
text
stringlengths 7
318k
| id
stringlengths 14
166
| metadata
dict | __index_level_0__
int64 0
439
|
|---|---|---|---|
#ifndef _qdq_5_cuh
#define _qdq_5_cuh
#include "qdq_util.cuh"
#include "../../config.h"
#if QMODE_5BIT == 1
// Permutation:
//
// v5555533 33311111 u4444422 22200000 (u, v lsb)
// vbbbbb99 99977777 uaaaaa88 88866666
// vhhhhhff fffddddd ugggggee eeeccccc
// vnnnnnll llljjjjj ummmmmkk kkkiiiii
// vtttttrr rrrppppp usssssqq qqqooooo
__forceinline__ __device__ void shuffle_5bit_32
(
uint32_t* q,
int stride
)
{
uint32_t qa = q[0 * stride];
uint32_t qb = q[1 * stride];
uint32_t qc = q[2 * stride];
uint32_t qd = q[3 * stride];
uint32_t qe = q[4 * stride];
// qa: 66555554 44443333 32222211 11100000
// qb: ccccbbbb baaaaa99 99988888 77777666
// qc: jiiiiihh hhhggggg fffffeee eedddddc
// qd: pppooooo nnnnnmmm mmlllllk kkkkjjjj
// qe: vvvvvuuu uuttttts ssssrrrr rqqqqqpp
uint32_t qf = qe >> 22;
qe <<= 8;
qe |= qd >> 24;
qd <<= 6;
qd |= qc >> 26;
qc <<= 4;
qc |= qb >> 28;
qb <<= 2;
qb |= qa >> 30;
// qa: 555554 44443333 32222211 11100000
// qb: bbbbba aaaa9999 98888877 77766666
// qc: hhhhhg ggggffff feeeeedd dddccccc
// qd: nnnnnm mmmmllll lkkkkkjj jjjiiiii
// qe: ttttts ssssrrrr rqqqqqpp pppooooo
// qf: vv vvvuuuuu
uint32_t za = 0;
uint32_t zb = 0;
uint32_t zc = 0;
uint32_t zd = 0;
uint32_t ze = 0;
for (int i = 0; i < 3; i++) { uint32_t t0 = qa & 0x1f; uint32_t t1 = (qa & 0x3e0) >> 5; qa >>= 10; za |= (t0 << (i * 5)); za |= (t1 << (i * 5 + 16)); }
for (int i = 0; i < 3; i++) { uint32_t t0 = qb & 0x1f; uint32_t t1 = (qb & 0x3e0) >> 5; qb >>= 10; zb |= (t0 << (i * 5)); zb |= (t1 << (i * 5 + 16)); }
for (int i = 0; i < 3; i++) { uint32_t t0 = qc & 0x1f; uint32_t t1 = (qc & 0x3e0) >> 5; qc >>= 10; zc |= (t0 << (i * 5)); zc |= (t1 << (i * 5 + 16)); }
for (int i = 0; i < 3; i++) { uint32_t t0 = qd & 0x1f; uint32_t t1 = (qd & 0x3e0) >> 5; qd >>= 10; zd |= (t0 << (i * 5)); zd |= (t1 << (i * 5 + 16)); }
for (int i = 0; i < 3; i++) { uint32_t t0 = qe & 0x1f; uint32_t t1 = (qe & 0x3e0) >> 5; qe >>= 10; ze |= (t0 << (i * 5)); ze |= (t1 << (i * 5 + 16)); }
// za: 5555533 33311111 4444422 22200000
// zb: bbbbb99 99977777 aaaaa88 88866666
// zc: hhhhhff fffddddd gggggee eeeccccc
// zd: nnnnnll llljjjjj mmmmmkk kkkiiiii
// ze: tttttrr rrrppppp sssssqq qqqooooo
// qf: vv vvvuuuuu
za |= ((qf & 0x001) >> 0) << 15;
zb |= ((qf & 0x002) >> 1) << 15;
zc |= ((qf & 0x004) >> 2) << 15;
zd |= ((qf & 0x008) >> 3) << 15;
ze |= ((qf & 0x010) >> 4) << 15;
za |= ((qf & 0x020) >> 5) << 31;
zb |= ((qf & 0x040) >> 6) << 31;
zc |= ((qf & 0x080) >> 7) << 31;
zd |= ((qf & 0x100) >> 8) << 31;
ze |= ((qf & 0x200) >> 9) << 31;
// za: v5555533 33311111 u4444422 22200000 (u, v lsb)
// zb: vbbbbb99 99977777 uaaaaa88 88866666
// zc: vhhhhhff fffddddd ugggggee eeeccccc
// zd: vnnnnnll llljjjjj ummmmmkk kkkiiiii
// ze: vtttttrr rrrppppp usssssqq qqqooooo
q[0 * stride] = za;
q[1 * stride] = zb;
q[2 * stride] = zc;
q[3 * stride] = zd;
q[4 * stride] = ze;
}
__forceinline__ __device__ void dequant_5bit_32
(
const uint32_t q_0,
const uint32_t q_1,
const uint32_t q_2,
const uint32_t q_3,
const uint32_t q_4,
half2 (&dq)[16],
int stride
)
{
const uint32_t c0 = 0x64006400;
const half y32_ = __float2half_rn(1.0f / 32.0f);
const half2 y32 = __halves2half2(y32_, y32_);
const half z1_ = __float2half_rn(-1024.0f - 16.0f);
const half z32_ = __float2half_rn(-1024.0f / 32.0f - 16.0f);
const half2 z1 = __halves2half2(z1_, z1_);
const half2 z32 = __halves2half2(z32_, z32_);
uint32_t qa = q_0;
uint32_t qb = q_1;
uint32_t qc = q_2;
uint32_t qd = q_3;
uint32_t qe = q_4;
half2_uint32 q0 ((qa & 0x001f001f) | c0); // half2(q[ 0], q[ 1]) + 1024
half2_uint32 q1 ((qa & 0x03e003e0) | c0); // half2(q[ 2], q[ 3]) * 32 + 1024
qa >>= 10;
half2_uint32 q2 ((qa & 0x001f001f) | c0); // half2(q[ 4], q[ 5]) + 1024
qa >>= 5;
qa &= 0x00010001;
half2_uint32 q3 ((qb & 0x001f001f) | c0); // half2(q[ 6], q[ 7]) + 1024
half2_uint32 q4 ((qb & 0x03e003e0) | c0); // half2(q[ 8], q[ 9]) * 32 + 1024
qb >>= 10;
half2_uint32 q5 ((qb & 0x001f001f) | c0); // half2(q[10], q[11]) + 1024
qb >>= 4;
qb &= 0x00020002;
half2_uint32 q6 ((qc & 0x001f001f) | c0); // half2(q[12], q[13]) + 1024
half2_uint32 q7 ((qc & 0x03e003e0) | c0); // half2(q[14], q[15]) * 32 + 1024
qc >>= 10;
half2_uint32 q8 ((qc & 0x001f001f) | c0); // half2(q[16], q[17]) + 1024
qc >>= 3;
qc &= 0x00040004;
half2_uint32 q9 ((qd & 0x001f001f) | c0); // half2(q[18], q[19]) + 1024
half2_uint32 q10((qd & 0x03e003e0) | c0); // half2(q[20], q[21]) * 32 + 1024
qd >>= 10;
half2_uint32 q11((qd & 0x001f001f) | c0); // half2(q[22], q[23]) + 1024
qd >>= 2;
qd &= 0x00080008;
half2_uint32 q12((qe & 0x001f001f) | c0); // half2(q[24], q[25]) + 1024
half2_uint32 q13((qe & 0x03e003e0) | c0); // half2(q[26], q[27]) * 32 + 1024
qe >>= 10;
half2_uint32 q14((qe & 0x001f001f) | c0); // half2(q[28], q[29]) + 1024
qe >>= 1;
qe &= 0x00100010;
half2_uint32 q15((qa | qb | qc | qd | qe) | c0);
dq[ 0] = __hadd2( q0.as_half2, z1);
dq[ 1] = __hfma2( q1.as_half2, y32, z32);
dq[ 2] = __hadd2( q2.as_half2, z1);
dq[ 3] = __hadd2( q3.as_half2, z1);
dq[ 4] = __hfma2( q4.as_half2, y32, z32);
dq[ 5] = __hadd2( q5.as_half2, z1);
dq[ 6] = __hadd2( q6.as_half2, z1);
dq[ 7] = __hfma2( q7.as_half2, y32, z32);
dq[ 8] = __hadd2( q8.as_half2, z1);
dq[ 9] = __hadd2( q9.as_half2, z1);
dq[10] = __hfma2(q10.as_half2, y32, z32);
dq[11] = __hadd2(q11.as_half2, z1);
dq[12] = __hadd2(q12.as_half2, z1);
dq[13] = __hfma2(q13.as_half2, y32, z32);
dq[14] = __hadd2(q14.as_half2, z1);
dq[15] = __hadd2(q15.as_half2, z1);
}
#else
__forceinline__ __device__ void shuffle_5bit_32
(
uint32_t* q,
int stride
)
{
}
__forceinline__ __device__ void dequant_5bit_32
(
const uint32_t q_0,
const uint32_t q_1,
const uint32_t q_2,
const uint32_t q_3,
const uint32_t q_4,
half2 (&dq)[16],
int stride
)
{
half dqh[32];
for (int i = 0; i < 6; i++) dqh[ i] = dq_ns(exb( q_0, i * 5 , 0x1f), 16);
dqh[ 6 ] = dq_ns(exb(q_1, q_0, 30, 0x1f), 16);
for (int i = 0; i < 5; i++) dqh[ 7 + i] = dq_ns(exb( q_1, i * 5 + 3, 0x1f), 16);
dqh[12 ] = dq_ns(exb(q_2, q_1, 28, 0x1f), 16);
for (int i = 0; i < 6; i++) dqh[13 + i] = dq_ns(exb( q_2, i * 5 + 1, 0x1f), 16);
dqh[19 ] = dq_ns(exb(q_3, q_2, 31, 0x1f), 16);
for (int i = 0; i < 5; i++) dqh[20 + i] = dq_ns(exb( q_3, i * 5 + 4, 0x1f), 16);
dqh[25 ] = dq_ns(exb(q_4, q_3, 29, 0x1f), 16);
for (int i = 0; i < 6; i++) dqh[26 + i] = dq_ns(exb( q_4, i * 5 + 2, 0x1f), 16);
for (int i = 0; i < 16; i++) dq[i] = __halves2half2(dqh[i * 2], dqh[i * 2 + 1]);
}
#endif
#endif | text-generation-inference/server/exllamav2_kernels/exllamav2_kernels/cuda/quant/qdq_5.cuh/0 | {
"file_path": "text-generation-inference/server/exllamav2_kernels/exllamav2_kernels/cuda/quant/qdq_5.cuh",
"repo_id": "text-generation-inference",
"token_count": 4271
} | 212 |
import pytest
from text_generation_server.pb import generate_pb2
from text_generation_server.models.causal_lm import CausalLMBatch
from text_generation_server.models.santacoder import SantaCoder
@pytest.fixture(scope="session")
def default_santacoder():
return SantaCoder("bigcode/santacoder")
@pytest.fixture
def default_pb_request(default_pb_parameters, default_pb_stop_parameters):
return generate_pb2.Request(
id=0,
inputs="def",
prefill_logprobs=True,
truncate=100,
parameters=default_pb_parameters,
stopping_parameters=default_pb_stop_parameters,
)
@pytest.fixture
def default_pb_batch(default_pb_request):
return generate_pb2.Batch(id=0, requests=[default_pb_request], size=1)
@pytest.fixture
def default_fim_pb_request(default_pb_parameters, default_pb_stop_parameters):
return generate_pb2.Request(
id=0,
inputs="<fim-prefix>def<fim-suffix>world<fim-middle>",
prefill_logprobs=True,
truncate=100,
parameters=default_pb_parameters,
stopping_parameters=default_pb_stop_parameters,
)
@pytest.fixture
def default_fim_pb_batch(default_fim_pb_request):
return generate_pb2.Batch(id=0, requests=[default_fim_pb_request], size=1)
@pytest.mark.skip
def test_santacoder_generate_token_completion(default_santacoder, default_pb_batch):
batch = CausalLMBatch.from_pb(
default_pb_batch,
default_santacoder.tokenizer,
default_santacoder.dtype,
default_santacoder.device,
)
next_batch = batch
for _ in range(batch.stopping_criterias[0].max_new_tokens - 1):
generations, next_batch, _ = default_santacoder.generate_token(next_batch)
assert len(generations) == len(next_batch)
generations, next_batch, _ = default_santacoder.generate_token(next_batch)
assert next_batch is None
assert len(generations) == 1
assert generations[0].generated_text.text == " test_get_all_users_with_"
assert generations[0].request_id == batch.requests[0].id
assert (
generations[0].generated_text.generated_tokens
== batch.stopping_criterias[0].max_new_tokens
)
@pytest.mark.skip
def test_fim_santacoder_generate_token_completion(
default_santacoder, default_fim_pb_batch
):
batch = CausalLMBatch.from_pb(
default_fim_pb_batch,
default_santacoder.tokenizer,
default_santacoder.dtype,
default_santacoder.device,
)
next_batch = batch
for _ in range(batch.stopping_criterias[0].max_new_tokens - 1):
generations, next_batch, _ = default_santacoder.generate_token(next_batch)
assert len(generations) == len(next_batch)
generations, next_batch, _ = default_santacoder.generate_token(next_batch)
assert next_batch is None
assert len(generations) == 1
assert (
generations[0].generated_text.text
== """ineProperty(exports, "__esModule", { value"""
)
assert generations[0].request_id == batch.requests[0].id
assert (
generations[0].generated_text.generated_tokens
== batch.stopping_criterias[0].max_new_tokens
)
| text-generation-inference/server/tests/models/test_santacoder.py/0 | {
"file_path": "text-generation-inference/server/tests/models/test_santacoder.py",
"repo_id": "text-generation-inference",
"token_count": 1306
} | 213 |
# coding=utf-8
# Copyright 2022 HuggingFace Inc. team and BigScience workshop.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""PyTorch BLOOM model."""
import math
import os
import warnings
from typing import Optional, Tuple, Union
import torch
import torch.distributed
import torch.utils.checkpoint
from torch import nn
from torch.nn import LayerNorm
from torch.nn import functional as F
from transformers.modeling_outputs import (
BaseModelOutputWithPastAndCrossAttentions,
CausalLMOutputWithCrossAttentions,
)
from transformers import BloomConfig, PreTrainedModel
from text_generation_server.utils.layers import (
TensorParallelColumnLinear,
TensorParallelEmbedding,
TensorParallelRowLinear,
TensorParallelHead,
)
CUSTOM_KERNELS_ENABLED = False
if (
torch.cuda.is_available()
and not os.environ.get("DISABLE_CUSTOM_KERNELS", "False") == "True"
):
try:
from custom_kernels import fused_bloom_attention_cuda
CUSTOM_KERNELS_ENABLED = True
except ImportError:
pass
_CHECKPOINT_FOR_DOC = "bigscience/bloom-560m"
_CONFIG_FOR_DOC = "BloomConfig"
BLOOM_PRETRAINED_MODEL_ARCHIVE_LIST = [
"bigscience/bigscience-small-testing",
"bigscience/bloom-560m",
"bigscience/bloom-1b1",
"bigscience/bloom-1b7",
"bigscience/bloom-3b",
"bigscience/bloom-7b1",
"bigscience/bloom",
]
def _make_causal_mask(
input_ids_shape: torch.Size, device: torch.device, past_key_values_length: int
) -> torch.BoolTensor:
"""
Make causal mask used for self-attention.
"""
batch_size, target_length = input_ids_shape
mask = torch.ones(
(target_length, target_length + past_key_values_length),
dtype=torch.bool,
device=device,
)
mask = mask.triu(1 + past_key_values_length)
expanded_mask = mask.unsqueeze(0).expand(
batch_size, target_length, target_length + past_key_values_length
)
return expanded_mask
def _expand_mask(mask: torch.Tensor, tgt_length: int) -> torch.BoolTensor:
"""
Expands attention_mask from `[batch_size, src_length]` to `[batch_size, 1, tgt_length, src_length]`.
"""
batch_size, src_length = mask.shape
tgt_length = tgt_length if tgt_length is not None else src_length
expanded_mask = ~(mask[:, None, :].to(torch.bool))
return expanded_mask.expand(batch_size, tgt_length, src_length)
def build_alibi_tensor(attention_mask: torch.Tensor, num_heads: int) -> torch.Tensor:
"""
Link to paper: https://arxiv.org/abs/2108.12409 Alibi tensor is not causal as the original paper mentions, it
relies on a translation invariance of softmax for quick implementation: with l being a tensor, and a fixed value
`softmax(l+a) = softmax(l)`. Based on
https://github.com/ofirpress/attention_with_linear_biases/blob/a35aaca144e0eb6b789dfcb46784c4b8e31b7983/fairseq/models/transformer.py#L742
TODO @thomasw21 this doesn't work as nicely due to the masking strategy, and so masking varies slightly.
Args:
Returns tensor shaped (batch_size * num_heads, 1, max_seq_len)
attention_mask (`torch.Tensor`):
Token-wise attention mask, this should be of shape (batch_size, max_seq_len).
num_heads (`int`, *required*):
number of heads
dtype (`torch.dtype`, *optional*, default=`torch.bfloat16`):
dtype of the output tensor
"""
batch_size, seq_length = attention_mask.shape
closest_power_of_2 = 2 ** math.floor(math.log2(num_heads))
base = torch.tensor(
2 ** (-(2 ** -(math.log2(closest_power_of_2) - 3))),
device=attention_mask.device,
dtype=torch.float32,
)
powers = torch.arange(
1, 1 + closest_power_of_2, device=attention_mask.device, dtype=torch.int32
)
slopes = torch.pow(base, powers)
if closest_power_of_2 != num_heads:
extra_base = torch.tensor(
2 ** (-(2 ** -(math.log2(2 * closest_power_of_2) - 3))),
device=attention_mask.device,
dtype=torch.float32,
)
num_remaining_heads = min(closest_power_of_2, num_heads - closest_power_of_2)
extra_powers = torch.arange(
1,
1 + 2 * num_remaining_heads,
2,
device=attention_mask.device,
dtype=torch.int32,
)
slopes = torch.cat([slopes, torch.pow(extra_base, extra_powers)], dim=0)
# Note: alibi will added to the attention bias that will be applied to the query, key product of attention
# => therefore alibi will have to be of shape (batch_size, num_heads, query_length, key_length)
# => here we set (batch_size=1, num_heads=num_heads, query_length=1, key_length=max_length)
# => the query_length dimension will then be broadcasted correctly
# This is more or less identical to T5's relative position bias:
# https://github.com/huggingface/transformers/blob/f681437203baa7671de3174b0fa583c349d9d5e1/src/transformers/models/t5/modeling_t5.py#L527
arange_tensor = ((attention_mask.cumsum(dim=-1) - 1) * attention_mask)[:, None, :]
alibi = slopes[..., None] * arange_tensor
return alibi
# @torch.jit.script
def dropout_add(
x: torch.Tensor, residual: torch.Tensor, prob: float, training: bool
) -> torch.Tensor:
"""
Dropout add function
Args:
x (`torch.tensor`, *required*):
input tensor
residual (`torch.tensor`, *required*):
esidual tensor
prob (`float`, *required*):
dropout probability
training (`bool`, *required*):
training mode
"""
out = F.dropout(x, p=prob, training=training)
out = residual + out
return out
# @torch.jit.script # this is shit for unknow reasons.
def _split_heads(
fused_qkv: torch.Tensor, num_heads: int, head_dim: int
) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
"""
Split the last dimension into (num_heads, head_dim) without making any copies, results share same memory
storage as `fused_qkv`
Args:
fused_qkv (`torch.tensor`, *required*): [batch_size, seq_length, num_heads * 3 * head_dim]
Returns:
query: [batch_size, seq_length, num_heads, head_dim] key: [batch_size, seq_length, num_heads, head_dim]
value: [batch_size, seq_length, num_heads, head_dim]
"""
batch_size, seq_length, three_times_hidden_size = fused_qkv.shape
fused_qkv = fused_qkv.view(batch_size, seq_length, num_heads, 3 * head_dim)
query_layer, key_layer, value_layer = fused_qkv.split(head_dim, dim=-1)
query_layer = query_layer.transpose(1, 2).reshape(
batch_size * num_heads, seq_length, head_dim
)
key_layer = key_layer.permute(0, 2, 3, 1).reshape(
batch_size * num_heads, head_dim, seq_length
)
value_layer = value_layer.transpose(1, 2).reshape(
batch_size * num_heads, seq_length, head_dim
)
return query_layer, key_layer, value_layer
# @torch.jit.script
def _merge_heads(x: torch.Tensor, num_heads: int, head_dim: int) -> torch.Tensor:
"""
Merge heads together over the last dimenstion
Args:
x: (`torch.tensor`, *required*): [batch_size * num_heads, seq_length, head_dim]
Returns:
torch.tensor: [batch_size, seq_length, num_heads * head_dim]
"""
# What we want to achieve is:
# batch_size * num_heads, seq_length, head_dim -> batch_size, seq_length, num_heads * head_dim
batch_size_and_num_heads, seq_length, _ = x.shape
batch_size = batch_size_and_num_heads // num_heads
# First view to decompose the batch size
# batch_size * num_heads, seq_length, head_dim -> batch_size, num_heads, seq_length, head_dim
x = x.view(batch_size, num_heads, seq_length, head_dim)
# batch_size, num_heads, seq_length, head_dim -> batch_size, seq_length, num_heads, head_dim
x = x.permute(0, 2, 1, 3)
# batch_size, seq_length, num_heads, head_dim -> batch_size, seq_length, num_heads * head_dim
return x.reshape(batch_size, seq_length, num_heads * head_dim)
class BloomAttention(nn.Module):
def __init__(self, prefix, config: BloomConfig, weights):
super().__init__()
self.pretraining_tp = config.pretraining_tp
self.slow_but_exact = config.slow_but_exact
self.process_group = weights.process_group
self.hidden_size = config.hidden_size
self.num_heads = config.n_head
self.head_dim = self.hidden_size // self.num_heads
self.split_size = self.hidden_size
self.hidden_dropout = config.hidden_dropout
if self.head_dim * self.num_heads != self.hidden_size:
raise ValueError(
f"`hidden_size` must be divisible by num_heads (got `hidden_size`: {self.hidden_size} and `num_heads`:"
f" {self.num_heads})."
)
# Layer-wise attention scaling
self.inv_norm_factor = 1.0 / math.sqrt(self.head_dim)
self.beta = 1.0
process_group = weights.process_group
if self.num_heads % process_group.size() != 0:
raise ValueError(
f"`num_heads` must be divisible by `num_shards` (got `num_heads`: {self.num_heads} "
f"and `num_shards`: {process_group.size()}"
)
self.num_heads = self.num_heads // process_group.size()
self.query_key_value = TensorParallelColumnLinear.load(
config=config,
prefix=f"{prefix}.query_key_value",
weights=weights,
bias=True,
)
self.dense = TensorParallelRowLinear.load(
config=config, prefix=f"{prefix}.dense", weights=weights, bias=True
)
self.attention_dropout = nn.Dropout(config.attention_dropout)
@staticmethod
def compute_attention(
fused_qkv: torch.Tensor,
layer_past: Optional[Tuple[torch.Tensor, torch.Tensor]],
alibi: torch.Tensor,
attention_mask: torch.Tensor,
head_mask: Optional[torch.Tensor],
beta: float,
inv_norm_factor: float,
num_heads: int,
use_cache: bool,
):
batch_size, q_length, three_times_hidden_size = fused_qkv.shape
head_dim = three_times_hidden_size // (3 * num_heads)
batch_size * num_heads
### TODO @thomasw21: this takes quite a bit of time, how do I accelerate that?
# 3 x [batch_size, seq_length, num_heads, head_dim]
(query_layer, key_layer, value_layer) = _split_heads(
fused_qkv, num_heads=num_heads, head_dim=head_dim
)
if layer_past is not None:
past_key, past_value = layer_past
# concatenate along seq_length dimension:
# - key: [batch_size * self.num_heads, head_dim, kv_length]
# - value: [batch_size * self.num_heads, kv_length, head_dim]
past_key = past_key.view(-1, *past_key.shape[-2:])
key_layer = torch.cat((past_key, key_layer), dim=2)
past_value = past_value.view(-1, *past_value.shape[-2:])
value_layer = torch.cat((past_value, value_layer), dim=1)
_, _, kv_length = key_layer.shape
if use_cache is True:
present = (key_layer, value_layer)
else:
present = None
###
# [batch_size * num_heads, q_length, kv_length]
# we use `torch.Tensor.baddbmm` instead of `torch.baddbmm` as the latter isn't supported by TorchScript v1.11
attention_scores = alibi.baddbmm(
batch1=query_layer,
batch2=key_layer,
beta=beta,
alpha=inv_norm_factor,
)
# cast attention scores to fp32, compute scaled softmax and cast back to initial dtype - [batch_size, num_heads, q_length, kv_length]
input_dtype = attention_scores.dtype
# `float16` has a minimum value of -65504.0, whereas `bfloat16` and `float32` have a minimum value of `-3.4e+38`
if input_dtype == torch.float16:
attention_scores = attention_scores.to(torch.float)
# torch.finfo not supported by torch.jit, we temporarily remplace with `-1e34`
attn_weights = attention_scores.masked_fill_(
attention_mask, torch.finfo(attention_scores.dtype).min
)
attention_probs = F.softmax(attn_weights, dim=-1, dtype=torch.float32).to(
input_dtype
)
# # [batch_size, num_heads, q_length, kv_length]
# attention_probs = self.attention_dropout(attention_probs)
if head_mask is not None:
attention_probs = attention_probs * head_mask
# matmul: [batch_size * num_heads, q_length, head_dim]
context_layer = torch.bmm(attention_probs, value_layer, out=query_layer)
# change view [batch_size, num_heads, q_length, head_dim]
context_layer = _merge_heads(
context_layer, num_heads=num_heads, head_dim=head_dim
)
return context_layer, present, attention_probs
def forward(
self,
hidden_states: torch.Tensor,
residual: torch.Tensor,
alibi: torch.Tensor,
attention_mask: torch.Tensor,
layer_past: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,
head_mask: Optional[torch.Tensor] = None,
use_cache: bool = False,
output_attentions: bool = False,
):
fused_qkv = self.query_key_value(
hidden_states
) # [batch_size, seq_length, 3 x hidden_size]
batch_size, q_length, _ = fused_qkv.shape
if layer_past is not None:
past_key, past_value = layer_past
layer_past = (
past_key.view(-1, *past_key.shape[-2:]),
past_value.view(-1, *past_value.shape[-2:]),
)
if CUSTOM_KERNELS_ENABLED:
assert self.training is False, "Only foward pass was implemented"
assert (
attention_mask.shape[-1] < 4096
), "Custom kernel support only up to 4096 tokens"
(
context_layer,
present,
attention_probs,
) = fused_bloom_attention_cuda.forward(
fused_qkv,
layer_past,
alibi,
attention_mask,
head_mask,
self.beta,
self.inv_norm_factor,
self.num_heads,
use_cache,
)
else:
context_layer, present, attention_probs = self.compute_attention(
fused_qkv=fused_qkv,
layer_past=layer_past,
alibi=alibi,
attention_mask=attention_mask,
head_mask=head_mask,
beta=self.beta,
inv_norm_factor=self.inv_norm_factor,
num_heads=self.num_heads,
use_cache=use_cache,
)
# aggregate results across tp ranks. See here: https://github.com/pytorch/pytorch/issues/76232
if self.pretraining_tp > 1 and self.slow_but_exact:
slices = self.hidden_size / self.pretraining_tp
output_tensor = torch.zeros_like(context_layer)
for i in range(self.pretraining_tp):
output_tensor = output_tensor + F.linear(
context_layer[:, :, int(i * slices) : int((i + 1) * slices)],
self.dense.weight[:, int(i * slices) : int((i + 1) * slices)],
)
else:
output_tensor = self.dense(context_layer)
# output_tensor = dropout_add(output_tensor, residual, self.hidden_dropout, self.training)
output_tensor += residual
outputs = (output_tensor, present)
if output_attentions:
outputs += (attention_probs,)
return outputs
class BloomMLP(nn.Module):
def __init__(self, prefix, config: BloomConfig, weights):
super().__init__()
self.pretraining_tp = config.pretraining_tp
self.slow_but_exact = config.slow_but_exact
self.dense_h_to_4h = TensorParallelColumnLinear.load(
config=config, prefix=f"{prefix}.dense_h_to_4h", weights=weights, bias=True
)
self.dense_4h_to_h = TensorParallelRowLinear.load(
config=config, prefix=f"{prefix}.dense_4h_to_h", weights=weights, bias=True
)
self.gelu_impl = torch.nn.GELU(approximate="tanh")
self.hidden_dropout = config.hidden_dropout
def forward(
self, hidden_states: torch.Tensor, residual: torch.Tensor
) -> torch.Tensor:
hidden_states = self.gelu_impl(self.dense_h_to_4h(hidden_states))
if self.pretraining_tp > 1 and self.slow_but_exact:
intermediate_output = torch.zeros_like(residual)
slices = self.dense_4h_to_h.weight.shape[-1] / self.pretraining_tp
for i in range(self.pretraining_tp):
intermediate_output = intermediate_output + F.linear(
hidden_states[:, :, int(i * slices) : int((i + 1) * slices)],
self.dense_4h_to_h.weight[
:, int(i * slices) : int((i + 1) * slices)
],
)
else:
intermediate_output = self.dense_4h_to_h(hidden_states)
# output = dropout_add(intermediate_output, residual, self.hidden_dropout, self.training)
intermediate_output += residual
return intermediate_output
class BloomBlock(nn.Module):
def __init__(self, layer_id: int, config: BloomConfig, weights):
super().__init__()
prefix = f"h.{layer_id}"
self.input_layernorm = LayerNorm.load(
prefix=f"{prefix}.input_layernorm",
weights=weights,
eps=config.layer_norm_epsilon,
)
self.num_heads = config.n_head
self.self_attention = BloomAttention(
prefix=f"{prefix}.self_attention", config=config, weights=weights
)
self.post_attention_layernorm = LayerNorm.load(
prefix=f"{prefix}.post_attention_layernorm",
weights=weights,
eps=config.layer_norm_epsilon,
)
self.mlp = BloomMLP(prefix=f"{prefix}.mlp", config=config, weights=weights)
self.apply_residual_connection_post_layernorm = (
config.apply_residual_connection_post_layernorm
)
self.hidden_dropout = config.hidden_dropout
def forward(
self,
hidden_states: torch.Tensor,
alibi: torch.Tensor,
attention_mask: torch.Tensor,
layer_past: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,
head_mask: Optional[torch.Tensor] = None,
use_cache: bool = False,
output_attentions: bool = False,
):
# hidden_states: [batch_size, seq_length, hidden_size]
# Layer norm at the beginning of the transformer layer.
layernorm_output = self.input_layernorm(hidden_states)
# Layer norm post the self attention.
if self.apply_residual_connection_post_layernorm:
residual = layernorm_output
else:
residual = hidden_states
# Self attention.
attn_outputs = self.self_attention(
layernorm_output,
residual,
layer_past=layer_past,
attention_mask=attention_mask,
alibi=alibi,
head_mask=head_mask,
use_cache=use_cache,
output_attentions=output_attentions,
)
attention_output = attn_outputs[0]
outputs = attn_outputs[1:]
layernorm_output = self.post_attention_layernorm(attention_output)
# Get residual
if self.apply_residual_connection_post_layernorm:
residual = layernorm_output
else:
residual = attention_output
# MLP.
output = self.mlp(layernorm_output, residual)
if use_cache:
outputs = (output,) + outputs
else:
outputs = (output,) + outputs[1:]
return outputs # hidden_states, present, attentions
class BloomPreTrainedModel(PreTrainedModel):
config_class = BloomConfig
base_model_prefix = "transformer"
_no_split_modules = ["BloomBlock"]
@staticmethod
def _convert_to_standard_cache(
past_key_value: Tuple[Tuple[torch.Tensor, torch.Tensor]], batch_size: int
) -> Tuple[Tuple[torch.Tensor, torch.Tensor]]:
"""
Standardizes the format of the cache so as to match most implementations, i.e. to tuple(tuple([batch_size,
num_heads, ...]))
"""
batch_size_times_num_heads, head_dim, seq_length = past_key_value[0][0].shape
num_heads = batch_size_times_num_heads // batch_size
# key: [batch_size * num_heads, head_dim, seq_length] -> [batch_size, num_heads, head_dim, seq_length]
# value: [batch_size * num_heads, seq_length, head_dim] -> [batch_size, num_heads, seq_length, head_dim]
return tuple(
(
layer_past[0].view(batch_size, num_heads, head_dim, seq_length),
layer_past[1].view(batch_size, num_heads, seq_length, head_dim),
)
for layer_past in past_key_value
)
@staticmethod
def _convert_to_bloom_cache(
past_key_value: Tuple[Tuple[torch.Tensor, torch.Tensor]]
) -> Tuple[Tuple[torch.Tensor, torch.Tensor]]:
"""
Converts the cache to the format expected by Bloom, i.e. to tuple(tuple([batch_size * num_heads, ...]))
"""
batch_size, num_heads, head_dim, seq_length = past_key_value[0][0].shape
batch_size_times_num_heads = batch_size * num_heads
# key: [batch_size, num_heads, head_dim, seq_length] -> [batch_size * num_heads, head_dim, seq_length]
# value: [batch_size, num_heads, seq_length, head_dim] -> [batch_size * num_heads, seq_length, head_dim]
return tuple(
(
layer_past[0].view(batch_size_times_num_heads, head_dim, seq_length),
layer_past[1].view(batch_size_times_num_heads, seq_length, head_dim),
)
for layer_past in past_key_value
)
class BloomModel(BloomPreTrainedModel):
def __init__(self, config: BloomConfig, weights):
super().__init__(config)
self.embed_dim = config.hidden_size
self.num_heads = config.n_head
process_group = weights.process_group
self.tp_rank = process_group.rank()
self.tp_world_size = process_group.size()
self.word_embeddings = TensorParallelEmbedding(
prefix="word_embeddings", weights=weights
)
self.word_embeddings_layernorm = LayerNorm.load(
prefix="word_embeddings_layernorm",
weights=weights,
eps=config.layer_norm_epsilon,
)
# Transformer blocks
self.h = nn.ModuleList(
[
BloomBlock(layer_id=layer_id, config=config, weights=weights)
for layer_id in range(config.num_hidden_layers)
]
)
# Final Layer Norm
self.ln_f = LayerNorm.load(
prefix="ln_f", weights=weights, eps=config.layer_norm_epsilon
)
def _prepare_attn_mask(
self,
attention_mask: torch.Tensor,
input_shape: Tuple[int, int],
past_key_values_length: int,
) -> torch.BoolTensor:
# create causal mask
# [batch_size, seq_length] -> [batch_size, tgt_length, src_length]
combined_attention_mask = None
device = attention_mask.device
_, src_length = input_shape
if src_length > 1:
combined_attention_mask = _make_causal_mask(
input_shape,
device=device,
past_key_values_length=past_key_values_length,
)
# [batch_size, seq_length] -> [batch_size, tgt_length, src_length]
expanded_attn_mask = _expand_mask(attention_mask, tgt_length=src_length)
combined_attention_mask = (
expanded_attn_mask
if combined_attention_mask is None
else expanded_attn_mask | combined_attention_mask
)
return combined_attention_mask
def set_input_embeddings(self, new_embeddings: torch.Tensor):
self.word_embeddings = new_embeddings
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
attention_mask: Optional[torch.Tensor] = None,
head_mask: Optional[torch.LongTensor] = None,
inputs_embeds: Optional[torch.LongTensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
**deprecated_arguments,
) -> Union[Tuple[torch.Tensor, ...], BaseModelOutputWithPastAndCrossAttentions]:
if deprecated_arguments.pop("position_ids", False) is not False:
# `position_ids` could have been `torch.Tensor` or `None` so defaulting pop to `False` allows to detect if users were passing explicitly `None`
warnings.warn(
"`position_ids` have no functionality in BLOOM and will be removed in v5.0.0. You can safely ignore"
" passing `position_ids`.",
FutureWarning,
)
if len(deprecated_arguments) > 0:
raise ValueError(f"Got unexpected arguments: {deprecated_arguments}")
output_attentions = (
output_attentions
if output_attentions is not None
else self.config.output_attentions
)
output_hidden_states = (
output_hidden_states
if output_hidden_states is not None
else self.config.output_hidden_states
)
use_cache = use_cache if use_cache is not None else self.config.use_cache
return_dict = (
return_dict if return_dict is not None else self.config.use_return_dict
)
if input_ids is not None and inputs_embeds is not None:
raise ValueError(
"You cannot specify both input_ids and inputs_embeds at the same time"
)
elif input_ids is not None:
batch_size, seq_length = input_ids.shape
elif inputs_embeds is not None:
batch_size, seq_length, _ = inputs_embeds.shape
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
if past_key_values is None:
past_key_values = tuple([None] * len(self.h))
# Prepare head mask if needed
# 1.0 in head_mask indicate we keep the head
# attention_probs has shape batch_size x num_heads x N x N
# head_mask has shape n_layer x batch x num_heads x N x N
head_mask = self.get_head_mask(head_mask, self.config.n_layer)
if inputs_embeds is None:
inputs_embeds = self.word_embeddings(input_ids)
hidden_states = self.word_embeddings_layernorm(inputs_embeds)
presents = () if use_cache else None
all_self_attentions = () if output_attentions else None
all_hidden_states = () if output_hidden_states else None
# Compute alibi tensor: check build_alibi_tensor documentation
seq_length_with_past = seq_length
past_key_values_length = 0
if past_key_values[0] is not None:
past_key_values_length = past_key_values[0][0].shape[-1]
seq_length_with_past = seq_length_with_past + past_key_values_length
if attention_mask is None:
attention_mask = torch.ones(
(batch_size, seq_length_with_past), device=hidden_states.device
)
else:
attention_mask = attention_mask.to(hidden_states.device)
alibi = build_alibi_tensor(attention_mask, self.num_heads)
causal_mask = self._prepare_attn_mask(
attention_mask,
input_shape=(batch_size, seq_length),
past_key_values_length=past_key_values_length,
)
if hasattr(self, "tp_rank"):
assert self.num_heads % self.tp_world_size == 0
block_size = self.num_heads // self.tp_world_size
alibi = alibi[
:, self.tp_rank * block_size : (self.tp_rank + 1) * block_size
]
alibi = alibi.reshape(batch_size * block_size, 1, seq_length_with_past)
causal_mask = torch.repeat_interleave(causal_mask, block_size, dim=0)
else:
alibi = alibi.reshape(batch_size * self.num_heads, 1, seq_length_with_past)
causal_mask = torch.repeat_interleave(causal_mask, self.num_heads, dim=0)
alibi = alibi.to(hidden_states.dtype)
for i, (block, layer_past) in enumerate(zip(self.h, past_key_values)):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
outputs = block(
hidden_states,
layer_past=layer_past,
attention_mask=causal_mask,
head_mask=head_mask[i],
use_cache=use_cache,
output_attentions=output_attentions,
alibi=alibi,
)
hidden_states = outputs[0]
if use_cache is True:
presents = presents + (outputs[1],)
if output_attentions:
all_self_attentions = all_self_attentions + (
outputs[2 if use_cache else 1],
)
# Add last hidden state
hidden_states = self.ln_f(hidden_states)
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
if not return_dict:
return tuple(
v
for v in [
hidden_states,
presents,
all_hidden_states,
all_self_attentions,
]
if v is not None
)
return BaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
past_key_values=presents,
hidden_states=all_hidden_states,
attentions=all_self_attentions,
)
class BloomForCausalLM(BloomPreTrainedModel):
def __init__(self, config, weights):
super().__init__(config)
self.transformer = BloomModel(config, weights)
self.lm_head = TensorParallelHead.load(
config,
prefix="word_embeddings",
weights=weights,
)
def prepare_inputs_for_generation(
self,
input_ids: torch.LongTensor,
past_key_values: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
inputs_embeds: Optional[torch.Tensor] = None,
**kwargs,
) -> dict:
# only last token for input_ids if past is not None
if past_key_values:
input_ids = input_ids[:, -1].unsqueeze(-1)
# the cache may be in the stardard format (e.g. in contrastive search), convert to bloom's format if needed
if past_key_values[0][0].shape[0] == input_ids.shape[0]:
past_key_values = self._convert_to_bloom_cache(past_key_values)
# if `inputs_embeds` are passed, we only want to use them in the 1st generation step
if inputs_embeds is not None and past_key_values is None:
model_inputs = {"inputs_embeds": inputs_embeds}
else:
model_inputs = {"input_ids": input_ids}
model_inputs.update(
{
"past_key_values": past_key_values,
"use_cache": kwargs.get("use_cache"),
"attention_mask": attention_mask,
}
)
return model_inputs
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
attention_mask: Optional[torch.Tensor] = None,
head_mask: Optional[torch.Tensor] = None,
inputs_embeds: Optional[torch.Tensor] = None,
labels: Optional[torch.Tensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
**deprecated_arguments,
) -> Union[Tuple[torch.Tensor], CausalLMOutputWithCrossAttentions]:
r"""
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Labels for language modeling. Note that the labels **are shifted** inside the model, i.e. you can set
`labels = input_ids` Indices are selected in `[-100, 0, ..., config.vocab_size]` All labels set to `-100`
are ignored (masked), the loss is only computed for labels in `[0, ..., config.vocab_size]`
"""
if deprecated_arguments.pop("position_ids", False) is not False:
# `position_ids` could have been `torch.Tensor` or `None` so defaulting pop to `False` allows to detect if users were passing explicitly `None`
warnings.warn(
"`position_ids` have no functionality in BLOOM and will be removed in v5.0.0. You can safely ignore"
" passing `position_ids`.",
FutureWarning,
)
if len(deprecated_arguments) > 0:
raise ValueError(f"Got unexpected arguments: {deprecated_arguments}")
return_dict = (
return_dict if return_dict is not None else self.config.use_return_dict
)
transformer_outputs = self.transformer(
input_ids,
past_key_values=past_key_values,
attention_mask=attention_mask,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
hidden_states = transformer_outputs[0]
lm_logits = self.lm_head(hidden_states)
loss = None
if not return_dict:
output = (lm_logits,) + transformer_outputs[1:]
return ((loss,) + output) if loss is not None else output
return CausalLMOutputWithCrossAttentions(
loss=loss,
logits=lm_logits,
past_key_values=transformer_outputs.past_key_values,
hidden_states=transformer_outputs.hidden_states,
attentions=transformer_outputs.attentions,
)
| text-generation-inference/server/text_generation_server/models/custom_modeling/bloom_modeling.py/0 | {
"file_path": "text-generation-inference/server/text_generation_server/models/custom_modeling/bloom_modeling.py",
"repo_id": "text-generation-inference",
"token_count": 16160
} | 214 |
# coding=utf-8
# Copyright 2022 The Fairseq Authors and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" PyTorch OPT model."""
import random
from typing import List, Optional, Tuple, Union
import torch
import torch.utils.checkpoint
from torch import nn
from transformers.activations import ACT2FN
from transformers.modeling_outputs import (
BaseModelOutputWithPast,
CausalLMOutputWithPast,
)
from transformers.modeling_utils import PreTrainedModel
from transformers import OPTConfig
from text_generation_server.utils.layers import (
FastLinear,
TensorParallelColumnLinear,
TensorParallelEmbedding,
TensorParallelRowLinear,
TensorParallelHead,
)
EPS = 1e-5
# Copied from transformers.models.bart.modeling_bart._make_causal_mask
def _make_causal_mask(
input_ids_shape: torch.Size,
dtype: torch.dtype,
device: torch.device,
past_key_values_length: int = 0,
):
"""
Make causal mask used for bi-directional self-attention.
"""
bsz, tgt_len = input_ids_shape
mask = torch.full(
(tgt_len, tgt_len),
torch.tensor(torch.finfo(dtype).min, device=device),
device=device,
)
mask_cond = torch.arange(mask.size(-1), device=device)
mask.masked_fill_(mask_cond < (mask_cond + 1).view(mask.size(-1), 1), 0)
mask = mask.to(dtype)
if past_key_values_length > 0:
mask = torch.cat(
[
torch.zeros(
tgt_len, past_key_values_length, dtype=dtype, device=device
),
mask,
],
dim=-1,
)
return mask[None, None, :, :].expand(
bsz, 1, tgt_len, tgt_len + past_key_values_length
)
def _expand_mask(mask: torch.Tensor, dtype: torch.dtype, tgt_len: Optional[int] = None):
"""
Expands attention_mask from `[bsz, seq_len]` to `[bsz, 1, tgt_seq_len, src_seq_len]`.
"""
bsz, src_len = mask.size()
tgt_len = tgt_len if tgt_len is not None else src_len
expanded_mask = mask[:, None, None, :].expand(bsz, 1, tgt_len, src_len).to(dtype)
inverted_mask = 1.0 - expanded_mask
return inverted_mask.masked_fill(
inverted_mask.to(torch.bool), torch.finfo(dtype).min
)
class OPTLearnedPositionalEmbedding(nn.Module):
"""
This module learns positional embeddings up to a fixed maximum size.
"""
def __init__(self, weights):
super().__init__()
self.offset = 2
self.weight = nn.Parameter(
weights.get_tensor("model.decoder.embed_positions.weight")
)
def forward(
self, attention_mask: torch.LongTensor, past_key_values_length: int = 0
):
"""`input_ids_shape` is expected to be [bsz x seqlen]."""
attention_mask = attention_mask.long()
# create positions depending on attention_mask
positions = (
torch.cumsum(attention_mask, dim=1).type_as(attention_mask) * attention_mask
).long() - 1
# cut positions if `past_key_values_length` is > 0
positions = positions[:, past_key_values_length:]
return torch.nn.functional.embedding(positions + self.offset, self.weight)
class OPTAttention(nn.Module):
"""Multi-headed attention from 'Attention Is All You Need' paper"""
def __init__(
self,
config,
prefix,
weights,
is_decoder: bool = False,
bias: bool = True,
process_group=None,
):
super().__init__()
hidden_size = config.hidden_size
num_heads = config.num_attention_heads
self.hidden_size = hidden_size
self.num_heads = num_heads
self.dropout = config.dropout
self.head_dim = hidden_size // num_heads
if (self.head_dim * num_heads) != self.hidden_size:
raise ValueError(
f"hidden_size must be divisible by num_heads (got `hidden_size`: {self.hidden_size}"
f" and `num_heads`: {num_heads})."
)
self.scaling = self.head_dim**-0.5
self.is_decoder = is_decoder
process_group = weights.process_group
if self.num_heads % weights.process_group.size() != 0:
raise ValueError(
f"`num_heads` must be divisible by `num_shards` (got `num_heads`: {self.num_heads} "
f"and `num_shards`: {weights.process_group.size()}"
)
self.num_heads = self.num_heads // process_group.size()
self.hidden_size = self.hidden_size // process_group.size()
self.q_proj = TensorParallelColumnLinear.load(
config, prefix=f"{prefix}.q_proj", weights=weights, bias=bias
)
self.k_proj = TensorParallelColumnLinear.load(
config, prefix=f"{prefix}.k_proj", weights=weights, bias=bias
)
self.v_proj = TensorParallelColumnLinear.load(
config, prefix=f"{prefix}.v_proj", weights=weights, bias=bias
)
self.out_proj = TensorParallelRowLinear.load(
config, prefix=f"{prefix}.out_proj", weights=weights, bias=bias
)
def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
return (
tensor.view(bsz, seq_len, self.num_heads, self.head_dim)
.transpose(1, 2)
.contiguous()
)
def forward(
self,
hidden_states: torch.Tensor,
key_value_states: Optional[torch.Tensor] = None,
past_key_value: Optional[Tuple[torch.Tensor]] = None,
attention_mask: Optional[torch.Tensor] = None,
layer_head_mask: Optional[torch.Tensor] = None,
output_attentions: bool = False,
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
"""Input shape: Batch x Time x Channel"""
# if key_value_states are provided this layer is used as a cross-attention layer
# for the decoder
is_cross_attention = key_value_states is not None
bsz, tgt_len, _ = hidden_states.size()
# get query proj
query_states = self.q_proj(hidden_states) * self.scaling
# get key, value proj
if is_cross_attention and past_key_value is not None:
# reuse k,v, cross_attentions
key_states = past_key_value[0]
value_states = past_key_value[1]
elif is_cross_attention:
# cross_attentions
key_states = self._shape(self.k_proj(key_value_states), -1, bsz)
value_states = self._shape(self.v_proj(key_value_states), -1, bsz)
elif past_key_value is not None:
# reuse k, v, self_attention
key_states = self._shape(self.k_proj(hidden_states), -1, bsz)
value_states = self._shape(self.v_proj(hidden_states), -1, bsz)
key_states = torch.cat([past_key_value[0], key_states], dim=2)
value_states = torch.cat([past_key_value[1], value_states], dim=2)
else:
# self_attention
key_states = self._shape(self.k_proj(hidden_states), -1, bsz)
value_states = self._shape(self.v_proj(hidden_states), -1, bsz)
if self.is_decoder:
# if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
# Further calls to cross_attention layer can then reuse all cross-attention
# key/value_states (first "if" case)
# if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
# all previous decoder key/value_states. Further calls to uni-directional self-attention
# can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
# if encoder bi-directional self-attention `past_key_value` is always `None`
past_key_value = (key_states, value_states)
proj_shape = (bsz * self.num_heads, -1, self.head_dim)
query_states = self._shape(query_states, tgt_len, bsz).view(*proj_shape)
key_states = key_states.view(*proj_shape)
value_states = value_states.view(*proj_shape)
src_len = key_states.size(1)
attn_weights = torch.bmm(query_states, key_states.transpose(1, 2))
if attn_weights.size() != (bsz * self.num_heads, tgt_len, src_len):
raise ValueError(
f"Attention weights should be of size {(bsz * self.num_heads, tgt_len, src_len)}, but is"
f" {attn_weights.size()}"
)
if attention_mask is not None:
if attention_mask.size() != (bsz, 1, tgt_len, src_len):
raise ValueError(
f"Attention mask should be of size {(bsz, 1, tgt_len, src_len)}, but is {attention_mask.size()}"
)
attn_weights = (
attn_weights.view(bsz, self.num_heads, tgt_len, src_len)
+ attention_mask
)
attn_weights = torch.max(
attn_weights, torch.tensor(torch.finfo(attn_weights.dtype).min)
)
attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len, src_len)
# upcast to fp32 if the weights are in fp16. Please see https://github.com/huggingface/transformers/pull/17437
if attn_weights.dtype == torch.float16:
attn_weights = nn.functional.softmax(
attn_weights, dim=-1, dtype=torch.float32
).to(torch.float16)
else:
attn_weights = nn.functional.softmax(attn_weights, dim=-1)
if layer_head_mask is not None:
if layer_head_mask.size() != (self.num_heads,):
raise ValueError(
f"Head mask for a single layer should be of size {(self.num_heads,)}, but is"
f" {layer_head_mask.size()}"
)
attn_weights = layer_head_mask.view(1, -1, 1, 1) * attn_weights.view(
bsz, self.num_heads, tgt_len, src_len
)
attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len, src_len)
if output_attentions:
# this operation is a bit awkward, but it's required to
# make sure that attn_weights keeps its gradient.
# In order to do so, attn_weights have to be reshaped
# twice and have to be reused in the following
attn_weights_reshaped = attn_weights.view(
bsz, self.num_heads, tgt_len, src_len
)
attn_weights = attn_weights_reshaped.view(
bsz * self.num_heads, tgt_len, src_len
)
else:
attn_weights_reshaped = None
attn_probs = nn.functional.dropout(
attn_weights, p=self.dropout, training=self.training
)
attn_output = torch.bmm(attn_probs, value_states)
if attn_output.size() != (bsz * self.num_heads, tgt_len, self.head_dim):
raise ValueError(
f"`attn_output` should be of size {(bsz, self.num_heads, tgt_len, self.head_dim)}, but is"
f" {attn_output.size()}"
)
attn_output = attn_output.view(bsz, self.num_heads, tgt_len, self.head_dim)
attn_output = attn_output.transpose(1, 2)
# Use the `hidden_size` from the config (stored in the class) rather than `hidden_state` because `attn_output` can be
# partitioned aross GPUs when using tensor-parallelism.
attn_output = attn_output.reshape(bsz, tgt_len, self.hidden_size)
attn_output = self.out_proj(attn_output)
return attn_output, attn_weights_reshaped, past_key_value
class OPTDecoderLayer(nn.Module):
def __init__(self, layer_id: int, config: OPTConfig, weights):
super().__init__()
self.process_group = weights.process_group
self.hidden_size = config.hidden_size
prefix = f"model.decoder.layers.{layer_id}"
self.self_attn = OPTAttention(
config,
prefix=f"{prefix}.self_attn",
weights=weights,
is_decoder=True,
bias=config.enable_bias,
)
self.do_layer_norm_before = config.do_layer_norm_before
self.dropout = config.dropout
self.activation_fn = ACT2FN[config.activation_function]
self.self_attn_layer_norm = nn.LayerNorm.load(
prefix=f"{prefix}.self_attn_layer_norm", weights=weights, eps=EPS
)
self.fc1 = TensorParallelColumnLinear.load(
config, prefix=f"{prefix}.fc1", weights=weights, bias=config.enable_bias
)
self.fc2 = TensorParallelRowLinear.load(
config, prefix=f"{prefix}.fc2", weights=weights, bias=config.enable_bias
)
self.final_layer_norm = nn.LayerNorm.load(
prefix=f"{prefix}.final_layer_norm", weights=weights, eps=EPS
)
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.Tensor] = None,
layer_head_mask: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = False,
use_cache: Optional[bool] = False,
past_key_value: Optional[Tuple[torch.Tensor]] = None,
) -> Tuple[
torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]
]:
"""
Args:
hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, hidden_size)`
attention_mask (`torch.FloatTensor`, *optional*): attention mask of size
`(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
layer_head_mask (`torch.FloatTensor`, *optional*): mask for attention heads in a given layer of size
`(encoder_attention_heads,)`.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more detail.
use_cache (`bool`, *optional*):
If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding
(see `past_key_values`).
past_key_value (`Tuple(torch.FloatTensor)`, *optional*): cached past key and value projection states
"""
residual = hidden_states
# 125m, 1.7B, ..., 175B applies layer norm BEFORE attention
if self.do_layer_norm_before:
hidden_states = self.self_attn_layer_norm(hidden_states)
# Self Attention
hidden_states, self_attn_weights, present_key_value = self.self_attn(
hidden_states=hidden_states,
past_key_value=past_key_value,
attention_mask=attention_mask,
layer_head_mask=layer_head_mask,
output_attentions=output_attentions,
)
hidden_states = nn.functional.dropout(
hidden_states, p=self.dropout, training=self.training
)
hidden_states = residual + hidden_states
# 350m applies layer norm AFTER attention
if not self.do_layer_norm_before:
hidden_states = self.self_attn_layer_norm(hidden_states)
# Fully Connected
hidden_states_shape = hidden_states.shape
hidden_states = hidden_states.reshape(-1, hidden_states.size(-1))
residual = hidden_states
# 125m, 1.7B, ..., 175B applies layer norm BEFORE attention
if self.do_layer_norm_before:
hidden_states = self.final_layer_norm(hidden_states)
hidden_states = self.fc1(hidden_states)
hidden_states = self.activation_fn(hidden_states)
hidden_states = self.fc2(hidden_states)
hidden_states = nn.functional.dropout(
hidden_states, p=self.dropout, training=self.training
)
hidden_states = (residual + hidden_states).view(hidden_states_shape)
# 350m applies layer norm AFTER attention
if not self.do_layer_norm_before:
hidden_states = self.final_layer_norm(hidden_states)
outputs = (hidden_states,)
if output_attentions:
outputs += (self_attn_weights,)
if use_cache:
outputs += (present_key_value,)
return outputs
class OPTPreTrainedModel(PreTrainedModel):
config_class = OPTConfig
class OPTDecoder(OPTPreTrainedModel):
def __init__(self, config: OPTConfig, weights):
super().__init__(config)
self.dropout = config.dropout
self.layerdrop = config.layerdrop
self.padding_idx = config.pad_token_id
self.max_target_positions = config.max_position_embeddings
self.vocab_size = config.vocab_size
self.embed_tokens = TensorParallelEmbedding(
prefix="model.decoder.embed_tokens", weights=weights
)
self.embed_positions = OPTLearnedPositionalEmbedding(weights)
if config.word_embed_proj_dim != config.hidden_size:
self.project_out = FastLinear.load(
config, prefix="model.decoder.project_out", weights=weights, bias=False
)
else:
self.project_out = None
if config.word_embed_proj_dim != config.hidden_size:
self.project_in = FastLinear.load(
config, prefix="model.decoder.project_in", weights=weights, bias=False
)
else:
self.project_in = None
# Note that the only purpose of `config._remove_final_layer_norm` is to keep backward compatibility
# with checkpoints that have been fine-tuned before transformers v4.20.1
# see https://github.com/facebookresearch/metaseq/pull/164
if config.do_layer_norm_before and not config._remove_final_layer_norm:
self.final_layer_norm = nn.LayerNorm.load(
prefix="model.decoder.final_layer_norm", weights=weights, eps=EPS
)
else:
self.final_layer_norm = None
self.layers = nn.ModuleList(
[
OPTDecoderLayer(layer_id, config, weights)
for layer_id in range(config.num_hidden_layers)
]
)
# Copied from transformers.models.bart.modeling_bart.BartDecoder._prepare_decoder_attention_mask
def _prepare_decoder_attention_mask(
self, attention_mask, input_shape, inputs_embeds, past_key_values_length
):
# create causal mask
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
combined_attention_mask = None
if input_shape[-1] > 1:
combined_attention_mask = _make_causal_mask(
input_shape,
inputs_embeds.dtype,
device=inputs_embeds.device,
past_key_values_length=past_key_values_length,
)
if attention_mask is not None:
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
expanded_attn_mask = _expand_mask(
attention_mask, inputs_embeds.dtype, tgt_len=input_shape[-1]
).to(inputs_embeds.device)
combined_attention_mask = (
expanded_attn_mask
if combined_attention_mask is None
else expanded_attn_mask + combined_attention_mask
)
return combined_attention_mask
def forward(
self,
input_ids: torch.LongTensor = None,
attention_mask: Optional[torch.Tensor] = None,
head_mask: Optional[torch.Tensor] = None,
past_key_values: Optional[List[torch.FloatTensor]] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, BaseModelOutputWithPast]:
r"""
Args:
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you
provide it.
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
[`PreTrainedTokenizer.__call__`] for details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
head_mask (`torch.Tensor` of shape `(num_hidden_layers, num_attention_heads)`, *optional*):
Mask to nullify selected heads of the attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of
shape `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of
Contains pre-computed hidden-states (key and values in the self-attention blocks and in the
cross-attention blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those
that don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of
all `decoder_input_ids` of shape `(batch_size, sequence_length)`.
inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation.
This is useful if you want more control over how to convert `input_ids` indices into associated vectors
than the model's internal embedding lookup matrix.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
for more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
output_attentions = (
output_attentions
if output_attentions is not None
else self.config.output_attentions
)
output_hidden_states = (
output_hidden_states
if output_hidden_states is not None
else self.config.output_hidden_states
)
use_cache = use_cache if use_cache is not None else self.config.use_cache
return_dict = (
return_dict if return_dict is not None else self.config.use_return_dict
)
# retrieve input_ids and inputs_embeds
if input_ids is not None and inputs_embeds is not None:
raise ValueError(
"You cannot specify both decoder_input_ids and decoder_inputs_embeds at the same time"
)
elif input_ids is not None:
input_shape = input_ids.size()
input_ids = input_ids.view(-1, input_shape[-1])
elif inputs_embeds is not None:
input_shape = inputs_embeds.size()[:-1]
else:
raise ValueError(
"You have to specify either decoder_input_ids or decoder_inputs_embeds"
)
if inputs_embeds is None:
inputs_embeds = self.embed_tokens(input_ids)
batch_size, seq_length = input_shape
past_key_values_length = (
past_key_values[0][0].shape[2] if past_key_values is not None else 0
)
# required mask seq length can be calculated via length of past
mask_seq_length = past_key_values_length + seq_length
# embed positions
if attention_mask is None:
attention_mask = torch.ones(
batch_size, mask_seq_length, device=inputs_embeds.device
)
causal_attention_mask = self._prepare_decoder_attention_mask(
attention_mask, input_shape, inputs_embeds, past_key_values_length
)
pos_embeds = self.embed_positions(attention_mask, past_key_values_length)
if self.project_in is not None:
inputs_embeds = self.project_in(inputs_embeds)
hidden_states = inputs_embeds + pos_embeds
# decoder layers
all_hidden_states = () if output_hidden_states else None
all_self_attns = () if output_attentions else None
next_decoder_cache = () if use_cache else None
# check if head_mask has a correct number of layers specified if desired
for attn_mask, mask_name in zip([head_mask], ["head_mask"]):
if attn_mask is not None:
if attn_mask.size()[0] != (len(self.layers)):
raise ValueError(
f"The `{mask_name}` should be specified for {len(self.layers)} layers, but it is for"
f" {head_mask.size()[0]}."
)
for idx, decoder_layer in enumerate(self.layers):
# add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
dropout_probability = random.uniform(0, 1)
if self.training and (dropout_probability < self.layerdrop):
continue
past_key_value = (
past_key_values[idx] if past_key_values is not None else None
)
layer_outputs = decoder_layer(
hidden_states,
attention_mask=causal_attention_mask,
layer_head_mask=(head_mask[idx] if head_mask is not None else None),
past_key_value=past_key_value,
output_attentions=output_attentions,
use_cache=use_cache,
)
hidden_states = layer_outputs[0]
if use_cache:
next_decoder_cache += (layer_outputs[2 if output_attentions else 1],)
if output_attentions:
all_self_attns += (layer_outputs[1],)
if self.final_layer_norm is not None:
hidden_states = self.final_layer_norm(hidden_states)
if self.project_out is not None:
hidden_states = self.project_out(hidden_states)
# add hidden states from the last decoder layer
if output_hidden_states:
all_hidden_states += (hidden_states,)
next_cache = next_decoder_cache if use_cache else None
if not return_dict:
return tuple(
v
for v in [hidden_states, next_cache, all_hidden_states, all_self_attns]
if v is not None
)
return BaseModelOutputWithPast(
last_hidden_state=hidden_states,
past_key_values=next_cache,
hidden_states=all_hidden_states,
attentions=all_self_attns,
)
class OPTModel(OPTPreTrainedModel):
def __init__(self, config: OPTConfig, weights):
super().__init__(config)
self.decoder = OPTDecoder(config, weights)
# Initialize weights and apply final processing
def forward(
self,
input_ids: torch.LongTensor = None,
attention_mask: Optional[torch.Tensor] = None,
head_mask: Optional[torch.Tensor] = None,
past_key_values: Optional[List[torch.FloatTensor]] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, BaseModelOutputWithPast]:
output_attentions = (
output_attentions
if output_attentions is not None
else self.config.output_attentions
)
output_hidden_states = (
output_hidden_states
if output_hidden_states is not None
else self.config.output_hidden_states
)
use_cache = use_cache if use_cache is not None else self.config.use_cache
return_dict = (
return_dict if return_dict is not None else self.config.use_return_dict
)
# decoder outputs consists of (dec_features, past_key_value, dec_hidden, dec_attn)
decoder_outputs = self.decoder(
input_ids=input_ids,
attention_mask=attention_mask,
head_mask=head_mask,
past_key_values=past_key_values,
inputs_embeds=inputs_embeds,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
if not return_dict:
return decoder_outputs
return BaseModelOutputWithPast(
last_hidden_state=decoder_outputs.last_hidden_state,
past_key_values=decoder_outputs.past_key_values,
hidden_states=decoder_outputs.hidden_states,
attentions=decoder_outputs.attentions,
)
class OPTForCausalLM(OPTPreTrainedModel):
def __init__(self, config, weights):
super().__init__(config)
self.model = OPTModel(config, weights)
self.lm_head = TensorParallelHead.load(
config, prefix="model.decoder.embed_tokens", weights=weights
)
def forward(
self,
input_ids: torch.LongTensor = None,
attention_mask: Optional[torch.Tensor] = None,
head_mask: Optional[torch.Tensor] = None,
past_key_values: Optional[List[torch.FloatTensor]] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
labels: Optional[torch.LongTensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, CausalLMOutputWithPast]:
output_attentions = (
output_attentions
if output_attentions is not None
else self.config.output_attentions
)
output_hidden_states = (
output_hidden_states
if output_hidden_states is not None
else self.config.output_hidden_states
)
return_dict = (
return_dict if return_dict is not None else self.config.use_return_dict
)
# decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
outputs = self.model.decoder(
input_ids=input_ids,
attention_mask=attention_mask,
head_mask=head_mask,
past_key_values=past_key_values,
inputs_embeds=inputs_embeds,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
logits = self.lm_head(outputs[0]).contiguous()
loss = None
return CausalLMOutputWithPast(
loss=loss,
logits=logits,
past_key_values=outputs.past_key_values,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
def prepare_inputs_for_generation(
self,
input_ids,
past_key_values=None,
attention_mask=None,
inputs_embeds=None,
**kwargs,
):
if past_key_values:
input_ids = input_ids[:, -1:]
# if `inputs_embeds` are passed, we only want to use them in the 1st generation step
if inputs_embeds is not None and past_key_values is None:
model_inputs = {"inputs_embeds": inputs_embeds}
else:
model_inputs = {"input_ids": input_ids}
model_inputs.update(
{
"past_key_values": past_key_values,
"use_cache": kwargs.get("use_cache"),
"attention_mask": attention_mask,
}
)
return model_inputs
@staticmethod
def _reorder_cache(past_key_values, beam_idx):
reordered_past = ()
for layer_past in past_key_values:
reordered_past += (
tuple(
past_state.index_select(0, beam_idx) for past_state in layer_past
),
)
return reordered_past
| text-generation-inference/server/text_generation_server/models/custom_modeling/opt_modeling.py/0 | {
"file_path": "text-generation-inference/server/text_generation_server/models/custom_modeling/opt_modeling.py",
"repo_id": "text-generation-inference",
"token_count": 15477
} | 215 |
import torch
import torch.distributed
from pathlib import Path
from typing import Optional, Type
from opentelemetry import trace
from transformers import AutoTokenizer, PretrainedConfig, PreTrainedTokenizerBase
from huggingface_hub import hf_hub_download
import json
from text_generation_server.models import CausalLM
from text_generation_server.models.causal_lm import CausalLMBatch
from text_generation_server.pb import generate_pb2
from text_generation_server.models.custom_modeling.mpt_modeling import (
MPTForCausalLM,
)
from text_generation_server.utils import (
initialize_torch_distributed,
weight_files,
Weights,
)
tracer = trace.get_tracer(__name__)
class MPTCausalLMBatch(CausalLMBatch):
@classmethod
def from_pb(
cls,
pb: generate_pb2.Batch,
tokenizer: PreTrainedTokenizerBase,
dtype: torch.dtype,
device: torch.device,
) -> "CausalLMBatch":
batch = super().from_pb(pb=pb, tokenizer=tokenizer, dtype=dtype, device=device)
batch.keys_head_dim_last = False
return batch
class MPTSharded(CausalLM):
def __init__(
self,
model_id: str,
revision: Optional[str] = None,
quantize: Optional[str] = None,
dtype: Optional[torch.dtype] = None,
trust_remote_code: bool = False,
):
self.process_group, rank, world_size = initialize_torch_distributed()
if torch.cuda.is_available():
device = torch.device(f"cuda:{rank}")
dtype = torch.float16 if dtype is None else dtype
else:
device = torch.device("cpu")
dtype = torch.float32 if dtype is None else dtype
tokenizer = AutoTokenizer.from_pretrained(
model_id,
revision=revision,
padding_side="left",
truncation_side="left",
trust_remote_code=trust_remote_code,
)
tokenizer.pad_token = tokenizer.eos_token
# If model_id is a local path, load the file directly
local_path = Path(model_id, "config.json")
if local_path.exists():
filename = str(local_path.resolve())
else:
filename = hf_hub_download(
model_id, revision=revision, filename="config.json"
)
with open(filename, "r") as f:
config = json.load(f)
config = PretrainedConfig(**config)
config.quantize = quantize
torch.distributed.barrier(group=self.process_group)
filenames = weight_files(model_id, revision=revision, extension=".safetensors")
weights = Weights(filenames, device, dtype, process_group=self.process_group)
if config.quantize == "gptq":
weights._set_gptq_params(model_id, revision)
config.quantize = quantize
model = MPTForCausalLM(config, weights)
torch.distributed.barrier(group=self.process_group)
super(CausalLM, self).__init__(
model=model,
tokenizer=tokenizer,
requires_padding=False,
dtype=dtype,
device=device,
rank=rank,
world_size=world_size,
)
@property
def batch_type(self) -> Type[CausalLMBatch]:
return MPTCausalLMBatch
| text-generation-inference/server/text_generation_server/models/mpt.py/0 | {
"file_path": "text-generation-inference/server/text_generation_server/models/mpt.py",
"repo_id": "text-generation-inference",
"token_count": 1440
} | 216 |
# https://github.com/fpgaminer/GPTQ-triton
"""
Mostly the same as the autotuner in Triton, but with a few changes like using 40 runs instead of 100.
"""
import builtins
import math
import time
from typing import Dict
import triton
class Autotuner(triton.KernelInterface):
def __init__(
self,
fn,
arg_names,
configs,
key,
reset_to_zero,
prune_configs_by: Dict = None,
nearest_power_of_two: bool = False,
):
"""
:param prune_configs_by: a dict of functions that are used to prune configs, fields:
'perf_model': performance model used to predicate running time with different configs, returns running time
'top_k': number of configs to bench
'prune_num_stages_by'(optional): a function used to prune num_stages. It take configs:List[Config] as its input, and returns pruned configs.
'nearest_power_of_two'(optional): whether to round key arguments to the nearest power of two when caching tuning results
"""
if not configs:
self.configs = [triton.Config({}, num_warps=4, num_stages=2)]
else:
self.configs = configs
self.key_idx = [arg_names.index(k) for k in key]
self.nearest_power_of_two = nearest_power_of_two
self.cache = {}
# hook to reset all required tensor to zeros before relaunching a kernel
self.hook = lambda args: 0
if reset_to_zero is not None:
self.reset_idx = [arg_names.index(k) for k in reset_to_zero]
def _hook(args):
for i in self.reset_idx:
args[i].zero_()
self.hook = _hook
self.arg_names = arg_names
# prune configs
if prune_configs_by:
perf_model, top_k = (
prune_configs_by["perf_model"],
prune_configs_by["top_k"],
)
if "early_config_prune" in prune_configs_by:
early_config_prune = prune_configs_by["early_config_prune"]
else:
perf_model, top_k, early_config_prune = None, None, None
self.perf_model, self.configs_top_k = perf_model, top_k
self.early_config_prune = early_config_prune
self.fn = fn
def _bench(self, *args, config, **meta):
# check for conflicts, i.e. meta-parameters both provided
# as kwargs and by the autotuner
conflicts = meta.keys() & config.kwargs.keys()
if conflicts:
raise ValueError(
f"Conflicting meta-parameters: {', '.join(conflicts)}."
" Make sure that you don't re-define auto-tuned symbols."
)
# augment meta-parameters with tunable ones
current = dict(meta, **config.kwargs)
def kernel_call():
if config.pre_hook:
config.pre_hook(self.nargs)
self.hook(args)
self.fn.run(
*args,
num_warps=config.num_warps,
num_stages=config.num_stages,
**current,
)
try:
# In testings using only 40 reps seems to be close enough and it appears to be what PyTorch uses
# PyTorch also sets fast_flush to True, but I didn't see any speedup so I'll leave the default
return triton.testing.do_bench(
kernel_call, quantiles=(0.5, 0.2, 0.8), rep=40
)
except triton.OutOfResources:
return (float("inf"), float("inf"), float("inf"))
def run(self, *args, **kwargs):
self.nargs = dict(zip(self.arg_names, args))
if len(self.configs) > 1:
key = tuple(args[i] for i in self.key_idx)
# This reduces the amount of autotuning by rounding the keys to the nearest power of two
# In my testing this gives decent results, and greatly reduces the amount of tuning required
if self.nearest_power_of_two:
key = tuple([2 ** int(math.log2(x) + 0.5) for x in key])
if key not in self.cache:
# prune configs
pruned_configs = self.prune_configs(kwargs)
bench_start = time.time()
timings = {
config: self._bench(*args, config=config, **kwargs)
for config in pruned_configs
}
bench_end = time.time()
self.bench_time = bench_end - bench_start
self.cache[key] = builtins.min(timings, key=timings.get)
self.hook(args)
self.configs_timings = timings
config = self.cache[key]
else:
config = self.configs[0]
self.best_config = config
if config.pre_hook is not None:
config.pre_hook(self.nargs)
return self.fn.run(
*args,
num_warps=config.num_warps,
num_stages=config.num_stages,
**kwargs,
**config.kwargs,
)
def prune_configs(self, kwargs):
pruned_configs = self.configs
if self.early_config_prune:
pruned_configs = self.early_config_prune(self.configs, self.nargs)
if self.perf_model:
top_k = self.configs_top_k
if isinstance(top_k, float) and top_k <= 1.0:
top_k = int(len(self.configs) * top_k)
if len(pruned_configs) > top_k:
est_timing = {
config: self.perf_model(
**self.nargs,
**kwargs,
**config.kwargs,
num_stages=config.num_stages,
num_warps=config.num_warps,
)
for config in pruned_configs
}
pruned_configs = sorted(est_timing.keys(), key=lambda x: est_timing[x])[
:top_k
]
return pruned_configs
def warmup(self, *args, **kwargs):
self.nargs = dict(zip(self.arg_names, args))
for config in self.prune_configs(kwargs):
self.fn.warmup(
*args,
num_warps=config.num_warps,
num_stages=config.num_stages,
**kwargs,
**config.kwargs,
)
self.nargs = None
def autotune(
configs, key, prune_configs_by=None, reset_to_zero=None, nearest_power_of_two=False
):
"""
Decorator for auto-tuning a :code:`triton.jit`'d function.
.. highlight:: python
.. code-block:: python
@triton.autotune(configs=[
triton.Config(meta={'BLOCK_SIZE': 128}, num_warps=4),
triton.Config(meta={'BLOCK_SIZE': 1024}, num_warps=8),
],
key=['x_size'] # the two above configs will be evaluated anytime
# the value of x_size changes
)
@triton.jit
def kernel(x_ptr, x_size, **META):
BLOCK_SIZE = META['BLOCK_SIZE']
:note: When all the configurations are evaluated, the kernel will run multiple time.
This means that whatever value the kernel updates will be updated multiple times.
To avoid this undesired behavior, you can use the `reset_to_zero` argument, which
reset the value of the provided tensor to `zero` before running any configuration.
:param configs: a list of :code:`triton.Config` objects
:type configs: list[triton.Config]
:param key: a list of argument names whose change in value will trigger the evaluation of all provided configs.
:type key: list[str]
:param prune_configs_by: a dict of functions that are used to prune configs, fields:
'perf_model': performance model used to predicate running time with different configs, returns running time
'top_k': number of configs to bench
'early_config_prune'(optional): a function used to do early prune (eg, num_stages). It take configs:List[Config] as its input, and returns pruned configs.
:param reset_to_zero: a list of argument names whose value will be reset to zero before evaluating any configs.
:type reset_to_zero: list[str]
"""
def decorator(fn):
return Autotuner(
fn,
fn.arg_names,
configs,
key,
reset_to_zero,
prune_configs_by,
nearest_power_of_two,
)
return decorator
def matmul248_kernel_config_pruner(configs, nargs):
"""
The main purpose of this function is to shrink BLOCK_SIZE_* when the corresponding dimension is smaller.
"""
m = max(2 ** int(math.ceil(math.log2(nargs["M"]))), 16)
n = max(2 ** int(math.ceil(math.log2(nargs["N"]))), 16)
k = max(2 ** int(math.ceil(math.log2(nargs["K"]))), 16)
used = set()
for config in configs:
block_size_m = min(m, config.kwargs["BLOCK_SIZE_M"])
block_size_n = min(n, config.kwargs["BLOCK_SIZE_N"])
block_size_k = min(k, config.kwargs["BLOCK_SIZE_K"])
group_size_m = config.kwargs["GROUP_SIZE_M"]
if (
block_size_m,
block_size_n,
block_size_k,
group_size_m,
config.num_stages,
config.num_warps,
) in used:
continue
used.add(
(
block_size_m,
block_size_n,
block_size_k,
group_size_m,
config.num_stages,
config.num_warps,
)
)
yield triton.Config(
{
"BLOCK_SIZE_M": block_size_m,
"BLOCK_SIZE_N": block_size_n,
"BLOCK_SIZE_K": block_size_k,
"GROUP_SIZE_M": group_size_m,
},
num_stages=config.num_stages,
num_warps=config.num_warps,
)
| text-generation-inference/server/text_generation_server/utils/gptq/custom_autotune.py/0 | {
"file_path": "text-generation-inference/server/text_generation_server/utils/gptq/custom_autotune.py",
"repo_id": "text-generation-inference",
"token_count": 5116
} | 217 |
import os
from pathlib import Path
from typing import List, Dict, Optional, Tuple
from safetensors import safe_open, SafetensorError
import torch
from loguru import logger
from huggingface_hub import hf_hub_download
import json
from text_generation_server.utils.log import log_once
class Weights:
def __init__(
self,
filenames: List[Path],
device,
dtype,
process_group,
aliases: Optional[Dict[str, List[str]]] = None,
prefix: Optional[str] = None,
):
routing = {}
for filename in filenames:
with safe_open(filename, framework="pytorch") as f:
for k in f.keys():
if k in routing:
raise RuntimeError(
f"Key {k} was found in multiple files: {filename} and {routing[k]}"
)
routing[k] = filename
if aliases is None:
aliases = {}
self.aliases = aliases
self.routing = routing
self.device = device
self.dtype = dtype
self.process_group = process_group
self.prefix = prefix
self._handles = {}
def _get_handle(self, filename):
if filename not in self._handles:
f = safe_open(filename, framework="pytorch")
self._handles[filename] = f
return self._handles[filename]
def get_filename(self, tensor_name: str) -> (str, str):
names = [tensor_name]
if self.prefix is not None:
prefixed = f"{self.prefix}.{tensor_name}"
names.append(prefixed)
for name in names:
filename = self.routing.get(name, None)
if filename is not None:
return str(filename), name
aliases = self.aliases.get(name, [])
for alias in aliases:
filename = self.routing.get(alias, None)
if filename is not None:
return str(filename), alias
raise RuntimeError(f"weight {tensor_name} does not exist")
def _get_slice(self, tensor_name: str):
filename, tensor_name = self.get_filename(tensor_name)
f = self._get_handle(filename)
slice_ = f.get_slice(tensor_name)
return slice_
def get_shape(self, tensor_name: str):
return self._get_slice(tensor_name).get_shape()
def get_tensor(self, tensor_name: str, to_device=True):
filename, tensor_name = self.get_filename(tensor_name)
f = self._get_handle(filename)
tensor = f.get_tensor(tensor_name)
# Special case for gptq which shouldn't convert
# u4 which are disguised as int32
if tensor.dtype not in [torch.int32, torch.int64]:
tensor = tensor.to(dtype=self.dtype)
if to_device:
tensor = tensor.to(device=self.device)
return tensor
def get_partial_sharded(self, tensor_name: str, dim: int):
filename, tensor_name = self.get_filename(tensor_name)
f = self._get_handle(filename)
slice_ = f.get_slice(tensor_name)
world_size = self.process_group.size()
rank = self.process_group.rank()
size = slice_.get_shape()[dim]
block_size = (size + world_size - 1) // world_size
start = rank * block_size
stop = (rank + 1) * block_size
if dim == 0:
tensor = slice_[start:stop]
elif dim == 1:
tensor = slice_[:, start:stop]
else:
raise NotImplementedError("Let's make that generic when needed")
# Special case for gptq which shouldn't convert
# u4 which are disguised as int32
if tensor.dtype != torch.int32:
tensor = tensor.to(dtype=self.dtype)
tensor = tensor.to(device=self.device)
return tensor
def get_sharded(self, tensor_name: str, dim: int):
filename, tensor_name = self.get_filename(tensor_name)
f = self._get_handle(filename)
slice_ = f.get_slice(tensor_name)
world_size = self.process_group.size()
size = slice_.get_shape()[dim]
assert (
size % world_size == 0
), f"The choosen size {size} is not compatible with sharding on {world_size} shards"
return self.get_partial_sharded(tensor_name, dim)
def _get_qweight(self, name: str):
slice_ = self._get_slice(name)
total_size = slice_.get_shape()[1]
assert total_size % 3 == 0, "Prepacked quantized qkv is not divisible by 3"
single_size = total_size // 3
world_size = self.process_group.size()
rank = self.process_group.rank()
assert (
single_size % world_size == 0
), f"Prepacked quantized qkv cannot be sharded across {world_size} shards"
block_size = single_size // world_size
start = rank * block_size
stop = (rank + 1) * block_size
q = slice_[:, start:stop]
k = slice_[:, start + single_size : stop + single_size]
v = slice_[:, start + 2 * single_size : stop + 2 * single_size]
weight = torch.cat([q, k, v], dim=1)
weight = weight.to(device=self.device)
return weight
def get_weights_col_packed_qkv(self, prefix: str, quantize: str):
"""
Highly specific when the underlying tensor is a simple cat of Q,K,V instead of being
already alternating Q,K,V within the main tensor
"""
if quantize in ["gptq", "awq"]:
try:
qweight = self._get_qweight(f"{prefix}.qweight")
except RuntimeError:
raise RuntimeError(
f"Cannot load `{quantize}` weight, make sure the model is already quantized."
)
qzeros = self._get_qweight(f"{prefix}.qzeros")
scales = self._get_qweight(f"{prefix}.scales")
scales = scales.to(dtype=self.dtype)
if quantize == "gptq":
g_idx = self.get_tensor(f"{prefix}.g_idx")
else:
g_idx = None
bits, groupsize, _ = self._get_gptq_params()
weight = (qweight, qzeros, scales, g_idx, bits, groupsize, False)
else:
slice_ = self._get_slice(f"{prefix}.weight")
total_size = slice_.get_shape()[0]
assert total_size % 3 == 0, "Prepacked qkv is not divisible by 3"
single_size = total_size // 3
world_size = self.process_group.size()
rank = self.process_group.rank()
assert (
single_size % world_size == 0
), f"Prepacked qkv cannot be sharded across {world_size} shards"
block_size = single_size // world_size
start = rank * block_size
stop = (rank + 1) * block_size
q = slice_[start:stop]
k = slice_[start + single_size : stop + single_size]
v = slice_[start + 2 * single_size : stop + 2 * single_size]
weight = torch.cat([q, k, v], dim=0)
weight = weight.to(device=self.device)
weight = weight.to(dtype=self.dtype)
return weight
def get_multi_weights_col(self, prefixes: List[str], quantize: str, dim: int):
if quantize in ["gptq", "awq"]:
try:
qweight = torch.cat(
[self.get_sharded(f"{p}.qweight", dim=1) for p in prefixes], dim=1
)
except RuntimeError:
raise RuntimeError(
f"Cannot load `{quantize}` weight, make sure the model is already quantized"
)
qzeros = torch.cat(
[self.get_sharded(f"{p}.qzeros", dim=1) for p in prefixes], dim=1
)
scales = torch.cat(
[self.get_sharded(f"{p}.scales", dim=1) for p in prefixes], dim=1
)
if quantize == "gptq":
w = [self.get_tensor(f"{p}.g_idx") for p in prefixes]
for w2 in w[1:]:
torch.testing.assert_close(w2, w[0])
g_idx = w[0]
else:
g_idx = None
bits, groupsize, desc_act = self._get_gptq_params()
from text_generation_server.utils.layers import HAS_EXLLAMA
use_exllama = (
bits == 4 and HAS_EXLLAMA and quantize == "gptq" and not desc_act
)
weight = (qweight, qzeros, scales, g_idx, bits, groupsize, use_exllama)
else:
w = [self.get_sharded(f"{p}.weight", dim=0) for p in prefixes]
weight = torch.cat(w, dim=dim)
return weight
def get_tensor_shard(self, var, dim):
world_size = self.process_group.size()
rank = self.process_group.rank()
block_size = var.size()[dim] // world_size
start = rank * block_size
stop = (rank + 1) * block_size
if dim == 0:
tensor = var[start:stop]
elif dim == 1:
tensor = var[:, start:stop]
else:
raise NotImplementedError("Let's make that generic when needed")
tensor = tensor.to(dtype=self.dtype)
tensor = tensor.to(device=self.device)
return tensor
def get_multi_weights_row(self, prefix: str, quantize: str):
if quantize == "gptq":
use_exllama = True
bits, groupsize, desc_act = self._get_gptq_params()
if bits != 4:
use_exllama = False
if desc_act:
log_once(logger.warning, "Disabling exllama because desc_act=True")
use_exllama = False
if self.process_group.size() > 1:
g_idx = self.get_tensor(f"{prefix}.g_idx")
if g_idx is not None:
if (
not torch.equal(
g_idx.cpu(),
torch.tensor(
[i // groupsize for i in range(g_idx.shape[0])],
dtype=torch.int32,
),
)
and not (g_idx == 0).all()
):
# Exllama implementation does not support row tensor parallelism with act-order, as
# it would require to reorder input activations that are split unto several GPUs
use_exllama = False
try:
qweight = self.get_sharded(f"{prefix}.qweight", dim=0)
except RuntimeError:
raise RuntimeError(
"Cannot load `gptq` weight, make sure the model is already quantized, or quantize it with `text-generation-server quantize ORIGINAL_MODEL_ID NEW_MODEL_ID`"
)
from text_generation_server.utils.layers import HAS_EXLLAMA, CAN_EXLLAMA
if use_exllama:
if not HAS_EXLLAMA:
if CAN_EXLLAMA:
log_once(
logger.warning,
"Exllama GPTQ cuda kernels (which are faster) could have been used, but are not currently installed, try using BUILD_EXTENSIONS=True",
)
use_exllama = False
else:
log_once(logger.info, f"Using exllama kernels v{HAS_EXLLAMA}")
g_idx = self.get_sharded(f"{prefix}.g_idx", dim=0)
if use_exllama and groupsize != -1:
qzeros = self.get_sharded(f"{prefix}.qzeros", dim=0)
scales = self.get_sharded(f"{prefix}.scales", dim=0)
else:
qzeros = self.get_tensor(f"{prefix}.qzeros")
scales = self.get_tensor(f"{prefix}.scales")
if use_exllama:
g_idx = g_idx - g_idx[0]
weight = (qweight, qzeros, scales, g_idx, bits, groupsize, use_exllama)
elif quantize == "awq":
bits, groupsize, _ = self._get_gptq_params()
try:
qweight = self.get_sharded(f"{prefix}.qweight", dim=0)
except RuntimeError:
raise RuntimeError(
"Cannot load `awq` weight, make sure the model is already quantized"
)
qzeros = self.get_sharded(f"{prefix}.qzeros", dim=0)
scales = self.get_sharded(f"{prefix}.scales", dim=0)
g_idx = None
use_exllama = False
weight = (qweight, qzeros, scales, g_idx, bits, groupsize, use_exllama)
else:
weight = self.get_sharded(f"{prefix}.weight", dim=1)
return weight
def _get_gptq_params(self) -> Tuple[int, int, int]:
try:
bits = self.get_tensor("gptq_bits").item()
groupsize = self.get_tensor("gptq_groupsize").item()
desc_act = False
except (SafetensorError, RuntimeError) as e:
try:
bits = self.gptq_bits
groupsize = self.gptq_groupsize
desc_act = getattr(self, "gptq_desc_act", False)
except Exception:
raise e
return bits, groupsize, desc_act
def _set_gptq_params(self, model_id, revision):
filename = "config.json"
try:
if os.path.exists(os.path.join(model_id, filename)):
filename = os.path.join(model_id, filename)
else:
filename = hf_hub_download(
model_id, filename=filename, revision=revision
)
with open(filename, "r") as f:
data = json.load(f)
self.gptq_bits = data["quantization_config"]["bits"]
self.gptq_groupsize = data["quantization_config"]["group_size"]
self.gptq_desc_act = data["quantization_config"]["desc_act"]
except Exception:
filename = "quantize_config.json"
try:
if os.path.exists(os.path.join(model_id, filename)):
filename = os.path.join(model_id, filename)
else:
filename = hf_hub_download(
model_id, filename=filename, revision=revision
)
with open(filename, "r") as f:
data = json.load(f)
self.gptq_bits = data["bits"]
self.gptq_groupsize = data["group_size"]
self.gptq_desc_act = data["desc_act"]
except Exception:
filename = "quant_config.json"
try:
if os.path.exists(os.path.join(model_id, filename)):
filename = os.path.join(model_id, filename)
else:
filename = hf_hub_download(
model_id, filename=filename, revision=revision
)
with open(filename, "r") as f:
data = json.load(f)
self.gptq_bits = data["w_bit"]
self.gptq_groupsize = data["q_group_size"]
self.gptq_desc_act = data["desc_act"]
except Exception:
pass
| text-generation-inference/server/text_generation_server/utils/weights.py/0 | {
"file_path": "text-generation-inference/server/text_generation_server/utils/weights.py",
"repo_id": "text-generation-inference",
"token_count": 7903
} | 218 |
<p align="center">
<br>
<img src="https://huggingface.co/landing/assets/tokenizers/tokenizers-logo.png" width="600"/>
<br>
<p>
<p align="center">
<img alt="Build" src="https://github.com/huggingface/tokenizers/workflows/Rust/badge.svg">
<a href="https://github.com/huggingface/tokenizers/blob/main/LICENSE">
<img alt="GitHub" src="https://img.shields.io/github/license/huggingface/tokenizers.svg?color=blue&cachedrop">
</a>
<a href="https://pepy.tech/project/tokenizers">
<img src="https://pepy.tech/badge/tokenizers/week" />
</a>
</p>
Provides an implementation of today's most used tokenizers, with a focus on performance and
versatility.
## Main features:
- Train new vocabularies and tokenize, using today's most used tokenizers.
- Extremely fast (both training and tokenization), thanks to the Rust implementation. Takes
less than 20 seconds to tokenize a GB of text on a server's CPU.
- Easy to use, but also extremely versatile.
- Designed for research and production.
- Normalization comes with alignments tracking. It's always possible to get the part of the
original sentence that corresponds to a given token.
- Does all the pre-processing: Truncate, Pad, add the special tokens your model needs.
## Bindings
We provide bindings to the following languages (more to come!):
- [Rust](https://github.com/huggingface/tokenizers/tree/main/tokenizers) (Original implementation)
- [Python](https://github.com/huggingface/tokenizers/tree/main/bindings/python)
- [Node.js](https://github.com/huggingface/tokenizers/tree/main/bindings/node)
- [Ruby](https://github.com/ankane/tokenizers-ruby) (Contributed by @ankane, external repo)
## Quick example using Python:
Choose your model between Byte-Pair Encoding, WordPiece or Unigram and instantiate a tokenizer:
```python
from tokenizers import Tokenizer
from tokenizers.models import BPE
tokenizer = Tokenizer(BPE())
```
You can customize how pre-tokenization (e.g., splitting into words) is done:
```python
from tokenizers.pre_tokenizers import Whitespace
tokenizer.pre_tokenizer = Whitespace()
```
Then training your tokenizer on a set of files just takes two lines of codes:
```python
from tokenizers.trainers import BpeTrainer
trainer = BpeTrainer(special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"])
tokenizer.train(files=["wiki.train.raw", "wiki.valid.raw", "wiki.test.raw"], trainer=trainer)
```
Once your tokenizer is trained, encode any text with just one line:
```python
output = tokenizer.encode("Hello, y'all! How are you 😁 ?")
print(output.tokens)
# ["Hello", ",", "y", "'", "all", "!", "How", "are", "you", "[UNK]", "?"]
```
Check the [documentation](https://huggingface.co/docs/tokenizers/index)
or the [quicktour](https://huggingface.co/docs/tokenizers/quicktour) to learn more!
| tokenizers/README.md/0 | {
"file_path": "tokenizers/README.md",
"repo_id": "tokenizers",
"token_count": 945
} | 219 |
/* eslint-disable */
var globRequire = require;
describe("pipelineExample", () => {
// This is a hack to let us require using path similar to what the user has to use
function require(mod: string) {
if (mod.startsWith("tokenizers")) {
// let path = mod.slice("tokenizers".length);
return globRequire("../../");
} else {
return globRequire(mod);
}
}
let console = {
log: (..._args: any[]) => {}
};
it("shows pipeline parts", async () => {
// START reload_tokenizer
let { Tokenizer } = require("tokenizers");
let tokenizer = Tokenizer.fromFile("data/tokenizer-wiki.json");
// END reload_tokenizer
// START setup_normalizer
let { sequenceNormalizer, nfdNormalizer, stripAccentsNormalizer } = require("tokenizers");
let normalizer = sequenceNormalizer([nfdNormalizer(), stripAccentsNormalizer()]);
// END setup_normalizer
// START test_normalizer
let normalized = normalizer.normalizeString("Héllò hôw are ü?")
// "Hello how are u?"
// END test_normalizer
expect(normalized).toEqual("Hello how are u?");
// START replace_normalizer
tokenizer.setNormalizer(normalizer)
// END replace_normalizer
// START setup_pre_tokenizer
let { whitespacePreTokenizer } = require("tokenizers");
var preTokenizer = whitespacePreTokenizer();
var preTokenized = preTokenizer.preTokenizeString("Hello! How are you? I'm fine, thank you.");
// END setup_pre_tokenizer
expect(preTokenized).toEqual([
["Hello", [0, 5]],
["!", [5, 6]],
["How", [7, 10]],
["are", [11, 14]],
["you", [15, 18]],
["?", [18, 19]],
["I", [20, 21]],
["'", [21, 22]],
['m', [22, 23]],
["fine", [24, 28]],
[",", [28, 29]],
["thank", [30, 35]],
["you", [36, 39]],
[".", [39, 40]]
]);
// START combine_pre_tokenizer
let { sequencePreTokenizer, digitsPreTokenizer } = require("tokenizers");
var preTokenizer = sequencePreTokenizer([whitespacePreTokenizer(), digitsPreTokenizer(true)]);
var preTokenized = preTokenizer.preTokenizeString("Call 911!");
// END combine_pre_tokenizer
// START replace_pre_tokenizer
tokenizer.setPreTokenizer(preTokenizer)
// END replace_pre_tokenizer
// START setup_processor
let { templateProcessing } = require("tokenizers");
tokenizer.setPostProcessor(templateProcessing(
"[CLS] $A [SEP]",
"[CLS] $A [SEP] $B:1 [SEP]:1",
[["[CLS]", 1], ["[SEP]", 2]]
));
// END setup_processor
// START test_decoding
let output = await tokenizer.encode("Hello, y'all! How are you 😁 ?");
console.log(output.getIds());
// [1, 27253, 16, 93, 11, 5097, 5, 7961, 5112, 6218, 0, 35, 2]
let decoded = await tokenizer.decode([1, 27253, 16, 93, 11, 5097, 5, 7961, 5112, 6218, 0, 35, 2], true);
// "Hello , y ' all ! How are you ?"
// END test_decoding
expect(decoded).toEqual("Hello , y ' all ! How are you ?");
});
it.skip("trains the tokenizer", async () => {
// START bert_setup_tokenizer
let { Tokenizer } = require("tokenizers");
let { WordPiece } = require("tokenizers");
let bertTokenizer = new Tokenizer(WordPiece.init({}, { unkToken: "[UNK]" }));
// END bert_setup_tokenizer
// START bert_setup_normalizer
let { sequenceNormalizer, lowercaseNormalizer, nfdNormalizer, stripAccentsNormalizer }
= require("tokenizers");
bertTokenizer.setNormalizer(sequenceNormalizer([
nfdNormalizer(), lowercaseNormalizer(), stripAccentsNormalizer()
]))
// END bert_setup_normalizer
// START bert_setup_pre_tokenizer
let { whitespacePreTokenizer } = require("tokenizers");
bertTokenizer.setPreTokenizer(whitespacePreTokenizer());
// END bert_setup_pre_tokenizer
// START bert_setup_processor
let { templateProcessing } = require("tokenizers");
bertTokenizer.setPostProcessor(templateProcessing(
"[CLS] $A [SEP]",
"[CLS] $A [SEP] $B:1 [SEP]:1",
[["[CLS]", 1], ["[SEP]", 2]]
));
// END bert_setup_processor
// START bert_train_tokenizer
let { wordPieceTrainer } = require("tokenizers");
let trainer = wordPieceTrainer({
vocabSize: 30522,
specialTokens: ["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"]
});
let files = ["test", "train", "valid"].map(split => `data/wikitext-103-raw/wiki.${split}.raw`);
bertTokenizer.train(files, trainer);
bertTokenizer.save("data/bert-wiki.json")
// END bert_train_tokenizer
});
it("shows a full bert example", async () => {
let { Tokenizer } = require("tokenizers");
let bertTokenizer = await Tokenizer.fromFile("data/bert-wiki.json")
// START bert_test_decoding
let output = await bertTokenizer.encode("Welcome to the 🤗 Tokenizers library.");
console.log(output.getTokens());
// ["[CLS]", "welcome", "to", "the", "[UNK]", "tok", "##eni", "##zer", "##s", "library", ".", "[SEP]"]
var decoded = await bertTokenizer.decode(output.getIds(), true);
// "welcome to the tok ##eni ##zer ##s library ."
// END bert_test_decoding
expect(decoded).toEqual("welcome to the tok ##eni ##zer ##s library .");
// START bert_proper_decoding
let { wordPieceDecoder } = require("tokenizers");
bertTokenizer.setDecoder(wordPieceDecoder());
var decoded = await bertTokenizer.decode(output.getIds(), true);
// "welcome to the tokenizers library."
// END bert_proper_decoding
expect(decoded).toEqual("welcome to the tokenizers library.");
});
});
| tokenizers/bindings/node/examples/documentation/pipeline.test.ts/0 | {
"file_path": "tokenizers/bindings/node/examples/documentation/pipeline.test.ts",
"repo_id": "tokenizers",
"token_count": 2710
} | 220 |
# `tokenizers-android-arm-eabi`
This is the **armv7-linux-androideabi** binary for `tokenizers`
| tokenizers/bindings/node/npm/android-arm-eabi/README.md/0 | {
"file_path": "tokenizers/bindings/node/npm/android-arm-eabi/README.md",
"repo_id": "tokenizers",
"token_count": 35
} | 221 |
# `tokenizers-linux-x64-gnu`
This is the **x86_64-unknown-linux-gnu** binary for `tokenizers`
| tokenizers/bindings/node/npm/linux-x64-gnu/README.md/0 | {
"file_path": "tokenizers/bindings/node/npm/linux-x64-gnu/README.md",
"repo_id": "tokenizers",
"token_count": 36
} | 222 |
use crate::arc_rwlock_serde;
use crate::tasks::models::{BPEFromFilesTask, WordLevelFromFilesTask, WordPieceFromFilesTask};
use crate::trainers::Trainer;
use napi::bindgen_prelude::*;
use napi_derive::napi;
use serde::{Deserialize, Serialize};
use std::collections::HashMap;
use std::path::{Path, PathBuf};
use std::sync::{Arc, RwLock};
use tokenizers as tk;
use tokenizers::models::bpe::{BpeBuilder, Merges, Vocab};
use tokenizers::models::wordlevel::WordLevelBuilder;
use tokenizers::models::wordpiece::WordPieceBuilder;
#[napi]
#[derive(Clone, Serialize, Deserialize)]
pub struct Model {
#[serde(flatten, with = "arc_rwlock_serde")]
pub(crate) model: Option<Arc<RwLock<tk::models::ModelWrapper>>>,
}
impl<M> From<M> for Model
where
M: Into<tk::models::ModelWrapper>,
{
fn from(wrapper: M) -> Self {
Self {
model: Some(Arc::new(RwLock::new(wrapper.into()))),
}
}
}
#[napi(js_name = "BPE")]
pub struct Bpe {}
#[napi]
impl Bpe {
#[napi(factory, ts_return_type = "Model")]
pub fn empty() -> Result<Model> {
let bpe = tk::models::bpe::BPE::default();
Ok(Model {
model: Some(Arc::new(RwLock::new(bpe.into()))),
})
}
#[napi(factory, ts_return_type = "Model")]
pub fn init(vocab: Vocab, merges: Merges, options: Option<BpeOptions>) -> Result<Model> {
let options = options.unwrap_or_default();
let mut builder = tk::models::bpe::BPE::builder().vocab_and_merges(vocab, merges);
builder = options.apply_to_bpe_builder(builder);
let model = builder
.build()
.map_err(|e| Error::from_reason(e.to_string()))?;
Ok(Model {
model: Some(Arc::new(RwLock::new(model.into()))),
})
}
#[napi(ts_return_type = "Promise<Model>")]
pub fn from_file(
vocab: String,
merges: String,
options: Option<BpeOptions>,
) -> AsyncTask<BPEFromFilesTask> {
let options = options.unwrap_or_default();
let mut builder = tk::models::bpe::BPE::from_file(&vocab, &merges);
builder = options.apply_to_bpe_builder(builder);
AsyncTask::new(BPEFromFilesTask {
builder: Some(builder),
})
}
}
impl tk::Model for Model {
type Trainer = Trainer;
fn tokenize(&self, sequence: &str) -> tk::Result<Vec<tk::Token>> {
self
.model
.as_ref()
.ok_or("Uninitialized Model")?
.read()
.unwrap()
.tokenize(sequence)
}
fn token_to_id(&self, token: &str) -> Option<u32> {
self.model.as_ref()?.read().unwrap().token_to_id(token)
}
fn id_to_token(&self, id: u32) -> Option<String> {
self.model.as_ref()?.read().unwrap().id_to_token(id)
}
fn get_vocab(&self) -> HashMap<String, u32> {
self
.model
.as_ref()
.expect("Uninitialized Model")
.read()
.unwrap()
.get_vocab()
}
fn get_vocab_size(&self) -> usize {
self
.model
.as_ref()
.expect("Uninitialized Model")
.read()
.unwrap()
.get_vocab_size()
}
fn save(&self, folder: &Path, name: Option<&str>) -> tk::Result<Vec<PathBuf>> {
self
.model
.as_ref()
.ok_or("Uninitialized Model")?
.read()
.unwrap()
.save(folder, name)
}
fn get_trainer(&self) -> Self::Trainer {
self
.model
.as_ref()
.expect("Uninitialized Model")
.read()
.unwrap()
.get_trainer()
.into()
}
}
#[derive(Default)]
#[napi(object)]
pub struct BpeOptions {
pub cache_capacity: Option<u32>,
pub dropout: Option<f64>,
pub unk_token: Option<String>,
pub continuing_subword_prefix: Option<String>,
pub end_of_word_suffix: Option<String>,
pub fuse_unk: Option<bool>,
pub byte_fallback: Option<bool>,
}
impl BpeOptions {
fn apply_to_bpe_builder(self, mut builder: BpeBuilder) -> BpeBuilder {
if let Some(cache_capacity) = self.cache_capacity {
builder = builder.cache_capacity(cache_capacity as usize);
}
if let Some(dropout) = self.dropout {
builder = builder.dropout(dropout as f32);
}
if let Some(unk_token) = self.unk_token {
builder = builder.unk_token(unk_token);
}
if let Some(continuing_subword_prefix) = self.continuing_subword_prefix {
builder = builder.continuing_subword_prefix(continuing_subword_prefix);
}
if let Some(end_of_word_suffix) = self.end_of_word_suffix {
builder = builder.end_of_word_suffix(end_of_word_suffix);
}
if let Some(fuse_unk) = self.fuse_unk {
builder = builder.fuse_unk(fuse_unk);
}
if let Some(byte_fallback) = self.byte_fallback {
builder = builder.byte_fallback(byte_fallback);
}
builder
}
}
#[derive(Default)]
#[napi(object)]
pub struct WordPieceOptions {
pub unk_token: Option<String>,
pub continuing_subword_prefix: Option<String>,
pub max_input_chars_per_word: Option<u32>,
}
impl WordPieceOptions {
fn apply_to_wordpiece_builder(self, mut builder: WordPieceBuilder) -> WordPieceBuilder {
if let Some(token) = self.unk_token {
builder = builder.unk_token(token);
}
if let Some(prefix) = self.continuing_subword_prefix {
builder = builder.continuing_subword_prefix(prefix);
}
if let Some(max) = self.max_input_chars_per_word {
builder = builder.max_input_chars_per_word(max as usize);
}
builder
}
}
#[napi]
pub struct WordPiece {}
#[napi]
impl WordPiece {
#[napi(factory, ts_return_type = "Model")]
pub fn init(vocab: Vocab, options: Option<WordPieceOptions>) -> Result<Model> {
let options = options.unwrap_or_default();
let mut builder = tk::models::wordpiece::WordPiece::builder().vocab(vocab);
builder = options.apply_to_wordpiece_builder(builder);
let model = builder
.build()
.map_err(|e| Error::from_reason(e.to_string()))?;
Ok(Model {
model: Some(Arc::new(RwLock::new(model.into()))),
})
}
#[napi(factory)]
pub fn empty() -> Model {
let wordpiece = tk::models::wordpiece::WordPiece::default();
Model {
model: Some(Arc::new(RwLock::new(wordpiece.into()))),
}
}
#[napi(ts_return_type = "Promise<Model>")]
pub fn from_file(
vocab: String,
options: Option<WordPieceOptions>,
) -> AsyncTask<WordPieceFromFilesTask> {
let options = options.unwrap_or_default();
let mut builder = tk::models::wordpiece::WordPiece::from_file(&vocab);
builder = options.apply_to_wordpiece_builder(builder);
AsyncTask::new(WordPieceFromFilesTask {
builder: Some(builder),
})
}
}
#[derive(Default)]
#[napi(object)]
pub struct WordLevelOptions {
pub unk_token: Option<String>,
}
impl WordLevelOptions {
fn apply_to_wordlevel_builder(self, mut builder: WordLevelBuilder) -> WordLevelBuilder {
if let Some(token) = self.unk_token {
builder = builder.unk_token(token);
}
builder
}
}
#[napi]
pub struct WordLevel {}
#[napi]
impl WordLevel {
#[napi(factory, ts_return_type = "Model")]
pub fn init(vocab: Vocab, options: Option<WordLevelOptions>) -> Result<Model> {
let options = options.unwrap_or_default();
let mut builder = tk::models::wordlevel::WordLevel::builder().vocab(vocab);
builder = options.apply_to_wordlevel_builder(builder);
let model = builder
.build()
.map_err(|e| Error::from_reason(e.to_string()))?;
Ok(Model {
model: Some(Arc::new(RwLock::new(model.into()))),
})
}
#[napi(factory)]
pub fn empty() -> Model {
let wordlevel = tk::models::wordlevel::WordLevel::default();
Model {
model: Some(Arc::new(RwLock::new(wordlevel.into()))),
}
}
#[napi(ts_return_type = "Promise<Model>")]
pub fn from_file(
vocab: String,
options: Option<WordLevelOptions>,
) -> AsyncTask<WordLevelFromFilesTask> {
let options = options.unwrap_or_default();
let mut builder = tk::models::wordlevel::WordLevel::builder().files(vocab);
builder = options.apply_to_wordlevel_builder(builder);
AsyncTask::new(WordLevelFromFilesTask {
builder: Some(builder),
})
}
}
#[derive(Default)]
#[napi(object)]
pub struct UnigramOptions {
pub unk_id: Option<u32>,
pub byte_fallback: Option<bool>,
}
#[napi]
pub struct Unigram {}
#[napi]
impl Unigram {
#[napi(factory, ts_return_type = "Model")]
pub fn init(vocab: Vec<(String, f64)>, options: Option<UnigramOptions>) -> Result<Model> {
let options = options.unwrap_or_default();
let unigram = tk::models::unigram::Unigram::from(
vocab,
options.unk_id.map(|u| u as usize),
options.byte_fallback.unwrap_or(false),
)
.map_err(|e| Error::from_reason(e.to_string()))?;
Ok(Model {
model: Some(Arc::new(RwLock::new(unigram.into()))),
})
}
#[napi(factory, ts_return_type = "Model")]
pub fn empty() -> Model {
let unigram = tk::models::unigram::Unigram::default();
Model {
model: Some(Arc::new(RwLock::new(unigram.into()))),
}
}
}
| tokenizers/bindings/node/src/models.rs/0 | {
"file_path": "tokenizers/bindings/node/src/models.rs",
"repo_id": "tokenizers",
"token_count": 3681
} | 223 |
[package]
name = "tokenizers-python"
version = "0.15.2-dev.0"
authors = ["Anthony MOI <[email protected]>"]
edition = "2021"
[lib]
name = "tokenizers"
crate-type = ["cdylib"]
[dependencies]
rayon = "1.8"
serde = { version = "1.0", features = [ "rc", "derive" ]}
serde_json = "1.0"
libc = "0.2"
env_logger = "0.10.0"
pyo3 = { version = "0.20" }
numpy = "0.20.0"
ndarray = "0.15"
onig = { version = "6.4", default-features = false }
itertools = "0.11"
[dependencies.tokenizers]
version = "0.15.2-dev.0"
path = "../../tokenizers"
[dev-dependencies]
tempfile = "3.8"
pyo3 = { version = "0.20", features = ["auto-initialize"] }
[features]
defaut = ["pyo3/extension-module"]
| tokenizers/bindings/python/Cargo.toml/0 | {
"file_path": "tokenizers/bindings/python/Cargo.toml",
"repo_id": "tokenizers",
"token_count": 302
} | 224 |
from typing import Dict, List, Optional, Tuple, Union
from tokenizers import AddedToken, EncodeInput, Encoding, InputSequence, Tokenizer
from tokenizers.decoders import Decoder
from tokenizers.models import Model
from tokenizers.normalizers import Normalizer
from tokenizers.pre_tokenizers import PreTokenizer
from tokenizers.processors import PostProcessor
Offsets = Tuple[int, int]
class BaseTokenizer:
def __init__(self, tokenizer: Tokenizer, parameters=None):
self._tokenizer = tokenizer
self._parameters = parameters if parameters is not None else {}
def __repr__(self):
return "Tokenizer(vocabulary_size={}, {})".format(
self._tokenizer.get_vocab_size(),
", ".join(k + "=" + str(v) for k, v in self._parameters.items()),
)
def num_special_tokens_to_add(self, is_pair: bool) -> int:
"""
Return the number of special tokens that would be added for single/pair sentences.
:param is_pair: Boolean indicating if the input would be a single sentence or a pair
:return:
"""
return self._tokenizer.num_special_tokens_to_add(is_pair)
def get_vocab(self, with_added_tokens: bool = True) -> Dict[str, int]:
"""Returns the vocabulary
Args:
with_added_tokens: boolean:
Whether to include the added tokens in the vocabulary
Returns:
The vocabulary
"""
return self._tokenizer.get_vocab(with_added_tokens=with_added_tokens)
def get_added_tokens_decoder(self) -> Dict[int, AddedToken]:
"""Returns the added reverse vocabulary
Returns:
The added vocabulary mapping ints to AddedTokens
"""
return self._tokenizer.get_added_tokens_decoder()
def get_vocab_size(self, with_added_tokens: bool = True) -> int:
"""Return the size of vocabulary, with or without added tokens.
Args:
with_added_tokens: (`optional`) bool:
Whether to count in added special tokens or not
Returns:
Size of vocabulary
"""
return self._tokenizer.get_vocab_size(with_added_tokens=with_added_tokens)
def enable_padding(
self,
direction: Optional[str] = "right",
pad_to_multiple_of: Optional[int] = None,
pad_id: Optional[int] = 0,
pad_type_id: Optional[int] = 0,
pad_token: Optional[str] = "[PAD]",
length: Optional[int] = None,
):
"""Change the padding strategy
Args:
direction: (`optional`) str:
Can be one of: `right` or `left`
pad_to_multiple_of: (`optional`) unsigned int:
If specified, the padding length should always snap to the next multiple of
the given value. For example if we were going to pad with a length of 250 but
`pad_to_multiple_of=8` then we will pad to 256.
pad_id: (`optional`) unsigned int:
The indice to be used when padding
pad_type_id: (`optional`) unsigned int:
The type indice to be used when padding
pad_token: (`optional`) str:
The pad token to be used when padding
length: (`optional`) unsigned int:
If specified, the length at which to pad. If not specified
we pad using the size of the longest sequence in a batch
"""
return self._tokenizer.enable_padding(
direction=direction,
pad_to_multiple_of=pad_to_multiple_of,
pad_id=pad_id,
pad_type_id=pad_type_id,
pad_token=pad_token,
length=length,
)
def no_padding(self):
"""Disable padding"""
return self._tokenizer.no_padding()
@property
def padding(self) -> Optional[dict]:
"""Get the current padding parameters
Returns:
None if padding is disabled, a dict with the currently set parameters
if the padding is enabled.
"""
return self._tokenizer.padding
def enable_truncation(self, max_length: int, stride: Optional[int] = 0, strategy: Optional[str] = "longest_first"):
"""Change the truncation options
Args:
max_length: unsigned int:
The maximum length at which to truncate
stride: (`optional`) unsigned int:
The length of the previous first sequence to be included
in the overflowing sequence
strategy: (`optional`) str:
Can be one of `longest_first`, `only_first` or `only_second`
"""
return self._tokenizer.enable_truncation(max_length, stride=stride, strategy=strategy)
def no_truncation(self):
"""Disable truncation"""
return self._tokenizer.no_truncation()
@property
def truncation(self) -> Optional[dict]:
"""Get the current truncation parameters
Returns:
None if truncation is disabled, a dict with the current truncation parameters if
truncation is enabled
"""
return self._tokenizer.truncation
def add_tokens(self, tokens: List[Union[str, AddedToken]]) -> int:
"""Add the given tokens to the vocabulary
Args:
tokens: List[Union[str, AddedToken]]:
A list of tokens to add to the vocabulary. Each token can either be
a string, or an instance of AddedToken
Returns:
The number of tokens that were added to the vocabulary
"""
return self._tokenizer.add_tokens(tokens)
def add_special_tokens(self, special_tokens: List[Union[str, AddedToken]]) -> int:
"""Add the given special tokens to the vocabulary, and treat them as special tokens.
The special tokens will never be processed by the model, and will be
removed while decoding.
Args:
tokens: List[Union[str, AddedToken]]:
A list of special tokens to add to the vocabulary. Each token can either be
a string, or an instance of AddedToken
Returns:
The number of tokens that were added to the vocabulary
"""
return self._tokenizer.add_special_tokens(special_tokens)
def normalize(self, sequence: str) -> str:
"""Normalize the given sequence
Args:
sequence: str:
The sequence to normalize
Returns:
The normalized string
"""
return self._tokenizer.normalize(sequence)
def encode(
self,
sequence: InputSequence,
pair: Optional[InputSequence] = None,
is_pretokenized: bool = False,
add_special_tokens: bool = True,
) -> Encoding:
"""Encode the given sequence and pair. This method can process raw text sequences as well
as already pre-tokenized sequences.
Args:
sequence: InputSequence:
The sequence we want to encode. This sequence can be either raw text or
pre-tokenized, according to the `is_pretokenized` argument:
- If `is_pretokenized=False`: `InputSequence` is expected to be `str`
- If `is_pretokenized=True`: `InputSequence` is expected to be
`Union[List[str], Tuple[str]]`
is_pretokenized: bool:
Whether the input is already pre-tokenized.
add_special_tokens: bool:
Whether to add the special tokens while encoding.
Returns:
An Encoding
"""
if sequence is None:
raise ValueError("encode: `sequence` can't be `None`")
return self._tokenizer.encode(sequence, pair, is_pretokenized, add_special_tokens)
def encode_batch(
self,
inputs: List[EncodeInput],
is_pretokenized: bool = False,
add_special_tokens: bool = True,
) -> List[Encoding]:
"""Encode the given inputs. This method accept both raw text sequences as well as already
pre-tokenized sequences.
Args:
inputs: List[EncodeInput]:
A list of single sequences or pair sequences to encode. Each `EncodeInput` is
expected to be of the following form:
`Union[InputSequence, Tuple[InputSequence, InputSequence]]`
Each `InputSequence` can either be raw text or pre-tokenized,
according to the `is_pretokenized` argument:
- If `is_pretokenized=False`: `InputSequence` is expected to be `str`
- If `is_pretokenized=True`: `InputSequence` is expected to be
`Union[List[str], Tuple[str]]`
is_pretokenized: bool:
Whether the input is already pre-tokenized.
add_special_tokens: bool:
Whether to add the special tokens while encoding.
Returns:
A list of Encoding
"""
if inputs is None:
raise ValueError("encode_batch: `inputs` can't be `None`")
return self._tokenizer.encode_batch(inputs, is_pretokenized, add_special_tokens)
def decode(self, ids: List[int], skip_special_tokens: Optional[bool] = True) -> str:
"""Decode the given list of ids to a string sequence
Args:
ids: List[unsigned int]:
A list of ids to be decoded
skip_special_tokens: (`optional`) boolean:
Whether to remove all the special tokens from the output string
Returns:
The decoded string
"""
if ids is None:
raise ValueError("None input is not valid. Should be a list of integers.")
return self._tokenizer.decode(ids, skip_special_tokens=skip_special_tokens)
def decode_batch(self, sequences: List[List[int]], skip_special_tokens: Optional[bool] = True) -> str:
"""Decode the list of sequences to a list of string sequences
Args:
sequences: List[List[unsigned int]]:
A list of sequence of ids to be decoded
skip_special_tokens: (`optional`) boolean:
Whether to remove all the special tokens from the output strings
Returns:
A list of decoded strings
"""
if sequences is None:
raise ValueError("None input is not valid. Should be list of list of integers.")
return self._tokenizer.decode_batch(sequences, skip_special_tokens=skip_special_tokens)
def token_to_id(self, token: str) -> Optional[int]:
"""Convert the given token to its corresponding id
Args:
token: str:
The token to convert
Returns:
The corresponding id if it exists, None otherwise
"""
return self._tokenizer.token_to_id(token)
def id_to_token(self, id: int) -> Optional[str]:
"""Convert the given token id to its corresponding string
Args:
token: id:
The token id to convert
Returns:
The corresponding string if it exists, None otherwise
"""
return self._tokenizer.id_to_token(id)
def save_model(self, directory: str, prefix: Optional[str] = None):
"""Save the current model to the given directory
Args:
directory: str:
A path to the destination directory
prefix: (Optional) str:
An optional prefix, used to prefix each file name
"""
return self._tokenizer.model.save(directory, prefix=prefix)
def save(self, path: str, pretty: bool = True):
"""Save the current Tokenizer at the given path
Args:
path: str:
A path to the destination Tokenizer file
"""
return self._tokenizer.save(path, pretty)
def to_str(self, pretty: bool = False):
"""Get a serialized JSON version of the Tokenizer as a str
Args:
pretty: bool:
Whether the JSON string should be prettified
Returns:
str
"""
return self._tokenizer.to_str(pretty)
def post_process(
self, encoding: Encoding, pair: Optional[Encoding] = None, add_special_tokens: bool = True
) -> Encoding:
"""Apply all the post-processing steps to the given encodings.
The various steps are:
1. Truncate according to global params (provided to `enable_truncation`)
2. Apply the PostProcessor
3. Pad according to global params. (provided to `enable_padding`)
Args:
encoding: Encoding:
The main Encoding to post process
pair: Optional[Encoding]:
An optional pair Encoding
add_special_tokens: bool:
Whether to add special tokens
Returns:
The resulting Encoding
"""
return self._tokenizer.post_process(encoding, pair, add_special_tokens)
@property
def model(self) -> Model:
return self._tokenizer.model
@model.setter
def model(self, model: Model):
self._tokenizer.model = model
@property
def normalizer(self) -> Normalizer:
return self._tokenizer.normalizer
@normalizer.setter
def normalizer(self, normalizer: Normalizer):
self._tokenizer.normalizer = normalizer
@property
def pre_tokenizer(self) -> PreTokenizer:
return self._tokenizer.pre_tokenizer
@pre_tokenizer.setter
def pre_tokenizer(self, pre_tokenizer: PreTokenizer):
self._tokenizer.pre_tokenizer = pre_tokenizer
@property
def post_processor(self) -> PostProcessor:
return self._tokenizer.post_processor
@post_processor.setter
def post_processor(self, post_processor: PostProcessor):
self._tokenizer.post_processor = post_processor
@property
def decoder(self) -> Decoder:
return self._tokenizer.decoder
@decoder.setter
def decoder(self, decoder: Decoder):
self._tokenizer.decoder = decoder
| tokenizers/bindings/python/py_src/tokenizers/implementations/base_tokenizer.py/0 | {
"file_path": "tokenizers/bindings/python/py_src/tokenizers/implementations/base_tokenizer.py",
"repo_id": "tokenizers",
"token_count": 6036
} | 225 |
import itertools
import os
import re
from string import Template
from typing import Any, Callable, Dict, List, NamedTuple, Optional, Tuple
from tokenizers import Encoding, Tokenizer
dirname = os.path.dirname(__file__)
css_filename = os.path.join(dirname, "visualizer-styles.css")
with open(css_filename) as f:
css = f.read()
class Annotation:
start: int
end: int
label: int
def __init__(self, start: int, end: int, label: str):
self.start = start
self.end = end
self.label = label
AnnotationList = List[Annotation]
PartialIntList = List[Optional[int]]
class CharStateKey(NamedTuple):
token_ix: Optional[int]
anno_ix: Optional[int]
class CharState:
char_ix: Optional[int]
def __init__(self, char_ix):
self.char_ix = char_ix
self.anno_ix: Optional[int] = None
self.tokens: List[int] = []
@property
def token_ix(self):
return self.tokens[0] if len(self.tokens) > 0 else None
@property
def is_multitoken(self):
"""
BPE tokenizers can output more than one token for a char
"""
return len(self.tokens) > 1
def partition_key(self) -> CharStateKey:
return CharStateKey(
token_ix=self.token_ix,
anno_ix=self.anno_ix,
)
class Aligned:
pass
class EncodingVisualizer:
"""
Build an EncodingVisualizer
Args:
tokenizer (:class:`~tokenizers.Tokenizer`):
A tokenizer instance
default_to_notebook (:obj:`bool`):
Whether to render html output in a notebook by default
annotation_converter (:obj:`Callable`, `optional`):
An optional (lambda) function that takes an annotation in any format and returns
an Annotation object
"""
unk_token_regex = re.compile("(.{1}\b)?(unk|oov)(\b.{1})?", flags=re.IGNORECASE)
def __init__(
self,
tokenizer: Tokenizer,
default_to_notebook: bool = True,
annotation_converter: Optional[Callable[[Any], Annotation]] = None,
):
if default_to_notebook:
try:
from IPython.core.display import HTML, display
except ImportError as e:
raise Exception(
"""We couldn't import IPython utils for html display.
