
code
stringlengths 2.5k
150k
| kind
stringclasses 1
value |
|---|---|
tcl_tk panedwindow panedwindow
===========
[NAME](panedwindow.htm#M2) panedwindow — Create and manipulate 'panedwindow' split container widgets
[SYNOPSIS](panedwindow.htm#M3)
[STANDARD OPTIONS](panedwindow.htm#M4)
[-background or -bg, background, Background](options.htm#M-background)
[-borderwidth or -bd, borderWidth, BorderWidth](options.htm#M-borderwidth)
[-cursor, cursor, Cursor](options.htm#M-cursor)
[-orient, orient, Orient](options.htm#M-orient)
[-relief, relief, Relief](options.htm#M-relief)
[WIDGET-SPECIFIC OPTIONS](panedwindow.htm#M5)
[-handlepad, handlePad, HandlePad](panedwindow.htm#M6)
[-handlesize, handleSize, HandleSize](panedwindow.htm#M7)
[-height, height, Height](panedwindow.htm#M8)
[-proxybackground, proxyBackground, ProxyBackground](panedwindow.htm#M9)
[-proxyborderwidth, proxyBorderWidth, ProxyBorderWidth](panedwindow.htm#M10)
[-proxyrelief, proxyRelief, ProxyRelief](panedwindow.htm#M11)
[-opaqueresize, opaqueResize, OpaqueResize](panedwindow.htm#M12)
[-sashcursor, sashCursor, SashCursor](panedwindow.htm#M13)
[-sashpad, sashPad, SashPad](panedwindow.htm#M14)
[-sashrelief, sashRelief, SashRelief](panedwindow.htm#M15)
[-sashwidth, sashWidth, SashWidth](panedwindow.htm#M16)
[-showhandle, showHandle, ShowHandle](panedwindow.htm#M17)
[-width, width, Width](panedwindow.htm#M18)
[DESCRIPTION](panedwindow.htm#M19)
[WIDGET COMMAND](panedwindow.htm#M20)
[*pathName* **add** *window* ?*window ...*? ?*option value ...*?](panedwindow.htm#M21)
[*pathName* **cget** *option*](panedwindow.htm#M22)
[*pathName* **configure** ?*option*? ?*value option value ...*?](panedwindow.htm#M23)
[*pathName* **forget** *window* ?*window ...*?](panedwindow.htm#M24)
[*pathName* **identify** *x y*](panedwindow.htm#M25)
[*pathName* **proxy** ?*args*?](panedwindow.htm#M26)
[*pathName* **proxy coord**](panedwindow.htm#M27)
[*pathName* **proxy forget**](panedwindow.htm#M28)
[*pathName* **proxy place** *x y*](panedwindow.htm#M29)
[*pathName* **sash** ?*args*?](panedwindow.htm#M30)
[*pathName* **sash coord** *index*](panedwindow.htm#M31)
[*pathName* **sash dragto** *index x y*](panedwindow.htm#M32)
[*pathName* **sash mark** *index x y*](panedwindow.htm#M33)
[*pathName* **sash place** *index x y*](panedwindow.htm#M34)
[*pathName* **panecget** *window option*](panedwindow.htm#M35)
[*pathName* **paneconfigure** *window* ?*option*? ?*value option value ...*?](panedwindow.htm#M36)
[**-after** *window*](panedwindow.htm#M37)
[**-before** *window*](panedwindow.htm#M38)
[**-height** *size*](panedwindow.htm#M39)
[**-hide** *boolean*](panedwindow.htm#M40)
[**-minsize** *n*](panedwindow.htm#M41)
[**-padx** *n*](panedwindow.htm#M42)
[**-pady** *n*](panedwindow.htm#M43)
[**-sticky** *style*](panedwindow.htm#M44)
[**-stretch** *when*](panedwindow.htm#M45)
[**always**](panedwindow.htm#M46)
[**first**](panedwindow.htm#M47)
[**last**](panedwindow.htm#M48)
[**middle**](panedwindow.htm#M49)
[**never**](panedwindow.htm#M50)
[**-width** *size*](panedwindow.htm#M51)
[*pathName* **panes**](panedwindow.htm#M52)
[RESIZING PANES](panedwindow.htm#M53)
[SEE ALSO](panedwindow.htm#M54)
[KEYWORDS](panedwindow.htm#M55)
Name
----
panedwindow — Create and manipulate 'panedwindow' split container widgets Synopsis
--------
**panedwindow** *pathName* ?*options*?
Standard options
----------------
**[-background or -bg, background, Background](options.htm#M-background)**
**[-borderwidth or -bd, borderWidth, BorderWidth](options.htm#M-borderwidth)**
**[-cursor, cursor, Cursor](options.htm#M-cursor)**
**[-orient, orient, Orient](options.htm#M-orient)**
**[-relief, relief, Relief](options.htm#M-relief)**
Widget-specific options
-----------------------
Command-Line Name: **-handlepad** Database Name: **handlePad** Database Class: **HandlePad**
When sash handles are drawn, specifies the distance from the top or left end of the sash (depending on the orientation of the widget) at which to draw the handle. May be any value accepted by **[Tk\_GetPixels](https://www.tcl.tk/man/tcl/TkLib/GetPixels.htm)**.
Command-Line Name: **-handlesize** Database Name: **handleSize** Database Class: **HandleSize**
Specifies the side length of a sash handle. Handles are always drawn as squares. May be any value accepted by **[Tk\_GetPixels](https://www.tcl.tk/man/tcl/TkLib/GetPixels.htm)**.
Command-Line Name: **-height** Database Name: **height** Database Class: **Height**
Specifies a desired height for the overall panedwindow widget. May be any value accepted by **[Tk\_GetPixels](https://www.tcl.tk/man/tcl/TkLib/GetPixels.htm)**. If an empty string, the widget will be made high enough to allow all contained widgets to have their natural height.
Command-Line Name: **-proxybackground** Database Name: **proxyBackground** Database Class: **ProxyBackground**
Background color to use when drawing the proxy. If an empty string, the value of the **-background** option will be used.
Command-Line Name: **-proxyborderwidth** Database Name: **proxyBorderWidth** Database Class: **ProxyBorderWidth**
Specifies the borderwidth of the proxy. May be any value accepted by **[Tk\_GetPixels](https://www.tcl.tk/man/tcl/TkLib/GetPixels.htm)**.
Command-Line Name: **-proxyrelief** Database Name: **proxyRelief** Database Class: **ProxyRelief**
Relief to use when drawing the proxy. May be any of the standard Tk relief values. If an empty string, the value of the **-sashrelief** option will be used.
Command-Line Name: **-opaqueresize** Database Name: **opaqueResize** Database Class: **OpaqueResize**
Specifies whether panes should be resized as a sash is moved (true), or if resizing should be deferred until the sash is placed (false).
Command-Line Name: **-sashcursor** Database Name: **sashCursor** Database Class: **SashCursor**
Mouse cursor to use when over a sash. If null, **sb\_h\_double\_arrow** will be used for horizontal panedwindows, and **sb\_v\_double\_arrow** will be used for vertical panedwindows.
Command-Line Name: **-sashpad** Database Name: **sashPad** Database Class: **SashPad**
Specifies the amount of padding to leave of each side of a sash. May be any value accepted by **[Tk\_GetPixels](https://www.tcl.tk/man/tcl/TkLib/GetPixels.htm)**.
Command-Line Name: **-sashrelief** Database Name: **sashRelief** Database Class: **SashRelief**
Relief to use when drawing a sash. May be any of the standard Tk relief values.
Command-Line Name: **-sashwidth** Database Name: **sashWidth** Database Class: **SashWidth**
Specifies the width of each sash. May be any value accepted by **[Tk\_GetPixels](https://www.tcl.tk/man/tcl/TkLib/GetPixels.htm)**.
Command-Line Name: **-showhandle** Database Name: **showHandle** Database Class: **ShowHandle**
Specifies whether sash handles should be shown. May be any valid Tcl boolean value.
Command-Line Name: **-width** Database Name: **width** Database Class: **Width**
Specifies a desired width for the overall panedwindow widget. May be any value accepted by **[Tk\_GetPixels](https://www.tcl.tk/man/tcl/TkLib/GetPixels.htm)**. If an empty string, the widget will be made wide enough to allow all contained widgets to have their natural width.
Description
-----------
The **panedwindow** command creates a new window (given by the *pathName* argument) and makes it into a panedwindow widget. Additional options, described above, may be specified on the command line or in the option database to configure aspects of the panedwindow such as its default background color and relief. The **panedwindow** command returns the path name of the new window. A panedwindow widget contains any number of panes, arranged horizontally or vertically, according to the value of the **-orient** option. Each pane contains one widget, and each pair of panes is separated by a moveable (via mouse movements) sash. Moving a sash causes the widgets on either side of the sash to be resized.
Widget command
--------------
The **panedwindow** command creates a new Tcl command whose name is the same as the path name of the panedwindow's window. This command may be used to invoke various operations on the widget. It has the following general form:
```
*pathName option* ?*arg arg ...*?
```
*PathName* is the name of the command, which is the same as the panedwindow widget's path name. *Option* and the *arg*s determine the exact behavior of the command. The following commands are possible for panedwindow widgets:
*pathName* **add** *window* ?*window ...*? ?*option value ...*?
Add one or more windows to the panedwindow, each in a separate pane. The arguments consist of the names of one or more windows followed by pairs of arguments that specify how to manage the windows. *Option* may have any of the values accepted by the **configure** subcommand.
*pathName* **cget** *option*
Returns the current value of the configuration option given by *option*. *Option* may have any of the values accepted by the **panedwindow** command.
*pathName* **configure** ?*option*? ?*value option value ...*?
Query or modify the configuration options of the widget. If no *option* is specified, returns a list describing all of the available options for *pathName* (see **[Tk\_ConfigureInfo](https://www.tcl.tk/man/tcl/TkLib/ConfigWidg.htm)** for information on the format of this list). If *option* is specified with no *value*, then the command returns a list describing the one named option (this list will be identical to the corresponding sublist of the value returned if no *option* is specified). If one or more *option-value* pairs are specified, then the command modifies the given widget option(s) to have the given value(s); in this case the command returns an empty string. *Option* may have any of the values accepted by the **panedwindow** command.
*pathName* **forget** *window* ?*window ...*?
Remove the pane containing *window* from the panedwindow. All geometry management options for *window* will be forgotten.
*pathName* **identify** *x y*
Identify the panedwindow component underneath the point given by *x* and *y*, in window coordinates. If the point is over a sash or a sash handle, the result is a two element list containing the index of the sash or handle, and a word indicating whether it is over a sash or a handle, such as {0 sash} or {2 handle}. If the point is over any other part of the panedwindow, the result is an empty list.
*pathName* **proxy** ?*args*?
This command is used to query and change the position of the sash proxy, used for rubberband-style pane resizing. It can take any of the following forms:
*pathName* **proxy coord**
Return a list containing the x and y coordinates of the most recent proxy location.
*pathName* **proxy forget**
Remove the proxy from the display.
*pathName* **proxy place** *x y*
Place the proxy at the given *x* and *y* coordinates.
*pathName* **sash** ?*args*?
This command is used to query and change the position of sashes in the panedwindow. It can take any of the following forms:
*pathName* **sash coord** *index*
Return the current x and y coordinate pair for the sash given by *index*. *Index* must be an integer between 0 and 1 less than the number of panes in the panedwindow. The coordinates given are those of the top left corner of the region containing the sash.
*pathName* **sash dragto** *index x y*
This command computes the difference between the given coordinates and the coordinates given to the last **sash mark** command for the given sash. It then moves that sash the computed difference. The return value is the empty string.
*pathName* **sash mark** *index x y*
Records *x* and *y* for the sash given by *index*; used in conjunction with later **sash dragto** commands to move the sash.
*pathName* **sash place** *index x y*
Place the sash given by *index* at the given coordinates.
*pathName* **panecget** *window option*
Query a management option for *window*. *Option* may be any value allowed by the **paneconfigure** subcommand.
*pathName* **paneconfigure** *window* ?*option*? ?*value option value ...*?
Query or modify the management options for *window*. If no *option* is specified, returns a list describing all of the available options for *pathName* (see **[Tk\_ConfigureInfo](https://www.tcl.tk/man/tcl/TkLib/ConfigWidg.htm)** for information on the format of this list). If *option* is specified with no *value*, then the command returns a list describing the one named option (this list will be identical to the corresponding sublist of the value returned if no *option* is specified). If one or more *option-value* pairs are specified, then the command modifies the given widget option(s) to have the given value(s); in this case the command returns an empty string. The following options are supported:
**-after** *window*
Insert the window after the window specified. *window* should be the name of a window already managed by *pathName*.
**-before** *window*
Insert the window before the window specified. *window* should be the name of a window already managed by *pathName*.
**-height** *size*
Specify a height for the window. The height will be the outer dimension of the window including its border, if any. If *size* is an empty string, or if **-height** is not specified, then the height requested internally by the window will be used initially; the height may later be adjusted by the movement of sashes in the panedwindow. *Size* may be any value accepted by **[Tk\_GetPixels](https://www.tcl.tk/man/tcl/TkLib/GetPixels.htm)**.
**-hide** *boolean*
Controls the visibility of a pane. When the *boolean* is true (according to **[Tcl\_GetBoolean](https://www.tcl.tk/man/tcl/TclLib/GetInt.htm)**) the pane will not be visible, but it will still be maintained in the list of panes.
**-minsize** *n*
Specifies that the size of the window cannot be made less than *n*. This constraint only affects the size of the widget in the paned dimension — the x dimension for horizontal panedwindows, the y dimension for vertical panedwindows. May be any value accepted by **[Tk\_GetPixels](https://www.tcl.tk/man/tcl/TkLib/GetPixels.htm)**.
**-padx** *n*
Specifies a non-negative value indicating how much extra space to leave on each side of the window in the X-direction. The value may have any of the forms accepted by **[Tk\_GetPixels](https://www.tcl.tk/man/tcl/TkLib/GetPixels.htm)**.
**-pady** *n*
Specifies a non-negative value indicating how much extra space to leave on each side of the window in the Y-direction. The value may have any of the forms accepted by **[Tk\_GetPixels](https://www.tcl.tk/man/tcl/TkLib/GetPixels.htm)**.
**-sticky** *style*
If a window's pane is larger than the requested dimensions of the window, this option may be used to position (or stretch) the window within its pane. *Style* is a string that contains zero or more of the characters **n**, **s**, **e** or **w**. The string can optionally contains spaces or commas, but they are ignored. Each letter refers to a side (north, south, east, or west) that the window will “stick” to. If both **n** and **s** (or **e** and **w**) are specified, the window will be stretched to fill the entire height (or width) of its cavity.
**-stretch** *when*
Controls how extra space is allocated to each of the panes. *When* is one of **always**, **first**, **last**, **middle**, and **never**. The panedwindow will calculate the required size of all its panes. Any remaining (or deficit) space will be distributed to those panes marked for stretching. The space will be distributed based on each panes current ratio of the whole. The *when* values have the following definition:
**always**
This pane will always stretch.
**first**
Only if this pane is the first pane (left-most or top-most) will it stretch.
**last**
Only if this pane is the last pane (right-most or bottom-most) will it stretch. This is the default value.
**middle**
Only if this pane is not the first or last pane will it stretch.
**never**
This pane will never stretch.
**-width** *size*
Specify a width for the window. The width will be the outer dimension of the window including its border, if any. If *size* is an empty string, or if **-width** is not specified, then the width requested internally by the window will be used initially; the width may later be adjusted by the movement of sashes in the panedwindow. *Size* may be any value accepted by **[Tk\_GetPixels](https://www.tcl.tk/man/tcl/TkLib/GetPixels.htm)**.
*pathName* **panes**
Returns an ordered list of the widgets managed by *pathName*.
Resizing panes
--------------
A pane is resized by grabbing the sash (or sash handle if present) and dragging with the mouse. This is accomplished via mouse motion bindings on the widget. When a sash is moved, the sizes of the panes on each side of the sash, and thus the widgets in those panes, are adjusted. When a pane is resized from outside (e.g. it is packed to expand and fill, and the containing toplevel is resized), space is added to the final (rightmost or bottommost) pane in the window.
Unlike slave windows managed by e.g. pack or grid, the panes managed by a panedwindow do not change width or height to accomodate changes in the requested widths or heights of the panes, once these have become mapped. Therefore it may be advisable, particularly when creating layouts interactively, to not add a pane to the panedwindow widget until after the geometry requests of that pane has been finalized (i.e., all components of the pane inserted, all options affecting geometry set to their proper values, etc.).
See also
--------
**[ttk::panedwindow](ttk_panedwindow.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TkCmd/panedwindow.htm>
tcl_tk tk_mac tk\_mac
=======
[NAME](tk_mac.htm#M2) tk::mac — Access Mac-Specific Functionality on OS X from Tk
[SYNOPSIS](tk_mac.htm#M3)
[EVENT HANDLER CALLBACKS](tk_mac.htm#M4)
[**::tk::mac::ShowPreferences**](tk_mac.htm#M5)
[**::tk::mac::OpenApplication**](tk_mac.htm#M6)
[**::tk::mac::ReopenApplication**](tk_mac.htm#M7)
[**::tk::mac::OpenDocument** *file...*](tk_mac.htm#M8)
[**::tk::mac::PrintDocument** *file...*](tk_mac.htm#M9)
[**::tk::mac::Quit**](tk_mac.htm#M10)
[**::tk::mac::OnHide**](tk_mac.htm#M11)
[**::tk::mac::OnShow**](tk_mac.htm#M12)
[**::tk::mac::ShowHelp**](tk_mac.htm#M13)
[ADDITIONAL DIALOGS](tk_mac.htm#M14)
[**::tk::mac::standardAboutPanel**](tk_mac.htm#M15)
[SYSTEM CONFIGURATION](tk_mac.htm#M16)
[**::tk::mac::useCompatibilityMetrics** *boolean*](tk_mac.htm#M17)
[**::tk::mac::CGAntialiasLimit** *limit*](tk_mac.htm#M18)
[**::tk::mac::antialiasedtext** *number*](tk_mac.htm#M19)
[**::tk::mac::useThemedToplevel** *boolean*](tk_mac.htm#M20)
[SUPPORT COMMANDS](tk_mac.htm#M21)
[**::tk::mac::iconBitmap** *name width height -kind value*](tk_mac.htm#M22)
[**-file**](tk_mac.htm#M23)
[**-fileType**](tk_mac.htm#M24)
[**-osType**](tk_mac.htm#M25)
[**-systemType**](tk_mac.htm#M26)
[**-namedImage**](tk_mac.htm#M27)
[**-imageFile**](tk_mac.htm#M28)
[SEE ALSO](tk_mac.htm#M29)
[KEYWORDS](tk_mac.htm#M30)
Name
----
tk::mac — Access Mac-Specific Functionality on OS X from Tk Synopsis
--------
**::tk::mac::ShowPreferences**
**::tk::mac::OpenApplication**
**::tk::mac::ReopenApplication**
**::tk::mac::OpenDocument** *file...*
**::tk::mac::PrintDocument** *file...*
**::tk::mac::Quit**
**::tk::mac::OnHide**
**::tk::mac::OnShow**
**::tk::mac::ShowHelp**
**::tk::mac::standardAboutPanel**
**::tk::mac::useCompatibilityMetrics** *boolean*
**::tk::mac::CGAntialiasLimit** *limit*
**::tk::mac::antialiasedtext** *number*
**::tk::mac::useThemedToplevel** *boolean*
**::tk::mac::iconBitmap** *name width height -kind value*
Event handler callbacks
-----------------------
The Aqua/Mac OS X application environment defines a number of additional events that applications should respond to. These events are mapped by Tk to calls to commands in the **::tk::mac** namespace; unless otherwise noted, if the command is absent, no action will be taken.
**::tk::mac::ShowPreferences**
The default Apple Event handler for kAEShowPreferences, “pref”. The application menu “Preferences” menu item is only enabled when this proc is defined. Typically this command is used to wrap a specific own preferences command, which pops up a preferences window. Something like:
```
proc ::tk::mac::ShowPreferences {} {
setPref
}
```
**::tk::mac::OpenApplication**
If a proc of this name is defined, this proc fill fire when your application is intially opened. It is the default Apple Event handler for kAEOpenApplication, “oapp”.
**::tk::mac::ReopenApplication**
If a proc of this name is defined it is the default Apple Event handler for kAEReopenApplication, “rapp”, the Apple Event sent when your application is opened when it is already running (e.g. by clicking its icon in the Dock). Here is a sample that raises a minimized window when the Dock icon is clicked:
```
proc ::tk::mac::ReopenApplication {} {
if {[wm state .] eq "withdrawn"} {
wm state . normal
} else {
wm deiconify .
}
raise .
}
```
**::tk::mac::OpenDocument** *file...*
If a proc of this name is defined it is the default Apple Event handler for kAEOpenDocuments, “odoc”, the Apple Event sent when your application is asked to open one or more documents (e.g., by drag & drop onto the app or by opening a document of a type associated to the app). The proc should take as arguments paths to the files to be opened, like so:
```
proc ::tk::mac::OpenDocument {args} {
foreach f $args {my_open_document $f}
}
```
**::tk::mac::PrintDocument** *file...*
If a proc of this name is defined it is the default Apple Event handler for kAEPrintDocuments, “pdoc”, the Apple Event sent when your application is asked to print one or more documents (e.g., via the Print menu item in the Finder). It works the same way as **tk::mac::OpenDocument** in terms of arguments.
**::tk::mac::Quit**
If a proc of this name is defined it is the default Apple Event handler for kAEQuitApplication, “quit”, the Apple Event sent when your application is asked to be quit, e.g. via the quit menu item in the application menu, the quit menu item in the Dock menu, or during a logout/restart/shutdown etc. If this is not defined, **[exit](../tclcmd/exit.htm)** is called instead.
**::tk::mac::OnHide**
If defined, this is called when your application receives a kEventAppHidden event, e.g. via the hide menu item in the application or Dock menus.
**::tk::mac::OnShow**
If defined, this is called when your application receives a kEventAppShown event, e.g. via the show all menu item in the application menu, or by clicking the Dock icon of a hidden application.
**::tk::mac::ShowHelp**
Customizes behavior of Apple Help menu; if this procedure is not defined, the platform-specific standard Help menu item “YourApp Help” performs the default Cocoa action of showing the Help Book configured in the application's Info.plist (or displaying an alert if no Help Book is set).
Additional dialogs
------------------
The Aqua/Mac OS X defines additional dialogs that applications should support.
**::tk::mac::standardAboutPanel**
Brings the standard Cocoa about panel to the front, with all its information filled in from your application bundle files (standard about panel with no options specified). See Apple Technote TN2179 and the AppKit documentation for -[NSApplication orderFrontStandardAboutPanelWithOptions:] for details on the Info.plist keys and app bundle files used by the about panel.
System configuration
--------------------
There are a number of additional global configuration options that control the details of how Tk renders by default.
**::tk::mac::useCompatibilityMetrics** *boolean*
Preserves compatibility with older Tk/Aqua metrics; set to **false** for more native spacing.
**::tk::mac::CGAntialiasLimit** *limit*
Sets the antialiasing limit; lines thinner that *limit* pixels will not be antialiased. Integer, set to 0 by default, making all lines be antialiased.
**::tk::mac::antialiasedtext** *number*
Sets anti-aliased text. Controls text antialiasing, possible values for *number* are -1 (default, use system default for text AA), 0 (no text AA), 1 (use text AA).
**::tk::mac::useThemedToplevel** *boolean*
Sets toplevel windows to draw with the modern grayish/ pinstripe Mac background. Equivalent to configuring the toplevel with “**-background systemWindowHeaderBackground**”, or to using a **[ttk::frame](ttk_frame.htm)**.
Support commands
----------------
**::tk::mac::iconBitmap** *name width height -kind value*
Renders native icons and bitmaps in Tk applications (including any image file readable by NSImage). A native bitmap name is interpreted as follows (in order):
* predefined builtin 32x32 icon name (**stop**, **caution**, **document**, etc.)
* *name*, as defined by **tk::mac::iconBitmap**
* NSImage named image name
* NSImage url string
* 4-char OSType of IconServices icon
The *width* and *height* arguments to **tk::mac::iconBitmap** define the dimensions of the image to create, and *-kind* must be one of:
**-file**
icon of file at given path
**-fileType**
icon of given file type
**-osType**
icon of given 4-char OSType file type
**-systemType**
icon for given IconServices 4-char OSType
**-namedImage**
named NSImage for given name
**-imageFile**
image at given path
See also
--------
**[bind](bind.htm)**, **[wm](wm.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TkCmd/tk_mac.htm>
| programming_docs |
tcl_tk clipboard clipboard
=========
Name
----
clipboard — Manipulate Tk clipboard Synopsis
--------
**clipboard** *option* ?*arg arg ...*?
Description
-----------
This command provides a Tcl interface to the Tk clipboard, which stores data for later retrieval using the selection mechanism (via the **-selection CLIPBOARD** option). In order to copy data into the clipboard, **clipboard clear** must be called, followed by a sequence of one or more calls to **clipboard append**. To ensure that the clipboard is updated atomically, all appends should be completed before returning to the event loop. The first argument to **clipboard** determines the format of the rest of the arguments and the behavior of the command. The following forms are currently supported:
**clipboard append** ?**-displayof** *window*? ?**-format** *format*? ?**-type** *type*? ?**--**? *data*
Appends *data* to the clipboard on *window*'s display in the form given by *type* with the representation given by *format* and claims ownership of the clipboard on *window*'s display. *Type* specifies the form in which the selection is to be returned (the desired “target” for conversion, in ICCCM terminology), and should be an atom name such as **STRING** or **FILE\_NAME**; see the Inter-Client Communication Conventions Manual for complete details. *Type* defaults to **STRING**.
The *format* argument specifies the representation that should be used to transmit the selection to the requester (the second column of Table 2 of the ICCCM), and defaults to **STRING**. If *format* is **STRING**, the selection is transmitted as 8-bit ASCII characters. If *format* is **ATOM**, then the *data* is divided into fields separated by white space; each field is converted to its atom value, and the 32-bit atom value is transmitted instead of the atom name. For any other *format*, *data* is divided into fields separated by white space and each field is converted to a 32-bit integer; an array of integers is transmitted to the selection requester. Note that strings passed to **clipboard append** are concatenated before conversion, so the caller must take care to ensure appropriate spacing across string boundaries. All items appended to the clipboard with the same *type* must have the same *format*.
The *format* argument is needed only for compatibility with clipboard requesters that do not use Tk. If the Tk toolkit is being used to retrieve the **CLIPBOARD** selection then the value is converted back to a string at the requesting end, so *format* is irrelevant.
A **--** argument may be specified to mark the end of options: the next argument will always be used as *data*. This feature may be convenient if, for example, *data* starts with a **-**.
**clipboard clear** ?**-displayof** *window*?
Claims ownership of the clipboard on *window*'s display and removes any previous contents. *Window* defaults to “.”. Returns an empty string.
**clipboard get** ?**-displayof** *window*? ?**-type** *type*?
Retrieve data from the clipboard on *window*'s display. *Window* defaults to “.”. *Type* specifies the form in which the data is to be returned and should be an atom name such as **STRING** or **FILE\_NAME**. *Type* defaults to **STRING**. This command is equivalent to “**[selection get](selection.htm)** **-selection CLIPBOARD**”. Note that on modern X11 systems, the most useful type to retrieve for transferred strings is not **STRING**, but rather **UTF8\_STRING**.
Examples
--------
Get the current contents of the clipboard.
```
if {[catch {**clipboard get**} contents]} {
# There were no clipboard contents at all
}
```
Set the clipboard to contain a fixed string.
```
**clipboard clear**
**clipboard append** "some fixed string"
```
You can put custom data into the clipboard by using a custom **-type** option. This is not necessarily portable, but can be very useful. The method of passing Tcl scripts this way is effective, but should be mixed with safe interpreters in production code.
```
# This is a very simple canvas serializer;
# it produces a script that recreates the item(s) when executed
proc getItemConfig {canvas tag} {
set script {}
foreach item [$canvas find withtag $tag] {
append script {$canvas create } [$canvas type $item]
append script { } [$canvas coords $item] { }
foreach config [$canvas itemconf $item] {
lassign $config name - - - value
append script [list $name $value] { }
}
append script \n
}
return [string trim $script]
}
# Set up a binding on a canvas to cut and paste an item
set c [canvas .c]
pack $c
$c create text 150 30 -text "cut and paste me"
bind $c <<Cut>> {
**clipboard clear**
**clipboard append -type** TkCanvasItem \
[getItemConfig %W current]
# Delete because this is cut, not copy.
%W delete current
}
bind $c <<Paste>> {
catch {
set canvas %W
eval [**clipboard get -type** TkCanvasItem]
}
}
```
See also
--------
**[interp](../tclcmd/interp.htm)**, **[selection](selection.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TkCmd/clipboard.htm>
tcl_tk entry entry
=====
[NAME](entry.htm#M2) entry — Create and manipulate 'entry' one-line text entry widgets
[SYNOPSIS](entry.htm#M3)
[STANDARD OPTIONS](entry.htm#M4)
[-background or -bg, background, Background](options.htm#M-background)
[-borderwidth or -bd, borderWidth, BorderWidth](options.htm#M-borderwidth)
[-cursor, cursor, Cursor](options.htm#M-cursor)
[-exportselection, exportSelection, ExportSelection](options.htm#M-exportselection)
[-font, font, Font](options.htm#M-font)
[-foreground or -fg, foreground, Foreground](options.htm#M-foreground)
[-highlightbackground, highlightBackground, HighlightBackground](options.htm#M-highlightbackground)
[-highlightcolor, highlightColor, HighlightColor](options.htm#M-highlightcolor)
[-highlightthickness, highlightThickness, HighlightThickness](options.htm#M-highlightthickness)
[-insertbackground, insertBackground, Foreground](options.htm#M-insertbackground)
[-insertborderwidth, insertBorderWidth, BorderWidth](options.htm#M-insertborderwidth)
[-insertofftime, insertOffTime, OffTime](options.htm#M-insertofftime)
[-insertontime, insertOnTime, OnTime](options.htm#M-insertontime)
[-insertwidth, insertWidth, InsertWidth](options.htm#M-insertwidth)
[-justify, justify, Justify](options.htm#M-justify)
[-relief, relief, Relief](options.htm#M-relief)
[-selectbackground, selectBackground, Foreground](options.htm#M-selectbackground)
[-selectborderwidth, selectBorderWidth, BorderWidth](options.htm#M-selectborderwidth)
[-selectforeground, selectForeground, Background](options.htm#M-selectforeground)
[-takefocus, takeFocus, TakeFocus](options.htm#M-takefocus)
[-textvariable, textVariable, Variable](options.htm#M-textvariable)
[-xscrollcommand, xScrollCommand, ScrollCommand](options.htm#M-xscrollcommand)
[WIDGET-SPECIFIC OPTIONS](entry.htm#M5)
[-disabledbackground, disabledBackground, DisabledBackground](entry.htm#M6)
[-disabledforeground, disabledForeground, DisabledForeground](entry.htm#M7)
[-invalidcommand or -invcmd, invalidCommand, InvalidCommand](entry.htm#M8)
[-readonlybackground, readonlyBackground, ReadonlyBackground](entry.htm#M9)
[-show, show, Show](entry.htm#M10)
[-state, state, State](entry.htm#M11)
[-validate, validate, Validate](entry.htm#M12)
[-validatecommand or -vcmd, validateCommand, ValidateCommand](entry.htm#M13)
[-width, width, Width](entry.htm#M14)
[DESCRIPTION](entry.htm#M15)
[VALIDATION](entry.htm#M16)
[**none**](entry.htm#M17)
[**focus**](entry.htm#M18)
[**focusin**](entry.htm#M19)
[**focusout**](entry.htm#M20)
[**key**](entry.htm#M21)
[**all**](entry.htm#M22)
[**%d**](entry.htm#M23)
[**%i**](entry.htm#M24)
[**%P**](entry.htm#M25)
[**%s**](entry.htm#M26)
[**%S**](entry.htm#M27)
[**%v**](entry.htm#M28)
[**%V**](entry.htm#M29)
[**%W**](entry.htm#M30)
[WIDGET COMMAND](entry.htm#M31)
[INDICES](entry.htm#M32)
[*number*](entry.htm#M33)
[**anchor**](entry.htm#M34)
[**end**](entry.htm#M35)
[**insert**](entry.htm#M36)
[**sel.first**](entry.htm#M37)
[**sel.last**](entry.htm#M38)
[**@***number*](entry.htm#M39)
[SUBCOMMANDS](entry.htm#M40)
[*pathName* **bbox** *index*](entry.htm#M41)
[*pathName* **cget** *option*](entry.htm#M42)
[*pathName* **configure** ?*option*? ?*value option value ...*?](entry.htm#M43)
[*pathName* **delete** *first* ?*last*?](entry.htm#M44)
[*pathName* **get**](entry.htm#M45)
[*pathName* **icursor** *index*](entry.htm#M46)
[*pathName* **index** *index*](entry.htm#M47)
[*pathName* **insert** *index string*](entry.htm#M48)
[*pathName* **scan** *option args*](entry.htm#M49)
[*pathName* **scan mark** *x*](entry.htm#M50)
[*pathName* **scan dragto** *x*](entry.htm#M51)
[*pathName* **selection** *option arg*](entry.htm#M52)
[*pathName* **selection adjust** *index*](entry.htm#M53)
[*pathName* **selection clear**](entry.htm#M54)
[*pathName* **selection from** *index*](entry.htm#M55)
[*pathName* **selection present**](entry.htm#M56)
[*pathName* **selection range** *start* *end*](entry.htm#M57)
[*pathName* **selection to** *index*](entry.htm#M58)
[*pathName* **validate**](entry.htm#M59)
[*pathName* **xview** *args*](entry.htm#M60)
[*pathName* **xview**](entry.htm#M61)
[*pathName* **xview** *index*](entry.htm#M62)
[*pathName* **xview moveto** *fraction*](entry.htm#M63)
[*pathName* **xview scroll** *number what*](entry.htm#M64)
[DEFAULT BINDINGS](entry.htm#M65)
[SEE ALSO](entry.htm#M66)
[KEYWORDS](entry.htm#M67)
Name
----
entry — Create and manipulate 'entry' one-line text entry widgets Synopsis
--------
**entry** *pathName* ?*options*?
Standard options
----------------
**[-background or -bg, background, Background](options.htm#M-background)**
**[-borderwidth or -bd, borderWidth, BorderWidth](options.htm#M-borderwidth)**
**[-cursor, cursor, Cursor](options.htm#M-cursor)**
**[-exportselection, exportSelection, ExportSelection](options.htm#M-exportselection)**
**[-font, font, Font](options.htm#M-font)**
**[-foreground or -fg, foreground, Foreground](options.htm#M-foreground)**
**[-highlightbackground, highlightBackground, HighlightBackground](options.htm#M-highlightbackground)**
**[-highlightcolor, highlightColor, HighlightColor](options.htm#M-highlightcolor)**
**[-highlightthickness, highlightThickness, HighlightThickness](options.htm#M-highlightthickness)**
**[-insertbackground, insertBackground, Foreground](options.htm#M-insertbackground)**
**[-insertborderwidth, insertBorderWidth, BorderWidth](options.htm#M-insertborderwidth)**
**[-insertofftime, insertOffTime, OffTime](options.htm#M-insertofftime)**
**[-insertontime, insertOnTime, OnTime](options.htm#M-insertontime)**
**[-insertwidth, insertWidth, InsertWidth](options.htm#M-insertwidth)**
**[-justify, justify, Justify](options.htm#M-justify)**
**[-relief, relief, Relief](options.htm#M-relief)**
**[-selectbackground, selectBackground, Foreground](options.htm#M-selectbackground)**
**[-selectborderwidth, selectBorderWidth, BorderWidth](options.htm#M-selectborderwidth)**
**[-selectforeground, selectForeground, Background](options.htm#M-selectforeground)**
**[-takefocus, takeFocus, TakeFocus](options.htm#M-takefocus)**
**[-textvariable, textVariable, Variable](options.htm#M-textvariable)**
**[-xscrollcommand, xScrollCommand, ScrollCommand](options.htm#M-xscrollcommand)**
Widget-specific options
-----------------------
Command-Line Name: **-disabledbackground** Database Name: **disabledBackground** Database Class: **DisabledBackground**
Specifies the background color to use when the entry is disabled. If this option is the empty string, the normal background color is used.
Command-Line Name: **-disabledforeground** Database Name: **disabledForeground** Database Class: **DisabledForeground**
Specifies the foreground color to use when the entry is disabled. If this option is the empty string, the normal foreground color is used.
Command-Line Name: **-invalidcommand or -invcmd** Database Name: **invalidCommand** Database Class: **InvalidCommand**
Specifies a script to eval when **-validatecommand** returns 0. Setting it to {} disables this feature (the default). The best use of this option is to set it to *bell*. See **[VALIDATION](#M16)** below for more information.
Command-Line Name: **-readonlybackground** Database Name: **readonlyBackground** Database Class: **ReadonlyBackground**
Specifies the background color to use when the entry is readonly. If this option is the empty string, the normal background color is used.
Command-Line Name: **-show** Database Name: **show** Database Class: **Show**
If this option is specified, then the true contents of the entry are not displayed in the window. Instead, each character in the entry's value will be displayed as the first character in the value of this option, such as “\*”. This is useful, for example, if the entry is to be used to enter a password. If characters in the entry are selected and copied elsewhere, the information copied will be what is displayed, not the true contents of the entry.
Command-Line Name: **-state** Database Name: **state** Database Class: **State**
Specifies one of three states for the entry: **normal**, **disabled**, or **readonly**. If the entry is readonly, then the value may not be changed using widget commands and no insertion cursor will be displayed, even if the input focus is in the widget; the contents of the widget may still be selected. If the entry is disabled, the value may not be changed, no insertion cursor will be displayed, the contents will not be selectable, and the entry may be displayed in a different color, depending on the values of the **-disabledforeground** and **-disabledbackground** options.
Command-Line Name: **-validate** Database Name: **validate** Database Class: **Validate**
Specifies the mode in which validation should operate: **none**, **[focus](focus.htm)**, **focusin**, **focusout**, **key**, or **all**. It defaults to **none**. When you want validation, you must explicitly state which mode you wish to use. See **[VALIDATION](#M16)** below for more.
Command-Line Name: **-validatecommand or -vcmd** Database Name: **validateCommand** Database Class: **ValidateCommand**
Specifies a script to eval when you want to validate the input into the entry widget. Setting it to {} disables this feature (the default). This command must return a valid Tcl boolean value. If it returns 0 (or the valid Tcl boolean equivalent) then it means you reject the new edition and it will not occur and the **-invalidcommand** will be evaluated if it is set. If it returns 1, then the new edition occurs. See **[VALIDATION](#M16)** below for more information.
Command-Line Name: **-width** Database Name: **width** Database Class: **Width**
Specifies an integer value indicating the desired width of the entry window, in average-size characters of the widget's font. If the value is less than or equal to zero, the widget picks a size just large enough to hold its current text.
Description
-----------
The **entry** command creates a new window (given by the *pathName* argument) and makes it into an entry widget. Additional options, described above, may be specified on the command line or in the option database to configure aspects of the entry such as its colors, font, and relief. The **entry** command returns its *pathName* argument. At the time this command is invoked, there must not exist a window named *pathName*, but *pathName*'s parent must exist. An entry is a widget that displays a one-line text string and allows that string to be edited using widget commands described below, which are typically bound to keystrokes and mouse actions. When first created, an entry's string is empty. A portion of the entry may be selected as described below. If an entry is exporting its selection (see the **-exportselection** option), then it will observe the standard X11 protocols for handling the selection; entry selections are available as type **STRING**. Entries also observe the standard Tk rules for dealing with the input focus. When an entry has the input focus it displays an *insertion cursor* to indicate where new characters will be inserted.
Entries are capable of displaying strings that are too long to fit entirely within the widget's window. In this case, only a portion of the string will be displayed; commands described below may be used to change the view in the window. Entries use the standard **-xscrollcommand** mechanism for interacting with scrollbars (see the description of the **-xscrollcommand** option for details). They also support scanning, as described below.
Validation
----------
Validation works by setting the **-validatecommand** option to a script (*validateCommand*) which will be evaluated according to the **-validate** option as follows:
**none**
Default. This means no validation will occur.
**focus**
*validateCommand* will be called when the entry receives or loses focus.
**focusin**
*validateCommand* will be called when the entry receives focus.
**focusout**
*validateCommand* will be called when the entry loses focus.
**key**
*validateCommand* will be called when the entry is edited.
**all**
*validateCommand* will be called for all above conditions.
It is possible to perform percent substitutions on the value of the **-validatecommand** and **-invalidcommand** options, just as you would in a **[bind](bind.htm)** script. The following substitutions are recognized:
**%d**
Type of action: 1 for **insert**, 0 for **delete**, or -1 for focus, forced or textvariable validation.
**%i**
Index of char string to be inserted/deleted, if any, otherwise -1.
**%P**
The value of the entry if the edit is allowed. If you are configuring the entry widget to have a new textvariable, this will be the value of that textvariable.
**%s**
The current value of entry prior to editing.
**%S**
The text string being inserted/deleted, if any, {} otherwise.
**%v**
The type of validation currently set.
**%V**
The type of validation that triggered the callback (key, focusin, focusout, forced).
**%W**
The name of the entry widget.
In general, the **-textvariable** and **-validatecommand** options can be dangerous to mix. Any problems have been overcome so that using the **-validatecommand** will not interfere with the traditional behavior of the entry widget. Using the **-textvariable** for read-only purposes will never cause problems. The danger comes when you try set the **-textvariable** to something that the **-validatecommand** would not accept, which causes **-validate** to become *none* (the **-invalidcommand** will not be triggered). The same happens when an error occurs evaluating the **-validatecommand**.
Primarily, an error will occur when the **-validatecommand** or **-invalidcommand** encounters an error in its script while evaluating or **-validatecommand** does not return a valid Tcl boolean value. The **-validate** option will also set itself to **none** when you edit the entry widget from within either the **-validatecommand** or the **-invalidcommand**. Such editions will override the one that was being validated. If you wish to edit the entry widget (for example set it to {}) during validation and still have the **-validate** option set, you should include the command
```
after idle {%W config -validate %v}
```
in the **-validatecommand** or **-invalidcommand** (whichever one you were editing the entry widget from). It is also recommended to not set an associated **-textvariable** during validation, as that can cause the entry widget to become out of sync with the **-textvariable**. Widget command
--------------
The **entry** command creates a new Tcl command whose name is *pathName*. This command may be used to invoke various operations on the widget. It has the following general form:
```
*pathName subcommand* ?*arg arg ...*?
```
*Subcommand* and the *arg*s determine the exact behavior of the command. ### Indices
Many of the widget commands for entries take one or more indices as arguments. An index specifies a particular character in the entry's string, in any of the following ways:
*number*
Specifies the character as a numerical index, where 0 corresponds to the first character in the string.
**anchor**
Indicates the anchor point for the selection, which is set with the **select from** and **select adjust** widget commands.
**end**
Indicates the character just after the last one in the entry's string. This is equivalent to specifying a numerical index equal to the length of the entry's string.
**insert**
Indicates the character adjacent to and immediately following the insertion cursor.
**sel.first**
Indicates the first character in the selection. It is an error to use this form if the selection is not in the entry window.
**sel.last**
Indicates the character just after the last one in the selection. It is an error to use this form if the selection is not in the entry window.
**@***number*
In this form, *number* is treated as an x-coordinate in the entry's window; the character spanning that x-coordinate is used. For example, “**@0**” indicates the left-most character in the window.
Abbreviations may be used for any of the forms above, e.g. “**e**” or “**sel.f**”. In general, out-of-range indices are automatically rounded to the nearest legal value.
### Subcommands
The following commands are possible for entry widgets:
*pathName* **bbox** *index*
Returns a list of four numbers describing the bounding box of the character given by *index*. The first two elements of the list give the x and y coordinates of the upper-left corner of the screen area covered by the character (in pixels relative to the widget) and the last two elements give the width and height of the character, in pixels. The bounding box may refer to a region outside the visible area of the window.
*pathName* **cget** *option*
Returns the current value of the configuration option given by *option*. *Option* may have any of the values accepted by the **entry** command.
*pathName* **configure** ?*option*? ?*value option value ...*?
Query or modify the configuration options of the widget. If no *option* is specified, returns a list describing all of the available options for *pathName* (see **[Tk\_ConfigureInfo](https://www.tcl.tk/man/tcl/TkLib/ConfigWidg.htm)** for information on the format of this list). If *option* is specified with no *value*, then the command returns a list describing the one named option (this list will be identical to the corresponding sublist of the value returned if no *option* is specified). If one or more *option-value* pairs are specified, then the command modifies the given widget option(s) to have the given value(s); in this case the command returns an empty string. *Option* may have any of the values accepted by the **entry** command.
*pathName* **delete** *first* ?*last*?
Delete one or more elements of the entry. *First* is the index of the first character to delete, and *last* is the index of the character just after the last one to delete. If *last* is not specified it defaults to *first*+1, i.e. a single character is deleted. This command returns an empty string.
*pathName* **get**
Returns the entry's string.
*pathName* **icursor** *index*
Arrange for the insertion cursor to be displayed just before the character given by *index*. Returns an empty string.
*pathName* **index** *index*
Returns the numerical index corresponding to *index*.
*pathName* **insert** *index string*
Insert the characters of *string* just before the character indicated by *index*. Returns an empty string.
*pathName* **scan** *option args*
This command is used to implement scanning on entries. It has two forms, depending on *option*:
*pathName* **scan mark** *x*
Records *x* and the current view in the entry window; used in conjunction with later **scan dragto** commands. Typically this command is associated with a mouse button press in the widget. It returns an empty string.
*pathName* **scan dragto** *x*
This command computes the difference between its *x* argument and the *x* argument to the last **scan mark** command for the widget. It then adjusts the view left or right by 10 times the difference in x-coordinates. This command is typically associated with mouse motion events in the widget, to produce the effect of dragging the entry at high speed through the window. The return value is an empty string.
*pathName* **selection** *option arg*
This command is used to adjust the selection within an entry. It has several forms, depending on *option*:
*pathName* **selection adjust** *index*
Locate the end of the selection nearest to the character given by *index*, and adjust that end of the selection to be at *index* (i.e. including but not going beyond *index*). The other end of the selection is made the anchor point for future **select to** commands. If the selection is not currently in the entry, then a new selection is created to include the characters between *index* and the most recent selection anchor point, inclusive. Returns an empty string.
*pathName* **selection clear**
Clear the selection if it is currently in this widget. If the selection is not in this widget then the command has no effect. Returns an empty string.
*pathName* **selection from** *index*
Set the selection anchor point to just before the character given by *index*. Does not change the selection. Returns an empty string.
*pathName* **selection present**
Returns 1 if there is are characters selected in the entry, 0 if nothing is selected.
*pathName* **selection range** *start* *end*
Sets the selection to include the characters starting with the one indexed by *start* and ending with the one just before *end*. If *end* refers to the same character as *start* or an earlier one, then the entry's selection is cleared.
*pathName* **selection to** *index*
If *index* is before the anchor point, set the selection to the characters from *index* up to but not including the anchor point. If *index* is the same as the anchor point, do nothing. If *index* is after the anchor point, set the selection to the characters from the anchor point up to but not including *index*. The anchor point is determined by the most recent **select from** or **select adjust** command in this widget. If the selection is not in this widget then a new selection is created using the most recent anchor point specified for the widget. Returns an empty string.
*pathName* **validate**
This command is used to force an evaluation of the **-validatecommand** independent of the conditions specified by the **-validate** option. This is done by temporarily setting the **-validate** option to **all**. It returns 0 or 1.
*pathName* **xview** *args*
This command is used to query and change the horizontal position of the text in the widget's window. It can take any of the following forms:
*pathName* **xview**
Returns a list containing two elements. Each element is a real fraction between 0 and 1; together they describe the horizontal span that is visible in the window. For example, if the first element is .2 and the second element is .6, 20% of the entry's text is off-screen to the left, the middle 40% is visible in the window, and 40% of the text is off-screen to the right. These are the same values passed to scrollbars via the **-xscrollcommand** option.
*pathName* **xview** *index*
Adjusts the view in the window so that the character given by *index* is displayed at the left edge of the window.
*pathName* **xview moveto** *fraction*
Adjusts the view in the window so that the character *fraction* of the way through the text appears at the left edge of the window. *Fraction* must be a fraction between 0 and 1.
*pathName* **xview scroll** *number what*
This command shifts the view in the window left or right according to *number* and *what*. *Number* must be an integer. *What* must be either **units** or **pages** or an abbreviation of one of these. If *what* is **units**, the view adjusts left or right by *number* average-width characters on the display; if it is **pages** then the view adjusts by *number* screenfuls. If *number* is negative then characters farther to the left become visible; if it is positive then characters farther to the right become visible.
Default bindings
----------------
Tk automatically creates class bindings for entries that give them the following default behavior. In the descriptions below, “word” refers to a contiguous group of letters, digits, or “\_” characters, or any single character other than these.
1. Clicking mouse button 1 positions the insertion cursor just before the character underneath the mouse cursor, sets the input focus to this widget, and clears any selection in the widget. Dragging with mouse button 1 strokes out a selection between the insertion cursor and the character under the mouse.
2. Double-clicking with mouse button 1 selects the word under the mouse and positions the insertion cursor at the end of the word. Dragging after a double click will stroke out a selection consisting of whole words.
3. Triple-clicking with mouse button 1 selects all of the text in the entry and positions the insertion cursor at the end of the line.
4. The ends of the selection can be adjusted by dragging with mouse button 1 while the Shift key is down; this will adjust the end of the selection that was nearest to the mouse cursor when button 1 was pressed. If the button is double-clicked before dragging then the selection will be adjusted in units of whole words.
5. Clicking mouse button 1 with the Control key down will position the insertion cursor in the entry without affecting the selection.
6. If any normal printing characters are typed in an entry, they are inserted at the point of the insertion cursor.
7. The view in the entry can be adjusted by dragging with mouse button 2. If mouse button 2 is clicked without moving the mouse, the selection is copied into the entry at the position of the mouse cursor.
8. If the mouse is dragged out of the entry on the left or right sides while button 1 is pressed, the entry will automatically scroll to make more text visible (if there is more text off-screen on the side where the mouse left the window).
9. The Left and Right keys move the insertion cursor one character to the left or right; they also clear any selection in the entry and set the selection anchor. If Left or Right is typed with the Shift key down, then the insertion cursor moves and the selection is extended to include the new character. Control-Left and Control-Right move the insertion cursor by words, and Control-Shift-Left and Control-Shift-Right move the insertion cursor by words and also extend the selection. Control-b and Control-f behave the same as Left and Right, respectively. Meta-b and Meta-f behave the same as Control-Left and Control-Right, respectively.
10. The Home key, or Control-a, will move the insertion cursor to the beginning of the entry and clear any selection in the entry. Shift-Home moves the insertion cursor to the beginning of the entry and also extends the selection to that point.
11. The End key, or Control-e, will move the insertion cursor to the end of the entry and clear any selection in the entry. Shift-End moves the cursor to the end and extends the selection to that point.
12. The Select key and Control-Space set the selection anchor to the position of the insertion cursor. They do not affect the current selection. Shift-Select and Control-Shift-Space adjust the selection to the current position of the insertion cursor, selecting from the anchor to the insertion cursor if there was not any selection previously.
13. Control-/ selects all the text in the entry.
14. Control-\ clears any selection in the entry.
15. The F16 key (labelled Copy on many Sun workstations) or Meta-w copies the selection in the widget to the clipboard, if there is a selection.
16. The F20 key (labelled Cut on many Sun workstations) or Control-w copies the selection in the widget to the clipboard and deletes the selection. If there is no selection in the widget then these keys have no effect.
17. The F18 key (labelled Paste on many Sun workstations) or Control-y inserts the contents of the clipboard at the position of the insertion cursor.
18. The Delete key deletes the selection, if there is one in the entry. If there is no selection, it deletes the character to the right of the insertion cursor.
19. The BackSpace key and Control-h delete the selection, if there is one in the entry. If there is no selection, it deletes the character to the left of the insertion cursor.
20. Control-d deletes the character to the right of the insertion cursor.
21. Meta-d deletes the word to the right of the insertion cursor.
22. Control-k deletes all the characters to the right of the insertion cursor.
23. Control-t reverses the order of the two characters to the right of the insertion cursor.
If the entry is disabled using the **-state** option, then the entry's view can still be adjusted and text in the entry can still be selected, but no insertion cursor will be displayed and no text modifications will take place except if the entry is linked to a variable using the **-textvariable** option, in which case any changes to the variable are reflected by the entry whatever the value of its **-state** option.
The behavior of entries can be changed by defining new bindings for individual widgets or by redefining the class bindings.
See also
--------
**[ttk::entry](ttk_entry.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TkCmd/entry.htm>
| programming_docs |
tcl_tk ttk_combobox ttk\_combobox
=============
[NAME](ttk_combobox.htm#M2) ttk::combobox — text field with popdown selection list
[SYNOPSIS](ttk_combobox.htm#M3)
[DESCRIPTION](ttk_combobox.htm#M4)
[STANDARD OPTIONS](ttk_combobox.htm#M5)
[-class, undefined, undefined](ttk_widget.htm#M-class)
[-cursor, cursor, Cursor](ttk_widget.htm#M-cursor)
[-style, style, Style](ttk_widget.htm#M-style)
[-takefocus, takeFocus, TakeFocus](ttk_widget.htm#M-takefocus)
[WIDGET-SPECIFIC OPTIONS](ttk_combobox.htm#M6)
[-exportselection, exportSelection, ExportSelection](ttk_combobox.htm#M7)
[-justify, justify, Justify](ttk_combobox.htm#M8)
[-height, height, Height](ttk_combobox.htm#M9)
[-postcommand, postCommand, PostCommand](ttk_combobox.htm#M10)
[-state, state, State](ttk_combobox.htm#M11)
[-textvariable, textVariable, TextVariable](ttk_combobox.htm#M12)
[-values, values, Values](ttk_combobox.htm#M13)
[-width, width, Width](ttk_combobox.htm#M14)
[WIDGET COMMAND](ttk_combobox.htm#M15)
[*pathName* **current** ?*newIndex*?](ttk_combobox.htm#M16)
[*pathName* **get**](ttk_combobox.htm#M17)
[*pathName* **set** *value*](ttk_combobox.htm#M18)
[VIRTUAL EVENTS](ttk_combobox.htm#M19)
[SEE ALSO](ttk_combobox.htm#M20)
[KEYWORDS](ttk_combobox.htm#M21)
Name
----
ttk::combobox — text field with popdown selection list Synopsis
--------
**ttk::combobox** *pathName* ?*options*?
Description
-----------
A **ttk::combobox** combines a text field with a pop-down list of values; the user may select the value of the text field from among the values in the list. Standard options
----------------
**[-class, undefined, undefined](ttk_widget.htm#M-class)**
**[-cursor, cursor, Cursor](ttk_widget.htm#M-cursor)**
**[-style, style, Style](ttk_widget.htm#M-style)**
**[-takefocus, takeFocus, TakeFocus](ttk_widget.htm#M-takefocus)**
Widget-specific options
-----------------------
Command-Line Name: **-exportselection** Database Name: **exportSelection** Database Class: **ExportSelection**
Boolean value. If set, the widget selection is linked to the X selection.
Command-Line Name: **-justify** Database Name: **justify** Database Class: **Justify**
Specifies how the text is aligned within the widget. Must be one of **left**, **center**, or **right**.
Command-Line Name: **-height** Database Name: **height** Database Class: **Height**
Specifies the height of the pop-down listbox, in rows.
Command-Line Name: **-postcommand** Database Name: **postCommand** Database Class: **PostCommand**
A Tcl script to evaluate immediately before displaying the listbox. The **-postcommand** script may specify the **-values** to display.
Command-Line Name: **-state** Database Name: **state** Database Class: **State**
One of **normal**, **readonly**, or **disabled**. In the **readonly** state, the value may not be edited directly, and the user can only select one of the **-values** from the dropdown list. In the **normal** state, the text field is directly editable. In the **disabled** state, no interaction is possible.
Command-Line Name: **-textvariable** Database Name: **textVariable** Database Class: **TextVariable**
Specifies the name of a global variable whose value is linked to the widget value. Whenever the variable changes value the widget value is updated, and vice versa.
Command-Line Name: **-values** Database Name: **values** Database Class: **Values**
Specifies the list of values to display in the drop-down listbox.
Command-Line Name: **-width** Database Name: **width** Database Class: **Width**
Specifies an integer value indicating the desired width of the entry window, in average-size characters of the widget's font.
Widget command
--------------
The following subcommands are possible for combobox widgets:
*pathName* **current** ?*newIndex*?
If *newIndex* is supplied, sets the combobox value to the element at position *newIndex* in the list of **-values**. Otherwise, returns the index of the current value in the list of **-values** or **-1** if the current value does not appear in the list.
*pathName* **get**
Returns the current value of the combobox.
*pathName* **set** *value*
Sets the value of the combobox to *value*.
The combobox widget also supports the following **[ttk::entry](ttk_entry.htm)** widget subcommands (see *ttk::entry(n)* for details):
| | | |
| --- | --- | --- |
| **bbox** | **delete** | **icursor** |
| **index** | **insert** | **selection** |
| **xview** |
The combobox widget also supports the following generic **[ttk::widget](ttk_widget.htm)** widget subcommands (see *ttk::widget(n)* for details):
| | | |
| --- | --- | --- |
| **cget** | **configure** | **identify** |
| **instate** | **state** |
Virtual events
--------------
The combobox widget generates a **<<ComboboxSelected>>** virtual event when the user selects an element from the list of values. If the selection action unposts the listbox, this event is delivered after the listbox is unposted. See also
--------
**[ttk::widget](ttk_widget.htm)**, **[ttk::entry](ttk_entry.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TkCmd/ttk_combobox.htm>
tcl_tk canvas canvas
======
[NAME](canvas.htm#M2) canvas — Create and manipulate 'canvas' hypergraphics drawing surface widgets
[SYNOPSIS](canvas.htm#M3)
[STANDARD OPTIONS](canvas.htm#M4)
[-background or -bg, background, Background](options.htm#M-background)
[-borderwidth or -bd, borderWidth, BorderWidth](options.htm#M-borderwidth)
[-cursor, cursor, Cursor](options.htm#M-cursor)
[-highlightbackground, highlightBackground, HighlightBackground](options.htm#M-highlightbackground)
[-highlightcolor, highlightColor, HighlightColor](options.htm#M-highlightcolor)
[-highlightthickness, highlightThickness, HighlightThickness](options.htm#M-highlightthickness)
[-insertbackground, insertBackground, Foreground](options.htm#M-insertbackground)
[-insertborderwidth, insertBorderWidth, BorderWidth](options.htm#M-insertborderwidth)
[-insertofftime, insertOffTime, OffTime](options.htm#M-insertofftime)
[-insertontime, insertOnTime, OnTime](options.htm#M-insertontime)
[-insertwidth, insertWidth, InsertWidth](options.htm#M-insertwidth)
[-relief, relief, Relief](options.htm#M-relief)
[-selectbackground, selectBackground, Foreground](options.htm#M-selectbackground)
[-selectborderwidth, selectBorderWidth, BorderWidth](options.htm#M-selectborderwidth)
[-selectforeground, selectForeground, Background](options.htm#M-selectforeground)
[-takefocus, takeFocus, TakeFocus](options.htm#M-takefocus)
[-xscrollcommand, xScrollCommand, ScrollCommand](options.htm#M-xscrollcommand)
[-yscrollcommand, yScrollCommand, ScrollCommand](options.htm#M-yscrollcommand)
[WIDGET-SPECIFIC OPTIONS](canvas.htm#M5)
[-closeenough, closeEnough, CloseEnough](canvas.htm#M6)
[-confine, confine, Confine](canvas.htm#M7)
[-height, height, Height](canvas.htm#M8)
[-scrollregion, scrollRegion, ScrollRegion](canvas.htm#M9)
[-state, state, State](canvas.htm#M10)
[-width, width, width](canvas.htm#M11)
[-xscrollincrement, xScrollIncrement, ScrollIncrement](canvas.htm#M12)
[-yscrollincrement, yScrollIncrement, ScrollIncrement](canvas.htm#M13)
[INTRODUCTION](canvas.htm#M14)
[DISPLAY LIST](canvas.htm#M15)
[ITEM IDS AND TAGS](canvas.htm#M16)
[COORDINATES](canvas.htm#M17)
[TRANSFORMATIONS](canvas.htm#M18)
[INDICES](canvas.htm#M19)
[*number*](canvas.htm#M20)
[**end**](canvas.htm#M21)
[**insert**](canvas.htm#M22)
[**sel.first**](canvas.htm#M23)
[**sel.last**](canvas.htm#M24)
[**@***x,y*](canvas.htm#M25)
[DASH PATTERNS](canvas.htm#M26)
[WIDGET COMMAND](canvas.htm#M27)
[*pathName* **addtag** *tag searchSpec* ?*arg arg ...*?](canvas.htm#M28)
[**above** *tagOrId*](canvas.htm#M29)
[**all**](canvas.htm#M30)
[**below** *tagOrId*](canvas.htm#M31)
[**closest** *x y* ?*halo*? ?*start*?](canvas.htm#M32)
[**enclosed** *x1* *y1* *x2* *y2*](canvas.htm#M33)
[**overlapping** *x1* *y1* *x2* *y2*](canvas.htm#M34)
[**withtag** *tagOrId*](canvas.htm#M35)
[*pathName* **bbox** *tagOrId* ?*tagOrId tagOrId ...*?](canvas.htm#M36)
[*pathName* **bind** *tagOrId* ?*sequence*? ?*command*?](canvas.htm#M37)
[*pathName* **canvasx** *screenx* ?*gridspacing*?](canvas.htm#M38)
[*pathName* **canvasy** *screeny* ?*gridspacing*?](canvas.htm#M39)
[*pathName* **cget** *option*](canvas.htm#M40)
[*pathName* **configure ?***option*? ?*value*? ?*option value ...*?](canvas.htm#M41)
[*pathName* **coords** *tagOrId* ?*x0 y0 ...*?](canvas.htm#M42)
[*pathName* **coords** *tagOrId* ?*coordList*?](canvas.htm#M43)
[*pathName* **create** *type x y* ?*x y ...*? ?*option value ...*?](canvas.htm#M44)
[*pathName* **create** *type coordList* ?*option value ...*?](canvas.htm#M45)
[*pathName* **dchars** *tagOrId first* ?*last*?](canvas.htm#M46)
[*pathName* **delete** ?*tagOrId tagOrId ...*?](canvas.htm#M47)
[*pathName* **dtag** *tagOrId* ?*tagToDelete*?](canvas.htm#M48)
[*pathName* **find** *searchCommand* ?*arg arg ...*?](canvas.htm#M49)
[*pathName* **focus** ?*tagOrId*?](canvas.htm#M50)
[*pathName* **gettags** *tagOrId*](canvas.htm#M51)
[*pathName* **icursor** *tagOrId index*](canvas.htm#M52)
[*pathName* **imove** *tagOrId index x y*](canvas.htm#M53)
[*pathName* **index** *tagOrId index*](canvas.htm#M54)
[*pathName* **insert** *tagOrId beforeThis string*](canvas.htm#M55)
[*pathName* **itemcget** *tagOrId* *option*](canvas.htm#M56)
[*pathName* **itemconfigure** *tagOrId* ?*option*? ?*value*? ?*option value ...*?](canvas.htm#M57)
[*pathName* **lower** *tagOrId* ?*belowThis*?](canvas.htm#M58)
[*pathName* **move** *tagOrId xAmount yAmount*](canvas.htm#M59)
[*pathName* **moveto** *tagOrId xPos yPos*](canvas.htm#M60)
[*pathName* **postscript** ?*option value option value ...*?](canvas.htm#M61)
[**-channel** *channelName*](canvas.htm#M62)
[**-colormap** *varName*](canvas.htm#M63)
[**-colormode** *mode*](canvas.htm#M64)
[**-file** *fileName*](canvas.htm#M65)
[**-fontmap** *varName*](canvas.htm#M66)
[**-height** *size*](canvas.htm#M67)
[**-pageanchor** *anchor*](canvas.htm#M68)
[**-pageheight** *size*](canvas.htm#M69)
[**-pagewidth** *size*](canvas.htm#M70)
[**-pagex** *position*](canvas.htm#M71)
[**-pagey** *position*](canvas.htm#M72)
[**-rotate** *boolean*](canvas.htm#M73)
[**-width** *size*](canvas.htm#M74)
[**-x** *position*](canvas.htm#M75)
[**-y** *position*](canvas.htm#M76)
[*pathName* **raise** *tagOrId* ?*aboveThis*?](canvas.htm#M77)
[*pathName* **rchars** *tagOrId first last string*](canvas.htm#M78)
[*pathName* **scale** *tagOrId xOrigin yOrigin xScale yScale*](canvas.htm#M79)
[*pathName* **scan** *option args*](canvas.htm#M80)
[*pathName* **scan mark** *x y*](canvas.htm#M81)
[*pathName* **scan dragto** *x y ?gain?*](canvas.htm#M82)
[*pathName* **select** *option* ?*tagOrId arg*?](canvas.htm#M83)
[*pathName* **select adjust** *tagOrId index*](canvas.htm#M84)
[*pathName* **select clear**](canvas.htm#M85)
[*pathName* **select from** *tagOrId index*](canvas.htm#M86)
[*pathName* **select item**](canvas.htm#M87)
[*pathName* **select to** *tagOrId index*](canvas.htm#M88)
[*pathName* **type** *tagOrId*](canvas.htm#M89)
[*pathName* **xview** ?*args*?](canvas.htm#M90)
[*pathName* **xview**](canvas.htm#M91)
[*pathName* **xview moveto** *fraction*](canvas.htm#M92)
[*pathName* **xview scroll** *number what*](canvas.htm#M93)
[*pathName* **yview** *?args*?](canvas.htm#M94)
[*pathName* **yview**](canvas.htm#M95)
[*pathName* **yview moveto** *fraction*](canvas.htm#M96)
[*pathName* **yview scroll** *number what*](canvas.htm#M97)
[OVERVIEW OF ITEM TYPES](canvas.htm#M98)
[COMMON ITEM OPTIONS](canvas.htm#M99)
[**-anchor** *anchorPos*](canvas.htm#M100)
[**-dash** *pattern*](canvas.htm#M101)
[**-activedash** *pattern*](canvas.htm#M102)
[**-disableddash** *pattern*](canvas.htm#M103)
[**-dashoffset** *offset*](canvas.htm#M104)
[**-fill** *color*](canvas.htm#M105)
[**-activefill** *color*](canvas.htm#M106)
[**-disabledfill** *color*](canvas.htm#M107)
[**-outline** *color*](canvas.htm#M108)
[**-activeoutline** *color*](canvas.htm#M109)
[**-disabledoutline** *color*](canvas.htm#M110)
[**-offset** *offset*](canvas.htm#M111)
[**-outlinestipple** *bitmap*](canvas.htm#M112)
[**-activeoutlinestipple** *bitmap*](canvas.htm#M113)
[**-disabledoutlinestipple** *bitmap*](canvas.htm#M114)
[**-outlineoffset** *offset*](canvas.htm#M115)
[**-stipple** *bitmap*](canvas.htm#M116)
[**-activestipple** *bitmap*](canvas.htm#M117)
[**-disabledstipple** *bitmap*](canvas.htm#M118)
[**-state** *state*](canvas.htm#M119)
[**-tags** *tagList*](canvas.htm#M120)
[**-width** *outlineWidth*](canvas.htm#M121)
[**-activewidth** *outlineWidth*](canvas.htm#M122)
[**-disabledwidth** *outlineWidth*](canvas.htm#M123)
[STANDARD ITEM TYPES](canvas.htm#M124)
[ARC ITEMS](canvas.htm#M125)
[**-extent** *degrees*](canvas.htm#M126)
[**-start** *degrees*](canvas.htm#M127)
[**-style** *type*](canvas.htm#M128)
[BITMAP ITEMS](canvas.htm#M129)
[**-background** *color*](canvas.htm#M130)
[**-activebackground** *color*](canvas.htm#M131)
[**-disabledbackground** *color*](canvas.htm#M132)
[**-bitmap** *bitmap*](canvas.htm#M133)
[**-activebitmap** *bitmap*](canvas.htm#M134)
[**-disabledbitmap** *bitmap*](canvas.htm#M135)
[**-foreground** *color*](canvas.htm#M136)
[**-activeforeground** *color*](canvas.htm#M137)
[**-disabledforeground** *color*](canvas.htm#M138)
[IMAGE ITEMS](canvas.htm#M139)
[**-image** *name*](canvas.htm#M140)
[**-activeimage** *name*](canvas.htm#M141)
[**-disabledimage** *name*](canvas.htm#M142)
[LINE ITEMS](canvas.htm#M143)
[**-arrow** *where*](canvas.htm#M144)
[**-arrowshape** *shape*](canvas.htm#M145)
[**-capstyle** *style*](canvas.htm#M146)
[**-joinstyle** *style*](canvas.htm#M147)
[**-smooth** *smoothMethod*](canvas.htm#M148)
[**-splinesteps** *number*](canvas.htm#M149)
[OVAL ITEMS](canvas.htm#M150)
[POLYGON ITEMS](canvas.htm#M151)
[**-joinstyle** *style*](canvas.htm#M152)
[**-smooth** *boolean*](canvas.htm#M153)
[**-splinesteps** *number*](canvas.htm#M154)
[RECTANGLE ITEMS](canvas.htm#M155)
[TEXT ITEMS](canvas.htm#M156)
[**-angle** *rotationDegrees*](canvas.htm#M157)
[**-font** *fontName*](canvas.htm#M158)
[**-justify** *how*](canvas.htm#M159)
[**-text** *string*](canvas.htm#M160)
[**-underline**](canvas.htm#M161)
[**-width** *lineLength*](canvas.htm#M162)
[WINDOW ITEMS](canvas.htm#M163)
[**-height** *pixels*](canvas.htm#M164)
[**-width** *pixels*](canvas.htm#M165)
[**-window** *pathName*](canvas.htm#M166)
[APPLICATION-DEFINED ITEM TYPES](canvas.htm#M167)
[BINDINGS](canvas.htm#M168)
[CREDITS](canvas.htm#M169)
[SEE ALSO](canvas.htm#M170)
[KEYWORDS](canvas.htm#M171)
Name
----
canvas — Create and manipulate 'canvas' hypergraphics drawing surface widgets Synopsis
--------
**canvas** *pathName* ?*options*?
Standard options
----------------
**[-background or -bg, background, Background](options.htm#M-background)**
**[-borderwidth or -bd, borderWidth, BorderWidth](options.htm#M-borderwidth)**
**[-cursor, cursor, Cursor](options.htm#M-cursor)**
**[-highlightbackground, highlightBackground, HighlightBackground](options.htm#M-highlightbackground)**
**[-highlightcolor, highlightColor, HighlightColor](options.htm#M-highlightcolor)**
**[-highlightthickness, highlightThickness, HighlightThickness](options.htm#M-highlightthickness)**
**[-insertbackground, insertBackground, Foreground](options.htm#M-insertbackground)**
**[-insertborderwidth, insertBorderWidth, BorderWidth](options.htm#M-insertborderwidth)**
**[-insertofftime, insertOffTime, OffTime](options.htm#M-insertofftime)**
**[-insertontime, insertOnTime, OnTime](options.htm#M-insertontime)**
**[-insertwidth, insertWidth, InsertWidth](options.htm#M-insertwidth)**
**[-relief, relief, Relief](options.htm#M-relief)**
**[-selectbackground, selectBackground, Foreground](options.htm#M-selectbackground)**
**[-selectborderwidth, selectBorderWidth, BorderWidth](options.htm#M-selectborderwidth)**
**[-selectforeground, selectForeground, Background](options.htm#M-selectforeground)**
**[-takefocus, takeFocus, TakeFocus](options.htm#M-takefocus)**
**[-xscrollcommand, xScrollCommand, ScrollCommand](options.htm#M-xscrollcommand)**
**[-yscrollcommand, yScrollCommand, ScrollCommand](options.htm#M-yscrollcommand)**
Widget-specific options
-----------------------
Command-Line Name: **-closeenough** Database Name: **closeEnough** Database Class: **CloseEnough**
Specifies a floating-point value indicating how close the mouse cursor must be to an item before it is considered to be “inside” the item. Defaults to 1.0.
Command-Line Name: **-confine** Database Name: **confine** Database Class: **Confine**
Specifies a boolean value that indicates whether or not it should be allowable to set the canvas's view outside the region defined by the **scrollRegion** argument. Defaults to true, which means that the view will be constrained within the scroll region.
Command-Line Name: **-height** Database Name: **height** Database Class: **Height**
Specifies a desired window height that the canvas widget should request from its geometry manager. The value may be specified in any of the forms described in the **[COORDINATES](#M17)** section below.
Command-Line Name: **-scrollregion** Database Name: **scrollRegion** Database Class: **ScrollRegion**
Specifies a list with four coordinates describing the left, top, right, and bottom coordinates of a rectangular region. This region is used for scrolling purposes and is considered to be the boundary of the information in the canvas. Each of the coordinates may be specified in any of the forms given in the **[COORDINATES](#M17)** section below.
Command-Line Name: **-state** Database Name: **state** Database Class: **State**
Modifies the default state of the canvas where *state* may be set to one of: **normal**, **disabled**, or **hidden**. Individual canvas objects all have their own state option which may override the default state. Many options can take separate specifications such that the appearance of the item can be different in different situations. The options that start with **active** control the appearance when the mouse pointer is over it, while the option starting with **disabled** controls the appearance when the state is disabled. Canvas items which are **disabled** will not react to canvas bindings.
Command-Line Name: **-width** Database Name: **width** Database Class: **width**
Specifies a desired window width that the canvas widget should request from its geometry manager. The value may be specified in any of the forms described in the **[COORDINATES](#M17)** section below.
Command-Line Name: **-xscrollincrement** Database Name: **xScrollIncrement** Database Class: **ScrollIncrement**
Specifies an increment for horizontal scrolling, in any of the usual forms permitted for screen distances. If the value of this option is greater than zero, the horizontal view in the window will be constrained so that the canvas x coordinate at the left edge of the window is always an even multiple of **xScrollIncrement**; furthermore, the units for scrolling (e.g., the change in view when the left and right arrows of a scrollbar are selected) will also be **xScrollIncrement**. If the value of this option is less than or equal to zero, then horizontal scrolling is unconstrained.
Command-Line Name: **-yscrollincrement** Database Name: **yScrollIncrement** Database Class: **ScrollIncrement**
Specifies an increment for vertical scrolling, in any of the usual forms permitted for screen distances. If the value of this option is greater than zero, the vertical view in the window will be constrained so that the canvas y coordinate at the top edge of the window is always an even multiple of **yScrollIncrement**; furthermore, the units for scrolling (e.g., the change in view when the top and bottom arrows of a scrollbar are selected) will also be **yScrollIncrement**. If the value of this option is less than or equal to zero, then vertical scrolling is unconstrained.
Introduction
------------
The **canvas** command creates a new window (given by the *pathName* argument) and makes it into a canvas widget. Additional options, described above, may be specified on the command line or in the option database to configure aspects of the canvas such as its colors and 3-D relief. The **canvas** command returns its *pathName* argument. At the time this command is invoked, there must not exist a window named *pathName*, but *pathName*'s parent must exist. Canvas widgets implement structured graphics. A canvas displays any number of *items*, which may be things like rectangles, circles, lines, and text. Items may be manipulated (e.g. moved or re-colored) and commands may be associated with items in much the same way that the **[bind](bind.htm)** command allows commands to be bound to widgets. For example, a particular command may be associated with the <Button-1> event so that the command is invoked whenever button 1 is pressed with the mouse cursor over an item. This means that items in a canvas can have behaviors defined by the Tcl scripts bound to them.
Display list
------------
The items in a canvas are ordered for purposes of display, with the first item in the display list being displayed first, followed by the next item in the list, and so on. Items later in the display list obscure those that are earlier in the display list and are sometimes referred to as being “on top” of earlier items. When a new item is created it is placed at the end of the display list, on top of everything else. Widget commands may be used to re-arrange the order of the display list. Window items are an exception to the above rules. The underlying window systems require them always to be drawn on top of other items. In addition, the stacking order of window items is not affected by any of the canvas widget commands; you must use the Tk **[raise](raise.htm)** command and **[lower](lower.htm)** command instead.
Item ids and tags
-----------------
Items in a canvas widget may be named in either of two ways: by id or by tag. Each item has a unique identifying number, which is assigned to that item when it is created. The id of an item never changes and id numbers are never re-used within the lifetime of a canvas widget. Each item may also have any number of *tags* associated with it. A tag is just a string of characters, and it may take any form except that of an integer. For example, “x123” is OK but “123” is not. The same tag may be associated with many different items. This is commonly done to group items in various interesting ways; for example, all selected items might be given the tag “selected”.
The tag **all** is implicitly associated with every item in the canvas; it may be used to invoke operations on all the items in the canvas.
The tag **current** is managed automatically by Tk; it applies to the *current item*, which is the topmost item whose drawn area covers the position of the mouse cursor (different item types interpret this in varying ways; see the individual item type documentation for details). If the mouse is not in the canvas widget or is not over an item, then no item has the **current** tag.
When specifying items in canvas widget commands, if the specifier is an integer then it is assumed to refer to the single item with that id. If the specifier is not an integer, then it is assumed to refer to all of the items in the canvas that have a tag matching the specifier. The symbol *tagOrId* is used below to indicate that an argument specifies either an id that selects a single item or a tag that selects zero or more items.
*tagOrId* may contain a logical expressions of tags by using operators: “**&&**”, “**||**”, “**^**”, “**!**”, and parenthesized subexpressions. For example:
```
.c find withtag {(a&&!b)||(!a&&b)}
```
or equivalently:
```
.c find withtag {a^b}
```
will find only those items with either “a” or “b” tags, but not both. Some widget commands only operate on a single item at a time; if *tagOrId* is specified in a way that names multiple items, then the normal behavior is for the command to use the first (lowest) of these items in the display list that is suitable for the command. Exceptions are noted in the widget command descriptions below.
Coordinates
-----------
All coordinates related to canvases are stored as floating-point numbers. Coordinates and distances are specified in screen units, which are floating-point numbers optionally followed by one of several letters. If no letter is supplied then the distance is in pixels. If the letter is **m** then the distance is in millimeters on the screen; if it is **c** then the distance is in centimeters; **i** means inches, and **p** means printers points (1/72 inch). Larger y-coordinates refer to points lower on the screen; larger x-coordinates refer to points farther to the right. Coordinates can be specified either as an even number of parameters, or as a single list parameter containing an even number of x and y coordinate values. ### Transformations
Normally the origin of the canvas coordinate system is at the upper-left corner of the window containing the canvas. It is possible to adjust the origin of the canvas coordinate system relative to the origin of the window using the **xview** and **yview** widget commands; this is typically used for scrolling. Canvases do not support scaling or rotation of the canvas coordinate system relative to the window coordinate system. Individual items may be moved or scaled using widget commands described below, but they may not be rotated.
Note that the default origin of the canvas's visible area is coincident with the origin for the whole window as that makes bindings using the mouse position easier to work with; you only need to use the **canvasx** and **canvasy** widget commands if you adjust the origin of the visible area. However, this also means that any focus ring (as controlled by the **-highlightthickness** option) and window border (as controlled by the **-borderwidth** option) must be taken into account before you get to the visible area of the canvas.
Indices
-------
Text items support the notion of an *index* for identifying particular positions within the item. In a similar fashion, line and polygon items support *index* for identifying, inserting and deleting subsets of their coordinates. Indices are used for commands such as inserting or deleting a range of characters or coordinates, and setting the insertion cursor position. An index may be specified in any of a number of ways, and different types of items may support different forms for specifying indices. Text items support the following forms for an index; if you define new types of text-like items, it would be advisable to support as many of these forms as practical. Note that it is possible to refer to the character just after the last one in the text item; this is necessary for such tasks as inserting new text at the end of the item. Lines and Polygons do not support the insertion cursor and the selection. Their indices are supposed to be even always, because coordinates always appear in pairs.
*number*
A decimal number giving the position of the desired character within the text item. 0 refers to the first character, 1 to the next character, and so on. If indexes are odd for lines and polygons, they will be automatically decremented by one. A number less than 0 is treated as if it were zero, and a number greater than the length of the text item is treated as if it were equal to the length of the text item. For polygons, numbers less than 0 or greater than the length of the coordinate list will be adjusted by adding or subtracting the length until the result is between zero and the length, inclusive.
**end**
Refers to the character or coordinate just after the last one in the item (same as the number of characters or coordinates in the item).
**insert**
Refers to the character just before which the insertion cursor is drawn in this item. Not valid for lines and polygons.
**sel.first**
Refers to the first selected character in the item. If the selection is not in this item then this form is illegal.
**sel.last**
Refers to the last selected character in the item. If the selection is not in this item then this form is illegal.
**@***x,y*
Refers to the character or coordinate at the point given by *x* and *y*, where *x* and *y* are specified in the coordinate system of the canvas. If *x* and *y* lie outside the coordinates covered by the text item, then they refer to the first or last character in the line that is closest to the given point.
Dash patterns
-------------
Many items support the notion of a dash pattern for outlines. The first possible syntax is a list of integers. Each element represents the number of pixels of a line segment. Only the odd segments are drawn using the “outline” color. The other segments are drawn transparent.
The second possible syntax is a character list containing only 5 possible characters “**.,-\_** ”. The space can be used to enlarge the space between other line elements, and cannot occur as the first position in the string. Some examples:
```
-dash . → -dash {2 4}
-dash - → -dash {6 4}
-dash -. → -dash {6 4 2 4}
-dash -.. → -dash {6 4 2 4 2 4}
-dash {. } → -dash {2 8}
-dash , → -dash {4 4}
```
The main difference of this syntax with the previous is that it is shape-conserving. This means that all values in the dash list will be multiplied by the line width before display. This assures that “.” will always be displayed as a dot and “-” always as a dash regardless of the line width.
On systems which support only a limited set of dash patterns, the dash pattern will be displayed as the closest dash pattern that is available. For example, on Windows only the first 4 of the above examples are available. The last 2 examples will be displayed identically to the first one.
Widget command
--------------
The **canvas** command creates a new Tcl command whose name is *pathName*. This command may be used to invoke various operations on the widget. It has the following general form:
```
*pathName option* ?*arg arg ...*?
```
*Option* and the *arg*s determine the exact behavior of the command. The following widget commands are possible for canvas widgets:
*pathName* **addtag** *tag searchSpec* ?*arg arg ...*?
For each item that meets the constraints specified by *searchSpec* and the *arg*s, add *tag* to the list of tags associated with the item if it is not already present on that list. It is possible that no items will satisfy the constraints given by *searchSpec* and *arg*s, in which case the command has no effect. This command returns an empty string as result. *SearchSpec* and *arg*'s may take any of the following forms:
**above** *tagOrId*
Selects the item just after (above) the one given by *tagOrId* in the display list. If *tagOrId* denotes more than one item, then the last (topmost) of these items in the display list is used.
**all**
Selects all the items in the canvas.
**below** *tagOrId*
Selects the item just before (below) the one given by *tagOrId* in the display list. If *tagOrId* denotes more than one item, then the first (lowest) of these items in the display list is used.
**closest** *x y* ?*halo*? ?*start*?
Selects the item closest to the point given by *x* and *y*. If more than one item is at the same closest distance (e.g. two items overlap the point), then the top-most of these items (the last one in the display list) is used. If *halo* is specified, then it must be a non-negative value. Any item closer than *halo* to the point is considered to overlap it. The *start* argument may be used to step circularly through all the closest items. If *start* is specified, it names an item using a tag or id (if by tag, it selects the first item in the display list with the given tag). Instead of selecting the topmost closest item, this form will select the topmost closest item that is below *start* in the display list; if no such item exists, then the selection behaves as if the *start* argument had not been specified.
**enclosed** *x1* *y1* *x2* *y2*
Selects all the items completely enclosed within the rectangular region given by *x1*, *y1*, *x2*, and *y2*. *X1* must be no greater than *x2* and *y1* must be no greater than *y2*.
**overlapping** *x1* *y1* *x2* *y2*
Selects all the items that overlap or are enclosed within the rectangular region given by *x1*, *y1*, *x2*, and *y2*. *X1* must be no greater than *x2* and *y1* must be no greater than *y2*.
**withtag** *tagOrId*
Selects all the items given by *tagOrId*.
*pathName* **bbox** *tagOrId* ?*tagOrId tagOrId ...*?
Returns a list with four elements giving an approximate bounding box for all the items named by the *tagOrId* arguments. The list has the form “*x1 y1 x2 y2*” such that the drawn areas of all the named elements are within the region bounded by *x1* on the left, *x2* on the right, *y1* on the top, and *y2* on the bottom. The return value may overestimate the actual bounding box by a few pixels. If no items match any of the *tagOrId* arguments or if the matching items have empty bounding boxes (i.e. they have nothing to display) then an empty string is returned.
*pathName* **bind** *tagOrId* ?*sequence*? ?*command*?
This command associates *command* with all the items given by *tagOrId* such that whenever the event sequence given by *sequence* occurs for one of the items the command will be invoked. This widget command is similar to the **[bind](bind.htm)** command except that it operates on items in a canvas rather than entire widgets. See the **[bind](bind.htm)** manual entry for complete details on the syntax of *sequence* and the substitutions performed on *command* before invoking it. If all arguments are specified then a new binding is created, replacing any existing binding for the same *sequence* and *tagOrId* (if the first character of *command* is “+” then *command* augments an existing binding rather than replacing it). In this case the return value is an empty string. If *command* is omitted then the command returns the *command* associated with *tagOrId* and *sequence* (an error occurs if there is no such binding). If both *command* and *sequence* are omitted then the command returns a list of all the sequences for which bindings have been defined for *tagOrId*. The only events for which bindings may be specified are those related to the mouse and keyboard (such as **Enter**, **Leave**, **ButtonPress**, **Motion**, and **KeyPress**) or virtual events. The handling of events in canvases uses the current item defined in **[ITEM IDS AND TAGS](#M16)** above. **Enter** and **Leave** events trigger for an item when it becomes the current item or ceases to be the current item; note that these events are different than **Enter** and **Leave** events for windows. Mouse-related events are directed to the current item, if any. Keyboard-related events are directed to the focus item, if any (see the **focus** widget command below for more on this). If a virtual event is used in a binding, that binding can trigger only if the virtual event is defined by an underlying mouse-related or keyboard-related event.
It is possible for multiple bindings to match a particular event. This could occur, for example, if one binding is associated with the item's id and another is associated with one of the item's tags. When this occurs, all of the matching bindings are invoked. A binding associated with the **all** tag is invoked first, followed by one binding for each of the item's tags (in order), followed by a binding associated with the item's id. If there are multiple matching bindings for a single tag, then only the most specific binding is invoked. A **[continue](../tclcmd/continue.htm)** command in a binding script terminates that script, and a **[break](../tclcmd/break.htm)** command terminates that script and skips any remaining scripts for the event, just as for the **[bind](bind.htm)** command.
If bindings have been created for a canvas window using the **[bind](bind.htm)** command, then they are invoked in addition to bindings created for the canvas's items using the **bind** widget command. The bindings for items will be invoked before any of the bindings for the window as a whole.
*pathName* **canvasx** *screenx* ?*gridspacing*?
Given a window x-coordinate in the canvas *screenx*, this command returns the canvas x-coordinate that is displayed at that location. If *gridspacing* is specified, then the canvas coordinate is rounded to the nearest multiple of *gridspacing* units.
*pathName* **canvasy** *screeny* ?*gridspacing*?
Given a window y-coordinate in the canvas *screeny* this command returns the canvas y-coordinate that is displayed at that location. If *gridspacing* is specified, then the canvas coordinate is rounded to the nearest multiple of *gridspacing* units.
*pathName* **cget** *option*
Returns the current value of the configuration option given by *option*. *Option* may have any of the values accepted by the **canvas** command.
*pathName* **configure ?***option*? ?*value*? ?*option value ...*?
Query or modify the configuration options of the widget. If no *option* is specified, returns a list describing all of the available options for *pathName* (see **[Tk\_ConfigureInfo](https://www.tcl.tk/man/tcl/TkLib/ConfigWidg.htm)** for information on the format of this list). If *option* is specified with no *value*, then the command returns a list describing the one named option (this list will be identical to the corresponding sublist of the value returned if no *option* is specified). If one or more *option-value* pairs are specified, then the command modifies the given widget option(s) to have the given value(s); in this case the command returns an empty string. *Option* may have any of the values accepted by the **canvas** command.
*pathName* **coords** *tagOrId* ?*x0 y0 ...*?
*pathName* **coords** *tagOrId* ?*coordList*?
Query or modify the coordinates that define an item. If no coordinates are specified, this command returns a list whose elements are the coordinates of the item named by *tagOrId*. If coordinates are specified, then they replace the current coordinates for the named item. If *tagOrId* refers to multiple items, then the first one in the display list is used.
*pathName* **create** *type x y* ?*x y ...*? ?*option value ...*?
*pathName* **create** *type coordList* ?*option value ...*?
Create a new item in *pathName* of type *type*. The exact format of the arguments after *type* depends on *type*, but usually they consist of the coordinates for one or more points, followed by specifications for zero or more item options. See the subsections on individual item types below for more on the syntax of this command. This command returns the id for the new item.
*pathName* **dchars** *tagOrId first* ?*last*?
For each item given by *tagOrId*, delete the characters, or coordinates, in the range given by *first* and *last*, inclusive. If some of the items given by *tagOrId* do not support indexing operations then they ignore this operation. Text items interpret *first* and *last* as indices to a character, line and polygon items interpret them as indices to a coordinate (an x,y pair). Indices are described in **[INDICES](#M19)** above. If *last* is omitted, it defaults to *first*. This command returns an empty string.
*pathName* **delete** ?*tagOrId tagOrId ...*?
Delete each of the items given by each *tagOrId*, and return an empty string.
*pathName* **dtag** *tagOrId* ?*tagToDelete*?
For each of the items given by *tagOrId*, delete the tag given by *tagToDelete* from the list of those associated with the item. If an item does not have the tag *tagToDelete* then the item is unaffected by the command. If *tagToDelete* is omitted then it defaults to *tagOrId*. This command returns an empty string.
*pathName* **find** *searchCommand* ?*arg arg ...*?
This command returns a list consisting of all the items that meet the constraints specified by *searchCommand* and *arg*'s. *SearchCommand* and *args* have any of the forms accepted by the **addtag** command. The items are returned in stacking order, with the lowest item first.
*pathName* **focus** ?*tagOrId*?
Set the keyboard focus for the canvas widget to the item given by *tagOrId*. If *tagOrId* refers to several items, then the focus is set to the first such item in the display list that supports the insertion cursor. If *tagOrId* does not refer to any items, or if none of them support the insertion cursor, then the focus is not changed. If *tagOrId* is an empty string, then the focus item is reset so that no item has the focus. If *tagOrId* is not specified then the command returns the id for the item that currently has the focus, or an empty string if no item has the focus. Once the focus has been set to an item, the item will display the insertion cursor and all keyboard events will be directed to that item. The focus item within a canvas and the focus window on the screen (set with the **[focus](focus.htm)** command) are totally independent: a given item does not actually have the input focus unless (a) its canvas is the focus window and (b) the item is the focus item within the canvas. In most cases it is advisable to follow the **focus** widget command with the **[focus](focus.htm)** command to set the focus window to the canvas (if it was not there already).
*pathName* **gettags** *tagOrId*
Return a list whose elements are the tags associated with the item given by *tagOrId*. If *tagOrId* refers to more than one item, then the tags are returned from the first such item in the display list. If *tagOrId* does not refer to any items, or if the item contains no tags, then an empty string is returned.
*pathName* **icursor** *tagOrId index*
Set the position of the insertion cursor for the item(s) given by *tagOrId* to just before the character whose position is given by *index*. If some or all of the items given by *tagOrId* do not support an insertion cursor then this command has no effect on them. See **[INDICES](#M19)** above for a description of the legal forms for *index*. Note: the insertion cursor is only displayed in an item if that item currently has the keyboard focus (see the **focus** widget command, above), but the cursor position may be set even when the item does not have the focus. This command returns an empty string.
*pathName* **imove** *tagOrId index x y*
This command causes the *index*'th coordinate of each of the items indicated by *tagOrId* to be relocated to the location (*x*,*y*). Each item interprets *index* independently according to the rules described in **[INDICES](#M19)** above. Out of the standard set of items, only line and polygon items may have their coordinates relocated this way.
*pathName* **index** *tagOrId index*
This command returns a decimal string giving the numerical index within *tagOrId* corresponding to *index*. *Index* gives a textual description of the desired position as described in **[INDICES](#M19)** above. Text items interpret *index* as an index to a character, line and polygon items interpret it as an index to a coordinate (an x,y pair). The return value is guaranteed to lie between 0 and the number of characters, or coordinates, within the item, inclusive. If *tagOrId* refers to multiple items, then the index is processed in the first of these items that supports indexing operations (in display list order).
*pathName* **insert** *tagOrId beforeThis string*
For each of the items given by *tagOrId*, if the item supports text or coordinate, insertion then *string* is inserted into the item's text just before the character, or coordinate, whose index is *beforeThis*. Text items interpret *beforeThis* as an index to a character, line and polygon items interpret it as an index to a coordinate (an x,y pair). For lines and polygons the *string* must be a valid coordinate sequence. See **[INDICES](#M19)** above for information about the forms allowed for *beforeThis*. This command returns an empty string.
*pathName* **itemcget** *tagOrId* *option*
Returns the current value of the configuration option for the item given by *tagOrId* whose name is *option*. This command is similar to the **cget** widget command except that it applies to a particular item rather than the widget as a whole. *Option* may have any of the values accepted by the **create** widget command when the item was created. If *tagOrId* is a tag that refers to more than one item, the first (lowest) such item is used.
*pathName* **itemconfigure** *tagOrId* ?*option*? ?*value*? ?*option value ...*?
This command is similar to the **configure** widget command except that it modifies item-specific options for the items given by *tagOrId* instead of modifying options for the overall canvas widget. If no *option* is specified, returns a list describing all of the available options for the first item given by *tagOrId* (see **[Tk\_ConfigureInfo](https://www.tcl.tk/man/tcl/TkLib/ConfigWidg.htm)** for information on the format of this list). If *option* is specified with no *value*, then the command returns a list describing the one named option (this list will be identical to the corresponding sublist of the value returned if no *option* is specified). If one or more *option-value* pairs are specified, then the command modifies the given widget option(s) to have the given value(s) in each of the items given by *tagOrId*; in this case the command returns an empty string. The *option*s and *value*s are the same as those permissible in the **create** widget command when the item(s) were created; see the sections describing individual item types below for details on the legal options.
*pathName* **lower** *tagOrId* ?*belowThis*?
Move all of the items given by *tagOrId* to a new position in the display list just before the item given by *belowThis*. If *tagOrId* refers to more than one item then all are moved but the relative order of the moved items will not be changed. *BelowThis* is a tag or id; if it refers to more than one item then the first (lowest) of these items in the display list is used as the destination location for the moved items. Note: this command has no effect on window items. Window items always obscure other item types, and the stacking order of window items is determined by the **[raise](raise.htm)** command and **[lower](lower.htm)** command, not the **raise** widget command and **lower** widget command for canvases. This command returns an empty string.
*pathName* **move** *tagOrId xAmount yAmount*
Move each of the items given by *tagOrId* in the canvas coordinate space by adding *xAmount* to the x-coordinate of each point associated with the item and *yAmount* to the y-coordinate of each point associated with the item. This command returns an empty string.
*pathName* **moveto** *tagOrId xPos yPos*
Move the items given by *tagOrId* in the canvas coordinate space so that the first coordinate pair of the bottommost item with tag *tagOrId* is located at position (*xPos*,*yPos*). *xPos* and *yPos* may be the empty string, in which case the corresponding coordinate will be unchanged. All items matching *tagOrId* remain in the same positions relative to each other. This command returns an empty string.
*pathName* **postscript** ?*option value option value ...*?
Generate a Postscript representation for part or all of the canvas. If the **-file** option is specified then the Postscript is written to a file and an empty string is returned; otherwise the Postscript is returned as the result of the command. If the interpreter that owns the canvas is marked as safe, the operation will fail because safe interpreters are not allowed to write files. If the **-channel** option is specified, the argument denotes the name of a channel already opened for writing. The Postscript is written to that channel, and the channel is left open for further writing at the end of the operation. The Postscript is created in Encapsulated Postscript form using version 3.0 of the Document Structuring Conventions. Note: by default Postscript is only generated for information that appears in the canvas's window on the screen. If the canvas is freshly created it may still have its initial size of 1x1 pixel so nothing will appear in the Postscript. To get around this problem either invoke the **[update](../tclcmd/update.htm)** command to wait for the canvas window to reach its final size, or else use the **-width** and **-height** options to specify the area of the canvas to print. The *option*-*value* argument pairs provide additional information to control the generation of Postscript. The following options are supported:
**-channel** *channelName*
Specifies the name of the channel to which to write the Postscript. If this option and the **-file** option are not specified then the Postscript is returned as the result of the command.
**-colormap** *varName*
*VarName* must be the name of an array variable that specifies a color mapping to use in the Postscript. Each element of *varName* must consist of Postscript code to set a particular color value (e.g. “**1.0 1.0 0.0 setrgbcolor**”). When outputting color information in the Postscript, Tk checks to see if there is an element of *varName* with the same name as the color. If so, Tk uses the value of the element as the Postscript command to set the color. If this option has not been specified, or if there is no entry in *varName* for a given color, then Tk uses the red, green, and blue intensities from the X color.
**-colormode** *mode*
Specifies how to output color information. *Mode* must be either **color** (for full color output), **gray** (convert all colors to their gray-scale equivalents) or **mono** (convert all colors to black or white).
**-file** *fileName*
Specifies the name of the file in which to write the Postscript. If this option and the **-channel** option are not specified then the Postscript is returned as the result of the command.
**-fontmap** *varName*
*VarName* must be the name of an array variable that specifies a font mapping to use in the Postscript. Each element of *varName* must consist of a Tcl list with two elements, which are the name and point size of a Postscript font. When outputting Postscript commands for a particular font, Tk checks to see if *varName* contains an element with the same name as the font. If there is such an element, then the font information contained in that element is used in the Postscript. Otherwise Tk attempts to guess what Postscript font to use. Tk's guesses generally only work for well-known fonts such as Times and Helvetica and Courier, and only if the X font name does not omit any dashes up through the point size. For example, **-\*-Courier-Bold-R-Normal--\*-120-\*** will work but **\*Courier-Bold-R-Normal\*120\*** will not; Tk needs the dashes to parse the font name).
**-height** *size*
Specifies the height of the area of the canvas to print. Defaults to the height of the canvas window.
**-pageanchor** *anchor*
Specifies which point of the printed area of the canvas should appear over the positioning point on the page (which is given by the **-pagex** and **-pagey** options). For example, **-pageanchor n** means that the top center of the area of the canvas being printed (as it appears in the canvas window) should be over the positioning point. Defaults to **center**.
**-pageheight** *size*
Specifies that the Postscript should be scaled in both x and y so that the printed area is *size* high on the Postscript page. *Size* consists of a floating-point number followed by **c** for centimeters, **i** for inches, **m** for millimeters, or **p** or nothing for printer's points (1/72 inch). Defaults to the height of the printed area on the screen. If both **-pageheight** and **-pagewidth** are specified then the scale factor from **-pagewidth** is used (non-uniform scaling is not implemented).
**-pagewidth** *size*
Specifies that the Postscript should be scaled in both x and y so that the printed area is *size* wide on the Postscript page. *Size* has the same form as for **-pageheight**. Defaults to the width of the printed area on the screen. If both **-pageheight** and **-pagewidth** are specified then the scale factor from **-pagewidth** is used (non-uniform scaling is not implemented).
**-pagex** *position*
*Position* gives the x-coordinate of the positioning point on the Postscript page, using any of the forms allowed for **-pageheight**. Used in conjunction with the **-pagey** and **-pageanchor** options to determine where the printed area appears on the Postscript page. Defaults to the center of the page.
**-pagey** *position*
*Position* gives the y-coordinate of the positioning point on the Postscript page, using any of the forms allowed for **-pageheight**. Used in conjunction with the **-pagex** and **-pageanchor** options to determine where the printed area appears on the Postscript page. Defaults to the center of the page.
**-rotate** *boolean*
*Boolean* specifies whether the printed area is to be rotated 90 degrees. In non-rotated output the x-axis of the printed area runs along the short dimension of the page (“portrait” orientation); in rotated output the x-axis runs along the long dimension of the page (“landscape” orientation). Defaults to non-rotated.
**-width** *size*
Specifies the width of the area of the canvas to print. Defaults to the width of the canvas window.
**-x** *position*
Specifies the x-coordinate of the left edge of the area of the canvas that is to be printed, in canvas coordinates, not window coordinates. Defaults to the coordinate of the left edge of the window.
**-y** *position*
Specifies the y-coordinate of the top edge of the area of the canvas that is to be printed, in canvas coordinates, not window coordinates. Defaults to the coordinate of the top edge of the window.
*pathName* **raise** *tagOrId* ?*aboveThis*?
Move all of the items given by *tagOrId* to a new position in the display list just after the item given by *aboveThis*. If *tagOrId* refers to more than one item then all are moved but the relative order of the moved items will not be changed. *AboveThis* is a tag or id; if it refers to more than one item then the last (topmost) of these items in the display list is used as the destination location for the moved items. This command returns an empty string. Note: this command has no effect on window items. Window items always obscure other item types, and the stacking order of window items is determined by the **[raise](raise.htm)** command and **[lower](lower.htm)** command, not the **raise** widget command and **lower** widget command for canvases.
*pathName* **rchars** *tagOrId first last string*
This command causes the text or coordinates between *first* and *last* for each of the items indicated by *tagOrId* to be replaced by *string*. Each item interprets *first* and *last* independently according to the rules described in **[INDICES](#M19)** above. Out of the standard set of items, text items support this operation by altering their text as directed, and line and polygon items support this operation by altering their coordinate list (in which case *string* should be a list of coordinates to use as a replacement). The other items ignore this operation.
*pathName* **scale** *tagOrId xOrigin yOrigin xScale yScale*
Rescale the coordinates of all of the items given by *tagOrId* in canvas coordinate space. *XOrigin* and *yOrigin* identify the origin for the scaling operation and *xScale* and *yScale* identify the scale factors for x- and y-coordinates, respectively (a scale factor of 1.0 implies no change to that coordinate). For each of the points defining each item, the x-coordinate is adjusted to change the distance from *xOrigin* by a factor of *xScale*. Similarly, each y-coordinate is adjusted to change the distance from *yOrigin* by a factor of *yScale*. This command returns an empty string. Note that some items have only a single pair of coordinates (e.g., text, images and windows) and so scaling of them by this command can only move them around.
*pathName* **scan** *option args*
This command is used to implement scanning on canvases. It has two forms, depending on *option*:
*pathName* **scan mark** *x y*
Records *x* and *y* and the canvas's current view; used in conjunction with later **scan dragto** commands. Typically this command is associated with a mouse button press in the widget and *x* and *y* are the coordinates of the mouse. It returns an empty string.
*pathName* **scan dragto** *x y ?gain?*
This command computes the difference between its *x* and *y* arguments (which are typically mouse coordinates) and the *x* and *y* arguments to the last **scan mark** command for the widget. It then adjusts the view by *gain* times the difference in coordinates, where *gain* defaults to 10. This command is typically associated with mouse motion events in the widget, to produce the effect of dragging the canvas at high speed through its window. The return value is an empty string.
*pathName* **select** *option* ?*tagOrId arg*?
Manipulates the selection in one of several ways, depending on *option*. The command may take any of the forms described below. In all of the descriptions below, *tagOrId* must refer to an item that supports indexing and selection; if it refers to multiple items then the first of these that supports indexing and the selection is used. *Index* gives a textual description of a position within *tagOrId*, as described in **[INDICES](#M19)** above.
*pathName* **select adjust** *tagOrId index*
Locate the end of the selection in *tagOrId* nearest to the character given by *index*, and adjust that end of the selection to be at *index* (i.e. including but not going beyond *index*). The other end of the selection is made the anchor point for future **select to** commands. If the selection is not currently in *tagOrId* then this command behaves the same as the **select to** widget command. Returns an empty string.
*pathName* **select clear**
Clear the selection if it is in this widget. If the selection is not in this widget then the command has no effect. Returns an empty string.
*pathName* **select from** *tagOrId index*
Set the selection anchor point for the widget to be just before the character given by *index* in the item given by *tagOrId*. This command does not change the selection; it just sets the fixed end of the selection for future **select to** commands. Returns an empty string.
*pathName* **select item**
Returns the id of the selected item, if the selection is in an item in this canvas. If the selection is not in this canvas then an empty string is returned.
*pathName* **select to** *tagOrId index*
Set the selection to consist of those characters of *tagOrId* between the selection anchor point and *index*. The new selection will include the character given by *index*; it will include the character given by the anchor point only if *index* is greater than or equal to the anchor point. The anchor point is determined by the most recent **select adjust** or **select from** command for this widget. If the selection anchor point for the widget is not currently in *tagOrId*, then it is set to the same character given by *index*. Returns an empty string.
*pathName* **type** *tagOrId*
Returns the type of the item given by *tagOrId*, such as **rectangle** or **text**. If *tagOrId* refers to more than one item, then the type of the first item in the display list is returned. If *tagOrId* does not refer to any items at all then an empty string is returned.
*pathName* **xview** ?*args*?
This command is used to query and change the horizontal position of the information displayed in the canvas's window. It can take any of the following forms:
*pathName* **xview**
Returns a list containing two elements. Each element is a real fraction between 0 and 1; together they describe the horizontal span that is visible in the window. For example, if the first element is .2 and the second element is .6, 20% of the canvas's area (as defined by the **-scrollregion** option) is off-screen to the left, the middle 40% is visible in the window, and 40% of the canvas is off-screen to the right. These are the same values passed to scrollbars via the **-xscrollcommand** option.
*pathName* **xview moveto** *fraction*
Adjusts the view in the window so that *fraction* of the total width of the canvas is off-screen to the left. *Fraction* must be a fraction between 0 and 1.
*pathName* **xview scroll** *number what*
This command shifts the view in the window left or right according to *number* and *what*. *Number* must be an integer. *What* must be either **units** or **pages** or an abbreviation of one of these. If *what* is **units**, the view adjusts left or right in units of the **xScrollIncrement** option, if it is greater than zero, or in units of one-tenth the window's width otherwise. If *what is* **pages** then the view adjusts in units of nine-tenths the window's width. If *number* is negative then information farther to the left becomes visible; if it is positive then information farther to the right becomes visible.
*pathName* **yview** *?args*?
This command is used to query and change the vertical position of the information displayed in the canvas's window. It can take any of the following forms:
*pathName* **yview**
Returns a list containing two elements. Each element is a real fraction between 0 and 1; together they describe the vertical span that is visible in the window. For example, if the first element is .6 and the second element is 1.0, the lowest 40% of the canvas's area (as defined by the **-scrollregion** option) is visible in the window. These are the same values passed to scrollbars via the **-yscrollcommand** option.
*pathName* **yview moveto** *fraction*
Adjusts the view in the window so that *fraction* of the canvas's area is off-screen to the top. *Fraction* is a fraction between 0 and 1.
*pathName* **yview scroll** *number what*
This command adjusts the view in the window up or down according to *number* and *what*. *Number* must be an integer. *What* must be either **units** or **pages**. If *what* is **units**, the view adjusts up or down in units of the **yScrollIncrement** option, if it is greater than zero, or in units of one-tenth the window's height otherwise. If *what* is **pages** then the view adjusts in units of nine-tenths the window's height. If *number* is negative then higher information becomes visible; if it is positive then lower information becomes visible.
Overview of item types
----------------------
The sections below describe the various types of items supported by canvas widgets. Each item type is characterized by two things: first, the form of the **create** command used to create instances of the type; and second, a set of configuration options for items of that type, which may be used in the **create** and **itemconfigure** widget commands. Most items do not support indexing or selection or the commands related to them, such as **index** and **insert**. Where items do support these facilities, it is noted explicitly in the descriptions below. At present, text, line and polygon items provide this support. For lines and polygons the indexing facility is used to manipulate the coordinates of the item. ### Common item options
Many items share a common set of options. These options are explained here, and then referred to be each widget type for brevity.
**-anchor** *anchorPos*
*AnchorPos* tells how to position the item relative to the positioning point for the item; it may have any of the forms accepted by **[Tk\_GetAnchor](https://www.tcl.tk/man/tcl/TkLib/GetAnchor.htm)**. For example, if *anchorPos* is **center** then the item is centered on the point; if *anchorPos* is **n** then the item will be drawn so that its top center point is at the positioning point. This option defaults to **center**.
**-dash** *pattern*
**-activedash** *pattern*
**-disableddash** *pattern*
This option specifies dash patterns for the normal, active state, and disabled state of an item. *pattern* may have any of the forms accepted by **[Tk\_GetDash](https://www.tcl.tk/man/tcl/TkLib/GetDash.htm)**. If the dash options are omitted then the default is a solid outline. See **[DASH PATTERNS](#M26)** for more information.
**-dashoffset** *offset*
The starting *offset* in pixels into the pattern provided by the **-dash** option. **-dashoffset** is ignored if there is no **-dash** pattern. The *offset* may have any of the forms described in the **[COORDINATES](#M17)** section above.
**-fill** *color*
**-activefill** *color*
**-disabledfill** *color*
Specifies the color to be used to fill item's area. in its normal, active, and disabled states, *Color* may have any of the forms accepted by **[Tk\_GetColor](https://www.tcl.tk/man/tcl/TkLib/GetColor.htm)**. If *color* is an empty string (the default), then the item will not be filled. For the line item, it specifies the color of the line drawn. For the text item, it specifies the foreground color of the text.
