widths = {}
13 for row in rows:
14 for idx, col in enumerate(row):
15 widths[idx] = max(widths.get(idx, 0), term_len(col))
16 return tuple(y for x, y in sorted(widths.items()))
17
18
19 def iter_rows(rows, col_count):
20 for row in rows:
21 row = tuple(row)
22 yield row + ('',) * (col_count - len(row))
23
24
25 def wrap_text(text, width=78, initial_indent='', subsequent_indent='',
26 preserve_paragraphs=False):
27 """A helper function that intelligently wraps text. By default, it
28 assumes that it operates on a single paragraph of text but if the
29 `preserve_paragraphs` parameter is provided it will intelligently
30 handle paragraphs (defined by two empty lines).
31
32 If paragraphs are handled, a paragraph can be prefixed with an empty
33 line containing the ``\\b`` character (``\\x08``) to indicate that
34 no rewrapping should happen in that block.
35
36 :param text: the text that should be rewrapped.
37 :param width: the maximum width for the text.
38 :param initial_indent: the initial indent that should be placed on the
39 first line as a string.
40 :param subsequent_indent: the indent string that should be placed on
41 each consecutive line.
42 :param preserve_paragraphs: if this flag is set then the wrapping will
43 intelligently handle paragraphs.
44 """
45 from ._textwrap import TextWrapper
46 text = text.expandtabs()
47 wrapper = TextWrapper(width, initial_indent=initial_indent,
48 subsequent_indent=subsequent_indent,
49 replace_whitespace=False)
50 if not preserve_paragraphs:
51 return wrapper.fill(text)
52
53 p = []
54 buf = []
55 indent = None
56
57 def _flush_par():
58 if not buf:
59 return
60 if buf[0].strip() == '\b':
61 p.append((indent or 0, True, '\n'.join(buf[1:])))
62 else:
63 p.append((indent or 0, False, ' '.join(buf)))
64 del buf[:]
65
66 for line in text.splitlines():
67 if not line:
68 _flush_par()
69 indent = None
70 else:
71 if indent is None:
72 orig_len = term_len(line)
73 line = line.lstrip()
74 indent = orig_len - term_len(line)
75 buf.append(line)
76 _flush_par()
77
78 rv = []
79 for indent, raw, text in p:
80 with wrapper.extra_indent(' ' * indent):
81 if raw:
82 rv.append(wrapper.indent_only(text))
83 else:
84 rv.append(wrapper.fill(text))
85
86 return '\n\n'.join(rv)
87
88
89 class HelpFormatter(object):
90 """This class helps with formatting text-based help pages. It's
91 usually just needed for very special internal cases, but it's also
92 exposed so that developers can write their own fancy outputs.
93
94 At present, it always writes into memory.
95
96 :param indent_increment: the additional increment for each level.
97 :param width: the width for the text. This defaults to the terminal
98 width clamped to a maximum of 78.
99 """
100
101 def __init__(self, indent_increment=2, width=None, max_width=None):
102 self.indent_increment = indent_increment
103 if max_width is None:
104 max_width = 80
105 if width is None:
106 width = FORCED_WIDTH
107 if width is None:
108 width = max(min(get_terminal_size()[0], max_width) - 2, 50)
109 self.width = width
110 self.current_indent = 0
111 self.buffer = []
112
113 def write(self, string):
114 """Writes a unicode string into the internal buffer."""
115 self.buffer.append(string)
116
117 def indent(self):
118 """Increases the indentation."""
119 self.current_indent += self.indent_increment
120
121 def dedent(self):
122 """Decreases the indentation."""
123 self.current_indent -= self.indent_increment
124
125 def write_usage(self, prog, args='', prefix='Usage: '):
126 """Writes a usage line into the buffer.
127
128 :param prog: the program name.
129 :param args: whitespace separated list of arguments.
130 :param prefix: the prefix for the first line.
131 """
132 usage_prefix = '%*s%s ' % (self.current_indent, prefix, prog)
133 text_width = self.width - self.current_indent
134
135 if text_width >= (term_len(usage_prefix) + 20):
136 # The arguments will fit to the right of the prefix.
137 indent = ' ' * term_len(usage_prefix)
138 self.write(wrap_text(args, text_width,
139 initial_indent=usage_prefix,
140 subsequent_indent=indent))
141 else:
142 # The prefix is too long, put the arguments on the next line.
143 self.write(usage_prefix)
144 self.write('\n')
145 indent = ' ' * (max(self.current_indent, term_len(prefix)) + 4)
146 self.write(wrap_text(args, text_width,
147 initial_indent=indent,
148 subsequent_indent=indent))
149
150 self.write('\n')
151
152 def write_heading(self, heading):
153 """Writes a heading into the buffer."""
154 self.write('%*s%s:\n' % (self.current_indent, '', heading))
155
156 def write_paragraph(self):
157 """Writes a paragraph into the buffer."""
158 if self.buffer:
159 self.write('\n')
160
161 def write_text(self, text):
162 """Writes re-indented text into the buffer. This rewraps and
163 preserves paragraphs.
164 """
165 text_width = max(self.width - self.current_indent, 11)
166 indent = ' ' * self.current_indent
167 self.write(wrap_text(text, text_width,
168 initial_indent=indent,
169 subsequent_indent=indent,
170 preserve_paragraphs=True))
171 self.write('\n')
172
173 def write_dl(self, rows, col_max=30, col_spacing=2):
174 """Writes a definition list into the buffer. This is how options
175 and commands are usually formatted.
176
177 :param rows: a list of two item tuples for the terms and values.
178 :param col_max: the maximum width of the first column.
179 :param col_spacing: the number of spaces between the first and
180 second column.
181 """
182 rows = list(rows)
183 widths = measure_table(rows)
184 if len(widths) != 2:
185 raise TypeError('Expected two columns for definition list')
186
187 first_col = min(widths[0], col_max) + col_spacing
188
189 for first, second in iter_rows(rows, len(widths)):
190 self.write('%*s%s' % (self.current_indent, '', first))
191 if not second:
192 self.write('\n')
193 continue
194 if term_len(first) <= first_col - col_spacing:
195 self.write(' ' * (first_col - term_len(first)))
196 else:
197 self.write('\n')
198 self.write(' ' * (first_col + self.current_indent))
199
200 text_width = max(self.width - first_col - 2, 10)
201 wrapped_text = wrap_text(second, text_width, preserve_paragraphs=True)
202 lines = wrapped_text.splitlines()
203
204 if lines:
205 self.write(lines[0] + '\n')
206
207 for line in lines[1:]:
208 self.write('%*s%s\n' % (first_col + self.current_indent, '', line))
209 else:
210 self.write('\n')
211
212 @contextmanager
213 def section(self, name):
214 """Helpful context manager that writes a paragraph, a heading,
215 and the indents.
216
217 :param name: the section name that is written as heading.
218 """
219 self.write_paragraph()
220 self.write_heading(name)
221 self.indent()
222 try:
223 yield
224 finally:
225 self.dedent()
226
227 @contextmanager
228 def indentation(self):
229 """A context manager that increases the indentation."""
230 self.indent()
231 try:
232 yield
233 finally:
234 self.dedent()
235
236 def getvalue(self):
237 """Returns the buffer contents."""
238 return ''.join(self.buffer)
239
240
241 def join_options(options):
242 """Given a list of option strings this joins them in the most appropriate
243 way and returns them in the form ``(formatted_string,
244 any_prefix_is_slash)`` where the second item in the tuple is a flag that
245 indicates if any of the option prefixes was a slash.
246 """
247 rv = []
248 any_prefix_is_slash = False
249 for opt in options:
250 prefix = split_opt(opt)[0]
251 if prefix == '/':
252 any_prefix_is_slash = True
253 rv.append((len(prefix), opt))
254
255 rv.sort(key=lambda x: x[0])
256
257 rv = ', '.join(x[1] for x in rv)
258 return rv, any_prefix_is_slash
259
[end of click/formatting.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/click/formatting.py b/click/formatting.py
--- a/click/formatting.py
+++ b/click/formatting.py
@@ -206,6 +206,10 @@
for line in lines[1:]:
self.write('%*s%s\n' % (first_col + self.current_indent, '', line))
+
+ if len(lines) > 1:
+ # separate long help from next option
+ self.write("\n")
else:
self.write('\n')
|
{"golden_diff": "diff --git a/click/formatting.py b/click/formatting.py\n--- a/click/formatting.py\n+++ b/click/formatting.py\n@@ -206,6 +206,10 @@\n \n for line in lines[1:]:\n self.write('%*s%s\\n' % (first_col + self.current_indent, '', line))\n+\n+ if len(lines) > 1:\n+ # separate long help from next option\n+ self.write(\"\\n\")\n else:\n self.write('\\n')\n", "issue": "Add newlines between options in help text\nIn case of multi-line help messages for options the list of options ``cmd --help`` gets difficult to read. It would be great to have an option to toggle extra newlines after multi-line help messages / in general between option help messages.\n", "before_files": [{"content": "from contextlib import contextmanager\nfrom .termui import get_terminal_size\nfrom .parser import split_opt\nfrom ._compat import term_len\n\n\n# Can force a width. This is used by the test system\nFORCED_WIDTH = None\n\n\ndef measure_table(rows):\n widths = {}\n for row in rows:\n for idx, col in enumerate(row):\n widths[idx] = max(widths.get(idx, 0), term_len(col))\n return tuple(y for x, y in sorted(widths.items()))\n\n\ndef iter_rows(rows, col_count):\n for row in rows:\n row = tuple(row)\n yield row + ('',) * (col_count - len(row))\n\n\ndef wrap_text(text, width=78, initial_indent='', subsequent_indent='',\n preserve_paragraphs=False):\n \"\"\"A helper function that intelligently wraps text. By default, it\n assumes that it operates on a single paragraph of text but if the\n `preserve_paragraphs` parameter is provided it will intelligently\n handle paragraphs (defined by two empty lines).\n\n If paragraphs are handled, a paragraph can be prefixed with an empty\n line containing the ``\\\\b`` character (``\\\\x08``) to indicate that\n no rewrapping should happen in that block.\n\n :param text: the text that should be rewrapped.\n :param width: the maximum width for the text.\n :param initial_indent: the initial indent that should be placed on the\n first line as a string.\n :param subsequent_indent: the indent string that should be placed on\n each consecutive line.\n :param preserve_paragraphs: if this flag is set then the wrapping will\n intelligently handle paragraphs.\n \"\"\"\n from ._textwrap import TextWrapper\n text = text.expandtabs()\n wrapper = TextWrapper(width, initial_indent=initial_indent,\n subsequent_indent=subsequent_indent,\n replace_whitespace=False)\n if not preserve_paragraphs:\n return wrapper.fill(text)\n\n p = []\n buf = []\n indent = None\n\n def _flush_par():\n if not buf:\n return\n if buf[0].strip() == '\\b':\n p.append((indent or 0, True, '\\n'.join(buf[1:])))\n else:\n p.append((indent or 0, False, ' '.join(buf)))\n del buf[:]\n\n for line in text.splitlines():\n if not line:\n _flush_par()\n indent = None\n else:\n if indent is None:\n orig_len = term_len(line)\n line = line.lstrip()\n indent = orig_len - term_len(line)\n buf.append(line)\n _flush_par()\n\n rv = []\n for indent, raw, text in p:\n with wrapper.extra_indent(' ' * indent):\n if raw:\n rv.append(wrapper.indent_only(text))\n else:\n rv.append(wrapper.fill(text))\n\n return '\\n\\n'.join(rv)\n\n\nclass HelpFormatter(object):\n \"\"\"This class helps with formatting text-based help pages. It's\n usually just needed for very special internal cases, but it's also\n exposed so that developers can write their own fancy outputs.\n\n At present, it always writes into memory.\n\n :param indent_increment: the additional increment for each level.\n :param width: the width for the text. This defaults to the terminal\n width clamped to a maximum of 78.\n \"\"\"\n\n def __init__(self, indent_increment=2, width=None, max_width=None):\n self.indent_increment = indent_increment\n if max_width is None:\n max_width = 80\n if width is None:\n width = FORCED_WIDTH\n if width is None:\n width = max(min(get_terminal_size()[0], max_width) - 2, 50)\n self.width = width\n self.current_indent = 0\n self.buffer = []\n\n def write(self, string):\n \"\"\"Writes a unicode string into the internal buffer.\"\"\"\n self.buffer.append(string)\n\n def indent(self):\n \"\"\"Increases the indentation.\"\"\"\n self.current_indent += self.indent_increment\n\n def dedent(self):\n \"\"\"Decreases the indentation.\"\"\"\n self.current_indent -= self.indent_increment\n\n def write_usage(self, prog, args='', prefix='Usage: '):\n \"\"\"Writes a usage line into the buffer.\n\n :param prog: the program name.\n :param args: whitespace separated list of arguments.\n :param prefix: the prefix for the first line.\n \"\"\"\n usage_prefix = '%*s%s ' % (self.current_indent, prefix, prog)\n text_width = self.width - self.current_indent\n\n if text_width >= (term_len(usage_prefix) + 20):\n # The arguments will fit to the right of the prefix.\n indent = ' ' * term_len(usage_prefix)\n self.write(wrap_text(args, text_width,\n initial_indent=usage_prefix,\n subsequent_indent=indent))\n else:\n # The prefix is too long, put the arguments on the next line.\n self.write(usage_prefix)\n self.write('\\n')\n indent = ' ' * (max(self.current_indent, term_len(prefix)) + 4)\n self.write(wrap_text(args, text_width,\n initial_indent=indent,\n subsequent_indent=indent))\n\n self.write('\\n')\n\n def write_heading(self, heading):\n \"\"\"Writes a heading into the buffer.\"\"\"\n self.write('%*s%s:\\n' % (self.current_indent, '', heading))\n\n def write_paragraph(self):\n \"\"\"Writes a paragraph into the buffer.\"\"\"\n if self.buffer:\n self.write('\\n')\n\n def write_text(self, text):\n \"\"\"Writes re-indented text into the buffer. This rewraps and\n preserves paragraphs.\n \"\"\"\n text_width = max(self.width - self.current_indent, 11)\n indent = ' ' * self.current_indent\n self.write(wrap_text(text, text_width,\n initial_indent=indent,\n subsequent_indent=indent,\n preserve_paragraphs=True))\n self.write('\\n')\n\n def write_dl(self, rows, col_max=30, col_spacing=2):\n \"\"\"Writes a definition list into the buffer. This is how options\n and commands are usually formatted.\n\n :param rows: a list of two item tuples for the terms and values.\n :param col_max: the maximum width of the first column.\n :param col_spacing: the number of spaces between the first and\n second column.\n \"\"\"\n rows = list(rows)\n widths = measure_table(rows)\n if len(widths) != 2:\n raise TypeError('Expected two columns for definition list')\n\n first_col = min(widths[0], col_max) + col_spacing\n\n for first, second in iter_rows(rows, len(widths)):\n self.write('%*s%s' % (self.current_indent, '', first))\n if not second:\n self.write('\\n')\n continue\n if term_len(first) <= first_col - col_spacing:\n self.write(' ' * (first_col - term_len(first)))\n else:\n self.write('\\n')\n self.write(' ' * (first_col + self.current_indent))\n\n text_width = max(self.width - first_col - 2, 10)\n wrapped_text = wrap_text(second, text_width, preserve_paragraphs=True)\n lines = wrapped_text.splitlines()\n\n if lines:\n self.write(lines[0] + '\\n')\n\n for line in lines[1:]:\n self.write('%*s%s\\n' % (first_col + self.current_indent, '', line))\n else:\n self.write('\\n')\n\n @contextmanager\n def section(self, name):\n \"\"\"Helpful context manager that writes a paragraph, a heading,\n and the indents.\n\n :param name: the section name that is written as heading.\n \"\"\"\n self.write_paragraph()\n self.write_heading(name)\n self.indent()\n try:\n yield\n finally:\n self.dedent()\n\n @contextmanager\n def indentation(self):\n \"\"\"A context manager that increases the indentation.\"\"\"\n self.indent()\n try:\n yield\n finally:\n self.dedent()\n\n def getvalue(self):\n \"\"\"Returns the buffer contents.\"\"\"\n return ''.join(self.buffer)\n\n\ndef join_options(options):\n \"\"\"Given a list of option strings this joins them in the most appropriate\n way and returns them in the form ``(formatted_string,\n any_prefix_is_slash)`` where the second item in the tuple is a flag that\n indicates if any of the option prefixes was a slash.\n \"\"\"\n rv = []\n any_prefix_is_slash = False\n for opt in options:\n prefix = split_opt(opt)[0]\n if prefix == '/':\n any_prefix_is_slash = True\n rv.append((len(prefix), opt))\n\n rv.sort(key=lambda x: x[0])\n\n rv = ', '.join(x[1] for x in rv)\n return rv, any_prefix_is_slash\n", "path": "click/formatting.py"}]}
| 3,213 | 114 |
gh_patches_debug_3304
|
rasdani/github-patches
|
git_diff
|
DataDog__dd-trace-py-2699
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
0.50 bug sanic APM
Thanks for taking the time for reporting an issue!
Before reporting an issue on dd-trace-py, please be sure to provide all
necessary information.
If you're hitting a bug, make sure that you're using the latest version of this
library.
### Which version of dd-trace-py are you using?
0.50.0
### Which version of pip are you using?
19.0.3
### Which version of the libraries are you using?
Package Version
------------------- ---------
aiofiles 0.7.0
aiohttp 3.6.2
aiomysql 0.0.20
astroid 2.3.3
async-timeout 3.0.1
attrs 19.3.0
certifi 2019.9.11
cffi 1.13.2
chardet 3.0.4
Click 7.0
cryptography 2.8
ddtrace 0.50.0
Deprecated 1.2.11
elasticsearch 7.5.1
elasticsearch-async 6.2.0
h11 0.8.1
h2 3.1.1
hpack 3.0.0
hstspreload 2020.1.7
httpcore 0.3.0
httptools 0.0.13
httpx 0.9.3
hyperframe 5.2.0
idna 2.8
isort 4.3.21
lazy-object-proxy 1.4.3
mccabe 0.6.1
motor 2.4.0
multidict 5.1.0
packaging 21.0
peewee 3.13.1
pip 19.0.3
protobuf 3.17.3
pycparser 2.19
PyJWT 1.7.1
pymongo 3.11.4
PyMySQL 0.9.2
pyparsing 2.4.7
pytz 2019.3
PyYAML 5.3
requests 2.22.0
requests-async 0.5.0
rfc3986 1.3.2
sanic 21.3.4
sanic-motor 0.5.0
sanic-routing 0.6.2
sanic-scheduler 1.0.7
setuptools 40.8.0
six 1.14.0
sniffio 1.1.0
stringcase 1.2.0
tenacity 8.0.1
typed-ast 1.4.1
ujson 1.35
urllib3 1.25.6
uvloop 0.13.0
websockets 8.1
wrapt 1.11.2
yarl 1.4.2
### How can we reproduce your problem?
#### Description
It's not working patch when apply APM on Sanic
If path variable type is int on sanic route
Case code
```
@app.route('/<gam_id:int>/slot/count', methods=['GET'])
async def slot_count(request, gam_id):
try:
pass
except Exception as e:
abort(500, e)
return json(response(200, 'Complete Successfully', {}))
```
Error
```
[2021-07-13 19:50:48 +0000] [13] [ERROR] Exception occurred while handling uri: 'http://xxxxxxxxx.xxx/25/slot/count'
NoneType: None
```
### What is the result that you get?
my production env is not working on Sanic
### What is the result that you expected?
I wanna use datadog APM on my production SANIC
I made already pull request
- https://github.com/DataDog/dd-trace-py/pull/2662
</issue>
<code>
[start of ddtrace/contrib/sanic/patch.py]
1 import asyncio
2
3 import sanic
4
5 import ddtrace
6 from ddtrace import config
7 from ddtrace.constants import ANALYTICS_SAMPLE_RATE_KEY
8 from ddtrace.ext import SpanTypes
9 from ddtrace.pin import Pin
10 from ddtrace.utils.wrappers import unwrap as _u
11 from ddtrace.vendor import wrapt
12 from ddtrace.vendor.wrapt import wrap_function_wrapper as _w
13
14 from .. import trace_utils
15 from ...internal.logger import get_logger
16
17
18 log = get_logger(__name__)
19
20 config._add("sanic", dict(_default_service="sanic", distributed_tracing=True))
21
22 SANIC_PRE_21 = None
23
24
25 def update_span(span, response):
26 if isinstance(response, sanic.response.BaseHTTPResponse):
27 status_code = response.status
28 response_headers = response.headers
29 else:
30 # invalid response causes ServerError exception which must be handled
31 status_code = 500
32 response_headers = None
33 trace_utils.set_http_meta(span, config.sanic, status_code=status_code, response_headers=response_headers)
34
35
36 def _wrap_response_callback(span, callback):
37 # Only for sanic 20 and older
38 # Wrap response callbacks (either sync or async function) to set HTTP
39 # response span tags
40
41 @wrapt.function_wrapper
42 def wrap_sync(wrapped, instance, args, kwargs):
43 r = wrapped(*args, **kwargs)
44 response = args[0]
45 update_span(span, response)
46 return r
47
48 @wrapt.function_wrapper
49 async def wrap_async(wrapped, instance, args, kwargs):
50 r = await wrapped(*args, **kwargs)
51 response = args[0]
52 update_span(span, response)
53 return r
54
55 if asyncio.iscoroutinefunction(callback):
56 return wrap_async(callback)
57
58 return wrap_sync(callback)
59
60
61 async def patch_request_respond(wrapped, instance, args, kwargs):
62 # Only for sanic 21 and newer
63 # Wrap the framework response to set HTTP response span tags
64 response = await wrapped(*args, **kwargs)
65 pin = Pin._find(instance.ctx)
66 if pin is not None and pin.enabled():
67 span = pin.tracer.current_span()
68 if span is not None:
69 update_span(span, response)
70 return response
71
72
73 def _get_path(request):
74 """Get path and replace path parameter values with names if route exists."""
75 path = request.path
76 try:
77 match_info = request.match_info
78 except sanic.exceptions.SanicException:
79 return path
80 for key, value in match_info.items():
81 path = path.replace(value, f"<{key}>")
82 return path
83
84
85 async def patch_run_request_middleware(wrapped, instance, args, kwargs):
86 # Set span resource from the framework request
87 request = args[0]
88 pin = Pin._find(request.ctx)
89 if pin is not None and pin.enabled():
90 span = pin.tracer.current_span()
91 if span is not None:
92 span.resource = "{} {}".format(request.method, _get_path(request))
93 return await wrapped(*args, **kwargs)
94
95
96 def patch():
97 """Patch the instrumented methods."""
98 global SANIC_PRE_21
99
100 if getattr(sanic, "__datadog_patch", False):
101 return
102 setattr(sanic, "__datadog_patch", True)
103
104 SANIC_PRE_21 = sanic.__version__[:2] < "21"
105
106 _w("sanic", "Sanic.handle_request", patch_handle_request)
107 if not SANIC_PRE_21:
108 _w("sanic", "Sanic._run_request_middleware", patch_run_request_middleware)
109 _w(sanic.request, "Request.respond", patch_request_respond)
110
111
112 def unpatch():
113 """Unpatch the instrumented methods."""
114 _u(sanic.Sanic, "handle_request")
115 if not SANIC_PRE_21:
116 _u(sanic.Sanic, "_run_request_middleware")
117 _u(sanic.request.Request, "respond")
118 if not getattr(sanic, "__datadog_patch", False):
119 return
120 setattr(sanic, "__datadog_patch", False)
121
122
123 async def patch_handle_request(wrapped, instance, args, kwargs):
124 """Wrapper for Sanic.handle_request"""
125
126 def unwrap(request, write_callback=None, stream_callback=None, **kwargs):
127 return request, write_callback, stream_callback, kwargs
128
129 request, write_callback, stream_callback, new_kwargs = unwrap(*args, **kwargs)
130
131 if request.scheme not in ("http", "https"):
132 return await wrapped(*args, **kwargs)
133
134 pin = Pin()
135 if SANIC_PRE_21:
136 # Set span resource from the framework request
137 resource = "{} {}".format(request.method, _get_path(request))
138 else:
139 # The path is not available anymore in 21.x. Get it from
140 # the _run_request_middleware instrumented method.
141 resource = None
142 pin.onto(request.ctx)
143
144 headers = request.headers.copy()
145
146 trace_utils.activate_distributed_headers(ddtrace.tracer, int_config=config.sanic, request_headers=headers)
147
148 with pin.tracer.trace(
149 "sanic.request",
150 service=trace_utils.int_service(None, config.sanic),
151 resource=resource,
152 span_type=SpanTypes.WEB,
153 ) as span:
154 sample_rate = config.sanic.get_analytics_sample_rate(use_global_config=True)
155 if sample_rate is not None:
156 span.set_tag(ANALYTICS_SAMPLE_RATE_KEY, sample_rate)
157
158 method = request.method
159 url = "{scheme}://{host}{path}".format(scheme=request.scheme, host=request.host, path=request.path)
160 query_string = request.query_string
161 if isinstance(query_string, bytes):
162 query_string = query_string.decode()
163 trace_utils.set_http_meta(
164 span, config.sanic, method=method, url=url, query=query_string, request_headers=headers
165 )
166
167 if write_callback is not None:
168 new_kwargs["write_callback"] = _wrap_response_callback(span, write_callback)
169 if stream_callback is not None:
170 new_kwargs["stream_callback"] = _wrap_response_callback(span, stream_callback)
171
172 return await wrapped(request, **new_kwargs)
173
[end of ddtrace/contrib/sanic/patch.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ddtrace/contrib/sanic/patch.py b/ddtrace/contrib/sanic/patch.py
--- a/ddtrace/contrib/sanic/patch.py
+++ b/ddtrace/contrib/sanic/patch.py
@@ -78,6 +78,11 @@
except sanic.exceptions.SanicException:
return path
for key, value in match_info.items():
+ try:
+ value = str(value)
+ except Exception:
+ # Best effort
+ continue
path = path.replace(value, f"<{key}>")
return path
|
{"golden_diff": "diff --git a/ddtrace/contrib/sanic/patch.py b/ddtrace/contrib/sanic/patch.py\n--- a/ddtrace/contrib/sanic/patch.py\n+++ b/ddtrace/contrib/sanic/patch.py\n@@ -78,6 +78,11 @@\n except sanic.exceptions.SanicException:\n return path\n for key, value in match_info.items():\n+ try:\n+ value = str(value)\n+ except Exception:\n+ # Best effort\n+ continue\n path = path.replace(value, f\"<{key}>\")\n return path\n", "issue": "0.50 bug sanic APM\nThanks for taking the time for reporting an issue!\r\n\r\nBefore reporting an issue on dd-trace-py, please be sure to provide all\r\nnecessary information.\r\n\r\nIf you're hitting a bug, make sure that you're using the latest version of this\r\nlibrary.\r\n\r\n### Which version of dd-trace-py are you using?\r\n0.50.0\r\n\r\n### Which version of pip are you using?\r\n19.0.3\r\n\r\n### Which version of the libraries are you using?\r\nPackage Version\r\n------------------- ---------\r\naiofiles 0.7.0\r\naiohttp 3.6.2\r\naiomysql 0.0.20\r\nastroid 2.3.3\r\nasync-timeout 3.0.1\r\nattrs 19.3.0\r\ncertifi 2019.9.11\r\ncffi 1.13.2\r\nchardet 3.0.4\r\nClick 7.0\r\ncryptography 2.8\r\nddtrace 0.50.0\r\nDeprecated 1.2.11\r\nelasticsearch 7.5.1\r\nelasticsearch-async 6.2.0\r\nh11 0.8.1\r\nh2 3.1.1\r\nhpack 3.0.0\r\nhstspreload 2020.1.7\r\nhttpcore 0.3.0\r\nhttptools 0.0.13\r\nhttpx 0.9.3\r\nhyperframe 5.2.0\r\nidna 2.8\r\nisort 4.3.21\r\nlazy-object-proxy 1.4.3\r\nmccabe 0.6.1\r\nmotor 2.4.0\r\nmultidict 5.1.0\r\npackaging 21.0\r\npeewee 3.13.1\r\npip 19.0.3\r\nprotobuf 3.17.3\r\npycparser 2.19\r\nPyJWT 1.7.1\r\npymongo 3.11.4\r\nPyMySQL 0.9.2\r\npyparsing 2.4.7\r\npytz 2019.3\r\nPyYAML 5.3\r\nrequests 2.22.0\r\nrequests-async 0.5.0\r\nrfc3986 1.3.2\r\nsanic 21.3.4\r\nsanic-motor 0.5.0\r\nsanic-routing 0.6.2\r\nsanic-scheduler 1.0.7\r\nsetuptools 40.8.0\r\nsix 1.14.0\r\nsniffio 1.1.0\r\nstringcase 1.2.0\r\ntenacity 8.0.1\r\ntyped-ast 1.4.1\r\nujson 1.35\r\nurllib3 1.25.6\r\nuvloop 0.13.0\r\nwebsockets 8.1\r\nwrapt 1.11.2\r\nyarl 1.4.2\r\n\r\n### How can we reproduce your problem?\r\n#### Description\r\nIt's not working patch when apply APM on Sanic\r\nIf path variable type is int on sanic route\r\n\r\nCase code\r\n```\r\[email protected]('/<gam_id:int>/slot/count', methods=['GET'])\r\nasync def slot_count(request, gam_id):\r\n try:\r\n pass\r\n except Exception as e:\r\n abort(500, e)\r\n return json(response(200, 'Complete Successfully', {}))\r\n\r\n```\r\n\r\nError\r\n```\r\n[2021-07-13 19:50:48 +0000] [13] [ERROR] Exception occurred while handling uri: 'http://xxxxxxxxx.xxx/25/slot/count'\r\nNoneType: None\r\n\r\n```\r\n\r\n### What is the result that you get?\r\nmy production env is not working on Sanic\r\n\r\n\r\n### What is the result that you expected?\r\nI wanna use datadog APM on my production SANIC\r\n\r\nI made already pull request\r\n- https://github.com/DataDog/dd-trace-py/pull/2662\r\n\n", "before_files": [{"content": "import asyncio\n\nimport sanic\n\nimport ddtrace\nfrom ddtrace import config\nfrom ddtrace.constants import ANALYTICS_SAMPLE_RATE_KEY\nfrom ddtrace.ext import SpanTypes\nfrom ddtrace.pin import Pin\nfrom ddtrace.utils.wrappers import unwrap as _u\nfrom ddtrace.vendor import wrapt\nfrom ddtrace.vendor.wrapt import wrap_function_wrapper as _w\n\nfrom .. import trace_utils\nfrom ...internal.logger import get_logger\n\n\nlog = get_logger(__name__)\n\nconfig._add(\"sanic\", dict(_default_service=\"sanic\", distributed_tracing=True))\n\nSANIC_PRE_21 = None\n\n\ndef update_span(span, response):\n if isinstance(response, sanic.response.BaseHTTPResponse):\n status_code = response.status\n response_headers = response.headers\n else:\n # invalid response causes ServerError exception which must be handled\n status_code = 500\n response_headers = None\n trace_utils.set_http_meta(span, config.sanic, status_code=status_code, response_headers=response_headers)\n\n\ndef _wrap_response_callback(span, callback):\n # Only for sanic 20 and older\n # Wrap response callbacks (either sync or async function) to set HTTP\n # response span tags\n\n @wrapt.function_wrapper\n def wrap_sync(wrapped, instance, args, kwargs):\n r = wrapped(*args, **kwargs)\n response = args[0]\n update_span(span, response)\n return r\n\n @wrapt.function_wrapper\n async def wrap_async(wrapped, instance, args, kwargs):\n r = await wrapped(*args, **kwargs)\n response = args[0]\n update_span(span, response)\n return r\n\n if asyncio.iscoroutinefunction(callback):\n return wrap_async(callback)\n\n return wrap_sync(callback)\n\n\nasync def patch_request_respond(wrapped, instance, args, kwargs):\n # Only for sanic 21 and newer\n # Wrap the framework response to set HTTP response span tags\n response = await wrapped(*args, **kwargs)\n pin = Pin._find(instance.ctx)\n if pin is not None and pin.enabled():\n span = pin.tracer.current_span()\n if span is not None:\n update_span(span, response)\n return response\n\n\ndef _get_path(request):\n \"\"\"Get path and replace path parameter values with names if route exists.\"\"\"\n path = request.path\n try:\n match_info = request.match_info\n except sanic.exceptions.SanicException:\n return path\n for key, value in match_info.items():\n path = path.replace(value, f\"<{key}>\")\n return path\n\n\nasync def patch_run_request_middleware(wrapped, instance, args, kwargs):\n # Set span resource from the framework request\n request = args[0]\n pin = Pin._find(request.ctx)\n if pin is not None and pin.enabled():\n span = pin.tracer.current_span()\n if span is not None:\n span.resource = \"{} {}\".format(request.method, _get_path(request))\n return await wrapped(*args, **kwargs)\n\n\ndef patch():\n \"\"\"Patch the instrumented methods.\"\"\"\n global SANIC_PRE_21\n\n if getattr(sanic, \"__datadog_patch\", False):\n return\n setattr(sanic, \"__datadog_patch\", True)\n\n SANIC_PRE_21 = sanic.__version__[:2] < \"21\"\n\n _w(\"sanic\", \"Sanic.handle_request\", patch_handle_request)\n if not SANIC_PRE_21:\n _w(\"sanic\", \"Sanic._run_request_middleware\", patch_run_request_middleware)\n _w(sanic.request, \"Request.respond\", patch_request_respond)\n\n\ndef unpatch():\n \"\"\"Unpatch the instrumented methods.\"\"\"\n _u(sanic.Sanic, \"handle_request\")\n if not SANIC_PRE_21:\n _u(sanic.Sanic, \"_run_request_middleware\")\n _u(sanic.request.Request, \"respond\")\n if not getattr(sanic, \"__datadog_patch\", False):\n return\n setattr(sanic, \"__datadog_patch\", False)\n\n\nasync def patch_handle_request(wrapped, instance, args, kwargs):\n \"\"\"Wrapper for Sanic.handle_request\"\"\"\n\n def unwrap(request, write_callback=None, stream_callback=None, **kwargs):\n return request, write_callback, stream_callback, kwargs\n\n request, write_callback, stream_callback, new_kwargs = unwrap(*args, **kwargs)\n\n if request.scheme not in (\"http\", \"https\"):\n return await wrapped(*args, **kwargs)\n\n pin = Pin()\n if SANIC_PRE_21:\n # Set span resource from the framework request\n resource = \"{} {}\".format(request.method, _get_path(request))\n else:\n # The path is not available anymore in 21.x. Get it from\n # the _run_request_middleware instrumented method.\n resource = None\n pin.onto(request.ctx)\n\n headers = request.headers.copy()\n\n trace_utils.activate_distributed_headers(ddtrace.tracer, int_config=config.sanic, request_headers=headers)\n\n with pin.tracer.trace(\n \"sanic.request\",\n service=trace_utils.int_service(None, config.sanic),\n resource=resource,\n span_type=SpanTypes.WEB,\n ) as span:\n sample_rate = config.sanic.get_analytics_sample_rate(use_global_config=True)\n if sample_rate is not None:\n span.set_tag(ANALYTICS_SAMPLE_RATE_KEY, sample_rate)\n\n method = request.method\n url = \"{scheme}://{host}{path}\".format(scheme=request.scheme, host=request.host, path=request.path)\n query_string = request.query_string\n if isinstance(query_string, bytes):\n query_string = query_string.decode()\n trace_utils.set_http_meta(\n span, config.sanic, method=method, url=url, query=query_string, request_headers=headers\n )\n\n if write_callback is not None:\n new_kwargs[\"write_callback\"] = _wrap_response_callback(span, write_callback)\n if stream_callback is not None:\n new_kwargs[\"stream_callback\"] = _wrap_response_callback(span, stream_callback)\n\n return await wrapped(request, **new_kwargs)\n", "path": "ddtrace/contrib/sanic/patch.py"}]}
| 3,277 | 127 |
gh_patches_debug_14171
|
rasdani/github-patches
|
git_diff
|
sql-machine-learning__elasticdl-373
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
When worker/master image creation failed, client should fail instead of trying to launch master.
</issue>
<code>
[start of elasticdl/client/client.py]
1 import argparse
2 import os
3 import inspect
4 import tempfile
5 import time
6 import getpass
7 import sys
8 from string import Template
9 import docker
10 import yaml
11 from kubernetes.client.apis import core_v1_api
12 from kubernetes import config
13
14
15 def _m_file_in_docker(model_file):
16 return "/model/" + os.path.basename(model_file)
17
18 def _build_docker_image(
19 m_file, image_name, image_base="elasticdl:dev",
20 repository=None
21 ):
22 DOCKER_TEMPLATE = """
23 FROM {}
24 COPY {} {}
25 """
26
27 with tempfile.NamedTemporaryFile(mode="w+", delete=False) as df:
28 df.write(DOCKER_TEMPLATE.format(image_base, m_file, _m_file_in_docker(m_file)))
29
30 client = docker.APIClient(base_url="unix://var/run/docker.sock")
31 print("===== Building Docker Image =====")
32 for line in client.build(
33 dockerfile=df.name, path=".", rm=True, tag=image_name, decode=True
34 ):
35 text = line.get("stream", None)
36 if text:
37 sys.stdout.write(text)
38 sys.stdout.flush()
39 print("===== Docker Image Built =====")
40 if repository != None:
41 for line in client.push(image_name, stream=True, decode=True):
42 print(line)
43
44 def _gen_master_def(image_name, model_file, job_name, argv):
45 master_yaml = """
46 apiVersion: v1
47 kind: Pod
48 metadata:
49 name: "elasticdl-master-{job_name}"
50 labels:
51 purpose: test-command
52 spec:
53 containers:
54 - name: "elasticdl-master-{job_name}"
55 image: "{image_name}"
56 command: ["python"]
57 args: [
58 "-m", "elasticdl.master.main",
59 "--job_name", "{job_name}",
60 "--worker_image", "{image_name}",
61 "--model_file", "{m_file}"
62 ]
63 imagePullPolicy: IfNotPresent
64 env:
65 - name: MY_POD_IP
66 valueFrom:
67 fieldRef:
68 fieldPath: status.podIP
69 restartPolicy: Never
70 """ .format(m_file=_m_file_in_docker(model_file), image_name=image_name, job_name=job_name)
71
72 master_def = yaml.safe_load(master_yaml)
73
74 # Build master arguments
75 master_def['spec']['containers'][0]['args'].extend(argv)
76 return master_def
77
78 def _submit(image_name, model_file, job_name, argv):
79 master_def = _gen_master_def(image_name, model_file, job_name, argv)
80 config.load_kube_config()
81 api = core_v1_api.CoreV1Api()
82 resp = api.create_namespaced_pod(body=master_def, namespace="default")
83 print("Master launched. status='%s'" % str(resp.status))
84
85 def main():
86 parser = argparse.ArgumentParser(description="ElasticDL Client")
87 # Rewrite model_file argument and pass all other arguments to master.
88 parser.add_argument("--model_file", help="Path to Model file", required=True)
89 parser.add_argument("--image_base", help="Base image containing elasticdl runtime environment.", required=True)
90 parser.add_argument("--repository", help="The repository to push docker image to.")
91 parser.add_argument("--job_name", help="ElasticDL job name", required=True)
92 args, argv = parser.parse_known_args()
93
94 job_name = args.job_name + "-" + str(int(round(time.time() * 1000)))
95 image_name = args.image_base + '_' + job_name
96 _build_docker_image(args.model_file, image_name, image_base=args.image_base,
97 repository=args.repository)
98 _submit(image_name, args.model_file, job_name, argv)
99
100
101 if __name__ == "__main__":
102 main()
103
[end of elasticdl/client/client.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/elasticdl/client/client.py b/elasticdl/client/client.py
--- a/elasticdl/client/client.py
+++ b/elasticdl/client/client.py
@@ -32,12 +32,14 @@
for line in client.build(
dockerfile=df.name, path=".", rm=True, tag=image_name, decode=True
):
+ if "error" in line:
+ raise RuntimeError("Docker image build failure: " % line["error"])
text = line.get("stream", None)
if text:
sys.stdout.write(text)
sys.stdout.flush()
print("===== Docker Image Built =====")
- if repository != None:
+ if repository is not None:
for line in client.push(image_name, stream=True, decode=True):
print(line)
|
{"golden_diff": "diff --git a/elasticdl/client/client.py b/elasticdl/client/client.py\n--- a/elasticdl/client/client.py\n+++ b/elasticdl/client/client.py\n@@ -32,12 +32,14 @@\n for line in client.build(\n dockerfile=df.name, path=\".\", rm=True, tag=image_name, decode=True\n ):\n+ if \"error\" in line:\n+ raise RuntimeError(\"Docker image build failure: \" % line[\"error\"])\n text = line.get(\"stream\", None)\n if text:\n sys.stdout.write(text)\n sys.stdout.flush()\n print(\"===== Docker Image Built =====\")\n- if repository != None:\n+ if repository is not None:\n for line in client.push(image_name, stream=True, decode=True):\n print(line)\n", "issue": "When worker/master image creation failed, client should fail instead of trying to launch master.\n\n", "before_files": [{"content": "import argparse\nimport os\nimport inspect\nimport tempfile\nimport time\nimport getpass\nimport sys\nfrom string import Template\nimport docker\nimport yaml\nfrom kubernetes.client.apis import core_v1_api\nfrom kubernetes import config\n\n\ndef _m_file_in_docker(model_file):\n return \"/model/\" + os.path.basename(model_file)\n\ndef _build_docker_image(\n m_file, image_name, image_base=\"elasticdl:dev\",\n repository=None\n):\n DOCKER_TEMPLATE = \"\"\"\nFROM {}\nCOPY {} {}\n\"\"\"\n\n with tempfile.NamedTemporaryFile(mode=\"w+\", delete=False) as df:\n df.write(DOCKER_TEMPLATE.format(image_base, m_file, _m_file_in_docker(m_file)))\n\n client = docker.APIClient(base_url=\"unix://var/run/docker.sock\")\n print(\"===== Building Docker Image =====\")\n for line in client.build(\n dockerfile=df.name, path=\".\", rm=True, tag=image_name, decode=True\n ):\n text = line.get(\"stream\", None)\n if text:\n sys.stdout.write(text)\n sys.stdout.flush()\n print(\"===== Docker Image Built =====\")\n if repository != None:\n for line in client.push(image_name, stream=True, decode=True):\n print(line)\n\ndef _gen_master_def(image_name, model_file, job_name, argv):\n master_yaml = \"\"\"\napiVersion: v1\nkind: Pod\nmetadata:\n name: \"elasticdl-master-{job_name}\"\n labels:\n purpose: test-command\nspec:\n containers:\n - name: \"elasticdl-master-{job_name}\"\n image: \"{image_name}\"\n command: [\"python\"]\n args: [\n \"-m\", \"elasticdl.master.main\",\n \"--job_name\", \"{job_name}\",\n \"--worker_image\", \"{image_name}\",\n \"--model_file\", \"{m_file}\"\n ]\n imagePullPolicy: IfNotPresent \n env:\n - name: MY_POD_IP\n valueFrom:\n fieldRef:\n fieldPath: status.podIP\n restartPolicy: Never\n\"\"\" .format(m_file=_m_file_in_docker(model_file), image_name=image_name, job_name=job_name)\n\n master_def = yaml.safe_load(master_yaml)\n\n # Build master arguments\n master_def['spec']['containers'][0]['args'].extend(argv)\n return master_def\n\ndef _submit(image_name, model_file, job_name, argv):\n master_def = _gen_master_def(image_name, model_file, job_name, argv)\n config.load_kube_config()\n api = core_v1_api.CoreV1Api()\n resp = api.create_namespaced_pod(body=master_def, namespace=\"default\")\n print(\"Master launched. status='%s'\" % str(resp.status))\n\ndef main():\n parser = argparse.ArgumentParser(description=\"ElasticDL Client\")\n # Rewrite model_file argument and pass all other arguments to master.\n parser.add_argument(\"--model_file\", help=\"Path to Model file\", required=True)\n parser.add_argument(\"--image_base\", help=\"Base image containing elasticdl runtime environment.\", required=True)\n parser.add_argument(\"--repository\", help=\"The repository to push docker image to.\")\n parser.add_argument(\"--job_name\", help=\"ElasticDL job name\", required=True)\n args, argv = parser.parse_known_args()\n\n job_name = args.job_name + \"-\" + str(int(round(time.time() * 1000)))\n image_name = args.image_base + '_' + job_name \n _build_docker_image(args.model_file, image_name, image_base=args.image_base,\n repository=args.repository)\n _submit(image_name, args.model_file, job_name, argv)\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "elasticdl/client/client.py"}]}
| 1,544 | 172 |
gh_patches_debug_2469
|
rasdani/github-patches
|
git_diff
|
ansible-collections__community.aws-1197
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ec2_customer_gateway: bgp_asn is not required
### Summary
The ec2_customer_gateway module has incorrect documentation for the bgp_asn parameter.
It says the ASN must be passed when state=present, but the code defaults to 25000 if the parameter is absent. See the ensure_cgw_present() method:
```
def ensure_cgw_present(self, bgp_asn, ip_address):
if not bgp_asn:
bgp_asn = 65000
response = self.ec2.create_customer_gateway(
DryRun=False,
Type='ipsec.1',
PublicIp=ip_address,
BgpAsn=bgp_asn,
)
return response
### Issue Type
Documentation Report
### Component Name
ec2_customer_gateway
### Ansible Version
```console (paste below)
$ ansible --version
ansible [core 2.12.4]
config file = None
configured module search path = ['/home/neil/.ansible/plugins/modules', '/usr/share/ansible/plugins/modules']
ansible python module location = /home/neil/.local/share/virtualenvs/community.aws-uRL047Ho/lib/python3.10/site-packages/ansible
ansible collection location = /home/neil/.ansible/collections:/usr/share/ansible/collections
executable location = /home/neil/.local/share/virtualenvs/community.aws-uRL047Ho/bin/ansible
python version = 3.10.1 (main, Jan 10 2022, 00:00:00) [GCC 11.2.1 20211203 (Red Hat 11.2.1-7)]
jinja version = 3.1.1
libyaml = True
```
### Collection Versions
```console (paste below)
$ ansible-galaxy collection list
```
### Configuration
```console (paste below)
$ ansible-config dump --only-changed
```
### OS / Environment
main branch, as of 2022-04-18.
### Additional Information
Suggested rewording:
```
options:
bgp_asn:
description:
- Border Gateway Protocol (BGP) Autonomous System Number (ASN), defaults to 25000.
type: int
```
### Code of Conduct
- [X] I agree to follow the Ansible Code of Conduct
</issue>
<code>
[start of plugins/modules/ec2_customer_gateway.py]
1 #!/usr/bin/python
2 #
3 # GNU General Public License v3.0+ (see COPYING or https://www.gnu.org/licenses/gpl-3.0.txt)
4
5 from __future__ import absolute_import, division, print_function
6 __metaclass__ = type
7
8
9 DOCUMENTATION = '''
10 ---
11 module: ec2_customer_gateway
12 version_added: 1.0.0
13 short_description: Manage an AWS customer gateway
14 description:
15 - Manage an AWS customer gateway.
16 author: Michael Baydoun (@MichaelBaydoun)
17 notes:
18 - You cannot create more than one customer gateway with the same IP address. If you run an identical request more than one time, the
19 first request creates the customer gateway, and subsequent requests return information about the existing customer gateway. The subsequent
20 requests do not create new customer gateway resources.
21 - Return values contain customer_gateway and customer_gateways keys which are identical dicts. You should use
22 customer_gateway. See U(https://github.com/ansible/ansible-modules-extras/issues/2773) for details.
23 options:
24 bgp_asn:
25 description:
26 - Border Gateway Protocol (BGP) Autonomous System Number (ASN), required when I(state=present).
27 type: int
28 ip_address:
29 description:
30 - Internet-routable IP address for customers gateway, must be a static address.
31 required: true
32 type: str
33 name:
34 description:
35 - Name of the customer gateway.
36 required: true
37 type: str
38 routing:
39 description:
40 - The type of routing.
41 choices: ['static', 'dynamic']
42 default: dynamic
43 type: str
44 state:
45 description:
46 - Create or terminate the Customer Gateway.
47 default: present
48 choices: [ 'present', 'absent' ]
49 type: str
50 extends_documentation_fragment:
51 - amazon.aws.aws
52 - amazon.aws.ec2
53
54 '''
55
56 EXAMPLES = '''
57 - name: Create Customer Gateway
58 community.aws.ec2_customer_gateway:
59 bgp_asn: 12345
60 ip_address: 1.2.3.4
61 name: IndianapolisOffice
62 region: us-east-1
63 register: cgw
64
65 - name: Delete Customer Gateway
66 community.aws.ec2_customer_gateway:
67 ip_address: 1.2.3.4
68 name: IndianapolisOffice
69 state: absent
70 region: us-east-1
71 register: cgw
72 '''
73
74 RETURN = '''
75 gateway.customer_gateways:
76 description: details about the gateway that was created.
77 returned: success
78 type: complex
79 contains:
80 bgp_asn:
81 description: The Border Gateway Autonomous System Number.
82 returned: when exists and gateway is available.
83 sample: 65123
84 type: str
85 customer_gateway_id:
86 description: gateway id assigned by amazon.
87 returned: when exists and gateway is available.
88 sample: cgw-cb6386a2
89 type: str
90 ip_address:
91 description: ip address of your gateway device.
92 returned: when exists and gateway is available.
93 sample: 1.2.3.4
94 type: str
95 state:
96 description: state of gateway.
97 returned: when gateway exists and is available.
98 sample: available
99 type: str
100 tags:
101 description: Any tags on the gateway.
102 returned: when gateway exists and is available, and when tags exist.
103 type: list
104 type:
105 description: encryption type.
106 returned: when gateway exists and is available.
107 sample: ipsec.1
108 type: str
109 '''
110
111 try:
112 import botocore
113 except ImportError:
114 pass # Handled by AnsibleAWSModule
115
116 from ansible.module_utils.common.dict_transformations import camel_dict_to_snake_dict
117
118 from ansible_collections.amazon.aws.plugins.module_utils.core import AnsibleAWSModule
119 from ansible_collections.amazon.aws.plugins.module_utils.ec2 import AWSRetry
120
121
122 class Ec2CustomerGatewayManager:
123
124 def __init__(self, module):
125 self.module = module
126
127 try:
128 self.ec2 = module.client('ec2')
129 except (botocore.exceptions.ClientError, botocore.exceptions.BotoCoreError) as e:
130 module.fail_json_aws(e, msg='Failed to connect to AWS')
131
132 @AWSRetry.jittered_backoff(delay=2, max_delay=30, retries=6, catch_extra_error_codes=['IncorrectState'])
133 def ensure_cgw_absent(self, gw_id):
134 response = self.ec2.delete_customer_gateway(
135 DryRun=False,
136 CustomerGatewayId=gw_id
137 )
138 return response
139
140 def ensure_cgw_present(self, bgp_asn, ip_address):
141 if not bgp_asn:
142 bgp_asn = 65000
143 response = self.ec2.create_customer_gateway(
144 DryRun=False,
145 Type='ipsec.1',
146 PublicIp=ip_address,
147 BgpAsn=bgp_asn,
148 )
149 return response
150
151 def tag_cgw_name(self, gw_id, name):
152 response = self.ec2.create_tags(
153 DryRun=False,
154 Resources=[
155 gw_id,
156 ],
157 Tags=[
158 {
159 'Key': 'Name',
160 'Value': name
161 },
162 ]
163 )
164 return response
165
166 def describe_gateways(self, ip_address):
167 response = self.ec2.describe_customer_gateways(
168 DryRun=False,
169 Filters=[
170 {
171 'Name': 'state',
172 'Values': [
173 'available',
174 ]
175 },
176 {
177 'Name': 'ip-address',
178 'Values': [
179 ip_address,
180 ]
181 }
182 ]
183 )
184 return response
185
186
187 def main():
188 argument_spec = dict(
189 bgp_asn=dict(required=False, type='int'),
190 ip_address=dict(required=True),
191 name=dict(required=True),
192 routing=dict(default='dynamic', choices=['dynamic', 'static']),
193 state=dict(default='present', choices=['present', 'absent']),
194 )
195
196 module = AnsibleAWSModule(
197 argument_spec=argument_spec,
198 supports_check_mode=True,
199 required_if=[
200 ('routing', 'dynamic', ['bgp_asn'])
201 ]
202 )
203
204 gw_mgr = Ec2CustomerGatewayManager(module)
205
206 name = module.params.get('name')
207
208 existing = gw_mgr.describe_gateways(module.params['ip_address'])
209
210 results = dict(changed=False)
211 if module.params['state'] == 'present':
212 if existing['CustomerGateways']:
213 existing['CustomerGateway'] = existing['CustomerGateways'][0]
214 results['gateway'] = existing
215 if existing['CustomerGateway']['Tags']:
216 tag_array = existing['CustomerGateway']['Tags']
217 for key, value in enumerate(tag_array):
218 if value['Key'] == 'Name':
219 current_name = value['Value']
220 if current_name != name:
221 results['name'] = gw_mgr.tag_cgw_name(
222 results['gateway']['CustomerGateway']['CustomerGatewayId'],
223 module.params['name'],
224 )
225 results['changed'] = True
226 else:
227 if not module.check_mode:
228 results['gateway'] = gw_mgr.ensure_cgw_present(
229 module.params['bgp_asn'],
230 module.params['ip_address'],
231 )
232 results['name'] = gw_mgr.tag_cgw_name(
233 results['gateway']['CustomerGateway']['CustomerGatewayId'],
234 module.params['name'],
235 )
236 results['changed'] = True
237
238 elif module.params['state'] == 'absent':
239 if existing['CustomerGateways']:
240 existing['CustomerGateway'] = existing['CustomerGateways'][0]
241 results['gateway'] = existing
242 if not module.check_mode:
243 results['gateway'] = gw_mgr.ensure_cgw_absent(
244 existing['CustomerGateway']['CustomerGatewayId']
245 )
246 results['changed'] = True
247
248 pretty_results = camel_dict_to_snake_dict(results)
249 module.exit_json(**pretty_results)
250
251
252 if __name__ == '__main__':
253 main()
254
[end of plugins/modules/ec2_customer_gateway.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/plugins/modules/ec2_customer_gateway.py b/plugins/modules/ec2_customer_gateway.py
--- a/plugins/modules/ec2_customer_gateway.py
+++ b/plugins/modules/ec2_customer_gateway.py
@@ -23,7 +23,8 @@
options:
bgp_asn:
description:
- - Border Gateway Protocol (BGP) Autonomous System Number (ASN), required when I(state=present).
+ - Border Gateway Protocol (BGP) Autonomous System Number (ASN).
+ - Defaults to C(65000) if not specified when I(state=present).
type: int
ip_address:
description:
|
{"golden_diff": "diff --git a/plugins/modules/ec2_customer_gateway.py b/plugins/modules/ec2_customer_gateway.py\n--- a/plugins/modules/ec2_customer_gateway.py\n+++ b/plugins/modules/ec2_customer_gateway.py\n@@ -23,7 +23,8 @@\n options:\n bgp_asn:\n description:\n- - Border Gateway Protocol (BGP) Autonomous System Number (ASN), required when I(state=present).\n+ - Border Gateway Protocol (BGP) Autonomous System Number (ASN).\n+ - Defaults to C(65000) if not specified when I(state=present).\n type: int\n ip_address:\n description:\n", "issue": "ec2_customer_gateway: bgp_asn is not required\n### Summary\n\nThe ec2_customer_gateway module has incorrect documentation for the bgp_asn parameter.\r\n\r\nIt says the ASN must be passed when state=present, but the code defaults to 25000 if the parameter is absent. See the ensure_cgw_present() method:\r\n\r\n```\r\n def ensure_cgw_present(self, bgp_asn, ip_address):\r\n if not bgp_asn:\r\n bgp_asn = 65000\r\n response = self.ec2.create_customer_gateway(\r\n DryRun=False,\r\n Type='ipsec.1',\r\n PublicIp=ip_address,\r\n BgpAsn=bgp_asn,\r\n )\r\n return response\n\n### Issue Type\n\nDocumentation Report\n\n### Component Name\n\nec2_customer_gateway\n\n### Ansible Version\n\n```console (paste below)\r\n$ ansible --version\r\nansible [core 2.12.4]\r\n config file = None\r\n configured module search path = ['/home/neil/.ansible/plugins/modules', '/usr/share/ansible/plugins/modules']\r\n ansible python module location = /home/neil/.local/share/virtualenvs/community.aws-uRL047Ho/lib/python3.10/site-packages/ansible\r\n ansible collection location = /home/neil/.ansible/collections:/usr/share/ansible/collections\r\n executable location = /home/neil/.local/share/virtualenvs/community.aws-uRL047Ho/bin/ansible\r\n python version = 3.10.1 (main, Jan 10 2022, 00:00:00) [GCC 11.2.1 20211203 (Red Hat 11.2.1-7)]\r\n jinja version = 3.1.1\r\n libyaml = True\r\n```\r\n\n\n### Collection Versions\n\n```console (paste below)\r\n$ ansible-galaxy collection list\r\n```\r\n\n\n### Configuration\n\n```console (paste below)\r\n$ ansible-config dump --only-changed\r\n\r\n```\r\n\n\n### OS / Environment\n\nmain branch, as of 2022-04-18.\n\n### Additional Information\n\nSuggested rewording:\r\n\r\n```\r\noptions:\r\n bgp_asn:\r\n description:\r\n - Border Gateway Protocol (BGP) Autonomous System Number (ASN), defaults to 25000.\r\n type: int\r\n```\n\n### Code of Conduct\n\n- [X] I agree to follow the Ansible Code of Conduct\n", "before_files": [{"content": "#!/usr/bin/python\n#\n# GNU General Public License v3.0+ (see COPYING or https://www.gnu.org/licenses/gpl-3.0.txt)\n\nfrom __future__ import absolute_import, division, print_function\n__metaclass__ = type\n\n\nDOCUMENTATION = '''\n---\nmodule: ec2_customer_gateway\nversion_added: 1.0.0\nshort_description: Manage an AWS customer gateway\ndescription:\n - Manage an AWS customer gateway.\nauthor: Michael Baydoun (@MichaelBaydoun)\nnotes:\n - You cannot create more than one customer gateway with the same IP address. If you run an identical request more than one time, the\n first request creates the customer gateway, and subsequent requests return information about the existing customer gateway. The subsequent\n requests do not create new customer gateway resources.\n - Return values contain customer_gateway and customer_gateways keys which are identical dicts. You should use\n customer_gateway. See U(https://github.com/ansible/ansible-modules-extras/issues/2773) for details.\noptions:\n bgp_asn:\n description:\n - Border Gateway Protocol (BGP) Autonomous System Number (ASN), required when I(state=present).\n type: int\n ip_address:\n description:\n - Internet-routable IP address for customers gateway, must be a static address.\n required: true\n type: str\n name:\n description:\n - Name of the customer gateway.\n required: true\n type: str\n routing:\n description:\n - The type of routing.\n choices: ['static', 'dynamic']\n default: dynamic\n type: str\n state:\n description:\n - Create or terminate the Customer Gateway.\n default: present\n choices: [ 'present', 'absent' ]\n type: str\nextends_documentation_fragment:\n- amazon.aws.aws\n- amazon.aws.ec2\n\n'''\n\nEXAMPLES = '''\n- name: Create Customer Gateway\n community.aws.ec2_customer_gateway:\n bgp_asn: 12345\n ip_address: 1.2.3.4\n name: IndianapolisOffice\n region: us-east-1\n register: cgw\n\n- name: Delete Customer Gateway\n community.aws.ec2_customer_gateway:\n ip_address: 1.2.3.4\n name: IndianapolisOffice\n state: absent\n region: us-east-1\n register: cgw\n'''\n\nRETURN = '''\ngateway.customer_gateways:\n description: details about the gateway that was created.\n returned: success\n type: complex\n contains:\n bgp_asn:\n description: The Border Gateway Autonomous System Number.\n returned: when exists and gateway is available.\n sample: 65123\n type: str\n customer_gateway_id:\n description: gateway id assigned by amazon.\n returned: when exists and gateway is available.\n sample: cgw-cb6386a2\n type: str\n ip_address:\n description: ip address of your gateway device.\n returned: when exists and gateway is available.\n sample: 1.2.3.4\n type: str\n state:\n description: state of gateway.\n returned: when gateway exists and is available.\n sample: available\n type: str\n tags:\n description: Any tags on the gateway.\n returned: when gateway exists and is available, and when tags exist.\n type: list\n type:\n description: encryption type.\n returned: when gateway exists and is available.\n sample: ipsec.1\n type: str\n'''\n\ntry:\n import botocore\nexcept ImportError:\n pass # Handled by AnsibleAWSModule\n\nfrom ansible.module_utils.common.dict_transformations import camel_dict_to_snake_dict\n\nfrom ansible_collections.amazon.aws.plugins.module_utils.core import AnsibleAWSModule\nfrom ansible_collections.amazon.aws.plugins.module_utils.ec2 import AWSRetry\n\n\nclass Ec2CustomerGatewayManager:\n\n def __init__(self, module):\n self.module = module\n\n try:\n self.ec2 = module.client('ec2')\n except (botocore.exceptions.ClientError, botocore.exceptions.BotoCoreError) as e:\n module.fail_json_aws(e, msg='Failed to connect to AWS')\n\n @AWSRetry.jittered_backoff(delay=2, max_delay=30, retries=6, catch_extra_error_codes=['IncorrectState'])\n def ensure_cgw_absent(self, gw_id):\n response = self.ec2.delete_customer_gateway(\n DryRun=False,\n CustomerGatewayId=gw_id\n )\n return response\n\n def ensure_cgw_present(self, bgp_asn, ip_address):\n if not bgp_asn:\n bgp_asn = 65000\n response = self.ec2.create_customer_gateway(\n DryRun=False,\n Type='ipsec.1',\n PublicIp=ip_address,\n BgpAsn=bgp_asn,\n )\n return response\n\n def tag_cgw_name(self, gw_id, name):\n response = self.ec2.create_tags(\n DryRun=False,\n Resources=[\n gw_id,\n ],\n Tags=[\n {\n 'Key': 'Name',\n 'Value': name\n },\n ]\n )\n return response\n\n def describe_gateways(self, ip_address):\n response = self.ec2.describe_customer_gateways(\n DryRun=False,\n Filters=[\n {\n 'Name': 'state',\n 'Values': [\n 'available',\n ]\n },\n {\n 'Name': 'ip-address',\n 'Values': [\n ip_address,\n ]\n }\n ]\n )\n return response\n\n\ndef main():\n argument_spec = dict(\n bgp_asn=dict(required=False, type='int'),\n ip_address=dict(required=True),\n name=dict(required=True),\n routing=dict(default='dynamic', choices=['dynamic', 'static']),\n state=dict(default='present', choices=['present', 'absent']),\n )\n\n module = AnsibleAWSModule(\n argument_spec=argument_spec,\n supports_check_mode=True,\n required_if=[\n ('routing', 'dynamic', ['bgp_asn'])\n ]\n )\n\n gw_mgr = Ec2CustomerGatewayManager(module)\n\n name = module.params.get('name')\n\n existing = gw_mgr.describe_gateways(module.params['ip_address'])\n\n results = dict(changed=False)\n if module.params['state'] == 'present':\n if existing['CustomerGateways']:\n existing['CustomerGateway'] = existing['CustomerGateways'][0]\n results['gateway'] = existing\n if existing['CustomerGateway']['Tags']:\n tag_array = existing['CustomerGateway']['Tags']\n for key, value in enumerate(tag_array):\n if value['Key'] == 'Name':\n current_name = value['Value']\n if current_name != name:\n results['name'] = gw_mgr.tag_cgw_name(\n results['gateway']['CustomerGateway']['CustomerGatewayId'],\n module.params['name'],\n )\n results['changed'] = True\n else:\n if not module.check_mode:\n results['gateway'] = gw_mgr.ensure_cgw_present(\n module.params['bgp_asn'],\n module.params['ip_address'],\n )\n results['name'] = gw_mgr.tag_cgw_name(\n results['gateway']['CustomerGateway']['CustomerGatewayId'],\n module.params['name'],\n )\n results['changed'] = True\n\n elif module.params['state'] == 'absent':\n if existing['CustomerGateways']:\n existing['CustomerGateway'] = existing['CustomerGateways'][0]\n results['gateway'] = existing\n if not module.check_mode:\n results['gateway'] = gw_mgr.ensure_cgw_absent(\n existing['CustomerGateway']['CustomerGatewayId']\n )\n results['changed'] = True\n\n pretty_results = camel_dict_to_snake_dict(results)\n module.exit_json(**pretty_results)\n\n\nif __name__ == '__main__':\n main()\n", "path": "plugins/modules/ec2_customer_gateway.py"}]}
| 3,462 | 136 |
gh_patches_debug_9153
|
rasdani/github-patches
|
git_diff
|
RedHatInsights__insights-core-2101
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
bash_version example doesn't work with json format
Running `insights run -p examples/rules -f json` results in a traceback because the `bash_version` rule puts an `InstalledRpm` object into its response:
```
TypeError: Object of type 'InstalledRpm' is not JSON serializable
```
</issue>
<code>
[start of examples/rules/bash_version.py]
1 """
2 Bash Version
3 ============
4
5 This is a simple rule and can be run against the local host
6 using the following command::
7
8 $ insights-run -p examples.rules.bash_version
9
10 or from the examples/rules directory::
11
12 $ python sample_rules.py
13 """
14 from insights.core.plugins import make_pass, rule
15 from insights.parsers.installed_rpms import InstalledRpms
16
17 KEY = "BASH_VERSION"
18
19 CONTENT = "Bash RPM Version: {{ bash_version }}"
20
21
22 @rule(InstalledRpms)
23 def report(rpms):
24 bash_ver = rpms.get_max('bash')
25 return make_pass(KEY, bash_version=bash_ver)
26
[end of examples/rules/bash_version.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/examples/rules/bash_version.py b/examples/rules/bash_version.py
--- a/examples/rules/bash_version.py
+++ b/examples/rules/bash_version.py
@@ -11,7 +11,7 @@
$ python sample_rules.py
"""
-from insights.core.plugins import make_pass, rule
+from insights.core.plugins import make_info, rule
from insights.parsers.installed_rpms import InstalledRpms
KEY = "BASH_VERSION"
@@ -21,5 +21,5 @@
@rule(InstalledRpms)
def report(rpms):
- bash_ver = rpms.get_max('bash')
- return make_pass(KEY, bash_version=bash_ver)
+ bash = rpms.get_max('bash')
+ return make_info(KEY, bash_version=bash.nvra)
|
{"golden_diff": "diff --git a/examples/rules/bash_version.py b/examples/rules/bash_version.py\n--- a/examples/rules/bash_version.py\n+++ b/examples/rules/bash_version.py\n@@ -11,7 +11,7 @@\n \n $ python sample_rules.py\n \"\"\"\n-from insights.core.plugins import make_pass, rule\n+from insights.core.plugins import make_info, rule\n from insights.parsers.installed_rpms import InstalledRpms\n \n KEY = \"BASH_VERSION\"\n@@ -21,5 +21,5 @@\n \n @rule(InstalledRpms)\n def report(rpms):\n- bash_ver = rpms.get_max('bash')\n- return make_pass(KEY, bash_version=bash_ver)\n+ bash = rpms.get_max('bash')\n+ return make_info(KEY, bash_version=bash.nvra)\n", "issue": "bash_version example doesn't work with json format\nRunning `insights run -p examples/rules -f json` results in a traceback because the `bash_version` rule puts an `InstalledRpm` object into its response:\r\n\r\n```\r\nTypeError: Object of type 'InstalledRpm' is not JSON serializable\r\n```\n", "before_files": [{"content": "\"\"\"\nBash Version\n============\n\nThis is a simple rule and can be run against the local host\nusing the following command::\n\n$ insights-run -p examples.rules.bash_version\n\nor from the examples/rules directory::\n\n$ python sample_rules.py\n\"\"\"\nfrom insights.core.plugins import make_pass, rule\nfrom insights.parsers.installed_rpms import InstalledRpms\n\nKEY = \"BASH_VERSION\"\n\nCONTENT = \"Bash RPM Version: {{ bash_version }}\"\n\n\n@rule(InstalledRpms)\ndef report(rpms):\n bash_ver = rpms.get_max('bash')\n return make_pass(KEY, bash_version=bash_ver)\n", "path": "examples/rules/bash_version.py"}]}
| 777 | 167 |
gh_patches_debug_1896
|
rasdani/github-patches
|
git_diff
|
graspologic-org__graspologic-207
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
GClust bug
<img width="558" alt="Screen Shot 2019-06-22 at 3 46 06 PM" src="https://user-images.githubusercontent.com/25714207/59968259-eb346c80-9504-11e9-984c-8c13dff93a37.png">
should be `- self.min_components` rather than `- 1`
This causes an indexing error when `min_components` does not equal 1
</issue>
<code>
[start of graspy/cluster/gclust.py]
1 # Copyright 2019 NeuroData (http://neurodata.io)
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import numpy as np
16 import pandas as pd
17 from sklearn.metrics import adjusted_rand_score
18 from sklearn.mixture import GaussianMixture
19 from sklearn.model_selection import ParameterGrid
20
21 from .base import BaseCluster
22
23
24 class GaussianCluster(BaseCluster):
25 r"""
26 Gaussian Mixture Model (GMM)
27
28 Representation of a Gaussian mixture model probability distribution.
29 This class allows to estimate the parameters of a Gaussian mixture
30 distribution. It computes all possible models from one component to
31 max_components. The best model is given by the lowest BIC score.
32
33 Parameters
34 ----------
35 min_components : int, default=2.
36 The minimum number of mixture components to consider (unless
37 max_components=None, in which case this is the maximum number of
38 components to consider). If max_componens is not None, min_components
39 must be less than or equal to max_components.
40
41 max_components : int or None, default=None.
42 The maximum number of mixture components to consider. Must be greater
43 than or equal to min_components.
44
45 covariance_type : {'full' (default), 'tied', 'diag', 'spherical'}, optional
46 String or list/array describing the type of covariance parameters to use.
47 If a string, it must be one of:
48
49 - 'full'
50 each component has its own general covariance matrix
51 - 'tied'
52 all components share the same general covariance matrix
53 - 'diag'
54 each component has its own diagonal covariance matrix
55 - 'spherical'
56 each component has its own single variance
57 - 'all'
58 considers all covariance structures in ['spherical', 'diag', 'tied', 'full']
59 If a list/array, it must be a list/array of strings containing only
60 'spherical', 'tied', 'diag', and/or 'spherical'.
61
62 random_state : int, RandomState instance or None, optional (default=None)
63 If int, random_state is the seed used by the random number generator;
64 If RandomState instance, random_state is the random number generator;
65 If None, the random number generator is the RandomState instance used
66 by ``np.random``.
67
68 Attributes
69 ----------
70 n_components_ : int
71 Optimal number of components based on BIC.
72 covariance_type_ : str
73 Optimal covariance type based on BIC.
74 model_ : GaussianMixture object
75 Fitted GaussianMixture object fitted with optimal numeber of components
76 and optimal covariance structure.
77 bic_ : pandas.DataFrame
78 A pandas DataFrame of BIC values computed for all possible number of clusters
79 given by range(min_components, max_components + 1) and all covariance
80 structures given by covariance_type.
81 ari_ : pandas.DataFrame
82 Only computed when y is given. Pandas Dataframe containing ARI values computed
83 for all possible number of clusters given by range(min_components,
84 max_components) and all covariance structures given by covariance_type.
85 """
86
87 def __init__(
88 self,
89 min_components=2,
90 max_components=None,
91 covariance_type="full",
92 random_state=None,
93 ):
94 if isinstance(min_components, int):
95 if min_components <= 0:
96 msg = "min_components must be >= 1."
97 raise ValueError(msg)
98 else:
99 msg = "min_components must be an integer, not {}.".format(
100 type(min_components)
101 )
102 raise TypeError(msg)
103
104 if isinstance(max_components, int):
105 if max_components <= 0:
106 msg = "max_components must be >= 1 or None."
107 raise ValueError(msg)
108 elif min_components > max_components:
109 msg = "min_components must be less than or equal to max_components."
110 raise ValueError(msg)
111 elif max_components is not None:
112 msg = "max_components must be an integer or None, not {}.".format(
113 type(max_components)
114 )
115 raise TypeError(msg)
116
117 if isinstance(covariance_type, (np.ndarray, list)):
118 covariance_type = np.unique(covariance_type)
119 elif isinstance(covariance_type, str):
120 if covariance_type == "all":
121 covariance_type = ["spherical", "diag", "tied", "full"]
122 else:
123 covariance_type = [covariance_type]
124 else:
125 msg = "covariance_type must be a numpy array, a list, or "
126 msg += "string, not {}".format(type(covariance_type))
127 raise TypeError(msg)
128
129 for cov in covariance_type:
130 if cov not in ["spherical", "diag", "tied", "full"]:
131 msg = (
132 "covariance structure must be one of "
133 + '["spherical", "diag", "tied", "full"]'
134 )
135 msg += " not {}".format(cov)
136 raise ValueError(msg)
137
138 new_covariance_type = []
139 for cov in ["spherical", "diag", "tied", "full"]:
140 if cov in covariance_type:
141 new_covariance_type.append(cov)
142
143 self.min_components = min_components
144 self.max_components = max_components
145 self.covariance_type = new_covariance_type
146 self.random_state = random_state
147
148 def fit(self, X, y=None):
149 """
150 Fits gaussian mixure model to the data.
151 Estimate model parameters with the EM algorithm.
152
153 Parameters
154 ----------
155 X : array-like, shape (n_samples, n_features)
156 List of n_features-dimensional data points. Each row
157 corresponds to a single data point.
158
159 y : array-like, shape (n_samples,), optional (default=None)
160 List of labels for X if available. Used to compute
161 ARI scores.
162
163 Returns
164 -------
165 self
166 """
167
168 # Deal with number of clusters
169 if self.max_components is None:
170 lower_ncomponents = 1
171 upper_ncomponents = self.min_components
172 else:
173 lower_ncomponents = self.min_components
174 upper_ncomponents = self.max_components
175
176 n_mixture_components = upper_ncomponents - lower_ncomponents + 1
177
178 if upper_ncomponents > X.shape[0]:
179 if self.max_components is None:
180 msg = "if max_components is None then min_components must be >= "
181 msg += "n_samples, but min_components = {}, n_samples = {}".format(
182 upper_ncomponents, X.shape[0]
183 )
184 else:
185 msg = "max_components must be >= n_samples, but max_components = "
186 msg += "{}, n_samples = {}".format(upper_ncomponents, X.shape[0])
187 raise ValueError(msg)
188 elif lower_ncomponents > X.shape[0]:
189 msg = "min_components must be <= n_samples, but min_components = "
190 msg += "{}, n_samples = {}".format(upper_ncomponents, X.shape[0])
191 raise ValueError(msg)
192
193 # Get parameters
194 random_state = self.random_state
195
196 param_grid = dict(
197 covariance_type=self.covariance_type,
198 n_components=range(lower_ncomponents, upper_ncomponents + 1),
199 random_state=[random_state],
200 )
201
202 param_grid = list(ParameterGrid(param_grid))
203
204 models = [[] for _ in range(n_mixture_components)]
205 bics = [[] for _ in range(n_mixture_components)]
206 aris = [[] for _ in range(n_mixture_components)]
207
208 for i, params in enumerate(param_grid):
209 model = GaussianMixture(**params)
210 model.fit(X)
211 models[i % n_mixture_components].append(model)
212 bics[i % n_mixture_components].append(model.bic(X))
213 if y is not None:
214 predictions = model.predict(X)
215 aris[i % n_mixture_components].append(
216 adjusted_rand_score(y, predictions)
217 )
218
219 self.bic_ = pd.DataFrame(
220 bics,
221 index=np.arange(lower_ncomponents, upper_ncomponents + 1),
222 columns=self.covariance_type,
223 )
224
225 if y is not None:
226 self.ari_ = pd.DataFrame(
227 aris,
228 index=np.arange(lower_ncomponents, upper_ncomponents + 1),
229 columns=self.covariance_type,
230 )
231 else:
232 self.ari_ = None
233
234 # Get the best cov type and its index within the dataframe
235 best_covariance = self.bic_.min(axis=0).idxmin()
236 best_covariance_idx = self.covariance_type.index(best_covariance)
237
238 # Get the index best component for best_covariance
239 best_component = self.bic_.idxmin()[best_covariance]
240
241 self.n_components_ = best_component
242 self.covariance_type_ = best_covariance
243 self.model_ = models[best_component - 1][best_covariance_idx]
244
245 return self
246
[end of graspy/cluster/gclust.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/graspy/cluster/gclust.py b/graspy/cluster/gclust.py
--- a/graspy/cluster/gclust.py
+++ b/graspy/cluster/gclust.py
@@ -240,6 +240,6 @@
self.n_components_ = best_component
self.covariance_type_ = best_covariance
- self.model_ = models[best_component - 1][best_covariance_idx]
+ self.model_ = models[best_component - self.min_components][best_covariance_idx]
return self
|
{"golden_diff": "diff --git a/graspy/cluster/gclust.py b/graspy/cluster/gclust.py\n--- a/graspy/cluster/gclust.py\n+++ b/graspy/cluster/gclust.py\n@@ -240,6 +240,6 @@\n \n self.n_components_ = best_component\n self.covariance_type_ = best_covariance\n- self.model_ = models[best_component - 1][best_covariance_idx]\n+ self.model_ = models[best_component - self.min_components][best_covariance_idx]\n \n return self\n", "issue": "GClust bug\n<img width=\"558\" alt=\"Screen Shot 2019-06-22 at 3 46 06 PM\" src=\"https://user-images.githubusercontent.com/25714207/59968259-eb346c80-9504-11e9-984c-8c13dff93a37.png\">\r\n\r\nshould be `- self.min_components` rather than `- 1`\r\n\r\nThis causes an indexing error when `min_components` does not equal 1\n", "before_files": [{"content": "# Copyright 2019 NeuroData (http://neurodata.io)\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport numpy as np\nimport pandas as pd\nfrom sklearn.metrics import adjusted_rand_score\nfrom sklearn.mixture import GaussianMixture\nfrom sklearn.model_selection import ParameterGrid\n\nfrom .base import BaseCluster\n\n\nclass GaussianCluster(BaseCluster):\n r\"\"\"\n Gaussian Mixture Model (GMM)\n\n Representation of a Gaussian mixture model probability distribution. \n This class allows to estimate the parameters of a Gaussian mixture \n distribution. It computes all possible models from one component to \n max_components. The best model is given by the lowest BIC score.\n\n Parameters\n ----------\n min_components : int, default=2. \n The minimum number of mixture components to consider (unless\n max_components=None, in which case this is the maximum number of\n components to consider). If max_componens is not None, min_components\n must be less than or equal to max_components.\n\n max_components : int or None, default=None.\n The maximum number of mixture components to consider. Must be greater \n than or equal to min_components.\n\n covariance_type : {'full' (default), 'tied', 'diag', 'spherical'}, optional\n String or list/array describing the type of covariance parameters to use.\n If a string, it must be one of:\n \n - 'full'\n each component has its own general covariance matrix\n - 'tied'\n all components share the same general covariance matrix\n - 'diag'\n each component has its own diagonal covariance matrix\n - 'spherical'\n each component has its own single variance\n - 'all'\n considers all covariance structures in ['spherical', 'diag', 'tied', 'full']\n If a list/array, it must be a list/array of strings containing only\n 'spherical', 'tied', 'diag', and/or 'spherical'.\n \n random_state : int, RandomState instance or None, optional (default=None)\n If int, random_state is the seed used by the random number generator;\n If RandomState instance, random_state is the random number generator;\n If None, the random number generator is the RandomState instance used\n by ``np.random``.\n\n Attributes\n ----------\n n_components_ : int\n Optimal number of components based on BIC.\n covariance_type_ : str\n Optimal covariance type based on BIC.\n model_ : GaussianMixture object\n Fitted GaussianMixture object fitted with optimal numeber of components \n and optimal covariance structure.\n bic_ : pandas.DataFrame\n A pandas DataFrame of BIC values computed for all possible number of clusters\n given by range(min_components, max_components + 1) and all covariance\n structures given by covariance_type.\n ari_ : pandas.DataFrame\n Only computed when y is given. Pandas Dataframe containing ARI values computed\n for all possible number of clusters given by range(min_components,\n max_components) and all covariance structures given by covariance_type.\n \"\"\"\n\n def __init__(\n self,\n min_components=2,\n max_components=None,\n covariance_type=\"full\",\n random_state=None,\n ):\n if isinstance(min_components, int):\n if min_components <= 0:\n msg = \"min_components must be >= 1.\"\n raise ValueError(msg)\n else:\n msg = \"min_components must be an integer, not {}.\".format(\n type(min_components)\n )\n raise TypeError(msg)\n\n if isinstance(max_components, int):\n if max_components <= 0:\n msg = \"max_components must be >= 1 or None.\"\n raise ValueError(msg)\n elif min_components > max_components:\n msg = \"min_components must be less than or equal to max_components.\"\n raise ValueError(msg)\n elif max_components is not None:\n msg = \"max_components must be an integer or None, not {}.\".format(\n type(max_components)\n )\n raise TypeError(msg)\n\n if isinstance(covariance_type, (np.ndarray, list)):\n covariance_type = np.unique(covariance_type)\n elif isinstance(covariance_type, str):\n if covariance_type == \"all\":\n covariance_type = [\"spherical\", \"diag\", \"tied\", \"full\"]\n else:\n covariance_type = [covariance_type]\n else:\n msg = \"covariance_type must be a numpy array, a list, or \"\n msg += \"string, not {}\".format(type(covariance_type))\n raise TypeError(msg)\n\n for cov in covariance_type:\n if cov not in [\"spherical\", \"diag\", \"tied\", \"full\"]:\n msg = (\n \"covariance structure must be one of \"\n + '[\"spherical\", \"diag\", \"tied\", \"full\"]'\n )\n msg += \" not {}\".format(cov)\n raise ValueError(msg)\n\n new_covariance_type = []\n for cov in [\"spherical\", \"diag\", \"tied\", \"full\"]:\n if cov in covariance_type:\n new_covariance_type.append(cov)\n\n self.min_components = min_components\n self.max_components = max_components\n self.covariance_type = new_covariance_type\n self.random_state = random_state\n\n def fit(self, X, y=None):\n \"\"\"\n Fits gaussian mixure model to the data. \n Estimate model parameters with the EM algorithm.\n\n Parameters\n ----------\n X : array-like, shape (n_samples, n_features)\n List of n_features-dimensional data points. Each row\n corresponds to a single data point.\n \n y : array-like, shape (n_samples,), optional (default=None)\n List of labels for X if available. Used to compute\n ARI scores.\n\n Returns\n -------\n self\n \"\"\"\n\n # Deal with number of clusters\n if self.max_components is None:\n lower_ncomponents = 1\n upper_ncomponents = self.min_components\n else:\n lower_ncomponents = self.min_components\n upper_ncomponents = self.max_components\n\n n_mixture_components = upper_ncomponents - lower_ncomponents + 1\n\n if upper_ncomponents > X.shape[0]:\n if self.max_components is None:\n msg = \"if max_components is None then min_components must be >= \"\n msg += \"n_samples, but min_components = {}, n_samples = {}\".format(\n upper_ncomponents, X.shape[0]\n )\n else:\n msg = \"max_components must be >= n_samples, but max_components = \"\n msg += \"{}, n_samples = {}\".format(upper_ncomponents, X.shape[0])\n raise ValueError(msg)\n elif lower_ncomponents > X.shape[0]:\n msg = \"min_components must be <= n_samples, but min_components = \"\n msg += \"{}, n_samples = {}\".format(upper_ncomponents, X.shape[0])\n raise ValueError(msg)\n\n # Get parameters\n random_state = self.random_state\n\n param_grid = dict(\n covariance_type=self.covariance_type,\n n_components=range(lower_ncomponents, upper_ncomponents + 1),\n random_state=[random_state],\n )\n\n param_grid = list(ParameterGrid(param_grid))\n\n models = [[] for _ in range(n_mixture_components)]\n bics = [[] for _ in range(n_mixture_components)]\n aris = [[] for _ in range(n_mixture_components)]\n\n for i, params in enumerate(param_grid):\n model = GaussianMixture(**params)\n model.fit(X)\n models[i % n_mixture_components].append(model)\n bics[i % n_mixture_components].append(model.bic(X))\n if y is not None:\n predictions = model.predict(X)\n aris[i % n_mixture_components].append(\n adjusted_rand_score(y, predictions)\n )\n\n self.bic_ = pd.DataFrame(\n bics,\n index=np.arange(lower_ncomponents, upper_ncomponents + 1),\n columns=self.covariance_type,\n )\n\n if y is not None:\n self.ari_ = pd.DataFrame(\n aris,\n index=np.arange(lower_ncomponents, upper_ncomponents + 1),\n columns=self.covariance_type,\n )\n else:\n self.ari_ = None\n\n # Get the best cov type and its index within the dataframe\n best_covariance = self.bic_.min(axis=0).idxmin()\n best_covariance_idx = self.covariance_type.index(best_covariance)\n\n # Get the index best component for best_covariance\n best_component = self.bic_.idxmin()[best_covariance]\n\n self.n_components_ = best_component\n self.covariance_type_ = best_covariance\n self.model_ = models[best_component - 1][best_covariance_idx]\n\n return self\n", "path": "graspy/cluster/gclust.py"}]}
| 3,316 | 128 |
gh_patches_debug_42116
|
rasdani/github-patches
|
git_diff
|
opsdroid__opsdroid-653
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add Google Style Docstrings
We should implement Google Style Docstrings to every function, method, class in opsdroid. This style will support existing documentation and will help in the future by generating documentation automatically.
This consists in a bit of effort so this issue can be worked by more than one contributor, just make sure that everyone knows what you are working on in order to avoid other contributors spending time on something that you are working on.
If you are unfamiliar with the Google Style Docstrings I'd recommend that you check these resources:
- [Sphix 1.8.0+ - Google Style Docstrings](https://sphinxcontrib-napoleon.readthedocs.io/en/latest/example_google.html)
Docstrings that need to be updated:
- main.py
- [x] configure_lang
- [ ] configure_log
- [ ] get_logging_level
- [ ] check_dependencies
- [ ] print_version
- [ ] print_example_config
- [ ] edit_files
- [x] welcome_message
- ~~helper.py~~
- [x] get_opsdroid
- [x] del_rw
- [x] move_config_to_appdir
- memory.py
- [x] Memory
- [x] get
- [x] put
- [x] _get_from_database
- [x] _put_to_database
- message.py
- [x] Message
- [x] __init__
- [x] _thinking_delay
- [x] _typing delay
- [x] respond
- [x] react
- web.py
- [ ] Web
- [x] get_port
- [x] get_host
- [x] get_ssl_context
- [ ] start
- [ ] build_response
- [ ] web_index_handler
- [ ] web_stats_handler
- matchers.py
- [ ] match_regex
- [ ] match_apiai_action
- [ ] match_apiai_intent
- [ ] match_dialogflow_action
- [ ] match_dialogflow_intent
- [ ] match_luisai_intent
- [ ] match_rasanlu
- [ ] match_recastai
- [ ] match_witai
- [ ] match_crontab
- [ ] match_webhook
- [ ] match_always
- core.py
- [ ] OpsDroid
- [ ] default_connector
- [ ] exit
- [ ] critical
- [ ] call_stop
- [ ] disconnect
- [ ] stop
- [ ] load
- [ ] start_loop
- [x] setup_skills
- [ ] train_parsers
- [ ] start_connector_tasks
- [ ] start_database
- [ ] run_skill
- [ ] get_ranked_skills
- [ ] parse
- loader.py
- [ ] Loader
- [x] import_module_from_spec
- [x] import_module
- [x] check_cache
- [x] build_module_import_path
- [x] build_module_install_path
- [x] git_clone
- [x] git_pull
- [x] pip_install_deps
- [x] create_default_config
- [x] load_config_file
- [ ] envvar_constructor
- [ ] include_constructor
- [x] setup_modules_directory
- [x] load_modules_from_config
- [x] _load_modules
- [x] _install_module
- [x] _update_module
- [ ] _install_git_module
- [x] _install_local_module
---- ORIGINAL POST ----
I've been wondering about this for a while now and I would like to know if we should replace/update all the docstrings in opsdroid with the Google Style doc strings.
I think this could help new and old contributors to contribute and commit to opsdroid since the Google Style docstrings give more information about every method/function and specifies clearly what sort of input the function/method expects, what will it return and what will be raised (if applicable).
The downsize of this style is that the length of every .py file will increase due to the doc strings, but since most IDE's allow you to hide those fields it shouldn't be too bad.
Here is a good example of Google Style Doc strings: [Sphix 1.8.0+ - Google Style Docstrings](http://www.sphinx-doc.org/en/master/ext/example_google.html)
I would like to know what you all think about this idea and if its worth spending time on it.
Add Google Style Docstrings
We should implement Google Style Docstrings to every function, method, class in opsdroid. This style will support existing documentation and will help in the future by generating documentation automatically.
This consists in a bit of effort so this issue can be worked by more than one contributor, just make sure that everyone knows what you are working on in order to avoid other contributors spending time on something that you are working on.
If you are unfamiliar with the Google Style Docstrings I'd recommend that you check these resources:
- [Sphix 1.8.0+ - Google Style Docstrings](https://sphinxcontrib-napoleon.readthedocs.io/en/latest/example_google.html)
Docstrings that need to be updated:
- main.py
- [x] configure_lang
- [ ] configure_log
- [ ] get_logging_level
- [ ] check_dependencies
- [ ] print_version
- [ ] print_example_config
- [ ] edit_files
- [x] welcome_message
- ~~helper.py~~
- [x] get_opsdroid
- [x] del_rw
- [x] move_config_to_appdir
- memory.py
- [x] Memory
- [x] get
- [x] put
- [x] _get_from_database
- [x] _put_to_database
- message.py
- [x] Message
- [x] __init__
- [x] _thinking_delay
- [x] _typing delay
- [x] respond
- [x] react
- web.py
- [ ] Web
- [x] get_port
- [x] get_host
- [x] get_ssl_context
- [ ] start
- [ ] build_response
- [ ] web_index_handler
- [ ] web_stats_handler
- matchers.py
- [ ] match_regex
- [ ] match_apiai_action
- [ ] match_apiai_intent
- [ ] match_dialogflow_action
- [ ] match_dialogflow_intent
- [ ] match_luisai_intent
- [ ] match_rasanlu
- [ ] match_recastai
- [ ] match_witai
- [ ] match_crontab
- [ ] match_webhook
- [ ] match_always
- core.py
- [ ] OpsDroid
- [ ] default_connector
- [ ] exit
- [ ] critical
- [ ] call_stop
- [ ] disconnect
- [ ] stop
- [ ] load
- [ ] start_loop
- [x] setup_skills
- [ ] train_parsers
- [ ] start_connector_tasks
- [ ] start_database
- [ ] run_skill
- [ ] get_ranked_skills
- [ ] parse
- loader.py
- [ ] Loader
- [x] import_module_from_spec
- [x] import_module
- [x] check_cache
- [x] build_module_import_path
- [x] build_module_install_path
- [x] git_clone
- [x] git_pull
- [x] pip_install_deps
- [x] create_default_config
- [x] load_config_file
- [ ] envvar_constructor
- [ ] include_constructor
- [x] setup_modules_directory
- [x] load_modules_from_config
- [x] _load_modules
- [x] _install_module
- [x] _update_module
- [ ] _install_git_module
- [x] _install_local_module
---- ORIGINAL POST ----
I've been wondering about this for a while now and I would like to know if we should replace/update all the docstrings in opsdroid with the Google Style doc strings.
I think this could help new and old contributors to contribute and commit to opsdroid since the Google Style docstrings give more information about every method/function and specifies clearly what sort of input the function/method expects, what will it return and what will be raised (if applicable).
The downsize of this style is that the length of every .py file will increase due to the doc strings, but since most IDE's allow you to hide those fields it shouldn't be too bad.
Here is a good example of Google Style Doc strings: [Sphix 1.8.0+ - Google Style Docstrings](http://www.sphinx-doc.org/en/master/ext/example_google.html)
I would like to know what you all think about this idea and if its worth spending time on it.
</issue>
<code>
[start of opsdroid/message.py]
1 """Class to encapsulate a message."""
2
3 from datetime import datetime
4 from copy import copy
5 import asyncio
6 from random import randrange
7
8 from opsdroid.helper import get_opsdroid
9
10
11 class Message:
12 # pylint: disable=too-few-public-methods
13 """A message object."""
14
15 def __init__(self, text, user, room, connector, raw_message=None):
16 """Create object with minimum properties."""
17 self.created = datetime.now()
18 self.text = text
19 self.user = user
20 self.room = room
21 self.connector = connector
22 self.raw_message = raw_message
23 self.regex = None
24 self.responded_to = False
25
26 async def _thinking_delay(self):
27 """Make opsdroid wait x-seconds before responding."""
28 seconds = self.connector.configuration.get('thinking-delay', 0)
29
30 if isinstance(seconds, list):
31 seconds = randrange(seconds[0], seconds[1])
32
33 await asyncio.sleep(seconds)
34
35 async def _typing_delay(self, text):
36 """Simulate typing, takes an int or float to delay reply."""
37 seconds = self.connector.configuration.get('typing-delay', 0)
38 char_count = len(text)
39
40 if isinstance(seconds, list):
41 seconds = randrange(seconds[0], seconds[1])
42
43 await asyncio.sleep(char_count*seconds)
44
45 async def respond(self, text, room=None):
46 """Respond to this message using the connector it was created by."""
47 opsdroid = get_opsdroid()
48 response = copy(self)
49 response.text = text
50
51 if 'thinking-delay' in self.connector.configuration or \
52 'typing-delay' in self.connector.configuration:
53 await self._thinking_delay()
54 await self._typing_delay(response.text)
55
56 await self.connector.respond(response, room)
57 if not self.responded_to:
58 now = datetime.now()
59 opsdroid.stats["total_responses"] = \
60 opsdroid.stats["total_responses"] + 1
61 opsdroid.stats["total_response_time"] = \
62 opsdroid.stats["total_response_time"] + \
63 (now - self.created).total_seconds()
64 self.responded_to = True
65
66 async def react(self, emoji):
67 """React to this message using the connector it was created by."""
68 if 'thinking-delay' in self.connector.configuration:
69 await self._thinking_delay()
70 return await self.connector.react(self, emoji)
71
[end of opsdroid/message.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/opsdroid/message.py b/opsdroid/message.py
--- a/opsdroid/message.py
+++ b/opsdroid/message.py
@@ -10,7 +10,31 @@
class Message:
# pylint: disable=too-few-public-methods
- """A message object."""
+ """A message object.
+
+ Stores messages in a format that allows OpsDroid to respond or react with
+ delays for thinking and typing as defined in configuration YAML file.
+
+ Args:
+ text: String text of message
+ user: String name of user sending message
+ room: String name of the room or chat channel in which message was sent
+ connector: Connector object used to interact with given chat service
+ raw_message: Raw message as provided by chat service. None by default
+
+ Attributes:
+ created: Local date and time that message object was created
+ text: Text of message as string
+ user: String name of user sending message
+ room: String name of the room or chat channel in which message was sent
+ connector: Connector object used to interact with given chat service
+ raw_message: Raw message provided by chat service
+ regex: A re match object for the regular expression message was matched
+ against
+ responded_to: Boolean initialized as False. True if message has been
+ responded to
+
+ """
def __init__(self, text, user, room, connector, raw_message=None):
"""Create object with minimum properties."""
@@ -24,7 +48,10 @@
self.responded_to = False
async def _thinking_delay(self):
- """Make opsdroid wait x-seconds before responding."""
+ """Make opsdroid wait x-seconds before responding.
+
+ Number of seconds defined in YAML config. file, accessed via connector.
+ """
seconds = self.connector.configuration.get('thinking-delay', 0)
if isinstance(seconds, list):
@@ -33,7 +60,11 @@
await asyncio.sleep(seconds)
async def _typing_delay(self, text):
- """Simulate typing, takes an int or float to delay reply."""
+ """Delays reply to simulate typing.
+
+ Seconds to delay equals number of characters in response multiplied by
+ number of seconds defined in YAML config. file, accessed via connector.
+ """
seconds = self.connector.configuration.get('typing-delay', 0)
char_count = len(text)
@@ -43,7 +74,13 @@
await asyncio.sleep(char_count*seconds)
async def respond(self, text, room=None):
- """Respond to this message using the connector it was created by."""
+ """Respond to this message using the connector it was created by.
+
+ Creates copy of this message with updated text as response.
+ Delays message if thinking or typing delay present in config. file.
+ Updates responded_to attribute to True if False.
+ Logs response and response time in OpsDroid object stats.
+ """
opsdroid = get_opsdroid()
response = copy(self)
response.text = text
@@ -64,7 +101,17 @@
self.responded_to = True
async def react(self, emoji):
- """React to this message using the connector it was created by."""
+ """React to this message with emoji using the specified connector.
+
+ Delays message if thinking delay present in config. file.
+
+ Args:
+ emoji: Sting name of emoji with which OpsDroid will react.
+
+ Returns:
+ bool: True for message successfully sent. False otherwise.
+
+ """
if 'thinking-delay' in self.connector.configuration:
await self._thinking_delay()
return await self.connector.react(self, emoji)
|
{"golden_diff": "diff --git a/opsdroid/message.py b/opsdroid/message.py\n--- a/opsdroid/message.py\n+++ b/opsdroid/message.py\n@@ -10,7 +10,31 @@\n \n class Message:\n # pylint: disable=too-few-public-methods\n- \"\"\"A message object.\"\"\"\n+ \"\"\"A message object.\n+\n+ Stores messages in a format that allows OpsDroid to respond or react with\n+ delays for thinking and typing as defined in configuration YAML file.\n+\n+ Args:\n+ text: String text of message\n+ user: String name of user sending message\n+ room: String name of the room or chat channel in which message was sent\n+ connector: Connector object used to interact with given chat service\n+ raw_message: Raw message as provided by chat service. None by default\n+\n+ Attributes:\n+ created: Local date and time that message object was created\n+ text: Text of message as string\n+ user: String name of user sending message\n+ room: String name of the room or chat channel in which message was sent\n+ connector: Connector object used to interact with given chat service\n+ raw_message: Raw message provided by chat service\n+ regex: A re match object for the regular expression message was matched\n+ against\n+ responded_to: Boolean initialized as False. True if message has been\n+ responded to\n+\n+ \"\"\"\n \n def __init__(self, text, user, room, connector, raw_message=None):\n \"\"\"Create object with minimum properties.\"\"\"\n@@ -24,7 +48,10 @@\n self.responded_to = False\n \n async def _thinking_delay(self):\n- \"\"\"Make opsdroid wait x-seconds before responding.\"\"\"\n+ \"\"\"Make opsdroid wait x-seconds before responding.\n+\n+ Number of seconds defined in YAML config. file, accessed via connector.\n+ \"\"\"\n seconds = self.connector.configuration.get('thinking-delay', 0)\n \n if isinstance(seconds, list):\n@@ -33,7 +60,11 @@\n await asyncio.sleep(seconds)\n \n async def _typing_delay(self, text):\n- \"\"\"Simulate typing, takes an int or float to delay reply.\"\"\"\n+ \"\"\"Delays reply to simulate typing.\n+\n+ Seconds to delay equals number of characters in response multiplied by\n+ number of seconds defined in YAML config. file, accessed via connector.\n+ \"\"\"\n seconds = self.connector.configuration.get('typing-delay', 0)\n char_count = len(text)\n \n@@ -43,7 +74,13 @@\n await asyncio.sleep(char_count*seconds)\n \n async def respond(self, text, room=None):\n- \"\"\"Respond to this message using the connector it was created by.\"\"\"\n+ \"\"\"Respond to this message using the connector it was created by.\n+\n+ Creates copy of this message with updated text as response.\n+ Delays message if thinking or typing delay present in config. file.\n+ Updates responded_to attribute to True if False.\n+ Logs response and response time in OpsDroid object stats.\n+ \"\"\"\n opsdroid = get_opsdroid()\n response = copy(self)\n response.text = text\n@@ -64,7 +101,17 @@\n self.responded_to = True\n \n async def react(self, emoji):\n- \"\"\"React to this message using the connector it was created by.\"\"\"\n+ \"\"\"React to this message with emoji using the specified connector.\n+\n+ Delays message if thinking delay present in config. file.\n+\n+ Args:\n+ emoji: Sting name of emoji with which OpsDroid will react.\n+\n+ Returns:\n+ bool: True for message successfully sent. False otherwise.\n+\n+ \"\"\"\n if 'thinking-delay' in self.connector.configuration:\n await self._thinking_delay()\n return await self.connector.react(self, emoji)\n", "issue": "Add Google Style Docstrings\nWe should implement Google Style Docstrings to every function, method, class in opsdroid. This style will support existing documentation and will help in the future by generating documentation automatically.\r\n\r\nThis consists in a bit of effort so this issue can be worked by more than one contributor, just make sure that everyone knows what you are working on in order to avoid other contributors spending time on something that you are working on.\r\n\r\nIf you are unfamiliar with the Google Style Docstrings I'd recommend that you check these resources:\r\n\r\n - [Sphix 1.8.0+ - Google Style Docstrings](https://sphinxcontrib-napoleon.readthedocs.io/en/latest/example_google.html)\r\n\r\n\r\n\r\nDocstrings that need to be updated:\r\n\r\n- main.py\r\n - [x] configure_lang\r\n - [ ] configure_log\r\n - [ ] get_logging_level\r\n - [ ] check_dependencies\r\n - [ ] print_version\r\n - [ ] print_example_config\r\n - [ ] edit_files\r\n - [x] welcome_message\r\n- ~~helper.py~~\r\n - [x] get_opsdroid\r\n - [x] del_rw\r\n - [x] move_config_to_appdir\r\n- memory.py\r\n - [x] Memory\r\n - [x] get\r\n - [x] put\r\n - [x] _get_from_database\r\n - [x] _put_to_database\r\n- message.py\r\n - [x] Message\r\n - [x] __init__\r\n - [x] _thinking_delay\r\n - [x] _typing delay\r\n - [x] respond\r\n - [x] react\r\n- web.py\r\n - [ ] Web\r\n - [x] get_port\r\n - [x] get_host\r\n - [x] get_ssl_context\r\n - [ ] start\r\n - [ ] build_response\r\n - [ ] web_index_handler\r\n - [ ] web_stats_handler\r\n- matchers.py\r\n - [ ] match_regex\r\n - [ ] match_apiai_action\r\n - [ ] match_apiai_intent\r\n - [ ] match_dialogflow_action\r\n - [ ] match_dialogflow_intent\r\n - [ ] match_luisai_intent\r\n - [ ] match_rasanlu\r\n - [ ] match_recastai\r\n - [ ] match_witai\r\n - [ ] match_crontab\r\n - [ ] match_webhook\r\n - [ ] match_always\r\n- core.py\r\n - [ ] OpsDroid\r\n - [ ] default_connector\r\n - [ ] exit\r\n - [ ] critical\r\n - [ ] call_stop\r\n - [ ] disconnect\r\n - [ ] stop\r\n - [ ] load\r\n - [ ] start_loop\r\n - [x] setup_skills\r\n - [ ] train_parsers\r\n - [ ] start_connector_tasks\r\n - [ ] start_database\r\n - [ ] run_skill\r\n - [ ] get_ranked_skills\r\n - [ ] parse\r\n- loader.py\r\n - [ ] Loader\r\n - [x] import_module_from_spec\r\n - [x] import_module\r\n - [x] check_cache\r\n - [x] build_module_import_path\r\n - [x] build_module_install_path\r\n - [x] git_clone\r\n - [x] git_pull\r\n - [x] pip_install_deps\r\n - [x] create_default_config\r\n - [x] load_config_file\r\n - [ ] envvar_constructor\r\n - [ ] include_constructor\r\n - [x] setup_modules_directory\r\n - [x] load_modules_from_config\r\n - [x] _load_modules\r\n - [x] _install_module\r\n - [x] _update_module\r\n - [ ] _install_git_module\r\n - [x] _install_local_module\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n---- ORIGINAL POST ---- \r\nI've been wondering about this for a while now and I would like to know if we should replace/update all the docstrings in opsdroid with the Google Style doc strings. \r\n\r\nI think this could help new and old contributors to contribute and commit to opsdroid since the Google Style docstrings give more information about every method/function and specifies clearly what sort of input the function/method expects, what will it return and what will be raised (if applicable).\r\n\r\nThe downsize of this style is that the length of every .py file will increase due to the doc strings, but since most IDE's allow you to hide those fields it shouldn't be too bad.\r\n\r\nHere is a good example of Google Style Doc strings: [Sphix 1.8.0+ - Google Style Docstrings](http://www.sphinx-doc.org/en/master/ext/example_google.html)\r\n\r\nI would like to know what you all think about this idea and if its worth spending time on it.\nAdd Google Style Docstrings\nWe should implement Google Style Docstrings to every function, method, class in opsdroid. This style will support existing documentation and will help in the future by generating documentation automatically.\r\n\r\nThis consists in a bit of effort so this issue can be worked by more than one contributor, just make sure that everyone knows what you are working on in order to avoid other contributors spending time on something that you are working on.\r\n\r\nIf you are unfamiliar with the Google Style Docstrings I'd recommend that you check these resources:\r\n\r\n - [Sphix 1.8.0+ - Google Style Docstrings](https://sphinxcontrib-napoleon.readthedocs.io/en/latest/example_google.html)\r\n\r\n\r\n\r\nDocstrings that need to be updated:\r\n\r\n- main.py\r\n - [x] configure_lang\r\n - [ ] configure_log\r\n - [ ] get_logging_level\r\n - [ ] check_dependencies\r\n - [ ] print_version\r\n - [ ] print_example_config\r\n - [ ] edit_files\r\n - [x] welcome_message\r\n- ~~helper.py~~\r\n - [x] get_opsdroid\r\n - [x] del_rw\r\n - [x] move_config_to_appdir\r\n- memory.py\r\n - [x] Memory\r\n - [x] get\r\n - [x] put\r\n - [x] _get_from_database\r\n - [x] _put_to_database\r\n- message.py\r\n - [x] Message\r\n - [x] __init__\r\n - [x] _thinking_delay\r\n - [x] _typing delay\r\n - [x] respond\r\n - [x] react\r\n- web.py\r\n - [ ] Web\r\n - [x] get_port\r\n - [x] get_host\r\n - [x] get_ssl_context\r\n - [ ] start\r\n - [ ] build_response\r\n - [ ] web_index_handler\r\n - [ ] web_stats_handler\r\n- matchers.py\r\n - [ ] match_regex\r\n - [ ] match_apiai_action\r\n - [ ] match_apiai_intent\r\n - [ ] match_dialogflow_action\r\n - [ ] match_dialogflow_intent\r\n - [ ] match_luisai_intent\r\n - [ ] match_rasanlu\r\n - [ ] match_recastai\r\n - [ ] match_witai\r\n - [ ] match_crontab\r\n - [ ] match_webhook\r\n - [ ] match_always\r\n- core.py\r\n - [ ] OpsDroid\r\n - [ ] default_connector\r\n - [ ] exit\r\n - [ ] critical\r\n - [ ] call_stop\r\n - [ ] disconnect\r\n - [ ] stop\r\n - [ ] load\r\n - [ ] start_loop\r\n - [x] setup_skills\r\n - [ ] train_parsers\r\n - [ ] start_connector_tasks\r\n - [ ] start_database\r\n - [ ] run_skill\r\n - [ ] get_ranked_skills\r\n - [ ] parse\r\n- loader.py\r\n - [ ] Loader\r\n - [x] import_module_from_spec\r\n - [x] import_module\r\n - [x] check_cache\r\n - [x] build_module_import_path\r\n - [x] build_module_install_path\r\n - [x] git_clone\r\n - [x] git_pull\r\n - [x] pip_install_deps\r\n - [x] create_default_config\r\n - [x] load_config_file\r\n - [ ] envvar_constructor\r\n - [ ] include_constructor\r\n - [x] setup_modules_directory\r\n - [x] load_modules_from_config\r\n - [x] _load_modules\r\n - [x] _install_module\r\n - [x] _update_module\r\n - [ ] _install_git_module\r\n - [x] _install_local_module\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n---- ORIGINAL POST ---- \r\nI've been wondering about this for a while now and I would like to know if we should replace/update all the docstrings in opsdroid with the Google Style doc strings. \r\n\r\nI think this could help new and old contributors to contribute and commit to opsdroid since the Google Style docstrings give more information about every method/function and specifies clearly what sort of input the function/method expects, what will it return and what will be raised (if applicable).\r\n\r\nThe downsize of this style is that the length of every .py file will increase due to the doc strings, but since most IDE's allow you to hide those fields it shouldn't be too bad.\r\n\r\nHere is a good example of Google Style Doc strings: [Sphix 1.8.0+ - Google Style Docstrings](http://www.sphinx-doc.org/en/master/ext/example_google.html)\r\n\r\nI would like to know what you all think about this idea and if its worth spending time on it.\n", "before_files": [{"content": "\"\"\"Class to encapsulate a message.\"\"\"\n\nfrom datetime import datetime\nfrom copy import copy\nimport asyncio\nfrom random import randrange\n\nfrom opsdroid.helper import get_opsdroid\n\n\nclass Message:\n # pylint: disable=too-few-public-methods\n \"\"\"A message object.\"\"\"\n\n def __init__(self, text, user, room, connector, raw_message=None):\n \"\"\"Create object with minimum properties.\"\"\"\n self.created = datetime.now()\n self.text = text\n self.user = user\n self.room = room\n self.connector = connector\n self.raw_message = raw_message\n self.regex = None\n self.responded_to = False\n\n async def _thinking_delay(self):\n \"\"\"Make opsdroid wait x-seconds before responding.\"\"\"\n seconds = self.connector.configuration.get('thinking-delay', 0)\n\n if isinstance(seconds, list):\n seconds = randrange(seconds[0], seconds[1])\n\n await asyncio.sleep(seconds)\n\n async def _typing_delay(self, text):\n \"\"\"Simulate typing, takes an int or float to delay reply.\"\"\"\n seconds = self.connector.configuration.get('typing-delay', 0)\n char_count = len(text)\n\n if isinstance(seconds, list):\n seconds = randrange(seconds[0], seconds[1])\n\n await asyncio.sleep(char_count*seconds)\n\n async def respond(self, text, room=None):\n \"\"\"Respond to this message using the connector it was created by.\"\"\"\n opsdroid = get_opsdroid()\n response = copy(self)\n response.text = text\n\n if 'thinking-delay' in self.connector.configuration or \\\n 'typing-delay' in self.connector.configuration:\n await self._thinking_delay()\n await self._typing_delay(response.text)\n\n await self.connector.respond(response, room)\n if not self.responded_to:\n now = datetime.now()\n opsdroid.stats[\"total_responses\"] = \\\n opsdroid.stats[\"total_responses\"] + 1\n opsdroid.stats[\"total_response_time\"] = \\\n opsdroid.stats[\"total_response_time\"] + \\\n (now - self.created).total_seconds()\n self.responded_to = True\n\n async def react(self, emoji):\n \"\"\"React to this message using the connector it was created by.\"\"\"\n if 'thinking-delay' in self.connector.configuration:\n await self._thinking_delay()\n return await self.connector.react(self, emoji)\n", "path": "opsdroid/message.py"}]}
| 3,255 | 844 |
gh_patches_debug_19148
|
rasdani/github-patches
|
git_diff
|
coala__coala-bears-1422
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Most YAML documents use document starts (---)
Hi,
I am the creator of yamllint, the linter coala uses for YAML.
Since #965 was merged three months ago, coala fails on many projects like Ansible, OpenStack and even yamllint itself, because coala doesn't accept document start markers (`---`) anymore.
Document start markers are commonly used, and required when declaring multiple documents in a single `.yaml` file (see [the spec](http://yaml.org/spec/1.2/spec.html#id2800132)).
The proposed fix in the original issue (#923) was to disable the rule, but the implemented fix (#965) made document starts forbidden.
My opinion is that coala should either require document starts, or disable the rule by default.
</issue>
<code>
[start of bears/yaml/YAMLLintBear.py]
1 from coalib.bearlib.abstractions.Linter import linter
2 from dependency_management.requirements.PipRequirement import PipRequirement
3 import yaml
4
5
6 @linter(executable='yamllint',
7 output_format='regex',
8 output_regex=r'.+:(?P<line>\d+):(?P<column>\d+): '
9 r'\[(?P<severity>error|warning)\] (?P<message>.+)')
10 class YAMLLintBear:
11 """
12 Check yaml code for errors and possible problems.
13
14 You can read more about capabilities at
15 <http://yamllint.readthedocs.org/en/latest/rules.html>.
16 """
17
18 LANGUAGES = {'YAML'}
19 REQUIREMENTS = {PipRequirement('yamllint', '1.5')}
20 AUTHORS = {'The coala developers'}
21 AUTHORS_EMAILS = {'[email protected]'}
22 LICENSE = 'AGPL-3.0'
23 CAN_DETECT = {'Syntax', 'Formatting'}
24
25 @staticmethod
26 def generate_config(filename, file,
27 document_start: bool=False):
28 """
29 :param document_start:
30 Use this rule to require or forbid the use of document start
31 marker (---).
32 """
33 yamllint_configs = {
34 'extends': 'default',
35 'rules': {
36 'document-start': {
37 'present': False
38 }
39 }
40 }
41 if document_start:
42 yamllint_configs['rules']['document-start']['present'] = True
43
44 return yaml.dump(yamllint_configs)
45
46 @staticmethod
47 def create_arguments(filename, file, config_file, yamllint_config: str=''):
48 """
49 :param yamllint_config: Path to a custom configuration file.
50 """
51 args = ('-f', 'parsable', filename)
52 if yamllint_config:
53 args += ('--config-file=' + yamllint_config,)
54 else:
55 args += ('--config-file=' + config_file,)
56 return args
57
[end of bears/yaml/YAMLLintBear.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/bears/yaml/YAMLLintBear.py b/bears/yaml/YAMLLintBear.py
--- a/bears/yaml/YAMLLintBear.py
+++ b/bears/yaml/YAMLLintBear.py
@@ -24,7 +24,7 @@
@staticmethod
def generate_config(filename, file,
- document_start: bool=False):
+ document_start: bool=None):
"""
:param document_start:
Use this rule to require or forbid the use of document start
@@ -33,13 +33,10 @@
yamllint_configs = {
'extends': 'default',
'rules': {
- 'document-start': {
- 'present': False
- }
- }
+ 'document-start': 'disable' if document_start is None
+ else {'present': document_start},
+ },
}
- if document_start:
- yamllint_configs['rules']['document-start']['present'] = True
return yaml.dump(yamllint_configs)
|
{"golden_diff": "diff --git a/bears/yaml/YAMLLintBear.py b/bears/yaml/YAMLLintBear.py\n--- a/bears/yaml/YAMLLintBear.py\n+++ b/bears/yaml/YAMLLintBear.py\n@@ -24,7 +24,7 @@\n \n @staticmethod\n def generate_config(filename, file,\n- document_start: bool=False):\n+ document_start: bool=None):\n \"\"\"\n :param document_start:\n Use this rule to require or forbid the use of document start\n@@ -33,13 +33,10 @@\n yamllint_configs = {\n 'extends': 'default',\n 'rules': {\n- 'document-start': {\n- 'present': False\n- }\n- }\n+ 'document-start': 'disable' if document_start is None\n+ else {'present': document_start},\n+ },\n }\n- if document_start:\n- yamllint_configs['rules']['document-start']['present'] = True\n \n return yaml.dump(yamllint_configs)\n", "issue": "Most YAML documents use document starts (---)\nHi,\r\n\r\nI am the creator of yamllint, the linter coala uses for YAML.\r\n\r\nSince #965 was merged three months ago, coala fails on many projects like Ansible, OpenStack and even yamllint itself, because coala doesn't accept document start markers (`---`) anymore.\r\n\r\nDocument start markers are commonly used, and required when declaring multiple documents in a single `.yaml` file (see [the spec](http://yaml.org/spec/1.2/spec.html#id2800132)).\r\n\r\nThe proposed fix in the original issue (#923) was to disable the rule, but the implemented fix (#965) made document starts forbidden.\r\n\r\nMy opinion is that coala should either require document starts, or disable the rule by default.\n", "before_files": [{"content": "from coalib.bearlib.abstractions.Linter import linter\nfrom dependency_management.requirements.PipRequirement import PipRequirement\nimport yaml\n\n\n@linter(executable='yamllint',\n output_format='regex',\n output_regex=r'.+:(?P<line>\\d+):(?P<column>\\d+): '\n r'\\[(?P<severity>error|warning)\\] (?P<message>.+)')\nclass YAMLLintBear:\n \"\"\"\n Check yaml code for errors and possible problems.\n\n You can read more about capabilities at\n <http://yamllint.readthedocs.org/en/latest/rules.html>.\n \"\"\"\n\n LANGUAGES = {'YAML'}\n REQUIREMENTS = {PipRequirement('yamllint', '1.5')}\n AUTHORS = {'The coala developers'}\n AUTHORS_EMAILS = {'[email protected]'}\n LICENSE = 'AGPL-3.0'\n CAN_DETECT = {'Syntax', 'Formatting'}\n\n @staticmethod\n def generate_config(filename, file,\n document_start: bool=False):\n \"\"\"\n :param document_start:\n Use this rule to require or forbid the use of document start\n marker (---).\n \"\"\"\n yamllint_configs = {\n 'extends': 'default',\n 'rules': {\n 'document-start': {\n 'present': False\n }\n }\n }\n if document_start:\n yamllint_configs['rules']['document-start']['present'] = True\n\n return yaml.dump(yamllint_configs)\n\n @staticmethod\n def create_arguments(filename, file, config_file, yamllint_config: str=''):\n \"\"\"\n :param yamllint_config: Path to a custom configuration file.\n \"\"\"\n args = ('-f', 'parsable', filename)\n if yamllint_config:\n args += ('--config-file=' + yamllint_config,)\n else:\n args += ('--config-file=' + config_file,)\n return args\n", "path": "bears/yaml/YAMLLintBear.py"}]}
| 1,255 | 232 |
gh_patches_debug_27778
|
rasdani/github-patches
|
git_diff
|
enthought__chaco-502
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Don't put Cythonized .c files in source control, but do ship in sdist
Currently we check-in .c files produced by Cython to the source tree alongside the .pyx files so that people building the source don't need to have Cython installed. This is awkward from the developer's perspective, however, and can result in noisy deltas.
Following discussion in #325 the the proposal is that we will only check in the .pyx files into source control, but we will ship the .c files as part of the sdist source distributions. This change will mean that people wishing to work from non-released versions will need to have Cython installed (as will the CI environment), but people wanting to build a release from source won't need it. Having Cython available is not as unreasonable a requirement as it was several years ago.
</issue>
<code>
[start of setup.py]
1 # Copyright (c) 2008-2019 by Enthought, Inc.
2 # All rights reserved.
3 import os
4 import re
5 import subprocess
6
7 from numpy import get_include
8 from setuptools import setup, Extension, find_packages
9
10 MAJOR = 4
11 MINOR = 8
12 MICRO = 1
13
14 IS_RELEASED = False
15
16 VERSION = '%d.%d.%d' % (MAJOR, MINOR, MICRO)
17
18 # Name of the directory containing the package.
19 PKG_PATHNAME = 'chaco'
20
21 # Name of the file containing the version information.
22 _VERSION_FILENAME = os.path.join(PKG_PATHNAME, '_version.py')
23
24
25 def read_version_py(path):
26 """ Read a _version.py file in a safe way. """
27 with open(path, 'r') as fp:
28 code = compile(fp.read(), 'chaco._version', 'exec')
29 context = {}
30 exec(code, context)
31 return context['git_revision'], context['full_version']
32
33
34 def git_version():
35 """ Parse version information from the current git commit.
36
37 Parse the output of `git describe` and return the git hash and the number
38 of commits since the last version tag.
39 """
40
41 def _minimal_ext_cmd(cmd):
42 # construct minimal environment
43 env = {}
44 for k in ['SYSTEMROOT', 'PATH', 'HOME']:
45 v = os.environ.get(k)
46 if v is not None:
47 env[k] = v
48 # LANGUAGE is used on win32
49 env['LANGUAGE'] = 'C'
50 env['LANG'] = 'C'
51 env['LC_ALL'] = 'C'
52 out = subprocess.Popen(
53 cmd, stdout=subprocess.PIPE, env=env,
54 ).communicate()[0]
55 return out
56
57 try:
58 # We ask git to find the latest tag matching a glob expression. The
59 # intention is to find a release tag of the form '4.50.2'. Strictly
60 # speaking, the glob expression also matches tags of the form
61 # '4abc.5xyz.2gtluuu', but it's very difficult with glob expressions
62 # to distinguish between the two cases, and the likelihood of a
63 # problem is minimal.
64 out = _minimal_ext_cmd(
65 ['git', 'describe', '--match', '[0-9]*.[0-9]*.[0-9]*', '--tags'])
66 except OSError:
67 out = ''
68
69 git_description = out.strip().decode('ascii')
70 expr = r'.*?\-(?P<count>\d+)-g(?P<hash>[a-fA-F0-9]+)'
71 match = re.match(expr, git_description)
72 if match is None:
73 git_revision, git_count = 'Unknown', '0'
74 else:
75 git_revision, git_count = match.group('hash'), match.group('count')
76
77 return git_revision, git_count
78
79
80 def write_version_py(filename=_VERSION_FILENAME):
81 """ Create a file containing the version information. """
82
83 template = """\
84 # This file was automatically generated from the `setup.py` script.
85 version = '{version}'
86 full_version = '{full_version}'
87 git_revision = '{git_revision}'
88 is_released = {is_released}
89
90 if not is_released:
91 version = full_version
92 """
93 # Adding the git rev number needs to be done inside
94 # write_version_py(), otherwise the import of _version messes
95 # up the build under Python 3.
96 fullversion = VERSION
97 chaco_version_path = os.path.join(
98 os.path.dirname(__file__), 'chaco', '_version.py')
99 if os.path.exists('.git'):
100 git_rev, dev_num = git_version()
101 elif os.path.exists(filename):
102 # must be a source distribution, use existing version file
103 try:
104 git_rev, fullversion = read_version_py(chaco_version_path)
105 except (SyntaxError, KeyError):
106 raise RuntimeError("Unable to read git_revision. Try removing "
107 "chaco/_version.py and the build directory "
108 "before building.")
109
110
111 match = re.match(r'.*?\.dev(?P<dev_num>\d+)', fullversion)
112 if match is None:
113 dev_num = '0'
114 else:
115 dev_num = match.group('dev_num')
116 else:
117 git_rev = 'Unknown'
118 dev_num = '0'
119
120 if not IS_RELEASED:
121 fullversion += '.dev{0}'.format(dev_num)
122
123 with open(filename, "wt") as fp:
124 fp.write(template.format(version=VERSION,
125 full_version=fullversion,
126 git_revision=git_rev,
127 is_released=IS_RELEASED))
128
129
130 if __name__ == "__main__":
131 write_version_py()
132 from chaco import __requires__, __version__
133
134 numpy_include_dir = get_include()
135
136 # Register Python extensions
137 contour = Extension(
138 'chaco.contour.contour',
139 sources=['chaco/contour/cntr.c'],
140 include_dirs=[numpy_include_dir],
141 define_macros=[('NUMPY', None)],
142 )
143
144 cython_speedups = Extension(
145 'chaco._cython_speedups',
146 sources=['chaco/_cython_speedups.c'],
147 include_dirs=[numpy_include_dir],
148 )
149
150 downsampling_lttb = Extension(
151 'chaco.downsample._lttb',
152 sources=['chaco/downsample/_lttb.c'],
153 include_dirs=[numpy_include_dir],
154 )
155
156 setup(
157 name = 'chaco',
158 version = __version__,
159 author = 'Peter Wang, et. al.',
160 author_email = '[email protected]',
161 maintainer = 'ETS Developers',
162 maintainer_email = '[email protected]',
163 url = 'http://docs.enthought.com/chaco',
164 download_url = 'https://github.com/enthought/chaco',
165 classifiers = [c.strip() for c in """\
166 Development Status :: 5 - Production/Stable
167 Intended Audience :: Developers
168 Intended Audience :: Science/Research
169 License :: OSI Approved :: BSD License
170 Operating System :: MacOS
171 Operating System :: Microsoft :: Windows
172 Operating System :: OS Independent
173 Operating System :: POSIX
174 Operating System :: Unix
175 Programming Language :: C
176 Programming Language :: Python
177 Topic :: Scientific/Engineering
178 Topic :: Software Development
179 Topic :: Software Development :: Libraries
180 """.splitlines() if len(c.strip()) > 0],
181 package_data={
182 'chaco': ['tools/toolbars/images/*.png',
183 'layers/data/*.svg',
184 'tests/data/PngSuite/*.png']
185 },
186 description = 'interactive 2-dimensional plotting',
187 long_description = open('README.rst').read(),
188 ext_modules = [contour, cython_speedups, downsampling_lttb],
189 include_package_data = True,
190 install_requires = __requires__,
191 license = 'BSD',
192 packages = find_packages(),
193 platforms = ["Windows", "Linux", "Mac OS-X", "Unix", "Solaris"],
194 zip_safe = False,
195 use_2to3=False,
196 )
197
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -6,6 +6,7 @@
from numpy import get_include
from setuptools import setup, Extension, find_packages
+from Cython.Build import cythonize
MAJOR = 4
MINOR = 8
@@ -143,16 +144,19 @@
cython_speedups = Extension(
'chaco._cython_speedups',
- sources=['chaco/_cython_speedups.c'],
+ sources=['chaco/_cython_speedups.pyx'],
include_dirs=[numpy_include_dir],
)
downsampling_lttb = Extension(
'chaco.downsample._lttb',
- sources=['chaco/downsample/_lttb.c'],
+ sources=['chaco/downsample/_lttb.pyx'],
include_dirs=[numpy_include_dir],
)
+ cython_extensions = cythonize([cython_speedups, downsampling_lttb])
+ extensions = [contour] + cython_extensions
+
setup(
name = 'chaco',
version = __version__,
@@ -185,7 +189,7 @@
},
description = 'interactive 2-dimensional plotting',
long_description = open('README.rst').read(),
- ext_modules = [contour, cython_speedups, downsampling_lttb],
+ ext_modules = extensions,
include_package_data = True,
install_requires = __requires__,
license = 'BSD',
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -6,6 +6,7 @@\n \n from numpy import get_include\n from setuptools import setup, Extension, find_packages\n+from Cython.Build import cythonize\n \n MAJOR = 4\n MINOR = 8\n@@ -143,16 +144,19 @@\n \n cython_speedups = Extension(\n 'chaco._cython_speedups',\n- sources=['chaco/_cython_speedups.c'],\n+ sources=['chaco/_cython_speedups.pyx'],\n include_dirs=[numpy_include_dir],\n )\n \n downsampling_lttb = Extension(\n 'chaco.downsample._lttb',\n- sources=['chaco/downsample/_lttb.c'],\n+ sources=['chaco/downsample/_lttb.pyx'],\n include_dirs=[numpy_include_dir],\n )\n \n+ cython_extensions = cythonize([cython_speedups, downsampling_lttb])\n+ extensions = [contour] + cython_extensions\n+\n setup(\n name = 'chaco',\n version = __version__,\n@@ -185,7 +189,7 @@\n },\n description = 'interactive 2-dimensional plotting',\n long_description = open('README.rst').read(),\n- ext_modules = [contour, cython_speedups, downsampling_lttb],\n+ ext_modules = extensions,\n include_package_data = True,\n install_requires = __requires__,\n license = 'BSD',\n", "issue": "Don't put Cythonized .c files in source control, but do ship in sdist\nCurrently we check-in .c files produced by Cython to the source tree alongside the .pyx files so that people building the source don't need to have Cython installed. This is awkward from the developer's perspective, however, and can result in noisy deltas.\r\n\r\nFollowing discussion in #325 the the proposal is that we will only check in the .pyx files into source control, but we will ship the .c files as part of the sdist source distributions. This change will mean that people wishing to work from non-released versions will need to have Cython installed (as will the CI environment), but people wanting to build a release from source won't need it. Having Cython available is not as unreasonable a requirement as it was several years ago.\n", "before_files": [{"content": "# Copyright (c) 2008-2019 by Enthought, Inc.\n# All rights reserved.\nimport os\nimport re\nimport subprocess\n\nfrom numpy import get_include\nfrom setuptools import setup, Extension, find_packages\n\nMAJOR = 4\nMINOR = 8\nMICRO = 1\n\nIS_RELEASED = False\n\nVERSION = '%d.%d.%d' % (MAJOR, MINOR, MICRO)\n\n# Name of the directory containing the package.\nPKG_PATHNAME = 'chaco'\n\n# Name of the file containing the version information.\n_VERSION_FILENAME = os.path.join(PKG_PATHNAME, '_version.py')\n\n\ndef read_version_py(path):\n \"\"\" Read a _version.py file in a safe way. \"\"\"\n with open(path, 'r') as fp:\n code = compile(fp.read(), 'chaco._version', 'exec')\n context = {}\n exec(code, context)\n return context['git_revision'], context['full_version']\n\n\ndef git_version():\n \"\"\" Parse version information from the current git commit.\n\n Parse the output of `git describe` and return the git hash and the number\n of commits since the last version tag.\n \"\"\"\n\n def _minimal_ext_cmd(cmd):\n # construct minimal environment\n env = {}\n for k in ['SYSTEMROOT', 'PATH', 'HOME']:\n v = os.environ.get(k)\n if v is not None:\n env[k] = v\n # LANGUAGE is used on win32\n env['LANGUAGE'] = 'C'\n env['LANG'] = 'C'\n env['LC_ALL'] = 'C'\n out = subprocess.Popen(\n cmd, stdout=subprocess.PIPE, env=env,\n ).communicate()[0]\n return out\n\n try:\n # We ask git to find the latest tag matching a glob expression. The\n # intention is to find a release tag of the form '4.50.2'. Strictly\n # speaking, the glob expression also matches tags of the form\n # '4abc.5xyz.2gtluuu', but it's very difficult with glob expressions\n # to distinguish between the two cases, and the likelihood of a\n # problem is minimal.\n out = _minimal_ext_cmd(\n ['git', 'describe', '--match', '[0-9]*.[0-9]*.[0-9]*', '--tags'])\n except OSError:\n out = ''\n\n git_description = out.strip().decode('ascii')\n expr = r'.*?\\-(?P<count>\\d+)-g(?P<hash>[a-fA-F0-9]+)'\n match = re.match(expr, git_description)\n if match is None:\n git_revision, git_count = 'Unknown', '0'\n else:\n git_revision, git_count = match.group('hash'), match.group('count')\n\n return git_revision, git_count\n\n\ndef write_version_py(filename=_VERSION_FILENAME):\n \"\"\" Create a file containing the version information. \"\"\"\n\n template = \"\"\"\\\n# This file was automatically generated from the `setup.py` script.\nversion = '{version}'\nfull_version = '{full_version}'\ngit_revision = '{git_revision}'\nis_released = {is_released}\n\nif not is_released:\n version = full_version\n\"\"\"\n # Adding the git rev number needs to be done inside\n # write_version_py(), otherwise the import of _version messes\n # up the build under Python 3.\n fullversion = VERSION\n chaco_version_path = os.path.join(\n os.path.dirname(__file__), 'chaco', '_version.py')\n if os.path.exists('.git'):\n git_rev, dev_num = git_version()\n elif os.path.exists(filename):\n # must be a source distribution, use existing version file\n try:\n git_rev, fullversion = read_version_py(chaco_version_path)\n except (SyntaxError, KeyError):\n raise RuntimeError(\"Unable to read git_revision. Try removing \"\n \"chaco/_version.py and the build directory \"\n \"before building.\")\n\n\n match = re.match(r'.*?\\.dev(?P<dev_num>\\d+)', fullversion)\n if match is None:\n dev_num = '0'\n else:\n dev_num = match.group('dev_num')\n else:\n git_rev = 'Unknown'\n dev_num = '0'\n\n if not IS_RELEASED:\n fullversion += '.dev{0}'.format(dev_num)\n\n with open(filename, \"wt\") as fp:\n fp.write(template.format(version=VERSION,\n full_version=fullversion,\n git_revision=git_rev,\n is_released=IS_RELEASED))\n\n\nif __name__ == \"__main__\":\n write_version_py()\n from chaco import __requires__, __version__\n\n numpy_include_dir = get_include()\n\n # Register Python extensions\n contour = Extension(\n 'chaco.contour.contour',\n sources=['chaco/contour/cntr.c'],\n include_dirs=[numpy_include_dir],\n define_macros=[('NUMPY', None)],\n )\n\n cython_speedups = Extension(\n 'chaco._cython_speedups',\n sources=['chaco/_cython_speedups.c'],\n include_dirs=[numpy_include_dir],\n )\n\n downsampling_lttb = Extension(\n 'chaco.downsample._lttb',\n sources=['chaco/downsample/_lttb.c'],\n include_dirs=[numpy_include_dir],\n )\n\n setup(\n name = 'chaco',\n version = __version__,\n author = 'Peter Wang, et. al.',\n author_email = '[email protected]',\n maintainer = 'ETS Developers',\n maintainer_email = '[email protected]',\n url = 'http://docs.enthought.com/chaco',\n download_url = 'https://github.com/enthought/chaco',\n classifiers = [c.strip() for c in \"\"\"\\\n Development Status :: 5 - Production/Stable\n Intended Audience :: Developers\n Intended Audience :: Science/Research\n License :: OSI Approved :: BSD License\n Operating System :: MacOS\n Operating System :: Microsoft :: Windows\n Operating System :: OS Independent\n Operating System :: POSIX\n Operating System :: Unix\n Programming Language :: C\n Programming Language :: Python\n Topic :: Scientific/Engineering\n Topic :: Software Development\n Topic :: Software Development :: Libraries\n \"\"\".splitlines() if len(c.strip()) > 0],\n package_data={\n 'chaco': ['tools/toolbars/images/*.png',\n 'layers/data/*.svg',\n 'tests/data/PngSuite/*.png']\n },\n description = 'interactive 2-dimensional plotting',\n long_description = open('README.rst').read(),\n ext_modules = [contour, cython_speedups, downsampling_lttb],\n include_package_data = True,\n install_requires = __requires__,\n license = 'BSD',\n packages = find_packages(),\n platforms = [\"Windows\", \"Linux\", \"Mac OS-X\", \"Unix\", \"Solaris\"],\n zip_safe = False,\n use_2to3=False,\n )\n", "path": "setup.py"}]}
| 2,729 | 335 |
gh_patches_debug_22852
|
rasdani/github-patches
|
git_diff
|
python__mypy-3330
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
mypy_extensions is listed as owned by David Foster
See https://github.com/python/mypy/blob/master/extensions/setup.py#L37
David Foster did indeed create the first version but I presume he doesn't want to be bothered about the subsequent additions?
We should probably change this to "The mypy developers" -- but where to point the email? Maybe it can be omitted. The url might also better point to GitHub.
Attn: @davidfstr
</issue>
<code>
[start of extensions/setup.py]
1 #!/usr/bin/env python
2
3 # NOTE: This package must support Python 2.7 in addition to Python 3.x
4
5 from distutils.core import setup
6
7 version = '0.2.0-dev'
8 description = 'Experimental type system extensions for programs checked with the mypy typechecker.'
9 long_description = '''
10 Mypy Extensions
11 ===============
12
13 The "mypy_extensions" module defines experimental extensions to the
14 standard "typing" module that are supported by the mypy typechecker.
15 '''.lstrip()
16
17 classifiers = [
18 'Development Status :: 2 - Pre-Alpha',
19 'Environment :: Console',
20 'Intended Audience :: Developers',
21 'License :: OSI Approved :: MIT License',
22 'Operating System :: POSIX',
23 'Programming Language :: Python :: 2',
24 'Programming Language :: Python :: 2.7',
25 'Programming Language :: Python :: 3',
26 'Programming Language :: Python :: 3.3',
27 'Programming Language :: Python :: 3.4',
28 'Programming Language :: Python :: 3.5',
29 'Topic :: Software Development',
30 ]
31
32 setup(
33 name='mypy_extensions',
34 version=version,
35 description=description,
36 long_description=long_description,
37 author='David Foster',
38 author_email='[email protected]',
39 url='http://www.mypy-lang.org/',
40 license='MIT License',
41 platforms=['POSIX'],
42 py_modules=['mypy_extensions'],
43 classifiers=classifiers,
44 )
45
[end of extensions/setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/extensions/setup.py b/extensions/setup.py
--- a/extensions/setup.py
+++ b/extensions/setup.py
@@ -4,7 +4,7 @@
from distutils.core import setup
-version = '0.2.0-dev'
+version = '0.2.0'
description = 'Experimental type system extensions for programs checked with the mypy typechecker.'
long_description = '''
Mypy Extensions
@@ -26,6 +26,7 @@
'Programming Language :: Python :: 3.3',
'Programming Language :: Python :: 3.4',
'Programming Language :: Python :: 3.5',
+ 'Programming Language :: Python :: 3.6',
'Topic :: Software Development',
]
@@ -34,8 +35,8 @@
version=version,
description=description,
long_description=long_description,
- author='David Foster',
- author_email='[email protected]',
+ author='The mypy developers',
+ author_email='[email protected]',
url='http://www.mypy-lang.org/',
license='MIT License',
platforms=['POSIX'],
|
{"golden_diff": "diff --git a/extensions/setup.py b/extensions/setup.py\n--- a/extensions/setup.py\n+++ b/extensions/setup.py\n@@ -4,7 +4,7 @@\n \n from distutils.core import setup\n \n-version = '0.2.0-dev'\n+version = '0.2.0'\n description = 'Experimental type system extensions for programs checked with the mypy typechecker.'\n long_description = '''\n Mypy Extensions\n@@ -26,6 +26,7 @@\n 'Programming Language :: Python :: 3.3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n+ 'Programming Language :: Python :: 3.6',\n 'Topic :: Software Development',\n ]\n \n@@ -34,8 +35,8 @@\n version=version,\n description=description,\n long_description=long_description,\n- author='David Foster',\n- author_email='[email protected]',\n+ author='The mypy developers',\n+ author_email='[email protected]',\n url='http://www.mypy-lang.org/',\n license='MIT License',\n platforms=['POSIX'],\n", "issue": "mypy_extensions is listed as owned by David Foster\nSee https://github.com/python/mypy/blob/master/extensions/setup.py#L37\r\n\r\nDavid Foster did indeed create the first version but I presume he doesn't want to be bothered about the subsequent additions?\r\n\r\nWe should probably change this to \"The mypy developers\" -- but where to point the email? Maybe it can be omitted. The url might also better point to GitHub.\r\n\r\nAttn: @davidfstr \n", "before_files": [{"content": "#!/usr/bin/env python\n\n# NOTE: This package must support Python 2.7 in addition to Python 3.x\n\nfrom distutils.core import setup\n\nversion = '0.2.0-dev'\ndescription = 'Experimental type system extensions for programs checked with the mypy typechecker.'\nlong_description = '''\nMypy Extensions\n===============\n\nThe \"mypy_extensions\" module defines experimental extensions to the\nstandard \"typing\" module that are supported by the mypy typechecker.\n'''.lstrip()\n\nclassifiers = [\n 'Development Status :: 2 - Pre-Alpha',\n 'Environment :: Console',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: MIT License',\n 'Operating System :: POSIX',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Topic :: Software Development',\n]\n\nsetup(\n name='mypy_extensions',\n version=version,\n description=description,\n long_description=long_description,\n author='David Foster',\n author_email='[email protected]',\n url='http://www.mypy-lang.org/',\n license='MIT License',\n platforms=['POSIX'],\n py_modules=['mypy_extensions'],\n classifiers=classifiers,\n)\n", "path": "extensions/setup.py"}]}
| 1,022 | 253 |
gh_patches_debug_4534
|
rasdani/github-patches
|
git_diff
|
bridgecrewio__checkov-4237
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
False positive for check CKV_AZURE_5: "Ensure RBAC is enabled on AKS clusters"
**Describe the issue**
The check CKV_AZURE_5 for terraform resource `azurerm_kubernetes_cluster` ensures that RBAC is enabled in the kubernetes cluster.
Depending on how the `role_based_access_control_enabled` property is set, the check result is exact or not :
- `role_based_access_control_enabled = true`: the check passes. It's ok.
- `role_based_access_control_enabled = false`: the check fails. It's ok.
- `role_based_access_control_enabled` not defined : check fails. It's NOT ok as default value of this property is `true` (see https://registry.terraform.io/providers/hashicorp/azurerm/latest/docs/resources/kubernetes_cluster#role_based_access_control_enabled)
**Examples**
This example will fails but it shouldn't:
```
resource "azurerm_resource_group" "foo" {
name = "foo"
location = "West Europe"
}
resource "azurerm_kubernetes_cluster" "foo" {
name = "foo"
resource_group_name = azurerm_resource_group.foo.name
location = azurerm_resource_group.foo.location
dns_prefix = "foo"
default_node_pool {
name = "default"
node_count = 1
vm_size = "Standard_D2_v2"
}
identity {
type = "SystemAssigned"
}
# role_based_access_control_enabled = true
}
```
**Version (please complete the following information):**
- Checkov Version : `2.2.252` (latest docker image)
**Additional context**
The problem is in this source file : https://github.com/bridgecrewio/checkov/blob/48abe40926c97bd2e6f8c80491369be462ce3edd/checkov/terraform/checks/resource/azure/AKSRbacEnabled.py#L19-L29
It returns `false` if the property is not found in the resource. It shouldn't be the case as the default value of the property is `true`
</issue>
<code>
[start of checkov/terraform/checks/resource/azure/AKSRbacEnabled.py]
1 import dpath.util
2 from checkov.common.models.enums import CheckCategories, CheckResult
3 from checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck
4
5
6 class AKSRbacEnabled(BaseResourceCheck):
7 def __init__(self):
8 name = "Ensure RBAC is enabled on AKS clusters"
9 id = "CKV_AZURE_5"
10 supported_resources = ["azurerm_kubernetes_cluster"]
11 categories = [CheckCategories.KUBERNETES]
12 super().__init__(
13 name=name,
14 id=id,
15 categories=categories,
16 supported_resources=supported_resources,
17 )
18
19 def scan_resource_conf(self, conf):
20 self.evaluated_keys = [
21 "role_based_access_control/[0]/enabled", # azurerm < 2.99.0
22 "role_based_access_control_enabled", # azurerm >= 2.99.0
23 ]
24
25 for key in self.evaluated_keys:
26 if dpath.search(conf, key) and dpath.get(conf, key)[0]:
27 return CheckResult.PASSED
28
29 return CheckResult.FAILED
30
31
32 check = AKSRbacEnabled()
33
[end of checkov/terraform/checks/resource/azure/AKSRbacEnabled.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/checkov/terraform/checks/resource/azure/AKSRbacEnabled.py b/checkov/terraform/checks/resource/azure/AKSRbacEnabled.py
--- a/checkov/terraform/checks/resource/azure/AKSRbacEnabled.py
+++ b/checkov/terraform/checks/resource/azure/AKSRbacEnabled.py
@@ -23,10 +23,10 @@
]
for key in self.evaluated_keys:
- if dpath.search(conf, key) and dpath.get(conf, key)[0]:
- return CheckResult.PASSED
+ if dpath.search(conf, key):
+ return CheckResult.PASSED if dpath.get(conf, key)[0] else CheckResult.FAILED
- return CheckResult.FAILED
+ return CheckResult.PASSED
check = AKSRbacEnabled()
|
{"golden_diff": "diff --git a/checkov/terraform/checks/resource/azure/AKSRbacEnabled.py b/checkov/terraform/checks/resource/azure/AKSRbacEnabled.py\n--- a/checkov/terraform/checks/resource/azure/AKSRbacEnabled.py\n+++ b/checkov/terraform/checks/resource/azure/AKSRbacEnabled.py\n@@ -23,10 +23,10 @@\n ]\n \n for key in self.evaluated_keys:\n- if dpath.search(conf, key) and dpath.get(conf, key)[0]:\n- return CheckResult.PASSED\n+ if dpath.search(conf, key):\n+ return CheckResult.PASSED if dpath.get(conf, key)[0] else CheckResult.FAILED\n \n- return CheckResult.FAILED\n+ return CheckResult.PASSED\n \n \n check = AKSRbacEnabled()\n", "issue": "False positive for check CKV_AZURE_5: \"Ensure RBAC is enabled on AKS clusters\"\n**Describe the issue**\r\nThe check CKV_AZURE_5 for terraform resource `azurerm_kubernetes_cluster` ensures that RBAC is enabled in the kubernetes cluster.\r\nDepending on how the `role_based_access_control_enabled` property is set, the check result is exact or not :\r\n- `role_based_access_control_enabled = true`: the check passes. It's ok.\r\n- `role_based_access_control_enabled = false`: the check fails. It's ok.\r\n- `role_based_access_control_enabled` not defined : check fails. It's NOT ok as default value of this property is `true` (see https://registry.terraform.io/providers/hashicorp/azurerm/latest/docs/resources/kubernetes_cluster#role_based_access_control_enabled)\r\n\r\n**Examples**\r\nThis example will fails but it shouldn't:\r\n```\r\nresource \"azurerm_resource_group\" \"foo\" {\r\n name = \"foo\"\r\n location = \"West Europe\"\r\n}\r\n\r\nresource \"azurerm_kubernetes_cluster\" \"foo\" {\r\n name = \"foo\"\r\n resource_group_name = azurerm_resource_group.foo.name\r\n location = azurerm_resource_group.foo.location\r\n dns_prefix = \"foo\"\r\n\r\n default_node_pool {\r\n name = \"default\"\r\n node_count = 1\r\n vm_size = \"Standard_D2_v2\"\r\n }\r\n\r\n identity {\r\n type = \"SystemAssigned\"\r\n }\r\n\r\n # role_based_access_control_enabled = true\r\n}\r\n```\r\n\r\n**Version (please complete the following information):**\r\n - Checkov Version : `2.2.252` (latest docker image)\r\n\r\n**Additional context**\r\nThe problem is in this source file : https://github.com/bridgecrewio/checkov/blob/48abe40926c97bd2e6f8c80491369be462ce3edd/checkov/terraform/checks/resource/azure/AKSRbacEnabled.py#L19-L29\r\n\r\nIt returns `false` if the property is not found in the resource. It shouldn't be the case as the default value of the property is `true`\r\n\n", "before_files": [{"content": "import dpath.util\nfrom checkov.common.models.enums import CheckCategories, CheckResult\nfrom checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck\n\n\nclass AKSRbacEnabled(BaseResourceCheck):\n def __init__(self):\n name = \"Ensure RBAC is enabled on AKS clusters\"\n id = \"CKV_AZURE_5\"\n supported_resources = [\"azurerm_kubernetes_cluster\"]\n categories = [CheckCategories.KUBERNETES]\n super().__init__(\n name=name,\n id=id,\n categories=categories,\n supported_resources=supported_resources,\n )\n\n def scan_resource_conf(self, conf):\n self.evaluated_keys = [\n \"role_based_access_control/[0]/enabled\", # azurerm < 2.99.0\n \"role_based_access_control_enabled\", # azurerm >= 2.99.0\n ]\n\n for key in self.evaluated_keys:\n if dpath.search(conf, key) and dpath.get(conf, key)[0]:\n return CheckResult.PASSED\n\n return CheckResult.FAILED\n\n\ncheck = AKSRbacEnabled()\n", "path": "checkov/terraform/checks/resource/azure/AKSRbacEnabled.py"}]}
| 1,333 | 188 |
gh_patches_debug_24671
|
rasdani/github-patches
|
git_diff
|
docker__docker-py-45
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Failure to import requests.packages.urllib3.connectionpool
With requests 1.2.3 (the version which gets installed), this happens.
Workaround: use requests 1.2.0.
``` ipython
$ pip install --user docker-py
Downloading/unpacking docker-py
Downloading docker-py-0.1.5.tar.gz
Running setup.py egg_info for package docker-py
Requirement already satisfied (use --upgrade to upgrade): requests in /usr/lib/python2.7/dist-packages (from docker-py)
Requirement already satisfied (use --upgrade to upgrade): six in /usr/lib/python2.7/dist-packages (from docker-py)
Installing collected packages: docker-py
Running setup.py install for docker-py
Successfully installed docker-py
Cleaning up...
pwaller@fractal:~$ ipython
imporPython 2.7.5+ (default, Jun 5 2013, 10:40:07)
Type "copyright", "credits" or "license" for more information.
IPython 1.1.0 -- An enhanced Interactive Python.
? -> Introduction and overview of IPython's features.
%quickref -> Quick reference.
help -> Python's own help system.
object? -> Details about 'object', use 'object??' for extra details.
In [1]: import docker
---------------------------------------------------------------------------
ImportError Traceback (most recent call last)
<ipython-input-1-3ac1c348f58a> in <module>()
----> 1 import docker
/home/pwaller/.local/lib/python2.7/site-packages/docker/__init__.py in <module>()
----> 1 from .client import Client
/home/pwaller/.local/lib/python2.7/site-packages/docker/client.py in <module>()
15 from requests.exceptions import HTTPError
16 from requests.adapters import HTTPAdapter
---> 17 from requests.packages.urllib3.connectionpool import HTTPConnectionPool
18
19 if six.PY3:
ImportError: No module named packages.urllib3.connectionpool
In [2]:
```
</issue>
<code>
[start of docker/unixconn.py]
1 # Copyright 2013 dotCloud inc.
2
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6
7 # http://www.apache.org/licenses/LICENSE-2.0
8
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import httplib
16 import requests.adapters
17 import requests.packages.urllib3.connectionpool
18 import socket
19
20 HTTPConnectionPool = requests.packages.urllib3.connectionpool.HTTPConnectionPool
21
22
23 class UnixHTTPConnection(httplib.HTTPConnection, object):
24 def __init__(self, base_url, unix_socket):
25 httplib.HTTPConnection.__init__(self, 'localhost')
26 self.base_url = base_url
27 self.unix_socket = unix_socket
28
29 def connect(self):
30 sock = socket.socket(socket.AF_UNIX, socket.SOCK_STREAM)
31 sock.connect(self.base_url.replace("unix:/",""))
32 self.sock = sock
33
34 def _extract_path(self, url):
35 #remove the base_url entirely..
36 return url.replace(self.base_url, "")
37
38 def request(self, method, url, **kwargs):
39 url = self._extract_path(self.unix_socket)
40 super(UnixHTTPConnection, self).request(method, url, **kwargs)
41
42
43 class UnixHTTPConnectionPool(HTTPConnectionPool):
44 def __init__(self, base_url, socket_path):
45 self.socket_path = socket_path
46 self.base_url = base_url
47 super(UnixHTTPConnectionPool, self).__init__(self, 'localhost')
48
49 def _new_conn(self):
50 return UnixHTTPConnection(self.base_url, self.socket_path)
51
52
53 class UnixAdapter(requests.adapters.HTTPAdapter):
54 def __init__(self, base_url):
55 self.base_url = base_url
56 super(UnixAdapter, self).__init__()
57
58 def get_connection(self, socket_path, proxies=None):
59 return UnixHTTPConnectionPool(self.base_url, socket_path)
60
[end of docker/unixconn.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/docker/unixconn.py b/docker/unixconn.py
--- a/docker/unixconn.py
+++ b/docker/unixconn.py
@@ -14,10 +14,12 @@
import httplib
import requests.adapters
-import requests.packages.urllib3.connectionpool
import socket
-HTTPConnectionPool = requests.packages.urllib3.connectionpool.HTTPConnectionPool
+try:
+ import requests.packages.urllib3.connectionpool as connectionpool
+except ImportError:
+ import urllib3.connectionpool as connectionpool
class UnixHTTPConnection(httplib.HTTPConnection, object):
@@ -28,7 +30,7 @@
def connect(self):
sock = socket.socket(socket.AF_UNIX, socket.SOCK_STREAM)
- sock.connect(self.base_url.replace("unix:/",""))
+ sock.connect(self.base_url.replace("unix:/", ""))
self.sock = sock
def _extract_path(self, url):
@@ -40,7 +42,7 @@
super(UnixHTTPConnection, self).request(method, url, **kwargs)
-class UnixHTTPConnectionPool(HTTPConnectionPool):
+class UnixHTTPConnectionPool(connectionpool.HTTPConnectionPool):
def __init__(self, base_url, socket_path):
self.socket_path = socket_path
self.base_url = base_url
|
{"golden_diff": "diff --git a/docker/unixconn.py b/docker/unixconn.py\n--- a/docker/unixconn.py\n+++ b/docker/unixconn.py\n@@ -14,10 +14,12 @@\n \n import httplib\n import requests.adapters\n-import requests.packages.urllib3.connectionpool\n import socket\n \n-HTTPConnectionPool = requests.packages.urllib3.connectionpool.HTTPConnectionPool\n+try:\n+ import requests.packages.urllib3.connectionpool as connectionpool\n+except ImportError:\n+ import urllib3.connectionpool as connectionpool\n \n \n class UnixHTTPConnection(httplib.HTTPConnection, object):\n@@ -28,7 +30,7 @@\n \n def connect(self):\n sock = socket.socket(socket.AF_UNIX, socket.SOCK_STREAM)\n- sock.connect(self.base_url.replace(\"unix:/\",\"\"))\n+ sock.connect(self.base_url.replace(\"unix:/\", \"\"))\n self.sock = sock\n \n def _extract_path(self, url):\n@@ -40,7 +42,7 @@\n super(UnixHTTPConnection, self).request(method, url, **kwargs)\n \n \n-class UnixHTTPConnectionPool(HTTPConnectionPool):\n+class UnixHTTPConnectionPool(connectionpool.HTTPConnectionPool):\n def __init__(self, base_url, socket_path):\n self.socket_path = socket_path\n self.base_url = base_url\n", "issue": "Failure to import requests.packages.urllib3.connectionpool\nWith requests 1.2.3 (the version which gets installed), this happens.\n\nWorkaround: use requests 1.2.0.\n\n``` ipython\n$ pip install --user docker-py\nDownloading/unpacking docker-py\n Downloading docker-py-0.1.5.tar.gz\n Running setup.py egg_info for package docker-py\n\nRequirement already satisfied (use --upgrade to upgrade): requests in /usr/lib/python2.7/dist-packages (from docker-py)\nRequirement already satisfied (use --upgrade to upgrade): six in /usr/lib/python2.7/dist-packages (from docker-py)\nInstalling collected packages: docker-py\n Running setup.py install for docker-py\n\nSuccessfully installed docker-py\nCleaning up...\npwaller@fractal:~$ ipython\nimporPython 2.7.5+ (default, Jun 5 2013, 10:40:07) \nType \"copyright\", \"credits\" or \"license\" for more information.\n\nIPython 1.1.0 -- An enhanced Interactive Python.\n? -> Introduction and overview of IPython's features.\n%quickref -> Quick reference.\nhelp -> Python's own help system.\nobject? -> Details about 'object', use 'object??' for extra details.\n\nIn [1]: import docker\n---------------------------------------------------------------------------\nImportError Traceback (most recent call last)\n<ipython-input-1-3ac1c348f58a> in <module>()\n----> 1 import docker\n\n/home/pwaller/.local/lib/python2.7/site-packages/docker/__init__.py in <module>()\n----> 1 from .client import Client\n\n/home/pwaller/.local/lib/python2.7/site-packages/docker/client.py in <module>()\n 15 from requests.exceptions import HTTPError\n 16 from requests.adapters import HTTPAdapter\n---> 17 from requests.packages.urllib3.connectionpool import HTTPConnectionPool\n 18 \n 19 if six.PY3:\n\nImportError: No module named packages.urllib3.connectionpool\n\nIn [2]: \n```\n\n", "before_files": [{"content": "# Copyright 2013 dotCloud inc.\n\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n\n# http://www.apache.org/licenses/LICENSE-2.0\n\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport httplib\nimport requests.adapters\nimport requests.packages.urllib3.connectionpool\nimport socket\n\nHTTPConnectionPool = requests.packages.urllib3.connectionpool.HTTPConnectionPool\n\n\nclass UnixHTTPConnection(httplib.HTTPConnection, object):\n def __init__(self, base_url, unix_socket):\n httplib.HTTPConnection.__init__(self, 'localhost')\n self.base_url = base_url\n self.unix_socket = unix_socket\n\n def connect(self):\n sock = socket.socket(socket.AF_UNIX, socket.SOCK_STREAM)\n sock.connect(self.base_url.replace(\"unix:/\",\"\"))\n self.sock = sock\n\n def _extract_path(self, url):\n #remove the base_url entirely..\n return url.replace(self.base_url, \"\")\n\n def request(self, method, url, **kwargs):\n url = self._extract_path(self.unix_socket)\n super(UnixHTTPConnection, self).request(method, url, **kwargs)\n\n\nclass UnixHTTPConnectionPool(HTTPConnectionPool):\n def __init__(self, base_url, socket_path):\n self.socket_path = socket_path\n self.base_url = base_url\n super(UnixHTTPConnectionPool, self).__init__(self, 'localhost')\n\n def _new_conn(self):\n return UnixHTTPConnection(self.base_url, self.socket_path)\n\n\nclass UnixAdapter(requests.adapters.HTTPAdapter):\n def __init__(self, base_url):\n self.base_url = base_url\n super(UnixAdapter, self).__init__()\n\n def get_connection(self, socket_path, proxies=None):\n return UnixHTTPConnectionPool(self.base_url, socket_path)\n", "path": "docker/unixconn.py"}]}
| 1,597 | 282 |
gh_patches_debug_7867
|
rasdani/github-patches
|
git_diff
|
arviz-devs__arviz-1096
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`plot_density` does not work for models with different variables
**Describe the bug**
When passing data of several models to `plot_density`, it throws an error if both models contain parameters that the other model does not have.
As long the the variables in the one model are a subset of the the variables of the other model it works.
I think that the problem lies in how `plot_density` determines the number of plots to create. It calculates the number of parameters in each model and then uses the maximum:
```
192 length_plotters = []
193 for plotters in to_plot:
194 length_plotters.append(len(plotters))
195 for var_name, selection, _ in plotters:
196 label = make_label(var_name, selection)
197 if label not in all_labels:
198 all_labels.append(label)
199 length_plotters = max(length_plotters)
```
That does not account for the situation where the union of parameters over all models is larger than the set parameters in each single model.
**To Reproduce**
This simple example should demonstrate what I mean:
```python
import numpy as np
import xarray as xr
import arviz
n_draws = 1000
model_ab = xr.Dataset({
"a": ("draw", np.random.normal(size=n_draws)),
"b": ("draw", np.random.normal(size=n_draws)),
})
model_b = xr.Dataset({
"b": ("draw", np.random.normal(size=n_draws)),
})
model_bc = xr.Dataset({
"c": ("draw", np.random.normal(size=n_draws)),
"b": ("draw", np.random.normal(size=n_draws)),
})
# Works
arviz.plot_density([model_ab, model_b], data_labels=["ab", "b"]);
# Does not work
arviz.plot_density([model_ab, model_bc], data_labels=["ab", "bc"]);
```
**Expected behavior**
In the second case, the code should create 3 subplots, for parameters a, b, and c. While the plots for a and c would contain only one density, the plot for b would contain two densities.
**Additional context**
arviz Version: 0.6.1
</issue>
<code>
[start of arviz/plots/densityplot.py]
1 """KDE and histogram plots for multiple variables."""
2 from itertools import cycle
3 import warnings
4
5 import matplotlib.pyplot as plt
6
7 from ..data import convert_to_dataset
8 from .plot_utils import (
9 _scale_fig_size,
10 make_label,
11 xarray_var_iter,
12 default_grid,
13 get_plotting_function,
14 )
15 from ..rcparams import rcParams
16 from ..utils import _var_names
17
18
19 # pylint:disable-msg=too-many-function-args
20 def plot_density(
21 data,
22 group="posterior",
23 data_labels=None,
24 var_names=None,
25 transform=None,
26 credible_interval=None,
27 point_estimate="auto",
28 colors="cycle",
29 outline=True,
30 hpd_markers="",
31 shade=0.0,
32 bw=4.5,
33 figsize=None,
34 textsize=None,
35 ax=None,
36 backend=None,
37 backend_kwargs=None,
38 show=None,
39 ):
40 """Generate KDE plots for continuous variables and histograms for discrete ones.
41
42 Plots are truncated at their 100*(1-alpha)% credible intervals. Plots are grouped per variable
43 and colors assigned to models.
44
45 Parameters
46 ----------
47 data : Union[Object, Iterator[Object]]
48 Any object that can be converted to an az.InferenceData object, or an Iterator returning
49 a sequence of such objects.
50 Refer to documentation of az.convert_to_dataset for details about such objects.
51 group: Optional[str]
52 Specifies which InferenceData group should be plotted. Defaults to 'posterior'.
53 Alternative values include 'prior' and any other strings used as dataset keys in the
54 InferenceData.
55 data_labels : Optional[List[str]]
56 List with names for the datasets passed as "data." Useful when plotting more than one
57 dataset. Must be the same shape as the data parameter. Defaults to None.
58 var_names: Optional[List[str]]
59 List of variables to plot. If multiple datasets are supplied and var_names is not None,
60 will print the same set of variables for each dataset. Defaults to None, which results in
61 all the variables being plotted.
62 transform : callable
63 Function to transform data (defaults to None i.e. the identity function)
64 credible_interval : float
65 Credible intervals. Should be in the interval (0, 1]. Defaults to 0.94.
66 point_estimate : Optional[str]
67 Plot point estimate per variable. Values should be 'mean', 'median', 'mode' or None.
68 Defaults to 'auto' i.e. it falls back to default set in rcParams.
69 colors : Optional[Union[List[str],str]]
70 List with valid matplotlib colors, one color per model. Alternative a string can be passed.
71 If the string is `cycle`, it will automatically choose a color per model from matplotlib's
72 cycle. If a single color is passed, e.g. 'k', 'C2' or 'red' this color will be used for all
73 models. Defaults to `cycle`.
74 outline : bool
75 Use a line to draw KDEs and histograms. Default to True
76 hpd_markers : str
77 A valid `matplotlib.markers` like 'v', used to indicate the limits of the hpd interval.
78 Defaults to empty string (no marker).
79 shade : Optional[float]
80 Alpha blending value for the shaded area under the curve, between 0 (no shade) and 1
81 (opaque). Defaults to 0.
82 bw : Optional[float]
83 Bandwidth scaling factor for the KDE. Should be larger than 0. The higher this number the
84 smoother the KDE will be. Defaults to 4.5 which is essentially the same as the Scott's rule
85 of thumb (the default rule used by SciPy).
86 figsize : Optional[Tuple[int, int]]
87 Figure size. If None it will be defined automatically.
88 textsize: Optional[float]
89 Text size scaling factor for labels, titles and lines. If None it will be autoscaled based
90 on figsize.
91 ax: axes, optional
92 Matplotlib axes or Bokeh figures.
93 backend: str, optional
94 Select plotting backend {"matplotlib","bokeh"}. Default "matplotlib".
95 backend_kwargs: bool, optional
96 These are kwargs specific to the backend being used. For additional documentation
97 check the plotting method of the backend.
98 show : bool, optional
99 Call backend show function.
100
101 Returns
102 -------
103 axes : matplotlib axes or bokeh figures
104
105
106 Examples
107 --------
108 Plot default density plot
109
110 .. plot::
111 :context: close-figs
112
113 >>> import arviz as az
114 >>> centered = az.load_arviz_data('centered_eight')
115 >>> non_centered = az.load_arviz_data('non_centered_eight')
116 >>> az.plot_density([centered, non_centered])
117
118 Plot subset variables by specifying variable name exactly
119
120 .. plot::
121 :context: close-figs
122
123 >>> az.plot_density([centered, non_centered], var_names=["mu"])
124
125 Plot a specific `az.InferenceData` group
126
127 .. plot::
128 :context: close-figs
129
130 >>> az.plot_density([centered, non_centered], var_names=["mu"], group="prior")
131
132 Specify credible interval
133
134 .. plot::
135 :context: close-figs
136
137 >>> az.plot_density([centered, non_centered], var_names=["mu"], credible_interval=.5)
138
139 Shade plots and/or remove outlines
140
141 .. plot::
142 :context: close-figs
143
144 >>> az.plot_density([centered, non_centered], var_names=["mu"], outline=False, shade=.8)
145
146 Specify binwidth for kernel density estimation
147
148 .. plot::
149 :context: close-figs
150
151 >>> az.plot_density([centered, non_centered], var_names=["mu"], bw=.9)
152 """
153 if transform is not None:
154 data = transform(data)
155 if not isinstance(data, (list, tuple)):
156 datasets = [convert_to_dataset(data, group=group)]
157 else:
158 datasets = [convert_to_dataset(datum, group=group) for datum in data]
159
160 var_names = _var_names(var_names, datasets)
161 n_data = len(datasets)
162
163 if data_labels is None:
164 if n_data > 1:
165 data_labels = ["{}".format(idx) for idx in range(n_data)]
166 else:
167 data_labels = [""]
168 elif len(data_labels) != n_data:
169 raise ValueError(
170 "The number of names for the models ({}) "
171 "does not match the number of models ({})".format(len(data_labels), n_data)
172 )
173
174 if colors == "cycle":
175 colors = [
176 prop
177 for _, prop in zip(
178 range(n_data), cycle(plt.rcParams["axes.prop_cycle"].by_key()["color"])
179 )
180 ]
181 elif isinstance(colors, str):
182 colors = [colors for _ in range(n_data)]
183
184 if credible_interval is None:
185 credible_interval = rcParams["stats.credible_interval"]
186 else:
187 if not 1 >= credible_interval > 0:
188 raise ValueError("The value of credible_interval should be in the interval (0, 1]")
189
190 to_plot = [list(xarray_var_iter(data, var_names, combined=True)) for data in datasets]
191 all_labels = []
192 length_plotters = []
193 for plotters in to_plot:
194 length_plotters.append(len(plotters))
195 for var_name, selection, _ in plotters:
196 label = make_label(var_name, selection)
197 if label not in all_labels:
198 all_labels.append(label)
199 length_plotters = max(length_plotters)
200 max_plots = rcParams["plot.max_subplots"]
201 max_plots = length_plotters if max_plots is None else max_plots
202 if length_plotters > max_plots:
203 warnings.warn(
204 "rcParams['plot.max_subplots'] ({max_plots}) is smaller than the number "
205 "of variables to plot ({len_plotters}) in plot_density, generating only "
206 "{max_plots} plots".format(max_plots=max_plots, len_plotters=length_plotters),
207 UserWarning,
208 )
209 all_labels = all_labels[:max_plots]
210 to_plot = [
211 [
212 (var_name, selection, values)
213 for var_name, selection, values in plotters
214 if make_label(var_name, selection) in all_labels
215 ]
216 for plotters in to_plot
217 ]
218 length_plotters = max_plots
219 rows, cols = default_grid(length_plotters, max_cols=3)
220
221 (figsize, _, titlesize, xt_labelsize, linewidth, markersize) = _scale_fig_size(
222 figsize, textsize, rows, cols
223 )
224
225 plot_density_kwargs = dict(
226 ax=ax,
227 all_labels=all_labels,
228 to_plot=to_plot,
229 colors=colors,
230 bw=bw,
231 figsize=figsize,
232 length_plotters=length_plotters,
233 rows=rows,
234 cols=cols,
235 titlesize=titlesize,
236 xt_labelsize=xt_labelsize,
237 linewidth=linewidth,
238 markersize=markersize,
239 credible_interval=credible_interval,
240 point_estimate=point_estimate,
241 hpd_markers=hpd_markers,
242 outline=outline,
243 shade=shade,
244 n_data=n_data,
245 data_labels=data_labels,
246 backend_kwargs=backend_kwargs,
247 show=show,
248 )
249
250 if backend is None:
251 backend = rcParams["plot.backend"]
252 backend = backend.lower()
253
254 if backend == "bokeh":
255
256 plot_density_kwargs["line_width"] = plot_density_kwargs.pop("linewidth")
257 plot_density_kwargs.pop("titlesize")
258 plot_density_kwargs.pop("xt_labelsize")
259 plot_density_kwargs.pop("n_data")
260
261 # TODO: Add backend kwargs
262 plot = get_plotting_function("plot_density", "densityplot", backend)
263 ax = plot(**plot_density_kwargs)
264 return ax
265
[end of arviz/plots/densityplot.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/arviz/plots/densityplot.py b/arviz/plots/densityplot.py
--- a/arviz/plots/densityplot.py
+++ b/arviz/plots/densityplot.py
@@ -196,7 +196,7 @@
label = make_label(var_name, selection)
if label not in all_labels:
all_labels.append(label)
- length_plotters = max(length_plotters)
+ length_plotters = len(all_labels)
max_plots = rcParams["plot.max_subplots"]
max_plots = length_plotters if max_plots is None else max_plots
if length_plotters > max_plots:
|
{"golden_diff": "diff --git a/arviz/plots/densityplot.py b/arviz/plots/densityplot.py\n--- a/arviz/plots/densityplot.py\n+++ b/arviz/plots/densityplot.py\n@@ -196,7 +196,7 @@\n label = make_label(var_name, selection)\n if label not in all_labels:\n all_labels.append(label)\n- length_plotters = max(length_plotters)\n+ length_plotters = len(all_labels)\n max_plots = rcParams[\"plot.max_subplots\"]\n max_plots = length_plotters if max_plots is None else max_plots\n if length_plotters > max_plots:\n", "issue": "`plot_density` does not work for models with different variables\n**Describe the bug**\r\nWhen passing data of several models to `plot_density`, it throws an error if both models contain parameters that the other model does not have.\r\nAs long the the variables in the one model are a subset of the the variables of the other model it works.\r\nI think that the problem lies in how `plot_density` determines the number of plots to create. It calculates the number of parameters in each model and then uses the maximum:\r\n```\r\n192 length_plotters = []\r\n193 for plotters in to_plot:\r\n194 length_plotters.append(len(plotters))\r\n195 for var_name, selection, _ in plotters:\r\n196 label = make_label(var_name, selection)\r\n197 if label not in all_labels:\r\n198 all_labels.append(label)\r\n199 length_plotters = max(length_plotters)\r\n```\r\nThat does not account for the situation where the union of parameters over all models is larger than the set parameters in each single model.\r\n\r\n**To Reproduce**\r\nThis simple example should demonstrate what I mean:\r\n```python\r\nimport numpy as np\r\nimport xarray as xr\r\nimport arviz\r\n\r\nn_draws = 1000\r\n\r\nmodel_ab = xr.Dataset({\r\n \"a\": (\"draw\", np.random.normal(size=n_draws)),\r\n \"b\": (\"draw\", np.random.normal(size=n_draws)),\r\n})\r\nmodel_b = xr.Dataset({\r\n \"b\": (\"draw\", np.random.normal(size=n_draws)),\r\n})\r\nmodel_bc = xr.Dataset({\r\n \"c\": (\"draw\", np.random.normal(size=n_draws)),\r\n \"b\": (\"draw\", np.random.normal(size=n_draws)),\r\n})\r\n\r\n# Works\r\narviz.plot_density([model_ab, model_b], data_labels=[\"ab\", \"b\"]);\r\n\r\n# Does not work\r\narviz.plot_density([model_ab, model_bc], data_labels=[\"ab\", \"bc\"]);\r\n```\r\n\r\n**Expected behavior**\r\nIn the second case, the code should create 3 subplots, for parameters a, b, and c. While the plots for a and c would contain only one density, the plot for b would contain two densities.\r\n\r\n**Additional context**\r\narviz Version: 0.6.1\r\n\n", "before_files": [{"content": "\"\"\"KDE and histogram plots for multiple variables.\"\"\"\nfrom itertools import cycle\nimport warnings\n\nimport matplotlib.pyplot as plt\n\nfrom ..data import convert_to_dataset\nfrom .plot_utils import (\n _scale_fig_size,\n make_label,\n xarray_var_iter,\n default_grid,\n get_plotting_function,\n)\nfrom ..rcparams import rcParams\nfrom ..utils import _var_names\n\n\n# pylint:disable-msg=too-many-function-args\ndef plot_density(\n data,\n group=\"posterior\",\n data_labels=None,\n var_names=None,\n transform=None,\n credible_interval=None,\n point_estimate=\"auto\",\n colors=\"cycle\",\n outline=True,\n hpd_markers=\"\",\n shade=0.0,\n bw=4.5,\n figsize=None,\n textsize=None,\n ax=None,\n backend=None,\n backend_kwargs=None,\n show=None,\n):\n \"\"\"Generate KDE plots for continuous variables and histograms for discrete ones.\n\n Plots are truncated at their 100*(1-alpha)% credible intervals. Plots are grouped per variable\n and colors assigned to models.\n\n Parameters\n ----------\n data : Union[Object, Iterator[Object]]\n Any object that can be converted to an az.InferenceData object, or an Iterator returning\n a sequence of such objects.\n Refer to documentation of az.convert_to_dataset for details about such objects.\n group: Optional[str]\n Specifies which InferenceData group should be plotted. Defaults to 'posterior'.\n Alternative values include 'prior' and any other strings used as dataset keys in the\n InferenceData.\n data_labels : Optional[List[str]]\n List with names for the datasets passed as \"data.\" Useful when plotting more than one\n dataset. Must be the same shape as the data parameter. Defaults to None.\n var_names: Optional[List[str]]\n List of variables to plot. If multiple datasets are supplied and var_names is not None,\n will print the same set of variables for each dataset. Defaults to None, which results in\n all the variables being plotted.\n transform : callable\n Function to transform data (defaults to None i.e. the identity function)\n credible_interval : float\n Credible intervals. Should be in the interval (0, 1]. Defaults to 0.94.\n point_estimate : Optional[str]\n Plot point estimate per variable. Values should be 'mean', 'median', 'mode' or None.\n Defaults to 'auto' i.e. it falls back to default set in rcParams.\n colors : Optional[Union[List[str],str]]\n List with valid matplotlib colors, one color per model. Alternative a string can be passed.\n If the string is `cycle`, it will automatically choose a color per model from matplotlib's\n cycle. If a single color is passed, e.g. 'k', 'C2' or 'red' this color will be used for all\n models. Defaults to `cycle`.\n outline : bool\n Use a line to draw KDEs and histograms. Default to True\n hpd_markers : str\n A valid `matplotlib.markers` like 'v', used to indicate the limits of the hpd interval.\n Defaults to empty string (no marker).\n shade : Optional[float]\n Alpha blending value for the shaded area under the curve, between 0 (no shade) and 1\n (opaque). Defaults to 0.\n bw : Optional[float]\n Bandwidth scaling factor for the KDE. Should be larger than 0. The higher this number the\n smoother the KDE will be. Defaults to 4.5 which is essentially the same as the Scott's rule\n of thumb (the default rule used by SciPy).\n figsize : Optional[Tuple[int, int]]\n Figure size. If None it will be defined automatically.\n textsize: Optional[float]\n Text size scaling factor for labels, titles and lines. If None it will be autoscaled based\n on figsize.\n ax: axes, optional\n Matplotlib axes or Bokeh figures.\n backend: str, optional\n Select plotting backend {\"matplotlib\",\"bokeh\"}. Default \"matplotlib\".\n backend_kwargs: bool, optional\n These are kwargs specific to the backend being used. For additional documentation\n check the plotting method of the backend.\n show : bool, optional\n Call backend show function.\n\n Returns\n -------\n axes : matplotlib axes or bokeh figures\n\n\n Examples\n --------\n Plot default density plot\n\n .. plot::\n :context: close-figs\n\n >>> import arviz as az\n >>> centered = az.load_arviz_data('centered_eight')\n >>> non_centered = az.load_arviz_data('non_centered_eight')\n >>> az.plot_density([centered, non_centered])\n\n Plot subset variables by specifying variable name exactly\n\n .. plot::\n :context: close-figs\n\n >>> az.plot_density([centered, non_centered], var_names=[\"mu\"])\n\n Plot a specific `az.InferenceData` group\n\n .. plot::\n :context: close-figs\n\n >>> az.plot_density([centered, non_centered], var_names=[\"mu\"], group=\"prior\")\n\n Specify credible interval\n\n .. plot::\n :context: close-figs\n\n >>> az.plot_density([centered, non_centered], var_names=[\"mu\"], credible_interval=.5)\n\n Shade plots and/or remove outlines\n\n .. plot::\n :context: close-figs\n\n >>> az.plot_density([centered, non_centered], var_names=[\"mu\"], outline=False, shade=.8)\n\n Specify binwidth for kernel density estimation\n\n .. plot::\n :context: close-figs\n\n >>> az.plot_density([centered, non_centered], var_names=[\"mu\"], bw=.9)\n \"\"\"\n if transform is not None:\n data = transform(data)\n if not isinstance(data, (list, tuple)):\n datasets = [convert_to_dataset(data, group=group)]\n else:\n datasets = [convert_to_dataset(datum, group=group) for datum in data]\n\n var_names = _var_names(var_names, datasets)\n n_data = len(datasets)\n\n if data_labels is None:\n if n_data > 1:\n data_labels = [\"{}\".format(idx) for idx in range(n_data)]\n else:\n data_labels = [\"\"]\n elif len(data_labels) != n_data:\n raise ValueError(\n \"The number of names for the models ({}) \"\n \"does not match the number of models ({})\".format(len(data_labels), n_data)\n )\n\n if colors == \"cycle\":\n colors = [\n prop\n for _, prop in zip(\n range(n_data), cycle(plt.rcParams[\"axes.prop_cycle\"].by_key()[\"color\"])\n )\n ]\n elif isinstance(colors, str):\n colors = [colors for _ in range(n_data)]\n\n if credible_interval is None:\n credible_interval = rcParams[\"stats.credible_interval\"]\n else:\n if not 1 >= credible_interval > 0:\n raise ValueError(\"The value of credible_interval should be in the interval (0, 1]\")\n\n to_plot = [list(xarray_var_iter(data, var_names, combined=True)) for data in datasets]\n all_labels = []\n length_plotters = []\n for plotters in to_plot:\n length_plotters.append(len(plotters))\n for var_name, selection, _ in plotters:\n label = make_label(var_name, selection)\n if label not in all_labels:\n all_labels.append(label)\n length_plotters = max(length_plotters)\n max_plots = rcParams[\"plot.max_subplots\"]\n max_plots = length_plotters if max_plots is None else max_plots\n if length_plotters > max_plots:\n warnings.warn(\n \"rcParams['plot.max_subplots'] ({max_plots}) is smaller than the number \"\n \"of variables to plot ({len_plotters}) in plot_density, generating only \"\n \"{max_plots} plots\".format(max_plots=max_plots, len_plotters=length_plotters),\n UserWarning,\n )\n all_labels = all_labels[:max_plots]\n to_plot = [\n [\n (var_name, selection, values)\n for var_name, selection, values in plotters\n if make_label(var_name, selection) in all_labels\n ]\n for plotters in to_plot\n ]\n length_plotters = max_plots\n rows, cols = default_grid(length_plotters, max_cols=3)\n\n (figsize, _, titlesize, xt_labelsize, linewidth, markersize) = _scale_fig_size(\n figsize, textsize, rows, cols\n )\n\n plot_density_kwargs = dict(\n ax=ax,\n all_labels=all_labels,\n to_plot=to_plot,\n colors=colors,\n bw=bw,\n figsize=figsize,\n length_plotters=length_plotters,\n rows=rows,\n cols=cols,\n titlesize=titlesize,\n xt_labelsize=xt_labelsize,\n linewidth=linewidth,\n markersize=markersize,\n credible_interval=credible_interval,\n point_estimate=point_estimate,\n hpd_markers=hpd_markers,\n outline=outline,\n shade=shade,\n n_data=n_data,\n data_labels=data_labels,\n backend_kwargs=backend_kwargs,\n show=show,\n )\n\n if backend is None:\n backend = rcParams[\"plot.backend\"]\n backend = backend.lower()\n\n if backend == \"bokeh\":\n\n plot_density_kwargs[\"line_width\"] = plot_density_kwargs.pop(\"linewidth\")\n plot_density_kwargs.pop(\"titlesize\")\n plot_density_kwargs.pop(\"xt_labelsize\")\n plot_density_kwargs.pop(\"n_data\")\n\n # TODO: Add backend kwargs\n plot = get_plotting_function(\"plot_density\", \"densityplot\", backend)\n ax = plot(**plot_density_kwargs)\n return ax\n", "path": "arviz/plots/densityplot.py"}]}
| 3,876 | 145 |
gh_patches_debug_27967
|
rasdani/github-patches
|
git_diff
|
bridgecrewio__checkov-1743
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
CKV_K8S_31 failure with DockerDefault configured
**Describe the bug**
CKV_K8S_31 failure when the seccompProfile type is configured as Docker/Default or Runtime/Default
**To Reproduce**
Define security context as below.
