
Id
stringlengths 1
6
| PostTypeId
stringclasses 7
values | AcceptedAnswerId
stringlengths 1
6
⌀ | ParentId
stringlengths 1
6
⌀ | Score
stringlengths 1
4
| ViewCount
stringlengths 1
7
⌀ | Body
stringlengths 0
38.7k
| Title
stringlengths 15
150
⌀ | ContentLicense
stringclasses 3
values | FavoriteCount
stringclasses 3
values | CreationDate
stringlengths 23
23
| LastActivityDate
stringlengths 23
23
| LastEditDate
stringlengths 23
23
⌀ | LastEditorUserId
stringlengths 1
6
⌀ | OwnerUserId
stringlengths 1
6
⌀ | Tags
sequence |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
321 | 1 | null | null | 15 | 4663 | There is a variant of boosting called [gentleboost](http://dx.doi.org/10.1214/aos/1016218223). How does gentle boosting differ from the better-known [AdaBoost](http://en.wikipedia.org/wiki/AdaBoost)?
| How does gentle boosting differ from AdaBoost? | CC BY-SA 2.5 | null | 2010-07-20T16:01:25.590 | 2010-09-08T17:30:41.103 | 2010-07-20T19:25:13.293 | 220 | 220 | [
"machine-learning",
"boosting"
] |
322 | 1 | 338 | null | 19 | 4213 | I'm looking for a book or online resource that explains different kinds of entropy such as Sample Entropy and Shannon Entropy and their advantages and disadvantages.
Can someone point me in the right direction?
| Good introduction into different kinds of entropy | CC BY-SA 2.5 | null | 2010-07-20T16:03:40.877 | 2017-09-02T20:13:27.850 | 2017-09-02T20:13:27.850 | 11887 | 3807 | [
"references",
"entropy"
] |
323 | 2 | null | 114 | 22 | null | [Statistical Modeling, Causal Inference, and Social Science](http://www.stat.columbia.edu/~cook/movabletype/mlm/) from Andrew Gelman is a good blog.
| null | CC BY-SA 2.5 | null | 2010-07-20T16:10:16.080 | 2010-07-20T16:10:16.080 | null | null | 3807 | null |
324 | 2 | null | 114 | 9 | null | [Darren Wilkinson's research blog](http://darrenjw.wordpress.com/)
| null | CC BY-SA 2.5 | null | 2010-07-20T16:12:08.700 | 2010-07-20T16:12:08.700 | null | null | 3807 | null |
326 | 2 | null | 114 | 12 | null | [XI'AN'S OG](http://xianblog.wordpress.com/)
| null | CC BY-SA 2.5 | null | 2010-07-20T16:13:03.643 | 2010-07-20T16:13:03.643 | null | null | 3807 | null |
327 | 2 | null | 62 | 3 | null | Malcom Gladewell analyses the problem in the book Outliers by analyzing Hockey Players.
| null | CC BY-SA 2.5 | null | 2010-07-20T16:19:51.750 | 2010-07-20T16:19:51.750 | null | null | 3807 | null |
328 | 1 | 329 | null | 9 | 4012 | I realize that the statistical analysis of financial data is a huge topic, but that is exactly why it is necessary for me to ask my question as I try to break into the world of financial analysis.
As at this point I know next to nothing about the subject, the results of my google searches are overwhelming. Many of the matches advocate learning specialized tools or the R programming language. While I will learn these when they are necessary, I'm first interested in books, articles or any other resources that explain modern methods of statistical analysis specifically for financial data. I assume there are a number of different wildly varied methods for analyzing data, so ideally I'm seeking an overview of the various methods that are practically applicable. I'd like something that utilizes real world examples that a beginner is capable of grasping but that aren't overly simplistic.
What are some good resources for learning bout the statistical analysis of financial data?
| Resources for learning about the Statistical Analysis of Financial Data | CC BY-SA 2.5 | null | 2010-07-20T16:27:08.763 | 2012-08-27T15:59:23.840 | 2010-09-17T20:53:00.430 | null | 75 | [
"references",
"finance"
] |
329 | 2 | null | 328 | 14 | null | You might start with this [series of lectures by Robert Shiller at Yale](http://oyc.yale.edu/economics/financial-markets/). He gives a good overview of the field.
My favorite books on the subject:
- I strongly recommend starting with Statistics and Finance, by David Ruppert (the R code for the book is available). This is a great introduction and covers the basics of finance and statistics so it's appropriate as a first book.
- Modeling Financial Time Series with S-Plus, by Eric Zivot
- Analysis of Financial Time Series, by Ruey Tsay
- Time Series Analysis, by Jonathan D. Cryer
Beyond that, you may want some general resources, and the "bible" of finance is [Options, Futures, and Other Derivatives](http://www.rotman.utoronto.ca/~hull/ofod/) by John Hull.
Lastly, in terms of some good general books, you might start with these two:
- A Random Walk Down Wall Street
- Against the Gods: The Remarkable Story of Risk
| null | CC BY-SA 2.5 | null | 2010-07-20T16:31:26.140 | 2010-07-20T16:49:17.697 | 2010-07-20T16:49:17.697 | 5 | 5 | null |
331 | 2 | null | 305 | 6 | null | Because exact results are preferable to approximations, and avoid odd edge cases where the approximation may lead to a different result than the exact method.
The Welch method isn't a quicker way to do any old t-test, it's a tractable approximation to an otherwise very hard problem: how to construct a t-test under unequal variances. The equal-variance case is well-understood, simple, and exact, and therefore should always be used when possible.
| null | CC BY-SA 2.5 | null | 2010-07-20T16:43:42.850 | 2010-07-20T16:43:42.850 | null | null | 61 | null |
333 | 2 | null | 328 | 3 | null | Ed Thorpe started the whole statistical arbitrage thing. He has a website, and some good articles.
[http://edwardothorp.com/](http://edwardothorp.com/)
You should also read Nassim Taleb's "Fooled By Randomness".
Also, go on Google Scholar and read the top articles by Markowitz, Sharpe, Fama, Modigliani. If you don't have full access, go to the nearest college and get a community library card.
| null | CC BY-SA 2.5 | null | 2010-07-20T17:17:21.007 | 2010-08-13T18:01:09.700 | 2010-08-13T18:01:09.700 | 74 | 74 | null |
337 | 2 | null | 322 | 2 | null | The entropy is only one (as a concept) -- the amount of information needed to describe some system; there are only many its generalizations. Sample entropy is only some entropy-like descriptor used in heart rate analysis.
| null | CC BY-SA 2.5 | null | 2010-07-20T17:20:41.267 | 2010-07-20T17:36:23.330 | 2010-07-20T17:36:23.330 | null | null | null |
338 | 2 | null | 322 | 10 | null | Cover and Thomas's book [Elements of Information Theory](http://rads.stackoverflow.com/amzn/click/0471062596) is a good source on entropy and its applications, although I don't know that it addresses exactly the issues you have in mind.
| null | CC BY-SA 2.5 | null | 2010-07-20T17:22:01.153 | 2010-09-02T09:52:44.180 | 2010-09-02T09:52:44.180 | 8 | 89 | null |
339 | 2 | null | 26 | 1 | null | If the information required is the distribution of data about the mean, standard deviation comes in handy.
The sum of the difference of each value from the mean is zero (obviously, since the value are evenly spread around the mean), hence we square each difference so as to convert negative values to positive, sum them across the population, and take their square root. This value is then divided by the number of samples (or, the size of the population). This gives the standard deviation.
| null | CC BY-SA 2.5 | null | 2010-07-20T17:31:49.313 | 2010-07-20T17:31:49.313 | null | null | 218 | null |
340 | 2 | null | 269 | 9 | null | The population is everything in the group of study. For example, if you are studying the price of Apple's shares, it is the historical, current, and even all future stock prices. Or, if you run an egg factory, it is all the eggs made by the factory.
You don't always have to sample, and do statistical tests. If your population is your immediate living family, you don't need to sample, as the population is small.
Sampling is popular for a variety of reasons:
- it is cheaper than a census (sampling the whole population)
- you don't have access to future data, so must sample the past
- you have to destroy some items by testing them, and don't want to destroy them all (say, eggs)
| null | CC BY-SA 2.5 | null | 2010-07-20T17:41:00.267 | 2010-07-20T17:41:00.267 | null | null | 74 | null |
341 | 1 | 385 | null | 11 | 25748 | Do you think that unbalanced classes is a big problem for k-nearest neighbor? If so, do you know any smart way to handle this?
| kNN and unbalanced classes | CC BY-SA 2.5 | null | 2010-07-20T18:12:29.550 | 2019-03-03T17:00:40.187 | 2010-07-21T06:50:32.437 | 190 | null | [
"k-nearest-neighbour",
"unbalanced-classes"
] |
342 | 2 | null | 134 | 7 | null | If you're willing to tolerate an approximation, there are other methods. For example, one approximation is a value whose rank is within some (user specified) distance from the true median. For example, the median has (normalized) rank 0.5, and if you specify an error term of 10%, you'd want an answer that has rank between 0.45 and 0.55.
If such an answer is appropriate, then there are many solutions that can work on sliding windows of data. The basic idea is to maintain a sample of the data of a certain size (roughly 1/error term) and compute the median on this sample. It can be shown that with high probability, regardless of the nature of the input, the resulting median satisfies the properties I mentioned above.