**-outline** *color*
**-activeoutline** *color*
**-disabledoutline** *color*
This option specifies the color that should be used to draw the outline of the item in its normal, active and disabled states. *Color* may have any of the forms accepted by **[Tk\_GetColor](https://www.tcl.tk/man/tcl/TkLib/GetColor.htm)**. This option defaults to **black**. If *color* is specified as an empty string then no outline is drawn for the item.
**-offset** *offset*
Specifies the offset of stipples. The offset value can be of the form **x,y** or *side*, where side can be **n**, **ne**, **e**, **se**, **s**, **sw**, **w**, **nw**, or **center**. In the first case the origin is the origin of the toplevel of the current window. For the canvas itself and canvas objects the origin is the canvas origin, but putting **#** in front of the coordinate pair indicates using the toplevel origin instead. For canvas objects, the **-offset** option is used for stippling as well. For the line and polygon canvas items you can also specify an index as argument, which connects the stipple origin to one of the coordinate points of the line/polygon. Note that stipple offsets are *only supported on X11*; they are silently ignored on other platforms.
**-outlinestipple** *bitmap*
**-activeoutlinestipple** *bitmap*
**-disabledoutlinestipple** *bitmap*
This option specifies stipple patterns that should be used to draw the outline of the item in its normal, active and disabled states. Indicates that the outline for the item should be drawn with a stipple pattern; *bitmap* specifies the stipple pattern to use, in any of the forms accepted by **[Tk\_GetBitmap](https://www.tcl.tk/man/tcl/TkLib/GetBitmap.htm)**. If the **-outline** option has not been specified then this option has no effect. If *bitmap* is an empty string (the default), then the outline is drawn in a solid fashion. *Note that stipples are not well supported on platforms that do not use X11 as their drawing API.*
**-outlineoffset** *offset*
Specifies the offset of the stipple pattern used for outlines, in the same way that the **-outline** option controls fill stipples. (See the **-outline** option for a description of the syntax of *offset*.)
**-stipple** *bitmap*
**-activestipple** *bitmap*
**-disabledstipple** *bitmap*
This option specifies stipple patterns that should be used to fill the item in its normal, active and disabled states. *bitmap* specifies the stipple pattern to use, in any of the forms accepted by **[Tk\_GetBitmap](https://www.tcl.tk/man/tcl/TkLib/GetBitmap.htm)**. If the **-fill** option has not been specified then this option has no effect. If *bitmap* is an empty string (the default), then filling is done in a solid fashion. For the text item, it affects the actual text. *Note that stipples are not well supported on platforms that do not use X11 as their drawing API.*
**-state** *state*
This allows an item to override the canvas widget's global *state* option. It takes the same values: *normal*, *disabled* or *hidden*.
**-tags** *tagList*
Specifies a set of tags to apply to the item. *TagList* consists of a list of tag names, which replace any existing tags for the item. *TagList* may be an empty list.
**-width** *outlineWidth*
**-activewidth** *outlineWidth*
**-disabledwidth** *outlineWidth*
Specifies the width of the outline to be drawn around the item's region, in its normal, active and disabled states. *outlineWidth* may be in any of the forms described in the **[COORDINATES](#M17)** section above. If the **-outline** option has been specified as an empty string then this option has no effect. This option defaults to 1.0. For arcs, wide outlines will be drawn centered on the edges of the arc's region.
Standard item types
-------------------
### Arc items
Items of type **arc** appear on the display as arc-shaped regions. An arc is a section of an oval delimited by two angles (specified by the **-start** and **-extent** options) and displayed in one of several ways (specified by the **-style** option). Arcs are created with widget commands of the following form:
```
*pathName* **create arc** *x1 y1 x2 y2* ?*option value ...*?
*pathName* **create arc** *coordList* ?*option value ...*?
```
The arguments *x1*, *y1*, *x2*, and *y2* or *coordList* give the coordinates of two diagonally opposite corners of a rectangular region enclosing the oval that defines the arc. After the coordinates there may be any number of *option*-*value* pairs, each of which sets one of the configuration options for the item. These same *option*-*value* pairs may be used in **itemconfigure** widget commands to change the item's configuration. An arc item becomes the current item when the mouse pointer is over any part that is painted or (when fully transparent) that would be painted if both the **-fill** and **-outline** options were non-empty. The following standard options are supported by arcs:
| | |
| --- | --- |
| **-dash** | **-activedash** |
| **-disableddash** | **-dashoffset** |
| **-fill** | **-activefill** |
| **-disabledfill** | **-offset** |
| **-outline** | **-activeoutline** |
| **-disabledoutline** | **-outlineoffset** |
| **-outlinestipple** | **-activeoutlinestipple** |
| **-disabledoutlinestipple** | **-stipple** |
| **-activestipple** | **-disabledstipple** |
| **-state** | **-tags** |
| **-width** | **-activewidth** |
| **-disabledwidth** |
The following extra options are supported for arcs:
**-extent** *degrees*
Specifies the size of the angular range occupied by the arc. The arc's range extends for *degrees* degrees counter-clockwise from the starting angle given by the **-start** option. *Degrees* may be negative. If it is greater than 360 or less than -360, then *degrees* modulo 360 is used as the extent.
**-start** *degrees*
Specifies the beginning of the angular range occupied by the arc. *Degrees* is given in units of degrees measured counter-clockwise from the 3-o'clock position; it may be either positive or negative.
**-style** *type*
Specifies how to draw the arc. If *type* is **pieslice** (the default) then the arc's region is defined by a section of the oval's perimeter plus two line segments, one between the center of the oval and each end of the perimeter section. If *type* is **chord** then the arc's region is defined by a section of the oval's perimeter plus a single line segment connecting the two end points of the perimeter section. If *type* is **arc** then the arc's region consists of a section of the perimeter alone. In this last case the **-fill** option is ignored.
### Bitmap items
Items of type **bitmap** appear on the display as images with two colors, foreground and background. Bitmaps are created with widget commands of the following form:
```
*pathName* **create bitmap** *x y* ?*option value ...*?
*pathName* **create bitmap** *coordList* ?*option value ...*?
```
The arguments *x* and *y* or *coordList* (which must have two elements) specify the coordinates of a point used to position the bitmap on the display, as controlled by the **-anchor** option. After the coordinates there may be any number of *option*-*value* pairs, each of which sets one of the configuration options for the item. These same *option*-*value* pairs may be used in **itemconfigure** widget commands to change the item's configuration. A bitmap item becomes the current item when the mouse pointer is over any part of its bounding box. The following standard options are supported by bitmaps:
| | |
| --- | --- |
| **-anchor** | **-state** |
| **-tags** |
The following extra options are supported for bitmaps:
**-background** *color*
**-activebackground** *color*
**-disabledbackground** *color*
Specifies the color to use for each of the bitmap's “0” valued pixels in its normal, active and disabled states. *Color* may have any of the forms accepted by **[Tk\_GetColor](https://www.tcl.tk/man/tcl/TkLib/GetColor.htm)**. If this option is not specified, or if it is specified as an empty string, then nothing is displayed where the bitmap pixels are 0; this produces a transparent effect.
**-bitmap** *bitmap*
**-activebitmap** *bitmap*
**-disabledbitmap** *bitmap*
Specifies the bitmaps to display in the item in its normal, active and disabled states. *Bitmap* may have any of the forms accepted by **[Tk\_GetBitmap](https://www.tcl.tk/man/tcl/TkLib/GetBitmap.htm)**.
**-foreground** *color*
**-activeforeground** *color*
**-disabledforeground** *color*
Specifies the color to use for each of the bitmap's “1” valued pixels in its normal, active and disabled states. *Color* may have any of the forms accepted by **[Tk\_GetColor](https://www.tcl.tk/man/tcl/TkLib/GetColor.htm)** and defaults to **black**.
### Image items
Items of type **image** are used to display images on a canvas. Images are created with widget commands of the following form:
```
*pathName* **create image** *x y* ?*option value ...*?
*pathName* **create image** *coordList* ?*option value ...*?
```
The arguments *x* and *y* or *coordList* specify the coordinates of a point used to position the image on the display, as controlled by the **-anchor** option. After the coordinates there may be any number of *option*-*value* pairs, each of which sets one of the configuration options for the item. These same *option*-*value* pairs may be used in **itemconfigure** widget commands to change the item's configuration. An image item becomes the current item when the mouse pointer is over any part of its bounding box. The following standard options are supported by images:
| | |
| --- | --- |
| **-anchor** | **-state** |
| **-tags** |
The following extra options are supported for images:
**-image** *name*
**-activeimage** *name*
**-disabledimage** *name*
Specifies the name of the images to display in the item in is normal, active and disabled states. This image must have been created previously with the **[image create](image.htm)** command.
### Line items
Items of type **line** appear on the display as one or more connected line segments or curves. Line items support coordinate indexing operations using the **dchars**, **index** and **insert** widget commands. Lines are created with widget commands of the following form:
```
*pathName* **create line** *x1 y1... xn yn* ?*option value ...*?
*pathName* **create line** *coordList* ?*option value ...*?
```
The arguments *x1* through *yn* or *coordList* give the coordinates for a series of two or more points that describe a series of connected line segments. After the coordinates there may be any number of *option*-*value* pairs, each of which sets one of the configuration options for the item. These same *option*-*value* pairs may be used in **itemconfigure** widget commands to change the item's configuration. A line item is the current item whenever the mouse pointer is over any segment of the line, whether drawn or not and whether or not the line is smoothed. The following standard options are supported by lines:
| | |
| --- | --- |
| **-dash** | **-activedash** |
| **-disableddash** | **-dashoffset** |
| **-fill** | **-activefill** |
| **-disabledfill** | **-stipple** |
| **-activestipple** | **-disabledstipple** |
| **-state** | **-tags** |
| **-width** | **-activewidth** |
| **-disabledwidth** |
The following extra options are supported for lines:
**-arrow** *where*
Indicates whether or not arrowheads are to be drawn at one or both ends of the line. *Where* must have one of the values **none** (for no arrowheads), **first** (for an arrowhead at the first point of the line), **last** (for an arrowhead at the last point of the line), or **both** (for arrowheads at both ends). This option defaults to **none**.
**-arrowshape** *shape*
This option indicates how to draw arrowheads. The *shape* argument must be a list with three elements, each specifying a distance in any of the forms described in the **[COORDINATES](#M17)** section above. The first element of the list gives the distance along the line from the neck of the arrowhead to its tip. The second element gives the distance along the line from the trailing points of the arrowhead to the tip, and the third element gives the distance from the outside edge of the line to the trailing points. If this option is not specified then Tk picks a “reasonable” shape.
**-capstyle** *style*
Specifies the ways in which caps are to be drawn at the endpoints of the line. *Style* may have any of the forms accepted by **[Tk\_GetCapStyle](https://www.tcl.tk/man/tcl/TkLib/GetCapStyl.htm)** (**butt**, **projecting**, or **round**). If this option is not specified then it defaults to **butt**. Where arrowheads are drawn the cap style is ignored.
**-joinstyle** *style*
Specifies the ways in which joints are to be drawn at the vertices of the line. *Style* may have any of the forms accepted by **[Tk\_GetJoinStyle](https://www.tcl.tk/man/tcl/TkLib/GetJoinStl.htm)** (**bevel**, **miter**, or **round**). If this option is not specified then it defaults to **round**. If the line only contains two points then this option is irrelevant.
**-smooth** *smoothMethod*
*smoothMethod* must have one of the forms accepted by **[Tcl\_GetBoolean](https://www.tcl.tk/man/tcl/TclLib/GetInt.htm)** or a line smoothing method. Only **true** and **raw** are supported in the core (with **bezier** being an alias for **true**), but more can be added at runtime. If a boolean false value or empty string is given, no smoothing is applied. A boolean truth value assumes **true** smoothing. If the smoothing method is **true**, this indicates that the line should be drawn as a curve, rendered as a set of quadratic splines: one spline is drawn for the first and second line segments, one for the second and third, and so on. Straight-line segments can be generated within a curve by duplicating the end-points of the desired line segment. If the smoothing method is **raw**, this indicates that the line should also be drawn as a curve but where the list of coordinates is such that the first coordinate pair (and every third coordinate pair thereafter) is a knot point on a cubic Bezier curve, and the other coordinates are control points on the cubic Bezier curve. Straight line segments can be generated within a curve by making control points equal to their neighbouring knot points. If the last point is a control point and not a knot point, the point is repeated (one or two times) so that it also becomes a knot point.
**-splinesteps** *number*
Specifies the degree of smoothness desired for curves: each spline will be approximated with *number* line segments. This option is ignored unless the **-smooth** option is true or **raw**.
### Oval items
Items of type **oval** appear as circular or oval regions on the display. Each oval may have an outline, a fill, or both. Ovals are created with widget commands of the following form:
```
*pathName* **create oval** *x1 y1 x2 y2* ?*option value ...*?
*pathName* **create oval** *coordList* ?*option value ...*?
```
The arguments *x1*, *y1*, *x2*, and *y2* or *coordList* give the coordinates of two diagonally opposite corners of a rectangular region enclosing the oval. The oval will include the top and left edges of the rectangle not the lower or right edges. If the region is square then the resulting oval is circular; otherwise it is elongated in shape. After the coordinates there may be any number of *option*-*value* pairs, each of which sets one of the configuration options for the item. These same *option*-*value* pairs may be used in **itemconfigure** widget commands to change the item's configuration. An oval item becomes the current item when the mouse pointer is over any part that is painted or (when fully transparent) that would be painted if both the **-fill** and **-outline** options were non-empty. The following standard options are supported by ovals:
| | |
| --- | --- |
| **-dash** | **-activedash** |
| **-disableddash** | **-dashoffset** |
| **-fill** | **-activefill** |
| **-disabledfill** | **-offset** |
| **-outline** | **-activeoutline** |
| **-disabledoutline** | **-outlineoffset** |
| **-outlinestipple** | **-activeoutlinestipple** |
| **-disabledoutlinestipple** | **-stipple** |
| **-activestipple** | **-disabledstipple** |
| **-state** | **-tags** |
| **-width** | **-activewidth** |
| **-disabledwidth** |
There are no oval-specific options. ### Polygon items
Items of type **polygon** appear as polygonal or curved filled regions on the display. Polygon items support coordinate indexing operations using the **dchars**, **index** and **insert** widget commands. Polygons are created with widget commands of the following form:
```
*pathName* **create polygon** *x1 y1 ... xn yn* ?*option value ...*?
*pathName* **create polygon** *coordList* ?*option value ...*?
```
The arguments *x1* through *yn* or *coordList* specify the coordinates for three or more points that define a polygon. The first point should not be repeated as the last to close the shape; Tk will automatically close the periphery between the first and last points. After the coordinates there may be any number of *option*-*value* pairs, each of which sets one of the configuration options for the item. These same *option*-*value* pairs may be used in **itemconfigure** widget commands to change the item's configuration. A polygon item is the current item whenever the mouse pointer is over any part of the polygon, whether drawn or not and whether or not the outline is smoothed. The following standard options are supported by polygons:
| | |
| --- | --- |
| **-dash** | **-activedash** |
| **-disableddash** | **-dashoffset** |
| **-fill** | **-activefill** |
| **-disabledfill** | **-offset** |
| **-outline** | **-activeoutline** |
| **-disabledoutline** | **-outlineoffset** |
| **-outlinestipple** | **-activeoutlinestipple** |
| **-disabledoutlinestipple** | **-stipple** |
| **-activestipple** | **-disabledstipple** |
| **-state** | **-tags** |
| **-width** | **-activewidth** |
| **-disabledwidth** |
The following extra options are supported for polygons:
**-joinstyle** *style*
Specifies the ways in which joints are to be drawn at the vertices of the outline. *Style* may have any of the forms accepted by **[Tk\_GetJoinStyle](https://www.tcl.tk/man/tcl/TkLib/GetJoinStl.htm)** (**bevel**, **miter**, or **round**). If this option is not specified then it defaults to **round**.
**-smooth** *boolean*
*Boolean* must have one of the forms accepted by **[Tcl\_GetBoolean](https://www.tcl.tk/man/tcl/TclLib/GetInt.htm)** or a line smoothing method. Only **true** and **raw** are supported in the core (with **bezier** being an alias for **true**), but more can be added at runtime. If a boolean false value or empty string is given, no smoothing is applied. A boolean truth value assumes **true** smoothing. If the smoothing method is **true**, this indicates that the polygon should be drawn as a curve, rendered as a set of quadratic splines: one spline is drawn for the first and second line segments, one for the second and third, and so on. Straight-line segments can be generated within a curve by duplicating the end-points of the desired line segment. If the smoothing method is **raw**, this indicates that the polygon should also be drawn as a curve but where the list of coordinates is such that the first coordinate pair (and every third coordinate pair thereafter) is a knot point on a cubic Bezier curve, and the other coordinates are control points on the cubic Bezier curve. Straight line segments can be venerated within a curve by making control points equal to their neighbouring knot points. If the last point is not the second point of a pair of control points, the point is repeated (one or two times) so that it also becomes the second point of a pair of control points (the associated knot point will be the first control point).
**-splinesteps** *number*
Specifies the degree of smoothness desired for curves: each spline will be approximated with *number* line segments. This option is ignored unless the **-smooth** option is true or **raw**.
Polygon items are different from other items such as rectangles, ovals and arcs in that interior points are considered to be “inside” a polygon (e.g. for purposes of the **find closest** and **find overlapping** widget commands) even if it is not filled. For most other item types, an interior point is considered to be inside the item only if the item is filled or if it has neither a fill nor an outline. If you would like an unfilled polygon whose interior points are not considered to be inside the polygon, use a line item instead.
### Rectangle items
Items of type **rectangle** appear as rectangular regions on the display. Each rectangle may have an outline, a fill, or both. Rectangles are created with widget commands of the following form:
```
*pathName* **create rectangle** *x1 y1 x2 y2* ?*option value ...*?
*pathName* **create rectangle** *coordList* ?*option value ...*?
```
The arguments *x1*, *y1*, *x2*, and *y2* or *coordList* (which must have four elements) give the coordinates of two diagonally opposite corners of the rectangle (the rectangle will include its upper and left edges but not its lower or right edges). After the coordinates there may be any number of *option*-*value* pairs, each of which sets one of the configuration options for the item. These same *option*-*value* pairs may be used in **itemconfigure** widget commands to change the item's configuration. A rectangle item becomes the current item when the mouse pointer is over any part that is painted or (when fully transparent) that would be painted if both the **-fill** and **-outline** options were non-empty. The following standard options are supported by rectangles:
| | |
| --- | --- |
| **-dash** | **-activedash** |
| **-disableddash** | **-dashoffset** |
| **-fill** | **-activefill** |
| **-disabledfill** | **-offset** |
| **-outline** | **-activeoutline** |
| **-disabledoutline** | **-outlineoffset** |
| **-outlinestipple** | **-activeoutlinestipple** |
| **-disabledoutlinestipple** | **-stipple** |
| **-activestipple** | **-disabledstipple** |
| **-state** | **-tags** |
| **-width** | **-activewidth** |
| **-disabledwidth** |
There are no rectangle-specific options. ### Text items
A text item displays a string of characters on the screen in one or more lines. Text items support indexing, editing and selection through the **dchars** widget command, the **focus** widget command, the **icursor** widget command, the **index** widget command, the **insert** widget command, and the **select** widget command. Text items are created with widget commands of the following form:
```
*pathName* **create text** *x y* ?*option value ...*?
*pathName* **create text** *coordList* ?*option value ...*?
```
The arguments *x* and *y* or *coordList* (which must have two elements) specify the coordinates of a point used to position the text on the display (see the options below for more information on how text is displayed). After the coordinates there may be any number of *option*-*value* pairs, each of which sets one of the configuration options for the item. These same *option*-*value* pairs may be used in **itemconfigure** widget commands to change the item's configuration. A text item becomes the current item when the mouse pointer is over any part of its bounding box. The following standard options are supported by text items:
| | |
| --- | --- |
| **-anchor** | **-fill** |
| **-activefill** | **-disabledfill** |
| **-stipple** | **-activestipple** |
| **-disabledstipple** | **-state** |
| **-tags** |
The following extra options are supported for text items:
**-angle** *rotationDegrees*
*RotationDegrees* tells how many degrees to rotate the text anticlockwise about the positioning point for the text; it may have any floating-point value from 0.0 to 360.0. For example, if *rotationDegrees* is **90**, then the text will be drawn vertically from bottom to top. This option defaults to **0.0**.
**-font** *fontName*
Specifies the font to use for the text item. *FontName* may be any string acceptable to **[Tk\_GetFont](https://www.tcl.tk/man/tcl/TkLib/GetFont.htm)**. If this option is not specified, it defaults to a system-dependent font.
**-justify** *how*
Specifies how to justify the text within its bounding region. *How* must be one of the values **left**, **right**, or **center**. This option will only matter if the text is displayed as multiple lines. If the option is omitted, it defaults to **left**.
**-text** *string*
*String* specifies the characters to be displayed in the text item. Newline characters cause line breaks. The characters in the item may also be changed with the **insert** and **delete** widget commands. This option defaults to an empty string.
**-underline**
Specifies the integer index of a character within the text to be underlined. 0 corresponds to the first character of the text displayed, 1 to the next character, and so on. -1 means that no underline should be drawn (if the whole text item is to be underlined, the appropriate font should be used instead).
**-width** *lineLength*
Specifies a maximum line length for the text, in any of the forms described in the **[COORDINATES](#M17)** section above. If this option is zero (the default) the text is broken into lines only at newline characters. However, if this option is non-zero then any line that would be longer than *lineLength* is broken just before a space character to make the line shorter than *lineLength*; the space character is treated as if it were a newline character.
### Window items
Items of type **window** cause a particular window to be displayed at a given position on the canvas. Window items are created with widget commands of the following form:
```
*pathName* **create window** *x y* ?*option value ...*?
*pathName* **create window** *coordList* ?*option value ...*?
```
The arguments *x* and *y* or *coordList* (which must have two elements) specify the coordinates of a point used to position the window on the display, as controlled by the **-anchor** option. After the coordinates there may be any number of *option*-*value* pairs, each of which sets one of the configuration options for the item. These same *option*-*value* pairs may be used in **itemconfigure** widget commands to change the item's configuration. Theoretically, a window item becomes the current item when the mouse pointer is over any part of its bounding box, but in practice this typically does not happen because the mouse pointer ceases to be over the canvas at that point. The following standard options are supported by window items:
| | |
| --- | --- |
| **-anchor** | **-state** |
| **-tags** |
The following extra options are supported for window items:
**-height** *pixels*
Specifies the height to assign to the item's window. *Pixels* may have any of the forms described in the **[COORDINATES](#M17)** section above. If this option is not specified, or if it is specified as zero, then the window is given whatever height it requests internally.
**-width** *pixels*
Specifies the width to assign to the item's window. *Pixels* may have any of the forms described in the **[COORDINATES](#M17)** section above. If this option is not specified, or if it is specified as zero, then the window is given whatever width it requests internally.
**-window** *pathName*
Specifies the window to associate with this item. The window specified by *pathName* must either be a child of the canvas widget or a child of some ancestor of the canvas widget. *PathName* may not refer to a top-level window.
Note: due to restrictions in the ways that windows are managed, it is not possible to draw other graphical items (such as lines and images) on top of window items. A window item always obscures any graphics that overlap it, regardless of their order in the display list. Also note that window items, unlike other canvas items, are not clipped for display by their containing canvas's border, and are instead clipped by the parent widget of the window specified by the **-window** option; when the parent widget is the canvas, this means that the window item can overlap the canvas's border.
Application-defined item types
------------------------------
It is possible for individual applications to define new item types for canvas widgets using C code. See the documentation for **[Tk\_CreateItemType](https://www.tcl.tk/man/tcl/TkLib/CrtItemType.htm)**. Bindings
--------
In the current implementation, new canvases are not given any default behavior: you will have to execute explicit Tcl commands to give the canvas its behavior. Credits
-------
Tk's canvas widget is a blatant ripoff of ideas from Joel Bartlett's *ezd* program. *Ezd* provides structured graphics in a Scheme environment and preceded canvases by a year or two. Its simple mechanisms for placing and animating graphical objects inspired the functions of canvases. See also
--------
**[bind](bind.htm)**, **[font](font.htm)**, **[image](image.htm)**, **[scrollbar](scrollbar.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TkCmd/canvas.htm>
| programming_docs |
tcl_tk radiobutton radiobutton
===========
[NAME](radiobutton.htm#M2) radiobutton — Create and manipulate 'radiobutton' pick-one widgets
[SYNOPSIS](radiobutton.htm#M3)
[STANDARD OPTIONS](radiobutton.htm#M4)
[-activebackground, activeBackground, Foreground](options.htm#M-activebackground)
[-activeforeground, activeForeground, Background](options.htm#M-activeforeground)
[-anchor, anchor, Anchor](options.htm#M-anchor)
[-background or -bg, background, Background](options.htm#M-background)
[-bitmap, bitmap, Bitmap](options.htm#M-bitmap)
[-borderwidth or -bd, borderWidth, BorderWidth](options.htm#M-borderwidth)
[-compound, compound, Compound](options.htm#M-compound)
[-cursor, cursor, Cursor](options.htm#M-cursor)
[-disabledforeground, disabledForeground, DisabledForeground](options.htm#M-disabledforeground)
[-font, font, Font](options.htm#M-font)
[-foreground or -fg, foreground, Foreground](options.htm#M-foreground)
[-highlightbackground, highlightBackground, HighlightBackground](options.htm#M-highlightbackground)
[-highlightcolor, highlightColor, HighlightColor](options.htm#M-highlightcolor)
[-highlightthickness, highlightThickness, HighlightThickness](options.htm#M-highlightthickness)
[-image, image, Image](options.htm#M-image)
[-justify, justify, Justify](options.htm#M-justify)
[-padx, padX, Pad](options.htm#M-padx)
[-pady, padY, Pad](options.htm#M-pady)
[-relief, relief, Relief](options.htm#M-relief)
[-takefocus, takeFocus, TakeFocus](options.htm#M-takefocus)
[-text, text, Text](options.htm#M-text)
[-textvariable, textVariable, Variable](options.htm#M-textvariable)
[-underline, underline, Underline](options.htm#M-underline)
[-wraplength, wrapLength, WrapLength](options.htm#M-wraplength)
[WIDGET-SPECIFIC OPTIONS](radiobutton.htm#M5)
[-command, command, Command](radiobutton.htm#M6)
[-height, height, Height](radiobutton.htm#M7)
[-indicatoron, indicatorOn, IndicatorOn](radiobutton.htm#M8)
[-selectcolor, selectColor, Background](radiobutton.htm#M9)
[-offrelief, offRelief, OffRelief](radiobutton.htm#M10)
[-overrelief, overRelief, OverRelief](radiobutton.htm#M11)
[-selectimage, selectImage, SelectImage](radiobutton.htm#M12)
[-state, state, State](radiobutton.htm#M13)
[-tristateimage, tristateImage, TristateImage](radiobutton.htm#M14)
[-tristatevalue, tristateValue, Value](radiobutton.htm#M15)
[-value, value, Value](radiobutton.htm#M16)
[-variable, variable, Variable](radiobutton.htm#M17)
[-width, width, Width](radiobutton.htm#M18)
[DESCRIPTION](radiobutton.htm#M19)
[WIDGET COMMAND](radiobutton.htm#M20)
[*pathName* **cget** *option*](radiobutton.htm#M21)
[*pathName* **configure** ?*option*? ?*value option value ...*?](radiobutton.htm#M22)
[*pathName* **deselect**](radiobutton.htm#M23)
[*pathName* **flash**](radiobutton.htm#M24)
[*pathName* **invoke**](radiobutton.htm#M25)
[*pathName* **select**](radiobutton.htm#M26)
[BINDINGS](radiobutton.htm#M27)
[SEE ALSO](radiobutton.htm#M28)
[KEYWORDS](radiobutton.htm#M29)
Name
----
radiobutton — Create and manipulate 'radiobutton' pick-one widgets Synopsis
--------
**radiobutton** *pathName* ?*options*?
Standard options
----------------
**[-activebackground, activeBackground, Foreground](options.htm#M-activebackground)**
**[-activeforeground, activeForeground, Background](options.htm#M-activeforeground)**
**[-anchor, anchor, Anchor](options.htm#M-anchor)**
**[-background or -bg, background, Background](options.htm#M-background)**
**[-bitmap, bitmap, Bitmap](options.htm#M-bitmap)**
**[-borderwidth or -bd, borderWidth, BorderWidth](options.htm#M-borderwidth)**
**[-compound, compound, Compound](options.htm#M-compound)**
**[-cursor, cursor, Cursor](options.htm#M-cursor)**
**[-disabledforeground, disabledForeground, DisabledForeground](options.htm#M-disabledforeground)**
**[-font, font, Font](options.htm#M-font)**
**[-foreground or -fg, foreground, Foreground](options.htm#M-foreground)**
**[-highlightbackground, highlightBackground, HighlightBackground](options.htm#M-highlightbackground)**
**[-highlightcolor, highlightColor, HighlightColor](options.htm#M-highlightcolor)**
**[-highlightthickness, highlightThickness, HighlightThickness](options.htm#M-highlightthickness)**
**[-image, image, Image](options.htm#M-image)**
**[-justify, justify, Justify](options.htm#M-justify)**
**[-padx, padX, Pad](options.htm#M-padx)**
**[-pady, padY, Pad](options.htm#M-pady)**
**[-relief, relief, Relief](options.htm#M-relief)**
**[-takefocus, takeFocus, TakeFocus](options.htm#M-takefocus)**
**[-text, text, Text](options.htm#M-text)**
**[-textvariable, textVariable, Variable](options.htm#M-textvariable)**
**[-underline, underline, Underline](options.htm#M-underline)**
**[-wraplength, wrapLength, WrapLength](options.htm#M-wraplength)**
Widget-specific options
-----------------------
Command-Line Name: **-command** Database Name: **command** Database Class: **Command**
Specifies a Tcl command to associate with the button. This command is typically invoked when mouse button 1 is released over the button window. The button's global variable (**-variable** option) will be updated before the command is invoked.
Command-Line Name: **-height** Database Name: **height** Database Class: **Height**
Specifies a desired height for the button. If an image or bitmap is being displayed in the button then the value is in screen units (i.e. any of the forms acceptable to **[Tk\_GetPixels](https://www.tcl.tk/man/tcl/TkLib/GetPixels.htm)**); for text it is in lines of text. If this option is not specified, the button's desired height is computed from the size of the image or bitmap or text being displayed in it.
Command-Line Name: **-indicatoron** Database Name: **indicatorOn** Database Class: **IndicatorOn**
Specifies whether or not the indicator should be drawn. Must be a proper boolean value. If false, the **-relief** option is ignored and the widget's relief is always sunken if the widget is selected and raised otherwise.
Command-Line Name: **-selectcolor** Database Name: **selectColor** Database Class: **Background**
Specifies a background color to use when the button is selected. If **-indicatoron** is true then the color applies to the indicator. Under Windows, this color is used as the background for the indicator regardless of the select state. If **-indicatoron** is false, this color is used as the background for the entire widget, in place of **-background** or **-activeBackground**, whenever the widget is selected. If specified as an empty string then no special color is used for displaying when the widget is selected.
Command-Line Name: **-offrelief** Database Name: **offRelief** Database Class: **OffRelief**
Specifies the relief for the checkbutton when the indicator is not drawn and the checkbutton is off. The default value is “raised”. By setting this option to “flat” and setting **-indicatoron** to false and **-overrelief** to “raised”, the effect is achieved of having a flat button that raises on mouse-over and which is depressed when activated. This is the behavior typically exhibited by the Align-Left, Align-Right, and Center radiobuttons on the toolbar of a word-processor, for example.
Command-Line Name: **-overrelief** Database Name: **overRelief** Database Class: **OverRelief**
Specifies an alternative relief for the radiobutton, to be used when the mouse cursor is over the widget. This option can be used to make toolbar buttons, by configuring **-relief flat -overrelief raised**. If the value of this option is the empty string, then no alternative relief is used when the mouse cursor is over the radiobutton. The empty string is the default value.
Command-Line Name: **-selectimage** Database Name: **selectImage** Database Class: **SelectImage**
Specifies an image to display (in place of the **-image** option) when the radiobutton is selected. This option is ignored unless the **-image** option has been specified.
Command-Line Name: **-state** Database Name: **state** Database Class: **State**
Specifies one of three states for the radiobutton: **normal**, **active**, or **disabled**. In normal state the radiobutton is displayed using the **-foreground** and **-background** options. The active state is typically used when the pointer is over the radiobutton. In active state the radiobutton is displayed using the **-activeforeground** and **-activebackground** options. Disabled state means that the radiobutton should be insensitive: the default bindings will refuse to activate the widget and will ignore mouse button presses. In this state the **-disabledforeground** and **-background** options determine how the radiobutton is displayed.
Command-Line Name: **-tristateimage** Database Name: **tristateImage** Database Class: **TristateImage**
Specifies an image to display (in place of the **-image** option) when the radiobutton is selected. This option is ignored unless the **-image** option has been specified.
Command-Line Name: **-tristatevalue** Database Name: **tristateValue** Database Class: **Value**
Specifies the value that causes the radiobutton to display the multi-value selection, also known as the tri-state mode. Defaults to “”.
Command-Line Name: **-value** Database Name: **value** Database Class: **Value**
Specifies value to store in the button's associated variable whenever this button is selected.
Command-Line Name: **-variable** Database Name: **[variable](../tclcmd/variable.htm)** Database Class: **[Variable](../tclcmd/variable.htm)**
Specifies the name of a global variable to set whenever this button is selected. Changes in this variable also cause the button to select or deselect itself. Defaults to the value **selectedButton**.
Command-Line Name: **-width** Database Name: **width** Database Class: **Width**
Specifies a desired width for the button. If an image or bitmap is being displayed in the button, the value is in screen units (i.e. any of the forms acceptable to **[Tk\_GetPixels](https://www.tcl.tk/man/tcl/TkLib/GetPixels.htm)**); for text it is in characters. If this option is not specified, the button's desired width is computed from the size of the image or bitmap or text being displayed in it.
Description
-----------
The **radiobutton** command creates a new window (given by the *pathName* argument) and makes it into a radiobutton widget. Additional options, described above, may be specified on the command line or in the option database to configure aspects of the radiobutton such as its colors, font, text, and initial relief. The **radiobutton** command returns its *pathName* argument. At the time this command is invoked, there must not exist a window named *pathName*, but *pathName*'s parent must exist. A radiobutton is a widget that displays a textual string, bitmap or image and a diamond or circle called an *indicator*. If text is displayed, it must all be in a single font, but it can occupy multiple lines on the screen (if it contains newlines or if wrapping occurs because of the **-wraplength** option) and one of the characters may optionally be underlined using the **-underline** option. A radiobutton has all of the behavior of a simple button: it can display itself in either of three different ways, according to the **-state** option; it can be made to appear raised, sunken, or flat; it can be made to flash; and it invokes a Tcl command whenever mouse button 1 is clicked over the check button.
In addition, radiobuttons can be *selected*. If a radiobutton is selected, the indicator is normally drawn with a selected appearance, and a Tcl variable associated with the radiobutton is set to a particular value (normally 1). Under Unix, the indicator is drawn with a sunken relief and a special color. Under Windows, the indicator is drawn with a round mark inside. If the radiobutton is not selected, then the indicator is drawn with a deselected appearance, and the associated variable is set to a different value (typically 0). The indicator is drawn without a round mark inside. Typically, several radiobuttons share a single variable and the value of the variable indicates which radiobutton is to be selected. When a radiobutton is selected it sets the value of the variable to indicate that fact; each radiobutton also monitors the value of the variable and automatically selects and deselects itself when the variable's value changes. If the variable's value matches the **-tristatevalue**, then the radiobutton is drawn using the tri-state mode. This mode is used to indicate mixed or multiple values. (This is used when the radiobutton represents the state of multiple items.) By default the variable **selectedButton** is used; its contents give the name of the button that is selected, or the empty string if no button associated with that variable is selected. The name of the variable for a radiobutton, plus the variable to be stored into it, may be modified with options on the command line or in the option database. Configuration options may also be used to modify the way the indicator is displayed (or whether it is displayed at all). By default a radiobutton is configured to select itself on button clicks.
Widget command
--------------
The **radiobutton** command creates a new Tcl command whose name is *pathName*. This command may be used to invoke various operations on the widget. It has the following general form:
```
*pathName option* ?*arg arg ...*?
```
*Option* and the *arg*s determine the exact behavior of the command. The following commands are possible for radiobutton widgets:
*pathName* **cget** *option*
Returns the current value of the configuration option given by *option*. *Option* may have any of the values accepted by the **radiobutton** command.
*pathName* **configure** ?*option*? ?*value option value ...*?
Query or modify the configuration options of the widget. If no *option* is specified, returns a list describing all of the available options for *pathName* (see **[Tk\_ConfigureInfo](https://www.tcl.tk/man/tcl/TkLib/ConfigWidg.htm)** for information on the format of this list). If *option* is specified with no *value*, the command returns a list describing the one named option (this list will be identical to the corresponding sublist of the value returned if no *option* is specified). If one or more *option-value* pairs are specified, the command modifies the given widget option(s) to have the given value(s); in this case the command returns an empty string. *Option* may have any of the values accepted by the **radiobutton** command.
*pathName* **deselect**
Deselects the radiobutton and sets the associated variable to an empty string. If this radiobutton was not currently selected, the command has no effect.
*pathName* **flash**
Flashes the radiobutton. This is accomplished by redisplaying the radiobutton several times, alternating between active and normal colors. At the end of the flash the radiobutton is left in the same normal/active state as when the command was invoked. This command is ignored if the radiobutton's state is **disabled**.
*pathName* **invoke**
Does just what would have happened if the user invoked the radiobutton with the mouse: selects the button and invokes its associated Tcl command, if there is one. The return value is the return value from the Tcl command, or an empty string if there is no command associated with the radiobutton. This command is ignored if the radiobutton's state is **disabled**.
*pathName* **select**
Selects the radiobutton and sets the associated variable to the value corresponding to this widget.
Bindings
--------
Tk automatically creates class bindings for radiobuttons that give them the following default behavior:
1. On Unix systems, a radiobutton activates whenever the mouse passes over it and deactivates whenever the mouse leaves the radiobutton. On Mac and Windows systems, when mouse button 1 is pressed over a radiobutton, the button activates whenever the mouse pointer is inside the button, and deactivates whenever the mouse pointer leaves the button.
2. When mouse button 1 is pressed over a radiobutton it is invoked (it becomes selected and the command associated with the button is invoked, if there is one).
3. When a radiobutton has the input focus, the space key causes the radiobutton to be invoked.
If the radiobutton's state is **disabled** then none of the above actions occur: the radiobutton is completely non-responsive.
The behavior of radiobuttons can be changed by defining new bindings for individual widgets or by redefining the class bindings.
See also
--------
**[checkbutton](checkbutton.htm)**, **[labelframe](labelframe.htm)**, **[listbox](listbox.htm)**, **[options](options.htm)**, **[scale](scale.htm)**, **[ttk::radiobutton](ttk_radiobutton.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TkCmd/radiobutton.htm>
tcl_tk keysyms keysyms
=======
Name
----
keysyms — keysyms recognized by Tk Description
-----------
Tk recognizes many keysyms when specifying key bindings (e.g., “**[bind](bind.htm)** **. <Key-***keysym***>**”). The following list enumerates the keysyms that will be recognized by Tk. Note that not all keysyms will be valid on all platforms. For example, on Unix systems, the presence of a particular keysym is dependant on the configuration of the keyboard modifier map. This list shows keysyms along with their decimal and hexadecimal values.
```
space 32 0x0020
exclam 33 0x0021
quotedbl 34 0x0022
numbersign 35 0x0023
dollar 36 0x0024
percent 37 0x0025
ampersand 38 0x0026
quoteright 39 0x0027
parenleft 40 0x0028
parenright 41 0x0029
asterisk 42 0x002a
plus 43 0x002b
comma 44 0x002c
minus 45 0x002d
period 46 0x002e
slash 47 0x002f
0 48 0x0030
1 49 0x0031
2 50 0x0032
3 51 0x0033
4 52 0x0034
5 53 0x0035
6 54 0x0036
7 55 0x0037
8 56 0x0038
9 57 0x0039
colon 58 0x003a
semicolon 59 0x003b
less 60 0x003c
equal 61 0x003d
greater 62 0x003e
question 63 0x003f
at 64 0x0040
A 65 0x0041
B 66 0x0042
C 67 0x0043
D 68 0x0044
E 69 0x0045
F 70 0x0046
G 71 0x0047
H 72 0x0048
I 73 0x0049
J 74 0x004a
K 75 0x004b
L 76 0x004c
M 77 0x004d
N 78 0x004e
O 79 0x004f
P 80 0x0050
Q 81 0x0051
R 82 0x0052
S 83 0x0053
T 84 0x0054
U 85 0x0055
V 86 0x0056
W 87 0x0057
X 88 0x0058
Y 89 0x0059
Z 90 0x005a
bracketleft 91 0x005b
backslash 92 0x005c
bracketright 93 0x005d
asciicircum 94 0x005e
underscore 95 0x005f
quoteleft 96 0x0060
a 97 0x0061
b 98 0x0062
c 99 0x0063
d 100 0x0064
e 101 0x0065
f 102 0x0066
g 103 0x0067
h 104 0x0068
i 105 0x0069
j 106 0x006a
k 107 0x006b
l 108 0x006c
m 109 0x006d
n 110 0x006e
o 111 0x006f
p 112 0x0070
q 113 0x0071
r 114 0x0072
s 115 0x0073
t 116 0x0074
u 117 0x0075
v 118 0x0076
w 119 0x0077
x 120 0x0078
y 121 0x0079
z 122 0x007a
braceleft 123 0x007b
bar 124 0x007c
braceright 125 0x007d
asciitilde 126 0x007e
nobreakspace 160 0x00a0
exclamdown 161 0x00a1
cent 162 0x00a2
sterling 163 0x00a3
currency 164 0x00a4
yen 165 0x00a5
brokenbar 166 0x00a6
section 167 0x00a7
diaeresis 168 0x00a8
copyright 169 0x00a9
ordfeminine 170 0x00aa
guillemotleft 171 0x00ab
notsign 172 0x00ac
hyphen 173 0x00ad
registered 174 0x00ae
macron 175 0x00af
degree 176 0x00b0
plusminus 177 0x00b1
twosuperior 178 0x00b2
threesuperior 179 0x00b3
acute 180 0x00b4
mu 181 0x00b5
paragraph 182 0x00b6
periodcentered 183 0x00b7
cedilla 184 0x00b8
onesuperior 185 0x00b9
masculine 186 0x00ba
guillemotright 187 0x00bb
onequarter 188 0x00bc
onehalf 189 0x00bd
threequarters 190 0x00be
questiondown 191 0x00bf
Agrave 192 0x00c0
Aacute 193 0x00c1
Acircumflex 194 0x00c2
Atilde 195 0x00c3
Adiaeresis 196 0x00c4
Aring 197 0x00c5
AE 198 0x00c6
Ccedilla 199 0x00c7
Egrave 200 0x00c8
Eacute 201 0x00c9
Ecircumflex 202 0x00ca
Ediaeresis 203 0x00cb
Igrave 204 0x00cc
Iacute 205 0x00cd
Icircumflex 206 0x00ce
Idiaeresis 207 0x00cf
Eth 208 0x00d0
Ntilde 209 0x00d1
Ograve 210 0x00d2
Oacute 211 0x00d3
Ocircumflex 212 0x00d4
Otilde 213 0x00d5
Odiaeresis 214 0x00d6
multiply 215 0x00d7
Ooblique 216 0x00d8
Ugrave 217 0x00d9
Uacute 218 0x00da
Ucircumflex 219 0x00db
Udiaeresis 220 0x00dc
Yacute 221 0x00dd
Thorn 222 0x00de
ssharp 223 0x00df
agrave 224 0x00e0
aacute 225 0x00e1
acircumflex 226 0x00e2
atilde 227 0x00e3
adiaeresis 228 0x00e4
aring 229 0x00e5
ae 230 0x00e6
ccedilla 231 0x00e7
egrave 232 0x00e8
eacute 233 0x00e9
ecircumflex 234 0x00ea
ediaeresis 235 0x00eb
igrave 236 0x00ec
iacute 237 0x00ed
icircumflex 238 0x00ee
idiaeresis 239 0x00ef
eth 240 0x00f0
ntilde 241 0x00f1
ograve 242 0x00f2
oacute 243 0x00f3
ocircumflex 244 0x00f4
otilde 245 0x00f5
odiaeresis 246 0x00f6
division 247 0x00f7
oslash 248 0x00f8
ugrave 249 0x00f9
uacute 250 0x00fa
ucircumflex 251 0x00fb
udiaeresis 252 0x00fc
yacute 253 0x00fd
thorn 254 0x00fe
ydiaeresis 255 0x00ff
Aogonek 417 0x01a1
breve 418 0x01a2
Lstroke 419 0x01a3
Lcaron 421 0x01a5
Sacute 422 0x01a6
Scaron 425 0x01a9
Scedilla 426 0x01aa
Tcaron 427 0x01ab
Zacute 428 0x01ac
```
```
Zcaron 430 0x01ae
Zabovedot 431 0x01af
aogonek 433 0x01b1
ogonek 434 0x01b2
lstroke 435 0x01b3
lcaron 437 0x01b5
sacute 438 0x01b6
caron 439 0x01b7
scaron 441 0x01b9
scedilla 442 0x01ba
tcaron 443 0x01bb
zacute 444 0x01bc
doubleacute 445 0x01bd
zcaron 446 0x01be
zabovedot 447 0x01bf
Racute 448 0x01c0
Abreve 451 0x01c3
Cacute 454 0x01c6
Ccaron 456 0x01c8
Eogonek 458 0x01ca
Ecaron 460 0x01cc
Dcaron 463 0x01cf
Nacute 465 0x01d1
Ncaron 466 0x01d2
Odoubleacute 469 0x01d5
Rcaron 472 0x01d8
Uring 473 0x01d9
Udoubleacute 475 0x01db
Tcedilla 478 0x01de
racute 480 0x01e0
abreve 483 0x01e3
cacute 486 0x01e6
ccaron 488 0x01e8
eogonek 490 0x01ea
ecaron 492 0x01ec
dcaron 495 0x01ef
nacute 497 0x01f1
ncaron 498 0x01f2
odoubleacute 501 0x01f5
rcaron 504 0x01f8
uring 505 0x01f9
udoubleacute 507 0x01fb
tcedilla 510 0x01fe
abovedot 511 0x01ff
Hstroke 673 0x02a1
Hcircumflex 678 0x02a6
Iabovedot 681 0x02a9
Gbreve 683 0x02ab
Jcircumflex 684 0x02ac
hstroke 689 0x02b1
hcircumflex 694 0x02b6
idotless 697 0x02b9
gbreve 699 0x02bb
jcircumflex 700 0x02bc
Cabovedot 709 0x02c5
Ccircumflex 710 0x02c6
Gabovedot 725 0x02d5
Gcircumflex 728 0x02d8
Ubreve 733 0x02dd
Scircumflex 734 0x02de
cabovedot 741 0x02e5
ccircumflex 742 0x02e6
gabovedot 757 0x02f5
gcircumflex 760 0x02f8
ubreve 765 0x02fd
scircumflex 766 0x02fe
kappa 930 0x03a2
Rcedilla 931 0x03a3
Itilde 933 0x03a5
Lcedilla 934 0x03a6
Emacron 938 0x03aa
Gcedilla 939 0x03ab
Tslash 940 0x03ac
rcedilla 947 0x03b3
itilde 949 0x03b5
lcedilla 950 0x03b6
emacron 954 0x03ba
gacute 955 0x03bb
tslash 956 0x03bc
ENG 957 0x03bd
eng 959 0x03bf
Amacron 960 0x03c0
Iogonek 967 0x03c7
Eabovedot 972 0x03cc
Imacron 975 0x03cf
Ncedilla 977 0x03d1
Omacron 978 0x03d2
Kcedilla 979 0x03d3
Uogonek 985 0x03d9
Utilde 989 0x03dd
Umacron 990 0x03de
amacron 992 0x03e0
iogonek 999 0x03e7
eabovedot 1004 0x03ec
imacron 1007 0x03ef
ncedilla 1009 0x03f1
omacron 1010 0x03f2
kcedilla 1011 0x03f3
uogonek 1017 0x03f9
utilde 1021 0x03fd
umacron 1022 0x03fe
overline 1150 0x047e
kana_fullstop 1185 0x04a1
kana_openingbracket 1186 0x04a2
kana_closingbracket 1187 0x04a3
kana_comma 1188 0x04a4
kana_middledot 1189 0x04a5
kana_WO 1190 0x04a6
kana_a 1191 0x04a7
kana_i 1192 0x04a8
kana_u 1193 0x04a9
kana_e 1194 0x04aa
kana_o 1195 0x04ab
kana_ya 1196 0x04ac
kana_yu 1197 0x04ad
kana_yo 1198 0x04ae
kana_tu 1199 0x04af
prolongedsound 1200 0x04b0
kana_A 1201 0x04b1
kana_I 1202 0x04b2
kana_U 1203 0x04b3
kana_E 1204 0x04b4
kana_O 1205 0x04b5
kana_KA 1206 0x04b6
kana_KI 1207 0x04b7
kana_KU 1208 0x04b8
kana_KE 1209 0x04b9
kana_KO 1210 0x04ba
kana_SA 1211 0x04bb
kana_SHI 1212 0x04bc
kana_SU 1213 0x04bd
kana_SE 1214 0x04be
kana_SO 1215 0x04bf
kana_TA 1216 0x04c0
kana_TI 1217 0x04c1
kana_TU 1218 0x04c2
kana_TE 1219 0x04c3
kana_TO 1220 0x04c4
kana_NA 1221 0x04c5
kana_NI 1222 0x04c6
kana_NU 1223 0x04c7
kana_NE 1224 0x04c8
kana_NO 1225 0x04c9
kana_HA 1226 0x04ca
kana_HI 1227 0x04cb
kana_HU 1228 0x04cc
kana_HE 1229 0x04cd
kana_HO 1230 0x04ce
kana_MA 1231 0x04cf
kana_MI 1232 0x04d0
kana_MU 1233 0x04d1
kana_ME 1234 0x04d2
kana_MO 1235 0x04d3
kana_YA 1236 0x04d4
kana_YU 1237 0x04d5
kana_YO 1238 0x04d6
kana_RA 1239 0x04d7
kana_RI 1240 0x04d8
kana_RU 1241 0x04d9
kana_RE 1242 0x04da
kana_RO 1243 0x04db
kana_WA 1244 0x04dc
kana_N 1245 0x04dd
voicedsound 1246 0x04de
semivoicedsound 1247 0x04df
Arabic_comma 1452 0x05ac
Arabic_semicolon 1467 0x05bb
Arabic_question_mark 1471 0x05bf
Arabic_hamza 1473 0x05c1
Arabic_maddaonalef 1474 0x05c2
Arabic_hamzaonalef 1475 0x05c3
Arabic_hamzaonwaw 1476 0x05c4
Arabic_hamzaunderalef 1477 0x05c5
Arabic_hamzaonyeh 1478 0x05c6
Arabic_alef 1479 0x05c7
Arabic_beh 1480 0x05c8
Arabic_tehmarbuta 1481 0x05c9
Arabic_teh 1482 0x05ca
Arabic_theh 1483 0x05cb
Arabic_jeem 1484 0x05cc
Arabic_hah 1485 0x05cd
Arabic_khah 1486 0x05ce
Arabic_dal 1487 0x05cf
Arabic_thal 1488 0x05d0
Arabic_ra 1489 0x05d1
Arabic_zain 1490 0x05d2
Arabic_seen 1491 0x05d3
Arabic_sheen 1492 0x05d4
Arabic_sad 1493 0x05d5
Arabic_dad 1494 0x05d6
Arabic_tah 1495 0x05d7
Arabic_zah 1496 0x05d8
Arabic_ain 1497 0x05d9
Arabic_ghain 1498 0x05da
Arabic_tatweel 1504 0x05e0
Arabic_feh 1505 0x05e1
Arabic_qaf 1506 0x05e2
Arabic_kaf 1507 0x05e3
Arabic_lam 1508 0x05e4
Arabic_meem 1509 0x05e5
```
```
Arabic_noon 1510 0x05e6
Arabic_heh 1511 0x05e7
Arabic_waw 1512 0x05e8
Arabic_alefmaksura 1513 0x05e9
Arabic_yeh 1514 0x05ea
Arabic_fathatan 1515 0x05eb
Arabic_dammatan 1516 0x05ec
Arabic_kasratan 1517 0x05ed
Arabic_fatha 1518 0x05ee
Arabic_damma 1519 0x05ef
Arabic_kasra 1520 0x05f0
Arabic_shadda 1521 0x05f1
Arabic_sukun 1522 0x05f2
Serbian_dje 1697 0x06a1
Macedonia_gje 1698 0x06a2
Cyrillic_io 1699 0x06a3
Ukranian_je 1700 0x06a4
Macedonia_dse 1701 0x06a5
Ukranian_i 1702 0x06a6
Ukranian_yi 1703 0x06a7
Serbian_je 1704 0x06a8
Serbian_lje 1705 0x06a9
Serbian_nje 1706 0x06aa
Serbian_tshe 1707 0x06ab
Macedonia_kje 1708 0x06ac
Byelorussian_shortu 1710 0x06ae
Serbian_dze 1711 0x06af
numerosign 1712 0x06b0
Serbian_DJE 1713 0x06b1
Macedonia_GJE 1714 0x06b2
Cyrillic_IO 1715 0x06b3
Ukranian_JE 1716 0x06b4
Macedonia_DSE 1717 0x06b5
Ukranian_I 1718 0x06b6
Ukranian_YI 1719 0x06b7
Serbian_JE 1720 0x06b8
Serbian_LJE 1721 0x06b9
Serbian_NJE 1722 0x06ba
Serbian_TSHE 1723 0x06bb
Macedonia_KJE 1724 0x06bc
Byelorussian_SHORTU 1726 0x06be
Serbian_DZE 1727 0x06bf
Cyrillic_yu 1728 0x06c0
Cyrillic_a 1729 0x06c1
Cyrillic_be 1730 0x06c2
Cyrillic_tse 1731 0x06c3
Cyrillic_de 1732 0x06c4
Cyrillic_ie 1733 0x06c5
Cyrillic_ef 1734 0x06c6
Cyrillic_ghe 1735 0x06c7
Cyrillic_ha 1736 0x06c8
Cyrillic_i 1737 0x06c9
Cyrillic_shorti 1738 0x06ca
Cyrillic_ka 1739 0x06cb
Cyrillic_el 1740 0x06cc
Cyrillic_em 1741 0x06cd
Cyrillic_en 1742 0x06ce
Cyrillic_o 1743 0x06cf
Cyrillic_pe 1744 0x06d0
Cyrillic_ya 1745 0x06d1
Cyrillic_er 1746 0x06d2
Cyrillic_es 1747 0x06d3
Cyrillic_te 1748 0x06d4
Cyrillic_u 1749 0x06d5
Cyrillic_zhe 1750 0x06d6
Cyrillic_ve 1751 0x06d7
Cyrillic_softsign 1752 0x06d8
Cyrillic_yeru 1753 0x06d9
Cyrillic_ze 1754 0x06da
Cyrillic_sha 1755 0x06db
Cyrillic_e 1756 0x06dc
Cyrillic_shcha 1757 0x06dd
Cyrillic_che 1758 0x06de
Cyrillic_hardsign 1759 0x06df
Cyrillic_YU 1760 0x06e0
Cyrillic_A 1761 0x06e1
Cyrillic_BE 1762 0x06e2
Cyrillic_TSE 1763 0x06e3
Cyrillic_DE 1764 0x06e4
Cyrillic_IE 1765 0x06e5
Cyrillic_EF 1766 0x06e6
Cyrillic_GHE 1767 0x06e7
Cyrillic_HA 1768 0x06e8
Cyrillic_I 1769 0x06e9
Cyrillic_SHORTI 1770 0x06ea
Cyrillic_KA 1771 0x06eb
Cyrillic_EL 1772 0x06ec
Cyrillic_EM 1773 0x06ed
Cyrillic_EN 1774 0x06ee
Cyrillic_O 1775 0x06ef
Cyrillic_PE 1776 0x06f0
Cyrillic_YA 1777 0x06f1
Cyrillic_ER 1778 0x06f2
Cyrillic_ES 1779 0x06f3
Cyrillic_TE 1780 0x06f4
Cyrillic_U 1781 0x06f5
Cyrillic_ZHE 1782 0x06f6
Cyrillic_VE 1783 0x06f7
Cyrillic_SOFTSIGN 1784 0x06f8
Cyrillic_YERU 1785 0x06f9
Cyrillic_ZE 1786 0x06fa
Cyrillic_SHA 1787 0x06fb
Cyrillic_E 1788 0x06fc
Cyrillic_SHCHA 1789 0x06fd
Cyrillic_CHE 1790 0x06fe
Cyrillic_HARDSIGN 1791 0x06ff
Greek_ALPHAaccent 1953 0x07a1
Greek_EPSILONaccent 1954 0x07a2
Greek_ETAaccent 1955 0x07a3
Greek_IOTAaccent 1956 0x07a4
Greek_IOTAdiaeresis 1957 0x07a5
Greek_IOTAaccentdiaeresis 1958 0x07a6
Greek_OMICRONaccent 1959 0x07a7
Greek_UPSILONaccent 1960 0x07a8
Greek_UPSILONdieresis 1961 0x07a9
Greek_UPSILONaccentdieresis 1962 0x07aa
Greek_OMEGAaccent 1963 0x07ab
Greek_alphaaccent 1969 0x07b1
Greek_epsilonaccent 1970 0x07b2
Greek_etaaccent 1971 0x07b3
Greek_iotaaccent 1972 0x07b4
Greek_iotadieresis 1973 0x07b5
Greek_iotaaccentdieresis 1974 0x07b6
Greek_omicronaccent 1975 0x07b7
Greek_upsilonaccent 1976 0x07b8
Greek_upsilondieresis 1977 0x07b9
Greek_upsilonaccentdieresis 1978 0x07ba
Greek_omegaaccent 1979 0x07bb
Greek_ALPHA 1985 0x07c1
Greek_BETA 1986 0x07c2
Greek_GAMMA 1987 0x07c3
Greek_DELTA 1988 0x07c4
Greek_EPSILON 1989 0x07c5
Greek_ZETA 1990 0x07c6
Greek_ETA 1991 0x07c7
Greek_THETA 1992 0x07c8
Greek_IOTA 1993 0x07c9
Greek_KAPPA 1994 0x07ca
Greek_LAMBDA 1995 0x07cb
Greek_MU 1996 0x07cc
Greek_NU 1997 0x07cd
Greek_XI 1998 0x07ce
Greek_OMICRON 1999 0x07cf
Greek_PI 2000 0x07d0
Greek_RHO 2001 0x07d1
Greek_SIGMA 2002 0x07d2
Greek_TAU 2004 0x07d4
Greek_UPSILON 2005 0x07d5
Greek_PHI 2006 0x07d6
Greek_CHI 2007 0x07d7
Greek_PSI 2008 0x07d8
Greek_OMEGA 2009 0x07d9
Greek_alpha 2017 0x07e1
Greek_beta 2018 0x07e2
Greek_gamma 2019 0x07e3
Greek_delta 2020 0x07e4
Greek_epsilon 2021 0x07e5
Greek_zeta 2022 0x07e6
Greek_eta 2023 0x07e7
Greek_theta 2024 0x07e8
Greek_iota 2025 0x07e9
Greek_kappa 2026 0x07ea
Greek_lambda 2027 0x07eb
Greek_mu 2028 0x07ec
Greek_nu 2029 0x07ed
Greek_xi 2030 0x07ee
Greek_omicron 2031 0x07ef
Greek_pi 2032 0x07f0
Greek_rho 2033 0x07f1
Greek_sigma 2034 0x07f2
Greek_finalsmallsigma 2035 0x07f3
Greek_tau 2036 0x07f4
Greek_upsilon 2037 0x07f5
Greek_phi 2038 0x07f6
Greek_chi 2039 0x07f7
Greek_psi 2040 0x07f8
Greek_omega 2041 0x07f9
leftradical 2209 0x08a1
topleftradical 2210 0x08a2
horizconnector 2211 0x08a3
topintegral 2212 0x08a4
botintegral 2213 0x08a5
vertconnector 2214 0x08a6
topleftsqbracket 2215 0x08a7
botleftsqbracket 2216 0x08a8
toprightsqbracket 2217 0x08a9
botrightsqbracket 2218 0x08aa
topleftparens 2219 0x08ab
botleftparens 2220 0x08ac
toprightparens 2221 0x08ad
botrightparens 2222 0x08ae
leftmiddlecurlybrace 2223 0x08af
rightmiddlecurlybrace 2224 0x08b0
topleftsummation 2225 0x08b1
botleftsummation 2226 0x08b2
topvertsummationconnector 2227 0x08b3
botvertsummationconnector 2228 0x08b4
toprightsummation 2229 0x08b5
botrightsummation 2230 0x08b6
rightmiddlesummation 2231 0x08b7
```
```
lessthanequal 2236 0x08bc
notequal 2237 0x08bd
greaterthanequal 2238 0x08be
integral 2239 0x08bf
therefore 2240 0x08c0
variation 2241 0x08c1
infinity 2242 0x08c2
nabla 2245 0x08c5
approximate 2248 0x08c8
similarequal 2249 0x08c9
ifonlyif 2253 0x08cd
implies 2254 0x08ce
identical 2255 0x08cf
radical 2262 0x08d6
includedin 2266 0x08da
includes 2267 0x08db
intersection 2268 0x08dc
union 2269 0x08dd
logicaland 2270 0x08de
logicalor 2271 0x08df
partialderivative 2287 0x08ef
function 2294 0x08f6
leftarrow 2299 0x08fb
uparrow 2300 0x08fc
rightarrow 2301 0x08fd
downarrow 2302 0x08fe
blank 2527 0x09df
soliddiamond 2528 0x09e0
checkerboard 2529 0x09e1
ht 2530 0x09e2
ff 2531 0x09e3
cr 2532 0x09e4
lf 2533 0x09e5
nl 2536 0x09e8
vt 2537 0x09e9
lowrightcorner 2538 0x09ea
uprightcorner 2539 0x09eb
upleftcorner 2540 0x09ec
lowleftcorner 2541 0x09ed
crossinglines 2542 0x09ee
horizlinescan1 2543 0x09ef
horizlinescan3 2544 0x09f0
horizlinescan5 2545 0x09f1
horizlinescan7 2546 0x09f2
horizlinescan9 2547 0x09f3
leftt 2548 0x09f4
rightt 2549 0x09f5
bott 2550 0x09f6
topt 2551 0x09f7
vertbar 2552 0x09f8
emspace 2721 0x0aa1
enspace 2722 0x0aa2
em3space 2723 0x0aa3
em4space 2724 0x0aa4
digitspace 2725 0x0aa5
punctspace 2726 0x0aa6
thinspace 2727 0x0aa7
hairspace 2728 0x0aa8
emdash 2729 0x0aa9
endash 2730 0x0aaa
signifblank 2732 0x0aac
ellipsis 2734 0x0aae
doubbaselinedot 2735 0x0aaf
onethird 2736 0x0ab0
twothirds 2737 0x0ab1
onefifth 2738 0x0ab2
twofifths 2739 0x0ab3
threefifths 2740 0x0ab4
fourfifths 2741 0x0ab5
onesixth 2742 0x0ab6
fivesixths 2743 0x0ab7
careof 2744 0x0ab8
figdash 2747 0x0abb
leftanglebracket 2748 0x0abc
decimalpoint 2749 0x0abd
rightanglebracket 2750 0x0abe
marker 2751 0x0abf
oneeighth 2755 0x0ac3
threeeighths 2756 0x0ac4
fiveeighths 2757 0x0ac5
seveneighths 2758 0x0ac6
trademark 2761 0x0ac9
signaturemark 2762 0x0aca
trademarkincircle 2763 0x0acb
leftopentriangle 2764 0x0acc
rightopentriangle 2765 0x0acd
emopencircle 2766 0x0ace
emopenrectangle 2767 0x0acf
leftsinglequotemark 2768 0x0ad0
rightsinglequotemark 2769 0x0ad1
leftdoublequotemark 2770 0x0ad2
rightdoublequotemark 2771 0x0ad3
prescription 2772 0x0ad4
minutes 2774 0x0ad6
seconds 2775 0x0ad7
latincross 2777 0x0ad9
hexagram 2778 0x0ada
filledrectbullet 2779 0x0adb
filledlefttribullet 2780 0x0adc
filledrighttribullet 2781 0x0add
emfilledcircle 2782 0x0ade
emfilledrect 2783 0x0adf
enopencircbullet 2784 0x0ae0
enopensquarebullet 2785 0x0ae1
openrectbullet 2786 0x0ae2
opentribulletup 2787 0x0ae3
opentribulletdown 2788 0x0ae4
openstar 2789 0x0ae5
enfilledcircbullet 2790 0x0ae6
enfilledsqbullet 2791 0x0ae7
filledtribulletup 2792 0x0ae8
filledtribulletdown 2793 0x0ae9
leftpointer 2794 0x0aea
rightpointer 2795 0x0aeb
club 2796 0x0aec
diamond 2797 0x0aed
heart 2798 0x0aee
maltesecross 2800 0x0af0
dagger 2801 0x0af1
doubledagger 2802 0x0af2
checkmark 2803 0x0af3
ballotcross 2804 0x0af4
musicalsharp 2805 0x0af5
musicalflat 2806 0x0af6
malesymbol 2807 0x0af7
femalesymbol 2808 0x0af8
telephone 2809 0x0af9
telephonerecorder 2810 0x0afa
phonographcopyright 2811 0x0afb
caret 2812 0x0afc
singlelowquotemark 2813 0x0afd
doublelowquotemark 2814 0x0afe
cursor 2815 0x0aff
leftcaret 2979 0x0ba3
rightcaret 2982 0x0ba6
downcaret 2984 0x0ba8
upcaret 2985 0x0ba9
overbar 3008 0x0bc0
downtack 3010 0x0bc2
upshoe 3011 0x0bc3
downstile 3012 0x0bc4
underbar 3014 0x0bc6
jot 3018 0x0bca
quad 3020 0x0bcc
uptack 3022 0x0bce
circle 3023 0x0bcf
upstile 3027 0x0bd3
downshoe 3030 0x0bd6
rightshoe 3032 0x0bd8
leftshoe 3034 0x0bda
lefttack 3036 0x0bdc
righttack 3068 0x0bfc
hebrew_aleph 3296 0x0ce0
hebrew_beth 3297 0x0ce1
hebrew_gimmel 3298 0x0ce2
hebrew_daleth 3299 0x0ce3
hebrew_he 3300 0x0ce4
hebrew_waw 3301 0x0ce5
hebrew_zayin 3302 0x0ce6
hebrew_het 3303 0x0ce7
hebrew_teth 3304 0x0ce8
hebrew_yod 3305 0x0ce9
hebrew_finalkaph 3306 0x0cea
hebrew_kaph 3307 0x0ceb
hebrew_lamed 3308 0x0cec
hebrew_finalmem 3309 0x0ced
hebrew_mem 3310 0x0cee
hebrew_finalnun 3311 0x0cef
hebrew_nun 3312 0x0cf0
hebrew_samekh 3313 0x0cf1
hebrew_ayin 3314 0x0cf2
hebrew_finalpe 3315 0x0cf3
hebrew_pe 3316 0x0cf4
hebrew_finalzadi 3317 0x0cf5
hebrew_zadi 3318 0x0cf6
hebrew_kuf 3319 0x0cf7
hebrew_resh 3320 0x0cf8
hebrew_shin 3321 0x0cf9
hebrew_taf 3322 0x0cfa
BackSpace 65288 0xff08
Tab 65289 0xff09
Linefeed 65290 0xff0a
Clear 65291 0xff0b
Return 65293 0xff0d
Pause 65299 0xff13
Scroll_Lock 65300 0xff14
Sys_Req 65301 0xff15
Escape 65307 0xff1b
Multi_key 65312 0xff20
Kanji 65313 0xff21
Home 65360 0xff50
Left 65361 0xff51
Up 65362 0xff52
Right 65363 0xff53
Down 65364 0xff54
Prior 65365 0xff55
Next 65366 0xff56
End 65367 0xff57
Begin 65368 0xff58
Win_L 65371 0xff5b
Win_R 65372 0xff5c
```
```
App 65373 0xff5d
Select 65376 0xff60
Print 65377 0xff61
Execute 65378 0xff62
Insert 65379 0xff63
Undo 65381 0xff65
Redo 65382 0xff66
Menu 65383 0xff67
Find 65384 0xff68
Cancel 65385 0xff69
Help 65386 0xff6a
Break 65387 0xff6b
Hebrew_switch 65406 0xff7e
Num_Lock 65407 0xff7f
KP_Space 65408 0xff80
KP_Tab 65417 0xff89
KP_Enter 65421 0xff8d
KP_F1 65425 0xff91
KP_F2 65426 0xff92
KP_F3 65427 0xff93
KP_F4 65428 0xff94
KP_Multiply 65450 0xffaa
KP_Add 65451 0xffab
KP_Separator 65452 0xffac
KP_Subtract 65453 0xffad
KP_Decimal 65454 0xffae
KP_Divide 65455 0xffaf
KP_0 65456 0xffb0
KP_1 65457 0xffb1
KP_2 65458 0xffb2
KP_3 65459 0xffb3
KP_4 65460 0xffb4
KP_5 65461 0xffb5
KP_6 65462 0xffb6
KP_7 65463 0xffb7
KP_8 65464 0xffb8
KP_9 65465 0xffb9
KP_Equal 65469 0xffbd
F1 65470 0xffbe
F2 65471 0xffbf
F3 65472 0xffc0
F4 65473 0xffc1
F5 65474 0xffc2
F6 65475 0xffc3
F7 65476 0xffc4
F8 65477 0xffc5
F9 65478 0xffc6
F10 65479 0xffc7
L1 65480 0xffc8
L2 65481 0xffc9
L3 65482 0xffca
L4 65483 0xffcb
L5 65484 0xffcc
L6 65485 0xffcd
L7 65486 0xffce
L8 65487 0xffcf
L9 65488 0xffd0
L10 65489 0xffd1
R1 65490 0xffd2
R2 65491 0xffd3
R3 65492 0xffd4
R4 65493 0xffd5
R5 65494 0xffd6
R6 65495 0xffd7
R7 65496 0xffd8
R8 65497 0xffd9
R9 65498 0xffda
R10 65499 0xffdb
R11 65500 0xffdc
R12 65501 0xffdd
F33 65502 0xffde
R14 65503 0xffdf
R15 65504 0xffe0
Shift_L 65505 0xffe1
Shift_R 65506 0xffe2
Control_L 65507 0xffe3
Control_R 65508 0xffe4
Caps_Lock 65509 0xffe5
Shift_Lock 65510 0xffe6
Meta_L 65511 0xffe7
Meta_R 65512 0xffe8
Alt_L 65513 0xffe9
Alt_R 65514 0xffea
Super_L 65515 0xffeb
Super_R 65516 0xffec
Hyper_L 65517 0xffed
Hyper_R 65518 0xffee
Delete 65535 0xffff
```
See also
--------
**[bind](bind.htm)**, **[event](event.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TkCmd/keysyms.htm>
| programming_docs |
tcl_tk console console
=======
[NAME](console.htm#M2) console — Control the console on systems without a real console
[SYNOPSIS](console.htm#M3)
[DESCRIPTION](console.htm#M4)
[**console eval** *script*](console.htm#M5)
[**console hide**](console.htm#M6)
[**console show**](console.htm#M7)
[**console title** ?*string*?](console.htm#M8)
[ACCESS TO THE MAIN INTERPRETER](console.htm#M9)
[**consoleinterp eval** *script*](console.htm#M10)
[**consoleinterp record** *script*](console.htm#M11)
[ADDITIONAL TRAP CALLS](console.htm#M12)
[DEFAULT BINDINGS](console.htm#M13)
[EXAMPLE](console.htm#M14)
[SEE ALSO](console.htm#M15)
[KEYWORDS](console.htm#M16)
Name
----
console — Control the console on systems without a real console Synopsis
--------
**console** *subcommand* ?*arg ...*?
Description
-----------
The console window is a replacement for a real console to allow input and output on the standard I/O channels on platforms that do not have a real console. It is implemented as a separate interpreter with the Tk toolkit loaded, and control over this interpreter is given through the **console** command. The behaviour of the console window is defined mainly through the contents of the *console.tcl* file in the Tk library. Except for TkAqua, this command is not available when Tk is loaded into a tclsh interpreter with “**package require Tk**”, as a conventional terminal is expected to be present in that case. In TkAqua, this command is only available when stdin is **/dev/null** (as is the case e.g. when the application embedding Tk is started from the Mac OS X Finder).
**console eval** *script*
Evaluate the *script* argument as a Tcl script in the console interpreter. The normal interpreter is accessed through the **consoleinterp** command in the console interpreter.
**console hide**
Hide the console window from view. Precisely equivalent to withdrawing the **.** window in the console interpreter.
**console show**
Display the console window. Precisely equivalent to deiconifying the **.** window in the console interpreter.
**console title** ?*string*?
Query or modify the title of the console window. If *string* is not specified, queries the title of the console window, and sets the title of the console window to *string* otherwise. Precisely equivalent to using the **[wm title](wm.htm)** command in the console interpreter.
Access to the main interpreter
------------------------------
The **consoleinterp** command in the console interpreter allows scripts to be evaluated in the main interpreter. It supports two subcommands: **eval** and **record**.
**consoleinterp eval** *script*
Evaluates *script* as a Tcl script at the global level in the main interpreter.
**consoleinterp record** *script*
Records and evaluates *script* as a Tcl script at the global level in the main interpreter as if *script* had been typed in at the console.
Additional trap calls
---------------------
There are several additional commands in the console interpreter that are called in response to activity in the main interpreter. *These are documented here for completeness only; they form part of the internal implementation of the console and are likely to change or be modified without warning.* Output to the console from the main interpreter via the stdout and stderr channels is handled by invoking the **tk::ConsoleOutput** command in the console interpreter with two arguments. The first argument is the name of the channel being written to, and the second argument is the string being written to the channel (after encoding and end-of-line translation processing has been performed.)
When the **.** window of the main interpreter is destroyed, the **tk::ConsoleExit** command in the console interpreter is called (assuming the console interpreter has not already been deleted itself, that is.)
Default bindings
----------------
The default script creates a console window (implemented using a text widget) that has the following behaviour:
1. Pressing the tab key inserts a TAB character (as defined by the Tcl \t escape.)
2. Pressing the return key causes the current line (if complete by the rules of **[info complete](../tclcmd/info.htm)**) to be passed to the main interpreter for evaluation.
3. Pressing the delete key deletes the selected text (if any text is selected) or the character to the right of the cursor (if not at the end of the line.)
4. Pressing the backspace key deletes the selected text (if any text is selected) or the character to the left of the cursor (of not at the start of the line.)
5. Pressing either Control+A or the home key causes the cursor to go to the start of the line (but after the prompt, if a prompt is present on the line.)
6. Pressing either Control+E or the end key causes the cursor to go to the end of the line.
7. Pressing either Control+P or the up key causes the previous entry in the command history to be selected.
8. Pressing either Control+N or the down key causes the next entry in the command history to be selected.
9. Pressing either Control+B or the left key causes the cursor to move one character backward as long as the cursor is not at the prompt.
10. Pressing either Control+F or the right key causes the cursor to move one character forward.
11. Pressing F9 rebuilds the console window by destroying all its children and reloading the Tcl script that defined the console's behaviour.
Most other behaviour is the same as a conventional text widget except for the way that the *<<Cut>>* event is handled identically to the *<<Copy>>* event.
Example
-------
Not all platforms have the **console** command, so debugging code often has the following code fragment in it so output produced by **[puts](../tclcmd/puts.htm)** can be seen while during development:
```
catch {**console show**}
```
See also
--------
**[destroy](destroy.htm)**, **[fconfigure](../tclcmd/fconfigure.htm)**, **[history](../tclcmd/history.htm)**, **[interp](../tclcmd/interp.htm)**, **[puts](../tclcmd/puts.htm)**, **[text](text.htm)**, **[wm](wm.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TkCmd/console.htm>
tcl_tk event event
=====
[NAME](event.htm#M2) event — Miscellaneous event facilities: define virtual events and generate events
[SYNOPSIS](event.htm#M3)
[DESCRIPTION](event.htm#M4)
[**event add <<***virtual***>>** *sequence* ?*sequence ...*?](event.htm#M5)
[**event delete <<***virtual***>>** ?*sequence* *sequence ...*?](event.htm#M6)
[**event generate** *window event* ?*option value option value ...*?](event.htm#M7)
[**event info** ?**<<***virtual***>>**?](event.htm#M8)
[EVENT FIELDS](event.htm#M9)
[**-above** *window*](event.htm#M10)
[**-borderwidth** *size*](event.htm#M11)
[**-button** *number*](event.htm#M12)
[**-count** *number*](event.htm#M13)
[**-data** *string*](event.htm#M14)
[**-delta** *number*](event.htm#M15)
[**-detail** *detail*](event.htm#M16)
[**-focus** *boolean*](event.htm#M17)
[**-height** *size*](event.htm#M18)
[**-keycode** *number*](event.htm#M19)
[**-keysym** *name*](event.htm#M20)
[**-mode** *notify*](event.htm#M21)
[**-override** *boolean*](event.htm#M22)
[**-place** *where*](event.htm#M23)
[**-root** *window*](event.htm#M24)
[**-rootx** *coord*](event.htm#M25)
[**-rooty** *coord*](event.htm#M26)
[**-sendevent** *boolean*](event.htm#M27)
[**-serial** *number*](event.htm#M28)
[**-state** *state*](event.htm#M29)
[**-subwindow** *window*](event.htm#M30)
[**-time** *integer*](event.htm#M31)
[**-warp** *boolean*](event.htm#M32)
[**-width** *size*](event.htm#M33)
[**-when** *when*](event.htm#M34)
[**now**](event.htm#M35)
[**tail**](event.htm#M36)
[**head**](event.htm#M37)
[**mark**](event.htm#M38)
[**-x** *coord*](event.htm#M39)
[**-y** *coord*](event.htm#M40)
[PREDEFINED VIRTUAL EVENTS](event.htm#M41)
[**<<AltUnderlined>>**](event.htm#M42)
[**<<Invoke>>**](event.htm#M43)
[**<<ListboxSelect>>**](event.htm#M44)
[**<<MenuSelect>>**](event.htm#M45)
[**<<Modified>>**](event.htm#M46)
[**<<Selection>>**](event.htm#M47)
[**<<ThemeChanged>>**](event.htm#M48)
[**<<TraverseIn>>**](event.htm#M49)
[**<<TraverseOut>>**](event.htm#M50)
[**<<UndoStack>>**](event.htm#M51)
[**<<WidgetViewSync>>**](event.htm#M52)
[**<<Clear>>**](event.htm#M53)
[**<<Copy>>**](event.htm#M54)
[**<<Cut>>**](event.htm#M55)
[**<<LineEnd>>**](event.htm#M56)
[**<<LineStart>>**](event.htm#M57)
[**<<NextChar>>**](event.htm#M58)
[**<<NextLine>>**](event.htm#M59)
[**<<NextPara>>**](event.htm#M60)
[**<<NextWord>>**](event.htm#M61)
[**<<Paste>>**](event.htm#M62)
[**<<PasteSelection>>**](event.htm#M63)
[**<<PrevChar>>**](event.htm#M64)
[**<<PrevLine>>**](event.htm#M65)
[**<<PrevPara>>**](event.htm#M66)
[**<<PrevWindow>>**](event.htm#M67)
[**<<PrevWord>>**](event.htm#M68)
[**<<Redo>>**](event.htm#M69)
[**<<SelectAll>>**](event.htm#M70)
[**<<SelectLineEnd>>**](event.htm#M71)
[**<<SelectLineStart>>**](event.htm#M72)
[**<<SelectNextChar>>**](event.htm#M73)
[**<<SelectNextLine>>**](event.htm#M74)
[**<<SelectNextPara>>**](event.htm#M75)
[**<<SelectNextWord>>**](event.htm#M76)
[**<<SelectNone>>**](event.htm#M77)
[**<<SelectPrevChar>>**](event.htm#M78)
[**<<SelectPrevLine>>**](event.htm#M79)
[**<<SelectPrevPara>>**](event.htm#M80)
[**<<SelectPrevWord>>**](event.htm#M81)
[**<<ToggleSelection>>**](event.htm#M82)
[**<<Undo>>**](event.htm#M83)
[EXAMPLES](event.htm#M84)
[MAPPING KEYS TO VIRTUAL EVENTS](event.htm#M85)
[MOVING THE MOUSE POINTER](event.htm#M86)
[SEE ALSO](event.htm#M87)
[KEYWORDS](event.htm#M88)
Name
----
event — Miscellaneous event facilities: define virtual events and generate events Synopsis
--------
**event** *option* ?*arg arg ...*?
Description
-----------
The **event** command provides several facilities for dealing with window system events, such as defining virtual events and synthesizing events. The command has several different forms, determined by the first argument. The following forms are currently supported:
**event add <<***virtual***>>** *sequence* ?*sequence ...*?
Associates the virtual event *virtual* with the physical event sequence(s) given by the *sequence* arguments, so that the virtual event will trigger whenever any one of the *sequence*s occurs. *Virtual* may be any string value and *sequence* may have any of the values allowed for the *sequence* argument to the **[bind](bind.htm)** command. If *virtual* is already defined, the new physical event sequences add to the existing sequences for the event.
**event delete <<***virtual***>>** ?*sequence* *sequence ...*?
Deletes each of the *sequence*s from those associated with the virtual event given by *virtual*. *Virtual* may be any string value and *sequence* may have any of the values allowed for the *sequence* argument to the **[bind](bind.htm)** command. Any *sequence*s not currently associated with *virtual* are ignored. If no *sequence* argument is provided, all physical event sequences are removed for *virtual*, so that the virtual event will not trigger anymore.
**event generate** *window event* ?*option value option value ...*?
Generates a window event and arranges for it to be processed just as if it had come from the window system. *Window* gives the path name of the window for which the event will be generated; it may also be an identifier (such as returned by **[winfo id](winfo.htm)**) as long as it is for a window in the current application. *Event* provides a basic description of the event, such as **<Shift-Button-2>** or **<<Paste>>**. If *Window* is empty the whole screen is meant, and coordinates are relative to the screen. *Event* may have any of the forms allowed for the *sequence* argument of the **[bind](bind.htm)** command except that it must consist of a single event pattern, not a sequence. *Option-value* pairs may be used to specify additional attributes of the event, such as the x and y mouse position; see **[EVENT FIELDS](#M9)** below. If the **-when** option is not specified, the event is processed immediately: all of the handlers for the event will complete before the **event generate** command returns. If the **-when** option is specified then it determines when the event is processed. Certain events, such as key events, require that the window has focus to receive the event properly.
**event info** ?**<<***virtual***>>**?
Returns information about virtual events. If the **<<***virtual***>>** argument is omitted, the return value is a list of all the virtual events that are currently defined. If **<<***virtual***>>** is specified then the return value is a list whose elements are the physical event sequences currently defined for the given virtual event; if the virtual event is not defined then an empty string is returned. Note that virtual events that are not bound to physical event sequences are *not* returned by **event info**.
Event fields
------------
The following options are supported for the **event generate** command. These correspond to the “%” expansions allowed in binding scripts for the **[bind](bind.htm)** command.
**-above** *window*
*Window* specifies the *above* field for the event, either as a window path name or as an integer window id. Valid for **Configure** events. Corresponds to the **%a** substitution for binding scripts.
**-borderwidth** *size*
*Size* must be a screen distance; it specifies the *border\_width* field for the event. Valid for **Configure** events. Corresponds to the **%B** substitution for binding scripts.
**-button** *number*
*Number* must be an integer; it specifies the *detail* field for a **ButtonPress** or **ButtonRelease** event, overriding any button number provided in the base *event* argument. Corresponds to the **%b** substitution for binding scripts.
**-count** *number*
*Number* must be an integer; it specifies the *count* field for the event. Valid for **Expose** events. Corresponds to the **%c** substitution for binding scripts.
**-data** *string*
*String* may be any value; it specifies the *user\_data* field for the event. Only valid for virtual events. Corresponds to the **%d** substitution for virtual events in binding scripts.
**-delta** *number*
*Number* must be an integer; it specifies the *delta* field for the **MouseWheel** event. The *delta* refers to the direction and magnitude the mouse wheel was rotated. Note the value is not a screen distance but are units of motion in the mouse wheel. Typically these values are multiples of 120. For example, 120 should scroll the text widget up 4 lines and -240 would scroll the text widget down 8 lines. Of course, other widgets may define different behaviors for mouse wheel motion. This field corresponds to the **%D** substitution for binding scripts.
**-detail** *detail*
*Detail* specifies the *detail* field for the event and must be one of the following:
| | |
| --- | --- |
| **NotifyAncestor** | **NotifyNonlinearVirtual** |
| **NotifyDetailNone** | **NotifyPointer** |
| **NotifyInferior** | **NotifyPointerRoot** |
| **NotifyNonlinear** | **NotifyVirtual** |
Valid for **Enter**, **Leave**, **FocusIn** and **FocusOut** events. Corresponds to the **%d** substitution for binding scripts.
**-focus** *boolean*
*Boolean* must be a boolean value; it specifies the *focus* field for the event. Valid for **Enter** and **Leave** events. Corresponds to the **%f** substitution for binding scripts.
**-height** *size*
*Size* must be a screen distance; it specifies the *height* field for the event. Valid for **Configure** events. Corresponds to the **%h** substitution for binding scripts.
**-keycode** *number*
*Number* must be an integer; it specifies the *keycode* field for the event. Valid for **KeyPress** and **KeyRelease** events. Corresponds to the **%k** substitution for binding scripts.
**-keysym** *name*
*Name* must be the name of a valid keysym, such as **g**, **space**, or **Return**; its corresponding keycode value is used as the *keycode* field for event, overriding any detail specified in the base *event* argument. Valid for **KeyPress** and **KeyRelease** events. Corresponds to the **%K** substitution for binding scripts.
**-mode** *notify*
*Notify* specifies the *mode* field for the event and must be one of **NotifyNormal**, **NotifyGrab**, **NotifyUngrab**, or **NotifyWhileGrabbed**. Valid for **Enter**, **Leave**, **FocusIn**, and **FocusOut** events. Corresponds to the **%m** substitution for binding scripts.
**-override** *boolean*
*Boolean* must be a boolean value; it specifies the *override\_redirect* field for the event. Valid for **Map**, **Reparent**, and **Configure** events. Corresponds to the **%o** substitution for binding scripts.
**-place** *where*
*Where* specifies the *place* field for the event; it must be either **PlaceOnTop** or **PlaceOnBottom**. Valid for **Circulate** events. Corresponds to the **%p** substitution for binding scripts.
**-root** *window*
*Window* must be either a window path name or an integer window identifier; it specifies the *root* field for the event. Valid for **KeyPress**, **KeyRelease**, **ButtonPress**, **ButtonRelease**, **Enter**, **Leave**, and **Motion** events. Corresponds to the **%R** substitution for binding scripts.
**-rootx** *coord*
*Coord* must be a screen distance; it specifies the *x\_root* field for the event. Valid for **KeyPress**, **KeyRelease**, **ButtonPress**, **ButtonRelease**, **Enter**, **Leave**, and **Motion** events. Corresponds to the **%X** substitution for binding scripts.
**-rooty** *coord*
*Coord* must be a screen distance; it specifies the *y\_root* field for the event. Valid for **KeyPress**, **KeyRelease**, **ButtonPress**, **ButtonRelease**, **Enter**, **Leave**, and **Motion** events. Corresponds to the **%Y** substitution for binding scripts.
**-sendevent** *boolean*
*Boolean* must be a boolean value; it specifies the *send\_event* field for the event. Valid for all events. Corresponds to the **%E** substitution for binding scripts.
**-serial** *number*
*Number* must be an integer; it specifies the *serial* field for the event. Valid for all events. Corresponds to the **%#** substitution for binding scripts.
**-state** *state*
*State* specifies the *state* field for the event. For **KeyPress**, **KeyRelease**, **ButtonPress**, **ButtonRelease**, **Enter**, **Leave**, and **Motion** events it must be an integer value. For **Visibility** events it must be one of **VisibilityUnobscured**, **VisibilityPartiallyObscured**, or **VisibilityFullyObscured**. This option overrides any modifiers such as **Meta** or **Control** specified in the base *event*. Corresponds to the **%s** substitution for binding scripts.
**-subwindow** *window*
*Window* specifies the *subwindow* field for the event, either as a path name for a Tk widget or as an integer window identifier. Valid for **KeyPress**, **KeyRelease**, **ButtonPress**, **ButtonRelease**, **Enter**, **Leave**, and **Motion** events. Similar to **%S** substitution for binding scripts.
**-time** *integer*
*Integer* must be an integer value; it specifies the *time* field for the event. Valid for **KeyPress**, **KeyRelease**, **ButtonPress**, **ButtonRelease**, **Enter**, **Leave**, **Motion**, and **Property** events. Corresponds to the **%t** substitution for binding scripts.
**-warp** *boolean*
*boolean* must be a boolean value; it specifies whether the screen pointer should be warped as well. Valid for **KeyPress**, **KeyRelease**, **ButtonPress**, **ButtonRelease**, and **Motion** events. The pointer will only warp to a window if it is mapped.
**-width** *size*
*Size* must be a screen distance; it specifies the *width* field for the event. Valid for **Configure** events. Corresponds to the **%w** substitution for binding scripts.
**-when** *when*
*When* determines when the event will be processed; it must have one of the following values:
**now**
Process the event immediately, before the command returns. This also happens if the **-when** option is omitted.
**tail**
Place the event on Tcl's event queue behind any events already queued for this application.
**head**
Place the event at the front of Tcl's event queue, so that it will be handled before any other events already queued.
**mark**
Place the event at the front of Tcl's event queue but behind any other events already queued with **-when mark**. This option is useful when generating a series of events that should be processed in order but at the front of the queue.
**-x** *coord*
*Coord* must be a screen distance; it specifies the *x* field for the event. Valid for **KeyPress**, **KeyRelease**, **ButtonPress**, **ButtonRelease**, **Motion**, **Enter**, **Leave**, **Expose**, **Configure**, **Gravity**, and **Reparent** events. Corresponds to the **%x** substitution for binding scripts. If *Window* is empty the coordinate is relative to the screen, and this option corresponds to the **%X** substitution for binding scripts.
**-y** *coord*
*Coord* must be a screen distance; it specifies the *y* field for the event. Valid for **KeyPress**, **KeyRelease**, **ButtonPress**, **ButtonRelease**, **Motion**, **Enter**, **Leave**, **Expose**, **Configure**, **Gravity**, and **Reparent** events. Corresponds to the **%y** substitution for binding scripts. If *Window* is empty the coordinate is relative to the screen, and this option corresponds to the **%Y** substitution for binding scripts.
Any options that are not specified when generating an event are filled with the value 0, except for *serial*, which is filled with the next X event serial number.
Predefined virtual events
-------------------------
Tk defines the following virtual events for the purposes of notification:
**<<AltUnderlined>>**
This is sent to widget to notify it that the letter it has underlined (as an accelerator indicator) with the **-underline** option has been pressed in combination with the Alt key. The usual response to this is to either focus into the widget (or some related widget) or to invoke the widget.
**<<Invoke>>**
This can be sent to some widgets (e.g. button, listbox, menu) as an alternative to <space>.
**<<ListboxSelect>>**
This is sent to a listbox when the set of selected item(s) in the listbox is updated.
**<<MenuSelect>>**
This is sent to a menu when the currently selected item in the menu changes. It is intended for use with context-sensitive help systems.
**<<Modified>>**
This is sent to a text widget when the contents of the widget are changed.
**<<Selection>>**
This is sent to a text widget when the selection in the widget is changed.
**<<ThemeChanged>>**
This is sent to a text widget when the ttk (Tile) theme changed.
**<<TraverseIn>>**
This is sent to a widget when the focus enters the widget because of a user-driven “tab to widget” action.
**<<TraverseOut>>**
This is sent to a widget when the focus leaves the widget because of a user-driven “tab to widget” action.
**<<UndoStack>>**
This is sent to a text widget when its undo stack or redo stack becomes empty or unempty.
**<<WidgetViewSync>>**
This is sent to a text widget when its internal data become obsolete, and again when these internal data are back in sync with the widget view. The detail field (%d substitution) is either true (when the widget is in sync) or false (when it is not).
Tk defines the following virtual events for the purposes of unifying bindings across multiple platforms. Users expect them to behave in the following way:
**<<Clear>>**
Delete the currently selected widget contents.
**<<Copy>>**
Copy the currently selected widget contents to the clipboard.
**<<Cut>>**
Move the currently selected widget contents to the clipboard.
**<<LineEnd>>**
Move to the end of the line in the current widget while deselecting any selected contents.
**<<LineStart>>**
Move to the start of the line in the current widget while deselecting any selected contents.
**<<NextChar>>**
Move to the next item (i.e., visible character) in the current widget while deselecting any selected contents.
**<<NextLine>>**
Move to the next line in the current widget while deselecting any selected contents.
**<<NextPara>>**
Move to the next paragraph in the current widget while deselecting any selected contents.
**<<NextWord>>**
Move to the next group of items (i.e., visible word) in the current widget while deselecting any selected contents.
**<<Paste>>**
Replace the currently selected widget contents with the contents of the clipboard.
**<<PasteSelection>>**
Insert the contents of the selection at the mouse location. (This event has meaningful **%x** and **%y** substitutions).
**<<PrevChar>>**
Move to the previous item (i.e., visible character) in the current widget while deselecting any selected contents.
**<<PrevLine>>**
Move to the previous line in the current widget while deselecting any selected contents.
**<<PrevPara>>**
Move to the previous paragraph in the current widget while deselecting any selected contents.
**<<PrevWindow>>**
Traverse to the previous window.
**<<PrevWord>>**
Move to the previous group of items (i.e., visible word) in the current widget while deselecting any selected contents.
**<<Redo>>**
Redo one undone action.
**<<SelectAll>>**
Set the range of selected contents to the complete widget.
**<<SelectLineEnd>>**
Move to the end of the line in the current widget while extending the range of selected contents.
**<<SelectLineStart>>**
Move to the start of the line in the current widget while extending the range of selected contents.
**<<SelectNextChar>>**
Move to the next item (i.e., visible character) in the current widget while extending the range of selected contents.
**<<SelectNextLine>>**
Move to the next line in the current widget while extending the range of selected contents.
**<<SelectNextPara>>**
Move to the next paragraph in the current widget while extending the range of selected contents.
**<<SelectNextWord>>**
Move to the next group of items (i.e., visible word) in the current widget while extending the range of selected contents.
**<<SelectNone>>**
Reset the range of selected contents to be empty.
**<<SelectPrevChar>>**
Move to the previous item (i.e., visible character) in the current widget while extending the range of selected contents.
**<<SelectPrevLine>>**
Move to the previous line in the current widget while extending the range of selected contents.
**<<SelectPrevPara>>**
Move to the previous paragraph in the current widget while extending the range of selected contents.
**<<SelectPrevWord>>**
Move to the previous group of items (i.e., visible word) in the current widget while extending the range of selected contents.
**<<ToggleSelection>>**
Toggle the selection.
**<<Undo>>**
Undo the last action.
Examples
--------
### Mapping keys to virtual events
In order for a virtual event binding to trigger, two things must happen. First, the virtual event must be defined with the **event add** command. Second, a binding must be created for the virtual event with the **[bind](bind.htm)** command. Consider the following virtual event definitions:
```
**event add** <<Paste>> <Control-y>
**event add** <<Paste>> <Button-2>
**event add** <<Save>> <Control-X><Control-S>
**event add** <<Save>> <Shift-F12>
if {[tk windowingsystem] eq "aqua"} {
**event add** <<Save>> <Command-s>
}
```
In the **[bind](bind.htm)** command, a virtual event can be bound like any other builtin event type as follows:
```
bind Entry <<Paste>> {%W insert [selection get]}
```
The double angle brackets are used to specify that a virtual event is being bound. If the user types Control-y or presses button 2, or if a **<<Paste>>** virtual event is synthesized with **event generate**, then the **<<Paste>>** binding will be invoked.
If a virtual binding has the exact same sequence as a separate physical binding, then the physical binding will take precedence. Consider the following example:
```
**event add** <<Paste>> <Control-y> <Meta-Control-y>
bind Entry <Control-y> {puts Control-y}
bind Entry <<Paste>> {puts Paste}
```
When the user types Control-y the **<Control-y>** binding will be invoked, because a physical event is considered more specific than a virtual event, all other things being equal. However, when the user types Meta-Control-y the **<<Paste>>** binding will be invoked, because the **Meta** modifier in the physical pattern associated with the virtual binding is more specific than the **<Control-y**> sequence for the physical event.
Bindings on a virtual event may be created before the virtual event exists. Indeed, the virtual event never actually needs to be defined, for instance, on platforms where the specific virtual event would be meaningless or ungeneratable.
When a definition of a virtual event changes at run time, all windows will respond immediately to the new definition. Starting from the preceding example, if the following code is executed:
```
bind Entry <Control-y> {}
**event add** <<Paste>> <Key-F6>
```
the behavior will change such in two ways. First, the shadowed **<<Paste>>** binding will emerge. Typing Control-y will no longer invoke the **<Control-y>** binding, but instead invoke the virtual event **<<Paste>>**. Second, pressing the F6 key will now also invoke the **<<Paste>>** binding.
### Moving the mouse pointer
Sometimes it is useful to be able to really move the mouse pointer. For example, if you have some software that is capable of demonstrating directly to the user how to use the program. To do this, you need to “warp” the mouse around by using **event generate**, like this:
```
for {set xy 0} {$xy < 200} {incr xy} {
**event generate** . <Motion> -x $xy -y $xy -warp 1
update
after 50
}
```
Note that it is usually considered bad style to move the mouse pointer for the user because it removes control from them. Therefore this technique should be used with caution. Also note that it is not guaranteed to function on all platforms.
See also
--------
**[bind](bind.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TkCmd/event.htm>
| programming_docs |
tcl_tk selection selection
=========
[NAME](selection.htm#M2) selection — Manipulate the X selection
[SYNOPSIS](selection.htm#M3)
[DESCRIPTION](selection.htm#M4)
[**selection clear** ?**-displayof** *window*? ?**-selection** *selection*?](selection.htm#M5)
[**selection get** ?**-displayof** *window*? ?**-selection** *selection*? ?**-type** *type*?](selection.htm#M6)
[**selection handle** ?**-selection** *s*? ?**-type** *t*? ?**-format** *f*? *window command*](selection.htm#M7)
[**selection own** ?**-displayof** *window*? ?**-selection** *selection*?](selection.htm#M8)
[**selection own** ?**-command** *command*? ?**-selection** *selection*? *window*](selection.htm#M9)
[EXAMPLES](selection.htm#M10)
[SEE ALSO](selection.htm#M11)
[KEYWORDS](selection.htm#M12)
Name
----
selection — Manipulate the X selection Synopsis
--------
**selection** *option* ?*arg arg ...*?
Description
-----------
This command provides a Tcl interface to the X selection mechanism and implements the full selection functionality described in the X Inter-Client Communication Conventions Manual (ICCCM). Note that for management of the **CLIPBOARD** selection (see below), the **[clipboard](clipboard.htm)** command may also be used.
The first argument to **selection** determines the format of the rest of the arguments and the behavior of the command. The following forms are currently supported:
**selection clear** ?**-displayof** *window*? ?**-selection** *selection*?
If *selection* exists anywhere on *window*'s display, clear it so that no window owns the selection anymore. *Selection* specifies the X selection that should be cleared, and should be an atom name such as **PRIMARY** or **CLIPBOARD**; see the Inter-Client Communication Conventions Manual for complete details. *Selection* defaults to **PRIMARY** and *window* defaults to “.”. Returns an empty string.
**selection get** ?**-displayof** *window*? ?**-selection** *selection*? ?**-type** *type*?
Retrieves the value of *selection* from *window*'s display and returns it as a result. *Selection* defaults to **PRIMARY** and *window* defaults to “.”. *Type* specifies the form in which the selection is to be returned (the desired “target” for conversion, in ICCCM terminology), and should be an atom name such as **STRING** or **FILE\_NAME**; see the Inter-Client Communication Conventions Manual for complete details. *Type* defaults to **STRING**. The selection owner may choose to return the selection in any of several different representation formats, such as **STRING**, **UTF8\_STRING**, **ATOM**, **INTEGER**, etc. (this format is different than the selection type; see the ICCCM for all the confusing details). If the selection is returned in a non-string format, such as **INTEGER** or **ATOM**, the **selection** command converts it to string format as a collection of fields separated by spaces: atoms are converted to their textual names, and anything else is converted to hexadecimal integers. Note that **selection get** does not retrieve the selection in the **UTF8\_STRING** format unless told to.
**selection handle** ?**-selection** *s*? ?**-type** *t*? ?**-format** *f*? *window command*
Creates a handler for selection requests, such that *command* will be executed whenever selection *s* is owned by *window* and someone attempts to retrieve it in the form given by type *t* (e.g. *t* is specified in the **selection get** command). *S* defaults to **PRIMARY**, *t* defaults to **STRING**, and *f* defaults to **STRING**. If *command* is an empty string then any existing handler for *window*, *t*, and *s* is removed. Note that when the selection is handled as type **STRING** it is also automatically handled as type **UTF8\_STRING** as well. When *selection* is requested, *window* is the selection owner, and *type* is the requested type, *command* will be executed as a Tcl command with two additional numbers appended to it (with space separators). The two additional numbers are *offset* and *maxChars*: *offset* specifies a starting character position in the selection and *maxChars* gives the maximum number of characters to retrieve. The command should return a value consisting of at most *maxChars* of the selection, starting at position *offset*. For very large selections (larger than *maxChars*) the selection will be retrieved using several invocations of *command* with increasing *offset* values. If *command* returns a string whose length is less than *maxChars*, the return value is assumed to include all of the remainder of the selection; if the length of *command*'s result is equal to *maxChars* then *command* will be invoked again, until it eventually returns a result shorter than *maxChars*. The value of *maxChars* will always be relatively large (thousands of characters).
If *command* returns an error then the selection retrieval is rejected just as if the selection did not exist at all.
The *format* argument specifies the representation that should be used to transmit the selection to the requester (the second column of Table 2 of the ICCCM), and defaults to **STRING**. If *format* is **STRING**, the selection is transmitted as 8-bit ASCII characters (i.e. just in the form returned by *command*, in the system **[encoding](../tclcmd/encoding.htm)**; the **UTF8\_STRING** format always uses UTF-8 as its encoding). If *format* is **ATOM**, then the return value from *command* is divided into fields separated by white space; each field is converted to its atom value, and the 32-bit atom value is transmitted instead of the atom name. For any other *format*, the return value from *command* is divided into fields separated by white space and each field is converted to a 32-bit integer; an array of integers is transmitted to the selection requester.
The *format* argument is needed only for compatibility with selection requesters that do not use Tk. If Tk is being used to retrieve the selection then the value is converted back to a string at the requesting end, so *format* is irrelevant.
**selection own** ?**-displayof** *window*? ?**-selection** *selection*?
**selection own** ?**-command** *command*? ?**-selection** *selection*? *window*
The first form of **selection own** returns the path name of the window in this application that owns *selection* on the display containing *window*, or an empty string if no window in this application owns the selection. *Selection* defaults to **PRIMARY** and *window* defaults to “.”. The second form of **selection own** causes *window* to become the new owner of *selection* on *window*'s display, returning an empty string as result. The existing owner, if any, is notified that it has lost the selection. If *command* is specified, it is a Tcl script to execute when some other window claims ownership of the selection away from *window*. *Selection* defaults to PRIMARY.
Examples
--------
On X11 platforms, one of the standard selections available is the **SECONDARY** selection. Hardly anything uses it, but here is how to read it using Tk:
```
set selContents [**selection get** -selection SECONDARY]
```
Many different types of data may be available for a selection; the special type **TARGETS** allows you to get a list of available types:
```
foreach type [**selection get** -type TARGETS] {
puts "Selection PRIMARY supports type $type"
}
```
To claim the selection, you must first set up a handler to supply the data for the selection. Then you have to claim the selection...
```
# Set up the data handler ready for incoming requests
set foo "This is a string with some data in it... blah blah"
**selection handle** -selection SECONDARY . getData
proc getData {offset maxChars} {
puts "Retrieving selection starting at $offset"
return [string range $::foo $offset [expr {$offset+$maxChars-1}]]
}
# Now we grab the selection itself
puts "Claiming selection"
**selection own** -command lost -selection SECONDARY .
proc lost {} {
puts "Lost selection"
}
```
See also
--------
**[clipboard](clipboard.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TkCmd/selection.htm>
tcl_tk ttk_button ttk\_button
===========
[NAME](ttk_button.htm#M2) ttk::button — Widget that issues a command when pressed
[SYNOPSIS](ttk_button.htm#M3)
[DESCRIPTION](ttk_button.htm#M4)
[STANDARD OPTIONS](ttk_button.htm#M5)
[-class, undefined, undefined](ttk_widget.htm#M-class)
[-compound, compound, Compound](ttk_widget.htm#M-compound)
[-cursor, cursor, Cursor](ttk_widget.htm#M-cursor)
[-image, image, Image](ttk_widget.htm#M-image)
[-state, state, State](ttk_widget.htm#M-state)
[-style, style, Style](ttk_widget.htm#M-style)
[-takefocus, takeFocus, TakeFocus](ttk_widget.htm#M-takefocus)
[-text, text, Text](ttk_widget.htm#M-text)
[-textvariable, textVariable, Variable](ttk_widget.htm#M-textvariable)
[-underline, underline, Underline](ttk_widget.htm#M-underline)
[-width, width, Width](ttk_widget.htm#M-width)
[WIDGET-SPECIFIC OPTIONS](ttk_button.htm#M6)
[-command, command, Command](ttk_button.htm#M7)
[-default, default, Default](ttk_button.htm#M8)
[-width, width, Width](ttk_button.htm#M9)
[WIDGET COMMAND](ttk_button.htm#M10)
[*pathName* **invoke**](ttk_button.htm#M11)
[STANDARD STYLES](ttk_button.htm#M12)
[COMPATIBILITY OPTIONS](ttk_button.htm#M13)
[-state, state, State](ttk_button.htm#M14)
[SEE ALSO](ttk_button.htm#M15)
[KEYWORDS](ttk_button.htm#M16)
Name
----
ttk::button — Widget that issues a command when pressed Synopsis
--------
**ttk::button** *pathName* ?*options*?
Description
-----------
A **ttk::button** widget displays a textual label and/or image, and evaluates a command when pressed. Standard options
----------------
**[-class, undefined, undefined](ttk_widget.htm#M-class)**
**[-compound, compound, Compound](ttk_widget.htm#M-compound)**
**[-cursor, cursor, Cursor](ttk_widget.htm#M-cursor)**
**[-image, image, Image](ttk_widget.htm#M-image)**
**[-state, state, State](ttk_widget.htm#M-state)**
**[-style, style, Style](ttk_widget.htm#M-style)**
**[-takefocus, takeFocus, TakeFocus](ttk_widget.htm#M-takefocus)**
**[-text, text, Text](ttk_widget.htm#M-text)**
**[-textvariable, textVariable, Variable](ttk_widget.htm#M-textvariable)**
**[-underline, underline, Underline](ttk_widget.htm#M-underline)**
**[-width, width, Width](ttk_widget.htm#M-width)**
Widget-specific options
-----------------------
Command-Line Name: **-command** Database Name: **command** Database Class: **Command**
A script to evaluate when the widget is invoked.
Command-Line Name: **-default** Database Name: **default** Database Class: **Default**
May be set to one of **normal**, **active**, or **disabled**. In a dialog box, one button may be designated the “default” button (meaning, roughly, “the one that gets invoked when the user presses <Enter>”). **active** indicates that this is currently the default button; **normal** means that it may become the default button, and **disabled** means that it is not defaultable. The default is **normal**. Depending on the theme, the default button may be displayed with an extra highlight ring, or with a different border color.
Command-Line Name: **-width** Database Name: **width** Database Class: **Width**
If greater than zero, specifies how much space, in character widths, to allocate for the text label. If less than zero, specifies a minimum width. If zero or unspecified, the natural width of the text label is used. Note that some themes may specify a non-zero **-width** in the style.
Widget command
--------------
In addition to the standard **cget**, **configure**, **identify**, **instate**, and **state** commands, buttons support the following additional widget commands:
*pathName* **invoke**
Invokes the command associated with the button.
Standard styles
---------------
**Ttk::button** widgets support the **Toolbutton** style in all standard themes, which is useful for creating widgets for toolbars. Compatibility options
---------------------
Command-Line Name: **-state** Database Name: **state** Database Class: **State**
May be set to **normal** or **disabled** to control the **disabled** state bit. This is a “write-only” option: setting it changes the widget state, but the **state** widget command does not affect the state option.
See also
--------
**[ttk::widget](ttk_widget.htm)**, **[button](button.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TkCmd/ttk_button.htm>
tcl_tk chooseColor chooseColor
===========
Name
----
tk\_chooseColor — pops up a dialog box for the user to select a color. Synopsis
--------
**tk\_chooseColor** ?*option value ...*?
Description
-----------
The procedure **tk\_chooseColor** pops up a dialog box for the user to select a color. The following *option-value* pairs are possible as command line arguments:
**-initialcolor** *color*
Specifies the color to display in the color dialog when it pops up. *color* must be in a form acceptable to the **[Tk\_GetColor](https://www.tcl.tk/man/tcl/TkLib/GetColor.htm)** function.