Are you running in a notebook?
You can also pass `default_to_notebook=False` to get back raw HTML
"""
)
self.tokenizer = tokenizer
self.default_to_notebook = default_to_notebook
self.annotation_coverter = annotation_converter
pass
def __call__(
self,
text: str,
annotations: AnnotationList = [],
default_to_notebook: Optional[bool] = None,
) -> Optional[str]:
"""
Build a visualization of the given text
Args:
text (:obj:`str`):
The text to tokenize
annotations (:obj:`List[Annotation]`, `optional`):
An optional list of annotations of the text. The can either be an annotation class
or anything else if you instantiated the visualizer with a converter function
default_to_notebook (:obj:`bool`, `optional`, defaults to `False`):
If True, will render the html in a notebook. Otherwise returns an html string.
Returns:
The HTML string if default_to_notebook is False, otherwise (default) returns None and
renders the HTML in the notebook
"""
final_default_to_notebook = self.default_to_notebook
if default_to_notebook is not None:
final_default_to_notebook = default_to_notebook
if final_default_to_notebook:
try:
from IPython.core.display import HTML, display
except ImportError as e:
raise Exception(
"""We couldn't import IPython utils for html display.
Are you running in a notebook?"""
)
if self.annotation_coverter is not None:
annotations = list(map(self.annotation_coverter, annotations))
encoding = self.tokenizer.encode(text)
html = EncodingVisualizer.__make_html(text, encoding, annotations)
if final_default_to_notebook:
display(HTML(html))
else:
return html
@staticmethod
def calculate_label_colors(annotations: AnnotationList) -> Dict[str, str]:
"""
Generates a color palette for all the labels in a given set of annotations
Args:
annotations (:obj:`Annotation`):
A list of annotations
Returns:
:obj:`dict`: A dictionary mapping labels to colors in HSL format
"""
if len(annotations) == 0:
return {}
labels = set(map(lambda x: x.label, annotations))
num_labels = len(labels)
h_step = int(255 / num_labels)
if h_step < 20:
h_step = 20
s = 32
l = 64
h = 10
colors = {}
for label in sorted(labels): # sort so we always get the same colors for a given set of labels
colors[label] = f"hsl({h},{s}%,{l}%"
h += h_step
return colors
@staticmethod
def consecutive_chars_to_html(
consecutive_chars_list: List[CharState],
text: str,
encoding: Encoding,
):
"""
Converts a list of "consecutive chars" into a single HTML element.
Chars are consecutive if they fall under the same word, token and annotation.
The CharState class is a named tuple with a "partition_key" method that makes it easy to
compare if two chars are consecutive.
Args:
consecutive_chars_list (:obj:`List[CharState]`):
A list of CharStates that have been grouped together
text (:obj:`str`):
The original text being processed
encoding (:class:`~tokenizers.Encoding`):
The encoding returned from the tokenizer
Returns:
:obj:`str`: The HTML span for a set of consecutive chars
"""
first = consecutive_chars_list[0]
if first.char_ix is None:
# its a special token
stoken = encoding.tokens[first.token_ix]
# special tokens are represented as empty spans. We use the data attribute and css
# magic to display it
return f'<span class="special-token" data-stoken={stoken}></span>'
# We're not in a special token so this group has a start and end.
last = consecutive_chars_list[-1]
start = first.char_ix
end = last.char_ix + 1
span_text = text[start:end]
css_classes = [] # What css classes will we apply on the resulting span
data_items = {} # What data attributes will we apply on the result span
if first.token_ix is not None:
# We can either be in a token or not (e.g. in white space)
css_classes.append("token")
if first.is_multitoken:
css_classes.append("multi-token")
if first.token_ix % 2:
# We use this to color alternating tokens.
# A token might be split by an annotation that ends in the middle of it, so this
# lets us visually indicate a consecutive token despite its possible splitting in
# the html markup
css_classes.append("odd-token")
else:
# Like above, but a different color so we can see the tokens alternate
css_classes.append("even-token")
if EncodingVisualizer.unk_token_regex.search(encoding.tokens[first.token_ix]) is not None:
# This is a special token that is in the text. probably UNK
css_classes.append("special-token")
# TODO is this the right name for the data attribute ?
data_items["stok"] = encoding.tokens[first.token_ix]
else:
# In this case we are looking at a group/single char that is not tokenized.
# e.g. white space
css_classes.append("non-token")
css = f'''class="{' '.join(css_classes)}"'''
data = ""
for key, val in data_items.items():
data += f' data-{key}="{val}"'
return f"<span {css} {data} >{span_text}</span>"
@staticmethod
def __make_html(text: str, encoding: Encoding, annotations: AnnotationList) -> str:
char_states = EncodingVisualizer.__make_char_states(text, encoding, annotations)
current_consecutive_chars = [char_states[0]]
prev_anno_ix = char_states[0].anno_ix
spans = []
label_colors_dict = EncodingVisualizer.calculate_label_colors(annotations)
cur_anno_ix = char_states[0].anno_ix
if cur_anno_ix is not None:
# If we started in an annotation make a span for it
anno = annotations[cur_anno_ix]
label = anno.label
color = label_colors_dict[label]
spans.append(f'<span class="annotation" style="color:{color}" data-label="{label}">')
for cs in char_states[1:]:
cur_anno_ix = cs.anno_ix
if cur_anno_ix != prev_anno_ix:
# If we've transitioned in or out of an annotation
spans.append(
# Create a span from the current consecutive characters
EncodingVisualizer.consecutive_chars_to_html(
current_consecutive_chars,
text=text,
encoding=encoding,
)
)
current_consecutive_chars = [cs]
if prev_anno_ix is not None:
# if we transitioned out of an annotation close it's span
spans.append("</span>")
if cur_anno_ix is not None:
# If we entered a new annotation make a span for it
anno = annotations[cur_anno_ix]
label = anno.label
color = label_colors_dict[label]
spans.append(f'<span class="annotation" style="color:{color}" data-label="{label}">')
prev_anno_ix = cur_anno_ix
if cs.partition_key() == current_consecutive_chars[0].partition_key():
# If the current charchter is in the same "group" as the previous one
current_consecutive_chars.append(cs)
else:
# Otherwise we make a span for the previous group
spans.append(
EncodingVisualizer.consecutive_chars_to_html(
current_consecutive_chars,
text=text,
encoding=encoding,
)
)
# An reset the consecutive_char_list to form a new group
current_consecutive_chars = [cs]
# All that's left is to fill out the final span
# TODO I think there is an edge case here where an annotation's span might not close
spans.append(
EncodingVisualizer.consecutive_chars_to_html(
current_consecutive_chars,
text=text,
encoding=encoding,
)
)
res = HTMLBody(spans) # Send the list of spans to the body of our html
return res
@staticmethod
def __make_anno_map(text: str, annotations: AnnotationList) -> PartialIntList:
"""
Args:
text (:obj:`str`):
The raw text we want to align to
annotations (:obj:`AnnotationList`):
A (possibly empty) list of annotations
Returns:
A list of length len(text) whose entry at index i is None if there is no annotation on
charachter i or k, the index of the annotation that covers index i where k is with
respect to the list of annotations
"""
annotation_map = [None] * len(text)
for anno_ix, a in enumerate(annotations):
for i in range(a.start, a.end):
annotation_map[i] = anno_ix
return annotation_map
@staticmethod
def __make_char_states(text: str, encoding: Encoding, annotations: AnnotationList) -> List[CharState]:
"""
For each character in the original text, we emit a tuple representing it's "state":
* which token_ix it corresponds to
* which word_ix it corresponds to
* which annotation_ix it corresponds to
Args:
text (:obj:`str`):
The raw text we want to align to
annotations (:obj:`List[Annotation]`):
A (possibly empty) list of annotations
encoding: (:class:`~tokenizers.Encoding`):
The encoding returned from the tokenizer
Returns:
:obj:`List[CharState]`: A list of CharStates, indicating for each char in the text what
it's state is
"""
annotation_map = EncodingVisualizer.__make_anno_map(text, annotations)
# Todo make this a dataclass or named tuple
char_states: List[CharState] = [CharState(char_ix) for char_ix in range(len(text))]
for token_ix, token in enumerate(encoding.tokens):
offsets = encoding.token_to_chars(token_ix)
if offsets is not None:
start, end = offsets
for i in range(start, end):
char_states[i].tokens.append(token_ix)
for char_ix, anno_ix in enumerate(annotation_map):
char_states[char_ix].anno_ix = anno_ix
return char_states
def HTMLBody(children: List[str], css_styles=css) -> str:
"""
Generates the full html with css from a list of html spans
Args:
children (:obj:`List[str]`):
A list of strings, assumed to be html elements
css_styles (:obj:`str`, `optional`):
Optional alternative implementation of the css
Returns:
:obj:`str`: An HTML string with style markup
"""
children_text = "".join(children)
return f"""
<html>
<head>
<style>
{css_styles}
</style>
</head>
<body>
<div class="tokenized-text" dir=auto>
{children_text}
</div>
</body>
</html>
"""
| tokenizers/bindings/python/py_src/tokenizers/tools/visualizer.py/0 | {
"file_path": "tokenizers/bindings/python/py_src/tokenizers/tools/visualizer.py",
"repo_id": "tokenizers",
"token_count": 6750
} | 226 |
use std::convert::TryInto;
use std::sync::Arc;
use pyo3::exceptions;
use pyo3::prelude::*;
use pyo3::types::*;
use crate::encoding::PyEncoding;
use crate::error::ToPyResult;
use serde::{Deserialize, Serialize};
use tk::processors::bert::BertProcessing;
use tk::processors::byte_level::ByteLevel;
use tk::processors::roberta::RobertaProcessing;
use tk::processors::sequence::Sequence;
use tk::processors::template::{SpecialToken, Template};
use tk::processors::PostProcessorWrapper;
use tk::{Encoding, PostProcessor};
use tokenizers as tk;
/// Base class for all post-processors
///
/// This class is not supposed to be instantiated directly. Instead, any implementation of
/// a PostProcessor will return an instance of this class when instantiated.
#[pyclass(
dict,
module = "tokenizers.processors",
name = "PostProcessor",
subclass
)]
#[derive(Clone, Deserialize, Serialize)]
pub struct PyPostProcessor {
#[serde(flatten)]
pub processor: Arc<PostProcessorWrapper>,
}
impl PyPostProcessor {
pub fn new(processor: Arc<PostProcessorWrapper>) -> Self {
PyPostProcessor { processor }
}
pub(crate) fn get_as_subtype(&self, py: Python<'_>) -> PyResult<PyObject> {
let base = self.clone();
Ok(match self.processor.as_ref() {
PostProcessorWrapper::ByteLevel(_) => Py::new(py, (PyByteLevel {}, base))?.into_py(py),
PostProcessorWrapper::Bert(_) => Py::new(py, (PyBertProcessing {}, base))?.into_py(py),
PostProcessorWrapper::Roberta(_) => {
Py::new(py, (PyRobertaProcessing {}, base))?.into_py(py)
}
PostProcessorWrapper::Template(_) => {
Py::new(py, (PyTemplateProcessing {}, base))?.into_py(py)
}
PostProcessorWrapper::Sequence(_) => Py::new(py, (PySequence {}, base))?.into_py(py),
})
}
}
impl PostProcessor for PyPostProcessor {
fn added_tokens(&self, is_pair: bool) -> usize {
self.processor.added_tokens(is_pair)
}
fn process_encodings(
&self,
encodings: Vec<Encoding>,
add_special_tokens: bool,
) -> tk::Result<Vec<Encoding>> {
self.processor
.process_encodings(encodings, add_special_tokens)
}
}
#[pymethods]
impl PyPostProcessor {
fn __getstate__(&self, py: Python) -> PyResult<PyObject> {
let data = serde_json::to_string(self.processor.as_ref()).map_err(|e| {
exceptions::PyException::new_err(format!(
"Error while attempting to pickle PostProcessor: {}",
e
))
})?;
Ok(PyBytes::new(py, data.as_bytes()).to_object(py))
}
fn __setstate__(&mut self, py: Python, state: PyObject) -> PyResult<()> {
match state.extract::<&PyBytes>(py) {
Ok(s) => {
self.processor = serde_json::from_slice(s.as_bytes()).map_err(|e| {
exceptions::PyException::new_err(format!(
"Error while attempting to unpickle PostProcessor: {}",
e
))
})?;
Ok(())
}
Err(e) => Err(e),
}
}
/// Return the number of special tokens that would be added for single/pair sentences.
///
/// Args:
/// is_pair (:obj:`bool`):
/// Whether the input would be a pair of sequences
///
/// Returns:
/// :obj:`int`: The number of tokens to add
#[pyo3(text_signature = "(self, is_pair)")]
fn num_special_tokens_to_add(&self, is_pair: bool) -> usize {
self.processor.added_tokens(is_pair)
}
/// Post-process the given encodings, generating the final one
///
/// Args:
/// encoding (:class:`~tokenizers.Encoding`):
/// The encoding for the first sequence
///
/// pair (:class:`~tokenizers.Encoding`, `optional`):
/// The encoding for the pair sequence
///
/// add_special_tokens (:obj:`bool`):
/// Whether to add the special tokens
///
/// Return:
/// :class:`~tokenizers.Encoding`: The final encoding
#[pyo3(signature = (encoding, pair = None, add_special_tokens = true))]
#[pyo3(text_signature = "(self, encoding, pair=None, add_special_tokens=True)")]
fn process(
&self,
encoding: &PyEncoding,
pair: Option<&PyEncoding>,
add_special_tokens: bool,
) -> PyResult<PyEncoding> {
let final_encoding = ToPyResult(self.processor.process(
encoding.encoding.clone(),
pair.map(|e| e.encoding.clone()),
add_special_tokens,
))
.into_py()?;
Ok(final_encoding.into())
}
}
/// This post-processor takes care of adding the special tokens needed by
/// a Bert model:
///
/// - a SEP token
/// - a CLS token
///
/// Args:
/// sep (:obj:`Tuple[str, int]`):
/// A tuple with the string representation of the SEP token, and its id
///
/// cls (:obj:`Tuple[str, int]`):
/// A tuple with the string representation of the CLS token, and its id
#[pyclass(extends=PyPostProcessor, module = "tokenizers.processors", name = "BertProcessing")]
pub struct PyBertProcessing {}
#[pymethods]
impl PyBertProcessing {
#[new]
#[pyo3(text_signature = "(self, sep, cls)")]
fn new(sep: (String, u32), cls: (String, u32)) -> (Self, PyPostProcessor) {
(
PyBertProcessing {},
PyPostProcessor::new(Arc::new(BertProcessing::new(sep, cls).into())),
)
}
fn __getnewargs__<'p>(&self, py: Python<'p>) -> &'p PyTuple {
PyTuple::new(py, [("", 0), ("", 0)])
}
}
/// This post-processor takes care of adding the special tokens needed by
/// a Roberta model:
///
/// - a SEP token
/// - a CLS token
///
/// It also takes care of trimming the offsets.
/// By default, the ByteLevel BPE might include whitespaces in the produced tokens. If you don't
/// want the offsets to include these whitespaces, then this PostProcessor should be initialized
/// with :obj:`trim_offsets=True`
///
/// Args:
/// sep (:obj:`Tuple[str, int]`):
/// A tuple with the string representation of the SEP token, and its id
///
/// cls (:obj:`Tuple[str, int]`):
/// A tuple with the string representation of the CLS token, and its id
///
/// trim_offsets (:obj:`bool`, `optional`, defaults to :obj:`True`):
/// Whether to trim the whitespaces from the produced offsets.
///
/// add_prefix_space (:obj:`bool`, `optional`, defaults to :obj:`True`):
/// Whether the add_prefix_space option was enabled during pre-tokenization. This
/// is relevant because it defines the way the offsets are trimmed out.
#[pyclass(extends=PyPostProcessor, module = "tokenizers.processors", name = "RobertaProcessing")]
pub struct PyRobertaProcessing {}
#[pymethods]
impl PyRobertaProcessing {
#[new]
#[pyo3(signature = (sep, cls, trim_offsets = true, add_prefix_space = true), text_signature = "(self, sep, cls, trim_offsets=True, add_prefix_space=True)")]
fn new(
sep: (String, u32),
cls: (String, u32),
trim_offsets: bool,
add_prefix_space: bool,
) -> (Self, PyPostProcessor) {
let proc = RobertaProcessing::new(sep, cls)
.trim_offsets(trim_offsets)
.add_prefix_space(add_prefix_space);
(
PyRobertaProcessing {},
PyPostProcessor::new(Arc::new(proc.into())),
)
}
fn __getnewargs__<'p>(&self, py: Python<'p>) -> &'p PyTuple {
PyTuple::new(py, [("", 0), ("", 0)])
}
}
/// This post-processor takes care of trimming the offsets.
///
/// By default, the ByteLevel BPE might include whitespaces in the produced tokens. If you don't
/// want the offsets to include these whitespaces, then this PostProcessor must be used.
///
/// Args:
/// trim_offsets (:obj:`bool`):
/// Whether to trim the whitespaces from the produced offsets.
#[pyclass(extends=PyPostProcessor, module = "tokenizers.processors", name = "ByteLevel")]
pub struct PyByteLevel {}
#[pymethods]
impl PyByteLevel {
#[new]
#[pyo3(signature = (trim_offsets = None, **_kwargs), text_signature = "(self, trim_offsets=True)")]
fn new(trim_offsets: Option<bool>, _kwargs: Option<&PyDict>) -> (Self, PyPostProcessor) {
let mut byte_level = ByteLevel::default();
if let Some(to) = trim_offsets {
byte_level = byte_level.trim_offsets(to);
}
(
PyByteLevel {},
PyPostProcessor::new(Arc::new(byte_level.into())),
)
}
}
#[derive(Clone, Debug)]
pub struct PySpecialToken(SpecialToken);
impl From<PySpecialToken> for SpecialToken {
fn from(v: PySpecialToken) -> Self {
v.0
}
}
impl FromPyObject<'_> for PySpecialToken {
fn extract(ob: &PyAny) -> PyResult<Self> {
if let Ok(v) = ob.extract::<(String, u32)>() {
Ok(Self(v.into()))
} else if let Ok(v) = ob.extract::<(u32, String)>() {
Ok(Self(v.into()))
} else if let Ok(d) = ob.downcast::<PyDict>() {
let id = d
.get_item("id")?
.ok_or_else(|| exceptions::PyValueError::new_err("`id` must be specified"))?
.extract::<String>()?;
let ids = d
.get_item("ids")?
.ok_or_else(|| exceptions::PyValueError::new_err("`ids` must be specified"))?
.extract::<Vec<u32>>()?;
let tokens = d
.get_item("tokens")?
.ok_or_else(|| exceptions::PyValueError::new_err("`tokens` must be specified"))?
.extract::<Vec<String>>()?;
Ok(Self(
ToPyResult(SpecialToken::new(id, ids, tokens)).into_py()?,
))
} else {
Err(exceptions::PyTypeError::new_err(
"Expected Union[Tuple[str, int], Tuple[int, str], dict]",
))
}
}
}
#[derive(Clone, Debug)]
pub struct PyTemplate(Template);
impl From<PyTemplate> for Template {
fn from(v: PyTemplate) -> Self {
v.0
}
}
impl FromPyObject<'_> for PyTemplate {
fn extract(ob: &PyAny) -> PyResult<Self> {
if let Ok(s) = ob.extract::<&str>() {
Ok(Self(
s.try_into().map_err(exceptions::PyValueError::new_err)?,
))
} else if let Ok(s) = ob.extract::<Vec<&str>>() {
Ok(Self(
s.try_into().map_err(exceptions::PyValueError::new_err)?,
))
} else {
Err(exceptions::PyTypeError::new_err(
"Expected Union[str, List[str]]",
))
}
}
}
/// Provides a way to specify templates in order to add the special tokens to each
/// input sequence as relevant.
///
/// Let's take :obj:`BERT` tokenizer as an example. It uses two special tokens, used to
/// delimitate each sequence. :obj:`[CLS]` is always used at the beginning of the first
/// sequence, and :obj:`[SEP]` is added at the end of both the first, and the pair
/// sequences. The final result looks like this:
///
/// - Single sequence: :obj:`[CLS] Hello there [SEP]`
/// - Pair sequences: :obj:`[CLS] My name is Anthony [SEP] What is my name? [SEP]`
///
/// With the type ids as following::
///
/// [CLS] ... [SEP] ... [SEP]
/// 0 0 0 1 1
///
/// You can achieve such behavior using a TemplateProcessing::
///
/// TemplateProcessing(
/// single="[CLS] $0 [SEP]",
/// pair="[CLS] $A [SEP] $B:1 [SEP]:1",
/// special_tokens=[("[CLS]", 1), ("[SEP]", 0)],
/// )
///
/// In this example, each input sequence is identified using a ``$`` construct. This identifier
/// lets us specify each input sequence, and the type_id to use. When nothing is specified,
/// it uses the default values. Here are the different ways to specify it:
///
/// - Specifying the sequence, with default ``type_id == 0``: ``$A`` or ``$B``
/// - Specifying the `type_id` with default ``sequence == A``: ``$0``, ``$1``, ``$2``, ...
/// - Specifying both: ``$A:0``, ``$B:1``, ...
///
/// The same construct is used for special tokens: ``<identifier>(:<type_id>)?``.
///
/// **Warning**: You must ensure that you are giving the correct tokens/ids as these
/// will be added to the Encoding without any further check. If the given ids correspond
/// to something totally different in a `Tokenizer` using this `PostProcessor`, it
/// might lead to unexpected results.
///
/// Args:
/// single (:obj:`Template`):
/// The template used for single sequences
///
/// pair (:obj:`Template`):
/// The template used when both sequences are specified
///
/// special_tokens (:obj:`Tokens`):
/// The list of special tokens used in each sequences
///
/// Types:
///
/// Template (:obj:`str` or :obj:`List`):
/// - If a :obj:`str` is provided, the whitespace is used as delimiter between tokens
/// - If a :obj:`List[str]` is provided, a list of tokens
///
/// Tokens (:obj:`List[Union[Tuple[int, str], Tuple[str, int], dict]]`):
/// - A :obj:`Tuple` with both a token and its associated ID, in any order
/// - A :obj:`dict` with the following keys:
/// - "id": :obj:`str` => The special token id, as specified in the Template
/// - "ids": :obj:`List[int]` => The associated IDs
/// - "tokens": :obj:`List[str]` => The associated tokens
///
/// The given dict expects the provided :obj:`ids` and :obj:`tokens` lists to have
/// the same length.
#[pyclass(extends=PyPostProcessor, module = "tokenizers.processors", name = "TemplateProcessing")]
pub struct PyTemplateProcessing {}
#[pymethods]
impl PyTemplateProcessing {
#[new]
#[pyo3(signature = (single = None, pair = None, special_tokens = None), text_signature = "(self, single, pair, special_tokens)")]
fn new(
single: Option<PyTemplate>,
pair: Option<PyTemplate>,
special_tokens: Option<Vec<PySpecialToken>>,
) -> PyResult<(Self, PyPostProcessor)> {
let mut builder = tk::processors::template::TemplateProcessing::builder();
if let Some(seq) = single {
builder.single(seq.into());
}
if let Some(seq) = pair {
builder.pair(seq.into());
}
if let Some(sp) = special_tokens {
builder.special_tokens(sp);
}
let processor = builder
.build()
.map_err(|e| exceptions::PyValueError::new_err(e.to_string()))?;
Ok((
PyTemplateProcessing {},
PyPostProcessor::new(Arc::new(processor.into())),
))
}
}
/// Sequence Processor
///
/// Args:
/// processors (:obj:`List[PostProcessor]`)
/// The processors that need to be chained
#[pyclass(extends=PyPostProcessor, module = "tokenizers.processors", name = "Sequence")]
pub struct PySequence {}
#[pymethods]
impl PySequence {
#[new]
#[pyo3(signature = (processors_py), text_signature = "(self, processors)")]
fn new(processors_py: &PyList) -> (Self, PyPostProcessor) {
let mut processors: Vec<PostProcessorWrapper> = Vec::with_capacity(processors_py.len());
for n in processors_py.iter() {
let processor: PyRef<PyPostProcessor> = n.extract().unwrap();
let processor = processor.processor.as_ref();
processors.push(processor.clone());
}
let sequence_processor = Sequence::new(processors);
(
PySequence {},
PyPostProcessor::new(Arc::new(PostProcessorWrapper::Sequence(sequence_processor))),
)
}
fn __getnewargs__<'p>(&self, py: Python<'p>) -> &'p PyTuple {
PyTuple::new(py, [PyList::empty(py)])
}
}
/// Processors Module
#[pymodule]
pub fn processors(_py: Python, m: &PyModule) -> PyResult<()> {
m.add_class::<PyPostProcessor>()?;
m.add_class::<PyBertProcessing>()?;
m.add_class::<PyRobertaProcessing>()?;
m.add_class::<PyByteLevel>()?;
m.add_class::<PyTemplateProcessing>()?;
m.add_class::<PySequence>()?;
Ok(())
}
#[cfg(test)]
mod test {
use std::sync::Arc;
use pyo3::prelude::*;
use tk::processors::bert::BertProcessing;
use tk::processors::PostProcessorWrapper;
use crate::processors::PyPostProcessor;
#[test]
fn get_subtype() {
Python::with_gil(|py| {
let py_proc = PyPostProcessor::new(Arc::new(
BertProcessing::new(("SEP".into(), 0), ("CLS".into(), 1)).into(),
));
let py_bert = py_proc.get_as_subtype(py).unwrap();
assert_eq!(
"BertProcessing",
py_bert.as_ref(py).get_type().name().unwrap()
);
})
}
#[test]
fn serialize() {
let rs_processing = BertProcessing::new(("SEP".into(), 0), ("CLS".into(), 1));
let rs_wrapper: PostProcessorWrapper = rs_processing.clone().into();
let rs_processing_ser = serde_json::to_string(&rs_processing).unwrap();
let rs_wrapper_ser = serde_json::to_string(&rs_wrapper).unwrap();
let py_processing = PyPostProcessor::new(Arc::new(rs_wrapper));
let py_ser = serde_json::to_string(&py_processing).unwrap();
assert_eq!(py_ser, rs_processing_ser);
assert_eq!(py_ser, rs_wrapper_ser);
let py_processing: PyPostProcessor = serde_json::from_str(&rs_processing_ser).unwrap();
match py_processing.processor.as_ref() {
PostProcessorWrapper::Bert(_) => (),
_ => panic!("Expected Bert postprocessor."),
}
let py_processing: PyPostProcessor = serde_json::from_str(&rs_wrapper_ser).unwrap();
match py_processing.processor.as_ref() {
PostProcessorWrapper::Bert(_) => (),
_ => panic!("Expected Bert postprocessor."),
}
}
}
| tokenizers/bindings/python/src/processors.rs/0 | {
"file_path": "tokenizers/bindings/python/src/processors.rs",
"repo_id": "tokenizers",
"token_count": 7873
} | 227 |
import pickle
import pytest
from tokenizers import NormalizedString, Tokenizer
from tokenizers.models import BPE
from tokenizers.normalizers import BertNormalizer, Lowercase, Normalizer, Sequence, Strip, Prepend
class TestBertNormalizer:
def test_instantiate(self):
assert isinstance(BertNormalizer(), Normalizer)
assert isinstance(BertNormalizer(), BertNormalizer)
assert isinstance(pickle.loads(pickle.dumps(BertNormalizer())), BertNormalizer)
def test_strip_accents(self):
normalizer = BertNormalizer(strip_accents=True, lowercase=False, handle_chinese_chars=False, clean_text=False)
output = normalizer.normalize_str("Héllò")
assert output == "Hello"
def test_handle_chinese_chars(self):
normalizer = BertNormalizer(strip_accents=False, lowercase=False, handle_chinese_chars=True, clean_text=False)
output = normalizer.normalize_str("你好")
assert output == " 你 好 "
def test_clean_text(self):
normalizer = BertNormalizer(strip_accents=False, lowercase=False, handle_chinese_chars=False, clean_text=True)
output = normalizer.normalize_str("\ufeffHello")
assert output == "Hello"
def test_lowercase(self):
normalizer = BertNormalizer(strip_accents=False, lowercase=True, handle_chinese_chars=False, clean_text=False)
output = normalizer.normalize_str("Héllò")
assert output == "héllò"
def test_can_modify(self):
normalizer = BertNormalizer(clean_text=True, handle_chinese_chars=True, strip_accents=True, lowercase=True)
assert normalizer.clean_text == True
assert normalizer.handle_chinese_chars == True
assert normalizer.strip_accents == True
assert normalizer.lowercase == True
# Modify these
normalizer.clean_text = False
assert normalizer.clean_text == False
normalizer.handle_chinese_chars = False
assert normalizer.handle_chinese_chars == False
normalizer.strip_accents = None
assert normalizer.strip_accents == None
normalizer.lowercase = False
assert normalizer.lowercase == False
class TestSequence:
def test_instantiate(self):
assert isinstance(Sequence([]), Normalizer)
assert isinstance(Sequence([]), Sequence)
assert isinstance(pickle.loads(pickle.dumps(Sequence([]))), Sequence)
def test_can_make_sequences(self):
normalizer = Sequence([Lowercase(), Strip()])
output = normalizer.normalize_str(" HELLO ")
assert output == "hello"
class TestLowercase:
def test_instantiate(self):
assert isinstance(Lowercase(), Normalizer)
assert isinstance(Lowercase(), Lowercase)
assert isinstance(pickle.loads(pickle.dumps(Lowercase())), Lowercase)
def test_lowercase(self):
normalizer = Lowercase()
output = normalizer.normalize_str("HELLO")
assert output == "hello"
class TestStrip:
def test_instantiate(self):
assert isinstance(Strip(), Normalizer)
assert isinstance(Strip(), Strip)
assert isinstance(pickle.loads(pickle.dumps(Strip())), Strip)
def test_left_strip(self):
normalizer = Strip(left=True, right=False)
output = normalizer.normalize_str(" hello ")
assert output == "hello "
def test_right_strip(self):
normalizer = Strip(left=False, right=True)
output = normalizer.normalize_str(" hello ")
assert output == " hello"
def test_full_strip(self):
normalizer = Strip(left=True, right=True)
output = normalizer.normalize_str(" hello ")
assert output == "hello"
def test_can_modify(self):
normalizer = Strip(left=True, right=True)
assert normalizer.left == True
assert normalizer.right == True
# Modify these
normalizer.left = False
assert normalizer.left == False
normalizer.right = False
assert normalizer.right == False
class TestPrepend:
def test_instantiate(self):
assert isinstance(Prepend("▁"), Normalizer)
assert isinstance(Prepend("▁"), Prepend)
assert isinstance(pickle.loads(pickle.dumps(Prepend("▁"))), Prepend)
def test_prepend(self):
normalizer = Prepend(prepend="▁")
output = normalizer.normalize_str("hello")
assert output == "▁hello"
def test_can_modify(self):
normalizer = Prepend("▁")
assert normalizer.prepend == "▁"
# Modify these
normalizer.prepend = "-"
assert normalizer.prepend == "-"
class TestCustomNormalizer:
class BadCustomNormalizer:
def normalize(self, normalized, wrong):
pass
class GoodCustomNormalizer:
def normalize(self, normalized):
self.kept_normalized = normalized
normalized.replace("there", "you")
def use_after_normalize(self):
self.kept_normalized.replace("something", "else")
def test_instantiate(self):
bad = Normalizer.custom(TestCustomNormalizer.BadCustomNormalizer())
good_custom = TestCustomNormalizer.GoodCustomNormalizer()
good = Normalizer.custom(good_custom)
assert isinstance(bad, Normalizer)
assert isinstance(good, Normalizer)
with pytest.raises(Exception, match="TypeError:.*normalize()"):
bad.normalize_str("Hey there!")
assert good.normalize_str("Hey there!") == "Hey you!"
with pytest.raises(Exception, match="Cannot use a NormalizedStringRefMut outside `normalize`"):
good_custom.use_after_normalize()
def test_normalizer_interface(self):
normalizer = Normalizer.custom(TestCustomNormalizer.GoodCustomNormalizer())
normalized = NormalizedString("Hey there!")
normalizer.normalize(normalized)
assert repr(normalized) == 'NormalizedString(original="Hey there!", normalized="Hey you!")'
assert str(normalized) == "Hey you!"
| tokenizers/bindings/python/tests/bindings/test_normalizers.py/0 | {
"file_path": "tokenizers/bindings/python/tests/bindings/test_normalizers.py",
"repo_id": "tokenizers",
"token_count": 2354
} | 228 |
import multiprocessing as mp
import os
import pytest
import requests
DATA_PATH = os.path.join("tests", "data")
def download(url, with_filename=None):
filename = with_filename if with_filename is not None else url.rsplit("/")[-1]
filepath = os.path.join(DATA_PATH, filename)
if not os.path.exists(filepath):
with open(filepath, "wb") as f:
response = requests.get(url, stream=True)
response.raise_for_status()
for chunk in response.iter_content(1024):
f.write(chunk)
return filepath
@pytest.fixture(scope="session")
def data_dir():
assert os.getcwd().endswith("python")
exist = os.path.exists(DATA_PATH) and os.path.isdir(DATA_PATH)
if not exist:
os.mkdir(DATA_PATH)
@pytest.fixture(scope="session")
def roberta_files(data_dir):
return {
"vocab": download("https://s3.amazonaws.com/models.huggingface.co/bert/roberta-base-vocab.json"),
"merges": download("https://s3.amazonaws.com/models.huggingface.co/bert/roberta-base-merges.txt"),
}
@pytest.fixture(scope="session")
def bert_files(data_dir):
return {
"vocab": download("https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased-vocab.txt"),
}
@pytest.fixture(scope="session")
def openai_files(data_dir):
return {
"vocab": download("https://s3.amazonaws.com/models.huggingface.co/bert/openai-gpt-vocab.json"),
"merges": download("https://s3.amazonaws.com/models.huggingface.co/bert/openai-gpt-merges.txt"),
}
@pytest.fixture(scope="session")
def train_files(data_dir):
big = download("https://norvig.com/big.txt")
small = os.path.join(DATA_PATH, "small.txt")
with open(small, "w") as f:
with open(big, "r") as g:
for i, line in enumerate(g):
f.write(line)
if i > 100:
break
return {
"small": small,
"big": big,
}
@pytest.fixture(scope="session")
def albert_base(data_dir):
return download("https://s3.amazonaws.com/models.huggingface.co/bert/albert-base-v1-tokenizer.json")
@pytest.fixture(scope="session")
def doc_wiki_tokenizer(data_dir):
return download(
"https://s3.amazonaws.com/models.huggingface.co/bert/anthony/doc-quicktour/tokenizer.json",
"tokenizer-wiki.json",
)
@pytest.fixture(scope="session")
def doc_pipeline_bert_tokenizer(data_dir):
return download(
"https://s3.amazonaws.com/models.huggingface.co/bert/anthony/doc-pipeline/tokenizer.json",
"bert-wiki.json",
)
# On MacOS Python 3.8+ the default was modified to `spawn`, we need `fork` in tests.
mp.set_start_method("fork")
def multiprocessing_with_parallelism(tokenizer, enabled: bool):
"""
This helper can be used to test that disabling parallelism avoids dead locks when the
same tokenizer is used after forking.
"""
# It's essential to this test that we call 'encode' or 'encode_batch'
# before the fork. This causes the main process to "lock" some resources
# provided by the Rust "rayon" crate that are needed for parallel processing.
tokenizer.encode("Hi")
tokenizer.encode_batch(["hi", "there"])
def encode(tokenizer):
tokenizer.encode("Hi")
tokenizer.encode_batch(["hi", "there"])
# Make sure this environment variable is set before the fork happens
os.environ["TOKENIZERS_PARALLELISM"] = str(enabled)
p = mp.Process(target=encode, args=(tokenizer,))
p.start()
p.join(timeout=1)
# At this point the process should have successfully exited, depending on whether parallelism
# was activated or not. So we check the status and kill it if needed
alive = p.is_alive()
if alive:
p.terminate()
assert (alive and mp.get_start_method() == "fork") == enabled
| tokenizers/bindings/python/tests/utils.py/0 | {
"file_path": "tokenizers/bindings/python/tests/utils.py",
"repo_id": "tokenizers",
"token_count": 1569
} | 229 |
Documentation
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
The node API has not been documented yet.
| tokenizers/docs/source/api/node.inc/0 | {
"file_path": "tokenizers/docs/source/api/node.inc",
"repo_id": "tokenizers",
"token_count": 22
} | 230 |
[package]
authors = ["Anthony MOI <[email protected]>", "Nicolas Patry <[email protected]>"]
edition = "2018"
name = "tokenizers"
version = "0.15.2-dev.0"
homepage = "https://github.com/huggingface/tokenizers"
repository = "https://github.com/huggingface/tokenizers"
documentation = "https://docs.rs/tokenizers/"
license = "Apache-2.0"
keywords = ["tokenizer", "NLP", "huggingface", "BPE", "WordPiece"]
readme = "./README.md"
description = """
Provides an implementation of today's most used tokenizers,
with a focus on performances and versatility.
"""
exclude = [ "rust-toolchain", "target/*", "Cargo.lock", "benches/*.txt", "benches/*.json", "data/*" ]
[lib]
name = "tokenizers"
path = "src/lib.rs"
bench = false
[[bin]]
name = "cli"
path = "src/cli.rs"
bench = false
required-features = ["cli"]
[[bench]]
name = "bpe_benchmark"
harness = false
[[bench]]
name = "bert_benchmark"
harness = false
[[bench]]
name = "layout_benchmark"
harness = false
[[bench]]
name = "unigram_benchmark"
harness = false
[dependencies]
lazy_static = "1.4"
rand = "0.8"
onig = { version = "6.4", default-features = false, optional = true }
regex = "1.9"
regex-syntax = "0.8"
rayon = "1.8"
rayon-cond = "0.3"
serde = { version = "1.0", features = [ "derive" ] }
serde_json = "1.0"
clap = { version = "4.4", features=["derive"], optional = true }
unicode-normalization-alignments = "0.1"
unicode_categories = "0.1"
unicode-segmentation = "1.10"
indicatif = {version = "0.17", optional = true}
itertools = "0.12"
log = "0.4"
derive_builder = "0.12"
spm_precompiled = "0.1"
hf-hub = { version = "0.3.2", optional = true }
aho-corasick = "1.1"
paste = "1.0.14"
macro_rules_attribute = "0.2.0"
thiserror = "1.0.49"
fancy-regex = { version = "0.13", optional = true}
getrandom = { version = "0.2.10" }
esaxx-rs = { version = "0.1.10", default-features = false, features=[]}
monostate = "0.1.9"
[features]
default = ["progressbar", "cli", "onig", "esaxx_fast"]
esaxx_fast = ["esaxx-rs/cpp"]
progressbar = ["indicatif"]
http = ["hf-hub"]
cli = ["clap"]
unstable_wasm = ["fancy-regex", "getrandom/js"]
[dev-dependencies]
criterion = "0.5"
tempfile = "3.8"
assert_approx_eq = "1.1"
[profile.release]
lto = "fat"
| tokenizers/tokenizers/Cargo.toml/0 | {
"file_path": "tokenizers/tokenizers/Cargo.toml",
"repo_id": "tokenizers",
"token_count": 903
} | 231 |
//! Test suite for the Web and headless browsers.
#![cfg(target_arch = "wasm32")]
extern crate wasm_bindgen_test;
use wasm_bindgen_test::*;
wasm_bindgen_test_configure!(run_in_browser);
#[wasm_bindgen_test]
fn pass() {
assert_eq!(1 + 1, 2);
}
| tokenizers/tokenizers/examples/unstable_wasm/tests/web.rs/0 | {
"file_path": "tokenizers/tokenizers/examples/unstable_wasm/tests/web.rs",
"repo_id": "tokenizers",
"token_count": 109
} | 232 |
use crate::tokenizer::{Decoder, Result};
use monostate::MustBe;
use serde::{Deserialize, Serialize};
#[derive(Deserialize, Clone, Debug, Serialize, Default)]
/// ByteFallback is a simple trick which converts tokens looking like `<0x61>`
/// to pure bytes, and attempts to make them into a string. If the tokens
/// cannot be decoded you will get � instead for each inconvertable byte token
#[non_exhaustive]
pub struct ByteFallback {
#[serde(rename = "type")]
type_: MustBe!("ByteFallback"),
}
impl ByteFallback {
pub fn new() -> Self {
Self {
type_: MustBe!("ByteFallback"),
}
}
}
impl Decoder for ByteFallback {
fn decode_chain(&self, tokens: Vec<String>) -> Result<Vec<String>> {
let mut new_tokens: Vec<String> = vec![];
let mut previous_byte_tokens: Vec<u8> = vec![];
for token in tokens {
let bytes = if token.len() == 6 && token.starts_with("<0x") && token.ends_with('>') {
if let Ok(byte) = u8::from_str_radix(&token[3..5], 16) {
Some(byte)
} else {
None
}
} else {
None
};
if let Some(bytes) = bytes {
previous_byte_tokens.push(bytes);
} else {
if !previous_byte_tokens.is_empty() {
if let Ok(string) = String::from_utf8(previous_byte_tokens.clone()) {
new_tokens.push(string);
} else {
for _ in 0..previous_byte_tokens.len() {
new_tokens.push("�".into());
}
}
previous_byte_tokens.clear();
}
new_tokens.push(token);
}
}
if !previous_byte_tokens.is_empty() {
if let Ok(string) = String::from_utf8(previous_byte_tokens.clone()) {
new_tokens.push(string);
} else {
for _ in 0..previous_byte_tokens.len() {
new_tokens.push("�".into());
}
}
}
Ok(new_tokens)
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn decode() {
let decoder = ByteFallback::new();
let res = decoder
.decode_chain(vec!["Hey".into(), "friend!".into()])
.unwrap();
assert_eq!(res, vec!["Hey", "friend!"]);
let res = decoder.decode_chain(vec!["<0x61>".into()]).unwrap();
assert_eq!(res, vec!["a"]);
let res = decoder.decode_chain(vec!["<0xE5>".into()]).unwrap();
assert_eq!(res, vec!["�"]);
let res = decoder
.decode_chain(vec!["<0xE5>".into(), "<0x8f>".into()])
.unwrap();
assert_eq!(res, vec!["�", "�"]);
// 叫
let res = decoder
.decode_chain(vec!["<0xE5>".into(), "<0x8f>".into(), "<0xab>".into()])
.unwrap();
assert_eq!(res, vec!["叫"]);
let res = decoder
.decode_chain(vec![
"<0xE5>".into(),
"<0x8f>".into(),
"<0xab>".into(),
"a".into(),
])
.unwrap();
assert_eq!(res, vec!["叫", "a"]);
let res = decoder
.decode_chain(vec!["<0xE5>".into(), "<0x8f>".into(), "a".into()])
.unwrap();
assert_eq!(res, vec!["�", "�", "a"]);
}
}
| tokenizers/tokenizers/src/decoders/byte_fallback.rs/0 | {
"file_path": "tokenizers/tokenizers/src/decoders/byte_fallback.rs",
"repo_id": "tokenizers",
"token_count": 1938
} | 233 |
use super::{
lattice::Lattice,
trainer::UnigramTrainer,
trie::{Trie, TrieBuilder},
};
use crate::tokenizer::{Model, Result, Token};
use crate::utils::cache::Cache;
use std::collections::HashMap;
use std::convert::TryInto;
use std::fs::read_to_string;
use std::path::{Path, PathBuf};
type TokenMap = HashMap<String, u32>;
type Vocab = Vec<(String, f64)>;
/// A `Unigram` model to encode sentences.
pub struct Unigram {
token_to_ids: TokenMap,
pub(crate) vocab: Vocab,
cache: Cache<String, Vec<String>>,
trie: Trie<u8>,
pub min_score: f64,
pub(super) unk_id: Option<usize>,
pub(super) bos_id: usize,
pub(super) eos_id: usize,
fuse_unk: bool,
is_optimized: bool,
byte_fallback: bool,
}
impl PartialEq for Unigram {
fn eq(&self, other: &Self) -> bool {
self.unk_id == other.unk_id && self.vocab == other.vocab
}
}
impl Clone for Unigram {
// `Clone` can't be derive because it's not implemented for `Cache`.
// To keep things simple when we clone, the new Unigram will start with a fresh cache.
fn clone(&self) -> Self {
let fresh_cache = self.cache.fresh();
Self {
vocab: self.vocab.clone(),
cache: fresh_cache,
token_to_ids: self.token_to_ids.clone(),
trie: self.trie.clone(),
min_score: self.min_score,
unk_id: self.unk_id,
bos_id: self.bos_id,
eos_id: self.eos_id,
fuse_unk: self.fuse_unk,
is_optimized: self.is_optimized,
byte_fallback: self.byte_fallback,
}
}
}
impl std::fmt::Debug for Unigram {
fn fmt(&self, fmt: &mut std::fmt::Formatter) -> std::fmt::Result {
fmt.debug_struct("Unigram")
.field("vocab", &self.vocab.len())
.field("unk_id", &self.unk_id)
.field("byte_fallback", &self.byte_fallback)
.finish()
}
}
static K_UNK_PENALTY: f64 = 10.0;
#[derive(thiserror::Error, Debug)]
pub enum UnigramError {
#[error("The vocabulary is empty but at least <unk> is needed")]
EmptyVocabulary,
#[error("The `unk_id` is larger than vocabulary size")]
UnkIdNotInVocabulary,
#[error("Encountered an unknown token but `unk_id` is missing")]
MissingUnkId,
}
impl Default for Unigram {
fn default() -> Self {
let vocab = vec![("<unk>".to_string(), 0.0)];
Self::from(vocab, Some(0), false).unwrap()
}
}
impl Unigram {
/// Create a `Unigram` model from a given vocabulary.
/// Vocabulary are the various tokens and their associated score which is a sort of a logprob of
/// their frequency, which will enable tokenization and sampling.
/// unk_id, is the index within the vocabulary.
/// For now `Unigram` *requires* at least `unk` because we might find a never seen char.
/// Further versions might allow that part to be hidden.
pub fn from(
vocab: Vec<(String, f64)>,
unk_id: Option<usize>,
byte_fallback: bool,
) -> Result<Self> {
let n = vocab.len();
let mut token_to_ids: TokenMap = HashMap::new();
let mut builder = TrieBuilder::default();
if let Some(unk_id) = unk_id {
if vocab.is_empty() {
return Err(Box::new(UnigramError::EmptyVocabulary));
}
if unk_id >= vocab.len() {
return Err(Box::new(UnigramError::UnkIdNotInVocabulary));
}
}
let bos_id = n + 1;
let eos_id = n + 2;
let mut min_score = f64::INFINITY;
for (id, (token, score)) in vocab.iter().enumerate() {
token_to_ids.insert(token.to_string(), id as u32);
let bytes: Vec<u8> = token.bytes().collect();
builder.push(&bytes);
if score < &min_score {
min_score = *score;
}
}
let trie = builder.build();
let fuse_unk = true;
let is_optimized = true;
Ok(Self {
vocab,
token_to_ids,
trie,
min_score,
bos_id,
eos_id,
unk_id,
fuse_unk,
cache: Cache::default(),
is_optimized,
byte_fallback,
})
}
#[cfg(test)]
pub(super) fn set_fuse_unk(&mut self, fuse_unk: bool) {
self.fuse_unk = fuse_unk;
self.cache = self.cache.fresh();
}
#[cfg(test)]
pub(super) fn set_optimized(&mut self, is_optimized: bool) {
self.is_optimized = is_optimized;
}
pub fn byte_fallback(&self) -> bool {
self.byte_fallback
}
pub(super) fn len(&self) -> usize {
self.vocab.len()
}
pub(super) fn populate_nodes(&self, lattice: &mut Lattice) {
let unk_score = self.min_score - K_UNK_PENALTY;
let len = lattice.len();
let mut begin_pos = 0;
while begin_pos < len {
let mblen = lattice.sentence[begin_pos..]
.chars()
.next()
.unwrap()
.len_utf8();
let mut has_single_node = false;
for bytes in self
.trie
.common_prefix_search(lattice.sentence.bytes().skip(begin_pos))
{
let n = bytes.len();
let tok = String::from_utf8(bytes).unwrap();
let id = *self.token_to_ids.get(&tok).unwrap();
let item = &self.vocab[id as usize];
assert_eq!(item.0, tok);
let score: f64 = item.1;
lattice.insert(begin_pos, n, score, id.try_into().unwrap());
if !has_single_node && n == mblen {
has_single_node = true;
}
}
if !has_single_node {
if let Some(unk_id) = self.unk_id {
lattice.insert(begin_pos, mblen, unk_score, unk_id);
}
}
begin_pos += mblen
}
}
/// This functions take a String, and will encode it in a Vec of Strings,
/// of the best tokenization available to the current model.
/// ```
/// use tokenizers::models::unigram::Unigram;
///
/// let pieces = vec![
/// ("<unk>".to_string(), 0.0),
/// ("a".to_string(), 0.0),
/// ("b".to_string(), 0.0),
/// ("c".to_string(), 0.0),
/// ("d".to_string(), 0.0),
/// ("cd".to_string(), 1.0),
/// ("ab".to_string(), 2.0),
/// ("abc".to_string(), 5.0),
/// ("abcd".to_string(), 10.0),
/// ];
/// let model = Unigram::from(pieces, Some(0), false).unwrap();
/// let result = model.encode("abcdacdxx").unwrap();
/// assert_eq!(result, vec!["abcd", "a", "cd", "xx"]);
/// ```
pub fn encode(&self, sentence: &str) -> Result<Vec<String>> {
if sentence.is_empty() {
return Ok(vec![]);
}
if let Some(result) = self.cache.get(sentence) {
Ok(result.to_vec())
} else {
let result = if self.is_optimized {
self.encode_optimized(sentence)?
} else {
self.encode_unoptimized(sentence)?
};
self.cache.set(sentence.to_owned(), result.clone());
Ok(result)
}
}
fn encode_optimized(&self, sentence: &str) -> Result<Vec<String>> {
// https://github.com/google/sentencepiece/blob/d48247191a6d50e469ed1a4a36e877befffd1851/src/unigram_model.cc#L600
#[derive(Debug, Clone)]
struct BestPathNode {
/// The vocab id. (maybe UNK)
id: usize,
/// The total score of the best path ending at this node.
best_path_score: f64,
/// The starting position (in utf-8) of this node. The entire best
/// path can be constructed by backtracking along this link.
starts_at: Option<usize>,
}
impl Default for BestPathNode {
fn default() -> Self {
Self {
id: 0,
best_path_score: 0.0,
starts_at: None,
}
}
}
let size = sentence.len();
let unk_score = self.min_score - K_UNK_PENALTY;
let mut best_path_ends_at = vec![BestPathNode::default(); size + 1];
let mut starts_at = 0;
while starts_at < size {
let best_path_score_till_here = best_path_ends_at[starts_at].best_path_score;
let mut has_single_node = false;
let mblen = sentence[starts_at..].chars().next().unwrap().len_utf8();
for tok_bytes in self
.trie
.common_prefix_search(sentence.bytes().skip(starts_at))
{
let key_pos = starts_at + tok_bytes.len();
let token: String = String::from_utf8(tok_bytes).unwrap();
let target_node = &mut best_path_ends_at[key_pos];
let length = key_pos - starts_at;
let id = self.token_to_ids.get(&token).unwrap();
let score = self.vocab.get(*id as usize).unwrap().1;
let candidate_best_path_score = score + best_path_score_till_here;
if target_node.starts_at.is_none()
|| candidate_best_path_score > target_node.best_path_score
{
target_node.best_path_score = candidate_best_path_score;
target_node.starts_at = Some(starts_at);
target_node.id = *id as usize;
}
if !has_single_node && length == mblen {
has_single_node = true;
}
}
if !has_single_node {
let target_node = &mut best_path_ends_at[starts_at + mblen];
let candidate_best_path_score = unk_score + best_path_score_till_here;
if target_node.starts_at.is_none()
|| candidate_best_path_score > target_node.best_path_score
{
target_node.best_path_score = candidate_best_path_score;
target_node.starts_at = Some(starts_at);
target_node.id = self.unk_id.ok_or(UnigramError::MissingUnkId)?;
}
}
starts_at += mblen
}
let mut ends_at = size;
let mut results: Vec<String> = vec![];
let mut token = vec![];
while ends_at > 0 {
let node = &best_path_ends_at[ends_at];
let starts_at = node.starts_at.unwrap();
if self.fuse_unk
&& self.unk_id.is_some()
&& node.id == self.unk_id.ok_or(UnigramError::MissingUnkId)?
{
token.push(
String::from_utf8(sentence[starts_at..ends_at].as_bytes().to_vec()).unwrap(),
);
} else {
if !token.is_empty() {
token.reverse();
results.push(token.concat());
token = vec![];
}
results.push(
String::from_utf8(sentence[starts_at..ends_at].as_bytes().to_vec()).unwrap(),
);
}
ends_at = starts_at;
}
if !token.is_empty() {
token.reverse();
results.push(token.concat());
}
results.reverse();
Ok(results)
}
fn encode_unoptimized(&self, sentence: &str) -> Result<Vec<String>> {
let mut lattice = Lattice::from(sentence, self.bos_id, self.eos_id);
self.populate_nodes(&mut lattice);
if self.fuse_unk {
let mut results = vec![];
let mut token = String::new();
for node in lattice.viterbi().iter() {
let item = lattice.piece(&node.borrow());
if node.borrow().id == self.unk_id.ok_or(UnigramError::MissingUnkId)? {
token.push_str(&item);
} else {
if !token.is_empty() {
results.push(token);
token = String::new();
}
results.push(item.to_string());
}
}
if !token.is_empty() {
results.push(token);
}
Ok(results)
} else {
Ok(lattice.tokens())
}
}
/// Iterate of vocabulary of the model as a pair of `(token, score)`.
pub fn iter(&self) -> UnigramIterator {
UnigramIterator { model: self, i: 0 }
}
/// Loads a SentencePiece output model after being trained by tokenizers.
/// After that you can use the model with tokenizers library.
/// ```no_run
/// use tokenizers::models::unigram::Unigram;
/// use std::path::Path;
///
/// let model = Unigram::load("mymodel-unigram.json").unwrap();
/// ```
pub fn load<P: AsRef<Path>>(path: P) -> Result<Unigram> {
let string = read_to_string(path)?;
Ok(serde_json::from_str(&string)?)
}
}
/// Iterator to iterate of vocabulary of the model, and their relative score.
pub struct UnigramIterator<'a> {
model: &'a Unigram,
i: usize,
}
impl<'a> Iterator for UnigramIterator<'a> {
type Item = &'a (String, f64);
fn next(&mut self) -> Option<Self::Item> {
let i = self.i;
if i < self.model.len() {
let r = Some(&self.model.vocab[i]);
self.i += 1;
r
} else {
None
}
}
}
impl Model for Unigram {
type Trainer = UnigramTrainer;
fn get_vocab(&self) -> HashMap<String, u32> {
self.token_to_ids.clone()
}
fn get_vocab_size(&self) -> usize {
self.vocab.len()
}
fn tokenize(&self, sentence: &str) -> Result<Vec<Token>> {
let str_tokens = self.encode(sentence)?;
let mut offset = 0;
let mut tokens = Vec::with_capacity(str_tokens.len());
for string in str_tokens {
let len = string.len();
let offsets = (offset, offset + len);
let id: u32 = match self.token_to_ids.get(&string) {
Some(id) => *id,
None => {
if self.byte_fallback {
let byte_tokens: Option<Vec<_>> = string
.bytes()
.map(|byte| -> Option<Token> {
let byte_string = format!("<0x{:02X}>", byte);
let id = self.token_to_ids.get(&byte_string);
id.map(|id| Token::new(*id, byte_string, (offset, offset + len)))
})
.collect();
if let Some(byte_tokens) = byte_tokens {
for token in byte_tokens {
tokens.push(token);
}
offset += len;
continue;
}
}
self.unk_id.ok_or(UnigramError::MissingUnkId)? as u32
}
};
offset += len;
tokens.push(Token::new(id, string, offsets));
}
Ok(tokens)
}
fn token_to_id(&self, token: &str) -> Option<u32> {
self.token_to_ids.get(token).copied()
}
fn id_to_token(&self, id: u32) -> Option<String> {
self.vocab.get(id as usize).map(|item| item.0.clone())
}
fn save(&self, folder: &Path, name: Option<&str>) -> Result<Vec<PathBuf>> {
let name = match name {
Some(name) => format!("{}-unigram.json", name),
None => "unigram.json".to_string(),
};
let mut fullpath = PathBuf::new();
fullpath.push(folder);
fullpath.push(name);
let string = serde_json::to_string_pretty(self)?;
std::fs::write(&fullpath, string)?;
Ok(vec![fullpath])
}
fn get_trainer(&self) -> Self::Trainer {
UnigramTrainer::default()
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn test_populate_nodes_unk() {
let pieces = vec![("<unk>".to_string(), 0.0)];
let model = Unigram::from(pieces, Some(0), false).unwrap();
let mut lattice = Lattice::from("abc", model.bos_id, model.eos_id);
model.populate_nodes(&mut lattice);
assert_eq!(lattice.begin_nodes[0].len(), 1);
assert_eq!(lattice.begin_nodes[1].len(), 1);
assert_eq!(lattice.begin_nodes[2].len(), 1);
assert_eq!(lattice.begin_nodes[0][0].borrow().id, 0);
assert_eq!(lattice.begin_nodes[1][0].borrow().id, 0);
assert_eq!(lattice.begin_nodes[2][0].borrow().id, 0);
assert_eq!(lattice.begin_nodes[0][0].borrow().node_id, 2);
assert_eq!(lattice.begin_nodes[1][0].borrow().node_id, 3);
assert_eq!(lattice.begin_nodes[2][0].borrow().node_id, 4);
}
#[test]
fn test_populate_nodes() {
let pieces = vec![
("<unk>".to_string(), 0.0),
("a".to_string(), 0.1),
("b".to_string(), 0.2),
("ab".to_string(), 0.3),
("bc".to_string(), 0.4),
];
let model = Unigram::from(pieces, Some(0), false).unwrap();
let mut lattice = Lattice::from("abc", model.bos_id, model.eos_id);
model.populate_nodes(&mut lattice);
assert_eq!(lattice.begin_nodes[0].len(), 2); // a, ab
assert_eq!(lattice.begin_nodes[1].len(), 2); // b, bc
assert_eq!(lattice.begin_nodes[2].len(), 1); // c(unk)
// Id is the vocabulary id from Unigram model
// node_id is simply the rank of the given node in the lattice.
assert_eq!(lattice.begin_nodes[0][0].borrow().id, 1);
assert_eq!(lattice.begin_nodes[0][1].borrow().id, 3);
assert_eq!(lattice.begin_nodes[1][0].borrow().id, 2);
assert_eq!(lattice.begin_nodes[1][1].borrow().id, 4);
assert_eq!(lattice.begin_nodes[2][0].borrow().id, 0);
assert_eq!(lattice.begin_nodes[0][0].borrow().node_id, 2);
assert_eq!(lattice.begin_nodes[0][1].borrow().node_id, 3);
assert_eq!(lattice.begin_nodes[1][0].borrow().node_id, 4);
assert_eq!(lattice.begin_nodes[1][1].borrow().node_id, 5);
assert_eq!(lattice.begin_nodes[2][0].borrow().node_id, 6);
}
#[test]
fn test_encode() {
let sentencepieces = vec![
("<unk>".to_string(), 0.0),
("a".to_string(), 0.0),
("b".to_string(), 0.0),
("c".to_string(), 0.0),
("d".to_string(), 0.0),
("cd".to_string(), 1.0),
("ab".to_string(), 2.0),
("abc".to_string(), 5.0),
("abcd".to_string(), 10.0),
];
let model = Unigram::from(sentencepieces, Some(0), false).unwrap();
let result = model.encode("abcd").unwrap();
assert_eq!(result, vec!["abcd"]);
}
#[test]
fn test_encode2() {
let sentencepieces = vec![
("<unk>".to_string(), 0.0),
("ab".to_string(), 0.0),
("cd".to_string(), -0.1),
("abc".to_string(), -0.2),
("a".to_string(), -0.3),
("b".to_string(), -0.4),
("c".to_string(), -0.5),
("ABC".to_string(), -0.5),
("abcdabcd".to_string(), 20.0), // User defined just max the scores.
("q".to_string(), 20.5),
("r".to_string(), 20.5),
("qr".to_string(), -0.5),
];
let mut model = Unigram::from(sentencepieces, Some(0), false).unwrap();
for is_optimized in &[true, false] {
model.set_optimized(*is_optimized);
println!("IsOptimized {:?}", is_optimized);
assert_eq!(model.encode("abc").unwrap(), vec!["abc"]);
assert_eq!(model.encode("AB").unwrap(), vec!["AB"]);
model.set_fuse_unk(false);
assert_eq!(model.encode("AB").unwrap(), vec!["A", "B"]);
model.set_fuse_unk(true);
assert_eq!(model.encode("AB").unwrap(), vec!["AB"]);
assert_eq!(model.encode("abcd").unwrap(), vec!["ab", "cd"]);
assert_eq!(model.encode("abcc").unwrap(), vec!["abc", "c"]);
assert_eq!(
model.encode("xabcabaabcdd").unwrap(),
vec!["x", "abc", "ab", "a", "ab", "cd", "d"]
);
model.set_fuse_unk(false);
assert_eq!(
model.encode("xyz東京").unwrap(),
vec!["x", "y", "z", "東", "京"]
);
model.set_fuse_unk(true);
assert_eq!(model.encode("xyz東京").unwrap(), vec!["xyz東京"]);
// User encoded in original version
assert_eq!(model.encode("ABC").unwrap(), vec!["ABC"]);
assert_eq!(model.encode("abABCcd").unwrap(), vec!["ab", "ABC", "cd"]);
assert_eq!(
model.encode("ababcdabcdcd").unwrap(),
vec!["ab", "abcdabcd", "cd"]
);
assert_eq!(model.encode("abqrcd").unwrap(), vec!["ab", "q", "r", "cd"]);
}
}
#[test]
fn test_unigram_bytefallback() {
// In [97]: processor.encode_as_pieces("⅐⅛⅑ ")
// Out[97]: ['▁', '<0xE2>', '<0x85>', '<0x90>', '⅛', '<0xE2>', '<0x85>', '<0x91>', '▁']
let sentencepieces = vec![
("<unk>".to_string(), 0.0),
("<0xC3>".to_string(), -0.01),
("<0xA9>".to_string(), -0.03),
];
let unigram = Unigram::from(sentencepieces, Some(0), true).unwrap();
let tokens: Vec<Token> = unigram.tokenize("é").unwrap();
assert_eq!(
tokens,
[
Token {
id: 1,
value: "<0xC3>".to_string(),
offsets: (0, 2)
},
Token {
id: 2,
value: "<0xA9>".to_string(),
offsets: (0, 2)
}
]
);
let tokens = unigram.tokenize("?é").unwrap();
assert_eq!(tokens[0].id, 0);
}
}
| tokenizers/tokenizers/src/models/unigram/model.rs/0 | {
"file_path": "tokenizers/tokenizers/src/models/unigram/model.rs",
"repo_id": "tokenizers",
"token_count": 11900
} | 234 |
use crate::tokenizer::{NormalizedString, Normalizer, Result};
use crate::utils::macro_rules_attribute;
#[derive(Default, Copy, Clone, Debug)]
#[macro_rules_attribute(impl_serde_type!)]
pub struct NFD;
impl Normalizer for NFD {
fn normalize(&self, normalized: &mut NormalizedString) -> Result<()> {
normalized.nfd();
Ok(())
}
}
#[derive(Default, Copy, Clone, Debug)]
#[macro_rules_attribute(impl_serde_type!)]
pub struct NFKD;
impl Normalizer for NFKD {
fn normalize(&self, normalized: &mut NormalizedString) -> Result<()> {
normalized.nfkd();
Ok(())
}
}
#[derive(Default, Copy, Clone, Debug)]
#[macro_rules_attribute(impl_serde_type!)]
pub struct NFC;
impl Normalizer for NFC {
fn normalize(&self, normalized: &mut NormalizedString) -> Result<()> {
normalized.nfc();
Ok(())
}
}
#[derive(Default, Copy, Clone, Debug)]
#[macro_rules_attribute(impl_serde_type!)]
pub struct NFKC;
impl Normalizer for NFKC {
fn normalize(&self, normalized: &mut NormalizedString) -> Result<()> {
normalized.nfkc();
Ok(())
}
}
fn do_nmt(normalized: &mut NormalizedString) {
// Ascii Control characters
normalized
.filter(|c| {
!matches!(
c as u32,
0x0001..=0x0008 |
0x000B |
0x000E..=0x001F |
0x007F |
0x008F |
0x009F
)
})
// Other code points considered as whitespace.
.map(|c| match c as u32 {
0x0009 => ' ',
0x000A => ' ',
0x000C => ' ',
0x000D => ' ',
0x1680 => ' ',
0x200B..=0x200F => ' ',
0x2028 => ' ',
0x2029 => ' ',
0x2581 => ' ',
0xFEFF => ' ',
0xFFFD => ' ',
_ => c,
});
}
#[derive(Default, Copy, Clone, Debug)]
#[macro_rules_attribute(impl_serde_type!)]
pub struct Nmt;
impl Normalizer for Nmt {
fn normalize(&self, normalized: &mut NormalizedString) -> Result<()> {
do_nmt(normalized);
Ok(())
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn test_nfkc() {
let original = "\u{fb01}".to_string();
let normalized = "fi".to_string();
let mut n = NormalizedString::from(original.clone());
NFKC.normalize(&mut n).unwrap();
assert_eq!(
n,
NormalizedString::new(original, normalized, vec![(0, 3), (0, 3)], 0)
);
assert_eq!(n.alignments_original(), vec![(0, 2), (0, 2), (0, 2)]);
}
}
| tokenizers/tokenizers/src/normalizers/unicode.rs/0 | {
"file_path": "tokenizers/tokenizers/src/normalizers/unicode.rs",
"repo_id": "tokenizers",
"token_count": 1317
} | 235 |
pub mod bert;
pub mod roberta;
pub mod sequence;
pub mod template;
// Re-export these as processors
pub use super::pre_tokenizers::byte_level;
use serde::{Deserialize, Serialize};
use crate::pre_tokenizers::byte_level::ByteLevel;
use crate::processors::bert::BertProcessing;
use crate::processors::roberta::RobertaProcessing;
use crate::processors::sequence::Sequence;
use crate::processors::template::TemplateProcessing;
use crate::{Encoding, PostProcessor, Result};
#[derive(Serialize, Deserialize, PartialEq, Debug, Clone, Eq)]
#[serde(untagged)]
pub enum PostProcessorWrapper {
// Roberta must be before Bert for deserialization (serde does not validate tags)
Roberta(RobertaProcessing),
Bert(BertProcessing),
ByteLevel(ByteLevel),
Template(TemplateProcessing),
Sequence(Sequence),
}
impl PostProcessor for PostProcessorWrapper {
fn added_tokens(&self, is_pair: bool) -> usize {
match self {
Self::Bert(bert) => bert.added_tokens(is_pair),
Self::ByteLevel(bl) => bl.added_tokens(is_pair),
Self::Roberta(roberta) => roberta.added_tokens(is_pair),
Self::Template(template) => template.added_tokens(is_pair),
Self::Sequence(bl) => bl.added_tokens(is_pair),
}
}
fn process_encodings(
&self,
encodings: Vec<Encoding>,
add_special_tokens: bool,
) -> Result<Vec<Encoding>> {
match self {
Self::Bert(bert) => bert.process_encodings(encodings, add_special_tokens),
Self::ByteLevel(bl) => bl.process_encodings(encodings, add_special_tokens),
Self::Roberta(roberta) => roberta.process_encodings(encodings, add_special_tokens),
Self::Template(template) => template.process_encodings(encodings, add_special_tokens),
Self::Sequence(bl) => bl.process_encodings(encodings, add_special_tokens),
}
}
}
impl_enum_from!(BertProcessing, PostProcessorWrapper, Bert);
impl_enum_from!(ByteLevel, PostProcessorWrapper, ByteLevel);
impl_enum_from!(RobertaProcessing, PostProcessorWrapper, Roberta);
impl_enum_from!(TemplateProcessing, PostProcessorWrapper, Template);
impl_enum_from!(Sequence, PostProcessorWrapper, Sequence);
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn deserialize_bert_roberta_correctly() {
let roberta = RobertaProcessing::default();
let roberta_r = r#"{
"type":"RobertaProcessing",
"sep":["</s>",2],
"cls":["<s>",0],
"trim_offsets":true,
"add_prefix_space":true
}"#
.replace(char::is_whitespace, "");
assert_eq!(serde_json::to_string(&roberta).unwrap(), roberta_r);
assert_eq!(
serde_json::from_str::<PostProcessorWrapper>(&roberta_r).unwrap(),
PostProcessorWrapper::Roberta(roberta)
);
let bert = BertProcessing::default();
let bert_r = r#"{"type":"BertProcessing","sep":["[SEP]",102],"cls":["[CLS]",101]}"#;
assert_eq!(serde_json::to_string(&bert).unwrap(), bert_r);
assert_eq!(
serde_json::from_str::<PostProcessorWrapper>(bert_r).unwrap(),
PostProcessorWrapper::Bert(bert)
);
}
}
| tokenizers/tokenizers/src/processors/mod.rs/0 | {
"file_path": "tokenizers/tokenizers/src/processors/mod.rs",
"repo_id": "tokenizers",
"token_count": 1426
} | 236 |
use crate::tokenizer::pattern::Pattern;
use crate::{Offsets, Result};
use onig::Regex;
use std::error::Error;
#[derive(Debug)]
pub struct SysRegex {
regex: Regex,
}
impl SysRegex {
pub fn find_iter<'r, 't>(&'r self, inside: &'t str) -> onig::FindMatches<'r, 't> {
self.regex.find_iter(inside)
}
pub fn new(
regex_str: &str,
) -> std::result::Result<Self, Box<dyn Error + Send + Sync + 'static>> {
Ok(Self {
regex: Regex::new(regex_str)?,
})
}
}
impl Pattern for &Regex {
fn find_matches(&self, inside: &str) -> Result<Vec<(Offsets, bool)>> {
if inside.is_empty() {
return Ok(vec![((0, 0), false)]);
}
let mut prev = 0;
let mut splits = Vec::with_capacity(inside.len());
for (start, end) in self.find_iter(inside) {
if prev != start {
splits.push(((prev, start), false));
}
splits.push(((start, end), true));
prev = end;
}
if prev != inside.len() {
splits.push(((prev, inside.len()), false))
}
Ok(splits)
}
}
| tokenizers/tokenizers/src/utils/onig.rs/0 | {
"file_path": "tokenizers/tokenizers/src/utils/onig.rs",
"repo_id": "tokenizers",
"token_count": 571
} | 237 |
[run]
source=transformers
omit =
# skip convertion scripts from testing for now
*/convert_*
*/__main__.py
[report]
exclude_lines =
pragma: no cover
raise
except
register_parameter | transformers/.coveragerc/0 | {
"file_path": "transformers/.coveragerc",
"repo_id": "transformers",
"token_count": 81
} | 238 |
apiVersion: v1
kind: PersistentVolume
metadata:
name: huggingface-cluster-disk
spec:
storageClassName: ""
capacity:
storage: 500Gi
accessModes:
- ReadOnlyMany
claimRef:
namespace: default
name: huggingface-cluster-disk-claim
gcePersistentDisk:
pdName: huggingface-cluster-disk
fsType: ext4
readOnly: true
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: huggingface-cluster-disk-claim
spec:
# Specify "" as the storageClassName so it matches the PersistentVolume's StorageClass.
# A nil storageClassName value uses the default StorageClass. For details, see
# https://kubernetes.io/docs/concepts/storage/persistent-volumes/#class-1
storageClassName: ""
accessModes:
- ReadOnlyMany
resources:
requests:
storage: 1Ki
| transformers/docker/transformers-pytorch-tpu/dataset.yaml/0 | {
"file_path": "transformers/docker/transformers-pytorch-tpu/dataset.yaml",
"repo_id": "transformers",
"token_count": 274
} | 239 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Ein Modell teilen
Die letzten beiden Tutorials haben gezeigt, wie man ein Modell mit PyTorch, Keras und 🤗 Accelerate für verteilte Setups feinabstimmen kann. Der nächste Schritt besteht darin, Ihr Modell mit der Community zu teilen! Bei Hugging Face glauben wir an den offenen Austausch von Wissen und Ressourcen, um künstliche Intelligenz für alle zu demokratisieren. Wir ermutigen Sie, Ihr Modell mit der Community zu teilen, um anderen zu helfen, Zeit und Ressourcen zu sparen.
In diesem Tutorial lernen Sie zwei Methoden kennen, wie Sie ein trainiertes oder verfeinertes Modell auf dem [Model Hub](https://huggingface.co/models) teilen können:
- Programmgesteuertes Übertragen Ihrer Dateien auf den Hub.
- Ziehen Sie Ihre Dateien per Drag-and-Drop über die Weboberfläche in den Hub.
<iframe width="560" height="315" src="https://www.youtube.com/embed/XvSGPZFEjDY" title="YouTube video player"
frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope;
picture-in-picture" allowfullscreen></iframe>
<Tip>
Um ein Modell mit der Öffentlichkeit zu teilen, benötigen Sie ein Konto auf [huggingface.co](https://huggingface.co/join). Sie können auch einer bestehenden Organisation beitreten oder eine neue Organisation gründen.
</Tip>
## Repository-Funktionen
Jedes Repository im Model Hub verhält sich wie ein typisches GitHub-Repository. Unsere Repositorys bieten Versionierung, Commit-Historie und die Möglichkeit, Unterschiede zu visualisieren.
Die integrierte Versionierung des Model Hub basiert auf Git und [git-lfs](https://git-lfs.github.com/). Mit anderen Worten: Sie können ein Modell als ein Repository behandeln, was eine bessere Zugriffskontrolle und Skalierbarkeit ermöglicht. Die Versionskontrolle ermöglicht *Revisionen*, eine Methode zum Anheften einer bestimmten Version eines Modells mit einem Commit-Hash, Tag oder Branch.
Folglich können Sie eine bestimmte Modellversion mit dem Parameter "Revision" laden:
```py
>>> model = AutoModel.from_pretrained(
... "julien-c/EsperBERTo-small", revision="v2.0.1" # tag name, or branch name, or commit hash
... )
```
Dateien lassen sich auch in einem Repository leicht bearbeiten, und Sie können die Commit-Historie sowie die Unterschiede einsehen:

## Einrichtung
Bevor Sie ein Modell für den Hub freigeben, benötigen Sie Ihre Hugging Face-Anmeldedaten. Wenn Sie Zugang zu einem Terminal haben, führen Sie den folgenden Befehl in der virtuellen Umgebung aus, in der 🤗 Transformers installiert ist. Dadurch werden Ihre Zugangsdaten in Ihrem Hugging Face-Cache-Ordner (standardmäßig `~/.cache/`) gespeichert:
```bash
huggingface-cli login
```
Wenn Sie ein Notebook wie Jupyter oder Colaboratory verwenden, stellen Sie sicher, dass Sie die [`huggingface_hub`](https://huggingface.co/docs/hub/adding-a-library) Bibliothek installiert haben. Diese Bibliothek ermöglicht Ihnen die programmatische Interaktion mit dem Hub.
```bash
pip install huggingface_hub
```
Verwenden Sie dann `notebook_login`, um sich beim Hub anzumelden, und folgen Sie dem Link [hier](https://huggingface.co/settings/token), um ein Token für die Anmeldung zu generieren:
```py
>>> from huggingface_hub import notebook_login
>>> notebook_login()
```
## Ein Modell für alle Frameworks konvertieren
Um sicherzustellen, dass Ihr Modell von jemandem verwendet werden kann, der mit einem anderen Framework arbeitet, empfehlen wir Ihnen, Ihr Modell sowohl mit PyTorch- als auch mit TensorFlow-Checkpoints zu konvertieren und hochzuladen. Während Benutzer immer noch in der Lage sind, Ihr Modell von einem anderen Framework zu laden, wenn Sie diesen Schritt überspringen, wird es langsamer sein, weil 🤗 Transformers den Checkpoint on-the-fly konvertieren müssen.
Die Konvertierung eines Checkpoints für ein anderes Framework ist einfach. Stellen Sie sicher, dass Sie PyTorch und TensorFlow installiert haben (siehe [hier](installation) für Installationsanweisungen), und finden Sie dann das spezifische Modell für Ihre Aufgabe in dem anderen Framework.
<frameworkcontent>
<pt>
Geben Sie `from_tf=True` an, um einen Prüfpunkt von TensorFlow nach PyTorch zu konvertieren:
```py
>>> pt_model = DistilBertForSequenceClassification.from_pretrained("path/to/awesome-name-you-picked", from_tf=True)
>>> pt_model.save_pretrained("path/to/awesome-name-you-picked")
```
</pt>
<tf>
Geben Sie `from_pt=True` an, um einen Prüfpunkt von PyTorch nach TensorFlow zu konvertieren:
```py
>>> tf_model = TFDistilBertForSequenceClassification.from_pretrained("path/to/awesome-name-you-picked", from_pt=True)
```
Dann können Sie Ihr neues TensorFlow-Modell mit seinem neuen Checkpoint speichern:
```py
>>> tf_model.save_pretrained("path/to/awesome-name-you-picked")
```
</tf>
<jax>
Wenn ein Modell in Flax verfügbar ist, können Sie auch einen Kontrollpunkt von PyTorch nach Flax konvertieren:
```py
>>> flax_model = FlaxDistilBertForSequenceClassification.from_pretrained(
... "path/to/awesome-name-you-picked", from_pt=True
... )
```
</jax>
</frameworkcontent>
## Ein Modell während des Trainings hochladen
<frameworkcontent>
<pt>
<Youtube id="Z1-XMy-GNLQ"/>
Die Weitergabe eines Modells an den Hub ist so einfach wie das Hinzufügen eines zusätzlichen Parameters oder Rückrufs. Erinnern Sie sich an das [Feinabstimmungs-Tutorial](training), in der Klasse [`TrainingArguments`] geben Sie Hyperparameter und zusätzliche Trainingsoptionen an. Eine dieser Trainingsoptionen beinhaltet die Möglichkeit, ein Modell direkt an den Hub zu pushen. Setzen Sie `push_to_hub=True` in Ihrer [`TrainingArguments`]:
```py
>>> training_args = TrainingArguments(output_dir="my-awesome-model", push_to_hub=True)
```
Übergeben Sie Ihre Trainingsargumente wie gewohnt an [`Trainer`]:
```py
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=small_train_dataset,
... eval_dataset=small_eval_dataset,
... compute_metrics=compute_metrics,
... )
```
Nach der Feinabstimmung Ihres Modells rufen Sie [`~transformers.Trainer.push_to_hub`] auf [`Trainer`] auf, um das trainierte Modell an den Hub zu übertragen. Transformers fügt sogar automatisch Trainings-Hyperparameter, Trainingsergebnisse und Framework-Versionen zu Ihrer Modellkarte hinzu!
```py
>>> trainer.push_to_hub()
```
</pt>
<tf>
Geben Sie ein Modell mit [`PushToHubCallback`] an den Hub weiter. In der [`PushToHubCallback`] Funktion, fügen Sie hinzu:
- Ein Ausgabeverzeichnis für Ihr Modell.
- Einen Tokenizer.
- Die `hub_model_id`, die Ihr Hub-Benutzername und Modellname ist.
```py
>>> from transformers import PushToHubCallback
>>> push_to_hub_callback = PushToHubCallback(
... output_dir="./your_model_save_path", tokenizer=tokenizer, hub_model_id="your-username/my-awesome-model"
... )
```
Fügen Sie den Callback zu [`fit`](https://keras.io/api/models/model_training_apis/) hinzu, und 🤗 Transformers wird das trainierte Modell an den Hub weiterleiten:
```py
>>> model.fit(tf_train_dataset, validation_data=tf_validation_dataset, epochs=3, callbacks=push_to_hub_callback)
```
</tf>
</frameworkcontent>
## Verwenden Sie die Funktion `push_to_hub`.
Sie können `push_to_hub` auch direkt für Ihr Modell aufrufen, um es in den Hub hochzuladen.
Geben Sie den Namen Ihres Modells in "push_to_hub" an:
```py
>>> pt_model.push_to_hub("my-awesome-model")
```
Dadurch wird ein Repository unter Ihrem Benutzernamen mit dem Modellnamen `my-awesome-model` erstellt. Benutzer können nun Ihr Modell mit der Funktion `from_pretrained` laden:
```py
>>> from transformers import AutoModel
>>> model = AutoModel.from_pretrained("your_username/my-awesome-model")
```
Wenn Sie zu einer Organisation gehören und Ihr Modell stattdessen unter dem Namen der Organisation pushen wollen, fügen Sie diesen einfach zur `repo_id` hinzu:
```py
>>> pt_model.push_to_hub("my-awesome-org/my-awesome-model")
```
Die Funktion "push_to_hub" kann auch verwendet werden, um andere Dateien zu einem Modell-Repository hinzuzufügen. Zum Beispiel kann man einen Tokenizer zu einem Modell-Repository hinzufügen:
```py
>>> tokenizer.push_to_hub("my-awesome-model")
```
Oder vielleicht möchten Sie die TensorFlow-Version Ihres fein abgestimmten PyTorch-Modells hinzufügen:
```py
>>> tf_model.push_to_hub("my-awesome-model")
```
Wenn Sie nun zu Ihrem Hugging Face-Profil navigieren, sollten Sie Ihr neu erstelltes Modell-Repository sehen. Wenn Sie auf die Registerkarte **Dateien** klicken, werden alle Dateien angezeigt, die Sie in das Repository hochgeladen haben.
Weitere Einzelheiten zum Erstellen und Hochladen von Dateien in ein Repository finden Sie in der Hub-Dokumentation [hier](https://huggingface.co/docs/hub/how-to-upstream).
## Hochladen mit der Weboberfläche
Benutzer, die einen no-code Ansatz bevorzugen, können ein Modell über das Webinterface des Hubs hochladen. Besuchen Sie [huggingface.co/new](https://huggingface.co/new) um ein neues Repository zu erstellen:

Fügen Sie von hier aus einige Informationen über Ihr Modell hinzu:
- Wählen Sie den **Besitzer** des Repositorys. Dies können Sie selbst oder eine der Organisationen sein, denen Sie angehören.
- Wählen Sie einen Namen für Ihr Modell, der auch der Name des Repositorys sein wird.
- Wählen Sie, ob Ihr Modell öffentlich oder privat ist.
- Geben Sie die Lizenzverwendung für Ihr Modell an.
Klicken Sie nun auf die Registerkarte **Dateien** und klicken Sie auf die Schaltfläche **Datei hinzufügen**, um eine neue Datei in Ihr Repository hochzuladen. Ziehen Sie dann eine Datei per Drag-and-Drop hoch und fügen Sie eine Übergabemeldung hinzu.

## Hinzufügen einer Modellkarte
Um sicherzustellen, dass die Benutzer die Fähigkeiten, Grenzen, möglichen Verzerrungen und ethischen Aspekte Ihres Modells verstehen, fügen Sie bitte eine Modellkarte zu Ihrem Repository hinzu. Die Modellkarte wird in der Datei `README.md` definiert. Sie können eine Modellkarte hinzufügen, indem Sie:
* Manuelles Erstellen und Hochladen einer "README.md"-Datei.
* Klicken Sie auf die Schaltfläche **Modellkarte bearbeiten** in Ihrem Modell-Repository.
Werfen Sie einen Blick auf die DistilBert [model card](https://huggingface.co/distilbert-base-uncased) als gutes Beispiel für die Art von Informationen, die eine Modellkarte enthalten sollte. Weitere Details über andere Optionen, die Sie in der Datei "README.md" einstellen können, wie z.B. den Kohlenstoff-Fußabdruck eines Modells oder Beispiele für Widgets, finden Sie in der Dokumentation [hier](https://huggingface.co/docs/hub/models-cards). | transformers/docs/source/de/model_sharing.md/0 | {
"file_path": "transformers/docs/source/de/model_sharing.md",
"repo_id": "transformers",
"token_count": 4283
} | 240 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# How to convert a 🤗 Transformers model to TensorFlow?
Having multiple frameworks available to use with 🤗 Transformers gives you flexibility to play their strengths when
designing your application, but it implies that compatibility must be added on a per-model basis. The good news is that
adding TensorFlow compatibility to an existing model is simpler than [adding a new model from scratch](add_new_model)!
Whether you wish to have a deeper understanding of large TensorFlow models, make a major open-source contribution, or
enable TensorFlow for your model of choice, this guide is for you.
This guide empowers you, a member of our community, to contribute TensorFlow model weights and/or
architectures to be used in 🤗 Transformers, with minimal supervision from the Hugging Face team. Writing a new model
is no small feat, but hopefully this guide will make it less of a rollercoaster 🎢 and more of a walk in the park 🚶.
Harnessing our collective experiences is absolutely critical to make this process increasingly easier, and thus we
highly encourage that you suggest improvements to this guide!
Before you dive deeper, it is recommended that you check the following resources if you're new to 🤗 Transformers:
- [General overview of 🤗 Transformers](add_new_model#general-overview-of-transformers)
- [Hugging Face's TensorFlow Philosophy](https://huggingface.co/blog/tensorflow-philosophy)
In the remainder of this guide, you will learn what's needed to add a new TensorFlow model architecture, the
procedure to convert PyTorch into TensorFlow model weights, and how to efficiently debug mismatches across ML
frameworks. Let's get started!
<Tip>
Are you unsure whether the model you wish to use already has a corresponding TensorFlow architecture?
Check the `model_type` field of the `config.json` of your model of choice
([example](https://huggingface.co/bert-base-uncased/blob/main/config.json#L14)). If the corresponding model folder in
🤗 Transformers has a file whose name starts with "modeling_tf", it means that it has a corresponding TensorFlow
architecture ([example](https://github.com/huggingface/transformers/tree/main/src/transformers/models/bert)).
</Tip>
## Step-by-step guide to add TensorFlow model architecture code
There are many ways to design a large model architecture, and multiple ways of implementing said design. However,
you might recall from our [general overview of 🤗 Transformers](add_new_model#general-overview-of-transformers)
that we are an opinionated bunch - the ease of use of 🤗 Transformers relies on consistent design choices. From
experience, we can tell you a few important things about adding TensorFlow models:
- Don't reinvent the wheel! More often than not, there are at least two reference implementations you should check: the
PyTorch equivalent of the model you are implementing and other TensorFlow models for the same class of problems.
- Great model implementations survive the test of time. This doesn't happen because the code is pretty, but rather
because the code is clear, easy to debug and build upon. If you make the life of the maintainers easy with your
TensorFlow implementation, by replicating the same patterns as in other TensorFlow models and minimizing the mismatch
to the PyTorch implementation, you ensure your contribution will be long lived.
- Ask for help when you're stuck! The 🤗 Transformers team is here to help, and we've probably found solutions to the same
problems you're facing.
Here's an overview of the steps needed to add a TensorFlow model architecture:
1. Select the model you wish to convert
2. Prepare transformers dev environment
3. (Optional) Understand theoretical aspects and the existing implementation
4. Implement the model architecture
5. Implement model tests
6. Submit the pull request
7. (Optional) Build demos and share with the world
### 1.-3. Prepare your model contribution
**1. Select the model you wish to convert**
Let's start off with the basics: the first thing you need to know is the architecture you want to convert. If you
don't have your eyes set on a specific architecture, asking the 🤗 Transformers team for suggestions is a great way to
maximize your impact - we will guide you towards the most prominent architectures that are missing on the TensorFlow
side. If the specific model you want to use with TensorFlow already has a TensorFlow architecture implementation in
🤗 Transformers but is lacking weights, feel free to jump straight into the
[weight conversion section](#adding-tensorflow-weights-to-hub)
of this page.
For simplicity, the remainder of this guide assumes you've decided to contribute with the TensorFlow version of
*BrandNewBert* (the same example as in the [guide](add_new_model) to add a new model from scratch).
<Tip>
Before starting the work on a TensorFlow model architecture, double-check that there is no ongoing effort to do so.
You can search for `BrandNewBert` on the
[pull request GitHub page](https://github.com/huggingface/transformers/pulls?q=is%3Apr) to confirm that there is no
TensorFlow-related pull request.
</Tip>
**2. Prepare transformers dev environment**
Having selected the model architecture, open a draft PR to signal your intention to work on it. Follow the
instructions below to set up your environment and open a draft PR.
1. Fork the [repository](https://github.com/huggingface/transformers) by clicking on the 'Fork' button on the
repository's page. This creates a copy of the code under your GitHub user account.
2. Clone your `transformers` fork to your local disk, and add the base repository as a remote:
```bash
git clone https://github.com/[your Github handle]/transformers.git
cd transformers
git remote add upstream https://github.com/huggingface/transformers.git
```
3. Set up a development environment, for instance by running the following command:
```bash
python -m venv .env
source .env/bin/activate
pip install -e ".[dev]"
```
Depending on your OS, and since the number of optional dependencies of Transformers is growing, you might get a
failure with this command. If that's the case make sure to install TensorFlow then do:
```bash
pip install -e ".[quality]"
```
**Note:** You don't need to have CUDA installed. Making the new model work on CPU is sufficient.
4. Create a branch with a descriptive name from your main branch
```bash
git checkout -b add_tf_brand_new_bert
```
5. Fetch and rebase to current main
```bash
git fetch upstream
git rebase upstream/main
```
6. Add an empty `.py` file in `transformers/src/models/brandnewbert/` named `modeling_tf_brandnewbert.py`. This will
be your TensorFlow model file.
7. Push the changes to your account using:
```bash
git add .
git commit -m "initial commit"
git push -u origin add_tf_brand_new_bert
```
8. Once you are satisfied, go to the webpage of your fork on GitHub. Click on “Pull request”. Make sure to add the
GitHub handle of some members of the Hugging Face team as reviewers, so that the Hugging Face team gets notified for
future changes.
9. Change the PR into a draft by clicking on “Convert to draft” on the right of the GitHub pull request web page.
Now you have set up a development environment to port *BrandNewBert* to TensorFlow in 🤗 Transformers.
**3. (Optional) Understand theoretical aspects and the existing implementation**
You should take some time to read *BrandNewBert's* paper, if such descriptive work exists. There might be large
sections of the paper that are difficult to understand. If this is the case, this is fine - don't worry! The goal is
not to get a deep theoretical understanding of the paper, but to extract the necessary information required to
effectively re-implement the model in 🤗 Transformers using TensorFlow. That being said, you don't have to spend too
much time on the theoretical aspects, but rather focus on the practical ones, namely the existing model documentation
page (e.g. [model docs for BERT](model_doc/bert)).
After you've grasped the basics of the models you are about to implement, it's important to understand the existing
implementation. This is a great chance to confirm that a working implementation matches your expectations for the
model, as well as to foresee technical challenges on the TensorFlow side.
It's perfectly natural that you feel overwhelmed with the amount of information that you've just absorbed. It is
definitely not a requirement that you understand all facets of the model at this stage. Nevertheless, we highly
encourage you to clear any pressing questions in our [forum](https://discuss.huggingface.co/).
### 4. Model implementation
Now it's time to finally start coding. Our suggested starting point is the PyTorch file itself: copy the contents of
`modeling_brand_new_bert.py` inside `src/transformers/models/brand_new_bert/` into
`modeling_tf_brand_new_bert.py`. The goal of this section is to modify the file and update the import structure of
🤗 Transformers such that you can import `TFBrandNewBert` and
`TFBrandNewBert.from_pretrained(model_repo, from_pt=True)` successfully loads a working TensorFlow *BrandNewBert* model.
Sadly, there is no prescription to convert a PyTorch model into TensorFlow. You can, however, follow our selection of
tips to make the process as smooth as possible:
- Prepend `TF` to the name of all classes (e.g. `BrandNewBert` becomes `TFBrandNewBert`).
- Most PyTorch operations have a direct TensorFlow replacement. For example, `torch.nn.Linear` corresponds to
`tf.keras.layers.Dense`, `torch.nn.Dropout` corresponds to `tf.keras.layers.Dropout`, etc. If you're not sure
about a specific operation, you can use the [TensorFlow documentation](https://www.tensorflow.org/api_docs/python/tf)
or the [PyTorch documentation](https://pytorch.org/docs/stable/).
- Look for patterns in the 🤗 Transformers codebase. If you come across a certain operation that doesn't have a direct
replacement, the odds are that someone else already had the same problem.
- By default, keep the same variable names and structure as in PyTorch. This will make it easier to debug, track
issues, and add fixes down the line.
- Some layers have different default values in each framework. A notable example is the batch normalization layer's
epsilon (`1e-5` in [PyTorch](https://pytorch.org/docs/stable/generated/torch.nn.BatchNorm2d.html#torch.nn.BatchNorm2d)
and `1e-3` in [TensorFlow](https://www.tensorflow.org/api_docs/python/tf/keras/layers/BatchNormalization)).
Double-check the documentation!
- PyTorch's `nn.Parameter` variables typically need to be initialized within TF Layer's `build()`. See the following
example: [PyTorch](https://github.com/huggingface/transformers/blob/655f72a6896c0533b1bdee519ed65a059c2425ac/src/transformers/models/vit_mae/modeling_vit_mae.py#L212) /
[TensorFlow](https://github.com/huggingface/transformers/blob/655f72a6896c0533b1bdee519ed65a059c2425ac/src/transformers/models/vit_mae/modeling_tf_vit_mae.py#L220)
- If the PyTorch model has a `#copied from ...` on top of a function, the odds are that your TensorFlow model can also
borrow that function from the architecture it was copied from, assuming it has a TensorFlow architecture.
- Assigning the `name` attribute correctly in TensorFlow functions is critical to do the `from_pt=True` weight
cross-loading. `name` is almost always the name of the corresponding variable in the PyTorch code. If `name` is not
properly set, you will see it in the error message when loading the model weights.
- The logic of the base model class, `BrandNewBertModel`, will actually reside in `TFBrandNewBertMainLayer`, a Keras
layer subclass ([example](https://github.com/huggingface/transformers/blob/4fd32a1f499e45f009c2c0dea4d81c321cba7e02/src/transformers/models/bert/modeling_tf_bert.py#L719)).
`TFBrandNewBertModel` will simply be a wrapper around this layer.
- Keras models need to be built in order to load pretrained weights. For that reason, `TFBrandNewBertPreTrainedModel`
will need to hold an example of inputs to the model, the `dummy_inputs`
([example](https://github.com/huggingface/transformers/blob/4fd32a1f499e45f009c2c0dea4d81c321cba7e02/src/transformers/models/bert/modeling_tf_bert.py#L916)).
- If you get stuck, ask for help - we're here to help you! 🤗
In addition to the model file itself, you will also need to add the pointers to the model classes and related
documentation pages. You can complete this part entirely following the patterns in other PRs
([example](https://github.com/huggingface/transformers/pull/18020/files)). Here's a list of the needed manual
changes:
- Include all public classes of *BrandNewBert* in `src/transformers/__init__.py`
- Add *BrandNewBert* classes to the corresponding Auto classes in `src/transformers/models/auto/modeling_tf_auto.py`
- Add the lazy loading classes related to *BrandNewBert* in `src/transformers/utils/dummy_tf_objects.py`
- Update the import structures for the public classes in `src/transformers/models/brand_new_bert/__init__.py`
- Add the documentation pointers to the public methods of *BrandNewBert* in `docs/source/en/model_doc/brand_new_bert.md`
- Add yourself to the list of contributors to *BrandNewBert* in `docs/source/en/model_doc/brand_new_bert.md`
- Finally, add a green tick ✅ to the TensorFlow column of *BrandNewBert* in `docs/source/en/index.md`
When you're happy with your implementation, run the following checklist to confirm that your model architecture is
ready:
1. All layers that behave differently at train time (e.g. Dropout) are called with a `training` argument, which is
propagated all the way from the top-level classes
2. You have used `#copied from ...` whenever possible
3. `TFBrandNewBertMainLayer` and all classes that use it have their `call` function decorated with `@unpack_inputs`
4. `TFBrandNewBertMainLayer` is decorated with `@keras_serializable`
5. A TensorFlow model can be loaded from PyTorch weights using `TFBrandNewBert.from_pretrained(model_repo, from_pt=True)`
6. You can call the TensorFlow model using the expected input format
### 5. Add model tests
Hurray, you've implemented a TensorFlow model! Now it's time to add tests to make sure that your model behaves as
expected. As in the previous section, we suggest you start by copying the `test_modeling_brand_new_bert.py` file in
`tests/models/brand_new_bert/` into `test_modeling_tf_brand_new_bert.py`, and continue by making the necessary
TensorFlow replacements. For now, in all `.from_pretrained()` calls, you should use the `from_pt=True` flag to load
the existing PyTorch weights.
After you're done, it's time for the moment of truth: run the tests! 😬
```bash
NVIDIA_TF32_OVERRIDE=0 RUN_SLOW=1 RUN_PT_TF_CROSS_TESTS=1 \
py.test -vv tests/models/brand_new_bert/test_modeling_tf_brand_new_bert.py
```
The most likely outcome is that you'll see a bunch of errors. Don't worry, this is expected! Debugging ML models is
notoriously hard, and the key ingredient to success is patience (and `breakpoint()`). In our experience, the hardest
problems arise from subtle mismatches between ML frameworks, for which we have a few pointers at the end of this guide.
In other cases, a general test might not be directly applicable to your model, in which case we suggest an override
at the model test class level. Regardless of the issue, don't hesitate to ask for help in your draft pull request if
you're stuck.
When all tests pass, congratulations, your model is nearly ready to be added to the 🤗 Transformers library! 🎉
### 6.-7. Ensure everyone can use your model
**6. Submit the pull request**
Once you're done with the implementation and the tests, it's time to submit a pull request. Before pushing your code,
run our code formatting utility, `make fixup` 🪄. This will automatically fix any formatting issues, which would cause
our automatic checks to fail.
It's now time to convert your draft pull request into a real pull request. To do so, click on the "Ready for
review" button and add Joao (`@gante`) and Matt (`@Rocketknight1`) as reviewers. A model pull request will need
at least 3 reviewers, but they will take care of finding appropriate additional reviewers for your model.
After all reviewers are happy with the state of your PR, the final action point is to remove the `from_pt=True` flag in
`.from_pretrained()` calls. Since there are no TensorFlow weights, you will have to add them! Check the section
below for instructions on how to do it.
Finally, when the TensorFlow weights get merged, you have at least 3 reviewer approvals, and all CI checks are
green, double-check the tests locally one last time
```bash
NVIDIA_TF32_OVERRIDE=0 RUN_SLOW=1 RUN_PT_TF_CROSS_TESTS=1 \
py.test -vv tests/models/brand_new_bert/test_modeling_tf_brand_new_bert.py
```
and we will merge your PR! Congratulations on the milestone 🎉
**7. (Optional) Build demos and share with the world**
One of the hardest parts about open-source is discovery. How can the other users learn about the existence of your
fabulous TensorFlow contribution? With proper communication, of course! 📣
There are two main ways to share your model with the community:
- Build demos. These include Gradio demos, notebooks, and other fun ways to show off your model. We highly
encourage you to add a notebook to our [community-driven demos](https://huggingface.co/docs/transformers/community).
- Share stories on social media like Twitter and LinkedIn. You should be proud of your work and share
your achievement with the community - your model can now be used by thousands of engineers and researchers around
the world 🌍! We will be happy to retweet your posts and help you share your work with the community.
## Adding TensorFlow weights to 🤗 Hub
Assuming that the TensorFlow model architecture is available in 🤗 Transformers, converting PyTorch weights into
TensorFlow weights is a breeze!
Here's how to do it:
1. Make sure you are logged into your Hugging Face account in your terminal. You can log in using the command
`huggingface-cli login` (you can find your access tokens [here](https://huggingface.co/settings/tokens))
2. Run `transformers-cli pt-to-tf --model-name foo/bar`, where `foo/bar` is the name of the model repository
containing the PyTorch weights you want to convert
3. Tag `@joaogante` and `@Rocketknight1` in the 🤗 Hub PR the command above has just created
That's it! 🎉
## Debugging mismatches across ML frameworks 🐛
At some point, when adding a new architecture or when creating TensorFlow weights for an existing architecture, you
might come across errors complaining about mismatches between PyTorch and TensorFlow. You might even decide to open the
model architecture code for the two frameworks, and find that they look identical. What's going on? 🤔
First of all, let's talk about why understanding these mismatches matters. Many community members will use 🤗
Transformers models out of the box, and trust that our models behave as expected. When there is a large mismatch
between the two frameworks, it implies that the model is not following the reference implementation for at least one
of the frameworks. This might lead to silent failures, in which the model runs but has poor performance. This is
arguably worse than a model that fails to run at all! To that end, we aim at having a framework mismatch smaller than
`1e-5` at all stages of the model.
As in other numerical problems, the devil is in the details. And as in any detail-oriented craft, the secret
ingredient here is patience. Here is our suggested workflow for when you come across this type of issues:
1. Locate the source of mismatches. The model you're converting probably has near identical inner variables up to a
certain point. Place `breakpoint()` statements in the two frameworks' architectures, and compare the values of the
numerical variables in a top-down fashion until you find the source of the problems.
2. Now that you've pinpointed the source of the issue, get in touch with the 🤗 Transformers team. It is possible
that we've seen a similar problem before and can promptly provide a solution. As a fallback, scan popular pages
like StackOverflow and GitHub issues.
3. If there is no solution in sight, it means you'll have to go deeper. The good news is that you've located the
issue, so you can focus on the problematic instruction, abstracting away the rest of the model! The bad news is
that you'll have to venture into the source implementation of said instruction. In some cases, you might find an
issue with a reference implementation - don't abstain from opening an issue in the upstream repository.
In some cases, in discussion with the 🤗 Transformers team, we might find that fixing the mismatch is infeasible.
When the mismatch is very small in the output layers of the model (but potentially large in the hidden states), we
might decide to ignore it in favor of distributing the model. The `pt-to-tf` CLI mentioned above has a `--max-error`
flag to override the error message at weight conversion time.
| transformers/docs/source/en/add_tensorflow_model.md/0 | {
"file_path": "transformers/docs/source/en/add_tensorflow_model.md",
"repo_id": "transformers",
"token_count": 5782
} | 241 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Text generation strategies
Text generation is essential to many NLP tasks, such as open-ended text generation, summarization, translation, and
more. It also plays a role in a variety of mixed-modality applications that have text as an output like speech-to-text
and vision-to-text. Some of the models that can generate text include
GPT2, XLNet, OpenAI GPT, CTRL, TransformerXL, XLM, Bart, T5, GIT, Whisper.
Check out a few examples that use [`~transformers.generation_utils.GenerationMixin.generate`] method to produce
text outputs for different tasks:
* [Text summarization](./tasks/summarization#inference)
* [Image captioning](./model_doc/git#transformers.GitForCausalLM.forward.example)
* [Audio transcription](./model_doc/whisper#transformers.WhisperForConditionalGeneration.forward.example)
Note that the inputs to the generate method depend on the model's modality. They are returned by the model's preprocessor
class, such as AutoTokenizer or AutoProcessor. If a model's preprocessor creates more than one kind of input, pass all
the inputs to generate(). You can learn more about the individual model's preprocessor in the corresponding model's documentation.
The process of selecting output tokens to generate text is known as decoding, and you can customize the decoding strategy
that the `generate()` method will use. Modifying a decoding strategy does not change the values of any trainable parameters.
However, it can have a noticeable impact on the quality of the generated output. It can help reduce repetition in the text
and make it more coherent.
This guide describes:
* default generation configuration
* common decoding strategies and their main parameters
* saving and sharing custom generation configurations with your fine-tuned model on 🤗 Hub
## Default text generation configuration
A decoding strategy for a model is defined in its generation configuration. When using pre-trained models for inference
within a [`pipeline`], the models call the `PreTrainedModel.generate()` method that applies a default generation
configuration under the hood. The default configuration is also used when no custom configuration has been saved with
the model.
When you load a model explicitly, you can inspect the generation configuration that comes with it through
`model.generation_config`:
```python
>>> from transformers import AutoModelForCausalLM
>>> model = AutoModelForCausalLM.from_pretrained("distilgpt2")
>>> model.generation_config
GenerationConfig {
"bos_token_id": 50256,
"eos_token_id": 50256,
}
```
Printing out the `model.generation_config` reveals only the values that are different from the default generation
configuration, and does not list any of the default values.
The default generation configuration limits the size of the output combined with the input prompt to a maximum of 20
tokens to avoid running into resource limitations. The default decoding strategy is greedy search, which is the simplest decoding strategy that picks a token with the highest probability as the next token. For many tasks
and small output sizes this works well. However, when used to generate longer outputs, greedy search can start
producing highly repetitive results.
## Customize text generation
You can override any `generation_config` by passing the parameters and their values directly to the [`generate`] method:
```python
>>> my_model.generate(**inputs, num_beams=4, do_sample=True) # doctest: +SKIP
```
Even if the default decoding strategy mostly works for your task, you can still tweak a few things. Some of the
commonly adjusted parameters include:
- `max_new_tokens`: the maximum number of tokens to generate. In other words, the size of the output sequence, not
including the tokens in the prompt. As an alternative to using the output's length as a stopping criteria, you can choose
to stop generation whenever the full generation exceeds some amount of time. To learn more, check [`StoppingCriteria`].
- `num_beams`: by specifying a number of beams higher than 1, you are effectively switching from greedy search to
beam search. This strategy evaluates several hypotheses at each time step and eventually chooses the hypothesis that
has the overall highest probability for the entire sequence. This has the advantage of identifying high-probability
sequences that start with a lower probability initial tokens and would've been ignored by the greedy search.
- `do_sample`: if set to `True`, this parameter enables decoding strategies such as multinomial sampling, beam-search
multinomial sampling, Top-K sampling and Top-p sampling. All these strategies select the next token from the probability
distribution over the entire vocabulary with various strategy-specific adjustments.
- `num_return_sequences`: the number of sequence candidates to return for each input. This option is only available for
the decoding strategies that support multiple sequence candidates, e.g. variations of beam search and sampling. Decoding
strategies like greedy search and contrastive search return a single output sequence.
## Save a custom decoding strategy with your model
If you would like to share your fine-tuned model with a specific generation configuration, you can:
* Create a [`GenerationConfig`] class instance
* Specify the decoding strategy parameters
* Save your generation configuration with [`GenerationConfig.save_pretrained`], making sure to leave its `config_file_name` argument empty
* Set `push_to_hub` to `True` to upload your config to the model's repo
```python
>>> from transformers import AutoModelForCausalLM, GenerationConfig
>>> model = AutoModelForCausalLM.from_pretrained("my_account/my_model") # doctest: +SKIP
>>> generation_config = GenerationConfig(
... max_new_tokens=50, do_sample=True, top_k=50, eos_token_id=model.config.eos_token_id
... )
>>> generation_config.save_pretrained("my_account/my_model", push_to_hub=True) # doctest: +SKIP
```
You can also store several generation configurations in a single directory, making use of the `config_file_name`
argument in [`GenerationConfig.save_pretrained`]. You can later instantiate them with [`GenerationConfig.from_pretrained`]. This is useful if you want to
store several generation configurations for a single model (e.g. one for creative text generation with sampling, and
one for summarization with beam search). You must have the right Hub permissions to add configuration files to a model.
```python
>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer, GenerationConfig
>>> tokenizer = AutoTokenizer.from_pretrained("t5-small")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("t5-small")
>>> translation_generation_config = GenerationConfig(
... num_beams=4,
... early_stopping=True,
... decoder_start_token_id=0,
... eos_token_id=model.config.eos_token_id,
... pad_token=model.config.pad_token_id,
... )
>>> # Tip: add `push_to_hub=True` to push to the Hub
>>> translation_generation_config.save_pretrained("/tmp", "translation_generation_config.json")
>>> # You could then use the named generation config file to parameterize generation
>>> generation_config = GenerationConfig.from_pretrained("/tmp", "translation_generation_config.json")
>>> inputs = tokenizer("translate English to French: Configuration files are easy to use!", return_tensors="pt")
>>> outputs = model.generate(**inputs, generation_config=generation_config)
>>> print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
['Les fichiers de configuration sont faciles à utiliser!']
```
## Streaming
The `generate()` supports streaming, through its `streamer` input. The `streamer` input is compatible with any instance
from a class that has the following methods: `put()` and `end()`. Internally, `put()` is used to push new tokens and
`end()` is used to flag the end of text generation.
<Tip warning={true}>
The API for the streamer classes is still under development and may change in the future.
</Tip>
In practice, you can craft your own streaming class for all sorts of purposes! We also have basic streaming classes
ready for you to use. For example, you can use the [`TextStreamer`] class to stream the output of `generate()` into
your screen, one word at a time:
```python
>>> from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
>>> tok = AutoTokenizer.from_pretrained("gpt2")
>>> model = AutoModelForCausalLM.from_pretrained("gpt2")
>>> inputs = tok(["An increasing sequence: one,"], return_tensors="pt")
>>> streamer = TextStreamer(tok)
>>> # Despite returning the usual output, the streamer will also print the generated text to stdout.
>>> _ = model.generate(**inputs, streamer=streamer, max_new_tokens=20)
An increasing sequence: one, two, three, four, five, six, seven, eight, nine, ten, eleven,
```
## Decoding strategies
Certain combinations of the `generate()` parameters, and ultimately `generation_config`, can be used to enable specific
decoding strategies. If you are new to this concept, we recommend reading [this blog post that illustrates how common decoding strategies work](https://huggingface.co/blog/how-to-generate).
Here, we'll show some of the parameters that control the decoding strategies and illustrate how you can use them.
### Greedy Search
[`generate`] uses greedy search decoding by default so you don't have to pass any parameters to enable it. This means the parameters `num_beams` is set to 1 and `do_sample=False`.
```python
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> prompt = "I look forward to"
>>> checkpoint = "distilgpt2"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> outputs = model.generate(**inputs)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['I look forward to seeing you all again!\n\n\n\n\n\n\n\n\n\n\n']
```
### Contrastive search
The contrastive search decoding strategy was proposed in the 2022 paper [A Contrastive Framework for Neural Text Generation](https://arxiv.org/abs/2202.06417).
It demonstrates superior results for generating non-repetitive yet coherent long outputs. To learn how contrastive search
works, check out [this blog post](https://huggingface.co/blog/introducing-csearch).
The two main parameters that enable and control the behavior of contrastive search are `penalty_alpha` and `top_k`:
```python
>>> from transformers import AutoTokenizer, AutoModelForCausalLM
>>> checkpoint = "gpt2-large"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> prompt = "Hugging Face Company is"
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> outputs = model.generate(**inputs, penalty_alpha=0.6, top_k=4, max_new_tokens=100)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['Hugging Face Company is a family owned and operated business. We pride ourselves on being the best
in the business and our customer service is second to none.\n\nIf you have any questions about our
products or services, feel free to contact us at any time. We look forward to hearing from you!']
```
### Multinomial sampling
As opposed to greedy search that always chooses a token with the highest probability as the
next token, multinomial sampling (also called ancestral sampling) randomly selects the next token based on the probability distribution over the entire
vocabulary given by the model. Every token with a non-zero probability has a chance of being selected, thus reducing the
risk of repetition.
To enable multinomial sampling set `do_sample=True` and `num_beams=1`.
```python
>>> from transformers import AutoTokenizer, AutoModelForCausalLM, set_seed
>>> set_seed(0) # For reproducibility
>>> checkpoint = "gpt2-large"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> prompt = "Today was an amazing day because"
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> outputs = model.generate(**inputs, do_sample=True, num_beams=1, max_new_tokens=100)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['Today was an amazing day because when you go to the World Cup and you don\'t, or when you don\'t get invited,
that\'s a terrible feeling."']
```
### Beam-search decoding
Unlike greedy search, beam-search decoding keeps several hypotheses at each time step and eventually chooses
the hypothesis that has the overall highest probability for the entire sequence. This has the advantage of identifying high-probability
sequences that start with lower probability initial tokens and would've been ignored by the greedy search.
To enable this decoding strategy, specify the `num_beams` (aka number of hypotheses to keep track of) that is greater than 1.
```python
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> prompt = "It is astonishing how one can"
>>> checkpoint = "gpt2-medium"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> outputs = model.generate(**inputs, num_beams=5, max_new_tokens=50)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['It is astonishing how one can have such a profound impact on the lives of so many people in such a short period of
time."\n\nHe added: "I am very proud of the work I have been able to do in the last few years.\n\n"I have']
```
### Beam-search multinomial sampling
As the name implies, this decoding strategy combines beam search with multinomial sampling. You need to specify
the `num_beams` greater than 1, and set `do_sample=True` to use this decoding strategy.
```python
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, set_seed
>>> set_seed(0) # For reproducibility
>>> prompt = "translate English to German: The house is wonderful."
>>> checkpoint = "t5-small"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
>>> outputs = model.generate(**inputs, num_beams=5, do_sample=True)
>>> tokenizer.decode(outputs[0], skip_special_tokens=True)
'Das Haus ist wunderbar.'
```
### Diverse beam search decoding
The diverse beam search decoding strategy is an extension of the beam search strategy that allows for generating a more diverse
set of beam sequences to choose from. To learn how it works, refer to [Diverse Beam Search: Decoding Diverse Solutions from Neural Sequence Models](https://arxiv.org/pdf/1610.02424.pdf).
This approach has three main parameters: `num_beams`, `num_beam_groups`, and `diversity_penalty`.
The diversity penalty ensures the outputs are distinct across groups, and beam search is used within each group.
```python
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> checkpoint = "google/pegasus-xsum"
>>> prompt = (
... "The Permaculture Design Principles are a set of universal design principles "
... "that can be applied to any location, climate and culture, and they allow us to design "
... "the most efficient and sustainable human habitation and food production systems. "
... "Permaculture is a design system that encompasses a wide variety of disciplines, such "
... "as ecology, landscape design, environmental science and energy conservation, and the "
... "Permaculture design principles are drawn from these various disciplines. Each individual "
... "design principle itself embodies a complete conceptual framework based on sound "
... "scientific principles. When we bring all these separate principles together, we can "
... "create a design system that both looks at whole systems, the parts that these systems "
... "consist of, and how those parts interact with each other to create a complex, dynamic, "
... "living system. Each design principle serves as a tool that allows us to integrate all "
... "the separate parts of a design, referred to as elements, into a functional, synergistic, "
... "whole system, where the elements harmoniously interact and work together in the most "
... "efficient way possible."
... )
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
>>> outputs = model.generate(**inputs, num_beams=5, num_beam_groups=5, max_new_tokens=30, diversity_penalty=1.0)
>>> tokenizer.decode(outputs[0], skip_special_tokens=True)
'The Design Principles are a set of universal design principles that can be applied to any location, climate and
culture, and they allow us to design the'
```
This guide illustrates the main parameters that enable various decoding strategies. More advanced parameters exist for the
[`generate`] method, which gives you even further control over the [`generate`] method's behavior.
For the complete list of the available parameters, refer to the [API documentation](./main_classes/text_generation.md).
### Speculative Decoding
Speculative decoding (also known as assisted decoding) is a modification of the decoding strategies above, that uses an
assistant model (ideally a much smaller one) with the same tokenizer, to generate a few candidate tokens. The main
model then validates the candidate tokens in a single forward pass, which speeds up the decoding process. If
`do_sample=True`, then the token validation with resampling introduced in the
[speculative decoding paper](https://arxiv.org/pdf/2211.17192.pdf) is used.
Currently, only greedy search and sampling are supported with assisted decoding, and assisted decoding doesn't support batched inputs.
To learn more about assisted decoding, check [this blog post](https://huggingface.co/blog/assisted-generation).
To enable assisted decoding, set the `assistant_model` argument with a model.
```python
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> prompt = "Alice and Bob"
>>> checkpoint = "EleutherAI/pythia-1.4b-deduped"
>>> assistant_checkpoint = "EleutherAI/pythia-160m-deduped"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> assistant_model = AutoModelForCausalLM.from_pretrained(assistant_checkpoint)
>>> outputs = model.generate(**inputs, assistant_model=assistant_model)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['Alice and Bob are sitting in a bar. Alice is drinking a beer and Bob is drinking a']
```
When using assisted decoding with sampling methods, you can use the `temperature` argument to control the randomness,
just like in multinomial sampling. However, in assisted decoding, reducing the temperature may help improve the latency.
```python
>>> from transformers import AutoModelForCausalLM, AutoTokenizer, set_seed
>>> set_seed(42) # For reproducibility
>>> prompt = "Alice and Bob"
>>> checkpoint = "EleutherAI/pythia-1.4b-deduped"
>>> assistant_checkpoint = "EleutherAI/pythia-160m-deduped"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> assistant_model = AutoModelForCausalLM.from_pretrained(assistant_checkpoint)
>>> outputs = model.generate(**inputs, assistant_model=assistant_model, do_sample=True, temperature=0.5)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['Alice and Bob are going to the same party. It is a small party, in a small']
```
| transformers/docs/source/en/generation_strategies.md/0 | {
"file_path": "transformers/docs/source/en/generation_strategies.md",
"repo_id": "transformers",
"token_count": 5515
} | 242 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Optimizing LLMs for Speed and Memory
[[open-in-colab]]
Large Language Models (LLMs) such as GPT3/4, [Falcon](https://huggingface.co/tiiuae/falcon-40b), and [Llama](https://huggingface.co/meta-llama/Llama-2-70b-hf) are rapidly advancing in their ability to tackle human-centric tasks, establishing themselves as essential tools in modern knowledge-based industries.
Deploying these models in real-world tasks remains challenging, however:
- To exhibit near-human text understanding and generation capabilities, LLMs currently require to be composed of billions of parameters (see [Kaplan et al](https://arxiv.org/abs/2001.08361), [Wei et. al](https://arxiv.org/abs/2206.07682)). This consequently amplifies the memory demands for inference.
- In many real-world tasks, LLMs need to be given extensive contextual information. This necessitates the model's capability to manage very long input sequences during inference.
The crux of these challenges lies in augmenting the computational and memory capabilities of LLMs, especially when handling expansive input sequences.
In this guide, we will go over the effective techniques for efficient LLM deployment:
1. **Lower Precision:** Research has shown that operating at reduced numerical precision, namely [8-bit and 4-bit](./main_classes/quantization.md) can achieve computational advantages without a considerable decline in model performance.
2. **Flash Attention:** Flash Attention is a variation of the attention algorithm that not only provides a more memory-efficient approach but also realizes increased efficiency due to optimized GPU memory utilization.
3. **Architectural Innovations:** Considering that LLMs are always deployed in the same way during inference, namely autoregressive text generation with a long input context, specialized model architectures have been proposed that allow for more efficient inference. The most important advancement in model architectures hereby are [Alibi](https://arxiv.org/abs/2108.12409), [Rotary embeddings](https://arxiv.org/abs/2104.09864), [Multi-Query Attention (MQA)](https://arxiv.org/abs/1911.02150) and [Grouped-Query-Attention (GQA)]((https://arxiv.org/abs/2305.13245)).
Throughout this guide, we will offer an analysis of auto-regressive generation from a tensor's perspective. We delve into the pros and cons of adopting lower precision, provide a comprehensive exploration of the latest attention algorithms, and discuss improved LLM architectures. While doing so, we run practical examples showcasing each of the feature improvements.
## 1. Lower Precision
Memory requirements of LLMs can be best understood by seeing the LLM as a set of weight matrices and vectors and the text inputs as a sequence of vectors. In the following, the definition *weights* will be used to signify all model weight matrices and vectors.
At the time of writing this guide, LLMs consist of at least a couple billion parameters. Each parameter thereby is made of a decimal number, e.g. `4.5689` which is usually stored in either [float32](https://en.wikipedia.org/wiki/Single-precision_floating-point_format), [bfloat16](https://en.wikipedia.org/wiki/Bfloat16_floating-point_format), or [float16](https://en.wikipedia.org/wiki/Half-precision_floating-point_format) format. This allows us to easily compute the memory requirement to load the LLM into memory:
> *Loading the weights of a model having X billion parameters requires roughly 4 * X GB of VRAM in float32 precision*
Nowadays, models are however rarely trained in full float32 precision, but usually in bfloat16 precision or less frequently in float16 precision. Therefore the rule of thumb becomes:
> *Loading the weights of a model having X billion parameters requires roughly 2 * X GB of VRAM in bfloat16/float16 precision*
For shorter text inputs (less than 1024 tokens), the memory requirement for inference is very much dominated by the memory requirement to load the weights. Therefore, for now, let's assume that the memory requirement for inference is equal to the memory requirement to load the model into the GPU VRAM.
To give some examples of how much VRAM it roughly takes to load a model in bfloat16:
- **GPT3** requires 2 \* 175 GB = **350 GB** VRAM
- [**Bloom**](https://huggingface.co/bigscience/bloom) requires 2 \* 176 GB = **352 GB** VRAM
- [**Llama-2-70b**](https://huggingface.co/meta-llama/Llama-2-70b-hf) requires 2 \* 70 GB = **140 GB** VRAM
- [**Falcon-40b**](https://huggingface.co/tiiuae/falcon-40b) requires 2 \* 40 GB = **80 GB** VRAM
- [**MPT-30b**](https://huggingface.co/mosaicml/mpt-30b) requires 2 \* 30 GB = **60 GB** VRAM
- [**bigcode/starcoder**](https://huggingface.co/bigcode/starcoder) requires 2 \* 15.5 = **31 GB** VRAM
As of writing this document, the largest GPU chip on the market is the A100 & H100 offering 80GB of VRAM. Most of the models listed before require more than 80GB just to be loaded and therefore necessarily require [tensor parallelism](https://huggingface.co/docs/transformers/perf_train_gpu_many#tensor-parallelism) and/or [pipeline parallelism](https://huggingface.co/docs/transformers/perf_train_gpu_many#naive-model-parallelism-vertical-and-pipeline-parallelism).
🤗 Transformers does not support tensor parallelism out of the box as it requires the model architecture to be written in a specific way. If you're interested in writing models in a tensor-parallelism-friendly way, feel free to have a look at [the text-generation-inference library](https://github.com/huggingface/text-generation-inference/tree/main/server/text_generation_server/models/custom_modeling).
Naive pipeline parallelism is supported out of the box. For this, simply load the model with `device="auto"` which will automatically place the different layers on the available GPUs as explained [here](https://huggingface.co/docs/accelerate/v0.22.0/en/concept_guides/big_model_inference).
Note, however that while very effective, this naive pipeline parallelism does not tackle the issues of GPU idling. For this more advanced pipeline parallelism is required as explained [here](https://huggingface.co/docs/transformers/en/perf_train_gpu_many#naive-model-parallelism-vertical-and-pipeline-parallelism).
If you have access to an 8 x 80GB A100 node, you could load BLOOM as follows
```bash
!pip install transformers accelerate bitsandbytes optimum
```
```python
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("bigscience/bloom", device_map="auto", pad_token_id=0)
```
By using `device_map="auto"` the attention layers would be equally distributed over all available GPUs.