Thus, the main question is how to maintain a running sample of the data of a certain size, and there are many approaches for that, including the technique known as reservoir sampling. For example, this paper: [http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.24.7136](http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.24.7136)
| null | CC BY-SA 2.5 | null | 2010-07-20T18:13:44.820 | 2010-07-20T18:13:44.820 | null | null | 139 | null |
343 | 2 | null | 258 | 3 | null | [kNN](http://en.wikipedia.org/wiki/K-nearest_neighbor_algorithm)
| null | CC BY-SA 2.5 | null | 2010-07-20T18:16:17.513 | 2010-07-20T18:16:17.513 | null | null | null | null |
344 | 2 | null | 258 | 3 | null | [Naive Bayes](http://en.wikipedia.org/wiki/Naive_bayes) and [Random Naive Bays](http://en.wikipedia.org/wiki/Random_naive_Bayes)
| null | CC BY-SA 2.5 | null | 2010-07-20T18:17:25.903 | 2010-07-20T18:17:25.903 | null | null | null | null |
345 | 2 | null | 328 | 1 | null | Also good is "Statistical Analysis of Financial Data in S-PLUS" by Rene A. Carmona
| null | CC BY-SA 2.5 | null | 2010-07-20T19:08:50.867 | 2010-07-20T19:08:50.867 | null | null | 247 | null |
346 | 1 | 428 | null | 57 | 30622 | I'm looking for a good algorithm (meaning minimal computation, minimal storage requirements) to estimate the median of a data set that is too large to store, such that each value can only be read once (unless you explicitly store that value). There are no bounds on the data that can be assumed.
Approximations are fine, as long as the accuracy is known.
Any pointers?
| What is a good algorithm for estimating the median of a huge read-once data set? | CC BY-SA 2.5 | null | 2010-07-20T19:21:16.220 | 2020-10-30T01:01:30.200 | 2020-05-25T15:20:58.260 | 1352 | 247 | [
"algorithms",
"median",
"large-data",
"online-algorithms"
] |
347 | 2 | null | 75 | 2 | null | I found this rather helpful: [http://cran.r-project.org/doc/contrib/Verzani-SimpleR.pdf](http://cran.r-project.org/doc/contrib/Verzani-SimpleR.pdf)
| null | CC BY-SA 2.5 | null | 2010-07-20T19:50:57.100 | 2010-07-20T19:50:57.100 | null | null | 15 | null |
349 | 2 | null | 346 | 14 | null | How about something like a binning procedure? Assume (for illustration purposes) that you know that the values are between 1 and 1 million. Set up N bins, of size S. So if S=10000, you'd have 100 bins, corresponding to values [1:10000, 10001:20000, ... , 990001:1000000]
Then, step through the values. Instead of storing each value, just increment the counter in the appropriate bin. Using the midpoint of each bin as an estimate, you can make a reasonable approximation of the median. You can scale this to as fine or coarse of a resolution as you want by changing the size of the bins. You're limited only by how much memory you have.
Since you don't know how big your values may get, just pick a bin size large enough that you aren't likely to run out of memory, using some quick back-of-the-envelope calculations. You might also store the bins sparsely, such that you only add a bin if it contains a value.
Edit:
The link ryfm provides gives an example of doing this, with the additional step of using the cumulative percentages to more accurately estimate the point within the median bin, instead of just using midpoints. This is a nice improvement.
| null | CC BY-SA 2.5 | null | 2010-07-20T19:59:33.833 | 2010-07-20T22:40:50.903 | 2010-07-20T22:40:50.903 | 54 | 54 | null |
351 | 2 | null | 7 | 4 | null | [Timetric](https://web.archive.org/web/20100109022706/http://timetric.com/) provides a web interface to data and provide a list of the [publicly available data sets](https://web.archive.org/web/20100704114934/http://timetric.com/dataset/) they use.
| null | CC BY-SA 4.0 | null | 2010-07-20T21:05:35.517 | 2022-11-30T05:35:00.977 | 2022-11-30T05:35:00.977 | 362671 | 16 | null |
352 | 2 | null | 346 | 3 | null | I've never had to do this, so this is just a suggestion.
I see two (other) possibilities.
Half data
- Load in half the data and sort
- Next read in the remaining values and compare against the your sorted list.
If the new value is larger, discard it.
else put the value in the sorted list and removing the largest value from that list.
Sampling distribution
The other option, is to use an approximation involving the sampling distribution. If your data is Normal, then the standard error for moderate n is:
1.253 * sd / sqrt(n)
To determine the size of n that you would be happy with, I ran a quick Monte-Carlo simulation in R
```
n = 10000
outside.ci.uni = 0
outside.ci.nor = 0
N=1000
for(i in 1:N){
#Theoretical median is 0
uni = runif(n, -10, 10)
nor = rnorm(n, 0, 10)
if(abs(median(uni)) > 1.96*1.253*sd(uni)/sqrt(n))
outside.ci.uni = outside.ci.uni + 1
if(abs(median(nor)) > 1.96*1.253*sd(nor)/sqrt(n))
outside.ci.nor = outside.ci.nor + 1
}
outside.ci.uni/N
outside.ci.nor/N
```
For n=10000, 15% of the uniform median estimates were outside the CI.
| null | CC BY-SA 2.5 | null | 2010-07-20T21:18:45.380 | 2010-07-21T15:29:25.620 | 2010-07-21T15:29:25.620 | 8 | 8 | null |
353 | 2 | null | 205 | 14 | null | Fisher's scoring is just a version of Newton's method that happens to be identified with GLMs, there's nothing particularly special about it, other than the fact that the Fisher's information matrix happens to be rather easy to find for random variables in the exponential family. It also ties in to a lot of other math-stat material that tends to come up about the same time, and gives a nice geometric intuition about what exactly Fisher information means.
There's absolutely no reason I can think of not to use some other optimizer if you prefer, other than that you might have to code it by hand rather than use a pre-existing package. I suspect that any strong emphasis on Fisher scoring is a combination of (in order of decreasing weight) pedagogy, ease-of-derivation, historical bias, and "not-invented-here" syndrome.
| null | CC BY-SA 2.5 | null | 2010-07-20T22:11:54.673 | 2010-07-20T22:11:54.673 | null | null | 61 | null |
354 | 1 | 176336 | null | 14 | 1012 | Why do we seek to minimize `x^2` instead of minimizing `|x|^1.95` or `|x|^2.05`.
Are there reasons why the number should be exactly two or is it simply a convention that has the advantage of simplifying the math?
| Bias towards natural numbers in the case of least squares | CC BY-SA 2.5 | null | 2010-07-20T22:26:26.083 | 2015-10-10T13:35:27.460 | 2010-11-28T12:04:24.103 | 930 | 3807 | [
"standard-deviation",
"least-squares"
] |
355 | 2 | null | 328 | 1 | null | Check out [Wilmott.com](http://wilmott.com/) as well. It's oriented toward more advanced practitioners, but if I had to choose one person from whom to learn financial math, it would be Paul Wilmott. Brilliant but grounded.
| null | CC BY-SA 2.5 | null | 2010-07-20T22:27:42.633 | 2010-07-20T22:27:42.633 | null | null | 158 | null |
356 | 2 | null | 288 | 3 | null | To fit the model you can use [JAGS](http://www-fis.iarc.fr/~martyn/software/jags/) or [Winbugs](http://www.mrc-bsu.cam.ac.uk/bugs/). In fact if you look at the week 3 of the lecture notes at Paul Hewson's [webpage](http://users.aims.ac.za/~paulhewson/), the rats JAGS example is a beta binomial model. He puts gamma priors on alpha and beta.
| null | CC BY-SA 2.5 | null | 2010-07-20T22:31:45.140 | 2010-07-20T22:31:45.140 | null | null | 8 | null |
357 | 2 | null | 2 | 6 | null | You can't know whether there normality and that's why you have to make an assumption that's there.
You can only prove the absence of normality with statistic tests.
Even worse, when you work with real world data it's almost certain that there isn't true normality in your data.
That means that your statistical test is always a bit biased. The question is whether you can live with it's bias.
To do that you have to understand your data and the kind of normality that your statistical tool assumes.
It's the reason why Frequentist tools are as subjective as Bayesian tools. You can't determine based on the data that it's normally distributed. You have to assume normality.
| null | CC BY-SA 3.0 | null | 2010-07-20T23:07:48.713 | 2011-10-21T19:44:18.317 | 2011-10-21T19:44:18.317 | 3807 | 3807 | null |
358 | 2 | null | 354 | 8 | null | We try to minimize the variance that is left within descriptors. Why variance? Read [this question](https://stats.stackexchange.com/questions/118/standard-deviation-why-square-the-difference-instead-of-taking-the-absolute-val); this also comes together with the (mostly silent) assumption that errors are normally distributed.
Extension:
Two additional arguments:
- For variances, we have this nice "law" that the sum of variances is equal to the variance of sum, for uncorrelated samples. If we assume that the error is not correlated with the case, minimizing residual of squares will work straightforward to maximizing explained variance, what is maybe a not-so-good but still popular quality measure.
- If we assume normality of an error, least squares error estimator is a maximal likelihood one.
| null | CC BY-SA 2.5 | null | 2010-07-20T23:21:05.400 | 2010-07-21T09:31:29.867 | 2017-04-13T12:44:41.607 | -1 | null | null |
359 | 1 | 457 | null | 11 | 1448 | The Wald, Likelihood Ratio and Lagrange Multiplier tests in the context of maximum likelihood estimation are asymptotically equivalent. However, for small samples, they tend to diverge quite a bit, and in some cases they result in different conclusions.