**-parent** *window*
Makes *window* the logical parent of the color dialog. The color dialog is displayed on top of its parent window.
**-title** *titleString*
Specifies a string to display as the title of the dialog box. If this option is not specified, then a default title will be displayed.
If the user selects a color, **tk\_chooseColor** will return the name of the color in a form acceptable to **[Tk\_GetColor](https://www.tcl.tk/man/tcl/TkLib/GetColor.htm)**. If the user cancels the operation, both commands will return the empty string.
Example
-------
```
button .b -bg [tk_chooseColor -initialcolor gray -title "Choose color"]
```
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TkCmd/chooseColor.htm>
tcl_tk image image
=====
[NAME](image.htm#M2) image — Create and manipulate images
[SYNOPSIS](image.htm#M3)
[DESCRIPTION](image.htm#M4)
[**image create** *type* ?*name*? ?*option value ...*?](image.htm#M5)
[**image delete** ?*name name* ...?](image.htm#M6)
[**image height** *name*](image.htm#M7)
[**image inuse** *name*](image.htm#M8)
[**image names**](image.htm#M9)
[**image type** *name*](image.htm#M10)
[**image types**](image.htm#M11)
[**image width** *name*](image.htm#M12)
[BUILT-IN IMAGE TYPES](image.htm#M13)
[**bitmap**](image.htm#M14)
[**photo**](image.htm#M15)
[SEE ALSO](image.htm#M16)
[KEYWORDS](image.htm#M17)
Name
----
image — Create and manipulate images Synopsis
--------
**image** *option* ?*arg arg ...*?
Description
-----------
The **image** command is used to create, delete, and query images. It can take several different forms, depending on the *option* argument. The legal forms are:
**image create** *type* ?*name*? ?*option value ...*?
Creates a new image and a command with the same name and returns its name. *type* specifies the type of the image, which must be one of the types currently defined (e.g., **[bitmap](bitmap.htm)**). *name* specifies the name for the image; if it is omitted then Tk picks a name of the form **image***x*, where *x* is an integer. There may be any number of *option*-*value* pairs, which provide configuration options for the new image. The legal set of options is defined separately for each image type; see below for details on the options for built-in image types. If an image already exists by the given name then it is replaced with the new image and any instances of that image will redisplay with the new contents. It is important to note that the image command will silently overwrite any procedure that may currently be defined by the given name, so choose the name wisely. It is recommended to use a separate namespace for image names (e.g., **::img::logo**, **::img::large**).
**image delete** ?*name name* ...?
Deletes each of the named images and returns an empty string. If there are instances of the images displayed in widgets, the images will not actually be deleted until all of the instances are released. However, the association between the instances and the image manager will be dropped. Existing instances will retain their sizes but redisplay as empty areas. If a deleted image is recreated with another call to **image create**, the existing instances will use the new image.
**image height** *name*
Returns a decimal string giving the height of image *name* in pixels.
**image inuse** *name*
Returns a boolean value indicating whether or not the image given by *name* is in use by any widgets.
**image names**
Returns a list containing the names of all existing images.
**image type** *name*
Returns the type of image *name* (the value of the *type* argument to **image create** when the image was created).
**image types**
Returns a list whose elements are all of the valid image types (i.e., all of the values that may be supplied for the *type* argument to **image create**).
**image width** *name*
Returns a decimal string giving the width of image *name* in pixels.
Additional operations (e.g. writing the image to a file) may be available as subcommands of the image instance command. See the manual page for the particular image type for details.
Built-in image types
--------------------
The following image types are defined by Tk so they will be available in any Tk application. Individual applications or extensions may define additional types.
**bitmap**
Each pixel in the image displays a foreground color, a background color, or nothing. See the **[bitmap](bitmap.htm)** manual entry for more information.
**photo**
Displays a variety of full-color images, using dithering to approximate colors on displays with limited color capabilities. See the **[photo](photo.htm)** manual entry for more information.
See also
--------
**[bitmap](bitmap.htm)**, **[options](options.htm)**, **[photo](photo.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TkCmd/image.htm>
tcl_tk font font
====
[NAME](font.htm#M2) font — Create and inspect fonts.
[SYNOPSIS](font.htm#M3)
[DESCRIPTION](font.htm#M4)
[**font actual** *font* ?**-displayof** *window*? ?*option*? ?**--**? ?*char*?](font.htm#M5)
[**font configure** *fontname* ?*option*? ?*value option value ...*?](font.htm#M6)
[**font create** ?*fontname*? ?*option value ...*?](font.htm#M7)
[**font delete** *fontname* ?*fontname ...*?](font.htm#M8)
[**font families** ?**-displayof** *window*?](font.htm#M9)
[**font measure** *font* ?**-displayof** *window*? *text*](font.htm#M10)
[**font metrics** *font* ?**-displayof** *window*? ?*option*?](font.htm#M11)
[**font names**](font.htm#M12)
[FONT DESCRIPTIONS](font.htm#M13)
[[1] *fontname*](font.htm#M14)
[[2] *systemfont*](font.htm#M15)
[[3] *family* ?*size*? ?*style*? ?*style ...*?](font.htm#M16)
[[4] X-font names (XLFD)](font.htm#M17)
[[5] *option value* ?*option value ...*?](font.htm#M18)
[FONT METRICS](font.htm#M19)
[**-ascent**](font.htm#M20)
[**-descent**](font.htm#M21)
[**-linespace**](font.htm#M22)
[**-fixed**](font.htm#M23)
[FONT OPTIONS](font.htm#M24)
[**-family** *name*](font.htm#M25)
[**-size** *size*](font.htm#M26)
[**-weight** *weight*](font.htm#M27)
[**-slant** *slant*](font.htm#M28)
[**-underline** *boolean*](font.htm#M29)
[**-overstrike** *boolean*](font.htm#M30)
[STANDARD FONTS](font.htm#M31)
[**TkDefaultFont**](font.htm#M32)
[**TkTextFont**](font.htm#M33)
[**TkFixedFont**](font.htm#M34)
[**TkMenuFont**](font.htm#M35)
[**TkHeadingFont**](font.htm#M36)
[**TkCaptionFont**](font.htm#M37)
[**TkSmallCaptionFont**](font.htm#M38)
[**TkIconFont**](font.htm#M39)
[**TkTooltipFont**](font.htm#M40)
[PLATFORM SPECIFIC FONTS](font.htm#M41)
[**X Windows**](font.htm#M42)
[**MS Windows**](font.htm#M43)
[**Mac OS X**](font.htm#M44)
[EXAMPLE](font.htm#M45)
[SEE ALSO](font.htm#M46)
[KEYWORDS](font.htm#M47)
Name
----
font — Create and inspect fonts. Synopsis
--------
**font** *option* ?*arg arg ...*?
Description
-----------
The **font** command provides several facilities for dealing with fonts, such as defining named fonts and inspecting the actual attributes of a font. The command has several different forms, determined by the first argument. The following forms are currently supported:
**font actual** *font* ?**-displayof** *window*? ?*option*? ?**--**? ?*char*?
Returns information about the actual attributes that are obtained when *font* is used on *window*'s display; the actual attributes obtained may differ from the attributes requested due to platform-dependent limitations, such as the availability of font families and point sizes. *font* is a font description; see **[FONT DESCRIPTIONS](#M13)** below. If the *window* argument is omitted, it defaults to the main window. If *option* is specified, returns the value of that attribute; if it is omitted, the return value is a list of all the attributes and their values. See **[FONT OPTIONS](#M24)** below for a list of the possible attributes. If the *char* argument is supplied, it must be a single character. The font attributes returned will be those of the specific font used to render that character, which will be different from the base font if the base font does not contain the given character. If *char* may be a hyphen, it should be preceded by **--** to distinguish it from a misspelled *option*.
**font configure** *fontname* ?*option*? ?*value option value ...*?
Query or modify the desired attributes for the named font called *fontname*. If no *option* is specified, returns a list describing all the options and their values for *fontname*. If a single *option* is specified with no *value*, then returns the current value of that attribute. If one or more *option*-*value* pairs are specified, then the command modifies the given named font to have the given values; in this case, all widgets using that font will redisplay themselves using the new attributes for the font. See **[FONT OPTIONS](#M24)** below for a list of the possible attributes. Note that on Aqua/Mac OS X, the system fonts (see **[PLATFORM SPECIFIC FONTS](#M41)** below) may not be actually altered because they are implemented by the system theme. To achieve the effect of modification, use **font actual** to get their configuration and **font create** to synthesize a copy of the font which can be modified.
**font create** ?*fontname*? ?*option value ...*?
Creates a new named font and returns its name. *fontname* specifies the name for the font; if it is omitted, then Tk generates a new name of the form **font***x*, where *x* is an integer. There may be any number of *option*-*value* pairs, which provide the desired attributes for the new named font. See **[FONT OPTIONS](#M24)** below for a list of the possible attributes.
**font delete** *fontname* ?*fontname ...*?
Delete the specified named fonts. If there are widgets using the named font, the named font will not actually be deleted until all the instances are released. Those widgets will continue to display using the last known values for the named font. If a deleted named font is subsequently recreated with another call to **font create**, the widgets will use the new named font and redisplay themselves using the new attributes of that font.
**font families** ?**-displayof** *window*?
The return value is a list of the case-insensitive names of all font families that exist on *window*'s display. If the *window* argument is omitted, it defaults to the main window.
**font measure** *font* ?**-displayof** *window*? *text*
Measures the amount of space the string *text* would use in the given *font* when displayed in *window*. *font* is a font description; see **[FONT DESCRIPTIONS](#M13)** below. If the *window* argument is omitted, it defaults to the main window. The return value is the total width in pixels of *text*, not including the extra pixels used by highly exaggerated characters such as cursive “f”. If the string contains newlines or tabs, those characters are not expanded or treated specially when measuring the string.
**font metrics** *font* ?**-displayof** *window*? ?*option*?
Returns information about the metrics (the font-specific data), for *font* when it is used on *window*'s display. *font* is a font description; see **[FONT DESCRIPTIONS](#M13)** below. If the *window* argument is omitted, it defaults to the main window. If *option* is specified, returns the value of that metric; if it is omitted, the return value is a list of all the metrics and their values. See **[FONT METRICS](#M19)** below for a list of the possible metrics.
**font names**
The return value is a list of all the named fonts that are currently defined.
Font descriptions
-----------------
The following formats are accepted as a font description anywhere *font* is specified as an argument above; these same forms are also permitted when specifying the **-font** option for widgets.
[1] *fontname*
The name of a named font, created using the **font create** command. When a widget uses a named font, it is guaranteed that this will never cause an error, as long as the named font exists, no matter what potentially invalid or meaningless set of attributes the named font has. If the named font cannot be displayed with exactly the specified attributes, some other close font will be substituted automatically.
[2] *systemfont*
The platform-specific name of a font, interpreted by the graphics server. This also includes, under X, an XLFD (see [4]) for which a single “**\***” character was used to elide more than one field in the middle of the name. See **[PLATFORM SPECIFIC FONTS](#M41)** for a list of the system fonts.
[3] *family* ?*size*? ?*style*? ?*style ...*?
A properly formed list whose first element is the desired font *family* and whose optional second element is the desired *size*. The interpretation of the *size* attribute follows the same rules described for **-size** in **[FONT OPTIONS](#M24)** below. Any additional optional arguments following the *size* are font *style*s. Possible values for the *style* arguments are as follows:
| | | | |
| --- | --- | --- | --- |
| **normal** | **bold** | **roman** | **italic** |
| **underline** | **overstrike** |
[4] X-font names (XLFD)
A Unix-centric font name of the form *-foundry-family-weight-slant-setwidth-addstyle-pixel-point-resx-resy-spacing-width-charset-encoding*. The “**\***” character may be used to skip individual fields that the user does not care about. There must be exactly one “**\***” for each field skipped, except that a “**\***” at the end of the XLFD skips any remaining fields; the shortest valid XLFD is simply “**\***”, signifying all fields as defaults. Any fields that were skipped are given default values. For compatibility, an XLFD always chooses a font of the specified pixel size (not point size); although this interpretation is not strictly correct, all existing applications using XLFDs assumed that one “point” was in fact one pixel and would display incorrectly (generally larger) if the correct size font were actually used.
[5] *option value* ?*option value ...*?
A properly formed list of *option*-*value* pairs that specify the desired attributes of the font, in the same format used when defining a named font; see **[FONT OPTIONS](#M24)** below.
When font description *font* is used, the system attempts to parse the description according to each of the above five rules, in the order specified. Cases [1] and [2] must match the name of an existing named font or of a system font. Cases [3], [4], and [5] are accepted on all platforms and the closest available font will be used. In some situations it may not be possible to find any close font (e.g., the font family was a garbage value); in that case, some system-dependent default font is chosen. If the font description does not match any of the above patterns, an error is generated.
Font metrics
------------
The following options are used by the **font metrics** command to query font-specific data determined when the font was created. These properties are for the whole font itself and not for individual characters drawn in that font. In the following definitions, the “baseline” of a font is the horizontal line where the bottom of most letters line up; certain letters, such as lower-case “g” stick below the baseline.
**-ascent**
The amount in pixels that the tallest letter sticks up above the baseline of the font, plus any extra blank space added by the designer of the font.
**-descent**
The largest amount in pixels that any letter sticks down below the baseline of the font, plus any extra blank space added by the designer of the font.
**-linespace**
Returns how far apart vertically in pixels two lines of text using the same font should be placed so that none of the characters in one line overlap any of the characters in the other line. This is generally the sum of the ascent above the baseline line plus the descent below the baseline.
**-fixed**
Returns a boolean flag that is “**1**” if this is a fixed-width font, where each normal character is the same width as all the other characters, or is “**0**” if this is a proportionally-spaced font, where individual characters have different widths. The widths of control characters, tab characters, and other non-printing characters are not included when calculating this value.
Font options
------------
The following options are supported on all platforms, and are used when constructing a named font or when specifying a font using style [5] as above:
**-family** *name*
The case-insensitive font family name. Tk guarantees to support the font families named **Courier** (a monospaced “typewriter” font), **Times** (a serifed “newspaper” font), and **Helvetica** (a sans-serif “European” font). The most closely matching native font family will automatically be substituted when one of the above font families is used. The *name* may also be the name of a native, platform-specific font family; in that case it will work as desired on one platform but may not display correctly on other platforms. If the family is unspecified or unrecognized, a platform-specific default font will be chosen.
**-size** *size*
The desired size of the font. If the *size* argument is a positive number, it is interpreted as a size in points. If *size* is a negative number, its absolute value is interpreted as a size in pixels. If a font cannot be displayed at the specified size, a nearby size will be chosen. If *size* is unspecified or zero, a platform-dependent default size will be chosen. Sizes should normally be specified in points so the application will remain the same ruler size on the screen, even when changing screen resolutions or moving scripts across platforms. However, specifying pixels is useful in certain circumstances such as when a piece of text must line up with respect to a fixed-size bitmap. The mapping between points and pixels is set when the application starts, based on properties of the installed monitor, but it can be overridden by calling the **[tk scaling](tk.htm)** command.
**-weight** *weight*
The nominal thickness of the characters in the font. The value **normal** specifies a normal weight font, while **bold** specifies a bold font. The closest available weight to the one specified will be chosen. The default weight is **normal**.
**-slant** *slant*
The amount the characters in the font are slanted away from the vertical. Valid values for slant are **roman** and **italic**. A roman font is the normal, upright appearance of a font, while an italic font is one that is tilted some number of degrees from upright. The closest available slant to the one specified will be chosen. The default slant is **roman**.
**-underline** *boolean*
The value is a boolean flag that specifies whether characters in this font should be underlined. The default value for underline is **false**.
**-overstrike** *boolean*
The value is a boolean flag that specifies whether a horizontal line should be drawn through the middle of characters in this font. The default value for overstrike is **false**.
Standard fonts
--------------
The following named fonts are supported on all systems, and default to values that match appropriate system defaults.
**TkDefaultFont**
This font is the default for all GUI items not otherwise specified.
**TkTextFont**
This font should be used for user text in entry widgets, listboxes etc.
**TkFixedFont**
This font is the standard fixed-width font.
**TkMenuFont**
This font is used for menu items.
**TkHeadingFont**
This font should be used for column headings in lists and tables.
**TkCaptionFont**
This font should be used for window and dialog caption bars.
**TkSmallCaptionFont**
This font should be used for captions on contained windows or tool dialogs.
**TkIconFont**
This font should be used for icon captions.
**TkTooltipFont**
This font should be used for tooltip windows (transient information windows).
It is *not* advised to change these fonts, as they may be modified by Tk itself in response to system changes. Instead, make a copy of the font and modify that.
Platform specific fonts
-----------------------
The following system fonts are supported:
**X Windows**
All valid X font names, including those listed by xlsfonts(1), are available.
**MS Windows**
The following fonts are supported, and are mapped to the user's style defaults.
| | | |
| --- | --- | --- |
| **system** | **ansi** | **device** |
| **systemfixed** | **ansifixed** | **oemfixed** |
**Mac OS X**
The following fonts are supported, and are mapped to the user's style defaults.
| | | |
| --- | --- | --- |
| **system** | **application** | **menu** |
Additionally, the following named fonts provide access to the Aqua theme fonts:
| | |
| --- | --- |
| **systemSystemFont** | **systemEmphasizedSystemFont** |
| **systemSmallSystemFont** | **systemSmallEmphasizedSystemFont** |
| **systemApplicationFont** | **systemLabelFont** |
| **systemViewsFont** | **systemMenuTitleFont** |
| **systemMenuItemFont** | **systemMenuItemMarkFont** |
| **systemMenuItemCmdKeyFont** | **systemWindowTitleFont** |
| **systemPushButtonFont** | **systemUtilityWindowTitleFont** |
| **systemAlertHeaderFont** | **systemToolbarFont** |
| **systemMiniSystemFont** | **systemDetailSystemFont** |
| **systemDetailEmphasizedSystemFont** |
Example
-------
Fill a text widget with lots of font demonstrators, one for every font family installed on your system:
```
pack [text .t -wrap none] -fill both -expand 1
set count 0
set tabwidth 0
foreach family [lsort -dictionary [**font families**]] {
.t tag configure f[incr count] -font [list $family 10]
.t insert end ${family}:\t {} \
"This is a simple sampler\n" f$count
set w [**font measure** [.t cget -font] ${family}:]
if {$w+5 > $tabwidth} {
set tabwidth [expr {$w+5}]
.t configure -tabs $tabwidth
}
}
```
See also
--------
**[options](options.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TkCmd/font.htm>
| programming_docs |
tcl_tk label label
=====
[NAME](label.htm#M2) label — Create and manipulate 'label' non-interactive text or image widgets
[SYNOPSIS](label.htm#M3)
[STANDARD OPTIONS](label.htm#M4)
[-activebackground, activeBackground, Foreground](options.htm#M-activebackground)
[-activeforeground, activeForeground, Background](options.htm#M-activeforeground)
[-anchor, anchor, Anchor](options.htm#M-anchor)
[-background or -bg, background, Background](options.htm#M-background)
[-bitmap, bitmap, Bitmap](options.htm#M-bitmap)
[-borderwidth or -bd, borderWidth, BorderWidth](options.htm#M-borderwidth)
[-compound, compound, Compound](options.htm#M-compound)
[-cursor, cursor, Cursor](options.htm#M-cursor)
[-disabledforeground, disabledForeground, DisabledForeground](options.htm#M-disabledforeground)
[-font, font, Font](options.htm#M-font)
[-foreground or -fg, foreground, Foreground](options.htm#M-foreground)
[-highlightbackground, highlightBackground, HighlightBackground](options.htm#M-highlightbackground)
[-highlightcolor, highlightColor, HighlightColor](options.htm#M-highlightcolor)
[-highlightthickness, highlightThickness, HighlightThickness](options.htm#M-highlightthickness)
[-image, image, Image](options.htm#M-image)
[-justify, justify, Justify](options.htm#M-justify)
[-padx, padX, Pad](options.htm#M-padx)
[-pady, padY, Pad](options.htm#M-pady)
[-relief, relief, Relief](options.htm#M-relief)
[-takefocus, takeFocus, TakeFocus](options.htm#M-takefocus)
[-text, text, Text](options.htm#M-text)
[-textvariable, textVariable, Variable](options.htm#M-textvariable)
[-underline, underline, Underline](options.htm#M-underline)
[-wraplength, wrapLength, WrapLength](options.htm#M-wraplength)
[WIDGET-SPECIFIC OPTIONS](label.htm#M5)
[-height, height, Height](label.htm#M6)
[-state, state, State](label.htm#M7)
[-width, width, Width](label.htm#M8)
[DESCRIPTION](label.htm#M9)
[WIDGET COMMAND](label.htm#M10)
[*pathName* **cget** *option*](label.htm#M11)
[*pathName* **configure** ?*option*? ?*value option value ...*?](label.htm#M12)
[BINDINGS](label.htm#M13)
[EXAMPLE](label.htm#M14)
[SEE ALSO](label.htm#M15)
[KEYWORDS](label.htm#M16)
Name
----
label — Create and manipulate 'label' non-interactive text or image widgets Synopsis
--------
**label** *pathName* ?*options*?
Standard options
----------------
**[-activebackground, activeBackground, Foreground](options.htm#M-activebackground)**
**[-activeforeground, activeForeground, Background](options.htm#M-activeforeground)**
**[-anchor, anchor, Anchor](options.htm#M-anchor)**
**[-background or -bg, background, Background](options.htm#M-background)**
**[-bitmap, bitmap, Bitmap](options.htm#M-bitmap)**
**[-borderwidth or -bd, borderWidth, BorderWidth](options.htm#M-borderwidth)**
**[-compound, compound, Compound](options.htm#M-compound)**
**[-cursor, cursor, Cursor](options.htm#M-cursor)**
**[-disabledforeground, disabledForeground, DisabledForeground](options.htm#M-disabledforeground)**
**[-font, font, Font](options.htm#M-font)**
**[-foreground or -fg, foreground, Foreground](options.htm#M-foreground)**
**[-highlightbackground, highlightBackground, HighlightBackground](options.htm#M-highlightbackground)**
**[-highlightcolor, highlightColor, HighlightColor](options.htm#M-highlightcolor)**
**[-highlightthickness, highlightThickness, HighlightThickness](options.htm#M-highlightthickness)**
**[-image, image, Image](options.htm#M-image)**
**[-justify, justify, Justify](options.htm#M-justify)**
**[-padx, padX, Pad](options.htm#M-padx)**
**[-pady, padY, Pad](options.htm#M-pady)**
**[-relief, relief, Relief](options.htm#M-relief)**
**[-takefocus, takeFocus, TakeFocus](options.htm#M-takefocus)**
**[-text, text, Text](options.htm#M-text)**
**[-textvariable, textVariable, Variable](options.htm#M-textvariable)**
**[-underline, underline, Underline](options.htm#M-underline)**
**[-wraplength, wrapLength, WrapLength](options.htm#M-wraplength)**
Widget-specific options
-----------------------
Command-Line Name: **-height** Database Name: **height** Database Class: **Height**
Specifies a desired height for the label. If an image or bitmap is being displayed in the label then the value is in screen units (i.e. any of the forms acceptable to **[Tk\_GetPixels](https://www.tcl.tk/man/tcl/TkLib/GetPixels.htm)**); for text it is in lines of text. If this option is not specified, the label's desired height is computed from the size of the image or bitmap or text being displayed in it.
Command-Line Name: **-state** Database Name: **state** Database Class: **State**
Specifies one of three states for the label: **normal**, **active**, or **disabled**. In normal state the button is displayed using the **-foreground** and **-background** options. In active state the label is displayed using the **-activeforeground** and **-activebackground** options. In the disabled state the **-disabledforeground** and **-background** options determine how the button is displayed.
Command-Line Name: **-width** Database Name: **width** Database Class: **Width**
Specifies a desired width for the label. If an image or bitmap is being displayed in the label then the value is in screen units (i.e. any of the forms acceptable to **[Tk\_GetPixels](https://www.tcl.tk/man/tcl/TkLib/GetPixels.htm)**); for text it is in characters. If this option is not specified, the label's desired width is computed from the size of the image or bitmap or text being displayed in it.
Description
-----------
The **label** command creates a new window (given by the *pathName* argument) and makes it into a label widget. Additional options, described above, may be specified on the command line or in the option database to configure aspects of the label such as its colors, font, text, and initial relief. The **label** command returns its *pathName* argument. At the time this command is invoked, there must not exist a window named *pathName*, but *pathName*'s parent must exist. A label is a widget that displays a textual string, bitmap or image. If text is displayed, it must all be in a single font, but it can occupy multiple lines on the screen (if it contains newlines or if wrapping occurs because of the **-wraplength** option) and one of the characters may optionally be underlined using the **-underline** option. The label can be manipulated in a few simple ways, such as changing its relief or text, using the commands described below.
Widget command
--------------
The **label** command creates a new Tcl command whose name is *pathName*. This command may be used to invoke various operations on the widget. It has the following general form:
```
*pathName option* ?*arg arg ...*?
```
*Option* and the *arg*s determine the exact behavior of the command. The following commands are possible for label widgets:
*pathName* **cget** *option*
Returns the current value of the configuration option given by *option*. *Option* may have any of the values accepted by the **label** command.
*pathName* **configure** ?*option*? ?*value option value ...*?
Query or modify the configuration options of the widget. If no *option* is specified, returns a list describing all of the available options for *pathName* (see **[Tk\_ConfigureInfo](https://www.tcl.tk/man/tcl/TkLib/ConfigWidg.htm)** for information on the format of this list). If *option* is specified with no *value*, then the command returns a list describing the one named option (this list will be identical to the corresponding sublist of the value returned if no *option* is specified). If one or more *option-value* pairs are specified, then the command modifies the given widget option(s) to have the given value(s); in this case the command returns an empty string. *Option* may have any of the values accepted by the **label** command.
Bindings
--------
When a new label is created, it has no default event bindings: labels are not intended to be interactive. Example
-------
```
# Make the widgets
**label** .t -text "This widget is at the top" -bg red
**label** .b -text "This widget is at the bottom" -bg green
**label** .l -text "Left\nHand\nSide"
**label** .r -text "Right\nHand\nSide"
text .mid
.mid insert end "This layout is like Java's BorderLayout"
# Lay them out
pack .t -side top -fill x
pack .b -side bottom -fill x
pack .l -side left -fill y
pack .r -side right -fill y
pack .mid -expand 1 -fill both
```
See also
--------
**[labelframe](labelframe.htm)**, **[button](button.htm)**, **[ttk::label](ttk_label.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TkCmd/label.htm>
tcl_tk checkbutton checkbutton
===========
[NAME](checkbutton.htm#M2) checkbutton — Create and manipulate 'checkbutton' boolean selection widgets
[SYNOPSIS](checkbutton.htm#M3)
[STANDARD OPTIONS](checkbutton.htm#M4)
[-activebackground, activeBackground, Foreground](options.htm#M-activebackground)
[-activeforeground, activeForeground, Background](options.htm#M-activeforeground)
[-anchor, anchor, Anchor](options.htm#M-anchor)
[-background or -bg, background, Background](options.htm#M-background)
[-bitmap, bitmap, Bitmap](options.htm#M-bitmap)
[-borderwidth or -bd, borderWidth, BorderWidth](options.htm#M-borderwidth)
[-compound, compound, Compound](options.htm#M-compound)
[-cursor, cursor, Cursor](options.htm#M-cursor)
[-disabledforeground, disabledForeground, DisabledForeground](options.htm#M-disabledforeground)
[-font, font, Font](options.htm#M-font)
[-foreground or -fg, foreground, Foreground](options.htm#M-foreground)
[-highlightbackground, highlightBackground, HighlightBackground](options.htm#M-highlightbackground)
[-highlightcolor, highlightColor, HighlightColor](options.htm#M-highlightcolor)
[-highlightthickness, highlightThickness, HighlightThickness](options.htm#M-highlightthickness)
[-image, image, Image](options.htm#M-image)
[-justify, justify, Justify](options.htm#M-justify)
[-padx, padX, Pad](options.htm#M-padx)
[-pady, padY, Pad](options.htm#M-pady)
[-relief, relief, Relief](options.htm#M-relief)
[-takefocus, takeFocus, TakeFocus](options.htm#M-takefocus)
[-text, text, Text](options.htm#M-text)
[-textvariable, textVariable, Variable](options.htm#M-textvariable)
[-underline, underline, Underline](options.htm#M-underline)
[-wraplength, wrapLength, WrapLength](options.htm#M-wraplength)
[WIDGET-SPECIFIC OPTIONS](checkbutton.htm#M5)
[-command, command, Command](checkbutton.htm#M6)
[-height, height, Height](checkbutton.htm#M7)
[-indicatoron, indicatorOn, IndicatorOn](checkbutton.htm#M8)
[-offrelief, offRelief, OffRelief](checkbutton.htm#M9)
[-offvalue, offValue, Value](checkbutton.htm#M10)
[-onvalue, onValue, Value](checkbutton.htm#M11)
[-overrelief, overRelief, OverRelief](checkbutton.htm#M12)
[-selectcolor, selectColor, Background](checkbutton.htm#M13)
[-selectimage, selectImage, SelectImage](checkbutton.htm#M14)
[-state, state, State](checkbutton.htm#M15)
[-tristateimage, tristateImage, TristateImage](checkbutton.htm#M16)
[-tristatevalue, tristateValue, Value](checkbutton.htm#M17)
[-variable, variable, Variable](checkbutton.htm#M18)
[-width, width, Width](checkbutton.htm#M19)
[DESCRIPTION](checkbutton.htm#M20)
[WIDGET COMMAND](checkbutton.htm#M21)
[*pathName* **cget** *option*](checkbutton.htm#M22)
[*pathName* **configure** ?*option*? ?*value option value ...*?](checkbutton.htm#M23)
[*pathName* **deselect**](checkbutton.htm#M24)
[*pathName* **flash**](checkbutton.htm#M25)
[*pathName* **invoke**](checkbutton.htm#M26)
[*pathName* **select**](checkbutton.htm#M27)
[*pathName* **toggle**](checkbutton.htm#M28)
[BINDINGS](checkbutton.htm#M29)
[EXAMPLE](checkbutton.htm#M30)
[SEE ALSO](checkbutton.htm#M31)
[KEYWORDS](checkbutton.htm#M32)
Name
----
checkbutton — Create and manipulate 'checkbutton' boolean selection widgets Synopsis
--------
**checkbutton** *pathName* ?*options*?
Standard options
----------------
**[-activebackground, activeBackground, Foreground](options.htm#M-activebackground)**
**[-activeforeground, activeForeground, Background](options.htm#M-activeforeground)**
**[-anchor, anchor, Anchor](options.htm#M-anchor)**
**[-background or -bg, background, Background](options.htm#M-background)**
**[-bitmap, bitmap, Bitmap](options.htm#M-bitmap)**
**[-borderwidth or -bd, borderWidth, BorderWidth](options.htm#M-borderwidth)**
**[-compound, compound, Compound](options.htm#M-compound)**
**[-cursor, cursor, Cursor](options.htm#M-cursor)**
**[-disabledforeground, disabledForeground, DisabledForeground](options.htm#M-disabledforeground)**
**[-font, font, Font](options.htm#M-font)**
**[-foreground or -fg, foreground, Foreground](options.htm#M-foreground)**
**[-highlightbackground, highlightBackground, HighlightBackground](options.htm#M-highlightbackground)**
**[-highlightcolor, highlightColor, HighlightColor](options.htm#M-highlightcolor)**
**[-highlightthickness, highlightThickness, HighlightThickness](options.htm#M-highlightthickness)**
**[-image, image, Image](options.htm#M-image)**
**[-justify, justify, Justify](options.htm#M-justify)**
**[-padx, padX, Pad](options.htm#M-padx)**
**[-pady, padY, Pad](options.htm#M-pady)**
**[-relief, relief, Relief](options.htm#M-relief)**
**[-takefocus, takeFocus, TakeFocus](options.htm#M-takefocus)**
**[-text, text, Text](options.htm#M-text)**
**[-textvariable, textVariable, Variable](options.htm#M-textvariable)**
**[-underline, underline, Underline](options.htm#M-underline)**
**[-wraplength, wrapLength, WrapLength](options.htm#M-wraplength)**
Widget-specific options
-----------------------
Command-Line Name: **-command** Database Name: **command** Database Class: **Command**
Specifies a Tcl command to associate with the button. This command is typically invoked when mouse button 1 is released over the button window. The button's global variable (**-variable** option) will be updated before the command is invoked.
Command-Line Name: **-height** Database Name: **height** Database Class: **Height**
Specifies a desired height for the button. If an image or bitmap is being displayed in the button then the value is in screen units (i.e. any of the forms acceptable to **[Tk\_GetPixels](https://www.tcl.tk/man/tcl/TkLib/GetPixels.htm)**); for text it is in lines of text. If this option is not specified, the button's desired height is computed from the size of the image or bitmap or text being displayed in it.
Command-Line Name: **-indicatoron** Database Name: **indicatorOn** Database Class: **IndicatorOn**
Specifies whether or not the indicator should be drawn. Must be a proper boolean value. If false, the **-relief** option is ignored and the widget's relief is always sunken if the widget is selected and raised otherwise.
Command-Line Name: **-offrelief** Database Name: **offRelief** Database Class: **OffRelief**
Specifies the relief for the checkbutton when the indicator is not drawn and the checkbutton is off. The default value is “raised”. By setting this option to “flat” and setting **-indicatoron** to false and **-overrelief** to “raised”, the effect is achieved of having a flat button that raises on mouse-over and which is depressed when activated. This is the behavior typically exhibited by the Bold, Italic, and Underline checkbuttons on the toolbar of a word-processor, for example.
Command-Line Name: **-offvalue** Database Name: **offValue** Database Class: **Value**
Specifies value to store in the button's associated variable whenever this button is deselected. Defaults to “0”.
Command-Line Name: **-onvalue** Database Name: **onValue** Database Class: **Value**
Specifies value to store in the button's associated variable whenever this button is selected. Defaults to “1”.
Command-Line Name: **-overrelief** Database Name: **overRelief** Database Class: **OverRelief**
Specifies an alternative relief for the checkbutton, to be used when the mouse cursor is over the widget. This option can be used to make toolbar buttons, by configuring **-relief flat -overrelief raised**. If the value of this option is the empty string, then no alternative relief is used when the mouse cursor is over the checkbutton. The empty string is the default value.
Command-Line Name: **-selectcolor** Database Name: **selectColor** Database Class: **Background**
Specifies a background color to use when the button is selected. If **indicatorOn** is true then the color is used as the background for the indicator regardless of the select state. If **indicatorOn** is false, this color is used as the background for the entire widget, in place of **background** or **activeBackground**, whenever the widget is selected. If specified as an empty string then no special color is used for displaying when the widget is selected.
Command-Line Name: **-selectimage** Database Name: **selectImage** Database Class: **SelectImage**
Specifies an image to display (in place of the **-image** option) when the checkbutton is selected. This option is ignored unless the **-image** option has been specified.
Command-Line Name: **-state** Database Name: **state** Database Class: **State**
Specifies one of three states for the checkbutton: **normal**, **active**, or **disabled**. In normal state the checkbutton is displayed using the **-foreground** and **-background** options. The active state is typically used when the pointer is over the checkbutton. In active state the checkbutton is displayed using the **-activeforeground** and **-activebackground** options. Disabled state means that the checkbutton should be insensitive: the default bindings will refuse to activate the widget and will ignore mouse button presses. In this state the **-disabledforeground** and **-background** options determine how the checkbutton is displayed.
Command-Line Name: **-tristateimage** Database Name: **tristateImage** Database Class: **TristateImage**
Specifies an image to display (in place of the **-image** option) when the checkbutton is in tri-state mode. This option is ignored unless the **-image** option has been specified.
Command-Line Name: **-tristatevalue** Database Name: **tristateValue** Database Class: **Value**
Specifies the value that causes the checkbutton to display the multi-value selection, also known as the tri-state mode. Defaults to “”.
Command-Line Name: **-variable** Database Name: **[variable](../tclcmd/variable.htm)** Database Class: **[Variable](../tclcmd/variable.htm)**
Specifies the name of a global variable to set to indicate whether or not this button is selected. Defaults to the name of the button within its parent (i.e. the last element of the button window's path name).
Command-Line Name: **-width** Database Name: **width** Database Class: **Width**
Specifies a desired width for the button. If an image or bitmap is being displayed in the button then the value is in screen units (i.e. any of the forms acceptable to **[Tk\_GetPixels](https://www.tcl.tk/man/tcl/TkLib/GetPixels.htm)**); for text it is in characters. If this option is not specified, the button's desired width is computed from the size of the image or bitmap or text being displayed in it.
Description
-----------
The **checkbutton** command creates a new window (given by the *pathName* argument) and makes it into a checkbutton widget. Additional options, described above, may be specified on the command line or in the option database to configure aspects of the checkbutton such as its colors, font, text, and initial relief. The **checkbutton** command returns its *pathName* argument. At the time this command is invoked, there must not exist a window named *pathName*, but *pathName*'s parent must exist. A checkbutton is a widget that displays a textual string, bitmap or image and a square called an *indicator*. If text is displayed, it must all be in a single font, but it can occupy multiple lines on the screen (if it contains newlines or if wrapping occurs because of the **-wraplength** option) and one of the characters may optionally be underlined using the **-underline** option. A checkbutton has all of the behavior of a simple button, including the following: it can display itself in either of three different ways, according to the **-state** option; it can be made to appear raised, sunken, or flat; it can be made to flash; and it invokes a Tcl command whenever mouse button 1 is clicked over the checkbutton.
In addition, checkbuttons can be *selected*. If a checkbutton is selected then the indicator is normally drawn with a selected appearance, and a Tcl variable associated with the checkbutton is set to a particular value (normally 1). The indicator is drawn with a check mark inside. If the checkbutton is not selected, then the indicator is drawn with a deselected appearance, and the associated variable is set to a different value (typically 0). The indicator is drawn without a check mark inside. In the special case where the variable (if specified) has a value that matches the tristatevalue, the indicator is drawn with a tri-state appearance and is in the tri-state mode indicating mixed or multiple values. (This is used when the check box represents the state of multiple items.) The indicator is drawn in a platform dependent manner. Under Unix and Windows, the background interior of the box is “grayed”. Under Mac, the indicator is drawn with a dash mark inside. By default, the name of the variable associated with a checkbutton is the same as the *name* used to create the checkbutton. The variable name, and the “on”, “off” and “tristate” values stored in it, may be modified with options on the command line or in the option database. Configuration options may also be used to modify the way the indicator is displayed (or whether it is displayed at all). By default a checkbutton is configured to select and deselect itself on alternate button clicks. In addition, each checkbutton monitors its associated variable and automatically selects and deselects itself when the variables value changes to and from the button's “on”, “off” and “tristate” values.
Widget command
--------------
The **checkbutton** command creates a new Tcl command whose name is *pathName*. This command may be used to invoke various operations on the widget. It has the following general form:
```
*pathName option* ?*arg arg ...*?
```
*Option* and the *arg*s determine the exact behavior of the command. The following commands are possible for checkbutton widgets:
*pathName* **cget** *option*
Returns the current value of the configuration option given by *option*. *Option* may have any of the values accepted by the **checkbutton** command.
*pathName* **configure** ?*option*? ?*value option value ...*?
Query or modify the configuration options of the widget. If no *option* is specified, returns a list describing all of the available options for *pathName* (see **[Tk\_ConfigureInfo](https://www.tcl.tk/man/tcl/TkLib/ConfigWidg.htm)** for information on the format of this list). If *option* is specified with no *value*, then the command returns a list describing the one named option (this list will be identical to the corresponding sublist of the value returned if no *option* is specified). If one or more *option-value* pairs are specified, then the command modifies the given widget option(s) to have the given value(s); in this case the command returns an empty string. *Option* may have any of the values accepted by the **checkbutton** command.
*pathName* **deselect**
Deselects the checkbutton and sets the associated variable to its “off” value.
*pathName* **flash**
Flashes the checkbutton. This is accomplished by redisplaying the checkbutton several times, alternating between active and normal colors. At the end of the flash the checkbutton is left in the same normal/active state as when the command was invoked. This command is ignored if the checkbutton's state is **disabled**.
*pathName* **invoke**
Does just what would have happened if the user invoked the checkbutton with the mouse: toggle the selection state of the button and invoke the Tcl command associated with the checkbutton, if there is one. The return value is the return value from the Tcl command, or an empty string if there is no command associated with the checkbutton. This command is ignored if the checkbutton's state is **disabled**.
*pathName* **select**
Selects the checkbutton and sets the associated variable to its “on” value.
*pathName* **toggle**
Toggles the selection state of the button, redisplaying it and modifying its associated variable to reflect the new state.
Bindings
--------
Tk automatically creates class bindings for checkbuttons that give them the following default behavior:
1. On Unix systems, a checkbutton activates whenever the mouse passes over it and deactivates whenever the mouse leaves the checkbutton. On Mac and Windows systems, when mouse button 1 is pressed over a checkbutton, the button activates whenever the mouse pointer is inside the button, and deactivates whenever the mouse pointer leaves the button.
2. When mouse button 1 is pressed over a checkbutton, it is invoked (its selection state toggles and the command associated with the button is invoked, if there is one).
3. When a checkbutton has the input focus, the space key causes the checkbutton to be invoked. Under Windows, there are additional key bindings; plus (**+**) and equal (**=**) select the button, and minus (**-**) deselects the button.
If the checkbutton's state is **disabled** then none of the above actions occur: the checkbutton is completely non-responsive.
The behavior of checkbuttons can be changed by defining new bindings for individual widgets or by redefining the class bindings.
Example
-------
This example shows a group of uncoupled checkbuttons.
```
labelframe .lbl -text "Steps:"
**checkbutton** .c1 -text Lights -variable lights
**checkbutton** .c2 -text Cameras -variable cameras
**checkbutton** .c3 -text Action! -variable action
pack .c1 .c2 .c3 -in .lbl
pack .lbl
```
See also
--------
**[button](button.htm)**, **[options](options.htm)**, **[radiobutton](radiobutton.htm)**, **[ttk::checkbutton](ttk_checkbutton.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TkCmd/checkbutton.htm>
| programming_docs |
tcl_tk ttk_frame ttk\_frame
==========
[NAME](ttk_frame.htm#M2) ttk::frame — Simple container widget
[SYNOPSIS](ttk_frame.htm#M3)
[DESCRIPTION](ttk_frame.htm#M4)
[STANDARD OPTIONS](ttk_frame.htm#M5)
[-class, undefined, undefined](ttk_widget.htm#M-class)
[-cursor, cursor, Cursor](ttk_widget.htm#M-cursor)
[-style, style, Style](ttk_widget.htm#M-style)
[-takefocus, takeFocus, TakeFocus](ttk_widget.htm#M-takefocus)
[WIDGET-SPECIFIC OPTIONS](ttk_frame.htm#M6)
[-borderwidth, borderWidth, BorderWidth](ttk_frame.htm#M7)
[-relief, relief, Relief](ttk_frame.htm#M8)
[-padding, padding, Padding](ttk_frame.htm#M9)
[-width, width, Width](ttk_frame.htm#M10)
[-height, height, Height](ttk_frame.htm#M11)
[WIDGET COMMAND](ttk_frame.htm#M12)
[NOTES](ttk_frame.htm#M13)
[SEE ALSO](ttk_frame.htm#M14)
[KEYWORDS](ttk_frame.htm#M15)
Name
----
ttk::frame — Simple container widget Synopsis
--------
**ttk::frame** *pathName* ?*options*?
Description
-----------
A **ttk::frame** widget is a container, used to group other widgets together. Standard options
----------------
**[-class, undefined, undefined](ttk_widget.htm#M-class)**
**[-cursor, cursor, Cursor](ttk_widget.htm#M-cursor)**
**[-style, style, Style](ttk_widget.htm#M-style)**
**[-takefocus, takeFocus, TakeFocus](ttk_widget.htm#M-takefocus)**
Widget-specific options
-----------------------
Command-Line Name: **-borderwidth** Database Name: **borderWidth** Database Class: **BorderWidth**
The desired width of the widget border. Defaults to 0.
Command-Line Name: **-relief** Database Name: **relief** Database Class: **Relief**
One of the standard Tk border styles: **flat**, **groove**, **raised**, **ridge**, **solid**, or **sunken**. Defaults to **flat**.
Command-Line Name: **-padding** Database Name: **padding** Database Class: **Padding**
Additional padding to include inside the border.
Command-Line Name: **-width** Database Name: **width** Database Class: **Width**
If specified, the widget's requested width in pixels.
Command-Line Name: **-height** Database Name: **height** Database Class: **Height**
If specified, the widget's requested height in pixels.
Widget command
--------------
Supports the standard widget commands **configure**, **cget**, **identify**, **instate**, and **state**; see *ttk::widget(n)*. Notes
-----
Note that if the **[pack](pack.htm)**, **[grid](grid.htm)**, or other geometry managers are used to manage the children of the **[frame](frame.htm)**, by the GM's requested size will normally take precedence over the **[frame](frame.htm)** widget's **-width** and **-height** options. **[pack propagate](pack.htm)** and **[grid propagate](grid.htm)** can be used to change this. See also
--------
**[ttk::widget](ttk_widget.htm)**, **[ttk::labelframe](ttk_labelframe.htm)**, **[frame](frame.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TkCmd/ttk_frame.htm>
tcl_tk getOpenFile getOpenFile
===========
[NAME](getopenfile.htm#M2) tk\_getOpenFile, tk\_getSaveFile — pop up a dialog box for the user to select a file to open or save.
[SYNOPSIS](getopenfile.htm#M3)
[DESCRIPTION](getopenfile.htm#M4)
[**-confirmoverwrite** *boolean*](getopenfile.htm#M5)
[**-defaultextension** *extension*](getopenfile.htm#M6)
[**-filetypes** *filePatternList*](getopenfile.htm#M7)
[**-initialdir** *directory*](getopenfile.htm#M8)
[**-initialfile** *filename*](getopenfile.htm#M9)
[**-message** *string*](getopenfile.htm#M10)
[**-multiple** *boolean*](getopenfile.htm#M11)
[**-parent** *window*](getopenfile.htm#M12)
[**-title** *titleString*](getopenfile.htm#M13)
[**-typevariable** *variableName*](getopenfile.htm#M14)
[SPECIFYING FILE PATTERNS](getopenfile.htm#M15)
[SPECIFYING EXTENSIONS](getopenfile.htm#M16)
[EXAMPLE](getopenfile.htm#M17)
[SEE ALSO](getopenfile.htm#M18)
[KEYWORDS](getopenfile.htm#M19)
Name
----
tk\_getOpenFile, tk\_getSaveFile — pop up a dialog box for the user to select a file to open or save. Synopsis
--------
**tk\_getOpenFile** ?*option value ...*?
**tk\_getSaveFile** ?*option value ...*?
Description
-----------
The procedures **tk\_getOpenFile** and **tk\_getSaveFile** pop up a dialog box for the user to select a file to open or save. The **tk\_getOpenFile** command is usually associated with the **Open** command in the **File** menu. Its purpose is for the user to select an existing file *only*. If the user enters a non-existent file, the dialog box gives the user an error prompt and requires the user to give an alternative selection. If an application allows the user to create new files, it should do so by providing a separate **New** menu command. The **tk\_getSaveFile** command is usually associated with the **Save as** command in the **File** menu. If the user enters a file that already exists, the dialog box prompts the user for confirmation whether the existing file should be overwritten or not.
The following *option-value* pairs are possible as command line arguments to these two commands:
**-confirmoverwrite** *boolean*
Configures how the Save dialog reacts when the selected file already exists, and saving would overwrite it. A true value requests a confirmation dialog be presented to the user. A false value requests that the overwrite take place without confirmation. Default value is true.
**-defaultextension** *extension*
Specifies a string that will be appended to the filename if the user enters a filename without an extension. The default value is the empty string, which means no extension will be appended to the filename in any case. This option is ignored on Mac OS X, which does not require extensions to filenames, and the UNIX implementation guesses reasonable values for this from the **-filetypes** option when this is not supplied.
**-filetypes** *filePatternList*
If a **[File types](../tclcmd/file.htm)** listbox exists in the file dialog on the particular platform, this option gives the *filetype*s in this listbox. When the user choose a filetype in the listbox, only the files of that type are listed. If this option is unspecified, or if it is set to the empty list, or if the **[File types](../tclcmd/file.htm)** listbox is not supported by the particular platform then all files are listed regardless of their types. See the section **[SPECIFYING FILE PATTERNS](#M15)** below for a discussion on the contents of *filePatternList*.
**-initialdir** *directory*
Specifies that the files in *directory* should be displayed when the dialog pops up. If this parameter is not specified, the initial directory defaults to the current working directory on non-Windows systems and on Windows systems prior to Vista. On Vista and later systems, the initial directory defaults to the last user-selected directory for the application. If the parameter specifies a relative path, the return value will convert the relative path to an absolute path.
**-initialfile** *filename*
Specifies a filename to be displayed in the dialog when it pops up.
**-message** *string*
Specifies a message to include in the client area of the dialog. This is only available on Mac OS X.
**-multiple** *boolean*
Allows the user to choose multiple files from the Open dialog.
**-parent** *window*
Makes *window* the logical parent of the file dialog. The file dialog is displayed on top of its parent window. On Mac OS X, this turns the file dialog into a sheet attached to the parent window.
**-title** *titleString*
Specifies a string to display as the title of the dialog box. If this option is not specified, then a default title is displayed.
**-typevariable** *variableName*
The global variable *variableName* is used to preselect which filter is used from *filterList* when the dialog box is opened and is updated when the dialog box is closed, to the last selected filter. The variable is read once at the beginning to select the appropriate filter. If the variable does not exist, or its value does not match any filter typename, or is empty (**{}**), the dialog box will revert to the default behavior of selecting the first filter in the list. If the dialog is canceled, the variable is not modified.
If the user selects a file, both **tk\_getOpenFile** and **tk\_getSaveFile** return the full pathname of this file. If the user cancels the operation, both commands return the empty string.
Specifying file patterns
------------------------
The *filePatternList* value given by the **-filetypes** option is a list of file patterns. Each file pattern is a list of the form
```
*typeName* {*extension* ?*extension ...*?} ?{*macType* ?*macType ...*?}?
```
*typeName* is the name of the file type described by this file pattern and is the text string that appears in the **[File types](../tclcmd/file.htm)** listbox. *extension* is a file extension for this file pattern. *macType* is a four-character Macintosh file type. The list of *macType*s is optional and may be omitted for applications that do not need to execute on the Macintosh platform. Several file patterns may have the same *typeName,* in which case they refer to the same file type and share the same entry in the listbox. When the user selects an entry in the listbox, all the files that match at least one of the file patterns corresponding to that entry are listed. Usually, each file pattern corresponds to a distinct type of file. The use of more than one file pattern for one type of file is only necessary on the Macintosh platform.
On the Macintosh platform, a file matches a file pattern if its name matches at least one of the *extension*(s) AND it belongs to at least one of the *macType*(s) of the file pattern. For example, the **C Source Files** file pattern in the sample code matches with files that have a **.c** extension AND belong to the *macType* **TEXT**. To use the OR rule instead, you can use two file patterns, one with the *extensions* only and the other with the *macType* only. The **GIF Files** file type in the sample code matches files that *either* have a **.gif** extension OR belong to the *macType* **GIFF**.
On the Unix and Windows platforms, a file matches a file pattern if its name matches at least one of the *extension*(s) of the file pattern. The *macType*s are ignored.
Specifying extensions
---------------------
On the Unix and Macintosh platforms, extensions are matched using glob-style pattern matching. On the Windows platform, extensions are matched by the underlying operating system. The types of possible extensions are:
1. the special extension “\*” matches any file;
2. the special extension “” matches any files that do not have an extension (i.e., the filename contains no full stop character);
3. any character string that does not contain any wild card characters (\* and ?).
Due to the different pattern matching rules on the various platforms, to ensure portability, wild card characters are not allowed in the extensions, except as in the special extension “\*”. Extensions without a full stop character (e.g. “~”) are allowed but may not work on all platforms.
Example
-------
```
set types {
{{Text Files} {.txt} }
{{TCL Scripts} {.tcl} }
{{C Source Files} {.c} TEXT}
{{GIF Files} {.gif} }
{{GIF Files} {} GIFF}
{{All Files} * }
}
set filename [**tk\_getOpenFile** -filetypes $types]
if {$filename ne ""} {
# Open the file ...
}
```
See also
--------
**tk\_chooseDirectory**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TkCmd/getOpenFile.htm>
tcl_tk lower lower
=====
Name
----
lower — Change a window's position in the stacking order Synopsis
--------
**lower** *window* ?*belowThis*?
Description
-----------
If the *belowThis* argument is omitted then the command lowers *window* so that it is below all of its siblings in the stacking order (it will be obscured by any siblings that overlap it and will not obscure any siblings). If *belowThis* is specified then it must be the path name of a window that is either a sibling of *window* or the descendant of a sibling of *window*. In this case the **lower** command will insert *window* into the stacking order just below *belowThis* (or the ancestor of *belowThis* that is a sibling of *window*); this could end up either raising or lowering *window*. All **[toplevel](toplevel.htm)** windows may be restacked with respect to each other, whatever their relative path names, but the window manager is not obligated to strictly honor requests to restack.
See also
--------
**[raise](raise.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TkCmd/lower.htm>
tcl_tk message message
=======
[NAME](message.htm#M2) message — Create and manipulate 'message' non-interactive text widgets
[SYNOPSIS](message.htm#M3)
[STANDARD OPTIONS](message.htm#M4)
[-anchor, anchor, Anchor](options.htm#M-anchor)
[-background or -bg, background, Background](options.htm#M-background)
[-borderwidth or -bd, borderWidth, BorderWidth](options.htm#M-borderwidth)
[-cursor, cursor, Cursor](options.htm#M-cursor)
[-font, font, Font](options.htm#M-font)
[-foreground or -fg, foreground, Foreground](options.htm#M-foreground)
[-highlightbackground, highlightBackground, HighlightBackground](options.htm#M-highlightbackground)
[-highlightcolor, highlightColor, HighlightColor](options.htm#M-highlightcolor)
[-highlightthickness, highlightThickness, HighlightThickness](options.htm#M-highlightthickness)
[-padx, padX, Pad](options.htm#M-padx)
[-pady, padY, Pad](options.htm#M-pady)
[-relief, relief, Relief](options.htm#M-relief)
[-takefocus, takeFocus, TakeFocus](options.htm#M-takefocus)
[-text, text, Text](options.htm#M-text)
[-textvariable, textVariable, Variable](options.htm#M-textvariable)
[WIDGET-SPECIFIC OPTIONS](message.htm#M5)
[-aspect, aspect, Aspect](message.htm#M6)
[-justify, justify, Justify](message.htm#M7)
[-width, width, Width](message.htm#M8)
[DESCRIPTION](message.htm#M9)
[WIDGET COMMAND](message.htm#M10)
[*pathName* **cget** *option*](message.htm#M11)
[*pathName* **configure** ?*option*? ?*value option value ...*?](message.htm#M12)
[DEFAULT BINDINGS](message.htm#M13)
[BUGS](message.htm#M14)
[SEE ALSO](message.htm#M15)
[KEYWORDS](message.htm#M16)
Name
----
message — Create and manipulate 'message' non-interactive text widgets Synopsis
--------
**message** *pathName* ?*options*?
Standard options
----------------
**[-anchor, anchor, Anchor](options.htm#M-anchor)**
**[-background or -bg, background, Background](options.htm#M-background)**
**[-borderwidth or -bd, borderWidth, BorderWidth](options.htm#M-borderwidth)**
**[-cursor, cursor, Cursor](options.htm#M-cursor)**
**[-font, font, Font](options.htm#M-font)**
**[-foreground or -fg, foreground, Foreground](options.htm#M-foreground)**
**[-highlightbackground, highlightBackground, HighlightBackground](options.htm#M-highlightbackground)**
**[-highlightcolor, highlightColor, HighlightColor](options.htm#M-highlightcolor)**
**[-highlightthickness, highlightThickness, HighlightThickness](options.htm#M-highlightthickness)**
**[-padx, padX, Pad](options.htm#M-padx)**
**[-pady, padY, Pad](options.htm#M-pady)**
**[-relief, relief, Relief](options.htm#M-relief)**
**[-takefocus, takeFocus, TakeFocus](options.htm#M-takefocus)**
**[-text, text, Text](options.htm#M-text)**
**[-textvariable, textVariable, Variable](options.htm#M-textvariable)**
Widget-specific options
-----------------------
Command-Line Name: **-aspect** Database Name: **aspect** Database Class: **Aspect**
Specifies a non-negative integer value indicating desired aspect ratio for the text. The aspect ratio is specified as 100\*width/height. 100 means the text should be as wide as it is tall, 200 means the text should be twice as wide as it is tall, 50 means the text should be twice as tall as it is wide, and so on. Used to choose line length for text if **-width** option is not specified. Defaults to 150.
Command-Line Name: **-justify** Database Name: **justify** Database Class: **Justify**
Specifies how to justify lines of text. Must be one of **left**, **center**, or **right**. Defaults to **left**. This option works together with the **-anchor**, **-aspect**, **-padx**, **-pady**, and **-width** options to provide a variety of arrangements of the text within the window. The **-aspect** and **-width** options determine the amount of screen space needed to display the text. The **-anchor**, **-padx**, and **-pady** options determine where this rectangular area is displayed within the widget's window, and the **-justify** option determines how each line is displayed within that rectangular region. For example, suppose **-anchor** is **e** and **-justify** is **left**, and that the message window is much larger than needed for the text. The text will be displayed so that the left edges of all the lines line up and the right edge of the longest line is **-padx** from the right side of the window; the entire text block will be centered in the vertical span of the window.
Command-Line Name: **-width** Database Name: **width** Database Class: **Width**
Specifies the length of lines in the window. The value may have any of the forms acceptable to **[Tk\_GetPixels](https://www.tcl.tk/man/tcl/TkLib/GetPixels.htm)**. If this option has a value greater than zero then the **-aspect** option is ignored and the **-width** option determines the line length. If this option has a value less than or equal to zero, then the **-aspect** option determines the line length.
Description
-----------
The **message** command creates a new window (given by the *pathName* argument) and makes it into a message widget. Additional options, described above, may be specified on the command line or in the option database to configure aspects of the message such as its colors, font, text, and initial relief. The **message** command returns its *pathName* argument. At the time this command is invoked, there must not exist a window named *pathName*, but *pathName*'s parent must exist. A message is a widget that displays a textual string. A message widget has three special features that differentiate it from a **[label](label.htm)** widget. First, it breaks up its string into lines in order to produce a given aspect ratio for the window. The line breaks are chosen at word boundaries wherever possible (if not even a single word would fit on a line, then the word will be split across lines). Newline characters in the string will force line breaks; they can be used, for example, to leave blank lines in the display.
The second feature of a message widget is justification. The text may be displayed left-justified (each line starts at the left side of the window), centered on a line-by-line basis, or right-justified (each line ends at the right side of the window).
The third feature of a message widget is that it handles control characters and non-printing characters specially. Tab characters are replaced with enough blank space to line up on the next 8-character boundary. Newlines cause line breaks. Other control characters (ASCII code less than 0x20) and characters not defined in the font are displayed as a four-character sequence **\x***hh* where *hh* is the two-digit hexadecimal number corresponding to the character. In the unusual case where the font does not contain all of the characters in “0123456789abcdef\x” then control characters and undefined characters are not displayed at all.
Widget command
--------------
The **message** command creates a new Tcl command whose name is *pathName*. This command may be used to invoke various operations on the widget. It has the following general form:
```
*pathName option* ?*arg arg ...*?
```
*Option* and the *arg*s determine the exact behavior of the command. The following commands are possible for message widgets:
*pathName* **cget** *option*
Returns the current value of the configuration option given by *option*. *Option* may have any of the values accepted by the **message** command.
*pathName* **configure** ?*option*? ?*value option value ...*?
Query or modify the configuration options of the widget. If no *option* is specified, returns a list describing all of the available options for *pathName* (see **[Tk\_ConfigureInfo](https://www.tcl.tk/man/tcl/TkLib/ConfigWidg.htm)** for information on the format of this list). If *option* is specified with no *value*, then the command returns a list describing the one named option (this list will be identical to the corresponding sublist of the value returned if no *option* is specified). If one or more *option-value* pairs are specified, then the command modifies the given widget option(s) to have the given value(s); in this case the command returns an empty string. *Option* may have any of the values accepted by the **message** command.
Default bindings
----------------
When a new message is created, it has no default event bindings: messages are intended for output purposes only. Bugs
----
Tabs do not work very well with text that is centered or right-justified. The most common result is that the line is justified wrong. See also
--------
**[label](label.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TkCmd/message.htm>
| programming_docs |
tcl_tk ttk_widget ttk\_widget
===========
[NAME](ttk_widget.htm#M2) ttk::widget — Standard options and commands supported by Tk themed widgets
[DESCRIPTION](ttk_widget.htm#M3)
[STANDARD OPTIONS](ttk_widget.htm#M4)
[-class, undefined, undefined](ttk_widget.htm#M-class)
[-cursor, cursor, Cursor](ttk_widget.htm#M-cursor)
[-takefocus, takeFocus, TakeFocus](ttk_widget.htm#M-takefocus)
[-style, style, Style](ttk_widget.htm#M-style)
[SCROLLABLE WIDGET OPTIONS](ttk_widget.htm#M5)
[-xscrollcommand, xScrollCommand, ScrollCommand](ttk_widget.htm#M-xscrollcommand)
[-yscrollcommand, yScrollCommand, ScrollCommand](ttk_widget.htm#M-yscrollcommand)
[LABEL OPTIONS](ttk_widget.htm#M6)
[-text, text, Text](ttk_widget.htm#M-text)
[-textvariable, textVariable, Variable](ttk_widget.htm#M-textvariable)
[-underline, underline, Underline](ttk_widget.htm#M-underline)
[-image, image, Image](ttk_widget.htm#M-image)
[-compound, compound, Compound](ttk_widget.htm#M-compound)
[text](ttk_widget.htm#M7)
[image](ttk_widget.htm#M8)
[center](ttk_widget.htm#M9)
[top](ttk_widget.htm#M10)
[bottom](ttk_widget.htm#M11)
[left](ttk_widget.htm#M12)
[right](ttk_widget.htm#M13)
[none](ttk_widget.htm#M14)
[-width, width, Width](ttk_widget.htm#M-width)
[COMPATIBILITY OPTIONS](ttk_widget.htm#M15)
[-state, state, State](ttk_widget.htm#M-state)
[COMMANDS](ttk_widget.htm#M16)
[*pathName* **cget** *option*](ttk_widget.htm#M17)
[*pathName* **configure** ?*option*? ?*value option value ...*?](ttk_widget.htm#M18)
[*pathName* **identify element** *x y*](ttk_widget.htm#M19)
[*pathName* **instate** *statespec* ?*script*?](ttk_widget.htm#M20)
[*pathName* **state** ?*stateSpec*?](ttk_widget.htm#M21)
[WIDGET STATES](ttk_widget.htm#M22)
[**active**](ttk_widget.htm#M23)
[**disabled**](ttk_widget.htm#M24)
[**focus**](ttk_widget.htm#M25)
[**pressed**](ttk_widget.htm#M26)
[**selected**](ttk_widget.htm#M27)
[**background**](ttk_widget.htm#M28)
[**readonly**](ttk_widget.htm#M29)
[**alternate**](ttk_widget.htm#M30)
[**invalid**](ttk_widget.htm#M31)
[**hover**](ttk_widget.htm#M32)
[EXAMPLES](ttk_widget.htm#M33)
[SEE ALSO](ttk_widget.htm#M34)
[KEYWORDS](ttk_widget.htm#M35)
Name
----
ttk::widget — Standard options and commands supported by Tk themed widgets Description
-----------
This manual describes common widget options and commands. Standard options
----------------
The following options are supported by all Tk themed widgets: Command-Line Name: **-class** Database Name: **undefined** Database Class: **undefined**
Specifies the window class. The class is used when querying the option database for the window's other options, to determine the default bindtags for the window, and to select the widget's default layout and style. This is a read-only option: it may only be specified when the window is created, and may not be changed with the **configure** widget command.
Command-Line Name: **-cursor** Database Name: **cursor** Database Class: **Cursor**
Specifies the mouse cursor to be used for the widget. See **[Tk\_GetCursor](https://www.tcl.tk/man/tcl/TkLib/GetCursor.htm)** and *cursors(n)* in the Tk reference manual for the legal values. If set to the empty string (the default), the cursor is inherited from the parent widget.
Command-Line Name: **-takefocus** Database Name: **takeFocus** Database Class: **TakeFocus**
Determines whether the window accepts the focus during keyboard traversal. Either **0**, **1**, a command prefix (to which the widget path is appended, and which should return **0** or **1**), or the empty string. See *options(n)* in the Tk reference manual for the full description.
Command-Line Name: **-style** Database Name: **[style](ttk_style.htm)** Database Class: **[Style](ttk_style.htm)**
May be used to specify a custom widget style.
Scrollable widget options
-------------------------
The following options are supported by widgets that are controllable by a scrollbar. See *scrollbar(n)* for more information Command-Line Name: **-xscrollcommand** Database Name: **xScrollCommand** Database Class: **ScrollCommand**
A command prefix, used to communicate with horizontal scrollbars. When the view in the widget's window changes, the widget will generate a Tcl command by concatenating the scroll command and two numbers. Each of the numbers is a fraction between 0 and 1 indicating a position in the document; 0 indicates the beginning, and 1 indicates the end. The first fraction indicates the first information in the widget that is visible in the window, and the second fraction indicates the information just after the last portion that is visible. Typically the **-xscrollcommand** option consists of the path name of a **[scrollbar](scrollbar.htm)** widget followed by “set”, e.g. “.x.scrollbar set”. This will cause the scrollbar to be updated whenever the view in the window changes.
If this option is set to the empty string (the default), then no command will be executed.
Command-Line Name: **-yscrollcommand** Database Name: **yScrollCommand** Database Class: **ScrollCommand**
A command prefix, used to communicate with vertical scrollbars. See the description of **-xscrollcommand** above for details.
Label options
-------------
The following options are supported by labels, buttons, and other button-like widgets: Command-Line Name: **-text** Database Name: **text** Database Class: **Text**
Specifies a text string to be displayed inside the widget (unless overridden by **-textvariable**).
Command-Line Name: **-textvariable** Database Name: **textVariable** Database Class: **Variable**
Specifies the name of a global variable whose value will be used in place of the **-text** resource.
Command-Line Name: **-underline** Database Name: **underline** Database Class: **Underline**
If set, specifies the integer index (0-based) of a character to underline in the text string. The underlined character is used for mnemonic activation.
Command-Line Name: **-image** Database Name: **image** Database Class: **Image**
Specifies an image to display. This is a list of 1 or more elements. The first element is the default image name. The rest of the list is a sequence of *statespec / value* pairs as per **[style map](ttk_style.htm)**, specifying different images to use when the widget is in a particular state or combination of states. All images in the list should have the same size.
Command-Line Name: **-compound** Database Name: **compound** Database Class: **Compound**
Specifies how to display the image relative to the text, in the case both **-text** and **-image** are present. Valid values are:
text
Display text only.
image
Display image only.
center
Display text centered on top of image.
top
bottom
left
right
Display image above, below, left of, or right of the text, respectively.
none
The default; display the image if present, otherwise the text.
Command-Line Name: **-width** Database Name: **width** Database Class: **Width**
If greater than zero, specifies how much space, in character widths, to allocate for the text label. If less than zero, specifies a minimum width. If zero or unspecified, the natural width of the text label is used.
Compatibility options
---------------------
Command-Line Name: **-state** Database Name: **state** Database Class: **State**
May be set to **normal** or **disabled** to control the **disabled** state bit. This is a write-only option: setting it changes the widget state, but the **state** widget command does not affect the **-state** option.
Commands
--------
*pathName* **cget** *option*
Returns the current value of the configuration option given by *option*.
*pathName* **configure** ?*option*? ?*value option value ...*?
Query or modify the configuration options of the widget. If one or more *option-value* pairs are specified, then the command modifies the given widget option(s) to have the given value(s); in this case the command returns an empty string. If *option* is specified with no *value*, then the command returns a list describing the named option: the elements of the list are the option name, database name, database class, default value, and current value. If no *option* is specified, returns a list describing all of the available options for *pathName*.
*pathName* **identify element** *x y*
Returns the name of the element under the point given by *x* and *y*, or an empty string if the point does not lie within any element. *x* and *y* are pixel coordinates relative to the widget. Some widgets accept other **identify** subcommands.
*pathName* **instate** *statespec* ?*script*?
Test the widget's state. If *script* is not specified, returns 1 if the widget state matches *statespec* and 0 otherwise. If *script* is specified, equivalent to
```
if {[*pathName* instate *stateSpec*]} *script*
```
*pathName* **state** ?*stateSpec*?
Modify or inquire widget state. If *stateSpec* is present, sets the widget state: for each flag in *stateSpec*, sets the corresponding flag or clears it if prefixed by an exclamation point. Returns a new state spec indicating which flags were changed:
```
set changes [*pathName* state *spec*]
*pathName* state $changes
```
will restore *pathName* to the original state. If *stateSpec* is not specified, returns a list of the currently-enabled state flags.
Widget states
-------------
The widget state is a bitmap of independent state flags. Widget state flags include:
**active**
The mouse cursor is over the widget and pressing a mouse button will cause some action to occur. (aka “prelight” (Gnome), “hot” (Windows), “hover”).
**disabled**
Widget is disabled under program control (aka “unavailable”, “inactive”).
**focus**
Widget has keyboard focus.
**pressed**
Widget is being pressed (aka “armed” in Motif).
**selected**
“On”, “true”, or “current” for things like checkbuttons and radiobuttons.
**background**
Windows and the Mac have a notion of an “active” or foreground window. The **background** state is set for widgets in a background window, and cleared for those in the foreground window.
**readonly**
Widget should not allow user modification.
**alternate**
A widget-specific alternate display format. For example, used for checkbuttons and radiobuttons in the “tristate” or “mixed” state, and for buttons with **-default active**.
**invalid**
The widget's value is invalid. (Potential uses: scale widget value out of bounds, entry widget value failed validation.)
**hover**
The mouse cursor is within the widget. This is similar to the **active** state; it is used in some themes for widgets that provide distinct visual feedback for the active widget in addition to the active element within the widget.
A *state specification* or *stateSpec* is a list of state names, optionally prefixed with an exclamation point (!) indicating that the bit is off.
Examples
--------
```
set b [ttk::button .b]
# Disable the widget:
$b **state** disabled
# Invoke the widget only if it is currently pressed and enabled:
$b **instate** {pressed !disabled} { .b invoke }
# Reenable widget:
$b **state** !disabled
```
See also
--------
**[ttk::intro](ttk_intro.htm)**, **[ttk::style](ttk_style.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TkCmd/ttk_widget.htm>
tcl_tk scale scale
=====
[NAME](scale.htm#M2) scale — Create and manipulate 'scale' value-controlled slider widgets
[SYNOPSIS](scale.htm#M3)
[STANDARD OPTIONS](scale.htm#M4)
[-activebackground, activeBackground, Foreground](options.htm#M-activebackground)
[-background or -bg, background, Background](options.htm#M-background)
[-borderwidth or -bd, borderWidth, BorderWidth](options.htm#M-borderwidth)
[-cursor, cursor, Cursor](options.htm#M-cursor)
[-font, font, Font](options.htm#M-font)
[-foreground or -fg, foreground, Foreground](options.htm#M-foreground)
[-highlightbackground, highlightBackground, HighlightBackground](options.htm#M-highlightbackground)
[-highlightcolor, highlightColor, HighlightColor](options.htm#M-highlightcolor)
[-highlightthickness, highlightThickness, HighlightThickness](options.htm#M-highlightthickness)
[-orient, orient, Orient](options.htm#M-orient)
[-relief, relief, Relief](options.htm#M-relief)
[-repeatdelay, repeatDelay, RepeatDelay](options.htm#M-repeatdelay)
[-repeatinterval, repeatInterval, RepeatInterval](options.htm#M-repeatinterval)
[-takefocus, takeFocus, TakeFocus](options.htm#M-takefocus)
[-troughcolor, troughColor, Background](options.htm#M-troughcolor)
[WIDGET-SPECIFIC OPTIONS](scale.htm#M5)
[-bigincrement, bigIncrement, BigIncrement](scale.htm#M6)
[-command, command, Command](scale.htm#M7)
[-digits, digits, Digits](scale.htm#M8)
[-from, from, From](scale.htm#M9)
[-label, label, Label](scale.htm#M10)
[-length, length, Length](scale.htm#M11)
[-resolution, resolution, Resolution](scale.htm#M12)
[-showvalue, showValue, ShowValue](scale.htm#M13)
[-sliderlength, sliderLength, SliderLength](scale.htm#M14)
[-sliderrelief, sliderRelief, SliderRelief](scale.htm#M15)
[-state, state, State](scale.htm#M16)
[-tickinterval, tickInterval, TickInterval](scale.htm#M17)
[-to, to, To](scale.htm#M18)
[-variable, variable, Variable](scale.htm#M19)
[-width, width, Width](scale.htm#M20)
[DESCRIPTION](scale.htm#M21)
[WIDGET COMMAND](scale.htm#M22)
[*pathName* **cget** *option*](scale.htm#M23)
[*pathName* **configure** ?*option*? ?*value option value ...*?](scale.htm#M24)
[*pathName* **coords** ?*value*?](scale.htm#M25)
[*pathName* **get** ?*x y*?](scale.htm#M26)
[*pathName* **identify** *x y*](scale.htm#M27)
[*pathName* **set** *value*](scale.htm#M28)
[BINDINGS](scale.htm#M29)
[SEE ALSO](scale.htm#M30)
[KEYWORDS](scale.htm#M31)
Name
----
scale — Create and manipulate 'scale' value-controlled slider widgets Synopsis
--------
**scale** *pathName* ?*options*?
Standard options
----------------
**[-activebackground, activeBackground, Foreground](options.htm#M-activebackground)**
**[-background or -bg, background, Background](options.htm#M-background)**
**[-borderwidth or -bd, borderWidth, BorderWidth](options.htm#M-borderwidth)**
**[-cursor, cursor, Cursor](options.htm#M-cursor)**
**[-font, font, Font](options.htm#M-font)**
**[-foreground or -fg, foreground, Foreground](options.htm#M-foreground)**
**[-highlightbackground, highlightBackground, HighlightBackground](options.htm#M-highlightbackground)**
**[-highlightcolor, highlightColor, HighlightColor](options.htm#M-highlightcolor)**
**[-highlightthickness, highlightThickness, HighlightThickness](options.htm#M-highlightthickness)**
**[-orient, orient, Orient](options.htm#M-orient)**
**[-relief, relief, Relief](options.htm#M-relief)**
**[-repeatdelay, repeatDelay, RepeatDelay](options.htm#M-repeatdelay)**
**[-repeatinterval, repeatInterval, RepeatInterval](options.htm#M-repeatinterval)**
**[-takefocus, takeFocus, TakeFocus](options.htm#M-takefocus)**
**[-troughcolor, troughColor, Background](options.htm#M-troughcolor)**
Widget-specific options
-----------------------
Command-Line Name: **-bigincrement** Database Name: **bigIncrement** Database Class: **BigIncrement**
Some interactions with the scale cause its value to change by “large” increments; this option specifies the size of the large increments. If specified as 0, the large increments default to 1/10 the range of the scale.
Command-Line Name: **-command** Database Name: **command** Database Class: **Command**
Specifies the prefix of a Tcl command to invoke whenever the scale's value is changed via a widget command. The actual command consists of this option followed by a space and a real number indicating the new value of the scale.
Command-Line Name: **-digits** Database Name: **digits** Database Class: **Digits**
An integer specifying how many significant digits should be retained when converting the value of the scale to a string. If the number is less than or equal to zero, then the scale picks the smallest value that guarantees that every possible slider position prints as a different string.
Command-Line Name: **-from** Database Name: **from** Database Class: **From**
A real value corresponding to the left or top end of the scale.
Command-Line Name: **-label** Database Name: **label** Database Class: **Label**
A string to display as a label for the scale. For vertical scales the label is displayed just to the right of the top end of the scale. For horizontal scales the label is displayed just above the left end of the scale. If the option is specified as an empty string, no label is displayed.
Command-Line Name: **-length** Database Name: **length** Database Class: **Length**
Specifies the desired long dimension of the scale in screen units (i.e. any of the forms acceptable to **[Tk\_GetPixels](https://www.tcl.tk/man/tcl/TkLib/GetPixels.htm)**). For vertical scales this is the scale's height; for horizontal scales it is the scale's width.
Command-Line Name: **-resolution** Database Name: **resolution** Database Class: **Resolution**
A real value specifying the resolution for the scale. If this value is greater than zero then the scale's value will always be rounded to an even multiple of this value, as will tick marks and the endpoints of the scale. If the value is less than zero then no rounding occurs. Defaults to 1 (i.e., the value will be integral).
Command-Line Name: **-showvalue** Database Name: **showValue** Database Class: **ShowValue**
Specifies a boolean value indicating whether or not the current value of the scale is to be displayed.
Command-Line Name: **-sliderlength** Database Name: **sliderLength** Database Class: **SliderLength**
Specifies the size of the slider, measured in screen units along the slider's long dimension. The value may be specified in any of the forms acceptable to **[Tk\_GetPixels](https://www.tcl.tk/man/tcl/TkLib/GetPixels.htm)**.
Command-Line Name: **-sliderrelief** Database Name: **sliderRelief** Database Class: **SliderRelief**
Specifies the relief to use when drawing the slider, such as **raised** or **sunken**.
Command-Line Name: **-state** Database Name: **state** Database Class: **State**
Specifies one of three states for the scale: **normal**, **active**, or **disabled**. If the scale is disabled then the value may not be changed and the scale will not activate. If the scale is active, the slider is displayed using the color specified by the **-activebackground** option.
Command-Line Name: **-tickinterval** Database Name: **tickInterval** Database Class: **TickInterval**
Must be a real value. Determines the spacing between numerical tick marks displayed below or to the left of the slider. If 0, no tick marks will be displayed.
Command-Line Name: **-to** Database Name: **to** Database Class: **To**
Specifies a real value corresponding to the right or bottom end of the scale. This value may be either less than or greater than the **-from** option.
Command-Line Name: **-variable** Database Name: **variable** Database Class: **Variable**
Specifies the name of a global variable to link to the scale. Whenever the value of the variable changes, the scale will update to reflect this value. Whenever the scale is manipulated interactively, the variable will be modified to reflect the scale's new value.
Command-Line Name: **-width** Database Name: **width** Database Class: **Width**
Specifies the desired narrow dimension of the trough in screen units (i.e. any of the forms acceptable to **[Tk\_GetPixels](https://www.tcl.tk/man/tcl/TkLib/GetPixels.htm)**). For vertical scales this is the trough's width; for horizontal scales this is the trough's height.
Description
-----------
The **scale** command creates a new window (given by the *pathName* argument) and makes it into a scale widget. Additional options, described above, may be specified on the command line or in the option database to configure aspects of the scale such as its colors, orientation, and relief. The **scale** command returns its *pathName* argument. At the time this command is invoked, there must not exist a window named *pathName*, but *pathName*'s parent must exist. A scale is a widget that displays a rectangular *trough* and a small *slider*. The trough corresponds to a range of real values (determined by the **-from**, **-to**, and **-resolution** options), and the position of the slider selects a particular real value. The slider's position (and hence the scale's value) may be adjusted with the mouse or keyboard as described in the **[BINDINGS](#M29)** section below. Whenever the scale's value is changed, a Tcl command is invoked (using the **-command** option) to notify other interested widgets of the change. In addition, the value of the scale can be linked to a Tcl variable (using the **-variable** option), so that changes in either are reflected in the other.
Three annotations may be displayed in a scale widget: a label appearing at the top right of the widget (top left for horizontal scales), a number displayed just to the left of the slider (just above the slider for horizontal scales), and a collection of numerical tick marks just to the left of the current value (just below the trough for horizontal scales). Each of these three annotations may be enabled or disabled using the configuration options.
Widget command
--------------
The **scale** command creates a new Tcl command whose name is *pathName*. This command may be used to invoke various operations on the widget. It has the following general form:
```
*pathName option* ?*arg arg ...*?
```
*Option* and the *arg*s determine the exact behavior of the command. The following commands are possible for scale widgets:
*pathName* **cget** *option*
Returns the current value of the configuration option given by *option*. *Option* may have any of the values accepted by the **scale** command.
*pathName* **configure** ?*option*? ?*value option value ...*?
Query or modify the configuration options of the widget. If no *option* is specified, returns a list describing all of the available options for *pathName* (see **[Tk\_ConfigureInfo](https://www.tcl.tk/man/tcl/TkLib/ConfigWidg.htm)** for information on the format of this list). If *option* is specified with no *value*, then the command returns a list describing the one named option (this list will be identical to the corresponding sublist of the value returned if no *option* is specified). If one or more *option-value* pairs are specified, then the command modifies the given widget option(s) to have the given value(s); in this case the command returns an empty string. *Option* may have any of the values accepted by the **scale** command.
*pathName* **coords** ?*value*?
Returns a list whose elements are the x and y coordinates of the point along the centerline of the trough that corresponds to *value*. If *value* is omitted then the scale's current value is used.
*pathName* **get** ?*x y*?
If *x* and *y* are omitted, returns the current value of the scale. If *x* and *y* are specified, they give pixel coordinates within the widget; the command returns the scale value corresponding to the given pixel. Only one of *x* or *y* is used: for horizontal scales *y* is ignored, and for vertical scales *x* is ignored.
*pathName* **identify** *x y*
Returns a string indicating what part of the scale lies under the coordinates given by *x* and *y*. A return value of **slider** means that the point is over the slider; **trough1** means that the point is over the portion of the slider above or to the left of the slider; and **trough2** means that the point is over the portion of the slider below or to the right of the slider. If the point is not over one of these elements, an empty string is returned.
*pathName* **set** *value*
This command is invoked to change the current value of the scale, and hence the position at which the slider is displayed. *Value* gives the new value for the scale. The command has no effect if the scale is disabled.
Bindings
--------
Tk automatically creates class bindings for scales that give them the following default behavior. Where the behavior is different for vertical and horizontal scales, the horizontal behavior is described in parentheses.
1. If button 1 is pressed in the trough, the scale's value will be incremented or decremented by the value of the **-resolution** option so that the slider moves in the direction of the cursor. If the button is held down, the action auto-repeats.
2. If button 1 is pressed over the slider, the slider can be dragged with the mouse.
3. If button 1 is pressed in the trough with the Control key down, the slider moves all the way to the end of its range, in the direction towards the mouse cursor.
4. If button 2 is pressed, the scale's value is set to the mouse position. If the mouse is dragged with button 2 down, the scale's value changes with the drag.
5. The Up and Left keys move the slider up (left) by the value of the **-resolution** option.
6. The Down and Right keys move the slider down (right) by the value of the **-resolution** option.
7. Control-Up and Control-Left move the slider up (left) by the value of the **-bigincrement** option.
8. Control-Down and Control-Right move the slider down (right) by the value of the **-bigincrement** option.
9. Home moves the slider to the top (left) end of its range.
10. End moves the slider to the bottom (right) end of its range.
If the scale is disabled using the **-state** option then none of the above bindings have any effect.
The behavior of scales can be changed by defining new bindings for individual widgets or by redefining the class bindings.
See also
--------
**[ttk::scale](ttk_scale.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TkCmd/scale.htm>
| programming_docs |
tcl_tk focusNext focusNext
=========
Name
----
tk\_focusNext, tk\_focusPrev, tk\_focusFollowsMouse — Utility procedures for managing the input focus. Synopsis
--------
**tk\_focusNext** *window*
**tk\_focusPrev** *window*
**tk\_focusFollowsMouse**
Description
-----------
**tk\_focusNext** is a utility procedure used for keyboard traversal. It returns the “next” window after *window* in focus order. The focus order is determined by the stacking order of windows and the structure of the window hierarchy. Among siblings, the focus order is the same as the stacking order, with the lowest window being first. If a window has children, the window is visited first, followed by its children (recursively), followed by its next sibling. Top-level windows other than *window* are skipped, so that **tk\_focusNext** never returns a window in a different top-level from *window*. After computing the next window, **tk\_focusNext** examines the window's **-takefocus** option to see whether it should be skipped. If so, **tk\_focusNext** continues on to the next window in the focus order, until it eventually finds a window that will accept the focus or returns back to *window*.
**tk\_focusPrev** is similar to **tk\_focusNext** except that it returns the window just before *window* in the focus order.
**tk\_focusFollowsMouse** changes the focus model for the application to an implicit one where the window under the mouse gets the focus. After this procedure is called, whenever the mouse enters a window Tk will automatically give it the input focus. The **[focus](focus.htm)** command may be used to move the focus to a window other than the one under the mouse, but as soon as the mouse moves into a new window the focus will jump to that window. Note: at present there is no built-in support for returning the application to an explicit focus model; to do this you will have to write a script that deletes the bindings created by **tk\_focusFollowsMouse**.
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TkCmd/focusNext.htm>
tcl_tk wm wm
==
[NAME](wm.htm#M2) wm — Communicate with window manager
[SYNOPSIS](wm.htm#M3)
[DESCRIPTION](wm.htm#M4)
[**wm aspect** *window* ?*minNumer minDenom maxNumer maxDenom*?](wm.htm#M5)
[**wm attributes** *window*](wm.htm#M6)
[**wm attributes** *window* ?**option**?](wm.htm#M7)
[**wm attributes** *window* ?**option value option value...**?](wm.htm#M8)
[**-alpha**](wm.htm#M9)
[**-fullscreen**](wm.htm#M10)
[**-topmost**](wm.htm#M11)
[**-disabled**](wm.htm#M12)
[**-toolwindow**](wm.htm#M13)
[**-transparentcolor**](wm.htm#M14)
[**-modified**](wm.htm#M15)
[**-notify**](wm.htm#M16)
[**-titlepath**](wm.htm#M17)
[**-transparent**](wm.htm#M18)
[**-type**](wm.htm#M19)
[**desktop**](wm.htm#M20)
[**dock**](wm.htm#M21)
[**toolbar**](wm.htm#M22)
[**menu**](wm.htm#M23)
[**utility**](wm.htm#M24)
[**splash**](wm.htm#M25)
[**dialog**](wm.htm#M26)
[**dropdown\_menu**](wm.htm#M27)
[**popup\_menu**](wm.htm#M28)
[**tooltip**](wm.htm#M29)
[**notification**](wm.htm#M30)
[**combo**](wm.htm#M31)
[**dnd**](wm.htm#M32)
[**normal**](wm.htm#M33)
[**-zoomed**](wm.htm#M34)
[**wm client** *window* ?*name*?](wm.htm#M35)
[**wm colormapwindows** *window* ?*windowList*?](wm.htm#M36)
[**wm command** *window* ?*value*?](wm.htm#M37)
[**wm deiconify** *window*](wm.htm#M38)
[**wm focusmodel** *window* ?**active**|**passive**?](wm.htm#M39)
[**wm forget** *window*](wm.htm#M40)
[**wm frame** *window*](wm.htm#M41)
[**wm geometry** *window* ?*newGeometry*?](wm.htm#M42)
[**wm grid** *window* ?*baseWidth baseHeight widthInc heightInc*?](wm.htm#M43)
[**wm group** *window* ?*pathName*?](wm.htm#M44)
[**wm iconbitmap** *window* ?*bitmap*?](wm.htm#M45)
[**wm iconbitmap** *window* ?**-default**? ?*image*?](wm.htm#M46)
[**wm iconify** *window*](wm.htm#M47)
[**wm iconmask** *window* ?*bitmap*?](wm.htm#M48)
[**wm iconname** *window* ?*newName*?](wm.htm#M49)
[**wm iconphoto** *window* ?**-default**? *image1* ?*image2 ...*?](wm.htm#M50)
[**wm iconposition** *window* ?*x y*?](wm.htm#M51)
[**wm iconwindow** *window* ?*pathName*?](wm.htm#M52)
[**wm manage** *widget*](wm.htm#M53)
[**wm maxsize** *window* ?*width height*?](wm.htm#M54)
[**wm minsize** *window* ?*width height*?](wm.htm#M55)
[**wm overrideredirect** *window* ?*boolean*?](wm.htm#M56)
[**wm positionfrom** *window* ?*who*?](wm.htm#M57)
[**wm protocol** *window* ?*name*? ?*command*?](wm.htm#M58)
[**wm resizable** *window* ?*width height*?](wm.htm#M59)
[**wm sizefrom** *window* ?*who*?](wm.htm#M60)
[**wm stackorder** *window* ?**isabove**|**isbelow** *window*?](wm.htm#M61)
[**wm state** *window* ?newstate?](wm.htm#M62)
[**wm title** *window* ?*string*?](wm.htm#M63)
[**wm transient** *window* ?*master*?](wm.htm#M64)
[**wm withdraw** *window*](wm.htm#M65)
[GEOMETRY MANAGEMENT](wm.htm#M66)
[GRIDDED GEOMETRY MANAGEMENT](wm.htm#M67)
[BUGS](wm.htm#M68)
[EXAMPLES](wm.htm#M69)
[SEE ALSO](wm.htm#M70)
[KEYWORDS](wm.htm#M71)
Name
----
wm — Communicate with window manager Synopsis
--------
**wm** *option window* ?*args*?
Description
-----------
The **wm** command is used to interact with window managers in order to control such things as the title for a window, its geometry, or the increments in terms of which it may be resized. The **wm** command can take any of a number of different forms, depending on the *option* argument. All of the forms expect at least one additional argument, *window*, which must be the path name of a top-level window. The legal forms for the **wm** command are:
**wm aspect** *window* ?*minNumer minDenom maxNumer maxDenom*?
If *minNumer*, *minDenom*, *maxNumer*, and *maxDenom* are all specified, then they will be passed to the window manager and the window manager should use them to enforce a range of acceptable aspect ratios for *window*. The aspect ratio of *window* (width/length) will be constrained to lie between *minNumer*/*minDenom* and *maxNumer*/*maxDenom*. If *minNumer* etc. are all specified as empty strings, then any existing aspect ratio restrictions are removed. If *minNumer* etc. are specified, then the command returns an empty string. Otherwise, it returns a Tcl list containing four elements, which are the current values of *minNumer*, *minDenom*, *maxNumer*, and *maxDenom* (if no aspect restrictions are in effect, then an empty string is returned).
**wm attributes** *window*
**wm attributes** *window* ?**option**?
**wm attributes** *window* ?**option value option value...**?
This subcommand returns or sets platform specific attributes associated with a window. The first form returns a list of the platform specific flags and their values. The second form returns the value for the specific option. The third form sets one or more of the values. The values are as follows: All platforms support the following attributes (though X11 users should see the notes below):
**-alpha**
Specifies the alpha transparency level of the toplevel. It accepts a value from **0.0** (fully transparent) to **1.0** (opaque). Values outside that range will be constrained. Where not supported, the **-alpha** value remains at **1.0**.
**-fullscreen**
Places the window in a mode that takes up the entire screen, has no borders, and covers the general use area (i.e. Start menu and taskbar on Windows, dock and menubar on OSX, general window decorations on X11).
**-topmost**
Specifies whether this is a topmost window (displays above all other windows).
On Windows, the following attributes may be set.
**-disabled**
Specifies whether the window is in a disabled state.
**-toolwindow**
Specifies a toolwindow style window (as defined in the MSDN).
**-transparentcolor**
Specifies the transparent color index of the toplevel. It takes any color value accepted by **[Tk\_GetColor](https://www.tcl.tk/man/tcl/TkLib/GetColor.htm)**. If the empty string is specified (default), no transparent color is used. This is supported on Windows 2000/XP+. Where not supported, the **-transparentcolor** value remains at **{}**.
On Mac OS X, the following attributes may be set.
**-modified**
Specifies the modification state of the window (determines whether the window close widget contains the modification indicator and whether the proxy icon is draggable).
**-notify**
Specifies process notification state (bouncing of the application dock icon).
**-titlepath**
Specifies the path of the file referenced as the window proxy icon (which can be dragged and dropped in lieu of the file's finder icon).
**-transparent**
Makes the window content area transparent and turns off the window shadow. For the transparency to be effective, the toplevel background needs to be set to a color with some alpha, e.g. “systemTransparent”.
On X11, the following attributes may be set. These are not supported by all window managers, and will have no effect under older WMs.
**-type**
Requests that the window should be interpreted by the window manager as being of the specified type(s). This may cause the window to be decorated in a different way or otherwise managed differently, though exactly what happens is entirely up to the window manager. A list of types may be used, in order of preference. The following values are mapped to constants defined in the EWMH specification (using others is possible, but not advised):
**desktop**
indicates a desktop feature,
**dock**
indicates a dock/panel feature,
**toolbar**
indicates a toolbar window that should be acting on behalf of another window, as indicated with **wm transient**,
**menu**
indicates a torn-off menu that should be acting on behalf of another window, as indicated with **wm transient**,
**utility**
indicates a utility window (e.g., palette or toolbox) that should be acting on behalf of another window, as indicated with **wm transient**,
**splash**
indicates a splash screen, displayed during application start up,
**dialog**
indicates a general dialog window, that should be acting on behalf of another window, as indicated with **wm transient**,
**dropdown\_menu**
indicates a menu summoned from a menu bar, which should usually also be set to be override-redirected (with **wm overrideredirect**),
**popup\_menu**
indicates a popup menu, which should usually also be set to be override-redirected (with **wm overrideredirect**),
**tooltip**
indicates a tooltip window, which should usually also be set to be override-redirected (with **wm overrideredirect**),
**notification**
indicates a window that provides a background notification of some event, which should usually also be set to be override-redirected (with **wm overrideredirect**),
**combo**
indicates the drop-down list of a combobox widget, which should usually also be set to be override-redirected (with **wm overrideredirect**),
**dnd**
indicates a window that represents something being dragged, which should usually also be set to be override-redirected (with **wm overrideredirect**),
**normal**
indicates a window that has no special interpretation.
**-zoomed**
Requests that the window should be maximized. This is the same as **wm state zoomed** on Windows and Mac OS X.
On X11, changes to window attributes are performed asynchronously. Querying the value of an attribute returns the current state, which will not be the same as the value most recently set if the window manager has not yet processed the request or if it does not support the attribute.
**wm client** *window* ?*name*?
If *name* is specified, this command stores *name* (which should be the name of the host on which the application is executing) in *window*'s **WM\_CLIENT\_MACHINE** property for use by the window manager or session manager. The command returns an empty string in this case. If *name* is not specified, the command returns the last name set in a **wm client** command for *window*. If *name* is specified as an empty string, the command deletes the **WM\_CLIENT\_MACHINE** property from *window*.
**wm colormapwindows** *window* ?*windowList*?
This command is used to manipulate the **WM\_COLORMAP\_WINDOWS** property, which provides information to the window managers about windows that have private colormaps. If *windowList* is not specified, the command returns a list whose elements are the names of the windows in the **WM\_COLORMAP\_WINDOWS** property. If *windowList* is specified, it consists of a list of window path names; the command overwrites the **WM\_COLORMAP\_WINDOWS** property with the given windows and returns an empty string. The **WM\_COLORMAP\_WINDOWS** property should normally contain a list of the internal windows within *window* whose colormaps differ from their parents.
The order of the windows in the property indicates a priority order: the window manager will attempt to install as many colormaps as possible from the head of this list when *window* gets the colormap focus. If *window* is not included among the windows in *windowList*, Tk implicitly adds it at the end of the **WM\_COLORMAP\_WINDOWS** property, so that its colormap is lowest in priority. If **wm colormapwindows** is not invoked, Tk will automatically set the property for each top-level window to all the internal windows whose colormaps differ from their parents, followed by the top-level itself; the order of the internal windows is undefined. See the ICCCM documentation for more information on the **WM\_COLORMAP\_WINDOWS** property.
**wm command** *window* ?*value*?
If *value* is specified, this command stores *value* in *window*'s **WM\_COMMAND** property for use by the window manager or session manager and returns an empty string. *Value* must have proper list structure; the elements should contain the words of the command used to invoke the application. If *value* is not specified then the command returns the last value set in a **wm command** command for *window*. If *value* is specified as an empty string, the command deletes the **WM\_COMMAND** property from *window*.
**wm deiconify** *window*
Arrange for *window* to be displayed in normal (non-iconified) form. This is done by mapping the window. If the window has never been mapped then this command will not map the window, but it will ensure that when the window is first mapped it will be displayed in de-iconified form. On Windows, a deiconified window will also be raised and be given the focus (made the active window). Returns an empty string.
**wm focusmodel** *window* ?**active**|**passive**?
If **active** or **passive** is supplied as an optional argument to the command, then it specifies the focus model for *window*. In this case the command returns an empty string. If no additional argument is supplied, then the command returns the current focus model for *window*. An **active** focus model means that *window* will claim the input focus for itself or its descendants, even at times when the focus is currently in some other application. **Passive** means that *window* will never claim the focus for itself: the window manager should give the focus to *window* at appropriate times. However, once the focus has been given to *window* or one of its descendants, the application may re-assign the focus among *window*'s descendants. The focus model defaults to **passive**, and Tk's **[focus](focus.htm)** command assumes a passive model of focusing.
**wm forget** *window*
The *window* will be unmapped from the screen and will no longer be managed by **wm**. Windows created with the **[toplevel](toplevel.htm)** command will be treated like **[frame](frame.htm)** windows once they are no longer managed by **wm**, however, the **-menu** configuration will be remembered and the menus will return once the widget is managed again.
**wm frame** *window*
If *window* has been reparented by the window manager into a decorative frame, the command returns the platform specific window identifier for the outermost frame that contains *window* (the window whose parent is the root or virtual root). If *window* has not been reparented by the window manager then the command returns the platform specific window identifier for *window*.
**wm geometry** *window* ?*newGeometry*?
If *newGeometry* is specified, then the geometry of *window* is changed and an empty string is returned. Otherwise the current geometry for *window* is returned (this is the most recent geometry specified either by manual resizing or in a **wm geometry** command). *NewGeometry* has the form **=***width***x***height***±***x***±***y*, where any of **=**, *width***x***height*, or **±***x***±***y* may be omitted. *Width* and *height* are positive integers specifying the desired dimensions of *window*. If *window* is gridded (see **[GRIDDED GEOMETRY MANAGEMENT](#M67)** below) then the dimensions are specified in grid units; otherwise they are specified in pixel units. *X* and *y* specify the desired location of *window* on the screen, in pixels. If *x* is preceded by **+**, it specifies the number of pixels between the left edge of the screen and the left edge of *window*'s border; if preceded by **-** then *x* specifies the number of pixels between the right edge of the screen and the right edge of *window*'s border. If *y* is preceded by **+** then it specifies the number of pixels between the top of the screen and the top of *window*'s border; if *y* is preceded by **-** then it specifies the number of pixels between the bottom of *window*'s border and the bottom of the screen.
If *newGeometry* is specified as an empty string then any existing user-specified geometry for *window* is cancelled, and the window will revert to the size requested internally by its widgets.
Note that this is related to **[winfo geometry](winfo.htm)**, but not the same. That can only query the geometry, and always reflects Tk's current understanding of the actual size and location of *window*, whereas **wm geometry** allows both setting and querying of the *window manager*'s understanding of the size and location of the window. This can vary significantly, for example to reflect the addition of decorative elements to *window* such as title bars, and window managers are not required to precisely follow the requests made through this command.
**wm grid** *window* ?*baseWidth baseHeight widthInc heightInc*?
This command indicates that *window* is to be managed as a gridded window. It also specifies the relationship between grid units and pixel units. *BaseWidth* and *baseHeight* specify the number of grid units corresponding to the pixel dimensions requested internally by *window* using **[Tk\_GeometryRequest](https://www.tcl.tk/man/tcl/TkLib/GeomReq.htm)**. *WidthInc* and *heightInc* specify the number of pixels in each horizontal and vertical grid unit. These four values determine a range of acceptable sizes for *window*, corresponding to grid-based widths and heights that are non-negative integers. Tk will pass this information to the window manager; during manual resizing, the window manager will restrict the window's size to one of these acceptable sizes. Furthermore, during manual resizing the window manager will display the window's current size in terms of grid units rather than pixels. If *baseWidth* etc. are all specified as empty strings, then *window* will no longer be managed as a gridded window. If *baseWidth* etc. are specified then the return value is an empty string.
Otherwise the return value is a Tcl list containing four elements corresponding to the current *baseWidth*, *baseHeight*, *widthInc*, and *heightInc*; if *window* is not currently gridded, then an empty string is returned.
Note: this command should not be needed very often, since the **[Tk\_SetGrid](https://www.tcl.tk/man/tcl/TkLib/SetGrid.htm)** library procedure and the **setGrid** option provide easier access to the same functionality.
**wm group** *window* ?*pathName*?
If *pathName* is specified, it gives the path name for the leader of a group of related windows. The window manager may use this information, for example, to unmap all of the windows in a group when the group's leader is iconified. *PathName* may be specified as an empty string to remove *window* from any group association. If *pathName* is specified then the command returns an empty string; otherwise it returns the path name of *window*'s current group leader, or an empty string if *window* is not part of any group.
**wm iconbitmap** *window* ?*bitmap*?
If *bitmap* is specified, then it names a bitmap in the standard forms accepted by Tk (see the **[Tk\_GetBitmap](https://www.tcl.tk/man/tcl/TkLib/GetBitmap.htm)** manual entry for details). This bitmap is passed to the window manager to be displayed in *window*'s icon, and the command returns an empty string. If an empty string is specified for *bitmap*, then any current icon bitmap is cancelled for *window*. If *bitmap* is specified then the command returns an empty string. Otherwise it returns the name of the current icon bitmap associated with *window*, or an empty string if *window* has no icon bitmap. On the Windows operating system, an additional flag is supported:
**wm iconbitmap** *window* ?**-default**? ?*image*?
If the **-default** flag is given, the icon is applied to all toplevel windows (existing and future) to which no other specific icon has yet been applied. In addition to bitmap image types, a full path specification to any file which contains a valid Windows icon is also accepted (usually .ico or .icr files), or any file for which the shell has assigned an icon. Tcl will first test if the file contains an icon, then if it has an assigned icon, and finally, if that fails, test for a bitmap.
**wm iconify** *window*
Arrange for *window* to be iconified. It *window* has not yet been mapped for the first time, this command will arrange for it to appear in the iconified state when it is eventually mapped.
**wm iconmask** *window* ?*bitmap*?
If *bitmap* is specified, then it names a bitmap in the standard forms accepted by Tk (see the **[Tk\_GetBitmap](https://www.tcl.tk/man/tcl/TkLib/GetBitmap.htm)** manual entry for details). This bitmap is passed to the window manager to be used as a mask in conjunction with the **iconbitmap** option: where the mask has zeroes no icon will be displayed; where it has ones, the bits from the icon bitmap will be displayed. If an empty string is specified for *bitmap* then any current icon mask is cancelled for *window* (this is equivalent to specifying a bitmap of all ones). If *bitmap* is specified then the command returns an empty string. Otherwise it returns the name of the current icon mask associated with *window*, or an empty string if no mask is in effect.
**wm iconname** *window* ?*newName*?
If *newName* is specified, then it is passed to the window manager; the window manager should display *newName* inside the icon associated with *window*. In this case an empty string is returned as result. If *newName* is not specified then the command returns the current icon name for *window*, or an empty string if no icon name has been specified (in this case the window manager will normally display the window's title, as specified with the **wm title** command).
**wm iconphoto** *window* ?**-default**? *image1* ?*image2 ...*?
Sets the titlebar icon for *window* based on the named photo images. If **-default** is specified, this is applied to all future created toplevels as well. The data in the images is taken as a snapshot at the time of invocation. If the images are later changed, this is not reflected to the titlebar icons. Multiple images are accepted to allow different images sizes (e.g., 16x16 and 32x32) to be provided. The window manager may scale provided icons to an appropriate size. On Windows, the images are packed into a Windows icon structure. This will override an ico specified to **wm iconbitmap**, and vice versa.
On X, the images are arranged into the \_NET\_WM\_ICON X property, which most modern window managers support. A **wm iconbitmap** may exist simultaneously. It is recommended to use not more than 2 icons, placing the larger icon first.
On Macintosh, this currently does nothing.
**wm iconposition** *window* ?*x y*?
If *x* and *y* are specified, they are passed to the window manager as a hint about where to position the icon for *window*. In this case an empty string is returned. If *x* and *y* are specified as empty strings then any existing icon position hint is cancelled. If neither *x* nor *y* is specified, then the command returns a Tcl list containing two values, which are the current icon position hints (if no hints are in effect then an empty string is returned).
**wm iconwindow** *window* ?*pathName*?
If *pathName* is specified, it is the path name for a window to use as icon for *window*: when *window* is iconified then *pathName* will be mapped to serve as icon, and when *window* is de-iconified then *pathName* will be unmapped again. If *pathName* is specified as an empty string then any existing icon window association for *window* will be cancelled. If the *pathName* argument is specified then an empty string is returned. Otherwise the command returns the path name of the current icon window for *window*, or an empty string if there is no icon window currently specified for *window*. Button press events are disabled for *window* as long as it is an icon window; this is needed in order to allow window managers to “own” those events. Note: not all window managers support the notion of an icon window.
**wm manage** *widget*
The *widget* specified will become a stand alone top-level window. The window will be decorated with the window managers title bar, etc. Only *frame*, *labelframe* and *toplevel* widgets can be used with this command. Attempting to pass any other widget type will raise an error. Attempting to manage a *toplevel* widget is benign and achieves nothing. See also **[GEOMETRY MANAGEMENT](#M66)**.
**wm maxsize** *window* ?*width height*?
If *width* and *height* are specified, they give the maximum permissible dimensions for *window*. For gridded windows the dimensions are specified in grid units; otherwise they are specified in pixel units. The window manager will restrict the window's dimensions to be less than or equal to *width* and *height*. If *width* and *height* are specified, then the command returns an empty string. Otherwise it returns a Tcl list with two elements, which are the maximum width and height currently in effect. The maximum size defaults to the size of the screen. See the sections on geometry management below for more information.
**wm minsize** *window* ?*width height*?
If *width* and *height* are specified, they give the minimum permissible dimensions for *window*. For gridded windows the dimensions are specified in grid units; otherwise they are specified in pixel units. The window manager will restrict the window's dimensions to be greater than or equal to *width* and *height*. If *width* and *height* are specified, then the command returns an empty string. Otherwise it returns a Tcl list with two elements, which are the minimum width and height currently in effect. The minimum size defaults to one pixel in each dimension. See the sections on geometry management below for more information.
**wm overrideredirect** *window* ?*boolean*?
If *boolean* is specified, it must have a proper boolean form and the override-redirect flag for *window* is set to that value. If *boolean* is not specified then **1** or **0** is returned to indicate whether or not the override-redirect flag is currently set for *window*. Setting the override-redirect flag for a window causes it to be ignored by the window manager; among other things, this means that the window will not be reparented from the root window into a decorative frame and the user will not be able to manipulate the window using the normal window manager mechanisms. Note that the override-redirect flag is only guaranteed to be taken notice of when the window is first mapped or when mapped after the state is changed from withdrawn to normal. Some, but not all, platforms will take notice at additional times.
**wm positionfrom** *window* ?*who*?
If *who* is specified, it must be either **program** or **user**, or an abbreviation of one of these two. It indicates whether *window*'s current position was requested by the program or by the user. Many window managers ignore program-requested initial positions and ask the user to manually position the window; if **user** is specified then the window manager should position the window at the given place without asking the user for assistance. If *who* is specified as an empty string, then the current position source is cancelled. If *who* is specified, then the command returns an empty string. Otherwise it returns **user** or **program** to indicate the source of the window's current position, or an empty string if no source has been specified yet. Most window managers interpret “no source” as equivalent to **program**. Tk will automatically set the position source to **user** when a **wm geometry** command is invoked, unless the source has been set explicitly to **program**.
**wm protocol** *window* ?*name*? ?*command*?
This command is used to manage window manager protocols such as **WM\_DELETE\_WINDOW**. *Name* is the name of an atom corresponding to a window manager protocol, such as **WM\_DELETE\_WINDOW** or **WM\_SAVE\_YOURSELF** or **WM\_TAKE\_FOCUS**. If both *name* and *command* are specified, then *command* is associated with the protocol specified by *name*. *Name* will be added to *window*'s **WM\_PROTOCOLS** property to tell the window manager that the application has a protocol handler for *name*, and *command* will be invoked in the future whenever the window manager sends a message to the client for that protocol. In this case the command returns an empty string. If *name* is specified but *command* is not, then the current command for *name* is returned, or an empty string if there is no handler defined for *name*. If *command* is specified as an empty string then the current handler for *name* is deleted and it is removed from the **WM\_PROTOCOLS** property on *window*; an empty string is returned. Lastly, if neither *name* nor *command* is specified, the command returns a list of all the protocols for which handlers are currently defined for *window*. Tk always defines a protocol handler for **WM\_DELETE\_WINDOW**, even if you have not asked for one with **wm protocol**. If a **WM\_DELETE\_WINDOW** message arrives when you have not defined a handler, then Tk handles the message by destroying the window for which it was received.
**wm resizable** *window* ?*width height*?
This command controls whether or not the user may interactively resize a top-level window. If *width* and *height* are specified, they are boolean values that determine whether the width and height of *window* may be modified by the user. In this case the command returns an empty string. If *width* and *height* are omitted then the command returns a list with two 0/1 elements that indicate whether the width and height of *window* are currently resizable. By default, windows are resizable in both dimensions. If resizing is disabled, then the window's size will be the size from the most recent interactive resize or **wm geometry** command. If there has been no such operation then the window's natural size will be used.
**wm sizefrom** *window* ?*who*?
If *who* is specified, it must be either **program** or **user**, or an abbreviation of one of these two. It indicates whether *window*'s current size was requested by the program or by the user. Some window managers ignore program-requested sizes and ask the user to manually size the window; if **user** is specified then the window manager should give the window its specified size without asking the user for assistance. If *who* is specified as an empty string, then the current size source is cancelled. If *who* is specified, then the command returns an empty string. Otherwise it returns **user** or **window** to indicate the source of the window's current size, or an empty string if no source has been specified yet. Most window managers interpret “no source” as equivalent to **program**.