In this guide, we will use [bigcode/octocoder](https://huggingface.co/bigcode/octocoder) as it can be run on a single 40 GB A100 GPU device chip. Note that all memory and speed optimizations that we will apply going forward, are equally applicable to models that require model or tensor parallelism.
Since the model is loaded in bfloat16 precision, using our rule of thumb above, we would expect the memory requirement to run inference with `bigcode/octocoder` to be around 31 GB VRAM. Let's give it a try.
We first load the model and tokenizer and then pass both to Transformers' [pipeline](https://huggingface.co/docs/transformers/main_classes/pipelines) object.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
import torch
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", torch_dtype=torch.bfloat16, device_map="auto", pad_token_id=0)
tokenizer = AutoTokenizer.from_pretrained("bigcode/octocoder")
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
```
```python
prompt = "Question: Please write a function in Python that transforms bytes to Giga bytes.\n\nAnswer:"
result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
result
```
**Output**:
```
Here is a Python function that transforms bytes to Giga bytes:\n\n```python\ndef bytes_to_giga_bytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```\n\nThis function takes a single
```
Nice, we can now directly use the result to convert bytes into Gigabytes.
```python
def bytes_to_giga_bytes(bytes):
return bytes / 1024 / 1024 / 1024
```
Let's call [`torch.cuda.max_memory_allocated`](https://pytorch.org/docs/stable/generated/torch.cuda.max_memory_allocated.html) to measure the peak GPU memory allocation.
```python
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
```
**Output**:
```bash
29.0260648727417
```
Close enough to our back-of-the-envelope computation! We can see the number is not exactly correct as going from bytes to kilobytes requires a multiplication of 1024 instead of 1000. Therefore the back-of-the-envelope formula can also be understood as an "at most X GB" computation.
Note that if we had tried to run the model in full float32 precision, a whopping 64 GB of VRAM would have been required.
> Almost all models are trained in bfloat16 nowadays, there is no reason to run the model in full float32 precision if [your GPU supports bfloat16](https://discuss.pytorch.org/t/bfloat16-native-support/117155/5). Float32 won't give better inference results than the precision that was used to train the model.
If you are unsure in which format the model weights are stored on the Hub, you can always look into the checkpoint's config under `"torch_dtype"`, *e.g.* [here](https://huggingface.co/meta-llama/Llama-2-7b-hf/blob/6fdf2e60f86ff2481f2241aaee459f85b5b0bbb9/config.json#L21). It is recommended to set the model to the same precision type as written in the config when loading with `from_pretrained(..., torch_dtype=...)` except when the original type is float32 in which case one can use both `float16` or `bfloat16` for inference.
Let's define a `flush(...)` function to free all allocated memory so that we can accurately measure the peak allocated GPU memory.
```python
del pipe
del model
import gc
import torch
def flush():
gc.collect()
torch.cuda.empty_cache()
torch.cuda.reset_peak_memory_stats()
```
Let's call it now for the next experiment.
```python
flush()
```
In the recent version of the accelerate library, you can also use an utility method called `release_memory()`
```python
from accelerate.utils import release_memory
# ...
release_memory(model)
```
Now what if your GPU does not have 32 GB of VRAM? It has been found that model weights can be quantized to 8-bit or 4-bits without a significant loss in performance (see [Dettmers et al.](https://arxiv.org/abs/2208.07339)).
Model can be quantized to even 3 or 2 bits with an acceptable loss in performance as shown in the recent [GPTQ paper](https://arxiv.org/abs/2210.17323) 🤯.
Without going into too many details, quantization schemes aim at reducing the precision of weights while trying to keep the model's inference results as accurate as possible (*a.k.a* as close as possible to bfloat16).
Note that quantization works especially well for text generation since all we care about is choosing the *set of most likely next tokens* and don't really care about the exact values of the next token *logit* distribution.
All that matters is that the next token *logit* distribution stays roughly the same so that an `argmax` or `topk` operation gives the same results.
There are various quantization techniques, which we won't discuss in detail here, but in general, all quantization techniques work as follows:
- 1. Quantize all weights to the target precision
- 2. Load the quantized weights, and pass the input sequence of vectors in bfloat16 precision
- 3. Dynamically dequantize weights to bfloat16 to perform the computation with their input vectors in bfloat16 precision
In a nutshell, this means that *inputs-weight matrix* multiplications, with \\( X \\) being the *inputs*, \\( W \\) being a weight matrix and \\( Y \\) being the output:
$$ Y = X * W $$
are changed to
$$ Y = X * \text{dequantize}(W) $$
for every matrix multiplication. Dequantization and re-quantization is performed sequentially for all weight matrices as the inputs run through the network graph.
Therefore, inference time is often **not** reduced when using quantized weights, but rather increases.
Enough theory, let's give it a try! To quantize the weights with Transformers, you need to make sure that
the [`bitsandbytes`](https://github.com/TimDettmers/bitsandbytes) library is installed.
```bash
!pip install bitsandbytes
```
We can then load models in 8-bit quantization by simply adding a `load_in_8bit=True` flag to `from_pretrained`.
```python
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", load_in_8bit=True, pad_token_id=0)
```
Now, let's run our example again and measure the memory usage.
```python
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
result
```
**Output**:
```
Here is a Python function that transforms bytes to Giga bytes:\n\n```python\ndef bytes_to_giga_bytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```\n\nThis function takes a single
```
Nice, we're getting the same result as before, so no loss in accuracy! Let's look at how much memory was used this time.
```python
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
```
**Output**:
```
15.219234466552734
```
Significantly less! We're down to just a bit over 15 GBs and could therefore run this model on consumer GPUs like the 4090.
We're seeing a very nice gain in memory efficiency and more or less no degradation to the model's output. However, we can also notice a slight slow-down during inference.
We delete the models and flush the memory again.
```python
del model
del pipe
```
```python
flush()
```
Let's see what peak GPU memory consumption 4-bit quantization gives. Quantizing the model to 4-bit can be done with the same API as before - this time by passing `load_in_4bit=True` instead of `load_in_8bit=True`.
```python
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", load_in_4bit=True, low_cpu_mem_usage=True, pad_token_id=0)
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
result
```
**Output**:
```
Here is a Python function that transforms bytes to Giga bytes:\n\n```\ndef bytes_to_gigabytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```\n\nThis function takes a single argument
```
We're almost seeing the same output text as before - just the `python` is missing just before the code snippet. Let's see how much memory was required.
```python
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
```
**Output**:
```
9.543574333190918
```
Just 9.5GB! That's really not a lot for a >15 billion parameter model.
While we see very little degradation in accuracy for our model here, 4-bit quantization can in practice often lead to different results compared to 8-bit quantization or full `bfloat16` inference. It is up to the user to try it out.
Also note that inference here was again a bit slower compared to 8-bit quantization which is due to the more aggressive quantization method used for 4-bit quantization leading to \\( \text{quantize} \\) and \\( \text{dequantize} \\) taking longer during inference.
```python
del model
del pipe
```
```python
flush()
```
Overall, we saw that running OctoCoder in 8-bit precision reduced the required GPU VRAM from 32G GPU VRAM to only 15GB and running the model in 4-bit precision further reduces the required GPU VRAM to just a bit over 9GB.
4-bit quantization allows the model to be run on GPUs such as RTX3090, V100, and T4 which are quite accessible for most people.
For more information on quantization and to see how one can quantize models to require even less GPU VRAM memory than 4-bit, we recommend looking into the [`AutoGPTQ`](https://huggingface.co/docs/transformers/main/en/main_classes/quantization#autogptq-integration%60) implementation.
> As a conclusion, it is important to remember that model quantization trades improved memory efficiency against accuracy and in some cases inference time.
If GPU memory is not a constraint for your use case, there is often no need to look into quantization. However many GPUs simply can't run LLMs without quantization methods and in this case, 4-bit and 8-bit quantization schemes are extremely useful tools.
For more in-detail usage information, we strongly recommend taking a look at the [Transformers Quantization Docs](https://huggingface.co/docs/transformers/main_classes/quantization#general-usage).
Next, let's look into how we can improve computational and memory efficiency by using better algorithms and an improved model architecture.
## 2. Flash Attention
Today's top-performing LLMs share more or less the same fundamental architecture that consists of feed-forward layers, activation layers, layer normalization layers, and most crucially, self-attention layers.
Self-attention layers are central to Large Language Models (LLMs) in that they enable the model to understand the contextual relationships between input tokens.
However, the peak GPU memory consumption for self-attention layers grows *quadratically* both in compute and memory complexity with number of input tokens (also called *sequence length*) that we denote in the following by \\( N \\) .
While this is not really noticeable for shorter input sequences (of up to 1000 input tokens), it becomes a serious problem for longer input sequences (at around 16000 input tokens).
Let's take a closer look. The formula to compute the output \\( \mathbf{O} \\) of a self-attention layer for an input \\( \mathbf{X} \\) of length \\( N \\) is:
$$ \textbf{O} = \text{Attn}(\mathbf{X}) = \mathbf{V} \times \text{Softmax}(\mathbf{QK}^T) \text{ with } \mathbf{Q} = \mathbf{W}_q \mathbf{X}, \mathbf{V} = \mathbf{W}_v \mathbf{X}, \mathbf{K} = \mathbf{W}_k \mathbf{X} $$
\\( \mathbf{X} = (\mathbf{x}_1, ... \mathbf{x}_{N}) \\) is thereby the input sequence to the attention layer. The projections \\( \mathbf{Q} \\) and \\( \mathbf{K} \\) will each consist of \\( N \\) vectors resulting in the \\( \mathbf{QK}^T \\) being of size \\( N^2 \\) .
LLMs usually have multiple attention heads, thus doing multiple self-attention computations in parallel.
Assuming, the LLM has 40 attention heads and runs in bfloat16 precision, we can calculate the memory requirement to store the \\( \mathbf{QK^T} \\) matrices to be \\( 40 * 2 * N^2 \\) bytes. For \\( N=1000 \\) only around 50 MB of VRAM are needed, however, for \\( N=16000 \\) we would need 19 GB of VRAM, and for \\( N=100,000 \\) we would need almost 1TB just to store the \\( \mathbf{QK}^T \\) matrices.
Long story short, the default self-attention algorithm quickly becomes prohibitively memory-expensive for large input contexts.
As LLMs improve in text comprehension and generation, they are applied to increasingly complex tasks. While models once handled the translation or summarization of a few sentences, they now manage entire pages, demanding the capability to process extensive input lengths.
How can we get rid of the exorbitant memory requirements for large input lengths? We need a new way to compute the self-attention mechanism that gets rid of the \\( QK^T \\) matrix. [Tri Dao et al.](https://arxiv.org/abs/2205.14135) developed exactly such a new algorithm and called it **Flash Attention**.
In a nutshell, Flash Attention breaks the \\(\mathbf{V} \times \text{Softmax}(\mathbf{QK}^T\\)) computation apart and instead computes smaller chunks of the output by iterating over multiple softmax computation steps:
$$ \textbf{O}_i \leftarrow s^a_{ij} * \textbf{O}_i + s^b_{ij} * \mathbf{V}_{j} \times \text{Softmax}(\mathbf{QK}^T_{i,j}) \text{ for multiple } i, j \text{ iterations} $$
with \\( s^a_{ij} \\) and \\( s^b_{ij} \\) being some softmax normalization statistics that need to be recomputed for every \\( i \\) and \\( j \\) .
Please note that the whole Flash Attention is a bit more complex and is greatly simplified here as going in too much depth is out of scope for this guide. The reader is invited to take a look at the well-written [Flash Attention paper](https://arxiv.org/abs/2205.14135) for more details.
The main takeaway here is:
> By keeping track of softmax normalization statistics and by using some smart mathematics, Flash Attention gives **numerical identical** outputs compared to the default self-attention layer at a memory cost that only increases linearly with \\( N \\) .
Looking at the formula, one would intuitively say that Flash Attention must be much slower compared to the default self-attention formula as more computation needs to be done. Indeed Flash Attention requires more FLOPs compared to normal attention as the softmax normalization statistics have to constantly be recomputed (see [paper](https://arxiv.org/abs/2205.14135) for more details if interested)
> However, Flash Attention is much faster in inference compared to default attention which comes from its ability to significantly reduce the demands on the slower, high-bandwidth memory of the GPU (VRAM), focusing instead on the faster on-chip memory (SRAM).
Essentially, Flash Attention makes sure that all intermediate write and read operations can be done using the fast *on-chip* SRAM memory instead of having to access the slower VRAM memory to compute the output vector \\( \mathbf{O} \\) .
In practice, there is currently absolutely no reason to **not** use Flash Attention if available. The algorithm gives mathematically the same outputs, and is both faster and more memory-efficient.
Let's look at a practical example.
Our OctoCoder model now gets a significantly longer input prompt which includes a so-called *system prompt*. System prompts are used to steer the LLM into a better assistant that is tailored to the users' task.
In the following, we use a system prompt that will make OctoCoder a better coding assistant.
```python
system_prompt = """Below are a series of dialogues between various people and an AI technical assistant.
The assistant tries to be helpful, polite, honest, sophisticated, emotionally aware, and humble but knowledgeable.
The assistant is happy to help with code questions and will do their best to understand exactly what is needed.
It also tries to avoid giving false or misleading information, and it caveats when it isn't entirely sure about the right answer.
That said, the assistant is practical really does its best, and doesn't let caution get too much in the way of being useful.
The Starcoder models are a series of 15.5B parameter models trained on 80+ programming languages from The Stack (v1.2) (excluding opt-out requests).
The model uses Multi Query Attention, was trained using the Fill-in-the-Middle objective, and with 8,192 tokens context window for a trillion tokens of heavily deduplicated data.
-----
Question: Write a function that takes two lists and returns a list that has alternating elements from each input list.
Answer: Sure. Here is a function that does that.
def alternating(list1, list2):
results = []
for i in range(len(list1)):
results.append(list1[i])
results.append(list2[i])
return results
Question: Can you write some test cases for this function?
Answer: Sure, here are some tests.
assert alternating([10, 20, 30], [1, 2, 3]) == [10, 1, 20, 2, 30, 3]
assert alternating([True, False], [4, 5]) == [True, 4, False, 5]
assert alternating([], []) == []
Question: Modify the function so that it returns all input elements when the lists have uneven length. The elements from the longer list should be at the end.
Answer: Here is the modified function.
def alternating(list1, list2):
results = []
for i in range(min(len(list1), len(list2))):
results.append(list1[i])
results.append(list2[i])
if len(list1) > len(list2):
results.extend(list1[i+1:])
else:
results.extend(list2[i+1:])
return results
-----
"""
```
For demonstration purposes, we duplicate the system prompt by ten so that the input length is long enough to observe Flash Attention's memory savings.
We append the original text prompt `"Question: Please write a function in Python that transforms bytes to Giga bytes.\n\nAnswer: Here"`
```python
long_prompt = 10 * system_prompt + prompt
```
We instantiate our model again in bfloat16 precision.
```python
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", torch_dtype=torch.bfloat16, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained("bigcode/octocoder")
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
```
Let's now run the model just like before *without Flash Attention* and measure the peak GPU memory requirement and inference time.
```python
import time
start_time = time.time()
result = pipe(long_prompt, max_new_tokens=60)[0]["generated_text"][len(long_prompt):]
print(f"Generated in {time.time() - start_time} seconds.")
result
```
**Output**:
```
Generated in 10.96854019165039 seconds.
Sure. Here is a function that does that.\n\ndef bytes_to_giga(bytes):\n return bytes / 1024 / 1024 / 1024\n\nAnswer: Sure. Here is a function that does that.\n\ndef
````
We're getting the same output as before, however this time, the model repeats the answer multiple times until it's 60 tokens cut-off. This is not surprising as we've repeated the system prompt ten times for demonstration purposes and thus cued the model to repeat itself.
**Note** that the system prompt should not be repeated ten times in real-world applications - one time is enough!
Let's measure the peak GPU memory requirement.
```python
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
```
**Output**:
```bash
37.668193340301514
```
As we can see the peak GPU memory requirement is now significantly higher than in the beginning, which is largely due to the longer input sequence. Also the generation takes a little over a minute now.
We call `flush()` to free GPU memory for our next experiment.
```python
flush()
```
For comparison, let's run the same function, but enable Flash Attention instead.
To do so, we convert the model to [BetterTransformer](https://huggingface.co/docs/optimum/bettertransformer/overview) and by doing so enabling PyTorch's [SDPA self-attention](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention) which in turn is able to use Flash Attention.
```python
model.to_bettertransformer()
```
Now we run the exact same code snippet as before and under the hood Transformers will make use of Flash Attention.
```py
start_time = time.time()
with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
result = pipe(long_prompt, max_new_tokens=60)[0]["generated_text"][len(long_prompt):]
print(f"Generated in {time.time() - start_time} seconds.")
result
```
**Output**:
```
Generated in 3.0211617946624756 seconds.
Sure. Here is a function that does that.\n\ndef bytes_to_giga(bytes):\n return bytes / 1024 / 1024 / 1024\n\nAnswer: Sure. Here is a function that does that.\n\ndef
```
We're getting the exact same result as before, but can observe a very significant speed-up thanks to Flash Attention.
Let's measure the memory consumption one last time.
```python
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
```
**Output**:
```
32.617331981658936
```
And we're almost back to our original 29GB peak GPU memory from the beginning.
We can observe that we only use roughly 100MB more GPU memory when passing a very long input sequence with Flash Attention compared to passing a short input sequence as done in the beginning.
```py
flush()
```
For more information on how to use Flash Attention, please have a look at [this doc page](https://huggingface.co/docs/transformers/en/perf_infer_gpu_one#flashattention-2).
## 3. Architectural Innovations
So far we have looked into improving computational and memory efficiency by:
- Casting the weights to a lower precision format
- Replacing the self-attention algorithm with a more memory- and compute efficient version
Let's now look into how we can change the architecture of an LLM so that it is most effective and efficient for task that require long text inputs, *e.g.*:
- Retrieval augmented Questions Answering,
- Summarization,
- Chat
Note that *chat* not only requires the LLM to handle long text inputs, but it also necessitates that the LLM is able to efficiently handle the back-and-forth dialogue between user and assistant (such as ChatGPT).
Once trained, the fundamental LLM architecture is difficult to change, so it is important to make considerations about the LLM's tasks beforehand and accordingly optimize the model's architecture.
There are two important components of the model architecture that quickly become memory and/or performance bottlenecks for large input sequences.
- The positional embeddings
- The key-value cache
Let's go over each component in more detail
### 3.1 Improving positional embeddings of LLMs
Self-attention puts each token in relation to each other's tokens.
As an example, the \\( \text{Softmax}(\mathbf{QK}^T) \\) matrix of the text input sequence *"Hello", "I", "love", "you"* could look as follows:
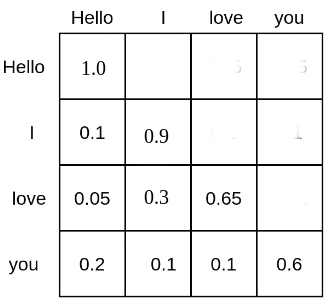
Each word token is given a probability mass at which it attends all other word tokens and, therefore is put into relation with all other word tokens. E.g. the word *"love"* attends to the word *"Hello"* with 5%, to *"I"* with 30%, and to itself with 65%.
A LLM based on self-attention, but without position embeddings would have great difficulties in understanding the positions of the text inputs to each other.
This is because the probability score computed by \\( \mathbf{QK}^T \\) relates each word token to each other word token in \\( O(1) \\) computations regardless of their relative positional distance to each other.
Therefore, for the LLM without position embeddings each token appears to have the same distance to all other tokens, *e.g.* differentiating between *"Hello I love you"* and *"You love I hello"* would be very challenging.
For the LLM to understand sentence order, an additional *cue* is needed and is usually applied in the form of *positional encodings* (or also called *positional embeddings*).
Positional encodings, encode the position of each token into a numerical presentation that the LLM can leverage to better understand sentence order.
The authors of the [*Attention Is All You Need*](https://arxiv.org/abs/1706.03762) paper introduced sinusoidal positional embeddings \\( \mathbf{P} = \mathbf{p}_1, \ldots, \mathbf{p}_N \\) .
where each vector \\( \mathbf{p}_i \\) is computed as a sinusoidal function of its position \\( i \\) .
The positional encodings are then simply added to the input sequence vectors \\( \mathbf{\hat{X}} = \mathbf{\hat{x}}_1, \ldots, \mathbf{\hat{x}}_N \\) = \\( \mathbf{x}_1 + \mathbf{p}_1, \ldots, \mathbf{x}_N + \mathbf{p}_N \\) thereby cueing the model to better learn sentence order.
Instead of using fixed position embeddings, others (such as [Devlin et al.](https://arxiv.org/abs/1810.04805)) used learned positional encodings for which the positional embeddings
\\( \mathbf{P} \\) are learned during training.
Sinusoidal and learned position embeddings used to be the predominant methods to encode sentence order into LLMs, but a couple of problems related to these positional encodings were found:
1. Sinusoidal and learned position embeddings are both absolute positional embeddings, *i.e.* encoding a unique embedding for each position id: \\( 0, \ldots, N \\) . As shown by [Huang et al.](https://arxiv.org/abs/2009.13658) and [Su et al.](https://arxiv.org/abs/2104.09864), absolute positional embeddings lead to poor LLM performance for long text inputs. For long text inputs, it is advantageous if the model learns the relative positional distance input tokens have to each other instead of their absolute position.
2. When using learned position embeddings, the LLM has to be trained on a fixed input length \\( N \\), which makes it difficult to extrapolate to an input length longer than what it was trained on.
Recently, relative positional embeddings that can tackle the above mentioned problems have become more popular, most notably:
- [Rotary Position Embedding (RoPE)](https://arxiv.org/abs/2104.09864)
- [ALiBi](https://arxiv.org/abs/2108.12409)
Both *RoPE* and *ALiBi* argue that it's best to cue the LLM about sentence order directly in the self-attention algorithm as it's there that word tokens are put into relation with each other. More specifically, sentence order should be cued by modifying the \\( \mathbf{QK}^T \\) computation.
Without going into too many details, *RoPE* notes that positional information can be encoded into query-key pairs, *e.g.* \\( \mathbf{q}_i \\) and \\( \mathbf{x}_j \\) by rotating each vector by an angle \\( \theta * i \\) and \\( \theta * j \\) respectively with \\( i, j \\) describing each vectors sentence position:
$$ \mathbf{\hat{q}}_i^T \mathbf{\hat{x}}_j = \mathbf{{q}}_i^T \mathbf{R}_{\theta, i -j} \mathbf{{x}}_j. $$
\\( \mathbf{R}_{\theta, i - j} \\) thereby represents a rotational matrix. \\( \theta \\) is *not* learned during training, but instead set to a pre-defined value that depends on the maximum input sequence length during training.
> By doing so, the propability score between \\( \mathbf{q}_i \\) and \\( \mathbf{q}_j \\) is only affected if \\( i \ne j \\) and solely depends on the relative distance \\( i - j \\) regardless of each vector's specific positions \\( i \\) and \\( j \\) .
*RoPE* is used in multiple of today's most important LLMs, such as:
- [**Falcon**](https://huggingface.co/tiiuae/falcon-40b)
- [**Llama**](https://arxiv.org/abs/2302.13971)
- [**PaLM**](https://arxiv.org/abs/2204.02311)
As an alternative, *ALiBi* proposes a much simpler relative position encoding scheme. The relative distance that input tokens have to each other is added as a negative integer scaled by a pre-defined value `m` to each query-key entry of the \\( \mathbf{QK}^T \\) matrix right before the softmax computation.
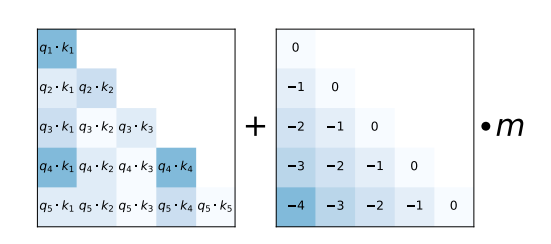
As shown in the [ALiBi](https://arxiv.org/abs/2108.12409) paper, this simple relative positional encoding allows the model to retain a high performance even at very long text input sequences.
*ALiBi* is used in multiple of today's most important LLMs, such as:
- [**MPT**](https://huggingface.co/mosaicml/mpt-30b)
- [**BLOOM**](https://huggingface.co/bigscience/bloom)
Both *RoPE* and *ALiBi* position encodings can extrapolate to input lengths not seen during training whereas it has been shown that extrapolation works much better out-of-the-box for *ALiBi* as compared to *RoPE*.
For ALiBi, one simply increases the values of the lower triangular position matrix to match the length of the input sequence.
For *RoPE*, keeping the same \\( \theta \\) that was used during training leads to poor results when passing text inputs much longer than those seen during training, *c.f* [Press et al.](https://arxiv.org/abs/2108.12409). However, the community has found a couple of effective tricks that adapt \\( \theta \\), thereby allowing *RoPE* position embeddings to work well for extrapolated text input sequences (see [here](https://github.com/huggingface/transformers/pull/24653)).
> Both RoPE and ALiBi are relative positional embeddings that are *not* learned during training, but instead are based on the following intuitions:
- Positional cues about the text inputs should be given directly to the \\( QK^T \\) matrix of the self-attention layer
- The LLM should be incentivized to learn a constant *relative* distance positional encodings have to each other
- The further text input tokens are from each other, the lower the probability of their query-value probability. Both RoPE and ALiBi lower the query-key probability of tokens far away from each other. RoPE by decreasing their vector product by increasing the angle between the query-key vectors. ALiBi by adding large negative numbers to the vector product
In conclusion, LLMs that are intended to be deployed in tasks that require handling large text inputs are better trained with relative positional embeddings, such as RoPE and ALiBi. Also note that even if an LLM with RoPE and ALiBi has been trained only on a fixed length of say \\( N_1 = 2048 \\) it can still be used in practice with text inputs much larger than \\( N_1 \\), like \\( N_2 = 8192 > N_1 \\) by extrapolating the positional embeddings.
### 3.2 The key-value cache
Auto-regressive text generation with LLMs works by iteratively putting in an input sequence, sampling the next token, appending the next token to the input sequence, and continuing to do so until the LLM produces a token that signifies that the generation has finished.
Please have a look at [Transformer's Generate Text Tutorial](https://huggingface.co/docs/transformers/llm_tutorial#generate-text) to get a more visual explanation of how auto-regressive generation works.
Let's run a quick code snippet to show how auto-regressive works in practice. We will simply take the most likely next token via `torch.argmax`.
```python
input_ids = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda")
for _ in range(5):
next_logits = model(input_ids)["logits"][:, -1:]
next_token_id = torch.argmax(next_logits,dim=-1)
input_ids = torch.cat([input_ids, next_token_id], dim=-1)
print("shape of input_ids", input_ids.shape)
generated_text = tokenizer.batch_decode(input_ids[:, -5:])
generated_text
```
**Output**:
```
shape of input_ids torch.Size([1, 21])
shape of input_ids torch.Size([1, 22])
shape of input_ids torch.Size([1, 23])
shape of input_ids torch.Size([1, 24])
shape of input_ids torch.Size([1, 25])
[' Here is a Python function']
```
As we can see every time we increase the text input tokens by the just sampled token.
With very few exceptions, LLMs are trained using the [causal language modeling objective](https://huggingface.co/docs/transformers/tasks/language_modeling#causal-language-modeling) and therefore mask the upper triangle matrix of the attention score - this is why in the two diagrams above the attention scores are left blank (*a.k.a* have 0 probability). For a quick recap on causal language modeling you can refer to the [*Illustrated Self Attention blog*](https://jalammar.github.io/illustrated-gpt2/#part-2-illustrated-self-attention).
As a consequence, tokens *never* depend on previous tokens, more specifically the \\( \mathbf{q}_i \\) vector is never put in relation with any key, values vectors \\( \mathbf{k}_j, \mathbf{v}_j \\) if \\( j > i \\) . Instead \\( \mathbf{q}_i \\) only attends to previous key-value vectors \\( \mathbf{k}_{m < i}, \mathbf{v}_{m < i} \text{ , for } m \in \{0, \ldots i - 1\} \\). In order to reduce unnecessary computation, one can therefore cache each layer's key-value vectors for all previous timesteps.
In the following, we will tell the LLM to make use of the key-value cache by retrieving and forwarding it for each forward pass.
In Transformers, we can retrieve the key-value cache by passing the `use_cache` flag to the `forward` call and can then pass it with the current token.
```python
past_key_values = None # past_key_values is the key-value cache
generated_tokens = []
next_token_id = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda")
for _ in range(5):
next_logits, past_key_values = model(next_token_id, past_key_values=past_key_values, use_cache=True).to_tuple()
next_logits = next_logits[:, -1:]
next_token_id = torch.argmax(next_logits, dim=-1)
print("shape of input_ids", next_token_id.shape)
print("length of key-value cache", len(past_key_values[0][0])) # past_key_values are of shape [num_layers, 0 for k, 1 for v, batch_size, length, hidden_dim]
generated_tokens.append(next_token_id.item())
generated_text = tokenizer.batch_decode(generated_tokens)
generated_text
```
**Output**:
```
shape of input_ids torch.Size([1, 1])
length of key-value cache 20
shape of input_ids torch.Size([1, 1])
length of key-value cache 21
shape of input_ids torch.Size([1, 1])
length of key-value cache 22
shape of input_ids torch.Size([1, 1])
length of key-value cache 23
shape of input_ids torch.Size([1, 1])
length of key-value cache 24
[' Here', ' is', ' a', ' Python', ' function']
```
As one can see, when using the key-value cache the text input tokens are *not* increased in length, but remain a single input vector. The length of the key-value cache on the other hand is increased by one at every decoding step.
> Making use of the key-value cache means that the \\( \mathbf{QK}^T \\) is essentially reduced to \\( \mathbf{q}_c\mathbf{K}^T \\) with \\( \mathbf{q}_c \\) being the query projection of the currently passed input token which is *always* just a single vector.
Using the key-value cache has two advantages:
- Significant increase in computational efficiency as less computations are performed compared to computing the full \\( \mathbf{QK}^T \\) matrix. This leads to an increase in inference speed
- The maximum required memory is not increased quadratically with the number of generated tokens, but only increases linearly.
> One should *always* make use of the key-value cache as it leads to identical results and a significant speed-up for longer input sequences. Transformers has the key-value cache enabled by default when making use of the text pipeline or the [`generate` method](https://huggingface.co/docs/transformers/main_classes/text_generation).
<Tip warning={true}>
Note that, despite our advice to use key-value caches, your LLM output may be slightly different when you use them. This is a property of the matrix multiplication kernels themselves -- you can read more about it [here](https://github.com/huggingface/transformers/issues/25420#issuecomment-1775317535).
</Tip>
#### 3.2.1 Multi-round conversation
The key-value cache is especially useful for applications such as chat where multiple passes of auto-regressive decoding are required. Let's look at an example.
```
User: How many people live in France?
Assistant: Roughly 75 million people live in France
User: And how many are in Germany?
Assistant: Germany has ca. 81 million inhabitants
```
In this chat, the LLM runs auto-regressive decoding twice:
1. The first time, the key-value cache is empty and the input prompt is `"User: How many people live in France?"` and the model auto-regressively generates the text `"Roughly 75 million people live in France"` while increasing the key-value cache at every decoding step.
2. The second time the input prompt is `"User: How many people live in France? \n Assistant: Roughly 75 million people live in France \n User: And how many in Germany?"`. Thanks to the cache, all key-value vectors for the first two sentences are already computed. Therefore the input prompt only consists of `"User: And how many in Germany?"`. While processing the shortened input prompt, it's computed key-value vectors are concatenated to the key-value cache of the first decoding. The second Assistant's answer `"Germany has ca. 81 million inhabitants"` is then auto-regressively generated with the key-value cache consisting of encoded key-value vectors of `"User: How many people live in France? \n Assistant: Roughly 75 million people live in France \n User: And how many are in Germany?"`.
Two things should be noted here:
1. Keeping all the context is crucial for LLMs deployed in chat so that the LLM understands all the previous context of the conversation. E.g. for the example above the LLM needs to understand that the user refers to the population when asking `"And how many are in Germany"`.
2. The key-value cache is extremely useful for chat as it allows us to continuously grow the encoded chat history instead of having to re-encode the chat history again from scratch (as e.g. would be the case when using an encoder-decoder architecture).
In `transformers`, a `generate` call will return `past_key_values` when `return_dict_in_generate=True` is passed, in addition to the default `use_cache=True`. Note that it is not yet available through the `pipeline` interface.
```python
# Generation as usual
prompt = system_prompt + "Question: Please write a function in Python that transforms bytes to Giga bytes.\n\nAnswer: Here"
model_inputs = tokenizer(prompt, return_tensors='pt')
generation_output = model.generate(**model_inputs, max_new_tokens=60, return_dict_in_generate=True)
decoded_output = tokenizer.batch_decode(generation_output.sequences)[0]
# Piping the returned `past_key_values` to speed up the next conversation round
prompt = decoded_output + "\nQuestion: How can I modify the function above to return Mega bytes instead?\n\nAnswer: Here"
model_inputs = tokenizer(prompt, return_tensors='pt')
generation_output = model.generate(
**model_inputs,
past_key_values=generation_output.past_key_values,
max_new_tokens=60,
return_dict_in_generate=True
)
tokenizer.batch_decode(generation_output.sequences)[0][len(prompt):]
```
**Output**:
```
is a modified version of the function that returns Mega bytes instead.
def bytes_to_megabytes(bytes):
return bytes / 1024 / 1024
Answer: The function takes a number of bytes as input and returns the number of
```
Great, no additional time is spent recomputing the same key and values for the attention layer! There is however one catch. While the required peak memory for the \\( \mathbf{QK}^T \\) matrix is significantly reduced, holding the key-value cache in memory can become very memory expensive for long input sequences or multi-turn chat. Remember that the key-value cache needs to store the key-value vectors for all previous input vectors \\( \mathbf{x}_i \text{, for } i \in \{1, \ldots, c - 1\} \\) for all self-attention layers and for all attention heads.
Let's compute the number of float values that need to be stored in the key-value cache for the LLM `bigcode/octocoder` that we used before.
The number of float values amounts to two times the sequence length times the number of attention heads times the attention head dimension and times the number of layers.
Computing this for our LLM at a hypothetical input sequence length of 16000 gives:
```python
config = model.config
2 * 16_000 * config.n_layer * config.n_head * config.n_embd // config.n_head
```
**Output**:
```
7864320000
```
Roughly 8 billion float values! Storing 8 billion float values in `float16` precision requires around 15 GB of RAM which is circa half as much as the model weights themselves!
Researchers have proposed two methods that allow to significantly reduce the memory cost of storing the key-value cache, which are explored in the next subsections.
#### 3.2.2 Multi-Query-Attention (MQA)
[Multi-Query-Attention](https://arxiv.org/abs/1911.02150) was proposed in Noam Shazeer's *Fast Transformer Decoding: One Write-Head is All You Need* paper. As the title says, Noam found out that instead of using `n_head` key-value projections weights, one can use a single head-value projection weight pair that is shared across all attention heads without that the model's performance significantly degrades.
> By using a single head-value projection weight pair, the key value vectors \\( \mathbf{k}_i, \mathbf{v}_i \\) have to be identical across all attention heads which in turn means that we only need to store 1 key-value projection pair in the cache instead of `n_head` ones.
As most LLMs use between 20 and 100 attention heads, MQA significantly reduces the memory consumption of the key-value cache. For the LLM used in this notebook we could therefore reduce the required memory consumption from 15 GB to less than 400 MB at an input sequence length of 16000.
In addition to memory savings, MQA also leads to improved computational efficiency as explained in the following.
In auto-regressive decoding, large key-value vectors need to be reloaded, concatenated with the current key-value vector pair to be then fed into the \\( \mathbf{q}_c\mathbf{K}^T \\) computation at every step. For auto-regressive decoding, the required memory bandwidth for the constant reloading can become a serious time bottleneck. By reducing the size of the key-value vectors less memory needs to be accessed, thus reducing the memory bandwidth bottleneck. For more detail, please have a look at [Noam's paper](https://arxiv.org/abs/1911.02150).
The important part to understand here is that reducing the number of key-value attention heads to 1 only makes sense if a key-value cache is used. The peak memory consumption of the model for a single forward pass without key-value cache stays unchanged as every attention head still has a unique query vector so that each attention head still has a different \\( \mathbf{QK}^T \\) matrix.
MQA has seen wide adoption by the community and is now used by many of the most popular LLMs:
- [**Falcon**](https://huggingface.co/tiiuae/falcon-40b)
- [**PaLM**](https://arxiv.org/abs/2204.02311)
- [**MPT**](https://huggingface.co/mosaicml/mpt-30b)
- [**BLOOM**](https://huggingface.co/bigscience/bloom)
Also, the checkpoint used in this notebook - `bigcode/octocoder` - makes use of MQA.
#### 3.2.3 Grouped-Query-Attention (GQA)
[Grouped-Query-Attention](https://arxiv.org/abs/2305.13245), as proposed by Ainslie et al. from Google, found that using MQA can often lead to quality degradation compared to using vanilla multi-key-value head projections. The paper argues that more model performance can be kept by less drastically reducing the number of query head projection weights. Instead of using just a single key-value projection weight, `n < n_head` key-value projection weights should be used. By choosing `n` to a significantly smaller value than `n_head`, such as 2,4 or 8 almost all of the memory and speed gains from MQA can be kept while sacrificing less model capacity and thus arguably less performance.
Moreover, the authors of GQA found out that existing model checkpoints can be *uptrained* to have a GQA architecture with as little as 5% of the original pre-training compute. While 5% of the original pre-training compute can still be a massive amount, GQA *uptraining* allows existing checkpoints to be useful for longer input sequences.
GQA was only recently proposed which is why there is less adoption at the time of writing this notebook.
The most notable application of GQA is [Llama-v2](https://huggingface.co/meta-llama/Llama-2-70b-hf).
> As a conclusion, it is strongly recommended to make use of either GQA or MQA if the LLM is deployed with auto-regressive decoding and is required to handle large input sequences as is the case for example for chat.
## Conclusion
The research community is constantly coming up with new, nifty ways to speed up inference time for ever-larger LLMs. As an example, one such promising research direction is [speculative decoding](https://arxiv.org/abs/2211.17192) where "easy tokens" are generated by smaller, faster language models and only "hard tokens" are generated by the LLM itself. Going into more detail is out of the scope of this notebook, but can be read upon in this [nice blog post](https://huggingface.co/blog/assisted-generation).
The reason massive LLMs such as GPT3/4, Llama-2-70b, Claude, PaLM can run so quickly in chat-interfaces such as [Hugging Face Chat](https://huggingface.co/chat/) or ChatGPT is to a big part thanks to the above-mentioned improvements in precision, algorithms, and architecture.
Going forward, accelerators such as GPUs, TPUs, etc... will only get faster and allow for more memory, but one should nevertheless always make sure to use the best available algorithms and architectures to get the most bang for your buck 🤗
| transformers/docs/source/en/llm_tutorial_optimization.md/0 | {
"file_path": "transformers/docs/source/en/llm_tutorial_optimization.md",
"repo_id": "transformers",
"token_count": 14705
} | 243 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Processors
Processors can mean two different things in the Transformers library:
- the objects that pre-process inputs for multi-modal models such as [Wav2Vec2](../model_doc/wav2vec2) (speech and text)
or [CLIP](../model_doc/clip) (text and vision)
- deprecated objects that were used in older versions of the library to preprocess data for GLUE or SQUAD.
## Multi-modal processors
Any multi-modal model will require an object to encode or decode the data that groups several modalities (among text,
vision and audio). This is handled by objects called processors, which group together two or more processing objects
such as tokenizers (for the text modality), image processors (for vision) and feature extractors (for audio).
Those processors inherit from the following base class that implements the saving and loading functionality:
[[autodoc]] ProcessorMixin
## Deprecated processors
All processors follow the same architecture which is that of the
[`~data.processors.utils.DataProcessor`]. The processor returns a list of
[`~data.processors.utils.InputExample`]. These
[`~data.processors.utils.InputExample`] can be converted to
[`~data.processors.utils.InputFeatures`] in order to be fed to the model.
[[autodoc]] data.processors.utils.DataProcessor
[[autodoc]] data.processors.utils.InputExample
[[autodoc]] data.processors.utils.InputFeatures
## GLUE
[General Language Understanding Evaluation (GLUE)](https://gluebenchmark.com/) is a benchmark that evaluates the
performance of models across a diverse set of existing NLU tasks. It was released together with the paper [GLUE: A
multi-task benchmark and analysis platform for natural language understanding](https://openreview.net/pdf?id=rJ4km2R5t7)
This library hosts a total of 10 processors for the following tasks: MRPC, MNLI, MNLI (mismatched), CoLA, SST2, STSB,
QQP, QNLI, RTE and WNLI.
Those processors are:
- [`~data.processors.utils.MrpcProcessor`]
- [`~data.processors.utils.MnliProcessor`]
- [`~data.processors.utils.MnliMismatchedProcessor`]
- [`~data.processors.utils.Sst2Processor`]
- [`~data.processors.utils.StsbProcessor`]
- [`~data.processors.utils.QqpProcessor`]
- [`~data.processors.utils.QnliProcessor`]
- [`~data.processors.utils.RteProcessor`]
- [`~data.processors.utils.WnliProcessor`]
Additionally, the following method can be used to load values from a data file and convert them to a list of
[`~data.processors.utils.InputExample`].
[[autodoc]] data.processors.glue.glue_convert_examples_to_features
## XNLI
[The Cross-Lingual NLI Corpus (XNLI)](https://www.nyu.edu/projects/bowman/xnli/) is a benchmark that evaluates the
quality of cross-lingual text representations. XNLI is crowd-sourced dataset based on [*MultiNLI*](http://www.nyu.edu/projects/bowman/multinli/): pairs of text are labeled with textual entailment annotations for 15
different languages (including both high-resource language such as English and low-resource languages such as Swahili).
It was released together with the paper [XNLI: Evaluating Cross-lingual Sentence Representations](https://arxiv.org/abs/1809.05053)
This library hosts the processor to load the XNLI data:
- [`~data.processors.utils.XnliProcessor`]
Please note that since the gold labels are available on the test set, evaluation is performed on the test set.
An example using these processors is given in the [run_xnli.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification/run_xnli.py) script.
## SQuAD
[The Stanford Question Answering Dataset (SQuAD)](https://rajpurkar.github.io/SQuAD-explorer//) is a benchmark that
evaluates the performance of models on question answering. Two versions are available, v1.1 and v2.0. The first version
(v1.1) was released together with the paper [SQuAD: 100,000+ Questions for Machine Comprehension of Text](https://arxiv.org/abs/1606.05250). The second version (v2.0) was released alongside the paper [Know What You Don't
Know: Unanswerable Questions for SQuAD](https://arxiv.org/abs/1806.03822).
This library hosts a processor for each of the two versions:
### Processors
Those processors are:
- [`~data.processors.utils.SquadV1Processor`]
- [`~data.processors.utils.SquadV2Processor`]
They both inherit from the abstract class [`~data.processors.utils.SquadProcessor`]
[[autodoc]] data.processors.squad.SquadProcessor
- all
Additionally, the following method can be used to convert SQuAD examples into
[`~data.processors.utils.SquadFeatures`] that can be used as model inputs.
[[autodoc]] data.processors.squad.squad_convert_examples_to_features
These processors as well as the aforementioned method can be used with files containing the data as well as with the
*tensorflow_datasets* package. Examples are given below.
### Example usage
Here is an example using the processors as well as the conversion method using data files:
```python
# Loading a V2 processor
processor = SquadV2Processor()
examples = processor.get_dev_examples(squad_v2_data_dir)
# Loading a V1 processor
processor = SquadV1Processor()
examples = processor.get_dev_examples(squad_v1_data_dir)
features = squad_convert_examples_to_features(
examples=examples,
tokenizer=tokenizer,
max_seq_length=max_seq_length,
doc_stride=args.doc_stride,
max_query_length=max_query_length,
is_training=not evaluate,
)
```
Using *tensorflow_datasets* is as easy as using a data file:
```python
# tensorflow_datasets only handle Squad V1.
tfds_examples = tfds.load("squad")
examples = SquadV1Processor().get_examples_from_dataset(tfds_examples, evaluate=evaluate)
features = squad_convert_examples_to_features(
examples=examples,
tokenizer=tokenizer,
max_seq_length=max_seq_length,
doc_stride=args.doc_stride,
max_query_length=max_query_length,
is_training=not evaluate,
)
```
Another example using these processors is given in the [run_squad.py](https://github.com/huggingface/transformers/tree/main/examples/legacy/question-answering/run_squad.py) script.
| transformers/docs/source/en/main_classes/processors.md/0 | {
"file_path": "transformers/docs/source/en/main_classes/processors.md",
"repo_id": "transformers",
"token_count": 2073
} | 244 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BertGeneration
## Overview
The BertGeneration model is a BERT model that can be leveraged for sequence-to-sequence tasks using
[`EncoderDecoderModel`] as proposed in [Leveraging Pre-trained Checkpoints for Sequence Generation
Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
The abstract from the paper is the following:
*Unsupervised pretraining of large neural models has recently revolutionized Natural Language Processing. By
warm-starting from the publicly released checkpoints, NLP practitioners have pushed the state-of-the-art on multiple
benchmarks while saving significant amounts of compute time. So far the focus has been mainly on the Natural Language
Understanding tasks. In this paper, we demonstrate the efficacy of pre-trained checkpoints for Sequence Generation. We
developed a Transformer-based sequence-to-sequence model that is compatible with publicly available pre-trained BERT,
GPT-2 and RoBERTa checkpoints and conducted an extensive empirical study on the utility of initializing our model, both
encoder and decoder, with these checkpoints. Our models result in new state-of-the-art results on Machine Translation,
Text Summarization, Sentence Splitting, and Sentence Fusion.*
This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The original code can be
found [here](https://tfhub.dev/s?module-type=text-generation&subtype=module,placeholder).
## Usage examples and tips
The model can be used in combination with the [`EncoderDecoderModel`] to leverage two pretrained BERT checkpoints for
subsequent fine-tuning:
```python
>>> # leverage checkpoints for Bert2Bert model...
>>> # use BERT's cls token as BOS token and sep token as EOS token
>>> encoder = BertGenerationEncoder.from_pretrained("bert-large-uncased", bos_token_id=101, eos_token_id=102)
>>> # add cross attention layers and use BERT's cls token as BOS token and sep token as EOS token
>>> decoder = BertGenerationDecoder.from_pretrained(
... "bert-large-uncased", add_cross_attention=True, is_decoder=True, bos_token_id=101, eos_token_id=102
... )
>>> bert2bert = EncoderDecoderModel(encoder=encoder, decoder=decoder)
>>> # create tokenizer...
>>> tokenizer = BertTokenizer.from_pretrained("bert-large-uncased")
>>> input_ids = tokenizer(
... "This is a long article to summarize", add_special_tokens=False, return_tensors="pt"
... ).input_ids
>>> labels = tokenizer("This is a short summary", return_tensors="pt").input_ids
>>> # train...
>>> loss = bert2bert(input_ids=input_ids, decoder_input_ids=labels, labels=labels).loss
>>> loss.backward()
```
Pretrained [`EncoderDecoderModel`] are also directly available in the model hub, e.g.:
```python
>>> # instantiate sentence fusion model
>>> sentence_fuser = EncoderDecoderModel.from_pretrained("google/roberta2roberta_L-24_discofuse")
>>> tokenizer = AutoTokenizer.from_pretrained("google/roberta2roberta_L-24_discofuse")
>>> input_ids = tokenizer(
... "This is the first sentence. This is the second sentence.", add_special_tokens=False, return_tensors="pt"
... ).input_ids
>>> outputs = sentence_fuser.generate(input_ids)
>>> print(tokenizer.decode(outputs[0]))
```
Tips:
- [`BertGenerationEncoder`] and [`BertGenerationDecoder`] should be used in
combination with [`EncoderDecoder`].
- For summarization, sentence splitting, sentence fusion and translation, no special tokens are required for the input.
Therefore, no EOS token should be added to the end of the input.
## BertGenerationConfig
[[autodoc]] BertGenerationConfig
## BertGenerationTokenizer
[[autodoc]] BertGenerationTokenizer
- save_vocabulary
## BertGenerationEncoder
[[autodoc]] BertGenerationEncoder
- forward
## BertGenerationDecoder
[[autodoc]] BertGenerationDecoder
- forward
| transformers/docs/source/en/model_doc/bert-generation.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/bert-generation.md",
"repo_id": "transformers",
"token_count": 1314
} | 245 |
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# ByT5
## Overview
The ByT5 model was presented in [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir
Kale, Adam Roberts, Colin Raffel.
The abstract from the paper is the following:
*Most widely-used pre-trained language models operate on sequences of tokens corresponding to word or subword units.
Encoding text as a sequence of tokens requires a tokenizer, which is typically created as an independent artifact from
the model. Token-free models that instead operate directly on raw text (bytes or characters) have many benefits: they
can process text in any language out of the box, they are more robust to noise, and they minimize technical debt by
removing complex and error-prone text preprocessing pipelines. Since byte or character sequences are longer than token
sequences, past work on token-free models has often introduced new model architectures designed to amortize the cost of
operating directly on raw text. In this paper, we show that a standard Transformer architecture can be used with
minimal modifications to process byte sequences. We carefully characterize the trade-offs in terms of parameter count,
training FLOPs, and inference speed, and show that byte-level models are competitive with their token-level
counterparts. We also demonstrate that byte-level models are significantly more robust to noise and perform better on
tasks that are sensitive to spelling and pronunciation. As part of our contribution, we release a new set of
pre-trained byte-level Transformer models based on the T5 architecture, as well as all code and data used in our
experiments.*
This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The original code can be
found [here](https://github.com/google-research/byt5).
<Tip>
ByT5's architecture is based on the T5v1.1 model, refer to [T5v1.1's documentation page](t5v1.1) for the API reference. They
only differ in how inputs should be prepared for the model, see the code examples below.
</Tip>
Since ByT5 was pre-trained unsupervisedly, there's no real advantage to using a task prefix during single-task
fine-tuning. If you are doing multi-task fine-tuning, you should use a prefix.
## Usage example
ByT5 works on raw UTF-8 bytes, so it can be used without a tokenizer:
```python
>>> from transformers import T5ForConditionalGeneration
>>> import torch
>>> model = T5ForConditionalGeneration.from_pretrained("google/byt5-small")
>>> num_special_tokens = 3
>>> # Model has 3 special tokens which take up the input ids 0,1,2 of ByT5.
>>> # => Need to shift utf-8 character encodings by 3 before passing ids to model.
>>> input_ids = torch.tensor([list("Life is like a box of chocolates.".encode("utf-8"))]) + num_special_tokens
>>> labels = torch.tensor([list("La vie est comme une boîte de chocolat.".encode("utf-8"))]) + num_special_tokens
>>> loss = model(input_ids, labels=labels).loss
>>> loss.item()
2.66
```
For batched inference and training it is however recommended to make use of the tokenizer:
```python
>>> from transformers import T5ForConditionalGeneration, AutoTokenizer
>>> model = T5ForConditionalGeneration.from_pretrained("google/byt5-small")
>>> tokenizer = AutoTokenizer.from_pretrained("google/byt5-small")
>>> model_inputs = tokenizer(
... ["Life is like a box of chocolates.", "Today is Monday."], padding="longest", return_tensors="pt"
... )
>>> labels_dict = tokenizer(
... ["La vie est comme une boîte de chocolat.", "Aujourd'hui c'est lundi."], padding="longest", return_tensors="pt"
... )
>>> labels = labels_dict.input_ids
>>> loss = model(**model_inputs, labels=labels).loss
>>> loss.item()
17.9
```
Similar to [T5](t5), ByT5 was trained on the span-mask denoising task. However,
since the model works directly on characters, the pretraining task is a bit
different. Let's corrupt some characters of the
input sentence `"The dog chases a ball in the park."` and ask ByT5 to predict them
for us.
```python
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("google/byt5-base")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("google/byt5-base")
>>> input_ids_prompt = "The dog chases a ball in the park."
>>> input_ids = tokenizer(input_ids_prompt).input_ids
>>> # Note that we cannot add "{extra_id_...}" to the string directly
>>> # as the Byte tokenizer would incorrectly merge the tokens
>>> # For ByT5, we need to work directly on the character level
>>> # Contrary to T5, ByT5 does not use sentinel tokens for masking, but instead
>>> # uses final utf character ids.
>>> # UTF-8 is represented by 8 bits and ByT5 has 3 special tokens.
>>> # => There are 2**8+2 = 259 input ids and mask tokens count down from index 258.
>>> # => mask to "The dog [258]a ball [257]park."
>>> input_ids = torch.tensor([input_ids[:8] + [258] + input_ids[14:21] + [257] + input_ids[28:]])
>>> input_ids
tensor([[ 87, 107, 104, 35, 103, 114, 106, 35, 258, 35, 100, 35, 101, 100, 111, 111, 257, 35, 115, 100, 117, 110, 49, 1]])
>>> # ByT5 produces only one char at a time so we need to produce many more output characters here -> set `max_length=100`.
>>> output_ids = model.generate(input_ids, max_length=100)[0].tolist()
>>> output_ids
[0, 258, 108, 118, 35, 119, 107, 104, 35, 114, 113, 104, 35, 122, 107, 114, 35, 103, 114, 104, 118, 257, 35, 108, 113, 35, 119, 107, 104, 35, 103, 108, 118, 102, 114, 256, 108, 113, 35, 119, 107, 104, 35, 115, 100, 117, 110, 49, 35, 87, 107, 104, 35, 103, 114, 106, 35, 108, 118, 35, 119, 107, 104, 35, 114, 113, 104, 35, 122, 107, 114, 35, 103, 114, 104, 118, 35, 100, 35, 101, 100, 111, 111, 35, 108, 113, 255, 35, 108, 113, 35, 119, 107, 104, 35, 115, 100, 117, 110, 49]
>>> # ^- Note how 258 descends to 257, 256, 255
>>> # Now we need to split on the sentinel tokens, let's write a short loop for this
>>> output_ids_list = []
>>> start_token = 0
>>> sentinel_token = 258
>>> while sentinel_token in output_ids:
... split_idx = output_ids.index(sentinel_token)
... output_ids_list.append(output_ids[start_token:split_idx])
... start_token = split_idx
... sentinel_token -= 1
>>> output_ids_list.append(output_ids[start_token:])
>>> output_string = tokenizer.batch_decode(output_ids_list)
>>> output_string
['<pad>', 'is the one who does', ' in the disco', 'in the park. The dog is the one who does a ball in', ' in the park.']
```
## ByT5Tokenizer
[[autodoc]] ByT5Tokenizer
See [`ByT5Tokenizer`] for all details.
| transformers/docs/source/en/model_doc/byt5.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/byt5.md",
"repo_id": "transformers",
"token_count": 2292
} | 246 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# CTRL
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=ctrl">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-ctrl-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/tiny-ctrl">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
</div>
## Overview
CTRL model was proposed in [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) by Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and
Richard Socher. It's a causal (unidirectional) transformer pre-trained using language modeling on a very large corpus
of ~140 GB of text data with the first token reserved as a control code (such as Links, Books, Wikipedia etc.).
The abstract from the paper is the following:
*Large-scale language models show promising text generation capabilities, but users cannot easily control particular
aspects of the generated text. We release CTRL, a 1.63 billion-parameter conditional transformer language model,
trained to condition on control codes that govern style, content, and task-specific behavior. Control codes were
derived from structure that naturally co-occurs with raw text, preserving the advantages of unsupervised learning while
providing more explicit control over text generation. These codes also allow CTRL to predict which parts of the
training data are most likely given a sequence. This provides a potential method for analyzing large amounts of data
via model-based source attribution.*
This model was contributed by [keskarnitishr](https://huggingface.co/keskarnitishr). The original code can be found
[here](https://github.com/salesforce/ctrl).
## Usage tips
- CTRL makes use of control codes to generate text: it requires generations to be started by certain words, sentences
or links to generate coherent text. Refer to the [original implementation](https://github.com/salesforce/ctrl) for
more information.
- CTRL is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
the left.
- CTRL was trained with a causal language modeling (CLM) objective and is therefore powerful at predicting the next
token in a sequence. Leveraging this feature allows CTRL to generate syntactically coherent text as it can be
observed in the *run_generation.py* example script.
- The PyTorch models can take the `past_key_values` as input, which is the previously computed key/value attention pairs.
TensorFlow models accepts `past` as input. Using the `past_key_values` value prevents the model from re-computing
pre-computed values in the context of text generation. See the [`forward`](model_doc/ctrl#transformers.CTRLModel.forward)
method for more information on the usage of this argument.
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Causal language modeling task guide](../tasks/language_modeling)
## CTRLConfig
[[autodoc]] CTRLConfig
## CTRLTokenizer
[[autodoc]] CTRLTokenizer
- save_vocabulary
<frameworkcontent>
<pt>
## CTRLModel
[[autodoc]] CTRLModel
- forward
## CTRLLMHeadModel
[[autodoc]] CTRLLMHeadModel
- forward
## CTRLForSequenceClassification
[[autodoc]] CTRLForSequenceClassification
- forward
</pt>
<tf>
## TFCTRLModel
[[autodoc]] TFCTRLModel
- call
## TFCTRLLMHeadModel
[[autodoc]] TFCTRLLMHeadModel
- call
## TFCTRLForSequenceClassification
[[autodoc]] TFCTRLForSequenceClassification
- call
</tf>
</frameworkcontent>
| transformers/docs/source/en/model_doc/ctrl.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/ctrl.md",
"repo_id": "transformers",
"token_count": 1209
} | 247 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# DiT
## Overview
DiT was proposed in [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) by Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
DiT applies the self-supervised objective of [BEiT](beit) (BERT pre-training of Image Transformers) to 42 million document images, allowing for state-of-the-art results on tasks including:
- document image classification: the [RVL-CDIP](https://www.cs.cmu.edu/~aharley/rvl-cdip/) dataset (a collection of
400,000 images belonging to one of 16 classes).
- document layout analysis: the [PubLayNet](https://github.com/ibm-aur-nlp/PubLayNet) dataset (a collection of more
than 360,000 document images constructed by automatically parsing PubMed XML files).
- table detection: the [ICDAR 2019 cTDaR](https://github.com/cndplab-founder/ICDAR2019_cTDaR) dataset (a collection of
600 training images and 240 testing images).
The abstract from the paper is the following:
*Image Transformer has recently achieved significant progress for natural image understanding, either using supervised (ViT, DeiT, etc.) or self-supervised (BEiT, MAE, etc.) pre-training techniques. In this paper, we propose DiT, a self-supervised pre-trained Document Image Transformer model using large-scale unlabeled text images for Document AI tasks, which is essential since no supervised counterparts ever exist due to the lack of human labeled document images. We leverage DiT as the backbone network in a variety of vision-based Document AI tasks, including document image classification, document layout analysis, as well as table detection. Experiment results have illustrated that the self-supervised pre-trained DiT model achieves new state-of-the-art results on these downstream tasks, e.g. document image classification (91.11 → 92.69), document layout analysis (91.0 → 94.9) and table detection (94.23 → 96.55). *
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/dit_architecture.jpg"
alt="drawing" width="600"/>
<small> Summary of the approach. Taken from the [original paper](https://arxiv.org/abs/2203.02378). </small>
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/dit).
## Usage tips
One can directly use the weights of DiT with the AutoModel API:
```python
from transformers import AutoModel
model = AutoModel.from_pretrained("microsoft/dit-base")
```
This will load the model pre-trained on masked image modeling. Note that this won't include the language modeling head on top, used to predict visual tokens.
To include the head, you can load the weights into a `BeitForMaskedImageModeling` model, like so:
```python
from transformers import BeitForMaskedImageModeling
model = BeitForMaskedImageModeling.from_pretrained("microsoft/dit-base")
```
You can also load a fine-tuned model from the [hub](https://huggingface.co/models?other=dit), like so:
```python
from transformers import AutoModelForImageClassification
model = AutoModelForImageClassification.from_pretrained("microsoft/dit-base-finetuned-rvlcdip")
```
This particular checkpoint was fine-tuned on [RVL-CDIP](https://www.cs.cmu.edu/~aharley/rvl-cdip/), an important benchmark for document image classification.
A notebook that illustrates inference for document image classification can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/DiT/Inference_with_DiT_(Document_Image_Transformer)_for_document_image_classification.ipynb).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with DiT.
<PipelineTag pipeline="image-classification"/>
- [`BeitForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
<Tip>
As DiT's architecture is equivalent to that of BEiT, one can refer to [BEiT's documentation page](beit) for all tips, code examples and notebooks.
</Tip>
| transformers/docs/source/en/model_doc/dit.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/dit.md",
"repo_id": "transformers",
"token_count": 1429
} | 248 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# FlauBERT
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=flaubert">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-flaubert-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/flaubert_small_cased">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
</div>
## Overview
The FlauBERT model was proposed in the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le et al. It's a transformer model pretrained using a masked language
modeling (MLM) objective (like BERT).
The abstract from the paper is the following:
*Language models have become a key step to achieve state-of-the art results in many different Natural Language
Processing (NLP) tasks. Leveraging the huge amount of unlabeled texts nowadays available, they provide an efficient way
to pre-train continuous word representations that can be fine-tuned for a downstream task, along with their
contextualization at the sentence level. This has been widely demonstrated for English using contextualized
representations (Dai and Le, 2015; Peters et al., 2018; Howard and Ruder, 2018; Radford et al., 2018; Devlin et al.,
2019; Yang et al., 2019b). In this paper, we introduce and share FlauBERT, a model learned on a very large and
heterogeneous French corpus. Models of different sizes are trained using the new CNRS (French National Centre for
Scientific Research) Jean Zay supercomputer. We apply our French language models to diverse NLP tasks (text
classification, paraphrasing, natural language inference, parsing, word sense disambiguation) and show that most of the
time they outperform other pretraining approaches. Different versions of FlauBERT as well as a unified evaluation
protocol for the downstream tasks, called FLUE (French Language Understanding Evaluation), are shared to the research
community for further reproducible experiments in French NLP.*
This model was contributed by [formiel](https://huggingface.co/formiel). The original code can be found [here](https://github.com/getalp/Flaubert).
Tips:
- Like RoBERTa, without the sentence ordering prediction (so just trained on the MLM objective).
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
- [Multiple choice task guide](../tasks/multiple_choice)
## FlaubertConfig
[[autodoc]] FlaubertConfig
## FlaubertTokenizer
[[autodoc]] FlaubertTokenizer
<frameworkcontent>
<pt>
## FlaubertModel
[[autodoc]] FlaubertModel
- forward
## FlaubertWithLMHeadModel
[[autodoc]] FlaubertWithLMHeadModel
- forward
## FlaubertForSequenceClassification
[[autodoc]] FlaubertForSequenceClassification
- forward
## FlaubertForMultipleChoice
[[autodoc]] FlaubertForMultipleChoice
- forward
## FlaubertForTokenClassification
[[autodoc]] FlaubertForTokenClassification
- forward
## FlaubertForQuestionAnsweringSimple
[[autodoc]] FlaubertForQuestionAnsweringSimple
- forward
## FlaubertForQuestionAnswering
[[autodoc]] FlaubertForQuestionAnswering
- forward
</pt>
<tf>
## TFFlaubertModel
[[autodoc]] TFFlaubertModel
- call
## TFFlaubertWithLMHeadModel
[[autodoc]] TFFlaubertWithLMHeadModel
- call
## TFFlaubertForSequenceClassification
[[autodoc]] TFFlaubertForSequenceClassification
- call
## TFFlaubertForMultipleChoice
[[autodoc]] TFFlaubertForMultipleChoice
- call
## TFFlaubertForTokenClassification
[[autodoc]] TFFlaubertForTokenClassification
- call
## TFFlaubertForQuestionAnsweringSimple
[[autodoc]] TFFlaubertForQuestionAnsweringSimple
- call
</tf>
</frameworkcontent>
| transformers/docs/source/en/model_doc/flaubert.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/flaubert.md",
"repo_id": "transformers",
"token_count": 1382
} | 249 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# GPTSAN-japanese
## Overview
The GPTSAN-japanese model was released in the repository by Toshiyuki Sakamoto (tanreinama).
GPTSAN is a Japanese language model using Switch Transformer. It has the same structure as the model introduced as Prefix LM
in the T5 paper, and support both Text Generation and Masked Language Modeling tasks. These basic tasks similarly can
fine-tune for translation or summarization.
### Usage example
The `generate()` method can be used to generate text using GPTSAN-Japanese model.
```python
>>> from transformers import AutoModel, AutoTokenizer
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("Tanrei/GPTSAN-japanese")
>>> model = AutoModel.from_pretrained("Tanrei/GPTSAN-japanese").cuda()
>>> x_tok = tokenizer("は、", prefix_text="織田信長", return_tensors="pt")
>>> torch.manual_seed(0)
>>> gen_tok = model.generate(x_tok.input_ids.cuda(), token_type_ids=x_tok.token_type_ids.cuda(), max_new_tokens=20)
>>> tokenizer.decode(gen_tok[0])
'織田信長は、2004年に『戦国BASARA』のために、豊臣秀吉'
```
## GPTSAN Features
GPTSAN has some unique features. It has a model structure of Prefix-LM. It works as a shifted Masked Language Model for Prefix Input tokens. Un-prefixed inputs behave like normal generative models.
The Spout vector is a GPTSAN specific input. Spout is pre-trained with random inputs, but you can specify a class of text or an arbitrary vector during fine-tuning. This allows you to indicate the tendency of the generated text.
GPTSAN has a sparse Feed Forward based on Switch-Transformer. You can also add other layers and train them partially. See the original GPTSAN repository for details.
### Prefix-LM Model
GPTSAN has the structure of the model named Prefix-LM in the `T5` paper. (The original GPTSAN repository calls it `hybrid`)
In GPTSAN, the `Prefix` part of Prefix-LM, that is, the input position that can be referenced by both tokens, can be specified with any length.
Arbitrary lengths can also be specified differently for each batch.
This length applies to the text entered in `prefix_text` for the tokenizer.
The tokenizer returns the mask of the `Prefix` part of Prefix-LM as `token_type_ids`.
The model treats the part where `token_type_ids` is 1 as a `Prefix` part, that is, the input can refer to both tokens before and after.
## Usage tips
Specifying the Prefix part is done with a mask passed to self-attention.
When token_type_ids=None or all zero, it is equivalent to regular causal mask
for example:
>>> x_token = tokenizer("アイウエ")
input_ids: | SOT | SEG | ア | イ | ウ | エ |
token_type_ids: | 1 | 0 | 0 | 0 | 0 | 0 |
prefix_lm_mask:
SOT | 1 0 0 0 0 0 |
SEG | 1 1 0 0 0 0 |
ア | 1 1 1 0 0 0 |
イ | 1 1 1 1 0 0 |
ウ | 1 1 1 1 1 0 |
エ | 1 1 1 1 1 1 |
>>> x_token = tokenizer("", prefix_text="アイウエ")
input_ids: | SOT | ア | イ | ウ | エ | SEG |
token_type_ids: | 1 | 1 | 1 | 1 | 1 | 0 |
prefix_lm_mask:
SOT | 1 1 1 1 1 0 |
ア | 1 1 1 1 1 0 |
イ | 1 1 1 1 1 0 |
ウ | 1 1 1 1 1 0 |
エ | 1 1 1 1 1 0 |
SEG | 1 1 1 1 1 1 |
>>> x_token = tokenizer("ウエ", prefix_text="アイ")
input_ids: | SOT | ア | イ | SEG | ウ | エ |
token_type_ids: | 1 | 1 | 1 | 0 | 0 | 0 |
prefix_lm_mask:
SOT | 1 1 1 0 0 0 |
ア | 1 1 1 0 0 0 |
イ | 1 1 1 0 0 0 |
SEG | 1 1 1 1 0 0 |
ウ | 1 1 1 1 1 0 |
エ | 1 1 1 1 1 1 |
### Spout Vector
A Spout Vector is a special vector for controlling text generation.
This vector is treated as the first embedding in self-attention to bring extraneous attention to the generated tokens.
In the pre-trained model published from `Tanrei/GPTSAN-japanese`, the Spout Vector is a 128-dimensional vector that passes through 8 fully connected layers in the model and is projected into the space acting as external attention.
The Spout Vector projected by the fully connected layer is split to be passed to all self-attentions.
## GPTSanJapaneseConfig
[[autodoc]] GPTSanJapaneseConfig
## GPTSanJapaneseTokenizer
[[autodoc]] GPTSanJapaneseTokenizer
## GPTSanJapaneseModel
[[autodoc]] GPTSanJapaneseModel
## GPTSanJapaneseForConditionalGeneration
[[autodoc]] GPTSanJapaneseForConditionalGeneration
- forward
| transformers/docs/source/en/model_doc/gptsan-japanese.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/gptsan-japanese.md",
"repo_id": "transformers",
"token_count": 1659
} | 250 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# LED
## Overview
The LED model was proposed in [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz
Beltagy, Matthew E. Peters, Arman Cohan.
The abstract from the paper is the following:
*Transformer-based models are unable to process long sequences due to their self-attention operation, which scales
quadratically with the sequence length. To address this limitation, we introduce the Longformer with an attention
mechanism that scales linearly with sequence length, making it easy to process documents of thousands of tokens or
longer. Longformer's attention mechanism is a drop-in replacement for the standard self-attention and combines a local
windowed attention with a task motivated global attention. Following prior work on long-sequence transformers, we
evaluate Longformer on character-level language modeling and achieve state-of-the-art results on text8 and enwik8. In
contrast to most prior work, we also pretrain Longformer and finetune it on a variety of downstream tasks. Our
pretrained Longformer consistently outperforms RoBERTa on long document tasks and sets new state-of-the-art results on
WikiHop and TriviaQA. We finally introduce the Longformer-Encoder-Decoder (LED), a Longformer variant for supporting
long document generative sequence-to-sequence tasks, and demonstrate its effectiveness on the arXiv summarization
dataset.*
## Usage tips
- [`LEDForConditionalGeneration`] is an extension of
[`BartForConditionalGeneration`] exchanging the traditional *self-attention* layer with
*Longformer*'s *chunked self-attention* layer. [`LEDTokenizer`] is an alias of
[`BartTokenizer`].
- LED works very well on long-range *sequence-to-sequence* tasks where the `input_ids` largely exceed a length of
1024 tokens.
- LED pads the `input_ids` to be a multiple of `config.attention_window` if required. Therefore a small speed-up is
gained, when [`LEDTokenizer`] is used with the `pad_to_multiple_of` argument.
- LED makes use of *global attention* by means of the `global_attention_mask` (see
[`LongformerModel`]). For summarization, it is advised to put *global attention* only on the first
`<s>` token. For question answering, it is advised to put *global attention* on all tokens of the question.
- To fine-tune LED on all 16384, *gradient checkpointing* can be enabled in case training leads to out-of-memory (OOM)
errors. This can be done by executing `model.gradient_checkpointing_enable()`.
Moreover, the `use_cache=False`
flag can be used to disable the caching mechanism to save memory.
- LED is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
the left.
This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten).
## Resources
- [A notebook showing how to evaluate LED](https://colab.research.google.com/drive/12INTTR6n64TzS4RrXZxMSXfrOd9Xzamo?usp=sharing).
- [A notebook showing how to fine-tune LED](https://colab.research.google.com/drive/12LjJazBl7Gam0XBPy_y0CTOJZeZ34c2v?usp=sharing).
- [Text classification task guide](../tasks/sequence_classification)
- [Question answering task guide](../tasks/question_answering)
- [Translation task guide](../tasks/translation)
- [Summarization task guide](../tasks/summarization)
## LEDConfig
[[autodoc]] LEDConfig
## LEDTokenizer
[[autodoc]] LEDTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## LEDTokenizerFast
[[autodoc]] LEDTokenizerFast
## LED specific outputs
[[autodoc]] models.led.modeling_led.LEDEncoderBaseModelOutput
[[autodoc]] models.led.modeling_led.LEDSeq2SeqModelOutput
[[autodoc]] models.led.modeling_led.LEDSeq2SeqLMOutput
[[autodoc]] models.led.modeling_led.LEDSeq2SeqSequenceClassifierOutput
[[autodoc]] models.led.modeling_led.LEDSeq2SeqQuestionAnsweringModelOutput
[[autodoc]] models.led.modeling_tf_led.TFLEDEncoderBaseModelOutput
[[autodoc]] models.led.modeling_tf_led.TFLEDSeq2SeqModelOutput
[[autodoc]] models.led.modeling_tf_led.TFLEDSeq2SeqLMOutput
<frameworkcontent>
<pt>
## LEDModel
[[autodoc]] LEDModel
- forward
## LEDForConditionalGeneration
[[autodoc]] LEDForConditionalGeneration
- forward
## LEDForSequenceClassification
[[autodoc]] LEDForSequenceClassification
- forward
## LEDForQuestionAnswering
[[autodoc]] LEDForQuestionAnswering
- forward
</pt>
<tf>
## TFLEDModel
[[autodoc]] TFLEDModel
- call
## TFLEDForConditionalGeneration
[[autodoc]] TFLEDForConditionalGeneration
- call
</tf>
</frameworkcontent>
| transformers/docs/source/en/model_doc/led.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/led.md",
"repo_id": "transformers",
"token_count": 1602
} | 251 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# MPNet
## Overview
The MPNet model was proposed in [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
MPNet adopts a novel pre-training method, named masked and permuted language modeling, to inherit the advantages of
masked language modeling and permuted language modeling for natural language understanding.
The abstract from the paper is the following:
*BERT adopts masked language modeling (MLM) for pre-training and is one of the most successful pre-training models.
Since BERT neglects dependency among predicted tokens, XLNet introduces permuted language modeling (PLM) for
pre-training to address this problem. However, XLNet does not leverage the full position information of a sentence and
thus suffers from position discrepancy between pre-training and fine-tuning. In this paper, we propose MPNet, a novel
pre-training method that inherits the advantages of BERT and XLNet and avoids their limitations. MPNet leverages the
dependency among predicted tokens through permuted language modeling (vs. MLM in BERT), and takes auxiliary position
information as input to make the model see a full sentence and thus reducing the position discrepancy (vs. PLM in
XLNet). We pre-train MPNet on a large-scale dataset (over 160GB text corpora) and fine-tune on a variety of
down-streaming tasks (GLUE, SQuAD, etc). Experimental results show that MPNet outperforms MLM and PLM by a large
margin, and achieves better results on these tasks compared with previous state-of-the-art pre-trained methods (e.g.,
BERT, XLNet, RoBERTa) under the same model setting.*
The original code can be found [here](https://github.com/microsoft/MPNet).
## Usage tips
MPNet doesn't have `token_type_ids`, you don't need to indicate which token belongs to which segment. Just
separate your segments with the separation token `tokenizer.sep_token` (or `[sep]`).
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
- [Multiple choice task guide](../tasks/multiple_choice)
## MPNetConfig
[[autodoc]] MPNetConfig
## MPNetTokenizer
[[autodoc]] MPNetTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## MPNetTokenizerFast
[[autodoc]] MPNetTokenizerFast
<frameworkcontent>
<pt>
## MPNetModel
[[autodoc]] MPNetModel
- forward
## MPNetForMaskedLM
[[autodoc]] MPNetForMaskedLM
- forward
## MPNetForSequenceClassification
[[autodoc]] MPNetForSequenceClassification
- forward
## MPNetForMultipleChoice
[[autodoc]] MPNetForMultipleChoice
- forward
## MPNetForTokenClassification
[[autodoc]] MPNetForTokenClassification
- forward
## MPNetForQuestionAnswering
[[autodoc]] MPNetForQuestionAnswering
- forward
</pt>
<tf>
## TFMPNetModel
[[autodoc]] TFMPNetModel
- call
## TFMPNetForMaskedLM
[[autodoc]] TFMPNetForMaskedLM
- call
## TFMPNetForSequenceClassification
[[autodoc]] TFMPNetForSequenceClassification
- call
## TFMPNetForMultipleChoice
[[autodoc]] TFMPNetForMultipleChoice
- call
## TFMPNetForTokenClassification
[[autodoc]] TFMPNetForTokenClassification
- call
## TFMPNetForQuestionAnswering
[[autodoc]] TFMPNetForQuestionAnswering
- call
</tf>
</frameworkcontent>
| transformers/docs/source/en/model_doc/mpnet.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/mpnet.md",
"repo_id": "transformers",
"token_count": 1255
} | 252 |
<!--Copyright 2021 NVIDIA Corporation and The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# QDQBERT
## Overview
The QDQBERT model can be referenced in [Integer Quantization for Deep Learning Inference: Principles and Empirical
Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius
Micikevicius.
The abstract from the paper is the following:
*Quantization techniques can reduce the size of Deep Neural Networks and improve inference latency and throughput by
taking advantage of high throughput integer instructions. In this paper we review the mathematical aspects of
quantization parameters and evaluate their choices on a wide range of neural network models for different application
domains, including vision, speech, and language. We focus on quantization techniques that are amenable to acceleration
by processors with high-throughput integer math pipelines. We also present a workflow for 8-bit quantization that is
able to maintain accuracy within 1% of the floating-point baseline on all networks studied, including models that are
more difficult to quantize, such as MobileNets and BERT-large.*
This model was contributed by [shangz](https://huggingface.co/shangz).
## Usage tips
- QDQBERT model adds fake quantization operations (pair of QuantizeLinear/DequantizeLinear ops) to (i) linear layer
inputs and weights, (ii) matmul inputs, (iii) residual add inputs, in BERT model.
- QDQBERT requires the dependency of [Pytorch Quantization Toolkit](https://github.com/NVIDIA/TensorRT/tree/master/tools/pytorch-quantization). To install `pip install pytorch-quantization --extra-index-url https://pypi.ngc.nvidia.com`
- QDQBERT model can be loaded from any checkpoint of HuggingFace BERT model (for example *bert-base-uncased*), and
perform Quantization Aware Training/Post Training Quantization.
- A complete example of using QDQBERT model to perform Quatization Aware Training and Post Training Quantization for
SQUAD task can be found at [transformers/examples/research_projects/quantization-qdqbert/](examples/research_projects/quantization-qdqbert/).
### Set default quantizers
QDQBERT model adds fake quantization operations (pair of QuantizeLinear/DequantizeLinear ops) to BERT by
`TensorQuantizer` in [Pytorch Quantization Toolkit](https://github.com/NVIDIA/TensorRT/tree/master/tools/pytorch-quantization). `TensorQuantizer` is the module
for quantizing tensors, with `QuantDescriptor` defining how the tensor should be quantized. Refer to [Pytorch
Quantization Toolkit userguide](https://docs.nvidia.com/deeplearning/tensorrt/pytorch-quantization-toolkit/docs/userguide.html) for more details.
Before creating QDQBERT model, one has to set the default `QuantDescriptor` defining default tensor quantizers.
Example:
```python
>>> import pytorch_quantization.nn as quant_nn
>>> from pytorch_quantization.tensor_quant import QuantDescriptor
>>> # The default tensor quantizer is set to use Max calibration method
>>> input_desc = QuantDescriptor(num_bits=8, calib_method="max")
>>> # The default tensor quantizer is set to be per-channel quantization for weights
>>> weight_desc = QuantDescriptor(num_bits=8, axis=((0,)))
>>> quant_nn.QuantLinear.set_default_quant_desc_input(input_desc)
>>> quant_nn.QuantLinear.set_default_quant_desc_weight(weight_desc)
```
### Calibration
Calibration is the terminology of passing data samples to the quantizer and deciding the best scaling factors for
tensors. After setting up the tensor quantizers, one can use the following example to calibrate the model:
```python
>>> # Find the TensorQuantizer and enable calibration
>>> for name, module in model.named_modules():
... if name.endswith("_input_quantizer"):
... module.enable_calib()
... module.disable_quant() # Use full precision data to calibrate
>>> # Feeding data samples
>>> model(x)
>>> # ...
>>> # Finalize calibration
>>> for name, module in model.named_modules():
... if name.endswith("_input_quantizer"):
... module.load_calib_amax()
... module.enable_quant()
>>> # If running on GPU, it needs to call .cuda() again because new tensors will be created by calibration process
>>> model.cuda()
>>> # Keep running the quantized model
>>> # ...
```
### Export to ONNX
The goal of exporting to ONNX is to deploy inference by [TensorRT](https://developer.nvidia.com/tensorrt). Fake
quantization will be broken into a pair of QuantizeLinear/DequantizeLinear ONNX ops. After setting static member of
TensorQuantizer to use Pytorch’s own fake quantization functions, fake quantized model can be exported to ONNX, follow
the instructions in [torch.onnx](https://pytorch.org/docs/stable/onnx.html). Example:
```python
>>> from pytorch_quantization.nn import TensorQuantizer
>>> TensorQuantizer.use_fb_fake_quant = True
>>> # Load the calibrated model
>>> ...
>>> # ONNX export
>>> torch.onnx.export(...)
```
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
- [Causal language modeling task guide](../tasks/language_modeling)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
- [Multiple choice task guide](../tasks/multiple_choice)
## QDQBertConfig
[[autodoc]] QDQBertConfig
## QDQBertModel
[[autodoc]] QDQBertModel
- forward
## QDQBertLMHeadModel
[[autodoc]] QDQBertLMHeadModel
- forward
## QDQBertForMaskedLM
[[autodoc]] QDQBertForMaskedLM
- forward
## QDQBertForSequenceClassification
[[autodoc]] QDQBertForSequenceClassification
- forward
## QDQBertForNextSentencePrediction
[[autodoc]] QDQBertForNextSentencePrediction
- forward
## QDQBertForMultipleChoice
[[autodoc]] QDQBertForMultipleChoice
- forward
## QDQBertForTokenClassification
[[autodoc]] QDQBertForTokenClassification
- forward
## QDQBertForQuestionAnswering
[[autodoc]] QDQBertForQuestionAnswering
- forward
| transformers/docs/source/en/model_doc/qdqbert.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/qdqbert.md",
"repo_id": "transformers",
"token_count": 1978
} | 253 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# T5
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=t5">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-t5-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/t5-base">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
<a href="https://huggingface.co/papers/1910.10683">
<img alt="Paper page" src="https://img.shields.io/badge/Paper%20page-1910.10683-green">
</a>
</div>
## Overview
The T5 model was presented in [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/pdf/1910.10683.pdf) by [Colin Raffel](https://huggingface.co/craffel), Noam Shazeer, [Adam Roberts](https://huggingface.co/adarob), Katherine Lee, Sharan Narang,
Michael Matena, Yanqi Zhou, Wei Li, [Peter J. Liu](https://huggingface.co/peterjliu).
The abstract from the paper is the following:
*Transfer learning, where a model is first pre-trained on a data-rich task before being fine-tuned on a downstream
task, has emerged as a powerful technique in natural language processing (NLP). The effectiveness of transfer learning
has given rise to a diversity of approaches, methodology, and practice. In this paper, we explore the landscape of
transfer learning techniques for NLP by introducing a unified framework that converts every language problem into a
text-to-text format. Our systematic study compares pretraining objectives, architectures, unlabeled datasets, transfer
approaches, and other factors on dozens of language understanding tasks. By combining the insights from our exploration
with scale and our new "Colossal Clean Crawled Corpus", we achieve state-of-the-art results on many benchmarks covering
summarization, question answering, text classification, and more. To facilitate future work on transfer learning for
NLP, we release our dataset, pre-trained models, and code.*
All checkpoints can be found on the [hub](https://huggingface.co/models?search=t5).
This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/google-research/text-to-text-transfer-transformer).
## Usage tips
- T5 is an encoder-decoder model pre-trained on a multi-task mixture of unsupervised and supervised tasks and for which
each task is converted into a text-to-text format. T5 works well on a variety of tasks out-of-the-box by prepending a
different prefix to the input corresponding to each task, e.g., for translation: *translate English to German: ...*,
for summarization: *summarize: ...*.
- The pretraining includes both supervised and self-supervised training. Supervised training is conducted on downstream tasks provided by the GLUE and SuperGLUE benchmarks (converting them into text-to-text tasks as explained above).
- Self-supervised training uses corrupted tokens, by randomly removing 15% of the tokens and replacing them with individual sentinel tokens (if several consecutive tokens are marked for removal, the whole group is replaced with a single sentinel token). The input of the encoder is the corrupted sentence, the input of the decoder is the original sentence and the target is then the dropped out tokens delimited by their sentinel tokens.
- T5 uses relative scalar embeddings. Encoder input padding can be done on the left and on the right.
- See the [training](#training), [inference](#inference) and [scripts](#scripts) sections below for all details regarding usage.
T5 comes in different sizes:
- [t5-small](https://huggingface.co/t5-small)
- [t5-base](https://huggingface.co/t5-base)
- [t5-large](https://huggingface.co/t5-large)
- [t5-3b](https://huggingface.co/t5-3b)
- [t5-11b](https://huggingface.co/t5-11b).
Based on the original T5 model, Google has released some follow-up works:
- **T5v1.1**: T5v1.1 is an improved version of T5 with some architectural tweaks, and is pre-trained on C4 only without
mixing in the supervised tasks. Refer to the documentation of T5v1.1 which can be found [here](t5v1.1).
- **mT5**: mT5 is a multilingual T5 model. It is pre-trained on the mC4 corpus, which includes 101 languages. Refer to
the documentation of mT5 which can be found [here](mt5).
- **byT5**: byT5 is a T5 model pre-trained on byte sequences rather than SentencePiece subword token sequences. Refer
to the documentation of byT5 which can be found [here](byt5).
- **UL2**: UL2 is a T5 like model pretrained on various denoising objectives
- **Flan-T5**: Flan is a pretraining methods that is based on prompting. The Flan-T5 are T5 models trained on the Flan collection of
datasets which include: `taskmaster2`, `djaym7/wiki_dialog`, `deepmind/code_contests`, `lambada`, `gsm8k`, `aqua_rat`, `esnli`, `quasc` and `qed`.
- **FLan-UL2** : the UL2 model finetuned using the "Flan" prompt tuning and dataset collection.
- **UMT5**: UmT5 is a multilingual T5 model trained on an improved and refreshed mC4 multilingual corpus, 29 trillion characters across 107 language, using a new sampling method, UniMax. Refer to
the documentation of mT5 which can be found [here](umt5).
## Training
T5 is an encoder-decoder model and converts all NLP problems into a text-to-text format. It is trained using teacher
forcing. This means that for training, we always need an input sequence and a corresponding target sequence. The input
sequence is fed to the model using `input_ids`. The target sequence is shifted to the right, i.e., prepended by a
start-sequence token and fed to the decoder using the `decoder_input_ids`. In teacher-forcing style, the target
sequence is then appended by the EOS token and corresponds to the `labels`. The PAD token is hereby used as the
start-sequence token. T5 can be trained / fine-tuned both in a supervised and unsupervised fashion.
One can use [`T5ForConditionalGeneration`] (or the Tensorflow/Flax variant), which includes the
language modeling head on top of the decoder.
- Unsupervised denoising training
In this setup, spans of the input sequence are masked by so-called sentinel tokens (*a.k.a* unique mask tokens) and
the output sequence is formed as a concatenation of the same sentinel tokens and the *real* masked tokens. Each
sentinel token represents a unique mask token for this sentence and should start with `<extra_id_0>`,
`<extra_id_1>`, ... up to `<extra_id_99>`. As a default, 100 sentinel tokens are available in
[`T5Tokenizer`].
For instance, the sentence "The cute dog walks in the park" with the masks put on "cute dog" and "the" should be
processed as follows:
```python
>>> from transformers import T5Tokenizer, T5ForConditionalGeneration
>>> tokenizer = T5Tokenizer.from_pretrained("t5-small")
>>> model = T5ForConditionalGeneration.from_pretrained("t5-small")
>>> input_ids = tokenizer("The <extra_id_0> walks in <extra_id_1> park", return_tensors="pt").input_ids
>>> labels = tokenizer("<extra_id_0> cute dog <extra_id_1> the <extra_id_2>", return_tensors="pt").input_ids
>>> # the forward function automatically creates the correct decoder_input_ids
>>> loss = model(input_ids=input_ids, labels=labels).loss
>>> loss.item()
3.7837
```
If you're interested in pre-training T5 on a new corpus, check out the [run_t5_mlm_flax.py](https://github.com/huggingface/transformers/tree/main/examples/flax/language-modeling) script in the Examples
directory.
- Supervised training
In this setup, the input sequence and output sequence are a standard sequence-to-sequence input-output mapping.
Suppose that we want to fine-tune the model for translation for example, and we have a training example: the input
sequence "The house is wonderful." and output sequence "Das Haus ist wunderbar.", then they should be prepared for
the model as follows:
```python
>>> from transformers import T5Tokenizer, T5ForConditionalGeneration
>>> tokenizer = T5Tokenizer.from_pretrained("t5-small")
>>> model = T5ForConditionalGeneration.from_pretrained("t5-small")
>>> input_ids = tokenizer("translate English to German: The house is wonderful.", return_tensors="pt").input_ids
>>> labels = tokenizer("Das Haus ist wunderbar.", return_tensors="pt").input_ids
>>> # the forward function automatically creates the correct decoder_input_ids
>>> loss = model(input_ids=input_ids, labels=labels).loss
>>> loss.item()
0.2542
```
As you can see, only 2 inputs are required for the model in order to compute a loss: `input_ids` (which are the
`input_ids` of the encoded input sequence) and `labels` (which are the `input_ids` of the encoded
target sequence). The model will automatically create the `decoder_input_ids` based on the `labels`, by
shifting them one position to the right and prepending the `config.decoder_start_token_id`, which for T5 is
equal to 0 (i.e. the id of the pad token). Also note the task prefix: we prepend the input sequence with 'translate
English to German: ' before encoding it. This will help in improving the performance, as this task prefix was used
during T5's pre-training.
However, the example above only shows a single training example. In practice, one trains deep learning models in
batches. This entails that we must pad/truncate examples to the same length. For encoder-decoder models, one
typically defines a `max_source_length` and `max_target_length`, which determine the maximum length of the
input and output sequences respectively (otherwise they are truncated). These should be carefully set depending on
the task.
In addition, we must make sure that padding token id's of the `labels` are not taken into account by the loss
function. In PyTorch and Tensorflow, this can be done by replacing them with -100, which is the `ignore_index`
of the `CrossEntropyLoss`. In Flax, one can use the `decoder_attention_mask` to ignore padded tokens from
the loss (see the [Flax summarization script](https://github.com/huggingface/transformers/tree/main/examples/flax/summarization) for details). We also pass
`attention_mask` as additional input to the model, which makes sure that padding tokens of the inputs are
ignored. The code example below illustrates all of this.
```python
>>> from transformers import T5Tokenizer, T5ForConditionalGeneration
>>> import torch
>>> tokenizer = T5Tokenizer.from_pretrained("t5-small")
>>> model = T5ForConditionalGeneration.from_pretrained("t5-small")
>>> # the following 2 hyperparameters are task-specific
>>> max_source_length = 512
>>> max_target_length = 128
>>> # Suppose we have the following 2 training examples:
>>> input_sequence_1 = "Welcome to NYC"
>>> output_sequence_1 = "Bienvenue à NYC"
>>> input_sequence_2 = "HuggingFace is a company"
>>> output_sequence_2 = "HuggingFace est une entreprise"
>>> # encode the inputs
>>> task_prefix = "translate English to French: "
>>> input_sequences = [input_sequence_1, input_sequence_2]
>>> encoding = tokenizer(
... [task_prefix + sequence for sequence in input_sequences],
... padding="longest",
... max_length=max_source_length,
... truncation=True,
... return_tensors="pt",
... )
>>> input_ids, attention_mask = encoding.input_ids, encoding.attention_mask
>>> # encode the targets
>>> target_encoding = tokenizer(
... [output_sequence_1, output_sequence_2],
... padding="longest",
... max_length=max_target_length,
... truncation=True,
... return_tensors="pt",
... )
>>> labels = target_encoding.input_ids
>>> # replace padding token id's of the labels by -100 so it's ignored by the loss
>>> labels[labels == tokenizer.pad_token_id] = -100
>>> # forward pass
>>> loss = model(input_ids=input_ids, attention_mask=attention_mask, labels=labels).loss
>>> loss.item()
0.188
```
Additional training tips:
- T5 models need a slightly higher learning rate than the default one set in the `Trainer` when using the AdamW
optimizer. Typically, 1e-4 and 3e-4 work well for most problems (classification, summarization, translation, question
answering, question generation). Note that T5 was pre-trained using the AdaFactor optimizer.
According to [this forum post](https://discuss.huggingface.co/t/t5-finetuning-tips/684), task prefixes matter when
(1) doing multi-task training (2) your task is similar or related to one of the supervised tasks used in T5's
pre-training mixture (see Appendix D of the [paper](https://arxiv.org/pdf/1910.10683.pdf) for the task prefixes
used).
If training on TPU, it is recommended to pad all examples of the dataset to the same length or make use of
*pad_to_multiple_of* to have a small number of predefined bucket sizes to fit all examples in. Dynamically padding
batches to the longest example is not recommended on TPU as it triggers a recompilation for every batch shape that is
encountered during training thus significantly slowing down the training. only padding up to the longest example in a
batch) leads to very slow training on TPU.
## Inference
At inference time, it is recommended to use [`~generation.GenerationMixin.generate`]. This
method takes care of encoding the input and feeding the encoded hidden states via cross-attention layers to the decoder
and auto-regressively generates the decoder output. Check out [this blog post](https://huggingface.co/blog/how-to-generate) to know all the details about generating text with Transformers.
There's also [this blog post](https://huggingface.co/blog/encoder-decoder#encoder-decoder) which explains how
generation works in general in encoder-decoder models.
```python
>>> from transformers import T5Tokenizer, T5ForConditionalGeneration
>>> tokenizer = T5Tokenizer.from_pretrained("t5-small")
>>> model = T5ForConditionalGeneration.from_pretrained("t5-small")
>>> input_ids = tokenizer("translate English to German: The house is wonderful.", return_tensors="pt").input_ids
>>> outputs = model.generate(input_ids)
>>> print(tokenizer.decode(outputs[0], skip_special_tokens=True))
Das Haus ist wunderbar.
```
Note that T5 uses the `pad_token_id` as the `decoder_start_token_id`, so when doing generation without using
[`~generation.GenerationMixin.generate`], make sure you start it with the `pad_token_id`.
The example above only shows a single example. You can also do batched inference, like so:
```python
>>> from transformers import T5Tokenizer, T5ForConditionalGeneration
>>> tokenizer = T5Tokenizer.from_pretrained("t5-small")
>>> model = T5ForConditionalGeneration.from_pretrained("t5-small")
>>> task_prefix = "translate English to German: "
>>> # use different length sentences to test batching
>>> sentences = ["The house is wonderful.", "I like to work in NYC."]
>>> inputs = tokenizer([task_prefix + sentence for sentence in sentences], return_tensors="pt", padding=True)
>>> output_sequences = model.generate(
... input_ids=inputs["input_ids"],
... attention_mask=inputs["attention_mask"],
... do_sample=False, # disable sampling to test if batching affects output
... )
>>> print(tokenizer.batch_decode(output_sequences, skip_special_tokens=True))
['Das Haus ist wunderbar.', 'Ich arbeite gerne in NYC.']
```
Because T5 has been trained with the span-mask denoising objective,
it can be used to predict the sentinel (masked-out) tokens during inference.
The predicted tokens will then be placed between the sentinel tokens.
```python
>>> from transformers import T5Tokenizer, T5ForConditionalGeneration
>>> tokenizer = T5Tokenizer.from_pretrained("t5-small")
>>> model = T5ForConditionalGeneration.from_pretrained("t5-small")
>>> input_ids = tokenizer("The <extra_id_0> walks in <extra_id_1> park", return_tensors="pt").input_ids
>>> sequence_ids = model.generate(input_ids)
>>> sequences = tokenizer.batch_decode(sequence_ids)
>>> sequences
['<pad><extra_id_0> park offers<extra_id_1> the<extra_id_2> park.</s>']
```
## Performance
If you'd like a faster training and inference performance, install [NVIDIA APEX](https://github.com/NVIDIA/apex#quick-start) for NVIDIA GPUs, or [ROCm APEX](https://github.com/ROCmSoftwarePlatform/apex) for AMD GPUs and then the model will automatically use `apex.normalization.FusedRMSNorm` instead of `T5LayerNorm`. The former uses an optimized fused kernel which is several times faster than the latter.
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with T5. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
<PipelineTag pipeline="text-classification"/>
- A notebook for how to [finetune T5 for classification and multiple choice](https://colab.research.google.com/github/patil-suraj/exploring-T5/blob/master/t5_fine_tuning.ipynb).
- A notebook for how to [finetune T5 for sentiment span extraction](https://colab.research.google.com/github/enzoampil/t5-intro/blob/master/t5_qa_training_pytorch_span_extraction.ipynb). 🌎
<PipelineTag pipeline="token-classification"/>
- A notebook for how to [finetune T5 for named entity recognition](https://colab.research.google.com/drive/1obr78FY_cBmWY5ODViCmzdY6O1KB65Vc?usp=sharing). 🌎
<PipelineTag pipeline="text-generation"/>
- A notebook for [Finetuning CodeT5 for generating docstrings from Ruby code](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/T5/Fine_tune_CodeT5_for_generating_docstrings_from_Ruby_code.ipynb).
<PipelineTag pipeline="summarization"/>
- A notebook to [Finetune T5-base-dutch to perform Dutch abstractive summarization on a TPU](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/T5/Fine_tuning_Dutch_T5_base_on_CNN_Daily_Mail_for_summarization_(on_TPU_using_HuggingFace_Accelerate).ipynb).
- A notebook for how to [finetune T5 for summarization in PyTorch and track experiments with WandB](https://colab.research.google.com/github/abhimishra91/transformers-tutorials/blob/master/transformers_summarization_wandb.ipynb#scrollTo=OKRpFvYhBauC). 🌎
- A blog post on [Distributed Training: Train BART/T5 for Summarization using 🤗 Transformers and Amazon SageMaker](https://huggingface.co/blog/sagemaker-distributed-training-seq2seq).
- [`T5ForConditionalGeneration`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/summarization.ipynb).
- [`TFT5ForConditionalGeneration`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/summarization) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/summarization-tf.ipynb).
- [`FlaxT5ForConditionalGeneration`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/summarization).
- [Summarization](https://huggingface.co/course/chapter7/5?fw=pt#summarization) chapter of the 🤗 Hugging Face course.
- [Summarization task guide](../tasks/summarization)
<PipelineTag pipeline="fill-mask"/>
- [`FlaxT5ForConditionalGeneration`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/language-modeling#t5-like-span-masked-language-modeling) for training T5 with a span-masked language model objective. The script also shows how to train a T5 tokenizer. [`FlaxT5ForConditionalGeneration`] is also supported by this [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/masked_language_modeling_flax.ipynb).
<PipelineTag pipeline="translation"/>
- [`T5ForConditionalGeneration`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/translation) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/translation.ipynb).
- [`TFT5ForConditionalGeneration`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/translation) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/translation-tf.ipynb).
- [Translation task guide](../tasks/translation)
<PipelineTag pipeline="question-answering"/>
- A notebook on how to [finetune T5 for question answering with TensorFlow 2](https://colab.research.google.com/github/snapthat/TF-T5-text-to-text/blob/master/snapthatT5/notebooks/TF-T5-Datasets%20Training.ipynb). 🌎
- A notebook on how to [finetune T5 for question answering on a TPU](https://colab.research.google.com/github/patil-suraj/exploring-T5/blob/master/T5_on_TPU.ipynb#scrollTo=QLGiFCDqvuil).
🚀 **Deploy**
- A blog post on how to deploy [T5 11B for inference for less than $500](https://www.philschmid.de/deploy-t5-11b).
## T5Config
[[autodoc]] T5Config
## T5Tokenizer
[[autodoc]] T5Tokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## T5TokenizerFast
[[autodoc]] T5TokenizerFast
<frameworkcontent>
<pt>
## T5Model
[[autodoc]] T5Model
- forward
## T5ForConditionalGeneration
[[autodoc]] T5ForConditionalGeneration
- forward
## T5EncoderModel
[[autodoc]] T5EncoderModel
- forward
## T5ForSequenceClassification
[[autodoc]] T5ForSequenceClassification
- forward
## T5ForTokenClassification
[[autodoc]] T5ForTokenClassification
- forward
## T5ForQuestionAnswering
[[autodoc]] T5ForQuestionAnswering
- forward
</pt>
<tf>
## TFT5Model
[[autodoc]] TFT5Model
- call
## TFT5ForConditionalGeneration
[[autodoc]] TFT5ForConditionalGeneration
- call
## TFT5EncoderModel
[[autodoc]] TFT5EncoderModel
- call
</tf>
<jax>
## FlaxT5Model
[[autodoc]] FlaxT5Model
- __call__
- encode
- decode
## FlaxT5ForConditionalGeneration
[[autodoc]] FlaxT5ForConditionalGeneration
- __call__
- encode
- decode
## FlaxT5EncoderModel
[[autodoc]] FlaxT5EncoderModel
- __call__
</jax>
</frameworkcontent>
| transformers/docs/source/en/model_doc/t5.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/t5.md",
"repo_id": "transformers",
"token_count": 6992
} | 254 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Video Vision Transformer (ViViT)
## Overview
The Vivit model was proposed in [ViViT: A Video Vision Transformer](https://arxiv.org/abs/2103.15691) by Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid.
The paper proposes one of the first successful pure-transformer based set of models for video understanding.
The abstract from the paper is the following:
*We present pure-transformer based models for video classification, drawing upon the recent success of such models in image classification. Our model extracts spatio-temporal tokens from the input video, which are then encoded by a series of transformer layers. In order to handle the long sequences of tokens encountered in video, we propose several, efficient variants of our model which factorise the spatial- and temporal-dimensions of the input. Although transformer-based models are known to only be effective when large training datasets are available, we show how we can effectively regularise the model during training and leverage pretrained image models to be able to train on comparatively small datasets. We conduct thorough ablation studies, and achieve state-of-the-art results on multiple video classification benchmarks including Kinetics 400 and 600, Epic Kitchens, Something-Something v2 and Moments in Time, outperforming prior methods based on deep 3D convolutional networks.*
This model was contributed by [jegormeister](https://huggingface.co/jegormeister). The original code (written in JAX) can be found [here](https://github.com/google-research/scenic/tree/main/scenic/projects/vivit).
## VivitConfig
[[autodoc]] VivitConfig
## VivitImageProcessor
[[autodoc]] VivitImageProcessor
- preprocess
## VivitModel
[[autodoc]] VivitModel
- forward
## VivitForVideoClassification
[[autodoc]] transformers.VivitForVideoClassification
- forward
| transformers/docs/source/en/model_doc/vivit.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/vivit.md",
"repo_id": "transformers",
"token_count": 618
} | 255 |
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# XLSR-Wav2Vec2
## Overview
The XLSR-Wav2Vec2 model was proposed in [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael
Auli.
The abstract from the paper is the following:
*This paper presents XLSR which learns cross-lingual speech representations by pretraining a single model from the raw
waveform of speech in multiple languages. We build on wav2vec 2.0 which is trained by solving a contrastive task over
masked latent speech representations and jointly learns a quantization of the latents shared across languages. The
resulting model is fine-tuned on labeled data and experiments show that cross-lingual pretraining significantly
outperforms monolingual pretraining. On the CommonVoice benchmark, XLSR shows a relative phoneme error rate reduction
of 72% compared to the best known results. On BABEL, our approach improves word error rate by 16% relative compared to
a comparable system. Our approach enables a single multilingual speech recognition model which is competitive to strong
individual models. Analysis shows that the latent discrete speech representations are shared across languages with
increased sharing for related languages. We hope to catalyze research in low-resource speech understanding by releasing
XLSR-53, a large model pretrained in 53 languages.*
The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/fairseq/models/wav2vec).
## Usage tips
- XLSR-Wav2Vec2 is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
- XLSR-Wav2Vec2 model was trained using connectionist temporal classification (CTC) so the model output has to be
decoded using [`Wav2Vec2CTCTokenizer`].
<Tip>
XLSR-Wav2Vec2's architecture is based on the Wav2Vec2 model, so one can refer to [Wav2Vec2's documentation page](wav2vec2).
</Tip>
| transformers/docs/source/en/model_doc/xlsr_wav2vec2.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/xlsr_wav2vec2.md",
"repo_id": "transformers",
"token_count": 699
} | 256 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Efficient Training on Multiple CPUs
When training on a single CPU is too slow, we can use multiple CPUs. This guide focuses on PyTorch-based DDP enabling
distributed CPU training efficiently on [bare metal](#usage-in-trainer) and [Kubernetes](#usage-with-kubernetes).
## Intel® oneCCL Bindings for PyTorch
[Intel® oneCCL](https://github.com/oneapi-src/oneCCL) (collective communications library) is a library for efficient distributed deep learning training implementing such collectives like allreduce, allgather, alltoall. For more information on oneCCL, please refer to the [oneCCL documentation](https://spec.oneapi.com/versions/latest/elements/oneCCL/source/index.html) and [oneCCL specification](https://spec.oneapi.com/versions/latest/elements/oneCCL/source/index.html).
Module `oneccl_bindings_for_pytorch` (`torch_ccl` before version 1.12) implements PyTorch C10D ProcessGroup API and can be dynamically loaded as external ProcessGroup and only works on Linux platform now
Check more detailed information for [oneccl_bind_pt](https://github.com/intel/torch-ccl).
### Intel® oneCCL Bindings for PyTorch installation
Wheel files are available for the following Python versions:
| Extension Version | Python 3.6 | Python 3.7 | Python 3.8 | Python 3.9 | Python 3.10 |
| :---------------: | :--------: | :--------: | :--------: | :--------: | :---------: |
| 2.1.0 | | √ | √ | √ | √ |
| 2.0.0 | | √ | √ | √ | √ |
| 1.13.0 | | √ | √ | √ | √ |
| 1.12.100 | | √ | √ | √ | √ |
| 1.12.0 | | √ | √ | √ | √ |
Please run `pip list | grep torch` to get your `pytorch_version`.
```
pip install oneccl_bind_pt=={pytorch_version} -f https://developer.intel.com/ipex-whl-stable-cpu
```
where `{pytorch_version}` should be your PyTorch version, for instance 2.1.0.
Check more approaches for [oneccl_bind_pt installation](https://github.com/intel/torch-ccl).
Versions of oneCCL and PyTorch must match.
<Tip warning={true}>
oneccl_bindings_for_pytorch 1.12.0 prebuilt wheel does not work with PyTorch 1.12.1 (it is for PyTorch 1.12.0)
PyTorch 1.12.1 should work with oneccl_bindings_for_pytorch 1.12.100
</Tip>
## Intel® MPI library
Use this standards-based MPI implementation to deliver flexible, efficient, scalable cluster messaging on Intel® architecture. This component is part of the Intel® oneAPI HPC Toolkit.
oneccl_bindings_for_pytorch is installed along with the MPI tool set. Need to source the environment before using it.
for Intel® oneCCL >= 1.12.0
```
oneccl_bindings_for_pytorch_path=$(python -c "from oneccl_bindings_for_pytorch import cwd; print(cwd)")
source $oneccl_bindings_for_pytorch_path/env/setvars.sh
```
for Intel® oneCCL whose version < 1.12.0
```
torch_ccl_path=$(python -c "import torch; import torch_ccl; import os; print(os.path.abspath(os.path.dirname(torch_ccl.__file__)))")
source $torch_ccl_path/env/setvars.sh
```
#### Intel® Extension for PyTorch installation
Intel Extension for PyTorch (IPEX) provides performance optimizations for CPU training with both Float32 and BFloat16 (refer to the [single CPU section](./perf_train_cpu) to learn more).
The following "Usage in Trainer" takes mpirun in Intel® MPI library as an example.
## Usage in Trainer
To enable multi CPU distributed training in the Trainer with the ccl backend, users should add **`--ddp_backend ccl`** in the command arguments.
Let's see an example with the [question-answering example](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering)
The following command enables training with 2 processes on one Xeon node, with one process running per one socket. The variables OMP_NUM_THREADS/CCL_WORKER_COUNT can be tuned for optimal performance.
```shell script
export CCL_WORKER_COUNT=1
export MASTER_ADDR=127.0.0.1
mpirun -n 2 -genv OMP_NUM_THREADS=23 \
python3 run_qa.py \
--model_name_or_path bert-large-uncased \
--dataset_name squad \
--do_train \
--do_eval \
--per_device_train_batch_size 12 \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /tmp/debug_squad/ \
--no_cuda \
--ddp_backend ccl \
--use_ipex
```
The following command enables training with a total of four processes on two Xeons (node0 and node1, taking node0 as the main process), ppn (processes per node) is set to 2, with one process running per one socket. The variables OMP_NUM_THREADS/CCL_WORKER_COUNT can be tuned for optimal performance.
In node0, you need to create a configuration file which contains the IP addresses of each node (for example hostfile) and pass that configuration file path as an argument.
```shell script
cat hostfile
xxx.xxx.xxx.xxx #node0 ip
xxx.xxx.xxx.xxx #node1 ip
```
Now, run the following command in node0 and **4DDP** will be enabled in node0 and node1 with BF16 auto mixed precision:
```shell script
export CCL_WORKER_COUNT=1
export MASTER_ADDR=xxx.xxx.xxx.xxx #node0 ip
mpirun -f hostfile -n 4 -ppn 2 \
-genv OMP_NUM_THREADS=23 \
python3 run_qa.py \
--model_name_or_path bert-large-uncased \
--dataset_name squad \
--do_train \
--do_eval \
--per_device_train_batch_size 12 \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /tmp/debug_squad/ \
--no_cuda \
--ddp_backend ccl \
--use_ipex \
--bf16
```
## Usage with Kubernetes
The same distributed training job from the previous section can be deployed to a Kubernetes cluster using the
[Kubeflow PyTorchJob training operator](https://www.kubeflow.org/docs/components/training/pytorch/).
### Setup
This example assumes that you have:
* Access to a Kubernetes cluster with [Kubeflow installed](https://www.kubeflow.org/docs/started/installing-kubeflow/)
* [`kubectl`](https://kubernetes.io/docs/tasks/tools/) installed and configured to access the Kubernetes cluster
* A [Persistent Volume Claim (PVC)](https://kubernetes.io/docs/concepts/storage/persistent-volumes/) that can be used
to store datasets and model files. There are multiple options for setting up the PVC including using an NFS
[storage class](https://kubernetes.io/docs/concepts/storage/storage-classes/) or a cloud storage bucket.
* A Docker container that includes your model training script and all the dependencies needed to run the script. For
distributed CPU training jobs, this typically includes PyTorch, Transformers, Intel Extension for PyTorch, Intel
oneCCL Bindings for PyTorch, and OpenSSH to communicate between the containers.
The snippet below is an example of a Dockerfile that uses a base image that supports distributed CPU training and then
extracts a Transformers release to the `/workspace` directory, so that the example scripts are included in the image:
```
FROM intel/ai-workflows:torch-2.0.1-huggingface-multinode-py3.9
WORKDIR /workspace
# Download and extract the transformers code
ARG HF_TRANSFORMERS_VER="4.35.2"
RUN mkdir transformers && \
curl -sSL --retry 5 https://github.com/huggingface/transformers/archive/refs/tags/v${HF_TRANSFORMERS_VER}.tar.gz | tar -C transformers --strip-components=1 -xzf -
```
The image needs to be built and copied to the cluster's nodes or pushed to a container registry prior to deploying the
PyTorchJob to the cluster.
### PyTorchJob Specification File
The [Kubeflow PyTorchJob](https://www.kubeflow.org/docs/components/training/pytorch/) is used to run the distributed
training job on the cluster. The yaml file for the PyTorchJob defines parameters such as:
* The name of the PyTorchJob
* The number of replicas (workers)
* The python script and it's parameters that will be used to run the training job
* The types of resources (node selector, memory, and CPU) needed for each worker
* The image/tag for the Docker container to use
* Environment variables
* A volume mount for the PVC
The volume mount defines a path where the PVC will be mounted in the container for each worker pod. This location can be
used for the dataset, checkpoint files, and the saved model after training completes.
The snippet below is an example of a yaml file for a PyTorchJob with 4 workers running the
[question-answering example](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering).
```yaml
apiVersion: "kubeflow.org/v1"
kind: PyTorchJob
metadata:
name: transformers-pytorchjob
namespace: kubeflow
spec:
elasticPolicy:
rdzvBackend: c10d
minReplicas: 1
maxReplicas: 4
maxRestarts: 10
pytorchReplicaSpecs:
Worker:
replicas: 4 # The number of worker pods
restartPolicy: OnFailure
template:
spec:
containers:
- name: pytorch
image: <image name>:<tag> # Specify the docker image to use for the worker pods
imagePullPolicy: IfNotPresent
command:
- torchrun
- /workspace/transformers/examples/pytorch/question-answering/run_qa.py
- --model_name_or_path
- "bert-large-uncased"
- --dataset_name
- "squad"
- --do_train
- --do_eval
- --per_device_train_batch_size
- "12"
- --learning_rate
- "3e-5"
- --num_train_epochs
- "2"
- --max_seq_length
- "384"
- --doc_stride
- "128"
- --output_dir
- "/tmp/pvc-mount/output"
- --no_cuda
- --ddp_backend
- "ccl"
- --use_ipex
- --bf16 # Specify --bf16 if your hardware supports bfloat16
env:
- name: LD_PRELOAD
value: "/usr/lib/x86_64-linux-gnu/libtcmalloc.so.4.5.9:/usr/local/lib/libiomp5.so"
- name: TRANSFORMERS_CACHE
value: "/tmp/pvc-mount/transformers_cache"
- name: HF_DATASETS_CACHE
value: "/tmp/pvc-mount/hf_datasets_cache"
- name: LOGLEVEL
value: "INFO"
- name: CCL_WORKER_COUNT
value: "1"
- name: OMP_NUM_THREADS # Can be tuned for optimal performance
- value: "56"
resources:
limits:
cpu: 200 # Update the CPU and memory limit values based on your nodes
memory: 128Gi
requests:
cpu: 200 # Update the CPU and memory request values based on your nodes
memory: 128Gi
volumeMounts:
- name: pvc-volume
mountPath: /tmp/pvc-mount
- mountPath: /dev/shm
name: dshm
restartPolicy: Never
nodeSelector: # Optionally use the node selector to specify what types of nodes to use for the workers
node-type: spr
volumes:
- name: pvc-volume
persistentVolumeClaim:
claimName: transformers-pvc
- name: dshm
emptyDir:
medium: Memory
```
To run this example, update the yaml based on your training script and the nodes in your cluster.
<Tip>
The CPU resource limits/requests in the yaml are defined in [cpu units](https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/#meaning-of-cpu)
where 1 CPU unit is equivalent to 1 physical CPU core or 1 virtual core (depending on whether the node is a physical
host or a VM). The amount of CPU and memory limits/requests defined in the yaml should be less than the amount of
available CPU/memory capacity on a single machine. It is usually a good idea to not use the entire machine's capacity in
order to leave some resources for the kubelet and OS. In order to get ["guaranteed"](https://kubernetes.io/docs/concepts/workloads/pods/pod-qos/#guaranteed)
[quality of service](https://kubernetes.io/docs/tasks/configure-pod-container/quality-service-pod/) for the worker pods,
set the same CPU and memory amounts for both the resource limits and requests.
</Tip>
### Deploy
After the PyTorchJob spec has been updated with values appropriate for your cluster and training job, it can be deployed
to the cluster using:
```
kubectl create -f pytorchjob.yaml
```
The `kubectl get pods -n kubeflow` command can then be used to list the pods in the `kubeflow` namespace. You should see
the worker pods for the PyTorchJob that was just deployed. At first, they will probably have a status of "Pending" as
the containers get pulled and created, then the status should change to "Running".
```
NAME READY STATUS RESTARTS AGE
...
transformers-pytorchjob-worker-0 1/1 Running 0 7m37s
transformers-pytorchjob-worker-1 1/1 Running 0 7m37s
transformers-pytorchjob-worker-2 1/1 Running 0 7m37s
transformers-pytorchjob-worker-3 1/1 Running 0 7m37s
...
```
The logs for worker can be viewed using `kubectl logs -n kubeflow <pod name>`. Add `-f` to stream the logs, for example:
```
kubectl logs -n kubeflow transformers-pytorchjob-worker-0 -f
```
After the training job completes, the trained model can be copied from the PVC or storage location. When you are done
with the job, the PyTorchJob resource can be deleted from the cluster using `kubectl delete -f pytorchjob.yaml`.
## Summary
This guide covered running distributed PyTorch training jobs using multiple CPUs on bare metal and on a Kubernetes
cluster. Both cases utilize Intel Extension for PyTorch and Intel oneCCL Bindings for PyTorch for optimal training
performance, and can be used as a template to run your own workload on multiple nodes.
| transformers/docs/source/en/perf_train_cpu_many.md/0 | {
"file_path": "transformers/docs/source/en/perf_train_cpu_many.md",
"repo_id": "transformers",
"token_count": 5789
} | 257 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Export to ONNX
Deploying 🤗 Transformers models in production environments often requires, or can benefit from exporting the models into
a serialized format that can be loaded and executed on specialized runtimes and hardware.
🤗 Optimum is an extension of Transformers that enables exporting models from PyTorch or TensorFlow to serialized formats
such as ONNX and TFLite through its `exporters` module. 🤗 Optimum also provides a set of performance optimization tools to train
and run models on targeted hardware with maximum efficiency.
This guide demonstrates how you can export 🤗 Transformers models to ONNX with 🤗 Optimum, for the guide on exporting models to TFLite,
please refer to the [Export to TFLite page](tflite).
## Export to ONNX
[ONNX (Open Neural Network eXchange)](http://onnx.ai) is an open standard that defines a common set of operators and a
common file format to represent deep learning models in a wide variety of frameworks, including PyTorch and
TensorFlow. When a model is exported to the ONNX format, these operators are used to
construct a computational graph (often called an _intermediate representation_) which
represents the flow of data through the neural network.
By exposing a graph with standardized operators and data types, ONNX makes it easy to
switch between frameworks. For example, a model trained in PyTorch can be exported to
ONNX format and then imported in TensorFlow (and vice versa).
Once exported to ONNX format, a model can be:
- optimized for inference via techniques such as [graph optimization](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/optimization) and [quantization](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/quantization).
- run with ONNX Runtime via [`ORTModelForXXX` classes](https://huggingface.co/docs/optimum/onnxruntime/package_reference/modeling_ort),
which follow the same `AutoModel` API as the one you are used to in 🤗 Transformers.
- run with [optimized inference pipelines](https://huggingface.co/docs/optimum/main/en/onnxruntime/usage_guides/pipelines),
which has the same API as the [`pipeline`] function in 🤗 Transformers.
🤗 Optimum provides support for the ONNX export by leveraging configuration objects. These configuration objects come
ready-made for a number of model architectures, and are designed to be easily extendable to other architectures.
For the list of ready-made configurations, please refer to [🤗 Optimum documentation](https://huggingface.co/docs/optimum/exporters/onnx/overview).
There are two ways to export a 🤗 Transformers model to ONNX, here we show both:
- export with 🤗 Optimum via CLI.
- export with 🤗 Optimum with `optimum.onnxruntime`.
### Exporting a 🤗 Transformers model to ONNX with CLI
To export a 🤗 Transformers model to ONNX, first install an extra dependency:
```bash
pip install optimum[exporters]
```
To check out all available arguments, refer to the [🤗 Optimum docs](https://huggingface.co/docs/optimum/exporters/onnx/usage_guides/export_a_model#exporting-a-model-to-onnx-using-the-cli),
or view help in command line:
```bash
optimum-cli export onnx --help
```
To export a model's checkpoint from the 🤗 Hub, for example, `distilbert-base-uncased-distilled-squad`, run the following command:
```bash
optimum-cli export onnx --model distilbert-base-uncased-distilled-squad distilbert_base_uncased_squad_onnx/
```
You should see the logs indicating progress and showing where the resulting `model.onnx` is saved, like this:
```bash
Validating ONNX model distilbert_base_uncased_squad_onnx/model.onnx...
-[✓] ONNX model output names match reference model (start_logits, end_logits)
- Validating ONNX Model output "start_logits":
-[✓] (2, 16) matches (2, 16)
-[✓] all values close (atol: 0.0001)
- Validating ONNX Model output "end_logits":
-[✓] (2, 16) matches (2, 16)
-[✓] all values close (atol: 0.0001)
The ONNX export succeeded and the exported model was saved at: distilbert_base_uncased_squad_onnx
```
The example above illustrates exporting a checkpoint from 🤗 Hub. When exporting a local model, first make sure that you
saved both the model's weights and tokenizer files in the same directory (`local_path`). When using CLI, pass the
`local_path` to the `model` argument instead of the checkpoint name on 🤗 Hub and provide the `--task` argument.
You can review the list of supported tasks in the [🤗 Optimum documentation](https://huggingface.co/docs/optimum/exporters/task_manager).
If `task` argument is not provided, it will default to the model architecture without any task specific head.
```bash
optimum-cli export onnx --model local_path --task question-answering distilbert_base_uncased_squad_onnx/
```
The resulting `model.onnx` file can then be run on one of the [many
accelerators](https://onnx.ai/supported-tools.html#deployModel) that support the ONNX
standard. For example, we can load and run the model with [ONNX
Runtime](https://onnxruntime.ai/) as follows:
```python
>>> from transformers import AutoTokenizer
>>> from optimum.onnxruntime import ORTModelForQuestionAnswering
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert_base_uncased_squad_onnx")
>>> model = ORTModelForQuestionAnswering.from_pretrained("distilbert_base_uncased_squad_onnx")
>>> inputs = tokenizer("What am I using?", "Using DistilBERT with ONNX Runtime!", return_tensors="pt")
>>> outputs = model(**inputs)
```
The process is identical for TensorFlow checkpoints on the Hub. For instance, here's how you would
export a pure TensorFlow checkpoint from the [Keras organization](https://huggingface.co/keras-io):
```bash
optimum-cli export onnx --model keras-io/transformers-qa distilbert_base_cased_squad_onnx/
```
### Exporting a 🤗 Transformers model to ONNX with `optimum.onnxruntime`
Alternative to CLI, you can export a 🤗 Transformers model to ONNX programmatically like so:
```python
>>> from optimum.onnxruntime import ORTModelForSequenceClassification
>>> from transformers import AutoTokenizer
>>> model_checkpoint = "distilbert_base_uncased_squad"
>>> save_directory = "onnx/"
>>> # Load a model from transformers and export it to ONNX
>>> ort_model = ORTModelForSequenceClassification.from_pretrained(model_checkpoint, export=True)
>>> tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
>>> # Save the onnx model and tokenizer
>>> ort_model.save_pretrained(save_directory)
>>> tokenizer.save_pretrained(save_directory)
```
### Exporting a model for an unsupported architecture
If you wish to contribute by adding support for a model that cannot be currently exported, you should first check if it is
supported in [`optimum.exporters.onnx`](https://huggingface.co/docs/optimum/exporters/onnx/overview),
and if it is not, [contribute to 🤗 Optimum](https://huggingface.co/docs/optimum/exporters/onnx/usage_guides/contribute)
directly.