How can they be ranked according to how likely they are to reject the null? What to do when the tests have conflicting answers? Can you just pick the one which gives the answer you want or is there a "rule" or "guideline" as to how to proceed?
| The trinity of tests in maximum likelihood: what to do when faced with contradicting conclusions? | CC BY-SA 2.5 | null | 2010-07-20T23:28:49.693 | 2010-09-20T02:40:27.090 | null | null | 90 | [
"hypothesis-testing",
"maximum-likelihood"
] |
360 | 2 | null | 173 | 6 | null | Does it really need some advanced model? Based on what I know about TB, in case there is no epidemy the infections are stochastic acts and so the count form month N shouldn't be correlated with count from month N-1. (You can check this assumption with autocorrelation). If so, analyzing just the distribution of monthly counts may be sufficient to decide if some count is significantly higher than normal.
On the other hand you can look for correlations with some other variables, like season, travel traffic, or anything that you can imagine that may be correlated. If you would found something like this, it could be then used for some data normalization.
| null | CC BY-SA 2.5 | null | 2010-07-20T23:56:33.933 | 2010-07-20T23:56:33.933 | null | null | null | null |
361 | 2 | null | 258 | 12 | null | [Logistic Regression](http://en.wikipedia.org/wiki/Logistic_regression):
- fast and perform well on most datasets
- almost no parameters to tune
- handles both discrete/continuous features
- model is easily interpretable
- (not really restricted to binary classifications)
| null | CC BY-SA 2.5 | null | 2010-07-21T00:09:09.960 | 2010-07-21T00:09:09.960 | null | null | 170 | null |
362 | 1 | 74954 | null | 41 | 147826 | What is the difference between the Shapiro–Wilk test of normality and the Kolmogorov–Smirnov test of normality? When will results from these two methods differ?
| What is the difference between the Shapiro–Wilk test of normality and the Kolmogorov–Smirnov test of normality? | CC BY-SA 4.0 | null | 2010-07-21T00:24:35.500 | 2022-01-08T20:20:25.947 | 2022-01-08T20:20:25.947 | 155836 | 196 | [
"distributions",
"statistical-significance",
"normality-assumption",
"kolmogorov-smirnov-test"
] |
363 | 1 | null | null | 89 | 16694 | If you could go back in time and tell yourself to read a specific book at the beginning of your career as a statistician, which book would it be?
| What is the single most influential book every statistician should read? | CC BY-SA 2.5 | null | 2010-07-21T00:44:08.597 | 2021-03-11T13:59:49.813 | null | null | 74 | [
"references"
] |
365 | 2 | null | 257 | 5 | null | Another option is [Gnuplot](http://www.gnuplot.info/)
| null | CC BY-SA 2.5 | null | 2010-07-21T01:04:08.710 | 2010-07-21T01:04:08.710 | null | null | 226 | null |
366 | 2 | null | 175 | 1 | null | For a linear regression you could use a repeated median straight line fit.
| null | CC BY-SA 2.5 | null | 2010-07-21T01:23:00.817 | 2010-07-21T01:23:00.817 | null | null | 226 | null |
367 | 2 | null | 363 | 28 | null | I am no statistician, and I haven't read that much on the topic, but perhaps
[Lady Tasting Tea: How Statistics Revolutionized Science in the Twentieth Century](http://rads.stackoverflow.com/amzn/click/0805071342)
should be mentioned? It is no textbook, but still worth reading.
| null | CC BY-SA 2.5 | null | 2010-07-21T01:35:13.500 | 2010-07-21T01:35:13.500 | null | null | 90 | null |
368 | 2 | null | 212 | 2 | null | Suppose that the text has N words and that you require that an ASR should correctly predict at least 95% of words in the text. You currently have the observed error rate for the two methods. You can perform two type of tests.
Test 1: Do the ASR models meet your criteria of 95% prediction?
Test 2: Are the two ASR models equally good in speech recognition?
You could make different type of assumptions regarding the data generating mechanism for your ASR models. The simplest, although a bit naive, would assume that word detection of each word in the text is an iid bernoulli variable.
Under the above assumption you could do a test of proportions where you check if the error rate for each model is consistent with a true error rate of 5% (test 1) or a test of difference in proportions where you check if the error rates between the two models is the same (test 2).
| null | CC BY-SA 2.5 | null | 2010-07-21T03:01:00.020 | 2010-07-21T03:01:00.020 | null | null | null | null |
369 | 1 | null | null | 7 | 921 | Say I've got a program that monitors a news feed and as I'm monitoring it I'd like to discover when a bunch of stories come out with a particular keyword in the title. Ideally I want to know when there are an unusual number of stories clustered around one another.
I'm entirely new to statistical analysis and I'm wondering how you would approach this problem. How do you select what variables to consider? What characteristics of the problem affect your choice of an algorithm? Then, what algorithm do you choose and why?
Thanks, and if the problem needs clarification please let me know.
| Working through a clustering problem | CC BY-SA 2.5 | null | 2010-07-21T03:47:17.577 | 2012-05-26T04:00:14.573 | 2010-09-17T20:53:12.380 | null | 191 | [
"clustering"
] |
370 | 2 | null | 363 | 40 | null | Here are two to put on the list:
[Tufte. The visual display of quantitative information](http://rads.stackoverflow.com/amzn/click/096139210X)
[Tukey. Exploratory data analysis](http://rads.stackoverflow.com/amzn/click/0201076160)
| null | CC BY-SA 2.5 | null | 2010-07-21T03:48:55.563 | 2010-07-21T03:48:55.563 | null | null | 159 | null |
371 | 2 | null | 363 | 22 | null | [Probability Theory: The Logic of Science](http://rads.stackoverflow.com/amzn/click/0521592712)
| null | CC BY-SA 2.5 | null | 2010-07-21T04:19:00.347 | 2010-07-21T04:19:00.347 | null | null | 34 | null |
372 | 1 | 381 | null | 4 | 1680 | What topics in statistics are most useful/relevant to data mining?
| What are the key statistical concepts that relate to data mining? | CC BY-SA 2.5 | null | 2010-07-21T04:26:07.550 | 2010-09-13T13:16:33.200 | 2010-08-12T13:24:12.943 | 509 | 252 | [
"probability",
"data-mining",
"cart"
] |
373 | 1 | 378 | null | 41 | 6973 | From Wikipedia :
>
Suppose you're on a game show, and
you're given the choice of three
doors: Behind one door is a car;
behind the others, goats. You pick a
door, say No. 1, and the host, who
knows what's behind the doors, opens
another door, say No. 3, which has a
goat. He then says to you, "Do you
want to pick door No. 2?" Is it to
your advantage to switch your choice?
The answer is, of course, yes - but it's incredibly un-inituitive. What misunderstanding do most people have about probability that leads to us scratching our heads -- or better put; what general rule can we take away from this puzzle to better train our intuition in the future?
| The Monty Hall Problem - where does our intuition fail us? | CC BY-SA 2.5 | null | 2010-07-21T04:30:50.663 | 2022-10-13T18:56:58.043 | 2016-12-22T02:30:47.107 | 12359 | 252 | [
"probability",
"intuition",
"puzzle"
] |
374 | 1 | 379 | null | 9 | 1793 | What are pivot tables, and how can they be helpful in analyzing data?
| What are pivot tables, and how can they be helpful in analyzing data? | CC BY-SA 2.5 | null | 2010-07-21T04:32:42.520 | 2015-11-04T05:47:31.513 | 2015-11-04T05:47:31.513 | 805 | 252 | [
"multivariate-analysis",
"pivot-table"
] |
375 | 1 | null | null | 7 | 492 | >
Possible Duplicate:
Testing random variate generation algorithms
What's a good way to test a series of numbers to see if they're random (or at least psuedo-random)? Is there a good statistical measure of randomness that can be used to determine how random a set is?
More importantly, how can one prove a method of generating numbers is psuedo-random?
| Testing (and proving) the randomness of numbers | CC BY-SA 2.5 | 0 | 2010-07-21T04:34:45.700 | 2010-07-26T20:12:15.570 | 2017-04-13T12:44:39.283 | -1 | 252 | [
"random-generation",
"proof",
"randomness"
] |
376 | 2 | null | 354 | 14 | null | There's no reason you couldn't try to minimize norms other than x^2, there have been entire books written on quantile regression, for instance, which is more or less minimizing |x| if you're working with the median. It's just generally harder to do and, depending on the error model, may not give good estimators (depending on whether that means low-variance or unbiased or low MSE estimators in the context).
As for why we prefer integer moments over real-number-valued moments, the main reason is likely that while integer powers of real numbers always result in real numbers, non-integer powers of negative real numbers create complex numbers, thus requiring the use of an absolute value. In other words, while the 3rd moment of a real-valued random variable is real, the 3.2nd moment is not necessarily real, and so causes interpretation problems.
Other than that...
- Analytical expressions for the integer moments of random variables are typically much easier to find than real-valued moments, be it by generating functions or some other method. Methods to minimize them are thus easier to write.
- The use of integer moments leads to expressions that are more tractable than real-valued moments.