```
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: clust3rf8ck
name: clust3rf8ck
namespace: clust3rf8ck
spec:
replicas: 2
selector:
matchLabels:
app: clust3rf8ck
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: clust3rf8ck
annotations:
seccomp.security.alpha.kubernetes.io/pod: "docker/default"
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- clust3rf8ck
topologyKey: "kubernetes.io/hostname"
containers:
- image: eurogig/clust3rf8ck@sha256:a374eb5853e0e17d06bcf37afc2fcb40892aa3477caf362ea3581c71373cb90a
name: clust3rf8ck
imagePullPolicy: Always
resources:
limits:
cpu: "1"
memory: "200Mi"
requests:
cpu: "0.6"
memory: "100Mi"
livenessProbe:
exec:
command:
- /bin/sh
- -c
- "[ -f /var/run/nginx.pid ] && ps -A | grep nginx"
initialDelaySeconds: 10
periodSeconds: 5
readinessProbe:
httpGet:
scheme: HTTP
path: /index.html
port: 8080
initialDelaySeconds: 10
periodSeconds: 5
securityContext:
readOnlyRootFilesystem: true
allowPrivilegeEscalation: false
capabilities:
drop:
- ALL
- NET_RAW
volumeMounts:
- mountPath: /var/cache/nginx
name: cache-volume
- mountPath: /var/run
name: pid-volume
automountServiceAccountToken: false
securityContext:
runAsNonRoot: true
runAsUser: 10014
runAsGroup: 10014
volumes:
- name: cache-volume
emptyDir: {}
- name: pid-volume
emptyDir: {}
status: {}
---
apiVersion: v1
kind: Service
metadata:
creationTimestamp: null
labels:
app: clust3rf8ck
name: cflb
namespace: clust3rf8ck
spec:
ports:
- name: 80-80
port: 80
protocol: TCP
targetPort: 8080
selector:
app: clust3rf8ck
type: LoadBalancer
```
2. Run checkov for kubernetes.
```
checkov --framework=kubernetes --quiet -d .
```
**Expected behavior**
CKV_K8S_31 to pass with the following configuration.
```
spec:
replicas: 2
selector:
matchLabels:
app: clust3rf8ck
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: clust3rf8ck
annotations:
seccomp.security.alpha.kubernetes.io/pod: "docker/default"
```
**Actual Behaviour**
```
[terraformpipeline] checkov --framework=kubernetes --quiet -d . 20:52:07 ☁ master ☂ ⚡
kubernetes scan results:
Passed checks: 89, Failed checks: 1, Skipped checks: 0
Check: CKV_K8S_31: "Ensure that the seccomp profile is set to docker/default or runtime/default"
FAILED for resource: Deployment.clust3rf8ck.clust3rf8ck
File: /k8s-sample.yaml:35-114
Guide: https://docs.bridgecrew.io/docs/bc_k8s_29
35 | apiVersion: apps/v1
36 | kind: Deployment
37 | metadata:
38 | labels:
39 | app: clust3rf8ck
40 | name: clust3rf8ck
41 | namespace: clust3rf8ck
42 | spec:
43 | replicas: 2
44 | selector:
45 | matchLabels:
46 | app: clust3rf8ck
47 | strategy: {}
48 | template:
49 | metadata:
50 | creationTimestamp: null
51 | labels:
52 | app: clust3rf8ck
53 | annotations:
54 | seccomp.security.alpha.kubernetes.io/pod: "docker/default"
55 | spec:
56 | affinity:
57 | podAntiAffinity:
58 | requiredDuringSchedulingIgnoredDuringExecution:
59 | - labelSelector:
60 | matchExpressions:
61 | - key: app
62 | operator: In
63 | values:
64 | - clust3rf8ck
65 | topologyKey: "kubernetes.io/hostname"
66 | containers:
67 | - image: eurogig/clust3rf8ck@sha256:a374eb5853e0e17d06bcf37afc2fcb40892aa3477caf362ea3581c71373cb90a
68 | name: clust3rf8ck
69 | imagePullPolicy: Always
70 | resources:
71 | limits:
72 | cpu: "1"
73 | memory: "200Mi"
74 | requests:
75 | cpu: "0.6"
76 | memory: "100Mi"
77 | livenessProbe:
78 | exec:
79 | command:
80 | - /bin/sh
81 | - -c
82 | - "[ -f /var/run/nginx.pid ] && ps -A | grep nginx"
83 | initialDelaySeconds: 10
84 | periodSeconds: 5
85 | readinessProbe:
86 | httpGet:
87 | scheme: HTTP
88 | path: /index.html
89 | port: 8080
90 | initialDelaySeconds: 10
91 | periodSeconds: 5
92 | securityContext:
93 | readOnlyRootFilesystem: true
94 | allowPrivilegeEscalation: false
95 | capabilities:
96 | drop:
97 | - ALL
98 | - NET_RAW
99 | volumeMounts:
100 | - mountPath: /var/cache/nginx
101 | name: cache-volume
102 | - mountPath: /var/run
103 | name: pid-volume
104 | automountServiceAccountToken: false
105 | securityContext:
106 | runAsNonRoot: true
107 | runAsUser: 10014
108 | runAsGroup: 10014
109 | volumes:
110 | - name: cache-volume
111 | emptyDir: {}
112 | - name: pid-volume
113 | emptyDir: {}
114 | status: {}
```
**Desktop (please complete the following information):**
- OS: Big Sur 11.5.2
- Checkov Version 2.0.479
**Additional context**
Took the K8s example from this blog https://bridgecrew.io/blog/creating-a-secure-kubernetes-nginx-deployment-using-checkov/
</issue>
<code>
[start of checkov/kubernetes/checks/Seccomp.py]
1 from checkov.common.models.enums import CheckCategories, CheckResult
2 from checkov.common.util.data_structures_utils import find_in_dict
3 from checkov.kubernetes.base_spec_check import BaseK8Check
4 from checkov.common.util.type_forcers import force_list
5
6
7 class Seccomp(BaseK8Check):
8
9 def __init__(self):
10 # CIS-1.5 5.7.2
11 name = "Ensure that the seccomp profile is set to docker/default or runtime/default"
12 id = "CKV_K8S_31"
13 # Location: Pod.metadata.annotations.seccomp.security.alpha.kubernetes.io/pod
14 # Location: CronJob.spec.jobTemplate.spec.template.metadata.annotations.seccomp.security.alpha.kubernetes.io/pod
15 # Location: *.spec.template.metadata.annotations.seccomp.security.alpha.kubernetes.io/pod
16 # Location: *.spec.securityContext.seccompProfile.type
17 supported_kind = ['Pod', 'Deployment', 'DaemonSet', 'StatefulSet', 'ReplicaSet', 'ReplicationController', 'Job', 'CronJob']
18 categories = [CheckCategories.KUBERNETES]
19 super().__init__(name=name, id=id, categories=categories, supported_entities=supported_kind)
20
21 def get_resource_id(self, conf):
22 if "namespace" in conf["metadata"]:
23 return "{}.{}.{}".format(conf["kind"], conf["metadata"]["name"], conf["metadata"]["namespace"])
24 else:
25 return "{}.{}.default".format(conf["kind"], conf["metadata"]["name"])
26
27 def scan_spec_conf(self, conf):
28 metadata = {}
29
30 if conf['kind'] == 'Pod':
31 security_profile = find_in_dict(conf, 'spec/securityContext/seccompProfile/type')
32 if security_profile:
33 return CheckResult.PASSED if security_profile == 'RuntimeDefault' else CheckResult.FAILED
34 if "metadata" in conf:
35 metadata = conf["metadata"]
36 if conf['kind'] == 'Deployment' or conf['kind'] == 'StatefulSet':
37 security_profile = find_in_dict(conf, 'spec/template/spec/securityContext/seccompProfile/type')
38 if security_profile:
39 return CheckResult.PASSED if security_profile == 'RuntimeDefault' else CheckResult.FAILED
40 if "metadata" in conf:
41 metadata = conf["metadata"]
42 elif conf['kind'] == 'CronJob':
43 if "spec" in conf:
44 if "jobTemplate" in conf["spec"]:
45 if "spec" in conf["spec"]["jobTemplate"]:
46 if "template" in conf["spec"]["jobTemplate"]["spec"]:
47 if "metadata" in conf["spec"]["jobTemplate"]["spec"]["template"]:
48 metadata = conf["spec"]["jobTemplate"]["spec"]["template"]["metadata"]
49 else:
50 inner_metadata = self.get_inner_entry(conf, "metadata")
51 metadata = inner_metadata if inner_metadata else metadata
52
53 if metadata:
54 if metadata.get('annotations'):
55 for annotation in force_list(metadata["annotations"]):
56 for key in annotation:
57 if "seccomp.security.alpha.kubernetes.io/pod" in key:
58 if "docker/default" in annotation[key] or "runtime/default" in annotation[key]:
59 return CheckResult.PASSED
60 return CheckResult.FAILED
61
62
63 check = Seccomp()
64
[end of checkov/kubernetes/checks/Seccomp.py]
[start of checkov/kubernetes/base_spec_check.py]
1 from abc import abstractmethod
2
3 from checkov.common.checks.base_check import BaseCheck
4 from checkov.common.multi_signature import multi_signature
5 from checkov.kubernetes.registry import registry
6
7
8 class BaseK8Check(BaseCheck):
9 def __init__(self, name, id, categories, supported_entities):
10 super().__init__(name=name, id=id, categories=categories, supported_entities=supported_entities,
11 block_type="k8")
12 self.supported_specs = supported_entities
13 registry.register(self)
14
15 @abstractmethod
16 def get_resource_id(self, conf):
17 pass
18
19 def scan_entity_conf(self, conf, entity_type):
20 return self.scan_spec_conf(conf, entity_type)
21
22 @multi_signature()
23 @abstractmethod
24 def scan_spec_conf(self, conf, entity_type):
25 raise NotImplementedError()
26
27 @classmethod
28 @scan_spec_conf.add_signature(args=["self", "conf"])
29 def _scan_spec_conf_self_conf(cls, wrapped):
30 def wrapper(self, conf, entity_type=None):
31 # keep default argument for entity_type so old code, that doesn't set it, will work.
32 return wrapped(self, conf)
33
34 return wrapper
35
36 @staticmethod
37 def get_inner_entry(conf, entry_name):
38 spec = {}
39 if conf.get("spec") and conf.get("spec").get("template"):
40 spec = conf.get("spec").get("template").get(entry_name, {})
41 return spec
42
[end of checkov/kubernetes/base_spec_check.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/checkov/kubernetes/base_spec_check.py b/checkov/kubernetes/base_spec_check.py
--- a/checkov/kubernetes/base_spec_check.py
+++ b/checkov/kubernetes/base_spec_check.py
@@ -1,4 +1,5 @@
from abc import abstractmethod
+from typing import Dict, Any
from checkov.common.checks.base_check import BaseCheck
from checkov.common.multi_signature import multi_signature
@@ -34,7 +35,7 @@
return wrapper
@staticmethod
- def get_inner_entry(conf, entry_name):
+ def get_inner_entry(conf: Dict[str, Any], entry_name: str) -> Dict[str, Any]:
spec = {}
if conf.get("spec") and conf.get("spec").get("template"):
spec = conf.get("spec").get("template").get(entry_name, {})
diff --git a/checkov/kubernetes/checks/Seccomp.py b/checkov/kubernetes/checks/Seccomp.py
--- a/checkov/kubernetes/checks/Seccomp.py
+++ b/checkov/kubernetes/checks/Seccomp.py
@@ -37,7 +37,9 @@
security_profile = find_in_dict(conf, 'spec/template/spec/securityContext/seccompProfile/type')
if security_profile:
return CheckResult.PASSED if security_profile == 'RuntimeDefault' else CheckResult.FAILED
- if "metadata" in conf:
+
+ metadata = self.get_inner_entry(conf, "metadata")
+ if not metadata and "metadata" in conf:
metadata = conf["metadata"]
elif conf['kind'] == 'CronJob':
if "spec" in conf:
|
{"golden_diff": "diff --git a/checkov/kubernetes/base_spec_check.py b/checkov/kubernetes/base_spec_check.py\n--- a/checkov/kubernetes/base_spec_check.py\n+++ b/checkov/kubernetes/base_spec_check.py\n@@ -1,4 +1,5 @@\n from abc import abstractmethod\n+from typing import Dict, Any\n \n from checkov.common.checks.base_check import BaseCheck\n from checkov.common.multi_signature import multi_signature\n@@ -34,7 +35,7 @@\n return wrapper\n \n @staticmethod\n- def get_inner_entry(conf, entry_name):\n+ def get_inner_entry(conf: Dict[str, Any], entry_name: str) -> Dict[str, Any]:\n spec = {}\n if conf.get(\"spec\") and conf.get(\"spec\").get(\"template\"):\n spec = conf.get(\"spec\").get(\"template\").get(entry_name, {})\ndiff --git a/checkov/kubernetes/checks/Seccomp.py b/checkov/kubernetes/checks/Seccomp.py\n--- a/checkov/kubernetes/checks/Seccomp.py\n+++ b/checkov/kubernetes/checks/Seccomp.py\n@@ -37,7 +37,9 @@\n security_profile = find_in_dict(conf, 'spec/template/spec/securityContext/seccompProfile/type')\n if security_profile:\n return CheckResult.PASSED if security_profile == 'RuntimeDefault' else CheckResult.FAILED\n- if \"metadata\" in conf:\n+\n+ metadata = self.get_inner_entry(conf, \"metadata\")\n+ if not metadata and \"metadata\" in conf:\n metadata = conf[\"metadata\"]\n elif conf['kind'] == 'CronJob':\n if \"spec\" in conf:\n", "issue": "CKV_K8S_31 failure with DockerDefault configured\n**Describe the bug**\r\nCKV_K8S_31 failure when the seccompProfile type is configured as Docker/Default or Runtime/Default\r\n\r\n**To Reproduce**\r\nDefine security context as below.\r\n\r\n```\r\napiVersion: apps/v1\r\nkind: Deployment\r\nmetadata:\r\n labels:\r\n app: clust3rf8ck\r\n name: clust3rf8ck\r\n namespace: clust3rf8ck\r\nspec:\r\n replicas: 2\r\n selector:\r\n matchLabels:\r\n app: clust3rf8ck\r\n strategy: {}\r\n template:\r\n metadata:\r\n creationTimestamp: null\r\n labels:\r\n app: clust3rf8ck\r\n annotations:\r\n seccomp.security.alpha.kubernetes.io/pod: \"docker/default\"\r\n spec:\r\n affinity:\r\n podAntiAffinity:\r\n requiredDuringSchedulingIgnoredDuringExecution:\r\n - labelSelector:\r\n matchExpressions:\r\n - key: app\r\n operator: In\r\n values:\r\n - clust3rf8ck\r\n topologyKey: \"kubernetes.io/hostname\"\r\n containers:\r\n - image: eurogig/clust3rf8ck@sha256:a374eb5853e0e17d06bcf37afc2fcb40892aa3477caf362ea3581c71373cb90a\r\n name: clust3rf8ck\r\n imagePullPolicy: Always\r\n resources:\r\n limits:\r\n cpu: \"1\"\r\n memory: \"200Mi\"\r\n requests:\r\n cpu: \"0.6\"\r\n memory: \"100Mi\"\r\n livenessProbe:\r\n exec:\r\n command:\r\n - /bin/sh\r\n - -c\r\n - \"[ -f /var/run/nginx.pid ] && ps -A | grep nginx\"\r\n initialDelaySeconds: 10\r\n periodSeconds: 5\r\n readinessProbe:\r\n httpGet:\r\n scheme: HTTP\r\n path: /index.html\r\n port: 8080\r\n initialDelaySeconds: 10\r\n periodSeconds: 5\r\n securityContext:\r\n readOnlyRootFilesystem: true\r\n allowPrivilegeEscalation: false\r\n capabilities:\r\n drop:\r\n - ALL\r\n - NET_RAW\r\n volumeMounts:\r\n - mountPath: /var/cache/nginx\r\n name: cache-volume\r\n - mountPath: /var/run\r\n name: pid-volume\r\n automountServiceAccountToken: false\r\n securityContext:\r\n runAsNonRoot: true\r\n runAsUser: 10014\r\n runAsGroup: 10014\r\n volumes:\r\n - name: cache-volume\r\n emptyDir: {}\r\n - name: pid-volume\r\n emptyDir: {}\r\nstatus: {}\r\n---\r\napiVersion: v1\r\nkind: Service\r\nmetadata:\r\n creationTimestamp: null\r\n labels:\r\n app: clust3rf8ck\r\n name: cflb\r\n namespace: clust3rf8ck\r\nspec:\r\n ports:\r\n - name: 80-80\r\n port: 80\r\n protocol: TCP\r\n targetPort: 8080\r\n selector:\r\n app: clust3rf8ck\r\n type: LoadBalancer\r\n```\r\n2. Run checkov for kubernetes.\r\n```\r\ncheckov --framework=kubernetes --quiet -d .\r\n```\r\n**Expected behavior**\r\nCKV_K8S_31 to pass with the following configuration.\r\n\r\n```\r\nspec:\r\n replicas: 2\r\n selector:\r\n matchLabels:\r\n app: clust3rf8ck\r\n strategy: {}\r\n template:\r\n metadata:\r\n creationTimestamp: null\r\n labels:\r\n app: clust3rf8ck\r\n annotations:\r\n seccomp.security.alpha.kubernetes.io/pod: \"docker/default\"\r\n```\r\n\r\n**Actual Behaviour**\r\n```\r\n[terraformpipeline] checkov --framework=kubernetes --quiet -d . 20:52:07 \u2601 master \u2602 \u26a1\r\nkubernetes scan results:\r\n\r\nPassed checks: 89, Failed checks: 1, Skipped checks: 0\r\n\r\nCheck: CKV_K8S_31: \"Ensure that the seccomp profile is set to docker/default or runtime/default\"\r\n\tFAILED for resource: Deployment.clust3rf8ck.clust3rf8ck\r\n\tFile: /k8s-sample.yaml:35-114\r\n\tGuide: https://docs.bridgecrew.io/docs/bc_k8s_29\r\n\r\n\t\t35 | apiVersion: apps/v1\r\n\t\t36 | kind: Deployment\r\n\t\t37 | metadata:\r\n\t\t38 | labels:\r\n\t\t39 | app: clust3rf8ck\r\n\t\t40 | name: clust3rf8ck\r\n\t\t41 | namespace: clust3rf8ck\r\n\t\t42 | spec:\r\n\t\t43 | replicas: 2\r\n\t\t44 | selector:\r\n\t\t45 | matchLabels:\r\n\t\t46 | app: clust3rf8ck\r\n\t\t47 | strategy: {}\r\n\t\t48 | template:\r\n\t\t49 | metadata:\r\n\t\t50 | creationTimestamp: null\r\n\t\t51 | labels:\r\n\t\t52 | app: clust3rf8ck\r\n\t\t53 | annotations:\r\n\t\t54 | seccomp.security.alpha.kubernetes.io/pod: \"docker/default\"\r\n\t\t55 | spec:\r\n\t\t56 | affinity:\r\n\t\t57 | podAntiAffinity:\r\n\t\t58 | requiredDuringSchedulingIgnoredDuringExecution:\r\n\t\t59 | - labelSelector:\r\n\t\t60 | matchExpressions:\r\n\t\t61 | - key: app\r\n\t\t62 | operator: In\r\n\t\t63 | values:\r\n\t\t64 | - clust3rf8ck\r\n\t\t65 | topologyKey: \"kubernetes.io/hostname\"\r\n\t\t66 | containers:\r\n\t\t67 | - image: eurogig/clust3rf8ck@sha256:a374eb5853e0e17d06bcf37afc2fcb40892aa3477caf362ea3581c71373cb90a\r\n\t\t68 | name: clust3rf8ck\r\n\t\t69 | imagePullPolicy: Always\r\n\t\t70 | resources:\r\n\t\t71 | limits:\r\n\t\t72 | cpu: \"1\"\r\n\t\t73 | memory: \"200Mi\"\r\n\t\t74 | requests:\r\n\t\t75 | cpu: \"0.6\"\r\n\t\t76 | memory: \"100Mi\"\r\n\t\t77 | livenessProbe:\r\n\t\t78 | exec:\r\n\t\t79 | command:\r\n\t\t80 | - /bin/sh\r\n\t\t81 | - -c\r\n\t\t82 | - \"[ -f /var/run/nginx.pid ] && ps -A | grep nginx\"\r\n\t\t83 | initialDelaySeconds: 10\r\n\t\t84 | periodSeconds: 5\r\n\t\t85 | readinessProbe:\r\n\t\t86 | httpGet:\r\n\t\t87 | scheme: HTTP\r\n\t\t88 | path: /index.html\r\n\t\t89 | port: 8080\r\n\t\t90 | initialDelaySeconds: 10\r\n\t\t91 | periodSeconds: 5\r\n\t\t92 | securityContext:\r\n\t\t93 | readOnlyRootFilesystem: true\r\n\t\t94 | allowPrivilegeEscalation: false\r\n\t\t95 | capabilities:\r\n\t\t96 | drop:\r\n\t\t97 | - ALL\r\n\t\t98 | - NET_RAW\r\n\t\t99 | volumeMounts:\r\n\t\t100 | - mountPath: /var/cache/nginx\r\n\t\t101 | name: cache-volume\r\n\t\t102 | - mountPath: /var/run\r\n\t\t103 | name: pid-volume\r\n\t\t104 | automountServiceAccountToken: false\r\n\t\t105 | securityContext:\r\n\t\t106 | runAsNonRoot: true\r\n\t\t107 | runAsUser: 10014\r\n\t\t108 | runAsGroup: 10014\r\n\t\t109 | volumes:\r\n\t\t110 | - name: cache-volume\r\n\t\t111 | emptyDir: {}\r\n\t\t112 | - name: pid-volume\r\n\t\t113 | emptyDir: {}\r\n\t\t114 | status: {}\r\n```\r\n\r\n\r\n**Desktop (please complete the following information):**\r\n - OS: Big Sur 11.5.2 \r\n - Checkov Version 2.0.479\r\n\r\n**Additional context**\r\nTook the K8s example from this blog https://bridgecrew.io/blog/creating-a-secure-kubernetes-nginx-deployment-using-checkov/\r\n\n", "before_files": [{"content": "from checkov.common.models.enums import CheckCategories, CheckResult\nfrom checkov.common.util.data_structures_utils import find_in_dict\nfrom checkov.kubernetes.base_spec_check import BaseK8Check\nfrom checkov.common.util.type_forcers import force_list\n\n\nclass Seccomp(BaseK8Check):\n\n def __init__(self):\n # CIS-1.5 5.7.2\n name = \"Ensure that the seccomp profile is set to docker/default or runtime/default\"\n id = \"CKV_K8S_31\"\n # Location: Pod.metadata.annotations.seccomp.security.alpha.kubernetes.io/pod\n # Location: CronJob.spec.jobTemplate.spec.template.metadata.annotations.seccomp.security.alpha.kubernetes.io/pod\n # Location: *.spec.template.metadata.annotations.seccomp.security.alpha.kubernetes.io/pod\n # Location: *.spec.securityContext.seccompProfile.type\n supported_kind = ['Pod', 'Deployment', 'DaemonSet', 'StatefulSet', 'ReplicaSet', 'ReplicationController', 'Job', 'CronJob']\n categories = [CheckCategories.KUBERNETES]\n super().__init__(name=name, id=id, categories=categories, supported_entities=supported_kind)\n\n def get_resource_id(self, conf):\n if \"namespace\" in conf[\"metadata\"]:\n return \"{}.{}.{}\".format(conf[\"kind\"], conf[\"metadata\"][\"name\"], conf[\"metadata\"][\"namespace\"])\n else:\n return \"{}.{}.default\".format(conf[\"kind\"], conf[\"metadata\"][\"name\"])\n\n def scan_spec_conf(self, conf):\n metadata = {}\n\n if conf['kind'] == 'Pod':\n security_profile = find_in_dict(conf, 'spec/securityContext/seccompProfile/type')\n if security_profile:\n return CheckResult.PASSED if security_profile == 'RuntimeDefault' else CheckResult.FAILED\n if \"metadata\" in conf:\n metadata = conf[\"metadata\"]\n if conf['kind'] == 'Deployment' or conf['kind'] == 'StatefulSet':\n security_profile = find_in_dict(conf, 'spec/template/spec/securityContext/seccompProfile/type')\n if security_profile:\n return CheckResult.PASSED if security_profile == 'RuntimeDefault' else CheckResult.FAILED\n if \"metadata\" in conf:\n metadata = conf[\"metadata\"]\n elif conf['kind'] == 'CronJob':\n if \"spec\" in conf:\n if \"jobTemplate\" in conf[\"spec\"]:\n if \"spec\" in conf[\"spec\"][\"jobTemplate\"]:\n if \"template\" in conf[\"spec\"][\"jobTemplate\"][\"spec\"]:\n if \"metadata\" in conf[\"spec\"][\"jobTemplate\"][\"spec\"][\"template\"]:\n metadata = conf[\"spec\"][\"jobTemplate\"][\"spec\"][\"template\"][\"metadata\"]\n else:\n inner_metadata = self.get_inner_entry(conf, \"metadata\")\n metadata = inner_metadata if inner_metadata else metadata\n\n if metadata:\n if metadata.get('annotations'):\n for annotation in force_list(metadata[\"annotations\"]):\n for key in annotation:\n if \"seccomp.security.alpha.kubernetes.io/pod\" in key:\n if \"docker/default\" in annotation[key] or \"runtime/default\" in annotation[key]:\n return CheckResult.PASSED\n return CheckResult.FAILED\n\n\ncheck = Seccomp()\n", "path": "checkov/kubernetes/checks/Seccomp.py"}, {"content": "from abc import abstractmethod\n\nfrom checkov.common.checks.base_check import BaseCheck\nfrom checkov.common.multi_signature import multi_signature\nfrom checkov.kubernetes.registry import registry\n\n\nclass BaseK8Check(BaseCheck):\n def __init__(self, name, id, categories, supported_entities):\n super().__init__(name=name, id=id, categories=categories, supported_entities=supported_entities,\n block_type=\"k8\")\n self.supported_specs = supported_entities\n registry.register(self)\n\n @abstractmethod\n def get_resource_id(self, conf):\n pass\n\n def scan_entity_conf(self, conf, entity_type):\n return self.scan_spec_conf(conf, entity_type)\n\n @multi_signature()\n @abstractmethod\n def scan_spec_conf(self, conf, entity_type):\n raise NotImplementedError()\n\n @classmethod\n @scan_spec_conf.add_signature(args=[\"self\", \"conf\"])\n def _scan_spec_conf_self_conf(cls, wrapped):\n def wrapper(self, conf, entity_type=None):\n # keep default argument for entity_type so old code, that doesn't set it, will work.\n return wrapped(self, conf)\n\n return wrapper\n\n @staticmethod\n def get_inner_entry(conf, entry_name):\n spec = {}\n if conf.get(\"spec\") and conf.get(\"spec\").get(\"template\"):\n spec = conf.get(\"spec\").get(\"template\").get(entry_name, {})\n return spec\n", "path": "checkov/kubernetes/base_spec_check.py"}]}
| 3,899 | 353 |
gh_patches_debug_31637
|
rasdani/github-patches
|
git_diff
|
optuna__optuna-3544
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`GridSearchSampler` raises `TypeError` when `choices` of `CategoricalDistribution` are not comparable
### Expected behavior
The folliwing grid search based optimisation works without any error because default sampler works fine.
```python
import optuna
def objective(trial):
x = trial.suggest_float("x", -100, 100)
y = trial.suggest_categorical("y", [None, 1])
if y is None:
y = -1
return x ** 2 + y
# Grid search.
search_space = {"x": [-50, 0, 50], "y": [None, 1]}
study = optuna.create_study(sampler=optuna.samplers.GridSampler(search_space))
study.optimize(objective, n_trials=20)
# Note Random search + TPE works well.
# study.optimize(objective, n_trials=20)
```
### Environment
- Optuna version: 3.0.0b1.dev
- Python version: 3.9.12
- OS: macOS-10.16-x86_64-i386-64bit
- (Optional) Other libraries and their versions:
### Error messages, stack traces, or logs
```shell
TypeError Traceback (most recent call last)
Input In [15], in <cell line: 17>()
14 study.optimize(objective, n_trials=20)
16 # Grid search
---> 17 study = optuna.create_study(sampler=optuna.samplers.GridSampler(search_space))
18 study.optimize(objective, n_trials=20)
File ~/Documents/optuna/optuna/samplers/_grid.py:112, in GridSampler.__init__(self, search_space)
109 for param_name, param_values in sorted(search_space.items(), key=lambda x: x[0]):
110 param_values = cast(SortableParamValueSequenceType, param_values)
--> 112 self._search_space[param_name] = sorted(param_values)
114 self._all_grids = list(itertools.product(*self._search_space.values()))
115 self._param_names = sorted(search_space.keys())
TypeError: '<' not supported between instances of 'int' and 'NoneType'
```
### Steps to reproduce
1. Run the code above
2.
3.
```python
# python code
```
### Additional context (optional)
Since grid search sampler implementation sorts `choices`, the current implementation assumes the choices are sortable.
</issue>
<code>
[start of optuna/samplers/_grid.py]
1 import collections
2 import itertools
3 import random
4 from typing import Any
5 from typing import cast
6 from typing import Dict
7 from typing import List
8 from typing import Mapping
9 from typing import Optional
10 from typing import Sequence
11 from typing import Union
12 import warnings
13
14 from optuna.distributions import BaseDistribution
15 from optuna.logging import get_logger
16 from optuna.samplers import BaseSampler
17 from optuna.study import Study
18 from optuna.trial import FrozenTrial
19 from optuna.trial import TrialState
20
21
22 GridValueType = Union[str, float, int, bool, None]
23 SortableParamValueSequenceType = Union[List[str], List[float], List[int], List[bool]]
24
25
26 _logger = get_logger(__name__)
27
28
29 class GridSampler(BaseSampler):
30 """Sampler using grid search.
31
32 With :class:`~optuna.samplers.GridSampler`, the trials suggest all combinations of parameters
33 in the given search space during the study.
34
35 Example:
36
37 .. testcode::
38
39 import optuna
40
41
42 def objective(trial):
43 x = trial.suggest_float("x", -100, 100)
44 y = trial.suggest_int("y", -100, 100)
45 return x**2 + y**2
46
47
48 search_space = {"x": [-50, 0, 50], "y": [-99, 0, 99]}
49 study = optuna.create_study(sampler=optuna.samplers.GridSampler(search_space))
50 study.optimize(objective)
51
52 Note:
53
54 :class:`~optuna.samplers.GridSampler` automatically stops the optimization if all
55 combinations in the passed ``search_space`` have already been evaluated, internally
56 invoking the :func:`~optuna.study.Study.stop` method.
57
58 Note:
59
60 :class:`~optuna.samplers.GridSampler` does not take care of a parameter's quantization
61 specified by discrete suggest methods but just samples one of values specified in the
62 search space. E.g., in the following code snippet, either of ``-0.5`` or ``0.5`` is
63 sampled as ``x`` instead of an integer point.
64
65 .. testcode::
66
67 import optuna
68
69
70 def objective(trial):
71 # The following suggest method specifies integer points between -5 and 5.
72 x = trial.suggest_float("x", -5, 5, step=1)
73 return x**2
74
75
76 # Non-int points are specified in the grid.
77 search_space = {"x": [-0.5, 0.5]}
78 study = optuna.create_study(sampler=optuna.samplers.GridSampler(search_space))
79 study.optimize(objective, n_trials=2)
80
81 Note:
82 A parameter configuration in the grid is not considered finished until its trial is
83 finished. Therefore, during distributed optimization where trials run concurrently,
84 different workers will occasionally suggest the same parameter configuration.
85 The total number of actual trials may therefore exceed the size of the grid.
86
87 Note:
88 The grid is randomly shuffled and the order in which parameter configurations are
89 suggested may vary. This is to reduce duplicate suggestions during distributed
90 optimization.
91
92 Note:
93 All parameters must be specified when using :class:`~optuna.samplers.GridSampler` with
94 :meth:`~optuna.study.Study.enqueue_trial`.
95
96 Args:
97 search_space:
98 A dictionary whose key and value are a parameter name and the corresponding candidates
99 of values, respectively.
100 """
101
102 def __init__(self, search_space: Mapping[str, Sequence[GridValueType]]) -> None:
103
104 for param_name, param_values in search_space.items():
105 for value in param_values:
106 self._check_value(param_name, value)
107
108 self._search_space = collections.OrderedDict()
109 for param_name, param_values in sorted(search_space.items(), key=lambda x: x[0]):
110 param_values = cast(SortableParamValueSequenceType, param_values)
111
112 self._search_space[param_name] = sorted(param_values)
113
114 self._all_grids = list(itertools.product(*self._search_space.values()))
115 self._param_names = sorted(search_space.keys())
116 self._n_min_trials = len(self._all_grids)
117
118 def infer_relative_search_space(
119 self, study: Study, trial: FrozenTrial
120 ) -> Dict[str, BaseDistribution]:
121
122 return {}
123
124 def sample_relative(
125 self, study: Study, trial: FrozenTrial, search_space: Dict[str, BaseDistribution]
126 ) -> Dict[str, Any]:
127 # Instead of returning param values, GridSampler puts the target grid id as a system attr,
128 # and the values are returned from `sample_independent`. This is because the distribution
129 # object is hard to get at the beginning of trial, while we need the access to the object
130 # to validate the sampled value.
131
132 # When the trial is created by RetryFailedTrialCallback or enqueue_trial, we should not
133 # assign a new grid_id.
134 if "grid_id" in trial.system_attrs or "fixed_params" in trial.system_attrs:
135 return {}
136
137 target_grids = self._get_unvisited_grid_ids(study)
138
139 if len(target_grids) == 0:
140 # This case may occur with distributed optimization or trial queue. If there is no
141 # target grid, `GridSampler` evaluates a visited, duplicated point with the current
142 # trial. After that, the optimization stops.
143
144 _logger.warning(
145 "`GridSampler` is re-evaluating a configuration because the grid has been "
146 "exhausted. This may happen due to a timing issue during distributed optimization "
147 "or when re-running optimizations on already finished studies."
148 )
149
150 # One of all grids is randomly picked up in this case.
151 target_grids = list(range(len(self._all_grids)))
152
153 # In distributed optimization, multiple workers may simultaneously pick up the same grid.
154 # To make the conflict less frequent, the grid is chosen randomly.
155 grid_id = random.choice(target_grids)
156
157 study._storage.set_trial_system_attr(trial._trial_id, "search_space", self._search_space)
158 study._storage.set_trial_system_attr(trial._trial_id, "grid_id", grid_id)
159
160 return {}
161
162 def sample_independent(
163 self,
164 study: Study,
165 trial: FrozenTrial,
166 param_name: str,
167 param_distribution: BaseDistribution,
168 ) -> Any:
169
170 if "grid_id" not in trial.system_attrs:
171 message = "All parameters must be specified when using GridSampler with enqueue_trial."
172 raise ValueError(message)
173
174 if param_name not in self._search_space:
175 message = "The parameter name, {}, is not found in the given grid.".format(param_name)
176 raise ValueError(message)
177
178 # TODO(c-bata): Reduce the number of duplicated evaluations on multiple workers.
179 # Current selection logic may evaluate the same parameters multiple times.
180 # See https://gist.github.com/c-bata/f759f64becb24eea2040f4b2e3afce8f for details.
181 grid_id = trial.system_attrs["grid_id"]
182 param_value = self._all_grids[grid_id][self._param_names.index(param_name)]
183 contains = param_distribution._contains(param_distribution.to_internal_repr(param_value))
184 if not contains:
185 warnings.warn(
186 f"The value `{param_value}` is out of range of the parameter `{param_name}`. "
187 f"The value will be used but the actual distribution is: `{param_distribution}`."
188 )
189
190 return param_value
191
192 def after_trial(
193 self,
194 study: Study,
195 trial: FrozenTrial,
196 state: TrialState,
197 values: Optional[Sequence[float]],
198 ) -> None:
199 target_grids = self._get_unvisited_grid_ids(study)
200
201 if len(target_grids) == 0:
202 study.stop()
203 elif len(target_grids) == 1:
204 grid_id = study._storage.get_trial_system_attrs(trial._trial_id)["grid_id"]
205 if grid_id == target_grids[0]:
206 study.stop()
207
208 @staticmethod
209 def _check_value(param_name: str, param_value: Any) -> None:
210
211 if param_value is None or isinstance(param_value, (str, int, float, bool)):
212 return
213
214 raise ValueError(
215 "{} contains a value with the type of {}, which is not supported by "
216 "`GridSampler`. Please make sure a value is `str`, `int`, `float`, `bool`"
217 " or `None`.".format(param_name, type(param_value))
218 )
219
220 def _get_unvisited_grid_ids(self, study: Study) -> List[int]:
221
222 # List up unvisited grids based on already finished ones.
223 visited_grids = []
224 running_grids = []
225
226 # We directly query the storage to get trials here instead of `study.get_trials`,
227 # since some pruners such as `HyperbandPruner` use the study transformed
228 # to filter trials. See https://github.com/optuna/optuna/issues/2327 for details.
229 trials = study._storage.get_all_trials(study._study_id, deepcopy=False)
230
231 for t in trials:
232 if "grid_id" in t.system_attrs and self._same_search_space(
233 t.system_attrs["search_space"]
234 ):
235 if t.state.is_finished():
236 visited_grids.append(t.system_attrs["grid_id"])
237 elif t.state == TrialState.RUNNING:
238 running_grids.append(t.system_attrs["grid_id"])
239
240 unvisited_grids = set(range(self._n_min_trials)) - set(visited_grids) - set(running_grids)
241
242 # If evaluations for all grids have been started, return grids that have not yet finished
243 # because all grids should be evaluated before stopping the optimization.
244 if len(unvisited_grids) == 0:
245 unvisited_grids = set(range(self._n_min_trials)) - set(visited_grids)
246
247 return list(unvisited_grids)
248
249 def _same_search_space(self, search_space: Mapping[str, Sequence[GridValueType]]) -> bool:
250
251 if set(search_space.keys()) != set(self._search_space.keys()):
252 return False
253
254 for param_name in search_space.keys():
255 if len(search_space[param_name]) != len(self._search_space[param_name]):
256 return False
257
258 param_values = cast(SortableParamValueSequenceType, search_space[param_name])
259 for i, param_value in enumerate(sorted(param_values)):
260 if param_value != self._search_space[param_name][i]:
261 return False
262
263 return True
264
[end of optuna/samplers/_grid.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/optuna/samplers/_grid.py b/optuna/samplers/_grid.py
--- a/optuna/samplers/_grid.py
+++ b/optuna/samplers/_grid.py
@@ -2,7 +2,6 @@
import itertools
import random
from typing import Any
-from typing import cast
from typing import Dict
from typing import List
from typing import Mapping
@@ -20,7 +19,6 @@
GridValueType = Union[str, float, int, bool, None]
-SortableParamValueSequenceType = Union[List[str], List[float], List[int], List[bool]]
_logger = get_logger(__name__)
@@ -106,10 +104,8 @@
self._check_value(param_name, value)
self._search_space = collections.OrderedDict()
- for param_name, param_values in sorted(search_space.items(), key=lambda x: x[0]):
- param_values = cast(SortableParamValueSequenceType, param_values)
-
- self._search_space[param_name] = sorted(param_values)
+ for param_name, param_values in sorted(search_space.items()):
+ self._search_space[param_name] = param_values
self._all_grids = list(itertools.product(*self._search_space.values()))
self._param_names = sorted(search_space.keys())
@@ -255,8 +251,7 @@
if len(search_space[param_name]) != len(self._search_space[param_name]):
return False
- param_values = cast(SortableParamValueSequenceType, search_space[param_name])
- for i, param_value in enumerate(sorted(param_values)):
+ for i, param_value in enumerate(search_space[param_name]):
if param_value != self._search_space[param_name][i]:
return False
|
{"golden_diff": "diff --git a/optuna/samplers/_grid.py b/optuna/samplers/_grid.py\n--- a/optuna/samplers/_grid.py\n+++ b/optuna/samplers/_grid.py\n@@ -2,7 +2,6 @@\n import itertools\n import random\n from typing import Any\n-from typing import cast\n from typing import Dict\n from typing import List\n from typing import Mapping\n@@ -20,7 +19,6 @@\n \n \n GridValueType = Union[str, float, int, bool, None]\n-SortableParamValueSequenceType = Union[List[str], List[float], List[int], List[bool]]\n \n \n _logger = get_logger(__name__)\n@@ -106,10 +104,8 @@\n self._check_value(param_name, value)\n \n self._search_space = collections.OrderedDict()\n- for param_name, param_values in sorted(search_space.items(), key=lambda x: x[0]):\n- param_values = cast(SortableParamValueSequenceType, param_values)\n-\n- self._search_space[param_name] = sorted(param_values)\n+ for param_name, param_values in sorted(search_space.items()):\n+ self._search_space[param_name] = param_values\n \n self._all_grids = list(itertools.product(*self._search_space.values()))\n self._param_names = sorted(search_space.keys())\n@@ -255,8 +251,7 @@\n if len(search_space[param_name]) != len(self._search_space[param_name]):\n return False\n \n- param_values = cast(SortableParamValueSequenceType, search_space[param_name])\n- for i, param_value in enumerate(sorted(param_values)):\n+ for i, param_value in enumerate(search_space[param_name]):\n if param_value != self._search_space[param_name][i]:\n return False\n", "issue": "`GridSearchSampler` raises `TypeError` when `choices` of `CategoricalDistribution` are not comparable\n### Expected behavior\r\n\r\nThe folliwing grid search based optimisation works without any error because default sampler works fine.\r\n```python\r\nimport optuna\r\n\r\n\r\ndef objective(trial):\r\n x = trial.suggest_float(\"x\", -100, 100)\r\n y = trial.suggest_categorical(\"y\", [None, 1])\r\n if y is None:\r\n y = -1\r\n return x ** 2 + y\r\n\r\n# Grid search.\r\nsearch_space = {\"x\": [-50, 0, 50], \"y\": [None, 1]}\r\nstudy = optuna.create_study(sampler=optuna.samplers.GridSampler(search_space))\r\nstudy.optimize(objective, n_trials=20)\r\n\r\n\r\n# Note Random search + TPE works well.\r\n# study.optimize(objective, n_trials=20)\r\n```\r\n\r\n### Environment\r\n\r\n- Optuna version: 3.0.0b1.dev\r\n- Python version: 3.9.12\r\n- OS: macOS-10.16-x86_64-i386-64bit\r\n- (Optional) Other libraries and their versions:\r\n\r\n\r\n### Error messages, stack traces, or logs\r\n\r\n```shell\r\nTypeError Traceback (most recent call last)\r\nInput In [15], in <cell line: 17>()\r\n 14 study.optimize(objective, n_trials=20)\r\n 16 # Grid search\r\n---> 17 study = optuna.create_study(sampler=optuna.samplers.GridSampler(search_space))\r\n 18 study.optimize(objective, n_trials=20)\r\n\r\nFile ~/Documents/optuna/optuna/samplers/_grid.py:112, in GridSampler.__init__(self, search_space)\r\n 109 for param_name, param_values in sorted(search_space.items(), key=lambda x: x[0]):\r\n 110 param_values = cast(SortableParamValueSequenceType, param_values)\r\n--> 112 self._search_space[param_name] = sorted(param_values)\r\n 114 self._all_grids = list(itertools.product(*self._search_space.values()))\r\n 115 self._param_names = sorted(search_space.keys())\r\n\r\nTypeError: '<' not supported between instances of 'int' and 'NoneType'\r\n```\r\n\r\n\r\n\r\n### Steps to reproduce\r\n\r\n1. Run the code above\r\n2.\r\n3.\r\n```python\r\n# python code\r\n```\r\n\r\n\r\n### Additional context (optional)\r\n\r\nSince grid search sampler implementation sorts `choices`, the current implementation assumes the choices are sortable. \n", "before_files": [{"content": "import collections\nimport itertools\nimport random\nfrom typing import Any\nfrom typing import cast\nfrom typing import Dict\nfrom typing import List\nfrom typing import Mapping\nfrom typing import Optional\nfrom typing import Sequence\nfrom typing import Union\nimport warnings\n\nfrom optuna.distributions import BaseDistribution\nfrom optuna.logging import get_logger\nfrom optuna.samplers import BaseSampler\nfrom optuna.study import Study\nfrom optuna.trial import FrozenTrial\nfrom optuna.trial import TrialState\n\n\nGridValueType = Union[str, float, int, bool, None]\nSortableParamValueSequenceType = Union[List[str], List[float], List[int], List[bool]]\n\n\n_logger = get_logger(__name__)\n\n\nclass GridSampler(BaseSampler):\n \"\"\"Sampler using grid search.\n\n With :class:`~optuna.samplers.GridSampler`, the trials suggest all combinations of parameters\n in the given search space during the study.\n\n Example:\n\n .. testcode::\n\n import optuna\n\n\n def objective(trial):\n x = trial.suggest_float(\"x\", -100, 100)\n y = trial.suggest_int(\"y\", -100, 100)\n return x**2 + y**2\n\n\n search_space = {\"x\": [-50, 0, 50], \"y\": [-99, 0, 99]}\n study = optuna.create_study(sampler=optuna.samplers.GridSampler(search_space))\n study.optimize(objective)\n\n Note:\n\n :class:`~optuna.samplers.GridSampler` automatically stops the optimization if all\n combinations in the passed ``search_space`` have already been evaluated, internally\n invoking the :func:`~optuna.study.Study.stop` method.\n\n Note:\n\n :class:`~optuna.samplers.GridSampler` does not take care of a parameter's quantization\n specified by discrete suggest methods but just samples one of values specified in the\n search space. E.g., in the following code snippet, either of ``-0.5`` or ``0.5`` is\n sampled as ``x`` instead of an integer point.\n\n .. testcode::\n\n import optuna\n\n\n def objective(trial):\n # The following suggest method specifies integer points between -5 and 5.\n x = trial.suggest_float(\"x\", -5, 5, step=1)\n return x**2\n\n\n # Non-int points are specified in the grid.\n search_space = {\"x\": [-0.5, 0.5]}\n study = optuna.create_study(sampler=optuna.samplers.GridSampler(search_space))\n study.optimize(objective, n_trials=2)\n\n Note:\n A parameter configuration in the grid is not considered finished until its trial is\n finished. Therefore, during distributed optimization where trials run concurrently,\n different workers will occasionally suggest the same parameter configuration.\n The total number of actual trials may therefore exceed the size of the grid.\n\n Note:\n The grid is randomly shuffled and the order in which parameter configurations are\n suggested may vary. This is to reduce duplicate suggestions during distributed\n optimization.\n\n Note:\n All parameters must be specified when using :class:`~optuna.samplers.GridSampler` with\n :meth:`~optuna.study.Study.enqueue_trial`.\n\n Args:\n search_space:\n A dictionary whose key and value are a parameter name and the corresponding candidates\n of values, respectively.\n \"\"\"\n\n def __init__(self, search_space: Mapping[str, Sequence[GridValueType]]) -> None:\n\n for param_name, param_values in search_space.items():\n for value in param_values:\n self._check_value(param_name, value)\n\n self._search_space = collections.OrderedDict()\n for param_name, param_values in sorted(search_space.items(), key=lambda x: x[0]):\n param_values = cast(SortableParamValueSequenceType, param_values)\n\n self._search_space[param_name] = sorted(param_values)\n\n self._all_grids = list(itertools.product(*self._search_space.values()))\n self._param_names = sorted(search_space.keys())\n self._n_min_trials = len(self._all_grids)\n\n def infer_relative_search_space(\n self, study: Study, trial: FrozenTrial\n ) -> Dict[str, BaseDistribution]:\n\n return {}\n\n def sample_relative(\n self, study: Study, trial: FrozenTrial, search_space: Dict[str, BaseDistribution]\n ) -> Dict[str, Any]:\n # Instead of returning param values, GridSampler puts the target grid id as a system attr,\n # and the values are returned from `sample_independent`. This is because the distribution\n # object is hard to get at the beginning of trial, while we need the access to the object\n # to validate the sampled value.\n\n # When the trial is created by RetryFailedTrialCallback or enqueue_trial, we should not\n # assign a new grid_id.\n if \"grid_id\" in trial.system_attrs or \"fixed_params\" in trial.system_attrs:\n return {}\n\n target_grids = self._get_unvisited_grid_ids(study)\n\n if len(target_grids) == 0:\n # This case may occur with distributed optimization or trial queue. If there is no\n # target grid, `GridSampler` evaluates a visited, duplicated point with the current\n # trial. After that, the optimization stops.\n\n _logger.warning(\n \"`GridSampler` is re-evaluating a configuration because the grid has been \"\n \"exhausted. This may happen due to a timing issue during distributed optimization \"\n \"or when re-running optimizations on already finished studies.\"\n )\n\n # One of all grids is randomly picked up in this case.\n target_grids = list(range(len(self._all_grids)))\n\n # In distributed optimization, multiple workers may simultaneously pick up the same grid.\n # To make the conflict less frequent, the grid is chosen randomly.\n grid_id = random.choice(target_grids)\n\n study._storage.set_trial_system_attr(trial._trial_id, \"search_space\", self._search_space)\n study._storage.set_trial_system_attr(trial._trial_id, \"grid_id\", grid_id)\n\n return {}\n\n def sample_independent(\n self,\n study: Study,\n trial: FrozenTrial,\n param_name: str,\n param_distribution: BaseDistribution,\n ) -> Any:\n\n if \"grid_id\" not in trial.system_attrs:\n message = \"All parameters must be specified when using GridSampler with enqueue_trial.\"\n raise ValueError(message)\n\n if param_name not in self._search_space:\n message = \"The parameter name, {}, is not found in the given grid.\".format(param_name)\n raise ValueError(message)\n\n # TODO(c-bata): Reduce the number of duplicated evaluations on multiple workers.\n # Current selection logic may evaluate the same parameters multiple times.\n # See https://gist.github.com/c-bata/f759f64becb24eea2040f4b2e3afce8f for details.\n grid_id = trial.system_attrs[\"grid_id\"]\n param_value = self._all_grids[grid_id][self._param_names.index(param_name)]\n contains = param_distribution._contains(param_distribution.to_internal_repr(param_value))\n if not contains:\n warnings.warn(\n f\"The value `{param_value}` is out of range of the parameter `{param_name}`. \"\n f\"The value will be used but the actual distribution is: `{param_distribution}`.\"\n )\n\n return param_value\n\n def after_trial(\n self,\n study: Study,\n trial: FrozenTrial,\n state: TrialState,\n values: Optional[Sequence[float]],\n ) -> None:\n target_grids = self._get_unvisited_grid_ids(study)\n\n if len(target_grids) == 0:\n study.stop()\n elif len(target_grids) == 1:\n grid_id = study._storage.get_trial_system_attrs(trial._trial_id)[\"grid_id\"]\n if grid_id == target_grids[0]:\n study.stop()\n\n @staticmethod\n def _check_value(param_name: str, param_value: Any) -> None:\n\n if param_value is None or isinstance(param_value, (str, int, float, bool)):\n return\n\n raise ValueError(\n \"{} contains a value with the type of {}, which is not supported by \"\n \"`GridSampler`. Please make sure a value is `str`, `int`, `float`, `bool`\"\n \" or `None`.\".format(param_name, type(param_value))\n )\n\n def _get_unvisited_grid_ids(self, study: Study) -> List[int]:\n\n # List up unvisited grids based on already finished ones.\n visited_grids = []\n running_grids = []\n\n # We directly query the storage to get trials here instead of `study.get_trials`,\n # since some pruners such as `HyperbandPruner` use the study transformed\n # to filter trials. See https://github.com/optuna/optuna/issues/2327 for details.\n trials = study._storage.get_all_trials(study._study_id, deepcopy=False)\n\n for t in trials:\n if \"grid_id\" in t.system_attrs and self._same_search_space(\n t.system_attrs[\"search_space\"]\n ):\n if t.state.is_finished():\n visited_grids.append(t.system_attrs[\"grid_id\"])\n elif t.state == TrialState.RUNNING:\n running_grids.append(t.system_attrs[\"grid_id\"])\n\n unvisited_grids = set(range(self._n_min_trials)) - set(visited_grids) - set(running_grids)\n\n # If evaluations for all grids have been started, return grids that have not yet finished\n # because all grids should be evaluated before stopping the optimization.\n if len(unvisited_grids) == 0:\n unvisited_grids = set(range(self._n_min_trials)) - set(visited_grids)\n\n return list(unvisited_grids)\n\n def _same_search_space(self, search_space: Mapping[str, Sequence[GridValueType]]) -> bool:\n\n if set(search_space.keys()) != set(self._search_space.keys()):\n return False\n\n for param_name in search_space.keys():\n if len(search_space[param_name]) != len(self._search_space[param_name]):\n return False\n\n param_values = cast(SortableParamValueSequenceType, search_space[param_name])\n for i, param_value in enumerate(sorted(param_values)):\n if param_value != self._search_space[param_name][i]:\n return False\n\n return True\n", "path": "optuna/samplers/_grid.py"}]}
| 4,087 | 389 |
gh_patches_debug_4916
|
rasdani/github-patches
|
git_diff
|
e-valuation__EvaP-566
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
colorize average grades on course detail pages
the numbers in the lower right should be css'd like the ones in the upper left.

</issue>
<code>
[start of evap/evaluation/templatetags/evaluation_templatetags.py]
1 from django.template import Library
2
3 register = Library()
4
5
6 @register.inclusion_tag("user_list_with_links.html")
7 def include_user_list_with_links(users):
8 return dict(users=users)
9
10
11 @register.inclusion_tag("sortable_form_js.html")
12 def include_sortable_form_js():
13 return dict()
14
15 @register.inclusion_tag("progress_bar.html")
16 def include_progress_bar(done, total, large=False):
17 return dict(done=done, total=total, large=large)
18
[end of evap/evaluation/templatetags/evaluation_templatetags.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/evap/evaluation/templatetags/evaluation_templatetags.py b/evap/evaluation/templatetags/evaluation_templatetags.py
--- a/evap/evaluation/templatetags/evaluation_templatetags.py
+++ b/evap/evaluation/templatetags/evaluation_templatetags.py
@@ -15,3 +15,7 @@
@register.inclusion_tag("progress_bar.html")
def include_progress_bar(done, total, large=False):
return dict(done=done, total=total, large=large)
+
[email protected]_tag("result_bar.html")
+def include_result_bar(result, show_grades, questionnaire_warning=False):
+ return dict(result=result, show_grades=show_grades, questionnaire_warning=questionnaire_warning)
|
{"golden_diff": "diff --git a/evap/evaluation/templatetags/evaluation_templatetags.py b/evap/evaluation/templatetags/evaluation_templatetags.py\n--- a/evap/evaluation/templatetags/evaluation_templatetags.py\n+++ b/evap/evaluation/templatetags/evaluation_templatetags.py\n@@ -15,3 +15,7 @@\n @register.inclusion_tag(\"progress_bar.html\")\n def include_progress_bar(done, total, large=False):\n return dict(done=done, total=total, large=large)\n+\[email protected]_tag(\"result_bar.html\")\n+def include_result_bar(result, show_grades, questionnaire_warning=False):\n+ return dict(result=result, show_grades=show_grades, questionnaire_warning=questionnaire_warning)\n", "issue": "colorize average grades on course detail pages\nthe numbers in the lower right should be css'd like the ones in the upper left.\n\n\n\n", "before_files": [{"content": "from django.template import Library\n\nregister = Library()\n\n\[email protected]_tag(\"user_list_with_links.html\")\ndef include_user_list_with_links(users):\n return dict(users=users)\n\n\[email protected]_tag(\"sortable_form_js.html\")\ndef include_sortable_form_js():\n return dict()\n\[email protected]_tag(\"progress_bar.html\")\ndef include_progress_bar(done, total, large=False):\n return dict(done=done, total=total, large=large)\n", "path": "evap/evaluation/templatetags/evaluation_templatetags.py"}]}
| 799 | 181 |
gh_patches_debug_32283
|
rasdani/github-patches
|
git_diff
|
zestedesavoir__zds-site-5611
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Date de publication future des News
Bonjour,
Ça ne regarde certainement que moi mais...
C'est pas logique. « Dans le futur » n'apporte **aucune information utile**. L’intérêt des news c'est d'avoir la date future, pour pouvoir géré et vérifier que la publication sera à la bonne date. Là, il faut ouvrir la news, et lire la date dans un format cryptique.

Il y a certainement plus claire comme format.
C'est tellement compliqué qu'au final, j'écris juste tout dans un fichier ou sur un boue de papier.
Quand les 10 prochains contenus sont marqués « Dans le futur » franchement on a le sentiment d'être pris pour un crétin par l'IHM.
______________________
Bref, c'est géré par la fonction `format_date`.
À votre avis comment on pourrait faire pour améliorer ça ?
</issue>
<code>
[start of zds/featured/forms.py]
1 from crispy_forms.bootstrap import StrictButton
2 from crispy_forms.helper import FormHelper
3 from crispy_forms.layout import Layout, Field, ButtonHolder
4 from django import forms
5 from django.urls import reverse
6 from django.utils.translation import ugettext_lazy as _
7
8 from zds.featured.models import FeaturedResource, FeaturedMessage
9
10
11 class FeaturedResourceForm(forms.ModelForm):
12 class Meta:
13 model = FeaturedResource
14
15 fields = ['title', 'type', 'authors', 'image_url', 'url']
16
17 widgets = {
18 'title': forms.TextInput(
19 attrs={
20 'placeholder': _('Titre de la Une')
21 }
22 ),
23
24 'type': forms.TextInput(
25 attrs={
26 'placeholder': _('ex: Un projet, Un article, Un tutoriel...')
27 }
28 ),
29
30 'authors': forms.TextInput(
31 attrs={
32 'placeholder': _('Des auteurs (ou pas) ?')
33 }
34 ),
35
36 'image_url': forms.URLInput(
37 attrs={
38 'placeholder': _('Lien vers l\'image de la Une (dimensions: 228x228px).')
39 }
40 ),
41
42 'url': forms.URLInput(
43 attrs={
44 'placeholder': _('Lien vers la ressource.')
45 }
46 )
47 }
48
49 major_update = forms.BooleanField(
50 label=_('Mise à jour majeure (fera passer la Une en première position lors d\'un changement)'),
51 initial=False,
52 required=False
53 )
54
55 pubdate = forms.DateTimeField(
56 label=_('Date de publication (exemple: 25/12/2015 15:00 ou 2015-12-25T15:00)'),
57 input_formats=[
58 '%d/%m/%Y %H:%M:%S', '%Y-%m-%d %H:%M:%S', # full format with second
59 '%Y-%m-%dT%H:%M', # datetime field format
60 '%Y-%m-%d %H:%M', '%d/%m/%Y %H:%M', # without second
61 '%Y-%m-%d', '%d/%m/%Y' # day only
62 ],
63 widget=forms.DateTimeInput(
64 attrs={'placeholder': _('Exemple : 25/12/2016 10:00'), 'type': 'datetime-local'},
65 format='%Y-%m-%dT%H:%M' # datetime field format
66 )
67 )
68
69 request = forms.IntegerField(widget=forms.HiddenInput(), required=False)
70
71 def __init__(self, *args, **kwargs):
72 hide_major_update_field = kwargs.pop('hide_major_update_field', False)
73
74 super(FeaturedResourceForm, self).__init__(*args, **kwargs)
75 self.helper = FormHelper()
76 self.helper.form_class = 'content-wrapper'
77 self.helper.form_method = 'post'
78 self.helper.form_action = reverse('featured-resource-create')
79
80 fields = [
81 Field('request'),
82 Field('title'),
83 Field('type'),
84 Field('authors'),
85 Field('image_url'),
86 Field('url')
87 ]
88
89 if not hide_major_update_field:
90 fields.append(Field('major_update'))
91
92 fields.extend([
93 Field('pubdate'),
94 ButtonHolder(
95 StrictButton(_('Enregistrer'), type='submit'),
96 )
97 ])
98
99 self.helper.layout = Layout(*fields)
100
101
102 class FeaturedMessageForm(forms.ModelForm):
103 class Meta:
104 model = FeaturedMessage
105
106 fields = ['hook', 'message', 'url']
107
108 widgets = {
109 'hook': forms.TextInput(
110 attrs={
111 'placeholder': _('Mot d\'accroche court ("Nouveau !")')
112 }
113 ),
114
115 'message': forms.TextInput(
116 attrs={
117 'placeholder': _('Message à afficher')
118 }
119 ),
120
121 'url': forms.URLInput(
122 attrs={
123 'placeholder': _('Lien vers la description de la ressource')
124 }
125 )
126 }
127
128 def __init__(self, *args, **kwargs):
129 super(FeaturedMessageForm, self).__init__(*args, **kwargs)
130 self.helper = FormHelper()
131 self.helper.form_class = 'content-wrapper'
132 self.helper.form_method = 'post'
133 self.helper.form_action = reverse('featured-message-create')
134
135 self.helper.layout = Layout(
136 Field('hook'),
137 Field('message'),
138 Field('url'),
139 ButtonHolder(
140 StrictButton(_('Enregistrer'), type='submit'),
141 ),
142 )
143
[end of zds/featured/forms.py]
[start of zds/utils/templatetags/date.py]
1 from datetime import datetime, timedelta
2
3 from django import template
4 from django.contrib.humanize.templatetags.humanize import naturaltime
5 from django.template.defaultfilters import date
6 from django.utils.timezone import get_default_timezone
7 from django.utils.translation import ugettext_lazy as _
8
9 register = template.Library()
10
11 """
12 Define a filter to format date.
13 """
14
15 # Date formatting constants
16
17 __DATE_FMT_FUTUR = _('Dans le futur')
18 __ABS_DATE_FMT_SMALL = _(r'd/m/y à H\hi') # Small format
19 __ABS_DATE_FMT_NORMAL = _(r'l d F Y à H\hi') # Normal format
20 __ABS_HUMAN_TIME_FMT = _('%d %b %Y, %H:%M:%S')
21
22
23 def date_formatter(value, tooltip, small):
24 """
25 Format a date to an human readable string.
26
27 :param value: Date to format.
28 :param bool tooltip: if `True`, format date to a tooltip label.
29 :param bool small: if `True`, create a shorter string.
30 :return:
31 """
32 if not isinstance(value, datetime):
33 return value
34
35 if getattr(value, 'tzinfo', None):
36 now = datetime.now(get_default_timezone())
37 else:
38 now = datetime.now()
39 now = now - timedelta(microseconds=now.microsecond)
40
41 if value > now:
42 return __DATE_FMT_FUTUR
43 else:
44 delta = now - value
45 # Natural time for today, absolute date after.
46 # Reverse if in tooltip
47 if (delta.days == 0) != tooltip:
48 return naturaltime(value)
49 else:
50 return date(value, str(__ABS_DATE_FMT_SMALL if small else __ABS_DATE_FMT_NORMAL))
51
52
53 @register.filter
54 def format_date(value, small=False):
55 """Format a date to an human readable string."""
56 return date_formatter(value, tooltip=False, small=small)
57
58
59 @register.filter
60 def tooltip_date(value):
61 """Format a date to an human readable string. To be used in tooltip."""
62 return date_formatter(value, tooltip=True, small=False)
63
64
65 @register.filter
66 def humane_time(timestamp):
67 """Render time (number of second from epoch) to an human readable string"""
68 return format_date(datetime.fromtimestamp(timestamp))
69
70
71 @register.filter
72 def from_elasticsearch_date(value):
73 try:
74 date = datetime.strptime(value, '%Y-%m-%dT%H:%M:%S.%f')
75 except ValueError:
76 date = datetime.strptime(value, '%Y-%m-%dT%H:%M:%S')
77 return date
78
[end of zds/utils/templatetags/date.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/zds/featured/forms.py b/zds/featured/forms.py
--- a/zds/featured/forms.py
+++ b/zds/featured/forms.py
@@ -61,8 +61,8 @@
'%Y-%m-%d', '%d/%m/%Y' # day only
],
widget=forms.DateTimeInput(
- attrs={'placeholder': _('Exemple : 25/12/2016 10:00'), 'type': 'datetime-local'},
- format='%Y-%m-%dT%H:%M' # datetime field format
+ attrs={'placeholder': _('Exemple : 25/12/2016 10:00'), 'type': 'text'},
+ format='%d/%m/%Y %H:%M' # datetime field format
)
)
diff --git a/zds/utils/templatetags/date.py b/zds/utils/templatetags/date.py
--- a/zds/utils/templatetags/date.py
+++ b/zds/utils/templatetags/date.py
@@ -20,7 +20,7 @@
__ABS_HUMAN_TIME_FMT = _('%d %b %Y, %H:%M:%S')
-def date_formatter(value, tooltip, small):
+def date_formatter(value, tooltip, small, ignore_future=False):
"""
Format a date to an human readable string.
@@ -38,7 +38,7 @@
now = datetime.now()
now = now - timedelta(microseconds=now.microsecond)
- if value > now:
+ if value > now and not ignore_future:
return __DATE_FMT_FUTUR
else:
delta = now - value
@@ -52,10 +52,22 @@
@register.filter
def format_date(value, small=False):
- """Format a date to an human readable string."""
+ """
+ Format a date to an human readable string.
+ If ``value`` is in future it is replaced by "In the future".
+ """
return date_formatter(value, tooltip=False, small=small)
[email protected]
+def format_date_no_future(value):
+ """
+ Format a date to an human readable string.
+ If ``value`` is in future it is formatted as a normal date.
+ """
+ return date_formatter(value, tooltip=False, small=True, ignore_future=True)
+
+
@register.filter
def tooltip_date(value):
"""Format a date to an human readable string. To be used in tooltip."""
|
{"golden_diff": "diff --git a/zds/featured/forms.py b/zds/featured/forms.py\n--- a/zds/featured/forms.py\n+++ b/zds/featured/forms.py\n@@ -61,8 +61,8 @@\n '%Y-%m-%d', '%d/%m/%Y' # day only\n ],\n widget=forms.DateTimeInput(\n- attrs={'placeholder': _('Exemple : 25/12/2016 10:00'), 'type': 'datetime-local'},\n- format='%Y-%m-%dT%H:%M' # datetime field format\n+ attrs={'placeholder': _('Exemple : 25/12/2016 10:00'), 'type': 'text'},\n+ format='%d/%m/%Y %H:%M' # datetime field format\n )\n )\n \ndiff --git a/zds/utils/templatetags/date.py b/zds/utils/templatetags/date.py\n--- a/zds/utils/templatetags/date.py\n+++ b/zds/utils/templatetags/date.py\n@@ -20,7 +20,7 @@\n __ABS_HUMAN_TIME_FMT = _('%d %b %Y, %H:%M:%S')\n \n \n-def date_formatter(value, tooltip, small):\n+def date_formatter(value, tooltip, small, ignore_future=False):\n \"\"\"\n Format a date to an human readable string.\n \n@@ -38,7 +38,7 @@\n now = datetime.now()\n now = now - timedelta(microseconds=now.microsecond)\n \n- if value > now:\n+ if value > now and not ignore_future:\n return __DATE_FMT_FUTUR\n else:\n delta = now - value\n@@ -52,10 +52,22 @@\n \n @register.filter\n def format_date(value, small=False):\n- \"\"\"Format a date to an human readable string.\"\"\"\n+ \"\"\"\n+ Format a date to an human readable string.\n+ If ``value`` is in future it is replaced by \"In the future\".\n+ \"\"\"\n return date_formatter(value, tooltip=False, small=small)\n \n \[email protected]\n+def format_date_no_future(value):\n+ \"\"\"\n+ Format a date to an human readable string.\n+ If ``value`` is in future it is formatted as a normal date.\n+ \"\"\"\n+ return date_formatter(value, tooltip=False, small=True, ignore_future=True)\n+\n+\n @register.filter\n def tooltip_date(value):\n \"\"\"Format a date to an human readable string. To be used in tooltip.\"\"\"\n", "issue": "Date de publication future des News\nBonjour,\r\n\r\n\u00c7a ne regarde certainement que moi mais...\r\n\r\n\r\n\r\nC'est pas logique. \u00ab Dans le futur \u00bb n'apporte **aucune information utile**. L\u2019int\u00e9r\u00eat des news c'est d'avoir la date future, pour pouvoir g\u00e9r\u00e9 et v\u00e9rifier que la publication sera \u00e0 la bonne date. L\u00e0, il faut ouvrir la news, et lire la date dans un format cryptique.\r\n\r\n\r\n\r\nIl y a certainement plus claire comme format.\r\n\r\nC'est tellement compliqu\u00e9 qu'au final, j'\u00e9cris juste tout dans un fichier ou sur un boue de papier.\r\n\r\nQuand les 10 prochains contenus sont marqu\u00e9s \u00ab Dans le futur \u00bb franchement on a le sentiment d'\u00eatre pris pour un cr\u00e9tin par l'IHM.\r\n\r\n______________________\r\n\r\n\r\nBref, c'est g\u00e9r\u00e9 par la fonction `format_date`. \r\n\u00c0 votre avis comment on pourrait faire pour am\u00e9liorer \u00e7a ?\n", "before_files": [{"content": "from crispy_forms.bootstrap import StrictButton\nfrom crispy_forms.helper import FormHelper\nfrom crispy_forms.layout import Layout, Field, ButtonHolder\nfrom django import forms\nfrom django.urls import reverse\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom zds.featured.models import FeaturedResource, FeaturedMessage\n\n\nclass FeaturedResourceForm(forms.ModelForm):\n class Meta:\n model = FeaturedResource\n\n fields = ['title', 'type', 'authors', 'image_url', 'url']\n\n widgets = {\n 'title': forms.TextInput(\n attrs={\n 'placeholder': _('Titre de la Une')\n }\n ),\n\n 'type': forms.TextInput(\n attrs={\n 'placeholder': _('ex: Un projet, Un article, Un tutoriel...')\n }\n ),\n\n 'authors': forms.TextInput(\n attrs={\n 'placeholder': _('Des auteurs (ou pas)\u00a0?')\n }\n ),\n\n 'image_url': forms.URLInput(\n attrs={\n 'placeholder': _('Lien vers l\\'image de la Une (dimensions: 228x228px).')\n }\n ),\n\n 'url': forms.URLInput(\n attrs={\n 'placeholder': _('Lien vers la ressource.')\n }\n )\n }\n\n major_update = forms.BooleanField(\n label=_('Mise \u00e0 jour majeure (fera passer la Une en premi\u00e8re position lors d\\'un changement)'),\n initial=False,\n required=False\n )\n\n pubdate = forms.DateTimeField(\n label=_('Date de publication (exemple: 25/12/2015 15:00 ou 2015-12-25T15:00)'),\n input_formats=[\n '%d/%m/%Y %H:%M:%S', '%Y-%m-%d %H:%M:%S', # full format with second\n '%Y-%m-%dT%H:%M', # datetime field format\n '%Y-%m-%d %H:%M', '%d/%m/%Y %H:%M', # without second\n '%Y-%m-%d', '%d/%m/%Y' # day only\n ],\n widget=forms.DateTimeInput(\n attrs={'placeholder': _('Exemple : 25/12/2016 10:00'), 'type': 'datetime-local'},\n format='%Y-%m-%dT%H:%M' # datetime field format\n )\n )\n\n request = forms.IntegerField(widget=forms.HiddenInput(), required=False)\n\n def __init__(self, *args, **kwargs):\n hide_major_update_field = kwargs.pop('hide_major_update_field', False)\n\n super(FeaturedResourceForm, self).__init__(*args, **kwargs)\n self.helper = FormHelper()\n self.helper.form_class = 'content-wrapper'\n self.helper.form_method = 'post'\n self.helper.form_action = reverse('featured-resource-create')\n\n fields = [\n Field('request'),\n Field('title'),\n Field('type'),\n Field('authors'),\n Field('image_url'),\n Field('url')\n ]\n\n if not hide_major_update_field:\n fields.append(Field('major_update'))\n\n fields.extend([\n Field('pubdate'),\n ButtonHolder(\n StrictButton(_('Enregistrer'), type='submit'),\n )\n ])\n\n self.helper.layout = Layout(*fields)\n\n\nclass FeaturedMessageForm(forms.ModelForm):\n class Meta:\n model = FeaturedMessage\n\n fields = ['hook', 'message', 'url']\n\n widgets = {\n 'hook': forms.TextInput(\n attrs={\n 'placeholder': _('Mot d\\'accroche court (\"Nouveau\u00a0!\")')\n }\n ),\n\n 'message': forms.TextInput(\n attrs={\n 'placeholder': _('Message \u00e0 afficher')\n }\n ),\n\n 'url': forms.URLInput(\n attrs={\n 'placeholder': _('Lien vers la description de la ressource')\n }\n )\n }\n\n def __init__(self, *args, **kwargs):\n super(FeaturedMessageForm, self).__init__(*args, **kwargs)\n self.helper = FormHelper()\n self.helper.form_class = 'content-wrapper'\n self.helper.form_method = 'post'\n self.helper.form_action = reverse('featured-message-create')\n\n self.helper.layout = Layout(\n Field('hook'),\n Field('message'),\n Field('url'),\n ButtonHolder(\n StrictButton(_('Enregistrer'), type='submit'),\n ),\n )\n", "path": "zds/featured/forms.py"}, {"content": "from datetime import datetime, timedelta\n\nfrom django import template\nfrom django.contrib.humanize.templatetags.humanize import naturaltime\nfrom django.template.defaultfilters import date\nfrom django.utils.timezone import get_default_timezone\nfrom django.utils.translation import ugettext_lazy as _\n\nregister = template.Library()\n\n\"\"\"\nDefine a filter to format date.\n\"\"\"\n\n# Date formatting constants\n\n__DATE_FMT_FUTUR = _('Dans le futur')\n__ABS_DATE_FMT_SMALL = _(r'd/m/y \u00e0 H\\hi') # Small format\n__ABS_DATE_FMT_NORMAL = _(r'l d F Y \u00e0 H\\hi') # Normal format\n__ABS_HUMAN_TIME_FMT = _('%d %b %Y, %H:%M:%S')\n\n\ndef date_formatter(value, tooltip, small):\n \"\"\"\n Format a date to an human readable string.\n\n :param value: Date to format.\n :param bool tooltip: if `True`, format date to a tooltip label.\n :param bool small: if `True`, create a shorter string.\n :return:\n \"\"\"\n if not isinstance(value, datetime):\n return value\n\n if getattr(value, 'tzinfo', None):\n now = datetime.now(get_default_timezone())\n else:\n now = datetime.now()\n now = now - timedelta(microseconds=now.microsecond)\n\n if value > now:\n return __DATE_FMT_FUTUR\n else:\n delta = now - value\n # Natural time for today, absolute date after.\n # Reverse if in tooltip\n if (delta.days == 0) != tooltip:\n return naturaltime(value)\n else:\n return date(value, str(__ABS_DATE_FMT_SMALL if small else __ABS_DATE_FMT_NORMAL))\n\n\[email protected]\ndef format_date(value, small=False):\n \"\"\"Format a date to an human readable string.\"\"\"\n return date_formatter(value, tooltip=False, small=small)\n\n\[email protected]\ndef tooltip_date(value):\n \"\"\"Format a date to an human readable string. To be used in tooltip.\"\"\"\n return date_formatter(value, tooltip=True, small=False)\n\n\[email protected]\ndef humane_time(timestamp):\n \"\"\"Render time (number of second from epoch) to an human readable string\"\"\"\n return format_date(datetime.fromtimestamp(timestamp))\n\n\[email protected]\ndef from_elasticsearch_date(value):\n try:\n date = datetime.strptime(value, '%Y-%m-%dT%H:%M:%S.%f')\n except ValueError:\n date = datetime.strptime(value, '%Y-%m-%dT%H:%M:%S')\n return date\n", "path": "zds/utils/templatetags/date.py"}]}
| 2,931 | 562 |
gh_patches_debug_17091
|
rasdani/github-patches
|
git_diff
|
Kinto__kinto-493
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add creation date and current kinto version to generated config file
Using comments for example:
``` ini
# Created at Thu, 03 Mar 2016 17:02:37 +0100
# Using Kinto version 1.11.2
[server:main]
use = egg:waitress#main
host = 0.0.0.0
port = 8888
```
</issue>
<code>
[start of kinto/config/__init__.py]
1 import os
2 import codecs
3
4 from cliquet import utils as cliquet_utils
5
6 from kinto import logger
7
8 HERE = os.path.abspath(os.path.dirname(__file__))
9
10
11 def render_template(template, destination, **kwargs):
12 template = os.path.join(HERE, template)
13 folder = os.path.dirname(destination)
14
15 if folder and not os.path.exists(folder):
16 os.makedirs(folder)
17
18 logger.info("Created config {}".format(os.path.abspath(destination)))
19
20 with codecs.open(template, 'r', encoding='utf-8') as f:
21 raw_template = f.read()
22 rendered = raw_template.format(**kwargs)
23 with codecs.open(destination, 'w+', encoding='utf-8') as output:
24 output.write(rendered)
25
26
27 def init(config_file, backend):
28 values = {}
29
30 values['secret'] = cliquet_utils.random_bytes_hex(32)
31
32 values['storage_backend'] = "cliquet.storage.%s" % backend
33 values['cache_backend'] = "cliquet.cache.%s" % backend
34 values['permission_backend'] = "cliquet.permission.%s" % backend
35
36 if backend == 'postgresql':
37 postgresql_url = "postgres://postgres:postgres@localhost/postgres"
38 values['storage_url'] = postgresql_url
39 values['cache_url'] = postgresql_url
40 values['permission_url'] = postgresql_url
41
42 elif backend == 'redis':
43 redis_url = "redis://localhost:6379"
44 values['storage_url'] = redis_url + "/1"
45 values['cache_url'] = redis_url + "/2"
46 values['permission_url'] = redis_url + "/3"
47
48 else:
49 values['storage_url'] = ''
50 values['cache_url'] = ''
51 values['permission_url'] = ''
52
53 render_template("kinto.tpl", config_file, **values)
54
[end of kinto/config/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kinto/config/__init__.py b/kinto/config/__init__.py
--- a/kinto/config/__init__.py
+++ b/kinto/config/__init__.py
@@ -1,9 +1,11 @@
import os
import codecs
+from time import strftime
from cliquet import utils as cliquet_utils
from kinto import logger
+from kinto import __version__
HERE = os.path.abspath(os.path.dirname(__file__))
@@ -29,6 +31,9 @@
values['secret'] = cliquet_utils.random_bytes_hex(32)
+ values['kinto_version'] = __version__
+ values['config_file_timestamp'] = strftime('%a, %d %b %Y %H:%M:%S %z')
+
values['storage_backend'] = "cliquet.storage.%s" % backend
values['cache_backend'] = "cliquet.cache.%s" % backend
values['permission_backend'] = "cliquet.permission.%s" % backend
|
{"golden_diff": "diff --git a/kinto/config/__init__.py b/kinto/config/__init__.py\n--- a/kinto/config/__init__.py\n+++ b/kinto/config/__init__.py\n@@ -1,9 +1,11 @@\n import os\n import codecs\n+from time import strftime\n \n from cliquet import utils as cliquet_utils\n \n from kinto import logger\n+from kinto import __version__\n \n HERE = os.path.abspath(os.path.dirname(__file__))\n \n@@ -29,6 +31,9 @@\n \n values['secret'] = cliquet_utils.random_bytes_hex(32)\n \n+ values['kinto_version'] = __version__\n+ values['config_file_timestamp'] = strftime('%a, %d %b %Y %H:%M:%S %z')\n+\n values['storage_backend'] = \"cliquet.storage.%s\" % backend\n values['cache_backend'] = \"cliquet.cache.%s\" % backend\n values['permission_backend'] = \"cliquet.permission.%s\" % backend\n", "issue": "Add creation date and current kinto version to generated config file\nUsing comments for example:\n\n``` ini\n# Created at Thu, 03 Mar 2016 17:02:37 +0100\n# Using Kinto version 1.11.2\n\n[server:main]\nuse = egg:waitress#main\nhost = 0.0.0.0\nport = 8888\n\n```\n\n", "before_files": [{"content": "import os\nimport codecs\n\nfrom cliquet import utils as cliquet_utils\n\nfrom kinto import logger\n\nHERE = os.path.abspath(os.path.dirname(__file__))\n\n\ndef render_template(template, destination, **kwargs):\n template = os.path.join(HERE, template)\n folder = os.path.dirname(destination)\n\n if folder and not os.path.exists(folder):\n os.makedirs(folder)\n\n logger.info(\"Created config {}\".format(os.path.abspath(destination)))\n\n with codecs.open(template, 'r', encoding='utf-8') as f:\n raw_template = f.read()\n rendered = raw_template.format(**kwargs)\n with codecs.open(destination, 'w+', encoding='utf-8') as output:\n output.write(rendered)\n\n\ndef init(config_file, backend):\n values = {}\n\n values['secret'] = cliquet_utils.random_bytes_hex(32)\n\n values['storage_backend'] = \"cliquet.storage.%s\" % backend\n values['cache_backend'] = \"cliquet.cache.%s\" % backend\n values['permission_backend'] = \"cliquet.permission.%s\" % backend\n\n if backend == 'postgresql':\n postgresql_url = \"postgres://postgres:postgres@localhost/postgres\"\n values['storage_url'] = postgresql_url\n values['cache_url'] = postgresql_url\n values['permission_url'] = postgresql_url\n\n elif backend == 'redis':\n redis_url = \"redis://localhost:6379\"\n values['storage_url'] = redis_url + \"/1\"\n values['cache_url'] = redis_url + \"/2\"\n values['permission_url'] = redis_url + \"/3\"\n\n else:\n values['storage_url'] = ''\n values['cache_url'] = ''\n values['permission_url'] = ''\n\n render_template(\"kinto.tpl\", config_file, **values)\n", "path": "kinto/config/__init__.py"}]}
| 1,138 | 225 |
gh_patches_debug_12115
|
rasdani/github-patches
|
git_diff
|
Miserlou__Zappa-2049
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Syntax warning due to comparison of literals using is in Python 3.8
## Context
Syntax warning due to comparison of literals using is.
## Possible Fix
Use == and != as suggested in the warning
## Steps to Reproduce
```
find . -iname '*.py' | xargs -P 4 -I{} python -Walways -m py_compile {}
./zappa/core.py:2026: SyntaxWarning: "is" with a literal. Did you mean "=="?
elif key is 'LambdaConfig':
./zappa/cli.py:1379: SyntaxWarning: "is" with a literal. Did you mean "=="?
if token.count('-') is 4 and token.replace('-', '').isalnum():
./zappa/cli.py:2513: SyntaxWarning: "is" with a literal. Did you mean "=="?
if (token.count('.') is 3 and token.replace('.', '').isnumeric()):
./zappa/cli.py:2548: SyntaxWarning: "is" with a literal. Did you mean "=="?
if token.count('-') is 4 and token.replace('-', '').isalnum():
./zappa/cli.py:2555: SyntaxWarning: "is" with a literal. Did you mean "=="?
if token.count('.') is 3 and token.replace('.', '').isnumeric():
./example/authmodule.py:78: DeprecationWarning: invalid escape sequence \*
pathRegex = "^[/.a-zA-Z0-9-\*]+$"
```
## Your Environment
<!--- Include as many relevant details about the environment you experienced the bug in -->
* Zappa version used: master
* Operating System and Python version: Python 3.8
* The output of `pip freeze`:
* Link to your project (optional):
* Your `zappa_settings.json`:
</issue>
<code>
[start of example/authmodule.py]
1 """
2 Copyright 2015-2016 Amazon.com, Inc. or its affiliates. All Rights Reserved.
3 Licensed under the Apache License, Version 2.0 (the "License"). You may not use this file except in compliance with the License. A copy of the License is located at
4 http://aws.amazon.com/apache2.0/
5 or in the "license" file accompanying this file. This file is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
6 """
7 import re
8 import time
9 import pprint
10 import json
11
12
13 def lambda_handler(event, context):
14 print("Client token: " + event['authorizationToken'])
15 print("Method ARN: " + event['methodArn'])
16 """validate the incoming token"""
17 """and produce the principal user identifier associated with the token"""
18
19 """this could be accomplished in a number of ways:"""
20 """1. Call out to OAuth provider"""
21 """2. Decode a JWT token inline"""
22 """3. Lookup in a self-managed DB"""
23 principalId = "user|a1b2c3d4"
24
25 """you can send a 401 Unauthorized response to the client by failing like so:"""
26 """raise Exception('Unauthorized')"""
27
28 """if the token is valid, a policy must be generated which will allow or deny access to the client"""
29
30 """if access is denied, the client will receive a 403 Access Denied response"""
31 """if access is allowed, API Gateway will proceed with the backend integration configured on the method that was called"""
32
33 """this function must generate a policy that is associated with the recognized principal user identifier."""
34 """depending on your use case, you might store policies in a DB, or generate them on the fly"""
35
36 """keep in mind, the policy is cached for 5 minutes by default (TTL is configurable in the authorizer)"""
37 """and will apply to subsequent calls to any method/resource in the RestApi"""
38 """made with the same token"""
39
40 """the example policy below denies access to all resources in the RestApi"""
41 tmp = event['methodArn'].split(':')
42 apiGatewayArnTmp = tmp[5].split('/')
43 awsAccountId = tmp[4]
44
45 policy = AuthPolicy(principalId, awsAccountId)
46 policy.restApiId = apiGatewayArnTmp[0]
47 policy.region = tmp[3]
48 policy.stage = apiGatewayArnTmp[1]
49
50 # Blueprint denies all methods by default
51 # policy.denyAllMethods()
52
53 # Example allows all methods
54 policy.allowAllMethods()
55
56 """policy.allowMethod(HttpVerb.GET, "/pets/*")"""
57
58 """finally, build the policy and exit the function using return"""
59 return policy.build()
60
61 class HttpVerb:
62 GET = "GET"
63 POST = "POST"
64 PUT = "PUT"
65 PATCH = "PATCH"
66 HEAD = "HEAD"
67 DELETE = "DELETE"
68 OPTIONS = "OPTIONS"
69 ALL = "*"
70
71 class AuthPolicy:
72 awsAccountId = ""
73 """The AWS account id the policy will be generated for. This is used to create the method ARNs."""
74 principalId = ""
75 """The principal used for the policy, this should be a unique identifier for the end user."""
76 version = "2012-10-17"
77 """The policy version used for the evaluation. This should always be '2012-10-17'"""
78 pathRegex = "^[/.a-zA-Z0-9-\*]+$"
79 """The regular expression used to validate resource paths for the policy"""
80
81 """these are the internal lists of allowed and denied methods. These are lists
82 of objects and each object has 2 properties: A resource ARN and a nullable
83 conditions statement.
84 the build method processes these lists and generates the appropriate
85 statements for the final policy"""
86 allowMethods = []
87 denyMethods = []
88
89 restApiId = "*"
90 """The API Gateway API id. By default this is set to '*'"""
91 region = "*"
92 """The region where the API is deployed. By default this is set to '*'"""
93 stage = "*"
94 """The name of the stage used in the policy. By default this is set to '*'"""
95
96 def __init__(self, principal, awsAccountId):
97 self.awsAccountId = awsAccountId
98 self.principalId = principal
99 self.allowMethods = []
100 self.denyMethods = []
101
102 def _addMethod(self, effect, verb, resource, conditions):
103 """Adds a method to the internal lists of allowed or denied methods. Each object in
104 the internal list contains a resource ARN and a condition statement. The condition
105 statement can be null."""
106 if verb != "*" and not hasattr(HttpVerb, verb):
107 raise NameError("Invalid HTTP verb " + verb + ". Allowed verbs in HttpVerb class")
108 resourcePattern = re.compile(self.pathRegex)
109 if not resourcePattern.match(resource):
110 raise NameError("Invalid resource path: " + resource + ". Path should match " + self.pathRegex)
111
112 if resource[:1] == "/":
113 resource = resource[1:]
114
115 resourceArn = ("arn:aws:execute-api:" +
116 self.region + ":" +
117 self.awsAccountId + ":" +
118 self.restApiId + "/" +
119 self.stage + "/" +
120 verb + "/" +
121 resource)
122
123 if effect.lower() == "allow":
124 self.allowMethods.append({
125 'resourceArn' : resourceArn,
126 'conditions' : conditions
127 })
128 elif effect.lower() == "deny":
129 self.denyMethods.append({
130 'resourceArn' : resourceArn,
131 'conditions' : conditions
132 })
133
134 def _getEmptyStatement(self, effect):
135 """Returns an empty statement object prepopulated with the correct action and the
136 desired effect."""
137 statement = {
138 'Action': 'execute-api:Invoke',
139 'Effect': effect[:1].upper() + effect[1:].lower(),
140 'Resource': []
141 }
142
143 return statement
144
145 def _getStatementForEffect(self, effect, methods):
146 """This function loops over an array of objects containing a resourceArn and
147 conditions statement and generates the array of statements for the policy."""
148 statements = []
149
150 if len(methods) > 0:
151 statement = self._getEmptyStatement(effect)
152
153 for curMethod in methods:
154 if curMethod['conditions'] is None or len(curMethod['conditions']) == 0:
155 statement['Resource'].append(curMethod['resourceArn'])
156 else:
157 conditionalStatement = self._getEmptyStatement(effect)
158 conditionalStatement['Resource'].append(curMethod['resourceArn'])
159 conditionalStatement['Condition'] = curMethod['conditions']
160 statements.append(conditionalStatement)
161
162 statements.append(statement)
163
164 return statements
165
166 def allowAllMethods(self):
167 """Adds a '*' allow to the policy to authorize access to all methods of an API"""
168 self._addMethod("Allow", HttpVerb.ALL, "*", [])
169
170 def denyAllMethods(self):
171 """Adds a '*' allow to the policy to deny access to all methods of an API"""
172 self._addMethod("Deny", HttpVerb.ALL, "*", [])
173
174 def allowMethod(self, verb, resource):
175 """Adds an API Gateway method (Http verb + Resource path) to the list of allowed
176 methods for the policy"""
177 self._addMethod("Allow", verb, resource, [])
178
179 def denyMethod(self, verb, resource):
180 """Adds an API Gateway method (Http verb + Resource path) to the list of denied
181 methods for the policy"""
182 self._addMethod("Deny", verb, resource, [])
183
184 def allowMethodWithConditions(self, verb, resource, conditions):
185 """Adds an API Gateway method (Http verb + Resource path) to the list of allowed
186 methods and includes a condition for the policy statement. More on AWS policy
187 conditions here: http://docs.aws.amazon.com/IAM/latest/UserGuide/reference_policies_elements.html#Condition"""
188 self._addMethod("Allow", verb, resource, conditions)
189
190 def denyMethodWithConditions(self, verb, resource, conditions):
191 """Adds an API Gateway method (Http verb + Resource path) to the list of denied
192 methods and includes a condition for the policy statement. More on AWS policy
193 conditions here: http://docs.aws.amazon.com/IAM/latest/UserGuide/reference_policies_elements.html#Condition"""
194 self._addMethod("Deny", verb, resource, conditions)
195
196 def build(self):
197 """Generates the policy document based on the internal lists of allowed and denied
198 conditions. This will generate a policy with two main statements for the effect:
199 one statement for Allow and one statement for Deny.
200 Methods that includes conditions will have their own statement in the policy."""
201 if ((self.allowMethods is None or len(self.allowMethods) == 0) and
202 (self.denyMethods is None or len(self.denyMethods) == 0)):
203 raise NameError("No statements defined for the policy")
204
205 policy = {
206 'principalId' : self.principalId,
207 'policyDocument' : {
208 'Version' : self.version,
209 'Statement' : []
210 }
211 }
212
213 policy['policyDocument']['Statement'].extend(self._getStatementForEffect("Allow", self.allowMethods))
214 policy['policyDocument']['Statement'].extend(self._getStatementForEffect("Deny", self.denyMethods))
215
216 return policy
217
[end of example/authmodule.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/example/authmodule.py b/example/authmodule.py
--- a/example/authmodule.py
+++ b/example/authmodule.py
@@ -75,7 +75,7 @@
"""The principal used for the policy, this should be a unique identifier for the end user."""
version = "2012-10-17"
"""The policy version used for the evaluation. This should always be '2012-10-17'"""
- pathRegex = "^[/.a-zA-Z0-9-\*]+$"
+ pathRegex = r"^[/.a-zA-Z0-9-\*]+$"
"""The regular expression used to validate resource paths for the policy"""
"""these are the internal lists of allowed and denied methods. These are lists
|
{"golden_diff": "diff --git a/example/authmodule.py b/example/authmodule.py\n--- a/example/authmodule.py\n+++ b/example/authmodule.py\n@@ -75,7 +75,7 @@\n \"\"\"The principal used for the policy, this should be a unique identifier for the end user.\"\"\"\n version = \"2012-10-17\"\n \"\"\"The policy version used for the evaluation. This should always be '2012-10-17'\"\"\"\n- pathRegex = \"^[/.a-zA-Z0-9-\\*]+$\"\n+ pathRegex = r\"^[/.a-zA-Z0-9-\\*]+$\"\n \"\"\"The regular expression used to validate resource paths for the policy\"\"\"\n \n \"\"\"these are the internal lists of allowed and denied methods. These are lists\n", "issue": "Syntax warning due to comparison of literals using is in Python 3.8\n## Context\r\n\r\nSyntax warning due to comparison of literals using is.\r\n\r\n## Possible Fix\r\n\r\nUse == and != as suggested in the warning\r\n\r\n## Steps to Reproduce\r\n\r\n```\r\nfind . -iname '*.py' | xargs -P 4 -I{} python -Walways -m py_compile {} \r\n\r\n./zappa/core.py:2026: SyntaxWarning: \"is\" with a literal. Did you mean \"==\"?\r\n elif key is 'LambdaConfig':\r\n./zappa/cli.py:1379: SyntaxWarning: \"is\" with a literal. Did you mean \"==\"?\r\n if token.count('-') is 4 and token.replace('-', '').isalnum():\r\n./zappa/cli.py:2513: SyntaxWarning: \"is\" with a literal. Did you mean \"==\"?\r\n if (token.count('.') is 3 and token.replace('.', '').isnumeric()):\r\n./zappa/cli.py:2548: SyntaxWarning: \"is\" with a literal. Did you mean \"==\"?\r\n if token.count('-') is 4 and token.replace('-', '').isalnum():\r\n./zappa/cli.py:2555: SyntaxWarning: \"is\" with a literal. Did you mean \"==\"?\r\n if token.count('.') is 3 and token.replace('.', '').isnumeric():\r\n./example/authmodule.py:78: DeprecationWarning: invalid escape sequence \\*\r\n pathRegex = \"^[/.a-zA-Z0-9-\\*]+$\"\r\n```\r\n\r\n## Your Environment\r\n<!--- Include as many relevant details about the environment you experienced the bug in -->\r\n* Zappa version used: master\r\n* Operating System and Python version: Python 3.8\r\n* The output of `pip freeze`:\r\n* Link to your project (optional):\r\n* Your `zappa_settings.json`: \r\n\n", "before_files": [{"content": "\"\"\"\nCopyright 2015-2016 Amazon.com, Inc. or its affiliates. All Rights Reserved.\nLicensed under the Apache License, Version 2.0 (the \"License\"). You may not use this file except in compliance with the License. A copy of the License is located at\n http://aws.amazon.com/apache2.0/\nor in the \"license\" file accompanying this file. This file is distributed on an \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.\n\"\"\"\nimport re\nimport time\nimport pprint\nimport json\n\n\ndef lambda_handler(event, context):\n print(\"Client token: \" + event['authorizationToken'])\n print(\"Method ARN: \" + event['methodArn'])\n \"\"\"validate the incoming token\"\"\"\n \"\"\"and produce the principal user identifier associated with the token\"\"\"\n\n \"\"\"this could be accomplished in a number of ways:\"\"\"\n \"\"\"1. Call out to OAuth provider\"\"\"\n \"\"\"2. Decode a JWT token inline\"\"\"\n \"\"\"3. Lookup in a self-managed DB\"\"\"\n principalId = \"user|a1b2c3d4\"\n\n \"\"\"you can send a 401 Unauthorized response to the client by failing like so:\"\"\"\n \"\"\"raise Exception('Unauthorized')\"\"\"\n\n \"\"\"if the token is valid, a policy must be generated which will allow or deny access to the client\"\"\"\n\n \"\"\"if access is denied, the client will receive a 403 Access Denied response\"\"\"\n \"\"\"if access is allowed, API Gateway will proceed with the backend integration configured on the method that was called\"\"\"\n\n \"\"\"this function must generate a policy that is associated with the recognized principal user identifier.\"\"\"\n \"\"\"depending on your use case, you might store policies in a DB, or generate them on the fly\"\"\"\n\n \"\"\"keep in mind, the policy is cached for 5 minutes by default (TTL is configurable in the authorizer)\"\"\"\n \"\"\"and will apply to subsequent calls to any method/resource in the RestApi\"\"\"\n \"\"\"made with the same token\"\"\"\n\n \"\"\"the example policy below denies access to all resources in the RestApi\"\"\"\n tmp = event['methodArn'].split(':')\n apiGatewayArnTmp = tmp[5].split('/')\n awsAccountId = tmp[4]\n\n policy = AuthPolicy(principalId, awsAccountId)\n policy.restApiId = apiGatewayArnTmp[0]\n policy.region = tmp[3]\n policy.stage = apiGatewayArnTmp[1]\n\n # Blueprint denies all methods by default\n # policy.denyAllMethods()\n\n # Example allows all methods\n policy.allowAllMethods()\n\n \"\"\"policy.allowMethod(HttpVerb.GET, \"/pets/*\")\"\"\"\n\n \"\"\"finally, build the policy and exit the function using return\"\"\"\n return policy.build()\n\nclass HttpVerb:\n GET = \"GET\"\n POST = \"POST\"\n PUT = \"PUT\"\n PATCH = \"PATCH\"\n HEAD = \"HEAD\"\n DELETE = \"DELETE\"\n OPTIONS = \"OPTIONS\"\n ALL = \"*\"\n\nclass AuthPolicy:\n awsAccountId = \"\"\n \"\"\"The AWS account id the policy will be generated for. This is used to create the method ARNs.\"\"\"\n principalId = \"\"\n \"\"\"The principal used for the policy, this should be a unique identifier for the end user.\"\"\"\n version = \"2012-10-17\"\n \"\"\"The policy version used for the evaluation. This should always be '2012-10-17'\"\"\"\n pathRegex = \"^[/.a-zA-Z0-9-\\*]+$\"\n \"\"\"The regular expression used to validate resource paths for the policy\"\"\"\n\n \"\"\"these are the internal lists of allowed and denied methods. These are lists\n of objects and each object has 2 properties: A resource ARN and a nullable\n conditions statement.\n the build method processes these lists and generates the appropriate\n statements for the final policy\"\"\"\n allowMethods = []\n denyMethods = []\n\n restApiId = \"*\"\n \"\"\"The API Gateway API id. By default this is set to '*'\"\"\"\n region = \"*\"\n \"\"\"The region where the API is deployed. By default this is set to '*'\"\"\"\n stage = \"*\"\n \"\"\"The name of the stage used in the policy. By default this is set to '*'\"\"\"\n\n def __init__(self, principal, awsAccountId):\n self.awsAccountId = awsAccountId\n self.principalId = principal\n self.allowMethods = []\n self.denyMethods = []\n\n def _addMethod(self, effect, verb, resource, conditions):\n \"\"\"Adds a method to the internal lists of allowed or denied methods. Each object in\n the internal list contains a resource ARN and a condition statement. The condition\n statement can be null.\"\"\"\n if verb != \"*\" and not hasattr(HttpVerb, verb):\n raise NameError(\"Invalid HTTP verb \" + verb + \". Allowed verbs in HttpVerb class\")\n resourcePattern = re.compile(self.pathRegex)\n if not resourcePattern.match(resource):\n raise NameError(\"Invalid resource path: \" + resource + \". Path should match \" + self.pathRegex)\n\n if resource[:1] == \"/\":\n resource = resource[1:]\n\n resourceArn = (\"arn:aws:execute-api:\" +\n self.region + \":\" +\n self.awsAccountId + \":\" +\n self.restApiId + \"/\" +\n self.stage + \"/\" +\n verb + \"/\" +\n resource)\n\n if effect.lower() == \"allow\":\n self.allowMethods.append({\n 'resourceArn' : resourceArn,\n 'conditions' : conditions\n })\n elif effect.lower() == \"deny\":\n self.denyMethods.append({\n 'resourceArn' : resourceArn,\n 'conditions' : conditions\n })\n\n def _getEmptyStatement(self, effect):\n \"\"\"Returns an empty statement object prepopulated with the correct action and the\n desired effect.\"\"\"\n statement = {\n 'Action': 'execute-api:Invoke',\n 'Effect': effect[:1].upper() + effect[1:].lower(),\n 'Resource': []\n }\n\n return statement\n\n def _getStatementForEffect(self, effect, methods):\n \"\"\"This function loops over an array of objects containing a resourceArn and\n conditions statement and generates the array of statements for the policy.\"\"\"\n statements = []\n\n if len(methods) > 0:\n statement = self._getEmptyStatement(effect)\n\n for curMethod in methods:\n if curMethod['conditions'] is None or len(curMethod['conditions']) == 0:\n statement['Resource'].append(curMethod['resourceArn'])\n else:\n conditionalStatement = self._getEmptyStatement(effect)\n conditionalStatement['Resource'].append(curMethod['resourceArn'])\n conditionalStatement['Condition'] = curMethod['conditions']\n statements.append(conditionalStatement)\n\n statements.append(statement)\n\n return statements\n\n def allowAllMethods(self):\n \"\"\"Adds a '*' allow to the policy to authorize access to all methods of an API\"\"\"\n self._addMethod(\"Allow\", HttpVerb.ALL, \"*\", [])\n\n def denyAllMethods(self):\n \"\"\"Adds a '*' allow to the policy to deny access to all methods of an API\"\"\"\n self._addMethod(\"Deny\", HttpVerb.ALL, \"*\", [])\n\n def allowMethod(self, verb, resource):\n \"\"\"Adds an API Gateway method (Http verb + Resource path) to the list of allowed\n methods for the policy\"\"\"\n self._addMethod(\"Allow\", verb, resource, [])\n\n def denyMethod(self, verb, resource):\n \"\"\"Adds an API Gateway method (Http verb + Resource path) to the list of denied\n methods for the policy\"\"\"\n self._addMethod(\"Deny\", verb, resource, [])\n\n def allowMethodWithConditions(self, verb, resource, conditions):\n \"\"\"Adds an API Gateway method (Http verb + Resource path) to the list of allowed\n methods and includes a condition for the policy statement. More on AWS policy\n conditions here: http://docs.aws.amazon.com/IAM/latest/UserGuide/reference_policies_elements.html#Condition\"\"\"\n self._addMethod(\"Allow\", verb, resource, conditions)\n\n def denyMethodWithConditions(self, verb, resource, conditions):\n \"\"\"Adds an API Gateway method (Http verb + Resource path) to the list of denied\n methods and includes a condition for the policy statement. More on AWS policy\n conditions here: http://docs.aws.amazon.com/IAM/latest/UserGuide/reference_policies_elements.html#Condition\"\"\"\n self._addMethod(\"Deny\", verb, resource, conditions)\n\n def build(self):\n \"\"\"Generates the policy document based on the internal lists of allowed and denied\n conditions. This will generate a policy with two main statements for the effect:\n one statement for Allow and one statement for Deny.\n Methods that includes conditions will have their own statement in the policy.\"\"\"\n if ((self.allowMethods is None or len(self.allowMethods) == 0) and\n (self.denyMethods is None or len(self.denyMethods) == 0)):\n raise NameError(\"No statements defined for the policy\")\n\n policy = {\n 'principalId' : self.principalId,\n 'policyDocument' : {\n 'Version' : self.version,\n 'Statement' : []\n }\n }\n\n policy['policyDocument']['Statement'].extend(self._getStatementForEffect(\"Allow\", self.allowMethods))\n policy['policyDocument']['Statement'].extend(self._getStatementForEffect(\"Deny\", self.denyMethods))\n\n return policy\n", "path": "example/authmodule.py"}]}
| 3,532 | 171 |
gh_patches_debug_7807
|
rasdani/github-patches
|
git_diff
|
locustio__locust-2609
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Report][Modern-UI] HTML report is blank
### Prerequisites
- [X] I am using [the latest version of Locust](https://github.com/locustio/locust/releases/)
- [X] I am reporting a bug, not asking a question
### Description
Run a test then open the HTML report -> Noticed that it is blank
Note: This bug occurs from 2.22.0, and did not occur on 2.21.0

### Command line
locust -f SimpleWeb.py -u 100 -r 10 -t 30s --html=samplelocust.html
### Locustfile contents
```python3
from locust import FastHttpUser, HttpUser, between, constant_pacing, events, task
from loguru import logger
class QuickstartUser(FastHttpUser):
wait_time = between(2, 5)
host = "http://127.0.0.1:5000"
# begin = time.time()
@task()
def get_tasks_1(self):
res = None
try:
payload = {}
headers = {"Cache-Control": "max-age=0, no-cache, no-store, must-revalidate"}
res = self.client.get("/api/tasks", headers=headers, data=payload, name="Get Tasks")
except Exception as exception:
logger.error(exception)
@task()
def post_lewin(self):
try:
payload = {}
headers = {"Cache-Control": "max-age=0, no-cache, no-store, must-revalidate"}
self.client.post("/api/lewin", headers=headers, data=payload, name="Post Lewin")
except Exception as exception:
logger.error(exception)
```
### Python version
3.9.18
### Locust version
2.23.1
### Operating system
macOS 14.2.1 (23C71)
</issue>
<code>
[start of examples/web_ui_auth.py]
1 """
2 Example of implementing authentication for Locust when the --web-login flag is given
3
4 This is only to serve as a starting point, proper authentication should be implemented
5 according to your projects specifications.
6
7 For more information, see https://docs.locust.io/en/stable/extending-locust.html#authentication
8 """
9 from locust import HttpUser, events
10
11 import json
12 import os
13
14 from flask import Blueprint, make_response, redirect, request, session, url_for
15 from flask_login import UserMixin, login_user
16
17
18 class LocustHttpUser(HttpUser):
19 pass
20
21
22 class AuthUser(UserMixin):
23 def __init__(self, username):
24 self.username = username
25
26 def get_id(self):
27 return self.username
28
29
30 auth_blueprint = Blueprint("auth", "web_ui_auth")
31
32
33 def load_user(user_id):
34 return AuthUser(session.get("username"))
35
36
37 @events.init.add_listener
38 def locust_init(environment, **kwargs):
39 if environment.web_ui:
40 environment.web_ui.login_manager.user_loader(load_user)
41
42 environment.web_ui.app.config["SECRET_KEY"] = os.getenv("FLASK_SECRET_KEY")
43
44 environment.web_ui.auth_args = {
45 "username_password_callback": "/login_submit",
46 "auth_providers": [
47 {
48 "label": "Github",
49 "callback_url": "/login/github",
50 "icon_url": "https://static-00.iconduck.com/assets.00/github-icon-1024x994-4h5sdmko.png",
51 },
52 ],
53 }
54
55 @auth_blueprint.route("/login/github")
56 def google_login():
57 # Implement authentication with desired auth provider
58 username = "username"
59 session["username"] = username
60 login_user(AuthUser("username"))
61
62 return redirect(url_for("index"))
63
64 @auth_blueprint.route("/login_submit")
65 def login_submit():
66 username = request.args.get("username")
67 password = request.args.get("password")
68
69 # Implement real password verification here
70 if password:
71 session["username"] = username
72 login_user(AuthUser(username))
73
74 return redirect(url_for("index"))
75
76 environment.web_ui.auth_args = {**environment.web_ui.auth_args, "error": "Invalid username or password"}
77
78 return redirect(url_for("login"))
79
80 environment.web_ui.app.register_blueprint(auth_blueprint)
81
[end of examples/web_ui_auth.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/examples/web_ui_auth.py b/examples/web_ui_auth.py
--- a/examples/web_ui_auth.py
+++ b/examples/web_ui_auth.py
@@ -6,7 +6,7 @@
For more information, see https://docs.locust.io/en/stable/extending-locust.html#authentication
"""
-from locust import HttpUser, events
+from locust import HttpUser, events, task
import json
import os
@@ -16,7 +16,9 @@
class LocustHttpUser(HttpUser):
- pass
+ @task
+ def example(self):
+ self.client.get("/")
class AuthUser(UserMixin):
|
{"golden_diff": "diff --git a/examples/web_ui_auth.py b/examples/web_ui_auth.py\n--- a/examples/web_ui_auth.py\n+++ b/examples/web_ui_auth.py\n@@ -6,7 +6,7 @@\n \n For more information, see https://docs.locust.io/en/stable/extending-locust.html#authentication\n \"\"\"\n-from locust import HttpUser, events\n+from locust import HttpUser, events, task\n \n import json\n import os\n@@ -16,7 +16,9 @@\n \n \n class LocustHttpUser(HttpUser):\n- pass\n+ @task\n+ def example(self):\n+ self.client.get(\"/\")\n \n \n class AuthUser(UserMixin):\n", "issue": "[Report][Modern-UI] HTML report is blank\n### Prerequisites\n\n- [X] I am using [the latest version of Locust](https://github.com/locustio/locust/releases/)\n- [X] I am reporting a bug, not asking a question\n\n### Description\n\nRun a test then open the HTML report -> Noticed that it is blank\r\nNote: This bug occurs from 2.22.0, and did not occur on 2.21.0 \r\n\r\n\n\n### Command line\n\nlocust -f SimpleWeb.py -u 100 -r 10 -t 30s --html=samplelocust.html\n\n### Locustfile contents\n\n```python3\nfrom locust import FastHttpUser, HttpUser, between, constant_pacing, events, task\r\nfrom loguru import logger\r\n\r\n\r\nclass QuickstartUser(FastHttpUser):\r\n wait_time = between(2, 5)\r\n\r\n\r\n host = \"http://127.0.0.1:5000\"\r\n # begin = time.time()\r\n\r\n @task()\r\n def get_tasks_1(self):\r\n res = None\r\n try:\r\n payload = {}\r\n headers = {\"Cache-Control\": \"max-age=0, no-cache, no-store, must-revalidate\"}\r\n res = self.client.get(\"/api/tasks\", headers=headers, data=payload, name=\"Get Tasks\")\r\n except Exception as exception:\r\n logger.error(exception)\r\n\r\n @task()\r\n def post_lewin(self):\r\n try:\r\n payload = {}\r\n headers = {\"Cache-Control\": \"max-age=0, no-cache, no-store, must-revalidate\"}\r\n self.client.post(\"/api/lewin\", headers=headers, data=payload, name=\"Post Lewin\")\r\n except Exception as exception:\r\n logger.error(exception)\n```\n\n\n### Python version\n\n3.9.18\n\n### Locust version\n\n2.23.1\n\n### Operating system\n\nmacOS 14.2.1 (23C71)\n", "before_files": [{"content": "\"\"\"\nExample of implementing authentication for Locust when the --web-login flag is given\n\nThis is only to serve as a starting point, proper authentication should be implemented\naccording to your projects specifications.\n\nFor more information, see https://docs.locust.io/en/stable/extending-locust.html#authentication\n\"\"\"\nfrom locust import HttpUser, events\n\nimport json\nimport os\n\nfrom flask import Blueprint, make_response, redirect, request, session, url_for\nfrom flask_login import UserMixin, login_user\n\n\nclass LocustHttpUser(HttpUser):\n pass\n\n\nclass AuthUser(UserMixin):\n def __init__(self, username):\n self.username = username\n\n def get_id(self):\n return self.username\n\n\nauth_blueprint = Blueprint(\"auth\", \"web_ui_auth\")\n\n\ndef load_user(user_id):\n return AuthUser(session.get(\"username\"))\n\n\[email protected]_listener\ndef locust_init(environment, **kwargs):\n if environment.web_ui:\n environment.web_ui.login_manager.user_loader(load_user)\n\n environment.web_ui.app.config[\"SECRET_KEY\"] = os.getenv(\"FLASK_SECRET_KEY\")\n\n environment.web_ui.auth_args = {\n \"username_password_callback\": \"/login_submit\",\n \"auth_providers\": [\n {\n \"label\": \"Github\",\n \"callback_url\": \"/login/github\",\n \"icon_url\": \"https://static-00.iconduck.com/assets.00/github-icon-1024x994-4h5sdmko.png\",\n },\n ],\n }\n\n @auth_blueprint.route(\"/login/github\")\n def google_login():\n # Implement authentication with desired auth provider\n username = \"username\"\n session[\"username\"] = username\n login_user(AuthUser(\"username\"))\n\n return redirect(url_for(\"index\"))\n\n @auth_blueprint.route(\"/login_submit\")\n def login_submit():\n username = request.args.get(\"username\")\n password = request.args.get(\"password\")\n\n # Implement real password verification here\n if password:\n session[\"username\"] = username\n login_user(AuthUser(username))\n\n return redirect(url_for(\"index\"))\n\n environment.web_ui.auth_args = {**environment.web_ui.auth_args, \"error\": \"Invalid username or password\"}\n\n return redirect(url_for(\"login\"))\n\n environment.web_ui.app.register_blueprint(auth_blueprint)\n", "path": "examples/web_ui_auth.py"}]}
| 1,676 | 143 |
gh_patches_debug_2867
|
rasdani/github-patches
|
git_diff
|
pantsbuild__pants-15341
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Use of relative PATH for docker-tool shims prevents use of credential helpers
**Describe the bug**
I'm trying to set up [tools](https://www.pantsbuild.org/docs/reference-docker#section-tools) in my repo's `docker` subsystem, to plug in the [ECR credential helper](https://github.com/awslabs/amazon-ecr-credential-helper). To do so I added the following to `pants.toml`:
```toml
[docker]
tools = ["docker-credential-ecr-login", "sh"]
```
When I run `./pants package path/to/Dockerfile`, I get the error:
```
failed to solve with frontend dockerfile.v0: failed to create LLB definition: rpc error: code = Unknown desc = error getting credentials - err: docker-credential-ecr-login resolves to executable in current directory (./.shims/bin/docker-credential-ecr-login), out: ``
```
If I run the above with `--no-process-cleanup` and `cd` into the tmpdir, I see:
1. There are shims for both tools under `.shims/bin`
2. The shims behave as expected when I use them directly
3. `__run.sh` sets `PATH=.shims/bin`
If I edit `__run.sh` to instead set `PATH=<absolute-path-to-tmpdir>/.shims/bin`, the build works.
**Pants version**
2.11.0+git9ac327d4
**OS**
MacOS
**Additional info**
Docker Desktop v4.7.1 (77678)
Docker Engine v20.10.14
</issue>
<code>
[start of src/python/pants/backend/docker/util_rules/docker_binary.py]
1 # Copyright 2021 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 from __future__ import annotations
5
6 import os
7 from dataclasses import dataclass
8 from typing import Mapping
9
10 from pants.backend.docker.subsystems.docker_options import DockerOptions
11 from pants.backend.docker.util_rules.docker_build_args import DockerBuildArgs
12 from pants.core.util_rules.system_binaries import (
13 BinaryPath,
14 BinaryPathRequest,
15 BinaryPaths,
16 BinaryPathTest,
17 BinaryShims,
18 BinaryShimsRequest,
19 )
20 from pants.engine.environment import Environment, EnvironmentRequest
21 from pants.engine.fs import Digest
22 from pants.engine.process import Process, ProcessCacheScope
23 from pants.engine.rules import Get, collect_rules, rule
24 from pants.util.logging import LogLevel
25 from pants.util.strutil import pluralize
26
27
28 # The base class is decorated with `frozen_after_init`.
29 @dataclass
30 class DockerBinary(BinaryPath):
31 """The `docker` binary."""
32
33 extra_env: Mapping[str, str]
34 extra_input_digests: Mapping[str, Digest] | None
35
36 def __init__(
37 self,
38 path: str,
39 fingerprint: str | None = None,
40 extra_env: Mapping[str, str] | None = None,
41 extra_input_digests: Mapping[str, Digest] | None = None,
42 ) -> None:
43 self.extra_env = {} if extra_env is None else extra_env
44 self.extra_input_digests = extra_input_digests
45 super().__init__(path, fingerprint)
46
47 def _get_process_environment(self, env: Mapping[str, str]) -> Mapping[str, str]:
48 if not self.extra_env:
49 return env
50
51 res = {**self.extra_env, **env}
52
53 # Merge the PATH entries, in case they are present in both `env` and `self.extra_env`.
54 res["PATH"] = os.pathsep.join(
55 p for p in (m.get("PATH") for m in (self.extra_env, env)) if p
56 )
57 return res
58
59 def build_image(
60 self,
61 tags: tuple[str, ...],
62 digest: Digest,
63 dockerfile: str,
64 build_args: DockerBuildArgs,
65 context_root: str,
66 env: Mapping[str, str],
67 extra_args: tuple[str, ...] = (),
68 ) -> Process:
69 args = [self.path, "build", *extra_args]
70
71 for tag in tags:
72 args.extend(["--tag", tag])
73
74 for build_arg in build_args:
75 args.extend(["--build-arg", build_arg])
76
77 args.extend(["--file", dockerfile])
78
79 # Docker context root.
80 args.append(context_root)
81
82 return Process(
83 argv=tuple(args),
84 description=(
85 f"Building docker image {tags[0]}"
86 + (f" +{pluralize(len(tags)-1, 'additional tag')}." if len(tags) > 1 else "")
87 ),
88 env=self._get_process_environment(env),
89 input_digest=digest,
90 immutable_input_digests=self.extra_input_digests,
91 cache_scope=ProcessCacheScope.PER_SESSION,
92 )
93
94 def push_image(self, tag: str, env: Mapping[str, str] | None = None) -> Process:
95 return Process(
96 argv=(self.path, "push", tag),
97 cache_scope=ProcessCacheScope.PER_SESSION,
98 description=f"Pushing docker image {tag}",
99 env=self._get_process_environment(env or {}),
100 immutable_input_digests=self.extra_input_digests,
101 )
102
103 def run_image(
104 self,
105 tag: str,
106 *,
107 docker_run_args: tuple[str, ...] | None = None,
108 image_args: tuple[str, ...] | None = None,
109 env: Mapping[str, str] | None = None,
110 ) -> Process:
111 return Process(
112 argv=(self.path, "run", *(docker_run_args or []), tag, *(image_args or [])),
113 cache_scope=ProcessCacheScope.PER_SESSION,
114 description=f"Running docker image {tag}",
115 env=self._get_process_environment(env or {}),
116 immutable_input_digests=self.extra_input_digests,
117 )
118
119
120 @dataclass(frozen=True)
121 class DockerBinaryRequest:
122 pass
123
124
125 @rule(desc="Finding the `docker` binary and related tooling", level=LogLevel.DEBUG)
126 async def find_docker(
127 docker_request: DockerBinaryRequest, docker_options: DockerOptions
128 ) -> DockerBinary:
129 env = await Get(Environment, EnvironmentRequest(["PATH"]))
130 search_path = docker_options.executable_search_path(env)
131 request = BinaryPathRequest(
132 binary_name="docker",
133 search_path=search_path,
134 test=BinaryPathTest(args=["-v"]),
135 )
136 paths = await Get(BinaryPaths, BinaryPathRequest, request)
137 first_path = paths.first_path_or_raise(request, rationale="interact with the docker daemon")
138
139 if not docker_options.tools:
140 return DockerBinary(first_path.path, first_path.fingerprint)
141
142 tools = await Get(
143 BinaryShims,
144 BinaryShimsRequest,
145 BinaryShimsRequest.for_binaries(
146 *docker_options.tools,
147 rationale="use docker",
148 output_directory="bin",
149 search_path=search_path,
150 ),
151 )
152 tools_path = ".shims"
153 extra_env = {"PATH": os.path.join(tools_path, tools.bin_directory)}
154 extra_input_digests = {tools_path: tools.digest}
155
156 return DockerBinary(
157 first_path.path,
158 first_path.fingerprint,
159 extra_env=extra_env,
160 extra_input_digests=extra_input_digests,
161 )
162
163
164 @rule
165 async def get_docker() -> DockerBinary:
166 return await Get(DockerBinary, DockerBinaryRequest())
167
168
169 def rules():
170 return collect_rules()
171
[end of src/python/pants/backend/docker/util_rules/docker_binary.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/python/pants/backend/docker/util_rules/docker_binary.py b/src/python/pants/backend/docker/util_rules/docker_binary.py
--- a/src/python/pants/backend/docker/util_rules/docker_binary.py
+++ b/src/python/pants/backend/docker/util_rules/docker_binary.py
@@ -150,7 +150,7 @@
),
)
tools_path = ".shims"
- extra_env = {"PATH": os.path.join(tools_path, tools.bin_directory)}
+ extra_env = {"PATH": os.path.join("{chroot}", tools_path, tools.bin_directory)}
extra_input_digests = {tools_path: tools.digest}
return DockerBinary(
|
{"golden_diff": "diff --git a/src/python/pants/backend/docker/util_rules/docker_binary.py b/src/python/pants/backend/docker/util_rules/docker_binary.py\n--- a/src/python/pants/backend/docker/util_rules/docker_binary.py\n+++ b/src/python/pants/backend/docker/util_rules/docker_binary.py\n@@ -150,7 +150,7 @@\n ),\n )\n tools_path = \".shims\"\n- extra_env = {\"PATH\": os.path.join(tools_path, tools.bin_directory)}\n+ extra_env = {\"PATH\": os.path.join(\"{chroot}\", tools_path, tools.bin_directory)}\n extra_input_digests = {tools_path: tools.digest}\n \n return DockerBinary(\n", "issue": "Use of relative PATH for docker-tool shims prevents use of credential helpers\n**Describe the bug**\r\nI'm trying to set up [tools](https://www.pantsbuild.org/docs/reference-docker#section-tools) in my repo's `docker` subsystem, to plug in the [ECR credential helper](https://github.com/awslabs/amazon-ecr-credential-helper). To do so I added the following to `pants.toml`:\r\n```toml\r\n[docker]\r\ntools = [\"docker-credential-ecr-login\", \"sh\"]\r\n```\r\nWhen I run `./pants package path/to/Dockerfile`, I get the error:\r\n```\r\nfailed to solve with frontend dockerfile.v0: failed to create LLB definition: rpc error: code = Unknown desc = error getting credentials - err: docker-credential-ecr-login resolves to executable in current directory (./.shims/bin/docker-credential-ecr-login), out: ``\r\n```\r\nIf I run the above with `--no-process-cleanup` and `cd` into the tmpdir, I see:\r\n1. There are shims for both tools under `.shims/bin`\r\n2. The shims behave as expected when I use them directly\r\n3. `__run.sh` sets `PATH=.shims/bin`\r\n\r\nIf I edit `__run.sh` to instead set `PATH=<absolute-path-to-tmpdir>/.shims/bin`, the build works.\r\n\r\n**Pants version**\r\n2.11.0+git9ac327d4\r\n\r\n**OS**\r\nMacOS\r\n\r\n**Additional info**\r\nDocker Desktop v4.7.1 (77678)\r\nDocker Engine v20.10.14\r\n\n", "before_files": [{"content": "# Copyright 2021 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\nfrom __future__ import annotations\n\nimport os\nfrom dataclasses import dataclass\nfrom typing import Mapping\n\nfrom pants.backend.docker.subsystems.docker_options import DockerOptions\nfrom pants.backend.docker.util_rules.docker_build_args import DockerBuildArgs\nfrom pants.core.util_rules.system_binaries import (\n BinaryPath,\n BinaryPathRequest,\n BinaryPaths,\n BinaryPathTest,\n BinaryShims,\n BinaryShimsRequest,\n)\nfrom pants.engine.environment import Environment, EnvironmentRequest\nfrom pants.engine.fs import Digest\nfrom pants.engine.process import Process, ProcessCacheScope\nfrom pants.engine.rules import Get, collect_rules, rule\nfrom pants.util.logging import LogLevel\nfrom pants.util.strutil import pluralize\n\n\n# The base class is decorated with `frozen_after_init`.\n@dataclass\nclass DockerBinary(BinaryPath):\n \"\"\"The `docker` binary.\"\"\"\n\n extra_env: Mapping[str, str]\n extra_input_digests: Mapping[str, Digest] | None\n\n def __init__(\n self,\n path: str,\n fingerprint: str | None = None,\n extra_env: Mapping[str, str] | None = None,\n extra_input_digests: Mapping[str, Digest] | None = None,\n ) -> None:\n self.extra_env = {} if extra_env is None else extra_env\n self.extra_input_digests = extra_input_digests\n super().__init__(path, fingerprint)\n\n def _get_process_environment(self, env: Mapping[str, str]) -> Mapping[str, str]:\n if not self.extra_env:\n return env\n\n res = {**self.extra_env, **env}\n\n # Merge the PATH entries, in case they are present in both `env` and `self.extra_env`.\n res[\"PATH\"] = os.pathsep.join(\n p for p in (m.get(\"PATH\") for m in (self.extra_env, env)) if p\n )\n return res\n\n def build_image(\n self,\n tags: tuple[str, ...],\n digest: Digest,\n dockerfile: str,\n build_args: DockerBuildArgs,\n context_root: str,\n env: Mapping[str, str],\n extra_args: tuple[str, ...] = (),\n ) -> Process:\n args = [self.path, \"build\", *extra_args]\n\n for tag in tags:\n args.extend([\"--tag\", tag])\n\n for build_arg in build_args:\n args.extend([\"--build-arg\", build_arg])\n\n args.extend([\"--file\", dockerfile])\n\n # Docker context root.\n args.append(context_root)\n\n return Process(\n argv=tuple(args),\n description=(\n f\"Building docker image {tags[0]}\"\n + (f\" +{pluralize(len(tags)-1, 'additional tag')}.\" if len(tags) > 1 else \"\")\n ),\n env=self._get_process_environment(env),\n input_digest=digest,\n immutable_input_digests=self.extra_input_digests,\n cache_scope=ProcessCacheScope.PER_SESSION,\n )\n\n def push_image(self, tag: str, env: Mapping[str, str] | None = None) -> Process:\n return Process(\n argv=(self.path, \"push\", tag),\n cache_scope=ProcessCacheScope.PER_SESSION,\n description=f\"Pushing docker image {tag}\",\n env=self._get_process_environment(env or {}),\n immutable_input_digests=self.extra_input_digests,\n )\n\n def run_image(\n self,\n tag: str,\n *,\n docker_run_args: tuple[str, ...] | None = None,\n image_args: tuple[str, ...] | None = None,\n env: Mapping[str, str] | None = None,\n ) -> Process:\n return Process(\n argv=(self.path, \"run\", *(docker_run_args or []), tag, *(image_args or [])),\n cache_scope=ProcessCacheScope.PER_SESSION,\n description=f\"Running docker image {tag}\",\n env=self._get_process_environment(env or {}),\n immutable_input_digests=self.extra_input_digests,\n )\n\n\n@dataclass(frozen=True)\nclass DockerBinaryRequest:\n pass\n\n\n@rule(desc=\"Finding the `docker` binary and related tooling\", level=LogLevel.DEBUG)\nasync def find_docker(\n docker_request: DockerBinaryRequest, docker_options: DockerOptions\n) -> DockerBinary:\n env = await Get(Environment, EnvironmentRequest([\"PATH\"]))\n search_path = docker_options.executable_search_path(env)\n request = BinaryPathRequest(\n binary_name=\"docker\",\n search_path=search_path,\n test=BinaryPathTest(args=[\"-v\"]),\n )\n paths = await Get(BinaryPaths, BinaryPathRequest, request)\n first_path = paths.first_path_or_raise(request, rationale=\"interact with the docker daemon\")\n\n if not docker_options.tools:\n return DockerBinary(first_path.path, first_path.fingerprint)\n\n tools = await Get(\n BinaryShims,\n BinaryShimsRequest,\n BinaryShimsRequest.for_binaries(\n *docker_options.tools,\n rationale=\"use docker\",\n output_directory=\"bin\",\n search_path=search_path,\n ),\n )\n tools_path = \".shims\"\n extra_env = {\"PATH\": os.path.join(tools_path, tools.bin_directory)}\n extra_input_digests = {tools_path: tools.digest}\n\n return DockerBinary(\n first_path.path,\n first_path.fingerprint,\n extra_env=extra_env,\n extra_input_digests=extra_input_digests,\n )\n\n\n@rule\nasync def get_docker() -> DockerBinary:\n return await Get(DockerBinary, DockerBinaryRequest())\n\n\ndef rules():\n return collect_rules()\n", "path": "src/python/pants/backend/docker/util_rules/docker_binary.py"}]}
| 2,550 | 142 |
gh_patches_debug_21237
|
rasdani/github-patches
|
git_diff
|
OpenCTI-Platform__connectors-1121
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Error KeyError: 'value' in Shodan-InternetDB connector
## Description
We get the following error in Shodan-InternetDB connector for every IP we try to process:
INFO:root:Reading StixCyberObservable {f14b0557-269b-478c-822d-dd206ce88060}.
ERROR:root:Error in message processing, reporting error to API
Traceback (most recent call last):
File "/usr/local/lib/python3.10/dist-packages/pycti/connector/opencti_connector_helper.py", line 181, in _data_handler
message = self.callback(json_data["event"])
File "/opt/opencti/connectors/internal-enrichment/shodan-internetdb/src/shodan_internetdb/connector.py", line 103, in _process_message
value = observable["value"]
KeyError: 'value'
INFO:root:Reporting work update_received work_6cbd1a73-9cfb-4825-9554-929cc42df702_2023-04-21T11:35:40.994Z
INFO:root:Message (delivery_tag=1) processed, thread terminated
## Environment
1. OS (where OpenCTI server runs): Ubuntu 22
2. OpenCTI version: 5.7.2
3. OpenCTI client: python
</issue>
<code>
[start of internal-enrichment/shodan-internetdb/src/shodan_internetdb/connector.py]
1 """Shodan InternetDB connector"""
2
3 from __future__ import annotations
4
5 import logging
6 from datetime import datetime, timedelta
7 from pathlib import Path
8 from typing import Any, Dict, List, Union
9
10 import pycti
11 import stix2
12 import validators
13 import yaml
14 from pycti.connector.opencti_connector_helper import OpenCTIConnectorHelper
15 from requests.exceptions import RequestException
16
17 from .client import ShodanInternetDbClient, ShodanResult
18 from .config import RootConfig
19
20 __all__ = [
21 "ShodanInternetDBConnector",
22 ]
23
24 log = logging.getLogger(__name__)
25
26
27 class ShodanInternetDBConnector:
28 """Shodan InternetDB connector"""
29
30 def __init__(self):
31 """Constructor"""
32 config_path = Path(__file__).parent.parent.joinpath("config.yml")
33 config = (
34 yaml.load(config_path.open(), Loader=yaml.SafeLoader)
35 if config_path.is_file()
36 else {}
37 )
38
39 self._config = RootConfig.parse_obj(config)
40 self._helper = OpenCTIConnectorHelper(config)
41
42 self._identity = self._helper.api.identity.create(
43 type="Organization",
44 name="Shodan",
45 description="Shodan is a search engine for Internet-connected devices.",
46 )
47 self._identity_id = self._identity["standard_id"]
48 self._object_marking_id = stix2.TLP_WHITE["id"]
49
50 self._client = ShodanInternetDbClient(verify=self._config.shodan.ssl_verify)
51
52 def start(self) -> None:
53 """
54 Start the connector
55 :return: None
56 """
57 self._helper.listen(self._process_message)
58
59 def _process_message(self, data: Dict[str, Any]) -> str:
60 """
61 Process the data message
62 :param data: Entity data
63 :return: None
64 """
65 # Fetch the observable being processed
66 entity_id = data["entity_id"]
67
68 custom_attributes = """
69 id
70 entity_type
71 objectMarking {
72 edges {
73 node {
74 id
75 definition_type
76 definition
77 }
78 }
79 }
80 observable_value
81 """
82 observable = self._helper.api.stix_cyber_observable.read(
83 id=entity_id, customAttributes=custom_attributes
84 )
85
86 if observable is None:
87 log.error("Observable not found with entity_id %s", entity_id)
88 return "Observable not found"
89
90 # Check TLP markings, do not submit higher than the max allowed
91 tlps = ["TLP:CLEAR"]
92 for marking_definition in observable.get("objectMarking", []):
93 if marking_definition["definition_type"] == "TLP":
94 tlps.append(marking_definition["definition"])
95
96 for tlp in tlps:
97 max_tlp_name = self._config.shodan.max_tlp.name
98 if not OpenCTIConnectorHelper.check_max_tlp(tlp, max_tlp_name):
99 log.debug("Skipping observable, TLP is greater than the MAX TLP")
100 return "Skipping observable (TLP)"
101
102 # Process the observable value
103 value = observable["value"]
104 if not validators.ipv4(value):
105 log.error("Observable value is not an IPv4 address")
106 return "Skipping observable (ipv4 validation)"
107
108 try:
109 result = self._client.query(value)
110 except RequestException:
111 log.exception("Shodan API error")
112 return "Skipping observable (Shodan API error)"
113
114 if result is None:
115 log.debug("No information available on %s", value)
116 return "Skipping observable (Shodan 404)"
117
118 # Process the result
119 log.debug("Processing %s", value)
120 self._process_domains(observable, result)
121 self._process_tags(observable, result)
122 self._process_vulns(observable, result)
123 self._process_note(observable, result)
124
125 return "Success"
126
127 def _process_note(
128 self,
129 observable: Dict[str, Any],
130 result: ShodanResult,
131 ) -> None:
132 """
133 Add an enrichment note to the observable
134 :param observable: Observable data
135 :param result: Shodan data
136 :return: None
137 """
138
139 def format_list(alist: List[Union[str, int]]) -> str:
140 """Format a list of primitives into a Markdown list"""
141 return "".join(f"\n- {name}" for name in alist) or "n/a"
142
143 value = observable["value"]
144 abstract = f"Shodan InternetDB enrichment of {value}"
145 content = f"""```
146 Shodan InternetDB:
147 ------------------
148 Hostnames: {format_list(result.hostnames)}
149 ------------------
150 Software: {format_list(result.cpes)}
151 ------------------
152 Vulnerabilities: {format_list(result.vulns)}
153 ------------------
154 Ports: {format_list(result.ports)}
155 ------------------
156 ```
157 """
158
159 self._helper.api.note.create(
160 stix_id=pycti.Note.generate_id(datetime.now().isoformat(), content),
161 createdBy=self._identity_id,
162 objectMarking=[self._object_marking_id],
163 confidence=self._helper.connect_confidence_level,
164 objects=[observable["id"]],
165 authors=[self._identity_id],
166 abstract=abstract,
167 content=content,
168 )
169
170 def _process_domains(
171 self,
172 observable: Dict[str, Any],
173 result: ShodanResult,
174 ) -> None:
175 """
176 Add additional domains to the observable
177 :param observable: Observable data
178 :param result: Shodan data
179 :return: None
180 """
181
182 markings = observable["objectMarkingIds"]
183 for name in result.hostnames:
184 log.debug("Adding domain %s", name)
185 domain = self._helper.api.stix_cyber_observable.create(
186 observableData=dict(
187 type="Domain-Name",
188 value=name,
189 ),
190 objectMarking=markings,
191 createdBy=self._identity_id,
192 update=True,
193 )
194
195 log.debug("Creating domain relationship")
196 self._helper.api.stix_nested_ref_relationship.create(
197 fromId=domain["id"],
198 toId=observable["id"],
199 relationship_type="resolves-to",
200 createdBy=self._identity_id,
201 objectMarking=markings,
202 confidence=self._helper.connect_confidence_level,
203 update=True,
204 )
205
206 def _process_tags(
207 self,
208 observable: Dict[str, Any],
209 result: ShodanResult,
210 ) -> None:
211 """
212 Add additional tags to the observable
213 :param observable: Observable data
214 :param result: Shodan data
215 :return: None
216 """
217
218 for name in result.tags:
219 log.debug("Creating label %s", name)
220 label = self._helper.api.label.create(value=name)
221
222 log.debug("Adding to observable")
223 self._helper.api.stix_cyber_observable.add_label(
224 id=observable["id"],
225 label_id=label["id"],
226 )
227
228 def _process_vulns(
229 self,
230 observable: Dict[str, Any],
231 result: ShodanResult,
232 ) -> None:
233 """
234 Add additional vulnerabilities to the observable
235 :param observable: Observable data
236 :param result: Shodan data
237 :return: None
238 """
239 now = datetime.utcnow()
240 vuln_eol = now + timedelta(days=60)
241
242 for name in result.vulns:
243 log.debug("Creating vulnerability %s", name)
244 vuln = self._helper.api.vulnerability.create(
245 stix_id=pycti.Vulnerability.generate_id(name),
246 name=name,
247 createdBy=self._identity_id,
248 objectMarking=[self._object_marking_id],
249 confidence=self._helper.connect_confidence_level,
250 update=True,
251 )
252
253 log.debug("Creating vulnerability relationship")
254 self._helper.api.stix_core_relationship.create(
255 fromId=observable["id"],
256 toId=vuln["id"],
257 relationship_type="related-to",
258 createdBy=self._identity_id,
259 start_time=now.strftime("%Y-%m-%dT%H:%M:%SZ"),
260 stop_time=vuln_eol.strftime("%Y-%m-%dT%H:%M:%SZ"),
261 confidence=self._helper.connect_confidence_level,
262 objectMarking=[self._object_marking_id],
263 update=True,
264 )
265
[end of internal-enrichment/shodan-internetdb/src/shodan_internetdb/connector.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/internal-enrichment/shodan-internetdb/src/shodan_internetdb/connector.py b/internal-enrichment/shodan-internetdb/src/shodan_internetdb/connector.py
--- a/internal-enrichment/shodan-internetdb/src/shodan_internetdb/connector.py
+++ b/internal-enrichment/shodan-internetdb/src/shodan_internetdb/connector.py
@@ -100,7 +100,7 @@
return "Skipping observable (TLP)"
# Process the observable value
- value = observable["value"]
+ value = observable["observable_value"]
if not validators.ipv4(value):
log.error("Observable value is not an IPv4 address")
return "Skipping observable (ipv4 validation)"
@@ -140,7 +140,7 @@
"""Format a list of primitives into a Markdown list"""
return "".join(f"\n- {name}" for name in alist) or "n/a"
- value = observable["value"]
+ value = observable["observable_value"]
abstract = f"Shodan InternetDB enrichment of {value}"
content = f"""```
Shodan InternetDB:
|
{"golden_diff": "diff --git a/internal-enrichment/shodan-internetdb/src/shodan_internetdb/connector.py b/internal-enrichment/shodan-internetdb/src/shodan_internetdb/connector.py\n--- a/internal-enrichment/shodan-internetdb/src/shodan_internetdb/connector.py\n+++ b/internal-enrichment/shodan-internetdb/src/shodan_internetdb/connector.py\n@@ -100,7 +100,7 @@\n return \"Skipping observable (TLP)\"\n \n # Process the observable value\n- value = observable[\"value\"]\n+ value = observable[\"observable_value\"]\n if not validators.ipv4(value):\n log.error(\"Observable value is not an IPv4 address\")\n return \"Skipping observable (ipv4 validation)\"\n@@ -140,7 +140,7 @@\n \"\"\"Format a list of primitives into a Markdown list\"\"\"\n return \"\".join(f\"\\n- {name}\" for name in alist) or \"n/a\"\n \n- value = observable[\"value\"]\n+ value = observable[\"observable_value\"]\n abstract = f\"Shodan InternetDB enrichment of {value}\"\n content = f\"\"\"```\n Shodan InternetDB:\n", "issue": "Error KeyError: 'value' in Shodan-InternetDB connector\n## Description\r\n\r\nWe get the following error in Shodan-InternetDB connector for every IP we try to process:\r\n\r\nINFO:root:Reading StixCyberObservable {f14b0557-269b-478c-822d-dd206ce88060}.\r\nERROR:root:Error in message processing, reporting error to API\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python3.10/dist-packages/pycti/connector/opencti_connector_helper.py\", line 181, in _data_handler\r\n message = self.callback(json_data[\"event\"])\r\n File \"/opt/opencti/connectors/internal-enrichment/shodan-internetdb/src/shodan_internetdb/connector.py\", line 103, in _process_message\r\n value = observable[\"value\"]\r\nKeyError: 'value'\r\nINFO:root:Reporting work update_received work_6cbd1a73-9cfb-4825-9554-929cc42df702_2023-04-21T11:35:40.994Z\r\nINFO:root:Message (delivery_tag=1) processed, thread terminated\r\n\r\n## Environment\r\n\r\n1. OS (where OpenCTI server runs): Ubuntu 22\r\n2. OpenCTI version: 5.7.2\r\n3. OpenCTI client: python\r\n\n", "before_files": [{"content": "\"\"\"Shodan InternetDB connector\"\"\"\n\nfrom __future__ import annotations\n\nimport logging\nfrom datetime import datetime, timedelta\nfrom pathlib import Path\nfrom typing import Any, Dict, List, Union\n\nimport pycti\nimport stix2\nimport validators\nimport yaml\nfrom pycti.connector.opencti_connector_helper import OpenCTIConnectorHelper\nfrom requests.exceptions import RequestException\n\nfrom .client import ShodanInternetDbClient, ShodanResult\nfrom .config import RootConfig\n\n__all__ = [\n \"ShodanInternetDBConnector\",\n]\n\nlog = logging.getLogger(__name__)\n\n\nclass ShodanInternetDBConnector:\n \"\"\"Shodan InternetDB connector\"\"\"\n\n def __init__(self):\n \"\"\"Constructor\"\"\"\n config_path = Path(__file__).parent.parent.joinpath(\"config.yml\")\n config = (\n yaml.load(config_path.open(), Loader=yaml.SafeLoader)\n if config_path.is_file()\n else {}\n )\n\n self._config = RootConfig.parse_obj(config)\n self._helper = OpenCTIConnectorHelper(config)\n\n self._identity = self._helper.api.identity.create(\n type=\"Organization\",\n name=\"Shodan\",\n description=\"Shodan is a search engine for Internet-connected devices.\",\n )\n self._identity_id = self._identity[\"standard_id\"]\n self._object_marking_id = stix2.TLP_WHITE[\"id\"]\n\n self._client = ShodanInternetDbClient(verify=self._config.shodan.ssl_verify)\n\n def start(self) -> None:\n \"\"\"\n Start the connector\n :return: None\n \"\"\"\n self._helper.listen(self._process_message)\n\n def _process_message(self, data: Dict[str, Any]) -> str:\n \"\"\"\n Process the data message\n :param data: Entity data\n :return: None\n \"\"\"\n # Fetch the observable being processed\n entity_id = data[\"entity_id\"]\n\n custom_attributes = \"\"\"\n id\n entity_type\n objectMarking {\n edges {\n node {\n id\n definition_type\n definition\n }\n }\n }\n observable_value\n \"\"\"\n observable = self._helper.api.stix_cyber_observable.read(\n id=entity_id, customAttributes=custom_attributes\n )\n\n if observable is None:\n log.error(\"Observable not found with entity_id %s\", entity_id)\n return \"Observable not found\"\n\n # Check TLP markings, do not submit higher than the max allowed\n tlps = [\"TLP:CLEAR\"]\n for marking_definition in observable.get(\"objectMarking\", []):\n if marking_definition[\"definition_type\"] == \"TLP\":\n tlps.append(marking_definition[\"definition\"])\n\n for tlp in tlps:\n max_tlp_name = self._config.shodan.max_tlp.name\n if not OpenCTIConnectorHelper.check_max_tlp(tlp, max_tlp_name):\n log.debug(\"Skipping observable, TLP is greater than the MAX TLP\")\n return \"Skipping observable (TLP)\"\n\n # Process the observable value\n value = observable[\"value\"]\n if not validators.ipv4(value):\n log.error(\"Observable value is not an IPv4 address\")\n return \"Skipping observable (ipv4 validation)\"\n\n try:\n result = self._client.query(value)\n except RequestException:\n log.exception(\"Shodan API error\")\n return \"Skipping observable (Shodan API error)\"\n\n if result is None:\n log.debug(\"No information available on %s\", value)\n return \"Skipping observable (Shodan 404)\"\n\n # Process the result\n log.debug(\"Processing %s\", value)\n self._process_domains(observable, result)\n self._process_tags(observable, result)\n self._process_vulns(observable, result)\n self._process_note(observable, result)\n\n return \"Success\"\n\n def _process_note(\n self,\n observable: Dict[str, Any],\n result: ShodanResult,\n ) -> None:\n \"\"\"\n Add an enrichment note to the observable\n :param observable: Observable data\n :param result: Shodan data\n :return: None\n \"\"\"\n\n def format_list(alist: List[Union[str, int]]) -> str:\n \"\"\"Format a list of primitives into a Markdown list\"\"\"\n return \"\".join(f\"\\n- {name}\" for name in alist) or \"n/a\"\n\n value = observable[\"value\"]\n abstract = f\"Shodan InternetDB enrichment of {value}\"\n content = f\"\"\"```\nShodan InternetDB:\n------------------\nHostnames: {format_list(result.hostnames)}\n------------------\nSoftware: {format_list(result.cpes)}\n------------------\nVulnerabilities: {format_list(result.vulns)}\n------------------\nPorts: {format_list(result.ports)}\n------------------\n```\n\"\"\"\n\n self._helper.api.note.create(\n stix_id=pycti.Note.generate_id(datetime.now().isoformat(), content),\n createdBy=self._identity_id,\n objectMarking=[self._object_marking_id],\n confidence=self._helper.connect_confidence_level,\n objects=[observable[\"id\"]],\n authors=[self._identity_id],\n abstract=abstract,\n content=content,\n )\n\n def _process_domains(\n self,\n observable: Dict[str, Any],\n result: ShodanResult,\n ) -> None:\n \"\"\"\n Add additional domains to the observable\n :param observable: Observable data\n :param result: Shodan data\n :return: None\n \"\"\"\n\n markings = observable[\"objectMarkingIds\"]\n for name in result.hostnames:\n log.debug(\"Adding domain %s\", name)\n domain = self._helper.api.stix_cyber_observable.create(\n observableData=dict(\n type=\"Domain-Name\",\n value=name,\n ),\n objectMarking=markings,\n createdBy=self._identity_id,\n update=True,\n )\n\n log.debug(\"Creating domain relationship\")\n self._helper.api.stix_nested_ref_relationship.create(\n fromId=domain[\"id\"],\n toId=observable[\"id\"],\n relationship_type=\"resolves-to\",\n createdBy=self._identity_id,\n objectMarking=markings,\n confidence=self._helper.connect_confidence_level,\n update=True,\n )\n\n def _process_tags(\n self,\n observable: Dict[str, Any],\n result: ShodanResult,\n ) -> None:\n \"\"\"\n Add additional tags to the observable\n :param observable: Observable data\n :param result: Shodan data\n :return: None\n \"\"\"\n\n for name in result.tags:\n log.debug(\"Creating label %s\", name)\n label = self._helper.api.label.create(value=name)\n\n log.debug(\"Adding to observable\")\n self._helper.api.stix_cyber_observable.add_label(\n id=observable[\"id\"],\n label_id=label[\"id\"],\n )\n\n def _process_vulns(\n self,\n observable: Dict[str, Any],\n result: ShodanResult,\n ) -> None:\n \"\"\"\n Add additional vulnerabilities to the observable\n :param observable: Observable data\n :param result: Shodan data\n :return: None\n \"\"\"\n now = datetime.utcnow()\n vuln_eol = now + timedelta(days=60)\n\n for name in result.vulns:\n log.debug(\"Creating vulnerability %s\", name)\n vuln = self._helper.api.vulnerability.create(\n stix_id=pycti.Vulnerability.generate_id(name),\n name=name,\n createdBy=self._identity_id,\n objectMarking=[self._object_marking_id],\n confidence=self._helper.connect_confidence_level,\n update=True,\n )\n\n log.debug(\"Creating vulnerability relationship\")\n self._helper.api.stix_core_relationship.create(\n fromId=observable[\"id\"],\n toId=vuln[\"id\"],\n relationship_type=\"related-to\",\n createdBy=self._identity_id,\n start_time=now.strftime(\"%Y-%m-%dT%H:%M:%SZ\"),\n stop_time=vuln_eol.strftime(\"%Y-%m-%dT%H:%M:%SZ\"),\n confidence=self._helper.connect_confidence_level,\n objectMarking=[self._object_marking_id],\n update=True,\n )\n", "path": "internal-enrichment/shodan-internetdb/src/shodan_internetdb/connector.py"}]}
| 3,383 | 264 |
gh_patches_debug_25468
|
rasdani/github-patches
|
git_diff
|
svthalia__concrexit-2711
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Unprocessed Thalia Pay payment without bank account
Apparently it is possible that people either pay with Thalia pay without having a valid bank account, or, it is possible to remove a bank account after a Thalia Pay payment is made but not processed (in which case it should not be possible)
Sentry Issue: [CONCREXIT-HD](https://sentry.io/organizations/thalia/issues/3640470247/?referrer=github_integration)
```
AttributeError: 'NoneType' object has no attribute 'last_used'
(8 additional frame(s) were not displayed)
...
File "django/utils/decorators.py", line 46, in _wrapper
return bound_method(*args, **kwargs)
File "django/contrib/auth/decorators.py", line 23, in _wrapped_view
return view_func(request, *args, **kwargs)
File "django/views/generic/base.py", line 119, in dispatch
return handler(request, *args, **kwargs)
File "payments/admin_views.py", line 107, in post
services.process_batch(batch)
File "payments/services.py", line 151, in process_batch
bank_account.last_used = batch.withdrawal_date
```
</issue>
<code>
[start of website/payments/services.py]
1 """The services defined by the payments package."""
2 import datetime
3 from typing import Union
4
5 from django.conf import settings
6 from django.db.models import Model, Q, QuerySet, Sum
7 from django.urls import reverse
8 from django.utils import timezone
9 from django.utils.translation import gettext_lazy as _
10
11 from members.models import Member
12 from utils.snippets import send_email
13
14 from .exceptions import PaymentError
15 from .models import BankAccount, Payment, PaymentUser
16 from .payables import Payable, payables
17
18
19 def create_payment(
20 model_payable: Union[Model, Payable],
21 processed_by: Member,
22 pay_type: Union[Payment.CASH, Payment.CARD, Payment.WIRE, Payment.TPAY],
23 ) -> Payment:
24 """Create a new payment from a payable object.
25
26 :param model_payable: Payable or Model object
27 :param processed_by: PaymentUser that processed this payment
28 :param pay_type: Payment type
29 :return: Payment object
30 """
31 if pay_type not in (Payment.CASH, Payment.CARD, Payment.WIRE, Payment.TPAY):
32 raise PaymentError("Invalid payment type")
33
34 if isinstance(model_payable, Payable):
35 payable = model_payable
36 else:
37 payable = payables.get_payable(model_payable)
38
39 payer = (
40 PaymentUser.objects.get(pk=payable.payment_payer.pk)
41 if payable.payment_payer
42 else None
43 )
44
45 if not (
46 (payer and payer == processed_by and pay_type == Payment.TPAY)
47 or (payable.can_manage_payment(processed_by) and pay_type != Payment.TPAY)
48 ):
49 raise PaymentError(
50 _("User processing payment does not have the right permissions")
51 )
52
53 if payable.payment_amount == 0:
54 raise PaymentError(_("Payment amount 0 is not accepted"))
55
56 if pay_type == Payment.TPAY and not payer.tpay_enabled:
57 raise PaymentError(_("This user does not have Thalia Pay enabled"))
58
59 if not payable.paying_allowed:
60 raise PaymentError(_("Payment restricted"))
61
62 if payable.payment is not None:
63 payable.payment.amount = payable.payment_amount
64 payable.payment.notes = payable.payment_notes
65 payable.payment.topic = payable.payment_topic
66 payable.payment.paid_by = payer
67 payable.payment.processed_by = processed_by
68 payable.payment.type = pay_type
69 payable.payment.save()
70 else:
71 payable.payment = Payment.objects.create(
72 processed_by=processed_by,
73 amount=payable.payment_amount,
74 notes=payable.payment_notes,
75 topic=payable.payment_topic,
76 paid_by=payer,
77 type=pay_type,
78 )
79 return payable.payment
80
81
82 def delete_payment(model: Model, member: Member = None, ignore_change_window=False):
83 """Remove a payment from a payable object.
84
85 :param model: Payable or Model object
86 :param member: member deleting the payment
87 :param ignore_change_window: ignore the payment change window
88 :return:
89 """
90 payable = payables.get_payable(model)
91
92 if member and not payable.can_manage_payment(member):
93 raise PaymentError(
94 _("User deleting payment does not have the right permissions.")
95 )
96
97 payment = payable.payment
98 if (
99 payment.created_at
100 < timezone.now() - timezone.timedelta(seconds=settings.PAYMENT_CHANGE_WINDOW)
101 and not ignore_change_window
102 ):
103 raise PaymentError(_("This payment cannot be deleted anymore."))
104 if payment.batch and payment.batch.processed:
105 raise PaymentError(
106 _("This payment has already been processed and hence cannot be deleted.")
107 )
108
109 payable.payment = None
110 payable.model.save()
111 payment.delete()
112
113
114 def update_last_used(queryset: QuerySet, date: datetime.date = None) -> int:
115 """Update the last used field of a BankAccount queryset.
116
117 :param queryset: Queryset of BankAccounts
118 :param date: date to set last_used to
119 :return: number of affected rows
120 """
121 if not date:
122 date = timezone.now().date()
123
124 result = queryset.filter(
125 (Q(valid_from__gte=timezone.now()) & Q(valid_until__lt=timezone.now()))
126 | Q(valid_until=None)
127 ).update(last_used=date)
128 return result
129
130
131 def revoke_old_mandates() -> int:
132 """Revoke all mandates that have not been used for 36 months or more.
133
134 :return: number of affected rows
135 """
136 return BankAccount.objects.filter(
137 last_used__lte=(timezone.now() - timezone.timedelta(days=36 * 30))
138 ).update(valid_until=timezone.now().date())
139
140
141 def process_batch(batch):
142 """Process a Thalia Pay batch.
143
144 :param batch: the batch to be processed
145 :return:
146 """
147 batch.processed = True
148
149 payments = batch.payments_set.select_related("paid_by")
150 for payment in payments:
151 bank_account = payment.paid_by.bank_accounts.last()
152 bank_account.last_used = batch.withdrawal_date
153 bank_account.save()
154
155 batch.save()
156
157 send_tpay_batch_processing_emails(batch)
158
159
160 def derive_next_mandate_no(member) -> str:
161 accounts = (
162 BankAccount.objects.filter(owner=PaymentUser.objects.get(pk=member.pk))
163 .exclude(mandate_no=None)
164 .filter(mandate_no__regex=BankAccount.MANDATE_NO_DEFAULT_REGEX)
165 )
166 new_mandate_no = 1 + max(
167 (int(account.mandate_no.split("-")[1]) for account in accounts), default=0
168 )
169 return f"{member.pk}-{new_mandate_no}"
170
171
172 def send_tpay_batch_processing_emails(batch):
173 """Send withdrawal notice emails to all members in a batch."""
174 member_payments = batch.payments_set.values("paid_by").annotate(total=Sum("amount"))
175 for member_row in member_payments:
176 member = PaymentUser.objects.get(pk=member_row["paid_by"])
177 total_amount = member_row["total"]
178
179 send_email(
180 member.email,
181 _("Thalia Pay withdrawal notice"),
182 "payments/email/tpay_withdrawal_notice_mail.txt",
183 {
184 "name": member.get_full_name(),
185 "batch": batch,
186 "bank_account": member.bank_accounts.filter(
187 mandate_no__isnull=False
188 ).last(),
189 "creditor_id": settings.SEPA_CREDITOR_ID,
190 "payments": batch.payments_set.filter(paid_by=member),
191 "total_amount": total_amount,
192 "payments_url": (
193 settings.BASE_URL
194 + reverse(
195 "payments:payment-list",
196 )
197 ),
198 },
199 )
200 return len(member_payments)
201
202
203 def execute_data_minimisation(dry_run=False):
204 """Anonymizes payments older than 7 years."""
205 # Sometimes years are 366 days of course, but better delete 1 or 2 days early than late
206 payment_deletion_period = timezone.now().date() - timezone.timedelta(days=(365 * 7))
207 bankaccount_deletion_period = timezone.now() - datetime.timedelta(days=(31 * 13))
208
209 queryset_payments = Payment.objects.filter(
210 created_at__lte=payment_deletion_period
211 ).exclude(paid_by__isnull=True)
212
213 # Delete bank accounts that are not valid anymore, and have not been used in the last 13 months
214 # (13 months is the required time we need to keep the mandates for)
215 queryset_bankaccounts = BankAccount.objects.all()
216 queryset_bankaccounts = queryset_bankaccounts.filter(
217 valid_until__lt=timezone.now()
218 ) # Keep valid bank accounts
219 queryset_bankaccounts = queryset_bankaccounts.exclude( # Also keep bank accounts that
220 Q(
221 owner__paid_payment_set__type=Payment.TPAY
222 ), # are used for Thalia Pay payments, AND
223 Q(
224 owner__paid_payment_set__batch__isnull=True
225 ) # have a payment that is in no batch, OR
226 | Q(
227 owner__paid_payment_set__batch__processed=False
228 ) # have an unprocessed batch, OR
229 | Q(
230 owner__paid_payment_set__batch__processing_date__gt=bankaccount_deletion_period # or have a processed batch that is not older than 13 months
231 ),
232 )
233
234 if not dry_run:
235 queryset_payments.update(paid_by=None, processed_by=None)
236 queryset_bankaccounts.delete()
237 return queryset_payments
238
[end of website/payments/services.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/website/payments/services.py b/website/payments/services.py
--- a/website/payments/services.py
+++ b/website/payments/services.py
@@ -149,8 +149,13 @@
payments = batch.payments_set.select_related("paid_by")
for payment in payments:
bank_account = payment.paid_by.bank_accounts.last()
- bank_account.last_used = batch.withdrawal_date
- bank_account.save()
+ if not bank_account: # pragma: no cover
+ # This should not happen, cannot haver, does not happen (right... ;p), but if it does, we don't want to crash, but just remove the payment from the batch (make it unprocessed)
+ payment.batch = None
+ payment.save()
+ else:
+ bank_account.last_used = batch.withdrawal_date
+ bank_account.save()
batch.save()
@@ -215,7 +220,7 @@
queryset_bankaccounts = BankAccount.objects.all()
queryset_bankaccounts = queryset_bankaccounts.filter(
valid_until__lt=timezone.now()
- ) # Keep valid bank accounts
+ ) # We must always keep valid bank accounts. so we only select the ones that are not valid anymore (valid_until < now)
queryset_bankaccounts = queryset_bankaccounts.exclude( # Also keep bank accounts that
Q(
owner__paid_payment_set__type=Payment.TPAY
|
{"golden_diff": "diff --git a/website/payments/services.py b/website/payments/services.py\n--- a/website/payments/services.py\n+++ b/website/payments/services.py\n@@ -149,8 +149,13 @@\n payments = batch.payments_set.select_related(\"paid_by\")\n for payment in payments:\n bank_account = payment.paid_by.bank_accounts.last()\n- bank_account.last_used = batch.withdrawal_date\n- bank_account.save()\n+ if not bank_account: # pragma: no cover\n+ # This should not happen, cannot haver, does not happen (right... ;p), but if it does, we don't want to crash, but just remove the payment from the batch (make it unprocessed)\n+ payment.batch = None\n+ payment.save()\n+ else:\n+ bank_account.last_used = batch.withdrawal_date\n+ bank_account.save()\n \n batch.save()\n \n@@ -215,7 +220,7 @@\n queryset_bankaccounts = BankAccount.objects.all()\n queryset_bankaccounts = queryset_bankaccounts.filter(\n valid_until__lt=timezone.now()\n- ) # Keep valid bank accounts\n+ ) # We must always keep valid bank accounts. so we only select the ones that are not valid anymore (valid_until < now)\n queryset_bankaccounts = queryset_bankaccounts.exclude( # Also keep bank accounts that\n Q(\n owner__paid_payment_set__type=Payment.TPAY\n", "issue": "Unprocessed Thalia Pay payment without bank account\nApparently it is possible that people either pay with Thalia pay without having a valid bank account, or, it is possible to remove a bank account after a Thalia Pay payment is made but not processed (in which case it should not be possible)\n\n\nSentry Issue: [CONCREXIT-HD](https://sentry.io/organizations/thalia/issues/3640470247/?referrer=github_integration)\n\n```\nAttributeError: 'NoneType' object has no attribute 'last_used'\n(8 additional frame(s) were not displayed)\n...\n File \"django/utils/decorators.py\", line 46, in _wrapper\n return bound_method(*args, **kwargs)\n File \"django/contrib/auth/decorators.py\", line 23, in _wrapped_view\n return view_func(request, *args, **kwargs)\n File \"django/views/generic/base.py\", line 119, in dispatch\n return handler(request, *args, **kwargs)\n File \"payments/admin_views.py\", line 107, in post\n services.process_batch(batch)\n File \"payments/services.py\", line 151, in process_batch\n bank_account.last_used = batch.withdrawal_date\n```\n", "before_files": [{"content": "\"\"\"The services defined by the payments package.\"\"\"\nimport datetime\nfrom typing import Union\n\nfrom django.conf import settings\nfrom django.db.models import Model, Q, QuerySet, Sum\nfrom django.urls import reverse\nfrom django.utils import timezone\nfrom django.utils.translation import gettext_lazy as _\n\nfrom members.models import Member\nfrom utils.snippets import send_email\n\nfrom .exceptions import PaymentError\nfrom .models import BankAccount, Payment, PaymentUser\nfrom .payables import Payable, payables\n\n\ndef create_payment(\n model_payable: Union[Model, Payable],\n processed_by: Member,\n pay_type: Union[Payment.CASH, Payment.CARD, Payment.WIRE, Payment.TPAY],\n) -> Payment:\n \"\"\"Create a new payment from a payable object.\n\n :param model_payable: Payable or Model object\n :param processed_by: PaymentUser that processed this payment\n :param pay_type: Payment type\n :return: Payment object\n \"\"\"\n if pay_type not in (Payment.CASH, Payment.CARD, Payment.WIRE, Payment.TPAY):\n raise PaymentError(\"Invalid payment type\")\n\n if isinstance(model_payable, Payable):\n payable = model_payable\n else:\n payable = payables.get_payable(model_payable)\n\n payer = (\n PaymentUser.objects.get(pk=payable.payment_payer.pk)\n if payable.payment_payer\n else None\n )\n\n if not (\n (payer and payer == processed_by and pay_type == Payment.TPAY)\n or (payable.can_manage_payment(processed_by) and pay_type != Payment.TPAY)\n ):\n raise PaymentError(\n _(\"User processing payment does not have the right permissions\")\n )\n\n if payable.payment_amount == 0:\n raise PaymentError(_(\"Payment amount 0 is not accepted\"))\n\n if pay_type == Payment.TPAY and not payer.tpay_enabled:\n raise PaymentError(_(\"This user does not have Thalia Pay enabled\"))\n\n if not payable.paying_allowed:\n raise PaymentError(_(\"Payment restricted\"))\n\n if payable.payment is not None:\n payable.payment.amount = payable.payment_amount\n payable.payment.notes = payable.payment_notes\n payable.payment.topic = payable.payment_topic\n payable.payment.paid_by = payer\n payable.payment.processed_by = processed_by\n payable.payment.type = pay_type\n payable.payment.save()\n else:\n payable.payment = Payment.objects.create(\n processed_by=processed_by,\n amount=payable.payment_amount,\n notes=payable.payment_notes,\n topic=payable.payment_topic,\n paid_by=payer,\n type=pay_type,\n )\n return payable.payment\n\n\ndef delete_payment(model: Model, member: Member = None, ignore_change_window=False):\n \"\"\"Remove a payment from a payable object.\n\n :param model: Payable or Model object\n :param member: member deleting the payment\n :param ignore_change_window: ignore the payment change window\n :return:\n \"\"\"\n payable = payables.get_payable(model)\n\n if member and not payable.can_manage_payment(member):\n raise PaymentError(\n _(\"User deleting payment does not have the right permissions.\")\n )\n\n payment = payable.payment\n if (\n payment.created_at\n < timezone.now() - timezone.timedelta(seconds=settings.PAYMENT_CHANGE_WINDOW)\n and not ignore_change_window\n ):\n raise PaymentError(_(\"This payment cannot be deleted anymore.\"))\n if payment.batch and payment.batch.processed:\n raise PaymentError(\n _(\"This payment has already been processed and hence cannot be deleted.\")\n )\n\n payable.payment = None\n payable.model.save()\n payment.delete()\n\n\ndef update_last_used(queryset: QuerySet, date: datetime.date = None) -> int:\n \"\"\"Update the last used field of a BankAccount queryset.\n\n :param queryset: Queryset of BankAccounts\n :param date: date to set last_used to\n :return: number of affected rows\n \"\"\"\n if not date:\n date = timezone.now().date()\n\n result = queryset.filter(\n (Q(valid_from__gte=timezone.now()) & Q(valid_until__lt=timezone.now()))\n | Q(valid_until=None)\n ).update(last_used=date)\n return result\n\n\ndef revoke_old_mandates() -> int:\n \"\"\"Revoke all mandates that have not been used for 36 months or more.\n\n :return: number of affected rows\n \"\"\"\n return BankAccount.objects.filter(\n last_used__lte=(timezone.now() - timezone.timedelta(days=36 * 30))\n ).update(valid_until=timezone.now().date())\n\n\ndef process_batch(batch):\n \"\"\"Process a Thalia Pay batch.\n\n :param batch: the batch to be processed\n :return:\n \"\"\"\n batch.processed = True\n\n payments = batch.payments_set.select_related(\"paid_by\")\n for payment in payments:\n bank_account = payment.paid_by.bank_accounts.last()\n bank_account.last_used = batch.withdrawal_date\n bank_account.save()\n\n batch.save()\n\n send_tpay_batch_processing_emails(batch)\n\n\ndef derive_next_mandate_no(member) -> str:\n accounts = (\n BankAccount.objects.filter(owner=PaymentUser.objects.get(pk=member.pk))\n .exclude(mandate_no=None)\n .filter(mandate_no__regex=BankAccount.MANDATE_NO_DEFAULT_REGEX)\n )\n new_mandate_no = 1 + max(\n (int(account.mandate_no.split(\"-\")[1]) for account in accounts), default=0\n )\n return f\"{member.pk}-{new_mandate_no}\"\n\n\ndef send_tpay_batch_processing_emails(batch):\n \"\"\"Send withdrawal notice emails to all members in a batch.\"\"\"\n member_payments = batch.payments_set.values(\"paid_by\").annotate(total=Sum(\"amount\"))\n for member_row in member_payments:\n member = PaymentUser.objects.get(pk=member_row[\"paid_by\"])\n total_amount = member_row[\"total\"]\n\n send_email(\n member.email,\n _(\"Thalia Pay withdrawal notice\"),\n \"payments/email/tpay_withdrawal_notice_mail.txt\",\n {\n \"name\": member.get_full_name(),\n \"batch\": batch,\n \"bank_account\": member.bank_accounts.filter(\n mandate_no__isnull=False\n ).last(),\n \"creditor_id\": settings.SEPA_CREDITOR_ID,\n \"payments\": batch.payments_set.filter(paid_by=member),\n \"total_amount\": total_amount,\n \"payments_url\": (\n settings.BASE_URL\n + reverse(\n \"payments:payment-list\",\n )\n ),\n },\n )\n return len(member_payments)\n\n\ndef execute_data_minimisation(dry_run=False):\n \"\"\"Anonymizes payments older than 7 years.\"\"\"\n # Sometimes years are 366 days of course, but better delete 1 or 2 days early than late\n payment_deletion_period = timezone.now().date() - timezone.timedelta(days=(365 * 7))\n bankaccount_deletion_period = timezone.now() - datetime.timedelta(days=(31 * 13))\n\n queryset_payments = Payment.objects.filter(\n created_at__lte=payment_deletion_period\n ).exclude(paid_by__isnull=True)\n\n # Delete bank accounts that are not valid anymore, and have not been used in the last 13 months\n # (13 months is the required time we need to keep the mandates for)\n queryset_bankaccounts = BankAccount.objects.all()\n queryset_bankaccounts = queryset_bankaccounts.filter(\n valid_until__lt=timezone.now()\n ) # Keep valid bank accounts\n queryset_bankaccounts = queryset_bankaccounts.exclude( # Also keep bank accounts that\n Q(\n owner__paid_payment_set__type=Payment.TPAY\n ), # are used for Thalia Pay payments, AND\n Q(\n owner__paid_payment_set__batch__isnull=True\n ) # have a payment that is in no batch, OR\n | Q(\n owner__paid_payment_set__batch__processed=False\n ) # have an unprocessed batch, OR\n | Q(\n owner__paid_payment_set__batch__processing_date__gt=bankaccount_deletion_period # or have a processed batch that is not older than 13 months\n ),\n )\n\n if not dry_run:\n queryset_payments.update(paid_by=None, processed_by=None)\n queryset_bankaccounts.delete()\n return queryset_payments\n", "path": "website/payments/services.py"}]}
| 3,235 | 320 |
gh_patches_debug_888
|
rasdani/github-patches
|
git_diff
|
helmholtz-analytics__heat-1268
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fix Pytorch release tracking workflows
## Due Diligence
<!--- Please address the following points before setting your PR "ready for review".