**wm stackorder** *window* ?**isabove**|**isbelow** *window*?
The **stackorder** command returns a list of toplevel windows in stacking order, from lowest to highest. When a single toplevel window is passed, the returned list recursively includes all of the window's children that are toplevels. Only those toplevels that are currently mapped to the screen are returned. The **stackorder** command can also be used to determine if one toplevel is positioned above or below a second toplevel. When two window arguments separated by either **isabove** or **isbelow** are passed, a boolean result indicates whether or not the first window is currently above or below the second window in the stacking order.
**wm state** *window* ?newstate?
If *newstate* is specified, the window will be set to the new state, otherwise it returns the current state of *window*: either **normal**, **iconic**, **withdrawn**, **icon**, or (Windows and Mac OS X only) **zoomed**. The difference between **iconic** and **icon** is that **iconic** refers to a window that has been iconified (e.g., with the **wm iconify** command) while **icon** refers to a window whose only purpose is to serve as the icon for some other window (via the **wm iconwindow** command). The **icon** state cannot be set.
**wm title** *window* ?*string*?
If *string* is specified, then it will be passed to the window manager for use as the title for *window* (the window manager should display this string in *window*'s title bar). In this case the command returns an empty string. If *string* is not specified then the command returns the current title for the *window*. The title for a window defaults to its name.
**wm transient** *window* ?*master*?
If *master* is specified, then the window manager is informed that *window* is a transient window (e.g. pull-down menu) working on behalf of *master* (where *master* is the path name for a top-level window). If *master* is specified as an empty string then *window* is marked as not being a transient window any more. Otherwise the command returns the path name of *window*'s current master, or an empty string if *window* is not currently a transient window. A transient window will mirror state changes in the master and inherit the state of the master when initially mapped. It is an error to attempt to make a window a transient of itself. The window manager may also decorate a transient window differently, removing some features normally present (e.g., minimize and maximize buttons) though this is entirely at the discretion of the window manager.
**wm withdraw** *window*
Arranges for *window* to be withdrawn from the screen. This causes the window to be unmapped and forgotten about by the window manager. If the window has never been mapped, then this command causes the window to be mapped in the withdrawn state. Not all window managers appear to know how to handle windows that are mapped in the withdrawn state. Note: it sometimes seems to be necessary to withdraw a window and then re-map it (e.g. with **wm deiconify**) to get some window managers to pay attention to changes in window attributes such as group.
Geometry management
-------------------
By default a top-level window appears on the screen in its *natural size*, which is the one determined internally by its widgets and geometry managers. If the natural size of a top-level window changes, then the window's size changes to match. A top-level window can be given a size other than its natural size in two ways. First, the user can resize the window manually using the facilities of the window manager, such as resize handles. Second, the application can request a particular size for a top-level window using the **wm geometry** command. These two cases are handled identically by Tk; in either case, the requested size overrides the natural size. You can return the window to its natural by invoking **wm geometry** with an empty *geometry* string. Normally a top-level window can have any size from one pixel in each dimension up to the size of its screen. However, you can use the **wm minsize** and **wm maxsize** commands to limit the range of allowable sizes. The range set by **wm minsize** and **wm maxsize** applies to all forms of resizing, including the window's natural size as well as manual resizes and the **wm geometry** command. You can also use the command **wm resizable** to completely disable interactive resizing in one or both dimensions.
The **wm manage** and **wm forget** commands may be used to perform undocking and docking of windows. After a widget is managed by **wm manage** command, all other **wm** subcommands may be used with the widget. Only widgets created using the toplevel command may have an attached menu via the **-menu** configure option. A toplevel widget may be used as a frame and managed with any of the other geometry managers after using the **wm forget** command. Any menu associated with a toplevel widget will be hidden when managed by another geometry managers. The menus will reappear once the window is managed by **wm**. All custom bindtags for widgets in a subtree that have their top-level widget changed via a **wm manage** or **wm forget** command, must be redone to adjust any top-level widget path in the bindtags. Bindtags that have not been customized do not have to be redone.
Gridded geometry management
---------------------------
Gridded geometry management occurs when one of the widgets of an application supports a range of useful sizes. This occurs, for example, in a text editor where the scrollbars, menus, and other adornments are fixed in size but the edit widget can support any number of lines of text or characters per line. In this case, it is usually desirable to let the user specify the number of lines or characters-per-line, either with the **wm geometry** command or by interactively resizing the window. In the case of text, and in other interesting cases also, only discrete sizes of the window make sense, such as integral numbers of lines and characters-per-line; arbitrary pixel sizes are not useful. Gridded geometry management provides support for this kind of application. Tk (and the window manager) assume that there is a grid of some sort within the application and that the application should be resized in terms of *grid units* rather than pixels. Gridded geometry management is typically invoked by turning on the **setGrid** option for a widget; it can also be invoked with the **wm grid** command or by calling **[Tk\_SetGrid](https://www.tcl.tk/man/tcl/TkLib/SetGrid.htm)**. In each of these approaches the particular widget (or sometimes code in the application as a whole) specifies the relationship between integral grid sizes for the window and pixel sizes. To return to non-gridded geometry management, invoke **wm grid** with empty argument strings.
When gridded geometry management is enabled then all the dimensions specified in **wm minsize**, **wm maxsize**, and **wm geometry** commands are treated as grid units rather than pixel units. Interactive resizing is also carried out in even numbers of grid units rather than pixels.
Bugs
----
Most existing window managers appear to have bugs that affect the operation of the **wm** command. For example, some changes will not take effect if the window is already active: the window will have to be withdrawn and de-iconified in order to make the change happen. Examples
--------
A fixed-size window that says that it is fixed-size too:
```
toplevel .fixed
**wm title** .fixed "Fixed-size Window"
**wm resizable** .fixed 0 0
```
A simple dialog-like window, centred on the screen:
```
# Create and arrange the dialog contents.
toplevel .msg
label .msg.l -text "This is a very simple dialog demo."
button .msg.ok -text OK -default active -command {destroy .msg}
pack .msg.ok -side bottom -fill x
pack .msg.l -expand 1 -fill both
# Now set the widget up as a centred dialog.
# But first, we need the geometry managers to finish setting
# up the interior of the dialog, for which we need to run the
# event loop with the widget hidden completely...
**wm withdraw** .msg
update
set x [expr {([winfo screenwidth .]-[winfo width .msg])/2}]
set y [expr {([winfo screenheight .]-[winfo height .msg])/2}]
**wm geometry** .msg +$x+$y
**wm transient** .msg .
**wm title** .msg "Dialog demo"
**wm deiconify** .msg
```
See also
--------
**[toplevel](toplevel.htm)**, **[winfo](winfo.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TkCmd/wm.htm>
| programming_docs |
tcl_tk spinbox spinbox
=======
[NAME](spinbox.htm#M2) spinbox — Create and manipulate 'spinbox' value spinner widgets
[SYNOPSIS](spinbox.htm#M3)
[STANDARD OPTIONS](spinbox.htm#M4)
[-activebackground, activeBackground, Foreground](options.htm#M-activebackground)
[-background or -bg, background, Background](options.htm#M-background)
[-borderwidth or -bd, borderWidth, BorderWidth](options.htm#M-borderwidth)
[-cursor, cursor, Cursor](options.htm#M-cursor)
[-exportselection, exportSelection, ExportSelection](options.htm#M-exportselection)
[-font, font, Font](options.htm#M-font)
[-foreground or -fg, foreground, Foreground](options.htm#M-foreground)
[-highlightbackground, highlightBackground, HighlightBackground](options.htm#M-highlightbackground)
[-highlightcolor, highlightColor, HighlightColor](options.htm#M-highlightcolor)
[-highlightthickness, highlightThickness, HighlightThickness](options.htm#M-highlightthickness)
[-insertbackground, insertBackground, Foreground](options.htm#M-insertbackground)
[-insertborderwidth, insertBorderWidth, BorderWidth](options.htm#M-insertborderwidth)
[-insertofftime, insertOffTime, OffTime](options.htm#M-insertofftime)
[-insertontime, insertOnTime, OnTime](options.htm#M-insertontime)
[-insertwidth, insertWidth, InsertWidth](options.htm#M-insertwidth)
[-justify, justify, Justify](options.htm#M-justify)
[-relief, relief, Relief](options.htm#M-relief)
[-repeatdelay, repeatDelay, RepeatDelay](options.htm#M-repeatdelay)
[-repeatinterval, repeatInterval, RepeatInterval](options.htm#M-repeatinterval)
[-selectbackground, selectBackground, Foreground](options.htm#M-selectbackground)
[-selectborderwidth, selectBorderWidth, BorderWidth](options.htm#M-selectborderwidth)
[-selectforeground, selectForeground, Background](options.htm#M-selectforeground)
[-takefocus, takeFocus, TakeFocus](options.htm#M-takefocus)
[-textvariable, textVariable, Variable](options.htm#M-textvariable)
[-xscrollcommand, xScrollCommand, ScrollCommand](options.htm#M-xscrollcommand)
[WIDGET-SPECIFIC OPTIONS](spinbox.htm#M5)
[-buttonbackground, buttonBackground, Background](spinbox.htm#M6)
[-buttoncursor, buttonCursor, Cursor](spinbox.htm#M7)
[-buttondownrelief, buttonDownRelief, Relief](spinbox.htm#M8)
[-buttonuprelief, buttonUpRelief, Relief](spinbox.htm#M9)
[-command, command, Command](spinbox.htm#M10)
[-disabledbackground, disabledBackground, DisabledBackground](spinbox.htm#M11)
[-disabledforeground, disabledForeground, DisabledForeground](spinbox.htm#M12)
[-format, format, Format](spinbox.htm#M13)
[-from, from, From](spinbox.htm#M14)
[-invalidcommand or -invcmd, invalidCommand, InvalidCommand](spinbox.htm#M15)
[-increment, increment, Increment](spinbox.htm#M16)
[-readonlybackground, readonlyBackground, ReadonlyBackground](spinbox.htm#M17)
[-state, state, State](spinbox.htm#M18)
[-to, to, To](spinbox.htm#M19)
[-validate, validate, Validate](spinbox.htm#M20)
[-validatecommand or -vcmd, validateCommand, ValidateCommand](spinbox.htm#M21)
[-values, values, Values](spinbox.htm#M22)
[-width, width, Width](spinbox.htm#M23)
[-wrap, wrap, wrap](spinbox.htm#M24)
[DESCRIPTION](spinbox.htm#M25)
[VALIDATION](spinbox.htm#M26)
[**none**](spinbox.htm#M27)
[**focus**](spinbox.htm#M28)
[**focusin**](spinbox.htm#M29)
[**focusout**](spinbox.htm#M30)
[**key**](spinbox.htm#M31)
[**all**](spinbox.htm#M32)
[**%d**](spinbox.htm#M33)
[**%i**](spinbox.htm#M34)
[**%P**](spinbox.htm#M35)
[**%s**](spinbox.htm#M36)
[**%S**](spinbox.htm#M37)
[**%v**](spinbox.htm#M38)
[**%V**](spinbox.htm#M39)
[**%W**](spinbox.htm#M40)
[WIDGET COMMAND](spinbox.htm#M41)
[INDICES](spinbox.htm#M42)
[*number*](spinbox.htm#M43)
[**anchor**](spinbox.htm#M44)
[**end**](spinbox.htm#M45)
[**insert**](spinbox.htm#M46)
[**sel.first**](spinbox.htm#M47)
[**sel.last**](spinbox.htm#M48)
[**@***number*](spinbox.htm#M49)
[SUBCOMMANDS](spinbox.htm#M50)
[*pathName* **bbox** *index*](spinbox.htm#M51)
[*pathName* **cget** *option*](spinbox.htm#M52)
[*pathName* **configure** ?*option*? ?*value option value ...*?](spinbox.htm#M53)
[*pathName* **delete** *first* ?*last*?](spinbox.htm#M54)
[*pathName* **get**](spinbox.htm#M55)
[*pathName* **icursor** *index*](spinbox.htm#M56)
[*pathName* **identify** *x y*](spinbox.htm#M57)
[*pathName* **index** *index*](spinbox.htm#M58)
[*pathName* **insert** *index string*](spinbox.htm#M59)
[*pathName* **invoke** *element*](spinbox.htm#M60)
[*pathName* **scan** *option args*](spinbox.htm#M61)
[*pathName* **scan mark** *x*](spinbox.htm#M62)
[*pathName* **scan dragto** *x*](spinbox.htm#M63)
[*pathName* **selection** *option arg*](spinbox.htm#M64)
[*pathName* **selection adjust** *index*](spinbox.htm#M65)
[*pathName* **selection clear**](spinbox.htm#M66)
[*pathName* **selection element** ?*element*?](spinbox.htm#M67)
[*pathName* **selection from** *index*](spinbox.htm#M68)
[*pathName* **selection present**](spinbox.htm#M69)
[*pathName* **selection range** *start end*](spinbox.htm#M70)
[*pathName* **selection to** *index*](spinbox.htm#M71)
[*pathName* **set** ?*string*?](spinbox.htm#M72)
[*pathName* **validate**](spinbox.htm#M73)
[*pathName* **xview** *args*](spinbox.htm#M74)
[*pathName* **xview**](spinbox.htm#M75)
[*pathName* **xview** *index*](spinbox.htm#M76)
[*pathName* **xview moveto** *fraction*](spinbox.htm#M77)
[*pathName* **xview scroll** *number what*](spinbox.htm#M78)
[DEFAULT BINDINGS](spinbox.htm#M79)
[SEE ALSO](spinbox.htm#M80)
[KEYWORDS](spinbox.htm#M81)
Name
----
spinbox — Create and manipulate 'spinbox' value spinner widgets Synopsis
--------
**spinbox** *pathName* ?*options*?
Standard options
----------------
**[-activebackground, activeBackground, Foreground](options.htm#M-activebackground)**
**[-background or -bg, background, Background](options.htm#M-background)**
**[-borderwidth or -bd, borderWidth, BorderWidth](options.htm#M-borderwidth)**
**[-cursor, cursor, Cursor](options.htm#M-cursor)**
**[-exportselection, exportSelection, ExportSelection](options.htm#M-exportselection)**
**[-font, font, Font](options.htm#M-font)**
**[-foreground or -fg, foreground, Foreground](options.htm#M-foreground)**
**[-highlightbackground, highlightBackground, HighlightBackground](options.htm#M-highlightbackground)**
**[-highlightcolor, highlightColor, HighlightColor](options.htm#M-highlightcolor)**
**[-highlightthickness, highlightThickness, HighlightThickness](options.htm#M-highlightthickness)**
**[-insertbackground, insertBackground, Foreground](options.htm#M-insertbackground)**
**[-insertborderwidth, insertBorderWidth, BorderWidth](options.htm#M-insertborderwidth)**
**[-insertofftime, insertOffTime, OffTime](options.htm#M-insertofftime)**
**[-insertontime, insertOnTime, OnTime](options.htm#M-insertontime)**
**[-insertwidth, insertWidth, InsertWidth](options.htm#M-insertwidth)**
**[-justify, justify, Justify](options.htm#M-justify)**
**[-relief, relief, Relief](options.htm#M-relief)**
**[-repeatdelay, repeatDelay, RepeatDelay](options.htm#M-repeatdelay)**
**[-repeatinterval, repeatInterval, RepeatInterval](options.htm#M-repeatinterval)**
**[-selectbackground, selectBackground, Foreground](options.htm#M-selectbackground)**
**[-selectborderwidth, selectBorderWidth, BorderWidth](options.htm#M-selectborderwidth)**
**[-selectforeground, selectForeground, Background](options.htm#M-selectforeground)**
**[-takefocus, takeFocus, TakeFocus](options.htm#M-takefocus)**
**[-textvariable, textVariable, Variable](options.htm#M-textvariable)**
**[-xscrollcommand, xScrollCommand, ScrollCommand](options.htm#M-xscrollcommand)**
Widget-specific options
-----------------------
Command-Line Name: **-buttonbackground** Database Name: **buttonBackground** Database Class: **Background**
The background color to be used for the spin buttons.
Command-Line Name: **-buttoncursor** Database Name: **buttonCursor** Database Class: **Cursor**
The cursor to be used when over the spin buttons. If this is empty (the default), a default cursor will be used.
Command-Line Name: **-buttondownrelief** Database Name: **buttonDownRelief** Database Class: **Relief**
The relief to be used for the upper spin button.
Command-Line Name: **-buttonuprelief** Database Name: **buttonUpRelief** Database Class: **Relief**
The relief to be used for the lower spin button.
Command-Line Name: **-command** Database Name: **command** Database Class: **Command**
Specifies a Tcl command to invoke whenever a spinbutton is invoked. The command recognizes several percent substitutions: **%W** for the widget path, **%s** for the current value of the widget, and **%d** for the direction of the button pressed (**up** or **down**).
Command-Line Name: **-disabledbackground** Database Name: **disabledBackground** Database Class: **DisabledBackground**
Specifies the background color to use when the spinbox is disabled. If this option is the empty string, the normal background color is used.
Command-Line Name: **-disabledforeground** Database Name: **disabledForeground** Database Class: **DisabledForeground**
Specifies the foreground color to use when the spinbox is disabled. If this option is the empty string, the normal foreground color is used.
Command-Line Name: **-format** Database Name: **[format](../tclcmd/format.htm)** Database Class: **[Format](../tclcmd/format.htm)**
Specifies an alternate format to use when setting the string value when using the **-from** and **-to** range. This must be a format specifier of the form **%<pad>.<pad>f**, as it will format a floating-point number.
Command-Line Name: **-from** Database Name: **from** Database Class: **From**
A floating-point value corresponding to the lowest value for a spinbox, to be used in conjunction with **-to** and **-increment**. When all are specified correctly, the spinbox will use these values to control its contents. This value must be less than the **-to** option. If **-values** is specified, it supersedes this option.
Command-Line Name: **-invalidcommand or -invcmd** Database Name: **invalidCommand** Database Class: **InvalidCommand**
Specifies a script to eval when **-validatecommand** returns 0. Setting it to an empty string disables this feature (the default). The best use of this option is to set it to *bell*. See **[VALIDATION](#M26)** below for more information.
Command-Line Name: **-increment** Database Name: **increment** Database Class: **Increment**
A floating-point value specifying the increment. When used with **-from** and **-to**, the value in the widget will be adjusted by **-increment** when a spin button is pressed (up adds the value, down subtracts the value).
Command-Line Name: **-readonlybackground** Database Name: **readonlyBackground** Database Class: **ReadonlyBackground**
Specifies the background color to use when the spinbox is readonly. If this option is the empty string, the normal background color is used.
Command-Line Name: **-state** Database Name: **state** Database Class: **State**
Specifies one of three states for the spinbox: **normal**, **disabled**, or **readonly**. If the spinbox is readonly, then the value may not be changed using widget commands and no insertion cursor will be displayed, even if the input focus is in the widget; the contents of the widget may still be selected. If the spinbox is disabled, the value may not be changed, no insertion cursor will be displayed, the contents will not be selectable, and the spinbox may be displayed in a different color, depending on the values of the **-disabledforeground** and **-disabledbackground** options.
Command-Line Name: **-to** Database Name: **to** Database Class: **To**
A floating-point value corresponding to the highest value for the spinbox, to be used in conjunction with **-from** and **-increment**. When all are specified correctly, the spinbox will use these values to control its contents. This value must be greater than the **-from** option. If **-values** is specified, it supersedes this option.
Command-Line Name: **-validate** Database Name: **validate** Database Class: **Validate**
Specifies the mode in which validation should operate: **none**, **[focus](focus.htm)**, **focusin**, **focusout**, **key**, or **all**. It defaults to **none**. When you want validation, you must explicitly state which mode you wish to use. See **[VALIDATION](#M26)** below for more.
Command-Line Name: **-validatecommand or -vcmd** Database Name: **validateCommand** Database Class: **ValidateCommand**
Specifies a script to evaluate when you want to validate the input in the widget. Setting it to an empty string disables this feature (the default). Validation occurs according to the value of **-validate**. This command must return a valid Tcl boolean value. If it returns 0 (or the valid Tcl boolean equivalent) then the value of the widget will not change and the **-invalidcommand** will be evaluated if it is set. If it returns 1, then value will be changed. See **[VALIDATION](#M26)** below for more information.
Command-Line Name: **-values** Database Name: **values** Database Class: **Values**
Must be a proper list value. If specified, the spinbox will use these values as to control its contents, starting with the first value. This option has precedence over the **-from** and **-to** range.
Command-Line Name: **-width** Database Name: **width** Database Class: **Width**
Specifies an integer value indicating the desired width of the spinbox window, in average-size characters of the widget's font. If the value is less than or equal to zero, the widget picks a size just large enough to hold its current text.
Command-Line Name: **-wrap** Database Name: **wrap** Database Class: **wrap**
Must be a proper boolean value. If on, the spinbox will wrap around the values of data in the widget.
Description
-----------
The **spinbox** command creates a new window (given by the *pathName* argument) and makes it into a spinbox widget. Additional options, described above, may be specified on the command line or in the option database to configure aspects of the spinbox such as its colors, font, and relief. The **spinbox** command returns its *pathName* argument. At the time this command is invoked, there must not exist a window named *pathName*, but *pathName*'s parent must exist. A **spinbox** is an extended **[entry](entry.htm)** widget that allows he user to move, or spin, through a fixed set of ascending or descending values such as times or dates in addition to editing the value as in an **[entry](entry.htm)**. When first created, a spinbox's string is empty. A portion of the spinbox may be selected as described below. If a spinbox is exporting its selection (see the **-exportselection** option), then it will observe the standard protocols for handling the selection; spinbox selections are available as type **[STRING](../tclcmd/string.htm)**. Spinboxes also observe the standard Tk rules for dealing with the input focus. When a spinbox has the input focus it displays an *insertion cursor* to indicate where new characters will be inserted.
Spinboxes are capable of displaying strings that are too long to fit entirely within the widget's window. In this case, only a portion of the string will be displayed; commands described below may be used to change the view in the window. Spinboxes use the standard **-xscrollcommand** mechanism for interacting with scrollbars (see the description of the **-xscrollcommand** option for details). They also support scanning, as described below.
Validation
----------
Validation works by setting the **-validatecommand** option to a script which will be evaluated according to the **-validate** option as follows:
**none**
Default. This means no validation will occur.
**focus**
The **-validatecommand** will be called when the spinbox receives or loses focus.
**focusin**
The **-validatecommand** will be called when the spinbox receives focus.
**focusout**
The **-validatecommand** will be called when the spinbox loses focus.
**key**
The **-validatecommand** will be called when the spinbox is edited.
**all**
The **-validatecommand** will be called for all above conditions.
It is possible to perform percent substitutions on the **-validatecommand** and **-invalidcommand** scripts, just as you would in a **[bind](bind.htm)** script. The following substitutions are recognized:
**%d**
Type of action: 1 for **insert**, 0 for **delete**, or -1 for focus, forced or textvariable validation.
**%i**
Index of char string to be inserted/deleted, if any, otherwise -1.
**%P**
The value of the spinbox should edition occur. If you are configuring the spinbox widget to have a new textvariable, this will be the value of that textvariable.
**%s**
The current value of spinbox before edition.
**%S**
The text string being inserted/deleted, if any. Otherwise it is an empty string.
**%v**
The type of validation currently set.
**%V**
The type of validation that triggered the callback (key, focusin, focusout, forced).
**%W**
The name of the spinbox widget.
In general, the **-textvariable** and **-validatecommand** can be dangerous to mix. Any problems have been overcome so that using the **-validatecommand** will not interfere with the traditional behavior of the spinbox widget. Using the **-textvariable** for read-only purposes will never cause problems. The danger comes when you try set the **-textvariable** to something that the **-validatecommand** would not accept, which causes **-validate** to become **none** (the **-invalidcommand** will not be triggered). The same happens when an error occurs evaluating the **-validatecommand**.
Primarily, an error will occur when the **-validatecommand** or **-invalidcommand** encounters an error in its script while evaluating or **-validatecommand** does not return a valid Tcl boolean value. The **-validate** option will also set itself to **none** when you edit the spinbox widget from within either the **-validatecommand** or the **-invalidcommand**. Such editions will override the one that was being validated. If you wish to edit the value of the widget during validation and still have the **-validate** option set, you should include the command
```
*%W config -validate %v*
```
in the **-validatecommand** or **-invalidcommand** (whichever one you were editing the spinbox widget from). It is also recommended to not set an associated **-textvariable** during validation, as that can cause the spinbox widget to become out of sync with the **-textvariable**. Also, the **validate** option will set itself to **none** when the spinbox value gets changed because of adjustment of **from** or **to** and the **validateCommand** returns false. For instance
```
*spinbox pathName -from 1 -to 10 -validate all -vcmd {return 0}*
```
will in fact set the **validate** option to **none** because the default value for the spinbox gets changed (due to the **from** and **to** options) to a value not accepted by the validation script. Widget command
--------------
The **spinbox** command creates a new Tcl command whose name is *pathName*. This command may be used to invoke various operations on the widget. It has the following general form:
```
*pathName option* ?*arg arg ...*?
```
*Option* and the *arg*s determine the exact behavior of the command. ### Indices
Many of the widget commands for spinboxes take one or more indices as arguments. An index specifies a particular character in the spinbox's string, in any of the following ways:
*number*
Specifies the character as a numerical index, where 0 corresponds to the first character in the string.
**anchor**
Indicates the anchor point for the selection, which is set with the **select from** and **select adjust** widget commands.
**end**
Indicates the character just after the last one in the spinbox's string. This is equivalent to specifying a numerical index equal to the length of the spinbox's string.
**insert**
Indicates the character adjacent to and immediately following the insertion cursor.
**sel.first**
Indicates the first character in the selection. It is an error to use this form if the selection is not in the spinbox window.
**sel.last**
Indicates the character just after the last one in the selection. It is an error to use this form if the selection is not in the spinbox window.
**@***number*
In this form, *number* is treated as an x-coordinate in the spinbox's window; the character spanning that x-coordinate is used. For example, “**@0**” indicates the left-most character in the window.
Abbreviations may be used for any of the forms above, e.g. “**e**” or “**sel.f**”. In general, out-of-range indices are automatically rounded to the nearest legal value.
### Subcommands
The following commands are possible for spinbox widgets:
*pathName* **bbox** *index*
Returns a list of four numbers describing the bounding box of the character given by *index*. The first two elements of the list give the x and y coordinates of the upper-left corner of the screen area covered by the character (in pixels relative to the widget) and the last two elements give the width and height of the character, in pixels. The bounding box may refer to a region outside the visible area of the window.
*pathName* **cget** *option*
Returns the current value of the configuration option given by *option*. *Option* may have any of the values accepted by the **spinbox** command.
*pathName* **configure** ?*option*? ?*value option value ...*?
Query or modify the configuration options of the widget. If no *option* is specified, returns a list describing all of the available options for *pathName* (see **[Tk\_ConfigureInfo](https://www.tcl.tk/man/tcl/TkLib/ConfigWidg.htm)** for information on the format of this list). If *option* is specified with no *value*, then the command returns a list describing the one named option (this list will be identical to the corresponding sublist of the value returned if no *option* is specified). If one or more *option-value* pairs are specified, then the command modifies the given widget option(s) to have the given value(s); in this case the command returns an empty string. *Option* may have any of the values accepted by the **spinbox** command.
*pathName* **delete** *first* ?*last*?
Delete one or more elements of the spinbox. *First* is the index of the first character to delete, and *last* is the index of the character just after the last one to delete. If *last* is not specified it defaults to *first*+1, i.e. a single character is deleted. This command returns an empty string.
*pathName* **get**
Returns the spinbox's string.
*pathName* **icursor** *index*
Arrange for the insertion cursor to be displayed just before the character given by *index*. Returns an empty string.
*pathName* **identify** *x y*
Returns the name of the window element corresponding to coordinates *x* and *y* in the spinbox. Return value is one of: **none**, **buttondown**, **buttonup**, **[entry](entry.htm)**.
*pathName* **index** *index*
Returns the numerical index corresponding to *index*.
*pathName* **insert** *index string*
Insert the characters of *string* just before the character indicated by *index*. Returns an empty string.
*pathName* **invoke** *element*
Causes the specified element, either **buttondown** or **buttonup**, to be invoked, triggering the action associated with it.
*pathName* **scan** *option args*
This command is used to implement scanning on spinboxes. It has two forms, depending on *option*:
*pathName* **scan mark** *x*
Records *x* and the current view in the spinbox window; used in conjunction with later **scan dragto** commands. Typically this command is associated with a mouse button press in the widget. It returns an empty string.
*pathName* **scan dragto** *x*
This command computes the difference between its *x* argument and the *x* argument to the last **scan mark** command for the widget. It then adjusts the view left or right by 10 times the difference in x-coordinates. This command is typically associated with mouse motion events in the widget, to produce the effect of dragging the spinbox at high speed through the window. The return value is an empty string.
*pathName* **selection** *option arg*
This command is used to adjust the selection within a spinbox. It has several forms, depending on *option*:
*pathName* **selection adjust** *index*
Locate the end of the selection nearest to the character given by *index*, and adjust that end of the selection to be at *index* (i.e. including but not going beyond *index*). The other end of the selection is made the anchor point for future **select to** commands. If the selection is not currently in the spinbox, then a new selection is created to include the characters between *index* and the most recent selection anchor point, inclusive. Returns an empty string.
*pathName* **selection clear**
Clear the selection if it is currently in this widget. If the selection is not in this widget then the command has no effect. Returns an empty string.
*pathName* **selection element** ?*element*?
Sets or gets the currently selected element. If a spinbutton element is specified, it will be displayed depressed.
*pathName* **selection from** *index*
Set the selection anchor point to just before the character given by *index*. Does not change the selection. Returns an empty string.
*pathName* **selection present**
Returns 1 if there is are characters selected in the spinbox, 0 if nothing is selected.
*pathName* **selection range** *start end*
Sets the selection to include the characters starting with the one indexed by *start* and ending with the one just before *end*. If *end* refers to the same character as *start* or an earlier one, then the spinbox's selection is cleared.
*pathName* **selection to** *index*
If *index* is before the anchor point, set the selection to the characters from *index* up to but not including the anchor point. If *index* is the same as the anchor point, do nothing. If *index* is after the anchor point, set the selection to the characters from the anchor point up to but not including *index*. The anchor point is determined by the most recent **select from** or **select adjust** command in this widget. If the selection is not in this widget then a new selection is created using the most recent anchor point specified for the widget. Returns an empty string.
*pathName* **set** ?*string*?
If *string* is specified, the spinbox will try and set it to this value, otherwise it just returns the spinbox's string. If validation is on, it will occur when setting the string.
*pathName* **validate**
This command is used to force an evaluation of the **-validatecommand** independent of the conditions specified by the **-validate** option. This is done by temporarily setting the **-validate** option to **all**. It returns 0 or 1.
*pathName* **xview** *args*
This command is used to query and change the horizontal position of the text in the widget's window. It can take any of the following forms:
*pathName* **xview**
Returns a list containing two elements. Each element is a real fraction between 0 and 1; together they describe the horizontal span that is visible in the window. For example, if the first element is .2 and the second element is .6, 20% of the spinbox's text is off-screen to the left, the middle 40% is visible in the window, and 40% of the text is off-screen to the right. These are the same values passed to scrollbars via the **-xscrollcommand** option.
*pathName* **xview** *index*
Adjusts the view in the window so that the character given by *index* is displayed at the left edge of the window.
*pathName* **xview moveto** *fraction*
Adjusts the view in the window so that the character *fraction* of the way through the text appears at the left edge of the window. *Fraction* must be a fraction between 0 and 1.
*pathName* **xview scroll** *number what*
This command shifts the view in the window left or right according to *number* and *what*. *Number* must be an integer. *What* must be either **units** or **pages** or an abbreviation of one of these. If *what* is **units**, the view adjusts left or right by *number* average-width characters on the display; if it is **pages** then the view adjusts by *number* screenfuls. If *number* is negative then characters farther to the left become visible; if it is positive then characters farther to the right become visible.
Default bindings
----------------
Tk automatically creates class bindings for spinboxes that give them the following default behavior. In the descriptions below, “word” refers to a contiguous group of letters, digits, or “\_” characters, or any single character other than these.
1. Clicking mouse button 1 positions the insertion cursor just before the character underneath the mouse cursor, sets the input focus to this widget, and clears any selection in the widget. Dragging with mouse button 1 strokes out a selection between the insertion cursor and the character under the mouse.
2. Double-clicking with mouse button 1 selects the word under the mouse and positions the insertion cursor at the beginning of the word. Dragging after a double click will stroke out a selection consisting of whole words.
3. Triple-clicking with mouse button 1 selects all of the text in the spinbox and positions the insertion cursor before the first character.
4. The ends of the selection can be adjusted by dragging with mouse button 1 while the Shift key is down; this will adjust the end of the selection that was nearest to the mouse cursor when button 1 was pressed. If the button is double-clicked before dragging then the selection will be adjusted in units of whole words.
5. Clicking mouse button 1 with the Control key down will position the insertion cursor in the spinbox without affecting the selection.
6. If any normal printing characters are typed in a spinbox, they are inserted at the point of the insertion cursor.
7. The view in the spinbox can be adjusted by dragging with mouse button 2. If mouse button 2 is clicked without moving the mouse, the selection is copied into the spinbox at the position of the mouse cursor.
8. If the mouse is dragged out of the spinbox on the left or right sides while button 1 is pressed, the spinbox will automatically scroll to make more text visible (if there is more text off-screen on the side where the mouse left the window).
9. The Left and Right keys move the insertion cursor one character to the left or right; they also clear any selection in the spinbox and set the selection anchor. If Left or Right is typed with the Shift key down, then the insertion cursor moves and the selection is extended to include the new character. Control-Left and Control-Right move the insertion cursor by words, and Control-Shift-Left and Control-Shift-Right move the insertion cursor by words and also extend the selection. Control-b and Control-f behave the same as Left and Right, respectively. Meta-b and Meta-f behave the same as Control-Left and Control-Right, respectively.
10. The Home key, or Control-a, will move the insertion cursor to the beginning of the spinbox and clear any selection in the spinbox. Shift-Home moves the insertion cursor to the beginning of the spinbox and also extends the selection to that point.
11. The End key, or Control-e, will move the insertion cursor to the end of the spinbox and clear any selection in the spinbox. Shift-End moves the cursor to the end and extends the selection to that point.
12. The Select key and Control-Space set the selection anchor to the position of the insertion cursor. They do not affect the current selection. Shift-Select and Control-Shift-Space adjust the selection to the current position of the insertion cursor, selecting from the anchor to the insertion cursor if there was not any selection previously.
13. Control-/ selects all the text in the spinbox.
14. Control-\ clears any selection in the spinbox.
15. The F16 key (labelled Copy on many Sun workstations) or Meta-w copies the selection in the widget to the clipboard, if there is a selection.
16. The F20 key (labelled Cut on many Sun workstations) or Control-w copies the selection in the widget to the clipboard and deletes the selection. If there is no selection in the widget then these keys have no effect.
17. The F18 key (labelled Paste on many Sun workstations) or Control-y inserts the contents of the clipboard at the position of the insertion cursor.
18. The Delete key deletes the selection, if there is one in the spinbox. If there is no selection, it deletes the character to the right of the insertion cursor.
19. The BackSpace key and Control-h delete the selection, if there is one in the spinbox. If there is no selection, it deletes the character to the left of the insertion cursor.
20. Control-d deletes the character to the right of the insertion cursor.
21. Meta-d deletes the word to the right of the insertion cursor.
22. Control-k deletes all the characters to the right of the insertion cursor.
23. Control-t reverses the order of the two characters to the right of the insertion cursor.
If the spinbox is disabled using the **-state** option, then the spinbox's view can still be adjusted and text in the spinbox can still be selected, but no insertion cursor will be displayed and no text modifications will take place.
The behavior of spinboxes can be changed by defining new bindings for individual widgets or by redefining the class bindings.
See also
--------
**[ttk::spinbox](ttk_spinbox.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TkCmd/spinbox.htm>
| programming_docs |
tcl_tk place place
=====
[NAME](place.htm#M2) place — Geometry manager for fixed or rubber-sheet placement
[SYNOPSIS](place.htm#M3)
[DESCRIPTION](place.htm#M4)
[**place** *window option value* ?*option value ...*?](place.htm#M5)
[**place configure** *window* ?*option*? ?*value option value ...*?](place.htm#M6)
[**-anchor** *where*](place.htm#M7)
[**-bordermode** *mode*](place.htm#M8)
[**-height** *size*](place.htm#M9)
[**-in** *master*](place.htm#M10)
[**-relheight** *size*](place.htm#M11)
[**-relwidth** *size*](place.htm#M12)
[**-relx** *location*](place.htm#M13)
[**-rely** *location*](place.htm#M14)
[**-width** *size*](place.htm#M15)
[**-x** *location*](place.htm#M16)
[**-y** *location*](place.htm#M17)
[**place forget** *window*](place.htm#M18)
[**place info** *window*](place.htm#M19)
[**place slaves** *window*](place.htm#M20)
[FINE POINTS](place.htm#M21)
[EXAMPLE](place.htm#M22)
[SEE ALSO](place.htm#M23)
[KEYWORDS](place.htm#M24)
Name
----
place — Geometry manager for fixed or rubber-sheet placement Synopsis
--------
**place** *option arg* ?*arg ...*?
Description
-----------
The placer is a geometry manager for Tk. It provides simple fixed placement of windows, where you specify the exact size and location of one window, called the *slave*, within another window, called the *master*. The placer also provides rubber-sheet placement, where you specify the size and location of the slave in terms of the dimensions of the master, so that the slave changes size and location in response to changes in the size of the master. Lastly, the placer allows you to mix these styles of placement so that, for example, the slave has a fixed width and height but is centered inside the master.
**place** *window option value* ?*option value ...*?
Arrange for the placer to manage the geometry of a slave whose pathName is *window*. The remaining arguments consist of one or more *option-value* pairs that specify the way in which *window*'s geometry is managed. *Option* may have any of the values accepted by the **place configure** command.
**place configure** *window* ?*option*? ?*value option value ...*?
Query or modify the geometry options of the slave given by *window*. If no *option* is specified, this command returns a list describing the available options (see **[Tk\_ConfigureInfo](https://www.tcl.tk/man/tcl/TkLib/ConfigWidg.htm)** for information on the format of this list). If *option* is specified with no *value*, then the command returns a list describing the one named option (this list will be identical to the corresponding sublist of the value returned if no *option* is specified). If one or more *option-value* pairs are specified, then the command modifies the given option(s) to have the given value(s); in this case the command returns an empty string. The following *option-value* pairs are supported:
**-anchor** *where*
*Where* specifies which point of *window* is to be positioned at the (x,y) location selected by the **-x**, **-y**, **-relx**, and **-rely** options. The anchor point is in terms of the outer area of *window* including its border, if any. Thus if *where* is **se** then the lower-right corner of *window*'s border will appear at the given (x,y) location in the master. The anchor position defaults to **nw**.
**-bordermode** *mode*
*Mode* determines the degree to which borders within the master are used in determining the placement of the slave. The default and most common value is **inside**. In this case the placer considers the area of the master to be the innermost area of the master, inside any border: an option of **-x 0** corresponds to an x-coordinate just inside the border and an option of **-relwidth 1.0** means *window* will fill the area inside the master's border. If *mode* is **outside** then the placer considers the area of the master to include its border; this mode is typically used when placing *window* outside its master, as with the options **-x 0 -y 0 -anchor ne**. Lastly, *mode* may be specified as **ignore**, in which case borders are ignored: the area of the master is considered to be its official X area, which includes any internal border but no external border. A bordermode of **ignore** is probably not very useful.
**-height** *size*
*Size* specifies the height for *window* in screen units (i.e. any of the forms accepted by **[Tk\_GetPixels](https://www.tcl.tk/man/tcl/TkLib/GetPixels.htm)**). The height will be the outer dimension of *window* including its border, if any. If *size* is an empty string, or if no **-height** or **-relheight** option is specified, then the height requested internally by the window will be used.
**-in** *master*
*Master* specifies the path name of the window relative to which *window* is to be placed. *Master* must either be *window*'s parent or a descendant of *window*'s parent. In addition, *master* and *window* must both be descendants of the same top-level window. These restrictions are necessary to guarantee that *window* is visible whenever *master* is visible. If this option is not specified then the master defaults to *window*'s parent.
**-relheight** *size*
*Size* specifies the height for *window*. In this case the height is specified as a floating-point number relative to the height of the master: 0.5 means *window* will be half as high as the master, 1.0 means *window* will have the same height as the master, and so on. If both **-height** and **-relheight** are specified for a slave, their values are summed. For example, **-relheight 1.0 -height -2** makes the slave 2 pixels shorter than the master.
**-relwidth** *size*
*Size* specifies the width for *window*. In this case the width is specified as a floating-point number relative to the width of the master: 0.5 means *window* will be half as wide as the master, 1.0 means *window* will have the same width as the master, and so on. If both **-width** and **-relwidth** are specified for a slave, their values are summed. For example, **-relwidth 1.0 -width 5** makes the slave 5 pixels wider than the master.
**-relx** *location*
*Location* specifies the x-coordinate within the master window of the anchor point for *window*. In this case the location is specified in a relative fashion as a floating-point number: 0.0 corresponds to the left edge of the master and 1.0 corresponds to the right edge of the master. *Location* need not be in the range 0.0-1.0. If both **-x** and **-relx** are specified for a slave then their values are summed. For example, **-relx 0.5 -x -2** positions the left edge of the slave 2 pixels to the left of the center of its master.
**-rely** *location*
*Location* specifies the y-coordinate within the master window of the anchor point for *window*. In this case the value is specified in a relative fashion as a floating-point number: 0.0 corresponds to the top edge of the master and 1.0 corresponds to the bottom edge of the master. *Location* need not be in the range 0.0-1.0. If both **-y** and **-rely** are specified for a slave then their values are summed. For example, **-rely 0.5 -x 3** positions the top edge of the slave 3 pixels below the center of its master.
**-width** *size*
*Size* specifies the width for *window* in screen units (i.e. any of the forms accepted by **[Tk\_GetPixels](https://www.tcl.tk/man/tcl/TkLib/GetPixels.htm)**). The width will be the outer width of *window* including its border, if any. If *size* is an empty string, or if no **-width** or **-relwidth** option is specified, then the width requested internally by the window will be used.
**-x** *location*
*Location* specifies the x-coordinate within the master window of the anchor point for *window*. The location is specified in screen units (i.e. any of the forms accepted by **[Tk\_GetPixels](https://www.tcl.tk/man/tcl/TkLib/GetPixels.htm)**) and need not lie within the bounds of the master window.
**-y** *location*
*Location* specifies the y-coordinate within the master window of the anchor point for *window*. The location is specified in screen units (i.e. any of the forms accepted by **[Tk\_GetPixels](https://www.tcl.tk/man/tcl/TkLib/GetPixels.htm)**) and need not lie within the bounds of the master window.
If the same value is specified separately with two different options, such as **-x** and **-relx**, then the most recent option is used and the older one is ignored.
**place forget** *window*
Causes the placer to stop managing the geometry of *window*. As a side effect of this command *window* will be unmapped so that it does not appear on the screen. If *window* is not currently managed by the placer then the command has no effect. This command returns an empty string.
**place info** *window*
Returns a list giving the current configuration of *window*. The list consists of *option-value* pairs in exactly the same form as might be specified to the **place configure** command.
**place slaves** *window*
Returns a list of all the slave windows for which *window* is the master. If there are no slaves for *window* then an empty string is returned.
If the configuration of a window has been retrieved with **place info**, that configuration can be restored later by first using **place forget** to erase any existing information for the window and then invoking **place configure** with the saved information.
Fine points
-----------
It is not necessary for the master window to be the parent of the slave window. This feature is useful in at least two situations. First, for complex window layouts it means you can create a hierarchy of subwindows whose only purpose is to assist in the layout of the parent. The “real children” of the parent (i.e. the windows that are significant for the application's user interface) can be children of the parent yet be placed inside the windows of the geometry-management hierarchy. This means that the path names of the “real children” do not reflect the geometry-management hierarchy and users can specify options for the real children without being aware of the structure of the geometry-management hierarchy. A second reason for having a master different than the slave's parent is to tie two siblings together. For example, the placer can be used to force a window always to be positioned centered just below one of its siblings by specifying the configuration
```
**-in** *sibling* **-relx 0.5 -rely 1.0 -anchor n -bordermode outside**
```
Whenever the sibling is repositioned in the future, the slave will be repositioned as well. Unlike many other geometry managers (such as the packer) the placer does not make any attempt to manipulate the geometry of the master windows or the parents of slave windows (i.e. it does not set their requested sizes). To control the sizes of these windows, make them windows like frames and canvases that provide configuration options for this purpose.
Example
-------
Make the label occupy the middle bit of the toplevel, no matter how it is resized:
```
label .l -text "In the\nMiddle!" -bg black -fg white
**place** .l -relwidth .3 -relx .35 -relheight .3 -rely .35
```
See also
--------
**[grid](grid.htm)**, **[pack](pack.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TkCmd/place.htm>
tcl_tk text text
====
[NAME](text.htm#M2) text, tk\_textCopy, tk\_textCut, tk\_textPaste — Create and manipulate 'text' hypertext editing widgets
[SYNOPSIS](text.htm#M3)
[STANDARD OPTIONS](text.htm#M4)
[-background or -bg, background, Background](options.htm#M-background)
[-borderwidth or -bd, borderWidth, BorderWidth](options.htm#M-borderwidth)
[-cursor, cursor, Cursor](options.htm#M-cursor)
[-exportselection, exportSelection, ExportSelection](options.htm#M-exportselection)
[-font, font, Font](options.htm#M-font)
[-foreground or -fg, foreground, Foreground](options.htm#M-foreground)
[-highlightbackground, highlightBackground, HighlightBackground](options.htm#M-highlightbackground)
[-highlightcolor, highlightColor, HighlightColor](options.htm#M-highlightcolor)
[-highlightthickness, highlightThickness, HighlightThickness](options.htm#M-highlightthickness)
[-insertbackground, insertBackground, Foreground](options.htm#M-insertbackground)
[-insertborderwidth, insertBorderWidth, BorderWidth](options.htm#M-insertborderwidth)
[-insertofftime, insertOffTime, OffTime](options.htm#M-insertofftime)
[-insertontime, insertOnTime, OnTime](options.htm#M-insertontime)
[-insertwidth, insertWidth, InsertWidth](options.htm#M-insertwidth)
[-padx, padX, Pad](options.htm#M-padx)
[-pady, padY, Pad](options.htm#M-pady)
[-relief, relief, Relief](options.htm#M-relief)
[-selectbackground, selectBackground, Foreground](options.htm#M-selectbackground)
[-selectborderwidth, selectBorderWidth, BorderWidth](options.htm#M-selectborderwidth)
[-selectforeground, selectForeground, Background](options.htm#M-selectforeground)
[-setgrid, setGrid, SetGrid](options.htm#M-setgrid)
[-takefocus, takeFocus, TakeFocus](options.htm#M-takefocus)
[-xscrollcommand, xScrollCommand, ScrollCommand](options.htm#M-xscrollcommand)
[-yscrollcommand, yScrollCommand, ScrollCommand](options.htm#M-yscrollcommand)
[WIDGET-SPECIFIC OPTIONS](text.htm#M5)
[-autoseparators, autoSeparators, AutoSeparators](text.htm#M6)
[-blockcursor, blockCursor, BlockCursor](text.htm#M7)
[-endline, endLine, EndLine](text.htm#M8)
[-height, height, Height](text.htm#M9)
[-inactiveselectbackground, inactiveSelectBackground, Foreground](text.htm#M10)
[-insertunfocussed, insertUnfocussed, InsertUnfocussed](text.htm#M11)
[-maxundo, maxUndo, MaxUndo](text.htm#M12)
[-spacing1, spacing1, Spacing1](text.htm#M13)
[-spacing2, spacing2, Spacing2](text.htm#M14)
[-spacing3, spacing3, Spacing3](text.htm#M15)
[-startline, startLine, StartLine](text.htm#M16)
[-state, state, State](text.htm#M17)
[-tabs, tabs, Tabs](text.htm#M18)
[-tabstyle, tabStyle, TabStyle](text.htm#M19)
[-undo, undo, Undo](text.htm#M20)
[-width, width, Width](text.htm#M21)
[-wrap, wrap, Wrap](text.htm#M22)
[DESCRIPTION](text.htm#M23)
[INDICES](text.htm#M24)
[*line***.***char*](text.htm#M25)
[**@***x***,***y*](text.htm#M26)
[**end**](text.htm#M27)
[*mark*](text.htm#M28)
[*tag***.first**](text.htm#M29)
[*tag***.last**](text.htm#M30)
[*pathName*](text.htm#M31)
[*imageName*](text.htm#M32)
[**+** *count* ?*submodifier*? **chars**](text.htm#M33)
[**-** *count* ?*submodifier*? **chars**](text.htm#M34)
[**+** *count* ?*submodifier*? **indices**](text.htm#M35)
[**-** *count* ?*submodifier*? **indices**](text.htm#M36)
[**+** *count* ?*submodifier*? **lines**](text.htm#M37)
[**-** *count* ?*submodifier*? **lines**](text.htm#M38)
[?*submodifier*? **linestart**](text.htm#M39)
[?*submodifier*? **lineend**](text.htm#M40)
[?*submodifier*? **wordstart**](text.htm#M41)
[?*submodifier*? **wordend**](text.htm#M42)
[TAGS](text.htm#M43)
[**-background** *color*](text.htm#M44)
[**-bgstipple** *bitmap*](text.htm#M45)
[**-borderwidth** *pixels*](text.htm#M46)
[**-elide** *boolean*](text.htm#M47)
[**-fgstipple** *bitmap*](text.htm#M48)
[**-font** *fontName*](text.htm#M49)
[**-foreground** *color*](text.htm#M50)
[**-justify** *justify*](text.htm#M51)
[**-lmargin1** *pixels*](text.htm#M52)
[**-lmargin2** *pixels*](text.htm#M53)
[**-lmargincolor** *color*](text.htm#M54)
[**-offset** *pixels*](text.htm#M55)
[**-overstrike** *boolean*](text.htm#M56)
[**-overstrikefg** *color*](text.htm#M57)
[**-relief** *relief*](text.htm#M58)
[**-rmargin** *pixels*](text.htm#M59)
[**-rmargincolor** *color*](text.htm#M60)
[**-selectbackground** *color*](text.htm#M61)
[**-selectforeground** *color*](text.htm#M62)
[**-spacing1** *pixels*](text.htm#M63)
[**-spacing2** *pixels*](text.htm#M64)
[**-spacing3** *pixels*](text.htm#M65)
[**-tabs** *tabList*](text.htm#M66)
[**-tabstyle** *style*](text.htm#M67)
[**-underline** *boolean*](text.htm#M68)
[**-underlinefg** *color*](text.htm#M69)
[**-wrap** *mode*](text.htm#M70)
[MARKS](text.htm#M71)
[EMBEDDED WINDOWS](text.htm#M72)
[**-align** *where*](text.htm#M73)
[**-create** *script*](text.htm#M74)
[**-padx** *pixels*](text.htm#M75)
[**-pady** *pixels*](text.htm#M76)
[**-stretch** *boolean*](text.htm#M77)
[**-window** *pathName*](text.htm#M78)
[EMBEDDED IMAGES](text.htm#M79)
[**-align** *where*](text.htm#M80)
[**-image** *image*](text.htm#M81)
[**-name** *ImageName*](text.htm#M82)
[**-padx** *pixels*](text.htm#M83)
[**-pady** *pixels*](text.htm#M84)
[THE SELECTION](text.htm#M85)
[THE INSERTION CURSOR](text.htm#M86)
[THE MODIFIED FLAG](text.htm#M87)
[THE UNDO MECHANISM](text.htm#M88)
[PEER WIDGETS](text.htm#M89)
[ASYNCHRONOUS UPDATE OF LINE HEIGHTS](text.htm#M90)
[WIDGET COMMAND](text.htm#M91)
[*pathName* **bbox** *index*](text.htm#M92)
[*pathName* **cget** *option*](text.htm#M93)
[*pathName* **compare** *index1 op index2*](text.htm#M94)
[*pathName* **configure** ?*option*? *?value option value ...*?](text.htm#M95)
[*pathName* **count** *?options*? *index1 index2*](text.htm#M96)
[**-chars**](text.htm#M97)
[**-displaychars**](text.htm#M98)
[**-displayindices**](text.htm#M99)
[**-displaylines**](text.htm#M100)
[**-indices**](text.htm#M101)
[**-lines**](text.htm#M102)
[**-xpixels**](text.htm#M103)
[**-ypixels**](text.htm#M104)
[*pathName* **debug** ?*boolean*?](text.htm#M105)
[*pathName* **delete** *index1* ?*index2 ...*?](text.htm#M106)
[*pathName* **dlineinfo** *index*](text.htm#M107)
[*pathName* **dump** ?*switches*? *index1* ?*index2*?](text.htm#M108)
[**-all**](text.htm#M109)
[**-command** *command*](text.htm#M110)
[**-image**](text.htm#M111)
[**-mark**](text.htm#M112)
[**-tag**](text.htm#M113)
[**-text**](text.htm#M114)
[**-window**](text.htm#M115)
[*pathName* **edit** *option* ?*arg arg ...*?](text.htm#M116)
[*pathName* **edit canredo**](text.htm#M117)
[*pathName* **edit canundo**](text.htm#M118)
[*pathName* **edit modified** ?*boolean*?](text.htm#M119)
[*pathName* **edit redo**](text.htm#M120)
[*pathName* **edit reset**](text.htm#M121)
[*pathName* **edit separator**](text.htm#M122)
[*pathName* **edit undo**](text.htm#M123)
[*pathName* **get** ?**-displaychars**? ?**--**? *index1* ?*index2 ...*?](text.htm#M124)
[*pathName* **image** *option* ?*arg arg ...*?](text.htm#M125)
[*pathName* **image cget** *index option*](text.htm#M126)
[*pathName* **image configure** *index* ?*option value ...*?](text.htm#M127)
[*pathName* **image create** *index* ?*option value ...*?](text.htm#M128)
[*pathName* **image names**](text.htm#M129)
[*pathName* **index** *index*](text.htm#M130)
[*pathName* **insert** *index chars* ?*tagList chars tagList ...*?](text.htm#M131)
[*pathName* **mark** *option* ?*arg arg ...*?](text.htm#M132)
[*pathName* **mark gravity** *markName* ?*direction*?](text.htm#M133)
[*pathName* **mark names**](text.htm#M134)
[*pathName* **mark next** *index*](text.htm#M135)
[*pathName* **mark previous** *index*](text.htm#M136)
[*pathName* **mark set** *markName index*](text.htm#M137)
[*pathName* **mark unset** *markName* ?*markName markName ...*?](text.htm#M138)
[*pathName* **peer** *option args*](text.htm#M139)
[*pathName* **peer create** *newPathName* ?*options*?](text.htm#M140)
[*pathName* **peer names**](text.htm#M141)
[*pathName* **pendingsync**](text.htm#M142)
[*pathName* **replace** *index1 index2 chars* ?*tagList chars tagList ...*?](text.htm#M143)
[*pathName* **scan** *option args*](text.htm#M144)
[*pathName* **scan mark** *x y*](text.htm#M145)
[*pathName* **scan dragto** *x y*](text.htm#M146)
[*pathName* **search** ?*switches*? *pattern index* ?*stopIndex*?](text.htm#M147)
[**-forwards**](text.htm#M148)
[**-backwards**](text.htm#M149)
[**-exact**](text.htm#M150)
[**-regexp**](text.htm#M151)
[**-nolinestop**](text.htm#M152)
[**-nocase**](text.htm#M153)
[**-count** *varName*](text.htm#M154)
[**-all**](text.htm#M155)
[**-overlap**](text.htm#M156)
[**-strictlimits**](text.htm#M157)
[**-elide**](text.htm#M158)
[**--**](text.htm#M159)
[*pathName* **see** *index*](text.htm#M160)
[*pathName* **sync** ?**-command** *command*?](text.htm#M161)
[*pathName* **sync**](text.htm#M162)
[*pathName* **sync -command** *command*](text.htm#M163)
[*pathName* **tag** *option* ?*arg arg ...*?](text.htm#M164)
[*pathName* **tag add** *tagName index1* ?*index2 index1 index2 ...*?](text.htm#M165)
[*pathName* **tag bind** *tagName* ?*sequence*? ?*script*?](text.htm#M166)
[*pathName* **tag cget** *tagName option*](text.htm#M167)
[*pathName* **tag configure** *tagName* ?*option*? ?*value*? ?*option value ...*?](text.htm#M168)
[*pathName* **tag delete** *tagName* ?*tagName ...*?](text.htm#M169)
[*pathName* **tag lower** *tagName* ?*belowThis*?](text.htm#M170)
[*pathName* **tag names** ?*index*?](text.htm#M171)
[*pathName* **tag nextrange** *tagName index1* ?*index2*?](text.htm#M172)
[*pathName* **tag prevrange** *tagName index1* ?*index2*?](text.htm#M173)
[*pathName* **tag raise** *tagName* ?*aboveThis*?](text.htm#M174)
[*pathName* **tag ranges** *tagName*](text.htm#M175)
[*pathName* **tag remove** *tagName index1* ?*index2 index1 index2 ...*?](text.htm#M176)
[*pathName* **window** *option* ?*arg arg ...*?](text.htm#M177)
[*pathName* **window cget** *index option*](text.htm#M178)
[*pathName* **window configure** *index* ?*option value ...*?](text.htm#M179)
[*pathName* **window create** *index* ?*option value ...*?](text.htm#M180)
[*pathName* **window names**](text.htm#M181)
[*pathName* **xview** *option args*](text.htm#M182)
[*pathName* **xview**](text.htm#M183)
[*pathName* **xview moveto** *fraction*](text.htm#M184)
[*pathName* **xview scroll** *number what*](text.htm#M185)
[*pathName* **yview** ?*args*?](text.htm#M186)
[*pathName* **yview**](text.htm#M187)
[*pathName* **yview moveto** *fraction*](text.htm#M188)
[*pathName* **yview scroll** *number what*](text.htm#M189)
[*pathName* **yview** ?**-pickplace**? *index*](text.htm#M190)
[*pathName* **yview** *number*](text.htm#M191)
[BINDINGS](text.htm#M192)
[KNOWN ISSUES](text.htm#M193)
[ISSUES CONCERNING CHARS AND INDICES](text.htm#M194)
[PERFORMANCE ISSUES](text.htm#M195)
[KNOWN BUGS](text.htm#M196)
[SEE ALSO](text.htm#M197)
[KEYWORDS](text.htm#M198)
Name
----
text, tk\_textCopy, tk\_textCut, tk\_textPaste — Create and manipulate 'text' hypertext editing widgets Synopsis
--------
**text** *pathName* ?*options*?
**tk\_textCopy** *pathName*
**tk\_textCut** *pathName*
**tk\_textPaste** *pathName*
Standard options
----------------
**[-background or -bg, background, Background](options.htm#M-background)**
**[-borderwidth or -bd, borderWidth, BorderWidth](options.htm#M-borderwidth)**
**[-cursor, cursor, Cursor](options.htm#M-cursor)**
**[-exportselection, exportSelection, ExportSelection](options.htm#M-exportselection)**
**[-font, font, Font](options.htm#M-font)**
**[-foreground or -fg, foreground, Foreground](options.htm#M-foreground)**
**[-highlightbackground, highlightBackground, HighlightBackground](options.htm#M-highlightbackground)**
**[-highlightcolor, highlightColor, HighlightColor](options.htm#M-highlightcolor)**
**[-highlightthickness, highlightThickness, HighlightThickness](options.htm#M-highlightthickness)**
**[-insertbackground, insertBackground, Foreground](options.htm#M-insertbackground)**
**[-insertborderwidth, insertBorderWidth, BorderWidth](options.htm#M-insertborderwidth)**
**[-insertofftime, insertOffTime, OffTime](options.htm#M-insertofftime)**
**[-insertontime, insertOnTime, OnTime](options.htm#M-insertontime)**
**[-insertwidth, insertWidth, InsertWidth](options.htm#M-insertwidth)**
**[-padx, padX, Pad](options.htm#M-padx)**
**[-pady, padY, Pad](options.htm#M-pady)**
**[-relief, relief, Relief](options.htm#M-relief)**
**[-selectbackground, selectBackground, Foreground](options.htm#M-selectbackground)**
**[-selectborderwidth, selectBorderWidth, BorderWidth](options.htm#M-selectborderwidth)**
**[-selectforeground, selectForeground, Background](options.htm#M-selectforeground)**
**[-setgrid, setGrid, SetGrid](options.htm#M-setgrid)**
**[-takefocus, takeFocus, TakeFocus](options.htm#M-takefocus)**
**[-xscrollcommand, xScrollCommand, ScrollCommand](options.htm#M-xscrollcommand)**
**[-yscrollcommand, yScrollCommand, ScrollCommand](options.htm#M-yscrollcommand)**
Widget-specific options
-----------------------
Command-Line Name: **-autoseparators** Database Name: **autoSeparators** Database Class: **AutoSeparators**
Specifies a boolean that says whether separators are automatically inserted in the undo stack. Only meaningful when the **-undo** option is true.
Command-Line Name: **-blockcursor** Database Name: **blockCursor** Database Class: **BlockCursor**
Specifies a boolean that says whether the blinking insertion cursor should be drawn as a character-sized rectangular block. If false (the default) a thin vertical line is used for the insertion cursor.
Command-Line Name: **-endline** Database Name: **endLine** Database Class: **EndLine**
Specifies an integer line index representing the line of the underlying textual data store that should be just after the last line contained in the widget. This allows a text widget to reflect only a portion of a larger piece of text. Instead of an integer, the empty string can be provided to this configuration option, which will configure the widget to end at the very last line in the textual data store.
Command-Line Name: **-height** Database Name: **height** Database Class: **Height**
Specifies the desired height for the window, in units of characters in the font given by the **-font** option. Must be at least one.
Command-Line Name: **-inactiveselectbackground** Database Name: **inactiveSelectBackground** Database Class: **Foreground**
Specifies the colour to use for the selection (the **sel** tag) when the window does not have the input focus. If empty, **{}**, then no selection is shown when the window does not have the focus.
Command-Line Name: **-insertunfocussed** Database Name: **insertUnfocussed** Database Class: **InsertUnfocussed**
Specifies how to display the insertion cursor when the widget does not have the focus. Must be **none** (the default) which means to not display the cursor, **hollow** which means to display a hollow box, or **solid** which means to display a solid box. Note that **hollow** and **solid** will appear very similar when the **-blockcursor** option is false.
Command-Line Name: **-maxundo** Database Name: **maxUndo** Database Class: **MaxUndo**
Specifies the maximum number of compound undo actions on the undo stack. A zero or a negative value imply an unlimited undo stack.
Command-Line Name: **-spacing1** Database Name: **spacing1** Database Class: **Spacing1**
Requests additional space above each text line in the widget, using any of the standard forms for screen distances. If a line wraps, this option only applies to the first line on the display. This option may be overridden with **-spacing1** options in tags.
Command-Line Name: **-spacing2** Database Name: **spacing2** Database Class: **Spacing2**
For lines that wrap (so that they cover more than one line on the display) this option specifies additional space to provide between the display lines that represent a single line of text. The value may have any of the standard forms for screen distances. This option may be overridden with **-spacing2** options in tags.
Command-Line Name: **-spacing3** Database Name: **spacing3** Database Class: **Spacing3**
Requests additional space below each text line in the widget, using any of the standard forms for screen distances. If a line wraps, this option only applies to the last line on the display. This option may be overridden with **-spacing3** options in tags.
Command-Line Name: **-startline** Database Name: **startLine** Database Class: **StartLine**
Specifies an integer line index representing the first line of the underlying textual data store that should be contained in the widget. This allows a text widget to reflect only a portion of a larger piece of text. Instead of an integer, the empty string can be provided to this configuration option, which will configure the widget to start at the very first line in the textual data store.
Command-Line Name: **-state** Database Name: **state** Database Class: **State**
Specifies one of two states for the text: **normal** or **disabled**. If the text is disabled then characters may not be inserted or deleted and no insertion cursor will be displayed, even if the input focus is in the widget.
Command-Line Name: **-tabs** Database Name: **tabs** Database Class: **Tabs**
Specifies a set of tab stops for the window. The option's value consists of a list of screen distances giving the positions of the tab stops, each of which is a distance relative to the left edge of the widget (excluding borders, padding, etc). Each position may optionally be followed in the next list element by one of the keywords **left**, **right**, **center**, or **numeric**, which specifies how to justify text relative to the tab stop. **Left** is the default; it causes the text following the tab character to be positioned with its left edge at the tab position. **Right** means that the right edge of the text following the tab character is positioned at the tab position, and **center** means that the text is centered at the tab position. **Numeric** means that the decimal point in the text is positioned at the tab position; if there is no decimal point then the least significant digit of the number is positioned just to the left of the tab position; if there is no number in the text then the text is right-justified at the tab position. For example, “**-tabs {2c left 4c 6c center}**” creates three tab stops at two-centimeter intervals; the first two use left justification and the third uses center justification. If the list of tab stops does not have enough elements to cover all of the tabs in a text line, then Tk extrapolates new tab stops using the spacing and alignment from the last tab stop in the list. Tab distances must be strictly positive, and must always increase from one tab stop to the next (if not, an error is thrown). The value of the **-tabs** option may be overridden by **-tabs** options in tags.
If no **-tabs** option is specified, or if it is specified as an empty list, then Tk uses default tabs spaced every eight (average size) characters. To achieve a different standard spacing, for example every 4 characters, simply configure the widget with “**-tabs "[expr {4 \* [font measure $font 0]}] left" -tabstyle wordprocessor**”.
Command-Line Name: **-tabstyle** Database Name: **tabStyle** Database Class: **TabStyle**
Specifies how to interpret the relationship between tab stops on a line and tabs in the text of that line. The value must be **tabular** (the default) or **wordprocessor**. Note that tabs are interpreted as they are encountered in the text. If the tab style is **tabular** then the *n*'th tab character in the line's text will be associated with the *n*'th tab stop defined for that line. If the tab character's x coordinate falls to the right of the *n*'th tab stop, then a gap of a single space will be inserted as a fallback. If the tab style is **wordprocessor** then any tab character being laid out will use (and be defined by) the first tab stop to the right of the preceding characters already laid out on that line. The value of the **-tabstyle** option may be overridden by **-tabstyle** options in tags.
Command-Line Name: **-undo** Database Name: **undo** Database Class: **Undo**
Specifies a boolean that says whether the undo mechanism is active or not.
Command-Line Name: **-width** Database Name: **width** Database Class: **Width**
Specifies the desired width for the window in units of characters in the font given by the **-font** option. If the font does not have a uniform width then the width of the character “0” is used in translating from character units to screen units.
Command-Line Name: **-wrap** Database Name: **wrap** Database Class: **Wrap**
Specifies how to handle lines in the text that are too long to be displayed in a single line of the text's window. The value must be **none** or **char** or **word**. A wrap mode of **none** means that each line of text appears as exactly one line on the screen; extra characters that do not fit on the screen are not displayed. In the other modes each line of text will be broken up into several screen lines if necessary to keep all the characters visible. In **char** mode a screen line break may occur after any character; in **word** mode a line break will only be made at word boundaries.
Description
-----------
The **text** command creates a new window (given by the *pathName* argument) and makes it into a text widget. Additional options, described above, may be specified on the command line or in the option database to configure aspects of the text such as its default background color and relief. The **text** command returns the path name of the new window. A text widget displays one or more lines of text and allows that text to be edited. Text widgets support four different kinds of annotations on the text, called tags, marks, embedded windows or embedded images. Tags allow different portions of the text to be displayed with different fonts and colors. In addition, Tcl commands can be associated with tags so that scripts are invoked when particular actions such as keystrokes and mouse button presses occur in particular ranges of the text. See **[TAGS](#M43)** below for more details.
The second form of annotation consists of floating markers in the text called “marks”. Marks are used to keep track of various interesting positions in the text as it is edited. See **[MARKS](#M71)** below for more details.
The third form of annotation allows arbitrary windows to be embedded in a text widget. See **[EMBEDDED WINDOWS](#M72)** below for more details.
The fourth form of annotation allows Tk images to be embedded in a text widget. See **[EMBEDDED IMAGES](#M79)** below for more details.
The text widget also has a built-in undo/redo mechanism. See **[THE UNDO MECHANISM](#M88)** below for more details.
The text widget allows for the creation of peer widgets. These are other text widgets which share the same underlying data (text, marks, tags, images, etc). See **[PEER WIDGETS](#M89)** below for more details.
Indices
-------
Many of the widget commands for texts take one or more indices as arguments. An index is a string used to indicate a particular place within a text, such as a place to insert characters or one endpoint of a range of characters to delete. Indices have the syntax
```
*base modifier modifier modifier ...*
```
Where *base* gives a starting point and the *modifier*s adjust the index from the starting point (e.g. move forward or backward one character). Every index must contain a *base*, but the *modifier*s are optional. Most modifiers (as documented below) allow an optional submodifier. Valid submodifiers are **any** and **display**. If the submodifier is abbreviated, then it must be followed by whitespace, but otherwise there need be no space between the submodifier and the following *modifier*. Typically the **display** submodifier adjusts the meaning of the following *modifier* to make it refer to visual or non-elided units rather than logical units, but this is explained for each relevant case below. Lastly, where *count* is used as part of a modifier, it can be positive or negative, so “*base* - -3 lines” is perfectly valid (and equivalent to “*base* +3lines”). The *base* for an index must have one of the following forms:
*line***.***char*
Indicates *char*'th character on line *line*. Lines are numbered from 1 for consistency with other UNIX programs that use this numbering scheme. Within a line, characters are numbered from 0. If *char* is **end** then it refers to the newline character that ends the line.
**@***x***,***y*
Indicates the character that covers the pixel whose x and y coordinates within the text's window are *x* and *y*.
**end**
Indicates the end of the text (the character just after the last newline).
*mark*
Indicates the character just after the mark whose name is *mark*.
*tag***.first**
Indicates the first character in the text that has been tagged with *tag*. This form generates an error if no characters are currently tagged with *tag*.
*tag***.last**
Indicates the character just after the last one in the text that has been tagged with *tag*. This form generates an error if no characters are currently tagged with *tag*.
*pathName*
Indicates the position of the embedded window whose name is *pathName*. This form generates an error if there is no embedded window by the given name.
*imageName*
Indicates the position of the embedded image whose name is *imageName*. This form generates an error if there is no embedded image by the given name.
If the *base* could match more than one of the above forms, such as a *mark* and *imageName* both having the same value, then the form earlier in the above list takes precedence. If modifiers follow the base index, each one of them must have one of the forms listed below. Keywords such as **chars** and **wordend** may be abbreviated as long as the abbreviation is unambiguous.
**+** *count* ?*submodifier*? **chars**
Adjust the index forward by *count* characters, moving to later lines in the text if necessary. If there are fewer than *count* characters in the text after the current index, then set the index to the last index in the text. Spaces on either side of *count* are optional. If the **display** submodifier is given, elided characters are skipped over without being counted. If **any** is given, then all characters are counted. For historical reasons, if neither modifier is given then the count actually takes place in units of index positions (see **[INDICES](#M24)** for details). This behaviour may be changed in a future major release, so if you need an index count, you are encouraged to use **indices** instead wherever possible.
**-** *count* ?*submodifier*? **chars**
Adjust the index backward by *count* characters, moving to earlier lines in the text if necessary. If there are fewer than *count* characters in the text before the current index, then set the index to the first index in the text (1.0). Spaces on either side of *count* are optional. If the **display** submodifier is given, elided characters are skipped over without being counted. If **any** is given, then all characters are counted. For historical reasons, if neither modifier is given then the count actually takes place in units of index positions (see **[INDICES](#M24)** for details). This behavior may be changed in a future major release, so if you need an index count, you are encouraged to use **indices** instead wherever possible.
**+** *count* ?*submodifier*? **indices**
Adjust the index forward by *count* index positions, moving to later lines in the text if necessary. If there are fewer than *count* index positions in the text after the current index, then set the index to the last index position in the text. Spaces on either side of *count* are optional. Note that an index position is either a single character or a single embedded image or embedded window. If the **display** submodifier is given, elided indices are skipped over without being counted. If **any** is given, then all indices are counted; this is also the default behaviour if no modifier is given.
**-** *count* ?*submodifier*? **indices**
Adjust the index backward by *count* index positions, moving to earlier lines in the text if necessary. If there are fewer than *count* index positions in the text before the current index, then set the index to the first index position (1.0) in the text. Spaces on either side of *count* are optional. If the **display** submodifier is given, elided indices are skipped over without being counted. If **any** is given, then all indices are counted; this is also the default behaviour if no modifier is given.
**+** *count* ?*submodifier*? **lines**
Adjust the index forward by *count* lines, retaining the same character position within the line. If there are fewer than *count* lines after the line containing the current index, then set the index to refer to the same character position on the last line of the text. Then, if the line is not long enough to contain a character at the indicated character position, adjust the character position to refer to the last character of the line (the newline). Spaces on either side of *count* are optional. If the **display** submodifier is given, then each visual display line is counted separately. Otherwise, if **any** (or no modifier) is given, then each logical line (no matter how many times it is visually wrapped) counts just once. If the relevant lines are not wrapped, then these two methods of counting are equivalent.
**-** *count* ?*submodifier*? **lines**
Adjust the index backward by *count* logical lines, retaining the same character position within the line. If there are fewer than *count* lines before the line containing the current index, then set the index to refer to the same character position on the first line of the text. Then, if the line is not long enough to contain a character at the indicated character position, adjust the character position to refer to the last character of the line (the newline). Spaces on either side of *count* are optional. If the **display** submodifier is given, then each visual display line is counted separately. Otherwise, if **any** (or no modifier) is given, then each logical line (no matter how many times it is visually wrapped) counts just once. If the relevant lines are not wrapped, then these two methods of counting are equivalent.
?*submodifier*? **linestart**
Adjust the index to refer to the first index on the line. If the **display** submodifier is given, this is the first index on the display line, otherwise on the logical line.
?*submodifier*? **lineend**
Adjust the index to refer to the last index on the line (the newline). If the **display** submodifier is given, this is the last index on the display line, otherwise on the logical line.
?*submodifier*? **wordstart**
Adjust the index to refer to the first character of the word containing the current index. A word consists of any number of adjacent characters that are letters, digits, or underscores, or a single character that is not one of these. If the **display** submodifier is given, this only examines non-elided characters, otherwise all characters (elided or not) are examined.
?*submodifier*? **wordend**
Adjust the index to refer to the character just after the last one of the word containing the current index. If the current index refers to the last character of the text then it is not modified. If the **display** submodifier is given, this only examines non-elided characters, otherwise all characters (elided or not) are examined.
If more than one modifier is present then they are applied in left-to-right order. For example, the index “**end - 1 chars**” refers to the next-to-last character in the text and “**insert wordstart - 1 c**” refers to the character just before the first one in the word containing the insertion cursor. Modifiers are applied one by one in this left to right order, and after each step the resulting index is constrained to be a valid index in the text widget. So, for example, the index “**1.0 -1c +1c**” refers to the index “**2.0**”.
Where modifiers result in index changes by display lines, display chars or display indices, and the *base* refers to an index inside an elided tag, that base index is considered to be equivalent to the first following non-elided index.
Tags
----
The first form of annotation in text widgets is a tag. A tag is a textual string that is associated with some of the characters in a text. Tags may contain arbitrary characters, but it is probably best to avoid using the characters “ ” (space), **+**, or **-**: these characters have special meaning in indices, so tags containing them cannot be used as indices. There may be any number of tags associated with characters in a text. Each tag may refer to a single character, a range of characters, or several ranges of characters. An individual character may have any number of tags associated with it. A priority order is defined among tags, and this order is used in implementing some of the tag-related functions described below. When a tag is defined (by associating it with characters or setting its display options or binding commands to it), it is given a priority higher than any existing tag. The priority order of tags may be redefined using the “*pathName* **tag raise**” and “*pathName* **tag lower**” widget commands.
Tags serve three purposes in text widgets. First, they control the way information is displayed on the screen. By default, characters are displayed as determined by the **-background**, **-font**, and **-foreground** options for the text widget. However, display options may be associated with individual tags using the “*pathName* **tag configure**” widget command. If a character has been tagged, then the display options associated with the tag override the default display style. The following options are currently supported for tags:
**-background** *color*
*Color* specifies the background color to use for characters associated with the tag. It may have any of the forms accepted by **[Tk\_GetColor](https://www.tcl.tk/man/tcl/TkLib/GetColor.htm)**.
**-bgstipple** *bitmap*
*Bitmap* specifies a bitmap that is used as a stipple pattern for the background. It may have any of the forms accepted by **[Tk\_GetBitmap](https://www.tcl.tk/man/tcl/TkLib/GetBitmap.htm)**. If *bitmap* has not been specified, or if it is specified as an empty string, then a solid fill will be used for the background.
**-borderwidth** *pixels*
*Pixels* specifies the width of a border to draw around the tag using any of the forms accepted by **[Tk\_GetPixels](https://www.tcl.tk/man/tcl/TkLib/GetPixels.htm)**. This option should be used in conjunction with the **-relief** option to provide the desired border.
**-elide** *boolean*
*Elide* specifies whether the data should be elided. Elided data (characters, images, embedded windows, etc.) is not displayed and takes no space on screen, but further on behaves just as normal data.
**-fgstipple** *bitmap*
*Bitmap* specifies a bitmap that is used as a stipple pattern when drawing text and other foreground information such as underlines. It may have any of the forms accepted by **[Tk\_GetBitmap](https://www.tcl.tk/man/tcl/TkLib/GetBitmap.htm)**. If *bitmap* has not been specified, or if it is specified as an empty string, then a solid fill will be used.
**-font** *fontName*
*FontName* is the name of a font to use for drawing characters. It may have any of the forms accepted by **[Tk\_GetFont](https://www.tcl.tk/man/tcl/TkLib/GetFont.htm)**.
**-foreground** *color*
*Color* specifies the color to use when drawing text and other foreground information such as underlines. It may have any of the forms accepted by **[Tk\_GetColor](https://www.tcl.tk/man/tcl/TkLib/GetColor.htm)**.
**-justify** *justify*
If the first non-elided character of a display line has a tag for which this option has been specified, then *justify* determines how to justify the line. It must be one of **left**, **right**, or **center**. If a line wraps, then the justification for each line on the display is determined by the first non-elided character of that display line.
**-lmargin1** *pixels*
If the first non-elided character of a text line has a tag for which this option has been specified, then *pixels* specifies how much the line should be indented from the left edge of the window. *Pixels* may have any of the standard forms for screen distances. If a line of text wraps, this option only applies to the first line on the display; the **-lmargin2** option controls the indentation for subsequent lines.
**-lmargin2** *pixels*
If the first non-elided character of a display line has a tag for which this option has been specified, and if the display line is not the first for its text line (i.e., the text line has wrapped), then *pixels* specifies how much the line should be indented from the left edge of the window. *Pixels* may have any of the standard forms for screen distances. This option is only used when wrapping is enabled, and it only applies to the second and later display lines for a text line.
**-lmargincolor** *color*
*Color* specifies the background color to use in regions that do not contain characters because they are indented by **-lmargin1** or **-lmargin2**. It may have any of the forms accepted by **[Tk\_GetColor](https://www.tcl.tk/man/tcl/TkLib/GetColor.htm)**.If *color* has not been specified, or if it is specified as an empty string, then the color specified by the **-background** widget option is used.
**-offset** *pixels*
*Pixels* specifies an amount by which the text's baseline should be offset vertically from the baseline of the overall line, in pixels. For example, a positive offset can be used for superscripts and a negative offset can be used for subscripts. *Pixels* may have any of the standard forms for screen distances.
**-overstrike** *boolean*
Specifies whether or not to draw a horizontal rule through the middle of characters. *Boolean* may have any of the forms accepted by **[Tcl\_GetBoolean](https://www.tcl.tk/man/tcl/TclLib/GetInt.htm)**.
**-overstrikefg** *color*
*Color* specifies the color to use when displaying the overstrike. It may have any of the forms accepted by **[Tk\_GetColor](https://www.tcl.tk/man/tcl/TkLib/GetColor.htm)**. If *color* has not been specified, or if it is specified as an empty string, then the color specified by the **-foreground** tag option is used.
**-relief** *relief*
*Relief* specifies the relief style to use for drawing the border, in any of the forms accepted by **[Tk\_GetRelief](https://www.tcl.tk/man/tcl/TkLib/GetRelief.htm)**. This option is used in conjunction with the **-borderwidth** option to enable to the desired border appearance.
**-rmargin** *pixels*
If the first non-elided character of a display line has a tag for which this option has been specified, then *pixels* specifies how wide a margin to leave between the end of the line and the right edge of the window. *Pixels* may have any of the standard forms for screen distances. This option is only used when wrapping is enabled. If a text line wraps, the right margin for each line on the display is determined by the first non-elided character of that display line.
**-rmargincolor** *color*
*Color* specifies the background color to use in regions that do not contain characters because they are indented by **-rmargin1**. It may have any of the forms accepted by **[Tk\_GetColor](https://www.tcl.tk/man/tcl/TkLib/GetColor.htm)**.If *color* has not been specified, or if it is specified as an empty string, then the color specified by the **-background** widget option is used.
**-selectbackground** *color*
*Color* specifies the background color to use when displaying selected items. It may have any of the forms accepted by **[Tk\_GetColor](https://www.tcl.tk/man/tcl/TkLib/GetColor.htm)**. If *color* has not been specified, or if it is specified as an empty string, then the color specified by the **-background** tag option is used.
**-selectforeground** *color*
*Color* specifies the foreground color to use when displaying selected items. It may have any of the forms accepted by **[Tk\_GetColor](https://www.tcl.tk/man/tcl/TkLib/GetColor.htm)**. If *color* has not been specified, or if it is specified as an empty string, then the color specified by the **-foreground** tag option is used.
**-spacing1** *pixels*
*Pixels* specifies how much additional space should be left above each text line, using any of the standard forms for screen distances. If a line wraps, this option only applies to the first line on the display.
**-spacing2** *pixels*
For lines that wrap, this option specifies how much additional space to leave between the display lines for a single text line. *Pixels* may have any of the standard forms for screen distances.
**-spacing3** *pixels*
*Pixels* specifies how much additional space should be left below each text line, using any of the standard forms for screen distances. If a line wraps, this option only applies to the last line on the display.
**-tabs** *tabList*
*TabList* specifies a set of tab stops in the same form as for the **-tabs** option for the text widget. This option only applies to a display line if it applies to the first non-elided character on that display line. If this option is specified as an empty string, it cancels the option, leaving it unspecified for the tag (the default). If the option is specified as a non-empty string that is an empty list, such as **-tags { }**, then it requests default 8-character tabs as described for the **-tags** widget option.
**-tabstyle** *style*
*Style* specifies either the *tabular* or *wordprocessor* style of tabbing to use for the text widget. This option only applies to a display line if it applies to the first non-elided character on that display line. If this option is specified as an empty string, it cancels the option, leaving it unspecified for the tag (the default).
**-underline** *boolean*
*Boolean* specifies whether or not to draw an underline underneath characters. It may have any of the forms accepted by **[Tcl\_GetBoolean](https://www.tcl.tk/man/tcl/TclLib/GetInt.htm)**.
**-underlinefg** *color*
*Color* specifies the color to use when displaying the underline. It may have any of the forms accepted by **[Tk\_GetColor](https://www.tcl.tk/man/tcl/TkLib/GetColor.htm)**. If *color* has not been specified, or if it is specified as an empty string, then the color specified by the **-foreground** tag option is used.
**-wrap** *mode*
*Mode* specifies how to handle lines that are wider than the text's window. It has the same legal values as the **-wrap** option for the text widget: **none**, **char**, or **word**. If this tag option is specified, it overrides the **-wrap** option for the text widget.
If a character has several tags associated with it, and if their display options conflict, then the options of the highest priority tag are used. If a particular display option has not been specified for a particular tag, or if it is specified as an empty string, then that option will never be used; the next-highest-priority tag's option will used instead. If no tag specifies a particular display option, then the default style for the widget will be used.
The second purpose for tags is event bindings. You can associate bindings with a tag in much the same way you can associate bindings with a widget class: whenever particular X events occur on characters with the given tag, a given Tcl command will be executed. Tag bindings can be used to give behaviors to ranges of characters; among other things, this allows hypertext-like features to be implemented. For details, see the description of the “*pathName* **tag bind**” widget command below. Tag bindings are shared between all peer widgets (including any bindings for the special **sel** tag).
The third use for tags is in managing the selection. See **[THE SELECTION](#M85)** below. With the exception of the special **sel** tag, all tags are shared between peer text widgets, and may be manipulated on an equal basis from any such widget. The **sel** tag exists separately and independently in each peer text widget (but any tag bindings to **sel** are shared).
Marks
-----
The second form of annotation in text widgets is a mark. Marks are used for remembering particular places in a text. They are something like tags, in that they have names and they refer to places in the file, but a mark is not associated with particular characters. Instead, a mark is associated with the gap between two characters. Only a single position may be associated with a mark at any given time. If the characters around a mark are deleted the mark will still remain; it will just have new neighbor characters. In contrast, if the characters containing a tag are deleted then the tag will no longer have an association with characters in the file. Marks may be manipulated with the “*pathName* **mark**” widget command, and their current locations may be determined by using the mark name as an index in widget commands. Each mark also has a “gravity”, which is either **left** or **right**. The gravity for a mark specifies what happens to the mark when text is inserted at the point of the mark. If a mark has left gravity, then the mark is treated as if it were attached to the character on its left, so the mark will remain to the left of any text inserted at the mark position. If the mark has right gravity, new text inserted at the mark position will appear to the left of the mark (so that the mark remains rightmost). The gravity for a mark defaults to **right**.
The name space for marks is different from that for tags: the same name may be used for both a mark and a tag, but they will refer to different things.
Two marks have special significance. First, the mark **insert** is associated with the insertion cursor, as described under **[THE INSERTION CURSOR](#M86)** below. Second, the mark **current** is associated with the character closest to the mouse and is adjusted automatically to track the mouse position and any changes to the text in the widget (one exception: **current** is not updated in response to mouse motions if a mouse button is down; the update will be deferred until all mouse buttons have been released). Neither of these special marks may be deleted. With the exception of these two special marks, all marks are shared between peer text widgets, and may be manipulated on an equal basis from any peer.
Embedded windows
----------------
The third form of annotation in text widgets is an embedded window. Each embedded window annotation causes a window to be displayed at a particular point in the text. There may be any number of embedded windows in a text widget, and any widget may be used as an embedded window (subject to the usual rules for geometry management, which require the text window to be the parent of the embedded window or a descendant of its parent). The embedded window's position on the screen will be updated as the text is modified or scrolled, and it will be mapped and unmapped as it moves into and out of the visible area of the text widget. Each embedded window occupies one unit's worth of index space in the text widget, and it may be referred to either by the name of its embedded window or by its position in the widget's index space. If the range of text containing the embedded window is deleted then the window is destroyed. Similarly if the text widget as a whole is deleted, then the window is destroyed.
Eliding an embedded window immediately after scheduling it for creation via *pathName* **window create** *index* **-create** will prevent it from being effectively created. Uneliding an elided embedded window scheduled for creation via *pathName* **window create** *index* **-create** will automatically trigger the associated creation script. After destroying an elided embedded window, the latter won't get automatically recreated.
When an embedded window is added to a text widget with the *pathName* **window create** widget command, several configuration options may be associated with it. These options may be modified later with the *pathName* **window configure** widget command. The following options are currently supported:
**-align** *where*
If the window is not as tall as the line in which it is displayed, this option determines where the window is displayed in the line. *Where* must have one of the values **top** (align the top of the window with the top of the line), **center** (center the window within the range of the line), **bottom** (align the bottom of the window with the bottom of the line's area), or **baseline** (align the bottom of the window with the baseline of the line).
**-create** *script*
Specifies a Tcl script that may be evaluated to create the window for the annotation. If no **-window** option has been specified for the annotation this script will be evaluated when the annotation is about to be displayed on the screen. *Script* must create a window for the annotation and return the name of that window as its result. Two substitutions will be performed in *script* before evaluation. *%W* will be substituted by the name of the parent text widget, and *%%* will be substituted by a single *%*. If the annotation's window should ever be deleted, *script* will be evaluated again the next time the annotation is displayed.
**-padx** *pixels*
*Pixels* specifies the amount of extra space to leave on each side of the embedded window. It may have any of the usual forms defined for a screen distance.
**-pady** *pixels*
*Pixels* specifies the amount of extra space to leave on the top and on the bottom of the embedded window. It may have any of the usual forms defined for a screen distance.
**-stretch** *boolean*
If the requested height of the embedded window is less than the height of the line in which it is displayed, this option can be used to specify whether the window should be stretched vertically to fill its line. If the **-pady** option has been specified as well, then the requested padding will be retained even if the window is stretched.
**-window** *pathName*
Specifies the name of a window to display in the annotation. Note that if a *pathName* has been set, then later configuring a window to the empty string will not delete the widget corresponding to the old *pathName*. Rather it will remove the association between the old *pathName* and the text widget. If multiple peer widgets are in use, it is usually simpler to use the **-create** option if embedded windows are desired in each peer.
Embedded images
---------------
The final form of annotation in text widgets is an embedded image. Each embedded image annotation causes an image to be displayed at a particular point in the text. There may be any number of embedded images in a text widget, and a particular image may be embedded in multiple places in the same text widget. The embedded image's position on the screen will be updated as the text is modified or scrolled. Each embedded image occupies one unit's worth of index space in the text widget, and it may be referred to either by its position in the widget's index space, or the name it is assigned when the image is inserted into the text widget with *pathName* **[image create](image.htm)**. If the range of text containing the embedded image is deleted then that copy of the image is removed from the screen.
Eliding an embedded image immediately after scheduling it for creation via *pathName* **image create** *index* **-create** will prevent it from being effectively created. Uneliding an elided embedded image scheduled for creation via *pathName* **image create** *index* **-create** will automatically trigger the associated creation script. After destroying an elided embedded image, the latter won't get automatically recreated.
When an embedded image is added to a text widget with the *pathName* **image create** widget command, a name unique to this instance of the image is returned. This name may then be used to refer to this image instance. The name is taken to be the value of the **-name** option (described below). If the **-name** option is not provided, the **-image** name is used instead. If the *imageName* is already in use in the text widget, then **#***nn* is added to the end of the *imageName*, where *nn* is an arbitrary integer. This insures the *imageName* is unique. Once this name is assigned to this instance of the image, it does not change, even though the **-image** or **-name** values can be changed with *pathName* **image configure**.
When an embedded image is added to a text widget with the *pathName* **image create** widget command, several configuration options may be associated with it. These options may be modified later with the *pathName* **image configure** widget command. The following options are currently supported:
**-align** *where*
If the image is not as tall as the line in which it is displayed, this option determines where the image is displayed in the line. *Where* must have one of the values **top** (align the top of the image with the top of the line), **center** (center the image within the range of the line), **bottom** (align the bottom of the image with the bottom of the line's area), or **baseline** (align the bottom of the image with the baseline of the line).
**-image** *image*
Specifies the name of the Tk image to display in the annotation. If *image* is not a valid Tk image, then an error is returned.
**-name** *ImageName*
Specifies the name by which this image instance may be referenced in the text widget. If *ImageName* is not supplied, then the name of the Tk image is used instead. If the *imageName* is already in use, *#nn* is appended to the end of the name as described above.
**-padx** *pixels*
*Pixels* specifies the amount of extra space to leave on each side of the embedded image. It may have any of the usual forms defined for a screen distance.
**-pady** *pixels*
*Pixels* specifies the amount of extra space to leave on the top and on the bottom of the embedded image. It may have any of the usual forms defined for a screen distance.
The selection
-------------
Selection support is implemented via tags. If the **-exportselection** option for the text widget is true then the **sel** tag will be associated with the selection:
1. Whenever characters are tagged with **sel** the text widget will claim ownership of the selection.
2. Attempts to retrieve the selection will be serviced by the text widget, returning all the characters with the **sel** tag.
3. If the selection is claimed away by another application or by another window within this application, then the **sel** tag will be removed from all characters in the text.
4. Whenever the **sel** tag range changes a virtual event **<<Selection>>** is generated.
The **sel** tag is automatically defined when a text widget is created, and it may not be deleted with the “*pathName* **tag delete**” widget command. Furthermore, the **-selectbackground**, **-selectborderwidth**, and **-selectforeground** options for the text widget are tied to the **-background**, **-borderwidth**, and **-foreground** options for the **sel** tag: changes in either will automatically be reflected in the other. Also the **-inactiveselectbackground** option for the text widget is used instead of **-selectbackground** when the text widget does not have the focus. This allows programmatic control over the visualization of the **sel** tag for foreground and background windows, or to have **sel** not shown at all (when **-inactiveselectbackground** is empty) for background windows. Each peer text widget has its own **sel** tag which can be separately configured and set.
The insertion cursor
--------------------
The mark named **insert** has special significance in text widgets. It is defined automatically when a text widget is created and it may not be unset with the “*pathName* **mark unset**” widget command. The **insert** mark represents the position of the insertion cursor, and the insertion cursor will automatically be drawn at this point whenever the text widget has the input focus. The modified flag
-----------------
The text widget can keep track of changes to the content of the widget by means of the modified flag. Inserting or deleting text will set this flag. The flag can be queried, set and cleared programmatically as well. Whenever the flag changes state a **<<Modified>>** virtual event is generated. See the *pathName* **edit modified** widget command for more details. The undo mechanism
------------------
The text widget has an unlimited undo and redo mechanism (when the **-undo** widget option is true) which records every insert and delete action on a stack. Boundaries (called “separators”) are inserted between edit actions. The purpose of these separators is to group inserts, deletes and replaces into one compound edit action. When undoing a change everything between two separators will be undone. The undone changes are then moved to the redo stack, so that an undone edit can be redone again. The redo stack is cleared whenever new edit actions are recorded on the undo stack. The undo and redo stacks can be cleared to keep their depth under control.
Separators are inserted automatically when the **-autoseparators** widget option is true. You can insert separators programmatically as well. If a separator is already present at the top of the undo stack no other will be inserted. That means that two separators on the undo stack are always separated by at least one insert or delete action.
The **<<UndoStack>>** virtual event is generated every time the undo stack or the redo stack becomes empty or unempty.
The undo mechanism is also linked to the modified flag. This means that undoing or redoing changes can take a modified text widget back to the unmodified state or vice versa. The modified flag will be set automatically to the appropriate state. This automatic coupling does not work when the modified flag has been set by the user, until the flag has been reset again.
See below for the *pathName* **edit** widget command that controls the undo mechanism.
Peer widgets
------------
The text widget has a separate store of all its data concerning each line's textual contents, marks, tags, images and windows, and the undo stack. While this data store cannot be accessed directly (i.e. without a text widget as an intermediary), multiple text widgets can be created, each of which present different views on the same underlying data. Such text widgets are known as peer text widgets.
As text is added, deleted, edited and coloured in any one widget, and as images, marks, tags are adjusted, all such changes will be reflected in all peers.
All data and markup is shared, except for a few small details. First, the **sel** tag may be set and configured (in its display style) differently for each peer. Second, each peer has its own **insert** and **current** mark positions (but all other marks are shared). Third, embedded windows, which are arbitrary other widgets, cannot be shared between peers. This means the **-window** option of embedded windows is independently set for each peer (it is advisable to use the **-create** script capabilities to allow each peer to create its own embedded windows as needed). Fourth, all of the configuration options of each peer (e.g. **-font**, etc) can be set independently, with the exception of **-undo**, **-maxundo**, **-autoseparators** (i.e. all undo, redo and modified state issues are shared).
Finally any single peer need not contain all lines from the underlying data store. When creating a peer, a contiguous range of lines (e.g. only lines 52 through 125) may be specified. This allows a peer to contain just a small portion of the overall text. The range of lines will expand and contract as text is inserted or deleted. The peer will only ever display complete lines of text (one cannot share just part of a line). If the peer's contents contracts to nothing (i.e. all complete lines in the peer widget have been deleted from another widget), then it is impossible for new lines to be inserted. The peer will simply become an empty shell on which the background can be configured, but which will never show any content (without manual reconfiguration of the start and end lines). Note that a peer which does not contain all of the underlying data store still has indices numbered from “1.0” to “end”. It is simply that those indices reflect a subset of the total data, and data outside the contained range is not accessible to the peer. This means that the command *peerName* **index end** may return quite different values in different peers. Similarly, commands like *peerName* **tag ranges** will not return index ranges outside that which is meaningful to the peer. The configuration options **-startline** and **-endline** may be used to control how much of the underlying data is contained in any given text widget.
Note that peers are really peers. Deleting the “original” text widget will not cause any other peers to be deleted, or otherwise affected.
See below for the *pathName* **peer** widget command that controls the creation of peer widgets.
Asynchronous update of line heights
-----------------------------------
In order to maintain a responsive user-experience, the text widget calculates lines metrics (line heights in pixels) asynchronously. Because of this, some commands of the text widget may return wrong results if the asynchronous calculations are not finished at the time of calling. This applies to *pathName* **count -ypixels** and *pathName* **yview**. Again for performance reasons, it would not be appropriate to let these commands always wait for the end of the update calculation each time they are called. In most use cases of these commands a more or less inaccurate result does not really matter compared to execution speed.
In case accurate result is needed (and if the text widget is managed by a geometry manager), one can resort to *pathName* **sync** and *pathName* **pendingsync** to control the synchronization of the view of text widgets.
The **<<WidgetViewSync>>** virtual event fires when the line heights of the text widget become obsolete (due to some editing command or configuration change), and again when the internal data of the text widget are back in sync with the widget view. The detail field (%d substitution) is either true (when the widget is in sync) or false (when it is not).
*pathName* **sync**, *pathName* **pendingsync** and **<<WidgetViewSync>>** apply to each text widget independently of its peers.
Examples of use:
```
## Example 1:
# immediately complete line metrics at any cost (GUI unresponsive)
$w sync
$w yview moveto $fraction
## Example 2:
# synchronously wait for up-to-date line metrics (GUI responsive)
# before executing the scheduled command, but don't block execution flow
$w sync -command [list $w yview moveto $fraction]
## Example 3:
# init
set yud($w) 0
proc updateaction w {
set ::yud($w) 1
# any other update action here...
}
# runtime, synchronously wait for up-to-date line metrics (GUI responsive)
$w sync -command [list updateaction $w]
vwait yud($w)
$w yview moveto $fraction
## Example 4:
# init
set todo($w) {}
proc updateaction w {
foreach cmd $::todo($w) {uplevel #0 $cmd}
set todo($w) {}
}
# runtime
lappend todo($w) [list $w yview moveto $fraction]
$w sync -command [list updateaction $w]
## Example 5:
# init
set todo($w) {}
bind $w <<WidgetViewSync>> {
if {%d} {
foreach cmd $todo(%W) {eval $cmd}
set todo(%W) {}
}
}
# runtime
if {![$w pendingsync]} {
$w yview moveto $fraction
} else {
lappend todo($w) [list $w yview moveto $fraction]
}
```
Widget command
--------------
The **text** command creates a new Tcl command whose name is the same as the path name of the text's window. This command may be used to invoke various operations on the widget. It has the following general form:
```
*pathName option* ?*arg arg ...*?
```
*PathName* is the name of the command, which is the same as the text widget's path name. *Option* and the *arg*s determine the exact behavior of the command. The following commands are possible for text widgets:
*pathName* **bbox** *index*
Returns a list of four elements describing the screen area of the character given by *index*. The first two elements of the list give the x and y coordinates of the upper-left corner of the area occupied by the character, and the last two elements give the width and height of the area. If the character is only partially visible on the screen, then the return value reflects just the visible part. If the character is not visible on the screen then the return value is an empty list.
*pathName* **cget** *option*
Returns the current value of the configuration option given by *option*. *Option* may have any of the values accepted by the **text** command.
*pathName* **compare** *index1 op index2*
Compares the indices given by *index1* and *index2* according to the relational operator given by *op*, and returns 1 if the relationship is satisfied and 0 if it is not. *Op* must be one of the operators <, <=, ==, >=, >, or !=. If *op* is == then 1 is returned if the two indices refer to the same character, if *op* is < then 1 is returned if *index1* refers to an earlier character in the text than *index2*, and so on.
*pathName* **configure** ?*option*? *?value option value ...*?
Query or modify the configuration options of the widget. If no *option* is specified, returns a list describing all of the available options for *pathName* (see **[Tk\_ConfigureInfo](https://www.tcl.tk/man/tcl/TkLib/ConfigWidg.htm)** for information on the format of this list). If *option* is specified with no *value*, then the command returns a list describing the one named option (this list will be identical to the corresponding sublist of the value returned if no *option* is specified). If one or more *option-value* pairs are specified, then the command modifies the given widget option(s) to have the given value(s); in this case the command returns an empty string. *Option* may have any of the values accepted by the **text** command.
*pathName* **count** *?options*? *index1 index2*
Counts the number of relevant things between the two indices. If *index1* is after *index2*, the result will be a negative number (and this holds for each of the possible options). The actual items which are counted depend on the options given. The result is a list of integers, one for the result of each counting option given. Valid counting options are **-chars**, **-displaychars**, **-displayindices**, **-displaylines**, **-indices**, **-lines**, **-xpixels** and **-ypixels**. The default value, if no option is specified, is **-indices**. There is an additional possible option **-update** which is a modifier. If given (and if the text widget is managed by a geometry manager), then all subsequent options ensure that any possible out of date information is recalculated. This currently only has any effect for the **-ypixels** count (which, if **-update** is not given, will use the text widget's current cached value for each line). This **-update** option is obsoleted by *pathName* **sync**, *pathName* **pendingsync** and **<<WidgetViewSync>>**. The count options are interpreted as follows:
**-chars**
count all characters, whether elided or not. Do not count embedded windows or images.
**-displaychars**
count all non-elided characters.
**-displayindices**
count all non-elided characters, windows and images.
**-displaylines**
count all display lines (i.e. counting one for each time a line wraps) from the line of the first index up to, but not including the display line of the second index. Therefore if they are both on the same display line, zero will be returned. By definition displaylines are visible and therefore this only counts portions of actual visible lines.
**-indices**
count all characters and embedded windows or images (i.e. everything which counts in text-widget index space), whether they are elided or not.
**-lines**
count all logical lines (irrespective of wrapping) from the line of the first index up to, but not including the line of the second index. Therefore if they are both on the same line, zero will be returned. Logical lines are counted whether they are currently visible (non-elided) or not.
**-xpixels**
count the number of horizontal pixels from the first pixel of the first index to (but not including) the first pixel of the second index. To count the total desired width of the text widget (assuming wrapping is not enabled), first find the longest line and then use “.text count -xpixels "${line}.0" "${line}.0 lineend"”.
**-ypixels**
count the number of vertical pixels from the first pixel of the first index to (but not including) the first pixel of the second index. If both indices are on the same display line, zero will be returned. To count the total number of vertical pixels in the text widget, use “.text count -ypixels 1.0 end”, and to ensure this is up to date, use “.text count -update -ypixels 1.0 end”.
The command returns a positive or negative integer corresponding to the number of items counted between the two indices. One such integer is returned for each counting option given, so a list is returned if more than one option was supplied. For example “.text count -xpixels -ypixels 1.3 4.5” is perfectly valid and will return a list of two elements.
*pathName* **debug** ?*boolean*?
If *boolean* is specified, then it must have one of the true or false values accepted by [Tcl\_GetBoolean](https://www.tcl.tk/man/tcl/TclLib/GetInt.htm). If the value is a true one then internal consistency checks will be turned on in the B-tree code associated with text widgets. If *boolean* has a false value then the debugging checks will be turned off. In either case the command returns an empty string. If *boolean* is not specified then the command returns **on** or **off** to indicate whether or not debugging is turned on. There is a single debugging switch shared by all text widgets: turning debugging on or off in any widget turns it on or off for all widgets. For widgets with large amounts of text, the consistency checks may cause a noticeable slow-down. When debugging is turned on, the drawing routines of the text widget set the global variables **tk\_textRedraw** and **tk\_textRelayout** to the lists of indices that are redrawn. The values of these variables are tested by Tk's test suite.
*pathName* **delete** *index1* ?*index2 ...*?
Delete a range of characters from the text. If both *index1* and *index2* are specified, then delete all the characters starting with the one given by *index1* and stopping just before *index2* (i.e. the character at *index2* is not deleted). If *index2* does not specify a position later in the text than *index1* then no characters are deleted. If *index2* is not specified then the single character at *index1* is deleted. Attempts to delete characters in a way that would leave the text without a newline as the last character will be tweaked by the text widget to avoid this. In particular, deletion of complete lines of text up to the end of the text will also delete the newline character just before the deleted block so that it is replaced by the new final newline of the text widget. The command returns an empty string. If more indices are given, multiple ranges of text will be deleted. All indices are first checked for validity before any deletions are made. They are sorted and the text is removed from the last range to the first range so deleted text does not cause an undesired index shifting side-effects. If multiple ranges with the same start index are given, then the longest range is used. If overlapping ranges are given, then they will be merged into spans that do not cause deletion of text outside the given ranges due to text shifted during deletion.
*pathName* **dlineinfo** *index*
Returns a list with five elements describing the area occupied by the display line containing *index*. The first two elements of the list give the x and y coordinates of the upper-left corner of the area occupied by the line, the third and fourth elements give the width and height of the area, and the fifth element gives the position of the baseline for the line, measured down from the top of the area. All of this information is measured in pixels. If the current wrap mode is **none** and the line extends beyond the boundaries of the window, the area returned reflects the entire area of the line, including the portions that are out of the window. If the line is shorter than the full width of the window then the area returned reflects just the portion of the line that is occupied by characters and embedded windows. If the display line containing *index* is not visible on the screen then the return value is an empty list.
*pathName* **dump** ?*switches*? *index1* ?*index2*?
Return the contents of the text widget from *index1* up to, but not including *index2*, including the text and information about marks, tags, and embedded windows. If *index2* is not specified, then it defaults to one character past *index1*. The information is returned in the following format: *key1 value1 index1 key2 value2 index2* ...
The possible *key* values are **text**, **mark**, **tagon**, **tagoff**, **[image](image.htm)**, and **window**. The corresponding *value* is the text, mark name, tag name, image name, or window name. The *index* information is the index of the start of the text, mark, tag transition, image or window. One or more of the following switches (or abbreviations thereof) may be specified to control the dump:
**-all**
Return information about all elements: text, marks, tags, images and windows. This is the default.
**-command** *command*
Instead of returning the information as the result of the dump operation, invoke the *command* on each element of the text widget within the range. The command has three arguments appended to it before it is evaluated: the *key*, *value*, and *index*.
**-image**
Include information about images in the dump results.
**-mark**
Include information about marks in the dump results.
**-tag**
Include information about tag transitions in the dump results. Tag information is returned as **tagon** and **tagoff** elements that indicate the begin and end of each range of each tag, respectively.
**-text**
Include information about text in the dump results. The value is the text up to the next element or the end of range indicated by *index2*. A text element does not span newlines. A multi-line block of text that contains no marks or tag transitions will still be dumped as a set of text segments that each end with a newline. The newline is part of the value.
**-window**
Include information about embedded windows in the dump results. The value of a window is its Tk pathname, unless the window has not been created yet. (It must have a create script.) In this case an empty string is returned, and you must query the window by its index position to get more information.
*pathName* **edit** *option* ?*arg arg ...*?
This command controls the undo mechanism and the modified flag. The exact behavior of the command depends on the *option* argument that follows the **edit** argument. The following forms of the command are currently supported:
*pathName* **edit canredo**
Returns a boolean true if redo is possible, i.e. when the redo stack is not empty. Otherwise returns false.
*pathName* **edit canundo**
Returns a boolean true if undo is possible, i.e. when the undo stack is not empty. Otherwise returns false.
*pathName* **edit modified** ?*boolean*?
If *boolean* is not specified, returns the modified flag of the widget. The insert, delete, edit undo and edit redo commands or the user can set or clear the modified flag. If *boolean* is specified, sets the modified flag of the widget to *boolean*.
*pathName* **edit redo**
When the **-undo** option is true, reapplies the last undone edits provided no other edits were done since then. Generates an error when the redo stack is empty. Does nothing when the **-undo** option is false.
*pathName* **edit reset**
Clears the undo and redo stacks.
*pathName* **edit separator**
Inserts a separator (boundary) on the undo stack. Does nothing when the **-undo** option is false.
*pathName* **edit undo**
Undoes the last edit action when the **-undo** option is true. An edit action is defined as all the insert and delete commands that are recorded on the undo stack in between two separators. Generates an error when the undo stack is empty. Does nothing when the **-undo** option is false.
*pathName* **get** ?**-displaychars**? ?**--**? *index1* ?*index2 ...*?
Return a range of characters from the text. The return value will be all the characters in the text starting with the one whose index is *index1* and ending just before the one whose index is *index2* (the character at *index2* will not be returned). If *index2* is omitted then the single character at *index1* is returned. If there are no characters in the specified range (e.g. *index1* is past the end of the file or *index2* is less than or equal to *index1*) then an empty string is returned. If the specified range contains embedded windows, no information about them is included in the returned string. If multiple index pairs are given, multiple ranges of text will be returned in a list. Invalid ranges will not be represented with empty strings in the list. The ranges are returned in the order passed to *pathName* **get**. If the **-displaychars** option is given, then, within each range, only those characters which are not elided will be returned. This may have the effect that some of the returned ranges are empty strings.
*pathName* **image** *option* ?*arg arg ...*?