- I can't think of a compelling reason that (for instance) the 1.95th moment of the absolute value of X would provide better fitting properties than (for instance) the 2nd moment of X, although that could be interesting to investigate
- Specific to the L2 norm (or squared error), it can be written via dot products, which can lead to vast improvements in speed of computation. It's also the only Lp space that's a Hilbert space, which is a nice feature to have.
| null | CC BY-SA 2.5 | null | 2010-07-21T04:48:50.457 | 2010-07-21T04:48:50.457 | null | null | 61 | null |
378 | 2 | null | 373 | 14 | null | Consider two simple variations of the problem:
- No doors are opened for the contestant. The host offers no help in picking a door. In this case it is obvious that the odds of picking the correct door are 1/3.
- Before the contestant is asked to venture a guess, the host opens a door and reveals a goat. After the host reveals a goat, the contestant has to pick the car from the two remaining doors. In this case it is obvious that the odds of picking the correct door is 1/2.
For a contestant to know the probability of his door choice being correct, he has to know how many positive outcomes are available to him and divide that number by the amount of possible outcomes. Because of the two simple cases outlined above, it is very natural to think of all the possible outcomes available as the number of doors to choose from, and the amount of positive outcomes as the number of doors that conceal a car. Given this intuitive assumption, even if the host opens a door to reveal a goat after the contestant makes a guess, the probability of either door containing a car remains 1/2.
In reality, probability recognizes a set of possible outcomes larger than the three doors and it recognizes a set of positive outcomes that is larger than the singular door with the car. In the correct analysis of the problem, the host provides the contestant with new information making a new question to be addressed: what is the probability that my original guess is such that the new information provided by the host is sufficient to inform me of the correct door? In answering this question, the set of positive outcomes and the set of possible outcomes are not tangible doors and cars but rather abstract arrangements of the goats and car. The three possible outcomes are the three possible arrangements of two goats and one car behind three doors. The two positive outcomes are the two possible arrangements where the first guess of the contestant is false. In each of these two arrangements, the information given by the host (one of the two remaining doors is empty) is sufficient for the contestant to determine the door that conceals the car.
In summation:
We have a tendency to look for a simple mapping between physical manifestations of our choices (the doors and the cars) and the number of possible outcomes and desired outcomes in a question of probability. This works fine in cases where no new information is provided to the contestant. However, if the contestant is provided with more information (ie one of the doors you didn't choose is certainly not a car), this mapping breaks down and the correct question to be asked is found to be more abstract.
| null | CC BY-SA 2.5 | null | 2010-07-21T05:54:25.527 | 2010-07-21T05:54:25.527 | null | null | 68 | null |
379 | 2 | null | 374 | 9 | null | A pivot-table is a tool to dynamically show a slice and group multivariate data in tabular form.
For example, when we have the following data structure
```
Region Year Product Sales
US 2008 Phones 125
EU 2008 Phones 352
US 2008 Mouses 52
EU 2008 Mouses 65
US 2009 Phones 140
EU 2009 Phones 320
US 2009 Mouses 60
EU 2009 Mouses 100
```
A pivot table can for example display a table with the sum of all products with in the rows the years and in the columns the regions.
All dimensions of the table can be switched easily. Also the data fields shown can be changed. This is called pivoting.
The tool is useful in exploratory data analyses. Because it is a dynamic tool, it can be used to visually detect patterns and outliers etc.
Most spreadsheet applications have support for this kind of tables.
An image from wikipedia: 
| null | CC BY-SA 2.5 | null | 2010-07-21T06:09:43.093 | 2010-07-21T08:00:10.447 | 2017-03-09T17:30:36.053 | -1 | 190 | null |
380 | 2 | null | 30 | 4 | null | You cannot prove, because it is impossible; you can only check if there are no any embarrassing autocorrelations or distribution disturbances, and indeed [Diehard](http://en.wikipedia.org/wiki/Diehard_tests) is a standard for it. This is for statistics/physics, cryptographers will also mainly check (among other things) how hard is it to fit the generator to the data to obtain the future values.
| null | CC BY-SA 2.5 | null | 2010-07-21T06:15:36.623 | 2010-07-21T06:15:36.623 | null | null | null | null |
381 | 2 | null | 372 | 7 | null | Understanding multivariate normal distribution [http://en.wikipedia.org/wiki/Multivariate_normal_distribution](http://en.wikipedia.org/wiki/Multivariate_normal_distribution) is important.
The concept of correlation and more generally (non linear) dependence is important.
Concentration of measure, asymptotic normality, convergence of random variables.... how to make something from random to deterministic! [http://en.wikipedia.org/wiki/Convergence_of_random_variables](http://en.wikipedia.org/wiki/Convergence_of_random_variables)
maximum likelihood estimation [http://en.wikipedia.org/wiki/Maximum_likelihood](http://en.wikipedia.org/wiki/Maximum_likelihood) and before that, statistical modeling :) and more generally minimum contrast estimation.
stationary process [http://en.wikipedia.org/wiki/Stationary_process](http://en.wikipedia.org/wiki/Stationary_process) and more generally stationnarity assumption and ergodic property.
as Peter said, the question is so broad ... that the answer couldn't be given in a post ...
| null | CC BY-SA 2.5 | null | 2010-07-21T06:22:51.820 | 2010-07-21T06:22:51.820 | null | null | 223 | null |
382 | 2 | null | 124 | 4 | null | Firstly I can recommend you the book [Foundations of statistical natural language processing](http://nlp.stanford.edu/fsnlp/) by Manning and Schütze.
The methods I would use are word-frequency distributions and ngram language models. The first works very well when you want to classify on topic and your topics are specific and expert (having keywords). Ngram modelling is the best way when you want to classify writing styles etc.
| null | CC BY-SA 2.5 | null | 2010-07-21T06:28:23.900 | 2010-07-21T06:28:23.900 | null | null | 190 | null |
383 | 2 | null | 4 | 5 | null | You might be interested in applying relative distribution methods. Call one group the reference group, and the other the comparison group. In a way similar to constructing a probability-probability plot, you can construct a relative CDF/PDF, which is a ratio of the densities. This relative density can be used for inference. If the distributions are identical, you expect a uniform relative distribution. There are tools, graphical and statistical, to explore and examine departures from uniformity.
A good starting point to get a better sense is [Applying Relative Distrbution Methods in R](http://www.csss.washington.edu/Papers/wp27.pdf) and the [reldist](http://cran.r-project.org/web/packages/reldist/index.html) package in R. For details, you'll need to refer to the book, [Relative Distribution Methods in the Social Sciences](http://csde.washington.edu/~handcock/RelDist/) by Handcock and Morris. There's also a [paper](http://www.jstor.org/pss/270964) by the authors covering the relevant techniques.
| null | CC BY-SA 2.5 | null | 2010-07-21T06:28:43.477 | 2010-07-21T06:28:43.477 | null | null | 251 | null |
384 | 2 | null | 369 | 1 | null | I would start with a frequency distribution. Collect for a big corpus the word-frequencies and select smartly the words that are keywords (not misspellings, with a very low frequency, and not stop words like "and", "or")
Then when you have a number of new feeds, compare their distribution with the distribution that you build from your training data. Look to the big differences in frequencies and select so the important keywords of that moment.
| null | CC BY-SA 2.5 | null | 2010-07-21T06:33:36.307 | 2010-07-21T06:33:36.307 | null | null | 190 | null |
385 | 2 | null | 341 | 0 | null | In principal, unbalanced classes are not a problem at all for the k-nearest neighbor algorithm.
Because the algorithm is not influenced in any way by the size of the class, it will not favor any on the basis of size. Try to run k-means with an obvious outlier and k+1 and you will see that most of the time the outlier will get its own class.
Of course, with hard datasets it is always advisable to run the algorithm multiple times. This is to avoid trouble due to a bad initialization.
| null | CC BY-SA 3.0 | null | 2010-07-21T06:39:38.230 | 2015-05-05T13:48:09.747 | 2015-05-05T13:48:09.747 | 7365 | 190 | null |
386 | 2 | null | 213 | 14 | null | I would do some sort of "leave one out testing algorithm" (n is the number of data):
for i=1 to n
- compute a density estimation of the data set obtained by throwing $X_i$ away. (This density estimate should be done with some assumption if the dimension is high, for example, a gaussian assumption for which the density estimate is easy: mean and covariance)
- Calculate the likelihood of $X_i$ for the density estimated in step 1. call it $L_i$.
end for
sort the $L_i$ (for i=1,..,n) and use a multiple hypothesis testing procedure to say which are not good ...