### Exporting a model with `transformers.onnx`
<Tip warning={true}>
`tranformers.onnx` is no longer maintained, please export models with 🤗 Optimum as described above. This section will be removed in the future versions.
</Tip>
To export a 🤗 Transformers model to ONNX with `tranformers.onnx`, install extra dependencies:
```bash
pip install transformers[onnx]
```
Use `transformers.onnx` package as a Python module to export a checkpoint using a ready-made configuration:
```bash
python -m transformers.onnx --model=distilbert-base-uncased onnx/
```
This exports an ONNX graph of the checkpoint defined by the `--model` argument. Pass any checkpoint on the 🤗 Hub or one that's stored locally.
The resulting `model.onnx` file can then be run on one of the many accelerators that support the ONNX standard. For example,
load and run the model with ONNX Runtime as follows:
```python
>>> from transformers import AutoTokenizer
>>> from onnxruntime import InferenceSession
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
>>> session = InferenceSession("onnx/model.onnx")
>>> # ONNX Runtime expects NumPy arrays as input
>>> inputs = tokenizer("Using DistilBERT with ONNX Runtime!", return_tensors="np")
>>> outputs = session.run(output_names=["last_hidden_state"], input_feed=dict(inputs))
```
The required output names (like `["last_hidden_state"]`) can be obtained by taking a look at the ONNX configuration of
each model. For example, for DistilBERT we have:
```python
>>> from transformers.models.distilbert import DistilBertConfig, DistilBertOnnxConfig
>>> config = DistilBertConfig()
>>> onnx_config = DistilBertOnnxConfig(config)
>>> print(list(onnx_config.outputs.keys()))
["last_hidden_state"]
```
The process is identical for TensorFlow checkpoints on the Hub. For example, export a pure TensorFlow checkpoint like so:
```bash
python -m transformers.onnx --model=keras-io/transformers-qa onnx/
```
To export a model that's stored locally, save the model's weights and tokenizer files in the same directory (e.g. `local-pt-checkpoint`),
then export it to ONNX by pointing the `--model` argument of the `transformers.onnx` package to the desired directory:
```bash
python -m transformers.onnx --model=local-pt-checkpoint onnx/
``` | transformers/docs/source/en/serialization.md/0 | {
"file_path": "transformers/docs/source/en/serialization.md",
"repo_id": "transformers",
"token_count": 2956
} | 258 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Export to TorchScript
<Tip>
This is the very beginning of our experiments with TorchScript and we are still
exploring its capabilities with variable-input-size models. It is a focus of interest to
us and we will deepen our analysis in upcoming releases, with more code examples, a more
flexible implementation, and benchmarks comparing Python-based codes with compiled
TorchScript.
</Tip>
According to the [TorchScript documentation](https://pytorch.org/docs/stable/jit.html):
> TorchScript is a way to create serializable and optimizable models from PyTorch code.
There are two PyTorch modules, [JIT and
TRACE](https://pytorch.org/docs/stable/jit.html), that allow developers to export their
models to be reused in other programs like efficiency-oriented C++ programs.
We provide an interface that allows you to export 🤗 Transformers models to TorchScript
so they can be reused in a different environment than PyTorch-based Python programs.
Here, we explain how to export and use our models using TorchScript.
Exporting a model requires two things:
- model instantiation with the `torchscript` flag
- a forward pass with dummy inputs
These necessities imply several things developers should be careful about as detailed
below.
## TorchScript flag and tied weights
The `torchscript` flag is necessary because most of the 🤗 Transformers language models
have tied weights between their `Embedding` layer and their `Decoding` layer.
TorchScript does not allow you to export models that have tied weights, so it is
necessary to untie and clone the weights beforehand.
Models instantiated with the `torchscript` flag have their `Embedding` layer and
`Decoding` layer separated, which means that they should not be trained down the line.
Training would desynchronize the two layers, leading to unexpected results.
This is not the case for models that do not have a language model head, as those do not
have tied weights. These models can be safely exported without the `torchscript` flag.
## Dummy inputs and standard lengths
The dummy inputs are used for a models forward pass. While the inputs' values are
propagated through the layers, PyTorch keeps track of the different operations executed
on each tensor. These recorded operations are then used to create the *trace* of the
model.
The trace is created relative to the inputs' dimensions. It is therefore constrained by
the dimensions of the dummy input, and will not work for any other sequence length or
batch size. When trying with a different size, the following error is raised:
```
`The expanded size of the tensor (3) must match the existing size (7) at non-singleton dimension 2`
```
We recommended you trace the model with a dummy input size at least as large as the
largest input that will be fed to the model during inference. Padding can help fill the
missing values. However, since the model is traced with a larger input size, the
dimensions of the matrix will also be large, resulting in more calculations.
Be careful of the total number of operations done on each input and follow the
performance closely when exporting varying sequence-length models.
## Using TorchScript in Python
This section demonstrates how to save and load models as well as how to use the trace
for inference.
### Saving a model
To export a `BertModel` with TorchScript, instantiate `BertModel` from the `BertConfig`
class and then save it to disk under the filename `traced_bert.pt`:
```python
from transformers import BertModel, BertTokenizer, BertConfig
import torch
enc = BertTokenizer.from_pretrained("bert-base-uncased")
# Tokenizing input text
text = "[CLS] Who was Jim Henson ? [SEP] Jim Henson was a puppeteer [SEP]"
tokenized_text = enc.tokenize(text)
# Masking one of the input tokens
masked_index = 8
tokenized_text[masked_index] = "[MASK]"
indexed_tokens = enc.convert_tokens_to_ids(tokenized_text)
segments_ids = [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]
# Creating a dummy input
tokens_tensor = torch.tensor([indexed_tokens])
segments_tensors = torch.tensor([segments_ids])
dummy_input = [tokens_tensor, segments_tensors]
# Initializing the model with the torchscript flag
# Flag set to True even though it is not necessary as this model does not have an LM Head.
config = BertConfig(
vocab_size_or_config_json_file=32000,
hidden_size=768,
num_hidden_layers=12,
num_attention_heads=12,
intermediate_size=3072,
torchscript=True,
)
# Instantiating the model
model = BertModel(config)
# The model needs to be in evaluation mode
model.eval()
# If you are instantiating the model with *from_pretrained* you can also easily set the TorchScript flag
model = BertModel.from_pretrained("bert-base-uncased", torchscript=True)
# Creating the trace
traced_model = torch.jit.trace(model, [tokens_tensor, segments_tensors])
torch.jit.save(traced_model, "traced_bert.pt")
```
### Loading a model
Now you can load the previously saved `BertModel`, `traced_bert.pt`, from disk and use
it on the previously initialised `dummy_input`:
```python
loaded_model = torch.jit.load("traced_bert.pt")
loaded_model.eval()
all_encoder_layers, pooled_output = loaded_model(*dummy_input)
```
### Using a traced model for inference
Use the traced model for inference by using its `__call__` dunder method:
```python
traced_model(tokens_tensor, segments_tensors)
```
## Deploy Hugging Face TorchScript models to AWS with the Neuron SDK
AWS introduced the [Amazon EC2 Inf1](https://aws.amazon.com/ec2/instance-types/inf1/)
instance family for low cost, high performance machine learning inference in the cloud.
The Inf1 instances are powered by the AWS Inferentia chip, a custom-built hardware
accelerator, specializing in deep learning inferencing workloads. [AWS
Neuron](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/#) is the SDK for
Inferentia that supports tracing and optimizing transformers models for deployment on
Inf1. The Neuron SDK provides:
1. Easy-to-use API with one line of code change to trace and optimize a TorchScript
model for inference in the cloud.
2. Out of the box performance optimizations for [improved
cost-performance](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/benchmark/>).
3. Support for Hugging Face transformers models built with either
[PyTorch](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/pytorch/bert_tutorial/tutorial_pretrained_bert.html)
or
[TensorFlow](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/tensorflow/huggingface_bert/huggingface_bert.html).
### Implications
Transformers models based on the [BERT (Bidirectional Encoder Representations from
Transformers)](https://huggingface.co/docs/transformers/main/model_doc/bert)
architecture, or its variants such as
[distilBERT](https://huggingface.co/docs/transformers/main/model_doc/distilbert) and
[roBERTa](https://huggingface.co/docs/transformers/main/model_doc/roberta) run best on
Inf1 for non-generative tasks such as extractive question answering, sequence
classification, and token classification. However, text generation tasks can still be
adapted to run on Inf1 according to this [AWS Neuron MarianMT
tutorial](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/pytorch/transformers-marianmt.html).
More information about models that can be converted out of the box on Inferentia can be
found in the [Model Architecture
Fit](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/models/models-inferentia.html#models-inferentia)
section of the Neuron documentation.
### Dependencies
Using AWS Neuron to convert models requires a [Neuron SDK
environment](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/neuron-frameworks/pytorch-neuron/index.html#installation-guide)
which comes preconfigured on [AWS Deep Learning
AMI](https://docs.aws.amazon.com/dlami/latest/devguide/tutorial-inferentia-launching.html).
### Converting a model for AWS Neuron
Convert a model for AWS NEURON using the same code from [Using TorchScript in
Python](torchscript#using-torchscript-in-python) to trace a `BertModel`. Import the
`torch.neuron` framework extension to access the components of the Neuron SDK through a
Python API:
```python
from transformers import BertModel, BertTokenizer, BertConfig
import torch
import torch.neuron
```
You only need to modify the following line:
```diff
- torch.jit.trace(model, [tokens_tensor, segments_tensors])
+ torch.neuron.trace(model, [token_tensor, segments_tensors])
```
This enables the Neuron SDK to trace the model and optimize it for Inf1 instances.
To learn more about AWS Neuron SDK features, tools, example tutorials and latest
updates, please see the [AWS NeuronSDK
documentation](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/index.html).
| transformers/docs/source/en/torchscript.md/0 | {
"file_path": "transformers/docs/source/en/torchscript.md",
"repo_id": "transformers",
"token_count": 2732
} | 259 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Usa los tokenizadores de 🤗 Tokenizers
[`PreTrainedTokenizerFast`] depende de la biblioteca [🤗 Tokenizers](https://huggingface.co/docs/tokenizers). Los tokenizadores obtenidos desde la biblioteca 🤗 Tokenizers pueden ser
cargados de forma muy sencilla en los 🤗 Transformers.
Antes de entrar en detalles, comencemos creando un tokenizador dummy en unas cuantas líneas:
```python
>>> from tokenizers import Tokenizer
>>> from tokenizers.models import BPE
>>> from tokenizers.trainers import BpeTrainer
>>> from tokenizers.pre_tokenizers import Whitespace
>>> tokenizer = Tokenizer(BPE(unk_token="[UNK]"))
>>> trainer = BpeTrainer(special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"])
>>> tokenizer.pre_tokenizer = Whitespace()
>>> files = [...]
>>> tokenizer.train(files, trainer)
```
Ahora tenemos un tokenizador entrenado en los archivos que definimos. Lo podemos seguir utilizando en ese entorno de ejecución (runtime en inglés), o puedes guardarlo
en un archivo JSON para reutilizarlo en un futuro.
## Cargando directamente desde el objeto tokenizador
Veamos cómo utilizar este objeto tokenizador en la biblioteca 🤗 Transformers. La clase
[`PreTrainedTokenizerFast`] permite una instanciación fácil, al aceptar el objeto
*tokenizer* instanciado como argumento:
```python
>>> from transformers import PreTrainedTokenizerFast
>>> fast_tokenizer = PreTrainedTokenizerFast(tokenizer_object=tokenizer)
```
Este objeto ya puede ser utilizado con todos los métodos compartidos por los tokenizadores de 🤗 Transformers! Visita la [página sobre tokenizadores
](main_classes/tokenizer) para más información.
## Cargando desde un archivo JSON
Para cargar un tokenizador desde un archivo JSON, comencemos por guardar nuestro tokenizador:
```python
>>> tokenizer.save("tokenizer.json")
```
La localización (path en inglés) donde este archivo es guardado puede ser incluida en el método de inicialización de [`PreTrainedTokenizerFast`]
utilizando el parámetro `tokenizer_file`:
```python
>>> from transformers import PreTrainedTokenizerFast
>>> fast_tokenizer = PreTrainedTokenizerFast(tokenizer_file="tokenizer.json")
```
Este objeto ya puede ser utilizado con todos los métodos compartidos por los tokenizadores de 🤗 Transformers! Visita la [página sobre tokenizadores
](main_classes/tokenizer) para más información.
| transformers/docs/source/es/fast_tokenizers.md/0 | {
"file_path": "transformers/docs/source/es/fast_tokenizers.md",
"repo_id": "transformers",
"token_count": 987
} | 260 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Exportar modelos 🤗 Transformers
Si necesitas implementar modelos 🤗 Transformers en entornos de producción, te
recomendamos exportarlos a un formato serializado que se pueda cargar y ejecutar
en tiempos de ejecución y hardware especializados. En esta guía, te mostraremos cómo
exportar modelos 🤗 Transformers en dos formatos ampliamente utilizados: ONNX y TorchScript.
Una vez exportado, un modelo puede optimizarse para la inferencia a través de técnicas
como la cuantización y _pruning_. Si estás interesado en optimizar tus modelos para
que funcionen con la máxima eficiencia, consulta la
[biblioteca de 🤗 Optimum](https://github.com/huggingface/optimum).
## ONNX
El proyecto [ONNX (Open Neural Network eXchange)](http://onnx.ai) es un
estándar abierto que define un conjunto común de operadores y un formato
de archivo común para representar modelos de aprendizaje profundo en una
amplia variedad de _frameworks_, incluidos PyTorch y TensorFlow. Cuando un modelo
se exporta al formato ONNX, estos operadores se usan para construir un
grafo computacional (a menudo llamado _representación intermedia_) que
representa el flujo de datos a través de la red neuronal.
Al exponer un grafo con operadores y tipos de datos estandarizados, ONNX facilita
el cambio entre frameworks. Por ejemplo, un modelo entrenado en PyTorch se puede
exportar a formato ONNX y luego importar en TensorFlow (y viceversa).
🤗 Transformers proporciona un paquete llamado `transformers.onnx`, el cual permite convertir
los checkpoints de un modelo en un grafo ONNX aprovechando los objetos de configuración.
Estos objetos de configuración están hechos a la medida de diferentes arquitecturas de modelos
y están diseñados para ser fácilmente extensibles a otras arquitecturas.
Las configuraciones a la medida incluyen las siguientes arquitecturas:
<!--This table is automatically generated by `make fix-copies`, do not fill manually!-->
- ALBERT
- BART
- BEiT
- BERT
- BigBird
- BigBird-Pegasus
- Blenderbot
- BlenderbotSmall
- BLOOM
- CamemBERT
- CLIP
- CodeGen
- ConvBERT
- ConvNeXT
- ConvNeXTV2
- Data2VecText
- Data2VecVision
- DeBERTa
- DeBERTa-v2
- DeiT
- DETR
- DistilBERT
- ELECTRA
- FlauBERT
- GPT Neo
- GPT-J
- I-BERT
- LayoutLM
- LayoutLMv3
- LeViT
- LongT5
- M2M100
- Marian
- mBART
- MobileBERT
- MobileViT
- MT5
- OpenAI GPT-2
- Perceiver
- PLBart
- ResNet
- RoBERTa
- RoFormer
- SqueezeBERT
- T5
- ViT
- XLM
- XLM-RoBERTa
- XLM-RoBERTa-XL
- YOLOS
En las próximas dos secciones, te mostraremos cómo:
* Exportar un modelo compatible utilizando el paquete `transformers.onnx`.
* Exportar un modelo personalizado para una arquitectura no compatible.
### Exportar un model a ONNX
Para exportar un modelo 🤗 Transformers a ONNX, tienes que instalar primero algunas
dependencias extra:
```bash
pip install transformers[onnx]
```
El paquete `transformers.onnx` puede ser usado luego como un módulo de Python:
```bash
python -m transformers.onnx --help
usage: Hugging Face Transformers ONNX exporter [-h] -m MODEL [--feature {causal-lm, ...}] [--opset OPSET] [--atol ATOL] output
positional arguments:
output Path indicating where to store generated ONNX model.
optional arguments:
-h, --help show this help message and exit
-m MODEL, --model MODEL
Model ID on huggingface.co or path on disk to load model from.
--feature {causal-lm, ...}
The type of features to export the model with.
--opset OPSET ONNX opset version to export the model with.
--atol ATOL Absolute difference tolerence when validating the model.
```
Exportar un checkpoint usando una configuración a la medida se puede hacer de la siguiente manera:
```bash
python -m transformers.onnx --model=distilbert-base-uncased onnx/
```
que debería mostrar los siguientes registros:
```bash
Validating ONNX model...
-[✓] ONNX model output names match reference model ({'last_hidden_state'})
- Validating ONNX Model output "last_hidden_state":
-[✓] (2, 8, 768) matches (2, 8, 768)
-[✓] all values close (atol: 1e-05)
All good, model saved at: onnx/model.onnx
```
Esto exporta un grafo ONNX del checkpoint definido por el argumento `--model`.
En este ejemplo, es un modelo `distilbert-base-uncased`, pero puede ser cualquier
checkpoint en Hugging Face Hub o que esté almacenado localmente.
El archivo `model.onnx` resultante se puede ejecutar en uno de los
[muchos aceleradores](https://onnx.ai/supported-tools.html#deployModel)
que admiten el estándar ONNX. Por ejemplo, podemos cargar y ejecutar el
modelo con [ONNX Runtime](https://onnxruntime.ai/) de la siguiente manera:
```python
>>> from transformers import AutoTokenizer
>>> from onnxruntime import InferenceSession
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
>>> session = InferenceSession("onnx/model.onnx")
>>> # ONNX Runtime expects NumPy arrays as input
>>> inputs = tokenizer("Using DistilBERT with ONNX Runtime!", return_tensors="np")
>>> outputs = session.run(output_names=["last_hidden_state"], input_feed=dict(inputs))
```
Los nombres necesarios de salida (es decir, `["last_hidden_state"]`) se pueden obtener
echando un vistazo a la configuración ONNX de cada modelo. Por ejemplo, para DistilBERT tenemos:
```python
>>> from transformers.models.distilbert import DistilBertConfig, DistilBertOnnxConfig
>>> config = DistilBertConfig()
>>> onnx_config = DistilBertOnnxConfig(config)
>>> print(list(onnx_config.outputs.keys()))
["last_hidden_state"]s
```
El proceso es idéntico para los checkpoints de TensorFlow en Hub.
Por ejemplo, podemos exportar un checkpoint puro de TensorFlow desde
[Keras](https://huggingface.co/keras-io) de la siguiente manera:
```bash
python -m transformers.onnx --model=keras-io/transformers-qa onnx/
```
Para exportar un modelo que está almacenado localmente, deberás tener los pesos
y tokenizadores del modelo almacenados en un directorio. Por ejemplo, podemos cargar
y guardar un checkpoint de la siguiente manera:
<frameworkcontent>
<pt>
```python
>>> from transformers import AutoTokenizer, AutoModelForSequenceClassification
>>> # Load tokenizer and PyTorch weights form the Hub
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
>>> pt_model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
>>> # Save to disk
>>> tokenizer.save_pretrained("local-pt-checkpoint")
>>> pt_model.save_pretrained("local-pt-checkpoint")
```
Una vez que se guarda el checkpoint, podemos exportarlo a ONNX usando el argumento `--model`
del paquete `transformers.onnx` al directorio deseado:
```bash
python -m transformers.onnx --model=local-pt-checkpoint onnx/
```
</pt>
<tf>
```python
>>> from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
>>> # Load tokenizer and TensorFlow weights from the Hub
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
>>> # Save to disk
>>> tokenizer.save_pretrained("local-tf-checkpoint")
>>> tf_model.save_pretrained("local-tf-checkpoint")
```
Una vez que se guarda el checkpoint, podemos exportarlo a ONNX usando el argumento `--model`
del paquete `transformers.onnx` al directorio deseado:
```bash
python -m transformers.onnx --model=local-tf-checkpoint onnx/
```
</tf>
</frameworkcontent>
### Seleccionar características para diferentes topologías de un modelo
Cada configuración a la medida viene con un conjunto de _características_ que te permiten exportar
modelos para diferentes tipos de topologías o tareas. Como se muestra en la siguiente tabla, cada
función está asociada con una auto-clase de automóvil diferente:
| Feature | Auto Class |
| ------------------------------------ | ------------------------------------ |
| `causal-lm`, `causal-lm-with-past` | `AutoModelForCausalLM` |
| `default`, `default-with-past` | `AutoModel` |
| `masked-lm` | `AutoModelForMaskedLM` |
| `question-answering` | `AutoModelForQuestionAnswering` |
| `seq2seq-lm`, `seq2seq-lm-with-past` | `AutoModelForSeq2SeqLM` |
| `sequence-classification` | `AutoModelForSequenceClassification` |
| `token-classification` | `AutoModelForTokenClassification` |
Para cada configuración, puedes encontrar la lista de funciones admitidas a través de `FeaturesManager`.
Por ejemplo, para DistilBERT tenemos:
```python
>>> from transformers.onnx.features import FeaturesManager
>>> distilbert_features = list(FeaturesManager.get_supported_features_for_model_type("distilbert").keys())
>>> print(distilbert_features)
["default", "masked-lm", "causal-lm", "sequence-classification", "token-classification", "question-answering"]
```
Le puedes pasar una de estas características al argumento `--feature` en el paquete `transformers.onnx`.
Por ejemplo, para exportar un modelo de clasificación de texto, podemos elegir un modelo ya ajustado del Hub y ejecutar:
```bash
python -m transformers.onnx --model=distilbert-base-uncased-finetuned-sst-2-english \
--feature=sequence-classification onnx/
```
que mostrará los siguientes registros:
```bash
Validating ONNX model...
-[✓] ONNX model output names match reference model ({'logits'})
- Validating ONNX Model output "logits":
-[✓] (2, 2) matches (2, 2)
-[✓] all values close (atol: 1e-05)
All good, model saved at: onnx/model.onnx
```
Ten en cuenta que, en este caso, los nombres de salida del modelo ajustado son `logits` en lugar de `last_hidden_state`
que vimos anteriormente con el checkpoint `distilbert-base-uncased`. Esto es de esperarse ya que el modelo ajustado
tiene un cabezal de clasificación secuencial.
<Tip>
Las características que tienen un sufijo 'with-past' (por ejemplo, 'causal-lm-with-past') corresponden a topologías
de modelo con estados ocultos precalculados (clave y valores en los bloques de atención) que se pueden usar para una
decodificación autorregresiva más rápida.
</Tip>
### Exportar un modelo para una arquitectura no compatible
Si deseas exportar un modelo cuya arquitectura no es compatible de forma nativa
con la biblioteca, debes seguir tres pasos principales:
1. Implementa una configuración personalizada en ONNX.
2. Exporta el modelo a ONNX.
3. Valide los resultados de PyTorch y los modelos exportados.
En esta sección, veremos cómo se implementó la serialización de DistilBERT
para mostrar lo que implica cada paso.
#### Implementar una configuración personalizada en ONNX
Comencemos con el objeto de configuración de ONNX. Proporcionamos tres clases abstractas
de las que debe heredar, según el tipo de arquitectura del modelo que quieras exportar:
* Modelos basados en el _Encoder_ inherente de [`~onnx.config.OnnxConfig`]
* Modelos basados en el _Decoder_ inherente de [`~onnx.config.OnnxConfigWithPast`]
* Modelos _Encoder-decoder_ inherente de [`~onnx.config.OnnxSeq2SeqConfigWithPast`]
<Tip>
Una buena manera de implementar una configuración personalizada en ONNX es observar la implementación
existente en el archivo `configuration_<model_name>.py` de una arquitectura similar.
</Tip>
Dado que DistilBERT es un modelo de tipo _encoder_, su configuración se hereda de `OnnxConfig`:
```python
>>> from typing import Mapping, OrderedDict
>>> from transformers.onnx import OnnxConfig
>>> class DistilBertOnnxConfig(OnnxConfig):
... @property
... def inputs(self) -> Mapping[str, Mapping[int, str]]:
... return OrderedDict(
... [
... ("input_ids", {0: "batch", 1: "sequence"}),
... ("attention_mask", {0: "batch", 1: "sequence"}),
... ]
... )
```
Cada objeto de configuración debe implementar la propiedad `inputs` y devolver un mapeo,
donde cada llave corresponde a una entrada esperada y cada valor indica el eje de esa entrada.
Para DistilBERT, podemos ver que se requieren dos entradas: `input_ids` y `attention_mask`.
Estas entradas tienen la misma forma de `(batch_size, sequence_length)`, es por lo que vemos
los mismos ejes utilizados en la configuración.
<Tip>
Observa que la propiedad `inputs` para `DistilBertOnnxConfig` devuelve un `OrderedDict`.
Esto nos asegura que las entradas coincidan con su posición relativa dentro del método
`PreTrainedModel.forward()` al rastrear el grafo. Recomendamos usar un `OrderedDict`
para las propiedades `inputs` y `outputs` al implementar configuraciones ONNX personalizadas.
</Tip>
Una vez que hayas implementado una configuración ONNX, puedes crear una
instancia proporcionando la configuración del modelo base de la siguiente manera:
```python
>>> from transformers import AutoConfig
>>> config = AutoConfig.from_pretrained("distilbert-base-uncased")
>>> onnx_config = DistilBertOnnxConfig(config)
```
El objeto resultante tiene varias propiedades útiles. Por ejemplo, puedes ver el conjunto de operadores ONNX que se
utilizará durante la exportación:
```python
>>> print(onnx_config.default_onnx_opset)
11
```
También puedes ver los resultados asociados con el modelo de la siguiente manera:
```python
>>> print(onnx_config.outputs)
OrderedDict([("last_hidden_state", {0: "batch", 1: "sequence"})])
```
Observa que la propiedad de salidas sigue la misma estructura que las entradas;
devuelve un objecto `OrderedDict` de salidas nombradas y sus formas. La estructura
de salida está vinculada a la elección de la función con la que se inicializa la configuración.
Por defecto, la configuración de ONNX se inicializa con la función `default` que
corresponde a exportar un modelo cargado con la clase `AutoModel`. Si quieres exportar
una topología de modelo diferente, simplemente proporciona una característica diferente
al argumento `task` cuando inicialices la configuración de ONNX. Por ejemplo, si quisiéramos
exportar DistilBERT con un cabezal de clasificación de secuencias, podríamos usar:
```python
>>> from transformers import AutoConfig
>>> config = AutoConfig.from_pretrained("distilbert-base-uncased")
>>> onnx_config_for_seq_clf = DistilBertOnnxConfig(config, task="sequence-classification")
>>> print(onnx_config_for_seq_clf.outputs)
OrderedDict([('logits', {0: 'batch'})])
```
<Tip>
Todas las propiedades base y métodos asociados con [`~onnx.config.OnnxConfig`] y las
otras clases de configuración se pueden sobreescribir si es necesario.
Consulte [`BartOnnxConfig`] para ver un ejemplo avanzado.
</Tip>
#### Exportar el modelo
Una vez que hayas implementado la configuración de ONNX, el siguiente paso es exportar el modelo.
Aquí podemos usar la función `export()` proporcionada por el paquete `transformers.onnx`.
Esta función espera la configuración de ONNX, junto con el modelo base y el tokenizador,
y la ruta para guardar el archivo exportado:
```python
>>> from pathlib import Path
>>> from transformers.onnx import export
>>> from transformers import AutoTokenizer, AutoModel
>>> onnx_path = Path("model.onnx")
>>> model_ckpt = "distilbert-base-uncased"
>>> base_model = AutoModel.from_pretrained(model_ckpt)
>>> tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
>>> onnx_inputs, onnx_outputs = export(tokenizer, base_model, onnx_config, onnx_config.default_onnx_opset, onnx_path)
```
Los objetos `onnx_inputs` y `onnx_outputs` devueltos por la función `export()`
son listas de llaves definidas en las propiedades `inputs` y `outputs` de la configuración.
Una vez exportado el modelo, puedes probar que el modelo está bien formado de la siguiente manera:
```python
>>> import onnx
>>> onnx_model = onnx.load("model.onnx")
>>> onnx.checker.check_model(onnx_model)
```
<Tip>
Si tu modelo tiene más de 2GB, verás que se crean muchos archivos adicionales durante la exportación.
Esto es _esperado_ porque ONNX usa [Búferes de protocolo](https://developers.google.com/protocol-buffers/)
para almacenar el modelo y éstos tienen un límite de tamaño de 2 GB. Consulta la
[documentación de ONNX](https://github.com/onnx/onnx/blob/master/docs/ExternalData.md) para obtener
instrucciones sobre cómo cargar modelos con datos externos.
</Tip>
#### Validar los resultados del modelo
El paso final es validar que los resultados del modelo base y exportado coincidan dentro
de cierta tolerancia absoluta. Aquí podemos usar la función `validate_model_outputs()`
proporcionada por el paquete `transformers.onnx` de la siguiente manera:
```python
>>> from transformers.onnx import validate_model_outputs
>>> validate_model_outputs(
... onnx_config, tokenizer, base_model, onnx_path, onnx_outputs, onnx_config.atol_for_validation
... )
```
Esta función usa el método `OnnxConfig.generate_dummy_inputs()` para generar entradas para el modelo base
y exportado, y la tolerancia absoluta se puede definir en la configuración. En general, encontramos una
concordancia numérica en el rango de 1e-6 a 1e-4, aunque es probable que cualquier valor menor que 1e-3 esté bien.
### Contribuir con una nueva configuración a 🤗 Transformers
¡Estamos buscando expandir el conjunto de configuraciones a la medida para usar y agradecemos las contribuciones de la comunidad!
Si deseas contribuir con su colaboración a la biblioteca, deberás:
* Implementa la configuración de ONNX en el archivo `configuration_<model_name>.py` correspondiente
* Incluye la arquitectura del modelo y las características correspondientes en [`~onnx.features.FeatureManager`]
* Agrega tu arquitectura de modelo a las pruebas en `test_onnx_v2.py`
Revisa cómo fue la contribución para la [configuración de IBERT](https://github.com/huggingface/transformers/pull/14868/files)
y así tener una idea de lo que necesito.
## TorchScript
<Tip>
Este es el comienzo de nuestros experimentos con TorchScript y todavía estamos explorando sus capacidades con modelos de
tamaño de entrada variable. Es un tema de interés y profundizaremos nuestro análisis en las próximas
versiones, con más ejemplos de código, una implementación más flexible y puntos de referencia que comparen códigos
basados en Python con TorchScript compilado.
</Tip>
Según la documentación de PyTorch: "TorchScript es una forma de crear modelos serializables y optimizables a partir del
código de PyTorch". Los dos módulos de Pytorch [JIT y TRACE](https://pytorch.org/docs/stable/jit.html) permiten al
desarrollador exportar su modelo para reutilizarlo en otros programas, como los programas C++ orientados a la eficiencia.
Hemos proporcionado una interfaz que permite exportar modelos de 🤗 Transformers a TorchScript para que puedan reutilizarse
en un entorno diferente al de un programa Python basado en PyTorch. Aquí explicamos cómo exportar y usar nuestros modelos
usando TorchScript.
Exportar un modelo requiere de dos cosas:
- un pase hacia adelante con entradas ficticias.
- instanciación del modelo con la indicador `torchscript`.
Estas necesidades implican varias cosas con las que los desarrolladores deben tener cuidado. Éstas se detallan a continuación.
### Indicador de TorchScript y pesos atados
Este indicador es necesario porque la mayoría de los modelos de lenguaje en este repositorio tienen pesos vinculados entre su capa
de `Embedding` y su capa de `Decoding`. TorchScript no permite la exportación de modelos que tengan pesos atados, por lo que es
necesario desvincular y clonar los pesos previamente.
Esto implica que los modelos instanciados con el indicador `torchscript` tienen su capa `Embedding` y `Decoding` separadas,
lo que significa que no deben entrenarse más adelante. El entrenamiento desincronizaría las dos capas, lo que generaría
resultados inesperados.
Este no es el caso de los modelos que no tienen un cabezal de modelo de lenguaje, ya que no tienen pesos atados.
Estos modelos se pueden exportar de forma segura sin el indicador `torchscript`.
### Entradas ficticias y longitudes estándar
Las entradas ficticias se utilizan para crear un modelo de pase hacia adelante. Mientras los valores de las entradas se
propagan a través de las capas, PyTorch realiza un seguimiento de las diferentes operaciones ejecutadas en cada tensor.
Estas operaciones registradas se utilizan luego para crear el "rastro" del modelo.
El rastro se crea en relación con las dimensiones de las entradas. Por lo tanto, está limitado por las dimensiones de la
entrada ficticia y no funcionará para ninguna otra longitud de secuencia o tamaño de lote. Al intentar con un tamaño diferente,
un error como:
`The expanded size of the tensor (3) must match the existing size (7) at non-singleton dimension 2`
aparecerá. Por lo tanto, se recomienda rastrear el modelo con un tamaño de entrada ficticia al menos tan grande como la
entrada más grande que se alimentará al modelo durante la inferencia. El _padding_ se puede realizar para completar los
valores que faltan. Sin embargo, como el modelo se habrá rastreado con un tamaño de entrada grande, las dimensiones de
las diferentes matrices también serán grandes, lo que dará como resultado más cálculos.
Se recomienda tener cuidado con el número total de operaciones realizadas en cada entrada y seguir de cerca el rendimiento
al exportar modelos de longitud de secuencia variable.
### Usar TorchScript en Python
A continuación se muestra un ejemplo que muestra cómo guardar, cargar modelos y cómo usar el rastreo para la inferencia.
#### Guardando un modelo
Este fragmento muestra cómo usar TorchScript para exportar un `BertModel`. Aquí, el `BertModel` se instancia de acuerdo
con la clase `BertConfig` y luego se guarda en el disco con el nombre de archivo `traced_bert.pt`
```python
from transformers import BertModel, BertTokenizer, BertConfig
import torch
enc = BertTokenizer.from_pretrained("bert-base-uncased")
# Tokenizing input text
text = "[CLS] Who was Jim Henson ? [SEP] Jim Henson was a puppeteer [SEP]"
tokenized_text = enc.tokenize(text)
# Masking one of the input tokens
masked_index = 8
tokenized_text[masked_index] = "[MASK]"
indexed_tokens = enc.convert_tokens_to_ids(tokenized_text)
segments_ids = [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]
# Creating a dummy input
tokens_tensor = torch.tensor([indexed_tokens])
segments_tensors = torch.tensor([segments_ids])
dummy_input = [tokens_tensor, segments_tensors]
# Initializing the model with the torchscript flag
# Flag set to True even though it is not necessary as this model does not have an LM Head.
config = BertConfig(
vocab_size_or_config_json_file=32000,
hidden_size=768,
num_hidden_layers=12,
num_attention_heads=12,
intermediate_size=3072,
torchscript=True,
)
# Instantiating the model
model = BertModel(config)
# The model needs to be in evaluation mode
model.eval()
# If you are instantiating the model with *from_pretrained* you can also easily set the TorchScript flag
model = BertModel.from_pretrained("bert-base-uncased", torchscript=True)
# Creating the trace
traced_model = torch.jit.trace(model, [tokens_tensor, segments_tensors])
torch.jit.save(traced_model, "traced_bert.pt")
```
#### Cargar un modelo
Este fragmento muestra cómo cargar el `BertModel` que se guardó previamente en el disco con el nombre `traced_bert.pt`.
Estamos reutilizando el `dummy_input` previamente inicializado.
```python
loaded_model = torch.jit.load("traced_bert.pt")
loaded_model.eval()
all_encoder_layers, pooled_output = loaded_model(*dummy_input)
```
#### Usar un modelo rastreado para la inferencia
Usar el modelo rastreado para la inferencia es tan simple como usar su método `__call__`:
```python
traced_model(tokens_tensor, segments_tensors)
```
### Implementar los modelos HuggingFace TorchScript en AWS mediante Neuron SDK
AWS presentó la familia de instancias [Amazon EC2 Inf1](https://aws.amazon.com/ec2/instance-types/inf1/) para la inferencia
de aprendizaje automático de bajo costo y alto rendimiento en la nube. Las instancias Inf1 funcionan con el chip AWS
Inferentia, un acelerador de hardware personalizado, que se especializa en cargas de trabajo de inferencia de aprendizaje
profundo. [AWS Neuron](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/#) es el kit de desarrollo para Inferentia
que admite el rastreo y la optimización de modelos de transformers para su implementación en Inf1. El SDK de Neuron proporciona:
1. API fácil de usar con una línea de cambio de código para rastrear y optimizar un modelo de TorchScript para la inferencia en la nube.
2. Optimizaciones de rendimiento listas para usar con un [costo-rendimiento mejorado](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/benchmark/>)
3. Soporte para modelos HuggingFace Transformers construidos con [PyTorch](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/pytorch/bert_tutorial/tutorial_pretrained_bert.html)
o [TensorFlow](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/tensorflow/huggingface_bert/huggingface_bert.html).
#### Implicaciones
Los modelos Transformers basados en la arquitectura
[BERT (Representaciones de _Enconder_ bidireccional de Transformers)](https://huggingface.co/docs/transformers/main/model_doc/bert),
o sus variantes, como [distilBERT](https://huggingface.co/docs/transformers/main/model_doc/distilbert) y
[roBERTa](https://huggingface.co/docs/transformers/main/model_doc/roberta), se ejecutarán mejor en Inf1 para tareas no
generativas, como la respuesta extractiva de preguntas, la clasificación de secuencias y la clasificación de tokens.
Como alternativa, las tareas de generación de texto se pueden adaptar para ejecutarse en Inf1, según este
[tutorial de AWS Neuron MarianMT](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/pytorch/transformers-marianmt.html).
Puedes encontrar más información sobre los modelos que están listos para usarse en Inferentia en la
[sección _Model Architecture Fit_ de la documentación de Neuron](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/models/models-inferentia.html#models-inferentia).
#### Dependencias
Usar AWS Neuron para convertir modelos requiere las siguientes dependencias y entornos:
* Un [entorno Neuron SDK](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/neuron-frameworks/pytorch-neuron/index.html#installation-guide),
que viene preconfigurado en [AWS Deep Learning AMI](https://docs.aws.amazon.com/dlami/latest/devguide/tutorial-inferentia-launching.html).
#### Convertir un modelo a AWS Neuron
Con el mismo script usado en [Uso de TorchScript en Python](https://huggingface.co/docs/transformers/main/es/serialization#using-torchscript-in-python)
para rastrear un "BertModel", puedes importar la extensión del _framework_ `torch.neuron` para acceder a los componentes
del SDK de Neuron a través de una API de Python.
```python
from transformers import BertModel, BertTokenizer, BertConfig
import torch
import torch.neuron
```
Y modificando la línea de código de rastreo de:
```python
torch.jit.trace(model, [tokens_tensor, segments_tensors])
```
con lo siguiente:
```python
torch.neuron.trace(model, [token_tensor, segments_tensors])
```
Este cambio permite a Neuron SDK rastrear el modelo y optimizarlo para ejecutarse en instancias Inf1.
Para obtener más información sobre las funciones, las herramientas, los tutoriales de ejemplo y las últimas actualizaciones
de AWS Neuron SDK, consulte la [documentación de AWS NeuronSDK](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/index.html).
| transformers/docs/source/es/serialization.md/0 | {
"file_path": "transformers/docs/source/es/serialization.md",
"repo_id": "transformers",
"token_count": 10461
} | 261 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# अनुमान के लिए पाइपलाइन
[`pipeline`] किसी भी भाषा, कंप्यूटर दृष्टि, भाषण और मल्टीमॉडल कार्यों पर अनुमान लगाने के लिए [Hub] (https://huggingface.co/models) से किसी भी मॉडल का उपयोग करना आसान बनाता है। भले ही आपके पास किसी विशिष्ट तौर-तरीके का अनुभव न हो या आप मॉडलों के पीछे अंतर्निहित कोड से परिचित न हों, फिर भी आप [`pipeline`] के अनुमान के लिए उनका उपयोग कर सकते हैं! यह ट्यूटोरियल आपको ये सिखाएगा:
* अनुमान के लिए [`pipeline`] का उपयोग करें।
* एक विशिष्ट टोकननाइज़र या मॉडल का उपयोग करें।
* ऑडियो, विज़न और मल्टीमॉडल कार्यों के लिए [`pipeline`] का उपयोग करें।
<Tip>
समर्थित कार्यों और उपलब्ध मापदंडों की पूरी सूची के लिए [`pipeline`] दस्तावेज़ पर एक नज़र डालें।
</Tip>
## पाइपलाइन का उपयोग
जबकि प्रत्येक कार्य में एक संबद्ध [`pipeline`] होता है, सामान्य [`pipeline`] अमूर्त का उपयोग करना आसान होता है जिसमें शामिल होता है
सभी कार्य-विशिष्ट पाइपलाइनें। [`pipeline`] स्वचालित रूप से एक डिफ़ॉल्ट मॉडल और सक्षम प्रीप्रोसेसिंग क्लास लोड करता है
आपके कार्य के लिए अनुमान का. आइए स्वचालित वाक् पहचान (एएसआर) के लिए [`pipeline`] का उपयोग करने का उदाहरण लें, या
वाक्-से-पाठ.
1. एक [`pipeline`] बनाकर प्रारंभ करें और अनुमान कार्य निर्दिष्ट करें:
```py
>>> from transformers import pipeline
>>> transcriber = pipeline(task="automatic-speech-recognition")
```
2. अपना इनपुट [`pipeline`] पर भेजें। वाक् पहचान के मामले में, यह एक ऑडियो इनपुट फ़ाइल है:
```py
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': 'I HAVE A DREAM BUT ONE DAY THIS NATION WILL RISE UP LIVE UP THE TRUE MEANING OF ITS TREES'}
```
क्या वह परिणाम नहीं जो आपके मन में था? कुछ [सबसे अधिक डाउनलोड किए गए स्वचालित वाक् पहचान मॉडल](https://huggingface.co/models?pipeline_tag=automatic-speech-recognition&sort=trending) देखें
यह देखने के लिए हब पर जाएं कि क्या आपको बेहतर ट्रांस्क्रिप्शन मिल सकता है।
आइए OpenAI से [व्हिस्पर लार्ज-v2](https://huggingface.co/openai/whisper-large) मॉडल आज़माएं। व्हिस्पर जारी किया गया
Wav2Vec2 की तुलना में 2 साल बाद, और लगभग 10 गुना अधिक डेटा पर प्रशिक्षित किया गया था। इस प्रकार, यह अधिकांश डाउनस्ट्रीम पर Wav2Vec2 को मात देता है
बेंचमार्क. इसमें विराम चिह्न और आवरण की भविष्यवाणी करने का अतिरिक्त लाभ भी है, जिनमें से कोई भी संभव नहीं है
Wav2Vec2.
आइए इसे यहां आज़माकर देखें कि यह कैसा प्रदर्शन करता है:
```py
>>> transcriber = pipeline(model="openai/whisper-large-v2")
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.'}
```
अब यह परिणाम अधिक सटीक दिखता है! Wav2Vec2 बनाम व्हिस्पर पर गहन तुलना के लिए, [ऑडियो ट्रांसफॉर्मर्स कोर्स] (https://huggingface.co/learn/audio-course/chapter5/asr_models) देखें।
हम वास्तव में आपको विभिन्न भाषाओं में मॉडल, आपके क्षेत्र में विशेषीकृत मॉडल और बहुत कुछ के लिए हब की जांच करने के लिए प्रोत्साहित करते हैं।
आप हब पर सीधे अपने ब्राउज़र से मॉडल परिणामों की जांच और तुलना कर सकते हैं कि यह फिट बैठता है या नहीं
अन्य मामलों की तुलना में कोने के मामलों को बेहतर ढंग से संभालता है।
और यदि आपको अपने उपयोग के मामले के लिए कोई मॉडल नहीं मिलता है, तो आप हमेशा अपना खुद का [प्रशिक्षण](training) शुरू कर सकते हैं!
यदि आपके पास कई इनपुट हैं, तो आप अपने इनपुट को एक सूची के रूप में पास कर सकते हैं:
```py
transcriber(
[
"https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac",
"https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/1.flac",
]
)
```
पाइपलाइनें प्रयोग के लिए बहुत अच्छी हैं क्योंकि एक मॉडल से दूसरे मॉडल पर स्विच करना मामूली काम है; हालाँकि, प्रयोग की तुलना में बड़े कार्यभार के लिए उन्हें अनुकूलित करने के कुछ तरीके हैं। संपूर्ण डेटासेट पर पुनरावृत्ति करने या वेबसर्वर में पाइपलाइनों का उपयोग करने के बारे में निम्नलिखित मार्गदर्शिकाएँ देखें:
दस्तावेज़ों में से:
* [डेटासेट पर पाइपलाइनों का उपयोग करना](#using-pipelines-on-a-dataset)
* [वेबसर्वर के लिए पाइपलाइनों का उपयोग करना](./pipeline_webserver)
## प्राचल
[`pipeline`] कई मापदंडों का समर्थन करता है; कुछ कार्य विशिष्ट हैं, और कुछ सभी पाइपलाइनों के लिए सामान्य हैं।
सामान्य तौर पर, आप अपनी इच्छानुसार कहीं भी पैरामीटर निर्दिष्ट कर सकते हैं:
```py
transcriber = pipeline(model="openai/whisper-large-v2", my_parameter=1)
out = transcriber(...) # This will use `my_parameter=1`.
out = transcriber(..., my_parameter=2) # This will override and use `my_parameter=2`.
out = transcriber(...) # This will go back to using `my_parameter=1`.
```
आइए 3 महत्वपूर्ण बातों पर गौर करें:
### उपकरण
यदि आप `device=0` का उपयोग करते हैं, तो पाइपलाइन स्वचालित रूप से मॉडल को निर्दिष्ट डिवाइस पर डाल देती है।
यह इस पर ध्यान दिए बिना काम करेगा कि आप PyTorch या Tensorflow का उपयोग कर रहे हैं या नहीं।
```py
transcriber = pipeline(model="openai/whisper-large-v2", device=0)
```
यदि मॉडल एकल GPU के लिए बहुत बड़ा है और आप PyTorch का उपयोग कर रहे हैं, तो आप `device_map="auto"` को स्वचालित रूप से सेट कर सकते हैं
निर्धारित करें कि मॉडल वज़न को कैसे लोड और संग्रहीत किया जाए। `device_map` तर्क का उपयोग करने के लिए 🤗 [Accelerate] (https://huggingface.co/docs/accelerate) की आवश्यकता होती है
पैकेट:
```bash
pip install --upgrade accelerate
```
निम्नलिखित कोड स्वचालित रूप से सभी डिवाइसों में मॉडल भार को लोड और संग्रहीत करता है:
```py
transcriber = pipeline(model="openai/whisper-large-v2", device_map="auto")
```
ध्यान दें कि यदि `device_map='auto'` पारित हो गया है, तो अपनी `pipeline` को चालू करते समय `device=device` तर्क जोड़ने की कोई आवश्यकता नहीं है क्योंकि आपको कुछ अप्रत्याशित व्यवहार का सामना करना पड़ सकता है!
### बैच का आकार
डिफ़ॉल्ट रूप से, पाइपलाइनें [यहां] (https://huggingface.co/docs/transformers/main_classes/pipelines#pipeline-batching) विस्तार से बताए गए कारणों के लिए बैच अनुमान नहीं लगाएंगी। इसका कारण यह है कि बैचिंग आवश्यक रूप से तेज़ नहीं है, और वास्तव में कुछ मामलों में काफी धीमी हो सकती है।
लेकिन अगर यह आपके उपयोग के मामले में काम करता है, तो आप इसका उपयोग कर सकते हैं:
```py
transcriber = pipeline(model="openai/whisper-large-v2", device=0, batch_size=2)
audio_filenames = [f"https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/{i}.flac" for i in range(1, 5)]
texts = transcriber(audio_filenames)
```
यह प्रदान की गई 4 ऑडियो फाइलों पर पाइपलाइन चलाता है, लेकिन यह उन्हें 2 के बैच में पास करेगा
आपसे किसी और कोड की आवश्यकता के बिना मॉडल (जो एक जीपीयू पर है, जहां बैचिंग से मदद मिलने की अधिक संभावना है) पर जाएं।
आउटपुट हमेशा उसी से मेल खाना चाहिए जो आपको बैचिंग के बिना प्राप्त हुआ होगा। इसका उद्देश्य केवल पाइपलाइन से अधिक गति प्राप्त करने में आपकी सहायता करना है।
पाइपलाइनें बैचिंग की कुछ जटिलताओं को भी कम कर सकती हैं क्योंकि, कुछ पाइपलाइनों के लिए, एक एकल आइटम (जैसे एक लंबी ऑडियो फ़ाइल) को एक मॉडल द्वारा संसाधित करने के लिए कई भागों में विभाजित करने की आवश्यकता होती है। पाइपलाइन आपके लिए यह [*chunk batching*](./main_classes/pipelines#pipeline-chunk-batching) करती है।
### कार्य विशिष्ट प्राचल
सभी कार्य कार्य विशिष्ट प्राचल प्रदान करते हैं जो आपको अपना काम पूरा करने में मदद करने के लिए अतिरिक्त लचीलेपन और विकल्पों की अनुमति देते हैं।
उदाहरण के लिए, [`transformers.AutomaticSpeechRecognitionPipeline.__call__`] विधि में एक `return_timestamps` प्राचल है जो वीडियो उपशीर्षक के लिए आशाजनक लगता है:
```py
>>> transcriber = pipeline(model="openai/whisper-large-v2", return_timestamps=True)
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.', 'chunks': [{'timestamp': (0.0, 11.88), 'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its'}, {'timestamp': (11.88, 12.38), 'text': ' creed.'}]}
```
जैसा कि आप देख सकते हैं, मॉडल ने पाठ का अनुमान लगाया और **when** विभिन्न वाक्यों का उच्चारण किया गया तो आउटपुट भी दिया।
प्रत्येक कार्य के लिए कई प्राचल उपलब्ध हैं, इसलिए यह देखने के लिए कि आप किसके साथ छेड़छाड़ कर सकते हैं, प्रत्येक कार्य का API संदर्भ देखें!
उदाहरण के लिए, [`~transformers.AutomaticSpeechRecognitionPipeline`] में एक `chunk_length_s` प्राचल है जो सहायक है
वास्तव में लंबी ऑडियो फ़ाइलों पर काम करने के लिए (उदाहरण के लिए, संपूर्ण फिल्मों या घंटे-लंबे वीडियो को उपशीर्षक देना) जो आमतौर पर एक मॉडल होता है
अपने आप संभाल नहीं सकता:
```python
>>> transcriber = pipeline(model="openai/whisper-large-v2", chunk_length_s=30, return_timestamps=True)
>>> transcriber("https://huggingface.co/datasets/sanchit-gandhi/librispeech_long/resolve/main/audio.wav")
{'text': " Chapter 16. I might have told you of the beginning of this liaison in a few lines, but I wanted you to see every step by which we came. I, too, agree to whatever Marguerite wished, Marguerite to be unable to live apart from me. It was the day after the evening...
```
यदि आपको कोई ऐसा पैरामीटर नहीं मिल रहा है जो वास्तव में आपकी मदद करेगा, तो बेझिझक [अनुरोध करें](https://github.com/huggingface/transformers/issues/new?assignees=&labels=feature&template=feature-request.yml)!
## डेटासेट पर पाइपलाइनों का उपयोग करना
पाइपलाइन बड़े डेटासेट पर भी अनुमान चला सकती है। ऐसा करने का सबसे आसान तरीका हम एक पुनरावर्तक का उपयोग करने की सलाह देते हैं:
```py
def data():
for i in range(1000):
yield f"My example {i}"
pipe = pipeline(model="gpt2", device=0)
generated_characters = 0
for out in pipe(data()):
generated_characters += len(out[0]["generated_text"])
```
पुनरावर्तक `data()` प्रत्येक परिणाम और पाइपलाइन स्वचालित रूप से उत्पन्न करता है
पहचानता है कि इनपुट पुनरावर्तनीय है और डेटा प्राप्त करना शुरू कर देगा
यह इसे GPU पर प्रोसेस करना जारी रखता है (यह हुड के तहत [DataLoader](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader) का उपयोग करता है)।
यह महत्वपूर्ण है क्योंकि आपको संपूर्ण डेटासेट के लिए मेमोरी आवंटित करने की आवश्यकता नहीं है
और आप जितनी जल्दी हो सके GPU को फीड कर सकते हैं।
चूंकि बैचिंग से चीज़ें तेज़ हो सकती हैं, इसलिए यहां `batch_size` प्राचल को ट्यून करने का प्रयास करना उपयोगी हो सकता है।
किसी डेटासेट पर पुनरावृति करने का सबसे सरल तरीका बस एक को 🤗 [Dataset](https://github.com/huggingface/datasets/) से लोड करना है:
```py
# KeyDataset is a util that will just output the item we're interested in.
from transformers.pipelines.pt_utils import KeyDataset
from datasets import load_dataset
pipe = pipeline(model="hf-internal-testing/tiny-random-wav2vec2", device=0)
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation[:10]")
for out in pipe(KeyDataset(dataset, "audio")):
print(out)
```
## वेबसर्वर के लिए पाइपलाइनों का उपयोग करना
<Tip>
एक अनुमान इंजन बनाना एक जटिल विषय है जो अपने आप में उपयुक्त है
पृष्ठ।
</Tip>
[Link](./pipeline_webserver)
## विज़न पाइपलाइन
दृष्टि कार्यों के लिए [`pipeline`] का उपयोग करना व्यावहारिक रूप से समान है।
अपना कार्य निर्दिष्ट करें और अपनी छवि क्लासिफायरियर को भेजें। छवि एक लिंक, एक स्थानीय पथ या बेस64-एन्कोडेड छवि हो सकती है। उदाहरण के लिए, बिल्ली की कौन सी प्रजाति नीचे दिखाई गई है?

```py
>>> from transformers import pipeline
>>> vision_classifier = pipeline(model="google/vit-base-patch16-224")
>>> preds = vision_classifier(
... images="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
... )
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> preds
[{'score': 0.4335, 'label': 'lynx, catamount'}, {'score': 0.0348, 'label': 'cougar, puma, catamount, mountain lion, painter, panther, Felis concolor'}, {'score': 0.0324, 'label': 'snow leopard, ounce, Panthera uncia'}, {'score': 0.0239, 'label': 'Egyptian cat'}, {'score': 0.0229, 'label': 'tiger cat'}]
```
## पाठ पाइपलाइन
NLP कार्यों के लिए [`pipeline`] का उपयोग करना व्यावहारिक रूप से समान है।
```py
>>> from transformers import pipeline
>>> # This model is a `zero-shot-classification` model.
>>> # It will classify text, except you are free to choose any label you might imagine
>>> classifier = pipeline(model="facebook/bart-large-mnli")
>>> classifier(
... "I have a problem with my iphone that needs to be resolved asap!!",
... candidate_labels=["urgent", "not urgent", "phone", "tablet", "computer"],
... )
{'sequence': 'I have a problem with my iphone that needs to be resolved asap!!', 'labels': ['urgent', 'phone', 'computer', 'not urgent', 'tablet'], 'scores': [0.504, 0.479, 0.013, 0.003, 0.002]}
```
## बहुविध पाइपलाइन
[`pipeline`] एक से अधिक तौर-तरीकों का समर्थन करती है। उदाहरण के लिए, एक दृश्य प्रश्न उत्तर (VQA) कार्य पाठ और छवि को जोड़ता है। अपनी पसंद के किसी भी छवि लिंक और छवि के बारे में कोई प्रश्न पूछने के लिए स्वतंत्र महसूस करें। छवि एक URL या छवि का स्थानीय पथ हो सकती है।
उदाहरण के लिए, यदि आप इस [invoice image](https://huggingface.co/spaces/impira/docquery/resolve/2359223c1837a7587402bda0f2643382a6eefeab/invoice.png) का उपयोग करते हैं:
```py
>>> from transformers import pipeline
>>> vqa = pipeline(model="impira/layoutlm-document-qa")
>>> vqa(
... image="https://huggingface.co/spaces/impira/docquery/resolve/2359223c1837a7587402bda0f2643382a6eefeab/invoice.png",
... question="What is the invoice number?",
... )
[{'score': 0.42515, 'answer': 'us-001', 'start': 16, 'end': 16}]
```
<Tip>
ऊपर दिए गए उदाहरण को चलाने के लिए आपको 🤗 ट्रांसफॉर्मर के अलावा [`pytesseract`](https://pypi.org/project/pytesseract/) इंस्टॉल करना होगा:
```bash
sudo apt install -y tesseract-ocr
pip install pytesseract
```
</Tip>
## 🤗 `त्वरण` के साथ बड़े मॉडलों पर `pipeline` का उपयोग करना:
आप 🤗 `accelerate` का उपयोग करके बड़े मॉडलों पर आसानी से `pipeline` चला सकते हैं! पहले सुनिश्चित करें कि आपने `accelerate` को `pip install accelerate` के साथ इंस्टॉल किया है।
सबसे पहले `device_map='auto'` का उपयोग करके अपना मॉडल लोड करें! हम अपने उदाहरण के लिए `facebook/opt-1.3b` का उपयोग करेंगे।
```py
# pip install accelerate
import torch
from transformers import pipeline
pipe = pipeline(model="facebook/opt-1.3b", torch_dtype=torch.bfloat16, device_map="auto")
output = pipe("This is a cool example!", do_sample=True, top_p=0.95)
```
यदि आप `bitsandbytes` इंस्टॉल करते हैं और `load_in_8bit=True` तर्क जोड़ते हैं तो आप 8-बिट लोडेड मॉडल भी पास कर सकते हैं
```py
# pip install accelerate bitsandbytes
import torch
from transformers import pipeline
pipe = pipeline(model="facebook/opt-1.3b", device_map="auto", model_kwargs={"load_in_8bit": True})
output = pipe("This is a cool example!", do_sample=True, top_p=0.95)
```
ध्यान दें कि आप चेकपॉइंट को किसी भी हगिंग फेस मॉडल से बदल सकते हैं जो BLOOM जैसे बड़े मॉडल लोडिंग का समर्थन करता है!
| transformers/docs/source/hi/pipeline_tutorial.md/0 | {
"file_path": "transformers/docs/source/hi/pipeline_tutorial.md",
"repo_id": "transformers",
"token_count": 13910
} | 262 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Condividi un modello
Gli ultimi due tutorial ti hanno mostrato come puoi fare fine-tuning di un modello con PyTorch, Keras e 🤗 Accelerate per configurazioni distribuite. Il prossimo passo è quello di condividere il tuo modello con la community! In Hugging Face, crediamo nella condivisione della conoscenza e delle risorse in modo da democratizzare l'intelligenza artificiale per chiunque. Ti incoraggiamo a considerare di condividere il tuo modello con la community per aiutare altre persone a risparmiare tempo e risorse.
In questo tutorial, imparerai due metodi per la condivisione di un modello trained o fine-tuned nel [Model Hub](https://huggingface.co/models):
- Condividi in modo programmatico i tuoi file nell'Hub.
- Trascina i tuoi file nell'Hub mediante interfaccia grafica.
<iframe width="560" height="315" src="https://www.youtube.com/embed/XvSGPZFEjDY" title="YouTube video player"
frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope;
picture-in-picture" allowfullscreen></iframe>
<Tip>
Per condividere un modello con la community, hai bisogno di un account su [huggingface.co](https://huggingface.co/join). Puoi anche unirti ad un'organizzazione esistente o crearne una nuova.
</Tip>
## Caratteristiche dei repository
Ogni repository nel Model Hub si comporta come un tipico repository di GitHub. I nostri repository offrono il versionamento, la cronologia dei commit, e la possibilità di visualizzare le differenze.
Il versionamento all'interno del Model Hub è basato su git e [git-lfs](https://git-lfs.github.com/). In altre parole, puoi trattare un modello come un unico repository, consentendo un maggiore controllo degli accessi e maggiore scalabilità. Il controllo delle versioni consente *revisions*, un metodo per appuntare una versione specifica di un modello con un hash di commit, un tag o un branch.
Come risultato, puoi caricare una specifica versione di un modello con il parametro `revision`:
```py
>>> model = AutoModel.from_pretrained(
... "julien-c/EsperBERTo-small", revision="v2.0.1" # nome di un tag, di un branch, o commit hash
... )
```
Anche i file possono essere modificati facilmente in un repository ed è possibile visualizzare la cronologia dei commit e le differenze:

## Configurazione
Prima di condividere un modello nell'Hub, hai bisogno delle tue credenziali di Hugging Face. Se hai accesso ad un terminale, esegui il seguente comando nell'ambiente virtuale in cui è installata la libreria 🤗 Transformers. Questo memorizzerà il tuo token di accesso nella cartella cache di Hugging Face (di default `~/.cache/`):
```bash
huggingface-cli login
```
Se stai usando un notebook come Jupyter o Colaboratory, assicurati di avere la libreria [`huggingface_hub`](https://huggingface.co/docs/hub/adding-a-library) installata. Questa libreria ti permette di interagire in maniera programmatica con l'Hub.
```bash
pip install huggingface_hub
```
Utilizza `notebook_login` per accedere all'Hub, e segui il link [qui](https://huggingface.co/settings/token) per generare un token con cui effettuare il login:
```py
>>> from huggingface_hub import notebook_login
>>> notebook_login()
```
## Converti un modello per tutti i framework
Per assicurarti che il tuo modello possa essere utilizzato da persone che lavorano con un framework differente, ti raccomandiamo di convertire e caricare il tuo modello sia con i checkpoint di PyTorch che con quelli di TensorFlow. Anche se è possibile caricare il modello da un framework diverso, se si salta questo passaggio, il caricamento sarà più lento perché 🤗 Transformers ha bisogno di convertire i checkpoint al momento.
Convertire un checkpoint per un altro framework è semplice. Assicurati di avere PyTorch e TensorFlow installati (vedi [qui](installation) per le istruzioni d'installazione), e poi trova il modello specifico per il tuo compito nell'altro framework.
<frameworkcontent>
<pt>
Specifica `from_tf=True` per convertire un checkpoint da TensorFlow a PyTorch:
```py
>>> pt_model = DistilBertForSequenceClassification.from_pretrained(
... "path/verso/il-nome-magnifico-che-hai-scelto", from_tf=True
... )
>>> pt_model.save_pretrained("path/verso/il-nome-magnifico-che-hai-scelto")
```
</pt>
<tf>
Specifica `from_pt=True` per convertire un checkpoint da PyTorch a TensorFlow:
```py
>>> tf_model = TFDistilBertForSequenceClassification.from_pretrained(
... "path/verso/il-nome-magnifico-che-hai-scelto", from_pt=True
... )
```
Poi puoi salvare il tuo nuovo modello in TensorFlow con il suo nuovo checkpoint:
```py
>>> tf_model.save_pretrained("path/verso/il-nome-magnifico-che-hai-scelto")
```
</tf>
<jax>
Se un modello è disponibile in Flax, puoi anche convertire un checkpoint da PyTorch a Flax:
```py
>>> flax_model = FlaxDistilBertForSequenceClassification.from_pretrained(
... "path/verso/il-nome-magnifico-che-hai-scelto", from_pt=True
... )
```
</jax>
</frameworkcontent>
## Condividi un modello durante il training
<frameworkcontent>
<pt>
<Youtube id="Z1-XMy-GNLQ"/>
Condividere un modello nell'Hub è tanto semplice quanto aggiungere un parametro extra o un callback. Ricorda dal [tutorial sul fine-tuning](training), la classe [`TrainingArguments`] è dove specifichi gli iperparametri e le opzioni addizionali per l'allenamento. Una di queste opzioni di training include l'abilità di condividere direttamente un modello nell'Hub. Imposta `push_to_hub=True` in [`TrainingArguments`]:
```py
>>> training_args = TrainingArguments(output_dir="il-mio-bellissimo-modello", push_to_hub=True)
```
Passa gli argomenti per il training come di consueto al [`Trainer`]:
```py
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=small_train_dataset,
... eval_dataset=small_eval_dataset,
... compute_metrics=compute_metrics,
... )
```
Dopo aver effettuato il fine-tuning del tuo modello, chiama [`~transformers.Trainer.push_to_hub`] sul [`Trainer`] per condividere il modello allenato nell'Hub. 🤗 Transformers aggiungerà in modo automatico persino gli iperparametri, i risultati del training e le versioni del framework alla scheda del tuo modello (model card, in inglese)!
```py
>>> trainer.push_to_hub()
```
</pt>
<tf>
Condividi un modello nell'Hub con [`PushToHubCallback`]. Nella funzione [`PushToHubCallback`], aggiungi:
- Una directory di output per il tuo modello.
- Un tokenizer.
- L'`hub_model_id`, che è il tuo username sull'Hub e il nome del modello.
```py
>>> from transformers import PushToHubCallback
>>> push_to_hub_callback = PushToHubCallback(
... output_dir="./il_path_dove_salvare_il_tuo_modello",
... tokenizer=tokenizer,
... hub_model_id="il-tuo-username/il-mio-bellissimo-modello",
... )
```
Aggiungi il callback a [`fit`](https://keras.io/api/models/model_training_apis/), e 🤗 Transformers caricherà il modello allenato nell'Hub:
```py
>>> model.fit(tf_train_dataset, validation_data=tf_validation_dataset, epochs=3, callbacks=push_to_hub_callback)
```
</tf>
</frameworkcontent>
## Utilizzare la funzione `push_to_hub`
Puoi anche chiamare `push_to_hub` direttamente sul tuo modello per caricarlo nell'Hub.
Specifica il nome del tuo modello in `push_to_hub`:
```py
>>> pt_model.push_to_hub("il-mio-bellissimo-modello")
```
Questo crea un repository sotto il proprio username con il nome del modello `il-mio-bellissimo-modello`. Ora chiunque può caricare il tuo modello con la funzione `from_pretrained`:
```py
>>> from transformers import AutoModel
>>> model = AutoModel.from_pretrained("il-tuo-username/il-mio-bellissimo-modello")
```
Se fai parte di un'organizzazione e vuoi invece condividere un modello sotto il nome dell'organizzazione, aggiungi il parametro `organization`:
```py
>>> pt_model.push_to_hub("il-mio-bellissimo-modello", organization="la-mia-fantastica-org")
```
La funzione `push_to_hub` può essere anche utilizzata per aggiungere altri file al repository del modello. Per esempio, aggiungi un tokenizer ad un repository di un modello:
```py
>>> tokenizer.push_to_hub("il-mio-bellissimo-modello")
```
O magari potresti voler aggiungere la versione di TensorFlow del tuo modello PyTorch a cui hai fatto fine-tuning:
```py
>>> tf_model.push_to_hub("il-mio-bellissimo-modello")
```
Ora quando navighi nel tuo profilo Hugging Face, dovresti vedere il tuo repository del modello appena creato. Premendo sulla scheda **Files** vengono visualizzati tutti i file caricati nel repository.
Per maggiori dettagli su come creare e caricare file ad un repository, fai riferimento alla documentazione [qui](https://huggingface.co/docs/hub/how-to-upstream).
## Carica un modello utilizzando l'interfaccia web
Chi preferisce un approccio senza codice può caricare un modello tramite l'interfaccia web dell'hub. Visita [huggingface.co/new](https://huggingface.co/new) per creare un nuovo repository:

Da qui, aggiungi alcune informazioni sul tuo modello:
- Seleziona il/la **owner** del repository. Puoi essere te o qualunque organizzazione di cui fai parte.
- Scegli un nome per il tuo modello, il quale sarà anche il nome del repository.
- Scegli se il tuo modello è pubblico o privato.
- Specifica la licenza utilizzata per il tuo modello.
Ora premi sulla scheda **Files** e premi sul pulsante **Add file** per caricare un nuovo file al tuo repository. Trascina poi un file per caricarlo e aggiungere un messaggio di commit.

## Aggiungi una scheda del modello
Per assicurarti che chiunque possa comprendere le abilità, limitazioni, i potenziali bias e le considerazioni etiche del tuo modello, per favore aggiungi una scheda del modello (model card, in inglese) al tuo repository. La scheda del modello è definita nel file `README.md`. Puoi aggiungere una scheda del modello:
* Creando manualmente e caricando un file `README.md`.
* Premendo sul pulsante **Edit model card** nel repository del tuo modello.
Dai un'occhiata alla [scheda del modello](https://huggingface.co/distilbert-base-uncased) di DistilBert per avere un buon esempio del tipo di informazioni che una scheda di un modello deve includere. Per maggiori dettagli legati ad altre opzioni che puoi controllare nel file `README.md`, come l'impatto ambientale o widget di esempio, fai riferimento alla documentazione [qui](https://huggingface.co/docs/hub/models-cards).
| transformers/docs/source/it/model_sharing.md/0 | {
"file_path": "transformers/docs/source/it/model_sharing.md",
"repo_id": "transformers",
"token_count": 4021
} | 263 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Esporta modelli 🤗 Transformers
Se devi implementare 🤗 modelli Transformers in ambienti di produzione, noi
consigliamo di esportarli in un formato serializzato che può essere caricato ed eseguito
su runtime e hardware specializzati. In questa guida ti mostreremo come farlo
esporta 🤗 Modelli Transformers in due formati ampiamente utilizzati: ONNX e TorchScript.
Una volta esportato, un modello può essere ottimizato per l'inferenza tramite tecniche come
la quantizzazione e soppressione. Se sei interessato a ottimizzare i tuoi modelli per l'esecuzione
con la massima efficienza, dai un'occhiata a [🤗 Optimum
library](https://github.com/huggingface/optimum).
## ONNX
Il progetto [ONNX (Open Neural Network eXchange)](http://onnx.ai) Il progetto onnx è un open
standard che definisce un insieme comune di operatori e un formato di file comune a
rappresentano modelli di deep learning in un'ampia varietà di framework, tra cui
PyTorch e TensorFlow. Quando un modello viene esportato nel formato ONNX, questi
operatori sono usati per costruire un grafico computazionale (often called an
_intermediate representation_) che rappresenta il flusso di dati attraverso la
rete neurale.
Esponendo un grafico con operatori e tipi di dati standardizzati, ONNX rende
più facile passare da un framework all'altro. Ad esempio, un modello allenato in PyTorch può
essere esportato in formato ONNX e quindi importato in TensorFlow (e viceversa).
🤗 Transformers fornisce un pacchetto `transformers.onnx` che ti consente di
convertire i checkpoint del modello in un grafico ONNX sfruttando gli oggetti di configurazione.
Questi oggetti di configurazione sono già pronti per una serie di architetture di modelli,
e sono progettati per essere facilmente estensibili ad altre architetture.
Le configurazioni pronte includono le seguenti architetture:
<!--This table is automatically generated by `make fix-copies`, do not fill manually!-->
- ALBERT
- BART
- BEiT
- BERT
- BigBird
- BigBird-Pegasus
- Blenderbot
- BlenderbotSmall
- CamemBERT
- ConvBERT
- Data2VecText
- Data2VecVision
- DeiT
- DistilBERT
- ELECTRA
- FlauBERT
- GPT Neo
- GPT-J
- I-BERT
- LayoutLM
- M2M100
- Marian
- mBART
- MobileBERT
- OpenAI GPT-2
- Perceiver
- PLBart
- RoBERTa
- RoFormer
- SqueezeBERT
- T5
- ViT
- XLM
- XLM-RoBERTa
- XLM-RoBERTa-XL
Nelle prossime due sezioni, ti mostreremo come:
* Esporta un modello supportato usando il pacchetto `transformers.onnx`.
* Esporta un modello personalizzato per un'architettura non supportata.
### Esportazione di un modello in ONNX
Per esportare un modello 🤗 Transformers in ONNX, dovrai prima installarne alcune
dipendenze extra:
```bash
pip install transformers[onnx]
```
Il pacchetto `transformers.onnx` può essere usato come modulo Python:
```bash
python -m transformers.onnx --help
usage: Hugging Face Transformers ONNX exporter [-h] -m MODEL [--feature {causal-lm, ...}] [--opset OPSET] [--atol ATOL] output
positional arguments:
output Path indicating where to store generated ONNX model.
optional arguments:
-h, --help show this help message and exit
-m MODEL, --model MODEL
Model ID on huggingface.co or path on disk to load model from.
--feature {causal-lm, ...}
The type of features to export the model with.
--opset OPSET ONNX opset version to export the model with.
--atol ATOL Absolute difference tolerance when validating the model.
```
L'esportazione di un checkpoint utilizzando una configurazione già pronta può essere eseguita come segue:
```bash
python -m transformers.onnx --model=distilbert-base-uncased onnx/
```
che dovrebbe mostrare i seguenti log:
```bash
Validating ONNX model...
-[✓] ONNX model output names match reference model ({'last_hidden_state'})
- Validating ONNX Model output "last_hidden_state":
-[✓] (2, 8, 768) matches (2, 8, 768)
-[✓] all values close (atol: 1e-05)
All good, model saved at: onnx/model.onnx
```
Questo esporta un grafico ONNX del checkpoint definito dall'argomento `--model`.
In questo esempio è `distilbert-base-uncased`, ma può essere qualsiasi checkpoint
Hugging Face Hub o uno memorizzato localmente.
Il file risultante `model.onnx` può quindi essere eseguito su uno dei [tanti
acceleratori](https://onnx.ai/supported-tools.html#deployModel) che supportano il
lo standard ONNX. Ad esempio, possiamo caricare ed eseguire il modello con [ONNX
Runtime](https://onnxruntime.ai/) come segue:
```python
>>> from transformers import AutoTokenizer
>>> from onnxruntime import InferenceSession
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
>>> session = InferenceSession("onnx/model.onnx")
>>> # ONNX Runtime expects NumPy arrays as input
>>> inputs = tokenizer("Using DistilBERT with ONNX Runtime!", return_tensors="np")
>>> outputs = session.run(output_names=["last_hidden_state"], input_feed=dict(inputs))
```
I nomi di output richiesti (cioè `["last_hidden_state"]`) possono essere ottenuti
dando un'occhiata alla configurazione ONNX di ogni modello. Ad esempio, per
DistilBERT abbiamo:
```python
>>> from transformers.models.distilbert import DistilBertConfig, DistilBertOnnxConfig
>>> config = DistilBertConfig()
>>> onnx_config = DistilBertOnnxConfig(config)
>>> print(list(onnx_config.outputs.keys()))
["last_hidden_state"]
```
Il processo è identico per i checkpoint TensorFlow sull'hub. Ad esempio, noi
possiamo esportare un checkpoint TensorFlow puro da [Keras
organizzazione](https://huggingface.co/keras-io) come segue:
```bash
python -m transformers.onnx --model=keras-io/transformers-qa onnx/
```
Per esportare un modello memorizzato localmente, devi disporre dei pesi del modello
e file tokenizer memorizzati in una directory. Ad esempio, possiamo caricare e salvare un
checkpoint come segue:
<frameworkcontent>
<pt>
```python
>>> from transformers import AutoTokenizer, AutoModelForSequenceClassification
>>> # Load tokenizer and PyTorch weights form the Hub
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
>>> pt_model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
>>> # Save to disk
>>> tokenizer.save_pretrained("local-pt-checkpoint")
>>> pt_model.save_pretrained("local-pt-checkpoint")
```
Una volta salvato il checkpoint, possiamo esportarlo su ONNX puntando l'argomento `--model`
del pacchetto `transformers.onnx` nella directory desiderata:
```bash
python -m transformers.onnx --model=local-pt-checkpoint onnx/
```
</pt>
<tf>
```python
>>> from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
>>> # Load tokenizer and TensorFlow weights from the Hub
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
>>> # Save to disk
>>> tokenizer.save_pretrained("local-tf-checkpoint")
>>> tf_model.save_pretrained("local-tf-checkpoint")
```
Once the checkpoint is saved, we can export it to ONNX by pointing the `--model`
argument of the `transformers.onnx` package to the desired directory:
```bash
python -m transformers.onnx --model=local-tf-checkpoint onnx/
```
</tf>
</frameworkcontent>
### Selezione delle caratteristiche per diverse topologie di modello
Ogni configurazione già pronta viene fornita con una serie di _caratteristiche_ che ti consentono di
esportare modelli per diversi tipi di topologie o attività. Come mostrato nella tabella
di seguito, ogni caratteristica è associata a una diversa Auto Class:
| Caratteristica | Auto Class |
| ------------------------------------ | ------------------------------------ |
| `causal-lm`, `causal-lm-with-past` | `AutoModelForCausalLM` |
| `default`, `default-with-past` | `AutoModel` |
| `masked-lm` | `AutoModelForMaskedLM` |
| `question-answering` | `AutoModelForQuestionAnswering` |
| `seq2seq-lm`, `seq2seq-lm-with-past` | `AutoModelForSeq2SeqLM` |
| `sequence-classification` | `AutoModelForSequenceClassification` |
| `token-classification` | `AutoModelForTokenClassification` |
Per ciascuna configurazione, puoi trovare l'elenco delle funzionalità supportate tramite il
`FeaturesManager`. Ad esempio, per DistilBERT abbiamo:
```python
>>> from transformers.onnx.features import FeaturesManager
>>> distilbert_features = list(FeaturesManager.get_supported_features_for_model_type("distilbert").keys())
>>> print(distilbert_features)
["default", "masked-lm", "causal-lm", "sequence-classification", "token-classification", "question-answering"]
```
Puoi quindi passare una di queste funzionalità all'argomento `--feature` nel
pacchetto `transformers.onnx`. Ad esempio, per esportare un modello di classificazione del testo
possiamo scegliere un modello ottimizzato dall'Hub ed eseguire:
```bash
python -m transformers.onnx --model=distilbert-base-uncased-finetuned-sst-2-english \
--feature=sequence-classification onnx/
```
che visualizzerà i seguenti registri:
```bash
Validating ONNX model...
-[✓] ONNX model output names match reference model ({'logits'})
- Validating ONNX Model output "logits":
-[✓] (2, 2) matches (2, 2)
-[✓] all values close (atol: 1e-05)
All good, model saved at: onnx/model.onnx
```
Puoi notare che in questo caso, i nomi di output del modello ottimizzato sono
`logits` invece di `last_hidden_state` che abbiamo visto con il
checkpoint `distilbert-base-uncased` precedente. Questo è previsto dal
modello ottimizato visto che ha una testa di e.
<Tip>
Le caratteristiche che hanno un suffisso `wtih-past` (ad es. `causal-lm-with-past`)
corrispondono a topologie di modello con stati nascosti precalcolati (chiave e valori
nei blocchi di attenzione) che possono essere utilizzati per la decodifica autoregressiva veloce.
</Tip>
### Esportazione di un modello per un'architettura non supportata
Se desideri esportare un modello la cui architettura non è nativamente supportata dalla
libreria, ci sono tre passaggi principali da seguire:
1. Implementare una configurazione ONNX personalizzata.
2. Esportare il modello in ONNX.
3. Convalidare gli output di PyTorch e dei modelli esportati.
In questa sezione, vedremo come DistilBERT è stato implementato per mostrare cosa è
coinvolto in ogni passaggio.
#### Implementazione di una configurazione ONNX personalizzata
Iniziamo con l'oggetto di configurazione ONNX. Forniamo tre classi
astratte da cui ereditare, a seconda del tipo di archittettura
del modello che desideri esportare:
* I modelli basati su encoder ereditano da [`~onnx.config.OnnxConfig`]
* I modelli basati su decoder ereditano da [`~onnx.config.OnnxConfigWithPast`]
* I modelli encoder-decoder ereditano da[`~onnx.config.OnnxSeq2SeqConfigWithPast`]
<Tip>
Un buon modo per implementare una configurazione ONNX personalizzata è guardare l'implementazione
esistente nel file `configuration_<model_name>.py` di un'architettura simile.
</Tip>
Poiché DistilBERT è un modello basato su encoder, la sua configurazione eredita da
`OnnxConfig`:
```python
>>> from typing import Mapping, OrderedDict
>>> from transformers.onnx import OnnxConfig
>>> class DistilBertOnnxConfig(OnnxConfig):
... @property
... def inputs(self) -> Mapping[str, Mapping[int, str]]:
... return OrderedDict(
... [
... ("input_ids", {0: "batch", 1: "sequence"}),
... ("attention_mask", {0: "batch", 1: "sequence"}),
... ]
... )
```
Ogni oggetto di configurazione deve implementare la proprietà `inputs` e restituire una
mappatura, dove ogni chiave corrisponde a un input previsto e ogni valore
indica l'asse di quell'input. Per DistilBERT, possiamo vedere che sono richiesti
due input: `input_ids` e `attention_mask`. Questi inputs hanno la stessa forma di
`(batch_size, sequence_length)` per questo motivo vediamo gli stessi assi usati nella
configurazione.
<Tip>
Puoi notare che la proprietà `inputs` per `DistilBertOnnxConfig` restituisce un
`OrdinatoDict`. Ciò garantisce che gli input corrispondano alla loro posizione
relativa all'interno del metodo `PreTrainedModel.forward()` durante il tracciamento del grafico.
Raccomandiamo di usare un `OrderedDict` per le proprietà `inputs` e `outputs`
quando si implementano configurazioni ONNX personalizzate.
</Tip>
Dopo aver implementato una configurazione ONNX, è possibile istanziarla
fornendo alla configurazione del modello base come segue:
```python
>>> from transformers import AutoConfig
>>> config = AutoConfig.from_pretrained("distilbert-base-uncased")
>>> onnx_config = DistilBertOnnxConfig(config)
```
L'oggetto risultante ha diverse proprietà utili. Ad esempio è possibile visualizzare il
Set operatore ONNX che verrà utilizzato durante l'esportazione:
```python
>>> print(onnx_config.default_onnx_opset)
11
```
È inoltre possibile visualizzare gli output associati al modello come segue:
```python
>>> print(onnx_config.outputs)
OrderedDict([("last_hidden_state", {0: "batch", 1: "sequence"})])
```
Puoi notare che la proprietà degli output segue la stessa struttura degli input; esso
restituisce un `OrderedDict` di output con nome e le loro forme. La struttura di output
è legato alla scelta della funzione con cui viene inizializzata la configurazione.
Per impostazione predefinita, la configurazione ONNX viene inizializzata con la funzione 'predefinita'
che corrisponde all'esportazione di un modello caricato con la classe `AutoModel`. Se tu
desideri esportare una topologia di modello diversa, è sufficiente fornire una funzionalità diversa a
l'argomento `task` quando inizializzi la configurazione ONNX. Ad esempio, se
volevamo esportare DistilBERT con una testa di classificazione per sequenze, potremmo
usare:
```python
>>> from transformers import AutoConfig
>>> config = AutoConfig.from_pretrained("distilbert-base-uncased")
>>> onnx_config_for_seq_clf = DistilBertOnnxConfig(config, task="sequence-classification")
>>> print(onnx_config_for_seq_clf.outputs)
OrderedDict([('logits', {0: 'batch'})])
```
<Tip>
Tutte le proprietà e i metodi di base associati a [`~onnx.config.OnnxConfig`] e le
altre classi di configurazione possono essere sovrascritte se necessario. Guarda
[`BartOnnxConfig`] per un esempio avanzato.
</Tip>
#### Esportazione del modello
Una volta implementata la configurazione ONNX, il passaggio successivo consiste nell'esportare il
modello. Qui possiamo usare la funzione `export()` fornita dal
pacchetto `transformers.onnx`. Questa funzione prevede la configurazione ONNX, insieme
con il modello base e il tokenizer e il percorso per salvare il file esportato:
```python
>>> from pathlib import Path
>>> from transformers.onnx import export
>>> from transformers import AutoTokenizer, AutoModel
>>> onnx_path = Path("model.onnx")
>>> model_ckpt = "distilbert-base-uncased"
>>> base_model = AutoModel.from_pretrained(model_ckpt)
>>> tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
>>> onnx_inputs, onnx_outputs = export(tokenizer, base_model, onnx_config, onnx_config.default_onnx_opset, onnx_path)
```
Gli `onnx_inputs` e `onnx_outputs` restituiti dalla funzione `export()` sono
liste di chiavi definite nelle proprietà di `input` e `output` della
configurazione. Una volta esportato il modello, puoi verificare che il modello sia ben
formato come segue:
```python
>>> import onnx
>>> onnx_model = onnx.load("model.onnx")
>>> onnx.checker.check_model(onnx_model)
```
<Tip>
Se il tuo modello è più largo di 2 GB, vedrai che molti file aggiuntivi sono
creati durante l'esportazione. Questo è _previsto_ perché ONNX utilizza [Protocol
Buffer](https://developers.google.com/protocol-buffers/) per memorizzare il modello e
questi hanno un limite di dimensione 2 GB. Vedi la [Documentazione
ONNX](https://github.com/onnx/onnx/blob/master/docs/ExternalData.md)
per istruzioni su come caricare modelli con dati esterni.
</Tip>
#### Convalida degli output del modello
Il passaggio finale consiste nel convalidare gli output dal modello di base e quello esportato
corrispondere entro una soglia di tolleranza assoluta. Qui possiamo usare la
Funzione `validate_model_outputs()` fornita dal pacchetto `transformers.onnx`
come segue:
```python
>>> from transformers.onnx import validate_model_outputs
>>> validate_model_outputs(
... onnx_config, tokenizer, base_model, onnx_path, onnx_outputs, onnx_config.atol_for_validation
... )
```
Questa funzione usa il metodo `OnnxConfig.generate_dummy_inputs()` per generare
input per il modello di base e quello esportato e la tolleranza assoluta può essere
definita nella configurazione. Generalmente troviamo una corrispondenza numerica nell'intervallo da 1e-6
a 1e-4, anche se è probabile che qualsiasi cosa inferiore a 1e-3 vada bene.
### Contribuire con una nuova configurazione a 🤗 Transformers
Stiamo cercando di espandere l'insieme di configurazioni già pronte e di accettare
contributi della community! Se vuoi contribuire con la tua aggiunta
nella libreria, dovrai:
* Implementare la configurazione ONNX nella corrispondente `configuration file
_<model_name>.py`
* Includere l'architettura del modello e le funzioni corrispondenti in [`~onnx.features.FeatureManager`]
* Aggiungere la tua architettura del modello ai test in `test_onnx_v2.py`
Scopri come stato contribuito la configurazione per [IBERT]
(https://github.com/huggingface/transformers/pull/14868/files) per
avere un'idea di cosa è coinvolto.
## TorchScript
<Tip>
Questo è l'inizio dei nostri esperimenti con TorchScript e stiamo ancora esplorando le sue capacità con
modelli con variable-input-size. È una nostra priorità e approfondiremo le nostre analisi nelle prossime versioni,
con più esempi di codici, un'implementazione più flessibile e benchmark che confrontano i codici basati su Python con quelli compilati con
TorchScript.
</Tip>
Secondo la documentazione di Pytorch: "TorchScript è un modo per creare modelli serializzabili e ottimizzabili da codice
Pytorch". I due moduli di Pytorch [JIT e TRACE](https://pytorch.org/docs/stable/jit.html) consentono allo sviluppatore di esportare
il loro modello da riutilizzare in altri programmi, come i programmi C++ orientati all'efficienza.
Abbiamo fornito un'interfaccia che consente l'esportazione di modelli 🤗 Transformers in TorchScript in modo che possano essere riutilizzati
in un ambiente diverso rispetto a un programma Python basato su Pytorch. Qui spieghiamo come esportare e utilizzare i nostri modelli utilizzando
TorchScript.
Esportare un modello richiede due cose:
- Un passaggio in avanti con input fittizzi.
- Istanziazione del modello con flag `torchscript`.
Queste necessità implicano diverse cose a cui gli sviluppatori dovrebbero prestare attenzione. Questi dettagli mostrati sotto.
### Flag TorchScript e pesi legati
Questo flag è necessario perché la maggior parte dei modelli linguistici in questo repository hanno pesi legati tra il loro
strato "Embedding" e lo strato "Decoding". TorchScript non consente l'esportazione di modelli che hanno pesi
legati, quindi è necessario prima slegare e clonare i pesi.
Ciò implica che i modelli istanziati con il flag `torchscript` hanno il loro strato `Embedding` e strato `Decoding`
separato, il che significa che non dovrebbero essere addestrati in futuro. L'allenamento de-sincronizza i due
strati, portando a risultati inaspettati.
Questo non è il caso per i modelli che non hanno una testa del modello linguistico, poiché quelli non hanno pesi legati. Questi modelli
può essere esportato in sicurezza senza il flag `torchscript`.
### Input fittizi e standard lengths
Gli input fittizzi sono usati per fare un modello passaggio in avanti . Mentre i valori degli input si propagano attraverso i strati,
Pytorch tiene traccia delle diverse operazioni eseguite su ciascun tensore. Queste operazioni registrate vengono quindi utilizzate per
creare la "traccia" del modello.
La traccia viene creata relativamente alle dimensioni degli input. È quindi vincolato dalle dimensioni dell'input
fittizio e non funzionerà per altre lunghezze di sequenza o dimensioni batch. Quando si proverà con una dimensione diversa, ci sarà errore
come:
`La dimensione espansa del tensore (3) deve corrispondere alla dimensione esistente (7) nella dimensione non singleton 2`
will be raised. Si consiglia pertanto di tracciare il modello con una dimensione di input fittizia grande almeno quanto il più grande
input che verrà fornito al modello durante l'inferenza. È possibile eseguire il padding per riempire i valori mancanti. Il modello
sarà tracciato con una grande dimensione di input, tuttavia, anche le dimensioni della diverse matrici saranno grandi,
risultando in più calcoli.
Si raccomanda di prestare attenzione al numero totale di operazioni eseguite su ciascun input e di seguire da vicino le prestazioni
durante l'esportazione di modelli di sequenza-lunghezza variabili.
### Usare TorchSscript in Python
Di seguito è riportato un esempio, che mostra come salvare, caricare modelli e come utilizzare la traccia per l'inferenza.
#### Salvare un modello
Questo frammento di codice mostra come usare TorchScript per esportare un `BertModel`. Qui il `BertModel` è istanziato secondo
una classe `BertConfig` e quindi salvato su disco con il nome del file `traced_bert.pt`
```python
from transformers import BertModel, BertTokenizer, BertConfig
import torch
enc = BertTokenizer.from_pretrained("bert-base-uncased")
# Tokenizing input text
text = "[CLS] Who was Jim Henson ? [SEP] Jim Henson was a puppeteer [SEP]"
tokenized_text = enc.tokenize(text)
# Masking one of the input tokens
masked_index = 8
tokenized_text[masked_index] = "[MASK]"
indexed_tokens = enc.convert_tokens_to_ids(tokenized_text)
segments_ids = [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]
# Creating a dummy input
tokens_tensor = torch.tensor([indexed_tokens])
segments_tensors = torch.tensor([segments_ids])
dummy_input = [tokens_tensor, segments_tensors]
# Initializing the model with the torchscript flag
# Flag set to True even though it is not necessary as this model does not have an LM Head.
config = BertConfig(
vocab_size_or_config_json_file=32000,
hidden_size=768,
num_hidden_layers=12,
num_attention_heads=12,
intermediate_size=3072,
torchscript=True,
)
# Instantiating the model
model = BertModel(config)
# The model needs to be in evaluation mode
model.eval()
# If you are instantiating the model with *from_pretrained* you can also easily set the TorchScript flag
model = BertModel.from_pretrained("bert-base-uncased", torchscript=True)
# Creating the trace
traced_model = torch.jit.trace(model, [tokens_tensor, segments_tensors])
torch.jit.save(traced_model, "traced_bert.pt")
```
#### Caricare un modello
Questo frammento di codice mostra come caricare il `BertModel` che era stato precedentemente salvato su disco con il nome `traced_bert.pt`.
Stiamo riutilizzando il `dummy_input` precedentemente inizializzato.
```python
loaded_model = torch.jit.load("traced_bert.pt")
loaded_model.eval()
all_encoder_layers, pooled_output = loaded_model(*dummy_input)
```
#### Utilizzare un modello tracciato per l'inferenza
Usare il modello tracciato per l'inferenza è semplice come usare il suo metodo dunder `__call__`:
```python
traced_model(tokens_tensor, segments_tensors)
```
###Implementare modelli HuggingFace TorchScript su AWS utilizzando Neuron SDK
AWS ha introdotto [Amazon EC2 Inf1](https://aws.amazon.com/ec2/instance-types/inf1/)
famiglia di istanze per l'inferenza di machine learning a basso costo e ad alte prestazioni nel cloud.
Le istanze Inf1 sono alimentate dal chip AWS Inferentia, un acceleratore hardware personalizzato,
specializzato in carichi di lavoro di inferenza di deep learning.
[AWS Neuron](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/#)
è l'SDK per Inferentia che supporta il tracciamento e l'ottimizzazione dei modelli transformers per
distribuzione su Inf1. L'SDK Neuron fornisce:
1. API di facile utilizzo con una riga di modifica del codice per tracciare e ottimizzare un modello TorchScript per l'inferenza nel cloud.
2. Ottimizzazioni delle prestazioni pronte all'uso per [miglioramento dei costi-prestazioni](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/benchmark/>)
3. Supporto per i modelli di trasformatori HuggingFace costruiti con [PyTorch](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/pytorch/bert_tutorial/tutorial_pretrained_bert.html)
o [TensorFlow](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/tensorflow/huggingface_bert/huggingface_bert.html).
#### Implicazioni
Modelli Transformers basati su architettura [BERT (Bidirectional Encoder Representations from Transformers)](https://huggingface.co/docs/transformers/main/model_doc/bert),
o sue varianti come [distilBERT](https://huggingface.co/docs/transformers/main/model_doc/distilbert)
e [roBERTa](https://huggingface.co/docs/transformers/main/model_doc/roberta)
funzioneranno meglio su Inf1 per attività non generative come la question answering estrattive,
Classificazione della sequenza, Classificazione dei token. In alternativa, generazione di testo
le attività possono essere adattate per essere eseguite su Inf1, secondo questo [tutorial AWS Neuron MarianMT](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/pytorch/transformers-marianmt.html).
Ulteriori informazioni sui modelli che possono essere convertiti fuori dagli schemi su Inferentia possono essere
trovati nella [sezione Model Architecture Fit della documentazione Neuron](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/models/models-inferentia.html#models-inferentia).
#### Dipendenze
L'utilizzo di AWS Neuron per convertire i modelli richiede le seguenti dipendenze e l'ambiente:
* A [Neuron SDK environment](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/neuron-frameworks/pytorch-neuron/index.html#installation-guide),
which comes pre-configured on [AWS Deep Learning AMI](https://docs.aws.amazon.com/dlami/latest/devguide/tutorial-inferentia-launching.html).
#### Convertire un modello per AWS Neuron
Usando lo stesso script come in [Usando TorchScipt in Python](https://huggingface.co/docs/transformers/main/en/serialization#using-torchscript-in-python)
per tracciare un "BertModel", importi l'estensione del framework `torch.neuron` per accedere
i componenti di Neuron SDK tramite un'API Python.
```python
from transformers import BertModel, BertTokenizer, BertConfig
import torch
import torch.neuron
```
E modificare solo la riga di codice di traccia
Da:
```python
torch.jit.trace(model, [tokens_tensor, segments_tensors])
```
A:
```python
torch.neuron.trace(model, [token_tensor, segments_tensors])
```
Questa modifica consente a Neuron SDK di tracciare il modello e ottimizzarlo per l'esecuzione nelle istanze Inf1.
Per ulteriori informazioni sulle funzionalità, gli strumenti, i tutorial di esempi e gli ultimi aggiornamenti di AWS Neuron SDK,
consultare la [documentazione AWS NeuronSDK](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/index.html). | transformers/docs/source/it/serialization.md/0 | {
"file_path": "transformers/docs/source/it/serialization.md",
"repo_id": "transformers",
"token_count": 10271
} | 264 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Use tokenizers from 🤗 Tokenizers
[`PreTrainedTokenizerFast`]は[🤗 Tokenizers](https://huggingface.co/docs/tokenizers)ライブラリに依存しています。🤗 Tokenizersライブラリから取得したトークナイザーは、非常に簡単に🤗 Transformersにロードできます。
具体的な内容に入る前に、まずはいくつかの行でダミーのトークナイザーを作成することから始めましょう:
```python
>>> from tokenizers import Tokenizer
>>> from tokenizers.models import BPE
>>> from tokenizers.trainers import BpeTrainer
>>> from tokenizers.pre_tokenizers import Whitespace
>>> tokenizer = Tokenizer(BPE(unk_token="[UNK]"))
>>> trainer = BpeTrainer(special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"])
>>> tokenizer.pre_tokenizer = Whitespace()
>>> files = [...]
>>> tokenizer.train(files, trainer)
```
私たちは今、定義したファイルにトレーニングされたトークナイザーを持っています。これをランタイムで引き続き使用するか、
将来の再利用のためにJSONファイルに保存することができます。
## Loading directly from the tokenizer object
🤗 Transformersライブラリでこのトークナイザーオブジェクトをどのように活用できるかを見てみましょう。[`PreTrainedTokenizerFast`]クラスは、
*tokenizer*オブジェクトを引数として受け入れ、簡単にインスタンス化できるようにします。
```python
>>> from transformers import PreTrainedTokenizerFast
>>> fast_tokenizer = PreTrainedTokenizerFast(tokenizer_object=tokenizer)
```
このオブジェクトは、🤗 Transformers トークナイザーが共有するすべてのメソッドと一緒に使用できます!詳細については、[トークナイザーページ](main_classes/tokenizer)をご覧ください。
## Loading from a JSON file
JSONファイルからトークナイザーを読み込むには、まずトークナイザーを保存することから始めましょう:
```python
>>> tokenizer.save("tokenizer.json")
```
このファイルを保存したパスは、`PreTrainedTokenizerFast` の初期化メソッドに `tokenizer_file` パラメータを使用して渡すことができます:
```python
>>> from transformers import PreTrainedTokenizerFast
>>> fast_tokenizer = PreTrainedTokenizerFast(tokenizer_file="tokenizer.json")
```
このオブジェクトは、🤗 Transformers トークナイザーが共有するすべてのメソッドと一緒に使用できるようになりました!詳細については、[トークナイザーページ](main_classes/tokenizer)をご覧ください。
| transformers/docs/source/ja/fast_tokenizers.md/0 | {
"file_path": "transformers/docs/source/ja/fast_tokenizers.md",
"repo_id": "transformers",
"token_count": 1187
} | 265 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# エージェントとツール
<Tip warning={true}>
Transformers Agents は実験的な API であり、いつでも変更される可能性があります。エージェントから返される結果
API または基礎となるモデルは変更される傾向があるため、変更される可能性があります。
</Tip>
エージェントとツールの詳細については、[入門ガイド](../transformers_agents) を必ずお読みください。このページ
基礎となるクラスの API ドキュメントが含まれています。
## エージェント
私たちは 3 種類のエージェントを提供します。[`HfAgent`] はオープンソース モデルの推論エンドポイントを使用し、[`LocalAgent`] は選択したモデルをローカルで使用し、[`OpenAiAgent`] は OpenAI クローズド モデルを使用します。
### HfAgent
[[autodoc]] HfAgent
### LocalAgent
[[autodoc]] LocalAgent
### OpenAiAgent
[[autodoc]] OpenAiAgent
### AzureOpenAiAgent
[[autodoc]] AzureOpenAiAgent
### Agent
[[autodoc]] Agent
- chat
- run
- prepare_for_new_chat
## Tools
### load_tool
[[autodoc]] load_tool
### Tool
[[autodoc]] Tool
### PipelineTool
[[autodoc]] PipelineTool
### RemoteTool
[[autodoc]] RemoteTool
### launch_gradio_demo
[[autodoc]] launch_gradio_demo
## エージェントの種類
エージェントはツール間であらゆる種類のオブジェクトを処理できます。ツールは完全にマルチモーダルであるため、受け取りと返品が可能です
テキスト、画像、オーディオ、ビデオなどのタイプ。ツール間の互換性を高めるためだけでなく、
これらの戻り値を ipython (jupyter、colab、ipython ノートブックなど) で正しくレンダリングするには、ラッパー クラスを実装します。
このタイプの周り。
ラップされたオブジェクトは最初と同じように動作し続けるはずです。テキストオブジェクトは依然として文字列または画像として動作する必要があります
オブジェクトは依然として `PIL.Image` として動作するはずです。
これらのタイプには、次の 3 つの特定の目的があります。
- 型に対して `to_raw` を呼び出すと、基になるオブジェクトが返されるはずです
- 型に対して `to_string` を呼び出すと、オブジェクトを文字列として返す必要があります。`AgentText` の場合は文字列になる可能性があります。
ただし、他のインスタンスのオブジェクトのシリアル化されたバージョンのパスになります。
- ipython カーネルで表示すると、オブジェクトが正しく表示されるはずです
### AgentText
[[autodoc]] transformers.tools.agent_types.AgentText
### AgentImage
[[autodoc]] transformers.tools.agent_types.AgentImage
### AgentAudio
[[autodoc]] transformers.tools.agent_types.AgentAudio
| transformers/docs/source/ja/main_classes/agent.md/0 | {
"file_path": "transformers/docs/source/ja/main_classes/agent.md",
"repo_id": "transformers",
"token_count": 1455
} | 266 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BERT
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=bert">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-bert-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/bert-base-uncased">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
</div>
## Overview
BERT モデルは、Jacob Devlin、Ming-Wei Chang、Kenton Lee、Kristina Toutanova によって [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) で提案されました。それは
マスクされた言語モデリング目標と次の文の組み合わせを使用して事前トレーニングされた双方向トランスフォーマー
Toronto Book Corpus と Wikipedia からなる大規模なコーパスでの予測。
論文の要約は次のとおりです。
*BERT と呼ばれる新しい言語表現モデルを導入します。これは Bidirectional Encoder Representations の略です
トランスフォーマーより。最近の言語表現モデルとは異なり、BERT は深い双方向性を事前にトレーニングするように設計されています。
すべてのレイヤーの左と右の両方のコンテキストを共同で条件付けすることにより、ラベルのないテキストから表現します。結果として、
事前トレーニングされた BERT モデルは、出力層を 1 つ追加するだけで微調整して、最先端のモデルを作成できます。
実質的なタスク固有のものを必要とせず、質問応答や言語推論などの幅広いタスクに対応
アーキテクチャの変更。*
*BERT は概念的にはシンプルですが、経験的に強力です。 11 の自然な要素に関する新しい最先端の結果が得られます。
言語処理タスク(GLUE スコアを 80.5% に押し上げる(7.7% ポイントの絶対改善)、MultiNLI を含む)
精度は 86.7% (絶対値 4.6% 向上)、SQuAD v1.1 質問応答テスト F1 は 93.2 (絶対値 1.5 ポイント)
改善) および SQuAD v2.0 テスト F1 から 83.1 (5.1 ポイントの絶対改善)。*
## Usage tips
- BERT は絶対位置埋め込みを備えたモデルであるため、通常は入力を右側にパディングすることをお勧めします。
左。
- BERT は、マスク言語モデリング (MLM) および次の文予測 (NSP) の目標を使用してトレーニングされました。それは
マスクされたトークンの予測や NLU では一般に効率的ですが、テキスト生成には最適ではありません。
- ランダム マスキングを使用して入力を破壊します。より正確には、事前トレーニング中に、トークンの指定された割合 (通常は 15%) が次によってマスクされます。
* 確率0.8の特別なマスクトークン
* 確率 0.1 でマスクされたトークンとは異なるランダムなトークン
* 確率 0.1 の同じトークン
- モデルは元の文を予測する必要がありますが、2 番目の目的があります。入力は 2 つの文 A と B (間に分離トークンあり) です。確率 50% では、文はコーパス内で連続していますが、残りの 50% では関連性がありません。モデルは、文が連続しているかどうかを予測する必要があります。
このモデルは [thomwolf](https://huggingface.co/thomwolf) によって提供されました。元のコードは [こちら](https://github.com/google-research/bert) にあります。
## Resources
BERT を始めるのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示される) リソースのリスト。ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
<PipelineTag pipeline="text-classification"/>
- に関するブログ投稿 [別の言語での BERT テキスト分類](https://www.philschmid.de/bert-text-classification-in-a-different-language)。
- [マルチラベル テキスト分類のための BERT (およびその友人) の微調整](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/BERT/Fine_tuning_BERT_(and_friends)_for_multi_label_text_classification.ipynb) のノートブック.
- 方法に関するノートブック [PyTorch を使用したマルチラベル分類のための BERT の微調整](https://colab.research.google.com/github/abhmishra91/transformers-tutorials/blob/master/transformers_multi_label_classification.ipynb)。
- 方法に関するノートブック [要約のために BERT を使用して EncoderDecoder モデルをウォームスタートする](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/BERT2BERT_for_CNN_Dailymail.ipynb)。
- [`BertForSequenceClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification.ipynb)。
- [`TFBertForSequenceClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/text-classification) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification-tf.ipynb)。
- [`FlaxBertForSequenceClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/flax/text-classification) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification_flax.ipynb)。
- [テキスト分類タスクガイド](../tasks/sequence_classification)
<PipelineTag pipeline="token-classification"/>
- [Hugging Face Transformers with Keras: Fine-tune a non-English BERT for Named Entity Recognition](https://www.philschmid.de/huggingface-transformers-keras-tf) の使用方法に関するブログ投稿。
- 各単語の最初の単語部分のみを使用した [固有表現認識のための BERT の微調整](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/Custom_Named_Entity_Recognition_with_BERT_only_first_wordpiece.ipynb) のノートブックトークン化中の単語ラベル内。単語のラベルをすべての単語部分に伝播するには、代わりにノートブックのこの [バージョン](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/BERT/Custom_Named_Entity_Recognition_with_BERT.ipynb) を参照してください。
- [`BertForTokenClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/token-classification) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification.ipynb)。
- [`TFBertForTokenClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/token-classification) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification-tf.ipynb)。
- [`FlaxBertForTokenClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/flax/token-classification) によってサポートされています。
- [トークン分類](https://huggingface.co/course/chapter7/2?fw=pt) 🤗 ハグフェイスコースの章。
- [トークン分類タスクガイド](../tasks/token_classification)
<PipelineTag pipeline="fill-mask"/>
- [`BertForMaskedLM`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling#robertabertdistilbert-and-masked-language-modeling) でサポートされており、 [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb)。
- [`TFBertForMaskedLM`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/lang-modeling#run_mlmpy) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb)。
- [`FlaxBertForMaskedLM`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/flax/language-modeling#masked-language-modeling) および [ノートブック]( https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/masked_language_modeling_flax.ipynb)。
- [マスクされた言語モデリング](https://huggingface.co/course/chapter7/3?fw=pt) 🤗 顔ハグ コースの章。
- [マスクされた言語モデリング タスク ガイド](../tasks/masked_lang_modeling)
<PipelineTag pipeline="question-answering"/>
- [`BertForQuestionAnswering`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering.ipynb)。
- [`TFBertForQuestionAnswering`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/question-answering) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering-tf.ipynb)。
- [`FlaxBertForQuestionAnswering`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/flax/question-answering) でサポートされています。
- [質問回答](https://huggingface.co/course/chapter7/7?fw=pt) 🤗 ハグフェイスコースの章。
- [質問回答タスク ガイド](../tasks/question_answering)
**複数の選択肢**
- [`BertForMultipleChoice`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/multiple-choice) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice.ipynb)。
- [`TFBertForMultipleChoice`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/multiple-choice) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice-tf.ipynb)。
- [多肢選択タスク ガイド](../tasks/multiple_choice)
⚡️ **推論**
- 方法に関するブログ投稿 [Hugging Face Transformers と AWS Inferentia を使用して BERT 推論を高速化する](https://huggingface.co/blog/bert-inferentia-sagemaker)。
- 方法に関するブログ投稿 [GPU 上の DeepSpeed-Inference を使用して BERT 推論を高速化する](https://www.philschmid.de/bert-deepspeed-inference)。
⚙️ **事前トレーニング**
- [Hugging Face Transformers と Habana Gaudi を使用した BERT の事前トレーニング] に関するブログ投稿 (https://www.philschmid.de/pre-training-bert-habana)。
🚀 **デプロイ**
- 方法に関するブログ投稿 [ハグフェイス最適化でトランスフォーマーを ONNX に変換する](https://www.philschmid.de/convert-transformers-to-onnx)。
- 方法に関するブログ投稿 [AWS 上の Habana Gaudi を使用したハグ顔トランスフォーマーのための深層学習環境のセットアップ](https://www.philschmid.de/getting-started-habana-gaudi#conclusion)。
- に関するブログ投稿 [Hugging Face Transformers、Amazon SageMaker、および Terraform モジュールを使用した自動スケーリング BERT](https://www.philschmid.de/terraform-huggingface-amazon-sagemaker-advanced)。
- に関するブログ投稿 [HuggingFace、AWS Lambda、Docker を使用したサーバーレス BERT](https://www.philschmid.de/serverless-bert-with-huggingface-aws-lambda-docker)。
- に関するブログ投稿 [Amazon SageMaker と Training Compiler を使用した Hugging Face Transformers BERT 微調整](https://www.philschmid.de/huggingface-amazon-sagemaker-training-compiler)。
- に関するブログ投稿 [Transformers と Amazon SageMaker を使用した BERT のタスク固有の知識の蒸留](https://www.philschmid.de/knowledge-distillation-bert-transformers)
## BertConfig
[[autodoc]] BertConfig
- all
## BertTokenizer
[[autodoc]] BertTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
<frameworkcontent>
<pt>
## BertTokenizerFast
[[autodoc]] BertTokenizerFast
</pt>
<tf>
## TFBertTokenizer
[[autodoc]] TFBertTokenizer
</tf>
</frameworkcontent>
## Bert specific outputs
[[autodoc]] models.bert.modeling_bert.BertForPreTrainingOutput
[[autodoc]] models.bert.modeling_tf_bert.TFBertForPreTrainingOutput
[[autodoc]] models.bert.modeling_flax_bert.FlaxBertForPreTrainingOutput
<frameworkcontent>
<pt>
## BertModel
[[autodoc]] BertModel
- forward
## BertForPreTraining
[[autodoc]] BertForPreTraining
- forward
## BertLMHeadModel
[[autodoc]] BertLMHeadModel
- forward
## BertForMaskedLM
[[autodoc]] BertForMaskedLM
- forward
## BertForNextSentencePrediction
[[autodoc]] BertForNextSentencePrediction
- forward
## BertForSequenceClassification
[[autodoc]] BertForSequenceClassification
- forward
## BertForMultipleChoice
[[autodoc]] BertForMultipleChoice
- forward
## BertForTokenClassification
[[autodoc]] BertForTokenClassification
- forward
## BertForQuestionAnswering
[[autodoc]] BertForQuestionAnswering
- forward
</pt>
<tf>
## TFBertModel
[[autodoc]] TFBertModel
- call
## TFBertForPreTraining
[[autodoc]] TFBertForPreTraining
- call
## TFBertModelLMHeadModel
[[autodoc]] TFBertLMHeadModel
- call
## TFBertForMaskedLM
[[autodoc]] TFBertForMaskedLM
- call
## TFBertForNextSentencePrediction
[[autodoc]] TFBertForNextSentencePrediction
- call
## TFBertForSequenceClassification
[[autodoc]] TFBertForSequenceClassification
- call
## TFBertForMultipleChoice
[[autodoc]] TFBertForMultipleChoice
- call
## TFBertForTokenClassification
[[autodoc]] TFBertForTokenClassification
- call
## TFBertForQuestionAnswering
[[autodoc]] TFBertForQuestionAnswering
- call
</tf>
<jax>
## FlaxBertModel
[[autodoc]] FlaxBertModel
- __call__
## FlaxBertForPreTraining
[[autodoc]] FlaxBertForPreTraining
- __call__
## FlaxBertForCausalLM
[[autodoc]] FlaxBertForCausalLM
- __call__
## FlaxBertForMaskedLM
[[autodoc]] FlaxBertForMaskedLM
- __call__
## FlaxBertForNextSentencePrediction
[[autodoc]] FlaxBertForNextSentencePrediction
- __call__
## FlaxBertForSequenceClassification
[[autodoc]] FlaxBertForSequenceClassification
- __call__
## FlaxBertForMultipleChoice
[[autodoc]] FlaxBertForMultipleChoice
- __call__
## FlaxBertForTokenClassification
[[autodoc]] FlaxBertForTokenClassification
- __call__
## FlaxBertForQuestionAnswering
[[autodoc]] FlaxBertForQuestionAnswering
- __call__
</jax>
</frameworkcontent> | transformers/docs/source/ja/model_doc/bert.md/0 | {
"file_path": "transformers/docs/source/ja/model_doc/bert.md",
"repo_id": "transformers",
"token_count": 6596
} | 267 |
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# CANINE
## Overview
CANINE モデルは、[CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language
Representation](https://arxiv.org/abs/2103.06874)、Jonathan H. Clark、Dan Garrette、Iulia Turc、John Wieting 著。その
明示的なトークン化ステップ (バイト ペアなど) を使用せずに Transformer をトレーニングする最初の論文の 1 つ
エンコーディング (BPE、WordPiece または SentencePiece)。代わりに、モデルは Unicode 文字レベルで直接トレーニングされます。
キャラクターレベルでのトレーニングでは必然的にシーケンスの長さが長くなりますが、CANINE はこれを効率的な方法で解決します。
ディープ Transformer エンコーダを適用する前に、ダウンサンプリング戦略を実行します。
論文の要約は次のとおりです。
*パイプライン NLP システムは、エンドツーエンドのニューラル モデリングに大部分が取って代わられていますが、一般的に使用されているほぼすべてのモデルは
依然として明示的なトークン化手順が必要です。最近のトークン化アプローチはデータ由来のサブワードに基づいていますが、
レキシコンは手動で作成されたトークナイザーよりも脆弱ではありませんが、これらの技術はすべての言語に等しく適しているわけではありません。
言語や固定語彙の使用により、モデルの適応能力が制限される可能性があります。この論文では、CANINE を紹介します。
明示的なトークン化や語彙を使用せずに、文字シーケンスを直接操作するニューラル エンコーダーと、
文字に直接作用するか、オプションでサブワードをソフト誘導バイアスとして使用する事前トレーニング戦略。
よりきめの細かい入力を効果的かつ効率的に使用するために、CANINE はダウンサンプリングを組み合わせて、入力を削減します。
コンテキストをエンコードするディープトランスフォーマースタックを備えたシーケンスの長さ。 CANINE は、同等の mBERT モデルよりも次の点で優れています。
TyDi QA の 2.8 F1 は、モデル パラメータが 28% 少ないにもかかわらず、困難な多言語ベンチマークです。*
このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。元のコードは [ここ](https://github.com/google-research/language/tree/master/language/canine) にあります。
## Usage tips
- CANINE は内部で少なくとも 3 つの Transformer エンコーダーを使用します: 2 つの「浅い」エンコーダー (単一のエンコーダーのみで構成)
レイヤー) と 1 つの「ディープ」エンコーダー (通常の BERT エンコーダー)。まず、「浅い」エンコーダを使用してコンテキストを設定します。
ローカル アテンションを使用した文字の埋め込み。次に、ダウンサンプリングの後、「ディープ」エンコーダーが適用されます。ついに、
アップサンプリング後、「浅い」エンコーダを使用して最終的な文字埋め込みが作成されます。アップと
ダウンサンプリングについては論文に記載されています。
- CANINE は、デフォルトで 2048 文字の最大シーケンス長を使用します。 [`CanineTokenizer`] を使用できます
モデル用のテキストを準備します。
- 特別な [CLS] トークンの最終的な非表示状態の上に線形レイヤーを配置することで分類を行うことができます。
(事前定義された Unicode コード ポイントがあります)。ただし、トークン分類タスクの場合は、ダウンサンプリングされたシーケンス
トークンは、元の文字シーケンスの長さ (2048) と一致するように再度アップサンプリングする必要があります。の
詳細については、論文を参照してください。
モデルのチェックポイント:
- [google/canine-c](https://huggingface.co/google/canine-c): 自己回帰文字損失で事前トレーニング済み、
12 レイヤー、768 隠し、12 ヘッド、121M パラメーター (サイズ ~500 MB)。
- [google/canine-s](https://huggingface.co/google/canine-s): サブワード損失で事前トレーニング済み、12 層、
768 個の非表示、12 ヘッド、121M パラメーター (サイズ ~500 MB)。
## Usage example
CANINE は生の文字で動作するため、**トークナイザーなし**で使用できます。
```python
>>> from transformers import CanineModel
>>> import torch
>>> model = CanineModel.from_pretrained("google/canine-c") # model pre-trained with autoregressive character loss
>>> text = "hello world"
>>> # use Python's built-in ord() function to turn each character into its unicode code point id
>>> input_ids = torch.tensor([[ord(char) for char in text]])
>>> outputs = model(input_ids) # forward pass
>>> pooled_output = outputs.pooler_output
>>> sequence_output = outputs.last_hidden_state
```
ただし、バッチ推論とトレーニングの場合は、トークナイザーを使用することをお勧めします(すべてをパディング/切り詰めるため)
シーケンスを同じ長さにします):
```python
>>> from transformers import CanineTokenizer, CanineModel
>>> model = CanineModel.from_pretrained("google/canine-c")
>>> tokenizer = CanineTokenizer.from_pretrained("google/canine-c")
>>> inputs = ["Life is like a box of chocolates.", "You never know what you gonna get."]
>>> encoding = tokenizer(inputs, padding="longest", truncation=True, return_tensors="pt")
>>> outputs = model(**encoding) # forward pass
>>> pooled_output = outputs.pooler_output
>>> sequence_output = outputs.last_hidden_state
```
## Resources
- [テキスト分類タスクガイド](../tasks/sequence_classification)
- [トークン分類タスクガイド](../tasks/token_classification)
- [質問回答タスク ガイド](../tasks/question_answering)
- [多肢選択タスク ガイド](../tasks/multiple_choice)
## CanineConfig
[[autodoc]] CanineConfig
## CanineTokenizer
[[autodoc]] CanineTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
## CANINE specific outputs
[[autodoc]] models.canine.modeling_canine.CanineModelOutputWithPooling
## CanineModel
[[autodoc]] CanineModel
- forward
## CanineForSequenceClassification
[[autodoc]] CanineForSequenceClassification
- forward
## CanineForMultipleChoice
[[autodoc]] CanineForMultipleChoice
- forward
## CanineForTokenClassification
[[autodoc]] CanineForTokenClassification
- forward
## CanineForQuestionAnswering
[[autodoc]] CanineForQuestionAnswering
- forward
| transformers/docs/source/ja/model_doc/canine.md/0 | {
"file_path": "transformers/docs/source/ja/model_doc/canine.md",
"repo_id": "transformers",
"token_count": 3007
} | 268 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Data2Vec
## Overview
Data2Vec モデルは、[data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/pdf/2202.03555) で Alexei Baevski、Wei-Ning Hsu、Qiantong Xu、バArun Babu, Jiatao Gu and Michael Auli.