--->
- General:
- [x] **base branch** must be `main` for new features, latest release branch (e.g. `release/1.3.x`) for bug fixes
- [x] **title** of the PR is suitable to appear in the [Release Notes](https://github.com/helmholtz-analytics/heat/releases/latest)
- Implementation:
- [x] unit tests: all split configurations tested
- [x] unit tests: multiple dtypes tested
- [x] documentation updated where needed
## Description
<!--- Include a summary of the change/s.
Please also include relevant motivation and context. List any dependencies that are required for this change.
--->
Issue/s resolved: #1241
## Changes proposed:
- upgrade to the latest version of checkout action
- delete the token parameter such that the default action token is used
## Type of change
<!--
i.e.
- Bug fix (non-breaking change which fixes an issue)
- New feature (non-breaking change which adds functionality)
- Breaking change (fix or feature that would cause existing functionality to not work as expected)
- Documentation update
--->
## Memory requirements
<!--- Compare memory requirements to previous implementation / relevant torch operations if applicable:
- in distributed and non-distributed mode
- with `split=None` and `split not None`
This can be done using https://github.com/pythonprofilers/memory_profiler for CPU memory measurements,
GPU measurements can be done with https://pytorch.org/docs/master/generated/torch.cuda.max_memory_allocated.html.
These tools only profile the memory used by each process, not the entire function.
--->
## Performance
<!--- Compare performance to previous implementation / relevant torch operations if applicable:
- in distributed and non-distributed mode
- with `split=None` and `split not None`
Python has an embedded profiler: https://docs.python.org/3.9/library/profile.html
Again, this will only profile the performance on each process. Printing the results with many processes
may be illegible. It may be easiest to save the output of each to a file.
--->
#### Does this change modify the behaviour of other functions? If so, which?
no
</issue>
<code>
[start of heat/core/version.py]
1 """This module contains Heat's version information."""
2
3
4 major: int = 1
5 """Indicates Heat's main version."""
6 minor: int = 3
7 """Indicates feature extension."""
8 micro: int = 0
9 """Indicates revisions for bugfixes."""
10 extension: str = "dev"
11 """Indicates special builds, e.g. for specific hardware."""
12
13 if not extension:
14 __version__: str = f"{major}.{minor}.{micro}"
15 """The combined version string, consisting out of major, minor, micro and possibly extension."""
16 else:
17 __version__: str = f"{major}.{minor}.{micro}-{extension}"
18
[end of heat/core/version.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/heat/core/version.py b/heat/core/version.py
--- a/heat/core/version.py
+++ b/heat/core/version.py
@@ -3,7 +3,7 @@
major: int = 1
"""Indicates Heat's main version."""
-minor: int = 3
+minor: int = 4
"""Indicates feature extension."""
micro: int = 0
"""Indicates revisions for bugfixes."""
|
{"golden_diff": "diff --git a/heat/core/version.py b/heat/core/version.py\n--- a/heat/core/version.py\n+++ b/heat/core/version.py\n@@ -3,7 +3,7 @@\n \n major: int = 1\n \"\"\"Indicates Heat's main version.\"\"\"\n-minor: int = 3\n+minor: int = 4\n \"\"\"Indicates feature extension.\"\"\"\n micro: int = 0\n \"\"\"Indicates revisions for bugfixes.\"\"\"\n", "issue": "Fix Pytorch release tracking workflows\n## Due Diligence\r\n<!--- Please address the following points before setting your PR \"ready for review\".\r\n--->\r\n- General:\r\n - [x] **base branch** must be `main` for new features, latest release branch (e.g. `release/1.3.x`) for bug fixes\r\n - [x] **title** of the PR is suitable to appear in the [Release Notes](https://github.com/helmholtz-analytics/heat/releases/latest)\r\n- Implementation:\r\n - [x] unit tests: all split configurations tested\r\n - [x] unit tests: multiple dtypes tested\r\n - [x] documentation updated where needed\r\n\r\n## Description\r\n\r\n<!--- Include a summary of the change/s.\r\nPlease also include relevant motivation and context. List any dependencies that are required for this change.\r\n--->\r\n\r\nIssue/s resolved: #1241 \r\n\r\n## Changes proposed:\r\n\r\n- upgrade to the latest version of checkout action\r\n- delete the token parameter such that the default action token is used\r\n\r\n## Type of change\r\n<!--\r\ni.e.\r\n- Bug fix (non-breaking change which fixes an issue)\r\n- New feature (non-breaking change which adds functionality)\r\n- Breaking change (fix or feature that would cause existing functionality to not work as expected)\r\n- Documentation update\r\n--->\r\n\r\n## Memory requirements\r\n<!--- Compare memory requirements to previous implementation / relevant torch operations if applicable:\r\n- in distributed and non-distributed mode\r\n- with `split=None` and `split not None`\r\n\r\nThis can be done using https://github.com/pythonprofilers/memory_profiler for CPU memory measurements,\r\nGPU measurements can be done with https://pytorch.org/docs/master/generated/torch.cuda.max_memory_allocated.html.\r\nThese tools only profile the memory used by each process, not the entire function.\r\n--->\r\n\r\n## Performance\r\n<!--- Compare performance to previous implementation / relevant torch operations if applicable:\r\n- in distributed and non-distributed mode\r\n- with `split=None` and `split not None`\r\n\r\nPython has an embedded profiler: https://docs.python.org/3.9/library/profile.html\r\nAgain, this will only profile the performance on each process. Printing the results with many processes\r\nmay be illegible. It may be easiest to save the output of each to a file.\r\n--->\r\n\r\n#### Does this change modify the behaviour of other functions? If so, which?\r\nno\r\n\n", "before_files": [{"content": "\"\"\"This module contains Heat's version information.\"\"\"\n\n\nmajor: int = 1\n\"\"\"Indicates Heat's main version.\"\"\"\nminor: int = 3\n\"\"\"Indicates feature extension.\"\"\"\nmicro: int = 0\n\"\"\"Indicates revisions for bugfixes.\"\"\"\nextension: str = \"dev\"\n\"\"\"Indicates special builds, e.g. for specific hardware.\"\"\"\n\nif not extension:\n __version__: str = f\"{major}.{minor}.{micro}\"\n \"\"\"The combined version string, consisting out of major, minor, micro and possibly extension.\"\"\"\nelse:\n __version__: str = f\"{major}.{minor}.{micro}-{extension}\"\n", "path": "heat/core/version.py"}]}
| 1,191 | 96 |
gh_patches_debug_23040
|
rasdani/github-patches
|
git_diff
|
ckan__ckan-5737
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
CKAN 2.9 changes order in which plugins are returned by PluginImplementations
## Summary
I'm porting a big project from CKAN 2.8 to 2.9. My plugin overrides a template from ckanext-scheming to customize the form. After upgrade, my changes weren't reflected because my custom template wasn't loaded.
Only after changing the ordering of the plugins in `ckan.plugins` it was picked up.
So on CKAN <= 2.8, in order for plugin `abc` to override `scheming_datasets` you needed:
```
ckan.plugins = abc scheming_datasets
```
In CKAN 2.9, you need:
```
ckan.plugins = scheming_datasets abc
```
### Why it is important
This is pretty significant change, which AFAICT wasn't mentioned in the changelog.
After initial investigation it looks like the issue is not how we parse the config option or load the plugins, but how the `PluginImplementations` iterator returns them. We use them in all places where we let plugins integrate with CKAN core. For instance in `environment.py` we call:
```python
for plugin in p.PluginImplementations(p.IConfigurer):
plugin.update_config(config)
```
This is one is relevant to my issue, as it registers template directories from plugins and stores them on a list in `config['extra_template_paths']`. Order is important, as the first template path found will be used to render.
At [this point](https://github.com/ckan/ckan/blob/8eec3e27c320baf29e0d99b2ce20ed14ae10b0d3/ckan/config/environment.py#L173) we get the following behaviour:
* On CKAN 2.8:
```python
[plugin for plugin in p.PluginImplementations(p.IConfigurer)]
# [<Plugin AbcPlugin 'abc'>, <Plugin SchemingDatasetsPlugin 'scheming_datasets'>]
config['extra_template_paths'].split(',')
# [
# u'/home/adria/dev/pyenvs/ckan/src/ckanext-abc/ckanext/abc/templates',
# u'/home/adria/dev/pyenvs/ckan/src/ckanext-scheming/ckanext/scheming/templates',
# ]
```
* On CKAN 2.9:
```python
[plugin for plugin in p.PluginImplementations(p.IConfigurer)]
# [<Plugin SchemingDatasetsPlugin 'scheming_datasets'>, <Plugin AbcPlugin 'abc'>]
config['extra_template_paths'].split(',')
# [
# u'/home/adria/dev/pyenvs/ckan/src/ckanext-scheming/ckanext/scheming/templates',
# u'/home/adria/dev/pyenvs/ckan/src/ckanext-abc/ckanext/abc/templates',
# ]
```
Apart from template loading issues this is likely to affect everywhere where the order of plugins is important, eg chained actions, chained auth functions.
### Root cause
After looking at [ckan/plugins/core.py](https://github.com/ckan/ckan/blob/master/ckan/plugins/core.py) my current thinking is that this is *not* related to the loading of the plugins. AFAICT we´ve always loaded them in the order that they are defined in `ckan.plugins`. It´s the actual iterator returned by `PluginImplementations` that changed the order of the returned plugins at some point between the two versions (pyutilib.component.core==4.6.4 in CKAN 2.8, PyUtilib==5.7.1 in CKAN 2.9). We are importing this class directly from Pyutillib. The only work done on this code between these two versions was https://github.com/ckan/ckan/pull/4886, and I don´t think it should affect the ordering (apart from upgrading the library of course)
### What should we do?
My ideas so far:
1. Change nothing and assume this is the new behaviour, *but* documenting it in the relevant places (2.9 Changelog, plugins docs, mail to ckan-dev). I don´t think we can leave a change like this undocumented
2. Create our own `PluginImplementations` wrapper that restores the old ordering (maybe optionally based on a config option). We would need to override the [`__iter__()`](https://github.com/PyUtilib/pyutilib/blob/5.7.3/pyutilib/component/core/core.py#L222) method, not sure how easy that is
Any thoughts or other ideas on what to do? @ckan/core
</issue>
<code>
[start of ckan/plugins/core.py]
1 # encoding: utf-8
2
3 '''
4 Provides plugin services to the CKAN
5 '''
6
7 from contextlib import contextmanager
8 import logging
9 from pkg_resources import iter_entry_points
10 from pyutilib.component.core import PluginGlobals, implements
11 from pyutilib.component.core import ExtensionPoint as PluginImplementations
12 from pyutilib.component.core import SingletonPlugin as _pca_SingletonPlugin
13 from pyutilib.component.core import Plugin as _pca_Plugin
14 from ckan.common import asbool
15 from six import string_types
16
17 from ckan.plugins import interfaces
18
19 from ckan.common import config
20
21
22 __all__ = [
23 'PluginImplementations', 'implements',
24 'PluginNotFoundException', 'Plugin', 'SingletonPlugin',
25 'load', 'load_all', 'unload', 'unload_all',
26 'get_plugin', 'plugins_update',
27 'use_plugin', 'plugin_loaded',
28 ]
29
30 log = logging.getLogger(__name__)
31
32 # Entry point group.
33 PLUGINS_ENTRY_POINT_GROUP = 'ckan.plugins'
34
35 # Entry point group for system plugins (those that are part of core ckan and
36 # do not need to be explicitly enabled by the user)
37 SYSTEM_PLUGINS_ENTRY_POINT_GROUP = 'ckan.system_plugins'
38
39 # Entry point for test plugins.
40 TEST_PLUGINS_ENTRY_POINT_GROUP = 'ckan.test_plugins'
41
42 GROUPS = [
43 PLUGINS_ENTRY_POINT_GROUP,
44 SYSTEM_PLUGINS_ENTRY_POINT_GROUP,
45 TEST_PLUGINS_ENTRY_POINT_GROUP,
46 ]
47 # These lists are used to ensure that the correct extensions are enabled.
48 _PLUGINS = []
49 _PLUGINS_CLASS = []
50
51 # To aid retrieving extensions by name
52 _PLUGINS_SERVICE = {}
53
54
55 @contextmanager
56 def use_plugin(*plugins):
57 '''Load plugin(s) for testing purposes
58
59 e.g.
60 ```
61 import ckan.plugins as p
62 with p.use_plugin('my_plugin') as my_plugin:
63 # run tests with plugin loaded
64 ```
65 '''
66
67 p = load(*plugins)
68 try:
69 yield p
70 finally:
71 unload(*plugins)
72
73
74 class PluginNotFoundException(Exception):
75 '''
76 Raised when a requested plugin cannot be found.
77 '''
78
79
80 class Plugin(_pca_Plugin):
81 '''
82 Base class for plugins which require multiple instances.
83
84 Unless you need multiple instances of your plugin object you should
85 probably use SingletonPlugin.
86 '''
87
88
89 class SingletonPlugin(_pca_SingletonPlugin):
90 '''
91 Base class for plugins which are singletons (ie most of them)
92
93 One singleton instance of this class will be created when the plugin is
94 loaded. Subsequent calls to the class constructor will always return the
95 same singleton instance.
96 '''
97
98
99 def get_plugin(plugin):
100 ''' Get an instance of a active plugin by name. This is helpful for
101 testing. '''
102 if plugin in _PLUGINS_SERVICE:
103 return _PLUGINS_SERVICE[plugin]
104
105
106 def plugins_update():
107 ''' This is run when plugins have been loaded or unloaded and allows us
108 to run any specific code to ensure that the new plugin setting are
109 correctly setup '''
110
111 # It is posible for extra SingletonPlugin extensions to be activated if
112 # the file containing them is imported, for example if two or more
113 # extensions are defined in the same file. Therefore we do a sanity
114 # check and disable any that should not be active.
115 for env in PluginGlobals.env.values():
116 for service, id_ in env.singleton_services.items():
117 if service not in _PLUGINS_CLASS:
118 PluginGlobals.plugin_instances[id_].deactivate()
119
120 # Reset CKAN to reflect the currently enabled extensions.
121 import ckan.config.environment as environment
122 environment.update_config()
123
124
125 def load_all():
126 '''
127 Load all plugins listed in the 'ckan.plugins' config directive.
128 '''
129 # Clear any loaded plugins
130 unload_all()
131
132 plugins = config.get('ckan.plugins', '').split() + find_system_plugins()
133 # Add the synchronous search plugin, unless already loaded or
134 # explicitly disabled
135 if 'synchronous_search' not in plugins and \
136 asbool(config.get('ckan.search.automatic_indexing', True)):
137 log.debug('Loading the synchronous search plugin')
138 plugins.append('synchronous_search')
139
140 load(*plugins)
141
142
143 def load(*plugins):
144 '''
145 Load named plugin(s).
146 '''
147 output = []
148
149 observers = PluginImplementations(interfaces.IPluginObserver)
150 for plugin in plugins:
151 if plugin in _PLUGINS:
152 raise Exception('Plugin `%s` already loaded' % plugin)
153
154 service = _get_service(plugin)
155 for observer_plugin in observers:
156 observer_plugin.before_load(service)
157 service.activate()
158 for observer_plugin in observers:
159 observer_plugin.after_load(service)
160
161 _PLUGINS.append(plugin)
162 _PLUGINS_CLASS.append(service.__class__)
163
164 if isinstance(service, SingletonPlugin):
165 _PLUGINS_SERVICE[plugin] = service
166
167 output.append(service)
168 plugins_update()
169
170 # Return extension instance if only one was loaded. If more that one
171 # has been requested then a list of instances is returned in the order
172 # they were asked for.
173 if len(output) == 1:
174 return output[0]
175 return output
176
177
178 def unload_all():
179 '''
180 Unload (deactivate) all loaded plugins in the reverse order that they
181 were loaded.
182 '''
183 unload(*reversed(_PLUGINS))
184
185
186 def unload(*plugins):
187 '''
188 Unload named plugin(s).
189 '''
190
191 observers = PluginImplementations(interfaces.IPluginObserver)
192
193 for plugin in plugins:
194 if plugin in _PLUGINS:
195 _PLUGINS.remove(plugin)
196 if plugin in _PLUGINS_SERVICE:
197 del _PLUGINS_SERVICE[plugin]
198 else:
199 raise Exception('Cannot unload plugin `%s`' % plugin)
200
201 service = _get_service(plugin)
202 for observer_plugin in observers:
203 observer_plugin.before_unload(service)
204
205 service.deactivate()
206
207 _PLUGINS_CLASS.remove(service.__class__)
208
209 for observer_plugin in observers:
210 observer_plugin.after_unload(service)
211 plugins_update()
212
213
214 def plugin_loaded(name):
215 '''
216 See if a particular plugin is loaded.
217 '''
218 if name in _PLUGINS:
219 return True
220 return False
221
222
223 def find_system_plugins():
224 '''
225 Return all plugins in the ckan.system_plugins entry point group.
226
227 These are essential for operation and therefore cannot be
228 enabled/disabled through the configuration file.
229 '''
230
231 eps = []
232 for ep in iter_entry_points(group=SYSTEM_PLUGINS_ENTRY_POINT_GROUP):
233 ep.load()
234 eps.append(ep.name)
235 return eps
236
237
238 def _get_service(plugin_name):
239 '''
240 Return a service (ie an instance of a plugin class).
241
242 :param plugin_name: the name of a plugin entry point
243 :type plugin_name: string
244
245 :return: the service object
246 '''
247
248 if isinstance(plugin_name, string_types):
249 for group in GROUPS:
250 iterator = iter_entry_points(
251 group=group,
252 name=plugin_name
253 )
254 plugin = next(iterator, None)
255 if plugin:
256 return plugin.load()(name=plugin_name)
257 raise PluginNotFoundException(plugin_name)
258 else:
259 raise TypeError('Expected a plugin name', plugin_name)
260
[end of ckan/plugins/core.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ckan/plugins/core.py b/ckan/plugins/core.py
--- a/ckan/plugins/core.py
+++ b/ckan/plugins/core.py
@@ -8,7 +8,7 @@
import logging
from pkg_resources import iter_entry_points
from pyutilib.component.core import PluginGlobals, implements
-from pyutilib.component.core import ExtensionPoint as PluginImplementations
+from pyutilib.component.core import ExtensionPoint
from pyutilib.component.core import SingletonPlugin as _pca_SingletonPlugin
from pyutilib.component.core import Plugin as _pca_Plugin
from ckan.common import asbool
@@ -71,6 +71,21 @@
unload(*plugins)
+class PluginImplementations(ExtensionPoint):
+
+ def __iter__(self):
+ '''
+ When we upgraded pyutilib on CKAN 2.9 the order in which
+ plugins were returned by `PluginImplementations` changed
+ so we use this wrapper to maintain the previous order
+ (which is the same as the ckan.plugins config option)
+ '''
+
+ iterator = super(PluginImplementations, self).__iter__()
+
+ return reversed(list(iterator))
+
+
class PluginNotFoundException(Exception):
'''
Raised when a requested plugin cannot be found.
|
{"golden_diff": "diff --git a/ckan/plugins/core.py b/ckan/plugins/core.py\n--- a/ckan/plugins/core.py\n+++ b/ckan/plugins/core.py\n@@ -8,7 +8,7 @@\n import logging\n from pkg_resources import iter_entry_points\n from pyutilib.component.core import PluginGlobals, implements\n-from pyutilib.component.core import ExtensionPoint as PluginImplementations\n+from pyutilib.component.core import ExtensionPoint\n from pyutilib.component.core import SingletonPlugin as _pca_SingletonPlugin\n from pyutilib.component.core import Plugin as _pca_Plugin\n from ckan.common import asbool\n@@ -71,6 +71,21 @@\n unload(*plugins)\n \n \n+class PluginImplementations(ExtensionPoint):\n+\n+ def __iter__(self):\n+ '''\n+ When we upgraded pyutilib on CKAN 2.9 the order in which\n+ plugins were returned by `PluginImplementations` changed\n+ so we use this wrapper to maintain the previous order\n+ (which is the same as the ckan.plugins config option)\n+ '''\n+\n+ iterator = super(PluginImplementations, self).__iter__()\n+\n+ return reversed(list(iterator))\n+\n+\n class PluginNotFoundException(Exception):\n '''\n Raised when a requested plugin cannot be found.\n", "issue": "CKAN 2.9 changes order in which plugins are returned by PluginImplementations\n## Summary\r\nI'm porting a big project from CKAN 2.8 to 2.9. My plugin overrides a template from ckanext-scheming to customize the form. After upgrade, my changes weren't reflected because my custom template wasn't loaded.\r\nOnly after changing the ordering of the plugins in `ckan.plugins` it was picked up.\r\n\r\nSo on CKAN <= 2.8, in order for plugin `abc` to override `scheming_datasets` you needed:\r\n\r\n```\r\nckan.plugins = abc scheming_datasets \r\n```\r\n\r\nIn CKAN 2.9, you need:\r\n```\r\nckan.plugins = scheming_datasets abc\r\n```\r\n\r\n### Why it is important\r\n\r\nThis is pretty significant change, which AFAICT wasn't mentioned in the changelog.\r\n\r\nAfter initial investigation it looks like the issue is not how we parse the config option or load the plugins, but how the `PluginImplementations` iterator returns them. We use them in all places where we let plugins integrate with CKAN core. For instance in `environment.py` we call:\r\n\r\n```python\r\n for plugin in p.PluginImplementations(p.IConfigurer): \r\n plugin.update_config(config) \r\n```\r\nThis is one is relevant to my issue, as it registers template directories from plugins and stores them on a list in `config['extra_template_paths']`. Order is important, as the first template path found will be used to render.\r\n\r\nAt [this point](https://github.com/ckan/ckan/blob/8eec3e27c320baf29e0d99b2ce20ed14ae10b0d3/ckan/config/environment.py#L173) we get the following behaviour:\r\n\r\n* On CKAN 2.8:\r\n\r\n```python \r\n[plugin for plugin in p.PluginImplementations(p.IConfigurer)]\r\n\r\n# [<Plugin AbcPlugin 'abc'>, <Plugin SchemingDatasetsPlugin 'scheming_datasets'>]\r\n\r\nconfig['extra_template_paths'].split(',')\r\n\r\n# [\r\n# u'/home/adria/dev/pyenvs/ckan/src/ckanext-abc/ckanext/abc/templates',\r\n# u'/home/adria/dev/pyenvs/ckan/src/ckanext-scheming/ckanext/scheming/templates',\r\n# ]\r\n```\r\n* On CKAN 2.9:\r\n\r\n```python\r\n[plugin for plugin in p.PluginImplementations(p.IConfigurer)]\r\n\r\n# [<Plugin SchemingDatasetsPlugin 'scheming_datasets'>, <Plugin AbcPlugin 'abc'>]\r\n\r\nconfig['extra_template_paths'].split(',')\r\n\r\n# [\r\n# u'/home/adria/dev/pyenvs/ckan/src/ckanext-scheming/ckanext/scheming/templates',\r\n# u'/home/adria/dev/pyenvs/ckan/src/ckanext-abc/ckanext/abc/templates',\r\n# ]\r\n```\r\n\r\nApart from template loading issues this is likely to affect everywhere where the order of plugins is important, eg chained actions, chained auth functions.\r\n\r\n### Root cause\r\n\r\nAfter looking at [ckan/plugins/core.py](https://github.com/ckan/ckan/blob/master/ckan/plugins/core.py) my current thinking is that this is *not* related to the loading of the plugins. AFAICT we\u00b4ve always loaded them in the order that they are defined in `ckan.plugins`. It\u00b4s the actual iterator returned by `PluginImplementations` that changed the order of the returned plugins at some point between the two versions (pyutilib.component.core==4.6.4 in CKAN 2.8, PyUtilib==5.7.1 in CKAN 2.9). We are importing this class directly from Pyutillib. The only work done on this code between these two versions was https://github.com/ckan/ckan/pull/4886, and I don\u00b4t think it should affect the ordering (apart from upgrading the library of course)\r\n\r\n### What should we do?\r\n\r\nMy ideas so far:\r\n\r\n1. Change nothing and assume this is the new behaviour, *but* documenting it in the relevant places (2.9 Changelog, plugins docs, mail to ckan-dev). I don\u00b4t think we can leave a change like this undocumented\r\n2. Create our own `PluginImplementations` wrapper that restores the old ordering (maybe optionally based on a config option). We would need to override the [`__iter__()`](https://github.com/PyUtilib/pyutilib/blob/5.7.3/pyutilib/component/core/core.py#L222) method, not sure how easy that is\r\n\r\nAny thoughts or other ideas on what to do? @ckan/core \r\n\n", "before_files": [{"content": "# encoding: utf-8\n\n'''\nProvides plugin services to the CKAN\n'''\n\nfrom contextlib import contextmanager\nimport logging\nfrom pkg_resources import iter_entry_points\nfrom pyutilib.component.core import PluginGlobals, implements\nfrom pyutilib.component.core import ExtensionPoint as PluginImplementations\nfrom pyutilib.component.core import SingletonPlugin as _pca_SingletonPlugin\nfrom pyutilib.component.core import Plugin as _pca_Plugin\nfrom ckan.common import asbool\nfrom six import string_types\n\nfrom ckan.plugins import interfaces\n\nfrom ckan.common import config\n\n\n__all__ = [\n 'PluginImplementations', 'implements',\n 'PluginNotFoundException', 'Plugin', 'SingletonPlugin',\n 'load', 'load_all', 'unload', 'unload_all',\n 'get_plugin', 'plugins_update',\n 'use_plugin', 'plugin_loaded',\n]\n\nlog = logging.getLogger(__name__)\n\n# Entry point group.\nPLUGINS_ENTRY_POINT_GROUP = 'ckan.plugins'\n\n# Entry point group for system plugins (those that are part of core ckan and\n# do not need to be explicitly enabled by the user)\nSYSTEM_PLUGINS_ENTRY_POINT_GROUP = 'ckan.system_plugins'\n\n# Entry point for test plugins.\nTEST_PLUGINS_ENTRY_POINT_GROUP = 'ckan.test_plugins'\n\nGROUPS = [\n PLUGINS_ENTRY_POINT_GROUP,\n SYSTEM_PLUGINS_ENTRY_POINT_GROUP,\n TEST_PLUGINS_ENTRY_POINT_GROUP,\n]\n# These lists are used to ensure that the correct extensions are enabled.\n_PLUGINS = []\n_PLUGINS_CLASS = []\n\n# To aid retrieving extensions by name\n_PLUGINS_SERVICE = {}\n\n\n@contextmanager\ndef use_plugin(*plugins):\n '''Load plugin(s) for testing purposes\n\n e.g.\n ```\n import ckan.plugins as p\n with p.use_plugin('my_plugin') as my_plugin:\n # run tests with plugin loaded\n ```\n '''\n\n p = load(*plugins)\n try:\n yield p\n finally:\n unload(*plugins)\n\n\nclass PluginNotFoundException(Exception):\n '''\n Raised when a requested plugin cannot be found.\n '''\n\n\nclass Plugin(_pca_Plugin):\n '''\n Base class for plugins which require multiple instances.\n\n Unless you need multiple instances of your plugin object you should\n probably use SingletonPlugin.\n '''\n\n\nclass SingletonPlugin(_pca_SingletonPlugin):\n '''\n Base class for plugins which are singletons (ie most of them)\n\n One singleton instance of this class will be created when the plugin is\n loaded. Subsequent calls to the class constructor will always return the\n same singleton instance.\n '''\n\n\ndef get_plugin(plugin):\n ''' Get an instance of a active plugin by name. This is helpful for\n testing. '''\n if plugin in _PLUGINS_SERVICE:\n return _PLUGINS_SERVICE[plugin]\n\n\ndef plugins_update():\n ''' This is run when plugins have been loaded or unloaded and allows us\n to run any specific code to ensure that the new plugin setting are\n correctly setup '''\n\n # It is posible for extra SingletonPlugin extensions to be activated if\n # the file containing them is imported, for example if two or more\n # extensions are defined in the same file. Therefore we do a sanity\n # check and disable any that should not be active.\n for env in PluginGlobals.env.values():\n for service, id_ in env.singleton_services.items():\n if service not in _PLUGINS_CLASS:\n PluginGlobals.plugin_instances[id_].deactivate()\n\n # Reset CKAN to reflect the currently enabled extensions.\n import ckan.config.environment as environment\n environment.update_config()\n\n\ndef load_all():\n '''\n Load all plugins listed in the 'ckan.plugins' config directive.\n '''\n # Clear any loaded plugins\n unload_all()\n\n plugins = config.get('ckan.plugins', '').split() + find_system_plugins()\n # Add the synchronous search plugin, unless already loaded or\n # explicitly disabled\n if 'synchronous_search' not in plugins and \\\n asbool(config.get('ckan.search.automatic_indexing', True)):\n log.debug('Loading the synchronous search plugin')\n plugins.append('synchronous_search')\n\n load(*plugins)\n\n\ndef load(*plugins):\n '''\n Load named plugin(s).\n '''\n output = []\n\n observers = PluginImplementations(interfaces.IPluginObserver)\n for plugin in plugins:\n if plugin in _PLUGINS:\n raise Exception('Plugin `%s` already loaded' % plugin)\n\n service = _get_service(plugin)\n for observer_plugin in observers:\n observer_plugin.before_load(service)\n service.activate()\n for observer_plugin in observers:\n observer_plugin.after_load(service)\n\n _PLUGINS.append(plugin)\n _PLUGINS_CLASS.append(service.__class__)\n\n if isinstance(service, SingletonPlugin):\n _PLUGINS_SERVICE[plugin] = service\n\n output.append(service)\n plugins_update()\n\n # Return extension instance if only one was loaded. If more that one\n # has been requested then a list of instances is returned in the order\n # they were asked for.\n if len(output) == 1:\n return output[0]\n return output\n\n\ndef unload_all():\n '''\n Unload (deactivate) all loaded plugins in the reverse order that they\n were loaded.\n '''\n unload(*reversed(_PLUGINS))\n\n\ndef unload(*plugins):\n '''\n Unload named plugin(s).\n '''\n\n observers = PluginImplementations(interfaces.IPluginObserver)\n\n for plugin in plugins:\n if plugin in _PLUGINS:\n _PLUGINS.remove(plugin)\n if plugin in _PLUGINS_SERVICE:\n del _PLUGINS_SERVICE[plugin]\n else:\n raise Exception('Cannot unload plugin `%s`' % plugin)\n\n service = _get_service(plugin)\n for observer_plugin in observers:\n observer_plugin.before_unload(service)\n\n service.deactivate()\n\n _PLUGINS_CLASS.remove(service.__class__)\n\n for observer_plugin in observers:\n observer_plugin.after_unload(service)\n plugins_update()\n\n\ndef plugin_loaded(name):\n '''\n See if a particular plugin is loaded.\n '''\n if name in _PLUGINS:\n return True\n return False\n\n\ndef find_system_plugins():\n '''\n Return all plugins in the ckan.system_plugins entry point group.\n\n These are essential for operation and therefore cannot be\n enabled/disabled through the configuration file.\n '''\n\n eps = []\n for ep in iter_entry_points(group=SYSTEM_PLUGINS_ENTRY_POINT_GROUP):\n ep.load()\n eps.append(ep.name)\n return eps\n\n\ndef _get_service(plugin_name):\n '''\n Return a service (ie an instance of a plugin class).\n\n :param plugin_name: the name of a plugin entry point\n :type plugin_name: string\n\n :return: the service object\n '''\n\n if isinstance(plugin_name, string_types):\n for group in GROUPS:\n iterator = iter_entry_points(\n group=group,\n name=plugin_name\n )\n plugin = next(iterator, None)\n if plugin:\n return plugin.load()(name=plugin_name)\n raise PluginNotFoundException(plugin_name)\n else:\n raise TypeError('Expected a plugin name', plugin_name)\n", "path": "ckan/plugins/core.py"}]}
| 3,788 | 280 |
gh_patches_debug_26870
|
rasdani/github-patches
|
git_diff
|
qutebrowser__qutebrowser-1939
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
QtWebKit: Handle visibility API
See https://github.com/OtterBrowser/otter-browser/commit/6500972092a562e23271ccf9aff4fdeed21d8290
</issue>
<code>
[start of qutebrowser/browser/webkit/webview.py]
1 # vim: ft=python fileencoding=utf-8 sts=4 sw=4 et:
2
3 # Copyright 2014-2016 Florian Bruhin (The Compiler) <[email protected]>
4 #
5 # This file is part of qutebrowser.
6 #
7 # qutebrowser is free software: you can redistribute it and/or modify
8 # it under the terms of the GNU General Public License as published by
9 # the Free Software Foundation, either version 3 of the License, or
10 # (at your option) any later version.
11 #
12 # qutebrowser is distributed in the hope that it will be useful,
13 # but WITHOUT ANY WARRANTY; without even the implied warranty of
14 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
15 # GNU General Public License for more details.
16 #
17 # You should have received a copy of the GNU General Public License
18 # along with qutebrowser. If not, see <http://www.gnu.org/licenses/>.
19
20 """The main browser widgets."""
21
22 import sys
23
24 from PyQt5.QtCore import pyqtSignal, pyqtSlot, Qt, QUrl
25 from PyQt5.QtGui import QPalette
26 from PyQt5.QtWidgets import QStyleFactory
27 from PyQt5.QtWebKit import QWebSettings
28 from PyQt5.QtWebKitWidgets import QWebView, QWebPage, QWebFrame
29
30 from qutebrowser.config import config
31 from qutebrowser.keyinput import modeman
32 from qutebrowser.utils import log, usertypes, utils, qtutils, objreg, debug
33 from qutebrowser.browser.webkit import webpage
34
35
36 class WebView(QWebView):
37
38 """Custom QWebView subclass with qutebrowser-specific features.
39
40 Attributes:
41 tab: The WebKitTab object for this WebView
42 hintmanager: The HintManager instance for this view.
43 scroll_pos: The current scroll position as (x%, y%) tuple.
44 win_id: The window ID of the view.
45 _tab_id: The tab ID of the view.
46 _old_scroll_pos: The old scroll position.
47
48 Signals:
49 scroll_pos_changed: Scroll percentage of current tab changed.
50 arg 1: x-position in %.
51 arg 2: y-position in %.
52 shutting_down: Emitted when the view is shutting down.
53 """
54
55 scroll_pos_changed = pyqtSignal(int, int)
56 shutting_down = pyqtSignal()
57
58 def __init__(self, win_id, tab_id, tab, parent=None):
59 super().__init__(parent)
60 if sys.platform == 'darwin' and qtutils.version_check('5.4'):
61 # WORKAROUND for https://bugreports.qt.io/browse/QTBUG-42948
62 # See https://github.com/The-Compiler/qutebrowser/issues/462
63 self.setStyle(QStyleFactory.create('Fusion'))
64 # FIXME:qtwebengine this is only used to set the zoom factor from
65 # the QWebPage - we should get rid of it somehow (signals?)
66 self.tab = tab
67 self.win_id = win_id
68 self.scroll_pos = (-1, -1)
69 self._old_scroll_pos = (-1, -1)
70 self._set_bg_color()
71 self._tab_id = tab_id
72
73 page = webpage.BrowserPage(self.win_id, self._tab_id, tab.data,
74 parent=self)
75 self.setPage(page)
76
77 mode_manager = objreg.get('mode-manager', scope='window',
78 window=win_id)
79 mode_manager.entered.connect(self.on_mode_entered)
80 mode_manager.left.connect(self.on_mode_left)
81 objreg.get('config').changed.connect(self._set_bg_color)
82
83 def __repr__(self):
84 url = utils.elide(self.url().toDisplayString(QUrl.EncodeUnicode), 100)
85 return utils.get_repr(self, tab_id=self._tab_id, url=url)
86
87 def __del__(self):
88 # Explicitly releasing the page here seems to prevent some segfaults
89 # when quitting.
90 # Copied from:
91 # https://code.google.com/p/webscraping/source/browse/webkit.py#325
92 try:
93 self.setPage(None)
94 except RuntimeError:
95 # It seems sometimes Qt has already deleted the QWebView and we
96 # get: RuntimeError: wrapped C/C++ object of type WebView has been
97 # deleted
98 pass
99
100 @config.change_filter('colors', 'webpage.bg')
101 def _set_bg_color(self):
102 """Set the webpage background color as configured.
103
104 FIXME:qtwebengine
105 For QtWebEngine, doing the same has no effect, so we do it in here.
106 """
107 col = config.get('colors', 'webpage.bg')
108 palette = self.palette()
109 if col is None:
110 col = self.style().standardPalette().color(QPalette.Base)
111 palette.setColor(QPalette.Base, col)
112 self.setPalette(palette)
113
114 def shutdown(self):
115 """Shut down the webview."""
116 self.shutting_down.emit()
117 # We disable javascript because that prevents some segfaults when
118 # quitting it seems.
119 log.destroy.debug("Shutting down {!r}.".format(self))
120 settings = self.settings()
121 settings.setAttribute(QWebSettings.JavascriptEnabled, False)
122 self.stop()
123 self.page().shutdown()
124
125 def openurl(self, url):
126 """Open a URL in the browser.
127
128 Args:
129 url: The URL to load as QUrl
130 """
131 self.load(url)
132 if url.scheme() == 'qute':
133 frame = self.page().mainFrame()
134 frame.javaScriptWindowObjectCleared.connect(self.add_js_bridge)
135
136 @pyqtSlot()
137 def add_js_bridge(self):
138 """Add the javascript bridge for qute:... pages."""
139 frame = self.sender()
140 if not isinstance(frame, QWebFrame):
141 log.webview.error("Got non-QWebFrame {!r} in "
142 "add_js_bridge!".format(frame))
143 return
144
145 if frame.url().scheme() == 'qute':
146 bridge = objreg.get('js-bridge')
147 frame.addToJavaScriptWindowObject('qute', bridge)
148
149 @pyqtSlot(usertypes.KeyMode)
150 def on_mode_entered(self, mode):
151 """Ignore attempts to focus the widget if in any status-input mode.
152
153 FIXME:qtwebengine
154 For QtWebEngine, doing the same has no effect, so we do it in here.
155 """
156 if mode in [usertypes.KeyMode.command, usertypes.KeyMode.prompt,
157 usertypes.KeyMode.yesno]:
158 log.webview.debug("Ignoring focus because mode {} was "
159 "entered.".format(mode))
160 self.setFocusPolicy(Qt.NoFocus)
161
162 @pyqtSlot(usertypes.KeyMode)
163 def on_mode_left(self, mode):
164 """Restore focus policy if status-input modes were left.
165
166 FIXME:qtwebengine
167 For QtWebEngine, doing the same has no effect, so we do it in here.
168 """
169 if mode in [usertypes.KeyMode.command, usertypes.KeyMode.prompt,
170 usertypes.KeyMode.yesno]:
171 log.webview.debug("Restoring focus policy because mode {} was "
172 "left.".format(mode))
173 self.setFocusPolicy(Qt.WheelFocus)
174
175 def createWindow(self, wintype):
176 """Called by Qt when a page wants to create a new window.
177
178 This function is called from the createWindow() method of the
179 associated QWebPage, each time the page wants to create a new window of
180 the given type. This might be the result, for example, of a JavaScript
181 request to open a document in a new window.
182
183 Args:
184 wintype: This enum describes the types of window that can be
185 created by the createWindow() function.
186
187 QWebPage::WebBrowserWindow: The window is a regular web
188 browser window.
189 QWebPage::WebModalDialog: The window acts as modal dialog.
190
191 Return:
192 The new QWebView object.
193 """
194 debug_type = debug.qenum_key(QWebPage, wintype)
195 log.webview.debug("createWindow with type {}".format(debug_type))
196 if wintype == QWebPage.WebModalDialog:
197 log.webview.warning("WebModalDialog requested, but we don't "
198 "support that!")
199 tabbed_browser = objreg.get('tabbed-browser', scope='window',
200 window=self.win_id)
201 # pylint: disable=protected-access
202 return tabbed_browser.tabopen(background=False)._widget
203
204 def paintEvent(self, e):
205 """Extend paintEvent to emit a signal if the scroll position changed.
206
207 This is a bit of a hack: We listen to repaint requests here, in the
208 hope a repaint will always be requested when scrolling, and if the
209 scroll position actually changed, we emit a signal.
210
211 QtWebEngine has a scrollPositionChanged signal, so it's not needed
212 there.
213
214 Args:
215 e: The QPaintEvent.
216
217 Return:
218 The superclass event return value.
219 """
220 frame = self.page().mainFrame()
221 new_pos = (frame.scrollBarValue(Qt.Horizontal),
222 frame.scrollBarValue(Qt.Vertical))
223 if self._old_scroll_pos != new_pos:
224 self._old_scroll_pos = new_pos
225 m = (frame.scrollBarMaximum(Qt.Horizontal),
226 frame.scrollBarMaximum(Qt.Vertical))
227 perc = (round(100 * new_pos[0] / m[0]) if m[0] != 0 else 0,
228 round(100 * new_pos[1] / m[1]) if m[1] != 0 else 0)
229 self.scroll_pos = perc
230 self.scroll_pos_changed.emit(*perc)
231 # Let superclass handle the event
232 super().paintEvent(e)
233
234 def contextMenuEvent(self, e):
235 """Save a reference to the context menu so we can close it.
236
237 This is not needed for QtWebEngine, so it's in here.
238 """
239 menu = self.page().createStandardContextMenu()
240 self.shutting_down.connect(menu.close)
241 modeman.instance(self.win_id).entered.connect(menu.close)
242 menu.exec_(e.globalPos())
243
[end of qutebrowser/browser/webkit/webview.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/qutebrowser/browser/webkit/webview.py b/qutebrowser/browser/webkit/webview.py
--- a/qutebrowser/browser/webkit/webview.py
+++ b/qutebrowser/browser/webkit/webview.py
@@ -72,6 +72,14 @@
page = webpage.BrowserPage(self.win_id, self._tab_id, tab.data,
parent=self)
+
+ try:
+ page.setVisibilityState(
+ QWebPage.VisibilityStateVisible if self.isVisible()
+ else QWebPage.VisibilityStateHidden)
+ except AttributeError:
+ pass
+
self.setPage(page)
mode_manager = objreg.get('mode-manager', scope='window',
@@ -240,3 +248,35 @@
self.shutting_down.connect(menu.close)
modeman.instance(self.win_id).entered.connect(menu.close)
menu.exec_(e.globalPos())
+
+ def showEvent(self, e):
+ """Extend showEvent to set the page visibility state to visible.
+
+ Args:
+ e: The QShowEvent.
+
+ Return:
+ The superclass event return value.
+ """
+ try:
+ self.page().setVisibilityState(QWebPage.VisibilityStateVisible)
+ except AttributeError:
+ pass
+
+ super().showEvent(e)
+
+ def hideEvent(self, e):
+ """Extend hideEvent to set the page visibility state to hidden.
+
+ Args:
+ e: The QHideEvent.
+
+ Return:
+ The superclass event return value.
+ """
+ try:
+ self.page().setVisibilityState(QWebPage.VisibilityStateHidden)
+ except AttributeError:
+ pass
+
+ super().hideEvent(e)
|
{"golden_diff": "diff --git a/qutebrowser/browser/webkit/webview.py b/qutebrowser/browser/webkit/webview.py\n--- a/qutebrowser/browser/webkit/webview.py\n+++ b/qutebrowser/browser/webkit/webview.py\n@@ -72,6 +72,14 @@\n \n page = webpage.BrowserPage(self.win_id, self._tab_id, tab.data,\n parent=self)\n+\n+ try:\n+ page.setVisibilityState(\n+ QWebPage.VisibilityStateVisible if self.isVisible()\n+ else QWebPage.VisibilityStateHidden)\n+ except AttributeError:\n+ pass\n+\n self.setPage(page)\n \n mode_manager = objreg.get('mode-manager', scope='window',\n@@ -240,3 +248,35 @@\n self.shutting_down.connect(menu.close)\n modeman.instance(self.win_id).entered.connect(menu.close)\n menu.exec_(e.globalPos())\n+\n+ def showEvent(self, e):\n+ \"\"\"Extend showEvent to set the page visibility state to visible.\n+\n+ Args:\n+ e: The QShowEvent.\n+\n+ Return:\n+ The superclass event return value.\n+ \"\"\"\n+ try:\n+ self.page().setVisibilityState(QWebPage.VisibilityStateVisible)\n+ except AttributeError:\n+ pass\n+\n+ super().showEvent(e)\n+\n+ def hideEvent(self, e):\n+ \"\"\"Extend hideEvent to set the page visibility state to hidden.\n+\n+ Args:\n+ e: The QHideEvent.\n+\n+ Return:\n+ The superclass event return value.\n+ \"\"\"\n+ try:\n+ self.page().setVisibilityState(QWebPage.VisibilityStateHidden)\n+ except AttributeError:\n+ pass\n+\n+ super().hideEvent(e)\n", "issue": "QtWebKit: Handle visibility API\nSee https://github.com/OtterBrowser/otter-browser/commit/6500972092a562e23271ccf9aff4fdeed21d8290\n\n", "before_files": [{"content": "# vim: ft=python fileencoding=utf-8 sts=4 sw=4 et:\n\n# Copyright 2014-2016 Florian Bruhin (The Compiler) <[email protected]>\n#\n# This file is part of qutebrowser.\n#\n# qutebrowser is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# qutebrowser is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with qutebrowser. If not, see <http://www.gnu.org/licenses/>.\n\n\"\"\"The main browser widgets.\"\"\"\n\nimport sys\n\nfrom PyQt5.QtCore import pyqtSignal, pyqtSlot, Qt, QUrl\nfrom PyQt5.QtGui import QPalette\nfrom PyQt5.QtWidgets import QStyleFactory\nfrom PyQt5.QtWebKit import QWebSettings\nfrom PyQt5.QtWebKitWidgets import QWebView, QWebPage, QWebFrame\n\nfrom qutebrowser.config import config\nfrom qutebrowser.keyinput import modeman\nfrom qutebrowser.utils import log, usertypes, utils, qtutils, objreg, debug\nfrom qutebrowser.browser.webkit import webpage\n\n\nclass WebView(QWebView):\n\n \"\"\"Custom QWebView subclass with qutebrowser-specific features.\n\n Attributes:\n tab: The WebKitTab object for this WebView\n hintmanager: The HintManager instance for this view.\n scroll_pos: The current scroll position as (x%, y%) tuple.\n win_id: The window ID of the view.\n _tab_id: The tab ID of the view.\n _old_scroll_pos: The old scroll position.\n\n Signals:\n scroll_pos_changed: Scroll percentage of current tab changed.\n arg 1: x-position in %.\n arg 2: y-position in %.\n shutting_down: Emitted when the view is shutting down.\n \"\"\"\n\n scroll_pos_changed = pyqtSignal(int, int)\n shutting_down = pyqtSignal()\n\n def __init__(self, win_id, tab_id, tab, parent=None):\n super().__init__(parent)\n if sys.platform == 'darwin' and qtutils.version_check('5.4'):\n # WORKAROUND for https://bugreports.qt.io/browse/QTBUG-42948\n # See https://github.com/The-Compiler/qutebrowser/issues/462\n self.setStyle(QStyleFactory.create('Fusion'))\n # FIXME:qtwebengine this is only used to set the zoom factor from\n # the QWebPage - we should get rid of it somehow (signals?)\n self.tab = tab\n self.win_id = win_id\n self.scroll_pos = (-1, -1)\n self._old_scroll_pos = (-1, -1)\n self._set_bg_color()\n self._tab_id = tab_id\n\n page = webpage.BrowserPage(self.win_id, self._tab_id, tab.data,\n parent=self)\n self.setPage(page)\n\n mode_manager = objreg.get('mode-manager', scope='window',\n window=win_id)\n mode_manager.entered.connect(self.on_mode_entered)\n mode_manager.left.connect(self.on_mode_left)\n objreg.get('config').changed.connect(self._set_bg_color)\n\n def __repr__(self):\n url = utils.elide(self.url().toDisplayString(QUrl.EncodeUnicode), 100)\n return utils.get_repr(self, tab_id=self._tab_id, url=url)\n\n def __del__(self):\n # Explicitly releasing the page here seems to prevent some segfaults\n # when quitting.\n # Copied from:\n # https://code.google.com/p/webscraping/source/browse/webkit.py#325\n try:\n self.setPage(None)\n except RuntimeError:\n # It seems sometimes Qt has already deleted the QWebView and we\n # get: RuntimeError: wrapped C/C++ object of type WebView has been\n # deleted\n pass\n\n @config.change_filter('colors', 'webpage.bg')\n def _set_bg_color(self):\n \"\"\"Set the webpage background color as configured.\n\n FIXME:qtwebengine\n For QtWebEngine, doing the same has no effect, so we do it in here.\n \"\"\"\n col = config.get('colors', 'webpage.bg')\n palette = self.palette()\n if col is None:\n col = self.style().standardPalette().color(QPalette.Base)\n palette.setColor(QPalette.Base, col)\n self.setPalette(palette)\n\n def shutdown(self):\n \"\"\"Shut down the webview.\"\"\"\n self.shutting_down.emit()\n # We disable javascript because that prevents some segfaults when\n # quitting it seems.\n log.destroy.debug(\"Shutting down {!r}.\".format(self))\n settings = self.settings()\n settings.setAttribute(QWebSettings.JavascriptEnabled, False)\n self.stop()\n self.page().shutdown()\n\n def openurl(self, url):\n \"\"\"Open a URL in the browser.\n\n Args:\n url: The URL to load as QUrl\n \"\"\"\n self.load(url)\n if url.scheme() == 'qute':\n frame = self.page().mainFrame()\n frame.javaScriptWindowObjectCleared.connect(self.add_js_bridge)\n\n @pyqtSlot()\n def add_js_bridge(self):\n \"\"\"Add the javascript bridge for qute:... pages.\"\"\"\n frame = self.sender()\n if not isinstance(frame, QWebFrame):\n log.webview.error(\"Got non-QWebFrame {!r} in \"\n \"add_js_bridge!\".format(frame))\n return\n\n if frame.url().scheme() == 'qute':\n bridge = objreg.get('js-bridge')\n frame.addToJavaScriptWindowObject('qute', bridge)\n\n @pyqtSlot(usertypes.KeyMode)\n def on_mode_entered(self, mode):\n \"\"\"Ignore attempts to focus the widget if in any status-input mode.\n\n FIXME:qtwebengine\n For QtWebEngine, doing the same has no effect, so we do it in here.\n \"\"\"\n if mode in [usertypes.KeyMode.command, usertypes.KeyMode.prompt,\n usertypes.KeyMode.yesno]:\n log.webview.debug(\"Ignoring focus because mode {} was \"\n \"entered.\".format(mode))\n self.setFocusPolicy(Qt.NoFocus)\n\n @pyqtSlot(usertypes.KeyMode)\n def on_mode_left(self, mode):\n \"\"\"Restore focus policy if status-input modes were left.\n\n FIXME:qtwebengine\n For QtWebEngine, doing the same has no effect, so we do it in here.\n \"\"\"\n if mode in [usertypes.KeyMode.command, usertypes.KeyMode.prompt,\n usertypes.KeyMode.yesno]:\n log.webview.debug(\"Restoring focus policy because mode {} was \"\n \"left.\".format(mode))\n self.setFocusPolicy(Qt.WheelFocus)\n\n def createWindow(self, wintype):\n \"\"\"Called by Qt when a page wants to create a new window.\n\n This function is called from the createWindow() method of the\n associated QWebPage, each time the page wants to create a new window of\n the given type. This might be the result, for example, of a JavaScript\n request to open a document in a new window.\n\n Args:\n wintype: This enum describes the types of window that can be\n created by the createWindow() function.\n\n QWebPage::WebBrowserWindow: The window is a regular web\n browser window.\n QWebPage::WebModalDialog: The window acts as modal dialog.\n\n Return:\n The new QWebView object.\n \"\"\"\n debug_type = debug.qenum_key(QWebPage, wintype)\n log.webview.debug(\"createWindow with type {}\".format(debug_type))\n if wintype == QWebPage.WebModalDialog:\n log.webview.warning(\"WebModalDialog requested, but we don't \"\n \"support that!\")\n tabbed_browser = objreg.get('tabbed-browser', scope='window',\n window=self.win_id)\n # pylint: disable=protected-access\n return tabbed_browser.tabopen(background=False)._widget\n\n def paintEvent(self, e):\n \"\"\"Extend paintEvent to emit a signal if the scroll position changed.\n\n This is a bit of a hack: We listen to repaint requests here, in the\n hope a repaint will always be requested when scrolling, and if the\n scroll position actually changed, we emit a signal.\n\n QtWebEngine has a scrollPositionChanged signal, so it's not needed\n there.\n\n Args:\n e: The QPaintEvent.\n\n Return:\n The superclass event return value.\n \"\"\"\n frame = self.page().mainFrame()\n new_pos = (frame.scrollBarValue(Qt.Horizontal),\n frame.scrollBarValue(Qt.Vertical))\n if self._old_scroll_pos != new_pos:\n self._old_scroll_pos = new_pos\n m = (frame.scrollBarMaximum(Qt.Horizontal),\n frame.scrollBarMaximum(Qt.Vertical))\n perc = (round(100 * new_pos[0] / m[0]) if m[0] != 0 else 0,\n round(100 * new_pos[1] / m[1]) if m[1] != 0 else 0)\n self.scroll_pos = perc\n self.scroll_pos_changed.emit(*perc)\n # Let superclass handle the event\n super().paintEvent(e)\n\n def contextMenuEvent(self, e):\n \"\"\"Save a reference to the context menu so we can close it.\n\n This is not needed for QtWebEngine, so it's in here.\n \"\"\"\n menu = self.page().createStandardContextMenu()\n self.shutting_down.connect(menu.close)\n modeman.instance(self.win_id).entered.connect(menu.close)\n menu.exec_(e.globalPos())\n", "path": "qutebrowser/browser/webkit/webview.py"}]}
| 3,421 | 377 |
gh_patches_debug_28436
|
rasdani/github-patches
|
git_diff
|
pyinstaller__pyinstaller-4749
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
shapely hook doesn't work on windows
Using current develop, the shapely hook fails when it runs `binaries += [(os.path.join(lib_dir, f), '') for f in os.listdir(lib_dir)]`. `lib_dir` here equals `Lib/site-packages/shapely/DLLs`. The actual directory on my conda python 3.6 installation is `Library/bin/`. My old spec file uses the following ugly code to copy these libraries over:
```
lib_dir = sys.executable.replace("python.exe", os.path.join("Library", "bin"))
binaries += [(os.path.join(lib_dir, 'geos_c.dll'), '')]
binaries += [(os.path.join(lib_dir, 'geos.dll'), '')]
binaries += [(os.path.join(lib_dir, 'mkl_*.dll'), '')]
```
Is there a better way to get a hold of this Library directory with some pyinstaller utility function? Does anyone know if other python environments (non-conda) have the directory used in the hook or @durden did you just guess on the Windows path?
Side issue: Shapely 1.6+ doesn't seem to work on at least windows (haven't updated on other platforms). It fails to find the geos libraries mentioned above unless you execute the pyinstaller-made (inno setup packaged) executable from the install directory (`C:\Program Files (x86)\myprgm\bin\`). For now I'm just downgrading to 1.5.17.
shapely hook doesn't work on windows
Using current develop, the shapely hook fails when it runs `binaries += [(os.path.join(lib_dir, f), '') for f in os.listdir(lib_dir)]`. `lib_dir` here equals `Lib/site-packages/shapely/DLLs`. The actual directory on my conda python 3.6 installation is `Library/bin/`. My old spec file uses the following ugly code to copy these libraries over:
```
lib_dir = sys.executable.replace("python.exe", os.path.join("Library", "bin"))
binaries += [(os.path.join(lib_dir, 'geos_c.dll'), '')]
binaries += [(os.path.join(lib_dir, 'geos.dll'), '')]
binaries += [(os.path.join(lib_dir, 'mkl_*.dll'), '')]
```
Is there a better way to get a hold of this Library directory with some pyinstaller utility function? Does anyone know if other python environments (non-conda) have the directory used in the hook or @durden did you just guess on the Windows path?
Side issue: Shapely 1.6+ doesn't seem to work on at least windows (haven't updated on other platforms). It fails to find the geos libraries mentioned above unless you execute the pyinstaller-made (inno setup packaged) executable from the install directory (`C:\Program Files (x86)\myprgm\bin\`). For now I'm just downgrading to 1.5.17.
</issue>
<code>
[start of PyInstaller/hooks/hook-shapely.py]
1 #-----------------------------------------------------------------------------
2 # Copyright (c) 2017-2020, PyInstaller Development Team.
3 #
4 # Distributed under the terms of the GNU General Public License (version 2
5 # or later) with exception for distributing the bootloader.
6 #
7 # The full license is in the file COPYING.txt, distributed with this software.
8 #
9 # SPDX-License-Identifier: (GPL-2.0-or-later WITH Bootloader-exception)
10 #-----------------------------------------------------------------------------
11
12 import os
13
14 from PyInstaller.utils.hooks import get_package_paths
15 from PyInstaller.utils.hooks import is_module_satisfies
16 from PyInstaller import compat
17
18 # Necessary when using the vectorized subpackage
19 hiddenimports = ['shapely.prepared']
20
21 pkg_base, pkg_dir = get_package_paths('shapely')
22
23
24 binaries = []
25 if compat.is_win:
26 if compat.is_conda:
27 lib_dir = os.path.join(compat.base_prefix, 'Library', 'bin')
28 else:
29 lib_dir = os.path.join(pkg_dir, 'DLLs')
30 dll_files = ['geos_c.dll', 'geos.dll']
31 binaries += [(os.path.join(lib_dir, f), '.') for f in dll_files]
32 elif compat.is_linux:
33 lib_dir = os.path.join(pkg_dir, '.libs')
34 dest_dir = os.path.join('shapely', '.libs')
35
36 # This duplicates the libgeos*.so* files in the build. PyInstaller will
37 # copy them into the root of the build by default, but shapely cannot load
38 # them from there in linux IF shapely was installed via a whl file. The
39 # whl bundles its' own libgeos with a different name, something like
40 # libgeos_c-*.so.* but shapely tries to load libgeos_c.so if there isn't a
41 # ./libs directory under its' package. There is a proposed fix for this in
42 # shapely but it has not been accepted it:
43 # https://github.com/Toblerity/Shapely/pull/485
44 if is_module_satisfies('shapely <= 1.6'):
45 binaries += [(os.path.join(lib_dir, f), dest_dir) for f in os.listdir(lib_dir)]
46
[end of PyInstaller/hooks/hook-shapely.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/PyInstaller/hooks/hook-shapely.py b/PyInstaller/hooks/hook-shapely.py
--- a/PyInstaller/hooks/hook-shapely.py
+++ b/PyInstaller/hooks/hook-shapely.py
@@ -10,6 +10,7 @@
#-----------------------------------------------------------------------------
import os
+from ctypes.util import find_library
from PyInstaller.utils.hooks import get_package_paths
from PyInstaller.utils.hooks import is_module_satisfies
@@ -23,12 +24,25 @@
binaries = []
if compat.is_win:
+ # Search conda directory if conda is active, then search standard
+ # directory. This is the same order of precidence used in shapely.
+ standard_path = os.path.join(pkg_dir, 'DLLs')
+ lib_paths = [standard_path, os.environ['PATH']]
if compat.is_conda:
- lib_dir = os.path.join(compat.base_prefix, 'Library', 'bin')
- else:
- lib_dir = os.path.join(pkg_dir, 'DLLs')
- dll_files = ['geos_c.dll', 'geos.dll']
- binaries += [(os.path.join(lib_dir, f), '.') for f in dll_files]
+ conda_path = os.path.join(compat.base_prefix, 'Library', 'bin')
+ lib_paths.insert(0, conda_path)
+ original_path = os.environ['PATH']
+ try:
+ os.environ['PATH'] = os.pathsep.join(lib_paths)
+ dll_path = find_library('geos_c')
+ finally:
+ os.environ['PATH'] = original_path
+ if dll_path is None:
+ raise SystemExit(
+ "Error: geos_c.dll not found, required by hook-shapely.py.\n"
+ "Please check your installation or provide a pull request to "
+ "PyInstaller to update hook-shapely.py.")
+ binaries += [(dll_path, '.')]
elif compat.is_linux:
lib_dir = os.path.join(pkg_dir, '.libs')
dest_dir = os.path.join('shapely', '.libs')
|
{"golden_diff": "diff --git a/PyInstaller/hooks/hook-shapely.py b/PyInstaller/hooks/hook-shapely.py\n--- a/PyInstaller/hooks/hook-shapely.py\n+++ b/PyInstaller/hooks/hook-shapely.py\n@@ -10,6 +10,7 @@\n #-----------------------------------------------------------------------------\n \n import os\n+from ctypes.util import find_library\n \n from PyInstaller.utils.hooks import get_package_paths\n from PyInstaller.utils.hooks import is_module_satisfies\n@@ -23,12 +24,25 @@\n \n binaries = []\n if compat.is_win:\n+ # Search conda directory if conda is active, then search standard\n+ # directory. This is the same order of precidence used in shapely.\n+ standard_path = os.path.join(pkg_dir, 'DLLs')\n+ lib_paths = [standard_path, os.environ['PATH']]\n if compat.is_conda:\n- lib_dir = os.path.join(compat.base_prefix, 'Library', 'bin')\n- else:\n- lib_dir = os.path.join(pkg_dir, 'DLLs')\n- dll_files = ['geos_c.dll', 'geos.dll']\n- binaries += [(os.path.join(lib_dir, f), '.') for f in dll_files]\n+ conda_path = os.path.join(compat.base_prefix, 'Library', 'bin')\n+ lib_paths.insert(0, conda_path)\n+ original_path = os.environ['PATH']\n+ try:\n+ os.environ['PATH'] = os.pathsep.join(lib_paths)\n+ dll_path = find_library('geos_c')\n+ finally:\n+ os.environ['PATH'] = original_path\n+ if dll_path is None:\n+ raise SystemExit(\n+ \"Error: geos_c.dll not found, required by hook-shapely.py.\\n\"\n+ \"Please check your installation or provide a pull request to \"\n+ \"PyInstaller to update hook-shapely.py.\")\n+ binaries += [(dll_path, '.')]\n elif compat.is_linux:\n lib_dir = os.path.join(pkg_dir, '.libs')\n dest_dir = os.path.join('shapely', '.libs')\n", "issue": "shapely hook doesn't work on windows\nUsing current develop, the shapely hook fails when it runs `binaries += [(os.path.join(lib_dir, f), '') for f in os.listdir(lib_dir)]`. `lib_dir` here equals `Lib/site-packages/shapely/DLLs`. The actual directory on my conda python 3.6 installation is `Library/bin/`. My old spec file uses the following ugly code to copy these libraries over:\r\n\r\n```\r\n lib_dir = sys.executable.replace(\"python.exe\", os.path.join(\"Library\", \"bin\"))\r\n binaries += [(os.path.join(lib_dir, 'geos_c.dll'), '')]\r\n binaries += [(os.path.join(lib_dir, 'geos.dll'), '')]\r\n binaries += [(os.path.join(lib_dir, 'mkl_*.dll'), '')]\r\n```\r\n\r\nIs there a better way to get a hold of this Library directory with some pyinstaller utility function? Does anyone know if other python environments (non-conda) have the directory used in the hook or @durden did you just guess on the Windows path?\r\n\r\nSide issue: Shapely 1.6+ doesn't seem to work on at least windows (haven't updated on other platforms). It fails to find the geos libraries mentioned above unless you execute the pyinstaller-made (inno setup packaged) executable from the install directory (`C:\\Program Files (x86)\\myprgm\\bin\\`). For now I'm just downgrading to 1.5.17.\nshapely hook doesn't work on windows\nUsing current develop, the shapely hook fails when it runs `binaries += [(os.path.join(lib_dir, f), '') for f in os.listdir(lib_dir)]`. `lib_dir` here equals `Lib/site-packages/shapely/DLLs`. The actual directory on my conda python 3.6 installation is `Library/bin/`. My old spec file uses the following ugly code to copy these libraries over:\r\n\r\n```\r\n lib_dir = sys.executable.replace(\"python.exe\", os.path.join(\"Library\", \"bin\"))\r\n binaries += [(os.path.join(lib_dir, 'geos_c.dll'), '')]\r\n binaries += [(os.path.join(lib_dir, 'geos.dll'), '')]\r\n binaries += [(os.path.join(lib_dir, 'mkl_*.dll'), '')]\r\n```\r\n\r\nIs there a better way to get a hold of this Library directory with some pyinstaller utility function? Does anyone know if other python environments (non-conda) have the directory used in the hook or @durden did you just guess on the Windows path?\r\n\r\nSide issue: Shapely 1.6+ doesn't seem to work on at least windows (haven't updated on other platforms). It fails to find the geos libraries mentioned above unless you execute the pyinstaller-made (inno setup packaged) executable from the install directory (`C:\\Program Files (x86)\\myprgm\\bin\\`). For now I'm just downgrading to 1.5.17.\n", "before_files": [{"content": "#-----------------------------------------------------------------------------\n# Copyright (c) 2017-2020, PyInstaller Development Team.\n#\n# Distributed under the terms of the GNU General Public License (version 2\n# or later) with exception for distributing the bootloader.\n#\n# The full license is in the file COPYING.txt, distributed with this software.\n#\n# SPDX-License-Identifier: (GPL-2.0-or-later WITH Bootloader-exception)\n#-----------------------------------------------------------------------------\n\nimport os\n\nfrom PyInstaller.utils.hooks import get_package_paths\nfrom PyInstaller.utils.hooks import is_module_satisfies\nfrom PyInstaller import compat\n\n# Necessary when using the vectorized subpackage\nhiddenimports = ['shapely.prepared']\n\npkg_base, pkg_dir = get_package_paths('shapely')\n\n\nbinaries = []\nif compat.is_win:\n if compat.is_conda:\n lib_dir = os.path.join(compat.base_prefix, 'Library', 'bin')\n else:\n lib_dir = os.path.join(pkg_dir, 'DLLs')\n dll_files = ['geos_c.dll', 'geos.dll']\n binaries += [(os.path.join(lib_dir, f), '.') for f in dll_files]\nelif compat.is_linux:\n lib_dir = os.path.join(pkg_dir, '.libs')\n dest_dir = os.path.join('shapely', '.libs')\n\n # This duplicates the libgeos*.so* files in the build. PyInstaller will\n # copy them into the root of the build by default, but shapely cannot load\n # them from there in linux IF shapely was installed via a whl file. The\n # whl bundles its' own libgeos with a different name, something like\n # libgeos_c-*.so.* but shapely tries to load libgeos_c.so if there isn't a\n # ./libs directory under its' package. There is a proposed fix for this in\n # shapely but it has not been accepted it:\n # https://github.com/Toblerity/Shapely/pull/485\n if is_module_satisfies('shapely <= 1.6'):\n binaries += [(os.path.join(lib_dir, f), dest_dir) for f in os.listdir(lib_dir)]\n", "path": "PyInstaller/hooks/hook-shapely.py"}]}
| 1,747 | 466 |
gh_patches_debug_30430
|
rasdani/github-patches
|
git_diff
|
pyca__cryptography-1716
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Move C code for padding into it's own .c and .h files
See `constant_time` for the same idea.
</issue>
<code>
[start of src/cryptography/hazmat/primitives/padding.py]
1 # This file is dual licensed under the terms of the Apache License, Version
2 # 2.0, and the BSD License. See the LICENSE file in the root of this repository
3 # for complete details.
4
5 from __future__ import absolute_import, division, print_function
6
7 import abc
8
9 import six
10
11 from cryptography import utils
12 from cryptography.exceptions import AlreadyFinalized
13 from cryptography.hazmat.bindings.utils import LazyLibrary, build_ffi
14
15
16 TYPES = """
17 uint8_t Cryptography_check_pkcs7_padding(const uint8_t *, uint8_t);
18 """
19
20 FUNCTIONS = """
21 /* Returns the value of the input with the most-significant-bit copied to all
22 of the bits. */
23 static uint8_t Cryptography_DUPLICATE_MSB_TO_ALL(uint8_t a) {
24 return (1 - (a >> (sizeof(uint8_t) * 8 - 1))) - 1;
25 }
26
27 /* This returns 0xFF if a < b else 0x00, but does so in a constant time
28 fashion */
29 static uint8_t Cryptography_constant_time_lt(uint8_t a, uint8_t b) {
30 a -= b;
31 return Cryptography_DUPLICATE_MSB_TO_ALL(a);
32 }
33
34 uint8_t Cryptography_check_pkcs7_padding(const uint8_t *data,
35 uint8_t block_len) {
36 uint8_t i;
37 uint8_t pad_size = data[block_len - 1];
38 uint8_t mismatch = 0;
39 for (i = 0; i < block_len; i++) {
40 unsigned int mask = Cryptography_constant_time_lt(i, pad_size);
41 uint8_t b = data[block_len - 1 - i];
42 mismatch |= (mask & (pad_size ^ b));
43 }
44
45 /* Check to make sure the pad_size was within the valid range. */
46 mismatch |= ~Cryptography_constant_time_lt(0, pad_size);
47 mismatch |= Cryptography_constant_time_lt(block_len, pad_size);
48
49 /* Make sure any bits set are copied to the lowest bit */
50 mismatch |= mismatch >> 4;
51 mismatch |= mismatch >> 2;
52 mismatch |= mismatch >> 1;
53 /* Now check the low bit to see if it's set */
54 return (mismatch & 1) == 0;
55 }
56 """
57
58
59 _ffi = build_ffi(cdef_source=TYPES, verify_source=FUNCTIONS)
60 _lib = LazyLibrary(_ffi)
61
62
63 @six.add_metaclass(abc.ABCMeta)
64 class PaddingContext(object):
65 @abc.abstractmethod
66 def update(self, data):
67 """
68 Pads the provided bytes and returns any available data as bytes.
69 """
70
71 @abc.abstractmethod
72 def finalize(self):
73 """
74 Finalize the padding, returns bytes.
75 """
76
77
78 class PKCS7(object):
79 def __init__(self, block_size):
80 if not (0 <= block_size < 256):
81 raise ValueError("block_size must be in range(0, 256).")
82
83 if block_size % 8 != 0:
84 raise ValueError("block_size must be a multiple of 8.")
85
86 self.block_size = block_size
87
88 def padder(self):
89 return _PKCS7PaddingContext(self.block_size)
90
91 def unpadder(self):
92 return _PKCS7UnpaddingContext(self.block_size)
93
94
95 @utils.register_interface(PaddingContext)
96 class _PKCS7PaddingContext(object):
97 def __init__(self, block_size):
98 self.block_size = block_size
99 # TODO: more copies than necessary, we should use zero-buffer (#193)
100 self._buffer = b""
101
102 def update(self, data):
103 if self._buffer is None:
104 raise AlreadyFinalized("Context was already finalized.")
105
106 if not isinstance(data, bytes):
107 raise TypeError("data must be bytes.")
108
109 self._buffer += data
110
111 finished_blocks = len(self._buffer) // (self.block_size // 8)
112
113 result = self._buffer[:finished_blocks * (self.block_size // 8)]
114 self._buffer = self._buffer[finished_blocks * (self.block_size // 8):]
115
116 return result
117
118 def finalize(self):
119 if self._buffer is None:
120 raise AlreadyFinalized("Context was already finalized.")
121
122 pad_size = self.block_size // 8 - len(self._buffer)
123 result = self._buffer + six.int2byte(pad_size) * pad_size
124 self._buffer = None
125 return result
126
127
128 @utils.register_interface(PaddingContext)
129 class _PKCS7UnpaddingContext(object):
130 def __init__(self, block_size):
131 self.block_size = block_size
132 # TODO: more copies than necessary, we should use zero-buffer (#193)
133 self._buffer = b""
134
135 def update(self, data):
136 if self._buffer is None:
137 raise AlreadyFinalized("Context was already finalized.")
138
139 if not isinstance(data, bytes):
140 raise TypeError("data must be bytes.")
141
142 self._buffer += data
143
144 finished_blocks = max(
145 len(self._buffer) // (self.block_size // 8) - 1,
146 0
147 )
148
149 result = self._buffer[:finished_blocks * (self.block_size // 8)]
150 self._buffer = self._buffer[finished_blocks * (self.block_size // 8):]
151
152 return result
153
154 def finalize(self):
155 if self._buffer is None:
156 raise AlreadyFinalized("Context was already finalized.")
157
158 if len(self._buffer) != self.block_size // 8:
159 raise ValueError("Invalid padding bytes.")
160
161 valid = _lib.Cryptography_check_pkcs7_padding(
162 self._buffer, self.block_size // 8
163 )
164
165 if not valid:
166 raise ValueError("Invalid padding bytes.")
167
168 pad_size = six.indexbytes(self._buffer, -1)
169 res = self._buffer[:-pad_size]
170 self._buffer = None
171 return res
172
[end of src/cryptography/hazmat/primitives/padding.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/cryptography/hazmat/primitives/padding.py b/src/cryptography/hazmat/primitives/padding.py
--- a/src/cryptography/hazmat/primitives/padding.py
+++ b/src/cryptography/hazmat/primitives/padding.py
@@ -6,6 +6,8 @@
import abc
+import os
+
import six
from cryptography import utils
@@ -13,47 +15,11 @@
from cryptography.hazmat.bindings.utils import LazyLibrary, build_ffi
-TYPES = """
-uint8_t Cryptography_check_pkcs7_padding(const uint8_t *, uint8_t);
-"""
-
-FUNCTIONS = """
-/* Returns the value of the input with the most-significant-bit copied to all
- of the bits. */
-static uint8_t Cryptography_DUPLICATE_MSB_TO_ALL(uint8_t a) {
- return (1 - (a >> (sizeof(uint8_t) * 8 - 1))) - 1;
-}
-
-/* This returns 0xFF if a < b else 0x00, but does so in a constant time
- fashion */
-static uint8_t Cryptography_constant_time_lt(uint8_t a, uint8_t b) {
- a -= b;
- return Cryptography_DUPLICATE_MSB_TO_ALL(a);
-}
-
-uint8_t Cryptography_check_pkcs7_padding(const uint8_t *data,
- uint8_t block_len) {
- uint8_t i;
- uint8_t pad_size = data[block_len - 1];
- uint8_t mismatch = 0;
- for (i = 0; i < block_len; i++) {
- unsigned int mask = Cryptography_constant_time_lt(i, pad_size);
- uint8_t b = data[block_len - 1 - i];
- mismatch |= (mask & (pad_size ^ b));
- }
-
- /* Check to make sure the pad_size was within the valid range. */
- mismatch |= ~Cryptography_constant_time_lt(0, pad_size);
- mismatch |= Cryptography_constant_time_lt(block_len, pad_size);
-
- /* Make sure any bits set are copied to the lowest bit */
- mismatch |= mismatch >> 4;
- mismatch |= mismatch >> 2;
- mismatch |= mismatch >> 1;
- /* Now check the low bit to see if it's set */
- return (mismatch & 1) == 0;
-}
-"""
+with open(os.path.join(os.path.dirname(__file__), "src/padding.h")) as f:
+ TYPES = f.read()
+
+with open(os.path.join(os.path.dirname(__file__), "src/padding.c")) as f:
+ FUNCTIONS = f.read()
_ffi = build_ffi(cdef_source=TYPES, verify_source=FUNCTIONS)
|
{"golden_diff": "diff --git a/src/cryptography/hazmat/primitives/padding.py b/src/cryptography/hazmat/primitives/padding.py\n--- a/src/cryptography/hazmat/primitives/padding.py\n+++ b/src/cryptography/hazmat/primitives/padding.py\n@@ -6,6 +6,8 @@\n \n import abc\n \n+import os\n+\n import six\n \n from cryptography import utils\n@@ -13,47 +15,11 @@\n from cryptography.hazmat.bindings.utils import LazyLibrary, build_ffi\n \n \n-TYPES = \"\"\"\n-uint8_t Cryptography_check_pkcs7_padding(const uint8_t *, uint8_t);\n-\"\"\"\n-\n-FUNCTIONS = \"\"\"\n-/* Returns the value of the input with the most-significant-bit copied to all\n- of the bits. */\n-static uint8_t Cryptography_DUPLICATE_MSB_TO_ALL(uint8_t a) {\n- return (1 - (a >> (sizeof(uint8_t) * 8 - 1))) - 1;\n-}\n-\n-/* This returns 0xFF if a < b else 0x00, but does so in a constant time\n- fashion */\n-static uint8_t Cryptography_constant_time_lt(uint8_t a, uint8_t b) {\n- a -= b;\n- return Cryptography_DUPLICATE_MSB_TO_ALL(a);\n-}\n-\n-uint8_t Cryptography_check_pkcs7_padding(const uint8_t *data,\n- uint8_t block_len) {\n- uint8_t i;\n- uint8_t pad_size = data[block_len - 1];\n- uint8_t mismatch = 0;\n- for (i = 0; i < block_len; i++) {\n- unsigned int mask = Cryptography_constant_time_lt(i, pad_size);\n- uint8_t b = data[block_len - 1 - i];\n- mismatch |= (mask & (pad_size ^ b));\n- }\n-\n- /* Check to make sure the pad_size was within the valid range. */\n- mismatch |= ~Cryptography_constant_time_lt(0, pad_size);\n- mismatch |= Cryptography_constant_time_lt(block_len, pad_size);\n-\n- /* Make sure any bits set are copied to the lowest bit */\n- mismatch |= mismatch >> 4;\n- mismatch |= mismatch >> 2;\n- mismatch |= mismatch >> 1;\n- /* Now check the low bit to see if it's set */\n- return (mismatch & 1) == 0;\n-}\n-\"\"\"\n+with open(os.path.join(os.path.dirname(__file__), \"src/padding.h\")) as f:\n+ TYPES = f.read()\n+\n+with open(os.path.join(os.path.dirname(__file__), \"src/padding.c\")) as f:\n+ FUNCTIONS = f.read()\n \n \n _ffi = build_ffi(cdef_source=TYPES, verify_source=FUNCTIONS)\n", "issue": "Move C code for padding into it's own .c and .h files\nSee `constant_time` for the same idea.\n\n", "before_files": [{"content": "# This file is dual licensed under the terms of the Apache License, Version\n# 2.0, and the BSD License. See the LICENSE file in the root of this repository\n# for complete details.\n\nfrom __future__ import absolute_import, division, print_function\n\nimport abc\n\nimport six\n\nfrom cryptography import utils\nfrom cryptography.exceptions import AlreadyFinalized\nfrom cryptography.hazmat.bindings.utils import LazyLibrary, build_ffi\n\n\nTYPES = \"\"\"\nuint8_t Cryptography_check_pkcs7_padding(const uint8_t *, uint8_t);\n\"\"\"\n\nFUNCTIONS = \"\"\"\n/* Returns the value of the input with the most-significant-bit copied to all\n of the bits. */\nstatic uint8_t Cryptography_DUPLICATE_MSB_TO_ALL(uint8_t a) {\n return (1 - (a >> (sizeof(uint8_t) * 8 - 1))) - 1;\n}\n\n/* This returns 0xFF if a < b else 0x00, but does so in a constant time\n fashion */\nstatic uint8_t Cryptography_constant_time_lt(uint8_t a, uint8_t b) {\n a -= b;\n return Cryptography_DUPLICATE_MSB_TO_ALL(a);\n}\n\nuint8_t Cryptography_check_pkcs7_padding(const uint8_t *data,\n uint8_t block_len) {\n uint8_t i;\n uint8_t pad_size = data[block_len - 1];\n uint8_t mismatch = 0;\n for (i = 0; i < block_len; i++) {\n unsigned int mask = Cryptography_constant_time_lt(i, pad_size);\n uint8_t b = data[block_len - 1 - i];\n mismatch |= (mask & (pad_size ^ b));\n }\n\n /* Check to make sure the pad_size was within the valid range. */\n mismatch |= ~Cryptography_constant_time_lt(0, pad_size);\n mismatch |= Cryptography_constant_time_lt(block_len, pad_size);\n\n /* Make sure any bits set are copied to the lowest bit */\n mismatch |= mismatch >> 4;\n mismatch |= mismatch >> 2;\n mismatch |= mismatch >> 1;\n /* Now check the low bit to see if it's set */\n return (mismatch & 1) == 0;\n}\n\"\"\"\n\n\n_ffi = build_ffi(cdef_source=TYPES, verify_source=FUNCTIONS)\n_lib = LazyLibrary(_ffi)\n\n\[email protected]_metaclass(abc.ABCMeta)\nclass PaddingContext(object):\n @abc.abstractmethod\n def update(self, data):\n \"\"\"\n Pads the provided bytes and returns any available data as bytes.\n \"\"\"\n\n @abc.abstractmethod\n def finalize(self):\n \"\"\"\n Finalize the padding, returns bytes.\n \"\"\"\n\n\nclass PKCS7(object):\n def __init__(self, block_size):\n if not (0 <= block_size < 256):\n raise ValueError(\"block_size must be in range(0, 256).\")\n\n if block_size % 8 != 0:\n raise ValueError(\"block_size must be a multiple of 8.\")\n\n self.block_size = block_size\n\n def padder(self):\n return _PKCS7PaddingContext(self.block_size)\n\n def unpadder(self):\n return _PKCS7UnpaddingContext(self.block_size)\n\n\[email protected]_interface(PaddingContext)\nclass _PKCS7PaddingContext(object):\n def __init__(self, block_size):\n self.block_size = block_size\n # TODO: more copies than necessary, we should use zero-buffer (#193)\n self._buffer = b\"\"\n\n def update(self, data):\n if self._buffer is None:\n raise AlreadyFinalized(\"Context was already finalized.\")\n\n if not isinstance(data, bytes):\n raise TypeError(\"data must be bytes.\")\n\n self._buffer += data\n\n finished_blocks = len(self._buffer) // (self.block_size // 8)\n\n result = self._buffer[:finished_blocks * (self.block_size // 8)]\n self._buffer = self._buffer[finished_blocks * (self.block_size // 8):]\n\n return result\n\n def finalize(self):\n if self._buffer is None:\n raise AlreadyFinalized(\"Context was already finalized.\")\n\n pad_size = self.block_size // 8 - len(self._buffer)\n result = self._buffer + six.int2byte(pad_size) * pad_size\n self._buffer = None\n return result\n\n\[email protected]_interface(PaddingContext)\nclass _PKCS7UnpaddingContext(object):\n def __init__(self, block_size):\n self.block_size = block_size\n # TODO: more copies than necessary, we should use zero-buffer (#193)\n self._buffer = b\"\"\n\n def update(self, data):\n if self._buffer is None:\n raise AlreadyFinalized(\"Context was already finalized.\")\n\n if not isinstance(data, bytes):\n raise TypeError(\"data must be bytes.\")\n\n self._buffer += data\n\n finished_blocks = max(\n len(self._buffer) // (self.block_size // 8) - 1,\n 0\n )\n\n result = self._buffer[:finished_blocks * (self.block_size // 8)]\n self._buffer = self._buffer[finished_blocks * (self.block_size // 8):]\n\n return result\n\n def finalize(self):\n if self._buffer is None:\n raise AlreadyFinalized(\"Context was already finalized.\")\n\n if len(self._buffer) != self.block_size // 8:\n raise ValueError(\"Invalid padding bytes.\")\n\n valid = _lib.Cryptography_check_pkcs7_padding(\n self._buffer, self.block_size // 8\n )\n\n if not valid:\n raise ValueError(\"Invalid padding bytes.\")\n\n pad_size = six.indexbytes(self._buffer, -1)\n res = self._buffer[:-pad_size]\n self._buffer = None\n return res\n", "path": "src/cryptography/hazmat/primitives/padding.py"}]}
| 2,264 | 613 |
gh_patches_debug_4112
|
rasdani/github-patches
|
git_diff
|
getsentry__sentry-12417
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Google Pubsub push messages mis-identified as crawler
## Important Details
How are you running Sentry?
* [ ] On-Premise docker [Version xyz]
* [x] Saas (sentry.io)
* [ ] Other [briefly describe your environment]
## Description
We get the Sentry API error `Sentry responded with an API error: APIError(Event dropped due to filter: web-crawlers)` when there's an exception in a [Google Pubsub push](https://cloud.google.com/pubsub/docs/push) handler.
Apparently the user agent is `APIs-Google`.
## Steps to Reproduce
1. Set up a Google Pubsub push HTTP event handler
2. Have an exception in the message handler code
3. Not get report in Sentry
### What you expected to happen
`APIs-Google` isn't identified as a web crawler.
### Possible Solution
Improve the regex? 😸
</issue>
<code>
[start of src/sentry/filters/web_crawlers.py]
1 from __future__ import absolute_import
2
3 import re
4
5 from .base import Filter
6 from sentry.utils.data_filters import FilterStatKeys
7 from sentry.utils.safe import get_path
8
9 # not all of these agents are guaranteed to execute JavaScript, but to avoid
10 # overhead of identifying which ones do, and which ones will over time we simply
11 # target all of the major ones
12 CRAWLERS = re.compile(
13 r'|'.join(
14 (
15 # various Google services
16 r'AdsBot',
17 # Google Adsense
18 r'Mediapartners',
19 # Google+ and Google web search
20 r'Google',
21 # Bing search
22 r'BingBot',
23 r'BingPreview',
24 # Baidu search
25 r'Baiduspider',
26 # Yahoo
27 r'Slurp',
28 # Sogou
29 r'Sogou',
30 # facebook
31 r'facebook',
32 # Alexa
33 r'ia_archiver',
34 # Generic bot
35 r'bots?[\/\s\)\;]',
36 # Generic spider
37 r'spider[\/\s\)\;]',
38 # Slack - see https://api.slack.com/robots
39 r'Slack',
40 # Google indexing bot
41 r'Calypso AppCrawler',
42 )
43 ),
44 re.I
45 )
46
47
48 class WebCrawlersFilter(Filter):
49 id = FilterStatKeys.WEB_CRAWLER
50 name = 'Filter out known web crawlers'
51 description = 'Some crawlers may execute pages in incompatible ways which then cause errors that are unlikely to be seen by a normal user.'
52 default = True
53
54 def get_user_agent(self, data):
55 try:
56 for key, value in get_path(data, 'request', 'headers', filter=True) or ():
57 if key.lower() == 'user-agent':
58 return value
59 except LookupError:
60 return ''
61
62 def test(self, data):
63 # TODO(dcramer): we could also look at UA parser and use the 'Spider'
64 # device type
65 user_agent = self.get_user_agent(data)
66 if not user_agent:
67 return False
68 return bool(CRAWLERS.search(user_agent))
69
[end of src/sentry/filters/web_crawlers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/sentry/filters/web_crawlers.py b/src/sentry/filters/web_crawlers.py
--- a/src/sentry/filters/web_crawlers.py
+++ b/src/sentry/filters/web_crawlers.py
@@ -16,8 +16,8 @@
r'AdsBot',
# Google Adsense
r'Mediapartners',
- # Google+ and Google web search
- r'Google',
+ # Google+ and Google web search, but not apis-google
+ r'(?<!APIs-)Google',
# Bing search
r'BingBot',
r'BingPreview',
|
{"golden_diff": "diff --git a/src/sentry/filters/web_crawlers.py b/src/sentry/filters/web_crawlers.py\n--- a/src/sentry/filters/web_crawlers.py\n+++ b/src/sentry/filters/web_crawlers.py\n@@ -16,8 +16,8 @@\n r'AdsBot',\n # Google Adsense\n r'Mediapartners',\n- # Google+ and Google web search\n- r'Google',\n+ # Google+ and Google web search, but not apis-google\n+ r'(?<!APIs-)Google',\n # Bing search\n r'BingBot',\n r'BingPreview',\n", "issue": "Google Pubsub push messages mis-identified as crawler\n## Important Details\r\n\r\nHow are you running Sentry?\r\n\r\n* [ ] On-Premise docker [Version xyz]\r\n* [x] Saas (sentry.io)\r\n* [ ] Other [briefly describe your environment]\r\n\r\n## Description\r\n\r\nWe get the Sentry API error `Sentry responded with an API error: APIError(Event dropped due to filter: web-crawlers)` when there's an exception in a [Google Pubsub push](https://cloud.google.com/pubsub/docs/push) handler.\r\n\r\nApparently the user agent is `APIs-Google`.\r\n\r\n## Steps to Reproduce\r\n\r\n1. Set up a Google Pubsub push HTTP event handler\r\n2. Have an exception in the message handler code\r\n3. Not get report in Sentry\r\n\r\n### What you expected to happen\r\n\r\n`APIs-Google` isn't identified as a web crawler.\r\n\r\n### Possible Solution\r\n\r\nImprove the regex? \ud83d\ude38 \r\n\n", "before_files": [{"content": "from __future__ import absolute_import\n\nimport re\n\nfrom .base import Filter\nfrom sentry.utils.data_filters import FilterStatKeys\nfrom sentry.utils.safe import get_path\n\n# not all of these agents are guaranteed to execute JavaScript, but to avoid\n# overhead of identifying which ones do, and which ones will over time we simply\n# target all of the major ones\nCRAWLERS = re.compile(\n r'|'.join(\n (\n # various Google services\n r'AdsBot',\n # Google Adsense\n r'Mediapartners',\n # Google+ and Google web search\n r'Google',\n # Bing search\n r'BingBot',\n r'BingPreview',\n # Baidu search\n r'Baiduspider',\n # Yahoo\n r'Slurp',\n # Sogou\n r'Sogou',\n # facebook\n r'facebook',\n # Alexa\n r'ia_archiver',\n # Generic bot\n r'bots?[\\/\\s\\)\\;]',\n # Generic spider\n r'spider[\\/\\s\\)\\;]',\n # Slack - see https://api.slack.com/robots\n r'Slack',\n # Google indexing bot\n r'Calypso AppCrawler',\n )\n ),\n re.I\n)\n\n\nclass WebCrawlersFilter(Filter):\n id = FilterStatKeys.WEB_CRAWLER\n name = 'Filter out known web crawlers'\n description = 'Some crawlers may execute pages in incompatible ways which then cause errors that are unlikely to be seen by a normal user.'\n default = True\n\n def get_user_agent(self, data):\n try:\n for key, value in get_path(data, 'request', 'headers', filter=True) or ():\n if key.lower() == 'user-agent':\n return value\n except LookupError:\n return ''\n\n def test(self, data):\n # TODO(dcramer): we could also look at UA parser and use the 'Spider'\n # device type\n user_agent = self.get_user_agent(data)\n if not user_agent:\n return False\n return bool(CRAWLERS.search(user_agent))\n", "path": "src/sentry/filters/web_crawlers.py"}]}
| 1,348 | 143 |
gh_patches_debug_18931
|
rasdani/github-patches
|
git_diff
|
scikit-hep__pyhf-2310
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
weakrefs to dead objects occuring when changing backends in pyhf benchmark
### Summary
I try to perform a benchmark of `pyhf` using `pytest-benchmark` quite similarly to the benchmark in the `tests/benchmarks` directory.
A short example of such a simple benchmark is given below. To reproduce this bug, the python code needs to be saved in a file of the format `test_<name>.py` and executed via `pytest test_<name>.py`.
The bug occurs only sometimes when the backend is changed between different benchmarking cases. Since the occurence of the bug includes some amount of randomness, it may happen that it doesn't occur on the first try but that the benchmark must be executed multiple times. The full benchmark takes around 1 min on my machine.
The suspected origin of this bug is that every time the backend is changed, an event called `tensorlib_changed` is triggered that in turn leads to the execution of some `_precompute()` functions on different objects (e.g. a `TensorViewer` object as in the error message). The problem occurs, when the referenced object no longer exists, as all references to it have been removed. The reference used to call the function does not change this as it is a weakref.
A proposed solution can be found in PR #2310.
### OS / Environment
```console
PRETTY_NAME="Ubuntu 22.04.3 LTS"
NAME="Ubuntu"
VERSION_ID="22.04"
VERSION="22.04.3 LTS (Jammy Jellyfish)"
VERSION_CODENAME=jammy
ID=ubuntu
ID_LIKE=debian
HOME_URL="https://www.ubuntu.com/"
SUPPORT_URL="https://help.ubuntu.com/"
BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/"
PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy"
UBUNTU_CODENAME=jammy
```
### Steps to Reproduce
<!--- Paste your minimal failing Python example code between the quotes below -->
```python (paste below)
# content of test_benchmark.py
import pytest
import pyhf
@pytest.fixture(
scope='function',
params=[
(pyhf.tensor.numpy_backend(), None),
(pyhf.tensor.pytorch_backend(), None),
(pyhf.tensor.pytorch_backend(precision='64b'), None),
(pyhf.tensor.tensorflow_backend(), None),
(pyhf.tensor.jax_backend(), None),
(
pyhf.tensor.numpy_backend(poisson_from_normal=True),
pyhf.optimize.minuit_optimizer(),
),
],
ids=['numpy', 'pytorch', 'pytorch64',
'tensorflow',
'jax', 'numpy_minuit'],
)
def backend(request):
# get the ids of all the backends
param_ids = request._fixturedef.ids
# the backend we're using: numpy, tensorflow, etc...
param_id = param_ids[request.param_index]
# name of function being called (with params), the original name is .originalname
func_name = request._pyfuncitem.name
pyhf.set_backend(*request.param)
yield request.param
def hypotest(data, pdf):
return pyhf.infer.hypotest(1.0, data, pdf, test_stat="qtilde", return_expected=True)
bins = [1, 2, 4, 8, 16, 32]
bin_ids = [f'{n_bins}_bins' for n_bins in bins]
@pytest.mark.parametrize('n_bins', bins, ids=bin_ids)
def test_hypotest(benchmark, backend, n_bins):
model = pyhf.simplemodels.uncorrelated_background(signal=[12.0]*n_bins, bkg=[50.0]*n_bins, bkg_uncertainty=[5.0]*n_bins)
data = [51.0]*n_bins + model.config.auxdata
assert benchmark(hypotest, data, model)
```
<!--- ...or if you have a failing CLI command paste it between the quotes below -->
```console (paste below)
pytest test_benchmark.py
```
### File Upload (optional)
_No response_
### Expected Results
The expected behavior is to output the benchmarking results for all considered cases as it can be observed when executing `pytest` in `pyhf/tests/benchmarks/`.
This output should not show any "test failures" as no normal tests are performed but only functions that run without an error, when called outside of the benchmark.
### Actual Results
```console
_________________________ ERROR at setup of test_hypotest[jax-1_bins] _________________________
request = <SubRequest 'backend' for <Function test_hypotest[jax-1_bins]>>
@pytest.fixture(
scope='function',
params=[
(pyhf.tensor.numpy_backend(), None),
(pyhf.tensor.pytorch_backend(), None),
(pyhf.tensor.pytorch_backend(precision='64b'), None),
(pyhf.tensor.tensorflow_backend(), None),
(pyhf.tensor.jax_backend(), None),
(
pyhf.tensor.numpy_backend(poisson_from_normal=True),
pyhf.optimize.minuit_optimizer(),
),
],
ids=['numpy', 'pytorch', 'pytorch64',
'tensorflow',
'jax', 'numpy_minuit'],
)
def backend(request):
# get the ids of all the backends
param_ids = request._fixturedef.ids
# the backend we're using: numpy, tensorflow, etc...
param_id = param_ids[request.param_index]
# name of function being called (with params), the original name is .originalname
func_name = request._pyfuncitem.name
> pyhf.set_backend(*request.param)
test_hypo_pyhf.py:29:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
../../pyhfDev/pyhf/src/pyhf/events.py:161: in register_wrapper
result = func(*args, **kwargs)
../../pyhfDev/pyhf/src/pyhf/tensor/manager.py:193: in set_backend
events.trigger("tensorlib_changed")()
../../pyhfDev/pyhf/src/pyhf/events.py:70: in __call__
func()(arg(), *args, **kwargs)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
self = None
def _precompute(self):
tensorlib, _ = get_backend()
> self.sorted_indices = tensorlib.astensor(self._sorted_indices, dtype='int')
E AttributeError: 'NoneType' object has no attribute '_sorted_indices'
../../pyhfDev/pyhf/src/pyhf/tensor/common.py:33: AttributeError
```
### pyhf Version
```console
pyhf, version 0.7.1.dev116
```
### Code of Conduct
- [X] I agree to follow the Code of Conduct
</issue>
<code>
[start of src/pyhf/events.py]
1 from __future__ import annotations
2
3 import weakref
4 from functools import wraps
5 from typing import Callable, TypeVar, cast
6
7 # See https://mypy.readthedocs.io/en/stable/generics.html#declaring-decorators
8 TCallable = TypeVar("TCallable", bound=Callable)
9
10
11 __events = {}
12 __disabled_events = set()
13
14 __all__ = ["Callables", "disable", "enable", "noop", "register", "subscribe", "trigger"]
15
16
17 def __dir__():
18 return __all__
19
20
21 def noop(*args, **kwargs):
22 pass
23
24
25 class Callables:
26 def __init__(self):
27 self._callbacks = []
28
29 @property
30 def callbacks(self):
31 """
32 Get the current list of living callbacks.
33 """
34 self._flush()
35 return self._callbacks
36
37 def append(self, callback):
38 """
39 Append a new bound method as a callback to the list of callables.
40 """
41 try:
42 # methods
43 callback_ref = weakref.ref(callback.__func__), weakref.ref(
44 callback.__self__
45 )
46 except AttributeError:
47 callback_ref = weakref.ref(callback), None
48 self._callbacks.append(callback_ref)
49
50 def _flush(self):
51 """
52 Flush the list of callbacks with those who are weakly-referencing deleted objects.
53
54 Note: must interact with the self._callbacks directly, and not
55 self.callbacks, to avoid infinite recursion.
56 """
57 _callbacks = []
58 for func, arg in self._callbacks:
59 if arg is not None:
60 arg_ref = arg()
61 if arg_ref is None:
62 continue
63 _callbacks.append((func, arg))
64 self._callbacks = _callbacks
65
66 def __call__(self, *args, **kwargs):
67 for func, arg in self.callbacks:
68 # weakref: needs to be de-ref'd first before calling
69 if arg is not None:
70 func()(arg(), *args, **kwargs)
71 else:
72 func()(*args, **kwargs)
73
74 def __iter__(self):
75 return iter(self.callbacks)
76
77 def __getitem__(self, index):
78 return self.callbacks[index]
79
80 def __len__(self):
81 return len(self.callbacks)
82
83 def __repr__(self):
84 return f"Callables({self.callbacks})"
85
86
87 def subscribe(event: str):
88 """
89 Subscribe a function or object method as a callback to an event.
90
91 .. note::
92
93 This is meant to be used as a decorator.
94
95 Args:
96 event (:obj:`str`): The name of the event to subscribe to.
97
98 Returns:
99 :obj:`function`: Decorated function.
100
101 Example:
102 >>> import pyhf
103 >>> @pyhf.events.subscribe("myevent")
104 ... def test(a, b):
105 ... print(a + b)
106 ...
107 >>> pyhf.events.trigger("myevent")(1, 2)
108 3
109
110 """
111
112 global __events
113
114 def __decorator(func: TCallable) -> TCallable:
115 __events.setdefault(event, Callables()).append(func)
116 return func
117
118 return cast(TCallable, __decorator)
119
120
121 def register(event: str) -> Callable[[TCallable], TCallable]:
122 """
123 Register a function or object method to trigger an event. This creates two
124 events: ``{event_name}::before`` and ``{event_name}::after``.
125
126 .. note::
127
128 This is meant to be used as a decorator.
129
130 Args:
131 event (:obj:`str`): The name of the event to subscribe to.
132
133 Returns:
134 :obj:`function`: Decorated function.
135
136 Example:
137 >>> import pyhf
138 >>> @pyhf.events.register("test_func")
139 ... def test(a, b):
140 ... print(a + b)
141 ...
142 >>> @pyhf.events.subscribe("test_func::before")
143 ... def precall():
144 ... print("before call")
145 ...
146 >>> @pyhf.events.subscribe("test_func::after")
147 ... def postcall():
148 ... print("after call")
149 ...
150 >>> test(1, 2)
151 before call
152 3
153 after call
154
155 """
156
157 def _register(func: TCallable) -> TCallable:
158 @wraps(func)
159 def register_wrapper(*args, **kwargs): # type: ignore
160 trigger(f"{event:s}::before")()
161 result = func(*args, **kwargs)
162 trigger(f"{event:s}::after")()
163 return result
164
165 return register_wrapper
166
167 return cast(TCallable, _register)
168
169
170 def trigger(event: str) -> Callables:
171 """
172 Trigger an event if not disabled.
173 """
174 global __events, __disabled_events, noop
175 is_noop = bool(event in __disabled_events or event not in __events)
176 return noop if is_noop else __events.get(event)
177
178
179 def disable(event: str):
180 """
181 Disable an event from firing.
182 """
183 global __disabled_events
184 __disabled_events.add(event)
185
186
187 def enable(event: str):
188 """
189 Enable an event to be fired if disabled.
190 """
191 global __disabled_events
192 __disabled_events.remove(event)
193
[end of src/pyhf/events.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/pyhf/events.py b/src/pyhf/events.py
--- a/src/pyhf/events.py
+++ b/src/pyhf/events.py
@@ -64,12 +64,20 @@
self._callbacks = _callbacks
def __call__(self, *args, **kwargs):
- for func, arg in self.callbacks:
+ for func, arg in self._callbacks:
# weakref: needs to be de-ref'd first before calling
if arg is not None:
- func()(arg(), *args, **kwargs)
+ arg_ref = arg()
+ if arg_ref is not None:
+ func()(arg_ref, *args, **kwargs)
else:
func()(*args, **kwargs)
+ # Flush after calling all the callbacks, not before, as callbacks in the
+ # beginning of the iteration might cause new dead arg weakrefs in
+ # callbacks that are iterated over later.
+ # Checking for dead weakrefs in each iteration and flushing at the end
+ # avoids redundant dead weakref checking in subsequent calls.
+ self._flush()
def __iter__(self):
return iter(self.callbacks)
|
{"golden_diff": "diff --git a/src/pyhf/events.py b/src/pyhf/events.py\n--- a/src/pyhf/events.py\n+++ b/src/pyhf/events.py\n@@ -64,12 +64,20 @@\n self._callbacks = _callbacks\n \n def __call__(self, *args, **kwargs):\n- for func, arg in self.callbacks:\n+ for func, arg in self._callbacks:\n # weakref: needs to be de-ref'd first before calling\n if arg is not None:\n- func()(arg(), *args, **kwargs)\n+ arg_ref = arg()\n+ if arg_ref is not None:\n+ func()(arg_ref, *args, **kwargs)\n else:\n func()(*args, **kwargs)\n+ # Flush after calling all the callbacks, not before, as callbacks in the\n+ # beginning of the iteration might cause new dead arg weakrefs in\n+ # callbacks that are iterated over later.\n+ # Checking for dead weakrefs in each iteration and flushing at the end\n+ # avoids redundant dead weakref checking in subsequent calls.\n+ self._flush()\n \n def __iter__(self):\n return iter(self.callbacks)\n", "issue": "weakrefs to dead objects occuring when changing backends in pyhf benchmark\n### Summary\n\nI try to perform a benchmark of `pyhf` using `pytest-benchmark` quite similarly to the benchmark in the `tests/benchmarks` directory.\r\nA short example of such a simple benchmark is given below. To reproduce this bug, the python code needs to be saved in a file of the format `test_<name>.py` and executed via `pytest test_<name>.py`.\r\nThe bug occurs only sometimes when the backend is changed between different benchmarking cases. Since the occurence of the bug includes some amount of randomness, it may happen that it doesn't occur on the first try but that the benchmark must be executed multiple times. The full benchmark takes around 1 min on my machine.\r\n\r\nThe suspected origin of this bug is that every time the backend is changed, an event called `tensorlib_changed` is triggered that in turn leads to the execution of some `_precompute()` functions on different objects (e.g. a `TensorViewer` object as in the error message). The problem occurs, when the referenced object no longer exists, as all references to it have been removed. The reference used to call the function does not change this as it is a weakref.\r\n\r\nA proposed solution can be found in PR #2310. \n\n### OS / Environment\n\n```console\nPRETTY_NAME=\"Ubuntu 22.04.3 LTS\"\r\nNAME=\"Ubuntu\"\r\nVERSION_ID=\"22.04\"\r\nVERSION=\"22.04.3 LTS (Jammy Jellyfish)\"\r\nVERSION_CODENAME=jammy\r\nID=ubuntu\r\nID_LIKE=debian\r\nHOME_URL=\"https://www.ubuntu.com/\"\r\nSUPPORT_URL=\"https://help.ubuntu.com/\"\r\nBUG_REPORT_URL=\"https://bugs.launchpad.net/ubuntu/\"\r\nPRIVACY_POLICY_URL=\"https://www.ubuntu.com/legal/terms-and-policies/privacy-policy\"\r\nUBUNTU_CODENAME=jammy\n```\n\n\n### Steps to Reproduce\n\n<!--- Paste your minimal failing Python example code between the quotes below -->\r\n```python (paste below)\r\n# content of test_benchmark.py\r\nimport pytest\r\nimport pyhf\r\n\r\[email protected](\r\n scope='function',\r\n params=[\r\n (pyhf.tensor.numpy_backend(), None),\r\n (pyhf.tensor.pytorch_backend(), None),\r\n (pyhf.tensor.pytorch_backend(precision='64b'), None),\r\n (pyhf.tensor.tensorflow_backend(), None),\r\n (pyhf.tensor.jax_backend(), None),\r\n (\r\n pyhf.tensor.numpy_backend(poisson_from_normal=True),\r\n pyhf.optimize.minuit_optimizer(),\r\n ),\r\n ],\r\n ids=['numpy', 'pytorch', 'pytorch64',\r\n 'tensorflow',\r\n 'jax', 'numpy_minuit'],\r\n)\r\ndef backend(request):\r\n # get the ids of all the backends\r\n param_ids = request._fixturedef.ids\r\n # the backend we're using: numpy, tensorflow, etc...\r\n param_id = param_ids[request.param_index]\r\n # name of function being called (with params), the original name is .originalname\r\n func_name = request._pyfuncitem.name\r\n\r\n pyhf.set_backend(*request.param)\r\n\r\n yield request.param\r\n\r\ndef hypotest(data, pdf):\r\n return pyhf.infer.hypotest(1.0, data, pdf, test_stat=\"qtilde\", return_expected=True)\r\n\r\nbins = [1, 2, 4, 8, 16, 32]\r\nbin_ids = [f'{n_bins}_bins' for n_bins in bins]\r\n\r\[email protected]('n_bins', bins, ids=bin_ids)\r\ndef test_hypotest(benchmark, backend, n_bins):\r\n model = pyhf.simplemodels.uncorrelated_background(signal=[12.0]*n_bins, bkg=[50.0]*n_bins, bkg_uncertainty=[5.0]*n_bins)\r\n data = [51.0]*n_bins + model.config.auxdata\r\n\r\n assert benchmark(hypotest, data, model)\r\n```\r\n\r\n<!--- ...or if you have a failing CLI command paste it between the quotes below -->\r\n```console (paste below)\r\npytest test_benchmark.py\r\n```\r\n\n\n### File Upload (optional)\n\n_No response_\n\n### Expected Results\n\nThe expected behavior is to output the benchmarking results for all considered cases as it can be observed when executing `pytest` in `pyhf/tests/benchmarks/`.\r\nThis output should not show any \"test failures\" as no normal tests are performed but only functions that run without an error, when called outside of the benchmark.\n\n### Actual Results\n\n```console\n_________________________ ERROR at setup of test_hypotest[jax-1_bins] _________________________\r\n\r\nrequest = <SubRequest 'backend' for <Function test_hypotest[jax-1_bins]>>\r\n\r\n @pytest.fixture(\r\n scope='function',\r\n params=[\r\n (pyhf.tensor.numpy_backend(), None),\r\n (pyhf.tensor.pytorch_backend(), None),\r\n (pyhf.tensor.pytorch_backend(precision='64b'), None),\r\n (pyhf.tensor.tensorflow_backend(), None),\r\n (pyhf.tensor.jax_backend(), None),\r\n (\r\n pyhf.tensor.numpy_backend(poisson_from_normal=True),\r\n pyhf.optimize.minuit_optimizer(),\r\n ),\r\n ],\r\n ids=['numpy', 'pytorch', 'pytorch64',\r\n 'tensorflow',\r\n 'jax', 'numpy_minuit'],\r\n )\r\n def backend(request):\r\n # get the ids of all the backends\r\n param_ids = request._fixturedef.ids\r\n # the backend we're using: numpy, tensorflow, etc...\r\n param_id = param_ids[request.param_index]\r\n # name of function being called (with params), the original name is .originalname\r\n func_name = request._pyfuncitem.name\r\n \r\n> pyhf.set_backend(*request.param)\r\n\r\ntest_hypo_pyhf.py:29: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _\r\n../../pyhfDev/pyhf/src/pyhf/events.py:161: in register_wrapper\r\n result = func(*args, **kwargs)\r\n../../pyhfDev/pyhf/src/pyhf/tensor/manager.py:193: in set_backend\r\n events.trigger(\"tensorlib_changed\")()\r\n../../pyhfDev/pyhf/src/pyhf/events.py:70: in __call__\r\n func()(arg(), *args, **kwargs)\r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _\r\n\r\nself = None\r\n\r\n def _precompute(self):\r\n tensorlib, _ = get_backend()\r\n> self.sorted_indices = tensorlib.astensor(self._sorted_indices, dtype='int')\r\nE AttributeError: 'NoneType' object has no attribute '_sorted_indices'\r\n\r\n../../pyhfDev/pyhf/src/pyhf/tensor/common.py:33: AttributeError\n```\n\n\n### pyhf Version\n\n```console\npyhf, version 0.7.1.dev116\n```\n\n\n### Code of Conduct\n\n- [X] I agree to follow the Code of Conduct\n", "before_files": [{"content": "from __future__ import annotations\n\nimport weakref\nfrom functools import wraps\nfrom typing import Callable, TypeVar, cast\n\n# See https://mypy.readthedocs.io/en/stable/generics.html#declaring-decorators\nTCallable = TypeVar(\"TCallable\", bound=Callable)\n\n\n__events = {}\n__disabled_events = set()\n\n__all__ = [\"Callables\", \"disable\", \"enable\", \"noop\", \"register\", \"subscribe\", \"trigger\"]\n\n\ndef __dir__():\n return __all__\n\n\ndef noop(*args, **kwargs):\n pass\n\n\nclass Callables:\n def __init__(self):\n self._callbacks = []\n\n @property\n def callbacks(self):\n \"\"\"\n Get the current list of living callbacks.\n \"\"\"\n self._flush()\n return self._callbacks\n\n def append(self, callback):\n \"\"\"\n Append a new bound method as a callback to the list of callables.\n \"\"\"\n try:\n # methods\n callback_ref = weakref.ref(callback.__func__), weakref.ref(\n callback.__self__\n )\n except AttributeError:\n callback_ref = weakref.ref(callback), None\n self._callbacks.append(callback_ref)\n\n def _flush(self):\n \"\"\"\n Flush the list of callbacks with those who are weakly-referencing deleted objects.\n\n Note: must interact with the self._callbacks directly, and not\n self.callbacks, to avoid infinite recursion.\n \"\"\"\n _callbacks = []\n for func, arg in self._callbacks:\n if arg is not None:\n arg_ref = arg()\n if arg_ref is None:\n continue\n _callbacks.append((func, arg))\n self._callbacks = _callbacks\n\n def __call__(self, *args, **kwargs):\n for func, arg in self.callbacks:\n # weakref: needs to be de-ref'd first before calling\n if arg is not None:\n func()(arg(), *args, **kwargs)\n else:\n func()(*args, **kwargs)\n\n def __iter__(self):\n return iter(self.callbacks)\n\n def __getitem__(self, index):\n return self.callbacks[index]\n\n def __len__(self):\n return len(self.callbacks)\n\n def __repr__(self):\n return f\"Callables({self.callbacks})\"\n\n\ndef subscribe(event: str):\n \"\"\"\n Subscribe a function or object method as a callback to an event.\n\n .. note::\n\n This is meant to be used as a decorator.\n\n Args:\n event (:obj:`str`): The name of the event to subscribe to.\n\n Returns:\n :obj:`function`: Decorated function.\n\n Example:\n >>> import pyhf\n >>> @pyhf.events.subscribe(\"myevent\")\n ... def test(a, b):\n ... print(a + b)\n ...\n >>> pyhf.events.trigger(\"myevent\")(1, 2)\n 3\n\n \"\"\"\n\n global __events\n\n def __decorator(func: TCallable) -> TCallable:\n __events.setdefault(event, Callables()).append(func)\n return func\n\n return cast(TCallable, __decorator)\n\n\ndef register(event: str) -> Callable[[TCallable], TCallable]:\n \"\"\"\n Register a function or object method to trigger an event. This creates two\n events: ``{event_name}::before`` and ``{event_name}::after``.\n\n .. note::\n\n This is meant to be used as a decorator.\n\n Args:\n event (:obj:`str`): The name of the event to subscribe to.\n\n Returns:\n :obj:`function`: Decorated function.\n\n Example:\n >>> import pyhf\n >>> @pyhf.events.register(\"test_func\")\n ... def test(a, b):\n ... print(a + b)\n ...\n >>> @pyhf.events.subscribe(\"test_func::before\")\n ... def precall():\n ... print(\"before call\")\n ...\n >>> @pyhf.events.subscribe(\"test_func::after\")\n ... def postcall():\n ... print(\"after call\")\n ...\n >>> test(1, 2)\n before call\n 3\n after call\n\n \"\"\"\n\n def _register(func: TCallable) -> TCallable:\n @wraps(func)\n def register_wrapper(*args, **kwargs): # type: ignore\n trigger(f\"{event:s}::before\")()\n result = func(*args, **kwargs)\n trigger(f\"{event:s}::after\")()\n return result\n\n return register_wrapper\n\n return cast(TCallable, _register)\n\n\ndef trigger(event: str) -> Callables:\n \"\"\"\n Trigger an event if not disabled.\n \"\"\"\n global __events, __disabled_events, noop\n is_noop = bool(event in __disabled_events or event not in __events)\n return noop if is_noop else __events.get(event)\n\n\ndef disable(event: str):\n \"\"\"\n Disable an event from firing.\n \"\"\"\n global __disabled_events\n __disabled_events.add(event)\n\n\ndef enable(event: str):\n \"\"\"\n Enable an event to be fired if disabled.\n \"\"\"\n global __disabled_events\n __disabled_events.remove(event)\n", "path": "src/pyhf/events.py"}]}
| 3,706 | 258 |
gh_patches_debug_30232
|
rasdani/github-patches
|
git_diff
|
hpcaitech__ColossalAI-5315
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[tensor] fix some unittests
[tensor] fix some unittests
[tensor] fix some unittests
</issue>
<code>
[start of colossalai/kernel/triton/rms_layernorm.py]
1 import torch
2
3 try:
4 import triton
5 import triton.language as tl
6
7 HAS_TRITON = True
8 except ImportError:
9 HAS_TRITON = False
10 print("please install triton from https://github.com/openai/triton")
11
12 if HAS_TRITON:
13 # CREDITS: These functions are adapted from the Triton tutorial
14 # https://triton-lang.org/main/getting-started/tutorials/05-layer-norm.html
15
16 @triton.jit
17 def _rmsnorm_kernel(
18 X, # pointer to the input
19 Y, # pointer to the output
20 W, # pointer to the weights
21 stride, # how much to increase the pointer when moving by 1 row
22 N, # number of columns in X
23 eps, # epsilon to avoid division by zero
24 BLOCK_SIZE: tl.constexpr,
25 ):
26
27 # This triton kernel implements Root Mean Square Layer Norm (RMSNorm).
28
29 # Map the program id to the row of X and Y it should compute.
30 row = tl.program_id(0)
31 Y += row * stride
32 X += row * stride
33 # Compute variance
34 _var = tl.zeros([BLOCK_SIZE], dtype=tl.float32)
35 for off in range(0, N, BLOCK_SIZE):
36 cols = off + tl.arange(0, BLOCK_SIZE)
37 x = tl.load(X + cols, mask=cols < N, other=0.0).to(tl.float32)
38 x = tl.where(cols < N, x, 0.0)
39 _var += x * x
40 var = tl.sum(_var, axis=0) / N
41 rstd = 1 / tl.sqrt(var + eps)
42 # Normalize and apply linear transformation
43 for off in range(0, N, BLOCK_SIZE):
44 cols = off + tl.arange(0, BLOCK_SIZE)
45 mask = cols < N
46 w = tl.load(W + cols, mask=mask)
47 x = tl.load(X + cols, mask=mask, other=0.0).to(tl.float32)
48 x_hat = x * rstd
49 y = x_hat * w
50 # Write output
51 tl.store(Y + cols, y.to(tl.float16), mask=mask)
52
53 @torch.no_grad()
54 def rms_layernorm(x, weight, eps):
55 # allocate output
56 y = torch.empty_like(x)
57 # reshape input data into 2D tensor
58 x_arg = x.reshape(-1, x.shape[-1])
59 M, N = x_arg.shape
60 # Less than 64KB per feature: enqueue fused kernel
61 MAX_FUSED_SIZE = 65536 // x.element_size()
62 BLOCK_SIZE = min(MAX_FUSED_SIZE, triton.next_power_of_2(N))
63 if N > BLOCK_SIZE:
64 raise RuntimeError("This layer norm doesn't support feature dim >= 64KB.")
65 # heuristics for number of warps
66 num_warps = min(max(BLOCK_SIZE // 256, 1), 8)
67 # enqueue kernel
68 _rmsnorm_kernel[(M,)](
69 x_arg, y, weight, x_arg.stride(0), N, eps, BLOCK_SIZE=BLOCK_SIZE, num_warps=num_warps
70 )
71 return y
72
[end of colossalai/kernel/triton/rms_layernorm.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/colossalai/kernel/triton/rms_layernorm.py b/colossalai/kernel/triton/rms_layernorm.py
--- a/colossalai/kernel/triton/rms_layernorm.py
+++ b/colossalai/kernel/triton/rms_layernorm.py
@@ -23,7 +23,6 @@
eps, # epsilon to avoid division by zero
BLOCK_SIZE: tl.constexpr,
):
-
# This triton kernel implements Root Mean Square Layer Norm (RMSNorm).
# Map the program id to the row of X and Y it should compute.
@@ -54,18 +53,19 @@
def rms_layernorm(x, weight, eps):
# allocate output
y = torch.empty_like(x)
- # reshape input data into 2D tensor
+ # reshape input data into 2D tensor, (total token, hidden_size)
x_arg = x.reshape(-1, x.shape[-1])
M, N = x_arg.shape
# Less than 64KB per feature: enqueue fused kernel
MAX_FUSED_SIZE = 65536 // x.element_size()
+
BLOCK_SIZE = min(MAX_FUSED_SIZE, triton.next_power_of_2(N))
- if N > BLOCK_SIZE:
+ if N > MAX_FUSED_SIZE:
raise RuntimeError("This layer norm doesn't support feature dim >= 64KB.")
+
# heuristics for number of warps
- num_warps = min(max(BLOCK_SIZE // 256, 1), 8)
+ num_warps = min(max(triton.next_power_of_2(N) // 256, 8), 32)
+
# enqueue kernel
- _rmsnorm_kernel[(M,)](
- x_arg, y, weight, x_arg.stride(0), N, eps, BLOCK_SIZE=BLOCK_SIZE, num_warps=num_warps
- )
+ _rmsnorm_kernel[(M,)](x_arg, y, weight, x_arg.stride(0), N, eps, BLOCK_SIZE=BLOCK_SIZE, num_warps=num_warps)
return y
|
{"golden_diff": "diff --git a/colossalai/kernel/triton/rms_layernorm.py b/colossalai/kernel/triton/rms_layernorm.py\n--- a/colossalai/kernel/triton/rms_layernorm.py\n+++ b/colossalai/kernel/triton/rms_layernorm.py\n@@ -23,7 +23,6 @@\n eps, # epsilon to avoid division by zero\n BLOCK_SIZE: tl.constexpr,\n ):\n-\n # This triton kernel implements Root Mean Square Layer Norm (RMSNorm).\n \n # Map the program id to the row of X and Y it should compute.\n@@ -54,18 +53,19 @@\n def rms_layernorm(x, weight, eps):\n # allocate output\n y = torch.empty_like(x)\n- # reshape input data into 2D tensor\n+ # reshape input data into 2D tensor, (total token, hidden_size)\n x_arg = x.reshape(-1, x.shape[-1])\n M, N = x_arg.shape\n # Less than 64KB per feature: enqueue fused kernel\n MAX_FUSED_SIZE = 65536 // x.element_size()\n+\n BLOCK_SIZE = min(MAX_FUSED_SIZE, triton.next_power_of_2(N))\n- if N > BLOCK_SIZE:\n+ if N > MAX_FUSED_SIZE:\n raise RuntimeError(\"This layer norm doesn't support feature dim >= 64KB.\")\n+\n # heuristics for number of warps\n- num_warps = min(max(BLOCK_SIZE // 256, 1), 8)\n+ num_warps = min(max(triton.next_power_of_2(N) // 256, 8), 32)\n+\n # enqueue kernel\n- _rmsnorm_kernel[(M,)](\n- x_arg, y, weight, x_arg.stride(0), N, eps, BLOCK_SIZE=BLOCK_SIZE, num_warps=num_warps\n- )\n+ _rmsnorm_kernel[(M,)](x_arg, y, weight, x_arg.stride(0), N, eps, BLOCK_SIZE=BLOCK_SIZE, num_warps=num_warps)\n return y\n", "issue": "[tensor] fix some unittests\n\n[tensor] fix some unittests\n\n[tensor] fix some unittests\n\n", "before_files": [{"content": "import torch\n\ntry:\n import triton\n import triton.language as tl\n\n HAS_TRITON = True\nexcept ImportError:\n HAS_TRITON = False\n print(\"please install triton from https://github.com/openai/triton\")\n\nif HAS_TRITON:\n # CREDITS: These functions are adapted from the Triton tutorial\n # https://triton-lang.org/main/getting-started/tutorials/05-layer-norm.html\n\n @triton.jit\n def _rmsnorm_kernel(\n X, # pointer to the input\n Y, # pointer to the output\n W, # pointer to the weights\n stride, # how much to increase the pointer when moving by 1 row\n N, # number of columns in X\n eps, # epsilon to avoid division by zero\n BLOCK_SIZE: tl.constexpr,\n ):\n\n # This triton kernel implements Root Mean Square Layer Norm (RMSNorm).\n\n # Map the program id to the row of X and Y it should compute.\n row = tl.program_id(0)\n Y += row * stride\n X += row * stride\n # Compute variance\n _var = tl.zeros([BLOCK_SIZE], dtype=tl.float32)\n for off in range(0, N, BLOCK_SIZE):\n cols = off + tl.arange(0, BLOCK_SIZE)\n x = tl.load(X + cols, mask=cols < N, other=0.0).to(tl.float32)\n x = tl.where(cols < N, x, 0.0)\n _var += x * x\n var = tl.sum(_var, axis=0) / N\n rstd = 1 / tl.sqrt(var + eps)\n # Normalize and apply linear transformation\n for off in range(0, N, BLOCK_SIZE):\n cols = off + tl.arange(0, BLOCK_SIZE)\n mask = cols < N\n w = tl.load(W + cols, mask=mask)\n x = tl.load(X + cols, mask=mask, other=0.0).to(tl.float32)\n x_hat = x * rstd\n y = x_hat * w\n # Write output\n tl.store(Y + cols, y.to(tl.float16), mask=mask)\n\n @torch.no_grad()\n def rms_layernorm(x, weight, eps):\n # allocate output\n y = torch.empty_like(x)\n # reshape input data into 2D tensor\n x_arg = x.reshape(-1, x.shape[-1])\n M, N = x_arg.shape\n # Less than 64KB per feature: enqueue fused kernel\n MAX_FUSED_SIZE = 65536 // x.element_size()\n BLOCK_SIZE = min(MAX_FUSED_SIZE, triton.next_power_of_2(N))\n if N > BLOCK_SIZE:\n raise RuntimeError(\"This layer norm doesn't support feature dim >= 64KB.\")\n # heuristics for number of warps\n num_warps = min(max(BLOCK_SIZE // 256, 1), 8)\n # enqueue kernel\n _rmsnorm_kernel[(M,)](\n x_arg, y, weight, x_arg.stride(0), N, eps, BLOCK_SIZE=BLOCK_SIZE, num_warps=num_warps\n )\n return y\n", "path": "colossalai/kernel/triton/rms_layernorm.py"}]}
| 1,442 | 482 |
gh_patches_debug_25017
|
rasdani/github-patches
|
git_diff
|
pydantic__pydantic-1272
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
@validate_arguments on instance methods
# Bug
Hello, I tried using the new `@validate_arguments` decorator and it doesn't work when used on instance methods.
I didn't see it on the ToDo in #1205 and it seems like an oversight, maybe due to the special treatment of `self`.
Output of `python -c "import pydantic.utils; print(pydantic.utils.version_info())"`:
```
$ python3 -c "import pydantic.utils; print(pydantic.utils.version_info())"
pydantic version: 1.4a1
pydantic compiled: False
install path: /home/[user]/git/pydantic/pydantic
python version: 3.7.5 (default, Nov 20 2019, 09:21:52) [GCC 9.2.1 20191008]
platform: Linux-5.3.0-29-generic-x86_64-with-Ubuntu-19.10-eoan
optional deps. installed: []
```
```py
from pydantic import validate_arguments
class SomeObject:
@validate_arguments
def some_function(self, i: int):
print(type(self), self)
print(type(i), i)
o = SomeObject()
o.some_function(1) # doesn't work, instead of `i` `self` becomes 1
#pydantic.error_wrappers.ValidationError: 1 validation error for SomeFunction
#i
# field required (type=value_error.missing)
o.some_function(o, 1) # works, but not the way instance methods are meant to be used
#<class '__main__.SomeObject'> <__main__.SomeObject object at 0x7f32911af3d0>
#<class 'int'> 1
```
</issue>
<code>
[start of pydantic/decorator.py]
1 from functools import update_wrapper
2 from typing import TYPE_CHECKING, Any, Dict, List, Mapping, Tuple, TypeVar, cast, get_type_hints
3
4 from . import validator
5 from .errors import ConfigError
6 from .main import BaseModel, Extra, create_model
7 from .utils import to_camel
8
9 __all__ = ('validate_arguments',)
10
11 if TYPE_CHECKING:
12 from .typing import AnyCallable
13
14 Callable = TypeVar('Callable', bound=AnyCallable)
15
16
17 def validate_arguments(function: 'Callable') -> 'Callable':
18 """
19 Decorator to validate the arguments passed to a function.
20 """
21 vd = ValidatedFunction(function)
22 vd = update_wrapper(vd, function) # type: ignore
23 return cast('Callable', vd)
24
25
26 ALT_V_ARGS = 'v__args'
27 ALT_V_KWARGS = 'v__kwargs'
28 V_POSITIONAL_ONLY_NAME = 'v__positional_only'
29
30
31 class ValidatedFunction:
32 def __init__(self, function: 'Callable'):
33 from inspect import signature, Parameter
34
35 parameters: Mapping[str, Parameter] = signature(function).parameters
36
37 if parameters.keys() & {ALT_V_ARGS, ALT_V_KWARGS, V_POSITIONAL_ONLY_NAME}:
38 raise ConfigError(
39 f'"{ALT_V_ARGS}", "{ALT_V_KWARGS}" and "{V_POSITIONAL_ONLY_NAME}" are not permitted as argument '
40 f'names when using the "{validate_arguments.__name__}" decorator'
41 )
42
43 self.raw_function = function
44 self.arg_mapping: Dict[int, str] = {}
45 self.positional_only_args = set()
46 self.v_args_name = 'args'
47 self.v_kwargs_name = 'kwargs'
48
49 type_hints = get_type_hints(function)
50 takes_args = False
51 takes_kwargs = False
52 fields: Dict[str, Tuple[Any, Any]] = {}
53 for i, (name, p) in enumerate(parameters.items()):
54 if p.annotation == p.empty:
55 annotation = Any
56 else:
57 annotation = type_hints[name]
58
59 default = ... if p.default == p.empty else p.default
60 if p.kind == Parameter.POSITIONAL_ONLY:
61 self.arg_mapping[i] = name
62 fields[name] = annotation, default
63 fields[V_POSITIONAL_ONLY_NAME] = List[str], None
64 self.positional_only_args.add(name)
65 elif p.kind == Parameter.POSITIONAL_OR_KEYWORD:
66 self.arg_mapping[i] = name
67 fields[name] = annotation, default
68 elif p.kind == Parameter.KEYWORD_ONLY:
69 fields[name] = annotation, default
70 elif p.kind == Parameter.VAR_POSITIONAL:
71 self.v_args_name = name
72 fields[name] = Tuple[annotation, ...], None
73 takes_args = True
74 else:
75 assert p.kind == Parameter.VAR_KEYWORD, p.kind
76 self.v_kwargs_name = name
77 fields[name] = Dict[str, annotation], None # type: ignore
78 takes_kwargs = True
79
80 # these checks avoid a clash between "args" and a field with that name
81 if not takes_args and self.v_args_name in fields:
82 self.v_args_name = ALT_V_ARGS
83
84 # same with "kwargs"
85 if not takes_kwargs and self.v_kwargs_name in fields:
86 self.v_kwargs_name = ALT_V_KWARGS
87
88 if not takes_args:
89 # we add the field so validation below can raise the correct exception
90 fields[self.v_args_name] = List[Any], None
91
92 if not takes_kwargs:
93 # same with kwargs
94 fields[self.v_kwargs_name] = Dict[Any, Any], None
95
96 self.create_model(fields, takes_args, takes_kwargs)
97
98 def __call__(self, *args: Any, **kwargs: Any) -> Any:
99 values = self.build_values(args, kwargs)
100 m = self.model(**values)
101 return self.execute(m)
102
103 def build_values(self, args: Tuple[Any, ...], kwargs: Dict[str, Any]) -> Dict[str, Any]:
104 values: Dict[str, Any] = {}
105 if args:
106 arg_iter = enumerate(args)
107 while True:
108 try:
109 i, a = next(arg_iter)
110 except StopIteration:
111 break
112 arg_name = self.arg_mapping.get(i)
113 if arg_name is not None:
114 values[arg_name] = a
115 else:
116 values[self.v_args_name] = [a] + [a for _, a in arg_iter]
117 break
118
119 var_kwargs = {}
120 wrong_positional_args = []
121 for k, v in kwargs.items():
122 if k in self.model.__fields__:
123 if k in self.positional_only_args:
124 wrong_positional_args.append(k)
125 values[k] = v
126 else:
127 var_kwargs[k] = v
128
129 if var_kwargs:
130 values[self.v_kwargs_name] = var_kwargs
131 if wrong_positional_args:
132 values[V_POSITIONAL_ONLY_NAME] = wrong_positional_args
133 return values
134
135 def execute(self, m: BaseModel) -> Any:
136 d = {k: v for k, v in m._iter() if k in m.__fields_set__}
137 kwargs = d.pop(self.v_kwargs_name, None)
138 if kwargs:
139 d.update(kwargs)
140
141 if self.v_args_name in d:
142 args_: List[Any] = []
143 in_kwargs = False
144 kwargs = {}
145 for name, value in d.items():
146 if in_kwargs:
147 kwargs[name] = value
148 elif name == self.v_args_name:
149 args_ += value
150 in_kwargs = True
151 else:
152 args_.append(value)
153 return self.raw_function(*args_, **kwargs)
154 elif self.positional_only_args:
155 args_ = []
156 kwargs = {}
157 for name, value in d.items():
158 if name in self.positional_only_args:
159 args_.append(value)
160 else:
161 kwargs[name] = value
162 return self.raw_function(*args_, **kwargs)
163 else:
164 return self.raw_function(**d)
165
166 def create_model(self, fields: Dict[str, Any], takes_args: bool, takes_kwargs: bool) -> None:
167 pos_args = len(self.arg_mapping)
168
169 class DecoratorBaseModel(BaseModel):
170 @validator(self.v_args_name, check_fields=False, allow_reuse=True)
171 def check_args(cls, v: List[Any]) -> List[Any]:
172 if takes_args:
173 return v
174
175 raise TypeError(f'{pos_args} positional arguments expected but {pos_args + len(v)} given')
176
177 @validator(self.v_kwargs_name, check_fields=False, allow_reuse=True)
178 def check_kwargs(cls, v: Dict[str, Any]) -> Dict[str, Any]:
179 if takes_kwargs:
180 return v
181
182 plural = '' if len(v) == 1 else 's'
183 keys = ', '.join(map(repr, v.keys()))
184 raise TypeError(f'unexpected keyword argument{plural}: {keys}')
185
186 @validator(V_POSITIONAL_ONLY_NAME, check_fields=False, allow_reuse=True)
187 def check_positional_only(cls, v: List[str]) -> None:
188 plural = '' if len(v) == 1 else 's'
189 keys = ', '.join(map(repr, v))
190 raise TypeError(f'positional-only argument{plural} passed as keyword argument{plural}: {keys}')
191
192 class Config:
193 extra = Extra.forbid
194
195 self.model = create_model(to_camel(self.raw_function.__name__), __base__=DecoratorBaseModel, **fields)
196
[end of pydantic/decorator.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pydantic/decorator.py b/pydantic/decorator.py
--- a/pydantic/decorator.py
+++ b/pydantic/decorator.py
@@ -1,4 +1,4 @@
-from functools import update_wrapper
+from functools import wraps
from typing import TYPE_CHECKING, Any, Dict, List, Mapping, Tuple, TypeVar, cast, get_type_hints
from . import validator
@@ -19,8 +19,15 @@
Decorator to validate the arguments passed to a function.
"""
vd = ValidatedFunction(function)
- vd = update_wrapper(vd, function) # type: ignore
- return cast('Callable', vd)
+
+ @wraps(function)
+ def wrapper_function(*args: Any, **kwargs: Any) -> Any:
+ return vd.call(*args, **kwargs)
+
+ wrapper_function.vd = vd # type: ignore
+ wrapper_function.raw_function = vd.raw_function # type: ignore
+ wrapper_function.model = vd.model # type: ignore
+ return cast('Callable', wrapper_function)
ALT_V_ARGS = 'v__args'
@@ -95,7 +102,7 @@
self.create_model(fields, takes_args, takes_kwargs)
- def __call__(self, *args: Any, **kwargs: Any) -> Any:
+ def call(self, *args: Any, **kwargs: Any) -> Any:
values = self.build_values(args, kwargs)
m = self.model(**values)
return self.execute(m)
|
{"golden_diff": "diff --git a/pydantic/decorator.py b/pydantic/decorator.py\n--- a/pydantic/decorator.py\n+++ b/pydantic/decorator.py\n@@ -1,4 +1,4 @@\n-from functools import update_wrapper\n+from functools import wraps\n from typing import TYPE_CHECKING, Any, Dict, List, Mapping, Tuple, TypeVar, cast, get_type_hints\n \n from . import validator\n@@ -19,8 +19,15 @@\n Decorator to validate the arguments passed to a function.\n \"\"\"\n vd = ValidatedFunction(function)\n- vd = update_wrapper(vd, function) # type: ignore\n- return cast('Callable', vd)\n+\n+ @wraps(function)\n+ def wrapper_function(*args: Any, **kwargs: Any) -> Any:\n+ return vd.call(*args, **kwargs)\n+\n+ wrapper_function.vd = vd # type: ignore\n+ wrapper_function.raw_function = vd.raw_function # type: ignore\n+ wrapper_function.model = vd.model # type: ignore\n+ return cast('Callable', wrapper_function)\n \n \n ALT_V_ARGS = 'v__args'\n@@ -95,7 +102,7 @@\n \n self.create_model(fields, takes_args, takes_kwargs)\n \n- def __call__(self, *args: Any, **kwargs: Any) -> Any:\n+ def call(self, *args: Any, **kwargs: Any) -> Any:\n values = self.build_values(args, kwargs)\n m = self.model(**values)\n return self.execute(m)\n", "issue": "@validate_arguments on instance methods\n# Bug\r\n\r\nHello, I tried using the new `@validate_arguments` decorator and it doesn't work when used on instance methods.\r\n\r\nI didn't see it on the ToDo in #1205 and it seems like an oversight, maybe due to the special treatment of `self`.\r\n\r\nOutput of `python -c \"import pydantic.utils; print(pydantic.utils.version_info())\"`:\r\n```\r\n$ python3 -c \"import pydantic.utils; print(pydantic.utils.version_info())\"\r\n pydantic version: 1.4a1\r\n pydantic compiled: False\r\n install path: /home/[user]/git/pydantic/pydantic\r\n python version: 3.7.5 (default, Nov 20 2019, 09:21:52) [GCC 9.2.1 20191008]\r\n platform: Linux-5.3.0-29-generic-x86_64-with-Ubuntu-19.10-eoan\r\n optional deps. installed: []\r\n```\r\n\r\n\r\n```py\r\nfrom pydantic import validate_arguments\r\n\r\n\r\nclass SomeObject:\r\n @validate_arguments\r\n def some_function(self, i: int):\r\n print(type(self), self)\r\n print(type(i), i)\r\n\r\no = SomeObject()\r\no.some_function(1) # doesn't work, instead of `i` `self` becomes 1\r\n#pydantic.error_wrappers.ValidationError: 1 validation error for SomeFunction\r\n#i\r\n# field required (type=value_error.missing)\r\n\r\no.some_function(o, 1) # works, but not the way instance methods are meant to be used\r\n#<class '__main__.SomeObject'> <__main__.SomeObject object at 0x7f32911af3d0>\r\n#<class 'int'> 1\r\n```\n", "before_files": [{"content": "from functools import update_wrapper\nfrom typing import TYPE_CHECKING, Any, Dict, List, Mapping, Tuple, TypeVar, cast, get_type_hints\n\nfrom . import validator\nfrom .errors import ConfigError\nfrom .main import BaseModel, Extra, create_model\nfrom .utils import to_camel\n\n__all__ = ('validate_arguments',)\n\nif TYPE_CHECKING:\n from .typing import AnyCallable\n\n Callable = TypeVar('Callable', bound=AnyCallable)\n\n\ndef validate_arguments(function: 'Callable') -> 'Callable':\n \"\"\"\n Decorator to validate the arguments passed to a function.\n \"\"\"\n vd = ValidatedFunction(function)\n vd = update_wrapper(vd, function) # type: ignore\n return cast('Callable', vd)\n\n\nALT_V_ARGS = 'v__args'\nALT_V_KWARGS = 'v__kwargs'\nV_POSITIONAL_ONLY_NAME = 'v__positional_only'\n\n\nclass ValidatedFunction:\n def __init__(self, function: 'Callable'):\n from inspect import signature, Parameter\n\n parameters: Mapping[str, Parameter] = signature(function).parameters\n\n if parameters.keys() & {ALT_V_ARGS, ALT_V_KWARGS, V_POSITIONAL_ONLY_NAME}:\n raise ConfigError(\n f'\"{ALT_V_ARGS}\", \"{ALT_V_KWARGS}\" and \"{V_POSITIONAL_ONLY_NAME}\" are not permitted as argument '\n f'names when using the \"{validate_arguments.__name__}\" decorator'\n )\n\n self.raw_function = function\n self.arg_mapping: Dict[int, str] = {}\n self.positional_only_args = set()\n self.v_args_name = 'args'\n self.v_kwargs_name = 'kwargs'\n\n type_hints = get_type_hints(function)\n takes_args = False\n takes_kwargs = False\n fields: Dict[str, Tuple[Any, Any]] = {}\n for i, (name, p) in enumerate(parameters.items()):\n if p.annotation == p.empty:\n annotation = Any\n else:\n annotation = type_hints[name]\n\n default = ... if p.default == p.empty else p.default\n if p.kind == Parameter.POSITIONAL_ONLY:\n self.arg_mapping[i] = name\n fields[name] = annotation, default\n fields[V_POSITIONAL_ONLY_NAME] = List[str], None\n self.positional_only_args.add(name)\n elif p.kind == Parameter.POSITIONAL_OR_KEYWORD:\n self.arg_mapping[i] = name\n fields[name] = annotation, default\n elif p.kind == Parameter.KEYWORD_ONLY:\n fields[name] = annotation, default\n elif p.kind == Parameter.VAR_POSITIONAL:\n self.v_args_name = name\n fields[name] = Tuple[annotation, ...], None\n takes_args = True\n else:\n assert p.kind == Parameter.VAR_KEYWORD, p.kind\n self.v_kwargs_name = name\n fields[name] = Dict[str, annotation], None # type: ignore\n takes_kwargs = True\n\n # these checks avoid a clash between \"args\" and a field with that name\n if not takes_args and self.v_args_name in fields:\n self.v_args_name = ALT_V_ARGS\n\n # same with \"kwargs\"\n if not takes_kwargs and self.v_kwargs_name in fields:\n self.v_kwargs_name = ALT_V_KWARGS\n\n if not takes_args:\n # we add the field so validation below can raise the correct exception\n fields[self.v_args_name] = List[Any], None\n\n if not takes_kwargs:\n # same with kwargs\n fields[self.v_kwargs_name] = Dict[Any, Any], None\n\n self.create_model(fields, takes_args, takes_kwargs)\n\n def __call__(self, *args: Any, **kwargs: Any) -> Any:\n values = self.build_values(args, kwargs)\n m = self.model(**values)\n return self.execute(m)\n\n def build_values(self, args: Tuple[Any, ...], kwargs: Dict[str, Any]) -> Dict[str, Any]:\n values: Dict[str, Any] = {}\n if args:\n arg_iter = enumerate(args)\n while True:\n try:\n i, a = next(arg_iter)\n except StopIteration:\n break\n arg_name = self.arg_mapping.get(i)\n if arg_name is not None:\n values[arg_name] = a\n else:\n values[self.v_args_name] = [a] + [a for _, a in arg_iter]\n break\n\n var_kwargs = {}\n wrong_positional_args = []\n for k, v in kwargs.items():\n if k in self.model.__fields__:\n if k in self.positional_only_args:\n wrong_positional_args.append(k)\n values[k] = v\n else:\n var_kwargs[k] = v\n\n if var_kwargs:\n values[self.v_kwargs_name] = var_kwargs\n if wrong_positional_args:\n values[V_POSITIONAL_ONLY_NAME] = wrong_positional_args\n return values\n\n def execute(self, m: BaseModel) -> Any:\n d = {k: v for k, v in m._iter() if k in m.__fields_set__}\n kwargs = d.pop(self.v_kwargs_name, None)\n if kwargs:\n d.update(kwargs)\n\n if self.v_args_name in d:\n args_: List[Any] = []\n in_kwargs = False\n kwargs = {}\n for name, value in d.items():\n if in_kwargs:\n kwargs[name] = value\n elif name == self.v_args_name:\n args_ += value\n in_kwargs = True\n else:\n args_.append(value)\n return self.raw_function(*args_, **kwargs)\n elif self.positional_only_args:\n args_ = []\n kwargs = {}\n for name, value in d.items():\n if name in self.positional_only_args:\n args_.append(value)\n else:\n kwargs[name] = value\n return self.raw_function(*args_, **kwargs)\n else:\n return self.raw_function(**d)\n\n def create_model(self, fields: Dict[str, Any], takes_args: bool, takes_kwargs: bool) -> None:\n pos_args = len(self.arg_mapping)\n\n class DecoratorBaseModel(BaseModel):\n @validator(self.v_args_name, check_fields=False, allow_reuse=True)\n def check_args(cls, v: List[Any]) -> List[Any]:\n if takes_args:\n return v\n\n raise TypeError(f'{pos_args} positional arguments expected but {pos_args + len(v)} given')\n\n @validator(self.v_kwargs_name, check_fields=False, allow_reuse=True)\n def check_kwargs(cls, v: Dict[str, Any]) -> Dict[str, Any]:\n if takes_kwargs:\n return v\n\n plural = '' if len(v) == 1 else 's'\n keys = ', '.join(map(repr, v.keys()))\n raise TypeError(f'unexpected keyword argument{plural}: {keys}')\n\n @validator(V_POSITIONAL_ONLY_NAME, check_fields=False, allow_reuse=True)\n def check_positional_only(cls, v: List[str]) -> None:\n plural = '' if len(v) == 1 else 's'\n keys = ', '.join(map(repr, v))\n raise TypeError(f'positional-only argument{plural} passed as keyword argument{plural}: {keys}')\n\n class Config:\n extra = Extra.forbid\n\n self.model = create_model(to_camel(self.raw_function.__name__), __base__=DecoratorBaseModel, **fields)\n", "path": "pydantic/decorator.py"}]}
| 3,049 | 348 |
gh_patches_debug_12269
|
rasdani/github-patches
|
git_diff
|
mathesar-foundation__mathesar-513
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Implement schema list page
**Problem**
<!-- Please provide a clear and concise description of the problem that this feature request is designed to solve.-->
Users should be able to create a new schema, edit schema names, and delete schemas.
**Proposed solution**
<!-- A clear and concise description of your proposed solution or feature. -->
We should provide a way to do these actions from the UI using the schema list page introduced in the [design spec](https://wiki.mathesar.org/en/design/specs/schemas).
**Additional context**
<!-- Add any other context or screenshots about the feature request here.-->
- #166
- #168
- #170
- #393
</issue>
<code>
[start of mathesar/urls.py]
1 from django.urls import include, path
2 from rest_framework_nested import routers
3
4 from mathesar.views import api, frontend
5
6
7 router = routers.DefaultRouter()
8 router.register(r'tables', api.TableViewSet, basename='table')
9 router.register(r'schemas', api.SchemaViewSet, basename='schema')
10 router.register(r'database_keys', api.DatabaseKeyViewSet, basename='database-key')
11 router.register(r'databases', api.DatabaseViewSet, basename='database')
12 router.register(r'data_files', api.DataFileViewSet, basename='data-file')
13
14 table_router = routers.NestedSimpleRouter(router, r'tables', lookup='table')
15 table_router.register(r'records', api.RecordViewSet, basename='table-record')
16 table_router.register(r'columns', api.ColumnViewSet, basename='table-column')
17
18 urlpatterns = [
19 path('', frontend.index, name="index"),
20 path('api/v0/', include(router.urls)),
21 path('api/v0/', include(table_router.urls)),
22 # TODO: Handle known urls like /favicon.ico etc.,
23 # Currenty, this catches all
24 path('<dbname>', frontend.index, name="index"),
25 ]
26
[end of mathesar/urls.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mathesar/urls.py b/mathesar/urls.py
--- a/mathesar/urls.py
+++ b/mathesar/urls.py
@@ -1,4 +1,4 @@
-from django.urls import include, path
+from django.urls import include, path, re_path
from rest_framework_nested import routers
from mathesar.views import api, frontend
@@ -20,6 +20,6 @@
path('api/v0/', include(router.urls)),
path('api/v0/', include(table_router.urls)),
# TODO: Handle known urls like /favicon.ico etc.,
- # Currenty, this catches all
- path('<dbname>', frontend.index, name="index"),
+ # Currently, this catches all
+ re_path(r'(?P<dbname>\w+)/.*$', frontend.index, name="index"),
]
|
{"golden_diff": "diff --git a/mathesar/urls.py b/mathesar/urls.py\n--- a/mathesar/urls.py\n+++ b/mathesar/urls.py\n@@ -1,4 +1,4 @@\n-from django.urls import include, path\n+from django.urls import include, path, re_path\n from rest_framework_nested import routers\n \n from mathesar.views import api, frontend\n@@ -20,6 +20,6 @@\n path('api/v0/', include(router.urls)),\n path('api/v0/', include(table_router.urls)),\n # TODO: Handle known urls like /favicon.ico etc.,\n- # Currenty, this catches all\n- path('<dbname>', frontend.index, name=\"index\"),\n+ # Currently, this catches all\n+ re_path(r'(?P<dbname>\\w+)/.*$', frontend.index, name=\"index\"),\n ]\n", "issue": "Implement schema list page\n**Problem**\r\n<!-- Please provide a clear and concise description of the problem that this feature request is designed to solve.-->\r\nUsers should be able to create a new schema, edit schema names, and delete schemas.\r\n\r\n**Proposed solution**\r\n<!-- A clear and concise description of your proposed solution or feature. -->\r\nWe should provide a way to do these actions from the UI using the schema list page introduced in the [design spec](https://wiki.mathesar.org/en/design/specs/schemas).\r\n\r\n**Additional context**\r\n<!-- Add any other context or screenshots about the feature request here.-->\r\n- #166\r\n- #168 \r\n- #170\r\n- #393\n", "before_files": [{"content": "from django.urls import include, path\nfrom rest_framework_nested import routers\n\nfrom mathesar.views import api, frontend\n\n\nrouter = routers.DefaultRouter()\nrouter.register(r'tables', api.TableViewSet, basename='table')\nrouter.register(r'schemas', api.SchemaViewSet, basename='schema')\nrouter.register(r'database_keys', api.DatabaseKeyViewSet, basename='database-key')\nrouter.register(r'databases', api.DatabaseViewSet, basename='database')\nrouter.register(r'data_files', api.DataFileViewSet, basename='data-file')\n\ntable_router = routers.NestedSimpleRouter(router, r'tables', lookup='table')\ntable_router.register(r'records', api.RecordViewSet, basename='table-record')\ntable_router.register(r'columns', api.ColumnViewSet, basename='table-column')\n\nurlpatterns = [\n path('', frontend.index, name=\"index\"),\n path('api/v0/', include(router.urls)),\n path('api/v0/', include(table_router.urls)),\n # TODO: Handle known urls like /favicon.ico etc.,\n # Currenty, this catches all\n path('<dbname>', frontend.index, name=\"index\"),\n]\n", "path": "mathesar/urls.py"}]}
| 958 | 181 |
gh_patches_debug_41643
|
rasdani/github-patches
|
git_diff
|
microsoft__Qcodes-1171
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Keithley 2400 does not get added to the station cleanly
The ":read:" command and possibly others does not work when output is off but fails with an error. This is called when getting volt and current are snapshotted
We should wrap these calls in checking that output is off
</issue>
<code>
[start of qcodes/instrument_drivers/tektronix/Keithley_2400.py]
1 from qcodes import VisaInstrument
2 from qcodes.utils.validators import Strings, Enum
3
4
5 class Keithley_2400(VisaInstrument):
6 """
7 QCoDeS driver for the Keithley 2400 voltage source.
8 """
9 def __init__(self, name, address, **kwargs):
10 super().__init__(name, address, terminator='\n', **kwargs)
11
12 self.add_parameter('rangev',
13 get_cmd='SENS:VOLT:RANG?',
14 get_parser=float,
15 set_cmd='SOUR:VOLT:RANG {:f}',
16 label='Voltage range')
17
18 self.add_parameter('rangei',
19 get_cmd='SENS:CURR:RANG?',
20 get_parser=float,
21 set_cmd='SOUR:CURR:RANG {:f}',
22 label='Current range')
23
24 self.add_parameter('compliancev',
25 get_cmd='SENS:VOLT:PROT?',
26 get_parser=float,
27 set_cmd='SENS:VOLT:PROT {:f}',
28 label='Voltage Compliance')
29
30 self.add_parameter('compliancei',
31 get_cmd='SENS:CURR:PROT?',
32 get_parser=float,
33 set_cmd='SENS:CURR:PROT {:f}',
34 label='Current Compliance')
35
36 self.add_parameter('volt',
37 get_cmd=':READ?',
38 get_parser=self._volt_parser,
39 set_cmd=':SOUR:VOLT:LEV {:.8f}',
40 label='Voltage',
41 unit='V')
42
43 self.add_parameter('curr',
44 get_cmd=':READ?',
45 get_parser=self._curr_parser,
46 set_cmd=':SOUR:CURR:LEV {:.8f}',
47 label='Current',
48 unit='A')
49
50 self.add_parameter('mode',
51 vals=Enum('VOLT', 'CURR'),
52 get_cmd=':SOUR:FUNC?',
53 set_cmd=self._set_mode_and_sense,
54 label='Mode')
55
56 self.add_parameter('sense',
57 vals=Strings(),
58 get_cmd=':SENS:FUNC?',
59 set_cmd=':SENS:FUNC "{:s}"',
60 label='Sense mode')
61
62 self.add_parameter('output',
63 get_parser=int,
64 set_cmd=':OUTP:STAT {:d}',
65 get_cmd=':OUTP:STAT?')
66
67 self.add_parameter('nplcv',
68 get_cmd='SENS:VOLT:NPLC?',
69 get_parser=float,
70 set_cmd='SENS:VOLT:NPLC {:f}',
71 label='Voltage integration time')
72
73 self.add_parameter('nplci',
74 get_cmd='SENS:CURR:NPLC?',
75 get_parser=float,
76 set_cmd='SENS:CURR:NPLC {:f}',
77 label='Current integration time')
78
79 self.add_parameter('resistance',
80 get_cmd=':READ?',
81 get_parser=self._resistance_parser,
82 label='Resistance',
83 unit='Ohm')
84
85 def _set_mode_and_sense(self, msg):
86 # This helps set the correct read out curr/volt
87 if msg == 'VOLT':
88 self.sense('CURR')
89 elif msg == 'CURR':
90 self.sense('VOLT')
91 else:
92 raise AttributeError('Mode does not exist')
93 self.write(':SOUR:FUNC {:s}'.format(msg))
94
95 def reset(self):
96 """
97 Reset the instrument. When the instrument is reset, it performs the
98 following actions.
99
100 Returns the SourceMeter to the GPIB default conditions.
101
102 Cancels all pending commands.
103
104 Cancels all previously send `*OPC` and `*OPC?`
105 """
106 self.write(':*RST')
107
108 def _volt_parser(self, msg):
109 fields = [float(x) for x in msg.split(',')]
110 return fields[0]
111
112 def _curr_parser(self, msg):
113 fields = [float(x) for x in msg.split(',')]
114 return fields[1]
115
116 def _resistance_parser(self, msg):
117 fields = [float(x) for x in msg.split(',')]
118 return fields[0]/fields[1]
119
[end of qcodes/instrument_drivers/tektronix/Keithley_2400.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/qcodes/instrument_drivers/tektronix/Keithley_2400.py b/qcodes/instrument_drivers/tektronix/Keithley_2400.py
--- a/qcodes/instrument_drivers/tektronix/Keithley_2400.py
+++ b/qcodes/instrument_drivers/tektronix/Keithley_2400.py
@@ -34,18 +34,31 @@
label='Current Compliance')
self.add_parameter('volt',
- get_cmd=':READ?',
+ get_cmd=self._get_read_output_protected,
get_parser=self._volt_parser,
set_cmd=':SOUR:VOLT:LEV {:.8f}',
label='Voltage',
- unit='V')
+ unit='V',
+ docstring="Sets voltage in 'VOLT' mode. "
+ "Get returns measured voltage if "
+ "sensing 'VOLT' otherwise it returns "
+ "setpoint value. "
+ "Note that it is an error to read voltage with "
+ "output off")
self.add_parameter('curr',
- get_cmd=':READ?',
+ get_cmd=self._get_read_output_protected,
get_parser=self._curr_parser,
set_cmd=':SOUR:CURR:LEV {:.8f}',
label='Current',
- unit='A')
+ unit='A',
+ docstring = "Sets current in 'CURR' mode. "
+ "Get returns measured current if "
+ "sensing 'CURR' otherwise it returns "
+ "setpoint value. "
+ "Note that it is an error to read current with "
+ "output off")
+
self.add_parameter('mode',
vals=Enum('VOLT', 'CURR'),
@@ -77,10 +90,32 @@
label='Current integration time')
self.add_parameter('resistance',
- get_cmd=':READ?',
+ get_cmd=self._get_read_output_protected,
get_parser=self._resistance_parser,
label='Resistance',
- unit='Ohm')
+ unit='Ohm',
+ docstring="Measure resistance from current and voltage "
+ "Note that it is an error to read current "
+ "and voltage with output off")
+
+ def _get_read_output_protected(self) -> str:
+ """
+ This wrapper function around ":READ?" exists because calling
+ ":READ?" on an instrument with output disabled is an error.
+ So first we check that output is on and if not we return
+ nan for volt, curr etc.
+ """
+ output = self.output.get_latest()
+ if output is None:
+ # if get_latest returns None we have
+ # to ask the instrument for the status of output
+ output = self.output.get()
+
+ if output == 1:
+ msg = self.ask(':READ?')
+ else:
+ raise RuntimeError("Cannot perform read with output off")
+ return msg
def _set_mode_and_sense(self, msg):
# This helps set the correct read out curr/volt
@@ -115,4 +150,5 @@
def _resistance_parser(self, msg):
fields = [float(x) for x in msg.split(',')]
- return fields[0]/fields[1]
+ res = fields[0] / fields[1]
+ return res
|
{"golden_diff": "diff --git a/qcodes/instrument_drivers/tektronix/Keithley_2400.py b/qcodes/instrument_drivers/tektronix/Keithley_2400.py\n--- a/qcodes/instrument_drivers/tektronix/Keithley_2400.py\n+++ b/qcodes/instrument_drivers/tektronix/Keithley_2400.py\n@@ -34,18 +34,31 @@\n label='Current Compliance')\n \n self.add_parameter('volt',\n- get_cmd=':READ?',\n+ get_cmd=self._get_read_output_protected,\n get_parser=self._volt_parser,\n set_cmd=':SOUR:VOLT:LEV {:.8f}',\n label='Voltage',\n- unit='V')\n+ unit='V',\n+ docstring=\"Sets voltage in 'VOLT' mode. \"\n+ \"Get returns measured voltage if \"\n+ \"sensing 'VOLT' otherwise it returns \"\n+ \"setpoint value. \"\n+ \"Note that it is an error to read voltage with \"\n+ \"output off\")\n \n self.add_parameter('curr',\n- get_cmd=':READ?',\n+ get_cmd=self._get_read_output_protected,\n get_parser=self._curr_parser,\n set_cmd=':SOUR:CURR:LEV {:.8f}',\n label='Current',\n- unit='A')\n+ unit='A',\n+ docstring = \"Sets current in 'CURR' mode. \"\n+ \"Get returns measured current if \"\n+ \"sensing 'CURR' otherwise it returns \"\n+ \"setpoint value. \"\n+ \"Note that it is an error to read current with \"\n+ \"output off\")\n+\n \n self.add_parameter('mode',\n vals=Enum('VOLT', 'CURR'),\n@@ -77,10 +90,32 @@\n label='Current integration time')\n \n self.add_parameter('resistance',\n- get_cmd=':READ?',\n+ get_cmd=self._get_read_output_protected,\n get_parser=self._resistance_parser,\n label='Resistance',\n- unit='Ohm')\n+ unit='Ohm',\n+ docstring=\"Measure resistance from current and voltage \"\n+ \"Note that it is an error to read current \"\n+ \"and voltage with output off\")\n+\n+ def _get_read_output_protected(self) -> str:\n+ \"\"\"\n+ This wrapper function around \":READ?\" exists because calling\n+ \":READ?\" on an instrument with output disabled is an error.\n+ So first we check that output is on and if not we return\n+ nan for volt, curr etc.\n+ \"\"\"\n+ output = self.output.get_latest()\n+ if output is None:\n+ # if get_latest returns None we have\n+ # to ask the instrument for the status of output\n+ output = self.output.get()\n+\n+ if output == 1:\n+ msg = self.ask(':READ?')\n+ else:\n+ raise RuntimeError(\"Cannot perform read with output off\")\n+ return msg\n \n def _set_mode_and_sense(self, msg):\n # This helps set the correct read out curr/volt\n@@ -115,4 +150,5 @@\n \n def _resistance_parser(self, msg):\n fields = [float(x) for x in msg.split(',')]\n- return fields[0]/fields[1]\n+ res = fields[0] / fields[1]\n+ return res\n", "issue": "Keithley 2400 does not get added to the station cleanly\nThe \":read:\" command and possibly others does not work when output is off but fails with an error. This is called when getting volt and current are snapshotted \r\n\r\nWe should wrap these calls in checking that output is off\n", "before_files": [{"content": "from qcodes import VisaInstrument\nfrom qcodes.utils.validators import Strings, Enum\n\n\nclass Keithley_2400(VisaInstrument):\n \"\"\"\n QCoDeS driver for the Keithley 2400 voltage source.\n \"\"\"\n def __init__(self, name, address, **kwargs):\n super().__init__(name, address, terminator='\\n', **kwargs)\n\n self.add_parameter('rangev',\n get_cmd='SENS:VOLT:RANG?',\n get_parser=float,\n set_cmd='SOUR:VOLT:RANG {:f}',\n label='Voltage range')\n\n self.add_parameter('rangei',\n get_cmd='SENS:CURR:RANG?',\n get_parser=float,\n set_cmd='SOUR:CURR:RANG {:f}',\n label='Current range')\n\n self.add_parameter('compliancev',\n get_cmd='SENS:VOLT:PROT?',\n get_parser=float,\n set_cmd='SENS:VOLT:PROT {:f}',\n label='Voltage Compliance')\n\n self.add_parameter('compliancei',\n get_cmd='SENS:CURR:PROT?',\n get_parser=float,\n set_cmd='SENS:CURR:PROT {:f}',\n label='Current Compliance')\n\n self.add_parameter('volt',\n get_cmd=':READ?',\n get_parser=self._volt_parser,\n set_cmd=':SOUR:VOLT:LEV {:.8f}',\n label='Voltage',\n unit='V')\n\n self.add_parameter('curr',\n get_cmd=':READ?',\n get_parser=self._curr_parser,\n set_cmd=':SOUR:CURR:LEV {:.8f}',\n label='Current',\n unit='A')\n\n self.add_parameter('mode',\n vals=Enum('VOLT', 'CURR'),\n get_cmd=':SOUR:FUNC?',\n set_cmd=self._set_mode_and_sense,\n label='Mode')\n\n self.add_parameter('sense',\n vals=Strings(),\n get_cmd=':SENS:FUNC?',\n set_cmd=':SENS:FUNC \"{:s}\"',\n label='Sense mode')\n\n self.add_parameter('output',\n get_parser=int,\n set_cmd=':OUTP:STAT {:d}',\n get_cmd=':OUTP:STAT?')\n\n self.add_parameter('nplcv',\n get_cmd='SENS:VOLT:NPLC?',\n get_parser=float,\n set_cmd='SENS:VOLT:NPLC {:f}',\n label='Voltage integration time')\n\n self.add_parameter('nplci',\n get_cmd='SENS:CURR:NPLC?',\n get_parser=float,\n set_cmd='SENS:CURR:NPLC {:f}',\n label='Current integration time')\n\n self.add_parameter('resistance',\n get_cmd=':READ?',\n get_parser=self._resistance_parser,\n label='Resistance',\n unit='Ohm')\n\n def _set_mode_and_sense(self, msg):\n # This helps set the correct read out curr/volt\n if msg == 'VOLT':\n self.sense('CURR')\n elif msg == 'CURR':\n self.sense('VOLT')\n else:\n raise AttributeError('Mode does not exist')\n self.write(':SOUR:FUNC {:s}'.format(msg))\n\n def reset(self):\n \"\"\"\n Reset the instrument. When the instrument is reset, it performs the\n following actions.\n\n Returns the SourceMeter to the GPIB default conditions.\n\n Cancels all pending commands.\n\n Cancels all previously send `*OPC` and `*OPC?`\n \"\"\"\n self.write(':*RST')\n\n def _volt_parser(self, msg):\n fields = [float(x) for x in msg.split(',')]\n return fields[0]\n\n def _curr_parser(self, msg):\n fields = [float(x) for x in msg.split(',')]\n return fields[1]\n\n def _resistance_parser(self, msg):\n fields = [float(x) for x in msg.split(',')]\n return fields[0]/fields[1]\n", "path": "qcodes/instrument_drivers/tektronix/Keithley_2400.py"}]}
| 1,755 | 765 |
gh_patches_debug_17250
|
rasdani/github-patches
|
git_diff
|
ibis-project__ibis-7472
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
bug(oracle): Failing metadata query
### What happened?
Metadata query for Oracle is failing due to filtering the nullable column between SELECT and FROM statements, which is only possible after WHERE.
### What version of ibis are you using?
7.0.0
### What backend(s) are you using, if any?
Oracle
### Relevant log output
```sh
sqlalchemy.exc.DatabaseError: (oracledb.exceptions.DatabaseError) ORA-00923: FROM keyword not found where expected
[SQL: SELECT all_tab_columns.column_name, all_tab_columns.data_type, all_tab_columns.data_precision, all_tab_columns.data_scale, all_tab_columns.nullable = :nullable_1 AS nullable
FROM all_tab_columns
WHERE all_tab_columns.table_name = :table_name_1]
[parameters: {'nullable_1': 'Y', 'table_name_1': '_ibis_oracle_metadata_7djjvezdl5bnrmqkf6grsevvjq'}]
```
```
### Code of Conduct
- [X] I agree to follow this project's Code of Conduct
</issue>
<code>
[start of ibis/backends/oracle/__init__.py]
1 """The Oracle backend."""
2
3 from __future__ import annotations
4
5 import atexit
6 import contextlib
7 import sys
8 import warnings
9 from typing import TYPE_CHECKING, Any
10
11 import oracledb
12 import sqlglot as sg
13
14 from ibis import util
15
16 # Wow, this is truly horrible
17 # Get out your clippers, it's time to shave a yak.
18 #
19 # 1. snowflake-sqlalchemy doesn't support sqlalchemy 2.0
20 # 2. oracledb is only supported in sqlalchemy 2.0
21 # 3. Ergo, module hacking is required to avoid doing a silly amount of work
22 # to create multiple lockfiles or port snowflake away from sqlalchemy
23 # 4. Also the version needs to be spoofed to be >= 7 or else the cx_Oracle
24 # dialect barfs
25 oracledb.__version__ = oracledb.version = "7"
26
27 sys.modules["cx_Oracle"] = oracledb
28
29 import sqlalchemy as sa # noqa: E402
30
31 import ibis.common.exceptions as exc # noqa: E402
32 import ibis.expr.datatypes as dt # noqa: E402
33 import ibis.expr.operations as ops # noqa: E402
34 import ibis.expr.schema as sch # noqa: E402
35 from ibis.backends.base.sql.alchemy import ( # noqa: E402
36 AlchemyCompiler,
37 AlchemyExprTranslator,
38 BaseAlchemyBackend,
39 )
40 from ibis.backends.oracle.datatypes import OracleType # noqa: E402
41 from ibis.backends.oracle.registry import operation_registry # noqa: E402
42 from ibis.expr.rewrites import rewrite_sample # noqa: E402
43
44 if TYPE_CHECKING:
45 from collections.abc import Iterable
46
47
48 class OracleExprTranslator(AlchemyExprTranslator):
49 _registry = operation_registry.copy()
50 _rewrites = AlchemyExprTranslator._rewrites.copy()
51 _dialect_name = "oracle"
52 _has_reduction_filter_syntax = False
53 _require_order_by = (
54 *AlchemyExprTranslator._require_order_by,
55 ops.Reduction,
56 ops.Lag,
57 ops.Lead,
58 )
59
60 _forbids_frame_clause = (
61 *AlchemyExprTranslator._forbids_frame_clause,
62 ops.Lag,
63 ops.Lead,
64 )
65
66 _quote_column_names = True
67 _quote_table_names = True
68
69 type_mapper = OracleType
70
71
72 class OracleCompiler(AlchemyCompiler):
73 translator_class = OracleExprTranslator
74 support_values_syntax_in_select = False
75 supports_indexed_grouping_keys = False
76 null_limit = None
77 rewrites = AlchemyCompiler.rewrites | rewrite_sample
78
79
80 class Backend(BaseAlchemyBackend):
81 name = "oracle"
82 compiler = OracleCompiler
83 supports_create_or_replace = False
84 supports_temporary_tables = True
85 _temporary_prefix = "GLOBAL TEMPORARY"
86
87 def do_connect(
88 self,
89 *,
90 user: str,
91 password: str,
92 host: str = "localhost",
93 port: int = 1521,
94 database: str | None = None,
95 sid: str | None = None,
96 service_name: str | None = None,
97 dsn: str | None = None,
98 **_: Any,
99 ) -> None:
100 """Create an Ibis client using the passed connection parameters.
101
102 Parameters
103 ----------
104 user
105 Username
106 password
107 Password
108 host
109 Hostname
110 port
111 Port
112 database
113 Used as an Oracle service name if provided.
114 sid
115 Unique name of an Oracle Instance, used to construct a DSN if
116 provided.