This command is used to manipulate embedded images. The behavior of the command depends on the *option* argument that follows the **tag** argument. The following forms of the command are currently supported:
*pathName* **image cget** *index option*
Returns the value of a configuration option for an embedded image. *Index* identifies the embedded image, and *option* specifies a particular configuration option, which must be one of the ones listed in the section **[EMBEDDED IMAGES](#M79)**.
*pathName* **image configure** *index* ?*option value ...*?
Query or modify the configuration options for an embedded image. If no *option* is specified, returns a list describing all of the available options for the embedded image at *index* (see **[Tk\_ConfigureInfo](https://www.tcl.tk/man/tcl/TkLib/ConfigWidg.htm)** for information on the format of this list). If *option* is specified with no *value*, then the command returns a list describing the one named option (this list will be identical to the corresponding sublist of the value returned if no *option* is specified). If one or more *option-value* pairs are specified, then the command modifies the given option(s) to have the given value(s); in this case the command returns an empty string. See **[EMBEDDED IMAGES](#M79)** for information on the options that are supported.
*pathName* **image create** *index* ?*option value ...*?
This command creates a new image annotation, which will appear in the text at the position given by *index*. Any number of *option-value* pairs may be specified to configure the annotation. Returns a unique identifier that may be used as an index to refer to this image. See **[EMBEDDED IMAGES](#M79)** for information on the options that are supported, and a description of the identifier returned.
*pathName* **image names**
Returns a list whose elements are the names of all image instances currently embedded in *window*.
*pathName* **index** *index*
Returns the position corresponding to *index* in the form *line.char* where *line* is the line number and *char* is the character number. *Index* may have any of the forms described under **[INDICES](#M24)** above.
*pathName* **insert** *index chars* ?*tagList chars tagList ...*?
Inserts all of the *chars* arguments just before the character at *index*. If *index* refers to the end of the text (the character after the last newline) then the new text is inserted just before the last newline instead. If there is a single *chars* argument and no *tagList*, then the new text will receive any tags that are present on both the character before and the character after the insertion point; if a tag is present on only one of these characters then it will not be applied to the new text. If *tagList* is specified then it consists of a list of tag names; the new characters will receive all of the tags in this list and no others, regardless of the tags present around the insertion point. If multiple *chars*-*tagList* argument pairs are present, they produce the same effect as if a separate *pathName* **insert** widget command had been issued for each pair, in order. The last *tagList* argument may be omitted.
*pathName* **mark** *option* ?*arg arg ...*?
This command is used to manipulate marks. The exact behavior of the command depends on the *option* argument that follows the **mark** argument. The following forms of the command are currently supported:
*pathName* **mark gravity** *markName* ?*direction*?
If *direction* is not specified, returns **left** or **right** to indicate which of its adjacent characters *markName* is attached to. If *direction* is specified, it must be **left** or **right**; the gravity of *markName* is set to the given value.
*pathName* **mark names**
Returns a list whose elements are the names of all the marks that are currently set.
*pathName* **mark next** *index*
Returns the name of the next mark at or after *index*. If *index* is specified in numerical form, then the search for the next mark begins at that index. If *index* is the name of a mark, then the search for the next mark begins immediately after that mark. This can still return a mark at the same position if there are multiple marks at the same index. These semantics mean that the **mark next** operation can be used to step through all the marks in a text widget in the same order as the mark information returned by the *pathName* **dump** operation. If a mark has been set to the special **end** index, then it appears to be *after* **end** with respect to the *pathName* **mark next** operation. An empty string is returned if there are no marks after *index*.
*pathName* **mark previous** *index*
Returns the name of the mark at or before *index*. If *index* is specified in numerical form, then the search for the previous mark begins with the character just before that index. If *index* is the name of a mark, then the search for the next mark begins immediately before that mark. This can still return a mark at the same position if there are multiple marks at the same index. These semantics mean that the *pathName* **mark previous** operation can be used to step through all the marks in a text widget in the reverse order as the mark information returned by the *pathName* **dump** operation. An empty string is returned if there are no marks before *index*.
*pathName* **mark set** *markName index*
Sets the mark named *markName* to a position just before the character at *index*. If *markName* already exists, it is moved from its old position; if it does not exist, a new mark is created. This command returns an empty string.
*pathName* **mark unset** *markName* ?*markName markName ...*?
Remove the mark corresponding to each of the *markName* arguments. The removed marks will not be usable in indices and will not be returned by future calls to “*pathName* **mark names**”. This command returns an empty string.
*pathName* **peer** *option args*
This command is used to create and query widget peers. It has two forms, depending on *option*:
*pathName* **peer create** *newPathName* ?*options*?
Creates a peer text widget with the given *newPathName*, and any optional standard configuration options (as for the *text* command). By default the peer will have the same start and end line as the parent widget, but these can be overridden with the standard configuration options.
*pathName* **peer names**
Returns a list of peers of this widget (this does not include the widget itself). The order within this list is undefined.
*pathName* **pendingsync**
Returns 1 if the line heights calculations are not up-to-date, 0 otherwise.
*pathName* **replace** *index1 index2 chars* ?*tagList chars tagList ...*?
Replaces the range of characters between *index1* and *index2* with the given characters and tags. See the section on *pathName* **insert** for an explanation of the handling of the *tagList...* arguments, and the section on *pathName* **delete** for an explanation of the handling of the indices. If *index2* corresponds to an index earlier in the text than *index1*, an error will be generated. The deletion and insertion are arranged so that no unnecessary scrolling of the window or movement of insertion cursor occurs. In addition the undo/redo stack are correctly modified, if undo operations are active in the text widget. The command returns an empty string.
*pathName* **scan** *option args*
This command is used to implement scanning on texts. It has two forms, depending on *option*:
*pathName* **scan mark** *x y*
Records *x* and *y* and the current view in the text window, for use in conjunction with later *pathName* **scan dragto** commands. Typically this command is associated with a mouse button press in the widget. It returns an empty string.
*pathName* **scan dragto** *x y*
This command computes the difference between its *x* and *y* arguments and the *x* and *y* arguments to the last *pathName* **scan mark** command for the widget. It then adjusts the view by 10 times the difference in coordinates. This command is typically associated with mouse motion events in the widget, to produce the effect of dragging the text at high speed through the window. The return value is an empty string.
*pathName* **search** ?*switches*? *pattern index* ?*stopIndex*?
Searches the text in *pathName* starting at *index* for a range of characters that matches *pattern*. If a match is found, the index of the first character in the match is returned as result; otherwise an empty string is returned. One or more of the following switches (or abbreviations thereof) may be specified to control the search:
**-forwards**
The search will proceed forward through the text, finding the first matching range starting at or after the position given by *index*. This is the default.
**-backwards**
The search will proceed backward through the text, finding the matching range closest to *index* whose first character is before *index* (it is not allowed to be at *index*). Note that, for a variety of reasons, backwards searches can be substantially slower than forwards searches (particularly when using **-regexp**), so it is recommended that performance-critical code use forward searches.
**-exact**
Use exact matching: the characters in the matching range must be identical to those in *pattern*. This is the default.
**-regexp**
Treat *pattern* as a regular expression and match it against the text using the rules for regular expressions (see the **[regexp](../tclcmd/regexp.htm)** command and the **[re\_syntax](../tclcmd/re_syntax.htm)** page for details). The default matching automatically passes both the **-lineanchor** and **-linestop** options to the regexp engine (unless **-nolinestop** is used), so that *^$* match beginning and end of line, and *.*, *[^* sequences will never match the newline character *\n*.
**-nolinestop**
This allows *.* and *[^* sequences to match the newline character *\n*, which they will otherwise not do (see the **[regexp](../tclcmd/regexp.htm)** command for details). This option is only meaningful if **-regexp** is also given, and an error will be thrown otherwise. For example, to match the entire text, use “*pathName* **search -nolinestop -regexp** ".\*" 1.0”.
**-nocase**
Ignore case differences between the pattern and the text.
**-count** *varName*
The argument following **-count** gives the name of a variable; if a match is found, the number of index positions between beginning and end of the matching range will be stored in the variable. If there are no embedded images or windows in the matching range (and there are no elided characters if **-elide** is not given), this is equivalent to the number of characters matched. In either case, the range *matchIdx* to *matchIdx + $count chars* will return the entire matched text.
**-all**
Find all matches in the given range and return a list of the indices of the first character of each match. If a **-count** *varName* switch is given, then *varName* is also set to a list containing one element for each successful match. Note that, even for exact searches, the elements of this list may be different, if there are embedded images, windows or hidden text. Searches with **-all** behave very similarly to the Tcl command **regexp -all**, in that overlapping matches are not normally returned. For example, applying an **-all** search of the pattern “\w+” against “hello there” will just match twice, once for each word, and matching “Z[a-z]+Z” against “ZooZooZoo” will just match once.
**-overlap**
When performing **-all** searches, the normal behaviour is that matches which overlap an already-found match will not be returned. This switch changes that behaviour so that all matches which are not totally enclosed within another match are returned. For example, applying an **-overlap** search of the pattern “\w+” against “hello there” will just match twice (i.e. no different to just **-all**), but matching “Z[a-z]+Z” against “ZooZooZoo” will now match twice. An error will be thrown if this switch is used without **-all**.
**-strictlimits**
When performing any search, the normal behaviour is that the start and stop limits are checked with respect to the start of the matching text. With the **-strictlimits** flag, the entire matching range must lie inside the start and stop limits specified for the match to be valid.
**-elide**
Find elided (hidden) text as well. By default only displayed text is searched.
**--**
This switch has no effect except to terminate the list of switches: the next argument will be treated as *pattern* even if it starts with **-**.
The matching range may be within a single line of text, or run across multiple lines (if parts of the pattern can match a new-line). For regular expression matching one can use the various newline-matching features such as **$** to match the end of a line, **^** to match the beginning of a line, and to control whether **.** is allowed to match a new-line. If *stopIndex* is specified, the search stops at that index: for forward searches, no match at or after *stopIndex* will be considered; for backward searches, no match earlier in the text than *stopIndex* will be considered. If *stopIndex* is omitted, the entire text will be searched: when the beginning or end of the text is reached, the search continues at the other end until the starting location is reached again; if *stopIndex* is specified, no wrap-around will occur. This means that, for example, if the search is **-forwards** but *stopIndex* is earlier in the text than *startIndex*, nothing will ever be found. See **[KNOWN BUGS](#M196)** below for a number of minor limitations of the *pathName* **search** command.
*pathName* **see** *index*
Adjusts the view in the window so that the character given by *index* is completely visible. If *index* is already visible then the command does nothing. If *index* is a short distance out of view, the command adjusts the view just enough to make *index* visible at the edge of the window. If *index* is far out of view, then the command centers *index* in the window.
*pathName* **sync** ?**-command** *command*?
Controls the synchronization of the view of the text widget.
*pathName* **sync**
Immediately brings the line metrics up-to-date by forcing computation of any outdated line heights. The command returns immediately if there is no such outdated line heights, otherwise it returns only at the end of the computation. The command returns an empty string.
*pathName* **sync -command** *command*
Schedules *command* to be executed (by the event loop) exactly once as soon as all line heights are up-to-date. If there are no pending line metrics calculations, the scheduling is immediate. The command returns the empty string. **[bgerror](../tclcmd/bgerror.htm)** is called on *command* failure.
*pathName* **tag** *option* ?*arg arg ...*?
This command is used to manipulate tags. The exact behavior of the command depends on the *option* argument that follows the **tag** argument. The following forms of the command are currently supported:
*pathName* **tag add** *tagName index1* ?*index2 index1 index2 ...*?
Associate the tag *tagName* with all of the characters starting with *index1* and ending just before *index2* (the character at *index2* is not tagged). A single command may contain any number of *index1*-*index2* pairs. If the last *index2* is omitted then the single character at *index1* is tagged. If there are no characters in the specified range (e.g. *index1* is past the end of the file or *index2* is less than or equal to *index1*) then the command has no effect.
*pathName* **tag bind** *tagName* ?*sequence*? ?*script*?
This command associates *script* with the tag given by *tagName*. Whenever the event sequence given by *sequence* occurs for a character that has been tagged with *tagName*, the script will be invoked. This widget command is similar to the **[bind](bind.htm)** command except that it operates on characters in a text rather than entire widgets. See the **[bind](bind.htm)** manual entry for complete details on the syntax of *sequence* and the substitutions performed on *script* before invoking it. If all arguments are specified then a new binding is created, replacing any existing binding for the same *sequence* and *tagName* (if the first character of *script* is “+” then *script* augments an existing binding rather than replacing it). In this case the return value is an empty string. If *script* is omitted then the command returns the *script* associated with *tagName* and *sequence* (an error occurs if there is no such binding). If both *script* and *sequence* are omitted then the command returns a list of all the sequences for which bindings have been defined for *tagName*. The only events for which bindings may be specified are those related to the mouse and keyboard (such as **Enter**, **Leave**, **ButtonPress**, **Motion**, and **KeyPress**) or virtual events. Event bindings for a text widget use the **current** mark described under **[MARKS](#M71)** above. An **Enter** event triggers for a tag when the tag first becomes present on the current character, and a **Leave** event triggers for a tag when it ceases to be present on the current character. **Enter** and **Leave** events can happen either because the **current** mark moved or because the character at that position changed. Note that these events are different than **Enter** and **Leave** events for windows. Mouse and keyboard events are directed to the current character. If a virtual event is used in a binding, that binding can trigger only if the virtual event is defined by an underlying mouse-related or keyboard-related event.
It is possible for the current character to have multiple tags, and for each of them to have a binding for a particular event sequence. When this occurs, one binding is invoked for each tag, in order from lowest-priority to highest priority. If there are multiple matching bindings for a single tag, then the most specific binding is chosen (see the manual entry for the **[bind](bind.htm)** command for details). **[continue](../tclcmd/continue.htm)** and **[break](../tclcmd/break.htm)** commands within binding scripts are processed in the same way as for bindings created with the **[bind](bind.htm)** command.
If bindings are created for the widget as a whole using the **[bind](bind.htm)** command, then those bindings will supplement the tag bindings. The tag bindings will be invoked first, followed by bindings for the window as a whole.
*pathName* **tag cget** *tagName option*
This command returns the current value of the option named *option* associated with the tag given by *tagName*. *Option* may have any of the values accepted by the *pathName* **tag configure** widget command.
*pathName* **tag configure** *tagName* ?*option*? ?*value*? ?*option value ...*?
This command is similar to the *pathName* **configure** widget command except that it modifies options associated with the tag given by *tagName* instead of modifying options for the overall text widget. If no *option* is specified, the command returns a list describing all of the available options for *tagName* (see **[Tk\_ConfigureInfo](https://www.tcl.tk/man/tcl/TkLib/ConfigWidg.htm)** for information on the format of this list). If *option* is specified with no *value*, then the command returns a list describing the one named option (this list will be identical to the corresponding sublist of the value returned if no *option* is specified). If one or more *option-value* pairs are specified, then the command modifies the given option(s) to have the given value(s) in *tagName*; in this case the command returns an empty string. See **[TAGS](#M43)** above for details on the options available for tags.
*pathName* **tag delete** *tagName* ?*tagName ...*?
Deletes all tag information for each of the *tagName* arguments. The command removes the tags from all characters in the file and also deletes any other information associated with the tags, such as bindings and display information. The command returns an empty string.
*pathName* **tag lower** *tagName* ?*belowThis*?
Changes the priority of tag *tagName* so that it is just lower in priority than the tag whose name is *belowThis*. If *belowThis* is omitted, then *tagName*'s priority is changed to make it lowest priority of all tags.
*pathName* **tag names** ?*index*?
Returns a list whose elements are the names of all the tags that are active at the character position given by *index*. If *index* is omitted, then the return value will describe all of the tags that exist for the text (this includes all tags that have been named in a “*pathName* **tag**” widget command but have not been deleted by a “*pathName* **tag delete**” widget command, even if no characters are currently marked with the tag). The list will be sorted in order from lowest priority to highest priority.
*pathName* **tag nextrange** *tagName index1* ?*index2*?
This command searches the text for a range of characters tagged with *tagName* where the first character of the range is no earlier than the character at *index1* and no later than the character just before *index2* (a range starting at *index2* will not be considered). If several matching ranges exist, the first one is chosen. The command's return value is a list containing two elements, which are the index of the first character of the range and the index of the character just after the last one in the range. If no matching range is found then the return value is an empty string. If *index2* is not given then it defaults to the end of the text.
*pathName* **tag prevrange** *tagName index1* ?*index2*?
This command searches the text for a range of characters tagged with *tagName* where the first character of the range is before the character at *index1* and no earlier than the character at *index2* (a range starting at *index2* will be considered). If several matching ranges exist, the one closest to *index1* is chosen. The command's return value is a list containing two elements, which are the index of the first character of the range and the index of the character just after the last one in the range. If no matching range is found then the return value is an empty string. If *index2* is not given then it defaults to the beginning of the text.
*pathName* **tag raise** *tagName* ?*aboveThis*?
Changes the priority of tag *tagName* so that it is just higher in priority than the tag whose name is *aboveThis*. If *aboveThis* is omitted, then *tagName*'s priority is changed to make it highest priority of all tags.
*pathName* **tag ranges** *tagName*
Returns a list describing all of the ranges of text that have been tagged with *tagName*. The first two elements of the list describe the first tagged range in the text, the next two elements describe the second range, and so on. The first element of each pair contains the index of the first character of the range, and the second element of the pair contains the index of the character just after the last one in the range. If there are no characters tagged with *tag* then an empty string is returned.
*pathName* **tag remove** *tagName index1* ?*index2 index1 index2 ...*?
Remove the tag *tagName* from all of the characters starting at *index1* and ending just before *index2* (the character at *index2* is not affected). A single command may contain any number of *index1*-*index2* pairs. If the last *index2* is omitted then the tag is removed from the single character at *index1*. If there are no characters in the specified range (e.g. *index1* is past the end of the file or *index2* is less than or equal to *index1*) then the command has no effect. This command returns an empty string.
*pathName* **window** *option* ?*arg arg ...*?
This command is used to manipulate embedded windows. The behavior of the command depends on the *option* argument that follows the **window** argument. The following forms of the command are currently supported:
*pathName* **window cget** *index option*
Returns the value of a configuration option for an embedded window. *Index* identifies the embedded window, and *option* specifies a particular configuration option, which must be one of the ones listed in the section **[EMBEDDED WINDOWS](#M72)**.
*pathName* **window configure** *index* ?*option value ...*?
Query or modify the configuration options for an embedded window. If no *option* is specified, returns a list describing all of the available options for the embedded window at *index* (see **[Tk\_ConfigureInfo](https://www.tcl.tk/man/tcl/TkLib/ConfigWidg.htm)** for information on the format of this list). If *option* is specified with no *value*, then the command returns a list describing the one named option (this list will be identical to the corresponding sublist of the value returned if no *option* is specified). If one or more *option-value* pairs are specified, then the command modifies the given option(s) to have the given value(s); in this case the command returns an empty string. See **[EMBEDDED WINDOWS](#M72)** for information on the options that are supported.
*pathName* **window create** *index* ?*option value ...*?
This command creates a new window annotation, which will appear in the text at the position given by *index*. Any number of *option-value* pairs may be specified to configure the annotation. See **[EMBEDDED WINDOWS](#M72)** for information on the options that are supported. Returns an empty string.
*pathName* **window names**
Returns a list whose elements are the names of all windows currently embedded in *window*.
*pathName* **xview** *option args*
This command is used to query and change the horizontal position of the text in the widget's window. It can take any of the following forms:
*pathName* **xview**
Returns a list containing two elements. Each element is a real fraction between 0 and 1; together they describe the portion of the document's horizontal span that is visible in the window. For example, if the first element is .2 and the second element is .6, 20% of the text is off-screen to the left, the middle 40% is visible in the window, and 40% of the text is off-screen to the right. The fractions refer only to the lines that are actually visible in the window: if the lines in the window are all very short, so that they are entirely visible, the returned fractions will be 0 and 1, even if there are other lines in the text that are much wider than the window. These are the same values passed to scrollbars via the **-xscrollcommand** option.
*pathName* **xview moveto** *fraction*
Adjusts the view in the window so that *fraction* of the horizontal span of the text is off-screen to the left. *Fraction* is a fraction between 0 and 1.
*pathName* **xview scroll** *number what*
This command shifts the view in the window left or right according to *number* and *what*. *What* must be **units**, **pages** or **pixels**. If *what* is **units** or **pages** then *number* must be an integer, otherwise number may be specified in any of the forms acceptable to **[Tk\_GetPixels](https://www.tcl.tk/man/tcl/TkLib/GetPixels.htm)**, such as “2.0c” or “1i” (the result is rounded to the nearest integer value. If no units are given, pixels are assumed). If *what* is **units**, the view adjusts left or right by *number* average-width characters on the display; if it is **pages** then the view adjusts by *number* screenfuls; if it is **pixels** then the view adjusts by *number* pixels. If *number* is negative then characters farther to the left become visible; if it is positive then characters farther to the right become visible.
*pathName* **yview** ?*args*?
This command is used to query and change the vertical position of the text in the widget's window. It can take any of the following forms:
*pathName* **yview**
Returns a list containing two elements, both of which are real fractions between 0 and 1. The first element gives the position of the first visible pixel of the first character (or image, etc) in the top line in the window, relative to the text as a whole (0.5 means it is halfway through the text, for example). The second element gives the position of the first pixel just after the last visible one in the bottom line of the window, relative to the text as a whole. These are the same values passed to scrollbars via the **-yscrollcommand** option.
*pathName* **yview moveto** *fraction*
Adjusts the view in the window so that the pixel given by *fraction* appears at the top of the top line of the window. *Fraction* is a fraction between 0 and 1; 0 indicates the first pixel of the first character in the text, 0.33 indicates the pixel that is one-third the way through the text; and so on. Values close to 1 will indicate values close to the last pixel in the text (1 actually refers to one pixel beyond the last pixel), but in such cases the widget will never scroll beyond the last pixel, and so a value of 1 will effectively be rounded back to whatever fraction ensures the last pixel is at the bottom of the window, and some other pixel is at the top.
*pathName* **yview scroll** *number what*
This command adjust the view in the window up or down according to *number* and *what*. *What* must be **units**, **pages** or **pixels**. If *what* is **units** or **pages** then *number* must be an integer, otherwise number may be specified in any of the forms acceptable to **[Tk\_GetPixels](https://www.tcl.tk/man/tcl/TkLib/GetPixels.htm)**, such as “2.0c” or “1i” (the result is rounded to the nearest integer value. If no units are given, pixels are assumed). If *what* is **units**, the view adjusts up or down by *number* lines on the display; if it is **pages** then the view adjusts by *number* screenfuls; if it is **pixels** then the view adjusts by *number* pixels. If *number* is negative then earlier positions in the text become visible; if it is positive then later positions in the text become visible.
*pathName* **yview** ?**-pickplace**? *index*
Changes the view in the widget's window to make *index* visible. If the **-pickplace** option is not specified then *index* will appear at the top of the window. If **-pickplace** is specified then the widget chooses where *index* appears in the window:
1. If *index* is already visible somewhere in the window then the command does nothing.
2. If *index* is only a few lines off-screen above the window then it will be positioned at the top of the window.
3. If *index* is only a few lines off-screen below the window then it will be positioned at the bottom of the window.
4. Otherwise, *index* will be centered in the window.
The **-pickplace** option has been obsoleted by the *pathName* **see** widget command (*pathName* **see** handles both x- and y-motion to make a location visible, whereas the **-pickplace** mode only handles motion in y).
*pathName* **yview** *number*
This command makes the first character on the line after the one given by *number* visible at the top of the window. *Number* must be an integer. This command used to be used for scrolling, but now it is obsolete.
Bindings
--------
Tk automatically creates class bindings for texts that give them the following default behavior. In the descriptions below, “word” is dependent on the value of the **[tcl\_wordchars](../tclcmd/tclvars.htm)** variable. See **[tclvars](../tclcmd/tclvars.htm)**(n).
1. Clicking mouse button 1 positions the insertion cursor just before the character underneath the mouse cursor, sets the input focus to this widget, and clears any selection in the widget. Dragging with mouse button 1 strokes out a selection between the insertion cursor and the character under the mouse.
2. Double-clicking with mouse button 1 selects the word under the mouse and positions the insertion cursor at the start of the word. Dragging after a double click will stroke out a selection consisting of whole words.
3. Triple-clicking with mouse button 1 selects the line under the mouse and positions the insertion cursor at the start of the line. Dragging after a triple click will stroke out a selection consisting of whole lines.
4. The ends of the selection can be adjusted by dragging with mouse button 1 while the Shift key is down; this will adjust the end of the selection that was nearest to the mouse cursor when button 1 was pressed. If the button is double-clicked before dragging then the selection will be adjusted in units of whole words; if it is triple-clicked then the selection will be adjusted in units of whole lines.
5. Clicking mouse button 1 with the Control key down will reposition the insertion cursor without affecting the selection.
6. If any normal printing characters are typed, they are inserted at the point of the insertion cursor.
7. The view in the widget can be adjusted by dragging with mouse button 2. If mouse button 2 is clicked without moving the mouse, the selection is copied into the text at the position of the mouse cursor. The Insert key also inserts the selection, but at the position of the insertion cursor.
8. If the mouse is dragged out of the widget while button 1 is pressed, the entry will automatically scroll to make more text visible (if there is more text off-screen on the side where the mouse left the window).
9. The Left and Right keys move the insertion cursor one character to the left or right; they also clear any selection in the text. If Left or Right is typed with the Shift key down, then the insertion cursor moves and the selection is extended to include the new character. Control-Left and Control-Right move the insertion cursor by words, and Control-Shift-Left and Control-Shift-Right move the insertion cursor by words and also extend the selection. Control-b and Control-f behave the same as Left and Right, respectively. Meta-b and Meta-f behave the same as Control-Left and Control-Right, respectively.
10. The Up and Down keys move the insertion cursor one line up or down and clear any selection in the text. If Up or Right is typed with the Shift key down, then the insertion cursor moves and the selection is extended to include the new character. Control-Up and Control-Down move the insertion cursor by paragraphs (groups of lines separated by blank lines), and Control-Shift-Up and Control-Shift-Down move the insertion cursor by paragraphs and also extend the selection. Control-p and Control-n behave the same as Up and Down, respectively.
11. The Next and Prior keys move the insertion cursor forward or backwards by one screenful and clear any selection in the text. If the Shift key is held down while Next or Prior is typed, then the selection is extended to include the new character.
12. Control-Next and Control-Prior scroll the view right or left by one page without moving the insertion cursor or affecting the selection.
13. Home and Control-a move the insertion cursor to the beginning of its display line and clear any selection in the widget. Shift-Home moves the insertion cursor to the beginning of the display line and also extends the selection to that point.
14. End and Control-e move the insertion cursor to the end of the display line and clear any selection in the widget. Shift-End moves the cursor to the end of the display line and extends the selection to that point.
15. Control-Home and Meta-< move the insertion cursor to the beginning of the text and clear any selection in the widget. Control-Shift-Home moves the insertion cursor to the beginning of the text and also extends the selection to that point.
16. Control-End and Meta-> move the insertion cursor to the end of the text and clear any selection in the widget. Control-Shift-End moves the cursor to the end of the text and extends the selection to that point.
17. The Select key and Control-Space set the selection anchor to the position of the insertion cursor. They do not affect the current selection. Shift-Select and Control-Shift-Space adjust the selection to the current position of the insertion cursor, selecting from the anchor to the insertion cursor if there was not any selection previously.
18. Control-/ selects the entire contents of the widget.
19. Control-\ clears any selection in the widget.
20. The F16 key (labelled Copy on many Sun workstations) or Meta-w copies the selection in the widget to the clipboard, if there is a selection. This action is carried out by the command **tk\_textCopy**.
21. The F20 key (labelled Cut on many Sun workstations) or Control-w copies the selection in the widget to the clipboard and deletes the selection. This action is carried out by the command **tk\_textCut**. If there is no selection in the widget then these keys have no effect.
22. The F18 key (labelled Paste on many Sun workstations) or Control-y inserts the contents of the clipboard at the position of the insertion cursor. This action is carried out by the command **tk\_textPaste**.
23. The Delete key deletes the selection, if there is one in the widget. If there is no selection, it deletes the character to the right of the insertion cursor.
24. Backspace and Control-h delete the selection, if there is one in the widget. If there is no selection, they delete the character to the left of the insertion cursor.
25. Control-d deletes the character to the right of the insertion cursor.
26. Meta-d deletes the word to the right of the insertion cursor.
27. Control-k deletes from the insertion cursor to the end of its line; if the insertion cursor is already at the end of a line, then Control-k deletes the newline character.
28. Control-o opens a new line by inserting a newline character in front of the insertion cursor without moving the insertion cursor.
29. Meta-backspace and Meta-Delete delete the word to the left of the insertion cursor.
30. Control-x deletes whatever is selected in the text widget after copying it to the clipboard.
31. Control-t reverses the order of the two characters to the right of the insertion cursor.
32. Control-z undoes the last edit action if the **-undo** option is true. Does nothing otherwise.
33. Control-Z (or Control-y on Windows) reapplies the last undone edit action if the **-undo** option is true. Does nothing otherwise.
If the widget is disabled using the **-state** option, then its view can still be adjusted and text can still be selected, but no insertion cursor will be displayed and no text modifications will take place.
The behavior of texts can be changed by defining new bindings for individual widgets or by redefining the class bindings.
Known issues
------------
### Issues concerning chars and indices
Before Tk 8.5, the widget used the string “chars” to refer to index positions (which included characters, embedded windows and embedded images). As of Tk 8.5 the text widget deals separately and correctly with “chars” and “indices”. For backwards compatibility, however, the index modifiers “+N chars” and “-N chars” continue to refer to indices. One must use any of the full forms “+N any chars” or “-N any chars” etc. to refer to actual character indices. This confusion may be fixed in a future release by making the widget correctly interpret “+N chars” as a synonym for “+N any chars”. ### Performance issues
Text widgets should run efficiently under a variety of conditions. The text widget uses about 2-3 bytes of main memory for each byte of text, so texts containing a megabyte or more should be practical on most workstations. Text is represented internally with a modified B-tree structure that makes operations relatively efficient even with large texts. Tags are included in the B-tree structure in a way that allows tags to span large ranges or have many disjoint smaller ranges without loss of efficiency. Marks are also implemented in a way that allows large numbers of marks. In most cases it is fine to have large numbers of unique tags, or a tag that has many distinct ranges. One performance problem can arise if you have hundreds or thousands of different tags that all have the following characteristics: the first and last ranges of each tag are near the beginning and end of the text, respectively, or a single tag range covers most of the text widget. The cost of adding and deleting tags like this is proportional to the number of other tags with the same properties. In contrast, there is no problem with having thousands of distinct tags if their overall ranges are localized and spread uniformly throughout the text.
Very long text lines can be expensive, especially if they have many marks and tags within them.
The display line with the insert cursor is redrawn each time the cursor blinks, which causes a steady stream of graphics traffic. Set the **-insertofftime** attribute to 0 avoid this.
### Known bugs
The *pathName* **search -regexp** sub-command attempts to perform sophisticated regexp matching across multiple lines in an efficient fashion (since Tk 8.5), examining each line individually, and then in small groups of lines, whether searching forwards or backwards. Under certain conditions the search result might differ from that obtained by applying the same regexp to the entire text from the widget in one go. For example, when searching with a greedy regexp, the widget will continue to attempt to add extra lines to the match as long as one of two conditions are true: either Tcl's regexp library returns a code to indicate a longer match is possible (but there are known bugs in Tcl which mean this code is not always correctly returned); or if each extra line added results in at least a partial match with the pattern. This means in the case where the first extra line added results in no match and Tcl's regexp system returns the incorrect code and adding a second extra line would actually match, the text widget will return the wrong result. In practice this is a rare problem, but it can occur, for example:
```
pack [**text** .t]
.t insert 1.0 "aaaa\nbbbb\ncccc\nbbbb\naaaa\n"
.t search -regexp -- {(a+|b+\nc+\nb+)+\na+} 1.0
```
will not find a match when one exists of 19 characters starting from the first “b”. Whenever one possible match is fully enclosed in another, the search command will attempt to ensure only the larger match is returned. When performing backwards regexp searches it is possible that Tcl will not always achieve this, in the case where a match is preceded by one or more short, non-overlapping matches, all of which are preceded by a large match which actually encompasses all of them. The search algorithm used by the widget does not look back arbitrarily far for a possible match which might cover large portions of the widget. For example:
```
pack [**text** .t]
.t insert 1.0 "aaaa\nbbbb\nbbbb\nbbbb\nbbbb\n"
.t search -regexp -backward -- {b+\n|a+\n(b+\n)+} end
```
matches at “5.0” when a true greedy match would match at “1.0”. Similarly if we add **-all** to this case, it matches at all of “5.0”, “4.0”, “3.0” and “1.0”, when really it should only match at “1.0” since that match encloses all the others. See also
--------
**[entry](entry.htm)**, **[scrollbar](scrollbar.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TkCmd/text.htm>
| programming_docs |
tcl_tk palette palette
=======
Name
----
tk\_setPalette, tk\_bisque — Modify the Tk color palette Synopsis
--------
**tk\_setPalette** *background*
**tk\_setPalette** *name value* ?*name value ...*?
**tk\_bisque**
Description
-----------
The **tk\_setPalette** procedure changes the color scheme for Tk. It does this by modifying the colors of existing widgets and by changing the option database so that future widgets will use the new color scheme. If **tk\_setPalette** is invoked with a single argument, the argument is the name of a color to use as the normal background color; **tk\_setPalette** will compute a complete color palette from this background color. Alternatively, the arguments to **tk\_setPalette** may consist of any number of *name*-*value* pairs, where the first argument of the pair is the name of an option in the Tk option database and the second argument is the new value to use for that option. The following database names are currently supported:
| | | |
| --- | --- | --- |
| **activeBackground** | **foreground** | **selectColor** |
| **activeForeground** | **highlightBackground** | **selectBackground** |
| **background** | **highlightColor** | **selectForeground** |
| **disabledForeground** | **insertBackground** | **troughColor** |
**tk\_setPalette** tries to compute reasonable defaults for any options that you do not specify. You can specify options other than the above ones and Tk will change those options on widgets as well. This feature may be useful if you are using custom widgets with additional color options. Once it has computed the new value to use for each of the color options, **tk\_setPalette** scans the widget hierarchy to modify the options of all existing widgets. For each widget, it checks to see if any of the above options is defined for the widget. If so, and if the option's current value is the default, then the value is changed; if the option has a value other than the default, **tk\_setPalette** will not change it. The default for an option is the one provided by the widget (**[lindex [$w configure $option] 3]**) unless **tk\_setPalette** has been run previously, in which case it is the value specified in the previous invocation of **tk\_setPalette**.
After modifying all the widgets in the application, **tk\_setPalette** adds options to the option database to change the defaults for widgets created in the future. The new options are added at priority **widgetDefault**, so they will be overridden by options from the .Xdefaults file or options specified on the command-line that creates a widget.
The procedure **tk\_bisque** is provided for backward compatibility: it restores the application's colors to the light brown (“bisque”) color scheme used in Tk 3.6 and earlier versions.
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TkCmd/palette.htm>
tcl_tk ttk_separator ttk\_separator
==============
[NAME](ttk_separator.htm#M2) ttk::separator — Separator bar
[SYNOPSIS](ttk_separator.htm#M3)
[DESCRIPTION](ttk_separator.htm#M4)
[STANDARD OPTIONS](ttk_separator.htm#M5)
[-class, undefined, undefined](ttk_widget.htm#M-class)
[-cursor, cursor, Cursor](ttk_widget.htm#M-cursor)
[-state, state, State](ttk_widget.htm#M-state)
[-style, style, Style](ttk_widget.htm#M-style)
[-takefocus, takeFocus, TakeFocus](ttk_widget.htm#M-takefocus)
[WIDGET-SPECIFIC OPTIONS](ttk_separator.htm#M6)
[-orient, orient, Orient](ttk_separator.htm#M7)
[WIDGET COMMAND](ttk_separator.htm#M8)
[SEE ALSO](ttk_separator.htm#M9)
[KEYWORDS](ttk_separator.htm#M10)
Name
----
ttk::separator — Separator bar Synopsis
--------
**ttk::separator** *pathName* ?*options*?
Description
-----------
A **ttk::separator** widget displays a horizontal or vertical separator bar. Standard options
----------------
**[-class, undefined, undefined](ttk_widget.htm#M-class)**
**[-cursor, cursor, Cursor](ttk_widget.htm#M-cursor)**
**[-state, state, State](ttk_widget.htm#M-state)**
**[-style, style, Style](ttk_widget.htm#M-style)**
**[-takefocus, takeFocus, TakeFocus](ttk_widget.htm#M-takefocus)**
Widget-specific options
-----------------------
Command-Line Name: **-orient** Database Name: **orient** Database Class: **Orient**
One of **horizontal** or **vertical**. Specifies the orientation of the separator.
Widget command
--------------
Separator widgets support the standard **cget**, **configure**, **identify**, **instate**, and **state** methods. No other widget methods are used. See also
--------
**[ttk::widget](ttk_widget.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TkCmd/ttk_separator.htm>
tcl_tk optionMenu optionMenu
==========
Name
----
tk\_optionMenu — Create an option menubutton and its menu Synopsis
--------
**tk\_optionMenu** *pathName varName value* ?*value value ...*?
Description
-----------
This procedure creates an option menubutton whose name is *pathName*, plus an associated menu. Together they allow the user to select one of the values given by the *value* arguments. The current value will be stored in the global variable whose name is given by *varName* and it will also be displayed as the label in the option menubutton. The user can click on the menubutton to display a menu containing all of the *value*s and thereby select a new value. Once a new value is selected, it will be stored in the variable and appear in the option menubutton. The current value can also be changed by setting the variable. The return value from **tk\_optionMenu** is the name of the menu associated with *pathName*, so that the caller can change its configuration options or manipulate it in other ways.
Example
-------
```
tk_optionMenu .foo myVar Foo Bar Boo Spong Wibble
pack .foo
```
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TkCmd/optionMenu.htm>
tcl_tk ttk_scrollbar ttk\_scrollbar
==============
[NAME](ttk_scrollbar.htm#M2) ttk::scrollbar — Control the viewport of a scrollable widget
[SYNOPSIS](ttk_scrollbar.htm#M3)
[DESCRIPTION](ttk_scrollbar.htm#M4)
[STANDARD OPTIONS](ttk_scrollbar.htm#M5)
[-class, undefined, undefined](ttk_widget.htm#M-class)
[-cursor, cursor, Cursor](ttk_widget.htm#M-cursor)
[-style, style, Style](ttk_widget.htm#M-style)
[-takefocus, takeFocus, TakeFocus](ttk_widget.htm#M-takefocus)
[WIDGET-SPECIFIC OPTIONS](ttk_scrollbar.htm#M6)
[-command, command, Command](ttk_scrollbar.htm#M7)
[-orient, orient, Orient](ttk_scrollbar.htm#M8)
[WIDGET COMMAND](ttk_scrollbar.htm#M9)
[*pathName* **cget** *option*](ttk_scrollbar.htm#M10)
[*pathName* **configure** ?*option*? ?*value option value ...*?](ttk_scrollbar.htm#M11)
[*pathName* **get**](ttk_scrollbar.htm#M12)
[*pathName* **identify** *x y*](ttk_scrollbar.htm#M13)
[*pathName* **instate** *statespec* ?*script*?](ttk_scrollbar.htm#M14)
[*pathName* **set** *first last*](ttk_scrollbar.htm#M15)
[*pathName* **state** ?*stateSpec*?](ttk_scrollbar.htm#M16)
[INTERNAL COMMANDS](ttk_scrollbar.htm#M17)
[*pathName* **delta** *deltaX deltaY*](ttk_scrollbar.htm#M18)
[*pathName* **fraction** *x y*](ttk_scrollbar.htm#M19)
[SCROLLING COMMANDS](ttk_scrollbar.htm#M20)
[*prefix* **moveto** *fraction*](ttk_scrollbar.htm#M21)
[*prefix* **scroll** *number* **units**](ttk_scrollbar.htm#M22)
[*prefix* **scroll** *number* **pages**](ttk_scrollbar.htm#M23)
[WIDGET STATES](ttk_scrollbar.htm#M24)
[EXAMPLE](ttk_scrollbar.htm#M25)
[SEE ALSO](ttk_scrollbar.htm#M26)
[KEYWORDS](ttk_scrollbar.htm#M27)
Name
----
ttk::scrollbar — Control the viewport of a scrollable widget Synopsis
--------
**ttk::scrollbar** *pathName* ?*options...*?
Description
-----------
**ttk::scrollbar** widgets are typically linked to an associated window that displays a document of some sort, such as a file being edited or a drawing. A scrollbar displays a *thumb* in the middle portion of the scrollbar, whose position and size provides information about the portion of the document visible in the associated window. The thumb may be dragged by the user to control the visible region. Depending on the theme, two or more arrow buttons may also be present; these are used to scroll the visible region in discrete units. Standard options
----------------
**[-class, undefined, undefined](ttk_widget.htm#M-class)**
**[-cursor, cursor, Cursor](ttk_widget.htm#M-cursor)**
**[-style, style, Style](ttk_widget.htm#M-style)**
**[-takefocus, takeFocus, TakeFocus](ttk_widget.htm#M-takefocus)**
Widget-specific options
-----------------------
Command-Line Name: **-command** Database Name: **command** Database Class: **Command**
A Tcl script prefix to evaluate to change the view in the widget associated with the scrollbar. Additional arguments are appended to the value of this option, as described in **[SCROLLING COMMANDS](#M20)** below, whenever the user requests a view change by manipulating the scrollbar. This option typically consists of a two-element list, containing the name of a scrollable widget followed by either **xview** (for horizontal scrollbars) or **yview** (for vertical scrollbars).
Command-Line Name: **-orient** Database Name: **orient** Database Class: **Orient**
One of **horizontal** or **vertical**. Specifies the orientation of the scrollbar.
Widget command
--------------
*pathName* **cget** *option*
Returns the current value of the specified *option*; see *ttk::widget(n)*.
*pathName* **configure** ?*option*? ?*value option value ...*?
Modify or query widget options; see *ttk::widget(n)*.
*pathName* **get**
Returns the scrollbar settings in the form of a list whose elements are the arguments to the most recent **set** widget command.
*pathName* **identify** *x y*
Returns the name of the element at position *x*, *y*. See *ttk::widget(n)*.
*pathName* **instate** *statespec* ?*script*?
Test the widget state; see *ttk::widget(n)*.
*pathName* **set** *first last*
This command is normally invoked by the scrollbar's associated widget from an **-xscrollcommand** or **-yscrollcommand** callback. Specifies the visible range to be displayed. *first* and *last* are real fractions between 0 and 1.
*pathName* **state** ?*stateSpec*?
Modify or query the widget state; see *ttk::widget(n)*.
Internal commands
-----------------
The following widget commands are used internally by the TScrollbar widget class bindings.
*pathName* **delta** *deltaX deltaY*
Returns a real number indicating the fractional change in the scrollbar setting that corresponds to a given change in thumb position. For example, if the scrollbar is horizontal, the result indicates how much the scrollbar setting must change to move the thumb *deltaX* pixels to the right (*deltaY* is ignored in this case). If the scrollbar is vertical, the result indicates how much the scrollbar setting must change to move the thumb *deltaY* pixels down. The arguments and the result may be zero or negative.
*pathName* **fraction** *x y*
Returns a real number between 0 and 1 indicating where the point given by *x* and *y* lies in the trough area of the scrollbar, where 0.0 corresponds to the top or left of the trough and 1.0 corresponds to the bottom or right. *X* and *y* are pixel coordinates relative to the scrollbar widget. If *x* and *y* refer to a point outside the trough, the closest point in the trough is used.
Scrolling commands
------------------
When the user interacts with the scrollbar, for example by dragging the thumb, the scrollbar notifies the associated widget that it must change its view. The scrollbar makes the notification by evaluating a Tcl command generated from the scrollbar's **-command** option. The command may take any of the following forms. In each case, *prefix* is the contents of the **-command** option, which usually has a form like **.t yview**
*prefix* **moveto** *fraction*
*Fraction* is a real number between 0 and 1. The widget should adjust its view so that the point given by *fraction* appears at the beginning of the widget. If *fraction* is 0 it refers to the beginning of the document. 1.0 refers to the end of the document, 0.333 refers to a point one-third of the way through the document, and so on.
*prefix* **scroll** *number* **units**
The widget should adjust its view by *number* units. The units are defined in whatever way makes sense for the widget, such as characters or lines in a text widget. *Number* is either 1, which means one unit should scroll off the top or left of the window, or -1, which means that one unit should scroll off the bottom or right of the window.
*prefix* **scroll** *number* **pages**
The widget should adjust its view by *number* pages. It is up to the widget to define the meaning of a page; typically it is slightly less than what fits in the window, so that there is a slight overlap between the old and new views. *Number* is either 1, which means the next page should become visible, or -1, which means that the previous page should become visible.
Widget states
-------------
The scrollbar automatically sets the **disabled** state bit. when the entire range is visible (range is 0.0 to 1.0), and clears it otherwise. It also sets the **active** and **pressed** state flags of individual elements, based on the position and state of the mouse pointer. Example
-------
```
set f [frame .f]
ttk::scrollbar $f.hsb -orient horizontal -command [list $f.t xview]
ttk::scrollbar $f.vsb -orient vertical -command [list $f.t yview]
text $f.t -xscrollcommand [list $f.hsb set] -yscrollcommand [list $f.vsb set]
grid $f.t -row 0 -column 0 -sticky nsew
grid $f.vsb -row 0 -column 1 -sticky nsew
grid $f.hsb -row 1 -column 0 -sticky nsew
grid columnconfigure $f 0 -weight 1
grid rowconfigure $f 0 -weight 1
```
See also
--------
**[ttk::widget](ttk_widget.htm)**, **[scrollbar](scrollbar.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TkCmd/ttk_scrollbar.htm>
tcl_tk bell bell
====
Name
----
bell — Ring a display's bell Synopsis
--------
**bell** ?**-displayof** *window*? ?**-nice**?
Description
-----------
This command rings the bell on the display for *window* and returns an empty string. If the **-displayof** option is omitted, the display of the application's main window is used by default. The command uses the current bell-related settings for the display, which may be modified with programs such as **xset**. If **-nice** is not specified, this command also resets the screen saver for the screen. Some screen savers will ignore this, but others will reset so that the screen becomes visible again.
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TkCmd/bell.htm>
tcl_tk self self
====
[NAME](self.htm#M2) self — method call internal introspection
[SYNOPSIS](self.htm#M3)
[DESCRIPTION](self.htm#M4)
[**self call**](self.htm#M5)
[**self caller**](self.htm#M6)
[**self class**](self.htm#M7)
[**self filter**](self.htm#M8)
[**self method**](self.htm#M9)
[**self namespace**](self.htm#M10)
[**self next**](self.htm#M11)
[**self object**](self.htm#M12)
[**self target**](self.htm#M13)
[EXAMPLES](self.htm#M14)
[SEE ALSO](self.htm#M15)
[KEYWORDS](self.htm#M16)
Name
----
self — method call internal introspection Synopsis
--------
package require TclOO
**self** ?*subcommand*?
Description
-----------
The **self** command, which should only be used from within the context of a call to a method (i.e. inside a method, constructor or destructor body) is used to allow the method to discover information about how it was called. It takes an argument, *subcommand*, that tells it what sort of information is actually desired; if omitted the result will be the same as if **self object** was invoked. The supported subcommands are:
**self call**
This returns a two-element list describing the method implementations used to implement the current call chain. The first element is the same as would be reported by **[info object](info.htm)** **call** for the current method (except that this also reports useful values from within constructors and destructors, whose names are reported as **<constructor>** and **<destructor>** respectively), and the second element is an index into the first element's list that indicates which actual implementation is currently executing (the first implementation to execute is always at index 0).
**self caller**
When the method was invoked from inside another object method, this subcommand returns a three element list describing the containing object and method. The first element describes the declaring object or class of the method, the second element is the name of the object on which the containing method was invoked, and the third element is the name of the method (with the strings **<constructor>** and **<destructor>** indicating constructors and destructors respectively).
**self class**
This returns the name of the class that the current method was defined within. Note that this will change as the chain of method implementations is traversed with **[next](next.htm)**, and that if the method was defined on an object then this will fail. If you want the class of the current object, you need to use this other construct:
```
info object class [**self object**]
```
**self filter**
When invoked inside a filter, this subcommand returns a three element list describing the filter. The first element gives the name of the object or class that declared the filter (note that this may be different from the object or class that provided the implementation of the filter), the second element is either **object** or **class** depending on whether the declaring entity was an object or class, and the third element is the name of the filter.
**self method**
This returns the name of the current method (with the strings **<constructor>** and **<destructor>** indicating constructors and destructors respectively).
**self namespace**
This returns the name of the unique namespace of the object that the method was invoked upon.
**self next**
When invoked from a method that is not at the end of a call chain (i.e. where the **[next](next.htm)** command will invoke an actual method implementation), this subcommand returns a two element list describing the next element in the method call chain; the first element is the name of the class or object that declares the next part of the call chain, and the second element is the name of the method (with the strings **<constructor>** and **<destructor>** indicating constructors and destructors respectively). If invoked from a method that is at the end of a call chain, this subcommand returns the empty string.
**self object**
This returns the name of the object that the method was invoked upon.
**self target**
When invoked inside a filter implementation, this subcommand returns a two element list describing the method being filtered. The first element will be the name of the declarer of the method, and the second element will be the actual name of the method.
Examples
--------
This example shows basic use of **self** to provide information about the current object:
```
oo::class create c {
method foo {} {
puts "this is the [**self**] object"
}
}
c create a
c create b
a foo *→ prints "this is the ::a object"*
b foo *→ prints "this is the ::b object"*
```
This demonstrates what a method call chain looks like, and how traversing along it changes the index into it:
```
oo::class create c {
method x {} {
puts "Cls: [**self call**]"
}
}
c create a
oo::objdefine a {
method x {} {
puts "Obj: [**self call**]"
next
puts "Obj: [**self call**]"
}
}
a x *→ Obj: {{method x object method} {method x ::c method}} 0*
*→ Cls: {{method x object method} {method x ::c method}} 1*
*→ Obj: {{method x object method} {method x ::c method}} 0*
```
See also
--------
**[info](info.htm)**, **[next](next.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/self.htm>
| programming_docs |
tcl_tk cd cd
==
Name
----
cd — Change working directory Synopsis
--------
**cd** ?*dirName*?
Description
-----------
Change the current working directory to *dirName*, or to the home directory (as specified in the HOME environment variable) if *dirName* is not given. Returns an empty string. Note that the current working directory is a per-process resource; the **cd** command changes the working directory for all interpreters and (in a threaded environment) all threads. Examples
--------
Change to the home directory of the user **fred**:
```
**cd** ~fred
```
Change to the directory **lib** that is a sibling directory of the current one:
```
**cd** ../lib
```
See also
--------
**[filename](filename.htm)**, **[glob](glob.htm)**, **[pwd](pwd.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/cd.htm>
tcl_tk platform_shell platform\_shell
===============
Name
----
platform::shell — System identification support code and utilities Synopsis
--------
**package require platform::shell ?1.1.4?**
**platform::shell::generic** *shell*
**platform::shell::identify** *shell*
**platform::shell::platform** *shell*
Description
-----------
The **platform::shell** package provides several utility commands useful for the identification of the architecture of a specific Tcl shell. This package allows the identification of the architecture of a specific Tcl shell different from the shell running the package. The only requirement is that the other shell (identified by its path), is actually executable on the current machine.
While for most platform this means that the architecture of the interrogated shell is identical to the architecture of the running shell this is not generally true. A counter example are all platforms which have 32 and 64 bit variants and where a 64bit system is able to run 32bit code. For these running and interrogated shell may have different 32/64 bit settings and thus different identifiers.
For applications like a code repository it is important to identify the architecture of the shell which will actually run the installed packages, versus the architecture of the shell running the repository software.
Commands
--------
**platform::shell::identify** *shell*
This command does the same identification as **platform::identify**, for the specified Tcl shell, in contrast to the running shell.
**platform::shell::generic** *shell*
This command does the same identification as **platform::generic**, for the specified Tcl shell, in contrast to the running shell.
**platform::shell::platform** *shell*
This command returns the contents of **tcl\_platform(platform)** for the specified Tcl shell.
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/platform_shell.htm>
tcl_tk msgcat msgcat
======
[NAME](msgcat.htm#M2) msgcat — Tcl message catalog
[SYNOPSIS](msgcat.htm#M3)
[DESCRIPTION](msgcat.htm#M4)
[COMMANDS](msgcat.htm#M5)
[**::msgcat::mc** *src-string* ?*arg arg ...*?](msgcat.htm#M6)
[**::msgcat::mcmax ?***src-string src-string ...*?](msgcat.htm#M7)
[**::msgcat::mcexists** ?**-exactnamespace**? ?**-exactlocale**? *src-string*](msgcat.htm#M8)
[**::msgcat::mclocale** ?*newLocale*?](msgcat.htm#M9)
[**::msgcat::mcpreferences**](msgcat.htm#M10)
[**::msgcat:mcloadedlocales subcommand** ?*locale*?](msgcat.htm#M11)
[**::msgcat::mcload** *dirname*](msgcat.htm#M12)
[**::msgcat::mcset** *locale src-string* ?*translate-string*?](msgcat.htm#M13)
[**::msgcat::mcmset** *locale src-trans-list*](msgcat.htm#M14)
[**::msgcat::mcflset** *src-string* ?*translate-string*?](msgcat.htm#M15)
[**::msgcat::mcflmset** *src-trans-list*](msgcat.htm#M16)
[**::msgcat::mcunknown** *locale src-string* ?*arg arg ...*?](msgcat.htm#M17)
[**::msgcat::mcforgetpackage**](msgcat.htm#M18)
[LOCALE SPECIFICATION](msgcat.htm#M19)
[NAMESPACES AND MESSAGE CATALOGS](msgcat.htm#M20)
[LOCATION AND FORMAT OF MESSAGE FILES](msgcat.htm#M21)
[RECOMMENDED MESSAGE SETUP FOR PACKAGES](msgcat.htm#M22)
[POSITIONAL CODES FOR FORMAT AND SCAN COMMANDS](msgcat.htm#M23)
[Package private locale](msgcat.htm#M24)
[**::msgcat::mcpackagelocale set** ?*locale*?](msgcat.htm#M25)
[**::msgcat::mcpackagelocale get**](msgcat.htm#M26)
[**::msgcat::mcpackagelocale preferences**](msgcat.htm#M27)
[**::msgcat::mcpackagelocale loaded**](msgcat.htm#M28)
[**::msgcat::mcpackagelocale isset**](msgcat.htm#M29)
[**::msgcat::mcpackagelocale unset**](msgcat.htm#M30)
[**::msgcat::mcpackagelocale present** *locale*](msgcat.htm#M31)
[**::msgcat::mcpackagelocale clear**](msgcat.htm#M32)
[Changing package options](msgcat.htm#M33)
[**::msgcat::mcpackageconfig get** *option*](msgcat.htm#M34)
[**::msgcat::mcpackageconfig isset** *option*](msgcat.htm#M35)
[**::msgcat::mcpackageconfig set** *option* *value*](msgcat.htm#M36)
[**::msgcat::mcpackageconfig unset** *option*](msgcat.htm#M37)
[Package options](msgcat.htm#M38)
[**mcfolder**](msgcat.htm#M39)
[**loadcmd**](msgcat.htm#M40)
[**changecmd**](msgcat.htm#M41)
[**unknowncmd**](msgcat.htm#M42)
[Callback invocation](msgcat.htm#M43)
[Examples](msgcat.htm#M44)
[CREDITS](msgcat.htm#M45)
[SEE ALSO](msgcat.htm#M46)
[KEYWORDS](msgcat.htm#M47)
Name
----
msgcat — Tcl message catalog Synopsis
--------
**package require Tcl 8.5**
**package require msgcat 1.6**
**::msgcat::mc** *src-string* ?*arg arg ...*?
**::msgcat::mcmax ?***src-string src-string ...*?
**::msgcat::mcexists** ?**-exactnamespace**? ?**-exactlocale**? *src-string*
**::msgcat::mclocale** ?*newLocale*?
**::msgcat::mcpreferences**
**::msgcat::mcloadedlocales subcommand** ?*locale*?
**::msgcat::mcload** *dirname*
**::msgcat::mcset** *locale src-string* ?*translate-string*?
**::msgcat::mcmset** *locale src-trans-list*
**::msgcat::mcflset** *src-string* ?*translate-string*?
**::msgcat::mcflmset** *src-trans-list*
**::msgcat::mcunknown** *locale src-string* ?*arg arg ...*?
**::msgcat::mcpackagelocale subcommand** ?*locale*?
**::msgcat::mcpackageconfig subcommand** *option* ?*value*?
**::msgcat::mcforgetpackage**
Description
-----------
The **msgcat** package provides a set of functions that can be used to manage multi-lingual user interfaces. Text strings are defined in a “message catalog” which is independent from the application, and which can be edited or localized without modifying the application source code. New languages or locales may be provided by adding a new file to the message catalog. **msgcat** distinguises packages by its namespace. Each package has its own message catalog and configuration settings in **msgcat**.
A *locale* is a specification string describing a user language like **de\_ch** for Swiss German. In **msgcat**, there is a global locale initialized by the system locale of the current system. Each package may decide to use the global locale or to use a package specific locale.
The global locale may be changed on demand, for example by a user initiated language change or within a multi user application like a web server.
Commands
--------
**::msgcat::mc** *src-string* ?*arg arg ...*?
Returns a translation of *src-string* according to the current locale. If additional arguments past *src-string* are given, the **[format](format.htm)** command is used to substitute the additional arguments in the translation of *src-string*. **::msgcat::mc** will search the messages defined in the current namespace for a translation of *src-string*; if none is found, it will search in the parent of the current namespace, and so on until it reaches the global namespace. If no translation string exists, **::msgcat::mcunknown** is called and the string returned from **::msgcat::mcunknown** is returned.
**::msgcat::mc** is the main function used to localize an application. Instead of using an English string directly, an application can pass the English string through **::msgcat::mc** and use the result. If an application is written for a single language in this fashion, then it is easy to add support for additional languages later simply by defining new message catalog entries.
**::msgcat::mcmax ?***src-string src-string ...*?
Given several source strings, **::msgcat::mcmax** returns the length of the longest translated string. This is useful when designing localized GUIs, which may require that all buttons, for example, be a fixed width (which will be the width of the widest button).
**::msgcat::mcexists** ?**-exactnamespace**? ?**-exactlocale**? *src-string*
Return true, if there is a translation for the given *src-string*.
The search may be limited by the option **-exactnamespace** to only check the current namespace and not any parent namespaces. It may also be limited by the option **-exactlocale** to only check the first prefered locale (e.g. first element returned by **::msgcat::mcpreferences** if global locale is used).
**::msgcat::mclocale** ?*newLocale*?
This function sets the locale to *newLocale*. If *newLocale* is omitted, the current locale is returned, otherwise the current locale is set to *newLocale*. msgcat stores and compares the locale in a case-insensitive manner, and returns locales in lowercase. The initial locale is determined by the locale specified in the user's environment. See **[LOCALE SPECIFICATION](#M19)** below for a description of the locale string format. If the locale is set, the preference list of locales is evaluated. Locales in this list are loaded now, if not jet loaded.
**::msgcat::mcpreferences**
Returns an ordered list of the locales preferred by the user, based on the user's language specification. The list is ordered from most specific to least preference. The list is derived from the current locale set in msgcat by **::msgcat::mclocale**, and cannot be set independently. For example, if the current locale is en\_US\_funky, then **::msgcat::mcpreferences** returns **{en\_us\_funky en\_us en {}}**.
**::msgcat:mcloadedlocales subcommand** ?*locale*?
This group of commands manage the list of loaded locales for packages not setting a package locale.
The subcommand **get** returns the list of currently loaded locales. The subcommand **present** requires the argument *locale* and returns true, if this locale is loaded.
The subcommand **clear** removes all locales and their data, which are not in the current preference list.
**::msgcat::mcload** *dirname*
Searches the specified directory for files that match the language specifications returned by **::msgcat::mcloadedlocales get** (or **msgcat::mcpackagelocale preferences** if a package locale is set) (note that these are all lowercase), extended by the file extension “.msg”. Each matching file is read in order, assuming a UTF-8 encoding. The file contents are then evaluated as a Tcl script. This means that Unicode characters may be present in the message file either directly in their UTF-8 encoded form, or by use of the backslash-u quoting recognized by Tcl evaluation. The number of message files which matched the specification and were loaded is returned. In addition, the given folder is stored in the **msgcat** package configuration option *mcfolder* to eventually load message catalog files required by a locale change.
**::msgcat::mcset** *locale src-string* ?*translate-string*?
Sets the translation for *src-string* to *translate-string* in the specified *locale* and the current namespace. If *translate-string* is not specified, *src-string* is used for both. The function returns *translate-string*.
**::msgcat::mcmset** *locale src-trans-list*
Sets the translation for multiple source strings in *src-trans-list* in the specified *locale* and the current namespace. *src-trans-list* must have an even number of elements and is in the form {*src-string translate-string* ?*src-string translate-string ...*?} **::msgcat::mcmset** can be significantly faster than multiple invocations of **::msgcat::mcset**. The function returns the number of translations set.
**::msgcat::mcflset** *src-string* ?*translate-string*?
Sets the translation for *src-string* to *translate-string* in the current namespace for the locale implied by the name of the message catalog being loaded via **::msgcat::mcload**. If *translate-string* is not specified, *src-string* is used for both. The function returns *translate-string*.
**::msgcat::mcflmset** *src-trans-list*
Sets the translation for multiple source strings in *src-trans-list* in the current namespace for the locale implied by the name of the message catalog being loaded via **::msgcat::mcload**. *src-trans-list* must have an even number of elements and is in the form {*src-string translate-string* ?*src-string translate-string ...*?} **::msgcat::mcflmset** can be significantly faster than multiple invocations of **::msgcat::mcflset**. The function returns the number of translations set.
**::msgcat::mcunknown** *locale src-string* ?*arg arg ...*?
This routine is called by **::msgcat::mc** in the case when a translation for *src-string* is not defined in the current locale. The default action is to return *src-string* passed by format if there are any arguments. This procedure can be redefined by the application, for example to log error messages for each unknown string. The **::msgcat::mcunknown** procedure is invoked at the same stack context as the call to **::msgcat::mc**. The return value of **::msgcat::mcunknown** is used as the return value for the call to **::msgcat::mc**. Note that this routine is only called if the concerned package did not set a package locale unknown command name.
**::msgcat::mcforgetpackage**
The calling package clears all its state within the **msgcat** package including all settings and translations.
Locale specification
--------------------
The locale is specified to **msgcat** by a locale string passed to **::msgcat::mclocale**. The locale string consists of a language code, an optional country code, and an optional system-specific code, each separated by “\_”. The country and language codes are specified in standards ISO-639 and ISO-3166. For example, the locale “en” specifies English and “en\_US” specifies U.S. English. When the msgcat package is first loaded, the locale is initialized according to the user's environment. The variables **env(LC\_ALL)**, **env(LC\_MESSAGES)**, and **env(LANG)** are examined in order. The first of them to have a non-empty value is used to determine the initial locale. The value is parsed according to the XPG4 pattern
```
language[_country][.codeset][@modifier]
```
to extract its parts. The initial locale is then set by calling **::msgcat::mclocale** with the argument
```
language[_country][_modifier]
```
On Windows and Cygwin, if none of those environment variables is set, msgcat will attempt to extract locale information from the registry. From Windows Vista on, the RFC4747 locale name "lang-script-country-options" is transformed to the locale as "lang\_country\_script" (Example: sr-Latn-CS -> sr\_cs\_latin). For Windows XP, the language id is transformed analoguously (Example: 0c1a -> sr\_yu\_cyrillic). If all these attempts to discover an initial locale from the user's environment fail, msgcat defaults to an initial locale of “C”.
When a locale is specified by the user, a “best match” search is performed during string translation. For example, if a user specifies en\_GB\_Funky, the locales “en\_gb\_funky”, “en\_gb”, “en” and “” (the empty string) are searched in order until a matching translation string is found. If no translation string is available, then the unknown handler is called.
Namespaces and message catalogs
-------------------------------
Strings stored in the message catalog are stored relative to the namespace from which they were added. This allows multiple packages to use the same strings without fear of collisions with other packages. It also allows the source string to be shorter and less prone to typographical error. For example, executing the code
```
**::msgcat::mcset** en hello "hello from ::"
namespace eval foo {
**::msgcat::mcset** en hello "hello from ::foo"
}
puts [**::msgcat::mc** hello]
namespace eval foo {puts [**::msgcat::mc** hello]}
```
will print
```
hello from ::
hello from ::foo
```
When searching for a translation of a message, the message catalog will search first the current namespace, then the parent of the current namespace, and so on until the global namespace is reached. This allows child namespaces to “inherit” messages from their parent namespace.
For example, executing (in the “en” locale) the code
```
**::msgcat::mcset** en m1 ":: message1"
**::msgcat::mcset** en m2 ":: message2"
**::msgcat::mcset** en m3 ":: message3"
namespace eval ::foo {
**::msgcat::mcset** en m2 "::foo message2"
**::msgcat::mcset** en m3 "::foo message3"
}
namespace eval ::foo::bar {
**::msgcat::mcset** en m3 "::foo::bar message3"
}
namespace import **::msgcat::mc**
puts "[**mc** m1]; [**mc** m2]; [**mc** m3]"
namespace eval ::foo {puts "[**mc** m1]; [**mc** m2]; [**mc** m3]"}
namespace eval ::foo::bar {puts "[**mc** m1]; [**mc** m2]; [**mc** m3]"}
```
will print
```
:: message1; :: message2; :: message3
:: message1; ::foo message2; ::foo message3
:: message1; ::foo message2; ::foo::bar message3
```
Location and format of message files
------------------------------------
Message files can be located in any directory, subject to the following conditions:
1. All message files for a package are in the same directory.
2. The message file name is a msgcat locale specifier (all lowercase) followed by “.msg”. For example:
```
es.msg — spanish
en_gb.msg — United Kingdom English
```
*Exception:* The message file for the root locale “” is called “**ROOT.msg**”. This exception is made so as not to cause peculiar behavior, such as marking the message file as “hidden” on Unix file systems.
1. The file contains a series of calls to **mcflset** and **mcflmset**, setting the necessary translation strings for the language, likely enclosed in a **[namespace eval](namespace.htm)** so that all source strings are tied to the namespace of the package. For example, a short **es.msg** might contain:
```
namespace eval ::mypackage {
**::msgcat::mcflset** "Free Beer" "Cerveza Gratis"
}
```
Recommended message setup for packages
--------------------------------------
If a package is installed into a subdirectory of the **[tcl\_pkgPath](tclvars.htm)** and loaded via **[package require](package.htm)**, the following procedure is recommended.
1. During package installation, create a subdirectory **msgs** under your package directory.
2. Copy your \*.msg files into that directory.
3. Add the following command to your package initialization script:
```
# load language files, stored in msgs subdirectory
**::msgcat::mcload** [file join [file dirname [info script]] msgs]
```
Positional codes for format and scan commands
---------------------------------------------
It is possible that a message string used as an argument to **[format](format.htm)** might have positionally dependent parameters that might need to be repositioned. For example, it might be syntactically desirable to rearrange the sentence structure while translating.
```
format "We produced %d units in location %s" $num $city
format "In location %s we produced %d units" $city $num
```
This can be handled by using the positional parameters:
```
format "We produced %1\$d units in location %2\$s" $num $city
format "In location %2\$s we produced %1\$d units" $num $city
```
Similarly, positional parameters can be used with **[scan](scan.htm)** to extract values from internationalized strings. Note that it is not necessary to pass the output of **::msgcat::mc** to **[format](format.htm)** directly; by passing the values to substitute in as arguments, the formatting substitution is done directly.
```
**msgcat::mc** {Produced %1$d at %2$s} $num $city
# ... where that key is mapped to one of the
# human-oriented versions by **msgcat::mcset**
```
Package private locale
----------------------
A package using **msgcat** may choose to use its own package private locale and its own set of loaded locales, independent to the global locale set by **::msgcat::mclocale**. This allows a package to change its locale without causing any locales load or removal in other packages and not to invoke the global locale change callback (see below).
This action is controled by the following ensemble:
**::msgcat::mcpackagelocale set** ?*locale*?
Set or change a package private locale. The package private locale is set to the given *locale* if the *locale* is given. If the option *locale* is not given, the package is set to package private locale mode, but no locale is changed (e.g. if the global locale was valid for the package before, it is copied to the package private locale).
This command may cause the load of locales.
**::msgcat::mcpackagelocale get**
Return the package private locale or the global locale, if no package private locale is set.
**::msgcat::mcpackagelocale preferences**
Return the package private preferences or the global preferences, if no package private locale is set.
**::msgcat::mcpackagelocale loaded**
Return the list of locales loaded for this package.
**::msgcat::mcpackagelocale isset**
Returns true, if a package private locale is set.
**::msgcat::mcpackagelocale unset**
Unset the package private locale and use the globale locale. Load and remove locales to adjust the list of loaded locales for the package to the global loaded locales list.
**::msgcat::mcpackagelocale present** *locale*
Returns true, if the given locale is loaded for the package.
**::msgcat::mcpackagelocale clear**
Clear any loaded locales of the package not present in the package preferences.
Changing package options
------------------------
Each package using msgcat has a set of options within **msgcat**. The package options are described in the next sectionPackage options. Each package option may be set or unset individually using the following ensemble:
**::msgcat::mcpackageconfig get** *option*
Return the current value of the given *option*. This call returns an error if the option is not set for the package.
**::msgcat::mcpackageconfig isset** *option*
Returns 1, if the given *option* is set for the package, 0 otherwise.
**::msgcat::mcpackageconfig set** *option* *value*
Set the given *option* to the given *value*. This may invoke additional actions in dependency of the *option*. The return value is 0 or the number of loaded packages for the option **mcfolder**.
**::msgcat::mcpackageconfig unset** *option*
Unsets the given *option* for the package. No action is taken if the *option* is not set for the package. The empty string is returned.
### Package options
The following package options are available for each package:
**mcfolder**
This is the message folder of the package. This option is set by mcload and by the subcommand set. Both are identical and both return the number of loaded message catalog files. Setting or changing this value will load all locales contained in the preferences valid for the package. This implies also to invoke any set loadcmd (see below).
Unsetting this value will disable message file load for the package.
**loadcmd**
This callback is invoked before a set of message catalog files are loaded for the package which has this property set.
This callback may be used to do any preparation work for message file load or to get the message data from another source like a data base. In this case, no message files are used (mcfolder is unset). See section **callback invocation** below. The parameter list appended to this callback is the list of locales to load.
If this callback is changed, it is called with the preferences valid for the package.
**changecmd**
This callback is invoked when a default local change was performed. Its purpose is to allow a package to update any dependency on the default locale like showing the GUI in another language.
See the callback invocation section below. The parameter list appended to this callback is **mcpreferences**. The registered callbacks are invoked in no particular order.
**unknowncmd**
Use a package locale mcunknown procedure instead of the standard version supplied by the msgcat package (msgcat::mcunknown).
The called procedure must return the formatted message which will finally be returned by msgcat::mc. A generic unknown handler is used if set to the empty string. This consists in returning the key if no arguments are given. With given arguments, format is used to process the arguments.
See section **callback invocation** below. The appended arguments are identical to **::msgcat::mcunknown**.
### Callback invocation
A package may decide to register one or multiple callbacks, as described above. Callbacks are invoked, if:
1. the callback command is set,
2. the command is not the empty string,
3. the registering namespace exists.
If a called routine fails with an error, the **[bgerror](bgerror.htm)** routine for the interpreter is invoked after command completion. Only exception is the callback **unknowncmd**, where an error causes the invoking **mc**-command to fail with that error.
### Examples
Packages which display a GUI may update their widgets when the global locale changes. To register to a callback, use:
```
namespace eval gui {
msgcat::mcpackageconfig changecmd updateGUI
proc updateGui args {
puts "New locale is '[lindex $args 0]'."
}
}
% msgcat::mclocale fr
fr
% New locale is 'fr'.
```
If locales (or additional locales) are contained in another source like a data base, a package may use the load callback and not mcload:
```
namespace eval db {
msgcat::mcpackageconfig loadcmd loadMessages
proc loadMessages args {
foreach locale $args {
if {[LocaleInDB $locale]} {
msgcat::mcmset $locale [GetLocaleList $locale]
}
}
}
}
```
The **[clock](clock.htm)** command implementation uses **msgcat** with a package locale to implement the command line parameter **-locale**. Here are some sketches of the implementation:
First, a package locale is initialized and the generic unknown function is desactivated:
```
msgcat::mcpackagelocale set
msgcat::mcpackageconfig unknowncmd ""
```
As an example, the user requires the week day in a certain locale as follows:
```
clock format clock seconds -format %A -locale fr
```
**[clock](clock.htm)** sets the package locale to **fr** and looks for the day name as follows:
```
msgcat::mcpackagelocale set $locale
return [lindex [msgcat::mc DAYS_OF_WEEK_FULL] $day]
### Returns "mercredi"
```
Within **[clock](clock.htm)**, some message-catalog items are heavy in computation and thus are dynamically cached using:
```
proc ::tcl::clock::LocalizeFormat { locale format } {
set key FORMAT_$format
if { [::msgcat::mcexists -exactlocale -exactnamespace $key] } {
return [mc $key]
}
#...expensive computation of format clipped...
mcset $locale $key $format
return $format
}
```
Credits
-------
The message catalog code was developed by Mark Harrison. See also
--------
**[format](format.htm)**, **[scan](scan.htm)**, **[namespace](namespace.htm)**, **[package](package.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/msgcat.htm>
| programming_docs |
tcl_tk TclCmd TclCmd
======
| | | | | |
| --- | --- | --- | --- | --- |
| [after](after.htm "Execute a command after a time delay") | [errorInfo](tclvars.htm "Variables used by Tcl") | [load](load.htm "Load machine code and initialize new commands") | [re\_syntax](re_syntax.htm "Syntax of Tcl regular expressions") | [tcl\_startOfNextWord](library.htm "Standard library of Tcl procedures") |
| [append](append.htm "Append to variable") | [eval](eval.htm "Evaluate a Tcl script") | [lrange](lrange.htm "Return one or more adjacent elements from a list") | [read](read.htm "Read from a channel") | [tcl\_startOfPreviousWord](library.htm "Standard library of Tcl procedures") |
| [apply](apply.htm "Apply an anonymous function") | [exec](exec.htm "Invoke subprocesses") | [lrepeat](lrepeat.htm "Build a list by repeating elements") | [refchan](refchan.htm "Command handler API of reflected channels") | [tcl\_traceCompile](tclvars.htm "Variables used by Tcl") |
| [argc](tclvars.htm "Variables used by Tcl") | [exit](exit.htm "End the application") | [lreplace](lreplace.htm "Replace elements in a list with new elements") | [regexp](regexp.htm "Match a regular expression against a string") | [tcl\_traceExec](tclvars.htm "Variables used by Tcl") |
| [argv](tclvars.htm "Variables used by Tcl") | [expr](expr.htm "Evaluate an expression") | [lreverse](lreverse.htm "Reverse the order of a list") | [registry](registry.htm "Manipulate the Windows registry") | [tcl\_version](tclvars.htm "Variables used by Tcl") |
| [argv0](tclvars.htm "Variables used by Tcl") | [fblocked](fblocked.htm "Test whether the last input operation exhausted all available input") | [lsearch](lsearch.htm "See if a list contains a particular element") | [regsub](regsub.htm "Perform substitutions based on regular expression pattern matching") | [tcl\_wordBreakAfter](library.htm "Standard library of Tcl procedures") |
| [array](array.htm "Manipulate array variables") | [fconfigure](fconfigure.htm "Set and get options on a channel") | [lset](lset.htm "Change an element in a list") | [rename](rename.htm "Rename or delete a command") | [tcl\_wordBreakBefore](library.htm "Standard library of Tcl procedures") |
| [auto\_execok](library.htm "Standard library of Tcl procedures") | [fcopy](fcopy.htm "Copy data from one channel to another") | [lsort](lsort.htm "Sort the elements of a list") | [return](return.htm "Return from a procedure, or set return code of a script") | [tcl\_wordchars](tclvars.htm "Variables used by Tcl") |
| [auto\_import](library.htm "Standard library of Tcl procedures") | [file](file.htm "Manipulate file names and attributes") | [mathfunc](mathfunc.htm "Mathematical functions for Tcl expressions") | [safe](safe.htm "Creating and manipulating safe interpreters") | [tcltest](tcltest.htm "Test harness support code and utilities") |
| [auto\_load](library.htm "Standard library of Tcl procedures") | [fileevent](fileevent.htm "Execute a script when a channel becomes readable or writable") | [mathop](mathop.htm "Mathematical operators as Tcl commands") | [scan](scan.htm "Parse string using conversion specifiers in the style of sscanf") | [tell](tell.htm "Return current access position for an open channel") |
| [auto\_mkindex](library.htm "Standard library of Tcl procedures") | [filename](filename.htm "File name conventions supported by Tcl commands") | [memory](memory.htm "Control Tcl memory debugging capabilities") | [seek](seek.htm "Change the access position for an open channel") | [throw](throw.htm "Generate a machine-readable error") |
| [auto\_path](tclvars.htm "Variables used by Tcl") | [flush](flush.htm "Flush buffered output for a channel") | [msgcat](msgcat.htm "Tcl message catalog") | [self](self.htm "Method call internal introspection") | [time](time.htm "Time the execution of a script") |
| [auto\_qualify](library.htm "Standard library of Tcl procedures") | [for](for.htm "'For' loop") | [my](my.htm "Invoke any method of current object") | [set](set.htm "Read and write variables") | [tm](tm.htm "Facilities for locating and loading of Tcl Modules") |
| [auto\_reset](library.htm "Standard library of Tcl procedures") | [foreach](foreach.htm "Iterate over all elements in one or more lists") | [namespace](namespace.htm "Create and manipulate contexts for commands and variables") | [socket](socket.htm "Open a TCP network connection") | [trace](trace.htm "Monitor variable accesses, command usages and command executions") |
| [bgerror](bgerror.htm "Command invoked to process background errors") | [format](format.htm "Format a string in the style of sprintf") | [next](next.htm "Invoke superclass method implementations") | [source](source.htm "Evaluate a file or resource as a Tcl script") | [transchan](transchan.htm "Command handler API of channel transforms") |
| [binary](binary.htm "Insert and extract fields from binary strings") | [gets](gets.htm "Read a line from a channel") | [nextto](next.htm "Invoke superclass method implementations") | [split](split.htm "Split a string into a proper Tcl list") | [try](try.htm "Trap and process errors and exceptions") |
| [break](break.htm "Abort looping command") | [glob](glob.htm "Return names of files that match patterns") | [oo::class](class.htm "Class of all classes") | [string](string.htm "Manipulate strings") | [unknown](unknown.htm "Handle attempts to use non-existent commands") |
| [catch](catch.htm "Evaluate script and trap exceptional returns") | [global](global.htm "Access global variables") | [oo::copy](copy.htm "Create copies of objects and classes") | [subst](subst.htm "Perform backslash, command, and variable substitutions") | [unload](unload.htm "Unload machine code") |
| [cd](cd.htm "Change working directory") | [history](history.htm "Manipulate the history list") | [oo::define](define.htm "Define and configure classes and objects") | [switch](switch.htm "Evaluate one of several scripts, depending on a given value") | [unset](unset.htm "Delete variables") |
| [chan](chan.htm "Read, write and manipulate channels") | [http](http.htm "Client-side implementation of the HTTP/1.1 protocol") | [oo::objdefine](define.htm "Define and configure classes and objects") | [tailcall](tailcall.htm "Replace the current procedure with another command") | [update](update.htm "Process pending events and idle callbacks") |
| [clock](clock.htm "Obtain and manipulate dates and times") | [if](if.htm "Execute scripts conditionally") | [oo::object](object.htm "Root class of the class hierarchy") | [Tcl](tcl.htm "Tool Command Language") | [uplevel](uplevel.htm "Execute a script in a different stack frame") |
| [close](close.htm "Close an open channel") | [incr](incr.htm "Increment the value of a variable") | [open](open.htm "Open a file-based or command pipeline channel") | [tcl::prefix](prefix.htm "Facilities for prefix matching") | [upvar](upvar.htm "Create link to variable in a different stack frame") |
| [concat](concat.htm "Join lists together") | [info](info.htm "Return information about the state of the Tcl interpreter") | [package](package.htm "Facilities for package loading and version control") | [tcl\_endOfWord](library.htm "Standard library of Tcl procedures") | [variable](variable.htm "Create and initialize a namespace variable") |
| [continue](continue.htm "Skip to the next iteration of a loop") | [interp](interp.htm "Create and manipulate Tcl interpreters") | [parray](library.htm "Standard library of Tcl procedures") | [tcl\_findLibrary](library.htm "Standard library of Tcl procedures") | [vwait](vwait.htm "Process events until a variable is written") |
| [coroutine](coroutine.htm "Create and produce values from coroutines") | [join](join.htm "Create a string by joining together list elements") | [pid](pid.htm "Retrieve process identifiers") | [tcl\_interactive](tclvars.htm "Variables used by Tcl") | [while](while.htm "Execute script repeatedly as long as a condition is met") |
| [dde](dde.htm "Execute a Dynamic Data Exchange command") | [lappend](lappend.htm "Append list elements onto a variable") | [pkg::create](packagens.htm "Construct an appropriate 'package ifneeded' command for a given package specification") | [tcl\_library](tclvars.htm "Variables used by Tcl") | [yield](coroutine.htm "Create and produce values from coroutines") |
| [dict](dict.htm "Manipulate dictionaries") | [lassign](lassign.htm "Assign list elements to variables") | [pkg\_mkIndex](pkgmkindex.htm "Build an index for automatic loading of packages") | [tcl\_nonwordchars](tclvars.htm "Variables used by Tcl") | [yieldto](coroutine.htm "Create and produce values from coroutines") |
| [encoding](encoding.htm "Manipulate encodings") | [lindex](lindex.htm "Retrieve an element from a list") | [platform](platform.htm "System identification support code and utilities") | [tcl\_patchLevel](tclvars.htm "Variables used by Tcl") | [zlib](zlib.htm "Compression and decompression operations") |
| [env](tclvars.htm "Variables used by Tcl") | [linsert](linsert.htm "Insert elements into a list") | [platform::shell](platform_shell.htm "System identification support code and utilities") | [tcl\_pkgPath](tclvars.htm "Variables used by Tcl") |
| [eof](eof.htm "Check for end of file condition on channel") | [list](list.htm "Create a list") | [proc](proc.htm "Create a Tcl procedure") | [tcl\_platform](tclvars.htm "Variables used by Tcl") |
| [error](error.htm "Generate an error") | [llength](llength.htm "Count the number of elements in a list") | [puts](puts.htm "Write to a channel") | [tcl\_precision](tclvars.htm "Variables used by Tcl") |
| [errorCode](tclvars.htm "Variables used by Tcl") | [lmap](lmap.htm "Iterate over all elements in one or more lists and collect results") | [pwd](pwd.htm "Return the absolute path of the current working directory") | [tcl\_rcFileName](tclvars.htm "Variables used by Tcl") |
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/contents.htm>
tcl_tk eval eval
====
Name
----
eval — Evaluate a Tcl script Synopsis
--------
**eval** *arg* ?*arg ...*?
Description
-----------
**Eval** takes one or more arguments, which together comprise a Tcl script containing one or more commands. **Eval** concatenates all its arguments in the same fashion as the **[concat](concat.htm)** command, passes the concatenated string to the Tcl interpreter recursively, and returns the result of that evaluation (or any error generated by it). Note that the **[list](list.htm)** command quotes sequences of words in such a way that they are not further expanded by the **eval** command. Examples
--------
Often, it is useful to store a fragment of a script in a variable and execute it later on with extra values appended. This technique is used in a number of places throughout the Tcl core (e.g. in **[fcopy](fcopy.htm)**, **[lsort](lsort.htm)** and **[trace](trace.htm)** command callbacks). This example shows how to do this using core Tcl commands:
```
set script {
puts "logging now"
lappend $myCurrentLogVar
}
set myCurrentLogVar log1
# Set up a switch of logging variable part way through!
after 20000 set myCurrentLogVar log2
for {set i 0} {$i<10} {incr i} {
# Introduce a random delay
after [expr {int(5000 * rand())}]
update ;# Check for the asynch log switch
**eval** $script $i [clock clicks]
}
```
Note that in the most common case (where the script fragment is actually just a list of words forming a command prefix), it is better to use **{\*}$script** when doing this sort of invocation pattern. It is less general than the **eval** command, and hence easier to make robust in practice. The following procedure acts in a way that is analogous to the **[lappend](lappend.htm)** command, except it inserts the argument values at the start of the list in the variable:
```
proc lprepend {varName args} {
upvar 1 $varName var
# Ensure that the variable exists and contains a list
lappend var
# Now we insert all the arguments in one go
set var [**eval** [list linsert $var 0] $args]
}
```
However, the last line would now normally be written without **eval**, like this:
```
set var [linsert $var 0 {*}$args]
```
See also
--------
**[catch](catch.htm)**, **[concat](concat.htm)**, **[error](error.htm)**, **[errorCode](tclvars.htm)**, **[errorInfo](tclvars.htm)**, **[interp](interp.htm)**, **[list](list.htm)**, **[namespace](namespace.htm)**, **[subst](subst.htm)**, **[uplevel](uplevel.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/eval.htm>
tcl_tk set set
===
Name
----
set — Read and write variables Synopsis
--------
**set** *varName* ?*value*?
Description
-----------
Returns the value of variable *varName*. If *value* is specified, then set the value of *varName* to *value*, creating a new variable if one does not already exist, and return its value. If *varName* contains an open parenthesis and ends with a close parenthesis, then it refers to an array element: the characters before the first open parenthesis are the name of the array, and the characters between the parentheses are the index within the array. Otherwise *varName* refers to a scalar variable. If *varName* includes namespace qualifiers (in the array name if it refers to an array element), or if *varName* is unqualified (does not include the names of any containing namespaces) but no procedure is active, *varName* refers to a namespace variable resolved according to the rules described under **NAME RESOLUTION** in the **[namespace](namespace.htm)** manual page.
If a procedure is active and *varName* is unqualified, then *varName* refers to a parameter or local variable of the procedure, unless *varName* was declared to resolve differently through one of the **[global](global.htm)**, **[variable](variable.htm)** or **[upvar](upvar.htm)** commands.
Examples
--------
Store a random number in the variable *r*:
```
**set** r [expr {rand()}]
```
Store a short message in an array element:
```
**set** anAry(msg) "Hello, World!"
```
Store a short message in an array element specified by a variable:
```
**set** elemName "msg"
**set** anAry($elemName) "Hello, World!"
```
Copy a value into the variable *out* from a variable whose name is stored in the *vbl* (note that it is often easier to use arrays in practice instead of doing double-dereferencing):
```
**set** in0 "small random"
**set** in1 "large random"
**set** vbl in[expr {rand() >= 0.5}]
**set** out [**set** $vbl]
```
See also
--------
**[expr](expr.htm)**, **[global](global.htm)**, **[namespace](namespace.htm)**, **[proc](proc.htm)**, **[trace](trace.htm)**, **[unset](unset.htm)**, **[upvar](upvar.htm)**, **[variable](variable.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/set.htm>
tcl_tk return return
======
[NAME](return.htm#M2) return — Return from a procedure, or set return code of a script
[SYNOPSIS](return.htm#M3)
[DESCRIPTION](return.htm#M4)
[EXCEPTIONAL RETURN CODES](return.htm#M5)
[**ok** (or **0**)](return.htm#M6)
[**error** (or **1**)](return.htm#M7)
[**return** (or **2**)](return.htm#M8)
[**break** (or **3**)](return.htm#M9)
[**continue** (or **4**)](return.htm#M10)
[*value*](return.htm#M11)
[RETURN OPTIONS](return.htm#M12)
[**-errorcode** *list*](return.htm#M13)
[**-errorinfo** *info*](return.htm#M14)
[**-errorstack** *list*](return.htm#M15)
[**-level** *level*](return.htm#M16)
[**-options** *options*](return.htm#M17)
[RETURN CODE HANDLING MECHANISMS](return.htm#M18)
[EXAMPLES](return.htm#M19)
[SEE ALSO](return.htm#M20)
[KEYWORDS](return.htm#M21)
Name
----
return — Return from a procedure, or set return code of a script Synopsis
--------
**return** ?*result*?
**return** ?**-code** *code*? ?*result*?
**return** ?*option value* ...? ?*result*?
Description
-----------
In its simplest usage, the **return** command is used without options in the body of a procedure to immediately return control to the caller of the procedure. If a *result* argument is provided, its value becomes the result of the procedure passed back to the caller. If *result* is not specified then an empty string will be returned to the caller as the result of the procedure. The **return** command serves a similar function within script files that are evaluated by the **[source](source.htm)** command. When **[source](source.htm)** evaluates the contents of a file as a script, an invocation of the **return** command will cause script evaluation to immediately cease, and the value *result* (or an empty string) will be returned as the result of the **[source](source.htm)** command.
Exceptional return codes
------------------------
In addition to the result of a procedure, the return code of a procedure may also be set by **return** through use of the **-code** option. In the usual case where the **-code** option is not specified the procedure will return normally. However, the **-code** option may be used to generate an exceptional return from the procedure. *Code* may have any of the following values:
**ok** (or **0**)
Normal return: same as if the option is omitted. The return code of the procedure is 0 (**[TCL\_OK](catch.htm)**).
**error** (or **1**)
Error return: the return code of the procedure is 1 (**[TCL\_ERROR](catch.htm)**). The procedure command behaves in its calling context as if it were the command **[error](error.htm)** *result*. See below for additional options.
**return** (or **2**)
The return code of the procedure is 2 (**[TCL\_RETURN](catch.htm)**). The procedure command behaves in its calling context as if it were the command **return** (with no arguments).
**break** (or **3**)
The return code of the procedure is 3 (**[TCL\_BREAK](catch.htm)**). The procedure command behaves in its calling context as if it were the command **[break](break.htm)**.
**continue** (or **4**)
The return code of the procedure is 4 (**[TCL\_CONTINUE](catch.htm)**). The procedure command behaves in its calling context as if it were the command **[continue](continue.htm)**.
*value*
*Value* must be an integer; it will be returned as the return code for the current procedure.
When a procedure wants to signal that it has received invalid arguments from its caller, it may use **return -code error** with *result* set to a suitable error message. Otherwise usage of the **return -code** option is mostly limited to procedures that implement a new control structure.
The **return -code** command acts similarly within script files that are evaluated by the **[source](source.htm)** command. During the evaluation of the contents of a file as a script by **[source](source.htm)**, an invocation of the **return -code** *code* command will cause the return code of **[source](source.htm)** to be *code*.
Return options
--------------
In addition to a result and a return code, evaluation of a command in Tcl also produces a dictionary of return options. In general usage, all *option value* pairs given as arguments to **return** become entries in the return options dictionary, and any values at all are acceptable except as noted below. The **[catch](catch.htm)** command may be used to capture all of this information — the return code, the result, and the return options dictionary — that arise from evaluation of a script. As documented above, the **-code** entry in the return options dictionary receives special treatment by Tcl. There are other return options also recognized and treated specially by Tcl. They are:
**-errorcode** *list*
The **-errorcode** option receives special treatment only when the value of the **-code** option is **[TCL\_ERROR](catch.htm)**. Then the *list* value is meant to be additional information about the error, presented as a Tcl list for further processing by programs. If no **-errorcode** option is provided to **return** when the **-code error** option is provided, Tcl will set the value of the **-errorcode** entry in the return options dictionary to the default value of **NONE**. The **-errorcode** return option will also be stored in the global variable **[errorCode](tclvars.htm)**.
**-errorinfo** *info*
The **-errorinfo** option receives special treatment only when the value of the **-code** option is **[TCL\_ERROR](catch.htm)**. Then *info* is the initial stack trace, meant to provide to a human reader additional information about the context in which the error occurred. The stack trace will also be stored in the global variable **[errorInfo](tclvars.htm)**. If no **-errorinfo** option is provided to **return** when the **-code error** option is provided, Tcl will provide its own initial stack trace value in the entry for **-errorinfo**. Tcl's initial stack trace will include only the call to the procedure, and stack unwinding will append information about higher stack levels, but there will be no information about the context of the error within the procedure. Typically the *info* value is supplied from the value of **-errorinfo** in a return options dictionary captured by the **[catch](catch.htm)** command (or from the copy of that information stored in the global variable **[errorInfo](tclvars.htm)**).
**-errorstack** *list*
The **-errorstack** option receives special treatment only when the value of the **-code** option is **[TCL\_ERROR](catch.htm)**. Then *list* is the initial error stack, recording actual argument values passed to each proc level. The error stack will also be reachable through **[info errorstack](info.htm)**. If no **-errorstack** option is provided to **return** when the **-code error** option is provided, Tcl will provide its own initial error stack in the entry for **-errorstack**. Tcl's initial error stack will include only the call to the procedure, and stack unwinding will append information about higher stack levels, but there will be no information about the context of the error within the procedure. Typically the *list* value is supplied from the value of **-errorstack** in a return options dictionary captured by the **[catch](catch.htm)** command (or from the copy of that information from **[info errorstack](info.htm)**).
**-level** *level*
The **-level** and **-code** options work together to set the return code to be returned by one of the commands currently being evaluated. The *level* value must be a non-negative integer representing a number of levels on the call stack. It defines the number of levels up the stack at which the return code of a command currently being evaluated should be *code*. If no **-level** option is provided, the default value of *level* is 1, so that **return** sets the return code that the current procedure returns to its caller, 1 level up the call stack. The mechanism by which these options work is described in more detail below.
**-options** *options*
The value *options* must be a valid dictionary. The entries of that dictionary are treated as additional *option value* pairs for the **return** command.
Return code handling mechanisms
-------------------------------
Return codes are used in Tcl to control program flow. A Tcl script is a sequence of Tcl commands. So long as each command evaluation returns a return code of **[TCL\_OK](catch.htm)**, evaluation will continue to the next command in the script. Any exceptional return code (non-**[TCL\_OK](catch.htm)**) returned by a command evaluation causes the flow on to the next command to be interrupted. Script evaluation ceases, and the exceptional return code from the command becomes the return code of the full script evaluation. This is the mechanism by which errors during script evaluation cause an interruption and unwinding of the call stack. It is also the mechanism by which commands like **[break](break.htm)**, **[continue](continue.htm)**, and **return** cause script evaluation to terminate without evaluating all commands in sequence. Some of Tcl's built-in commands evaluate scripts as part of their functioning. These commands can make use of exceptional return codes to enable special features. For example, the built-in Tcl commands that provide loops — such as **[while](while.htm)**, **[for](for.htm)**, and **[foreach](foreach.htm)** — evaluate a script that is the body of the loop. If evaluation of the loop body returns the return code of **[TCL\_BREAK](catch.htm)** or **[TCL\_CONTINUE](catch.htm)**, the loop command can react in such a way as to give the **[break](break.htm)** and **[continue](continue.htm)** commands their documented interpretation in loops.
Procedure invocation also involves evaluation of a script, the body of the procedure. Procedure invocation provides special treatment when evaluation of the procedure body returns the return code **[TCL\_RETURN](catch.htm)**. In that circumstance, the **-level** entry in the return options dictionary is decremented. If after decrementing, the value of the **-level** entry is 0, then the value of the **-code** entry becomes the return code of the procedure. If after decrementing, the value of the **-level** entry is greater than zero, then the return code of the procedure is **[TCL\_RETURN](catch.htm)**. If the procedure invocation occurred during the evaluation of the body of another procedure, the process will repeat itself up the call stack, decrementing the value of the **-level** entry at each level, so that the *code* will be the return code of the current command *level* levels up the call stack. The **[source](source.htm)** command performs the same handling of the **[TCL\_RETURN](catch.htm)** return code, which explains the similarity of **return** invocation during a **[source](source.htm)** to **return** invocation within a procedure.
The return code of the **return** command itself triggers this special handling by procedure invocation. If **return** is provided the option **-level 0**, then the return code of the **return** command itself will be the value *code* of the **-code** option (or **[TCL\_OK](catch.htm)** by default). Any other value for the **-level** option (including the default value of 1) will cause the return code of the **return** command itself to be **[TCL\_RETURN](catch.htm)**, triggering a return from the enclosing procedure.
Examples
--------
First, a simple example of using **return** to return from a procedure, interrupting the procedure body.
```
proc printOneLine {} {
puts "line 1" ;# This line will be printed.
**return**
puts "line 2" ;# This line will not be printed.
}
```
Next, an example of using **return** to set the value returned by the procedure.
```
proc returnX {} {**return** X}
puts [returnX] ;# prints "X"
```
Next, a more complete example, using **return -code error** to report invalid arguments.
```
proc factorial {n} {
if {![string is integer $n] || ($n < 0)} {
**return** -code error \
"expected non-negative integer,\
but got \"$n\""
}
if {$n < 2} {
**return** 1
}
set m [expr {$n - 1}]
set code [catch {factorial $m} factor]
if {$code != 0} {
**return** -code $code $factor
}
set product [expr {$n * $factor}]
if {$product < 0} {
**return** -code error \
"overflow computing factorial of $n"
}
**return** $product
}
```
Next, a procedure replacement for **[break](break.htm)**.
```
proc myBreak {} {
**return** -code break
}
```
With the **-level 0** option, **return** itself can serve as a replacement for **[break](break.htm)**, with the help of **[interp alias](interp.htm)**.
```
interp alias {} Break {} **return** -level 0 -code break
```
An example of using **[catch](catch.htm)** and **return -options** to re-raise a caught error:
```
proc doSomething {} {
set resource [allocate]
catch {
# Long script of operations
# that might raise an error
} result options
deallocate $resource
**return** -options $options $result
}
```
Finally an example of advanced use of the **return** options to create a procedure replacement for **return** itself:
```
proc myReturn {args} {
set result ""
if {[llength $args] % 2} {
set result [lindex $args end]
set args [lrange $args 0 end-1]
}
set options [dict merge {-level 1} $args]
dict incr options -level
**return** -options $options $result
}
```
See also
--------
**[break](break.htm)**, **[catch](catch.htm)**, **[continue](continue.htm)**, **[dict](dict.htm)**, **[error](error.htm)**, **[errorCode](tclvars.htm)**, **[errorInfo](tclvars.htm)**, **[proc](proc.htm)**, **[source](source.htm)**, **[throw](throw.htm)**, **[try](try.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/return.htm>
| programming_docs |
tcl_tk foreach foreach
=======
Name
----
foreach — Iterate over all elements in one or more lists Synopsis
--------
**foreach** *varname list body*
**foreach** *varlist1 list1* ?*varlist2 list2 ...*? *body*
Description
-----------
The **foreach** command implements a loop where the loop variable(s) take on values from one or more lists. In the simplest case there is one loop variable, *varname*, and one list, *list*, that is a list of values to assign to *varname*. The *body* argument is a Tcl script. For each element of *list* (in order from first to last), **foreach** assigns the contents of the element to *varname* as if the **[lindex](lindex.htm)** command had been used to extract the element, then calls the Tcl interpreter to execute *body*. In the general case there can be more than one value list (e.g., *list1* and *list2*), and each value list can be associated with a list of loop variables (e.g., *varlist1* and *varlist2*). During each iteration of the loop the variables of each *varlist* are assigned consecutive values from the corresponding *list*. Values in each *list* are used in order from first to last, and each value is used exactly once. The total number of loop iterations is large enough to use up all the values from all the value lists. If a value list does not contain enough elements for each of its loop variables in each iteration, empty values are used for the missing elements.
The **[break](break.htm)** and **[continue](continue.htm)** statements may be invoked inside *body*, with the same effect as in the **[for](for.htm)** command. **Foreach** returns an empty string.
Examples
--------
This loop prints every value in a list together with the square and cube of the value:
```
set values {1 3 5 7 2 4 6 8} ;# Odd numbers first, for fun!
puts "Value\tSquare\tCube" ;# Neat-looking header
**foreach** x $values { ;# Now loop and print...
puts " $x\t [expr {$x**2}]\t [expr {$x**3}]"
}
```
The following loop uses i and j as loop variables to iterate over pairs of elements of a single list.
```
set x {}
**foreach** {i j} {a b c d e f} {
lappend x $j $i
}
# The value of x is "b a d c f e"
# There are 3 iterations of the loop.
```
The next loop uses i and j to iterate over two lists in parallel.
```
set x {}
**foreach** i {a b c} j {d e f g} {
lappend x $i $j
}
# The value of x is "a d b e c f {} g"
# There are 4 iterations of the loop.
```
The two forms are combined in the following example.
```
set x {}
**foreach** i {a b c} {j k} {d e f g} {
lappend x $i $j $k
}
# The value of x is "a d e b f g c {} {}"
# There are 3 iterations of the loop.
```
See also
--------
**[for](for.htm)**, **[while](while.htm)**, **[break](break.htm)**, **[continue](continue.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/foreach.htm>
tcl_tk Tcl Tcl
===
[NAME](tcl.htm#M2) Tcl — Tool Command Language
[SYNOPSIS](tcl.htm#M3)
[DESCRIPTION](tcl.htm#M4)
[[1] **Commands.**](tcl.htm#M5)
[[2] **Evaluation.**](tcl.htm#M6)
[[3] **Words.**](tcl.htm#M7)
[[4] **Double quotes.**](tcl.htm#M8)
[[5] **Argument expansion.**](tcl.htm#M9)
[[6] **Braces.**](tcl.htm#M10)
[[7] **Command substitution.**](tcl.htm#M11)
[[8] **Variable substitution.**](tcl.htm#M12)
[**$***name*](tcl.htm#M13)
[**$***name***(***index***)**](tcl.htm#M14)
[**${***name***}**](tcl.htm#M15)
[[9] **Backslash substitution.**](tcl.htm#M16)
[\**a**](tcl.htm#M17)
[\**b**](tcl.htm#M18)
[\**f**](tcl.htm#M19)
[\**n**](tcl.htm#M20)
[\**r**](tcl.htm#M21)
[\**t**](tcl.htm#M22)
[\**v**](tcl.htm#M23)
[\**<newline>***whiteSpace*](tcl.htm#M24)
[\\](tcl.htm#M25)
[\*ooo*](tcl.htm#M26)
[\**x***hh*](tcl.htm#M27)
[\**u***hhhh*](tcl.htm#M28)
[\**U***hhhhhhhh*](tcl.htm#M29)
[[10] **Comments.**](tcl.htm#M30)
[[11] **Order of substitution.**](tcl.htm#M31)
[[12] **Substitution and word boundaries.**](tcl.htm#M32)
[KEYWORDS](tcl.htm#M33)
Name
----
Tcl — Tool Command Language Synopsis
--------
Summary of Tcl language syntax.
Description
-----------
The following rules define the syntax and semantics of the Tcl language:
[1] **Commands.**
A Tcl script is a string containing one or more commands. Semi-colons and newlines are command separators unless quoted as described below. Close brackets are command terminators during command substitution (see below) unless quoted.
[2] **Evaluation.**
A command is evaluated in two steps. First, the Tcl interpreter breaks the command into *words* and performs substitutions as described below. These substitutions are performed in the same way for all commands. Secondly, the first word is used to locate a command procedure to carry out the command, then all of the words of the command are passed to the command procedure. The command procedure is free to interpret each of its words in any way it likes, such as an integer, variable name, list, or Tcl script. Different commands interpret their words differently.
[3] **Words.**
Words of a command are separated by white space (except for newlines, which are command separators).
[4] **Double quotes.**
If the first character of a word is double-quote (“"”) then the word is terminated by the next double-quote character. If semi-colons, close brackets, or white space characters (including newlines) appear between the quotes then they are treated as ordinary characters and included in the word. Command substitution, variable substitution, and backslash substitution are performed on the characters between the quotes as described below. The double-quotes are not retained as part of the word.
[5] **Argument expansion.**
If a word starts with the string “{\*}” followed by a non-whitespace character, then the leading “{\*}” is removed and the rest of the word is parsed and substituted as any other word. After substitution, the word is parsed as a list (without command or variable substitutions; backslash substitutions are performed as is normal for a list and individual internal words may be surrounded by either braces or double-quote characters), and its words are added to the command being substituted. For instance, “cmd a {\*}{b [c]} d {\*}{$e f {g h}}” is equivalent to “cmd a b {[c]} d {$e} f {g h}”.
[6] **Braces.**
If the first character of a word is an open brace (“{”) and rule [5] does not apply, then the word is terminated by the matching close brace (“}”). Braces nest within the word: for each additional open brace there must be an additional close brace (however, if an open brace or close brace within the word is quoted with a backslash then it is not counted in locating the matching close brace). No substitutions are performed on the characters between the braces except for backslash-newline substitutions described below, nor do semi-colons, newlines, close brackets, or white space receive any special interpretation. The word will consist of exactly the characters between the outer braces, not including the braces themselves.
[7] **Command substitution.**
If a word contains an open bracket (“[”) then Tcl performs *command substitution*. To do this it invokes the Tcl interpreter recursively to process the characters following the open bracket as a Tcl script. The script may contain any number of commands and must be terminated by a close bracket (“]”). The result of the script (i.e. the result of its last command) is substituted into the word in place of the brackets and all of the characters between them. There may be any number of command substitutions in a single word. Command substitution is not performed on words enclosed in braces.
[8] **Variable substitution.**
If a word contains a dollar-sign (“$”) followed by one of the forms described below, then Tcl performs *variable substitution*: the dollar-sign and the following characters are replaced in the word by the value of a variable. Variable substitution may take any of the following forms:
**$***name*
*Name* is the name of a scalar variable; the name is a sequence of one or more characters that are a letter, digit, underscore, or namespace separators (two or more colons). Letters and digits are *only* the standard ASCII ones (**0**–**9**, **A**–**Z** and **a**–**z**).
**$***name***(***index***)**
*Name* gives the name of an array variable and *index* gives the name of an element within that array. *Name* must contain only letters, digits, underscores, and namespace separators, and may be an empty string. Letters and digits are *only* the standard ASCII ones (**0**–**9**, **A**–**Z** and **a**–**z**). Command substitutions, variable substitutions, and backslash substitutions are performed on the characters of *index*.
**${***name***}**
*Name* is the name of a scalar variable or array element. It may contain any characters whatsoever except for close braces. It indicates an array element if *name* is in the form “*arrayName***(***index***)**” where *arrayName* does not contain any open parenthesis characters, “**(**”, or close brace characters, “**}**”, and *index* can be any sequence of characters except for close brace characters. No further substitutions are performed during the parsing of *name*.
There may be any number of variable substitutions in a single word. Variable substitution is not performed on words enclosed in braces.
Note that variables may contain character sequences other than those listed above, but in that case other mechanisms must be used to access them (e.g., via the **[set](set.htm)** command's single-argument form).
[9] **Backslash substitution.**
If a backslash (“\”) appears within a word then *backslash substitution* occurs. In all cases but those described below the backslash is dropped and the following character is treated as an ordinary character and included in the word. This allows characters such as double quotes, close brackets, and dollar signs to be included in words without triggering special processing. The following table lists the backslash sequences that are handled specially, along with the value that replaces each sequence.
\**a**
Audible alert (bell) (Unicode U+000007).
\**b**
Backspace (Unicode U+000008).
\**f**
Form feed (Unicode U+00000C).
\**n**
Newline (Unicode U+00000A).
\**r**
Carriage-return (Unicode U+00000D).
\**t**
Tab (Unicode U+000009).
\**v**
Vertical tab (Unicode U+00000B).
\**<newline>***whiteSpace*
A single space character replaces the backslash, newline, and all spaces and tabs after the newline. This backslash sequence is unique in that it is replaced in a separate pre-pass before the command is actually parsed. This means that it will be replaced even when it occurs between braces, and the resulting space will be treated as a word separator if it is not in braces or quotes.
\\
Backslash (“\”).
\*ooo*
The digits *ooo* (one, two, or three of them) give a eight-bit octal value for the Unicode character that will be inserted, in the range *000*–*377* (i.e., the range U+000000–U+0000FF). The parser will stop just before this range overflows, or when the maximum of three digits is reached. The upper bits of the Unicode character will be 0.
\**x***hh*
The hexadecimal digits *hh* (one or two of them) give an eight-bit hexadecimal value for the Unicode character that will be inserted. The upper bits of the Unicode character will be 0 (i.e., the character will be in the range U+000000–U+0000FF).
\**u***hhhh*
The hexadecimal digits *hhhh* (one, two, three, or four of them) give a sixteen-bit hexadecimal value for the Unicode character that will be inserted. The upper bits of the Unicode character will be 0 (i.e., the character will be in the range U+000000–U+00FFFF).
\**U***hhhhhhhh*
The hexadecimal digits *hhhhhhhh* (one up to eight of them) give a twenty-one-bit hexadecimal value for the Unicode character that will be inserted, in the range U+000000–U+10FFFF. The parser will stop just before this range overflows, or when the maximum of eight digits is reached. The upper bits of the Unicode character will be 0. The range U+010000–U+10FFFD is reserved for the future.
Backslash substitution is not performed on words enclosed in braces, except for backslash-newline as described above.
[10] **Comments.**
If a hash character (“#”) appears at a point where Tcl is expecting the first character of the first word of a command, then the hash character and the characters that follow it, up through the next newline, are treated as a comment and ignored. The comment character only has significance when it appears at the beginning of a command.
[11] **Order of substitution.**
Each character is processed exactly once by the Tcl interpreter as part of creating the words of a command. For example, if variable substitution occurs then no further substitutions are performed on the value of the variable; the value is inserted into the word verbatim. If command substitution occurs then the nested command is processed entirely by the recursive call to the Tcl interpreter; no substitutions are performed before making the recursive call and no additional substitutions are performed on the result of the nested script. Substitutions take place from left to right, and each substitution is evaluated completely before attempting to evaluate the next. Thus, a sequence like
```
set y [set x 0][incr x][incr x]
```
will always set the variable *y* to the value, *012*.