Data2Vec は、テキスト、音声、画像などのさまざまなデータ モダリティにわたる自己教師あり学習のための統一フレームワークを提案します。
重要なのは、事前トレーニングの予測ターゲットは、モダリティ固有のコンテキストに依存しないターゲットではなく、入力のコンテキスト化された潜在表現であることです。
論文の要約は次のとおりです。
*自己教師あり学習の一般的な考え方はどのモダリティでも同じですが、実際のアルゴリズムと
単一のモダリティを念頭に置いて開発されたため、目的は大きく異なります。一般に近づけるために
自己教師あり学習では、どちらの音声に対しても同じ学習方法を使用するフレームワークである data2vec を紹介します。
NLP またはコンピューター ビジョン。中心となるアイデアは、完全な入力データの潜在的な表現を、
標準の Transformer アーキテクチャを使用した自己蒸留セットアップの入力のマスクされたビュー。
単語、視覚的トークン、人間の音声単位などのモダリティ固有のターゲットを予測するのではなく、
本質的にローカルであるため、data2vec は、からの情報を含む文脈化された潜在表現を予測します。
入力全体。音声認識、画像分類、および
自然言語理解は、新しい最先端技術や、主流のアプローチに匹敵するパフォーマンスを実証します。
モデルとコードは、www.github.com/pytorch/fairseq/tree/master/examples/data2vec.* で入手できます。
このモデルは、[edugp](https://huggingface.co/edugp) および [patrickvonplaten](https://huggingface.co/patrickvonplaten) によって提供されました。
[sayakpaul](https://github.com/sayakpaul) と [Rocketknight1](https://github.com/Rocketknight1) は、TensorFlow のビジョンに Data2Vec を提供しました。
元のコード (NLP および音声用) は、[こちら](https://github.com/pytorch/fairseq/tree/main/examples/data2vec) にあります。
ビジョンの元のコードは [こちら](https://github.com/facebookresearch/data2vec_vision/tree/main/beit) にあります。
## Usage tips
- Data2VecAudio、Data2VecText、および Data2VecVision はすべて、同じ自己教師あり学習方法を使用してトレーニングされています。
- Data2VecAudio の場合、前処理は特徴抽出を含めて [`Wav2Vec2Model`] と同じです。
- Data2VecText の場合、前処理はトークン化を含めて [`RobertaModel`] と同じです。
- Data2VecVision の場合、前処理は特徴抽出を含めて [`BeitModel`] と同じです。
## Resources
Data2Vec の使用を開始するのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示される) リソースのリスト。
<PipelineTag pipeline="image-classification"/>
- [`Data2VecVisionForImageClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) および [ノートブック](https://cola.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb)。
- カスタム データセットで [`TFData2VecVisionForImageClassification`] を微調整するには、[このノートブック](https://colab.research.google.com/github/sayakpaul/TF-2.0-Hacks/blob/master/data2vec_vision_image_classification.ipynb) を参照してください。 )。
**Data2VecText ドキュメント リソース**
- [テキスト分類タスクガイド](../tasks/sequence_classification)
- [トークン分類タスクガイド](../tasks/token_classification)
- [質問回答タスク ガイド](../tasks/question_answering)
- [因果言語モデリング タスク ガイド](../tasks/language_modeling)
- [マスク言語モデリング タスク ガイド](../tasks/masked_language_modeling)
- [多肢選択タスク ガイド](../tasks/multiple_choice)
**Data2VecAudio ドキュメント リソース**
- [音声分類タスクガイド](../tasks/audio_classification)
- [自動音声認識タスクガイド](../tasks/asr)
**Data2VecVision ドキュメント リソース**
- [画像分類](../tasks/image_classification)
- [セマンティック セグメンテーション](../tasks/semantic_segmentation)
ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
## Data2VecTextConfig
[[autodoc]] Data2VecTextConfig
## Data2VecAudioConfig
[[autodoc]] Data2VecAudioConfig
## Data2VecVisionConfig
[[autodoc]] Data2VecVisionConfig
<frameworkcontent>
<pt>
## Data2VecAudioModel
[[autodoc]] Data2VecAudioModel
- forward
## Data2VecAudioForAudioFrameClassification
[[autodoc]] Data2VecAudioForAudioFrameClassification
- forward
## Data2VecAudioForCTC
[[autodoc]] Data2VecAudioForCTC
- forward
## Data2VecAudioForSequenceClassification
[[autodoc]] Data2VecAudioForSequenceClassification
- forward
## Data2VecAudioForXVector
[[autodoc]] Data2VecAudioForXVector
- forward
## Data2VecTextModel
[[autodoc]] Data2VecTextModel
- forward
## Data2VecTextForCausalLM
[[autodoc]] Data2VecTextForCausalLM
- forward
## Data2VecTextForMaskedLM
[[autodoc]] Data2VecTextForMaskedLM
- forward
## Data2VecTextForSequenceClassification
[[autodoc]] Data2VecTextForSequenceClassification
- forward
## Data2VecTextForMultipleChoice
[[autodoc]] Data2VecTextForMultipleChoice
- forward
## Data2VecTextForTokenClassification
[[autodoc]] Data2VecTextForTokenClassification
- forward
## Data2VecTextForQuestionAnswering
[[autodoc]] Data2VecTextForQuestionAnswering
- forward
## Data2VecVisionModel
[[autodoc]] Data2VecVisionModel
- forward
## Data2VecVisionForImageClassification
[[autodoc]] Data2VecVisionForImageClassification
- forward
## Data2VecVisionForSemanticSegmentation
[[autodoc]] Data2VecVisionForSemanticSegmentation
- forward
</pt>
<tf>
## TFData2VecVisionModel
[[autodoc]] TFData2VecVisionModel
- call
## TFData2VecVisionForImageClassification
[[autodoc]] TFData2VecVisionForImageClassification
- call
## TFData2VecVisionForSemanticSegmentation
[[autodoc]] TFData2VecVisionForSemanticSegmentation
- call
</tf>
</frameworkcontent>
| transformers/docs/source/ja/model_doc/data2vec.md/0 | {
"file_path": "transformers/docs/source/ja/model_doc/data2vec.md",
"repo_id": "transformers",
"token_count": 3072
} | 269 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Load adapters with 🤗 PEFT
[[open-in-colab]]
[Parameter-Efficient Fine Tuning (PEFT)](https://huggingface.co/blog/peft) メソッドは、事前学習済みモデルのパラメータをファインチューニング中に凍結し、その上にわずかな訓練可能なパラメータ(アダプター)を追加するアプローチです。アダプターは、タスク固有の情報を学習するために訓練されます。このアプローチは、メモリ使用量が少なく、完全にファインチューニングされたモデルと比較して計算リソースを低く抑えつつ、同等の結果を生成することが示されています。
PEFTで訓練されたアダプターは通常、完全なモデルのサイズよりも1桁小さく、共有、保存、読み込むのが便利です。
<div class="flex flex-col justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/PEFT-hub-screenshot.png"/>
<figcaption class="text-center">Hubに格納されているOPTForCausalLMモデルのアダプター重みは、モデルの全体サイズの約6MBで、モデル重みの全サイズは約700MBです。</figcaption>
</div>
🤗 PEFTライブラリについて詳しく知りたい場合は、[ドキュメンテーション](https://huggingface.co/docs/peft/index)をご覧ください。
## Setup
🤗 PEFTをインストールして始めましょう:
```bash
pip install peft
```
新機能を試してみたい場合、ソースからライブラリをインストールすることに興味があるかもしれません:
```bash
pip install git+https://github.com/huggingface/peft.git
```
## Supported PEFT models
🤗 Transformersは、いくつかのPEFT(Parameter Efficient Fine-Tuning)メソッドをネイティブにサポートしており、ローカルまたはHubに格納されたアダプターウェイトを簡単に読み込んで実行またはトレーニングできます。以下のメソッドがサポートされています:
- [Low Rank Adapters](https://huggingface.co/docs/peft/conceptual_guides/lora)
- [IA3](https://huggingface.co/docs/peft/conceptual_guides/ia3)
- [AdaLoRA](https://arxiv.org/abs/2303.10512)
他のPEFTメソッドを使用したい場合、プロンプト学習やプロンプト調整などについて詳しく知りたい場合、または🤗 PEFTライブラリ全般については、[ドキュメンテーション](https://huggingface.co/docs/peft/index)を参照してください。
## Load a PEFT adapter
🤗 TransformersからPEFTアダプターモデルを読み込んで使用するには、Hubリポジトリまたはローカルディレクトリに `adapter_config.json` ファイルとアダプターウェイトが含まれていることを確認してください。次に、`AutoModelFor` クラスを使用してPEFTアダプターモデルを読み込むことができます。たとえば、因果言語モデリング用のPEFTアダプターモデルを読み込むには:
1. PEFTモデルのIDを指定します。
2. それを[`AutoModelForCausalLM`] クラスに渡します。
```py
from transformers import AutoModelForCausalLM, AutoTokenizer
peft_model_id = "ybelkada/opt-350m-lora"
model = AutoModelForCausalLM.from_pretrained(peft_model_id)
```
<Tip>
PEFTアダプターを`AutoModelFor`クラスまたは基本モデルクラス(`OPTForCausalLM`または`LlamaForCausalLM`など)で読み込むことができます。
</Tip>
また、`load_adapter`メソッドを呼び出すことで、PEFTアダプターを読み込むこともできます:
```py
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "facebook/opt-350m"
peft_model_id = "ybelkada/opt-350m-lora"
model = AutoModelForCausalLM.from_pretrained(model_id)
model.load_adapter(peft_model_id)
```
## Load in 8bit or 4bit
`bitsandbytes` 統合は、8ビットおよび4ビットの精度データ型をサポートしており、大規模なモデルを読み込む際にメモリを節約するのに役立ちます(詳細については `bitsandbytes` 統合の[ガイド](./quantization#bitsandbytes-integration)を参照してください)。[`~PreTrainedModel.from_pretrained`] に `load_in_8bit` または `load_in_4bit` パラメータを追加し、`device_map="auto"` を設定してモデルを効果的にハードウェアに分散配置できます:
```py
from transformers import AutoModelForCausalLM, AutoTokenizer
peft_model_id = "ybelkada/opt-350m-lora"
model = AutoModelForCausalLM.from_pretrained(peft_model_id, device_map="auto", load_in_8bit=True)
```
## Add a new adapter
既存のアダプターを持つモデルに新しいアダプターを追加するために [`~peft.PeftModel.add_adapter`] を使用できます。ただし、新しいアダプターは現在のアダプターと同じタイプである限り、これを行うことができます。たとえば、モデルに既存の LoRA アダプターがアタッチされている場合:
```py
from transformers import AutoModelForCausalLM, OPTForCausalLM, AutoTokenizer
from peft import PeftConfig
model_id = "facebook/opt-350m"
model = AutoModelForCausalLM.from_pretrained(model_id)
lora_config = LoraConfig(
target_modules=["q_proj", "k_proj"],
init_lora_weights=False
)
model.add_adapter(lora_config, adapter_name="adapter_1")
```
新しいアダプタを追加するには:
```py
# attach new adapter with same config
model.add_adapter(lora_config, adapter_name="adapter_2")
```
[`~peft.PeftModel.set_adapter`] を使用して、どのアダプターを使用するかを設定できます:
```py
# use adapter_1
model.set_adapter("adapter_1")
output = model.generate(**inputs)
print(tokenizer.decode(output_disabled[0], skip_special_tokens=True))
# use adapter_2
model.set_adapter("adapter_2")
output_enabled = model.generate(**inputs)
print(tokenizer.decode(output_enabled[0], skip_special_tokens=True))
```
## Enable and disable adapters
モデルにアダプターを追加したら、アダプターモジュールを有効または無効にすることができます。アダプターモジュールを有効にするには、次の手順を実行します:
```py
from transformers import AutoModelForCausalLM, OPTForCausalLM, AutoTokenizer
from peft import PeftConfig
model_id = "facebook/opt-350m"
adapter_model_id = "ybelkada/opt-350m-lora"
tokenizer = AutoTokenizer.from_pretrained(model_id)
text = "Hello"
inputs = tokenizer(text, return_tensors="pt")
model = AutoModelForCausalLM.from_pretrained(model_id)
peft_config = PeftConfig.from_pretrained(adapter_model_id)
# to initiate with random weights
peft_config.init_lora_weights = False
model.add_adapter(peft_config)
model.enable_adapters()
output = model.generate(**inputs)
```
アダプターモジュールを無効にするには:
```py
model.disable_adapters()
output = model.generate(**inputs)
```
## Train a PEFT adapter
PEFTアダプターは[`Trainer`]クラスでサポートされており、特定のユースケースに対してアダプターをトレーニングすることができます。数行のコードを追加するだけで済みます。たとえば、LoRAアダプターをトレーニングする場合:
<Tip>
[`Trainer`]を使用したモデルの微調整に慣れていない場合は、[事前トレーニング済みモデルの微調整](training)チュートリアルをご覧ください。
</Tip>
1. タスクタイプとハイパーパラメータに対するアダプターの構成を定義します(ハイパーパラメータの詳細については[`~peft.LoraConfig`]を参照してください)。
```py
from peft import LoraConfig
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="none",
task_type="CAUSAL_LM",
)
```
2. モデルにアダプターを追加する。
```py
model.add_adapter(peft_config)
```
3. これで、モデルを [`Trainer`] に渡すことができます!
```py
trainer = Trainer(model=model, ...)
trainer.train()
```
保存するトレーニング済みアダプタとそれを読み込むための手順:
| transformers/docs/source/ja/peft.md/0 | {
"file_path": "transformers/docs/source/ja/peft.md",
"repo_id": "transformers",
"token_count": 3654
} | 270 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Knowledge Distillation for Computer Vision
[[open-in-colab]]
知識の蒸留は、より大規模で複雑なモデル (教師) からより小規模で単純なモデル (生徒) に知識を伝達するために使用される手法です。あるモデルから別のモデルに知識を抽出するには、特定のタスク (この場合は画像分類) でトレーニングされた事前トレーニング済み教師モデルを取得し、画像分類でトレーニングされる生徒モデルをランダムに初期化します。次に、学生モデルをトレーニングして、その出力と教師の出力の差を最小限に抑え、動作を模倣します。これは [Distilling the Knowledge in a Neural Network by Hinton et al](https://arxiv.org/abs/1503.02531) で最初に導入されました。このガイドでは、タスク固有の知識の蒸留を行います。これには [Beans データセット](https://huggingface.co/datasets/beans) を使用します。
このガイドでは、[微調整された ViT モデル](https://huggingface.co/merve/vit-mobilenet-beans-224) (教師モデル) を抽出して [MobileNet](https://huggingface. co/google/mobilenet_v2_1.4_224) (学生モデル) 🤗 Transformers の [Trainer API](https://huggingface.co/docs/transformers/en/main_classes/trainer#trainer) を使用します。
蒸留とプロセスの評価に必要なライブラリをインストールしましょう。
```bash
pip install transformers datasets accelerate tensorboard evaluate --upgrade
```
この例では、教師モデルとして`merve/beans-vit-224`モデルを使用しています。これは、Bean データセットに基づいて微調整された`google/vit-base-patch16-224-in21k`に基づく画像分類モデルです。このモデルをランダムに初期化された MobileNetV2 に抽出します。
次に、データセットをロードします。
```python
from datasets import load_dataset
dataset = load_dataset("beans")
```
この場合、同じ解像度で同じ出力が返されるため、どちらのモデルの画像プロセッサも使用できます。 `dataset`の`map()`メソッドを使用して、データセットのすべての分割に前処理を適用します。
```python
from transformers import AutoImageProcessor
teacher_processor = AutoImageProcessor.from_pretrained("merve/beans-vit-224")
def process(examples):
processed_inputs = teacher_processor(examples["image"])
return processed_inputs
processed_datasets = dataset.map(process, batched=True)
```
基本的に、我々は生徒モデル(ランダムに初期化されたMobileNet)が教師モデル(微調整されたビジョン変換器)を模倣することを望む。これを実現するために、まず教師と生徒からロジット出力を得る。次に、それぞれのソフトターゲットの重要度を制御するパラメータ`temperature`で分割する。`lambda`と呼ばれるパラメータは蒸留ロスの重要度を量る。この例では、`temperature=5`、`lambda=0.5`とする。生徒と教師の間の発散を計算するために、Kullback-Leibler発散損失を使用します。2つのデータPとQが与えられたとき、KLダイバージェンスはQを使ってPを表現するためにどれだけの余分な情報が必要かを説明します。もし2つが同じであれば、QからPを説明するために必要な他の情報はないので、それらのKLダイバージェンスはゼロになります。
```python
from transformers import TrainingArguments, Trainer
import torch
import torch.nn as nn
import torch.nn.functional as F
class ImageDistilTrainer(Trainer):
def __init__(self, *args, teacher_model=None, **kwargs):
super().__init__(*args, **kwargs)
self.teacher = teacher_model
self.student = student_model
self.loss_function = nn.KLDivLoss(reduction="batchmean")
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.teacher.to(device)
self.teacher.eval()
self.temperature = temperature
self.lambda_param = lambda_param
def compute_loss(self, student, inputs, return_outputs=False):
student_output = self.student(**inputs)
with torch.no_grad():
teacher_output = self.teacher(**inputs)
# Compute soft targets for teacher and student
soft_teacher = F.softmax(teacher_output.logits / self.temperature, dim=-1)
soft_student = F.log_softmax(student_output.logits / self.temperature, dim=-1)
# Compute the loss
distillation_loss = self.loss_function(soft_student, soft_teacher) * (self.temperature ** 2)
# Compute the true label loss
student_target_loss = student_output.loss
# Calculate final loss
loss = (1. - self.lambda_param) * student_target_loss + self.lambda_param * distillation_loss
return (loss, student_output) if return_outputs else loss
```
次に、Hugging Face Hub にログインして、`trainer`を通じてモデルを Hugging Face Hub にプッシュできるようにします。
```python
from huggingface_hub import notebook_login
notebook_login()
```
教師モデルと生徒モデルである`TrainingArguments`を設定しましょう。
```python
from transformers import AutoModelForImageClassification, MobileNetV2Config, MobileNetV2ForImageClassification
training_args = TrainingArguments(
output_dir="my-awesome-model",
num_train_epochs=30,
fp16=True,
logging_dir=f"{repo_name}/logs",
logging_strategy="epoch",
evaluation_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
metric_for_best_model="accuracy",
report_to="tensorboard",
push_to_hub=True,
hub_strategy="every_save",
hub_model_id=repo_name,
)
num_labels = len(processed_datasets["train"].features["labels"].names)
# initialize models
teacher_model = AutoModelForImageClassification.from_pretrained(
"merve/beans-vit-224",
num_labels=num_labels,
ignore_mismatched_sizes=True
)
# training MobileNetV2 from scratch
student_config = MobileNetV2Config()
student_config.num_labels = num_labels
student_model = MobileNetV2ForImageClassification(student_config)
```
`compute_metrics` 関数を使用して、テスト セットでモデルを評価できます。この関数は、トレーニング プロセス中にモデルの`accuracy`と`f1`を計算するために使用されます。
```python
import evaluate
import numpy as np
accuracy = evaluate.load("accuracy")
def compute_metrics(eval_pred):
predictions, labels = eval_pred
acc = accuracy.compute(references=labels, predictions=np.argmax(predictions, axis=1))
return {"accuracy": acc["accuracy"]}
```
定義したトレーニング引数を使用して`Trainer`を初期化しましょう。データ照合装置も初期化します。
```python
from transformers import DefaultDataCollator
data_collator = DefaultDataCollator()
trainer = ImageDistilTrainer(
student_model=student_model,
teacher_model=teacher_model,
training_args=training_args,
train_dataset=processed_datasets["train"],
eval_dataset=processed_datasets["validation"],
data_collator=data_collator,
tokenizer=teacher_extractor,
compute_metrics=compute_metrics,
temperature=5,
lambda_param=0.5
)
```
これでモデルをトレーニングできるようになりました。
```python
trainer.train()
```
テスト セットでモデルを評価できます。
```python
trainer.evaluate(processed_datasets["test"])
```
テスト セットでは、モデルの精度は 72% に達します。蒸留効率の健全性チェックを行うために、同じハイパーパラメータを使用して Bean データセットで MobileNet を最初からトレーニングし、テスト セットで 63% の精度を観察しました。読者の皆様には、さまざまな事前トレーニング済み教師モデル、学生アーキテクチャ、蒸留パラメータを試していただき、その結果を報告していただくようお勧めします。抽出されたモデルのトレーニング ログとチェックポイントは [このリポジトリ](https://huggingface.co/merve/vit-mobilenet-beans-224) にあり、最初からトレーニングされた MobileNetV2 はこの [リポジトリ]( https://huggingface.co/merve/resnet-mobilenet-beans-5)。
| transformers/docs/source/ja/tasks/knowledge_distillation_for_image_classification.md/0 | {
"file_path": "transformers/docs/source/ja/tasks/knowledge_distillation_for_image_classification.md",
"repo_id": "transformers",
"token_count": 3677
} | 271 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Zero-shot image classification
[[open-in-colab]]
ゼロショット画像分類は、次のモデルを使用して画像をさまざまなカテゴリに分類するタスクです。
これらの特定のカテゴリのラベル付きの例を含むデータに対して明示的にトレーニングされていない。
従来、画像分類には、ラベル付き画像の特定のセットでモデルをトレーニングする必要があり、このモデルは次のことを学習します。
特定の画像の特徴をラベルに「マッピング」します。分類タスクにそのようなモデルを使用する必要がある場合、
新しいラベルのセットでは、モデルを "再調整" するために微調整が必要です。
対照的に、ゼロショットまたはオープン語彙画像分類モデルは、通常、大規模なシステムでトレーニングされたマルチモーダル モデルです。
画像と関連する説明のデータセット。これらのモデルは、ゼロショット画像分類を含む多くの下流タスクに使用できる、調整された視覚言語表現を学習します。
これは、画像分類に対するより柔軟なアプローチであり、モデルを新しいまだ見たことのないカテゴリに一般化できるようになります。
追加のトレーニング データを必要とせず、ユーザーはターゲット オブジェクトの自由形式のテキスト説明を含む画像をクエリできるようになります。
このガイドでは、次の方法を学びます。
* ゼロショット画像分類パイプラインを作成する
* 手動でゼロショット画像分類推論を実行します
始める前に、必要なライブラリがすべてインストールされていることを確認してください。
```bash
pip install -q transformers
```
## Zero-shot image classification pipeline
ゼロショット画像分類をサポートするモデルで推論を試す最も簡単な方法は、対応する [`パイプライン`] を使用することです。
[Hugging Face Hub のチェックポイント](https://huggingface.co/models?pipeline_tag=zero-shot-image-classification&sort=downloads) からパイプラインをインスタンス化します。
```python
>>> from transformers import pipeline
>>> checkpoint = "openai/clip-vit-large-patch14"
>>> detector = pipeline(model=checkpoint, task="zero-shot-image-classification")
```
次に、分類したい画像を選択します。
```py
>>> from PIL import Image
>>> import requests
>>> url = "https://unsplash.com/photos/g8oS8-82DxI/download?ixid=MnwxMjA3fDB8MXx0b3BpY3x8SnBnNktpZGwtSGt8fHx8fDJ8fDE2NzgxMDYwODc&force=true&w=640"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/owl.jpg" alt="Photo of an owl"/>
</div>
画像と候補オブジェクトのラベルをパイプラインに渡します。ここでは画像を直接渡します。他の適切なオプション
画像へのローカル パスまたは画像 URL を含めます。
候補ラベルは、この例のように単純な単語にすることも、より説明的な単語にすることもできます。
```py
>>> predictions = detector(image, candidate_labels=["fox", "bear", "seagull", "owl"])
>>> predictions
[{'score': 0.9996670484542847, 'label': 'owl'},
{'score': 0.000199399160919711, 'label': 'seagull'},
{'score': 7.392891711788252e-05, 'label': 'fox'},
{'score': 5.96074532950297e-05, 'label': 'bear'}]
```
## Zero-shot image classification by hand
ゼロショット画像分類パイプラインの使用方法を理解したところで、ゼロショットを実行する方法を見てみましょう。
画像を手動で分類します。
まず、[Hugging Face Hub のチェックポイント](https://huggingface.co/models?pipeline_tag=zero-shot-image-classification&sort=downloads) からモデルと関連プロセッサをロードします。
ここでは、前と同じチェックポイントを使用します。
```py
>>> from transformers import AutoProcessor, AutoModelForZeroShotImageClassification
>>> model = AutoModelForZeroShotImageClassification.from_pretrained(checkpoint)
>>> processor = AutoProcessor.from_pretrained(checkpoint)
```
気分を変えて、別の画像を撮ってみましょう。
```py
>>> from PIL import Image
>>> import requests
>>> url = "https://unsplash.com/photos/xBRQfR2bqNI/download?ixid=MnwxMjA3fDB8MXxhbGx8fHx8fHx8fHwxNjc4Mzg4ODEx&force=true&w=640"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/car.jpg" alt="Photo of a car"/>
</div>
プロセッサを使用してモデルの入力を準備します。プロセッサーは、
サイズ変更と正規化によるモデルの画像、およびテキスト入力を処理するトークナイザー。
```py
>>> candidate_labels = ["tree", "car", "bike", "cat"]
>>> inputs = processor(images=image, text=candidate_labels, return_tensors="pt", padding=True)
```
入力をモデルに渡し、結果を後処理します。
```py
>>> import torch
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> logits = outputs.logits_per_image[0]
>>> probs = logits.softmax(dim=-1).numpy()
>>> scores = probs.tolist()
>>> result = [
... {"score": score, "label": candidate_label}
... for score, candidate_label in sorted(zip(probs, candidate_labels), key=lambda x: -x[0])
... ]
>>> result
[{'score': 0.998572, 'label': 'car'},
{'score': 0.0010570387, 'label': 'bike'},
{'score': 0.0003393686, 'label': 'tree'},
{'score': 3.1572064e-05, 'label': 'cat'}]
```
| transformers/docs/source/ja/tasks/zero_shot_image_classification.md/0 | {
"file_path": "transformers/docs/source/ja/tasks/zero_shot_image_classification.md",
"repo_id": "transformers",
"token_count": 2709
} | 272 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 어떻게 🤗 Transformers 모델을 TensorFlow로 변환하나요? [[how-to-convert-a-transformers-model-to-tensorflow]]
🤗 Transformers에서처럼 사용할 수 있는 여러 가지 프레임워크가 있다는 것은 애플리케이션을 설계할 때 그들의 강점을 유연하게 이용할 수 있다는 장점이 있지만, 모델 별로 호환성을 추가해야 한다는 단점 또한 존재한다는 것을 의미합니다. 좋은 소식은 기존 모델에 TensorFlow 호환성을 추가하는 것이 [처음부터 새로운 모델을 추가하는 것](add_new_model)보다도 간단하다는 것입니다!
만약 대규모 TensorFlow 모델을 더 깊이 이해하려거나, 오픈 소스에 큰 기여를 하려거나, 선택한 모델에 Tensorflow를 활용하려한다면, 이 안내서는 여러분께 도움이 될 것입니다.
이 가이드는 Hugging Face 팀의 최소한의 감독 아래에서 🤗 Transformers에서 사용되는 TensorFlow 모델 가중치와/또는 아키텍처를 기여할 수 있는 커뮤니티 구성원인 여러분을 대상으로 합니다.
새로운 모델을 작성하는 것은 쉬운 일이 아니지만, 이 가이드를 통해 조금 덜 힘들고 훨씬 쉬운 작업으로 만들 수 있습니다.
모두의 경험을 모으는 것은 이 작업을 점차적으로 더 쉽게 만드는 데 굉장히 중요하기 때문에, 이 가이드를 개선시킬만한 제안이 떠오르면 공유하시는걸 적극적으로 권장합니다!
더 깊이 알아보기 전에, 🤗 Transformers를 처음 접하는 경우 다음 자료를 확인하는 것이 좋습니다:
- [🤗 Transformers의 일반 개요](add_new_model#general-overview-of-transformers)
- [Hugging Face의 TensorFlow 철학](https://huggingface.co/blog/tensorflow-philosophy)
이 가이드의 나머지 부분에서는 새로운 TensorFlow 모델 아키텍처를 추가하는 데 필요한 단계, Pytorch를 TensorFlow 모델 가중치로 변환하는 절차 및 ML 프레임워크 간의 불일치를 효율적으로 디버깅하는 방법을 알게 될 것입니다. 시작해봅시다!
<Tip>
사용하려는 모델이 이미 해당하는 TensorFlow 아키텍처가 있는지 확실하지 않나요?
선택한 모델([예](https://huggingface.co/bert-base-uncased/blob/main/config.json#L14))의 `config.json`의 `model_type` 필드를 확인해보세요. 🤗 Transformers의 해당 모델 폴더에는 "modeling_tf"로 시작하는 파일이 있는 경우, 해당 모델에는 해당 TensorFlow 아키텍처([예](https://github.com/huggingface/transformers/tree/main/src/transformers/models/bert))가 있다는 의미입니다.
</Tip>
## TensorFlow 모델 아키텍처 코드 추가하는 단계별 가이드 [[step-by-step-guide-to add-tensorFlow-model-architecture-code]]
대규모 아키텍처를 가진 모델을 설계하는 방법에는 여러가지가 있으며, 해당 설계를 구현하는 방법도 여러 가지입니다.
그러나 우리는 [🤗 Transformers 일반 개요](add_new_model#general-overview-of-transformers)에서 언급한 대로 일관된 설계 선택에 따라야지만 🤗 Transformers를 사용하기 편할 것이라는 확고한 의견을 가지고 있습니다.
우리의 경험을 통해 TensorFlow 모델을 추가하는 데 관련된 중요한 몇 가지 사항을 알려 드릴 수 있습니다:
- 이미 있는걸 다시 개발하려 하지 마세요! 최소한 2개의 이미 구현된 모델을 대개 참조해야 합니다. 구현하려는 모델과 기능상 동일한 Pytorch 모델 하나와 같은 문제 유형을 풀고 있는 다른 TensorFlow 모델 하나를 살펴보세요.
- 우수한 모델 구현은 시간이 지나도 남아있습니다. 이것은 코드가 아름답다는 이유가 아니라 코드가 명확하고 디버깅 및 개선이 쉽기 때문입니다. TensorFlow 구현에서 다른 모델들과 패턴을 똑같이 하고 Pytorch 구현과의 불일치를 최소화하여 메인테이너의 업무를 쉽게 한다면, 기여한 코드가 오래도록 유지될 수 있습니다.
- 필요하다면 도움을 요청하세요! 🤗 Transformers 팀은 여러분을 돕기 위해 있으며, 여러분이 직면한 동일한 문제에 대한 해결책을 이미 찾은 경우도 있을 수 있습니다.
TensorFlow 모델 아키텍처를 추가하는 데 필요한 단계를 개략적으로 써보면:
1. 변환하려는 모델 선택
2. transformers 개발 환경 준비
3. (선택 사항) 이론적 측면 및 기존 구현 이해
4. 모델 아키텍처 구현
5. 모델 테스트 구현
6. PR (pull request) 제출
7. (선택 사항) 데모 빌드 및 공유
### 1.-3. 모델 기여 준비 [[1.-3.-prepare-your-model-contribution]]
**1. 변환하려는 모델 선택**
우선 기본 사항부터 시작해 보겠습니다. 먼저 변환하려는 아키텍처를 알아야 합니다.
특정 아키텍처에 대한 관심 없는 경우, 🤗 Transformers 팀에게 제안을 요청하는 것은 여러분의 영향력을 극대화하는 좋은 방법입니다.
우리는 TensorFlow에서 빠져 있는 가장 유명한 아키텍처로 이끌어 드리겠습니다.
TensorFlow에서 사용할 모델이 이미 🤗 Transformers에 TensorFlow 아키텍처 구현이 있지만 가중치가 없는 경우,
이 페이지의 [가중치 추가 섹션](#adding-tensorflow-weights-to-hub)으로 바로 이동하셔도 됩니다.
간단히 말해서, 이 안내서의 나머지 부분은 TensorFlow 버전의 *BrandNewBert*([가이드](add_new_model)와 동일한 예제)를 기여하려고 결정했다고 가정합니다.
<Tip>
TensorFlow 모델 아키텍처에 작업을 시작하기 전에 해당 작업이 진행 중인지 확인하세요.
`BrandNewBert`를 검색하여
[pull request GitHub 페이지](https://github.com/huggingface/transformers/pulls?q=is%3Apr)에서 TensorFlow 관련 pull request가 없는지 확인할 수 있습니다.
</Tip>
**2. transformers 개발 환경 준비**
모델 아키텍처를 선택한 후, 관련 작업을 수행할 의도를 미리 알리기 위해 Draft PR을 여세요. 아래 지침대로 하시면 환경을 설정하고 Draft PR을 열 수 있습니다.
1. 'Fork' 버튼을 클릭하여 [리포지터리](https://github.com/huggingface/transformers)를 포크하세요. 이렇게 하면 GitHub 사용자 계정에 코드의 사본이 생성됩니다.
2. `transformers` 포크를 로컬 디스크에 클론하고 원본 리포지터리를 원격 리포지터리로 추가하세요.
```bash
git clone https://github.com/[your Github handle]/transformers.git
cd transformers
git remote add upstream https://github.com/huggingface/transformers.git
```
3. 개발 환경을 설정하세요. 예를 들어, 다음 명령을 실행하여 개발 환경을 설정할 수 있습니다.
```bash
python -m venv .env
source .env/bin/activate
pip install -e ".[dev]"
```
운영 체제에 따라서 Transformers의 선택적 종속성이 증가하면서 위 명령이 실패할 수도 있습니다. 그런 경우 TensorFlow를 설치한 후 다음을 실행하세요.
```bash
pip install -e ".[quality]"
```
**참고:** CUDA를 설치할 필요는 없습니다. 새로운 모델이 CPU에서 작동하도록 만드는 것만으로 충분합니다.
4. 메인 브랜치에서 만드려는 기능이 잘 표현되는 이름으로 브랜치를 만듭니다.
```bash
git checkout -b add_tf_brand_new_bert
```
5. 메인 브랜치의 현재 상태를 페치(fetch)하고 리베이스하세요.
```bash
git fetch upstream
git rebase upstream/main
```
6. `transformers/src/models/brandnewbert/`에 `modeling_tf_brandnewbert.py`라는 빈 `.py` 파일을 추가하세요. 이 파일이 TensorFlow 모델 파일이 될 것입니다.
7. 변경 사항을 계정에 푸시하세요.
```bash
git add .
git commit -m "initial commit"
git push -u origin add_tf_brand_new_bert
```
8. 만족스러운 경우 GitHub에서 포크된 웹 페이지로 이동합니다. "Pull request"를 클릭합니다. Hugging Face 팀의 GitHub ID를 리뷰어로 추가해서, 앞으로의 변경 사항에 대해 Hugging Face 팀이 알림을 받을 수 있도록 합니다.
9. GitHub Pull Requests 페이지의 오른쪽에 있는 "Convert to draft"를 클릭하여 PR을 초안으로 변경하세요.
이제 🤗 Transformers에서 *BrandNewBert*를 TensorFlow로 변환할 개발 환경을 설정했습니다.
**3. (선택 사항) 이론적 측면 및 기존 구현 이해**
*BrandNewBert*처럼 자세한 글이 있다면 시간을 내어 논문을 읽는걸 추천드립니다. 이해하기 어려운 부분이 많을 수 있습니다. 그렇다고 해서 걱정하지 마세요! 목표는 논문의 심도있는 이론적 이해가 아니라 TensorFlow를 사용하여 🤗 Transformers에 모델을 효과적으로 다시 구현하는 데 필요한 필수 정보를 추출하는 것입니다. 많은 시간을 이론적 이해에 투자할 필요는 없지만 실용적인 측면에서 현재 존재하는 모델 문서 페이지(e.g. [model docs for BERT](model_doc/bert))에 집중하는 것이 좋습니다.
모델의 기본 사항을 이해한 후, 기존 구현을 이해하는 것이 중요합니다. 이는 작업 중인 모델에 대한 실제 구현이 여러분의 기대와 일치함을 확인하고, TensorFlow 측면에서의 기술적 문제를 예상할 수 있습니다.
막대한 양의 정보를 처음으로 학습할 때 압도당하는 것은 자연스러운 일입니다. 이 단계에서 모델의 모든 측면을 이해해야 하는 필요는 전혀 없습니다. 그러나 우리는 Hugging Face의 [포럼](https://discuss.huggingface.co/)을 통해 질문이 있는 경우 대답을 구할 것을 권장합니다.
### 4. 모델 구현 [[4-model-implementation]]
이제 드디어 코딩을 시작할 시간입니다. 우리의 제안된 시작점은 PyTorch 파일 자체입니다: `modeling_brand_new_bert.py`의 내용을
`src/transformers/models/brand_new_bert/` 내부의
`modeling_tf_brand_new_bert.py`에 복사합니다. 이 섹션의 목표는 파일을 수정하고 🤗 Transformers의 import 구조를 업데이트하여 `TFBrandNewBert` 및 `TFBrandNewBert.from_pretrained(model_repo, from_pt=True)`가 성공적으로 작동하는 TensorFlow *BrandNewBert* 모델을 가져올 수 있도록 하는 것입니다.
유감스럽게도, PyTorch 모델을 TensorFlow로 변환하는 규칙은 없습니다. 그러나 프로세스를 가능한한 원활하게 만들기 위해 다음 팁을 따를 수 있습니다.
- 모든 클래스 이름 앞에 `TF`를 붙입니다(예: `BrandNewBert`는 `TFBrandNewBert`가 됩니다).
- 대부분의 PyTorch 작업에는 직접적인 TensorFlow 대체가 있습니다. 예를 들어, `torch.nn.Linear`는 `tf.keras.layers.Dense`에 해당하고, `torch.nn.Dropout`은 `tf.keras.layers.Dropout`에 해당합니다. 특정 작업에 대해 확신이 없는 경우 [TensorFlow 문서](https://www.tensorflow.org/api_docs/python/tf)나 [PyTorch 문서](https://pytorch.org/docs/stable/)를 참조할 수 있습니다.
- 🤗 Transformers 코드베이스에서 패턴을 찾으세요. 직접적인 대체가 없는 특정 작업을 만나면 다른 사람이 이미 동일한 문제를 해결한 경우가 많습니다.
- 기본적으로 PyTorch와 동일한 변수 이름과 구조를 유지하세요. 이렇게 하면 디버깅과 문제 추적, 그리고 문제 해결 추가가 더 쉬워집니다.
- 일부 레이어는 각 프레임워크마다 다른 기본값을 가지고 있습니다. 대표적인 예로 배치 정규화 레이어의 epsilon은 [PyTorch](https://pytorch.org/docs/stable/generated/torch.nn.BatchNorm2d.html#torch.nn.BatchNorm2d)에서 `1e-5`이고 [TensorFlow](https://www.tensorflow.org/api_docs/python/tf/keras/layers/BatchNormalization)에서 `1e-3`입니다. 문서를 모두 확인하세요!
- PyTorch의 `nn.Parameter` 변수는 일반적으로 TF 레이어의 `build()` 내에서 초기화해야 합니다. 다음 예를 참조하세요: [PyTorch](https://github.com/huggingface/transformers/blob/655f72a6896c0533b1bdee519ed65a059c2425ac/src/transformers/models/vit_mae/modeling_vit_mae.py#L212) /
[TensorFlow](https://github.com/huggingface/transformers/blob/655f72a6896c0533b1bdee519ed65a059c2425ac/src/transformers/models/vit_mae/modeling_tf_vit_mae.py#L220)
- PyTorch 모델의 함수 상단에 `#copied from ...`가 있는 경우, TensorFlow 모델에 TensorFlow 아키텍처가 있다면 TensorFlow 모델이 해당 함수를 복사한 아키텍처에서 사용할 수 있습니다.
- TensorFlow 함수에서 `name` 속성을 올바르게 할당하는 것은 `from_pt=True` 가중치 교차 로딩을 수행하는 데 중요합니다. `name`은 대부분 PyTorch 코드의 해당 변수의 이름입니다. `name`이 제대로 설정되지 않으면 모델 가중치를 로드할 때 오류 메시지에서 확인할 수 있습니다.
- 기본 모델 클래스인 `BrandNewBertModel`의 로직은 실제로 Keras 레이어 서브클래스([예시](https://github.com/huggingface/transformers/blob/4fd32a1f499e45f009c2c0dea4d81c321cba7e02/src/transformers/models/bert/modeling_tf_bert.py#L719))인 `TFBrandNewBertMainLayer`에 있습니다. `TFBrandNewBertModel`은 이 레이어를 감싸기만 하는 래퍼 역할을 합니다.
- Keras 모델은 사전 훈련된 가중치를 로드하기 위해 빌드되어야 합니다. 따라서 `TFBrandNewBertPreTrainedModel`은 모델의 입력 예제인 `dummy_inputs`([예시](https://github.com/huggingface/transformers/blob/4fd32a1f499e45f009c2c0dea4d81c321cba7e02/src/transformers/models/bert/modeling_tf_bert.py#L916)) 유지해야 합니다.
- 도움이 필요한 경우 도움을 요청하세요. 우리는 여기 있어서 도움을 드리기 위해 있는 것입니다! 🤗
모델 파일 자체 외에도 모델 클래스 및 관련 문서 페이지에 대한 포인터를 추가해야 합니다. 이 부분은 다른 PR([예시](https://github.com/huggingface/transformers/pull/18020/files))의 패턴을 따라 완전히 완료할 수 있습니다. 다음은 필요한 수동 변경 목록입니다.
- `src/transformers/__init__.py`에 *BrandNewBert*의 모든 공개 클래스를 포함합니다.
- `src/transformers/models/auto/modeling_tf_auto.py`에서 *BrandNewBert* 클래스를 해당 Auto 클래스에 추가합니다.
- `src/transformers/utils/dummy_tf_objects.py`에 *BrandNewBert*와 관련된 레이지 로딩 클래스를 추가합니다.
- `src/transformers/models/brand_new_bert/__init__.py`에서 공개 클래스에 대한 import 구조를 업데이트합니다.
- `docs/source/en/model_doc/brand_new_bert.md`에서 *BrandNewBert*의 공개 메서드에 대한 문서 포인터를 추가합니다.
- `docs/source/en/model_doc/brand_new_bert.md`의 *BrandNewBert* 기여자 목록에 자신을 추가합니다.
- 마지막으로 ✅ 녹색 체크박스를 TensorFlow 열 docs/source/en/index.md 안 BrandNewBert에 추가합니다.
구현이 만족하면 다음 체크리스트를 실행하여 모델 아키텍처가 준비되었는지 확인하세요.
1. 훈련 시간에 다르게 동작하는 `training` 인수로 불리는 모든 레이어(예: Dropout)는 최상위 클래스에서 전파됩니다.
2. #copied from ...가능할 때마다 사용했습니다.
3. `TFBrandNewBertMainLayer`와 그것을 사용하는 모든 클래스는 `call`함수로 `@unpack_inputs`와 함께 데코레이터 됩니다.
4. `TFBrandNewBertMainLayer`는 `@keras_serializable`로 데코레이터 됩니다.
5. TensorFlow 모델은 `TFBrandNewBert.from_pretrained(model_repo, from_pt=True)`를 사용하여 PyTorch 가중치에서 로드할 수 있습니다.
6. 예상 입력 형식을 사용하여 TensorFlow 모델을 호출할 수 있습니다.
### 5. 모델 테스트 구현 [[5-add-model-tests]]
TensorFlow 모델 아키텍처를 구현하는 데 성공했습니다! 이제 TensorFlow 모델을 테스트하는 구현을 작성할 차례입니다. 이를 통해 모델이 예상대로 작동하는지 확인할 수 있습니다. 이전에 우리는 `test_modeling_brand_new_bert.py` 파일을 `tests/models/brand_new_bert/ into test_modeling_tf_brand_new_bert.py`에 복사한 뒤, TensorFlow로 교체하는 것이 좋습니다. 지금은, 모든 `.from_pretrained()`을 `from_pt=True`를 사용하여 존재하는 Pytorch 가중치를 가져오도록 해야합니다.
완료하셨으면, 이제 진실의 순간이 찾아왔습니다: 테스트를 실행해 보세요! 😬
```bash
NVIDIA_TF32_OVERRIDE=0 RUN_SLOW=1 RUN_PT_TF_CROSS_TESTS=1 \
py.test -vv tests/models/brand_new_bert/test_modeling_tf_brand_new_bert.py
```
오류가 많이 나타날 것이지만 괜찮습니다! 기계 학습 모델을 디버깅하는 것은 악명높게 어려우며 성공의 핵심 요소는 인내심입니다 (`breakpoint()`도 필요합니다). 우리의 경험상으로는 ML 프레임워크 사이의 미묘한 불일치로 인해 가장 어려운 문제가 발생합니다. 이에 대한 몇 가지 지침이 이 가이드의 끝 부분에 있습니다. 다른 경우에는 일반 테스트가 직접 모델에 적용되지 않을 수 있으며, 이 경우 모델 테스트 클래스 레벨에서 재정의를 제안합니다. 문제가 무엇이든지 상관없이 문제가 있으면 당신이 고립되었다면 draft pull request에서 도움을 요청하는 것이 좋습니다.
모든 테스트가 통과되면 축하합니다. 이제 모델을 🤗 Transformers 라이브러리에 추가할 준비가 거의 완료된 것입니다! 🎉
테스트를 추가하는 방법에 대한 자세한 내용은 [🤗 Transformers의 테스트 가이드](https://huggingface.co/transformers/contributing.html#running-tests)를 참조하세요.
### 6.-7. 모든 사용자가 당신의 모델을 사용할 수 있게 하기 [[6.-7.-ensure-everyone -can-use-your-model]]
**6. 풀 요청 제출하기**
구현과 테스트가 완료되면 풀 요청을 제출할 시간입니다. 코드를 푸시하기 전에 코드 서식 맞추기 유틸리티인 `make fixup` 🪄 를 실행하세요. 이렇게 하면 자동으로 서식 오류를 수정하며 자동 검사가 실패하는 것을 방지할 수 있습니다.
이제 드래프트 풀 요청을 실제 풀 요청으로 변환하는 시간입니다. "리뷰 준비됨" 버튼을 클릭하고 Joao (`@gante`)와 Matt (`@Rocketknight1`)를 리뷰어로 추가하세요. 모델 풀 요청에는 적어도 3명의 리뷰어가 필요하지만, 그들이 당신의 모델에 적절한 추가 리뷰어를 찾을 것입니다.
모든 리뷰어들이 PR 상태에 만족하면 마지막으로 `.from_pretrained()` 호출에서 `from_pt=True` 플래그를 제거하는 것입니다. TensorFlow 가중치가 없기 때문에 이를 추가해야 합니다! 이를 수행하는 방법은 아래 섹션의 지침을 확인하세요.
마침내 TensorFlow 가중치가 병합되고, 적어도 3명의 리뷰어 승인을 받았으며 모든 CI 검사가 통과되었다면, 로컬로 테스트를 한 번 더 확인하세요.
```bash
NVIDIA_TF32_OVERRIDE=0 RUN_SLOW=1 RUN_PT_TF_CROSS_TESTS=1 \
py.test -vv tests/models/brand_new_bert/test_modeling_tf_brand_new_bert.py
```
그리고 우리는 당신의 PR을 병합할 것입니다! 마일스톤 달성을 축하드립니다! 🎉
**7. (선택 사항) 데모를 만들고 세상과 공유하기**
오픈 소스의 가장 어려운 부분 중 하나는 발견입니다. 다른 사용자들이 당신의 멋진 TensorFlow 기여를 어떻게 알 수 있을까요? 물론 적절한 커뮤니케이션으로 가능합니다! 📣
커뮤니티와 모델을 공유하는 두 가지 주요 방법이 있습니다:
- 데모 만들기. Gradio 데모, 노트북 및 모델을 자랑하는 다른 재미있는 방법을 포함합니다. [커뮤니티 기반 데모](https://huggingface.co/docs/transformers/community)에 노트북을 추가하는 것을 적극 권장합니다.
- Twitter와 LinkedIn과 같은 소셜 미디어에 이야기 공유하기. 당신의 작업에 자랑스러워하고 커뮤니티와 당신의 업적을 공유해야 합니다. 이제 당신의 모델은 전 세계의 수천 명의 엔지니어와 연구원들에 의해 사용될 수 있습니다 🌍! 우리는 당신의 게시물을 리트윗하고 커뮤니티와 함께 당신의 작업을 공유하는 데 도움이 될 것입니다.
## 🤗 허브에 TensorFlow 가중치 추가하기 [[adding-tensorFlow-weights-to-🤗-hub]]
TensorFlow 모델 아키텍처가 🤗 Transformers에서 사용 가능하다고 가정하고, PyTorch 가중치를 TensorFlow 가중치로 변환하는 것은 쉽습니다!
다음은 그 방법입니다:
1. 터미널에서 Hugging Face 계정으로 로그인되어 있는지 확인하십시오. `huggingface-cli login` 명령어를 사용하여 로그인할 수 있습니다. (액세스 토큰은 [여기](https://huggingface.co/settings/tokens)에서 찾을 수 있습니다.)
2. `transformers-cli pt-to-tf --model-name foo/bar`를 실행하십시오. 여기서 `foo/bar`는 변환하려는 PyTorch 가중치가 있는 모델 저장소의 이름입니다.
3. 방금 만든 🤗 허브 PR에서 `@joaogante`와 `@Rocketknight1`을 태그합니다.
그게 다입니다! 🎉
## ML 프레임워크 간 디버깅 🐛[[debugging-mismatches-across-ml-frameworks]]
새로운 아키텍처를 추가하거나 기존 아키텍처에 대한 TensorFlow 가중치를 생성할 때, PyTorch와 TensorFlow 간의 불일치로 인한 오류가 발생할 수 있습니다. 심지어 두 프레임워크의 모델 아키텍처 코드가 동일해 보일 수도 있습니다. 무슨 일이 벌어지고 있는 걸까요? 🤔
먼저, 이러한 불일치를 이해하는 이유에 대해 이야기해 보겠습니다. 많은 커뮤니티 멤버들은 🤗 Transformers 모델을 그대로 사용하고, 우리의 모델이 예상대로 작동할 것이라고 믿습니다. 두 프레임워크 간에 큰 불일치가 있으면 모델이 적어도 하나의 프레임워크에 대한 참조 구현을 따르지 않음을 의미합니다. 이는 모델이 의도한 대로 작동하지 않을 수 있음을 나타냅니다. 이는 아예 실행되지 않는 모델보다 나쁠 수 있습니다! 따라서 우리는 모든 모델의 프레임워크 불일치를 `1e-5`보다 작게 유지하는 것을 목표로 합니다.
기타 숫자 문제와 마찬가지로, 세세한 문제가 있습니다. 그리고 세세함에 집중하는 공정에서 필수 요소는 인내심입니다. 이러한 종류의 문제가 발생할 때 권장되는 작업 흐름은 다음과 같습니다:
1. 불일치의 원인을 찾아보십시오. 변환 중인 모델은 아마도 특정 지점까지 거의 동일한 내부 변수를 가지고 있을 것입니다. 두 프레임워크의 아키텍처에 `breakpoint()` 문을 넣고, 위에서 아래로 숫자 변수의 값을 비교하여 문제의 근원을 찾아냅니다.
2. 이제 문제의 근원을 찾았으므로 🤗 Transformers 팀에 연락하세요. 우리는 비슷한 문제를 이전에 겪었을 수 있으며 빠르게 해결책을 제공할 수 있습니다. 예외적인 경우에는 StackOverflow와 GitHub 이슈와 같은 인기있는 페이지를 확인하십시오.
3. 더 이상 해결책이 없는 경우, 더 깊이 들어가야 합니다. 좋은 소식은 문제의 원인을 찾았으므로 나머지 모델을 추상화하고 문제가 있는 명령어에 초점을 맞출 수 있습니다! 나쁜 소식은 해당 명령어의 소스 구현에 대해 알아봐야 한다는 것입니다. 일부 경우에는 참조 구현에 문제가 있을 수도 있으니 업스트림 저장소에서 이슈를 열기를 꺼리지 마십시오.
어떤 경우에는 🤗 Transformers 팀과의 토론을 통해 불일치를 수정할 수 없을 수도 있습니다. 모델의 출력 레이어에서 불일치가 매우 작지만 숨겨진 상태에서 크게 나타날 수 있기 때문입니다. 이 경우 모델을 배포하는 것을 우선시하기 위해 불일치를 무시하기로 결정할 수도 있습니다. 위에서 언급한 `pt-to-tf` CLI에는 가중치 변환 시 오류 메시지를 무시하는 `--max-error` 플래그가 있습니다.
| transformers/docs/source/ko/add_tensorflow_model.md/0 | {
"file_path": "transformers/docs/source/ko/add_tensorflow_model.md",
"repo_id": "transformers",
"token_count": 18335
} | 273 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 대규모 언어 모델로 생성하기 [[generation-with-llms]]
[[open-in-colab]]
LLM 또는 대규모 언어 모델은 텍스트 생성의 핵심 구성 요소입니다. 간단히 말하면, 주어진 입력 텍스트에 대한 다음 단어(정확하게는 토큰)를 예측하기 위해 훈련된 대규모 사전 훈련 변환기 모델로 구성됩니다. 토큰을 한 번에 하나씩 예측하기 때문에 새로운 문장을 생성하려면 모델을 호출하는 것 외에 더 복잡한 작업을 수행해야 합니다. 즉, 자기회귀 생성을 수행해야 합니다.
자기회귀 생성은 몇 개의 초기 입력값을 제공한 후, 그 출력을 다시 모델에 입력으로 사용하여 반복적으로 호출하는 추론 과정입니다. 🤗 Transformers에서는 [`~generation.GenerationMixin.generate`] 메소드가 이 역할을 하며, 이는 생성 기능을 가진 모든 모델에서 사용 가능합니다.
이 튜토리얼에서는 다음 내용을 다루게 됩니다:
* LLM으로 텍스트 생성
* 일반적으로 발생하는 문제 해결
* LLM을 최대한 활용하기 위한 다음 단계
시작하기 전에 필요한 모든 라이브러리가 설치되어 있는지 확인하세요:
```bash
pip install transformers bitsandbytes>=0.39.0 -q
```
## 텍스트 생성 [[generate-text]]
[인과적 언어 모델링(causal language modeling)](tasks/language_modeling)을 목적으로 학습된 언어 모델은 일련의 텍스트 토큰을 입력으로 사용하고, 그 결과로 다음 토큰이 나올 확률 분포를 제공합니다.
<!-- [GIF 1 -- FWD PASS] -->
<figure class="image table text-center m-0 w-full">
<video
style="max-width: 90%; margin: auto;"
autoplay loop muted playsinline
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/assisted-generation/gif_1_1080p.mov"
></video>
<figcaption>"LLM의 전방 패스"</figcaption>
</figure>
LLM과 자기회귀 생성을 함께 사용할 때 핵심적인 부분은 이 확률 분포로부터 다음 토큰을 어떻게 고를 것인지입니다. 다음 반복 과정에 사용될 토큰을 결정하는 한, 어떠한 방법도 가능합니다. 확률 분포에서 가장 가능성이 높은 토큰을 선택하는 것처럼 간단할 수도 있고, 결과 분포에서 샘플링하기 전에 수십 가지 변환을 적용하는 것처럼 복잡할 수도 있습니다.
<!-- [GIF 2 -- TEXT GENERATION] -->
<figure class="image table text-center m-0 w-full">
<video
style="max-width: 90%; margin: auto;"
autoplay loop muted playsinline
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/assisted-generation/gif_2_1080p.mov"
></video>
<figcaption>"자기회귀 생성은 확률 분포에서 다음 토큰을 반복적으로 선택하여 텍스트를 생성합니다."</figcaption>
</figure>
위에서 설명한 과정은 어떤 종료 조건이 충족될 때까지 반복적으로 수행됩니다. 모델이 시퀀스의 끝(EOS 토큰)을 출력할 때까지를 종료 조건으로 하는 것이 이상적입니다. 그렇지 않은 경우에는 미리 정의된 최대 길이에 도달했을 때 생성이 중단됩니다.
모델이 예상대로 동작하기 위해선 토큰 선택 단계와 정지 조건을 올바르게 설정하는 것이 중요합니다. 이러한 이유로, 각 모델에는 기본 생성 설정이 잘 정의된 [`~generation.GenerationConfig`] 파일이 함께 제공됩니다.
코드를 확인해봅시다!
<Tip>
기본 LLM 사용에 관심이 있다면, 우리의 [`Pipeline`](pipeline_tutorial) 인터페이스로 시작하는 것을 추천합니다. 그러나 LLM은 양자화나 토큰 선택 단계에서의 미세한 제어와 같은 고급 기능들을 종종 필요로 합니다. 이러한 작업은 [`~generation.GenerationMixin.generate`]를 통해 가장 잘 수행될 수 있습니다. LLM을 이용한 자기회귀 생성은 자원을 많이 소모하므로, 적절한 처리량을 위해 GPU에서 실행되어야 합니다.
</Tip>
먼저, 모델을 불러오세요.
```python
>>> from transformers import AutoModelForCausalLM
>>> model = AutoModelForCausalLM.from_pretrained(
... "mistralai/Mistral-7B-v0.1", device_map="auto", load_in_4bit=True
... )
```
`from_pretrained` 함수를 호출할 때 2개의 플래그를 주목하세요:
- `device_map`은 모델이 GPU로 이동되도록 합니다.
- `load_in_4bit`는 리소스 요구 사항을 크게 줄이기 위해 [4비트 동적 양자화](main_classes/quantization)를 적용합니다.
이 외에도 모델을 초기화하는 다양한 방법이 있지만, LLM을 처음 시작할 때 이 설정을 추천합니다.
이어서 텍스트 입력을 [토크나이저](tokenizer_summary)으로 전처리하세요.
```python
>>> from transformers import AutoTokenizer
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1")
>>> device = "cuda" if torch.cuda.is_available() else "cpu"
>>> model_inputs = tokenizer(["A list of colors: red, blue"], return_tensors="pt").to(device)
```
`model_inputs` 변수에는 토큰화된 텍스트 입력과 함께 어텐션 마스크가 들어 있습니다. [`~generation.GenerationMixin.generate`]는 어텐션 마스크가 제공되지 않았을 경우에도 이를 추론하려고 노력하지만, 최상의 성능을 위해서는 가능하면 어텐션 마스크를 전달하는 것을 권장합니다.
마지막으로 [`~generation.GenerationMixin.generate`] 메소드를 호출해 생성된 토큰을 얻은 후, 이를 출력하기 전에 텍스트 형태로 변환하세요.
```python
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'A list of colors: red, blue, green, yellow, black, white, and brown'
```
이게 전부입니다! 몇 줄의 코드만으로 LLM의 능력을 활용할 수 있게 되었습니다.
## 일반적으로 발생하는 문제 [[common-pitfalls]]
[생성 전략](generation_strategies)이 많고, 기본값이 항상 사용 사례에 적합하지 않을 수 있습니다. 출력이 예상과 다를 때 흔히 발생하는 문제와 이를 해결하는 방법에 대한 목록을 만들었습니다.
```py
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1")
>>> tokenizer.pad_token = tokenizer.eos_token # Mistral has no pad token by default
>>> model = AutoModelForCausalLM.from_pretrained(
... "mistralai/Mistral-7B-v0.1", device_map="auto", load_in_4bit=True
... )
```
### 생성된 출력이 너무 짧거나 길다 [[generated-output-is-too-shortlong]]
[`~generation.GenerationConfig`] 파일에서 별도로 지정하지 않으면, `generate`는 기본적으로 최대 20개의 토큰을 반환합니다. `generate` 호출에서 `max_new_tokens`을 수동으로 설정하여 반환할 수 있는 새 토큰의 최대 수를 설정하는 것이 좋습니다. LLM(정확하게는 [디코더 전용 모델](https://huggingface.co/learn/nlp-course/chapter1/6?fw=pt))은 입력 프롬프트도 출력의 일부로 반환합니다.
```py
>>> model_inputs = tokenizer(["A sequence of numbers: 1, 2"], return_tensors="pt").to("cuda")
>>> # By default, the output will contain up to 20 tokens
>>> generated_ids = model.generate(**model_inputs, pad_token_id=tokenizer.eos_token_id)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'A sequence of numbers: 1, 2, 3, 4, 5'
>>> # Setting `max_new_tokens` allows you to control the maximum length
>>> generated_ids = model.generate(**model_inputs, pad_token_id=tokenizer.eos_token_id, max_new_tokens=50)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'A sequence of numbers: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,'
```
### 잘못된 생성 모드 [[incorrect-generation-mode]]
기본적으로 [`~generation.GenerationConfig`] 파일에서 별도로 지정하지 않으면, `generate`는 각 반복에서 가장 확률이 높은 토큰을 선택합니다(그리디 디코딩). 하려는 작업에 따라 이 방법은 바람직하지 않을 수 있습니다. 예를 들어, 챗봇이나 에세이 작성과 같은 창의적인 작업은 샘플링이 적합할 수 있습니다. 반면, 오디오를 텍스트로 변환하거나 번역과 같은 입력 기반 작업은 그리디 디코딩이 더 적합할 수 있습니다. `do_sample=True`로 샘플링을 활성화할 수 있으며, 이 주제에 대한 자세한 내용은 이 [블로그 포스트](https://huggingface.co/blog/how-to-generate)에서 볼 수 있습니다.
```python
>>> # Set seed or reproducibility -- you don't need this unless you want full reproducibility
>>> from transformers import set_seed
>>> set_seed(0)
>>> model_inputs = tokenizer(["I am a cat."], return_tensors="pt").to("cuda")
>>> # LLM + greedy decoding = repetitive, boring output
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'I am a cat. I am a cat. I am a cat. I am a cat'
>>> # With sampling, the output becomes more creative!
>>> generated_ids = model.generate(**model_inputs, do_sample=True)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'I am a cat.\nI just need to be. I am always.\nEvery time'
```
### 잘못된 패딩 [[wrong-padding-side]]
LLM은 [디코더 전용](https://huggingface.co/learn/nlp-course/chapter1/6?fw=pt) 구조를 가지고 있어, 입력 프롬프트에 대해 지속적으로 반복 처리를 합니다. 입력 데이터의 길이가 다르면 패딩 작업이 필요합니다. LLM은 패딩 토큰에서 작동을 이어가도록 설계되지 않았기 때문에, 입력 왼쪽에 패딩이 추가 되어야 합니다. 그리고 어텐션 마스크도 꼭 `generate` 함수에 전달되어야 합니다!
```python
>>> # The tokenizer initialized above has right-padding active by default: the 1st sequence,
>>> # which is shorter, has padding on the right side. Generation fails.
>>> model_inputs = tokenizer(
... ["1, 2, 3", "A, B, C, D, E"], padding=True, return_tensors="pt"
... ).to("cuda")
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids[0], skip_special_tokens=True)[0]
''
>>> # With left-padding, it works as expected!
>>> tokenizer = AutoTokenizer.from_pretrained("openlm-research/open_llama_7b", padding_side="left")
>>> tokenizer.pad_token = tokenizer.eos_token # Llama has no pad token by default
>>> model_inputs = tokenizer(
... ["1, 2, 3", "A, B, C, D, E"], padding=True, return_tensors="pt"
... ).to("cuda")
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'1, 2, 3, 4, 5, 6,'
```
<!-- TODO: when the prompting guide is ready, mention the importance of setting the right prompt in this section -->
## 추가 자료 [[further-resources]]
자기회귀 생성 프로세스는 상대적으로 단순한 편이지만, LLM을 최대한 활용하려면 여러 가지 요소를 고려해야 하므로 쉽지 않을 수 있습니다. LLM에 대한 더 깊은 이해와 활용을 위한 다음 단계는 아래와 같습니다:
<!-- TODO: complete with new guides -->
### 고급 생성 사용 [[advanced-generate-usage]]
1. [가이드](generation_strategies)는 다양한 생성 방법을 제어하는 방법, 생성 설정 파일을 설정하는 방법, 출력을 스트리밍하는 방법에 대해 설명합니다.
2. [`~generation.GenerationConfig`]와 [`~generation.GenerationMixin.generate`], [generate-related classes](internal/generation_utils)를 참조해보세요.
### LLM 리더보드 [[llm-leaderboards]]
1. [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)는 오픈 소스 모델의 품질에 중점을 둡니다.
2. [Open LLM-Perf Leaderboard](https://huggingface.co/spaces/optimum/llm-perf-leaderboard)는 LLM 처리량에 중점을 둡니다.
### 지연 시간 및 처리량 [[latency-and-throughput]]
1. 메모리 요구 사항을 줄이려면, 동적 양자화에 대한 [가이드](main_classes/quantization)를 참조하세요.
### 관련 라이브러리 [[related-libraries]]
1. [`text-generation-inference`](https://github.com/huggingface/text-generation-inference)는 LLM을 위한 실제 운영 환경에 적합한 서버입니다.
2. [`optimum`](https://github.com/huggingface/optimum)은 특정 하드웨어 장치에서 LLM을 최적화하기 위해 🤗 Transformers를 확장한 것입니다.
| transformers/docs/source/ko/llm_tutorial.md/0 | {
"file_path": "transformers/docs/source/ko/llm_tutorial.md",
"repo_id": "transformers",
"token_count": 8185
} | 274 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 다중 GPU에서 효율적인 훈련 [[efficient-training-on-multiple-gpus]]
단일 GPU에서의 훈련이 너무 느리거나 모델 가중치가 단일 GPU의 메모리에 맞지 않는 경우, 다중-GPU 설정을 사용합니다. 단일 GPU에서 다중 GPU로 전환하기 위해서는 작업을 분산해야 합니다. 데이터, 텐서 또는 파이프라인과 같은 병렬화 기법을 사용하여 작업을 병렬로 처리할 수 있습니다. 그러나 이러한 설정을 모두에게 적용할 수 있는 완벽한 해결책은 없으며, 어떤 설정이 가장 적합한지는 사용하는 하드웨어에 따라 달라집니다. 이 문서는 주로 PyTorch 기반의 구현을 중심으로 설명하며, 대부분의 개념은 다른 프레임워크에도 적용될 수 있을 것으로 예상됩니다.
<Tip>
참고: [단일 GPU 섹션](perf_train_gpu_one)에서 소개된 전략(혼합 정밀도 훈련 또는 그래디언트 누적 등)은 일반적으로 모델 훈련에 적용되며, 다중-GPU 또는 CPU 훈련과 같은 다음 섹션으로 진입하기 전에 해당 섹션을 참고하는 것이 좋습니다.
</Tip>
먼저 1D 병렬화 기술에 대해 자세히 논의한 후, 이러한 기술을 결합하여 2D 및 3D 병렬화를 구현하여 더 빠른 훈련과 더 큰 모델을 지원하는 방법을 살펴볼 것입니다. 또한 다른 효과적인 대안 방식도 소개될 예정입니다.
## 개념 [[concepts]]
다음은 이 문서에서 자세히 설명될 주요 개념에 대한 간단한 설명입니다.
1. **DataParallel (DP)** - 동일한 설정이 여러 번 복제되고, 각 설정에 데이터 일부를 받습니다. 처리는 병렬로 수행되며 모든 설정은 각 훈련 단계의 끝날 때 동기화됩니다.
2. **TensorParallel (TP)** - 각 텐서는 여러 개의 묶음으로 분할되기에, 전체 텐서가 단일 GPU에 상주하는 대신 텐서의 각 샤드가 지정된 GPU에 상주합니다. 처리하는 동안 각 샤드는 서로 다른 GPU에서 개별적으로 병렬 처리되며 결과는 단계가 끝날 때 동기화됩니다. 분할이 수평 수준에서 이루어지기 때문에 이를 수평 병렬 처리라고 부를 수 있습니다.
3. **PipelineParallel (PP)** - 모델이 수직으로 (레이어 수준) 여러 GPU에 분할되어 모델의 단일 GPU에는 하나 또는 여러 레이어가 배치됩니다. 각 GPU는 파이프라인의 서로 다른 단계를 병렬로 처리하며 작은 배치 묶음에서 작동합니다.
4. **Zero Redundancy Optimizer (ZeRO)** - TP와 유사하게 텐서를 샤딩하지만, 전체 텐서는 순방향 또는 역방향 계산을 위해 재구성되므로 모델을 수정할 필요가 없습니다. 또한 제한된 GPU 메모리를 보완하기 위해 다양한 오프로드 기술을 지원합니다.
5. **Sharded DDP** - ZeRO의 기본 개념으로 다른 ZeRO 구현에서도 사용되는 용어입니다.
각 개념의 구체적인 내용에 대해 자세히 들어가기 전에 대규모 인프라에서 대규모 모델을 훈련하는 경우의 대략적인 결정 과정을 살펴보겠습니다.
## 확장성 전략 [[scalability-strategy]]
**⇨ 단일 노드 / 다중-GPU**
* 모델이 단일 GPU에 맞는 경우:
1. DDP - 분산 DP
2. ZeRO - 상황과 구성에 따라 더 빠를 수도 있고 그렇지 않을 수도 있음
* 모델이 단일 GPU에 맞지 않는 경우:
1. PP
2. ZeRO
3. TP
노드 내 연결 속도가 매우 빠른 NVLINK 또는 NVSwitch의 경우 세 가지 방법은 대부분 비슷한 성능을 보여야 하며, PP가 없는 경우 TP 또는 ZeRO보다 빠를 것입니다. TP의 정도도 차이를 만들 수 있습니다. 특정 설정에서 승자를 찾기 위해 실험하는 것이 가장 좋습니다.
TP는 거의 항상 단일 노드 내에서 사용됩니다. 즉, TP 크기 <= 노드당 GPU 수입니다.
* 가장 큰 레이어가 단일 GPU에 맞지 않는 경우:
1. ZeRO를 사용하지 않는 경우 - PP만으로는 맞지 않으므로 TP를 반드시 사용해야 함
2. ZeRO를 사용하는 경우에는 위의 "단일 GPU" 항목과 동일
**⇨ 다중 노드 / 다중 GPU**
* 노드 간 연결 속도가 빠른 경우:
1. ZeRO - 모델에 대부분의 수정을 필요로 하지 않음
2. PP+TP+DP - 통신이 적지만 모델에 대대적인 변경이 필요함
* 노드 간 연결 속도가 느리며, GPU 메모리가 여전히 부족한 경우:
1. DP+PP+TP+ZeRO-1
## 데이터 병렬화 [[data-parallelism]]
2개의 GPU만으로도 대부분의 사용자들은 `DataParallel` (DP)과 `DistributedDataParallel` (DDP)을 통해 향상된 훈련 속도를 누릴 수 있습니다. 이는 PyTorch의 내장 기능입니다. 일반적으로 DDP를 사용하는 것이 좋으며, DP는 일부 모델에서 작동하지 않을 수 있으므로 주의해야 합니다. [PyTorch 문서](https://pytorch.org/docs/master/generated/torch.nn.DataParallel.html)에서도 DDP의 사용을 권장합니다.
### DP vs DDP [[dp-vs-ddp]]
`DistributedDataParallel` (DDP)은 일반적으로 `DataParallel` (DP)보다 빠르지만, 항상 그렇지는 않습니다:
* DP는 파이썬 스레드 기반인 반면, DDP는 다중 프로세스 기반이기 때문에 GIL과 같은 파이썬 스레드 제한이 없습니다.
* 그러나 GPU 카드 간의 느린 상호 연결성은 DDP로 인해 실제로 느린 결과를 낼 수 있습니다.
이 두 모드 간의 GPU 간 통신 오버헤드의 주요 차이점은 다음과 같습니다:
[DDP](https://pytorch.org/docs/master/notes/ddp.html):
- 시작할 때, 주 프로세스가 모델을 gpu 0에서 다른 모든 gpu로 복제합니다.
- 그런 다음 각 배치에 대해:
1. 각 gpu는 자체 미니 배치 데이터를 직접 사용합니다.
2. `backward` 동안 로컬 그래디언트가 준비되면, 모든 프로세스에 평균화됩니다.
[DP](https://pytorch.org/docs/master/generated/torch.nn.DataParallel.html):
각 배치에 대해:
1. gpu 0은 데이터 배치를 읽고 각 gpu에 미니 배치를 보냅니다.
2. 업데이트된 모델을 gpu 0에서 각 gpu로 복제합니다.
3. `forward`를 실행하고 각 gpu의 출력을 gpu 0으로 보내고 손실을 계산합니다.
4. gpu 0에서 모든 gpu로 손실을 분산하고 `backward`를 실행합니다.
5. 각 gpu에서 그래디언트를 gpu 0으로 보내고 이를 평균화합니다.
DDP는 각 배치마다 그래디언트를 보내는 통신만을 수행하며, DP는 배치마다 5개의 다른 데이터 교환을 수행합니다.
DP는 파이썬 스레드를 통해 프로세스 내에서 데이터를 복제하며, DDP는 [torch.distributed](https://pytorch.org/docs/master/distributed.html)를 통해 데이터를 복제합니다.
DP에서는 gpu 0이 다른 gpu보다 훨씬 더 많은 작업을 수행하므로, gpu의 활용도가 낮아집니다.
DDP는 여러 대의 컴퓨터에서 사용할 수 있지만, DP의 경우는 그렇지 않습니다.
DP와 DDP 사이에는 다른 차이점이 있지만, 이 토론과는 관련이 없습니다.
이 2가지 모드를 깊게 이해하고 싶다면, [이 문서](https://www.telesens.co/2019/04/04/distributed-data-parallel-training-using-pytorch-on-aws/)를 강력히 추천합니다. 이 문서는 멋진 다이어그램을 포함하고 있으며, 다양한 하드웨어에서 여러 벤치마크와 프로파일러 출력을 설명하여 필요한 세부 사항을 모두 설명합니다.
실제 벤치마크를 살펴보겠습니다:
| Type | NVlink | Time |
| :----- | ----- | ---: |
| 2:DP | Y | 110s |
| 2:DDP | Y | 101s |
| 2:DDP | N | 131s |
분석:
여기서 DP는 NVlink가 있는 DDP보다 약 10% 느립니다. 그러나 NVlink가 없는 DDP보다 약 15% 빠릅니다.
실제 차이는 각 GPU가 다른 GPU와 동기화해야 하는 데이터 양에 따라 달라질 것입니다. 동기화할 데이터가 많을수록 느린 링크가 총 실행 시간을 늦출 수 있습니다.
다음은 전체 벤치마크 코드와 출력입니다:
해당 벤치마크에서 `NCCL_P2P_DISABLE=1`을 사용하여 NVLink 기능을 비활성화했습니다.
```
# DP
rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 \
python examples/pytorch/language-modeling/run_clm.py \
--model_name_or_path gpt2 --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 \
--do_train --output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
{'train_runtime': 110.5948, 'train_samples_per_second': 1.808, 'epoch': 0.69}
# DDP w/ NVlink
rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 \
torchrun --nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py \
--model_name_or_path gpt2 --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 \
--do_train --output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
{'train_runtime': 101.9003, 'train_samples_per_second': 1.963, 'epoch': 0.69}
# DDP w/o NVlink
rm -r /tmp/test-clm; NCCL_P2P_DISABLE=1 CUDA_VISIBLE_DEVICES=0,1 \
torchrun --nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py \
--model_name_or_path gpt2 --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 \
--do_train --output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
{'train_runtime': 131.4367, 'train_samples_per_second': 1.522, 'epoch': 0.69}
```
하드웨어: 각각 24GB의 TITAN RTX 2개 + NVlink과 2개의 NVLink (`nvidia-smi topo -m`에서 `NV2`입니다.)
소프트웨어: `pytorch-1.8-to-be` + `cuda-11.0` / `transformers==4.3.0.dev0`
## ZeRO 데이터 병렬화 [[zero-data-parallelism]]
ZeRO를 기반으로 한 데이터 병렬화 (ZeRO-DP)는 다음 [블로그 글](https://www.microsoft.com/en-us/research/blog/zero-deepspeed-new-system-optimizations-enable-training-models-with-over-100-billion-parameters/)의 다음 다이어그램에서 설명되고 있습니다.

이 개념은 이해하기 어려울 수 있지만, 실제로는 매우 간단한 개념입니다. 이는 일반적인 `DataParallel` (DP)과 동일하지만, 전체 모델 매개변수, 그래디언트 및 옵티마이저 상태를 복제하는 대신 각 GPU는 그 중 일부만 저장합니다. 그리고 실행 시간에는 주어진 레이어에 대해 전체 레이어 매개변수가 필요할 때 각 GPU가 서로에게 필요한 부분을 제공하기 위해 동기화됩니다 - 그게 전부입니다.
각각 3개의 레이어와 3개의 매개변수가 있는 간단한 모델을 생각해 봅시다:
```
La | Lb | Lc
---|----|---
a0 | b0 | c0
a1 | b1 | c1
a2 | b2 | c2
```
레이어 La에는 가중치 a0, a1 및 a2가 있습니다.
3개의 GPU가 있는 경우, Sharded DDP (= Zero-DP)는 다음과 같이 모델을 3개의 GPU에 분할합니다:
```
GPU0:
La | Lb | Lc
---|----|---
a0 | b0 | c0
GPU1:
La | Lb | Lc
---|----|---
a1 | b1 | c1
GPU2:
La | Lb | Lc
---|----|---
a2 | b2 | c2
```
일반적인 DNN 다이어그램을 상상해보면 이는 텐서 병렬 처리와 같은 수평 슬라이싱입니다. 수직 슬라이싱은 전체 레이어 그룹을 다른 GPU에 배치하는 것입니다. 이는 시작에 불과합니다.
이제 이러한 각각의 GPU는 DP에서 작동하는 것과 마찬가지로 일반적인 미니 배치를 받습니다:
```
x0 => GPU0
x1 => GPU1
x2 => GPU2
```
입력은 수정되지 않은 상태로 일반 모델에 의해 처리될 것으로 간주합니다.
먼저, 입력은 레이어 La에 도달합니다.
GPU0에만 집중해 보겠습니다. x0은 순방향 경로를 수행하기 위해 a0, a1, a2 파라미터가 필요하지만 GPU0에는 a0만 있습니다. GPU1에서 a1을, GPU2에서 a2를 전송받아 모델의 모든 조각을 하나로 모읍니다.
병렬적으로, GPU1은 미니 배치 x1을 받고 a1만 가지고 있지만, a0 및 a2 매개변수가 필요합니다. 따라서 GPU0 및 GPU2에서 이를 가져옵니다.
GPU2도 동일한 작업을 수행합니다. 입력 x2를 받고 GPU0 및 GPU1에서 각각 a0과 a1을, 그리고 자신의 a2와 함께 전체 텐서를 복원합니다.
3개의 GPU는 복원된 전체 텐서를 받고 forward가 수행됩니다.
계산이 완료되면 더 이상 필요하지 않은 데이터는 삭제되고, 해당 데이터는 계산 중에만 사용됩니다. 복원은 사전 패치를 통해 효율적으로 수행됩니다.
그리고 전체 프로세스는 레이어 Lb에 대해 반복되고, 그 다음 Lc로 순방향으로, 그다음은 역방향으로 Lc -> Lb -> La로 반복됩니다.
개인적으로 이것은 효율적인 그룹 배낭 여행자의 중량 분배 전략처럼 들립니다:
1. 사람 A가 텐트를 운반합니다.
2. 사람 B가 난로를 운반합니다.
3. 사람 C가 도끼를 운반합니다.
이제 매일 밤 각자 가진 것을 다른 사람들과 공유하고, 가지지 않은 것은 다른 사람들로부터 받고, 아침에는 할당된 유형의 장비를 싸고 계속해서 여행을 진행합니다. 이것이 Sharded DDP / Zero DP입니다.
이 전략을 각각 자신의 텐트, 난로 및 도끼를 개별적으로 운반해야 하는 단순한 전략과 비교해보면 훨씬 비효율적일 것입니다. 이것이 Pytorch의 DataParallel (DP 및 DDP)입니다.
이 주제에 대해 논문을 읽을 때 다음 동의어를 만날 수 있습니다: Sharded, Partitioned.
ZeRO가 모델 가중치를 분할하는 방식을 자세히 살펴보면, 텐서 병렬화와 매우 유사한 것을 알 수 있습니다. 이는 이후에 설명될 수직 모델 병렬화와는 달리 각 레이어의 가중치를 분할/분할하기 때문입니다.
구현:
- [DeepSpeed](https://www.deepspeed.ai/tutorials/zero/)는 1단계 + 2단계 + 3단계의 ZeRO-DP를 제공합니다.
- [Fairscale](https://github.com/facebookresearch/fairscale/#optimizer-state-sharding-zero)은 1단계 + 2단계 + 3단계의 ZeRO-DP를 제공합니다.
- [`transformers` 통합](main_classes/trainer#trainer-integrations)
## 네이티브 모델 병렬 처리(수직적) 및 파이프라인 병렬 처리[[naive-model-parallelism-vertical-and-pipeline-parallelism]]
Naive Model Parallelism (MP)은 모델 레이어 그룹을 다중 GPU에 분산하는 방식입니다. 메커니즘은 상대적으로 간단합니다. 원하는 레이어를 `.to()`를 사용하여 원하는 장치로 전환하면 데이터가 해당 레이어로 들어오고 나갈 때 데이터도 레이어와 동일한 장치로 전환되고 나머지는 수정되지 않습니다.
대부분의 모델이 그려지는 방식이 레이어를 세로로 슬라이스하기 때문에 이를 수직 모델 병렬화라고 부릅니다. 예를 들어 다음 다이어그램은 8레이어 모델을 보여줍니다:
```
=================== ===================
| 0 | 1 | 2 | 3 | | 4 | 5 | 6 | 7 |
=================== ===================
gpu0 gpu1
```
우리는 모델을 수직으로 2개로 분할하여 레이어 0-3을 GPU0에 배치하고 레이어 4-7을 GPU1에 배치했습니다.
이제 데이터가 레이어 0에서 1로, 1에서 2로, 2에서 3으로 이동하는 동안에는 일반적인 모델입니다. 그러나 데이터가 레이어 3에서 레이어 4로 전달되어야 할 때는 GPU0에서 GPU1로 이동해야 하므로 통신 오버헤드가 발생합니다. 참여하는 GPU가 동일한 컴퓨팅 노드(예: 동일한 물리적인 기계)에 있는 경우 이 복사는 매우 빠릅니다. 그러나 GPU가 서로 다른 컴퓨팅 노드(예: 여러 기계)에 위치한 경우 통신 오버헤드는 상당히 크게 될 수 있습니다.
그런 다음 레이어 4부터 5로, 6으로, 7로 진행되는 것은 일반적인 모델과 동일하게 진행되고, 7번째 레이어가 완료되면 데이터를 다시 레이어 0으로 보내거나 또는 레이블을 마지막 레이어로 보내야 할 필요가 있습니다. 이제 손실을 계산하고 옵티마이저가 작동할 수 있습니다.
문제점:
- 이 방식을 "naive" MP라고 부르는 이유는 주어진 상황에 하나의 GPU를 제외한 모든 GPU가 유휴 상태라는 점입니다. 따라서 4개의 GPU를 사용하는 경우 단일 GPU의 메모리 양을 4배로 늘리고 나머지 하드웨어는 무시하는 것과 거의 동일합니다. 또한 장치 간 데이터 복사의 오버헤드도 있습니다. 따라서 4개의 6GB 카드는 naive MP를 사용하여 1개의 24GB 카드와 동일한 크기를 수용할 수 있지만, 후자는 데이터 복사의 오버헤드가 없으므로 훈련을 더 빨리 완료합니다. 그러나 예를 들어 40GB 카드가 있고 45GB 모델을 맞추어야 할 경우 4개의 40GB 카드로 맞출 수 있습니다 (하지만 그래디언트와 옵티마이저 상태 때문에 가까스로 가능합니다).
- 공유 임베딩은 GPU 간에 복사해야 할 수도 있습니다.
파이프라인 병렬화 (PP)은 거의 naive MP와 동일하지만 GPU 유휴 상태 문제를 해결하기 위해 들어오는 배치를 마이크로 배치로 나누고 인공적으로 파이프라인을 생성하여 서로 다른 GPU가 동시에 계산에 참여할 수 있게 합니다.
[GPipe 논문](https://ai.googleblog.com/2019/03/introducing-gpipe-open-source-library.html)에서 가져온 그림은 상단에 naive MP를, 하단에는 PP를 보여줍니다:

하단 다이어그램에서 PP가 유휴 영역이 적은 것을 쉽게 볼 수 있습니다. 유휴 부분을 "bubble"이라고 합니다.
다이어그램의 양쪽 부분은 참여하는 GPU가 4개인 병렬성을 보여줍니다. 즉, 4개의 GPU가 파이프라인에 참여합니다. 따라서 4개의 파이프 단계 F0, F1, F2 및 F3의 순방향 경로와 B3, B2, B1 및 B0의 역방향 경로가 있습니다.
PP는 조정해야 할 새로운 하이퍼파라미터인 `chunks`를 도입합니다. 이는 동일한 파이프 단계를 통해 일련의 데이터를 묶어서 보내는 방식을 정의합니다. 예를 들어, 아래 다이어그램에서 `chunks=4`를 볼 수 있습니다. GPU0은 0, 1, 2 및 3 (F0,0, F0,1, F0,2, F0,3) 묶음에서 동일한 순방향 경로를 수행하고, 다른 GPU가 작업을 수행하기 시작하고 완료가 시작될 때만 GPU0이 묶음의 역순으로 3, 2, 1 및 0 (B0,3, B0,2, B0,1, B0,0) 경로를 수행합니다.
개념적으로 이는 그래디언트 누적 단계 (GAS)와 동일한 개념입니다. 파이토치에서는 `chunks`를 사용하고 DeepSpeed에서는 동일한 하이퍼파라미터를 GAS로 참조합니다.
묶음으로 인해 PP는 마이크로 배치 (MBS)의 개념을 도입합니다. DP는 전역 데이터 배치 크기를 미니 배치로 나눕니다. 따라서 DP 차수가 4이고 전역 배치 크기가 1024이면 256씩 4개의 미니 배치로 분할됩니다 (1024/4). 그리고 `chunks` (또는 GAS)의 수가 32이면 마이크로 배치 크기는 8이 됩니다 (256/32). 각 파이프라인 단계는 한 번에 하나의 마이크로 배치와 함께 작동합니다.
DP + PP 설정의 전역 배치 크기를 계산하려면 `mbs*chunks*dp_degree` (`8*32*4=1024`)를 수행합니다.
다이어그램으로 돌아가 보겠습니다.
`chunks=1`로 설정하면 매우 비효율적인 naive MP가 생성되며, 매우 큰 `chunks` 값으로 설정하면 아주 작은 마이크로 배치 크기가 생성되어 효율적이지 않을 수 있습니다. 따라서 가장 효율적인 GPU 활용을 위해 어떤 값이 가장 적절한지 실험을 해야 합니다.
다이어그램에서 보이는 것처럼 "dead" 시간의 버블이 존재하여 마지막 `forward` 단계가 `backward` 단계가 파이프라인을 완료하기를 기다려야 하는 상황이 발생하지만, `chunks`의 가장 적절한 값을 찾는 것의 목적은 모든 참여하는 GPU에서 동시에 고도로 활용되는 GPU 활용을 가능하게 하여 버블의 크기를 최소화하는 것입니다.
해결책은 전통적인 파이프라인 API와 더 현대적인 솔루션으로 나뉩니다. 전통적인 파이프라인 API 솔루션과 현대적인 솔루션에 대해 알아보겠습니다.
전통적인 파이프라인 API 솔루션:
- 파이토치
- FairScale
- DeepSpeed
- Megatron-LM
현대적인 솔루션:
- Varuna
- Sagemaker
전통적인 파이프라인 API 솔루션의 문제점:
- 모델을 상당히 수정해야 한다는 점이 문제입니다. 파이프라인은 모듈의 정상적인 흐름을 `nn.Sequential` 시퀀스로 다시 작성해야 하므로 모델의 설계를 변경해야 할 수 있습니다.
- 현재 파이프라인 API는 매우 제한적입니다. 파이프라인의 매우 첫 번째 단계에서 전달되는 많은 파이썬 변수가 있는 경우 이를 해결해야 합니다. 현재 파이프라인 인터페이스는 하나의 텐서 또는 텐서의 튜플을 유일한 입력 및 출력으로 요구합니다. 이러한 텐서는 마이크로 배치로 미니 배치로 묶을 것이므로 첫 번째 차원으로 배치 크기가 있어야 합니다. 가능한 개선 사항은 여기에서 논의되고 있습니다. https://github.com/pytorch/pytorch/pull/50693
- 파이프 단계 수준에서 조건부 제어 흐름은 불가능합니다. 예를 들어, T5와 같은 인코더-디코더 모델은 조건부 인코더 단계를 처리하기 위해 특별한 해결책이 필요합니다.
- 각 레이어를 정렬하여 하나의 모델의 출력이 다른 모델의 입력이 되도록해야 합니다.
우리는 아직 Varuna와 SageMaker로 실험하지 않았지만, 해당 논문들은 위에서 언급한 문제들의 목록을 극복했고 사용자의 모델에 대한 변경 사항이 훨씬 적게 필요하다고 보고하고 있습니다.
구현:
- [파이토치](https://pytorch.org/docs/stable/pipeline.html) (파이토치-1.8에서 초기 지원, 1.9에서 점진적으로 개선되고 1.10에서 더 개선됨). [예제](https://github.com/pytorch/pytorch/blob/master/benchmarks/distributed/pipeline/pipe.py)도 참고하세요.
- [FairScale](https://fairscale.readthedocs.io/en/latest/tutorials/pipe.html)
- [DeepSpeed](https://www.deepspeed.ai/tutorials/pipeline/)
- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)은 내부 구현을 가지고 있습니다 - API 없음.
- [Varuna](https://github.com/microsoft/varuna)
- [SageMaker](https://arxiv.org/abs/2111.05972) - 이는 AWS에서만 사용할 수 있는 소유 솔루션입니다.
- [OSLO](https://github.com/tunib-ai/oslo) - 이는 Hugging Face Transformers를 기반으로 구현된 파이프라인 병렬화입니다.
🤗 Transformers 상태: 이 작성 시점에서 모델 중 어느 것도 완전한 PP를 지원하지 않습니다. GPT2와 T5 모델은 naive MP를 지원합니다. 주요 장애물은 모델을 `nn.Sequential`로 변환하고 모든 입력을 텐서로 가져와야 하는 것을 처리할 수 없기 때문입니다. 현재 모델에는 이러한 변환을 매우 복잡하게 만드는 많은 기능이 포함되어 있어 제거해야 합니다.
기타 접근 방법:
DeepSpeed, Varuna 및 SageMaker는 [교차 파이프라인(Interleaved Pipeline)](https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel-core-features.html) 개념을 사용합니다.

여기서는 버블(유휴 시간)을 역방향 패스에 우선순위를 부여하여 최소화합니다.
Varuna는 가장 효율적인 스케줄링을 찾기 위해 시뮬레이션을 사용하여 스케줄을 개선하려고 합니다.
OSLO는 `nn.Sequential`로 변환하지 않고 Transformers를 기반으로 한 파이프라인 병렬화를 구현했습니다.
## 텐서 병렬 처리 [[tensor-parallelism]]
텐서 병렬 처리에서는 각 GPU가 텐서의 일부분만 처리하고 전체 텐서가 필요한 연산에 대해서만 전체 텐서를 집계합니다.
이 섹션에서는 [Megatron-LM](https://github.com/NVIDIA/Megatron-LM) 논문인 [Efficient Large-Scale Language Model Training on GPU Clusters](https://arxiv.org/abs/2104.04473)에서의 개념과 다이어그램을 사용합니다.
Transformer의 주요 구성 요소는 fully connected `nn.Linear`와 비선형 활성화 함수인 `GeLU`입니다.
Megatron 논문의 표기법을 따라 행렬의 점곱 부분을 `Y = GeLU(XA)`로 표현할 수 있습니다. 여기서 `X`와 `Y`는 입력 및 출력 벡터이고 `A`는 가중치 행렬입니다.
행렬 형태로 계산을 살펴보면, 행렬 곱셈을 다중 GPU로 분할할 수 있는 방법을 쉽게 알 수 있습니다:

가중치 행렬 `A`를 `N`개의 GPU에 대해 열별로 분할하고 병렬로 행렬 곱셈 `XA_1`에서 `XA_n`까지 수행하면 `N`개의 출력 벡터 `Y_1, Y_2, ..., Y_n`가 생성되며 독립적으로 `GeLU`에 전달될 수 있습니다:

이 원리를 사용하여 동기화가 필요하지 않은 GPU 간의 임의 깊이의 MLP를 업데이트할 수 있습니다. 그러나 결과 벡터를 샤드로부터 재구성해야 하는 마지막 단계까지는 GPU 간의 동기화가 필요합니다. Megatron-LM 논문의 저자들은 이에 대한 유용한 그림을 제공합니다:

다중 헤드 어텐션 레이어의 병렬화는 더욱 간단합니다. 이미 독립적인 다중 헤드를 가지고 있기 때문에 이미 병렬화되어 있습니다!

특별 고려사항: TP는 매우 빠른 네트워크가 필요하므로 한 개 이상의 노드에서 TP를 수행하는 것은 권장되지 않습니다. 실제로 노드에 4개의 GPU가 있는 경우 TP의 최대 차수는 4입니다. TP 차수가 8인 경우 최소한 8개의 GPU가 있는 노드를 사용해야 합니다.
이 섹션은 원래의 [더 자세한 TP 개요](https://github.com/huggingface/transformers/issues/10321#issuecomment-783543530)를 기반으로 합니다.
작성자는 [@anton-l](https://github.com/anton-l)입니다.
SageMaker는 더 효율적인 처리를 위해 TP와 DP를 결합합니다.
대체 이름:
- DeepSpeed는 이를 [텐서 슬라이싱](https://www.deepspeed.ai/training/#model-parallelism)이라고 부릅니다.
구현:
- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)은 내부 구현을 가지고 있으므로 모델에 매우 특화되어 있습니다.
- [parallelformers](https://github.com/tunib-ai/parallelformers) (현재는 추론에만 해당)
- [SageMaker](https://arxiv.org/abs/2111.05972) - 이는 AWS에서만 사용할 수 있는 소유 솔루션입니다.
- [OSLO](https://github.com/tunib-ai/oslo)은 Transformers를 기반으로 한 텐서 병렬 처리 구현을 가지고 있습니다.
🤗 Transformers 현황:
- core: 아직 핵심 부분에 구현되지 않음
- 그러나 추론을 하려면 [parallelformers](https://github.com/tunib-ai/parallelformers)가 대부분의 모델을 지원합니다. 따라서 핵심 부분에 구현되기 전까지 그들의 것을 사용할 수 있습니다. 그리고 훈련 모드도 지원될 예정입니다.
- Deepspeed-Inference는 CUDA 커널을 기반으로 하는 매우 빠른 추론 모드에서 BERT, GPT-2 및 GPT-Neo 모델을 지원합니다. 자세한 내용은 [여기](https://www.deepspeed.ai/tutorials/inference-tutorial/)를 참조하세요.
## DP+PP [[dppp]]
DeepSpeed [pipeline tutorial](https://www.deepspeed.ai/tutorials/pipeline/)에서 다음 다이어그램은 DP와 PP를 결합하는 방법을 보여줍니다.

여기서 DP 랭크 0은 GPU2를 보지 못하고, DP 랭크 1은 GPU3을 보지 못하는 것이 중요합니다. DP에게는 딱 2개의 GPU인 것처럼 데이터를 공급합니다. GPU0은 PP를 사용하여 GPU2에게 일부 작업을 "비밀리에" 할당합니다. 그리고 GPU1도 GPU3을 도움으로 삼아 같은 방식으로 작업합니다.
각 차원마다 적어도 2개의 GPU가 필요하므로 최소한 4개의 GPU가 필요합니다.
구현:
- [DeepSpeed](https://github.com/microsoft/DeepSpeed)
- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)
- [Varuna](https://github.com/microsoft/varuna)
- [SageMaker](https://arxiv.org/abs/2111.05972)
- [OSLO](https://github.com/tunib-ai/oslo)
🤗 Transformers 현황: 아직 구현되지 않음
## DP+PP+TP [[dppptp]]
더 효율적인 훈련을 위해 PP와 TP 및 DP를 결합하여 3D 병렬 처리를 사용합니다. 다음 다이어그램에서 이를 확인할 수 있습니다.

이 다이어그램은 [3D parallelism: Scaling to trillion-parameter models](https://www.microsoft.com/en-us/research/blog/deepspeed-extreme-scale-model-training-for-everyone/)이라는 블로그 글에서 확인할 수 있습니다.
각 차원마다 적어도 2개의 GPU가 필요하므로 최소한 8개의 GPU가 필요합니다.
구현:
- [DeepSpeed](https://github.com/microsoft/DeepSpeed) - DeepSpeed는 더욱 효율적인 DP인 ZeRO-DP라고도 부릅니다.
- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)
- [Varuna](https://github.com/microsoft/varuna)
- [SageMaker](https://arxiv.org/abs/2111.05972)
- [OSLO](https://github.com/tunib-ai/oslo)
🤗 Transformers 현황: 아직 구현되지 않음. PP와 TP가 없기 때문입니다.
## ZeRO DP+PP+TP [[zero-dppptp]]
DeepSpeed의 주요 기능 중 하나는 DP의 확장인 ZeRO입니다. ZeRO-DP에 대해 이미 [ZeRO Data Parallelism](#zero-data-parallelism)에서 논의되었습니다. 일반적으로 이는 PP나 TP를 필요로하지 않는 독립적인 기능입니다. 그러나 PP와 TP와 결합할 수도 있습니다.
ZeRO-DP가 PP와 (선택적으로 TP와) 결합되면 일반적으로 ZeRO 단계 1(옵티마이저 분할)만 활성화됩니다.
이론적으로는 ZeRO 단계 2(그라디언트 분할)를 파이프라인 병렬 처리와 함께 사용할 수도 있지만, 이는 성능에 나쁜 영향을 미칠 것입니다. 각 마이크로 배치마다 그라디언트를 샤딩하기 전에 추가적인 리듀스-스캐터 컬렉티브가 필요하며, 이는 잠재적으로 상당한 통신 오버헤드를 추가합니다. 파이프라인 병렬 처리의 특성상 작은 마이크로 배치가 사용되며, 산술 연산 강도(마이크로 배치 크기)를 균형 있게 유지하면서 파이프라인 버블(마이크로 배치 수)을 최소화하는 것에 중점을 둡니다. 따라서 해당 통신 비용은 문제가 될 것입니다.
또한, PP로 인해 정상보다 적은 수의 레이어가 있으므로 메모리 절약은 크지 않을 것입니다. PP는 이미 그래디언트 크기를 ``1/PP``로 줄이기 때문에 그래디언트 샤딩의 절약 효과는 순수 DP보다는 미미합니다.
ZeRO 단계 3도 같은 이유로 좋은 선택이 아닙니다 - 더 많은 노드 간 통신이 필요합니다.
그리고 ZeRO가 있기 때문에 다른 이점은 ZeRO-Offload입니다. 이는 단계 1이므로 옵티마이저 상태를 CPU로 오프로드할 수 있습니다.
구현:
- [Megatron-DeepSpeed](https://github.com/microsoft/Megatron-DeepSpeed) 및 [BigScience의 Megatron-Deepspeed](https://github.com/bigscience-workshop/Megatron-DeepSpeed), 이전 저장소의 포크입니다.
- [OSLO](https://github.com/tunib-ai/oslo)
중요한 논문:
- [Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model](
https://arxiv.org/abs/2201.11990)
🤗 Transformers 현황: 아직 구현되지 않음, PP와 TP가 없기 때문입니다.
## FlexFlow [[flexflow]]
[FlexFlow](https://github.com/flexflow/FlexFlow)는 약간 다른 방식으로 병렬화 문제를 해결합니다.
논문: ["Beyond Data and Model Parallelism for Deep Neural Networks" by Zhihao Jia, Matei Zaharia, Alex Aiken](https://arxiv.org/abs/1807.05358)
이는 Sample-Operator-Attribute-Parameter를 기반으로 하는 일종의 4D 병렬화를 수행합니다.
1. Sample = 데이터 병렬화 (샘플별 병렬)
2. Operator = 단일 연산을 여러 하위 연산으로 병렬화
3. Attribute = 데이터 병렬화 (길이별 병렬)
4. Parameter = 모델 병렬화 (수평 또는 수직과 관계없이)
예시:
* Sample
512 길이의 10개의 배치를 가정해 봅시다. 이를 sample 차원으로 2개의 장치에 병렬화하면, 10 x 512는 5 x 2 x 512가 됩니다.
* Operator
레이어 정규화를 수행한다면, 우선 std를 계산하고 두 번째로 mean을 계산한 다음 데이터를 정규화할 수 있습니다. Operator 병렬화는 std와 mean을 병렬로 계산할 수 있도록 합니다. 따라서 operator 차원으로 2개의 장치 (cuda:0, cuda:1)에 병렬화하면, 먼저 입력 데이터를 두 장치로 복사한 다음 cuda:0에서 std를 계산하고 cuda:1에서 동시에 mean을 계산합니다.
* Attribute
512 길이의 10개의 배치가 있습니다. 이를 attribute 차원으로 2개의 장치에 병렬화하면, 10 x 512는 10 x 2 x 256이 됩니다.
* Parameter
이는 tensor 모델 병렬화 또는 naive layer-wise 모델 병렬화와 유사합니다.

이 프레임워크의 중요한 점은 (1) GPU/TPU/CPU 대 (2) RAM/DRAM 대 (3) 빠른 인트라-커넥트 대 느린 인터-커넥트와 같은 리소스를 고려하여 어디에서 어떤 병렬화를 사용할지를 알고리즘적으로 자동으로 최적화한다는 것입니다.
하나 매우 중요한 측면은 FlexFlow가 정적이고 고정된 워크로드를 가진 모델에 대한 DNN 병렬화를 최적화하기 위해 설계되었다는 것입니다. 동적인 동작을 가진 모델은 반복마다 다른 병렬화 전략을 선호할 수 있습니다.
따라서 이 프레임워크의 장점은 선택한 클러스터에서 30분 동안 시뮬레이션을 실행하고 이 특정 환경을 최적으로 활용하기 위한 최상의 전략을 제안한다는 것입니다. 부품을 추가/제거/교체하면 실행하고 그에 대한 계획을 다시 최적화한 후 훈련할 수 있습니다. 다른 설정은 자체적인 사용자 정의 최적화를 가질 수 있습니다.
🤗 Transformers 현황: 아직 통합되지 않음. 이미 [transformers.utils.fx](https://github.com/huggingface/transformers/blob/master/src/transformers/utils/fx.py)를 통해 모델을 FX-추적할 수 있으며, 이는 FlexFlow의 선행 조건입니다. 따라서 어떤 작업을 수행해야 FlexFlow가 우리의 모델과 함께 작동할 수 있는지 파악해야 합니다.
## 어떤 전략을 사용해야 할까요? [[which-strategy-to-use-when]]
다음은 어떤 병렬화 전략을 언제 사용해야 하는지에 대한 매우 대략적인 개요입니다. 각 목록의 첫 번째 전략이 일반적으로 더 빠릅니다.
**⇨ 단일 GPU**
* 모델이 단일 GPU에 맞는 경우:
1. 일반적인 사용
* 모델이 단일 GPU에 맞지 않는 경우:
1. ZeRO + CPU 및 옵션으로 NVMe 언로드
2. 위와 동일하게 사용하되, 가장 큰 레이어가 단일 GPU에 맞지 않는 경우 Memory Centric Tiling(자세한 내용은 아래 참조)을 추가적으로 사용
* 가장 큰 레이어가 단일 GPU에 맞지 않는 경우:
1. ZeRO - [Memory Centric Tiling](https://deepspeed.readthedocs.io/en/latest/zero3.html#memory-centric-tiling) (MCT) 활성화. 이를 통해 크기가 매우 큰 레이어를 임의로 분할하여 순차적으로 실행할 수 있습니다. MCT는 GPU에 활성화된 매개변수의 수를 줄이지만 활성화 메모리에는 영향을 주지 않습니다. 현재 작성 기준으로 이 요구사항은 매우 드물기 때문에 사용자가 `torch.nn.Linear`를 수동으로 수정해야 합니다.
**⇨ 단일 노드 / 다중 GPU**
* 모델이 단일 GPU에 맞는 경우:
1. DDP - 분산 DP
2. ZeRO - 상황과 구성에 따라 빠를 수도 있고 그렇지 않을 수도 있습니다.
* 모델이 단일 GPU에 맞지 않는 경우:
1. PP
2. ZeRO
3. TP
NVLINK 또는 NVSwitch를 통한 매우 빠른 인트라-노드 연결이 있는 경우 이 세 가지 방법은 거의 동등할 것이며, 이러한 연결이 없는 경우 PP가 TP나 ZeRO보다 빠를 것입니다. 또한 TP의 차수도 영향을 줄 수 있습니다. 특정 설정에서 우승자를 찾기 위해 실험하는 것이 가장 좋습니다.
TP는 거의 항상 단일 노드 내에서 사용됩니다. 즉, TP 크기 <= 노드당 GPU 수입니다.
* 가장 큰 레이어가 단일 GPU에 맞지 않는 경우:
1. ZeRO를 사용하지 않을 경우 - PP만 사용할 수 없으므로 TP를 사용해야 합니다.
2. ZeRO를 사용할 경우, "단일 GPU"의 항목과 동일한 항목 참조
**⇨ 다중 노드 / 다중 GPU**
* 빠른 노드 간 연결이 있는 경우:
1. ZeRO - 모델에 대한 수정이 거의 필요하지 않습니다.
2. PP+TP+DP - 통신이 적지만 모델에 대한 대규모 변경이 필요합니다.
* 느린 노드 간 연결 및 GPU 메모리 부족한 경우:
1. DP+PP+TP+ZeRO-1
| transformers/docs/source/ko/perf_train_gpu_many.md/0 | {
"file_path": "transformers/docs/source/ko/perf_train_gpu_many.md",
"repo_id": "transformers",
"token_count": 28483
} | 275 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 제로샷(zero-shot) 이미지 분류[[zeroshot-image-classification]]
[[open-in-colab]]
제로샷(zero-shot) 이미지 분류는 특정 카테고리의 예시가 포함된 데이터를 학습되지 않은 모델을 사용해 이미지 분류를 수행하는 작업입니다.
일반적으로 이미지 분류를 위해서는 레이블이 달린 특정 이미지 데이터로 모델 학습이 필요하며, 이 모델은 특정 이미지의 특징을 레이블에 "매핑"하는 방법을 학습합니다.
새로운 레이블이 있는 분류 작업에 이러한 모델을 사용해야 하는 경우에는, 모델을 "재보정"하기 위해 미세 조정이 필요합니다.
이와 대조적으로, 제로샷 또는 개방형 어휘(open vocabulary) 이미지 분류 모델은 일반적으로 대규모 이미지 데이터와 해당 설명에 대해 학습된 멀티모달(multimodal) 모델입니다.
이러한 모델은 제로샷 이미지 분류를 포함한 많은 다운스트림 작업에 사용할 수 있는 정렬된(aligned) 비전 언어 표현을 학습합니다.
이는 이미지 분류에 대한 보다 유연한 접근 방식으로, 추가 학습 데이터 없이 새로운 레이블이나 학습하지 못한 카테고리에 대해 모델을 일반화할 수 있습니다.
또한, 사용자가 대상 개체에 대한 자유 형식의 텍스트 설명으로 이미지를 검색할 수 있습니다.
이번 가이드에서 배울 내용은 다음과 같습니다:
* 제로샷 이미지 분류 파이프라인 만들기
* 직접 제로샷 이미지 분류 모델 추론 실행하기
시작하기 전에 필요한 라이브러리가 모두 설치되어 있는지 확인하세요:
```bash
pip install -q transformers
```
## 제로샷(zero-shot) 이미지 분류 파이프라인[[zeroshot-image-classification-pipeline]]
[`pipeline`]을 활용하면 가장 간단하게 제로샷 이미지 분류를 지원하는 모델로 추론해볼 수 있습니다.
[Hugging Face Hub에 업로드된 체크포인트](https://huggingface.co/models?pipeline_tag=zero-shot-image-classification&sort=downloads)에서 파이프라인을 인스턴스화합니다.
```python
>>> from transformers import pipeline
>>> checkpoint = "openai/clip-vit-large-patch14"
>>> detector = pipeline(model=checkpoint, task="zero-shot-image-classification")
```
다음으로, 분류하고 싶은 이미지를 선택하세요.
```py
>>> from PIL import Image
>>> import requests
>>> url = "https://unsplash.com/photos/g8oS8-82DxI/download?ixid=MnwxMjA3fDB8MXx0b3BpY3x8SnBnNktpZGwtSGt8fHx8fDJ8fDE2NzgxMDYwODc&force=true&w=640"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/owl.jpg" alt="Photo of an owl"/>
</div>
이미지와 해당 이미지의 후보 레이블인 `candidate_labels`를 파이프라인으로 전달합니다.
여기서는 이미지를 직접 전달하지만, 컴퓨터에 저장된 이미지의 경로나 url로 전달할 수도 있습니다.
`candidate_labels`는 이 예시처럼 간단한 단어일 수도 있고 좀 더 설명적인 단어일 수도 있습니다.
```py
>>> predictions = classifier(image, candidate_labels=["fox", "bear", "seagull", "owl"])
>>> predictions
[{'score': 0.9996670484542847, 'label': 'owl'},
{'score': 0.000199399160919711, 'label': 'seagull'},
{'score': 7.392891711788252e-05, 'label': 'fox'},
{'score': 5.96074532950297e-05, 'label': 'bear'}]
```
## 직접 제로샷(zero-shot) 이미지 분류하기[[zeroshot-image-classification-by-hand]]
이제 제로샷 이미지 분류 파이프라인 사용 방법을 살펴보았으니, 실행하는 방법을 살펴보겠습니다.
[Hugging Face Hub에 업로드된 체크포인트](https://huggingface.co/models?pipeline_tag=zero-shot-image-classification&sort=downloads)에서 모델과 프로세서를 가져오는 것으로 시작합니다.
여기서는 이전과 동일한 체크포인트를 사용하겠습니다:
```py
>>> from transformers import AutoProcessor, AutoModelForZeroShotImageClassification
>>> model = AutoModelForZeroShotImageClassification.from_pretrained(checkpoint)
>>> processor = AutoProcessor.from_pretrained(checkpoint)
```
다른 이미지를 사용해 보겠습니다.
```py
>>> from PIL import Image
>>> import requests
>>> url = "https://unsplash.com/photos/xBRQfR2bqNI/download?ixid=MnwxMjA3fDB8MXxhbGx8fHx8fHx8fHwxNjc4Mzg4ODEx&force=true&w=640"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/car.jpg" alt="Photo of a car"/>
</div>
프로세서를 사용해 모델의 입력을 준비합니다.
프로세서는 모델의 입력으로 사용하기 위해 이미지 크기를 변환하고 정규화하는 이미지 프로세서와 텍스트 입력을 처리하는 토크나이저로 구성됩니다.
```py
>>> candidate_labels = ["tree", "car", "bike", "cat"]
>>> inputs = processor(images=image, text=candidate_labels, return_tensors="pt", padding=True)
```
모델에 입력을 전달하고, 결과를 후처리합니다:
```py
>>> import torch
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> logits = outputs.logits_per_image[0]
>>> probs = logits.softmax(dim=-1).numpy()
>>> scores = probs.tolist()
>>> result = [
... {"score": score, "label": candidate_label}
... for score, candidate_label in sorted(zip(probs, candidate_labels), key=lambda x: -x[0])
... ]
>>> result
[{'score': 0.998572, 'label': 'car'},
{'score': 0.0010570387, 'label': 'bike'},
{'score': 0.0003393686, 'label': 'tree'},
{'score': 3.1572064e-05, 'label': 'cat'}]
``` | transformers/docs/source/ko/tasks/zero_shot_image_classification.md/0 | {
"file_path": "transformers/docs/source/ko/tasks/zero_shot_image_classification.md",
"repo_id": "transformers",
"token_count": 3889
} | 276 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Convertendo checkpoints do TensorFlow para Pytorch
Uma interface de linha de comando é fornecida para converter os checkpoints originais Bert/GPT/GPT-2/Transformer-XL/XLNet/XLM em modelos
que podem ser carregados usando os métodos `from_pretrained` da biblioteca.
<Tip>
A partir da versão 2.3.0 o script de conversão agora faz parte do transformers CLI (**transformers-cli**) disponível em qualquer instalação
transformers >= 2.3.0.
A documentação abaixo reflete o formato do comando **transformers-cli convert**.
</Tip>
## BERT
Você pode converter qualquer checkpoint do BERT em TensorFlow (em particular [os modelos pré-treinados lançados pelo Google](https://github.com/google-research/bert#pre-trained-models)) em um arquivo PyTorch usando um
[convert_bert_original_tf_checkpoint_to_pytorch.py](https://github.com/huggingface/transformers/tree/main/src/transformers/models/bert/convert_bert_original_tf_checkpoint_to_pytorch.py) script.
Esta Interface de Linha de Comando (CLI) recebe como entrada um checkpoint do TensorFlow (três arquivos começando com `bert_model.ckpt`) e o
arquivo de configuração (`bert_config.json`), e então cria um modelo PyTorch para esta configuração, carrega os pesos
do checkpoint do TensorFlow no modelo PyTorch e salva o modelo resultante em um arquivo PyTorch que pode
ser importado usando `from_pretrained()` (veja o exemplo em [quicktour](quicktour) , [run_glue.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification/run_glue.py) ).
Você só precisa executar este script de conversão **uma vez** para obter um modelo PyTorch. Você pode então desconsiderar o checkpoint em
TensorFlow (os três arquivos começando com `bert_model.ckpt`), mas certifique-se de manter o arquivo de configuração (\
`bert_config.json`) e o arquivo de vocabulário (`vocab.txt`), pois eles também são necessários para o modelo PyTorch.
Para executar este script de conversão específico, você precisará ter o TensorFlow e o PyTorch instalados (`pip install tensorflow`). O resto do repositório requer apenas o PyTorch.
Aqui está um exemplo do processo de conversão para um modelo `BERT-Base Uncased` pré-treinado:
```bash
export BERT_BASE_DIR=/path/to/bert/uncased_L-12_H-768_A-12
transformers-cli convert --model_type bert \
--tf_checkpoint $BERT_BASE_DIR/bert_model.ckpt \
--config $BERT_BASE_DIR/bert_config.json \
--pytorch_dump_output $BERT_BASE_DIR/pytorch_model.bin
```
Você pode baixar os modelos pré-treinados do Google para a conversão [aqui](https://github.com/google-research/bert#pre-trained-models).
## ALBERT
Converta os checkpoints do modelo ALBERT em TensorFlow para PyTorch usando o
[convert_albert_original_tf_checkpoint_to_pytorch.py](https://github.com/huggingface/transformers/tree/main/src/transformers/models/albert/convert_albert_original_tf_checkpoint_to_pytorch.py) script.
A Interface de Linha de Comando (CLI) recebe como entrada um checkpoint do TensorFlow (três arquivos começando com `model.ckpt-best`) e o
arquivo de configuração (`albert_config.json`), então cria e salva um modelo PyTorch. Para executar esta conversão, você
precisa ter o TensorFlow e o PyTorch instalados.
Aqui está um exemplo do processo de conversão para o modelo `ALBERT Base` pré-treinado:
```bash
export ALBERT_BASE_DIR=/path/to/albert/albert_base
transformers-cli convert --model_type albert \
--tf_checkpoint $ALBERT_BASE_DIR/model.ckpt-best \
--config $ALBERT_BASE_DIR/albert_config.json \
--pytorch_dump_output $ALBERT_BASE_DIR/pytorch_model.bin
```
Você pode baixar os modelos pré-treinados do Google para a conversão [aqui](https://github.com/google-research/albert#pre-trained-models).
## OpenAI GPT
Aqui está um exemplo do processo de conversão para um modelo OpenAI GPT pré-treinado, supondo que seu checkpoint NumPy
foi salvo com o mesmo formato do modelo pré-treinado OpenAI (veja [aqui](https://github.com/openai/finetune-transformer-lm)\
)
```bash
export OPENAI_GPT_CHECKPOINT_FOLDER_PATH=/path/to/openai/pretrained/numpy/weights
transformers-cli convert --model_type gpt \
--tf_checkpoint $OPENAI_GPT_CHECKPOINT_FOLDER_PATH \
--pytorch_dump_output $PYTORCH_DUMP_OUTPUT \
[--config OPENAI_GPT_CONFIG] \
[--finetuning_task_name OPENAI_GPT_FINETUNED_TASK] \
```
## OpenAI GPT-2
Aqui está um exemplo do processo de conversão para um modelo OpenAI GPT-2 pré-treinado (consulte [aqui](https://github.com/openai/gpt-2))
```bash
export OPENAI_GPT2_CHECKPOINT_PATH=/path/to/gpt2/pretrained/weights
transformers-cli convert --model_type gpt2 \
--tf_checkpoint $OPENAI_GPT2_CHECKPOINT_PATH \
--pytorch_dump_output $PYTORCH_DUMP_OUTPUT \
[--config OPENAI_GPT2_CONFIG] \
[--finetuning_task_name OPENAI_GPT2_FINETUNED_TASK]
```
## XLNet
Aqui está um exemplo do processo de conversão para um modelo XLNet pré-treinado:
```bash
export TRANSFO_XL_CHECKPOINT_PATH=/path/to/xlnet/checkpoint
export TRANSFO_XL_CONFIG_PATH=/path/to/xlnet/config
transformers-cli convert --model_type xlnet \
--tf_checkpoint $TRANSFO_XL_CHECKPOINT_PATH \
--config $TRANSFO_XL_CONFIG_PATH \
--pytorch_dump_output $PYTORCH_DUMP_OUTPUT \
[--finetuning_task_name XLNET_FINETUNED_TASK] \
```
## XLM
Aqui está um exemplo do processo de conversão para um modelo XLM pré-treinado:
```bash
export XLM_CHECKPOINT_PATH=/path/to/xlm/checkpoint
transformers-cli convert --model_type xlm \
--tf_checkpoint $XLM_CHECKPOINT_PATH \
--pytorch_dump_output $PYTORCH_DUMP_OUTPUT
[--config XML_CONFIG] \
[--finetuning_task_name XML_FINETUNED_TASK]
```
## T5
Aqui está um exemplo do processo de conversão para um modelo T5 pré-treinado:
```bash
export T5=/path/to/t5/uncased_L-12_H-768_A-12
transformers-cli convert --model_type t5 \
--tf_checkpoint $T5/t5_model.ckpt \
--config $T5/t5_config.json \
--pytorch_dump_output $T5/pytorch_model.bin
```
| transformers/docs/source/pt/converting_tensorflow_models.md/0 | {
"file_path": "transformers/docs/source/pt/converting_tensorflow_models.md",
"repo_id": "transformers",
"token_count": 2437
} | 277 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# శీఘ్ర పర్యటన
[[ఓపెన్-ఇన్-కోలాబ్]]
🤗 ట్రాన్స్ఫార్మర్లతో లేచి పరుగెత్తండి! మీరు డెవలపర్ అయినా లేదా రోజువారీ వినియోగదారు అయినా, ఈ శీఘ్ర పర్యటన మీకు ప్రారంభించడానికి సహాయం చేస్తుంది మరియు [`pipeline`] అనుమితి కోసం ఎలా ఉపయోగించాలో మీకు చూపుతుంది, [AutoClass](./model_doc/auto) తో ప్రీట్రైన్డ్ మోడల్ మరియు ప్రిప్రాసెసర్/ ఆటో, మరియు PyTorch లేదా TensorFlowతో మోడల్కు త్వరగా శిక్షణ ఇవ్వండి. మీరు ఒక అనుభవశూన్యుడు అయితే, ఇక్కడ పరిచయం చేయబడిన భావనల గురించి మరింత లోతైన వివరణల కోసం మా ట్యుటోరియల్స్ లేదా [course](https://huggingface.co/course/chapter1/1)ని తనిఖీ చేయమని మేము సిఫార్సు చేస్తున్నాము.
మీరు ప్రారంభించడానికి ముందు, మీరు అవసరమైన అన్ని లైబ్రరీలను ఇన్స్టాల్ చేశారని నిర్ధారించుకోండి:
```bash
!pip install transformers datasets
```
మీరు మీ ప్రాధాన్య యంత్ర అభ్యాస ఫ్రేమ్వర్క్ను కూడా ఇన్స్టాల్ చేయాలి:
<frameworkcontent>
<pt>
```bash
pip install torch
```
</pt>
<tf>
```bash
pip install tensorflow
```
</tf>
</frameworkcontent>
## పైప్లైన్
<Youtube id="tiZFewofSLM"/>
[`pipeline`] అనుమితి కోసం ముందుగా శిక్షణ పొందిన నమూనాను ఉపయోగించడానికి సులభమైన మరియు వేగవంతమైన మార్గం. మీరు వివిధ పద్ధతులలో అనేక పనుల కోసం [`pipeline`] వెలుపల ఉపయోగించవచ్చు, వాటిలో కొన్ని క్రింది పట్టికలో చూపబడ్డాయి:
<Tip>
అందుబాటులో ఉన్న పనుల పూర్తి జాబితా కోసం, [పైప్లైన్ API సూచన](./main_classes/pipelines)ని తనిఖీ చేయండి.
</Tip>
Here is the translation in Telugu:
| **పని** | **వివరణ** | **మోడాలిటీ** | **పైప్లైన్ ఐడెంటిఫైయర్** |
|------------------------------|--------------------------------------------------------------------------------------------------------|-----------------|------------------------------------------|
| వచన వర్గీకరణు | కొన్ని వచనాల అంతా ఒక లేబుల్ను కొడి | NLP | pipeline(task=“sentiment-analysis”) |
| వచన సృష్టి | ప్రమ్పుటం కలిగినంత వచనం సృష్టించండి | NLP | pipeline(task=“text-generation”) |
| సంక్షేపణ | వచనం లేదా పత్రం కొరకు సంక్షేపణ తయారుచేసండి | NLP | pipeline(task=“summarization”) |
| చిత్రం వర్గీకరణు | చిత్రంలో ఒక లేబుల్ను కొడి | కంప్యూటర్ విషయం | pipeline(task=“image-classification”) |
| చిత్రం విభజన | ఒక చిత్రంలో ప్రతి వ్యక్తిగత పిక్సల్ను ఒక లేబుల్గా నమోదు చేయండి (సెమాంటిక్, పానొప్టిక్, మరియు ఇన్స్టన్స్ విభజనలను మద్దతు చేస్తుంది) | కంప్యూటర్ విషయం | pipeline(task=“image-segmentation”) |
| వస్త్రం గుర్తువు | ఒక చిత్రంలో పదాల యొక్క బౌండింగ్ బాక్స్లను మరియు వస్త్రాల వర్గాలను అంచనా చేయండి | కంప్యూటర్ విషయం | pipeline(task=“object-detection”) |
| ఆడియో గుర్తువు | కొన్ని ఆడియో డేటానికి ఒక లేబుల్ను కొడి | ఆడియో | pipeline(task=“audio-classification”) |
| స్వయంచలన ప్రసంగ గుర్తువు | ప్రసంగాన్ని వచనంగా వర్ణించండి | ఆడియో | pipeline(task=“automatic-speech-recognition”) |
| దృశ్య ప్రశ్న సంవాదం | వచనం మరియు ప్రశ్నను నమోదు చేసిన చిత్రంతో ప్రశ్నకు సమాధానం ఇవ్వండి | బహుమూలిక | pipeline(task=“vqa”) |
| పత్రం ప్రశ్న సంవాదం | ప్రశ్నను పత్రం లేదా డాక్యుమెంట్తో సమాధానం ఇవ్వండి | బహుమూలిక | pipeline(task="document-question-answering") |
| చిత్రం వ్రాసాయింగ్ | కొన్ని చిత్రానికి పిటియార్లను సృష్టించండి | బహుమూలిక | pipeline(task="image-to-text") |
[`pipeline`] యొక్క ఉదాహరణను సృష్టించడం ద్వారా మరియు మీరు దానిని ఉపయోగించాలనుకుంటున్న పనిని పేర్కొనడం ద్వారా ప్రారంభించండి. ఈ గైడ్లో, మీరు సెంటిమెంట్ విశ్లేషణ కోసం [`pipeline`]ని ఉదాహరణగా ఉపయోగిస్తారు:
```py
>>> from transformers import pipeline
>>> classifier = pipeline("sentiment-analysis")
```
సెంటిమెంట్ విశ్లేషణ కోసం [`pipeline`] డిఫాల్ట్ [ప్రీట్రైన్డ్ మోడల్](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english) మరియు టోకెనైజర్ని డౌన్లోడ్ చేస్తుంది మరియు కాష్ చేస్తుంది. ఇప్పుడు మీరు మీ లక్ష్య వచనంలో `classifier`ని ఉపయోగించవచ్చు:
```py
>>> classifier("We are very happy to show you the 🤗 Transformers library.")
[{'label': 'POSITIVE', 'score': 0.9998}]
```
మీరు ఒకటి కంటే ఎక్కువ ఇన్పుట్లను కలిగి ఉంటే, నిఘంటువుల జాబితాను అందించడానికి మీ ఇన్పుట్లను జాబితాగా [`pipeline`]కి పంపండి:
```py
>>> results = classifier(["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."])
>>> for result in results:
... print(f"label: {result['label']}, with score: {round(result['score'], 4)}")
label: POSITIVE, with score: 0.9998
label: NEGATIVE, with score: 0.5309
```
[`pipeline`] మీకు నచ్చిన ఏదైనా పని కోసం మొత్తం డేటాసెట్ను కూడా పునరావృతం చేయగలదు. ఈ ఉదాహరణ కోసం, స్వయంచాలక ప్రసంగ గుర్తింపును మన పనిగా ఎంచుకుందాం:
```py
>>> import torch
>>> from transformers import pipeline
>>> speech_recognizer = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-960h")
```
మీరు మళ్లీ మళ్లీ చెప్పాలనుకుంటున్న ఆడియో డేటాసెట్ను లోడ్ చేయండి (మరిన్ని వివరాల కోసం 🤗 డేటాసెట్లు [త్వరిత ప్రారంభం](https://huggingface.co/docs/datasets/quickstart#audio) చూడండి. ఉదాహరణకు, [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) డేటాసెట్ను లోడ్ చేయండి:
```py
>>> from datasets import load_dataset, Audio
>>> dataset = load_dataset("PolyAI/minds14", name="en-US", split="train") # doctest: +IGNORE_RESULT
```
డేటాసెట్ యొక్క నమూనా రేటు నమూనాతో సరిపోలుతుందని మీరు నిర్ధారించుకోవాలి
రేటు [`facebook/wav2vec2-base-960h`](https://huggingface.co/facebook/wav2vec2-base-960h) దీనిపై శిక్షణ పొందింది:
```py
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=speech_recognizer.feature_extractor.sampling_rate))
```
`"ఆడియో"` కాలమ్కి కాల్ చేస్తున్నప్పుడు ఆడియో ఫైల్లు స్వయంచాలకంగా లోడ్ చేయబడతాయి మరియు మళ్లీ నమూనా చేయబడతాయి.