117 service_name
118 Oracle service name, used to construct a DSN if provided. Only one
119 of database and service_name should be provided.
120 dsn
121 An Oracle Data Source Name. If provided, overrides all other
122 connection arguments except username and password.
123 """
124 # SID: unique name of an INSTANCE running an oracle process (a single, identifiable machine)
125 # service name: an ALIAS to one (or many) individual instances that can
126 # be hotswapped without the client knowing / caring
127 if dsn is not None and (
128 database is not None or sid is not None or service_name is not None
129 ):
130 warnings.warn(
131 "Oracle DSN provided, overriding additional provided connection arguments"
132 )
133
134 if service_name is not None and database is not None:
135 raise exc.IbisInputError(
136 "Values provided for both service_name and database. "
137 "Both of these values map to an Oracle service_name, "
138 "please provide only one of them."
139 )
140
141 if service_name is None and database is not None:
142 service_name = database
143
144 if dsn is None:
145 dsn = oracledb.makedsn(host, port, service_name=service_name, sid=sid)
146 url = sa.engine.url.make_url(f"oracle://{user}:{password}@{dsn}")
147
148 engine = sa.create_engine(
149 url,
150 poolclass=sa.pool.StaticPool,
151 # We set the statement cache size to 0 because Oracle will otherwise
152 # attempt to reuse prepared statements even if the type of the bound variable
153 # has changed.
154 # This is apparently accepted behavior.
155 # https://python-oracledb.readthedocs.io/en/latest/user_guide/appendix_b.html#statement-caching-in-thin-and-thick-modes
156 connect_args={"stmtcachesize": 0},
157 )
158
159 super().do_connect(engine)
160
161 def normalize_name(name):
162 if name is None:
163 return None
164 elif not name:
165 return ""
166 elif name.lower() == name:
167 return sa.sql.quoted_name(name, quote=True)
168 else:
169 return name
170
171 self.con.dialect.normalize_name = normalize_name
172
173 def _from_url(self, url: str, **kwargs):
174 return self.do_connect(user=url.username, password=url.password, dsn=url.host)
175
176 @property
177 def current_database(self) -> str:
178 return self._scalar_query("SELECT * FROM global_name")
179
180 def list_tables(self, like=None, database=None, schema=None):
181 """List the tables in the database.
182
183 Parameters
184 ----------
185 like
186 A pattern to use for listing tables.
187 database
188 (deprecated) The database to perform the list against.
189 schema
190 The schema to perform the list against.
191
192 ::: {.callout-warning}
193 ## `schema` refers to database hierarchy
194
195 The `schema` parameter does **not** refer to the column names and
196 types of `table`.
197 :::
198 """
199 if database is not None:
200 util.warn_deprecated(
201 "database",
202 instead="Use the `schema` keyword argument instead",
203 as_of="7.1",
204 removed_in="8.0",
205 )
206 schema = schema or database
207 tables = self.inspector.get_table_names(schema=schema)
208 views = self.inspector.get_view_names(schema=schema)
209 return self._filter_with_like(tables + views, like)
210
211 def _metadata(self, query: str) -> Iterable[tuple[str, dt.DataType]]:
212 from sqlalchemy_views import CreateView, DropView
213
214 name = util.gen_name("oracle_metadata")
215
216 try:
217 sg_expr = sg.parse_one(query, into=sg.exp.Table, dialect="oracle")
218 except sg.ParseError:
219 sg_expr = sg.parse_one(query, dialect="oracle")
220
221 # If query is a table, adjust the query accordingly
222 if isinstance(sg_expr, sg.exp.Table):
223 sg_expr = sg.select("*").from_(sg_expr)
224
225 query = sg_expr.sql(dialect="oracle")
226
227 view = sa.table(name)
228 create_view = CreateView(view, sa.text(query))
229 drop_view = DropView(view, if_exists=False)
230
231 t = sa.table(
232 "all_tab_columns",
233 sa.column("table_name"),
234 sa.column("column_name"),
235 sa.column("data_type"),
236 sa.column("data_precision"),
237 sa.column("data_scale"),
238 sa.column("nullable"),
239 )
240 metadata_query = sa.select(
241 t.c.column_name,
242 t.c.data_type,
243 t.c.data_precision,
244 t.c.data_scale,
245 (t.c.nullable == "Y").label("nullable"),
246 ).where(t.c.table_name == name)
247
248 with self.begin() as con:
249 con.execute(create_view)
250 try:
251 results = con.execute(metadata_query).fetchall()
252 finally:
253 # drop the view no matter what
254 con.execute(drop_view)
255
256 for name, type_string, precision, scale, nullable in results:
257 if precision is not None and scale is not None and precision != 0:
258 typ = dt.Decimal(precision=precision, scale=scale, nullable=nullable)
259 elif precision == 0:
260 # TODO: how to disambiguate between int and float here without inspecting the value?
261 typ = dt.float
262 else:
263 typ = OracleType.from_string(type_string, nullable=nullable)
264 yield name, typ
265
266 def _table_from_schema(
267 self,
268 name: str,
269 schema: sch.Schema,
270 temp: bool = False,
271 database: str | None = None,
272 **kwargs: Any,
273 ) -> sa.Table:
274 if temp:
275 kwargs["oracle_on_commit"] = "PRESERVE ROWS"
276 t = super()._table_from_schema(name, schema, temp, database, **kwargs)
277 if temp:
278 atexit.register(self._clean_up_tmp_table, t)
279 return t
280
281 def _clean_up_tmp_table(self, name: str) -> None:
282 tmptable = self._get_sqla_table(name, autoload=False)
283 with self.begin() as bind:
284 # global temporary tables cannot be dropped without first truncating them
285 #
286 # https://stackoverflow.com/questions/32423397/force-oracle-drop-global-temp-table
287 #
288 # ignore DatabaseError exceptions because the table may not exist
289 # because it's already been deleted
290 with contextlib.suppress(sa.exc.DatabaseError):
291 bind.exec_driver_sql(f'TRUNCATE TABLE "{tmptable.name}"')
292 with contextlib.suppress(sa.exc.DatabaseError):
293 tmptable.drop(bind=bind)
294
295 def _clean_up_cached_table(self, op):
296 self._clean_up_tmp_table(op.name)
297
[end of ibis/backends/oracle/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ibis/backends/oracle/__init__.py b/ibis/backends/oracle/__init__.py
--- a/ibis/backends/oracle/__init__.py
+++ b/ibis/backends/oracle/__init__.py
@@ -209,6 +209,7 @@
return self._filter_with_like(tables + views, like)
def _metadata(self, query: str) -> Iterable[tuple[str, dt.DataType]]:
+ from sqlalchemy import case
from sqlalchemy_views import CreateView, DropView
name = util.gen_name("oracle_metadata")
@@ -242,7 +243,7 @@
t.c.data_type,
t.c.data_precision,
t.c.data_scale,
- (t.c.nullable == "Y").label("nullable"),
+ case((t.c.nullable == "Y", True), else_=False).label("nullable"),
).where(t.c.table_name == name)
with self.begin() as con:
|
{"golden_diff": "diff --git a/ibis/backends/oracle/__init__.py b/ibis/backends/oracle/__init__.py\n--- a/ibis/backends/oracle/__init__.py\n+++ b/ibis/backends/oracle/__init__.py\n@@ -209,6 +209,7 @@\n return self._filter_with_like(tables + views, like)\n \n def _metadata(self, query: str) -> Iterable[tuple[str, dt.DataType]]:\n+ from sqlalchemy import case\n from sqlalchemy_views import CreateView, DropView\n \n name = util.gen_name(\"oracle_metadata\")\n@@ -242,7 +243,7 @@\n t.c.data_type,\n t.c.data_precision,\n t.c.data_scale,\n- (t.c.nullable == \"Y\").label(\"nullable\"),\n+ case((t.c.nullable == \"Y\", True), else_=False).label(\"nullable\"),\n ).where(t.c.table_name == name)\n \n with self.begin() as con:\n", "issue": "bug(oracle): Failing metadata query\n### What happened?\n\nMetadata query for Oracle is failing due to filtering the nullable column between SELECT and FROM statements, which is only possible after WHERE.\n\n### What version of ibis are you using?\n\n7.0.0\n\n### What backend(s) are you using, if any?\n\nOracle\n\n### Relevant log output\n\n```sh\nsqlalchemy.exc.DatabaseError: (oracledb.exceptions.DatabaseError) ORA-00923: FROM keyword not found where expected\r\n[SQL: SELECT all_tab_columns.column_name, all_tab_columns.data_type, all_tab_columns.data_precision, all_tab_columns.data_scale, all_tab_columns.nullable = :nullable_1 AS nullable\r\nFROM all_tab_columns\r\nWHERE all_tab_columns.table_name = :table_name_1]\r\n[parameters: {'nullable_1': 'Y', 'table_name_1': '_ibis_oracle_metadata_7djjvezdl5bnrmqkf6grsevvjq'}]\r\n```\n```\n\n\n### Code of Conduct\n\n- [X] I agree to follow this project's Code of Conduct\n", "before_files": [{"content": "\"\"\"The Oracle backend.\"\"\"\n\nfrom __future__ import annotations\n\nimport atexit\nimport contextlib\nimport sys\nimport warnings\nfrom typing import TYPE_CHECKING, Any\n\nimport oracledb\nimport sqlglot as sg\n\nfrom ibis import util\n\n# Wow, this is truly horrible\n# Get out your clippers, it's time to shave a yak.\n#\n# 1. snowflake-sqlalchemy doesn't support sqlalchemy 2.0\n# 2. oracledb is only supported in sqlalchemy 2.0\n# 3. Ergo, module hacking is required to avoid doing a silly amount of work\n# to create multiple lockfiles or port snowflake away from sqlalchemy\n# 4. Also the version needs to be spoofed to be >= 7 or else the cx_Oracle\n# dialect barfs\noracledb.__version__ = oracledb.version = \"7\"\n\nsys.modules[\"cx_Oracle\"] = oracledb\n\nimport sqlalchemy as sa # noqa: E402\n\nimport ibis.common.exceptions as exc # noqa: E402\nimport ibis.expr.datatypes as dt # noqa: E402\nimport ibis.expr.operations as ops # noqa: E402\nimport ibis.expr.schema as sch # noqa: E402\nfrom ibis.backends.base.sql.alchemy import ( # noqa: E402\n AlchemyCompiler,\n AlchemyExprTranslator,\n BaseAlchemyBackend,\n)\nfrom ibis.backends.oracle.datatypes import OracleType # noqa: E402\nfrom ibis.backends.oracle.registry import operation_registry # noqa: E402\nfrom ibis.expr.rewrites import rewrite_sample # noqa: E402\n\nif TYPE_CHECKING:\n from collections.abc import Iterable\n\n\nclass OracleExprTranslator(AlchemyExprTranslator):\n _registry = operation_registry.copy()\n _rewrites = AlchemyExprTranslator._rewrites.copy()\n _dialect_name = \"oracle\"\n _has_reduction_filter_syntax = False\n _require_order_by = (\n *AlchemyExprTranslator._require_order_by,\n ops.Reduction,\n ops.Lag,\n ops.Lead,\n )\n\n _forbids_frame_clause = (\n *AlchemyExprTranslator._forbids_frame_clause,\n ops.Lag,\n ops.Lead,\n )\n\n _quote_column_names = True\n _quote_table_names = True\n\n type_mapper = OracleType\n\n\nclass OracleCompiler(AlchemyCompiler):\n translator_class = OracleExprTranslator\n support_values_syntax_in_select = False\n supports_indexed_grouping_keys = False\n null_limit = None\n rewrites = AlchemyCompiler.rewrites | rewrite_sample\n\n\nclass Backend(BaseAlchemyBackend):\n name = \"oracle\"\n compiler = OracleCompiler\n supports_create_or_replace = False\n supports_temporary_tables = True\n _temporary_prefix = \"GLOBAL TEMPORARY\"\n\n def do_connect(\n self,\n *,\n user: str,\n password: str,\n host: str = \"localhost\",\n port: int = 1521,\n database: str | None = None,\n sid: str | None = None,\n service_name: str | None = None,\n dsn: str | None = None,\n **_: Any,\n ) -> None:\n \"\"\"Create an Ibis client using the passed connection parameters.\n\n Parameters\n ----------\n user\n Username\n password\n Password\n host\n Hostname\n port\n Port\n database\n Used as an Oracle service name if provided.\n sid\n Unique name of an Oracle Instance, used to construct a DSN if\n provided.\n service_name\n Oracle service name, used to construct a DSN if provided. Only one\n of database and service_name should be provided.\n dsn\n An Oracle Data Source Name. If provided, overrides all other\n connection arguments except username and password.\n \"\"\"\n # SID: unique name of an INSTANCE running an oracle process (a single, identifiable machine)\n # service name: an ALIAS to one (or many) individual instances that can\n # be hotswapped without the client knowing / caring\n if dsn is not None and (\n database is not None or sid is not None or service_name is not None\n ):\n warnings.warn(\n \"Oracle DSN provided, overriding additional provided connection arguments\"\n )\n\n if service_name is not None and database is not None:\n raise exc.IbisInputError(\n \"Values provided for both service_name and database. \"\n \"Both of these values map to an Oracle service_name, \"\n \"please provide only one of them.\"\n )\n\n if service_name is None and database is not None:\n service_name = database\n\n if dsn is None:\n dsn = oracledb.makedsn(host, port, service_name=service_name, sid=sid)\n url = sa.engine.url.make_url(f\"oracle://{user}:{password}@{dsn}\")\n\n engine = sa.create_engine(\n url,\n poolclass=sa.pool.StaticPool,\n # We set the statement cache size to 0 because Oracle will otherwise\n # attempt to reuse prepared statements even if the type of the bound variable\n # has changed.\n # This is apparently accepted behavior.\n # https://python-oracledb.readthedocs.io/en/latest/user_guide/appendix_b.html#statement-caching-in-thin-and-thick-modes\n connect_args={\"stmtcachesize\": 0},\n )\n\n super().do_connect(engine)\n\n def normalize_name(name):\n if name is None:\n return None\n elif not name:\n return \"\"\n elif name.lower() == name:\n return sa.sql.quoted_name(name, quote=True)\n else:\n return name\n\n self.con.dialect.normalize_name = normalize_name\n\n def _from_url(self, url: str, **kwargs):\n return self.do_connect(user=url.username, password=url.password, dsn=url.host)\n\n @property\n def current_database(self) -> str:\n return self._scalar_query(\"SELECT * FROM global_name\")\n\n def list_tables(self, like=None, database=None, schema=None):\n \"\"\"List the tables in the database.\n\n Parameters\n ----------\n like\n A pattern to use for listing tables.\n database\n (deprecated) The database to perform the list against.\n schema\n The schema to perform the list against.\n\n ::: {.callout-warning}\n ## `schema` refers to database hierarchy\n\n The `schema` parameter does **not** refer to the column names and\n types of `table`.\n :::\n \"\"\"\n if database is not None:\n util.warn_deprecated(\n \"database\",\n instead=\"Use the `schema` keyword argument instead\",\n as_of=\"7.1\",\n removed_in=\"8.0\",\n )\n schema = schema or database\n tables = self.inspector.get_table_names(schema=schema)\n views = self.inspector.get_view_names(schema=schema)\n return self._filter_with_like(tables + views, like)\n\n def _metadata(self, query: str) -> Iterable[tuple[str, dt.DataType]]:\n from sqlalchemy_views import CreateView, DropView\n\n name = util.gen_name(\"oracle_metadata\")\n\n try:\n sg_expr = sg.parse_one(query, into=sg.exp.Table, dialect=\"oracle\")\n except sg.ParseError:\n sg_expr = sg.parse_one(query, dialect=\"oracle\")\n\n # If query is a table, adjust the query accordingly\n if isinstance(sg_expr, sg.exp.Table):\n sg_expr = sg.select(\"*\").from_(sg_expr)\n\n query = sg_expr.sql(dialect=\"oracle\")\n\n view = sa.table(name)\n create_view = CreateView(view, sa.text(query))\n drop_view = DropView(view, if_exists=False)\n\n t = sa.table(\n \"all_tab_columns\",\n sa.column(\"table_name\"),\n sa.column(\"column_name\"),\n sa.column(\"data_type\"),\n sa.column(\"data_precision\"),\n sa.column(\"data_scale\"),\n sa.column(\"nullable\"),\n )\n metadata_query = sa.select(\n t.c.column_name,\n t.c.data_type,\n t.c.data_precision,\n t.c.data_scale,\n (t.c.nullable == \"Y\").label(\"nullable\"),\n ).where(t.c.table_name == name)\n\n with self.begin() as con:\n con.execute(create_view)\n try:\n results = con.execute(metadata_query).fetchall()\n finally:\n # drop the view no matter what\n con.execute(drop_view)\n\n for name, type_string, precision, scale, nullable in results:\n if precision is not None and scale is not None and precision != 0:\n typ = dt.Decimal(precision=precision, scale=scale, nullable=nullable)\n elif precision == 0:\n # TODO: how to disambiguate between int and float here without inspecting the value?\n typ = dt.float\n else:\n typ = OracleType.from_string(type_string, nullable=nullable)\n yield name, typ\n\n def _table_from_schema(\n self,\n name: str,\n schema: sch.Schema,\n temp: bool = False,\n database: str | None = None,\n **kwargs: Any,\n ) -> sa.Table:\n if temp:\n kwargs[\"oracle_on_commit\"] = \"PRESERVE ROWS\"\n t = super()._table_from_schema(name, schema, temp, database, **kwargs)\n if temp:\n atexit.register(self._clean_up_tmp_table, t)\n return t\n\n def _clean_up_tmp_table(self, name: str) -> None:\n tmptable = self._get_sqla_table(name, autoload=False)\n with self.begin() as bind:\n # global temporary tables cannot be dropped without first truncating them\n #\n # https://stackoverflow.com/questions/32423397/force-oracle-drop-global-temp-table\n #\n # ignore DatabaseError exceptions because the table may not exist\n # because it's already been deleted\n with contextlib.suppress(sa.exc.DatabaseError):\n bind.exec_driver_sql(f'TRUNCATE TABLE \"{tmptable.name}\"')\n with contextlib.suppress(sa.exc.DatabaseError):\n tmptable.drop(bind=bind)\n\n def _clean_up_cached_table(self, op):\n self._clean_up_tmp_table(op.name)\n", "path": "ibis/backends/oracle/__init__.py"}]}
| 3,838 | 220 |
gh_patches_debug_17736
|
rasdani/github-patches
|
git_diff
|
beeware__toga-31
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
"ImportError: cannot import name WebKit" on Ubuntu 14.04
Installed toga via global `sudo pip install toga`. Then, tried to import it:
```
>>> import toga
ERROR:root:Could not find any typelib for WebKit
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python2.7/dist-packages/toga/__init__.py", line 86, in <module>
from .platform.gtk.app import *
File "/usr/local/lib/python2.7/dist-packages/toga/platform/gtk/app.py", line 7, in <module>
from .window import Window
File "/usr/local/lib/python2.7/dist-packages/toga/platform/gtk/window.py", line 6, in <module>
from .command import SEPARATOR, SPACER, EXPANDING_SPACER
File "/usr/local/lib/python2.7/dist-packages/toga/platform/gtk/command.py", line 1, in <module>
from .widgets import Icon
File "/usr/local/lib/python2.7/dist-packages/toga/platform/gtk/widgets/__init__.py", line 17, in <module>
from .webview import WebView
File "/usr/local/lib/python2.7/dist-packages/toga/platform/gtk/widgets/webview.py", line 3, in <module>
from gi.repository import Gtk, WebKit
ImportError: cannot import name WebKit
```
Did a `sudo apt-get install python-webkit`, but still getting the same import error. I'm running Ubuntu under Crouton on a Chromebook, which doesn't always contain the full set of packages.
Since the application I aim to create (a GUI launcher for [KA Lite](https://github.com/learningequality/ka-lite/)) would rely on toga's awesome dedication to being pure Python and not needing any extra packages to be installed to work cross-platform, and since we wouldn't be needing the WebView, would it be possible to have it handle a lack of WebKit more gracefully, only erroring out if a WebView was actually used? Thanks!
</issue>
<code>
[start of toga/platform/gtk/widgets/webview.py]
1 from __future__ import print_function, absolute_import, division
2
3 from gi.repository import Gtk, WebKit
4
5 from .base import Widget
6
7
8 class WebView(Widget):
9 def __init__(self, url=None):
10 super(WebView, self).__init__()
11 self._url = url
12
13 self._webview = None
14
15 def _startup(self):
16 self._impl = Gtk.ScrolledWindow()
17 self._impl.set_policy(Gtk.PolicyType.AUTOMATIC, Gtk.PolicyType.AUTOMATIC)
18
19 self._webview = WebKit.WebView()
20
21 if self._url:
22 self._webview.load_uri(self._url)
23
24 self._impl.add(self._webview)
25 self._impl.set_min_content_width(200)
26 self._impl.set_min_content_height(200)
27
28 @property
29 def url(self):
30 return self._url
31
32 @url.setter
33 def url(self, value):
34 self._url = value
35 if self._impl:
36 self._webview.load_uri(self._url)
37
[end of toga/platform/gtk/widgets/webview.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/toga/platform/gtk/widgets/webview.py b/toga/platform/gtk/widgets/webview.py
--- a/toga/platform/gtk/widgets/webview.py
+++ b/toga/platform/gtk/widgets/webview.py
@@ -1,6 +1,13 @@
from __future__ import print_function, absolute_import, division
-from gi.repository import Gtk, WebKit
+from gi.repository import Gtk
+
+# The following import sometimes fails; handle failure gracefully
+# (see https://github.com/pybee/toga/issues/26)
+try:
+ from gi.repository import WebKit
+except ImportError:
+ WebKit = None
from .base import Widget
@@ -13,6 +20,12 @@
self._webview = None
def _startup(self):
+
+ if WebKit is None:
+ raise RuntimeError(
+ "Import 'from gi.repository import WebKit' failed;" +
+ " may need to install gir1.2-webkit-3.0 or similar.")
+
self._impl = Gtk.ScrolledWindow()
self._impl.set_policy(Gtk.PolicyType.AUTOMATIC, Gtk.PolicyType.AUTOMATIC)
|
{"golden_diff": "diff --git a/toga/platform/gtk/widgets/webview.py b/toga/platform/gtk/widgets/webview.py\n--- a/toga/platform/gtk/widgets/webview.py\n+++ b/toga/platform/gtk/widgets/webview.py\n@@ -1,6 +1,13 @@\n from __future__ import print_function, absolute_import, division\n \n-from gi.repository import Gtk, WebKit\n+from gi.repository import Gtk\n+\n+# The following import sometimes fails; handle failure gracefully\n+# (see https://github.com/pybee/toga/issues/26)\n+try:\n+ from gi.repository import WebKit\n+except ImportError:\n+ WebKit = None\n \n from .base import Widget\n \n@@ -13,6 +20,12 @@\n self._webview = None\n \n def _startup(self):\n+\n+ if WebKit is None:\n+ raise RuntimeError(\n+ \"Import 'from gi.repository import WebKit' failed;\" +\n+ \" may need to install gir1.2-webkit-3.0 or similar.\")\n+\n self._impl = Gtk.ScrolledWindow()\n self._impl.set_policy(Gtk.PolicyType.AUTOMATIC, Gtk.PolicyType.AUTOMATIC)\n", "issue": "\"ImportError: cannot import name WebKit\" on Ubuntu 14.04\nInstalled toga via global `sudo pip install toga`. Then, tried to import it:\n\n```\n>>> import toga\nERROR:root:Could not find any typelib for WebKit\nTraceback (most recent call last):\n File \"<stdin>\", line 1, in <module>\n File \"/usr/local/lib/python2.7/dist-packages/toga/__init__.py\", line 86, in <module>\n from .platform.gtk.app import *\n File \"/usr/local/lib/python2.7/dist-packages/toga/platform/gtk/app.py\", line 7, in <module>\n from .window import Window\n File \"/usr/local/lib/python2.7/dist-packages/toga/platform/gtk/window.py\", line 6, in <module>\n from .command import SEPARATOR, SPACER, EXPANDING_SPACER\n File \"/usr/local/lib/python2.7/dist-packages/toga/platform/gtk/command.py\", line 1, in <module>\n from .widgets import Icon\n File \"/usr/local/lib/python2.7/dist-packages/toga/platform/gtk/widgets/__init__.py\", line 17, in <module>\n from .webview import WebView\n File \"/usr/local/lib/python2.7/dist-packages/toga/platform/gtk/widgets/webview.py\", line 3, in <module>\n from gi.repository import Gtk, WebKit\nImportError: cannot import name WebKit\n```\n\nDid a `sudo apt-get install python-webkit`, but still getting the same import error. I'm running Ubuntu under Crouton on a Chromebook, which doesn't always contain the full set of packages.\n\nSince the application I aim to create (a GUI launcher for [KA Lite](https://github.com/learningequality/ka-lite/)) would rely on toga's awesome dedication to being pure Python and not needing any extra packages to be installed to work cross-platform, and since we wouldn't be needing the WebView, would it be possible to have it handle a lack of WebKit more gracefully, only erroring out if a WebView was actually used? Thanks!\n\n", "before_files": [{"content": "from __future__ import print_function, absolute_import, division\n\nfrom gi.repository import Gtk, WebKit\n\nfrom .base import Widget\n\n\nclass WebView(Widget):\n def __init__(self, url=None):\n super(WebView, self).__init__()\n self._url = url\n\n self._webview = None\n\n def _startup(self):\n self._impl = Gtk.ScrolledWindow()\n self._impl.set_policy(Gtk.PolicyType.AUTOMATIC, Gtk.PolicyType.AUTOMATIC)\n\n self._webview = WebKit.WebView()\n\n if self._url:\n self._webview.load_uri(self._url)\n\n self._impl.add(self._webview)\n self._impl.set_min_content_width(200)\n self._impl.set_min_content_height(200)\n\n @property\n def url(self):\n return self._url\n\n @url.setter\n def url(self, value):\n self._url = value\n if self._impl:\n self._webview.load_uri(self._url)\n", "path": "toga/platform/gtk/widgets/webview.py"}]}
| 1,299 | 254 |
gh_patches_debug_6994
|
rasdani/github-patches
|
git_diff
|
comic__grand-challenge.org-2146
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Count of results displayed on the challenge card does not match leaderboard count
**Describe the bug**
The card for the node21 challenge currently notes there are 21 results. Clicking on this brings you to the leaderboard where only 2 results are present. It seems that the count is including submissions which failed and/or submissions where the evaluation failed, which is misleading.
**To Reproduce**
Steps to reproduce the behavior:
- Choose a challenge where the database includes many failed submissions or failed evaluations (e.g. node21 at present)
- View the card for this challenge (currently it is on the GC front page)
- Verify that the number of results shown on the card does not match the number of results on the leaderboard (click the number shown on the card).
**Expected behavior**
The number of reported results should match the number of results on the leaderboard
**Screenshots**

</issue>
<code>
[start of app/grandchallenge/challenges/tasks.py]
1 from celery import shared_task
2 from django.contrib.auth import get_user_model
3 from django.core.mail import mail_managers
4 from django.db.models import Count, Max
5 from requests import exceptions, get
6
7 from grandchallenge.challenges.models import Challenge, ExternalChallenge
8 from grandchallenge.evaluation.models import Evaluation
9 from grandchallenge.subdomains.utils import reverse
10
11
12 @shared_task
13 def update_challenge_results_cache():
14 challenges = Challenge.objects.all()
15 evaluation_info = (
16 Evaluation.objects.filter(published=True)
17 .values("submission__phase__challenge_id")
18 .annotate(
19 cached_num_results=Count("submission__phase__challenge_id"),
20 cached_latest_result=Max("created"),
21 )
22 )
23 evaluation_info_by_challenge = {
24 str(v["submission__phase__challenge_id"]): v for v in evaluation_info
25 }
26 participant_counts = (
27 get_user_model()
28 .objects.values("groups__participants_of_challenge")
29 .annotate(cached_num_participants=Count("pk"))
30 )
31 participant_counts_by_challenge = {
32 str(v["groups__participants_of_challenge"]): v
33 for v in participant_counts
34 }
35
36 for c in challenges:
37 c.cached_num_results = evaluation_info_by_challenge.get(
38 str(c.pk), {}
39 ).get("cached_num_results", 0)
40 c.cached_latest_result = evaluation_info_by_challenge.get(
41 str(c.pk), {}
42 ).get("cached_latest_result", None)
43 c.cached_num_participants = participant_counts_by_challenge.get(
44 str(c.pk), {}
45 ).get("cached_num_participants", 0)
46
47 Challenge.objects.bulk_update(
48 challenges,
49 [
50 "cached_num_results",
51 "cached_num_participants",
52 "cached_latest_result",
53 ],
54 )
55
56
57 @shared_task
58 def check_external_challenge_urls():
59 """
60 Checks that all external challenge urls are reachable.
61
62 Emails the managers if any of the challenges are not.
63 """
64 challenges = ExternalChallenge.objects.filter(hidden=False)
65 errors = []
66
67 for challenge in challenges:
68 try:
69 url = challenge.homepage
70 if not url.startswith("http"):
71 url = "http://" + url
72 r = get(url, timeout=60)
73 # raise an exception when we receive a http error (e.g., 404)
74 r.raise_for_status()
75 except exceptions.RequestException as err:
76 update_url = reverse(
77 "challenges:external-update",
78 kwargs={"short_name": challenge.short_name},
79 )
80 errors.append(
81 f"Error when trying to access '{challenge}': {err}. You can "
82 f"update it here: {update_url}"
83 )
84
85 if errors:
86 mail_managers(
87 subject=f"Unreachable external challenges ({len(errors)})",
88 message="\n\n".join(errors),
89 )
90
[end of app/grandchallenge/challenges/tasks.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/app/grandchallenge/challenges/tasks.py b/app/grandchallenge/challenges/tasks.py
--- a/app/grandchallenge/challenges/tasks.py
+++ b/app/grandchallenge/challenges/tasks.py
@@ -13,7 +13,7 @@
def update_challenge_results_cache():
challenges = Challenge.objects.all()
evaluation_info = (
- Evaluation.objects.filter(published=True)
+ Evaluation.objects.filter(published=True, rank__gt=0)
.values("submission__phase__challenge_id")
.annotate(
cached_num_results=Count("submission__phase__challenge_id"),
|
{"golden_diff": "diff --git a/app/grandchallenge/challenges/tasks.py b/app/grandchallenge/challenges/tasks.py\n--- a/app/grandchallenge/challenges/tasks.py\n+++ b/app/grandchallenge/challenges/tasks.py\n@@ -13,7 +13,7 @@\n def update_challenge_results_cache():\n challenges = Challenge.objects.all()\n evaluation_info = (\n- Evaluation.objects.filter(published=True)\n+ Evaluation.objects.filter(published=True, rank__gt=0)\n .values(\"submission__phase__challenge_id\")\n .annotate(\n cached_num_results=Count(\"submission__phase__challenge_id\"),\n", "issue": "Count of results displayed on the challenge card does not match leaderboard count\n**Describe the bug**\r\nThe card for the node21 challenge currently notes there are 21 results. Clicking on this brings you to the leaderboard where only 2 results are present. It seems that the count is including submissions which failed and/or submissions where the evaluation failed, which is misleading. \r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n - Choose a challenge where the database includes many failed submissions or failed evaluations (e.g. node21 at present)\r\n- View the card for this challenge (currently it is on the GC front page)\r\n - Verify that the number of results shown on the card does not match the number of results on the leaderboard (click the number shown on the card).\r\n\r\n**Expected behavior**\r\nThe number of reported results should match the number of results on the leaderboard\r\n\r\n**Screenshots**\r\n\r\n\r\n\n", "before_files": [{"content": "from celery import shared_task\nfrom django.contrib.auth import get_user_model\nfrom django.core.mail import mail_managers\nfrom django.db.models import Count, Max\nfrom requests import exceptions, get\n\nfrom grandchallenge.challenges.models import Challenge, ExternalChallenge\nfrom grandchallenge.evaluation.models import Evaluation\nfrom grandchallenge.subdomains.utils import reverse\n\n\n@shared_task\ndef update_challenge_results_cache():\n challenges = Challenge.objects.all()\n evaluation_info = (\n Evaluation.objects.filter(published=True)\n .values(\"submission__phase__challenge_id\")\n .annotate(\n cached_num_results=Count(\"submission__phase__challenge_id\"),\n cached_latest_result=Max(\"created\"),\n )\n )\n evaluation_info_by_challenge = {\n str(v[\"submission__phase__challenge_id\"]): v for v in evaluation_info\n }\n participant_counts = (\n get_user_model()\n .objects.values(\"groups__participants_of_challenge\")\n .annotate(cached_num_participants=Count(\"pk\"))\n )\n participant_counts_by_challenge = {\n str(v[\"groups__participants_of_challenge\"]): v\n for v in participant_counts\n }\n\n for c in challenges:\n c.cached_num_results = evaluation_info_by_challenge.get(\n str(c.pk), {}\n ).get(\"cached_num_results\", 0)\n c.cached_latest_result = evaluation_info_by_challenge.get(\n str(c.pk), {}\n ).get(\"cached_latest_result\", None)\n c.cached_num_participants = participant_counts_by_challenge.get(\n str(c.pk), {}\n ).get(\"cached_num_participants\", 0)\n\n Challenge.objects.bulk_update(\n challenges,\n [\n \"cached_num_results\",\n \"cached_num_participants\",\n \"cached_latest_result\",\n ],\n )\n\n\n@shared_task\ndef check_external_challenge_urls():\n \"\"\"\n Checks that all external challenge urls are reachable.\n\n Emails the managers if any of the challenges are not.\n \"\"\"\n challenges = ExternalChallenge.objects.filter(hidden=False)\n errors = []\n\n for challenge in challenges:\n try:\n url = challenge.homepage\n if not url.startswith(\"http\"):\n url = \"http://\" + url\n r = get(url, timeout=60)\n # raise an exception when we receive a http error (e.g., 404)\n r.raise_for_status()\n except exceptions.RequestException as err:\n update_url = reverse(\n \"challenges:external-update\",\n kwargs={\"short_name\": challenge.short_name},\n )\n errors.append(\n f\"Error when trying to access '{challenge}': {err}. You can \"\n f\"update it here: {update_url}\"\n )\n\n if errors:\n mail_managers(\n subject=f\"Unreachable external challenges ({len(errors)})\",\n message=\"\\n\\n\".join(errors),\n )\n", "path": "app/grandchallenge/challenges/tasks.py"}]}
| 1,557 | 127 |
gh_patches_debug_29843
|
rasdani/github-patches
|
git_diff
|
pwndbg__pwndbg-2017
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
pwndbg might fail to show the state of the GOT of i386 libc
```console
$ cat a.c
#include <stdio.h>
int main(){puts("hello world");return 0;}
$ gcc -m32 a.c
$ gdb -q a.out -ex 'break main' -ex 'run' -ex 'got -p libc'
```
<img width="1514" alt="image" src="https://github.com/pwndbg/pwndbg/assets/61896187/e0492360-8c33-495a-aad1-99e0a91ad4c8">
The above error was triggered with i386 libc with version: `2.35-0ubuntu3.6`.
</issue>
<code>
[start of pwndbg/commands/got.py]
1 from __future__ import annotations
2
3 import argparse
4 from typing import Dict
5 from typing import List
6 from typing import Union
7
8 from elftools.elf.elffile import ELFFile
9
10 import pwndbg.chain
11 import pwndbg.color.memory as M
12 import pwndbg.commands
13 import pwndbg.enhance
14 import pwndbg.gdblib.arch
15 import pwndbg.gdblib.file
16 import pwndbg.gdblib.info
17 import pwndbg.gdblib.proc
18 import pwndbg.gdblib.qemu
19 import pwndbg.gdblib.vmmap
20 import pwndbg.wrappers.checksec
21 import pwndbg.wrappers.readelf
22 from pwndbg.color import message
23 from pwndbg.commands import CommandCategory
24 from pwndbg.wrappers.readelf import RelocationType
25
26 parser = argparse.ArgumentParser(
27 formatter_class=argparse.RawTextHelpFormatter,
28 description="""Show the state of the Global Offset Table.
29
30 Examples:
31 got
32 got puts
33 got -p libc
34 got -a
35 """,
36 )
37 group = parser.add_mutually_exclusive_group()
38 group.add_argument(
39 "-p",
40 "--path",
41 help="Filter results by library/objfile path.",
42 type=str,
43 default="",
44 dest="path_filter",
45 )
46 group.add_argument(
47 "-a",
48 "--all",
49 help="Process all libs/obfjiles including the target executable.",
50 action="store_true",
51 default=False,
52 dest="all_",
53 )
54 parser.add_argument(
55 "-r",
56 "--show-readonly",
57 help="Also display read-only entries (which are filtered out by default).",
58 action="store_true",
59 default=False,
60 dest="accept_readonly",
61 )
62 parser.add_argument(
63 "symbol_filter", help="Filter results by symbol name.", type=str, nargs="?", default=""
64 )
65
66
67 @pwndbg.commands.ArgparsedCommand(parser, category=CommandCategory.LINUX)
68 @pwndbg.commands.OnlyWhenRunning
69 def got(path_filter: str, all_: bool, accept_readonly: bool, symbol_filter: str) -> None:
70 if pwndbg.gdblib.qemu.is_qemu_usermode():
71 print(
72 "QEMU target detected - the result might not be accurate when checking if the entry is writable and getting the information for libraries/objfiles"
73 )
74 print()
75 # Show the filters we are using
76 if path_filter:
77 print("Filtering by lib/objfile path: " + message.hint(path_filter))
78 if symbol_filter:
79 print("Filtering by symbol name: " + message.hint(symbol_filter))
80 if not accept_readonly:
81 print("Filtering out read-only entries (display them with -r or --show-readonly)")
82
83 if path_filter or not accept_readonly or symbol_filter:
84 print()
85
86 # Calculate the base address
87 if not path_filter:
88 first_print = False
89 _got(pwndbg.gdblib.proc.exe, accept_readonly, symbol_filter)
90 else:
91 first_print = True
92
93 if not all_ and not path_filter:
94 return
95 # TODO: We might fail to find shared libraries if GDB can't find them (can't show them in `info sharedlibrary`)
96 paths = pwndbg.gdblib.info.sharedlibrary_paths()
97 for path in paths:
98 if path_filter not in path:
99 continue
100 if not first_print:
101 print()
102 first_print = False
103 _got(path, accept_readonly, symbol_filter)
104
105 # Maybe user have a typo or something in the path filter, show the available shared libraries
106 if first_print and path_filter:
107 print(message.error("No shared library matching the path filter found."))
108 if paths:
109 print(message.notice("Available shared libraries:"))
110 for path in paths:
111 print(" " + path)
112
113
114 def _got(path: str, accept_readonly: bool, symbol_filter: str) -> None:
115 # Maybe download the file from remote
116 local_path = pwndbg.gdblib.file.get_file(path, try_local_path=True)
117
118 relro_status = pwndbg.wrappers.checksec.relro_status(local_path)
119 pie_status = pwndbg.wrappers.checksec.pie_status(local_path)
120 got_entry = pwndbg.wrappers.readelf.get_got_entry(local_path)
121
122 # The following code is inspired by the "got" command of https://github.com/bata24/gef/blob/dev/gef.py by @bata24, thank you!
123 # TODO/FIXME: Maybe a -v option to show more information will be better
124 outputs: List[Dict[str, Union[str, int]]] = []
125 if path == pwndbg.gdblib.proc.exe:
126 bin_base_offset = pwndbg.gdblib.proc.binary_base_addr if "PIE enabled" in pie_status else 0
127 else:
128 # TODO/FIXME: Is there a better way to get the base address of the loaded shared library?
129 # I guess parsing the vmmap result might also work, but what if it's not reliable or not available? (e.g. debugging with qemu-user)
130 text_section_addr = pwndbg.gdblib.info.parsed_sharedlibrary()[path][0]
131 with open(local_path, "rb") as f:
132 bin_base_offset = (
133 text_section_addr - ELFFile(f).get_section_by_name(".text").header["sh_addr"]
134 )
135
136 # Parse the output of readelf line by line
137 for category, lines in got_entry.items():
138 for line in lines:
139 # line might be something like:
140 # 00000000001ec018 0000000000000025 R_X86_64_IRELATIVE a0480
141 # or something like:
142 # 00000000001ec030 0000020a00000007 R_X86_64_JUMP_SLOT 000000000009ae80 realloc@@GLIBC_2.2.5 + 0
143 offset, _, rtype, *rest = line.split()[:5]
144 if len(rest) == 1:
145 value = rest[0]
146 name = ""
147 else:
148 value, name = rest
149 address = int(offset, 16) + bin_base_offset
150 # TODO/FIXME: This check might not work correctly if we failed to get the correct vmmap result
151 if not accept_readonly and not pwndbg.gdblib.vmmap.find(address).write:
152 continue
153 if not name and category == RelocationType.IRELATIVE:
154 # TODO/FIXME: I don't know the naming logic behind this yet, I'm just modifying @bata24's code here :p
155 # We might need to add some comments here to explain the logic in the future, and also fix it if something wrong
156 if pwndbg.gdblib.arch.name == "i386":
157 name = "*ABS*"
158 else:
159 name = f"*ABS*+0x{int(value, 16):x}"
160 if symbol_filter not in name:
161 continue
162 outputs.append(
163 {
164 "name": name or "????",
165 "address": address,
166 }
167 )
168 # By sorting the outputs by address, we can get a more intuitive output
169 outputs.sort(key=lambda x: x["address"])
170 relro_color = message.off
171 if "Partial" in relro_status:
172 relro_color = message.warn
173 elif "Full" in relro_status:
174 relro_color = message.on
175 print(f"State of the GOT of {message.notice(path)}:")
176 print(
177 f"GOT protection: {relro_color(relro_status)} | Found {message.hint(len(outputs))} GOT entries passing the filter"
178 )
179 for output in outputs:
180 print(
181 f"[{M.get(output['address'])}] {message.hint(output['name'])} -> {pwndbg.chain.format(pwndbg.gdblib.memory.pvoid(output['address']))}" # type: ignore[arg-type]
182 )
183
[end of pwndbg/commands/got.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pwndbg/commands/got.py b/pwndbg/commands/got.py
--- a/pwndbg/commands/got.py
+++ b/pwndbg/commands/got.py
@@ -136,15 +136,23 @@
# Parse the output of readelf line by line
for category, lines in got_entry.items():
for line in lines:
- # line might be something like:
- # 00000000001ec018 0000000000000025 R_X86_64_IRELATIVE a0480
- # or something like:
- # 00000000001ec030 0000020a00000007 R_X86_64_JUMP_SLOT 000000000009ae80 realloc@@GLIBC_2.2.5 + 0
- offset, _, rtype, *rest = line.split()[:5]
- if len(rest) == 1:
- value = rest[0]
+ # There are 5 fields in the output of readelf:
+ # "Offset", "Info", "Type", "Sym. Value", and "Symbol's Name"
+ # We only care about "Offset", "Sym. Value" and "Symbol's Name" here
+ offset, _, _, *rest = line.split()[:5]
+ if len(rest) < 2:
+ # "Sym. Value" or "Symbol's Name" are not present in this case
+ # The output of readelf might look like this (missing both value and name):
+ # 00004e88 00000008 R_386_RELATIVE
+ # or something like this (only missing name):
+ # 00000000001ec018 0000000000000025 R_X86_64_IRELATIVE a0480
+ # TODO: Is it possible that we are missing the value but not the name?
+ value = rest[0] if rest else ""
name = ""
else:
+ # Every fields are present in this case
+ # The output of readelf might look like this:
+ # 00000000001ec030 0000020a00000007 R_X86_64_JUMP_SLOT 000000000009ae80 realloc@@GLIBC_2.2.5 + 0
value, name = rest
address = int(offset, 16) + bin_base_offset
# TODO/FIXME: This check might not work correctly if we failed to get the correct vmmap result
|
{"golden_diff": "diff --git a/pwndbg/commands/got.py b/pwndbg/commands/got.py\n--- a/pwndbg/commands/got.py\n+++ b/pwndbg/commands/got.py\n@@ -136,15 +136,23 @@\n # Parse the output of readelf line by line\n for category, lines in got_entry.items():\n for line in lines:\n- # line might be something like:\n- # 00000000001ec018 0000000000000025 R_X86_64_IRELATIVE a0480\n- # or something like:\n- # 00000000001ec030 0000020a00000007 R_X86_64_JUMP_SLOT 000000000009ae80 realloc@@GLIBC_2.2.5 + 0\n- offset, _, rtype, *rest = line.split()[:5]\n- if len(rest) == 1:\n- value = rest[0]\n+ # There are 5 fields in the output of readelf:\n+ # \"Offset\", \"Info\", \"Type\", \"Sym. Value\", and \"Symbol's Name\"\n+ # We only care about \"Offset\", \"Sym. Value\" and \"Symbol's Name\" here\n+ offset, _, _, *rest = line.split()[:5]\n+ if len(rest) < 2:\n+ # \"Sym. Value\" or \"Symbol's Name\" are not present in this case\n+ # The output of readelf might look like this (missing both value and name):\n+ # 00004e88 00000008 R_386_RELATIVE\n+ # or something like this (only missing name):\n+ # 00000000001ec018 0000000000000025 R_X86_64_IRELATIVE a0480\n+ # TODO: Is it possible that we are missing the value but not the name?\n+ value = rest[0] if rest else \"\"\n name = \"\"\n else:\n+ # Every fields are present in this case\n+ # The output of readelf might look like this:\n+ # 00000000001ec030 0000020a00000007 R_X86_64_JUMP_SLOT 000000000009ae80 realloc@@GLIBC_2.2.5 + 0\n value, name = rest\n address = int(offset, 16) + bin_base_offset\n # TODO/FIXME: This check might not work correctly if we failed to get the correct vmmap result\n", "issue": "pwndbg might fail to show the state of the GOT of i386 libc\n```console\r\n$ cat a.c\r\n#include <stdio.h>\r\nint main(){puts(\"hello world\");return 0;}\r\n$ gcc -m32 a.c\r\n$ gdb -q a.out -ex 'break main' -ex 'run' -ex 'got -p libc'\r\n```\r\n\r\n<img width=\"1514\" alt=\"image\" src=\"https://github.com/pwndbg/pwndbg/assets/61896187/e0492360-8c33-495a-aad1-99e0a91ad4c8\">\r\n\r\nThe above error was triggered with i386 libc with version: `2.35-0ubuntu3.6`.\n", "before_files": [{"content": "from __future__ import annotations\n\nimport argparse\nfrom typing import Dict\nfrom typing import List\nfrom typing import Union\n\nfrom elftools.elf.elffile import ELFFile\n\nimport pwndbg.chain\nimport pwndbg.color.memory as M\nimport pwndbg.commands\nimport pwndbg.enhance\nimport pwndbg.gdblib.arch\nimport pwndbg.gdblib.file\nimport pwndbg.gdblib.info\nimport pwndbg.gdblib.proc\nimport pwndbg.gdblib.qemu\nimport pwndbg.gdblib.vmmap\nimport pwndbg.wrappers.checksec\nimport pwndbg.wrappers.readelf\nfrom pwndbg.color import message\nfrom pwndbg.commands import CommandCategory\nfrom pwndbg.wrappers.readelf import RelocationType\n\nparser = argparse.ArgumentParser(\n formatter_class=argparse.RawTextHelpFormatter,\n description=\"\"\"Show the state of the Global Offset Table.\n\nExamples:\n got\n got puts\n got -p libc\n got -a\n\"\"\",\n)\ngroup = parser.add_mutually_exclusive_group()\ngroup.add_argument(\n \"-p\",\n \"--path\",\n help=\"Filter results by library/objfile path.\",\n type=str,\n default=\"\",\n dest=\"path_filter\",\n)\ngroup.add_argument(\n \"-a\",\n \"--all\",\n help=\"Process all libs/obfjiles including the target executable.\",\n action=\"store_true\",\n default=False,\n dest=\"all_\",\n)\nparser.add_argument(\n \"-r\",\n \"--show-readonly\",\n help=\"Also display read-only entries (which are filtered out by default).\",\n action=\"store_true\",\n default=False,\n dest=\"accept_readonly\",\n)\nparser.add_argument(\n \"symbol_filter\", help=\"Filter results by symbol name.\", type=str, nargs=\"?\", default=\"\"\n)\n\n\[email protected](parser, category=CommandCategory.LINUX)\[email protected]\ndef got(path_filter: str, all_: bool, accept_readonly: bool, symbol_filter: str) -> None:\n if pwndbg.gdblib.qemu.is_qemu_usermode():\n print(\n \"QEMU target detected - the result might not be accurate when checking if the entry is writable and getting the information for libraries/objfiles\"\n )\n print()\n # Show the filters we are using\n if path_filter:\n print(\"Filtering by lib/objfile path: \" + message.hint(path_filter))\n if symbol_filter:\n print(\"Filtering by symbol name: \" + message.hint(symbol_filter))\n if not accept_readonly:\n print(\"Filtering out read-only entries (display them with -r or --show-readonly)\")\n\n if path_filter or not accept_readonly or symbol_filter:\n print()\n\n # Calculate the base address\n if not path_filter:\n first_print = False\n _got(pwndbg.gdblib.proc.exe, accept_readonly, symbol_filter)\n else:\n first_print = True\n\n if not all_ and not path_filter:\n return\n # TODO: We might fail to find shared libraries if GDB can't find them (can't show them in `info sharedlibrary`)\n paths = pwndbg.gdblib.info.sharedlibrary_paths()\n for path in paths:\n if path_filter not in path:\n continue\n if not first_print:\n print()\n first_print = False\n _got(path, accept_readonly, symbol_filter)\n\n # Maybe user have a typo or something in the path filter, show the available shared libraries\n if first_print and path_filter:\n print(message.error(\"No shared library matching the path filter found.\"))\n if paths:\n print(message.notice(\"Available shared libraries:\"))\n for path in paths:\n print(\" \" + path)\n\n\ndef _got(path: str, accept_readonly: bool, symbol_filter: str) -> None:\n # Maybe download the file from remote\n local_path = pwndbg.gdblib.file.get_file(path, try_local_path=True)\n\n relro_status = pwndbg.wrappers.checksec.relro_status(local_path)\n pie_status = pwndbg.wrappers.checksec.pie_status(local_path)\n got_entry = pwndbg.wrappers.readelf.get_got_entry(local_path)\n\n # The following code is inspired by the \"got\" command of https://github.com/bata24/gef/blob/dev/gef.py by @bata24, thank you!\n # TODO/FIXME: Maybe a -v option to show more information will be better\n outputs: List[Dict[str, Union[str, int]]] = []\n if path == pwndbg.gdblib.proc.exe:\n bin_base_offset = pwndbg.gdblib.proc.binary_base_addr if \"PIE enabled\" in pie_status else 0\n else:\n # TODO/FIXME: Is there a better way to get the base address of the loaded shared library?\n # I guess parsing the vmmap result might also work, but what if it's not reliable or not available? (e.g. debugging with qemu-user)\n text_section_addr = pwndbg.gdblib.info.parsed_sharedlibrary()[path][0]\n with open(local_path, \"rb\") as f:\n bin_base_offset = (\n text_section_addr - ELFFile(f).get_section_by_name(\".text\").header[\"sh_addr\"]\n )\n\n # Parse the output of readelf line by line\n for category, lines in got_entry.items():\n for line in lines:\n # line might be something like:\n # 00000000001ec018 0000000000000025 R_X86_64_IRELATIVE a0480\n # or something like:\n # 00000000001ec030 0000020a00000007 R_X86_64_JUMP_SLOT 000000000009ae80 realloc@@GLIBC_2.2.5 + 0\n offset, _, rtype, *rest = line.split()[:5]\n if len(rest) == 1:\n value = rest[0]\n name = \"\"\n else:\n value, name = rest\n address = int(offset, 16) + bin_base_offset\n # TODO/FIXME: This check might not work correctly if we failed to get the correct vmmap result\n if not accept_readonly and not pwndbg.gdblib.vmmap.find(address).write:\n continue\n if not name and category == RelocationType.IRELATIVE:\n # TODO/FIXME: I don't know the naming logic behind this yet, I'm just modifying @bata24's code here :p\n # We might need to add some comments here to explain the logic in the future, and also fix it if something wrong\n if pwndbg.gdblib.arch.name == \"i386\":\n name = \"*ABS*\"\n else:\n name = f\"*ABS*+0x{int(value, 16):x}\"\n if symbol_filter not in name:\n continue\n outputs.append(\n {\n \"name\": name or \"????\",\n \"address\": address,\n }\n )\n # By sorting the outputs by address, we can get a more intuitive output\n outputs.sort(key=lambda x: x[\"address\"])\n relro_color = message.off\n if \"Partial\" in relro_status:\n relro_color = message.warn\n elif \"Full\" in relro_status:\n relro_color = message.on\n print(f\"State of the GOT of {message.notice(path)}:\")\n print(\n f\"GOT protection: {relro_color(relro_status)} | Found {message.hint(len(outputs))} GOT entries passing the filter\"\n )\n for output in outputs:\n print(\n f\"[{M.get(output['address'])}] {message.hint(output['name'])} -> {pwndbg.chain.format(pwndbg.gdblib.memory.pvoid(output['address']))}\" # type: ignore[arg-type]\n )\n", "path": "pwndbg/commands/got.py"}]}
| 2,945 | 679 |
gh_patches_debug_11634
|
rasdani/github-patches
|
git_diff
|
encode__uvicorn-623
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Duplicate logs when using root logger with 'gunicorn -k uvicorn.workers.UvicornWorker ...'
Here is a small test file with minimal gunicorn and uvicorn apps. But my real interest is the log statements at the top of the file.
```
import logging
logging.error('TEST 1 -- LOGGING ERROR')
logging.getLogger().error('TEST 2 -- ROOT LOGGER ERROR')
logging.getLogger('foo').error('TEST 3 -- FOO LOGGER ERROR')
# minimal gunicorn app
def appG(environ, start_response):
data = b'Hello, World!\n'
status = '200 OK'
response_headers = [
('Content-type', 'text/plain'),
('Content-Length', str(len(data)))
]
start_response(status, response_headers)
return iter([data])
# minimal uvicorn app
async def appU(scope, receive, send):
assert scope['type'] == 'http'
await send({
'type': 'http.response.start',
'status': 200,
'headers': [
[b'content-type', b'text/plain'],
]
})
await send({
'type': 'http.response.body',
'body': b'Hello, world!',
})
```
The logs "work" when the file is run by gunicorn or uvicorn individually.
But when I use gunicorn and uvicorn **together**, I get doubled uvicorn logs.
```
$ gunicorn -k uvicorn.workers.UvicornWorker test3:appU
[2020-04-07 22:47:53 -0400] [16015] [INFO] Starting gunicorn 20.0.4
[2020-04-07 22:47:53 -0400] [16015] [INFO] Listening at: http://127.0.0.1:8000 (16015)
[2020-04-07 22:47:53 -0400] [16015] [INFO] Using worker: uvicorn.workers.UvicornWorker
[2020-04-07 22:47:53 -0400] [16018] [INFO] Booting worker with pid: 16018
ERROR:root:TEST 1 -- LOGGING ERROR
ERROR:root:TEST 2 -- ROOT LOGGER ERROR
ERROR:foo:TEST 3 -- FOO LOGGER ERROR
[2020-04-07 22:47:53 -0400] [16018] [INFO] Started server process [16018]
INFO:uvicorn.error:Started server process [16018]
[2020-04-07 22:47:53 -0400] [16018] [INFO] Waiting for application startup.
INFO:uvicorn.error:Waiting for application startup.
[2020-04-07 22:47:53 -0400] [16018] [INFO] ASGI 'lifespan' protocol appears unsupported.
INFO:uvicorn.error:ASGI 'lifespan' protocol appears unsupported.
[2020-04-07 22:47:53 -0400] [16018] [INFO] Application startup complete.
INFO:uvicorn.error:Application startup complete.
```
Note the last several lines are double logged with different formats. (Two handlers?)
FYI,
```
$ pip freeze |grep corn
gunicorn==20.0.4
uvicorn==0.11.3
```
I'd love a work around for **both** `gunicorn -k uvicorn.workers.UvicornWorker ...` and `uvicorn ...` that has an inheritable root logger.
</issue>
<code>
[start of uvicorn/workers.py]
1 import asyncio
2 import logging
3
4 from gunicorn.workers.base import Worker
5 from uvicorn.config import Config
6 from uvicorn.main import Server
7
8
9 class UvicornWorker(Worker):
10 """
11 A worker class for Gunicorn that interfaces with an ASGI consumer callable,
12 rather than a WSGI callable.
13 """
14
15 CONFIG_KWARGS = {"loop": "uvloop", "http": "httptools"}
16
17 def __init__(self, *args, **kwargs):
18 super(UvicornWorker, self).__init__(*args, **kwargs)
19
20 logger = logging.getLogger("uvicorn.error")
21 logger.handlers = self.log.error_log.handlers
22 logger.setLevel(self.log.error_log.level)
23
24 logger = logging.getLogger("uvicorn.access")
25 logger.handlers = self.log.access_log.handlers
26 logger.setLevel(self.log.access_log.level)
27
28 config_kwargs = {
29 "app": None,
30 "log_config": None,
31 "timeout_keep_alive": self.cfg.keepalive,
32 "timeout_notify": self.timeout,
33 "callback_notify": self.callback_notify,
34 "limit_max_requests": self.max_requests,
35 }
36
37 if self.cfg.is_ssl:
38 ssl_kwargs = {
39 "ssl_keyfile": self.cfg.ssl_options.get("keyfile"),
40 "ssl_certfile": self.cfg.ssl_options.get("certfile"),
41 "ssl_version": self.cfg.ssl_options.get("ssl_version"),
42 "ssl_cert_reqs": self.cfg.ssl_options.get("cert_reqs"),
43 "ssl_ca_certs": self.cfg.ssl_options.get("ca_certs"),
44 "ssl_ciphers": self.cfg.ssl_options.get("ciphers"),
45 }
46 config_kwargs.update(ssl_kwargs)
47
48 if self.cfg.settings["backlog"].value:
49 config_kwargs["backlog"] = self.cfg.settings["backlog"].value
50
51 config_kwargs.update(self.CONFIG_KWARGS)
52
53 self.config = Config(**config_kwargs)
54
55 def init_process(self):
56 self.config.setup_event_loop()
57 super(UvicornWorker, self).init_process()
58
59 def init_signals(self):
60 pass
61
62 def run(self):
63 self.config.app = self.wsgi
64 server = Server(config=self.config)
65 loop = asyncio.get_event_loop()
66 loop.run_until_complete(server.serve(sockets=self.sockets))
67
68 async def callback_notify(self):
69 self.notify()
70
71
72 class UvicornH11Worker(UvicornWorker):
73 CONFIG_KWARGS = {"loop": "asyncio", "http": "h11"}
74
[end of uvicorn/workers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/uvicorn/workers.py b/uvicorn/workers.py
--- a/uvicorn/workers.py
+++ b/uvicorn/workers.py
@@ -20,10 +20,12 @@
logger = logging.getLogger("uvicorn.error")
logger.handlers = self.log.error_log.handlers
logger.setLevel(self.log.error_log.level)
+ logger.propagate = False
logger = logging.getLogger("uvicorn.access")
logger.handlers = self.log.access_log.handlers
logger.setLevel(self.log.access_log.level)
+ logger.propagate = False
config_kwargs = {
"app": None,
|
{"golden_diff": "diff --git a/uvicorn/workers.py b/uvicorn/workers.py\n--- a/uvicorn/workers.py\n+++ b/uvicorn/workers.py\n@@ -20,10 +20,12 @@\n logger = logging.getLogger(\"uvicorn.error\")\n logger.handlers = self.log.error_log.handlers\n logger.setLevel(self.log.error_log.level)\n+ logger.propagate = False\n \n logger = logging.getLogger(\"uvicorn.access\")\n logger.handlers = self.log.access_log.handlers\n logger.setLevel(self.log.access_log.level)\n+ logger.propagate = False\n \n config_kwargs = {\n \"app\": None,\n", "issue": "Duplicate logs when using root logger with 'gunicorn -k uvicorn.workers.UvicornWorker ...'\nHere is a small test file with minimal gunicorn and uvicorn apps. But my real interest is the log statements at the top of the file.\r\n\r\n```\r\nimport logging\r\n\r\nlogging.error('TEST 1 -- LOGGING ERROR')\r\nlogging.getLogger().error('TEST 2 -- ROOT LOGGER ERROR')\r\nlogging.getLogger('foo').error('TEST 3 -- FOO LOGGER ERROR')\r\n\r\n\r\n# minimal gunicorn app\r\ndef appG(environ, start_response):\r\n data = b'Hello, World!\\n'\r\n status = '200 OK'\r\n response_headers = [\r\n ('Content-type', 'text/plain'),\r\n ('Content-Length', str(len(data)))\r\n ]\r\n start_response(status, response_headers)\r\n return iter([data])\r\n\r\n\r\n# minimal uvicorn app\r\nasync def appU(scope, receive, send):\r\n assert scope['type'] == 'http'\r\n await send({\r\n 'type': 'http.response.start',\r\n 'status': 200,\r\n 'headers': [\r\n [b'content-type', b'text/plain'],\r\n ]\r\n })\r\n await send({\r\n 'type': 'http.response.body',\r\n 'body': b'Hello, world!',\r\n })\r\n```\r\n\r\nThe logs \"work\" when the file is run by gunicorn or uvicorn individually.\r\n\r\nBut when I use gunicorn and uvicorn **together**, I get doubled uvicorn logs.\r\n\r\n```\r\n$ gunicorn -k uvicorn.workers.UvicornWorker test3:appU\r\n[2020-04-07 22:47:53 -0400] [16015] [INFO] Starting gunicorn 20.0.4\r\n[2020-04-07 22:47:53 -0400] [16015] [INFO] Listening at: http://127.0.0.1:8000 (16015)\r\n[2020-04-07 22:47:53 -0400] [16015] [INFO] Using worker: uvicorn.workers.UvicornWorker\r\n[2020-04-07 22:47:53 -0400] [16018] [INFO] Booting worker with pid: 16018\r\nERROR:root:TEST 1 -- LOGGING ERROR\r\nERROR:root:TEST 2 -- ROOT LOGGER ERROR\r\nERROR:foo:TEST 3 -- FOO LOGGER ERROR\r\n[2020-04-07 22:47:53 -0400] [16018] [INFO] Started server process [16018]\r\nINFO:uvicorn.error:Started server process [16018]\r\n[2020-04-07 22:47:53 -0400] [16018] [INFO] Waiting for application startup.\r\nINFO:uvicorn.error:Waiting for application startup.\r\n[2020-04-07 22:47:53 -0400] [16018] [INFO] ASGI 'lifespan' protocol appears unsupported.\r\nINFO:uvicorn.error:ASGI 'lifespan' protocol appears unsupported.\r\n[2020-04-07 22:47:53 -0400] [16018] [INFO] Application startup complete.\r\nINFO:uvicorn.error:Application startup complete.\r\n```\r\nNote the last several lines are double logged with different formats. (Two handlers?)\r\n\r\nFYI,\r\n```\r\n$ pip freeze |grep corn\r\ngunicorn==20.0.4\r\nuvicorn==0.11.3\r\n```\r\n\r\nI'd love a work around for **both** `gunicorn -k uvicorn.workers.UvicornWorker ...` and `uvicorn ...` that has an inheritable root logger.\r\n\n", "before_files": [{"content": "import asyncio\nimport logging\n\nfrom gunicorn.workers.base import Worker\nfrom uvicorn.config import Config\nfrom uvicorn.main import Server\n\n\nclass UvicornWorker(Worker):\n \"\"\"\n A worker class for Gunicorn that interfaces with an ASGI consumer callable,\n rather than a WSGI callable.\n \"\"\"\n\n CONFIG_KWARGS = {\"loop\": \"uvloop\", \"http\": \"httptools\"}\n\n def __init__(self, *args, **kwargs):\n super(UvicornWorker, self).__init__(*args, **kwargs)\n\n logger = logging.getLogger(\"uvicorn.error\")\n logger.handlers = self.log.error_log.handlers\n logger.setLevel(self.log.error_log.level)\n\n logger = logging.getLogger(\"uvicorn.access\")\n logger.handlers = self.log.access_log.handlers\n logger.setLevel(self.log.access_log.level)\n\n config_kwargs = {\n \"app\": None,\n \"log_config\": None,\n \"timeout_keep_alive\": self.cfg.keepalive,\n \"timeout_notify\": self.timeout,\n \"callback_notify\": self.callback_notify,\n \"limit_max_requests\": self.max_requests,\n }\n\n if self.cfg.is_ssl:\n ssl_kwargs = {\n \"ssl_keyfile\": self.cfg.ssl_options.get(\"keyfile\"),\n \"ssl_certfile\": self.cfg.ssl_options.get(\"certfile\"),\n \"ssl_version\": self.cfg.ssl_options.get(\"ssl_version\"),\n \"ssl_cert_reqs\": self.cfg.ssl_options.get(\"cert_reqs\"),\n \"ssl_ca_certs\": self.cfg.ssl_options.get(\"ca_certs\"),\n \"ssl_ciphers\": self.cfg.ssl_options.get(\"ciphers\"),\n }\n config_kwargs.update(ssl_kwargs)\n\n if self.cfg.settings[\"backlog\"].value:\n config_kwargs[\"backlog\"] = self.cfg.settings[\"backlog\"].value\n\n config_kwargs.update(self.CONFIG_KWARGS)\n\n self.config = Config(**config_kwargs)\n\n def init_process(self):\n self.config.setup_event_loop()\n super(UvicornWorker, self).init_process()\n\n def init_signals(self):\n pass\n\n def run(self):\n self.config.app = self.wsgi\n server = Server(config=self.config)\n loop = asyncio.get_event_loop()\n loop.run_until_complete(server.serve(sockets=self.sockets))\n\n async def callback_notify(self):\n self.notify()\n\n\nclass UvicornH11Worker(UvicornWorker):\n CONFIG_KWARGS = {\"loop\": \"asyncio\", \"http\": \"h11\"}\n", "path": "uvicorn/workers.py"}]}
| 2,105 | 135 |
gh_patches_debug_1153
|
rasdani/github-patches
|
git_diff
|
scverse__scanpy-997
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`datasets.pbmc68k_reduced` isn't contained in the pypi package anymore
This still works in `1.4.4.post1`. It's very likely caused by changes to `setup.py`. I experienced similar problems before and fixed them via `package_data`. But this got removed. It's probably only a problem for the source-based installs.
https://github.com/theislab/scanpy/commit/881f0bef31cdfe0df7333641dc847a60894b5c41#diff-2eeaed663bd0d25b7e608891384b7298
```
>>> import scanpy
>>> scanpy.__version__
<Version('1.4.5.post2')>
>>> scanpy.datasets.pbmc68k_reduced()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/alexwolf/miniconda3/lib/python3.6/site-packages/scanpy/datasets/__init__.py", line 239, in pbmc68k_reduced
return read(filename)
File "/Users/alexwolf/miniconda3/lib/python3.6/site-packages/scanpy/readwrite.py", line 114, in read
**kwargs,
File "/Users/alexwolf/miniconda3/lib/python3.6/site-packages/scanpy/readwrite.py", line 524, in _read
return read_h5ad(filename, backed=backed)
File "/Users/alexwolf/miniconda3/lib/python3.6/site-packages/anndata/readwrite/read.py", line 447, in read_h5ad
constructor_args = _read_args_from_h5ad(filename=filename, chunk_size=chunk_size)
File "/Users/alexwolf/miniconda3/lib/python3.6/site-packages/anndata/readwrite/read.py", line 481, in _read_args_from_h5ad
f = h5py.File(filename, 'r')
File "/Users/alexwolf/miniconda3/lib/python3.6/site-packages/anndata/h5py/h5sparse.py", line 162, in __init__
**kwds,
File "/Users/alexwolf/miniconda3/lib/python3.6/site-packages/h5py/_hl/files.py", line 312, in __init__
fid = make_fid(name, mode, userblock_size, fapl, swmr=swmr)
File "/Users/alexwolf/miniconda3/lib/python3.6/site-packages/h5py/_hl/files.py", line 142, in make_fid
fid = h5f.open(name, flags, fapl=fapl)
File "h5py/_objects.pyx", line 54, in h5py._objects.with_phil.wrapper
File "h5py/_objects.pyx", line 55, in h5py._objects.with_phil.wrapper
File "h5py/h5f.pyx", line 78, in h5py.h5f.open
```
</issue>
<code>
[start of setup.py]
1 import sys
2
3 if sys.version_info < (3, 6):
4 sys.exit('scanpy requires Python >= 3.6')
5 from pathlib import Path
6
7 from setuptools import setup, find_packages
8
9
10 try:
11 from scanpy import __author__, __email__
12 except ImportError: # Deps not yet installed
13 __author__ = __email__ = ''
14
15 setup(
16 name='scanpy',
17 use_scm_version=True,
18 setup_requires=['setuptools_scm'],
19 description='Single-Cell Analysis in Python.',
20 long_description=Path('README.rst').read_text('utf-8'),
21 url='http://github.com/theislab/scanpy',
22 author=__author__,
23 author_email=__email__,
24 license='BSD',
25 python_requires='>=3.6',
26 install_requires=[
27 l.strip() for l in Path('requirements.txt').read_text('utf-8').splitlines()
28 ],
29 extras_require=dict(
30 louvain=['python-igraph', 'louvain>=0.6'],
31 leiden=['python-igraph', 'leidenalg'],
32 bbknn=['bbknn'],
33 rapids=['cudf', 'cuml', 'cugraph'],
34 magic=['magic-impute>=2.0'],
35 doc=[
36 'sphinx',
37 'sphinx_rtd_theme',
38 'sphinx_autodoc_typehints',
39 'scanpydoc>=0.4.3',
40 'typing_extensions; python_version < "3.8"', # for `Literal`
41 ],
42 test=[
43 'pytest>=4.4',
44 'dask[array]',
45 'fsspec',
46 'zappy',
47 'zarr',
48 'black',
49 'profimp',
50 ],
51 ),
52 packages=find_packages(),
53 entry_points=dict(console_scripts=['scanpy=scanpy.cli:console_main']),
54 zip_safe=False,
55 classifiers=[
56 'Development Status :: 5 - Production/Stable',
57 'Environment :: Console',
58 'Framework :: Jupyter',
59 'Intended Audience :: Developers',
60 'Intended Audience :: Science/Research',
61 'Natural Language :: English',
62 'Operating System :: MacOS :: MacOS X',
63 'Operating System :: Microsoft :: Windows',
64 'Operating System :: POSIX :: Linux',
65 'Programming Language :: Python :: 3',
66 'Programming Language :: Python :: 3.5',
67 'Programming Language :: Python :: 3.6',
68 'Programming Language :: Python :: 3.7',
69 'Topic :: Scientific/Engineering :: Bio-Informatics',
70 'Topic :: Scientific/Engineering :: Visualization',
71 ],
72 )
73
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -50,6 +50,7 @@
],
),
packages=find_packages(),
+ include_package_data=True,
entry_points=dict(console_scripts=['scanpy=scanpy.cli:console_main']),
zip_safe=False,
classifiers=[
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -50,6 +50,7 @@\n ],\n ),\n packages=find_packages(),\n+ include_package_data=True,\n entry_points=dict(console_scripts=['scanpy=scanpy.cli:console_main']),\n zip_safe=False,\n classifiers=[\n", "issue": "`datasets.pbmc68k_reduced` isn't contained in the pypi package anymore\nThis still works in `1.4.4.post1`. It's very likely caused by changes to `setup.py`. I experienced similar problems before and fixed them via `package_data`. But this got removed. It's probably only a problem for the source-based installs.\r\n\r\nhttps://github.com/theislab/scanpy/commit/881f0bef31cdfe0df7333641dc847a60894b5c41#diff-2eeaed663bd0d25b7e608891384b7298\r\n\r\n```\r\n>>> import scanpy\r\n>>> scanpy.__version__\r\n<Version('1.4.5.post2')>\r\n>>> scanpy.datasets.pbmc68k_reduced()\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/Users/alexwolf/miniconda3/lib/python3.6/site-packages/scanpy/datasets/__init__.py\", line 239, in pbmc68k_reduced\r\n return read(filename)\r\n File \"/Users/alexwolf/miniconda3/lib/python3.6/site-packages/scanpy/readwrite.py\", line 114, in read\r\n **kwargs,\r\n File \"/Users/alexwolf/miniconda3/lib/python3.6/site-packages/scanpy/readwrite.py\", line 524, in _read\r\n return read_h5ad(filename, backed=backed)\r\n File \"/Users/alexwolf/miniconda3/lib/python3.6/site-packages/anndata/readwrite/read.py\", line 447, in read_h5ad\r\n constructor_args = _read_args_from_h5ad(filename=filename, chunk_size=chunk_size)\r\n File \"/Users/alexwolf/miniconda3/lib/python3.6/site-packages/anndata/readwrite/read.py\", line 481, in _read_args_from_h5ad\r\n f = h5py.File(filename, 'r')\r\n File \"/Users/alexwolf/miniconda3/lib/python3.6/site-packages/anndata/h5py/h5sparse.py\", line 162, in __init__\r\n **kwds,\r\n File \"/Users/alexwolf/miniconda3/lib/python3.6/site-packages/h5py/_hl/files.py\", line 312, in __init__\r\n fid = make_fid(name, mode, userblock_size, fapl, swmr=swmr)\r\n File \"/Users/alexwolf/miniconda3/lib/python3.6/site-packages/h5py/_hl/files.py\", line 142, in make_fid\r\n fid = h5f.open(name, flags, fapl=fapl)\r\n File \"h5py/_objects.pyx\", line 54, in h5py._objects.with_phil.wrapper\r\n File \"h5py/_objects.pyx\", line 55, in h5py._objects.with_phil.wrapper\r\n File \"h5py/h5f.pyx\", line 78, in h5py.h5f.open\r\n```\n", "before_files": [{"content": "import sys\n\nif sys.version_info < (3, 6):\n sys.exit('scanpy requires Python >= 3.6')\nfrom pathlib import Path\n\nfrom setuptools import setup, find_packages\n\n\ntry:\n from scanpy import __author__, __email__\nexcept ImportError: # Deps not yet installed\n __author__ = __email__ = ''\n\nsetup(\n name='scanpy',\n use_scm_version=True,\n setup_requires=['setuptools_scm'],\n description='Single-Cell Analysis in Python.',\n long_description=Path('README.rst').read_text('utf-8'),\n url='http://github.com/theislab/scanpy',\n author=__author__,\n author_email=__email__,\n license='BSD',\n python_requires='>=3.6',\n install_requires=[\n l.strip() for l in Path('requirements.txt').read_text('utf-8').splitlines()\n ],\n extras_require=dict(\n louvain=['python-igraph', 'louvain>=0.6'],\n leiden=['python-igraph', 'leidenalg'],\n bbknn=['bbknn'],\n rapids=['cudf', 'cuml', 'cugraph'],\n magic=['magic-impute>=2.0'],\n doc=[\n 'sphinx',\n 'sphinx_rtd_theme',\n 'sphinx_autodoc_typehints',\n 'scanpydoc>=0.4.3',\n 'typing_extensions; python_version < \"3.8\"', # for `Literal`\n ],\n test=[\n 'pytest>=4.4',\n 'dask[array]',\n 'fsspec',\n 'zappy',\n 'zarr',\n 'black',\n 'profimp',\n ],\n ),\n packages=find_packages(),\n entry_points=dict(console_scripts=['scanpy=scanpy.cli:console_main']),\n zip_safe=False,\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Environment :: Console',\n 'Framework :: Jupyter',\n 'Intended Audience :: Developers',\n 'Intended Audience :: Science/Research',\n 'Natural Language :: English',\n 'Operating System :: MacOS :: MacOS X',\n 'Operating System :: Microsoft :: Windows',\n 'Operating System :: POSIX :: Linux',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Topic :: Scientific/Engineering :: Bio-Informatics',\n 'Topic :: Scientific/Engineering :: Visualization',\n ],\n)\n", "path": "setup.py"}]}
| 1,912 | 73 |
gh_patches_debug_30970
|
rasdani/github-patches
|
git_diff
|
open-telemetry__opentelemetry-python-1512
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Check if ThreadLocalRuntimeContext can be removed since python3.4 support is dropped
https://github.com/open-telemetry/opentelemetry-python/blob/master/opentelemetry-api/src/opentelemetry/context/threadlocal_context.py#L21
</issue>
<code>
[start of opentelemetry-api/src/opentelemetry/context/threadlocal_context.py]
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import threading
16
17 from opentelemetry.context.context import Context, RuntimeContext
18
19
20 class ThreadLocalRuntimeContext(RuntimeContext):
21 """An implementation of the RuntimeContext interface
22 which uses thread-local storage under the hood. This
23 implementation is available for usage with Python 3.4.
24 """
25
26 class Token:
27 def __init__(self, context: Context) -> None:
28 self._context = context
29
30 _CONTEXT_KEY = "current_context"
31
32 def __init__(self) -> None:
33 self._current_context = threading.local()
34
35 def attach(self, context: Context) -> object:
36 """See `opentelemetry.context.RuntimeContext.attach`."""
37 current = self.get_current()
38 setattr(self._current_context, self._CONTEXT_KEY, context)
39 return self.Token(current)
40
41 def get_current(self) -> Context:
42 """See `opentelemetry.context.RuntimeContext.get_current`."""
43 if not hasattr(self._current_context, self._CONTEXT_KEY):
44 setattr(
45 self._current_context, self._CONTEXT_KEY, Context(),
46 )
47 context = getattr(
48 self._current_context, self._CONTEXT_KEY
49 ) # type: Context
50 return context
51
52 def detach(self, token: object) -> None:
53 """See `opentelemetry.context.RuntimeContext.detach`."""
54 if not isinstance(token, self.Token):
55 raise ValueError("invalid token")
56 # pylint: disable=protected-access
57 setattr(self._current_context, self._CONTEXT_KEY, token._context)
58
59
60 __all__ = ["ThreadLocalRuntimeContext"]
61
[end of opentelemetry-api/src/opentelemetry/context/threadlocal_context.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/opentelemetry-api/src/opentelemetry/context/threadlocal_context.py b/opentelemetry-api/src/opentelemetry/context/threadlocal_context.py
deleted file mode 100644
--- a/opentelemetry-api/src/opentelemetry/context/threadlocal_context.py
+++ /dev/null
@@ -1,60 +0,0 @@
-# Copyright The OpenTelemetry Authors
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import threading
-
-from opentelemetry.context.context import Context, RuntimeContext
-
-
-class ThreadLocalRuntimeContext(RuntimeContext):
- """An implementation of the RuntimeContext interface
- which uses thread-local storage under the hood. This
- implementation is available for usage with Python 3.4.
- """
-
- class Token:
- def __init__(self, context: Context) -> None:
- self._context = context
-
- _CONTEXT_KEY = "current_context"
-
- def __init__(self) -> None:
- self._current_context = threading.local()
-
- def attach(self, context: Context) -> object:
- """See `opentelemetry.context.RuntimeContext.attach`."""
- current = self.get_current()
- setattr(self._current_context, self._CONTEXT_KEY, context)
- return self.Token(current)
-
- def get_current(self) -> Context:
- """See `opentelemetry.context.RuntimeContext.get_current`."""
- if not hasattr(self._current_context, self._CONTEXT_KEY):
- setattr(
- self._current_context, self._CONTEXT_KEY, Context(),
- )
- context = getattr(
- self._current_context, self._CONTEXT_KEY
- ) # type: Context
- return context
-
- def detach(self, token: object) -> None:
- """See `opentelemetry.context.RuntimeContext.detach`."""
- if not isinstance(token, self.Token):
- raise ValueError("invalid token")
- # pylint: disable=protected-access
- setattr(self._current_context, self._CONTEXT_KEY, token._context)
-
-
-__all__ = ["ThreadLocalRuntimeContext"]
|
{"golden_diff": "diff --git a/opentelemetry-api/src/opentelemetry/context/threadlocal_context.py b/opentelemetry-api/src/opentelemetry/context/threadlocal_context.py\ndeleted file mode 100644\n--- a/opentelemetry-api/src/opentelemetry/context/threadlocal_context.py\n+++ /dev/null\n@@ -1,60 +0,0 @@\n-# Copyright The OpenTelemetry Authors\n-#\n-# Licensed under the Apache License, Version 2.0 (the \"License\");\n-# you may not use this file except in compliance with the License.\n-# You may obtain a copy of the License at\n-#\n-# http://www.apache.org/licenses/LICENSE-2.0\n-#\n-# Unless required by applicable law or agreed to in writing, software\n-# distributed under the License is distributed on an \"AS IS\" BASIS,\n-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n-# See the License for the specific language governing permissions and\n-# limitations under the License.\n-\n-import threading\n-\n-from opentelemetry.context.context import Context, RuntimeContext\n-\n-\n-class ThreadLocalRuntimeContext(RuntimeContext):\n- \"\"\"An implementation of the RuntimeContext interface\n- which uses thread-local storage under the hood. This\n- implementation is available for usage with Python 3.4.\n- \"\"\"\n-\n- class Token:\n- def __init__(self, context: Context) -> None:\n- self._context = context\n-\n- _CONTEXT_KEY = \"current_context\"\n-\n- def __init__(self) -> None:\n- self._current_context = threading.local()\n-\n- def attach(self, context: Context) -> object:\n- \"\"\"See `opentelemetry.context.RuntimeContext.attach`.\"\"\"\n- current = self.get_current()\n- setattr(self._current_context, self._CONTEXT_KEY, context)\n- return self.Token(current)\n-\n- def get_current(self) -> Context:\n- \"\"\"See `opentelemetry.context.RuntimeContext.get_current`.\"\"\"\n- if not hasattr(self._current_context, self._CONTEXT_KEY):\n- setattr(\n- self._current_context, self._CONTEXT_KEY, Context(),\n- )\n- context = getattr(\n- self._current_context, self._CONTEXT_KEY\n- ) # type: Context\n- return context\n-\n- def detach(self, token: object) -> None:\n- \"\"\"See `opentelemetry.context.RuntimeContext.detach`.\"\"\"\n- if not isinstance(token, self.Token):\n- raise ValueError(\"invalid token\")\n- # pylint: disable=protected-access\n- setattr(self._current_context, self._CONTEXT_KEY, token._context)\n-\n-\n-__all__ = [\"ThreadLocalRuntimeContext\"]\n", "issue": "Check if ThreadLocalRuntimeContext can be removed since python3.4 support is dropped\nhttps://github.com/open-telemetry/opentelemetry-python/blob/master/opentelemetry-api/src/opentelemetry/context/threadlocal_context.py#L21\n", "before_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport threading\n\nfrom opentelemetry.context.context import Context, RuntimeContext\n\n\nclass ThreadLocalRuntimeContext(RuntimeContext):\n \"\"\"An implementation of the RuntimeContext interface\n which uses thread-local storage under the hood. This\n implementation is available for usage with Python 3.4.\n \"\"\"\n\n class Token:\n def __init__(self, context: Context) -> None:\n self._context = context\n\n _CONTEXT_KEY = \"current_context\"\n\n def __init__(self) -> None:\n self._current_context = threading.local()\n\n def attach(self, context: Context) -> object:\n \"\"\"See `opentelemetry.context.RuntimeContext.attach`.\"\"\"\n current = self.get_current()\n setattr(self._current_context, self._CONTEXT_KEY, context)\n return self.Token(current)\n\n def get_current(self) -> Context:\n \"\"\"See `opentelemetry.context.RuntimeContext.get_current`.\"\"\"\n if not hasattr(self._current_context, self._CONTEXT_KEY):\n setattr(\n self._current_context, self._CONTEXT_KEY, Context(),\n )\n context = getattr(\n self._current_context, self._CONTEXT_KEY\n ) # type: Context\n return context\n\n def detach(self, token: object) -> None:\n \"\"\"See `opentelemetry.context.RuntimeContext.detach`.\"\"\"\n if not isinstance(token, self.Token):\n raise ValueError(\"invalid token\")\n # pylint: disable=protected-access\n setattr(self._current_context, self._CONTEXT_KEY, token._context)\n\n\n__all__ = [\"ThreadLocalRuntimeContext\"]\n", "path": "opentelemetry-api/src/opentelemetry/context/threadlocal_context.py"}]}
| 1,177 | 584 |
gh_patches_debug_2310
|
rasdani/github-patches
|
git_diff
|
frappe__frappe-4935
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Auto Email Report Should be fetched from site_config
#### Expected Behaviour
Adding the `max_reports_per_user` field in site_config should be fetched for Auto Email Report limit instead of the static 3 used currently.
Reference: https://discuss.erpnext.com/t/auto-email-report-why-there-is-a-limit-of-3-user-field/23296/4
Frappé version: 10.0.16
</issue>
<code>
[start of frappe/email/doctype/auto_email_report/auto_email_report.py]
1 # -*- coding: utf-8 -*-
2 # Copyright (c) 2015, Frappe Technologies and contributors
3 # For license information, please see license.txt
4
5 from __future__ import unicode_literals
6 import frappe, json
7 from frappe import _
8 from frappe.model.document import Document
9 from datetime import timedelta
10 import frappe.utils
11 from frappe.utils import now, global_date_format, format_time
12 from frappe.utils.xlsxutils import make_xlsx
13 from frappe.utils.csvutils import to_csv
14
15 max_reports_per_user = 3
16
17 class AutoEmailReport(Document):
18 def autoname(self):
19 self.name = _(self.report)
20
21 def validate(self):
22 self.validate_report_count()
23 self.validate_emails()
24 self.validate_report_format()
25
26 def validate_emails(self):
27 '''Cleanup list of emails'''
28 if ',' in self.email_to:
29 self.email_to.replace(',', '\n')
30
31 valid = []
32 for email in self.email_to.split():
33 if email:
34 frappe.utils.validate_email_add(email, True)
35 valid.append(email)
36
37 self.email_to = '\n'.join(valid)
38
39 def validate_report_count(self):
40 '''check that there are only 3 enabled reports per user'''
41 count = frappe.db.sql('select count(*) from `tabAuto Email Report` where user=%s and enabled=1', self.user)[0][0]
42 if count > max_reports_per_user + (-1 if self.flags.in_insert else 0):
43 frappe.throw(_('Only {0} emailed reports are allowed per user').format(max_reports_per_user))
44
45 def validate_report_format(self):
46 """ check if user has select correct report format """
47 valid_report_formats = ["HTML", "XLSX", "CSV"]
48 if self.format not in valid_report_formats:
49 frappe.throw(_("%s is not a valid report format. Report format should \
50 one of the following %s"%(frappe.bold(self.format), frappe.bold(", ".join(valid_report_formats)))))
51
52 def get_report_content(self):
53 '''Returns file in for the report in given format'''
54 report = frappe.get_doc('Report', self.report)
55
56 if self.report_type=='Report Builder' and self.data_modified_till:
57 self.filters = json.loads(self.filters) if self.filters else {}
58 self.filters['modified'] = ('>', frappe.utils.now_datetime() - timedelta(hours=self.data_modified_till))
59
60 columns, data = report.get_data(limit=self.no_of_rows or 100, user = self.user,
61 filters = self.filters, as_dict=True)
62
63 # add serial numbers
64 columns.insert(0, frappe._dict(fieldname='idx', label='', width='30px'))
65 for i in range(len(data)):
66 data[i]['idx'] = i+1
67
68 if len(data)==0 and self.send_if_data:
69 return None
70
71 if self.format == 'HTML':
72 return self.get_html_table(columns, data)
73
74 elif self.format == 'XLSX':
75 spreadsheet_data = self.get_spreadsheet_data(columns, data)
76 xlsx_file = make_xlsx(spreadsheet_data, "Auto Email Report")
77 return xlsx_file.getvalue()
78
79 elif self.format == 'CSV':
80 spreadsheet_data = self.get_spreadsheet_data(columns, data)
81 return to_csv(spreadsheet_data)
82
83 else:
84 frappe.throw(_('Invalid Output Format'))
85
86 def get_html_table(self, columns=None, data=None):
87
88 date_time = global_date_format(now()) + ' ' + format_time(now())
89 report_doctype = frappe.db.get_value('Report', self.report, 'ref_doctype')
90
91 return frappe.render_template('frappe/templates/emails/auto_email_report.html', {
92 'title': self.name,
93 'description': self.description,
94 'date_time': date_time,
95 'columns': columns,
96 'data': data,
97 'report_url': frappe.utils.get_url_to_report(self.report,
98 self.report_type, report_doctype),
99 'report_name': self.report,
100 'edit_report_settings': frappe.utils.get_link_to_form('Auto Email Report',
101 self.name)
102 })
103
104 @staticmethod
105 def get_spreadsheet_data(columns, data):
106 out = [[_(df.label) for df in columns], ]
107 for row in data:
108 new_row = []
109 out.append(new_row)
110 for df in columns:
111 new_row.append(frappe.format(row[df.fieldname], df, row))
112
113 return out
114
115 def get_file_name(self):
116 return "{0}.{1}".format(self.report.replace(" ", "-").replace("/", "-"), self.format.lower())
117
118 def send(self):
119 if self.filter_meta and not self.filters:
120 frappe.throw(_("Please set filters value in Report Filter table."))
121
122 data = self.get_report_content()
123 if not data:
124 return
125
126 attachments = None
127 if self.format == "HTML":
128 message = data
129 else:
130 message = self.get_html_table()
131
132 if not self.format=='HTML':
133 attachments = [{
134 'fname': self.get_file_name(),
135 'fcontent': data
136 }]
137
138 frappe.sendmail(
139 recipients = self.email_to.split(),
140 subject = self.name,
141 message = message,
142 attachments = attachments,
143 reference_doctype = self.doctype,
144 reference_name = self.name
145 )
146
147 @frappe.whitelist()
148 def download(name):
149 '''Download report locally'''
150 auto_email_report = frappe.get_doc('Auto Email Report', name)
151 auto_email_report.check_permission()
152 data = auto_email_report.get_report_content()
153
154 if not data:
155 frappe.msgprint(_('No Data'))
156 return
157
158 frappe.local.response.filecontent = data
159 frappe.local.response.type = "download"
160 frappe.local.response.filename = auto_email_report.get_file_name()
161
162 @frappe.whitelist()
163 def send_now(name):
164 '''Send Auto Email report now'''
165 auto_email_report = frappe.get_doc('Auto Email Report', name)
166 auto_email_report.check_permission()
167 auto_email_report.send()
168
169 def send_daily():
170 '''Check reports to be sent daily'''
171 now = frappe.utils.now_datetime()
172 for report in frappe.get_all('Auto Email Report',
173 {'enabled': 1, 'frequency': ('in', ('Daily', 'Weekly'))}):
174 auto_email_report = frappe.get_doc('Auto Email Report', report.name)
175
176 # if not correct weekday, skip
177 if auto_email_report.frequency=='Weekly':
178 if now.weekday()!={'Monday':0,'Tuesday':1,'Wednesday':2,
179 'Thursday':3,'Friday':4,'Saturday':5,'Sunday':6}[auto_email_report.day_of_week]:
180 continue
181
182 auto_email_report.send()
183
184
185 def send_monthly():
186 '''Check reports to be sent monthly'''
187 for report in frappe.get_all('Auto Email Report', {'enabled': 1, 'frequency': 'Monthly'}):
188 frappe.get_doc('Auto Email Report', report.name).send()
189
[end of frappe/email/doctype/auto_email_report/auto_email_report.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/frappe/email/doctype/auto_email_report/auto_email_report.py b/frappe/email/doctype/auto_email_report/auto_email_report.py
--- a/frappe/email/doctype/auto_email_report/auto_email_report.py
+++ b/frappe/email/doctype/auto_email_report/auto_email_report.py
@@ -12,7 +12,7 @@
from frappe.utils.xlsxutils import make_xlsx
from frappe.utils.csvutils import to_csv
-max_reports_per_user = 3
+max_reports_per_user = frappe.local.conf.max_reports_per_user or 3
class AutoEmailReport(Document):
def autoname(self):
|
{"golden_diff": "diff --git a/frappe/email/doctype/auto_email_report/auto_email_report.py b/frappe/email/doctype/auto_email_report/auto_email_report.py\n--- a/frappe/email/doctype/auto_email_report/auto_email_report.py\n+++ b/frappe/email/doctype/auto_email_report/auto_email_report.py\n@@ -12,7 +12,7 @@\n from frappe.utils.xlsxutils import make_xlsx\n from frappe.utils.csvutils import to_csv\n \n-max_reports_per_user = 3\n+max_reports_per_user = frappe.local.conf.max_reports_per_user or 3\n \n class AutoEmailReport(Document):\n \tdef autoname(self):\n", "issue": "Auto Email Report Should be fetched from site_config\n#### Expected Behaviour\r\nAdding the `max_reports_per_user` field in site_config should be fetched for Auto Email Report limit instead of the static 3 used currently.\r\n\r\nReference: https://discuss.erpnext.com/t/auto-email-report-why-there-is-a-limit-of-3-user-field/23296/4\r\n\r\nFrapp\u00e9 version: 10.0.16\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# Copyright (c) 2015, Frappe Technologies and contributors\n# For license information, please see license.txt\n\nfrom __future__ import unicode_literals\nimport frappe, json\nfrom frappe import _\nfrom frappe.model.document import Document\nfrom datetime import timedelta\nimport frappe.utils\nfrom frappe.utils import now, global_date_format, format_time\nfrom frappe.utils.xlsxutils import make_xlsx\nfrom frappe.utils.csvutils import to_csv\n\nmax_reports_per_user = 3\n\nclass AutoEmailReport(Document):\n\tdef autoname(self):\n\t\tself.name = _(self.report)\n\n\tdef validate(self):\n\t\tself.validate_report_count()\n\t\tself.validate_emails()\n\t\tself.validate_report_format()\n\n\tdef validate_emails(self):\n\t\t'''Cleanup list of emails'''\n\t\tif ',' in self.email_to:\n\t\t\tself.email_to.replace(',', '\\n')\n\n\t\tvalid = []\n\t\tfor email in self.email_to.split():\n\t\t\tif email:\n\t\t\t\tfrappe.utils.validate_email_add(email, True)\n\t\t\t\tvalid.append(email)\n\n\t\tself.email_to = '\\n'.join(valid)\n\n\tdef validate_report_count(self):\n\t\t'''check that there are only 3 enabled reports per user'''\n\t\tcount = frappe.db.sql('select count(*) from `tabAuto Email Report` where user=%s and enabled=1', self.user)[0][0]\n\t\tif count > max_reports_per_user + (-1 if self.flags.in_insert else 0):\n\t\t\tfrappe.throw(_('Only {0} emailed reports are allowed per user').format(max_reports_per_user))\n\n\tdef validate_report_format(self):\n\t\t\"\"\" check if user has select correct report format \"\"\"\n\t\tvalid_report_formats = [\"HTML\", \"XLSX\", \"CSV\"]\n\t\tif self.format not in valid_report_formats:\n\t\t\tfrappe.throw(_(\"%s is not a valid report format. Report format should \\\n\t\t\t\tone of the following %s\"%(frappe.bold(self.format), frappe.bold(\", \".join(valid_report_formats)))))\n\n\tdef get_report_content(self):\n\t\t'''Returns file in for the report in given format'''\n\t\treport = frappe.get_doc('Report', self.report)\n\n\t\tif self.report_type=='Report Builder' and self.data_modified_till:\n\t\t\tself.filters = json.loads(self.filters) if self.filters else {}\n\t\t\tself.filters['modified'] = ('>', frappe.utils.now_datetime() - timedelta(hours=self.data_modified_till))\n\n\t\tcolumns, data = report.get_data(limit=self.no_of_rows or 100, user = self.user,\n\t\t\tfilters = self.filters, as_dict=True)\n\n\t\t# add serial numbers\n\t\tcolumns.insert(0, frappe._dict(fieldname='idx', label='', width='30px'))\n\t\tfor i in range(len(data)):\n\t\t\tdata[i]['idx'] = i+1\n\n\t\tif len(data)==0 and self.send_if_data:\n\t\t\treturn None\n\n\t\tif self.format == 'HTML':\n\t\t\treturn self.get_html_table(columns, data)\n\n\t\telif self.format == 'XLSX':\n\t\t\tspreadsheet_data = self.get_spreadsheet_data(columns, data)\n\t\t\txlsx_file = make_xlsx(spreadsheet_data, \"Auto Email Report\")\n\t\t\treturn xlsx_file.getvalue()\n\n\t\telif self.format == 'CSV':\n\t\t\tspreadsheet_data = self.get_spreadsheet_data(columns, data)\n\t\t\treturn to_csv(spreadsheet_data)\n\n\t\telse:\n\t\t\tfrappe.throw(_('Invalid Output Format'))\n\n\tdef get_html_table(self, columns=None, data=None):\n\n\t\tdate_time = global_date_format(now()) + ' ' + format_time(now())\n\t\treport_doctype = frappe.db.get_value('Report', self.report, 'ref_doctype')\n\n\t\treturn frappe.render_template('frappe/templates/emails/auto_email_report.html', {\n\t\t\t'title': self.name,\n\t\t\t'description': self.description,\n\t\t\t'date_time': date_time,\n\t\t\t'columns': columns,\n\t\t\t'data': data,\n\t\t\t'report_url': frappe.utils.get_url_to_report(self.report,\n\t\t\t\tself.report_type, report_doctype),\n\t\t\t'report_name': self.report,\n\t\t\t'edit_report_settings': frappe.utils.get_link_to_form('Auto Email Report',\n\t\t\t\tself.name)\n\t\t})\n\n\t@staticmethod\n\tdef get_spreadsheet_data(columns, data):\n\t\tout = [[_(df.label) for df in columns], ]\n\t\tfor row in data:\n\t\t\tnew_row = []\n\t\t\tout.append(new_row)\n\t\t\tfor df in columns:\n\t\t\t\tnew_row.append(frappe.format(row[df.fieldname], df, row))\n\n\t\treturn out\n\n\tdef get_file_name(self):\n\t\treturn \"{0}.{1}\".format(self.report.replace(\" \", \"-\").replace(\"/\", \"-\"), self.format.lower())\n\n\tdef send(self):\n\t\tif self.filter_meta and not self.filters:\n\t\t\tfrappe.throw(_(\"Please set filters value in Report Filter table.\"))\n\n\t\tdata = self.get_report_content()\n\t\tif not data:\n\t\t\treturn\n\n\t\tattachments = None\n\t\tif self.format == \"HTML\":\n\t\t\tmessage = data\n\t\telse:\n\t\t\tmessage = self.get_html_table()\n\n\t\tif not self.format=='HTML':\n\t\t\tattachments = [{\n\t\t\t\t'fname': self.get_file_name(),\n\t\t\t\t'fcontent': data\n\t\t\t}]\n\n\t\tfrappe.sendmail(\n\t\t\trecipients = self.email_to.split(),\n\t\t\tsubject = self.name,\n\t\t\tmessage = message,\n\t\t\tattachments = attachments,\n\t\t\treference_doctype = self.doctype,\n\t\t\treference_name = self.name\n\t\t)\n\[email protected]()\ndef download(name):\n\t'''Download report locally'''\n\tauto_email_report = frappe.get_doc('Auto Email Report', name)\n\tauto_email_report.check_permission()\n\tdata = auto_email_report.get_report_content()\n\n\tif not data:\n\t\tfrappe.msgprint(_('No Data'))\n\t\treturn\n\n\tfrappe.local.response.filecontent = data\n\tfrappe.local.response.type = \"download\"\n\tfrappe.local.response.filename = auto_email_report.get_file_name()\n\[email protected]()\ndef send_now(name):\n\t'''Send Auto Email report now'''\n\tauto_email_report = frappe.get_doc('Auto Email Report', name)\n\tauto_email_report.check_permission()\n\tauto_email_report.send()\n\ndef send_daily():\n\t'''Check reports to be sent daily'''\n\tnow = frappe.utils.now_datetime()\n\tfor report in frappe.get_all('Auto Email Report',\n\t\t{'enabled': 1, 'frequency': ('in', ('Daily', 'Weekly'))}):\n\t\tauto_email_report = frappe.get_doc('Auto Email Report', report.name)\n\n\t\t# if not correct weekday, skip\n\t\tif auto_email_report.frequency=='Weekly':\n\t\t\tif now.weekday()!={'Monday':0,'Tuesday':1,'Wednesday':2,\n\t\t\t\t'Thursday':3,'Friday':4,'Saturday':5,'Sunday':6}[auto_email_report.day_of_week]:\n\t\t\t\tcontinue\n\n\t\tauto_email_report.send()\n\n\ndef send_monthly():\n\t'''Check reports to be sent monthly'''\n\tfor report in frappe.get_all('Auto Email Report', {'enabled': 1, 'frequency': 'Monthly'}):\n\t\tfrappe.get_doc('Auto Email Report', report.name).send()\n", "path": "frappe/email/doctype/auto_email_report/auto_email_report.py"}]}
| 2,664 | 132 |
gh_patches_debug_30159
|
rasdani/github-patches
|
git_diff
|
elastic__apm-agent-python-1129
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Redis: Support publish and subscribe methods
While running the examples from the blog post [How to instrument a polyglot microservices application with Elastic APM](https://www.elastic.co/blog/how-to-instrument-a-polyglot-microservices-application-with-elastic-apm), I noticed Redis doesn't show up on the service map as being connected to the Python service in this example.
It looks like that's because [according to our documentation we don't have the `publish` and `subscribe` methods instrumented](https://www.elastic.co/guide/en/apm/agent/python/5.x/supported-technologies.html#automatic-instrumentation-db-redis).
If these methods were instrumented we would be able to see Redis on service maps for applications that are using it for pub/sub.
</issue>
<code>
[start of elasticapm/instrumentation/packages/asyncio/aioredis.py]
1 # BSD 3-Clause License
2 #
3 # Copyright (c) 2019, Elasticsearch BV
4 # All rights reserved.
5 #
6 # Redistribution and use in source and binary forms, with or without
7 # modification, are permitted provided that the following conditions are met:
8 #
9 # * Redistributions of source code must retain the above copyright notice, this
10 # list of conditions and the following disclaimer.
11 #
12 # * Redistributions in binary form must reproduce the above copyright notice,
13 # this list of conditions and the following disclaimer in the documentation
14 # and/or other materials provided with the distribution.
15 #
16 # * Neither the name of the copyright holder nor the names of its
17 # contributors may be used to endorse or promote products derived from
18 # this software without specific prior written permission.
19 #
20 # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
21 # AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
22 # IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
23 # DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
24 # FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
25 # DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
26 # SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
27 # CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
28 # OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
29 # OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
30
31 from __future__ import absolute_import
32
33 from elasticapm.contrib.asyncio.traces import async_capture_span
34 from elasticapm.instrumentation.packages.base import AbstractInstrumentedModule
35 from elasticapm.traces import execution_context
36
37
38 class RedisConnectionPoolInstrumentation(AbstractInstrumentedModule):
39 name = "aioredis"
40
41 instrument_list = [("aioredis.pool", "ConnectionsPool.execute")]
42
43 def call(self, module, method, wrapped, instance, args, kwargs):
44 if len(args) > 0:
45 wrapped_name = args[0].decode()
46 else:
47 wrapped_name = self.get_wrapped_name(wrapped, instance, method)
48
49 with async_capture_span(
50 wrapped_name, span_type="db", span_subtype="redis", span_action="query", leaf=True
51 ) as span:
52 span.context["destination"] = _get_destination_info(instance)
53
54 return wrapped(*args, **kwargs)
55
56
57 class RedisPipelineInstrumentation(AbstractInstrumentedModule):
58 name = "aioredis"
59
60 instrument_list = [("aioredis.commands.transaction", "Pipeline.execute")]
61
62 def call(self, module, method, wrapped, instance, args, kwargs):
63 wrapped_name = self.get_wrapped_name(wrapped, instance, method)
64
65 with async_capture_span(
66 wrapped_name, span_type="db", span_subtype="redis", span_action="query", leaf=True
67 ) as span:
68 span.context["destination"] = _get_destination_info(instance)
69
70 return wrapped(*args, **kwargs)
71
72
73 class RedisConnectionInstrumentation(AbstractInstrumentedModule):
74 name = "aioredis"
75
76 instrument_list = (("aioredis.connection", "RedisConnection.execute"),)
77
78 def call(self, module, method, wrapped, instance, args, kwargs):
79 span = execution_context.get_span()
80 if span and span.subtype == "aioredis":
81 span.context["destination"] = _get_destination_info(instance)
82 return wrapped(*args, **kwargs)
83
84
85 def _get_destination_info(connection):
86 destination_info = {"service": {"name": "aioredis", "resource": "redis", "type": "db"}}
87
88 if hasattr(connection, "_pool_or_conn"):
89 destination_info["port"] = connection._pool_or_conn.address[1]
90 destination_info["address"] = connection._pool_or_conn.address[0]
91 else:
92 destination_info["port"] = connection.address[1]
93 destination_info["address"] = connection.address[0]
94
95 return destination_info
96
[end of elasticapm/instrumentation/packages/asyncio/aioredis.py]
[start of elasticapm/instrumentation/packages/redis.py]
1 # BSD 3-Clause License
2 #
3 # Copyright (c) 2019, Elasticsearch BV
4 # All rights reserved.
5 #
6 # Redistribution and use in source and binary forms, with or without
7 # modification, are permitted provided that the following conditions are met:
8 #
9 # * Redistributions of source code must retain the above copyright notice, this
10 # list of conditions and the following disclaimer.
11 #
12 # * Redistributions in binary form must reproduce the above copyright notice,
13 # this list of conditions and the following disclaimer in the documentation
14 # and/or other materials provided with the distribution.
15 #
16 # * Neither the name of the copyright holder nor the names of its
17 # contributors may be used to endorse or promote products derived from
18 # this software without specific prior written permission.
19 #
20 # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
21 # AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
22 # IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
23 # DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
24 # FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
25 # DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
26 # SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
27 # CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
28 # OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
29 # OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
30
31 from __future__ import absolute_import
32
33 from elasticapm.instrumentation.packages.base import AbstractInstrumentedModule
34 from elasticapm.traces import capture_span, execution_context
35
36
37 class Redis3CheckMixin(object):
38 instrument_list_3 = []
39 instrument_list = []
40
41 def get_instrument_list(self):
42 try:
43 from redis import VERSION
44
45 if VERSION[0] >= 3:
46 return self.instrument_list_3
47 return self.instrument_list
48 except ImportError:
49 return self.instrument_list
50
51
52 class RedisInstrumentation(Redis3CheckMixin, AbstractInstrumentedModule):
53 name = "redis"
54
55 # no need to instrument StrictRedis in redis-py >= 3.0
56 instrument_list_3 = [("redis.client", "Redis.execute_command")]
57 instrument_list = [("redis.client", "Redis.execute_command"), ("redis.client", "StrictRedis.execute_command")]
58
59 def call(self, module, method, wrapped, instance, args, kwargs):
60 if len(args) > 0:
61 wrapped_name = str(args[0])
62 else:
63 wrapped_name = self.get_wrapped_name(wrapped, instance, method)
64
65 with capture_span(wrapped_name, span_type="db", span_subtype="redis", span_action="query", leaf=True):
66 return wrapped(*args, **kwargs)
67
68
69 class RedisPipelineInstrumentation(Redis3CheckMixin, AbstractInstrumentedModule):
70 name = "redis"
71
72 # BasePipeline has been renamed to Pipeline in redis-py 3
73 instrument_list_3 = [("redis.client", "Pipeline.execute")]
74 instrument_list = [("redis.client", "BasePipeline.execute")]
75
76 def call(self, module, method, wrapped, instance, args, kwargs):
77 wrapped_name = self.get_wrapped_name(wrapped, instance, method)
78 with capture_span(wrapped_name, span_type="db", span_subtype="redis", span_action="query", leaf=True):
79 return wrapped(*args, **kwargs)
80
81
82 class RedisConnectionInstrumentation(AbstractInstrumentedModule):
83 name = "redis"
84
85 instrument_list = (("redis.connection", "Connection.send_packed_command"),)
86
87 def call(self, module, method, wrapped, instance, args, kwargs):
88 span = execution_context.get_span()
89 if span and span.subtype == "redis":
90 span.context["destination"] = get_destination_info(instance)
91 return wrapped(*args, **kwargs)
92
93
94 def get_destination_info(connection):
95 destination_info = {"service": {"name": "redis", "resource": "redis", "type": "db"}}
96 if hasattr(connection, "port"):
97 destination_info["port"] = connection.port
98 destination_info["address"] = connection.host
99 elif hasattr(connection, "path"):
100 destination_info["port"] = None
101 destination_info["address"] = "unix://" + connection.path
102 return destination_info
103
[end of elasticapm/instrumentation/packages/redis.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/elasticapm/instrumentation/packages/asyncio/aioredis.py b/elasticapm/instrumentation/packages/asyncio/aioredis.py
--- a/elasticapm/instrumentation/packages/asyncio/aioredis.py
+++ b/elasticapm/instrumentation/packages/asyncio/aioredis.py
@@ -38,7 +38,8 @@
class RedisConnectionPoolInstrumentation(AbstractInstrumentedModule):
name = "aioredis"
- instrument_list = [("aioredis.pool", "ConnectionsPool.execute")]
+ instrument_list = [("aioredis.pool", "ConnectionsPool.execute"),
+ ("aioredis.pool", "ConnectionsPool.execute_pubsub")]
def call(self, module, method, wrapped, instance, args, kwargs):
if len(args) > 0:
@@ -73,7 +74,8 @@
class RedisConnectionInstrumentation(AbstractInstrumentedModule):
name = "aioredis"
- instrument_list = (("aioredis.connection", "RedisConnection.execute"),)
+ instrument_list = (("aioredis.connection", "RedisConnection.execute"),
+ ("aioredis.pool", "ConnectionsPool.execute_pubsub"))
def call(self, module, method, wrapped, instance, args, kwargs):
span = execution_context.get_span()
diff --git a/elasticapm/instrumentation/packages/redis.py b/elasticapm/instrumentation/packages/redis.py
--- a/elasticapm/instrumentation/packages/redis.py
+++ b/elasticapm/instrumentation/packages/redis.py
@@ -53,7 +53,7 @@
name = "redis"
# no need to instrument StrictRedis in redis-py >= 3.0
- instrument_list_3 = [("redis.client", "Redis.execute_command")]
+ instrument_list_3 = [("redis.client", "Redis.execute_command"), ("redis.client", "PubSub.execute_command")]
instrument_list = [("redis.client", "Redis.execute_command"), ("redis.client", "StrictRedis.execute_command")]
def call(self, module, method, wrapped, instance, args, kwargs):
|
{"golden_diff": "diff --git a/elasticapm/instrumentation/packages/asyncio/aioredis.py b/elasticapm/instrumentation/packages/asyncio/aioredis.py\n--- a/elasticapm/instrumentation/packages/asyncio/aioredis.py\n+++ b/elasticapm/instrumentation/packages/asyncio/aioredis.py\n@@ -38,7 +38,8 @@\n class RedisConnectionPoolInstrumentation(AbstractInstrumentedModule):\n name = \"aioredis\"\n \n- instrument_list = [(\"aioredis.pool\", \"ConnectionsPool.execute\")]\n+ instrument_list = [(\"aioredis.pool\", \"ConnectionsPool.execute\"),\n+ (\"aioredis.pool\", \"ConnectionsPool.execute_pubsub\")]\n \n def call(self, module, method, wrapped, instance, args, kwargs):\n if len(args) > 0:\n@@ -73,7 +74,8 @@\n class RedisConnectionInstrumentation(AbstractInstrumentedModule):\n name = \"aioredis\"\n \n- instrument_list = ((\"aioredis.connection\", \"RedisConnection.execute\"),)\n+ instrument_list = ((\"aioredis.connection\", \"RedisConnection.execute\"),\n+ (\"aioredis.pool\", \"ConnectionsPool.execute_pubsub\"))\n \n def call(self, module, method, wrapped, instance, args, kwargs):\n span = execution_context.get_span()\ndiff --git a/elasticapm/instrumentation/packages/redis.py b/elasticapm/instrumentation/packages/redis.py\n--- a/elasticapm/instrumentation/packages/redis.py\n+++ b/elasticapm/instrumentation/packages/redis.py\n@@ -53,7 +53,7 @@\n name = \"redis\"\n \n # no need to instrument StrictRedis in redis-py >= 3.0\n- instrument_list_3 = [(\"redis.client\", \"Redis.execute_command\")]\n+ instrument_list_3 = [(\"redis.client\", \"Redis.execute_command\"), (\"redis.client\", \"PubSub.execute_command\")]\n instrument_list = [(\"redis.client\", \"Redis.execute_command\"), (\"redis.client\", \"StrictRedis.execute_command\")]\n \n def call(self, module, method, wrapped, instance, args, kwargs):\n", "issue": "Redis: Support publish and subscribe methods\nWhile running the examples from the blog post [How to instrument a polyglot microservices application with Elastic APM](https://www.elastic.co/blog/how-to-instrument-a-polyglot-microservices-application-with-elastic-apm), I noticed Redis doesn't show up on the service map as being connected to the Python service in this example.\r\n\r\nIt looks like that's because [according to our documentation we don't have the `publish` and `subscribe` methods instrumented](https://www.elastic.co/guide/en/apm/agent/python/5.x/supported-technologies.html#automatic-instrumentation-db-redis).\r\n\r\nIf these methods were instrumented we would be able to see Redis on service maps for applications that are using it for pub/sub.\n", "before_files": [{"content": "# BSD 3-Clause License\n#\n# Copyright (c) 2019, Elasticsearch BV\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n#\n# * Redistributions of source code must retain the above copyright notice, this\n# list of conditions and the following disclaimer.\n#\n# * Redistributions in binary form must reproduce the above copyright notice,\n# this list of conditions and the following disclaimer in the documentation\n# and/or other materials provided with the distribution.\n#\n# * Neither the name of the copyright holder nor the names of its\n# contributors may be used to endorse or promote products derived from\n# this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE\n# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL\n# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR\n# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,\n# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.\n\nfrom __future__ import absolute_import\n\nfrom elasticapm.contrib.asyncio.traces import async_capture_span\nfrom elasticapm.instrumentation.packages.base import AbstractInstrumentedModule\nfrom elasticapm.traces import execution_context\n\n\nclass RedisConnectionPoolInstrumentation(AbstractInstrumentedModule):\n name = \"aioredis\"\n\n instrument_list = [(\"aioredis.pool\", \"ConnectionsPool.execute\")]\n\n def call(self, module, method, wrapped, instance, args, kwargs):\n if len(args) > 0:\n wrapped_name = args[0].decode()\n else:\n wrapped_name = self.get_wrapped_name(wrapped, instance, method)\n\n with async_capture_span(\n wrapped_name, span_type=\"db\", span_subtype=\"redis\", span_action=\"query\", leaf=True\n ) as span:\n span.context[\"destination\"] = _get_destination_info(instance)\n\n return wrapped(*args, **kwargs)\n\n\nclass RedisPipelineInstrumentation(AbstractInstrumentedModule):\n name = \"aioredis\"\n\n instrument_list = [(\"aioredis.commands.transaction\", \"Pipeline.execute\")]\n\n def call(self, module, method, wrapped, instance, args, kwargs):\n wrapped_name = self.get_wrapped_name(wrapped, instance, method)\n\n with async_capture_span(\n wrapped_name, span_type=\"db\", span_subtype=\"redis\", span_action=\"query\", leaf=True\n ) as span:\n span.context[\"destination\"] = _get_destination_info(instance)\n\n return wrapped(*args, **kwargs)\n\n\nclass RedisConnectionInstrumentation(AbstractInstrumentedModule):\n name = \"aioredis\"\n\n instrument_list = ((\"aioredis.connection\", \"RedisConnection.execute\"),)\n\n def call(self, module, method, wrapped, instance, args, kwargs):\n span = execution_context.get_span()\n if span and span.subtype == \"aioredis\":\n span.context[\"destination\"] = _get_destination_info(instance)\n return wrapped(*args, **kwargs)\n\n\ndef _get_destination_info(connection):\n destination_info = {\"service\": {\"name\": \"aioredis\", \"resource\": \"redis\", \"type\": \"db\"}}\n\n if hasattr(connection, \"_pool_or_conn\"):\n destination_info[\"port\"] = connection._pool_or_conn.address[1]\n destination_info[\"address\"] = connection._pool_or_conn.address[0]\n else:\n destination_info[\"port\"] = connection.address[1]\n destination_info[\"address\"] = connection.address[0]\n\n return destination_info\n", "path": "elasticapm/instrumentation/packages/asyncio/aioredis.py"}, {"content": "# BSD 3-Clause License\n#\n# Copyright (c) 2019, Elasticsearch BV\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n#\n# * Redistributions of source code must retain the above copyright notice, this\n# list of conditions and the following disclaimer.\n#\n# * Redistributions in binary form must reproduce the above copyright notice,\n# this list of conditions and the following disclaimer in the documentation\n# and/or other materials provided with the distribution.\n#\n# * Neither the name of the copyright holder nor the names of its\n# contributors may be used to endorse or promote products derived from\n# this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE\n# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL\n# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR\n# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,\n# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.\n\nfrom __future__ import absolute_import\n\nfrom elasticapm.instrumentation.packages.base import AbstractInstrumentedModule\nfrom elasticapm.traces import capture_span, execution_context\n\n\nclass Redis3CheckMixin(object):\n instrument_list_3 = []\n instrument_list = []\n\n def get_instrument_list(self):\n try:\n from redis import VERSION\n\n if VERSION[0] >= 3:\n return self.instrument_list_3\n return self.instrument_list\n except ImportError:\n return self.instrument_list\n\n\nclass RedisInstrumentation(Redis3CheckMixin, AbstractInstrumentedModule):\n name = \"redis\"\n\n # no need to instrument StrictRedis in redis-py >= 3.0\n instrument_list_3 = [(\"redis.client\", \"Redis.execute_command\")]\n instrument_list = [(\"redis.client\", \"Redis.execute_command\"), (\"redis.client\", \"StrictRedis.execute_command\")]\n\n def call(self, module, method, wrapped, instance, args, kwargs):\n if len(args) > 0:\n wrapped_name = str(args[0])\n else:\n wrapped_name = self.get_wrapped_name(wrapped, instance, method)\n\n with capture_span(wrapped_name, span_type=\"db\", span_subtype=\"redis\", span_action=\"query\", leaf=True):\n return wrapped(*args, **kwargs)\n\n\nclass RedisPipelineInstrumentation(Redis3CheckMixin, AbstractInstrumentedModule):\n name = \"redis\"\n\n # BasePipeline has been renamed to Pipeline in redis-py 3\n instrument_list_3 = [(\"redis.client\", \"Pipeline.execute\")]\n instrument_list = [(\"redis.client\", \"BasePipeline.execute\")]\n\n def call(self, module, method, wrapped, instance, args, kwargs):\n wrapped_name = self.get_wrapped_name(wrapped, instance, method)\n with capture_span(wrapped_name, span_type=\"db\", span_subtype=\"redis\", span_action=\"query\", leaf=True):\n return wrapped(*args, **kwargs)\n\n\nclass RedisConnectionInstrumentation(AbstractInstrumentedModule):\n name = \"redis\"\n\n instrument_list = ((\"redis.connection\", \"Connection.send_packed_command\"),)\n\n def call(self, module, method, wrapped, instance, args, kwargs):\n span = execution_context.get_span()\n if span and span.subtype == \"redis\":\n span.context[\"destination\"] = get_destination_info(instance)\n return wrapped(*args, **kwargs)\n\n\ndef get_destination_info(connection):\n destination_info = {\"service\": {\"name\": \"redis\", \"resource\": \"redis\", \"type\": \"db\"}}\n if hasattr(connection, \"port\"):\n destination_info[\"port\"] = connection.port\n destination_info[\"address\"] = connection.host\n elif hasattr(connection, \"path\"):\n destination_info[\"port\"] = None\n destination_info[\"address\"] = \"unix://\" + connection.path\n return destination_info\n", "path": "elasticapm/instrumentation/packages/redis.py"}]}
| 2,954 | 463 |
gh_patches_debug_35742
|
rasdani/github-patches
|
git_diff
|
electricitymaps__electricitymaps-contrib-1123
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Generation from "Pumped storage" in France FR
At the moment, the bar charts on the map only show pumped storage consumption for France. But RTE also has data for pumped storage generation. This is currently not displayed on the map, because the "hydro" category of RTE includes all three types "hydro storage+run of river+pumped storage". But there is a seperate "pumping" category for consumption of the pumped storages (pumping).
http://www.rte-france.com/en/eco2mix/eco2mix-mix-energetique-en
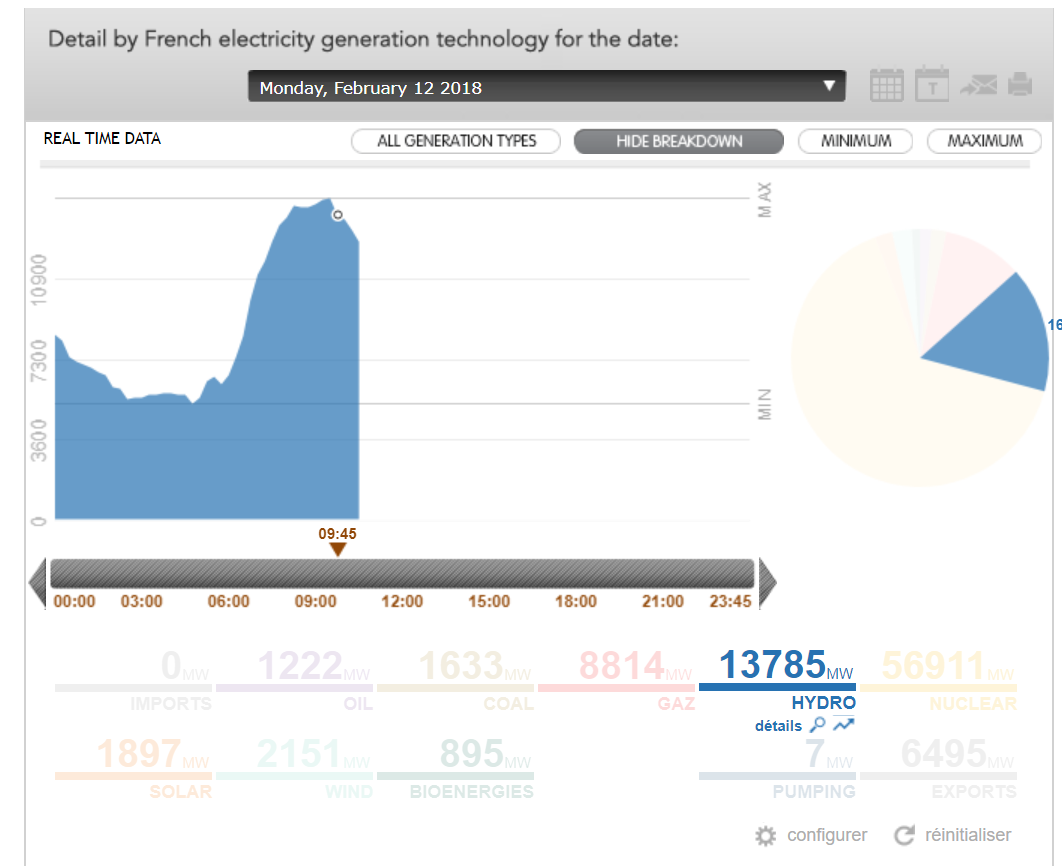
After selecting the hydro category, you'll see "details" below it. Selecting "details" you will see this, incuding the breakdown by hydro type:
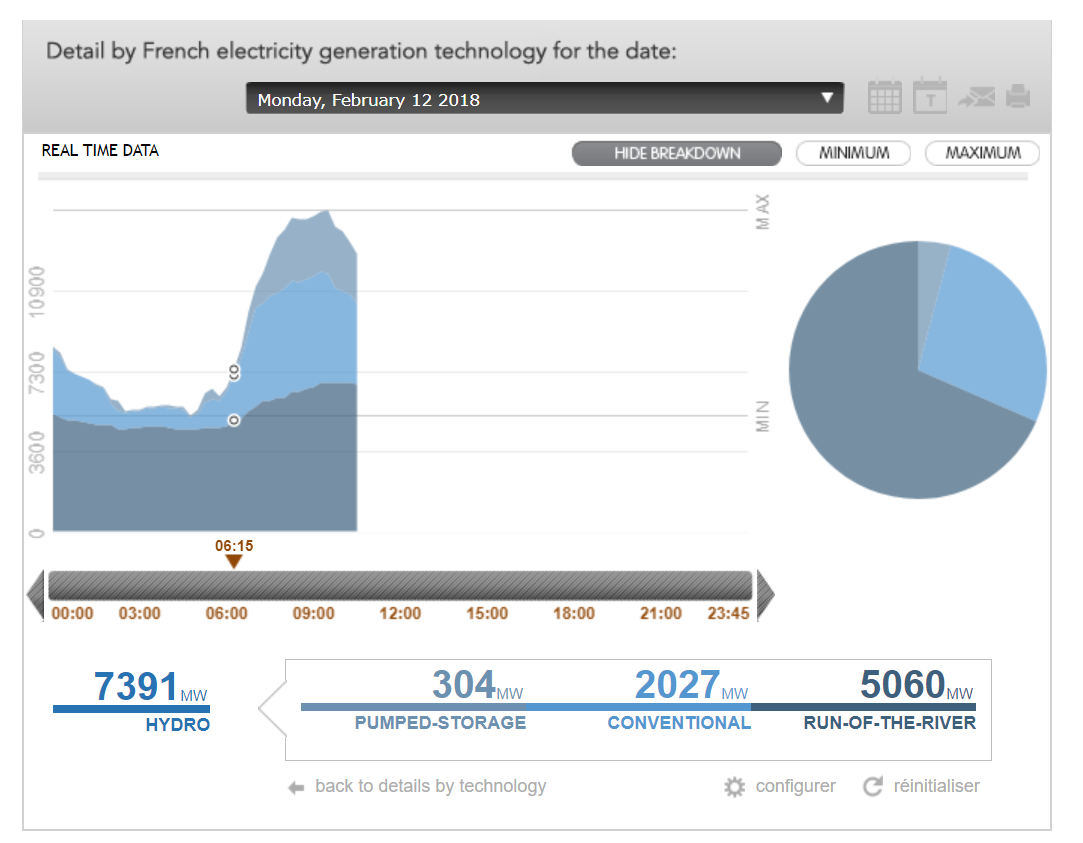
The most recent dataset for France can also be downloaded here:
http://www.rte-france.com/en/eco2mix/eco2mix-telechargement-en
The FR.py parser seems to use this URL http://www.rte-france.com/getEco2MixXml.php?type=donneesMarche&dateDeb={}&dateFin={}&mode=NORM for getting the data. Maybe there is a similar one for the hydro breakdown by type to seperate pumped storage generation from it.
</issue>
<code>
[start of parsers/FR.py]
1 #!/usr/bin/env python3
2
3 import arrow
4 import requests
5 import xml.etree.ElementTree as ET
6
7 MAP_GENERATION = {
8 u'Nucl\xe9aire': 'nuclear',
9 'Charbon': 'coal',
10 'Gaz': 'gas',
11 'Fioul': 'oil',
12 'Hydraulique': 'hydro',
13 'Eolien': 'wind',
14 'Solaire': 'solar',
15 'Autres': 'biomass'
16 }
17 MAP_STORAGE = {
18 'Pompage': 'hydro',
19 }
20
21
22 def fetch_production(country_code='FR', session=None):
23 r = session or requests.session()
24 formatted_date = arrow.now(tz='Europe/Paris').format('DD/MM/YYYY')
25 url = 'http://www.rte-france.com/getEco2MixXml.php?type=mix&&dateDeb={}&dateFin={}&mode=NORM'.format(formatted_date, formatted_date)
26 response = r.get(url)
27 obj = ET.fromstring(response.content)
28 mixtr = obj[7]
29 data = {
30 'countryCode': country_code,
31 'production': {},
32 'storage': {},
33 'source': 'rte-france.com',
34 }
35 for item in mixtr.getchildren():
36 if item.get('granularite') != 'Global':
37 continue
38 key = item.get('v')
39 value = None
40 for value in item.getchildren():
41 pass
42 if key in MAP_GENERATION:
43 data['production'][MAP_GENERATION[key]] = float(value.text)
44 elif key in MAP_STORAGE:
45 data['storage'][MAP_STORAGE[key]] = -1 * float(value.text)
46
47 data['datetime'] = arrow.get(arrow.get(obj[1].text).datetime,
48 'Europe/Paris').replace(minutes=+(int(value.attrib['periode']) * 15.0)).datetime
49
50 # Fetch imports
51 # url = 'http://www.rte-france.com/getEco2MixXml.php?type=echcom&&dateDeb={}&dateFin={}&mode=NORM'.format(formatted_date, formatted_date)
52 # response = r.get(url)
53 # obj = ET.fromstring(response.content)
54 # parsed = {}
55 # for item in obj[7].getchildren():
56 # value = None
57 # for value in item: pass
58 # parsed[item.get('v')] = float(value.text)
59
60 # data['exchange'] = {
61 # 'CH': parsed['CH'],
62 # 'GB': parsed['GB'],
63 # 'ES': parsed['ES'],
64 # 'IT': parsed['IT'],
65 # 'DE': parsed['DB'] # Germany + Belgium redirected to Germany
66 # }
67
68 return data
69
70
71 def fetch_price(country_code, session=None, from_date=None, to_date=None):
72 r = session or requests.session()
73 dt_now = arrow.now(tz='Europe/Paris')
74 formatted_from = from_date or dt_now.format('DD/MM/YYYY')
75 formatted_to = to_date or dt_now.format('DD/MM/YYYY')
76
77 url = 'http://www.rte-france.com/getEco2MixXml.php?type=donneesMarche&dateDeb={}&dateFin={}&mode=NORM'.format(formatted_from, formatted_to)
78 response = r.get(url)
79 obj = ET.fromstring(response.content)
80 mixtr = obj[5]
81
82 prices = []
83 datetimes = []
84
85 date_str = mixtr.get('date')
86 date = arrow.get(arrow.get(date_str).datetime, 'Europe/Paris')
87 for country_item in mixtr.getchildren():
88 if country_item.get('granularite') != 'Global':
89 continue
90 country_c = country_item.get('perimetre')
91 if country_code != country_c:
92 continue
93 value = None
94 for value in country_item.getchildren():
95 if value.text == 'ND':
96 continue
97 datetime = date.replace(hours=+int(value.attrib['periode'])).datetime
98 if datetime > dt_now:
99 continue
100 datetimes.append(datetime)
101 prices.append(float(value.text))
102
103 data = {
104 'countryCode': country_code,
105 'currency': 'EUR',
106 'datetime': datetimes[-1],
107 'price': prices[-1],
108 'source': 'rte-france.com',
109 }
110 return data
111
112
113 if __name__ == '__main__':
114 print(fetch_production())
115
[end of parsers/FR.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/parsers/FR.py b/parsers/FR.py
--- a/parsers/FR.py
+++ b/parsers/FR.py
@@ -16,6 +16,7 @@
}
MAP_STORAGE = {
'Pompage': 'hydro',
+ 'Hydraulique': 'hydro',
}
@@ -33,38 +34,36 @@
'source': 'rte-france.com',
}
for item in mixtr.getchildren():
- if item.get('granularite') != 'Global':
- continue
key = item.get('v')
+ granularite = item.get('granularite')
value = None
for value in item.getchildren():
pass
- if key in MAP_GENERATION:
- data['production'][MAP_GENERATION[key]] = float(value.text)
- elif key in MAP_STORAGE:
- data['storage'][MAP_STORAGE[key]] = -1 * float(value.text)
+ if key == 'Hydraulique':
+ # Hydro is a special case!
+ if granularite == 'Global':
+ continue
+ elif granularite in ['FEE', 'LAC']:
+ if not MAP_GENERATION[key] in data['production']:
+ data['production'][MAP_GENERATION[key]] = 0
+ # Run of the river or conventional
+ data['production'][MAP_GENERATION[key]] += float(value.text)
+ elif granularite == 'STT':
+ if not MAP_STORAGE[key] in data['storage']:
+ data['storage'][MAP_STORAGE[key]] = 0
+ # Pumped storage generation
+ data['storage'][MAP_STORAGE[key]] += -1 * float(value.text)
+ elif granularite == 'Global':
+ if key in MAP_GENERATION:
+ data['production'][MAP_GENERATION[key]] = float(value.text)
+ elif key in MAP_STORAGE:
+ if not MAP_STORAGE[key] in data['storage']:
+ data['storage'][MAP_STORAGE[key]] = 0
+ data['storage'][MAP_STORAGE[key]] += -1 * float(value.text)
data['datetime'] = arrow.get(arrow.get(obj[1].text).datetime,
'Europe/Paris').replace(minutes=+(int(value.attrib['periode']) * 15.0)).datetime
- # Fetch imports
- # url = 'http://www.rte-france.com/getEco2MixXml.php?type=echcom&&dateDeb={}&dateFin={}&mode=NORM'.format(formatted_date, formatted_date)
- # response = r.get(url)
- # obj = ET.fromstring(response.content)
- # parsed = {}
- # for item in obj[7].getchildren():
- # value = None
- # for value in item: pass
- # parsed[item.get('v')] = float(value.text)
-
- # data['exchange'] = {
- # 'CH': parsed['CH'],
- # 'GB': parsed['GB'],
- # 'ES': parsed['ES'],
- # 'IT': parsed['IT'],
- # 'DE': parsed['DB'] # Germany + Belgium redirected to Germany
- # }
-
return data
|
{"golden_diff": "diff --git a/parsers/FR.py b/parsers/FR.py\n--- a/parsers/FR.py\n+++ b/parsers/FR.py\n@@ -16,6 +16,7 @@\n }\n MAP_STORAGE = {\n 'Pompage': 'hydro',\n+ 'Hydraulique': 'hydro',\n }\n \n \n@@ -33,38 +34,36 @@\n 'source': 'rte-france.com',\n }\n for item in mixtr.getchildren():\n- if item.get('granularite') != 'Global':\n- continue\n key = item.get('v')\n+ granularite = item.get('granularite')\n value = None\n for value in item.getchildren():\n pass\n- if key in MAP_GENERATION:\n- data['production'][MAP_GENERATION[key]] = float(value.text)\n- elif key in MAP_STORAGE:\n- data['storage'][MAP_STORAGE[key]] = -1 * float(value.text)\n+ if key == 'Hydraulique':\n+ # Hydro is a special case!\n+ if granularite == 'Global':\n+ continue\n+ elif granularite in ['FEE', 'LAC']:\n+ if not MAP_GENERATION[key] in data['production']:\n+ data['production'][MAP_GENERATION[key]] = 0\n+ # Run of the river or conventional\n+ data['production'][MAP_GENERATION[key]] += float(value.text)\n+ elif granularite == 'STT':\n+ if not MAP_STORAGE[key] in data['storage']:\n+ data['storage'][MAP_STORAGE[key]] = 0\n+ # Pumped storage generation\n+ data['storage'][MAP_STORAGE[key]] += -1 * float(value.text)\n+ elif granularite == 'Global':\n+ if key in MAP_GENERATION:\n+ data['production'][MAP_GENERATION[key]] = float(value.text)\n+ elif key in MAP_STORAGE:\n+ if not MAP_STORAGE[key] in data['storage']:\n+ data['storage'][MAP_STORAGE[key]] = 0\n+ data['storage'][MAP_STORAGE[key]] += -1 * float(value.text)\n \n data['datetime'] = arrow.get(arrow.get(obj[1].text).datetime,\n 'Europe/Paris').replace(minutes=+(int(value.attrib['periode']) * 15.0)).datetime\n \n- # Fetch imports\n- # url = 'http://www.rte-france.com/getEco2MixXml.php?type=echcom&&dateDeb={}&dateFin={}&mode=NORM'.format(formatted_date, formatted_date)\n- # response = r.get(url)\n- # obj = ET.fromstring(response.content)\n- # parsed = {}\n- # for item in obj[7].getchildren():\n- # value = None\n- # for value in item: pass\n- # parsed[item.get('v')] = float(value.text)\n-\n- # data['exchange'] = {\n- # 'CH': parsed['CH'],\n- # 'GB': parsed['GB'],\n- # 'ES': parsed['ES'],\n- # 'IT': parsed['IT'],\n- # 'DE': parsed['DB'] # Germany + Belgium redirected to Germany\n- # }\n-\n return data\n", "issue": "Generation from \"Pumped storage\" in France FR\nAt the moment, the bar charts on the map only show pumped storage consumption for France. But RTE also has data for pumped storage generation. This is currently not displayed on the map, because the \"hydro\" category of RTE includes all three types \"hydro storage+run of river+pumped storage\". But there is a seperate \"pumping\" category for consumption of the pumped storages (pumping).\r\nhttp://www.rte-france.com/en/eco2mix/eco2mix-mix-energetique-en\r\n\r\n\r\n\r\nAfter selecting the hydro category, you'll see \"details\" below it. Selecting \"details\" you will see this, incuding the breakdown by hydro type:\r\n\r\n\r\nThe most recent dataset for France can also be downloaded here:\r\nhttp://www.rte-france.com/en/eco2mix/eco2mix-telechargement-en\r\n\r\nThe FR.py parser seems to use this URL http://www.rte-france.com/getEco2MixXml.php?type=donneesMarche&dateDeb={}&dateFin={}&mode=NORM for getting the data. Maybe there is a similar one for the hydro breakdown by type to seperate pumped storage generation from it.\n", "before_files": [{"content": "#!/usr/bin/env python3\n\nimport arrow\nimport requests\nimport xml.etree.ElementTree as ET\n\nMAP_GENERATION = {\n u'Nucl\\xe9aire': 'nuclear',\n 'Charbon': 'coal',\n 'Gaz': 'gas',\n 'Fioul': 'oil',\n 'Hydraulique': 'hydro',\n 'Eolien': 'wind',\n 'Solaire': 'solar',\n 'Autres': 'biomass'\n}\nMAP_STORAGE = {\n 'Pompage': 'hydro',\n}\n\n\ndef fetch_production(country_code='FR', session=None):\n r = session or requests.session()\n formatted_date = arrow.now(tz='Europe/Paris').format('DD/MM/YYYY')\n url = 'http://www.rte-france.com/getEco2MixXml.php?type=mix&&dateDeb={}&dateFin={}&mode=NORM'.format(formatted_date, formatted_date)\n response = r.get(url)\n obj = ET.fromstring(response.content)\n mixtr = obj[7]\n data = {\n 'countryCode': country_code,\n 'production': {},\n 'storage': {},\n 'source': 'rte-france.com',\n }\n for item in mixtr.getchildren():\n if item.get('granularite') != 'Global':\n continue\n key = item.get('v')\n value = None\n for value in item.getchildren():\n pass\n if key in MAP_GENERATION:\n data['production'][MAP_GENERATION[key]] = float(value.text)\n elif key in MAP_STORAGE:\n data['storage'][MAP_STORAGE[key]] = -1 * float(value.text)\n\n data['datetime'] = arrow.get(arrow.get(obj[1].text).datetime,\n 'Europe/Paris').replace(minutes=+(int(value.attrib['periode']) * 15.0)).datetime\n\n # Fetch imports\n # url = 'http://www.rte-france.com/getEco2MixXml.php?type=echcom&&dateDeb={}&dateFin={}&mode=NORM'.format(formatted_date, formatted_date)\n # response = r.get(url)\n # obj = ET.fromstring(response.content)\n # parsed = {}\n # for item in obj[7].getchildren():\n # value = None\n # for value in item: pass\n # parsed[item.get('v')] = float(value.text)\n\n # data['exchange'] = {\n # 'CH': parsed['CH'],\n # 'GB': parsed['GB'],\n # 'ES': parsed['ES'],\n # 'IT': parsed['IT'],\n # 'DE': parsed['DB'] # Germany + Belgium redirected to Germany\n # }\n\n return data\n\n\ndef fetch_price(country_code, session=None, from_date=None, to_date=None):\n r = session or requests.session()\n dt_now = arrow.now(tz='Europe/Paris')\n formatted_from = from_date or dt_now.format('DD/MM/YYYY')\n formatted_to = to_date or dt_now.format('DD/MM/YYYY')\n\n url = 'http://www.rte-france.com/getEco2MixXml.php?type=donneesMarche&dateDeb={}&dateFin={}&mode=NORM'.format(formatted_from, formatted_to)\n response = r.get(url)\n obj = ET.fromstring(response.content)\n mixtr = obj[5]\n\n prices = []\n datetimes = []\n\n date_str = mixtr.get('date')\n date = arrow.get(arrow.get(date_str).datetime, 'Europe/Paris')\n for country_item in mixtr.getchildren():\n if country_item.get('granularite') != 'Global':\n continue\n country_c = country_item.get('perimetre')\n if country_code != country_c:\n continue\n value = None\n for value in country_item.getchildren():\n if value.text == 'ND':\n continue\n datetime = date.replace(hours=+int(value.attrib['periode'])).datetime\n if datetime > dt_now:\n continue\n datetimes.append(datetime)\n prices.append(float(value.text))\n\n data = {\n 'countryCode': country_code,\n 'currency': 'EUR',\n 'datetime': datetimes[-1],\n 'price': prices[-1],\n 'source': 'rte-france.com',\n }\n return data\n\n\nif __name__ == '__main__':\n print(fetch_production())\n", "path": "parsers/FR.py"}]}
| 2,107 | 721 |
gh_patches_debug_14512
|
rasdani/github-patches
|
git_diff
|
safe-global__safe-config-service-698
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
500 Error on unsanitized URL query params
**Describe the bug**
Error response with 500 Internal server Error is returned to the clients when a unsanitized URL query param is sent to the service.
**To Reproduce**
Steps to reproduce the behavior:
- Check: https://safe-config.safe.global/api/v1/safe-apps/?url=%00
**Expected behavior**
URL input is sanitized beforehand.
**Environment**
- Staging & production
- All chains
</issue>
<code>
[start of src/safe_apps/views.py]
1 from typing import Any
2
3 from django.db.models import Q, QuerySet
4 from django.utils.decorators import method_decorator
5 from django.views.decorators.cache import cache_page
6 from drf_yasg import openapi
7 from drf_yasg.utils import swagger_auto_schema
8 from rest_framework.generics import ListAPIView
9 from rest_framework.request import Request
10 from rest_framework.response import Response
11
12 from .models import SafeApp
13 from .serializers import SafeAppsResponseSerializer
14
15
16 class SafeAppsListView(ListAPIView):
17 serializer_class = SafeAppsResponseSerializer
18 pagination_class = None
19
20 _swagger_chain_id_param = openapi.Parameter(
21 "chainId",
22 openapi.IN_QUERY,
23 description="Used to filter Safe Apps that are available on `chainId`",
24 type=openapi.TYPE_INTEGER,
25 )
26 _swagger_client_url_param = openapi.Parameter(
27 "clientUrl",
28 openapi.IN_QUERY,
29 description="Used to filter Safe Apps that are available on `clientUrl`",
30 type=openapi.TYPE_STRING,
31 )
32 _swagger_url_param = openapi.Parameter(
33 "url",
34 openapi.IN_QUERY,
35 description="Filter Safe Apps available from `url`. `url` needs to be an exact match",
36 type=openapi.TYPE_STRING,
37 )
38
39 @method_decorator(cache_page(60 * 10, cache="safe-apps")) # Cache 10 minutes
40 @swagger_auto_schema(
41 manual_parameters=[
42 _swagger_chain_id_param,
43 _swagger_client_url_param,
44 _swagger_url_param,
45 ]
46 ) # type: ignore[misc]
47 def get(self, request: Request, *args: Any, **kwargs: Any) -> Response:
48 """
49 Returns a collection of Safe Apps (across different chains).
50 Each Safe App can optionally include the information about the `Provider`
51 """
52 return super().get(request, *args, **kwargs)
53
54 def get_queryset(self) -> QuerySet[SafeApp]:
55 queryset = SafeApp.objects.filter(visible=True)
56
57 chain_id = self.request.query_params.get("chainId")
58 if chain_id is not None and chain_id.isdigit():
59 queryset = queryset.filter(chain_ids__contains=[chain_id])
60
61 client_url = self.request.query_params.get("clientUrl")
62 if client_url:
63 queryset = queryset.filter(
64 Q(exclusive_clients__url=client_url) | Q(exclusive_clients__isnull=True)
65 )
66
67 url = self.request.query_params.get("url")
68 if url:
69 queryset = queryset.filter(url=url)
70
71 return queryset
72
[end of src/safe_apps/views.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/safe_apps/views.py b/src/safe_apps/views.py
--- a/src/safe_apps/views.py
+++ b/src/safe_apps/views.py
@@ -59,13 +59,13 @@
queryset = queryset.filter(chain_ids__contains=[chain_id])
client_url = self.request.query_params.get("clientUrl")
- if client_url:
+ if client_url and "\0" not in client_url:
queryset = queryset.filter(
Q(exclusive_clients__url=client_url) | Q(exclusive_clients__isnull=True)
)
url = self.request.query_params.get("url")
- if url:
+ if url and "\0" not in url:
queryset = queryset.filter(url=url)
return queryset
|
{"golden_diff": "diff --git a/src/safe_apps/views.py b/src/safe_apps/views.py\n--- a/src/safe_apps/views.py\n+++ b/src/safe_apps/views.py\n@@ -59,13 +59,13 @@\n queryset = queryset.filter(chain_ids__contains=[chain_id])\n \n client_url = self.request.query_params.get(\"clientUrl\")\n- if client_url:\n+ if client_url and \"\\0\" not in client_url:\n queryset = queryset.filter(\n Q(exclusive_clients__url=client_url) | Q(exclusive_clients__isnull=True)\n )\n \n url = self.request.query_params.get(\"url\")\n- if url:\n+ if url and \"\\0\" not in url:\n queryset = queryset.filter(url=url)\n \n return queryset\n", "issue": "500 Error on unsanitized URL query params \n**Describe the bug**\r\nError response with 500 Internal server Error is returned to the clients when a unsanitized URL query param is sent to the service.\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n- Check: https://safe-config.safe.global/api/v1/safe-apps/?url=%00\r\n\r\n**Expected behavior**\r\nURL input is sanitized beforehand.\r\n\r\n**Environment**\r\n - Staging & production\r\n - All chains\r\n\n", "before_files": [{"content": "from typing import Any\n\nfrom django.db.models import Q, QuerySet\nfrom django.utils.decorators import method_decorator\nfrom django.views.decorators.cache import cache_page\nfrom drf_yasg import openapi\nfrom drf_yasg.utils import swagger_auto_schema\nfrom rest_framework.generics import ListAPIView\nfrom rest_framework.request import Request\nfrom rest_framework.response import Response\n\nfrom .models import SafeApp\nfrom .serializers import SafeAppsResponseSerializer\n\n\nclass SafeAppsListView(ListAPIView):\n serializer_class = SafeAppsResponseSerializer\n pagination_class = None\n\n _swagger_chain_id_param = openapi.Parameter(\n \"chainId\",\n openapi.IN_QUERY,\n description=\"Used to filter Safe Apps that are available on `chainId`\",\n type=openapi.TYPE_INTEGER,\n )\n _swagger_client_url_param = openapi.Parameter(\n \"clientUrl\",\n openapi.IN_QUERY,\n description=\"Used to filter Safe Apps that are available on `clientUrl`\",\n type=openapi.TYPE_STRING,\n )\n _swagger_url_param = openapi.Parameter(\n \"url\",\n openapi.IN_QUERY,\n description=\"Filter Safe Apps available from `url`. `url` needs to be an exact match\",\n type=openapi.TYPE_STRING,\n )\n\n @method_decorator(cache_page(60 * 10, cache=\"safe-apps\")) # Cache 10 minutes\n @swagger_auto_schema(\n manual_parameters=[\n _swagger_chain_id_param,\n _swagger_client_url_param,\n _swagger_url_param,\n ]\n ) # type: ignore[misc]\n def get(self, request: Request, *args: Any, **kwargs: Any) -> Response:\n \"\"\"\n Returns a collection of Safe Apps (across different chains).\n Each Safe App can optionally include the information about the `Provider`\n \"\"\"\n return super().get(request, *args, **kwargs)\n\n def get_queryset(self) -> QuerySet[SafeApp]:\n queryset = SafeApp.objects.filter(visible=True)\n\n chain_id = self.request.query_params.get(\"chainId\")\n if chain_id is not None and chain_id.isdigit():\n queryset = queryset.filter(chain_ids__contains=[chain_id])\n\n client_url = self.request.query_params.get(\"clientUrl\")\n if client_url:\n queryset = queryset.filter(\n Q(exclusive_clients__url=client_url) | Q(exclusive_clients__isnull=True)\n )\n\n url = self.request.query_params.get(\"url\")\n if url:\n queryset = queryset.filter(url=url)\n\n return queryset\n", "path": "src/safe_apps/views.py"}]}
| 1,319 | 168 |
gh_patches_debug_25253
|
rasdani/github-patches
|
git_diff
|
liqd__a4-meinberlin-2368
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
take out secret dev notes visible in frontend :-)

</issue>
<code>
[start of meinberlin/apps/projects/templatetags/meinberlin_project_tags.py]
1 from django import template
2
3 from adhocracy4.comments.models import Comment
4 from meinberlin.apps.budgeting.models import Proposal as budget_proposal
5 from meinberlin.apps.ideas.models import Idea
6 from meinberlin.apps.kiezkasse.models import Proposal as kiezkasse_proposal
7 from meinberlin.apps.mapideas.models import MapIdea
8 from meinberlin.apps.projects import get_project_type
9
10 register = template.Library()
11
12
13 @register.filter
14 def project_url(project):
15 if get_project_type(project) in ('external', 'bplan'):
16 return project.externalproject.url
17 return project.get_absolute_url()
18
19
20 @register.filter
21 def project_type(project):
22 return get_project_type(project)
23
24
25 @register.filter
26 def is_external(project):
27 return get_project_type(project) in ('external', 'bplan')
28
29
30 @register.filter
31 def is_container(project):
32 return get_project_type(project) == 'container'
33
34
35 @register.simple_tag
36 def to_class_name(value):
37 return value.__class__.__name__
38
39
40 @register.simple_tag
41 def get_num_entries(module):
42 """Count all user-generated items."""
43 item_count = Idea.objects.filter(module=module).count() \
44 + MapIdea.objects.filter(module=module).count() \
45 + budget_proposal.objects.filter(module=module).count() \
46 + kiezkasse_proposal.objects.filter(module=module).count() \
47 + Comment.objects.filter(idea__module=module).count() \
48 + Comment.objects.filter(mapidea__module=module).count() \
49 + Comment.objects.filter(budget_proposal__module=module).count() \
50 + Comment.objects.filter(kiezkasse_proposal__module=module).count()
51 return item_count
52
[end of meinberlin/apps/projects/templatetags/meinberlin_project_tags.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/meinberlin/apps/projects/templatetags/meinberlin_project_tags.py b/meinberlin/apps/projects/templatetags/meinberlin_project_tags.py
--- a/meinberlin/apps/projects/templatetags/meinberlin_project_tags.py
+++ b/meinberlin/apps/projects/templatetags/meinberlin_project_tags.py
@@ -40,12 +40,18 @@
@register.simple_tag
def get_num_entries(module):
"""Count all user-generated items."""
- item_count = Idea.objects.filter(module=module).count() \
+ item_count = \
+ Idea.objects.filter(module=module).count() \
+ MapIdea.objects.filter(module=module).count() \
+ budget_proposal.objects.filter(module=module).count() \
+ kiezkasse_proposal.objects.filter(module=module).count() \
+ Comment.objects.filter(idea__module=module).count() \
+ Comment.objects.filter(mapidea__module=module).count() \
+ Comment.objects.filter(budget_proposal__module=module).count() \
- + Comment.objects.filter(kiezkasse_proposal__module=module).count()
+ + Comment.objects.filter(kiezkasse_proposal__module=module).count() \
+ + Comment.objects.filter(topic__module=module).count() \
+ + Comment.objects.filter(maptopic__module=module).count() \
+ + Comment.objects.filter(paragraph__chapter__module=module).count() \
+ + Comment.objects.filter(chapter__module=module).count() \
+ + Comment.objects.filter(poll__module=module).count()
return item_count
|
{"golden_diff": "diff --git a/meinberlin/apps/projects/templatetags/meinberlin_project_tags.py b/meinberlin/apps/projects/templatetags/meinberlin_project_tags.py\n--- a/meinberlin/apps/projects/templatetags/meinberlin_project_tags.py\n+++ b/meinberlin/apps/projects/templatetags/meinberlin_project_tags.py\n@@ -40,12 +40,18 @@\n @register.simple_tag\n def get_num_entries(module):\n \"\"\"Count all user-generated items.\"\"\"\n- item_count = Idea.objects.filter(module=module).count() \\\n+ item_count = \\\n+ Idea.objects.filter(module=module).count() \\\n + MapIdea.objects.filter(module=module).count() \\\n + budget_proposal.objects.filter(module=module).count() \\\n + kiezkasse_proposal.objects.filter(module=module).count() \\\n + Comment.objects.filter(idea__module=module).count() \\\n + Comment.objects.filter(mapidea__module=module).count() \\\n + Comment.objects.filter(budget_proposal__module=module).count() \\\n- + Comment.objects.filter(kiezkasse_proposal__module=module).count()\n+ + Comment.objects.filter(kiezkasse_proposal__module=module).count() \\\n+ + Comment.objects.filter(topic__module=module).count() \\\n+ + Comment.objects.filter(maptopic__module=module).count() \\\n+ + Comment.objects.filter(paragraph__chapter__module=module).count() \\\n+ + Comment.objects.filter(chapter__module=module).count() \\\n+ + Comment.objects.filter(poll__module=module).count()\n return item_count\n", "issue": "take out secret dev notes visible in frontend :-)\n\r\n\r\n\r\n\r\n\n", "before_files": [{"content": "from django import template\n\nfrom adhocracy4.comments.models import Comment\nfrom meinberlin.apps.budgeting.models import Proposal as budget_proposal\nfrom meinberlin.apps.ideas.models import Idea\nfrom meinberlin.apps.kiezkasse.models import Proposal as kiezkasse_proposal\nfrom meinberlin.apps.mapideas.models import MapIdea\nfrom meinberlin.apps.projects import get_project_type\n\nregister = template.Library()\n\n\[email protected]\ndef project_url(project):\n if get_project_type(project) in ('external', 'bplan'):\n return project.externalproject.url\n return project.get_absolute_url()\n\n\[email protected]\ndef project_type(project):\n return get_project_type(project)\n\n\[email protected]\ndef is_external(project):\n return get_project_type(project) in ('external', 'bplan')\n\n\[email protected]\ndef is_container(project):\n return get_project_type(project) == 'container'\n\n\[email protected]_tag\ndef to_class_name(value):\n return value.__class__.__name__\n\n\[email protected]_tag\ndef get_num_entries(module):\n \"\"\"Count all user-generated items.\"\"\"\n item_count = Idea.objects.filter(module=module).count() \\\n + MapIdea.objects.filter(module=module).count() \\\n + budget_proposal.objects.filter(module=module).count() \\\n + kiezkasse_proposal.objects.filter(module=module).count() \\\n + Comment.objects.filter(idea__module=module).count() \\\n + Comment.objects.filter(mapidea__module=module).count() \\\n + Comment.objects.filter(budget_proposal__module=module).count() \\\n + Comment.objects.filter(kiezkasse_proposal__module=module).count()\n return item_count\n", "path": "meinberlin/apps/projects/templatetags/meinberlin_project_tags.py"}]}
| 1,123 | 367 |
gh_patches_debug_6788
|
rasdani/github-patches
|
git_diff
|
learningequality__kolibri-1733
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Login ID and Password fields for a learner/user should not be case sensitive.
## Summary
Login ID and Password fields for a learner/user should not be case sensitive, this is especially for young learners and they struggle a lot to login itself.
Please consider this change for Nalanda branch.
## System information
- Version: Kolibri 0.4.0beta9
- Operating system: Ubuntu 14.04 LTS
- Browser: Chrome
</issue>
<code>
[start of kolibri/auth/backends.py]
1 """
2 Implements custom auth backends as described in the Django docs, for our custom user classes -- FacilityUser and
3 DeviceOwner. The appropriate classes should be listed in the AUTHENTICATION_BACKENDS. Note that authentication
4 backends are checked in the order they're listed.
5 """
6
7 from kolibri.auth.models import DeviceOwner, FacilityUser
8
9
10 class FacilityUserBackend(object):
11 """
12 A class that implements authentication for FacilityUsers.
13 """
14
15 def authenticate(self, username=None, password=None, facility=None):
16 """
17 Authenticates the user if the credentials correspond to a FacilityUser for the specified Facility.
18
19 :param username: a string
20 :param password: a string
21 :param facility: a Facility
22 :return: A FacilityUser instance if successful, or None if authentication failed.
23 """
24 users = FacilityUser.objects.filter(username=username)
25 if facility:
26 users = users.filter(facility=facility)
27 for user in users:
28 if user.check_password(password):
29 return user
30 # Allow login without password for learners for facilities that allow this.
31 # Must specify the facility, to prevent accidental logins
32 elif facility and user.dataset.learner_can_login_with_no_password and not user.roles.count():
33 return user
34 return None
35
36 def get_user(self, user_id):
37 """
38 Gets a user. Auth backends are required to implement this.
39
40 :param user_id: A FacilityUser pk
41 :return: A FacilityUser instance if a BaseUser with that pk is found, else None.
42 """
43 try:
44 return FacilityUser.objects.get(pk=user_id)
45 except FacilityUser.DoesNotExist:
46 return None
47
48
49 class DeviceOwnerBackend(object):
50 """
51 A class that implements authentication for DeviceOwners.
52 """
53
54 def authenticate(self, username=None, password=None, **kwargs):
55 """
56 Authenticates the user if the credentials correspond to a DeviceOwner.
57
58 :param username: a string
59 :param password: a string
60 :return: A DeviceOwner instance if successful, or None if authentication failed.
61 """
62 try:
63 user = DeviceOwner.objects.get(username=username)
64 if user.check_password(password):
65 return user
66 else:
67 return None
68 except DeviceOwner.DoesNotExist:
69 return None
70
71 def get_user(self, user_id):
72 """
73 Gets a user. Auth backends are required to implement this.
74
75 :param user_id: A BaseUser pk
76 :return: A DeviceOwner instance if a BaseUser with that pk is found, else None.
77 """
78 try:
79 return DeviceOwner.objects.get(pk=user_id)
80 except DeviceOwner.DoesNotExist:
81 return None
82
[end of kolibri/auth/backends.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kolibri/auth/backends.py b/kolibri/auth/backends.py
--- a/kolibri/auth/backends.py
+++ b/kolibri/auth/backends.py
@@ -21,7 +21,7 @@
:param facility: a Facility
:return: A FacilityUser instance if successful, or None if authentication failed.
"""
- users = FacilityUser.objects.filter(username=username)
+ users = FacilityUser.objects.filter(username__iexact=username)
if facility:
users = users.filter(facility=facility)
for user in users:
|
{"golden_diff": "diff --git a/kolibri/auth/backends.py b/kolibri/auth/backends.py\n--- a/kolibri/auth/backends.py\n+++ b/kolibri/auth/backends.py\n@@ -21,7 +21,7 @@\n :param facility: a Facility\n :return: A FacilityUser instance if successful, or None if authentication failed.\n \"\"\"\n- users = FacilityUser.objects.filter(username=username)\n+ users = FacilityUser.objects.filter(username__iexact=username)\n if facility:\n users = users.filter(facility=facility)\n for user in users:\n", "issue": "Login ID and Password fields for a learner/user should not be case sensitive.\n## Summary\r\n\r\nLogin ID and Password fields for a learner/user should not be case sensitive, this is especially for young learners and they struggle a lot to login itself.\r\n\r\nPlease consider this change for Nalanda branch.\r\n\r\n## System information\r\n - Version: Kolibri 0.4.0beta9\r\n - Operating system: Ubuntu 14.04 LTS\r\n - Browser: Chrome\r\n\n", "before_files": [{"content": "\"\"\"\nImplements custom auth backends as described in the Django docs, for our custom user classes -- FacilityUser and\nDeviceOwner. The appropriate classes should be listed in the AUTHENTICATION_BACKENDS. Note that authentication\nbackends are checked in the order they're listed.\n\"\"\"\n\nfrom kolibri.auth.models import DeviceOwner, FacilityUser\n\n\nclass FacilityUserBackend(object):\n \"\"\"\n A class that implements authentication for FacilityUsers.\n \"\"\"\n\n def authenticate(self, username=None, password=None, facility=None):\n \"\"\"\n Authenticates the user if the credentials correspond to a FacilityUser for the specified Facility.\n\n :param username: a string\n :param password: a string\n :param facility: a Facility\n :return: A FacilityUser instance if successful, or None if authentication failed.\n \"\"\"\n users = FacilityUser.objects.filter(username=username)\n if facility:\n users = users.filter(facility=facility)\n for user in users:\n if user.check_password(password):\n return user\n # Allow login without password for learners for facilities that allow this.\n # Must specify the facility, to prevent accidental logins\n elif facility and user.dataset.learner_can_login_with_no_password and not user.roles.count():\n return user\n return None\n\n def get_user(self, user_id):\n \"\"\"\n Gets a user. Auth backends are required to implement this.\n\n :param user_id: A FacilityUser pk\n :return: A FacilityUser instance if a BaseUser with that pk is found, else None.\n \"\"\"\n try:\n return FacilityUser.objects.get(pk=user_id)\n except FacilityUser.DoesNotExist:\n return None\n\n\nclass DeviceOwnerBackend(object):\n \"\"\"\n A class that implements authentication for DeviceOwners.\n \"\"\"\n\n def authenticate(self, username=None, password=None, **kwargs):\n \"\"\"\n Authenticates the user if the credentials correspond to a DeviceOwner.\n\n :param username: a string\n :param password: a string\n :return: A DeviceOwner instance if successful, or None if authentication failed.\n \"\"\"\n try:\n user = DeviceOwner.objects.get(username=username)\n if user.check_password(password):\n return user\n else:\n return None\n except DeviceOwner.DoesNotExist:\n return None\n\n def get_user(self, user_id):\n \"\"\"\n Gets a user. Auth backends are required to implement this.\n\n :param user_id: A BaseUser pk\n :return: A DeviceOwner instance if a BaseUser with that pk is found, else None.\n \"\"\"\n try:\n return DeviceOwner.objects.get(pk=user_id)\n except DeviceOwner.DoesNotExist:\n return None\n", "path": "kolibri/auth/backends.py"}]}
| 1,351 | 126 |
gh_patches_debug_63150
|
rasdani/github-patches
|
git_diff
|
frappe__frappe-15449
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
pymysql.err.ProgrammingError: ('DocType', 'Webhook')
```
> bench --site all migrate --skip-failing
...
Migrating my-site
Traceback (most recent call last):
File "/usr/lib/python3.6/runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "/usr/lib/python3.6/runpy.py", line 85, in _run_code
exec(code, run_globals)
File "/home/frappe/frappe-bench/apps/frappe/frappe/utils/bench_helper.py", line 104, in <module>
main()
File "/home/frappe/frappe-bench/apps/frappe/frappe/utils/bench_helper.py", line 19, in main
click.Group(commands=commands)(prog_name='bench')
File "/home/frappe/frappe-bench/env/lib/python3.6/site-packages/click/core.py", line 829, in __call__
return self.main(*args, **kwargs)
File "/home/frappe/frappe-bench/env/lib/python3.6/site-packages/click/core.py", line 782, in main
rv = self.invoke(ctx)
File "/home/frappe/frappe-bench/env/lib/python3.6/site-packages/click/core.py", line 1259, in invoke
return _process_result(sub_ctx.command.invoke(sub_ctx))
File "/home/frappe/frappe-bench/env/lib/python3.6/site-packages/click/core.py", line 1259, in invoke
return _process_result(sub_ctx.command.invoke(sub_ctx))
File "/home/frappe/frappe-bench/env/lib/python3.6/site-packages/click/core.py", line 1066, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "/home/frappe/frappe-bench/env/lib/python3.6/site-packages/click/core.py", line 610, in invoke
return callback(*args, **kwargs)
File "/home/frappe/frappe-bench/env/lib/python3.6/site-packages/click/decorators.py", line 21, in new_func
return f(get_current_context(), *args, **kwargs)
File "/home/frappe/frappe-bench/apps/frappe/frappe/commands/__init__.py", line 27, in _func
ret = f(frappe._dict(ctx.obj), *args, **kwargs)
File "/home/frappe/frappe-bench/apps/frappe/frappe/commands/site.py", line 309, in migrate
skip_search_index=skip_search_index
File "/home/frappe/frappe-bench/apps/frappe/frappe/migrate.py", line 78, in migrate
skip_search_index=skip_search_index
File "/home/frappe/frappe-bench/apps/frappe/frappe/migrate.py", line 78, in migrate
sync_languages()
File "/home/frappe/frappe-bench/apps/frappe/frappe/core/doctype/language/language.py", line 43, in sync_languages
'language_name': l['name']
File "/home/frappe/frappe-bench/apps/frappe/frappe/model/document.py", line 231, in insert
self.run_method("before_insert")
File "/home/frappe/frappe-bench/apps/frappe/frappe/model/document.py", line 870, in run_method
run_webhooks(self, method)
File "/home/frappe/frappe-bench/apps/frappe/frappe/integrations/doctype/webhook/__init__.py", line 25, in run_webhooks
filters={"enabled": True}
File "/home/frappe/frappe-bench/apps/frappe/frappe/__init__.py", line 1469, in get_all
return get_list(doctype, *args, **kwargs)
File "/home/frappe/frappe-bench/apps/frappe/frappe/__init__.py", line 1442, in get_list
return frappe.model.db_query.DatabaseQuery(doctype).execute(*args, **kwargs)
File "/home/frappe/frappe-bench/apps/frappe/frappe/model/db_query.py", line 102, in execute
self.columns = self.get_table_columns()
File "/home/frappe/frappe-bench/apps/frappe/frappe/model/db_query.py", line 339, in get_table_columns
return get_table_columns(self.doctype)
File "/home/frappe/frappe-bench/apps/frappe/frappe/model/meta.py", line 49, in get_table_columns
return frappe.db.get_table_columns(doctype)
File "/home/frappe/frappe-bench/apps/frappe/frappe/database/database.py", line 902, in get_table_columns
raise self.TableMissingError('DocType', doctype)
pymysql.err.ProgrammingError: ('DocType', 'Webhook')
```
Migrating from `version-13-beta` to `version-13` (13.17)
### Versions
```
> bench version
erpnext 13.17.0
frappe 13.17.1
```
</issue>
<code>
[start of frappe/integrations/doctype/webhook/__init__.py]
1 # -*- coding: utf-8 -*-
2 # Copyright (c) 2017, Frappe Technologies and contributors
3 # License: MIT. See LICENSE
4
5 import frappe
6
7
8 def run_webhooks(doc, method):
9 '''Run webhooks for this method'''
10 if frappe.flags.in_import or frappe.flags.in_patch or frappe.flags.in_install:
11 return
12
13 if frappe.flags.webhooks_executed is None:
14 frappe.flags.webhooks_executed = {}
15
16 if frappe.flags.webhooks is None:
17 # load webhooks from cache
18 webhooks = frappe.cache().get_value('webhooks')
19 if webhooks is None:
20 # query webhooks
21 webhooks_list = frappe.get_all('Webhook',
22 fields=["name", "`condition`", "webhook_docevent", "webhook_doctype"],
23 filters={"enabled": True}
24 )
25
26 # make webhooks map for cache
27 webhooks = {}
28 for w in webhooks_list:
29 webhooks.setdefault(w.webhook_doctype, []).append(w)
30 frappe.cache().set_value('webhooks', webhooks)
31
32 frappe.flags.webhooks = webhooks
33
34 # get webhooks for this doctype
35 webhooks_for_doc = frappe.flags.webhooks.get(doc.doctype, None)
36
37 if not webhooks_for_doc:
38 # no webhooks, quit
39 return
40
41 def _webhook_request(webhook):
42 if webhook.name not in frappe.flags.webhooks_executed.get(doc.name, []):
43 frappe.enqueue("frappe.integrations.doctype.webhook.webhook.enqueue_webhook",
44 enqueue_after_commit=True, doc=doc, webhook=webhook)
45
46 # keep list of webhooks executed for this doc in this request
47 # so that we don't run the same webhook for the same document multiple times
48 # in one request
49 frappe.flags.webhooks_executed.setdefault(doc.name, []).append(webhook.name)
50
51 event_list = ["on_update", "after_insert", "on_submit", "on_cancel", "on_trash"]
52
53 if not doc.flags.in_insert:
54 # value change is not applicable in insert
55 event_list.append('on_change')
56 event_list.append('before_update_after_submit')
57
58 from frappe.integrations.doctype.webhook.webhook import get_context
59
60 for webhook in webhooks_for_doc:
61 trigger_webhook = False
62 event = method if method in event_list else None
63 if not webhook.condition:
64 trigger_webhook = True
65 elif frappe.safe_eval(webhook.condition, eval_locals=get_context(doc)):
66 trigger_webhook = True
67
68 if trigger_webhook and event and webhook.webhook_docevent == event:
69 _webhook_request(webhook)
70
[end of frappe/integrations/doctype/webhook/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/frappe/integrations/doctype/webhook/__init__.py b/frappe/integrations/doctype/webhook/__init__.py
--- a/frappe/integrations/doctype/webhook/__init__.py
+++ b/frappe/integrations/doctype/webhook/__init__.py
@@ -7,7 +7,7 @@
def run_webhooks(doc, method):
'''Run webhooks for this method'''
- if frappe.flags.in_import or frappe.flags.in_patch or frappe.flags.in_install:
+ if frappe.flags.in_import or frappe.flags.in_patch or frappe.flags.in_install or frappe.flags.in_migrate:
return
if frappe.flags.webhooks_executed is None:
|
{"golden_diff": "diff --git a/frappe/integrations/doctype/webhook/__init__.py b/frappe/integrations/doctype/webhook/__init__.py\n--- a/frappe/integrations/doctype/webhook/__init__.py\n+++ b/frappe/integrations/doctype/webhook/__init__.py\n@@ -7,7 +7,7 @@\n \n def run_webhooks(doc, method):\n \t'''Run webhooks for this method'''\n-\tif frappe.flags.in_import or frappe.flags.in_patch or frappe.flags.in_install:\n+\tif frappe.flags.in_import or frappe.flags.in_patch or frappe.flags.in_install or frappe.flags.in_migrate:\n \t\treturn\n \n \tif frappe.flags.webhooks_executed is None:\n", "issue": "pymysql.err.ProgrammingError: ('DocType', 'Webhook')\n```\r\n> bench --site all migrate --skip-failing \r\n...\r\nMigrating my-site\r\n\r\nTraceback (most recent call last):\r\n File \"/usr/lib/python3.6/runpy.py\", line 193, in _run_module_as_main\r\n \"__main__\", mod_spec)\r\n File \"/usr/lib/python3.6/runpy.py\", line 85, in _run_code\r\n exec(code, run_globals)\r\n File \"/home/frappe/frappe-bench/apps/frappe/frappe/utils/bench_helper.py\", line 104, in <module>\r\n main()\r\n File \"/home/frappe/frappe-bench/apps/frappe/frappe/utils/bench_helper.py\", line 19, in main\r\n click.Group(commands=commands)(prog_name='bench')\r\n File \"/home/frappe/frappe-bench/env/lib/python3.6/site-packages/click/core.py\", line 829, in __call__\r\n return self.main(*args, **kwargs)\r\n File \"/home/frappe/frappe-bench/env/lib/python3.6/site-packages/click/core.py\", line 782, in main\r\n rv = self.invoke(ctx)\r\n File \"/home/frappe/frappe-bench/env/lib/python3.6/site-packages/click/core.py\", line 1259, in invoke\r\n return _process_result(sub_ctx.command.invoke(sub_ctx))\r\n File \"/home/frappe/frappe-bench/env/lib/python3.6/site-packages/click/core.py\", line 1259, in invoke\r\n return _process_result(sub_ctx.command.invoke(sub_ctx))\r\n File \"/home/frappe/frappe-bench/env/lib/python3.6/site-packages/click/core.py\", line 1066, in invoke\r\n return ctx.invoke(self.callback, **ctx.params)\r\n File \"/home/frappe/frappe-bench/env/lib/python3.6/site-packages/click/core.py\", line 610, in invoke\r\n return callback(*args, **kwargs)\r\n File \"/home/frappe/frappe-bench/env/lib/python3.6/site-packages/click/decorators.py\", line 21, in new_func\r\n return f(get_current_context(), *args, **kwargs)\r\n File \"/home/frappe/frappe-bench/apps/frappe/frappe/commands/__init__.py\", line 27, in _func\r\n ret = f(frappe._dict(ctx.obj), *args, **kwargs)\r\n File \"/home/frappe/frappe-bench/apps/frappe/frappe/commands/site.py\", line 309, in migrate\r\n skip_search_index=skip_search_index\r\n File \"/home/frappe/frappe-bench/apps/frappe/frappe/migrate.py\", line 78, in migrate\r\n skip_search_index=skip_search_index\r\n File \"/home/frappe/frappe-bench/apps/frappe/frappe/migrate.py\", line 78, in migrate\r\n sync_languages()\r\n File \"/home/frappe/frappe-bench/apps/frappe/frappe/core/doctype/language/language.py\", line 43, in sync_languages\r\n 'language_name': l['name']\r\n File \"/home/frappe/frappe-bench/apps/frappe/frappe/model/document.py\", line 231, in insert\r\n self.run_method(\"before_insert\")\r\n File \"/home/frappe/frappe-bench/apps/frappe/frappe/model/document.py\", line 870, in run_method\r\n run_webhooks(self, method)\r\n File \"/home/frappe/frappe-bench/apps/frappe/frappe/integrations/doctype/webhook/__init__.py\", line 25, in run_webhooks\r\n filters={\"enabled\": True}\r\n File \"/home/frappe/frappe-bench/apps/frappe/frappe/__init__.py\", line 1469, in get_all\r\n return get_list(doctype, *args, **kwargs)\r\n File \"/home/frappe/frappe-bench/apps/frappe/frappe/__init__.py\", line 1442, in get_list\r\n return frappe.model.db_query.DatabaseQuery(doctype).execute(*args, **kwargs)\r\n File \"/home/frappe/frappe-bench/apps/frappe/frappe/model/db_query.py\", line 102, in execute\r\n self.columns = self.get_table_columns()\r\n File \"/home/frappe/frappe-bench/apps/frappe/frappe/model/db_query.py\", line 339, in get_table_columns\r\n return get_table_columns(self.doctype)\r\n File \"/home/frappe/frappe-bench/apps/frappe/frappe/model/meta.py\", line 49, in get_table_columns\r\n return frappe.db.get_table_columns(doctype)\r\n File \"/home/frappe/frappe-bench/apps/frappe/frappe/database/database.py\", line 902, in get_table_columns\r\n raise self.TableMissingError('DocType', doctype)\r\npymysql.err.ProgrammingError: ('DocType', 'Webhook')\r\n```\r\n\r\nMigrating from `version-13-beta` to `version-13` (13.17)\r\n\r\n### Versions\r\n\r\n```\r\n> bench version\r\nerpnext 13.17.0\r\nfrappe 13.17.1\r\n```\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# Copyright (c) 2017, Frappe Technologies and contributors\n# License: MIT. See LICENSE\n\nimport frappe\n\n\ndef run_webhooks(doc, method):\n\t'''Run webhooks for this method'''\n\tif frappe.flags.in_import or frappe.flags.in_patch or frappe.flags.in_install:\n\t\treturn\n\n\tif frappe.flags.webhooks_executed is None:\n\t\tfrappe.flags.webhooks_executed = {}\n\n\tif frappe.flags.webhooks is None:\n\t\t# load webhooks from cache\n\t\twebhooks = frappe.cache().get_value('webhooks')\n\t\tif webhooks is None:\n\t\t\t# query webhooks\n\t\t\twebhooks_list = frappe.get_all('Webhook',\n\t\t\t\t\t\tfields=[\"name\", \"`condition`\", \"webhook_docevent\", \"webhook_doctype\"],\n\t\t\t\t\t\tfilters={\"enabled\": True}\n\t\t\t\t\t)\n\n\t\t\t# make webhooks map for cache\n\t\t\twebhooks = {}\n\t\t\tfor w in webhooks_list:\n\t\t\t\twebhooks.setdefault(w.webhook_doctype, []).append(w)\n\t\t\tfrappe.cache().set_value('webhooks', webhooks)\n\n\t\tfrappe.flags.webhooks = webhooks\n\n\t# get webhooks for this doctype\n\twebhooks_for_doc = frappe.flags.webhooks.get(doc.doctype, None)\n\n\tif not webhooks_for_doc:\n\t\t# no webhooks, quit\n\t\treturn\n\n\tdef _webhook_request(webhook):\n\t\tif webhook.name not in frappe.flags.webhooks_executed.get(doc.name, []):\n\t\t\tfrappe.enqueue(\"frappe.integrations.doctype.webhook.webhook.enqueue_webhook\",\n\t\t\t\tenqueue_after_commit=True, doc=doc, webhook=webhook)\n\n\t\t\t# keep list of webhooks executed for this doc in this request\n\t\t\t# so that we don't run the same webhook for the same document multiple times\n\t\t\t# in one request\n\t\t\tfrappe.flags.webhooks_executed.setdefault(doc.name, []).append(webhook.name)\n\n\tevent_list = [\"on_update\", \"after_insert\", \"on_submit\", \"on_cancel\", \"on_trash\"]\n\n\tif not doc.flags.in_insert:\n\t\t# value change is not applicable in insert\n\t\tevent_list.append('on_change')\n\t\tevent_list.append('before_update_after_submit')\n\n\tfrom frappe.integrations.doctype.webhook.webhook import get_context\n\n\tfor webhook in webhooks_for_doc:\n\t\ttrigger_webhook = False\n\t\tevent = method if method in event_list else None\n\t\tif not webhook.condition:\n\t\t\ttrigger_webhook = True\n\t\telif frappe.safe_eval(webhook.condition, eval_locals=get_context(doc)):\n\t\t\ttrigger_webhook = True\n\n\t\tif trigger_webhook and event and webhook.webhook_docevent == event:\n\t\t\t_webhook_request(webhook)\n", "path": "frappe/integrations/doctype/webhook/__init__.py"}]}
| 2,427 | 155 |
gh_patches_debug_39006
|
rasdani/github-patches
|
git_diff
|
MycroftAI__mycroft-core-2538
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Skills and Enclosure background services fail to stop and are killed...