This will work if n is sufficiently large... you can also use "leave k out strategy" which can be more relevent when you have "groups" of outliers ...
| null | CC BY-SA 3.0 | null | 2010-07-21T06:46:11.897 | 2011-06-14T18:26:43.130 | 2011-06-14T18:26:43.130 | 223 | 223 | null |
387 | 2 | null | 7 | 49 | null | The following list contains many data sets you may be interested:
- America's Best Colleges - U.S. News & World Reports
- American FactFinder
- The Baseball Archive
- The Bureau of Justice Statistics
- The Bureau of Labor Statistics
- The Bureau of Transportation Statistics
- The Census Bureau
- Data and Story Library (DASL)
- Data Sets, UCLA Statistics Department
- DIG Stats
- Economic Research Service, US Department of Agriculture
- Energy Information Administration
- Eurostat
- Exploring Data
- FedStats
- The Gallop Organization
- International Fuel Prices
- Journal of Statistics Education Data Archive
- Kentucky Derby Race Statistics
- National Center for Education Statistics
- National Center for Health Statistics
- National Climatic Data Center
- National Geophysical Data Center
- National Oceanic and Atmospheric Administration
- Sports Data Resources
- Statistics Canada
- StatLib---Datasets Archive
- UK Government Statistical Service
- United Nations: Cyber SchoolBus Resources
| null | CC BY-SA 4.0 | null | 2010-07-21T07:04:26.103 | 2022-11-22T02:50:37.240 | 2022-11-22T02:50:37.240 | 362671 | 69 | null |
388 | 2 | null | 363 | 6 | null | On the math/foundations side: Harald Cramér's [Mathematical Methods of Statistics](http://rads.stackoverflow.com/amzn/click/0691005478).
| null | CC BY-SA 2.5 | null | 2010-07-21T07:15:54.857 | 2010-07-21T07:15:54.857 | null | null | 251 | null |
389 | 2 | null | 175 | 22 | null | I do think there is something to be said for just excluding the outliers. A regression line is supposed to summarise the data. Because of leverage you can have a situation where 1% of your data points affects the slope by 50%.
It's only dangerous from a moral and scientific point of view if you don't tell anybody that you excluded the outliers. As long as you point them out you can say:
"This regression line fits pretty well for most of the data. 1% of the time a value will come along that doesn't fit this trend, but hey, it's a crazy world, no system is perfect"
| null | CC BY-SA 2.5 | null | 2010-07-21T07:51:34.243 | 2010-07-21T07:51:34.243 | null | null | 199 | null |
390 | 2 | null | 363 | 4 | null | [Fooled By Randomness](http://rads.stackoverflow.com/amzn/click/1587990717) by Taleb
Taleb is a professor at Columbia and an options trader. He made about $800 million dollars in 2008 betting against the market. He also wrote Black Swan. He discusses the absurdity of using the normal distribution to model markets, and philosophizes on our ability to use induction.
| null | CC BY-SA 2.5 | null | 2010-07-21T08:01:54.403 | 2010-09-09T20:46:31.427 | 2010-09-09T20:46:31.427 | 74 | 74 | null |
392 | 2 | null | 257 | 6 | null | Take a look at the sample galleries for three popular visualization libraries:
- matplotlib gallery (Python)
- R graph gallery (R) -- (also see ggplot2, scroll down to reference)
- prefuse visualization gallery (Java)
For the first two, you can even view the associated source code -- the simple stuff is simple, not many lines of code. The prefuse case will have the requisite Java boilerplate code. All three support a number of backends/devices/renderers (pdf, ps, png, etc). All three are clearly capable of high quality graphics.
I think it pretty much boils down to which language are you most comfortable working in. Go with that.
| null | CC BY-SA 2.5 | null | 2010-07-21T08:19:36.577 | 2010-07-21T08:19:36.577 | null | null | 251 | null |
393 | 2 | null | 363 | 36 | null | The Elements of Statistical Learning from Hastie, Tibshirani and Friedman [http://www-stat.stanford.edu/~tibs/ElemStatLearn/](http://www-stat.stanford.edu/~tibs/ElemStatLearn/) should be in any statistician's library !
| null | CC BY-SA 4.0 | null | 2010-07-21T09:02:11.717 | 2019-02-08T00:10:58.393 | 2019-02-08T00:10:58.393 | 40067 | 223 | null |
394 | 2 | null | 354 | 1 | null | My understanding is that because we are trying to minimise errors, we need to find a way of not getting ourselves in a situation where the sum of the negative difference in errors is equal to the sum of the positive difference in errors but we haven't found a good fit. We do this by squaring the sum of the difference in errors which means the negative and positive difference in errors both become positive ($-1\times-1 = 1$). If we raised $x$ to the power of anything other than a positive integer we wouldn't address this problem because the errors would not have the same sign, or if we raised to the power of something that isn't an integer we'd enter the realms of complex numbers.
| null | CC BY-SA 3.0 | null | 2010-07-21T09:53:40.083 | 2013-01-09T21:19:25.140 | 2013-01-09T21:19:25.140 | 17230 | 210 | null |
395 | 1 | null | null | 5 | 230 | I have a data set where a series of measurements are being taken each week. In general the data set shows a +/- 1mm change each week with a mean measurement staying at about 0mm. In plotting the data this week it appears that some noticeable movement has occurred at two points and looking back at the data set, it is also possible that movement occurred last week as well.
What is the best way of looking at this data set to see how likely it is that the movements that have been seen are real movements rather than just some effect caused by the natural tolerance in the readings.
Edit
Some more information on the data set. Measurements have been taken at 39 locations which should behave in a similar way although only some of the points may show signs of movement. At each point the readings have now been taken 10 times on a bi-weekly basis and up until the most recent set of readings the measurements were between -1mm and 1mm. The measurements can only be taken with mm accuracy so we only receive results to the nearest mm. The results for one of the points showing a movement is 0mm, 1mm, 0mm, -1mm, -1mm, 0mm, -1mm, -1mm, 1mm, 3mm. We are not looking for statistically significant information, just an indicator of what might have occurred. The reason is that if a measurement reaches 5mm in a subsequent week we have a problem and we'd like to be forewarned that this might occur.
| How to tell if something happened in a data set which monitors a value over time | CC BY-SA 2.5 | null | 2010-07-21T10:13:25.813 | 2011-02-09T11:30:29.170 | 2011-02-09T11:30:29.170 | 556 | 210 | [
"variance",
"monitoring"
] |
396 | 1 | 399 | null | 45 | 6608 | I usually make my own idiosyncratic choices when preparing plots. However, I wonder if there are any best practices for generating plots.
Note: [Rob's comment](https://stats.stackexchange.com/questions/257/what-is-the-easiest-way-to-create-publication-quality-plots-under-linux#comment152_261) to an answer to this [question](https://stats.stackexchange.com/questions/257/what-is-the-easiest-way-to-create-publication-quality-plots-under-linux) is very relevant here.
| What best practices should I follow when preparing plots? | CC BY-SA 3.0 | null | 2010-07-21T11:00:44.557 | 2022-11-23T09:56:13.210 | 2017-04-13T12:44:53.513 | -1 | null | [
"data-visualization",
"references"
] |
397 | 2 | null | 30 | 10 | null | Just to add a bit to honk's answer, the [Diehard Test Suite](http://en.wikipedia.org/wiki/Diehard_tests) (developed by George Marsaglia) are the standard tests for PRNG.
There's a nice [Diehard C library](https://webhome.phy.duke.edu/%7Ergb/General/dieharder.php) that gives you access to these tests. As well as the standard Diehard tests it also provides functions for a few other PRNG tests involving (amongst other things) checking bit order. There is also a facilty for testing the speed of the RNG and writing your own tests.
There is a R interface to the Dieharder library, called [RDieHarder](http://dirk.eddelbuettel.com/code/rdieharder.html):
```
library(RDieHarder)
dhtest = dieharder(rng="randu", test=10, psamples=100, seed=12345)
print(dhtest)
Diehard Count the 1s Test (byte)
data: Created by RNG `randu' with seed=12345,
sample of size 100 p-value < 2.2e-16
```
This shows that the [RANDU](http://en.wikipedia.org/wiki/RANDU) RNG generator fails the minimum-distance / 2dsphere test.
| null | CC BY-SA 4.0 | null | 2010-07-21T11:11:47.037 | 2022-12-05T08:26:28.510 | 2022-12-05T08:26:28.510 | 362671 | 8 | null |
398 | 2 | null | 396 | 15 | null | We could stay here all day denoting best practices, but you should start by reading Tufte. My primary recommendation:
Keep it simple.
Often people try to load up their charts with information. But you should really just have one main idea that you're trying to convey and if someone doesn't get your message almost immediately, then you should rethink how you have presented it. So don't start working on your chart until the message itself is clear. Occam's razor applies here too.
| null | CC BY-SA 2.5 | null | 2010-07-21T11:16:55.077 | 2010-07-21T11:16:55.077 | null | null | 5 | null |
399 | 2 | null | 396 | 26 | null | The Tufte principles are very good practices when preparing plots. See also his book [Beautiful Evidence](http://rads.stackoverflow.com/amzn/click/0961392177)
The principles include:
- Keep a high data-ink ratio
- Remove chart junk
- Give graphical element multiple functions
- Keep in mind the data density
The term to search for is Information Visualization
| null | CC BY-SA 2.5 | null | 2010-07-21T11:18:56.323 | 2010-07-21T11:18:56.323 | null | null | 190 | null |
400 | 2 | null | 396 | 13 | null | One rule of thumb that I don't always follow but which is on occasion useful is to take into account that it is likely that your plot will at some point in its future be
- sent by fax,
- photocopied, and/or
- reproduced in black-and-white.
You need to try and make your plots clear enough that even if they are imprecisely reproduced in the future, the information the plot is trying to convey is still legible.
| null | CC BY-SA 3.0 | null | 2010-07-21T11:20:45.167 | 2016-09-17T13:44:39.513 | 2016-09-17T13:44:39.513 | 22047 | 210 | null |
401 | 2 | null | 369 | 2 | null | This problem you are asking about is known as text mining!
There are a few things you need to consider. For example in your question you mentioned using keywords in titles. One may ask "why not the text in the article rather than just the title?" which brings me to the first consideration: What data do you limit yourself to?