మొదటి 4 నమూనాల నుండి ముడి వేవ్ఫార్మ్ శ్రేణులను సంగ్రహించి, పైప్లైన్కు జాబితాగా పాస్ చేయండి:
```py
>>> result = speech_recognizer(dataset[:4]["audio"])
>>> print([d["text"] for d in result])
['I WOULD LIKE TO SET UP A JOINT ACCOUNT WITH MY PARTNER HOW DO I PROCEED WITH DOING THAT', "FONDERING HOW I'D SET UP A JOIN TO HELL T WITH MY WIFE AND WHERE THE AP MIGHT BE", "I I'D LIKE TOY SET UP A JOINT ACCOUNT WITH MY PARTNER I'M NOT SEEING THE OPTION TO DO IT ON THE APSO I CALLED IN TO GET SOME HELP CAN I JUST DO IT OVER THE PHONE WITH YOU AND GIVE YOU THE INFORMATION OR SHOULD I DO IT IN THE AP AN I'M MISSING SOMETHING UQUETTE HAD PREFERRED TO JUST DO IT OVER THE PHONE OF POSSIBLE THINGS", 'HOW DO I FURN A JOINA COUT']
```
ఇన్పుట్లు పెద్దగా ఉన్న పెద్ద డేటాసెట్ల కోసం (స్పీచ్ లేదా విజన్ వంటివి), మెమరీలోని అన్ని ఇన్పుట్లను లోడ్ చేయడానికి మీరు జాబితాకు బదులుగా జెనరేటర్ను పాస్ చేయాలనుకుంటున్నారు. మరింత సమాచారం కోసం [పైప్లైన్ API సూచన](./main_classes/pipelines)ని చూడండి.
### పైప్లైన్లో మరొక మోడల్ మరియు టోకెనైజర్ని ఉపయోగించండి
[`pipeline`] [Hub](https://huggingface.co/models) నుండి ఏదైనా మోడల్ను కలిగి ఉంటుంది, దీని వలన ఇతర వినియోగ-కేసుల కోసం [`pipeline`]ని సులభంగా స్వీకరించవచ్చు. ఉదాహరణకు, మీరు ఫ్రెంచ్ టెక్స్ట్ను హ్యాండిల్ చేయగల మోడల్ కావాలనుకుంటే, తగిన మోడల్ కోసం ఫిల్టర్ చేయడానికి హబ్లోని ట్యాగ్లను ఉపయోగించండి. అగ్ర ఫిల్టర్ చేసిన ఫలితం మీరు ఫ్రెంచ్ టెక్స్ట్ కోసం ఉపయోగించగల సెంటిమెంట్ విశ్లేషణ కోసం ఫైన్ట్యూన్ చేయబడిన బహుభాషా [BERT మోడల్](https://huggingface.co/nlptown/bert-base-multilingual-uncased-sentiment)ని అందిస్తుంది:
```py
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
```
<frameworkcontent>
<pt>
ముందుగా శిక్షణ పొందిన మోడల్ను లోడ్ చేయడానికి [`AutoModelForSequenceClassification`] మరియు [`AutoTokenizer`]ని ఉపయోగించండి మరియు దాని అనుబంధిత టోకెనైజర్ (తదుపరి విభాగంలో `AutoClass`పై మరిన్ని):
```py
>>> from transformers import AutoTokenizer, AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained(model_name)
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
```
</pt>
<tf>
ముందుగా శిక్షణ పొందిన మోడల్ను లోడ్ చేయడానికి [`TFAutoModelForSequenceClassification`] మరియు [`AutoTokenizer`]ని ఉపయోగించండి మరియు దాని అనుబంధిత టోకెనైజర్ (తదుపరి విభాగంలో `TFAutoClass`పై మరిన్ని):
```py
>>> from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
```
</tf>
</frameworkcontent>
[`pipeline`]లో మోడల్ మరియు టోకెనైజర్ను పేర్కొనండి మరియు ఇప్పుడు మీరు ఫ్రెంచ్ టెక్స్ట్పై `క్లాసిఫైయర్`ని వర్తింపజేయవచ్చు:
```py
>>> classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
>>> classifier("Nous sommes très heureux de vous présenter la bibliothèque 🤗 Transformers.")
[{'label': '5 stars', 'score': 0.7273}]
```
మీరు మీ వినియోగ-కేస్ కోసం మోడల్ను కనుగొనలేకపోతే, మీరు మీ డేటాపై ముందుగా శిక్షణ పొందిన మోడల్ను చక్కగా మార్చాలి. ఎలాగో తెలుసుకోవడానికి మా [ఫైన్ట్యూనింగ్ ట్యుటోరియల్](./training)ని చూడండి. చివరగా, మీరు మీ ప్రీట్రైన్డ్ మోడల్ని ఫైన్ట్యూన్ చేసిన తర్వాత, దయచేసి అందరి కోసం మెషిన్ లెర్నింగ్ని డెమోక్రటైజ్ చేయడానికి హబ్లోని సంఘంతో మోడల్ను [షేరింగ్](./model_sharing) పరిగణించండి! 🤗
## AutoClass
<Youtube id="AhChOFRegn4"/>
హుడ్ కింద, మీరు పైన ఉపయోగించిన [`pipeline`]కి శక్తిని అందించడానికి [`AutoModelForSequenceClassification`] మరియు [`AutoTokenizer`] తరగతులు కలిసి పని చేస్తాయి. ఒక [AutoClass](./model_doc/auto) అనేది ముందుగా శిక్షణ పొందిన మోడల్ యొక్క ఆర్కిటెక్చర్ను దాని పేరు లేదా మార్గం నుండి స్వయంచాలకంగా తిరిగి పొందే సత్వరమార్గం. మీరు మీ టాస్క్ కోసం తగిన `ఆటోక్లాస్`ని మాత్రమే ఎంచుకోవాలి మరియు ఇది అనుబంధిత ప్రీప్రాసెసింగ్ క్లాస్.
మునుపటి విభాగం నుండి ఉదాహరణకి తిరిగి వెళ్లి, [`pipeline`] ఫలితాలను ప్రతిబింబించడానికి మీరు `ఆటోక్లాస్`ని ఎలా ఉపయోగించవచ్చో చూద్దాం.
### AutoTokenizer
ఒక మోడల్కు ఇన్పుట్లుగా సంఖ్యల శ్రేణిలో వచనాన్ని ప్రీప్రాసెసింగ్ చేయడానికి టోకెనైజర్ బాధ్యత వహిస్తుంది. పదాన్ని ఎలా విభజించాలి మరియు ఏ స్థాయిలో పదాలను విభజించాలి ([tokenizer సారాంశం](./tokenizer_summary)లో టోకనైజేషన్ గురించి మరింత తెలుసుకోండి) సహా టోకనైజేషన్ ప్రక్రియను నియంత్రించే అనేక నియమాలు ఉన్నాయి. గుర్తుంచుకోవలసిన ముఖ్యమైన విషయం ఏమిటంటే, మీరు మోడల్కు ముందే శిక్షణ పొందిన అదే టోకనైజేషన్ నియమాలను ఉపయోగిస్తున్నారని నిర్ధారించుకోవడానికి మీరు అదే మోడల్ పేరుతో టోకెనైజర్ను తక్షణం చేయాలి.
[`AutoTokenizer`]తో టోకెనైజర్ను లోడ్ చేయండి:
```py
>>> from transformers import AutoTokenizer
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
```
మీ వచనాన్ని టోకెనైజర్కు పంపండి:
```py
>>> encoding = tokenizer("We are very happy to show you the 🤗 Transformers library.")
>>> print(encoding)
{'input_ids': [101, 11312, 10320, 12495, 19308, 10114, 11391, 10855, 10103, 100, 58263, 13299, 119, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
```
టోకెనైజర్ వీటిని కలిగి ఉన్న నిఘంటువుని అందిస్తుంది:
* [input_ids](./glossary#input-ids): మీ టోకెన్ల సంఖ్యాపరమైన ప్రాతినిధ్యం.
* [అటెన్షన్_మాస్క్](./glossary#attention-mask): ఏ టోకెన్లకు హాజరు కావాలో సూచిస్తుంది.
ఒక టోకెనైజర్ ఇన్పుట్ల జాబితాను కూడా ఆమోదించగలదు మరియు ఏకరీతి పొడవుతో బ్యాచ్ను తిరిగి ఇవ్వడానికి టెక్స్ట్ను ప్యాడ్ చేసి కత్తిరించవచ్చు:
<frameworkcontent>
<pt>
```py
>>> pt_batch = tokenizer(
... ["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
... padding=True,
... truncation=True,
... max_length=512,
... return_tensors="pt",
... )
```
</pt>
<tf>
```py
>>> tf_batch = tokenizer(
... ["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
... padding=True,
... truncation=True,
... max_length=512,
... return_tensors="tf",
... )
```
</tf>
</frameworkcontent>
<Tip>
టోకనైజేషన్ గురించి మరిన్ని వివరాల కోసం [ప్రీప్రాసెస్](./preprocessing) ట్యుటోరియల్ని చూడండి మరియు ఇమేజ్, ఆడియో మరియు మల్టీమోడల్ ఇన్పుట్లను ప్రీప్రాసెస్ చేయడానికి [`AutoImageProcessor`], [`AutoFeatureExtractor`] మరియు [`AutoProcessor`] ఎలా ఉపయోగించాలి.
</Tip>
### AutoModel
<frameworkcontent>
<pt>
🤗 ట్రాన్స్ఫార్మర్లు ప్రీట్రైన్డ్ ఇన్స్టాన్స్లను లోడ్ చేయడానికి సులభమైన మరియు ఏకీకృత మార్గాన్ని అందిస్తాయి. దీని అర్థం మీరు [`AutoTokenizer`]ని లోడ్ చేసినట్లుగా [`AutoModel`]ని లోడ్ చేయవచ్చు. టాస్క్ కోసం సరైన [`AutoModel`]ని ఎంచుకోవడం మాత్రమే తేడా. టెక్స్ట్ (లేదా సీక్వెన్స్) వర్గీకరణ కోసం, మీరు [`AutoModelForSequenceClassification`]ని లోడ్ చేయాలి:
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> pt_model = AutoModelForSequenceClassification.from_pretrained(model_name)
```
<Tip>
[`AutoModel`] క్లాస్ ద్వారా సపోర్ట్ చేసే టాస్క్ల కోసం [టాస్క్ సారాంశం](./task_summary)ని చూడండి.
</Tip>
ఇప్పుడు మీ ప్రీప్రాసెస్ చేయబడిన బ్యాచ్ ఇన్పుట్లను నేరుగా మోడల్కి పంపండి. మీరు `**`ని జోడించడం ద్వారా నిఘంటువుని అన్ప్యాక్ చేయాలి:
```py
>>> pt_outputs = pt_model(**pt_batch)
```
మోడల్ తుది యాక్టివేషన్లను `logits` లక్షణంలో అవుట్పుట్ చేస్తుంది. సంభావ్యతలను తిరిగి పొందడానికి సాఫ్ట్మాక్స్ ఫంక్షన్ను `logits` కు వర్తింపజేయండి:
```py
>>> from torch import nn
>>> pt_predictions = nn.functional.softmax(pt_outputs.logits, dim=-1)
>>> print(pt_predictions)
tensor([[0.0021, 0.0018, 0.0115, 0.2121, 0.7725],
[0.2084, 0.1826, 0.1969, 0.1755, 0.2365]], grad_fn=<SoftmaxBackward0>)
```
</pt>
<tf>
🤗 ట్రాన్స్ఫార్మర్లు ప్రీట్రైన్డ్ ఇన్స్టాన్స్లను లోడ్ చేయడానికి సులభమైన మరియు ఏకీకృత మార్గాన్ని అందిస్తాయి. మీరు [`AutoTokenizer`]ని లోడ్ చేసినట్లుగా మీరు [`TFAutoModel`]ని లోడ్ చేయవచ్చని దీని అర్థం. టాస్క్ కోసం సరైన [`TFAutoModel`]ని ఎంచుకోవడం మాత్రమే తేడా. టెక్స్ట్ (లేదా సీక్వెన్స్) వర్గీకరణ కోసం, మీరు [`TFAutoModelForSequenceClassification`]ని లోడ్ చేయాలి:
```py
>>> from transformers import TFAutoModelForSequenceClassification
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
```
<Tip>
[`AutoModel`] క్లాస్ ద్వారా సపోర్ట్ చేసే టాస్క్ల కోసం [టాస్క్ సారాంశం](./task_summary)ని చూడండి.
</Tip>
ఇప్పుడు మీ ప్రీప్రాసెస్ చేయబడిన బ్యాచ్ ఇన్పుట్లను నేరుగా మోడల్కి పంపండి. మీరు టెన్సర్లను ఇలా పాస్ చేయవచ్చు:
```py
>>> tf_outputs = tf_model(tf_batch)
```
మోడల్ తుది యాక్టివేషన్లను `logits` లక్షణంలో అవుట్పుట్ చేస్తుంది. సంభావ్యతలను తిరిగి పొందడానికి సాఫ్ట్మాక్స్ ఫంక్షన్ను `logits`కు వర్తింపజేయండి:
```py
>>> import tensorflow as tf
>>> tf_predictions = tf.nn.softmax(tf_outputs.logits, axis=-1)
>>> tf_predictions # doctest: +IGNORE_RESULT
```
</tf>
</frameworkcontent>
<Tip>
అన్ని 🤗 ట్రాన్స్ఫార్మర్స్ మోడల్లు (PyTorch లేదా TensorFlow) తుది యాక్టివేషన్కు *ముందు* టెన్సర్లను అవుట్పుట్ చేస్తాయి
ఫంక్షన్ (softmax వంటిది) ఎందుకంటే చివరి యాక్టివేషన్ ఫంక్షన్ తరచుగా నష్టంతో కలిసిపోతుంది. మోడల్ అవుట్పుట్లు ప్రత్యేక డేటాక్లాస్లు కాబట్టి వాటి లక్షణాలు IDEలో స్వయంచాలకంగా పూర్తి చేయబడతాయి. మోడల్ అవుట్పుట్లు టుపుల్ లేదా డిక్షనరీ లాగా ప్రవర్తిస్తాయి (మీరు పూర్ణాంకం, స్లైస్ లేదా స్ట్రింగ్తో ఇండెక్స్ చేయవచ్చు) ఈ సందర్భంలో, ఏదీ లేని గుణాలు విస్మరించబడతాయి.
</Tip>
### మోడల్ను సేవ్ చేయండి
<frameworkcontent>
<pt>
మీ మోడల్ చక్కగా ట్యూన్ చేయబడిన తర్వాత, మీరు దానిని [`PreTrainedModel.save_pretrained`]ని ఉపయోగించి దాని టోకెనైజర్తో సేవ్ చేయవచ్చు:
```py
>>> pt_save_directory = "./pt_save_pretrained"
>>> tokenizer.save_pretrained(pt_save_directory) # doctest: +IGNORE_RESULT
>>> pt_model.save_pretrained(pt_save_directory)
```
మీరు మోడల్ని మళ్లీ ఉపయోగించడానికి సిద్ధంగా ఉన్నప్పుడు, దాన్ని [`PreTrainedModel.from_pretrained`]తో రీలోడ్ చేయండి:
```py
>>> pt_model = AutoModelForSequenceClassification.from_pretrained("./pt_save_pretrained")
```
</pt>
<tf>
మీ మోడల్ చక్కగా ట్యూన్ చేయబడిన తర్వాత, మీరు దానిని [`TFPreTrainedModel.save_pretrained`]ని ఉపయోగించి దాని టోకెనైజర్తో సేవ్ చేయవచ్చు:
```py
>>> tf_save_directory = "./tf_save_pretrained"
>>> tokenizer.save_pretrained(tf_save_directory) # doctest: +IGNORE_RESULT
>>> tf_model.save_pretrained(tf_save_directory)
```
మీరు మోడల్ని మళ్లీ ఉపయోగించడానికి సిద్ధంగా ఉన్నప్పుడు, దాన్ని [`TFPreTrainedModel.from_pretrained`]తో రీలోడ్ చేయండి:
```py
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained("./tf_save_pretrained")
```
</tf>
</frameworkcontent>
ఒక ప్రత్యేకించి అద్భుతమైన 🤗 ట్రాన్స్ఫార్మర్స్ ఫీచర్ మోడల్ను సేవ్ చేయగల సామర్థ్యం మరియు దానిని PyTorch లేదా TensorFlow మోడల్గా రీలోడ్ చేయగలదు. `from_pt` లేదా `from_tf` పరామితి మోడల్ను ఒక ఫ్రేమ్వర్క్ నుండి మరొక ఫ్రేమ్వర్క్కి మార్చగలదు:
<frameworkcontent>
<pt>
```py
>>> from transformers import AutoModel
>>> tokenizer = AutoTokenizer.from_pretrained(tf_save_directory)
>>> pt_model = AutoModelForSequenceClassification.from_pretrained(tf_save_directory, from_tf=True)
```
</pt>
<tf>
```py
>>> from transformers import TFAutoModel
>>> tokenizer = AutoTokenizer.from_pretrained(pt_save_directory)
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(pt_save_directory, from_pt=True)
```
</tf>
</frameworkcontent>
## కస్టమ్ మోడల్ బిల్డ్స్
మోడల్ ఎలా నిర్మించబడుతుందో మార్చడానికి మీరు మోడల్ కాన్ఫిగరేషన్ క్లాస్ని సవరించవచ్చు. దాచిన లేయర్లు లేదా అటెన్షన్ హెడ్ల సంఖ్య వంటి మోడల్ లక్షణాలను కాన్ఫిగరేషన్ నిర్దేశిస్తుంది. మీరు కస్టమ్ కాన్ఫిగరేషన్ క్లాస్ నుండి మోడల్ను ప్రారంభించినప్పుడు మీరు మొదటి నుండి ప్రారంభిస్తారు. మోడల్ అట్రిబ్యూట్లు యాదృచ్ఛికంగా ప్రారంభించబడ్డాయి మరియు అర్థవంతమైన ఫలితాలను పొందడానికి మీరు మోడల్ను ఉపయోగించే ముందు దానికి శిక్షణ ఇవ్వాలి.
[`AutoConfig`]ని దిగుమతి చేయడం ద్వారా ప్రారంభించండి, ఆపై మీరు సవరించాలనుకుంటున్న ప్రీట్రైన్డ్ మోడల్ను లోడ్ చేయండి. [`AutoConfig.from_pretrained`]లో, మీరు అటెన్షన్ హెడ్ల సంఖ్య వంటి మీరు మార్చాలనుకుంటున్న లక్షణాన్ని పేర్కొనవచ్చు:
```py
>>> from transformers import AutoConfig
>>> my_config = AutoConfig.from_pretrained("distilbert-base-uncased", n_heads=12)
```
<frameworkcontent>
<pt>
[`AutoModel.from_config`]తో మీ అనుకూల కాన్ఫిగరేషన్ నుండి మోడల్ను సృష్టించండి:
```py
>>> from transformers import AutoModel
>>> my_model = AutoModel.from_config(my_config)
```
</pt>
<tf>
[`TFAutoModel.from_config`]తో మీ అనుకూల కాన్ఫిగరేషన్ నుండి మోడల్ను సృష్టించండి:
```py
>>> from transformers import TFAutoModel
>>> my_model = TFAutoModel.from_config(my_config)
```
</tf>
</frameworkcontent>
అనుకూల కాన్ఫిగరేషన్లను రూపొందించడం గురించి మరింత సమాచారం కోసం [కస్టమ్ ఆర్కిటెక్చర్ని సృష్టించండి](./create_a_model) గైడ్ను చూడండి.
## శిక్షకుడు - పైటార్చ్ ఆప్టిమైజ్ చేసిన శిక్షణ లూప్
అన్ని మోడల్లు ప్రామాణికమైన [`torch.nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) కాబట్టి మీరు వాటిని ఏదైనా సాధారణ శిక్షణ లూప్లో ఉపయోగించవచ్చు. మీరు మీ స్వంత శిక్షణ లూప్ను వ్రాయగలిగినప్పటికీ, 🤗 ట్రాన్స్ఫార్మర్లు PyTorch కోసం [`ట్రైనర్`] తరగతిని అందజేస్తాయి, ఇందులో ప్రాథమిక శిక్షణ లూప్ ఉంటుంది మరియు పంపిణీ చేయబడిన శిక్షణ, మిశ్రమ ఖచ్చితత్వం మరియు మరిన్ని వంటి ఫీచర్ల కోసం అదనపు కార్యాచరణను జోడిస్తుంది.
మీ విధిని బట్టి, మీరు సాధారణంగా కింది పారామితులను [`ట్రైనర్`]కి పంపుతారు:
1. మీరు [`PreTrainedModel`] లేదా [`torch.nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module)తో ప్రారంభిస్తారు:
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
2. [`TrainingArguments`] మీరు నేర్చుకునే రేటు, బ్యాచ్ పరిమాణం మరియు శిక్షణ పొందవలసిన యుగాల సంఖ్య వంటి మార్చగల మోడల్ హైపర్పారామీటర్లను కలిగి ఉంది. మీరు ఎలాంటి శిక్షణా వాదనలను పేర్కొనకుంటే డిఫాల్ట్ విలువలు ఉపయోగించబడతాయి:
```py
>>> from transformers import TrainingArguments
>>> training_args = TrainingArguments(
... output_dir="path/to/save/folder/",
... learning_rate=2e-5,
... per_device_train_batch_size=8,
... per_device_eval_batch_size=8,
... num_train_epochs=2,
... )
```
3. టోకెనైజర్, ఇమేజ్ ప్రాసెసర్, ఫీచర్ ఎక్స్ట్రాక్టర్ లేదా ప్రాసెసర్ వంటి ప్రీప్రాసెసింగ్ క్లాస్ని లోడ్ చేయండి:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
```
4. డేటాసెట్ను లోడ్ చేయండి:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("rotten_tomatoes") # doctest: +IGNORE_RESULT
```
5. డేటాసెట్ను టోకనైజ్ చేయడానికి ఒక ఫంక్షన్ను సృష్టించండి:
```py
>>> def tokenize_dataset(dataset):
... return tokenizer(dataset["text"])
```
ఆపై దానిని [`~datasets.Dataset.map`]తో మొత్తం డేటాసెట్లో వర్తింపజేయండి:
```py
>>> dataset = dataset.map(tokenize_dataset, batched=True)
```
6. మీ డేటాసెట్ నుండి ఉదాహరణల సమూహాన్ని సృష్టించడానికి [`DataCollatorWithPadding`]:
```py
>>> from transformers import DataCollatorWithPadding
>>> data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
```
ఇప్పుడు ఈ తరగతులన్నింటినీ [`Trainer`]లో సేకరించండి:
```py
>>> from transformers import Trainer
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=dataset["train"],
... eval_dataset=dataset["test"],
... tokenizer=tokenizer,
... data_collator=data_collator,
... ) # doctest: +SKIP
```
మీరు సిద్ధంగా ఉన్నప్పుడు, శిక్షణను ప్రారంభించడానికి [`~Trainer.train`]కి కాల్ చేయండి:
```py
>>> trainer.train() # doctest: +SKIP
```
<Tip>
సీక్వెన్స్-టు-సీక్వెన్స్ మోడల్ని ఉపయోగించే - అనువాదం లేదా సారాంశం వంటి పనుల కోసం, బదులుగా [`Seq2SeqTrainer`] మరియు [`Seq2SeqTrainingArguments`] తరగతులను ఉపయోగించండి.
</Tip>
మీరు [`Trainer`] లోపల ఉన్న పద్ధతులను ఉపవర్గీకరించడం ద్వారా శిక్షణ లూప్ ప్రవర్తనను అనుకూలీకరించవచ్చు. ఇది లాస్ ఫంక్షన్, ఆప్టిమైజర్ మరియు షెడ్యూలర్ వంటి లక్షణాలను అనుకూలీకరించడానికి మిమ్మల్ని అనుమతిస్తుంది. ఉపవర్గీకరించబడే పద్ధతుల కోసం [`Trainer`] సూచనను పరిశీలించండి.
శిక్షణ లూప్ను అనుకూలీకరించడానికి మరొక మార్గం [కాల్బ్యాక్లు](./main_classes/callbacks). మీరు ఇతర లైబ్రరీలతో అనుసంధానం చేయడానికి కాల్బ్యాక్లను ఉపయోగించవచ్చు మరియు పురోగతిపై నివేదించడానికి శిక్షణ లూప్ను తనిఖీ చేయవచ్చు లేదా శిక్షణను ముందుగానే ఆపవచ్చు. శిక్షణ లూప్లోనే కాల్బ్యాక్లు దేనినీ సవరించవు. లాస్ ఫంక్షన్ వంటివాటిని అనుకూలీకరించడానికి, మీరు బదులుగా [`Trainer`]ని ఉపవర్గం చేయాలి.
## TensorFlowతో శిక్షణ పొందండి
అన్ని మోడల్లు ప్రామాణికమైన [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) కాబట్టి వాటిని [Keras]తో TensorFlowలో శిక్షణ పొందవచ్చు(https: //keras.io/) API. 🤗 ట్రాన్స్ఫార్మర్లు మీ డేటాసెట్ని సులభంగా `tf.data.Dataset`గా లోడ్ చేయడానికి [`~TFPreTrainedModel.prepare_tf_dataset`] పద్ధతిని అందజేస్తుంది కాబట్టి మీరు వెంటనే Keras' [`compile`](https://keras.io /api/models/model_training_apis/#compile-method) మరియు [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) పద్ధతులు.
1. మీరు [`TFPreTrainedModel`] లేదా [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model)తో ప్రారంభిస్తారు:
```py
>>> from transformers import TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
2. టోకెనైజర్, ఇమేజ్ ప్రాసెసర్, ఫీచర్ ఎక్స్ట్రాక్టర్ లేదా ప్రాసెసర్ వంటి ప్రీప్రాసెసింగ్ క్లాస్ని లోడ్ చేయండి:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
```
3. డేటాసెట్ను టోకనైజ్ చేయడానికి ఒక ఫంక్షన్ను సృష్టించండి:
```py
>>> def tokenize_dataset(dataset):
... return tokenizer(dataset["text"]) # doctest: +SKIP
```
4. [`~datasets.Dataset.map`]తో మొత్తం డేటాసెట్పై టోకెనైజర్ని వర్తింపజేయి, ఆపై డేటాసెట్ మరియు టోకెనైజర్ను [`~TFPreTrainedModel.prepare_tf_dataset`]కి పంపండి. మీరు కావాలనుకుంటే బ్యాచ్ పరిమాణాన్ని కూడా మార్చవచ్చు మరియు డేటాసెట్ను ఇక్కడ షఫుల్ చేయవచ్చు:
```py
>>> dataset = dataset.map(tokenize_dataset) # doctest: +SKIP
>>> tf_dataset = model.prepare_tf_dataset(
... dataset["train"], batch_size=16, shuffle=True, tokenizer=tokenizer
... ) # doctest: +SKIP
```
5. మీరు సిద్ధంగా ఉన్నప్పుడు, శిక్షణను ప్రారంభించడానికి మీరు `కంపైల్` మరియు `ఫిట్`కి కాల్ చేయవచ్చు. ట్రాన్స్ఫార్మర్స్ మోడల్స్ అన్నీ డిఫాల్ట్ టాస్క్-సంబంధిత లాస్ ఫంక్షన్ని కలిగి ఉన్నాయని గుర్తుంచుకోండి, కాబట్టి మీరు కోరుకునే వరకు మీరు ఒకదానిని పేర్కొనవలసిన అవసరం లేదు:
```py
>>> from tensorflow.keras.optimizers import Adam
>>> model.compile(optimizer=Adam(3e-5)) # No loss argument!
>>> model.fit(tf_dataset) # doctest: +SKIP
```
## తరవాత ఏంటి?
ఇప్పుడు మీరు 🤗 ట్రాన్స్ఫార్మర్స్ త్వరిత పర్యటనను పూర్తి చేసారు, మా గైడ్లను తనిఖీ చేయండి మరియు అనుకూల మోడల్ను వ్రాయడం, టాస్క్ కోసం మోడల్ను చక్కగా తీర్చిదిద్దడం మరియు స్క్రిప్ట్తో మోడల్కు శిక్షణ ఇవ్వడం వంటి మరింత నిర్దిష్టమైన పనులను ఎలా చేయాలో తెలుసుకోండి. 🤗 ట్రాన్స్ఫార్మర్స్ కోర్ కాన్సెప్ట్ల గురించి మరింత తెలుసుకోవడానికి మీకు ఆసక్తి ఉంటే, ఒక కప్పు కాఫీ తాగి, మా కాన్సెప్టువల్ గైడ్లను చూడండి!
| transformers/docs/source/te/quicktour.md/0 | {
"file_path": "transformers/docs/source/te/quicktour.md",
"repo_id": "transformers",
"token_count": 37552
} | 278 |
<!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# 🤗 Benchmark results
Here, you can find a list of the different benchmark results created by the community.
If you would like to list benchmark results on your favorite models of the [model hub](https://huggingface.co/models) here, please open a Pull Request and add it below.
| Benchmark description | Results | Environment info | Author |
|:----------|:-------------|:-------------|------:|
| PyTorch Benchmark on inference for `bert-base-cased` |[memory](https://github.com/patrickvonplaten/files_to_link_to/blob/master/bert_benchmark/inference_memory.csv) | [env](https://github.com/patrickvonplaten/files_to_link_to/blob/master/bert_benchmark/env.csv) | [Partick von Platen](https://github.com/patrickvonplaten) |
| PyTorch Benchmark on inference for `bert-base-cased` |[time](https://github.com/patrickvonplaten/files_to_link_to/blob/master/bert_benchmark/inference_time.csv) | [env](https://github.com/patrickvonplaten/files_to_link_to/blob/master/bert_benchmark/env.csv) | [Partick von Platen](https://github.com/patrickvonplaten) |
| transformers/examples/legacy/benchmarking/README.md/0 | {
"file_path": "transformers/examples/legacy/benchmarking/README.md",
"repo_id": "transformers",
"token_count": 493
} | 279 |
#!/usr/bin/env python
import torch
from transformers import CamembertForMaskedLM, CamembertTokenizer
def fill_mask(masked_input, model, tokenizer, topk=5):
# Adapted from https://github.com/pytorch/fairseq/blob/master/fairseq/models/roberta/hub_interface.py
assert masked_input.count("<mask>") == 1
input_ids = torch.tensor(tokenizer.encode(masked_input, add_special_tokens=True)).unsqueeze(0) # Batch size 1
logits = model(input_ids)[0] # The last hidden-state is the first element of the output tuple
masked_index = (input_ids.squeeze() == tokenizer.mask_token_id).nonzero().item()
logits = logits[0, masked_index, :]
prob = logits.softmax(dim=0)
values, indices = prob.topk(k=topk, dim=0)
topk_predicted_token_bpe = " ".join(
[tokenizer.convert_ids_to_tokens(indices[i].item()) for i in range(len(indices))]
)
masked_token = tokenizer.mask_token
topk_filled_outputs = []
for index, predicted_token_bpe in enumerate(topk_predicted_token_bpe.split(" ")):
predicted_token = predicted_token_bpe.replace("\u2581", " ")
if " {0}".format(masked_token) in masked_input:
topk_filled_outputs.append(
(
masked_input.replace(" {0}".format(masked_token), predicted_token),
values[index].item(),
predicted_token,
)
)
else:
topk_filled_outputs.append(
(
masked_input.replace(masked_token, predicted_token),
values[index].item(),
predicted_token,
)
)
return topk_filled_outputs
tokenizer = CamembertTokenizer.from_pretrained("camembert-base")
model = CamembertForMaskedLM.from_pretrained("camembert-base")
model.eval()
masked_input = "Le camembert est <mask> :)"
print(fill_mask(masked_input, model, tokenizer, topk=3))
| transformers/examples/legacy/run_camembert.py/0 | {
"file_path": "transformers/examples/legacy/run_camembert.py",
"repo_id": "transformers",
"token_count": 880
} | 280 |
# coding=utf-8
# Copyright 2020 Huggingface
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import io
import json
import unittest
from parameterized import parameterized
from transformers import FSMTForConditionalGeneration, FSMTTokenizer
from transformers.testing_utils import get_tests_dir, require_torch, slow, torch_device
from utils import calculate_bleu
filename = get_tests_dir() + "/test_data/fsmt/fsmt_val_data.json"
with io.open(filename, "r", encoding="utf-8") as f:
bleu_data = json.load(f)
@require_torch
class ModelEvalTester(unittest.TestCase):
def get_tokenizer(self, mname):
return FSMTTokenizer.from_pretrained(mname)
def get_model(self, mname):
model = FSMTForConditionalGeneration.from_pretrained(mname).to(torch_device)
if torch_device == "cuda":
model.half()
return model
@parameterized.expand(
[
["en-ru", 26.0],
["ru-en", 22.0],
["en-de", 22.0],
["de-en", 29.0],
]
)
@slow
def test_bleu_scores(self, pair, min_bleu_score):
# note: this test is not testing the best performance since it only evals a small batch
# but it should be enough to detect a regression in the output quality
mname = f"facebook/wmt19-{pair}"
tokenizer = self.get_tokenizer(mname)
model = self.get_model(mname)
src_sentences = bleu_data[pair]["src"]
tgt_sentences = bleu_data[pair]["tgt"]
batch = tokenizer(src_sentences, return_tensors="pt", truncation=True, padding="longest").to(torch_device)
outputs = model.generate(
input_ids=batch.input_ids,
num_beams=8,
)
decoded_sentences = tokenizer.batch_decode(
outputs, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
scores = calculate_bleu(decoded_sentences, tgt_sentences)
print(scores)
self.assertGreaterEqual(scores["bleu"], min_bleu_score)
| transformers/examples/legacy/seq2seq/old_test_fsmt_bleu_score.py/0 | {
"file_path": "transformers/examples/legacy/seq2seq/old_test_fsmt_bleu_score.py",
"repo_id": "transformers",
"token_count": 997
} | 281 |
#!/usr/bin/env python
import io
import json
import subprocess
pairs = [
["en", "ru"],
["ru", "en"],
["en", "de"],
["de", "en"],
]
n_objs = 8
def get_all_data(pairs, n_objs):
text = {}
for src, tgt in pairs:
pair = f"{src}-{tgt}"
cmd = f"sacrebleu -t wmt19 -l {pair} --echo src".split()
src_lines = subprocess.run(cmd, stdout=subprocess.PIPE).stdout.decode("utf-8").splitlines()
cmd = f"sacrebleu -t wmt19 -l {pair} --echo ref".split()
tgt_lines = subprocess.run(cmd, stdout=subprocess.PIPE).stdout.decode("utf-8").splitlines()
text[pair] = {"src": src_lines[:n_objs], "tgt": tgt_lines[:n_objs]}
return text
text = get_all_data(pairs, n_objs)
filename = "./fsmt_val_data.json"
with io.open(filename, "w", encoding="utf-8") as f:
bleu_data = json.dump(text, f, indent=2, ensure_ascii=False)
| transformers/examples/legacy/seq2seq/test_data/fsmt/build-eval-data.py/0 | {
"file_path": "transformers/examples/legacy/seq2seq/test_data/fsmt/build-eval-data.py",
"repo_id": "transformers",
"token_count": 410
} | 282 |
## Token classification
Based on the scripts [`run_ner.py`](https://github.com/huggingface/transformers/blob/main/examples/legacy/token-classification/run_ner.py).
The following examples are covered in this section:
* NER on the GermEval 2014 (German NER) dataset
* Emerging and Rare Entities task: WNUT’17 (English NER) dataset
Details and results for the fine-tuning provided by @stefan-it.
### GermEval 2014 (German NER) dataset
#### Data (Download and pre-processing steps)
Data can be obtained from the [GermEval 2014](https://sites.google.com/site/germeval2014ner/data) shared task page.
Here are the commands for downloading and pre-processing train, dev and test datasets. The original data format has four (tab-separated) columns, in a pre-processing step only the two relevant columns (token and outer span NER annotation) are extracted:
```bash
curl -L 'https://drive.google.com/uc?export=download&id=1Jjhbal535VVz2ap4v4r_rN1UEHTdLK5P' \
| grep -v "^#" | cut -f 2,3 | tr '\t' ' ' > train.txt.tmp
curl -L 'https://drive.google.com/uc?export=download&id=1ZfRcQThdtAR5PPRjIDtrVP7BtXSCUBbm' \
| grep -v "^#" | cut -f 2,3 | tr '\t' ' ' > dev.txt.tmp
curl -L 'https://drive.google.com/uc?export=download&id=1u9mb7kNJHWQCWyweMDRMuTFoOHOfeBTH' \
| grep -v "^#" | cut -f 2,3 | tr '\t' ' ' > test.txt.tmp
```
The GermEval 2014 dataset contains some strange "control character" tokens like `'\x96', '\u200e', '\x95', '\xad' or '\x80'`.
One problem with these tokens is, that `BertTokenizer` returns an empty token for them, resulting in misaligned `InputExample`s.
The `preprocess.py` script located in the `scripts` folder a) filters these tokens and b) splits longer sentences into smaller ones (once the max. subtoken length is reached).
Let's define some variables that we need for further pre-processing steps and training the model:
```bash
export MAX_LENGTH=128
export BERT_MODEL=bert-base-multilingual-cased
```
Run the pre-processing script on training, dev and test datasets:
```bash
python3 scripts/preprocess.py train.txt.tmp $BERT_MODEL $MAX_LENGTH > train.txt
python3 scripts/preprocess.py dev.txt.tmp $BERT_MODEL $MAX_LENGTH > dev.txt
python3 scripts/preprocess.py test.txt.tmp $BERT_MODEL $MAX_LENGTH > test.txt
```
The GermEval 2014 dataset has much more labels than CoNLL-2002/2003 datasets, so an own set of labels must be used:
```bash
cat train.txt dev.txt test.txt | cut -d " " -f 2 | grep -v "^$"| sort | uniq > labels.txt
```
#### Prepare the run
Additional environment variables must be set:
```bash
export OUTPUT_DIR=germeval-model
export BATCH_SIZE=32
export NUM_EPOCHS=3
export SAVE_STEPS=750
export SEED=1
```
#### Run the Pytorch version
To start training, just run:
```bash
python3 run_ner.py --data_dir ./ \
--labels ./labels.txt \
--model_name_or_path $BERT_MODEL \
--output_dir $OUTPUT_DIR \
--max_seq_length $MAX_LENGTH \
--num_train_epochs $NUM_EPOCHS \
--per_device_train_batch_size $BATCH_SIZE \
--save_steps $SAVE_STEPS \
--seed $SEED \
--do_train \
--do_eval \
--do_predict
```
If your GPU supports half-precision training, just add the `--fp16` flag. After training, the model will be both evaluated on development and test datasets.
#### JSON-based configuration file
Instead of passing all parameters via commandline arguments, the `run_ner.py` script also supports reading parameters from a json-based configuration file:
```json
{
"data_dir": ".",
"labels": "./labels.txt",
"model_name_or_path": "bert-base-multilingual-cased",
"output_dir": "germeval-model",
"max_seq_length": 128,
"num_train_epochs": 3,
"per_device_train_batch_size": 32,
"save_steps": 750,
"seed": 1,
"do_train": true,
"do_eval": true,
"do_predict": true
}
```
It must be saved with a `.json` extension and can be used by running `python3 run_ner.py config.json`.
#### Evaluation
Evaluation on development dataset outputs the following for our example:
```bash
10/04/2019 00:42:06 - INFO - __main__ - ***** Eval results *****
10/04/2019 00:42:06 - INFO - __main__ - f1 = 0.8623348017621146
10/04/2019 00:42:06 - INFO - __main__ - loss = 0.07183869666975543
10/04/2019 00:42:06 - INFO - __main__ - precision = 0.8467916366258111
10/04/2019 00:42:06 - INFO - __main__ - recall = 0.8784592370979806
```
On the test dataset the following results could be achieved:
```bash
10/04/2019 00:42:42 - INFO - __main__ - ***** Eval results *****
10/04/2019 00:42:42 - INFO - __main__ - f1 = 0.8614389652384803
10/04/2019 00:42:42 - INFO - __main__ - loss = 0.07064602487454782
10/04/2019 00:42:42 - INFO - __main__ - precision = 0.8604651162790697
10/04/2019 00:42:42 - INFO - __main__ - recall = 0.8624150210424085
```
#### Run the Tensorflow 2 version
To start training, just run:
```bash
python3 run_tf_ner.py --data_dir ./ \
--labels ./labels.txt \
--model_name_or_path $BERT_MODEL \
--output_dir $OUTPUT_DIR \
--max_seq_length $MAX_LENGTH \
--num_train_epochs $NUM_EPOCHS \
--per_device_train_batch_size $BATCH_SIZE \
--save_steps $SAVE_STEPS \
--seed $SEED \
--do_train \
--do_eval \
--do_predict
```
Such as the Pytorch version, if your GPU supports half-precision training, just add the `--fp16` flag. After training, the model will be both evaluated on development and test datasets.
#### Evaluation
Evaluation on development dataset outputs the following for our example:
```bash
precision recall f1-score support
LOCderiv 0.7619 0.6154 0.6809 52
PERpart 0.8724 0.8997 0.8858 4057
OTHpart 0.9360 0.9466 0.9413 711
ORGpart 0.7015 0.6989 0.7002 269
LOCpart 0.7668 0.8488 0.8057 496
LOC 0.8745 0.9191 0.8963 235
ORGderiv 0.7723 0.8571 0.8125 91
OTHderiv 0.4800 0.6667 0.5581 18
OTH 0.5789 0.6875 0.6286 16
PERderiv 0.5385 0.3889 0.4516 18
PER 0.5000 0.5000 0.5000 2
ORG 0.0000 0.0000 0.0000 3
micro avg 0.8574 0.8862 0.8715 5968
macro avg 0.8575 0.8862 0.8713 5968
```
On the test dataset the following results could be achieved:
```bash
precision recall f1-score support
PERpart 0.8847 0.8944 0.8896 9397
OTHpart 0.9376 0.9353 0.9365 1639
ORGpart 0.7307 0.7044 0.7173 697
LOC 0.9133 0.9394 0.9262 561
LOCpart 0.8058 0.8157 0.8107 1150
ORG 0.0000 0.0000 0.0000 8
OTHderiv 0.5882 0.4762 0.5263 42
PERderiv 0.6571 0.5227 0.5823 44
OTH 0.4906 0.6667 0.5652 39
ORGderiv 0.7016 0.7791 0.7383 172
LOCderiv 0.8256 0.6514 0.7282 109
PER 0.0000 0.0000 0.0000 11
micro avg 0.8722 0.8774 0.8748 13869
macro avg 0.8712 0.8774 0.8740 13869
```
### Emerging and Rare Entities task: WNUT’17 (English NER) dataset
Description of the WNUT’17 task from the [shared task website](http://noisy-text.github.io/2017/index.html):
> The WNUT’17 shared task focuses on identifying unusual, previously-unseen entities in the context of emerging discussions.
> Named entities form the basis of many modern approaches to other tasks (like event clustering and summarization), but recall on
> them is a real problem in noisy text - even among annotators. This drop tends to be due to novel entities and surface forms.
Six labels are available in the dataset. An overview can be found on this [page](http://noisy-text.github.io/2017/files/).
#### Data (Download and pre-processing steps)
The dataset can be downloaded from the [official GitHub](https://github.com/leondz/emerging_entities_17) repository.
The following commands show how to prepare the dataset for fine-tuning:
```bash
mkdir -p data_wnut_17
curl -L 'https://github.com/leondz/emerging_entities_17/raw/master/wnut17train.conll' | tr '\t' ' ' > data_wnut_17/train.txt.tmp
curl -L 'https://github.com/leondz/emerging_entities_17/raw/master/emerging.dev.conll' | tr '\t' ' ' > data_wnut_17/dev.txt.tmp
curl -L 'https://raw.githubusercontent.com/leondz/emerging_entities_17/master/emerging.test.annotated' | tr '\t' ' ' > data_wnut_17/test.txt.tmp
```
Let's define some variables that we need for further pre-processing steps:
```bash
export MAX_LENGTH=128
export BERT_MODEL=bert-large-cased
```
Here we use the English BERT large model for fine-tuning.
The `preprocess.py` scripts splits longer sentences into smaller ones (once the max. subtoken length is reached):
```bash
python3 scripts/preprocess.py data_wnut_17/train.txt.tmp $BERT_MODEL $MAX_LENGTH > data_wnut_17/train.txt
python3 scripts/preprocess.py data_wnut_17/dev.txt.tmp $BERT_MODEL $MAX_LENGTH > data_wnut_17/dev.txt
python3 scripts/preprocess.py data_wnut_17/test.txt.tmp $BERT_MODEL $MAX_LENGTH > data_wnut_17/test.txt
```
In the last pre-processing step, the `labels.txt` file needs to be generated. This file contains all available labels:
```bash
cat data_wnut_17/train.txt data_wnut_17/dev.txt data_wnut_17/test.txt | cut -d " " -f 2 | grep -v "^$"| sort | uniq > data_wnut_17/labels.txt
```
#### Run the Pytorch version
Fine-tuning with the PyTorch version can be started using the `run_ner.py` script. In this example we use a JSON-based configuration file.
This configuration file looks like:
```json
{
"data_dir": "./data_wnut_17",
"labels": "./data_wnut_17/labels.txt",
"model_name_or_path": "bert-large-cased",
"output_dir": "wnut-17-model-1",
"max_seq_length": 128,
"num_train_epochs": 3,
"per_device_train_batch_size": 32,
"save_steps": 425,
"seed": 1,
"do_train": true,
"do_eval": true,
"do_predict": true,
"fp16": false
}
```
If your GPU supports half-precision training, please set `fp16` to `true`.
Save this JSON-based configuration under `wnut_17.json`. The fine-tuning can be started with `python3 run_ner_old.py wnut_17.json`.
#### Evaluation
Evaluation on development dataset outputs the following:
```bash
05/29/2020 23:33:44 - INFO - __main__ - ***** Eval results *****
05/29/2020 23:33:44 - INFO - __main__ - eval_loss = 0.26505235286212275
05/29/2020 23:33:44 - INFO - __main__ - eval_precision = 0.7008264462809918
05/29/2020 23:33:44 - INFO - __main__ - eval_recall = 0.507177033492823
05/29/2020 23:33:44 - INFO - __main__ - eval_f1 = 0.5884802220680084
05/29/2020 23:33:44 - INFO - __main__ - epoch = 3.0
```
On the test dataset the following results could be achieved:
```bash
05/29/2020 23:33:44 - INFO - transformers.trainer - ***** Running Prediction *****
05/29/2020 23:34:02 - INFO - __main__ - eval_loss = 0.30948806500973547
05/29/2020 23:34:02 - INFO - __main__ - eval_precision = 0.5840108401084011
05/29/2020 23:34:02 - INFO - __main__ - eval_recall = 0.3994439295644115
05/29/2020 23:34:02 - INFO - __main__ - eval_f1 = 0.47440836543753434
```
WNUT’17 is a very difficult task. Current state-of-the-art results on this dataset can be found [here](https://nlpprogress.com/english/named_entity_recognition.html).
| transformers/examples/legacy/token-classification/README.md/0 | {
"file_path": "transformers/examples/legacy/token-classification/README.md",
"repo_id": "transformers",
"token_count": 4550
} | 283 |
#!/usr/bin/env python
# coding=utf-8
# Copyright 2022 The HuggingFace Team All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Training a CLIP like dual encoder models using text and vision encoders in the library.
The script can be used to train CLIP like models for languages other than English by using
a text encoder pre-trained in the desired language. Currently this script supports the following vision
and text models:
Vision models: ViT(https://huggingface.co/models?filter=vit), CLIP (https://huggingface.co/models?filter=clip)
Text models: BERT, ROBERTa (https://huggingface.co/models?filter=fill-mask)
"""
import logging
import os
import sys
import warnings
from dataclasses import dataclass, field
from typing import Optional
import torch
from datasets import load_dataset
from PIL import Image
from torchvision.io import ImageReadMode, read_image
from torchvision.transforms import CenterCrop, ConvertImageDtype, Normalize, Resize
from torchvision.transforms.functional import InterpolationMode
import transformers
from transformers import (
AutoImageProcessor,
AutoModel,
AutoTokenizer,
HfArgumentParser,
Trainer,
TrainingArguments,
set_seed,
)
from transformers.trainer_utils import get_last_checkpoint
from transformers.utils import check_min_version, send_example_telemetry
from transformers.utils.versions import require_version
logger = logging.getLogger(__name__)
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/contrastive-image-text/requirements.txt")
@dataclass
class ModelArguments:
"""
Arguments pertaining to which model/config/tokenizer we are going to fine-tune, or train from scratch.
"""
model_name_or_path: str = field(
metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"},
)
config_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
)
tokenizer_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
)
image_processor_name: str = field(default=None, metadata={"help": "Name or path of preprocessor config."})
cache_dir: Optional[str] = field(
default=None, metadata={"help": "Where do you want to store the pretrained models downloaded from s3"}
)
model_revision: str = field(
default="main",
metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
)
use_fast_tokenizer: bool = field(
default=True,
metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
)
token: str = field(
default=None,
metadata={
"help": (
"The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
"generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
)
},
)
use_auth_token: bool = field(
default=None,
metadata={
"help": "The `use_auth_token` argument is deprecated and will be removed in v4.34. Please use `token` instead."
},
)
trust_remote_code: bool = field(
default=False,
metadata={
"help": (
"Whether or not to allow for custom models defined on the Hub in their own modeling files. This option "
"should only be set to `True` for repositories you trust and in which you have read the code, as it will "
"execute code present on the Hub on your local machine."
)
},
)
freeze_vision_model: bool = field(
default=False, metadata={"help": "Whether to freeze the vision model parameters or not."}
)
freeze_text_model: bool = field(
default=False, metadata={"help": "Whether to freeze the text model parameters or not."}
)
@dataclass
class DataTrainingArguments:
"""
Arguments pertaining to what data we are going to input our model for training and eval.
"""
dataset_name: Optional[str] = field(
default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
)
dataset_config_name: Optional[str] = field(
default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
)
data_dir: Optional[str] = field(default=None, metadata={"help": "The data directory containing input files."})
image_column: Optional[str] = field(
default="image_path",
metadata={"help": "The name of the column in the datasets containing the full image file paths."},
)
caption_column: Optional[str] = field(
default="caption",
metadata={"help": "The name of the column in the datasets containing the image captions."},
)
train_file: Optional[str] = field(
default=None, metadata={"help": "The input training data file (a jsonlines file)."}
)
validation_file: Optional[str] = field(
default=None,
metadata={"help": "An optional input evaluation data file (a jsonlines file)."},
)
test_file: Optional[str] = field(
default=None,
metadata={"help": "An optional input testing data file (a jsonlines file)."},
)
max_seq_length: Optional[int] = field(
default=128,
metadata={
"help": (
"The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
)
},
)
max_train_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set."
)
},
)
max_eval_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of evaluation examples to this "
"value if set."
)
},
)
overwrite_cache: bool = field(
default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
)
preprocessing_num_workers: Optional[int] = field(
default=None,
metadata={"help": "The number of processes to use for the preprocessing."},
)
def __post_init__(self):
if self.dataset_name is None and self.train_file is None and self.validation_file is None:
raise ValueError("Need either a dataset name or a training/validation file.")
else:
if self.train_file is not None:
extension = self.train_file.split(".")[-1]
assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
if self.validation_file is not None:
extension = self.validation_file.split(".")[-1]
assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
if self.validation_file is not None:
extension = self.validation_file.split(".")[-1]
assert extension == "json", "`validation_file` should be a json file."
dataset_name_mapping = {
"image_caption_dataset.py": ("image_path", "caption"),
}
# We use torchvision for faster image pre-processing. The transforms are implemented as nn.Module,
# so we jit it to be faster.
class Transform(torch.nn.Module):
def __init__(self, image_size, mean, std):
super().__init__()
self.transforms = torch.nn.Sequential(
Resize([image_size], interpolation=InterpolationMode.BICUBIC),
CenterCrop(image_size),
ConvertImageDtype(torch.float),
Normalize(mean, std),
)
def forward(self, x) -> torch.Tensor:
"""`x` should be an instance of `PIL.Image.Image`"""
with torch.no_grad():
x = self.transforms(x)
return x
def collate_fn(examples):
pixel_values = torch.stack([example["pixel_values"] for example in examples])
input_ids = torch.tensor([example["input_ids"] for example in examples], dtype=torch.long)
attention_mask = torch.tensor([example["attention_mask"] for example in examples], dtype=torch.long)
return {
"pixel_values": pixel_values,
"input_ids": input_ids,
"attention_mask": attention_mask,
"return_loss": True,
}
def main():
# 1. Parse input arguments
# See all possible arguments in src/transformers/training_args.py
# or by passing the --help flag to this script.
# We now keep distinct sets of args, for a cleaner separation of concerns.
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
# If we pass only one argument to the script and it's the path to a json file,
# let's parse it to get our arguments.
model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
else:
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
if model_args.use_auth_token is not None:
warnings.warn(
"The `use_auth_token` argument is deprecated and will be removed in v4.34. Please use `token` instead.",
FutureWarning,
)
if model_args.token is not None:
raise ValueError("`token` and `use_auth_token` are both specified. Please set only the argument `token`.")
model_args.token = model_args.use_auth_token
# Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
# information sent is the one passed as arguments along with your Python/PyTorch versions.
send_example_telemetry("run_clip", model_args, data_args)
# 2. Setup logging
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
handlers=[logging.StreamHandler(sys.stdout)],
)
if training_args.should_log:
# The default of training_args.log_level is passive, so we set log level at info here to have that default.
transformers.utils.logging.set_verbosity_info()
log_level = training_args.get_process_log_level()
logger.setLevel(log_level)
transformers.utils.logging.set_verbosity(log_level)
transformers.utils.logging.enable_default_handler()
transformers.utils.logging.enable_explicit_format()
# Log on each process the small summary:
logger.warning(
f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}, "
+ f"distributed training: {training_args.parallel_mode.value == 'distributed'}, 16-bits training: {training_args.fp16}"
)
logger.info(f"Training/evaluation parameters {training_args}")
# 3. Detecting last checkpoint and eventually continue from last checkpoint
last_checkpoint = None
if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
last_checkpoint = get_last_checkpoint(training_args.output_dir)
if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
raise ValueError(
f"Output directory ({training_args.output_dir}) already exists and is not empty. "
"Use --overwrite_output_dir to overcome."
)
elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
logger.info(
f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
"the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
)
# 4. Load dataset
# Get the datasets: you can either provide your own CSV/JSON training and evaluation files (see below)
# or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
# (the dataset will be downloaded automatically from the datasets Hub).
#
# For CSV/JSON files this script will use the first column for the full image path and the second column for the
# captions (unless you specify column names for this with the `image_column` and `caption_column` arguments).
#
if data_args.dataset_name is not None:
# Downloading and loading a dataset from the hub.
dataset = load_dataset(
data_args.dataset_name,
data_args.dataset_config_name,
cache_dir=model_args.cache_dir,
keep_in_memory=False,
data_dir=data_args.data_dir,
token=model_args.token,
)
else:
data_files = {}
if data_args.train_file is not None:
data_files["train"] = data_args.train_file
extension = data_args.train_file.split(".")[-1]
if data_args.validation_file is not None:
data_files["validation"] = data_args.validation_file
extension = data_args.validation_file.split(".")[-1]
if data_args.test_file is not None:
data_files["test"] = data_args.test_file
extension = data_args.test_file.split(".")[-1]
dataset = load_dataset(
extension,
data_files=data_files,
cache_dir=model_args.cache_dir,
token=model_args.token,
)
# See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
# https://huggingface.co/docs/datasets/loading_datasets.
# 5. Load pretrained model, tokenizer, and image processor
if model_args.tokenizer_name:
tokenizer = AutoTokenizer.from_pretrained(
model_args.tokenizer_name,
cache_dir=model_args.cache_dir,
use_fast=model_args.use_fast_tokenizer,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
)
elif model_args.model_name_or_path:
tokenizer = AutoTokenizer.from_pretrained(
model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
use_fast=model_args.use_fast_tokenizer,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
)
else:
raise ValueError(
"You are instantiating a new tokenizer from scratch. This is not supported by this script. "
"You can do it from another script, save it, and load it from here, using --tokenizer_name."
)
# Load image_processor, in this script we only use this to get the mean and std for normalization.
image_processor = AutoImageProcessor.from_pretrained(
model_args.image_processor_name or model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
)
model = AutoModel.from_pretrained(
model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
)
config = model.config
def _freeze_params(module):
for param in module.parameters():
param.requires_grad = False
if model_args.freeze_vision_model:
_freeze_params(model.vision_model)
if model_args.freeze_text_model:
_freeze_params(model.text_model)
# set seed for torch dataloaders
set_seed(training_args.seed)
# Preprocessing the datasets.
# We need to tokenize inputs and targets.
if training_args.do_train:
column_names = dataset["train"].column_names
elif training_args.do_eval:
column_names = dataset["validation"].column_names
elif training_args.do_predict:
column_names = dataset["test"].column_names
else:
logger.info("There is nothing to do. Please pass `do_train`, `do_eval` and/or `do_predict`.")
return
# 6. Get the column names for input/target.
dataset_columns = dataset_name_mapping.get(data_args.dataset_name, None)
if data_args.image_column is None:
image_column = dataset_columns[0] if dataset_columns is not None else column_names[0]
else:
image_column = data_args.image_column
if image_column not in column_names:
raise ValueError(
f"--image_column' value '{data_args.image_column}' needs to be one of: {', '.join(column_names)}"
)
if data_args.caption_column is None:
caption_column = dataset_columns[1] if dataset_columns is not None else column_names[1]
else:
caption_column = data_args.caption_column
if caption_column not in column_names:
raise ValueError(
f"--caption_column' value '{data_args.caption_column}' needs to be one of: {', '.join(column_names)}"
)
# 7. Preprocessing the datasets.
# Initialize torchvision transforms and jit it for faster processing.
image_transformations = Transform(
config.vision_config.image_size, image_processor.image_mean, image_processor.image_std
)
image_transformations = torch.jit.script(image_transformations)
# Preprocessing the datasets.
# We need to tokenize input captions and transform the images.
def tokenize_captions(examples):
captions = list(examples[caption_column])
text_inputs = tokenizer(captions, max_length=data_args.max_seq_length, padding="max_length", truncation=True)
examples["input_ids"] = text_inputs.input_ids
examples["attention_mask"] = text_inputs.attention_mask
return examples
def transform_images(examples):
images = [read_image(image_file, mode=ImageReadMode.RGB) for image_file in examples[image_column]]
examples["pixel_values"] = [image_transformations(image) for image in images]
return examples
def filter_corrupt_images(examples):
"""remove problematic images"""
valid_images = []
for image_file in examples[image_column]:
try:
Image.open(image_file)
valid_images.append(True)
except Exception:
valid_images.append(False)
return valid_images
if training_args.do_train:
if "train" not in dataset:
raise ValueError("--do_train requires a train dataset")
train_dataset = dataset["train"]
if data_args.max_train_samples is not None:
max_train_samples = min(len(train_dataset), data_args.max_train_samples)
train_dataset = train_dataset.select(range(max_train_samples))
train_dataset = train_dataset.filter(
filter_corrupt_images, batched=True, num_proc=data_args.preprocessing_num_workers
)
train_dataset = train_dataset.map(
function=tokenize_captions,
batched=True,
remove_columns=[col for col in column_names if col != image_column],
num_proc=data_args.preprocessing_num_workers,
load_from_cache_file=not data_args.overwrite_cache,
desc="Running tokenizer on train dataset",
)
# Transform images on the fly as doing it on the whole dataset takes too much time.
train_dataset.set_transform(transform_images)
if training_args.do_eval:
if "validation" not in dataset:
raise ValueError("--do_eval requires a train validation")
eval_dataset = dataset["validation"]
if data_args.max_eval_samples is not None:
max_eval_samples = min(len(eval_dataset), data_args.max_eval_samples)
eval_dataset = eval_dataset.select(range(max_eval_samples))
eval_dataset = eval_dataset.filter(
filter_corrupt_images, batched=True, num_proc=data_args.preprocessing_num_workers
)
eval_dataset = eval_dataset.map(
function=tokenize_captions,
batched=True,
num_proc=data_args.preprocessing_num_workers,
remove_columns=[col for col in column_names if col != image_column],
load_from_cache_file=not data_args.overwrite_cache,
desc="Running tokenizer on validation dataset",
)
# Transform images on the fly as doing it on the whole dataset takes too much time.
eval_dataset.set_transform(transform_images)
if training_args.do_predict:
if "test" not in dataset:
raise ValueError("--do_predict requires a test dataset")
test_dataset = dataset["test"]
if data_args.max_eval_samples is not None:
max_eval_samples = min(len(test_dataset), data_args.max_eval_samples)
test_dataset = test_dataset.select(range(max_eval_samples))
test_dataset = test_dataset.filter(
filter_corrupt_images, batched=True, num_proc=data_args.preprocessing_num_workers
)
test_dataset = test_dataset.map(
function=tokenize_captions,
batched=True,
num_proc=data_args.preprocessing_num_workers,
remove_columns=[col for col in column_names if col != image_column],
load_from_cache_file=not data_args.overwrite_cache,
desc="Running tokenizer on test dataset",
)
# Transform images on the fly as doing it on the whole dataset takes too much time.
test_dataset.set_transform(transform_images)
# 8. Initialize our trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
data_collator=collate_fn,
)
# 9. Training
if training_args.do_train:
checkpoint = None
if training_args.resume_from_checkpoint is not None:
checkpoint = training_args.resume_from_checkpoint
elif last_checkpoint is not None:
checkpoint = last_checkpoint
train_result = trainer.train(resume_from_checkpoint=checkpoint)
trainer.save_model()
tokenizer.save_pretrained(training_args.output_dir)
image_processor.save_pretrained(training_args.output_dir)
trainer.log_metrics("train", train_result.metrics)
trainer.save_metrics("train", train_result.metrics)
trainer.save_state()
# 10. Evaluation
if training_args.do_eval:
metrics = trainer.evaluate()
trainer.log_metrics("eval", metrics)
trainer.save_metrics("eval", metrics)
# 11. Write Training Stats and push to hub.
finetuned_from = model_args.model_name_or_path
# If from a local directory, don't set `finetuned_from` as this is required to be a valid repo. id on the Hub.
if os.path.isdir(finetuned_from):
finetuned_from = None
kwargs = {"finetuned_from": finetuned_from, "tasks": "contrastive-image-text-modeling"}
if data_args.dataset_name is not None:
kwargs["dataset_tags"] = data_args.dataset_name
if data_args.dataset_config_name is not None:
kwargs["dataset_args"] = data_args.dataset_config_name
kwargs["dataset"] = f"{data_args.dataset_name} {data_args.dataset_config_name}"
else:
kwargs["dataset"] = data_args.dataset_name
if training_args.push_to_hub:
trainer.push_to_hub(**kwargs)
else:
trainer.create_model_card(**kwargs)
if __name__ == "__main__":
main()
| transformers/examples/pytorch/contrastive-image-text/run_clip.py/0 | {
"file_path": "transformers/examples/pytorch/contrastive-image-text/run_clip.py",
"repo_id": "transformers",
"token_count": 9756
} | 284 |
#!/usr/bin/env python
# coding=utf-8
# Copyright 2020 The HuggingFace Team All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Fine-tuning the library models for permutation language modeling.
"""
# You can also adapt this script on your own permutation language modeling task. Pointers for this are left as comments.
import logging
import math
import os
import sys
import warnings
from dataclasses import dataclass, field
from itertools import chain
from typing import Optional
import datasets
from datasets import load_dataset
import transformers
from transformers import (
AutoConfig,
AutoTokenizer,
DataCollatorForPermutationLanguageModeling,
HfArgumentParser,
Trainer,
TrainingArguments,
XLNetConfig,
XLNetLMHeadModel,
set_seed,
)
from transformers.trainer_utils import get_last_checkpoint
from transformers.utils import check_min_version, send_example_telemetry
from transformers.utils.versions import require_version
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/language-modeling/requirements.txt")
logger = logging.getLogger(__name__)
@dataclass
class ModelArguments:
"""
Arguments pertaining to which model/config/tokenizer we are going to fine-tune, or train from scratch.
"""
model_name_or_path: Optional[str] = field(
default=None,
metadata={
"help": (
"The model checkpoint for weights initialization. Don't set if you want to train a model from scratch."
)
},
)
config_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
)
config_overrides: Optional[str] = field(
default=None,
metadata={
"help": (
"Override some existing default config settings when a model is trained from scratch. Example: "
"n_embd=10,resid_pdrop=0.2,scale_attn_weights=false,summary_type=cls_index"
)
},
)
tokenizer_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
)
cache_dir: Optional[str] = field(
default=None,
metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
)
use_fast_tokenizer: bool = field(
default=True,
metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
)
model_revision: str = field(
default="main",
metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
)
token: str = field(
default=None,
metadata={
"help": (
"The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
"generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
)
},
)
use_auth_token: bool = field(
default=None,
metadata={
"help": "The `use_auth_token` argument is deprecated and will be removed in v4.34. Please use `token` instead."
},
)
low_cpu_mem_usage: bool = field(
default=False,
metadata={
"help": (
"It is an option to create the model as an empty shell, then only materialize its parameters when the pretrained weights are loaded. "
"set True will benefit LLM loading time and RAM consumption."
)
},
)
def __post_init__(self):
if self.config_overrides is not None and (self.config_name is not None or self.model_name_or_path is not None):
raise ValueError(
"--config_overrides can't be used in combination with --config_name or --model_name_or_path"
)
@dataclass
class DataTrainingArguments:
"""
Arguments pertaining to what data we are going to input our model for training and eval.
"""
dataset_name: Optional[str] = field(
default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
)
dataset_config_name: Optional[str] = field(
default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
)
train_file: Optional[str] = field(default=None, metadata={"help": "The input training data file (a text file)."})
validation_file: Optional[str] = field(
default=None,
metadata={"help": "An optional input evaluation data file to evaluate the perplexity on (a text file)."},
)
overwrite_cache: bool = field(
default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
)
validation_split_percentage: Optional[int] = field(
default=5,
metadata={
"help": "The percentage of the train set used as validation set in case there's no validation split"
},
)
max_seq_length: int = field(
default=512,
metadata={
"help": (
"The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated."
)
},
)
preprocessing_num_workers: Optional[int] = field(
default=None,
metadata={"help": "The number of processes to use for the preprocessing."},
)
plm_probability: float = field(
default=1 / 6,
metadata={
"help": (
"Ratio of length of a span of masked tokens to surrounding context length for "
"permutation language modeling."
)
},
)
max_span_length: int = field(
default=5, metadata={"help": "Maximum length of a span of masked tokens for permutation language modeling."}
)
line_by_line: bool = field(
default=False,
metadata={"help": "Whether distinct lines of text in the dataset are to be handled as distinct sequences."},
)
pad_to_max_length: bool = field(
default=False,
metadata={
"help": (
"Whether to pad all samples to `max_seq_length`. "
"If False, will pad the samples dynamically when batching to the maximum length in the batch."
)
},
)
max_train_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set."
)
},
)
max_eval_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of evaluation examples to this "
"value if set."
)
},
)
def __post_init__(self):
if self.dataset_name is None and self.train_file is None and self.validation_file is None:
raise ValueError("Need either a dataset name or a training/validation file.")
else:
if self.train_file is not None:
extension = self.train_file.split(".")[-1]
assert extension in ["csv", "json", "txt"], "`train_file` should be a csv, a json or a txt file."
if self.validation_file is not None:
extension = self.validation_file.split(".")[-1]
assert extension in ["csv", "json", "txt"], "`validation_file` should be a csv, a json or a txt file."
def main():
# See all possible arguments in src/transformers/training_args.py
# or by passing the --help flag to this script.
# We now keep distinct sets of args, for a cleaner separation of concerns.
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
# If we pass only one argument to the script and it's the path to a json file,
# let's parse it to get our arguments.
model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
else:
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
if model_args.use_auth_token is not None:
warnings.warn(
"The `use_auth_token` argument is deprecated and will be removed in v4.34. Please use `token` instead.",
FutureWarning,
)
if model_args.token is not None:
raise ValueError("`token` and `use_auth_token` are both specified. Please set only the argument `token`.")
model_args.token = model_args.use_auth_token
# Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
# information sent is the one passed as arguments along with your Python/PyTorch versions.
send_example_telemetry("run_plm", model_args, data_args)
# Setup logging
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
handlers=[logging.StreamHandler(sys.stdout)],
)
if training_args.should_log:
# The default of training_args.log_level is passive, so we set log level at info here to have that default.
transformers.utils.logging.set_verbosity_info()
log_level = training_args.get_process_log_level()
logger.setLevel(log_level)
datasets.utils.logging.set_verbosity(log_level)
transformers.utils.logging.set_verbosity(log_level)
transformers.utils.logging.enable_default_handler()
transformers.utils.logging.enable_explicit_format()
# Log on each process the small summary:
logger.warning(
f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}, "
+ f"distributed training: {training_args.parallel_mode.value == 'distributed'}, 16-bits training: {training_args.fp16}"
)
logger.info(f"Training/evaluation parameters {training_args}")
# Detecting last checkpoint.
last_checkpoint = None
if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
last_checkpoint = get_last_checkpoint(training_args.output_dir)
if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
raise ValueError(
f"Output directory ({training_args.output_dir}) already exists and is not empty. "
"Use --overwrite_output_dir to overcome."
)
elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
logger.info(
f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
"the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
)
# Set seed before initializing model.
set_seed(training_args.seed)
# Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
# or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
# (the dataset will be downloaded automatically from the datasets Hub).
#
# For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
# 'text' is found. You can easily tweak this behavior (see below).
#
# In distributed training, the load_dataset function guarantee that only one local process can concurrently
# download the dataset.
if data_args.dataset_name is not None:
# Downloading and loading a dataset from the hub.
raw_datasets = load_dataset(
data_args.dataset_name,
data_args.dataset_config_name,
cache_dir=model_args.cache_dir,
token=model_args.token,
)
if "validation" not in raw_datasets.keys():
raw_datasets["validation"] = load_dataset(
data_args.dataset_name,
data_args.dataset_config_name,
split=f"train[:{data_args.validation_split_percentage}%]",
cache_dir=model_args.cache_dir,
token=model_args.token,
)
raw_datasets["train"] = load_dataset(
data_args.dataset_name,
data_args.dataset_config_name,
split=f"train[{data_args.validation_split_percentage}%:]",
cache_dir=model_args.cache_dir,
token=model_args.token,
)
else:
data_files = {}
if data_args.train_file is not None:
data_files["train"] = data_args.train_file
extension = data_args.train_file.split(".")[-1]
if data_args.validation_file is not None:
data_files["validation"] = data_args.validation_file
extension = data_args.validation_file.split(".")[-1]
if extension == "txt":
extension = "text"
raw_datasets = load_dataset(extension, data_files=data_files, cache_dir=model_args.cache_dir)
# If no validation data is there, validation_split_percentage will be used to divide the dataset.
if "validation" not in raw_datasets.keys():
raw_datasets["validation"] = load_dataset(
extension,
data_files=data_files,
split=f"train[:{data_args.validation_split_percentage}%]",
cache_dir=model_args.cache_dir,
token=model_args.token,
)
raw_datasets["train"] = load_dataset(
extension,
data_files=data_files,
split=f"train[{data_args.validation_split_percentage}%:]",
cache_dir=model_args.cache_dir,
token=model_args.token,
)
# See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
# https://huggingface.co/docs/datasets/loading_datasets.
# Load pretrained model and tokenizer
#
# Distributed training:
# The .from_pretrained methods guarantee that only one local process can concurrently
# download model & vocab.
config_kwargs = {
"cache_dir": model_args.cache_dir,
"revision": model_args.model_revision,
"token": model_args.token,
}
if model_args.config_name:
config = AutoConfig.from_pretrained(model_args.config_name, **config_kwargs)
elif model_args.model_name_or_path:
config = AutoConfig.from_pretrained(model_args.model_name_or_path, **config_kwargs)
else:
config = XLNetConfig()
logger.warning("You are instantiating a new config instance from scratch.")
if model_args.config_overrides is not None:
logger.info(f"Overriding config: {model_args.config_overrides}")
config.update_from_string(model_args.config_overrides)
logger.info(f"New config: {config}")
tokenizer_kwargs = {
"cache_dir": model_args.cache_dir,
"use_fast": model_args.use_fast_tokenizer,
"revision": model_args.model_revision,
"token": model_args.token,
}
if model_args.tokenizer_name:
tokenizer = AutoTokenizer.from_pretrained(model_args.tokenizer_name, **tokenizer_kwargs)
elif model_args.model_name_or_path:
tokenizer = AutoTokenizer.from_pretrained(model_args.model_name_or_path, **tokenizer_kwargs)
else:
raise ValueError(
"You are instantiating a new tokenizer from scratch. This is not supported by this script. "
"You can do it from another script, save it, and load it from here, using --tokenizer_name."
)
if model_args.model_name_or_path:
model = XLNetLMHeadModel.from_pretrained(
model_args.model_name_or_path,
from_tf=bool(".ckpt" in model_args.model_name_or_path),
config=config,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
token=model_args.token,
low_cpu_mem_usage=model_args.low_cpu_mem_usage,
)
else:
logger.info("Training new model from scratch")
model = XLNetLMHeadModel(config)
# We resize the embeddings only when necessary to avoid index errors. If you are creating a model from scratch
# on a small vocab and want a smaller embedding size, remove this test.
embedding_size = model.get_input_embeddings().weight.shape[0]
if len(tokenizer) > embedding_size:
model.resize_token_embeddings(len(tokenizer))
# Preprocessing the datasets.
# First we tokenize all the texts.
if training_args.do_train:
column_names = raw_datasets["train"].column_names
else:
column_names = raw_datasets["validation"].column_names
text_column_name = "text" if "text" in column_names else column_names[0]
if data_args.max_seq_length > tokenizer.model_max_length:
logger.warning(
f"The max_seq_length passed ({data_args.max_seq_length}) is larger than the maximum length for the "
f"model ({tokenizer.model_max_length}). Using max_seq_length={tokenizer.model_max_length}."
)
max_seq_length = min(data_args.max_seq_length, tokenizer.model_max_length)
if data_args.line_by_line:
# When using line_by_line, we just tokenize each nonempty line.
padding = "max_length" if data_args.pad_to_max_length else False
def tokenize_function(examples):
# Remove empty lines
examples["text"] = [line for line in examples["text"] if len(line) > 0 and not line.isspace()]
return tokenizer(examples["text"], padding=padding, truncation=True, max_length=max_seq_length)
with training_args.main_process_first(desc="dataset map tokenization"):
tokenized_datasets = raw_datasets.map(
tokenize_function,
batched=True,
num_proc=data_args.preprocessing_num_workers,
remove_columns=[text_column_name],
load_from_cache_file=not data_args.overwrite_cache,
desc="Running tokenizer on dataset line_by_line",
)
else:
# Otherwise, we tokenize every text, then concatenate them together before splitting them in smaller parts.
def tokenize_function(examples):
return tokenizer(examples[text_column_name])
with training_args.main_process_first(desc="dataset map tokenization"):
tokenized_datasets = raw_datasets.map(
tokenize_function,
batched=True,
num_proc=data_args.preprocessing_num_workers,
remove_columns=column_names,
load_from_cache_file=not data_args.overwrite_cache,
desc="Running tokenizer on every text in dataset",
)
# Main data processing function that will concatenate all texts from our dataset and generate chunks of
# max_seq_length.
def group_texts(examples):
# Concatenate all texts.
concatenated_examples = {k: list(chain(*examples[k])) for k in examples.keys()}
total_length = len(concatenated_examples[list(examples.keys())[0]])
# We drop the small remainder, and if the total_length < max_seq_length we exclude this batch and return an empty dict.
# We could add padding if the model supported it instead of this drop, you can customize this part to your needs.
total_length = (total_length // max_seq_length) * max_seq_length
# Split by chunks of max_len.
result = {
k: [t[i : i + max_seq_length] for i in range(0, total_length, max_seq_length)]
for k, t in concatenated_examples.items()
}
return result
# Note that with `batched=True`, this map processes 1,000 texts together, so group_texts throws away a
# remainder for each of those groups of 1,000 texts. You can adjust that batch_size here but a higher value
# might be slower to preprocess.
#
# To speed up this part, we use multiprocessing. See the documentation of the map method for more information:
# https://huggingface.co/docs/datasets/process#map
with training_args.main_process_first(desc="grouping texts together"):
tokenized_datasets = tokenized_datasets.map(
group_texts,
batched=True,
num_proc=data_args.preprocessing_num_workers,
load_from_cache_file=not data_args.overwrite_cache,
desc=f"Grouping texts in chunks of {max_seq_length}",
)
if training_args.do_train:
if "train" not in tokenized_datasets:
raise ValueError("--do_train requires a train dataset")
train_dataset = tokenized_datasets["train"]
if data_args.max_train_samples is not None:
max_train_samples = min(len(train_dataset), data_args.max_train_samples)
train_dataset = train_dataset.select(range(max_train_samples))
if training_args.do_eval:
if "validation" not in tokenized_datasets:
raise ValueError("--do_eval requires a validation dataset")
eval_dataset = tokenized_datasets["validation"]
if data_args.max_eval_samples is not None:
max_eval_samples = min(len(eval_dataset), data_args.max_eval_samples)
eval_dataset = eval_dataset.select(range(max_eval_samples))
# Data collator
data_collator = DataCollatorForPermutationLanguageModeling(
tokenizer=tokenizer,
plm_probability=data_args.plm_probability,
max_span_length=data_args.max_span_length,
)
# Initialize our Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
tokenizer=tokenizer,
data_collator=data_collator,
)
# Training
if training_args.do_train:
checkpoint = None
if training_args.resume_from_checkpoint is not None:
checkpoint = training_args.resume_from_checkpoint
elif last_checkpoint is not None:
checkpoint = last_checkpoint
train_result = trainer.train(resume_from_checkpoint=checkpoint)
trainer.save_model() # Saves the tokenizer too for easy upload
metrics = train_result.metrics
max_train_samples = (
data_args.max_train_samples if data_args.max_train_samples is not None else len(train_dataset)
)
metrics["train_samples"] = min(max_train_samples, len(train_dataset))
trainer.log_metrics("train", metrics)
trainer.save_metrics("train", metrics)
trainer.save_state()
# Evaluation
if training_args.do_eval:
logger.info("*** Evaluate ***")
metrics = trainer.evaluate()
max_eval_samples = data_args.max_eval_samples if data_args.max_eval_samples is not None else len(eval_dataset)
metrics["eval_samples"] = min(max_eval_samples, len(eval_dataset))
try:
perplexity = math.exp(metrics["eval_loss"])
except OverflowError:
perplexity = float("inf")
metrics["perplexity"] = perplexity
trainer.log_metrics("eval", metrics)
trainer.save_metrics("eval", metrics)
kwargs = {"finetuned_from": model_args.model_name_or_path, "tasks": "language-modeling"}
if data_args.dataset_name is not None:
kwargs["dataset_tags"] = data_args.dataset_name
if data_args.dataset_config_name is not None:
kwargs["dataset_args"] = data_args.dataset_config_name
kwargs["dataset"] = f"{data_args.dataset_name} {data_args.dataset_config_name}"
else:
kwargs["dataset"] = data_args.dataset_name
if training_args.push_to_hub:
trainer.push_to_hub(**kwargs)
else:
trainer.create_model_card(**kwargs)
def _mp_fn(index):
# For xla_spawn (TPUs)
main()
if __name__ == "__main__":
main()
| transformers/examples/pytorch/language-modeling/run_plm.py/0 | {
"file_path": "transformers/examples/pytorch/language-modeling/run_plm.py",
"repo_id": "transformers",
"token_count": 10316
} | 285 |
#!/usr/bin/env python
# coding=utf-8
# Copyright The HuggingFace Team and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Fine-tuning a 🤗 Transformers model on summarization.
"""
# You can also adapt this script on your own summarization task. Pointers for this are left as comments.
import argparse
import json
import logging
import math
import os
import random
from pathlib import Path
import datasets
import evaluate
import nltk
import numpy as np
import torch
from accelerate import Accelerator
from accelerate.logging import get_logger
from accelerate.utils import set_seed
from datasets import load_dataset
from filelock import FileLock
from huggingface_hub import Repository, create_repo
from torch.utils.data import DataLoader
from tqdm.auto import tqdm
import transformers
from transformers import (
CONFIG_MAPPING,
MODEL_MAPPING,
AutoConfig,
AutoModelForSeq2SeqLM,
AutoTokenizer,
DataCollatorForSeq2Seq,
SchedulerType,
get_scheduler,
)
from transformers.utils import check_min_version, is_offline_mode, send_example_telemetry
from transformers.utils.versions import require_version
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
check_min_version("4.38.0.dev0")
logger = get_logger(__name__)
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/summarization/requirements.txt")
# You should update this to your particular problem to have better documentation of `model_type`
MODEL_CONFIG_CLASSES = list(MODEL_MAPPING.keys())
MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
try:
nltk.data.find("tokenizers/punkt")
except (LookupError, OSError):
if is_offline_mode():
raise LookupError(
"Offline mode: run this script without TRANSFORMERS_OFFLINE first to download nltk data files"
)
with FileLock(".lock") as lock:
nltk.download("punkt", quiet=True)
summarization_name_mapping = {
"amazon_reviews_multi": ("review_body", "review_title"),
"big_patent": ("description", "abstract"),
"cnn_dailymail": ("article", "highlights"),
"orange_sum": ("text", "summary"),
"pn_summary": ("article", "summary"),
"psc": ("extract_text", "summary_text"),
"samsum": ("dialogue", "summary"),
"thaisum": ("body", "summary"),
"xglue": ("news_body", "news_title"),
"xsum": ("document", "summary"),
"wiki_summary": ("article", "highlights"),
}
def parse_args():
parser = argparse.ArgumentParser(description="Finetune a transformers model on a summarization task")
parser.add_argument(
"--dataset_name",
type=str,
default=None,
help="The name of the dataset to use (via the datasets library).",
)
parser.add_argument(
"--dataset_config_name",
type=str,
default=None,
help="The configuration name of the dataset to use (via the datasets library).",
)
parser.add_argument(
"--train_file", type=str, default=None, help="A csv or a json file containing the training data."
)
parser.add_argument(
"--validation_file", type=str, default=None, help="A csv or a json file containing the validation data."
)
parser.add_argument(
"--ignore_pad_token_for_loss",
type=bool,
default=True,
help="Whether to ignore the tokens corresponding to padded labels in the loss computation or not.",
)
parser.add_argument(
"--max_source_length",
type=int,
default=1024,
help=(
"The maximum total input sequence length after "
"tokenization.Sequences longer than this will be truncated, sequences shorter will be padded."
),
)
parser.add_argument(
"--source_prefix",
type=str,
default=None,
help="A prefix to add before every source text (useful for T5 models).",
)
parser.add_argument(
"--preprocessing_num_workers",
type=int,
default=None,
help="The number of processes to use for the preprocessing.",
)
parser.add_argument(
"--overwrite_cache", action="store_true", help="Overwrite the cached training and evaluation sets"
)
parser.add_argument(
"--max_target_length",
type=int,
default=128,
help=(
"The maximum total sequence length for target text after "
"tokenization. Sequences longer than this will be truncated, sequences shorter will be padded. "
"during ``evaluate`` and ``predict``."
),
)
parser.add_argument(
"--val_max_target_length",
type=int,
default=None,
help=(
"The maximum total sequence length for validation "
"target text after tokenization.Sequences longer than this will be truncated, sequences shorter will be "
"padded. Will default to `max_target_length`.This argument is also used to override the ``max_length`` "
"param of ``model.generate``, which is used during ``evaluate`` and ``predict``."
),
)
parser.add_argument(
"--num_beams",
type=int,
default=None,
help=(
"Number of beams to use for evaluation. This argument will be "
"passed to ``model.generate``, which is used during ``evaluate`` and ``predict``."
),
)
parser.add_argument(
"--pad_to_max_length",
action="store_true",
help="If passed, pad all samples to `max_length`. Otherwise, dynamic padding is used.",
)
parser.add_argument(
"--model_name_or_path",
type=str,
help="Path to pretrained model or model identifier from huggingface.co/models.",
required=False,
)
parser.add_argument(
"--config_name",
type=str,
default=None,
help="Pretrained config name or path if not the same as model_name",
)
parser.add_argument(
"--tokenizer_name",
type=str,
default=None,
help="Pretrained tokenizer name or path if not the same as model_name",
)
parser.add_argument(
"--text_column",
type=str,
default=None,
help="The name of the column in the datasets containing the full texts (for summarization).",
)
parser.add_argument(
"--summary_column",
type=str,
default=None,
help="The name of the column in the datasets containing the summaries (for summarization).",
)
parser.add_argument(
"--use_slow_tokenizer",
action="store_true",
help="If passed, will use a slow tokenizer (not backed by the 🤗 Tokenizers library).",
)
parser.add_argument(
"--per_device_train_batch_size",
type=int,
default=8,
help="Batch size (per device) for the training dataloader.",
)
parser.add_argument(
"--per_device_eval_batch_size",
type=int,
default=8,
help="Batch size (per device) for the evaluation dataloader.",
)
parser.add_argument(
"--learning_rate",
type=float,
default=5e-5,
help="Initial learning rate (after the potential warmup period) to use.",
)
parser.add_argument("--weight_decay", type=float, default=0.0, help="Weight decay to use.")
parser.add_argument("--num_train_epochs", type=int, default=3, help="Total number of training epochs to perform.")
parser.add_argument(
"--max_train_steps",
type=int,
default=None,
help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
)
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
parser.add_argument(
"--lr_scheduler_type",
type=SchedulerType,
default="linear",
help="The scheduler type to use.",
choices=["linear", "cosine", "cosine_with_restarts", "polynomial", "constant", "constant_with_warmup"],
)
parser.add_argument(
"--num_warmup_steps", type=int, default=0, help="Number of steps for the warmup in the lr scheduler."
)
parser.add_argument("--output_dir", type=str, default=None, help="Where to store the final model.")
parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
parser.add_argument(
"--model_type",
type=str,
default=None,
help="Model type to use if training from scratch.",
choices=MODEL_TYPES,
)
parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
parser.add_argument(
"--hub_model_id", type=str, help="The name of the repository to keep in sync with the local `output_dir`."
)
parser.add_argument("--hub_token", type=str, help="The token to use to push to the Model Hub.")
parser.add_argument(
"--trust_remote_code",
type=bool,
default=False,
help=(
"Whether or not to allow for custom models defined on the Hub in their own modeling files. This option "
"should only be set to `True` for repositories you trust and in which you have read the code, as it will "
"execute code present on the Hub on your local machine."
),
)
parser.add_argument(
"--checkpointing_steps",
type=str,
default=None,
help="Whether the various states should be saved at the end of every n steps, or 'epoch' for each epoch.",
)
parser.add_argument(
"--resume_from_checkpoint",
type=str,
default=None,
help="If the training should continue from a checkpoint folder.",
)
parser.add_argument(
"--with_tracking",
action="store_true",
help="Whether to enable experiment trackers for logging.",
)
parser.add_argument(
"--report_to",
type=str,
default="all",
help=(
'The integration to report the results and logs to. Supported platforms are `"tensorboard"`,'
' `"wandb"`, `"comet_ml"` and `"clearml"`. Use `"all"` (default) to report to all integrations. '
"Only applicable when `--with_tracking` is passed."
),
)
args = parser.parse_args()
# Sanity checks
if args.dataset_name is None and args.train_file is None and args.validation_file is None:
raise ValueError("Need either a dataset name or a training/validation file.")
else:
if args.train_file is not None:
extension = args.train_file.split(".")[-1]
assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
if args.validation_file is not None:
extension = args.validation_file.split(".")[-1]
assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
if args.push_to_hub:
assert args.output_dir is not None, "Need an `output_dir` to create a repo when `--push_to_hub` is passed."
return args
def main():
args = parse_args()
# Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
# information sent is the one passed as arguments along with your Python/PyTorch versions.
send_example_telemetry("run_summarization_no_trainer", args)
# Initialize the accelerator. We will let the accelerator handle device placement for us in this example.
# If we're using tracking, we also need to initialize it here and it will by default pick up all supported trackers
# in the environment
accelerator_log_kwargs = {}
if args.with_tracking:
accelerator_log_kwargs["log_with"] = args.report_to
accelerator_log_kwargs["project_dir"] = args.output_dir
accelerator = Accelerator(gradient_accumulation_steps=args.gradient_accumulation_steps, **accelerator_log_kwargs)
if args.source_prefix is None and args.model_name_or_path in [
"t5-small",
"t5-base",
"t5-large",
"t5-3b",
"t5-11b",
]:
logger.warning(
"You're running a t5 model but didn't provide a source prefix, which is the expected, e.g. with "
"`--source_prefix 'summarize: ' `"
)
# Make one log on every process with the configuration for debugging.
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
logger.info(accelerator.state, main_process_only=False)
if accelerator.is_local_main_process:
datasets.utils.logging.set_verbosity_warning()
transformers.utils.logging.set_verbosity_info()
else:
datasets.utils.logging.set_verbosity_error()
transformers.utils.logging.set_verbosity_error()
# If passed along, set the training seed now.
if args.seed is not None:
set_seed(args.seed)
# Handle the repository creation
if accelerator.is_main_process:
if args.push_to_hub:
# Retrieve of infer repo_name
repo_name = args.hub_model_id
if repo_name is None:
repo_name = Path(args.output_dir).absolute().name
# Create repo and retrieve repo_id
repo_id = create_repo(repo_name, exist_ok=True, token=args.hub_token).repo_id
# Clone repo locally
repo = Repository(args.output_dir, clone_from=repo_id, token=args.hub_token)
with open(os.path.join(args.output_dir, ".gitignore"), "w+") as gitignore:
if "step_*" not in gitignore:
gitignore.write("step_*\n")
if "epoch_*" not in gitignore:
gitignore.write("epoch_*\n")
elif args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
accelerator.wait_for_everyone()
# Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
# or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
# (the dataset will be downloaded automatically from the datasets Hub).
#
# For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
# 'text' is found. You can easily tweak this behavior (see below).
#
# In distributed training, the load_dataset function guarantee that only one local process can concurrently
# download the dataset.
if args.dataset_name is not None:
# Downloading and loading a dataset from the hub.
raw_datasets = load_dataset(args.dataset_name, args.dataset_config_name)
else:
data_files = {}
if args.train_file is not None:
data_files["train"] = args.train_file
extension = args.train_file.split(".")[-1]
if args.validation_file is not None:
data_files["validation"] = args.validation_file
extension = args.validation_file.split(".")[-1]
raw_datasets = load_dataset(extension, data_files=data_files)
# See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
# https://huggingface.co/docs/datasets/loading_datasets.
# Load pretrained model and tokenizer
#
# In distributed training, the .from_pretrained methods guarantee that only one local process can concurrently
# download model & vocab.
if args.config_name:
config = AutoConfig.from_pretrained(args.config_name, trust_remote_code=args.trust_remote_code)
elif args.model_name_or_path:
config = AutoConfig.from_pretrained(args.model_name_or_path, trust_remote_code=args.trust_remote_code)
else:
config = CONFIG_MAPPING[args.model_type]()
logger.warning("You are instantiating a new config instance from scratch.")
if args.tokenizer_name:
tokenizer = AutoTokenizer.from_pretrained(
args.tokenizer_name, use_fast=not args.use_slow_tokenizer, trust_remote_code=args.trust_remote_code
)
elif args.model_name_or_path:
tokenizer = AutoTokenizer.from_pretrained(
args.model_name_or_path, use_fast=not args.use_slow_tokenizer, trust_remote_code=args.trust_remote_code
)
else:
raise ValueError(
"You are instantiating a new tokenizer from scratch. This is not supported by this script. "
"You can do it from another script, save it, and load it from here, using --tokenizer_name."
)
if args.model_name_or_path:
model = AutoModelForSeq2SeqLM.from_pretrained(
args.model_name_or_path,
from_tf=bool(".ckpt" in args.model_name_or_path),
config=config,
trust_remote_code=args.trust_remote_code,
)
else:
logger.info("Training new model from scratch")
model = AutoModelForSeq2SeqLM.from_config(config, trust_remote_code=args.trust_remote_code)
# We resize the embeddings only when necessary to avoid index errors. If you are creating a model from scratch
# on a small vocab and want a smaller embedding size, remove this test.
embedding_size = model.get_input_embeddings().weight.shape[0]
if len(tokenizer) > embedding_size:
model.resize_token_embeddings(len(tokenizer))
if model.config.decoder_start_token_id is None:
raise ValueError("Make sure that `config.decoder_start_token_id` is correctly defined")
prefix = args.source_prefix if args.source_prefix is not None else ""
# Preprocessing the datasets.
# First we tokenize all the texts.
column_names = raw_datasets["train"].column_names
# Get the column names for input/target.
dataset_columns = summarization_name_mapping.get(args.dataset_name, None)
if args.text_column is None:
text_column = dataset_columns[0] if dataset_columns is not None else column_names[0]
else:
text_column = args.text_column
if text_column not in column_names:
raise ValueError(
f"--text_column' value '{args.text_column}' needs to be one of: {', '.join(column_names)}"
)
if args.summary_column is None:
summary_column = dataset_columns[1] if dataset_columns is not None else column_names[1]
else:
summary_column = args.summary_column
if summary_column not in column_names:
raise ValueError(
f"--summary_column' value '{args.summary_column}' needs to be one of: {', '.join(column_names)}"
)
if args.val_max_target_length is None:
args.val_max_target_length = args.max_target_length
# Temporarily set max_target_length for training.
max_target_length = args.max_target_length
padding = "max_length" if args.pad_to_max_length else False
def preprocess_function(examples):
inputs = examples[text_column]
targets = examples[summary_column]
inputs = [prefix + inp for inp in inputs]
model_inputs = tokenizer(inputs, max_length=args.max_source_length, padding=padding, truncation=True)
# Tokenize targets with the `text_target` keyword argument
labels = tokenizer(text_target=targets, max_length=max_target_length, padding=padding, truncation=True)
# If we are padding here, replace all tokenizer.pad_token_id in the labels by -100 when we want to ignore
# padding in the loss.
if padding == "max_length" and args.ignore_pad_token_for_loss:
labels["input_ids"] = [
[(l if l != tokenizer.pad_token_id else -100) for l in label] for label in labels["input_ids"]
]
model_inputs["labels"] = labels["input_ids"]
return model_inputs
with accelerator.main_process_first():
train_dataset = raw_datasets["train"].map(
preprocess_function,
batched=True,
num_proc=args.preprocessing_num_workers,
remove_columns=column_names,
load_from_cache_file=not args.overwrite_cache,
desc="Running tokenizer on dataset",
)
# Temporarily set max_target_length for validation.
max_target_length = args.val_max_target_length
eval_dataset = raw_datasets["validation"].map(
preprocess_function,
batched=True,
num_proc=args.preprocessing_num_workers,
remove_columns=column_names,
load_from_cache_file=not args.overwrite_cache,
desc="Running tokenizer on dataset",
)
# Log a few random samples from the training set:
for index in random.sample(range(len(train_dataset)), 1):
logger.info(f"Sample {index} of the training set: {train_dataset[index]}.")
label_pad_token_id = -100 if args.ignore_pad_token_for_loss else tokenizer.pad_token_id
data_collator = DataCollatorForSeq2Seq(
tokenizer,
model=model,
label_pad_token_id=label_pad_token_id,
pad_to_multiple_of=8 if accelerator.use_fp16 else None,
)
def postprocess_text(preds, labels):
preds = [pred.strip() for pred in preds]
labels = [label.strip() for label in labels]
# rougeLSum expects newline after each sentence
preds = ["\n".join(nltk.sent_tokenize(pred)) for pred in preds]
labels = ["\n".join(nltk.sent_tokenize(label)) for label in labels]
return preds, labels
train_dataloader = DataLoader(
train_dataset, shuffle=True, collate_fn=data_collator, batch_size=args.per_device_train_batch_size
)
eval_dataloader = DataLoader(eval_dataset, collate_fn=data_collator, batch_size=args.per_device_eval_batch_size)
# Optimizer
# Split weights in two groups, one with weight decay and the other not.
no_decay = ["bias", "LayerNorm.weight", "layer_norm.weight"]
optimizer_grouped_parameters = [
{
"params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
"weight_decay": args.weight_decay,
},
{
"params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
"weight_decay": 0.0,
},
]
optimizer = torch.optim.AdamW(optimizer_grouped_parameters, lr=args.learning_rate)
# Scheduler and math around the number of training steps.
overrode_max_train_steps = False
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if args.max_train_steps is None:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
overrode_max_train_steps = True
lr_scheduler = get_scheduler(
name=args.lr_scheduler_type,
optimizer=optimizer,
num_warmup_steps=args.num_warmup_steps * accelerator.num_processes,
num_training_steps=args.max_train_steps
if overrode_max_train_steps
else args.max_train_steps * accelerator.num_processes,
)
# Prepare everything with our `accelerator`.
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler
)
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if overrode_max_train_steps:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
# Afterwards we recalculate our number of training epochs
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
# Figure out how many steps we should save the Accelerator states
checkpointing_steps = args.checkpointing_steps
if checkpointing_steps is not None and checkpointing_steps.isdigit():
checkpointing_steps = int(checkpointing_steps)
# We need to initialize the trackers we use, and also store our configuration.
# The trackers initializes automatically on the main process.
if args.with_tracking:
experiment_config = vars(args)
# TensorBoard cannot log Enums, need the raw value
experiment_config["lr_scheduler_type"] = experiment_config["lr_scheduler_type"].value
accelerator.init_trackers("summarization_no_trainer", experiment_config)
# Metric
metric = evaluate.load("rouge")
# Train!
total_batch_size = args.per_device_train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
logger.info("***** Running training *****")
logger.info(f" Num examples = {len(train_dataset)}")
logger.info(f" Num Epochs = {args.num_train_epochs}")
logger.info(f" Instantaneous batch size per device = {args.per_device_train_batch_size}")
logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
logger.info(f" Total optimization steps = {args.max_train_steps}")
# Only show the progress bar once on each machine.
progress_bar = tqdm(range(args.max_train_steps), disable=not accelerator.is_local_main_process)
completed_steps = 0
starting_epoch = 0
# Potentially load in the weights and states from a previous save
if args.resume_from_checkpoint:
if args.resume_from_checkpoint is not None or args.resume_from_checkpoint != "":
checkpoint_path = args.resume_from_checkpoint
path = os.path.basename(args.resume_from_checkpoint)
else:
# Get the most recent checkpoint
dirs = [f.name for f in os.scandir(os.getcwd()) if f.is_dir()]
dirs.sort(key=os.path.getctime)
path = dirs[-1] # Sorts folders by date modified, most recent checkpoint is the last
checkpoint_path = path
path = os.path.basename(checkpoint_path)
accelerator.print(f"Resumed from checkpoint: {checkpoint_path}")
accelerator.load_state(checkpoint_path)
# Extract `epoch_{i}` or `step_{i}`
training_difference = os.path.splitext(path)[0]
if "epoch" in training_difference:
starting_epoch = int(training_difference.replace("epoch_", "")) + 1
resume_step = None
completed_steps = starting_epoch * num_update_steps_per_epoch
else:
# need to multiply `gradient_accumulation_steps` to reflect real steps
resume_step = int(training_difference.replace("step_", "")) * args.gradient_accumulation_steps
starting_epoch = resume_step // len(train_dataloader)
completed_steps = resume_step // args.gradient_accumulation_steps
resume_step -= starting_epoch * len(train_dataloader)
# update the progress_bar if load from checkpoint
progress_bar.update(completed_steps)
for epoch in range(starting_epoch, args.num_train_epochs):
model.train()
if args.with_tracking:
total_loss = 0
if args.resume_from_checkpoint and epoch == starting_epoch and resume_step is not None:
# We skip the first `n` batches in the dataloader when resuming from a checkpoint
active_dataloader = accelerator.skip_first_batches(train_dataloader, resume_step)
else:
active_dataloader = train_dataloader
for step, batch in enumerate(active_dataloader):
with accelerator.accumulate(model):
outputs = model(**batch)
loss = outputs.loss
# We keep track of the loss at each epoch
if args.with_tracking:
total_loss += loss.detach().float()
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
# Checks if the accelerator has performed an optimization step behind the scenes
if accelerator.sync_gradients:
progress_bar.update(1)
completed_steps += 1
if isinstance(checkpointing_steps, int):
if completed_steps % checkpointing_steps == 0:
output_dir = f"step_{completed_steps}"
if args.output_dir is not None:
output_dir = os.path.join(args.output_dir, output_dir)
accelerator.save_state(output_dir)
if completed_steps >= args.max_train_steps:
break
model.eval()
gen_kwargs = {
"max_length": args.val_max_target_length,
"num_beams": args.num_beams,
}
for step, batch in enumerate(eval_dataloader):
with torch.no_grad():
generated_tokens = accelerator.unwrap_model(model).generate(
batch["input_ids"],
attention_mask=batch["attention_mask"],
**gen_kwargs,
)
generated_tokens = accelerator.pad_across_processes(
generated_tokens, dim=1, pad_index=tokenizer.pad_token_id
)
labels = batch["labels"]
if not args.pad_to_max_length:
# If we did not pad to max length, we need to pad the labels too
labels = accelerator.pad_across_processes(batch["labels"], dim=1, pad_index=tokenizer.pad_token_id)
generated_tokens, labels = accelerator.gather_for_metrics((generated_tokens, labels))
generated_tokens = generated_tokens.cpu().numpy()
labels = labels.cpu().numpy()
if args.ignore_pad_token_for_loss:
# Replace -100 in the labels as we can't decode them.
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
if isinstance(generated_tokens, tuple):
generated_tokens = generated_tokens[0]
decoded_preds = tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
decoded_preds, decoded_labels = postprocess_text(decoded_preds, decoded_labels)
metric.add_batch(
predictions=decoded_preds,
references=decoded_labels,
)
result = metric.compute(use_stemmer=True)
result = {k: round(v * 100, 4) for k, v in result.items()}
logger.info(result)
if args.with_tracking:
result["train_loss"] = total_loss.item() / len(train_dataloader)
result["epoch"] = epoch
result["step"] = completed_steps
accelerator.log(result, step=completed_steps)
if args.push_to_hub and epoch < args.num_train_epochs - 1:
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(
args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
)
if accelerator.is_main_process:
tokenizer.save_pretrained(args.output_dir)
repo.push_to_hub(
commit_message=f"Training in progress epoch {epoch}", blocking=False, auto_lfs_prune=True
)
if args.checkpointing_steps == "epoch":
output_dir = f"epoch_{epoch}"
if args.output_dir is not None:
output_dir = os.path.join(args.output_dir, output_dir)
accelerator.save_state(output_dir)
if args.output_dir is not None:
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(
args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
)
if accelerator.is_main_process:
tokenizer.save_pretrained(args.output_dir)
if args.push_to_hub:
repo.push_to_hub(commit_message="End of training", auto_lfs_prune=True)
all_results = {f"eval_{k}": v for k, v in result.items()}
with open(os.path.join(args.output_dir, "all_results.json"), "w") as f:
json.dump(all_results, f)
if __name__ == "__main__":
main()
| transformers/examples/pytorch/summarization/run_summarization_no_trainer.py/0 | {
"file_path": "transformers/examples/pytorch/summarization/run_summarization_no_trainer.py",
"repo_id": "transformers",
"token_count": 13687
} | 286 |
#!/usr/bin/env python
# coding=utf-8
# Copyright 2020 The HuggingFace Team All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Fine-tuning the library models for token classification.
"""
# You can also adapt this script on your own token classification task and datasets. Pointers for this are left as
# comments.
import logging
import os
import sys
import warnings
from dataclasses import dataclass, field
from typing import Optional
import datasets
import evaluate
import numpy as np
from datasets import ClassLabel, load_dataset
import transformers
from transformers import (
AutoConfig,
AutoModelForTokenClassification,
AutoTokenizer,
DataCollatorForTokenClassification,
HfArgumentParser,
PretrainedConfig,
PreTrainedTokenizerFast,
Trainer,
TrainingArguments,
set_seed,
)
from transformers.trainer_utils import get_last_checkpoint
from transformers.utils import check_min_version, send_example_telemetry
from transformers.utils.versions import require_version
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
check_min_version("4.38.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/token-classification/requirements.txt")
logger = logging.getLogger(__name__)
@dataclass
class ModelArguments:
"""
Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
"""
model_name_or_path: str = field(
metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
)
config_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
)
tokenizer_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
)
cache_dir: Optional[str] = field(
default=None,
metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
)
model_revision: str = field(
default="main",
metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
)
token: str = field(
default=None,
metadata={
"help": (
"The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
"generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
)
},
)
use_auth_token: bool = field(
default=None,
metadata={
"help": "The `use_auth_token` argument is deprecated and will be removed in v4.34. Please use `token` instead."
},
)
trust_remote_code: bool = field(
default=False,
metadata={
"help": (
"Whether or not to allow for custom models defined on the Hub in their own modeling files. This option "
"should only be set to `True` for repositories you trust and in which you have read the code, as it will "
"execute code present on the Hub on your local machine."
)
},
)
ignore_mismatched_sizes: bool = field(
default=False,
metadata={"help": "Will enable to load a pretrained model whose head dimensions are different."},
)
@dataclass
class DataTrainingArguments:
"""
Arguments pertaining to what data we are going to input our model for training and eval.
"""
task_name: Optional[str] = field(default="ner", metadata={"help": "The name of the task (ner, pos...)."})
dataset_name: Optional[str] = field(
default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
)
dataset_config_name: Optional[str] = field(
default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
)
train_file: Optional[str] = field(
default=None, metadata={"help": "The input training data file (a csv or JSON file)."}
)
validation_file: Optional[str] = field(
default=None,
metadata={"help": "An optional input evaluation data file to evaluate on (a csv or JSON file)."},
)
test_file: Optional[str] = field(
default=None,
metadata={"help": "An optional input test data file to predict on (a csv or JSON file)."},
)
text_column_name: Optional[str] = field(
default=None, metadata={"help": "The column name of text to input in the file (a csv or JSON file)."}
)
label_column_name: Optional[str] = field(
default=None, metadata={"help": "The column name of label to input in the file (a csv or JSON file)."}
)
overwrite_cache: bool = field(
default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
)
preprocessing_num_workers: Optional[int] = field(
default=None,
metadata={"help": "The number of processes to use for the preprocessing."},
)
max_seq_length: int = field(
default=None,
metadata={
"help": (
"The maximum total input sequence length after tokenization. If set, sequences longer "
"than this will be truncated, sequences shorter will be padded."
)
},
)
pad_to_max_length: bool = field(
default=False,
metadata={
"help": (
"Whether to pad all samples to model maximum sentence length. "
"If False, will pad the samples dynamically when batching to the maximum length in the batch. More "
"efficient on GPU but very bad for TPU."
)
},
)
max_train_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set."
)
},
)
max_eval_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of evaluation examples to this "
"value if set."
)
},
)
max_predict_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of prediction examples to this "
"value if set."
)
},
)
label_all_tokens: bool = field(
default=False,
metadata={
"help": (
"Whether to put the label for one word on all tokens of generated by that word or just on the "
"one (in which case the other tokens will have a padding index)."
)
},
)
return_entity_level_metrics: bool = field(
default=False,
metadata={"help": "Whether to return all the entity levels during evaluation or just the overall ones."},
)
def __post_init__(self):
if self.dataset_name is None and self.train_file is None and self.validation_file is None:
raise ValueError("Need either a dataset name or a training/validation file.")
else:
if self.train_file is not None:
extension = self.train_file.split(".")[-1]
assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
if self.validation_file is not None:
extension = self.validation_file.split(".")[-1]
assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
self.task_name = self.task_name.lower()
def main():
# See all possible arguments in src/transformers/training_args.py
# or by passing the --help flag to this script.
# We now keep distinct sets of args, for a cleaner separation of concerns.
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
# If we pass only one argument to the script and it's the path to a json file,
# let's parse it to get our arguments.
model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
else:
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
if model_args.use_auth_token is not None:
warnings.warn(
"The `use_auth_token` argument is deprecated and will be removed in v4.34. Please use `token` instead.",
FutureWarning,
)
if model_args.token is not None:
raise ValueError("`token` and `use_auth_token` are both specified. Please set only the argument `token`.")
model_args.token = model_args.use_auth_token
# Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
# information sent is the one passed as arguments along with your Python/PyTorch versions.
send_example_telemetry("run_ner", model_args, data_args)
# Setup logging
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
handlers=[logging.StreamHandler(sys.stdout)],
)
if training_args.should_log:
# The default of training_args.log_level is passive, so we set log level at info here to have that default.
transformers.utils.logging.set_verbosity_info()
log_level = training_args.get_process_log_level()
logger.setLevel(log_level)
datasets.utils.logging.set_verbosity(log_level)
transformers.utils.logging.set_verbosity(log_level)
transformers.utils.logging.enable_default_handler()
transformers.utils.logging.enable_explicit_format()
# Log on each process the small summary:
logger.warning(
f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}, "
+ f"distributed training: {training_args.parallel_mode.value == 'distributed'}, 16-bits training: {training_args.fp16}"
)
logger.info(f"Training/evaluation parameters {training_args}")
# Detecting last checkpoint.
last_checkpoint = None
if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
last_checkpoint = get_last_checkpoint(training_args.output_dir)
if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
raise ValueError(
f"Output directory ({training_args.output_dir}) already exists and is not empty. "
"Use --overwrite_output_dir to overcome."
)
elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
logger.info(
f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
"the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
)
# Set seed before initializing model.
set_seed(training_args.seed)
# Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
# or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
# (the dataset will be downloaded automatically from the datasets Hub).
#
# For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
# 'text' is found. You can easily tweak this behavior (see below).
#
# In distributed training, the load_dataset function guarantee that only one local process can concurrently
# download the dataset.
if data_args.dataset_name is not None:
# Downloading and loading a dataset from the hub.
raw_datasets = load_dataset(
data_args.dataset_name,
data_args.dataset_config_name,
cache_dir=model_args.cache_dir,
token=model_args.token,
)
else:
data_files = {}
if data_args.train_file is not None:
data_files["train"] = data_args.train_file
extension = data_args.train_file.split(".")[-1]
if data_args.validation_file is not None:
data_files["validation"] = data_args.validation_file
extension = data_args.validation_file.split(".")[-1]
if data_args.test_file is not None:
data_files["test"] = data_args.test_file
extension = data_args.test_file.split(".")[-1]
raw_datasets = load_dataset(extension, data_files=data_files, cache_dir=model_args.cache_dir)
# See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
# https://huggingface.co/docs/datasets/loading_datasets.
if training_args.do_train:
column_names = raw_datasets["train"].column_names
features = raw_datasets["train"].features
else:
column_names = raw_datasets["validation"].column_names
features = raw_datasets["validation"].features
if data_args.text_column_name is not None:
text_column_name = data_args.text_column_name
elif "tokens" in column_names:
text_column_name = "tokens"
else:
text_column_name = column_names[0]
if data_args.label_column_name is not None:
label_column_name = data_args.label_column_name
elif f"{data_args.task_name}_tags" in column_names:
label_column_name = f"{data_args.task_name}_tags"
else:
label_column_name = column_names[1]
# In the event the labels are not a `Sequence[ClassLabel]`, we will need to go through the dataset to get the
# unique labels.
def get_label_list(labels):
unique_labels = set()
for label in labels:
unique_labels = unique_labels | set(label)
label_list = list(unique_labels)
label_list.sort()
return label_list
# If the labels are of type ClassLabel, they are already integers and we have the map stored somewhere.
# Otherwise, we have to get the list of labels manually.
labels_are_int = isinstance(features[label_column_name].feature, ClassLabel)
if labels_are_int:
label_list = features[label_column_name].feature.names
label_to_id = {i: i for i in range(len(label_list))}
else:
label_list = get_label_list(raw_datasets["train"][label_column_name])
label_to_id = {l: i for i, l in enumerate(label_list)}
num_labels = len(label_list)
# Load pretrained model and tokenizer
#
# Distributed training:
# The .from_pretrained methods guarantee that only one local process can concurrently
# download model & vocab.
config = AutoConfig.from_pretrained(
model_args.config_name if model_args.config_name else model_args.model_name_or_path,
num_labels=num_labels,
finetuning_task=data_args.task_name,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
)
tokenizer_name_or_path = model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path
if config.model_type in {"bloom", "gpt2", "roberta"}:
tokenizer = AutoTokenizer.from_pretrained(
tokenizer_name_or_path,
cache_dir=model_args.cache_dir,
use_fast=True,
revision=model_args.model_revision,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
add_prefix_space=True,
)
else:
tokenizer = AutoTokenizer.from_pretrained(
tokenizer_name_or_path,
cache_dir=model_args.cache_dir,
use_fast=True,
revision=model_args.model_revision,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
)
model = AutoModelForTokenClassification.from_pretrained(
model_args.model_name_or_path,
from_tf=bool(".ckpt" in model_args.model_name_or_path),
config=config,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
ignore_mismatched_sizes=model_args.ignore_mismatched_sizes,
)
# Tokenizer check: this script requires a fast tokenizer.
if not isinstance(tokenizer, PreTrainedTokenizerFast):
raise ValueError(
"This example script only works for models that have a fast tokenizer. Checkout the big table of models at"
" https://huggingface.co/transformers/index.html#supported-frameworks to find the model types that meet"
" this requirement"
)
# Model has labels -> use them.
if model.config.label2id != PretrainedConfig(num_labels=num_labels).label2id:
if sorted(model.config.label2id.keys()) == sorted(label_list):
# Reorganize `label_list` to match the ordering of the model.
if labels_are_int:
label_to_id = {i: int(model.config.label2id[l]) for i, l in enumerate(label_list)}
label_list = [model.config.id2label[i] for i in range(num_labels)]
else:
label_list = [model.config.id2label[i] for i in range(num_labels)]
label_to_id = {l: i for i, l in enumerate(label_list)}
else:
logger.warning(
"Your model seems to have been trained with labels, but they don't match the dataset: ",
f"model labels: {sorted(model.config.label2id.keys())}, dataset labels:"
f" {sorted(label_list)}.\nIgnoring the model labels as a result.",
)
# Set the correspondences label/ID inside the model config
model.config.label2id = {l: i for i, l in enumerate(label_list)}
model.config.id2label = dict(enumerate(label_list))
# Map that sends B-Xxx label to its I-Xxx counterpart
b_to_i_label = []
for idx, label in enumerate(label_list):
if label.startswith("B-") and label.replace("B-", "I-") in label_list:
b_to_i_label.append(label_list.index(label.replace("B-", "I-")))
else:
b_to_i_label.append(idx)
# Preprocessing the dataset
# Padding strategy
padding = "max_length" if data_args.pad_to_max_length else False
# Tokenize all texts and align the labels with them.
def tokenize_and_align_labels(examples):
tokenized_inputs = tokenizer(
examples[text_column_name],
padding=padding,
truncation=True,
max_length=data_args.max_seq_length,
# We use this argument because the texts in our dataset are lists of words (with a label for each word).
is_split_into_words=True,
)
labels = []
for i, label in enumerate(examples[label_column_name]):
word_ids = tokenized_inputs.word_ids(batch_index=i)
previous_word_idx = None
label_ids = []
for word_idx in word_ids:
# Special tokens have a word id that is None. We set the label to -100 so they are automatically
# ignored in the loss function.
if word_idx is None:
label_ids.append(-100)
# We set the label for the first token of each word.
elif word_idx != previous_word_idx:
label_ids.append(label_to_id[label[word_idx]])
# For the other tokens in a word, we set the label to either the current label or -100, depending on
# the label_all_tokens flag.
else:
if data_args.label_all_tokens:
label_ids.append(b_to_i_label[label_to_id[label[word_idx]]])
else:
label_ids.append(-100)
previous_word_idx = word_idx
labels.append(label_ids)
tokenized_inputs["labels"] = labels
return tokenized_inputs
if training_args.do_train:
if "train" not in raw_datasets:
raise ValueError("--do_train requires a train dataset")
train_dataset = raw_datasets["train"]
if data_args.max_train_samples is not None:
max_train_samples = min(len(train_dataset), data_args.max_train_samples)
train_dataset = train_dataset.select(range(max_train_samples))
with training_args.main_process_first(desc="train dataset map pre-processing"):
train_dataset = train_dataset.map(
tokenize_and_align_labels,
batched=True,
num_proc=data_args.preprocessing_num_workers,
load_from_cache_file=not data_args.overwrite_cache,
desc="Running tokenizer on train dataset",
)
if training_args.do_eval:
if "validation" not in raw_datasets:
raise ValueError("--do_eval requires a validation dataset")
eval_dataset = raw_datasets["validation"]
if data_args.max_eval_samples is not None:
max_eval_samples = min(len(eval_dataset), data_args.max_eval_samples)
eval_dataset = eval_dataset.select(range(max_eval_samples))
with training_args.main_process_first(desc="validation dataset map pre-processing"):
eval_dataset = eval_dataset.map(
tokenize_and_align_labels,
batched=True,
num_proc=data_args.preprocessing_num_workers,
load_from_cache_file=not data_args.overwrite_cache,
desc="Running tokenizer on validation dataset",
)
if training_args.do_predict:
if "test" not in raw_datasets:
raise ValueError("--do_predict requires a test dataset")
predict_dataset = raw_datasets["test"]
if data_args.max_predict_samples is not None:
max_predict_samples = min(len(predict_dataset), data_args.max_predict_samples)
predict_dataset = predict_dataset.select(range(max_predict_samples))
with training_args.main_process_first(desc="prediction dataset map pre-processing"):
predict_dataset = predict_dataset.map(
tokenize_and_align_labels,
batched=True,
num_proc=data_args.preprocessing_num_workers,
load_from_cache_file=not data_args.overwrite_cache,
desc="Running tokenizer on prediction dataset",
)
# Data collator
data_collator = DataCollatorForTokenClassification(tokenizer, pad_to_multiple_of=8 if training_args.fp16 else None)
# Metrics
metric = evaluate.load("seqeval", cache_dir=model_args.cache_dir)
def compute_metrics(p):
predictions, labels = p
predictions = np.argmax(predictions, axis=2)
# Remove ignored index (special tokens)
true_predictions = [
[label_list[p] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
true_labels = [
[label_list[l] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
results = metric.compute(predictions=true_predictions, references=true_labels)
if data_args.return_entity_level_metrics:
# Unpack nested dictionaries
final_results = {}
for key, value in results.items():
if isinstance(value, dict):
for n, v in value.items():
final_results[f"{key}_{n}"] = v
else:
final_results[key] = value
return final_results
else:
return {
"precision": results["overall_precision"],
"recall": results["overall_recall"],
"f1": results["overall_f1"],
"accuracy": results["overall_accuracy"],
}
# Initialize our Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
# Training
if training_args.do_train:
checkpoint = None
if training_args.resume_from_checkpoint is not None:
checkpoint = training_args.resume_from_checkpoint
elif last_checkpoint is not None:
checkpoint = last_checkpoint
train_result = trainer.train(resume_from_checkpoint=checkpoint)
metrics = train_result.metrics
trainer.save_model() # Saves the tokenizer too for easy upload
max_train_samples = (
data_args.max_train_samples if data_args.max_train_samples is not None else len(train_dataset)
)
metrics["train_samples"] = min(max_train_samples, len(train_dataset))
trainer.log_metrics("train", metrics)
trainer.save_metrics("train", metrics)
trainer.save_state()
# Evaluation
if training_args.do_eval:
logger.info("*** Evaluate ***")
metrics = trainer.evaluate()
max_eval_samples = data_args.max_eval_samples if data_args.max_eval_samples is not None else len(eval_dataset)
metrics["eval_samples"] = min(max_eval_samples, len(eval_dataset))
trainer.log_metrics("eval", metrics)
trainer.save_metrics("eval", metrics)
# Predict
if training_args.do_predict:
logger.info("*** Predict ***")
predictions, labels, metrics = trainer.predict(predict_dataset, metric_key_prefix="predict")
predictions = np.argmax(predictions, axis=2)
# Remove ignored index (special tokens)
true_predictions = [
[label_list[p] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
trainer.log_metrics("predict", metrics)
trainer.save_metrics("predict", metrics)
# Save predictions
output_predictions_file = os.path.join(training_args.output_dir, "predictions.txt")
if trainer.is_world_process_zero():
with open(output_predictions_file, "w") as writer:
for prediction in true_predictions:
writer.write(" ".join(prediction) + "\n")
kwargs = {"finetuned_from": model_args.model_name_or_path, "tasks": "token-classification"}
if data_args.dataset_name is not None:
kwargs["dataset_tags"] = data_args.dataset_name
if data_args.dataset_config_name is not None:
kwargs["dataset_args"] = data_args.dataset_config_name
kwargs["dataset"] = f"{data_args.dataset_name} {data_args.dataset_config_name}"
else:
kwargs["dataset"] = data_args.dataset_name
if training_args.push_to_hub:
trainer.push_to_hub(**kwargs)
else:
trainer.create_model_card(**kwargs)
def _mp_fn(index):
# For xla_spawn (TPUs)
main()
if __name__ == "__main__":
main()
| transformers/examples/pytorch/token-classification/run_ner.py/0 | {
"file_path": "transformers/examples/pytorch/token-classification/run_ner.py",
"repo_id": "transformers",
"token_count": 11698
} | 287 |
# coding=utf-8
# Copyright 2020 The Google AI Language Team Authors, The HuggingFace Inc. team and Microsoft Corporation.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""PyTorch BERT model with Patience-based Early Exit. """
import logging
import torch
from torch import nn
from torch.nn import CrossEntropyLoss, MSELoss
from transformers.file_utils import add_start_docstrings, add_start_docstrings_to_model_forward
from transformers.models.bert.modeling_bert import (
BERT_INPUTS_DOCSTRING,
BERT_START_DOCSTRING,
BertEncoder,
BertModel,
BertPreTrainedModel,
)
logger = logging.getLogger(__name__)
class BertEncoderWithPabee(BertEncoder):
def adaptive_forward(self, hidden_states, current_layer, attention_mask=None, head_mask=None):
layer_outputs = self.layer[current_layer](hidden_states, attention_mask, head_mask[current_layer])
hidden_states = layer_outputs[0]
return hidden_states
@add_start_docstrings(
"The bare Bert Model transformer with PABEE outputting raw hidden-states without any specific head on top.",
BERT_START_DOCSTRING,
)
class BertModelWithPabee(BertModel):
"""
The model can behave as an encoder (with only self-attention) as well
as a decoder, in which case a layer of cross-attention is added between
the self-attention layers, following the architecture described in `Attention is all you need`_ by Ashish Vaswani,
Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.
To behave as a decoder the model needs to be initialized with the
:obj:`is_decoder` argument of the configuration set to :obj:`True`; an
:obj:`encoder_hidden_states` is expected as an input to the forward pass.