[12] **Substitution and word boundaries.**
Substitutions do not affect the word boundaries of a command, except for argument expansion as specified in rule [5]. For example, during variable substitution the entire value of the variable becomes part of a single word, even if the variable's value contains spaces.
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/Tcl.htm>
tcl_tk coroutine coroutine
=========
Name
----
coroutine, yield, yieldto — Create and produce values from coroutines Synopsis
--------
**coroutine** *name command* ?*arg...*?
**yield** ?*value*?
**yieldto** *command* ?*arg...*?
*name* ?*value...*?
Description
-----------
The **coroutine** command creates a new coroutine context (with associated command) named *name* and executes that context by calling *command*, passing in the other remaining arguments without further interpretation. Once *command* returns normally or with an exception (e.g., an error) the coroutine context *name* is deleted. Within the context, values may be generated as results by using the **yield** command; if no *value* is supplied, the empty string is used. When that is called, the context will suspend execution and the **coroutine** command will return the argument to **yield**. The execution of the context can then be resumed by calling the context command, optionally passing in the *single* value to use as the result of the **yield** call that caused the context to be suspended. If the coroutine context never yields and instead returns conventionally, the result of the **coroutine** command will be the result of the evaluation of the context.
The coroutine may also suspend its execution by use of the **yieldto** command, which instead of returning, cedes execution to some command called *command* (resolved in the context of the coroutine) and to which *any number* of arguments may be passed. Since every coroutine has a context command, **yieldto** can be used to transfer control directly from one coroutine to another (this is only advisable if the two coroutines are expecting this to happen) but *any* command may be the target. If a coroutine is suspended by this mechanism, the coroutine processing can be resumed by calling the context command optionally passing in an arbitrary number of arguments. The return value of the **yieldto** call will be the list of arguments passed to the context command; it is up to the caller to decide what to do with those values.
The recommended way of writing a version of **yield** that allows resumption with multiple arguments is by using **yieldto** and the **[return](return.htm)** command, like this:
```
proc yieldm {value} {
**yieldto** return -level 0 $value
}
```
The coroutine can also be deleted by destroying the command *name*, and the name of the current coroutine can be retrieved by using **[info coroutine](info.htm)**. If there are deletion traces on variables in the coroutine's implementation, they will fire at the point when the coroutine is explicitly deleted (or, naturally, if the command returns conventionally).
At the point when *command* is called, the current namespace will be the global namespace and there will be no stack frames above it (in the sense of **[upvar](upvar.htm)** and **[uplevel](uplevel.htm)**). However, which command to call will be determined in the namespace that the **coroutine** command was called from.
Examples
--------
This example shows a coroutine that will produce an infinite sequence of even values, and a loop that consumes the first ten of them.
```
proc allNumbers {} {
**yield**
set i 0
while 1 {
**yield** $i
incr i 2
}
}
**coroutine** nextNumber allNumbers
for {set i 0} {$i < 10} {incr i} {
puts "received [*nextNumber*]"
}
rename nextNumber {}
```
In this example, the coroutine acts to add up the arguments passed to it.
```
**coroutine** accumulator apply {{} {
set x 0
while 1 {
incr x [**yield** $x]
}
}}
for {set i 0} {$i < 10} {incr i} {
puts "$i -> [*accumulator* $i]"
}
```
This example demonstrates the use of coroutines to implement the classic Sieve of Eratosthenes algorithm for finding prime numbers. Note the creation of coroutines inside a coroutine.
```
proc filterByFactor {source n} {
**yield** [info coroutine]
while 1 {
set x [*$source*]
if {$x % $n} {
**yield** $x
}
}
}
**coroutine** allNumbers apply {{} {while 1 {**yield** [incr x]}}}
**coroutine** eratosthenes apply {c {
**yield**
while 1 {
set n [*$c*]
**yield** $n
set c [**coroutine** prime$n filterByFactor $c $n]
}
}} allNumbers
for {set i 1} {$i <= 20} {incr i} {
puts "prime#$i = [*eratosthenes*]"
}
```
This example shows how a value can be passed around a group of three coroutines that yield to each other:
```
proc juggler {name target {value ""}} {
if {$value eq ""} {
set value [**yield** [info coroutine]]
}
while {$value ne ""} {
puts "$name : $value"
set value [string range $value 0 end-1]
lassign [**yieldto** $target $value] value
}
}
**coroutine** j1 juggler Larry [
**coroutine** j2 juggler Curly [
**coroutine** j3 juggler Moe j1]] "Nyuck!Nyuck!Nyuck!"
```
### Detailed semantics
This example demonstrates that coroutines start from the global namespace, and that *command* resolution happens before the coroutine stack is created.
```
proc report {where level} {
# Where was the caller called from?
set ns [uplevel 2 {namespace current}]
**yield** "made $where $level context=$ns name=[info coroutine]"
}
proc example {} {
report outer [info level]
}
namespace eval demo {
proc example {} {
report inner [info level]
}
proc makeExample {} {
puts "making from [info level]"
puts [**coroutine** coroEg example]
}
makeExample
}
```
Which produces the output below. In particular, we can see that stack manipulation has occurred (comparing the levels from the first and second line) and that the parent level in the coroutine is the global namespace. We can also see that coroutine names are local to the current namespace if not qualified, and that coroutines may yield at depth (e.g., in called procedures).
```
making from 2
made inner 1 context=:: name=::demo::coroEg
```
See also
--------
**[apply](apply.htm)**, **[info](info.htm)**, **[proc](proc.htm)**, **[return](return.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/coroutine.htm>
| programming_docs |
tcl_tk fconfigure fconfigure
==========
[NAME](fconfigure.htm#M2) fconfigure — Set and get options on a channel
[SYNOPSIS](fconfigure.htm#M3)
[DESCRIPTION](fconfigure.htm#M4)
[**-blocking** *boolean*](fconfigure.htm#M5)
[**-buffering** *newValue*](fconfigure.htm#M6)
[**-buffersize** *newSize*](fconfigure.htm#M7)
[**-encoding** *name*](fconfigure.htm#M8)
[**-eofchar** *char*](fconfigure.htm#M9)
[**-eofchar** **{***inChar outChar***}**](fconfigure.htm#M10)
[**-translation** *mode*](fconfigure.htm#M11)
[**-translation** **{***inMode outMode***}**](fconfigure.htm#M12)
[**auto**](fconfigure.htm#M13)
[**binary**](fconfigure.htm#M14)
[**cr**](fconfigure.htm#M15)
[**crlf**](fconfigure.htm#M16)
[**lf**](fconfigure.htm#M17)
[STANDARD CHANNELS](fconfigure.htm#M18)
[EXAMPLES](fconfigure.htm#M19)
[SEE ALSO](fconfigure.htm#M20)
[KEYWORDS](fconfigure.htm#M21)
Name
----
fconfigure — Set and get options on a channel Synopsis
--------
**fconfigure** *channelId*
**fconfigure** *channelId* *name*
**fconfigure** *channelId* *name value* ?*name value ...*?
Description
-----------
The **fconfigure** command sets and retrieves options for channels. *ChannelId* identifies the channel for which to set or query an option and must refer to an open channel such as a Tcl standard channel (**[stdin](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)**, **[stdout](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)**, or **[stderr](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)**), the return value from an invocation of **[open](open.htm)** or **[socket](socket.htm)**, or the result of a channel creation command provided by a Tcl extension.
If no *name* or *value* arguments are supplied, the command returns a list containing alternating option names and values for the channel. If *name* is supplied but no *value* then the command returns the current value of the given option. If one or more pairs of *name* and *value* are supplied, the command sets each of the named options to the corresponding *value*; in this case the return value is an empty string.
The options described below are supported for all channels. In addition, each channel type may add options that only it supports. See the manual entry for the command that creates each type of channels for the options that that specific type of channel supports. For example, see the manual entry for the **[socket](socket.htm)** command for additional options for sockets, and the **[open](open.htm)** command for additional options for serial devices.
**-blocking** *boolean*
The **-blocking** option determines whether I/O operations on the channel can cause the process to block indefinitely. The value of the option must be a proper boolean value. Channels are normally in blocking mode; if a channel is placed into nonblocking mode it will affect the operation of the **[gets](gets.htm)**, **[read](read.htm)**, **[puts](puts.htm)**, **[flush](flush.htm)**, and **[close](close.htm)** commands by allowing them to operate asynchronously; see the documentation for those commands for details. For nonblocking mode to work correctly, the application must be using the Tcl event loop (e.g. by calling **[Tcl\_DoOneEvent](https://www.tcl.tk/man/tcl/TclLib/DoOneEvent.htm)** or invoking the **[vwait](vwait.htm)** command).
**-buffering** *newValue*
If *newValue* is **full** then the I/O system will buffer output until its internal buffer is full or until the **[flush](flush.htm)** command is invoked. If *newValue* is **line**, then the I/O system will automatically flush output for the channel whenever a newline character is output. If *newValue* is **none**, the I/O system will flush automatically after every output operation. The default is for **-buffering** to be set to **full** except for channels that connect to terminal-like devices; for these channels the initial setting is **line**. Additionally, **[stdin](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)** and **[stdout](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)** are initially set to **line**, and **[stderr](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)** is set to **none**.
**-buffersize** *newSize*
*Newvalue* must be an integer; its value is used to set the size of buffers, in bytes, subsequently allocated for this channel to store input or output. *Newvalue* must be between one and one million, allowing buffers of one to one million bytes in size.
**-encoding** *name*
This option is used to specify the encoding of the channel, so that the data can be converted to and from Unicode for use in Tcl. For instance, in order for Tcl to read characters from a Japanese file in **shiftjis** and properly process and display the contents, the encoding would be set to **shiftjis**. Thereafter, when reading from the channel, the bytes in the Japanese file would be converted to Unicode as they are read. Writing is also supported - as Tcl strings are written to the channel they will automatically be converted to the specified encoding on output. If a file contains pure binary data (for instance, a JPEG image), the encoding for the channel should be configured to be **[binary](binary.htm)**. Tcl will then assign no interpretation to the data in the file and simply read or write raw bytes. The Tcl **[binary](binary.htm)** command can be used to manipulate this byte-oriented data. It is usually better to set the **-translation** option to **[binary](binary.htm)** when you want to transfer binary data, as this turns off the other automatic interpretations of the bytes in the stream as well.
The default encoding for newly opened channels is the same platform- and locale-dependent system encoding used for interfacing with the operating system, as returned by **[encoding system](encoding.htm)**.
**-eofchar** *char*
**-eofchar** **{***inChar outChar***}**
This option supports DOS file systems that use Control-z (\x1a) as an end of file marker. If *char* is not an empty string, then this character signals end-of-file when it is encountered during input. For output, the end-of-file character is output when the channel is closed. If *char* is the empty string, then there is no special end of file character marker. For read-write channels, a two-element list specifies the end of file marker for input and output, respectively. As a convenience, when setting the end-of-file character for a read-write channel you can specify a single value that will apply to both reading and writing. When querying the end-of-file character of a read-write channel, a two-element list will always be returned. The default value for **-eofchar** is the empty string in all cases except for files under Windows. In that case the **-eofchar** is Control-z (\x1a) for reading and the empty string for writing. The acceptable range for **-eofchar** values is \x01 - \x7f; attempting to set **-eofchar** to a value outside of this range will generate an error.
**-translation** *mode*
**-translation** **{***inMode outMode***}**
In Tcl scripts the end of a line is always represented using a single newline character (\n). However, in actual files and devices the end of a line may be represented differently on different platforms, or even for different devices on the same platform. For example, under UNIX newlines are used in files, whereas carriage-return-linefeed sequences are normally used in network connections. On input (i.e., with **[gets](gets.htm)** and **[read](read.htm)**) the Tcl I/O system automatically translates the external end-of-line representation into newline characters. Upon output (i.e., with **[puts](puts.htm)**), the I/O system translates newlines to the external end-of-line representation. The default translation mode, **auto**, handles all the common cases automatically, but the **-translation** option provides explicit control over the end of line translations. The value associated with **-translation** is a single item for read-only and write-only channels. The value is a two-element list for read-write channels; the read translation mode is the first element of the list, and the write translation mode is the second element. As a convenience, when setting the translation mode for a read-write channel you can specify a single value that will apply to both reading and writing. When querying the translation mode of a read-write channel, a two-element list will always be returned. The following values are currently supported:
**auto**
As the input translation mode, **auto** treats any of newline (**lf**), carriage return (**cr**), or carriage return followed by a newline (**crlf**) as the end of line representation. The end of line representation can even change from line-to-line, and all cases are translated to a newline. As the output translation mode, **auto** chooses a platform specific representation; for sockets on all platforms Tcl chooses **crlf**, for all Unix flavors, it chooses **lf**, and for the various flavors of Windows it chooses **crlf**. The default setting for **-translation** is **auto** for both input and output.
**binary**
No end-of-line translations are performed. This is nearly identical to **lf** mode, except that in addition **[binary](binary.htm)** mode also sets the end-of-file character to the empty string (which disables it) and sets the encoding to **[binary](binary.htm)** (which disables encoding filtering). See the description of **-eofchar** and **-encoding** for more information. Internally, i.e. when it comes to the actual behaviour of the translator this value **is** identical to **lf** and is therefore reported as such when queried. Even if **[binary](binary.htm)** was used to set the translation.
**cr**
The end of a line in the underlying file or device is represented by a single carriage return character. As the input translation mode, **cr** mode converts carriage returns to newline characters. As the output translation mode, **cr** mode translates newline characters to carriage returns.
**crlf**
The end of a line in the underlying file or device is represented by a carriage return character followed by a linefeed character. As the input translation mode, **crlf** mode converts carriage-return-linefeed sequences to newline characters. As the output translation mode, **crlf** mode translates newline characters to carriage-return-linefeed sequences. This mode is typically used on Windows platforms and for network connections.
**lf**
The end of a line in the underlying file or device is represented by a single newline (linefeed) character. In this mode no translations occur during either input or output. This mode is typically used on UNIX platforms.
Standard channels
-----------------
The Tcl standard channels (**[stdin](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)**, **[stdout](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)**, and **[stderr](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)**) can be configured through this command like every other channel opened by the Tcl library. Beyond the standard options described above they will also support any special option according to their current type. If, for example, a Tcl application is started by the **inet** super-server common on Unix system its Tcl standard channels will be sockets and thus support the socket options. Examples
--------
Instruct Tcl to always send output to **[stdout](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)** immediately, whether or not it is to a terminal:
```
**fconfigure** stdout -buffering none
```
Open a socket and read lines from it without ever blocking the processing of other events:
```
set s [socket some.where.com 12345]
**fconfigure** $s -blocking 0
fileevent $s readable "readMe $s"
proc readMe chan {
if {[gets $chan line] < 0} {
if {[eof $chan]} {
close $chan
return
}
# Could not read a complete line this time; Tcl's
# internal buffering will hold the partial line for us
# until some more data is available over the socket.
} else {
puts stdout $line
}
}
```
Read a PPM-format image from a file:
```
# Open the file and put it into Unix ASCII mode
set f [open teapot.ppm]
**fconfigure** $f -encoding ascii -translation lf
# Get the header
if {[gets $f] ne "P6"} {
error "not a raw-bits PPM"
}
# Read lines until we have got non-comment lines
# that supply us with three decimal values.
set words {}
while {[llength $words] < 3} {
gets $f line
if {[string match "#*" $line]} continue
lappend words {*}[join [scan $line %d%d%d]]
}
# Those words supply the size of the image and its
# overall depth per channel. Assign to variables.
lassign $words xSize ySize depth
# Now switch to binary mode to pull in the data,
# one byte per channel (red,green,blue) per pixel.
**fconfigure** $f -translation binary
set numDataBytes [expr {3 * $xSize * $ySize}]
set data [read $f $numDataBytes]
close $f
```
See also
--------
**[close](close.htm)**, **[flush](flush.htm)**, **[gets](gets.htm)**, **[open](open.htm)**, **[puts](puts.htm)**, **[read](read.htm)**, **[socket](socket.htm)**, **[Tcl\_StandardChannels](https://www.tcl.tk/man/tcl/TclLib/StdChannels.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/fconfigure.htm>
tcl_tk read read
====
Name
----
read — Read from a channel Synopsis
--------
**read** ?**-nonewline**? *channelId*
**read** *channelId numChars*
Description
-----------
In the first form, the **read** command reads all of the data from *channelId* up to the end of the file. If the **-nonewline** switch is specified then the last character of the file is discarded if it is a newline. In the second form, the extra argument specifies how many characters to read. Exactly that many characters will be read and returned, unless there are fewer than *numChars* left in the file; in this case all the remaining characters are returned. If the channel is configured to use a multi-byte encoding, then the number of characters read may not be the same as the number of bytes read. *ChannelId* must be an identifier for an open channel such as the Tcl standard input channel (**[stdin](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)**), the return value from an invocation of **[open](open.htm)** or **[socket](socket.htm)**, or the result of a channel creation command provided by a Tcl extension. The channel must have been opened for input.
If *channelId* is in nonblocking mode, the command may not read as many characters as requested: once all available input has been read, the command will return the data that is available rather than blocking for more input. If the channel is configured to use a multi-byte encoding, then there may actually be some bytes remaining in the internal buffers that do not form a complete character. These bytes will not be returned until a complete character is available or end-of-file is reached. The **-nonewline** switch is ignored if the command returns before reaching the end of the file.
**Read** translates end-of-line sequences in the input into newline characters according to the **-translation** option for the channel. See the **[fconfigure](fconfigure.htm)** manual entry for a discussion on ways in which **[fconfigure](fconfigure.htm)** will alter input.
Use with serial ports
---------------------
For most applications a channel connected to a serial port should be configured to be nonblocking: **[fconfigure](fconfigure.htm)** *channelId* **-blocking** *0*. Then **read** behaves much like described above. Care must be taken when using **read** on blocking serial ports:
**read** *channelId numChars*
In this form **read** blocks until *numChars* have been received from the serial port.
**read** *channelId*
In this form **read** blocks until the reception of the end-of-file character, see **[fconfigure](fconfigure.htm)** **-eofchar**. If there no end-of-file character has been configured for the channel, then **read** will block forever.
Example
-------
This example code reads a file all at once, and splits it into a list, with each line in the file corresponding to an element in the list:
```
set fl [open /proc/meminfo]
set data [**read** $fl]
close $fl
set lines [split $data \n]
```
See also
--------
**[file](file.htm)**, **[eof](eof.htm)**, **[fblocked](fblocked.htm)**, **[fconfigure](fconfigure.htm)**, **[Tcl\_StandardChannels](https://www.tcl.tk/man/tcl/TclLib/StdChannels.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/read.htm>
tcl_tk eof eof
===
Name
----
eof — Check for end of file condition on channel Synopsis
--------
**eof** *channelId*
Description
-----------
Returns 1 if an end of file condition occurred during the most recent input operation on *channelId* (such as **[gets](gets.htm)**), 0 otherwise. *ChannelId* must be an identifier for an open channel such as a Tcl standard channel (**[stdin](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)**, **[stdout](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)**, or **[stderr](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)**), the return value from an invocation of **[open](open.htm)** or **[socket](socket.htm)**, or the result of a channel creation command provided by a Tcl extension.
Examples
--------
Read and print out the contents of a file line-by-line:
```
set f [open somefile.txt]
while {1} {
set line [gets $f]
if {[**eof** $f]} {
close $f
break
}
puts "Read line: $line"
}
```
Read and print out the contents of a file by fixed-size records:
```
set f [open somefile.dat]
fconfigure $f -translation binary
set recordSize 40
while {1} {
set record [read $f $recordSize]
if {[**eof** $f]} {
close $f
break
}
puts "Read record: $record"
}
```
See also
--------
**[file](file.htm)**, **[open](open.htm)**, **[close](close.htm)**, **[fblocked](fblocked.htm)**, **[Tcl\_StandardChannels](https://www.tcl.tk/man/tcl/TclLib/StdChannels.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/eof.htm>
tcl_tk lreverse lreverse
========
Name
----
lreverse — Reverse the order of a list Synopsis
--------
**lreverse** *list*
Description
-----------
The **lreverse** command returns a list that has the same elements as its input list, *list*, except with the elements in the reverse order. Examples
--------
```
**lreverse** {a a b c}
*→ c b a a*
**lreverse** {a b {c d} e f}
*→ f e {c d} b a*
```
See also
--------
**[list](list.htm)**, **[lsearch](lsearch.htm)**, **[lsort](lsort.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/lreverse.htm>
tcl_tk tm tm
==
[NAME](tm.htm#M2) tm — Facilities for locating and loading of Tcl Modules
[SYNOPSIS](tm.htm#M3)
[DESCRIPTION](tm.htm#M4)
[**::tcl::tm::path add** ?*path*...?](tm.htm#M5)
[**::tcl::tm::path remove** ?*path*...?](tm.htm#M6)
[**::tcl::tm::path list**](tm.htm#M7)
[**::tcl::tm::roots** ?*path*...?](tm.htm#M8)
[MODULE DEFINITION](tm.htm#M9)
[FINDING MODULES](tm.htm#M10)
[DEFAULT PATHS](tm.htm#M11)
[SYSTEM SPECIFIC PATHS](tm.htm#M12)
[**file normalize [info library]/../tcl***X***/***X***.***y*](tm.htm#M13)
[**file normalize EXEC/tcl***X***/***X***.***y*](tm.htm#M14)
[SITE SPECIFIC PATHS](tm.htm#M15)
[**file normalize [info library]/../tcl***X***/site-tcl**](tm.htm#M16)
[USER SPECIFIC PATHS](tm.htm#M17)
[**$::env(TCL***X***\_***y***\_TM\_PATH)**](tm.htm#M18)
[**$::env(TCL***X***.***y***\_TM\_PATH)**](tm.htm#M19)
[SEE ALSO](tm.htm#M20)
[KEYWORDS](tm.htm#M21)
Name
----
tm — Facilities for locating and loading of Tcl Modules Synopsis
--------
**::tcl::tm::path add** ?*path*...?
**::tcl::tm::path remove** ?*path*...?
**::tcl::tm::path list**
**::tcl::tm::roots** ?*path*...?
Description
-----------
This document describes the facilities for locating and loading Tcl Modules (see **[MODULE DEFINITION](#M9)** for the definition of a Tcl Module). The following commands are supported:
**::tcl::tm::path add** ?*path*...?
The paths are added at the head to the list of module paths, in order of appearance. This means that the last argument ends up as the new head of the list. The command enforces the restriction that no path may be an ancestor directory of any other path on the list. If any of the new paths violates this restriction an error will be raised, before any of the paths have been added. In other words, if only one path argument violates the restriction then none will be added.
If a path is already present as is, no error will be raised and no action will be taken.
Paths are searched later in the order of their appearance in the list. As they are added to the front of the list they are searched in reverse order of addition. In other words, the paths added last are looked at first.
**::tcl::tm::path remove** ?*path*...?
Removes the paths from the list of module paths. The command silently ignores all paths which are not on the list.
**::tcl::tm::path list**
Returns a list containing all registered module paths, in the order that they are searched for modules.
**::tcl::tm::roots** ?*path*...?
Similar to **path add**, and layered on top of it. This command takes a list of paths, extends each with “**tcl***X***/site-tcl**”, and “**tcl***X***/***X***.***y*”, for major version *X* of the Tcl interpreter and minor version *y* less than or equal to the minor version of the interpreter, and adds the resulting set of paths to the list of paths to search. This command is used internally by the system to set up the system-specific default paths.
The command has been exposed to allow a build system to define additional root paths beyond those described by this document.
Module definition
-----------------
A Tcl Module is a Tcl Package contained in a single file, and no other files required by it. This file has to be **[source](source.htm)**able. In other words, a Tcl Module is always imported via:
```
source module_file
```
The **[load](load.htm)** command is not directly used. This restriction is not an actual limitation, as some may believe. Ever since 8.4 the Tcl **[source](source.htm)** command reads only until the first ^Z character. This allows us to combine an arbitrary Tcl script with arbitrary binary data into one file, where the script processes the attached data in any it chooses to fully import and activate the package.
The name of a module file has to match the regular expression:
```
([_[:alpha:]][:_[:alnum:]]*)-([[:digit:]].*)\.tm
```
The first capturing parentheses provides the name of the package, the second clause its version. In addition to matching the pattern, the extracted version number must not raise an error when used in the command:
```
package vcompare $version 0
```
Finding modules
---------------
The directory tree for storing Tcl modules is separate from other parts of the filesystem and independent of **[auto\_path](tclvars.htm)**. Tcl Modules are searched for in all directories listed in the result of the command **::tcl::tm::path list**. This is called the *Module path*. Neither the **[auto\_path](tclvars.htm)** nor the **[tcl\_pkgPath](tclvars.htm)** variables are used. All directories on the module path have to obey one restriction:
For any two directories, neither is an ancestor directory of the other.
This is required to avoid ambiguities in package naming. If for example the two directories “*foo/*” and “*foo/cool*” were on the path a package named **cool::ice** could be found via the names **cool::ice** or **ice**, the latter potentially obscuring a package named **ice**, unqualified.
Before the search is started, the name of the requested package is translated into a partial path, using the following algorithm:
All occurrences of “**::**” in the package name are replaced by the appropriate directory separator character for the platform we are on. On Unix, for example, this is “**/**”.
Example:
The requested package is **encoding::base64**. The generated partial path is “*encoding/base64*”.
After this translation the package is looked for in all module paths, by combining them one-by-one, first to last with the partial path to form a complete search pattern. Note that the search algorithm rejects all files where the filename does not match the regular expression given in the section **[MODULE DEFINITION](#M9)**. For the remaining files *provide scripts* are generated and added to the package ifneeded database.
The algorithm falls back to the previous unknown handler when none of the found module files satisfy the request. If the request was satisfied the fall-back is ignored.
Note that packages in module form have *no* control over the *index* and *provide script*s entered into the package database for them. For a module file **MF** the *index script* is always:
```
package ifneeded **PNAME PVERSION** [list source **MF**]
```
and the *provide script* embedded in the above is:
```
source **MF**
```
Both package name **PNAME** and package version **PVERSION** are extracted from the filename **MF** according to the definition below:
```
**MF** = /module_path/**PNAME′**-**PVERSION**.tm
```
Where **PNAME′** is the partial path of the module as defined in section **[FINDING MODULES](#M10)**, and translated into **PNAME** by changing all directory separators to “**::**”, and **module\_path** is the path (from the list of paths to search) that we found the module file under.
Note also that we are here creating a connection between package names and paths. Tcl is case-sensitive when it comes to comparing package names, but there are filesystems which are not, like NTFS. Luckily these filesystems do store the case of the name, despite not using the information when comparing.
Given the above we allow the names for packages in Tcl modules to have mixed-case, but also require that there are no collisions when comparing names in a case-insensitive manner. In other words, if a package **Foo** is deployed in the form of a Tcl Module, packages like **foo**, **fOo**, etc. are not allowed anymore.
Default paths
-------------
The default list of paths on the module path is computed by a **[tclsh](../usercmd/tclsh.htm)** as follows, where *X* is the major version of the Tcl interpreter and *y* is less than or equal to the minor version of the Tcl interpreter. All the default paths are added to the module path, even those paths which do not exist. Non-existent paths are filtered out during actual searches. This enables a user to create one of the paths searched when needed and all running applications will automatically pick up any modules placed in them.
The paths are added in the order as they are listed below, and for lists of paths defined by an environment variable in the order they are found in the variable.
### System specific paths
**file normalize [info library]/../tcl***X***/***X***.***y*
In other words, the interpreter will look into a directory specified by its major version and whose minor versions are less than or equal to the minor version of the interpreter. For example for Tcl 8.4 the paths searched are:
```
**[info library]/../tcl8/8.4**
**[info library]/../tcl8/8.3**
**[info library]/../tcl8/8.2**
**[info library]/../tcl8/8.1**
**[info library]/../tcl8/8.0**
```
This definition assumes that a package defined for Tcl *X***.***y* can also be used by all interpreters which have the same major number *X* and a minor number greater than *y*.
**file normalize EXEC/tcl***X***/***X***.***y*
Where **EXEC** is **file normalize [info nameofexecutable]/../lib** or **file normalize [::tcl::pkgconfig get libdir,runtime]** This sets of paths is handled equivalently to the set coming before, except that it is anchored in **EXEC\_PREFIX**. For a build with **PREFIX** = **EXEC\_PREFIX** the two sets are identical.
### Site specific paths
**file normalize [info library]/../tcl***X***/site-tcl**
Note that this is always a single entry because *X* is always a specific value (the current major version of Tcl).
### User specific paths
**$::env(TCL***X***\_***y***\_TM\_PATH)**
A list of paths, separated by either **:** (Unix) or **;** (Windows). This is user and site specific as this environment variable can be set not only by the user's profile, but by system configuration scripts as well.
**$::env(TCL***X***.***y***\_TM\_PATH)**
Same meaning and content as the previous variable. However the use of dot '.' to separate major and minor version number makes this name less to non-portable and its use is discouraged. Support of this variable has been kept only for backward compatibility with the original specification, i.e. TIP 189.
These paths are seen and therefore shared by all Tcl shells in the **$::env(PATH)** of the user.
Note that *X* and *y* follow the general rules set out above. In other words, Tcl 8.4, for example, will look at these 10 environment variables:
```
**$::env(TCL8.4\_TM\_PATH)** **$::env(TCL8\_4\_TM\_PATH)**
**$::env(TCL8.3\_TM\_PATH)** **$::env(TCL8\_3\_TM\_PATH)**
**$::env(TCL8.2\_TM\_PATH)** **$::env(TCL8\_2\_TM\_PATH)**
**$::env(TCL8.1\_TM\_PATH)** **$::env(TCL8\_1\_TM\_PATH)**
**$::env(TCL8.0\_TM\_PATH)** **$::env(TCL8\_0\_TM\_PATH)**
```
See also
--------
**[package](package.htm)**, **Tcl Improvement Proposal #189 “*Tcl Modules*” (online at <http://tip.tcl.tk/189.html>)**, **Tcl Improvement Proposal #190 “*Implementation Choices for Tcl Modules*” (online at <http://tip.tcl.tk/190.html>)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/tm.htm>
| programming_docs |
tcl_tk switch switch
======
[NAME](switch.htm#M2) switch — Evaluate one of several scripts, depending on a given value
[SYNOPSIS](switch.htm#M3)
[DESCRIPTION](switch.htm#M4)
[**-exact**](switch.htm#M5)
[**-glob**](switch.htm#M6)
[**-regexp**](switch.htm#M7)
[**-nocase**](switch.htm#M8)
[**-matchvar** *varName*](switch.htm#M9)
[**-indexvar** *varName*](switch.htm#M10)
[**--**](switch.htm#M11)
[EXAMPLES](switch.htm#M12)
[SEE ALSO](switch.htm#M13)
[KEYWORDS](switch.htm#M14)
Name
----
switch — Evaluate one of several scripts, depending on a given value Synopsis
--------
**switch** ?*options*? *string pattern body* ?*pattern body* ...?
**switch** ?*options*? *string* {*pattern body* ?*pattern body* ...?}
Description
-----------
The **switch** command matches its *string* argument against each of the *pattern* arguments in order. As soon as it finds a *pattern* that matches *string* it evaluates the following *body* argument by passing it recursively to the Tcl interpreter and returns the result of that evaluation. If the last *pattern* argument is **default** then it matches anything. If no *pattern* argument matches *string* and no default is given, then the **switch** command returns an empty string. If the initial arguments to **switch** start with **-** then they are treated as options unless there are exactly two arguments to **switch** (in which case the first must the *string* and the second must be the *pattern*/*body* list). The following options are currently supported:
**-exact**
Use exact matching when comparing *string* to a pattern. This is the default.
**-glob**
When matching *string* to the patterns, use glob-style matching (i.e. the same as implemented by the **[string match](string.htm)** command).
**-regexp**
When matching *string* to the patterns, use regular expression matching (as described in the **[re\_syntax](re_syntax.htm)** reference page).
**-nocase**
Causes comparisons to be handled in a case-insensitive manner.
**-matchvar** *varName*
This option (only legal when **-regexp** is also specified) specifies the name of a variable into which the list of matches found by the regular expression engine will be written. The first element of the list written will be the overall substring of the input string (i.e. the *string* argument to **switch**) matched, the second element of the list will be the substring matched by the first capturing parenthesis in the regular expression that matched, and so on. When a **default** branch is taken, the variable will have the empty list written to it. This option may be specified at the same time as the **-indexvar** option.
**-indexvar** *varName*
This option (only legal when **-regexp** is also specified) specifies the name of a variable into which the list of indices referring to matching substrings found by the regular expression engine will be written. The first element of the list written will be a two-element list specifying the index of the start and index of the first character after the end of the overall substring of the input string (i.e. the *string* argument to **switch**) matched, in a similar way to the **-indices** option to the **[regexp](regexp.htm)** can obtain. Similarly, the second element of the list refers to the first capturing parenthesis in the regular expression that matched, and so on. When a **default** branch is taken, the variable will have the empty list written to it. This option may be specified at the same time as the **-matchvar** option.
**--**
Marks the end of options. The argument following this one will be treated as *string* even if it starts with a **-**. This is not required when the matching patterns and bodies are grouped together in a single argument.
Two syntaxes are provided for the *pattern* and *body* arguments. The first uses a separate argument for each of the patterns and commands; this form is convenient if substitutions are desired on some of the patterns or commands. The second form places all of the patterns and commands together into a single argument; the argument must have proper list structure, with the elements of the list being the patterns and commands. The second form makes it easy to construct multi-line switch commands, since the braces around the whole list make it unnecessary to include a backslash at the end of each line. Since the *pattern* arguments are in braces in the second form, no command or variable substitutions are performed on them; this makes the behavior of the second form different than the first form in some cases.
If a *body* is specified as “**-**” it means that the *body* for the next pattern should also be used as the body for this pattern (if the next pattern also has a body of “**-**” then the body after that is used, and so on). This feature makes it possible to share a single *body* among several patterns.
Beware of how you place comments in **switch** commands. Comments should only be placed **inside** the execution body of one of the patterns, and not intermingled with the patterns.
Examples
--------
The **switch** command can match against variables and not just literals, as shown here (the result is *2*):
```
set foo "abc"
**switch** abc a - b {expr {1}} $foo {expr {2}} default {expr {3}}
```
Using glob matching and the fall-through body is an alternative to writing regular expressions with alternations, as can be seen here (this returns *1*):
```
**switch** -glob aaab {
a*b -
b {expr {1}}
a* {expr {2}}
default {expr {3}}
}
```
Whenever nothing matches, the **default** clause (which must be last) is taken. This example has a result of *3*:
```
**switch** xyz {
a -
b {
# Correct Comment Placement
expr {1}
}
c {
expr {2}
}
default {
expr {3}
}
}
```
When matching against regular expressions, information about what exactly matched is easily obtained using the **-matchvar** option:
```
**switch** -regexp -matchvar foo -- $bar {
a(b*)c {
puts "Found [string length [lindex $foo 1]] 'b's"
}
d(e*)f(g*)h {
puts "Found [string length [lindex $foo 1]] 'e's and\
[string length [lindex $foo 2]] 'g's"
}
}
```
See also
--------
**[for](for.htm)**, **[if](if.htm)**, **[regexp](regexp.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/switch.htm>
tcl_tk info info
====
[NAME](info.htm#M2) info — Return information about the state of the Tcl interpreter
[SYNOPSIS](info.htm#M3)
[DESCRIPTION](info.htm#M4)
[**info args** *procname*](info.htm#M5)
[**info body** *procname*](info.htm#M6)
[**info class** *subcommand class* ?*arg ...*](info.htm#M7)
[**info cmdcount**](info.htm#M8)
[**info commands** ?*pattern*?](info.htm#M9)
[**info complete** *command*](info.htm#M10)
[**info coroutine**](info.htm#M11)
[**info default** *procname arg varname*](info.htm#M12)
[**info errorstack** ?*interp*?](info.htm#M13)
[**info exists** *varName*](info.htm#M14)
[**info frame** ?*number*?](info.htm#M15)
[**type**](info.htm#M16)
[**source**](info.htm#M17)
[**proc**](info.htm#M18)
[**eval**](info.htm#M19)
[**precompiled**](info.htm#M20)
[**line**](info.htm#M21)
[**file**](info.htm#M22)
[**cmd**](info.htm#M23)
[**proc**](info.htm#M24)
[**lambda**](info.htm#M25)
[**level**](info.htm#M26)
[**info functions** ?*pattern*?](info.htm#M27)
[**info globals** ?*pattern*?](info.htm#M28)
[**info hostname**](info.htm#M29)
[**info level** ?*number*?](info.htm#M30)
[**info library**](info.htm#M31)
[**info loaded** ?*interp*?](info.htm#M32)
[**info locals** ?*pattern*?](info.htm#M33)
[**info nameofexecutable**](info.htm#M34)
[**info object** *subcommand object* ?*arg ...*](info.htm#M35)
[**info patchlevel**](info.htm#M36)
[**info procs** ?*pattern*?](info.htm#M37)
[**info script** ?*filename*?](info.htm#M38)
[**info sharedlibextension**](info.htm#M39)
[**info tclversion**](info.htm#M40)
[**info vars** ?*pattern*?](info.htm#M41)
[CLASS INTROSPECTION](info.htm#M42)
[**info class call** *class method*](info.htm#M43)
[**info class constructor** *class*](info.htm#M44)
[**info class definition** *class method*](info.htm#M45)
[**info class destructor** *class*](info.htm#M46)
[**info class filters** *class*](info.htm#M47)
[**info class forward** *class method*](info.htm#M48)
[**info class instances** *class* ?*pattern*?](info.htm#M49)
[**info class methods** *class* ?*options...*?](info.htm#M50)
[**-all**](info.htm#M51)
[**-private**](info.htm#M52)
[**info class methodtype** *class method*](info.htm#M53)
[**info class mixins** *class*](info.htm#M54)
[**info class subclasses** *class* ?*pattern*?](info.htm#M55)
[**info class superclasses** *class*](info.htm#M56)
[**info class variables** *class*](info.htm#M57)
[OBJECT INTROSPECTION](info.htm#M58)
[**info object call** *object method*](info.htm#M59)
[**info object class** *object* ?*className*?](info.htm#M60)
[**info object definition** *object method*](info.htm#M61)
[**info object filters** *object*](info.htm#M62)
[**info object forward** *object method*](info.htm#M63)
[**info object isa** *category object* ?*arg*?](info.htm#M64)
[**info object isa class** *object*](info.htm#M65)
[**info object isa metaclass** *object*](info.htm#M66)
[**info object isa mixin** *object class*](info.htm#M67)
[**info object isa object** *object*](info.htm#M68)
[**info object isa typeof** *object class*](info.htm#M69)
[**info object methods** *object* ?*option...*?](info.htm#M70)
[**-all**](info.htm#M71)
[**-private**](info.htm#M72)
[**info object methodtype** *object method*](info.htm#M73)
[**info object mixins** *object*](info.htm#M74)
[**info object namespace** *object*](info.htm#M75)
[**info object variables** *object*](info.htm#M76)
[**info object vars** *object* ?*pattern*?](info.htm#M77)
[EXAMPLES](info.htm#M78)
[EXAMPLES WITH OBJECTS](info.htm#M79)
[SEE ALSO](info.htm#M80)
[KEYWORDS](info.htm#M81)
Name
----
info — Return information about the state of the Tcl interpreter Synopsis
--------
**info** *option* ?*arg arg ...*?
Description
-----------
This command provides information about various internals of the Tcl interpreter. The legal *option*s (which may be abbreviated) are:
**info args** *procname*
Returns a list containing the names of the arguments to procedure *procname*, in order. *Procname* must be the name of a Tcl command procedure.
**info body** *procname*
Returns the body of procedure *procname*. *Procname* must be the name of a Tcl command procedure.
**info class** *subcommand class* ?*arg ...*
Returns information about the class, *class*. The *subcommand*s are described in **[CLASS INTROSPECTION](#M42)** below.
**info cmdcount**
Returns a count of the total number of commands that have been invoked in this interpreter.
**info commands** ?*pattern*?
If *pattern* is not specified, returns a list of names of all the Tcl commands visible (i.e. executable without using a qualified name) to the current namespace, including both the built-in commands written in C and the command procedures defined using the **[proc](proc.htm)** command. If *pattern* is specified, only those names matching *pattern* are returned. Matching is determined using the same rules as for **[string match](string.htm)**. *pattern* can be a qualified name like **Foo::print\***. That is, it may specify a particular namespace using a sequence of namespace names separated by double colons (**::**), and may have pattern matching special characters at the end to specify a set of commands in that namespace. If *pattern* is a qualified name, the resulting list of command names has each one qualified with the name of the specified namespace, and only the commands defined in the named namespace are returned.
**info complete** *command*
Returns 1 if *command* is a complete Tcl command in the sense of having no unclosed quotes, braces, brackets or array element names. If the command does not appear to be complete then 0 is returned. This command is typically used in line-oriented input environments to allow users to type in commands that span multiple lines; if the command is not complete, the script can delay evaluating it until additional lines have been typed to complete the command.
**info coroutine**
Returns the name of the currently executing **[coroutine](coroutine.htm)**, or the empty string if either no coroutine is currently executing, or the current coroutine has been deleted (but has not yet returned or yielded since deletion).
**info default** *procname arg varname*
*Procname* must be the name of a Tcl command procedure and *arg* must be the name of an argument to that procedure. If *arg* does not have a default value then the command returns **0**. Otherwise it returns **1** and places the default value of *arg* into variable *varname*.
**info errorstack** ?*interp*?
Returns, in a form that is programmatically easy to parse, the function names and arguments at each level from the call stack of the last error in the given *interp*, or in the current one if not specified. This form is an even-sized list alternating tokens and parameters. Tokens are currently either **CALL**, **UP**, or **INNER**, but other values may be introduced in the future. **CALL** indicates a procedure call, and its parameter is the corresponding **info level** **0**. **UP** indicates a shift in variable frames generated by **[uplevel](uplevel.htm)** or similar, and applies to the previous **CALL** item. Its parameter is the level offset. **INNER** identifies the “inner context”, which is the innermost atomic command or bytecode instruction that raised the error, along with its arguments when available. While **CALL** and **UP** allow to follow complex call paths, **INNER** homes in on the offending operation in the innermost procedure call, even going to sub-expression granularity.
This information is also present in the **-errorstack** entry of the options dictionary returned by 3-argument **[catch](catch.htm)**; **info errorstack** is a convenient way of retrieving it for uncaught errors at top-level in an interactive **[tclsh](../usercmd/tclsh.htm)**.
**info exists** *varName*
Returns **1** if the variable named *varName* exists in the current context (either as a global or local variable) and has been defined by being given a value, returns **0** otherwise.
**info frame** ?*number*?
This command provides access to all frames on the stack, even those hidden from **info level**. If *number* is not specified, this command returns a number giving the frame level of the command. This is 1 if the command is invoked at top-level. If *number* is specified, then the result is a dictionary containing the location information for the command at the *number*ed level on the stack. If *number* is positive (> 0) then it selects a particular stack level (1 refers to the outer-most active command, 2 to the command it called, and so on, up to the current frame level which refers to **info frame** itself); otherwise it gives a level relative to the current command (0 refers to the current command, i.e., **info frame** itself, -1 to its caller, and so on).
This is similar to how **info level** works, except that this subcommand reports all frames, like **[source](source.htm)**d scripts, **[eval](eval.htm)**s, **[uplevel](uplevel.htm)**s, etc.
Note that for nested commands, like “foo [bar [x]]”, only “x” will be seen by an **info frame** invoked within “x”. This is the same as for **info level** and error stack traces.
The result dictionary may contain the keys listed below, with the specified meanings for their values:
**type**
This entry is always present and describes the nature of the location for the command. The recognized values are **[source](source.htm)**, **[proc](proc.htm)**, **[eval](eval.htm)**, and **precompiled**.
**source**
means that the command is found in a script loaded by the **[source](source.htm)** command.
**proc**
means that the command is found in dynamically created procedure body.
**eval**
means that the command is executed by **[eval](eval.htm)** or **[uplevel](uplevel.htm)**.
**precompiled**
means that the command is found in a pre-compiled script (loadable by the package **tbcload**), and no further information will be available.
**line**
This entry provides the number of the line the command is at inside of the script it is a part of. This information is not present for type **precompiled**. For type **[source](source.htm)** this information is counted relative to the beginning of the file, whereas for the last two types the line is counted relative to the start of the script.
**file**
This entry is present only for type **[source](source.htm)**. It provides the normalized path of the file the command is in.
**cmd**
This entry provides the string representation of the command. This is usually the unsubstituted form, however for commands which are a canonically-constructed list (e.g., as produced by the **[list](list.htm)** command) executed by **[eval](eval.htm)** it is the substituted form as they have no other string representation. Care is taken that the canonicality property of the latter is not spoiled.
**proc**
This entry is present only if the command is found in the body of a regular Tcl procedure. It then provides the name of that procedure.
**lambda**
This entry is present only if the command is found in the body of an anonymous Tcl procedure, i.e. a lambda. It then provides the entire definition of the lambda in question.
**level**
This entry is present only if the queried frame has a corresponding frame returned by **info level**. It provides the index of this frame, relative to the current level (0 and negative numbers).
A thing of note is that for procedures statically defined in files the locations of commands in their bodies will be reported with type **[source](source.htm)** and absolute line numbers, and not as type **[proc](proc.htm)**. The same is true for procedures nested in statically defined procedures, and literal eval scripts in files or statically defined procedures.
In contrast, procedure definitions and **[eval](eval.htm)** within a dynamically **[eval](eval.htm)**uated environment count line numbers relative to the start of their script, even if they would be able to count relative to the start of the outer dynamic script. That type of number usually makes more sense.
A different way of describing this behaviour is that file based locations are tracked as deeply as possible, and where this is not possible the lines are counted based on the smallest possible **[eval](eval.htm)** or procedure body, as that scope is usually easier to find than any dynamic outer scope.
The syntactic form **{\*}** is handled like **[eval](eval.htm)**. I.e. if it is given a literal list argument the system tracks the line number within the list words as well, and otherwise all line numbers are counted relative to the start of each word (smallest scope)
**info functions** ?*pattern*?
If *pattern* is not specified, returns a list of all the math functions currently defined. If *pattern* is specified, only those functions whose name matches *pattern* are returned. Matching is determined using the same rules as for **[string match](string.htm)**.
**info globals** ?*pattern*?
If *pattern* is not specified, returns a list of all the names of currently-defined global variables. Global variables are variables in the global namespace. If *pattern* is specified, only those names matching *pattern* are returned. Matching is determined using the same rules as for **[string match](string.htm)**.
**info hostname**
Returns the name of the computer on which this invocation is being executed. Note that this name is not guaranteed to be the fully qualified domain name of the host. Where machines have several different names (as is common on systems with both TCP/IP (DNS) and NetBIOS-based networking installed,) it is the name that is suitable for TCP/IP networking that is returned.
**info level** ?*number*?
If *number* is not specified, this command returns a number giving the stack level of the invoking procedure, or 0 if the command is invoked at top-level. If *number* is specified, then the result is a list consisting of the name and arguments for the procedure call at level *number* on the stack. If *number* is positive then it selects a particular stack level (1 refers to the top-most active procedure, 2 to the procedure it called, and so on); otherwise it gives a level relative to the current level (0 refers to the current procedure, -1 to its caller, and so on). See the **[uplevel](uplevel.htm)** command for more information on what stack levels mean.
**info library**
Returns the name of the library directory in which standard Tcl scripts are stored. This is actually the value of the **[tcl\_library](tclvars.htm)** variable and may be changed by setting **[tcl\_library](tclvars.htm)**.
**info loaded** ?*interp*?
Returns a list describing all of the packages that have been loaded into *interp* with the **[load](load.htm)** command. Each list element is a sub-list with two elements consisting of the name of the file from which the package was loaded and the name of the package. For statically-loaded packages the file name will be an empty string. If *interp* is omitted then information is returned for all packages loaded in any interpreter in the process. To get a list of just the packages in the current interpreter, specify an empty string for the *interp* argument.
**info locals** ?*pattern*?
If *pattern* is not specified, returns a list of all the names of currently-defined local variables, including arguments to the current procedure, if any. Variables defined with the **[global](global.htm)**, **[upvar](upvar.htm)** and **[variable](variable.htm)** commands will not be returned. If *pattern* is specified, only those names matching *pattern* are returned. Matching is determined using the same rules as for **[string match](string.htm)**.
**info nameofexecutable**
Returns the full path name of the binary file from which the application was invoked. If Tcl was unable to identify the file, then an empty string is returned.
**info object** *subcommand object* ?*arg ...*
Returns information about the object, *object*. The *subcommand*s are described in **[OBJECT INTROSPECTION](#M58)** below.
**info patchlevel**
Returns the value of the global variable **tcl\_patchLevel**, which holds the exact version of the Tcl library by default.
**info procs** ?*pattern*?
If *pattern* is not specified, returns a list of all the names of Tcl command procedures in the current namespace. If *pattern* is specified, only those procedure names in the current namespace matching *pattern* are returned. Matching is determined using the same rules as for **[string match](string.htm)**. If *pattern* contains any namespace separators, they are used to select a namespace relative to the current namespace (or relative to the global namespace if *pattern* starts with **::**) to match within; the matching pattern is taken to be the part after the last namespace separator.
**info script** ?*filename*?
If a Tcl script file is currently being evaluated (i.e. there is a call to **[Tcl\_EvalFile](https://www.tcl.tk/man/tcl/TclLib/Eval.htm)** active or there is an active invocation of the **[source](source.htm)** command), then this command returns the name of the innermost file being processed. If *filename* is specified, then the return value of this command will be modified for the duration of the active invocation to return that name. This is useful in virtual file system applications. Otherwise the command returns an empty string.
**info sharedlibextension**
Returns the extension used on this platform for the names of files containing shared libraries (for example, **.so** under Solaris). If shared libraries are not supported on this platform then an empty string is returned.
**info tclversion**
Returns the value of the global variable **[tcl\_version](tclvars.htm)**, which holds the major and minor version of the Tcl library by default.
**info vars** ?*pattern*?
If *pattern* is not specified, returns a list of all the names of currently-visible variables. This includes locals and currently-visible globals. If *pattern* is specified, only those names matching *pattern* are returned. Matching is determined using the same rules as for **[string match](string.htm)**. *pattern* can be a qualified name like **Foo::option\***. That is, it may specify a particular namespace using a sequence of namespace names separated by double colons (**::**), and may have pattern matching special characters at the end to specify a set of variables in that namespace. If *pattern* is a qualified name, the resulting list of variable names has each matching namespace variable qualified with the name of its namespace. Note that a currently-visible variable may not yet “exist” if it has not been set (e.g. a variable declared but not set by **[variable](variable.htm)**).
### Class introspection
The following *subcommand* values are supported by **info class**:
**info class call** *class method*
Returns a description of the method implementations that are used to provide a stereotypical instance of *class*'s implementation of *method* (stereotypical instances being objects instantiated by a class without having any object-specific definitions added). This consists of a list of lists of four elements, where each sublist consists of a word that describes the general type of method implementation (being one of **method** for an ordinary method, **filter** for an applied filter, and **[unknown](unknown.htm)** for a method that is invoked as part of unknown method handling), a word giving the name of the particular method invoked (which is always the same as *method* for the **method** type, and “**[unknown](unknown.htm)**” for the **[unknown](unknown.htm)** type), a word giving the fully qualified name of the class that defined the method, and a word describing the type of method implementation (see **info class methodtype**). Note that there is no inspection of whether the method implementations actually use **[next](next.htm)** to transfer control along the call chain.
**info class constructor** *class*
This subcommand returns a description of the definition of the constructor of class *class*. The definition is described as a two element list; the first element is the list of arguments to the constructor in a form suitable for passing to another call to **[proc](proc.htm)** or a method definition, and the second element is the body of the constructor. If no constructor is present, this returns the empty list.
**info class definition** *class method*
This subcommand returns a description of the definition of the method named *method* of class *class*. The definition is described as a two element list; the first element is the list of arguments to the method in a form suitable for passing to another call to **[proc](proc.htm)** or a method definition, and the second element is the body of the method.
**info class destructor** *class*
This subcommand returns the body of the destructor of class *class*. If no destructor is present, this returns the empty string.
**info class filters** *class*
This subcommand returns the list of filter methods set on the class.
**info class forward** *class method*
This subcommand returns the argument list for the method forwarding called *method* that is set on the class called *class*.
**info class instances** *class* ?*pattern*?
This subcommand returns a list of instances of class *class*. If the optional *pattern* argument is present, it constrains the list of returned instances to those that match it according to the rules of **[string match](string.htm)**.
**info class methods** *class* ?*options...*?
This subcommand returns a list of all public (i.e. exported) methods of the class called *class*. Any of the following *option*s may be specified, controlling exactly which method names are returned:
**-all**
If the **-all** flag is given, the list of methods will include those methods defined not just by the class, but also by the class's superclasses and mixins.
**-private**
If the **-private** flag is given, the list of methods will also include the private (i.e. non-exported) methods of the class (and superclasses and mixins, if **-all** is also given).
**info class methodtype** *class method*
This subcommand returns a description of the type of implementation used for the method named *method* of class *class*. When the result is **method**, further information can be discovered with **info class definition**, and when the result is **forward**, further information can be discovered with **info class forward**.
**info class mixins** *class*
This subcommand returns a list of all classes that have been mixed into the class named *class*.
**info class subclasses** *class* ?*pattern*?
This subcommand returns a list of direct subclasses of class *class*. If the optional *pattern* argument is present, it constrains the list of returned classes to those that match it according to the rules of **[string match](string.htm)**.
**info class superclasses** *class*
This subcommand returns a list of direct superclasses of class *class* in inheritance precedence order.
**info class variables** *class*
This subcommand returns a list of all variables that have been declared for the class named *class* (i.e. that are automatically present in the class's methods, constructor and destructor).
### Object introspection
The following *subcommand* values are supported by **info object**:
**info object call** *object method*
Returns a description of the method implementations that are used to provide *object*'s implementation of *method*. This consists of a list of lists of four elements, where each sublist consists of a word that describes the general type of method implementation (being one of **method** for an ordinary method, **filter** for an applied filter, and **[unknown](unknown.htm)** for a method that is invoked as part of unknown method handling), a word giving the name of the particular method invoked (which is always the same as *method* for the **method** type, and “**[unknown](unknown.htm)**” for the **[unknown](unknown.htm)** type), a word giving what defined the method (the fully qualified name of the class, or the literal string **object** if the method implementation is on an instance), and a word describing the type of method implementation (see **info object methodtype**). Note that there is no inspection of whether the method implementations actually use **[next](next.htm)** to transfer control along the call chain.
**info object class** *object* ?*className*?
If *className* is unspecified, this subcommand returns class of the *object* object. If *className* is present, this subcommand returns a boolean value indicating whether the *object* is of that class.
**info object definition** *object method*
This subcommand returns a description of the definition of the method named *method* of object *object*. The definition is described as a two element list; the first element is the list of arguments to the method in a form suitable for passing to another call to **[proc](proc.htm)** or a method definition, and the second element is the body of the method.
**info object filters** *object*
This subcommand returns the list of filter methods set on the object.
**info object forward** *object method*
This subcommand returns the argument list for the method forwarding called *method* that is set on the object called *object*.
**info object isa** *category object* ?*arg*?
This subcommand tests whether an object belongs to a particular category, returning a boolean value that indicates whether the *object* argument meets the criteria for the category. The supported categories are:
**info object isa class** *object*
This returns whether *object* is a class (i.e. an instance of **[oo::class](class.htm)** or one of its subclasses).
**info object isa metaclass** *object*
This returns whether *object* is a class that can manufacture classes (i.e. is **[oo::class](class.htm)** or a subclass of it).
**info object isa mixin** *object class*
This returns whether *class* is directly mixed into *object*.
**info object isa object** *object*
This returns whether *object* really is an object.
**info object isa typeof** *object class*
This returns whether *class* is the type of *object* (i.e. whether *object* is an instance of *class* or one of its subclasses, whether direct or indirect).
**info object methods** *object* ?*option...*?
This subcommand returns a list of all public (i.e. exported) methods of the object called *object*. Any of the following *option*s may be specified, controlling exactly which method names are returned:
**-all**
If the **-all** flag is given, the list of methods will include those methods defined not just by the object, but also by the object's class and mixins, plus the superclasses of those classes.
**-private**
If the **-private** flag is given, the list of methods will also include the private (i.e. non-exported) methods of the object (and classes, if **-all** is also given).
**info object methodtype** *object method*
This subcommand returns a description of the type of implementation used for the method named *method* of object *object*. When the result is **method**, further information can be discovered with **info object definition**, and when the result is **forward**, further information can be discovered with **info object forward**.
**info object mixins** *object*
This subcommand returns a list of all classes that have been mixed into the object named *object*.
**info object namespace** *object*
This subcommand returns the name of the internal namespace of the object named *object*.
**info object variables** *object*
This subcommand returns a list of all variables that have been declared for the object named *object* (i.e. that are automatically present in the object's methods).
**info object vars** *object* ?*pattern*?
This subcommand returns a list of all variables in the private namespace of the object named *object*. If the optional *pattern* argument is given, it is a filter (in the syntax of a **[string match](string.htm)** glob pattern) that constrains the list of variables returned. Note that this is different from the list returned by **info object variables**; that can include variables that are currently unset, whereas this can include variables that are not automatically included by any of *object*'s methods (or those of its class, superclasses or mixins).
Examples
--------
This command prints out a procedure suitable for saving in a Tcl script:
```
proc printProc {procName} {
set result [list proc $procName]
set formals {}
foreach var [**info args** $procName] {
if {[**info default** $procName $var def]} {
lappend formals [list $var $def]
} else {
# Still need the list-quoting because variable
# names may properly contain spaces.
lappend formals [list $var]
}
}
puts [lappend result $formals [**info body** $procName]]
}
```
### Examples with objects
Every object necessarily knows what its class is; this information is trivially extractable through introspection:
```
oo::class create c
c create o
puts [**info object class** o]
*→ prints "::c"*
puts [**info object class** c]
*→ prints "::oo::class"*
```
The introspection capabilities can be used to discover what class implements a method and get how it is defined. This procedure illustrates how:
```
proc getDef {obj method} {
foreach inf [**info object call** $obj $method] {
lassign $inf calltype name locus methodtype
# Assume no forwards or filters, and hence no $calltype
# or $methodtype checks...
if {$locus eq "object"} {
return [**info object definition** $obj $name]
} else {
return [**info class definition** $locus $name]
}
}
error "no definition for $method"
}
```
This is an alternate way of looking up the definition; it is implemented by manually scanning the list of methods up the inheritance tree. This code assumes that only single inheritance is in use, and that there is no complex use of mixed-in classes (in such cases, using **info object call** as above is the simplest way of doing this by far):
```
proc getDef {obj method} {
if {$method in [**info object methods** $obj]} {
# Assume no forwards
return [**info object definition** $obj $method]
}
set cls [**info object class** $obj]
while {$method ni [**info class methods** $cls]} {
# Assume the simple case
set cls [lindex [**info class superclass** $cls] 0]
if {$cls eq ""} {
error "no definition for $method"
}
}
# Assume no forwards
return [**info class definition** $cls $method]
}
```
See also
--------
**[global](global.htm)**, **[oo::class](class.htm)**, **[oo::define](define.htm)**, **[oo::object](object.htm)**, **[proc](proc.htm)**, **[self](self.htm)**, **[tcl\_library](tclvars.htm)**, **tcl\_patchLevel**, **[tcl\_version](tclvars.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/info.htm>
| programming_docs |
tcl_tk mathfunc mathfunc
========
[NAME](mathfunc.htm#M2) mathfunc — Mathematical functions for Tcl expressions
[SYNOPSIS](mathfunc.htm#M3)
[DESCRIPTION](mathfunc.htm#M4)
[DETAILED DEFINITIONS](mathfunc.htm#M5)
[**abs** *arg*](mathfunc.htm#M6)
[**acos** *arg*](mathfunc.htm#M7)
[**asin** *arg*](mathfunc.htm#M8)
[**atan** *arg*](mathfunc.htm#M9)
[**atan2** *y x*](mathfunc.htm#M10)
[**bool** *arg*](mathfunc.htm#M11)
[**ceil** *arg*](mathfunc.htm#M12)
[**cos** *arg*](mathfunc.htm#M13)
[**cosh** *arg*](mathfunc.htm#M14)
[**double** *arg*](mathfunc.htm#M15)
[**entier** *arg*](mathfunc.htm#M16)
[**exp** *arg*](mathfunc.htm#M17)
[**floor** *arg*](mathfunc.htm#M18)
[**fmod** *x y*](mathfunc.htm#M19)
[**hypot** *x y*](mathfunc.htm#M20)
[**int** *arg*](mathfunc.htm#M21)
[**isqrt** *arg*](mathfunc.htm#M22)
[**log** *arg*](mathfunc.htm#M23)
[**log10** *arg*](mathfunc.htm#M24)
[**max** *arg**...*](mathfunc.htm#M25)
[**min** *arg**...*](mathfunc.htm#M26)
[**pow** *x y*](mathfunc.htm#M27)
[**rand**](mathfunc.htm#M28)
[**round** *arg*](mathfunc.htm#M29)
[**sin** *arg*](mathfunc.htm#M30)
[**sinh** *arg*](mathfunc.htm#M31)
[**sqrt** *arg*](mathfunc.htm#M32)
[**srand** *arg*](mathfunc.htm#M33)
[**tan** *arg*](mathfunc.htm#M34)
[**tanh** *arg*](mathfunc.htm#M35)
[**wide** *arg*](mathfunc.htm#M36)
[SEE ALSO](mathfunc.htm#M37)
[COPYRIGHT](mathfunc.htm#M38)
Name
----
mathfunc — Mathematical functions for Tcl expressions Synopsis
--------
package require **Tcl 8.5**
**::tcl::mathfunc::abs** *arg*
**::tcl::mathfunc::acos** *arg*
**::tcl::mathfunc::asin** *arg*
**::tcl::mathfunc::atan** *arg*
**::tcl::mathfunc::atan2** *y* *x*
**::tcl::mathfunc::bool** *arg*
**::tcl::mathfunc::ceil** *arg*
**::tcl::mathfunc::cos** *arg*
**::tcl::mathfunc::cosh** *arg*
**::tcl::mathfunc::double** *arg*
**::tcl::mathfunc::entier** *arg*
**::tcl::mathfunc::exp** *arg*
**::tcl::mathfunc::floor** *arg*
**::tcl::mathfunc::fmod** *x* *y*
**::tcl::mathfunc::hypot** *x* *y*
**::tcl::mathfunc::int** *arg*
**::tcl::mathfunc::isqrt** *arg*
**::tcl::mathfunc::log** *arg*
**::tcl::mathfunc::log10** *arg*
**::tcl::mathfunc::max** *arg* ?*arg* ...?
**::tcl::mathfunc::min** *arg* ?*arg* ...?
**::tcl::mathfunc::pow** *x* *y*
**::tcl::mathfunc::rand**
**::tcl::mathfunc::round** *arg*
**::tcl::mathfunc::sin** *arg*
**::tcl::mathfunc::sinh** *arg*
**::tcl::mathfunc::sqrt** *arg*
**::tcl::mathfunc::srand** *arg*
**::tcl::mathfunc::tan** *arg*
**::tcl::mathfunc::tanh** *arg*
**::tcl::mathfunc::wide** *arg*
Description
-----------
The **[expr](expr.htm)** command handles mathematical functions of the form **sin($x)** or **atan2($y,$x)** by converting them to calls of the form **[tcl::mathfunc::sin [expr {$x}]]** or **[tcl::mathfunc::atan2 [expr {$y}] [expr {$x}]]**. A number of math functions are available by default within the namespace **::tcl::mathfunc**; these functions are also available for code apart from **[expr](expr.htm)**, by invoking the given commands directly. Tcl supports the following mathematical functions in expressions, all of which work solely with floating-point numbers unless otherwise noted:
| | | | |
| --- | --- | --- | --- |
| **abs** | **acos** | **asin** | **atan** |
| **atan2** | **bool** | **ceil** | **cos** |
| **cosh** | **double** | **entier** | **exp** |
| **floor** | **fmod** | **hypot** | **int** |
| **isqrt** | **log** | **log10** | **max** |
| **min** | **pow** | **rand** | **round** |
| **sin** | **sinh** | **sqrt** | **srand** |
| **tan** | **tanh** | **wide** |
In addition to these predefined functions, applications may define additional functions by using **[proc](proc.htm)** (or any other method, such as **[interp alias](interp.htm)** or **[Tcl\_CreateObjCommand](https://www.tcl.tk/man/tcl/TclLib/CrtObjCmd.htm)**) to define new commands in the **tcl::mathfunc** namespace. In addition, an obsolete interface named **[Tcl\_CreateMathFunc](https://www.tcl.tk/man/tcl/TclLib/CrtMathFnc.htm)**() is available to extensions that are written in C. The latter interface is not recommended for new implementations.
### Detailed definitions
**abs** *arg*
Returns the absolute value of *arg*. *Arg* may be either integer or floating-point, and the result is returned in the same form.
**acos** *arg*
Returns the arc cosine of *arg*, in the range [*0*,*pi*] radians. *Arg* should be in the range [*-1*,*1*].
**asin** *arg*
Returns the arc sine of *arg*, in the range [*-pi/2*,*pi/2*] radians. *Arg* should be in the range [*-1*,*1*].
**atan** *arg*
Returns the arc tangent of *arg*, in the range [*-pi/2*,*pi/2*] radians.
**atan2** *y x*
Returns the arc tangent of *y*/*x*, in the range [*-pi*,*pi*] radians. *x* and *y* cannot both be 0. If *x* is greater than *0*, this is equivalent to “**atan** [**[expr](expr.htm)** {*y***/***x*}]”.
**bool** *arg*
Accepts any numeric value, or any string acceptable to **string is boolean**, and returns the corresponding boolean value **0** or **1**. Non-zero numbers are true. Other numbers are false. Non-numeric strings produce boolean value in agreement with **string is true** and **string is false**.
**ceil** *arg*
Returns the smallest integral floating-point value (i.e. with a zero fractional part) not less than *arg*. The argument may be any numeric value.
**cos** *arg*
Returns the cosine of *arg*, measured in radians.
**cosh** *arg*
Returns the hyperbolic cosine of *arg*. If the result would cause an overflow, an error is returned.
**double** *arg*
The argument may be any numeric value, If *arg* is a floating-point value, returns *arg*, otherwise converts *arg* to floating-point and returns the converted value. May return **Inf** or **-Inf** when the argument is a numeric value that exceeds the floating-point range.
**entier** *arg*
The argument may be any numeric value. The integer part of *arg* is determined and returned. The integer range returned by this function is unlimited, unlike **int** and **wide** which truncate their range to fit in particular storage widths.
**exp** *arg*
Returns the exponential of *arg*, defined as *e*\*\**arg*. If the result would cause an overflow, an error is returned.
**floor** *arg*
Returns the largest integral floating-point value (i.e. with a zero fractional part) not greater than *arg*. The argument may be any numeric value.
**fmod** *x y*
Returns the floating-point remainder of the division of *x* by *y*. If *y* is 0, an error is returned.
**hypot** *x y*
Computes the length of the hypotenuse of a right-angled triangle, approximately “**sqrt** [**[expr](expr.htm)** {*x***\****x***+***y***\****y*}]” except for being more numerically stable when the two arguments have substantially different magnitudes.
**int** *arg*
The argument may be any numeric value. The integer part of *arg* is determined, and then the low order bits of that integer value up to the machine word size are returned as an integer value. For reference, the number of bytes in the machine word are stored in the **wordSize** element of the **[tcl\_platform](tclvars.htm)** array.
**isqrt** *arg*
Computes the integer part of the square root of *arg*. *Arg* must be a positive value, either an integer or a floating point number. Unlike **sqrt**, which is limited to the precision of a floating point number, *isqrt* will return a result of arbitrary precision.
**log** *arg*
Returns the natural logarithm of *arg*. *Arg* must be a positive value.
**log10** *arg*
Returns the base 10 logarithm of *arg*. *Arg* must be a positive value.
**max** *arg**...*
Accepts one or more numeric arguments. Returns the one argument with the greatest value.
**min** *arg**...*
Accepts one or more numeric arguments. Returns the one argument with the least value.
**pow** *x y*
Computes the value of *x* raised to the power *y*. If *x* is negative, *y* must be an integer value.
**rand**
Returns a pseudo-random floating-point value in the range (*0*,*1*). The generator algorithm is a simple linear congruential generator that is not cryptographically secure. Each result from **rand** completely determines all future results from subsequent calls to **rand**, so **rand** should not be used to generate a sequence of secrets, such as one-time passwords. The seed of the generator is initialized from the internal clock of the machine or may be set with the **srand** function.
**round** *arg*
If *arg* is an integer value, returns *arg*, otherwise converts *arg* to integer by rounding and returns the converted value.
**sin** *arg*
Returns the sine of *arg*, measured in radians.
**sinh** *arg*
Returns the hyperbolic sine of *arg*. If the result would cause an overflow, an error is returned.
**sqrt** *arg*
The argument may be any non-negative numeric value. Returns a floating-point value that is the square root of *arg*. May return **Inf** when the argument is a numeric value that exceeds the square of the maximum value of the floating-point range.
**srand** *arg*
The *arg*, which must be an integer, is used to reset the seed for the random number generator of **rand**. Returns the first random number (see **rand**) from that seed. Each interpreter has its own seed.
**tan** *arg*
Returns the tangent of *arg*, measured in radians.
**tanh** *arg*
Returns the hyperbolic tangent of *arg*.
**wide** *arg*
The argument may be any numeric value. The integer part of *arg* is determined, and then the low order 64 bits of that integer value are returned as an integer value.
See also
--------
**[expr](expr.htm)**, **[mathop](mathop.htm)**, **[namespace](namespace.htm)** Copyright
---------
Copyright (c) 1993 The Regents of the University of California.
Copyright (c) 1994-2000 Sun Microsystems Incorporated.
Copyright (c) 2005, 2006 by Kevin B. Kenny <[email protected]>.
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/mathfunc.htm>
tcl_tk memory memory
======
[NAME](memory.htm#M2) memory — Control Tcl memory debugging capabilities
[SYNOPSIS](memory.htm#M3)
[DESCRIPTION](memory.htm#M4)
[**memory active** *file*](memory.htm#M5)
[**memory break\_on\_malloc** *count*](memory.htm#M6)
[**memory info**](memory.htm#M7)
[**memory init** [**on**|**off**]](memory.htm#M8)
[**memory objs** *file*](memory.htm#M9)
[**memory onexit** *file*](memory.htm#M10)
[**memory tag** *string*](memory.htm#M11)
[**memory trace** [**on**|**off**]](memory.htm#M12)
[**memory trace\_on\_at\_malloc** *count*](memory.htm#M13)
[**memory validate** [**on**|**off**]](memory.htm#M14)
[SEE ALSO](memory.htm#M15)
[KEYWORDS](memory.htm#M16)
Name
----
memory — Control Tcl memory debugging capabilities Synopsis
--------
**memory** *option* ?*arg arg ...*?
Description
-----------
The **memory** command gives the Tcl developer control of Tcl's memory debugging capabilities. The memory command has several suboptions, which are described below. It is only available when Tcl has been compiled with memory debugging enabled (when **TCL\_MEM\_DEBUG** is defined at compile time), and after **[Tcl\_InitMemory](https://www.tcl.tk/man/tcl/TclLib/DumpActiveMemory.htm)** has been called.
**memory active** *file*
Write a list of all currently allocated memory to the specified *file*.
**memory break\_on\_malloc** *count*
After the *count* allocations have been performed, **[ckalloc](https://www.tcl.tk/man/tcl/TclLib/Alloc.htm)** outputs a message to this effect and that it is now attempting to enter the C debugger. Tcl will then issue a *SIGINT* signal against itself. If you are running Tcl under a C debugger, it should then enter the debugger command mode.
**memory info**
Returns a report containing the total allocations and frees since Tcl began, the current packets allocated (the current number of calls to **[ckalloc](https://www.tcl.tk/man/tcl/TclLib/Alloc.htm)** not met by a corresponding call to **[ckfree](https://www.tcl.tk/man/tcl/TclLib/Alloc.htm)**), the current bytes allocated, and the maximum number of packets and bytes allocated.
**memory init** [**on**|**off**]
Turn on or off the pre-initialization of all allocated memory with bogus bytes. Useful for detecting the use of uninitialized values.
**memory objs** *file*
Causes a list of all allocated [Tcl\_Obj](https://www.tcl.tk/man/tcl/TclLib/Object.htm) values to be written to the specified *file* immediately, together with where they were allocated. Useful for checking for leaks of values.
**memory onexit** *file*
Causes a list of all allocated memory to be written to the specified *file* during the finalization of Tcl's memory subsystem. Useful for checking that memory is properly cleaned up during process exit.
**memory tag** *string*
Each packet of memory allocated by **[ckalloc](https://www.tcl.tk/man/tcl/TclLib/Alloc.htm)** can have associated with it a string-valued tag. In the lists of allocated memory generated by **memory active** and **memory onexit**, the tag for each packet is printed along with other information about the packet. The **memory tag** command sets the tag value for subsequent calls to **[ckalloc](https://www.tcl.tk/man/tcl/TclLib/Alloc.htm)** to be *string*.
**memory trace** [**on**|**off**]
Turns memory tracing on or off. When memory tracing is on, every call to **[ckalloc](https://www.tcl.tk/man/tcl/TclLib/Alloc.htm)** causes a line of trace information to be written to *stderr*, consisting of the word *ckalloc*, followed by the address returned, the amount of memory allocated, and the C filename and line number of the code performing the allocation. For example:
```
ckalloc 40e478 98 tclProc.c 1406
```
Calls to **[ckfree](https://www.tcl.tk/man/tcl/TclLib/Alloc.htm)** are traced in the same manner.
**memory trace\_on\_at\_malloc** *count*
Enable memory tracing after *count* **[ckalloc](https://www.tcl.tk/man/tcl/TclLib/Alloc.htm)**s have been performed. For example, if you enter **memory trace\_on\_at\_malloc 100**, after the 100th call to **[ckalloc](https://www.tcl.tk/man/tcl/TclLib/Alloc.htm)**, memory trace information will begin being displayed for all allocations and frees. Since there can be a lot of memory activity before a problem occurs, judicious use of this option can reduce the slowdown caused by tracing (and the amount of trace information produced), if you can identify a number of allocations that occur before the problem sets in. The current number of memory allocations that have occurred since Tcl started is printed on a guard zone failure.
**memory validate** [**on**|**off**]
Turns memory validation on or off. When memory validation is enabled, on every call to **[ckalloc](https://www.tcl.tk/man/tcl/TclLib/Alloc.htm)** or **[ckfree](https://www.tcl.tk/man/tcl/TclLib/Alloc.htm)**, the guard zones are checked for every piece of memory currently in existence that was allocated by **[ckalloc](https://www.tcl.tk/man/tcl/TclLib/Alloc.htm)**. This has a large performance impact and should only be used when overwrite problems are strongly suspected. The advantage of enabling memory validation is that a guard zone overwrite can be detected on the first call to **[ckalloc](https://www.tcl.tk/man/tcl/TclLib/Alloc.htm)** or **[ckfree](https://www.tcl.tk/man/tcl/TclLib/Alloc.htm)** after the overwrite occurred, rather than when the specific memory with the overwritten guard zone(s) is freed, which may occur long after the overwrite occurred.
See also
--------
**[ckalloc](https://www.tcl.tk/man/tcl/TclLib/Alloc.htm)**, **[ckfree](https://www.tcl.tk/man/tcl/TclLib/Alloc.htm)**, **[Tcl\_ValidateAllMemory](https://www.tcl.tk/man/tcl/TclLib/DumpActiveMemory.htm)**, **[Tcl\_DumpActiveMemory](https://www.tcl.tk/man/tcl/TclLib/DumpActiveMemory.htm)**, **TCL\_MEM\_DEBUG**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/memory.htm>
tcl_tk tclvars tclvars
=======
[NAME](tclvars.htm#M2) argc, argv, argv0, auto\_path, env, errorCode, errorInfo, tcl\_interactive, tcl\_library, tcl\_nonwordchars, tcl\_patchLevel, tcl\_pkgPath, tcl\_platform, tcl\_precision, tcl\_rcFileName, tcl\_traceCompile, tcl\_traceExec, tcl\_wordchars, tcl\_version — Variables used by Tcl
[DESCRIPTION](tclvars.htm#M3)
[**auto\_path**](tclvars.htm#M4)
[**env**](tclvars.htm#M5)
[**env(HOME)**](tclvars.htm#M6)
[**env(TCL\_LIBRARY)**](tclvars.htm#M7)
[**env(TCLLIBPATH)**](tclvars.htm#M8)
[**env(TCL\_TZ)**, **env(TZ)**](tclvars.htm#M9)
[**env(LC\_ALL)**, **env(LC\_MESSAGES)**, **env(LANG)**](tclvars.htm#M10)
[**env(TCL\_INTERP\_DEBUG\_FRAME)**](tclvars.htm#M11)
[**errorCode**](tclvars.htm#M12)
[**ARITH** *code msg*](tclvars.htm#M13)
[**CHILDKILLED** *pid sigName msg*](tclvars.htm#M14)
[**CHILDSTATUS** *pid code*](tclvars.htm#M15)
[**CHILDSUSP** *pid sigName msg*](tclvars.htm#M16)
[**NONE**](tclvars.htm#M17)
[**POSIX** *errName msg*](tclvars.htm#M18)
[**TCL** ...](tclvars.htm#M19)
[**errorInfo**](tclvars.htm#M20)
[**tcl\_library**](tclvars.htm#M21)
[**tcl\_patchLevel**](tclvars.htm#M22)
[**tcl\_pkgPath**](tclvars.htm#M23)
[**tcl\_platform**](tclvars.htm#M24)
[**byteOrder**](tclvars.htm#M25)
[**debug**](tclvars.htm#M26)
[**engine**](tclvars.htm#M27)
[**machine**](tclvars.htm#M28)
[**os**](tclvars.htm#M29)
[**osVersion**](tclvars.htm#M30)
[**pathSeparator**](tclvars.htm#M31)
[**platform**](tclvars.htm#M32)
[**pointerSize**](tclvars.htm#M33)
[**threaded**](tclvars.htm#M34)
[**user**](tclvars.htm#M35)
[**wordSize**](tclvars.htm#M36)
[**tcl\_precision**](tclvars.htm#M37)
[**tcl\_rcFileName**](tclvars.htm#M38)
[**tcl\_traceCompile**](tclvars.htm#M39)
[**tcl\_traceExec**](tclvars.htm#M40)
[**tcl\_wordchars**](tclvars.htm#M41)
[**tcl\_nonwordchars**](tclvars.htm#M42)
[**tcl\_version**](tclvars.htm#M43)
[OTHER GLOBAL VARIABLES](tclvars.htm#M44)
[**argc**](tclvars.htm#M45)
[**argv**](tclvars.htm#M46)
[**argv0**](tclvars.htm#M47)
[**tcl\_interactive**](tclvars.htm#M48)
[EXAMPLES](tclvars.htm#M49)
[SEE ALSO](tclvars.htm#M50)
[KEYWORDS](tclvars.htm#M51)
Name
----
argc, argv, argv0, auto\_path, env, errorCode, errorInfo, tcl\_interactive, tcl\_library, tcl\_nonwordchars, tcl\_patchLevel, tcl\_pkgPath, tcl\_platform, tcl\_precision, tcl\_rcFileName, tcl\_traceCompile, tcl\_traceExec, tcl\_wordchars, tcl\_version — Variables used by Tcl Description
-----------
The following global variables are created and managed automatically by the Tcl library. Except where noted below, these variables should normally be treated as read-only by application-specific code and by users.
**auto\_path**
If set, then it must contain a valid Tcl list giving directories to search during auto-load operations (including for package index files when using the default **[package unknown](package.htm)** handler). This variable is initialized during startup to contain, in order: the directories listed in the **TCLLIBPATH** environment variable, the directory named by the **tcl\_library** global variable, the parent directory of **tcl\_library**, the directories listed in the **tcl\_pkgPath** variable. Additional locations to look for files and package indices should normally be added to this variable using **[lappend](lappend.htm)**. Additional variables relating to package management exist. More details are listed in the **VARIABLES** section of the **[library](library.htm)** manual page.
**env**
This variable is maintained by Tcl as an array whose elements are the environment variables for the process. Reading an element will return the value of the corresponding environment variable. Setting an element of the array will modify the corresponding environment variable or create a new one if it does not already exist. Unsetting an element of **env** will remove the corresponding environment variable. Changes to the **env** array will affect the environment passed to children by commands like **[exec](exec.htm)**. If the entire **env** array is unset then Tcl will stop monitoring **env** accesses and will not update environment variables. Under Windows, the environment variables PATH and COMSPEC in any capitalization are converted automatically to upper case. For instance, the PATH variable could be exported by the operating system as “path”, “Path”, “PaTh”, etc., causing otherwise simple Tcl code to have to support many special cases. All other environment variables inherited by Tcl are left unmodified. Setting an env array variable to blank is the same as unsetting it as this is the behavior of the underlying Windows OS. It should be noted that relying on an existing and empty environment variable will not work on Windows and is discouraged for cross-platform usage.
The following elements of **env** are special to Tcl:
**env(HOME)**
This environment variable, if set, gives the location of the directory considered to be the current user's home directory, and to which a call of **[cd](cd.htm)** without arguments or with just “~” as an argument will change into. Most platforms set this correctly by default; it does not normally need to be set by user code.
**env(TCL\_LIBRARY)**
If set, then it specifies the location of the directory containing library scripts (the value of this variable will be assigned to the **tcl\_library** variable and therefore returned by the command **[info library](info.htm)**). If this variable is not set then a default value is used. Note that this environment variable should *not* normally be set.
**env(TCLLIBPATH)**
If set, then it must contain a valid Tcl list giving directories to search during auto-load operations. Directories must be specified in Tcl format, using “/” as the path separator, regardless of platform. This variable is only used when initializing the **auto\_path** variable.
**env(TCL\_TZ)**, **env(TZ)**
These specify the default timezone used for parsing and formatting times and dates in the **[clock](clock.htm)** command. On many platforms, the TZ environment variable is set up by the operating system.
**env(LC\_ALL)**, **env(LC\_MESSAGES)**, **env(LANG)**
These environment variables are used by the **[msgcat](msgcat.htm)** package to determine what locale to format messages using.
**env(TCL\_INTERP\_DEBUG\_FRAME)**
If existing, it has the same effect as running **[interp debug](interp.htm)** **{} -frame 1** as the very first command of each new Tcl interpreter.
**errorCode**
This variable holds the value of the **-errorcode** return option set by the most recent error that occurred in this interpreter. This list value represents additional information about the error in a form that is easy to process with programs. The first element of the list identifies a general class of errors, and determines the format of the rest of the list. The following formats for **-errorcode** return options are used by the Tcl core; individual applications may define additional formats.
**ARITH** *code msg*
This format is used when an arithmetic error occurs (e.g. an attempt to divide zero by zero in the **[expr](expr.htm)** command). *Code* identifies the precise error and *msg* provides a human-readable description of the error. *Code* will be either DIVZERO (for an attempt to divide by zero), DOMAIN (if an argument is outside the domain of a function, such as acos(-3)), IOVERFLOW (for integer overflow), OVERFLOW (for a floating-point overflow), or UNKNOWN (if the cause of the error cannot be determined). Detection of these errors depends in part on the underlying hardware and system libraries.
**CHILDKILLED** *pid sigName msg*
This format is used when a child process has been killed because of a signal. The *pid* element will be the process's identifier (in decimal). The *sigName* element will be the symbolic name of the signal that caused the process to terminate; it will be one of the names from the include file signal.h, such as **SIGPIPE**. The *msg* element will be a short human-readable message describing the signal, such as “write on pipe with no readers” for **SIGPIPE**.
**CHILDSTATUS** *pid code*
This format is used when a child process has exited with a non-zero exit status. The *pid* element will be the process's identifier (in decimal) and the *code* element will be the exit code returned by the process (also in decimal).
**CHILDSUSP** *pid sigName msg*
This format is used when a child process has been suspended because of a signal. The *pid* element will be the process's identifier, in decimal. The *sigName* element will be the symbolic name of the signal that caused the process to suspend; this will be one of the names from the include file signal.h, such as **SIGTTIN**. The *msg* element will be a short human-readable message describing the signal, such as “background tty read” for **SIGTTIN**.
**NONE**
This format is used for errors where no additional information is available for an error besides the message returned with the error. In these cases the **-errorcode** return option will consist of a list containing a single element whose contents are **NONE**.
**POSIX** *errName msg*
If the first element is **POSIX**, then the error occurred during a POSIX kernel call. The *errName* element will contain the symbolic name of the error that occurred, such as **ENOENT**; this will be one of the values defined in the include file errno.h. The *msg* element will be a human-readable message corresponding to *errName*, such as “no such file or directory” for the **ENOENT** case.
**TCL** ...
Indicates some sort of problem generated in relation to Tcl itself, e.g. a failure to look up a channel or variable.
To set the **-errorcode** return option, applications should use library procedures such as **[Tcl\_SetObjErrorCode](https://www.tcl.tk/man/tcl/TclLib/AddErrInfo.htm)**, **[Tcl\_SetReturnOptions](https://www.tcl.tk/man/tcl/TclLib/AddErrInfo.htm)**, and **[Tcl\_PosixError](https://www.tcl.tk/man/tcl/TclLib/AddErrInfo.htm)**, or they may invoke the **-errorcode** option of the **[return](return.htm)** command. If none of these methods for setting the error code has been used, the Tcl interpreter will reset the variable to **NONE** after the next error.
**errorInfo**
This variable holds the value of the **-errorinfo** return option set by the most recent error that occurred in this interpreter. This string value will contain one or more lines identifying the Tcl commands and procedures that were being executed when the most recent error occurred. Its contents take the form of a stack trace showing the various nested Tcl commands that had been invoked at the time of the error.
**tcl\_library**
This variable holds the name of a directory containing the system library of Tcl scripts, such as those used for auto-loading. The value of this variable is returned by the **[info library](info.htm)** command. See the **[library](library.htm)** manual entry for details of the facilities provided by the Tcl script library. Normally each application or package will have its own application-specific script library in addition to the Tcl script library; each application should set a global variable with a name like **$***app***\_library** (where *app* is the application's name) to hold the network file name for that application's library directory. The initial value of **tcl\_library** is set when an interpreter is created by searching several different directories until one is found that contains an appropriate Tcl startup script. If the **TCL\_LIBRARY** environment variable exists, then the directory it names is checked first. If **TCL\_LIBRARY** is not set or doesn't refer to an appropriate directory, then Tcl checks several other directories based on a compiled-in default location, the location of the binary containing the application, and the current working directory.
**tcl\_patchLevel**
When an interpreter is created Tcl initializes this variable to hold a string giving the current patch level for Tcl, such as **8.4.16** for Tcl 8.4 with the first sixteen official patches, or **8.5b3** for the third beta release of Tcl 8.5. The value of this variable is returned by the **[info patchlevel](info.htm)** command.
**tcl\_pkgPath**
This variable holds a list of directories indicating where packages are normally installed. It is not used on Windows. It typically contains either one or two entries; if it contains two entries, the first is normally a directory for platform-dependent packages (e.g., shared library binaries) and the second is normally a directory for platform-independent packages (e.g., script files). Typically a package is installed as a subdirectory of one of the entries in the **tcl\_pkgPath** variable. The directories in the **tcl\_pkgPath** variable are included by default in the **auto\_path** variable, so they and their immediate subdirectories are automatically searched for packages during **[package require](package.htm)** commands. Note: **tcl\_pkgPath** is not intended to be modified by the application. Its value is added to **auto\_path** at startup; changes to **tcl\_pkgPath** are not reflected in **auto\_path**. If you want Tcl to search additional directories for packages you should add the names of those directories to **auto\_path**, not **tcl\_pkgPath**.
**tcl\_platform**
This is an associative array whose elements contain information about the platform on which the application is running, such as the name of the operating system, its current release number, and the machine's instruction set. The elements listed below will always be defined, but they may have empty strings as values if Tcl could not retrieve any relevant information. In addition, extensions and applications may add additional values to the array. The predefined elements are:
**byteOrder**
The native byte order of this machine: either **littleEndian** or **bigEndian**.
**debug**
If this variable exists, then the interpreter was compiled with and linked to a debug-enabled C run-time. This variable will only exist on Windows, so extension writers can specify which package to load depending on the C run-time library that is in use. This is not an indication that this core contains symbols.
**engine**
The name of the Tcl language implementation. When the interpreter is first created, this is always set to the string **[Tcl](tcl.htm)**.
**machine**
The instruction set executed by this machine, such as **intel**, **PPC**, **68k**, or **sun4m**. On UNIX machines, this is the value returned by **uname -m**.
**os**
The name of the operating system running on this machine, such as **Windows NT** or **SunOS**. On UNIX machines, this is the value returned by **uname -s**.
**osVersion**
The version number for the operating system running on this machine. On UNIX machines, this is the value returned by **uname -r**.
**pathSeparator**
The character that should be used to **[split](split.htm)** PATH-like environment variables into their corresponding list of directory names.
**platform**
Either **windows**, or **unix**. This identifies the general operating environment of the machine.
**pointerSize**
This gives the size of the native-machine pointer in bytes (strictly, it is same as the result of evaluating *sizeof(void\*)* in C.)
**threaded**
If this variable exists, then the interpreter was compiled with threads enabled.
**user**
This identifies the current user based on the login information available on the platform. This value comes from the getuid() and getpwuid() system calls on Unix, and the value from the GetUserName() system call on Windows.
**wordSize**
This gives the size of the native-machine word in bytes (strictly, it is same as the result of evaluating *sizeof(long)* in C.)
**tcl\_precision**
This variable controls the number of digits to generate when converting floating-point values to strings. It defaults to 0. *Applications should not change this value;* it is provided for compatibility with legacy code.
The default value of 0 is special, meaning that Tcl should convert numbers using as few digits as possible while still distinguishing any floating point number from its nearest neighbours. It differs from using an arbitrarily high value for *tcl\_precision* in that an inexact number like *1.4* will convert as *1.4* rather than *1.3999999999999999* even though the latter is nearer to the exact value of the binary number.
If **tcl\_precision** is not zero, then when Tcl converts a floating point number, it creates a decimal representation of at most **tcl\_precision** significant digits; the result may be shorter if the shorter result represents the original number exactly. If no result of at most **tcl\_precision** digits is an exact representation of the original number, the one that is closest to the original number is chosen. If the original number lies precisely between two equally accurate decimal representations, then the one with an even value for the least significant digit is chosen; for instance, if **tcl\_precision** is 3, then 0.3125 will convert to 0.312, not 0.313, while 0.6875 will convert to 0.688, not 0.687. Any string of trailing zeroes that remains is trimmed.
a **tcl\_precision** value of 17 digits is “perfect” for IEEE floating-point in that it allows double-precision values to be converted to strings and back to binary with no loss of information. For this reason, you will often see it as a value in legacy code that must run on Tcl versions before 8.5. It is no longer recommended; as noted above, a zero value is the preferred method.
All interpreters in a thread share a single **tcl\_precision** value: changing it in one interpreter will affect all other interpreters as well. Safe interpreters are not allowed to modify the variable.
Valid values for **tcl\_precision** range from 0 to 17.
**tcl\_rcFileName**
This variable is used during initialization to indicate the name of a user-specific startup file. If it is set by application-specific initialization, then the Tcl startup code will check for the existence of this file and **[source](source.htm)** it if it exists. For example, for **[wish](../usercmd/wish.htm)** the variable is set to **~/.wishrc** for Unix and **~/wishrc.tcl** for Windows.
**tcl\_traceCompile**
The value of this variable can be set to control how much tracing information is displayed during bytecode compilation. By default, **tcl\_traceCompile** is zero and no information is displayed. Setting **tcl\_traceCompile** to 1 generates a one-line summary in **[stdout](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)** whenever a procedure or top-level command is compiled. Setting it to 2 generates a detailed listing in **[stdout](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)** of the bytecode instructions emitted during every compilation. This variable is useful in tracking down suspected problems with the Tcl compiler.
This variable and functionality only exist if **TCL\_COMPILE\_DEBUG** was defined during Tcl's compilation.
**tcl\_traceExec**
The value of this variable can be set to control how much tracing information is displayed during bytecode execution. By default, **tcl\_traceExec** is zero and no information is displayed. Setting **tcl\_traceExec** to 1 generates a one-line trace in **[stdout](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)** on each call to a Tcl procedure. Setting it to 2 generates a line of output whenever any Tcl command is invoked that contains the name of the command and its arguments. Setting it to 3 produces a detailed trace showing the result of executing each bytecode instruction. Note that when **tcl\_traceExec** is 2 or 3, commands such as **[set](set.htm)** and **[incr](incr.htm)** that have been entirely replaced by a sequence of bytecode instructions are not shown. Setting this variable is useful in tracking down suspected problems with the bytecode compiler and interpreter.
This variable and functionality only exist if **TCL\_COMPILE\_DEBUG** was defined during Tcl's compilation.
**tcl\_wordchars**
The value of this variable is a regular expression that can be set to control what are considered “word” characters, for instances like selecting a word by double-clicking in text in Tk. It is platform dependent. On Windows, it defaults to **\S**, meaning anything but a Unicode space character. Otherwise it defaults to **\w**, which is any Unicode word character (number, letter, or underscore).
**tcl\_nonwordchars**
The value of this variable is a regular expression that can be set to control what are considered “non-word” characters, for instances like selecting a word by double-clicking in text in Tk. It is platform dependent. On Windows, it defaults to **\s**, meaning any Unicode space character. Otherwise it defaults to **\W**, which is anything but a Unicode word character (number, letter, or underscore).
**tcl\_version**
When an interpreter is created Tcl initializes this variable to hold the version number for this version of Tcl in the form *x.y*. Changes to *x* represent major changes with probable incompatibilities and changes to *y* represent small enhancements and bug fixes that retain backward compatibility. The value of this variable is returned by the **[info tclversion](info.htm)** command.
Other global variables
----------------------
The following variables are only guaranteed to exist in **[tclsh](../usercmd/tclsh.htm)** and **[wish](../usercmd/wish.htm)** executables; the Tcl library does not define them itself but many Tcl environments do.
**argc**
The number of arguments to **[tclsh](../usercmd/tclsh.htm)** or **[wish](../usercmd/wish.htm)**.
**argv**
Tcl list of arguments to **[tclsh](../usercmd/tclsh.htm)** or **[wish](../usercmd/wish.htm)**.
**argv0**
The script that **[tclsh](../usercmd/tclsh.htm)** or **[wish](../usercmd/wish.htm)** started executing (if it was specified) or otherwise the name by which **[tclsh](../usercmd/tclsh.htm)** or **[wish](../usercmd/wish.htm)** was invoked.
**tcl\_interactive**
Contains 1 if **[tclsh](../usercmd/tclsh.htm)** or **[wish](../usercmd/wish.htm)** is running interactively (no script was specified and standard input is a terminal-like device), 0 otherwise.
Examples
--------
To add a directory to the collection of locations searched by **[package require](package.htm)**, e.g., because of some application-specific packages that are used, the **auto\_path** variable needs to be updated:
```
lappend ::**auto\_path** [file join [pwd] "theLibDir"]
```
A simple though not very robust way to handle command line arguments of the form “-foo 1 -bar 2” is to load them into an array having first loaded in the default settings:
```
array set arguments {-foo 0 -bar 0 -grill 0}
array set arguments $::**argv**
puts "foo is $arguments(-foo)"
puts "bar is $arguments(-bar)"
puts "grill is $arguments(-grill)"
```
The **argv0** global variable can be used (in conjunction with the **[info script](info.htm)** command) to determine whether the current script is being executed as the main script or loaded as a library. This is useful because it allows a single script to be used as both a library and a demonstration of that library:
```
if {$::**argv0** eq [info script]} {
# running as: tclsh example.tcl
} else {
package provide Example 1.0
}
```
See also
--------
**[eval](eval.htm)**, **[library](library.htm)**, **[tclsh](../usercmd/tclsh.htm)**, **tkvars**, **[wish](../usercmd/wish.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/tclvars.htm>
| programming_docs |
tcl_tk unload unload
======
[NAME](unload.htm#M2) unload — Unload machine code
[SYNOPSIS](unload.htm#M3)
[DESCRIPTION](unload.htm#M4)
[**-nocomplain**](unload.htm#M5)
[**-keeplibrary**](unload.htm#M6)
[**--**](unload.htm#M7)
[UNLOAD OPERATION](unload.htm#M8)
[UNLOAD HOOK PROTOTYPE](unload.htm#M9)
[NOTES](unload.htm#M10)
[PORTABILITY ISSUES](unload.htm#M11)
[**Unix**](unload.htm#M12)
[BUGS](unload.htm#M13)
[EXAMPLE](unload.htm#M14)
[SEE ALSO](unload.htm#M15)
[KEYWORDS](unload.htm#M16)
Name
----
unload — Unload machine code Synopsis
--------
**unload** ?*switches*? *fileName*
**unload** ?*switches*? *fileName packageName*
**unload** ?*switches*? *fileName packageName interp*
Description
-----------
This command tries to unload shared libraries previously loaded with **[load](load.htm)** from the application's address space. *fileName* is the name of the file containing the library file to be unload; it must be the same as the filename provided to **[load](load.htm)** for loading the library. The *packageName* argument is the name of the package (as determined by or passed to **[load](load.htm)**), and is used to compute the name of the unload procedure; if not supplied, it is computed from *fileName* in the same manner as **[load](load.htm)**. The *interp* argument is the path name of the interpreter from which to unload the package (see the **[interp](interp.htm)** manual entry for details); if *interp* is omitted, it defaults to the interpreter in which the **unload** command was invoked. If the initial arguments to **unload** start with **-** then they are treated as switches. The following switches are currently supported:
**-nocomplain**
Suppresses all error messages. If this switch is given, **unload** will never report an error.
**-keeplibrary**
This switch will prevent **unload** from issuing the operating system call that will unload the library from the process.
**--**
Marks the end of switches. The argument following this one will be treated as a *fileName* even if it starts with a **-**.
### Unload operation
When a file containing a shared library is loaded through the **[load](load.htm)** command, Tcl associates two reference counts to the library file. The first counter shows how many times the library has been loaded into normal (trusted) interpreters while the second describes how many times the library has been loaded into safe interpreters. As a file containing a shared library can be loaded only once by Tcl (with the first **[load](load.htm)** call on the file), these counters track how many interpreters use the library. Each subsequent call to **[load](load.htm)** after the first simply increments the proper reference count. **unload** works in the opposite direction. As a first step, **unload** will check whether the library is unloadable: an unloadable library exports a special unload procedure. The name of the unload procedure is determined by *packageName* and whether or not the target interpreter is a safe one. For normal interpreters the name of the initialization procedure will have the form *pkg***\_Unload**, where *pkg* is the same as *packageName* except that the first letter is converted to upper case and all other letters are converted to lower case. For example, if *packageName* is **foo** or **FOo**, the initialization procedure's name will be **Foo\_Unload**. If the target interpreter is a safe interpreter, then the name of the initialization procedure will be *pkg***\_SafeUnload** instead of *pkg***\_Unload**.
If **unload** determines that a library is not unloadable (or unload functionality has been disabled during compilation), an error will be returned. If the library is unloadable, then **unload** will call the unload procedure. If the unload procedure returns **[TCL\_OK](catch.htm)**, **unload** will proceed and decrease the proper reference count (depending on the target interpreter type). When both reference counts have reached 0, the library will be detached from the process.
### Unload hook prototype
The unload procedure must match the following prototype:
```
typedef int **Tcl\_PackageUnloadProc**(
[Tcl\_Interp](https://www.tcl.tk/man/tcl/TclLib/Interp.htm) **interp*,
int *flags*);
```
The *interp* argument identifies the interpreter from which the library is to be unloaded. The unload procedure must return **[TCL\_OK](catch.htm)** or **[TCL\_ERROR](catch.htm)** to indicate whether or not it completed successfully; in the event of an error it should set the interpreter's result to point to an error message. In this case, the result of the **unload** command will be the result returned by the unload procedure.
The *flags* argument can be either **TCL\_UNLOAD\_DETACH\_FROM\_INTERPRETER** or **TCL\_UNLOAD\_DETACH\_FROM\_PROCESS**. In case the library will remain attached to the process after the unload procedure returns (i.e. because the library is used by other interpreters), **TCL\_UNLOAD\_DETACH\_FROM\_INTERPRETER** will be defined. However, if the library is used only by the target interpreter and the library will be detached from the application as soon as the unload procedure returns, the *flags* argument will be set to **TCL\_UNLOAD\_DETACH\_FROM\_PROCESS**.
### Notes
The **unload** command cannot unload libraries that are statically linked with the application. If *fileName* is an empty string, then the *packageName* argument must be specified. If *packageName* is omitted or specified as an empty string, Tcl tries to guess the name of the package. This may be done differently on different platforms. The default guess, which is used on most UNIX platforms, is to take the last element of *fileName*, strip off the first three characters if they are **lib**, and use any following alphabetic and underline characters as the module name. For example, the command **unload libxyz4.2.so** uses the module name **xyz** and the command **unload bin/last.so {}** uses the module name **last**.
Portability issues
------------------
**Unix**
Not all unix operating systems support library unloading. Under such an operating system **unload** returns an error (unless **-nocomplain** has been specified).
Bugs
----
If the same file is **[load](load.htm)**ed by different *fileName*s, it will be loaded into the process's address space multiple times. The behavior of this varies from system to system (some systems may detect the redundant loads, others may not). In case a library has been silently detached by the operating system (and as a result Tcl thinks the library is still loaded), it may be dangerous to use **unload** on such a library (as the library will be completely detached from the application while some interpreters will continue to use it). Example
-------
If an unloadable module in the file **foobar.dll** had been loaded using the **[load](load.htm)** command like this (on Windows):
```
load c:/some/dir/foobar.dll
```
then it would be unloaded like this:
```
**unload** c:/some/dir/foobar.dll
```
This allows a C code module to be installed temporarily into a long-running Tcl program and then removed again (either because it is no longer needed or because it is being updated with a new version) without having to shut down the overall Tcl process.
See also
--------
**[info sharedlibextension](info.htm)**, **[load](load.htm)**, **[safe](safe.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/unload.htm>
tcl_tk rename rename
======
Name
----
rename — Rename or delete a command Synopsis
--------
**rename** *oldName newName*
Description
-----------
Rename the command that used to be called *oldName* so that it is now called *newName*. If *newName* is an empty string then *oldName* is deleted. *oldName* and *newName* may include namespace qualifiers (names of containing namespaces). If a command is renamed into a different namespace, future invocations of it will execute in the new namespace. The **rename** command returns an empty string as result. Example
-------
The **rename** command can be used to wrap the standard Tcl commands with your own monitoring machinery. For example, you might wish to count how often the **[source](source.htm)** command is called:
```
**rename** ::source ::theRealSource
set sourceCount 0
proc ::source args {
global sourceCount
puts "called source for the [incr sourceCount]'th time"
uplevel 1 ::theRealSource $args
}
```
See also
--------
**[namespace](namespace.htm)**, **[proc](proc.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/rename.htm>
tcl_tk dde dde
===
[NAME](dde.htm#M2) dde — Execute a Dynamic Data Exchange command
[SYNOPSIS](dde.htm#M3)
[DESCRIPTION](dde.htm#M4)
[DDE COMMANDS](dde.htm#M5)
[**dde servername** ?**-force**? ?**-handler** *proc*? ?**--**? ?*topic*?](dde.htm#M6)
[**dde execute** ?**-async**? ?**-binary**? *service topic data*](dde.htm#M7)
[**dde poke** ?**-binary**? *service topic item data*](dde.htm#M8)
[**dde request** ?**-binary**? *service topic item*](dde.htm#M9)
[**dde services** *service topic*](dde.htm#M10)
[**dde eval** ?**-async**? *topic cmd* ?*arg arg ...*?](dde.htm#M11)
[DDE AND TCL](dde.htm#M12)
[EXAMPLE](dde.htm#M13)
[SEE ALSO](dde.htm#M14)
[KEYWORDS](dde.htm#M15)
Name
----
dde — Execute a Dynamic Data Exchange command Synopsis
--------
**package require dde 1.4**
**dde servername** ?**-force**? ?**-handler** *proc*? ?**--**? ?*topic*?
**dde execute** ?**-async**? ?**-binary**? *service topic data*
**dde poke** ?**-binary**? *service topic item data*
**dde request** ?**-binary**? *service topic item*
**dde services** *service topic*
**dde eval** ?**-async**? *topic cmd* ?*arg arg ...*?
Description
-----------
This command allows an application to send Dynamic Data Exchange (DDE) command when running under Microsoft Windows. Dynamic Data Exchange is a mechanism where applications can exchange raw data. Each DDE transaction needs a *service name* and a *topic*. Both the *service name* and *topic* are application defined; Tcl uses the service name **TclEval**, while the topic name is the name of the interpreter given by **dde servername**. Other applications have their own *service names* and *topics*. For instance, Microsoft Excel has the service name **Excel**.
Dde commands
------------
The following commands are a subset of the full Dynamic Data Exchange set of commands.
**dde servername** ?**-force**? ?**-handler** *proc*? ?**--**? ?*topic*?
**dde servername** registers the interpreter as a DDE server with the service name **TclEval** and the topic name specified by *topic*. If no *topic* is given, **dde servername** returns the name of the current topic or the empty string if it is not registered as a service. If the given *topic* name is already in use, then a suffix of the form “ #2” or “ #3” is appended to the name to make it unique. The command's result will be the name actually used. The **-force** option is used to force registration of precisely the given *topic* name. The **-handler** option specifies a Tcl procedure that will be called to process calls to the dde server. If the package has been loaded into a safe interpreter then a **-handler** procedure must be defined. The procedure is called with all the arguments provided by the remote call.
**dde execute** ?**-async**? ?**-binary**? *service topic data*
**dde execute** takes the *data* and sends it to the server indicated by *service* with the topic indicated by *topic*. Typically, *service* is the name of an application, and *topic* is a file to work on. The *data* field is given to the remote application. Typically, the application treats the *data* field as a script, and the script is run in the application. The **-async** option requests asynchronous invocation. The command returns an error message if the script did not run, unless the **-async** flag was used, in which case the command returns immediately with no error. Without the **-binary** option all data will be sent in unicode. For dde clients which don't implement the CF\_UNICODE clipboard format, this will automatically be translated to the system encoding. You can use the **-binary** option in combination with the result of **[encoding convertto](encoding.htm)** to send data in any other encoding.
**dde poke** ?**-binary**? *service topic item data*
**dde poke** passes the *data* to the server indicated by *service* using the *topic* and *item* specified. Typically, *service* is the name of an application. *topic* is application specific but can be a command to the server or the name of a file to work on. The *item* is also application specific and is often not used, but it must always be non-null. The *data* field is given to the remote application. Without the **-binary** option all data will be sent in unicode. For dde clients which don't implement the CF\_UNICODE clipboard format, this will automatically be translated to the system encoding. You can use the **-binary** option in combination with the result of **[encoding convertto](encoding.htm)** to send data in any other encoding.
**dde request** ?**-binary**? *service topic item*
**dde request** is typically used to get the value of something; the value of a cell in Microsoft Excel or the text of a selection in Microsoft Word. *service* is typically the name of an application, *topic* is typically the name of the file, and *item* is application-specific. The command returns the value of *item* as defined in the application. Normally this is interpreted to be a string with terminating null. If **-binary** is specified, the result is returned as a byte array.
**dde services** *service topic*
**dde services** returns a list of service-topic pairs that currently exist on the machine. If *service* and *topic* are both empty strings ({}), then all service-topic pairs currently available on the system are returned. If *service* is empty and *topic* is not, then all services with the specified topic are returned. If *service* is non-empty and *topic* is, all topics for a given service are returned. If both are non-empty, if that service-topic pair currently exists, it is returned; otherwise, an empty string is returned.
**dde eval** ?**-async**? *topic cmd* ?*arg arg ...*?
**dde eval** evaluates a command and its arguments using the interpreter specified by *topic*. The DDE service must be the **TclEval** service. The **-async** option requests asynchronous invocation. The command returns an error message if the script did not run, unless the **-async** flag was used, in which case the command returns immediately with no error. This command can be used to replace send on Windows.
Dde and tcl
-----------
A Tcl interpreter always has a service name of **TclEval**. Each different interpreter of all running Tcl applications must be given a unique name specified by **dde servername**. Each interp is available as a DDE topic only if the **dde servername** command was used to set the name of the topic for each interp. So a **dde services TclEval {}** command will return a list of service-topic pairs, where each of the currently running interps will be a topic. When Tcl processes a **dde execute** command, the data for the execute is run as a script in the interp named by the topic of the **dde execute** command.
When Tcl processes a **dde request** command, it returns the value of the variable given in the dde command in the context of the interp named by the dde topic. Tcl reserves the variable **$TCLEVAL$EXECUTE$RESULT** for internal use, and **dde request** commands for that variable will give unpredictable results.
An external application which wishes to run a script in Tcl should have that script store its result in a variable, run the **dde execute** command, and then run **dde request** to get the value of the variable.
When using DDE, be careful to ensure that the event queue is flushed using either **[update](update.htm)** or **[vwait](vwait.htm)**. This happens by default when using **[wish](../usercmd/wish.htm)** unless a blocking command is called (such as **[exec](exec.htm)** without adding the **&** to place the process in the background). If for any reason the event queue is not flushed, DDE commands may hang until the event queue is flushed. This can create a deadlock situation.