## Be clear about the software, hardware and version you are running
For example:
in CLI
>> what version are you running
>> I am running mycroft-core version 20 oh 2, release 0
>> You are on the latest version.
Opensuse Leap 15.1
## Try to provide steps that we can use to replicate the Issue
For example:
1. CTRL+C in CLI
2. Enter ./stop_mycroft.sh
3. Skills and Enclosure services are eventually killed.
4. Takes about 30 seconds total
## Be as specific as possible about the expected condition, and the deviation from expected condition.
user@LinuxOS:~/mycroft-core> ./stop-mycroft.sh skills
Stopping skills (5579)...stopped.
user@LinuxOS:~/mycroft-core> ./stop-mycroft.sh enclosure
Stopping enclosure (5588)...failed to stop.
Killing enclosure (5588)...killed.
user@LinuxOS:~/mycroft-core> ./stop-mycroft.sh
Stopping all mycroft-core services
Stopping messagebus.service (5576)...stopped.
Stopping audio (5582)...stopped.
Stopping speech (5585)...stopped.
...
user@LinuxOS:~/mycroft-core> ./stop-mycroft.sh
Stopping all mycroft-core services
Stopping messagebus.service (18995)...stopped.
Stopping skills (18998)...failed to stop.
Killing skills (18998)...killed.
Stopping audio (19001)...stopped.
Stopping speech (19004)...stopped.
Stopping enclosure (19007)...failed to stop.
Killing enclosure (19007)...killed.
user@LinuxOS:~/mycroft-core>
</issue>
<code>
[start of mycroft/client/enclosure/__main__.py]
1 # Copyright 2017 Mycroft AI Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 #
15 import sys
16
17 from mycroft.util.log import LOG
18 from mycroft.messagebus.client import MessageBusClient
19 from mycroft.configuration import Configuration, LocalConf, SYSTEM_CONFIG
20
21
22 def main():
23 # Read the system configuration
24 system_config = LocalConf(SYSTEM_CONFIG)
25 platform = system_config.get("enclosure", {}).get("platform")
26
27 if platform == "mycroft_mark_1":
28 LOG.debug("Creating Mark I Enclosure")
29 from mycroft.client.enclosure.mark1 import EnclosureMark1
30 enclosure = EnclosureMark1()
31 elif platform == "mycroft_mark_2":
32 LOG.debug("Creating Mark II Enclosure")
33 from mycroft.client.enclosure.mark2 import EnclosureMark2
34 enclosure = EnclosureMark2()
35 else:
36 LOG.debug("Creating generic enclosure, platform='{}'".format(platform))
37
38 # TODO: Mechanism to load from elsewhere. E.g. read a script path from
39 # the mycroft.conf, then load/launch that script.
40 from mycroft.client.enclosure.generic import EnclosureGeneric
41 enclosure = EnclosureGeneric()
42
43 if enclosure:
44 try:
45 LOG.debug("Enclosure started!")
46 enclosure.run()
47 except Exception as e:
48 print(e)
49 finally:
50 sys.exit()
51 else:
52 LOG.debug("No enclosure available for this hardware, running headless")
53
54
55 if __name__ == "__main__":
56 main()
57
[end of mycroft/client/enclosure/__main__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mycroft/client/enclosure/__main__.py b/mycroft/client/enclosure/__main__.py
--- a/mycroft/client/enclosure/__main__.py
+++ b/mycroft/client/enclosure/__main__.py
@@ -12,44 +12,67 @@
# See the License for the specific language governing permissions and
# limitations under the License.
#
-import sys
+"""Entrypoint for enclosure service.
+This provides any "enclosure" specific functionality, for example GUI or
+control over the Mark-1 Faceplate.
+"""
+from mycroft.configuration import LocalConf, SYSTEM_CONFIG
from mycroft.util.log import LOG
-from mycroft.messagebus.client import MessageBusClient
-from mycroft.configuration import Configuration, LocalConf, SYSTEM_CONFIG
+from mycroft.util import (create_daemon, wait_for_exit_signal,
+ reset_sigint_handler)
-def main():
- # Read the system configuration
- system_config = LocalConf(SYSTEM_CONFIG)
- platform = system_config.get("enclosure", {}).get("platform")
+def create_enclosure(platform):
+ """Create an enclosure based on the provided platform string.
+ Arguments:
+ platform (str): platform name string
+
+ Returns:
+ Enclosure object
+ """
if platform == "mycroft_mark_1":
- LOG.debug("Creating Mark I Enclosure")
+ LOG.info("Creating Mark I Enclosure")
from mycroft.client.enclosure.mark1 import EnclosureMark1
enclosure = EnclosureMark1()
elif platform == "mycroft_mark_2":
- LOG.debug("Creating Mark II Enclosure")
+ LOG.info("Creating Mark II Enclosure")
from mycroft.client.enclosure.mark2 import EnclosureMark2
enclosure = EnclosureMark2()
else:
- LOG.debug("Creating generic enclosure, platform='{}'".format(platform))
+ LOG.info("Creating generic enclosure, platform='{}'".format(platform))
# TODO: Mechanism to load from elsewhere. E.g. read a script path from
# the mycroft.conf, then load/launch that script.
from mycroft.client.enclosure.generic import EnclosureGeneric
enclosure = EnclosureGeneric()
+ return enclosure
+
+
+def main():
+ """Launch one of the available enclosure implementations.
+
+ This depends on the configured platform and can currently either be
+ mycroft_mark_1 or mycroft_mark_2, if unconfigured a generic enclosure with
+ only the GUI bus will be started.
+ """
+ # Read the system configuration
+ system_config = LocalConf(SYSTEM_CONFIG)
+ platform = system_config.get("enclosure", {}).get("platform")
+
+ enclosure = create_enclosure(platform)
if enclosure:
try:
LOG.debug("Enclosure started!")
- enclosure.run()
+ reset_sigint_handler()
+ create_daemon(enclosure.run)
+ wait_for_exit_signal()
except Exception as e:
print(e)
- finally:
- sys.exit()
else:
- LOG.debug("No enclosure available for this hardware, running headless")
+ LOG.info("No enclosure available for this hardware, running headless")
if __name__ == "__main__":
|
{"golden_diff": "diff --git a/mycroft/client/enclosure/__main__.py b/mycroft/client/enclosure/__main__.py\n--- a/mycroft/client/enclosure/__main__.py\n+++ b/mycroft/client/enclosure/__main__.py\n@@ -12,44 +12,67 @@\n # See the License for the specific language governing permissions and\n # limitations under the License.\n #\n-import sys\n+\"\"\"Entrypoint for enclosure service.\n \n+This provides any \"enclosure\" specific functionality, for example GUI or\n+control over the Mark-1 Faceplate.\n+\"\"\"\n+from mycroft.configuration import LocalConf, SYSTEM_CONFIG\n from mycroft.util.log import LOG\n-from mycroft.messagebus.client import MessageBusClient\n-from mycroft.configuration import Configuration, LocalConf, SYSTEM_CONFIG\n+from mycroft.util import (create_daemon, wait_for_exit_signal,\n+ reset_sigint_handler)\n \n \n-def main():\n- # Read the system configuration\n- system_config = LocalConf(SYSTEM_CONFIG)\n- platform = system_config.get(\"enclosure\", {}).get(\"platform\")\n+def create_enclosure(platform):\n+ \"\"\"Create an enclosure based on the provided platform string.\n \n+ Arguments:\n+ platform (str): platform name string\n+\n+ Returns:\n+ Enclosure object\n+ \"\"\"\n if platform == \"mycroft_mark_1\":\n- LOG.debug(\"Creating Mark I Enclosure\")\n+ LOG.info(\"Creating Mark I Enclosure\")\n from mycroft.client.enclosure.mark1 import EnclosureMark1\n enclosure = EnclosureMark1()\n elif platform == \"mycroft_mark_2\":\n- LOG.debug(\"Creating Mark II Enclosure\")\n+ LOG.info(\"Creating Mark II Enclosure\")\n from mycroft.client.enclosure.mark2 import EnclosureMark2\n enclosure = EnclosureMark2()\n else:\n- LOG.debug(\"Creating generic enclosure, platform='{}'\".format(platform))\n+ LOG.info(\"Creating generic enclosure, platform='{}'\".format(platform))\n \n # TODO: Mechanism to load from elsewhere. E.g. read a script path from\n # the mycroft.conf, then load/launch that script.\n from mycroft.client.enclosure.generic import EnclosureGeneric\n enclosure = EnclosureGeneric()\n \n+ return enclosure\n+\n+\n+def main():\n+ \"\"\"Launch one of the available enclosure implementations.\n+\n+ This depends on the configured platform and can currently either be\n+ mycroft_mark_1 or mycroft_mark_2, if unconfigured a generic enclosure with\n+ only the GUI bus will be started.\n+ \"\"\"\n+ # Read the system configuration\n+ system_config = LocalConf(SYSTEM_CONFIG)\n+ platform = system_config.get(\"enclosure\", {}).get(\"platform\")\n+\n+ enclosure = create_enclosure(platform)\n if enclosure:\n try:\n LOG.debug(\"Enclosure started!\")\n- enclosure.run()\n+ reset_sigint_handler()\n+ create_daemon(enclosure.run)\n+ wait_for_exit_signal()\n except Exception as e:\n print(e)\n- finally:\n- sys.exit()\n else:\n- LOG.debug(\"No enclosure available for this hardware, running headless\")\n+ LOG.info(\"No enclosure available for this hardware, running headless\")\n \n \n if __name__ == \"__main__\":\n", "issue": "Skills and Enclosure background services fail to stop and are killed...\n## Be clear about the software, hardware and version you are running\r\n\r\nFor example: \r\n\r\nin CLI\r\n >> what version are you running \r\n >> I am running mycroft-core version 20 oh 2, release 0 \r\n >> You are on the latest version.\r\n\r\nOpensuse Leap 15.1\r\n## Try to provide steps that we can use to replicate the Issue\r\n\r\nFor example: \r\n\r\n1. CTRL+C in CLI\r\n2. Enter ./stop_mycroft.sh \r\n3. Skills and Enclosure services are eventually killed.\r\n4. Takes about 30 seconds total\r\n\r\n## Be as specific as possible about the expected condition, and the deviation from expected condition. \r\n\r\nuser@LinuxOS:~/mycroft-core> ./stop-mycroft.sh skills\r\nStopping skills (5579)...stopped.\r\nuser@LinuxOS:~/mycroft-core> ./stop-mycroft.sh enclosure\r\nStopping enclosure (5588)...failed to stop.\r\n Killing enclosure (5588)...killed.\r\nuser@LinuxOS:~/mycroft-core> ./stop-mycroft.sh\r\nStopping all mycroft-core services\r\nStopping messagebus.service (5576)...stopped.\r\nStopping audio (5582)...stopped.\r\nStopping speech (5585)...stopped.\r\n...\r\nuser@LinuxOS:~/mycroft-core> ./stop-mycroft.sh\r\nStopping all mycroft-core services\r\nStopping messagebus.service (18995)...stopped.\r\nStopping skills (18998)...failed to stop.\r\n Killing skills (18998)...killed.\r\nStopping audio (19001)...stopped.\r\nStopping speech (19004)...stopped.\r\nStopping enclosure (19007)...failed to stop.\r\n Killing enclosure (19007)...killed.\r\nuser@LinuxOS:~/mycroft-core> \r\n\r\n\n", "before_files": [{"content": "# Copyright 2017 Mycroft AI Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\nimport sys\n\nfrom mycroft.util.log import LOG\nfrom mycroft.messagebus.client import MessageBusClient\nfrom mycroft.configuration import Configuration, LocalConf, SYSTEM_CONFIG\n\n\ndef main():\n # Read the system configuration\n system_config = LocalConf(SYSTEM_CONFIG)\n platform = system_config.get(\"enclosure\", {}).get(\"platform\")\n\n if platform == \"mycroft_mark_1\":\n LOG.debug(\"Creating Mark I Enclosure\")\n from mycroft.client.enclosure.mark1 import EnclosureMark1\n enclosure = EnclosureMark1()\n elif platform == \"mycroft_mark_2\":\n LOG.debug(\"Creating Mark II Enclosure\")\n from mycroft.client.enclosure.mark2 import EnclosureMark2\n enclosure = EnclosureMark2()\n else:\n LOG.debug(\"Creating generic enclosure, platform='{}'\".format(platform))\n\n # TODO: Mechanism to load from elsewhere. E.g. read a script path from\n # the mycroft.conf, then load/launch that script.\n from mycroft.client.enclosure.generic import EnclosureGeneric\n enclosure = EnclosureGeneric()\n\n if enclosure:\n try:\n LOG.debug(\"Enclosure started!\")\n enclosure.run()\n except Exception as e:\n print(e)\n finally:\n sys.exit()\n else:\n LOG.debug(\"No enclosure available for this hardware, running headless\")\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "mycroft/client/enclosure/__main__.py"}]}
| 1,500 | 710 |
gh_patches_debug_29429
|
rasdani/github-patches
|
git_diff
|
encode__starlette-109
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
scope["server"] can be None
From https://asgi.readthedocs.io/en/latest/specs/www.html#connection-scope
> server: A two-item iterable of [host, port], where host is the listening address for this server as a unicode string, and port is the integer listening port. Optional, defaults to None.
https://github.com/encode/starlette/blob/master/starlette/datastructures.py#L11 doesn't handle that option, it assumes scope["server"] is always a two-pair
</issue>
<code>
[start of starlette/datastructures.py]
1 import typing
2 from starlette.types import Scope
3 from urllib.parse import parse_qsl, unquote, urlparse, ParseResult
4
5
6 class URL:
7 def __init__(self, url: str = "", scope: Scope = None) -> None:
8 if scope is not None:
9 assert not url, 'Cannot set both "url" and "scope".'
10 scheme = scope["scheme"]
11 host, port = scope["server"]
12 path = scope.get("root_path", "") + scope["path"]
13 query_string = scope["query_string"]
14
15 default_port = {"http": 80, "https": 443, "ws": 80, "wss": 443}[scheme]
16 if port == default_port:
17 url = "%s://%s%s" % (scheme, host, path)
18 else:
19 url = "%s://%s:%s%s" % (scheme, host, port, path)
20
21 if query_string:
22 url += "?" + unquote(query_string.decode())
23 self._url = url
24
25 @property
26 def components(self) -> ParseResult:
27 if not hasattr(self, "_components"):
28 self._components = urlparse(self._url)
29 return self._components
30
31 @property
32 def scheme(self) -> str:
33 return self.components.scheme
34
35 @property
36 def netloc(self) -> str:
37 return self.components.netloc
38
39 @property
40 def path(self) -> str:
41 return self.components.path
42
43 @property
44 def params(self) -> str:
45 return self.components.params
46
47 @property
48 def query(self) -> str:
49 return self.components.query
50
51 @property
52 def fragment(self) -> str:
53 return self.components.fragment
54
55 @property
56 def username(self) -> typing.Union[None, str]:
57 return self.components.username
58
59 @property
60 def password(self) -> typing.Union[None, str]:
61 return self.components.password
62
63 @property
64 def hostname(self) -> typing.Union[None, str]:
65 return self.components.hostname
66
67 @property
68 def port(self) -> typing.Optional[int]:
69 return self.components.port
70
71 def replace(self, **kwargs: typing.Any) -> "URL":
72 if "hostname" in kwargs or "port" in kwargs:
73 hostname = kwargs.pop("hostname", self.hostname)
74 port = kwargs.pop("port", self.port)
75 if port is None:
76 kwargs["netloc"] = hostname
77 else:
78 kwargs["netloc"] = "%s:%d" % (hostname, port)
79 components = self.components._replace(**kwargs)
80 return URL(components.geturl())
81
82 def __eq__(self, other):
83 return str(self) == str(other)
84
85 def __str__(self):
86 return self._url
87
88
89 # Type annotations for valid `__init__` values to QueryParams and Headers.
90 StrPairs = typing.Sequence[typing.Tuple[str, str]]
91 BytesPairs = typing.List[typing.Tuple[bytes, bytes]]
92 StrDict = typing.Mapping[str, str]
93
94
95 class QueryParams(StrDict):
96 """
97 An immutable multidict.
98 """
99
100 def __init__(
101 self, value: typing.Union[str, typing.Union[StrDict, StrPairs]] = None
102 ) -> None:
103 if value is None:
104 value = []
105 elif isinstance(value, str):
106 value = parse_qsl(value)
107
108 if hasattr(value, "items"):
109 items = list(typing.cast(StrDict, value).items())
110 else:
111 items = list(typing.cast(StrPairs, value))
112 self._dict = {k: v for k, v in reversed(items)}
113 self._list = items
114
115 def getlist(self, key: typing.Any) -> typing.List[str]:
116 return [item_value for item_key, item_value in self._list if item_key == key]
117
118 def keys(self) -> typing.List[str]: # type: ignore
119 return [key for key, value in self._list]
120
121 def values(self) -> typing.List[str]: # type: ignore
122 return [value for key, value in self._list]
123
124 def items(self) -> StrPairs: # type: ignore
125 return list(self._list)
126
127 def get(self, key: typing.Any, default: typing.Any = None) -> typing.Any:
128 if key in self._dict:
129 return self._dict[key]
130 else:
131 return default
132
133 def __getitem__(self, key: typing.Any) -> str:
134 return self._dict[key]
135
136 def __contains__(self, key: typing.Any) -> bool:
137 return key in self._dict
138
139 def __iter__(self) -> typing.Iterator[typing.Any]:
140 return iter(self._list)
141
142 def __len__(self) -> int:
143 return len(self._list)
144
145 def __eq__(self, other: typing.Any) -> bool:
146 if not isinstance(other, QueryParams):
147 other = QueryParams(other)
148 return sorted(self._list) == sorted(other._list)
149
150 def __repr__(self) -> str:
151 return "QueryParams(%s)" % repr(self._list)
152
153
154 class Headers(typing.Mapping[str, str]):
155 """
156 An immutable, case-insensitive multidict.
157 """
158
159 def __init__(self, raw_headers: typing.Optional[BytesPairs] = None) -> None:
160 if raw_headers is None:
161 self._list = [] # type: BytesPairs
162 else:
163 for header_key, header_value in raw_headers:
164 assert isinstance(header_key, bytes)
165 assert isinstance(header_value, bytes)
166 assert header_key == header_key.lower()
167 self._list = raw_headers
168
169 def keys(self) -> typing.List[str]: # type: ignore
170 return [key.decode("latin-1") for key, value in self._list]
171
172 def values(self) -> typing.List[str]: # type: ignore
173 return [value.decode("latin-1") for key, value in self._list]
174
175 def items(self) -> StrPairs: # type: ignore
176 return [
177 (key.decode("latin-1"), value.decode("latin-1"))
178 for key, value in self._list
179 ]
180
181 def get(self, key: str, default: typing.Any = None) -> typing.Any:
182 try:
183 return self[key]
184 except KeyError:
185 return default
186
187 def getlist(self, key: str) -> typing.List[str]:
188 get_header_key = key.lower().encode("latin-1")
189 return [
190 item_value.decode("latin-1")
191 for item_key, item_value in self._list
192 if item_key == get_header_key
193 ]
194
195 def mutablecopy(self) -> "MutableHeaders":
196 return MutableHeaders(self._list[:])
197
198 def __getitem__(self, key: str) -> str:
199 get_header_key = key.lower().encode("latin-1")
200 for header_key, header_value in self._list:
201 if header_key == get_header_key:
202 return header_value.decode("latin-1")
203 raise KeyError(key)
204
205 def __contains__(self, key: typing.Any) -> bool:
206 get_header_key = key.lower().encode("latin-1")
207 for header_key, header_value in self._list:
208 if header_key == get_header_key:
209 return True
210 return False
211
212 def __iter__(self) -> typing.Iterator[typing.Any]:
213 return iter(self.items())
214
215 def __len__(self) -> int:
216 return len(self._list)
217
218 def __eq__(self, other: typing.Any) -> bool:
219 if not isinstance(other, Headers):
220 return False
221 return sorted(self._list) == sorted(other._list)
222
223 def __repr__(self) -> str:
224 return "%s(%s)" % (self.__class__.__name__, repr(self.items()))
225
226
227 class MutableHeaders(Headers):
228 def __setitem__(self, key: str, value: str) -> None:
229 """
230 Set the header `key` to `value`, removing any duplicate entries.
231 Retains insertion order.
232 """
233 set_key = key.lower().encode("latin-1")
234 set_value = value.encode("latin-1")
235
236 found_indexes = []
237 for idx, (item_key, item_value) in enumerate(self._list):
238 if item_key == set_key:
239 found_indexes.append(idx)
240
241 for idx in reversed(found_indexes[1:]):
242 del self._list[idx]
243
244 if found_indexes:
245 idx = found_indexes[0]
246 self._list[idx] = (set_key, set_value)
247 else:
248 self._list.append((set_key, set_value))
249
250 def __delitem__(self, key: str) -> None:
251 """
252 Remove the header `key`.
253 """
254 del_key = key.lower().encode("latin-1")
255
256 pop_indexes = []
257 for idx, (item_key, item_value) in enumerate(self._list):
258 if item_key == del_key:
259 pop_indexes.append(idx)
260
261 for idx in reversed(pop_indexes):
262 del (self._list[idx])
263
264 def setdefault(self, key: str, value: str) -> str:
265 """
266 If the header `key` does not exist, then set it to `value`.
267 Returns the header value.
268 """
269 set_key = key.lower().encode("latin-1")
270 set_value = value.encode("latin-1")
271
272 for idx, (item_key, item_value) in enumerate(self._list):
273 if item_key == set_key:
274 return item_value.decode("latin-1")
275 self._list.append((set_key, set_value))
276 return value
277
278 def update(self, other: dict):
279 for key, val in other.items():
280 self[key] = val
281
[end of starlette/datastructures.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/starlette/datastructures.py b/starlette/datastructures.py
--- a/starlette/datastructures.py
+++ b/starlette/datastructures.py
@@ -7,16 +7,20 @@
def __init__(self, url: str = "", scope: Scope = None) -> None:
if scope is not None:
assert not url, 'Cannot set both "url" and "scope".'
- scheme = scope["scheme"]
- host, port = scope["server"]
+ scheme = scope.get("scheme", "http")
+ server = scope.get("server", None)
path = scope.get("root_path", "") + scope["path"]
query_string = scope["query_string"]
- default_port = {"http": 80, "https": 443, "ws": 80, "wss": 443}[scheme]
- if port == default_port:
- url = "%s://%s%s" % (scheme, host, path)
+ if server is None:
+ url = path
else:
- url = "%s://%s:%s%s" % (scheme, host, port, path)
+ host, port = server
+ default_port = {"http": 80, "https": 443, "ws": 80, "wss": 443}[scheme]
+ if port == default_port:
+ url = "%s://%s%s" % (scheme, host, path)
+ else:
+ url = "%s://%s:%s%s" % (scheme, host, port, path)
if query_string:
url += "?" + unquote(query_string.decode())
@@ -85,6 +89,9 @@
def __str__(self):
return self._url
+ def __repr__(self):
+ return "%s(%s)" % (self.__class__.__name__, repr(self._url))
+
# Type annotations for valid `__init__` values to QueryParams and Headers.
StrPairs = typing.Sequence[typing.Tuple[str, str]]
|
{"golden_diff": "diff --git a/starlette/datastructures.py b/starlette/datastructures.py\n--- a/starlette/datastructures.py\n+++ b/starlette/datastructures.py\n@@ -7,16 +7,20 @@\n def __init__(self, url: str = \"\", scope: Scope = None) -> None:\n if scope is not None:\n assert not url, 'Cannot set both \"url\" and \"scope\".'\n- scheme = scope[\"scheme\"]\n- host, port = scope[\"server\"]\n+ scheme = scope.get(\"scheme\", \"http\")\n+ server = scope.get(\"server\", None)\n path = scope.get(\"root_path\", \"\") + scope[\"path\"]\n query_string = scope[\"query_string\"]\n \n- default_port = {\"http\": 80, \"https\": 443, \"ws\": 80, \"wss\": 443}[scheme]\n- if port == default_port:\n- url = \"%s://%s%s\" % (scheme, host, path)\n+ if server is None:\n+ url = path\n else:\n- url = \"%s://%s:%s%s\" % (scheme, host, port, path)\n+ host, port = server\n+ default_port = {\"http\": 80, \"https\": 443, \"ws\": 80, \"wss\": 443}[scheme]\n+ if port == default_port:\n+ url = \"%s://%s%s\" % (scheme, host, path)\n+ else:\n+ url = \"%s://%s:%s%s\" % (scheme, host, port, path)\n \n if query_string:\n url += \"?\" + unquote(query_string.decode())\n@@ -85,6 +89,9 @@\n def __str__(self):\n return self._url\n \n+ def __repr__(self):\n+ return \"%s(%s)\" % (self.__class__.__name__, repr(self._url))\n+\n \n # Type annotations for valid `__init__` values to QueryParams and Headers.\n StrPairs = typing.Sequence[typing.Tuple[str, str]]\n", "issue": "scope[\"server\"] can be None\nFrom https://asgi.readthedocs.io/en/latest/specs/www.html#connection-scope\r\n\r\n> server: A two-item iterable of [host, port], where host is the listening address for this server as a unicode string, and port is the integer listening port. Optional, defaults to None.\r\n\r\nhttps://github.com/encode/starlette/blob/master/starlette/datastructures.py#L11 doesn't handle that option, it assumes scope[\"server\"] is always a two-pair\r\n\r\n\n", "before_files": [{"content": "import typing\nfrom starlette.types import Scope\nfrom urllib.parse import parse_qsl, unquote, urlparse, ParseResult\n\n\nclass URL:\n def __init__(self, url: str = \"\", scope: Scope = None) -> None:\n if scope is not None:\n assert not url, 'Cannot set both \"url\" and \"scope\".'\n scheme = scope[\"scheme\"]\n host, port = scope[\"server\"]\n path = scope.get(\"root_path\", \"\") + scope[\"path\"]\n query_string = scope[\"query_string\"]\n\n default_port = {\"http\": 80, \"https\": 443, \"ws\": 80, \"wss\": 443}[scheme]\n if port == default_port:\n url = \"%s://%s%s\" % (scheme, host, path)\n else:\n url = \"%s://%s:%s%s\" % (scheme, host, port, path)\n\n if query_string:\n url += \"?\" + unquote(query_string.decode())\n self._url = url\n\n @property\n def components(self) -> ParseResult:\n if not hasattr(self, \"_components\"):\n self._components = urlparse(self._url)\n return self._components\n\n @property\n def scheme(self) -> str:\n return self.components.scheme\n\n @property\n def netloc(self) -> str:\n return self.components.netloc\n\n @property\n def path(self) -> str:\n return self.components.path\n\n @property\n def params(self) -> str:\n return self.components.params\n\n @property\n def query(self) -> str:\n return self.components.query\n\n @property\n def fragment(self) -> str:\n return self.components.fragment\n\n @property\n def username(self) -> typing.Union[None, str]:\n return self.components.username\n\n @property\n def password(self) -> typing.Union[None, str]:\n return self.components.password\n\n @property\n def hostname(self) -> typing.Union[None, str]:\n return self.components.hostname\n\n @property\n def port(self) -> typing.Optional[int]:\n return self.components.port\n\n def replace(self, **kwargs: typing.Any) -> \"URL\":\n if \"hostname\" in kwargs or \"port\" in kwargs:\n hostname = kwargs.pop(\"hostname\", self.hostname)\n port = kwargs.pop(\"port\", self.port)\n if port is None:\n kwargs[\"netloc\"] = hostname\n else:\n kwargs[\"netloc\"] = \"%s:%d\" % (hostname, port)\n components = self.components._replace(**kwargs)\n return URL(components.geturl())\n\n def __eq__(self, other):\n return str(self) == str(other)\n\n def __str__(self):\n return self._url\n\n\n# Type annotations for valid `__init__` values to QueryParams and Headers.\nStrPairs = typing.Sequence[typing.Tuple[str, str]]\nBytesPairs = typing.List[typing.Tuple[bytes, bytes]]\nStrDict = typing.Mapping[str, str]\n\n\nclass QueryParams(StrDict):\n \"\"\"\n An immutable multidict.\n \"\"\"\n\n def __init__(\n self, value: typing.Union[str, typing.Union[StrDict, StrPairs]] = None\n ) -> None:\n if value is None:\n value = []\n elif isinstance(value, str):\n value = parse_qsl(value)\n\n if hasattr(value, \"items\"):\n items = list(typing.cast(StrDict, value).items())\n else:\n items = list(typing.cast(StrPairs, value))\n self._dict = {k: v for k, v in reversed(items)}\n self._list = items\n\n def getlist(self, key: typing.Any) -> typing.List[str]:\n return [item_value for item_key, item_value in self._list if item_key == key]\n\n def keys(self) -> typing.List[str]: # type: ignore\n return [key for key, value in self._list]\n\n def values(self) -> typing.List[str]: # type: ignore\n return [value for key, value in self._list]\n\n def items(self) -> StrPairs: # type: ignore\n return list(self._list)\n\n def get(self, key: typing.Any, default: typing.Any = None) -> typing.Any:\n if key in self._dict:\n return self._dict[key]\n else:\n return default\n\n def __getitem__(self, key: typing.Any) -> str:\n return self._dict[key]\n\n def __contains__(self, key: typing.Any) -> bool:\n return key in self._dict\n\n def __iter__(self) -> typing.Iterator[typing.Any]:\n return iter(self._list)\n\n def __len__(self) -> int:\n return len(self._list)\n\n def __eq__(self, other: typing.Any) -> bool:\n if not isinstance(other, QueryParams):\n other = QueryParams(other)\n return sorted(self._list) == sorted(other._list)\n\n def __repr__(self) -> str:\n return \"QueryParams(%s)\" % repr(self._list)\n\n\nclass Headers(typing.Mapping[str, str]):\n \"\"\"\n An immutable, case-insensitive multidict.\n \"\"\"\n\n def __init__(self, raw_headers: typing.Optional[BytesPairs] = None) -> None:\n if raw_headers is None:\n self._list = [] # type: BytesPairs\n else:\n for header_key, header_value in raw_headers:\n assert isinstance(header_key, bytes)\n assert isinstance(header_value, bytes)\n assert header_key == header_key.lower()\n self._list = raw_headers\n\n def keys(self) -> typing.List[str]: # type: ignore\n return [key.decode(\"latin-1\") for key, value in self._list]\n\n def values(self) -> typing.List[str]: # type: ignore\n return [value.decode(\"latin-1\") for key, value in self._list]\n\n def items(self) -> StrPairs: # type: ignore\n return [\n (key.decode(\"latin-1\"), value.decode(\"latin-1\"))\n for key, value in self._list\n ]\n\n def get(self, key: str, default: typing.Any = None) -> typing.Any:\n try:\n return self[key]\n except KeyError:\n return default\n\n def getlist(self, key: str) -> typing.List[str]:\n get_header_key = key.lower().encode(\"latin-1\")\n return [\n item_value.decode(\"latin-1\")\n for item_key, item_value in self._list\n if item_key == get_header_key\n ]\n\n def mutablecopy(self) -> \"MutableHeaders\":\n return MutableHeaders(self._list[:])\n\n def __getitem__(self, key: str) -> str:\n get_header_key = key.lower().encode(\"latin-1\")\n for header_key, header_value in self._list:\n if header_key == get_header_key:\n return header_value.decode(\"latin-1\")\n raise KeyError(key)\n\n def __contains__(self, key: typing.Any) -> bool:\n get_header_key = key.lower().encode(\"latin-1\")\n for header_key, header_value in self._list:\n if header_key == get_header_key:\n return True\n return False\n\n def __iter__(self) -> typing.Iterator[typing.Any]:\n return iter(self.items())\n\n def __len__(self) -> int:\n return len(self._list)\n\n def __eq__(self, other: typing.Any) -> bool:\n if not isinstance(other, Headers):\n return False\n return sorted(self._list) == sorted(other._list)\n\n def __repr__(self) -> str:\n return \"%s(%s)\" % (self.__class__.__name__, repr(self.items()))\n\n\nclass MutableHeaders(Headers):\n def __setitem__(self, key: str, value: str) -> None:\n \"\"\"\n Set the header `key` to `value`, removing any duplicate entries.\n Retains insertion order.\n \"\"\"\n set_key = key.lower().encode(\"latin-1\")\n set_value = value.encode(\"latin-1\")\n\n found_indexes = []\n for idx, (item_key, item_value) in enumerate(self._list):\n if item_key == set_key:\n found_indexes.append(idx)\n\n for idx in reversed(found_indexes[1:]):\n del self._list[idx]\n\n if found_indexes:\n idx = found_indexes[0]\n self._list[idx] = (set_key, set_value)\n else:\n self._list.append((set_key, set_value))\n\n def __delitem__(self, key: str) -> None:\n \"\"\"\n Remove the header `key`.\n \"\"\"\n del_key = key.lower().encode(\"latin-1\")\n\n pop_indexes = []\n for idx, (item_key, item_value) in enumerate(self._list):\n if item_key == del_key:\n pop_indexes.append(idx)\n\n for idx in reversed(pop_indexes):\n del (self._list[idx])\n\n def setdefault(self, key: str, value: str) -> str:\n \"\"\"\n If the header `key` does not exist, then set it to `value`.\n Returns the header value.\n \"\"\"\n set_key = key.lower().encode(\"latin-1\")\n set_value = value.encode(\"latin-1\")\n\n for idx, (item_key, item_value) in enumerate(self._list):\n if item_key == set_key:\n return item_value.decode(\"latin-1\")\n self._list.append((set_key, set_value))\n return value\n\n def update(self, other: dict):\n for key, val in other.items():\n self[key] = val\n", "path": "starlette/datastructures.py"}]}
| 3,519 | 458 |
gh_patches_debug_14965
|
rasdani/github-patches
|
git_diff
|
huggingface__transformers-7248
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[example/glue] run_glue compute metrics fail for bart like models
This PR #7126 introduced multiple predictions for trainer. This breaks the `compute_metrics_fn` of `run_glue.py` for `bart` like models which return multiple predictions.
For `BartForSequenceClassfication` `p.predictions` is a `tuple`, so following code fails
https://github.com/huggingface/transformers/blob/1d90d0f386af2af52017d51c421e71a51ec94de0/examples/text-classification/run_glue.py#L154
@sgugger
</issue>
<code>
[start of examples/text-classification/run_glue.py]
1 # coding=utf-8
2 # Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
3 # Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
4 #
5 # Licensed under the Apache License, Version 2.0 (the "License");
6 # you may not use this file except in compliance with the License.
7 # You may obtain a copy of the License at
8 #
9 # http://www.apache.org/licenses/LICENSE-2.0
10 #
11 # Unless required by applicable law or agreed to in writing, software
12 # distributed under the License is distributed on an "AS IS" BASIS,
13 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 # See the License for the specific language governing permissions and
15 # limitations under the License.
16 """ Finetuning the library models for sequence classification on GLUE."""
17
18
19 import dataclasses
20 import logging
21 import os
22 import sys
23 from dataclasses import dataclass, field
24 from typing import Callable, Dict, Optional
25
26 import numpy as np
27
28 from transformers import AutoConfig, AutoModelForSequenceClassification, AutoTokenizer, EvalPrediction, GlueDataset
29 from transformers import GlueDataTrainingArguments as DataTrainingArguments
30 from transformers import (
31 HfArgumentParser,
32 Trainer,
33 TrainingArguments,
34 glue_compute_metrics,
35 glue_output_modes,
36 glue_tasks_num_labels,
37 set_seed,
38 )
39
40
41 logger = logging.getLogger(__name__)
42
43
44 @dataclass
45 class ModelArguments:
46 """
47 Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
48 """
49
50 model_name_or_path: str = field(
51 metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
52 )
53 config_name: Optional[str] = field(
54 default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
55 )
56 tokenizer_name: Optional[str] = field(
57 default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
58 )
59 cache_dir: Optional[str] = field(
60 default=None, metadata={"help": "Where do you want to store the pretrained models downloaded from s3"}
61 )
62
63
64 def main():
65 # See all possible arguments in src/transformers/training_args.py
66 # or by passing the --help flag to this script.
67 # We now keep distinct sets of args, for a cleaner separation of concerns.
68
69 parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
70
71 if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
72 # If we pass only one argument to the script and it's the path to a json file,
73 # let's parse it to get our arguments.
74 model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
75 else:
76 model_args, data_args, training_args = parser.parse_args_into_dataclasses()
77
78 if (
79 os.path.exists(training_args.output_dir)
80 and os.listdir(training_args.output_dir)
81 and training_args.do_train
82 and not training_args.overwrite_output_dir
83 ):
84 raise ValueError(
85 f"Output directory ({training_args.output_dir}) already exists and is not empty. Use --overwrite_output_dir to overcome."
86 )
87
88 # Setup logging
89 logging.basicConfig(
90 format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
91 datefmt="%m/%d/%Y %H:%M:%S",
92 level=logging.INFO if training_args.local_rank in [-1, 0] else logging.WARN,
93 )
94 logger.warning(
95 "Process rank: %s, device: %s, n_gpu: %s, distributed training: %s, 16-bits training: %s",
96 training_args.local_rank,
97 training_args.device,
98 training_args.n_gpu,
99 bool(training_args.local_rank != -1),
100 training_args.fp16,
101 )
102 logger.info("Training/evaluation parameters %s", training_args)
103
104 # Set seed
105 set_seed(training_args.seed)
106
107 try:
108 num_labels = glue_tasks_num_labels[data_args.task_name]
109 output_mode = glue_output_modes[data_args.task_name]
110 except KeyError:
111 raise ValueError("Task not found: %s" % (data_args.task_name))
112
113 # Load pretrained model and tokenizer
114 #
115 # Distributed training:
116 # The .from_pretrained methods guarantee that only one local process can concurrently
117 # download model & vocab.
118
119 config = AutoConfig.from_pretrained(
120 model_args.config_name if model_args.config_name else model_args.model_name_or_path,
121 num_labels=num_labels,
122 finetuning_task=data_args.task_name,
123 cache_dir=model_args.cache_dir,
124 )
125 tokenizer = AutoTokenizer.from_pretrained(
126 model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
127 cache_dir=model_args.cache_dir,
128 )
129 model = AutoModelForSequenceClassification.from_pretrained(
130 model_args.model_name_or_path,
131 from_tf=bool(".ckpt" in model_args.model_name_or_path),
132 config=config,
133 cache_dir=model_args.cache_dir,
134 )
135
136 # Get datasets
137 train_dataset = (
138 GlueDataset(data_args, tokenizer=tokenizer, cache_dir=model_args.cache_dir) if training_args.do_train else None
139 )
140 eval_dataset = (
141 GlueDataset(data_args, tokenizer=tokenizer, mode="dev", cache_dir=model_args.cache_dir)
142 if training_args.do_eval
143 else None
144 )
145 test_dataset = (
146 GlueDataset(data_args, tokenizer=tokenizer, mode="test", cache_dir=model_args.cache_dir)
147 if training_args.do_predict
148 else None
149 )
150
151 def build_compute_metrics_fn(task_name: str) -> Callable[[EvalPrediction], Dict]:
152 def compute_metrics_fn(p: EvalPrediction):
153 if output_mode == "classification":
154 preds = np.argmax(p.predictions, axis=1)
155 elif output_mode == "regression":
156 preds = np.squeeze(p.predictions)
157 return glue_compute_metrics(task_name, preds, p.label_ids)
158
159 return compute_metrics_fn
160
161 # Initialize our Trainer
162 trainer = Trainer(
163 model=model,
164 args=training_args,
165 train_dataset=train_dataset,
166 eval_dataset=eval_dataset,
167 compute_metrics=build_compute_metrics_fn(data_args.task_name),
168 )
169
170 # Training
171 if training_args.do_train:
172 trainer.train(
173 model_path=model_args.model_name_or_path if os.path.isdir(model_args.model_name_or_path) else None
174 )
175 trainer.save_model()
176 # For convenience, we also re-save the tokenizer to the same directory,
177 # so that you can share your model easily on huggingface.co/models =)
178 if trainer.is_world_master():
179 tokenizer.save_pretrained(training_args.output_dir)
180
181 # Evaluation
182 eval_results = {}
183 if training_args.do_eval:
184 logger.info("*** Evaluate ***")
185
186 # Loop to handle MNLI double evaluation (matched, mis-matched)
187 eval_datasets = [eval_dataset]
188 if data_args.task_name == "mnli":
189 mnli_mm_data_args = dataclasses.replace(data_args, task_name="mnli-mm")
190 eval_datasets.append(
191 GlueDataset(mnli_mm_data_args, tokenizer=tokenizer, mode="dev", cache_dir=model_args.cache_dir)
192 )
193
194 for eval_dataset in eval_datasets:
195 trainer.compute_metrics = build_compute_metrics_fn(eval_dataset.args.task_name)
196 eval_result = trainer.evaluate(eval_dataset=eval_dataset)
197
198 output_eval_file = os.path.join(
199 training_args.output_dir, f"eval_results_{eval_dataset.args.task_name}.txt"
200 )
201 if trainer.is_world_master():
202 with open(output_eval_file, "w") as writer:
203 logger.info("***** Eval results {} *****".format(eval_dataset.args.task_name))
204 for key, value in eval_result.items():
205 logger.info(" %s = %s", key, value)
206 writer.write("%s = %s\n" % (key, value))
207
208 eval_results.update(eval_result)
209
210 if training_args.do_predict:
211 logging.info("*** Test ***")
212 test_datasets = [test_dataset]
213 if data_args.task_name == "mnli":
214 mnli_mm_data_args = dataclasses.replace(data_args, task_name="mnli-mm")
215 test_datasets.append(
216 GlueDataset(mnli_mm_data_args, tokenizer=tokenizer, mode="test", cache_dir=model_args.cache_dir)
217 )
218
219 for test_dataset in test_datasets:
220 predictions = trainer.predict(test_dataset=test_dataset).predictions
221 if output_mode == "classification":
222 predictions = np.argmax(predictions, axis=1)
223
224 output_test_file = os.path.join(
225 training_args.output_dir, f"test_results_{test_dataset.args.task_name}.txt"
226 )
227 if trainer.is_world_master():
228 with open(output_test_file, "w") as writer:
229 logger.info("***** Test results {} *****".format(test_dataset.args.task_name))
230 writer.write("index\tprediction\n")
231 for index, item in enumerate(predictions):
232 if output_mode == "regression":
233 writer.write("%d\t%3.3f\n" % (index, item))
234 else:
235 item = test_dataset.get_labels()[item]
236 writer.write("%d\t%s\n" % (index, item))
237 return eval_results
238
239
240 def _mp_fn(index):
241 # For xla_spawn (TPUs)
242 main()
243
244
245 if __name__ == "__main__":
246 main()
247
[end of examples/text-classification/run_glue.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/examples/text-classification/run_glue.py b/examples/text-classification/run_glue.py
--- a/examples/text-classification/run_glue.py
+++ b/examples/text-classification/run_glue.py
@@ -150,10 +150,11 @@
def build_compute_metrics_fn(task_name: str) -> Callable[[EvalPrediction], Dict]:
def compute_metrics_fn(p: EvalPrediction):
+ preds = p.predictions[0] if type(p.predictions) == tuple else p.predictions
if output_mode == "classification":
- preds = np.argmax(p.predictions, axis=1)
- elif output_mode == "regression":
- preds = np.squeeze(p.predictions)
+ preds = np.argmax(preds, axis=1)
+ else: # regression
+ preds = np.squeeze(preds)
return glue_compute_metrics(task_name, preds, p.label_ids)
return compute_metrics_fn
|
{"golden_diff": "diff --git a/examples/text-classification/run_glue.py b/examples/text-classification/run_glue.py\n--- a/examples/text-classification/run_glue.py\n+++ b/examples/text-classification/run_glue.py\n@@ -150,10 +150,11 @@\n \n def build_compute_metrics_fn(task_name: str) -> Callable[[EvalPrediction], Dict]:\n def compute_metrics_fn(p: EvalPrediction):\n+ preds = p.predictions[0] if type(p.predictions) == tuple else p.predictions\n if output_mode == \"classification\":\n- preds = np.argmax(p.predictions, axis=1)\n- elif output_mode == \"regression\":\n- preds = np.squeeze(p.predictions)\n+ preds = np.argmax(preds, axis=1)\n+ else: # regression\n+ preds = np.squeeze(preds)\n return glue_compute_metrics(task_name, preds, p.label_ids)\n \n return compute_metrics_fn\n", "issue": "[example/glue] run_glue compute metrics fail for bart like models\nThis PR #7126 introduced multiple predictions for trainer. This breaks the `compute_metrics_fn` of `run_glue.py` for `bart` like models which return multiple predictions.\r\n\r\nFor `BartForSequenceClassfication` `p.predictions` is a `tuple`, so following code fails\r\nhttps://github.com/huggingface/transformers/blob/1d90d0f386af2af52017d51c421e71a51ec94de0/examples/text-classification/run_glue.py#L154\r\n\r\n@sgugger \r\n\n", "before_files": [{"content": "# coding=utf-8\n# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.\n# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\" Finetuning the library models for sequence classification on GLUE.\"\"\"\n\n\nimport dataclasses\nimport logging\nimport os\nimport sys\nfrom dataclasses import dataclass, field\nfrom typing import Callable, Dict, Optional\n\nimport numpy as np\n\nfrom transformers import AutoConfig, AutoModelForSequenceClassification, AutoTokenizer, EvalPrediction, GlueDataset\nfrom transformers import GlueDataTrainingArguments as DataTrainingArguments\nfrom transformers import (\n HfArgumentParser,\n Trainer,\n TrainingArguments,\n glue_compute_metrics,\n glue_output_modes,\n glue_tasks_num_labels,\n set_seed,\n)\n\n\nlogger = logging.getLogger(__name__)\n\n\n@dataclass\nclass ModelArguments:\n \"\"\"\n Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.\n \"\"\"\n\n model_name_or_path: str = field(\n metadata={\"help\": \"Path to pretrained model or model identifier from huggingface.co/models\"}\n )\n config_name: Optional[str] = field(\n default=None, metadata={\"help\": \"Pretrained config name or path if not the same as model_name\"}\n )\n tokenizer_name: Optional[str] = field(\n default=None, metadata={\"help\": \"Pretrained tokenizer name or path if not the same as model_name\"}\n )\n cache_dir: Optional[str] = field(\n default=None, metadata={\"help\": \"Where do you want to store the pretrained models downloaded from s3\"}\n )\n\n\ndef main():\n # See all possible arguments in src/transformers/training_args.py\n # or by passing the --help flag to this script.\n # We now keep distinct sets of args, for a cleaner separation of concerns.\n\n parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))\n\n if len(sys.argv) == 2 and sys.argv[1].endswith(\".json\"):\n # If we pass only one argument to the script and it's the path to a json file,\n # let's parse it to get our arguments.\n model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))\n else:\n model_args, data_args, training_args = parser.parse_args_into_dataclasses()\n\n if (\n os.path.exists(training_args.output_dir)\n and os.listdir(training_args.output_dir)\n and training_args.do_train\n and not training_args.overwrite_output_dir\n ):\n raise ValueError(\n f\"Output directory ({training_args.output_dir}) already exists and is not empty. Use --overwrite_output_dir to overcome.\"\n )\n\n # Setup logging\n logging.basicConfig(\n format=\"%(asctime)s - %(levelname)s - %(name)s - %(message)s\",\n datefmt=\"%m/%d/%Y %H:%M:%S\",\n level=logging.INFO if training_args.local_rank in [-1, 0] else logging.WARN,\n )\n logger.warning(\n \"Process rank: %s, device: %s, n_gpu: %s, distributed training: %s, 16-bits training: %s\",\n training_args.local_rank,\n training_args.device,\n training_args.n_gpu,\n bool(training_args.local_rank != -1),\n training_args.fp16,\n )\n logger.info(\"Training/evaluation parameters %s\", training_args)\n\n # Set seed\n set_seed(training_args.seed)\n\n try:\n num_labels = glue_tasks_num_labels[data_args.task_name]\n output_mode = glue_output_modes[data_args.task_name]\n except KeyError:\n raise ValueError(\"Task not found: %s\" % (data_args.task_name))\n\n # Load pretrained model and tokenizer\n #\n # Distributed training:\n # The .from_pretrained methods guarantee that only one local process can concurrently\n # download model & vocab.\n\n config = AutoConfig.from_pretrained(\n model_args.config_name if model_args.config_name else model_args.model_name_or_path,\n num_labels=num_labels,\n finetuning_task=data_args.task_name,\n cache_dir=model_args.cache_dir,\n )\n tokenizer = AutoTokenizer.from_pretrained(\n model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,\n cache_dir=model_args.cache_dir,\n )\n model = AutoModelForSequenceClassification.from_pretrained(\n model_args.model_name_or_path,\n from_tf=bool(\".ckpt\" in model_args.model_name_or_path),\n config=config,\n cache_dir=model_args.cache_dir,\n )\n\n # Get datasets\n train_dataset = (\n GlueDataset(data_args, tokenizer=tokenizer, cache_dir=model_args.cache_dir) if training_args.do_train else None\n )\n eval_dataset = (\n GlueDataset(data_args, tokenizer=tokenizer, mode=\"dev\", cache_dir=model_args.cache_dir)\n if training_args.do_eval\n else None\n )\n test_dataset = (\n GlueDataset(data_args, tokenizer=tokenizer, mode=\"test\", cache_dir=model_args.cache_dir)\n if training_args.do_predict\n else None\n )\n\n def build_compute_metrics_fn(task_name: str) -> Callable[[EvalPrediction], Dict]:\n def compute_metrics_fn(p: EvalPrediction):\n if output_mode == \"classification\":\n preds = np.argmax(p.predictions, axis=1)\n elif output_mode == \"regression\":\n preds = np.squeeze(p.predictions)\n return glue_compute_metrics(task_name, preds, p.label_ids)\n\n return compute_metrics_fn\n\n # Initialize our Trainer\n trainer = Trainer(\n model=model,\n args=training_args,\n train_dataset=train_dataset,\n eval_dataset=eval_dataset,\n compute_metrics=build_compute_metrics_fn(data_args.task_name),\n )\n\n # Training\n if training_args.do_train:\n trainer.train(\n model_path=model_args.model_name_or_path if os.path.isdir(model_args.model_name_or_path) else None\n )\n trainer.save_model()\n # For convenience, we also re-save the tokenizer to the same directory,\n # so that you can share your model easily on huggingface.co/models =)\n if trainer.is_world_master():\n tokenizer.save_pretrained(training_args.output_dir)\n\n # Evaluation\n eval_results = {}\n if training_args.do_eval:\n logger.info(\"*** Evaluate ***\")\n\n # Loop to handle MNLI double evaluation (matched, mis-matched)\n eval_datasets = [eval_dataset]\n if data_args.task_name == \"mnli\":\n mnli_mm_data_args = dataclasses.replace(data_args, task_name=\"mnli-mm\")\n eval_datasets.append(\n GlueDataset(mnli_mm_data_args, tokenizer=tokenizer, mode=\"dev\", cache_dir=model_args.cache_dir)\n )\n\n for eval_dataset in eval_datasets:\n trainer.compute_metrics = build_compute_metrics_fn(eval_dataset.args.task_name)\n eval_result = trainer.evaluate(eval_dataset=eval_dataset)\n\n output_eval_file = os.path.join(\n training_args.output_dir, f\"eval_results_{eval_dataset.args.task_name}.txt\"\n )\n if trainer.is_world_master():\n with open(output_eval_file, \"w\") as writer:\n logger.info(\"***** Eval results {} *****\".format(eval_dataset.args.task_name))\n for key, value in eval_result.items():\n logger.info(\" %s = %s\", key, value)\n writer.write(\"%s = %s\\n\" % (key, value))\n\n eval_results.update(eval_result)\n\n if training_args.do_predict:\n logging.info(\"*** Test ***\")\n test_datasets = [test_dataset]\n if data_args.task_name == \"mnli\":\n mnli_mm_data_args = dataclasses.replace(data_args, task_name=\"mnli-mm\")\n test_datasets.append(\n GlueDataset(mnli_mm_data_args, tokenizer=tokenizer, mode=\"test\", cache_dir=model_args.cache_dir)\n )\n\n for test_dataset in test_datasets:\n predictions = trainer.predict(test_dataset=test_dataset).predictions\n if output_mode == \"classification\":\n predictions = np.argmax(predictions, axis=1)\n\n output_test_file = os.path.join(\n training_args.output_dir, f\"test_results_{test_dataset.args.task_name}.txt\"\n )\n if trainer.is_world_master():\n with open(output_test_file, \"w\") as writer:\n logger.info(\"***** Test results {} *****\".format(test_dataset.args.task_name))\n writer.write(\"index\\tprediction\\n\")\n for index, item in enumerate(predictions):\n if output_mode == \"regression\":\n writer.write(\"%d\\t%3.3f\\n\" % (index, item))\n else:\n item = test_dataset.get_labels()[item]\n writer.write(\"%d\\t%s\\n\" % (index, item))\n return eval_results\n\n\ndef _mp_fn(index):\n # For xla_spawn (TPUs)\n main()\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "examples/text-classification/run_glue.py"}]}
| 3,374 | 206 |
gh_patches_debug_12965
|
rasdani/github-patches
|
git_diff
|
getredash__redash-5812
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Timing out when connecting to a MSSQL database on non-default port using ODBC driver
I had to use "Microsoft SQL Server (ODBC)" data source because the "Microsoft SQL Server" one does not currently support using SSL. However, when trying to connect to my server on a port different than 1433, connection timed out.
After a bit of digging, I found this:
> Microsoft's ODBC drivers for SQL Server do not use a PORT= parameter. The port number, if any, is appended to the server name/IP with a comma
source: https://stackoverflow.com/a/50051708/1277401
</issue>
<code>
[start of redash/query_runner/mssql_odbc.py]
1 import logging
2 import sys
3 import uuid
4
5 from redash.query_runner import *
6 from redash.query_runner.mssql import types_map
7 from redash.utils import json_dumps, json_loads
8
9 logger = logging.getLogger(__name__)
10
11 try:
12 import pyodbc
13
14 enabled = True
15 except ImportError:
16 enabled = False
17
18
19 class SQLServerODBC(BaseSQLQueryRunner):
20 should_annotate_query = False
21 noop_query = "SELECT 1"
22
23 @classmethod
24 def configuration_schema(cls):
25 return {
26 "type": "object",
27 "properties": {
28 "server": {"type": "string"},
29 "port": {"type": "number", "default": 1433},
30 "user": {"type": "string"},
31 "password": {"type": "string"},
32 "db": {"type": "string", "title": "Database Name"},
33 "charset": {
34 "type": "string",
35 "default": "UTF-8",
36 "title": "Character Set",
37 },
38 "use_ssl": {"type": "boolean", "title": "Use SSL", "default": False,},
39 "verify_ssl": {
40 "type": "boolean",
41 "title": "Verify SSL certificate",
42 "default": True,
43 },
44 },
45 "order": [
46 "server",
47 "port",
48 "user",
49 "password",
50 "db",
51 "charset",
52 "use_ssl",
53 "verify_ssl",
54 ],
55 "required": ["server", "user", "password", "db"],
56 "secret": ["password"],
57 "extra_options": ["verify_ssl", "use_ssl"],
58 }
59
60 @classmethod
61 def enabled(cls):
62 return enabled
63
64 @classmethod
65 def name(cls):
66 return "Microsoft SQL Server (ODBC)"
67
68 @classmethod
69 def type(cls):
70 return "mssql_odbc"
71
72 @property
73 def supports_auto_limit(self):
74 return False
75
76 def _get_tables(self, schema):
77 query = """
78 SELECT table_schema, table_name, column_name
79 FROM INFORMATION_SCHEMA.COLUMNS
80 WHERE table_schema NOT IN ('guest','INFORMATION_SCHEMA','sys','db_owner','db_accessadmin'
81 ,'db_securityadmin','db_ddladmin','db_backupoperator','db_datareader'
82 ,'db_datawriter','db_denydatareader','db_denydatawriter'
83 );
84 """
85
86 results, error = self.run_query(query, None)
87
88 if error is not None:
89 self._handle_run_query_error(error)
90
91 results = json_loads(results)
92
93 for row in results["rows"]:
94 if row["table_schema"] != self.configuration["db"]:
95 table_name = "{}.{}".format(row["table_schema"], row["table_name"])
96 else:
97 table_name = row["table_name"]
98
99 if table_name not in schema:
100 schema[table_name] = {"name": table_name, "columns": []}
101
102 schema[table_name]["columns"].append(row["column_name"])
103
104 return list(schema.values())
105
106 def run_query(self, query, user):
107 connection = None
108
109 try:
110 server = self.configuration.get("server")
111 user = self.configuration.get("user", "")
112 password = self.configuration.get("password", "")
113 db = self.configuration["db"]
114 port = self.configuration.get("port", 1433)
115 charset = self.configuration.get("charset", "UTF-8")
116
117 connection_string_fmt = "DRIVER={{ODBC Driver 17 for SQL Server}};PORT={};SERVER={};DATABASE={};UID={};PWD={}"
118 connection_string = connection_string_fmt.format(
119 port, server, db, user, password
120 )
121
122 if self.configuration.get("use_ssl", False):
123 connection_string += ";Encrypt=YES"
124
125 if not self.configuration.get("verify_ssl"):
126 connection_string += ";TrustServerCertificate=YES"
127
128 connection = pyodbc.connect(connection_string)
129 cursor = connection.cursor()
130 logger.debug("SQLServerODBC running query: %s", query)
131 cursor.execute(query)
132 data = cursor.fetchall()
133
134 if cursor.description is not None:
135 columns = self.fetch_columns(
136 [(i[0], types_map.get(i[1], None)) for i in cursor.description]
137 )
138 rows = [
139 dict(zip((column["name"] for column in columns), row))
140 for row in data
141 ]
142
143 data = {"columns": columns, "rows": rows}
144 json_data = json_dumps(data)
145 error = None
146 else:
147 error = "No data was returned."
148 json_data = None
149
150 cursor.close()
151 except pyodbc.Error as e:
152 try:
153 # Query errors are at `args[1]`
154 error = e.args[1]
155 except IndexError:
156 # Connection errors are `args[0][1]`
157 error = e.args[0][1]
158 json_data = None
159 except (KeyboardInterrupt, JobTimeoutException):
160 connection.cancel()
161 raise
162 finally:
163 if connection:
164 connection.close()
165
166 return json_data, error
167
168
169 register(SQLServerODBC)
170
[end of redash/query_runner/mssql_odbc.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/redash/query_runner/mssql_odbc.py b/redash/query_runner/mssql_odbc.py
--- a/redash/query_runner/mssql_odbc.py
+++ b/redash/query_runner/mssql_odbc.py
@@ -114,9 +114,9 @@
port = self.configuration.get("port", 1433)
charset = self.configuration.get("charset", "UTF-8")
- connection_string_fmt = "DRIVER={{ODBC Driver 17 for SQL Server}};PORT={};SERVER={};DATABASE={};UID={};PWD={}"
+ connection_string_fmt = "DRIVER={{ODBC Driver 17 for SQL Server}};SERVER={},{};DATABASE={};UID={};PWD={}"
connection_string = connection_string_fmt.format(
- port, server, db, user, password
+ server, port, db, user, password
)
if self.configuration.get("use_ssl", False):
|
{"golden_diff": "diff --git a/redash/query_runner/mssql_odbc.py b/redash/query_runner/mssql_odbc.py\n--- a/redash/query_runner/mssql_odbc.py\n+++ b/redash/query_runner/mssql_odbc.py\n@@ -114,9 +114,9 @@\n port = self.configuration.get(\"port\", 1433)\n charset = self.configuration.get(\"charset\", \"UTF-8\")\n \n- connection_string_fmt = \"DRIVER={{ODBC Driver 17 for SQL Server}};PORT={};SERVER={};DATABASE={};UID={};PWD={}\"\n+ connection_string_fmt = \"DRIVER={{ODBC Driver 17 for SQL Server}};SERVER={},{};DATABASE={};UID={};PWD={}\"\n connection_string = connection_string_fmt.format(\n- port, server, db, user, password\n+ server, port, db, user, password\n )\n \n if self.configuration.get(\"use_ssl\", False):\n", "issue": "Timing out when connecting to a MSSQL database on non-default port using ODBC driver\nI had to use \"Microsoft SQL Server (ODBC)\" data source because the \"Microsoft SQL Server\" one does not currently support using SSL. However, when trying to connect to my server on a port different than 1433, connection timed out.\r\n\r\nAfter a bit of digging, I found this:\r\n> Microsoft's ODBC drivers for SQL Server do not use a PORT= parameter. The port number, if any, is appended to the server name/IP with a comma\r\n\r\nsource: https://stackoverflow.com/a/50051708/1277401\n", "before_files": [{"content": "import logging\nimport sys\nimport uuid\n\nfrom redash.query_runner import *\nfrom redash.query_runner.mssql import types_map\nfrom redash.utils import json_dumps, json_loads\n\nlogger = logging.getLogger(__name__)\n\ntry:\n import pyodbc\n\n enabled = True\nexcept ImportError:\n enabled = False\n\n\nclass SQLServerODBC(BaseSQLQueryRunner):\n should_annotate_query = False\n noop_query = \"SELECT 1\"\n\n @classmethod\n def configuration_schema(cls):\n return {\n \"type\": \"object\",\n \"properties\": {\n \"server\": {\"type\": \"string\"},\n \"port\": {\"type\": \"number\", \"default\": 1433},\n \"user\": {\"type\": \"string\"},\n \"password\": {\"type\": \"string\"},\n \"db\": {\"type\": \"string\", \"title\": \"Database Name\"},\n \"charset\": {\n \"type\": \"string\",\n \"default\": \"UTF-8\",\n \"title\": \"Character Set\",\n },\n \"use_ssl\": {\"type\": \"boolean\", \"title\": \"Use SSL\", \"default\": False,},\n \"verify_ssl\": {\n \"type\": \"boolean\",\n \"title\": \"Verify SSL certificate\",\n \"default\": True,\n },\n },\n \"order\": [\n \"server\",\n \"port\",\n \"user\",\n \"password\",\n \"db\",\n \"charset\",\n \"use_ssl\",\n \"verify_ssl\",\n ],\n \"required\": [\"server\", \"user\", \"password\", \"db\"],\n \"secret\": [\"password\"],\n \"extra_options\": [\"verify_ssl\", \"use_ssl\"],\n }\n\n @classmethod\n def enabled(cls):\n return enabled\n\n @classmethod\n def name(cls):\n return \"Microsoft SQL Server (ODBC)\"\n\n @classmethod\n def type(cls):\n return \"mssql_odbc\"\n\n @property\n def supports_auto_limit(self):\n return False\n\n def _get_tables(self, schema):\n query = \"\"\"\n SELECT table_schema, table_name, column_name\n FROM INFORMATION_SCHEMA.COLUMNS\n WHERE table_schema NOT IN ('guest','INFORMATION_SCHEMA','sys','db_owner','db_accessadmin'\n ,'db_securityadmin','db_ddladmin','db_backupoperator','db_datareader'\n ,'db_datawriter','db_denydatareader','db_denydatawriter'\n );\n \"\"\"\n\n results, error = self.run_query(query, None)\n\n if error is not None:\n self._handle_run_query_error(error)\n\n results = json_loads(results)\n\n for row in results[\"rows\"]:\n if row[\"table_schema\"] != self.configuration[\"db\"]:\n table_name = \"{}.{}\".format(row[\"table_schema\"], row[\"table_name\"])\n else:\n table_name = row[\"table_name\"]\n\n if table_name not in schema:\n schema[table_name] = {\"name\": table_name, \"columns\": []}\n\n schema[table_name][\"columns\"].append(row[\"column_name\"])\n\n return list(schema.values())\n\n def run_query(self, query, user):\n connection = None\n\n try:\n server = self.configuration.get(\"server\")\n user = self.configuration.get(\"user\", \"\")\n password = self.configuration.get(\"password\", \"\")\n db = self.configuration[\"db\"]\n port = self.configuration.get(\"port\", 1433)\n charset = self.configuration.get(\"charset\", \"UTF-8\")\n\n connection_string_fmt = \"DRIVER={{ODBC Driver 17 for SQL Server}};PORT={};SERVER={};DATABASE={};UID={};PWD={}\"\n connection_string = connection_string_fmt.format(\n port, server, db, user, password\n )\n\n if self.configuration.get(\"use_ssl\", False):\n connection_string += \";Encrypt=YES\"\n\n if not self.configuration.get(\"verify_ssl\"):\n connection_string += \";TrustServerCertificate=YES\"\n\n connection = pyodbc.connect(connection_string)\n cursor = connection.cursor()\n logger.debug(\"SQLServerODBC running query: %s\", query)\n cursor.execute(query)\n data = cursor.fetchall()\n\n if cursor.description is not None:\n columns = self.fetch_columns(\n [(i[0], types_map.get(i[1], None)) for i in cursor.description]\n )\n rows = [\n dict(zip((column[\"name\"] for column in columns), row))\n for row in data\n ]\n\n data = {\"columns\": columns, \"rows\": rows}\n json_data = json_dumps(data)\n error = None\n else:\n error = \"No data was returned.\"\n json_data = None\n\n cursor.close()\n except pyodbc.Error as e:\n try:\n # Query errors are at `args[1]`\n error = e.args[1]\n except IndexError:\n # Connection errors are `args[0][1]`\n error = e.args[0][1]\n json_data = None\n except (KeyboardInterrupt, JobTimeoutException):\n connection.cancel()\n raise\n finally:\n if connection:\n connection.close()\n\n return json_data, error\n\n\nregister(SQLServerODBC)\n", "path": "redash/query_runner/mssql_odbc.py"}]}
| 2,200 | 209 |
gh_patches_debug_5342
|
rasdani/github-patches
|
git_diff
|
googleapis__google-api-python-client-1185
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
HttpError error_details isn't populated unless __repr__ is called first
I was trying to handle an HttpError by looking at the contents of the `error_details` attribute. I noticed the attribute is a null-string unless I trigger the `__repr__` function first. For example, this does not work as the error_details is always `""`. I made a simple test that demonstrates the error:
```
from googleapiclient import discovery, errors
client = discovery.build(
"discovery", "v1"
)
req = client.apis().getRest(api='fake_api', version='v1')
try:
resp = req.execute()
except errors.HttpError as err:
print(f'Error details are currently: "{err.error_details}"')
print(f'Exception string representation is: "{err}"')
print(f'Error details are currently: "{err.error_details}"')
```
The output of the above code:
```
Error details are currently: ""
Exception string representation is: "<HttpError 404 when requesting https://www.googleapis.com/discovery/v1/apis/fake_api/v1/rest?alt=json returned "Requested entity was not found.". Details: "Requested entity was not found.">"
Error details are currently: "Requested entity was not found."
```
I tested and the behavior is the same on both `google-api-python-client-1.12.8` and `google-api-python-client-2.0.2`
</issue>
<code>
[start of googleapiclient/errors.py]
1 # Copyright 2014 Google Inc. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Errors for the library.
16
17 All exceptions defined by the library
18 should be defined in this file.
19 """
20 from __future__ import absolute_import
21
22 __author__ = "[email protected] (Joe Gregorio)"
23
24 import json
25
26 from googleapiclient import _helpers as util
27
28
29 class Error(Exception):
30 """Base error for this module."""
31
32 pass
33
34
35 class HttpError(Error):
36 """HTTP data was invalid or unexpected."""
37
38 @util.positional(3)
39 def __init__(self, resp, content, uri=None):
40 self.resp = resp
41 if not isinstance(content, bytes):
42 raise TypeError("HTTP content should be bytes")
43 self.content = content
44 self.uri = uri
45 self.error_details = ""
46
47 def _get_reason(self):
48 """Calculate the reason for the error from the response content."""
49 reason = self.resp.reason
50 try:
51 try:
52 data = json.loads(self.content.decode("utf-8"))
53 except json.JSONDecodeError:
54 # In case it is not json
55 data = self.content.decode("utf-8")
56 if isinstance(data, dict):
57 reason = data["error"]["message"]
58 error_detail_keyword = next((kw for kw in ["detail", "details", "message"] if kw in data["error"]), "")
59 if error_detail_keyword:
60 self.error_details = data["error"][error_detail_keyword]
61 elif isinstance(data, list) and len(data) > 0:
62 first_error = data[0]
63 reason = first_error["error"]["message"]
64 if "details" in first_error["error"]:
65 self.error_details = first_error["error"]["details"]
66 else:
67 self.error_details = data
68 except (ValueError, KeyError, TypeError):
69 pass
70 if reason is None:
71 reason = ""
72 return reason
73
74 def __repr__(self):
75 reason = self._get_reason()
76 if self.error_details:
77 return '<HttpError %s when requesting %s returned "%s". Details: "%s">' % (
78 self.resp.status,
79 self.uri,
80 reason.strip(),
81 self.error_details,
82 )
83 elif self.uri:
84 return '<HttpError %s when requesting %s returned "%s">' % (
85 self.resp.status,
86 self.uri,
87 self._get_reason().strip(),
88 )
89 else:
90 return '<HttpError %s "%s">' % (self.resp.status, self._get_reason())
91
92 __str__ = __repr__
93
94
95 class InvalidJsonError(Error):
96 """The JSON returned could not be parsed."""
97
98 pass
99
100
101 class UnknownFileType(Error):
102 """File type unknown or unexpected."""
103
104 pass
105
106
107 class UnknownLinkType(Error):
108 """Link type unknown or unexpected."""
109
110 pass
111
112
113 class UnknownApiNameOrVersion(Error):
114 """No API with that name and version exists."""
115
116 pass
117
118
119 class UnacceptableMimeTypeError(Error):
120 """That is an unacceptable mimetype for this operation."""
121
122 pass
123
124
125 class MediaUploadSizeError(Error):
126 """Media is larger than the method can accept."""
127
128 pass
129
130
131 class ResumableUploadError(HttpError):
132 """Error occurred during resumable upload."""
133
134 pass
135
136
137 class InvalidChunkSizeError(Error):
138 """The given chunksize is not valid."""
139
140 pass
141
142
143 class InvalidNotificationError(Error):
144 """The channel Notification is invalid."""
145
146 pass
147
148
149 class BatchError(HttpError):
150 """Error occurred during batch operations."""
151
152 @util.positional(2)
153 def __init__(self, reason, resp=None, content=None):
154 self.resp = resp
155 self.content = content
156 self.reason = reason
157
158 def __repr__(self):
159 if getattr(self.resp, "status", None) is None:
160 return '<BatchError "%s">' % (self.reason)
161 else:
162 return '<BatchError %s "%s">' % (self.resp.status, self.reason)
163
164 __str__ = __repr__
165
166
167 class UnexpectedMethodError(Error):
168 """Exception raised by RequestMockBuilder on unexpected calls."""
169
170 @util.positional(1)
171 def __init__(self, methodId=None):
172 """Constructor for an UnexpectedMethodError."""
173 super(UnexpectedMethodError, self).__init__(
174 "Received unexpected call %s" % methodId
175 )
176
177
178 class UnexpectedBodyError(Error):
179 """Exception raised by RequestMockBuilder on unexpected bodies."""
180
181 def __init__(self, expected, provided):
182 """Constructor for an UnexpectedMethodError."""
183 super(UnexpectedBodyError, self).__init__(
184 "Expected: [%s] - Provided: [%s]" % (expected, provided)
185 )
186
[end of googleapiclient/errors.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/googleapiclient/errors.py b/googleapiclient/errors.py
--- a/googleapiclient/errors.py
+++ b/googleapiclient/errors.py
@@ -43,6 +43,12 @@
self.content = content
self.uri = uri
self.error_details = ""
+ self._get_reason()
+
+ @property
+ def status_code(self):
+ """Return the HTTP status code from the response content."""
+ return self.resp.status
def _get_reason(self):
"""Calculate the reason for the error from the response content."""
|
{"golden_diff": "diff --git a/googleapiclient/errors.py b/googleapiclient/errors.py\n--- a/googleapiclient/errors.py\n+++ b/googleapiclient/errors.py\n@@ -43,6 +43,12 @@\n self.content = content\n self.uri = uri\n self.error_details = \"\"\n+ self._get_reason()\n+\n+ @property\n+ def status_code(self):\n+ \"\"\"Return the HTTP status code from the response content.\"\"\"\n+ return self.resp.status\n \n def _get_reason(self):\n \"\"\"Calculate the reason for the error from the response content.\"\"\"\n", "issue": "HttpError error_details isn't populated unless __repr__ is called first\nI was trying to handle an HttpError by looking at the contents of the `error_details` attribute. I noticed the attribute is a null-string unless I trigger the `__repr__` function first. For example, this does not work as the error_details is always `\"\"`. I made a simple test that demonstrates the error:\r\n\r\n```\r\nfrom googleapiclient import discovery, errors\r\n\r\nclient = discovery.build(\r\n \"discovery\", \"v1\"\r\n)\r\n\r\nreq = client.apis().getRest(api='fake_api', version='v1')\r\n\r\ntry:\r\n resp = req.execute()\r\nexcept errors.HttpError as err:\r\n print(f'Error details are currently: \"{err.error_details}\"')\r\n print(f'Exception string representation is: \"{err}\"')\r\n print(f'Error details are currently: \"{err.error_details}\"')\r\n```\r\n\r\nThe output of the above code:\r\n\r\n```\r\nError details are currently: \"\"\r\nException string representation is: \"<HttpError 404 when requesting https://www.googleapis.com/discovery/v1/apis/fake_api/v1/rest?alt=json returned \"Requested entity was not found.\". Details: \"Requested entity was not found.\">\"\r\nError details are currently: \"Requested entity was not found.\"\r\n```\r\n\r\nI tested and the behavior is the same on both `google-api-python-client-1.12.8` and `google-api-python-client-2.0.2`\n", "before_files": [{"content": "# Copyright 2014 Google Inc. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Errors for the library.\n\nAll exceptions defined by the library\nshould be defined in this file.\n\"\"\"\nfrom __future__ import absolute_import\n\n__author__ = \"[email protected] (Joe Gregorio)\"\n\nimport json\n\nfrom googleapiclient import _helpers as util\n\n\nclass Error(Exception):\n \"\"\"Base error for this module.\"\"\"\n\n pass\n\n\nclass HttpError(Error):\n \"\"\"HTTP data was invalid or unexpected.\"\"\"\n\n @util.positional(3)\n def __init__(self, resp, content, uri=None):\n self.resp = resp\n if not isinstance(content, bytes):\n raise TypeError(\"HTTP content should be bytes\")\n self.content = content\n self.uri = uri\n self.error_details = \"\"\n\n def _get_reason(self):\n \"\"\"Calculate the reason for the error from the response content.\"\"\"\n reason = self.resp.reason\n try:\n try:\n data = json.loads(self.content.decode(\"utf-8\"))\n except json.JSONDecodeError:\n # In case it is not json\n data = self.content.decode(\"utf-8\")\n if isinstance(data, dict):\n reason = data[\"error\"][\"message\"]\n error_detail_keyword = next((kw for kw in [\"detail\", \"details\", \"message\"] if kw in data[\"error\"]), \"\")\n if error_detail_keyword:\n self.error_details = data[\"error\"][error_detail_keyword]\n elif isinstance(data, list) and len(data) > 0:\n first_error = data[0]\n reason = first_error[\"error\"][\"message\"]\n if \"details\" in first_error[\"error\"]:\n self.error_details = first_error[\"error\"][\"details\"]\n else:\n self.error_details = data\n except (ValueError, KeyError, TypeError):\n pass\n if reason is None:\n reason = \"\"\n return reason\n\n def __repr__(self):\n reason = self._get_reason()\n if self.error_details:\n return '<HttpError %s when requesting %s returned \"%s\". Details: \"%s\">' % (\n self.resp.status,\n self.uri,\n reason.strip(),\n self.error_details,\n )\n elif self.uri:\n return '<HttpError %s when requesting %s returned \"%s\">' % (\n self.resp.status,\n self.uri,\n self._get_reason().strip(),\n )\n else:\n return '<HttpError %s \"%s\">' % (self.resp.status, self._get_reason())\n\n __str__ = __repr__\n\n\nclass InvalidJsonError(Error):\n \"\"\"The JSON returned could not be parsed.\"\"\"\n\n pass\n\n\nclass UnknownFileType(Error):\n \"\"\"File type unknown or unexpected.\"\"\"\n\n pass\n\n\nclass UnknownLinkType(Error):\n \"\"\"Link type unknown or unexpected.\"\"\"\n\n pass\n\n\nclass UnknownApiNameOrVersion(Error):\n \"\"\"No API with that name and version exists.\"\"\"\n\n pass\n\n\nclass UnacceptableMimeTypeError(Error):\n \"\"\"That is an unacceptable mimetype for this operation.\"\"\"\n\n pass\n\n\nclass MediaUploadSizeError(Error):\n \"\"\"Media is larger than the method can accept.\"\"\"\n\n pass\n\n\nclass ResumableUploadError(HttpError):\n \"\"\"Error occurred during resumable upload.\"\"\"\n\n pass\n\n\nclass InvalidChunkSizeError(Error):\n \"\"\"The given chunksize is not valid.\"\"\"\n\n pass\n\n\nclass InvalidNotificationError(Error):\n \"\"\"The channel Notification is invalid.\"\"\"\n\n pass\n\n\nclass BatchError(HttpError):\n \"\"\"Error occurred during batch operations.\"\"\"\n\n @util.positional(2)\n def __init__(self, reason, resp=None, content=None):\n self.resp = resp\n self.content = content\n self.reason = reason\n\n def __repr__(self):\n if getattr(self.resp, \"status\", None) is None:\n return '<BatchError \"%s\">' % (self.reason)\n else:\n return '<BatchError %s \"%s\">' % (self.resp.status, self.reason)\n\n __str__ = __repr__\n\n\nclass UnexpectedMethodError(Error):\n \"\"\"Exception raised by RequestMockBuilder on unexpected calls.\"\"\"\n\n @util.positional(1)\n def __init__(self, methodId=None):\n \"\"\"Constructor for an UnexpectedMethodError.\"\"\"\n super(UnexpectedMethodError, self).__init__(\n \"Received unexpected call %s\" % methodId\n )\n\n\nclass UnexpectedBodyError(Error):\n \"\"\"Exception raised by RequestMockBuilder on unexpected bodies.\"\"\"\n\n def __init__(self, expected, provided):\n \"\"\"Constructor for an UnexpectedMethodError.\"\"\"\n super(UnexpectedBodyError, self).__init__(\n \"Expected: [%s] - Provided: [%s]\" % (expected, provided)\n )\n", "path": "googleapiclient/errors.py"}]}
| 2,429 | 127 |
gh_patches_debug_29205
|
rasdani/github-patches
|
git_diff
|
open-telemetry__opentelemetry-python-2119
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
update pylint to 2.11.0
The version of pylint in this repo is falling behind. I tried running it w/ pylint 2.11.0 and came across a bunch of warnings in the following categories:
- [x] #2130
- [x] #2125
- [x] #2126
- [x] #2132
- [x] #2134
I will submit separate PRs for each of those, before submitting a PR to bump pylint to 2.11.0.
</issue>
<code>
[start of opentelemetry-api/src/opentelemetry/util/_time.py]
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from logging import getLogger
16 from sys import version_info
17
18 if version_info.minor < 7:
19 getLogger(__name__).warning( # pylint: disable=logging-not-lazy
20 "You are using Python 3.%s. This version does not support timestamps "
21 "with nanosecond precision and the OpenTelemetry SDK will use "
22 "millisecond precision instead. Please refer to PEP 564 for more "
23 "information. Please upgrade to Python 3.7 or newer to use nanosecond "
24 "precision." % version_info.minor
25 )
26 from time import time
27
28 def _time_ns() -> int:
29 return int(time() * 1e9)
30
31
32 else:
33 from time import time_ns
34
35 _time_ns = time_ns
36
[end of opentelemetry-api/src/opentelemetry/util/_time.py]
[start of opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap.py]
1 #!/usr/bin/env python3
2
3 # Copyright The OpenTelemetry Authors
4 #
5 # Licensed under the Apache License, Version 2.0 (the "License");
6 # you may not use this file except in compliance with the License.
7 # You may obtain a copy of the License at
8 #
9 # http://www.apache.org/licenses/LICENSE-2.0
10 #
11 # Unless required by applicable law or agreed to in writing, software
12 # distributed under the License is distributed on an "AS IS" BASIS,
13 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 # See the License for the specific language governing permissions and
15 # limitations under the License.
16
17 import argparse
18 import logging
19 import subprocess
20 import sys
21
22 import pkg_resources
23
24 from opentelemetry.instrumentation.bootstrap_gen import (
25 default_instrumentations,
26 libraries,
27 )
28
29 logger = logging.getLogger(__file__)
30
31
32 def _syscall(func):
33 def wrapper(package=None):
34 try:
35 if package:
36 return func(package)
37 return func()
38 except subprocess.SubprocessError as exp:
39 cmd = getattr(exp, "cmd", None)
40 if cmd:
41 msg = f'Error calling system command "{" ".join(cmd)}"'
42 if package:
43 msg = f'{msg} for package "{package}"'
44 raise RuntimeError(msg)
45
46 return wrapper
47
48
49 @_syscall
50 def _sys_pip_install(package):
51 # explicit upgrade strategy to override potential pip config
52 subprocess.check_call(
53 [
54 sys.executable,
55 "-m",
56 "pip",
57 "install",
58 "-U",
59 "--upgrade-strategy",
60 "only-if-needed",
61 package,
62 ]
63 )
64
65
66 def _pip_check():
67 """Ensures none of the instrumentations have dependency conflicts.
68 Clean check reported as:
69 'No broken requirements found.'
70 Dependency conflicts are reported as:
71 'opentelemetry-instrumentation-flask 1.0.1 has requirement opentelemetry-sdk<2.0,>=1.0, but you have opentelemetry-sdk 0.5.'
72 To not be too restrictive, we'll only check for relevant packages.
73 """
74 check_pipe = subprocess.Popen(
75 [sys.executable, "-m", "pip", "check"], stdout=subprocess.PIPE
76 )
77 pip_check = check_pipe.communicate()[0].decode()
78 pip_check_lower = pip_check.lower()
79 for package_tup in libraries.values():
80 for package in package_tup:
81 if package.lower() in pip_check_lower:
82 raise RuntimeError(f"Dependency conflict found: {pip_check}")
83
84
85 def _is_installed(req):
86 if req in sys.modules:
87 return True
88
89 try:
90 pkg_resources.get_distribution(req)
91 except pkg_resources.DistributionNotFound:
92 return False
93 except pkg_resources.VersionConflict as exc:
94 logger.warning(
95 "instrumentation for package %s is available but version %s is installed. Skipping.",
96 exc.req,
97 exc.dist.as_requirement(), # pylint: disable=no-member
98 )
99 return False
100 return True
101
102
103 def _find_installed_libraries():
104 libs = default_instrumentations[:]
105 libs.extend(
106 [
107 v["instrumentation"]
108 for _, v in libraries.items()
109 if _is_installed(v["library"])
110 ]
111 )
112 return libs
113
114
115 def _run_requirements():
116 logger.setLevel(logging.ERROR)
117 print("\n".join(_find_installed_libraries()), end="")
118
119
120 def _run_install():
121 for lib in _find_installed_libraries():
122 _sys_pip_install(lib)
123 _pip_check()
124
125
126 def run() -> None:
127 action_install = "install"
128 action_requirements = "requirements"
129
130 parser = argparse.ArgumentParser(
131 description="""
132 opentelemetry-bootstrap detects installed libraries and automatically
133 installs the relevant instrumentation packages for them.
134 """
135 )
136 parser.add_argument(
137 "-a",
138 "--action",
139 choices=[action_install, action_requirements],
140 default=action_requirements,
141 help="""
142 install - uses pip to install the new requirements using to the
143 currently active site-package.
144 requirements - prints out the new requirements to stdout. Action can
145 be piped and appended to a requirements.txt file.
146 """,
147 )
148 args = parser.parse_args()
149
150 cmd = {
151 action_install: _run_install,
152 action_requirements: _run_requirements,
153 }[args.action]
154 cmd()
155
[end of opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/opentelemetry-api/src/opentelemetry/util/_time.py b/opentelemetry-api/src/opentelemetry/util/_time.py
--- a/opentelemetry-api/src/opentelemetry/util/_time.py
+++ b/opentelemetry-api/src/opentelemetry/util/_time.py
@@ -17,7 +17,7 @@
if version_info.minor < 7:
getLogger(__name__).warning( # pylint: disable=logging-not-lazy
- "You are using Python 3.%s. This version does not support timestamps "
+ "You are using Python 3.%s. This version does not support timestamps " # pylint: disable=C0209
"with nanosecond precision and the OpenTelemetry SDK will use "
"millisecond precision instead. Please refer to PEP 564 for more "
"information. Please upgrade to Python 3.7 or newer to use nanosecond "
diff --git a/opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap.py b/opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap.py
--- a/opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap.py
+++ b/opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap.py
@@ -71,11 +71,11 @@
'opentelemetry-instrumentation-flask 1.0.1 has requirement opentelemetry-sdk<2.0,>=1.0, but you have opentelemetry-sdk 0.5.'
To not be too restrictive, we'll only check for relevant packages.
"""
- check_pipe = subprocess.Popen(
+ with subprocess.Popen(
[sys.executable, "-m", "pip", "check"], stdout=subprocess.PIPE
- )
- pip_check = check_pipe.communicate()[0].decode()
- pip_check_lower = pip_check.lower()
+ ) as check_pipe:
+ pip_check = check_pipe.communicate()[0].decode()
+ pip_check_lower = pip_check.lower()
for package_tup in libraries.values():
for package in package_tup:
if package.lower() in pip_check_lower:
|
{"golden_diff": "diff --git a/opentelemetry-api/src/opentelemetry/util/_time.py b/opentelemetry-api/src/opentelemetry/util/_time.py\n--- a/opentelemetry-api/src/opentelemetry/util/_time.py\n+++ b/opentelemetry-api/src/opentelemetry/util/_time.py\n@@ -17,7 +17,7 @@\n \n if version_info.minor < 7:\n getLogger(__name__).warning( # pylint: disable=logging-not-lazy\n- \"You are using Python 3.%s. This version does not support timestamps \"\n+ \"You are using Python 3.%s. This version does not support timestamps \" # pylint: disable=C0209\n \"with nanosecond precision and the OpenTelemetry SDK will use \"\n \"millisecond precision instead. Please refer to PEP 564 for more \"\n \"information. Please upgrade to Python 3.7 or newer to use nanosecond \"\ndiff --git a/opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap.py b/opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap.py\n--- a/opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap.py\n+++ b/opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap.py\n@@ -71,11 +71,11 @@\n 'opentelemetry-instrumentation-flask 1.0.1 has requirement opentelemetry-sdk<2.0,>=1.0, but you have opentelemetry-sdk 0.5.'\n To not be too restrictive, we'll only check for relevant packages.\n \"\"\"\n- check_pipe = subprocess.Popen(\n+ with subprocess.Popen(\n [sys.executable, \"-m\", \"pip\", \"check\"], stdout=subprocess.PIPE\n- )\n- pip_check = check_pipe.communicate()[0].decode()\n- pip_check_lower = pip_check.lower()\n+ ) as check_pipe:\n+ pip_check = check_pipe.communicate()[0].decode()\n+ pip_check_lower = pip_check.lower()\n for package_tup in libraries.values():\n for package in package_tup:\n if package.lower() in pip_check_lower:\n", "issue": "update pylint to 2.11.0\nThe version of pylint in this repo is falling behind. I tried running it w/ pylint 2.11.0 and came across a bunch of warnings in the following categories:\r\n\r\n- [x] #2130\r\n- [x] #2125\r\n- [x] #2126\r\n- [x] #2132\r\n- [x] #2134\r\n\r\nI will submit separate PRs for each of those, before submitting a PR to bump pylint to 2.11.0.\n", "before_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom logging import getLogger\nfrom sys import version_info\n\nif version_info.minor < 7:\n getLogger(__name__).warning( # pylint: disable=logging-not-lazy\n \"You are using Python 3.%s. This version does not support timestamps \"\n \"with nanosecond precision and the OpenTelemetry SDK will use \"\n \"millisecond precision instead. Please refer to PEP 564 for more \"\n \"information. Please upgrade to Python 3.7 or newer to use nanosecond \"\n \"precision.\" % version_info.minor\n )\n from time import time\n\n def _time_ns() -> int:\n return int(time() * 1e9)\n\n\nelse:\n from time import time_ns\n\n _time_ns = time_ns\n", "path": "opentelemetry-api/src/opentelemetry/util/_time.py"}, {"content": "#!/usr/bin/env python3\n\n# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport argparse\nimport logging\nimport subprocess\nimport sys\n\nimport pkg_resources\n\nfrom opentelemetry.instrumentation.bootstrap_gen import (\n default_instrumentations,\n libraries,\n)\n\nlogger = logging.getLogger(__file__)\n\n\ndef _syscall(func):\n def wrapper(package=None):\n try:\n if package:\n return func(package)\n return func()\n except subprocess.SubprocessError as exp:\n cmd = getattr(exp, \"cmd\", None)\n if cmd:\n msg = f'Error calling system command \"{\" \".join(cmd)}\"'\n if package:\n msg = f'{msg} for package \"{package}\"'\n raise RuntimeError(msg)\n\n return wrapper\n\n\n@_syscall\ndef _sys_pip_install(package):\n # explicit upgrade strategy to override potential pip config\n subprocess.check_call(\n [\n sys.executable,\n \"-m\",\n \"pip\",\n \"install\",\n \"-U\",\n \"--upgrade-strategy\",\n \"only-if-needed\",\n package,\n ]\n )\n\n\ndef _pip_check():\n \"\"\"Ensures none of the instrumentations have dependency conflicts.\n Clean check reported as:\n 'No broken requirements found.'\n Dependency conflicts are reported as:\n 'opentelemetry-instrumentation-flask 1.0.1 has requirement opentelemetry-sdk<2.0,>=1.0, but you have opentelemetry-sdk 0.5.'\n To not be too restrictive, we'll only check for relevant packages.\n \"\"\"\n check_pipe = subprocess.Popen(\n [sys.executable, \"-m\", \"pip\", \"check\"], stdout=subprocess.PIPE\n )\n pip_check = check_pipe.communicate()[0].decode()\n pip_check_lower = pip_check.lower()\n for package_tup in libraries.values():\n for package in package_tup:\n if package.lower() in pip_check_lower:\n raise RuntimeError(f\"Dependency conflict found: {pip_check}\")\n\n\ndef _is_installed(req):\n if req in sys.modules:\n return True\n\n try:\n pkg_resources.get_distribution(req)\n except pkg_resources.DistributionNotFound:\n return False\n except pkg_resources.VersionConflict as exc:\n logger.warning(\n \"instrumentation for package %s is available but version %s is installed. Skipping.\",\n exc.req,\n exc.dist.as_requirement(), # pylint: disable=no-member\n )\n return False\n return True\n\n\ndef _find_installed_libraries():\n libs = default_instrumentations[:]\n libs.extend(\n [\n v[\"instrumentation\"]\n for _, v in libraries.items()\n if _is_installed(v[\"library\"])\n ]\n )\n return libs\n\n\ndef _run_requirements():\n logger.setLevel(logging.ERROR)\n print(\"\\n\".join(_find_installed_libraries()), end=\"\")\n\n\ndef _run_install():\n for lib in _find_installed_libraries():\n _sys_pip_install(lib)\n _pip_check()\n\n\ndef run() -> None:\n action_install = \"install\"\n action_requirements = \"requirements\"\n\n parser = argparse.ArgumentParser(\n description=\"\"\"\n opentelemetry-bootstrap detects installed libraries and automatically\n installs the relevant instrumentation packages for them.\n \"\"\"\n )\n parser.add_argument(\n \"-a\",\n \"--action\",\n choices=[action_install, action_requirements],\n default=action_requirements,\n help=\"\"\"\n install - uses pip to install the new requirements using to the\n currently active site-package.\n requirements - prints out the new requirements to stdout. Action can\n be piped and appended to a requirements.txt file.\n \"\"\",\n )\n args = parser.parse_args()\n\n cmd = {\n action_install: _run_install,\n action_requirements: _run_requirements,\n }[args.action]\n cmd()\n", "path": "opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap.py"}]}
| 2,362 | 468 |
gh_patches_debug_7798
|
rasdani/github-patches
|
git_diff
|
ESMCI__cime-3725
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Missing chem_mech files in E3SM CaseDocs after renaming CAM to EAM
After [renaming CAM to EAM in E3SM](https://github.com/E3SM-Project/E3SM/pull/3845), the following two files are not copied to CaseDocs
```
chem_mech.doc
chem_mech.in
```
Need to change the 'cam' substring in 'camconf' near the end of cime/scripts/lib/CIME/case/preview_namelists.py. The piece of codes are copied below
```
# Copy over chemistry mechanism docs if they exist
if (os.path.isdir(os.path.join(casebuild, "camconf"))):
for file_to_copy in glob.glob(os.path.join(casebuild, "camconf", "*chem_mech*")):
safe_copy(file_to_copy, docdir)
```
To make it work for both cam and eam, need help to replace the substring 'cam' with the atm COMP_NAME. Thanks.
</issue>
<code>
[start of scripts/lib/CIME/case/preview_namelists.py]
1 """
2 API for preview namelist
3 create_dirs and create_namelists are members of Class case from file case.py
4 """
5
6 from CIME.XML.standard_module_setup import *
7 from CIME.utils import run_sub_or_cmd, safe_copy
8 import time, glob
9 logger = logging.getLogger(__name__)
10
11 def create_dirs(self):
12 """
13 Make necessary directories for case
14 """
15 # Get data from XML
16 exeroot = self.get_value("EXEROOT")
17 libroot = self.get_value("LIBROOT")
18 incroot = self.get_value("INCROOT")
19 rundir = self.get_value("RUNDIR")
20 caseroot = self.get_value("CASEROOT")
21 docdir = os.path.join(caseroot, "CaseDocs")
22 dirs_to_make = []
23 models = self.get_values("COMP_CLASSES")
24 for model in models:
25 dirname = model.lower()
26 dirs_to_make.append(os.path.join(exeroot, dirname, "obj"))
27
28 dirs_to_make.extend([exeroot, libroot, incroot, rundir, docdir])
29
30 for dir_to_make in dirs_to_make:
31 if (not os.path.isdir(dir_to_make) and not os.path.islink(dir_to_make)):
32 try:
33 logger.debug("Making dir '{}'".format(dir_to_make))
34 os.makedirs(dir_to_make)
35 except OSError as e:
36 # In a multithreaded situation, we may have lost a race to create this dir.
37 # We do not want to crash if that's the case.
38 if not os.path.isdir(dir_to_make):
39 expect(False, "Could not make directory '{}', error: {}".format(dir_to_make, e))
40
41 # As a convenience write the location of the case directory in the bld and run directories
42 for dir_ in (exeroot, rundir):
43 with open(os.path.join(dir_,"CASEROOT"),"w+") as fd:
44 fd.write(caseroot+"\n")
45
46 def create_namelists(self, component=None):
47 """
48 Create component namelists
49 """
50 self.flush()
51
52 create_dirs(self)
53
54 casebuild = self.get_value("CASEBUILD")
55 caseroot = self.get_value("CASEROOT")
56 rundir = self.get_value("RUNDIR")
57
58 docdir = os.path.join(caseroot, "CaseDocs")
59
60 # Load modules
61 self.load_env()
62
63 self.stage_refcase()
64
65 # Create namelists - must have cpl last in the list below
66 # Note - cpl must be last in the loop below so that in generating its namelist,
67 # it can use xml vars potentially set by other component's buildnml scripts
68 models = self.get_values("COMP_CLASSES")
69 models += [models.pop(0)]
70 for model in models:
71 model_str = model.lower()
72 logger.info(" {} {} ".format(time.strftime("%Y-%m-%d %H:%M:%S"),model_str))
73 config_file = self.get_value("CONFIG_{}_FILE".format(model_str.upper()))
74 config_dir = os.path.dirname(config_file)
75 if model_str == "cpl":
76 compname = "drv"
77 else:
78 compname = self.get_value("COMP_{}".format(model_str.upper()))
79 if component is None or component == model_str or compname=="ufsatm":
80 # first look in the case SourceMods directory
81 cmd = os.path.join(caseroot, "SourceMods", "src."+compname, "buildnml")
82 if os.path.isfile(cmd):
83 logger.warning("\nWARNING: Using local buildnml file {}\n".format(cmd))
84 else:
85 # otherwise look in the component config_dir
86 cmd = os.path.join(config_dir, "buildnml")
87 expect(os.path.isfile(cmd), "Could not find buildnml file for component {}".format(compname))
88 logger.info("Create namelist for component {}".format(compname))
89 run_sub_or_cmd(cmd, (caseroot), "buildnml",
90 (self, caseroot, compname), case=self)
91
92 logger.debug("Finished creating component namelists, component {} models = {}".format(component, models))
93
94 # Save namelists to docdir
95 if (not os.path.isdir(docdir)):
96 os.makedirs(docdir)
97 try:
98 with open(os.path.join(docdir, "README"), "w") as fd:
99 fd.write(" CESM Resolved Namelist Files\n For documentation only DO NOT MODIFY\n")
100 except (OSError, IOError) as e:
101 expect(False, "Failed to write {}/README: {}".format(docdir, e))
102
103 for cpglob in ["*_in_[0-9]*", "*modelio*", "*_in", "nuopc.runconfig",
104 "*streams*txt*", "*streams.xml", "*stxt", "*maps.rc", "*cism.config*", "nuopc.runseq"]:
105 for file_to_copy in glob.glob(os.path.join(rundir, cpglob)):
106 logger.debug("Copy file from '{}' to '{}'".format(file_to_copy, docdir))
107 safe_copy(file_to_copy, docdir)
108
109 # Copy over chemistry mechanism docs if they exist
110 if (os.path.isdir(os.path.join(casebuild, "camconf"))):
111 for file_to_copy in glob.glob(os.path.join(casebuild, "camconf", "*chem_mech*")):
112 safe_copy(file_to_copy, docdir)
113
[end of scripts/lib/CIME/case/preview_namelists.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/scripts/lib/CIME/case/preview_namelists.py b/scripts/lib/CIME/case/preview_namelists.py
--- a/scripts/lib/CIME/case/preview_namelists.py
+++ b/scripts/lib/CIME/case/preview_namelists.py
@@ -107,6 +107,7 @@
safe_copy(file_to_copy, docdir)
# Copy over chemistry mechanism docs if they exist
- if (os.path.isdir(os.path.join(casebuild, "camconf"))):
- for file_to_copy in glob.glob(os.path.join(casebuild, "camconf", "*chem_mech*")):
+ atmconf = self.get_value("COMP_ATM") + "conf"
+ if (os.path.isdir(os.path.join(casebuild, atmconf))):
+ for file_to_copy in glob.glob(os.path.join(casebuild, atmconf, "*chem_mech*")):
safe_copy(file_to_copy, docdir)
|
{"golden_diff": "diff --git a/scripts/lib/CIME/case/preview_namelists.py b/scripts/lib/CIME/case/preview_namelists.py\n--- a/scripts/lib/CIME/case/preview_namelists.py\n+++ b/scripts/lib/CIME/case/preview_namelists.py\n@@ -107,6 +107,7 @@\n safe_copy(file_to_copy, docdir)\n \n # Copy over chemistry mechanism docs if they exist\n- if (os.path.isdir(os.path.join(casebuild, \"camconf\"))):\n- for file_to_copy in glob.glob(os.path.join(casebuild, \"camconf\", \"*chem_mech*\")):\n+ atmconf = self.get_value(\"COMP_ATM\") + \"conf\"\n+ if (os.path.isdir(os.path.join(casebuild, atmconf))):\n+ for file_to_copy in glob.glob(os.path.join(casebuild, atmconf, \"*chem_mech*\")):\n safe_copy(file_to_copy, docdir)\n", "issue": "Missing chem_mech files in E3SM CaseDocs after renaming CAM to EAM\nAfter [renaming CAM to EAM in E3SM](https://github.com/E3SM-Project/E3SM/pull/3845), the following two files are not copied to CaseDocs\r\n```\r\nchem_mech.doc\r\nchem_mech.in\r\n```\r\nNeed to change the 'cam' substring in 'camconf' near the end of cime/scripts/lib/CIME/case/preview_namelists.py. The piece of codes are copied below\r\n```\r\n# Copy over chemistry mechanism docs if they exist\r\n if (os.path.isdir(os.path.join(casebuild, \"camconf\"))):\r\n for file_to_copy in glob.glob(os.path.join(casebuild, \"camconf\", \"*chem_mech*\")):\r\n safe_copy(file_to_copy, docdir)\r\n```\r\nTo make it work for both cam and eam, need help to replace the substring 'cam' with the atm COMP_NAME. Thanks.\n", "before_files": [{"content": "\"\"\"\nAPI for preview namelist\ncreate_dirs and create_namelists are members of Class case from file case.py\n\"\"\"\n\nfrom CIME.XML.standard_module_setup import *\nfrom CIME.utils import run_sub_or_cmd, safe_copy\nimport time, glob\nlogger = logging.getLogger(__name__)\n\ndef create_dirs(self):\n \"\"\"\n Make necessary directories for case\n \"\"\"\n # Get data from XML\n exeroot = self.get_value(\"EXEROOT\")\n libroot = self.get_value(\"LIBROOT\")\n incroot = self.get_value(\"INCROOT\")\n rundir = self.get_value(\"RUNDIR\")\n caseroot = self.get_value(\"CASEROOT\")\n docdir = os.path.join(caseroot, \"CaseDocs\")\n dirs_to_make = []\n models = self.get_values(\"COMP_CLASSES\")\n for model in models:\n dirname = model.lower()\n dirs_to_make.append(os.path.join(exeroot, dirname, \"obj\"))\n\n dirs_to_make.extend([exeroot, libroot, incroot, rundir, docdir])\n\n for dir_to_make in dirs_to_make:\n if (not os.path.isdir(dir_to_make) and not os.path.islink(dir_to_make)):\n try:\n logger.debug(\"Making dir '{}'\".format(dir_to_make))\n os.makedirs(dir_to_make)\n except OSError as e:\n # In a multithreaded situation, we may have lost a race to create this dir.\n # We do not want to crash if that's the case.\n if not os.path.isdir(dir_to_make):\n expect(False, \"Could not make directory '{}', error: {}\".format(dir_to_make, e))\n\n # As a convenience write the location of the case directory in the bld and run directories\n for dir_ in (exeroot, rundir):\n with open(os.path.join(dir_,\"CASEROOT\"),\"w+\") as fd:\n fd.write(caseroot+\"\\n\")\n\ndef create_namelists(self, component=None):\n \"\"\"\n Create component namelists\n \"\"\"\n self.flush()\n\n create_dirs(self)\n\n casebuild = self.get_value(\"CASEBUILD\")\n caseroot = self.get_value(\"CASEROOT\")\n rundir = self.get_value(\"RUNDIR\")\n\n docdir = os.path.join(caseroot, \"CaseDocs\")\n\n # Load modules\n self.load_env()\n\n self.stage_refcase()\n\n # Create namelists - must have cpl last in the list below\n # Note - cpl must be last in the loop below so that in generating its namelist,\n # it can use xml vars potentially set by other component's buildnml scripts\n models = self.get_values(\"COMP_CLASSES\")\n models += [models.pop(0)]\n for model in models:\n model_str = model.lower()\n logger.info(\" {} {} \".format(time.strftime(\"%Y-%m-%d %H:%M:%S\"),model_str))\n config_file = self.get_value(\"CONFIG_{}_FILE\".format(model_str.upper()))\n config_dir = os.path.dirname(config_file)\n if model_str == \"cpl\":\n compname = \"drv\"\n else:\n compname = self.get_value(\"COMP_{}\".format(model_str.upper()))\n if component is None or component == model_str or compname==\"ufsatm\":\n # first look in the case SourceMods directory\n cmd = os.path.join(caseroot, \"SourceMods\", \"src.\"+compname, \"buildnml\")\n if os.path.isfile(cmd):\n logger.warning(\"\\nWARNING: Using local buildnml file {}\\n\".format(cmd))\n else:\n # otherwise look in the component config_dir\n cmd = os.path.join(config_dir, \"buildnml\")\n expect(os.path.isfile(cmd), \"Could not find buildnml file for component {}\".format(compname))\n logger.info(\"Create namelist for component {}\".format(compname))\n run_sub_or_cmd(cmd, (caseroot), \"buildnml\",\n (self, caseroot, compname), case=self)\n\n logger.debug(\"Finished creating component namelists, component {} models = {}\".format(component, models))\n\n # Save namelists to docdir\n if (not os.path.isdir(docdir)):\n os.makedirs(docdir)\n try:\n with open(os.path.join(docdir, \"README\"), \"w\") as fd:\n fd.write(\" CESM Resolved Namelist Files\\n For documentation only DO NOT MODIFY\\n\")\n except (OSError, IOError) as e:\n expect(False, \"Failed to write {}/README: {}\".format(docdir, e))\n\n for cpglob in [\"*_in_[0-9]*\", \"*modelio*\", \"*_in\", \"nuopc.runconfig\",\n \"*streams*txt*\", \"*streams.xml\", \"*stxt\", \"*maps.rc\", \"*cism.config*\", \"nuopc.runseq\"]:\n for file_to_copy in glob.glob(os.path.join(rundir, cpglob)):\n logger.debug(\"Copy file from '{}' to '{}'\".format(file_to_copy, docdir))\n safe_copy(file_to_copy, docdir)\n\n # Copy over chemistry mechanism docs if they exist\n if (os.path.isdir(os.path.join(casebuild, \"camconf\"))):\n for file_to_copy in glob.glob(os.path.join(casebuild, \"camconf\", \"*chem_mech*\")):\n safe_copy(file_to_copy, docdir)\n", "path": "scripts/lib/CIME/case/preview_namelists.py"}]}
| 2,156 | 208 |
gh_patches_debug_4275
|
rasdani/github-patches
|
git_diff
|
comic__grand-challenge.org-37
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Country is not stored in db on signup
When a user signs up the country is not stored in the db
</issue>
<code>
[start of django/profiles/forms.py]
1 from django import forms
2 from django.utils.translation import ugettext_lazy as _
3 from django_countries.countries import COUNTRIES
4
5 from userena.forms import SignupForm
6
7 class SignupFormExtra(SignupForm):
8 institution = forms.CharField(label=_(u'Institution'),
9 max_length = 100,
10 required = True,
11 help_text=_(u'Institution you are affiliated to.'))
12 department = forms.CharField(label=_(u'Department'),
13 max_length = 100,
14 required = True,
15 help_text=_(u'Department you represent.'))
16 country = forms.ChoiceField(label=_(u'Country'),
17 choices=COUNTRIES,
18 required = True)
19 website = forms.CharField(label=_(u'Website'),
20 max_length = 150,
21 required = False)
22 first_name = forms.CharField(label=_(u'First Name'),
23 max_length = 30,
24 required = True)
25 last_name = forms.CharField(label=_(u'Last Name'),
26 max_length = 30,
27 required = True)
28
29 def __init__(self, *args, **kw):
30 """ Bit of hackery to get the first and last name at the top of the form.
31 """
32 super(SignupFormExtra,self).__init__(*args,**kw)
33 # Put the first and last name at the top.
34 new_order = self.fields.keyOrder[:-2]
35 new_order.insert(0, 'first_name')
36 new_order.insert(1, 'last_name')
37 self.fields.keyOrder = new_order
38
39 def save(self):
40 user = super(SignupFormExtra,self).save()
41 user.first_name = self.cleaned_data['first_name']
42 user.last_name = self.cleaned_data['last_name']
43 user.save()
44 user_profile = user.get_profile()
45 user_profile.institution = self.cleaned_data['institution']
46 user_profile.department = self.cleaned_data['department']
47 user_profile.save()
48
49 return user
50
[end of django/profiles/forms.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/django/profiles/forms.py b/django/profiles/forms.py
--- a/django/profiles/forms.py
+++ b/django/profiles/forms.py
@@ -44,6 +44,7 @@
user_profile = user.get_profile()
user_profile.institution = self.cleaned_data['institution']
user_profile.department = self.cleaned_data['department']
+ user_profile.country = self.cleaned_data['country']
user_profile.save()
return user
|
{"golden_diff": "diff --git a/django/profiles/forms.py b/django/profiles/forms.py\n--- a/django/profiles/forms.py\n+++ b/django/profiles/forms.py\n@@ -44,6 +44,7 @@\n user_profile = user.get_profile()\n user_profile.institution = self.cleaned_data['institution']\n user_profile.department = self.cleaned_data['department']\n+ user_profile.country = self.cleaned_data['country']\n user_profile.save()\n \n return user\n", "issue": "Country is not stored in db on signup\nWhen a user signs up the country is not stored in the db\n\n", "before_files": [{"content": "from django import forms\nfrom django.utils.translation import ugettext_lazy as _\nfrom django_countries.countries import COUNTRIES\n\nfrom userena.forms import SignupForm\n\nclass SignupFormExtra(SignupForm):\n institution = forms.CharField(label=_(u'Institution'),\n max_length = 100,\n required = True,\n help_text=_(u'Institution you are affiliated to.'))\n department = forms.CharField(label=_(u'Department'),\n max_length = 100,\n required = True,\n help_text=_(u'Department you represent.'))\n country = forms.ChoiceField(label=_(u'Country'),\n choices=COUNTRIES,\n required = True)\n website = forms.CharField(label=_(u'Website'),\n max_length = 150,\n required = False)\n first_name = forms.CharField(label=_(u'First Name'),\n max_length = 30,\n required = True)\n last_name = forms.CharField(label=_(u'Last Name'),\n max_length = 30,\n required = True)\n\n def __init__(self, *args, **kw):\n \"\"\" Bit of hackery to get the first and last name at the top of the form.\n \"\"\"\n super(SignupFormExtra,self).__init__(*args,**kw)\n # Put the first and last name at the top.\n new_order = self.fields.keyOrder[:-2]\n new_order.insert(0, 'first_name')\n new_order.insert(1, 'last_name')\n self.fields.keyOrder = new_order\n\n def save(self):\n user = super(SignupFormExtra,self).save()\n user.first_name = self.cleaned_data['first_name']\n user.last_name = self.cleaned_data['last_name']\n user.save()\n user_profile = user.get_profile()\n user_profile.institution = self.cleaned_data['institution']\n user_profile.department = self.cleaned_data['department']\n user_profile.save()\n\n return user\n", "path": "django/profiles/forms.py"}]}
| 1,073 | 101 |
gh_patches_debug_26386
|
rasdani/github-patches
|
git_diff
|
scverse__scanpy-2879
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
scanpy 1.10.0rc1 breaks anndata pre-release tests
### Please make sure these conditions are met
- [X] I have checked that this issue has not already been reported.
- [X] I have confirmed this bug exists on the latest version of scanpy.
- [X] (optional) I have confirmed this bug exists on the master branch of scanpy.
### What happened?
`@doctest_needs` decorator causes test failures on scanpy import in anndata test suite
https://dev.azure.com/scverse/anndata/_build/results?buildId=5802&view=logs&jobId=0497d03e-5796-547f-cc56-989f8152a63c&j=0497d03e-5796-547f-cc56-989f8152a63c&t=ea3acdad-0250-5b8b-a1da-6cd02463cf17
### Minimal code sample
```python
NA
```
### Error output
```pytb
else:
enum_member = enum_class._new_member_(enum_class, *args)
if not hasattr(enum_member, '_value_'):
if enum_class._member_type_ is object:
enum_member._value_ = value
else:
try:
enum_member._value_ = enum_class._member_type_(*args)
except Exception as exc:
new_exc = TypeError(
'_value_ not set in __new__, unable to create it'
)
new_exc.__cause__ = exc
> raise new_exc
E TypeError: _value_ not set in __new__, unable to create it
```
### Versions
<details>
```
See anndata test failure
```
</details>
</issue>
<code>
[start of scanpy/__init__.py]
1 """Single-Cell Analysis in Python."""
2 from __future__ import annotations
3
4 try: # See https://github.com/maresb/hatch-vcs-footgun-example
5 from setuptools_scm import get_version
6
7 __version__ = get_version(root="..", relative_to=__file__)
8 del get_version
9 except (ImportError, LookupError):
10 try:
11 from ._version import __version__
12 except ModuleNotFoundError:
13 raise RuntimeError(
14 "scanpy is not correctly installed. Please install it, e.g. with pip."
15 )
16
17 from ._utils import check_versions
18
19 check_versions()
20 del check_versions
21
22 # the actual API
23 # (start with settings as several tools are using it)
24 from anndata import (
25 AnnData,
26 concat,
27 read_csv,
28 read_excel,
29 read_h5ad,
30 read_hdf,
31 read_loom,
32 read_mtx,
33 read_text,
34 read_umi_tools,
35 )
36
37 from . import datasets, experimental, external, get, logging, metrics, queries
38 from . import plotting as pl
39 from . import preprocessing as pp
40 from . import tools as tl
41 from ._settings import Verbosity, settings
42 from .neighbors import Neighbors
43 from .readwrite import read, read_10x_h5, read_10x_mtx, read_visium, write
44
45 set_figure_params = settings.set_figure_params
46
47 # has to be done at the end, after everything has been imported
48 import sys
49
50 sys.modules.update({f"{__name__}.{m}": globals()[m] for m in ["tl", "pp", "pl"]})
51 from ._utils import annotate_doc_types
52
53 annotate_doc_types(sys.modules[__name__], "scanpy")
54 del sys, annotate_doc_types
55
56 __all__ = [
57 "__version__",
58 "AnnData",
59 "concat",
60 "read_csv",
61 "read_excel",
62 "read_h5ad",
63 "read_hdf",
64 "read_loom",
65 "read_mtx",
66 "read_text",
67 "read_umi_tools",
68 "read",
69 "read_10x_h5",
70 "read_10x_mtx",
71 "read_visium",
72 "write",
73 "datasets",
74 "experimental",
75 "external",
76 "get",
77 "logging",
78 "metrics",
79 "queries",
80 "pl",
81 "pp",
82 "tl",
83 "Verbosity",
84 "settings",
85 "Neighbors",
86 "set_figure_params",
87 ]
88
[end of scanpy/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/scanpy/__init__.py b/scanpy/__init__.py
--- a/scanpy/__init__.py
+++ b/scanpy/__init__.py
@@ -1,6 +1,8 @@
"""Single-Cell Analysis in Python."""
from __future__ import annotations
+import sys
+
try: # See https://github.com/maresb/hatch-vcs-footgun-example
from setuptools_scm import get_version
@@ -21,6 +23,11 @@
# the actual API
# (start with settings as several tools are using it)
+
+from ._settings import Verbosity, settings
+
+set_figure_params = settings.set_figure_params
+
from anndata import (
AnnData,
concat,
@@ -38,15 +45,10 @@
from . import plotting as pl
from . import preprocessing as pp
from . import tools as tl
-from ._settings import Verbosity, settings
from .neighbors import Neighbors
from .readwrite import read, read_10x_h5, read_10x_mtx, read_visium, write
-set_figure_params = settings.set_figure_params
-
# has to be done at the end, after everything has been imported
-import sys
-
sys.modules.update({f"{__name__}.{m}": globals()[m] for m in ["tl", "pp", "pl"]})
from ._utils import annotate_doc_types
|
{"golden_diff": "diff --git a/scanpy/__init__.py b/scanpy/__init__.py\n--- a/scanpy/__init__.py\n+++ b/scanpy/__init__.py\n@@ -1,6 +1,8 @@\n \"\"\"Single-Cell Analysis in Python.\"\"\"\n from __future__ import annotations\n \n+import sys\n+\n try: # See https://github.com/maresb/hatch-vcs-footgun-example\n from setuptools_scm import get_version\n \n@@ -21,6 +23,11 @@\n \n # the actual API\n # (start with settings as several tools are using it)\n+\n+from ._settings import Verbosity, settings\n+\n+set_figure_params = settings.set_figure_params\n+\n from anndata import (\n AnnData,\n concat,\n@@ -38,15 +45,10 @@\n from . import plotting as pl\n from . import preprocessing as pp\n from . import tools as tl\n-from ._settings import Verbosity, settings\n from .neighbors import Neighbors\n from .readwrite import read, read_10x_h5, read_10x_mtx, read_visium, write\n \n-set_figure_params = settings.set_figure_params\n-\n # has to be done at the end, after everything has been imported\n-import sys\n-\n sys.modules.update({f\"{__name__}.{m}\": globals()[m] for m in [\"tl\", \"pp\", \"pl\"]})\n from ._utils import annotate_doc_types\n", "issue": "scanpy 1.10.0rc1 breaks anndata pre-release tests\n### Please make sure these conditions are met\n\n- [X] I have checked that this issue has not already been reported.\n- [X] I have confirmed this bug exists on the latest version of scanpy.\n- [X] (optional) I have confirmed this bug exists on the master branch of scanpy.\n\n### What happened?\n\n`@doctest_needs` decorator causes test failures on scanpy import in anndata test suite\r\n\r\nhttps://dev.azure.com/scverse/anndata/_build/results?buildId=5802&view=logs&jobId=0497d03e-5796-547f-cc56-989f8152a63c&j=0497d03e-5796-547f-cc56-989f8152a63c&t=ea3acdad-0250-5b8b-a1da-6cd02463cf17\r\n\r\n\n\n### Minimal code sample\n\n```python\nNA\n```\n\n\n### Error output\n\n```pytb\nelse:\r\n enum_member = enum_class._new_member_(enum_class, *args)\r\n if not hasattr(enum_member, '_value_'):\r\n if enum_class._member_type_ is object:\r\n enum_member._value_ = value\r\n else:\r\n try:\r\n enum_member._value_ = enum_class._member_type_(*args)\r\n except Exception as exc:\r\n new_exc = TypeError(\r\n '_value_ not set in __new__, unable to create it'\r\n )\r\n new_exc.__cause__ = exc\r\n> raise new_exc\r\nE TypeError: _value_ not set in __new__, unable to create it\n```\n\n\n### Versions\n\n<details>\r\n\r\n```\r\nSee anndata test failure\r\n```\r\n\r\n</details>\r\n\n", "before_files": [{"content": "\"\"\"Single-Cell Analysis in Python.\"\"\"\nfrom __future__ import annotations\n\ntry: # See https://github.com/maresb/hatch-vcs-footgun-example\n from setuptools_scm import get_version\n\n __version__ = get_version(root=\"..\", relative_to=__file__)\n del get_version\nexcept (ImportError, LookupError):\n try:\n from ._version import __version__\n except ModuleNotFoundError:\n raise RuntimeError(\n \"scanpy is not correctly installed. Please install it, e.g. with pip.\"\n )\n\nfrom ._utils import check_versions\n\ncheck_versions()\ndel check_versions\n\n# the actual API\n# (start with settings as several tools are using it)\nfrom anndata import (\n AnnData,\n concat,\n read_csv,\n read_excel,\n read_h5ad,\n read_hdf,\n read_loom,\n read_mtx,\n read_text,\n read_umi_tools,\n)\n\nfrom . import datasets, experimental, external, get, logging, metrics, queries\nfrom . import plotting as pl\nfrom . import preprocessing as pp\nfrom . import tools as tl\nfrom ._settings import Verbosity, settings\nfrom .neighbors import Neighbors\nfrom .readwrite import read, read_10x_h5, read_10x_mtx, read_visium, write\n\nset_figure_params = settings.set_figure_params\n\n# has to be done at the end, after everything has been imported\nimport sys\n\nsys.modules.update({f\"{__name__}.{m}\": globals()[m] for m in [\"tl\", \"pp\", \"pl\"]})\nfrom ._utils import annotate_doc_types\n\nannotate_doc_types(sys.modules[__name__], \"scanpy\")\ndel sys, annotate_doc_types\n\n__all__ = [\n \"__version__\",\n \"AnnData\",\n \"concat\",\n \"read_csv\",\n \"read_excel\",\n \"read_h5ad\",\n \"read_hdf\",\n \"read_loom\",\n \"read_mtx\",\n \"read_text\",\n \"read_umi_tools\",\n \"read\",\n \"read_10x_h5\",\n \"read_10x_mtx\",\n \"read_visium\",\n \"write\",\n \"datasets\",\n \"experimental\",\n \"external\",\n \"get\",\n \"logging\",\n \"metrics\",\n \"queries\",\n \"pl\",\n \"pp\",\n \"tl\",\n \"Verbosity\",\n \"settings\",\n \"Neighbors\",\n \"set_figure_params\",\n]\n", "path": "scanpy/__init__.py"}]}
| 1,652 | 311 |
gh_patches_debug_14509
|
rasdani/github-patches
|
git_diff
|
nilearn__nilearn-2819
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
BUG: broken reference in example
<!--Provide a brief description of the bug.-->
Broken reference to vol_to_surf in:
examples/01_plotting/plot_3d_map_to_surface_projection.py
</issue>
<code>
[start of examples/01_plotting/plot_3d_map_to_surface_projection.py]
1 """
2 Making a surface plot of a 3D statistical map
3 =============================================
4
5 project a 3D statistical map onto a cortical mesh using
6 :func:`nilearn.surface.vol_to_surf`. Display a surface plot of the projected
7 map using :func:`nilearn.plotting.plot_surf_stat_map` and adding contours of
8 regions of interest using :func:`nilearn.plotting.plot_surf_contours`.
9
10 """
11
12 ##############################################################################
13 # Get a statistical map
14 # ---------------------
15
16 from nilearn import datasets
17
18 motor_images = datasets.fetch_neurovault_motor_task()
19 stat_img = motor_images.images[0]
20
21
22 ##############################################################################
23 # Get a cortical mesh
24 # -------------------
25
26 fsaverage = datasets.fetch_surf_fsaverage()
27
28 ##############################################################################
29 # Sample the 3D data around each node of the mesh
30 # -----------------------------------------------
31
32 from nilearn import surface
33
34 texture = surface.vol_to_surf(stat_img, fsaverage.pial_right)
35
36 ##############################################################################
37 # Plot the result
38 # ---------------
39
40 from nilearn import plotting
41
42 plotting.plot_surf_stat_map(fsaverage.infl_right, texture, hemi='right',
43 title='Surface right hemisphere', colorbar=True,
44 threshold=1., bg_map=fsaverage.sulc_right)
45
46 ##############################################################################
47 # Plot 3D image for comparison
48 # ----------------------------
49
50 plotting.plot_glass_brain(stat_img, display_mode='r', plot_abs=False,
51 title='Glass brain', threshold=2.)
52
53 plotting.plot_stat_map(stat_img, display_mode='x', threshold=1.,
54 cut_coords=range(0, 51, 10), title='Slices')
55
56 ##############################################################################
57 # Use an atlas and choose regions to outline
58 # ------------------------------------------
59
60 import numpy as np
61
62 destrieux_atlas = datasets.fetch_atlas_surf_destrieux()
63 parcellation = destrieux_atlas['map_right']
64
65 # these are the regions we want to outline
66 regions_dict = {b'G_postcentral': 'Postcentral gyrus',
67 b'G_precentral': 'Precentral gyrus'}
68
69 # get indices in atlas for these labels
70 regions_indices = [np.where(np.array(destrieux_atlas['labels']) == region)[0][0]
71 for region in regions_dict]
72
73 labels = list(regions_dict.values())
74
75 ##############################################################################
76 # Display outlines of the regions of interest on top of a statistical map
77 # -----------------------------------------------------------------------
78
79 figure = plotting.plot_surf_stat_map(fsaverage.infl_right, texture, hemi='right',
80 title='Surface right hemisphere',
81 colorbar=True, threshold=1.,
82 bg_map=fsaverage.sulc_right)
83
84 plotting.plot_surf_contours(fsaverage.infl_right, parcellation, labels=labels,
85 levels=regions_indices, figure=figure, legend=True,
86 colors=['g', 'k'])
87 plotting.show()
88
89 ##############################################################################
90 # Plot with higher-resolution mesh
91 # --------------------------------
92 #
93 # `fetch_surf_fsaverage` takes a "mesh" argument which specifies
94 # wether to fetch the low-resolution fsaverage5 mesh, or the high-resolution
95 # fsaverage mesh. using mesh="fsaverage" will result in more memory usage and
96 # computation time, but finer visualizations.
97
98 big_fsaverage = datasets.fetch_surf_fsaverage('fsaverage')
99 big_texture = surface.vol_to_surf(stat_img, big_fsaverage.pial_right)
100
101 plotting.plot_surf_stat_map(big_fsaverage.infl_right,
102 big_texture, hemi='right', colorbar=True,
103 title='Surface right hemisphere: fine mesh',
104 threshold=1., bg_map=big_fsaverage.sulc_right)
105
106
107 ##############################################################################
108 # Plot multiple views of the 3D volume on a surface
109 # -------------------------------------------------
110 #
111 # *plot_img_on_surf* takes a statistical map and projects it onto a surface.
112 # It supports multiple choices of orientations, and can plot either one or both
113 # hemispheres. If no *surf_mesh* is given, *plot_img_on_surf* projects the
114 # images onto `FreeSurfer <https://surfer.nmr.mgh.harvard.edu/>`_\'s
115 # fsaverage5.
116
117 plotting.plot_img_on_surf(stat_img,
118 views=['lateral', 'medial'],
119 hemispheres=['left', 'right'],
120 colorbar=True)
121 plotting.show()
122
123 ##############################################################################
124 # 3D visualization in a web browser
125 # ---------------------------------
126 # An alternative to :func:`nilearn.plotting.plot_surf_stat_map` is to use
127 # :func:`nilearn.plotting.view_surf` or
128 # :func:`nilearn.plotting.view_img_on_surf` that give more interactive
129 # visualizations in a web browser. See :ref:`interactive-surface-plotting` for
130 # more details.
131
132 view = plotting.view_surf(fsaverage.infl_right, texture, threshold='90%',
133 bg_map=fsaverage.sulc_right)
134
135 # In a Jupyter notebook, if ``view`` is the output of a cell, it will
136 # be displayed below the cell
137 view
138
139 ##############################################################################
140
141 # uncomment this to open the plot in a web browser:
142 # view.open_in_browser()
143
144 ##############################################################################
145 # We don't need to do the projection ourselves, we can use view_img_on_surf:
146
147 view = plotting.view_img_on_surf(stat_img, threshold='90%')
148 # view.open_in_browser()
149
150 view
151
152 ##############################################################################
153 # Impact of plot parameters on visualization
154 # ------------------------------------------
155 # You can specify arguments to be passed on to the function
156 # :func:`nilearn.plotting.vol_to_surf` using `vol_to_surf_kwargs`. This allows
157 # fine-grained control of how the input 3D image is resampled and interpolated -
158 # for example if you are viewing a volumetric atlas, you would want to avoid
159 # averaging the labels between neighboring regions. Using nearest-neighbor
160 # interpolation with zero radius will achieve this.
161
162 destrieux = datasets.fetch_atlas_destrieux_2009()
163
164 view = plotting.view_img_on_surf(
165 destrieux.maps,
166 surf_mesh="fsaverage",
167 vol_to_surf_kwargs={"n_samples": 1, "radius": 0.0, "interpolation": "nearest"},
168 symmetric_cmap=False,
169 )
170
171 # view.open_in_browser()
172 view
173
[end of examples/01_plotting/plot_3d_map_to_surface_projection.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/examples/01_plotting/plot_3d_map_to_surface_projection.py b/examples/01_plotting/plot_3d_map_to_surface_projection.py
--- a/examples/01_plotting/plot_3d_map_to_surface_projection.py
+++ b/examples/01_plotting/plot_3d_map_to_surface_projection.py
@@ -153,7 +153,7 @@
# Impact of plot parameters on visualization
# ------------------------------------------
# You can specify arguments to be passed on to the function
-# :func:`nilearn.plotting.vol_to_surf` using `vol_to_surf_kwargs`. This allows
+# :func:`nilearn.surface.vol_to_surf` using `vol_to_surf_kwargs`. This allows
# fine-grained control of how the input 3D image is resampled and interpolated -
# for example if you are viewing a volumetric atlas, you would want to avoid
# averaging the labels between neighboring regions. Using nearest-neighbor
|
{"golden_diff": "diff --git a/examples/01_plotting/plot_3d_map_to_surface_projection.py b/examples/01_plotting/plot_3d_map_to_surface_projection.py\n--- a/examples/01_plotting/plot_3d_map_to_surface_projection.py\n+++ b/examples/01_plotting/plot_3d_map_to_surface_projection.py\n@@ -153,7 +153,7 @@\n # Impact of plot parameters on visualization\n # ------------------------------------------\n # You can specify arguments to be passed on to the function\n-# :func:`nilearn.plotting.vol_to_surf` using `vol_to_surf_kwargs`. This allows\n+# :func:`nilearn.surface.vol_to_surf` using `vol_to_surf_kwargs`. This allows\n # fine-grained control of how the input 3D image is resampled and interpolated -\n # for example if you are viewing a volumetric atlas, you would want to avoid\n # averaging the labels between neighboring regions. Using nearest-neighbor\n", "issue": "BUG: broken reference in example\n<!--Provide a brief description of the bug.-->\r\nBroken reference to vol_to_surf in:\r\n\r\nexamples/01_plotting/plot_3d_map_to_surface_projection.py\r\n\r\n\n", "before_files": [{"content": "\"\"\"\nMaking a surface plot of a 3D statistical map\n=============================================\n\nproject a 3D statistical map onto a cortical mesh using\n:func:`nilearn.surface.vol_to_surf`. Display a surface plot of the projected\nmap using :func:`nilearn.plotting.plot_surf_stat_map` and adding contours of\nregions of interest using :func:`nilearn.plotting.plot_surf_contours`.\n\n\"\"\"\n\n##############################################################################\n# Get a statistical map\n# ---------------------\n\nfrom nilearn import datasets\n\nmotor_images = datasets.fetch_neurovault_motor_task()\nstat_img = motor_images.images[0]\n\n\n##############################################################################\n# Get a cortical mesh\n# -------------------\n\nfsaverage = datasets.fetch_surf_fsaverage()\n\n##############################################################################\n# Sample the 3D data around each node of the mesh\n# -----------------------------------------------\n\nfrom nilearn import surface\n\ntexture = surface.vol_to_surf(stat_img, fsaverage.pial_right)\n\n##############################################################################\n# Plot the result\n# ---------------\n\nfrom nilearn import plotting\n\nplotting.plot_surf_stat_map(fsaverage.infl_right, texture, hemi='right',\n title='Surface right hemisphere', colorbar=True,\n threshold=1., bg_map=fsaverage.sulc_right)\n\n##############################################################################\n# Plot 3D image for comparison\n# ----------------------------\n\nplotting.plot_glass_brain(stat_img, display_mode='r', plot_abs=False,\n title='Glass brain', threshold=2.)\n\nplotting.plot_stat_map(stat_img, display_mode='x', threshold=1.,\n cut_coords=range(0, 51, 10), title='Slices')\n\n##############################################################################\n# Use an atlas and choose regions to outline\n# ------------------------------------------\n\nimport numpy as np\n\ndestrieux_atlas = datasets.fetch_atlas_surf_destrieux()\nparcellation = destrieux_atlas['map_right']\n\n# these are the regions we want to outline\nregions_dict = {b'G_postcentral': 'Postcentral gyrus',\n b'G_precentral': 'Precentral gyrus'}\n\n# get indices in atlas for these labels\nregions_indices = [np.where(np.array(destrieux_atlas['labels']) == region)[0][0]\n for region in regions_dict]\n\nlabels = list(regions_dict.values())\n\n##############################################################################\n# Display outlines of the regions of interest on top of a statistical map\n# -----------------------------------------------------------------------\n\nfigure = plotting.plot_surf_stat_map(fsaverage.infl_right, texture, hemi='right',\n title='Surface right hemisphere',\n colorbar=True, threshold=1.,\n bg_map=fsaverage.sulc_right)\n\nplotting.plot_surf_contours(fsaverage.infl_right, parcellation, labels=labels,\n levels=regions_indices, figure=figure, legend=True,\n colors=['g', 'k'])\nplotting.show()\n\n##############################################################################\n# Plot with higher-resolution mesh\n# --------------------------------\n#\n# `fetch_surf_fsaverage` takes a \"mesh\" argument which specifies\n# wether to fetch the low-resolution fsaverage5 mesh, or the high-resolution\n# fsaverage mesh. using mesh=\"fsaverage\" will result in more memory usage and\n# computation time, but finer visualizations.\n\nbig_fsaverage = datasets.fetch_surf_fsaverage('fsaverage')\nbig_texture = surface.vol_to_surf(stat_img, big_fsaverage.pial_right)\n\nplotting.plot_surf_stat_map(big_fsaverage.infl_right,\n big_texture, hemi='right', colorbar=True,\n title='Surface right hemisphere: fine mesh',\n threshold=1., bg_map=big_fsaverage.sulc_right)\n\n\n##############################################################################\n# Plot multiple views of the 3D volume on a surface\n# -------------------------------------------------\n#\n# *plot_img_on_surf* takes a statistical map and projects it onto a surface.\n# It supports multiple choices of orientations, and can plot either one or both\n# hemispheres. If no *surf_mesh* is given, *plot_img_on_surf* projects the\n# images onto `FreeSurfer <https://surfer.nmr.mgh.harvard.edu/>`_\\'s\n# fsaverage5.\n\nplotting.plot_img_on_surf(stat_img,\n views=['lateral', 'medial'],\n hemispheres=['left', 'right'],\n colorbar=True)\nplotting.show()\n\n##############################################################################\n# 3D visualization in a web browser\n# ---------------------------------\n# An alternative to :func:`nilearn.plotting.plot_surf_stat_map` is to use\n# :func:`nilearn.plotting.view_surf` or\n# :func:`nilearn.plotting.view_img_on_surf` that give more interactive\n# visualizations in a web browser. See :ref:`interactive-surface-plotting` for\n# more details.\n\nview = plotting.view_surf(fsaverage.infl_right, texture, threshold='90%',\n bg_map=fsaverage.sulc_right)\n\n# In a Jupyter notebook, if ``view`` is the output of a cell, it will\n# be displayed below the cell\nview\n\n##############################################################################\n\n# uncomment this to open the plot in a web browser:\n# view.open_in_browser()\n\n##############################################################################\n# We don't need to do the projection ourselves, we can use view_img_on_surf:\n\nview = plotting.view_img_on_surf(stat_img, threshold='90%')\n# view.open_in_browser()\n\nview\n\n##############################################################################\n# Impact of plot parameters on visualization\n# ------------------------------------------\n# You can specify arguments to be passed on to the function\n# :func:`nilearn.plotting.vol_to_surf` using `vol_to_surf_kwargs`. This allows\n# fine-grained control of how the input 3D image is resampled and interpolated -\n# for example if you are viewing a volumetric atlas, you would want to avoid\n# averaging the labels between neighboring regions. Using nearest-neighbor\n# interpolation with zero radius will achieve this.\n\ndestrieux = datasets.fetch_atlas_destrieux_2009()\n\nview = plotting.view_img_on_surf(\n destrieux.maps,\n surf_mesh=\"fsaverage\",\n vol_to_surf_kwargs={\"n_samples\": 1, \"radius\": 0.0, \"interpolation\": \"nearest\"},\n symmetric_cmap=False,\n)\n\n# view.open_in_browser()\nview\n", "path": "examples/01_plotting/plot_3d_map_to_surface_projection.py"}]}
| 2,325 | 210 |
gh_patches_debug_7128
|
rasdani/github-patches
|
git_diff
|
CTFd__CTFd-2419
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Dynamic challenges do not show a Next Challenge
<!--
If this is a bug report please fill out the template below.
If this is a feature request please describe the behavior that you'd like to see.
-->
**Environment**:
- CTFd Version/Commit: 3.6.0/8ead306f8b57c059192cd8b137f37ee41a078a41
- Operating System: All
- Web Browser and Version: All
**What happened?**
TLDR: *dynamic* challenges do not serve `next_id` to the frontend.
**How to reproduce your issue**
1. I created two challenges A and B with dynamic scoring.
2. I opened the admin configuration for challenge A.
3. I clicked "Next"
4. I selected challenge B from the dropdown.
5. I clicked the "Save" button.
6. The input field is empty.
**What did you expect to happen?**
The input field shows "Challenge B".
**Any associated stack traces or error logs**
The issue arises from the lack of `next_id` field in API responses for dynamic challenges [here](https://github.com/CTFd/CTFd/blob/8ead306f8b57c059192cd8b137f37ee41a078a41/CTFd/plugins/dynamic_challenges/__init__.py#L60-L89).
</issue>
<code>
[start of CTFd/plugins/dynamic_challenges/__init__.py]
1 from flask import Blueprint
2
3 from CTFd.models import Challenges, db
4 from CTFd.plugins import register_plugin_assets_directory
5 from CTFd.plugins.challenges import CHALLENGE_CLASSES, BaseChallenge
6 from CTFd.plugins.dynamic_challenges.decay import DECAY_FUNCTIONS, logarithmic
7 from CTFd.plugins.migrations import upgrade
8
9
10 class DynamicChallenge(Challenges):
11 __mapper_args__ = {"polymorphic_identity": "dynamic"}
12 id = db.Column(
13 db.Integer, db.ForeignKey("challenges.id", ondelete="CASCADE"), primary_key=True
14 )
15 initial = db.Column(db.Integer, default=0)
16 minimum = db.Column(db.Integer, default=0)
17 decay = db.Column(db.Integer, default=0)
18 function = db.Column(db.String(32), default="logarithmic")
19
20 def __init__(self, *args, **kwargs):
21 super(DynamicChallenge, self).__init__(**kwargs)
22 self.value = kwargs["initial"]
23
24
25 class DynamicValueChallenge(BaseChallenge):
26 id = "dynamic" # Unique identifier used to register challenges
27 name = "dynamic" # Name of a challenge type
28 templates = (
29 { # Handlebars templates used for each aspect of challenge editing & viewing
30 "create": "/plugins/dynamic_challenges/assets/create.html",
31 "update": "/plugins/dynamic_challenges/assets/update.html",
32 "view": "/plugins/dynamic_challenges/assets/view.html",
33 }
34 )
35 scripts = { # Scripts that are loaded when a template is loaded
36 "create": "/plugins/dynamic_challenges/assets/create.js",
37 "update": "/plugins/dynamic_challenges/assets/update.js",
38 "view": "/plugins/dynamic_challenges/assets/view.js",
39 }
40 # Route at which files are accessible. This must be registered using register_plugin_assets_directory()
41 route = "/plugins/dynamic_challenges/assets/"
42 # Blueprint used to access the static_folder directory.
43 blueprint = Blueprint(
44 "dynamic_challenges",
45 __name__,
46 template_folder="templates",
47 static_folder="assets",
48 )
49 challenge_model = DynamicChallenge
50
51 @classmethod
52 def calculate_value(cls, challenge):
53 f = DECAY_FUNCTIONS.get(challenge.function, logarithmic)
54 value = f(challenge)
55
56 challenge.value = value
57 db.session.commit()
58 return challenge
59
60 @classmethod
61 def read(cls, challenge):
62 """
63 This method is in used to access the data of a challenge in a format processable by the front end.
64
65 :param challenge:
66 :return: Challenge object, data dictionary to be returned to the user
67 """
68 challenge = DynamicChallenge.query.filter_by(id=challenge.id).first()
69 data = {
70 "id": challenge.id,
71 "name": challenge.name,
72 "value": challenge.value,
73 "initial": challenge.initial,
74 "decay": challenge.decay,
75 "minimum": challenge.minimum,
76 "description": challenge.description,
77 "connection_info": challenge.connection_info,
78 "category": challenge.category,
79 "state": challenge.state,
80 "max_attempts": challenge.max_attempts,
81 "type": challenge.type,
82 "type_data": {
83 "id": cls.id,
84 "name": cls.name,
85 "templates": cls.templates,
86 "scripts": cls.scripts,
87 },
88 }
89 return data
90
91 @classmethod
92 def update(cls, challenge, request):
93 """
94 This method is used to update the information associated with a challenge. This should be kept strictly to the
95 Challenges table and any child tables.
96
97 :param challenge:
98 :param request:
99 :return:
100 """
101 data = request.form or request.get_json()
102
103 for attr, value in data.items():
104 # We need to set these to floats so that the next operations don't operate on strings
105 if attr in ("initial", "minimum", "decay"):
106 value = float(value)
107 setattr(challenge, attr, value)
108
109 return DynamicValueChallenge.calculate_value(challenge)
110
111 @classmethod
112 def solve(cls, user, team, challenge, request):
113 super().solve(user, team, challenge, request)
114
115 DynamicValueChallenge.calculate_value(challenge)
116
117
118 def load(app):
119 upgrade(plugin_name="dynamic_challenges")
120 CHALLENGE_CLASSES["dynamic"] = DynamicValueChallenge
121 register_plugin_assets_directory(
122 app, base_path="/plugins/dynamic_challenges/assets/"
123 )
124
[end of CTFd/plugins/dynamic_challenges/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/CTFd/plugins/dynamic_challenges/__init__.py b/CTFd/plugins/dynamic_challenges/__init__.py
--- a/CTFd/plugins/dynamic_challenges/__init__.py
+++ b/CTFd/plugins/dynamic_challenges/__init__.py
@@ -75,6 +75,7 @@
"minimum": challenge.minimum,
"description": challenge.description,
"connection_info": challenge.connection_info,
+ "next_id": challenge.next_id,
"category": challenge.category,
"state": challenge.state,
"max_attempts": challenge.max_attempts,
|
{"golden_diff": "diff --git a/CTFd/plugins/dynamic_challenges/__init__.py b/CTFd/plugins/dynamic_challenges/__init__.py\n--- a/CTFd/plugins/dynamic_challenges/__init__.py\n+++ b/CTFd/plugins/dynamic_challenges/__init__.py\n@@ -75,6 +75,7 @@\n \"minimum\": challenge.minimum,\n \"description\": challenge.description,\n \"connection_info\": challenge.connection_info,\n+ \"next_id\": challenge.next_id,\n \"category\": challenge.category,\n \"state\": challenge.state,\n \"max_attempts\": challenge.max_attempts,\n", "issue": "Dynamic challenges do not show a Next Challenge\n<!--\r\nIf this is a bug report please fill out the template below.\r\n\r\nIf this is a feature request please describe the behavior that you'd like to see.\r\n-->\r\n\r\n**Environment**:\r\n\r\n- CTFd Version/Commit: 3.6.0/8ead306f8b57c059192cd8b137f37ee41a078a41\r\n- Operating System: All\r\n- Web Browser and Version: All\r\n\r\n**What happened?**\r\n\r\nTLDR: *dynamic* challenges do not serve `next_id` to the frontend.\r\n\r\n**How to reproduce your issue**\r\n\r\n1. I created two challenges A and B with dynamic scoring.\r\n2. I opened the admin configuration for challenge A.\r\n3. I clicked \"Next\"\r\n4. I selected challenge B from the dropdown.\r\n5. I clicked the \"Save\" button.\r\n6. The input field is empty.\r\n\r\n**What did you expect to happen?**\r\n\r\nThe input field shows \"Challenge B\".\r\n\r\n**Any associated stack traces or error logs**\r\n\r\nThe issue arises from the lack of `next_id` field in API responses for dynamic challenges [here](https://github.com/CTFd/CTFd/blob/8ead306f8b57c059192cd8b137f37ee41a078a41/CTFd/plugins/dynamic_challenges/__init__.py#L60-L89).\r\n\n", "before_files": [{"content": "from flask import Blueprint\n\nfrom CTFd.models import Challenges, db\nfrom CTFd.plugins import register_plugin_assets_directory\nfrom CTFd.plugins.challenges import CHALLENGE_CLASSES, BaseChallenge\nfrom CTFd.plugins.dynamic_challenges.decay import DECAY_FUNCTIONS, logarithmic\nfrom CTFd.plugins.migrations import upgrade\n\n\nclass DynamicChallenge(Challenges):\n __mapper_args__ = {\"polymorphic_identity\": \"dynamic\"}\n id = db.Column(\n db.Integer, db.ForeignKey(\"challenges.id\", ondelete=\"CASCADE\"), primary_key=True\n )\n initial = db.Column(db.Integer, default=0)\n minimum = db.Column(db.Integer, default=0)\n decay = db.Column(db.Integer, default=0)\n function = db.Column(db.String(32), default=\"logarithmic\")\n\n def __init__(self, *args, **kwargs):\n super(DynamicChallenge, self).__init__(**kwargs)\n self.value = kwargs[\"initial\"]\n\n\nclass DynamicValueChallenge(BaseChallenge):\n id = \"dynamic\" # Unique identifier used to register challenges\n name = \"dynamic\" # Name of a challenge type\n templates = (\n { # Handlebars templates used for each aspect of challenge editing & viewing\n \"create\": \"/plugins/dynamic_challenges/assets/create.html\",\n \"update\": \"/plugins/dynamic_challenges/assets/update.html\",\n \"view\": \"/plugins/dynamic_challenges/assets/view.html\",\n }\n )\n scripts = { # Scripts that are loaded when a template is loaded\n \"create\": \"/plugins/dynamic_challenges/assets/create.js\",\n \"update\": \"/plugins/dynamic_challenges/assets/update.js\",\n \"view\": \"/plugins/dynamic_challenges/assets/view.js\",\n }\n # Route at which files are accessible. This must be registered using register_plugin_assets_directory()\n route = \"/plugins/dynamic_challenges/assets/\"\n # Blueprint used to access the static_folder directory.\n blueprint = Blueprint(\n \"dynamic_challenges\",\n __name__,\n template_folder=\"templates\",\n static_folder=\"assets\",\n )\n challenge_model = DynamicChallenge\n\n @classmethod\n def calculate_value(cls, challenge):\n f = DECAY_FUNCTIONS.get(challenge.function, logarithmic)\n value = f(challenge)\n\n challenge.value = value\n db.session.commit()\n return challenge\n\n @classmethod\n def read(cls, challenge):\n \"\"\"\n This method is in used to access the data of a challenge in a format processable by the front end.\n\n :param challenge:\n :return: Challenge object, data dictionary to be returned to the user\n \"\"\"\n challenge = DynamicChallenge.query.filter_by(id=challenge.id).first()\n data = {\n \"id\": challenge.id,\n \"name\": challenge.name,\n \"value\": challenge.value,\n \"initial\": challenge.initial,\n \"decay\": challenge.decay,\n \"minimum\": challenge.minimum,\n \"description\": challenge.description,\n \"connection_info\": challenge.connection_info,\n \"category\": challenge.category,\n \"state\": challenge.state,\n \"max_attempts\": challenge.max_attempts,\n \"type\": challenge.type,\n \"type_data\": {\n \"id\": cls.id,\n \"name\": cls.name,\n \"templates\": cls.templates,\n \"scripts\": cls.scripts,\n },\n }\n return data\n\n @classmethod\n def update(cls, challenge, request):\n \"\"\"\n This method is used to update the information associated with a challenge. This should be kept strictly to the\n Challenges table and any child tables.\n\n :param challenge:\n :param request:\n :return:\n \"\"\"\n data = request.form or request.get_json()\n\n for attr, value in data.items():\n # We need to set these to floats so that the next operations don't operate on strings\n if attr in (\"initial\", \"minimum\", \"decay\"):\n value = float(value)\n setattr(challenge, attr, value)\n\n return DynamicValueChallenge.calculate_value(challenge)\n\n @classmethod\n def solve(cls, user, team, challenge, request):\n super().solve(user, team, challenge, request)\n\n DynamicValueChallenge.calculate_value(challenge)\n\n\ndef load(app):\n upgrade(plugin_name=\"dynamic_challenges\")\n CHALLENGE_CLASSES[\"dynamic\"] = DynamicValueChallenge\n register_plugin_assets_directory(\n app, base_path=\"/plugins/dynamic_challenges/assets/\"\n )\n", "path": "CTFd/plugins/dynamic_challenges/__init__.py"}]}
| 2,083 | 128 |
gh_patches_debug_64222
|
rasdani/github-patches
|
git_diff
|
scrapy__scrapy-1313
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
HTTP_PROXY variable with username and empty password not supported
Scrapy doesn't support proxy authentication when the password is empty when using the HTTP_PROXY environment variable to supply the proxy argument.
</issue>
<code>
[start of scrapy/downloadermiddlewares/httpproxy.py]
1 import base64
2 from six.moves.urllib.request import getproxies, proxy_bypass
3 from six.moves.urllib.parse import unquote
4 try:
5 from urllib2 import _parse_proxy
6 except ImportError:
7 from urllib.request import _parse_proxy
8 from six.moves.urllib.parse import urlunparse
9
10 from scrapy.utils.httpobj import urlparse_cached
11 from scrapy.exceptions import NotConfigured
12
13
14 class HttpProxyMiddleware(object):
15
16 def __init__(self):
17 self.proxies = {}
18 for type, url in getproxies().items():
19 self.proxies[type] = self._get_proxy(url, type)
20
21 if not self.proxies:
22 raise NotConfigured
23
24 def _get_proxy(self, url, orig_type):
25 proxy_type, user, password, hostport = _parse_proxy(url)
26 proxy_url = urlunparse((proxy_type or orig_type, hostport, '', '', '', ''))
27
28 if user and password:
29 user_pass = '%s:%s' % (unquote(user), unquote(password))
30 creds = base64.b64encode(user_pass).strip()
31 else:
32 creds = None
33
34 return creds, proxy_url
35
36 def process_request(self, request, spider):
37 # ignore if proxy is already seted
38 if 'proxy' in request.meta:
39 return
40
41 parsed = urlparse_cached(request)
42 scheme = parsed.scheme
43
44 # 'no_proxy' is only supported by http schemes
45 if scheme in ('http', 'https') and proxy_bypass(parsed.hostname):
46 return
47
48 if scheme in self.proxies:
49 self._set_proxy(request, scheme)
50
51 def _set_proxy(self, request, scheme):
52 creds, proxy = self.proxies[scheme]
53 request.meta['proxy'] = proxy
54 if creds:
55 request.headers['Proxy-Authorization'] = 'Basic ' + creds
56
[end of scrapy/downloadermiddlewares/httpproxy.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/scrapy/downloadermiddlewares/httpproxy.py b/scrapy/downloadermiddlewares/httpproxy.py
--- a/scrapy/downloadermiddlewares/httpproxy.py
+++ b/scrapy/downloadermiddlewares/httpproxy.py
@@ -25,7 +25,7 @@
proxy_type, user, password, hostport = _parse_proxy(url)
proxy_url = urlunparse((proxy_type or orig_type, hostport, '', '', '', ''))
- if user and password:
+ if user:
user_pass = '%s:%s' % (unquote(user), unquote(password))
creds = base64.b64encode(user_pass).strip()
else:
|
{"golden_diff": "diff --git a/scrapy/downloadermiddlewares/httpproxy.py b/scrapy/downloadermiddlewares/httpproxy.py\n--- a/scrapy/downloadermiddlewares/httpproxy.py\n+++ b/scrapy/downloadermiddlewares/httpproxy.py\n@@ -25,7 +25,7 @@\n proxy_type, user, password, hostport = _parse_proxy(url)\n proxy_url = urlunparse((proxy_type or orig_type, hostport, '', '', '', ''))\n \n- if user and password:\n+ if user:\n user_pass = '%s:%s' % (unquote(user), unquote(password))\n creds = base64.b64encode(user_pass).strip()\n else:\n", "issue": "HTTP_PROXY variable with username and empty password not supported\nScrapy doesn't support proxy authentication when the password is empty when using the HTTP_PROXY environment variable to supply the proxy argument.\n\n", "before_files": [{"content": "import base64\nfrom six.moves.urllib.request import getproxies, proxy_bypass\nfrom six.moves.urllib.parse import unquote\ntry:\n from urllib2 import _parse_proxy\nexcept ImportError:\n from urllib.request import _parse_proxy\nfrom six.moves.urllib.parse import urlunparse\n\nfrom scrapy.utils.httpobj import urlparse_cached\nfrom scrapy.exceptions import NotConfigured\n\n\nclass HttpProxyMiddleware(object):\n\n def __init__(self):\n self.proxies = {}\n for type, url in getproxies().items():\n self.proxies[type] = self._get_proxy(url, type)\n\n if not self.proxies:\n raise NotConfigured\n\n def _get_proxy(self, url, orig_type):\n proxy_type, user, password, hostport = _parse_proxy(url)\n proxy_url = urlunparse((proxy_type or orig_type, hostport, '', '', '', ''))\n\n if user and password:\n user_pass = '%s:%s' % (unquote(user), unquote(password))\n creds = base64.b64encode(user_pass).strip()\n else:\n creds = None\n\n return creds, proxy_url\n\n def process_request(self, request, spider):\n # ignore if proxy is already seted\n if 'proxy' in request.meta:\n return\n\n parsed = urlparse_cached(request)\n scheme = parsed.scheme\n\n # 'no_proxy' is only supported by http schemes\n if scheme in ('http', 'https') and proxy_bypass(parsed.hostname):\n return\n\n if scheme in self.proxies:\n self._set_proxy(request, scheme)\n\n def _set_proxy(self, request, scheme):\n creds, proxy = self.proxies[scheme]\n request.meta['proxy'] = proxy\n if creds:\n request.headers['Proxy-Authorization'] = 'Basic ' + creds\n", "path": "scrapy/downloadermiddlewares/httpproxy.py"}]}
| 1,088 | 156 |
gh_patches_debug_21249
|
rasdani/github-patches
|
git_diff
|
statsmodels__statsmodels-3439
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
API/DOCS: newer correlation tools are missing in api and docs
`stats.api` and http://www.statsmodels.org/dev/stats.html#moment-helpers
only shows the original functions, not those added by Kerby
(I'm trying to figure out where we should put new correlation and covariance function, hypothesis tests, robust, regularized covariance and correlation.)
</issue>
<code>
[start of statsmodels/stats/api.py]
1 # pylint: disable=W0611
2 from . import diagnostic
3 from .diagnostic import (
4 acorr_ljungbox, acorr_breusch_godfrey,
5 CompareCox, compare_cox, CompareJ, compare_j,
6 HetGoldfeldQuandt, het_goldfeldquandt,
7 het_breuschpagan, het_white, het_arch,
8 linear_harvey_collier, linear_rainbow, linear_lm,
9 breaks_cusumolsresid, breaks_hansen, recursive_olsresiduals,
10 unitroot_adf,
11 normal_ad, lilliefors,
12 # deprecated because of misspelling:
13 lillifors, het_breushpagan, acorr_breush_godfrey
14 )
15
16 from . import multicomp
17 from .multitest import (multipletests, fdrcorrection, fdrcorrection_twostage)
18 from .multicomp import tukeyhsd
19 from . import gof
20 from .gof import (powerdiscrepancy, gof_chisquare_discrete,
21 chisquare_effectsize)
22 from . import stattools
23 from .stattools import durbin_watson, omni_normtest, jarque_bera
24
25 from . import sandwich_covariance
26 from .sandwich_covariance import (
27 cov_cluster, cov_cluster_2groups, cov_nw_panel,
28 cov_hac, cov_white_simple,
29 cov_hc0, cov_hc1, cov_hc2, cov_hc3,
30 se_cov
31 )
32
33 from .weightstats import (DescrStatsW, CompareMeans, ttest_ind, ttost_ind,
34 ttost_paired, ztest, ztost, zconfint)
35
36 from .proportion import (binom_test_reject_interval, binom_test,
37 binom_tost, binom_tost_reject_interval,
38 power_binom_tost, power_ztost_prop,
39 proportion_confint, proportion_effectsize,
40 proportions_chisquare, proportions_chisquare_allpairs,
41 proportions_chisquare_pairscontrol, proportions_ztest,
42 proportions_ztost)
43
44 from .power import (TTestPower, TTestIndPower, GofChisquarePower,
45 NormalIndPower, FTestAnovaPower, FTestPower,
46 tt_solve_power, tt_ind_solve_power, zt_ind_solve_power)
47
48 from .descriptivestats import Describe
49
50 from .anova import anova_lm
51
52 from . import moment_helpers
53 from .correlation_tools import corr_nearest, corr_clipped, cov_nearest
54
55 from statsmodels.sandbox.stats.runs import (Runs, runstest_1samp, runstest_2samp)
56
57 from statsmodels.stats.contingency_tables import (mcnemar, cochrans_q,
58 SquareTable,
59 Table2x2,
60 Table,
61 StratifiedTable)
62
[end of statsmodels/stats/api.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/statsmodels/stats/api.py b/statsmodels/stats/api.py
--- a/statsmodels/stats/api.py
+++ b/statsmodels/stats/api.py
@@ -39,7 +39,7 @@
proportion_confint, proportion_effectsize,
proportions_chisquare, proportions_chisquare_allpairs,
proportions_chisquare_pairscontrol, proportions_ztest,
- proportions_ztost)
+ proportions_ztost, multinomial_proportions_confint)
from .power import (TTestPower, TTestIndPower, GofChisquarePower,
NormalIndPower, FTestAnovaPower, FTestPower,
@@ -50,7 +50,9 @@
from .anova import anova_lm
from . import moment_helpers
-from .correlation_tools import corr_nearest, corr_clipped, cov_nearest
+from .correlation_tools import (corr_clipped, corr_nearest,
+ corr_nearest_factor, corr_thresholded, cov_nearest,
+ cov_nearest_factor_homog, FactoredPSDMatrix)
from statsmodels.sandbox.stats.runs import (Runs, runstest_1samp, runstest_2samp)
|
{"golden_diff": "diff --git a/statsmodels/stats/api.py b/statsmodels/stats/api.py\n--- a/statsmodels/stats/api.py\n+++ b/statsmodels/stats/api.py\n@@ -39,7 +39,7 @@\n proportion_confint, proportion_effectsize,\n proportions_chisquare, proportions_chisquare_allpairs,\n proportions_chisquare_pairscontrol, proportions_ztest,\n- proportions_ztost)\n+ proportions_ztost, multinomial_proportions_confint)\n \n from .power import (TTestPower, TTestIndPower, GofChisquarePower,\n NormalIndPower, FTestAnovaPower, FTestPower,\n@@ -50,7 +50,9 @@\n from .anova import anova_lm\n \n from . import moment_helpers\n-from .correlation_tools import corr_nearest, corr_clipped, cov_nearest\n+from .correlation_tools import (corr_clipped, corr_nearest,\n+ corr_nearest_factor, corr_thresholded, cov_nearest,\n+ cov_nearest_factor_homog, FactoredPSDMatrix)\n \n from statsmodels.sandbox.stats.runs import (Runs, runstest_1samp, runstest_2samp)\n", "issue": "API/DOCS: newer correlation tools are missing in api and docs\n`stats.api` and http://www.statsmodels.org/dev/stats.html#moment-helpers\nonly shows the original functions, not those added by Kerby\n\n(I'm trying to figure out where we should put new correlation and covariance function, hypothesis tests, robust, regularized covariance and correlation.)\n\n", "before_files": [{"content": "# pylint: disable=W0611\nfrom . import diagnostic\nfrom .diagnostic import (\n acorr_ljungbox, acorr_breusch_godfrey,\n CompareCox, compare_cox, CompareJ, compare_j,\n HetGoldfeldQuandt, het_goldfeldquandt,\n het_breuschpagan, het_white, het_arch,\n linear_harvey_collier, linear_rainbow, linear_lm,\n breaks_cusumolsresid, breaks_hansen, recursive_olsresiduals,\n unitroot_adf,\n normal_ad, lilliefors,\n # deprecated because of misspelling:\n lillifors, het_breushpagan, acorr_breush_godfrey\n )\n\nfrom . import multicomp\nfrom .multitest import (multipletests, fdrcorrection, fdrcorrection_twostage)\nfrom .multicomp import tukeyhsd\nfrom . import gof\nfrom .gof import (powerdiscrepancy, gof_chisquare_discrete,\n chisquare_effectsize)\nfrom . import stattools\nfrom .stattools import durbin_watson, omni_normtest, jarque_bera\n\nfrom . import sandwich_covariance\nfrom .sandwich_covariance import (\n cov_cluster, cov_cluster_2groups, cov_nw_panel,\n cov_hac, cov_white_simple,\n cov_hc0, cov_hc1, cov_hc2, cov_hc3,\n se_cov\n )\n\nfrom .weightstats import (DescrStatsW, CompareMeans, ttest_ind, ttost_ind,\n ttost_paired, ztest, ztost, zconfint)\n\nfrom .proportion import (binom_test_reject_interval, binom_test,\n binom_tost, binom_tost_reject_interval,\n power_binom_tost, power_ztost_prop,\n proportion_confint, proportion_effectsize,\n proportions_chisquare, proportions_chisquare_allpairs,\n proportions_chisquare_pairscontrol, proportions_ztest,\n proportions_ztost)\n\nfrom .power import (TTestPower, TTestIndPower, GofChisquarePower,\n NormalIndPower, FTestAnovaPower, FTestPower,\n tt_solve_power, tt_ind_solve_power, zt_ind_solve_power)\n\nfrom .descriptivestats import Describe\n\nfrom .anova import anova_lm\n\nfrom . import moment_helpers\nfrom .correlation_tools import corr_nearest, corr_clipped, cov_nearest\n\nfrom statsmodels.sandbox.stats.runs import (Runs, runstest_1samp, runstest_2samp)\n\nfrom statsmodels.stats.contingency_tables import (mcnemar, cochrans_q,\n SquareTable,\n Table2x2,\n Table,\n StratifiedTable)\n", "path": "statsmodels/stats/api.py"}]}
| 1,348 | 254 |
gh_patches_debug_12624
|
rasdani/github-patches
|
git_diff
|
secdev__scapy-2631
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Use nextproto property instead of nextprotocol
This is just a checklist to guide you. You can remove it safely.
**Checklist:**
- [x ] If you are new to Scapy: I have checked <https://github.com/secdev/scapy/blob/master/CONTRIBUTING.md> (esp. section submitting-pull-requests)
- [ ] I squashed commits belonging together
- [ ] I added unit tests or explained why they are not relevant
- [ ] I executed the regression tests for Python2 and Python3 (using `tox` or, `cd test && ./run_tests_py2, cd test && ./run_tests_py3`)
- [ ] If the PR is still not finished, please create a [Draft Pull Request](https://github.blog/2019-02-14-introducing-draft-pull-requests/)
> brief description what this PR will do, e.g. fixes broken dissection of XXX
Fix wrong property in `bind_layers` function of NSH protocol. In the NSH class, it defines `nextproto` for next protocol property.
I changed from `nextprotocol` to `nextproto` in `bind_layers` functions.
> if required - short explanation why you fixed something in a way that may look more complicated as it actually is
> if required - outline impacts on other parts of the library
</issue>
<code>
[start of scapy/contrib/nsh.py]
1 # This file is part of Scapy
2 # Scapy is free software: you can redistribute it and/or modify
3 # it under the terms of the GNU General Public License as published by
4 # the Free Software Foundation, either version 2 of the License, or
5 # any later version.
6 #
7 # Scapy is distributed in the hope that it will be useful,
8 # but WITHOUT ANY WARRANTY; without even the implied warranty of
9 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
10 # GNU General Public License for more details.
11 #
12 # You should have received a copy of the GNU General Public License
13 # along with Scapy. If not, see <http://www.gnu.org/licenses/>.
14
15 # scapy.contrib.description = Network Services Headers (NSH)
16 # scapy.contrib.status = loads
17
18 from scapy.all import bind_layers
19 from scapy.fields import BitField, ByteField, ByteEnumField, BitEnumField, \
20 ShortField, X3BytesField, XIntField, XStrFixedLenField, \
21 ConditionalField, PacketListField, BitFieldLenField
22 from scapy.layers.inet import Ether, IP
23 from scapy.layers.inet6 import IPv6
24 from scapy.layers.vxlan import VXLAN
25 from scapy.packet import Packet
26 from scapy.layers.l2 import GRE
27
28 from scapy.contrib.mpls import MPLS
29
30 #
31 # NSH Support
32 # https://www.rfc-editor.org/rfc/rfc8300.txt January 2018
33 #
34
35
36 class NSHTLV(Packet):
37 "NSH MD-type 2 - Variable Length Context Headers"
38 name = "NSHTLV"
39 fields_desc = [
40 ShortField('class', 0),
41 BitField('type', 0, 8),
42 BitField('reserved', 0, 1),
43 BitField('length', 0, 7),
44 PacketListField('metadata', None, XIntField, count_from='length')
45 ]
46
47
48 class NSH(Packet):
49 """Network Service Header.