.. _`Attention is all you need`:
https://arxiv.org/abs/1706.03762
"""
def __init__(self, config):
super().__init__(config)
self.encoder = BertEncoderWithPabee(config)
self.init_weights()
self.patience = 0
self.inference_instances_num = 0
self.inference_layers_num = 0
self.regression_threshold = 0
def set_regression_threshold(self, threshold):
self.regression_threshold = threshold
def set_patience(self, patience):
self.patience = patience
def reset_stats(self):
self.inference_instances_num = 0
self.inference_layers_num = 0
def log_stats(self):
avg_inf_layers = self.inference_layers_num / self.inference_instances_num
message = (
f"*** Patience = {self.patience} Avg. Inference Layers = {avg_inf_layers:.2f} Speed Up ="
f" {1 - avg_inf_layers / self.config.num_hidden_layers:.2f} ***"
)
print(message)
@add_start_docstrings_to_model_forward(BERT_INPUTS_DOCSTRING)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
output_dropout=None,
output_layers=None,
regression=False,
):
r"""
Return:
:obj:`tuple(torch.FloatTensor)` comprising various elements depending on the configuration (:class:`~transformers.BertConfig`) and inputs:
last_hidden_state (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`):
Sequence of hidden-states at the output of the last layer of the model.
pooler_output (:obj:`torch.FloatTensor`: of shape :obj:`(batch_size, hidden_size)`):
Last layer hidden-state of the first token of the sequence (classification token)
further processed by a Linear layer and a Tanh activation function. The Linear
layer weights are trained from the next sentence prediction (classification)
objective during pre-training.
This output is usually *not* a good summary
of the semantic content of the input, you're often better with averaging or pooling
the sequence of hidden-states for the whole input sequence.
hidden_states (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_hidden_states=True``):
Tuple of :obj:`torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer)
of shape :obj:`(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
attentions (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_attentions=True``):
Tuple of :obj:`torch.FloatTensor` (one for each layer) of shape
:obj:`(batch_size, num_heads, sequence_length, sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
"""
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
elif input_ids is not None:
input_shape = input_ids.size()
elif inputs_embeds is not None:
input_shape = inputs_embeds.size()[:-1]
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
device = input_ids.device if input_ids is not None else inputs_embeds.device
if attention_mask is None:
attention_mask = torch.ones(input_shape, device=device)
if token_type_ids is None:
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)
# We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
# ourselves in which case we just need to make it broadcastable to all heads.
extended_attention_mask: torch.Tensor = self.get_extended_attention_mask(attention_mask, input_shape, device)
# If a 2D ou 3D attention mask is provided for the cross-attention
# we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length]
if self.config.is_decoder and encoder_hidden_states is not None:
encoder_batch_size, encoder_sequence_length, _ = encoder_hidden_states.size()
encoder_hidden_shape = (encoder_batch_size, encoder_sequence_length)
if encoder_attention_mask is None:
encoder_attention_mask = torch.ones(encoder_hidden_shape, device=device)
encoder_extended_attention_mask = self.invert_attention_mask(encoder_attention_mask)
else:
encoder_extended_attention_mask = None
# Prepare head mask if needed
# 1.0 in head_mask indicate we keep the head
# attention_probs has shape bsz x n_heads x N x N
# input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
# and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
embedding_output = self.embeddings(
input_ids=input_ids, position_ids=position_ids, token_type_ids=token_type_ids, inputs_embeds=inputs_embeds
)
encoder_outputs = embedding_output
if self.training:
res = []
for i in range(self.config.num_hidden_layers):
encoder_outputs = self.encoder.adaptive_forward(
encoder_outputs, current_layer=i, attention_mask=extended_attention_mask, head_mask=head_mask
)
pooled_output = self.pooler(encoder_outputs)
logits = output_layers[i](output_dropout(pooled_output))
res.append(logits)
elif self.patience == 0: # Use all layers for inference
encoder_outputs = self.encoder(
embedding_output,
attention_mask=extended_attention_mask,
head_mask=head_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_extended_attention_mask,
)
pooled_output = self.pooler(encoder_outputs[0])
res = [output_layers[self.config.num_hidden_layers - 1](pooled_output)]
else:
patient_counter = 0
patient_result = None
calculated_layer_num = 0
for i in range(self.config.num_hidden_layers):
calculated_layer_num += 1
encoder_outputs = self.encoder.adaptive_forward(
encoder_outputs, current_layer=i, attention_mask=extended_attention_mask, head_mask=head_mask
)
pooled_output = self.pooler(encoder_outputs)
logits = output_layers[i](pooled_output)
if regression:
labels = logits.detach()
if patient_result is not None:
patient_labels = patient_result.detach()
if (patient_result is not None) and torch.abs(patient_result - labels) < self.regression_threshold:
patient_counter += 1
else:
patient_counter = 0
else:
labels = logits.detach().argmax(dim=1)
if patient_result is not None:
patient_labels = patient_result.detach().argmax(dim=1)
if (patient_result is not None) and torch.all(labels.eq(patient_labels)):
patient_counter += 1
else:
patient_counter = 0
patient_result = logits
if patient_counter == self.patience:
break
res = [patient_result]
self.inference_layers_num += calculated_layer_num
self.inference_instances_num += 1
return res
@add_start_docstrings(
"""Bert Model transformer with PABEE and a sequence classification/regression head on top (a linear layer on top of
the pooled output) e.g. for GLUE tasks. """,
BERT_START_DOCSTRING,
)
class BertForSequenceClassificationWithPabee(BertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.bert = BertModelWithPabee(config)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.classifiers = nn.ModuleList(
[nn.Linear(config.hidden_size, self.config.num_labels) for _ in range(config.num_hidden_layers)]
)
self.init_weights()
@add_start_docstrings_to_model_forward(BERT_INPUTS_DOCSTRING)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
labels=None,
):
r"""
labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size,)`, `optional`):
Labels for computing the sequence classification/regression loss.
Indices should be in :obj:`[0, ..., config.num_labels - 1]`.
If :obj:`config.num_labels == 1` a regression loss is computed (Mean-Square loss),
If :obj:`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
Returns:
:obj:`tuple(torch.FloatTensor)` comprising various elements depending on the configuration (:class:`~transformers.BertConfig`) and inputs:
loss (:obj:`torch.FloatTensor` of shape :obj:`(1,)`, `optional`, returned when :obj:`label` is provided):
Classification (or regression if config.num_labels==1) loss.
logits (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, config.num_labels)`):
Classification (or regression if config.num_labels==1) scores (before SoftMax).
hidden_states (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_hidden_states=True``):
Tuple of :obj:`torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer)
of shape :obj:`(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
attentions (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_attentions=True``):
Tuple of :obj:`torch.FloatTensor` (one for each layer) of shape
:obj:`(batch_size, num_heads, sequence_length, sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
Examples::
from transformers import BertTokenizer, BertForSequenceClassification
from pabee import BertForSequenceClassificationWithPabee
from torch import nn
import torch
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassificationWithPabee.from_pretrained('bert-base-uncased')
input_ids = torch.tensor(tokenizer.encode("Hello, my dog is cute", add_special_tokens=True)).unsqueeze(0) # Batch size 1
labels = torch.tensor([1]).unsqueeze(0) # Batch size 1
outputs = model(input_ids, labels=labels)
loss, logits = outputs[:2]
"""
logits = self.bert(
input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_dropout=self.dropout,
output_layers=self.classifiers,
regression=self.num_labels == 1,
)
outputs = (logits[-1],)
if labels is not None:
total_loss = None
total_weights = 0
for ix, logits_item in enumerate(logits):
if self.num_labels == 1:
# We are doing regression
loss_fct = MSELoss()
loss = loss_fct(logits_item.view(-1), labels.view(-1))
else:
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits_item.view(-1, self.num_labels), labels.view(-1))
if total_loss is None:
total_loss = loss
else:
total_loss += loss * (ix + 1)
total_weights += ix + 1
outputs = (total_loss / total_weights,) + outputs
return outputs
| transformers/examples/research_projects/bert-loses-patience/pabee/modeling_pabee_bert.py/0 | {
"file_path": "transformers/examples/research_projects/bert-loses-patience/pabee/modeling_pabee_bert.py",
"repo_id": "transformers",
"token_count": 6750
} | 288 |
# CodeParrot 🦜
<p align="center">
<img src="https://huggingface.co/datasets/lvwerra/repo-images/raw/main/code-highlighting-streamlit.png" alt="drawing" width="350"/>
</p>
## What is this about?
This is an open-source effort to train and evaluate code generation models. CodeParrot 🦜 is a GPT-2 model trained from scratch on Python code. The highlights of this project are:
- initialize and train a GPT-2 language model from scratch for code generation
- train a custom tokenizer adapted for Python code
- clean and deduplicate a large (>100GB) dataset with `datasets`
- train with `accelerate` on multiple GPUs using data parallelism and mixed precision
- continuously push checkpoints to the hub with `huggingface_hub`
- stream the dataset with `datasets` during training to avoid disk bottlenecks
- apply the `code_eval` metric in `datasets` to evaluate on [OpenAI's _HumanEval_ benchmark](https://huggingface.co/datasets/openai_humaneval)
- showcase examples for downstream tasks with code models in [examples](https://github.com/huggingface/transformers/tree/main/examples/research_projects/codeparrot/examples) folder:
- Algorithmic complexity prediction
- Code generation from english text
- Code explanation
## Installation
To install the dependencies simply run the following command:
```bash
pip install -r requirements.txt
```
To reproduce the results you can follow the scripts in the following sections. Note that we don't always show all possible arguments to the scripts. To get the full list of arguments with descriptions you can run the following command on any script:
```bash
python scripts/some_script.py --help
```
Before you run any of the scripts make sure you are logged in and can push to the hub:
```bash
huggingface-cli login
```
Additionally, sure you have git-lfs installed. You can find instructions for how to install it [here](https://git-lfs.github.com/).
## Dataset
The source of the dataset is the GitHub dump available on Google's [BigQuery](https://cloud.google.com/blog/topics/public-datasets/github-on-bigquery-analyze-all-the-open-source-code). The database was queried for all Python files with less than 1MB in size resulting in a 180GB dataset with over 20M files. The dataset is available on the Hugging Face Hub [here](https://huggingface.co/datasets/transformersbook/codeparrot).
### Preprocessing
The raw dataset contains many duplicates. We deduplicated and filtered the dataset using the heuristics proposed in OpenAI's Codex [paper](https://arxiv.org/abs/2107.03374) and some new ones:
- exact deduplication using each file's hash after having removed whistespaces.
- near deduplication using MinHash and Jaccard similarity. MinHash with a Jaccard threshold (default=0.85) is first used to create duplicate clusters. Then these clusters are then reduced to unique files based on the exact Jaccard similarity. See `deduplicate_dataset` in `minhash_deduplication.py` for a detailed description.
- filtering files with max line length > 1000
- filtering files with mean line length > 100
- fraction of alphanumeric characters < 0.25
- containing the word "auto-generated" or similar in the first 5 lines
- filtering with a probability of 0.7 of files with a mention of "test file" or "configuration file" or similar in the first 5 lines
- filtering with a probability of 0.7 of files with high occurrence of the keywords "test " or "config"
- filtering with a probability of 0.7 of files without a mention of the keywords `def` , `for`, `while` and `class`
- filtering files that use the assignment operator `=` less than 5 times
- filtering files with ratio between number of characters and number of tokens after tokenization < 1.5 (the average ratio is 3.6)
The script to process the full dataset can be found in `scripts/preprocessing.py`. Executing the script on 16 vCPUs takes roughly 3h and removes 70% of the original dataset. The cleaned [train](https://huggingface.co/datasets/codeparrot/codeparrot-clean-train-v2) and [validation](https://huggingface.co/datasets/codeparrot/codeparrot-clean-valid-v2) splits are also available on the Hub if you want to skip this step or use the data for another project.
To execute the preprocessing run the following command:
```bash
python scripts/preprocessing.py \
--dataset_name transformersbook/codeparrot \
--output_dir codeparrot-clean
```
During preprocessing the dataset is downloaded and stored locally as well as caches of the computations. Make sure you have more than 500GB free disk space to execute it.
### Pretokenization
The tokenization of the data might be slow during the training especially for small models. We provide code to pretokenize the data beforehand in `scripts/pretokenizing.py`, but this step is optional. The dataset is downloaded and stored locally and the tokenized data is pushed to the hub. The tokenized clean [train](https://huggingface.co/datasets/codeparrot/tokenized-codeparrot-train) and [validation](https://huggingface.co/datasets/codeparrot/tokenized-codeparrot-valid) datasets are available if you want to use them directly.
To execute the pretokenization, for the clean train data for instance, run the following command:
```bash
python scripts/pretokenizing.py \
--dataset_name codeparrot/codeparrot-clean-train \
--tokenized_data_repo tokenized-codeparrot-train
```
## Tokenizer
Before training a new model for code we create a new tokenizer that is efficient at code tokenization. To train the tokenizer you can run the following command:
```bash
python scripts/bpe_training.py \
--base_tokenizer gpt2 \
--dataset_name codeparrot/codeparrot-clean-train
```
_Note:_ We originally trained the tokenizer on the unprocessed train split of the dataset `transformersbook/codeparrot-train`.
## Training
The models are randomly initialized and trained from scratch. To initialize a new model you can run:
```bash
python scripts/initialize_model.py \
--config_name gpt2-large \
--tokenizer_name codeparrot/codeparrot \
--model_name codeparrot \
--push_to_hub True
```
This will initialize a new model with the architecture and configuration of `gpt2-large` and use the tokenizer to appropriately size the input embeddings. Finally, the initilaized model is pushed the hub.
We can either pass the name of a text dataset or a pretokenized dataset which speeds up training a bit.
Now that the tokenizer and model are also ready we can start training the model. The main training script is built with `accelerate` to scale across a wide range of platforms and infrastructure scales. We train two models with [110M](https://huggingface.co/codeparrot/codeparrot-small/) and [1.5B](https://huggingface.co/codeparrot/codeparrot/) parameters for 25-30B tokens on a 16xA100 (40GB) machine which takes 1 day and 1 week, respectively.
First you need to configure `accelerate` and login to Weights & Biases:
```bash
accelerate config
wandb login
```
Note that during the `accelerate` configuration we enabled FP16. Then to train the large model you can run
```bash
accelerate launch scripts/codeparrot_training.py
```
If you want to train the small model you need to make some modifications:
```bash
accelerate launch scripts/codeparrot_training.py \
--model_ckpt codeparrot/codeparrot-small \
--train_batch_size 12 \
--valid_batch_size 12 \
--learning_rate 5e-4 \
--num_warmup_steps 2000 \
--gradient_accumulation 1 \
--gradient_checkpointing False \
--max_train_steps 150000 \
--save_checkpoint_steps 15000
```
Recall that you can see the full set of possible options with descriptions (for all scripts) by running:
```bash
python scripts/codeparrot_training.py --help
```
Instead of streaming the dataset from the hub you can also stream it from disk. This can be helpful for long training runs where the connection can be interrupted sometimes. To stream locally you simply need to clone the datasets and replace the dataset name with their path. In this example we store the data in a folder called `data`:
```bash
git lfs install
mkdir data
git -C "./data" clone https://huggingface.co/datasets/codeparrot/codeparrot-clean-train
git -C "./data" clone https://huggingface.co/datasets/codeparrot/codeparrot-clean-valid
```
And then pass the paths to the datasets when we run the training script:
```bash
accelerate launch scripts/codeparrot_training.py \
--model_ckpt codeparrot/codeparrot-small \
--dataset_name_train ./data/codeparrot-clean-train \
--dataset_name_valid ./data/codeparrot-clean-valid \
--train_batch_size 12 \
--valid_batch_size 12 \
--learning_rate 5e-4 \
--num_warmup_steps 2000 \
--gradient_accumulation 1 \
--gradient_checkpointing False \
--max_train_steps 150000 \
--save_checkpoint_steps 15000
```
## Evaluation
For evaluating the language modeling loss on the validation set or any other dataset you can use the following command:
```bash
python scripts/validation_loss.py \
--model_ckpt codeparrot/codeparrot \
--dataset_name codeparrot/codeparrot-clean-valid
```
In addition we evaluate the model on OpenAI's _HumanEval_ benchmark. You can run the evaluation with the following command:
```bash
accelerate launch scripts/human_eval.py --model_ckpt codeparrot/codeparrot \
--do_sample True \
--temperature 0.2 \
--top_p 0.95 \
--n_samples=200 \
--HF_ALLOW_CODE_EVAL="0"
```
The results as well as reference values are shown in the following table:
| Model | pass@1 | pass@10 | pass@100|
|-------|--------|---------|---------|
|CodeParrot 🦜 (110M) | 3.80% | 6.57% | 12.78% |
|CodeParrot 🦜 (1.5B) | 3.99% | 8.69% | 17.88% |
|||||
|Codex (25M)| 3.21% | 7.1% | 12.89%|
|Codex (85M)| 8.22% | 12.81% | 22.40% |
|Codex (300M)| 13.17%| 20.37% | 36.27% |
|Codex (12B)| 28.81%| 46.81% | 72.31% |
|||||
|GPT-neo (125M)| 0.75% | 1.88% | 2.97% |
|GPT-neo (1.5B)| 4.79% | 7.47% | 16.30% |
|GPT-neo (2.7B)| 6.41% | 11.27% | 21.37% |
|GPT-J (6B)| 11.62% | 15.74% | 27.74% |
The numbers were obtained by sampling with `T = [0.2, 0.6, 0.8]` and picking the best value for each metric. Both CodeParrot 🦜 models are still underfitted and longer training would likely improve the performance.
## Demo
Give the model a shot yourself! There are three demos to interact with CodeParrot 🦜:
- [Code generation](https://huggingface.co/spaces/codeparrot/codeparrot-generation)
- [Code highlighting](https://huggingface.co/spaces/codeparrot/codeparrot-highlighting)
- [Comparison to other code models](https://huggingface.co/spaces/codeparrot/loubnabnl/code-generation-models)
## Training with Megatron
[Megatron](https://github.com/NVIDIA/Megatron-LM) is a framework developed by NVIDIA for training large transformer models. While the CodeParrot code is easy to follow and modify to your needs the Megatron framework lets you train models faster. Below we explain how to use it.
### Setup
You can pull an NVIDIA PyTorch Container that comes with all the required installations from [NGC](https://catalog.ngc.nvidia.com/orgs/nvidia/containers/pytorch). See [documentation](https://docs.nvidia.com/deeplearning/frameworks/pytorch-release-notes/index.html) for more details:
With the following Docker command you can run the container (`xx.xx` denotes your Docker version), and clone [Megatron repository](https://github.com/NVIDIA/Megatron-LM) into it:
```bash
docker run --gpus all -it --rm nvcr.io/nvidia/pytorch:xx.xx-py3
git clone https://github.com/NVIDIA/Megatron-LM
```
You also need to add the vocabulary file and merges table of the tokenizer that you trained on code into the container. You can also find these files in [vocab.json](https://huggingface.co/codeparrot/codeparrot/raw/main/vocab.json) and [merges.txt](https://huggingface.co/codeparrot/codeparrot/raw/main/merges.txt).
```bash
sudo docker cp vocab.json CONTAINER_ID:/workspace/Megatron-LM
sudo docker cp merges.txt CONTAINER_ID:/workspace/Megatron-LM
```
### Data preprocessing
The training data requires preprocessing. First, you need to convert it into a loose json format, with one json containing a text sample per line. In python this can be done this way:
```python
from datasets import load_dataset
train_data = load_dataset('codeparrot/codeparrot-clean-train', split='train')
train_data.to_json("codeparrot_data.json", lines=True)
```
The data is then tokenized, shuffled and processed into a binary format for training using the following command:
```bash
pip install nltk
cd Megatron-LM
python tools/preprocess_data.py \
--input codeparrot_data.json \
--output-prefix codeparrot \
--vocab vocab.json \
--dataset-impl mmap \
--tokenizer-type GPT2BPETokenizer \
--merge-file merges.txt \
--json-keys content \
--workers 32 \
--chunk-size 25 \
--append-eod
```
This outputs two files `codeparrot_content_document.idx` and `codeparrot_content_document.bin` which are used in the training.
### Training
You can configure the model architecture and training parameters as shown below, or put it in a bash script that you will run. This runs on 8 GPUs the 110M parameter CodeParrot pretraining, with the same settings as before. Note that the data is partitioned by default into a 969:30:1 ratio for training/validation/test sets.
```bash
GPUS_PER_NODE=8
MASTER_ADDR=localhost
MASTER_PORT=6001
NNODES=1
NODE_RANK=0
WORLD_SIZE=$(($GPUS_PER_NODE*$NNODES))
DISTRIBUTED_ARGS="--nproc_per_node $GPUS_PER_NODE --nnodes $NNODES --node_rank $NODE_RANK --master_addr $MASTER_ADDR --master_port $MASTER_PORT"
CHECKPOINT_PATH=/workspace/Megatron-LM/experiments/codeparrot-small
VOCAB_FILE=vocab.json
MERGE_FILE=merges.txt
DATA_PATH=codeparrot_content_document
GPT_ARGS="--num-layers 12
--hidden-size 768
--num-attention-heads 12
--seq-length 1024
--max-position-embeddings 1024
--micro-batch-size 12
--global-batch-size 192
--lr 0.0005
--train-iters 150000
--lr-decay-iters 150000
--lr-decay-style cosine
--lr-warmup-iters 2000
--weight-decay .1
--adam-beta2 .999
--fp16
--log-interval 10
--save-interval 2000
--eval-interval 200
--eval-iters 10
"
TENSORBOARD_ARGS="--tensorboard-dir experiments/tensorboard"
python3 -m torch.distributed.launch $DISTRIBUTED_ARGS \
pretrain_gpt.py \
--tensor-model-parallel-size 1 \
--pipeline-model-parallel-size 1 \
$GPT_ARGS \
--vocab-file $VOCAB_FILE \
--merge-file $MERGE_FILE \
--save $CHECKPOINT_PATH \
--load $CHECKPOINT_PATH \
--data-path $DATA_PATH \
$TENSORBOARD_ARGS
```
The training takes almost 12 hours in this setting.
### Convert model to `transformers`
After training we want to use the model in `transformers` e.g. to evaluate it on HumanEval. You can convert it to `transformers` following [this](https://huggingface.co/nvidia/megatron-gpt2-345m) tutorial. For instance, after the training is finished you can copy the weights of the last iteration 150k and convert the `model_optim_rng.pt` file to a `pytorch_model.bin` file that is supported by `transformers`.
```bash
mkdir -p nvidia/megatron-codeparrot-small
sudo docker cp CONTAINER_ID:/workspace/Megatron-LM/experiments/codeparrot-small/iter_0150000/mp_rank_00/model_optim_rng.pt nvidia/megatron-codeparrot-small
git clone https://github.com/huggingface/transformers.git
git clone https://github.com/NVIDIA/Megatron-LM.git
export PYTHONPATH=Megatron-LM
python transformers/src/transformers/models/megatron_gpt2/convert_megatron_gpt2_checkpoint.py nvidia/megatron-codeparrot-small/model_optim_rng.pt
```
Be careful, you will need to replace the generated vocabulary file and merges table after the conversion, with the original ones if you plan to load the tokenizer from there.
## Further Resources
A detailed description of the project can be found in the chapter "Training Transformers from Scratch" in the upcoming O'Reilly book [Natural Language Processing with Transformers](https://learning.oreilly.com/library/view/natural-language-processing/9781098103231/).
This example was provided by [Leandro von Werra](www.github.com/lvwerra).
| transformers/examples/research_projects/codeparrot/README.md/0 | {
"file_path": "transformers/examples/research_projects/codeparrot/README.md",
"repo_id": "transformers",
"token_count": 5019
} | 289 |
import setuptools
with open("README.md", "r", encoding="utf-8") as fh:
long_description = fh.read()
setuptools.setup(
name="fsner",
version="0.0.1",
author="msi sayef",
author_email="[email protected]",
description="Few-shot Named Entity Recognition",
long_description=long_description,
long_description_content_type="text/markdown",
url="https://github.com/huggingface/transformers/tree/main/examples/research_projects/fsner",
project_urls={
"Bug Tracker": "https://github.com/huggingface/transformers/issues",
},
classifiers=[
"Programming Language :: Python :: 3",
"Operating System :: OS Independent",
],
package_dir={"": "src"},
packages=setuptools.find_packages(where="src"),
python_requires=">=3.6",
install_requires=["torch>=1.9.0", "transformers>=4.9.2"],
)
| transformers/examples/research_projects/fsner/setup.py/0 | {
"file_path": "transformers/examples/research_projects/fsner/setup.py",
"repo_id": "transformers",
"token_count": 341
} | 290 |
"""
coding=utf-8
Copyright 2018, Antonio Mendoza Hao Tan, Mohit Bansal
Adapted From Facebook Inc, Detectron2
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.import copy
"""
import colorsys
import io
import cv2
import matplotlib as mpl
import matplotlib.colors as mplc
import matplotlib.figure as mplfigure
import numpy as np
import torch
from matplotlib.backends.backend_agg import FigureCanvasAgg
from utils import img_tensorize
_SMALL_OBJ = 1000
class SingleImageViz:
def __init__(
self,
img,
scale=1.2,
edgecolor="g",
alpha=0.5,
linestyle="-",
saveas="test_out.jpg",
rgb=True,
pynb=False,
id2obj=None,
id2attr=None,
pad=0.7,
):
"""
img: an RGB image of shape (H, W, 3).
"""
if isinstance(img, torch.Tensor):
img = img.numpy().astype("np.uint8")
if isinstance(img, str):
img = img_tensorize(img)
assert isinstance(img, np.ndarray)
width, height = img.shape[1], img.shape[0]
fig = mplfigure.Figure(frameon=False)
dpi = fig.get_dpi()
width_in = (width * scale + 1e-2) / dpi
height_in = (height * scale + 1e-2) / dpi
fig.set_size_inches(width_in, height_in)
ax = fig.add_axes([0.0, 0.0, 1.0, 1.0])
ax.axis("off")
ax.set_xlim(0.0, width)
ax.set_ylim(height)
self.saveas = saveas
self.rgb = rgb
self.pynb = pynb
self.img = img
self.edgecolor = edgecolor
self.alpha = 0.5
self.linestyle = linestyle
self.font_size = int(np.sqrt(min(height, width)) * scale // 3)
self.width = width
self.height = height
self.scale = scale
self.fig = fig
self.ax = ax
self.pad = pad
self.id2obj = id2obj
self.id2attr = id2attr
self.canvas = FigureCanvasAgg(fig)
def add_box(self, box, color=None):
if color is None:
color = self.edgecolor
(x0, y0, x1, y1) = box
width = x1 - x0
height = y1 - y0
self.ax.add_patch(
mpl.patches.Rectangle(
(x0, y0),
width,
height,
fill=False,
edgecolor=color,
linewidth=self.font_size // 3,
alpha=self.alpha,
linestyle=self.linestyle,
)
)
def draw_boxes(self, boxes, obj_ids=None, obj_scores=None, attr_ids=None, attr_scores=None):
if len(boxes.shape) > 2:
boxes = boxes[0]
if len(obj_ids.shape) > 1:
obj_ids = obj_ids[0]
if len(obj_scores.shape) > 1:
obj_scores = obj_scores[0]
if len(attr_ids.shape) > 1:
attr_ids = attr_ids[0]
if len(attr_scores.shape) > 1:
attr_scores = attr_scores[0]
if isinstance(boxes, torch.Tensor):
boxes = boxes.numpy()
if isinstance(boxes, list):
boxes = np.array(boxes)
assert isinstance(boxes, np.ndarray)
areas = np.prod(boxes[:, 2:] - boxes[:, :2], axis=1)
sorted_idxs = np.argsort(-areas).tolist()
boxes = boxes[sorted_idxs] if boxes is not None else None
obj_ids = obj_ids[sorted_idxs] if obj_ids is not None else None
obj_scores = obj_scores[sorted_idxs] if obj_scores is not None else None
attr_ids = attr_ids[sorted_idxs] if attr_ids is not None else None
attr_scores = attr_scores[sorted_idxs] if attr_scores is not None else None
assigned_colors = [self._random_color(maximum=1) for _ in range(len(boxes))]
assigned_colors = [assigned_colors[idx] for idx in sorted_idxs]
if obj_ids is not None:
labels = self._create_text_labels_attr(obj_ids, obj_scores, attr_ids, attr_scores)
for i in range(len(boxes)):
color = assigned_colors[i]
self.add_box(boxes[i], color)
self.draw_labels(labels[i], boxes[i], color)
def draw_labels(self, label, box, color):
x0, y0, x1, y1 = box
text_pos = (x0, y0)
instance_area = (y1 - y0) * (x1 - x0)
small = _SMALL_OBJ * self.scale
if instance_area < small or y1 - y0 < 40 * self.scale:
if y1 >= self.height - 5:
text_pos = (x1, y0)
else:
text_pos = (x0, y1)
height_ratio = (y1 - y0) / np.sqrt(self.height * self.width)
lighter_color = self._change_color_brightness(color, brightness_factor=0.7)
font_size = np.clip((height_ratio - 0.02) / 0.08 + 1, 1.2, 2)
font_size *= 0.75 * self.font_size
self.draw_text(
text=label,
position=text_pos,
color=lighter_color,
)
def draw_text(
self,
text,
position,
color="g",
ha="left",
):
rotation = 0
font_size = self.font_size
color = np.maximum(list(mplc.to_rgb(color)), 0.2)
color[np.argmax(color)] = max(0.8, np.max(color))
bbox = {
"facecolor": "black",
"alpha": self.alpha,
"pad": self.pad,
"edgecolor": "none",
}
x, y = position
self.ax.text(
x,
y,
text,
size=font_size * self.scale,
family="sans-serif",
bbox=bbox,
verticalalignment="top",
horizontalalignment=ha,
color=color,
zorder=10,
rotation=rotation,
)
def save(self, saveas=None):
if saveas is None:
saveas = self.saveas
if saveas.lower().endswith(".jpg") or saveas.lower().endswith(".png"):
cv2.imwrite(
saveas,
self._get_buffer()[:, :, ::-1],
)
else:
self.fig.savefig(saveas)
def _create_text_labels_attr(self, classes, scores, attr_classes, attr_scores):
labels = [self.id2obj[i] for i in classes]
attr_labels = [self.id2attr[i] for i in attr_classes]
labels = [
f"{label} {score:.2f} {attr} {attr_score:.2f}"
for label, score, attr, attr_score in zip(labels, scores, attr_labels, attr_scores)
]
return labels
def _create_text_labels(self, classes, scores):
labels = [self.id2obj[i] for i in classes]
if scores is not None:
if labels is None:
labels = ["{:.0f}%".format(s * 100) for s in scores]
else:
labels = ["{} {:.0f}%".format(li, s * 100) for li, s in zip(labels, scores)]
return labels
def _random_color(self, maximum=255):
idx = np.random.randint(0, len(_COLORS))
ret = _COLORS[idx] * maximum
if not self.rgb:
ret = ret[::-1]
return ret
def _get_buffer(self):
if not self.pynb:
s, (width, height) = self.canvas.print_to_buffer()
if (width, height) != (self.width, self.height):
img = cv2.resize(self.img, (width, height))
else:
img = self.img
else:
buf = io.BytesIO() # works for cairo backend
self.canvas.print_rgba(buf)
width, height = self.width, self.height
s = buf.getvalue()
img = self.img
buffer = np.frombuffer(s, dtype="uint8")
img_rgba = buffer.reshape(height, width, 4)
rgb, alpha = np.split(img_rgba, [3], axis=2)
try:
import numexpr as ne # fuse them with numexpr
visualized_image = ne.evaluate("img * (1 - alpha / 255.0) + rgb * (alpha / 255.0)")
except ImportError:
alpha = alpha.astype("float32") / 255.0
visualized_image = img * (1 - alpha) + rgb * alpha
return visualized_image.astype("uint8")
def _change_color_brightness(self, color, brightness_factor):
assert brightness_factor >= -1.0 and brightness_factor <= 1.0
color = mplc.to_rgb(color)
polygon_color = colorsys.rgb_to_hls(*mplc.to_rgb(color))
modified_lightness = polygon_color[1] + (brightness_factor * polygon_color[1])
modified_lightness = 0.0 if modified_lightness < 0.0 else modified_lightness
modified_lightness = 1.0 if modified_lightness > 1.0 else modified_lightness
modified_color = colorsys.hls_to_rgb(polygon_color[0], modified_lightness, polygon_color[2])
return modified_color
# Color map
_COLORS = (
np.array(
[
0.000,
0.447,
0.741,
0.850,
0.325,
0.098,
0.929,
0.694,
0.125,
0.494,
0.184,
0.556,
0.466,
0.674,
0.188,
0.301,
0.745,
0.933,
0.635,
0.078,
0.184,
0.300,
0.300,
0.300,
0.600,
0.600,
0.600,
1.000,
0.000,
0.000,
1.000,
0.500,
0.000,
0.749,
0.749,
0.000,
0.000,
1.000,
0.000,
0.000,
0.000,
1.000,
0.667,
0.000,
1.000,
0.333,
0.333,
0.000,
0.333,
0.667,
0.000,
0.333,
1.000,
0.000,
0.667,
0.333,
0.000,
0.667,
0.667,
0.000,
0.667,
1.000,
0.000,
1.000,
0.333,
0.000,
1.000,
0.667,
0.000,
1.000,
1.000,
0.000,
0.000,
0.333,
0.500,
0.000,
0.667,
0.500,
0.000,
1.000,
0.500,
0.333,
0.000,
0.500,
0.333,
0.333,
0.500,
0.333,
0.667,
0.500,
0.333,
1.000,
0.500,
0.667,
0.000,
0.500,
0.667,
0.333,
0.500,
0.667,
0.667,
0.500,
0.667,
1.000,
0.500,
1.000,
0.000,
0.500,
1.000,
0.333,
0.500,
1.000,
0.667,
0.500,
1.000,
1.000,
0.500,
0.000,
0.333,
1.000,
0.000,
0.667,
1.000,
0.000,
1.000,
1.000,
0.333,
0.000,
1.000,
0.333,
0.333,
1.000,
0.333,
0.667,
1.000,
0.333,
1.000,
1.000,
0.667,
0.000,
1.000,
0.667,
0.333,
1.000,
0.667,
0.667,
1.000,
0.667,
1.000,
1.000,
1.000,
0.000,
1.000,
1.000,
0.333,
1.000,
1.000,
0.667,
1.000,
0.333,
0.000,
0.000,
0.500,
0.000,
0.000,
0.667,
0.000,
0.000,
0.833,
0.000,
0.000,
1.000,
0.000,
0.000,
0.000,
0.167,
0.000,
0.000,
0.333,
0.000,
0.000,
0.500,
0.000,
0.000,
0.667,
0.000,
0.000,
0.833,
0.000,
0.000,
1.000,
0.000,
0.000,
0.000,
0.167,
0.000,
0.000,
0.333,
0.000,
0.000,
0.500,
0.000,
0.000,
0.667,
0.000,
0.000,
0.833,
0.000,
0.000,
1.000,
0.000,
0.000,
0.000,
0.143,
0.143,
0.143,
0.857,
0.857,
0.857,
1.000,
1.000,
1.000,
]
)
.astype(np.float32)
.reshape(-1, 3)
)
| transformers/examples/research_projects/lxmert/visualizing_image.py/0 | {
"file_path": "transformers/examples/research_projects/lxmert/visualizing_image.py",
"repo_id": "transformers",
"token_count": 8182
} | 291 |
# coding=utf-8
# Copyright 2020-present, AllenAI Authors, University of Illinois Urbana-Champaign,
# Intel Nervana Systems and the HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Binarizers take a (real value) matrix as input and produce a binary (values in {0,1}) mask of the same shape.
"""
import torch
from torch import autograd
class ThresholdBinarizer(autograd.Function):
"""
Thresholdd binarizer.
Computes a binary mask M from a real value matrix S such that `M_{i,j} = 1` if and only if `S_{i,j} > \tau`
where `\tau` is a real value threshold.
Implementation is inspired from:
https://github.com/arunmallya/piggyback
Piggyback: Adapting a Single Network to Multiple Tasks by Learning to Mask Weights
Arun Mallya, Dillon Davis, Svetlana Lazebnik
"""
@staticmethod
def forward(ctx, inputs: torch.tensor, threshold: float, sigmoid: bool):
"""
Args:
inputs (`torch.FloatTensor`)
The input matrix from which the binarizer computes the binary mask.
threshold (`float`)
The threshold value (in R).
sigmoid (`bool`)
If set to ``True``, we apply the sigmoid function to the `inputs` matrix before comparing to `threshold`.
In this case, `threshold` should be a value between 0 and 1.
Returns:
mask (`torch.FloatTensor`)
Binary matrix of the same size as `inputs` acting as a mask (1 - the associated weight is
retained, 0 - the associated weight is pruned).
"""
nb_elems = inputs.numel()
nb_min = int(0.005 * nb_elems) + 1
if sigmoid:
mask = (torch.sigmoid(inputs) > threshold).type(inputs.type())
else:
mask = (inputs > threshold).type(inputs.type())
if mask.sum() < nb_min:
# We limit the pruning so that at least 0.5% (half a percent) of the weights are remaining
k_threshold = inputs.flatten().kthvalue(max(nb_elems - nb_min, 1)).values
mask = (inputs > k_threshold).type(inputs.type())
return mask
@staticmethod
def backward(ctx, gradOutput):
return gradOutput, None, None
class TopKBinarizer(autograd.Function):
"""
Top-k Binarizer.
Computes a binary mask M from a real value matrix S such that `M_{i,j} = 1` if and only if `S_{i,j}`
is among the k% highest values of S.
Implementation is inspired from:
https://github.com/allenai/hidden-networks
What's hidden in a randomly weighted neural network?
Vivek Ramanujan*, Mitchell Wortsman*, Aniruddha Kembhavi, Ali Farhadi, Mohammad Rastegari
"""
@staticmethod
def forward(ctx, inputs: torch.tensor, threshold: float):
"""
Args:
inputs (`torch.FloatTensor`)
The input matrix from which the binarizer computes the binary mask.
threshold (`float`)
The percentage of weights to keep (the rest is pruned).
`threshold` is a float between 0 and 1.
Returns:
mask (`torch.FloatTensor`)
Binary matrix of the same size as `inputs` acting as a mask (1 - the associated weight is
retained, 0 - the associated weight is pruned).
"""
# Get the subnetwork by sorting the inputs and using the top threshold %
mask = inputs.clone()
_, idx = inputs.flatten().sort(descending=True)
j = int(threshold * inputs.numel())
# flat_out and mask access the same memory.
flat_out = mask.flatten()
flat_out[idx[j:]] = 0
flat_out[idx[:j]] = 1
return mask
@staticmethod
def backward(ctx, gradOutput):
return gradOutput, None
class MagnitudeBinarizer(object):
"""
Magnitude Binarizer.
Computes a binary mask M from a real value matrix S such that `M_{i,j} = 1` if and only if `S_{i,j}`
is among the k% highest values of |S| (absolute value).
Implementation is inspired from https://github.com/NervanaSystems/distiller/blob/2291fdcc2ea642a98d4e20629acb5a9e2e04b4e6/distiller/pruning/automated_gradual_pruner.py#L24
"""
@staticmethod
def apply(inputs: torch.tensor, threshold: float):
"""
Args:
inputs (`torch.FloatTensor`)
The input matrix from which the binarizer computes the binary mask.
This input marix is typically the weight matrix.
threshold (`float`)
The percentage of weights to keep (the rest is pruned).
`threshold` is a float between 0 and 1.
Returns:
mask (`torch.FloatTensor`)
Binary matrix of the same size as `inputs` acting as a mask (1 - the associated weight is
retained, 0 - the associated weight is pruned).
"""
# Get the subnetwork by sorting the inputs and using the top threshold %
mask = inputs.clone()
_, idx = inputs.abs().flatten().sort(descending=True)
j = int(threshold * inputs.numel())
# flat_out and mask access the same memory.
flat_out = mask.flatten()
flat_out[idx[j:]] = 0
flat_out[idx[:j]] = 1
return mask
| transformers/examples/research_projects/movement-pruning/emmental/modules/binarizer.py/0 | {
"file_path": "transformers/examples/research_projects/movement-pruning/emmental/modules/binarizer.py",
"repo_id": "transformers",
"token_count": 2366
} | 292 |
# Plug and Play Language Models: a Simple Approach to Controlled Text Generation
Authors: [Sumanth Dathathri](https://dathath.github.io/), [Andrea Madotto](https://andreamad8.github.io/), Janice Lan, Jane Hung, Eric Frank, [Piero Molino](https://w4nderlu.st/), [Jason Yosinski](http://yosinski.com/), and [Rosanne Liu](http://www.rosanneliu.com/)
This folder contains the original code used to run the Plug and Play Language Model (PPLM).
Paper link: https://arxiv.org/abs/1912.02164
Blog link: https://eng.uber.com/pplm
Please check out the repo under uber-research for more information: https://github.com/uber-research/PPLM
# Note
⚠️ This project should be run with pytorch-lightning==1.0.4 which has a potential security vulnerability
## Setup
```bash
git clone https://github.com/huggingface/transformers && cd transformers
pip install .
pip install nltk torchtext # additional requirements.
cd examples/research_projects/pplm
```
## PPLM-BoW
### Example command for bag-of-words control
```bash
python run_pplm.py -B military --cond_text "The potato" --length 50 --gamma 1.5 --num_iterations 3 --num_samples 10 --stepsize 0.03 --window_length 5 --kl_scale 0.01 --gm_scale 0.99 --colorama --sample
```
### Tuning hyperparameters for bag-of-words control
1. Increase `--stepsize` to intensify topic control, and decrease its value to soften the control. `--stepsize 0` recovers the original uncontrolled GPT-2 model.
2. If the language being generated is repetitive (For e.g. "science science experiment experiment"), there are several options to consider: </br>
a) Reduce the `--stepsize` </br>
b) Increase `--kl_scale` (the KL-loss coefficient) or decrease `--gm_scale` (the gm-scaling term) </br>
c) Add `--grad-length xx` where xx is an (integer <= length, e.g. `--grad-length 30`).</br>
## PPLM-Discrim
### Example command for discriminator based sentiment control
```bash
python run_pplm.py -D sentiment --class_label 2 --cond_text "My dog died" --length 50 --gamma 1.0 --num_iterations 10 --num_samples 10 --stepsize 0.04 --kl_scale 0.01 --gm_scale 0.95 --sample
```
### Tuning hyperparameters for discriminator control
1. Increase `--stepsize` to intensify topic control, and decrease its value to soften the control. `--stepsize 0` recovers the original uncontrolled GPT-2 model.
2. Use `--class_label 3` for negative, and `--class_label 2` for positive
| transformers/examples/research_projects/pplm/README.md/0 | {
"file_path": "transformers/examples/research_projects/pplm/README.md",
"repo_id": "transformers",
"token_count": 747
} | 293 |
import logging
from pathlib import Path
import numpy as np
import pytorch_lightning as pl
import torch
from pytorch_lightning.callbacks import EarlyStopping, ModelCheckpoint
from pytorch_lightning.utilities import rank_zero_only
from utils_rag import save_json
def count_trainable_parameters(model):
model_parameters = filter(lambda p: p.requires_grad, model.parameters())
params = sum([np.prod(p.size()) for p in model_parameters])
return params
logger = logging.getLogger(__name__)
def get_checkpoint_callback(output_dir, metric):
"""Saves the best model by validation EM score."""
if metric == "rouge2":
exp = "{val_avg_rouge2:.4f}-{step_count}"
elif metric == "bleu":
exp = "{val_avg_bleu:.4f}-{step_count}"
elif metric == "em":
exp = "{val_avg_em:.4f}-{step_count}"
elif metric == "loss":
exp = "{val_avg_loss:.4f}-{step_count}"
else:
raise NotImplementedError(
f"seq2seq callbacks only support rouge2 and bleu, got {metric}, You can make your own by adding to this"
" function."
)
checkpoint_callback = ModelCheckpoint(
dirpath=output_dir,
filename=exp,
monitor=f"val_{metric}",
mode="max",
save_top_k=1,
every_n_epochs=1, # works only with PL > 1.3
)
return checkpoint_callback
def get_early_stopping_callback(metric, patience):
return EarlyStopping(
monitor=f"val_{metric}", # does this need avg?
mode="min" if "loss" in metric else "max",
patience=patience,
verbose=True,
)
class Seq2SeqLoggingCallback(pl.Callback):
def on_batch_end(self, trainer, pl_module):
lrs = {f"lr_group_{i}": param["lr"] for i, param in enumerate(pl_module.trainer.optimizers[0].param_groups)}
pl_module.logger.log_metrics(lrs)
@rank_zero_only
def _write_logs(
self, trainer: pl.Trainer, pl_module: pl.LightningModule, type_path: str, save_generations=True
) -> None:
logger.info(f"***** {type_path} results at step {trainer.global_step:05d} *****")
metrics = trainer.callback_metrics
trainer.logger.log_metrics({k: v for k, v in metrics.items() if k not in ["log", "progress_bar", "preds"]})
# Log results
od = Path(pl_module.hparams.output_dir)
if type_path == "test":
results_file = od / "test_results.txt"
generations_file = od / "test_generations.txt"
else:
# this never gets hit. I prefer not to save intermediate generations, and results are in metrics.json
# If people want this it will be easy enough to add back.
results_file = od / f"{type_path}_results/{trainer.global_step:05d}.txt"
generations_file = od / f"{type_path}_generations/{trainer.global_step:05d}.txt"
results_file.parent.mkdir(exist_ok=True)
generations_file.parent.mkdir(exist_ok=True)
with open(results_file, "a+") as writer:
for key in sorted(metrics):
if key in ["log", "progress_bar", "preds"]:
continue
val = metrics[key]
if isinstance(val, torch.Tensor):
val = val.item()
msg = f"{key}: {val:.6f}\n"
writer.write(msg)
if not save_generations:
return
if "preds" in metrics:
content = "\n".join(metrics["preds"])
generations_file.open("w+").write(content)
@rank_zero_only
def on_train_start(self, trainer, pl_module):
try:
npars = pl_module.model.model.num_parameters()
except AttributeError:
npars = pl_module.model.num_parameters()
n_trainable_pars = count_trainable_parameters(pl_module)
# mp stands for million parameters
trainer.logger.log_metrics({"n_params": npars, "mp": npars / 1e6, "grad_mp": n_trainable_pars / 1e6})
@rank_zero_only
def on_test_end(self, trainer: pl.Trainer, pl_module: pl.LightningModule):
save_json(pl_module.metrics, pl_module.metrics_save_path)
return self._write_logs(trainer, pl_module, "test")
@rank_zero_only
def on_validation_end(self, trainer: pl.Trainer, pl_module):
save_json(pl_module.metrics, pl_module.metrics_save_path)
# Uncommenting this will save val generations
# return self._write_logs(trainer, pl_module, "valid")
| transformers/examples/research_projects/rag-end2end-retriever/callbacks_rag.py/0 | {
"file_path": "transformers/examples/research_projects/rag-end2end-retriever/callbacks_rag.py",
"repo_id": "transformers",
"token_count": 1977
} | 294 |
export PYTHONPATH="../":"${PYTHONPATH}"
python use_own_knowledge_dataset.py
ray start --head
python finetune_rag.py \
--model_name_or_path facebook/rag-token-base \
--model_type rag_token \
--context_encoder_name facebook/dpr-ctx_encoder-multiset-base \
--fp16 \
--gpus 1 \
--profile \
--end2end \
--index_name custom
ray stop
| transformers/examples/research_projects/rag-end2end-retriever/test_run/test_rag_new_features.sh/0 | {
"file_path": "transformers/examples/research_projects/rag-end2end-retriever/test_run/test_rag_new_features.sh",
"repo_id": "transformers",
"token_count": 153
} | 295 |
import tempfile
import unittest
from make_student import create_student_by_copying_alternating_layers
from transformers import AutoConfig
from transformers.file_utils import cached_property
from transformers.testing_utils import require_torch
TINY_BART = "sshleifer/bart-tiny-random"
TINY_T5 = "patrickvonplaten/t5-tiny-random"
@require_torch
class MakeStudentTester(unittest.TestCase):
@cached_property
def teacher_config(self):
return AutoConfig.from_pretrained(TINY_BART)
def test_valid_t5(self):
student, *_ = create_student_by_copying_alternating_layers(TINY_T5, tempfile.mkdtemp(), e=1, d=1)
self.assertEqual(student.config.num_hidden_layers, 1)
def test_asymmetric_t5(self):
student, *_ = create_student_by_copying_alternating_layers(TINY_T5, tempfile.mkdtemp(), e=1, d=None)
def test_same_decoder_small_encoder(self):
student, *_ = create_student_by_copying_alternating_layers(TINY_BART, tempfile.mkdtemp(), e=1, d=None)
self.assertEqual(student.config.encoder_layers, 1)
self.assertEqual(student.config.decoder_layers, self.teacher_config.encoder_layers)
def test_small_enc_small_dec(self):
student, *_ = create_student_by_copying_alternating_layers(TINY_BART, tempfile.mkdtemp(), e=1, d=1)
self.assertEqual(student.config.encoder_layers, 1)
self.assertEqual(student.config.decoder_layers, 1)
def test_raises_assert(self):
with self.assertRaises(AssertionError):
create_student_by_copying_alternating_layers(TINY_BART, tempfile.mkdtemp(), e=None, d=None)
| transformers/examples/research_projects/seq2seq-distillation/_test_make_student.py/0 | {
"file_path": "transformers/examples/research_projects/seq2seq-distillation/_test_make_student.py",
"repo_id": "transformers",
"token_count": 660
} | 296 |
### Saved Pseudo-Labels
These are the generations of various large models on various large **training** sets. All in all they took about 200 GPU hours to produce.
### Available Pseudo-labels
| Dataset | Model | Link | Rouge Scores | Notes
|---------|-----------------------------|----------------------------------------------------------------------------------------|--------------------|-------------------------------------------------------------------------------------------------------------
| XSUM | `facebook/bart-large-xsum` | [download](https://cdn-datasets.huggingface.co/pseudo/xsum/bart_xsum_pl.tgz) | 49.8/28.0/42.5 |
| XSUM | `google/pegasus-xsum` | [download](https://cdn-datasets.huggingface.co/pseudo/xsum/pegasus_xsum.tgz) | 53.3/32.7/46.5 |
| XSUM | `facebook/bart-large-xsum` | [download](https://cdn-datasets.huggingface.co/pseudo/xsum/xsum_pl2_bart.tgz) | | Bart pseudolabels filtered to those with Rouge2 > 10.0 w GT.
| CNN/DM | `sshleifer/pegasus-cnn-ft-v2` | [download](https://cdn-datasets.huggingface.co/pseudo/cnn_dm/pegasus_cnn_cnn_pls.tgz) | 47.316/26.65/44.56 | do not worry about the fact that train.source is one line shorter.
| CNN/DM | `facebook/bart-large-cnn` | [download](https://cdn-datasets.huggingface.co/pseudo/cnn_dm/cnn_bart_pl.tgz) | | 5K (2%) are missing, there should be 282173
| CNN/DM | `google/pegasus-xsum` | [download](https://cdn-datasets.huggingface.co/pseudo/cnn_dm/pegasus_xsum_on_cnn.tgz) | 21.5/6.76/25 | extra labels for xsum distillation Used max_source_length=512, (and all other pegasus-xsum configuration).
| EN-RO | `Helsinki-NLP/opus-mt-en-ro` | [download](https://cdn-datasets.huggingface.co/pseudo/wmt_en_ro/opus_mt_en_ro.tgz) | |
| EN-RO | `facebook/mbart-large-en-ro` | [download](https://cdn-datasets.huggingface.co/pseudo/wmt_en_ro/mbart_large_en_ro.tgz) | |
(EN_RO = WMT 2016 English-Romanian).
Example Download Command:
```bash
curl -S https://cdn-datasets.huggingface.co/pseudo/xsum/bart_xsum_pl.tgz | tar -xvz -C .
```
### Generating New Pseudolabels
Here is the command I used to generate the pseudolabels in the second row of the table, after downloading XSUM from [here](https://cdn-datasets.huggingface.co/summarization/xsum.tar.gz).
```bash
python -m torch.distributed.launch --nproc_per_node=8 run_distributed_eval.py \
--model_name google/pegasus-xsum \
--save_dir pegasus_xsum \
--data_dir xsum \
--bs 8 --sync_timeout 60000 \
--max_source_length 512 \
--type_path train
```
+ These commands takes a while to run. For example, `pegasus_cnn_cnn_pls.tgz` took 8 hours on 8 GPUs.
+ Pegasus does not work in fp16 :(, Bart, mBART and Marian do.
+ Even if you have 1 GPU, `run_distributed_eval.py` is 10-20% faster than `run_eval.py` because it uses `SortishSampler` to minimize padding computation.
### Contributions
Feel free to contribute your own pseudolabels via PR. Add a row to this table with a new google drive link (or other command line downloadable link).
| transformers/examples/research_projects/seq2seq-distillation/precomputed_pseudo_labels.md/0 | {
"file_path": "transformers/examples/research_projects/seq2seq-distillation/precomputed_pseudo_labels.md",
"repo_id": "transformers",
"token_count": 1861
} | 297 |
#!/usr/bin/env python
# coding=utf-8
# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
""" Fine-tuning a 🤗 Transformers pretrained speech model on the XTREME-S benchmark tasks"""
import json
import logging
import os
import re
import sys
from collections import OrderedDict, defaultdict
from dataclasses import dataclass, field
from typing import Dict, List, Optional, Union
import datasets
import numpy as np
import torch
from datasets import DatasetDict, load_dataset, load_metric
import transformers
from transformers import (
AutoConfig,
AutoFeatureExtractor,
AutoModelForAudioClassification,
AutoModelForCTC,
AutoModelForSpeechSeq2Seq,
AutoProcessor,
AutoTokenizer,
HfArgumentParser,
Seq2SeqTrainer,
Seq2SeqTrainingArguments,
Trainer,
set_seed,
)
from transformers.trainer_utils import get_last_checkpoint, is_main_process
from transformers.utils import check_min_version
from transformers.utils.versions import require_version
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
check_min_version("4.18.0.dev0")
require_version("datasets>=1.18.0", "To fix: pip install -r examples/pytorch/speech-recognition/requirements.txt")
logger = logging.getLogger(__name__)
def list_field(default=None, metadata=None):
return field(default_factory=lambda: default, metadata=metadata)
TASK_TO_TARGET_COLUMN_NAME = {
"fleurs-asr": "transcription",
"fleurs-lang_id": "lang_id",
"mls": "transcription",
"voxpopuli": "transcription",
"covost2": "translation",
"minds14": "intent_class",
"babel": "transcription",
}
@dataclass
class ModelArguments:
"""
Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
"""
model_name_or_path: str = field(
metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
)
tokenizer_name_or_path: Optional[str] = field(
default=None,
metadata={"help": "Path to pretrained tokenizer or tokenizer identifier from huggingface.co/models"},
)
cache_dir: Optional[str] = field(
default=None,
metadata={
"help": "Where do you want to store the pretrained models and datasets downloaded from huggingface.co"
},
)
freeze_feature_encoder: bool = field(
default=True, metadata={"help": "Whether to freeze the feature encoder layers of the model."}
)
attention_dropout: float = field(
default=0.0, metadata={"help": "The dropout ratio for the attention probabilities."}
)
activation_dropout: float = field(
default=0.0, metadata={"help": "The dropout ratio for activations inside the fully connected layer."}
)
feat_proj_dropout: float = field(default=0.0, metadata={"help": "The dropout ratio for the projected features."})
hidden_dropout: float = field(
default=0.0,
metadata={
"help": "The dropout probability for all fully connected layers in the embeddings, encoder, and pooler."
},
)
final_dropout: float = field(
default=0.0,
metadata={"help": "The dropout probability for the final projection layer."},
)
mask_time_prob: float = field(
default=0.05,
metadata={
"help": (
"Probability of each feature vector along the time axis to be chosen as the start of the vector "
"span to be masked. Approximately ``mask_time_prob * sequence_length // mask_time_length`` feature "
"vectors will be masked along the time axis."
)
},
)
mask_time_length: int = field(
default=10,
metadata={"help": "Length of vector span to mask along the time axis."},
)
mask_feature_prob: float = field(
default=0.0,
metadata={
"help": (
"Probability of each feature vector along the feature axis to be chosen as the start of the vectorspan"
" to be masked. Approximately ``mask_feature_prob * sequence_length // mask_feature_length`` feature"
" bins will be masked along the time axis."
)
},
)
mask_feature_length: int = field(
default=10,
metadata={"help": "Length of vector span to mask along the feature axis."},
)
layerdrop: float = field(default=0.0, metadata={"help": "The LayerDrop probability."})
ctc_zero_infinity: bool = field(
default=False,
metadata={"help": "Whether to zero infinite losses and the associated gradients of `torch.nn.CTCLoss`."},
)
ctc_loss_reduction: Optional[str] = field(
default="mean", metadata={"help": "The way the ctc loss should be reduced. Should be one of 'mean' or 'sum'."}
)
@dataclass
class DataTrainingArguments:
"""
Arguments pertaining to what data we are going to input our model for training and eval.
Using `HfArgumentParser` we can turn this class
into argparse arguments to be able to specify them on
the command line.
"""
dataset_name: str = field(
default="google/xtreme_s",
metadata={"help": "The name of the dataset to use (via the datasets library). Defaults to 'google/xtreme_s'"},
)
task: str = field(
default=None,
metadata={
"help": (
"The task name of the benchmark to use (via the datasets library). Should be on of: "
"'fleurs-asr', 'mls', 'voxpopuli', 'covost2', 'minds14', 'fleurs-lang_id', 'babel'."
)
},
)
language: str = field(
default="all",
metadata={"help": "The language id as defined in the datasets config name or `all` for all languages."},
)
language_group: str = field(
default=None,
metadata={
"help": (
"The language group to select a subset of languages to train on. "
"This option is only used the 'fleurs-asr' task. Should be one of: "
"'western_european_we', 'eastern_european_ee', 'central_asia_middle_north_african_cmn', "
"'sub_saharan_african_ssa', 'south_asian_sa', 'south_east_asian_sea', 'chinese_japanase_korean_cjk'."
)
},
)
train_split_name: str = field(
default="train",
metadata={
"help": "The name of the training dataset split to use (via the datasets library). Defaults to 'train'"
},
)
eval_split_name: str = field(
default="validation",
metadata={
"help": (
"The name of the evaluation dataset split to use (via the datasets library). Defaults to 'validation'"
)
},
)
predict_split_name: str = field(
default="test",
metadata={
"help": "The name of the prediction dataset split to use (via the datasets library). Defaults to 'test'"
},
)
audio_column_name: str = field(
default="audio",
metadata={"help": "The name of the dataset column containing the audio data. Defaults to 'audio'"},
)
target_column_name: str = field(
default=None,
metadata={
"help": (
"The name of the dataset column containing the target data (transcription/translation/label). If None,"
" the name will be inferred from the task. Defaults to None."
)
},
)
overwrite_cache: bool = field(
default=False, metadata={"help": "Overwrite the cached preprocessed datasets or not."}
)
preprocessing_num_workers: Optional[int] = field(
default=None,
metadata={"help": "The number of processes to use for the preprocessing."},
)
max_train_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set."
)
},
)
max_eval_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of validation examples to this "
"value if set."
)
},
)
max_predict_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of prediction examples to this "
"value if set."
)
},
)
chars_to_ignore: Optional[List[str]] = list_field(
default=', ? . ! - ; : " “ % ‘ ” �'.split(" "),
metadata={"help": "A list of characters to remove from the transcripts."},
)
max_duration_in_seconds: float = field(
default=30.0,
metadata={
"help": (
"Filter audio files that are longer than `max_duration_in_seconds` seconds to"
" 'max_duration_in_seconds`"
)
},
)
min_duration_in_seconds: float = field(
default=0.0, metadata={"help": "Filter audio files that are shorter than `min_duration_in_seconds` seconds"}
)
preprocessing_only: bool = field(
default=False,
metadata={
"help": (
"Whether to only do data preprocessing and skip training. This is especially useful when data"
" preprocessing errors out in distributed training due to timeout. In this case, one should run the"
" preprocessing in a non-distributed setup with `preprocessing_only=True` so that the cached datasets"
" can consequently be loaded in distributed training"
)
},
)
use_auth_token: bool = field(
default=False,
metadata={
"help": (
"If :obj:`True`, will use the token generated when running"
":obj:`huggingface-cli login` as HTTP bearer authorization for remote files."
)
},
)
unk_token: str = field(
default="[UNK]",
metadata={"help": "The unk token for the tokenizer"},
)
pad_token: str = field(
default="[PAD]",
metadata={"help": "The padding token for the tokenizer"},
)
word_delimiter_token: str = field(
default="|",
metadata={"help": "The word delimiter token for the tokenizer"},
)
phoneme_language: Optional[str] = field(
default=None,
metadata={
"help": (
"The target language that should be used be"
" passed to the tokenizer for tokenization. Note that"
" this is only relevant if the model classifies the"
" input audio to a sequence of phoneme sequences."
)
},
)
per_lang_metrics: bool = field(
default=True,
metadata={
"help": (
"If `True`, compute the test metrics separately for each language, and average the results. "
"If `False` compute the average test metrics in a single pass for all languages at once."
)
},
)
@dataclass
class SpeechDataCollatorWithPadding:
processor: AutoProcessor
decoder_start_token_id: Optional[int] = None
padding: Union[bool, str] = "longest"
pad_labels: Optional[int] = True
pad_to_multiple_of: Optional[int] = None
pad_to_multiple_of_labels: Optional[int] = None
def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
# split inputs and labels since they have to be of different lengths and need
# different padding methods
input_features = [{"input_values": feature["input_values"]} for feature in features]
batch = self.processor.pad(
input_features,
padding=self.padding,
pad_to_multiple_of=self.pad_to_multiple_of,
return_tensors="pt",
)
if self.pad_labels:
label_features = [{"input_ids": feature["labels"]} for feature in features]
labels_batch = self.processor.pad(
labels=label_features,
padding=self.padding,
pad_to_multiple_of=self.pad_to_multiple_of_labels,
return_tensors="pt",
)
# replace padding with -100 to ignore loss correctly
labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
# if bos token is appended in previous tokenization step,
# cut bos token here as it's append later anyways
if (
self.decoder_start_token_id is not None
and (labels[:, 0] == self.decoder_start_token_id).all().cpu().item()
):
labels = labels[:, 1:]
batch["labels"] = labels
else:
batch["labels"] = torch.tensor([feature["labels"] for feature in features])
return batch
def create_vocabulary_from_data(
datasets: DatasetDict,
word_delimiter_token: Optional[str] = None,
unk_token: Optional[str] = None,
pad_token: Optional[str] = None,
):
# Given training and test labels create vocabulary
def extract_all_chars(batch):
all_text = " ".join(batch["target_text"])
vocab = list(set(all_text))
return {"vocab": [vocab], "all_text": [all_text]}
vocabs = datasets.map(
extract_all_chars,
batched=True,
batch_size=-1,
keep_in_memory=True,
remove_columns=datasets["train"].column_names,
)
# take union of all unique characters in each dataset
vocab_set = (
(set(vocabs["train"]["vocab"][0]) if "train" in vocabs else set())
| (set(vocabs["eval"]["vocab"][0]) if "eval" in vocabs else set())
| (set(vocabs["predict"]["vocab"][0]) if "predict" in vocabs else set())
)
vocab_dict = {v: k for k, v in enumerate(sorted(vocab_set))}
# replace white space with delimiter token
if word_delimiter_token is not None:
vocab_dict[word_delimiter_token] = vocab_dict[" "]
del vocab_dict[" "]
# add unk and pad token
if unk_token is not None:
vocab_dict[unk_token] = len(vocab_dict)
if pad_token is not None:
vocab_dict[pad_token] = len(vocab_dict)
return vocab_dict
def main():
# See all possible arguments in src/transformers/training_args.py
# or by passing the --help flag to this script.
# We now keep distinct sets of args, for a cleaner separation of concerns.
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, Seq2SeqTrainingArguments))
if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
# If we pass only one argument to the script and it's the path to a json file,
# let's parse it to get our arguments.
model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
else:
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
# Detecting last checkpoint.
last_checkpoint = None
if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
last_checkpoint = get_last_checkpoint(training_args.output_dir)
if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
raise ValueError(
f"Output directory ({training_args.output_dir}) already exists and is not empty. "
"Use --overwrite_output_dir to overcome."
)
elif last_checkpoint is not None:
logger.info(
f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
"the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
)
# Setup logging
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
handlers=[logging.StreamHandler(sys.stdout)],
)
logger.setLevel(logging.INFO if is_main_process(training_args.local_rank) else logging.WARN)
# Log on each process the small summary:
logger.warning(
f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}, "
f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
)
# Set the verbosity to info of the Transformers logger (on main process only):
if is_main_process(training_args.local_rank):
transformers.utils.logging.set_verbosity_info()
logger.info("Training/evaluation parameters %s", training_args)
# Set seed before initializing model.
set_seed(training_args.seed)
# 1. First, let's load the dataset
raw_datasets = DatasetDict()
task_name = data_args.task
lang_id = data_args.language
if task_name is None:
raise ValueError(
"Set --task should be set to '<xtreme_s_task>' (e.g. 'fleurs-asr', 'mls', 'covost2', 'minds14') "
)
if lang_id is None:
raise ValueError(
"Set --language should be set to the language id of the sub dataset "
"config to be used (e.g. 'pl', 'en.tr', 'fr-FR') or 'all'"
" for multi-lingual fine-tuning."
)
if data_args.language_group is not None:
if data_args.task != "fleurs-asr":
raise ValueError("--language_group should only be used with --task=fleurs-asr")
if data_args.language != "all":
raise ValueError("--language_group should only be used with --language=all")
if data_args.target_column_name is None:
target_column_name = TASK_TO_TARGET_COLUMN_NAME[task_name]
else:
target_column_name = data_args.target_column_name
# here we differentiate between tasks with text as the target and classification tasks
is_text_target = target_column_name in ("transcription", "translation")
config_name = ".".join([task_name.split("-")[0], lang_id])
if training_args.do_train:
raw_datasets["train"] = load_dataset(
data_args.dataset_name,
config_name,
split=data_args.train_split_name,
token=data_args.use_auth_token,
cache_dir=model_args.cache_dir,
)
if data_args.audio_column_name not in raw_datasets["train"].column_names:
raise ValueError(
f"--audio_column_name '{data_args.audio_column_name}' not found in dataset '{data_args.dataset_name}'."
" Make sure to set `--audio_column_name` to the correct audio column - one of"
f" {', '.join(raw_datasets['train'].column_names)}."
)
if target_column_name not in raw_datasets["train"].column_names:
raise ValueError(
f"--target_column_name {target_column_name} not found in dataset '{data_args.dataset_name}'. "
"Make sure to set `--target_column_name` to the correct text column - one of "
f"{', '.join(raw_datasets['train'].column_names)}."
)
if data_args.max_train_samples is not None:
raw_datasets["train"] = raw_datasets["train"].select(range(data_args.max_train_samples))
if training_args.do_eval:
raw_datasets["eval"] = load_dataset(
data_args.dataset_name,
config_name,
split=data_args.eval_split_name,
token=data_args.use_auth_token,
cache_dir=model_args.cache_dir,
)
if data_args.max_eval_samples is not None:
raw_datasets["eval"] = raw_datasets["eval"].select(range(data_args.max_eval_samples))
if training_args.do_predict:
raw_datasets["predict"] = load_dataset(
data_args.dataset_name,
config_name,
split=data_args.predict_split_name,
token=data_args.use_auth_token,
cache_dir=model_args.cache_dir,
)
if data_args.max_predict_samples is not None:
raw_datasets["predict"] = raw_datasets["predict"].select(range(data_args.max_predict_samples))
lang_list = next(iter(raw_datasets.values())).features["lang_id"].names
if not is_text_target:
label_list = next(iter(raw_datasets.values())).features[target_column_name].names
num_labels = len(label_list)
num_workers = data_args.preprocessing_num_workers
lang_group = data_args.language_group
if lang_group is not None:
with training_args.main_process_first(desc="language group filter"):
lang_group_id = next(iter(raw_datasets.values())).features["lang_group_id"].str2int(lang_group)
raw_datasets = raw_datasets.filter(
lambda lang_group: lang_group == lang_group_id,
num_proc=num_workers,
input_columns=["lang_group_id"],
)
# 2. We remove some special characters from the datasets
# that make training complicated and do not help in transcribing the speech
# E.g. characters, such as `,` and `.` do not really have an acoustic characteristic
# that could be easily picked up by the model
chars_to_ignore_regex = (
f'[{"".join(data_args.chars_to_ignore)}]' if data_args.chars_to_ignore is not None else None
)
def remove_special_characters(batch):
if chars_to_ignore_regex is not None:
batch["target_text"] = re.sub(chars_to_ignore_regex, "", batch[target_column_name]).lower() + " "
else:
batch["target_text"] = batch[target_column_name].lower() + " "
return batch
if is_text_target:
with training_args.main_process_first(desc="dataset map special characters removal"):
raw_datasets = raw_datasets.map(
remove_special_characters,
remove_columns=[target_column_name],
desc="remove special characters from datasets",
)
# save special tokens for tokenizer
word_delimiter_token = data_args.word_delimiter_token
unk_token = data_args.unk_token
pad_token = data_args.pad_token
# 3. Next, let's load the config as we might need it to create
# the tokenizer
config = AutoConfig.from_pretrained(
model_args.model_name_or_path, cache_dir=model_args.cache_dir, token=data_args.use_auth_token
)
if is_text_target:
# 4. (Optional, for ASR and translation) If no tokenizer file is defined,
# we create the vocabulary of the model by extracting all unique characters from
# the training and evaluation datasets
# We need to make sure that only first rank saves vocabulary
# make sure all processes wait until vocab is created
tokenizer_name_or_path = model_args.tokenizer_name_or_path
tokenizer_kwargs = {}
if tokenizer_name_or_path is None:
# save vocab in training output dir
tokenizer_name_or_path = training_args.output_dir
vocab_file = os.path.join(tokenizer_name_or_path, "vocab.json")
with training_args.main_process_first():
if training_args.overwrite_output_dir and os.path.isfile(vocab_file):
os.remove(vocab_file)
with training_args.main_process_first(desc="dataset map vocabulary creation"):
if not os.path.isfile(vocab_file):
os.makedirs(tokenizer_name_or_path, exist_ok=True)
vocab_dict = create_vocabulary_from_data(
raw_datasets,
word_delimiter_token=word_delimiter_token,
unk_token=unk_token,
pad_token=pad_token,
)
# save vocab dict to be loaded into tokenizer
with open(vocab_file, "w") as file:
json.dump(vocab_dict, file)
# if tokenizer has just been created
# it is defined by `tokenizer_class` if present in config else by `model_type`
if not config.is_encoder_decoder:
tokenizer_kwargs = {
"config": config if config.tokenizer_class is not None else None,
"tokenizer_type": config.model_type if config.tokenizer_class is None else None,
"unk_token": unk_token,
"pad_token": pad_token,
"word_delimiter_token": word_delimiter_token,
}
else:
tokenizer_kwargs = {}
# 5. Now we can instantiate the feature extractor, tokenizer and model
# Note for distributed training, the .from_pretrained methods guarantee that only
# one local process can concurrently download model & vocab.
# load feature_extractor and tokenizer
if is_text_target:
tokenizer = AutoTokenizer.from_pretrained(
tokenizer_name_or_path,
token=data_args.use_auth_token,
**tokenizer_kwargs,
)
feature_extractor = AutoFeatureExtractor.from_pretrained(
model_args.model_name_or_path, cache_dir=model_args.cache_dir, token=data_args.use_auth_token
)
# adapt config
# (speech translation requires pre-configured seq2seq models)
if task_name != "covost2":
config.update(
{
"feat_proj_dropout": model_args.feat_proj_dropout,
"attention_dropout": model_args.attention_dropout,
"hidden_dropout": model_args.hidden_dropout,
"final_dropout": model_args.final_dropout,
"mask_time_prob": model_args.mask_time_prob,
"mask_time_length": model_args.mask_time_length,
"mask_feature_prob": model_args.mask_feature_prob,
"mask_feature_length": model_args.mask_feature_length,
"gradient_checkpointing": training_args.gradient_checkpointing,
"layerdrop": model_args.layerdrop,
"ctc_zero_infinity": model_args.ctc_zero_infinity,
"ctc_loss_reduction": model_args.ctc_loss_reduction,
"activation_dropout": model_args.activation_dropout,
}
)
if training_args.do_train:
if is_text_target:
config.pad_token_id = tokenizer.pad_token_id
config.vocab_size = len(tokenizer)
else:
label_to_id = {v: i for i, v in enumerate(label_list)}
config.label2id = label_to_id
config.id2label = {id: label for label, id in label_to_id.items()}
config.num_labels = num_labels
# create model
if target_column_name == "transcription":
model = AutoModelForCTC.from_pretrained(
model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
config=config,
token=data_args.use_auth_token,
)
elif config.is_encoder_decoder:
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
config=config,
token=data_args.use_auth_token,
)
if model.config.decoder_start_token_id is None:
raise ValueError("Make sure that `config.decoder_start_token_id` is correctly defined")
else:
model = AutoModelForAudioClassification.from_pretrained(
model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
config=config,
token=data_args.use_auth_token,
)
# freeze encoder
if model_args.freeze_feature_encoder:
model.freeze_feature_encoder()
# 6. Now we preprocess the datasets including loading the audio, resampling and normalization
# Thankfully, `datasets` takes care of automatically loading and resampling the audio,
# so that we just need to set the correct target sampling rate and normalize the input
# via the `feature_extractor`
# make sure that dataset decodes audio with correct sampling rate
dataset_sampling_rate = next(iter(raw_datasets.values())).features[data_args.audio_column_name].sampling_rate
if dataset_sampling_rate != feature_extractor.sampling_rate:
raw_datasets = raw_datasets.cast_column(
data_args.audio_column_name, datasets.features.Audio(sampling_rate=feature_extractor.sampling_rate)
)
# derive max & min input length for sample rate & max duration
max_input_length = data_args.max_duration_in_seconds * feature_extractor.sampling_rate
min_input_length = data_args.min_duration_in_seconds * feature_extractor.sampling_rate
audio_column_name = data_args.audio_column_name
# `phoneme_language` is only relevant if the model is fine-tuned on phoneme classification
phoneme_language = data_args.phoneme_language
# Preprocessing the datasets.
# We need to read the audio files as arrays and tokenize the targets.
def prepare_dataset(batch):
# load audio
sample = batch[audio_column_name]
inputs = feature_extractor(sample["array"], sampling_rate=sample["sampling_rate"])
batch["input_values"] = inputs.input_values[0]
batch["length"] = len(batch["input_values"])
# encode targets
additional_kwargs = {}
if phoneme_language is not None:
additional_kwargs["phonemizer_lang"] = phoneme_language
if is_text_target:
batch["labels"] = tokenizer(batch["target_text"], **additional_kwargs).input_ids
else:
batch["labels"] = batch[target_column_name]
batch["lang"] = batch["lang_id"]
return batch
with training_args.main_process_first(desc="dataset map preprocessing"):
vectorized_datasets = raw_datasets.map(
prepare_dataset,
remove_columns=next(iter(raw_datasets.values())).column_names,
num_proc=num_workers,
desc="preprocess datasets",
)
if training_args.do_train:
def is_audio_in_length_range(length):
return length > min_input_length and length < max_input_length
# filter data that is shorter than min_input_length
vectorized_datasets["train"] = vectorized_datasets["train"].filter(
is_audio_in_length_range,
num_proc=num_workers,
input_columns=["length"],
)
# 7. Next, we can prepare for the training step.
# Let's use the appropriate XTREME-S evaluation metric,
# instantiate a data collator and the trainer
# Define evaluation metrics during training, *i.e.* word error rate, character error rate
eval_metric = load_metric("xtreme_s", task_name)
# for large datasets it is advised to run the preprocessing on a
# single machine first with ``args.preprocessing_only`` since there will mostly likely
# be a timeout when running the script in distributed mode.
# In a second step ``args.preprocessing_only`` can then be set to `False` to load the
# cached dataset
if data_args.preprocessing_only:
logger.info(f"Data preprocessing finished. Files cached at {vectorized_datasets.cache_files}")
return
def asr_logits_argmax(logits, labels):
return logits.argmax(dim=-1)
def compute_asr_metric(pred):
pred.label_ids[pred.label_ids == -100] = tokenizer.pad_token_id
pred_str = tokenizer.batch_decode(pred.predictions)
# we do not want to group tokens when computing the metrics
label_str = tokenizer.batch_decode(pred.label_ids, group_tokens=False)
metric = eval_metric.compute(predictions=pred_str, references=label_str)
return metric
def compute_classification_metric(pred):
pred_ids = np.argmax(pred.predictions, axis=1)
metric = eval_metric.compute(predictions=pred_ids, references=pred.label_ids)
return metric
# Now save everything to be able to create a single processor later
if is_main_process(training_args.local_rank):
# save feature extractor, tokenizer and config
feature_extractor.save_pretrained(training_args.output_dir)
if is_text_target:
tokenizer.save_pretrained(training_args.output_dir)
config.save_pretrained(training_args.output_dir)
# wait until configs are saved in the main process before loading the processor
if training_args.local_rank != -1:
torch.distributed.barrier()
if is_text_target:
processor = AutoProcessor.from_pretrained(training_args.output_dir)
else:
processor = AutoFeatureExtractor.from_pretrained(training_args.output_dir)
# Instantiate custom data collator
data_collator = SpeechDataCollatorWithPadding(processor=processor, pad_labels=is_text_target)
# Initialize Trainer
if target_column_name == "translation":
trainer = Seq2SeqTrainer(
model=model,
data_collator=data_collator,
args=training_args,
preprocess_logits_for_metrics=asr_logits_argmax if training_args.predict_with_generate else None,
compute_metrics=compute_asr_metric if training_args.predict_with_generate else None,
train_dataset=vectorized_datasets["train"] if training_args.do_train else None,
eval_dataset=vectorized_datasets["eval"] if training_args.do_eval else None,
tokenizer=feature_extractor,
)
else:
trainer = Trainer(
model=model,
data_collator=data_collator,
args=training_args,
preprocess_logits_for_metrics=asr_logits_argmax if is_text_target else None,
compute_metrics=compute_asr_metric if is_text_target else compute_classification_metric,
train_dataset=vectorized_datasets["train"] if training_args.do_train else None,
eval_dataset=vectorized_datasets["eval"] if training_args.do_eval else None,
tokenizer=feature_extractor,
)
# 8. Finally, we can start training
# Training
if training_args.do_train:
# use last checkpoint if exist
if last_checkpoint is not None:
checkpoint = last_checkpoint
elif os.path.isdir(model_args.model_name_or_path):
checkpoint = model_args.model_name_or_path
else:
checkpoint = None
train_result = trainer.train(resume_from_checkpoint=checkpoint)
trainer.save_model()
metrics = train_result.metrics
max_train_samples = (
data_args.max_train_samples
if data_args.max_train_samples is not None
else len(vectorized_datasets["train"])
)
metrics["train_samples"] = min(max_train_samples, len(vectorized_datasets["train"]))
trainer.log_metrics("train", metrics)
trainer.save_metrics("train", metrics)
trainer.save_state()
# Evaluation on the test set
results = {}
if training_args.do_predict:
logger.info(f"*** Evaluating on the `{data_args.predict_split_name}` set ***")
if data_args.per_lang_metrics:
# separate the `test` dataset into language-specific subsets and compute metrics for each of them
metrics = {}
average_metrics = defaultdict(list)
for lang_id in range(len(lang_list)):
lang_name = lang_list[lang_id]
with training_args.main_process_first(desc="per-language dataset filter"):
lang_dataset = vectorized_datasets["predict"].filter(
lambda lang: lang == lang_id,
num_proc=num_workers,
input_columns=["lang"],
)
lang_metrics = trainer.evaluate(lang_dataset)
redundant_metrics = ["eval_runtime", "eval_samples_per_second", "eval_steps_per_second", "eval_epoch"]
for metric_name, value in lang_metrics.items():
average_metrics[metric_name].append(value)
if metric_name not in redundant_metrics:
metrics[f"{metric_name}_{lang_name}"] = value
for metric_name, value in average_metrics.items():
metrics[metric_name] = np.mean(value)
else:
metrics = trainer.evaluate(vectorized_datasets["predict"])
max_predict_samples = (
data_args.max_predict_samples
if data_args.max_predict_samples is not None
else len(vectorized_datasets["predict"])
)
metrics["predict_samples"] = min(max_predict_samples, len(vectorized_datasets["predict"]))
# make sure that the `predict` metrics end up in the log history for the model card
trainer.log(OrderedDict(sorted(metrics.items())))
trainer.log_metrics("predict", metrics)
trainer.save_metrics("predict", metrics)
# Write model card and (optionally) push to hub
kwargs = {
"finetuned_from": model_args.model_name_or_path,
"tasks": task_name,
"tags": [task_name, data_args.dataset_name],
"dataset_args": (
f"Config: {config_name}, Training split: {data_args.train_split_name}, Eval split:"
f" {data_args.eval_split_name}, Predict split: {data_args.predict_split_name}"
),
"dataset": f"{data_args.dataset_name.upper()} - {config_name.upper()}",
"language": data_args.language,
}
if training_args.push_to_hub:
trainer.push_to_hub(**kwargs)
else:
trainer.create_model_card(**kwargs)
return results
if __name__ == "__main__":
main()
| transformers/examples/research_projects/xtreme-s/run_xtreme_s.py/0 | {
"file_path": "transformers/examples/research_projects/xtreme-s/run_xtreme_s.py",
"repo_id": "transformers",
"token_count": 16446
} | 298 |
# Training a masked language model end-to-end from scratch on TPUs
In this example, we're going to demonstrate how to train a TensorFlow model from 🤗 Transformers from scratch. If you're interested in some background theory on training Hugging Face models with TensorFlow on TPU, please check out our
[tutorial doc](https://huggingface.co/docs/transformers/main/perf_train_tpu_tf) on this topic!
If you're interested in smaller-scale TPU training from a pre-trained checkpoint, you can also check out the [TPU fine-tuning example](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/tpu_training-tf.ipynb).
This example will demonstrate pre-training language models at the 100M-1B parameter scale, similar to BERT or GPT-2. More concretely, we will show how to train a [RoBERTa](https://huggingface.co/docs/transformers/model_doc/roberta) (base model) from scratch on the [WikiText dataset (v1)](https://huggingface.co/datasets/wikitext).
We've tried to ensure that all the practices we show you here are scalable, though - with relatively few changes, the code could be scaled up to much larger models.
Google's gargantuan [PaLM model](https://arxiv.org/abs/2204.02311), with
over 500B parameters, is a good example of how far you can go with pure TPU training, though gathering the dataset and the budget to train at that scale is not an easy task!
### Table of contents
- [Setting up a TPU-VM](#setting-up-a-tpu-vm)
- [Training a tokenizer](#training-a-tokenizer)
- [Preparing the dataset](#preparing-the-dataset)
- [Training the model](#training-the-model)
- [Inference](#inference)
## Setting up a TPU-VM
Since this example focuses on using TPUs, the first step is to set up access to TPU hardware. For this example, we chose to use a TPU v3-8 VM. Follow [this guide](https://cloud.google.com/tpu/docs/run-calculation-tensorflow) to quickly create a TPU VM with TensorFlow pre-installed.
> 💡 **Note**: You don't need a TPU-enabled hardware for tokenizer training and TFRecord shard preparation.
## Training a tokenizer
To train a language model from scratch, the first step is to tokenize text. In most Hugging Face examples, we begin from a pre-trained model and use its tokenizer. However, in this example, we're going to train a tokenizer from scratch as well. The script for this is `train_unigram.py`. An example command is:
```bash
python train_unigram.py --batch_size 1000 --vocab_size 25000 --export_to_hub
```
The script will automatically load the `train` split of the WikiText dataset and train a [Unigram tokenizer](https://huggingface.co/course/chapter6/7?fw=pt) on it.
> 💡 **Note**: In order for `export_to_hub` to work, you must authenticate yourself with the `huggingface-cli`. Run `huggingface-cli login` and follow the on-screen instructions.
## Preparing the dataset
The next step is to prepare the dataset. This consists of loading a text dataset from the Hugging Face Hub, tokenizing it and grouping it into chunks of a fixed length ready for training. The script for this is `prepare_tfrecord_shards.py`.
The reason we create TFRecord output files from this step is that these files work well with [`tf.data` pipelines](https://www.tensorflow.org/guide/data_performance). This makes them very suitable for scalable TPU training - the dataset can easily be sharded and read in parallel just by tweaking a few parameters in the pipeline. An example command is:
```bash
python prepare_tfrecord_shards.py \
--tokenizer_name_or_path tf-tpu/unigram-tokenizer-wikitext \
--shard_size 5000 \
--split test
--max_length 128 \
--output_dir gs://tf-tpu-training-resources
```
**Notes**:
* While running the above script, you need to specify the `split` accordingly. The example command above will only filter the `test` split of the dataset.
* If you append `gs://` in your `output_dir` the TFRecord shards will be directly serialized to a Google Cloud Storage (GCS) bucket. Ensure that you have already [created the GCS bucket](https://cloud.google.com/storage/docs).
* If you're using a TPU node, you must stream data from a GCS bucket. Otherwise, if you're using a TPU VM,you can store the data locally. You may need to [attach](https://cloud.google.com/tpu/docs/setup-persistent-disk) a persistent storage to the VM.
* Additional CLI arguments are also supported. We encourage you to run `python prepare_tfrecord_shards.py -h` to know more about them.
## Training the model
Once that's done, the model is ready for training. By default, training takes place on TPU, but you can use the `--no_tpu` flag to train on CPU for testing purposes. An example command is:
```bash
python3 run_mlm.py \
--train_dataset gs://tf-tpu-training-resources/train/ \
--eval_dataset gs://tf-tpu-training-resources/validation/ \
--tokenizer tf-tpu/unigram-tokenizer-wikitext \
--output_dir trained_model
```
If you had specified a `hub_model_id` while launching training, then your model will be pushed to a model repository on the Hugging Face Hub. You can find such an example repository here:
[tf-tpu/roberta-base-epochs-500-no-wd](https://huggingface.co/tf-tpu/roberta-base-epochs-500-no-wd).
## Inference
Once the model is trained, you can use 🤗 Pipelines to perform inference:
```python
from transformers import pipeline
model_id = "tf-tpu/roberta-base-epochs-500-no-wd"
unmasker = pipeline("fill-mask", model=model_id, framework="tf")
unmasker("Goal of my life is to [MASK].")
[{'score': 0.1003185287117958,
'token': 52,
'token_str': 'be',
'sequence': 'Goal of my life is to be.'},
{'score': 0.032648514956235886,
'token': 5,
'token_str': '',
'sequence': 'Goal of my life is to .'},
{'score': 0.02152673341333866,
'token': 138,
'token_str': 'work',
'sequence': 'Goal of my life is to work.'},
{'score': 0.019547373056411743,
'token': 984,
'token_str': 'act',
'sequence': 'Goal of my life is to act.'},
{'score': 0.01939118467271328,
'token': 73,
'token_str': 'have',
'sequence': 'Goal of my life is to have.'}]
```
You can also try out inference using the [Inference Widget](https://huggingface.co/tf-tpu/roberta-base-epochs-500-no-wd?text=Goal+of+my+life+is+to+%5BMASK%5D.) from the model page. | transformers/examples/tensorflow/language-modeling-tpu/README.md/0 | {
"file_path": "transformers/examples/tensorflow/language-modeling-tpu/README.md",
"repo_id": "transformers",
"token_count": 1947
} | 299 |
<!---
Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Summarization example
This script shows an example of training a *summarization* model with the 🤗 Transformers library.
For straightforward use-cases you may be able to use these scripts without modification, although we have also
included comments in the code to indicate areas that you may need to adapt to your own projects.
### Multi-GPU and TPU usage
By default, these scripts use a `MirroredStrategy` and will use multiple GPUs effectively if they are available. TPUs
can also be used by passing the name of the TPU resource with the `--tpu` argument.
### Example command
```
python run_summarization.py \
--model_name_or_path facebook/bart-base \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 16 \
--num_train_epochs 3 \
--do_train \
--do_eval
``` | transformers/examples/tensorflow/summarization/README.md/0 | {
"file_path": "transformers/examples/tensorflow/summarization/README.md",
"repo_id": "transformers",
"token_count": 415
} | 300 |
# this is the process of uploading the updated models to s3. As I can't upload them directly to the correct orgs, this script shows how this is done
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
1. upload updated models to my account
transformers-cli upload -y wmt19-ru-en
transformers-cli upload -y wmt19-en-ru
transformers-cli upload -y wmt19-de-en
transformers-cli upload -y wmt19-en-de
transformers-cli upload -y wmt19-de-en-6-6-base
transformers-cli upload -y wmt19-de-en-6-6-big
transformers-cli upload -y wmt16-en-de-dist-12-1
transformers-cli upload -y wmt16-en-de-dist-6-1
transformers-cli upload -y wmt16-en-de-12-1
2. ask someone to move them to:
* to facebook: "wmt19-ru-en", "wmt19-en-ru", "wmt19-en-de", "wmt19-de-en"
* to allenai: "wmt16-en-de-dist-12-1", "wmt16-en-de-dist-6-1", "wmt16-en-de-12-1", "wmt19-de-en-6-6-base", "wmt19-de-en-6-6-big"
export b="s3://models.huggingface.co/bert"
stas_to_fb () {
src=$1
shift
aws s3 sync $b/stas/$src $b/facebook/$src $@
}
stas_to_allenai () {
src=$1
shift
aws s3 sync $b/stas/$src $b/allenai/$src $@
}
stas_to_fb wmt19-en-ru
stas_to_fb wmt19-ru-en
stas_to_fb wmt19-en-de
stas_to_fb wmt19-de-en
stas_to_allenai wmt16-en-de-dist-12-1
stas_to_allenai wmt16-en-de-dist-6-1
stas_to_allenai wmt16-en-de-6-1
stas_to_allenai wmt16-en-de-12-1
stas_to_allenai wmt19-de-en-6-6-base
stas_to_allenai wmt19-de-en-6-6-big
3. and then remove all these model files from my account
transformers-cli s3 rm wmt16-en-de-12-1/config.json
transformers-cli s3 rm wmt16-en-de-12-1/merges.txt
transformers-cli s3 rm wmt16-en-de-12-1/pytorch_model.bin
transformers-cli s3 rm wmt16-en-de-12-1/tokenizer_config.json
transformers-cli s3 rm wmt16-en-de-12-1/vocab-src.json
transformers-cli s3 rm wmt16-en-de-12-1/vocab-tgt.json
transformers-cli s3 rm wmt16-en-de-dist-12-1/config.json
transformers-cli s3 rm wmt16-en-de-dist-12-1/merges.txt
transformers-cli s3 rm wmt16-en-de-dist-12-1/pytorch_model.bin
transformers-cli s3 rm wmt16-en-de-dist-12-1/tokenizer_config.json
transformers-cli s3 rm wmt16-en-de-dist-12-1/vocab-src.json
transformers-cli s3 rm wmt16-en-de-dist-12-1/vocab-tgt.json
transformers-cli s3 rm wmt16-en-de-dist-6-1/config.json
transformers-cli s3 rm wmt16-en-de-dist-6-1/merges.txt
transformers-cli s3 rm wmt16-en-de-dist-6-1/pytorch_model.bin
transformers-cli s3 rm wmt16-en-de-dist-6-1/tokenizer_config.json
transformers-cli s3 rm wmt16-en-de-dist-6-1/vocab-src.json
transformers-cli s3 rm wmt16-en-de-dist-6-1/vocab-tgt.json
transformers-cli s3 rm wmt19-de-en-6-6-base/config.json
transformers-cli s3 rm wmt19-de-en-6-6-base/merges.txt
transformers-cli s3 rm wmt19-de-en-6-6-base/pytorch_model.bin
transformers-cli s3 rm wmt19-de-en-6-6-base/tokenizer_config.json
transformers-cli s3 rm wmt19-de-en-6-6-base/vocab-src.json
transformers-cli s3 rm wmt19-de-en-6-6-base/vocab-tgt.json
transformers-cli s3 rm wmt19-de-en-6-6-big/config.json
transformers-cli s3 rm wmt19-de-en-6-6-big/merges.txt
transformers-cli s3 rm wmt19-de-en-6-6-big/pytorch_model.bin
transformers-cli s3 rm wmt19-de-en-6-6-big/tokenizer_config.json
transformers-cli s3 rm wmt19-de-en-6-6-big/vocab-src.json
transformers-cli s3 rm wmt19-de-en-6-6-big/vocab-tgt.json
transformers-cli s3 rm wmt19-de-en/config.json
transformers-cli s3 rm wmt19-de-en/merges.txt
transformers-cli s3 rm wmt19-de-en/pytorch_model.bin
transformers-cli s3 rm wmt19-de-en/tokenizer_config.json
transformers-cli s3 rm wmt19-de-en/vocab-src.json
transformers-cli s3 rm wmt19-de-en/vocab-tgt.json
transformers-cli s3 rm wmt19-en-de/config.json
transformers-cli s3 rm wmt19-en-de/merges.txt
transformers-cli s3 rm wmt19-en-de/pytorch_model.bin
transformers-cli s3 rm wmt19-en-de/tokenizer_config.json
transformers-cli s3 rm wmt19-en-de/vocab-src.json
transformers-cli s3 rm wmt19-en-de/vocab-tgt.json
transformers-cli s3 rm wmt19-en-ru/config.json
transformers-cli s3 rm wmt19-en-ru/merges.txt
transformers-cli s3 rm wmt19-en-ru/pytorch_model.bin
transformers-cli s3 rm wmt19-en-ru/tokenizer_config.json
transformers-cli s3 rm wmt19-en-ru/vocab-src.json
transformers-cli s3 rm wmt19-en-ru/vocab-tgt.json
transformers-cli s3 rm wmt19-ru-en/config.json
transformers-cli s3 rm wmt19-ru-en/merges.txt
transformers-cli s3 rm wmt19-ru-en/pytorch_model.bin
transformers-cli s3 rm wmt19-ru-en/tokenizer_config.json
transformers-cli s3 rm wmt19-ru-en/vocab-src.json
transformers-cli s3 rm wmt19-ru-en/vocab-tgt.json
| transformers/scripts/fsmt/s3-move.sh/0 | {
"file_path": "transformers/scripts/fsmt/s3-move.sh",
"repo_id": "transformers",
"token_count": 2133
} | 301 |
# coding=utf-8
# Copyright 2018 The HuggingFace Inc. team.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Benchmarking the library on inference and training in PyTorch.
"""
import random
import timeit
from functools import wraps
from typing import Callable, Optional
from ..configuration_utils import PretrainedConfig
from ..models.auto.modeling_tf_auto import TF_MODEL_MAPPING, TF_MODEL_WITH_LM_HEAD_MAPPING
from ..utils import is_py3nvml_available, is_tf_available, logging
from .benchmark_utils import (
Benchmark,
Memory,
MemorySummary,
measure_peak_memory_cpu,
start_memory_tracing,
stop_memory_tracing,
)
if is_tf_available():
import tensorflow as tf
from tensorflow.python.framework.errors_impl import ResourceExhaustedError
from .benchmark_args_tf import TensorFlowBenchmarkArguments
if is_py3nvml_available():
import py3nvml.py3nvml as nvml
logger = logging.get_logger(__name__)
def run_with_tf_optimizations(do_eager_mode: bool, use_xla: bool):
def run_func(func):
@wraps(func)
def run_in_eager_mode(*args, **kwargs):
return func(*args, **kwargs)
@wraps(func)
@tf.function(experimental_compile=use_xla)
def run_in_graph_mode(*args, **kwargs):
return func(*args, **kwargs)
if do_eager_mode is True:
if use_xla is not False:
raise ValueError(
"Cannot run model in XLA, if `args.eager_mode` is set to `True`. Please set `args.eager_mode=False`."
)
return run_in_eager_mode
else:
return run_in_graph_mode
return run_func
def random_input_ids(batch_size: int, sequence_length: int, vocab_size: int) -> ["tf.Tensor"]:
rng = random.Random()
values = [rng.randint(0, vocab_size - 1) for i in range(batch_size * sequence_length)]
return tf.constant(values, shape=(batch_size, sequence_length), dtype=tf.int32)
class TensorFlowBenchmark(Benchmark):
args: TensorFlowBenchmarkArguments
configs: PretrainedConfig
framework: str = "TensorFlow"
@property
def framework_version(self):
return tf.__version__
def _inference_speed(self, model_name: str, batch_size: int, sequence_length: int) -> float:
# initialize GPU on separate process
strategy = self.args.strategy
if strategy is None:
raise ValueError("A device strategy has to be initialized before using TensorFlow.")
_inference = self._prepare_inference_func(model_name, batch_size, sequence_length)
return self._measure_speed(_inference)
def _train_speed(self, model_name: str, batch_size: int, sequence_length: int) -> float:
strategy = self.args.strategy
if strategy is None:
raise ValueError("A device strategy has to be initialized before using TensorFlow.")
_train = self._prepare_train_func(model_name, batch_size, sequence_length)
return self._measure_speed(_train)
def _inference_memory(
self, model_name: str, batch_size: int, sequence_length: int
) -> [Memory, Optional[MemorySummary]]:
# initialize GPU on separate process
if self.args.is_gpu:
tf.config.experimental.set_memory_growth(self.args.gpu_list[self.args.device_idx], True)
strategy = self.args.strategy
if strategy is None:
raise ValueError("A device strategy has to be initialized before using TensorFlow.")
_inference = self._prepare_inference_func(model_name, batch_size, sequence_length)
return self._measure_memory(_inference)
def _train_memory(
self, model_name: str, batch_size: int, sequence_length: int
) -> [Memory, Optional[MemorySummary]]:
if self.args.is_gpu:
tf.config.experimental.set_memory_growth(self.args.gpu_list[self.args.device_idx], True)
strategy = self.args.strategy
if strategy is None:
raise ValueError("A device strategy has to be initialized before using TensorFlow.")
_train = self._prepare_train_func(model_name, batch_size, sequence_length)
return self._measure_memory(_train)
def _prepare_inference_func(self, model_name: str, batch_size: int, sequence_length: int) -> Callable[[], None]:
config = self.config_dict[model_name]
if self.args.fp16:
raise NotImplementedError("Mixed precision is currently not supported.")
has_model_class_in_config = (
hasattr(config, "architectures")
and isinstance(config.architectures, list)
and len(config.architectures) > 0
)
if not self.args.only_pretrain_model and has_model_class_in_config:
try:
model_class = "TF" + config.architectures[0] # prepend 'TF' for tensorflow model
transformers_module = __import__("transformers", fromlist=[model_class])
model_cls = getattr(transformers_module, model_class)
model = model_cls(config)
except ImportError:
raise ImportError(
f"{model_class} does not exist. If you just want to test the pretrained model, you might want to"
" set `--only_pretrain_model` or `args.only_pretrain_model=True`."
)
else:
model = TF_MODEL_MAPPING[config.__class__](config)
# encoder-decoder has vocab size saved differently
vocab_size = config.vocab_size if hasattr(config, "vocab_size") else config.encoder.vocab_size
input_ids = random_input_ids(batch_size, sequence_length, vocab_size)
@run_with_tf_optimizations(self.args.eager_mode, self.args.use_xla)
def encoder_decoder_forward():
return model(input_ids, decoder_input_ids=input_ids, training=False)
@run_with_tf_optimizations(self.args.eager_mode, self.args.use_xla)
def encoder_forward():
return model(input_ids, training=False)
_inference = encoder_decoder_forward if config.is_encoder_decoder else encoder_forward
return _inference
def _prepare_train_func(self, model_name: str, batch_size: int, sequence_length: int) -> Callable[[], None]:
config = self.config_dict[model_name]
if self.args.eager_mode is not False:
raise ValueError("Training cannot be done in eager mode. Please make sure that `args.eager_mode = False`.")
if self.args.fp16:
raise NotImplementedError("Mixed precision is currently not supported.")
has_model_class_in_config = (
hasattr(config, "architectures")
and isinstance(config.architectures, list)
and len(config.architectures) > 0
)
if not self.args.only_pretrain_model and has_model_class_in_config:
try:
model_class = "TF" + config.architectures[0] # prepend 'TF' for tensorflow model
transformers_module = __import__("transformers", fromlist=[model_class])
model_cls = getattr(transformers_module, model_class)
model = model_cls(config)
except ImportError:
raise ImportError(
f"{model_class} does not exist. If you just want to test the pretrained model, you might want to"
" set `--only_pretrain_model` or `args.only_pretrain_model=True`."
)
else:
model = TF_MODEL_WITH_LM_HEAD_MAPPING[config.__class__](config)
# encoder-decoder has vocab size saved differently
vocab_size = config.vocab_size if hasattr(config, "vocab_size") else config.encoder.vocab_size
input_ids = random_input_ids(batch_size, sequence_length, vocab_size)
@run_with_tf_optimizations(self.args.eager_mode, self.args.use_xla)
def encoder_decoder_train():
loss = model(input_ids, decoder_input_ids=input_ids, labels=input_ids, training=True)[0]
gradients = tf.gradients(loss, model.trainable_variables)
return gradients
@run_with_tf_optimizations(self.args.eager_mode, self.args.use_xla)
def encoder_train():
loss = model(input_ids, labels=input_ids, training=True)[0]
gradients = tf.gradients(loss, model.trainable_variables)
return gradients
_train = encoder_decoder_train if config.is_encoder_decoder else encoder_train
return _train
def _measure_speed(self, func) -> float:
with self.args.strategy.scope():
try:
if self.args.is_tpu or self.args.use_xla:
# run additional 10 times to stabilize compilation for tpu
logger.info("Do inference on TPU. Running model 5 times to stabilize compilation")
timeit.repeat(func, repeat=1, number=5)
# as written in https://docs.python.org/2/library/timeit.html#timeit.Timer.repeat, min should be taken rather than the average
runtimes = timeit.repeat(
func,
repeat=self.args.repeat,
number=10,
)
return min(runtimes) / 10.0
except ResourceExhaustedError as e:
self.print_fn(f"Doesn't fit on GPU. {e}")
def _measure_memory(self, func: Callable[[], None]) -> [Memory, MemorySummary]:
logger.info(
"Note that TensorFlow allocates more memory than "
"it might need to speed up computation. "
"The memory reported here corresponds to the memory "
"reported by `nvidia-smi`, which can vary depending "
"on total available memory on the GPU that is used."
)
with self.args.strategy.scope():
try:
if self.args.trace_memory_line_by_line:
if not self.args.eager_mode:
raise ValueError(
"`args.eager_mode` is set to `False`. Make sure to run model in eager mode to measure memory"
" consumption line by line."
)
trace = start_memory_tracing("transformers")
if self.args.is_tpu:
# tpu
raise NotImplementedError(
"Memory Benchmarking is currently not implemented for TPU. Please disable memory benchmarking"
" with `args.memory=False`"
)
elif self.args.is_gpu:
# gpu
if not is_py3nvml_available():
logger.warning(
"py3nvml not installed, we won't log GPU memory usage. "
"Install py3nvml (pip install py3nvml) to log information about GPU."
)
memory = "N/A"
else:
logger.info(
"Measuring total GPU usage on GPU device. Make sure to not have additional processes"
" running on the same GPU."
)
# init nvml
nvml.nvmlInit()
func()
handle = nvml.nvmlDeviceGetHandleByIndex(self.args.device_idx)
meminfo = nvml.nvmlDeviceGetMemoryInfo(handle)
max_bytes_in_use = meminfo.used
memory = Memory(max_bytes_in_use)
# shutdown nvml
nvml.nvmlShutdown()
else:
# cpu
if self.args.trace_memory_line_by_line:
logger.info(
"When enabling line by line tracing, the max peak memory for CPU is inaccurate in"
" TensorFlow."
)
memory = None
else:
memory_bytes = measure_peak_memory_cpu(func)
memory = Memory(memory_bytes) if isinstance(memory_bytes, int) else memory_bytes
if self.args.trace_memory_line_by_line:
summary = stop_memory_tracing(trace)
if memory is None:
memory = summary.total
else:
summary = None
return memory, summary
except ResourceExhaustedError as e:
self.print_fn(f"Doesn't fit on GPU. {e}")
return "N/A", None
| transformers/src/transformers/benchmark/benchmark_tf.py/0 | {
"file_path": "transformers/src/transformers/benchmark/benchmark_tf.py",
"repo_id": "transformers",
"token_count": 6063
} | 302 |
# coding=utf-8
# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Configuration base class and utilities."""
import copy
import json
import os
import re
import warnings
from typing import Any, Dict, List, Optional, Tuple, Union
from packaging import version
from . import __version__
from .dynamic_module_utils import custom_object_save
from .utils import (
CONFIG_NAME,
PushToHubMixin,
add_model_info_to_auto_map,
cached_file,
copy_func,
download_url,
extract_commit_hash,
is_remote_url,
is_torch_available,
logging,
)
logger = logging.get_logger(__name__)
_re_configuration_file = re.compile(r"config\.(.*)\.json")
class PretrainedConfig(PushToHubMixin):
# no-format
r"""
Base class for all configuration classes. Handles a few parameters common to all models' configurations as well as
methods for loading/downloading/saving configurations.
<Tip>
A configuration file can be loaded and saved to disk. Loading the configuration file and using this file to
initialize a model does **not** load the model weights. It only affects the model's configuration.
</Tip>
Class attributes (overridden by derived classes):
- **model_type** (`str`) -- An identifier for the model type, serialized into the JSON file, and used to recreate
the correct object in [`~transformers.AutoConfig`].
- **is_composition** (`bool`) -- Whether the config class is composed of multiple sub-configs. In this case the
config has to be initialized from two or more configs of type [`~transformers.PretrainedConfig`] like:
[`~transformers.EncoderDecoderConfig`] or [`~RagConfig`].
- **keys_to_ignore_at_inference** (`List[str]`) -- A list of keys to ignore by default when looking at dictionary
outputs of the model during inference.
- **attribute_map** (`Dict[str, str]`) -- A dict that maps model specific attribute names to the standardized
naming of attributes.
Common attributes (present in all subclasses):
- **vocab_size** (`int`) -- The number of tokens in the vocabulary, which is also the first dimension of the
embeddings matrix (this attribute may be missing for models that don't have a text modality like ViT).
- **hidden_size** (`int`) -- The hidden size of the model.
- **num_attention_heads** (`int`) -- The number of attention heads used in the multi-head attention layers of the
model.
- **num_hidden_layers** (`int`) -- The number of blocks in the model.
Arg:
name_or_path (`str`, *optional*, defaults to `""`):
Store the string that was passed to [`PreTrainedModel.from_pretrained`] or
[`TFPreTrainedModel.from_pretrained`] as `pretrained_model_name_or_path` if the configuration was created
with such a method.
output_hidden_states (`bool`, *optional*, defaults to `False`):
Whether or not the model should return all hidden-states.
output_attentions (`bool`, *optional*, defaults to `False`):
Whether or not the model should returns all attentions.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not the model should return a [`~transformers.utils.ModelOutput`] instead of a plain tuple.
is_encoder_decoder (`bool`, *optional*, defaults to `False`):
Whether the model is used as an encoder/decoder or not.
is_decoder (`bool`, *optional*, defaults to `False`):
Whether the model is used as decoder or not (in which case it's used as an encoder).
cross_attention_hidden_size** (`bool`, *optional*):
The hidden size of the cross-attention layer in case the model is used as a decoder in an encoder-decoder
setting and the cross-attention hidden dimension differs from `self.config.hidden_size`.
add_cross_attention (`bool`, *optional*, defaults to `False`):
Whether cross-attention layers should be added to the model. Note, this option is only relevant for models
that can be used as decoder models within the [`EncoderDecoderModel`] class, which consists of all models
in `AUTO_MODELS_FOR_CAUSAL_LM`.
tie_encoder_decoder (`bool`, *optional*, defaults to `False`):
Whether all encoder weights should be tied to their equivalent decoder weights. This requires the encoder
and decoder model to have the exact same parameter names.
prune_heads (`Dict[int, List[int]]`, *optional*, defaults to `{}`):
Pruned heads of the model. The keys are the selected layer indices and the associated values, the list of
heads to prune in said layer.
For instance `{1: [0, 2], 2: [2, 3]}` will prune heads 0 and 2 on layer 1 and heads 2 and 3 on layer 2.
chunk_size_feed_forward (`int`, *optional*, defaults to `0`):
The chunk size of all feed forward layers in the residual attention blocks. A chunk size of `0` means that
the feed forward layer is not chunked. A chunk size of n means that the feed forward layer processes `n` <
sequence_length embeddings at a time. For more information on feed forward chunking, see [How does Feed
Forward Chunking work?](../glossary.html#feed-forward-chunking).
> Parameters for sequence generation
max_length (`int`, *optional*, defaults to 20):
Maximum length that will be used by default in the `generate` method of the model.
min_length (`int`, *optional*, defaults to 0):
Minimum length that will be used by default in the `generate` method of the model.
do_sample (`bool`, *optional*, defaults to `False`):
Flag that will be used by default in the `generate` method of the model. Whether or not to use sampling ;
use greedy decoding otherwise.
early_stopping (`bool`, *optional*, defaults to `False`):
Flag that will be used by default in the `generate` method of the model. Whether to stop the beam search
when at least `num_beams` sentences are finished per batch or not.
num_beams (`int`, *optional*, defaults to 1):
Number of beams for beam search that will be used by default in the `generate` method of the model. 1 means
no beam search.
num_beam_groups (`int`, *optional*, defaults to 1):
Number of groups to divide `num_beams` into in order to ensure diversity among different groups of beams
that will be used by default in the `generate` method of the model. 1 means no group beam search.
diversity_penalty (`float`, *optional*, defaults to 0.0):
Value to control diversity for group beam search. that will be used by default in the `generate` method of
the model. 0 means no diversity penalty. The higher the penalty, the more diverse are the outputs.
temperature (`float`, *optional*, defaults to 1.0):
The value used to module the next token probabilities that will be used by default in the `generate` method
of the model. Must be strictly positive.
top_k (`int`, *optional*, defaults to 50):
Number of highest probability vocabulary tokens to keep for top-k-filtering that will be used by default in
the `generate` method of the model.
top_p (`float`, *optional*, defaults to 1):
Value that will be used by default in the `generate` method of the model for `top_p`. If set to float < 1,
only the most probable tokens with probabilities that add up to `top_p` or higher are kept for generation.
typical_p (`float`, *optional*, defaults to 1):
Local typicality measures how similar the conditional probability of predicting a target token next is to
the expected conditional probability of predicting a random token next, given the partial text already
generated. If set to float < 1, the smallest set of the most locally typical tokens with probabilities that
add up to `typical_p` or higher are kept for generation. See [this
paper](https://arxiv.org/pdf/2202.00666.pdf) for more details.
repetition_penalty (`float`, *optional*, defaults to 1):
Parameter for repetition penalty that will be used by default in the `generate` method of the model. 1.0
means no penalty.
length_penalty (`float`, *optional*, defaults to 1):
Exponential penalty to the length that is used with beam-based generation. It is applied as an exponent to
the sequence length, which in turn is used to divide the score of the sequence. Since the score is the log
likelihood of the sequence (i.e. negative), `length_penalty` > 0.0 promotes longer sequences, while
`length_penalty` < 0.0 encourages shorter sequences.
no_repeat_ngram_size (`int`, *optional*, defaults to 0) -- Value that will be used by default in the
`generate` method of the model for `no_repeat_ngram_size`. If set to int > 0, all ngrams of that size can
only occur once.
encoder_no_repeat_ngram_size (`int`, *optional*, defaults to 0) -- Value that will be used by
default in the `generate` method of the model for `encoder_no_repeat_ngram_size`. If set to int > 0, all
ngrams of that size that occur in the `encoder_input_ids` cannot occur in the `decoder_input_ids`.
bad_words_ids (`List[int]`, *optional*):
List of token ids that are not allowed to be generated that will be used by default in the `generate`
method of the model. In order to get the tokens of the words that should not appear in the generated text,
use `tokenizer.encode(bad_word, add_prefix_space=True)`.
num_return_sequences (`int`, *optional*, defaults to 1):
Number of independently computed returned sequences for each element in the batch that will be used by
default in the `generate` method of the model.
output_scores (`bool`, *optional*, defaults to `False`):
Whether the model should return the logits when used for generation.
return_dict_in_generate (`bool`, *optional*, defaults to `False`):
Whether the model should return a [`~transformers.utils.ModelOutput`] instead of a `torch.LongTensor`.
forced_bos_token_id (`int`, *optional*):
The id of the token to force as the first generated token after the `decoder_start_token_id`. Useful for
multilingual models like [mBART](../model_doc/mbart) where the first generated token needs to be the target
language token.
forced_eos_token_id (`int`, *optional*):
The id of the token to force as the last generated token when `max_length` is reached.
remove_invalid_values (`bool`, *optional*):
Whether to remove possible _nan_ and _inf_ outputs of the model to prevent the generation method to crash.
Note that using `remove_invalid_values` can slow down generation.
> Parameters for fine-tuning tasks
architectures (`List[str]`, *optional*):
Model architectures that can be used with the model pretrained weights.
finetuning_task (`str`, *optional*):
Name of the task used to fine-tune the model. This can be used when converting from an original (TensorFlow
or PyTorch) checkpoint.
id2label (`Dict[int, str]`, *optional*):
A map from index (for instance prediction index, or target index) to label.
label2id (`Dict[str, int]`, *optional*): A map from label to index for the model.
num_labels (`int`, *optional*):
Number of labels to use in the last layer added to the model, typically for a classification task.
task_specific_params (`Dict[str, Any]`, *optional*):
Additional keyword arguments to store for the current task.
problem_type (`str`, *optional*):
Problem type for `XxxForSequenceClassification` models. Can be one of `"regression"`,
`"single_label_classification"` or `"multi_label_classification"`.
> Parameters linked to the tokenizer
tokenizer_class (`str`, *optional*):
The name of the associated tokenizer class to use (if none is set, will use the tokenizer associated to the
model by default).
prefix (`str`, *optional*):
A specific prompt that should be added at the beginning of each text before calling the model.
bos_token_id (`int`, *optional*): The id of the _beginning-of-stream_ token.
pad_token_id (`int`, *optional*): The id of the _padding_ token.
eos_token_id (`int`, *optional*): The id of the _end-of-stream_ token.
decoder_start_token_id (`int`, *optional*):
If an encoder-decoder model starts decoding with a different token than _bos_, the id of that token.
sep_token_id (`int`, *optional*): The id of the _separation_ token.
> PyTorch specific parameters
torchscript (`bool`, *optional*, defaults to `False`):
Whether or not the model should be used with Torchscript.
tie_word_embeddings (`bool`, *optional*, defaults to `True`):
Whether the model's input and output word embeddings should be tied. Note that this is only relevant if the
model has a output word embedding layer.
torch_dtype (`str`, *optional*):
The `dtype` of the weights. This attribute can be used to initialize the model to a non-default `dtype`
(which is normally `float32`) and thus allow for optimal storage allocation. For example, if the saved
model is `float16`, ideally we want to load it back using the minimal amount of memory needed to load
`float16` weights. Since the config object is stored in plain text, this attribute contains just the
floating type string without the `torch.` prefix. For example, for `torch.float16` ``torch_dtype` is the
`"float16"` string.
This attribute is currently not being used during model loading time, but this may change in the future
versions. But we can already start preparing for the future by saving the dtype with save_pretrained.
attn_implementation (`str`, *optional*):
The attention implementation to use in the model. Can be any of `"eager"` (manual implementation of the attention), `"sdpa"` (attention using [`torch.nn.functional.scaled_dot_product_attention`](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention.html)), or `"flash_attention_2"` (attention using [Dao-AILab/flash-attention](https://github.com/Dao-AILab/flash-attention)). By default, if available, SDPA will be used for torch>=2.1.1. The default is otherwise the manual `"eager"` implementation.
> TensorFlow specific parameters
use_bfloat16 (`bool`, *optional*, defaults to `False`):
Whether or not the model should use BFloat16 scalars (only used by some TensorFlow models).
tf_legacy_loss (`bool`, *optional*, defaults to `False`):
Whether the model should use legacy TensorFlow losses. Legacy losses have variable output shapes and may
not be XLA-compatible. This option is here for backward compatibility and will be removed in Transformers
v5.
"""
model_type: str = ""
is_composition: bool = False
attribute_map: Dict[str, str] = {}
_auto_class: Optional[str] = None
def __setattr__(self, key, value):
if key in super().__getattribute__("attribute_map"):
key = super().__getattribute__("attribute_map")[key]
super().__setattr__(key, value)
def __getattribute__(self, key):
if key != "attribute_map" and key in super().__getattribute__("attribute_map"):
key = super().__getattribute__("attribute_map")[key]
return super().__getattribute__(key)
def __init__(self, **kwargs):
# Attributes with defaults
self.return_dict = kwargs.pop("return_dict", True)
self.output_hidden_states = kwargs.pop("output_hidden_states", False)
self.output_attentions = kwargs.pop("output_attentions", False)
self.torchscript = kwargs.pop("torchscript", False) # Only used by PyTorch models
self.torch_dtype = kwargs.pop("torch_dtype", None) # Only used by PyTorch models
self.use_bfloat16 = kwargs.pop("use_bfloat16", False)
self.tf_legacy_loss = kwargs.pop("tf_legacy_loss", False) # Only used by TensorFlow models
self.pruned_heads = kwargs.pop("pruned_heads", {})
self.tie_word_embeddings = kwargs.pop(
"tie_word_embeddings", True
) # Whether input and output word embeddings should be tied for all MLM, LM and Seq2Seq models.
self.chunk_size_feed_forward = kwargs.pop("chunk_size_feed_forward", 0)
# Is decoder is used in encoder-decoder models to differentiate encoder from decoder
self.is_encoder_decoder = kwargs.pop("is_encoder_decoder", False)
self.is_decoder = kwargs.pop("is_decoder", False)
self.cross_attention_hidden_size = kwargs.pop("cross_attention_hidden_size", None)
self.add_cross_attention = kwargs.pop("add_cross_attention", False)
self.tie_encoder_decoder = kwargs.pop("tie_encoder_decoder", False)
# Retrocompatibility: Parameters for sequence generation. While we will keep the ability to load these
# parameters, saving them will be deprecated. In a distant future, we won't need to load them.
for parameter_name, default_value in self._get_generation_defaults().items():
setattr(self, parameter_name, kwargs.pop(parameter_name, default_value))
# Fine-tuning task arguments
self.architectures = kwargs.pop("architectures", None)
self.finetuning_task = kwargs.pop("finetuning_task", None)
self.id2label = kwargs.pop("id2label", None)
self.label2id = kwargs.pop("label2id", None)
if self.label2id is not None and not isinstance(self.label2id, dict):
raise ValueError("Argument label2id should be a dictionary.")
if self.id2label is not None:
if not isinstance(self.id2label, dict):
raise ValueError("Argument id2label should be a dictionary.")
num_labels = kwargs.pop("num_labels", None)
if num_labels is not None and len(self.id2label) != num_labels:
logger.warning(
f"You passed along `num_labels={num_labels}` with an incompatible id to label map: "
f"{self.id2label}. The number of labels wil be overwritten to {self.num_labels}."
)
self.id2label = {int(key): value for key, value in self.id2label.items()}
# Keys are always strings in JSON so convert ids to int here.
else:
self.num_labels = kwargs.pop("num_labels", 2)
if self.torch_dtype is not None and isinstance(self.torch_dtype, str):
# we will start using self.torch_dtype in v5, but to be consistent with
# from_pretrained's torch_dtype arg convert it to an actual torch.dtype object
if is_torch_available():
import torch
self.torch_dtype = getattr(torch, self.torch_dtype)
# Tokenizer arguments TODO: eventually tokenizer and models should share the same config
self.tokenizer_class = kwargs.pop("tokenizer_class", None)
self.prefix = kwargs.pop("prefix", None)
self.bos_token_id = kwargs.pop("bos_token_id", None)
self.pad_token_id = kwargs.pop("pad_token_id", None)
self.eos_token_id = kwargs.pop("eos_token_id", None)
self.sep_token_id = kwargs.pop("sep_token_id", None)
self.decoder_start_token_id = kwargs.pop("decoder_start_token_id", None)
# task specific arguments
self.task_specific_params = kwargs.pop("task_specific_params", None)
# regression / multi-label classification
self.problem_type = kwargs.pop("problem_type", None)
allowed_problem_types = ("regression", "single_label_classification", "multi_label_classification")
if self.problem_type is not None and self.problem_type not in allowed_problem_types:
raise ValueError(
f"The config parameter `problem_type` was not understood: received {self.problem_type} "
"but only 'regression', 'single_label_classification' and 'multi_label_classification' are valid."
)
# TPU arguments
if kwargs.pop("xla_device", None) is not None:
logger.warning(
"The `xla_device` argument has been deprecated in v4.4.0 of Transformers. It is ignored and you can "
"safely remove it from your `config.json` file."
)
# Name or path to the pretrained checkpoint
self._name_or_path = str(kwargs.pop("name_or_path", ""))
# Config hash
self._commit_hash = kwargs.pop("_commit_hash", None)
# Attention implementation to use, if relevant.
self._attn_implementation_internal = kwargs.pop("attn_implementation", None)
# Drop the transformers version info
self.transformers_version = kwargs.pop("transformers_version", None)
# Deal with gradient checkpointing
if kwargs.get("gradient_checkpointing", False):
warnings.warn(
"Passing `gradient_checkpointing` to a config initialization is deprecated and will be removed in v5 "
"Transformers. Using `model.gradient_checkpointing_enable()` instead, or if you are using the "
"`Trainer` API, pass `gradient_checkpointing=True` in your `TrainingArguments`."
)
# Additional attributes without default values
for key, value in kwargs.items():
try:
setattr(self, key, value)
except AttributeError as err:
logger.error(f"Can't set {key} with value {value} for {self}")
raise err
@property
def name_or_path(self) -> str:
return getattr(self, "_name_or_path", None)
@name_or_path.setter
def name_or_path(self, value):
self._name_or_path = str(value) # Make sure that name_or_path is a string (for JSON encoding)
@property
def use_return_dict(self) -> bool:
"""
`bool`: Whether or not return [`~utils.ModelOutput`] instead of tuples.
"""
# If torchscript is set, force `return_dict=False` to avoid jit errors
return self.return_dict and not self.torchscript
@property
def num_labels(self) -> int:
"""
`int`: The number of labels for classification models.
"""
return len(self.id2label)
@num_labels.setter
def num_labels(self, num_labels: int):
if not hasattr(self, "id2label") or self.id2label is None or len(self.id2label) != num_labels:
self.id2label = {i: f"LABEL_{i}" for i in range(num_labels)}
self.label2id = dict(zip(self.id2label.values(), self.id2label.keys()))
@property
def _attn_implementation(self):
# This property is made private for now (as it cannot be changed and a PreTrainedModel.use_attn_implementation method needs to be implemented.)
if hasattr(self, "_attn_implementation_internal"):
if self._attn_implementation_internal is None:
# `config.attn_implementation` should never be None, for backward compatibility.
return "eager"
else:
return self._attn_implementation_internal
else:
return "eager"
@_attn_implementation.setter
def _attn_implementation(self, value):
self._attn_implementation_internal = value
def save_pretrained(self, save_directory: Union[str, os.PathLike], push_to_hub: bool = False, **kwargs):
"""
Save a configuration object to the directory `save_directory`, so that it can be re-loaded using the
[`~PretrainedConfig.from_pretrained`] class method.