Example
-------
This asks Internet Explorer (which must already be running) to go to a particularly important website:
```
package require dde
**dde execute** -async iexplore WWW_OpenURL <http://www.tcl.tk/>
```
See also
--------
**[tk](../tkcmd/tk.htm)**, **[winfo](../tkcmd/winfo.htm)**, **[send](../tkcmd/send.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/dde.htm>
tcl_tk variable variable
========
Name
----
variable — create and initialize a namespace variable Synopsis
--------
**variable** *name*
**variable** ?*name value...*?
Description
-----------
This command is normally used within a **[namespace eval](namespace.htm)** command to create one or more variables within a namespace. Each variable *name* is initialized with *value*. The *value* for the last variable is optional. If a variable *name* does not exist, it is created. In this case, if *value* is specified, it is assigned to the newly created variable. If no *value* is specified, the new variable is left undefined. If the variable already exists, it is set to *value* if *value* is specified or left unchanged if no *value* is given. Normally, *name* is unqualified (does not include the names of any containing namespaces), and the variable is created in the current namespace. If *name* includes any namespace qualifiers, the variable is created in the specified namespace. If the variable is not defined, it will be visible to the **[namespace which](namespace.htm)** command, but not to the **[info exists](info.htm)** command.
If the **variable** command is executed inside a Tcl procedure, it creates local variables linked to the corresponding namespace variables (and therefore these variables are listed by **[info vars](info.htm)**.) In this way the **variable** command resembles the **[global](global.htm)** command, although the **[global](global.htm)** command only links to variables in the global namespace. If any *value*s are given, they are used to modify the values of the associated namespace variables. If a namespace variable does not exist, it is created and optionally initialized.
A *name* argument cannot reference an element within an array. Instead, *name* should reference the entire array, and the initialization *value* should be left off. After the variable has been declared, elements within the array can be set using ordinary **[set](set.htm)** or **[array](array.htm)** commands.
Examples
--------
Create a variable in a namespace:
```
namespace eval foo {
**variable** bar 12345
}
```
Create an array in a namespace:
```
namespace eval someNS {
**variable** someAry
array set someAry {
someName someValue
otherName otherValue
}
}
```
Access variables in namespaces from a procedure:
```
namespace eval foo {
proc spong {} {
# Variable in this namespace
**variable** bar
puts "bar is $bar"
# Variable in another namespace
**variable** ::someNS::someAry
parray someAry
}
}
```
See also
--------
**[global](global.htm)**, **[namespace](namespace.htm)**, **[upvar](upvar.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/variable.htm>
tcl_tk global global
======
Name
----
global — Access global variables Synopsis
--------
**global** ?*varname ...*?
Description
-----------
This command has no effect unless executed in the context of a proc body. If the **global** command is executed in the context of a proc body, it creates local variables linked to the corresponding global variables (though these linked variables, like those created by **[upvar](upvar.htm)**, are not included in the list returned by **[info locals](info.htm)**). If *varname* contains namespace qualifiers, the local variable's name is the unqualified name of the global variable, as determined by the **[namespace tail](namespace.htm)** command.
*varname* is always treated as the name of a variable, not an array element. An error is returned if the name looks like an array element, such as **a(b)**.
Examples
--------
This procedure sets the namespace variable *::a::x*
```
proc reset {} {
**global** a::x
set x 0
}
```
This procedure accumulates the strings passed to it in a global buffer, separated by newlines. It is useful for situations when you want to build a message piece-by-piece (as if with **[puts](puts.htm)**) but send that full message in a single piece (e.g. over a connection opened with **[socket](socket.htm)** or as part of a counted HTTP response).
```
proc accum {string} {
**global** accumulator
append accumulator $string \n
}
```
See also
--------
**[namespace](namespace.htm)**, **[upvar](upvar.htm)**, **[variable](variable.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/global.htm>
| programming_docs |
tcl_tk unknown unknown
=======
Name
----
unknown — Handle attempts to use non-existent commands Synopsis
--------
**unknown** *cmdName* ?*arg arg ...*?
Description
-----------
This command is invoked by the Tcl interpreter whenever a script tries to invoke a command that does not exist. The default implementation of **unknown** is a library procedure defined when Tcl initializes an interpreter. You can override the default **unknown** to change its functionality, or you can register a new handler for individual namespaces using the **[namespace unknown](namespace.htm)** command. Note that there is no default implementation of **unknown** in a safe interpreter. If the Tcl interpreter encounters a command name for which there is not a defined command (in either the current namespace, or the global namespace), then Tcl checks for the existence of an unknown handler for the current namespace. By default, this handler is a command named **::unknown**. If there is no such command, then the interpreter returns an error. If the **unknown** command exists (or a new handler has been registered for the current namespace), then it is invoked with arguments consisting of the fully-substituted name and arguments for the original non-existent command. The **unknown** command typically does things like searching through library directories for a command procedure with the name *cmdName*, or expanding abbreviated command names to full-length, or automatically executing unknown commands as sub-processes. In some cases (such as expanding abbreviations) **unknown** will change the original command slightly and then (re-)execute it. The result of the **unknown** command is used as the result for the original non-existent command.
The default implementation of **unknown** behaves as follows. It first calls the **[auto\_load](library.htm)** library procedure to load the command. If this succeeds, then it executes the original command with its original arguments. If the auto-load fails then **unknown** calls **[auto\_execok](library.htm)** to see if there is an executable file by the name *cmd*. If so, it invokes the Tcl **[exec](exec.htm)** command with *cmd* and all the *args* as arguments. If *cmd* cannot be auto-executed, **unknown** checks to see if the command was invoked at top-level and outside of any script. If so, then **unknown** takes two additional steps. First, it sees if *cmd* has one of the following three forms: **!!**, **!***event*, or **^***old***^***new*?**^**?. If so, then **unknown** carries out history substitution in the same way that **csh** would for these constructs. Finally, **unknown** checks to see if *cmd* is a unique abbreviation for an existing Tcl command. If so, it expands the command name and executes the command with the original arguments. If none of the above efforts has been able to execute the command, **unknown** generates an error return. If the global variable **auto\_noload** is defined, then the auto-load step is skipped. If the global variable **auto\_noexec** is defined then the auto-exec step is skipped. Under normal circumstances the return value from **unknown** is the return value from the command that was eventually executed.
Example
-------
Arrange for the **unknown** command to have its standard behavior except for first logging the fact that a command was not found:
```
# Save the original one so we can chain to it
rename **unknown** _original_unknown
# Provide our own implementation
proc **unknown** args {
puts stderr "WARNING: unknown command: $args"
uplevel 1 [list _original_unknown {*}$args]
}
```
See also
--------
**[info](info.htm)**, **[proc](proc.htm)**, **[interp](interp.htm)**, **[library](library.htm)**, **[namespace](namespace.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/unknown.htm>
tcl_tk lsearch lsearch
=======
[NAME](lsearch.htm#M2) lsearch — See if a list contains a particular element
[SYNOPSIS](lsearch.htm#M3)
[DESCRIPTION](lsearch.htm#M4)
[MATCHING STYLE OPTIONS](lsearch.htm#M5)
[**-exact**](lsearch.htm#M6)
[**-glob**](lsearch.htm#M7)
[**-regexp**](lsearch.htm#M8)
[**-sorted**](lsearch.htm#M9)
[GENERAL MODIFIER OPTIONS](lsearch.htm#M10)
[**-all**](lsearch.htm#M11)
[**-inline**](lsearch.htm#M12)
[**-not**](lsearch.htm#M13)
[**-start** *index*](lsearch.htm#M14)
[CONTENTS DESCRIPTION OPTIONS](lsearch.htm#M15)
[**-ascii**](lsearch.htm#M16)
[**-dictionary**](lsearch.htm#M17)
[**-integer**](lsearch.htm#M18)
[**-nocase**](lsearch.htm#M19)
[**-real**](lsearch.htm#M20)
[SORTED LIST OPTIONS](lsearch.htm#M21)
[**-decreasing**](lsearch.htm#M22)
[**-increasing**](lsearch.htm#M23)
[**-bisect**](lsearch.htm#M24)
[NESTED LIST OPTIONS](lsearch.htm#M25)
[**-index** *indexList*](lsearch.htm#M26)
[**-subindices**](lsearch.htm#M27)
[EXAMPLES](lsearch.htm#M28)
[SEE ALSO](lsearch.htm#M29)
[KEYWORDS](lsearch.htm#M30)
Name
----
lsearch — See if a list contains a particular element Synopsis
--------
**lsearch** ?*options*? *list pattern*
Description
-----------
This command searches the elements of *list* to see if one of them matches *pattern*. If so, the command returns the index of the first matching element (unless the options **-all** or **-inline** are specified.) If not, the command returns **-1**. The *option* arguments indicates how the elements of the list are to be matched against *pattern* and must have one of the values below: ### Matching style options
If all matching style options are omitted, the default matching style is **-glob**. If more than one matching style is specified, the last matching style given takes precedence.
**-exact**
*Pattern* is a literal string that is compared for exact equality against each list element.
**-glob**
*Pattern* is a glob-style pattern which is matched against each list element using the same rules as the **[string match](string.htm)** command.
**-regexp**
*Pattern* is treated as a regular expression and matched against each list element using the rules described in the **[re\_syntax](re_syntax.htm)** reference page.
**-sorted**
The list elements are in sorted order. If this option is specified, **lsearch** will use a more efficient searching algorithm to search *list*. If no other options are specified, *list* is assumed to be sorted in increasing order, and to contain ASCII strings. This option is mutually exclusive with **-glob** and **-regexp**, and is treated exactly like **-exact** when either **-all** or **-not** are specified.
### General modifier options
These options may be given with all matching styles.
**-all**
Changes the result to be the list of all matching indices (or all matching values if **-inline** is specified as well.) If indices are returned, the indices will be in numeric order. If values are returned, the order of the values will be the order of those values within the input *list*.
**-inline**
The matching value is returned instead of its index (or an empty string if no value matches.) If **-all** is also specified, then the result of the command is the list of all values that matched.
**-not**
This negates the sense of the match, returning the index of the first non-matching value in the list.
**-start** *index*
The list is searched starting at position *index*. The interpretation of the *index* value is the same as for the command **[string index](string.htm)**, supporting simple index arithmetic and indices relative to the end of the list.
### Contents description options
These options describe how to interpret the items in the list being searched. They are only meaningful when used with the **-exact** and **-sorted** options. If more than one is specified, the last one takes precedence. The default is **-ascii**.
**-ascii**
The list elements are to be examined as Unicode strings (the name is for backward-compatibility reasons.)
**-dictionary**
The list elements are to be compared using dictionary-style comparisons (see **[lsort](lsort.htm)** for a fuller description). Note that this only makes a meaningful difference from the **-ascii** option when the **-sorted** option is given, because values are only dictionary-equal when exactly equal.
**-integer**
The list elements are to be compared as integers.
**-nocase**
Causes comparisons to be handled in a case-insensitive manner. Has no effect if combined with the **-dictionary**, **-integer**, or **-real** options.
**-real**
The list elements are to be compared as floating-point values.
### Sorted list options
These options (only meaningful with the **-sorted** option) specify how the list is sorted. If more than one is given, the last one takes precedence. The default option is **-increasing**.
**-decreasing**
The list elements are sorted in decreasing order. This option is only meaningful when used with **-sorted**.
**-increasing**
The list elements are sorted in increasing order. This option is only meaningful when used with **-sorted**.
**-bisect**
Inexact search when the list elements are in sorted order. For an increasing list the last index where the element is less than or equal to the pattern is returned. For a decreasing list the last index where the element is greater than or equal to the pattern is returned. If the pattern is before the first element or the list is empty, -1 is returned. This option implies **-sorted** and cannot be used with either **-all** or **-not**.
### Nested list options
These options are used to search lists of lists. They may be used with any other options.
**-index** *indexList*
This option is designed for use when searching within nested lists. The *indexList* argument gives a path of indices (much as might be used with the **[lindex](lindex.htm)** or **[lset](lset.htm)** commands) within each element to allow the location of the term being matched against.
**-subindices**
If this option is given, the index result from this command (or every index result when **-all** is also specified) will be a complete path (suitable for use with **[lindex](lindex.htm)** or **[lset](lset.htm)**) within the overall list to the term found. This option has no effect unless the **-index** is also specified, and is just a convenience short-cut.
Examples
--------
Basic searching:
```
**lsearch** {a b c d e} c
*→ 2*
**lsearch** -all {a b c a b c} c
*→ 2 5*
```
Using **lsearch** to filter lists:
```
**lsearch** -inline {a20 b35 c47} b*
*→ b35*
**lsearch** -inline -not {a20 b35 c47} b*
*→ a20*
**lsearch** -all -inline -not {a20 b35 c47} b*
*→ a20 c47*
**lsearch** -all -not {a20 b35 c47} b*
*→ 0 2*
```
This can even do a “set-like” removal operation:
```
**lsearch** -all -inline -not -exact {a b c a d e a f g a} a
*→ b c d e f g*
```
Searching may start part-way through the list:
```
**lsearch** -start 3 {a b c a b c} c
*→ 5*
```
It is also possible to search inside elements:
```
**lsearch** -index 1 -all -inline {{a abc} {b bcd} {c cde}} *bc*
*→ {a abc} {b bcd}*
```
See also
--------
**[foreach](foreach.htm)**, **[list](list.htm)**, **[lappend](lappend.htm)**, **[lindex](lindex.htm)**, **[linsert](linsert.htm)**, **[llength](llength.htm)**, **[lset](lset.htm)**, **[lsort](lsort.htm)**, **[lrange](lrange.htm)**, **[lreplace](lreplace.htm)**, **[string](string.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/lsearch.htm>
tcl_tk transchan transchan
=========
[NAME](transchan.htm#M2) transchan — command handler API of channel transforms
[SYNOPSIS](transchan.htm#M3)
[DESCRIPTION](transchan.htm#M4)
[GENERIC SUBCOMMANDS](transchan.htm#M5)
[*cmdPrefix* **clear** *handle*](transchan.htm#M6)
[*cmdPrefix* **finalize** *handle*](transchan.htm#M7)
[*cmdPrefix* **initialize** *handle mode*](transchan.htm#M8)
[**write**](transchan.htm#M9)
[**read**](transchan.htm#M10)
[READ-RELATED SUBCOMMANDS](transchan.htm#M11)
[*cmdPrefix* **drain** *handle*](transchan.htm#M12)
[*cmdPrefix* **limit?** *handle*](transchan.htm#M13)
[*cmdPrefix* **read** *handle buffer*](transchan.htm#M14)
[WRITE-RELATED SUBCOMMANDS](transchan.htm#M15)
[*cmdPrefix* **flush** *handle*](transchan.htm#M16)
[*cmdPrefix* **write** *handle buffer*](transchan.htm#M17)
[SEE ALSO](transchan.htm#M18)
[KEYWORDS](transchan.htm#M19)
Name
----
transchan — command handler API of channel transforms Synopsis
--------
**cmdPrefix** *option* ?*arg arg ...*?
Description
-----------
The Tcl-level handler for a channel transformation has to be a command with subcommands (termed an *ensemble* despite not implying that it must be created with **namespace ensemble create**; this mechanism is not tied to **[namespace ensemble](namespace.htm)** in any way). Note that *cmdPrefix* is whatever was specified in the call to **[chan push](chan.htm)**, and may consist of multiple arguments; this will be expanded to multiple words in place of the prefix. Of all the possible subcommands, the handler *must* support **initialize** and **finalize**. Transformations for writable channels must also support **write**, and transformations for readable channels must also support **[read](read.htm)**.
Note that in the descriptions below *cmdPrefix* may be more than one word, and *handle* is the value returned by the **[chan push](chan.htm)** call used to create the transformation.
### Generic subcommands
The following subcommands are relevant to all types of channel.
*cmdPrefix* **clear** *handle*
This optional subcommand is called to signify to the transformation that any data stored in internal buffers (either incoming or outgoing) must be cleared. It is called when a **[chan seek](chan.htm)** is performed on the channel being transformed.
*cmdPrefix* **finalize** *handle*
This mandatory subcommand is called last for the given *handle*, and then never again, and it exists to allow for cleaning up any Tcl-level data structures associated with the transformation. *Warning!* Any errors thrown by this subcommand will be ignored. It is not guaranteed to be called if the interpreter is deleted.
*cmdPrefix* **initialize** *handle mode*
This mandatory subcommand is called first, and then never again (for the given *handle*). Its responsibility is to initialize all parts of the transformation at the Tcl level. The *mode* is a list containing any of **read** and **write**.
**write**
implies that the channel is writable.
**read**
implies that the channel is readable.
The return value of the subcommand should be a list containing the names of all subcommands supported by this handler. Any error thrown by the subcommand will prevent the creation of the transformation. The thrown error will appear as error thrown by **[chan push](chan.htm)**.
### Read-related subcommands
These subcommands are used for handling transformations applied to readable channels; though strictly **read** is optional, it must be supported if any of the others is or the channel will be made non-readable.
*cmdPrefix* **drain** *handle*
This optional subcommand is called whenever data in the transformation input (i.e. read) buffer has to be forced upward, i.e. towards the user or script. The result returned by the method is taken as the *binary* data to push upward to the level above this transformation (the reader or a higher-level transformation). In other words, when this method is called the transformation cannot defer the actual transformation operation anymore and has to transform all data waiting in its internal read buffers and return the result of that action.
*cmdPrefix* **limit?** *handle*
This optional subcommand is called to allow the Tcl I/O engine to determine how far ahead it should read. If present, it should return an integer number greater than zero which indicates how many bytes ahead should be read, or an integer less than zero to indicate that the I/O engine may read as far ahead as it likes.
*cmdPrefix* **read** *handle buffer*
This subcommand, which must be present if the transformation is to work with readable channels, is called whenever the base channel, or a transformation below this transformation, pushes data upward. The *buffer* contains the binary data which has been given to us from below. It is the responsibility of this subcommand to actually transform the data. The result returned by the subcommand is taken as the binary data to push further upward to the transformation above this transformation. This can also be the user or script that originally read from the channel. Note that the result is allowed to be empty, or even less than the data we received; the transformation is not required to transform everything given to it right now. It is allowed to store incoming data in internal buffers and to defer the actual transformation until it has more data.
### Write-related subcommands
These subcommands are used for handling transformations applied to writable channels; though strictly **write** is optional, it must be supported if any of the others is or the channel will be made non-writable.
*cmdPrefix* **flush** *handle*
This optional subcommand is called whenever data in the transformation 'write' buffer has to be forced downward, i.e. towards the base channel. The result returned by the subcommand is taken as the binary data to write to the transformation below the current transformation. This can be the base channel as well. In other words, when this subcommand is called the transformation cannot defer the actual transformation operation anymore and has to transform all data waiting in its internal write buffers and return the result of that action.
*cmdPrefix* **write** *handle buffer*
This subcommand, which must be present if the transformation is to work with writable channels, is called whenever the user, or a transformation above this transformation, writes data downward. The *buffer* contains the binary data which has been written to us. It is the responsibility of this subcommand to actually transform the data. The result returned by the subcommand is taken as the binary data to write to the transformation below this transformation. This can be the base channel as well. Note that the result is allowed to be empty, or less than the data we got; the transformation is not required to transform everything which was written to it right now. It is allowed to store this data in internal buffers and to defer the actual transformation until it has more data.
See also
--------
**[chan](chan.htm)**, **[refchan](refchan.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/transchan.htm>
tcl_tk pid pid
===
Name
----
pid — Retrieve process identifiers Synopsis
--------
**pid** ?*fileId*?
Description
-----------
If the *fileId* argument is given then it should normally refer to a process pipeline created with the **[open](open.htm)** command. In this case the **pid** command will return a list whose elements are the process identifiers of all the processes in the pipeline, in order. The list will be empty if *fileId* refers to an open file that is not a process pipeline. If no *fileId* argument is given then **pid** returns the process identifier of the current process. All process identifiers are returned as decimal strings. Example
-------
Print process information about the processes in a pipeline using the SysV **ps** program before reading the output of that pipeline:
```
set pipeline [open "| zcat somefile.gz | grep foobar | sort -u"]
# Print process information
exec ps -fp [**pid** $pipeline] >@stdout
# Print a separator and then the output of the pipeline
puts [string repeat - 70]
puts [read $pipeline]
close $pipeline
```
See also
--------
**[exec](exec.htm)**, **[open](open.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/pid.htm>
| programming_docs |
tcl_tk llength llength
=======
Name
----
llength — Count the number of elements in a list Synopsis
--------
**llength** *list*
Description
-----------
Treats *list* as a list and returns a decimal string giving the number of elements in it. Examples
--------
The result is the number of elements:
```
% **llength** {a b c d e}
5
% **llength** {a b c}
3
% **llength** {}
0
```
Elements are not guaranteed to be exactly words in a dictionary sense of course, especially when quoting is used:
```
% **llength** {a b {c d} e}
4
% **llength** {a b { } c d e}
6
```
An empty list is not necessarily an empty string:
```
% set var { }; puts "[string length $var],[**llength** $var]"
1,0
```
See also
--------
**[list](list.htm)**, **[lappend](lappend.htm)**, **[lindex](lindex.htm)**, **[linsert](linsert.htm)**, **[lsearch](lsearch.htm)**, **[lset](lset.htm)**, **[lsort](lsort.htm)**, **[lrange](lrange.htm)**, **[lreplace](lreplace.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/llength.htm>
tcl_tk glob glob
====
[NAME](glob.htm#M2) glob — Return names of files that match patterns
[SYNOPSIS](glob.htm#M3)
[DESCRIPTION](glob.htm#M4)
[OPTIONS](glob.htm#M5)
[**-directory** *directory*](glob.htm#M6)
[**-join**](glob.htm#M7)
[**-nocomplain**](glob.htm#M8)
[**-path** *pathPrefix*](glob.htm#M9)
[**-tails**](glob.htm#M10)
[**-types** *typeList*](glob.htm#M11)
[**--**](glob.htm#M12)
[GLOBBING PATTERNS](glob.htm#M13)
[**?**](glob.htm#M14)
[**\***](glob.htm#M15)
[**[***chars***]**](glob.htm#M16)
[**\***x*](glob.htm#M17)
[**{***a***,***b***,***...*}](glob.htm#M18)
[WINDOWS PORTABILITY ISSUES](glob.htm#M19)
[EXAMPLES](glob.htm#M20)
[SEE ALSO](glob.htm#M21)
[KEYWORDS](glob.htm#M22)
Name
----
glob — Return names of files that match patterns Synopsis
--------
**glob** ?*switches*? ?*pattern ...*?
Description
-----------
This command performs file name “globbing” in a fashion similar to the csh shell or bash shell. It returns a list of the files whose names match any of the *pattern* arguments. No particular order is guaranteed in the list, so if a sorted list is required the caller should use **[lsort](lsort.htm)**. ### Options
If the initial arguments to **glob** start with **-** then they are treated as switches. The following switches are currently supported:
**-directory** *directory*
Search for files which match the given patterns starting in the given *directory*. This allows searching of directories whose name contains glob-sensitive characters without the need to quote such characters explicitly. This option may not be used in conjunction with **-path**, which is used to allow searching for complete file paths whose names may contain glob-sensitive characters.
**-join**
The remaining pattern arguments, after option processing, are treated as a single pattern obtained by joining the arguments with directory separators.
**-nocomplain**
Allows an empty list to be returned without error; without this switch an error is returned if the result list would be empty.
**-path** *pathPrefix*
Search for files with the given *pathPrefix* where the rest of the name matches the given patterns. This allows searching for files with names similar to a given file (as opposed to a directory) even when the names contain glob-sensitive characters. This option may not be used in conjunction with **-directory**. For example, to find all files with the same root name as $path, but differing extensions, you should use “**glob -path [file rootname $path] .\***” which will work even if **$path** contains numerous glob-sensitive characters.
**-tails**
Only return the part of each file found which follows the last directory named in any **-directory** or **-path** path specification. Thus “**glob -tails -directory $dir \***” is equivalent to “**set pwd [pwd]; cd $dir; glob \*; cd $pwd**”. For **-path** specifications, the returned names will include the last path segment, so “**glob -tails -path [file rootname ~/foo.tex] .\***” will return paths like **foo.aux foo.bib foo.tex** etc.
**-types** *typeList*
Only list files or directories which match *typeList*, where the items in the list have two forms. The first form is like the -type option of the Unix find command: *b* (block special file), *c* (character special file), *d* (directory), *f* (plain file), *l* (symbolic link), *p* (named pipe), or *s* (socket), where multiple types may be specified in the list. **Glob** will return all files which match at least one of the types given. Note that symbolic links will be returned both if **-types l** is given, or if the target of a link matches the requested type. So, a link to a directory will be returned if **-types d** was specified. The second form specifies types where all the types given must match. These are *r*, *w*, *x* as file permissions, and *readonly*, *hidden* as special permission cases. On the Macintosh, MacOS types and creators are also supported, where any item which is four characters long is assumed to be a MacOS type (e.g. **[TEXT](../tkcmd/text.htm)**). Items which are of the form *{macintosh type XXXX}* or *{macintosh creator XXXX}* will match types or creators respectively. Unrecognized types, or specifications of multiple MacOS types/creators will signal an error.
The two forms may be mixed, so **-types {d f r w}** will find all regular files OR directories that have both read AND write permissions. The following are equivalent:
```
**glob -type d \***
**glob \*/**
```
except that the first case doesn't return the trailing “/” and is more platform independent.
**--**
Marks the end of switches. The argument following this one will be treated as a *pattern* even if it starts with a **-**.
### Globbing patterns
The *pattern* arguments may contain any of the following special characters, which are a superset of those supported by **[string match](string.htm)**:
**?**
Matches any single character.
**\***
Matches any sequence of zero or more characters.
**[***chars***]**
Matches any single character in *chars*. If *chars* contains a sequence of the form *a***-***b* then any character between *a* and *b* (inclusive) will match.
**\***x*
Matches the character *x*.
**{***a***,***b***,***...*}
Matches any of the sub-patterns *a*, *b*, etc.
On Unix, as with csh, a “.” at the beginning of a file's name or just after a “/” must be matched explicitly or with a {} construct, unless the **-types hidden** flag is given (since “.” at the beginning of a file's name indicates that it is hidden). On other platforms, files beginning with a “.” are handled no differently to any others, except the special directories “.” and “..” which must be matched explicitly (this is to avoid a recursive pattern like “glob -join \* \* \* \*” from recursing up the directory hierarchy as well as down). In addition, all “/” characters must be matched explicitly.
If the first character in a *pattern* is “~” then it refers to the home directory for the user whose name follows the “~”. If the “~” is followed immediately by “/” then the value of the HOME environment variable is used.
The **glob** command differs from csh globbing in two ways. First, it does not sort its result list (use the **[lsort](lsort.htm)** command if you want the list sorted). Second, **glob** only returns the names of files that actually exist; in csh no check for existence is made unless a pattern contains a ?, \*, or [] construct.
When the **glob** command returns relative paths whose filenames start with a tilde “~” (for example through **glob \*** or **glob -tails**, the returned list will not quote the tilde with “./”. This means care must be taken if those names are later to be used with **[file join](file.htm)**, to avoid them being interpreted as absolute paths pointing to a given user's home directory.
Windows portability issues
--------------------------
For Windows UNC names, the servername and sharename components of the path may not contain ?, \*, or [] constructs. On Windows NT, if *pattern* is of the form “**~***username***@***domain*”, it refers to the home directory of the user whose account information resides on the specified NT domain server. Otherwise, user account information is obtained from the local computer. Since the backslash character has a special meaning to the glob command, glob patterns containing Windows style path separators need special care. The pattern “*C:\\foo\\\**” is interpreted as “*C:\foo\\**” where “*\f*” will match the single character “*f*” and “*\\**” will match the single character “*\**” and will not be interpreted as a wildcard character. One solution to this problem is to use the Unix style forward slash as a path separator. Windows style paths can be converted to Unix style paths with the command “**[file join](file.htm)** **$path**” or “**[file normalize](file.htm)** **$path**”.
Examples
--------
Find all the Tcl files in the current directory:
```
**glob** *.tcl
```
Find all the Tcl files in the user's home directory, irrespective of what the current directory is:
```
**glob** -directory ~ *.tcl
```
Find all subdirectories of the current directory:
```
**glob** -type d *
```
Find all files whose name contains an “a”, a “b” or the sequence “cde”:
```
**glob** -type f *{a,b,cde}*
```
See also
--------
**[file](file.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/glob.htm>
tcl_tk fcopy fcopy
=====
Name
----
fcopy — Copy data from one channel to another Synopsis
--------
**fcopy** *inchan* *outchan* ?**-size** *size*? ?**-command** *callback*?
Description
-----------
The **fcopy** command copies data from one I/O channel, *inchan* to another I/O channel, *outchan*. The **fcopy** command leverages the buffering in the Tcl I/O system to avoid extra copies and to avoid buffering too much data in main memory when copying large files to slow destinations like network sockets. The **fcopy** command transfers data from *inchan* until end of file or *size* bytes or characters have been transferred; *size* is in bytes if the two channels are using the same encoding, and is in characters otherwise. If no **-size** argument is given, then the copy goes until end of file. All the data read from *inchan* is copied to *outchan*. Without the **-command** option, **fcopy** blocks until the copy is complete and returns the number of bytes or characters (using the same rules as for the **-size** option) written to *outchan*.
The **-command** argument makes **fcopy** work in the background. In this case it returns immediately and the *callback* is invoked later when the copy completes. The *callback* is called with one or two additional arguments that indicates how many bytes were written to *outchan*. If an error occurred during the background copy, the second argument is the error string associated with the error. With a background copy, it is not necessary to put *inchan* or *outchan* into non-blocking mode; the **fcopy** command takes care of that automatically. However, it is necessary to enter the event loop by using the **[vwait](vwait.htm)** command or by using Tk.
You are not allowed to do other input operations with *inchan*, or output operations with *outchan*, during a background **fcopy**. The converse is entirely legitimate, as exhibited by the bidirectional fcopy example below.
If either *inchan* or *outchan* get closed while the copy is in progress, the current copy is stopped and the command callback is *not* made. If *inchan* is closed, then all data already queued for *outchan* is written out.
Note that *inchan* can become readable during a background copy. You should turn off any **[fileevent](fileevent.htm)** handlers during a background copy so those handlers do not interfere with the copy. Any wrong-sided I/O attempted (by a **[fileevent](fileevent.htm)** handler or otherwise) will get a “channel busy” error.
**Fcopy** translates end-of-line sequences in *inchan* and *outchan* according to the **-translation** option for these channels. See the manual entry for **[fconfigure](fconfigure.htm)** for details on the **-translation** option. The translations mean that the number of bytes read from *inchan* can be different than the number of bytes written to *outchan*. Only the number of bytes written to *outchan* is reported, either as the return value of a synchronous **fcopy** or as the argument to the callback for an asynchronous **fcopy**.
**Fcopy** obeys the encodings and character translations configured for the channels. This means that the incoming characters are converted internally first UTF-8 and then into the encoding of the channel **fcopy** writes to. See the manual entry for **[fconfigure](fconfigure.htm)** for details on the **-encoding** and **-translation** options. No conversion is done if both channels are set to encoding “binary” and have matching translations. If only the output channel is set to encoding “binary” the system will write the internal UTF-8 representation of the incoming characters. If only the input channel is set to encoding “binary” the system will assume that the incoming bytes are valid UTF-8 characters and convert them according to the output encoding. The behaviour of the system for bytes which are not valid UTF-8 characters is undefined in this case.
Examples
--------
The first example transfers the contents of one channel exactly to another. Note that when copying one file to another, it is better to use **[file copy](file.htm)** which also copies file metadata (e.g. the file access permissions) where possible.
```
fconfigure $in -translation binary
fconfigure $out -translation binary
**fcopy** $in $out
```
This second example shows how the callback gets passed the number of bytes transferred. It also uses vwait to put the application into the event loop. Of course, this simplified example could be done without the command callback.
```
proc Cleanup {in out bytes {error {}}} {
global total
set total $bytes
close $in
close $out
if {[string length $error] != 0} {
# error occurred during the copy
}
}
set in [open $file1]
set out [socket $server $port]
**fcopy** $in $out -command [list Cleanup $in $out]
vwait total
```
The third example copies in chunks and tests for end of file in the command callback.
```
proc CopyMore {in out chunk bytes {error {}}} {
global total done
incr total $bytes
if {([string length $error] != 0) || [eof $in]} {
set done $total
close $in
close $out
} else {
**fcopy** $in $out -size $chunk \
-command [list CopyMore $in $out $chunk]
}
}
set in [open $file1]
set out [socket $server $port]
set chunk 1024
set total 0
**fcopy** $in $out -size $chunk \
-command [list CopyMore $in $out $chunk]
vwait done
```
The fourth example starts an asynchronous, bidirectional fcopy between two sockets. Those could also be pipes from two [open "|hal 9000" r+] (though their conversation would remain secret to the script, since all four fileevent slots are busy).
```
set flows 2
proc Done {dir args} {
global flows done
puts "$dir is over."
incr flows -1
if {$flows<=0} {set done 1}
}
**fcopy** $sok1 $sok2 -command [list Done UP]
**fcopy** $sok2 $sok1 -command [list Done DOWN]
vwait done
```
See also
--------
**[eof](eof.htm)**, **[fblocked](fblocked.htm)**, **[fconfigure](fconfigure.htm)**, **[file](file.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/fcopy.htm>
tcl_tk incr incr
====
Name
----
incr — Increment the value of a variable Synopsis
--------
**incr** *varName* ?*increment*?
Description
-----------
Increments the value stored in the variable whose name is *varName*. The value of the variable must be an integer. If *increment* is supplied then its value (which must be an integer) is added to the value of variable *varName*; otherwise 1 is added to *varName*. The new value is stored as a decimal string in variable *varName* and also returned as result. Starting with the Tcl 8.5 release, the variable *varName* passed to **incr** may be unset, and in that case, it will be set to the value *increment* or to the default increment value of **1**.
Examples
--------
Add one to the contents of the variable *x*:
```
**incr** x
```
Add 42 to the contents of the variable *x*:
```
**incr** x 42
```
Add the contents of the variable *y* to the contents of the variable *x*:
```
**incr** x $y
```
Add nothing at all to the variable *x* (often useful for checking whether an argument to a procedure is actually integral and generating an error if it is not):
```
**incr** x 0
```
See also
--------
**[expr](expr.htm)**, **[set](set.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/incr.htm>
tcl_tk platform platform
========
Name
----
platform — System identification support code and utilities Synopsis
--------
**package require platform ?1.0.10?**
**platform::generic**
**platform::identify**
**platform::patterns** *identifier*
Description
-----------
The **platform** package provides several utility commands useful for the identification of the architecture of a machine running Tcl. Whilst Tcl provides the **[tcl\_platform](tclvars.htm)** array for identifying the current architecture (in particular, the platform and machine elements) this is not always sufficient. This is because (on Unix machines) **[tcl\_platform](tclvars.htm)** reflects the values returned by the **uname** command and these are not standardized across platforms and architectures. In addition, on at least one platform (AIX) the **tcl\_platform(machine)** contains the CPU serial number.
Consequently, individual applications need to manipulate the values in **[tcl\_platform](tclvars.htm)** (along with the output of system specific utilities) - which is both inconvenient for developers, and introduces the potential for inconsistencies in identifying architectures and in naming conventions.
The **platform** package prevents such fragmentation - i.e., it establishes a standard naming convention for architectures running Tcl and makes it more convenient for developers to identify the current architecture a Tcl program is running on.
Commands
--------
**platform::identify**
This command returns an identifier describing the platform the Tcl core is running on. The returned identifier has the general format *OS*-*CPU*. The *OS* part of the identifier may contain details like kernel version, libc version, etc., and this information may contain dashes as well. The *CPU* part will not contain dashes, making the preceding dash the last dash in the result.
**platform::generic**
This command returns a simplified identifier describing the platform the Tcl core is running on. In contrast to **platform::identify** it leaves out details like kernel version, libc version, etc. The returned identifier has the general format *OS*-*CPU*.
**platform::patterns** *identifier*
This command takes an identifier as returned by **platform::identify** and returns a list of identifiers describing compatible architectures.
Example
-------
This can be used to allow an application to be shipped with multiple builds of a shared library, so that the same package works on many versions of an operating system. For example:
```
**package require platform**
# Assume that app script is .../theapp/bin/theapp.tcl
set binDir [file dirname [file normalize [info script]]]
set libDir [file join $binDir .. lib]
set platLibDir [file join $libDir [**platform::identify**]]
load [file join $platLibDir support[info sharedlibextension]]
```
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/platform.htm>
| programming_docs |
tcl_tk lrange lrange
======
Name
----
lrange — Return one or more adjacent elements from a list Synopsis
--------
**lrange** *list first last*
Description
-----------
*List* must be a valid Tcl list. This command will return a new list consisting of elements *first* through *last*, inclusive. The index values *first* and *last* are interpreted the same as index values for the command **[string index](string.htm)**, supporting simple index arithmetic and indices relative to the end of the list. If *first* is less than zero, it is treated as if it were zero. If *last* is greater than or equal to the number of elements in the list, then it is treated as if it were **end**. If *first* is greater than *last* then an empty string is returned. Note: “**lrange** *list first first*” does not always produce the same result as “**lindex** *list first*” (although it often does for simple fields that are not enclosed in braces); it does, however, produce exactly the same results as “**list [lindex** *list first***]**” Examples
--------
Selecting the first two elements:
```
% **lrange** {a b c d e} 0 1
a b
```
Selecting the last three elements:
```
% **lrange** {a b c d e} end-2 end
c d e
```
Selecting everything except the first and last element:
```
% **lrange** {a b c d e} 1 end-1
b c d
```
Selecting a single element with **lrange** is not the same as doing so with **[lindex](lindex.htm)**:
```
% set var {some {elements to} select}
some {elements to} select
% lindex $var 1
elements to
% **lrange** $var 1 1
{elements to}
```
See also
--------
**[list](list.htm)**, **[lappend](lappend.htm)**, **[lindex](lindex.htm)**, **[linsert](linsert.htm)**, **[llength](llength.htm)**, **[lsearch](lsearch.htm)**, **[lset](lset.htm)**, **[lreplace](lreplace.htm)**, **[lsort](lsort.htm)**, **[string](string.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/lrange.htm>
tcl_tk exit exit
====
Name
----
exit — End the application Synopsis
--------
**exit** ?*returnCode*?
Description
-----------
Terminate the process, returning *returnCode* to the system as the exit status. If *returnCode* is not specified then it defaults to 0. Example
-------
Since non-zero exit codes are usually interpreted as error cases by the calling process, the **exit** command is an important part of signaling that something fatal has gone wrong. This code fragment is useful in scripts to act as a general problem trap:
```
proc main {} {
# ... put the real main code in here ...
}
if {[catch {main} msg options]} {
puts stderr "unexpected script error: $msg"
if {[info exists env(DEBUG)]} {
puts stderr "---- BEGIN TRACE ----"
puts stderr [dict get $options -errorinfo]
puts stderr "---- END TRACE ----"
}
# Reserve code 1 for "expected" error exits...
**exit** 2
}
```
See also
--------
**[exec](exec.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/exit.htm>
tcl_tk http http
====
[NAME](http.htm#M2) http — Client-side implementation of the HTTP/1.1 protocol
[SYNOPSIS](http.htm#M3)
[DESCRIPTION](http.htm#M4)
[COMMANDS](http.htm#M5)
[**::http::config** ?*options*?](http.htm#M6)
[**-accept** *mimetypes*](http.htm#M7)
[**-proxyhost** *hostname*](http.htm#M8)
[**-proxyport** *number*](http.htm#M9)
[**-proxyfilter** *command*](http.htm#M10)
[**-urlencoding** *encoding*](http.htm#M11)
[**-useragent** *string*](http.htm#M12)
[**::http::geturl** *url* ?*options*?](http.htm#M13)
[**-binary** *boolean*](http.htm#M14)
[**-blocksize** *size*](http.htm#M15)
[**-channel** *name*](http.htm#M16)
[**-command** *callback*](http.htm#M17)
[**-handler** *callback*](http.htm#M18)
[**-headers** *keyvaluelist*](http.htm#M19)
[**-keepalive** *boolean*](http.htm#M20)
[**-method** *type*](http.htm#M21)
[**-myaddr** *address*](http.htm#M22)
[**-progress** *callback*](http.htm#M23)
[**-protocol** *version*](http.htm#M24)
[**-query** *query*](http.htm#M25)
[**-queryblocksize** *size*](http.htm#M26)
[**-querychannel** *channelID*](http.htm#M27)
[**-queryprogress** *callback*](http.htm#M28)
[**-strict** *boolean*](http.htm#M29)
[**-timeout** *milliseconds*](http.htm#M30)
[**-type** *mime-type*](http.htm#M31)
[**-validate** *boolean*](http.htm#M32)
[**::http::formatQuery** *key value* ?*key value* ...?](http.htm#M33)
[**::http::reset** *token* ?*why*?](http.htm#M34)
[**::http::wait** *token*](http.htm#M35)
[**::http::data** *token*](http.htm#M36)
[**::http::error** *token*](http.htm#M37)
[**::http::status** *token*](http.htm#M38)
[**::http::code** *token*](http.htm#M39)
[**::http::ncode** *token*](http.htm#M40)
[**::http::size** *token*](http.htm#M41)
[**::http::meta** *token*](http.htm#M42)
[**::http::cleanup** *token*](http.htm#M43)
[**::http::register** *proto port command*](http.htm#M44)
[**::http::unregister** *proto*](http.htm#M45)
[ERRORS](http.htm#M46)
[**ok**](http.htm#M47)
[**eof**](http.htm#M48)
[**error**](http.htm#M49)
[STATE ARRAY](http.htm#M50)
[**body**](http.htm#M51)
[**charset**](http.htm#M52)
[**coding**](http.htm#M53)
[**currentsize**](http.htm#M54)
[**error**](http.htm#M55)
[**http**](http.htm#M56)
[**meta**](http.htm#M57)
[**Content-Type**](http.htm#M58)
[**Content-Length**](http.htm#M59)
[**Location**](http.htm#M60)
[**posterror**](http.htm#M61)
[**status**](http.htm#M62)
[**totalsize**](http.htm#M63)
[**type**](http.htm#M64)
[**url**](http.htm#M65)
[EXAMPLE](http.htm#M66)
[SEE ALSO](http.htm#M67)
[KEYWORDS](http.htm#M68)
Name
----
http — Client-side implementation of the HTTP/1.1 protocol Synopsis
--------
**package require http ?2.7?**
**::http::config ?***-option value* ...?
**::http::geturl** *url* ?*-option value* ...?
**::http::formatQuery** *key value* ?*key value* ...?
**::http::reset** *token* ?*why*?
**::http::wait** *token*
**::http::status** *token*
**::http::size** *token*
**::http::code** *token*
**::http::ncode** *token*
**::http::meta** *token*
**::http::data** *token*
**::http::error** *token*
**::http::cleanup** *token*
**::http::register** *proto port command*
**::http::unregister** *proto*
Description
-----------
The **http** package provides the client side of the HTTP/1.1 protocol, as defined in RFC 2616. The package implements the GET, POST, and HEAD operations of HTTP/1.1. It allows configuration of a proxy host to get through firewalls. The package is compatible with the **Safesock** security policy, so it can be used by untrusted applets to do URL fetching from a restricted set of hosts. This package can be extended to support additional HTTP transport protocols, such as HTTPS, by providing a custom **[socket](socket.htm)** command, via **::http::register**. The **::http::geturl** procedure does a HTTP transaction. Its *options* determine whether a GET, POST, or HEAD transaction is performed. The return value of **::http::geturl** is a token for the transaction. The value is also the name of an array in the ::http namespace that contains state information about the transaction. The elements of this array are described in the **[STATE ARRAY](#M50)** section.
If the **-command** option is specified, then the HTTP operation is done in the background. **::http::geturl** returns immediately after generating the HTTP request and the callback is invoked when the transaction completes. For this to work, the Tcl event loop must be active. In Tk applications this is always true. For pure-Tcl applications, the caller can use **::http::wait** after calling **::http::geturl** to start the event loop.
Commands
--------
**::http::config** ?*options*?
The **::http::config** command is used to set and query the name of the proxy server and port, and the User-Agent name used in the HTTP requests. If no options are specified, then the current configuration is returned. If a single argument is specified, then it should be one of the flags described below. In this case the current value of that setting is returned. Otherwise, the options should be a set of flags and values that define the configuration:
**-accept** *mimetypes*
The Accept header of the request. The default is \*/\*, which means that all types of documents are accepted. Otherwise you can supply a comma-separated list of mime type patterns that you are willing to receive. For example, “image/gif, image/jpeg, text/\*”.
**-proxyhost** *hostname*
The name of the proxy host, if any. If this value is the empty string, the URL host is contacted directly.
**-proxyport** *number*
The proxy port number.
**-proxyfilter** *command*
The command is a callback that is made during **::http::geturl** to determine if a proxy is required for a given host. One argument, a host name, is added to *command* when it is invoked. If a proxy is required, the callback should return a two-element list containing the proxy server and proxy port. Otherwise the filter should return an empty list. The default filter returns the values of the **-proxyhost** and **-proxyport** settings if they are non-empty.
**-urlencoding** *encoding*
The *encoding* used for creating the x-url-encoded URLs with **::http::formatQuery**. The default is **utf-8**, as specified by RFC 2718. Prior to http 2.5 this was unspecified, and that behavior can be returned by specifying the empty string (**{}**), although *iso8859-1* is recommended to restore similar behavior but without the **::http::formatQuery** throwing an error processing non-latin-1 characters.
**-useragent** *string*
The value of the User-Agent header in the HTTP request. The default is “**Tcl http client package 2.7**”.
**::http::geturl** *url* ?*options*?
The **::http::geturl** command is the main procedure in the package. The **-query** option causes a POST operation and the **-validate** option causes a HEAD operation; otherwise, a GET operation is performed. The **::http::geturl** command returns a *token* value that can be used to get information about the transaction. See the **[STATE ARRAY](#M50)** and **[ERRORS](#M46)** section for details. The **::http::geturl** command blocks until the operation completes, unless the **-command** option specifies a callback that is invoked when the HTTP transaction completes. **::http::geturl** takes several options:
**-binary** *boolean*
Specifies whether to force interpreting the URL data as binary. Normally this is auto-detected (anything not beginning with a **[text](../tkcmd/text.htm)** content type or whose content encoding is **gzip** or **compress** is considered binary data).
**-blocksize** *size*
The block size used when reading the URL. At most *size* bytes are read at once. After each block, a call to the **-progress** callback is made (if that option is specified).
**-channel** *name*
Copy the URL contents to channel *name* instead of saving it in **state(body)**.
**-command** *callback*
Invoke *callback* after the HTTP transaction completes. This option causes **::http::geturl** to return immediately. The *callback* gets an additional argument that is the *token* returned from **::http::geturl**. This token is the name of an array that is described in the **[STATE ARRAY](#M50)** section. Here is a template for the callback:
```
proc httpCallback {token} {
upvar #0 $token state
# Access state as a Tcl array
}
```
**-handler** *callback*
Invoke *callback* whenever HTTP data is available; if present, nothing else will be done with the HTTP data. This procedure gets two additional arguments: the socket for the HTTP data and the *token* returned from **::http::geturl**. The token is the name of a global array that is described in the **[STATE ARRAY](#M50)** section. The procedure is expected to return the number of bytes read from the socket. Here is a template for the callback:
```
proc httpHandlerCallback {socket token} {
upvar #0 $token state
# Access socket, and state as a Tcl array
# For example...
...
set data [read $socket 1000]
set nbytes [string length $data]
...
return $nbytes
}
```
**-headers** *keyvaluelist*
This option is used to add headers not already specified by **::http::config** to the HTTP request. The *keyvaluelist* argument must be a list with an even number of elements that alternate between keys and values. The keys become header field names. Newlines are stripped from the values so the header cannot be corrupted. For example, if *keyvaluelist* is **Pragma no-cache** then the following header is included in the HTTP request:
```
Pragma: no-cache
```
**-keepalive** *boolean*
If true, attempt to keep the connection open for servicing multiple requests. Default is 0.
**-method** *type*
Force the HTTP request method to *type*. **::http::geturl** will auto-select GET, POST or HEAD based on other options, but this option enables choices like PUT and DELETE for webdav support.
**-myaddr** *address*
Pass an specific local address to the underlying **[socket](socket.htm)** call in case multiple interfaces are available.
**-progress** *callback*
The *callback* is made after each transfer of data from the URL. The callback gets three additional arguments: the *token* from **::http::geturl**, the expected total size of the contents from the **Content-Length** meta-data, and the current number of bytes transferred so far. The expected total size may be unknown, in which case zero is passed to the callback. Here is a template for the progress callback:
```
proc httpProgress {token total current} {
upvar #0 $token state
}
```
**-protocol** *version*
Select the HTTP protocol version to use. This should be 1.0 or 1.1 (the default). Should only be necessary for servers that do not understand or otherwise complain about HTTP/1.1.
**-query** *query*
This flag causes **::http::geturl** to do a POST request that passes the *query* to the server. The *query* must be an x-url-encoding formatted query. The **::http::formatQuery** procedure can be used to do the formatting.
**-queryblocksize** *size*
The block size used when posting query data to the URL. At most *size* bytes are written at once. After each block, a call to the **-queryprogress** callback is made (if that option is specified).
**-querychannel** *channelID*
This flag causes **::http::geturl** to do a POST request that passes the data contained in *channelID* to the server. The data contained in *channelID* must be an x-url-encoding formatted query unless the **-type** option below is used. If a Content-Length header is not specified via the **-headers** options, **::http::geturl** attempts to determine the size of the post data in order to create that header. If it is unable to determine the size, it returns an error.
**-queryprogress** *callback*
The *callback* is made after each transfer of data to the URL (i.e. POST) and acts exactly like the **-progress** option (the callback format is the same).
**-strict** *boolean*
Whether to enforce RFC 3986 URL validation on the request. Default is 1.
**-timeout** *milliseconds*
If *milliseconds* is non-zero, then **::http::geturl** sets up a timeout to occur after the specified number of milliseconds. A timeout results in a call to **::http::reset** and to the **-command** callback, if specified. The return value of **::http::status** is **timeout** after a timeout has occurred.
**-type** *mime-type*
Use *mime-type* as the **Content-Type** value, instead of the default value (**application/x-www-form-urlencoded**) during a POST operation.
**-validate** *boolean*
If *boolean* is non-zero, then **::http::geturl** does an HTTP HEAD request. This request returns meta information about the URL, but the contents are not returned. The meta information is available in the **state(meta)** variable after the transaction. See the **[STATE ARRAY](#M50)** section for details.
**::http::formatQuery** *key value* ?*key value* ...?
This procedure does x-url-encoding of query data. It takes an even number of arguments that are the keys and values of the query. It encodes the keys and values, and generates one string that has the proper & and = separators. The result is suitable for the **-query** value passed to **::http::geturl**.
**::http::reset** *token* ?*why*?
This command resets the HTTP transaction identified by *token*, if any. This sets the **state(status)** value to *why*, which defaults to **reset**, and then calls the registered **-command** callback.
**::http::wait** *token*
This is a convenience procedure that blocks and waits for the transaction to complete. This only works in trusted code because it uses **[vwait](vwait.htm)**. Also, it is not useful for the case where **::http::geturl** is called *without* the **-command** option because in this case the **::http::geturl** call does not return until the HTTP transaction is complete, and thus there is nothing to wait for.
**::http::data** *token*
This is a convenience procedure that returns the **body** element (i.e., the URL data) of the state array.
**::http::error** *token*
This is a convenience procedure that returns the **[error](error.htm)** element of the state array.
**::http::status** *token*
This is a convenience procedure that returns the **status** element of the state array.
**::http::code** *token*
This is a convenience procedure that returns the **http** element of the state array.
**::http::ncode** *token*
This is a convenience procedure that returns just the numeric return code (200, 404, etc.) from the **http** element of the state array.
**::http::size** *token*
This is a convenience procedure that returns the **currentsize** element of the state array, which represents the number of bytes received from the URL in the **::http::geturl** call.
**::http::meta** *token*
This is a convenience procedure that returns the **meta** element of the state array which contains the HTTP response headers. See below for an explanation of this element.
**::http::cleanup** *token*
This procedure cleans up the state associated with the connection identified by *token*. After this call, the procedures like **::http::data** cannot be used to get information about the operation. It is *strongly* recommended that you call this function after you are done with a given HTTP request. Not doing so will result in memory not being freed, and if your app calls **::http::geturl** enough times, the memory leak could cause a performance hit...or worse.
**::http::register** *proto port command*
This procedure allows one to provide custom HTTP transport types such as HTTPS, by registering a prefix, the default port, and the command to execute to create the Tcl **channel**. E.g.:
```
package require http
package require tls
::http::register https 443 ::tls::socket
set token [::http::geturl https://my.secure.site/]
```
**::http::unregister** *proto*
This procedure unregisters a protocol handler that was previously registered via **::http::register**.
Errors
------
The **::http::geturl** procedure will raise errors in the following cases: invalid command line options, an invalid URL, a URL on a non-existent host, or a URL at a bad port on an existing host. These errors mean that it cannot even start the network transaction. It will also raise an error if it gets an I/O error while writing out the HTTP request header. For synchronous **::http::geturl** calls (where **-command** is not specified), it will raise an error if it gets an I/O error while reading the HTTP reply headers or data. Because **::http::geturl** does not return a token in these cases, it does all the required cleanup and there is no issue of your app having to call **::http::cleanup**. For asynchronous **::http::geturl** calls, all of the above error situations apply, except that if there is any error while reading the HTTP reply headers or data, no exception is thrown. This is because after writing the HTTP headers, **::http::geturl** returns, and the rest of the HTTP transaction occurs in the background. The command callback can check if any error occurred during the read by calling **::http::status** to check the status and if its *error*, calling **::http::error** to get the error message.
Alternatively, if the main program flow reaches a point where it needs to know the result of the asynchronous HTTP request, it can call **::http::wait** and then check status and error, just as the callback does.
In any case, you must still call **::http::cleanup** to delete the state array when you are done.
There are other possible results of the HTTP transaction determined by examining the status from **::http::status**. These are described below.
**ok**
If the HTTP transaction completes entirely, then status will be **ok**. However, you should still check the **::http::code** value to get the HTTP status. The **::http::ncode** procedure provides just the numeric error (e.g., 200, 404 or 500) while the **::http::code** procedure returns a value like “HTTP 404 File not found”.
**eof**
If the server closes the socket without replying, then no error is raised, but the status of the transaction will be **[eof](eof.htm)**.
**error**
The error message will also be stored in the **[error](error.htm)** status array element, accessible via **::http::error**.
Another error possibility is that **::http::geturl** is unable to write all the post query data to the server before the server responds and closes the socket. The error message is saved in the **posterror** status array element and then **::http::geturl** attempts to complete the transaction. If it can read the server's response it will end up with an **ok** status, otherwise it will have an **[eof](eof.htm)** status.
State array
-----------
The **::http::geturl** procedure returns a *token* that can be used to get to the state of the HTTP transaction in the form of a Tcl array. Use this construct to create an easy-to-use array variable:
```
upvar #0 $token state
```
Once the data associated with the URL is no longer needed, the state array should be unset to free up storage. The **::http::cleanup** procedure is provided for that purpose. The following elements of the array are supported:
**body**
The contents of the URL. This will be empty if the **-channel** option has been specified. This value is returned by the **::http::data** command.
**charset**
The value of the charset attribute from the **Content-Type** meta-data value. If none was specified, this defaults to the RFC standard **iso8859-1**, or the value of **$::http::defaultCharset**. Incoming text data will be automatically converted from this charset to utf-8.
**coding**
A copy of the **Content-Encoding** meta-data value.
**currentsize**
The current number of bytes fetched from the URL. This value is returned by the **::http::size** command.
**error**
If defined, this is the error string seen when the HTTP transaction was aborted.
**http**
The HTTP status reply from the server. This value is returned by the **::http::code** command. The format of this value is:
```
*HTTP/1.1 code string*
```
The *code* is a three-digit number defined in the HTTP standard. A code of 200 is OK. Codes beginning with 4 or 5 indicate errors. Codes beginning with 3 are redirection errors. In this case the **Location** meta-data specifies a new URL that contains the requested information.
**meta**
The HTTP protocol returns meta-data that describes the URL contents. The **meta** element of the state array is a list of the keys and values of the meta-data. This is in a format useful for initializing an array that just contains the meta-data:
```
array set meta $state(meta)
```
Some of the meta-data keys are listed below, but the HTTP standard defines more, and servers are free to add their own.
**Content-Type**
The type of the URL contents. Examples include **text/html**, **image/gif,** **application/postscript** and **application/x-tcl**.
**Content-Length**
The advertised size of the contents. The actual size obtained by **::http::geturl** is available as **state(currentsize)**.
**Location**
An alternate URL that contains the requested data.
**posterror**
The error, if any, that occurred while writing the post query data to the server.
**status**
Either **ok**, for successful completion, **reset** for user-reset, **timeout** if a timeout occurred before the transaction could complete, or **[error](error.htm)** for an error condition. During the transaction this value is the empty string.
**totalsize**
A copy of the **Content-Length** meta-data value.
**type**
A copy of the **Content-Type** meta-data value.
**url**
The requested URL.
Example
-------
This example creates a procedure to copy a URL to a file while printing a progress meter, and prints the meta-data associated with the URL.
```
proc httpcopy { url file {chunk 4096} } {
set out [open $file w]
set token [**::http::geturl** $url -channel $out \
-progress httpCopyProgress -blocksize $chunk]
close $out
# This ends the line started by httpCopyProgress
puts stderr ""
upvar #0 $token state
set max 0
foreach {name value} $state(meta) {
if {[string length $name] > $max} {
set max [string length $name]
}
if {[regexp -nocase ^location$ $name]} {
# Handle URL redirects
puts stderr "Location:$value"
return [httpcopy [string trim $value] $file $chunk]
}
}
incr max
foreach {name value} $state(meta) {
puts [format "%-*s %s" $max $name: $value]
}
return $token
}
proc httpCopyProgress {args} {
puts -nonewline stderr .
flush stderr
}
```
See also
--------
**[safe](safe.htm)**, **[socket](socket.htm)**, **safesock**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/http.htm>
| programming_docs |
tcl_tk after after
=====
[NAME](after.htm#M2) after — Execute a command after a time delay
[SYNOPSIS](after.htm#M3)
[DESCRIPTION](after.htm#M4)
[**after** *ms*](after.htm#M5)
[**after** *ms* ?*script script script ...*?](after.htm#M6)
[**after cancel** *id*](after.htm#M7)
[**after cancel** *script script ...*](after.htm#M8)
[**after idle** *script* ?*script script ...*?](after.htm#M9)
[**after info** ?*id*?](after.htm#M10)
[EXAMPLES](after.htm#M11)
[SEE ALSO](after.htm#M12)
[KEYWORDS](after.htm#M13)
Name
----
after — Execute a command after a time delay Synopsis
--------
**after** *ms*
**after** *ms* ?*script script script ...*?
**after cancel** *id*
**after cancel** *script script script ...*
**after idle** ?*script script script ...*?
**after info** ?*id*?
Description
-----------
This command is used to delay execution of the program or to execute a command in background sometime in the future. It has several forms, depending on the first argument to the command:
**after** *ms*
*Ms* must be an integer giving a time in milliseconds. The command sleeps for *ms* milliseconds and then returns. While the command is sleeping the application does not respond to events.
**after** *ms* ?*script script script ...*?
In this form the command returns immediately, but it arranges for a Tcl command to be executed *ms* milliseconds later as an event handler. The command will be executed exactly once, at the given time. The delayed command is formed by concatenating all the *script* arguments in the same fashion as the **[concat](concat.htm)** command. The command will be executed at global level (outside the context of any Tcl procedure). If an error occurs while executing the delayed command then the background error will be reported by the command registered with **[interp bgerror](interp.htm)**. The **after** command returns an identifier that can be used to cancel the delayed command using **after cancel**.
**after cancel** *id*
Cancels the execution of a delayed command that was previously scheduled. *Id* indicates which command should be canceled; it must have been the return value from a previous **after** command. If the command given by *id* has already been executed then the **after cancel** command has no effect.
**after cancel** *script script ...*
This command also cancels the execution of a delayed command. The *script* arguments are concatenated together with space separators (just as in the **[concat](concat.htm)** command). If there is a pending command that matches the string, it is canceled and will never be executed; if no such command is currently pending then the **after cancel** command has no effect.
**after idle** *script* ?*script script ...*?
Concatenates the *script* arguments together with space separators (just as in the **[concat](concat.htm)** command), and arranges for the resulting script to be evaluated later as an idle callback. The script will be run exactly once, the next time the event loop is entered and there are no events to process. The command returns an identifier that can be used to cancel the delayed command using **after cancel**. If an error occurs while executing the script then the background error will be reported by the command registered with **[interp bgerror](interp.htm)**.
**after info** ?*id*?
This command returns information about existing event handlers. If no *id* argument is supplied, the command returns a list of the identifiers for all existing event handlers created by the **after** command for this interpreter. If *id* is supplied, it specifies an existing handler; *id* must have been the return value from some previous call to **after** and it must not have triggered yet or been canceled. In this case the command returns a list with two elements. The first element of the list is the script associated with *id*, and the second element is either **idle** or **timer** to indicate what kind of event handler it is.
The **after** *ms* and **after idle** forms of the command assume that the application is event driven: the delayed commands will not be executed unless the application enters the event loop. In applications that are not normally event-driven, such as **[tclsh](../usercmd/tclsh.htm)**, the event loop can be entered with the **[vwait](vwait.htm)** and **[update](update.htm)** commands.
Examples
--------
This defines a command to make Tcl do nothing at all for *N* seconds:
```
proc sleep {N} {
**after** [expr {int($N * 1000)}]
}
```
This arranges for the command *wake\_up* to be run in eight hours (providing the event loop is active at that time):
```
**after** [expr {1000 * 60 * 60 * 8}] wake_up
```
The following command can be used to do long-running calculations (as represented here by *::my\_calc::one\_step*, which is assumed to return a boolean indicating whether another step should be performed) in a step-by-step fashion, though the calculation itself needs to be arranged so it can work step-wise. This technique is extra careful to ensure that the event loop is not starved by the rescheduling of processing steps (arranging for the next step to be done using an already-triggered timer event only when the event queue has been drained) and is useful when you want to ensure that a Tk GUI remains responsive during a slow task.
```
proc doOneStep {} {
if {[::my_calc::one_step]} {
**after idle** [list **after** 0 doOneStep]
}
}
doOneStep
```
See also
--------
**[concat](concat.htm)**, **[interp](interp.htm)**, **[update](update.htm)**, **[vwait](vwait.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/after.htm>
tcl_tk string string
======
[NAME](string.htm#M2) string — Manipulate strings
[SYNOPSIS](string.htm#M3)
[DESCRIPTION](string.htm#M4)
[**string cat** ?*string1*? ?*string2...*?](string.htm#M5)
[**string compare** ?**-nocase**? ?**-length** *length*? *string1 string2*](string.htm#M6)
[**string equal** ?**-nocase**? ?**-length** *length*? *string1 string2*](string.htm#M7)
[**string first** *needleString haystackString* ?*startIndex*?](string.htm#M8)
[**string index** *string charIndex*](string.htm#M9)
[**string is** *class* ?**-strict**? ?**-failindex** *varname*? *string*](string.htm#M10)
[**alnum**](string.htm#M11)
[**alpha**](string.htm#M12)
[**ascii**](string.htm#M13)
[**boolean**](string.htm#M14)
[**control**](string.htm#M15)
[**digit**](string.htm#M16)
[**double**](string.htm#M17)
[**entier**](string.htm#M18)
[**false**](string.htm#M19)
[**graph**](string.htm#M20)
[**integer**](string.htm#M21)
[**list**](string.htm#M22)
[**lower**](string.htm#M23)
[**print**](string.htm#M24)
[**punct**](string.htm#M25)
[**space**](string.htm#M26)
[**true**](string.htm#M27)
[**upper**](string.htm#M28)
[**wideinteger**](string.htm#M29)
[**wordchar**](string.htm#M30)
[**xdigit**](string.htm#M31)
[**string last** *needleString haystackString* ?*lastIndex*?](string.htm#M32)
[**string length** *string*](string.htm#M33)
[**string map** ?**-nocase**? *mapping string*](string.htm#M34)
[**string match** ?**-nocase**? *pattern* *string*](string.htm#M35)
[**\***](string.htm#M36)
[**?**](string.htm#M37)
[**[***chars***]**](string.htm#M38)
[**\***x*](string.htm#M39)
[**string range** *string first last*](string.htm#M40)
[**string repeat** *string count*](string.htm#M41)
[**string replace** *string first last* ?*newstring*?](string.htm#M42)
[**string reverse** *string*](string.htm#M43)
[**string tolower** *string* ?*first*? ?*last*?](string.htm#M44)
[**string totitle** *string* ?*first*? ?*last*?](string.htm#M45)
[**string toupper** *string* ?*first*? ?*last*?](string.htm#M46)
[**string trim** *string* ?*chars*?](string.htm#M47)
[**string trimleft** *string* ?*chars*?](string.htm#M48)
[**string trimright** *string* ?*chars*?](string.htm#M49)
[OBSOLETE SUBCOMMANDS](string.htm#M50)
[**string bytelength** *string*](string.htm#M51)
[**string wordend** *string charIndex*](string.htm#M52)
[**string wordstart** *string charIndex*](string.htm#M53)
[STRING INDICES](string.htm#M54)
[*integer*](string.htm#M55)
[**end**](string.htm#M56)
[**end-***N*](string.htm#M57)
[**end+***N*](string.htm#M58)
[*M***+***N*](string.htm#M59)
[*M***-***N*](string.htm#M60)
[EXAMPLE](string.htm#M61)
[SEE ALSO](string.htm#M62)
[KEYWORDS](string.htm#M63)
Name
----
string — Manipulate strings Synopsis
--------
**string** *option arg* ?*arg ...?*
Description
-----------
Performs one of several string operations, depending on *option*. The legal *option*s (which may be abbreviated) are:
**string cat** ?*string1*? ?*string2...*?
Concatenate the given *string*s just like placing them directly next to each other and return the resulting compound string. If no *string*s are present, the result is an empty string. This primitive is occasionally handier than juxtaposition of strings when mixed quoting is wanted, or when the aim is to return the result of a concatenation without resorting to **[return](return.htm)** **-level 0**, and is more efficient than building a list of arguments and using **[join](join.htm)** with an empty join string.
**string compare** ?**-nocase**? ?**-length** *length*? *string1 string2*
Perform a character-by-character comparison of strings *string1* and *string2*. Returns -1, 0, or 1, depending on whether *string1* is lexicographically less than, equal to, or greater than *string2*. If **-length** is specified, then only the first *length* characters are used in the comparison. If **-length** is negative, it is ignored. If **-nocase** is specified, then the strings are compared in a case-insensitive manner.
**string equal** ?**-nocase**? ?**-length** *length*? *string1 string2*
Perform a character-by-character comparison of strings *string1* and *string2*. Returns 1 if *string1* and *string2* are identical, or 0 when not. If **-length** is specified, then only the first *length* characters are used in the comparison. If **-length** is negative, it is ignored. If **-nocase** is specified, then the strings are compared in a case-insensitive manner.
**string first** *needleString haystackString* ?*startIndex*?
Search *haystackString* for a sequence of characters that exactly match the characters in *needleString*. If found, return the index of the first character in the first such match within *haystackString*. If not found, return -1. If *startIndex* is specified (in any of the forms described in **[STRING INDICES](#M54)**), then the search is constrained to start with the character in *haystackString* specified by the index. For example,
```
**string first a 0a23456789abcdef 5**
```
will return **10**, but
```
**string first a 0123456789abcdef 11**
```
will return **-1**.
**string index** *string charIndex*
Returns the *charIndex*'th character of the *string* argument. A *charIndex* of 0 corresponds to the first character of the string. *charIndex* may be specified as described in the **[STRING INDICES](#M54)** section. If *charIndex* is less than 0 or greater than or equal to the length of the string then this command returns an empty string.
**string is** *class* ?**-strict**? ?**-failindex** *varname*? *string*
Returns 1 if *string* is a valid member of the specified character class, otherwise returns 0. If **-strict** is specified, then an empty string returns 0, otherwise an empty string will return 1 on any class. If **-failindex** is specified, then if the function returns 0, the index in the string where the class was no longer valid will be stored in the variable named *varname*. The *varname* will not be set if **string is** returns 1. The following character classes are recognized (the class name can be abbreviated):
**alnum**
Any Unicode alphabet or digit character.
**alpha**
Any Unicode alphabet character.
**ascii**
Any character with a value less than \u0080 (those that are in the 7-bit ascii range).
**boolean**
Any of the forms allowed to **[Tcl\_GetBoolean](https://www.tcl.tk/man/tcl/TclLib/GetInt.htm)**.
**control**
Any Unicode control character.
**digit**
Any Unicode digit character. Note that this includes characters outside of the [0-9] range.
**double**
Any of the valid forms for a double in Tcl, with optional surrounding whitespace. In case of under/overflow in the value, 0 is returned and the *varname* will contain -1.
**entier**
Any of the valid string formats for an integer value of arbitrary size in Tcl, with optional surrounding whitespace. The formats accepted are exactly those accepted by the C routine **[Tcl\_GetBignumFromObj](https://www.tcl.tk/man/tcl/TclLib/IntObj.htm)**.
**false**
Any of the forms allowed to **[Tcl\_GetBoolean](https://www.tcl.tk/man/tcl/TclLib/GetInt.htm)** where the value is false.
**graph**
Any Unicode printing character, except space.
**integer**
Any of the valid string formats for a 32-bit integer value in Tcl, with optional surrounding whitespace. In case of under/overflow in the value, 0 is returned and the *varname* will contain -1.
**list**
Any proper list structure, with optional surrounding whitespace. In case of improper list structure, 0 is returned and the *varname* will contain the index of the “element” where the list parsing fails, or -1 if this cannot be determined.
**lower**
Any Unicode lower case alphabet character.
**print**
Any Unicode printing character, including space.
**punct**
Any Unicode punctuation character.
**space**
Any Unicode whitespace character, mongolian vowel separator (U+180e), zero width space (U+200b), word joiner (U+2060) or zero width no-break space (U+feff) (=BOM).
**true**
Any of the forms allowed to **[Tcl\_GetBoolean](https://www.tcl.tk/man/tcl/TclLib/GetInt.htm)** where the value is true.
**upper**
Any upper case alphabet character in the Unicode character set.
**wideinteger**
Any of the valid forms for a wide integer in Tcl, with optional surrounding whitespace. In case of under/overflow in the value, 0 is returned and the *varname* will contain -1.
**wordchar**
Any Unicode word character. That is any alphanumeric character, and any Unicode connector punctuation characters (e.g. underscore).
**xdigit**
Any hexadecimal digit character ([0-9A-Fa-f]).
In the case of **boolean**, **true** and **false**, if the function will return 0, then the *varname* will always be set to 0, due to the varied nature of a valid boolean value.
**string last** *needleString haystackString* ?*lastIndex*?
Search *haystackString* for a sequence of characters that exactly match the characters in *needleString*. If found, return the index of the first character in the last such match within *haystackString*. If there is no match, then return -1. If *lastIndex* is specified (in any of the forms described in **[STRING INDICES](#M54)**), then only the characters in *haystackString* at or before the specified *lastIndex* will be considered by the search. For example,
```
**string last a 0a23456789abcdef 15**
```
will return **10**, but
```
**string last a 0a23456789abcdef 9**
```
will return **1**.
**string length** *string*
Returns a decimal string giving the number of characters in *string*. Note that this is not necessarily the same as the number of bytes used to store the string. If the value is a byte array value (such as those returned from reading a binary encoded channel), then this will return the actual byte length of the value.
**string map** ?**-nocase**? *mapping string*
Replaces substrings in *string* based on the key-value pairs in *mapping*. *mapping* is a list of *key value key value ...* as in the form returned by **[array get](array.htm)**. Each instance of a key in the string will be replaced with its corresponding value. If **-nocase** is specified, then matching is done without regard to case differences. Both *key* and *value* may be multiple characters. Replacement is done in an ordered manner, so the key appearing first in the list will be checked first, and so on. *string* is only iterated over once, so earlier key replacements will have no affect for later key matches. For example,
```
**string map {abc 1 ab 2 a 3 1 0} 1abcaababcabababc**
```
will return the string **01321221**.
Note that if an earlier *key* is a prefix of a later one, it will completely mask the later one. So if the previous example is reordered like this,
```
**string map {1 0 ab 2 a 3 abc 1} 1abcaababcabababc**
```
it will return the string **02c322c222c**.
**string match** ?**-nocase**? *pattern* *string*
See if *pattern* matches *string*; return 1 if it does, 0 if it does not. If **-nocase** is specified, then the pattern attempts to match against the string in a case insensitive manner. For the two strings to match, their contents must be identical except that the following special sequences may appear in *pattern*:
**\***
Matches any sequence of characters in *string*, including a null string.
**?**
Matches any single character in *string*.
**[***chars***]**
Matches any character in the set given by *chars*. If a sequence of the form *x***-***y* appears in *chars*, then any character between *x* and *y*, inclusive, will match. When used with **-nocase**, the end points of the range are converted to lower case first. Whereas {[A-z]} matches “\_” when matching case-sensitively (since “\_” falls between the “Z” and “a”), with **-nocase** this is considered like {[A-Za-z]} (and probably what was meant in the first place).
**\***x*
Matches the single character *x*. This provides a way of avoiding the special interpretation of the characters **\*?[]\** in *pattern*.
**string range** *string first last*
Returns a range of consecutive characters from *string*, starting with the character whose index is *first* and ending with the character whose index is *last*. An index of 0 refers to the first character of the string. *first* and *last* may be specified as for the **index** method. If *first* is less than zero then it is treated as if it were zero, and if *last* is greater than or equal to the length of the string then it is treated as if it were **end**. If *first* is greater than *last* then an empty string is returned.
**string repeat** *string count*
Returns *string* repeated *count* number of times.
**string replace** *string first last* ?*newstring*?
Removes a range of consecutive characters from *string*, starting with the character whose index is *first* and ending with the character whose index is *last*. An index of 0 refers to the first character of the string. *First* and *last* may be specified as for the **index** method. If *newstring* is specified, then it is placed in the removed character range. If *first* is less than zero then it is treated as if it were zero, and if *last* is greater than or equal to the length of the string then it is treated as if it were **end**. If *first* is greater than *last* or the length of the initial string, or *last* is less than 0, then the initial string is returned untouched.
**string reverse** *string*
Returns a string that is the same length as *string* but with its characters in the reverse order.
**string tolower** *string* ?*first*? ?*last*?
Returns a value equal to *string* except that all upper (or title) case letters have been converted to lower case. If *first* is specified, it refers to the first char index in the string to start modifying. If *last* is specified, it refers to the char index in the string to stop at (inclusive). *first* and *last* may be specified using the forms described in **[STRING INDICES](#M54)**.
**string totitle** *string* ?*first*? ?*last*?
Returns a value equal to *string* except that the first character in *string* is converted to its Unicode title case variant (or upper case if there is no title case variant) and the rest of the string is converted to lower case. If *first* is specified, it refers to the first char index in the string to start modifying. If *last* is specified, it refers to the char index in the string to stop at (inclusive). *first* and *last* may be specified using the forms described in **[STRING INDICES](#M54)**.
**string toupper** *string* ?*first*? ?*last*?
Returns a value equal to *string* except that all lower (or title) case letters have been converted to upper case. If *first* is specified, it refers to the first char index in the string to start modifying. If *last* is specified, it refers to the char index in the string to stop at (inclusive). *first* and *last* may be specified using the forms described in **[STRING INDICES](#M54)**.
**string trim** *string* ?*chars*?
Returns a value equal to *string* except that any leading or trailing characters present in the string given by *chars* are removed. If *chars* is not specified then white space is removed (any character for which **string is space** returns 1, and " ").
**string trimleft** *string* ?*chars*?
Returns a value equal to *string* except that any leading characters present in the string given by *chars* are removed. If *chars* is not specified then white space is removed (any character for which **string is space** returns 1, and " ").
**string trimright** *string* ?*chars*?
Returns a value equal to *string* except that any trailing characters present in the string given by *chars* are removed. If *chars* is not specified then white space is removed (any character for which **string is space** returns 1, and " ").
### Obsolete subcommands
These subcommands are currently supported, but are likely to go away in a future release as their functionality is either virtually never used or highly misleading.
**string bytelength** *string*
Returns a decimal string giving the number of bytes used to represent *string* in memory when encoded as Tcl's internal modified UTF-8; Tcl may use other encodings for *string* as well, and does not guarantee to only use a single encoding for a particular *string*. Because UTF-8 uses a variable number of bytes to represent Unicode characters, the byte length will not be the same as the character length in general. The cases where a script cares about the byte length are rare. In almost all cases, you should use the **string length** operation (including determining the length of a Tcl byte array value). Refer to the **[Tcl\_NumUtfChars](https://www.tcl.tk/man/tcl/TclLib/Utf.htm)** manual entry for more details on the UTF-8 representation.
Formally, the **string bytelength** operation returns the content of the *length* field of the **[Tcl\_Obj](https://www.tcl.tk/man/tcl/TclLib/Object.htm)** structure, after calling **[Tcl\_GetString](https://www.tcl.tk/man/tcl/TclLib/StringObj.htm)** to ensure that the *bytes* field is populated. This is highly unlikely to be useful to Tcl scripts, as Tcl's internal encoding is not strict UTF-8, but rather a modified CESU-8 with a denormalized NUL (identical to that used in a number of places by Java's serialization mechanism) to enable basic processing with non-Unicode-aware C functions. As this representation should only ever be used by Tcl's implementation, the number of bytes used to store the representation is of very low value (except to C extension code, which has direct access for the purpose of memory management, etc.)
*Compatibility note:* it is likely that this subcommand will be withdrawn in a future version of Tcl. It is better to use the **[encoding convertto](encoding.htm)** command to convert a string to a known encoding and then apply **string length** to that.
```
**string length** [encoding convertto utf-8 $theString]
```
**string wordend** *string charIndex*
Returns the index of the character just after the last one in the word containing character *charIndex* of *string*. *charIndex* may be specified using the forms in **[STRING INDICES](#M54)**. A word is considered to be any contiguous range of alphanumeric (Unicode letters or decimal digits) or underscore (Unicode connector punctuation) characters, or any single character other than these.
**string wordstart** *string charIndex*
Returns the index of the first character in the word containing character *charIndex* of *string*. *charIndex* may be specified using the forms in **[STRING INDICES](#M54)**. A word is considered to be any contiguous range of alphanumeric (Unicode letters or decimal digits) or underscore (Unicode connector punctuation) characters, or any single character other than these.
String indices
--------------
When referring to indices into a string (e.g., for **string index** or **string range**) the following formats are supported:
*integer*
For any index value that passes **string is integer -strict**, the char specified at this integral index (e.g., **2** would refer to the “c” in “abcd”).
**end**
The last char of the string (e.g., **end** would refer to the “d” in “abcd”).
**end-***N*
The last char of the string minus the specified integer offset *N* (e.g., “**end-1**” would refer to the “c” in “abcd”).
**end+***N*
The last char of the string plus the specified integer offset *N* (e.g., “**end+-1**” would refer to the “c” in “abcd”).
*M***+***N*
The char specified at the integral index that is the sum of integer values *M* and *N* (e.g., “**1+1**” would refer to the “c” in “abcd”).
*M***-***N*
The char specified at the integral index that is the difference of integer values *M* and *N* (e.g., “**2-1**” would refer to the “b” in “abcd”).
In the specifications above, the integer value *M* contains no trailing whitespace and the integer value *N* contains no leading whitespace.
Example
-------
Test if the string in the variable *string* is a proper non-empty prefix of the string **foobar**.
```
set length [**string length** $string]
if {$length == 0} {
set isPrefix 0
} else {
set isPrefix [**string equal** -length $length $string "foobar"]
}
```
See also
--------
**[expr](expr.htm)**, **[list](list.htm)**
| programming_docs |
tcl_tk my my
==
Name
----
my — invoke any method of current object Synopsis
--------
package require TclOO
**my** *methodName* ?*arg ...*?
Description
-----------
The **my** command is used to allow methods of objects to invoke any method of the object (or its class). In particular, the set of valid values for *methodName* is the set of all methods supported by an object and its superclasses, including those that are not exported. The object upon which the method is invoked is always the one that is the current context of the method (i.e. the object that is returned by **[self object](self.htm)**) from which the **my** command is invoked. Each object has its own **my** command, contained in its instance namespace.
Examples
--------
This example shows basic use of **my** to use the **variables** method of the **[oo::object](object.htm)** class, which is not publicly visible by default:
```
oo::class create c {
method count {} {
**my** variable counter
puts [incr counter]
}
}
c create o
o count *→ prints "1"*
o count *→ prints "2"*
o count *→ prints "3"*
```
See also
--------
**[next](next.htm)**, **[oo::object](object.htm)**, **[self](self.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/my.htm>
tcl_tk update update
======
Name
----
update — Process pending events and idle callbacks Synopsis
--------
**update** ?**idletasks**?
Description
-----------
This command is used to bring the application “up to date” by entering the event loop repeatedly until all pending events (including idle callbacks) have been processed. If the **idletasks** keyword is specified as an argument to the command, then no new events or errors are processed; only idle callbacks are invoked. This causes operations that are normally deferred, such as display updates and window layout calculations, to be performed immediately.
The **update idletasks** command is useful in scripts where changes have been made to the application's state and you want those changes to appear on the display immediately, rather than waiting for the script to complete. Most display updates are performed as idle callbacks, so **update idletasks** will cause them to run. However, there are some kinds of updates that only happen in response to events, such as those triggered by window size changes; these updates will not occur in **update idletasks**.
The **update** command with no options is useful in scripts where you are performing a long-running computation but you still want the application to respond to events such as user interactions; if you occasionally call **update** then user input will be processed during the next call to **update**.
Example
-------
Run computations for about a second and then finish:
```
set x 1000
set done 0
after 1000 set done 1
while {!$done} {
# A very silly example!
set x [expr {log($x) ** 2.8}]
# Test to see if our time-limit has been hit. This would
# also give a chance for serving network sockets and, if
# the Tk package is loaded, updating a user interface.
**update**
}
```
See also
--------
**[after](after.htm)**, **[interp](interp.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/update.htm>
tcl_tk packagens packagens
=========
[NAME](packagens.htm#M2) pkg::create — Construct an appropriate 'package ifneeded' command for a given package specification
[SYNOPSIS](packagens.htm#M3)
[DESCRIPTION](packagens.htm#M4)
[OPTIONS](packagens.htm#M5)
[**-name** *packageName*](packagens.htm#M6)
[**-version** *packageVersion*](packagens.htm#M7)
[**-load** *filespec*](packagens.htm#M8)
[**-source** *filespec*](packagens.htm#M9)
[SEE ALSO](packagens.htm#M10)
[KEYWORDS](packagens.htm#M11)
Name
----
pkg::create — Construct an appropriate 'package ifneeded' command for a given package specification Synopsis
--------
**::pkg::create** **-name** *packageName* **-version** *packageVersion* ?**-load** *filespec*? ... ?**-source** *filespec*? ...
Description
-----------
**::pkg::create** is a utility procedure that is part of the standard Tcl library. It is used to create an appropriate **[package ifneeded](package.htm)** command for a given package specification. It can be used to construct a **pkgIndex.tcl** file for use with the **[package](package.htm)** mechanism. Options
-------
The parameters supported are:
**-name** *packageName*
This parameter specifies the name of the package. It is required.
**-version** *packageVersion*
This parameter specifies the version of the package. It is required.
**-load** *filespec*
This parameter specifies a binary library that must be loaded with the **[load](load.htm)** command. *filespec* is a list with two elements. The first element is the name of the file to load. The second, optional element is a list of commands supplied by loading that file. If the list of procedures is empty or omitted, **::pkg::create** will set up the library for direct loading (see **pkg\_mkIndex**). Any number of **-load** parameters may be specified.
**-source** *filespec*
This parameter is similar to the **-load** parameter, except that it specifies a Tcl library that must be loaded with the **[source](source.htm)** command. Any number of **-source** parameters may be specified.
At least one **-load** or **-source** parameter must be given.
See also
--------
**[package](package.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/packagens.htm>
tcl_tk socket socket
======
[NAME](socket.htm#M2) socket — Open a TCP network connection
[SYNOPSIS](socket.htm#M3)
[DESCRIPTION](socket.htm#M4)
[CLIENT SOCKETS](socket.htm#M5)
[**-myaddr** *addr*](socket.htm#M6)
[**-myport** *port*](socket.htm#M7)
[**-async**](socket.htm#M8)
[SERVER SOCKETS](socket.htm#M9)
[**-myaddr** *addr*](socket.htm#M10)
[CONFIGURATION OPTIONS](socket.htm#M11)
[**-error**](socket.htm#M12)
[**-sockname**](socket.htm#M13)
[**-peername**](socket.htm#M14)
[**-connecting**](socket.htm#M15)
[EXAMPLES](socket.htm#M16)
[HISTORY](socket.htm#M17)
[SEE ALSO](socket.htm#M18)
[KEYWORDS](socket.htm#M19)
Name
----
socket — Open a TCP network connection Synopsis
--------
**socket** ?*options*? *host port*
**socket** **-server** *command* ?*options*? *port*
Description
-----------
This command opens a network socket and returns a channel identifier that may be used in future invocations of commands like **[read](read.htm)**, **[puts](puts.htm)** and **[flush](flush.htm)**. At present only the TCP network protocol is supported over IPv4 and IPv6; future releases may include support for additional protocols. The **socket** command may be used to open either the client or server side of a connection, depending on whether the **-server** switch is specified. Note that the default encoding for *all* sockets is the system encoding, as returned by **[encoding system](encoding.htm)**. Most of the time, you will need to use **[chan configure](chan.htm)** to alter this to something else, such as *utf-8* (ideal for communicating with other Tcl processes) or *iso8859-1* (useful for many network protocols, especially the older ones).
Client sockets
--------------
If the **-server** option is not specified, then the client side of a connection is opened and the command returns a channel identifier that can be used for both reading and writing. *Port* and *host* specify a port to connect to; there must be a server accepting connections on this port. *Port* is an integer port number (or service name, where supported and understood by the host operating system) and *host* is either a domain-style name such as **www.tcl.tk** or a numerical IPv4 or IPv6 address such as **127.0.0.1** or **2001:DB8::1**. Use *localhost* to refer to the host on which the command is invoked. The following options may also be present before *host* to specify additional information about the connection:
**-myaddr** *addr*
*Addr* gives the domain-style name or numerical IP address of the client-side network interface to use for the connection. This option may be useful if the client machine has multiple network interfaces. If the option is omitted then the client-side interface will be chosen by the system software.
**-myport** *port*
*Port* specifies an integer port number (or service name, where supported and understood by the host operating system) to use for the client's side of the connection. If this option is omitted, the client's port number will be chosen at random by the system software.
**-async**
This option will cause the client socket to be connected asynchronously. This means that the socket will be created immediately but may not yet be connected to the server, when the call to **socket** returns. When a **[gets](gets.htm)** or **[flush](flush.htm)** is done on the socket before the connection attempt succeeds or fails, if the socket is in blocking mode, the operation will wait until the connection is completed or fails. If the socket is in nonblocking mode and a **[gets](gets.htm)** or **[flush](flush.htm)** is done on the socket before the connection attempt succeeds or fails, the operation returns immediately and **[fblocked](fblocked.htm)** on the socket returns 1. Synchronous client sockets may be switched (after they have connected) to operating in asynchronous mode using:
```
**chan configure** *chan* **-blocking 0**
```
See the **[chan configure](chan.htm)** command for more details.
The Tcl event loop should be running while an asynchronous connection is in progress, because it may have to do several connection attempts in the background. Running the event loop also allows you to set up a writable channel event on the socket to get notified when the asynchronous connection has succeeded or failed. See the **[vwait](vwait.htm)** and the **[chan](chan.htm)** commands for more details on the event loop and channel events.
The **[chan configure](chan.htm)** option **-connecting** may be used to check if the connect is still running. To verify a successful connect, the option **-error** may be checked when **-connecting** returned 0.
Operation without the event queue requires at the moment calls to **[chan configure](chan.htm)** to advance the internal state machine.
Server sockets
--------------
If the **-server** option is specified then the new socket will be a server that listens on the given *port* (either an integer or a service name, where supported and understood by the host operating system; if *port* is zero, the operating system will allocate a free port to the server socket which may be discovered by using **[chan configure](chan.htm)** to read the **-sockname** option). If the host supports both, IPv4 and IPv6, the socket will listen on both address families. Tcl will automatically accept connections to the given port. For each connection Tcl will create a new channel that may be used to communicate with the client. Tcl then invokes *command* (properly a command prefix list, see the **[EXAMPLES](#M16)** below) with three additional arguments: the name of the new channel, the address, in network address notation, of the client's host, and the client's port number. The following additional option may also be specified before *port*:
**-myaddr** *addr*
*Addr* gives the domain-style name or numerical IP address of the server-side network interface to use for the connection. This option may be useful if the server machine has multiple network interfaces. If the option is omitted then the server socket is bound to the wildcard address so that it can accept connections from any interface. If *addr* is a domain name that resolves to multiple IP addresses that are available on the local machine, the socket will listen on all of them.
Server channels cannot be used for input or output; their sole use is to accept new client connections. The channels created for each incoming client connection are opened for input and output. Closing the server channel shuts down the server so that no new connections will be accepted; however, existing connections will be unaffected.
Server sockets depend on the Tcl event mechanism to find out when new connections are opened. If the application does not enter the event loop, for example by invoking the **[vwait](vwait.htm)** command or calling the C procedure **[Tcl\_DoOneEvent](https://www.tcl.tk/man/tcl/TclLib/DoOneEvent.htm)**, then no connections will be accepted.
If *port* is specified as zero, the operating system will allocate an unused port for use as a server socket. The port number actually allocated may be retrieved from the created server socket using the **[chan configure](chan.htm)** command to retrieve the **-sockname** option as described below.
Configuration options
---------------------
The **[chan configure](chan.htm)** command can be used to query several readonly configuration options for socket channels:
**-error**
This option gets the current error status of the given socket. This is useful when you need to determine if an asynchronous connect operation succeeded. If there was an error, the error message is returned. If there was no error, an empty string is returned. Note that the error status is reset by the read operation; this mimics the underlying getsockopt(SO\_ERROR) call.
**-sockname**
For client sockets (including the channels that get created when a client connects to a server socket) this option returns a list of three elements, the address, the host name and the port number for the socket. If the host name cannot be computed, the second element is identical to the address, the first element of the list. For server sockets this option returns a list of a multiple of three elements each group of which have the same meaning as described above. The list contains more than one group when the server socket was created without **-myaddr** or with the argument to **-myaddr** being a domain name that resolves multiple IP addresses that are local to the invoking host.
**-peername**
This option is not supported by server sockets. For client and accepted sockets, this option returns a list of three elements; these are the address, the host name and the port to which the peer socket is connected or bound. If the host name cannot be computed, the second element of the list is identical to the address, its first element.
**-connecting**
This option is not supported by server sockets. For client sockets, this option returns 1 if an asyncroneous connect is still in progress, 0 otherwise.
Examples
--------
Here is a very simple time server:
```
proc Server {startTime channel clientaddr clientport} {
puts "Connection from $clientaddr registered"
set now [clock seconds]
puts $channel [clock format $now]
puts $channel "[expr {$now - $startTime}] since start"
close $channel
}
**socket -server** [list Server [clock seconds]] 9900
vwait forever
```
And here is the corresponding client to talk to the server and extract some information:
```
set server localhost
set sockChan [**socket** $server 9900]
gets $sockChan line1
gets $sockChan line2
close $sockChan
puts "The time on $server is $line1"
puts "That is [lindex $line2 0]s since the server started"
```
History
-------
Support for IPv6 was added in Tcl 8.6. See also
--------
**[chan](chan.htm)**, **[flush](flush.htm)**, **[open](open.htm)**, **[read](read.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/socket.htm>
tcl_tk tcltest tcltest
=======
[NAME](tcltest.htm#M2) tcltest — Test harness support code and utilities
[SYNOPSIS](tcltest.htm#M3)
[DESCRIPTION](tcltest.htm#M4)
[COMMANDS](tcltest.htm#M5)
[**test** *name description* ?*-option value ...*?](tcltest.htm#M6)
[**test** *name description* ?*constraints*? *body result*](tcltest.htm#M7)
[**loadTestedCommands**](tcltest.htm#M8)
[**makeFile** *contents name* ?*directory*?](tcltest.htm#M9)
[**removeFile** *name* ?*directory*?](tcltest.htm#M10)
[**makeDirectory** *name* ?*directory*?](tcltest.htm#M11)
[**removeDirectory** *name* ?*directory*?](tcltest.htm#M12)
[**viewFile** *file* ?*directory*?](tcltest.htm#M13)
[**cleanupTests**](tcltest.htm#M14)
[**runAllTests**](tcltest.htm#M15)
[CONFIGURATION COMMANDS](tcltest.htm#M16)
[**configure**](tcltest.htm#M17)
[**configure** *option*](tcltest.htm#M18)
[**configure** *option value* ?*-option value ...*?](tcltest.htm#M19)
[**customMatch** *mode script*](tcltest.htm#M20)
[**testConstraint** *constraint* ?*boolean*?](tcltest.htm#M21)
[**interpreter** ?*executableName*?](tcltest.htm#M22)
[**outputChannel** ?*channelID*?](tcltest.htm#M23)
[**errorChannel** ?*channelID*?](tcltest.htm#M24)
[SHORTCUT CONFIGURATION COMMANDS](tcltest.htm#M25)
[**debug** ?*level*?](tcltest.htm#M26)
[**errorFile** ?*filename*?](tcltest.htm#M27)
[**limitConstraints** ?*boolean*?](tcltest.htm#M28)
[**loadFile** ?*filename*?](tcltest.htm#M29)
[**loadScript** ?*script*?](tcltest.htm#M30)
[**match** ?*patternList*?](tcltest.htm#M31)
[**matchDirectories** ?*patternList*?](tcltest.htm#M32)
[**matchFiles** ?*patternList*?](tcltest.htm#M33)
[**outputFile** ?*filename*?](tcltest.htm#M34)
[**preserveCore** ?*level*?](tcltest.htm#M35)
[**singleProcess** ?*boolean*?](tcltest.htm#M36)
[**skip** ?*patternList*?](tcltest.htm#M37)
[**skipDirectories** ?*patternList*?](tcltest.htm#M38)
[**skipFiles** ?*patternList*?](tcltest.htm#M39)
[**temporaryDirectory** ?*directory*?](tcltest.htm#M40)
[**testsDirectory** ?*directory*?](tcltest.htm#M41)
[**verbose** ?*level*?](tcltest.htm#M42)
[OTHER COMMANDS](tcltest.htm#M43)
[**test** *name description optionList*](tcltest.htm#M44)
[**workingDirectory** ?*directoryName*?](tcltest.htm#M45)
[**normalizeMsg** *msg*](tcltest.htm#M46)
[**normalizePath** *pathVar*](tcltest.htm#M47)
[**bytestring** *string*](tcltest.htm#M48)
[TESTS](tcltest.htm#M49)
[**-constraints** *keywordList*|*expression*](tcltest.htm#M50)
[**-setup** *script*](tcltest.htm#M51)
[**-body** *script*](tcltest.htm#M52)
[**-cleanup** *script*](tcltest.htm#M53)
[**-match** *mode*](tcltest.htm#M54)
[**-result** *expectedValue*](tcltest.htm#M55)
[**-output** *expectedValue*](tcltest.htm#M56)
[**-errorOutput** *expectedValue*](tcltest.htm#M57)
[**-returnCodes** *expectedCodeList*](tcltest.htm#M58)
[TEST CONSTRAINTS](tcltest.htm#M59)
[*singleTestInterp*](tcltest.htm#M60)
[*unix*](tcltest.htm#M61)
[*win*](tcltest.htm#M62)
[*nt*](tcltest.htm#M63)
[*mac*](tcltest.htm#M64)
[*unixOrWin*](tcltest.htm#M65)
[*macOrWin*](tcltest.htm#M66)
[*macOrUnix*](tcltest.htm#M67)
[*tempNotWin*](tcltest.htm#M68)
[*tempNotMac*](tcltest.htm#M69)
[*unixCrash*](tcltest.htm#M70)
[*winCrash*](tcltest.htm#M71)
[*macCrash*](tcltest.htm#M72)
[*emptyTest*](tcltest.htm#M73)
[*knownBug*](tcltest.htm#M74)
[*nonPortable*](tcltest.htm#M75)
[*userInteraction*](tcltest.htm#M76)
[*interactive*](tcltest.htm#M77)
[*nonBlockFiles*](tcltest.htm#M78)
[*asyncPipeClose*](tcltest.htm#M79)
[*unixExecs*](tcltest.htm#M80)
[*hasIsoLocale*](tcltest.htm#M81)
[*root*](tcltest.htm#M82)
[*notRoot*](tcltest.htm#M83)
[*eformat*](tcltest.htm#M84)
[*stdio*](tcltest.htm#M85)
[RUNNING ALL TESTS](tcltest.htm#M86)
[CONFIGURABLE OPTIONS](tcltest.htm#M87)
[**-singleproc** *boolean*](tcltest.htm#M88)
[**-debug** *level*](tcltest.htm#M89)
[0](tcltest.htm#M90)
[1](tcltest.htm#M91)
[2](tcltest.htm#M92)
[3](tcltest.htm#M93)
[**-verbose** *level*](tcltest.htm#M94)
[body (**b**)](tcltest.htm#M95)
[pass (**p**)](tcltest.htm#M96)
[skip (**s**)](tcltest.htm#M97)
[start (**t**)](tcltest.htm#M98)
[error (**e**)](tcltest.htm#M99)
[line (**l**)](tcltest.htm#M100)
[msec (**m**)](tcltest.htm#M101)
[usec (**u**)](tcltest.htm#M102)
[**-preservecore** *level*](tcltest.htm#M103)
[0](tcltest.htm#M104)
[1](tcltest.htm#M105)
[2](tcltest.htm#M106)
[**-limitconstraints** *boolean*](tcltest.htm#M107)
[**-constraints** *list*](tcltest.htm#M108)
[**-tmpdir** *directory*](tcltest.htm#M109)
[**-testdir** *directory*](tcltest.htm#M110)
[**-file** *patternList*](tcltest.htm#M111)
[**-notfile** *patternList*](tcltest.htm#M112)
[**-relateddir** *patternList*](tcltest.htm#M113)
[**-asidefromdir** *patternList*](tcltest.htm#M114)
[**-match** *patternList*](tcltest.htm#M115)
[**-skip** *patternList*](tcltest.htm#M116)
[**-load** *script*](tcltest.htm#M117)
[**-loadfile** *filename*](tcltest.htm#M118)
[**-outfile** *filename*](tcltest.htm#M119)
[**-errfile** *filename*](tcltest.htm#M120)
[CREATING TEST SUITES WITH TCLTEST](tcltest.htm#M121)
[COMPATIBILITY](tcltest.htm#M122)
[KNOWN ISSUES](tcltest.htm#M123)
[KEYWORDS](tcltest.htm#M124)
Name
----
tcltest — Test harness support code and utilities Synopsis
--------
**package require tcltest** ?**2.3**?
**tcltest::test** *name description* ?*-option value ...*?
**tcltest::test** *name description* ?*constraints*? *body result*
**tcltest::loadTestedCommands**
**tcltest::makeDirectory** *name* ?*directory*?
**tcltest::removeDirectory** *name* ?*directory*?
**tcltest::makeFile** *contents name* ?*directory*?
**tcltest::removeFile** *name* ?*directory*?
**tcltest::viewFile** *name* ?*directory*?
**tcltest::cleanupTests** ?*runningMultipleTests*?
**tcltest::runAllTests**
**tcltest::configure**
**tcltest::configure** *-option*
**tcltest::configure** *-option value* ?*-option value ...*?
**tcltest::customMatch** *mode command*
**tcltest::testConstraint** *constraint* ?*value*?
**tcltest::outputChannel** ?*channelID*?
**tcltest::errorChannel** ?*channelID*?
**tcltest::interpreter** ?*interp*?
**tcltest::debug** ?*level*?
**tcltest::errorFile** ?*filename*?
**tcltest::limitConstraints** ?*boolean*?
**tcltest::loadFile** ?*filename*?
**tcltest::loadScript** ?*script*?
**tcltest::match** ?*patternList*?
**tcltest::matchDirectories** ?*patternList*?
**tcltest::matchFiles** ?*patternList*?
**tcltest::outputFile** ?*filename*?
**tcltest::preserveCore** ?*level*?
**tcltest::singleProcess** ?*boolean*?
**tcltest::skip** ?*patternList*?
**tcltest::skipDirectories** ?*patternList*?
**tcltest::skipFiles** ?*patternList*?
**tcltest::temporaryDirectory** ?*directory*?
**tcltest::testsDirectory** ?*directory*?
**tcltest::verbose** ?*level*?
**tcltest::test** *name description optionList*
**tcltest::bytestring** *string*
**tcltest::normalizeMsg** *msg*
**tcltest::normalizePath** *pathVar*
**tcltest::workingDirectory** ?*dir*?
Description
-----------
The **tcltest** package provides several utility commands useful in the construction of test suites for code instrumented to be run by evaluation of Tcl commands. Notably the built-in commands of the Tcl library itself are tested by a test suite using the tcltest package. All the commands provided by the **tcltest** package are defined in and exported from the **::tcltest** namespace, as indicated in the **[SYNOPSIS](#M3)** above. In the following sections, all commands will be described by their simple names, in the interest of brevity.
The central command of **tcltest** is **test** that defines and runs a test. Testing with **test** involves evaluation of a Tcl script and comparing the result to an expected result, as configured and controlled by a number of options. Several other commands provided by **tcltest** govern the configuration of **test** and the collection of many **test** commands into test suites.
See **[CREATING TEST SUITES WITH TCLTEST](#M121)** below for an extended example of how to use the commands of **tcltest** to produce test suites for your Tcl-enabled code.
Commands
--------
**test** *name description* ?*-option value ...*?
Defines and possibly runs a test with the name *name* and description *description*. The name and description of a test are used in messages reported by **test** during the test, as configured by the options of **tcltest**. The remaining *option value* arguments to **test** define the test, including the scripts to run, the conditions under which to run them, the expected result, and the means by which the expected and actual results should be compared. See **[TESTS](#M49)** below for a complete description of the valid options and how they define a test. The **test** command returns an empty string.
**test** *name description* ?*constraints*? *body result*
This form of **test** is provided to support test suites written for version 1 of the **tcltest** package, and also a simpler interface for a common usage. It is the same as “**test** *name description* **-constraints** *constraints* **-body** *body* **-result** *result*”. All other options to **test** take their default values. When *constraints* is omitted, this form of **test** can be distinguished from the first because all *option*s begin with “-”.
**loadTestedCommands**
Evaluates in the caller's context the script specified by **configure -load** or **configure -loadfile**. Returns the result of that script evaluation, including any error raised by the script. Use this command and the related configuration options to provide the commands to be tested to the interpreter running the test suite.
**makeFile** *contents name* ?*directory*?
Creates a file named *name* relative to directory *directory* and write *contents* to that file using the encoding **[encoding system](encoding.htm)**. If *contents* does not end with a newline, a newline will be appended so that the file named *name* does end with a newline. Because the system encoding is used, this command is only suitable for making text files. The file will be removed by the next evaluation of **cleanupTests**, unless it is removed by **removeFile** first. The default value of *directory* is the directory **configure -tmpdir**. Returns the full path of the file created. Use this command to create any text file required by a test with contents as needed.
**removeFile** *name* ?*directory*?
Forces the file referenced by *name* to be removed. This file name should be relative to *directory*. The default value of *directory* is the directory **configure -tmpdir**. Returns an empty string. Use this command to delete files created by **makeFile**.
**makeDirectory** *name* ?*directory*?
Creates a directory named *name* relative to directory *directory*. The directory will be removed by the next evaluation of **cleanupTests**, unless it is removed by **removeDirectory** first. The default value of *directory* is the directory **configure -tmpdir**. Returns the full path of the directory created. Use this command to create any directories that are required to exist by a test.
**removeDirectory** *name* ?*directory*?
Forces the directory referenced by *name* to be removed. This directory should be relative to *directory*. The default value of *directory* is the directory **configure -tmpdir**. Returns an empty string. Use this command to delete any directories created by **makeDirectory**.
**viewFile** *file* ?*directory*?
Returns the contents of *file*, except for any final newline, just as **read -nonewline** would return. This file name should be relative to *directory*. The default value of *directory* is the directory **configure -tmpdir**. Use this command as a convenient way to turn the contents of a file generated by a test into the result of that test for matching against an expected result. The contents of the file are read using the system encoding, so its usefulness is limited to text files.
**cleanupTests**
Intended to clean up and summarize after several tests have been run. Typically called once per test file, at the end of the file after all tests have been completed. For best effectiveness, be sure that the **cleanupTests** is evaluated even if an error occurs earlier in the test file evaluation. Prints statistics about the tests run and removes files that were created by **makeDirectory** and **makeFile** since the last **cleanupTests**. Names of files and directories in the directory **configure -tmpdir** created since the last **cleanupTests**, but not created by **makeFile** or **makeDirectory** are printed to **outputChannel**. This command also restores the original shell environment, as described by the global **[env](tclvars.htm)** array. Returns an empty string.
**runAllTests**
This is a master command meant to run an entire suite of tests, spanning multiple files and/or directories, as governed by the configurable options of **tcltest**. See **[RUNNING ALL TESTS](#M86)** below for a complete description of the many variations possible with **runAllTests**.
### Configuration commands
**configure**
Returns the list of configurable options supported by **tcltest**. See **[CONFIGURABLE OPTIONS](#M87)** below for the full list of options, their valid values, and their effect on **tcltest** operations.
**configure** *option*
Returns the current value of the supported configurable option *option*. Raises an error if *option* is not a supported configurable option.
**configure** *option value* ?*-option value ...*?
Sets the value of each configurable option *option* to the corresponding value *value*, in order. Raises an error if an *option* is not a supported configurable option, or if *value* is not a valid value for the corresponding *option*, or if a *value* is not provided. When an error is raised, the operation of **configure** is halted, and subsequent *option value* arguments are not processed. If the environment variable **::env(TCLTEST\_OPTIONS)** exists when the **tcltest** package is loaded (by **[package require](package.htm)** **tcltest**) then its value is taken as a list of arguments to pass to **configure**. This allows the default values of the configuration options to be set by the environment.
**customMatch** *mode script*
Registers *mode* as a new legal value of the **-match** option to **test**. When the **-match** *mode* option is passed to **test**, the script *script* will be evaluated to compare the actual result of evaluating the body of the test to the expected result. To perform the match, the *script* is completed with two additional words, the expected result, and the actual result, and the completed script is evaluated in the global namespace. The completed script is expected to return a boolean value indicating whether or not the results match. The built-in matching modes of **test** are **exact**, **[glob](glob.htm)**, and **[regexp](regexp.htm)**.
**testConstraint** *constraint* ?*boolean*?
Sets or returns the boolean value associated with the named *constraint*. See **[TEST CONSTRAINTS](#M59)** below for more information.
**interpreter** ?*executableName*?
Sets or returns the name of the executable to be **[exec](exec.htm)**ed by **runAllTests** to run each test file when **configure -singleproc** is false. The default value for **interpreter** is the name of the currently running program as returned by **[info nameofexecutable](info.htm)**.
**outputChannel** ?*channelID*?
Sets or returns the output channel ID. This defaults to **[stdout](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)**. Any test that prints test related output should send that output to **outputChannel** rather than letting that output default to **[stdout](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)**.
**errorChannel** ?*channelID*?
Sets or returns the error channel ID. This defaults to **[stderr](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)**. Any test that prints error messages should send that output to **errorChannel** rather than printing directly to **[stderr](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)**.
### Shortcut configuration commands
**debug** ?*level*?
Same as “**configure -debug** ?*level*?”.
**errorFile** ?*filename*?
Same as “**configure -errfile** ?*filename*?”.
**limitConstraints** ?*boolean*?
Same as “**configure -limitconstraints** ?*boolean*?”.
**loadFile** ?*filename*?
Same as “**configure -loadfile** ?*filename*?”.
**loadScript** ?*script*?
Same as “**configure -load** ?*script*?”.
**match** ?*patternList*?
Same as “**configure -match** ?*patternList*?”.
**matchDirectories** ?*patternList*?
Same as “**configure -relateddir** ?*patternList*?”.
**matchFiles** ?*patternList*?
Same as “**configure -file** ?*patternList*?”.
**outputFile** ?*filename*?
Same as “**configure -outfile** ?*filename*?”.
**preserveCore** ?*level*?
Same as “**configure -preservecore** ?*level*?”.
**singleProcess** ?*boolean*?
Same as “**configure -singleproc** ?*boolean*?”.
**skip** ?*patternList*?
Same as “**configure -skip** ?*patternList*?”.
**skipDirectories** ?*patternList*?
Same as “**configure -asidefromdir** ?*patternList*?”.
**skipFiles** ?*patternList*?
Same as “**configure -notfile** ?*patternList*?”.
**temporaryDirectory** ?*directory*?
Same as “**configure -tmpdir** ?*directory*?”.
**testsDirectory** ?*directory*?
Same as “**configure -testdir** ?*directory*?”.
**verbose** ?*level*?
Same as “**configure -verbose** ?*level*?”.
### Other commands
The remaining commands provided by **tcltest** have better alternatives provided by **tcltest** or **[Tcl](tcl.htm)** itself. They are retained to support existing test suites, but should be avoided in new code.
**test** *name description optionList*
This form of **test** was provided to enable passing many options spanning several lines to **test** as a single argument quoted by braces, rather than needing to backslash quote the newlines between arguments to **test**. The *optionList* argument is expected to be a list with an even number of elements representing *option* and *value* arguments to pass to **test**. However, these values are not passed directly, as in the alternate forms of **[switch](switch.htm)**. Instead, this form makes an unfortunate attempt to overthrow Tcl's substitution rules by performing substitutions on some of the list elements as an attempt to implement a “do what I mean” interpretation of a brace-enclosed “block”. The result is nearly impossible to document clearly, and for that reason this form is not recommended. See the examples in **[CREATING TEST SUITES WITH TCLTEST](#M121)** below to see that this form is really not necessary to avoid backslash-quoted newlines. If you insist on using this form, examine the source code of **tcltest** if you want to know the substitution details, or just enclose the third through last argument to **test** in braces and hope for the best.