Secondly, as the previous answer suggests, using frequencies is a great start. To take the analysis further you may start looking at what words occur frequently together! For example, the word 'happy' may occur very frequently... however if always accompanied by a 'not' your conclusions would be very different!
There is a very nice Australian piece of software I have used in the past called Leximancer. I would advise anybody interested in text mining to have a look at their site and the examples they have... from memory one of which analysed speeches by 2 U.S. presidential candidates. It makes for some very interesting reading!
| null | CC BY-SA 3.0 | null | 2010-07-21T12:22:21.570 | 2012-05-26T04:00:14.573 | 2012-05-26T04:00:14.573 | 5505 | 256 | null |
402 | 2 | null | 173 | 4 | null | You might consider applying a [Tukey Control chart](http://gunston.gmu.edu/708/frTukey.asp) to the data.
| null | CC BY-SA 2.5 | null | 2010-07-21T12:30:43.210 | 2010-07-21T12:30:43.210 | null | null | 226 | null |
403 | 2 | null | 192 | 1 | null | I must agree.. there is no single best analysis!
not just in cross tabulations or analysis of categorical data but in any data analysis... and thank god for that!
if there was just a single best way to address these analyses well many of us would not have a job to start with... not to mention the loss of the thrill of the hunt!
the joy of analysis is the unknown and the search for answers and evidence and how one question leads to another... that is what i love about statistics!
So back to the categorical data analysis... it really depends on what your doing. Are you looking to find how different variables affect each other as in drug tests for example we may look at treatment vs placebo crossed with disease and no disease... the question here is does treatment reduce disease.... chi square usually does well here (given a good sample size).
Another context ihad today was looking at missing value trends... i was looking to find if missing values in one categorical variable relate to another... in some cases i knew the result should be missing and yet there were observations that had values... a completely different context to the drug test!
| null | CC BY-SA 2.5 | null | 2010-07-21T12:33:43.903 | 2010-07-21T12:33:43.903 | null | null | 256 | null |
404 | 2 | null | 173 | 7 | null | You might want to have a look at [strucchange](http://cran.r-project.org/web/packages/strucchange/index.html):
>
Testing, monitoring and dating structural changes in (linear) regression models. strucchange features tests/methods from the generalized fluctuation test framework as well as from the F test (Chow test) framework. This includes methods to fit, plot and test fluctuation processes (e.g., CUSUM, MOSUM, recursive/moving estimates) and F statistics, respectively. It is possible to monitor incoming data online using fluctuation processes. Finally, the breakpoints in regression models with structural changes can be estimated together with confidence intervals. Emphasis is always given to methods for visualizing the data."
PS. Nice graphics ;)
| null | CC BY-SA 2.5 | null | 2010-07-21T12:37:31.977 | 2010-07-21T12:37:31.977 | null | null | 46 | null |
405 | 2 | null | 395 | 1 | null | What kind of movement are we talking about?
You could of course fit a distribution over your data and see whether the new weeks fit in this distribution or are in the tail of it (which means it is likely something significant, real that you are observing)
However, more information from your side would be helpful. Maybe you could provide a part of the dataset?
| null | CC BY-SA 2.5 | null | 2010-07-21T12:38:51.197 | 2010-07-21T12:38:51.197 | null | null | 190 | null |
406 | 2 | null | 6 | 27 | null | I disagree with this question as it suggests that machine learning and statistics are different or conflicting sciences.... when the opposite is true!
machine learning makes extensive use of statistics... a quick survey of any Machine learning or data mining software package will reveal Clustering techniques such as k-means also found in statistics.... will also show dimension reduction techniques such as Principal components analysis also a statistical technique... even logistic regression yet another.
In my view the main difference is that traditionally statistics was used to proove a pre conceived theory and usually the analysis was design around that principal theory. Where with data mining or machine learning the opposite approach is usually the norm in that we have the outcome we just want to find a way to predict it rather than ask the question or form the theory is this the outcome!
| null | CC BY-SA 2.5 | null | 2010-07-21T12:43:00.080 | 2010-07-21T12:43:00.080 | null | null | 256 | null |
407 | 2 | null | 213 | 1 | null | One of the above answers touched in mahalanobis distances.... perhaps anpther step further and calculating simultaneous confidence intervals would help detect outliers!
| null | CC BY-SA 2.5 | null | 2010-07-21T12:59:00.577 | 2010-07-21T12:59:00.577 | null | null | 256 | null |
408 | 2 | null | 396 | 8 | null | In addition to conveying a clear message I always try to remember the plotsmanship:
- font sizes for labels and legends should be big enough, preferably the same font size and font used in the final publication.
- linewidths should be big enough (1 pt lines tend to disappear if plots are shrunk only slightly). I try to go to linewidths of 3 to 5 pt.
- if plotting multiple datasets/curves with color make sure that they can be understood if printed in black-and-white, e.g. by using different symbols or linestyles in addition to color.
- always use a lossless (or close to lossless) format, e.g. a vector format like pdf, ps or svg or high resolution png or gif (jpeg doesn't work at all and was never designed for line art).
- prepare graphics in the final aspect ratio to be used in the publication. Changing the aspect ratio later can give irritating font or symbol shapes.
- always remove useless clutter from the plotting program like unused histogram information, trend lines (hardly useful) or default titles.
I have configured my plotting software (matplotlib, ROOT or root2matplotlib) to do most of this right by default. Before I was using `gnuplot` which needed extra care here.
| null | CC BY-SA 3.0 | null | 2010-07-21T13:01:39.883 | 2016-09-17T13:38:21.213 | 2016-09-17T13:38:21.213 | 7482 | 56 | null |
409 | 1 | null | null | 3 | 521 | At the moment I use standard deviation of the mean to estimate uncertainty:
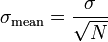
where N is in hundreds and mean is a time series (monthly) mean. I
present it then like this:  for each element (month) in the (annual) time series.
Is this valid? Is this appropriate for time series?
| How to approximate measurement uncertainty? | CC BY-SA 4.0 | null | 2010-07-21T13:11:33.167 | 2019-01-01T14:07:19.890 | 2019-01-01T14:07:19.890 | 79696 | 219 | [
"time-series",
"standard-deviation",
"mean",
"uncertainty"
] |
410 | 2 | null | 409 | 2 | null | The answer to this question depends a lot on how your measurement uncertainty arises. If it is due to to uncorrelated normally distributed fluctuations in your measurement your measurement outcomes will also be normally distributed.
If this assumption is valid can be hard to prove, but plotting histograms of outcomes of independent measurement should give you a feeling for the shape (and size) of the uncertainty.
Since the normal distribution works on a unlimited range of values, typical cases where measurements are not normally distributed are counting experiments where the number to be measured is small (e.g. less than 20) and/or fluctuations are large, or when the measured quantity is defined to be in a range, e.g. a fraction. One might still use normal approximation in a certain range though.
| null | CC BY-SA 2.5 | null | 2010-07-21T13:20:53.847 | 2010-07-21T13:20:53.847 | null | null | 56 | null |
411 | 1 | null | null | 51 | 15106 | There are many ways to measure how similar two probability distributions are. Among methods which are popular (in different circles) are:
- the Kolmogorov distance: the sup-distance between the distribution functions;
- the Kantorovich-Rubinstein distance: the maximum difference between the expectations w.r.t. the two distributions of functions with Lipschitz constant $1$, which also turns out to be the $L^1$ distance between the distribution functions;
- the bounded-Lipschitz distance: like the K-R distance but the functions are also required to have absolute value at most $1$.
These have different advantages and disadvantages. Only convergence in the sense of 3. actually corresponds precisely to convergence in distribution; convergence in the sense of 1. or 2. is slightly stronger in general. (In particular, if $X_n=\frac{1}{n}$ with probability $1$, then $X_n$ converges to $0$ in distribution, but not in the Kolmogorov distance. However, if the limit distribution is continuous then this pathology doesn't occur.)
From the perspective of elementary probability or measure theory, 1. is very natural because it compares the probabilities of being in some set. A more sophisticated probabilistic perspective, on the other hand, tends to focus more on expectations than probabilities. Also, from the perspective of functional analysis, distances like 2. or 3. based on duality with some function space are very appealing, because there is a large set of mathematical tools for working with such things.
However, my impression (correct me if I'm wrong!) is that in statistics, the Kolmogorov distance is the usually preferred way of measuring similarity of distributions. I can guess one reason: if one of the distributions is discrete with finite support -- in particular, if it is the distribution of some real-world data -- then the Kolmogorov distance to a model distribution is easy to compute. (The K-R distance would be slightly harder to compute, and the B-L distance would probably be impossible in practical terms.)
So my question (finally) is, are there other reasons, either practical or theoretical, to favor the Kolmogorov distance (or some other distance) for statistical purposes?
| Motivation for Kolmogorov distance between distributions | CC BY-SA 3.0 | null | 2010-07-21T13:39:06.783 | 2022-08-03T22:46:15.427 | 2013-09-04T01:41:58.663 | 29617 | 89 | [
"distributions",
"probability",
"hypothesis-testing",
"mathematical-statistics"
] |
412 | 2 | null | 395 | 5 | null | I think you need look at statistical [control charts](http://en.wikipedia.org/wiki/Control_chart). The most common of which are cusum and Shewhart charts.
Basically, data arrives sequentially and is tested against a number of rules. For example,
- Is the data far away from the cumulative mean - say 3 standard deviations
- Has the data been increasing for the last few points.
- Does the data alternate between positive and negative values.