Args:
save_directory (`str` or `os.PathLike`):
Directory where the configuration JSON file will be saved (will be created if it does not exist).
push_to_hub (`bool`, *optional*, defaults to `False`):
Whether or not to push your model to the Hugging Face model hub after saving it. You can specify the
repository you want to push to with `repo_id` (will default to the name of `save_directory` in your
namespace).
kwargs (`Dict[str, Any]`, *optional*):
Additional key word arguments passed along to the [`~utils.PushToHubMixin.push_to_hub`] method.
"""
self._set_token_in_kwargs(kwargs)
if os.path.isfile(save_directory):
raise AssertionError(f"Provided path ({save_directory}) should be a directory, not a file")
non_default_generation_parameters = {}
for parameter_name, default_value in self._get_generation_defaults().items():
if hasattr(self, parameter_name) and getattr(self, parameter_name) != default_value:
non_default_generation_parameters[parameter_name] = getattr(self, parameter_name)
if len(non_default_generation_parameters) > 0:
logger.warning(
"Some non-default generation parameters are set in the model config. These should go into a "
"GenerationConfig file (https://huggingface.co/docs/transformers/generation_strategies#save-a-custom-decoding-strategy-with-your-model) "
"instead. This warning will be raised to an exception in v4.41.\n"
f"Non-default generation parameters: {str(non_default_generation_parameters)}"
)
os.makedirs(save_directory, exist_ok=True)
if push_to_hub:
commit_message = kwargs.pop("commit_message", None)
repo_id = kwargs.pop("repo_id", save_directory.split(os.path.sep)[-1])
repo_id = self._create_repo(repo_id, **kwargs)
files_timestamps = self._get_files_timestamps(save_directory)
# If we have a custom config, we copy the file defining it in the folder and set the attributes so it can be
# loaded from the Hub.
if self._auto_class is not None:
custom_object_save(self, save_directory, config=self)
# If we save using the predefined names, we can load using `from_pretrained`
output_config_file = os.path.join(save_directory, CONFIG_NAME)
self.to_json_file(output_config_file, use_diff=True)
logger.info(f"Configuration saved in {output_config_file}")
if push_to_hub:
self._upload_modified_files(
save_directory,
repo_id,
files_timestamps,
commit_message=commit_message,
token=kwargs.get("token"),
)
@staticmethod
def _set_token_in_kwargs(kwargs, token=None):
"""Temporary method to deal with `token` and `use_auth_token`.
This method is to avoid apply the same changes in all model config classes that overwrite `from_pretrained`.
Need to clean up `use_auth_token` in a follow PR.
"""
# Some model config classes like CLIP define their own `from_pretrained` without the new argument `token` yet.
if token is None:
token = kwargs.pop("token", None)
use_auth_token = kwargs.pop("use_auth_token", None)
if use_auth_token is not None:
warnings.warn(
"The `use_auth_token` argument is deprecated and will be removed in v5 of Transformers. Please use `token` instead.",
FutureWarning,
)
if token is not None:
raise ValueError(
"`token` and `use_auth_token` are both specified. Please set only the argument `token`."
)
token = use_auth_token
if token is not None:
kwargs["token"] = token
@classmethod
def from_pretrained(
cls,
pretrained_model_name_or_path: Union[str, os.PathLike],
cache_dir: Optional[Union[str, os.PathLike]] = None,
force_download: bool = False,
local_files_only: bool = False,
token: Optional[Union[str, bool]] = None,
revision: str = "main",
**kwargs,
) -> "PretrainedConfig":
r"""
Instantiate a [`PretrainedConfig`] (or a derived class) from a pretrained model configuration.
Args:
pretrained_model_name_or_path (`str` or `os.PathLike`):
This can be either:
- a string, the *model id* of a pretrained model configuration hosted inside a model repo on
huggingface.co. Valid model ids can be located at the root-level, like `bert-base-uncased`, or
namespaced under a user or organization name, like `dbmdz/bert-base-german-cased`.
- a path to a *directory* containing a configuration file saved using the
[`~PretrainedConfig.save_pretrained`] method, e.g., `./my_model_directory/`.
- a path or url to a saved configuration JSON *file*, e.g., `./my_model_directory/configuration.json`.
cache_dir (`str` or `os.PathLike`, *optional*):
Path to a directory in which a downloaded pretrained model configuration should be cached if the
standard cache should not be used.
force_download (`bool`, *optional*, defaults to `False`):
Whether or not to force to (re-)download the configuration files and override the cached versions if
they exist.
resume_download (`bool`, *optional*, defaults to `False`):
Whether or not to delete incompletely received file. Attempts to resume the download if such a file
exists.
proxies (`Dict[str, str]`, *optional*):
A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
'http://hostname': 'foo.bar:4012'}.` The proxies are used on each request.
token (`str` or `bool`, *optional*):
The token to use as HTTP bearer authorization for remote files. If `True`, or not specified, will use
the token generated when running `huggingface-cli login` (stored in `~/.huggingface`).
revision (`str`, *optional*, defaults to `"main"`):
The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
identifier allowed by git.
<Tip>
To test a pull request you made on the Hub, you can pass `revision="refs/pr/<pr_number>".
</Tip>
return_unused_kwargs (`bool`, *optional*, defaults to `False`):
If `False`, then this function returns just the final configuration object.
If `True`, then this functions returns a `Tuple(config, unused_kwargs)` where *unused_kwargs* is a
dictionary consisting of the key/value pairs whose keys are not configuration attributes: i.e., the
part of `kwargs` which has not been used to update `config` and is otherwise ignored.
subfolder (`str`, *optional*, defaults to `""`):
In case the relevant files are located inside a subfolder of the model repo on huggingface.co, you can
specify the folder name here.
kwargs (`Dict[str, Any]`, *optional*):
The values in kwargs of any keys which are configuration attributes will be used to override the loaded
values. Behavior concerning key/value pairs whose keys are *not* configuration attributes is controlled
by the `return_unused_kwargs` keyword parameter.
Returns:
[`PretrainedConfig`]: The configuration object instantiated from this pretrained model.
Examples:
```python
# We can't instantiate directly the base class *PretrainedConfig* so let's show the examples on a
# derived class: BertConfig
config = BertConfig.from_pretrained(
"bert-base-uncased"
) # Download configuration from huggingface.co and cache.
config = BertConfig.from_pretrained(
"./test/saved_model/"
) # E.g. config (or model) was saved using *save_pretrained('./test/saved_model/')*
config = BertConfig.from_pretrained("./test/saved_model/my_configuration.json")
config = BertConfig.from_pretrained("bert-base-uncased", output_attentions=True, foo=False)
assert config.output_attentions == True
config, unused_kwargs = BertConfig.from_pretrained(
"bert-base-uncased", output_attentions=True, foo=False, return_unused_kwargs=True
)
assert config.output_attentions == True
assert unused_kwargs == {"foo": False}
```"""
kwargs["cache_dir"] = cache_dir
kwargs["force_download"] = force_download
kwargs["local_files_only"] = local_files_only
kwargs["revision"] = revision
cls._set_token_in_kwargs(kwargs, token)
config_dict, kwargs = cls.get_config_dict(pretrained_model_name_or_path, **kwargs)
if "model_type" in config_dict and hasattr(cls, "model_type") and config_dict["model_type"] != cls.model_type:
logger.warning(
f"You are using a model of type {config_dict['model_type']} to instantiate a model of type "
f"{cls.model_type}. This is not supported for all configurations of models and can yield errors."
)
return cls.from_dict(config_dict, **kwargs)
@classmethod
def get_config_dict(
cls, pretrained_model_name_or_path: Union[str, os.PathLike], **kwargs
) -> Tuple[Dict[str, Any], Dict[str, Any]]:
"""
From a `pretrained_model_name_or_path`, resolve to a dictionary of parameters, to be used for instantiating a
[`PretrainedConfig`] using `from_dict`.
Parameters:
pretrained_model_name_or_path (`str` or `os.PathLike`):
The identifier of the pre-trained checkpoint from which we want the dictionary of parameters.
Returns:
`Tuple[Dict, Dict]`: The dictionary(ies) that will be used to instantiate the configuration object.
"""
cls._set_token_in_kwargs(kwargs)
original_kwargs = copy.deepcopy(kwargs)
# Get config dict associated with the base config file
config_dict, kwargs = cls._get_config_dict(pretrained_model_name_or_path, **kwargs)
if "_commit_hash" in config_dict:
original_kwargs["_commit_hash"] = config_dict["_commit_hash"]
# That config file may point us toward another config file to use.
if "configuration_files" in config_dict:
configuration_file = get_configuration_file(config_dict["configuration_files"])
config_dict, kwargs = cls._get_config_dict(
pretrained_model_name_or_path, _configuration_file=configuration_file, **original_kwargs
)
return config_dict, kwargs
@classmethod
def _get_config_dict(
cls, pretrained_model_name_or_path: Union[str, os.PathLike], **kwargs
) -> Tuple[Dict[str, Any], Dict[str, Any]]:
cache_dir = kwargs.pop("cache_dir", None)
force_download = kwargs.pop("force_download", False)
resume_download = kwargs.pop("resume_download", False)
proxies = kwargs.pop("proxies", None)
token = kwargs.pop("token", None)
local_files_only = kwargs.pop("local_files_only", False)
revision = kwargs.pop("revision", None)
trust_remote_code = kwargs.pop("trust_remote_code", None)
subfolder = kwargs.pop("subfolder", "")
from_pipeline = kwargs.pop("_from_pipeline", None)
from_auto_class = kwargs.pop("_from_auto", False)
commit_hash = kwargs.pop("_commit_hash", None)
if trust_remote_code is True:
logger.warning(
"The argument `trust_remote_code` is to be used with Auto classes. It has no effect here and is"
" ignored."
)
user_agent = {"file_type": "config", "from_auto_class": from_auto_class}
if from_pipeline is not None:
user_agent["using_pipeline"] = from_pipeline
pretrained_model_name_or_path = str(pretrained_model_name_or_path)
is_local = os.path.isdir(pretrained_model_name_or_path)
if os.path.isfile(os.path.join(subfolder, pretrained_model_name_or_path)):
# Special case when pretrained_model_name_or_path is a local file
resolved_config_file = pretrained_model_name_or_path
is_local = True
elif is_remote_url(pretrained_model_name_or_path):
configuration_file = pretrained_model_name_or_path
resolved_config_file = download_url(pretrained_model_name_or_path)
else:
configuration_file = kwargs.pop("_configuration_file", CONFIG_NAME)
try:
# Load from local folder or from cache or download from model Hub and cache
resolved_config_file = cached_file(
pretrained_model_name_or_path,
configuration_file,
cache_dir=cache_dir,
force_download=force_download,
proxies=proxies,
resume_download=resume_download,
local_files_only=local_files_only,
token=token,
user_agent=user_agent,
revision=revision,
subfolder=subfolder,
_commit_hash=commit_hash,
)
commit_hash = extract_commit_hash(resolved_config_file, commit_hash)
except EnvironmentError:
# Raise any environment error raise by `cached_file`. It will have a helpful error message adapted to
# the original exception.
raise
except Exception:
# For any other exception, we throw a generic error.
raise EnvironmentError(
f"Can't load the configuration of '{pretrained_model_name_or_path}'. If you were trying to load it"
" from 'https://huggingface.co/models', make sure you don't have a local directory with the same"
f" name. Otherwise, make sure '{pretrained_model_name_or_path}' is the correct path to a directory"
f" containing a {configuration_file} file"
)
try:
# Load config dict
config_dict = cls._dict_from_json_file(resolved_config_file)
config_dict["_commit_hash"] = commit_hash
except (json.JSONDecodeError, UnicodeDecodeError):
raise EnvironmentError(
f"It looks like the config file at '{resolved_config_file}' is not a valid JSON file."
)
if is_local:
logger.info(f"loading configuration file {resolved_config_file}")
else:
logger.info(f"loading configuration file {configuration_file} from cache at {resolved_config_file}")
if "auto_map" in config_dict and not is_local:
config_dict["auto_map"] = add_model_info_to_auto_map(
config_dict["auto_map"], pretrained_model_name_or_path
)
return config_dict, kwargs
@classmethod
def from_dict(cls, config_dict: Dict[str, Any], **kwargs) -> "PretrainedConfig":
"""
Instantiates a [`PretrainedConfig`] from a Python dictionary of parameters.
Args:
config_dict (`Dict[str, Any]`):
Dictionary that will be used to instantiate the configuration object. Such a dictionary can be
retrieved from a pretrained checkpoint by leveraging the [`~PretrainedConfig.get_config_dict`] method.
kwargs (`Dict[str, Any]`):
Additional parameters from which to initialize the configuration object.
Returns:
[`PretrainedConfig`]: The configuration object instantiated from those parameters.
"""
return_unused_kwargs = kwargs.pop("return_unused_kwargs", False)
# Those arguments may be passed along for our internal telemetry.
# We remove them so they don't appear in `return_unused_kwargs`.
kwargs.pop("_from_auto", None)
kwargs.pop("_from_pipeline", None)
# The commit hash might have been updated in the `config_dict`, we don't want the kwargs to erase that update.
if "_commit_hash" in kwargs and "_commit_hash" in config_dict:
kwargs["_commit_hash"] = config_dict["_commit_hash"]
# We remove it from kwargs so that it does not appear in `return_unused_kwargs`.
config_dict["attn_implementation"] = kwargs.pop("attn_implementation", None)
config = cls(**config_dict)
if hasattr(config, "pruned_heads"):
config.pruned_heads = {int(key): value for key, value in config.pruned_heads.items()}
# Update config with kwargs if needed
if "num_labels" in kwargs and "id2label" in kwargs:
num_labels = kwargs["num_labels"]
id2label = kwargs["id2label"] if kwargs["id2label"] is not None else []
if len(id2label) != num_labels:
raise ValueError(
f"You passed along `num_labels={num_labels }` with an incompatible id to label map: "
f"{kwargs['id2label']}. Since those arguments are inconsistent with each other, you should remove "
"one of them."
)
to_remove = []
for key, value in kwargs.items():
if hasattr(config, key):
current_attr = getattr(config, key)
# To authorize passing a custom subconfig as kwarg in models that have nested configs.
if isinstance(current_attr, PretrainedConfig) and isinstance(value, dict):
value = current_attr.__class__(**value)
setattr(config, key, value)
if key != "torch_dtype":
to_remove.append(key)
for key in to_remove:
kwargs.pop(key, None)
logger.info(f"Model config {config}")
if return_unused_kwargs:
return config, kwargs
else:
return config
@classmethod
def from_json_file(cls, json_file: Union[str, os.PathLike]) -> "PretrainedConfig":
"""
Instantiates a [`PretrainedConfig`] from the path to a JSON file of parameters.
Args:
json_file (`str` or `os.PathLike`):
Path to the JSON file containing the parameters.
Returns:
[`PretrainedConfig`]: The configuration object instantiated from that JSON file.
"""
config_dict = cls._dict_from_json_file(json_file)
return cls(**config_dict)
@classmethod
def _dict_from_json_file(cls, json_file: Union[str, os.PathLike]):
with open(json_file, "r", encoding="utf-8") as reader:
text = reader.read()
return json.loads(text)
def __eq__(self, other):
return isinstance(other, PretrainedConfig) and (self.__dict__ == other.__dict__)
def __repr__(self):
return f"{self.__class__.__name__} {self.to_json_string()}"
def to_diff_dict(self) -> Dict[str, Any]:
"""
Removes all attributes from config which correspond to the default config attributes for better readability and
serializes to a Python dictionary.
Returns:
`Dict[str, Any]`: Dictionary of all the attributes that make up this configuration instance,
"""
config_dict = self.to_dict()
# get the default config dict
default_config_dict = PretrainedConfig().to_dict()
# get class specific config dict
class_config_dict = self.__class__().to_dict() if not self.is_composition else {}
serializable_config_dict = {}
# only serialize values that differ from the default config
for key, value in config_dict.items():
if (
isinstance(getattr(self, key, None), PretrainedConfig)
and key in class_config_dict
and isinstance(class_config_dict[key], dict)
):
# For nested configs we need to clean the diff recursively
diff = recursive_diff_dict(value, class_config_dict[key], config_obj=getattr(self, key, None))
if "model_type" in value:
# Needs to be set even if it's not in the diff
diff["model_type"] = value["model_type"]
if len(diff) > 0:
serializable_config_dict[key] = diff
elif (
key not in default_config_dict
or key == "transformers_version"
or value != default_config_dict[key]
or (key in class_config_dict and value != class_config_dict[key])
):
serializable_config_dict[key] = value
if hasattr(self, "quantization_config"):
serializable_config_dict["quantization_config"] = (
self.quantization_config.to_dict()
if not isinstance(self.quantization_config, dict)
else self.quantization_config
)
# pop the `_pre_quantization_dtype` as torch.dtypes are not serializable.
_ = serializable_config_dict.pop("_pre_quantization_dtype", None)
self.dict_torch_dtype_to_str(serializable_config_dict)
if "_attn_implementation_internal" in serializable_config_dict:
del serializable_config_dict["_attn_implementation_internal"]
return serializable_config_dict
def to_dict(self) -> Dict[str, Any]:
"""
Serializes this instance to a Python dictionary.
Returns:
`Dict[str, Any]`: Dictionary of all the attributes that make up this configuration instance.
"""
output = copy.deepcopy(self.__dict__)
if hasattr(self.__class__, "model_type"):
output["model_type"] = self.__class__.model_type
if "_auto_class" in output:
del output["_auto_class"]
if "_commit_hash" in output:
del output["_commit_hash"]
if "_attn_implementation_internal" in output:
del output["_attn_implementation_internal"]
# Transformers version when serializing the model
output["transformers_version"] = __version__
for key, value in output.items():
# Deal with nested configs like CLIP
if isinstance(value, PretrainedConfig):
value = value.to_dict()
del value["transformers_version"]
output[key] = value
if hasattr(self, "quantization_config"):
output["quantization_config"] = (
self.quantization_config.to_dict()
if not isinstance(self.quantization_config, dict)
else self.quantization_config
)
# pop the `_pre_quantization_dtype` as torch.dtypes are not serializable.
_ = output.pop("_pre_quantization_dtype", None)
self.dict_torch_dtype_to_str(output)
return output
def to_json_string(self, use_diff: bool = True) -> str:
"""
Serializes this instance to a JSON string.
Args:
use_diff (`bool`, *optional*, defaults to `True`):
If set to `True`, only the difference between the config instance and the default `PretrainedConfig()`
is serialized to JSON string.
Returns:
`str`: String containing all the attributes that make up this configuration instance in JSON format.
"""
if use_diff is True:
config_dict = self.to_diff_dict()
else:
config_dict = self.to_dict()
return json.dumps(config_dict, indent=2, sort_keys=True) + "\n"
def to_json_file(self, json_file_path: Union[str, os.PathLike], use_diff: bool = True):
"""
Save this instance to a JSON file.
Args:
json_file_path (`str` or `os.PathLike`):
Path to the JSON file in which this configuration instance's parameters will be saved.
use_diff (`bool`, *optional*, defaults to `True`):
If set to `True`, only the difference between the config instance and the default `PretrainedConfig()`
is serialized to JSON file.
"""
with open(json_file_path, "w", encoding="utf-8") as writer:
writer.write(self.to_json_string(use_diff=use_diff))
def update(self, config_dict: Dict[str, Any]):
"""
Updates attributes of this class with attributes from `config_dict`.
Args:
config_dict (`Dict[str, Any]`): Dictionary of attributes that should be updated for this class.
"""
for key, value in config_dict.items():
setattr(self, key, value)
def update_from_string(self, update_str: str):
"""
Updates attributes of this class with attributes from `update_str`.
The expected format is ints, floats and strings as is, and for booleans use `true` or `false`. For example:
"n_embd=10,resid_pdrop=0.2,scale_attn_weights=false,summary_type=cls_index"
The keys to change have to already exist in the config object.
Args:
update_str (`str`): String with attributes that should be updated for this class.
"""
d = dict(x.split("=") for x in update_str.split(","))
for k, v in d.items():
if not hasattr(self, k):
raise ValueError(f"key {k} isn't in the original config dict")
old_v = getattr(self, k)
if isinstance(old_v, bool):
if v.lower() in ["true", "1", "y", "yes"]:
v = True
elif v.lower() in ["false", "0", "n", "no"]:
v = False
else:
raise ValueError(f"can't derive true or false from {v} (key {k})")
elif isinstance(old_v, int):
v = int(v)
elif isinstance(old_v, float):
v = float(v)
elif not isinstance(old_v, str):
raise ValueError(
f"You can only update int, float, bool or string values in the config, got {v} for key {k}"
)
setattr(self, k, v)
def dict_torch_dtype_to_str(self, d: Dict[str, Any]) -> None:
"""
Checks whether the passed dictionary and its nested dicts have a *torch_dtype* key and if it's not None,
converts torch.dtype to a string of just the type. For example, `torch.float32` get converted into *"float32"*
string, which can then be stored in the json format.
"""
if d.get("torch_dtype", None) is not None and not isinstance(d["torch_dtype"], str):
d["torch_dtype"] = str(d["torch_dtype"]).split(".")[1]
for value in d.values():
if isinstance(value, dict):
self.dict_torch_dtype_to_str(value)
@classmethod
def register_for_auto_class(cls, auto_class="AutoConfig"):
"""
Register this class with a given auto class. This should only be used for custom configurations as the ones in
the library are already mapped with `AutoConfig`.
<Tip warning={true}>
This API is experimental and may have some slight breaking changes in the next releases.
</Tip>
Args:
auto_class (`str` or `type`, *optional*, defaults to `"AutoConfig"`):
The auto class to register this new configuration with.
"""
if not isinstance(auto_class, str):
auto_class = auto_class.__name__
import transformers.models.auto as auto_module
if not hasattr(auto_module, auto_class):
raise ValueError(f"{auto_class} is not a valid auto class.")
cls._auto_class = auto_class
@staticmethod
def _get_generation_defaults() -> Dict[str, Any]:
return {
"max_length": 20,
"min_length": 0,
"do_sample": False,
"early_stopping": False,
"num_beams": 1,
"num_beam_groups": 1,
"diversity_penalty": 0.0,
"temperature": 1.0,
"top_k": 50,
"top_p": 1.0,
"typical_p": 1.0,
"repetition_penalty": 1.0,
"length_penalty": 1.0,
"no_repeat_ngram_size": 0,
"encoder_no_repeat_ngram_size": 0,
"bad_words_ids": None,
"num_return_sequences": 1,
"output_scores": False,
"return_dict_in_generate": False,
"forced_bos_token_id": None,
"forced_eos_token_id": None,
"remove_invalid_values": False,
"exponential_decay_length_penalty": None,
"suppress_tokens": None,
"begin_suppress_tokens": None,
}
def _has_non_default_generation_parameters(self) -> bool:
"""
Whether or not this instance holds non-default generation parameters.
"""
for parameter_name, default_value in self._get_generation_defaults().items():
if hasattr(self, parameter_name) and getattr(self, parameter_name) != default_value:
return True
return False
def get_configuration_file(configuration_files: List[str]) -> str:
"""
Get the configuration file to use for this version of transformers.
Args:
configuration_files (`List[str]`): The list of available configuration files.
Returns:
`str`: The configuration file to use.
"""
configuration_files_map = {}
for file_name in configuration_files:
search = _re_configuration_file.search(file_name)
if search is not None:
v = search.groups()[0]
configuration_files_map[v] = file_name
available_versions = sorted(configuration_files_map.keys())
# Defaults to FULL_CONFIGURATION_FILE and then try to look at some newer versions.
configuration_file = CONFIG_NAME
transformers_version = version.parse(__version__)
for v in available_versions:
if version.parse(v) <= transformers_version:
configuration_file = configuration_files_map[v]
else:
# No point going further since the versions are sorted.
break
return configuration_file
def recursive_diff_dict(dict_a, dict_b, config_obj=None):
"""
Helper function to recursively take the diff between two nested dictionaries. The resulting diff only contains the
values from `dict_a` that are different from values in `dict_b`.
"""
diff = {}
default = config_obj.__class__().to_dict() if config_obj is not None else {}
for key, value in dict_a.items():
obj_value = getattr(config_obj, str(key), None)
if isinstance(obj_value, PretrainedConfig) and key in dict_b and isinstance(dict_b[key], dict):
diff_value = recursive_diff_dict(value, dict_b[key], config_obj=obj_value)
if len(diff_value) > 0:
diff[key] = diff_value
elif key not in dict_b or value != dict_b[key] or key not in default or value != default[key]:
diff[key] = value
return diff
PretrainedConfig.push_to_hub = copy_func(PretrainedConfig.push_to_hub)
if PretrainedConfig.push_to_hub.__doc__ is not None:
PretrainedConfig.push_to_hub.__doc__ = PretrainedConfig.push_to_hub.__doc__.format(
object="config", object_class="AutoConfig", object_files="configuration file"
)
| transformers/src/transformers/configuration_utils.py/0 | {
"file_path": "transformers/src/transformers/configuration_utils.py",
"repo_id": "transformers",
"token_count": 23255
} | 303 |
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import json
import os
from functools import partial
from multiprocessing import Pool, cpu_count
import numpy as np
from tqdm import tqdm
from ...models.bert.tokenization_bert import whitespace_tokenize
from ...tokenization_utils_base import BatchEncoding, PreTrainedTokenizerBase, TruncationStrategy
from ...utils import is_tf_available, is_torch_available, logging
from .utils import DataProcessor
# Store the tokenizers which insert 2 separators tokens
MULTI_SEP_TOKENS_TOKENIZERS_SET = {"roberta", "camembert", "bart", "mpnet"}
if is_torch_available():
import torch
from torch.utils.data import TensorDataset
if is_tf_available():
import tensorflow as tf
logger = logging.get_logger(__name__)
def _improve_answer_span(doc_tokens, input_start, input_end, tokenizer, orig_answer_text):
"""Returns tokenized answer spans that better match the annotated answer."""
tok_answer_text = " ".join(tokenizer.tokenize(orig_answer_text))
for new_start in range(input_start, input_end + 1):
for new_end in range(input_end, new_start - 1, -1):
text_span = " ".join(doc_tokens[new_start : (new_end + 1)])
if text_span == tok_answer_text:
return (new_start, new_end)
return (input_start, input_end)
def _check_is_max_context(doc_spans, cur_span_index, position):
"""Check if this is the 'max context' doc span for the token."""
best_score = None
best_span_index = None
for span_index, doc_span in enumerate(doc_spans):
end = doc_span.start + doc_span.length - 1
if position < doc_span.start:
continue
if position > end:
continue
num_left_context = position - doc_span.start
num_right_context = end - position
score = min(num_left_context, num_right_context) + 0.01 * doc_span.length
if best_score is None or score > best_score:
best_score = score
best_span_index = span_index
return cur_span_index == best_span_index
def _new_check_is_max_context(doc_spans, cur_span_index, position):
"""Check if this is the 'max context' doc span for the token."""
# if len(doc_spans) == 1:
# return True
best_score = None
best_span_index = None
for span_index, doc_span in enumerate(doc_spans):
end = doc_span["start"] + doc_span["length"] - 1
if position < doc_span["start"]:
continue
if position > end:
continue
num_left_context = position - doc_span["start"]
num_right_context = end - position
score = min(num_left_context, num_right_context) + 0.01 * doc_span["length"]
if best_score is None or score > best_score:
best_score = score
best_span_index = span_index
return cur_span_index == best_span_index
def _is_whitespace(c):
if c == " " or c == "\t" or c == "\r" or c == "\n" or ord(c) == 0x202F:
return True
return False
def squad_convert_example_to_features(
example, max_seq_length, doc_stride, max_query_length, padding_strategy, is_training
):
features = []
if is_training and not example.is_impossible:
# Get start and end position
start_position = example.start_position
end_position = example.end_position
# If the answer cannot be found in the text, then skip this example.
actual_text = " ".join(example.doc_tokens[start_position : (end_position + 1)])
cleaned_answer_text = " ".join(whitespace_tokenize(example.answer_text))
if actual_text.find(cleaned_answer_text) == -1:
logger.warning(f"Could not find answer: '{actual_text}' vs. '{cleaned_answer_text}'")
return []
tok_to_orig_index = []
orig_to_tok_index = []
all_doc_tokens = []
for i, token in enumerate(example.doc_tokens):
orig_to_tok_index.append(len(all_doc_tokens))
if tokenizer.__class__.__name__ in [
"RobertaTokenizer",
"LongformerTokenizer",
"BartTokenizer",
"RobertaTokenizerFast",
"LongformerTokenizerFast",
"BartTokenizerFast",
]:
sub_tokens = tokenizer.tokenize(token, add_prefix_space=True)
else:
sub_tokens = tokenizer.tokenize(token)
for sub_token in sub_tokens:
tok_to_orig_index.append(i)
all_doc_tokens.append(sub_token)
if is_training and not example.is_impossible:
tok_start_position = orig_to_tok_index[example.start_position]
if example.end_position < len(example.doc_tokens) - 1:
tok_end_position = orig_to_tok_index[example.end_position + 1] - 1
else:
tok_end_position = len(all_doc_tokens) - 1
(tok_start_position, tok_end_position) = _improve_answer_span(
all_doc_tokens, tok_start_position, tok_end_position, tokenizer, example.answer_text
)
spans = []
truncated_query = tokenizer.encode(
example.question_text, add_special_tokens=False, truncation=True, max_length=max_query_length
)
# Tokenizers who insert 2 SEP tokens in-between <context> & <question> need to have special handling
# in the way they compute mask of added tokens.
tokenizer_type = type(tokenizer).__name__.replace("Tokenizer", "").lower()
sequence_added_tokens = (
tokenizer.model_max_length - tokenizer.max_len_single_sentence + 1
if tokenizer_type in MULTI_SEP_TOKENS_TOKENIZERS_SET
else tokenizer.model_max_length - tokenizer.max_len_single_sentence
)
sequence_pair_added_tokens = tokenizer.model_max_length - tokenizer.max_len_sentences_pair
span_doc_tokens = all_doc_tokens
while len(spans) * doc_stride < len(all_doc_tokens):
# Define the side we want to truncate / pad and the text/pair sorting
if tokenizer.padding_side == "right":
texts = truncated_query
pairs = span_doc_tokens
truncation = TruncationStrategy.ONLY_SECOND.value
else:
texts = span_doc_tokens
pairs = truncated_query
truncation = TruncationStrategy.ONLY_FIRST.value
encoded_dict = tokenizer.encode_plus( # TODO(thom) update this logic
texts,
pairs,
truncation=truncation,
padding=padding_strategy,
max_length=max_seq_length,
return_overflowing_tokens=True,
stride=max_seq_length - doc_stride - len(truncated_query) - sequence_pair_added_tokens,
return_token_type_ids=True,
)
paragraph_len = min(
len(all_doc_tokens) - len(spans) * doc_stride,
max_seq_length - len(truncated_query) - sequence_pair_added_tokens,
)
if tokenizer.pad_token_id in encoded_dict["input_ids"]:
if tokenizer.padding_side == "right":
non_padded_ids = encoded_dict["input_ids"][: encoded_dict["input_ids"].index(tokenizer.pad_token_id)]
else:
last_padding_id_position = (
len(encoded_dict["input_ids"]) - 1 - encoded_dict["input_ids"][::-1].index(tokenizer.pad_token_id)
)
non_padded_ids = encoded_dict["input_ids"][last_padding_id_position + 1 :]
else:
non_padded_ids = encoded_dict["input_ids"]
tokens = tokenizer.convert_ids_to_tokens(non_padded_ids)
token_to_orig_map = {}
for i in range(paragraph_len):
index = len(truncated_query) + sequence_added_tokens + i if tokenizer.padding_side == "right" else i
token_to_orig_map[index] = tok_to_orig_index[len(spans) * doc_stride + i]
encoded_dict["paragraph_len"] = paragraph_len
encoded_dict["tokens"] = tokens
encoded_dict["token_to_orig_map"] = token_to_orig_map
encoded_dict["truncated_query_with_special_tokens_length"] = len(truncated_query) + sequence_added_tokens
encoded_dict["token_is_max_context"] = {}
encoded_dict["start"] = len(spans) * doc_stride
encoded_dict["length"] = paragraph_len
spans.append(encoded_dict)
if "overflowing_tokens" not in encoded_dict or (
"overflowing_tokens" in encoded_dict and len(encoded_dict["overflowing_tokens"]) == 0
):
break
span_doc_tokens = encoded_dict["overflowing_tokens"]
for doc_span_index in range(len(spans)):
for j in range(spans[doc_span_index]["paragraph_len"]):
is_max_context = _new_check_is_max_context(spans, doc_span_index, doc_span_index * doc_stride + j)
index = (
j
if tokenizer.padding_side == "left"
else spans[doc_span_index]["truncated_query_with_special_tokens_length"] + j
)
spans[doc_span_index]["token_is_max_context"][index] = is_max_context
for span in spans:
# Identify the position of the CLS token
cls_index = span["input_ids"].index(tokenizer.cls_token_id)
# p_mask: mask with 1 for token than cannot be in the answer (0 for token which can be in an answer)
# Original TF implementation also keep the classification token (set to 0)
p_mask = np.ones_like(span["token_type_ids"])
if tokenizer.padding_side == "right":
p_mask[len(truncated_query) + sequence_added_tokens :] = 0
else:
p_mask[-len(span["tokens"]) : -(len(truncated_query) + sequence_added_tokens)] = 0
pad_token_indices = np.where(span["input_ids"] == tokenizer.pad_token_id)
special_token_indices = np.asarray(
tokenizer.get_special_tokens_mask(span["input_ids"], already_has_special_tokens=True)
).nonzero()
p_mask[pad_token_indices] = 1
p_mask[special_token_indices] = 1
# Set the cls index to 0: the CLS index can be used for impossible answers
p_mask[cls_index] = 0
span_is_impossible = example.is_impossible
start_position = 0
end_position = 0
if is_training and not span_is_impossible:
# For training, if our document chunk does not contain an annotation
# we throw it out, since there is nothing to predict.
doc_start = span["start"]
doc_end = span["start"] + span["length"] - 1
out_of_span = False
if not (tok_start_position >= doc_start and tok_end_position <= doc_end):
out_of_span = True
if out_of_span:
start_position = cls_index
end_position = cls_index
span_is_impossible = True
else:
if tokenizer.padding_side == "left":
doc_offset = 0
else:
doc_offset = len(truncated_query) + sequence_added_tokens
start_position = tok_start_position - doc_start + doc_offset
end_position = tok_end_position - doc_start + doc_offset
features.append(
SquadFeatures(
span["input_ids"],
span["attention_mask"],
span["token_type_ids"],
cls_index,
p_mask.tolist(),
example_index=0, # Can not set unique_id and example_index here. They will be set after multiple processing.
unique_id=0,
paragraph_len=span["paragraph_len"],
token_is_max_context=span["token_is_max_context"],
tokens=span["tokens"],
token_to_orig_map=span["token_to_orig_map"],
start_position=start_position,
end_position=end_position,
is_impossible=span_is_impossible,
qas_id=example.qas_id,
)
)
return features
def squad_convert_example_to_features_init(tokenizer_for_convert: PreTrainedTokenizerBase):
global tokenizer
tokenizer = tokenizer_for_convert
def squad_convert_examples_to_features(
examples,
tokenizer,
max_seq_length,
doc_stride,
max_query_length,
is_training,
padding_strategy="max_length",
return_dataset=False,
threads=1,
tqdm_enabled=True,
):
"""
Converts a list of examples into a list of features that can be directly given as input to a model. It is
model-dependant and takes advantage of many of the tokenizer's features to create the model's inputs.
Args:
examples: list of [`~data.processors.squad.SquadExample`]
tokenizer: an instance of a child of [`PreTrainedTokenizer`]
max_seq_length: The maximum sequence length of the inputs.
doc_stride: The stride used when the context is too large and is split across several features.
max_query_length: The maximum length of the query.
is_training: whether to create features for model evaluation or model training.
padding_strategy: Default to "max_length". Which padding strategy to use
return_dataset: Default False. Either 'pt' or 'tf'.
if 'pt': returns a torch.data.TensorDataset, if 'tf': returns a tf.data.Dataset
threads: multiple processing threads.
Returns:
list of [`~data.processors.squad.SquadFeatures`]
Example:
```python
processor = SquadV2Processor()
examples = processor.get_dev_examples(data_dir)
features = squad_convert_examples_to_features(
examples=examples,
tokenizer=tokenizer,
max_seq_length=args.max_seq_length,
doc_stride=args.doc_stride,
max_query_length=args.max_query_length,
is_training=not evaluate,
)
```"""
# Defining helper methods
features = []
threads = min(threads, cpu_count())
with Pool(threads, initializer=squad_convert_example_to_features_init, initargs=(tokenizer,)) as p:
annotate_ = partial(
squad_convert_example_to_features,
max_seq_length=max_seq_length,
doc_stride=doc_stride,
max_query_length=max_query_length,
padding_strategy=padding_strategy,
is_training=is_training,
)
features = list(
tqdm(
p.imap(annotate_, examples, chunksize=32),
total=len(examples),
desc="convert squad examples to features",
disable=not tqdm_enabled,
)
)
new_features = []
unique_id = 1000000000
example_index = 0
for example_features in tqdm(
features, total=len(features), desc="add example index and unique id", disable=not tqdm_enabled
):
if not example_features:
continue
for example_feature in example_features:
example_feature.example_index = example_index
example_feature.unique_id = unique_id
new_features.append(example_feature)
unique_id += 1
example_index += 1
features = new_features
del new_features
if return_dataset == "pt":
if not is_torch_available():
raise RuntimeError("PyTorch must be installed to return a PyTorch dataset.")
# Convert to Tensors and build dataset
all_input_ids = torch.tensor([f.input_ids for f in features], dtype=torch.long)
all_attention_masks = torch.tensor([f.attention_mask for f in features], dtype=torch.long)
all_token_type_ids = torch.tensor([f.token_type_ids for f in features], dtype=torch.long)
all_cls_index = torch.tensor([f.cls_index for f in features], dtype=torch.long)
all_p_mask = torch.tensor([f.p_mask for f in features], dtype=torch.float)
all_is_impossible = torch.tensor([f.is_impossible for f in features], dtype=torch.float)
if not is_training:
all_feature_index = torch.arange(all_input_ids.size(0), dtype=torch.long)
dataset = TensorDataset(
all_input_ids, all_attention_masks, all_token_type_ids, all_feature_index, all_cls_index, all_p_mask
)
else:
all_start_positions = torch.tensor([f.start_position for f in features], dtype=torch.long)
all_end_positions = torch.tensor([f.end_position for f in features], dtype=torch.long)
dataset = TensorDataset(
all_input_ids,
all_attention_masks,
all_token_type_ids,
all_start_positions,
all_end_positions,
all_cls_index,
all_p_mask,
all_is_impossible,
)
return features, dataset
elif return_dataset == "tf":
if not is_tf_available():
raise RuntimeError("TensorFlow must be installed to return a TensorFlow dataset.")
def gen():
for i, ex in enumerate(features):
if ex.token_type_ids is None:
yield (
{
"input_ids": ex.input_ids,
"attention_mask": ex.attention_mask,
"feature_index": i,
"qas_id": ex.qas_id,
},
{
"start_positions": ex.start_position,
"end_positions": ex.end_position,
"cls_index": ex.cls_index,
"p_mask": ex.p_mask,
"is_impossible": ex.is_impossible,
},
)
else:
yield (
{
"input_ids": ex.input_ids,
"attention_mask": ex.attention_mask,
"token_type_ids": ex.token_type_ids,
"feature_index": i,
"qas_id": ex.qas_id,
},
{
"start_positions": ex.start_position,
"end_positions": ex.end_position,
"cls_index": ex.cls_index,
"p_mask": ex.p_mask,
"is_impossible": ex.is_impossible,
},
)
# Why have we split the batch into a tuple? PyTorch just has a list of tensors.
if "token_type_ids" in tokenizer.model_input_names:
train_types = (
{
"input_ids": tf.int32,
"attention_mask": tf.int32,
"token_type_ids": tf.int32,
"feature_index": tf.int64,
"qas_id": tf.string,
},
{
"start_positions": tf.int64,
"end_positions": tf.int64,
"cls_index": tf.int64,
"p_mask": tf.int32,
"is_impossible": tf.int32,
},
)
train_shapes = (
{
"input_ids": tf.TensorShape([None]),
"attention_mask": tf.TensorShape([None]),
"token_type_ids": tf.TensorShape([None]),
"feature_index": tf.TensorShape([]),
"qas_id": tf.TensorShape([]),
},
{
"start_positions": tf.TensorShape([]),
"end_positions": tf.TensorShape([]),
"cls_index": tf.TensorShape([]),
"p_mask": tf.TensorShape([None]),
"is_impossible": tf.TensorShape([]),
},
)
else:
train_types = (
{"input_ids": tf.int32, "attention_mask": tf.int32, "feature_index": tf.int64, "qas_id": tf.string},
{
"start_positions": tf.int64,
"end_positions": tf.int64,
"cls_index": tf.int64,
"p_mask": tf.int32,
"is_impossible": tf.int32,
},
)
train_shapes = (
{
"input_ids": tf.TensorShape([None]),
"attention_mask": tf.TensorShape([None]),
"feature_index": tf.TensorShape([]),
"qas_id": tf.TensorShape([]),
},
{
"start_positions": tf.TensorShape([]),
"end_positions": tf.TensorShape([]),
"cls_index": tf.TensorShape([]),
"p_mask": tf.TensorShape([None]),
"is_impossible": tf.TensorShape([]),
},
)
return tf.data.Dataset.from_generator(gen, train_types, train_shapes)
else:
return features
class SquadProcessor(DataProcessor):
"""
Processor for the SQuAD data set. overridden by SquadV1Processor and SquadV2Processor, used by the version 1.1 and
version 2.0 of SQuAD, respectively.
"""
train_file = None
dev_file = None
def _get_example_from_tensor_dict(self, tensor_dict, evaluate=False):
if not evaluate:
answer = tensor_dict["answers"]["text"][0].numpy().decode("utf-8")
answer_start = tensor_dict["answers"]["answer_start"][0].numpy()
answers = []
else:
answers = [
{"answer_start": start.numpy(), "text": text.numpy().decode("utf-8")}
for start, text in zip(tensor_dict["answers"]["answer_start"], tensor_dict["answers"]["text"])
]
answer = None
answer_start = None
return SquadExample(
qas_id=tensor_dict["id"].numpy().decode("utf-8"),
question_text=tensor_dict["question"].numpy().decode("utf-8"),
context_text=tensor_dict["context"].numpy().decode("utf-8"),
answer_text=answer,
start_position_character=answer_start,
title=tensor_dict["title"].numpy().decode("utf-8"),
answers=answers,
)
def get_examples_from_dataset(self, dataset, evaluate=False):
"""
Creates a list of [`~data.processors.squad.SquadExample`] using a TFDS dataset.
Args:
dataset: The tfds dataset loaded from *tensorflow_datasets.load("squad")*
evaluate: Boolean specifying if in evaluation mode or in training mode
Returns:
List of SquadExample
Examples:
```python
>>> import tensorflow_datasets as tfds
>>> dataset = tfds.load("squad")
>>> training_examples = get_examples_from_dataset(dataset, evaluate=False)
>>> evaluation_examples = get_examples_from_dataset(dataset, evaluate=True)
```"""
if evaluate:
dataset = dataset["validation"]
else:
dataset = dataset["train"]
examples = []
for tensor_dict in tqdm(dataset):
examples.append(self._get_example_from_tensor_dict(tensor_dict, evaluate=evaluate))
return examples
def get_train_examples(self, data_dir, filename=None):
"""
Returns the training examples from the data directory.
Args:
data_dir: Directory containing the data files used for training and evaluating.
filename: None by default, specify this if the training file has a different name than the original one
which is `train-v1.1.json` and `train-v2.0.json` for squad versions 1.1 and 2.0 respectively.
"""
if data_dir is None:
data_dir = ""
if self.train_file is None:
raise ValueError("SquadProcessor should be instantiated via SquadV1Processor or SquadV2Processor")
with open(
os.path.join(data_dir, self.train_file if filename is None else filename), "r", encoding="utf-8"
) as reader:
input_data = json.load(reader)["data"]
return self._create_examples(input_data, "train")
def get_dev_examples(self, data_dir, filename=None):
"""
Returns the evaluation example from the data directory.
Args:
data_dir: Directory containing the data files used for training and evaluating.
filename: None by default, specify this if the evaluation file has a different name than the original one
which is `dev-v1.1.json` and `dev-v2.0.json` for squad versions 1.1 and 2.0 respectively.
"""
if data_dir is None:
data_dir = ""
if self.dev_file is None:
raise ValueError("SquadProcessor should be instantiated via SquadV1Processor or SquadV2Processor")
with open(
os.path.join(data_dir, self.dev_file if filename is None else filename), "r", encoding="utf-8"
) as reader:
input_data = json.load(reader)["data"]
return self._create_examples(input_data, "dev")
def _create_examples(self, input_data, set_type):
is_training = set_type == "train"
examples = []
for entry in tqdm(input_data):
title = entry["title"]
for paragraph in entry["paragraphs"]:
context_text = paragraph["context"]
for qa in paragraph["qas"]:
qas_id = qa["id"]
question_text = qa["question"]
start_position_character = None
answer_text = None
answers = []
is_impossible = qa.get("is_impossible", False)
if not is_impossible:
if is_training:
answer = qa["answers"][0]
answer_text = answer["text"]
start_position_character = answer["answer_start"]
else:
answers = qa["answers"]
example = SquadExample(
qas_id=qas_id,
question_text=question_text,
context_text=context_text,
answer_text=answer_text,
start_position_character=start_position_character,
title=title,
is_impossible=is_impossible,
answers=answers,
)
examples.append(example)
return examples
class SquadV1Processor(SquadProcessor):
train_file = "train-v1.1.json"
dev_file = "dev-v1.1.json"
class SquadV2Processor(SquadProcessor):
train_file = "train-v2.0.json"
dev_file = "dev-v2.0.json"
class SquadExample:
"""
A single training/test example for the Squad dataset, as loaded from disk.
Args:
qas_id: The example's unique identifier
question_text: The question string
context_text: The context string
answer_text: The answer string
start_position_character: The character position of the start of the answer
title: The title of the example
answers: None by default, this is used during evaluation. Holds answers as well as their start positions.
is_impossible: False by default, set to True if the example has no possible answer.
"""
def __init__(
self,
qas_id,
question_text,
context_text,
answer_text,
start_position_character,
title,
answers=[],
is_impossible=False,
):
self.qas_id = qas_id
self.question_text = question_text
self.context_text = context_text
self.answer_text = answer_text
self.title = title
self.is_impossible = is_impossible
self.answers = answers
self.start_position, self.end_position = 0, 0
doc_tokens = []
char_to_word_offset = []
prev_is_whitespace = True
# Split on whitespace so that different tokens may be attributed to their original position.
for c in self.context_text:
if _is_whitespace(c):
prev_is_whitespace = True
else:
if prev_is_whitespace:
doc_tokens.append(c)
else:
doc_tokens[-1] += c
prev_is_whitespace = False
char_to_word_offset.append(len(doc_tokens) - 1)
self.doc_tokens = doc_tokens
self.char_to_word_offset = char_to_word_offset
# Start and end positions only has a value during evaluation.
if start_position_character is not None and not is_impossible:
self.start_position = char_to_word_offset[start_position_character]
self.end_position = char_to_word_offset[
min(start_position_character + len(answer_text) - 1, len(char_to_word_offset) - 1)
]
class SquadFeatures:
"""
Single squad example features to be fed to a model. Those features are model-specific and can be crafted from
[`~data.processors.squad.SquadExample`] using the
:method:*~transformers.data.processors.squad.squad_convert_examples_to_features* method.
Args:
input_ids: Indices of input sequence tokens in the vocabulary.
attention_mask: Mask to avoid performing attention on padding token indices.
token_type_ids: Segment token indices to indicate first and second portions of the inputs.
cls_index: the index of the CLS token.
p_mask: Mask identifying tokens that can be answers vs. tokens that cannot.
Mask with 1 for tokens than cannot be in the answer and 0 for token that can be in an answer
example_index: the index of the example
unique_id: The unique Feature identifier
paragraph_len: The length of the context
token_is_max_context:
List of booleans identifying which tokens have their maximum context in this feature object. If a token
does not have their maximum context in this feature object, it means that another feature object has more
information related to that token and should be prioritized over this feature for that token.
tokens: list of tokens corresponding to the input ids
token_to_orig_map: mapping between the tokens and the original text, needed in order to identify the answer.
start_position: start of the answer token index
end_position: end of the answer token index
encoding: optionally store the BatchEncoding with the fast-tokenizer alignment methods.
"""
def __init__(
self,
input_ids,
attention_mask,
token_type_ids,
cls_index,
p_mask,
example_index,
unique_id,
paragraph_len,
token_is_max_context,
tokens,
token_to_orig_map,
start_position,
end_position,
is_impossible,
qas_id: str = None,
encoding: BatchEncoding = None,
):
self.input_ids = input_ids
self.attention_mask = attention_mask
self.token_type_ids = token_type_ids
self.cls_index = cls_index
self.p_mask = p_mask
self.example_index = example_index
self.unique_id = unique_id
self.paragraph_len = paragraph_len
self.token_is_max_context = token_is_max_context
self.tokens = tokens
self.token_to_orig_map = token_to_orig_map
self.start_position = start_position
self.end_position = end_position
self.is_impossible = is_impossible
self.qas_id = qas_id
self.encoding = encoding
class SquadResult:
"""
Constructs a SquadResult which can be used to evaluate a model's output on the SQuAD dataset.
Args:
unique_id: The unique identifier corresponding to that example.
start_logits: The logits corresponding to the start of the answer
end_logits: The logits corresponding to the end of the answer
"""
def __init__(self, unique_id, start_logits, end_logits, start_top_index=None, end_top_index=None, cls_logits=None):
self.start_logits = start_logits
self.end_logits = end_logits
self.unique_id = unique_id
if start_top_index:
self.start_top_index = start_top_index
self.end_top_index = end_top_index
self.cls_logits = cls_logits
| transformers/src/transformers/data/processors/squad.py/0 | {
"file_path": "transformers/src/transformers/data/processors/squad.py",
"repo_id": "transformers",
"token_count": 15578
} | 304 |
# coding=utf-8
# Copyright 2021 The HuggingFace Inc. team
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import inspect
import jax
import jax.lax as lax
import jax.numpy as jnp
from ..utils import add_start_docstrings
from ..utils.logging import get_logger
logger = get_logger(__name__)
LOGITS_PROCESSOR_INPUTS_DOCSTRING = r"""
Args:
input_ids (`jnp.ndarray` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary.
Indices can be obtained using [`PreTrainedTokenizer`]. See [`PreTrainedTokenizer.encode`] and
[`PreTrainedTokenizer.__call__`] for details.
[What are input IDs?](../glossary#input-ids)
scores (`jnp.ndarray` of shape `(batch_size, config.vocab_size)`):
Prediction scores of a language modeling head. These can be logits for each vocabulary when not using beam
search or log softmax for each vocabulary token when using beam search
kwargs (`Dict[str, Any]`, *optional*):
Additional logits processor specific kwargs.
Return:
`jnp.ndarray` of shape `(batch_size, config.vocab_size)`: The processed prediction scores.
"""
class FlaxLogitsProcessor:
"""Abstract base class for all logit processors that can be applied during generation."""
@add_start_docstrings(LOGITS_PROCESSOR_INPUTS_DOCSTRING)
def __call__(self, input_ids: jnp.ndarray, scores: jnp.ndarray) -> jnp.ndarray:
"""Flax method for processing logits."""
raise NotImplementedError(
f"{self.__class__} is an abstract class. Only classes inheriting this class can be called."
)
class FlaxLogitsWarper:
"""Abstract base class for all logit warpers that can be applied during generation with multinomial sampling."""
@add_start_docstrings(LOGITS_PROCESSOR_INPUTS_DOCSTRING)
def __call__(self, input_ids: jnp.ndarray, scores: jnp.ndarray) -> jnp.ndarray:
"""Flax method for warping logits."""
raise NotImplementedError(
f"{self.__class__} is an abstract class. Only classes inheriting this class can be called."
)
class FlaxLogitsProcessorList(list):
"""
This class can be used to create a list of [`FlaxLogitsProcessor`] or [`FlaxLogitsWarper`] to subsequently process
a `scores` input tensor. This class inherits from list and adds a specific *__call__* method to apply each
[`FlaxLogitsProcessor`] or [`FlaxLogitsWarper`] to the inputs.
"""
@add_start_docstrings(LOGITS_PROCESSOR_INPUTS_DOCSTRING)
def __call__(self, input_ids: jnp.ndarray, scores: jnp.ndarray, cur_len: int, **kwargs) -> jnp.ndarray:
for processor in self:
function_args = inspect.signature(processor.__call__).parameters
if len(function_args) > 3:
if not all(arg in kwargs for arg in list(function_args.keys())[2:]):
raise ValueError(
f"Make sure that all the required parameters: {list(function_args.keys())} for "
f"{processor.__class__} are passed to the logits processor."
)
scores = processor(input_ids, scores, cur_len, **kwargs)
else:
scores = processor(input_ids, scores, cur_len)
return scores
class FlaxTemperatureLogitsWarper(FlaxLogitsWarper):
r"""
[`FlaxLogitsWarper`] for temperature (exponential scaling output probability distribution).
Args:
temperature (`float`):
The value used to module the logits distribution.
"""
def __init__(self, temperature: float):
if not isinstance(temperature, float) or not (temperature > 0):
raise ValueError(f"`temperature` has to be a strictly positive float, but is {temperature}")
self.temperature = temperature
def __call__(self, input_ids: jnp.ndarray, scores: jnp.ndarray, cur_len: int) -> jnp.ndarray:
scores = scores / self.temperature
return scores
class FlaxTopPLogitsWarper(FlaxLogitsWarper):
"""
[`FlaxLogitsWarper`] that performs top-p, i.e. restricting to top tokens summing to prob_cut_off <= prob_cut_off.
Args:
top_p (`float`):
If set to < 1, only the smallest set of most probable tokens with probabilities that add up to `top_p` or
higher are kept for generation.
filter_value (`float`, *optional*, defaults to -inf):
All filtered values will be set to this float value.
min_tokens_to_keep (`int`, *optional*, defaults to 1):
Minimum number of tokens that cannot be filtered.
"""
def __init__(self, top_p: float, filter_value: float = -float("Inf"), min_tokens_to_keep: int = 1):
if not isinstance(top_p, float) or (top_p < 0 or top_p > 1.0):
raise ValueError(f"`top_p` has to be a float > 0 and < 1, but is {top_p}")
if not isinstance(min_tokens_to_keep, int) or (min_tokens_to_keep < 1):
raise ValueError(f"`min_tokens_to_keep` has to be a positive integer, but is {min_tokens_to_keep}")
self.top_p = top_p
self.filter_value = filter_value
self.min_tokens_to_keep = min_tokens_to_keep
def __call__(self, input_ids: jnp.ndarray, scores: jnp.ndarray, cur_len: int) -> jnp.ndarray:
topk_scores, topk_indices = lax.top_k(scores, scores.shape[-1])
mask_scores = jnp.full_like(scores, self.filter_value)
cumulative_probs = jax.nn.softmax(topk_scores, axis=-1).cumsum(axis=-1)
score_mask = cumulative_probs < self.top_p
# include the token that is higher than top_p as well
score_mask = jnp.roll(score_mask, 1)
score_mask |= score_mask.at[:, 0].set(True)
# min tokens to keep
score_mask = score_mask.at[:, : self.min_tokens_to_keep].set(True)
topk_next_scores = jnp.where(score_mask, topk_scores, mask_scores)
next_scores = jax.lax.sort_key_val(topk_indices, topk_next_scores)[-1]
return next_scores
class FlaxTopKLogitsWarper(FlaxLogitsWarper):
r"""
[`FlaxLogitsWarper`] that performs top-k, i.e. restricting to the k highest probability elements.
Args:
top_k (`int`):
The number of highest probability vocabulary tokens to keep for top-k-filtering.
filter_value (`float`, *optional*, defaults to -inf):
All filtered values will be set to this float value.
min_tokens_to_keep (`int`, *optional*, defaults to 1):
Minimum number of tokens that cannot be filtered.
"""
def __init__(self, top_k: int, filter_value: float = -float("Inf"), min_tokens_to_keep: int = 1):
if not isinstance(top_k, int) or top_k <= 0:
raise ValueError(f"`top_k` has to be a strictly positive integer, but is {top_k}")
self.top_k = max(top_k, min_tokens_to_keep)
self.filter_value = filter_value
def __call__(self, input_ids: jnp.ndarray, scores: jnp.ndarray, cur_len: int) -> jnp.ndarray:
batch_size, vocab_size = scores.shape
next_scores_flat = jnp.full(batch_size * vocab_size, self.filter_value)
topk = min(self.top_k, scores.shape[-1]) # Safety check
topk_scores, topk_indices = lax.top_k(scores, topk)
shift = jnp.broadcast_to((jnp.arange(batch_size) * vocab_size)[:, None], (batch_size, topk)).flatten()
topk_scores_flat = topk_scores.flatten()
topk_indices_flat = topk_indices.flatten() + shift
next_scores_flat = next_scores_flat.at[topk_indices_flat].set(topk_scores_flat)
next_scores = next_scores_flat.reshape(batch_size, vocab_size)
return next_scores
class FlaxForcedBOSTokenLogitsProcessor(FlaxLogitsProcessor):
r"""
[`FlaxLogitsProcessor`] that enforces the specified token as the first generated token.
Args:
bos_token_id (`int`):
The id of the token to force as the first generated token.
"""
def __init__(self, bos_token_id: int):
self.bos_token_id = bos_token_id
def __call__(self, input_ids: jnp.ndarray, scores: jnp.ndarray, cur_len: int) -> jnp.ndarray:
new_scores = jnp.full(scores.shape, -float("inf"))
apply_penalty = 1 - jnp.bool_(cur_len - 1)
scores = jnp.where(apply_penalty, new_scores.at[:, self.bos_token_id].set(0), scores)
return scores
class FlaxForcedEOSTokenLogitsProcessor(FlaxLogitsProcessor):
r"""
[`FlaxLogitsProcessor`] that enforces the specified token as the last generated token when `max_length` is reached.
Args:
max_length (`int`):
The maximum length of the sequence to be generated.
eos_token_id (`int`):
The id of the token to force as the last generated token when `max_length` is reached.
"""
def __init__(self, max_length: int, eos_token_id: int):
self.max_length = max_length
self.eos_token_id = eos_token_id
def __call__(self, input_ids: jnp.ndarray, scores: jnp.ndarray, cur_len: int) -> jnp.ndarray:
new_scores = jnp.full(scores.shape, -float("inf"))
apply_penalty = 1 - jnp.bool_(cur_len - self.max_length + 1)
scores = jnp.where(apply_penalty, new_scores.at[:, self.eos_token_id].set(0), scores)
return scores
class FlaxMinLengthLogitsProcessor(FlaxLogitsProcessor):
r"""
[`FlaxLogitsProcessor`] enforcing a min-length by setting EOS probability to 0.
Args:
min_length (`int`):
The minimum length below which the score of `eos_token_id` is set to `-float("Inf")`.
eos_token_id (`int`):
The id of the *end-of-sequence* token.
"""
def __init__(self, min_length: int, eos_token_id: int):
if not isinstance(min_length, int) or min_length < 0:
raise ValueError(f"`min_length` has to be a positive integer, but is {min_length}")
if not isinstance(eos_token_id, int) or eos_token_id < 0:
raise ValueError(f"`eos_token_id` has to be a positive integer, but is {eos_token_id}")
self.min_length = min_length
self.eos_token_id = eos_token_id
def __call__(self, input_ids: jnp.ndarray, scores: jnp.ndarray, cur_len: int) -> jnp.ndarray:
# create boolean flag to decide if min length penalty should be applied
apply_penalty = 1 - jnp.clip(cur_len - self.min_length, 0, 1)
scores = jnp.where(apply_penalty, scores.at[:, self.eos_token_id].set(-float("inf")), scores)
return scores
class FlaxSuppressTokensAtBeginLogitsProcessor(FlaxLogitsProcessor):
r"""
[`FlaxLogitsProcessor`] supressing a list of tokens as soon as the `generate` function starts generating using
`begin_index` tokens. This should ensure that the tokens defined by `begin_suppress_tokens` are not sampled at the
begining of the generation.
Args:
begin_suppress_tokens (`List[int]`):
Tokens to not sample.
begin_index (`int`):
Index where the tokens are suppressed.
"""
def __init__(self, begin_suppress_tokens, begin_index):
self.begin_suppress_tokens = list(begin_suppress_tokens)
self.begin_index = begin_index
def __call__(self, input_ids, scores, cur_len: int):
apply_penalty = 1 - jnp.bool_(cur_len - self.begin_index)
scores = jnp.where(apply_penalty, scores.at[:, self.begin_suppress_tokens].set(-float("inf")), scores)
return scores
class FlaxSuppressTokensLogitsProcessor(FlaxLogitsProcessor):
r"""
[`FlaxLogitsProcessor`] suppressing a list of tokens at each decoding step. The processor will set their log probs
to be `-inf` so they are not sampled.
Args:
suppress_tokens (`list`):
Tokens to not sample.
"""
def __init__(self, suppress_tokens: list):
self.suppress_tokens = list(suppress_tokens)
def __call__(self, input_ids: jnp.ndarray, scores: jnp.ndarray, cur_len: int) -> jnp.ndarray:
scores = scores.at[..., self.suppress_tokens].set(-float("inf"))
return scores
class FlaxForceTokensLogitsProcessor(FlaxLogitsProcessor):
r"""
[`FlaxLogitsProcessor`] that takes a list of pairs of integers which indicates a mapping from generation indices to
token indices that will be forced before sampling. The processor will set their log probs to 0 and all other tokens
to `-inf` so that they are sampled at their corresponding index.
Args:
force_token_map (`list`):
Map giving token ids and indices where they will be forced to be sampled.
"""
def __init__(self, force_token_map):
force_token_map = dict(force_token_map)
# Converts the dictionary of format {index: token} containing the tokens to be forced to an array, where the
# index of the array corresponds to the index of the token to be forced, for XLA compatibility.
# Indexes without forced tokens will have a negative value.
force_token_array = jnp.ones((max(force_token_map.keys()) + 1), dtype=jnp.int32) * -1
for index, token in force_token_map.items():
if token is not None:
force_token_array = force_token_array.at[index].set(token)
self.force_token_array = jnp.int32(force_token_array)
def __call__(self, input_ids: jnp.ndarray, scores: jnp.ndarray, cur_len: int) -> jnp.ndarray:
def _force_token(generation_idx):
batch_size = scores.shape[0]
current_token = self.force_token_array[generation_idx]
new_scores = jnp.ones_like(scores, dtype=scores.dtype) * -float("inf")
updates = jnp.zeros((batch_size, 1), dtype=scores.dtype)
new_scores = lax.dynamic_update_slice(new_scores, updates, (0, current_token))
return new_scores
scores = lax.cond(
cur_len >= self.force_token_array.shape[0],
# If the current length is geq than the length of force_token_array, the processor does nothing.
lambda: scores,
# Otherwise, it may force a certain token.
lambda: lax.cond(
self.force_token_array[cur_len] >= 0,
# Only valid (positive) tokens are forced
lambda: _force_token(cur_len),
# Otherwise, the processor does nothing.
lambda: scores,
),
)
return scores
class FlaxWhisperTimeStampLogitsProcessor(FlaxLogitsProcessor):
r"""
Whisper specific Processor. This processor can be used to force a list of tokens. The processor will set their log
probs to `inf` so that they are sampled at their corresponding index.
Args:
generate_config (`GenerateConfig`):
The generate config used to generate the output. The following parameters are required:
eos_token_id (`int`, *optional*, defaults to 50257):
The id of the *end-of-sequence* token.
no_timestamps_token_id (`int`, *optional*, defaults to 50363):
The id of the `"<|notimestamps|>"` token.
max_initial_timestamp_index (`int`, *optional*, defaults to 1):
Used to set the maximum value of the initial timestamp. This is used to prevent the model from
predicting timestamps that are too far in the future.
"""
def __init__(self, generate_config, model_config, decoder_input_length):
self.eos_token_id = generate_config.eos_token_id
self.no_timestamps_token_id = generate_config.no_timestamps_token_id
self.timestamp_begin = generate_config.no_timestamps_token_id + 1
self.begin_index = decoder_input_length + 1
if generate_config.is_multilingual:
# room for language token and task token
self.begin_index += 2
if hasattr(generate_config, "max_initial_timestamp_index"):
self.max_initial_timestamp_index = generate_config.max_initial_timestamp_index
else:
self.max_initial_timestamp_index = model_config.vocab_size
if self.max_initial_timestamp_index is None:
self.max_initial_timestamp_index = model_config.vocab_size
def __call__(self, input_ids, scores, cur_len):
# suppress <|notimestamps|> which is handled by without_timestamps
scores = scores.at[:, self.no_timestamps_token_id].set(-float("inf"))
def handle_pairs(input_ids_k, scores_k):
last_was_timestamp = jnp.where((cur_len - self.begin_index) >= 1, True, False)
last_was_timestamp = jnp.where(
input_ids_k[cur_len - 1] >= self.timestamp_begin,
True and last_was_timestamp,
False,
)
penultimate_was_timestamp = jnp.where((cur_len - self.begin_index) < 2, True, False)
penultimate_was_timestamp = jnp.where(
input_ids_k[cur_len - 2] >= self.timestamp_begin,
True,
penultimate_was_timestamp,
)
return jnp.where(
last_was_timestamp,
jnp.where(
penultimate_was_timestamp > 0,
scores_k.at[self.timestamp_begin :].set(-float("inf")),
scores_k.at[: self.eos_token_id].set(-float("inf")),
),
scores_k,
)
scores = jax.vmap(handle_pairs)(input_ids, scores)
apply_max_initial_timestamp = jnp.where(cur_len == self.begin_index, True, False)
apply_max_initial_timestamp = jnp.where(
self.max_initial_timestamp_index is not None,
True and apply_max_initial_timestamp,
False,
)
last_allowed = self.timestamp_begin + self.max_initial_timestamp_index
scores = jnp.where(
apply_max_initial_timestamp,
scores.at[:, last_allowed + 1 :].set(-float("inf")),
scores,
)
# if sum of probability over timestamps is above any other token, sample timestamp
logprobs = jax.nn.log_softmax(scores, axis=-1)
def handle_cumulative_probs(logprobs_k, scores_k):
timestamp_logprob = jax.nn.logsumexp(logprobs_k[self.timestamp_begin :], axis=-1)
max_text_token_logprob = jnp.max(logprobs_k[: self.timestamp_begin])
return jnp.where(
timestamp_logprob > max_text_token_logprob,
scores_k.at[: self.timestamp_begin].set(-float("inf")),
scores_k,
)
scores = jax.vmap(handle_cumulative_probs)(logprobs, scores)
return scores
| transformers/src/transformers/generation/flax_logits_process.py/0 | {
"file_path": "transformers/src/transformers/generation/flax_logits_process.py",
"repo_id": "transformers",
"token_count": 8086
} | 305 |
# Copyright 2023 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from typing import TYPE_CHECKING
from ..utils import _LazyModule
_import_structure = {
"awq": ["fuse_awq_modules", "replace_with_awq_linear"],
"bitsandbytes": [
"get_keys_to_not_convert",
"replace_8bit_linear",
"replace_with_bnb_linear",
"set_module_8bit_tensor_to_device",
"set_module_quantized_tensor_to_device",
],
"deepspeed": [
"HfDeepSpeedConfig",
"HfTrainerDeepSpeedConfig",
"deepspeed_config",
"deepspeed_init",
"deepspeed_load_checkpoint",
"deepspeed_optim_sched",
"is_deepspeed_available",
"is_deepspeed_zero3_enabled",
"set_hf_deepspeed_config",
"unset_hf_deepspeed_config",
],
"integration_utils": [
"INTEGRATION_TO_CALLBACK",
"AzureMLCallback",
"ClearMLCallback",
"CodeCarbonCallback",
"CometCallback",
"DagsHubCallback",
"DVCLiveCallback",
"FlyteCallback",
"MLflowCallback",
"NeptuneCallback",
"NeptuneMissingConfiguration",
"TensorBoardCallback",
"WandbCallback",
"get_available_reporting_integrations",
"get_reporting_integration_callbacks",
"hp_params",
"is_azureml_available",
"is_clearml_available",
"is_codecarbon_available",
"is_comet_available",
"is_dagshub_available",
"is_dvclive_available",
"is_flyte_deck_standard_available",
"is_flytekit_available",
"is_mlflow_available",
"is_neptune_available",
"is_optuna_available",
"is_ray_available",
"is_ray_tune_available",
"is_sigopt_available",
"is_tensorboard_available",
"is_wandb_available",
"rewrite_logs",
"run_hp_search_optuna",
"run_hp_search_ray",
"run_hp_search_sigopt",
"run_hp_search_wandb",
],
"peft": ["PeftAdapterMixin"],
}
if TYPE_CHECKING:
from .awq import fuse_awq_modules, replace_with_awq_linear
from .bitsandbytes import (
get_keys_to_not_convert,
replace_8bit_linear,
replace_with_bnb_linear,
set_module_8bit_tensor_to_device,
set_module_quantized_tensor_to_device,
)
from .deepspeed import (
HfDeepSpeedConfig,
HfTrainerDeepSpeedConfig,
deepspeed_config,
deepspeed_init,
deepspeed_load_checkpoint,
deepspeed_optim_sched,
is_deepspeed_available,
is_deepspeed_zero3_enabled,
set_hf_deepspeed_config,
unset_hf_deepspeed_config,
)
from .integration_utils import (
INTEGRATION_TO_CALLBACK,
AzureMLCallback,
ClearMLCallback,
CodeCarbonCallback,
CometCallback,
DagsHubCallback,
DVCLiveCallback,
FlyteCallback,
MLflowCallback,
NeptuneCallback,
NeptuneMissingConfiguration,
TensorBoardCallback,
WandbCallback,
get_available_reporting_integrations,
get_reporting_integration_callbacks,
hp_params,
is_azureml_available,
is_clearml_available,
is_codecarbon_available,
is_comet_available,
is_dagshub_available,
is_dvclive_available,
is_flyte_deck_standard_available,
is_flytekit_available,
is_mlflow_available,
is_neptune_available,
is_optuna_available,
is_ray_available,
is_ray_tune_available,
is_sigopt_available,
is_tensorboard_available,
is_wandb_available,
rewrite_logs,
run_hp_search_optuna,
run_hp_search_ray,
run_hp_search_sigopt,
run_hp_search_wandb,
)
from .peft import PeftAdapterMixin
else:
import sys
sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure, module_spec=__spec__)
| transformers/src/transformers/integrations/__init__.py/0 | {
"file_path": "transformers/src/transformers/integrations/__init__.py",
"repo_id": "transformers",
"token_count": 2097
} | 306 |
#define WARP_SIZE 32
#define FULL_MASK 0xffffffff
#define OPTIMAL_THREADS 256
__global__ void index_max_cuda_kernel(
float *index_vals, // [batch_size, 32, num_block]
int *indices, // [batch_size, num_block]
float *max_vals, // [batch_size, A_num_block * 32]
float *max_vals_scatter, // [batch_size, 32, num_block]
long batch_size,
long A_num_block,
long B_num_block,
long num_block
);
__global__ void mm_to_sparse_cuda_kernel(
float *dense_A, // [batch_size, A_num_block, dim, 32]
float *dense_B, // [batch_size, B_num_block, dim, 32]
int *indices, // [batch_size, num_block]
float *sparse_C, // [batch_size, num_block, 32, 32]
long batch_size,
long A_num_block,
long B_num_block,
long dim,
long num_block
);
__global__ void sparse_dense_mm_cuda_kernel(
float *sparse_A, // [batch_size, num_block, 32, 32]
int *indices, // [batch_size, num_block]
float *dense_B, // [batch_size, B_num_block, dim, 32]
float *dense_C, // [batch_size, A_num_block, dim, 32]
long batch_size,
long A_num_block,
long B_num_block,
long dim,
long num_block
);
__global__ void reduce_sum_cuda_kernel(
float *sparse_A, // [batch_size, num_block, 32, 32]
int *indices, // [batch_size, num_block]
float *dense_C, // [batch_size, A_num_block, 32]
long batch_size,
long A_num_block,
long B_num_block,
long num_block
);
__global__ void scatter_cuda_kernel(
float *dense_A, // [batch_size, A_num_block, 32]
int *indices, // [batch_size, num_block]
float *sparse_C, // [batch_size, num_block, 32, 32]
long batch_size,
long A_num_block,
long B_num_block,
long num_block
);
| transformers/src/transformers/kernels/mra/cuda_kernel.h/0 | {
"file_path": "transformers/src/transformers/kernels/mra/cuda_kernel.h",
"repo_id": "transformers",
"token_count": 729
} | 307 |
# Copyright 2023 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from dataclasses import dataclass
from typing import List, Optional, Tuple, Union
import torch
@dataclass
class AttentionMaskConverter:
"""
A utility attention mask class that allows one to:
- Create a causal 4d mask
- Create a causal 4d mask with slided window
- Convert a 2d attention mask (batch_size, query_length) to a 4d attention mask (batch_size, 1, query_length,
key_value_length) that can be multiplied with attention scores
Examples:
```python
>>> import torch
>>> from transformers.modeling_attn_mask_utils import AttentionMaskConverter
>>> converter = AttentionMaskConverter(True)
>>> converter.to_4d(torch.tensor([[0, 0, 0, 1, 1]]), 5, key_value_length=5, dtype=torch.float32)
tensor([[[[-3.4028e+38, -3.4028e+38, -3.4028e+38, -3.4028e+38, -3.4028e+38],
[-3.4028e+38, -3.4028e+38, -3.4028e+38, -3.4028e+38, -3.4028e+38],
[-3.4028e+38, -3.4028e+38, -3.4028e+38, -3.4028e+38, -3.4028e+38],
[-3.4028e+38, -3.4028e+38, -3.4028e+38, 0.0000e+00, -3.4028e+38],
[-3.4028e+38, -3.4028e+38, -3.4028e+38, 0.0000e+00, 0.0000e+00]]]])
```
Parameters:
is_causal (`bool`):
Whether the attention mask should be a uni-directional (causal) or bi-directional mask.
sliding_window (`int`, *optional*):
Optionally, the sliding window masks can be created if `sliding_window` is defined to a positive integer.
"""
is_causal: bool
sliding_window: int
def __init__(self, is_causal: bool, sliding_window: Optional[int] = None):
self.is_causal = is_causal
self.sliding_window = sliding_window
if self.sliding_window is not None and self.sliding_window <= 0:
raise ValueError(
f"Make sure that when passing `sliding_window` that its value is a strictly positive integer, not `{self.sliding_window}`"
)
def to_causal_4d(
self,
batch_size: int,
query_length: int,
key_value_length: int,
dtype: torch.dtype,
device: Union[torch.device, "str"] = "cpu",
) -> Optional[torch.Tensor]:
"""
Creates a causal 4D mask of (bsz, head_dim=1, query_length, key_value_length) shape and adds large negative
bias to upper right hand triangular matrix (causal mask).
"""
if not self.is_causal:
raise ValueError(f"Please use `to_causal_4d` only if {self.__class__} has `is_causal` set to True.")
# If shape is not cached, create a new causal mask and cache it
input_shape = (batch_size, query_length)
past_key_values_length = key_value_length - query_length
# create causal mask
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
causal_4d_mask = None
if input_shape[-1] > 1 or self.sliding_window is not None:
causal_4d_mask = self._make_causal_mask(
input_shape,
dtype,
device=device,
past_key_values_length=past_key_values_length,
sliding_window=self.sliding_window,
)
return causal_4d_mask
def to_4d(
self,
attention_mask_2d: torch.Tensor,
query_length: int,
dtype: torch.dtype,
key_value_length: Optional[int] = None,
) -> torch.Tensor:
"""
Converts 2D attention mask to 4D attention mask by expanding mask to (bsz, head_dim=1, query_length,
key_value_length) shape and by adding a large negative bias to not-attended positions. If attention_mask is
causal, a causal mask will be added.
"""
input_shape = (attention_mask_2d.shape[0], query_length)
# create causal mask
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
causal_4d_mask = None
if (input_shape[-1] > 1 or self.sliding_window is not None) and self.is_causal:
if key_value_length is None:
raise ValueError(
"This attention mask converter is causal. Make sure to pass `key_value_length` to correctly create a causal mask."
)
past_key_values_length = key_value_length - query_length
causal_4d_mask = self._make_causal_mask(
input_shape,
dtype,
device=attention_mask_2d.device,
past_key_values_length=past_key_values_length,
sliding_window=self.sliding_window,
)
elif self.sliding_window is not None:
raise NotImplementedError("Sliding window is currently only implemented for causal masking")
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
expanded_attn_mask = self._expand_mask(attention_mask_2d, dtype, tgt_len=input_shape[-1]).to(
attention_mask_2d.device
)
if causal_4d_mask is not None:
expanded_attn_mask = causal_4d_mask.masked_fill(expanded_attn_mask.bool(), torch.finfo(dtype).min)
# expanded_attn_mask + causal_4d_mask can cause some overflow
expanded_4d_mask = expanded_attn_mask
return expanded_4d_mask
@staticmethod
def _make_causal_mask(
input_ids_shape: torch.Size,
dtype: torch.dtype,
device: torch.device,
past_key_values_length: int = 0,
sliding_window: Optional[int] = None,
):
"""
Make causal mask used for bi-directional self-attention.
"""
bsz, tgt_len = input_ids_shape
mask = torch.full((tgt_len, tgt_len), torch.finfo(dtype).min, device=device)
mask_cond = torch.arange(mask.size(-1), device=device)
mask.masked_fill_(mask_cond < (mask_cond + 1).view(mask.size(-1), 1), 0)
mask = mask.to(dtype)
if past_key_values_length > 0:
mask = torch.cat([torch.zeros(tgt_len, past_key_values_length, dtype=dtype, device=device), mask], dim=-1)
# add lower triangular sliding window mask if necessary
if sliding_window is not None:
diagonal = past_key_values_length - sliding_window + 1
context_mask = 1 - torch.triu(torch.ones_like(mask, dtype=torch.int), diagonal=diagonal)
mask.masked_fill_(context_mask.bool(), torch.finfo(dtype).min)
return mask[None, None, :, :].expand(bsz, 1, tgt_len, tgt_len + past_key_values_length)
@staticmethod
def _expand_mask(mask: torch.Tensor, dtype: torch.dtype, tgt_len: Optional[int] = None):
"""
Expands attention_mask from `[bsz, seq_len]` to `[bsz, 1, tgt_seq_len, src_seq_len]`.
"""
bsz, src_len = mask.size()
tgt_len = tgt_len if tgt_len is not None else src_len
expanded_mask = mask[:, None, None, :].expand(bsz, 1, tgt_len, src_len).to(dtype)
inverted_mask = 1.0 - expanded_mask
return inverted_mask.masked_fill(inverted_mask.to(torch.bool), torch.finfo(dtype).min)
@staticmethod
def _unmask_unattended(
expanded_mask: torch.Tensor, attention_mask: torch.Tensor, unmasked_value: Union[bool, float]
):
# fmt: off
"""
Attend to all tokens in masked rows from the expanded attention mask, for example the relevant first rows when
using left padding. This is required by F.scaled_dot_product_attention memory-efficient attention path.
Details: https://github.com/pytorch/pytorch/issues/110213
`expanded_mask` is [bsz, num_masks, tgt_seq_len, src_seq_len] or [bsz, tgt_seq_len, src_seq_len].
`attention_mask` is [bsz, src_seq_len].
The dimension num_masks of `expanded_mask` is most often 1, but it can also be the number of heads in the case of alibi attention bias.
For example, if `attention_mask` is
```
[[0, 0, 1],
[1, 1, 1],
[0, 1, 1]]
```
and `expanded_mask` is (e.g. here left-padding case)
```
[[[[0, 0, 0],
[0, 0, 0],
[0, 0, 1]]],
[[[1, 0, 0],
[1, 1, 0],
[1, 1, 1]]],
[[[0, 0, 0],
[0, 1, 0],
[0, 1, 1]]]]
```
then the modified `expanded_mask` will be
```
[[[[1, 1, 1], <-- modified
[1, 1, 1], <-- modified
[0, 0, 1]]],
[[[1, 0, 0],
[1, 1, 0],
[1, 1, 1]]],
[[[1, 1, 1], <-- modified
[0, 1, 0],
[0, 1, 1]]]]
```
"""
# fmt: on
# Get the index of the first non-zero value for every sample in the batch.
# In the above example, indices = [[2], [0], [1]]]
tmp = torch.arange(attention_mask.shape[1], 0, -1)
indices = torch.argmax(attention_mask.cpu() * tmp, 1, keepdim=True)
# Find the batch indexes that have unattended tokens on the leftmost side (e.g. [0, 0, 1, 1, 1]), for which the first rows of the
# expanded mask will be completely unattended.
left_masked_rows = torch.where(indices > 0)[0]
if left_masked_rows.shape[0] == 0:
return expanded_mask
indices = indices[left_masked_rows]
max_len = torch.max(indices)
range_tensor = torch.arange(max_len).unsqueeze(0)
range_tensor = range_tensor.repeat(indices.size(0), 1)
# Avoid unmasking tokens at relevant target positions (on the row axis), by rather unmasking possibly several times the first row that should always be unmasked as we filtered out the batch above.
range_tensor[range_tensor >= indices] = 0
# TODO: we may drop support for 3D attention mask as the refactor from Patrick maybe dropped this case
if expanded_mask.dim() == 4:
num_masks = expanded_mask.shape[1]
if num_masks == 1:
# Broadcast [left_masked_rows, 1], [left_masked_rows, max_len]
mask_slice = (left_masked_rows[:, None], 0, range_tensor)
else:
# Broadcast [left_masked_rows, 1, 1], [1, num_masks, 1], [left_masked_rows, 1, max_len]
mask_slice = (
left_masked_rows[:, None, None],
torch.arange(num_masks)[None, :, None],
range_tensor[:, None, :],
)
else:
# Broadcast [left_masked_rows, 1], [left_masked_rows, max_len]
mask_slice = (left_masked_rows[:, None], range_tensor)
expanded_mask[mask_slice] = unmasked_value
return expanded_mask
def _prepare_4d_causal_attention_mask(
attention_mask: Optional[torch.Tensor],
input_shape: Union[torch.Size, Tuple, List],
inputs_embeds: torch.Tensor,
past_key_values_length: int,
sliding_window: Optional[int] = None,
):
"""
Creates a causal 4D mask of shape `(batch_size, 1, query_length, key_value_length)` from a 2D mask of shape
`(batch_size, key_value_length)`
Args:
attention_mask (`torch.Tensor` or `None`):
A 2D attention mask of shape `(batch_size, key_value_length)`
input_shape (`tuple(int)` or `list(int)` or `torch.Size`):
The input shape should be a tuple that defines `(batch_size, query_length)`.
inputs_embeds (`torch.Tensor`):
The embedded inputs as a torch Tensor.
past_key_values_length (`int`):
The length of the key value cache.
sliding_window (`int`, *optional*):
If the model uses windowed attention, a sliding window should be passed.
"""
attn_mask_converter = AttentionMaskConverter(is_causal=True, sliding_window=sliding_window)
key_value_length = input_shape[-1] + past_key_values_length
# 4d mask is passed through the layers
if attention_mask is not None and len(attention_mask.shape) == 2:
attention_mask = attn_mask_converter.to_4d(
attention_mask, input_shape[-1], key_value_length=key_value_length, dtype=inputs_embeds.dtype
)
elif attention_mask is not None and len(attention_mask.shape) == 4:
expected_shape = (input_shape[0], 1, input_shape[1], key_value_length)
if tuple(attention_mask.shape) != expected_shape:
raise ValueError(
f"Incorrect 4D attention_mask shape: {tuple(attention_mask.shape)}; expected: {expected_shape}."
)
else:
# if the 4D mask has correct shape - invert it and fill with negative infinity
inverted_mask = 1.0 - attention_mask
attention_mask = inverted_mask.masked_fill(
inverted_mask.to(torch.bool), torch.finfo(inputs_embeds.dtype).min
)
else:
attention_mask = attn_mask_converter.to_causal_4d(
input_shape[0], input_shape[-1], key_value_length, dtype=inputs_embeds.dtype, device=inputs_embeds.device
)
return attention_mask
# Adapted from _prepare_4d_causal_attention_mask
def _prepare_4d_causal_attention_mask_for_sdpa(
attention_mask: Optional[torch.Tensor],
input_shape: Union[torch.Size, Tuple, List],
inputs_embeds: torch.Tensor,
past_key_values_length: int,
sliding_window: Optional[int] = None,
):
"""
Prepares the correct `attn_mask` argument to be used by `torch.nn.functional.scaled_dot_product_attention`.
In case no token is masked in the `attention_mask` argument, we simply set it to `None` for the cases `query_length == 1` and
`key_value_length == query_length`, and rely instead on SDPA `is_causal` argument to use causal/non-causal masks,
allowing to dispatch to the flash attention kernel (that can otherwise not be used if a custom `attn_mask` is passed).
"""
attn_mask_converter = AttentionMaskConverter(is_causal=True, sliding_window=sliding_window)
key_value_length = input_shape[-1] + past_key_values_length
batch_size, query_length = input_shape
# torch.jit.trace, symbolic_trace and torchdynamo with fullgraph=True are unable to capture the controlflow `is_causal=attention_mask is None and q_len > 1`
# used as an SDPA argument. We keep compatibility with these tracing tools by always using SDPA's `attn_mask` argument in case we are tracing.
# TODO: Fix this as well when using torchdynamo with fullgraph=True.
is_tracing = torch.jit.is_tracing() or isinstance(inputs_embeds, torch.fx.Proxy)
if attention_mask is not None:
# 4d mask is passed through
if len(attention_mask.shape) == 4:
expected_shape = (input_shape[0], 1, input_shape[1], key_value_length)
if tuple(attention_mask.shape) != expected_shape:
raise ValueError(
f"Incorrect 4D attention_mask shape: {tuple(attention_mask.shape)}; expected: {expected_shape}."
)
else:
# if the 4D mask has correct shape - invert it and fill with negative infinity
inverted_mask = 1.0 - attention_mask.to(inputs_embeds.dtype)
attention_mask = inverted_mask.masked_fill(
inverted_mask.to(torch.bool), torch.finfo(inputs_embeds.dtype).min
)
return attention_mask
elif not is_tracing and torch.all(attention_mask == 1):
if query_length == 1:
# For query_length == 1, causal attention and bi-directional attention are the same.
attention_mask = None
elif key_value_length == query_length:
attention_mask = None
else:
# Unfortunately, for query_length > 1 and key_value_length != query_length, we cannot generally ignore the attention mask, as SDPA causal mask generation
# may be wrong. We will set `is_causal=False` in SDPA and rely on Transformers attention_mask instead, hence not setting it to None here.
# Reference: https://github.com/pytorch/pytorch/issues/108108
pass
elif query_length > 1 and key_value_length != query_length:
# See the comment above (https://github.com/pytorch/pytorch/issues/108108).
# Ugly: we set it to True here to dispatch in the following controlflow to `to_causal_4d`.
attention_mask = True
elif is_tracing:
raise ValueError(
'Attention using SDPA can not be traced with torch.jit.trace when no attention_mask is provided. To solve this issue, please either load your model with the argument `attn_implementation="eager"` or pass an attention_mask input when tracing the model.'
)
if attention_mask is None:
expanded_4d_mask = None
elif attention_mask is True:
expanded_4d_mask = attn_mask_converter.to_causal_4d(
input_shape[0], input_shape[-1], key_value_length, dtype=inputs_embeds.dtype, device=inputs_embeds.device
)
else:
expanded_4d_mask = attn_mask_converter.to_4d(
attention_mask,
input_shape[-1],
dtype=inputs_embeds.dtype,
key_value_length=key_value_length,
)
# From PyTorch 2.1 onwards, F.scaled_dot_product_attention with the memory-efficient attention backend
# produces nans if sequences are completely unattended in the attention mask. Details: https://github.com/pytorch/pytorch/issues/110213
#
# This fix is not applied in case we are tracing with torch.jit.trace or symbolic_trace, as _unmask_unattended has a data-dependent
# controlflow that can not be captured properly.
# TODO: _unmask_unattended does not work either with torch.compile when using fullgraph=True. We should find a way to detect this case.
if query_length > 1 and not is_tracing:
expanded_4d_mask = AttentionMaskConverter._unmask_unattended(
expanded_4d_mask, attention_mask, unmasked_value=0.0
)
return expanded_4d_mask
def _prepare_4d_attention_mask(mask: torch.Tensor, dtype: torch.dtype, tgt_len: Optional[int] = None):
"""
Creates a non-causal 4D mask of shape `(batch_size, 1, query_length, key_value_length)` from a 2D mask of shape
`(batch_size, key_value_length)`
Args:
mask (`torch.Tensor` or `None`):
A 2D attention mask of shape `(batch_size, key_value_length)`
dtype (`torch.dtype`):
The torch dtype the created mask shall have.
tgt_len (`int`):
The target length or query length the created mask shall have.
"""
return AttentionMaskConverter._expand_mask(mask=mask, dtype=dtype, tgt_len=tgt_len)
def _prepare_4d_attention_mask_for_sdpa(mask: torch.Tensor, dtype: torch.dtype, tgt_len: Optional[int] = None):
"""
Creates a non-causal 4D mask of shape `(batch_size, 1, query_length, key_value_length)` from a 2D mask of shape
`(batch_size, key_value_length)`
Args:
mask (`torch.Tensor` or `None`):
A 2D attention mask of shape `(batch_size, key_value_length)`
dtype (`torch.dtype`):
The torch dtype the created mask shall have.
tgt_len (`int`):
The target length or query length the created mask shall have.
"""
batch_size, key_value_length = mask.shape
tgt_len = tgt_len if tgt_len is not None else key_value_length
# torch.jit.trace and torchdynamo with fullgraph=True are unable to capture the controlflow `is_causal=attention_mask is None and q_len > 1`
# used as an SDPA argument. We keep compatibility with these tracing tools by always using SDPA's `attn_mask` argument in case we are tracing.
# TODO: Fix this as well when using torchdynamo with fullgraph=True.
is_tracing = torch.jit.is_tracing()
if torch.all(mask == 1):
if is_tracing:
pass
elif tgt_len == 1:
# For query_length == 1, causal attention and bi-directional attention are the same.
return None
elif key_value_length == tgt_len:
return None
else:
# Unfortunately, for query_length > 1 and key_value_length != query_length, we can not generally ignore the attention mask, as SDPA causal mask generation
# may be wrong. We will set is_causal=False in SDPA and rely on Transformers attention_mask instead, hence not setting it to None here.
# Reference: https://github.com/pytorch/pytorch/issues/108108
return AttentionMaskConverter._expand_mask(mask=mask, dtype=dtype, tgt_len=tgt_len)
else:
return AttentionMaskConverter._expand_mask(mask=mask, dtype=dtype, tgt_len=tgt_len)
def _create_4d_causal_attention_mask(
input_shape: Union[torch.Size, Tuple, List],
dtype: torch.dtype,
device: torch.device,
past_key_values_length: int = 0,
sliding_window: Optional[int] = None,
) -> Optional[torch.Tensor]:
"""
Creates a causal 4D mask of shape `(batch_size, 1, query_length, key_value_length)`
Args:
input_shape (`tuple(int)` or `list(int)` or `torch.Size`):
The input shape should be a tuple that defines `(batch_size, query_length)`.
dtype (`torch.dtype`):
The torch dtype the created mask shall have.
device (`int`):
The torch device the created mask shall have.
sliding_window (`int`, *optional*):
If the model uses windowed attention, a sliding window should be passed.
"""
attn_mask_converter = AttentionMaskConverter(is_causal=True, sliding_window=sliding_window)
key_value_length = past_key_values_length + input_shape[-1]
attention_mask = attn_mask_converter.to_causal_4d(
input_shape[0], input_shape[-1], key_value_length, dtype=dtype, device=device
)
return attention_mask
| transformers/src/transformers/modeling_attn_mask_utils.py/0 | {
"file_path": "transformers/src/transformers/modeling_attn_mask_utils.py",
"repo_id": "transformers",
"token_count": 9638
} | 308 |
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from typing import TYPE_CHECKING
from ...utils import (
OptionalDependencyNotAvailable,
_LazyModule,
is_flax_available,
is_tf_available,
is_torch_available,
)
_import_structure = {
"auto_factory": ["get_values"],
"configuration_auto": ["ALL_PRETRAINED_CONFIG_ARCHIVE_MAP", "CONFIG_MAPPING", "MODEL_NAMES_MAPPING", "AutoConfig"],
"feature_extraction_auto": ["FEATURE_EXTRACTOR_MAPPING", "AutoFeatureExtractor"],
"image_processing_auto": ["IMAGE_PROCESSOR_MAPPING", "AutoImageProcessor"],
"processing_auto": ["PROCESSOR_MAPPING", "AutoProcessor"],
"tokenization_auto": ["TOKENIZER_MAPPING", "AutoTokenizer"],
}
try:
if not is_torch_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
_import_structure["modeling_auto"] = [
"MODEL_FOR_AUDIO_CLASSIFICATION_MAPPING",
"MODEL_FOR_AUDIO_FRAME_CLASSIFICATION_MAPPING",
"MODEL_FOR_AUDIO_XVECTOR_MAPPING",
"MODEL_FOR_BACKBONE_MAPPING",
"MODEL_FOR_CAUSAL_IMAGE_MODELING_MAPPING",
"MODEL_FOR_CAUSAL_LM_MAPPING",
"MODEL_FOR_CTC_MAPPING",
"MODEL_FOR_DOCUMENT_QUESTION_ANSWERING_MAPPING",
"MODEL_FOR_DEPTH_ESTIMATION_MAPPING",
"MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING",
"MODEL_FOR_IMAGE_SEGMENTATION_MAPPING",
"MODEL_FOR_IMAGE_TO_IMAGE_MAPPING",
"MODEL_FOR_INSTANCE_SEGMENTATION_MAPPING",
"MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING",
"MODEL_FOR_MASKED_LM_MAPPING",
"MODEL_FOR_MASK_GENERATION_MAPPING",
"MODEL_FOR_MULTIPLE_CHOICE_MAPPING",
"MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING",
"MODEL_FOR_OBJECT_DETECTION_MAPPING",
"MODEL_FOR_PRETRAINING_MAPPING",
"MODEL_FOR_QUESTION_ANSWERING_MAPPING",
"MODEL_FOR_SEMANTIC_SEGMENTATION_MAPPING",
"MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING",
"MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING",
"MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING",
"MODEL_FOR_TABLE_QUESTION_ANSWERING_MAPPING",
"MODEL_FOR_TEXT_ENCODING_MAPPING",
"MODEL_FOR_TEXT_TO_WAVEFORM_MAPPING",
"MODEL_FOR_TEXT_TO_SPECTROGRAM_MAPPING",
"MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING",
"MODEL_FOR_UNIVERSAL_SEGMENTATION_MAPPING",
"MODEL_FOR_VIDEO_CLASSIFICATION_MAPPING",
"MODEL_FOR_VISION_2_SEQ_MAPPING",
"MODEL_FOR_VISUAL_QUESTION_ANSWERING_MAPPING",
"MODEL_MAPPING",
"MODEL_WITH_LM_HEAD_MAPPING",
"MODEL_FOR_ZERO_SHOT_IMAGE_CLASSIFICATION_MAPPING",
"MODEL_FOR_ZERO_SHOT_OBJECT_DETECTION_MAPPING",
"MODEL_FOR_TIME_SERIES_CLASSIFICATION_MAPPING",
"MODEL_FOR_TIME_SERIES_REGRESSION_MAPPING",
"AutoModel",
"AutoBackbone",
"AutoModelForAudioClassification",
"AutoModelForAudioFrameClassification",
"AutoModelForAudioXVector",
"AutoModelForCausalLM",
"AutoModelForCTC",
"AutoModelForDepthEstimation",
"AutoModelForImageClassification",
"AutoModelForImageSegmentation",
"AutoModelForImageToImage",
"AutoModelForInstanceSegmentation",
"AutoModelForMaskGeneration",
"AutoModelForTextEncoding",
"AutoModelForMaskedImageModeling",
"AutoModelForMaskedLM",
"AutoModelForMultipleChoice",
"AutoModelForNextSentencePrediction",
"AutoModelForObjectDetection",
"AutoModelForPreTraining",
"AutoModelForQuestionAnswering",
"AutoModelForSemanticSegmentation",
"AutoModelForSeq2SeqLM",
"AutoModelForSequenceClassification",
"AutoModelForSpeechSeq2Seq",
"AutoModelForTableQuestionAnswering",
"AutoModelForTextToSpectrogram",
"AutoModelForTextToWaveform",
"AutoModelForTokenClassification",
"AutoModelForUniversalSegmentation",
"AutoModelForVideoClassification",
"AutoModelForVision2Seq",
"AutoModelForVisualQuestionAnswering",
"AutoModelForDocumentQuestionAnswering",
"AutoModelWithLMHead",
"AutoModelForZeroShotImageClassification",
"AutoModelForZeroShotObjectDetection",
]
try:
if not is_tf_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
_import_structure["modeling_tf_auto"] = [
"TF_MODEL_FOR_AUDIO_CLASSIFICATION_MAPPING",
"TF_MODEL_FOR_CAUSAL_LM_MAPPING",
"TF_MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING",
"TF_MODEL_FOR_MASK_GENERATION_MAPPING",
"TF_MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING",
"TF_MODEL_FOR_MASKED_LM_MAPPING",
"TF_MODEL_FOR_MULTIPLE_CHOICE_MAPPING",
"TF_MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING",
"TF_MODEL_FOR_PRETRAINING_MAPPING",
"TF_MODEL_FOR_QUESTION_ANSWERING_MAPPING",
"TF_MODEL_FOR_DOCUMENT_QUESTION_ANSWERING_MAPPING",
"TF_MODEL_FOR_SEMANTIC_SEGMENTATION_MAPPING",
"TF_MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING",
"TF_MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING",
"TF_MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING",
"TF_MODEL_FOR_TABLE_QUESTION_ANSWERING_MAPPING",
"TF_MODEL_FOR_TEXT_ENCODING_MAPPING",
"TF_MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING",
"TF_MODEL_FOR_VISION_2_SEQ_MAPPING",
"TF_MODEL_FOR_ZERO_SHOT_IMAGE_CLASSIFICATION_MAPPING",
"TF_MODEL_MAPPING",
"TF_MODEL_WITH_LM_HEAD_MAPPING",
"TFAutoModel",
"TFAutoModelForAudioClassification",
"TFAutoModelForCausalLM",
"TFAutoModelForImageClassification",
"TFAutoModelForMaskedImageModeling",
"TFAutoModelForMaskedLM",
"TFAutoModelForMaskGeneration",
"TFAutoModelForMultipleChoice",
"TFAutoModelForNextSentencePrediction",
"TFAutoModelForPreTraining",
"TFAutoModelForDocumentQuestionAnswering",
"TFAutoModelForQuestionAnswering",
"TFAutoModelForSemanticSegmentation",
"TFAutoModelForSeq2SeqLM",
"TFAutoModelForSequenceClassification",
"TFAutoModelForSpeechSeq2Seq",
"TFAutoModelForTableQuestionAnswering",
"TFAutoModelForTextEncoding",
"TFAutoModelForTokenClassification",
"TFAutoModelForVision2Seq",
"TFAutoModelForZeroShotImageClassification",
"TFAutoModelWithLMHead",
]
try:
if not is_flax_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
_import_structure["modeling_flax_auto"] = [
"FLAX_MODEL_FOR_AUDIO_CLASSIFICATION_MAPPING",
"FLAX_MODEL_FOR_CAUSAL_LM_MAPPING",
"FLAX_MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING",
"FLAX_MODEL_FOR_MASKED_LM_MAPPING",
"FLAX_MODEL_FOR_MULTIPLE_CHOICE_MAPPING",
"FLAX_MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING",
"FLAX_MODEL_FOR_PRETRAINING_MAPPING",
"FLAX_MODEL_FOR_QUESTION_ANSWERING_MAPPING",
"FLAX_MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING",
"FLAX_MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING",
"FLAX_MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING",
"FLAX_MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING",
"FLAX_MODEL_FOR_VISION_2_SEQ_MAPPING",
"FLAX_MODEL_MAPPING",
"FlaxAutoModel",
"FlaxAutoModelForCausalLM",
"FlaxAutoModelForImageClassification",
"FlaxAutoModelForMaskedLM",
"FlaxAutoModelForMultipleChoice",
"FlaxAutoModelForNextSentencePrediction",
"FlaxAutoModelForPreTraining",
"FlaxAutoModelForQuestionAnswering",
"FlaxAutoModelForSeq2SeqLM",
"FlaxAutoModelForSequenceClassification",
"FlaxAutoModelForSpeechSeq2Seq",
"FlaxAutoModelForTokenClassification",
"FlaxAutoModelForVision2Seq",
]
if TYPE_CHECKING:
from .auto_factory import get_values
from .configuration_auto import ALL_PRETRAINED_CONFIG_ARCHIVE_MAP, CONFIG_MAPPING, MODEL_NAMES_MAPPING, AutoConfig
from .feature_extraction_auto import FEATURE_EXTRACTOR_MAPPING, AutoFeatureExtractor
from .image_processing_auto import IMAGE_PROCESSOR_MAPPING, AutoImageProcessor
from .processing_auto import PROCESSOR_MAPPING, AutoProcessor
from .tokenization_auto import TOKENIZER_MAPPING, AutoTokenizer
try:
if not is_torch_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
from .modeling_auto import (
MODEL_FOR_AUDIO_CLASSIFICATION_MAPPING,
MODEL_FOR_AUDIO_FRAME_CLASSIFICATION_MAPPING,
MODEL_FOR_AUDIO_XVECTOR_MAPPING,
MODEL_FOR_BACKBONE_MAPPING,
MODEL_FOR_CAUSAL_IMAGE_MODELING_MAPPING,
MODEL_FOR_CAUSAL_LM_MAPPING,
MODEL_FOR_CTC_MAPPING,
MODEL_FOR_DEPTH_ESTIMATION_MAPPING,
MODEL_FOR_DOCUMENT_QUESTION_ANSWERING_MAPPING,
MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING,
MODEL_FOR_IMAGE_SEGMENTATION_MAPPING,
MODEL_FOR_IMAGE_TO_IMAGE_MAPPING,
MODEL_FOR_INSTANCE_SEGMENTATION_MAPPING,
MODEL_FOR_MASK_GENERATION_MAPPING,
MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING,
MODEL_FOR_MASKED_LM_MAPPING,
MODEL_FOR_MULTIPLE_CHOICE_MAPPING,
MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING,
MODEL_FOR_OBJECT_DETECTION_MAPPING,
MODEL_FOR_PRETRAINING_MAPPING,
MODEL_FOR_QUESTION_ANSWERING_MAPPING,
MODEL_FOR_SEMANTIC_SEGMENTATION_MAPPING,
MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING,
MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING,
MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING,
MODEL_FOR_TABLE_QUESTION_ANSWERING_MAPPING,
MODEL_FOR_TEXT_ENCODING_MAPPING,
MODEL_FOR_TEXT_TO_SPECTROGRAM_MAPPING,
MODEL_FOR_TEXT_TO_WAVEFORM_MAPPING,
MODEL_FOR_TIME_SERIES_CLASSIFICATION_MAPPING,
MODEL_FOR_TIME_SERIES_REGRESSION_MAPPING,
MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING,
MODEL_FOR_UNIVERSAL_SEGMENTATION_MAPPING,
MODEL_FOR_VIDEO_CLASSIFICATION_MAPPING,
MODEL_FOR_VISION_2_SEQ_MAPPING,
MODEL_FOR_VISUAL_QUESTION_ANSWERING_MAPPING,
MODEL_FOR_ZERO_SHOT_IMAGE_CLASSIFICATION_MAPPING,
MODEL_FOR_ZERO_SHOT_OBJECT_DETECTION_MAPPING,
MODEL_MAPPING,
MODEL_WITH_LM_HEAD_MAPPING,
AutoBackbone,
AutoModel,
AutoModelForAudioClassification,
AutoModelForAudioFrameClassification,
AutoModelForAudioXVector,
AutoModelForCausalLM,
AutoModelForCTC,
AutoModelForDepthEstimation,
AutoModelForDocumentQuestionAnswering,
AutoModelForImageClassification,
AutoModelForImageSegmentation,
AutoModelForImageToImage,
AutoModelForInstanceSegmentation,
AutoModelForMaskedImageModeling,
AutoModelForMaskedLM,
AutoModelForMaskGeneration,
AutoModelForMultipleChoice,
AutoModelForNextSentencePrediction,
AutoModelForObjectDetection,
AutoModelForPreTraining,
AutoModelForQuestionAnswering,
AutoModelForSemanticSegmentation,
AutoModelForSeq2SeqLM,
AutoModelForSequenceClassification,
AutoModelForSpeechSeq2Seq,
AutoModelForTableQuestionAnswering,
AutoModelForTextEncoding,
AutoModelForTextToSpectrogram,
AutoModelForTextToWaveform,
AutoModelForTokenClassification,
AutoModelForUniversalSegmentation,
AutoModelForVideoClassification,
AutoModelForVision2Seq,
AutoModelForVisualQuestionAnswering,
AutoModelForZeroShotImageClassification,
AutoModelForZeroShotObjectDetection,
AutoModelWithLMHead,
)
try:
if not is_tf_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
from .modeling_tf_auto import (
TF_MODEL_FOR_AUDIO_CLASSIFICATION_MAPPING,
TF_MODEL_FOR_CAUSAL_LM_MAPPING,
TF_MODEL_FOR_DOCUMENT_QUESTION_ANSWERING_MAPPING,
TF_MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING,
TF_MODEL_FOR_MASK_GENERATION_MAPPING,
TF_MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING,
TF_MODEL_FOR_MASKED_LM_MAPPING,
TF_MODEL_FOR_MULTIPLE_CHOICE_MAPPING,
TF_MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING,
TF_MODEL_FOR_PRETRAINING_MAPPING,
TF_MODEL_FOR_QUESTION_ANSWERING_MAPPING,
TF_MODEL_FOR_SEMANTIC_SEGMENTATION_MAPPING,
TF_MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING,
TF_MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING,
TF_MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING,
TF_MODEL_FOR_TABLE_QUESTION_ANSWERING_MAPPING,
TF_MODEL_FOR_TEXT_ENCODING_MAPPING,
TF_MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING,
TF_MODEL_FOR_VISION_2_SEQ_MAPPING,
TF_MODEL_FOR_ZERO_SHOT_IMAGE_CLASSIFICATION_MAPPING,
TF_MODEL_MAPPING,
TF_MODEL_WITH_LM_HEAD_MAPPING,
TFAutoModel,
TFAutoModelForAudioClassification,
TFAutoModelForCausalLM,
TFAutoModelForDocumentQuestionAnswering,
TFAutoModelForImageClassification,
TFAutoModelForMaskedImageModeling,
TFAutoModelForMaskedLM,
TFAutoModelForMaskGeneration,
TFAutoModelForMultipleChoice,
TFAutoModelForNextSentencePrediction,
TFAutoModelForPreTraining,
TFAutoModelForQuestionAnswering,
TFAutoModelForSemanticSegmentation,
TFAutoModelForSeq2SeqLM,
TFAutoModelForSequenceClassification,
TFAutoModelForSpeechSeq2Seq,
TFAutoModelForTableQuestionAnswering,
TFAutoModelForTextEncoding,
TFAutoModelForTokenClassification,
TFAutoModelForVision2Seq,
TFAutoModelForZeroShotImageClassification,
TFAutoModelWithLMHead,
)
try:
if not is_flax_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
from .modeling_flax_auto import (
FLAX_MODEL_FOR_AUDIO_CLASSIFICATION_MAPPING,
FLAX_MODEL_FOR_CAUSAL_LM_MAPPING,
FLAX_MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING,
FLAX_MODEL_FOR_MASKED_LM_MAPPING,
FLAX_MODEL_FOR_MULTIPLE_CHOICE_MAPPING,
FLAX_MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING,
FLAX_MODEL_FOR_PRETRAINING_MAPPING,
FLAX_MODEL_FOR_QUESTION_ANSWERING_MAPPING,
FLAX_MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING,
FLAX_MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING,
FLAX_MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING,
FLAX_MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING,
FLAX_MODEL_FOR_VISION_2_SEQ_MAPPING,
FLAX_MODEL_MAPPING,
FlaxAutoModel,
FlaxAutoModelForCausalLM,
FlaxAutoModelForImageClassification,
FlaxAutoModelForMaskedLM,
FlaxAutoModelForMultipleChoice,
FlaxAutoModelForNextSentencePrediction,
FlaxAutoModelForPreTraining,
FlaxAutoModelForQuestionAnswering,
FlaxAutoModelForSeq2SeqLM,
FlaxAutoModelForSequenceClassification,
FlaxAutoModelForSpeechSeq2Seq,
FlaxAutoModelForTokenClassification,
FlaxAutoModelForVision2Seq,
)
else:
import sys
sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure, module_spec=__spec__)
| transformers/src/transformers/models/auto/__init__.py/0 | {
"file_path": "transformers/src/transformers/models/auto/__init__.py",
"repo_id": "transformers",
"token_count": 8231
} | 309 |
# coding=utf-8
# Copyright 2023 The Suno AI Authors and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" BARK model generation configuration"""
import copy
from typing import Dict
from ...generation.configuration_utils import GenerationConfig
from ...utils import logging
logger = logging.get_logger(__name__)
class BarkSemanticGenerationConfig(GenerationConfig):
model_type = "semantic"
def __init__(
self,
eos_token_id=10_000,
renormalize_logits=True,
max_new_tokens=768,
output_scores=False,
return_dict_in_generate=False,
output_hidden_states=False,
output_attentions=False,
temperature=1.0,
do_sample=False,
text_encoding_offset=10_048,
text_pad_token=129_595,
semantic_infer_token=129_599,
semantic_vocab_size=10_000,
max_input_semantic_length=256,
semantic_rate_hz=49.9,
min_eos_p=None,
**kwargs,
):
"""Class that holds a generation configuration for [`BarkSemanticModel`].
This configuration inherit from [`GenerationConfig`] and can be used to control the model generation. Read the
documentation from [`GenerationConfig`] for more information.
Args:
eos_token_id (`int`, *optional*, defaults to 10_000):
The id of the *end-of-sequence* token.
renormalize_logits (`bool`, *optional*, defaults to `True`):
Whether to renormalize the logits after applying all the logits processors or warpers (including the
custom ones). It's highly recommended to set this flag to `True` as the search algorithms suppose the
score logits are normalized but some logit processors or warpers break the normalization.
max_new_tokens (`int`, *optional*, defaults to 768):
The maximum numbers of tokens to generate, ignoring the number of tokens in the prompt.
output_scores (`bool`, *optional*, defaults to `False`):
Whether or not to return the prediction scores. See `scores` under returned tensors for more details.
return_dict_in_generate (`bool`, *optional*, defaults to `False`):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
output_hidden_states (`bool`, *optional*, defaults to `False`):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
for more details.
output_attentions (`bool`, *optional*, defaults to `False`):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more details.
temperature (`float`, *optional*, defaults to 1.0):
The value used to modulate the next token probabilities.
do_sample (`bool`, *optional*, defaults to `False`):
Whether or not to use sampling ; use greedy decoding otherwise.
text_encoding_offset (`int`, *optional*, defaults to 10_048):
Text encoding offset.
text_pad_token (`int`, *optional*, defaults to 129_595):
Text pad token.
semantic_infer_token (`int`, *optional*, defaults to 129_599):
Semantic infer token.
semantic_vocab_size (`int`, *optional*, defaults to 10_000):
Semantic vocab size.
max_input_semantic_length (`int`, *optional*, defaults to 256):
Max length of semantic input vector.
semantic_rate_hz (`float`, *optional*, defaults to 49.9):
Semantic rate in Hertz.
min_eos_p (`float`, *optional*):
Minimum threshold of the probability of the EOS token for it to be sampled. This is an early stopping
strategy to mitigate potential unwanted generations at the end of a prompt. The original implementation
suggests a default value of 0.2.
"""
super().__init__(
temperature=temperature,
do_sample=do_sample,
eos_token_id=eos_token_id,
renormalize_logits=renormalize_logits,
max_new_tokens=max_new_tokens,
output_scores=output_scores,
return_dict_in_generate=return_dict_in_generate,
output_hidden_states=output_hidden_states,
output_attentions=output_attentions,
**kwargs,
)
self.text_encoding_offset = text_encoding_offset
self.text_pad_token = text_pad_token
self.semantic_pad_token = eos_token_id
self.semantic_infer_token = semantic_infer_token
self.semantic_vocab_size = semantic_vocab_size
self.max_input_semantic_length = max_input_semantic_length
self.semantic_rate_hz = semantic_rate_hz
self.min_eos_p = min_eos_p
class BarkCoarseGenerationConfig(GenerationConfig):
model_type = "coarse_acoustics"
def __init__(
self,
renormalize_logits=True,
output_scores=False,
return_dict_in_generate=False,
output_hidden_states=False,
output_attentions=False,
temperature=1.0,
do_sample=False,
coarse_semantic_pad_token=12_048,
coarse_rate_hz=75,
n_coarse_codebooks=2,
coarse_infer_token=12_050,
max_coarse_input_length=256,
max_coarse_history: int = 630,
sliding_window_len: int = 60,
**kwargs,
):
"""Class that holds a generation configuration for [`BarkCoarseModel`].
This configuration inherit from [`GenerationConfig`] and can be used to control the model generation. Read the
documentation from [`GenerationConfig`] for more information.
Args:
renormalize_logits (`bool`, *optional*, defaults to `True`):
Whether to renormalize the logits after applying all the logits processors or warpers (including the
custom ones). It's highly recommended to set this flag to `True` as the search algorithms suppose the
score logits are normalized but some logit processors or warpers break the normalization.
output_scores (`bool`, *optional*, defaults to `False`):
Whether or not to return the prediction scores. See `scores` under returned tensors for more details.
return_dict_in_generate (`bool`, *optional*, defaults to `False`):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
output_hidden_states (`bool`, *optional*, defaults to `False`):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
for more details.
output_attentions (`bool`, *optional*, defaults to `False`):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more details.
temperature (`float`, *optional*, defaults to 1.0):
The value used to modulate the next token probabilities.
do_sample (`bool`, *optional*, defaults to `False`):
Whether or not to use sampling ; use greedy decoding otherwise.
coarse_semantic_pad_token (`int`, *optional*, defaults to 12_048):
Coarse semantic pad token.
coarse_rate_hz (`int`, *optional*, defaults to 75):
Coarse rate in Hertz.
n_coarse_codebooks (`int`, *optional*, defaults to 2):
Number of coarse codebooks.
coarse_infer_token (`int`, *optional*, defaults to 12_050):
Coarse infer token.
max_coarse_input_length (`int`, *optional*, defaults to 256):
Max length of input coarse vector.
max_coarse_history (`int`, *optional*, defaults to 630):
Max length of the output of the coarse acoustics model used in the fine generation step.
sliding_window_len (`int`, *optional*, defaults to 60):
The coarse generation step uses a sliding window to generate raw audio.
"""
super().__init__(
temperature=temperature,
do_sample=do_sample,
renormalize_logits=renormalize_logits,
output_scores=output_scores,
return_dict_in_generate=return_dict_in_generate,
output_hidden_states=output_hidden_states,
output_attentions=output_attentions,
**kwargs,
)
self.coarse_semantic_pad_token = coarse_semantic_pad_token
self.coarse_rate_hz = coarse_rate_hz
self.n_coarse_codebooks = n_coarse_codebooks
self.coarse_infer_token = coarse_infer_token
self.max_coarse_input_length = max_coarse_input_length
self.max_coarse_history = max_coarse_history
self.sliding_window_len = sliding_window_len
class BarkFineGenerationConfig(GenerationConfig):
model_type = "fine_acoustics"
def __init__(
self,
temperature=1.0,
max_fine_history_length=512,
max_fine_input_length=1024,
n_fine_codebooks=8,
**kwargs,
):
"""Class that holds a generation configuration for [`BarkFineModel`].
[`BarkFineModel`] is an autoencoder model, so should not usually be used for generation. However, under the
hood, it uses `temperature` when used by [`BarkModel`]
This configuration inherit from [`GenerationConfig`] and can be used to control the model generation. Read the
documentation from [`GenerationConfig`] for more information.
Args:
temperature (`float`, *optional*):
The value used to modulate the next token probabilities.
max_fine_history_length (`int`, *optional*, defaults to 512):
Max length of the fine history vector.
max_fine_input_length (`int`, *optional*, defaults to 1024):
Max length of fine input vector.
n_fine_codebooks (`int`, *optional*, defaults to 8):
Number of codebooks used.
"""
super().__init__(temperature=temperature)
self.max_fine_history_length = max_fine_history_length
self.max_fine_input_length = max_fine_input_length
self.n_fine_codebooks = n_fine_codebooks
def validate(self, **kwargs):
"""
Overrides GenerationConfig.validate because BarkFineGenerationConfig don't use any parameters outside
temperature.
"""
pass
class BarkGenerationConfig(GenerationConfig):
model_type = "bark"
is_composition = True
# TODO (joao): nested from_dict
def __init__(
self,
semantic_config: Dict = None,
coarse_acoustics_config: Dict = None,
fine_acoustics_config: Dict = None,
sample_rate=24_000,
codebook_size=1024,
**kwargs,
):
"""Class that holds a generation configuration for [`BarkModel`].
The [`BarkModel`] does not have a `generate` method, but uses this class to generate speeches with a nested
[`BarkGenerationConfig`] which uses [`BarkSemanticGenerationConfig`], [`BarkCoarseGenerationConfig`],
[`BarkFineGenerationConfig`].
This configuration inherit from [`GenerationConfig`] and can be used to control the model generation. Read the
documentation from [`GenerationConfig`] for more information.
Args:
semantic_config (`Dict`, *optional*):
Semantic generation configuration.
coarse_acoustics_config (`Dict`, *optional*):
Coarse generation configuration.
fine_acoustics_config (`Dict`, *optional*):
Fine generation configuration.
sample_rate (`int`, *optional*, defaults to 24_000):
Sample rate.
codebook_size (`int`, *optional*, defaults to 1024):
Vector length for each codebook.
"""
if semantic_config is None:
semantic_config = {}
logger.info("semantic_config is None. initializing the semantic model with default values.")
if coarse_acoustics_config is None:
coarse_acoustics_config = {}
logger.info("coarse_acoustics_config is None. initializing the coarse model with default values.")
if fine_acoustics_config is None:
fine_acoustics_config = {}
logger.info("fine_acoustics_config is None. initializing the fine model with default values.")
self.semantic_config = BarkSemanticGenerationConfig(**semantic_config)
self.coarse_acoustics_config = BarkCoarseGenerationConfig(**coarse_acoustics_config)
self.fine_acoustics_config = BarkFineGenerationConfig(**fine_acoustics_config)
self.sample_rate = sample_rate
self.codebook_size = codebook_size
@classmethod
def from_sub_model_configs(
cls,
semantic_config: BarkSemanticGenerationConfig,
coarse_acoustics_config: BarkCoarseGenerationConfig,
fine_acoustics_config: BarkFineGenerationConfig,
**kwargs,
):
r"""
Instantiate a [`BarkGenerationConfig`] (or a derived class) from bark sub-models generation configuration.
Returns:
[`BarkGenerationConfig`]: An instance of a configuration object
"""
return cls(
semantic_config=semantic_config.to_dict(),
coarse_acoustics_config=coarse_acoustics_config.to_dict(),
fine_acoustics_config=fine_acoustics_config.to_dict(),
**kwargs,
)
def to_dict(self):
"""
Serializes this instance to a Python dictionary. Override the default [`~PretrainedConfig.to_dict`].
Returns:
`Dict[str, any]`: Dictionary of all the attributes that make up this configuration instance,
"""
output = copy.deepcopy(self.__dict__)
output["semantic_config"] = self.semantic_config.to_dict()
output["coarse_acoustics_config"] = self.coarse_acoustics_config.to_dict()
output["fine_acoustics_config"] = self.fine_acoustics_config.to_dict()
output["model_type"] = self.__class__.model_type
return output
| transformers/src/transformers/models/bark/generation_configuration_bark.py/0 | {
"file_path": "transformers/src/transformers/models/bark/generation_configuration_bark.py",
"repo_id": "transformers",
"token_count": 6156
} | 310 |
# Copyright 2021 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from typing import TYPE_CHECKING
from ...utils import (
OptionalDependencyNotAvailable,
_LazyModule,
is_flax_available,
is_torch_available,
is_vision_available,
)
_import_structure = {"configuration_beit": ["BEIT_PRETRAINED_CONFIG_ARCHIVE_MAP", "BeitConfig", "BeitOnnxConfig"]}
try:
if not is_vision_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
_import_structure["feature_extraction_beit"] = ["BeitFeatureExtractor"]
_import_structure["image_processing_beit"] = ["BeitImageProcessor"]
try:
if not is_torch_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
_import_structure["modeling_beit"] = [
"BEIT_PRETRAINED_MODEL_ARCHIVE_LIST",
"BeitForImageClassification",
"BeitForMaskedImageModeling",
"BeitForSemanticSegmentation",
"BeitModel",
"BeitPreTrainedModel",
"BeitBackbone",
]
try:
if not is_flax_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
_import_structure["modeling_flax_beit"] = [
"FlaxBeitForImageClassification",
"FlaxBeitForMaskedImageModeling",
"FlaxBeitModel",
"FlaxBeitPreTrainedModel",
]
if TYPE_CHECKING:
from .configuration_beit import BEIT_PRETRAINED_CONFIG_ARCHIVE_MAP, BeitConfig, BeitOnnxConfig
try:
if not is_vision_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
from .feature_extraction_beit import BeitFeatureExtractor
from .image_processing_beit import BeitImageProcessor
try:
if not is_torch_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
from .modeling_beit import (
BEIT_PRETRAINED_MODEL_ARCHIVE_LIST,
BeitBackbone,
BeitForImageClassification,
BeitForMaskedImageModeling,
BeitForSemanticSegmentation,
BeitModel,
BeitPreTrainedModel,
)
try:
if not is_flax_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
from .modeling_flax_beit import (
FlaxBeitForImageClassification,
FlaxBeitForMaskedImageModeling,
FlaxBeitModel,
FlaxBeitPreTrainedModel,
)
else:
import sys
sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure, module_spec=__spec__)
| transformers/src/transformers/models/beit/__init__.py/0 | {
"file_path": "transformers/src/transformers/models/beit/__init__.py",
"repo_id": "transformers",
"token_count": 1337
} | 311 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.