50 NSH MD-type 1 if there is no ContextHeaders"""
51 name = "NSH"
52
53 fields_desc = [
54 BitField('ver', 0, 2),
55 BitField('oam', 0, 1),
56 BitField('unused1', 0, 1),
57 BitField('ttl', 63, 6),
58 BitFieldLenField('length', None, 6,
59 count_of='vlch',
60 adjust=lambda pkt, x: 6 if pkt.mdtype == 1
61 else x + 2),
62 BitField('unused2', 0, 4),
63 BitEnumField('mdtype', 1, 4, {0: 'Reserved MDType',
64 1: 'Fixed Length',
65 2: 'Variable Length',
66 0xF: 'Experimental MDType'}),
67 ByteEnumField('nextproto', 3, {1: 'IPv4',
68 2: 'IPv6',
69 3: 'Ethernet',
70 4: 'NSH',
71 5: 'MPLS',
72 0xFE: 'Experiment 1',
73 0xFF: 'Experiment 2'}),
74 X3BytesField('spi', 0),
75 ByteField('si', 0xFF),
76 ConditionalField(XStrFixedLenField("context_header", "", 16),
77 lambda pkt: pkt.mdtype == 1),
78 ConditionalField(PacketListField("vlch", None, NSHTLV,
79 count_from="length"),
80 lambda pkt: pkt.mdtype == 2)
81 ]
82
83 def mysummary(self):
84 return self.sprintf("SPI: %spi% - SI: %si%")
85
86
87 bind_layers(Ether, NSH, {'type': 0x894F}, type=0x894F)
88 bind_layers(VXLAN, NSH, {'flags': 0xC, 'nextprotocol': 4}, nextprotocol=4)
89 bind_layers(GRE, NSH, {'proto': 0x894F}, proto=0x894F)
90
91 bind_layers(NSH, IP, {'nextprotocol': 1}, nextprotocol=1)
92 bind_layers(NSH, IPv6, {'nextprotocol': 2}, nextprotocol=2)
93 bind_layers(NSH, Ether, {'nextprotocol': 3}, nextprotocol=3)
94 bind_layers(NSH, NSH, {'nextprotocol': 4}, nextprotocol=4)
95 bind_layers(NSH, MPLS, {'nextprotocol': 5}, nextprotocol=5)
96
[end of scapy/contrib/nsh.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/scapy/contrib/nsh.py b/scapy/contrib/nsh.py
--- a/scapy/contrib/nsh.py
+++ b/scapy/contrib/nsh.py
@@ -85,11 +85,11 @@
bind_layers(Ether, NSH, {'type': 0x894F}, type=0x894F)
-bind_layers(VXLAN, NSH, {'flags': 0xC, 'nextprotocol': 4}, nextprotocol=4)
+bind_layers(VXLAN, NSH, {'flags': 0xC, 'nextproto': 4}, nextproto=4)
bind_layers(GRE, NSH, {'proto': 0x894F}, proto=0x894F)
-bind_layers(NSH, IP, {'nextprotocol': 1}, nextprotocol=1)
-bind_layers(NSH, IPv6, {'nextprotocol': 2}, nextprotocol=2)
-bind_layers(NSH, Ether, {'nextprotocol': 3}, nextprotocol=3)
-bind_layers(NSH, NSH, {'nextprotocol': 4}, nextprotocol=4)
-bind_layers(NSH, MPLS, {'nextprotocol': 5}, nextprotocol=5)
+bind_layers(NSH, IP, nextproto=1)
+bind_layers(NSH, IPv6, nextproto=2)
+bind_layers(NSH, Ether, nextproto=3)
+bind_layers(NSH, NSH, nextproto=4)
+bind_layers(NSH, MPLS, nextproto=5)
|
{"golden_diff": "diff --git a/scapy/contrib/nsh.py b/scapy/contrib/nsh.py\n--- a/scapy/contrib/nsh.py\n+++ b/scapy/contrib/nsh.py\n@@ -85,11 +85,11 @@\n \n \n bind_layers(Ether, NSH, {'type': 0x894F}, type=0x894F)\n-bind_layers(VXLAN, NSH, {'flags': 0xC, 'nextprotocol': 4}, nextprotocol=4)\n+bind_layers(VXLAN, NSH, {'flags': 0xC, 'nextproto': 4}, nextproto=4)\n bind_layers(GRE, NSH, {'proto': 0x894F}, proto=0x894F)\n \n-bind_layers(NSH, IP, {'nextprotocol': 1}, nextprotocol=1)\n-bind_layers(NSH, IPv6, {'nextprotocol': 2}, nextprotocol=2)\n-bind_layers(NSH, Ether, {'nextprotocol': 3}, nextprotocol=3)\n-bind_layers(NSH, NSH, {'nextprotocol': 4}, nextprotocol=4)\n-bind_layers(NSH, MPLS, {'nextprotocol': 5}, nextprotocol=5)\n+bind_layers(NSH, IP, nextproto=1)\n+bind_layers(NSH, IPv6, nextproto=2)\n+bind_layers(NSH, Ether, nextproto=3)\n+bind_layers(NSH, NSH, nextproto=4)\n+bind_layers(NSH, MPLS, nextproto=5)\n", "issue": "Use nextproto property instead of nextprotocol\nThis is just a checklist to guide you. You can remove it safely.\r\n\r\n**Checklist:**\r\n\r\n- [x ] If you are new to Scapy: I have checked <https://github.com/secdev/scapy/blob/master/CONTRIBUTING.md> (esp. section submitting-pull-requests)\r\n- [ ] I squashed commits belonging together\r\n- [ ] I added unit tests or explained why they are not relevant\r\n- [ ] I executed the regression tests for Python2 and Python3 (using `tox` or, `cd test && ./run_tests_py2, cd test && ./run_tests_py3`)\r\n- [ ] If the PR is still not finished, please create a [Draft Pull Request](https://github.blog/2019-02-14-introducing-draft-pull-requests/)\r\n\r\n> brief description what this PR will do, e.g. fixes broken dissection of XXX\r\nFix wrong property in `bind_layers` function of NSH protocol. In the NSH class, it defines `nextproto` for next protocol property. \r\n\r\nI changed from `nextprotocol` to `nextproto` in `bind_layers` functions.\r\n\r\n> if required - short explanation why you fixed something in a way that may look more complicated as it actually is\r\n\r\n> if required - outline impacts on other parts of the library\r\n\n", "before_files": [{"content": "# This file is part of Scapy\n# Scapy is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 2 of the License, or\n# any later version.\n#\n# Scapy is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Scapy. If not, see <http://www.gnu.org/licenses/>.\n\n# scapy.contrib.description = Network Services Headers (NSH)\n# scapy.contrib.status = loads\n\nfrom scapy.all import bind_layers\nfrom scapy.fields import BitField, ByteField, ByteEnumField, BitEnumField, \\\n ShortField, X3BytesField, XIntField, XStrFixedLenField, \\\n ConditionalField, PacketListField, BitFieldLenField\nfrom scapy.layers.inet import Ether, IP\nfrom scapy.layers.inet6 import IPv6\nfrom scapy.layers.vxlan import VXLAN\nfrom scapy.packet import Packet\nfrom scapy.layers.l2 import GRE\n\nfrom scapy.contrib.mpls import MPLS\n\n#\n# NSH Support\n# https://www.rfc-editor.org/rfc/rfc8300.txt January 2018\n#\n\n\nclass NSHTLV(Packet):\n \"NSH MD-type 2 - Variable Length Context Headers\"\n name = \"NSHTLV\"\n fields_desc = [\n ShortField('class', 0),\n BitField('type', 0, 8),\n BitField('reserved', 0, 1),\n BitField('length', 0, 7),\n PacketListField('metadata', None, XIntField, count_from='length')\n ]\n\n\nclass NSH(Packet):\n \"\"\"Network Service Header.\n NSH MD-type 1 if there is no ContextHeaders\"\"\"\n name = \"NSH\"\n\n fields_desc = [\n BitField('ver', 0, 2),\n BitField('oam', 0, 1),\n BitField('unused1', 0, 1),\n BitField('ttl', 63, 6),\n BitFieldLenField('length', None, 6,\n count_of='vlch',\n adjust=lambda pkt, x: 6 if pkt.mdtype == 1\n else x + 2),\n BitField('unused2', 0, 4),\n BitEnumField('mdtype', 1, 4, {0: 'Reserved MDType',\n 1: 'Fixed Length',\n 2: 'Variable Length',\n 0xF: 'Experimental MDType'}),\n ByteEnumField('nextproto', 3, {1: 'IPv4',\n 2: 'IPv6',\n 3: 'Ethernet',\n 4: 'NSH',\n 5: 'MPLS',\n 0xFE: 'Experiment 1',\n 0xFF: 'Experiment 2'}),\n X3BytesField('spi', 0),\n ByteField('si', 0xFF),\n ConditionalField(XStrFixedLenField(\"context_header\", \"\", 16),\n lambda pkt: pkt.mdtype == 1),\n ConditionalField(PacketListField(\"vlch\", None, NSHTLV,\n count_from=\"length\"),\n lambda pkt: pkt.mdtype == 2)\n ]\n\n def mysummary(self):\n return self.sprintf(\"SPI: %spi% - SI: %si%\")\n\n\nbind_layers(Ether, NSH, {'type': 0x894F}, type=0x894F)\nbind_layers(VXLAN, NSH, {'flags': 0xC, 'nextprotocol': 4}, nextprotocol=4)\nbind_layers(GRE, NSH, {'proto': 0x894F}, proto=0x894F)\n\nbind_layers(NSH, IP, {'nextprotocol': 1}, nextprotocol=1)\nbind_layers(NSH, IPv6, {'nextprotocol': 2}, nextprotocol=2)\nbind_layers(NSH, Ether, {'nextprotocol': 3}, nextprotocol=3)\nbind_layers(NSH, NSH, {'nextprotocol': 4}, nextprotocol=4)\nbind_layers(NSH, MPLS, {'nextprotocol': 5}, nextprotocol=5)\n", "path": "scapy/contrib/nsh.py"}]}
| 1,994 | 335 |
gh_patches_debug_11202
|
rasdani/github-patches
|
git_diff
|
fossasia__open-event-server-2181
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Move Payment Gateways to own subtab
On `admin/settings/` add a subtab "Payment Gateways" and move the Paypal and Stripe here.


</issue>
<code>
[start of app/settings/__init__.py]
1 import stripe
2 from flask import current_app
3 from sqlalchemy import desc
4 from app.models.setting import Setting
5 from app.models.fees import TicketFees
6
7
8 def get_settings():
9 """
10 Use this to get latest system settings
11 """
12 if 'custom_settings' in current_app.config:
13 return current_app.config['custom_settings']
14 s = Setting.query.order_by(desc(Setting.id)).first()
15 if s is None:
16 set_settings(secret='super secret key')
17 else:
18 current_app.config['custom_settings'] = make_dict(s)
19 return current_app.config['custom_settings']
20
21
22 def set_settings(**kwargs):
23 """
24 Update system settings
25 """
26
27 if 'service_fee' in kwargs:
28 ticket_service_fees = kwargs.get('service_fee')
29 ticket_maximum_fees = kwargs.get('maximum_fee')
30 from app.helpers.data_getter import DataGetter
31 from app.helpers.data import save_to_db
32 currencies = DataGetter.get_payment_currencies()
33 for i, currency in enumerate(currencies):
34 currency = currency.split(' ')[0]
35 ticket_fee = TicketFees(currency=currency,
36 service_fee=ticket_service_fees[i],
37 maximum_fee=ticket_maximum_fees[i])
38 save_to_db(ticket_fee, "Ticket Fees settings saved")
39 else:
40 setting = Setting(**kwargs)
41 from app.helpers.data import save_to_db
42 save_to_db(setting, 'Setting saved')
43 current_app.secret_key = setting.secret
44 stripe.api_key = setting.stripe_secret_key
45 current_app.config['custom_settings'] = make_dict(setting)
46
47
48 def make_dict(s):
49 arguments = {}
50 for name, column in s.__mapper__.columns.items():
51 if not (column.primary_key or column.unique):
52 arguments[name] = getattr(s, name)
53 return arguments
54
[end of app/settings/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/app/settings/__init__.py b/app/settings/__init__.py
--- a/app/settings/__init__.py
+++ b/app/settings/__init__.py
@@ -30,7 +30,7 @@
from app.helpers.data_getter import DataGetter
from app.helpers.data import save_to_db
currencies = DataGetter.get_payment_currencies()
- for i, currency in enumerate(currencies):
+ for i, (currency, has_paypal, has_stripe) in enumerate(currencies):
currency = currency.split(' ')[0]
ticket_fee = TicketFees(currency=currency,
service_fee=ticket_service_fees[i],
|
{"golden_diff": "diff --git a/app/settings/__init__.py b/app/settings/__init__.py\n--- a/app/settings/__init__.py\n+++ b/app/settings/__init__.py\n@@ -30,7 +30,7 @@\n from app.helpers.data_getter import DataGetter\n from app.helpers.data import save_to_db\n currencies = DataGetter.get_payment_currencies()\n- for i, currency in enumerate(currencies):\n+ for i, (currency, has_paypal, has_stripe) in enumerate(currencies):\n currency = currency.split(' ')[0]\n ticket_fee = TicketFees(currency=currency,\n service_fee=ticket_service_fees[i],\n", "issue": "Move Payment Gateways to own subtab\nOn `admin/settings/` add a subtab \"Payment Gateways\" and move the Paypal and Stripe here.\n\n\n\n\n\n", "before_files": [{"content": "import stripe\nfrom flask import current_app\nfrom sqlalchemy import desc\nfrom app.models.setting import Setting\nfrom app.models.fees import TicketFees\n\n\ndef get_settings():\n \"\"\"\n Use this to get latest system settings\n \"\"\"\n if 'custom_settings' in current_app.config:\n return current_app.config['custom_settings']\n s = Setting.query.order_by(desc(Setting.id)).first()\n if s is None:\n set_settings(secret='super secret key')\n else:\n current_app.config['custom_settings'] = make_dict(s)\n return current_app.config['custom_settings']\n\n\ndef set_settings(**kwargs):\n \"\"\"\n Update system settings\n \"\"\"\n\n if 'service_fee' in kwargs:\n ticket_service_fees = kwargs.get('service_fee')\n ticket_maximum_fees = kwargs.get('maximum_fee')\n from app.helpers.data_getter import DataGetter\n from app.helpers.data import save_to_db\n currencies = DataGetter.get_payment_currencies()\n for i, currency in enumerate(currencies):\n currency = currency.split(' ')[0]\n ticket_fee = TicketFees(currency=currency,\n service_fee=ticket_service_fees[i],\n maximum_fee=ticket_maximum_fees[i])\n save_to_db(ticket_fee, \"Ticket Fees settings saved\")\n else:\n setting = Setting(**kwargs)\n from app.helpers.data import save_to_db\n save_to_db(setting, 'Setting saved')\n current_app.secret_key = setting.secret\n stripe.api_key = setting.stripe_secret_key\n current_app.config['custom_settings'] = make_dict(setting)\n\n\ndef make_dict(s):\n arguments = {}\n for name, column in s.__mapper__.columns.items():\n if not (column.primary_key or column.unique):\n arguments[name] = getattr(s, name)\n return arguments\n", "path": "app/settings/__init__.py"}]}
| 1,214 | 141 |
gh_patches_debug_23885
|
rasdani/github-patches
|
git_diff
|
kedro-org__kedro-3587
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add official support for Python 3.12
## Description
<!-- Is your feature request related to a problem? A clear and concise description of what the problem is: "I'm always frustrated when ..." -->
Kedro itself probably works on Python 3.12 already, it would be nice to declare official support.
However, installing Kedro is one thing, but installing the typical dependencies might not be straightforward. For example, I just tested the spaceflights starter and most of the dependencies have already published precompiled wheels for Python 3.12 (at least for M1 Mac), but two of them are still problematic as of today:
- aiohttp https://github.com/aio-libs/aiohttp/issues/7739 worked by installing the beta version as advised there, so it will be solved soon (edit: fixed ✔️)
- pyzmq https://github.com/zeromq/pyzmq/issues/1907 (M1 specific), didn't work after installing the ZMQ header libraries with mamba (edit: fixed ✔️)
## Context
<!-- Why is this change important to you? How would you use it? How can it benefit other users? -->
#2815 was already completed, but officially Kedro does not support Python 3.12 yet.
You can use Kedro on Python 3.12 by manually disabling the warning.
## Possible Implementation
<!-- (Optional) Suggest an idea for implementing the addition or change. -->
Wait a bit until at least the spaceflights starter can be safely installed in most mainstream platforms.
## Possible Alternatives
<!-- (Optional) Describe any alternative solutions or features you've considered. -->
Declare Python 3.12 support already, at the cost of creating some grievance of users that then proceed to install some dependencies.
</issue>
<code>
[start of kedro/__init__.py]
1 """Kedro is a framework that makes it easy to build robust and scalable
2 data pipelines by providing uniform project templates, data abstraction,
3 configuration and pipeline assembly.
4 """
5
6 import sys
7 import warnings
8
9 __version__ = "0.19.3"
10
11
12 class KedroDeprecationWarning(DeprecationWarning):
13 """Custom class for warnings about deprecated Kedro features."""
14
15
16 class KedroPythonVersionWarning(UserWarning):
17 """Custom class for warnings about incompatibilities with Python versions."""
18
19
20 if not sys.warnoptions:
21 warnings.simplefilter("default", KedroDeprecationWarning)
22 warnings.simplefilter("error", KedroPythonVersionWarning)
23
24 if sys.version_info >= (3, 12):
25 warnings.warn(
26 """Kedro is not yet fully compatible with this Python version.
27 To proceed at your own risk and ignore this warning,
28 run Kedro with `python -W "default:Kedro is not yet fully compatible" -m kedro ...`
29 or set the PYTHONWARNINGS environment variable accordingly.""",
30 KedroPythonVersionWarning,
31 )
32
[end of kedro/__init__.py]
[start of kedro/config/abstract_config.py]
1 """This module provides ``kedro.abstract_config`` with the baseline
2 class model for a `ConfigLoader` implementation.
3 """
4 from __future__ import annotations
5
6 from collections import UserDict
7 from typing import Any
8
9
10 class AbstractConfigLoader(UserDict):
11 """``AbstractConfigLoader`` is the abstract base class
12 for all `ConfigLoader` implementations.
13 All user-defined `ConfigLoader` implementations should inherit
14 from `AbstractConfigLoader` and implement all relevant abstract methods.
15 """
16
17 def __init__(
18 self,
19 conf_source: str,
20 env: str | None = None,
21 runtime_params: dict[str, Any] | None = None,
22 **kwargs: Any,
23 ):
24 super().__init__()
25 self.conf_source = conf_source
26 self.env = env
27 self.runtime_params = runtime_params or {}
28
29
30 class BadConfigException(Exception):
31 """Raised when a configuration file cannot be loaded, for instance
32 due to wrong syntax or poor formatting.
33 """
34
35 pass
36
37
38 class MissingConfigException(Exception):
39 """Raised when no configuration files can be found within a config path"""
40
41 pass
42
[end of kedro/config/abstract_config.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kedro/__init__.py b/kedro/__init__.py
--- a/kedro/__init__.py
+++ b/kedro/__init__.py
@@ -21,7 +21,7 @@
warnings.simplefilter("default", KedroDeprecationWarning)
warnings.simplefilter("error", KedroPythonVersionWarning)
-if sys.version_info >= (3, 12):
+if sys.version_info >= (3, 13):
warnings.warn(
"""Kedro is not yet fully compatible with this Python version.
To proceed at your own risk and ignore this warning,
diff --git a/kedro/config/abstract_config.py b/kedro/config/abstract_config.py
--- a/kedro/config/abstract_config.py
+++ b/kedro/config/abstract_config.py
@@ -26,6 +26,17 @@
self.env = env
self.runtime_params = runtime_params or {}
+ # As of Python 3.12 __getitem__ is no longer called in the inherited UserDict.get()
+ # This causes AbstractConfigLoader.get() to break
+ # See: https://github.com/python/cpython/issues/105524
+ # Overwrite the inherited get function with the implementation from 3.11 and prior
+ def get(self, key: str, default: Any = None) -> Any:
+ "D.get(k[,d]) -> D[k] if k in D, else d. d defaults to None."
+ try:
+ return self[key]
+ except KeyError:
+ return default
+
class BadConfigException(Exception):
"""Raised when a configuration file cannot be loaded, for instance
|
{"golden_diff": "diff --git a/kedro/__init__.py b/kedro/__init__.py\n--- a/kedro/__init__.py\n+++ b/kedro/__init__.py\n@@ -21,7 +21,7 @@\n warnings.simplefilter(\"default\", KedroDeprecationWarning)\n warnings.simplefilter(\"error\", KedroPythonVersionWarning)\n \n-if sys.version_info >= (3, 12):\n+if sys.version_info >= (3, 13):\n warnings.warn(\n \"\"\"Kedro is not yet fully compatible with this Python version.\n To proceed at your own risk and ignore this warning,\ndiff --git a/kedro/config/abstract_config.py b/kedro/config/abstract_config.py\n--- a/kedro/config/abstract_config.py\n+++ b/kedro/config/abstract_config.py\n@@ -26,6 +26,17 @@\n self.env = env\n self.runtime_params = runtime_params or {}\n \n+ # As of Python 3.12 __getitem__ is no longer called in the inherited UserDict.get()\n+ # This causes AbstractConfigLoader.get() to break\n+ # See: https://github.com/python/cpython/issues/105524\n+ # Overwrite the inherited get function with the implementation from 3.11 and prior\n+ def get(self, key: str, default: Any = None) -> Any:\n+ \"D.get(k[,d]) -> D[k] if k in D, else d. d defaults to None.\"\n+ try:\n+ return self[key]\n+ except KeyError:\n+ return default\n+\n \n class BadConfigException(Exception):\n \"\"\"Raised when a configuration file cannot be loaded, for instance\n", "issue": "Add official support for Python 3.12\n## Description\r\n<!-- Is your feature request related to a problem? A clear and concise description of what the problem is: \"I'm always frustrated when ...\" -->\r\nKedro itself probably works on Python 3.12 already, it would be nice to declare official support.\r\n\r\nHowever, installing Kedro is one thing, but installing the typical dependencies might not be straightforward. For example, I just tested the spaceflights starter and most of the dependencies have already published precompiled wheels for Python 3.12 (at least for M1 Mac), but two of them are still problematic as of today:\r\n\r\n- aiohttp https://github.com/aio-libs/aiohttp/issues/7739 worked by installing the beta version as advised there, so it will be solved soon (edit: fixed \u2714\ufe0f)\r\n- pyzmq https://github.com/zeromq/pyzmq/issues/1907 (M1 specific), didn't work after installing the ZMQ header libraries with mamba (edit: fixed \u2714\ufe0f)\r\n\r\n## Context\r\n<!-- Why is this change important to you? How would you use it? How can it benefit other users? -->\r\n#2815 was already completed, but officially Kedro does not support Python 3.12 yet.\r\n\r\nYou can use Kedro on Python 3.12 by manually disabling the warning.\r\n\r\n## Possible Implementation\r\n<!-- (Optional) Suggest an idea for implementing the addition or change. -->\r\nWait a bit until at least the spaceflights starter can be safely installed in most mainstream platforms.\r\n\r\n## Possible Alternatives\r\n<!-- (Optional) Describe any alternative solutions or features you've considered. -->\r\nDeclare Python 3.12 support already, at the cost of creating some grievance of users that then proceed to install some dependencies.\r\n\n", "before_files": [{"content": "\"\"\"Kedro is a framework that makes it easy to build robust and scalable\ndata pipelines by providing uniform project templates, data abstraction,\nconfiguration and pipeline assembly.\n\"\"\"\n\nimport sys\nimport warnings\n\n__version__ = \"0.19.3\"\n\n\nclass KedroDeprecationWarning(DeprecationWarning):\n \"\"\"Custom class for warnings about deprecated Kedro features.\"\"\"\n\n\nclass KedroPythonVersionWarning(UserWarning):\n \"\"\"Custom class for warnings about incompatibilities with Python versions.\"\"\"\n\n\nif not sys.warnoptions:\n warnings.simplefilter(\"default\", KedroDeprecationWarning)\n warnings.simplefilter(\"error\", KedroPythonVersionWarning)\n\nif sys.version_info >= (3, 12):\n warnings.warn(\n \"\"\"Kedro is not yet fully compatible with this Python version.\nTo proceed at your own risk and ignore this warning,\nrun Kedro with `python -W \"default:Kedro is not yet fully compatible\" -m kedro ...`\nor set the PYTHONWARNINGS environment variable accordingly.\"\"\",\n KedroPythonVersionWarning,\n )\n", "path": "kedro/__init__.py"}, {"content": "\"\"\"This module provides ``kedro.abstract_config`` with the baseline\nclass model for a `ConfigLoader` implementation.\n\"\"\"\nfrom __future__ import annotations\n\nfrom collections import UserDict\nfrom typing import Any\n\n\nclass AbstractConfigLoader(UserDict):\n \"\"\"``AbstractConfigLoader`` is the abstract base class\n for all `ConfigLoader` implementations.\n All user-defined `ConfigLoader` implementations should inherit\n from `AbstractConfigLoader` and implement all relevant abstract methods.\n \"\"\"\n\n def __init__(\n self,\n conf_source: str,\n env: str | None = None,\n runtime_params: dict[str, Any] | None = None,\n **kwargs: Any,\n ):\n super().__init__()\n self.conf_source = conf_source\n self.env = env\n self.runtime_params = runtime_params or {}\n\n\nclass BadConfigException(Exception):\n \"\"\"Raised when a configuration file cannot be loaded, for instance\n due to wrong syntax or poor formatting.\n \"\"\"\n\n pass\n\n\nclass MissingConfigException(Exception):\n \"\"\"Raised when no configuration files can be found within a config path\"\"\"\n\n pass\n", "path": "kedro/config/abstract_config.py"}]}
| 1,550 | 378 |
gh_patches_debug_17700
|
rasdani/github-patches
|
git_diff
|
DDMAL__CantusDB-210
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Chant-edit page doesn't load for Admin user
The chant-edit page (e.g., http://127.0.0.1:3122/edit-volpiano/702611?pk=705019) takes forever to load for Admin user.
I was logged in with my Admin account (i.e., superuser). Ideally, this should give me power to access and change anything.
I also check with my project manager account and it loaded fine.
</issue>
<code>
[start of django/cantusdb_project/users/managers.py]
1 # https://testdriven.io/blog/django-custom-user-model/#:~:text=The%20default%20User%20model%20in,either%20subclassing%20AbstractUser%20or%20AbstractBaseUser%20.
2
3 from django.contrib.auth.base_user import BaseUserManager
4 from django.utils.translation import gettext_lazy as _
5
6
7 class CustomUserManager(BaseUserManager):
8 """
9 Custom user model manager where email is the unique identifiers
10 for authentication instead of usernames.
11 """
12 def create_user(self, email, password, **extra_fields):
13 """
14 Create and save a User with the given email and password.
15 """
16 if not email:
17 raise ValueError(_('The Email must be set'))
18 email = self.normalize_email(email)
19 user = self.model(email=email, **extra_fields)
20 user.set_password(password)
21 user.save()
22 return user
23
24 def create_superuser(self, email, password, **extra_fields):
25 """
26 Create and save a SuperUser with the given email and password.
27 """
28 extra_fields.setdefault('is_staff', True)
29 extra_fields.setdefault('is_superuser', True)
30 extra_fields.setdefault('is_active', True)
31
32 if extra_fields.get('is_staff') is not True:
33 raise ValueError(_('Superuser must have is_staff=True.'))
34 if extra_fields.get('is_superuser') is not True:
35 raise ValueError(_('Superuser must have is_superuser=True.'))
36 return self.create_user(email, password, **extra_fields)
[end of django/cantusdb_project/users/managers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/django/cantusdb_project/users/managers.py b/django/cantusdb_project/users/managers.py
--- a/django/cantusdb_project/users/managers.py
+++ b/django/cantusdb_project/users/managers.py
@@ -2,7 +2,7 @@
from django.contrib.auth.base_user import BaseUserManager
from django.utils.translation import gettext_lazy as _
-
+from django.contrib.auth.models import Group
class CustomUserManager(BaseUserManager):
"""
@@ -33,4 +33,7 @@
raise ValueError(_('Superuser must have is_staff=True.'))
if extra_fields.get('is_superuser') is not True:
raise ValueError(_('Superuser must have is_superuser=True.'))
- return self.create_user(email, password, **extra_fields)
\ No newline at end of file
+ user = self.create_user(email, password, **extra_fields)
+ pm = Group.objects.get(name='project manager')
+ pm.user_set.add(user)
+ return user
\ No newline at end of file
|
{"golden_diff": "diff --git a/django/cantusdb_project/users/managers.py b/django/cantusdb_project/users/managers.py\n--- a/django/cantusdb_project/users/managers.py\n+++ b/django/cantusdb_project/users/managers.py\n@@ -2,7 +2,7 @@\n \n from django.contrib.auth.base_user import BaseUserManager\n from django.utils.translation import gettext_lazy as _\n-\n+from django.contrib.auth.models import Group\n \n class CustomUserManager(BaseUserManager):\n \"\"\"\n@@ -33,4 +33,7 @@\n raise ValueError(_('Superuser must have is_staff=True.'))\n if extra_fields.get('is_superuser') is not True:\n raise ValueError(_('Superuser must have is_superuser=True.'))\n- return self.create_user(email, password, **extra_fields)\n\\ No newline at end of file\n+ user = self.create_user(email, password, **extra_fields)\n+ pm = Group.objects.get(name='project manager') \n+ pm.user_set.add(user)\n+ return user\n\\ No newline at end of file\n", "issue": "Chant-edit page doesn't load for Admin user\nThe chant-edit page (e.g., http://127.0.0.1:3122/edit-volpiano/702611?pk=705019) takes forever to load for Admin user. \r\nI was logged in with my Admin account (i.e., superuser). Ideally, this should give me power to access and change anything. \r\n\r\nI also check with my project manager account and it loaded fine.\n", "before_files": [{"content": "# https://testdriven.io/blog/django-custom-user-model/#:~:text=The%20default%20User%20model%20in,either%20subclassing%20AbstractUser%20or%20AbstractBaseUser%20.\n\nfrom django.contrib.auth.base_user import BaseUserManager\nfrom django.utils.translation import gettext_lazy as _\n\n\nclass CustomUserManager(BaseUserManager):\n \"\"\"\n Custom user model manager where email is the unique identifiers\n for authentication instead of usernames.\n \"\"\"\n def create_user(self, email, password, **extra_fields):\n \"\"\"\n Create and save a User with the given email and password.\n \"\"\"\n if not email:\n raise ValueError(_('The Email must be set'))\n email = self.normalize_email(email)\n user = self.model(email=email, **extra_fields)\n user.set_password(password)\n user.save()\n return user\n\n def create_superuser(self, email, password, **extra_fields):\n \"\"\"\n Create and save a SuperUser with the given email and password.\n \"\"\"\n extra_fields.setdefault('is_staff', True)\n extra_fields.setdefault('is_superuser', True)\n extra_fields.setdefault('is_active', True)\n\n if extra_fields.get('is_staff') is not True:\n raise ValueError(_('Superuser must have is_staff=True.'))\n if extra_fields.get('is_superuser') is not True:\n raise ValueError(_('Superuser must have is_superuser=True.'))\n return self.create_user(email, password, **extra_fields)", "path": "django/cantusdb_project/users/managers.py"}]}
| 1,040 | 229 |
gh_patches_debug_41565
|
rasdani/github-patches
|
git_diff
|
mitmproxy__mitmproxy-2259
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Sticky cookies are improperly formatted.
##### Steps to reproduce the problem:
1. Go to http://www.html-kit.com/tools/cookietester/
2. Click 'Set Test Cookie'
3. Observe that one cookie is sent to the server.
4. Remove the cookie.
5. launch mitmproxy with `mitmproxy -t html-kit\.com` and tell your browser to use it as a proxy
6. Reload the page.
7. Click 'Set Test Cookie'
8. Observe that two 'cookies' are sent to the server.
##### Any other comments? What have you tried so far?
There appears to be a comma in the output of mitmproxy, even though it is surrounded by quotes. It's possible, then that this is a parsing fail on the tool's end caused by a difference in what's sent back for the format of the date. Still, should it really be changing that?
##### System information
Arch Linux, freshly updated.
Mitmproxy version: 2.0.1 (release version)
Python version: 3.6.0
Platform: Linux-4.10.6-1-ARCH-x86_64-with-glibc2.3.4
SSL version: OpenSSL 1.0.2k 26 Jan 2017
</issue>
<code>
[start of mitmproxy/addons/stickycookie.py]
1 import collections
2 from http import cookiejar
3
4 from mitmproxy.net.http import cookies
5
6 from mitmproxy import exceptions
7 from mitmproxy import flowfilter
8 from mitmproxy import ctx
9
10
11 def ckey(attrs, f):
12 """
13 Returns a (domain, port, path) tuple.
14 """
15 domain = f.request.host
16 path = "/"
17 if "domain" in attrs:
18 domain = attrs["domain"]
19 if "path" in attrs:
20 path = attrs["path"]
21 return (domain, f.request.port, path)
22
23
24 def domain_match(a, b):
25 if cookiejar.domain_match(a, b):
26 return True
27 elif cookiejar.domain_match(a, b.strip(".")):
28 return True
29 return False
30
31
32 class StickyCookie:
33 def __init__(self):
34 self.jar = collections.defaultdict(dict)
35 self.flt = None
36
37 def configure(self, updated):
38 if "stickycookie" in updated:
39 if ctx.options.stickycookie:
40 flt = flowfilter.parse(ctx.options.stickycookie)
41 if not flt:
42 raise exceptions.OptionsError(
43 "stickycookie: invalid filter expression: %s" % ctx.options.stickycookie
44 )
45 self.flt = flt
46 else:
47 self.flt = None
48
49 def response(self, flow):
50 if self.flt:
51 for name, (value, attrs) in flow.response.cookies.items(multi=True):
52 # FIXME: We now know that Cookie.py screws up some cookies with
53 # valid RFC 822/1123 datetime specifications for expiry. Sigh.
54 dom_port_path = ckey(attrs, flow)
55
56 if domain_match(flow.request.host, dom_port_path[0]):
57 if cookies.is_expired(attrs):
58 # Remove the cookie from jar
59 self.jar[dom_port_path].pop(name, None)
60
61 # If all cookies of a dom_port_path have been removed
62 # then remove it from the jar itself
63 if not self.jar[dom_port_path]:
64 self.jar.pop(dom_port_path, None)
65 else:
66 b = attrs.copy()
67 b.insert(0, name, value)
68 self.jar[dom_port_path][name] = b
69
70 def request(self, flow):
71 if self.flt:
72 l = []
73 if flowfilter.match(self.flt, flow):
74 for domain, port, path in self.jar.keys():
75 match = [
76 domain_match(flow.request.host, domain),
77 flow.request.port == port,
78 flow.request.path.startswith(path)
79 ]
80 if all(match):
81 c = self.jar[(domain, port, path)]
82 l.extend([cookies.format_cookie_header(c[name].items(multi=True)) for name in c.keys()])
83 if l:
84 # FIXME: we need to formalise this...
85 flow.request.stickycookie = True
86 flow.request.headers["cookie"] = "; ".join(l)
87
[end of mitmproxy/addons/stickycookie.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mitmproxy/addons/stickycookie.py b/mitmproxy/addons/stickycookie.py
--- a/mitmproxy/addons/stickycookie.py
+++ b/mitmproxy/addons/stickycookie.py
@@ -1,14 +1,14 @@
import collections
from http import cookiejar
+from typing import List, Tuple, Dict, Optional # noqa
+from mitmproxy import http, flowfilter, ctx, exceptions
from mitmproxy.net.http import cookies
-from mitmproxy import exceptions
-from mitmproxy import flowfilter
-from mitmproxy import ctx
+TOrigin = Tuple[str, int, str]
-def ckey(attrs, f):
+def ckey(attrs: Dict[str, str], f: http.HTTPFlow) -> TOrigin:
"""
Returns a (domain, port, path) tuple.
"""
@@ -21,18 +21,18 @@
return (domain, f.request.port, path)
-def domain_match(a, b):
- if cookiejar.domain_match(a, b):
+def domain_match(a: str, b: str) -> bool:
+ if cookiejar.domain_match(a, b): # type: ignore
return True
- elif cookiejar.domain_match(a, b.strip(".")):
+ elif cookiejar.domain_match(a, b.strip(".")): # type: ignore
return True
return False
class StickyCookie:
def __init__(self):
- self.jar = collections.defaultdict(dict)
- self.flt = None
+ self.jar = collections.defaultdict(dict) # type: Dict[TOrigin, Dict[str, str]]
+ self.flt = None # type: Optional[flowfilter.TFilter]
def configure(self, updated):
if "stickycookie" in updated:
@@ -46,7 +46,7 @@
else:
self.flt = None
- def response(self, flow):
+ def response(self, flow: http.HTTPFlow):
if self.flt:
for name, (value, attrs) in flow.response.cookies.items(multi=True):
# FIXME: We now know that Cookie.py screws up some cookies with
@@ -63,24 +63,21 @@
if not self.jar[dom_port_path]:
self.jar.pop(dom_port_path, None)
else:
- b = attrs.copy()
- b.insert(0, name, value)
- self.jar[dom_port_path][name] = b
+ self.jar[dom_port_path][name] = value
- def request(self, flow):
+ def request(self, flow: http.HTTPFlow):
if self.flt:
- l = []
+ cookie_list = [] # type: List[Tuple[str,str]]
if flowfilter.match(self.flt, flow):
- for domain, port, path in self.jar.keys():
+ for (domain, port, path), c in self.jar.items():
match = [
domain_match(flow.request.host, domain),
flow.request.port == port,
flow.request.path.startswith(path)
]
if all(match):
- c = self.jar[(domain, port, path)]
- l.extend([cookies.format_cookie_header(c[name].items(multi=True)) for name in c.keys()])
- if l:
+ cookie_list.extend(c.items())
+ if cookie_list:
# FIXME: we need to formalise this...
- flow.request.stickycookie = True
- flow.request.headers["cookie"] = "; ".join(l)
+ flow.metadata["stickycookie"] = True
+ flow.request.headers["cookie"] = cookies.format_cookie_header(cookie_list)
|
{"golden_diff": "diff --git a/mitmproxy/addons/stickycookie.py b/mitmproxy/addons/stickycookie.py\n--- a/mitmproxy/addons/stickycookie.py\n+++ b/mitmproxy/addons/stickycookie.py\n@@ -1,14 +1,14 @@\n import collections\n from http import cookiejar\n+from typing import List, Tuple, Dict, Optional # noqa\n \n+from mitmproxy import http, flowfilter, ctx, exceptions\n from mitmproxy.net.http import cookies\n \n-from mitmproxy import exceptions\n-from mitmproxy import flowfilter\n-from mitmproxy import ctx\n+TOrigin = Tuple[str, int, str]\n \n \n-def ckey(attrs, f):\n+def ckey(attrs: Dict[str, str], f: http.HTTPFlow) -> TOrigin:\n \"\"\"\n Returns a (domain, port, path) tuple.\n \"\"\"\n@@ -21,18 +21,18 @@\n return (domain, f.request.port, path)\n \n \n-def domain_match(a, b):\n- if cookiejar.domain_match(a, b):\n+def domain_match(a: str, b: str) -> bool:\n+ if cookiejar.domain_match(a, b): # type: ignore\n return True\n- elif cookiejar.domain_match(a, b.strip(\".\")):\n+ elif cookiejar.domain_match(a, b.strip(\".\")): # type: ignore\n return True\n return False\n \n \n class StickyCookie:\n def __init__(self):\n- self.jar = collections.defaultdict(dict)\n- self.flt = None\n+ self.jar = collections.defaultdict(dict) # type: Dict[TOrigin, Dict[str, str]]\n+ self.flt = None # type: Optional[flowfilter.TFilter]\n \n def configure(self, updated):\n if \"stickycookie\" in updated:\n@@ -46,7 +46,7 @@\n else:\n self.flt = None\n \n- def response(self, flow):\n+ def response(self, flow: http.HTTPFlow):\n if self.flt:\n for name, (value, attrs) in flow.response.cookies.items(multi=True):\n # FIXME: We now know that Cookie.py screws up some cookies with\n@@ -63,24 +63,21 @@\n if not self.jar[dom_port_path]:\n self.jar.pop(dom_port_path, None)\n else:\n- b = attrs.copy()\n- b.insert(0, name, value)\n- self.jar[dom_port_path][name] = b\n+ self.jar[dom_port_path][name] = value\n \n- def request(self, flow):\n+ def request(self, flow: http.HTTPFlow):\n if self.flt:\n- l = []\n+ cookie_list = [] # type: List[Tuple[str,str]]\n if flowfilter.match(self.flt, flow):\n- for domain, port, path in self.jar.keys():\n+ for (domain, port, path), c in self.jar.items():\n match = [\n domain_match(flow.request.host, domain),\n flow.request.port == port,\n flow.request.path.startswith(path)\n ]\n if all(match):\n- c = self.jar[(domain, port, path)]\n- l.extend([cookies.format_cookie_header(c[name].items(multi=True)) for name in c.keys()])\n- if l:\n+ cookie_list.extend(c.items())\n+ if cookie_list:\n # FIXME: we need to formalise this...\n- flow.request.stickycookie = True\n- flow.request.headers[\"cookie\"] = \"; \".join(l)\n+ flow.metadata[\"stickycookie\"] = True\n+ flow.request.headers[\"cookie\"] = cookies.format_cookie_header(cookie_list)\n", "issue": "Sticky cookies are improperly formatted.\n##### Steps to reproduce the problem:\r\n\r\n1. Go to http://www.html-kit.com/tools/cookietester/\r\n2. Click 'Set Test Cookie'\r\n3. Observe that one cookie is sent to the server.\r\n4. Remove the cookie.\r\n5. launch mitmproxy with `mitmproxy -t html-kit\\.com` and tell your browser to use it as a proxy\r\n6. Reload the page.\r\n7. Click 'Set Test Cookie'\r\n8. Observe that two 'cookies' are sent to the server.\r\n\r\n##### Any other comments? What have you tried so far?\r\nThere appears to be a comma in the output of mitmproxy, even though it is surrounded by quotes. It's possible, then that this is a parsing fail on the tool's end caused by a difference in what's sent back for the format of the date. Still, should it really be changing that?\r\n\r\n##### System information\r\nArch Linux, freshly updated.\r\n\r\nMitmproxy version: 2.0.1 (release version) \r\nPython version: 3.6.0\r\nPlatform: Linux-4.10.6-1-ARCH-x86_64-with-glibc2.3.4\r\nSSL version: OpenSSL 1.0.2k 26 Jan 2017\r\n\n", "before_files": [{"content": "import collections\nfrom http import cookiejar\n\nfrom mitmproxy.net.http import cookies\n\nfrom mitmproxy import exceptions\nfrom mitmproxy import flowfilter\nfrom mitmproxy import ctx\n\n\ndef ckey(attrs, f):\n \"\"\"\n Returns a (domain, port, path) tuple.\n \"\"\"\n domain = f.request.host\n path = \"/\"\n if \"domain\" in attrs:\n domain = attrs[\"domain\"]\n if \"path\" in attrs:\n path = attrs[\"path\"]\n return (domain, f.request.port, path)\n\n\ndef domain_match(a, b):\n if cookiejar.domain_match(a, b):\n return True\n elif cookiejar.domain_match(a, b.strip(\".\")):\n return True\n return False\n\n\nclass StickyCookie:\n def __init__(self):\n self.jar = collections.defaultdict(dict)\n self.flt = None\n\n def configure(self, updated):\n if \"stickycookie\" in updated:\n if ctx.options.stickycookie:\n flt = flowfilter.parse(ctx.options.stickycookie)\n if not flt:\n raise exceptions.OptionsError(\n \"stickycookie: invalid filter expression: %s\" % ctx.options.stickycookie\n )\n self.flt = flt\n else:\n self.flt = None\n\n def response(self, flow):\n if self.flt:\n for name, (value, attrs) in flow.response.cookies.items(multi=True):\n # FIXME: We now know that Cookie.py screws up some cookies with\n # valid RFC 822/1123 datetime specifications for expiry. Sigh.\n dom_port_path = ckey(attrs, flow)\n\n if domain_match(flow.request.host, dom_port_path[0]):\n if cookies.is_expired(attrs):\n # Remove the cookie from jar\n self.jar[dom_port_path].pop(name, None)\n\n # If all cookies of a dom_port_path have been removed\n # then remove it from the jar itself\n if not self.jar[dom_port_path]:\n self.jar.pop(dom_port_path, None)\n else:\n b = attrs.copy()\n b.insert(0, name, value)\n self.jar[dom_port_path][name] = b\n\n def request(self, flow):\n if self.flt:\n l = []\n if flowfilter.match(self.flt, flow):\n for domain, port, path in self.jar.keys():\n match = [\n domain_match(flow.request.host, domain),\n flow.request.port == port,\n flow.request.path.startswith(path)\n ]\n if all(match):\n c = self.jar[(domain, port, path)]\n l.extend([cookies.format_cookie_header(c[name].items(multi=True)) for name in c.keys()])\n if l:\n # FIXME: we need to formalise this...\n flow.request.stickycookie = True\n flow.request.headers[\"cookie\"] = \"; \".join(l)\n", "path": "mitmproxy/addons/stickycookie.py"}]}
| 1,613 | 797 |
gh_patches_debug_19676
|
rasdani/github-patches
|
git_diff
|
holoviz__holoviews-1845
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Table broken with bokeh 0.12.7
When displaying a Table with bokeh 0.12.7 I currently see the following error:
```
Javascript error adding output!
Error: SlickGrid's 'enableColumnReorder = true' option requires jquery-ui.sortable module to be loaded
See your browser Javascript console for more details.
```
</issue>
<code>
[start of holoviews/plotting/bokeh/tabular.py]
1 from bokeh.models.widgets import DataTable, TableColumn
2
3 import param
4
5 import numpy as np
6 from ...core import Dataset
7 from ...element import ItemTable
8 from ..plot import GenericElementPlot
9 from .plot import BokehPlot
10
11 class TablePlot(BokehPlot, GenericElementPlot):
12
13 height = param.Number(default=None)
14
15 width = param.Number(default=400)
16
17 style_opts = ['row_headers', 'selectable', 'editable',
18 'sortable', 'fit_columns', 'width', 'height']
19
20 finalize_hooks = param.HookList(default=[], doc="""
21 Optional list of hooks called when finalizing a column.
22 The hook is passed the plot object and the displayed
23 object, and other plotting handles can be accessed via plot.handles.""")
24
25 _update_handles = ['source', 'glyph']
26
27 def __init__(self, element, plot=None, **params):
28 super(TablePlot, self).__init__(element, **params)
29 self.handles = {} if plot is None else self.handles['plot']
30 element_ids = self.hmap.traverse(lambda x: id(x), [Dataset, ItemTable])
31 self.static = len(set(element_ids)) == 1 and len(self.keys) == len(self.hmap)
32 self.callbacks = [] # Callback support on tables not implemented
33
34
35 def _execute_hooks(self, element):
36 """
37 Executes finalize hooks
38 """
39 for hook in self.finalize_hooks:
40 try:
41 hook(self, element)
42 except Exception as e:
43 self.warning("Plotting hook %r could not be applied:\n\n %s" % (hook, e))
44
45
46 def get_data(self, element, ranges=None, empty=False):
47 dims = element.dimensions()
48 data = {d: np.array([]) if empty else element.dimension_values(d)
49 for d in dims}
50 mapping = {d.name: d.name for d in dims}
51 data = {d.name: values if values.dtype.kind in "if" else list(map(d.pprint_value, values))
52 for d, values in data.items()}
53 return data, mapping
54
55
56 def initialize_plot(self, ranges=None, plot=None, plots=None, source=None):
57 """
58 Initializes a new plot object with the last available frame.
59 """
60 # Get element key and ranges for frame
61 element = self.hmap.last
62 key = self.keys[-1]
63 self.current_frame = element
64 self.current_key = key
65
66 data, _ = self.get_data(element, ranges)
67 if source is None:
68 source = self._init_datasource(data)
69 self.handles['source'] = source
70
71 dims = element.dimensions()
72 columns = [TableColumn(field=d.name, title=d.pprint_label) for d in dims]
73 properties = self.lookup_options(element, 'style')[self.cyclic_index]
74 table = DataTable(source=source, columns=columns, height=self.height,
75 width=self.width, **properties)
76 self.handles['plot'] = table
77 self.handles['glyph_renderer'] = table
78 self._execute_hooks(element)
79 self.drawn = True
80
81 return table
82
83
84 @property
85 def current_handles(self):
86 """
87 Returns a list of the plot objects to update.
88 """
89 handles = []
90 if self.static and not self.dynamic:
91 return handles
92
93
94 element = self.current_frame
95 previous_id = self.handles.get('previous_id', None)
96 current_id = None if self.current_frame is None else element._plot_id
97 for handle in self._update_handles:
98 if (handle == 'source' and self.dynamic and current_id == previous_id):
99 continue
100 if handle in self.handles:
101 handles.append(self.handles[handle])
102
103 # Cache frame object id to skip updating if unchanged
104 if self.dynamic:
105 self.handles['previous_id'] = current_id
106
107 return handles
108
109
110 def update_frame(self, key, ranges=None, plot=None):
111 """
112 Updates an existing plot with data corresponding
113 to the key.
114 """
115 element = self._get_frame(key)
116 source = self.handles['source']
117 data, _ = self.get_data(element, ranges)
118 self._update_datasource(source, data)
119
[end of holoviews/plotting/bokeh/tabular.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/holoviews/plotting/bokeh/tabular.py b/holoviews/plotting/bokeh/tabular.py
--- a/holoviews/plotting/bokeh/tabular.py
+++ b/holoviews/plotting/bokeh/tabular.py
@@ -7,6 +7,8 @@
from ...element import ItemTable
from ..plot import GenericElementPlot
from .plot import BokehPlot
+from .util import bokeh_version
+
class TablePlot(BokehPlot, GenericElementPlot):
@@ -71,6 +73,8 @@
dims = element.dimensions()
columns = [TableColumn(field=d.name, title=d.pprint_label) for d in dims]
properties = self.lookup_options(element, 'style')[self.cyclic_index]
+ if bokeh_version > '0.12.7':
+ properties['reorderable'] = False
table = DataTable(source=source, columns=columns, height=self.height,
width=self.width, **properties)
self.handles['plot'] = table
|
{"golden_diff": "diff --git a/holoviews/plotting/bokeh/tabular.py b/holoviews/plotting/bokeh/tabular.py\n--- a/holoviews/plotting/bokeh/tabular.py\n+++ b/holoviews/plotting/bokeh/tabular.py\n@@ -7,6 +7,8 @@\n from ...element import ItemTable\n from ..plot import GenericElementPlot\n from .plot import BokehPlot\n+from .util import bokeh_version\n+\n \n class TablePlot(BokehPlot, GenericElementPlot):\n \n@@ -71,6 +73,8 @@\n dims = element.dimensions()\n columns = [TableColumn(field=d.name, title=d.pprint_label) for d in dims]\n properties = self.lookup_options(element, 'style')[self.cyclic_index]\n+ if bokeh_version > '0.12.7':\n+ properties['reorderable'] = False\n table = DataTable(source=source, columns=columns, height=self.height,\n width=self.width, **properties)\n self.handles['plot'] = table\n", "issue": "Table broken with bokeh 0.12.7\nWhen displaying a Table with bokeh 0.12.7 I currently see the following error:\r\n\r\n```\r\nJavascript error adding output!\r\nError: SlickGrid's 'enableColumnReorder = true' option requires jquery-ui.sortable module to be loaded\r\nSee your browser Javascript console for more details.\r\n```\n", "before_files": [{"content": "from bokeh.models.widgets import DataTable, TableColumn\n\nimport param\n\nimport numpy as np\nfrom ...core import Dataset\nfrom ...element import ItemTable\nfrom ..plot import GenericElementPlot\nfrom .plot import BokehPlot\n\nclass TablePlot(BokehPlot, GenericElementPlot):\n\n height = param.Number(default=None)\n\n width = param.Number(default=400)\n\n style_opts = ['row_headers', 'selectable', 'editable',\n 'sortable', 'fit_columns', 'width', 'height']\n\n finalize_hooks = param.HookList(default=[], doc=\"\"\"\n Optional list of hooks called when finalizing a column.\n The hook is passed the plot object and the displayed\n object, and other plotting handles can be accessed via plot.handles.\"\"\")\n\n _update_handles = ['source', 'glyph']\n\n def __init__(self, element, plot=None, **params):\n super(TablePlot, self).__init__(element, **params)\n self.handles = {} if plot is None else self.handles['plot']\n element_ids = self.hmap.traverse(lambda x: id(x), [Dataset, ItemTable])\n self.static = len(set(element_ids)) == 1 and len(self.keys) == len(self.hmap)\n self.callbacks = [] # Callback support on tables not implemented\n\n\n def _execute_hooks(self, element):\n \"\"\"\n Executes finalize hooks\n \"\"\"\n for hook in self.finalize_hooks:\n try:\n hook(self, element)\n except Exception as e:\n self.warning(\"Plotting hook %r could not be applied:\\n\\n %s\" % (hook, e))\n\n\n def get_data(self, element, ranges=None, empty=False):\n dims = element.dimensions()\n data = {d: np.array([]) if empty else element.dimension_values(d)\n for d in dims}\n mapping = {d.name: d.name for d in dims}\n data = {d.name: values if values.dtype.kind in \"if\" else list(map(d.pprint_value, values))\n for d, values in data.items()}\n return data, mapping\n\n\n def initialize_plot(self, ranges=None, plot=None, plots=None, source=None):\n \"\"\"\n Initializes a new plot object with the last available frame.\n \"\"\"\n # Get element key and ranges for frame\n element = self.hmap.last\n key = self.keys[-1]\n self.current_frame = element\n self.current_key = key\n\n data, _ = self.get_data(element, ranges)\n if source is None:\n source = self._init_datasource(data)\n self.handles['source'] = source\n\n dims = element.dimensions()\n columns = [TableColumn(field=d.name, title=d.pprint_label) for d in dims]\n properties = self.lookup_options(element, 'style')[self.cyclic_index]\n table = DataTable(source=source, columns=columns, height=self.height,\n width=self.width, **properties)\n self.handles['plot'] = table\n self.handles['glyph_renderer'] = table\n self._execute_hooks(element)\n self.drawn = True\n\n return table\n\n\n @property\n def current_handles(self):\n \"\"\"\n Returns a list of the plot objects to update.\n \"\"\"\n handles = []\n if self.static and not self.dynamic:\n return handles\n\n\n element = self.current_frame\n previous_id = self.handles.get('previous_id', None)\n current_id = None if self.current_frame is None else element._plot_id\n for handle in self._update_handles:\n if (handle == 'source' and self.dynamic and current_id == previous_id):\n continue\n if handle in self.handles:\n handles.append(self.handles[handle])\n\n # Cache frame object id to skip updating if unchanged\n if self.dynamic:\n self.handles['previous_id'] = current_id\n\n return handles\n\n\n def update_frame(self, key, ranges=None, plot=None):\n \"\"\"\n Updates an existing plot with data corresponding\n to the key.\n \"\"\"\n element = self._get_frame(key)\n source = self.handles['source']\n data, _ = self.get_data(element, ranges)\n self._update_datasource(source, data)\n", "path": "holoviews/plotting/bokeh/tabular.py"}]}
| 1,793 | 240 |
gh_patches_debug_20905
|
rasdani/github-patches
|
git_diff
|
nvaccess__nvda-11972
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Dev docs: globalVars.appDir is not defined when attempting to build docs with Sphinx
Hi,
Related to #11970 and actually blocks it:
### Steps to reproduce:
When trying to build dev docs using "scons devDocs":
1. Run scons devDocs.
2. Once Sphinx is instlaled and ready, Sphinx will try to build dev docs for the source code.
### Actual behavior:
A traceback shows up, ending with:
AttributeError: module 'globalVars' has no attribute 'appDir'
### Expected behavior:
No errors with the dev docs building completing.
### System configuration
#### NVDA installed/portable/running from source:
Source
#### NVDA version:
Alpha-21561,7e5ffde2391c
#### Windows version:
Windows 10 Version 20H2 (build 19042.685)
#### Name and version of other software in use when reproducing the issue:
Python 3.7.9
#### Other information about your system:
N/A
### Other questions
#### Does the issue still occur after restarting your computer?
Yes
#### Have you tried any other versions of NVDA? If so, please report their behaviors.
Not applicable
#### If addons are disabled, is your problem still occurring?
Not applicable
#### Did you try to run the COM registry fixing tool in NVDA menu / tools?
Not applicable
### Cause:
This is caused by config file error, specifically when a mock config.conf instance is created. Prior to this, importing config module fails because globalVars.appDir is not defined by the time scons devDocs is run.
### Solution:
one solution is to define globalVars.appDir to point to the source directory.
Thanks.
</issue>
<code>
[start of devDocs/conf.py]
1 # A part of NonVisual Desktop Access (NVDA)
2 # Copyright (C) 2019 NV Access Limited, Leonard de Ruijter
3 # This file is covered by the GNU General Public License.
4 # See the file COPYING for more details.
5
6 # Configuration file for the Sphinx documentation builder.
7
8 # -- Path setup --------------------------------------------------------------
9
10 import os
11 import sys
12 sys.path.insert(0, os.path.abspath('../source'))
13 import sourceEnv # noqa: F401, E402
14
15 # Initialize languageHandler so that sphinx is able to deal with translatable strings.
16 import languageHandler # noqa: E402
17 languageHandler.setLanguage("en")
18
19 # Initialize globalvars.appArgs to something sensible.
20 import globalVars # noqa: E402
21
22
23 class AppArgs:
24 # Set an empty comnfig path
25 # This is never used as we don't initialize config, but some modules expect this to be set.
26 configPath = ""
27 secure = False
28 disableAddons = True
29 launcher = False
30
31
32 globalVars.appArgs = AppArgs()
33
34 # Import NVDA's versionInfo module.
35 import versionInfo # noqa: E402
36 # Set a suitable updateVersionType for the updateCheck module to be imported
37 versionInfo.updateVersionType = "stable"
38
39 # -- Project information -----------------------------------------------------
40
41 project = versionInfo.name
42 copyright = versionInfo.copyright
43 author = versionInfo.publisher
44
45 # The major project version
46 version = versionInfo.formatVersionForGUI(
47 versionInfo.version_year,
48 versionInfo.version_major,
49 versionInfo.version_minor
50 )
51
52 # The full version, including alpha/beta/rc tags
53 release = versionInfo.version
54
55 # -- General configuration ---------------------------------------------------
56
57 default_role = 'py:obj'
58
59 # Add any Sphinx extension module names here, as strings. They can be
60 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
61 # ones.
62 extensions = [
63 'sphinx.ext.autodoc',
64 ]
65
66 # Add any paths that contain templates here, relative to this directory.
67 templates_path = ['_templates']
68
69 # List of patterns, relative to source directory, that match files and
70 # directories to ignore when looking for source files.
71 # This pattern also affects html_static_path and html_extra_path.
72 exclude_patterns = [
73 "_build"
74 ]
75
76
77 # -- Options for HTML output -------------------------------------------------
78
79 # The theme to use for HTML and HTML Help pages.
80
81 html_theme = "sphinx_rtd_theme"
82
83 # Add any paths that contain custom static files (such as style sheets) here,
84 # relative to this directory. They are copied after the builtin static files,
85 # so a file named "default.css" will overwrite the builtin "default.css".
86 html_static_path = ['_static']
87
88 # -- Extension configuration -------------------------------------------------
89
90 # sphinx.ext.autodoc configuration
91
92 # Both the class’ and the __init__ method’s docstring are concatenated and inserted.
93 autoclass_content = "both"
94 autodoc_member_order = 'bysource'
95 autodoc_mock_imports = [
96 "louis", # Not our project
97 ]
98
99 # Perform some manual mocking of specific objects.
100 # autodoc can only mock modules, not objects.
101 from sphinx.ext.autodoc.mock import _make_subclass # noqa: E402
102
103 import config # noqa: E402
104 # Mock an instance of the configuration manager.
105 config.conf = _make_subclass("conf", "config")()
106
[end of devDocs/conf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/devDocs/conf.py b/devDocs/conf.py
--- a/devDocs/conf.py
+++ b/devDocs/conf.py
@@ -1,5 +1,5 @@
# A part of NonVisual Desktop Access (NVDA)
-# Copyright (C) 2019 NV Access Limited, Leonard de Ruijter
+# Copyright (C) 2019-2020 NV Access Limited, Leonard de Ruijter, Joseph Lee
# This file is covered by the GNU General Public License.
# See the file COPYING for more details.
@@ -16,7 +16,7 @@
import languageHandler # noqa: E402
languageHandler.setLanguage("en")
-# Initialize globalvars.appArgs to something sensible.
+# Initialize globalVars.appArgs to something sensible.
import globalVars # noqa: E402
@@ -30,6 +30,11 @@
globalVars.appArgs = AppArgs()
+# #11971: NVDA is not running, therefore app dir is undefined.
+# Therefore tell NVDA that apt source directory is app dir.
+appDir = os.path.join("..", "source")
+globalVars.appDir = os.path.abspath(appDir)
+
# Import NVDA's versionInfo module.
import versionInfo # noqa: E402
|
{"golden_diff": "diff --git a/devDocs/conf.py b/devDocs/conf.py\n--- a/devDocs/conf.py\n+++ b/devDocs/conf.py\n@@ -1,5 +1,5 @@\n # A part of NonVisual Desktop Access (NVDA)\n-# Copyright (C) 2019 NV Access Limited, Leonard de Ruijter\n+# Copyright (C) 2019-2020 NV Access Limited, Leonard de Ruijter, Joseph Lee\n # This file is covered by the GNU General Public License.\n # See the file COPYING for more details.\n \n@@ -16,7 +16,7 @@\n import languageHandler # noqa: E402\n languageHandler.setLanguage(\"en\")\n \n-# Initialize globalvars.appArgs to something sensible.\n+# Initialize globalVars.appArgs to something sensible.\n import globalVars # noqa: E402\n \n \n@@ -30,6 +30,11 @@\n \n \n globalVars.appArgs = AppArgs()\n+# #11971: NVDA is not running, therefore app dir is undefined.\n+# Therefore tell NVDA that apt source directory is app dir.\n+appDir = os.path.join(\"..\", \"source\")\n+globalVars.appDir = os.path.abspath(appDir)\n+\n \n # Import NVDA's versionInfo module.\n import versionInfo # noqa: E402\n", "issue": "Dev docs: globalVars.appDir is not defined when attempting to build docs with Sphinx\nHi,\r\nRelated to #11970 and actually blocks it:\r\n\r\n### Steps to reproduce:\r\nWhen trying to build dev docs using \"scons devDocs\":\r\n\r\n1. Run scons devDocs.\r\n2. Once Sphinx is instlaled and ready, Sphinx will try to build dev docs for the source code.\r\n\r\n### Actual behavior:\r\nA traceback shows up, ending with:\r\nAttributeError: module 'globalVars' has no attribute 'appDir'\r\n\r\n### Expected behavior:\r\nNo errors with the dev docs building completing.\r\n\r\n### System configuration\r\n#### NVDA installed/portable/running from source:\r\nSource\r\n\r\n#### NVDA version:\r\nAlpha-21561,7e5ffde2391c\r\n\r\n#### Windows version:\r\nWindows 10 Version 20H2 (build 19042.685)\r\n\r\n#### Name and version of other software in use when reproducing the issue:\r\nPython 3.7.9\r\n\r\n#### Other information about your system:\r\nN/A\r\n\r\n### Other questions\r\n#### Does the issue still occur after restarting your computer?\r\nYes\r\n\r\n#### Have you tried any other versions of NVDA? If so, please report their behaviors.\r\nNot applicable\r\n\r\n#### If addons are disabled, is your problem still occurring?\r\nNot applicable\r\n\r\n#### Did you try to run the COM registry fixing tool in NVDA menu / tools?\r\nNot applicable\r\n\r\n### Cause:\r\nThis is caused by config file error, specifically when a mock config.conf instance is created. Prior to this, importing config module fails because globalVars.appDir is not defined by the time scons devDocs is run.\r\n\r\n### Solution:\r\none solution is to define globalVars.appDir to point to the source directory.\r\n\r\nThanks.\n", "before_files": [{"content": "# A part of NonVisual Desktop Access (NVDA)\n# Copyright (C) 2019 NV Access Limited, Leonard de Ruijter\n# This file is covered by the GNU General Public License.\n# See the file COPYING for more details.\n\n# Configuration file for the Sphinx documentation builder.\n\n# -- Path setup --------------------------------------------------------------\n\nimport os\nimport sys\nsys.path.insert(0, os.path.abspath('../source'))\nimport sourceEnv # noqa: F401, E402\n\n# Initialize languageHandler so that sphinx is able to deal with translatable strings.\nimport languageHandler # noqa: E402\nlanguageHandler.setLanguage(\"en\")\n\n# Initialize globalvars.appArgs to something sensible.\nimport globalVars # noqa: E402\n\n\nclass AppArgs:\n\t# Set an empty comnfig path\n\t# This is never used as we don't initialize config, but some modules expect this to be set.\n\tconfigPath = \"\"\n\tsecure = False\n\tdisableAddons = True\n\tlauncher = False\n\n\nglobalVars.appArgs = AppArgs()\n\n# Import NVDA's versionInfo module.\nimport versionInfo # noqa: E402\n# Set a suitable updateVersionType for the updateCheck module to be imported\nversionInfo.updateVersionType = \"stable\"\n\n# -- Project information -----------------------------------------------------\n\nproject = versionInfo.name\ncopyright = versionInfo.copyright\nauthor = versionInfo.publisher\n\n# The major project version\nversion = versionInfo.formatVersionForGUI(\n\tversionInfo.version_year,\n\tversionInfo.version_major,\n\tversionInfo.version_minor\n)\n\n# The full version, including alpha/beta/rc tags\nrelease = versionInfo.version\n\n# -- General configuration ---------------------------------------------------\n\ndefault_role = 'py:obj'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n\t'sphinx.ext.autodoc',\n]\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This pattern also affects html_static_path and html_extra_path.\nexclude_patterns = [\n\t\"_build\"\n]\n\n\n# -- Options for HTML output -------------------------------------------------\n\n# The theme to use for HTML and HTML Help pages.\n\nhtml_theme = \"sphinx_rtd_theme\"\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = ['_static']\n\n# -- Extension configuration -------------------------------------------------\n\n# sphinx.ext.autodoc configuration\n\n# Both the class\u2019 and the __init__ method\u2019s docstring are concatenated and inserted.\nautoclass_content = \"both\"\nautodoc_member_order = 'bysource'\nautodoc_mock_imports = [\n\t\"louis\", # Not our project\n]\n\n# Perform some manual mocking of specific objects.\n# autodoc can only mock modules, not objects.\nfrom sphinx.ext.autodoc.mock import _make_subclass # noqa: E402\n\nimport config # noqa: E402\n# Mock an instance of the configuration manager.\nconfig.conf = _make_subclass(\"conf\", \"config\")()\n", "path": "devDocs/conf.py"}]}
| 1,864 | 291 |
gh_patches_debug_27466
|
rasdani/github-patches
|
git_diff
|
vyperlang__vyper-543
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Question] Attack Vector described in Vipercoin's `approve` annotation
In [L89 of `vipercoin.v.py`](https://github.com/ethereum/viper/blob/master/examples/tokens/vipercoin.v.py#L89), the `approve` method has an annotation that begins like this
>To prevent attack vectors like the one described here and discussed here,
I don't see any description of the attack vectors described, perhaps there should be an external link here? Point me in the right direction and I can make the PR for it. :)
Thanks!
</issue>
<code>
[start of examples/tokens/vipercoin.v.py]
1 # Viper Port of MyToken
2 # THIS CONTRACT HAS NOT BEEN AUDITED!
3 # ERC20 details at:
4 # https://theethereum.wiki/w/index.php/ERC20_Token_Standard
5 # https://github.com/ethereum/EIPs/blob/master/EIPS/eip-20-token-standard.md
6 # Events of the token.
7 Transfer: __log__({_from: indexed(address), _to: indexed(address), _value: num256})
8 Approval: __log__({_owner: indexed(address), _spender: indexed(address), _value: num256})
9
10
11 # Variables of the token.
12 name: bytes32
13 symbol: bytes32
14 totalSupply: num
15 decimals: num
16 balances: num[address]
17 allowed: num[address][address]
18
19 @public
20 def __init__(_name: bytes32, _symbol: bytes32, _decimals: num, _initialSupply: num):
21
22 self.name = _name
23 self.symbol = _symbol
24 self.decimals = _decimals
25 self.totalSupply = _initialSupply * 10 ** _decimals
26 self.balances[msg.sender] = self.totalSupply
27
28 @public
29 @constant
30 def symbol() -> bytes32:
31
32 return self.symbol
33
34 @public
35 @constant
36 def name() -> bytes32:
37
38 return self.name
39
40
41 # What is the balance of a particular account?
42 @public
43 @constant
44 def balanceOf(_owner: address) -> num256:
45
46 return as_num256(self.balances[_owner])
47
48
49 # Return total supply of token.
50 @public
51 @constant
52 def totalSupply() -> num256:
53
54 return as_num256(self.totalSupply)
55
56
57 # Send `_value` tokens to `_to` from your account
58 @public
59 def transfer(_to: address, _amount: num(num256)) -> bool:
60
61 assert self.balances[msg.sender] >= _amount
62 assert self.balances[_to] + _amount >= self.balances[_to]
63
64 self.balances[msg.sender] -= _amount # Subtract from the sender
65 self.balances[_to] += _amount # Add the same to the recipient
66 log.Transfer(msg.sender, _to, as_num256(_amount)) # log transfer event.
67
68 return True
69
70
71 # Transfer allowed tokens from a specific account to another.
72 @public
73 def transferFrom(_from: address, _to: address, _value: num(num256)) -> bool:
74
75 assert _value <= self.allowed[_from][msg.sender]
76 assert _value <= self.balances[_from]
77
78 self.balances[_from] -= _value # decrease balance of from address.
79 self.allowed[_from][msg.sender] -= _value # decrease allowance.
80 self.balances[_to] += _value # incease balance of to address.
81 log.Transfer(_from, _to, as_num256(_value)) # log transfer event.
82
83 return True
84
85
86 # Allow _spender to withdraw from your account, multiple times, up to the _value amount.
87 # If this function is called again it overwrites the current allowance with _value.
88 #
89 # NOTE: To prevent attack vectors like the one described here and discussed here,
90 # clients SHOULD make sure to create user interfaces in such a way that they
91 # set the allowance first to 0 before setting it to another value for the
92 # same spender. THOUGH The contract itself shouldn't enforce it, to allow
93 # backwards compatilibilty with contracts deployed before.
94 #
95 @public
96 def approve(_spender: address, _amount: num(num256)) -> bool:
97
98 self.allowed[msg.sender][_spender] = _amount
99 log.Approval(msg.sender, _spender, as_num256(_amount))
100
101 return True
102
103
104 # Get the allowance an address has to spend anothers' token.
105 @public
106 def allowance(_owner: address, _spender: address) -> num256:
107
108 return as_num256(self.allowed[_owner][_spender])
109
[end of examples/tokens/vipercoin.v.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/examples/tokens/vipercoin.v.py b/examples/tokens/vipercoin.v.py
--- a/examples/tokens/vipercoin.v.py
+++ b/examples/tokens/vipercoin.v.py
@@ -86,12 +86,15 @@
# Allow _spender to withdraw from your account, multiple times, up to the _value amount.
# If this function is called again it overwrites the current allowance with _value.
#
-# NOTE: To prevent attack vectors like the one described here and discussed here,
-# clients SHOULD make sure to create user interfaces in such a way that they
+# NOTE: We would like to prevent attack vectors like the one described here:
+# https://docs.google.com/document/d/1YLPtQxZu1UAvO9cZ1O2RPXBbT0mooh4DYKjA_jp-RLM/edit#heading=h.m9fhqynw2xvt
+# and discussed here:
+# https://github.com/ethereum/EIPs/issues/20#issuecomment-263524729
+#
+# Clients SHOULD make sure to create user interfaces in such a way that they
# set the allowance first to 0 before setting it to another value for the
# same spender. THOUGH The contract itself shouldn't enforce it, to allow
# backwards compatilibilty with contracts deployed before.
-#
@public
def approve(_spender: address, _amount: num(num256)) -> bool:
@@ -101,7 +104,7 @@
return True
-# Get the allowance an address has to spend anothers' token.
+# Get the allowance an address has to spend another's token.
@public
def allowance(_owner: address, _spender: address) -> num256:
|
{"golden_diff": "diff --git a/examples/tokens/vipercoin.v.py b/examples/tokens/vipercoin.v.py\n--- a/examples/tokens/vipercoin.v.py\n+++ b/examples/tokens/vipercoin.v.py\n@@ -86,12 +86,15 @@\n # Allow _spender to withdraw from your account, multiple times, up to the _value amount.\n # If this function is called again it overwrites the current allowance with _value.\n #\n-# NOTE: To prevent attack vectors like the one described here and discussed here,\n-# clients SHOULD make sure to create user interfaces in such a way that they\n+# NOTE: We would like to prevent attack vectors like the one described here:\n+# https://docs.google.com/document/d/1YLPtQxZu1UAvO9cZ1O2RPXBbT0mooh4DYKjA_jp-RLM/edit#heading=h.m9fhqynw2xvt\n+# and discussed here:\n+# https://github.com/ethereum/EIPs/issues/20#issuecomment-263524729\n+#\n+# Clients SHOULD make sure to create user interfaces in such a way that they\n # set the allowance first to 0 before setting it to another value for the\n # same spender. THOUGH The contract itself shouldn't enforce it, to allow\n # backwards compatilibilty with contracts deployed before.\n-#\n @public\n def approve(_spender: address, _amount: num(num256)) -> bool:\n \n@@ -101,7 +104,7 @@\n return True\n \n \n-# Get the allowance an address has to spend anothers' token.\n+# Get the allowance an address has to spend another's token.\n @public\n def allowance(_owner: address, _spender: address) -> num256:\n", "issue": "[Question] Attack Vector described in Vipercoin's `approve` annotation\nIn [L89 of `vipercoin.v.py`](https://github.com/ethereum/viper/blob/master/examples/tokens/vipercoin.v.py#L89), the `approve` method has an annotation that begins like this\r\n\r\n>To prevent attack vectors like the one described here and discussed here,\r\n\r\nI don't see any description of the attack vectors described, perhaps there should be an external link here? Point me in the right direction and I can make the PR for it. :)\r\n\r\nThanks!\n", "before_files": [{"content": "# Viper Port of MyToken\n# THIS CONTRACT HAS NOT BEEN AUDITED!\n# ERC20 details at:\n# https://theethereum.wiki/w/index.php/ERC20_Token_Standard\n# https://github.com/ethereum/EIPs/blob/master/EIPS/eip-20-token-standard.md\n# Events of the token.\nTransfer: __log__({_from: indexed(address), _to: indexed(address), _value: num256})\nApproval: __log__({_owner: indexed(address), _spender: indexed(address), _value: num256})\n\n\n# Variables of the token.\nname: bytes32\nsymbol: bytes32\ntotalSupply: num\ndecimals: num\nbalances: num[address]\nallowed: num[address][address]\n\n@public\ndef __init__(_name: bytes32, _symbol: bytes32, _decimals: num, _initialSupply: num):\n \n self.name = _name\n self.symbol = _symbol\n self.decimals = _decimals\n self.totalSupply = _initialSupply * 10 ** _decimals\n self.balances[msg.sender] = self.totalSupply\n\n@public\n@constant\ndef symbol() -> bytes32:\n\n return self.symbol\n\n@public\n@constant\ndef name() -> bytes32:\n\n return self.name\n\n\n# What is the balance of a particular account?\n@public\n@constant\ndef balanceOf(_owner: address) -> num256:\n\n return as_num256(self.balances[_owner])\n\n\n# Return total supply of token.\n@public\n@constant\ndef totalSupply() -> num256:\n\n return as_num256(self.totalSupply)\n\n\n# Send `_value` tokens to `_to` from your account\n@public\ndef transfer(_to: address, _amount: num(num256)) -> bool:\n\n assert self.balances[msg.sender] >= _amount\n assert self.balances[_to] + _amount >= self.balances[_to]\n\n self.balances[msg.sender] -= _amount # Subtract from the sender\n self.balances[_to] += _amount # Add the same to the recipient\n log.Transfer(msg.sender, _to, as_num256(_amount)) # log transfer event.\n\n return True\n\n\n# Transfer allowed tokens from a specific account to another.\n@public\ndef transferFrom(_from: address, _to: address, _value: num(num256)) -> bool:\n\n assert _value <= self.allowed[_from][msg.sender]\n assert _value <= self.balances[_from]\n\n self.balances[_from] -= _value # decrease balance of from address.\n self.allowed[_from][msg.sender] -= _value # decrease allowance.\n self.balances[_to] += _value # incease balance of to address.\n log.Transfer(_from, _to, as_num256(_value)) # log transfer event.\n \n return True\n\n\n# Allow _spender to withdraw from your account, multiple times, up to the _value amount.\n# If this function is called again it overwrites the current allowance with _value.\n#\n# NOTE: To prevent attack vectors like the one described here and discussed here,\n# clients SHOULD make sure to create user interfaces in such a way that they\n# set the allowance first to 0 before setting it to another value for the\n# same spender. THOUGH The contract itself shouldn't enforce it, to allow\n# backwards compatilibilty with contracts deployed before.\n#\n@public\ndef approve(_spender: address, _amount: num(num256)) -> bool:\n\n self.allowed[msg.sender][_spender] = _amount\n log.Approval(msg.sender, _spender, as_num256(_amount))\n\n return True\n\n\n# Get the allowance an address has to spend anothers' token.\n@public\ndef allowance(_owner: address, _spender: address) -> num256:\n\n return as_num256(self.allowed[_owner][_spender])\n", "path": "examples/tokens/vipercoin.v.py"}]}
| 1,782 | 400 |
gh_patches_debug_22788
|
rasdani/github-patches
|
git_diff
|
CTPUG__wafer-193
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Remove'unicode' calls from wafer
Current wafer using python 3 fails on several admin tasks because `UserProfile.__str__` tries to call `unicode`, which is obviously not defined.
We should handle the difference between python 2 and python 3 correctly in this situation.
There are a couple of other calls to unicode() that look dangerous in the error paths in /registration/views.py that should probably be fixed as well.
</issue>
<code>
[start of wafer/users/models.py]
1 from django.contrib.auth.models import User
2 from django.db import models
3 from django.db.models.signals import post_save
4 from django.utils.encoding import python_2_unicode_compatible
5
6 from libravatar import libravatar_url
7 try:
8 from urllib2 import urlparse
9 except ImportError:
10 from urllib import parse as urlparse
11 from django.utils.http import urlquote
12
13 from wafer.talks.models import ACCEPTED, PENDING
14
15
16 @python_2_unicode_compatible
17 class UserProfile(models.Model):
18 user = models.OneToOneField(User)
19 contact_number = models.CharField(max_length=16, null=True, blank=True)
20 bio = models.TextField(null=True, blank=True)
21
22 homepage = models.CharField(max_length=256, null=True, blank=True)
23 # We should probably do social auth instead
24 # And care about other code hosting sites...
25 twitter_handle = models.CharField(max_length=15, null=True, blank=True)
26 github_username = models.CharField(max_length=32, null=True, blank=True)
27
28 def __str__(self):
29 return unicode(self.user)
30
31 def accepted_talks(self):
32 return self.user.talks.filter(status=ACCEPTED)
33
34 def pending_talks(self):
35 return self.user.talks.filter(status=PENDING)
36
37 def avatar_url(self, size=96, https=True, default='mm'):
38 if not self.user.email:
39 return None
40 return libravatar_url(self.user.email, size=size, https=https,
41 default=default)
42
43 def homepage_url(self):
44 """Try ensure we prepend http: to the url if there's nothing there
45
46 This is to ensure we're not generating relative links in the
47 user templates."""
48 if not self.homepage:
49 return self.homepage
50 parsed = urlparse.urlparse(self.homepage)
51 if parsed.scheme:
52 return self.homepage
53 # Vague sanity check
54 abs_url = ''.join(['http://', self.homepage])
55 if urlparse.urlparse(abs_url).scheme == 'http':
56 return abs_url
57 return self.homepage
58
59 def display_name(self):
60 return self.user.get_full_name() or self.user.username
61
62
63 def create_user_profile(sender, instance, created, raw=False, **kwargs):
64 if raw:
65 return
66 if created:
67 UserProfile.objects.create(user=instance)
68
69 post_save.connect(create_user_profile, sender=User)
70
[end of wafer/users/models.py]
[start of wafer/registration/views.py]
1 import urllib
2
3 from django.contrib.auth import login
4 from django.contrib import messages
5 from django.core.urlresolvers import reverse
6 from django.conf import settings
7 from django.http import Http404, HttpResponseRedirect
8
9 from wafer.registration.sso import SSOError, debian_sso, github_sso
10
11
12 def redirect_profile(request):
13 '''
14 The default destination from logging in, redirect to the actual profile URL
15 '''
16 if request.user.is_authenticated():
17 return HttpResponseRedirect(reverse('wafer_user_profile',
18 args=(request.user.username,)))
19 else:
20 return HttpResponseRedirect(reverse('wafer_page', args=('index',)))
21
22
23 def github_login(request):
24 if 'github' not in settings.WAFER_SSO:
25 raise Http404()
26
27 if 'code' not in request.GET:
28 return HttpResponseRedirect(
29 'https://github.com/login/oauth/authorize?' + urllib.urlencode({
30 'client_id': settings.WAFER_GITHUB_CLIENT_ID,
31 'redirect_uri': request.build_absolute_uri(
32 reverse(github_login)),
33 'scope': 'user:email',
34 'state': request.META['CSRF_COOKIE'],
35 }))
36
37 try:
38 if request.GET['state'] != request.META['CSRF_COOKIE']:
39 raise SSOError('Incorrect state')
40
41 user = github_sso(request.GET['code'])
42 except SSOError as e:
43 messages.error(request, unicode(e))
44 return HttpResponseRedirect(reverse('auth_login'))
45
46 login(request, user)
47 return redirect_profile(request)
48
49
50 def debian_login(request):
51 if 'debian' not in settings.WAFER_SSO:
52 raise Http404()
53
54 try:
55 user = debian_sso(request.META)
56 except SSOError as e:
57 messages.error(request, unicode(e))
58 return HttpResponseRedirect(reverse('auth_login'))
59
60 login(request, user)
61 return redirect_profile(request)
62
[end of wafer/registration/views.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/wafer/registration/views.py b/wafer/registration/views.py
--- a/wafer/registration/views.py
+++ b/wafer/registration/views.py
@@ -40,7 +40,7 @@
user = github_sso(request.GET['code'])
except SSOError as e:
- messages.error(request, unicode(e))
+ messages.error(request, u'%s' % e)
return HttpResponseRedirect(reverse('auth_login'))
login(request, user)
@@ -54,7 +54,7 @@
try:
user = debian_sso(request.META)
except SSOError as e:
- messages.error(request, unicode(e))
+ messages.error(request, u'%s' % e)
return HttpResponseRedirect(reverse('auth_login'))
login(request, user)
diff --git a/wafer/users/models.py b/wafer/users/models.py
--- a/wafer/users/models.py
+++ b/wafer/users/models.py
@@ -26,7 +26,7 @@
github_username = models.CharField(max_length=32, null=True, blank=True)
def __str__(self):
- return unicode(self.user)
+ return u'%s' % self.user
def accepted_talks(self):
return self.user.talks.filter(status=ACCEPTED)
|
{"golden_diff": "diff --git a/wafer/registration/views.py b/wafer/registration/views.py\n--- a/wafer/registration/views.py\n+++ b/wafer/registration/views.py\n@@ -40,7 +40,7 @@\n \n user = github_sso(request.GET['code'])\n except SSOError as e:\n- messages.error(request, unicode(e))\n+ messages.error(request, u'%s' % e)\n return HttpResponseRedirect(reverse('auth_login'))\n \n login(request, user)\n@@ -54,7 +54,7 @@\n try:\n user = debian_sso(request.META)\n except SSOError as e:\n- messages.error(request, unicode(e))\n+ messages.error(request, u'%s' % e)\n return HttpResponseRedirect(reverse('auth_login'))\n \n login(request, user)\ndiff --git a/wafer/users/models.py b/wafer/users/models.py\n--- a/wafer/users/models.py\n+++ b/wafer/users/models.py\n@@ -26,7 +26,7 @@\n github_username = models.CharField(max_length=32, null=True, blank=True)\n \n def __str__(self):\n- return unicode(self.user)\n+ return u'%s' % self.user\n \n def accepted_talks(self):\n return self.user.talks.filter(status=ACCEPTED)\n", "issue": "Remove'unicode' calls from wafer\nCurrent wafer using python 3 fails on several admin tasks because `UserProfile.__str__` tries to call `unicode`, which is obviously not defined.\n\nWe should handle the difference between python 2 and python 3 correctly in this situation.\n\nThere are a couple of other calls to unicode() that look dangerous in the error paths in /registration/views.py that should probably be fixed as well.\n\n", "before_files": [{"content": "from django.contrib.auth.models import User\nfrom django.db import models\nfrom django.db.models.signals import post_save\nfrom django.utils.encoding import python_2_unicode_compatible\n\nfrom libravatar import libravatar_url\ntry:\n from urllib2 import urlparse\nexcept ImportError:\n from urllib import parse as urlparse\nfrom django.utils.http import urlquote\n\nfrom wafer.talks.models import ACCEPTED, PENDING\n\n\n@python_2_unicode_compatible\nclass UserProfile(models.Model):\n user = models.OneToOneField(User)\n contact_number = models.CharField(max_length=16, null=True, blank=True)\n bio = models.TextField(null=True, blank=True)\n\n homepage = models.CharField(max_length=256, null=True, blank=True)\n # We should probably do social auth instead\n # And care about other code hosting sites...\n twitter_handle = models.CharField(max_length=15, null=True, blank=True)\n github_username = models.CharField(max_length=32, null=True, blank=True)\n\n def __str__(self):\n return unicode(self.user)\n\n def accepted_talks(self):\n return self.user.talks.filter(status=ACCEPTED)\n\n def pending_talks(self):\n return self.user.talks.filter(status=PENDING)\n\n def avatar_url(self, size=96, https=True, default='mm'):\n if not self.user.email:\n return None\n return libravatar_url(self.user.email, size=size, https=https,\n default=default)\n\n def homepage_url(self):\n \"\"\"Try ensure we prepend http: to the url if there's nothing there\n\n This is to ensure we're not generating relative links in the\n user templates.\"\"\"\n if not self.homepage:\n return self.homepage\n parsed = urlparse.urlparse(self.homepage)\n if parsed.scheme:\n return self.homepage\n # Vague sanity check\n abs_url = ''.join(['http://', self.homepage])\n if urlparse.urlparse(abs_url).scheme == 'http':\n return abs_url\n return self.homepage\n\n def display_name(self):\n return self.user.get_full_name() or self.user.username\n\n\ndef create_user_profile(sender, instance, created, raw=False, **kwargs):\n if raw:\n return\n if created:\n UserProfile.objects.create(user=instance)\n\npost_save.connect(create_user_profile, sender=User)\n", "path": "wafer/users/models.py"}, {"content": "import urllib\n\nfrom django.contrib.auth import login\nfrom django.contrib import messages\nfrom django.core.urlresolvers import reverse\nfrom django.conf import settings\nfrom django.http import Http404, HttpResponseRedirect\n\nfrom wafer.registration.sso import SSOError, debian_sso, github_sso\n\n\ndef redirect_profile(request):\n '''\n The default destination from logging in, redirect to the actual profile URL\n '''\n if request.user.is_authenticated():\n return HttpResponseRedirect(reverse('wafer_user_profile',\n args=(request.user.username,)))\n else:\n return HttpResponseRedirect(reverse('wafer_page', args=('index',)))\n\n\ndef github_login(request):\n if 'github' not in settings.WAFER_SSO:\n raise Http404()\n\n if 'code' not in request.GET:\n return HttpResponseRedirect(\n 'https://github.com/login/oauth/authorize?' + urllib.urlencode({\n 'client_id': settings.WAFER_GITHUB_CLIENT_ID,\n 'redirect_uri': request.build_absolute_uri(\n reverse(github_login)),\n 'scope': 'user:email',\n 'state': request.META['CSRF_COOKIE'],\n }))\n\n try:\n if request.GET['state'] != request.META['CSRF_COOKIE']:\n raise SSOError('Incorrect state')\n\n user = github_sso(request.GET['code'])\n except SSOError as e:\n messages.error(request, unicode(e))\n return HttpResponseRedirect(reverse('auth_login'))\n\n login(request, user)\n return redirect_profile(request)\n\n\ndef debian_login(request):\n if 'debian' not in settings.WAFER_SSO:\n raise Http404()\n\n try:\n user = debian_sso(request.META)\n except SSOError as e:\n messages.error(request, unicode(e))\n return HttpResponseRedirect(reverse('auth_login'))\n\n login(request, user)\n return redirect_profile(request)\n", "path": "wafer/registration/views.py"}]}
| 1,798 | 292 |
gh_patches_debug_14315
|
rasdani/github-patches
|
git_diff
|
open-telemetry__opentelemetry-python-contrib-1664
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fix fastapi version
CI in `main` is failing right now because of `opentelemetery-instrumentation-fastapi` failures, fix `fastapi` version.
</issue>
<code>
[start of instrumentation/opentelemetry-instrumentation-fastapi/src/opentelemetry/instrumentation/fastapi/package.py]
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15
16 _instruments = ("fastapi ~= 0.58",)
17
18 _supports_metrics = True
19
[end of instrumentation/opentelemetry-instrumentation-fastapi/src/opentelemetry/instrumentation/fastapi/package.py]
[start of opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap_gen.py]
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 # DO NOT EDIT. THIS FILE WAS AUTOGENERATED FROM INSTRUMENTATION PACKAGES.
16 # RUN `python scripts/generate_instrumentation_bootstrap.py` TO REGENERATE.
17
18 libraries = {
19 "aio_pika": {
20 "library": "aio_pika >= 7.2.0, < 9.0.0",
21 "instrumentation": "opentelemetry-instrumentation-aio-pika==0.37b0.dev",
22 },
23 "aiohttp": {
24 "library": "aiohttp ~= 3.0",
25 "instrumentation": "opentelemetry-instrumentation-aiohttp-client==0.37b0.dev",
26 },
27 "aiopg": {
28 "library": "aiopg >= 0.13.0, < 2.0.0",
29 "instrumentation": "opentelemetry-instrumentation-aiopg==0.37b0.dev",
30 },
31 "asgiref": {
32 "library": "asgiref ~= 3.0",
33 "instrumentation": "opentelemetry-instrumentation-asgi==0.37b0.dev",
34 },
35 "asyncpg": {
36 "library": "asyncpg >= 0.12.0",
37 "instrumentation": "opentelemetry-instrumentation-asyncpg==0.37b0.dev",
38 },
39 "boto": {
40 "library": "boto~=2.0",
41 "instrumentation": "opentelemetry-instrumentation-boto==0.37b0.dev",
42 },
43 "boto3": {
44 "library": "boto3 ~= 1.0",
45 "instrumentation": "opentelemetry-instrumentation-boto3sqs==0.37b0.dev",
46 },
47 "botocore": {
48 "library": "botocore ~= 1.0",
49 "instrumentation": "opentelemetry-instrumentation-botocore==0.37b0.dev",
50 },
51 "celery": {
52 "library": "celery >= 4.0, < 6.0",
53 "instrumentation": "opentelemetry-instrumentation-celery==0.37b0.dev",
54 },
55 "confluent-kafka": {
56 "library": "confluent-kafka >= 1.8.2, < 2.0.0",
57 "instrumentation": "opentelemetry-instrumentation-confluent-kafka==0.37b0.dev",
58 },
59 "django": {
60 "library": "django >= 1.10",
61 "instrumentation": "opentelemetry-instrumentation-django==0.37b0.dev",
62 },
63 "elasticsearch": {
64 "library": "elasticsearch >= 2.0",
65 "instrumentation": "opentelemetry-instrumentation-elasticsearch==0.37b0.dev",
66 },
67 "falcon": {
68 "library": "falcon >= 1.4.1, < 4.0.0",
69 "instrumentation": "opentelemetry-instrumentation-falcon==0.37b0.dev",
70 },
71 "fastapi": {
72 "library": "fastapi ~= 0.58",
73 "instrumentation": "opentelemetry-instrumentation-fastapi==0.37b0.dev",
74 },
75 "flask": {
76 "library": "flask >= 1.0, < 3.0",
77 "instrumentation": "opentelemetry-instrumentation-flask==0.37b0.dev",
78 },
79 "grpcio": {
80 "library": "grpcio ~= 1.27",
81 "instrumentation": "opentelemetry-instrumentation-grpc==0.37b0.dev",
82 },
83 "httpx": {
84 "library": "httpx >= 0.18.0, <= 0.23.0",
85 "instrumentation": "opentelemetry-instrumentation-httpx==0.37b0.dev",
86 },
87 "jinja2": {
88 "library": "jinja2 >= 2.7, < 4.0",
89 "instrumentation": "opentelemetry-instrumentation-jinja2==0.37b0.dev",
90 },
91 "kafka-python": {
92 "library": "kafka-python >= 2.0",
93 "instrumentation": "opentelemetry-instrumentation-kafka-python==0.37b0.dev",
94 },
95 "mysql-connector-python": {
96 "library": "mysql-connector-python ~= 8.0",
97 "instrumentation": "opentelemetry-instrumentation-mysql==0.37b0.dev",
98 },
99 "pika": {
100 "library": "pika >= 0.12.0",
101 "instrumentation": "opentelemetry-instrumentation-pika==0.37b0.dev",
102 },
103 "psycopg2": {
104 "library": "psycopg2 >= 2.7.3.1",
105 "instrumentation": "opentelemetry-instrumentation-psycopg2==0.37b0.dev",
106 },
107 "pymemcache": {
108 "library": "pymemcache >= 1.3.5, < 4",
109 "instrumentation": "opentelemetry-instrumentation-pymemcache==0.37b0.dev",
110 },
111 "pymongo": {
112 "library": "pymongo >= 3.1, < 5.0",
113 "instrumentation": "opentelemetry-instrumentation-pymongo==0.37b0.dev",
114 },
115 "PyMySQL": {
116 "library": "PyMySQL < 2",
117 "instrumentation": "opentelemetry-instrumentation-pymysql==0.37b0.dev",
118 },
119 "pyramid": {
120 "library": "pyramid >= 1.7",
121 "instrumentation": "opentelemetry-instrumentation-pyramid==0.37b0.dev",
122 },
123 "redis": {
124 "library": "redis >= 2.6",
125 "instrumentation": "opentelemetry-instrumentation-redis==0.37b0.dev",
126 },
127 "remoulade": {
128 "library": "remoulade >= 0.50",
129 "instrumentation": "opentelemetry-instrumentation-remoulade==0.37b0.dev",
130 },
131 "requests": {
132 "library": "requests ~= 2.0",
133 "instrumentation": "opentelemetry-instrumentation-requests==0.37b0.dev",
134 },
135 "scikit-learn": {
136 "library": "scikit-learn ~= 0.24.0",
137 "instrumentation": "opentelemetry-instrumentation-sklearn==0.37b0.dev",
138 },
139 "sqlalchemy": {
140 "library": "sqlalchemy",
141 "instrumentation": "opentelemetry-instrumentation-sqlalchemy==0.37b0.dev",
142 },
143 "starlette": {
144 "library": "starlette ~= 0.13.0",
145 "instrumentation": "opentelemetry-instrumentation-starlette==0.37b0.dev",
146 },
147 "psutil": {
148 "library": "psutil >= 5",
149 "instrumentation": "opentelemetry-instrumentation-system-metrics==0.37b0.dev",
150 },
151 "tornado": {
152 "library": "tornado >= 5.1.1",
153 "instrumentation": "opentelemetry-instrumentation-tornado==0.37b0.dev",
154 },
155 "tortoise-orm": {
156 "library": "tortoise-orm >= 0.17.0",
157 "instrumentation": "opentelemetry-instrumentation-tortoiseorm==0.37b0.dev",
158 },
159 "pydantic": {
160 "library": "pydantic >= 1.10.2",
161 "instrumentation": "opentelemetry-instrumentation-tortoiseorm==0.37b0.dev",
162 },
163 "urllib3": {
164 "library": "urllib3 >= 1.0.0, < 2.0.0",
165 "instrumentation": "opentelemetry-instrumentation-urllib3==0.37b0.dev",
166 },
167 }
168 default_instrumentations = [
169 "opentelemetry-instrumentation-aws-lambda==0.37b0.dev",
170 "opentelemetry-instrumentation-dbapi==0.37b0.dev",
171 "opentelemetry-instrumentation-logging==0.37b0.dev",
172 "opentelemetry-instrumentation-sqlite3==0.37b0.dev",
173 "opentelemetry-instrumentation-urllib==0.37b0.dev",
174 "opentelemetry-instrumentation-wsgi==0.37b0.dev",
175 ]
176
[end of opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap_gen.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/instrumentation/opentelemetry-instrumentation-fastapi/src/opentelemetry/instrumentation/fastapi/package.py b/instrumentation/opentelemetry-instrumentation-fastapi/src/opentelemetry/instrumentation/fastapi/package.py
--- a/instrumentation/opentelemetry-instrumentation-fastapi/src/opentelemetry/instrumentation/fastapi/package.py
+++ b/instrumentation/opentelemetry-instrumentation-fastapi/src/opentelemetry/instrumentation/fastapi/package.py
@@ -13,6 +13,6 @@
# limitations under the License.
-_instruments = ("fastapi ~= 0.58",)
+_instruments = ("fastapi <= 0.90.1",)
_supports_metrics = True
diff --git a/opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap_gen.py b/opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap_gen.py
--- a/opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap_gen.py
+++ b/opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap_gen.py
@@ -69,7 +69,7 @@
"instrumentation": "opentelemetry-instrumentation-falcon==0.37b0.dev",
},
"fastapi": {
- "library": "fastapi ~= 0.58",
+ "library": "fastapi <= 0.90.1",
"instrumentation": "opentelemetry-instrumentation-fastapi==0.37b0.dev",
},
"flask": {
|
{"golden_diff": "diff --git a/instrumentation/opentelemetry-instrumentation-fastapi/src/opentelemetry/instrumentation/fastapi/package.py b/instrumentation/opentelemetry-instrumentation-fastapi/src/opentelemetry/instrumentation/fastapi/package.py\n--- a/instrumentation/opentelemetry-instrumentation-fastapi/src/opentelemetry/instrumentation/fastapi/package.py\n+++ b/instrumentation/opentelemetry-instrumentation-fastapi/src/opentelemetry/instrumentation/fastapi/package.py\n@@ -13,6 +13,6 @@\n # limitations under the License.\n \n \n-_instruments = (\"fastapi ~= 0.58\",)\n+_instruments = (\"fastapi <= 0.90.1\",)\n \n _supports_metrics = True\ndiff --git a/opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap_gen.py b/opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap_gen.py\n--- a/opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap_gen.py\n+++ b/opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap_gen.py\n@@ -69,7 +69,7 @@\n \"instrumentation\": \"opentelemetry-instrumentation-falcon==0.37b0.dev\",\n },\n \"fastapi\": {\n- \"library\": \"fastapi ~= 0.58\",\n+ \"library\": \"fastapi <= 0.90.1\",\n \"instrumentation\": \"opentelemetry-instrumentation-fastapi==0.37b0.dev\",\n },\n \"flask\": {\n", "issue": "Fix fastapi version\nCI in `main` is failing right now because of `opentelemetery-instrumentation-fastapi` failures, fix `fastapi` version.\n", "before_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\n_instruments = (\"fastapi ~= 0.58\",)\n\n_supports_metrics = True\n", "path": "instrumentation/opentelemetry-instrumentation-fastapi/src/opentelemetry/instrumentation/fastapi/package.py"}, {"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n# DO NOT EDIT. THIS FILE WAS AUTOGENERATED FROM INSTRUMENTATION PACKAGES.\n# RUN `python scripts/generate_instrumentation_bootstrap.py` TO REGENERATE.\n\nlibraries = {\n \"aio_pika\": {\n \"library\": \"aio_pika >= 7.2.0, < 9.0.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-aio-pika==0.37b0.dev\",\n },\n \"aiohttp\": {\n \"library\": \"aiohttp ~= 3.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-aiohttp-client==0.37b0.dev\",\n },\n \"aiopg\": {\n \"library\": \"aiopg >= 0.13.0, < 2.0.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-aiopg==0.37b0.dev\",\n },\n \"asgiref\": {\n \"library\": \"asgiref ~= 3.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-asgi==0.37b0.dev\",\n },\n \"asyncpg\": {\n \"library\": \"asyncpg >= 0.12.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-asyncpg==0.37b0.dev\",\n },\n \"boto\": {\n \"library\": \"boto~=2.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-boto==0.37b0.dev\",\n },\n \"boto3\": {\n \"library\": \"boto3 ~= 1.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-boto3sqs==0.37b0.dev\",\n },\n \"botocore\": {\n \"library\": \"botocore ~= 1.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-botocore==0.37b0.dev\",\n },\n \"celery\": {\n \"library\": \"celery >= 4.0, < 6.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-celery==0.37b0.dev\",\n },\n \"confluent-kafka\": {\n \"library\": \"confluent-kafka >= 1.8.2, < 2.0.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-confluent-kafka==0.37b0.dev\",\n },\n \"django\": {\n \"library\": \"django >= 1.10\",\n \"instrumentation\": \"opentelemetry-instrumentation-django==0.37b0.dev\",\n },\n \"elasticsearch\": {\n \"library\": \"elasticsearch >= 2.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-elasticsearch==0.37b0.dev\",\n },\n \"falcon\": {\n \"library\": \"falcon >= 1.4.1, < 4.0.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-falcon==0.37b0.dev\",\n },\n \"fastapi\": {\n \"library\": \"fastapi ~= 0.58\",\n \"instrumentation\": \"opentelemetry-instrumentation-fastapi==0.37b0.dev\",\n },\n \"flask\": {\n \"library\": \"flask >= 1.0, < 3.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-flask==0.37b0.dev\",\n },\n \"grpcio\": {\n \"library\": \"grpcio ~= 1.27\",\n \"instrumentation\": \"opentelemetry-instrumentation-grpc==0.37b0.dev\",\n },\n \"httpx\": {\n \"library\": \"httpx >= 0.18.0, <= 0.23.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-httpx==0.37b0.dev\",\n },\n \"jinja2\": {\n \"library\": \"jinja2 >= 2.7, < 4.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-jinja2==0.37b0.dev\",\n },\n \"kafka-python\": {\n \"library\": \"kafka-python >= 2.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-kafka-python==0.37b0.dev\",\n },\n \"mysql-connector-python\": {\n \"library\": \"mysql-connector-python ~= 8.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-mysql==0.37b0.dev\",\n },\n \"pika\": {\n \"library\": \"pika >= 0.12.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-pika==0.37b0.dev\",\n },\n \"psycopg2\": {\n \"library\": \"psycopg2 >= 2.7.3.1\",\n \"instrumentation\": \"opentelemetry-instrumentation-psycopg2==0.37b0.dev\",\n },\n \"pymemcache\": {\n \"library\": \"pymemcache >= 1.3.5, < 4\",\n \"instrumentation\": \"opentelemetry-instrumentation-pymemcache==0.37b0.dev\",\n },\n \"pymongo\": {\n \"library\": \"pymongo >= 3.1, < 5.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-pymongo==0.37b0.dev\",\n },\n \"PyMySQL\": {\n \"library\": \"PyMySQL < 2\",\n \"instrumentation\": \"opentelemetry-instrumentation-pymysql==0.37b0.dev\",\n },\n \"pyramid\": {\n \"library\": \"pyramid >= 1.7\",\n \"instrumentation\": \"opentelemetry-instrumentation-pyramid==0.37b0.dev\",\n },\n \"redis\": {\n \"library\": \"redis >= 2.6\",\n \"instrumentation\": \"opentelemetry-instrumentation-redis==0.37b0.dev\",\n },\n \"remoulade\": {\n \"library\": \"remoulade >= 0.50\",\n \"instrumentation\": \"opentelemetry-instrumentation-remoulade==0.37b0.dev\",\n },\n \"requests\": {\n \"library\": \"requests ~= 2.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-requests==0.37b0.dev\",\n },\n \"scikit-learn\": {\n \"library\": \"scikit-learn ~= 0.24.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-sklearn==0.37b0.dev\",\n },\n \"sqlalchemy\": {\n \"library\": \"sqlalchemy\",\n \"instrumentation\": \"opentelemetry-instrumentation-sqlalchemy==0.37b0.dev\",\n },\n \"starlette\": {\n \"library\": \"starlette ~= 0.13.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-starlette==0.37b0.dev\",\n },\n \"psutil\": {\n \"library\": \"psutil >= 5\",\n \"instrumentation\": \"opentelemetry-instrumentation-system-metrics==0.37b0.dev\",\n },\n \"tornado\": {\n \"library\": \"tornado >= 5.1.1\",\n \"instrumentation\": \"opentelemetry-instrumentation-tornado==0.37b0.dev\",\n },\n \"tortoise-orm\": {\n \"library\": \"tortoise-orm >= 0.17.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-tortoiseorm==0.37b0.dev\",\n },\n \"pydantic\": {\n \"library\": \"pydantic >= 1.10.2\",\n \"instrumentation\": \"opentelemetry-instrumentation-tortoiseorm==0.37b0.dev\",\n },\n \"urllib3\": {\n \"library\": \"urllib3 >= 1.0.0, < 2.0.0\",\n \"instrumentation\": \"opentelemetry-instrumentation-urllib3==0.37b0.dev\",\n },\n}\ndefault_instrumentations = [\n \"opentelemetry-instrumentation-aws-lambda==0.37b0.dev\",\n \"opentelemetry-instrumentation-dbapi==0.37b0.dev\",\n \"opentelemetry-instrumentation-logging==0.37b0.dev\",\n \"opentelemetry-instrumentation-sqlite3==0.37b0.dev\",\n \"opentelemetry-instrumentation-urllib==0.37b0.dev\",\n \"opentelemetry-instrumentation-wsgi==0.37b0.dev\",\n]\n", "path": "opentelemetry-instrumentation/src/opentelemetry/instrumentation/bootstrap_gen.py"}]}
| 3,359 | 340 |
gh_patches_debug_11094
|
rasdani/github-patches
|
git_diff
|
facebookresearch__dynabench-766
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Creating a task with the "Task Code" as a number doesn't work as expected.
After creating a task with the task code as a number, and accepting the task, when users want to navigate to the task, it should ideally take us to a page which says "The task owner still needs to activate this task.", but in this case, we are shown the respective page for a millisecond, and taken back to the home page, which I think is unexpected behaviour.
A demonstration is given in the following screen recording of the same issue.
**Steps to reproduce**:
- Create a task proposal with the "Task Code" field as a number
- Accept the task as the admin user.
- Now try to click on the respective task from your "Tasks" page. It should just take you back to the homepage.
This seems to happen only for a purely numeric "Task Code" and not for an alphanumeric "Task Code"
https://user-images.githubusercontent.com/48560219/135757335-d98f116f-b7d6-44dc-a1fd-0c8b6fac7c61.mov
</issue>
<code>
[start of api/controllers/task_proposals.py]
1 # Copyright (c) Facebook, Inc. and its affiliates.
2 # This source code is licensed under the MIT license found in the
3 # LICENSE file in the root directory of this source tree.
4
5 import re
6
7 import bottle
8
9 import common.auth as _auth
10 import common.helpers as util
11 from common.logging import logger
12 from models.base import DBSession as dbs
13 from models.task import TaskModel
14 from models.task_proposal import TaskProposal, TaskProposalModel
15 from models.user import UserModel
16
17
18 @bottle.get("/task_proposals/user/<page:int>/<limit:int>")
19 @_auth.requires_auth
20 def get_user_task_proposals(credentials, page, limit):
21 tpm = TaskProposalModel()
22 proposals = tpm.getByUid(credentials["id"])
23 identifiers = []
24 for proposal in proposals:
25 identifiers.append(proposal.to_dict())
26 return util.json_encode(
27 {
28 "data": identifiers[page * limit : page * limit + limit],
29 "count": len(identifiers),
30 }
31 )
32
33
34 @bottle.get("/task_proposals/all/<page:int>/<limit:int>")
35 @_auth.requires_auth
36 def get_all_task_proposals(credentials, page, limit):
37 um = UserModel()
38 user = um.get(credentials["id"])
39 if not user.admin:
40 bottle.abort(403, "Access denied")
41
42 proposals = dbs.query(TaskProposal)
43 identifiers = []
44 for proposal in proposals:
45 identifiers.append(proposal.to_dict())
46 return util.json_encode(
47 {
48 "data": identifiers[page * limit : page * limit + limit],
49 "count": len(identifiers),
50 }
51 )
52
53
54 @bottle.post("/task_proposals/create")
55 @_auth.requires_auth
56 def create_task_proposal(credentials):
57 data = bottle.request.json
58
59 if not util.check_fields(data, ["task_code", "name", "desc", "longdesc"]):
60 bottle.abort(400, "Missing data")
61
62 tm = TaskModel()
63 if tm.getByTaskCode(data["task_code"]):
64 bottle.abort(400, "Invalid task code; this task code is already taken")
65
66 if tm.getByName(data["name"]):
67 bottle.abort(400, "Invalid name; this name is already taken")
68
69 if not bool(re.search("^[a-zA-Z0-9_-]*$", data["task_code"])):
70 bottle.abort(
71 400,
72 "Invalid task code (no special characters allowed besides underscores "
73 + "and dashes)",
74 )
75
76 try:
77 tp = TaskProposal(
78 uid=credentials["id"],
79 task_code=data["task_code"],
80 name=data["name"],
81 desc=data["desc"],
82 longdesc=data["longdesc"],
83 )
84
85 tm.dbs.add(tp)
86 tm.dbs.flush()
87 tm.dbs.commit()
88 logger.info("Added task proposal (%s)" % (tp.id))
89
90 except Exception as error_message:
91 logger.error("Could not create task proposal (%s)" % error_message)
92 return False
93
94 return util.json_encode({"success": "ok", "id": tp.id})
95
[end of api/controllers/task_proposals.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/api/controllers/task_proposals.py b/api/controllers/task_proposals.py
--- a/api/controllers/task_proposals.py
+++ b/api/controllers/task_proposals.py
@@ -66,11 +66,13 @@
if tm.getByName(data["name"]):
bottle.abort(400, "Invalid name; this name is already taken")
- if not bool(re.search("^[a-zA-Z0-9_-]*$", data["task_code"])):
+ if not bool(
+ re.search("(?=^[a-zA-Z0-9_-]*$)(?=.*[a-zA-Z].*).*$", data["task_code"])
+ ):
bottle.abort(
400,
"Invalid task code (no special characters allowed besides underscores "
- + "and dashes)",
+ + "and dashes. At least one letter required)",
)
try:
|
{"golden_diff": "diff --git a/api/controllers/task_proposals.py b/api/controllers/task_proposals.py\n--- a/api/controllers/task_proposals.py\n+++ b/api/controllers/task_proposals.py\n@@ -66,11 +66,13 @@\n if tm.getByName(data[\"name\"]):\n bottle.abort(400, \"Invalid name; this name is already taken\")\n \n- if not bool(re.search(\"^[a-zA-Z0-9_-]*$\", data[\"task_code\"])):\n+ if not bool(\n+ re.search(\"(?=^[a-zA-Z0-9_-]*$)(?=.*[a-zA-Z].*).*$\", data[\"task_code\"])\n+ ):\n bottle.abort(\n 400,\n \"Invalid task code (no special characters allowed besides underscores \"\n- + \"and dashes)\",\n+ + \"and dashes. At least one letter required)\",\n )\n \n try:\n", "issue": "Creating a task with the \"Task Code\" as a number doesn't work as expected.\nAfter creating a task with the task code as a number, and accepting the task, when users want to navigate to the task, it should ideally take us to a page which says \"The task owner still needs to activate this task.\", but in this case, we are shown the respective page for a millisecond, and taken back to the home page, which I think is unexpected behaviour.\r\n\r\nA demonstration is given in the following screen recording of the same issue.\r\n\r\n**Steps to reproduce**:\r\n- Create a task proposal with the \"Task Code\" field as a number\r\n- Accept the task as the admin user.\r\n- Now try to click on the respective task from your \"Tasks\" page. It should just take you back to the homepage.\r\n\r\nThis seems to happen only for a purely numeric \"Task Code\" and not for an alphanumeric \"Task Code\"\r\n\r\nhttps://user-images.githubusercontent.com/48560219/135757335-d98f116f-b7d6-44dc-a1fd-0c8b6fac7c61.mov\r\n\r\n\n", "before_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates.\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\nimport re\n\nimport bottle\n\nimport common.auth as _auth\nimport common.helpers as util\nfrom common.logging import logger\nfrom models.base import DBSession as dbs\nfrom models.task import TaskModel\nfrom models.task_proposal import TaskProposal, TaskProposalModel\nfrom models.user import UserModel\n\n\[email protected](\"/task_proposals/user/<page:int>/<limit:int>\")\n@_auth.requires_auth\ndef get_user_task_proposals(credentials, page, limit):\n tpm = TaskProposalModel()\n proposals = tpm.getByUid(credentials[\"id\"])\n identifiers = []\n for proposal in proposals:\n identifiers.append(proposal.to_dict())\n return util.json_encode(\n {\n \"data\": identifiers[page * limit : page * limit + limit],\n \"count\": len(identifiers),\n }\n )\n\n\[email protected](\"/task_proposals/all/<page:int>/<limit:int>\")\n@_auth.requires_auth\ndef get_all_task_proposals(credentials, page, limit):\n um = UserModel()\n user = um.get(credentials[\"id\"])\n if not user.admin:\n bottle.abort(403, \"Access denied\")\n\n proposals = dbs.query(TaskProposal)\n identifiers = []\n for proposal in proposals:\n identifiers.append(proposal.to_dict())\n return util.json_encode(\n {\n \"data\": identifiers[page * limit : page * limit + limit],\n \"count\": len(identifiers),\n }\n )\n\n\[email protected](\"/task_proposals/create\")\n@_auth.requires_auth\ndef create_task_proposal(credentials):\n data = bottle.request.json\n\n if not util.check_fields(data, [\"task_code\", \"name\", \"desc\", \"longdesc\"]):\n bottle.abort(400, \"Missing data\")\n\n tm = TaskModel()\n if tm.getByTaskCode(data[\"task_code\"]):\n bottle.abort(400, \"Invalid task code; this task code is already taken\")\n\n if tm.getByName(data[\"name\"]):\n bottle.abort(400, \"Invalid name; this name is already taken\")\n\n if not bool(re.search(\"^[a-zA-Z0-9_-]*$\", data[\"task_code\"])):\n bottle.abort(\n 400,\n \"Invalid task code (no special characters allowed besides underscores \"\n + \"and dashes)\",\n )\n\n try:\n tp = TaskProposal(\n uid=credentials[\"id\"],\n task_code=data[\"task_code\"],\n name=data[\"name\"],\n desc=data[\"desc\"],\n longdesc=data[\"longdesc\"],\n )\n\n tm.dbs.add(tp)\n tm.dbs.flush()\n tm.dbs.commit()\n logger.info(\"Added task proposal (%s)\" % (tp.id))\n\n except Exception as error_message:\n logger.error(\"Could not create task proposal (%s)\" % error_message)\n return False\n\n return util.json_encode({\"success\": \"ok\", \"id\": tp.id})\n", "path": "api/controllers/task_proposals.py"}]}
| 1,624 | 193 |
gh_patches_debug_4002
|
rasdani/github-patches
|
git_diff
|
pypa__cibuildwheel-199
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
cibuildwheel CI tests failing on Azure for windows
`cibuildwheel` CI tests which are using the sample configuration in README are failing on Windows following Azure update to support python 3.8
Given the number of CI providers now tested, I guess we can try to test `cibuildwheel` on python 2.7, 3.5, 3.6, 3.7 and 3.8 without too much overhead on test time by dispatching the python versions running `cibuildwheel` across CI providers.
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3
4 try:
5 from setuptools import setup
6 except ImportError:
7 from distutils.core import setup
8
9 setup(
10 name='cibuildwheel',
11 version='0.12.0',
12 install_requires=['bashlex!=0.13'],
13 description="Build Python wheels on CI with minimal configuration.",
14 long_description='For readme please see http://github.com/joerick/cibuildwheel',
15 author="Joe Rickerby",
16 author_email='[email protected]',
17 url='https://github.com/joerick/cibuildwheel',
18 packages=['cibuildwheel',],
19 license="BSD",
20 zip_safe=False,
21 package_data={
22 'cibuildwheel': ['resources/*'],
23 },
24 keywords='ci wheel packaging pypi travis appveyor macos linux windows',
25 classifiers=[
26 'Intended Audience :: Developers',
27 'Natural Language :: English',
28 'Programming Language :: Python :: 2',
29 'Programming Language :: Python :: 3',
30 'Development Status :: 4 - Beta',
31 'License :: OSI Approved :: BSD License',
32 'Programming Language :: Python :: Implementation :: CPython',
33 'Topic :: Software Development :: Build Tools',
34 ],
35 entry_points={
36 'console_scripts': [
37 'cibuildwheel = cibuildwheel.__main__:main',
38 ],
39 },
40 )
41
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -21,6 +21,8 @@
package_data={
'cibuildwheel': ['resources/*'],
},
+ # Supported python versions
+ python_requires='>=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, !=3.4.*',
keywords='ci wheel packaging pypi travis appveyor macos linux windows',
classifiers=[
'Intended Audience :: Developers',
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -21,6 +21,8 @@\n package_data={\n 'cibuildwheel': ['resources/*'],\n },\n+ # Supported python versions\n+ python_requires='>=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, !=3.4.*',\n keywords='ci wheel packaging pypi travis appveyor macos linux windows',\n classifiers=[\n 'Intended Audience :: Developers',\n", "issue": "cibuildwheel CI tests failing on Azure for windows\n`cibuildwheel` CI tests which are using the sample configuration in README are failing on Windows following Azure update to support python 3.8\r\n\r\nGiven the number of CI providers now tested, I guess we can try to test `cibuildwheel` on python 2.7, 3.5, 3.6, 3.7 and 3.8 without too much overhead on test time by dispatching the python versions running `cibuildwheel` across CI providers.\r\n\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\ntry:\n from setuptools import setup\nexcept ImportError:\n from distutils.core import setup\n\nsetup(\n name='cibuildwheel',\n version='0.12.0',\n install_requires=['bashlex!=0.13'],\n description=\"Build Python wheels on CI with minimal configuration.\",\n long_description='For readme please see http://github.com/joerick/cibuildwheel',\n author=\"Joe Rickerby\",\n author_email='[email protected]',\n url='https://github.com/joerick/cibuildwheel',\n packages=['cibuildwheel',],\n license=\"BSD\",\n zip_safe=False,\n package_data={\n 'cibuildwheel': ['resources/*'],\n },\n keywords='ci wheel packaging pypi travis appveyor macos linux windows',\n classifiers=[\n 'Intended Audience :: Developers',\n 'Natural Language :: English',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 3',\n 'Development Status :: 4 - Beta',\n 'License :: OSI Approved :: BSD License',\n 'Programming Language :: Python :: Implementation :: CPython',\n 'Topic :: Software Development :: Build Tools',\n ],\n entry_points={\n 'console_scripts': [\n 'cibuildwheel = cibuildwheel.__main__:main',\n ],\n },\n)\n", "path": "setup.py"}]}
| 1,021 | 120 |
gh_patches_debug_65044
|
rasdani/github-patches
|
git_diff
|
kserve__kserve-1583
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
CommandException: No URLs matched: gs://kfserving-examples/models/mnist
/kind bug
I would like to run the kafka mnist example but when I run:
```bash
gsutil cp gs://kfserving-examples/models/mnist .
```
As per the readme, I get
```
CommandException: No URLs matched: gs://kfserving-examples/models/mnist
```
**What did you expect to happen:**
I expected to be able to download the model checkpoint.
</issue>
<code>
[start of docs/samples/kafka/setup.py]
1 # Copyright 2019 kubeflow.org.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from setuptools import setup, find_packages
16
17 tests_require = [
18 'pytest',
19 'pytest-tornasync',
20 'mypy'
21 ]
22
23 setup(
24 name='transformer',
25 version='0.1.0',
26 author_email='[email protected]',
27 license='../../LICENSE.txt',
28 url='https://github.com/kubeflow/kfserving/docs/sameples/transformer',
29 description='Transformer',
30 long_description=open('README.md').read(),
31 python_requires='>=3.6',
32 packages=find_packages("transformer"),
33 install_requires=[
34 "kfserving>=0.2.1",
35 "argparse>=1.4.0",
36 "requests>=2.22.0",
37 "joblib>=0.13.2",
38 "pandas>=0.24.2",
39 "numpy>=1.16.3",
40 "kubernetes >= 9.0.0",
41 "opencv-python-headless==4.0.0.21",
42 "boto3==1.7.2"
43 ],
44 tests_require=tests_require,
45 extras_require={'test': tests_require}
46 )
47
[end of docs/samples/kafka/setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/docs/samples/kafka/setup.py b/docs/samples/kafka/setup.py
--- a/docs/samples/kafka/setup.py
+++ b/docs/samples/kafka/setup.py
@@ -25,7 +25,7 @@
version='0.1.0',
author_email='[email protected]',
license='../../LICENSE.txt',
- url='https://github.com/kubeflow/kfserving/docs/sameples/transformer',
+ url='https://github.com/kubeflow/kfserving/tree/master/docs/samples#deploy-inferenceservice-with-transformer',
description='Transformer',
long_description=open('README.md').read(),
python_requires='>=3.6',
|
{"golden_diff": "diff --git a/docs/samples/kafka/setup.py b/docs/samples/kafka/setup.py\n--- a/docs/samples/kafka/setup.py\n+++ b/docs/samples/kafka/setup.py\n@@ -25,7 +25,7 @@\n version='0.1.0',\n author_email='[email protected]',\n license='../../LICENSE.txt',\n- url='https://github.com/kubeflow/kfserving/docs/sameples/transformer',\n+ url='https://github.com/kubeflow/kfserving/tree/master/docs/samples#deploy-inferenceservice-with-transformer',\n description='Transformer',\n long_description=open('README.md').read(),\n python_requires='>=3.6',\n", "issue": "CommandException: No URLs matched: gs://kfserving-examples/models/mnist\n/kind bug \r\n\r\nI would like to run the kafka mnist example but when I run:\r\n```bash\r\ngsutil cp gs://kfserving-examples/models/mnist .\r\n```\r\nAs per the readme, I get\r\n```\r\nCommandException: No URLs matched: gs://kfserving-examples/models/mnist\r\n```\r\n\r\n**What did you expect to happen:**\r\nI expected to be able to download the model checkpoint. \r\n\n", "before_files": [{"content": "# Copyright 2019 kubeflow.org.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom setuptools import setup, find_packages\n\ntests_require = [\n 'pytest',\n 'pytest-tornasync',\n 'mypy'\n]\n\nsetup(\n name='transformer',\n version='0.1.0',\n author_email='[email protected]',\n license='../../LICENSE.txt',\n url='https://github.com/kubeflow/kfserving/docs/sameples/transformer',\n description='Transformer',\n long_description=open('README.md').read(),\n python_requires='>=3.6',\n packages=find_packages(\"transformer\"),\n install_requires=[\n \"kfserving>=0.2.1\",\n \"argparse>=1.4.0\",\n \"requests>=2.22.0\",\n \"joblib>=0.13.2\",\n \"pandas>=0.24.2\",\n \"numpy>=1.16.3\",\n \"kubernetes >= 9.0.0\",\n \"opencv-python-headless==4.0.0.21\",\n \"boto3==1.7.2\"\n ],\n tests_require=tests_require,\n extras_require={'test': tests_require}\n)\n", "path": "docs/samples/kafka/setup.py"}]}
| 1,121 | 158 |
gh_patches_debug_10991
|
rasdani/github-patches
|
git_diff
|
biolab__orange3-text-526
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Word Enrichment: sort by p-value
<!--
This is an issue template. Please fill in the relevant details in the
sections below.
-->
##### Text version
<!-- From menu _Options→Add-ons→Orange3-Text_ or code `orangecontrib.text.version.full_version` -->
0.8.0
##### Orange version
<!-- From menu _Help→About→Version_ or code `Orange.version.full_version` -->
3.26.0.dev
##### Expected behavior
Word Enrichment sorts by p-value by default.
##### Actual behavior
It sorts by words (alphabetically).
</issue>
<code>
[start of orangecontrib/text/widgets/owwordenrichment.py]
1 from types import SimpleNamespace
2 from typing import List, Optional, Any
3
4 import numpy as np
5 from AnyQt.QtWidgets import QTreeWidget, QTreeView, QTreeWidgetItem
6
7 from Orange.data import Table, Domain
8 from Orange.widgets import gui
9 from Orange.widgets.settings import Setting
10 from Orange.widgets.utils.concurrent import ConcurrentWidgetMixin, TaskState
11 from Orange.widgets.widget import OWWidget, Msg, Input
12 from Orange.statistics.util import FDR
13 from PyQt5.QtCore import QSize
14 from orangecontrib.text import Corpus
15 from orangecontrib.text.util import np_sp_sum
16 from orangecontrib.text.stats import hypergeom_p_values
17
18
19 class Result(SimpleNamespace):
20 words: Optional[List[str]] = None
21 p_values: Optional[List[float]] = None
22 fdr_values: Optional[List[float]] = None
23
24
25 class Runner:
26 @staticmethod
27 def run(
28 selected_data_transformed: Table,
29 data: Table,
30 result: Result,
31 state: TaskState
32 ) -> None:
33 state.set_status("Listing words")
34 result.words = [
35 i.name for i in selected_data_transformed.domain.attributes]
36 state.set_status("Computing p-values")
37 result.p_values = hypergeom_p_values(
38 data.X, selected_data_transformed.X,
39 callback=state.set_progress_value
40 )
41 state.set_status("Computing FDR values")
42 result.fdr_values = FDR(result.p_values)
43
44
45 class OWWordEnrichment(OWWidget, ConcurrentWidgetMixin):
46 # Basic widget info
47 name = "Word Enrichment"
48 description = "Word enrichment analysis for selected documents."
49 icon = "icons/SetEnrichment.svg"
50 priority = 600
51
52 # Input/output
53 class Inputs:
54 selected_data = Input("Selected Data", Table)
55 data = Input("Data", Table)
56
57 want_main_area = True
58
59 class Error(OWWidget.Error):
60 no_bow_features = Msg('No bag-of-words features!')
61 no_words_overlap = Msg('No words overlap!')
62 empty_selection = Msg('Selected data is empty!')
63 all_selected = Msg('All examples can not be selected!')
64
65 # Settings
66 filter_by_p: bool = Setting(False)
67 filter_p_value: float = Setting(0.01)
68 filter_by_fdr: bool = Setting(True)
69 filter_fdr_value: float = Setting(0.2)
70
71 def __init__(self):
72 OWWidget.__init__(self)
73 ConcurrentWidgetMixin.__init__(self)
74
75 # Init data
76 self.data = None
77 self.selected_data = None
78 # used for transforming the 'selected data' into the 'data' domain
79 self.selected_data_transformed = None
80
81 self.results = Result()
82
83 # info box
84 fbox = gui.widgetBox(self.controlArea, "Info")
85 self.info_fil = gui.label(fbox, self, 'Words displayed: 0')
86
87 # Filtering settings
88 fbox = gui.widgetBox(self.controlArea, "Filter")
89 hbox = gui.widgetBox(fbox, orientation=0)
90
91 self.chb_p = gui.checkBox(hbox, self, "filter_by_p", "p-value",
92 callback=self.filter_and_display,
93 tooltip="Filter by word p-value")
94 self.spin_p = gui.doubleSpin(hbox, self, 'filter_p_value',
95 1e-4, 1, step=1e-4, labelWidth=15,
96 callback=self.filter_and_display,
97 tooltip="Max p-value for word")
98 self.spin_p.setEnabled(self.filter_by_p)
99
100 hbox = gui.widgetBox(fbox, orientation=0)
101 self.chb_fdr = gui.checkBox(hbox, self, "filter_by_fdr", "FDR",
102 callback=self.filter_and_display,
103 tooltip="Filter by word FDR")
104 self.spin_fdr = gui.doubleSpin(hbox, self, 'filter_fdr_value',
105 1e-4, 1, step=1e-4, labelWidth=15,
106 callback=self.filter_and_display,
107 tooltip="Max p-value for word")
108 self.spin_fdr.setEnabled(self.filter_by_fdr)
109 gui.rubber(self.controlArea)
110
111 # Word's list view
112 self.cols = ['Word', 'p-value', 'FDR']
113 self.sig_words = QTreeWidget()
114 self.sig_words.setColumnCount(len(self.cols))
115 self.sig_words.setHeaderLabels(self.cols)
116 self.sig_words.setSortingEnabled(True)
117 self.sig_words.setSelectionMode(QTreeView.NoSelection)
118 self.sig_words.sortByColumn(2, 0) # 0 is ascending order
119 for i in range(len(self.cols)):
120 self.sig_words.resizeColumnToContents(i)
121 self.mainArea.layout().addWidget(self.sig_words)
122
123 def sizeHint(self):
124 return QSize(450, 240)
125
126 @Inputs.data
127 def set_data(self, data=None):
128 self.data = data
129 # selected data transformed depends on data domain
130 self.selected_data_transformed = None
131
132 @Inputs.selected_data
133 def set_data_selected(self, data=None):
134 self.selected_data = data
135
136 def handleNewSignals(self):
137 self.check_data()
138
139 def get_bow_domain(self):
140 domain = self.data.domain
141 return Domain(
142 attributes=[a for a in domain.attributes
143 if a.attributes.get('bow-feature', False)],
144 class_vars=domain.class_vars,
145 metas=domain.metas,
146 source=domain)
147
148 def check_data(self):
149 self.Error.clear()
150 if isinstance(self.data, Table) and \
151 isinstance(self.selected_data, Table):
152 if len(self.selected_data) == 0:
153 self.Error.empty_selection()
154 self.clear()
155 return
156
157 # keep only BoW features
158 bow_domain = self.get_bow_domain()
159 if len(bow_domain.attributes) == 0:
160 self.Error.no_bow_features()
161 self.clear()
162 return
163 self.data = Corpus.from_table(bow_domain, self.data)
164 self.selected_data_transformed = Corpus.from_table(
165 bow_domain, self.selected_data)
166
167 if np_sp_sum(self.selected_data_transformed.X) == 0:
168 self.Error.no_words_overlap()
169 self.clear()
170 elif len(self.data) == len(self.selected_data):
171 self.Error.all_selected()
172 self.clear()
173 else:
174 self.set_input_info()
175 self.apply()
176 else:
177 self.clear()
178
179 def clear(self):
180 self.sig_words.clear()
181 self.info.set_input_summary(self.info.NoInput)
182 self.set_displayed_info(0)
183
184 def filter_enabled(self, b):
185 self.chb_p.setEnabled(b)
186 self.chb_fdr.setEnabled(b)
187 self.spin_p.setEnabled(b)
188 self.spin_fdr.setEnabled(b)
189
190 def filter_and_display(self):
191 self.spin_p.setEnabled(self.filter_by_p)
192 self.spin_fdr.setEnabled(self.filter_by_fdr)
193 self.sig_words.clear()
194
195 if self.selected_data_transformed is None: # do nothing when no Data
196 return
197
198 if self.results.words:
199 count = self.build_tree()
200 else:
201 count = 0
202
203 for i in range(len(self.cols)):
204 self.sig_words.resizeColumnToContents(i)
205 self.set_displayed_info(count)
206
207 def build_tree(self) -> int:
208 count = 0
209 for word, pval, fval in zip(
210 self.results.words,
211 self.results.p_values,
212 self.results.fdr_values
213 ):
214 if ((not self.filter_by_p or pval <= self.filter_p_value) and
215 (not self.filter_by_fdr or fval <= self.filter_fdr_value)):
216 it = EATreeWidgetItem(word, pval, fval, self.sig_words)
217 self.sig_words.addTopLevelItem(it)
218 count += 1
219 return count
220
221 def set_input_info(self) -> None:
222 cluster_words = len(self.selected_data_transformed.domain.attributes)
223 selected_words = np.count_nonzero(np_sp_sum(
224 self.selected_data_transformed.X, axis=0))
225
226 self.info.set_input_summary(
227 f"{cluster_words}|{selected_words}",
228 f"Total words: {cluster_words}\n"
229 f"Words in subset: {selected_words}")
230
231 def set_displayed_info(self, count: int) -> None:
232 self.info_fil.setText(f"Words displayed: {count}")
233
234 def apply(self):
235 self.sig_words.clear()
236 self.filter_enabled(False)
237 self.start(
238 Runner.run,
239 self.selected_data_transformed,
240 self.data,
241 self.results
242 )
243
244 def on_done(self, result: Result) -> None:
245 self.filter_and_display()
246 self.filter_enabled(True)
247
248 def on_exception(self, ex: Exception) -> None:
249 self.filter_enabled(True)
250
251 def tree_to_table(self):
252 view = [self.cols]
253 items = self.sig_words.topLevelItemCount()
254 for i in range(items):
255 line = []
256 for j in range(3):
257 line.append(self.sig_words.topLevelItem(i).text(j))
258 view.append(line)
259 return view
260
261 def send_report(self):
262 if self.results.words:
263 self.report_table("Enriched words", self.tree_to_table())
264
265
266 fp = lambda score: "%0.5f" % score if score > 10e-3 else "%0.1e" % score
267 fpt = lambda score: "%0.9f" % score if score > 10e-3 else "%0.5e" % score
268
269
270 class EATreeWidgetItem(QTreeWidgetItem):
271 def __init__(self, word, p_value, f_value, parent):
272 super().__init__(parent)
273 self.data = [word, p_value, f_value]
274 self.setText(0, word)
275 self.setText(1, fp(p_value))
276 self.setToolTip(1, fpt(p_value))
277 self.setText(2, fp(f_value))
278 self.setToolTip(2, fpt(f_value))
279
280 def __lt__(self, other):
281 col = self.treeWidget().sortColumn()
282 return self.data[col] < other.data[col]
283
284
285 if __name__ == '__main__':
286 from orangewidget.utils.widgetpreview import WidgetPreview
287 from orangecontrib.text.vectorization import BowVectorizer
288
289 corpus = Corpus.from_file('book-excerpts')
290 vect = BowVectorizer()
291 corpus_vect = vect.transform(corpus)
292 WidgetPreview(OWWordEnrichment).run(
293 set_data_selected=corpus_vect[:10], set_data=corpus_vect)
294
[end of orangecontrib/text/widgets/owwordenrichment.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/orangecontrib/text/widgets/owwordenrichment.py b/orangecontrib/text/widgets/owwordenrichment.py
--- a/orangecontrib/text/widgets/owwordenrichment.py
+++ b/orangecontrib/text/widgets/owwordenrichment.py
@@ -115,7 +115,7 @@
self.sig_words.setHeaderLabels(self.cols)
self.sig_words.setSortingEnabled(True)
self.sig_words.setSelectionMode(QTreeView.NoSelection)
- self.sig_words.sortByColumn(2, 0) # 0 is ascending order
+ self.sig_words.sortByColumn(1, 0) # 0 is ascending order
for i in range(len(self.cols)):
self.sig_words.resizeColumnToContents(i)
self.mainArea.layout().addWidget(self.sig_words)
|
{"golden_diff": "diff --git a/orangecontrib/text/widgets/owwordenrichment.py b/orangecontrib/text/widgets/owwordenrichment.py\n--- a/orangecontrib/text/widgets/owwordenrichment.py\n+++ b/orangecontrib/text/widgets/owwordenrichment.py\n@@ -115,7 +115,7 @@\n self.sig_words.setHeaderLabels(self.cols)\n self.sig_words.setSortingEnabled(True)\n self.sig_words.setSelectionMode(QTreeView.NoSelection)\n- self.sig_words.sortByColumn(2, 0) # 0 is ascending order\n+ self.sig_words.sortByColumn(1, 0) # 0 is ascending order\n for i in range(len(self.cols)):\n self.sig_words.resizeColumnToContents(i)\n self.mainArea.layout().addWidget(self.sig_words)\n", "issue": "Word Enrichment: sort by p-value\n<!--\r\nThis is an issue template. Please fill in the relevant details in the\r\nsections below.\r\n-->\r\n\r\n##### Text version\r\n<!-- From menu _Options\u2192Add-ons\u2192Orange3-Text_ or code `orangecontrib.text.version.full_version` -->\r\n0.8.0\r\n\r\n##### Orange version\r\n<!-- From menu _Help\u2192About\u2192Version_ or code `Orange.version.full_version` -->\r\n3.26.0.dev\r\n\r\n##### Expected behavior\r\nWord Enrichment sorts by p-value by default.\r\n\r\n\r\n##### Actual behavior\r\nIt sorts by words (alphabetically).\r\n\r\n\r\n\n", "before_files": [{"content": "from types import SimpleNamespace\nfrom typing import List, Optional, Any\n\nimport numpy as np\nfrom AnyQt.QtWidgets import QTreeWidget, QTreeView, QTreeWidgetItem\n\nfrom Orange.data import Table, Domain\nfrom Orange.widgets import gui\nfrom Orange.widgets.settings import Setting\nfrom Orange.widgets.utils.concurrent import ConcurrentWidgetMixin, TaskState\nfrom Orange.widgets.widget import OWWidget, Msg, Input\nfrom Orange.statistics.util import FDR\nfrom PyQt5.QtCore import QSize\nfrom orangecontrib.text import Corpus\nfrom orangecontrib.text.util import np_sp_sum\nfrom orangecontrib.text.stats import hypergeom_p_values\n\n\nclass Result(SimpleNamespace):\n words: Optional[List[str]] = None\n p_values: Optional[List[float]] = None\n fdr_values: Optional[List[float]] = None\n\n\nclass Runner:\n @staticmethod\n def run(\n selected_data_transformed: Table,\n data: Table,\n result: Result,\n state: TaskState\n ) -> None:\n state.set_status(\"Listing words\")\n result.words = [\n i.name for i in selected_data_transformed.domain.attributes]\n state.set_status(\"Computing p-values\")\n result.p_values = hypergeom_p_values(\n data.X, selected_data_transformed.X,\n callback=state.set_progress_value\n )\n state.set_status(\"Computing FDR values\")\n result.fdr_values = FDR(result.p_values)\n\n\nclass OWWordEnrichment(OWWidget, ConcurrentWidgetMixin):\n # Basic widget info\n name = \"Word Enrichment\"\n description = \"Word enrichment analysis for selected documents.\"\n icon = \"icons/SetEnrichment.svg\"\n priority = 600\n\n # Input/output\n class Inputs:\n selected_data = Input(\"Selected Data\", Table)\n data = Input(\"Data\", Table)\n\n want_main_area = True\n\n class Error(OWWidget.Error):\n no_bow_features = Msg('No bag-of-words features!')\n no_words_overlap = Msg('No words overlap!')\n empty_selection = Msg('Selected data is empty!')\n all_selected = Msg('All examples can not be selected!')\n\n # Settings\n filter_by_p: bool = Setting(False)\n filter_p_value: float = Setting(0.01)\n filter_by_fdr: bool = Setting(True)\n filter_fdr_value: float = Setting(0.2)\n\n def __init__(self):\n OWWidget.__init__(self)\n ConcurrentWidgetMixin.__init__(self)\n\n # Init data\n self.data = None\n self.selected_data = None\n # used for transforming the 'selected data' into the 'data' domain\n self.selected_data_transformed = None\n\n self.results = Result()\n\n # info box\n fbox = gui.widgetBox(self.controlArea, \"Info\")\n self.info_fil = gui.label(fbox, self, 'Words displayed: 0')\n\n # Filtering settings\n fbox = gui.widgetBox(self.controlArea, \"Filter\")\n hbox = gui.widgetBox(fbox, orientation=0)\n\n self.chb_p = gui.checkBox(hbox, self, \"filter_by_p\", \"p-value\",\n callback=self.filter_and_display,\n tooltip=\"Filter by word p-value\")\n self.spin_p = gui.doubleSpin(hbox, self, 'filter_p_value',\n 1e-4, 1, step=1e-4, labelWidth=15,\n callback=self.filter_and_display,\n tooltip=\"Max p-value for word\")\n self.spin_p.setEnabled(self.filter_by_p)\n\n hbox = gui.widgetBox(fbox, orientation=0)\n self.chb_fdr = gui.checkBox(hbox, self, \"filter_by_fdr\", \"FDR\",\n callback=self.filter_and_display,\n tooltip=\"Filter by word FDR\")\n self.spin_fdr = gui.doubleSpin(hbox, self, 'filter_fdr_value',\n 1e-4, 1, step=1e-4, labelWidth=15,\n callback=self.filter_and_display,\n tooltip=\"Max p-value for word\")\n self.spin_fdr.setEnabled(self.filter_by_fdr)\n gui.rubber(self.controlArea)\n\n # Word's list view\n self.cols = ['Word', 'p-value', 'FDR']\n self.sig_words = QTreeWidget()\n self.sig_words.setColumnCount(len(self.cols))\n self.sig_words.setHeaderLabels(self.cols)\n self.sig_words.setSortingEnabled(True)\n self.sig_words.setSelectionMode(QTreeView.NoSelection)\n self.sig_words.sortByColumn(2, 0) # 0 is ascending order\n for i in range(len(self.cols)):\n self.sig_words.resizeColumnToContents(i)\n self.mainArea.layout().addWidget(self.sig_words)\n\n def sizeHint(self):\n return QSize(450, 240)\n\n @Inputs.data\n def set_data(self, data=None):\n self.data = data\n # selected data transformed depends on data domain\n self.selected_data_transformed = None\n\n @Inputs.selected_data\n def set_data_selected(self, data=None):\n self.selected_data = data\n\n def handleNewSignals(self):\n self.check_data()\n\n def get_bow_domain(self):\n domain = self.data.domain\n return Domain(\n attributes=[a for a in domain.attributes\n if a.attributes.get('bow-feature', False)],\n class_vars=domain.class_vars,\n metas=domain.metas,\n source=domain)\n\n def check_data(self):\n self.Error.clear()\n if isinstance(self.data, Table) and \\\n isinstance(self.selected_data, Table):\n if len(self.selected_data) == 0:\n self.Error.empty_selection()\n self.clear()\n return\n\n # keep only BoW features\n bow_domain = self.get_bow_domain()\n if len(bow_domain.attributes) == 0:\n self.Error.no_bow_features()\n self.clear()\n return\n self.data = Corpus.from_table(bow_domain, self.data)\n self.selected_data_transformed = Corpus.from_table(\n bow_domain, self.selected_data)\n\n if np_sp_sum(self.selected_data_transformed.X) == 0:\n self.Error.no_words_overlap()\n self.clear()\n elif len(self.data) == len(self.selected_data):\n self.Error.all_selected()\n self.clear()\n else:\n self.set_input_info()\n self.apply()\n else:\n self.clear()\n\n def clear(self):\n self.sig_words.clear()\n self.info.set_input_summary(self.info.NoInput)\n self.set_displayed_info(0)\n\n def filter_enabled(self, b):\n self.chb_p.setEnabled(b)\n self.chb_fdr.setEnabled(b)\n self.spin_p.setEnabled(b)\n self.spin_fdr.setEnabled(b)\n\n def filter_and_display(self):\n self.spin_p.setEnabled(self.filter_by_p)\n self.spin_fdr.setEnabled(self.filter_by_fdr)\n self.sig_words.clear()\n\n if self.selected_data_transformed is None: # do nothing when no Data\n return\n\n if self.results.words:\n count = self.build_tree()\n else:\n count = 0\n\n for i in range(len(self.cols)):\n self.sig_words.resizeColumnToContents(i)\n self.set_displayed_info(count)\n\n def build_tree(self) -> int:\n count = 0\n for word, pval, fval in zip(\n self.results.words,\n self.results.p_values,\n self.results.fdr_values\n ):\n if ((not self.filter_by_p or pval <= self.filter_p_value) and\n (not self.filter_by_fdr or fval <= self.filter_fdr_value)):\n it = EATreeWidgetItem(word, pval, fval, self.sig_words)\n self.sig_words.addTopLevelItem(it)\n count += 1\n return count\n\n def set_input_info(self) -> None:\n cluster_words = len(self.selected_data_transformed.domain.attributes)\n selected_words = np.count_nonzero(np_sp_sum(\n self.selected_data_transformed.X, axis=0))\n\n self.info.set_input_summary(\n f\"{cluster_words}|{selected_words}\",\n f\"Total words: {cluster_words}\\n\"\n f\"Words in subset: {selected_words}\")\n\n def set_displayed_info(self, count: int) -> None:\n self.info_fil.setText(f\"Words displayed: {count}\")\n\n def apply(self):\n self.sig_words.clear()\n self.filter_enabled(False)\n self.start(\n Runner.run,\n self.selected_data_transformed,\n self.data,\n self.results\n )\n\n def on_done(self, result: Result) -> None:\n self.filter_and_display()\n self.filter_enabled(True)\n\n def on_exception(self, ex: Exception) -> None:\n self.filter_enabled(True)\n\n def tree_to_table(self):\n view = [self.cols]\n items = self.sig_words.topLevelItemCount()\n for i in range(items):\n line = []\n for j in range(3):\n line.append(self.sig_words.topLevelItem(i).text(j))\n view.append(line)\n return view\n\n def send_report(self):\n if self.results.words:\n self.report_table(\"Enriched words\", self.tree_to_table())\n\n\nfp = lambda score: \"%0.5f\" % score if score > 10e-3 else \"%0.1e\" % score\nfpt = lambda score: \"%0.9f\" % score if score > 10e-3 else \"%0.5e\" % score\n\n\nclass EATreeWidgetItem(QTreeWidgetItem):\n def __init__(self, word, p_value, f_value, parent):\n super().__init__(parent)\n self.data = [word, p_value, f_value]\n self.setText(0, word)\n self.setText(1, fp(p_value))\n self.setToolTip(1, fpt(p_value))\n self.setText(2, fp(f_value))\n self.setToolTip(2, fpt(f_value))\n\n def __lt__(self, other):\n col = self.treeWidget().sortColumn()\n return self.data[col] < other.data[col]\n\n\nif __name__ == '__main__':\n from orangewidget.utils.widgetpreview import WidgetPreview\n from orangecontrib.text.vectorization import BowVectorizer\n\n corpus = Corpus.from_file('book-excerpts')\n vect = BowVectorizer()\n corpus_vect = vect.transform(corpus)\n WidgetPreview(OWWordEnrichment).run(\n set_data_selected=corpus_vect[:10], set_data=corpus_vect)\n", "path": "orangecontrib/text/widgets/owwordenrichment.py"}]}
| 3,729 | 177 |
gh_patches_debug_29047
|
rasdani/github-patches
|
git_diff
|
enthought__chaco-93
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ZoomTool "zoom history" keys are not working
From the examples/data_labels.py docstring:
> Pressing "z" brings up the Zoom Box, and you can click-drag a rectangular region to
> zoom. If you use a sequence of zoom boxes, pressing alt-left-arrow and
> alt-right-arrow moves you forwards and backwards through the "zoom history".
but the alt-right-arrow and alt-left-arrow keys don't seem to have any effect.
</issue>
<code>
[start of examples/demo/data_labels.py]
1 #!/usr/bin/env python
2 """
3 Draws a line plot with several points labelled. Demonstrates how to annotate
4 plots.
5
6 Left-drag pans the plot.
7
8 Mousewheel up and down zooms the plot in and out.
9
10 Pressing "z" brings up the Zoom Box, and you can click-drag a rectangular
11 region to zoom. If you use a sequence of zoom boxes, pressing alt-left-arrow
12 and alt-right-arrow moves you forwards and backwards through the
13 "zoom history".
14
15 Right-drag is enabled on some of the labels.
16 """
17
18 # Major library imports
19 from numpy import linspace
20 from scipy.special import jn
21
22 # Enthought library imports
23 from enable.api import Component, ComponentEditor
24 from traits.api import Float, HasTraits, Instance, Int
25 from traitsui.api import Item, View
26
27 # Chaco imports
28 from chaco.api import create_line_plot, add_default_axes, add_default_grids, \
29 OverlayPlotContainer, DataLabel
30 from chaco.example_support import COLOR_PALETTE
31 from chaco.tools.api import PanTool, ZoomTool, DataLabelTool
32
33
34 class PlotExample(HasTraits):
35 plot = Instance(Component)
36 numpoints = Int(100)
37 low = Float(-5.0)
38 high = Float(15.0)
39
40 traits_view = View(Item('plot', editor=ComponentEditor(),
41 show_label=False),
42 width=800, height=700, resizable=True,
43 title="Data label example")
44
45 def _plot_default(self):
46
47 container = OverlayPlotContainer(padding=50, fill_padding=True,
48 bgcolor="lightgray",
49 use_backbuffer=True)
50
51 # Create the initial X-series of data
52 numpoints = self.numpoints
53 low = self.low
54 high = self.high
55 x = linspace(low, high, numpoints + 1)
56 y = jn(0, x)
57 plot = create_line_plot((x, y), color=tuple(COLOR_PALETTE[0]),
58 width=2.0)
59 plot.index.sort_order = "ascending"
60 plot.bgcolor = "white"
61 plot.border_visible = True
62 add_default_grids(plot)
63 add_default_axes(plot)
64
65 # Add some tools
66 plot.tools.append(PanTool(plot))
67 zoom = ZoomTool(plot, tool_mode="box", always_on=False)
68 plot.overlays.append(zoom)
69
70 # Add a dynamic label. This can be dragged and moved around using the
71 # right mouse button. Note the use of padding to offset the label
72 # from its data point.
73 label = DataLabel(component=plot, data_point=(x[40], y[40]),
74 label_position="top left", padding=40,
75 bgcolor="lightgray",
76 border_visible=False)
77 plot.overlays.append(label)
78 tool = DataLabelTool(label, drag_button="right", auto_arrow_root=True)
79 label.tools.append(tool)
80
81 # Add some static labels.
82 label2 = DataLabel(component=plot, data_point=(x[20], y[20]),
83 label_position="bottom right",
84 border_visible=False,
85 bgcolor="transparent",
86 marker_color="blue",
87 marker_line_color="transparent",
88 marker="diamond",
89 font='modern 14',
90 arrow_visible=False)
91 plot.overlays.append(label2)
92
93 label3 = DataLabel(component=plot, data_point=(x[80], y[80]),
94 label_position="top", padding_bottom=20,
95 marker_color="transparent",
96 marker_size=8,
97 marker="circle",
98 arrow_visible=False)
99 plot.overlays.append(label3)
100
101 # This label uses label_style='bubble'.
102 label4 = DataLabel(component=plot, data_point=(x[60], y[60]),
103 border_padding=10,
104 marker_color="red",
105 marker_size=3,
106 label_position=(20, 50),
107 label_style='bubble',
108 label_text="Something interesting",
109 label_format="at x=%(x).2f, y=%(y).2f",
110 font='modern 18',
111 bgcolor=(1, 1, 0.75, 1),
112 )
113 plot.overlays.append(label4)
114 tool4 = DataLabelTool(label4, drag_button="right",
115 auto_arrow_root=True)
116 label4.tools.append(tool4)
117
118 # Another 'bubble' label. This one sets arrow_min_length=20, so
119 # the arrow is not drawn when the label is close to the data point.
120 label5 = DataLabel(component=plot, data_point=(x[65], y[65]),
121 border_padding=10,
122 marker_color="green",
123 marker_size=4,
124 show_label_coords=False,
125 label_style='bubble',
126 label_position=(25, 5),
127 label_text="Label with\narrow_min_length=20",
128 border_visible=False,
129 arrow_min_length=20,
130 font='modern 14',
131 bgcolor=(0.75, 0.75, 0.75, 1),
132 )
133 plot.overlays.append(label5)
134 tool5 = DataLabelTool(label5, drag_button="right",
135 auto_arrow_root=True)
136 label5.tools.append(tool5)
137
138 container.add(plot)
139
140 return container
141
142 demo = PlotExample()
143
144 if __name__ == "__main__":
145 demo.configure_traits()
146
[end of examples/demo/data_labels.py]
[start of examples/demo/edit_line.py]
1 #!/usr/bin/env python
2 """
3 Allows editing of a line plot.
4
5 Left-dragging a point will move its position.
6
7 Right-drag pans the plot.
8
9 Mousewheel up and down zooms the plot in and out.
10
11 Pressing "z" brings up the Zoom Box, and you can click-drag a rectangular region to
12 zoom. If you use a sequence of zoom boxes, pressing alt-left-arrow and
13 alt-right-arrow moves you forwards and backwards through the "zoom history".
14 """
15
16 # Major library imports
17 from numpy import linspace
18 from scipy.special import jn
19
20 from chaco.example_support import COLOR_PALETTE
21
22 # Enthought library imports
23 from enable.tools.api import DragTool
24 from enable.api import Component, ComponentEditor
25 from traits.api import HasTraits, Instance, Int, Tuple
26 from traitsui.api import UItem, View
27
28 # Chaco imports
29 from chaco.api import add_default_axes, add_default_grids, \
30 OverlayPlotContainer, PlotLabel, ScatterPlot, create_line_plot
31 from chaco.tools.api import PanTool, ZoomTool
32
33
34
35 class PointDraggingTool(DragTool):
36
37 component = Instance(Component)
38
39 # The pixel distance from a point that the cursor is still considered
40 # to be 'on' the point
41 threshold = Int(5)
42
43 # The index of the point being dragged
44 _drag_index = Int(-1)
45
46 # The original dataspace values of the index and value datasources
47 # corresponding to _drag_index
48 _orig_value = Tuple
49
50 def is_draggable(self, x, y):
51 # Check to see if (x,y) are over one of the points in self.component
52 if self._lookup_point(x, y) is not None:
53 return True
54 else:
55 return False
56
57 def normal_mouse_move(self, event):
58 plot = self.component
59
60 ndx = plot.map_index((event.x, event.y), self.threshold)
61 if ndx is None:
62 if plot.index.metadata.has_key('selections'):
63 del plot.index.metadata['selections']
64 else:
65 plot.index.metadata['selections'] = [ndx]
66
67 plot.invalidate_draw()
68 plot.request_redraw()
69
70
71 def drag_start(self, event):
72 plot = self.component
73 ndx = plot.map_index((event.x, event.y), self.threshold)
74 if ndx is None:
75 return
76 self._drag_index = ndx
77 self._orig_value = (plot.index.get_data()[ndx], plot.value.get_data()[ndx])
78
79 def dragging(self, event):
80 plot = self.component
81
82 data_x, data_y = plot.map_data((event.x, event.y))
83
84 plot.index._data[self._drag_index] = data_x
85 plot.value._data[self._drag_index] = data_y
86 plot.index.data_changed = True
87 plot.value.data_changed = True
88 plot.request_redraw()
89
90 def drag_cancel(self, event):
91 plot = self.component
92 plot.index._data[self._drag_index] = self._orig_value[0]
93 plot.value._data[self._drag_index] = self._orig_value[1]
94 plot.index.data_changed = True
95 plot.value.data_changed = True
96 plot.request_redraw()
97
98 def drag_end(self, event):
99 plot = self.component
100 if plot.index.metadata.has_key('selections'):
101 del plot.index.metadata['selections']
102 plot.invalidate_draw()
103 plot.request_redraw()
104
105 def _lookup_point(self, x, y):
106 """ Finds the point closest to a screen point if it is within self.threshold
107
108 Parameters
109 ==========
110 x : float
111 screen x-coordinate
112 y : float
113 screen y-coordinate
114
115 Returns
116 =======
117 (screen_x, screen_y, distance) of datapoint nearest to the input *(x,y)*.
118 If no data points are within *self.threshold* of *(x,y)*, returns None.
119 """
120
121 if hasattr(self.component, 'get_closest_point'):
122 # This is on BaseXYPlots
123 return self.component.get_closest_point((x,y), threshold=self.threshold)
124
125 return None
126
127
128 #===============================================================================
129 # # Create the Chaco plot.
130 #===============================================================================
131 def _create_plot_component():
132
133 container = OverlayPlotContainer(padding = 50, fill_padding = True,
134 bgcolor = "lightgray", use_backbuffer=True)
135
136 # Create the initial X-series of data
137 numpoints = 30
138 low = -5
139 high = 15.0
140 x = linspace(low, high, numpoints)
141 y = jn(0, x)
142
143 lineplot = create_line_plot((x,y), color=tuple(COLOR_PALETTE[0]), width=2.0)
144 lineplot.selected_color = "none"
145 scatter = ScatterPlot(index = lineplot.index,
146 value = lineplot.value,
147 index_mapper = lineplot.index_mapper,
148 value_mapper = lineplot.value_mapper,
149 color = tuple(COLOR_PALETTE[0]),
150 marker_size = 5)
151 scatter.index.sort_order = "ascending"
152
153 scatter.bgcolor = "white"
154 scatter.border_visible = True
155
156 add_default_grids(scatter)
157 add_default_axes(scatter)
158
159 scatter.tools.append(PanTool(scatter, drag_button="right"))
160
161 # The ZoomTool tool is stateful and allows drawing a zoom
162 # box to select a zoom region.
163 zoom = ZoomTool(scatter, tool_mode="box", always_on=False, drag_button=None)
164 scatter.overlays.append(zoom)
165
166 scatter.tools.append(PointDraggingTool(scatter))
167
168 container.add(lineplot)
169 container.add(scatter)
170
171 # Add the title at the top
172 container.overlays.append(PlotLabel("Line Editor",
173 component=container,
174 font = "swiss 16",
175 overlay_position="top"))
176
177 return container
178
179
180 #===============================================================================
181 # Attributes to use for the plot view.
182 size=(800,700)
183 title="Simple line plot"
184
185 #===============================================================================
186 # # Demo class that is used by the demo.py application.
187 #===============================================================================
188 class Demo(HasTraits):
189 plot = Instance(Component)
190
191 traits_view = View(UItem('plot', editor=ComponentEditor()),
192 width=size[0], height=size[1], resizable=True,
193 title=title
194 )
195
196 def _plot_default(self):
197 return _create_plot_component()
198
199 demo = Demo()
200
201 if __name__ == "__main__":
202 demo.configure_traits()
203
204 #--EOF---
205
[end of examples/demo/edit_line.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/examples/demo/data_labels.py b/examples/demo/data_labels.py
--- a/examples/demo/data_labels.py
+++ b/examples/demo/data_labels.py
@@ -8,9 +8,9 @@
Mousewheel up and down zooms the plot in and out.
Pressing "z" brings up the Zoom Box, and you can click-drag a rectangular
-region to zoom. If you use a sequence of zoom boxes, pressing alt-left-arrow
-and alt-right-arrow moves you forwards and backwards through the
-"zoom history".
+region to zoom. If you use a sequence of zoom boxes, pressing control-y
+and control-z (Meta-y and Meta-z on Mac) moves you forwards and backwards
+through the "zoom history".
Right-drag is enabled on some of the labels.
"""
diff --git a/examples/demo/edit_line.py b/examples/demo/edit_line.py
--- a/examples/demo/edit_line.py
+++ b/examples/demo/edit_line.py
@@ -8,9 +8,10 @@
Mousewheel up and down zooms the plot in and out.
-Pressing "z" brings up the Zoom Box, and you can click-drag a rectangular region to
-zoom. If you use a sequence of zoom boxes, pressing alt-left-arrow and
-alt-right-arrow moves you forwards and backwards through the "zoom history".
+Pressing "z" brings up the Zoom Box, and you can click-drag a rectangular
+region to zoom. If you use a sequence of zoom boxes, pressing control-y and
+control-z (use Meta-y and Meta-z on Mac) moves you forwards and backwards
+through the "zoom history".
"""
# Major library imports
@@ -160,7 +161,7 @@
# The ZoomTool tool is stateful and allows drawing a zoom
# box to select a zoom region.
- zoom = ZoomTool(scatter, tool_mode="box", always_on=False, drag_button=None)
+ zoom = ZoomTool(scatter, tool_mode="box", always_on=False)
scatter.overlays.append(zoom)
scatter.tools.append(PointDraggingTool(scatter))
|
{"golden_diff": "diff --git a/examples/demo/data_labels.py b/examples/demo/data_labels.py\n--- a/examples/demo/data_labels.py\n+++ b/examples/demo/data_labels.py\n@@ -8,9 +8,9 @@\n Mousewheel up and down zooms the plot in and out.\n \n Pressing \"z\" brings up the Zoom Box, and you can click-drag a rectangular\n-region to zoom. If you use a sequence of zoom boxes, pressing alt-left-arrow\n-and alt-right-arrow moves you forwards and backwards through the\n-\"zoom history\".\n+region to zoom. If you use a sequence of zoom boxes, pressing control-y\n+and control-z (Meta-y and Meta-z on Mac) moves you forwards and backwards\n+through the \"zoom history\".\n \n Right-drag is enabled on some of the labels.\n \"\"\"\ndiff --git a/examples/demo/edit_line.py b/examples/demo/edit_line.py\n--- a/examples/demo/edit_line.py\n+++ b/examples/demo/edit_line.py\n@@ -8,9 +8,10 @@\n \n Mousewheel up and down zooms the plot in and out.\n \n-Pressing \"z\" brings up the Zoom Box, and you can click-drag a rectangular region to\n-zoom. If you use a sequence of zoom boxes, pressing alt-left-arrow and\n-alt-right-arrow moves you forwards and backwards through the \"zoom history\".\n+Pressing \"z\" brings up the Zoom Box, and you can click-drag a rectangular\n+region to zoom. If you use a sequence of zoom boxes, pressing control-y and\n+control-z (use Meta-y and Meta-z on Mac) moves you forwards and backwards\n+through the \"zoom history\".\n \"\"\"\n \n # Major library imports\n@@ -160,7 +161,7 @@\n \n # The ZoomTool tool is stateful and allows drawing a zoom\n # box to select a zoom region.\n- zoom = ZoomTool(scatter, tool_mode=\"box\", always_on=False, drag_button=None)\n+ zoom = ZoomTool(scatter, tool_mode=\"box\", always_on=False)\n scatter.overlays.append(zoom)\n \n scatter.tools.append(PointDraggingTool(scatter))\n", "issue": "ZoomTool \"zoom history\" keys are not working\nFrom the examples/data_labels.py docstring:\n\n> Pressing \"z\" brings up the Zoom Box, and you can click-drag a rectangular region to\n> zoom. If you use a sequence of zoom boxes, pressing alt-left-arrow and\n> alt-right-arrow moves you forwards and backwards through the \"zoom history\".\n\nbut the alt-right-arrow and alt-left-arrow keys don't seem to have any effect.\n\n", "before_files": [{"content": "#!/usr/bin/env python\n\"\"\"\nDraws a line plot with several points labelled. Demonstrates how to annotate\nplots.\n\nLeft-drag pans the plot.\n\nMousewheel up and down zooms the plot in and out.\n\nPressing \"z\" brings up the Zoom Box, and you can click-drag a rectangular\nregion to zoom. If you use a sequence of zoom boxes, pressing alt-left-arrow\nand alt-right-arrow moves you forwards and backwards through the\n\"zoom history\".\n\nRight-drag is enabled on some of the labels.\n\"\"\"\n\n# Major library imports\nfrom numpy import linspace\nfrom scipy.special import jn\n\n# Enthought library imports\nfrom enable.api import Component, ComponentEditor\nfrom traits.api import Float, HasTraits, Instance, Int\nfrom traitsui.api import Item, View\n\n# Chaco imports\nfrom chaco.api import create_line_plot, add_default_axes, add_default_grids, \\\n OverlayPlotContainer, DataLabel\nfrom chaco.example_support import COLOR_PALETTE\nfrom chaco.tools.api import PanTool, ZoomTool, DataLabelTool\n\n\nclass PlotExample(HasTraits):\n plot = Instance(Component)\n numpoints = Int(100)\n low = Float(-5.0)\n high = Float(15.0)\n\n traits_view = View(Item('plot', editor=ComponentEditor(),\n show_label=False),\n width=800, height=700, resizable=True,\n title=\"Data label example\")\n\n def _plot_default(self):\n\n container = OverlayPlotContainer(padding=50, fill_padding=True,\n bgcolor=\"lightgray\",\n use_backbuffer=True)\n\n # Create the initial X-series of data\n numpoints = self.numpoints\n low = self.low\n high = self.high\n x = linspace(low, high, numpoints + 1)\n y = jn(0, x)\n plot = create_line_plot((x, y), color=tuple(COLOR_PALETTE[0]),\n width=2.0)\n plot.index.sort_order = \"ascending\"\n plot.bgcolor = \"white\"\n plot.border_visible = True\n add_default_grids(plot)\n add_default_axes(plot)\n\n # Add some tools\n plot.tools.append(PanTool(plot))\n zoom = ZoomTool(plot, tool_mode=\"box\", always_on=False)\n plot.overlays.append(zoom)\n\n # Add a dynamic label. This can be dragged and moved around using the\n # right mouse button. Note the use of padding to offset the label\n # from its data point.\n label = DataLabel(component=plot, data_point=(x[40], y[40]),\n label_position=\"top left\", padding=40,\n bgcolor=\"lightgray\",\n border_visible=False)\n plot.overlays.append(label)\n tool = DataLabelTool(label, drag_button=\"right\", auto_arrow_root=True)\n label.tools.append(tool)\n\n # Add some static labels.\n label2 = DataLabel(component=plot, data_point=(x[20], y[20]),\n label_position=\"bottom right\",\n border_visible=False,\n bgcolor=\"transparent\",\n marker_color=\"blue\",\n marker_line_color=\"transparent\",\n marker=\"diamond\",\n font='modern 14',\n arrow_visible=False)\n plot.overlays.append(label2)\n\n label3 = DataLabel(component=plot, data_point=(x[80], y[80]),\n label_position=\"top\", padding_bottom=20,\n marker_color=\"transparent\",\n marker_size=8,\n marker=\"circle\",\n arrow_visible=False)\n plot.overlays.append(label3)\n\n # This label uses label_style='bubble'.\n label4 = DataLabel(component=plot, data_point=(x[60], y[60]),\n border_padding=10,\n marker_color=\"red\",\n marker_size=3,\n label_position=(20, 50),\n label_style='bubble',\n label_text=\"Something interesting\",\n label_format=\"at x=%(x).2f, y=%(y).2f\",\n font='modern 18',\n bgcolor=(1, 1, 0.75, 1),\n )\n plot.overlays.append(label4)\n tool4 = DataLabelTool(label4, drag_button=\"right\",\n auto_arrow_root=True)\n label4.tools.append(tool4)\n\n # Another 'bubble' label. This one sets arrow_min_length=20, so\n # the arrow is not drawn when the label is close to the data point.\n label5 = DataLabel(component=plot, data_point=(x[65], y[65]),\n border_padding=10,\n marker_color=\"green\",\n marker_size=4,\n show_label_coords=False,\n label_style='bubble',\n label_position=(25, 5),\n label_text=\"Label with\\narrow_min_length=20\",\n border_visible=False,\n arrow_min_length=20,\n font='modern 14',\n bgcolor=(0.75, 0.75, 0.75, 1),\n )\n plot.overlays.append(label5)\n tool5 = DataLabelTool(label5, drag_button=\"right\",\n auto_arrow_root=True)\n label5.tools.append(tool5)\n\n container.add(plot)\n\n return container\n\ndemo = PlotExample()\n\nif __name__ == \"__main__\":\n demo.configure_traits()\n", "path": "examples/demo/data_labels.py"}, {"content": "#!/usr/bin/env python\n\"\"\"\nAllows editing of a line plot.\n\nLeft-dragging a point will move its position.\n\nRight-drag pans the plot.\n\nMousewheel up and down zooms the plot in and out.\n\nPressing \"z\" brings up the Zoom Box, and you can click-drag a rectangular region to\nzoom. If you use a sequence of zoom boxes, pressing alt-left-arrow and\nalt-right-arrow moves you forwards and backwards through the \"zoom history\".\n\"\"\"\n\n# Major library imports\nfrom numpy import linspace\nfrom scipy.special import jn\n\nfrom chaco.example_support import COLOR_PALETTE\n\n# Enthought library imports\nfrom enable.tools.api import DragTool\nfrom enable.api import Component, ComponentEditor\nfrom traits.api import HasTraits, Instance, Int, Tuple\nfrom traitsui.api import UItem, View\n\n# Chaco imports\nfrom chaco.api import add_default_axes, add_default_grids, \\\n OverlayPlotContainer, PlotLabel, ScatterPlot, create_line_plot\nfrom chaco.tools.api import PanTool, ZoomTool\n\n\n\nclass PointDraggingTool(DragTool):\n\n component = Instance(Component)\n\n # The pixel distance from a point that the cursor is still considered\n # to be 'on' the point\n threshold = Int(5)\n\n # The index of the point being dragged\n _drag_index = Int(-1)\n\n # The original dataspace values of the index and value datasources\n # corresponding to _drag_index\n _orig_value = Tuple\n\n def is_draggable(self, x, y):\n # Check to see if (x,y) are over one of the points in self.component\n if self._lookup_point(x, y) is not None:\n return True\n else:\n return False\n\n def normal_mouse_move(self, event):\n plot = self.component\n\n ndx = plot.map_index((event.x, event.y), self.threshold)\n if ndx is None:\n if plot.index.metadata.has_key('selections'):\n del plot.index.metadata['selections']\n else:\n plot.index.metadata['selections'] = [ndx]\n\n plot.invalidate_draw()\n plot.request_redraw()\n\n\n def drag_start(self, event):\n plot = self.component\n ndx = plot.map_index((event.x, event.y), self.threshold)\n if ndx is None:\n return\n self._drag_index = ndx\n self._orig_value = (plot.index.get_data()[ndx], plot.value.get_data()[ndx])\n\n def dragging(self, event):\n plot = self.component\n\n data_x, data_y = plot.map_data((event.x, event.y))\n\n plot.index._data[self._drag_index] = data_x\n plot.value._data[self._drag_index] = data_y\n plot.index.data_changed = True\n plot.value.data_changed = True\n plot.request_redraw()\n\n def drag_cancel(self, event):\n plot = self.component\n plot.index._data[self._drag_index] = self._orig_value[0]\n plot.value._data[self._drag_index] = self._orig_value[1]\n plot.index.data_changed = True\n plot.value.data_changed = True\n plot.request_redraw()\n\n def drag_end(self, event):\n plot = self.component\n if plot.index.metadata.has_key('selections'):\n del plot.index.metadata['selections']\n plot.invalidate_draw()\n plot.request_redraw()\n\n def _lookup_point(self, x, y):\n \"\"\" Finds the point closest to a screen point if it is within self.threshold\n\n Parameters\n ==========\n x : float\n screen x-coordinate\n y : float\n screen y-coordinate\n\n Returns\n =======\n (screen_x, screen_y, distance) of datapoint nearest to the input *(x,y)*.\n If no data points are within *self.threshold* of *(x,y)*, returns None.\n \"\"\"\n\n if hasattr(self.component, 'get_closest_point'):\n # This is on BaseXYPlots\n return self.component.get_closest_point((x,y), threshold=self.threshold)\n\n return None\n\n\n#===============================================================================\n# # Create the Chaco plot.\n#===============================================================================\ndef _create_plot_component():\n\n container = OverlayPlotContainer(padding = 50, fill_padding = True,\n bgcolor = \"lightgray\", use_backbuffer=True)\n\n # Create the initial X-series of data\n numpoints = 30\n low = -5\n high = 15.0\n x = linspace(low, high, numpoints)\n y = jn(0, x)\n\n lineplot = create_line_plot((x,y), color=tuple(COLOR_PALETTE[0]), width=2.0)\n lineplot.selected_color = \"none\"\n scatter = ScatterPlot(index = lineplot.index,\n value = lineplot.value,\n index_mapper = lineplot.index_mapper,\n value_mapper = lineplot.value_mapper,\n color = tuple(COLOR_PALETTE[0]),\n marker_size = 5)\n scatter.index.sort_order = \"ascending\"\n\n scatter.bgcolor = \"white\"\n scatter.border_visible = True\n\n add_default_grids(scatter)\n add_default_axes(scatter)\n\n scatter.tools.append(PanTool(scatter, drag_button=\"right\"))\n\n # The ZoomTool tool is stateful and allows drawing a zoom\n # box to select a zoom region.\n zoom = ZoomTool(scatter, tool_mode=\"box\", always_on=False, drag_button=None)\n scatter.overlays.append(zoom)\n\n scatter.tools.append(PointDraggingTool(scatter))\n\n container.add(lineplot)\n container.add(scatter)\n\n # Add the title at the top\n container.overlays.append(PlotLabel(\"Line Editor\",\n component=container,\n font = \"swiss 16\",\n overlay_position=\"top\"))\n\n return container\n\n\n#===============================================================================\n# Attributes to use for the plot view.\nsize=(800,700)\ntitle=\"Simple line plot\"\n\n#===============================================================================\n# # Demo class that is used by the demo.py application.\n#===============================================================================\nclass Demo(HasTraits):\n plot = Instance(Component)\n\n traits_view = View(UItem('plot', editor=ComponentEditor()),\n width=size[0], height=size[1], resizable=True,\n title=title\n )\n\n def _plot_default(self):\n return _create_plot_component()\n\ndemo = Demo()\n\nif __name__ == \"__main__\":\n demo.configure_traits()\n\n#--EOF---\n", "path": "examples/demo/edit_line.py"}]}
| 4,088 | 456 |
gh_patches_debug_39370
|
rasdani/github-patches
|
git_diff
|
alltheplaces__alltheplaces-8335
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Use clean_address function to join multiple free text lines together
The `clean_address` method added in #7568 allows a standardised approach to taking messy ordered multiple line address strings (of any type of composition) and joining them together into a single string.
We can now use `clean_address` to replace the many variants throughout spiders of attempting to join these multi-line address strings. An added benefit is being able to quickly find where multi-line address strings are parsed (via searching for `clean_address` instances), making it easier to change address handling in the future.