In R you can use the [qcc](http://cran.r-project.org/web/packages/qcc/index.html) package.
For example,
```
#Taken from the documentation
library(qcc)
data(orangejuice)
attach(orangejuice)
plot(qcc(D[trial], sizes=size[trial], type="p"))
```
Gives the following plot, with possible problem points highlighted in red.
[control chart http://img805.imageshack.us/img805/5858/tmp.jpg](http://img805.imageshack.us/img805/5858/tmp.jpg)
| null | CC BY-SA 2.5 | null | 2010-07-21T13:40:02.007 | 2010-07-21T13:40:02.007 | null | null | 8 | null |
413 | 2 | null | 6 | 11 | null | I don't really know what the conceptual/historical difference between machine learning and statistic is but I am sure it is not that obvious... and I am not really interest in knowing if I am a machine learner or a statistician, I think 10 years after Breiman's paper, lots of people are both...
Anyway, I found interesting the question about predictive accuracy of models. We have to remember that it is not always possible to measure the accuracy of a model and more precisely we are most often implicitly making some modeling when measuring errors.
For Example, mean absolute error in time series forecast is a mean over time and it measures the performance of a procedure to forecast the median with the assumption that performance is, in some sense, stationary and shows some ergodic property. If (for some reason) you need to forecast the mean temperature on earth for the next 50 years and if your modeling performs well for the last 50 years... it does not means that...
More generally, (if I remember, it is called no free lunch) you can't do anything without modeling... In addition, I think statistic is trying to find an answer to the question : "is something significant or not ", this is a very important question in science and can't be answered through a learning process. To state John Tukey (was he a statistician ?) :
>
The combination of some data and an aching desire for an answer does not ensure that a reasonable answer can be extracted from a given body of data
Hope this helps !
| null | CC BY-SA 2.5 | null | 2010-07-21T13:48:15.687 | 2010-07-21T13:48:15.687 | null | null | 223 | null |
414 | 1 | 439 | null | 60 | 20615 | What is a good introduction to statistics for a mathematician who is already well-versed in probability? I have two distinct motivations for asking, which may well lead to different suggestions:
- I'd like to better understand the statistics motivation behind many problems considered by probabilists.
- I'd like to know how to better interpret the results of Monte Carlo simulations which I sometimes do to form mathematical conjectures.
I'm open to the possibility that the best way to go is not to look for something like "Statistics for Probabilists" and just go to a more introductory source.
| Introduction to statistics for mathematicians | CC BY-SA 2.5 | null | 2010-07-21T13:50:08.847 | 2023-02-11T10:15:04.673 | 2010-08-13T17:20:39.927 | 509 | 89 | [
"references"
] |
415 | 2 | null | 414 | 8 | null | I think you should take a look to the similar [post](https://mathoverflow.net/questions/31655/statistics-for-mathematicians/31665#31665) from mathoverflow.
My answer to this post was [Asymptotic Statistics](https://www.cambridge.org/core/books/asymptotic-statistics/A3C7DAD3F7E66A1FA60E9C8FE132EE1D) by Van der Vaart.
| null | CC BY-SA 4.0 | null | 2010-07-21T13:53:13.193 | 2023-02-11T10:11:57.943 | 2023-02-11T10:11:57.943 | 362671 | 223 | null |
416 | 2 | null | 269 | 41 | null | The population is the set of entities under study. For example, the mean height of men. This is a hypothetical population because it includes all men that have lived, are alive and will live in the future. I like this example because it drives home the point that we, as analysts, choose the population that we wish to study. Typically it is impossible to survey/measure the entire population because not all members are observable (e.g. men who will exist in the future). If it is possible to enumerate the entire population it is often costly to do so and would take a great deal of time. In the example above we have a population "men" and a parameter of interest, their height.
Instead, we could take a subset of this population called a sample and use this sample to draw inferences about the population under study, given some conditions. Thus we could measure the mean height of men in a sample of the population which we call a statistic and use this to draw inferences about the parameter of interest in the population. It is an inference because there will be some uncertainty and inaccuracy involved in drawing conclusions about the population based upon a sample. This should be obvious - we have fewer members in our sample than our population therefore we have lost some information.
There are many ways to select a sample and the study of this is called sampling theory. A commonly used method is called Simple Random Sampling (SRS). In SRS each member of the population has an equal probability of being included in the sample, hence the term "random". There are many other sampling methods e.g. stratified sampling, cluster sampling, etc which all have their advantages and disadvantages.
It is important to remember that the sample we draw from the population is only one from a large number of potential samples. If ten researchers were all studying the same population, drawing their own samples then they may obtain different answers. Returning to our earlier example, each of the ten researchers may come up with a different mean height of men i.e. the statistic in question (mean height) varies of sample to sample -- it has a distribution called a sampling distribution. We can use this distribution to understand the uncertainty in our estimate of the population parameter.
The sampling distribution of the sample mean is known to be a normal distribution with a standard deviation equal to the sample standard deviation divided by the sample size. Because this could easily be confused with the standard deviation of the sample it more common to call the standard deviation of the sampling distribution the standard error.
| null | CC BY-SA 2.5 | null | 2010-07-21T14:00:03.147 | 2010-07-21T14:00:03.147 | null | null | 215 | null |
417 | 2 | null | 414 | 15 | null | [Mathematical Methods of Statistics](http://www.powells.com/biblio/61-9780691005478-1), Harald Cramér is really great if you're coming to Statistics from the mathematical side. It's a bit dated, but still relevant for all the basic mathematical statistics.
Two other noteworthy books come to mind for inference and estimation theory:
- Theory of Point Estimation, E. L. Lehmann
- Theory of Statistics, Schervish
Not entirely sure if this is what you wanted, but you can check out the reviews and see if they meet your expectations.
| null | CC BY-SA 2.5 | null | 2010-07-21T14:01:46.887 | 2010-07-21T14:01:46.887 | null | null | 251 | null |
418 | 1 | 113367 | null | 35 | 10303 | Coming from the field of computer vision, I've often used the [RANSAC](http://en.wikipedia.org/wiki/RANSAC) (Random Sample Consensus) method for fitting models to data with lots of outliers.
However, I've never seen it used by statisticians, and I've always been under the impression that it wasn't considered a "statistically-sound" method. Why is that so? It is random in nature, which makes it harder to analyze, but so are bootstrapping methods.
Or is simply a case of academic silos not talking to one another?
| Why isn't RANSAC most widely used in statistics? | CC BY-SA 2.5 | null | 2010-07-21T14:30:42.197 | 2015-05-10T20:52:28.663 | 2010-07-21T17:30:38.037 | null | 77 | [
"outliers",
"bootstrap",
"robust"
] |
419 | 2 | null | 373 | 7 | null | I agree that students find this problem very difficult. The typical response I get is that after you've been shown a goat there's a 50:50 chance of getting the car so why does it matter? Students seem to divorce their first choice from the decision they're now being asked to make i.e. they view these two actions as independent. I then remind them that they were twice as likely to have chosen the wrong door initially hence why they're better off switching.
In recent years I've started actually playing the game in glass and it helps students to understand the problem much better. I use three cardboard toilet roll "middles" and in two of them are paper clips and in the third is a £5 note.
| null | CC BY-SA 2.5 | null | 2010-07-21T14:43:31.513 | 2010-07-21T14:43:31.513 | null | null | 215 | null |
420 | 2 | null | 373 | 11 | null | I'd modify what Graham Cookson said slightly. I think the really crucial thing that people overlook is not their first choice, but the host's choice, and the assumption that the host made sure not to reveal the car.
In fact, when I discuss this problem in a class, I present it in part as a case study in being clear on your assumptions. It is to your advantage to switch if the host is making sure only to reveal a goat. On the other hand, if the host picked randomly between doors 2 and 3, and happened to reveal a goat, then there is no advantage to switching.
(Of course, the practical upshot is that if you don't know the host's strategy, you should switch anyway.)
| null | CC BY-SA 2.5 | null | 2010-07-21T14:55:06.430 | 2010-07-21T14:55:06.430 | null | null | 89 | null |
421 | 1 | null | null | 106 | 37759 | What book would you recommend for scientists who are not statisticians?
Clear delivery is most appreciated. As well as the explanation of the appropriate techniques and methods for typical tasks: time series analysis, presentation and aggregation of large data sets.
| What book would you recommend for non-statistician scientists? | CC BY-SA 3.0 | null | 2010-07-21T15:01:21.127 | 2023-04-30T09:27:17.000 | 2017-01-21T09:27:37.137 | 28666 | 219 | [
"references"
] |
422 | 2 | null | 421 | 0 | null | That'll depend very much on their background, but I found ["Statistics in a Nutshell"](http://www.amazon.co.uk/Statistics-Nutshell-Desktop-Reference-OReilly/dp/0596510497) to be pretty good.
| null | CC BY-SA 3.0 | null | 2010-07-21T15:09:11.543 | 2012-08-03T10:07:04.063 | 2012-08-03T10:07:04.063 | null | 247 | null |
423 | 1 | null | null | 377 | 179622 | Data analysis cartoons can be useful for many reasons: they help communicate; they show that quantitative people have a sense of humor too; they can instigate good teaching moments; and they can help us remember important principles and lessons.