Related to #5598
</issue>
<code>
[start of locations/spiders/zizzi_gb.py]
1 import scrapy
2
3 from locations.dict_parser import DictParser
4
5
6 class ZizziGBSpider(scrapy.Spider):
7 name = "zizzi_gb"
8 item_attributes = {"brand": "Zizzi", "brand_wikidata": "Q8072944"}
9 start_urls = ["https://www.zizzi.co.uk/wp-json/locations/get_venues"]
10
11 def parse(self, response):
12 for store in response.json()["data"]:
13 item = DictParser.parse(store)
14 item["addr_full"] = ", ".join(store["address"].split("\r\n"))
15 item["image"] = store["featured_image"]
16 item["website"] = store["link"]
17
18 if store["region"] == "Ireland":
19 item.pop("state")
20 item["country"] = "IE"
21 else:
22 item["country"] = "GB"
23
24 yield item
25
[end of locations/spiders/zizzi_gb.py]
[start of locations/spiders/zambrero_au.py]
1 import re
2
3 from scrapy import Spider
4 from scrapy.http import Request
5
6 from locations.categories import Categories
7 from locations.hours import OpeningHours
8 from locations.items import Feature
9
10
11 class ZambreroAUSpider(Spider):
12 name = "zambrero_au"
13 item_attributes = {"brand": "Zambrero", "brand_wikidata": "Q18636431", "extras": Categories.FAST_FOOD.value}
14 allowed_domains = ["www.zambrero.com.au"]
15
16 def start_requests(self):
17 yield Request(url=f"https://{self.allowed_domains[0]}/locations", callback=self.parse_location_list)
18
19 def parse_location_list(self, response):
20 location_urls = response.xpath('//div[@data-location-id]//a[@title="Order & Store Info"]/@href').getall()
21 for location_url in location_urls:
22 yield Request(url=location_url, callback=self.parse_location)
23
24 def parse_location(self, response):
25 properties = {
26 "ref": response.xpath("//@data-location-id").get(),
27 "name": re.sub(r"\s+", " ", response.xpath("//div[@data-location-id]/h4/text()").get()).strip(),
28 "lat": response.xpath("//@data-lat").get(),
29 "lon": response.xpath("///@data-lng").get(),
30 "addr_full": re.sub(
31 r"\s+",
32 " ",
33 " ".join(response.xpath('//div[@data-location-id]//span[contains(@class, "address")]/text()').getall()),
34 ).strip(),
35 "phone": response.xpath('//a[contains(@class, "phone")]/@href').get().replace("tel:", ""),
36 "email": response.xpath('//a[contains(@href, "mailto:")]/@href').get().replace("mailto:", ""),
37 "website": response.url,
38 "opening_hours": OpeningHours(),
39 }
40 if "Temporarily Closed" in properties["name"]:
41 return
42 if properties["phone"] == "0":
43 properties.pop("phone")
44
45 hours_text = re.sub(
46 r"\s+", " ", " ".join(response.xpath('//div[contains(@class, "hours-item")]/span/text()').getall())
47 )
48 properties["opening_hours"].add_ranges_from_string(hours_text)
49
50 # Some store names and URLs contain "Opening Soon" but numerous of
51 # these are already open and the URL hasn't been changed. A more
52 # reliable way of knowing a store is not yet open is that it has
53 # no opening hours specified.
54 if not properties["opening_hours"].as_opening_hours():
55 return
56
57 yield Feature(**properties)
58
[end of locations/spiders/zambrero_au.py]
[start of locations/spiders/woolworths_au.py]
1 import scrapy
2
3 from locations.dict_parser import DictParser
4
5
6 class WoolworthsAUSpider(scrapy.Spider):
7 name = "woolworths_au"
8 item_attributes = {"brand": "Woolworths", "brand_wikidata": "Q3249145"}
9 allowed_domains = ["woolworths.com.au"]
10 start_urls = [
11 "https://www.woolworths.com.au/apis/ui/StoreLocator/Stores?Max=10000&Division=SUPERMARKETS,PETROL,CALTEXWOW,AMPOLMETRO,AMPOL&Facility=&postcode=*"
12 ]
13 custom_settings = {"ROBOTSTXT_OBEY": False}
14 requires_proxy = "AU"
15
16 def parse(self, response):
17 data = response.json()
18
19 for i in data["Stores"]:
20 if not i["IsOpen"]:
21 continue
22
23 i["street_address"] = ", ".join(filter(None, [i["AddressLine1"], i["AddressLine2"]]))
24 i["ref"] = i.pop("StoreNo")
25 i["city"] = i.pop("Suburb")
26
27 item = DictParser.parse(i)
28
29 item["website"] = (
30 "https://www.woolworths.com.au/shop/storelocator/"
31 + "-".join([item["state"], item["city"], item["ref"], i["Division"]]).lower()
32 )
33
34 # TODO: types needs some work, NSI seems out of date too
35 item["extras"] = {"type": i["Division"]}
36
37 yield item
38
[end of locations/spiders/woolworths_au.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/locations/spiders/woolworths_au.py b/locations/spiders/woolworths_au.py
--- a/locations/spiders/woolworths_au.py
+++ b/locations/spiders/woolworths_au.py
@@ -1,6 +1,7 @@
import scrapy
from locations.dict_parser import DictParser
+from locations.pipelines.address_clean_up import clean_address
class WoolworthsAUSpider(scrapy.Spider):
@@ -20,7 +21,7 @@
if not i["IsOpen"]:
continue
- i["street_address"] = ", ".join(filter(None, [i["AddressLine1"], i["AddressLine2"]]))
+ i["street_address"] = clean_address([i["AddressLine1"], i["AddressLine2"]])
i["ref"] = i.pop("StoreNo")
i["city"] = i.pop("Suburb")
diff --git a/locations/spiders/zambrero_au.py b/locations/spiders/zambrero_au.py
--- a/locations/spiders/zambrero_au.py
+++ b/locations/spiders/zambrero_au.py
@@ -6,6 +6,7 @@
from locations.categories import Categories
from locations.hours import OpeningHours
from locations.items import Feature
+from locations.pipelines.address_clean_up import clean_address
class ZambreroAUSpider(Spider):
@@ -27,11 +28,9 @@
"name": re.sub(r"\s+", " ", response.xpath("//div[@data-location-id]/h4/text()").get()).strip(),
"lat": response.xpath("//@data-lat").get(),
"lon": response.xpath("///@data-lng").get(),
- "addr_full": re.sub(
- r"\s+",
- " ",
- " ".join(response.xpath('//div[@data-location-id]//span[contains(@class, "address")]/text()').getall()),
- ).strip(),
+ "addr_full": clean_address(
+ " ".join(response.xpath('//div[@data-location-id]//span[contains(@class, "address")]/text()').getall())
+ ),
"phone": response.xpath('//a[contains(@class, "phone")]/@href').get().replace("tel:", ""),
"email": response.xpath('//a[contains(@href, "mailto:")]/@href').get().replace("mailto:", ""),
"website": response.url,
diff --git a/locations/spiders/zizzi_gb.py b/locations/spiders/zizzi_gb.py
--- a/locations/spiders/zizzi_gb.py
+++ b/locations/spiders/zizzi_gb.py
@@ -1,6 +1,7 @@
import scrapy
from locations.dict_parser import DictParser
+from locations.pipelines.address_clean_up import clean_address
class ZizziGBSpider(scrapy.Spider):
@@ -11,7 +12,7 @@
def parse(self, response):
for store in response.json()["data"]:
item = DictParser.parse(store)
- item["addr_full"] = ", ".join(store["address"].split("\r\n"))
+ item["addr_full"] = clean_address(store["address"].split("\r\n"))
item["image"] = store["featured_image"]
item["website"] = store["link"]
|
{"golden_diff": "diff --git a/locations/spiders/woolworths_au.py b/locations/spiders/woolworths_au.py\n--- a/locations/spiders/woolworths_au.py\n+++ b/locations/spiders/woolworths_au.py\n@@ -1,6 +1,7 @@\n import scrapy\n \n from locations.dict_parser import DictParser\n+from locations.pipelines.address_clean_up import clean_address\n \n \n class WoolworthsAUSpider(scrapy.Spider):\n@@ -20,7 +21,7 @@\n if not i[\"IsOpen\"]:\n continue\n \n- i[\"street_address\"] = \", \".join(filter(None, [i[\"AddressLine1\"], i[\"AddressLine2\"]]))\n+ i[\"street_address\"] = clean_address([i[\"AddressLine1\"], i[\"AddressLine2\"]])\n i[\"ref\"] = i.pop(\"StoreNo\")\n i[\"city\"] = i.pop(\"Suburb\")\n \ndiff --git a/locations/spiders/zambrero_au.py b/locations/spiders/zambrero_au.py\n--- a/locations/spiders/zambrero_au.py\n+++ b/locations/spiders/zambrero_au.py\n@@ -6,6 +6,7 @@\n from locations.categories import Categories\n from locations.hours import OpeningHours\n from locations.items import Feature\n+from locations.pipelines.address_clean_up import clean_address\n \n \n class ZambreroAUSpider(Spider):\n@@ -27,11 +28,9 @@\n \"name\": re.sub(r\"\\s+\", \" \", response.xpath(\"//div[@data-location-id]/h4/text()\").get()).strip(),\n \"lat\": response.xpath(\"//@data-lat\").get(),\n \"lon\": response.xpath(\"///@data-lng\").get(),\n- \"addr_full\": re.sub(\n- r\"\\s+\",\n- \" \",\n- \" \".join(response.xpath('//div[@data-location-id]//span[contains(@class, \"address\")]/text()').getall()),\n- ).strip(),\n+ \"addr_full\": clean_address(\n+ \" \".join(response.xpath('//div[@data-location-id]//span[contains(@class, \"address\")]/text()').getall())\n+ ),\n \"phone\": response.xpath('//a[contains(@class, \"phone\")]/@href').get().replace(\"tel:\", \"\"),\n \"email\": response.xpath('//a[contains(@href, \"mailto:\")]/@href').get().replace(\"mailto:\", \"\"),\n \"website\": response.url,\ndiff --git a/locations/spiders/zizzi_gb.py b/locations/spiders/zizzi_gb.py\n--- a/locations/spiders/zizzi_gb.py\n+++ b/locations/spiders/zizzi_gb.py\n@@ -1,6 +1,7 @@\n import scrapy\n \n from locations.dict_parser import DictParser\n+from locations.pipelines.address_clean_up import clean_address\n \n \n class ZizziGBSpider(scrapy.Spider):\n@@ -11,7 +12,7 @@\n def parse(self, response):\n for store in response.json()[\"data\"]:\n item = DictParser.parse(store)\n- item[\"addr_full\"] = \", \".join(store[\"address\"].split(\"\\r\\n\"))\n+ item[\"addr_full\"] = clean_address(store[\"address\"].split(\"\\r\\n\"))\n item[\"image\"] = store[\"featured_image\"]\n item[\"website\"] = store[\"link\"]\n", "issue": "Use clean_address function to join multiple free text lines together\nThe `clean_address` method added in #7568 allows a standardised approach to taking messy ordered multiple line address strings (of any type of composition) and joining them together into a single string.\r\n\r\nWe can now use `clean_address` to replace the many variants throughout spiders of attempting to join these multi-line address strings. An added benefit is being able to quickly find where multi-line address strings are parsed (via searching for `clean_address` instances), making it easier to change address handling in the future.\r\n\r\nRelated to #5598\n", "before_files": [{"content": "import scrapy\n\nfrom locations.dict_parser import DictParser\n\n\nclass ZizziGBSpider(scrapy.Spider):\n name = \"zizzi_gb\"\n item_attributes = {\"brand\": \"Zizzi\", \"brand_wikidata\": \"Q8072944\"}\n start_urls = [\"https://www.zizzi.co.uk/wp-json/locations/get_venues\"]\n\n def parse(self, response):\n for store in response.json()[\"data\"]:\n item = DictParser.parse(store)\n item[\"addr_full\"] = \", \".join(store[\"address\"].split(\"\\r\\n\"))\n item[\"image\"] = store[\"featured_image\"]\n item[\"website\"] = store[\"link\"]\n\n if store[\"region\"] == \"Ireland\":\n item.pop(\"state\")\n item[\"country\"] = \"IE\"\n else:\n item[\"country\"] = \"GB\"\n\n yield item\n", "path": "locations/spiders/zizzi_gb.py"}, {"content": "import re\n\nfrom scrapy import Spider\nfrom scrapy.http import Request\n\nfrom locations.categories import Categories\nfrom locations.hours import OpeningHours\nfrom locations.items import Feature\n\n\nclass ZambreroAUSpider(Spider):\n name = \"zambrero_au\"\n item_attributes = {\"brand\": \"Zambrero\", \"brand_wikidata\": \"Q18636431\", \"extras\": Categories.FAST_FOOD.value}\n allowed_domains = [\"www.zambrero.com.au\"]\n\n def start_requests(self):\n yield Request(url=f\"https://{self.allowed_domains[0]}/locations\", callback=self.parse_location_list)\n\n def parse_location_list(self, response):\n location_urls = response.xpath('//div[@data-location-id]//a[@title=\"Order & Store Info\"]/@href').getall()\n for location_url in location_urls:\n yield Request(url=location_url, callback=self.parse_location)\n\n def parse_location(self, response):\n properties = {\n \"ref\": response.xpath(\"//@data-location-id\").get(),\n \"name\": re.sub(r\"\\s+\", \" \", response.xpath(\"//div[@data-location-id]/h4/text()\").get()).strip(),\n \"lat\": response.xpath(\"//@data-lat\").get(),\n \"lon\": response.xpath(\"///@data-lng\").get(),\n \"addr_full\": re.sub(\n r\"\\s+\",\n \" \",\n \" \".join(response.xpath('//div[@data-location-id]//span[contains(@class, \"address\")]/text()').getall()),\n ).strip(),\n \"phone\": response.xpath('//a[contains(@class, \"phone\")]/@href').get().replace(\"tel:\", \"\"),\n \"email\": response.xpath('//a[contains(@href, \"mailto:\")]/@href').get().replace(\"mailto:\", \"\"),\n \"website\": response.url,\n \"opening_hours\": OpeningHours(),\n }\n if \"Temporarily Closed\" in properties[\"name\"]:\n return\n if properties[\"phone\"] == \"0\":\n properties.pop(\"phone\")\n\n hours_text = re.sub(\n r\"\\s+\", \" \", \" \".join(response.xpath('//div[contains(@class, \"hours-item\")]/span/text()').getall())\n )\n properties[\"opening_hours\"].add_ranges_from_string(hours_text)\n\n # Some store names and URLs contain \"Opening Soon\" but numerous of\n # these are already open and the URL hasn't been changed. A more\n # reliable way of knowing a store is not yet open is that it has\n # no opening hours specified.\n if not properties[\"opening_hours\"].as_opening_hours():\n return\n\n yield Feature(**properties)\n", "path": "locations/spiders/zambrero_au.py"}, {"content": "import scrapy\n\nfrom locations.dict_parser import DictParser\n\n\nclass WoolworthsAUSpider(scrapy.Spider):\n name = \"woolworths_au\"\n item_attributes = {\"brand\": \"Woolworths\", \"brand_wikidata\": \"Q3249145\"}\n allowed_domains = [\"woolworths.com.au\"]\n start_urls = [\n \"https://www.woolworths.com.au/apis/ui/StoreLocator/Stores?Max=10000&Division=SUPERMARKETS,PETROL,CALTEXWOW,AMPOLMETRO,AMPOL&Facility=&postcode=*\"\n ]\n custom_settings = {\"ROBOTSTXT_OBEY\": False}\n requires_proxy = \"AU\"\n\n def parse(self, response):\n data = response.json()\n\n for i in data[\"Stores\"]:\n if not i[\"IsOpen\"]:\n continue\n\n i[\"street_address\"] = \", \".join(filter(None, [i[\"AddressLine1\"], i[\"AddressLine2\"]]))\n i[\"ref\"] = i.pop(\"StoreNo\")\n i[\"city\"] = i.pop(\"Suburb\")\n\n item = DictParser.parse(i)\n\n item[\"website\"] = (\n \"https://www.woolworths.com.au/shop/storelocator/\"\n + \"-\".join([item[\"state\"], item[\"city\"], item[\"ref\"], i[\"Division\"]]).lower()\n )\n\n # TODO: types needs some work, NSI seems out of date too\n item[\"extras\"] = {\"type\": i[\"Division\"]}\n\n yield item\n", "path": "locations/spiders/woolworths_au.py"}]}
| 2,039 | 728 |
gh_patches_debug_15517
|
rasdani/github-patches
|
git_diff
|
InstaPy__InstaPy-458
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Unfollow end prematurelly
Hello I made the following script, but after it unfollows 19 people it neatly ends the session.
Why is it ending prematurly?
from instapy import InstaPy
import os
session = InstaPy(username='login', password='pass')
session.login()
session.set_do_follow(enabled=True, percentage=97, times=1)
##session.set_upper_follower_count(limit = 6500)
#session.set_dont_like('nsfw')
#session.set_dont_like('#exactmatch', '[startswith', ']endswith', 'broadmatch')
session.unfollow_users(amount=500)
#session.follow_by_list(accs, times=1)
session.end()
**Here is the CMD line:**
Logged in successfully!
Number of people followed automatically remaining: 776
--> Ongoing Unfollow 1, now unfollowing: b'amar_tafilovic'
--> Ongoing Unfollow 2, now unfollowing: b'super_car_heaven_'
--> Ongoing Unfollow 3, now unfollowing: b'la2natural'
--> Ongoing Unfollow 4, now unfollowing: b'lusinelusarts'
--> Ongoing Unfollow 5, now unfollowing: b'khfitfam'
--> Ongoing Unfollow 6, now unfollowing: b'nicksforzarealty'
--> Ongoing Unfollow 7, now unfollowing: b'kymu.motivation'
--> Ongoing Unfollow 8, now unfollowing: b'roger.despres'
--> Ongoing Unfollow 9, now unfollowing: b'biene141291'
--> Ongoing Unfollow 10, now unfollowing: b'trendynclassy_acce
sleeping for about 10min
--> Ongoing Unfollow 11, now unfollowing: b'lizzy.pg'
--> Ongoing Unfollow 12, now unfollowing: b'chrisprandy'
--> Ongoing Unfollow 13, now unfollowing: b'faits.n.quotes'
--> Ongoing Unfollow 14, now unfollowing: b'mindsetleader'
--> Ongoing Unfollow 15, now unfollowing: b'55totalpackage55'
--> Ongoing Unfollow 16, now unfollowing: b'sorelleshoes'
--> Ongoing Unfollow 17, now unfollowing: b'babymugglemom'
--> Ongoing Unfollow 18, now unfollowing: b'karrcomedy'
--> Ongoing Unfollow 19, now unfollowing: b'roninisgolden'
--> Total people unfollowed : 19
Session ended
-------------
Thank you in advance,
Jeffrey
</issue>
<code>
[start of instapy/unfollow_util.py]
1 """Module which handles the follow features like unfollowing and following"""
2 import json
3 import csv
4 from .time_util import sleep
5 from random import randint
6 from .util import delete_line_from_file
7 from .util import scroll_bottom
8 from .print_log_writer import log_followed_pool
9
10
11 def set_automated_followed_pool(username):
12 automatedFollowedPool = []
13 try:
14 with open('./logs/' + username + '_followedPool.csv') as followedPoolFile:
15 reader = csv.reader(followedPoolFile)
16 automatedFollowedPool = [row[0] for row in reader]
17
18 print("Number of people followed automatically remaining: {}".format(len(automatedFollowedPool)))
19 followedPoolFile.close()
20
21 except BaseException as e:
22 print("set_automated_followed_pool error \n", str(e))
23
24 return automatedFollowedPool
25
26
27 def unfollow(browser, username, amount, dont_include, onlyInstapyFollowed, automatedFollowedPool):
28 """unfollows the given amount of users"""
29 unfollowNum = 0
30
31 browser.get('https://www.instagram.com/' + username)
32
33 # check how many poeple we are following
34 allfollowing = browser.find_element_by_xpath("//li[3]/a/span").text
35 allfollowing = allfollowing.replace(',', '').replace('.', '')
36 allfollowing = int(allfollowing.replace('k', '00').replace('m', '00000'))
37
38 # throw RuntimeWarning if we are 0 people following
39 if (allfollowing == 0):
40 raise RuntimeWarning('There are 0 people to unfollow')
41
42 try:
43 following_link = browser.find_elements_by_xpath('//header/div[2]//li[3]')
44 following_link[0].click()
45 except BaseException as e:
46 print("following_link error \n", str(e))
47
48 sleep(2)
49
50 # find dialog box
51
52 dialog = browser.find_element_by_xpath('/html/body/div[3]/div/div[2]/div/div[2]')
53
54 # scroll down the page
55 scroll_bottom(browser, dialog, allfollowing)
56
57 # get persons, unfollow buttons, and length of followed pool
58 person_list_a = dialog.find_elements_by_tag_name("a")
59 person_list = []
60
61 for person in person_list_a:
62
63 if person and hasattr(person, 'text') and person.text:
64 person_list.append(person.text)
65
66 follow_buttons = dialog.find_elements_by_tag_name('button')
67 automatedFollowedPoolLength = len(automatedFollowedPool)
68
69 # unfollow loop
70 try:
71 hasSlept = False
72
73 for button, person in zip(follow_buttons, person_list):
74 if unfollowNum >= amount:
75 print("--> Total unfollowNum reached it's amount given ", unfollowNum)
76 break
77
78 if onlyInstapyFollowed == True and unfollowNum >= automatedFollowedPoolLength:
79 print("--> Total unfollowNum exeeded the pool of automated followed ", unfollowNum)
80 break
81
82 if unfollowNum != 0 and hasSlept == False and unfollowNum % 10 == 0:
83 print('sleeping for about 10min')
84 sleep(600)
85 hasSlept = True
86 continue
87
88 if person not in dont_include:
89 if onlyInstapyFollowed == True and person in automatedFollowedPool:
90 unfollowNum += 1
91 button.click()
92 delete_line_from_file('./logs/' + username + '_followedPool.csv', person + ",\n")
93
94 print('--> Ongoing Unfollow From InstaPy ' + str(unfollowNum) + ', now unfollowing: {}'.format(
95 person.encode('utf-8')))
96 sleep(15)
97 # To only sleep once until there is the next unfollow
98 if hasSlept: hasSlept = False
99
100 continue
101
102 elif onlyInstapyFollowed != True:
103 unfollowNum += 1
104 button.click()
105
106 print('--> Ongoing Unfollow ' + str(unfollowNum) + ', now unfollowing: {}'.format(
107 person.encode('utf-8')))
108 sleep(15)
109 # To only sleep once until there is the next unfollow
110 if hasSlept: hasSlept = False
111
112 continue
113
114 else:
115 continue
116
117 except BaseException as e:
118 print("unfollow loop error \n", str(e))
119
120 return unfollowNum
121
122
123 def follow_user(browser, follow_restrict, login, user_name):
124 """Follows the user of the currently opened image"""
125
126 follow_button = browser.find_element_by_xpath("//article/header/span/button")
127 sleep(2)
128
129 if follow_button.text == 'Follow':
130 follow_button.click()
131 print('--> Now following')
132 log_followed_pool(login, user_name)
133 follow_restrict[user_name] = follow_restrict.get(user_name, 0) + 1
134 sleep(3)
135 return 1
136
137 else:
138 print('--> Already following')
139 sleep(1)
140 return 0
141
142
143 def follow_given_user(browser, acc_to_follow, follow_restrict):
144 """Follows a given user."""
145 browser.get('https://www.instagram.com/' + acc_to_follow)
146 print('--> {} instagram account is opened...'.format(acc_to_follow))
147 follow_button = browser.find_element_by_xpath("//*[contains(text(), 'Follow')]")
148 sleep(10)
149 if follow_button.text == 'Follow':
150 follow_button.click()
151 print('---> Now following: {}'.format(acc_to_follow))
152 print('*' * 20)
153 follow_restrict[acc_to_follow] = follow_restrict.get(acc_to_follow, 0) + 1
154 sleep(3)
155 return 1
156 else:
157 print('---> {} is already followed'.format(acc_to_follow))
158 print('*' * 20)
159 sleep(3)
160 return 0
161
162
163 def dump_follow_restriction(followRes):
164 """Dumps the given dictionary to a file using the json format"""
165 with open('./logs/followRestriction.json', 'w') as followResFile:
166 json.dump(followRes, followResFile)
167
168
169 def load_follow_restriction():
170 """Loads the saved """
171 with open('./logs/followRestriction.json') as followResFile:
172 return json.load(followResFile)
173
[end of instapy/unfollow_util.py]
[start of instapy/util.py]
1 from .time_util import sleep
2 from random import randint
3 from random import choice
4
5
6 def delete_line_from_file(filepath, lineToDelete):
7 try:
8 f = open(filepath, "r")
9 lines = f.readlines()
10 f.close()
11 f = open(filepath, "w")
12
13 for line in lines:
14
15 if line != lineToDelete:
16 f.write(line)
17 f.close()
18 except BaseException as e:
19 print("delete_line_from_file error \n", str(e))
20
21
22 def scroll_bottom(browser, element, range_int):
23 # put a limit to the scrolling
24 if range_int > 50: range_int = 1
25
26 for i in range(int(range_int / 2)):
27 browser.execute_script("arguments[0].scrollTop = arguments[0].scrollHeight", element)
28 sleep(1)
29
30 return
31
[end of instapy/util.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/instapy/unfollow_util.py b/instapy/unfollow_util.py
--- a/instapy/unfollow_util.py
+++ b/instapy/unfollow_util.py
@@ -49,7 +49,7 @@
# find dialog box
- dialog = browser.find_element_by_xpath('/html/body/div[3]/div/div[2]/div/div[2]')
+ dialog = browser.find_element_by_xpath('/html/body/div[4]/div/div[2]/div/div[2]/div/div[2]')
# scroll down the page
scroll_bottom(browser, dialog, allfollowing)
diff --git a/instapy/util.py b/instapy/util.py
--- a/instapy/util.py
+++ b/instapy/util.py
@@ -21,7 +21,7 @@
def scroll_bottom(browser, element, range_int):
# put a limit to the scrolling
- if range_int > 50: range_int = 1
+ if range_int > 50: range_int = 50
for i in range(int(range_int / 2)):
browser.execute_script("arguments[0].scrollTop = arguments[0].scrollHeight", element)
|
{"golden_diff": "diff --git a/instapy/unfollow_util.py b/instapy/unfollow_util.py\n--- a/instapy/unfollow_util.py\n+++ b/instapy/unfollow_util.py\n@@ -49,7 +49,7 @@\n \n # find dialog box\n \n- dialog = browser.find_element_by_xpath('/html/body/div[3]/div/div[2]/div/div[2]')\n+ dialog = browser.find_element_by_xpath('/html/body/div[4]/div/div[2]/div/div[2]/div/div[2]')\n \n # scroll down the page\n scroll_bottom(browser, dialog, allfollowing)\ndiff --git a/instapy/util.py b/instapy/util.py\n--- a/instapy/util.py\n+++ b/instapy/util.py\n@@ -21,7 +21,7 @@\n \n def scroll_bottom(browser, element, range_int):\n # put a limit to the scrolling\n- if range_int > 50: range_int = 1\n+ if range_int > 50: range_int = 50\n \n for i in range(int(range_int / 2)):\n browser.execute_script(\"arguments[0].scrollTop = arguments[0].scrollHeight\", element)\n", "issue": "Unfollow end prematurelly \nHello I made the following script, but after it unfollows 19 people it neatly ends the session.\r\nWhy is it ending prematurly? \r\n\r\nfrom instapy import InstaPy\r\nimport os\r\nsession = InstaPy(username='login', password='pass')\r\nsession.login()\r\nsession.set_do_follow(enabled=True, percentage=97, times=1)\r\n##session.set_upper_follower_count(limit = 6500)\r\n#session.set_dont_like('nsfw')\r\n#session.set_dont_like('#exactmatch', '[startswith', ']endswith', 'broadmatch')\r\nsession.unfollow_users(amount=500)\r\n\r\n#session.follow_by_list(accs, times=1)\r\n\r\nsession.end()\r\n\r\n\r\n**Here is the CMD line:**\r\n\r\nLogged in successfully!\r\nNumber of people followed automatically remaining: 776\r\n--> Ongoing Unfollow 1, now unfollowing: b'amar_tafilovic'\r\n--> Ongoing Unfollow 2, now unfollowing: b'super_car_heaven_'\r\n--> Ongoing Unfollow 3, now unfollowing: b'la2natural'\r\n--> Ongoing Unfollow 4, now unfollowing: b'lusinelusarts'\r\n--> Ongoing Unfollow 5, now unfollowing: b'khfitfam'\r\n--> Ongoing Unfollow 6, now unfollowing: b'nicksforzarealty'\r\n--> Ongoing Unfollow 7, now unfollowing: b'kymu.motivation'\r\n--> Ongoing Unfollow 8, now unfollowing: b'roger.despres'\r\n--> Ongoing Unfollow 9, now unfollowing: b'biene141291'\r\n--> Ongoing Unfollow 10, now unfollowing: b'trendynclassy_acce\r\nsleeping for about 10min\r\n--> Ongoing Unfollow 11, now unfollowing: b'lizzy.pg'\r\n--> Ongoing Unfollow 12, now unfollowing: b'chrisprandy'\r\n--> Ongoing Unfollow 13, now unfollowing: b'faits.n.quotes'\r\n--> Ongoing Unfollow 14, now unfollowing: b'mindsetleader'\r\n--> Ongoing Unfollow 15, now unfollowing: b'55totalpackage55'\r\n--> Ongoing Unfollow 16, now unfollowing: b'sorelleshoes'\r\n--> Ongoing Unfollow 17, now unfollowing: b'babymugglemom'\r\n--> Ongoing Unfollow 18, now unfollowing: b'karrcomedy'\r\n--> Ongoing Unfollow 19, now unfollowing: b'roninisgolden'\r\n--> Total people unfollowed : 19\r\n\r\nSession ended\r\n-------------\r\n\r\n\r\nThank you in advance,\r\nJeffrey\n", "before_files": [{"content": "\"\"\"Module which handles the follow features like unfollowing and following\"\"\"\nimport json\nimport csv\nfrom .time_util import sleep\nfrom random import randint\nfrom .util import delete_line_from_file\nfrom .util import scroll_bottom\nfrom .print_log_writer import log_followed_pool\n\n\ndef set_automated_followed_pool(username):\n automatedFollowedPool = []\n try:\n with open('./logs/' + username + '_followedPool.csv') as followedPoolFile:\n reader = csv.reader(followedPoolFile)\n automatedFollowedPool = [row[0] for row in reader]\n\n print(\"Number of people followed automatically remaining: {}\".format(len(automatedFollowedPool)))\n followedPoolFile.close()\n\n except BaseException as e:\n print(\"set_automated_followed_pool error \\n\", str(e))\n\n return automatedFollowedPool\n\n\ndef unfollow(browser, username, amount, dont_include, onlyInstapyFollowed, automatedFollowedPool):\n \"\"\"unfollows the given amount of users\"\"\"\n unfollowNum = 0\n\n browser.get('https://www.instagram.com/' + username)\n\n # check how many poeple we are following\n allfollowing = browser.find_element_by_xpath(\"//li[3]/a/span\").text\n allfollowing = allfollowing.replace(',', '').replace('.', '')\n allfollowing = int(allfollowing.replace('k', '00').replace('m', '00000'))\n\n # throw RuntimeWarning if we are 0 people following\n if (allfollowing == 0):\n raise RuntimeWarning('There are 0 people to unfollow')\n\n try:\n following_link = browser.find_elements_by_xpath('//header/div[2]//li[3]')\n following_link[0].click()\n except BaseException as e:\n print(\"following_link error \\n\", str(e))\n\n sleep(2)\n\n # find dialog box\n\n dialog = browser.find_element_by_xpath('/html/body/div[3]/div/div[2]/div/div[2]')\n\n # scroll down the page\n scroll_bottom(browser, dialog, allfollowing)\n\n # get persons, unfollow buttons, and length of followed pool\n person_list_a = dialog.find_elements_by_tag_name(\"a\")\n person_list = []\n\n for person in person_list_a:\n\n if person and hasattr(person, 'text') and person.text:\n person_list.append(person.text)\n\n follow_buttons = dialog.find_elements_by_tag_name('button')\n automatedFollowedPoolLength = len(automatedFollowedPool)\n\n # unfollow loop\n try:\n hasSlept = False\n\n for button, person in zip(follow_buttons, person_list):\n if unfollowNum >= amount:\n print(\"--> Total unfollowNum reached it's amount given \", unfollowNum)\n break\n\n if onlyInstapyFollowed == True and unfollowNum >= automatedFollowedPoolLength:\n print(\"--> Total unfollowNum exeeded the pool of automated followed \", unfollowNum)\n break\n\n if unfollowNum != 0 and hasSlept == False and unfollowNum % 10 == 0:\n print('sleeping for about 10min')\n sleep(600)\n hasSlept = True\n continue\n\n if person not in dont_include:\n if onlyInstapyFollowed == True and person in automatedFollowedPool:\n unfollowNum += 1\n button.click()\n delete_line_from_file('./logs/' + username + '_followedPool.csv', person + \",\\n\")\n\n print('--> Ongoing Unfollow From InstaPy ' + str(unfollowNum) + ', now unfollowing: {}'.format(\n person.encode('utf-8')))\n sleep(15)\n # To only sleep once until there is the next unfollow\n if hasSlept: hasSlept = False\n\n continue\n\n elif onlyInstapyFollowed != True:\n unfollowNum += 1\n button.click()\n\n print('--> Ongoing Unfollow ' + str(unfollowNum) + ', now unfollowing: {}'.format(\n person.encode('utf-8')))\n sleep(15)\n # To only sleep once until there is the next unfollow\n if hasSlept: hasSlept = False\n\n continue\n\n else:\n continue\n\n except BaseException as e:\n print(\"unfollow loop error \\n\", str(e))\n\n return unfollowNum\n\n\ndef follow_user(browser, follow_restrict, login, user_name):\n \"\"\"Follows the user of the currently opened image\"\"\"\n\n follow_button = browser.find_element_by_xpath(\"//article/header/span/button\")\n sleep(2)\n\n if follow_button.text == 'Follow':\n follow_button.click()\n print('--> Now following')\n log_followed_pool(login, user_name)\n follow_restrict[user_name] = follow_restrict.get(user_name, 0) + 1\n sleep(3)\n return 1\n\n else:\n print('--> Already following')\n sleep(1)\n return 0\n\n\ndef follow_given_user(browser, acc_to_follow, follow_restrict):\n \"\"\"Follows a given user.\"\"\"\n browser.get('https://www.instagram.com/' + acc_to_follow)\n print('--> {} instagram account is opened...'.format(acc_to_follow))\n follow_button = browser.find_element_by_xpath(\"//*[contains(text(), 'Follow')]\")\n sleep(10)\n if follow_button.text == 'Follow':\n follow_button.click()\n print('---> Now following: {}'.format(acc_to_follow))\n print('*' * 20)\n follow_restrict[acc_to_follow] = follow_restrict.get(acc_to_follow, 0) + 1\n sleep(3)\n return 1\n else:\n print('---> {} is already followed'.format(acc_to_follow))\n print('*' * 20)\n sleep(3)\n return 0\n\n\ndef dump_follow_restriction(followRes):\n \"\"\"Dumps the given dictionary to a file using the json format\"\"\"\n with open('./logs/followRestriction.json', 'w') as followResFile:\n json.dump(followRes, followResFile)\n\n\ndef load_follow_restriction():\n \"\"\"Loads the saved \"\"\"\n with open('./logs/followRestriction.json') as followResFile:\n return json.load(followResFile)\n", "path": "instapy/unfollow_util.py"}, {"content": "from .time_util import sleep\nfrom random import randint\nfrom random import choice\n\n\ndef delete_line_from_file(filepath, lineToDelete):\n try:\n f = open(filepath, \"r\")\n lines = f.readlines()\n f.close()\n f = open(filepath, \"w\")\n\n for line in lines:\n\n if line != lineToDelete:\n f.write(line)\n f.close()\n except BaseException as e:\n print(\"delete_line_from_file error \\n\", str(e))\n\n\ndef scroll_bottom(browser, element, range_int):\n # put a limit to the scrolling\n if range_int > 50: range_int = 1\n\n for i in range(int(range_int / 2)):\n browser.execute_script(\"arguments[0].scrollTop = arguments[0].scrollHeight\", element)\n sleep(1)\n\n return\n", "path": "instapy/util.py"}]}
| 3,209 | 263 |
gh_patches_debug_42193
|
rasdani/github-patches
|
git_diff
|
scoutapp__scout_apm_python-438
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Instrument non-index Elasticsearch client methods
There are many methods on the `elasticsearch-py` client class that we aren't instrumenting, for example `ping()`, because they don't operate on an index.
We should capture all these calls too - I'm sure many applications have such calls that would be good to show on traces.
https://github.com/elastic/elasticsearch-py/blob/master/elasticsearch/client/__init__.py
</issue>
<code>
[start of src/scout_apm/instruments/elasticsearch.py]
1 # coding=utf-8
2 from __future__ import absolute_import, division, print_function, unicode_literals
3
4 import logging
5
6 import wrapt
7
8 from scout_apm.core.tracked_request import TrackedRequest
9
10 try:
11 from elasticsearch import Elasticsearch, Transport
12 except ImportError: # pragma: no cover
13 Elasticsearch = None
14 Transport = None
15
16 logger = logging.getLogger(__name__)
17
18
19 def ensure_installed():
20 logger.info("Ensuring elasticsearch instrumentation is installed.")
21
22 if Elasticsearch is None:
23 logger.info("Unable to import elasticsearch.Elasticsearch")
24 else:
25 ensure_client_instrumented()
26 ensure_transport_instrumented()
27
28
29 CLIENT_METHODS = [
30 "bulk",
31 "count",
32 "create",
33 "delete",
34 "delete_by_query",
35 "exists",
36 "exists_source",
37 "explain",
38 "field_caps",
39 "get",
40 "get_source",
41 "index",
42 "mget",
43 "msearch",
44 "msearch_template",
45 "mtermvectors",
46 "reindex",
47 "reindex_rethrottle",
48 "search",
49 "search_shards",
50 "search_template",
51 "termvectors",
52 "update",
53 "update_by_query",
54 ]
55
56
57 have_patched_client = False
58
59
60 def ensure_client_instrumented():
61 global have_patched_client
62
63 if not have_patched_client:
64 for name in CLIENT_METHODS:
65 try:
66 setattr(
67 Elasticsearch,
68 name,
69 wrap_client_method(getattr(Elasticsearch, name)),
70 )
71 except Exception as exc:
72 logger.warning(
73 "Unable to instrument elasticsearch.Elasticsearch.%s: %r",
74 name,
75 exc,
76 exc_info=exc,
77 )
78
79 have_patched_client = True
80
81
82 @wrapt.decorator
83 def wrap_client_method(wrapped, instance, args, kwargs):
84 def _get_index(index, *args, **kwargs):
85 return index
86
87 try:
88 index = _get_index(*args, **kwargs)
89 except TypeError:
90 index = "Unknown"
91 else:
92 if not index:
93 index = "Unknown"
94 if isinstance(index, (list, tuple)):
95 index = ",".join(index)
96 index = index.title()
97 camel_name = "".join(c.title() for c in wrapped.__name__.split("_"))
98 operation = "Elasticsearch/{}/{}".format(index, camel_name)
99 tracked_request = TrackedRequest.instance()
100 tracked_request.start_span(operation=operation, ignore_children=True)
101
102 try:
103 return wrapped(*args, **kwargs)
104 finally:
105 tracked_request.stop_span()
106
107
108 have_patched_transport = False
109
110
111 def ensure_transport_instrumented():
112 global have_patched_transport
113
114 if not have_patched_transport:
115 try:
116 Transport.perform_request = wrapped_perform_request(
117 Transport.perform_request
118 )
119 except Exception as exc:
120 logger.warning(
121 "Unable to instrument elasticsearch.Transport.perform_request: %r",
122 exc,
123 exc_info=exc,
124 )
125
126 have_patched_transport = True
127
128
129 def _sanitize_name(name):
130 try:
131 op = name.split("/")[-1]
132 op = op[1:] # chop leading '_' from op
133 known_names = (
134 "bench",
135 "bulk",
136 "count",
137 "exists",
138 "explain",
139 "field_stats",
140 "health",
141 "mget",
142 "mlt",
143 "mpercolate",
144 "msearch",
145 "mtermvectors",
146 "percolate",
147 "query",
148 "scroll",
149 "search_shards",
150 "source",
151 "suggest",
152 "template",
153 "termvectors",
154 "update",
155 "search",
156 )
157 if op in known_names:
158 return op.title()
159 return "Unknown"
160 except Exception:
161 return "Unknown"
162
163
164 @wrapt.decorator
165 def wrapped_perform_request(wrapped, instance, args, kwargs):
166 try:
167 op = _sanitize_name(args[1])
168 except IndexError:
169 op = "Unknown"
170
171 tracked_request = TrackedRequest.instance()
172 tracked_request.start_span(
173 operation="Elasticsearch/{}".format(op), ignore_children=True
174 )
175
176 try:
177 return wrapped(*args, **kwargs)
178 finally:
179 tracked_request.stop_span()
180
[end of src/scout_apm/instruments/elasticsearch.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/scout_apm/instruments/elasticsearch.py b/src/scout_apm/instruments/elasticsearch.py
--- a/src/scout_apm/instruments/elasticsearch.py
+++ b/src/scout_apm/instruments/elasticsearch.py
@@ -2,6 +2,7 @@
from __future__ import absolute_import, division, print_function, unicode_literals
import logging
+from collections import namedtuple
import wrapt
@@ -26,31 +27,46 @@
ensure_transport_instrumented()
+ClientMethod = namedtuple("ClientMethod", ["name", "takes_index_argument"])
+
CLIENT_METHODS = [
- "bulk",
- "count",
- "create",
- "delete",
- "delete_by_query",
- "exists",
- "exists_source",
- "explain",
- "field_caps",
- "get",
- "get_source",
- "index",
- "mget",
- "msearch",
- "msearch_template",
- "mtermvectors",
- "reindex",
- "reindex_rethrottle",
- "search",
- "search_shards",
- "search_template",
- "termvectors",
- "update",
- "update_by_query",
+ ClientMethod("bulk", True),
+ ClientMethod("clear_scroll", False),
+ ClientMethod("count", True),
+ ClientMethod("create", True),
+ ClientMethod("delete", True),
+ ClientMethod("delete_by_query", True),
+ ClientMethod("delete_by_query_rethrottle", False),
+ ClientMethod("delete_script", False),
+ ClientMethod("exists", True),
+ ClientMethod("exists_source", True),
+ ClientMethod("explain", True),
+ ClientMethod("field_caps", True),
+ ClientMethod("get", True),
+ ClientMethod("get_script", False),
+ ClientMethod("get_source", True),
+ ClientMethod("index", True),
+ ClientMethod("info", False),
+ ClientMethod("mget", True),
+ ClientMethod("msearch", True),
+ ClientMethod("msearch_template", True),
+ ClientMethod("mtermvectors", True),
+ ClientMethod("ping", False),
+ ClientMethod("put_script", False),
+ ClientMethod("rank_eval", True),
+ ClientMethod("reindex", False),
+ ClientMethod("reindex_rethrottle", False),
+ ClientMethod("render_search_template", False),
+ ClientMethod("scripts_painless_context", False),
+ ClientMethod("scripts_painless_execute", False),
+ ClientMethod("scroll", False),
+ ClientMethod("search", True),
+ ClientMethod("search_shards", True),
+ ClientMethod("search_template", True),
+ ClientMethod("termvectors", True),
+ ClientMethod("update", True),
+ ClientMethod("update_by_query", True),
+ ClientMethod("update_by_query_rethrottle", False),
]
@@ -61,13 +77,14 @@
global have_patched_client
if not have_patched_client:
- for name in CLIENT_METHODS:
+ for name, takes_index_argument in CLIENT_METHODS:
try:
- setattr(
- Elasticsearch,
- name,
- wrap_client_method(getattr(Elasticsearch, name)),
- )
+ method = getattr(Elasticsearch, name)
+ if takes_index_argument:
+ wrapped = wrap_client_index_method(method)
+ else:
+ wrapped = wrap_client_method(method)
+ setattr(Elasticsearch, name, wrapped)
except Exception as exc:
logger.warning(
"Unable to instrument elasticsearch.Elasticsearch.%s: %r",
@@ -80,7 +97,7 @@
@wrapt.decorator
-def wrap_client_method(wrapped, instance, args, kwargs):
+def wrap_client_index_method(wrapped, instance, args, kwargs):
def _get_index(index, *args, **kwargs):
return index
@@ -105,6 +122,19 @@
tracked_request.stop_span()
[email protected]
+def wrap_client_method(wrapped, instance, args, kwargs):
+ camel_name = "".join(c.title() for c in wrapped.__name__.split("_"))
+ operation = "Elasticsearch/{}".format(camel_name)
+ tracked_request = TrackedRequest.instance()
+ tracked_request.start_span(operation=operation, ignore_children=True)
+
+ try:
+ return wrapped(*args, **kwargs)
+ finally:
+ tracked_request.stop_span()
+
+
have_patched_transport = False
|
{"golden_diff": "diff --git a/src/scout_apm/instruments/elasticsearch.py b/src/scout_apm/instruments/elasticsearch.py\n--- a/src/scout_apm/instruments/elasticsearch.py\n+++ b/src/scout_apm/instruments/elasticsearch.py\n@@ -2,6 +2,7 @@\n from __future__ import absolute_import, division, print_function, unicode_literals\n \n import logging\n+from collections import namedtuple\n \n import wrapt\n \n@@ -26,31 +27,46 @@\n ensure_transport_instrumented()\n \n \n+ClientMethod = namedtuple(\"ClientMethod\", [\"name\", \"takes_index_argument\"])\n+\n CLIENT_METHODS = [\n- \"bulk\",\n- \"count\",\n- \"create\",\n- \"delete\",\n- \"delete_by_query\",\n- \"exists\",\n- \"exists_source\",\n- \"explain\",\n- \"field_caps\",\n- \"get\",\n- \"get_source\",\n- \"index\",\n- \"mget\",\n- \"msearch\",\n- \"msearch_template\",\n- \"mtermvectors\",\n- \"reindex\",\n- \"reindex_rethrottle\",\n- \"search\",\n- \"search_shards\",\n- \"search_template\",\n- \"termvectors\",\n- \"update\",\n- \"update_by_query\",\n+ ClientMethod(\"bulk\", True),\n+ ClientMethod(\"clear_scroll\", False),\n+ ClientMethod(\"count\", True),\n+ ClientMethod(\"create\", True),\n+ ClientMethod(\"delete\", True),\n+ ClientMethod(\"delete_by_query\", True),\n+ ClientMethod(\"delete_by_query_rethrottle\", False),\n+ ClientMethod(\"delete_script\", False),\n+ ClientMethod(\"exists\", True),\n+ ClientMethod(\"exists_source\", True),\n+ ClientMethod(\"explain\", True),\n+ ClientMethod(\"field_caps\", True),\n+ ClientMethod(\"get\", True),\n+ ClientMethod(\"get_script\", False),\n+ ClientMethod(\"get_source\", True),\n+ ClientMethod(\"index\", True),\n+ ClientMethod(\"info\", False),\n+ ClientMethod(\"mget\", True),\n+ ClientMethod(\"msearch\", True),\n+ ClientMethod(\"msearch_template\", True),\n+ ClientMethod(\"mtermvectors\", True),\n+ ClientMethod(\"ping\", False),\n+ ClientMethod(\"put_script\", False),\n+ ClientMethod(\"rank_eval\", True),\n+ ClientMethod(\"reindex\", False),\n+ ClientMethod(\"reindex_rethrottle\", False),\n+ ClientMethod(\"render_search_template\", False),\n+ ClientMethod(\"scripts_painless_context\", False),\n+ ClientMethod(\"scripts_painless_execute\", False),\n+ ClientMethod(\"scroll\", False),\n+ ClientMethod(\"search\", True),\n+ ClientMethod(\"search_shards\", True),\n+ ClientMethod(\"search_template\", True),\n+ ClientMethod(\"termvectors\", True),\n+ ClientMethod(\"update\", True),\n+ ClientMethod(\"update_by_query\", True),\n+ ClientMethod(\"update_by_query_rethrottle\", False),\n ]\n \n \n@@ -61,13 +77,14 @@\n global have_patched_client\n \n if not have_patched_client:\n- for name in CLIENT_METHODS:\n+ for name, takes_index_argument in CLIENT_METHODS:\n try:\n- setattr(\n- Elasticsearch,\n- name,\n- wrap_client_method(getattr(Elasticsearch, name)),\n- )\n+ method = getattr(Elasticsearch, name)\n+ if takes_index_argument:\n+ wrapped = wrap_client_index_method(method)\n+ else:\n+ wrapped = wrap_client_method(method)\n+ setattr(Elasticsearch, name, wrapped)\n except Exception as exc:\n logger.warning(\n \"Unable to instrument elasticsearch.Elasticsearch.%s: %r\",\n@@ -80,7 +97,7 @@\n \n \n @wrapt.decorator\n-def wrap_client_method(wrapped, instance, args, kwargs):\n+def wrap_client_index_method(wrapped, instance, args, kwargs):\n def _get_index(index, *args, **kwargs):\n return index\n \n@@ -105,6 +122,19 @@\n tracked_request.stop_span()\n \n \[email protected]\n+def wrap_client_method(wrapped, instance, args, kwargs):\n+ camel_name = \"\".join(c.title() for c in wrapped.__name__.split(\"_\"))\n+ operation = \"Elasticsearch/{}\".format(camel_name)\n+ tracked_request = TrackedRequest.instance()\n+ tracked_request.start_span(operation=operation, ignore_children=True)\n+\n+ try:\n+ return wrapped(*args, **kwargs)\n+ finally:\n+ tracked_request.stop_span()\n+\n+\n have_patched_transport = False\n", "issue": "Instrument non-index Elasticsearch client methods\nThere are many methods on the `elasticsearch-py` client class that we aren't instrumenting, for example `ping()`, because they don't operate on an index.\r\n\r\nWe should capture all these calls too - I'm sure many applications have such calls that would be good to show on traces.\r\n\r\nhttps://github.com/elastic/elasticsearch-py/blob/master/elasticsearch/client/__init__.py\n", "before_files": [{"content": "# coding=utf-8\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nimport logging\n\nimport wrapt\n\nfrom scout_apm.core.tracked_request import TrackedRequest\n\ntry:\n from elasticsearch import Elasticsearch, Transport\nexcept ImportError: # pragma: no cover\n Elasticsearch = None\n Transport = None\n\nlogger = logging.getLogger(__name__)\n\n\ndef ensure_installed():\n logger.info(\"Ensuring elasticsearch instrumentation is installed.\")\n\n if Elasticsearch is None:\n logger.info(\"Unable to import elasticsearch.Elasticsearch\")\n else:\n ensure_client_instrumented()\n ensure_transport_instrumented()\n\n\nCLIENT_METHODS = [\n \"bulk\",\n \"count\",\n \"create\",\n \"delete\",\n \"delete_by_query\",\n \"exists\",\n \"exists_source\",\n \"explain\",\n \"field_caps\",\n \"get\",\n \"get_source\",\n \"index\",\n \"mget\",\n \"msearch\",\n \"msearch_template\",\n \"mtermvectors\",\n \"reindex\",\n \"reindex_rethrottle\",\n \"search\",\n \"search_shards\",\n \"search_template\",\n \"termvectors\",\n \"update\",\n \"update_by_query\",\n]\n\n\nhave_patched_client = False\n\n\ndef ensure_client_instrumented():\n global have_patched_client\n\n if not have_patched_client:\n for name in CLIENT_METHODS:\n try:\n setattr(\n Elasticsearch,\n name,\n wrap_client_method(getattr(Elasticsearch, name)),\n )\n except Exception as exc:\n logger.warning(\n \"Unable to instrument elasticsearch.Elasticsearch.%s: %r\",\n name,\n exc,\n exc_info=exc,\n )\n\n have_patched_client = True\n\n\[email protected]\ndef wrap_client_method(wrapped, instance, args, kwargs):\n def _get_index(index, *args, **kwargs):\n return index\n\n try:\n index = _get_index(*args, **kwargs)\n except TypeError:\n index = \"Unknown\"\n else:\n if not index:\n index = \"Unknown\"\n if isinstance(index, (list, tuple)):\n index = \",\".join(index)\n index = index.title()\n camel_name = \"\".join(c.title() for c in wrapped.__name__.split(\"_\"))\n operation = \"Elasticsearch/{}/{}\".format(index, camel_name)\n tracked_request = TrackedRequest.instance()\n tracked_request.start_span(operation=operation, ignore_children=True)\n\n try:\n return wrapped(*args, **kwargs)\n finally:\n tracked_request.stop_span()\n\n\nhave_patched_transport = False\n\n\ndef ensure_transport_instrumented():\n global have_patched_transport\n\n if not have_patched_transport:\n try:\n Transport.perform_request = wrapped_perform_request(\n Transport.perform_request\n )\n except Exception as exc:\n logger.warning(\n \"Unable to instrument elasticsearch.Transport.perform_request: %r\",\n exc,\n exc_info=exc,\n )\n\n have_patched_transport = True\n\n\ndef _sanitize_name(name):\n try:\n op = name.split(\"/\")[-1]\n op = op[1:] # chop leading '_' from op\n known_names = (\n \"bench\",\n \"bulk\",\n \"count\",\n \"exists\",\n \"explain\",\n \"field_stats\",\n \"health\",\n \"mget\",\n \"mlt\",\n \"mpercolate\",\n \"msearch\",\n \"mtermvectors\",\n \"percolate\",\n \"query\",\n \"scroll\",\n \"search_shards\",\n \"source\",\n \"suggest\",\n \"template\",\n \"termvectors\",\n \"update\",\n \"search\",\n )\n if op in known_names:\n return op.title()\n return \"Unknown\"\n except Exception:\n return \"Unknown\"\n\n\[email protected]\ndef wrapped_perform_request(wrapped, instance, args, kwargs):\n try:\n op = _sanitize_name(args[1])\n except IndexError:\n op = \"Unknown\"\n\n tracked_request = TrackedRequest.instance()\n tracked_request.start_span(\n operation=\"Elasticsearch/{}\".format(op), ignore_children=True\n )\n\n try:\n return wrapped(*args, **kwargs)\n finally:\n tracked_request.stop_span()\n", "path": "src/scout_apm/instruments/elasticsearch.py"}]}
| 2,000 | 1,023 |
gh_patches_debug_31899
|
rasdani/github-patches
|
git_diff
|
sql-machine-learning__elasticdl-1380
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Do not save ElasticDL embedding's variables in the master
In current code, ElasticDL embedding layer create trainable variables and use them only for training under graph mode (i.e. under tf.function decorator). These variables are used for training and thus should only be created in workers.
However, now ElasticDL embedding layer creates these variables in `__init__` function. The master (or PS) creates these variables when it creates a model instance, and then save these variables in `self._model`.
I propose that ElasticDL embedding layer should not create these variables in `__init__` function. Instead, creating them before the training process only in worker is enough.
</issue>
<code>
[start of elasticdl/python/elasticdl/layers/embedding.py]
1 import collections
2
3 import numpy as np
4 import tensorflow as tf
5 from tensorflow.python.keras.utils import tf_utils
6
7 from elasticdl.python.master.embedding_service import EmbeddingService
8
9 EmbeddingAndIds = collections.namedtuple(
10 "EmbeddingAndIds", ["batch_embedding", "batch_ids"]
11 )
12
13
14 class Embedding(tf.keras.layers.Layer):
15 """
16 Input: indexes for the embedding entries with a shape of
17 (batch_size, input_length). Input can be either dense tensor
18 or SparseTensor.
19 Output:
20 corresponding (combined) embeddings with a shape of
21 (batch_size, input_length, output_dim) if combiner is None
22 (batch_size, output_dim) if combiner is not None
23 Arguments:
24 output_dim: the dimension of the embedding vector
25 embedding_initializer: Initializer for embedding table
26 mask_zero: Whether or not the input value 0 is a special "padding"
27 value that should be masked out.
28 If input is SparseTensor, mask_zero must be False.
29 input_length: Length of input sequences, when it is constant.
30 This argument is required if you are going to connect
31 `Flatten` then `Dense` layers upstream
32 (without it, the shape of the dense outputs cannot be computed).
33 combiner: A string specifying the reduction op or None if not used.
34 "mean", "sqrtn" and "sum" are supported for the reduction op.
35 If input is SparseTensor, combiner must set as a reduction op.
36 """
37
38 def __init__(
39 self,
40 output_dim,
41 embedding_initializer="uniform",
42 mask_zero=False,
43 input_length=None,
44 combiner=None,
45 embedding_service_endpoint=None,
46 **kwargs
47 ):
48 if "input_shape" not in kwargs and input_length:
49 kwargs["input_shape"] = (input_length,)
50 super(Embedding, self).__init__(**kwargs)
51
52 self.output_dim = output_dim
53 self.embedding_initializer = embedding_initializer
54 self.supports_masking = mask_zero
55 self.input_length = input_length
56 self.combiner = combiner
57 self.embedding_service_endpoint = embedding_service_endpoint
58 self.tape = None
59 self.lookup_func = None
60
61 self._embedding_and_ids_eagerly = []
62
63 # BET's shape and ids' shape in `self._embedding_and_ids_graph` have
64 # `None` dimension. This is because they have different shapes in
65 # different iterations.
66 # `tf.Variable` requires initial value if shape has `None` dimension.
67 self._embedding_and_ids_graph = [
68 EmbeddingAndIds(
69 batch_embedding=tf.Variable(
70 initial_value=tf.zeros((1, self.output_dim)),
71 shape=tf.TensorShape((None, self.output_dim)),
72 dtype=tf.float32,
73 trainable=True,
74 ),
75 batch_ids=tf.Variable(
76 initial_value=tf.zeros((1, 1), dtype=tf.int64),
77 shape=tf.TensorShape(None),
78 dtype=tf.int64,
79 trainable=False,
80 ),
81 )
82 ]
83
84 @tf_utils.shape_type_conversion
85 def compute_output_shape(self, input_shape):
86 # this function is taken from
87 # tf.keras.layers.Embedding.compute_output_shape
88 # https://github.com/tensorflow/tensorflow/blob/3f3c728bf80e0fd6653744318cbbfe1454c6ddca/tensorflow/python/keras/layers/embeddings.py#L156
89 if self.input_length is None:
90 return input_shape + (self.output_dim,)
91 else:
92 if isinstance(self.input_length, (list, tuple)):
93 in_lens = list(self.input_length)
94 else:
95 in_lens = [self.input_length]
96 if len(in_lens) != len(input_shape) - 1:
97 raise ValueError(
98 '"input_length" is %s, '
99 "but received input has shape %s"
100 % (str(self.input_length), str(input_shape))
101 )
102 else:
103 for i, (s1, s2) in enumerate(zip(in_lens, input_shape[1:])):
104 if s1 is not None and s2 is not None and s1 != s2:
105 raise ValueError(
106 '"input_length" is %s, '
107 "but received input has shape %s"
108 % (str(self.input_length), str(input_shape))
109 )
110 elif s1 is None:
111 in_lens[i] = s2
112 return (input_shape[0],) + tuple(in_lens) + (self.output_dim,)
113
114 @property
115 def name(self):
116 return self._name
117
118 @staticmethod
119 def get_key(name_list):
120 return "-".join(map(str, name_list))
121
122 def lookup_embedding(self, unique_ids):
123 ids = unique_ids.numpy()
124 keys = [Embedding.get_key([self._name, id]) for id in ids]
125 (
126 embedding_vectors,
127 unknown_keys_index,
128 ) = EmbeddingService.lookup_embedding(
129 keys=keys,
130 embedding_service_endpoint=self.embedding_service_endpoint,
131 )
132
133 if unknown_keys_index:
134 # Initialize unknown_keys' embedding vectors and write into Redis.
135 unknown_keys = [keys[index] for index in unknown_keys_index]
136 initializer = tf.keras.initializers.get(self.embedding_initializer)
137 embedding_vector_init = [
138 initializer(shape=[1, self.output_dim]).numpy()
139 for _ in unknown_keys
140 ]
141 embedding_vector_init = np.concatenate(
142 embedding_vector_init, axis=0
143 )
144 EmbeddingService.update_embedding(
145 keys=unknown_keys,
146 embedding_vectors=embedding_vector_init,
147 embedding_service_endpoint=self.embedding_service_endpoint,
148 set_if_not_exist=True,
149 )
150 # Lookup unknown_keys' embedding vectors
151 (
152 embedding_vectors_new,
153 unknown_keys_idx_new,
154 ) = EmbeddingService.lookup_embedding(
155 keys=unknown_keys,
156 embedding_service_endpoint=self.embedding_service_endpoint,
157 )
158 if unknown_keys_idx_new:
159 raise Exception(
160 "Update embedding vector: %s failed."
161 % str(
162 [unknown_keys[index] for index in unknown_keys_idx_new]
163 )
164 )
165 for key_index, vector in zip(
166 unknown_keys_index, embedding_vectors_new
167 ):
168 embedding_vectors[key_index] = vector
169 embedding_vectors = np.concatenate(embedding_vectors, axis=0)
170 return embedding_vectors.reshape((len(keys), self.output_dim))
171
172 def _record_gradients(self, batch_embedding, ids):
173 if tf.executing_eagerly():
174 self.tape.watch(batch_embedding)
175 self._embedding_and_ids_eagerly.append(
176 EmbeddingAndIds(batch_embedding, ids)
177 )
178 else:
179 # In graph mode, assigning tensors to trainable variables is
180 # allowed and tape can record the gradients of trainable
181 # variables automatically.
182 embedding_and_ids = self._embedding_and_ids_graph[0]
183 embedding_and_ids.batch_embedding.assign(batch_embedding)
184 embedding_and_ids.batch_ids.assign(ids)
185 batch_embedding = embedding_and_ids.batch_embedding
186 return batch_embedding
187
188 def call(self, input):
189 input = tf.cast(input, tf.int64)
190 if isinstance(input, tf.SparseTensor):
191 return self._sparse_input_call(input)
192
193 ids = tf.convert_to_tensor(input, name="embedding_ids")
194 flat_ids = tf.reshape(ids, [-1])
195 unique_ids, idx = tf.unique(flat_ids)
196 # Gradient for `batch_embedding` is SparseTensor here due to
197 # `tf.gather` op. `tf.gather` accesses tensor slices, resulting in
198 # sparse tensor gradient.
199 batch_embedding = tf.py_function(
200 self.lookup_embedding, inp=[unique_ids], Tout=tf.float32
201 )
202 # TODO: use tf.cond rather than python if statement
203 if self.tape:
204 batch_embedding = self._record_gradients(batch_embedding, flat_ids)
205
206 outputs = tf.gather(batch_embedding, idx)
207 # tf.reshape does not support shape with None. Replace None with -1.
208 if ids.get_shape().rank == 2:
209 input_length = ids.get_shape()[1]
210 if input_length is None:
211 outputs.set_shape(shape=(None, None, self.output_dim))
212 return outputs
213 output_shape = (-1, input_length, self.output_dim)
214 else:
215 output_shape = ids.get_shape().concatenate(self.output_dim)
216 outputs = tf.reshape(outputs, output_shape)
217 # TODO: support combiner for dense input
218 return outputs
219
220 def _sparse_input_call(self, sparse_input):
221 if self.combiner not in ["sum", "mean", "sqrtn"]:
222 raise ValueError(
223 "combiner must set sum, mean or sqrtn for sparse input"
224 )
225 unique_ids, idx = tf.unique(sparse_input.values)
226 # Gradient for `batch_embedding` is dense tensor.
227 batch_embedding = tf.py_function(
228 self.lookup_embedding, inp=[unique_ids], Tout=tf.float32
229 )
230 # TODO: use tf.cond rather than python if statement
231 if self.tape:
232 batch_embedding = self._record_gradients(
233 batch_embedding, unique_ids
234 )
235
236 segment_ids = sparse_input.indices[:, 0]
237 if segment_ids.dtype != tf.int32:
238 segment_ids = tf.cast(segment_ids, tf.int32)
239
240 if self.combiner == "sum":
241 batch_embedding = tf.sparse.segment_sum(
242 batch_embedding, idx, segment_ids
243 )
244 elif self.combiner == "mean":
245 batch_embedding = tf.sparse.segment_mean(
246 batch_embedding, idx, segment_ids
247 )
248 elif self.combiner == "sqrtn":
249 batch_embedding = tf.sparse.segment_sqrt_n(
250 batch_embedding, idx, segment_ids
251 )
252 return batch_embedding
253
254 def compute_mask(self, inputs, mask=None):
255 if isinstance(input, tf.SparseTensor):
256 raise ValueError("SparseTensor inputs do not support mask_zero")
257 if not self.supports_masking:
258 return None
259 return tf.math.not_equal(inputs, 0)
260
261 def reset(self):
262 self._embedding_and_ids_eagerly = []
263 self.tape = None
264
265 def set_tape(self, tape):
266 self.tape = tape
267
268 def set_endpoint(self, endpoint):
269 self.embedding_service_endpoint = endpoint
270
271 @property
272 def embedding_and_ids(self):
273 """
274 Return bet and ids pairs.
275 """
276 if self._embedding_and_ids_eagerly:
277 return self._embedding_and_ids_eagerly
278 return self._embedding_and_ids_graph
279
[end of elasticdl/python/elasticdl/layers/embedding.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/elasticdl/python/elasticdl/layers/embedding.py b/elasticdl/python/elasticdl/layers/embedding.py
--- a/elasticdl/python/elasticdl/layers/embedding.py
+++ b/elasticdl/python/elasticdl/layers/embedding.py
@@ -64,16 +64,21 @@
# `None` dimension. This is because they have different shapes in
# different iterations.
# `tf.Variable` requires initial value if shape has `None` dimension.
+ self._embedding_and_ids_graph = []
+
+ def _init_for_graph_mode(self):
self._embedding_and_ids_graph = [
EmbeddingAndIds(
batch_embedding=tf.Variable(
- initial_value=tf.zeros((1, self.output_dim)),
+ # In some cases, `tf.Variable` requires that initial value
+ # is callable.
+ initial_value=lambda: tf.zeros((1, self.output_dim)),
shape=tf.TensorShape((None, self.output_dim)),
dtype=tf.float32,
trainable=True,
),
batch_ids=tf.Variable(
- initial_value=tf.zeros((1, 1), dtype=tf.int64),
+ initial_value=lambda: tf.zeros((1, 1), dtype=tf.int64),
shape=tf.TensorShape(None),
dtype=tf.int64,
trainable=False,
@@ -186,6 +191,13 @@
return batch_embedding
def call(self, input):
+ if (
+ self.tape
+ and not tf.executing_eagerly()
+ and not self._embedding_and_ids_graph
+ ):
+ self._init_for_graph_mode()
+
input = tf.cast(input, tf.int64)
if isinstance(input, tf.SparseTensor):
return self._sparse_input_call(input)
|
{"golden_diff": "diff --git a/elasticdl/python/elasticdl/layers/embedding.py b/elasticdl/python/elasticdl/layers/embedding.py\n--- a/elasticdl/python/elasticdl/layers/embedding.py\n+++ b/elasticdl/python/elasticdl/layers/embedding.py\n@@ -64,16 +64,21 @@\n # `None` dimension. This is because they have different shapes in\n # different iterations.\n # `tf.Variable` requires initial value if shape has `None` dimension.\n+ self._embedding_and_ids_graph = []\n+\n+ def _init_for_graph_mode(self):\n self._embedding_and_ids_graph = [\n EmbeddingAndIds(\n batch_embedding=tf.Variable(\n- initial_value=tf.zeros((1, self.output_dim)),\n+ # In some cases, `tf.Variable` requires that initial value\n+ # is callable.\n+ initial_value=lambda: tf.zeros((1, self.output_dim)),\n shape=tf.TensorShape((None, self.output_dim)),\n dtype=tf.float32,\n trainable=True,\n ),\n batch_ids=tf.Variable(\n- initial_value=tf.zeros((1, 1), dtype=tf.int64),\n+ initial_value=lambda: tf.zeros((1, 1), dtype=tf.int64),\n shape=tf.TensorShape(None),\n dtype=tf.int64,\n trainable=False,\n@@ -186,6 +191,13 @@\n return batch_embedding\n \n def call(self, input):\n+ if (\n+ self.tape\n+ and not tf.executing_eagerly()\n+ and not self._embedding_and_ids_graph\n+ ):\n+ self._init_for_graph_mode()\n+\n input = tf.cast(input, tf.int64)\n if isinstance(input, tf.SparseTensor):\n return self._sparse_input_call(input)\n", "issue": "Do not save ElasticDL embedding's variables in the master\nIn current code, ElasticDL embedding layer create trainable variables and use them only for training under graph mode (i.e. under tf.function decorator). These variables are used for training and thus should only be created in workers. \r\n\r\nHowever, now ElasticDL embedding layer creates these variables in `__init__` function. The master (or PS) creates these variables when it creates a model instance, and then save these variables in `self._model`. \r\n\r\nI propose that ElasticDL embedding layer should not create these variables in `__init__` function. Instead, creating them before the training process only in worker is enough.\n", "before_files": [{"content": "import collections\n\nimport numpy as np\nimport tensorflow as tf\nfrom tensorflow.python.keras.utils import tf_utils\n\nfrom elasticdl.python.master.embedding_service import EmbeddingService\n\nEmbeddingAndIds = collections.namedtuple(\n \"EmbeddingAndIds\", [\"batch_embedding\", \"batch_ids\"]\n)\n\n\nclass Embedding(tf.keras.layers.Layer):\n \"\"\"\n Input: indexes for the embedding entries with a shape of\n (batch_size, input_length). Input can be either dense tensor\n or SparseTensor.\n Output:\n corresponding (combined) embeddings with a shape of\n (batch_size, input_length, output_dim) if combiner is None\n (batch_size, output_dim) if combiner is not None\n Arguments:\n output_dim: the dimension of the embedding vector\n embedding_initializer: Initializer for embedding table\n mask_zero: Whether or not the input value 0 is a special \"padding\"\n value that should be masked out.\n If input is SparseTensor, mask_zero must be False.\n input_length: Length of input sequences, when it is constant.\n This argument is required if you are going to connect\n `Flatten` then `Dense` layers upstream\n (without it, the shape of the dense outputs cannot be computed).\n combiner: A string specifying the reduction op or None if not used.\n \"mean\", \"sqrtn\" and \"sum\" are supported for the reduction op.\n If input is SparseTensor, combiner must set as a reduction op.\n \"\"\"\n\n def __init__(\n self,\n output_dim,\n embedding_initializer=\"uniform\",\n mask_zero=False,\n input_length=None,\n combiner=None,\n embedding_service_endpoint=None,\n **kwargs\n ):\n if \"input_shape\" not in kwargs and input_length:\n kwargs[\"input_shape\"] = (input_length,)\n super(Embedding, self).__init__(**kwargs)\n\n self.output_dim = output_dim\n self.embedding_initializer = embedding_initializer\n self.supports_masking = mask_zero\n self.input_length = input_length\n self.combiner = combiner\n self.embedding_service_endpoint = embedding_service_endpoint\n self.tape = None\n self.lookup_func = None\n\n self._embedding_and_ids_eagerly = []\n\n # BET's shape and ids' shape in `self._embedding_and_ids_graph` have\n # `None` dimension. This is because they have different shapes in\n # different iterations.\n # `tf.Variable` requires initial value if shape has `None` dimension.\n self._embedding_and_ids_graph = [\n EmbeddingAndIds(\n batch_embedding=tf.Variable(\n initial_value=tf.zeros((1, self.output_dim)),\n shape=tf.TensorShape((None, self.output_dim)),\n dtype=tf.float32,\n trainable=True,\n ),\n batch_ids=tf.Variable(\n initial_value=tf.zeros((1, 1), dtype=tf.int64),\n shape=tf.TensorShape(None),\n dtype=tf.int64,\n trainable=False,\n ),\n )\n ]\n\n @tf_utils.shape_type_conversion\n def compute_output_shape(self, input_shape):\n # this function is taken from\n # tf.keras.layers.Embedding.compute_output_shape\n # https://github.com/tensorflow/tensorflow/blob/3f3c728bf80e0fd6653744318cbbfe1454c6ddca/tensorflow/python/keras/layers/embeddings.py#L156\n if self.input_length is None:\n return input_shape + (self.output_dim,)\n else:\n if isinstance(self.input_length, (list, tuple)):\n in_lens = list(self.input_length)\n else:\n in_lens = [self.input_length]\n if len(in_lens) != len(input_shape) - 1:\n raise ValueError(\n '\"input_length\" is %s, '\n \"but received input has shape %s\"\n % (str(self.input_length), str(input_shape))\n )\n else:\n for i, (s1, s2) in enumerate(zip(in_lens, input_shape[1:])):\n if s1 is not None and s2 is not None and s1 != s2:\n raise ValueError(\n '\"input_length\" is %s, '\n \"but received input has shape %s\"\n % (str(self.input_length), str(input_shape))\n )\n elif s1 is None:\n in_lens[i] = s2\n return (input_shape[0],) + tuple(in_lens) + (self.output_dim,)\n\n @property\n def name(self):\n return self._name\n\n @staticmethod\n def get_key(name_list):\n return \"-\".join(map(str, name_list))\n\n def lookup_embedding(self, unique_ids):\n ids = unique_ids.numpy()\n keys = [Embedding.get_key([self._name, id]) for id in ids]\n (\n embedding_vectors,\n unknown_keys_index,\n ) = EmbeddingService.lookup_embedding(\n keys=keys,\n embedding_service_endpoint=self.embedding_service_endpoint,\n )\n\n if unknown_keys_index:\n # Initialize unknown_keys' embedding vectors and write into Redis.\n unknown_keys = [keys[index] for index in unknown_keys_index]\n initializer = tf.keras.initializers.get(self.embedding_initializer)\n embedding_vector_init = [\n initializer(shape=[1, self.output_dim]).numpy()\n for _ in unknown_keys\n ]\n embedding_vector_init = np.concatenate(\n embedding_vector_init, axis=0\n )\n EmbeddingService.update_embedding(\n keys=unknown_keys,\n embedding_vectors=embedding_vector_init,\n embedding_service_endpoint=self.embedding_service_endpoint,\n set_if_not_exist=True,\n )\n # Lookup unknown_keys' embedding vectors\n (\n embedding_vectors_new,\n unknown_keys_idx_new,\n ) = EmbeddingService.lookup_embedding(\n keys=unknown_keys,\n embedding_service_endpoint=self.embedding_service_endpoint,\n )\n if unknown_keys_idx_new:\n raise Exception(\n \"Update embedding vector: %s failed.\"\n % str(\n [unknown_keys[index] for index in unknown_keys_idx_new]\n )\n )\n for key_index, vector in zip(\n unknown_keys_index, embedding_vectors_new\n ):\n embedding_vectors[key_index] = vector\n embedding_vectors = np.concatenate(embedding_vectors, axis=0)\n return embedding_vectors.reshape((len(keys), self.output_dim))\n\n def _record_gradients(self, batch_embedding, ids):\n if tf.executing_eagerly():\n self.tape.watch(batch_embedding)\n self._embedding_and_ids_eagerly.append(\n EmbeddingAndIds(batch_embedding, ids)\n )\n else:\n # In graph mode, assigning tensors to trainable variables is\n # allowed and tape can record the gradients of trainable\n # variables automatically.\n embedding_and_ids = self._embedding_and_ids_graph[0]\n embedding_and_ids.batch_embedding.assign(batch_embedding)\n embedding_and_ids.batch_ids.assign(ids)\n batch_embedding = embedding_and_ids.batch_embedding\n return batch_embedding\n\n def call(self, input):\n input = tf.cast(input, tf.int64)\n if isinstance(input, tf.SparseTensor):\n return self._sparse_input_call(input)\n\n ids = tf.convert_to_tensor(input, name=\"embedding_ids\")\n flat_ids = tf.reshape(ids, [-1])\n unique_ids, idx = tf.unique(flat_ids)\n # Gradient for `batch_embedding` is SparseTensor here due to\n # `tf.gather` op. `tf.gather` accesses tensor slices, resulting in\n # sparse tensor gradient.\n batch_embedding = tf.py_function(\n self.lookup_embedding, inp=[unique_ids], Tout=tf.float32\n )\n # TODO: use tf.cond rather than python if statement\n if self.tape:\n batch_embedding = self._record_gradients(batch_embedding, flat_ids)\n\n outputs = tf.gather(batch_embedding, idx)\n # tf.reshape does not support shape with None. Replace None with -1.\n if ids.get_shape().rank == 2:\n input_length = ids.get_shape()[1]\n if input_length is None:\n outputs.set_shape(shape=(None, None, self.output_dim))\n return outputs\n output_shape = (-1, input_length, self.output_dim)\n else:\n output_shape = ids.get_shape().concatenate(self.output_dim)\n outputs = tf.reshape(outputs, output_shape)\n # TODO: support combiner for dense input\n return outputs\n\n def _sparse_input_call(self, sparse_input):\n if self.combiner not in [\"sum\", \"mean\", \"sqrtn\"]:\n raise ValueError(\n \"combiner must set sum, mean or sqrtn for sparse input\"\n )\n unique_ids, idx = tf.unique(sparse_input.values)\n # Gradient for `batch_embedding` is dense tensor.\n batch_embedding = tf.py_function(\n self.lookup_embedding, inp=[unique_ids], Tout=tf.float32\n )\n # TODO: use tf.cond rather than python if statement\n if self.tape:\n batch_embedding = self._record_gradients(\n batch_embedding, unique_ids\n )\n\n segment_ids = sparse_input.indices[:, 0]\n if segment_ids.dtype != tf.int32:\n segment_ids = tf.cast(segment_ids, tf.int32)\n\n if self.combiner == \"sum\":\n batch_embedding = tf.sparse.segment_sum(\n batch_embedding, idx, segment_ids\n )\n elif self.combiner == \"mean\":\n batch_embedding = tf.sparse.segment_mean(\n batch_embedding, idx, segment_ids\n )\n elif self.combiner == \"sqrtn\":\n batch_embedding = tf.sparse.segment_sqrt_n(\n batch_embedding, idx, segment_ids\n )\n return batch_embedding\n\n def compute_mask(self, inputs, mask=None):\n if isinstance(input, tf.SparseTensor):\n raise ValueError(\"SparseTensor inputs do not support mask_zero\")\n if not self.supports_masking:\n return None\n return tf.math.not_equal(inputs, 0)\n\n def reset(self):\n self._embedding_and_ids_eagerly = []\n self.tape = None\n\n def set_tape(self, tape):\n self.tape = tape\n\n def set_endpoint(self, endpoint):\n self.embedding_service_endpoint = endpoint\n\n @property\n def embedding_and_ids(self):\n \"\"\"\n Return bet and ids pairs.\n \"\"\"\n if self._embedding_and_ids_eagerly:\n return self._embedding_and_ids_eagerly\n return self._embedding_and_ids_graph\n", "path": "elasticdl/python/elasticdl/layers/embedding.py"}]}
| 3,678 | 394 |
gh_patches_debug_20404
|
rasdani/github-patches
|
git_diff
|
ietf-tools__datatracker-5075
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Possible timezone related failure
### Describe the issue
https://github.com/ietf-tools/datatracker/actions/runs/4071644533/jobs/7013629899
### Code of Conduct
- [X] I agree to follow the [IETF's Code of Conduct](https://github.com/ietf-tools/.github/blob/main/CODE_OF_CONDUCT.md)
</issue>
<code>
[start of ietf/group/factories.py]
1 # Copyright The IETF Trust 2015-2022, All Rights Reserved
2 import datetime
3 import debug # pyflakes:ignore
4 import factory
5
6 from typing import List # pyflakes:ignore
7
8 from django.utils import timezone
9
10 from ietf.group.models import Group, Role, GroupEvent, GroupMilestone, \
11 GroupHistory, RoleHistory
12 from ietf.review.factories import ReviewTeamSettingsFactory
13
14 class GroupFactory(factory.django.DjangoModelFactory):
15 class Meta:
16 model = Group
17 django_get_or_create = ('acronym',)
18
19 name = factory.Faker('sentence',nb_words=6)
20 acronym = factory.Sequence(lambda n: 'acronym%d' %n)
21 state_id = 'active'
22 type_id = 'wg'
23 list_email = factory.LazyAttribute(lambda a: '%[email protected]'% a.acronym)
24 uses_milestone_dates = True
25 used_roles = [] # type: List[str]
26
27 @factory.lazy_attribute
28 def parent(self):
29 if self.type_id in ['wg','ag']:
30 return GroupFactory(type_id='area')
31 elif self.type_id in ['rg','rag']:
32 return GroupFactory(acronym='irtf', type_id='irtf')
33 else:
34 return None
35
36 class ReviewTeamFactory(GroupFactory):
37
38 type_id = 'review'
39
40 @factory.post_generation
41 def settings(obj, create, extracted, **kwargs):
42 ReviewTeamSettingsFactory.create(group=obj,**kwargs)
43
44 class RoleFactory(factory.django.DjangoModelFactory):
45 class Meta:
46 model = Role
47
48 group = factory.SubFactory(GroupFactory)
49 person = factory.SubFactory('ietf.person.factories.PersonFactory')
50 email = factory.LazyAttribute(lambda obj: obj.person.email())
51
52 class GroupEventFactory(factory.django.DjangoModelFactory):
53 class Meta:
54 model = GroupEvent
55
56 group = factory.SubFactory(GroupFactory)
57 by = factory.SubFactory('ietf.person.factories.PersonFactory')
58 type = 'comment'
59 desc = factory.Faker('paragraph')
60
61 class BaseGroupMilestoneFactory(factory.django.DjangoModelFactory):
62 class Meta:
63 model = GroupMilestone
64
65 group = factory.SubFactory(GroupFactory)
66 state_id = 'active'
67 desc = factory.Faker('sentence')
68
69 class DatedGroupMilestoneFactory(BaseGroupMilestoneFactory):
70 group = factory.SubFactory(GroupFactory, uses_milestone_dates=True)
71 due = timezone.now()+datetime.timedelta(days=180)
72
73 class DatelessGroupMilestoneFactory(BaseGroupMilestoneFactory):
74 group = factory.SubFactory(GroupFactory, uses_milestone_dates=False)
75 order = factory.Sequence(lambda n: n)
76
77 class GroupHistoryFactory(factory.django.DjangoModelFactory):
78 class Meta:
79 model=GroupHistory
80
81 time = lambda: timezone.now()
82 group = factory.SubFactory(GroupFactory, state_id='active')
83
84 name = factory.LazyAttribute(lambda obj: obj.group.name)
85 state_id = factory.LazyAttribute(lambda obj: obj.group.state_id)
86 type_id = factory.LazyAttribute(lambda obj: obj.group.type_id)
87 parent = factory.LazyAttribute(lambda obj: obj.group.parent)
88 uses_milestone_dates = factory.LazyAttribute(lambda obj: obj.group.uses_milestone_dates)
89 used_roles = factory.LazyAttribute(lambda obj: obj.group.used_roles)
90 description = factory.LazyAttribute(lambda obj: obj.group.description)
91 list_email = factory.LazyAttribute(lambda obj: '%[email protected]'% obj.group.acronym) #TODO : move this to GroupFactory
92 list_subscribe = factory.LazyAttribute(lambda obj: obj.group.list_subscribe)
93 list_archive = factory.LazyAttribute(lambda obj: obj.group.list_archive)
94 comments = factory.LazyAttribute(lambda obj: obj.group.comments)
95 meeting_seen_as_area = factory.LazyAttribute(lambda obj: obj.group.meeting_seen_as_area)
96 acronym = factory.LazyAttribute(lambda obj: obj.group.acronym)
97
98 @factory.post_generation
99 def unused_states(obj, create, extracted, **kwargs):
100 if create:
101 if extracted:
102 obj.unused_states.set(extracted)
103 else:
104 obj.unused_states.set(obj.group.unused_states.all())
105 @factory.post_generation
106 def unused_tags(obj, create, extracted, **kwargs):
107 if create:
108 if extracted:
109 obj.unused_tags.set(extracted)
110 else:
111 obj.unused_tags.set(obj.group.unused_states.all())
112
113 class RoleHistoryFactory(factory.django.DjangoModelFactory):
114 class Meta:
115 model=RoleHistory
116
117 group = factory.SubFactory(GroupHistoryFactory)
118 person = factory.SubFactory('ietf.person.factories.PersonFactory')
119 email = factory.LazyAttribute(lambda obj: obj.person.email())
120
121
[end of ietf/group/factories.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ietf/group/factories.py b/ietf/group/factories.py
--- a/ietf/group/factories.py
+++ b/ietf/group/factories.py
@@ -10,6 +10,8 @@
from ietf.group.models import Group, Role, GroupEvent, GroupMilestone, \
GroupHistory, RoleHistory
from ietf.review.factories import ReviewTeamSettingsFactory
+from ietf.utils.timezone import date_today
+
class GroupFactory(factory.django.DjangoModelFactory):
class Meta:
@@ -68,7 +70,7 @@
class DatedGroupMilestoneFactory(BaseGroupMilestoneFactory):
group = factory.SubFactory(GroupFactory, uses_milestone_dates=True)
- due = timezone.now()+datetime.timedelta(days=180)
+ due = date_today() + datetime.timedelta(days=180)
class DatelessGroupMilestoneFactory(BaseGroupMilestoneFactory):
group = factory.SubFactory(GroupFactory, uses_milestone_dates=False)
|
{"golden_diff": "diff --git a/ietf/group/factories.py b/ietf/group/factories.py\n--- a/ietf/group/factories.py\n+++ b/ietf/group/factories.py\n@@ -10,6 +10,8 @@\n from ietf.group.models import Group, Role, GroupEvent, GroupMilestone, \\\n GroupHistory, RoleHistory\n from ietf.review.factories import ReviewTeamSettingsFactory\n+from ietf.utils.timezone import date_today\n+\n \n class GroupFactory(factory.django.DjangoModelFactory):\n class Meta:\n@@ -68,7 +70,7 @@\n \n class DatedGroupMilestoneFactory(BaseGroupMilestoneFactory):\n group = factory.SubFactory(GroupFactory, uses_milestone_dates=True)\n- due = timezone.now()+datetime.timedelta(days=180)\n+ due = date_today() + datetime.timedelta(days=180)\n \n class DatelessGroupMilestoneFactory(BaseGroupMilestoneFactory):\n group = factory.SubFactory(GroupFactory, uses_milestone_dates=False)\n", "issue": "Possible timezone related failure\n### Describe the issue\n\nhttps://github.com/ietf-tools/datatracker/actions/runs/4071644533/jobs/7013629899\n\n### Code of Conduct\n\n- [X] I agree to follow the [IETF's Code of Conduct](https://github.com/ietf-tools/.github/blob/main/CODE_OF_CONDUCT.md)\n", "before_files": [{"content": "# Copyright The IETF Trust 2015-2022, All Rights Reserved\nimport datetime\nimport debug # pyflakes:ignore\nimport factory\n\nfrom typing import List # pyflakes:ignore\n\nfrom django.utils import timezone\n\nfrom ietf.group.models import Group, Role, GroupEvent, GroupMilestone, \\\n GroupHistory, RoleHistory\nfrom ietf.review.factories import ReviewTeamSettingsFactory\n\nclass GroupFactory(factory.django.DjangoModelFactory):\n class Meta:\n model = Group\n django_get_or_create = ('acronym',)\n\n name = factory.Faker('sentence',nb_words=6)\n acronym = factory.Sequence(lambda n: 'acronym%d' %n)\n state_id = 'active'\n type_id = 'wg'\n list_email = factory.LazyAttribute(lambda a: '%[email protected]'% a.acronym)\n uses_milestone_dates = True\n used_roles = [] # type: List[str]\n\n @factory.lazy_attribute\n def parent(self):\n if self.type_id in ['wg','ag']:\n return GroupFactory(type_id='area')\n elif self.type_id in ['rg','rag']:\n return GroupFactory(acronym='irtf', type_id='irtf')\n else:\n return None\n\nclass ReviewTeamFactory(GroupFactory):\n\n type_id = 'review'\n\n @factory.post_generation\n def settings(obj, create, extracted, **kwargs):\n ReviewTeamSettingsFactory.create(group=obj,**kwargs)\n\nclass RoleFactory(factory.django.DjangoModelFactory):\n class Meta:\n model = Role\n\n group = factory.SubFactory(GroupFactory)\n person = factory.SubFactory('ietf.person.factories.PersonFactory')\n email = factory.LazyAttribute(lambda obj: obj.person.email())\n\nclass GroupEventFactory(factory.django.DjangoModelFactory):\n class Meta:\n model = GroupEvent\n\n group = factory.SubFactory(GroupFactory)\n by = factory.SubFactory('ietf.person.factories.PersonFactory')\n type = 'comment'\n desc = factory.Faker('paragraph')\n\nclass BaseGroupMilestoneFactory(factory.django.DjangoModelFactory):\n class Meta:\n model = GroupMilestone\n\n group = factory.SubFactory(GroupFactory)\n state_id = 'active'\n desc = factory.Faker('sentence')\n\nclass DatedGroupMilestoneFactory(BaseGroupMilestoneFactory):\n group = factory.SubFactory(GroupFactory, uses_milestone_dates=True)\n due = timezone.now()+datetime.timedelta(days=180)\n\nclass DatelessGroupMilestoneFactory(BaseGroupMilestoneFactory):\n group = factory.SubFactory(GroupFactory, uses_milestone_dates=False)\n order = factory.Sequence(lambda n: n)\n\nclass GroupHistoryFactory(factory.django.DjangoModelFactory):\n class Meta:\n model=GroupHistory\n\n time = lambda: timezone.now()\n group = factory.SubFactory(GroupFactory, state_id='active')\n\n name = factory.LazyAttribute(lambda obj: obj.group.name)\n state_id = factory.LazyAttribute(lambda obj: obj.group.state_id)\n type_id = factory.LazyAttribute(lambda obj: obj.group.type_id)\n parent = factory.LazyAttribute(lambda obj: obj.group.parent)\n uses_milestone_dates = factory.LazyAttribute(lambda obj: obj.group.uses_milestone_dates)\n used_roles = factory.LazyAttribute(lambda obj: obj.group.used_roles)\n description = factory.LazyAttribute(lambda obj: obj.group.description)\n list_email = factory.LazyAttribute(lambda obj: '%[email protected]'% obj.group.acronym) #TODO : move this to GroupFactory\n list_subscribe = factory.LazyAttribute(lambda obj: obj.group.list_subscribe)\n list_archive = factory.LazyAttribute(lambda obj: obj.group.list_archive)\n comments = factory.LazyAttribute(lambda obj: obj.group.comments)\n meeting_seen_as_area = factory.LazyAttribute(lambda obj: obj.group.meeting_seen_as_area)\n acronym = factory.LazyAttribute(lambda obj: obj.group.acronym)\n\n @factory.post_generation\n def unused_states(obj, create, extracted, **kwargs):\n if create:\n if extracted:\n obj.unused_states.set(extracted)\n else:\n obj.unused_states.set(obj.group.unused_states.all())\n @factory.post_generation\n def unused_tags(obj, create, extracted, **kwargs):\n if create:\n if extracted:\n obj.unused_tags.set(extracted)\n else:\n obj.unused_tags.set(obj.group.unused_states.all()) \n\nclass RoleHistoryFactory(factory.django.DjangoModelFactory):\n class Meta:\n model=RoleHistory\n\n group = factory.SubFactory(GroupHistoryFactory)\n person = factory.SubFactory('ietf.person.factories.PersonFactory')\n email = factory.LazyAttribute(lambda obj: obj.person.email())\n\n", "path": "ietf/group/factories.py"}]}
| 1,901 | 216 |
gh_patches_debug_4593
|
rasdani/github-patches
|
git_diff
|
docker__docker-py-1189
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
NpipeSocket.makefile crashes when bufsize < 0
**Original report**: https://github.com/docker/compose/issues/3901#issuecomment-244828701
Negative `bufsize` should be handled.
</issue>
<code>
[start of docker/transport/npipesocket.py]
1 import functools
2 import io
3
4 import win32file
5 import win32pipe
6
7 cSECURITY_SQOS_PRESENT = 0x100000
8 cSECURITY_ANONYMOUS = 0
9 cPIPE_READMODE_MESSAGE = 2
10
11
12 def check_closed(f):
13 @functools.wraps(f)
14 def wrapped(self, *args, **kwargs):
15 if self._closed:
16 raise RuntimeError(
17 'Can not reuse socket after connection was closed.'
18 )
19 return f(self, *args, **kwargs)
20 return wrapped
21
22
23 class NpipeSocket(object):
24 """ Partial implementation of the socket API over windows named pipes.
25 This implementation is only designed to be used as a client socket,
26 and server-specific methods (bind, listen, accept...) are not
27 implemented.
28 """
29 def __init__(self, handle=None):
30 self._timeout = win32pipe.NMPWAIT_USE_DEFAULT_WAIT
31 self._handle = handle
32 self._closed = False
33
34 def accept(self):
35 raise NotImplementedError()
36
37 def bind(self, address):
38 raise NotImplementedError()
39
40 def close(self):
41 self._handle.Close()
42 self._closed = True
43
44 @check_closed
45 def connect(self, address):
46 win32pipe.WaitNamedPipe(address, self._timeout)
47 handle = win32file.CreateFile(
48 address,
49 win32file.GENERIC_READ | win32file.GENERIC_WRITE,
50 0,
51 None,
52 win32file.OPEN_EXISTING,
53 cSECURITY_ANONYMOUS | cSECURITY_SQOS_PRESENT,
54 0
55 )
56 self.flags = win32pipe.GetNamedPipeInfo(handle)[0]
57
58 self._handle = handle
59 self._address = address
60
61 @check_closed
62 def connect_ex(self, address):
63 return self.connect(address)
64
65 @check_closed
66 def detach(self):
67 self._closed = True
68 return self._handle
69
70 @check_closed
71 def dup(self):
72 return NpipeSocket(self._handle)
73
74 @check_closed
75 def fileno(self):
76 return int(self._handle)
77
78 def getpeername(self):
79 return self._address
80
81 def getsockname(self):
82 return self._address
83
84 def getsockopt(self, level, optname, buflen=None):
85 raise NotImplementedError()
86
87 def ioctl(self, control, option):
88 raise NotImplementedError()
89
90 def listen(self, backlog):
91 raise NotImplementedError()
92
93 def makefile(self, mode=None, bufsize=None):
94 if mode.strip('b') != 'r':
95 raise NotImplementedError()
96 rawio = NpipeFileIOBase(self)
97 if bufsize is None:
98 bufsize = io.DEFAULT_BUFFER_SIZE
99 return io.BufferedReader(rawio, buffer_size=bufsize)
100
101 @check_closed
102 def recv(self, bufsize, flags=0):
103 err, data = win32file.ReadFile(self._handle, bufsize)
104 return data
105
106 @check_closed
107 def recvfrom(self, bufsize, flags=0):
108 data = self.recv(bufsize, flags)
109 return (data, self._address)
110
111 @check_closed
112 def recvfrom_into(self, buf, nbytes=0, flags=0):
113 return self.recv_into(buf, nbytes, flags), self._address
114
115 @check_closed
116 def recv_into(self, buf, nbytes=0):
117 readbuf = buf
118 if not isinstance(buf, memoryview):
119 readbuf = memoryview(buf)
120
121 err, data = win32file.ReadFile(
122 self._handle,
123 readbuf[:nbytes] if nbytes else readbuf
124 )
125 return len(data)
126
127 @check_closed
128 def send(self, string, flags=0):
129 err, nbytes = win32file.WriteFile(self._handle, string)
130 return nbytes
131
132 @check_closed
133 def sendall(self, string, flags=0):
134 return self.send(string, flags)
135
136 @check_closed
137 def sendto(self, string, address):
138 self.connect(address)
139 return self.send(string)
140
141 def setblocking(self, flag):
142 if flag:
143 return self.settimeout(None)
144 return self.settimeout(0)
145
146 def settimeout(self, value):
147 if value is None:
148 self._timeout = win32pipe.NMPWAIT_NOWAIT
149 elif not isinstance(value, (float, int)) or value < 0:
150 raise ValueError('Timeout value out of range')
151 elif value == 0:
152 self._timeout = win32pipe.NMPWAIT_USE_DEFAULT_WAIT
153 else:
154 self._timeout = value
155
156 def gettimeout(self):
157 return self._timeout
158
159 def setsockopt(self, level, optname, value):
160 raise NotImplementedError()
161
162 @check_closed
163 def shutdown(self, how):
164 return self.close()
165
166
167 class NpipeFileIOBase(io.RawIOBase):
168 def __init__(self, npipe_socket):
169 self.sock = npipe_socket
170
171 def close(self):
172 super(NpipeFileIOBase, self).close()
173 self.sock = None
174
175 def fileno(self):
176 return self.sock.fileno()
177
178 def isatty(self):
179 return False
180
181 def readable(self):
182 return True
183
184 def readinto(self, buf):
185 return self.sock.recv_into(buf)
186
187 def seekable(self):
188 return False
189
190 def writable(self):
191 return False
192
[end of docker/transport/npipesocket.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/docker/transport/npipesocket.py b/docker/transport/npipesocket.py
--- a/docker/transport/npipesocket.py
+++ b/docker/transport/npipesocket.py
@@ -94,7 +94,7 @@
if mode.strip('b') != 'r':
raise NotImplementedError()
rawio = NpipeFileIOBase(self)
- if bufsize is None:
+ if bufsize is None or bufsize < 0:
bufsize = io.DEFAULT_BUFFER_SIZE
return io.BufferedReader(rawio, buffer_size=bufsize)
|
{"golden_diff": "diff --git a/docker/transport/npipesocket.py b/docker/transport/npipesocket.py\n--- a/docker/transport/npipesocket.py\n+++ b/docker/transport/npipesocket.py\n@@ -94,7 +94,7 @@\n if mode.strip('b') != 'r':\n raise NotImplementedError()\n rawio = NpipeFileIOBase(self)\n- if bufsize is None:\n+ if bufsize is None or bufsize < 0:\n bufsize = io.DEFAULT_BUFFER_SIZE\n return io.BufferedReader(rawio, buffer_size=bufsize)\n", "issue": "NpipeSocket.makefile crashes when bufsize < 0\n**Original report**: https://github.com/docker/compose/issues/3901#issuecomment-244828701\n\nNegative `bufsize` should be handled.\n\n", "before_files": [{"content": "import functools\nimport io\n\nimport win32file\nimport win32pipe\n\ncSECURITY_SQOS_PRESENT = 0x100000\ncSECURITY_ANONYMOUS = 0\ncPIPE_READMODE_MESSAGE = 2\n\n\ndef check_closed(f):\n @functools.wraps(f)\n def wrapped(self, *args, **kwargs):\n if self._closed:\n raise RuntimeError(\n 'Can not reuse socket after connection was closed.'\n )\n return f(self, *args, **kwargs)\n return wrapped\n\n\nclass NpipeSocket(object):\n \"\"\" Partial implementation of the socket API over windows named pipes.\n This implementation is only designed to be used as a client socket,\n and server-specific methods (bind, listen, accept...) are not\n implemented.\n \"\"\"\n def __init__(self, handle=None):\n self._timeout = win32pipe.NMPWAIT_USE_DEFAULT_WAIT\n self._handle = handle\n self._closed = False\n\n def accept(self):\n raise NotImplementedError()\n\n def bind(self, address):\n raise NotImplementedError()\n\n def close(self):\n self._handle.Close()\n self._closed = True\n\n @check_closed\n def connect(self, address):\n win32pipe.WaitNamedPipe(address, self._timeout)\n handle = win32file.CreateFile(\n address,\n win32file.GENERIC_READ | win32file.GENERIC_WRITE,\n 0,\n None,\n win32file.OPEN_EXISTING,\n cSECURITY_ANONYMOUS | cSECURITY_SQOS_PRESENT,\n 0\n )\n self.flags = win32pipe.GetNamedPipeInfo(handle)[0]\n\n self._handle = handle\n self._address = address\n\n @check_closed\n def connect_ex(self, address):\n return self.connect(address)\n\n @check_closed\n def detach(self):\n self._closed = True\n return self._handle\n\n @check_closed\n def dup(self):\n return NpipeSocket(self._handle)\n\n @check_closed\n def fileno(self):\n return int(self._handle)\n\n def getpeername(self):\n return self._address\n\n def getsockname(self):\n return self._address\n\n def getsockopt(self, level, optname, buflen=None):\n raise NotImplementedError()\n\n def ioctl(self, control, option):\n raise NotImplementedError()\n\n def listen(self, backlog):\n raise NotImplementedError()\n\n def makefile(self, mode=None, bufsize=None):\n if mode.strip('b') != 'r':\n raise NotImplementedError()\n rawio = NpipeFileIOBase(self)\n if bufsize is None:\n bufsize = io.DEFAULT_BUFFER_SIZE\n return io.BufferedReader(rawio, buffer_size=bufsize)\n\n @check_closed\n def recv(self, bufsize, flags=0):\n err, data = win32file.ReadFile(self._handle, bufsize)\n return data\n\n @check_closed\n def recvfrom(self, bufsize, flags=0):\n data = self.recv(bufsize, flags)\n return (data, self._address)\n\n @check_closed\n def recvfrom_into(self, buf, nbytes=0, flags=0):\n return self.recv_into(buf, nbytes, flags), self._address\n\n @check_closed\n def recv_into(self, buf, nbytes=0):\n readbuf = buf\n if not isinstance(buf, memoryview):\n readbuf = memoryview(buf)\n\n err, data = win32file.ReadFile(\n self._handle,\n readbuf[:nbytes] if nbytes else readbuf\n )\n return len(data)\n\n @check_closed\n def send(self, string, flags=0):\n err, nbytes = win32file.WriteFile(self._handle, string)\n return nbytes\n\n @check_closed\n def sendall(self, string, flags=0):\n return self.send(string, flags)\n\n @check_closed\n def sendto(self, string, address):\n self.connect(address)\n return self.send(string)\n\n def setblocking(self, flag):\n if flag:\n return self.settimeout(None)\n return self.settimeout(0)\n\n def settimeout(self, value):\n if value is None:\n self._timeout = win32pipe.NMPWAIT_NOWAIT\n elif not isinstance(value, (float, int)) or value < 0:\n raise ValueError('Timeout value out of range')\n elif value == 0:\n self._timeout = win32pipe.NMPWAIT_USE_DEFAULT_WAIT\n else:\n self._timeout = value\n\n def gettimeout(self):\n return self._timeout\n\n def setsockopt(self, level, optname, value):\n raise NotImplementedError()\n\n @check_closed\n def shutdown(self, how):\n return self.close()\n\n\nclass NpipeFileIOBase(io.RawIOBase):\n def __init__(self, npipe_socket):\n self.sock = npipe_socket\n\n def close(self):\n super(NpipeFileIOBase, self).close()\n self.sock = None\n\n def fileno(self):\n return self.sock.fileno()\n\n def isatty(self):\n return False\n\n def readable(self):\n return True\n\n def readinto(self, buf):\n return self.sock.recv_into(buf)\n\n def seekable(self):\n return False\n\n def writable(self):\n return False\n", "path": "docker/transport/npipesocket.py"}]}
| 2,248 | 122 |
gh_patches_debug_22473
|
rasdani/github-patches
|
git_diff
|
pytorch__TensorRT-2363
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add documentation in user guide on `torch.compile` usage
- `torch.compile` "from-scratch" usage
</issue>
<code>
[start of py/torch_tensorrt/dynamo/_settings.py]
1 from dataclasses import dataclass, field
2 from typing import Optional, Set
3
4 import torch
5 from torch_tensorrt._Device import Device
6 from torch_tensorrt.dynamo._defaults import (
7 DEBUG,
8 ENABLE_EXPERIMENTAL_DECOMPOSITIONS,
9 MAX_AUX_STREAMS,
10 MIN_BLOCK_SIZE,
11 OPTIMIZATION_LEVEL,
12 PASS_THROUGH_BUILD_FAILURES,
13 PRECISION,
14 REQUIRE_FULL_COMPILATION,
15 TRUNCATE_LONG_AND_DOUBLE,
16 USE_FAST_PARTITIONER,
17 USE_PYTHON_RUNTIME,
18 VERSION_COMPATIBLE,
19 WORKSPACE_SIZE,
20 default_device,
21 )
22
23
24 @dataclass
25 class CompilationSettings:
26 """Compilation settings for Torch-TensorRT Dynamo Paths
27
28 Args:
29 precision (torch.dtype): Model Layer precision
30 debug (bool): Whether to print out verbose debugging information
31 workspace_size (int): Workspace TRT is allowed to use for the module (0 is default)
32 min_block_size (int): Minimum number of operators per TRT-Engine Block
33 torch_executed_ops (Sequence[str]): Sequence of operations to run in Torch, regardless of converter coverage
34 pass_through_build_failures (bool): Whether to fail on TRT engine build errors (True) or not (False)
35 max_aux_streams (Optional[int]): Maximum number of allowed auxiliary TRT streams for each engine
36 version_compatible (bool): Provide version forward-compatibility for engine plan files
37 optimization_level (Optional[int]): Builder optimization 0-5, higher levels imply longer build time,
38 searching for more optimization options. TRT defaults to 3
39 use_python_runtime (Optional[bool]): Whether to strictly use Python runtime or C++ runtime. To auto-select a runtime
40 based on C++ dependency presence (preferentially choosing C++ runtime if available), leave the
41 argument as None
42 truncate_long_and_double (bool): Truncate int64/float64 TRT engine inputs or weights to int32/float32
43 enable_experimental_decompositions (bool): Whether to enable all core aten decompositions
44 or only a selected subset of them
45 """
46
47 precision: torch.dtype = PRECISION
48 debug: bool = DEBUG
49 workspace_size: int = WORKSPACE_SIZE
50 min_block_size: int = MIN_BLOCK_SIZE
51 torch_executed_ops: Set[str] = field(default_factory=set)
52 pass_through_build_failures: bool = PASS_THROUGH_BUILD_FAILURES
53 max_aux_streams: Optional[int] = MAX_AUX_STREAMS
54 version_compatible: bool = VERSION_COMPATIBLE
55 optimization_level: Optional[int] = OPTIMIZATION_LEVEL
56 use_python_runtime: Optional[bool] = USE_PYTHON_RUNTIME
57 truncate_long_and_double: bool = TRUNCATE_LONG_AND_DOUBLE
58 use_fast_partitioner: bool = USE_FAST_PARTITIONER
59 enable_experimental_decompositions: bool = ENABLE_EXPERIMENTAL_DECOMPOSITIONS
60 device: Device = field(default_factory=default_device)
61 require_full_compilation: bool = REQUIRE_FULL_COMPILATION
62
[end of py/torch_tensorrt/dynamo/_settings.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/py/torch_tensorrt/dynamo/_settings.py b/py/torch_tensorrt/dynamo/_settings.py
--- a/py/torch_tensorrt/dynamo/_settings.py
+++ b/py/torch_tensorrt/dynamo/_settings.py
@@ -39,9 +39,13 @@
use_python_runtime (Optional[bool]): Whether to strictly use Python runtime or C++ runtime. To auto-select a runtime
based on C++ dependency presence (preferentially choosing C++ runtime if available), leave the
argument as None
- truncate_long_and_double (bool): Truncate int64/float64 TRT engine inputs or weights to int32/float32
+ truncate_long_and_double (bool): Whether to truncate int64/float64 TRT engine inputs or weights to int32/float32
+ use_fast_partitioner (bool): Whether to use the fast or global graph partitioning system
enable_experimental_decompositions (bool): Whether to enable all core aten decompositions
or only a selected subset of them
+ device (Device): GPU to compile the model on
+ require_full_compilation (bool): Whether to require the graph is fully compiled in TensorRT.
+ Only applicable for `ir="dynamo"`; has no effect for `torch.compile` path
"""
precision: torch.dtype = PRECISION
|
{"golden_diff": "diff --git a/py/torch_tensorrt/dynamo/_settings.py b/py/torch_tensorrt/dynamo/_settings.py\n--- a/py/torch_tensorrt/dynamo/_settings.py\n+++ b/py/torch_tensorrt/dynamo/_settings.py\n@@ -39,9 +39,13 @@\n use_python_runtime (Optional[bool]): Whether to strictly use Python runtime or C++ runtime. To auto-select a runtime\n based on C++ dependency presence (preferentially choosing C++ runtime if available), leave the\n argument as None\n- truncate_long_and_double (bool): Truncate int64/float64 TRT engine inputs or weights to int32/float32\n+ truncate_long_and_double (bool): Whether to truncate int64/float64 TRT engine inputs or weights to int32/float32\n+ use_fast_partitioner (bool): Whether to use the fast or global graph partitioning system\n enable_experimental_decompositions (bool): Whether to enable all core aten decompositions\n or only a selected subset of them\n+ device (Device): GPU to compile the model on\n+ require_full_compilation (bool): Whether to require the graph is fully compiled in TensorRT.\n+ Only applicable for `ir=\"dynamo\"`; has no effect for `torch.compile` path\n \"\"\"\n \n precision: torch.dtype = PRECISION\n", "issue": "Add documentation in user guide on `torch.compile` usage\n- `torch.compile` \"from-scratch\" usage\n", "before_files": [{"content": "from dataclasses import dataclass, field\nfrom typing import Optional, Set\n\nimport torch\nfrom torch_tensorrt._Device import Device\nfrom torch_tensorrt.dynamo._defaults import (\n DEBUG,\n ENABLE_EXPERIMENTAL_DECOMPOSITIONS,\n MAX_AUX_STREAMS,\n MIN_BLOCK_SIZE,\n OPTIMIZATION_LEVEL,\n PASS_THROUGH_BUILD_FAILURES,\n PRECISION,\n REQUIRE_FULL_COMPILATION,\n TRUNCATE_LONG_AND_DOUBLE,\n USE_FAST_PARTITIONER,\n USE_PYTHON_RUNTIME,\n VERSION_COMPATIBLE,\n WORKSPACE_SIZE,\n default_device,\n)\n\n\n@dataclass\nclass CompilationSettings:\n \"\"\"Compilation settings for Torch-TensorRT Dynamo Paths\n\n Args:\n precision (torch.dtype): Model Layer precision\n debug (bool): Whether to print out verbose debugging information\n workspace_size (int): Workspace TRT is allowed to use for the module (0 is default)\n min_block_size (int): Minimum number of operators per TRT-Engine Block\n torch_executed_ops (Sequence[str]): Sequence of operations to run in Torch, regardless of converter coverage\n pass_through_build_failures (bool): Whether to fail on TRT engine build errors (True) or not (False)\n max_aux_streams (Optional[int]): Maximum number of allowed auxiliary TRT streams for each engine\n version_compatible (bool): Provide version forward-compatibility for engine plan files\n optimization_level (Optional[int]): Builder optimization 0-5, higher levels imply longer build time,\n searching for more optimization options. TRT defaults to 3\n use_python_runtime (Optional[bool]): Whether to strictly use Python runtime or C++ runtime. To auto-select a runtime\n based on C++ dependency presence (preferentially choosing C++ runtime if available), leave the\n argument as None\n truncate_long_and_double (bool): Truncate int64/float64 TRT engine inputs or weights to int32/float32\n enable_experimental_decompositions (bool): Whether to enable all core aten decompositions\n or only a selected subset of them\n \"\"\"\n\n precision: torch.dtype = PRECISION\n debug: bool = DEBUG\n workspace_size: int = WORKSPACE_SIZE\n min_block_size: int = MIN_BLOCK_SIZE\n torch_executed_ops: Set[str] = field(default_factory=set)\n pass_through_build_failures: bool = PASS_THROUGH_BUILD_FAILURES\n max_aux_streams: Optional[int] = MAX_AUX_STREAMS\n version_compatible: bool = VERSION_COMPATIBLE\n optimization_level: Optional[int] = OPTIMIZATION_LEVEL\n use_python_runtime: Optional[bool] = USE_PYTHON_RUNTIME\n truncate_long_and_double: bool = TRUNCATE_LONG_AND_DOUBLE\n use_fast_partitioner: bool = USE_FAST_PARTITIONER\n enable_experimental_decompositions: bool = ENABLE_EXPERIMENTAL_DECOMPOSITIONS\n device: Device = field(default_factory=default_device)\n require_full_compilation: bool = REQUIRE_FULL_COMPILATION\n", "path": "py/torch_tensorrt/dynamo/_settings.py"}]}
| 1,325 | 301 |
gh_patches_debug_59440
|
rasdani/github-patches
|
git_diff
|
Pycord-Development__pycord-576
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
SlashCommand Groups Issues
This issue is to keep track of the issues since we reworked groups.
</issue>
<code>
[start of examples/app_commands/slash_groups.py]
1 import discord
2
3 bot = discord.Bot()
4
5 # If you use commands.Bot, @bot.slash_command should be used for
6 # slash commands. You can use @bot.slash_command with discord.Bot as well
7
8 math = bot.command_group(
9 "math", "Commands related to mathematics."
10 ) # create a slash command group
11
12
13 @math.command(guild_ids=[...]) # create a slash command
14 async def add(ctx, num1: int, num2: int):
15 """Get the sum of 2 integers."""
16 await ctx.respond(f"The sum of these numbers is **{num1+num2}**")
17
18
19 # another way, creating the class manually
20
21 from discord.commands import SlashCommandGroup
22
23 math = SlashCommandGroup("math", "Commands related to mathematics.")
24
25
26 @math.command(guild_ids=[...])
27 async def add(ctx, num1: int, num2: int):
28 ...
29
30
31 bot.add_application_command(math)
32
33 bot.run("TOKEN")
34
[end of examples/app_commands/slash_groups.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/examples/app_commands/slash_groups.py b/examples/app_commands/slash_groups.py
--- a/examples/app_commands/slash_groups.py
+++ b/examples/app_commands/slash_groups.py
@@ -5,7 +5,7 @@
# If you use commands.Bot, @bot.slash_command should be used for
# slash commands. You can use @bot.slash_command with discord.Bot as well
-math = bot.command_group(
+math = bot.create_group(
"math", "Commands related to mathematics."
) # create a slash command group
|
{"golden_diff": "diff --git a/examples/app_commands/slash_groups.py b/examples/app_commands/slash_groups.py\n--- a/examples/app_commands/slash_groups.py\n+++ b/examples/app_commands/slash_groups.py\n@@ -5,7 +5,7 @@\n # If you use commands.Bot, @bot.slash_command should be used for\r\n # slash commands. You can use @bot.slash_command with discord.Bot as well\r\n \r\n-math = bot.command_group(\r\n+math = bot.create_group(\r\n \"math\", \"Commands related to mathematics.\"\r\n ) # create a slash command group\n", "issue": "SlashCommand Groups Issues\nThis issue is to keep track of the issues since we reworked groups.\n", "before_files": [{"content": "import discord\r\n\r\nbot = discord.Bot()\r\n\r\n# If you use commands.Bot, @bot.slash_command should be used for\r\n# slash commands. You can use @bot.slash_command with discord.Bot as well\r\n\r\nmath = bot.command_group(\r\n \"math\", \"Commands related to mathematics.\"\r\n) # create a slash command group\r\n\r\n\r\[email protected](guild_ids=[...]) # create a slash command\r\nasync def add(ctx, num1: int, num2: int):\r\n \"\"\"Get the sum of 2 integers.\"\"\"\r\n await ctx.respond(f\"The sum of these numbers is **{num1+num2}**\")\r\n\r\n\r\n# another way, creating the class manually\r\n\r\nfrom discord.commands import SlashCommandGroup\r\n\r\nmath = SlashCommandGroup(\"math\", \"Commands related to mathematics.\")\r\n\r\n\r\[email protected](guild_ids=[...])\r\nasync def add(ctx, num1: int, num2: int):\r\n ...\r\n\r\n\r\nbot.add_application_command(math)\r\n\r\nbot.run(\"TOKEN\")\r\n", "path": "examples/app_commands/slash_groups.py"}]}
| 829 | 119 |
gh_patches_debug_12195
|
rasdani/github-patches
|
git_diff
|
fossasia__open-event-server-5124
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
HTTP 500 on /oauth/<provider>
**Describe the bug**
<!-- A clear and concise description of what the bug is. -->
The server returns HTTP 500 when a request is made to /oauth/<provider>. It is probably because I haven't configured facebook keys in the settings.
**Expected behavior**
<!-- A clear and concise description of what you expected to happen. -->
It shouldn't error out in any case. If something is improperly configured then it should return that message rather than the HTTP 500.
**Stacktrace**
```
INFO:werkzeug:127.0.0.1 - - [17/Jul/2018 04:40:54] "GET /v1/auth/oauth/facebook HTTP/1.1" 500 -
Traceback (most recent call last):
File "/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py", line 2309, in __call__
return self.wsgi_app(environ, start_response)
File "/media/srv_twry/work/Projects/Community-Projects/Fossasia/open-event-server/app/__init__.py", line 66, in __call__
return self.app(environ, start_response)
File "/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py", line 2295, in wsgi_app
response = self.handle_exception(e)
File "/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask_cors/extension.py", line 161, in wrapped_function
return cors_after_request(app.make_response(f(*args, **kwargs)))
File "/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask_cors/extension.py", line 161, in wrapped_function
return cors_after_request(app.make_response(f(*args, **kwargs)))
File "/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py", line 1741, in handle_exception
reraise(exc_type, exc_value, tb)
File "/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/_compat.py", line 35, in reraise
raise value
File "/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py", line 2292, in wsgi_app
response = self.full_dispatch_request()
File "/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py", line 1815, in full_dispatch_request
rv = self.handle_user_exception(e)
File "/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask_cors/extension.py", line 161, in wrapped_function
return cors_after_request(app.make_response(f(*args, **kwargs)))
File "/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask_cors/extension.py", line 161, in wrapped_function
return cors_after_request(app.make_response(f(*args, **kwargs)))
File "/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py", line 1718, in handle_user_exception
reraise(exc_type, exc_value, tb)
File "/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/_compat.py", line 35, in reraise
raise value
File "/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py", line 1813, in full_dispatch_request
rv = self.dispatch_request()
File "/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py", line 1799, in dispatch_request
return self.view_functions[rule.endpoint](**req.view_args)
File "/media/srv_twry/work/Projects/Community-Projects/Fossasia/open-event-server/app/api/auth.py", line 39, in redirect_uri
provider_class.get_client_id() + '&redirect_uri=' +\
TypeError: must be str, not NoneType
```
</issue>
<code>
[start of app/api/auth.py]
1 import base64
2 from flask import request, jsonify, make_response, Blueprint
3 from flask_jwt import current_identity as current_user, jwt_required
4 from sqlalchemy.orm.exc import NoResultFound
5 import requests
6
7 from app import get_settings
8 from app.api.helpers.db import save_to_db
9 from app.api.helpers.files import make_frontend_url
10 from app.api.helpers.mail import send_email_with_action, \
11 send_email_confirmation
12 from app.api.helpers.notification import send_notification_with_action
13
14 from app.api.helpers.utilities import get_serializer, str_generator
15 from app.models.mail import PASSWORD_RESET, PASSWORD_CHANGE, \
16 USER_REGISTER_WITH_PASSWORD
17 from app.models.notification import PASSWORD_CHANGE as PASSWORD_CHANGE_NOTIF
18 from app.models.user import User
19 from app.api.helpers.errors import UnprocessableEntityError, NotFoundError, BadRequestError
20 from app.api.helpers.third_party_auth import GoogleOAuth, FbOAuth, TwitterOAuth, InstagramOAuth
21
22 auth_routes = Blueprint('auth', __name__, url_prefix='/v1/auth')
23
24
25 @auth_routes.route('/oauth/<provider>', methods=['GET'])
26 def redirect_uri(provider):
27 if provider == 'facebook':
28 provider_class = FbOAuth()
29 elif provider == 'google':
30 provider_class = GoogleOAuth()
31 elif provider == 'twitter':
32 provider_class = TwitterOAuth()
33 elif provider == 'instagram':
34 provider_class = InstagramOAuth()
35 else:
36 return make_response(jsonify(
37 message="No support for {}".format(provider)), 404)
38 url = provider_class.get_auth_uri() + '?client_id=' +\
39 provider_class.get_client_id() + '&redirect_uri=' +\
40 provider_class.get_redirect_uri()
41 return make_response(jsonify(url=url), 200)
42
43
44 @auth_routes.route('/oauth/token/<provider>', methods=['GET'])
45 def get_token(provider):
46 if provider == 'facebook':
47 provider_class = FbOAuth()
48 payload = {
49 'grant_type': 'client_credentials',
50 'client_id': provider_class.get_client_id(),
51 'client_secret': provider_class.get_client_secret()
52 }
53 elif provider == 'google':
54 provider_class = GoogleOAuth()
55 payload = {
56 'client_id': provider_class.get_client_id(),
57 'client_secret': provider_class.get_client_secret()
58 }
59 elif provider == 'twitter':
60 provider_class = TwitterOAuth()
61 payload = {
62 'client_id': provider_class.get_client_id(),
63 'client_secret': provider_class.get_client_secret()
64 }
65 elif provider == 'instagram':
66 provider_class = InstagramOAuth()
67 payload = {
68 'client_id': provider_class.get_client_id(),
69 'client_secret': provider_class.get_client_secret()
70 }
71 else:
72 return make_response(jsonify(
73 message="No support for {}".format(provider)), 200)
74 response = requests.post(provider_class.get_token_uri(), params=payload)
75 return make_response(jsonify(token=response.json()), 200)
76
77
78 @auth_routes.route('/verify-email', methods=['POST'])
79 def verify_email():
80 token = base64.b64decode(request.json['data']['token'])
81 s = get_serializer()
82
83 try:
84 data = s.loads(token)
85 except Exception:
86 return BadRequestError({'source': ''}, 'Invalid Token').respond()
87
88 try:
89 user = User.query.filter_by(email=data[0]).one()
90 except Exception:
91 return BadRequestError({'source': ''}, 'Invalid Token').respond()
92 else:
93 user.is_verified = True
94 save_to_db(user)
95 return make_response(jsonify(message="Email Verified"), 200)
96
97
98 @auth_routes.route('/resend-verification-email', methods=['POST'])
99 def resend_verification_email():
100 try:
101 email = request.json['data']['email']
102 except TypeError:
103 return BadRequestError({'source': ''}, 'Bad Request Error').respond()
104
105 try:
106 user = User.query.filter_by(email=email).one()
107 except NoResultFound:
108 return UnprocessableEntityError(
109 {'source': ''}, 'User with email: ' + email + ' not found.').respond()
110 else:
111 serializer = get_serializer()
112 hash_ = str(base64.b64encode(str(serializer.dumps(
113 [user.email, str_generator()])).encode()), 'utf-8')
114 link = make_frontend_url(
115 '/email/verify'.format(id=user.id), {'token': hash_})
116 send_email_with_action(
117 user, USER_REGISTER_WITH_PASSWORD,
118 app_name=get_settings()['app_name'], email=user.email)
119 send_email_confirmation(user.email, link)
120
121 return make_response(jsonify(message="Verification email resent"), 200)
122
123
124 @auth_routes.route('/reset-password', methods=['POST'])
125 def reset_password_post():
126 try:
127 email = request.json['data']['email']
128 except TypeError:
129 return BadRequestError({'source': ''}, 'Bad Request Error').respond()
130
131 try:
132 user = User.query.filter_by(email=email).one()
133 except NoResultFound:
134 return UnprocessableEntityError({'source': ''}, 'User not found').respond()
135 else:
136 link = make_frontend_url('/reset-password', {'token': user.reset_password})
137 send_email_with_action(user, PASSWORD_RESET, app_name=get_settings()['app_name'], link=link)
138
139 return make_response(jsonify(message="Email Sent"), 200)
140
141
142 @auth_routes.route('/reset-password', methods=['PATCH'])
143 def reset_password_patch():
144 token = request.json['data']['token']
145 password = request.json['data']['password']
146
147 try:
148 user = User.query.filter_by(reset_password=token).one()
149 except NoResultFound:
150 return NotFoundError({'source': ''}, 'User Not Found').respond()
151 else:
152 user.password = password
153 save_to_db(user)
154
155 return jsonify({
156 "id": user.id,
157 "email": user.email,
158 "name": user.fullname if user.fullname else None
159 })
160
161
162 @auth_routes.route('/change-password', methods=['POST'])
163 @jwt_required()
164 def change_password():
165 old_password = request.json['data']['old-password']
166 new_password = request.json['data']['new-password']
167
168 try:
169 user = User.query.filter_by(id=current_user.id).one()
170 except NoResultFound:
171 return NotFoundError({'source': ''}, 'User Not Found').respond()
172 else:
173 if user.is_correct_password(old_password):
174
175 user.password = new_password
176 save_to_db(user)
177 send_email_with_action(user, PASSWORD_CHANGE,
178 app_name=get_settings()['app_name'])
179 send_notification_with_action(user, PASSWORD_CHANGE_NOTIF,
180 app_name=get_settings()['app_name'])
181 else:
182 return BadRequestError({'source': ''}, 'Wrong Password').respond()
183
184 return jsonify({
185 "id": user.id,
186 "email": user.email,
187 "name": user.fullname if user.fullname else None,
188 "password-changed": True
189 })
190
[end of app/api/auth.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/app/api/auth.py b/app/api/auth.py
--- a/app/api/auth.py
+++ b/app/api/auth.py
@@ -35,8 +35,14 @@
else:
return make_response(jsonify(
message="No support for {}".format(provider)), 404)
+
+ client_id = provider_class.get_client_id()
+ if not client_id:
+ return make_response(jsonify(
+ message="{} client id is not configured on the server".format(provider)), 404)
+
url = provider_class.get_auth_uri() + '?client_id=' +\
- provider_class.get_client_id() + '&redirect_uri=' +\
+ client_id + '&redirect_uri=' +\
provider_class.get_redirect_uri()
return make_response(jsonify(url=url), 200)
|
{"golden_diff": "diff --git a/app/api/auth.py b/app/api/auth.py\n--- a/app/api/auth.py\n+++ b/app/api/auth.py\n@@ -35,8 +35,14 @@\n else:\n return make_response(jsonify(\n message=\"No support for {}\".format(provider)), 404)\n+\n+ client_id = provider_class.get_client_id()\n+ if not client_id:\n+ return make_response(jsonify(\n+ message=\"{} client id is not configured on the server\".format(provider)), 404)\n+\n url = provider_class.get_auth_uri() + '?client_id=' +\\\n- provider_class.get_client_id() + '&redirect_uri=' +\\\n+ client_id + '&redirect_uri=' +\\\n provider_class.get_redirect_uri()\n return make_response(jsonify(url=url), 200)\n", "issue": "HTTP 500 on /oauth/<provider>\n**Describe the bug**\r\n<!-- A clear and concise description of what the bug is. -->\r\nThe server returns HTTP 500 when a request is made to /oauth/<provider>. It is probably because I haven't configured facebook keys in the settings.\r\n\r\n**Expected behavior**\r\n<!-- A clear and concise description of what you expected to happen. -->\r\nIt shouldn't error out in any case. If something is improperly configured then it should return that message rather than the HTTP 500.\r\n\r\n**Stacktrace**\r\n```\r\nINFO:werkzeug:127.0.0.1 - - [17/Jul/2018 04:40:54] \"GET /v1/auth/oauth/facebook HTTP/1.1\" 500 -\r\nTraceback (most recent call last):\r\n File \"/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py\", line 2309, in __call__\r\n return self.wsgi_app(environ, start_response)\r\n File \"/media/srv_twry/work/Projects/Community-Projects/Fossasia/open-event-server/app/__init__.py\", line 66, in __call__\r\n return self.app(environ, start_response)\r\n File \"/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py\", line 2295, in wsgi_app\r\n response = self.handle_exception(e)\r\n File \"/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask_cors/extension.py\", line 161, in wrapped_function\r\n return cors_after_request(app.make_response(f(*args, **kwargs)))\r\n File \"/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask_cors/extension.py\", line 161, in wrapped_function\r\n return cors_after_request(app.make_response(f(*args, **kwargs)))\r\n File \"/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py\", line 1741, in handle_exception\r\n reraise(exc_type, exc_value, tb)\r\n File \"/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/_compat.py\", line 35, in reraise\r\n raise value\r\n File \"/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py\", line 2292, in wsgi_app\r\n response = self.full_dispatch_request()\r\n File \"/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py\", line 1815, in full_dispatch_request\r\n rv = self.handle_user_exception(e)\r\n File \"/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask_cors/extension.py\", line 161, in wrapped_function\r\n return cors_after_request(app.make_response(f(*args, **kwargs)))\r\n File \"/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask_cors/extension.py\", line 161, in wrapped_function\r\n return cors_after_request(app.make_response(f(*args, **kwargs)))\r\n File \"/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py\", line 1718, in handle_user_exception\r\n reraise(exc_type, exc_value, tb)\r\n File \"/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/_compat.py\", line 35, in reraise\r\n raise value\r\n File \"/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py\", line 1813, in full_dispatch_request\r\n rv = self.dispatch_request()\r\n File \"/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py\", line 1799, in dispatch_request\r\n return self.view_functions[rule.endpoint](**req.view_args)\r\n File \"/media/srv_twry/work/Projects/Community-Projects/Fossasia/open-event-server/app/api/auth.py\", line 39, in redirect_uri\r\n provider_class.get_client_id() + '&redirect_uri=' +\\\r\nTypeError: must be str, not NoneType\r\n```\n", "before_files": [{"content": "import base64\nfrom flask import request, jsonify, make_response, Blueprint\nfrom flask_jwt import current_identity as current_user, jwt_required\nfrom sqlalchemy.orm.exc import NoResultFound\nimport requests\n\nfrom app import get_settings\nfrom app.api.helpers.db import save_to_db\nfrom app.api.helpers.files import make_frontend_url\nfrom app.api.helpers.mail import send_email_with_action, \\\n send_email_confirmation\nfrom app.api.helpers.notification import send_notification_with_action\n\nfrom app.api.helpers.utilities import get_serializer, str_generator\nfrom app.models.mail import PASSWORD_RESET, PASSWORD_CHANGE, \\\n USER_REGISTER_WITH_PASSWORD\nfrom app.models.notification import PASSWORD_CHANGE as PASSWORD_CHANGE_NOTIF\nfrom app.models.user import User\nfrom app.api.helpers.errors import UnprocessableEntityError, NotFoundError, BadRequestError\nfrom app.api.helpers.third_party_auth import GoogleOAuth, FbOAuth, TwitterOAuth, InstagramOAuth\n\nauth_routes = Blueprint('auth', __name__, url_prefix='/v1/auth')\n\n\n@auth_routes.route('/oauth/<provider>', methods=['GET'])\ndef redirect_uri(provider):\n if provider == 'facebook':\n provider_class = FbOAuth()\n elif provider == 'google':\n provider_class = GoogleOAuth()\n elif provider == 'twitter':\n provider_class = TwitterOAuth()\n elif provider == 'instagram':\n provider_class = InstagramOAuth()\n else:\n return make_response(jsonify(\n message=\"No support for {}\".format(provider)), 404)\n url = provider_class.get_auth_uri() + '?client_id=' +\\\n provider_class.get_client_id() + '&redirect_uri=' +\\\n provider_class.get_redirect_uri()\n return make_response(jsonify(url=url), 200)\n\n\n@auth_routes.route('/oauth/token/<provider>', methods=['GET'])\ndef get_token(provider):\n if provider == 'facebook':\n provider_class = FbOAuth()\n payload = {\n 'grant_type': 'client_credentials',\n 'client_id': provider_class.get_client_id(),\n 'client_secret': provider_class.get_client_secret()\n }\n elif provider == 'google':\n provider_class = GoogleOAuth()\n payload = {\n 'client_id': provider_class.get_client_id(),\n 'client_secret': provider_class.get_client_secret()\n }\n elif provider == 'twitter':\n provider_class = TwitterOAuth()\n payload = {\n 'client_id': provider_class.get_client_id(),\n 'client_secret': provider_class.get_client_secret()\n }\n elif provider == 'instagram':\n provider_class = InstagramOAuth()\n payload = {\n 'client_id': provider_class.get_client_id(),\n 'client_secret': provider_class.get_client_secret()\n }\n else:\n return make_response(jsonify(\n message=\"No support for {}\".format(provider)), 200)\n response = requests.post(provider_class.get_token_uri(), params=payload)\n return make_response(jsonify(token=response.json()), 200)\n\n\n@auth_routes.route('/verify-email', methods=['POST'])\ndef verify_email():\n token = base64.b64decode(request.json['data']['token'])\n s = get_serializer()\n\n try:\n data = s.loads(token)\n except Exception:\n return BadRequestError({'source': ''}, 'Invalid Token').respond()\n\n try:\n user = User.query.filter_by(email=data[0]).one()\n except Exception:\n return BadRequestError({'source': ''}, 'Invalid Token').respond()\n else:\n user.is_verified = True\n save_to_db(user)\n return make_response(jsonify(message=\"Email Verified\"), 200)\n\n\n@auth_routes.route('/resend-verification-email', methods=['POST'])\ndef resend_verification_email():\n try:\n email = request.json['data']['email']\n except TypeError:\n return BadRequestError({'source': ''}, 'Bad Request Error').respond()\n\n try:\n user = User.query.filter_by(email=email).one()\n except NoResultFound:\n return UnprocessableEntityError(\n {'source': ''}, 'User with email: ' + email + ' not found.').respond()\n else:\n serializer = get_serializer()\n hash_ = str(base64.b64encode(str(serializer.dumps(\n [user.email, str_generator()])).encode()), 'utf-8')\n link = make_frontend_url(\n '/email/verify'.format(id=user.id), {'token': hash_})\n send_email_with_action(\n user, USER_REGISTER_WITH_PASSWORD,\n app_name=get_settings()['app_name'], email=user.email)\n send_email_confirmation(user.email, link)\n\n return make_response(jsonify(message=\"Verification email resent\"), 200)\n\n\n@auth_routes.route('/reset-password', methods=['POST'])\ndef reset_password_post():\n try:\n email = request.json['data']['email']\n except TypeError:\n return BadRequestError({'source': ''}, 'Bad Request Error').respond()\n\n try:\n user = User.query.filter_by(email=email).one()\n except NoResultFound:\n return UnprocessableEntityError({'source': ''}, 'User not found').respond()\n else:\n link = make_frontend_url('/reset-password', {'token': user.reset_password})\n send_email_with_action(user, PASSWORD_RESET, app_name=get_settings()['app_name'], link=link)\n\n return make_response(jsonify(message=\"Email Sent\"), 200)\n\n\n@auth_routes.route('/reset-password', methods=['PATCH'])\ndef reset_password_patch():\n token = request.json['data']['token']\n password = request.json['data']['password']\n\n try:\n user = User.query.filter_by(reset_password=token).one()\n except NoResultFound:\n return NotFoundError({'source': ''}, 'User Not Found').respond()\n else:\n user.password = password\n save_to_db(user)\n\n return jsonify({\n \"id\": user.id,\n \"email\": user.email,\n \"name\": user.fullname if user.fullname else None\n })\n\n\n@auth_routes.route('/change-password', methods=['POST'])\n@jwt_required()\ndef change_password():\n old_password = request.json['data']['old-password']\n new_password = request.json['data']['new-password']\n\n try:\n user = User.query.filter_by(id=current_user.id).one()\n except NoResultFound:\n return NotFoundError({'source': ''}, 'User Not Found').respond()\n else:\n if user.is_correct_password(old_password):\n\n user.password = new_password\n save_to_db(user)\n send_email_with_action(user, PASSWORD_CHANGE,\n app_name=get_settings()['app_name'])\n send_notification_with_action(user, PASSWORD_CHANGE_NOTIF,\n app_name=get_settings()['app_name'])\n else:\n return BadRequestError({'source': ''}, 'Wrong Password').respond()\n\n return jsonify({\n \"id\": user.id,\n \"email\": user.email,\n \"name\": user.fullname if user.fullname else None,\n \"password-changed\": True\n })\n", "path": "app/api/auth.py"}]}
| 3,475 | 179 |
gh_patches_debug_67111
|
rasdani/github-patches
|
git_diff
|
beeware__toga-1619
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Scroll container not expanding to width of container
```
import toga
from toga.style import Pack
from toga.style.pack import COLUMN, ROW
class AFV(toga.App):
def startup(self):
self.main_window = toga.MainWindow(title=self.formal_name)
box_test = toga.Box(style=Pack(direction=COLUMN, padding=5))
self.label_1 = toga.Label('TESTE 1')
self.lineEdit_1 = toga.TextInput()
self.label_2 = toga.Label('TESTE 2')
self.lineEdit_2 = toga.TextInput()
self.label_3 = toga.Label('TESTE 3')
self.lineEdit_3 = toga.TextInput()
self.label_4 = toga.Label('TESTE 4')
self.lineEdit_4 = toga.TextInput()
self.label_5 = toga.Label('TESTE 5')
self.lineEdit_5 = toga.TextInput()
box_test.add(self.label_1, self.lineEdit_1,
self.label_2, self.lineEdit_2,
self.label_3, self.lineEdit_3,
self.label_4, self.lineEdit_4,
self.label_5, self.lineEdit_5)
self.container = toga.ScrollContainer(horizontal=True, vertical=True)
self.container.content = box_test
self.main_window.content = self.container
self.main_window.show()
def main():
return AFV()
```
When using the widget it leaves the widgets in the wrong shape and size on the screen.
The ScrollContainer doesn't make the TextInput widget fill to the bottom of the screen, it measures according to the size of the Label text.

Worked on Briefcase 0.3.9; new screenshot is from Briefcase 0.3.10.
</issue>
<code>
[start of src/android/toga_android/widgets/scrollcontainer.py]
1 from travertino.size import at_least
2
3 from toga_android.window import AndroidViewport
4
5 from ..libs.android.view import (
6 Gravity,
7 View__MeasureSpec,
8 View__OnTouchListener
9 )
10 from ..libs.android.widget import (
11 HorizontalScrollView,
12 LinearLayout__LayoutParams,
13 ScrollView
14 )
15 from .base import Widget
16
17
18 class TogaOnTouchListener(View__OnTouchListener):
19 is_scrolling_enabled = True
20
21 def __init__(self):
22 super().__init__()
23
24 def onTouch(self, view, motion_event):
25 if self.is_scrolling_enabled:
26 return view.onTouchEvent(motion_event)
27 else:
28 return True
29
30
31 class ScrollContainer(Widget):
32 vScrollListener = None
33 hScrollView = None
34 hScrollListener = None
35
36 def create(self):
37 vScrollView = ScrollView(self._native_activity)
38 vScrollView_layout_params = LinearLayout__LayoutParams(
39 LinearLayout__LayoutParams.MATCH_PARENT,
40 LinearLayout__LayoutParams.MATCH_PARENT
41 )
42 vScrollView_layout_params.gravity = Gravity.TOP
43 vScrollView.setLayoutParams(vScrollView_layout_params)
44 self.vScrollListener = TogaOnTouchListener()
45 self.vScrollListener.is_scrolling_enabled = self.interface.vertical
46 vScrollView.setOnTouchListener(self.vScrollListener)
47 self.native = vScrollView
48 self.hScrollView = HorizontalScrollView(self._native_activity)
49 hScrollView_layout_params = LinearLayout__LayoutParams(
50 LinearLayout__LayoutParams.MATCH_PARENT,
51 LinearLayout__LayoutParams.MATCH_PARENT
52 )
53 hScrollView_layout_params.gravity = Gravity.LEFT
54 self.hScrollListener = TogaOnTouchListener()
55 self.hScrollListener.is_scrolling_enabled = self.interface.horizontal
56 self.hScrollView.setOnTouchListener(self.hScrollListener)
57 vScrollView.addView(self.hScrollView, hScrollView_layout_params)
58 if self.interface.content is not None:
59 self.set_content(self.interface.content)
60
61 def set_content(self, widget):
62 widget.viewport = AndroidViewport(widget.native)
63 content_view_params = LinearLayout__LayoutParams(
64 LinearLayout__LayoutParams.MATCH_PARENT,
65 LinearLayout__LayoutParams.MATCH_PARENT
66 )
67 if widget.container:
68 widget.container = None
69 if self.interface.content:
70 self.hScrollView.removeAllViews()
71 self.hScrollView.addView(widget.native, content_view_params)
72 for child in widget.interface.children:
73 if child._impl.container:
74 child._impl.container = None
75 child._impl.container = widget
76
77 def set_vertical(self, value):
78 self.vScrollListener.is_scrolling_enabled = value
79
80 def set_horizontal(self, value):
81 self.hScrollListener.is_scrolling_enabled = value
82
83 def set_on_scroll(self, on_scroll):
84 self.interface.factory.not_implemented("ScrollContainer.set_on_scroll()")
85
86 def get_vertical_position(self):
87 self.interface.factory.not_implemented(
88 "ScrollContainer.get_vertical_position()"
89 )
90 return 0
91
92 def set_vertical_position(self, vertical_position):
93 self.interface.factory.not_implemented(
94 "ScrollContainer.set_vertical_position()"
95 )
96
97 def get_horizontal_position(self):
98 self.interface.factory.not_implemented(
99 "ScrollContainer.get_horizontal_position()"
100 )
101 return 0
102
103 def set_horizontal_position(self, horizontal_position):
104 self.interface.factory.not_implemented(
105 "ScrollContainer.set_horizontal_position()"
106 )
107
108 def rehint(self):
109 # Android can crash when rendering some widgets until they have their layout params set. Guard for that case.
110 if not self.native.getLayoutParams():
111 return
112 self.native.measure(
113 View__MeasureSpec.UNSPECIFIED,
114 View__MeasureSpec.UNSPECIFIED,
115 )
116 self.interface.intrinsic.width = at_least(self.native.getMeasuredWidth())
117 self.interface.intrinsic.height = at_least(self.native.getMeasuredHeight())
118
[end of src/android/toga_android/widgets/scrollcontainer.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/android/toga_android/widgets/scrollcontainer.py b/src/android/toga_android/widgets/scrollcontainer.py
--- a/src/android/toga_android/widgets/scrollcontainer.py
+++ b/src/android/toga_android/widgets/scrollcontainer.py
@@ -59,7 +59,7 @@
self.set_content(self.interface.content)
def set_content(self, widget):
- widget.viewport = AndroidViewport(widget.native)
+ widget.viewport = AndroidViewport(self.native)
content_view_params = LinearLayout__LayoutParams(
LinearLayout__LayoutParams.MATCH_PARENT,
LinearLayout__LayoutParams.MATCH_PARENT
|
{"golden_diff": "diff --git a/src/android/toga_android/widgets/scrollcontainer.py b/src/android/toga_android/widgets/scrollcontainer.py\n--- a/src/android/toga_android/widgets/scrollcontainer.py\n+++ b/src/android/toga_android/widgets/scrollcontainer.py\n@@ -59,7 +59,7 @@\n self.set_content(self.interface.content)\n \n def set_content(self, widget):\n- widget.viewport = AndroidViewport(widget.native)\n+ widget.viewport = AndroidViewport(self.native)\n content_view_params = LinearLayout__LayoutParams(\n LinearLayout__LayoutParams.MATCH_PARENT,\n LinearLayout__LayoutParams.MATCH_PARENT\n", "issue": "Scroll container not expanding to width of container\n```\r\nimport toga\r\nfrom toga.style import Pack\r\nfrom toga.style.pack import COLUMN, ROW\r\n\r\nclass AFV(toga.App):\r\n\r\n def startup(self):\r\n self.main_window = toga.MainWindow(title=self.formal_name)\r\n\r\n box_test = toga.Box(style=Pack(direction=COLUMN, padding=5))\r\n self.label_1 = toga.Label('TESTE 1')\r\n self.lineEdit_1 = toga.TextInput()\r\n self.label_2 = toga.Label('TESTE 2')\r\n self.lineEdit_2 = toga.TextInput()\r\n self.label_3 = toga.Label('TESTE 3')\r\n self.lineEdit_3 = toga.TextInput()\r\n self.label_4 = toga.Label('TESTE 4')\r\n self.lineEdit_4 = toga.TextInput()\r\n self.label_5 = toga.Label('TESTE 5')\r\n self.lineEdit_5 = toga.TextInput()\r\n\r\n box_test.add(self.label_1, self.lineEdit_1, \r\n self.label_2, self.lineEdit_2, \r\n self.label_3, self.lineEdit_3, \r\n self.label_4, self.lineEdit_4, \r\n self.label_5, self.lineEdit_5)\r\n self.container = toga.ScrollContainer(horizontal=True, vertical=True)\r\n self.container.content = box_test\r\n\r\n\r\n self.main_window.content = self.container\r\n self.main_window.show()\r\n\r\n\r\ndef main():\r\n return AFV()\r\n```\r\n\r\n\r\nWhen using the widget it leaves the widgets in the wrong shape and size on the screen.\r\nThe ScrollContainer doesn't make the TextInput widget fill to the bottom of the screen, it measures according to the size of the Label text.\r\n\r\n\r\n\r\nWorked on Briefcase 0.3.9; new screenshot is from Briefcase 0.3.10.\n", "before_files": [{"content": "from travertino.size import at_least\n\nfrom toga_android.window import AndroidViewport\n\nfrom ..libs.android.view import (\n Gravity,\n View__MeasureSpec,\n View__OnTouchListener\n)\nfrom ..libs.android.widget import (\n HorizontalScrollView,\n LinearLayout__LayoutParams,\n ScrollView\n)\nfrom .base import Widget\n\n\nclass TogaOnTouchListener(View__OnTouchListener):\n is_scrolling_enabled = True\n\n def __init__(self):\n super().__init__()\n\n def onTouch(self, view, motion_event):\n if self.is_scrolling_enabled:\n return view.onTouchEvent(motion_event)\n else:\n return True\n\n\nclass ScrollContainer(Widget):\n vScrollListener = None\n hScrollView = None\n hScrollListener = None\n\n def create(self):\n vScrollView = ScrollView(self._native_activity)\n vScrollView_layout_params = LinearLayout__LayoutParams(\n LinearLayout__LayoutParams.MATCH_PARENT,\n LinearLayout__LayoutParams.MATCH_PARENT\n )\n vScrollView_layout_params.gravity = Gravity.TOP\n vScrollView.setLayoutParams(vScrollView_layout_params)\n self.vScrollListener = TogaOnTouchListener()\n self.vScrollListener.is_scrolling_enabled = self.interface.vertical\n vScrollView.setOnTouchListener(self.vScrollListener)\n self.native = vScrollView\n self.hScrollView = HorizontalScrollView(self._native_activity)\n hScrollView_layout_params = LinearLayout__LayoutParams(\n LinearLayout__LayoutParams.MATCH_PARENT,\n LinearLayout__LayoutParams.MATCH_PARENT\n )\n hScrollView_layout_params.gravity = Gravity.LEFT\n self.hScrollListener = TogaOnTouchListener()\n self.hScrollListener.is_scrolling_enabled = self.interface.horizontal\n self.hScrollView.setOnTouchListener(self.hScrollListener)\n vScrollView.addView(self.hScrollView, hScrollView_layout_params)\n if self.interface.content is not None:\n self.set_content(self.interface.content)\n\n def set_content(self, widget):\n widget.viewport = AndroidViewport(widget.native)\n content_view_params = LinearLayout__LayoutParams(\n LinearLayout__LayoutParams.MATCH_PARENT,\n LinearLayout__LayoutParams.MATCH_PARENT\n )\n if widget.container:\n widget.container = None\n if self.interface.content:\n self.hScrollView.removeAllViews()\n self.hScrollView.addView(widget.native, content_view_params)\n for child in widget.interface.children:\n if child._impl.container:\n child._impl.container = None\n child._impl.container = widget\n\n def set_vertical(self, value):\n self.vScrollListener.is_scrolling_enabled = value\n\n def set_horizontal(self, value):\n self.hScrollListener.is_scrolling_enabled = value\n\n def set_on_scroll(self, on_scroll):\n self.interface.factory.not_implemented(\"ScrollContainer.set_on_scroll()\")\n\n def get_vertical_position(self):\n self.interface.factory.not_implemented(\n \"ScrollContainer.get_vertical_position()\"\n )\n return 0\n\n def set_vertical_position(self, vertical_position):\n self.interface.factory.not_implemented(\n \"ScrollContainer.set_vertical_position()\"\n )\n\n def get_horizontal_position(self):\n self.interface.factory.not_implemented(\n \"ScrollContainer.get_horizontal_position()\"\n )\n return 0\n\n def set_horizontal_position(self, horizontal_position):\n self.interface.factory.not_implemented(\n \"ScrollContainer.set_horizontal_position()\"\n )\n\n def rehint(self):\n # Android can crash when rendering some widgets until they have their layout params set. Guard for that case.\n if not self.native.getLayoutParams():\n return\n self.native.measure(\n View__MeasureSpec.UNSPECIFIED,\n View__MeasureSpec.UNSPECIFIED,\n )\n self.interface.intrinsic.width = at_least(self.native.getMeasuredWidth())\n self.interface.intrinsic.height = at_least(self.native.getMeasuredHeight())\n", "path": "src/android/toga_android/widgets/scrollcontainer.py"}]}
| 2,011 | 124 |
gh_patches_debug_17407
|
rasdani/github-patches
|
git_diff
|
pypi__warehouse-1485
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Refuse account creation when using disposable email addresses.
long term it makes no sense to accept accounts which use an email address which is disposable for managing legit packages. short/near term it opens an easy door for spammers to create accounts on PyPI.
i've implemented blacklisting for account signup and email swaps which use the blacklist at https://github.com/martenson/disposable-email-domains for legacy pypi.
</issue>
<code>
[start of warehouse/accounts/forms.py]
1 # Licensed under the Apache License, Version 2.0 (the "License");
2 # you may not use this file except in compliance with the License.
3 # You may obtain a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS,
9 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
10 # See the License for the specific language governing permissions and
11 # limitations under the License.
12 import re
13
14 import wtforms
15 import wtforms.fields.html5
16
17 from warehouse import forms, recaptcha
18
19
20 class CredentialsMixin:
21 username = wtforms.StringField(
22 validators=[
23 wtforms.validators.DataRequired(),
24 wtforms.validators.Length(max=50),
25 ],
26 )
27
28 password = wtforms.PasswordField(
29 validators=[
30 wtforms.validators.DataRequired(),
31 ],
32 )
33
34 def __init__(self, *args, user_service, **kwargs):
35 super().__init__(*args, **kwargs)
36 self.user_service = user_service
37
38
39 # XXX: This is a naive password strength validator, but something that can
40 # easily be replicated in JS for client-side feedback.
41 # see: https://github.com/pypa/warehouse/issues/6
42 PWD_MIN_LEN = 8
43 PWD_RE = re.compile(r"""
44 ^ # start
45 (?=.*[A-Z]+.*) # >= 1 upper case
46 (?=.*[a-z]+.*) # >= 1 lower case
47 (?=.*[0-9]+.*) # >= 1 number
48 (?=.*[.*~`\!@#$%^&\*\(\)_+-={}|\[\]\\:";'<>?,\./]+.*) # >= 1 special char
49 .{""" + str(PWD_MIN_LEN) + """,} # >= 8 chars
50 $ # end
51 """, re.X)
52
53
54 class RegistrationForm(CredentialsMixin, forms.Form):
55 password_confirm = wtforms.PasswordField(
56 validators=[
57 wtforms.validators.DataRequired(),
58 wtforms.validators.EqualTo(
59 "password", "Passwords must match."
60 ),
61 ],
62 )
63
64 full_name = wtforms.StringField()
65
66 email = wtforms.fields.html5.EmailField(
67 validators=[
68 wtforms.validators.DataRequired(),
69 wtforms.validators.Email(),
70 ],
71 )
72
73 g_recaptcha_response = wtforms.StringField()
74
75 def __init__(self, *args, recaptcha_service, **kwargs):
76 super().__init__(*args, **kwargs)
77 self.recaptcha_service = recaptcha_service
78
79 def validate_username(self, field):
80 if self.user_service.find_userid(field.data) is not None:
81 raise wtforms.validators.ValidationError(
82 "Username exists.")
83
84 def validate_email(self, field):
85 if self.user_service.find_userid_by_email(field.data) is not None:
86 raise wtforms.validators.ValidationError("Email exists.")
87
88 def validate_g_recaptcha_response(self, field):
89 # do required data validation here due to enabled flag being required
90 if self.recaptcha_service.enabled and not field.data:
91 raise wtforms.validators.ValidationError("Recaptcha error.")
92 try:
93 self.recaptcha_service.verify_response(field.data)
94 except recaptcha.RecaptchaError:
95 # TODO: log error
96 # don't want to provide the user with any detail
97 raise wtforms.validators.ValidationError("Recaptcha error.")
98
99 def validate_password(self, field):
100 if not PWD_RE.match(field.data):
101 raise wtforms.validators.ValidationError(
102 "Password must contain an upper case letter, a lower case "
103 "letter, a number, a special character and be at least "
104 "%d characters in length" % PWD_MIN_LEN
105 )
106
107
108 class LoginForm(CredentialsMixin, forms.Form):
109 def validate_username(self, field):
110 userid = self.user_service.find_userid(field.data)
111
112 if userid is None:
113 raise wtforms.validators.ValidationError("Invalid user.")
114
115 def validate_password(self, field):
116 userid = self.user_service.find_userid(self.username.data)
117 if userid is not None:
118 if not self.user_service.check_password(userid, field.data):
119 raise wtforms.validators.ValidationError("Invalid password.")
120
[end of warehouse/accounts/forms.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/warehouse/accounts/forms.py b/warehouse/accounts/forms.py
--- a/warehouse/accounts/forms.py
+++ b/warehouse/accounts/forms.py
@@ -11,6 +11,7 @@
# limitations under the License.
import re
+import disposable_email_domains
import wtforms
import wtforms.fields.html5
@@ -84,6 +85,9 @@
def validate_email(self, field):
if self.user_service.find_userid_by_email(field.data) is not None:
raise wtforms.validators.ValidationError("Email exists.")
+ domain = field.data.split('@')[-1]
+ if domain in disposable_email_domains.blacklist:
+ raise wtforms.validators.ValidationError("Disposable email.")
def validate_g_recaptcha_response(self, field):
# do required data validation here due to enabled flag being required
|
{"golden_diff": "diff --git a/warehouse/accounts/forms.py b/warehouse/accounts/forms.py\n--- a/warehouse/accounts/forms.py\n+++ b/warehouse/accounts/forms.py\n@@ -11,6 +11,7 @@\n # limitations under the License.\n import re\n \n+import disposable_email_domains\n import wtforms\n import wtforms.fields.html5\n \n@@ -84,6 +85,9 @@\n def validate_email(self, field):\n if self.user_service.find_userid_by_email(field.data) is not None:\n raise wtforms.validators.ValidationError(\"Email exists.\")\n+ domain = field.data.split('@')[-1]\n+ if domain in disposable_email_domains.blacklist:\n+ raise wtforms.validators.ValidationError(\"Disposable email.\")\n \n def validate_g_recaptcha_response(self, field):\n # do required data validation here due to enabled flag being required\n", "issue": "Refuse account creation when using disposable email addresses.\nlong term it makes no sense to accept accounts which use an email address which is disposable for managing legit packages. short/near term it opens an easy door for spammers to create accounts on PyPI.\n\ni've implemented blacklisting for account signup and email swaps which use the blacklist at https://github.com/martenson/disposable-email-domains for legacy pypi.\n\n", "before_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport re\n\nimport wtforms\nimport wtforms.fields.html5\n\nfrom warehouse import forms, recaptcha\n\n\nclass CredentialsMixin:\n username = wtforms.StringField(\n validators=[\n wtforms.validators.DataRequired(),\n wtforms.validators.Length(max=50),\n ],\n )\n\n password = wtforms.PasswordField(\n validators=[\n wtforms.validators.DataRequired(),\n ],\n )\n\n def __init__(self, *args, user_service, **kwargs):\n super().__init__(*args, **kwargs)\n self.user_service = user_service\n\n\n# XXX: This is a naive password strength validator, but something that can\n# easily be replicated in JS for client-side feedback.\n# see: https://github.com/pypa/warehouse/issues/6\nPWD_MIN_LEN = 8\nPWD_RE = re.compile(r\"\"\"\n^ # start\n(?=.*[A-Z]+.*) # >= 1 upper case\n(?=.*[a-z]+.*) # >= 1 lower case\n(?=.*[0-9]+.*) # >= 1 number\n(?=.*[.*~`\\!@#$%^&\\*\\(\\)_+-={}|\\[\\]\\\\:\";'<>?,\\./]+.*) # >= 1 special char\n.{\"\"\" + str(PWD_MIN_LEN) + \"\"\",} # >= 8 chars\n$ # end\n\"\"\", re.X)\n\n\nclass RegistrationForm(CredentialsMixin, forms.Form):\n password_confirm = wtforms.PasswordField(\n validators=[\n wtforms.validators.DataRequired(),\n wtforms.validators.EqualTo(\n \"password\", \"Passwords must match.\"\n ),\n ],\n )\n\n full_name = wtforms.StringField()\n\n email = wtforms.fields.html5.EmailField(\n validators=[\n wtforms.validators.DataRequired(),\n wtforms.validators.Email(),\n ],\n )\n\n g_recaptcha_response = wtforms.StringField()\n\n def __init__(self, *args, recaptcha_service, **kwargs):\n super().__init__(*args, **kwargs)\n self.recaptcha_service = recaptcha_service\n\n def validate_username(self, field):\n if self.user_service.find_userid(field.data) is not None:\n raise wtforms.validators.ValidationError(\n \"Username exists.\")\n\n def validate_email(self, field):\n if self.user_service.find_userid_by_email(field.data) is not None:\n raise wtforms.validators.ValidationError(\"Email exists.\")\n\n def validate_g_recaptcha_response(self, field):\n # do required data validation here due to enabled flag being required\n if self.recaptcha_service.enabled and not field.data:\n raise wtforms.validators.ValidationError(\"Recaptcha error.\")\n try:\n self.recaptcha_service.verify_response(field.data)\n except recaptcha.RecaptchaError:\n # TODO: log error\n # don't want to provide the user with any detail\n raise wtforms.validators.ValidationError(\"Recaptcha error.\")\n\n def validate_password(self, field):\n if not PWD_RE.match(field.data):\n raise wtforms.validators.ValidationError(\n \"Password must contain an upper case letter, a lower case \"\n \"letter, a number, a special character and be at least \"\n \"%d characters in length\" % PWD_MIN_LEN\n )\n\n\nclass LoginForm(CredentialsMixin, forms.Form):\n def validate_username(self, field):\n userid = self.user_service.find_userid(field.data)\n\n if userid is None:\n raise wtforms.validators.ValidationError(\"Invalid user.\")\n\n def validate_password(self, field):\n userid = self.user_service.find_userid(self.username.data)\n if userid is not None:\n if not self.user_service.check_password(userid, field.data):\n raise wtforms.validators.ValidationError(\"Invalid password.\")\n", "path": "warehouse/accounts/forms.py"}]}
| 1,772 | 176 |
gh_patches_debug_39390
|
rasdani/github-patches
|
git_diff
|
streamlink__streamlink-5881
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
plugins.ustvnow: pluginmatcher URL update needed
### Checklist
- [X] This is a plugin issue and not a different kind of issue
- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)
- [X] [I have checked the list of open and recently closed plugin issues](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22)
- [X] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)
### Streamlink version
Latest build from the master branch
### Description
You need to replace the search template in ustvnow.py plugin with the one below.
```
@pluginmatcher(re.compile(
r"https?://(?:www\.)?ustvnow\.com/channel/live/(?P<chname>\w+)",
))
```
What is in the code now - does not work due to changes that have occurred on the site www.ustvnow.com
### Debug log
```text
The log cannot be retrieved because changes must be made to the template of the link it "serves"
```
</issue>
<code>
[start of src/streamlink/plugins/ustvnow.py]
1 """
2 $description US live TV channels. OTT service from USTVnow.
3 $url ustvnow.com
4 $type live
5 $account Required, additional subscription required by some streams
6 """
7
8 import base64
9 import json
10 import logging
11 import re
12 from urllib.parse import urljoin, urlparse
13 from uuid import uuid4
14
15 from streamlink.plugin import Plugin, PluginError, pluginargument, pluginmatcher
16 from streamlink.stream.hls import HLSStream
17 from streamlink.utils.crypto import AES, SHA256, pad, unpad
18
19
20 log = logging.getLogger(__name__)
21
22
23 @pluginmatcher(re.compile(
24 r"https?://(?:www\.)?ustvnow\.com/live/(?P<scode>\w+)/-(?P<id>\d+)",
25 ))
26 @pluginargument(
27 "username",
28 required=True,
29 requires=["password"],
30 metavar="USERNAME",
31 help="Your USTV Now account username",
32 )
33 @pluginargument(
34 "password",
35 required=True,
36 sensitive=True,
37 metavar="PASSWORD",
38 help="Your USTV Now account password",
39 )
40 class USTVNow(Plugin):
41 _main_js_re = re.compile(r"""src=['"](main\..*\.js)['"]""")
42 _enc_key_re = re.compile(r'(?P<key>AES_(?:Key|IV))\s*:\s*"(?P<value>[^"]+)"')
43
44 TENANT_CODE = "ustvnow"
45 _api_url = "https://teleupapi.revlet.net/service/api/v1/"
46 _token_url = _api_url + "get/token"
47 _signin_url = "https://www.ustvnow.com/signin"
48
49 def __init__(self, *args, **kwargs):
50 super().__init__(*args, **kwargs)
51 self._encryption_config = {}
52 self._token = None
53
54 @classmethod
55 def encrypt_data(cls, data, key, iv):
56 rkey = "".join(reversed(key)).encode("utf8")
57 riv = "".join(reversed(iv)).encode("utf8")
58
59 fkey = SHA256.new(rkey).hexdigest()[:32].encode("utf8")
60
61 cipher = AES.new(fkey, AES.MODE_CBC, riv)
62 encrypted = cipher.encrypt(pad(data, 16, "pkcs7"))
63 return base64.b64encode(encrypted)
64
65 @classmethod
66 def decrypt_data(cls, data, key, iv):
67 rkey = "".join(reversed(key)).encode("utf8")
68 riv = "".join(reversed(iv)).encode("utf8")
69
70 fkey = SHA256.new(rkey).hexdigest()[:32].encode("utf8")
71
72 cipher = AES.new(fkey, AES.MODE_CBC, riv)
73 decrypted = cipher.decrypt(base64.b64decode(data))
74 if decrypted:
75 return unpad(decrypted, 16, "pkcs7")
76 else:
77 return decrypted
78
79 def _get_encryption_config(self, url):
80 # find the path to the main.js
81 # load the main.js and extract the config
82 if not self._encryption_config:
83 res = self.session.http.get(url)
84 m = self._main_js_re.search(res.text)
85 main_js_path = m and m.group(1)
86 if main_js_path:
87 res = self.session.http.get(urljoin(url, main_js_path))
88 self._encryption_config = dict(self._enc_key_re.findall(res.text))
89
90 return self._encryption_config.get("AES_Key"), self._encryption_config.get("AES_IV")
91
92 @property
93 def box_id(self):
94 if not self.cache.get("box_id"):
95 self.cache.set("box_id", str(uuid4()))
96 return self.cache.get("box_id")
97
98 def get_token(self):
99 """
100 Get the token for USTVNow
101 :return: a valid token
102 """
103
104 if not self._token:
105 log.debug("Getting new session token")
106 res = self.session.http.get(self._token_url, params={
107 "tenant_code": self.TENANT_CODE,
108 "box_id": self.box_id,
109 "product": self.TENANT_CODE,
110 "device_id": 5,
111 "display_lang_code": "ENG",
112 "device_sub_type": "",
113 "timezone": "UTC",
114 })
115
116 data = res.json()
117 if data["status"]:
118 self._token = data["response"]["sessionId"]
119 log.debug("New token: {}".format(self._token))
120 else:
121 log.error("Token acquisition failed: {details} ({detail})".format(**data["error"]))
122 raise PluginError("could not obtain token")
123
124 return self._token
125
126 def api_request(self, path, data, metadata=None):
127 key, iv = self._get_encryption_config(self._signin_url)
128 post_data = {
129 "data": self.encrypt_data(json.dumps(data).encode("utf8"), key, iv).decode("utf8"),
130 "metadata": self.encrypt_data(json.dumps(metadata).encode("utf8"), key, iv).decode("utf8"),
131 }
132 headers = {"box-id": self.box_id,
133 "session-id": self.get_token(),
134 "tenant-code": self.TENANT_CODE,
135 "content-type": "application/json"}
136 res = self.session.http.post(self._api_url + path, data=json.dumps(post_data), headers=headers).json()
137 data = {k: v and json.loads(self.decrypt_data(v, key, iv)) for k, v in res.items()}
138 return data
139
140 def login(self, username, password):
141 log.debug("Trying to login...")
142 resp = self.api_request(
143 "send",
144 {
145 "login_id": username,
146 "login_key": password,
147 "login_mode": "1",
148 "manufacturer": "123",
149 },
150 {"request": "signin"},
151 )
152
153 return resp["data"]["status"]
154
155 def _get_streams(self):
156 """
157 Finds the streams from ustvnow.com.
158 """
159 if self.login(self.get_option("username"), self.get_option("password")):
160 path = urlparse(self.url).path.strip("/")
161 resp = self.api_request("send", {"path": path}, {"request": "page/stream"})
162 if resp["data"]["status"]:
163 for stream in resp["data"]["response"]["streams"]:
164 if stream["keys"]["licenseKey"]:
165 log.warning("Stream possibly protected by DRM")
166 yield from HLSStream.parse_variant_playlist(self.session, stream["url"]).items()
167 else:
168 log.error("Could not find any streams: {code}: {message}".format(**resp["data"]["error"]))
169 else:
170 log.error("Failed to login, check username and password")
171
172
173 __plugin__ = USTVNow
174
[end of src/streamlink/plugins/ustvnow.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/streamlink/plugins/ustvnow.py b/src/streamlink/plugins/ustvnow.py
--- a/src/streamlink/plugins/ustvnow.py
+++ b/src/streamlink/plugins/ustvnow.py
@@ -21,7 +21,7 @@
@pluginmatcher(re.compile(
- r"https?://(?:www\.)?ustvnow\.com/live/(?P<scode>\w+)/-(?P<id>\d+)",
+ r"https?://(?:www\.)?ustvnow\.com/channel/live/(?P<chname>\w+)",
))
@pluginargument(
"username",
@@ -96,11 +96,6 @@
return self.cache.get("box_id")
def get_token(self):
- """
- Get the token for USTVNow
- :return: a valid token
- """
-
if not self._token:
log.debug("Getting new session token")
res = self.session.http.get(self._token_url, params={
@@ -114,13 +109,13 @@
})
data = res.json()
- if data["status"]:
- self._token = data["response"]["sessionId"]
- log.debug("New token: {}".format(self._token))
- else:
+ if not data["status"]:
log.error("Token acquisition failed: {details} ({detail})".format(**data["error"]))
raise PluginError("could not obtain token")
+ self._token = data["response"]["sessionId"]
+ log.debug(f"New token: {self._token}")
+
return self._token
def api_request(self, path, data, metadata=None):
@@ -153,21 +148,20 @@
return resp["data"]["status"]
def _get_streams(self):
- """
- Finds the streams from ustvnow.com.
- """
- if self.login(self.get_option("username"), self.get_option("password")):
- path = urlparse(self.url).path.strip("/")
- resp = self.api_request("send", {"path": path}, {"request": "page/stream"})
- if resp["data"]["status"]:
- for stream in resp["data"]["response"]["streams"]:
- if stream["keys"]["licenseKey"]:
- log.warning("Stream possibly protected by DRM")
- yield from HLSStream.parse_variant_playlist(self.session, stream["url"]).items()
- else:
- log.error("Could not find any streams: {code}: {message}".format(**resp["data"]["error"]))
- else:
+ if not self.login(self.get_option("username"), self.get_option("password")):
log.error("Failed to login, check username and password")
+ return
+
+ path = urlparse(self.url).path.strip("/")
+ resp = self.api_request("send", {"path": path}, {"request": "page/stream"})
+ if not resp["data"]["status"]:
+ log.error("Could not find any streams: {code}: {message}".format(**resp["data"]["error"]))
+ return
+
+ for stream in resp["data"]["response"]["streams"]:
+ if stream["keys"]["licenseKey"]:
+ log.warning("Stream possibly protected by DRM")
+ yield from HLSStream.parse_variant_playlist(self.session, stream["url"]).items()
__plugin__ = USTVNow
|
{"golden_diff": "diff --git a/src/streamlink/plugins/ustvnow.py b/src/streamlink/plugins/ustvnow.py\n--- a/src/streamlink/plugins/ustvnow.py\n+++ b/src/streamlink/plugins/ustvnow.py\n@@ -21,7 +21,7 @@\n \n \n @pluginmatcher(re.compile(\n- r\"https?://(?:www\\.)?ustvnow\\.com/live/(?P<scode>\\w+)/-(?P<id>\\d+)\",\n+ r\"https?://(?:www\\.)?ustvnow\\.com/channel/live/(?P<chname>\\w+)\",\n ))\n @pluginargument(\n \"username\",\n@@ -96,11 +96,6 @@\n return self.cache.get(\"box_id\")\n \n def get_token(self):\n- \"\"\"\n- Get the token for USTVNow\n- :return: a valid token\n- \"\"\"\n-\n if not self._token:\n log.debug(\"Getting new session token\")\n res = self.session.http.get(self._token_url, params={\n@@ -114,13 +109,13 @@\n })\n \n data = res.json()\n- if data[\"status\"]:\n- self._token = data[\"response\"][\"sessionId\"]\n- log.debug(\"New token: {}\".format(self._token))\n- else:\n+ if not data[\"status\"]:\n log.error(\"Token acquisition failed: {details} ({detail})\".format(**data[\"error\"]))\n raise PluginError(\"could not obtain token\")\n \n+ self._token = data[\"response\"][\"sessionId\"]\n+ log.debug(f\"New token: {self._token}\")\n+\n return self._token\n \n def api_request(self, path, data, metadata=None):\n@@ -153,21 +148,20 @@\n return resp[\"data\"][\"status\"]\n \n def _get_streams(self):\n- \"\"\"\n- Finds the streams from ustvnow.com.\n- \"\"\"\n- if self.login(self.get_option(\"username\"), self.get_option(\"password\")):\n- path = urlparse(self.url).path.strip(\"/\")\n- resp = self.api_request(\"send\", {\"path\": path}, {\"request\": \"page/stream\"})\n- if resp[\"data\"][\"status\"]:\n- for stream in resp[\"data\"][\"response\"][\"streams\"]:\n- if stream[\"keys\"][\"licenseKey\"]:\n- log.warning(\"Stream possibly protected by DRM\")\n- yield from HLSStream.parse_variant_playlist(self.session, stream[\"url\"]).items()\n- else:\n- log.error(\"Could not find any streams: {code}: {message}\".format(**resp[\"data\"][\"error\"]))\n- else:\n+ if not self.login(self.get_option(\"username\"), self.get_option(\"password\")):\n log.error(\"Failed to login, check username and password\")\n+ return\n+\n+ path = urlparse(self.url).path.strip(\"/\")\n+ resp = self.api_request(\"send\", {\"path\": path}, {\"request\": \"page/stream\"})\n+ if not resp[\"data\"][\"status\"]:\n+ log.error(\"Could not find any streams: {code}: {message}\".format(**resp[\"data\"][\"error\"]))\n+ return\n+\n+ for stream in resp[\"data\"][\"response\"][\"streams\"]:\n+ if stream[\"keys\"][\"licenseKey\"]:\n+ log.warning(\"Stream possibly protected by DRM\")\n+ yield from HLSStream.parse_variant_playlist(self.session, stream[\"url\"]).items()\n \n \n __plugin__ = USTVNow\n", "issue": "plugins.ustvnow: pluginmatcher URL update needed\n### Checklist\n\n- [X] This is a plugin issue and not a different kind of issue\n- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)\n- [X] [I have checked the list of open and recently closed plugin issues](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22)\n- [X] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)\n\n### Streamlink version\n\nLatest build from the master branch\n\n### Description\n\nYou need to replace the search template in ustvnow.py plugin with the one below.\r\n\r\n```\r\n@pluginmatcher(re.compile( \r\n r\"https?://(?:www\\.)?ustvnow\\.com/channel/live/(?P<chname>\\w+)\", \r\n))\r\n```\r\nWhat is in the code now - does not work due to changes that have occurred on the site www.ustvnow.com\n\n### Debug log\n\n```text\nThe log cannot be retrieved because changes must be made to the template of the link it \"serves\"\n```\n\n", "before_files": [{"content": "\"\"\"\n$description US live TV channels. OTT service from USTVnow.\n$url ustvnow.com\n$type live\n$account Required, additional subscription required by some streams\n\"\"\"\n\nimport base64\nimport json\nimport logging\nimport re\nfrom urllib.parse import urljoin, urlparse\nfrom uuid import uuid4\n\nfrom streamlink.plugin import Plugin, PluginError, pluginargument, pluginmatcher\nfrom streamlink.stream.hls import HLSStream\nfrom streamlink.utils.crypto import AES, SHA256, pad, unpad\n\n\nlog = logging.getLogger(__name__)\n\n\n@pluginmatcher(re.compile(\n r\"https?://(?:www\\.)?ustvnow\\.com/live/(?P<scode>\\w+)/-(?P<id>\\d+)\",\n))\n@pluginargument(\n \"username\",\n required=True,\n requires=[\"password\"],\n metavar=\"USERNAME\",\n help=\"Your USTV Now account username\",\n)\n@pluginargument(\n \"password\",\n required=True,\n sensitive=True,\n metavar=\"PASSWORD\",\n help=\"Your USTV Now account password\",\n)\nclass USTVNow(Plugin):\n _main_js_re = re.compile(r\"\"\"src=['\"](main\\..*\\.js)['\"]\"\"\")\n _enc_key_re = re.compile(r'(?P<key>AES_(?:Key|IV))\\s*:\\s*\"(?P<value>[^\"]+)\"')\n\n TENANT_CODE = \"ustvnow\"\n _api_url = \"https://teleupapi.revlet.net/service/api/v1/\"\n _token_url = _api_url + \"get/token\"\n _signin_url = \"https://www.ustvnow.com/signin\"\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self._encryption_config = {}\n self._token = None\n\n @classmethod\n def encrypt_data(cls, data, key, iv):\n rkey = \"\".join(reversed(key)).encode(\"utf8\")\n riv = \"\".join(reversed(iv)).encode(\"utf8\")\n\n fkey = SHA256.new(rkey).hexdigest()[:32].encode(\"utf8\")\n\n cipher = AES.new(fkey, AES.MODE_CBC, riv)\n encrypted = cipher.encrypt(pad(data, 16, \"pkcs7\"))\n return base64.b64encode(encrypted)\n\n @classmethod\n def decrypt_data(cls, data, key, iv):\n rkey = \"\".join(reversed(key)).encode(\"utf8\")\n riv = \"\".join(reversed(iv)).encode(\"utf8\")\n\n fkey = SHA256.new(rkey).hexdigest()[:32].encode(\"utf8\")\n\n cipher = AES.new(fkey, AES.MODE_CBC, riv)\n decrypted = cipher.decrypt(base64.b64decode(data))\n if decrypted:\n return unpad(decrypted, 16, \"pkcs7\")\n else:\n return decrypted\n\n def _get_encryption_config(self, url):\n # find the path to the main.js\n # load the main.js and extract the config\n if not self._encryption_config:\n res = self.session.http.get(url)\n m = self._main_js_re.search(res.text)\n main_js_path = m and m.group(1)\n if main_js_path:\n res = self.session.http.get(urljoin(url, main_js_path))\n self._encryption_config = dict(self._enc_key_re.findall(res.text))\n\n return self._encryption_config.get(\"AES_Key\"), self._encryption_config.get(\"AES_IV\")\n\n @property\n def box_id(self):\n if not self.cache.get(\"box_id\"):\n self.cache.set(\"box_id\", str(uuid4()))\n return self.cache.get(\"box_id\")\n\n def get_token(self):\n \"\"\"\n Get the token for USTVNow\n :return: a valid token\n \"\"\"\n\n if not self._token:\n log.debug(\"Getting new session token\")\n res = self.session.http.get(self._token_url, params={\n \"tenant_code\": self.TENANT_CODE,\n \"box_id\": self.box_id,\n \"product\": self.TENANT_CODE,\n \"device_id\": 5,\n \"display_lang_code\": \"ENG\",\n \"device_sub_type\": \"\",\n \"timezone\": \"UTC\",\n })\n\n data = res.json()\n if data[\"status\"]:\n self._token = data[\"response\"][\"sessionId\"]\n log.debug(\"New token: {}\".format(self._token))\n else:\n log.error(\"Token acquisition failed: {details} ({detail})\".format(**data[\"error\"]))\n raise PluginError(\"could not obtain token\")\n\n return self._token\n\n def api_request(self, path, data, metadata=None):\n key, iv = self._get_encryption_config(self._signin_url)\n post_data = {\n \"data\": self.encrypt_data(json.dumps(data).encode(\"utf8\"), key, iv).decode(\"utf8\"),\n \"metadata\": self.encrypt_data(json.dumps(metadata).encode(\"utf8\"), key, iv).decode(\"utf8\"),\n }\n headers = {\"box-id\": self.box_id,\n \"session-id\": self.get_token(),\n \"tenant-code\": self.TENANT_CODE,\n \"content-type\": \"application/json\"}\n res = self.session.http.post(self._api_url + path, data=json.dumps(post_data), headers=headers).json()\n data = {k: v and json.loads(self.decrypt_data(v, key, iv)) for k, v in res.items()}\n return data\n\n def login(self, username, password):\n log.debug(\"Trying to login...\")\n resp = self.api_request(\n \"send\",\n {\n \"login_id\": username,\n \"login_key\": password,\n \"login_mode\": \"1\",\n \"manufacturer\": \"123\",\n },\n {\"request\": \"signin\"},\n )\n\n return resp[\"data\"][\"status\"]\n\n def _get_streams(self):\n \"\"\"\n Finds the streams from ustvnow.com.\n \"\"\"\n if self.login(self.get_option(\"username\"), self.get_option(\"password\")):\n path = urlparse(self.url).path.strip(\"/\")\n resp = self.api_request(\"send\", {\"path\": path}, {\"request\": \"page/stream\"})\n if resp[\"data\"][\"status\"]:\n for stream in resp[\"data\"][\"response\"][\"streams\"]:\n if stream[\"keys\"][\"licenseKey\"]:\n log.warning(\"Stream possibly protected by DRM\")\n yield from HLSStream.parse_variant_playlist(self.session, stream[\"url\"]).items()\n else:\n log.error(\"Could not find any streams: {code}: {message}\".format(**resp[\"data\"][\"error\"]))\n else:\n log.error(\"Failed to login, check username and password\")\n\n\n__plugin__ = USTVNow\n", "path": "src/streamlink/plugins/ustvnow.py"}]}
| 2,690 | 736 |
gh_patches_debug_12917
|
rasdani/github-patches
|
git_diff
|
elastic__apm-agent-python-724
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
'AsyncTransport' has no attribute '_start_event_processor'
**Describe the bug**: ...
After upgrading to `elastic-apm==5.4.1` I now get an error when Celery starts:
```
<function _register_worker_signals.<locals>.worker_startup at 0x7feae4beb620> raised: AttributeError("'AsyncTransport' object has no attribute '_start_event_processor'",)
Traceback (most recent call last):
File "/venv/lib/python3.6/site-packages/celery/utils/dispatch/signal.py", line 288, in send
response = receiver(signal=self, sender=sender, **named)
File "/venv/1.37.1/lib/python3.6/site-packages/elasticapm/contrib/celery/__init__.py", line 80, in worker_startup
client._transport._start_event_processor()
AttributeError: 'AsyncTransport' object has no attribute '_start_event_processor'
```
**Environment (please complete the following information)**
- OS: Linux-3.10.0-1062.9.1.el7.x86_64-x86_64-with-centos-7.7.1908-Core 2020-02-18 16:24:31
- Python version: Python 3.6.8
- Framework and version:
celery 4.4.0
Django 3.0.3
- APM Server version: ?