[This is one of my favorites:](https://xkcd.com/552/)

As a service to those who value this kind of resource, please share your favorite data analysis cartoon. They probably don't need any explanation (if they do, they're probably not good cartoons!) As always, one entry per answer. (This is in the vein of the Stack Overflow question [What’s your favorite “programmer” cartoon?](https://stackoverflow.com/questions/84556/whats-your-favorite-programmer-cartoon).)
P.S. Do not hotlink the cartoon without the site's permission please.
| What is your favorite "data analysis" cartoon? | CC BY-SA 4.0 | null | 2010-07-21T15:13:21.493 | 2022-10-16T03:37:54.007 | 2021-04-27T18:32:58.423 | 919 | 5 | [
"references",
"teaching",
"humor"
] |
424 | 2 | null | 423 | 244 | null | Was XKCD, so time for Dilbert:

Source: [http://dilbert.com/strip/2001-10-25](http://dilbert.com/strip/2001-10-25)
| null | CC BY-SA 3.0 | null | 2010-07-21T15:21:33.883 | 2015-01-28T20:57:36.773 | 2017-03-09T17:30:36.163 | -1 | null | null |
425 | 2 | null | 423 | 180 | null | One of my favorites from [xckd](http://www.xkcd.com):
## Random Number
[](http://xkcd.com/221/)
>
RFC 1149.5 specifies 4 as the standard IEEE-vetted random number.
| null | CC BY-SA 3.0 | null | 2010-07-21T15:23:53.183 | 2017-01-25T13:00:27.543 | 2020-06-11T14:32:37.003 | -1 | 13 | null |
427 | 2 | null | 31 | 50 | null | Before touching this topic, I always make sure that students are happy moving between percentages, decimals, odds and fractions. If they are not completely happy with this then they can get confused very quickly.
I like to explain hypothesis testing for the first time (and therefore p-values and test statistics) through Fisher's classic tea experiment. I have several reasons for this:
(i) I think working through an experiment and defining the terms as we go along makes more sense that just defining all of these terms to begin with.
(ii) You don't need to rely explicitly on probability distributions, areas under the curve, etc to get over the key points of hypothesis testing.
(iii) It explains this ridiculous notion of "as or more extreme than those observed" in a fairly sensible manner
(iv) I find students like to understand the history, origins and back story of what they are studying as it makes it more real than some abstract theories.
(v) It doesn't matter what discipline or subject the students come from, they can relate to the example of tea (N.B. Some international students have difficulty with this peculiarly British institution of tea with milk.)
[Note: I originally got this idea from Dennis Lindley's wonderful article "The Analysis of Experimental Data: The Appreciation of Tea & Wine" in which he demonstrates why Bayesian methods are superior to classical methods.]
The back story is that Muriel Bristol visits Fisher one afternoon in the 1920's at Rothamsted Experimental Station for a cup of tea. When Fisher put the milk in last she complained saying that she could also tell whether the milk was poured first (or last) and that she preferred the former. To put this to the test he designed his classic tea experiment where Muriel is presented with a pair of tea cups and she must identify which one had the milk added first. This is repeated with six pairs of tea cups. Her choices are either Right (R) or Wrong (W) and her results are: RRRRRW.
Suppose that Muriel is actually just guessing and has no ability to discriminate whatsoever. This is called the Null Hypothesis. According to Fisher the purpose of the experiment is to discredit this null hypothesis. If Muriel is guessing she will identify the tea cup correctly with probability 0.5 on each turn and as they are independent the observed result has 0.5$^6$ = 0.016 (or 1/64). Fisher then argues that either:
(a) the null hypothesis (Muriel is guessing) is true and an event of small probability has occurred or,
(b) the null hypothesis is false and Muriel has discriminatory powers.
The p-value (or probability value) is the probability of observing this outcome (RRRRRW) given the null hypothesis is true - it's the small probability referred to in (a), above. In this instance it's 0.016. Since events with small probabilities only occur rarely (by definition) situation (b) might be a more preferable explanation of what occurred than situation (a). When we reject the null hypothesis we're in fact accepting the opposite hypothesis which is we call the alternative hypothesis. In this example, Muriel has discriminatory powers is the alternative hypothesis.
An important consideration is what do we class as a "small" probability? What's the cutoff point at which we're willing to say that an event is unlikely? The standard benchmark is 5% (0.05) and this is called the significance level. When the p-value is smaller than the significance level we reject the null hypothesis as being false and accept our alternative hypothesis. It is common parlance to claim a result is "significant" when the p-value is smaller than the significance level i.e. when the probability of what we observed occurring given the null hypothesis is true is smaller than our cutoff point. It is important to be clear that using 5% is completely subjective (as is using the other common significance levels of 1% and 10%).
Fisher realised that this doesn't work; every possible outcome with one wrong pair was equally suggestive of discriminatory powers. The relevant probability for situation (a), above, is therefore 6(0.5)^6 = 0.094 (or 6/64) which now is not significant at a significance level of 5%. To overcome this Fisher argued that if 1 error in 6 is considered evidence of discriminatory powers then so is no errors i.e. outcomes that more strongly indicate discriminatory powers than the one observed should be included when calculating the p-value. This resulted in the following amendment to the reasoning, either:
(a) the null hypothesis (Muriel is guessing) is true and the probability of events as, or more, extreme than that observed is small, or
(b) the null hypothesis is false and Muriel has discriminatory powers.
Back to our tea experiment and we find that the p-value under this set-up is 7(0.5)^6 = 0.109 which still is not significant at the 5% threshold.
I then get students to work with some other examples such as coin tossing to work out whether or not a coin is fair. This drills home the concepts of the null/alternative hypothesis, p-values and significance levels. We then move onto the case of a continuous variable and introduce the notion of a test-statistic. As we have already covered the normal distribution, standard normal distribution and the z-transformation in depth it's merely a matter of bolting together several concepts.
As well as calculating test-statistics, p-values and making a decision (significant/not significant) I get students to work through published papers in a fill in the missing blanks game.
| null | CC BY-SA 3.0 | null | 2010-07-21T15:33:11.690 | 2017-04-02T18:42:04.937 | 2017-04-02T18:42:04.937 | 148472 | 215 | null |
428 | 2 | null | 346 | 7 | null | Could you group the data set into much smaller data sets (say 100 or 1000 or 10,000 data points) If you then calculated the median of each of the groups. If you did this with enough data sets you could plot something like the average of the results of each of the smaller sets and this woul, by running enough smaller data sets converge to an 'average' solution.
| null | CC BY-SA 2.5 | null | 2010-07-21T15:35:45.560 | 2010-07-21T15:35:45.560 | null | null | 210 | null |
429 | 2 | null | 362 | 27 | null | Briefly stated, the Shapiro-Wilk test is a specific test for normality, whereas the method used by [Kolmogorov-Smirnov test](http://www.itl.nist.gov/div898/handbook/eda/section3/eda35g.htm) is more general, but less powerful (meaning it correctly rejects the null hypothesis of normality less often). Both statistics take normality as the null and establishes a test statistic based on the sample, but how they do so is different from one another in ways that make them more or less sensitive to features of normal distributions.
How exactly W (the test statistic for Shapiro-Wilk) is calculated is [a bit involved](http://www.itl.nist.gov/div898/software/dataplot/refman1/auxillar/wilkshap.htm), but conceptually, it involves arraying the sample values by size and measuring fit against expected means, variances and covariances. These multiple comparisons against normality, as I understand it, give the test more power than the the Kolmogorov-Smirnov test, which is one way in which they may differ.
By contrast, the Kolmogorov-Smirnov test for normality is derived from a general approach for assessing goodness of fit by comparing the expected cumulative distribution against the empirical cumulative distribution, vis:
As such, it is sensitive at the center of the distribution, and not the tails. However, the K-S is test is convergent, in the sense that as n tends to infinity, the test converges to the true answer in probability (I believe that [Glivenko-Cantelli Theorem](http://en.wikipedia.org/wiki/Glivenko%E2%80%93Cantelli_theorem) applies here, but someone may correct me). These are two more ways in which these two tests might differ in their evaluation of normality.
| null | CC BY-SA 4.0 | null | 2010-07-21T15:36:34.687 | 2019-01-03T01:08:04.550 | 2019-01-03T01:08:04.550 | 79696 | 39 | null |
430 | 2 | null | 373 | 23 | null | I find that people find the solution more intuitive if you change it to 100 doors, close first, second, to 98 doors. Similarly for 50 doors, etc.
| null | CC BY-SA 2.5 | null | 2010-07-21T15:37:17.370 | 2010-07-22T00:37:06.953 | 2010-07-22T00:37:06.953 | 251 | 251 | null |
431 | 2 | null | 363 | 11 | null | I think every statistician should read Stigler's [The History of Statistics: The Measurement of Uncertainty before 1900](http://rads.stackoverflow.com/amzn/click/067440341X)
It is beautifully written, thorough and it isn't a historian's perspective but a mathematician's, hence it doesn't avoid the technical details.
| null | CC BY-SA 2.5 | null | 2010-07-21T15:38:11.677 | 2011-02-20T02:34:07.180 | 2011-02-20T02:34:07.180 | 159 | 215 | null |
432 | 2 | null | 423 | 208 | null | My favourite Dilbert cartoon:

Source: [http://dilbert.com/strip/2008-05-07](http://dilbert.com/strip/2008-05-07)
| null | CC BY-SA 3.0 | null | 2010-07-21T15:38:46.170 | 2015-01-27T20:43:00.943 | 2015-01-27T20:43:00.943 | 8 | 8 | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.