- Agent version: 5.4.1
I see the same error mentioned in issue #704, but I don't seem to have an issue with restarting Celery workers.
</issue>
<code>
[start of elasticapm/contrib/celery/__init__.py]
1 # BSD 3-Clause License
2 #
3 # Copyright (c) 2012, the Sentry Team, see AUTHORS for more details
4 # Copyright (c) 2019, Elasticsearch BV
5 # All rights reserved.
6 #
7 # Redistribution and use in source and binary forms, with or without
8 # modification, are permitted provided that the following conditions are met:
9 #
10 # * Redistributions of source code must retain the above copyright notice, this
11 # list of conditions and the following disclaimer.
12 #
13 # * Redistributions in binary form must reproduce the above copyright notice,
14 # this list of conditions and the following disclaimer in the documentation
15 # and/or other materials provided with the distribution.
16 #
17 # * Neither the name of the copyright holder nor the names of its
18 # contributors may be used to endorse or promote products derived from
19 # this software without specific prior written permission.
20 #
21 # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
22 # AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
23 # IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
24 # DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
25 # FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
26 # DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
27 # SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
28 # CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
29 # OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
30
31
32 from celery import signals
33
34 from elasticapm.utils import get_name_from_func
35
36
37 class CeleryFilter(object):
38 def filter(self, record):
39 if record.funcName in ("_log_error",):
40 return 0
41 else:
42 return 1
43
44
45 def register_exception_tracking(client):
46 dispatch_uid = "elasticapm-exc-tracking"
47
48 def process_failure_signal(sender, task_id, exception, args, kwargs, traceback, einfo, **kw):
49 client.capture_exception(
50 extra={"task_id": task_id, "task": sender, "args": args, "kwargs": kwargs}, handled=False
51 )
52
53 signals.task_failure.disconnect(process_failure_signal, dispatch_uid=dispatch_uid)
54 signals.task_failure.connect(process_failure_signal, weak=False, dispatch_uid=dispatch_uid)
55 _register_worker_signals(client)
56
57
58 def register_instrumentation(client):
59 def begin_transaction(*args, **kwargs):
60 client.begin_transaction("celery")
61
62 def end_transaction(task_id, task, *args, **kwargs):
63 name = get_name_from_func(task)
64 client.end_transaction(name, kwargs.get("state", "None"))
65
66 dispatch_uid = "elasticapm-tracing-%s"
67
68 # unregister any existing clients
69 signals.task_prerun.disconnect(begin_transaction, dispatch_uid=dispatch_uid % "prerun")
70 signals.task_postrun.disconnect(end_transaction, dispatch_uid=dispatch_uid % "postrun")
71
72 # register for this client
73 signals.task_prerun.connect(begin_transaction, dispatch_uid=dispatch_uid % "prerun", weak=False)
74 signals.task_postrun.connect(end_transaction, weak=False, dispatch_uid=dispatch_uid % "postrun")
75 _register_worker_signals(client)
76
77
78 def _register_worker_signals(client):
79 def worker_startup(*args, **kwargs):
80 client._transport._start_event_processor()
81
82 def worker_shutdown(*args, **kwargs):
83 client.close()
84
85 def connect_worker_process_init(*args, **kwargs):
86 signals.worker_process_init.connect(worker_startup, dispatch_uid="elasticapm-start-worker", weak=False)
87 signals.worker_process_shutdown.connect(worker_shutdown, dispatch_uid="elasticapm-shutdown-worker", weak=False)
88
89 signals.worker_init.connect(
90 connect_worker_process_init, dispatch_uid="elasticapm-connect-start-threads", weak=False
91 )
92
[end of elasticapm/contrib/celery/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/elasticapm/contrib/celery/__init__.py b/elasticapm/contrib/celery/__init__.py
--- a/elasticapm/contrib/celery/__init__.py
+++ b/elasticapm/contrib/celery/__init__.py
@@ -76,14 +76,10 @@
def _register_worker_signals(client):
- def worker_startup(*args, **kwargs):
- client._transport._start_event_processor()
-
def worker_shutdown(*args, **kwargs):
client.close()
def connect_worker_process_init(*args, **kwargs):
- signals.worker_process_init.connect(worker_startup, dispatch_uid="elasticapm-start-worker", weak=False)
signals.worker_process_shutdown.connect(worker_shutdown, dispatch_uid="elasticapm-shutdown-worker", weak=False)
signals.worker_init.connect(
|
{"golden_diff": "diff --git a/elasticapm/contrib/celery/__init__.py b/elasticapm/contrib/celery/__init__.py\n--- a/elasticapm/contrib/celery/__init__.py\n+++ b/elasticapm/contrib/celery/__init__.py\n@@ -76,14 +76,10 @@\n \n \n def _register_worker_signals(client):\n- def worker_startup(*args, **kwargs):\n- client._transport._start_event_processor()\n-\n def worker_shutdown(*args, **kwargs):\n client.close()\n \n def connect_worker_process_init(*args, **kwargs):\n- signals.worker_process_init.connect(worker_startup, dispatch_uid=\"elasticapm-start-worker\", weak=False)\n signals.worker_process_shutdown.connect(worker_shutdown, dispatch_uid=\"elasticapm-shutdown-worker\", weak=False)\n \n signals.worker_init.connect(\n", "issue": "'AsyncTransport' has no attribute '_start_event_processor'\n**Describe the bug**: ...\r\n\r\nAfter upgrading to `elastic-apm==5.4.1` I now get an error when Celery starts:\r\n\r\n```\r\n<function _register_worker_signals.<locals>.worker_startup at 0x7feae4beb620> raised: AttributeError(\"'AsyncTransport' object has no attribute '_start_event_processor'\",)\r\nTraceback (most recent call last):\r\n File \"/venv/lib/python3.6/site-packages/celery/utils/dispatch/signal.py\", line 288, in send\r\n response = receiver(signal=self, sender=sender, **named)\r\n File \"/venv/1.37.1/lib/python3.6/site-packages/elasticapm/contrib/celery/__init__.py\", line 80, in worker_startup\r\n client._transport._start_event_processor()\r\nAttributeError: 'AsyncTransport' object has no attribute '_start_event_processor' \r\n```\r\n\r\n**Environment (please complete the following information)**\r\n- OS: Linux-3.10.0-1062.9.1.el7.x86_64-x86_64-with-centos-7.7.1908-Core 2020-02-18 16:24:31\r\n- Python version: Python 3.6.8\r\n- Framework and version: \r\n celery 4.4.0\r\n Django 3.0.3\r\n- APM Server version: ?\r\n- Agent version: 5.4.1\r\n\r\nI see the same error mentioned in issue #704, but I don't seem to have an issue with restarting Celery workers.\n", "before_files": [{"content": "# BSD 3-Clause License\n#\n# Copyright (c) 2012, the Sentry Team, see AUTHORS for more details\n# Copyright (c) 2019, Elasticsearch BV\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n#\n# * Redistributions of source code must retain the above copyright notice, this\n# list of conditions and the following disclaimer.\n#\n# * Redistributions in binary form must reproduce the above copyright notice,\n# this list of conditions and the following disclaimer in the documentation\n# and/or other materials provided with the distribution.\n#\n# * Neither the name of the copyright holder nor the names of its\n# contributors may be used to endorse or promote products derived from\n# this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE\n# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL\n# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR\n# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,\n# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n\n\nfrom celery import signals\n\nfrom elasticapm.utils import get_name_from_func\n\n\nclass CeleryFilter(object):\n def filter(self, record):\n if record.funcName in (\"_log_error\",):\n return 0\n else:\n return 1\n\n\ndef register_exception_tracking(client):\n dispatch_uid = \"elasticapm-exc-tracking\"\n\n def process_failure_signal(sender, task_id, exception, args, kwargs, traceback, einfo, **kw):\n client.capture_exception(\n extra={\"task_id\": task_id, \"task\": sender, \"args\": args, \"kwargs\": kwargs}, handled=False\n )\n\n signals.task_failure.disconnect(process_failure_signal, dispatch_uid=dispatch_uid)\n signals.task_failure.connect(process_failure_signal, weak=False, dispatch_uid=dispatch_uid)\n _register_worker_signals(client)\n\n\ndef register_instrumentation(client):\n def begin_transaction(*args, **kwargs):\n client.begin_transaction(\"celery\")\n\n def end_transaction(task_id, task, *args, **kwargs):\n name = get_name_from_func(task)\n client.end_transaction(name, kwargs.get(\"state\", \"None\"))\n\n dispatch_uid = \"elasticapm-tracing-%s\"\n\n # unregister any existing clients\n signals.task_prerun.disconnect(begin_transaction, dispatch_uid=dispatch_uid % \"prerun\")\n signals.task_postrun.disconnect(end_transaction, dispatch_uid=dispatch_uid % \"postrun\")\n\n # register for this client\n signals.task_prerun.connect(begin_transaction, dispatch_uid=dispatch_uid % \"prerun\", weak=False)\n signals.task_postrun.connect(end_transaction, weak=False, dispatch_uid=dispatch_uid % \"postrun\")\n _register_worker_signals(client)\n\n\ndef _register_worker_signals(client):\n def worker_startup(*args, **kwargs):\n client._transport._start_event_processor()\n\n def worker_shutdown(*args, **kwargs):\n client.close()\n\n def connect_worker_process_init(*args, **kwargs):\n signals.worker_process_init.connect(worker_startup, dispatch_uid=\"elasticapm-start-worker\", weak=False)\n signals.worker_process_shutdown.connect(worker_shutdown, dispatch_uid=\"elasticapm-shutdown-worker\", weak=False)\n\n signals.worker_init.connect(\n connect_worker_process_init, dispatch_uid=\"elasticapm-connect-start-threads\", weak=False\n )\n", "path": "elasticapm/contrib/celery/__init__.py"}]}
| 1,937 | 186 |
gh_patches_debug_9210
|
rasdani/github-patches
|
git_diff
|
chainer__chainer-3237
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
DictDataset throws an internal error only in Python 3.
The following code throws an internal error only in Python 3 environment with the latest version of Chainer. (3.0.0b1, 8bcac6f)
```py
from chainer.datasets import DictDataset
def main():
a = range(10)
b = range(10, 20)
dataset = DictDataset(x=a, y=b)
print(dataset[0:5])
if __name__ == '__main__':
main()
```
In Python 3.6.1,
```sh
$ python --version
Python 3.6.1
$ python poc.py
Traceback (most recent call last):
File "poc.py", line 12, in <module>
main()
File "poc.py", line 8, in main
print(dataset[0:5])
File "/home/igarashi/projects/chainer/chainer/datasets/dict_dataset.py", line 34, in __getitem__
length = len(six.itervalues(batches).next())
AttributeError: 'dict_valueiterator' object has no attribute 'next'
```
In Python 2.7.13,
```sh
$ python --version
Python 2.7.13
$ python poc.py
[{'y': 10, 'x': 0}, {'y': 11, 'x': 1}, {'y': 12, 'x': 2}, {'y': 13, 'x': 3}, {'y': 14, 'x': 4}]
```
It is because an instance of `six.Iterator` doesn't have `next()` method in the Python 3 environment.
[Reference](http://pythonhosted.org/six/#six.Iterator)
</issue>
<code>
[start of chainer/datasets/dict_dataset.py]
1 import six
2
3
4 class DictDataset(object):
5
6 """Dataset of a dictionary of datasets.
7
8 It combines multiple datasets into one dataset. Each example is represented
9 by a dictionary mapping a key to an example of the corresponding dataset.
10
11 Args:
12 datasets: Underlying datasets. The keys are used as the keys of each
13 example. All datasets must have the same length.
14
15 """
16
17 def __init__(self, **datasets):
18 if not datasets:
19 raise ValueError('no datasets are given')
20 length = None
21 for key, dataset in six.iteritems(datasets):
22 if length is None:
23 length = len(dataset)
24 elif length != len(dataset):
25 raise ValueError(
26 'dataset length conflicts at "{}"'.format(key))
27 self._datasets = datasets
28 self._length = length
29
30 def __getitem__(self, index):
31 batches = {key: dataset[index]
32 for key, dataset in six.iteritems(self._datasets)}
33 if isinstance(index, slice):
34 length = len(six.itervalues(batches).next())
35 return [{key: batch[i] for key, batch in six.iteritems(batches)}
36 for i in six.moves.range(length)]
37 else:
38 return batches
39
40 def __len__(self):
41 return self._length
42
[end of chainer/datasets/dict_dataset.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/chainer/datasets/dict_dataset.py b/chainer/datasets/dict_dataset.py
--- a/chainer/datasets/dict_dataset.py
+++ b/chainer/datasets/dict_dataset.py
@@ -31,7 +31,7 @@
batches = {key: dataset[index]
for key, dataset in six.iteritems(self._datasets)}
if isinstance(index, slice):
- length = len(six.itervalues(batches).next())
+ length = len(six.next(six.itervalues(batches)))
return [{key: batch[i] for key, batch in six.iteritems(batches)}
for i in six.moves.range(length)]
else:
|
{"golden_diff": "diff --git a/chainer/datasets/dict_dataset.py b/chainer/datasets/dict_dataset.py\n--- a/chainer/datasets/dict_dataset.py\n+++ b/chainer/datasets/dict_dataset.py\n@@ -31,7 +31,7 @@\n batches = {key: dataset[index]\n for key, dataset in six.iteritems(self._datasets)}\n if isinstance(index, slice):\n- length = len(six.itervalues(batches).next())\n+ length = len(six.next(six.itervalues(batches)))\n return [{key: batch[i] for key, batch in six.iteritems(batches)}\n for i in six.moves.range(length)]\n else:\n", "issue": "DictDataset throws an internal error only in Python 3.\nThe following code throws an internal error only in Python 3 environment with the latest version of Chainer. (3.0.0b1, 8bcac6f)\r\n```py\r\nfrom chainer.datasets import DictDataset\r\n\r\ndef main():\r\n a = range(10)\r\n b = range(10, 20)\r\n dataset = DictDataset(x=a, y=b)\r\n print(dataset[0:5])\r\n\r\nif __name__ == '__main__':\r\n main()\r\n```\r\n\r\nIn Python 3.6.1,\r\n```sh\r\n$ python --version\r\n Python 3.6.1\r\n$ python poc.py\r\n Traceback (most recent call last):\r\n File \"poc.py\", line 12, in <module>\r\n main()\r\n File \"poc.py\", line 8, in main\r\n print(dataset[0:5])\r\n File \"/home/igarashi/projects/chainer/chainer/datasets/dict_dataset.py\", line 34, in __getitem__\r\n length = len(six.itervalues(batches).next())\r\nAttributeError: 'dict_valueiterator' object has no attribute 'next'\r\n```\r\n\r\nIn Python 2.7.13, \r\n```sh\r\n$ python --version\r\n Python 2.7.13\r\n$ python poc.py\r\n [{'y': 10, 'x': 0}, {'y': 11, 'x': 1}, {'y': 12, 'x': 2}, {'y': 13, 'x': 3}, {'y': 14, 'x': 4}]\r\n```\r\n\r\nIt is because an instance of `six.Iterator` doesn't have `next()` method in the Python 3 environment.\r\n[Reference](http://pythonhosted.org/six/#six.Iterator)\r\n\n", "before_files": [{"content": "import six\n\n\nclass DictDataset(object):\n\n \"\"\"Dataset of a dictionary of datasets.\n\n It combines multiple datasets into one dataset. Each example is represented\n by a dictionary mapping a key to an example of the corresponding dataset.\n\n Args:\n datasets: Underlying datasets. The keys are used as the keys of each\n example. All datasets must have the same length.\n\n \"\"\"\n\n def __init__(self, **datasets):\n if not datasets:\n raise ValueError('no datasets are given')\n length = None\n for key, dataset in six.iteritems(datasets):\n if length is None:\n length = len(dataset)\n elif length != len(dataset):\n raise ValueError(\n 'dataset length conflicts at \"{}\"'.format(key))\n self._datasets = datasets\n self._length = length\n\n def __getitem__(self, index):\n batches = {key: dataset[index]\n for key, dataset in six.iteritems(self._datasets)}\n if isinstance(index, slice):\n length = len(six.itervalues(batches).next())\n return [{key: batch[i] for key, batch in six.iteritems(batches)}\n for i in six.moves.range(length)]\n else:\n return batches\n\n def __len__(self):\n return self._length\n", "path": "chainer/datasets/dict_dataset.py"}]}
| 1,286 | 145 |
gh_patches_debug_35186
|
rasdani/github-patches
|
git_diff
|
vnpy__vnpy-1795
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Bug:rqdata.py 中 RqdataClient 类的 to_rq_symbol 方法对连续和指数合约转换有问题
## 环境
* 操作系统: 如Windows 10
* Anaconda版本: Anaconda 18.12 Python 3.7 64位
* vn.py版本: v2.0.3
## Issue类型
三选一:Bug
## 预期程序行为
正确将合约名转换至rqdata中的合约名
## 实际程序行为
错误的将郑商所的合约连续和指数合约转换,例如将AP888会转换为AP2888,AP99会转换至AP199导致无法下载到数据。
## 重现步骤
在回测模块中下载AP88数据即可。
针对Bug类型Issue,请提供具体重现步骤以及报错截图
</issue>
<code>
[start of vnpy/trader/rqdata.py]
1 from datetime import datetime, timedelta
2 from typing import List
3
4 from rqdatac import init as rqdata_init
5 from rqdatac.services.basic import all_instruments as rqdata_all_instruments
6 from rqdatac.services.get_price import get_price as rqdata_get_price
7
8 from .setting import SETTINGS
9 from .constant import Exchange, Interval
10 from .object import BarData, HistoryRequest
11
12
13 INTERVAL_VT2RQ = {
14 Interval.MINUTE: "1m",
15 Interval.HOUR: "60m",
16 Interval.DAILY: "1d",
17 }
18
19 INTERVAL_ADJUSTMENT_MAP = {
20 Interval.MINUTE: timedelta(minutes=1),
21 Interval.HOUR: timedelta(hours=1),
22 Interval.DAILY: timedelta() # no need to adjust for daily bar
23 }
24
25
26 class RqdataClient:
27 """
28 Client for querying history data from RQData.
29 """
30
31 def __init__(self):
32 """"""
33 self.username = SETTINGS["rqdata.username"]
34 self.password = SETTINGS["rqdata.password"]
35
36 self.inited = False
37 self.symbols = set()
38
39 def init(self):
40 """"""
41 if self.inited:
42 return True
43
44 if not self.username or not self.password:
45 return False
46
47 rqdata_init(self.username, self.password,
48 ('rqdatad-pro.ricequant.com', 16011))
49
50 try:
51 df = rqdata_all_instruments(date=datetime.now())
52 for ix, row in df.iterrows():
53 self.symbols.add(row['order_book_id'])
54 except RuntimeError:
55 return False
56
57 self.inited = True
58 return True
59
60 def to_rq_symbol(self, symbol: str, exchange: Exchange):
61 """
62 CZCE product of RQData has symbol like "TA1905" while
63 vt symbol is "TA905.CZCE" so need to add "1" in symbol.
64 """
65 if exchange in [Exchange.SSE, Exchange.SZSE]:
66 if exchange == Exchange.SSE:
67 rq_symbol = f"{symbol}.XSHG"
68 else:
69 rq_symbol = f"{symbol}.XSHE"
70 else:
71 if exchange is not Exchange.CZCE:
72 return symbol.upper()
73
74 for count, word in enumerate(symbol):
75 if word.isdigit():
76 break
77
78 # noinspection PyUnboundLocalVariable
79 product = symbol[:count]
80 year = symbol[count]
81 month = symbol[count + 1:]
82
83 if year == "9":
84 year = "1" + year
85 else:
86 year = "2" + year
87
88 rq_symbol = f"{product}{year}{month}".upper()
89
90 return rq_symbol
91
92 def query_history(self, req: HistoryRequest):
93 """
94 Query history bar data from RQData.
95 """
96 symbol = req.symbol
97 exchange = req.exchange
98 interval = req.interval
99 start = req.start
100 end = req.end
101
102 rq_symbol = self.to_rq_symbol(symbol, exchange)
103 if rq_symbol not in self.symbols:
104 return None
105
106 rq_interval = INTERVAL_VT2RQ.get(interval)
107 if not rq_interval:
108 return None
109
110 # For adjust timestamp from bar close point (RQData) to open point (VN Trader)
111 adjustment = INTERVAL_ADJUSTMENT_MAP[interval]
112
113 # For querying night trading period data
114 end += timedelta(1)
115
116 df = rqdata_get_price(
117 rq_symbol,
118 frequency=rq_interval,
119 fields=["open", "high", "low", "close", "volume"],
120 start_date=start,
121 end_date=end
122 )
123
124 data: List[BarData] = []
125 for ix, row in df.iterrows():
126 bar = BarData(
127 symbol=symbol,
128 exchange=exchange,
129 interval=interval,
130 datetime=row.name.to_pydatetime() - adjustment,
131 open_price=row["open"],
132 high_price=row["high"],
133 low_price=row["low"],
134 close_price=row["close"],
135 volume=row["volume"],
136 gateway_name="RQ"
137 )
138 data.append(bar)
139
140 return data
141
142
143 rqdata_client = RqdataClient()
144
[end of vnpy/trader/rqdata.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/vnpy/trader/rqdata.py b/vnpy/trader/rqdata.py
--- a/vnpy/trader/rqdata.py
+++ b/vnpy/trader/rqdata.py
@@ -36,11 +36,15 @@
self.inited = False
self.symbols = set()
- def init(self):
+ def init(self, username="", password=""):
""""""
if self.inited:
return True
+ if username and password:
+ self.username = username
+ self.password = password
+
if not self.username or not self.password:
return False
@@ -75,6 +79,11 @@
if word.isdigit():
break
+ # Check for index symbol
+ time_str = symbol[count:]
+ if time_str in ["88", "888", "99"]:
+ return symbol
+
# noinspection PyUnboundLocalVariable
product = symbol[:count]
year = symbol[count]
@@ -118,24 +127,27 @@
frequency=rq_interval,
fields=["open", "high", "low", "close", "volume"],
start_date=start,
- end_date=end
+ end_date=end,
+ adjust_type="none"
)
data: List[BarData] = []
- for ix, row in df.iterrows():
- bar = BarData(
- symbol=symbol,
- exchange=exchange,
- interval=interval,
- datetime=row.name.to_pydatetime() - adjustment,
- open_price=row["open"],
- high_price=row["high"],
- low_price=row["low"],
- close_price=row["close"],
- volume=row["volume"],
- gateway_name="RQ"
- )
- data.append(bar)
+
+ if df is not None:
+ for ix, row in df.iterrows():
+ bar = BarData(
+ symbol=symbol,
+ exchange=exchange,
+ interval=interval,
+ datetime=row.name.to_pydatetime() - adjustment,
+ open_price=row["open"],
+ high_price=row["high"],
+ low_price=row["low"],
+ close_price=row["close"],
+ volume=row["volume"],
+ gateway_name="RQ"
+ )
+ data.append(bar)
return data
|
{"golden_diff": "diff --git a/vnpy/trader/rqdata.py b/vnpy/trader/rqdata.py\n--- a/vnpy/trader/rqdata.py\n+++ b/vnpy/trader/rqdata.py\n@@ -36,11 +36,15 @@\n self.inited = False\n self.symbols = set()\n \n- def init(self):\n+ def init(self, username=\"\", password=\"\"):\n \"\"\"\"\"\"\n if self.inited:\n return True\n \n+ if username and password:\n+ self.username = username\n+ self.password = password\n+\n if not self.username or not self.password:\n return False\n \n@@ -75,6 +79,11 @@\n if word.isdigit():\n break\n \n+ # Check for index symbol\n+ time_str = symbol[count:]\n+ if time_str in [\"88\", \"888\", \"99\"]:\n+ return symbol\n+\n # noinspection PyUnboundLocalVariable\n product = symbol[:count]\n year = symbol[count]\n@@ -118,24 +127,27 @@\n frequency=rq_interval,\n fields=[\"open\", \"high\", \"low\", \"close\", \"volume\"],\n start_date=start,\n- end_date=end\n+ end_date=end,\n+ adjust_type=\"none\"\n )\n \n data: List[BarData] = []\n- for ix, row in df.iterrows():\n- bar = BarData(\n- symbol=symbol,\n- exchange=exchange,\n- interval=interval,\n- datetime=row.name.to_pydatetime() - adjustment,\n- open_price=row[\"open\"],\n- high_price=row[\"high\"],\n- low_price=row[\"low\"],\n- close_price=row[\"close\"],\n- volume=row[\"volume\"],\n- gateway_name=\"RQ\"\n- )\n- data.append(bar)\n+\n+ if df is not None:\n+ for ix, row in df.iterrows():\n+ bar = BarData(\n+ symbol=symbol,\n+ exchange=exchange,\n+ interval=interval,\n+ datetime=row.name.to_pydatetime() - adjustment,\n+ open_price=row[\"open\"],\n+ high_price=row[\"high\"],\n+ low_price=row[\"low\"],\n+ close_price=row[\"close\"],\n+ volume=row[\"volume\"],\n+ gateway_name=\"RQ\"\n+ )\n+ data.append(bar)\n \n return data\n", "issue": "Bug\uff1arqdata.py \u4e2d RqdataClient \u7c7b\u7684 to_rq_symbol \u65b9\u6cd5\u5bf9\u8fde\u7eed\u548c\u6307\u6570\u5408\u7ea6\u8f6c\u6362\u6709\u95ee\u9898\n## \u73af\u5883\r\n\r\n* \u64cd\u4f5c\u7cfb\u7edf: \u5982Windows 10\r\n* Anaconda\u7248\u672c: Anaconda 18.12 Python 3.7 64\u4f4d\r\n* vn.py\u7248\u672c: v2.0.3\r\n\r\n## Issue\u7c7b\u578b\r\n\u4e09\u9009\u4e00\uff1aBug\r\n\r\n## \u9884\u671f\u7a0b\u5e8f\u884c\u4e3a\r\n\u6b63\u786e\u5c06\u5408\u7ea6\u540d\u8f6c\u6362\u81f3rqdata\u4e2d\u7684\u5408\u7ea6\u540d\r\n\r\n## \u5b9e\u9645\u7a0b\u5e8f\u884c\u4e3a\r\n\u9519\u8bef\u7684\u5c06\u90d1\u5546\u6240\u7684\u5408\u7ea6\u8fde\u7eed\u548c\u6307\u6570\u5408\u7ea6\u8f6c\u6362\uff0c\u4f8b\u5982\u5c06AP888\u4f1a\u8f6c\u6362\u4e3aAP2888\uff0cAP99\u4f1a\u8f6c\u6362\u81f3AP199\u5bfc\u81f4\u65e0\u6cd5\u4e0b\u8f7d\u5230\u6570\u636e\u3002\r\n\r\n## \u91cd\u73b0\u6b65\u9aa4\r\n\u5728\u56de\u6d4b\u6a21\u5757\u4e2d\u4e0b\u8f7dAP88\u6570\u636e\u5373\u53ef\u3002\r\n\r\n\u9488\u5bf9Bug\u7c7b\u578bIssue\uff0c\u8bf7\u63d0\u4f9b\u5177\u4f53\u91cd\u73b0\u6b65\u9aa4\u4ee5\u53ca\u62a5\u9519\u622a\u56fe\r\n\r\n\r\n\n", "before_files": [{"content": "from datetime import datetime, timedelta\nfrom typing import List\n\nfrom rqdatac import init as rqdata_init\nfrom rqdatac.services.basic import all_instruments as rqdata_all_instruments\nfrom rqdatac.services.get_price import get_price as rqdata_get_price\n\nfrom .setting import SETTINGS\nfrom .constant import Exchange, Interval\nfrom .object import BarData, HistoryRequest\n\n\nINTERVAL_VT2RQ = {\n Interval.MINUTE: \"1m\",\n Interval.HOUR: \"60m\",\n Interval.DAILY: \"1d\",\n}\n\nINTERVAL_ADJUSTMENT_MAP = {\n Interval.MINUTE: timedelta(minutes=1),\n Interval.HOUR: timedelta(hours=1),\n Interval.DAILY: timedelta() # no need to adjust for daily bar\n}\n\n\nclass RqdataClient:\n \"\"\"\n Client for querying history data from RQData.\n \"\"\"\n\n def __init__(self):\n \"\"\"\"\"\"\n self.username = SETTINGS[\"rqdata.username\"]\n self.password = SETTINGS[\"rqdata.password\"]\n\n self.inited = False\n self.symbols = set()\n\n def init(self):\n \"\"\"\"\"\"\n if self.inited:\n return True\n\n if not self.username or not self.password:\n return False\n\n rqdata_init(self.username, self.password,\n ('rqdatad-pro.ricequant.com', 16011))\n\n try:\n df = rqdata_all_instruments(date=datetime.now())\n for ix, row in df.iterrows():\n self.symbols.add(row['order_book_id'])\n except RuntimeError:\n return False\n\n self.inited = True\n return True\n\n def to_rq_symbol(self, symbol: str, exchange: Exchange):\n \"\"\"\n CZCE product of RQData has symbol like \"TA1905\" while\n vt symbol is \"TA905.CZCE\" so need to add \"1\" in symbol.\n \"\"\"\n if exchange in [Exchange.SSE, Exchange.SZSE]:\n if exchange == Exchange.SSE:\n rq_symbol = f\"{symbol}.XSHG\"\n else:\n rq_symbol = f\"{symbol}.XSHE\"\n else:\n if exchange is not Exchange.CZCE:\n return symbol.upper()\n\n for count, word in enumerate(symbol):\n if word.isdigit():\n break\n\n # noinspection PyUnboundLocalVariable\n product = symbol[:count]\n year = symbol[count]\n month = symbol[count + 1:]\n\n if year == \"9\":\n year = \"1\" + year\n else:\n year = \"2\" + year\n\n rq_symbol = f\"{product}{year}{month}\".upper()\n\n return rq_symbol\n\n def query_history(self, req: HistoryRequest):\n \"\"\"\n Query history bar data from RQData.\n \"\"\"\n symbol = req.symbol\n exchange = req.exchange\n interval = req.interval\n start = req.start\n end = req.end\n\n rq_symbol = self.to_rq_symbol(symbol, exchange)\n if rq_symbol not in self.symbols:\n return None\n\n rq_interval = INTERVAL_VT2RQ.get(interval)\n if not rq_interval:\n return None\n\n # For adjust timestamp from bar close point (RQData) to open point (VN Trader)\n adjustment = INTERVAL_ADJUSTMENT_MAP[interval]\n\n # For querying night trading period data\n end += timedelta(1)\n\n df = rqdata_get_price(\n rq_symbol,\n frequency=rq_interval,\n fields=[\"open\", \"high\", \"low\", \"close\", \"volume\"],\n start_date=start,\n end_date=end\n )\n\n data: List[BarData] = []\n for ix, row in df.iterrows():\n bar = BarData(\n symbol=symbol,\n exchange=exchange,\n interval=interval,\n datetime=row.name.to_pydatetime() - adjustment,\n open_price=row[\"open\"],\n high_price=row[\"high\"],\n low_price=row[\"low\"],\n close_price=row[\"close\"],\n volume=row[\"volume\"],\n gateway_name=\"RQ\"\n )\n data.append(bar)\n\n return data\n\n\nrqdata_client = RqdataClient()\n", "path": "vnpy/trader/rqdata.py"}]}
| 1,965 | 527 |
gh_patches_debug_66272
|
rasdani/github-patches
|
git_diff
|
Kinto__kinto-1184
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Swagger spec still invalid
The Swagger spec is still invalid it seems
Extract:
```json
/{prefix}/{api_ver:\\d+}/{application_guid}/{application_ver}/{metrics:.*}": {
"parameters": [
{
"name": "prefix",
"type": "string",
"required": true,
"in": "path"
},
{
"name": "api_ver:\\d+",
"type": "string",
"required": true,
"in": "path"
},
{
"name": "application_guid",
"type": "string",
"required": true,
"in": "path"
},
{
"name": "application_ver",
"type": "string",
"required": true,
"in": "path"
},
{
"name": "metrics:.*",
"type": "string",
"required": true,
"in": "path"
}
],
```
In this API definitions, smwogger will choke on api_ver and metrics because their definitions in the parameter list should not include the regexp and just be the name of the parameter
The right definition should be
```json
/{prefix}/{api_ver:\\d+}/{application_guid}/{application_ver}/{metrics:.*}": {
"parameters": [
{
"name": "prefix",
"type": "string",
"required": true,
"in": "path"
},
{
"name": "api_ver",
"type": "string",
"required": true,
"in": "path"
},
{
"name": "application_guid",
"type": "string",
"required": true,
"in": "path"
},
{
"name": "application_ver",
"type": "string",
"required": true,
"in": "path"
},
{
"name": "metrics",
"type": "string",
"required": true,
"in": "path"
}
],
```
To validate that it works, you can try this small program with Smowgger to print all operations:
```python
import asyncio
from smwogger import API
async def print_operations():
async with API('http://path.to.kinto/v1/__api__') as api:
print(api.operations)
loop = asyncio.get_event_loop()
try:
loop.run_until_complete(print_operations())
finally:
loop.close()
```
cc @gabisurita @chartjes
Swagger spec still invalid
The Swagger spec is still invalid it seems
Extract:
```json
/{prefix}/{api_ver:\\d+}/{application_guid}/{application_ver}/{metrics:.*}": {
"parameters": [
{
"name": "prefix",
"type": "string",
"required": true,
"in": "path"
},
{
"name": "api_ver:\\d+",
"type": "string",
"required": true,
"in": "path"
},
{
"name": "application_guid",
"type": "string",
"required": true,
"in": "path"
},
{
"name": "application_ver",
"type": "string",
"required": true,
"in": "path"
},
{
"name": "metrics:.*",
"type": "string",
"required": true,
"in": "path"
}
],
```
In this API definitions, smwogger will choke on api_ver and metrics because their definitions in the parameter list should not include the regexp and just be the name of the parameter
The right definition should be
```json
/{prefix}/{api_ver:\\d+}/{application_guid}/{application_ver}/{metrics:.*}": {
"parameters": [
{
"name": "prefix",
"type": "string",
"required": true,
"in": "path"
},
{
"name": "api_ver",
"type": "string",
"required": true,
"in": "path"
},
{
"name": "application_guid",
"type": "string",
"required": true,
"in": "path"
},
{
"name": "application_ver",
"type": "string",
"required": true,
"in": "path"
},
{
"name": "metrics",
"type": "string",
"required": true,
"in": "path"
}
],
```
To validate that it works, you can try this small program with Smowgger to print all operations:
```python
import asyncio
from smwogger import API
async def print_operations():
async with API('http://path.to.kinto/v1/__api__') as api:
print(api.operations)
loop = asyncio.get_event_loop()
try:
loop.run_until_complete(print_operations())
finally:
loop.close()
```
cc @gabisurita @chartjes
</issue>
<code>
[start of setup.py]
1 import codecs
2 import os
3 from setuptools import setup, find_packages
4
5 here = os.path.abspath(os.path.dirname(__file__))
6
7
8 def read_file(filename):
9 """Open a related file and return its content."""
10 with codecs.open(os.path.join(here, filename), encoding='utf-8') as f:
11 content = f.read()
12 return content
13
14
15 README = read_file('README.rst')
16 CHANGELOG = read_file('CHANGELOG.rst')
17 CONTRIBUTORS = read_file('CONTRIBUTORS.rst')
18
19 REQUIREMENTS = [
20 'bcrypt',
21 'colander >= 1.3.2',
22 'cornice >= 2.4',
23 'cornice_swagger >= 0.5',
24 'jsonschema',
25 'jsonpatch',
26 'logging-color-formatter >= 1.0.1', # Message interpolations.
27 'python-dateutil',
28 'pyramid > 1.8',
29 'pyramid_multiauth >= 0.8', # User on policy selected event.
30 'transaction',
31 'pyramid_tm',
32 'requests',
33 'waitress',
34 'ujson >= 1.35'
35 ]
36
37 POSTGRESQL_REQUIRES = [
38 'SQLAlchemy',
39 'psycopg2 > 2.5',
40 'zope.sqlalchemy',
41 ]
42
43 REDIS_REQUIRES = [
44 'kinto_redis'
45 ]
46
47 SETUP_REQUIRES = [
48 'pytest-runner'
49 ]
50
51 TEST_REQUIREMENTS = [
52 'bravado_core',
53 'pytest',
54 'WebTest'
55 ]
56
57 DEPENDENCY_LINKS = [
58 ]
59
60 MONITORING_REQUIRES = [
61 'raven',
62 'statsd',
63 'newrelic',
64 'werkzeug',
65 ]
66
67 ENTRY_POINTS = {
68 'paste.app_factory': [
69 'main = kinto:main',
70 ],
71 'console_scripts': [
72 'kinto = kinto.__main__:main'
73 ],
74 }
75
76
77 setup(name='kinto',
78 version='7.0.0.dev0',
79 description='Kinto Web Service - Store, Sync, Share, and Self-Host.',
80 long_description="{}\n\n{}\n\n{}".format(README, CHANGELOG, CONTRIBUTORS),
81 license='Apache License (2.0)',
82 classifiers=[
83 "Programming Language :: Python",
84 "Programming Language :: Python :: 3",
85 "Programming Language :: Python :: 3.5",
86 "Programming Language :: Python :: 3.6",
87 "Programming Language :: Python :: Implementation :: CPython",
88 "Topic :: Internet :: WWW/HTTP",
89 "Topic :: Internet :: WWW/HTTP :: WSGI :: Application",
90 "License :: OSI Approved :: Apache Software License"
91 ],
92 keywords="web sync json storage services",
93 author='Mozilla Services',
94 author_email='[email protected]',
95 url='https://github.com/Kinto/kinto',
96 packages=find_packages(),
97 package_data={'': ['*.rst', '*.py', '*.yaml']},
98 include_package_data=True,
99 zip_safe=False,
100 setup_requires=SETUP_REQUIRES,
101 tests_require=TEST_REQUIREMENTS,
102 install_requires=REQUIREMENTS,
103 extras_require={
104 'redis': REDIS_REQUIRES,
105 'postgresql': POSTGRESQL_REQUIRES,
106 'monitoring': MONITORING_REQUIRES,
107 },
108 test_suite="tests",
109 dependency_links=DEPENDENCY_LINKS,
110 entry_points=ENTRY_POINTS)
111
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -20,7 +20,7 @@
'bcrypt',
'colander >= 1.3.2',
'cornice >= 2.4',
- 'cornice_swagger >= 0.5',
+ 'cornice_swagger >= 0.5.1',
'jsonschema',
'jsonpatch',
'logging-color-formatter >= 1.0.1', # Message interpolations.
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -20,7 +20,7 @@\n 'bcrypt',\n 'colander >= 1.3.2',\n 'cornice >= 2.4',\n- 'cornice_swagger >= 0.5',\n+ 'cornice_swagger >= 0.5.1',\n 'jsonschema',\n 'jsonpatch',\n 'logging-color-formatter >= 1.0.1', # Message interpolations.\n", "issue": "Swagger spec still invalid\nThe Swagger spec is still invalid it seems\r\n\r\nExtract:\r\n\r\n```json\r\n/{prefix}/{api_ver:\\\\d+}/{application_guid}/{application_ver}/{metrics:.*}\": {\r\n \"parameters\": [\r\n {\r\n \"name\": \"prefix\",\r\n \"type\": \"string\",\r\n \"required\": true,\r\n \"in\": \"path\"\r\n },\r\n {\r\n \"name\": \"api_ver:\\\\d+\",\r\n \"type\": \"string\",\r\n \"required\": true,\r\n \"in\": \"path\"\r\n },\r\n {\r\n \"name\": \"application_guid\",\r\n \"type\": \"string\",\r\n \"required\": true,\r\n \"in\": \"path\"\r\n },\r\n {\r\n \"name\": \"application_ver\",\r\n \"type\": \"string\",\r\n \"required\": true,\r\n \"in\": \"path\"\r\n },\r\n {\r\n \"name\": \"metrics:.*\",\r\n \"type\": \"string\",\r\n \"required\": true,\r\n \"in\": \"path\"\r\n }\r\n ],\r\n```\r\n\r\nIn this API definitions, smwogger will choke on api_ver and metrics because their definitions in the parameter list should not include the regexp and just be the name of the parameter\r\n\r\nThe right definition should be\r\n\r\n```json\r\n/{prefix}/{api_ver:\\\\d+}/{application_guid}/{application_ver}/{metrics:.*}\": {\r\n \"parameters\": [\r\n {\r\n \"name\": \"prefix\",\r\n \"type\": \"string\",\r\n \"required\": true,\r\n \"in\": \"path\"\r\n },\r\n {\r\n \"name\": \"api_ver\",\r\n \"type\": \"string\",\r\n \"required\": true,\r\n \"in\": \"path\"\r\n },\r\n {\r\n \"name\": \"application_guid\",\r\n \"type\": \"string\",\r\n \"required\": true,\r\n \"in\": \"path\"\r\n },\r\n {\r\n \"name\": \"application_ver\",\r\n \"type\": \"string\",\r\n \"required\": true,\r\n \"in\": \"path\"\r\n },\r\n {\r\n \"name\": \"metrics\",\r\n \"type\": \"string\",\r\n \"required\": true,\r\n \"in\": \"path\"\r\n }\r\n ],\r\n```\r\n\r\nTo validate that it works, you can try this small program with Smowgger to print all operations:\r\n\r\n```python\r\nimport asyncio\r\nfrom smwogger import API\r\n\r\n\r\nasync def print_operations():\r\n async with API('http://path.to.kinto/v1/__api__') as api:\r\n print(api.operations)\r\n\r\nloop = asyncio.get_event_loop()\r\ntry:\r\n loop.run_until_complete(print_operations())\r\nfinally:\r\n loop.close()\r\n```\r\n\r\n\r\ncc @gabisurita @chartjes \nSwagger spec still invalid\nThe Swagger spec is still invalid it seems\r\n\r\nExtract:\r\n\r\n```json\r\n/{prefix}/{api_ver:\\\\d+}/{application_guid}/{application_ver}/{metrics:.*}\": {\r\n \"parameters\": [\r\n {\r\n \"name\": \"prefix\",\r\n \"type\": \"string\",\r\n \"required\": true,\r\n \"in\": \"path\"\r\n },\r\n {\r\n \"name\": \"api_ver:\\\\d+\",\r\n \"type\": \"string\",\r\n \"required\": true,\r\n \"in\": \"path\"\r\n },\r\n {\r\n \"name\": \"application_guid\",\r\n \"type\": \"string\",\r\n \"required\": true,\r\n \"in\": \"path\"\r\n },\r\n {\r\n \"name\": \"application_ver\",\r\n \"type\": \"string\",\r\n \"required\": true,\r\n \"in\": \"path\"\r\n },\r\n {\r\n \"name\": \"metrics:.*\",\r\n \"type\": \"string\",\r\n \"required\": true,\r\n \"in\": \"path\"\r\n }\r\n ],\r\n```\r\n\r\nIn this API definitions, smwogger will choke on api_ver and metrics because their definitions in the parameter list should not include the regexp and just be the name of the parameter\r\n\r\nThe right definition should be\r\n\r\n```json\r\n/{prefix}/{api_ver:\\\\d+}/{application_guid}/{application_ver}/{metrics:.*}\": {\r\n \"parameters\": [\r\n {\r\n \"name\": \"prefix\",\r\n \"type\": \"string\",\r\n \"required\": true,\r\n \"in\": \"path\"\r\n },\r\n {\r\n \"name\": \"api_ver\",\r\n \"type\": \"string\",\r\n \"required\": true,\r\n \"in\": \"path\"\r\n },\r\n {\r\n \"name\": \"application_guid\",\r\n \"type\": \"string\",\r\n \"required\": true,\r\n \"in\": \"path\"\r\n },\r\n {\r\n \"name\": \"application_ver\",\r\n \"type\": \"string\",\r\n \"required\": true,\r\n \"in\": \"path\"\r\n },\r\n {\r\n \"name\": \"metrics\",\r\n \"type\": \"string\",\r\n \"required\": true,\r\n \"in\": \"path\"\r\n }\r\n ],\r\n```\r\n\r\nTo validate that it works, you can try this small program with Smowgger to print all operations:\r\n\r\n```python\r\nimport asyncio\r\nfrom smwogger import API\r\n\r\n\r\nasync def print_operations():\r\n async with API('http://path.to.kinto/v1/__api__') as api:\r\n print(api.operations)\r\n\r\nloop = asyncio.get_event_loop()\r\ntry:\r\n loop.run_until_complete(print_operations())\r\nfinally:\r\n loop.close()\r\n```\r\n\r\n\r\ncc @gabisurita @chartjes \n", "before_files": [{"content": "import codecs\nimport os\nfrom setuptools import setup, find_packages\n\nhere = os.path.abspath(os.path.dirname(__file__))\n\n\ndef read_file(filename):\n \"\"\"Open a related file and return its content.\"\"\"\n with codecs.open(os.path.join(here, filename), encoding='utf-8') as f:\n content = f.read()\n return content\n\n\nREADME = read_file('README.rst')\nCHANGELOG = read_file('CHANGELOG.rst')\nCONTRIBUTORS = read_file('CONTRIBUTORS.rst')\n\nREQUIREMENTS = [\n 'bcrypt',\n 'colander >= 1.3.2',\n 'cornice >= 2.4',\n 'cornice_swagger >= 0.5',\n 'jsonschema',\n 'jsonpatch',\n 'logging-color-formatter >= 1.0.1', # Message interpolations.\n 'python-dateutil',\n 'pyramid > 1.8',\n 'pyramid_multiauth >= 0.8', # User on policy selected event.\n 'transaction',\n 'pyramid_tm',\n 'requests',\n 'waitress',\n 'ujson >= 1.35'\n]\n\nPOSTGRESQL_REQUIRES = [\n 'SQLAlchemy',\n 'psycopg2 > 2.5',\n 'zope.sqlalchemy',\n]\n\nREDIS_REQUIRES = [\n 'kinto_redis'\n]\n\nSETUP_REQUIRES = [\n 'pytest-runner'\n]\n\nTEST_REQUIREMENTS = [\n 'bravado_core',\n 'pytest',\n 'WebTest'\n]\n\nDEPENDENCY_LINKS = [\n]\n\nMONITORING_REQUIRES = [\n 'raven',\n 'statsd',\n 'newrelic',\n 'werkzeug',\n]\n\nENTRY_POINTS = {\n 'paste.app_factory': [\n 'main = kinto:main',\n ],\n 'console_scripts': [\n 'kinto = kinto.__main__:main'\n ],\n}\n\n\nsetup(name='kinto',\n version='7.0.0.dev0',\n description='Kinto Web Service - Store, Sync, Share, and Self-Host.',\n long_description=\"{}\\n\\n{}\\n\\n{}\".format(README, CHANGELOG, CONTRIBUTORS),\n license='Apache License (2.0)',\n classifiers=[\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: Implementation :: CPython\",\n \"Topic :: Internet :: WWW/HTTP\",\n \"Topic :: Internet :: WWW/HTTP :: WSGI :: Application\",\n \"License :: OSI Approved :: Apache Software License\"\n ],\n keywords=\"web sync json storage services\",\n author='Mozilla Services',\n author_email='[email protected]',\n url='https://github.com/Kinto/kinto',\n packages=find_packages(),\n package_data={'': ['*.rst', '*.py', '*.yaml']},\n include_package_data=True,\n zip_safe=False,\n setup_requires=SETUP_REQUIRES,\n tests_require=TEST_REQUIREMENTS,\n install_requires=REQUIREMENTS,\n extras_require={\n 'redis': REDIS_REQUIRES,\n 'postgresql': POSTGRESQL_REQUIRES,\n 'monitoring': MONITORING_REQUIRES,\n },\n test_suite=\"tests\",\n dependency_links=DEPENDENCY_LINKS,\n entry_points=ENTRY_POINTS)\n", "path": "setup.py"}]}
| 2,574 | 116 |
gh_patches_debug_28025
|
rasdani/github-patches
|
git_diff
|
twisted__twisted-12013
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Read The Docs documentation website search not working
You can test this link
https://docs.twisted.org/en/twisted-23.8.0/search.html?q=threads&check_keywords=yes&area=default#
it looks like jquery is not included
</issue>
<code>
[start of docs/conf.py]
1 #
2 # Twisted documentation build configuration file, created by
3 # sphinx-quickstart on Tue Jan 14 11:31:15 2014.
4 #
5 # This file is execfile()d with the current directory set to its
6 # containing dir.
7 #
8 # Note that not all possible configuration values are present in this
9 # autogenerated file.
10 #
11 # All configuration values have a default; values that are commented out
12 # serve to show the default.
13
14 import os
15 import pathlib
16 import subprocess
17 import sys
18 from datetime import date
19 from pprint import pprint
20
21 import sphinx_rtd_theme
22
23 # If extensions (or modules to document with autodoc) are in another directory,
24 # add these directories to sys.path here. If the directory is relative to the
25 # documentation root, use os.path.abspath to make it absolute, like shown here.
26 sys.path.insert(0, os.path.abspath("./_extensions"))
27 sys.path.insert(0, os.path.abspath(".."))
28
29 # -- General configuration ------------------------------------------------
30
31 # See pyproject.toml for the Sphinx version required to build the documentation.
32 # needs_sphinx is not use to avoid duplication and getting these values
33 # out of sync.
34
35 # Add any Sphinx extension module names here, as strings. They can be
36 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
37 # ones.
38 extensions = [
39 "sphinx.ext.intersphinx",
40 "pydoctor.sphinx_ext.build_apidocs",
41 ]
42
43 try:
44 import rst2pdf.pdfbuilder
45
46 extensions.append("rst2pdf.pdfbuilder")
47 except ImportError:
48 pass
49
50 from twisted import version as twisted_version_object
51
52 # Add any paths that contain templates here, relative to this directory.
53 templates_path = ["_templates"]
54
55 # The suffix of source filenames.
56 source_suffix = ".rst"
57
58 # The encoding of source files.
59 # source_encoding = 'utf-8-sig'
60
61 # The master toctree document.
62 master_doc = "index"
63
64 _today = date.today()
65 # General information about the project.
66 project = "Twisted"
67 copyright = "{}, Twisted Matrix Labs. Ver {}. Built on {}".format(
68 _today.year,
69 twisted_version_object.public(),
70 _today.isoformat(),
71 )
72
73 # The version info for the project you're documenting, acts as replacement for
74 # |version| and |release|, also used in various other places throughout the
75 # built documents.
76 #
77 # The short X.Y version.
78 version = "{major}.{minor}".format(
79 major=twisted_version_object.major, minor=twisted_version_object.minor
80 )
81 # The full version, including alpha/beta/rc tags.
82 release = twisted_version_object.short()
83
84 # There are two options for replacing |today|: either, you set today to some
85 # non-false value, then it is used:
86 # today = ''
87 # Else, today_fmt is used as the format for a strftime call.
88 # today_fmt = '%B %d, %Y'
89
90 # List of patterns, relative to source directory, that match files and
91 # directories to ignore when looking for source files.
92 exclude_patterns = ["_build"]
93
94 # The name of the Pygments (syntax highlighting) style to use.
95 pygments_style = "sphinx"
96
97 # -- Options for HTML output ----------------------------------------------
98
99 # Only the RTD theme is used. Both for local development and for the public site.
100 html_theme = "sphinx_rtd_theme"
101 html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]
102
103 # Add any paths that contain custom static files (such as style sheets) here,
104 # relative to this directory. They are copied after the builtin static files,
105 # so a file named "default.css" will overwrite the builtin "default.css".
106 html_static_path = ["_static"]
107
108
109 # These paths are either relative to html_static_path
110 # or fully qualified paths (eg. https://...)
111 html_js_files = [
112 "js/custom.js",
113 # Here we have a Sphinx HTML injection hack to make the JS script load without blocking.
114 'https://sidecar.gitter.im/dist/sidecar.v1.js" defer hack="',
115 ]
116
117 # Output file base name for HTML help builder.
118 htmlhelp_basename = "Twisteddoc"
119
120
121 # -- Options for LaTeX output ---------------------------------------------
122
123 latex_elements = {
124 # The paper size ('letterpaper' or 'a4paper').
125 #'papersize': 'letterpaper',
126 # The font size ('10pt', '11pt' or '12pt').
127 #'pointsize': '10pt',
128 # Additional stuff for the LaTeX preamble.
129 #'preamble': '',
130 }
131
132 # Grouping the document tree into LaTeX files. List of tuples
133 # (source start file, target name, title,
134 # author, documentclass [howto, manual, or own class]).
135 latex_documents = [
136 ("index", "Twisted.tex", "Twisted Documentation", "Twisted Matrix Labs", "manual"),
137 ]
138
139
140 # -- Options for manual page output ---------------------------------------
141
142 # One entry per manual page. List of tuples
143 # (source start file, name, description, authors, manual section).
144 man_pages = [("index", "twisted", "Twisted Documentation", ["Twisted Matrix Labs"], 1)]
145
146
147 # -- Options for Texinfo output -------------------------------------------
148
149 # Grouping the document tree into Texinfo files. List of tuples
150 # (source start file, target name, title, author,
151 # dir menu entry, description, category)
152 texinfo_documents = [
153 (
154 "index",
155 "Twisted",
156 "Twisted Documentation",
157 "Twisted Matrix Labs",
158 "Twisted",
159 "One line description of project.",
160 "Miscellaneous",
161 ),
162 ]
163
164
165 # -- Options for Epub output ----------------------------------------------
166
167 # Bibliographic Dublin Core info.
168 epub_title = "Twisted"
169 epub_author = "Twisted Matrix Labs"
170 epub_publisher = "Twisted Matrix Labs"
171 epub_copyright = "2020, Twisted Matrix Labs"
172
173
174 # -- Extension configuration ----------------------------------------------
175 _git_reference = subprocess.run(
176 ["git", "rev-parse", "--abbrev-ref", "HEAD"],
177 text=True,
178 encoding="utf8",
179 capture_output=True,
180 check=True,
181 ).stdout
182
183
184 print(f"== Environment dump for {_git_reference} ===")
185 pprint(dict(os.environ))
186 print("======")
187
188
189 # Try to find URL fragment for the GitHub source page based on current
190 # branch or tag.
191
192 if _git_reference == "HEAD":
193 # It looks like the branch has no name.
194 # Fallback to commit ID.
195 _git_reference = subprocess.getoutput("git rev-parse HEAD")
196
197 if os.environ.get("READTHEDOCS", "") == "True":
198 rtd_version = os.environ.get("READTHEDOCS_VERSION", "")
199 if "." in rtd_version:
200 # It looks like we have a tag build.
201 _git_reference = rtd_version
202
203 _project_root = pathlib.Path(__file__).parent.parent
204 _source_root = _project_root / "src"
205 pydoctor_args = [
206 "--quiet",
207 # pydoctor should not fail the sphinx build, we have another tox environment for that.
208 f"--config={_project_root}/setup.cfg",
209 f"--html-viewsource-base=https://github.com/twisted/twisted/tree/{_git_reference}/src",
210 f"--project-base-dir={_source_root}",
211 f"--template-dir={_source_root}/twisted/python/_pydoctortemplates",
212 "--html-output={outdir}/api",
213 str(_source_root / "twisted"),
214 ]
215
216 pydoctor_url_path = "/en/{rtd_version}/api/"
217
218 # A dict mapping unique IDs (which can be used to disambiguate references) to a
219 # tuple of (<external sphinx documentation URI>, <inventory file location>).
220 # The inventory file may be None to use the default location at the given URI.
221 intersphinx_mapping = {
222 "py3": ("https://docs.python.org/3", None),
223 "zopeinterface": ("https://zopeinterface.readthedocs.io/en/latest", None),
224 }
225 # How long to cache remote inventories. Positive is a number of days,
226 # negative means infinite. The default is 5 days, which should be fine
227 # for standard library documentation that does not typically change
228 # significantly after release.
229 # intersphinx_cache_limit = 5
230
[end of docs/conf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -20,6 +20,8 @@
import sphinx_rtd_theme
+from twisted import version as twisted_version_object
+
# If extensions (or modules to document with autodoc) are in another directory,
# add these directories to sys.path here. If the directory is relative to the
# documentation root, use os.path.abspath to make it absolute, like shown here.
@@ -37,18 +39,10 @@
# ones.
extensions = [
"sphinx.ext.intersphinx",
+ "sphinxcontrib.jquery",
"pydoctor.sphinx_ext.build_apidocs",
]
-try:
- import rst2pdf.pdfbuilder
-
- extensions.append("rst2pdf.pdfbuilder")
-except ImportError:
- pass
-
-from twisted import version as twisted_version_object
-
# Add any paths that contain templates here, relative to this directory.
templates_path = ["_templates"]
@@ -106,14 +100,6 @@
html_static_path = ["_static"]
-# These paths are either relative to html_static_path
-# or fully qualified paths (eg. https://...)
-html_js_files = [
- "js/custom.js",
- # Here we have a Sphinx HTML injection hack to make the JS script load without blocking.
- 'https://sidecar.gitter.im/dist/sidecar.v1.js" defer hack="',
-]
-
# Output file base name for HTML help builder.
htmlhelp_basename = "Twisteddoc"
|
{"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -20,6 +20,8 @@\n \n import sphinx_rtd_theme\n \n+from twisted import version as twisted_version_object\n+\n # If extensions (or modules to document with autodoc) are in another directory,\n # add these directories to sys.path here. If the directory is relative to the\n # documentation root, use os.path.abspath to make it absolute, like shown here.\n@@ -37,18 +39,10 @@\n # ones.\n extensions = [\n \"sphinx.ext.intersphinx\",\n+ \"sphinxcontrib.jquery\",\n \"pydoctor.sphinx_ext.build_apidocs\",\n ]\n \n-try:\n- import rst2pdf.pdfbuilder\n-\n- extensions.append(\"rst2pdf.pdfbuilder\")\n-except ImportError:\n- pass\n-\n-from twisted import version as twisted_version_object\n-\n # Add any paths that contain templates here, relative to this directory.\n templates_path = [\"_templates\"]\n \n@@ -106,14 +100,6 @@\n html_static_path = [\"_static\"]\n \n \n-# These paths are either relative to html_static_path\n-# or fully qualified paths (eg. https://...)\n-html_js_files = [\n- \"js/custom.js\",\n- # Here we have a Sphinx HTML injection hack to make the JS script load without blocking.\n- 'https://sidecar.gitter.im/dist/sidecar.v1.js\" defer hack=\"',\n-]\n-\n # Output file base name for HTML help builder.\n htmlhelp_basename = \"Twisteddoc\"\n", "issue": "Read The Docs documentation website search not working\n\r\nYou can test this link\r\n\r\nhttps://docs.twisted.org/en/twisted-23.8.0/search.html?q=threads&check_keywords=yes&area=default#\r\n\r\nit looks like jquery is not included\r\n\n", "before_files": [{"content": "#\n# Twisted documentation build configuration file, created by\n# sphinx-quickstart on Tue Jan 14 11:31:15 2014.\n#\n# This file is execfile()d with the current directory set to its\n# containing dir.\n#\n# Note that not all possible configuration values are present in this\n# autogenerated file.\n#\n# All configuration values have a default; values that are commented out\n# serve to show the default.\n\nimport os\nimport pathlib\nimport subprocess\nimport sys\nfrom datetime import date\nfrom pprint import pprint\n\nimport sphinx_rtd_theme\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\nsys.path.insert(0, os.path.abspath(\"./_extensions\"))\nsys.path.insert(0, os.path.abspath(\"..\"))\n\n# -- General configuration ------------------------------------------------\n\n# See pyproject.toml for the Sphinx version required to build the documentation.\n# needs_sphinx is not use to avoid duplication and getting these values\n# out of sync.\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n \"sphinx.ext.intersphinx\",\n \"pydoctor.sphinx_ext.build_apidocs\",\n]\n\ntry:\n import rst2pdf.pdfbuilder\n\n extensions.append(\"rst2pdf.pdfbuilder\")\nexcept ImportError:\n pass\n\nfrom twisted import version as twisted_version_object\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = [\"_templates\"]\n\n# The suffix of source filenames.\nsource_suffix = \".rst\"\n\n# The encoding of source files.\n# source_encoding = 'utf-8-sig'\n\n# The master toctree document.\nmaster_doc = \"index\"\n\n_today = date.today()\n# General information about the project.\nproject = \"Twisted\"\ncopyright = \"{}, Twisted Matrix Labs. Ver {}. Built on {}\".format(\n _today.year,\n twisted_version_object.public(),\n _today.isoformat(),\n)\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n#\n# The short X.Y version.\nversion = \"{major}.{minor}\".format(\n major=twisted_version_object.major, minor=twisted_version_object.minor\n)\n# The full version, including alpha/beta/rc tags.\nrelease = twisted_version_object.short()\n\n# There are two options for replacing |today|: either, you set today to some\n# non-false value, then it is used:\n# today = ''\n# Else, today_fmt is used as the format for a strftime call.\n# today_fmt = '%B %d, %Y'\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\nexclude_patterns = [\"_build\"]\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = \"sphinx\"\n\n# -- Options for HTML output ----------------------------------------------\n\n# Only the RTD theme is used. Both for local development and for the public site.\nhtml_theme = \"sphinx_rtd_theme\"\nhtml_theme_path = [sphinx_rtd_theme.get_html_theme_path()]\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = [\"_static\"]\n\n\n# These paths are either relative to html_static_path\n# or fully qualified paths (eg. https://...)\nhtml_js_files = [\n \"js/custom.js\",\n # Here we have a Sphinx HTML injection hack to make the JS script load without blocking.\n 'https://sidecar.gitter.im/dist/sidecar.v1.js\" defer hack=\"',\n]\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = \"Twisteddoc\"\n\n\n# -- Options for LaTeX output ---------------------------------------------\n\nlatex_elements = {\n # The paper size ('letterpaper' or 'a4paper').\n #'papersize': 'letterpaper',\n # The font size ('10pt', '11pt' or '12pt').\n #'pointsize': '10pt',\n # Additional stuff for the LaTeX preamble.\n #'preamble': '',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n (\"index\", \"Twisted.tex\", \"Twisted Documentation\", \"Twisted Matrix Labs\", \"manual\"),\n]\n\n\n# -- Options for manual page output ---------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [(\"index\", \"twisted\", \"Twisted Documentation\", [\"Twisted Matrix Labs\"], 1)]\n\n\n# -- Options for Texinfo output -------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n (\n \"index\",\n \"Twisted\",\n \"Twisted Documentation\",\n \"Twisted Matrix Labs\",\n \"Twisted\",\n \"One line description of project.\",\n \"Miscellaneous\",\n ),\n]\n\n\n# -- Options for Epub output ----------------------------------------------\n\n# Bibliographic Dublin Core info.\nepub_title = \"Twisted\"\nepub_author = \"Twisted Matrix Labs\"\nepub_publisher = \"Twisted Matrix Labs\"\nepub_copyright = \"2020, Twisted Matrix Labs\"\n\n\n# -- Extension configuration ----------------------------------------------\n_git_reference = subprocess.run(\n [\"git\", \"rev-parse\", \"--abbrev-ref\", \"HEAD\"],\n text=True,\n encoding=\"utf8\",\n capture_output=True,\n check=True,\n).stdout\n\n\nprint(f\"== Environment dump for {_git_reference} ===\")\npprint(dict(os.environ))\nprint(\"======\")\n\n\n# Try to find URL fragment for the GitHub source page based on current\n# branch or tag.\n\nif _git_reference == \"HEAD\":\n # It looks like the branch has no name.\n # Fallback to commit ID.\n _git_reference = subprocess.getoutput(\"git rev-parse HEAD\")\n\nif os.environ.get(\"READTHEDOCS\", \"\") == \"True\":\n rtd_version = os.environ.get(\"READTHEDOCS_VERSION\", \"\")\n if \".\" in rtd_version:\n # It looks like we have a tag build.\n _git_reference = rtd_version\n\n_project_root = pathlib.Path(__file__).parent.parent\n_source_root = _project_root / \"src\"\npydoctor_args = [\n \"--quiet\",\n # pydoctor should not fail the sphinx build, we have another tox environment for that.\n f\"--config={_project_root}/setup.cfg\",\n f\"--html-viewsource-base=https://github.com/twisted/twisted/tree/{_git_reference}/src\",\n f\"--project-base-dir={_source_root}\",\n f\"--template-dir={_source_root}/twisted/python/_pydoctortemplates\",\n \"--html-output={outdir}/api\",\n str(_source_root / \"twisted\"),\n]\n\npydoctor_url_path = \"/en/{rtd_version}/api/\"\n\n# A dict mapping unique IDs (which can be used to disambiguate references) to a\n# tuple of (<external sphinx documentation URI>, <inventory file location>).\n# The inventory file may be None to use the default location at the given URI.\nintersphinx_mapping = {\n \"py3\": (\"https://docs.python.org/3\", None),\n \"zopeinterface\": (\"https://zopeinterface.readthedocs.io/en/latest\", None),\n}\n# How long to cache remote inventories. Positive is a number of days,\n# negative means infinite. The default is 5 days, which should be fine\n# for standard library documentation that does not typically change\n# significantly after release.\n# intersphinx_cache_limit = 5\n", "path": "docs/conf.py"}]}
| 2,957 | 347 |
gh_patches_debug_8600
|
rasdani/github-patches
|
git_diff
|
marshmallow-code__webargs-356
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
bug: webargs 5.0 introduces incompatibility with Flask < 1.0
https://github.com/marshmallow-code/webargs/blob/5.0.0/webargs/flaskparser.py#L63
`_get_data_for_json` is only available since Flask >= 1.0
for Flask < 1.0, there is an error as follows:
```
File "/usr/local/lib/python2.7/site-packages/webargs/flaskparser.py", line 63, in parse_json
data = req._get_data_for_json(cache=True)
File "/usr/local/lib/python2.7/site-packages/werkzeug/local.py", line 347, in __getattr__
return getattr(self._get_current_object(), name)
AttributeError: 'Request' object has no attribute '_get_data_for_json'
```
I had to downgrade webargs to 4.4.1 to get it work.
So you need to update this framework requirement https://github.com/marshmallow-code/webargs/blob/dev/setup.py#L11 or update the code for the backward compatibility.
IMHO, using `_get_data_for_json` should be avoided because it's considered private and can be changed/removed anytime.
</issue>
<code>
[start of webargs/flaskparser.py]
1 # -*- coding: utf-8 -*-
2 """Flask request argument parsing module.
3
4 Example: ::
5
6 from flask import Flask
7
8 from webargs import fields
9 from webargs.flaskparser import use_args
10
11 app = Flask(__name__)
12
13 hello_args = {
14 'name': fields.Str(required=True)
15 }
16
17 @app.route('/')
18 @use_args(hello_args)
19 def index(args):
20 return 'Hello ' + args['name']
21 """
22 import flask
23 from werkzeug.exceptions import HTTPException
24
25 from webargs import core
26 from webargs.core import json
27
28
29 def abort(http_status_code, exc=None, **kwargs):
30 """Raise a HTTPException for the given http_status_code. Attach any keyword
31 arguments to the exception for later processing.
32
33 From Flask-Restful. See NOTICE file for license information.
34 """
35 try:
36 flask.abort(http_status_code)
37 except HTTPException as err:
38 err.data = kwargs
39 err.exc = exc
40 raise err
41
42
43 def is_json_request(req):
44 return core.is_json(req.mimetype)
45
46
47 class FlaskParser(core.Parser):
48 """Flask request argument parser."""
49
50 __location_map__ = dict(view_args="parse_view_args", **core.Parser.__location_map__)
51
52 def parse_view_args(self, req, name, field):
53 """Pull a value from the request's ``view_args``."""
54 return core.get_value(req.view_args, name, field)
55
56 def parse_json(self, req, name, field):
57 """Pull a json value from the request."""
58 json_data = self._cache.get("json")
59 if json_data is None:
60 # We decode the json manually here instead of
61 # using req.get_json() so that we can handle
62 # JSONDecodeErrors consistently
63 data = req._get_data_for_json(cache=True)
64 try:
65 self._cache["json"] = json_data = core.parse_json(data)
66 except json.JSONDecodeError as e:
67 if e.doc == "":
68 return core.missing
69 else:
70 return self.handle_invalid_json_error(e, req)
71 return core.get_value(json_data, name, field, allow_many_nested=True)
72
73 def parse_querystring(self, req, name, field):
74 """Pull a querystring value from the request."""
75 return core.get_value(req.args, name, field)
76
77 def parse_form(self, req, name, field):
78 """Pull a form value from the request."""
79 try:
80 return core.get_value(req.form, name, field)
81 except AttributeError:
82 pass
83 return core.missing
84
85 def parse_headers(self, req, name, field):
86 """Pull a value from the header data."""
87 return core.get_value(req.headers, name, field)
88
89 def parse_cookies(self, req, name, field):
90 """Pull a value from the cookiejar."""
91 return core.get_value(req.cookies, name, field)
92
93 def parse_files(self, req, name, field):
94 """Pull a file from the request."""
95 return core.get_value(req.files, name, field)
96
97 def handle_error(self, error, req, schema, error_status_code, error_headers):
98 """Handles errors during parsing. Aborts the current HTTP request and
99 responds with a 422 error.
100 """
101 status_code = error_status_code or self.DEFAULT_VALIDATION_STATUS
102 abort(
103 status_code,
104 exc=error,
105 messages=error.messages,
106 schema=schema,
107 headers=error_headers,
108 )
109
110 def handle_invalid_json_error(self, error, req, *args, **kwargs):
111 abort(400, exc=error, messages={"json": ["Invalid JSON body."]})
112
113 def get_default_request(self):
114 """Override to use Flask's thread-local request objec by default"""
115 return flask.request
116
117
118 parser = FlaskParser()
119 use_args = parser.use_args
120 use_kwargs = parser.use_kwargs
121
[end of webargs/flaskparser.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/webargs/flaskparser.py b/webargs/flaskparser.py
--- a/webargs/flaskparser.py
+++ b/webargs/flaskparser.py
@@ -60,7 +60,7 @@
# We decode the json manually here instead of
# using req.get_json() so that we can handle
# JSONDecodeErrors consistently
- data = req._get_data_for_json(cache=True)
+ data = req.get_data(cache=True)
try:
self._cache["json"] = json_data = core.parse_json(data)
except json.JSONDecodeError as e:
|
{"golden_diff": "diff --git a/webargs/flaskparser.py b/webargs/flaskparser.py\n--- a/webargs/flaskparser.py\n+++ b/webargs/flaskparser.py\n@@ -60,7 +60,7 @@\n # We decode the json manually here instead of\n # using req.get_json() so that we can handle\n # JSONDecodeErrors consistently\n- data = req._get_data_for_json(cache=True)\n+ data = req.get_data(cache=True)\n try:\n self._cache[\"json\"] = json_data = core.parse_json(data)\n except json.JSONDecodeError as e:\n", "issue": "bug: webargs 5.0 introduces incompatibility with Flask < 1.0\nhttps://github.com/marshmallow-code/webargs/blob/5.0.0/webargs/flaskparser.py#L63\r\n\r\n`_get_data_for_json` is only available since Flask >= 1.0\r\n\r\nfor Flask < 1.0, there is an error as follows:\r\n\r\n```\r\n File \"/usr/local/lib/python2.7/site-packages/webargs/flaskparser.py\", line 63, in parse_json\r\n data = req._get_data_for_json(cache=True)\r\n File \"/usr/local/lib/python2.7/site-packages/werkzeug/local.py\", line 347, in __getattr__\r\n return getattr(self._get_current_object(), name)\r\nAttributeError: 'Request' object has no attribute '_get_data_for_json'\r\n```\r\n\r\nI had to downgrade webargs to 4.4.1 to get it work.\r\n\r\nSo you need to update this framework requirement https://github.com/marshmallow-code/webargs/blob/dev/setup.py#L11 or update the code for the backward compatibility.\r\n\r\nIMHO, using `_get_data_for_json` should be avoided because it's considered private and can be changed/removed anytime.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"Flask request argument parsing module.\n\nExample: ::\n\n from flask import Flask\n\n from webargs import fields\n from webargs.flaskparser import use_args\n\n app = Flask(__name__)\n\n hello_args = {\n 'name': fields.Str(required=True)\n }\n\n @app.route('/')\n @use_args(hello_args)\n def index(args):\n return 'Hello ' + args['name']\n\"\"\"\nimport flask\nfrom werkzeug.exceptions import HTTPException\n\nfrom webargs import core\nfrom webargs.core import json\n\n\ndef abort(http_status_code, exc=None, **kwargs):\n \"\"\"Raise a HTTPException for the given http_status_code. Attach any keyword\n arguments to the exception for later processing.\n\n From Flask-Restful. See NOTICE file for license information.\n \"\"\"\n try:\n flask.abort(http_status_code)\n except HTTPException as err:\n err.data = kwargs\n err.exc = exc\n raise err\n\n\ndef is_json_request(req):\n return core.is_json(req.mimetype)\n\n\nclass FlaskParser(core.Parser):\n \"\"\"Flask request argument parser.\"\"\"\n\n __location_map__ = dict(view_args=\"parse_view_args\", **core.Parser.__location_map__)\n\n def parse_view_args(self, req, name, field):\n \"\"\"Pull a value from the request's ``view_args``.\"\"\"\n return core.get_value(req.view_args, name, field)\n\n def parse_json(self, req, name, field):\n \"\"\"Pull a json value from the request.\"\"\"\n json_data = self._cache.get(\"json\")\n if json_data is None:\n # We decode the json manually here instead of\n # using req.get_json() so that we can handle\n # JSONDecodeErrors consistently\n data = req._get_data_for_json(cache=True)\n try:\n self._cache[\"json\"] = json_data = core.parse_json(data)\n except json.JSONDecodeError as e:\n if e.doc == \"\":\n return core.missing\n else:\n return self.handle_invalid_json_error(e, req)\n return core.get_value(json_data, name, field, allow_many_nested=True)\n\n def parse_querystring(self, req, name, field):\n \"\"\"Pull a querystring value from the request.\"\"\"\n return core.get_value(req.args, name, field)\n\n def parse_form(self, req, name, field):\n \"\"\"Pull a form value from the request.\"\"\"\n try:\n return core.get_value(req.form, name, field)\n except AttributeError:\n pass\n return core.missing\n\n def parse_headers(self, req, name, field):\n \"\"\"Pull a value from the header data.\"\"\"\n return core.get_value(req.headers, name, field)\n\n def parse_cookies(self, req, name, field):\n \"\"\"Pull a value from the cookiejar.\"\"\"\n return core.get_value(req.cookies, name, field)\n\n def parse_files(self, req, name, field):\n \"\"\"Pull a file from the request.\"\"\"\n return core.get_value(req.files, name, field)\n\n def handle_error(self, error, req, schema, error_status_code, error_headers):\n \"\"\"Handles errors during parsing. Aborts the current HTTP request and\n responds with a 422 error.\n \"\"\"\n status_code = error_status_code or self.DEFAULT_VALIDATION_STATUS\n abort(\n status_code,\n exc=error,\n messages=error.messages,\n schema=schema,\n headers=error_headers,\n )\n\n def handle_invalid_json_error(self, error, req, *args, **kwargs):\n abort(400, exc=error, messages={\"json\": [\"Invalid JSON body.\"]})\n\n def get_default_request(self):\n \"\"\"Override to use Flask's thread-local request objec by default\"\"\"\n return flask.request\n\n\nparser = FlaskParser()\nuse_args = parser.use_args\nuse_kwargs = parser.use_kwargs\n", "path": "webargs/flaskparser.py"}]}
| 1,893 | 130 |
gh_patches_debug_12423
|
rasdani/github-patches
|
git_diff
|
mathesar-foundation__mathesar-284
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
API tests using wrong tables database
**Describe the bug**
The django API tests are running on the `test_mathesar_db_test_database`, which differs from the `mathesar_db_test_database` tables database we should be using. As a result, we don't have a proper reference to the database being used by the API functions, which prevents us from certain operations like installing types for a test.
**Expected behavior**
We should ensure `pytest-django` doesn't build a separate tables database.
**Additional context**
Currently blocking #276
</issue>
<code>
[start of config/settings.py]
1 """
2 Django settings for config project.
3
4 Generated by 'django-admin startproject' using Django 3.1.7.
5
6 For more information on this file, see
7 https://docs.djangoproject.com/en/3.1/topics/settings/
8
9 For the full list of settings and their values, see
10 https://docs.djangoproject.com/en/3.1/ref/settings/
11 """
12
13 import os
14 from pathlib import Path
15
16 from decouple import Csv, config as decouple_config
17 from dj_database_url import parse as db_url
18
19 # Build paths inside the project like this: BASE_DIR / 'subdir'.
20 BASE_DIR = Path(__file__).resolve().parent.parent
21
22 # Application definition
23
24 INSTALLED_APPS = [
25 "django.contrib.admin",
26 "django.contrib.auth",
27 "django.contrib.contenttypes",
28 "django.contrib.sessions",
29 "django.contrib.messages",
30 "django.contrib.staticfiles",
31 "rest_framework",
32 "django_filters",
33 "django_property_filter",
34 "mathesar",
35 ]
36
37 MIDDLEWARE = [
38 "django.middleware.security.SecurityMiddleware",
39 "django.contrib.sessions.middleware.SessionMiddleware",
40 "django.middleware.common.CommonMiddleware",
41 "django.middleware.csrf.CsrfViewMiddleware",
42 "django.contrib.auth.middleware.AuthenticationMiddleware",
43 "django.contrib.messages.middleware.MessageMiddleware",
44 "django.middleware.clickjacking.XFrameOptionsMiddleware",
45 ]
46
47 ROOT_URLCONF = "config.urls"
48
49 TEMPLATES = [
50 {
51 "BACKEND": "django.template.backends.django.DjangoTemplates",
52 "DIRS": [],
53 "APP_DIRS": True,
54 "OPTIONS": {
55 "context_processors": [
56 "config.context_processors.get_settings",
57 "django.template.context_processors.debug",
58 "django.template.context_processors.request",
59 "django.contrib.auth.context_processors.auth",
60 "django.contrib.messages.context_processors.messages",
61 ],
62 },
63 },
64 ]
65
66 WSGI_APPLICATION = "config.wsgi.application"
67
68 # Database
69 # https://docs.djangoproject.com/en/3.1/ref/settings/#databases
70
71 # TODO: Add to documentation that database keys should not be than 128 characters.
72 DATABASES = {
73 decouple_config('DJANGO_DATABASE_KEY'): decouple_config('DJANGO_DATABASE_URL', cast=db_url),
74 decouple_config('MATHESAR_DATABASE_KEY'): decouple_config('MATHESAR_DATABASE_URL', cast=db_url)
75 }
76
77
78 # Quick-start development settings - unsuitable for production
79 # See https://docs.djangoproject.com/en/3.1/howto/deployment/checklist/
80
81 # SECURITY WARNING: keep the secret key used in production secret!
82 SECRET_KEY = decouple_config('SECRET_KEY')
83
84 # SECURITY WARNING: don't run with debug turned on in production!
85 DEBUG = decouple_config('DEBUG', default=False, cast=bool)
86
87 ALLOWED_HOSTS = decouple_config('ALLOWED_HOSTS', cast=Csv())
88
89 # Password validation
90 # https://docs.djangoproject.com/en/3.1/ref/settings/#auth-password-validators
91
92 AUTH_PASSWORD_VALIDATORS = [
93 {
94 "NAME": "django.contrib.auth.password_validation.UserAttributeSimilarityValidator",
95 },
96 {
97 "NAME": "django.contrib.auth.password_validation.MinimumLengthValidator",
98 },
99 {
100 "NAME": "django.contrib.auth.password_validation.CommonPasswordValidator",
101 },
102 {
103 "NAME": "django.contrib.auth.password_validation.NumericPasswordValidator",
104 },
105 ]
106
107
108 # Internationalization
109 # https://docs.djangoproject.com/en/3.1/topics/i18n/
110
111 LANGUAGE_CODE = "en-us"
112
113 TIME_ZONE = "UTC"
114
115 USE_I18N = True
116
117 USE_L10N = True
118
119 USE_TZ = True
120
121
122 # Static files (CSS, JavaScript, Images)
123 # https://docs.djangoproject.com/en/3.1/howto/static-files/
124
125 STATIC_URL = "/static/"
126
127 CLIENT_DEV_URL = "http://localhost:3000"
128
129
130 # Media files (uploaded by the user)
131
132 MEDIA_ROOT = os.path.join(BASE_DIR, '.media/')
133
134 MEDIA_URL = "/media/"
135
[end of config/settings.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/config/settings.py b/config/settings.py
--- a/config/settings.py
+++ b/config/settings.py
@@ -74,6 +74,13 @@
decouple_config('MATHESAR_DATABASE_KEY'): decouple_config('MATHESAR_DATABASE_URL', cast=db_url)
}
+# pytest-django will create a new database named 'test_{DATABASES[table_db]['NAME']}'
+# and use it for our API tests if we don't specify DATABASES[table_db]['TEST']['NAME']
+if decouple_config('TEST', default=False, cast=bool):
+ DATABASES[decouple_config('MATHESAR_DATABASE_KEY')]['TEST'] = {
+ 'NAME': DATABASES[decouple_config('MATHESAR_DATABASE_KEY')]['NAME']
+ }
+
# Quick-start development settings - unsuitable for production
# See https://docs.djangoproject.com/en/3.1/howto/deployment/checklist/
|
{"golden_diff": "diff --git a/config/settings.py b/config/settings.py\n--- a/config/settings.py\n+++ b/config/settings.py\n@@ -74,6 +74,13 @@\n decouple_config('MATHESAR_DATABASE_KEY'): decouple_config('MATHESAR_DATABASE_URL', cast=db_url)\n }\n \n+# pytest-django will create a new database named 'test_{DATABASES[table_db]['NAME']}'\n+# and use it for our API tests if we don't specify DATABASES[table_db]['TEST']['NAME']\n+if decouple_config('TEST', default=False, cast=bool):\n+ DATABASES[decouple_config('MATHESAR_DATABASE_KEY')]['TEST'] = {\n+ 'NAME': DATABASES[decouple_config('MATHESAR_DATABASE_KEY')]['NAME']\n+ }\n+\n \n # Quick-start development settings - unsuitable for production\n # See https://docs.djangoproject.com/en/3.1/howto/deployment/checklist/\n", "issue": "API tests using wrong tables database\n**Describe the bug**\r\nThe django API tests are running on the `test_mathesar_db_test_database`, which differs from the `mathesar_db_test_database` tables database we should be using. As a result, we don't have a proper reference to the database being used by the API functions, which prevents us from certain operations like installing types for a test. \r\n\r\n**Expected behavior**\r\nWe should ensure `pytest-django` doesn't build a separate tables database.\r\n\r\n**Additional context**\r\nCurrently blocking #276 \r\n\n", "before_files": [{"content": "\"\"\"\nDjango settings for config project.\n\nGenerated by 'django-admin startproject' using Django 3.1.7.\n\nFor more information on this file, see\nhttps://docs.djangoproject.com/en/3.1/topics/settings/\n\nFor the full list of settings and their values, see\nhttps://docs.djangoproject.com/en/3.1/ref/settings/\n\"\"\"\n\nimport os\nfrom pathlib import Path\n\nfrom decouple import Csv, config as decouple_config\nfrom dj_database_url import parse as db_url\n\n# Build paths inside the project like this: BASE_DIR / 'subdir'.\nBASE_DIR = Path(__file__).resolve().parent.parent\n\n# Application definition\n\nINSTALLED_APPS = [\n \"django.contrib.admin\",\n \"django.contrib.auth\",\n \"django.contrib.contenttypes\",\n \"django.contrib.sessions\",\n \"django.contrib.messages\",\n \"django.contrib.staticfiles\",\n \"rest_framework\",\n \"django_filters\",\n \"django_property_filter\",\n \"mathesar\",\n]\n\nMIDDLEWARE = [\n \"django.middleware.security.SecurityMiddleware\",\n \"django.contrib.sessions.middleware.SessionMiddleware\",\n \"django.middleware.common.CommonMiddleware\",\n \"django.middleware.csrf.CsrfViewMiddleware\",\n \"django.contrib.auth.middleware.AuthenticationMiddleware\",\n \"django.contrib.messages.middleware.MessageMiddleware\",\n \"django.middleware.clickjacking.XFrameOptionsMiddleware\",\n]\n\nROOT_URLCONF = \"config.urls\"\n\nTEMPLATES = [\n {\n \"BACKEND\": \"django.template.backends.django.DjangoTemplates\",\n \"DIRS\": [],\n \"APP_DIRS\": True,\n \"OPTIONS\": {\n \"context_processors\": [\n \"config.context_processors.get_settings\",\n \"django.template.context_processors.debug\",\n \"django.template.context_processors.request\",\n \"django.contrib.auth.context_processors.auth\",\n \"django.contrib.messages.context_processors.messages\",\n ],\n },\n },\n]\n\nWSGI_APPLICATION = \"config.wsgi.application\"\n\n# Database\n# https://docs.djangoproject.com/en/3.1/ref/settings/#databases\n\n# TODO: Add to documentation that database keys should not be than 128 characters.\nDATABASES = {\n decouple_config('DJANGO_DATABASE_KEY'): decouple_config('DJANGO_DATABASE_URL', cast=db_url),\n decouple_config('MATHESAR_DATABASE_KEY'): decouple_config('MATHESAR_DATABASE_URL', cast=db_url)\n}\n\n\n# Quick-start development settings - unsuitable for production\n# See https://docs.djangoproject.com/en/3.1/howto/deployment/checklist/\n\n# SECURITY WARNING: keep the secret key used in production secret!\nSECRET_KEY = decouple_config('SECRET_KEY')\n\n# SECURITY WARNING: don't run with debug turned on in production!\nDEBUG = decouple_config('DEBUG', default=False, cast=bool)\n\nALLOWED_HOSTS = decouple_config('ALLOWED_HOSTS', cast=Csv())\n\n# Password validation\n# https://docs.djangoproject.com/en/3.1/ref/settings/#auth-password-validators\n\nAUTH_PASSWORD_VALIDATORS = [\n {\n \"NAME\": \"django.contrib.auth.password_validation.UserAttributeSimilarityValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.MinimumLengthValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.CommonPasswordValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.NumericPasswordValidator\",\n },\n]\n\n\n# Internationalization\n# https://docs.djangoproject.com/en/3.1/topics/i18n/\n\nLANGUAGE_CODE = \"en-us\"\n\nTIME_ZONE = \"UTC\"\n\nUSE_I18N = True\n\nUSE_L10N = True\n\nUSE_TZ = True\n\n\n# Static files (CSS, JavaScript, Images)\n# https://docs.djangoproject.com/en/3.1/howto/static-files/\n\nSTATIC_URL = \"/static/\"\n\nCLIENT_DEV_URL = \"http://localhost:3000\"\n\n\n# Media files (uploaded by the user)\n\nMEDIA_ROOT = os.path.join(BASE_DIR, '.media/')\n\nMEDIA_URL = \"/media/\"\n", "path": "config/settings.py"}]}
| 1,790 | 201 |
gh_patches_debug_9068
|
rasdani/github-patches
|
git_diff
|
techmatters__terraso-backend-368
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
feat: Handle error for SSO signup if user does not have email set
## Description
With Google and Apple SSO it seems we have a guarantee that the user will have their email set. This is good for us; the email is a required column in our user table. However, with Microsoft it seems like we do not have this guarantee, which causes us to display an ugly error message in the case where the user does not have an email defined. There are several ways we could handle this:
1) Display an error message that instructs the user to set their email. This is definitely less user friendly, but may be easier to implement.
2) Allow the user to set their email interactively. This is what is done, for example, with Kobo. The idea here would be to set up a signup page as the final signup step. This page would be pre-populated with whatever content we get from Microsoft, but it will allow the user to manually set their email if it is not present.
Any other options you see?
</issue>
<code>
[start of terraso_backend/apps/auth/services.py]
1 # Copyright © 2021-2023 Technology Matters
2 #
3 # This program is free software: you can redistribute it and/or modify
4 # it under the terms of the GNU Affero General Public License as published
5 # by the Free Software Foundation, either version 3 of the License, or
6 # (at your option) any later version.
7 #
8 # This program is distributed in the hope that it will be useful,
9 # but WITHOUT ANY WARRANTY; without even the implied warranty of
10 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
11 # GNU Affero General Public License for more details.
12 #
13 # You should have received a copy of the GNU Affero General Public License
14 # along with this program. If not, see https://www.gnu.org/licenses/.
15
16 import ipaddress
17 from datetime import timedelta
18 from typing import Any, Optional
19 from urllib.parse import urlparse
20 from uuid import uuid4
21
22 import httpx
23 import jwt
24 import structlog
25 from django.conf import settings
26 from django.contrib.auth import get_user_model
27 from django.utils import timezone
28
29 from apps.storage.services import ProfileImageService
30
31 from .providers import AppleProvider, GoogleProvider, MicrosoftProvider
32
33 logger = structlog.get_logger(__name__)
34 User = get_user_model()
35
36
37 class AccountService:
38 def sign_up_with_google(self, authorization_code):
39 provider = GoogleProvider()
40 tokens = provider.fetch_auth_tokens(authorization_code)
41
42 if not tokens.is_valid:
43 error_msg = f"Error fetching auth tokens: {tokens.error_description}"
44 logger.error(error_msg)
45 raise Exception(error_msg)
46
47 return self._persist_user(
48 tokens.open_id.email,
49 first_name=tokens.open_id.given_name,
50 last_name=tokens.open_id.family_name,
51 profile_image_url=tokens.open_id.picture,
52 )
53
54 def sign_up_with_apple(self, authorization_code, first_name="", last_name=""):
55 provider = AppleProvider()
56 tokens = provider.fetch_auth_tokens(authorization_code)
57
58 if not tokens.is_valid:
59 error_msg = f"Error fetching auth tokens: {tokens.error_description}"
60 logger.error(error_msg)
61 raise Exception(error_msg)
62
63 return self._persist_user(tokens.open_id.email, first_name=first_name, last_name=last_name)
64
65 def sign_up_with_microsoft(self, authorization_code):
66 provider = MicrosoftProvider()
67 tokens = provider.fetch_auth_tokens(authorization_code)
68 if not tokens.is_valid:
69 error_msg = f"Error fetching auth tokens: {tokens.error_description}"
70 logger.error(error_msg)
71 raise Exception(error_msg)
72 return self._persist_user(
73 tokens.open_id.email,
74 first_name=tokens.open_id.given_name,
75 last_name=tokens.open_id.family_name,
76 profile_image_url=tokens.open_id.picture,
77 )
78
79 def _persist_user(self, email, first_name="", last_name="", profile_image_url=None):
80 user, created = User.objects.get_or_create(email=email)
81
82 self._update_profile_image(user, profile_image_url)
83
84 if not created:
85 return user, False
86
87 update_name = first_name or last_name
88
89 if first_name:
90 user.first_name = first_name
91
92 if last_name:
93 user.last_name = last_name
94
95 if update_name:
96 user.save()
97
98 return user, True
99
100 def _update_profile_image(self, user, profile_image_url):
101 if not profile_image_url:
102 return
103
104 profile_image_service = ProfileImageService()
105 user_id = str(user.id)
106
107 try:
108 user.profile_image = profile_image_service.upload_url(user_id, profile_image_url)
109 user.save()
110 except Exception:
111 logger.exception("Failed to upload profile image. User ID: {}".format(user_id))
112
113
114 class JWTService:
115 JWT_SECRET = settings.JWT_SECRET
116 JWT_ALGORITHM = settings.JWT_ALGORITHM
117 JWT_ACCESS_EXP_DELTA_SECONDS = settings.JWT_ACCESS_EXP_DELTA_SECONDS
118 JWT_REFRESH_EXP_DELTA_SECONDS = settings.JWT_REFRESH_EXP_DELTA_SECONDS
119 JWT_ISS = settings.JWT_ISS
120
121 def create_access_token(self, user):
122 payload = self._get_base_payload(user)
123 payload["exp"] = timezone.now() + timedelta(seconds=self.JWT_ACCESS_EXP_DELTA_SECONDS)
124
125 return jwt.encode(payload, self.JWT_SECRET, algorithm=self.JWT_ALGORITHM)
126
127 def create_refresh_token(self, user):
128 payload = self._get_base_payload(user)
129 payload["exp"] = timezone.now() + timedelta(seconds=self.JWT_REFRESH_EXP_DELTA_SECONDS)
130
131 return jwt.encode(payload, self.JWT_SECRET, algorithm=self.JWT_ALGORITHM)
132
133 def verify_token(self, token):
134 return jwt.decode(token, self.JWT_SECRET, algorithms=self.JWT_ALGORITHM)
135
136 def _get_base_payload(self, user):
137 return {
138 "iss": self.JWT_ISS,
139 "iat": timezone.now(),
140 "sub": str(user.id),
141 "jti": uuid4().hex,
142 "email": user.email,
143 }
144
145
146 class PlausibleService:
147 """Service for making API calls to plausible service.
148
149 See documentation at https://plausible.io/docs/events-api .
150 """
151
152 PLAUSIBLE_URL = settings.PLAUSIBLE_URL
153 FRONTEND_URL = settings.WEB_CLIENT_URL
154 # fake URL here, because there is no real "signup" URL
155 # see Plausible API docs for "url" param
156 EVENT_URL = f"{FRONTEND_URL}/signup"
157
158 @staticmethod
159 def _prepare_headers(user_agent: str, ip_address: str) -> dict[str, str]:
160 return {
161 "User-Agent": user_agent,
162 "X-Forwarded-For": ip_address,
163 "Content-Type": "application/json",
164 }
165
166 @classmethod
167 def _prepare_body_params(
168 cls, event_name: str, event_url: str, referrer: str, props: Optional[dict[str, Any]]
169 ):
170 return {
171 "domain": urlparse(cls.FRONTEND_URL).hostname,
172 "name": event_name,
173 "url": event_url,
174 "referrer": referrer,
175 "props": props,
176 }
177
178 @staticmethod
179 def _get_first_ip_address(string: str):
180 addresses = string.split(",")
181 for addr in addresses:
182 try:
183 ip_address = ipaddress.ip_address(addr)
184 break
185 except ValueError:
186 pass
187 else:
188 # we only get to this branch if we never break
189 # i.e. none of the candidates are valid ip addresses
190 return None
191 return str(ip_address)
192
193 def track_event(
194 self,
195 event_name: str,
196 user_agent: str,
197 ip_address: str,
198 event_url: str,
199 props: Optional[dict[str, Any]] = None,
200 referrer: str = "",
201 ) -> None:
202 """Send a tracking event to Plausible through the HTTP API.
203 Throws exception if not succesful."""
204 headers = self._prepare_headers(user_agent, ip_address)
205 data = self._prepare_body_params(event_name, event_url, referrer, props)
206 resp = httpx.post(self.PLAUSIBLE_URL, headers=headers, json=data)
207
208 resp.raise_for_status()
209
210 def track_signup(self, auth_provider: str, req) -> None:
211 """Track a successful signup. Include information on which service was used for signup."""
212 event_name = "User signup"
213 if "user-agent" not in req.headers:
214 logger.error("During signup tracking, request missing header 'user-agent'")
215 return
216 user_agent = req.headers["user-agent"]
217 # here we just assume we are testing locally if 'x-forwarded-for' header is not present
218 # this is a mandatory header for the Plausible API, see docs for details
219 ip_address = "127.0.0.1"
220 if "x-forwarded-for" in req.headers:
221 ip_address = self._get_first_ip_address(req.headers["x-forwarded-for"])
222 if not ip_address:
223 logger.error(
224 "During signup tracking, request header 'x-forwarded-for' was set,"
225 " but no valid ip addresses were found"
226 )
227 return
228 props = {"service": auth_provider}
229 self.track_event(event_name, user_agent, ip_address, self.EVENT_URL, props)
230
[end of terraso_backend/apps/auth/services.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/terraso_backend/apps/auth/services.py b/terraso_backend/apps/auth/services.py
--- a/terraso_backend/apps/auth/services.py
+++ b/terraso_backend/apps/auth/services.py
@@ -77,6 +77,10 @@
)
def _persist_user(self, email, first_name="", last_name="", profile_image_url=None):
+ if not email:
+ # it is possible for the email not to be set, notably with Microsoft
+ # here throw a more descriptive error message
+ raise ValueError("Could not create account, user email is empty")
user, created = User.objects.get_or_create(email=email)
self._update_profile_image(user, profile_image_url)
|
{"golden_diff": "diff --git a/terraso_backend/apps/auth/services.py b/terraso_backend/apps/auth/services.py\n--- a/terraso_backend/apps/auth/services.py\n+++ b/terraso_backend/apps/auth/services.py\n@@ -77,6 +77,10 @@\n )\n \n def _persist_user(self, email, first_name=\"\", last_name=\"\", profile_image_url=None):\n+ if not email:\n+ # it is possible for the email not to be set, notably with Microsoft\n+ # here throw a more descriptive error message\n+ raise ValueError(\"Could not create account, user email is empty\")\n user, created = User.objects.get_or_create(email=email)\n \n self._update_profile_image(user, profile_image_url)\n", "issue": "feat: Handle error for SSO signup if user does not have email set\n## Description\r\n\r\nWith Google and Apple SSO it seems we have a guarantee that the user will have their email set. This is good for us; the email is a required column in our user table. However, with Microsoft it seems like we do not have this guarantee, which causes us to display an ugly error message in the case where the user does not have an email defined. There are several ways we could handle this:\r\n\r\n1) Display an error message that instructs the user to set their email. This is definitely less user friendly, but may be easier to implement.\r\n\r\n2) Allow the user to set their email interactively. This is what is done, for example, with Kobo. The idea here would be to set up a signup page as the final signup step. This page would be pre-populated with whatever content we get from Microsoft, but it will allow the user to manually set their email if it is not present.\r\n\r\nAny other options you see?\r\n\n", "before_files": [{"content": "# Copyright \u00a9 2021-2023 Technology Matters\n#\n# This program is free software: you can redistribute it and/or modify\n# it under the terms of the GNU Affero General Public License as published\n# by the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU Affero General Public License for more details.\n#\n# You should have received a copy of the GNU Affero General Public License\n# along with this program. If not, see https://www.gnu.org/licenses/.\n\nimport ipaddress\nfrom datetime import timedelta\nfrom typing import Any, Optional\nfrom urllib.parse import urlparse\nfrom uuid import uuid4\n\nimport httpx\nimport jwt\nimport structlog\nfrom django.conf import settings\nfrom django.contrib.auth import get_user_model\nfrom django.utils import timezone\n\nfrom apps.storage.services import ProfileImageService\n\nfrom .providers import AppleProvider, GoogleProvider, MicrosoftProvider\n\nlogger = structlog.get_logger(__name__)\nUser = get_user_model()\n\n\nclass AccountService:\n def sign_up_with_google(self, authorization_code):\n provider = GoogleProvider()\n tokens = provider.fetch_auth_tokens(authorization_code)\n\n if not tokens.is_valid:\n error_msg = f\"Error fetching auth tokens: {tokens.error_description}\"\n logger.error(error_msg)\n raise Exception(error_msg)\n\n return self._persist_user(\n tokens.open_id.email,\n first_name=tokens.open_id.given_name,\n last_name=tokens.open_id.family_name,\n profile_image_url=tokens.open_id.picture,\n )\n\n def sign_up_with_apple(self, authorization_code, first_name=\"\", last_name=\"\"):\n provider = AppleProvider()\n tokens = provider.fetch_auth_tokens(authorization_code)\n\n if not tokens.is_valid:\n error_msg = f\"Error fetching auth tokens: {tokens.error_description}\"\n logger.error(error_msg)\n raise Exception(error_msg)\n\n return self._persist_user(tokens.open_id.email, first_name=first_name, last_name=last_name)\n\n def sign_up_with_microsoft(self, authorization_code):\n provider = MicrosoftProvider()\n tokens = provider.fetch_auth_tokens(authorization_code)\n if not tokens.is_valid:\n error_msg = f\"Error fetching auth tokens: {tokens.error_description}\"\n logger.error(error_msg)\n raise Exception(error_msg)\n return self._persist_user(\n tokens.open_id.email,\n first_name=tokens.open_id.given_name,\n last_name=tokens.open_id.family_name,\n profile_image_url=tokens.open_id.picture,\n )\n\n def _persist_user(self, email, first_name=\"\", last_name=\"\", profile_image_url=None):\n user, created = User.objects.get_or_create(email=email)\n\n self._update_profile_image(user, profile_image_url)\n\n if not created:\n return user, False\n\n update_name = first_name or last_name\n\n if first_name:\n user.first_name = first_name\n\n if last_name:\n user.last_name = last_name\n\n if update_name:\n user.save()\n\n return user, True\n\n def _update_profile_image(self, user, profile_image_url):\n if not profile_image_url:\n return\n\n profile_image_service = ProfileImageService()\n user_id = str(user.id)\n\n try:\n user.profile_image = profile_image_service.upload_url(user_id, profile_image_url)\n user.save()\n except Exception:\n logger.exception(\"Failed to upload profile image. User ID: {}\".format(user_id))\n\n\nclass JWTService:\n JWT_SECRET = settings.JWT_SECRET\n JWT_ALGORITHM = settings.JWT_ALGORITHM\n JWT_ACCESS_EXP_DELTA_SECONDS = settings.JWT_ACCESS_EXP_DELTA_SECONDS\n JWT_REFRESH_EXP_DELTA_SECONDS = settings.JWT_REFRESH_EXP_DELTA_SECONDS\n JWT_ISS = settings.JWT_ISS\n\n def create_access_token(self, user):\n payload = self._get_base_payload(user)\n payload[\"exp\"] = timezone.now() + timedelta(seconds=self.JWT_ACCESS_EXP_DELTA_SECONDS)\n\n return jwt.encode(payload, self.JWT_SECRET, algorithm=self.JWT_ALGORITHM)\n\n def create_refresh_token(self, user):\n payload = self._get_base_payload(user)\n payload[\"exp\"] = timezone.now() + timedelta(seconds=self.JWT_REFRESH_EXP_DELTA_SECONDS)\n\n return jwt.encode(payload, self.JWT_SECRET, algorithm=self.JWT_ALGORITHM)\n\n def verify_token(self, token):\n return jwt.decode(token, self.JWT_SECRET, algorithms=self.JWT_ALGORITHM)\n\n def _get_base_payload(self, user):\n return {\n \"iss\": self.JWT_ISS,\n \"iat\": timezone.now(),\n \"sub\": str(user.id),\n \"jti\": uuid4().hex,\n \"email\": user.email,\n }\n\n\nclass PlausibleService:\n \"\"\"Service for making API calls to plausible service.\n\n See documentation at https://plausible.io/docs/events-api .\n \"\"\"\n\n PLAUSIBLE_URL = settings.PLAUSIBLE_URL\n FRONTEND_URL = settings.WEB_CLIENT_URL\n # fake URL here, because there is no real \"signup\" URL\n # see Plausible API docs for \"url\" param\n EVENT_URL = f\"{FRONTEND_URL}/signup\"\n\n @staticmethod\n def _prepare_headers(user_agent: str, ip_address: str) -> dict[str, str]:\n return {\n \"User-Agent\": user_agent,\n \"X-Forwarded-For\": ip_address,\n \"Content-Type\": \"application/json\",\n }\n\n @classmethod\n def _prepare_body_params(\n cls, event_name: str, event_url: str, referrer: str, props: Optional[dict[str, Any]]\n ):\n return {\n \"domain\": urlparse(cls.FRONTEND_URL).hostname,\n \"name\": event_name,\n \"url\": event_url,\n \"referrer\": referrer,\n \"props\": props,\n }\n\n @staticmethod\n def _get_first_ip_address(string: str):\n addresses = string.split(\",\")\n for addr in addresses:\n try:\n ip_address = ipaddress.ip_address(addr)\n break\n except ValueError:\n pass\n else:\n # we only get to this branch if we never break\n # i.e. none of the candidates are valid ip addresses\n return None\n return str(ip_address)\n\n def track_event(\n self,\n event_name: str,\n user_agent: str,\n ip_address: str,\n event_url: str,\n props: Optional[dict[str, Any]] = None,\n referrer: str = \"\",\n ) -> None:\n \"\"\"Send a tracking event to Plausible through the HTTP API.\n Throws exception if not succesful.\"\"\"\n headers = self._prepare_headers(user_agent, ip_address)\n data = self._prepare_body_params(event_name, event_url, referrer, props)\n resp = httpx.post(self.PLAUSIBLE_URL, headers=headers, json=data)\n\n resp.raise_for_status()\n\n def track_signup(self, auth_provider: str, req) -> None:\n \"\"\"Track a successful signup. Include information on which service was used for signup.\"\"\"\n event_name = \"User signup\"\n if \"user-agent\" not in req.headers:\n logger.error(\"During signup tracking, request missing header 'user-agent'\")\n return\n user_agent = req.headers[\"user-agent\"]\n # here we just assume we are testing locally if 'x-forwarded-for' header is not present\n # this is a mandatory header for the Plausible API, see docs for details\n ip_address = \"127.0.0.1\"\n if \"x-forwarded-for\" in req.headers:\n ip_address = self._get_first_ip_address(req.headers[\"x-forwarded-for\"])\n if not ip_address:\n logger.error(\n \"During signup tracking, request header 'x-forwarded-for' was set,\"\n \" but no valid ip addresses were found\"\n )\n return\n props = {\"service\": auth_provider}\n self.track_event(event_name, user_agent, ip_address, self.EVENT_URL, props)\n", "path": "terraso_backend/apps/auth/services.py"}]}
| 3,089 | 160 |
gh_patches_debug_14759
|
rasdani/github-patches
|
git_diff
|
saulpw__visidata-1901
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Keystroke ] not detected on Windows
In Powershell and cmd.exe I encountered that sorting didn't work in both orders. The `[` shortcut was detected and had its effect, but the `]` didn't. I narrowed it down to a problem with `windows-curses`, and in turn with its dependency `PDCurses`: https://github.com/zephyrproject-rtos/windows-curses/issues/41
Here's my plan on how to address it. I hope I'll get around to it somewhere next week.
- [ ] Improve the mapping in `PDCurses` and submit a pull request
- [ ] Bump the git submodule in `windows-curses` to the `PDCurses` version that has the fix and ask/wait for a release of this package
- [ ] Address the issue in this repository, perhaps by pinning `windows-curses` to a version of at least the newly released package.
I'm making this issue here just to document it and track progress. If you're reading this because you have this issue, I would recommend using WSL instead. (WSL is not an option for me unfortunately).
I didn't include the `.vd`-file to reproduce this issue. The simplest way to reproduce it is to get a Windows computer, run `visidata` from Powershell or cmd.exe and sort any column by pressing `]`.
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python3
2
3 from setuptools import setup
4 # tox can't actually run python3 setup.py: https://github.com/tox-dev/tox/issues/96
5 #from visidata import __version__
6 __version__ = '2.12dev'
7
8 setup(name='visidata',
9 version=__version__,
10 description='terminal interface for exploring and arranging tabular data',
11 long_description=open('README.md').read(),
12 long_description_content_type='text/markdown',
13 author='Saul Pwanson',
14 python_requires='>=3.7',
15 author_email='[email protected]',
16 url='https://visidata.org',
17 download_url='https://github.com/saulpw/visidata/tarball/' + __version__,
18 scripts=['bin/vd'],
19 entry_points={'console_scripts': [
20 'visidata=visidata.main:vd_cli'
21 ],
22 },
23 py_modules=['visidata'],
24 install_requires=[
25 'python-dateutil',
26 'windows-curses; platform_system == "Windows"',
27 'importlib-metadata >= 3.6',
28 ],
29 packages=['visidata', 'visidata.loaders', 'visidata.vendor', 'visidata.tests', 'visidata.ddw', 'visidata.man', 'visidata.themes', 'visidata.features', 'visidata.experimental', 'visidata.apps', 'visidata.apps.vgit', 'visidata.apps.vdsql', 'visidata.desktop'],
30 data_files=[('share/man/man1', ['visidata/man/vd.1', 'visidata/man/visidata.1']), ('share/applications/', ['visidata/desktop/visidata.desktop'])],
31 package_data={'visidata.man': ['vd.1', 'vd.txt'], 'visidata.ddw': ['input.ddw'], 'visidata.tests': ['sample.tsv'], 'visidata.desktop': ['visidata.desktop']},
32 license='GPLv3',
33 classifiers=[
34 'Development Status :: 5 - Production/Stable',
35 'Environment :: Console',
36 'Environment :: Console :: Curses',
37 'Intended Audience :: Developers',
38 'Intended Audience :: Science/Research',
39 'Intended Audience :: System Administrators',
40 'License :: OSI Approved :: GNU General Public License v3 (GPLv3)',
41 'Operating System :: OS Independent',
42 'Programming Language :: Python :: 3',
43 'Topic :: Database :: Front-Ends',
44 'Topic :: Scientific/Engineering',
45 'Topic :: Office/Business :: Financial :: Spreadsheet',
46 'Topic :: Scientific/Engineering :: Visualization',
47 'Topic :: Utilities',
48 ],
49 keywords=('console tabular data spreadsheet terminal viewer textpunk'
50 'curses csv hdf5 h5 xlsx excel tsv'),
51 )
52
53
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -23,7 +23,7 @@
py_modules=['visidata'],
install_requires=[
'python-dateutil',
- 'windows-curses; platform_system == "Windows"',
+ 'windows-curses<2.3.1; platform_system == "Windows"', #1841
'importlib-metadata >= 3.6',
],
packages=['visidata', 'visidata.loaders', 'visidata.vendor', 'visidata.tests', 'visidata.ddw', 'visidata.man', 'visidata.themes', 'visidata.features', 'visidata.experimental', 'visidata.apps', 'visidata.apps.vgit', 'visidata.apps.vdsql', 'visidata.desktop'],
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -23,7 +23,7 @@\n py_modules=['visidata'],\n install_requires=[\n 'python-dateutil',\n- 'windows-curses; platform_system == \"Windows\"',\n+ 'windows-curses<2.3.1; platform_system == \"Windows\"', #1841\n 'importlib-metadata >= 3.6',\n ],\n packages=['visidata', 'visidata.loaders', 'visidata.vendor', 'visidata.tests', 'visidata.ddw', 'visidata.man', 'visidata.themes', 'visidata.features', 'visidata.experimental', 'visidata.apps', 'visidata.apps.vgit', 'visidata.apps.vdsql', 'visidata.desktop'],\n", "issue": "Keystroke ] not detected on Windows\nIn Powershell and cmd.exe I encountered that sorting didn't work in both orders. The `[` shortcut was detected and had its effect, but the `]` didn't. I narrowed it down to a problem with `windows-curses`, and in turn with its dependency `PDCurses`: https://github.com/zephyrproject-rtos/windows-curses/issues/41\r\n\r\nHere's my plan on how to address it. I hope I'll get around to it somewhere next week.\r\n- [ ] Improve the mapping in `PDCurses` and submit a pull request\r\n- [ ] Bump the git submodule in `windows-curses` to the `PDCurses` version that has the fix and ask/wait for a release of this package\r\n- [ ] Address the issue in this repository, perhaps by pinning `windows-curses` to a version of at least the newly released package.\r\n\r\nI'm making this issue here just to document it and track progress. If you're reading this because you have this issue, I would recommend using WSL instead. (WSL is not an option for me unfortunately).\r\n\r\nI didn't include the `.vd`-file to reproduce this issue. The simplest way to reproduce it is to get a Windows computer, run `visidata` from Powershell or cmd.exe and sort any column by pressing `]`.\n", "before_files": [{"content": "#!/usr/bin/env python3\n\nfrom setuptools import setup\n# tox can't actually run python3 setup.py: https://github.com/tox-dev/tox/issues/96\n#from visidata import __version__\n__version__ = '2.12dev'\n\nsetup(name='visidata',\n version=__version__,\n description='terminal interface for exploring and arranging tabular data',\n long_description=open('README.md').read(),\n long_description_content_type='text/markdown',\n author='Saul Pwanson',\n python_requires='>=3.7',\n author_email='[email protected]',\n url='https://visidata.org',\n download_url='https://github.com/saulpw/visidata/tarball/' + __version__,\n scripts=['bin/vd'],\n entry_points={'console_scripts': [\n 'visidata=visidata.main:vd_cli'\n ],\n },\n py_modules=['visidata'],\n install_requires=[\n 'python-dateutil',\n 'windows-curses; platform_system == \"Windows\"',\n 'importlib-metadata >= 3.6',\n ],\n packages=['visidata', 'visidata.loaders', 'visidata.vendor', 'visidata.tests', 'visidata.ddw', 'visidata.man', 'visidata.themes', 'visidata.features', 'visidata.experimental', 'visidata.apps', 'visidata.apps.vgit', 'visidata.apps.vdsql', 'visidata.desktop'],\n data_files=[('share/man/man1', ['visidata/man/vd.1', 'visidata/man/visidata.1']), ('share/applications/', ['visidata/desktop/visidata.desktop'])],\n package_data={'visidata.man': ['vd.1', 'vd.txt'], 'visidata.ddw': ['input.ddw'], 'visidata.tests': ['sample.tsv'], 'visidata.desktop': ['visidata.desktop']},\n license='GPLv3',\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Environment :: Console',\n 'Environment :: Console :: Curses',\n 'Intended Audience :: Developers',\n 'Intended Audience :: Science/Research',\n 'Intended Audience :: System Administrators',\n 'License :: OSI Approved :: GNU General Public License v3 (GPLv3)',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python :: 3',\n 'Topic :: Database :: Front-Ends',\n 'Topic :: Scientific/Engineering',\n 'Topic :: Office/Business :: Financial :: Spreadsheet',\n 'Topic :: Scientific/Engineering :: Visualization',\n 'Topic :: Utilities',\n ],\n keywords=('console tabular data spreadsheet terminal viewer textpunk'\n 'curses csv hdf5 h5 xlsx excel tsv'),\n )\n\n", "path": "setup.py"}]}
| 1,495 | 175 |
gh_patches_debug_19208
|
rasdani/github-patches
|
git_diff
|
microsoft__promptflow-576
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[BUG] Streaming requires Generator where Iterator should suffice
**Describe the bug**
For the user code to provide streaming content, instead of the more generic Iterator protocol, Promptflow relies on the more specific `GeneratorType`. That is requiring the user to unnecessarily wrap their iterators in generators to stream content in more generic scenarios (such as streaming langchain results). Is there a reason PF depends on GeneratorType instead of the iterator protocol? Also, see this note in the [python source](https://github.com/python/cpython/blob/f65497fd252a4a4df960da04d68e8316b58624c0/Lib/types.py#L6-L10):
```
# Iterators in Python aren't a matter of type but of protocol. A large
# and changing number of builtin types implement *some* flavor of
# iterator. Don't check the type! Use hasattr to check for both
# "__iter__" and "__next__" attributes instead.
```
**Concrete Issue:**
When returning an iterator from my tool to enable streaming, I get the following error when running `pf flow test`
```
Flow test failed with UserErrorException: Exception: The output 'answer' for flow is incorrect. The output value is
not JSON serializable. JSON dump failed: (TypeError) Object of type WordIterator is not JSON serializable. Please
verify your flow output and make sure the value serializable.
```
**How To Reproduce the bug**
Here is my flow.dag.yaml:
```yaml
id: template_chat_flow
name: Template Chat Flow
inputs:
chat_history:
type: list
default: []
question:
type: string
default: What is the meaning of life?
outputs:
answer:
type: string
is_chat_output: true
reference: ${stream.output}
nodes:
- name: stream
type: python
source:
type: code
path: stream.py
inputs:
input: ${inputs.question}
```
And here is my stream.py
```python
from promptflow import tool
class WordIterator:
def __init__(self, input: str):
self.input = input
def __iter__(self):
return self
def __next__(self):
if self.input:
word, *rest = self.input.split(" ")
self.input = " ".join(rest)
return f"{word} "
else:
raise StopIteration
@tool
def my_python_tool(input: str):
iterator = WordIterator(input)
assert hasattr(iterator, "__iter__")
assert hasattr(iterator, "__next__")
return iterator
```
With the above PF run `pf flow test --flow .` -- I get this error:
```
2023-09-19 11:01:17 +0200 42558 execution INFO Start to run 1 nodes with concurrency level 16.
2023-09-19 11:01:17 +0200 42558 execution.flow INFO Executing node stream. node run id: c4ddaddd-6a38-44fd-9ab1-3258fb88bb37_stream_0
2023-09-19 11:01:17 +0200 42558 execution.flow WARNING Output of stream is not json serializable, use str to store it.
2023-09-19 11:01:17 +0200 42558 execution.flow INFO Node stream completes.
Flow test failed with UserErrorException: Exception: The output 'answer' for flow is incorrect. The output value is not JSON serializable. JSON dump failed: (TypeError) Object of type WordIterator is not JSON serializable. Please verify your flow output and make sure the value serializable.
```
**Expected behavior**
It should read out the iterator and stream the chunks to the caller -- `pf flow test --flow .` should look like this:
```
2023-09-19 10:34:05 +0200 40375 execution INFO Start to run 1 nodes with concurrency level 16.
2023-09-19 10:34:05 +0200 40375 execution.flow INFO Executing node stream. node run id: 24e60c4d-606a-4fc5-8e4c-cc4a5c41d6c8_stream_0
2023-09-19 10:34:05 +0200 40375 execution.flow WARNING Output of stream is not json serializable, use str to store it.
2023-09-19 10:34:05 +0200 40375 execution.flow INFO Node stream completes.
{
"answer": "What is the meaning of life? "
}
```
**Running Information(please complete the following information):**
- Promptflow Package Version using `pf -v`: 0.1.0b6
- Operating System:
```
ProductName: macOS
ProductVersion: 13.5.2
BuildVersion: 22G91
```
- Python Version using `python --version`: Python 3.10.12
**Additional context**
If I wrap the iterator in a generator, everything works as expected:
```python
from promptflow import tool
class WordIterator:
def __init__(self, input: str):
self.input = input
def __iter__(self):
return self
def __next__(self):
if self.input:
word, *rest = self.input.split(" ")
self.input = " ".join(rest)
return f"{word} "
else:
raise StopIteration
def to_generator(self):
try:
while True:
yield next(self)
except StopIteration:
pass
@tool
def my_python_tool(input: str):
iterator = WordIterator(input).to_generator()
assert hasattr(iterator, "__iter__")
assert hasattr(iterator, "__next__")
return iterator
```
</issue>
<code>
[start of src/promptflow/promptflow/_core/tracer.py]
1 # ---------------------------------------------------------
2 # Copyright (c) Microsoft Corporation. All rights reserved.
3 # ---------------------------------------------------------
4
5 import inspect
6 import json
7 import logging
8 from contextvars import ContextVar
9 from datetime import datetime
10 from types import GeneratorType
11 from typing import Optional
12
13 from promptflow._core.generator_proxy import GeneratorProxy, generate_from_proxy
14 from promptflow._utils.dataclass_serializer import serialize
15 from promptflow.contracts.tool import ConnectionType
16 from promptflow.contracts.trace import Trace, TraceType
17
18 from .thread_local_singleton import ThreadLocalSingleton
19
20
21 class Tracer(ThreadLocalSingleton):
22 CONTEXT_VAR_NAME = "Tracer"
23 context_var = ContextVar(CONTEXT_VAR_NAME, default=None)
24
25 def __init__(self, run_id):
26 self._run_id = run_id
27 self._traces = []
28 self._trace_stack = []
29
30 @classmethod
31 def start_tracing(cls, run_id):
32 tracer = cls(run_id)
33 tracer._activate_in_context()
34
35 @classmethod
36 def end_tracing(cls, raise_ex=False):
37 tracer = cls.active_instance()
38 if not tracer:
39 msg = "Try end tracing but no active tracer in current context."
40 if raise_ex:
41 raise Exception(msg)
42 logging.warning(msg)
43 return []
44 tracer._deactivate_in_context()
45 return tracer.to_json()
46
47 @classmethod
48 def push_tool(cls, f, args, kwargs):
49 obj = cls.active_instance()
50 sig = inspect.signature(f).parameters
51 all_kwargs = {**{k: v for k, v in zip(sig.keys(), args)}, **kwargs}
52 all_kwargs = {
53 k: ConnectionType.serialize_conn(v) if ConnectionType.is_connection_value(v) else v
54 for k, v in all_kwargs.items()
55 }
56 # TODO: put parameters in self to inputs for builtin tools
57 all_kwargs.pop("self", None)
58 trace = Trace(
59 name=f.__qualname__,
60 type=TraceType.TOOL,
61 start_time=datetime.utcnow().timestamp(),
62 inputs=all_kwargs,
63 )
64 obj._push(trace)
65 return trace
66
67 @classmethod
68 def push(cls, trace: Trace):
69 obj = cls.active_instance()
70 if not obj:
71 logging.warning("Try to push trace but no active tracer in current context.")
72 return
73 obj._push(trace)
74
75 @staticmethod
76 def to_serializable(obj):
77 if isinstance(obj, dict) and all(isinstance(k, str) for k in obj.keys()):
78 return {k: Tracer.to_serializable(v) for k, v in obj.items()}
79 if isinstance(obj, GeneratorProxy):
80 return obj
81 try:
82 obj = serialize(obj)
83 json.dumps(obj)
84 except Exception:
85 # We don't want to fail the whole function call because of a serialization error,
86 # so we simply convert it to str if it cannot be serialized.
87 obj = str(obj)
88 return obj
89
90 def _push(self, trace: Trace):
91 if trace.inputs:
92 trace.inputs = self.to_serializable(trace.inputs)
93 if not trace.start_time:
94 trace.start_time = datetime.utcnow().timestamp()
95 if not self._trace_stack:
96 self._traces.append(trace)
97 else:
98 self._trace_stack[-1].children = self._trace_stack[-1].children or []
99 self._trace_stack[-1].children.append(trace)
100 self._trace_stack.append(trace)
101
102 @classmethod
103 def pop(cls, output=None, error: Optional[Exception] = None):
104 obj = cls.active_instance()
105 return obj._pop(output, error)
106
107 def _pop(self, output=None, error: Optional[Exception] = None):
108 last_trace = self._trace_stack[-1]
109 if isinstance(output, GeneratorType):
110 output = GeneratorProxy(output)
111 if output is not None:
112 last_trace.output = self.to_serializable(output)
113 if error is not None:
114 last_trace.error = self._format_error(error)
115 self._trace_stack[-1].end_time = datetime.utcnow().timestamp()
116 self._trace_stack.pop()
117
118 if isinstance(output, GeneratorProxy):
119 return generate_from_proxy(output)
120 else:
121 return output
122
123 def to_json(self) -> list:
124 return serialize(self._traces)
125
126 @staticmethod
127 def _format_error(error: Exception) -> dict:
128 return {
129 "message": str(error),
130 "type": type(error).__qualname__,
131 }
132
[end of src/promptflow/promptflow/_core/tracer.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/promptflow/promptflow/_core/tracer.py b/src/promptflow/promptflow/_core/tracer.py
--- a/src/promptflow/promptflow/_core/tracer.py
+++ b/src/promptflow/promptflow/_core/tracer.py
@@ -5,9 +5,9 @@
import inspect
import json
import logging
+from collections.abc import Iterator
from contextvars import ContextVar
from datetime import datetime
-from types import GeneratorType
from typing import Optional
from promptflow._core.generator_proxy import GeneratorProxy, generate_from_proxy
@@ -106,7 +106,7 @@
def _pop(self, output=None, error: Optional[Exception] = None):
last_trace = self._trace_stack[-1]
- if isinstance(output, GeneratorType):
+ if isinstance(output, Iterator):
output = GeneratorProxy(output)
if output is not None:
last_trace.output = self.to_serializable(output)
|
{"golden_diff": "diff --git a/src/promptflow/promptflow/_core/tracer.py b/src/promptflow/promptflow/_core/tracer.py\n--- a/src/promptflow/promptflow/_core/tracer.py\n+++ b/src/promptflow/promptflow/_core/tracer.py\n@@ -5,9 +5,9 @@\n import inspect\n import json\n import logging\n+from collections.abc import Iterator\n from contextvars import ContextVar\n from datetime import datetime\n-from types import GeneratorType\n from typing import Optional\n \n from promptflow._core.generator_proxy import GeneratorProxy, generate_from_proxy\n@@ -106,7 +106,7 @@\n \n def _pop(self, output=None, error: Optional[Exception] = None):\n last_trace = self._trace_stack[-1]\n- if isinstance(output, GeneratorType):\n+ if isinstance(output, Iterator):\n output = GeneratorProxy(output)\n if output is not None:\n last_trace.output = self.to_serializable(output)\n", "issue": "[BUG] Streaming requires Generator where Iterator should suffice\n**Describe the bug**\r\nFor the user code to provide streaming content, instead of the more generic Iterator protocol, Promptflow relies on the more specific `GeneratorType`. That is requiring the user to unnecessarily wrap their iterators in generators to stream content in more generic scenarios (such as streaming langchain results). Is there a reason PF depends on GeneratorType instead of the iterator protocol? Also, see this note in the [python source](https://github.com/python/cpython/blob/f65497fd252a4a4df960da04d68e8316b58624c0/Lib/types.py#L6-L10):\r\n```\r\n# Iterators in Python aren't a matter of type but of protocol. A large\r\n# and changing number of builtin types implement *some* flavor of\r\n# iterator. Don't check the type! Use hasattr to check for both\r\n# \"__iter__\" and \"__next__\" attributes instead.\r\n```\r\n\r\n**Concrete Issue:** \r\nWhen returning an iterator from my tool to enable streaming, I get the following error when running `pf flow test`\r\n```\r\nFlow test failed with UserErrorException: Exception: The output 'answer' for flow is incorrect. The output value is \r\nnot JSON serializable. JSON dump failed: (TypeError) Object of type WordIterator is not JSON serializable. Please \r\nverify your flow output and make sure the value serializable.\r\n```\r\n\r\n**How To Reproduce the bug**\r\nHere is my flow.dag.yaml:\r\n```yaml\r\nid: template_chat_flow\r\nname: Template Chat Flow\r\ninputs:\r\n chat_history:\r\n type: list\r\n default: []\r\n question:\r\n type: string\r\n default: What is the meaning of life?\r\noutputs:\r\n answer:\r\n type: string\r\n is_chat_output: true\r\n reference: ${stream.output}\r\nnodes:\r\n- name: stream\r\n type: python\r\n source:\r\n type: code\r\n path: stream.py\r\n inputs:\r\n input: ${inputs.question}\r\n```\r\n\r\nAnd here is my stream.py\r\n```python\r\nfrom promptflow import tool\r\n\r\nclass WordIterator:\r\n def __init__(self, input: str):\r\n self.input = input\r\n\r\n def __iter__(self):\r\n return self\r\n\r\n def __next__(self):\r\n if self.input:\r\n word, *rest = self.input.split(\" \")\r\n self.input = \" \".join(rest)\r\n return f\"{word} \"\r\n else:\r\n raise StopIteration \r\n\r\n@tool\r\ndef my_python_tool(input: str):\r\n iterator = WordIterator(input)\r\n assert hasattr(iterator, \"__iter__\")\r\n assert hasattr(iterator, \"__next__\")\r\n return iterator\r\n```\r\nWith the above PF run `pf flow test --flow .` -- I get this error:\r\n```\r\n2023-09-19 11:01:17 +0200 42558 execution INFO Start to run 1 nodes with concurrency level 16.\r\n2023-09-19 11:01:17 +0200 42558 execution.flow INFO Executing node stream. node run id: c4ddaddd-6a38-44fd-9ab1-3258fb88bb37_stream_0\r\n2023-09-19 11:01:17 +0200 42558 execution.flow WARNING Output of stream is not json serializable, use str to store it.\r\n2023-09-19 11:01:17 +0200 42558 execution.flow INFO Node stream completes.\r\nFlow test failed with UserErrorException: Exception: The output 'answer' for flow is incorrect. The output value is not JSON serializable. JSON dump failed: (TypeError) Object of type WordIterator is not JSON serializable. Please verify your flow output and make sure the value serializable.\r\n```\r\n\r\n**Expected behavior**\r\nIt should read out the iterator and stream the chunks to the caller -- `pf flow test --flow .` should look like this:\r\n```\r\n2023-09-19 10:34:05 +0200 40375 execution INFO Start to run 1 nodes with concurrency level 16.\r\n2023-09-19 10:34:05 +0200 40375 execution.flow INFO Executing node stream. node run id: 24e60c4d-606a-4fc5-8e4c-cc4a5c41d6c8_stream_0\r\n2023-09-19 10:34:05 +0200 40375 execution.flow WARNING Output of stream is not json serializable, use str to store it.\r\n2023-09-19 10:34:05 +0200 40375 execution.flow INFO Node stream completes.\r\n{\r\n \"answer\": \"What is the meaning of life? \"\r\n}\r\n```\r\n\r\n**Running Information(please complete the following information):**\r\n - Promptflow Package Version using `pf -v`: 0.1.0b6\r\n - Operating System: \r\n```\r\nProductName: macOS\r\nProductVersion: 13.5.2\r\nBuildVersion: 22G91\r\n```\r\n - Python Version using `python --version`: Python 3.10.12\r\n\r\n**Additional context**\r\nIf I wrap the iterator in a generator, everything works as expected:\r\n\r\n```python\r\nfrom promptflow import tool\r\n\r\nclass WordIterator:\r\n def __init__(self, input: str):\r\n self.input = input\r\n\r\n def __iter__(self):\r\n return self\r\n\r\n def __next__(self):\r\n if self.input:\r\n word, *rest = self.input.split(\" \")\r\n self.input = \" \".join(rest)\r\n return f\"{word} \"\r\n else:\r\n raise StopIteration \r\n \r\n def to_generator(self):\r\n try:\r\n while True:\r\n yield next(self)\r\n except StopIteration:\r\n pass\r\n\r\n@tool\r\ndef my_python_tool(input: str):\r\n iterator = WordIterator(input).to_generator()\r\n assert hasattr(iterator, \"__iter__\")\r\n assert hasattr(iterator, \"__next__\")\r\n return iterator\r\n```\r\n\n", "before_files": [{"content": "# ---------------------------------------------------------\n# Copyright (c) Microsoft Corporation. All rights reserved.\n# ---------------------------------------------------------\n\nimport inspect\nimport json\nimport logging\nfrom contextvars import ContextVar\nfrom datetime import datetime\nfrom types import GeneratorType\nfrom typing import Optional\n\nfrom promptflow._core.generator_proxy import GeneratorProxy, generate_from_proxy\nfrom promptflow._utils.dataclass_serializer import serialize\nfrom promptflow.contracts.tool import ConnectionType\nfrom promptflow.contracts.trace import Trace, TraceType\n\nfrom .thread_local_singleton import ThreadLocalSingleton\n\n\nclass Tracer(ThreadLocalSingleton):\n CONTEXT_VAR_NAME = \"Tracer\"\n context_var = ContextVar(CONTEXT_VAR_NAME, default=None)\n\n def __init__(self, run_id):\n self._run_id = run_id\n self._traces = []\n self._trace_stack = []\n\n @classmethod\n def start_tracing(cls, run_id):\n tracer = cls(run_id)\n tracer._activate_in_context()\n\n @classmethod\n def end_tracing(cls, raise_ex=False):\n tracer = cls.active_instance()\n if not tracer:\n msg = \"Try end tracing but no active tracer in current context.\"\n if raise_ex:\n raise Exception(msg)\n logging.warning(msg)\n return []\n tracer._deactivate_in_context()\n return tracer.to_json()\n\n @classmethod\n def push_tool(cls, f, args, kwargs):\n obj = cls.active_instance()\n sig = inspect.signature(f).parameters\n all_kwargs = {**{k: v for k, v in zip(sig.keys(), args)}, **kwargs}\n all_kwargs = {\n k: ConnectionType.serialize_conn(v) if ConnectionType.is_connection_value(v) else v\n for k, v in all_kwargs.items()\n }\n # TODO: put parameters in self to inputs for builtin tools\n all_kwargs.pop(\"self\", None)\n trace = Trace(\n name=f.__qualname__,\n type=TraceType.TOOL,\n start_time=datetime.utcnow().timestamp(),\n inputs=all_kwargs,\n )\n obj._push(trace)\n return trace\n\n @classmethod\n def push(cls, trace: Trace):\n obj = cls.active_instance()\n if not obj:\n logging.warning(\"Try to push trace but no active tracer in current context.\")\n return\n obj._push(trace)\n\n @staticmethod\n def to_serializable(obj):\n if isinstance(obj, dict) and all(isinstance(k, str) for k in obj.keys()):\n return {k: Tracer.to_serializable(v) for k, v in obj.items()}\n if isinstance(obj, GeneratorProxy):\n return obj\n try:\n obj = serialize(obj)\n json.dumps(obj)\n except Exception:\n # We don't want to fail the whole function call because of a serialization error,\n # so we simply convert it to str if it cannot be serialized.\n obj = str(obj)\n return obj\n\n def _push(self, trace: Trace):\n if trace.inputs:\n trace.inputs = self.to_serializable(trace.inputs)\n if not trace.start_time:\n trace.start_time = datetime.utcnow().timestamp()\n if not self._trace_stack:\n self._traces.append(trace)\n else:\n self._trace_stack[-1].children = self._trace_stack[-1].children or []\n self._trace_stack[-1].children.append(trace)\n self._trace_stack.append(trace)\n\n @classmethod\n def pop(cls, output=None, error: Optional[Exception] = None):\n obj = cls.active_instance()\n return obj._pop(output, error)\n\n def _pop(self, output=None, error: Optional[Exception] = None):\n last_trace = self._trace_stack[-1]\n if isinstance(output, GeneratorType):\n output = GeneratorProxy(output)\n if output is not None:\n last_trace.output = self.to_serializable(output)\n if error is not None:\n last_trace.error = self._format_error(error)\n self._trace_stack[-1].end_time = datetime.utcnow().timestamp()\n self._trace_stack.pop()\n\n if isinstance(output, GeneratorProxy):\n return generate_from_proxy(output)\n else:\n return output\n\n def to_json(self) -> list:\n return serialize(self._traces)\n\n @staticmethod\n def _format_error(error: Exception) -> dict:\n return {\n \"message\": str(error),\n \"type\": type(error).__qualname__,\n }\n", "path": "src/promptflow/promptflow/_core/tracer.py"}]}
| 3,196 | 211 |
gh_patches_debug_9310
|
rasdani/github-patches
|
git_diff
|
python__mypy-9445
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
mypy fails with *-stubs is not a valid Python package name
According to PEP 561 [stub-only package](https://www.python.org/dev/peps/pep-0561/#stub-only-packages):
> The name of the stub package MUST follow the scheme foopkg-stubs for type stubs for the package named foopkg.
However if we invoke mypy on such package providing only path it fails with
> *-stubs is not a valid Python package name
This can be reproduced on the [example package](https://github.com/ethanhs/stub-package):
```
git clone https://github.com/ethanhs/stub-package
cd stub-package
mypy ./typedpkg-stubs
typedpkg-stubs is not a valid Python package name
```
Invoking `mypy` with `-p` option works
```
mypy -p typedpkg-stubs
Success: no issues found in 2 source files
```
but the former behavior is rather confusing.
Expected behavior:
- mypy should recognize `*-stubs` paths as roots of stub-only packages.
Tested with:
- mypy 0.761
- mypy-0.770+dev.9101707bd0c96624d09cb31fe573d7e25c89a35c
</issue>
<code>
[start of mypy/find_sources.py]
1 """Routines for finding the sources that mypy will check"""
2
3 import os.path
4
5 from typing import List, Sequence, Set, Tuple, Optional, Dict
6 from typing_extensions import Final
7
8 from mypy.modulefinder import BuildSource, PYTHON_EXTENSIONS
9 from mypy.fscache import FileSystemCache
10 from mypy.options import Options
11
12 PY_EXTENSIONS = tuple(PYTHON_EXTENSIONS) # type: Final
13
14
15 class InvalidSourceList(Exception):
16 """Exception indicating a problem in the list of sources given to mypy."""
17
18
19 def create_source_list(files: Sequence[str], options: Options,
20 fscache: Optional[FileSystemCache] = None,
21 allow_empty_dir: bool = False) -> List[BuildSource]:
22 """From a list of source files/directories, makes a list of BuildSources.
23
24 Raises InvalidSourceList on errors.
25 """
26 fscache = fscache or FileSystemCache()
27 finder = SourceFinder(fscache)
28
29 targets = []
30 for f in files:
31 if f.endswith(PY_EXTENSIONS):
32 # Can raise InvalidSourceList if a directory doesn't have a valid module name.
33 name, base_dir = finder.crawl_up(os.path.normpath(f))
34 targets.append(BuildSource(f, name, None, base_dir))
35 elif fscache.isdir(f):
36 sub_targets = finder.expand_dir(os.path.normpath(f))
37 if not sub_targets and not allow_empty_dir:
38 raise InvalidSourceList("There are no .py[i] files in directory '{}'"
39 .format(f))
40 targets.extend(sub_targets)
41 else:
42 mod = os.path.basename(f) if options.scripts_are_modules else None
43 targets.append(BuildSource(f, mod, None))
44 return targets
45
46
47 def keyfunc(name: str) -> Tuple[int, str]:
48 """Determines sort order for directory listing.
49
50 The desirable property is foo < foo.pyi < foo.py.
51 """
52 base, suffix = os.path.splitext(name)
53 for i, ext in enumerate(PY_EXTENSIONS):
54 if suffix == ext:
55 return (i, base)
56 return (-1, name)
57
58
59 class SourceFinder:
60 def __init__(self, fscache: FileSystemCache) -> None:
61 self.fscache = fscache
62 # A cache for package names, mapping from directory path to module id and base dir
63 self.package_cache = {} # type: Dict[str, Tuple[str, str]]
64
65 def expand_dir(self, arg: str, mod_prefix: str = '') -> List[BuildSource]:
66 """Convert a directory name to a list of sources to build."""
67 f = self.get_init_file(arg)
68 if mod_prefix and not f:
69 return []
70 seen = set() # type: Set[str]
71 sources = []
72 top_mod, base_dir = self.crawl_up_dir(arg)
73 if f and not mod_prefix:
74 mod_prefix = top_mod + '.'
75 if mod_prefix:
76 sources.append(BuildSource(f, mod_prefix.rstrip('.'), None, base_dir))
77 names = self.fscache.listdir(arg)
78 names.sort(key=keyfunc)
79 for name in names:
80 # Skip certain names altogether
81 if (name == '__pycache__' or name == 'py.typed'
82 or name.startswith('.')
83 or name.endswith(('~', '.pyc', '.pyo'))):
84 continue
85 path = os.path.join(arg, name)
86 if self.fscache.isdir(path):
87 sub_sources = self.expand_dir(path, mod_prefix + name + '.')
88 if sub_sources:
89 seen.add(name)
90 sources.extend(sub_sources)
91 else:
92 base, suffix = os.path.splitext(name)
93 if base == '__init__':
94 continue
95 if base not in seen and '.' not in base and suffix in PY_EXTENSIONS:
96 seen.add(base)
97 src = BuildSource(path, mod_prefix + base, None, base_dir)
98 sources.append(src)
99 return sources
100
101 def crawl_up(self, arg: str) -> Tuple[str, str]:
102 """Given a .py[i] filename, return module and base directory
103
104 We crawl up the path until we find a directory without
105 __init__.py[i], or until we run out of path components.
106 """
107 dir, mod = os.path.split(arg)
108 mod = strip_py(mod) or mod
109 base, base_dir = self.crawl_up_dir(dir)
110 if mod == '__init__' or not mod:
111 mod = base
112 else:
113 mod = module_join(base, mod)
114
115 return mod, base_dir
116
117 def crawl_up_dir(self, dir: str) -> Tuple[str, str]:
118 """Given a directory name, return the corresponding module name and base directory
119
120 Use package_cache to cache results.
121 """
122 if dir in self.package_cache:
123 return self.package_cache[dir]
124
125 parent_dir, base = os.path.split(dir)
126 if not dir or not self.get_init_file(dir) or not base:
127 res = ''
128 base_dir = dir or '.'
129 else:
130 # Ensure that base is a valid python module name
131 if not base.isidentifier():
132 raise InvalidSourceList('{} is not a valid Python package name'.format(base))
133 parent, base_dir = self.crawl_up_dir(parent_dir)
134 res = module_join(parent, base)
135
136 self.package_cache[dir] = res, base_dir
137 return res, base_dir
138
139 def get_init_file(self, dir: str) -> Optional[str]:
140 """Check whether a directory contains a file named __init__.py[i].
141
142 If so, return the file's name (with dir prefixed). If not, return
143 None.
144
145 This prefers .pyi over .py (because of the ordering of PY_EXTENSIONS).
146 """
147 for ext in PY_EXTENSIONS:
148 f = os.path.join(dir, '__init__' + ext)
149 if self.fscache.isfile(f):
150 return f
151 if ext == '.py' and self.fscache.init_under_package_root(f):
152 return f
153 return None
154
155
156 def module_join(parent: str, child: str) -> str:
157 """Join module ids, accounting for a possibly empty parent."""
158 if parent:
159 return parent + '.' + child
160 else:
161 return child
162
163
164 def strip_py(arg: str) -> Optional[str]:
165 """Strip a trailing .py or .pyi suffix.
166
167 Return None if no such suffix is found.
168 """
169 for ext in PY_EXTENSIONS:
170 if arg.endswith(ext):
171 return arg[:-len(ext)]
172 return None
173
[end of mypy/find_sources.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mypy/find_sources.py b/mypy/find_sources.py
--- a/mypy/find_sources.py
+++ b/mypy/find_sources.py
@@ -128,6 +128,8 @@
base_dir = dir or '.'
else:
# Ensure that base is a valid python module name
+ if base.endswith('-stubs'):
+ base = base[:-6] # PEP-561 stub-only directory
if not base.isidentifier():
raise InvalidSourceList('{} is not a valid Python package name'.format(base))
parent, base_dir = self.crawl_up_dir(parent_dir)
|
{"golden_diff": "diff --git a/mypy/find_sources.py b/mypy/find_sources.py\n--- a/mypy/find_sources.py\n+++ b/mypy/find_sources.py\n@@ -128,6 +128,8 @@\n base_dir = dir or '.'\n else:\n # Ensure that base is a valid python module name\n+ if base.endswith('-stubs'):\n+ base = base[:-6] # PEP-561 stub-only directory\n if not base.isidentifier():\n raise InvalidSourceList('{} is not a valid Python package name'.format(base))\n parent, base_dir = self.crawl_up_dir(parent_dir)\n", "issue": "mypy fails with *-stubs is not a valid Python package name\nAccording to PEP 561 [stub-only package](https://www.python.org/dev/peps/pep-0561/#stub-only-packages):\r\n\r\n> The name of the stub package MUST follow the scheme foopkg-stubs for type stubs for the package named foopkg. \r\n\r\nHowever if we invoke mypy on such package providing only path it fails with \r\n\r\n> *-stubs is not a valid Python package name\r\n\r\nThis can be reproduced on the [example package](https://github.com/ethanhs/stub-package):\r\n\r\n```\r\ngit clone https://github.com/ethanhs/stub-package\r\ncd stub-package\r\nmypy ./typedpkg-stubs\r\ntypedpkg-stubs is not a valid Python package name\r\n```\r\n\r\nInvoking `mypy` with `-p` option works\r\n\r\n```\r\nmypy -p typedpkg-stubs\r\nSuccess: no issues found in 2 source files\r\n```\r\n\r\nbut the former behavior is rather confusing.\r\n\r\nExpected behavior:\r\n\r\n- mypy should recognize `*-stubs` paths as roots of stub-only packages.\r\n\r\n\r\nTested with:\r\n\r\n- mypy 0.761\r\n- mypy-0.770+dev.9101707bd0c96624d09cb31fe573d7e25c89a35c\r\n\r\n\n", "before_files": [{"content": "\"\"\"Routines for finding the sources that mypy will check\"\"\"\n\nimport os.path\n\nfrom typing import List, Sequence, Set, Tuple, Optional, Dict\nfrom typing_extensions import Final\n\nfrom mypy.modulefinder import BuildSource, PYTHON_EXTENSIONS\nfrom mypy.fscache import FileSystemCache\nfrom mypy.options import Options\n\nPY_EXTENSIONS = tuple(PYTHON_EXTENSIONS) # type: Final\n\n\nclass InvalidSourceList(Exception):\n \"\"\"Exception indicating a problem in the list of sources given to mypy.\"\"\"\n\n\ndef create_source_list(files: Sequence[str], options: Options,\n fscache: Optional[FileSystemCache] = None,\n allow_empty_dir: bool = False) -> List[BuildSource]:\n \"\"\"From a list of source files/directories, makes a list of BuildSources.\n\n Raises InvalidSourceList on errors.\n \"\"\"\n fscache = fscache or FileSystemCache()\n finder = SourceFinder(fscache)\n\n targets = []\n for f in files:\n if f.endswith(PY_EXTENSIONS):\n # Can raise InvalidSourceList if a directory doesn't have a valid module name.\n name, base_dir = finder.crawl_up(os.path.normpath(f))\n targets.append(BuildSource(f, name, None, base_dir))\n elif fscache.isdir(f):\n sub_targets = finder.expand_dir(os.path.normpath(f))\n if not sub_targets and not allow_empty_dir:\n raise InvalidSourceList(\"There are no .py[i] files in directory '{}'\"\n .format(f))\n targets.extend(sub_targets)\n else:\n mod = os.path.basename(f) if options.scripts_are_modules else None\n targets.append(BuildSource(f, mod, None))\n return targets\n\n\ndef keyfunc(name: str) -> Tuple[int, str]:\n \"\"\"Determines sort order for directory listing.\n\n The desirable property is foo < foo.pyi < foo.py.\n \"\"\"\n base, suffix = os.path.splitext(name)\n for i, ext in enumerate(PY_EXTENSIONS):\n if suffix == ext:\n return (i, base)\n return (-1, name)\n\n\nclass SourceFinder:\n def __init__(self, fscache: FileSystemCache) -> None:\n self.fscache = fscache\n # A cache for package names, mapping from directory path to module id and base dir\n self.package_cache = {} # type: Dict[str, Tuple[str, str]]\n\n def expand_dir(self, arg: str, mod_prefix: str = '') -> List[BuildSource]:\n \"\"\"Convert a directory name to a list of sources to build.\"\"\"\n f = self.get_init_file(arg)\n if mod_prefix and not f:\n return []\n seen = set() # type: Set[str]\n sources = []\n top_mod, base_dir = self.crawl_up_dir(arg)\n if f and not mod_prefix:\n mod_prefix = top_mod + '.'\n if mod_prefix:\n sources.append(BuildSource(f, mod_prefix.rstrip('.'), None, base_dir))\n names = self.fscache.listdir(arg)\n names.sort(key=keyfunc)\n for name in names:\n # Skip certain names altogether\n if (name == '__pycache__' or name == 'py.typed'\n or name.startswith('.')\n or name.endswith(('~', '.pyc', '.pyo'))):\n continue\n path = os.path.join(arg, name)\n if self.fscache.isdir(path):\n sub_sources = self.expand_dir(path, mod_prefix + name + '.')\n if sub_sources:\n seen.add(name)\n sources.extend(sub_sources)\n else:\n base, suffix = os.path.splitext(name)\n if base == '__init__':\n continue\n if base not in seen and '.' not in base and suffix in PY_EXTENSIONS:\n seen.add(base)\n src = BuildSource(path, mod_prefix + base, None, base_dir)\n sources.append(src)\n return sources\n\n def crawl_up(self, arg: str) -> Tuple[str, str]:\n \"\"\"Given a .py[i] filename, return module and base directory\n\n We crawl up the path until we find a directory without\n __init__.py[i], or until we run out of path components.\n \"\"\"\n dir, mod = os.path.split(arg)\n mod = strip_py(mod) or mod\n base, base_dir = self.crawl_up_dir(dir)\n if mod == '__init__' or not mod:\n mod = base\n else:\n mod = module_join(base, mod)\n\n return mod, base_dir\n\n def crawl_up_dir(self, dir: str) -> Tuple[str, str]:\n \"\"\"Given a directory name, return the corresponding module name and base directory\n\n Use package_cache to cache results.\n \"\"\"\n if dir in self.package_cache:\n return self.package_cache[dir]\n\n parent_dir, base = os.path.split(dir)\n if not dir or not self.get_init_file(dir) or not base:\n res = ''\n base_dir = dir or '.'\n else:\n # Ensure that base is a valid python module name\n if not base.isidentifier():\n raise InvalidSourceList('{} is not a valid Python package name'.format(base))\n parent, base_dir = self.crawl_up_dir(parent_dir)\n res = module_join(parent, base)\n\n self.package_cache[dir] = res, base_dir\n return res, base_dir\n\n def get_init_file(self, dir: str) -> Optional[str]:\n \"\"\"Check whether a directory contains a file named __init__.py[i].\n\n If so, return the file's name (with dir prefixed). If not, return\n None.\n\n This prefers .pyi over .py (because of the ordering of PY_EXTENSIONS).\n \"\"\"\n for ext in PY_EXTENSIONS:\n f = os.path.join(dir, '__init__' + ext)\n if self.fscache.isfile(f):\n return f\n if ext == '.py' and self.fscache.init_under_package_root(f):\n return f\n return None\n\n\ndef module_join(parent: str, child: str) -> str:\n \"\"\"Join module ids, accounting for a possibly empty parent.\"\"\"\n if parent:\n return parent + '.' + child\n else:\n return child\n\n\ndef strip_py(arg: str) -> Optional[str]:\n \"\"\"Strip a trailing .py or .pyi suffix.\n\n Return None if no such suffix is found.\n \"\"\"\n for ext in PY_EXTENSIONS:\n if arg.endswith(ext):\n return arg[:-len(ext)]\n return None\n", "path": "mypy/find_sources.py"}]}
| 2,659 | 136 |
gh_patches_debug_31281
|
rasdani/github-patches
|
git_diff
|
ytdl-org__youtube-dl-7382
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
MioMio youtube-dl failing with HTTPError()
I get an HTTP Error 404 when try to download video from MioMio.
I experience this error only in MioMio.
Pretty sure download from MioMio was working till last week.
#
pi@raspberrypi2 ~ $ youtube-dl --version
2015.11.02
pi@raspberrypi2 ~ $ youtube-dl --verbose 'http://www.miomio.tv/watch/cc223353/'
[debug] System config: []
[debug] User config: []
[debug] Command-line args: [u'--verbose', u'http://www.miomio.tv/watch/cc223353/']
[debug] Encodings: locale UTF-8, fs UTF-8, out UTF-8, pref UTF-8
[debug] youtube-dl version 2015.11.02
[debug] Python version 2.7.3 - Linux-4.1.6-v7+-armv7l-with-debian-7.8
[debug] exe versions: avconv 9.14-6, avprobe 9.14-6, ffmpeg 0.8.17-6
[debug] Proxy map: {}
[miomio.tv] 223353: Downloading webpage
[miomio.tv] 223353: Downloading webpage
[miomio.tv] 223353: Downloading XML
ERROR: Unable to download XML: HTTP Error 404: Not Found (caused by HTTPError()); please report this issue on https://yt-dl.org/bug . Make sure you are using the latest version; see https://yt-dl.org/update on how to update. Be sure to call youtube-dl with the --verbose flag and include its complete output.
File "/usr/local/lib/python2.7/dist-packages/youtube_dl/extractor/common.py", line 329, in _request_webpage
return self._downloader.urlopen(url_or_request)
File "/usr/local/lib/python2.7/dist-packages/youtube_dl/YoutubeDL.py", line 1873, in urlopen
return self._opener.open(req, timeout=self._socket_timeout)
File "/usr/lib/python2.7/urllib2.py", line 407, in open
response = meth(req, response)
File "/usr/lib/python2.7/urllib2.py", line 520, in http_response
'http', request, response, code, msg, hdrs)
File "/usr/lib/python2.7/urllib2.py", line 439, in error
result = self._call_chain(_args)
File "/usr/lib/python2.7/urllib2.py", line 379, in _call_chain
result = func(_args)
File "/usr/lib/python2.7/urllib2.py", line 626, in http_error_302
return self.parent.open(new, timeout=req.timeout)
File "/usr/lib/python2.7/urllib2.py", line 407, in open
response = meth(req, response)
File "/usr/lib/python2.7/urllib2.py", line 520, in http_response
'http', request, response, code, msg, hdrs)
File "/usr/lib/python2.7/urllib2.py", line 445, in error
return self._call_chain(_args)
File "/usr/lib/python2.7/urllib2.py", line 379, in _call_chain
result = func(_args)
File "/usr/lib/python2.7/urllib2.py", line 528, in http_error_default
raise HTTPError(req.get_full_url(), code, msg, hdrs, fp)
pi@raspberrypi2 ~ $
#
Best Regards
</issue>
<code>
[start of youtube_dl/extractor/miomio.py]
1 # coding: utf-8
2 from __future__ import unicode_literals
3
4 import random
5
6 from .common import InfoExtractor
7 from ..utils import (
8 xpath_text,
9 int_or_none,
10 ExtractorError,
11 )
12
13
14 class MioMioIE(InfoExtractor):
15 IE_NAME = 'miomio.tv'
16 _VALID_URL = r'https?://(?:www\.)?miomio\.tv/watch/cc(?P<id>[0-9]+)'
17 _TESTS = [{
18 # "type=video" in flashvars
19 'url': 'http://www.miomio.tv/watch/cc88912/',
20 'md5': '317a5f7f6b544ce8419b784ca8edae65',
21 'info_dict': {
22 'id': '88912',
23 'ext': 'flv',
24 'title': '【SKY】字幕 铠武昭和VS平成 假面骑士大战FEAT战队 魔星字幕组 字幕',
25 'duration': 5923,
26 },
27 }, {
28 'url': 'http://www.miomio.tv/watch/cc184024/',
29 'info_dict': {
30 'id': '43729',
31 'title': '《动漫同人插画绘制》',
32 },
33 'playlist_mincount': 86,
34 'skip': 'This video takes time too long for retrieving the URL',
35 }, {
36 'url': 'http://www.miomio.tv/watch/cc173113/',
37 'info_dict': {
38 'id': '173113',
39 'title': 'The New Macbook 2015 上手试玩与简评'
40 },
41 'playlist_mincount': 2,
42 }]
43
44 def _real_extract(self, url):
45 video_id = self._match_id(url)
46 webpage = self._download_webpage(url, video_id)
47
48 title = self._html_search_meta(
49 'description', webpage, 'title', fatal=True)
50
51 mioplayer_path = self._search_regex(
52 r'src="(/mioplayer/[^"]+)"', webpage, 'ref_path')
53
54 xml_config = self._search_regex(
55 r'flashvars="type=(?:sina|video)&(.+?)&',
56 webpage, 'xml config')
57
58 # skipping the following page causes lags and eventually connection drop-outs
59 self._request_webpage(
60 'http://www.miomio.tv/mioplayer/mioplayerconfigfiles/xml.php?id=%s&r=%s' % (id, random.randint(100, 999)),
61 video_id)
62
63 # the following xml contains the actual configuration information on the video file(s)
64 vid_config = self._download_xml(
65 'http://www.miomio.tv/mioplayer/mioplayerconfigfiles/sina.php?{0}'.format(xml_config),
66 video_id)
67
68 http_headers = {
69 'Referer': 'http://www.miomio.tv%s' % mioplayer_path,
70 }
71
72 if not int_or_none(xpath_text(vid_config, 'timelength')):
73 raise ExtractorError('Unable to load videos!', expected=True)
74
75 entries = []
76 for f in vid_config.findall('./durl'):
77 segment_url = xpath_text(f, 'url', 'video url')
78 if not segment_url:
79 continue
80 order = xpath_text(f, 'order', 'order')
81 segment_id = video_id
82 segment_title = title
83 if order:
84 segment_id += '-%s' % order
85 segment_title += ' part %s' % order
86 entries.append({
87 'id': segment_id,
88 'url': segment_url,
89 'title': segment_title,
90 'duration': int_or_none(xpath_text(f, 'length', 'duration'), 1000),
91 'http_headers': http_headers,
92 })
93
94 if len(entries) == 1:
95 segment = entries[0]
96 segment['id'] = video_id
97 segment['title'] = title
98 return segment
99
100 return {
101 '_type': 'multi_video',
102 'id': video_id,
103 'entries': entries,
104 'title': title,
105 'http_headers': http_headers,
106 }
107
[end of youtube_dl/extractor/miomio.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/youtube_dl/extractor/miomio.py b/youtube_dl/extractor/miomio.py
--- a/youtube_dl/extractor/miomio.py
+++ b/youtube_dl/extractor/miomio.py
@@ -4,6 +4,7 @@
import random
from .common import InfoExtractor
+from ..compat import compat_urllib_request
from ..utils import (
xpath_text,
int_or_none,
@@ -51,6 +52,8 @@
mioplayer_path = self._search_regex(
r'src="(/mioplayer/[^"]+)"', webpage, 'ref_path')
+ http_headers = {'Referer': 'http://www.miomio.tv%s' % mioplayer_path,}
+
xml_config = self._search_regex(
r'flashvars="type=(?:sina|video)&(.+?)&',
webpage, 'xml config')
@@ -60,14 +63,12 @@
'http://www.miomio.tv/mioplayer/mioplayerconfigfiles/xml.php?id=%s&r=%s' % (id, random.randint(100, 999)),
video_id)
- # the following xml contains the actual configuration information on the video file(s)
- vid_config = self._download_xml(
+ vid_config_request = compat_urllib_request.Request(
'http://www.miomio.tv/mioplayer/mioplayerconfigfiles/sina.php?{0}'.format(xml_config),
- video_id)
+ headers=http_headers)
- http_headers = {
- 'Referer': 'http://www.miomio.tv%s' % mioplayer_path,
- }
+ # the following xml contains the actual configuration information on the video file(s)
+ vid_config = self._download_xml(vid_config_request, video_id)
if not int_or_none(xpath_text(vid_config, 'timelength')):
raise ExtractorError('Unable to load videos!', expected=True)
|
{"golden_diff": "diff --git a/youtube_dl/extractor/miomio.py b/youtube_dl/extractor/miomio.py\n--- a/youtube_dl/extractor/miomio.py\n+++ b/youtube_dl/extractor/miomio.py\n@@ -4,6 +4,7 @@\n import random\n \n from .common import InfoExtractor\n+from ..compat import compat_urllib_request\n from ..utils import (\n xpath_text,\n int_or_none,\n@@ -51,6 +52,8 @@\n mioplayer_path = self._search_regex(\n r'src=\"(/mioplayer/[^\"]+)\"', webpage, 'ref_path')\n \n+ http_headers = {'Referer': 'http://www.miomio.tv%s' % mioplayer_path,}\n+\n xml_config = self._search_regex(\n r'flashvars=\"type=(?:sina|video)&(.+?)&',\n webpage, 'xml config')\n@@ -60,14 +63,12 @@\n 'http://www.miomio.tv/mioplayer/mioplayerconfigfiles/xml.php?id=%s&r=%s' % (id, random.randint(100, 999)),\n video_id)\n \n- # the following xml contains the actual configuration information on the video file(s)\n- vid_config = self._download_xml(\n+ vid_config_request = compat_urllib_request.Request(\n 'http://www.miomio.tv/mioplayer/mioplayerconfigfiles/sina.php?{0}'.format(xml_config),\n- video_id)\n+ headers=http_headers)\n \n- http_headers = {\n- 'Referer': 'http://www.miomio.tv%s' % mioplayer_path,\n- }\n+ # the following xml contains the actual configuration information on the video file(s)\n+ vid_config = self._download_xml(vid_config_request, video_id)\n \n if not int_or_none(xpath_text(vid_config, 'timelength')):\n raise ExtractorError('Unable to load videos!', expected=True)\n", "issue": "MioMio youtube-dl failing with HTTPError()\nI get an HTTP Error 404 when try to download video from MioMio.\nI experience this error only in MioMio.\nPretty sure download from MioMio was working till last week.\n# \n\npi@raspberrypi2 ~ $ youtube-dl --version\n2015.11.02\npi@raspberrypi2 ~ $ youtube-dl --verbose 'http://www.miomio.tv/watch/cc223353/'\n[debug] System config: []\n[debug] User config: []\n[debug] Command-line args: [u'--verbose', u'http://www.miomio.tv/watch/cc223353/']\n[debug] Encodings: locale UTF-8, fs UTF-8, out UTF-8, pref UTF-8\n[debug] youtube-dl version 2015.11.02\n[debug] Python version 2.7.3 - Linux-4.1.6-v7+-armv7l-with-debian-7.8\n[debug] exe versions: avconv 9.14-6, avprobe 9.14-6, ffmpeg 0.8.17-6\n[debug] Proxy map: {}\n[miomio.tv] 223353: Downloading webpage\n[miomio.tv] 223353: Downloading webpage\n[miomio.tv] 223353: Downloading XML\nERROR: Unable to download XML: HTTP Error 404: Not Found (caused by HTTPError()); please report this issue on https://yt-dl.org/bug . Make sure you are using the latest version; see https://yt-dl.org/update on how to update. Be sure to call youtube-dl with the --verbose flag and include its complete output.\n File \"/usr/local/lib/python2.7/dist-packages/youtube_dl/extractor/common.py\", line 329, in _request_webpage\n return self._downloader.urlopen(url_or_request)\n File \"/usr/local/lib/python2.7/dist-packages/youtube_dl/YoutubeDL.py\", line 1873, in urlopen\n return self._opener.open(req, timeout=self._socket_timeout)\n File \"/usr/lib/python2.7/urllib2.py\", line 407, in open\n response = meth(req, response)\n File \"/usr/lib/python2.7/urllib2.py\", line 520, in http_response\n 'http', request, response, code, msg, hdrs)\n File \"/usr/lib/python2.7/urllib2.py\", line 439, in error\n result = self._call_chain(_args)\n File \"/usr/lib/python2.7/urllib2.py\", line 379, in _call_chain\n result = func(_args)\n File \"/usr/lib/python2.7/urllib2.py\", line 626, in http_error_302\n return self.parent.open(new, timeout=req.timeout)\n File \"/usr/lib/python2.7/urllib2.py\", line 407, in open\n response = meth(req, response)\n File \"/usr/lib/python2.7/urllib2.py\", line 520, in http_response\n 'http', request, response, code, msg, hdrs)\n File \"/usr/lib/python2.7/urllib2.py\", line 445, in error\n return self._call_chain(_args)\n File \"/usr/lib/python2.7/urllib2.py\", line 379, in _call_chain\n result = func(_args)\n File \"/usr/lib/python2.7/urllib2.py\", line 528, in http_error_default\n raise HTTPError(req.get_full_url(), code, msg, hdrs, fp)\n\npi@raspberrypi2 ~ $\n# \n\nBest Regards\n\n", "before_files": [{"content": "# coding: utf-8\nfrom __future__ import unicode_literals\n\nimport random\n\nfrom .common import InfoExtractor\nfrom ..utils import (\n xpath_text,\n int_or_none,\n ExtractorError,\n)\n\n\nclass MioMioIE(InfoExtractor):\n IE_NAME = 'miomio.tv'\n _VALID_URL = r'https?://(?:www\\.)?miomio\\.tv/watch/cc(?P<id>[0-9]+)'\n _TESTS = [{\n # \"type=video\" in flashvars\n 'url': 'http://www.miomio.tv/watch/cc88912/',\n 'md5': '317a5f7f6b544ce8419b784ca8edae65',\n 'info_dict': {\n 'id': '88912',\n 'ext': 'flv',\n 'title': '\u3010SKY\u3011\u5b57\u5e55 \u94e0\u6b66\u662d\u548cVS\u5e73\u6210 \u5047\u9762\u9a91\u58eb\u5927\u6218FEAT\u6218\u961f \u9b54\u661f\u5b57\u5e55\u7ec4 \u5b57\u5e55',\n 'duration': 5923,\n },\n }, {\n 'url': 'http://www.miomio.tv/watch/cc184024/',\n 'info_dict': {\n 'id': '43729',\n 'title': '\u300a\u52a8\u6f2b\u540c\u4eba\u63d2\u753b\u7ed8\u5236\u300b',\n },\n 'playlist_mincount': 86,\n 'skip': 'This video takes time too long for retrieving the URL',\n }, {\n 'url': 'http://www.miomio.tv/watch/cc173113/',\n 'info_dict': {\n 'id': '173113',\n 'title': 'The New Macbook 2015 \u4e0a\u624b\u8bd5\u73a9\u4e0e\u7b80\u8bc4'\n },\n 'playlist_mincount': 2,\n }]\n\n def _real_extract(self, url):\n video_id = self._match_id(url)\n webpage = self._download_webpage(url, video_id)\n\n title = self._html_search_meta(\n 'description', webpage, 'title', fatal=True)\n\n mioplayer_path = self._search_regex(\n r'src=\"(/mioplayer/[^\"]+)\"', webpage, 'ref_path')\n\n xml_config = self._search_regex(\n r'flashvars=\"type=(?:sina|video)&(.+?)&',\n webpage, 'xml config')\n\n # skipping the following page causes lags and eventually connection drop-outs\n self._request_webpage(\n 'http://www.miomio.tv/mioplayer/mioplayerconfigfiles/xml.php?id=%s&r=%s' % (id, random.randint(100, 999)),\n video_id)\n\n # the following xml contains the actual configuration information on the video file(s)\n vid_config = self._download_xml(\n 'http://www.miomio.tv/mioplayer/mioplayerconfigfiles/sina.php?{0}'.format(xml_config),\n video_id)\n\n http_headers = {\n 'Referer': 'http://www.miomio.tv%s' % mioplayer_path,\n }\n\n if not int_or_none(xpath_text(vid_config, 'timelength')):\n raise ExtractorError('Unable to load videos!', expected=True)\n\n entries = []\n for f in vid_config.findall('./durl'):\n segment_url = xpath_text(f, 'url', 'video url')\n if not segment_url:\n continue\n order = xpath_text(f, 'order', 'order')\n segment_id = video_id\n segment_title = title\n if order:\n segment_id += '-%s' % order\n segment_title += ' part %s' % order\n entries.append({\n 'id': segment_id,\n 'url': segment_url,\n 'title': segment_title,\n 'duration': int_or_none(xpath_text(f, 'length', 'duration'), 1000),\n 'http_headers': http_headers,\n })\n\n if len(entries) == 1:\n segment = entries[0]\n segment['id'] = video_id\n segment['title'] = title\n return segment\n\n return {\n '_type': 'multi_video',\n 'id': video_id,\n 'entries': entries,\n 'title': title,\n 'http_headers': http_headers,\n }\n", "path": "youtube_dl/extractor/miomio.py"}]}
| 2,588 | 439 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.