**workingDirectory** ?*directoryName*?
Sets or returns the current working directory when the test suite is running. The default value for workingDirectory is the directory in which the test suite was launched. The Tcl commands **[cd](cd.htm)** and **[pwd](pwd.htm)** are sufficient replacements.
**normalizeMsg** *msg*
Returns the result of removing the “extra” newlines from *msg*, where “extra” is rather imprecise. Tcl offers plenty of string processing commands to modify strings as you wish, and **customMatch** allows flexible matching of actual and expected results.
**normalizePath** *pathVar*
Resolves symlinks in a path, thus creating a path without internal redirection. It is assumed that *pathVar* is absolute. *pathVar* is modified in place. The Tcl command **[file normalize](file.htm)** is a sufficient replacement.
**bytestring** *string*
Construct a string that consists of the requested sequence of bytes, as opposed to a string of properly formed UTF-8 characters using the value supplied in *string*. This allows the tester to create denormalized or improperly formed strings to pass to C procedures that are supposed to accept strings with embedded NULL types and confirm that a string result has a certain pattern of bytes. This is exactly equivalent to the Tcl command **[encoding convertfrom](encoding.htm)** **identity**.
Tests
-----
The **test** command is the heart of the **tcltest** package. Its essential function is to evaluate a Tcl script and compare the result with an expected result. The options of **test** define the test script, the environment in which to evaluate it, the expected result, and how the compare the actual result to the expected result. Some configuration options of **tcltest** also influence how **test** operates. The valid options for **test** are summarized:
```
**test** *name* *description*
?**-constraints** *keywordList|expression*?
?**-setup** *setupScript*?
?**-body** *testScript*?
?**-cleanup** *cleanupScript*?
?**-result** *expectedAnswer*?
?**-output** *expectedOutput*?
?**-errorOutput** *expectedError*?
?**-returnCodes** *codeList*?
?**-match** *mode*?
```
The *name* may be any string. It is conventional to choose a *name* according to the pattern:
```
*target*-*majorNum*.*minorNum*
```
For white-box (regression) tests, the target should be the name of the C function or Tcl procedure being tested. For black-box tests, the target should be the name of the feature being tested. Some conventions call for the names of black-box tests to have the suffix **\_bb**. Related tests should share a major number. As a test suite evolves, it is best to have the same test name continue to correspond to the same test, so that it remains meaningful to say things like “Test foo-1.3 passed in all releases up to 3.4, but began failing in release 3.5.”
During evaluation of **test**, the *name* will be compared to the lists of string matching patterns returned by **configure -match**, and **configure -skip**. The test will be run only if *name* matches any of the patterns from **configure -match** and matches none of the patterns from **configure -skip**.
The *description* should be a short textual description of the test. The *description* is included in output produced by the test, typically test failure messages. Good *description* values should briefly explain the purpose of the test to users of a test suite. The name of a Tcl or C function being tested should be included in the description for regression tests. If the test case exists to reproduce a bug, include the bug ID in the description.
Valid attributes and associated values are:
**-constraints** *keywordList*|*expression*
The optional **-constraints** attribute can be list of one or more keywords or an expression. If the **-constraints** value is a list of keywords, each of these keywords should be the name of a constraint defined by a call to **testConstraint**. If any of the listed constraints is false or does not exist, the test is skipped. If the **-constraints** value is an expression, that expression is evaluated. If the expression evaluates to true, then the test is run. Note that the expression form of **-constraints** may interfere with the operation of **configure -constraints** and **configure -limitconstraints**, and is not recommended. Appropriate constraints should be added to any tests that should not always be run. That is, conditional evaluation of a test should be accomplished by the **-constraints** option, not by conditional evaluation of **test**. In that way, the same number of tests are always reported by the test suite, though the number skipped may change based on the testing environment. The default value is an empty list. See **[TEST CONSTRAINTS](#M59)** below for a list of built-in constraints and information on how to add your own constraints.
**-setup** *script*
The optional **-setup** attribute indicates a *script* that will be run before the script indicated by the **-body** attribute. If evaluation of *script* raises an error, the test will fail. The default value is an empty script.
**-body** *script*
The **-body** attribute indicates the *script* to run to carry out the test, which must return a result that can be checked for correctness. If evaluation of *script* raises an error, the test will fail (unless the **-returnCodes** option is used to state that an error is expected). The default value is an empty script.
**-cleanup** *script*
The optional **-cleanup** attribute indicates a *script* that will be run after the script indicated by the **-body** attribute. If evaluation of *script* raises an error, the test will fail. The default value is an empty script.
**-match** *mode*
The **-match** attribute determines how expected answers supplied by **-result**, **-output**, and **-errorOutput** are compared. Valid values for *mode* are **[regexp](regexp.htm)**, **[glob](glob.htm)**, **exact**, and any value registered by a prior call to **customMatch**. The default value is **exact**.
**-result** *expectedValue*
The **-result** attribute supplies the *expectedValue* against which the return value from script will be compared. The default value is an empty string.
**-output** *expectedValue*
The **-output** attribute supplies the *expectedValue* against which any output sent to **[stdout](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)** or **outputChannel** during evaluation of the script(s) will be compared. Note that only output printed using the global **[puts](puts.htm)** command is used for comparison. If **-output** is not specified, output sent to **[stdout](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)** and **outputChannel** is not processed for comparison.
**-errorOutput** *expectedValue*
The **-errorOutput** attribute supplies the *expectedValue* against which any output sent to **[stderr](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)** or **errorChannel** during evaluation of the script(s) will be compared. Note that only output printed using the global **[puts](puts.htm)** command is used for comparison. If **-errorOutput** is not specified, output sent to **[stderr](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)** and **errorChannel** is not processed for comparison.
**-returnCodes** *expectedCodeList*
The optional **-returnCodes** attribute supplies *expectedCodeList*, a list of return codes that may be accepted from evaluation of the **-body** script. If evaluation of the **-body** script returns a code not in the *expectedCodeList*, the test fails. All return codes known to **[return](return.htm)**, in both numeric and symbolic form, including extended return codes, are acceptable elements in the *expectedCodeList*. Default value is “**ok return**”.
To pass, a test must successfully evaluate its **-setup**, **-body**, and **-cleanup** scripts. The return code of the **-body** script and its result must match expected values, and if specified, output and error data from the test must match expected **-output** and **-errorOutput** values. If any of these conditions are not met, then the test fails. Note that all scripts are evaluated in the context of the caller of **test**.
As long as **test** is called with valid syntax and legal values for all attributes, it will not raise an error. Test failures are instead reported as output written to **outputChannel**. In default operation, a successful test produces no output. The output messages produced by **test** are controlled by the **configure -verbose** option as described in **[CONFIGURABLE OPTIONS](#M87)** below. Any output produced by the test scripts themselves should be produced using **[puts](puts.htm)** to **outputChannel** or **errorChannel**, so that users of the test suite may easily capture output with the **configure -outfile** and **configure -errfile** options, and so that the **-output** and **-errorOutput** attributes work properly.
### Test constraints
Constraints are used to determine whether or not a test should be skipped. Each constraint has a name, which may be any string, and a boolean value. Each **test** has a **-constraints** value which is a list of constraint names. There are two modes of constraint control. Most frequently, the default mode is used, indicated by a setting of **configure -limitconstraints** to false. The test will run only if all constraints in the list are true-valued. Thus, the **-constraints** option of **test** is a convenient, symbolic way to define any conditions required for the test to be possible or meaningful. For example, a **test** with **-constraints unix** will only be run if the constraint **unix** is true, which indicates the test suite is being run on a Unix platform. Each **test** should include whatever **-constraints** are required to constrain it to run only where appropriate. Several constraints are pre-defined in the **tcltest** package, listed below. The registration of user-defined constraints is performed by the **testConstraint** command. User-defined constraints may appear within a test file, or within the script specified by the **configure -load** or **configure -loadfile** options.
The following is a list of constraints pre-defined by the **tcltest** package itself:
*singleTestInterp*
This test can only be run if all test files are sourced into a single interpreter.
*unix*
This test can only be run on any Unix platform.
*win*
This test can only be run on any Windows platform.
*nt*
This test can only be run on any Windows NT platform.
*mac*
This test can only be run on any Mac platform.
*unixOrWin*
This test can only be run on a Unix or Windows platform.
*macOrWin*
This test can only be run on a Mac or Windows platform.
*macOrUnix*
This test can only be run on a Mac or Unix platform.
*tempNotWin*
This test can not be run on Windows. This flag is used to temporarily disable a test.
*tempNotMac*
This test can not be run on a Mac. This flag is used to temporarily disable a test.
*unixCrash*
This test crashes if it is run on Unix. This flag is used to temporarily disable a test.
*winCrash*
This test crashes if it is run on Windows. This flag is used to temporarily disable a test.
*macCrash*
This test crashes if it is run on a Mac. This flag is used to temporarily disable a test.
*emptyTest*
This test is empty, and so not worth running, but it remains as a place-holder for a test to be written in the future. This constraint has value false to cause tests to be skipped unless the user specifies otherwise.
*knownBug*
This test is known to fail and the bug is not yet fixed. This constraint has value false to cause tests to be skipped unless the user specifies otherwise.
*nonPortable*
This test can only be run in some known development environment. Some tests are inherently non-portable because they depend on things like word length, file system configuration, window manager, etc. This constraint has value false to cause tests to be skipped unless the user specifies otherwise.
*userInteraction*
This test requires interaction from the user. This constraint has value false to causes tests to be skipped unless the user specifies otherwise.
*interactive*
This test can only be run in if the interpreter is in interactive mode (when the global tcl\_interactive variable is set to 1).
*nonBlockFiles*
This test can only be run if platform supports setting files into nonblocking mode.
*asyncPipeClose*
This test can only be run if platform supports async flush and async close on a pipe.
*unixExecs*
This test can only be run if this machine has Unix-style commands **cat**, **echo**, **sh**, **wc**, **rm**, **sleep**, **fgrep**, **ps**, **chmod**, and **mkdir** available.
*hasIsoLocale*
This test can only be run if can switch to an ISO locale.
*root*
This test can only run if Unix user is root.
*notRoot*
This test can only run if Unix user is not root.
*eformat*
This test can only run if app has a working version of sprintf with respect to the “e” format of floating-point numbers.
*stdio*
This test can only be run if **interpreter** can be **[open](open.htm)**ed as a pipe.
The alternative mode of constraint control is enabled by setting **configure -limitconstraints** to true. With that configuration setting, all existing constraints other than those in the constraint list returned by **configure -constraints** are set to false. When the value of **configure -constraints** is set, all those constraints are set to true. The effect is that when both options **configure -constraints** and **configure -limitconstraints** are in use, only those tests including only constraints from the **configure -constraints** list are run; all others are skipped. For example, one might set up a configuration with
```
**configure** -constraints knownBug \
-limitconstraints true \
-verbose pass
```
to run exactly those tests that exercise known bugs, and discover whether any of them pass, indicating the bug had been fixed.
### Running all tests
The single command **runAllTests** is evaluated to run an entire test suite, spanning many files and directories. The configuration options of **tcltest** control the precise operations. The **runAllTests** command begins by printing a summary of its configuration to **outputChannel**. Test files to be evaluated are sought in the directory **configure -testdir**. The list of files in that directory that match any of the patterns in **configure -file** and match none of the patterns in **configure -notfile** is generated and sorted. Then each file will be evaluated in turn. If **configure -singleproc** is true, then each file will be **[source](source.htm)**d in the caller's context. If it is false, then a copy of **interpreter** will be **[exec](exec.htm)**'d to evaluate each file. The multi-process operation is useful when testing can cause errors so severe that a process terminates. Although such an error may terminate a child process evaluating one file, the master process can continue with the rest of the test suite. In multi-process operation, the configuration of **tcltest** in the master process is passed to the child processes as command line arguments, with the exception of **configure -outfile**. The **runAllTests** command in the master process collects all output from the child processes and collates their results into one master report. Any reports of individual test failures, or messages requested by a **configure -verbose** setting are passed directly on to **outputChannel** by the master process.
After evaluating all selected test files, a summary of the results is printed to **outputChannel**. The summary includes the total number of **test**s evaluated, broken down into those skipped, those passed, and those failed. The summary also notes the number of files evaluated, and the names of any files with failing tests or errors. A list of the constraints that caused tests to be skipped, and the number of tests skipped for each is also printed. Also, messages are printed if it appears that evaluation of a test file has caused any temporary files to be left behind in **configure -tmpdir**.
Having completed and summarized all selected test files, **runAllTests** then recursively acts on subdirectories of **configure -testdir**. All subdirectories that match any of the patterns in **configure -relateddir** and do not match any of the patterns in **configure -asidefromdir** are examined. If a file named **all.tcl** is found in such a directory, it will be **[source](source.htm)**d in the caller's context. Whether or not an examined directory contains an **all.tcl** file, its subdirectories are also scanned against the **configure -relateddir** and **configure -asidefromdir** patterns. In this way, many directories in a directory tree can have all their test files evaluated by a single **runAllTests** command.
Configurable options
--------------------
The **configure** command is used to set and query the configurable options of **tcltest**. The valid options are:
**-singleproc** *boolean*
Controls whether or not **runAllTests** spawns a child process for each test file. No spawning when *boolean* is true. Default value is false.
**-debug** *level*
Sets the debug level to *level*, an integer value indicating how much debugging information should be printed to **[stdout](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)**. Note that debug messages always go to **[stdout](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)**, independent of the value of **configure -outfile**. Default value is 0. Levels are defined as:
0
Do not display any debug information.
1
Display information regarding whether a test is skipped because it does not match any of the tests that were specified using by **configure -match** (userSpecifiedNonMatch) or matches any of the tests specified by **configure -skip** (userSpecifiedSkip). Also print warnings about possible lack of cleanup or balance in test files. Also print warnings about any re-use of test names.
2
Display the flag array parsed by the command line processor, the contents of the global **[env](tclvars.htm)** array, and all user-defined variables that exist in the current namespace as they are used.
3
Display information regarding what individual procs in the test harness are doing.
**-verbose** *level*
Sets the type of output verbosity desired to *level*, a list of zero or more of the elements **body**, **pass**, **skip**, **start**, **error**, **line**, **msec** and **usec**. Default value is “**body error**”. Levels are defined as:
body (**b**)
Display the body of failed tests
pass (**p**)
Print output when a test passes
skip (**s**)
Print output when a test is skipped
start (**t**)
Print output whenever a test starts
error (**e**)
Print errorInfo and errorCode, if they exist, when a test return code does not match its expected return code
line (**l**)
Print source file line information of failed tests
msec (**m**)
Print each test's execution time in milliseconds
usec (**u**)
Print each test's execution time in microseconds
Note that the **msec** and **usec** verbosity levels are provided as indicative measures only. They do not tackle the problem of repeatibility which should be considered in performance tests or benchmarks. To use these verbosity levels to thoroughly track performance degradations, consider wrapping your test bodies with **[time](time.htm)** commands.
The single letter abbreviations noted above are also recognized so that “**configure -verbose pt**” is the same as “**configure -verbose {pass start}**”.
**-preservecore** *level*
Sets the core preservation level to *level*. This level determines how stringent checks for core files are. Default value is 0. Levels are defined as:
0
No checking — do not check for core files at the end of each test command, but do check for them in **runAllTests** after all test files have been evaluated.
1
Also check for core files at the end of each **test** command.
2
Check for core files at all times described above, and save a copy of each core file produced in **configure -tmpdir**.
**-limitconstraints** *boolean*
Sets the mode by which **test** honors constraints as described in **[TESTS](#M49)** above. Default value is false.
**-constraints** *list*
Sets all the constraints in *list* to true. Also used in combination with **configure -limitconstraints true** to control an alternative constraint mode as described in **[TESTS](#M49)** above. Default value is an empty list.
**-tmpdir** *directory*
Sets the temporary directory to be used by **makeFile**, **makeDirectory**, **viewFile**, **removeFile**, and **removeDirectory** as the default directory where temporary files and directories created by test files should be created. Default value is **workingDirectory**.
**-testdir** *directory*
Sets the directory searched by **runAllTests** for test files and subdirectories. Default value is **workingDirectory**.
**-file** *patternList*
Sets the list of patterns used by **runAllTests** to determine what test files to evaluate. Default value is “**\*.test**”.
**-notfile** *patternList*
Sets the list of patterns used by **runAllTests** to determine what test files to skip. Default value is “**l.\*.test**”, so that any SCCS lock files are skipped.
**-relateddir** *patternList*
Sets the list of patterns used by **runAllTests** to determine what subdirectories to search for an **all.tcl** file. Default value is “**\***”.
**-asidefromdir** *patternList*
Sets the list of patterns used by **runAllTests** to determine what subdirectories to skip when searching for an **all.tcl** file. Default value is an empty list.
**-match** *patternList*
Set the list of patterns used by **test** to determine whether a test should be run. Default value is “**\***”.
**-skip** *patternList*
Set the list of patterns used by **test** to determine whether a test should be skipped. Default value is an empty list.
**-load** *script*
Sets a script to be evaluated by **loadTestedCommands**. Default value is an empty script.
**-loadfile** *filename*
Sets the filename from which to read a script to be evaluated by **loadTestedCommands**. This is an alternative to **-load**. They cannot be used together.
**-outfile** *filename*
Sets the file to which all output produced by tcltest should be written. A file named *filename* will be **[open](open.htm)**ed for writing, and the resulting channel will be set as the value of **outputChannel**.
**-errfile** *filename*
Sets the file to which all error output produced by tcltest should be written. A file named *filename* will be **[open](open.htm)**ed for writing, and the resulting channel will be set as the value of **errorChannel**.
Creating test suites with tcltest
---------------------------------
The fundamental element of a test suite is the individual **test** command. We begin with several examples.
1. Test of a script that returns normally.
```
**test** example-1.0 {normal return} {
format %s value
} value
```
2. Test of a script that requires context setup and cleanup. Note the bracing and indenting style that avoids any need for line continuation.
```
**test** example-1.1 {test file existence} -setup {
set file [makeFile {} test]
} -body {
file exists $file
} -cleanup {
removeFile test
} -result 1
```
3. Test of a script that raises an error.
```
**test** example-1.2 {error return} -body {
error message
} -returnCodes error -result message
```
4. Test with a constraint.
```
**test** example-1.3 {user owns created files} -constraints {
unix
} -setup {
set file [makeFile {} test]
} -body {
file attributes $file -owner
} -cleanup {
removeFile test
} -result $::tcl_platform(user)
```
At the next higher layer of organization, several **test** commands are gathered together into a single test file. Test files should have names with the “**.test**” extension, because that is the default pattern used by **runAllTests** to find test files. It is a good rule of thumb to have one test file for each source code file of your project. It is good practice to edit the test file and the source code file together, keeping tests synchronized with code changes.
Most of the code in the test file should be the **test** commands. Use constraints to skip tests, rather than conditional evaluation of **test**.
1. Recommended system for writing conditional tests, using constraints to guard:
```
**testConstraint** X [expr $myRequirement]
**test** goodConditionalTest {} X {
# body
} result
```
2. Discouraged system for writing conditional tests, using **[if](if.htm)** to guard:
```
if $myRequirement {
**test** badConditionalTest {} {
#body
} result
}
```
Use the **-setup** and **-cleanup** options to establish and release all context requirements of the test body. Do not make tests depend on prior tests in the file. Those prior tests might be skipped. If several consecutive tests require the same context, the appropriate setup and cleanup scripts may be stored in variable for passing to each tests **-setup** and **-cleanup** options. This is a better solution than performing setup outside of **test** commands, because the setup will only be done if necessary, and any errors during setup will be reported, and not cause the test file to abort.
A test file should be able to be combined with other test files and not interfere with them, even when **configure -singleproc 1** causes all files to be evaluated in a common interpreter. A simple way to achieve this is to have your tests define all their commands and variables in a namespace that is deleted when the test file evaluation is complete. A good namespace to use is a child namespace **test** of the namespace of the module you are testing.
A test file should also be able to be evaluated directly as a script, not depending on being called by a master **runAllTests**. This means that each test file should process command line arguments to give the tester all the configuration control that **tcltest** provides.
After all **test**s in a test file, the command **cleanupTests** should be called.
1. Here is a sketch of a sample test file illustrating those points:
```
package require tcltest 2.2
eval **::tcltest::configure** $argv
package require example
namespace eval ::example::test {
namespace import ::tcltest::*
**testConstraint** X [expr {...}]
variable SETUP {#common setup code}
variable CLEANUP {#common cleanup code}
**test** example-1 {} -setup $SETUP -body {
# First test
} -cleanup $CLEANUP -result {...}
**test** example-2 {} -constraints X -setup $SETUP -body {
# Second test; constrained
} -cleanup $CLEANUP -result {...}
**test** example-3 {} {
# Third test; no context required
} {...}
**cleanupTests**
}
namespace delete ::example::test
```
The next level of organization is a full test suite, made up of several test files. One script is used to control the entire suite. The basic function of this script is to call **runAllTests** after doing any necessary setup. This script is usually named **all.tcl** because that is the default name used by **runAllTests** when combining multiple test suites into one testing run.
1. Here is a sketch of a sample test suite master script:
```
package require Tcl 8.4
package require tcltest 2.2
package require example
**::tcltest::configure** -testdir \
[file dirname [file normalize [info script]]]
eval **::tcltest::configure** $argv
**::tcltest::runAllTests**
```
Compatibility
-------------
A number of commands and variables in the **::tcltest** namespace provided by earlier releases of **tcltest** have not been documented here. They are no longer part of the supported public interface of **tcltest** and should not be used in new test suites. However, to continue to support existing test suites written to the older interface specifications, many of those deprecated commands and variables still work as before. For example, in many circumstances, **configure** will be automatically called shortly after **[package require](package.htm)** **tcltest 2.1** succeeds with arguments from the variable **::argv**. This is to support test suites that depend on the old behavior that **tcltest** was automatically configured from command line arguments. New test files should not depend on this, but should explicitly include
```
eval **::tcltest::configure** $::argv
```
or
```
**::tcltest::configure** {*}$::argv
```
to establish a configuration from command line arguments.
Known issues
------------
There are two known issues related to nested evaluations of **test**. The first issue relates to the stack level in which test scripts are executed. Tests nested within other tests may be executed at the same stack level as the outermost test. For example, in the following code:
```
**test** level-1.1 {level 1} {
-body {
**test** level-2.1 {level 2} {
}
}
}
```
any script executed in level-2.1 may be executed at the same stack level as the script defined for level-1.1.
In addition, while two **test**s have been run, results will only be reported by **cleanupTests** for tests at the same level as test level-1.1. However, test results for all tests run prior to level-1.1 will be available when test level-2.1 runs. What this means is that if you try to access the test results for test level-2.1, it will may say that “m” tests have run, “n” tests have been skipped, “o” tests have passed and “p” tests have failed, where “m”, “n”, “o”, and “p” refer to tests that were run at the same test level as test level-1.1.
Implementation of output and error comparison in the test command depends on usage of **[puts](puts.htm)** in your application code. Output is intercepted by redefining the global **[puts](puts.htm)** command while the defined test script is being run. Errors thrown by C procedures or printed directly from C applications will not be caught by the **test** command. Therefore, usage of the **-output** and **-errorOutput** options to **test** is useful only for pure Tcl applications that use **[puts](puts.htm)** to produce output.
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/tcltest.htm>
| programming_docs |
tcl_tk safe safe
====
[NAME](safe.htm#M2) safe — Creating and manipulating safe interpreters
[SYNOPSIS](safe.htm#M3)
[OPTIONS](safe.htm#M4)
[DESCRIPTION](safe.htm#M5)
[COMMANDS](safe.htm#M6)
[**::safe::interpCreate** ?*slave*? ?*options...*?](safe.htm#M7)
[**::safe::interpInit** *slave* ?*options...*?](safe.htm#M8)
[**::safe::interpConfigure** *slave* ?*options...*?](safe.htm#M9)
[**::safe::interpDelete** *slave*](safe.htm#M10)
[**::safe::interpFindInAccessPath** *slave* *directory*](safe.htm#M11)
[**::safe::interpAddToAccessPath** *slave* *directory*](safe.htm#M12)
[**::safe::setLogCmd** ?*cmd arg...*?](safe.htm#M13)
[OPTIONS](safe.htm#M14)
[**-accessPath** *directoryList*](safe.htm#M15)
[**-statics** *boolean*](safe.htm#M16)
[**-noStatics**](safe.htm#M17)
[**-nested** *boolean*](safe.htm#M18)
[**-nestedLoadOk**](safe.htm#M19)
[**-deleteHook** *script*](safe.htm#M20)
[ALIASES](safe.htm#M21)
[**source** *fileName*](safe.htm#M22)
[**load** *fileName*](safe.htm#M23)
[**file** ?*subCmd args...*?](safe.htm#M24)
[**encoding** ?*subCmd args...*?](safe.htm#M25)
[**exit**](safe.htm#M26)
[SECURITY](safe.htm#M27)
[SEE ALSO](safe.htm#M28)
[KEYWORDS](safe.htm#M29)
Name
----
safe — Creating and manipulating safe interpreters Synopsis
--------
**::safe::interpCreate** ?*slave*? ?*options...*?
**::safe::interpInit** *slave* ?*options...*?
**::safe::interpConfigure** *slave* ?*options...*?
**::safe::interpDelete** *slave*
**::safe::interpAddToAccessPath** *slave* *directory*
**::safe::interpFindInAccessPath** *slave* *directory*
**::safe::setLogCmd** ?*cmd arg...*?
### Options
?**-accessPath** *pathList*? ?**-statics** *boolean*? ?**-noStatics**? ?**-nested** *boolean*? ?**-nestedLoadOk**? ?**-deleteHook** *script*? Description
-----------
Safe Tcl is a mechanism for executing untrusted Tcl scripts safely and for providing mediated access by such scripts to potentially dangerous functionality. Safe Tcl ensures that untrusted Tcl scripts cannot harm the hosting application. It prevents integrity and privacy attacks. Untrusted Tcl scripts are prevented from corrupting the state of the hosting application or computer. Untrusted scripts are also prevented from disclosing information stored on the hosting computer or in the hosting application to any party.
Safe Tcl allows a master interpreter to create safe, restricted interpreters that contain a set of predefined aliases for the **[source](source.htm)**, **[load](load.htm)**, **[file](file.htm)**, **[encoding](encoding.htm)**, and **[exit](exit.htm)** commands and are able to use the auto-loading and package mechanisms.
No knowledge of the file system structure is leaked to the safe interpreter, because it has access only to a virtualized path containing tokens. When the safe interpreter requests to source a file, it uses the token in the virtual path as part of the file name to source; the master interpreter transparently translates the token into a real directory name and executes the requested operation (see the section **[SECURITY](#M27)** below for details). Different levels of security can be selected by using the optional flags of the commands described below.
All commands provided in the master interpreter by Safe Tcl reside in the **safe** namespace.
Commands
--------
The following commands are provided in the master interpreter:
**::safe::interpCreate** ?*slave*? ?*options...*?
Creates a safe interpreter, installs the aliases described in the section **[ALIASES](#M21)** and initializes the auto-loading and package mechanism as specified by the supplied *options*. See the **[OPTIONS](#M14)** section below for a description of the optional arguments. If the *slave* argument is omitted, a name will be generated. **::safe::interpCreate** always returns the interpreter name.
**::safe::interpInit** *slave* ?*options...*?
This command is similar to **interpCreate** except it that does not create the safe interpreter. *slave* must have been created by some other means, like **[interp create](interp.htm)** **-safe**.
**::safe::interpConfigure** *slave* ?*options...*?
If no *options* are given, returns the settings for all options for the named safe interpreter as a list of options and their current values for that *slave*. If a single additional argument is provided, it will return a list of 2 elements *name* and *value* where *name* is the full name of that option and *value* the current value for that option and the *slave*. If more than two additional arguments are provided, it will reconfigure the safe interpreter and change each and only the provided options. See the section on **[OPTIONS](#M14)** below for options description. Example of use:
```
# Create new interp with the same configuration as "$i0":
set i1 [safe::interpCreate {*}[safe::interpConfigure $i0]]
# Get the current deleteHook
set dh [safe::interpConfigure $i0 -del]
# Change (only) the statics loading ok attribute of an
# interp and its deleteHook (leaving the rest unchanged):
safe::interpConfigure $i0 -delete {foo bar} -statics 0
```
**::safe::interpDelete** *slave*
Deletes the safe interpreter and cleans up the corresponding master interpreter data structures. If a *deleteHook* script was specified for this interpreter it is evaluated before the interpreter is deleted, with the name of the interpreter as an additional argument.
**::safe::interpFindInAccessPath** *slave* *directory*
This command finds and returns the token for the real directory *directory* in the safe interpreter's current virtual access path. It generates an error if the directory is not found. Example of use:
```
$slave eval [list set tk_library \
[::safe::interpFindInAccessPath $name $tk_library]]
```
**::safe::interpAddToAccessPath** *slave* *directory*
This command adds *directory* to the virtual path maintained for the safe interpreter in the master, and returns the token that can be used in the safe interpreter to obtain access to files in that directory. If the directory is already in the virtual path, it only returns the token without adding the directory to the virtual path again. Example of use:
```
$slave eval [list set tk_library \
[::safe::interpAddToAccessPath $name $tk_library]]
```
**::safe::setLogCmd** ?*cmd arg...*?
This command installs a script that will be called when interesting life cycle events occur for a safe interpreter. When called with no arguments, it returns the currently installed script. When called with one argument, an empty string, the currently installed script is removed and logging is turned off. The script will be invoked with one additional argument, a string describing the event of interest. The main purpose is to help in debugging safe interpreters. Using this facility you can get complete error messages while the safe interpreter gets only generic error messages. This prevents a safe interpreter from seeing messages about failures and other events that might contain sensitive information such as real directory names. Example of use:
```
::safe::setLogCmd puts stderr
```
Below is the output of a sample session in which a safe interpreter attempted to source a file not found in its virtual access path. Note that the safe interpreter only received an error message saying that the file was not found:
```
NOTICE for slave interp10 : Created
NOTICE for slave interp10 : Setting accessPath=(/foo/bar) staticsok=1 nestedok=0 deletehook=()
NOTICE for slave interp10 : auto_path in interp10 has been set to {$p(:0:)}
ERROR for slave interp10 : /foo/bar/init.tcl: no such file or directory
```
### Options
The following options are common to **::safe::interpCreate**, **::safe::interpInit**, and **::safe::interpConfigure**. Any option name can be abbreviated to its minimal non-ambiguous name. Option names are not case sensitive.
**-accessPath** *directoryList*
This option sets the list of directories from which the safe interpreter can **[source](source.htm)** and **[load](load.htm)** files. If this option is not specified, or if it is given as the empty list, the safe interpreter will use the same directories as its master for auto-loading. See the section **[SECURITY](#M27)** below for more detail about virtual paths, tokens and access control.
**-statics** *boolean*
This option specifies if the safe interpreter will be allowed to load statically linked packages (like **load {} Tk**). The default value is **true** : safe interpreters are allowed to load statically linked packages.
**-noStatics**
This option is a convenience shortcut for **-statics false** and thus specifies that the safe interpreter will not be allowed to load statically linked packages.
**-nested** *boolean*
This option specifies if the safe interpreter will be allowed to load packages into its own sub-interpreters. The default value is **false** : safe interpreters are not allowed to load packages into their own sub-interpreters.
**-nestedLoadOk**
This option is a convenience shortcut for **-nested true** and thus specifies the safe interpreter will be allowed to load packages into its own sub-interpreters.
**-deleteHook** *script*
When this option is given a non-empty *script*, it will be evaluated in the master with the name of the safe interpreter as an additional argument just before actually deleting the safe interpreter. Giving an empty value removes any currently installed deletion hook script for that safe interpreter. The default value (**{}**) is not to have any deletion call back.
Aliases
-------
The following aliases are provided in a safe interpreter:
**source** *fileName*
The requested file, a Tcl source file, is sourced into the safe interpreter if it is found. The **[source](source.htm)** alias can only source files from directories in the virtual path for the safe interpreter. The **[source](source.htm)** alias requires the safe interpreter to use one of the token names in its virtual path to denote the directory in which the file to be sourced can be found. See the section on **[SECURITY](#M27)** for more discussion of restrictions on valid filenames.
**load** *fileName*
The requested file, a shared object file, is dynamically loaded into the safe interpreter if it is found. The filename must contain a token name mentioned in the virtual path for the safe interpreter for it to be found successfully. Additionally, the shared object file must contain a safe entry point; see the manual page for the **[load](load.htm)** command for more details.
**file** ?*subCmd args...*?
The **[file](file.htm)** alias provides access to a safe subset of the subcommands of the **[file](file.htm)** command; it allows only **dirname**, **join**, **extension**, **root**, **tail**, **pathname** and **split** subcommands. For more details on what these subcommands do see the manual page for the **[file](file.htm)** command.
**encoding** ?*subCmd args...*?
The **[encoding](encoding.htm)** alias provides access to a safe subset of the subcommands of the **[encoding](encoding.htm)** command; it disallows setting of the system encoding, but allows all other subcommands including **system** to check the current encoding.
**exit**
The calling interpreter is deleted and its computation is stopped, but the Tcl process in which this interpreter exists is not terminated.
Security
--------
Safe Tcl does not attempt to completely prevent annoyance and denial of service attacks. These forms of attack prevent the application or user from temporarily using the computer to perform useful work, for example by consuming all available CPU time or all available screen real estate. These attacks, while aggravating, are deemed to be of lesser importance in general than integrity and privacy attacks that Safe Tcl is to prevent. The commands available in a safe interpreter, in addition to the safe set as defined in **[interp](interp.htm)** manual page, are mediated aliases for **[source](source.htm)**, **[load](load.htm)**, **[exit](exit.htm)**, and safe subsets of **[file](file.htm)** and **[encoding](encoding.htm)**. The safe interpreter can also auto-load code and it can request that packages be loaded.
Because some of these commands access the local file system, there is a potential for information leakage about its directory structure. To prevent this, commands that take file names as arguments in a safe interpreter use tokens instead of the real directory names. These tokens are translated to the real directory name while a request to, e.g., source a file is mediated by the master interpreter. This virtual path system is maintained in the master interpreter for each safe interpreter created by **::safe::interpCreate** or initialized by **::safe::interpInit** and the path maps tokens accessible in the safe interpreter into real path names on the local file system thus preventing safe interpreters from gaining knowledge about the structure of the file system of the host on which the interpreter is executing. The only valid file names arguments for the **[source](source.htm)** and **[load](load.htm)** aliases provided to the slave are path in the form of **[file join** *token filename***]** (i.e. when using the native file path formats: *token***/***filename* on Unix and *token***\***filename* on Windows), where *token* is representing one of the directories of the *accessPath* list and *filename* is one file in that directory (no sub directories access are allowed).
When a token is used in a safe interpreter in a request to source or load a file, the token is checked and translated to a real path name and the file to be sourced or loaded is located on the file system. The safe interpreter never gains knowledge of the actual path name under which the file is stored on the file system.
To further prevent potential information leakage from sensitive files that are accidentally included in the set of files that can be sourced by a safe interpreter, the **[source](source.htm)** alias restricts access to files meeting the following constraints: the file name must fourteen characters or shorter, must not contain more than one dot (“**.**”), must end up with the extension (“**.tcl**”) or be called (“**tclIndex**”.)
Each element of the initial access path list will be assigned a token that will be set in the slave **[auto\_path](tclvars.htm)** and the first element of that list will be set as the **[tcl\_library](tclvars.htm)** for that slave.
If the access path argument is not given or is the empty list, the default behavior is to let the slave access the same packages as the master has access to (Or to be more precise: only packages written in Tcl (which by definition cannot be dangerous as they run in the slave interpreter) and C extensions that provides a \_SafeInit entry point). For that purpose, the master's **[auto\_path](tclvars.htm)** will be used to construct the slave access path. In order that the slave successfully loads the Tcl library files (which includes the auto-loading mechanism itself) the **[tcl\_library](tclvars.htm)** will be added or moved to the first position if necessary, in the slave access path, so the slave **[tcl\_library](tclvars.htm)** will be the same as the master's (its real path will still be invisible to the slave though). In order that auto-loading works the same for the slave and the master in this by default case, the first-level sub directories of each directory in the master **[auto\_path](tclvars.htm)** will also be added (if not already included) to the slave access path. You can always specify a more restrictive path for which sub directories will never be searched by explicitly specifying your directory list with the **-accessPath** flag instead of relying on this default mechanism.
When the *accessPath* is changed after the first creation or initialization (i.e. through **interpConfigure -accessPath** *list*), an **[auto\_reset](library.htm)** is automatically evaluated in the safe interpreter to synchronize its **auto\_index** with the new token list.
See also
--------
**[interp](interp.htm)**, **[library](library.htm)**, **[load](load.htm)**, **[package](package.htm)**, **[source](source.htm)**, **[unknown](unknown.htm)** [safe interpreter](#),
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/safe.htm>
tcl_tk define define
======
[NAME](define.htm#M2) oo::define, oo::objdefine — define and configure classes and objects
[SYNOPSIS](define.htm#M3)
[DESCRIPTION](define.htm#M4)
[CONFIGURING CLASSES](define.htm#M5)
[**constructor** *argList bodyScript*](define.htm#M6)
[**deletemethod** *name* ?*name ...*](define.htm#M7)
[**destructor** *bodyScript*](define.htm#M8)
[**export** *name* ?*name ...*?](define.htm#M9)
[**filter** ?*-slotOperation*? ?*methodName ...*?](define.htm#M10)
[**forward** *name cmdName* ?*arg ...*?](define.htm#M11)
[**method** *name argList bodyScript*](define.htm#M12)
[**mixin** ?*-slotOperation*? ?*className ...*?](define.htm#M13)
[**renamemethod** *fromName toName*](define.htm#M14)
[**self** *subcommand arg ...*](define.htm#M15)
[**self** *script*](define.htm#M16)
[**superclass** ?*-slotOperation*? ?*className ...*?](define.htm#M17)
[**unexport** *name* ?*name ...*?](define.htm#M18)
[**variable** ?*-slotOperation*? ?*name ...*?](define.htm#M19)
[CONFIGURING OBJECTS](define.htm#M20)
[**class** *className*](define.htm#M21)
[**deletemethod** *name* ?*name ...*](define.htm#M22)
[**export** *name* ?*name ...*?](define.htm#M23)
[**filter** ?*-slotOperation*? ?*methodName ...*?](define.htm#M24)
[**forward** *name cmdName* ?*arg ...*?](define.htm#M25)
[**method** *name argList bodyScript*](define.htm#M26)
[**mixin** ?*-slotOperation*? ?*className ...*?](define.htm#M27)
[**renamemethod** *fromName toName*](define.htm#M28)
[**unexport** *name* ?*name ...*?](define.htm#M29)
[**variable** ?*-slotOperation*? ?*name ...*?](define.htm#M30)
[SLOTTED DEFINITIONS](define.htm#M31)
[*slot* **-append** ?*member ...*?](define.htm#M32)
[*slot* **-clear**](define.htm#M33)
[*slot* **-set** ?*member ...*?](define.htm#M34)
[SLOT IMPLEMENTATION](define.htm#M35)
[*slot* **Get**](define.htm#M36)
[*slot* **Set** *elementList*](define.htm#M37)
[EXAMPLES](define.htm#M38)
[SEE ALSO](define.htm#M39)
[KEYWORDS](define.htm#M40)
Name
----
oo::define, oo::objdefine — define and configure classes and objects Synopsis
--------
package require TclOO
**oo::define** *class defScript*
**oo::define** *class subcommand arg* ?*arg ...*?
**oo::objdefine** *object defScript*
**oo::objdefine** *object subcommand arg* ?*arg ...*?
Description
-----------
The **oo::define** command is used to control the configuration of classes, and the **oo::objdefine** command is used to control the configuration of objects (including classes as instance objects), with the configuration being applied to the entity named in the *class* or the *object* argument. Configuring a class also updates the configuration of all subclasses of the class and all objects that are instances of that class or which mix it in (as modified by any per-instance configuration). The way in which the configuration is done is controlled by either the *defScript* argument or by the *subcommand* and following *arg* arguments; when the second is present, it is exactly as if all the arguments from *subcommand* onwards are made into a list and that list is used as the *defScript* argument. ### Configuring classes
The following commands are supported in the *defScript* for **oo::define**, each of which may also be used in the *subcommand* form:
**constructor** *argList bodyScript*
This creates or updates the constructor for a class. The formal arguments to the constructor (defined using the same format as for the Tcl **[proc](proc.htm)** command) will be *argList*, and the body of the constructor will be *bodyScript*. When the body of the constructor is evaluated, the current namespace of the constructor will be a namespace that is unique to the object being constructed. Within the constructor, the **[next](next.htm)** command should be used to call the superclasses' constructors. If *bodyScript* is the empty string, the constructor will be deleted.
**deletemethod** *name* ?*name ...*
This deletes each of the methods called *name* from a class. The methods must have previously existed in that class. Does not affect the superclasses of the class, nor does it affect the subclasses or instances of the class (except when they have a call chain through the class being modified).
**destructor** *bodyScript*
This creates or updates the destructor for a class. Destructors take no arguments, and the body of the destructor will be *bodyScript*. The destructor is called when objects of the class are deleted, and when called will have the object's unique namespace as the current namespace. Destructors should use the **[next](next.htm)** command to call the superclasses' destructors. Note that destructors are not called in all situations (e.g. if the interpreter is destroyed). If *bodyScript* is the empty string, the destructor will be deleted. Note that errors during the evaluation of a destructor *are not returned* to the code that causes the destruction of an object. Instead, they are passed to the currently-defined **[bgerror](bgerror.htm)** handler.
**export** *name* ?*name ...*?
This arranges for each of the named methods, *name*, to be exported (i.e. usable outside an instance through the instance object's command) by the class being defined. Note that the methods themselves may be actually defined by a superclass; subclass exports override superclass visibility, and may in turn be overridden by instances.
**filter** ?*-slotOperation*? ?*methodName ...*?
This slot (see **[SLOTTED DEFINITIONS](#M31)** below) sets or updates the list of method names that are used to guard whether method call to instances of the class may be called and what the method's results are. Each *methodName* names a single filtering method (which may be exposed or not exposed); it is not an error for a non-existent method to be named since they may be defined by subclasses. By default, this slot works by appending.
**forward** *name cmdName* ?*arg ...*?
This creates or updates a forwarded method called *name*. The method is defined be forwarded to the command called *cmdName*, with additional arguments, *arg* etc., added before those arguments specified by the caller of the method. The *cmdName* will always be resolved using the rules of the invoking objects' namespaces, i.e., when *cmdName* is not fully-qualified, the command will be searched for in each object's namespace, using the instances' namespace's path, or by looking in the global namespace. The method will be exported if *name* starts with a lower-case letter, and non-exported otherwise.
**method** *name argList bodyScript*
This creates or updates a method that is implemented as a procedure-like script. The name of the method is *name*, the formal arguments to the method (defined using the same format as for the Tcl **[proc](proc.htm)** command) will be *argList*, and the body of the method will be *bodyScript*. When the body of the method is evaluated, the current namespace of the method will be a namespace that is unique to the current object. The method will be exported if *name* starts with a lower-case letter, and non-exported otherwise; this behavior can be overridden via **export** and **unexport**.
**mixin** ?*-slotOperation*? ?*className ...*?
This slot (see **[SLOTTED DEFINITIONS](#M31)** below) sets or updates the list of additional classes that are to be mixed into all the instances of the class being defined. Each *className* argument names a single class that is to be mixed in. By default, this slot works by replacement.
**renamemethod** *fromName toName*
This renames the method called *fromName* in a class to *toName*. The method must have previously existed in the class, and *toName* must not previously refer to a method in that class. Does not affect the superclasses of the class, nor does it affect the subclasses or instances of the class (except when they have a call chain through the class being modified). Does not change the export status of the method; if it was exported before, it will be afterwards.
**self** *subcommand arg ...*
**self** *script*
This command is equivalent to calling **oo::objdefine** on the class being defined (see **[CONFIGURING OBJECTS](#M20)** below for a description of the supported values of *subcommand*). It follows the same general pattern of argument handling as the **oo::define** and **oo::objdefine** commands, and “**oo::define** *cls* **[self](self.htm)** *subcommand ...*” operates identically to “**oo::objdefine** *cls subcommand ...*”.
**superclass** ?*-slotOperation*? ?*className ...*?
This slot (see **[SLOTTED DEFINITIONS](#M31)** below) allows the alteration of the superclasses of the class being defined. Each *className* argument names one class that is to be a superclass of the defined class. Note that objects must not be changed from being classes to being non-classes or vice-versa, that an empty parent class is equivalent to **[oo::object](object.htm)**, and that the parent classes of **[oo::object](object.htm)** and **[oo::class](class.htm)** may not be modified. By default, this slot works by replacement.
**unexport** *name* ?*name ...*?
This arranges for each of the named methods, *name*, to be not exported (i.e. not usable outside the instance through the instance object's command, but instead just through the **[my](my.htm)** command visible in each object's context) by the class being defined. Note that the methods themselves may be actually defined by a superclass; subclass unexports override superclass visibility, and may be overridden by instance unexports.
**variable** ?*-slotOperation*? ?*name ...*?
This slot (see **[SLOTTED DEFINITIONS](#M31)** below) arranges for each of the named variables to be automatically made available in the methods, constructor and destructor declared by the class being defined. Each variable name must not have any namespace separators and must not look like an array access. All variables will be actually present in the instance object on which the method is executed. Note that the variable lists declared by a superclass or subclass are completely disjoint, as are variable lists declared by instances; the list of variable names is just for methods (and constructors and destructors) declared by this class. By default, this slot works by appending.
### Configuring objects
The following commands are supported in the *defScript* for **oo::objdefine**, each of which may also be used in the *subcommand* form:
**class** *className*
This allows the class of an object to be changed after creation. Note that the class's constructors are not called when this is done, and so the object may well be in an inconsistent state unless additional configuration work is done.
**deletemethod** *name* ?*name ...*
This deletes each of the methods called *name* from an object. The methods must have previously existed in that object. Does not affect the classes that the object is an instance of.
**export** *name* ?*name ...*?
This arranges for each of the named methods, *name*, to be exported (i.e. usable outside the object through the object's command) by the object being defined. Note that the methods themselves may be actually defined by a class or superclass; object exports override class visibility.
**filter** ?*-slotOperation*? ?*methodName ...*?
This slot (see **[SLOTTED DEFINITIONS](#M31)** below) sets or updates the list of method names that are used to guard whether a method call to the object may be called and what the method's results are. Each *methodName* names a single filtering method (which may be exposed or not exposed); it is not an error for a non-existent method to be named. Note that the actual list of filters also depends on the filters set upon any classes that the object is an instance of. By default, this slot works by appending.
**forward** *name cmdName* ?*arg ...*?
This creates or updates a forwarded object method called *name*. The method is defined be forwarded to the command called *cmdName*, with additional arguments, *arg* etc., added before those arguments specified by the caller of the method. Forwarded methods should be deleted using the **method** subcommand. The method will be exported if *name* starts with a lower-case letter, and non-exported otherwise.
**method** *name argList bodyScript*
This creates, updates or deletes an object method. The name of the method is *name*, the formal arguments to the method (defined using the same format as for the Tcl **[proc](proc.htm)** command) will be *argList*, and the body of the method will be *bodyScript*. When the body of the method is evaluated, the current namespace of the method will be a namespace that is unique to the object. The method will be exported if *name* starts with a lower-case letter, and non-exported otherwise.
**mixin** ?*-slotOperation*? ?*className ...*?
This slot (see **[SLOTTED DEFINITIONS](#M31)** below) sets or updates a per-object list of additional classes that are to be mixed into the object. Each argument, *className*, names a single class that is to be mixed in. By default, this slot works by replacement.
**renamemethod** *fromName toName*
This renames the method called *fromName* in an object to *toName*. The method must have previously existed in the object, and *toName* must not previously refer to a method in that object. Does not affect the classes that the object is an instance of. Does not change the export status of the method; if it was exported before, it will be afterwards.
**unexport** *name* ?*name ...*?
This arranges for each of the named methods, *name*, to be not exported (i.e. not usable outside the object through the object's command, but instead just through the **[my](my.htm)** command visible in the object's context) by the object being defined. Note that the methods themselves may be actually defined by a class; instance unexports override class visibility.
**variable** ?*-slotOperation*? ?*name ...*?
This slot (see **[SLOTTED DEFINITIONS](#M31)** below) arranges for each of the named variables to be automatically made available in the methods declared by the object being defined. Each variable name must not have any namespace separators and must not look like an array access. All variables will be actually present in the object on which the method is executed. Note that the variable lists declared by the classes and mixins of which the object is an instance are completely disjoint; the list of variable names is just for methods declared by this object. By default, this slot works by appending.
Slotted definitions
-------------------
Some of the configurable definitions of a class or object are *slotted definitions*. This means that the configuration is implemented by a slot object, that is an instance of the class **oo::Slot**, which manages a list of values (class names, variable names, etc.) that comprises the contents of the slot. The class defines three operations (as methods) that may be done on the slot:
*slot* **-append** ?*member ...*?
This appends the given *member* elements to the slot definition.
*slot* **-clear**
This sets the slot definition to the empty list.
*slot* **-set** ?*member ...*?
This replaces the slot definition with the given *member* elements.
A consequence of this is that any use of a slot's default operation where the first member argument begins with a hyphen will be an error. One of the above operations should be used explicitly in those circumstances.
### Slot implementation
Internally, slot objects also define a method **--default-operation** which is forwarded to the default operation of the slot (thus, for the class “**[variable](variable.htm)**” slot, this is forwarded to “**my -append**”), and these methods which provide the implementation interface:
*slot* **Get**
Returns a list that is the current contents of the slot. This method must always be called from a stack frame created by a call to **oo::define** or **oo::objdefine**.
*slot* **Set** *elementList*
Sets the contents of the slot to the list *elementList* and returns the empty string. This method must always be called from a stack frame created by a call to **oo::define** or **oo::objdefine**.
The implementation of these methods is slot-dependent (and responsible for accessing the correct part of the class or object definition). Slots also have an unknown method handler to tie all these pieces together, and they hide their **[destroy](../tkcmd/destroy.htm)** method so that it is not invoked inadvertently. It is *recommended* that any user changes to the slot mechanism be restricted to defining new operations whose names start with a hyphen.
Examples
--------
This example demonstrates how to use both forms of the **oo::define** and **oo::objdefine** commands (they work in the same way), as well as illustrating four of the subcommands of them.
```
oo::class create c
c create o
**oo::define** c **method** foo {} {
puts "world"
}
**oo::objdefine** o {
**method** bar {} {
my Foo "hello "
my foo
}
**forward** Foo ::puts -nonewline
**unexport** foo
}
o bar *→ prints "hello world"*
o foo *→ error "unknown method foo"*
o Foo Bar *→ error "unknown method Foo"*
**oo::objdefine** o **renamemethod** bar lollipop
o lollipop *→ prints "hello world"*
```
This example shows how additional classes can be mixed into an object. It also shows how **mixin** is a slot that supports appending:
```
oo::object create inst
inst m1 *→ error "unknown method m1"*
inst m2 *→ error "unknown method m2"*
oo::class create A {
**method** m1 {} {
puts "red brick"
}
}
**oo::objdefine** inst {
**mixin** A
}
inst m1 *→ prints "red brick"*
inst m2 *→ error "unknown method m2"*
oo::class create B {
**method** m2 {} {
puts "blue brick"
}
}
**oo::objdefine** inst {
**mixin -append** B
}
inst m1 *→ prints "red brick"*
inst m2 *→ prints "blue brick"*
```
See also
--------
**[next](next.htm)**, **[oo::class](class.htm)**, **[oo::object](object.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/define.htm>
| programming_docs |
tcl_tk binary binary
======
[NAME](binary.htm#M2) binary — Insert and extract fields from binary strings
[SYNOPSIS](binary.htm#M3)
[DESCRIPTION](binary.htm#M4)
[BINARY ENCODE AND DECODE](binary.htm#M5)
[**base64**](binary.htm#M6)
[**-maxlen** *length*](binary.htm#M7)
[**-wrapchar** *character*](binary.htm#M8)
[**-strict**](binary.htm#M9)
[**hex**](binary.htm#M10)
[**-strict**](binary.htm#M11)
[**uuencode**](binary.htm#M12)
[**-maxlen** *length*](binary.htm#M13)
[**-wrapchar** *character*](binary.htm#M14)
[**-strict**](binary.htm#M15)
[BINARY FORMAT](binary.htm#M16)
[**a**](binary.htm#M17)
[**A**](binary.htm#M18)
[**b**](binary.htm#M19)
[**B**](binary.htm#M20)
[**H**](binary.htm#M21)
[**h**](binary.htm#M22)
[**c**](binary.htm#M23)
[**s**](binary.htm#M24)
[**S**](binary.htm#M25)
[**t**](binary.htm#M26)
[**i**](binary.htm#M27)
[**I**](binary.htm#M28)
[**n**](binary.htm#M29)
[**w**](binary.htm#M30)
[**W**](binary.htm#M31)
[**m**](binary.htm#M32)
[**f**](binary.htm#M33)
[**r**](binary.htm#M34)
[**R**](binary.htm#M35)
[**d**](binary.htm#M36)
[**q**](binary.htm#M37)
[**Q**](binary.htm#M38)
[**x**](binary.htm#M39)
[**X**](binary.htm#M40)
[**@**](binary.htm#M41)
[BINARY SCAN](binary.htm#M42)
[**a**](binary.htm#M43)
[**A**](binary.htm#M44)
[**b**](binary.htm#M45)
[**B**](binary.htm#M46)
[**H**](binary.htm#M47)
[**h**](binary.htm#M48)
[**c**](binary.htm#M49)
[**s**](binary.htm#M50)
[**S**](binary.htm#M51)
[**t**](binary.htm#M52)
[**i**](binary.htm#M53)
[**I**](binary.htm#M54)
[**n**](binary.htm#M55)
[**w**](binary.htm#M56)
[**W**](binary.htm#M57)
[**m**](binary.htm#M58)
[**f**](binary.htm#M59)
[**r**](binary.htm#M60)
[**R**](binary.htm#M61)
[**d**](binary.htm#M62)
[**q**](binary.htm#M63)
[**Q**](binary.htm#M64)
[**x**](binary.htm#M65)
[**X**](binary.htm#M66)
[**@**](binary.htm#M67)
[PORTABILITY ISSUES](binary.htm#M68)
[EXAMPLES](binary.htm#M69)
[SEE ALSO](binary.htm#M70)
[KEYWORDS](binary.htm#M71)
Name
----
binary — Insert and extract fields from binary strings Synopsis
--------
**binary decode** *format* ?*-option value ...*? *data*
**binary encode** *format* ?*-option value ...*? *data*
**binary format** *formatString* ?*arg arg ...*?
**binary scan** *string formatString* ?*varName varName ...*?
Description
-----------
This command provides facilities for manipulating binary data. The subcommand **binary format** creates a binary string from normal Tcl values. For example, given the values 16 and 22, on a 32-bit architecture, it might produce an 8-byte binary string consisting of two 4-byte integers, one for each of the numbers. The subcommand **binary scan**, does the opposite: it extracts data from a binary string and returns it as ordinary Tcl string values. The **binary encode** and **binary decode** subcommands convert binary data to or from string encodings such as base64 (used in MIME messages for example). Note that other operations on binary data, such as taking a subsequence of it, getting its length, or reinterpreting it as a string in some encoding, are done by other Tcl commands (respectively **[string range](string.htm)**, **[string length](string.htm)** and **[encoding convertfrom](encoding.htm)** in the example cases). A binary string in Tcl is merely one where all the characters it contains are in the range \u0000-\u00FF.
Binary encode and decode
------------------------
When encoding binary data as a readable string, the starting binary data is passed to the **binary encode** command, together with the name of the encoding to use and any encoding-specific options desired. Data which has been encoded can be converted back to binary form using **binary decode**. The following formats and options are supported.
**base64**
The **base64** binary encoding is commonly used in mail messages and XML documents, and uses mostly upper and lower case letters and digits. It has the distinction of being able to be rewrapped arbitrarily without losing information. During encoding, the following options are supported:
**-maxlen** *length*
Indicates that the output should be split into lines of no more than *length* characters. By default, lines are not split.
**-wrapchar** *character*
Indicates that, when lines are split because of the **-maxlen** option, *character* should be used to separate lines. By default, this is a newline character, “\n”.
During decoding, the following options are supported:
**-strict**
Instructs the decoder to throw an error if it encounters whitespace characters. Otherwise it ignores them.
**hex**
The **hex** binary encoding converts each byte to a pair of hexadecimal digits in big-endian form. No options are supported during encoding. During decoding, the following options are supported:
**-strict**
Instructs the decoder to throw an error if it encounters whitespace characters. Otherwise it ignores them.
**uuencode**
The **uuencode** binary encoding used to be common for transfer of data between Unix systems and on USENET, but is less common these days, having been largely superseded by the **base64** binary encoding. During encoding, the following options are supported (though changing them may produce files that other implementations of decoders cannot process):
**-maxlen** *length*
Indicates that the output should be split into lines of no more than *length* characters. By default, lines are split every 61 characters, and this must be in the range 3 to 85 due to limitations in the encoding.
**-wrapchar** *character*
Indicates that, when lines are split because of the **-maxlen** option, *character* should be used to separate lines. By default, this is a newline character, “\n”.
During decoding, the following options are supported:
**-strict**
Instructs the decoder to throw an error if it encounters unexpected whitespace characters. Otherwise it ignores them.
Note that neither the encoder nor the decoder handle the header and footer of the uuencode format.
Binary format
-------------
The **binary format** command generates a binary string whose layout is specified by the *formatString* and whose contents come from the additional arguments. The resulting binary value is returned. The *formatString* consists of a sequence of zero or more field specifiers separated by zero or more spaces. Each field specifier is a single type character followed by an optional flag character followed by an optional numeric *count*. Most field specifiers consume one argument to obtain the value to be formatted. The type character specifies how the value is to be formatted. The *count* typically indicates how many items of the specified type are taken from the value. If present, the *count* is a non-negative decimal integer or **\***, which normally indicates that all of the items in the value are to be used. If the number of arguments does not match the number of fields in the format string that consume arguments, then an error is generated. The flag character is ignored for **binary format**.
Here is a small example to clarify the relation between the field specifiers and the arguments:
```
**binary format** d3d {1.0 2.0 3.0 4.0} 0.1
```
The first argument is a list of four numbers, but because of the count of 3 for the associated field specifier, only the first three will be used. The second argument is associated with the second field specifier. The resulting binary string contains the four numbers 1.0, 2.0, 3.0 and 0.1.
Each type-count pair moves an imaginary cursor through the binary data, storing bytes at the current position and advancing the cursor to just after the last byte stored. The cursor is initially at position 0 at the beginning of the data. The type may be any one of the following characters:
**a**
Stores a byte string of length *count* in the output string. Every character is taken as modulo 256 (i.e. the low byte of every character is used, and the high byte discarded) so when storing character strings not wholly expressible using the characters \u0000-\u00ff, the **[encoding convertto](encoding.htm)** command should be used first to change the string into an external representation if this truncation is not desired (i.e. if the characters are not part of the ISO 8859-1 character set.) If *arg* has fewer than *count* bytes, then additional zero bytes are used to pad out the field. If *arg* is longer than the specified length, the extra characters will be ignored. If *count* is **\***, then all of the bytes in *arg* will be formatted. If *count* is omitted, then one character will be formatted. For example,
```
**binary format** a7a*a alpha bravo charlie
```
will return a string equivalent to **alpha\000\000bravoc**,
```
**binary format** a* [encoding convertto utf-8 \u20ac]
```
will return a string equivalent to **\342\202\254** (which is the UTF-8 byte sequence for a Euro-currency character) and
```
**binary format** a* [encoding convertto iso8859-15 \u20ac]
```
will return a string equivalent to **\244** (which is the ISO 8859-15 byte sequence for a Euro-currency character). Contrast these last two with:
```
**binary format** a* \u20ac
```
which returns a string equivalent to **\254** (i.e. **\xac**) by truncating the high-bits of the character, and which is probably not what is desired.
**A**
This form is the same as **a** except that spaces are used for padding instead of nulls. For example,
```
**binary format** A6A*A alpha bravo charlie
```
will return **alpha bravoc**.
**b**
Stores a string of *count* binary digits in low-to-high order within each byte in the output string. *Arg* must contain a sequence of **1** and **0** characters. The resulting bytes are emitted in first to last order with the bits being formatted in low-to-high order within each byte. If *arg* has fewer than *count* digits, then zeros will be used for the remaining bits. If *arg* has more than the specified number of digits, the extra digits will be ignored. If *count* is **\***, then all of the digits in *arg* will be formatted. If *count* is omitted, then one digit will be formatted. If the number of bits formatted does not end at a byte boundary, the remaining bits of the last byte will be zeros. For example,
```
**binary format** b5b* 11100 111000011010
```
will return a string equivalent to **\x07\x87\x05**.
**B**
This form is the same as **b** except that the bits are stored in high-to-low order within each byte. For example,
```
**binary format** B5B* 11100 111000011010
```
will return a string equivalent to **\xe0\xe1\xa0**.
**H**
Stores a string of *count* hexadecimal digits in high-to-low within each byte in the output string. *Arg* must contain a sequence of characters in the set “0123456789abcdefABCDEF”. The resulting bytes are emitted in first to last order with the hex digits being formatted in high-to-low order within each byte. If *arg* has fewer than *count* digits, then zeros will be used for the remaining digits. If *arg* has more than the specified number of digits, the extra digits will be ignored. If *count* is **\***, then all of the digits in *arg* will be formatted. If *count* is omitted, then one digit will be formatted. If the number of digits formatted does not end at a byte boundary, the remaining bits of the last byte will be zeros. For example,
```
**binary format** H3H*H2 ab DEF 987
```
will return a string equivalent to **\xab\x00\xde\xf0\x98**.
**h**
This form is the same as **H** except that the digits are stored in low-to-high order within each byte. This is seldom required. For example,
```
**binary format** h3h*h2 AB def 987
```
will return a string equivalent to **\xba\x00\xed\x0f\x89**.
**c**
Stores one or more 8-bit integer values in the output string. If no *count* is specified, then *arg* must consist of an integer value. If *count* is specified, *arg* must consist of a list containing at least that many integers. The low-order 8 bits of each integer are stored as a one-byte value at the cursor position. If *count* is **\***, then all of the integers in the list are formatted. If the number of elements in the list is greater than *count*, then the extra elements are ignored. For example,
```
**binary format** c3cc* {3 -3 128 1} 260 {2 5}
```
will return a string equivalent to **\x03\xfd\x80\x04\x02\x05**, whereas
```
**binary format** c {2 5}
```
will generate an error.
**s**
This form is the same as **c** except that it stores one or more 16-bit integers in little-endian byte order in the output string. The low-order 16-bits of each integer are stored as a two-byte value at the cursor position with the least significant byte stored first. For example,
```
**binary format** s3 {3 -3 258 1}
```
will return a string equivalent to **\x03\x00\xfd\xff\x02\x01**.
**S**
This form is the same as **s** except that it stores one or more 16-bit integers in big-endian byte order in the output string. For example,
```
**binary format** S3 {3 -3 258 1}
```
will return a string equivalent to **\x00\x03\xff\xfd\x01\x02**.
**t**
This form (mnemonically *tiny*) is the same as **s** and **S** except that it stores the 16-bit integers in the output string in the native byte order of the machine where the Tcl script is running. To determine what the native byte order of the machine is, refer to the **byteOrder** element of the **[tcl\_platform](tclvars.htm)** array.
**i**
This form is the same as **c** except that it stores one or more 32-bit integers in little-endian byte order in the output string. The low-order 32-bits of each integer are stored as a four-byte value at the cursor position with the least significant byte stored first. For example,
```
**binary format** i3 {3 -3 65536 1}
```
will return a string equivalent to **\x03\x00\x00\x00\xfd\xff\xff\xff\x00\x00\x01\x00**
**I**
This form is the same as **i** except that it stores one or more one or more 32-bit integers in big-endian byte order in the output string. For example,
```
**binary format** I3 {3 -3 65536 1}
```
will return a string equivalent to **\x00\x00\x00\x03\xff\xff\xff\xfd\x00\x01\x00\x00**
**n**
This form (mnemonically *number* or *normal*) is the same as **i** and **I** except that it stores the 32-bit integers in the output string in the native byte order of the machine where the Tcl script is running. To determine what the native byte order of the machine is, refer to the **byteOrder** element of the **[tcl\_platform](tclvars.htm)** array.
**w**
This form is the same as **c** except that it stores one or more 64-bit integers in little-endian byte order in the output string. The low-order 64-bits of each integer are stored as an eight-byte value at the cursor position with the least significant byte stored first. For example,
```
**binary format** w 7810179016327718216
```
will return the string **HelloTcl**
**W**
This form is the same as **w** except that it stores one or more one or more 64-bit integers in big-endian byte order in the output string. For example,
```
**binary format** Wc 4785469626960341345 110
```
will return the string **BigEndian**
**m**
This form (mnemonically the mirror of **w**) is the same as **w** and **W** except that it stores the 64-bit integers in the output string in the native byte order of the machine where the Tcl script is running. To determine what the native byte order of the machine is, refer to the **byteOrder** element of the **[tcl\_platform](tclvars.htm)** array.
**f**
This form is the same as **c** except that it stores one or more one or more single-precision floating point numbers in the machine's native representation in the output string. This representation is not portable across architectures, so it should not be used to communicate floating point numbers across the network. The size of a floating point number may vary across architectures, so the number of bytes that are generated may vary. If the value overflows the machine's native representation, then the value of FLT\_MAX as defined by the system will be used instead. Because Tcl uses double-precision floating point numbers internally, there may be some loss of precision in the conversion to single-precision. For example, on a Windows system running on an Intel Pentium processor,
```
**binary format** f2 {1.6 3.4}
```
will return a string equivalent to **\xcd\xcc\xcc\x3f\x9a\x99\x59\x40**.
**r**
This form (mnemonically *real*) is the same as **f** except that it stores the single-precision floating point numbers in little-endian order. This conversion only produces meaningful output when used on machines which use the IEEE floating point representation (very common, but not universal.)
**R**
This form is the same as **r** except that it stores the single-precision floating point numbers in big-endian order.
**d**
This form is the same as **f** except that it stores one or more one or more double-precision floating point numbers in the machine's native representation in the output string. For example, on a Windows system running on an Intel Pentium processor,
```
**binary format** d1 {1.6}
```
will return a string equivalent to **\x9a\x99\x99\x99\x99\x99\xf9\x3f**.
**q**
This form (mnemonically the mirror of **d**) is the same as **d** except that it stores the double-precision floating point numbers in little-endian order. This conversion only produces meaningful output when used on machines which use the IEEE floating point representation (very common, but not universal.)
**Q**
This form is the same as **q** except that it stores the double-precision floating point numbers in big-endian order.
**x**
Stores *count* null bytes in the output string. If *count* is not specified, stores one null byte. If *count* is **\***, generates an error. This type does not consume an argument. For example,
```
**binary format** a3xa3x2a3 abc def ghi
```
will return a string equivalent to **abc\000def\000\000ghi**.
**X**
Moves the cursor back *count* bytes in the output string. If *count* is **\*** or is larger than the current cursor position, then the cursor is positioned at location 0 so that the next byte stored will be the first byte in the result string. If *count* is omitted then the cursor is moved back one byte. This type does not consume an argument. For example,
```
**binary format** a3X*a3X2a3 abc def ghi
```
will return **dghi**.
**@**
Moves the cursor to the absolute location in the output string specified by *count*. Position 0 refers to the first byte in the output string. If *count* refers to a position beyond the last byte stored so far, then null bytes will be placed in the uninitialized locations and the cursor will be placed at the specified location. If *count* is **\***, then the cursor is moved to the current end of the output string. If *count* is omitted, then an error will be generated. This type does not consume an argument. For example,
```
**binary format** a5@2a1@*a3@10a1 abcde f ghi j
```
will return **abfdeghi\000\000j**.
Binary scan
-----------
The **binary scan** command parses fields from a binary string, returning the number of conversions performed. *String* gives the input bytes to be parsed (one byte per character, and characters not representable as a byte have their high bits chopped) and *formatString* indicates how to parse it. Each *varName* gives the name of a variable; when a field is scanned from *string* the result is assigned to the corresponding variable. As with **binary format**, the *formatString* consists of a sequence of zero or more field specifiers separated by zero or more spaces. Each field specifier is a single type character followed by an optional flag character followed by an optional numeric *count*. Most field specifiers consume one argument to obtain the variable into which the scanned values should be placed. The type character specifies how the binary data is to be interpreted. The *count* typically indicates how many items of the specified type are taken from the data. If present, the *count* is a non-negative decimal integer or **\***, which normally indicates that all of the remaining items in the data are to be used. If there are not enough bytes left after the current cursor position to satisfy the current field specifier, then the corresponding variable is left untouched and **binary scan** returns immediately with the number of variables that were set. If there are not enough arguments for all of the fields in the format string that consume arguments, then an error is generated. The flag character “u” may be given to cause some types to be read as unsigned values. The flag is accepted for all field types but is ignored for non-integer fields.
A similar example as with **binary format** should explain the relation between field specifiers and arguments in case of the binary scan subcommand:
```
**binary scan** $bytes s3s first second
```
This command (provided the binary string in the variable *bytes* is long enough) assigns a list of three integers to the variable *first* and assigns a single value to the variable *second*. If *bytes* contains fewer than 8 bytes (i.e. four 2-byte integers), no assignment to *second* will be made, and if *bytes* contains fewer than 6 bytes (i.e. three 2-byte integers), no assignment to *first* will be made. Hence:
```
puts [**binary scan** abcdefg s3s first second]
puts $first
puts $second
```
will print (assuming neither variable is set previously):
```
1
25185 25699 26213
can't read "second": no such variable
```
It is *important* to note that the **c**, **s**, and **S** (and **i** and **I** on 64bit systems) will be scanned into long data size values. In doing this, values that have their high bit set (0x80 for chars, 0x8000 for shorts, 0x80000000 for ints), will be sign extended. Thus the following will occur:
```
set signShort [**binary format** s1 0x8000]
**binary scan** $signShort s1 val; *# val == 0xFFFF8000*
```
If you require unsigned values you can include the “u” flag character following the field type. For example, to read an unsigned short value:
```
set signShort [**binary format** s1 0x8000]
**binary scan** $signShort su1 val; *# val == 0x00008000*
```
Each type-count pair moves an imaginary cursor through the binary data, reading bytes from the current position. The cursor is initially at position 0 at the beginning of the data. The type may be any one of the following characters:
**a**
The data is a byte string of length *count*. If *count* is **\***, then all of the remaining bytes in *string* will be scanned into the variable. If *count* is omitted, then one byte will be scanned. All bytes scanned will be interpreted as being characters in the range \u0000-\u00ff so the **[encoding convertfrom](encoding.htm)** command will be needed if the string is not a binary string or a string encoded in ISO 8859-1. For example,
```
**binary scan** abcde\000fghi a6a10 var1 var2
```
will return **1** with the string equivalent to **abcde\000** stored in *var1* and *var2* left unmodified, and
```
**binary scan** \342\202\254 a* var1
set var2 [encoding convertfrom utf-8 $var1]
```
will store a Euro-currency character in *var2*.
**A**
This form is the same as **a**, except trailing blanks and nulls are stripped from the scanned value before it is stored in the variable. For example,
```
**binary scan** "abc efghi \000" A* var1
```
will return **1** with **abc efghi** stored in *var1*.
**b**
The data is turned into a string of *count* binary digits in low-to-high order represented as a sequence of “1” and “0” characters. The data bytes are scanned in first to last order with the bits being taken in low-to-high order within each byte. Any extra bits in the last byte are ignored. If *count* is **\***, then all of the remaining bits in *string* will be scanned. If *count* is omitted, then one bit will be scanned. For example,
```
**binary scan** \x07\x87\x05 b5b* var1 var2
```
will return **2** with **11100** stored in *var1* and **1110000110100000** stored in *var2*.
**B**
This form is the same as **b**, except the bits are taken in high-to-low order within each byte. For example,
```
**binary scan** \x70\x87\x05 B5B* var1 var2
```
will return **2** with **01110** stored in *var1* and **1000011100000101** stored in *var2*.
**H**
The data is turned into a string of *count* hexadecimal digits in high-to-low order represented as a sequence of characters in the set “0123456789abcdef”. The data bytes are scanned in first to last order with the hex digits being taken in high-to-low order within each byte. Any extra bits in the last byte are ignored. If *count* is **\***, then all of the remaining hex digits in *string* will be scanned. If *count* is omitted, then one hex digit will be scanned. For example,
```
**binary scan** \x07\xC6\x05\x1f\x34 H3H* var1 var2
```
will return **2** with **07c** stored in *var1* and **051f34** stored in *var2*.
**h**
This form is the same as **H**, except the digits are taken in reverse (low-to-high) order within each byte. For example,
```
**binary scan** \x07\x86\x05\x12\x34 h3h* var1 var2
```
will return **2** with **706** stored in *var1* and **502143** stored in *var2*. Note that most code that wishes to parse the hexadecimal digits from multiple bytes in order should use the **H** format.
**c**
The data is turned into *count* 8-bit signed integers and stored in the corresponding variable as a list. If *count* is **\***, then all of the remaining bytes in *string* will be scanned. If *count* is omitted, then one 8-bit integer will be scanned. For example,
```
**binary scan** \x07\x86\x05 c2c* var1 var2
```
will return **2** with **7 -122** stored in *var1* and **5** stored in *var2*. Note that the integers returned are signed, but they can be converted to unsigned 8-bit quantities using an expression like:
```
set num [expr { $num & 0xff }]
```
**s**
The data is interpreted as *count* 16-bit signed integers represented in little-endian byte order. The integers are stored in the corresponding variable as a list. If *count* is **\***, then all of the remaining bytes in *string* will be scanned. If *count* is omitted, then one 16-bit integer will be scanned. For example,
```
**binary scan** \x05\x00\x07\x00\xf0\xff s2s* var1 var2
```
will return **2** with **5 7** stored in *var1* and **-16** stored in *var2*. Note that the integers returned are signed, but they can be converted to unsigned 16-bit quantities using an expression like:
```
set num [expr { $num & 0xffff }]
```
**S**
This form is the same as **s** except that the data is interpreted as *count* 16-bit signed integers represented in big-endian byte order. For example,
```
**binary scan** \x00\x05\x00\x07\xff\xf0 S2S* var1 var2
```
will return **2** with **5 7** stored in *var1* and **-16** stored in *var2*.
**t**
The data is interpreted as *count* 16-bit signed integers represented in the native byte order of the machine running the Tcl script. It is otherwise identical to **s** and **S**. To determine what the native byte order of the machine is, refer to the **byteOrder** element of the **[tcl\_platform](tclvars.htm)** array.
**i**
The data is interpreted as *count* 32-bit signed integers represented in little-endian byte order. The integers are stored in the corresponding variable as a list. If *count* is **\***, then all of the remaining bytes in *string* will be scanned. If *count* is omitted, then one 32-bit integer will be scanned. For example,
```
set str \x05\x00\x00\x00\x07\x00\x00\x00\xf0\xff\xff\xff
**binary scan** $str i2i* var1 var2
```
will return **2** with **5 7** stored in *var1* and **-16** stored in *var2*. Note that the integers returned are signed, but they can be converted to unsigned 32-bit quantities using an expression like:
```
set num [expr { $num & 0xffffffff }]
```
**I**
This form is the same as **I** except that the data is interpreted as *count* 32-bit signed integers represented in big-endian byte order. For example,
```
set str \x00\x00\x00\x05\x00\x00\x00\x07\xff\xff\xff\xf0
**binary scan** $str I2I* var1 var2
```
will return **2** with **5 7** stored in *var1* and **-16** stored in *var2*.
**n**
The data is interpreted as *count* 32-bit signed integers represented in the native byte order of the machine running the Tcl script. It is otherwise identical to **i** and **I**. To determine what the native byte order of the machine is, refer to the **byteOrder** element of the **[tcl\_platform](tclvars.htm)** array.
**w**
The data is interpreted as *count* 64-bit signed integers represented in little-endian byte order. The integers are stored in the corresponding variable as a list. If *count* is **\***, then all of the remaining bytes in *string* will be scanned. If *count* is omitted, then one 64-bit integer will be scanned. For example,
```
set str \x05\x00\x00\x00\x07\x00\x00\x00\xf0\xff\xff\xff
**binary scan** $str wi* var1 var2
```
will return **2** with **30064771077** stored in *var1* and **-16** stored in *var2*. Note that the integers returned are signed and cannot be represented by Tcl as unsigned values.
**W**
This form is the same as **w** except that the data is interpreted as *count* 64-bit signed integers represented in big-endian byte order. For example,
```
set str \x00\x00\x00\x05\x00\x00\x00\x07\xff\xff\xff\xf0
**binary scan** $str WI* var1 var2
```
will return **2** with **21474836487** stored in *var1* and **-16** stored in *var2*.
**m**
The data is interpreted as *count* 64-bit signed integers represented in the native byte order of the machine running the Tcl script. It is otherwise identical to **w** and **W**. To determine what the native byte order of the machine is, refer to the **byteOrder** element of the **[tcl\_platform](tclvars.htm)** array.
**f**
The data is interpreted as *count* single-precision floating point numbers in the machine's native representation. The floating point numbers are stored in the corresponding variable as a list. If *count* is **\***, then all of the remaining bytes in *string* will be scanned. If *count* is omitted, then one single-precision floating point number will be scanned. The size of a floating point number may vary across architectures, so the number of bytes that are scanned may vary. If the data does not represent a valid floating point number, the resulting value is undefined and compiler dependent. For example, on a Windows system running on an Intel Pentium processor,
```
**binary scan** \x3f\xcc\xcc\xcd f var1
```
will return **1** with **1.6000000238418579** stored in *var1*.
**r**
This form is the same as **f** except that the data is interpreted as *count* single-precision floating point number in little-endian order. This conversion is not portable to the minority of systems not using IEEE floating point representations.
**R**
This form is the same as **f** except that the data is interpreted as *count* single-precision floating point number in big-endian order. This conversion is not portable to the minority of systems not using IEEE floating point representations.
**d**
This form is the same as **f** except that the data is interpreted as *count* double-precision floating point numbers in the machine's native representation. For example, on a Windows system running on an Intel Pentium processor,
```
**binary scan** \x9a\x99\x99\x99\x99\x99\xf9\x3f d var1
```
will return **1** with **1.6000000000000001** stored in *var1*.
**q**
This form is the same as **d** except that the data is interpreted as *count* double-precision floating point number in little-endian order. This conversion is not portable to the minority of systems not using IEEE floating point representations.
**Q**
This form is the same as **d** except that the data is interpreted as *count* double-precision floating point number in big-endian order. This conversion is not portable to the minority of systems not using IEEE floating point representations.
**x**
Moves the cursor forward *count* bytes in *string*. If *count* is **\*** or is larger than the number of bytes after the current cursor position, then the cursor is positioned after the last byte in *string*. If *count* is omitted, then the cursor is moved forward one byte. Note that this type does not consume an argument. For example,
```
**binary scan** \x01\x02\x03\x04 x2H* var1
```
will return **1** with **0304** stored in *var1*.
**X**
Moves the cursor back *count* bytes in *string*. If *count* is **\*** or is larger than the current cursor position, then the cursor is positioned at location 0 so that the next byte scanned will be the first byte in *string*. If *count* is omitted then the cursor is moved back one byte. Note that this type does not consume an argument. For example,
```
**binary scan** \x01\x02\x03\x04 c2XH* var1 var2
```
will return **2** with **1 2** stored in *var1* and **020304** stored in *var2*.
**@**
Moves the cursor to the absolute location in the data string specified by *count*. Note that position 0 refers to the first byte in *string*. If *count* refers to a position beyond the end of *string*, then the cursor is positioned after the last byte. If *count* is omitted, then an error will be generated. For example,
```
**binary scan** \x01\x02\x03\x04 c2@1H* var1 var2
```
will return **2** with **1 2** stored in *var1* and **020304** stored in *var2*.
Portability issues
------------------
The **r**, **R**, **q** and **Q** conversions will only work reliably for transferring data between computers which are all using IEEE floating point representations. This is very common, but not universal. To transfer floating-point numbers portably between all architectures, use their textual representation (as produced by **[format](format.htm)**) instead. Examples
--------
This is a procedure to write a Tcl string to a binary-encoded channel as UTF-8 data preceded by a length word:
```
proc *writeString* {channel string} {
set data [encoding convertto utf-8 $string]
puts -nonewline [**binary format** Ia* \
[string length $data] $data]
}
```
This procedure reads a string from a channel that was written by the previously presented *writeString* procedure:
```
proc *readString* {channel} {
if {![**binary scan** [read $channel 4] I length]} {
error "missing length"
}
set data [read $channel $length]
return [encoding convertfrom utf-8 $data]
}
```
This converts the contents of a file (named in the variable *filename*) to base64 and prints them:
```
set f [open $filename rb]
set data [read $f]
close $f
puts [**binary encode** base64 -maxlen 64 $data]
```
See also
--------
**[encoding](encoding.htm)**, **[format](format.htm)**, **[scan](scan.htm)**, **[string](string.htm)**, **[tcl\_platform](tclvars.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/binary.htm>
| programming_docs |
tcl_tk file file
====
[NAME](file.htm#M2) file — Manipulate file names and attributes
[SYNOPSIS](file.htm#M3)
[DESCRIPTION](file.htm#M4)
[**file atime** *name* ?*time*?](file.htm#M5)
[**file attributes** *name*](file.htm#M6)
[**file attributes** *name* ?*option*?](file.htm#M7)
[**file attributes** *name* ?*option value option value...*?](file.htm#M8)
[**file channels** ?*pattern*?](file.htm#M9)
[**file copy** ?**-force**? ?**--**? *source* *target*](file.htm#M10)
[**file copy** ?**-force**? ?**--**? *source* ?*source* ...? *targetDir*](file.htm#M11)
[**file delete** ?**-force**? ?**--**? ?*pathname* ... ?](file.htm#M12)
[**file dirname** *name*](file.htm#M13)
[**file executable** *name*](file.htm#M14)
[**file exists** *name*](file.htm#M15)
[**file extension** *name*](file.htm#M16)
[**file isdirectory** *name*](file.htm#M17)
[**file isfile** *name*](file.htm#M18)
[**file join** *name* ?*name ...*?](file.htm#M19)
[**file link** ?*-linktype*? *linkName* ?*target*?](file.htm#M20)
[**file lstat** *name varName*](file.htm#M21)
[**file mkdir** ?*dir* ...?](file.htm#M22)
[**file mtime** *name* ?*time*?](file.htm#M23)
[**file nativename** *name*](file.htm#M24)
[**file normalize** *name*](file.htm#M25)
[**file owned** *name*](file.htm#M26)
[**file pathtype** *name*](file.htm#M27)
[**file readable** *name*](file.htm#M28)
[**file readlink** *name*](file.htm#M29)
[**file rename** ?**-force**? ?**--**? *source* *target*](file.htm#M30)
[**file rename** ?**-force**? ?**--**? *source* ?*source* ...? *targetDir*](file.htm#M31)
[**file rootname** *name*](file.htm#M32)
[**file separator** ?*name*?](file.htm#M33)
[**file size** *name*](file.htm#M34)
[**file split** *name*](file.htm#M35)
[**file stat** *name varName*](file.htm#M36)
[**file system** *name*](file.htm#M37)
[**file tail** *name*](file.htm#M38)
[**file tempfile** ?*nameVar*? ?*template*?](file.htm#M39)
[**file type** *name*](file.htm#M40)
[**file volumes**](file.htm#M41)
[**file writable** *name*](file.htm#M42)
[PORTABILITY ISSUES](file.htm#M43)
[**Unix**](file.htm#M44)
[**Windows**](file.htm#M45)
[EXAMPLES](file.htm#M46)
[SEE ALSO](file.htm#M47)
[KEYWORDS](file.htm#M48)
Name
----
file — Manipulate file names and attributes Synopsis
--------
**file** *option* *name* ?*arg arg ...*?
Description
-----------
This command provides several operations on a file's name or attributes. *Name* is the name of a file; if it starts with a tilde, then tilde substitution is done before executing the command (see the manual entry for **[filename](filename.htm)** for details). *Option* indicates what to do with the file name. Any unique abbreviation for *option* is acceptable. The valid options are:
**file atime** *name* ?*time*?
Returns a decimal string giving the time at which file *name* was last accessed. If *time* is specified, it is an access time to set for the file. The time is measured in the standard POSIX fashion as seconds from a fixed starting time (often January 1, 1970). If the file does not exist or its access time cannot be queried or set then an error is generated. On Windows, FAT file systems do not support access time.
**file attributes** *name*
**file attributes** *name* ?*option*?
**file attributes** *name* ?*option value option value...*?
This subcommand returns or sets platform specific values associated with a file. The first form returns a list of the platform specific flags and their values. The second form returns the value for the specific option. The third form sets one or more of the values. The values are as follows: On Unix, **-group** gets or sets the group name for the file. A group id can be given to the command, but it returns a group name. **-owner** gets or sets the user name of the owner of the file. The command returns the owner name, but the numerical id can be passed when setting the owner. **-permissions** sets or retrieves the octal code that chmod(1) uses. This command does also has limited support for setting using the symbolic attributes for chmod(1), of the form [ugo]?[[+-=][rwxst],[...]], where multiple symbolic attributes can be separated by commas (example: **u+s,go-rw** add sticky bit for user, remove read and write permissions for group and other). A simplified **ls** style string, of the form rwxrwxrwx (must be 9 characters), is also supported (example: **rwxr-xr-t** is equivalent to 01755). On versions of Unix supporting file flags, **-readonly** gives the value or sets or clears the readonly attribute of the file, i.e. the user immutable flag **uchg** to chflags(1).
On Windows, **-archive** gives the value or sets or clears the archive attribute of the file. **-hidden** gives the value or sets or clears the hidden attribute of the file. **-longname** will expand each path element to its long version. This attribute cannot be set. **-readonly** gives the value or sets or clears the readonly attribute of the file. **-shortname** gives a string where every path element is replaced with its short (8.3) version of the name. This attribute cannot be set. **-system** gives or sets or clears the value of the system attribute of the file.
On Mac OS X and Darwin, **-creator** gives or sets the Finder creator type of the file. **-hidden** gives or sets or clears the hidden attribute of the file. **-readonly** gives or sets or clears the readonly attribute of the file. **-rsrclength** gives the length of the resource fork of the file, this attribute can only be set to the value 0, which results in the resource fork being stripped off the file.
**file channels** ?*pattern*?
If *pattern* is not specified, returns a list of names of all registered open channels in this interpreter. If *pattern* is specified, only those names matching *pattern* are returned. Matching is determined using the same rules as for **[string match](string.htm)**.
**file copy** ?**-force**? ?**--**? *source* *target*
**file copy** ?**-force**? ?**--**? *source* ?*source* ...? *targetDir*
The first form makes a copy of the file or directory *source* under the pathname *target*. If *target* is an existing directory, then the second form is used. The second form makes a copy inside *targetDir* of each *source* file listed. If a directory is specified as a *source*, then the contents of the directory will be recursively copied into *targetDir*. Existing files will not be overwritten unless the **-force** option is specified (when Tcl will also attempt to adjust permissions on the destination file or directory if that is necessary to allow the copy to proceed). When copying within a single filesystem, *file copy* will copy soft links (i.e. the links themselves are copied, not the things they point to). Trying to overwrite a non-empty directory, overwrite a directory with a file, or overwrite a file with a directory will all result in errors even if **-force** was specified. Arguments are processed in the order specified, halting at the first error, if any. A **--** marks the end of switches; the argument following the **--** will be treated as a *source* even if it starts with a **-**.
**file delete** ?**-force**? ?**--**? ?*pathname* ... ?
Removes the file or directory specified by each *pathname* argument. Non-empty directories will be removed only if the **-force** option is specified. When operating on symbolic links, the links themselves will be deleted, not the objects they point to. Trying to delete a non-existent file is not considered an error. Trying to delete a read-only file will cause the file to be deleted, even if the **-force** flags is not specified. If the **-force** option is specified on a directory, Tcl will attempt both to change permissions and move the current directory “pwd” out of the given path if that is necessary to allow the deletion to proceed. Arguments are processed in the order specified, halting at the first error, if any. A **--** marks the end of switches; the argument following the **--** will be treated as a *pathname* even if it starts with a **-**.
**file dirname** *name*
Returns a name comprised of all of the path components in *name* excluding the last element. If *name* is a relative file name and only contains one path element, then returns “**.**”. If *name* refers to a root directory, then the root directory is returned. For example,
```
**file dirname** c:/
```
returns **c:/**.
Note that tilde substitution will only be performed if it is necessary to complete the command. For example,
```
**file dirname** ~/src/foo.c
```
returns **~/src**, whereas
```
**file dirname** ~
```
returns **/home** (or something similar).
**file executable** *name*
Returns **1** if file *name* is executable by the current user, **0** otherwise. On Windows, which does not have an executable attribute, the command treats all directories and any files with extensions **exe**, **com**, **cmd** or **bat** as executable.
**file exists** *name*
Returns **1** if file *name* exists and the current user has search privileges for the directories leading to it, **0** otherwise.
**file extension** *name*
Returns all of the characters in *name* after and including the last dot in the last element of *name*. If there is no dot in the last element of *name* then returns the empty string.
**file isdirectory** *name*
Returns **1** if file *name* is a directory, **0** otherwise.
**file isfile** *name*
Returns **1** if file *name* is a regular file, **0** otherwise.
**file join** *name* ?*name ...*?
Takes one or more file names and combines them, using the correct path separator for the current platform. If a particular *name* is relative, then it will be joined to the previous file name argument. Otherwise, any earlier arguments will be discarded, and joining will proceed from the current argument. For example,
```
**file join** a b /foo bar
```
returns **/foo/bar**.
Note that any of the names can contain separators, and that the result is always canonical for the current platform: **/** for Unix and Windows.
**file link** ?*-linktype*? *linkName* ?*target*?
If only one argument is given, that argument is assumed to be *linkName*, and this command returns the value of the link given by *linkName* (i.e. the name of the file it points to). If *linkName* is not a link or its value cannot be read (as, for example, seems to be the case with hard links, which look just like ordinary files), then an error is returned. If 2 arguments are given, then these are assumed to be *linkName* and *target*. If *linkName* already exists, or if *target* does not exist, an error will be returned. Otherwise, Tcl creates a new link called *linkName* which points to the existing filesystem object at *target* (which is also the returned value), where the type of the link is platform-specific (on Unix a symbolic link will be the default). This is useful for the case where the user wishes to create a link in a cross-platform way, and does not care what type of link is created.
If the user wishes to make a link of a specific type only, (and signal an error if for some reason that is not possible), then the optional *-linktype* argument should be given. Accepted values for *-linktype* are “**-symbolic**” and “**-hard**”.
On Unix, symbolic links can be made to relative paths, and those paths must be relative to the actual *linkName*'s location (not to the cwd), but on all other platforms where relative links are not supported, target paths will always be converted to absolute, normalized form before the link is created (and therefore relative paths are interpreted as relative to the cwd). Furthermore, “~user” paths are always expanded to absolute form. When creating links on filesystems that either do not support any links, or do not support the specific type requested, an error message will be returned. Most Unix platforms support both symbolic and hard links (the latter for files only). Windows supports symbolic directory links and hard file links on NTFS drives.
**file lstat** *name varName*
Same as **stat** option (see below) except uses the *lstat* kernel call instead of *stat*. This means that if *name* refers to a symbolic link the information returned in *varName* is for the link rather than the file it refers to. On systems that do not support symbolic links this option behaves exactly the same as the **stat** option.
**file mkdir** ?*dir* ...?
Creates each directory specified. For each pathname *dir* specified, this command will create all non-existing parent directories as well as *dir* itself. If an existing directory is specified, then no action is taken and no error is returned. Trying to overwrite an existing file with a directory will result in an error. Arguments are processed in the order specified, halting at the first error, if any.
**file mtime** *name* ?*time*?
Returns a decimal string giving the time at which file *name* was last modified. If *time* is specified, it is a modification time to set for the file (equivalent to Unix **touch**). The time is measured in the standard POSIX fashion as seconds from a fixed starting time (often January 1, 1970). If the file does not exist or its modified time cannot be queried or set then an error is generated.
**file nativename** *name*
Returns the platform-specific name of the file. This is useful if the filename is needed to pass to a platform-specific call, such as to a subprocess via **[exec](exec.htm)** under Windows (see **[EXAMPLES](#M46)** below).
**file normalize** *name*
Returns a unique normalized path representation for the file-system object (file, directory, link, etc), whose string value can be used as a unique identifier for it. A normalized path is an absolute path which has all “../” and “./” removed. Also it is one which is in the “standard” format for the native platform. On Unix, this means the segments leading up to the path must be free of symbolic links/aliases (but the very last path component may be a symbolic link), and on Windows it also means we want the long form with that form's case-dependence (which gives us a unique, case-dependent path). The one exception concerning the last link in the path is necessary, because Tcl or the user may wish to operate on the actual symbolic link itself (for example **file delete**, **file rename**, **file copy** are defined to operate on symbolic links, not on the things that they point to).
**file owned** *name*
Returns **1** if file *name* is owned by the current user, **0** otherwise.
**file pathtype** *name*
Returns one of **absolute**, **relative**, **volumerelative**. If *name* refers to a specific file on a specific volume, the path type will be **absolute**. If *name* refers to a file relative to the current working directory, then the path type will be **relative**. If *name* refers to a file relative to the current working directory on a specified volume, or to a specific file on the current working volume, then the path type is **volumerelative**.
**file readable** *name*
Returns **1** if file *name* is readable by the current user, **0** otherwise.
**file readlink** *name*
Returns the value of the symbolic link given by *name* (i.e. the name of the file it points to). If *name* is not a symbolic link or its value cannot be read, then an error is returned. On systems that do not support symbolic links this option is undefined.
**file rename** ?**-force**? ?**--**? *source* *target*
**file rename** ?**-force**? ?**--**? *source* ?*source* ...? *targetDir*
The first form takes the file or directory specified by pathname *source* and renames it to *target*, moving the file if the pathname *target* specifies a name in a different directory. If *target* is an existing directory, then the second form is used. The second form moves each *source* file or directory into the directory *targetDir*. Existing files will not be overwritten unless the **-force** option is specified. When operating inside a single filesystem, Tcl will rename symbolic links rather than the things that they point to. Trying to overwrite a non-empty directory, overwrite a directory with a file, or a file with a directory will all result in errors. Arguments are processed in the order specified, halting at the first error, if any. A **--** marks the end of switches; the argument following the **--** will be treated as a *source* even if it starts with a **-**.
**file rootname** *name*
Returns all of the characters in *name* up to but not including the last “.” character in the last component of name. If the last component of *name* does not contain a dot, then returns *name*.
**file separator** ?*name*?
If no argument is given, returns the character which is used to separate path segments for native files on this platform. If a path is given, the filesystem responsible for that path is asked to return its separator character. If no file system accepts *name*, an error is generated.
**file size** *name*
Returns a decimal string giving the size of file *name* in bytes. If the file does not exist or its size cannot be queried then an error is generated.
**file split** *name*
Returns a list whose elements are the path components in *name*. The first element of the list will have the same path type as *name*. All other elements will be relative. Path separators will be discarded unless they are needed to ensure that an element is unambiguously relative. For example, under Unix
```
**file split** /foo/~bar/baz
```
returns “**/ foo ./~bar baz**” to ensure that later commands that use the third component do not attempt to perform tilde substitution.
**file stat** *name varName*
Invokes the **stat** kernel call on *name*, and uses the variable given by *varName* to hold information returned from the kernel call. *VarName* is treated as an array variable, and the following elements of that variable are set: **atime**, **ctime**, **dev**, **gid**, **ino**, **mode**, **mtime**, **nlink**, **size**, **type**, **uid**. Each element except **type** is a decimal string with the value of the corresponding field from the **stat** return structure; see the manual entry for **stat** for details on the meanings of the values. The **type** element gives the type of the file in the same form returned by the command **file type**. This command returns an empty string.
**file system** *name*
Returns a list of one or two elements, the first of which is the name of the filesystem to use for the file, and the second, if given, an arbitrary string representing the filesystem-specific nature or type of the location within that filesystem. If a filesystem only supports one type of file, the second element may not be supplied. For example the native files have a first element “native”, and a second element which when given is a platform-specific type name for the file's system (e.g. “NTFS”, “FAT”, on Windows). A generic virtual file system might return the list “vfs ftp” to represent a file on a remote ftp site mounted as a virtual filesystem through an extension called “vfs”. If the file does not belong to any filesystem, an error is generated.
**file tail** *name*
Returns all of the characters in the last filesystem component of *name*. Any trailing directory separator in *name* is ignored. If *name* contains no separators then returns *name*. So, **file tail a/b**, **file tail a/b/** and **file tail b** all return **b**.
**file tempfile** ?*nameVar*? ?*template*?
Creates a temporary file and returns a read-write channel opened on that file. If the *nameVar* is given, it specifies a variable that the name of the temporary file will be written into; if absent, Tcl will attempt to arrange for the temporary file to be deleted once it is no longer required. If the *template* is present, it specifies parts of the template of the filename to use when creating it (such as the directory, base-name or extension) though some platforms may ignore some or all of these parts and use a built-in default instead. Note that temporary files are *only* ever created on the native filesystem. As such, they can be relied upon to be used with operating-system native APIs and external programs that require a filename.
**file type** *name*
Returns a string giving the type of file *name*, which will be one of **file**, **directory**, **characterSpecial**, **blockSpecial**, **fifo**, **link**, or **[socket](socket.htm)**.
**file volumes**
Returns the absolute paths to the volumes mounted on the system, as a proper Tcl list. Without any virtual filesystems mounted as root volumes, on UNIX, the command will always return “/”, since all filesystems are locally mounted. On Windows, it will return a list of the available local drives (e.g. “a:/ c:/”). If any virtual filesystem has mounted additional volumes, they will be in the returned list.
**file writable** *name*
Returns **1** if file *name* is writable by the current user, **0** otherwise.
Portability issues
------------------
**Unix**
These commands always operate using the real user and group identifiers, not the effective ones.
**Windows**
The **file owned** subcommand uses the user identifier (SID) of the process token, not the thread token which may be impersonating some other user.
Examples
--------
This procedure shows how to search for C files in a given directory that have a correspondingly-named object file in the current directory:
```
proc findMatchingCFiles {dir} {
set files {}
switch $::tcl_platform(platform) {
windows {
set ext .obj
}
unix {
set ext .o
}
}
foreach file [glob -nocomplain -directory $dir *.c] {
set objectFile [**file tail** [**file rootname** $file]]$ext
if {[**file exists** $objectFile]} {
lappend files $file
}
}
return $files
}
```
Rename a file and leave a symbolic link pointing from the old location to the new place:
```
set oldName foobar.txt
set newName foo/bar.txt
# Make sure that where we're going to move to exists...
if {![**file isdirectory** [**file dirname** $newName]]} {
**file mkdir** [**file dirname** $newName]
}
**file rename** $oldName $newName
**file link** -symbolic $oldName $newName
```
On Windows, a file can be “started” easily enough (equivalent to double-clicking on it in the Explorer interface) but the name passed to the operating system must be in native format:
```
exec {*}[auto_execok start] {} [**file nativename** ~/example.txt]
```
See also
--------
**[filename](filename.htm)**, **[open](open.htm)**, **[close](close.htm)**, **[eof](eof.htm)**, **[gets](gets.htm)**, **[tell](tell.htm)**, **[seek](seek.htm)**, **[fblocked](fblocked.htm)**, **[flush](flush.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/file.htm>
| programming_docs |
tcl_tk join join
====
Name
----
join — Create a string by joining together list elements Synopsis
--------
**join** *list* ?*joinString*?
Description
-----------
The *list* argument must be a valid Tcl list. This command returns the string formed by joining all of the elements of *list* together with *joinString* separating each adjacent pair of elements. The *joinString* argument defaults to a space character. Examples
--------
Making a comma-separated list:
```
set data {1 2 3 4 5}
**join** $data ", "
**→ 1, 2, 3, 4, 5**
```
Using **join** to flatten a list by a single level:
```
set data {1 {2 3} 4 {5 {6 7} 8}}
**join** $data
**→ 1 2 3 4 5 {6 7} 8**
```
See also
--------
**[list](list.htm)**, **[lappend](lappend.htm)**, **[split](split.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/join.htm>
tcl_tk pkgMkIndex pkgMkIndex
==========
[NAME](pkgmkindex.htm#M2) pkg\_mkIndex — Build an index for automatic loading of packages
[SYNOPSIS](pkgmkindex.htm#M3)
[DESCRIPTION](pkgmkindex.htm#M4)
[OPTIONS](pkgmkindex.htm#M5)
[**-direct**](pkgmkindex.htm#M6)
[**-lazy**](pkgmkindex.htm#M7)
[**-load** *pkgPat*](pkgmkindex.htm#M8)
[**-verbose**](pkgmkindex.htm#M9)
[**--**](pkgmkindex.htm#M10)
[PACKAGES AND THE AUTO-LOADER](pkgmkindex.htm#M11)
[HOW IT WORKS](pkgmkindex.htm#M12)
[DIRECT LOADING](pkgmkindex.htm#M13)
[COMPLEX CASES](pkgmkindex.htm#M14)
[SEE ALSO](pkgmkindex.htm#M15)
[KEYWORDS](pkgmkindex.htm#M16)
Name
----
pkg\_mkIndex — Build an index for automatic loading of packages Synopsis
--------
**pkg\_mkIndex** ?*options...*? *dir* ?*pattern pattern ...*?
Description
-----------
**Pkg\_mkIndex** is a utility procedure that is part of the standard Tcl library. It is used to create index files that allow packages to be loaded automatically when **[package require](package.htm)** commands are executed. To use **pkg\_mkIndex**, follow these steps:
1. Create the package(s). Each package may consist of one or more Tcl script files or binary files. Binary files must be suitable for loading with the **[load](load.htm)** command with a single argument; for example, if the file is **test.so** it must be possible to load this file with the command **load test.so**. Each script file must contain a **[package provide](package.htm)** command to declare the package and version number, and each binary file must contain a call to **[Tcl\_PkgProvide](https://www.tcl.tk/man/tcl/TclLib/PkgRequire.htm)**.
2. Create the index by invoking **pkg\_mkIndex**. The *dir* argument gives the name of a directory and each *pattern* argument is a **[glob](glob.htm)**-style pattern that selects script or binary files in *dir*. The default pattern is **\*.tcl** and **\*.[info sharedlibextension]**. **Pkg\_mkIndex** will create a file **pkgIndex.tcl** in *dir* with package information about all the files given by the *pattern* arguments. It does this by loading each file into a slave interpreter and seeing what packages and new commands appear (this is why it is essential to have **[package provide](package.htm)** commands or **[Tcl\_PkgProvide](https://www.tcl.tk/man/tcl/TclLib/PkgRequire.htm)** calls in the files, as described above). If you have a package split among scripts and binary files, or if you have dependencies among files, you may have to use the **-load** option or adjust the order in which **pkg\_mkIndex** processes the files. See **[COMPLEX CASES](#M14)** below.
3. Install the package as a subdirectory of one of the directories given by the **[tcl\_pkgPath](tclvars.htm)** variable. If **$tcl\_pkgPath** contains more than one directory, machine-dependent packages (e.g., those that contain binary shared libraries) should normally be installed under the first directory and machine-independent packages (e.g., those that contain only Tcl scripts) should be installed under the second directory. The subdirectory should include the package's script and/or binary files as well as the **pkgIndex.tcl** file. As long as the package is installed as a subdirectory of a directory in **$tcl\_pkgPath** it will automatically be found during **[package require](package.htm)** commands. If you install the package anywhere else, then you must ensure that the directory containing the package is in the **[auto\_path](tclvars.htm)** global variable or an immediate subdirectory of one of the directories in **[auto\_path](tclvars.htm)**. **[Auto\_path](tclvars.htm)** contains a list of directories that are searched by both the auto-loader and the package loader; by default it includes **$tcl\_pkgPath**. The package loader also checks all of the subdirectories of the directories in **[auto\_path](tclvars.htm)**. You can add a directory to **[auto\_path](tclvars.htm)** explicitly in your application, or you can add the directory to your **TCLLIBPATH** environment variable: if this environment variable is present, Tcl initializes **[auto\_path](tclvars.htm)** from it during application startup.
4. Once the above steps have been taken, all you need to do to use a package is to invoke **[package require](package.htm)**. For example, if versions 2.1, 2.3, and 3.1 of package **Test** have been indexed by **pkg\_mkIndex**, the command **package require Test** will make version 3.1 available and the command **package require -exact Test 2.1** will make version 2.1 available. There may be many versions of a package in the various index files in **[auto\_path](tclvars.htm)**, but only one will actually be loaded in a given interpreter, based on the first call to **[package require](package.htm)**. Different versions of a package may be loaded in different interpreters.
Options
-------
The optional switches are:
**-direct**
The generated index will implement direct loading of the package upon **[package require](package.htm)**. This is the default.
**-lazy**
The generated index will manage to delay loading the package until the use of one of the commands provided by the package, instead of loading it immediately upon **[package require](package.htm)**. This is not compatible with the use of *auto\_reset*, and therefore its use is discouraged.
**-load** *pkgPat*
The index process will pre-load any packages that exist in the current interpreter and match *pkgPat* into the slave interpreter used to generate the index. The pattern match uses string match rules, but without making case distinctions. See **[COMPLEX CASES](#M14)** below.
**-verbose**
Generate output during the indexing process. Output is via the **tclLog** procedure, which by default prints to stderr.
**--**
End of the flags, in case *dir* begins with a dash.
Packages and the auto-loader
----------------------------
The package management facilities overlap somewhat with the auto-loader, in that both arrange for files to be loaded on-demand. However, package management is a higher-level mechanism that uses the auto-loader for the last step in the loading process. It is generally better to index a package with **pkg\_mkIndex** rather than **[auto\_mkindex](library.htm)** because the package mechanism provides version control: several versions of a package can be made available in the index files, with different applications using different versions based on **[package require](package.htm)** commands. In contrast, **[auto\_mkindex](library.htm)** does not understand versions so it can only handle a single version of each package. It is probably not a good idea to index a given package with both **pkg\_mkIndex** and **[auto\_mkindex](library.htm)**. If you use **pkg\_mkIndex** to index a package, its commands cannot be invoked until **[package require](package.htm)** has been used to select a version; in contrast, packages indexed with **[auto\_mkindex](library.htm)** can be used immediately since there is no version control. How it works
------------
**Pkg\_mkIndex** depends on the **[package unknown](package.htm)** command, the **[package ifneeded](package.htm)** command, and the auto-loader. The first time a **[package require](package.htm)** command is invoked, the **[package unknown](package.htm)** script is invoked. This is set by Tcl initialization to a script that evaluates all of the **pkgIndex.tcl** files in the **[auto\_path](tclvars.htm)**. The **pkgIndex.tcl** files contain **[package ifneeded](package.htm)** commands for each version of each available package; these commands invoke **[package provide](package.htm)** commands to announce the availability of the package, and they setup auto-loader information to load the files of the package. If the **-lazy** flag was provided when the **pkgIndex.tcl** was generated, a given file of a given version of a given package is not actually loaded until the first time one of its commands is invoked. Thus, after invoking **[package require](package.htm)** you may not see the package's commands in the interpreter, but you will be able to invoke the commands and they will be auto-loaded. Direct loading
--------------
Some packages, for instance packages which use namespaces and export commands or those which require special initialization, might select that their package files be loaded immediately upon **[package require](package.htm)** instead of delaying the actual loading to the first use of one of the package's command. This is the default mode when generating the package index. It can be overridden by specifying the **-lazy** argument. Complex cases
-------------
Most complex cases of dependencies among scripts and binary files, and packages being split among scripts and binary files are handled OK. However, you may have to adjust the order in which files are processed by **pkg\_mkIndex**. These issues are described in detail below. If each script or file contains one package, and packages are only contained in one file, then things are easy. You simply specify all files to be indexed in any order with some glob patterns.
In general, it is OK for scripts to have dependencies on other packages. If scripts contain **[package require](package.htm)** commands, these are stubbed out in the interpreter used to process the scripts, so these do not cause problems. If scripts call into other packages in global code, these calls are handled by a stub **[unknown](unknown.htm)** command. However, if scripts make variable references to other package's variables in global code, these will cause errors. That is also bad coding style.
If binary files have dependencies on other packages, things can become tricky because it is not possible to stub out C-level APIs such as **[Tcl\_PkgRequire](https://www.tcl.tk/man/tcl/TclLib/PkgRequire.htm)** API when loading a binary file. For example, suppose the BLT package requires Tk, and expresses this with a call to **[Tcl\_PkgRequire](https://www.tcl.tk/man/tcl/TclLib/PkgRequire.htm)** in its **Blt\_Init** routine. To support this, you must run **pkg\_mkIndex** in an interpreter that has Tk loaded. You can achieve this with the **-load** *pkgPat* option. If you specify this option, **pkg\_mkIndex** will load any packages listed by **[info loaded](info.htm)** and that match *pkgPat* into the interpreter used to process files. In most cases this will satisfy the **[Tcl\_PkgRequire](https://www.tcl.tk/man/tcl/TclLib/PkgRequire.htm)** calls made by binary files.
If you are indexing two binary files and one depends on the other, you should specify the one that has dependencies last. This way the one without dependencies will get loaded and indexed, and then the package it provides will be available when the second file is processed. You may also need to load the first package into the temporary interpreter used to create the index by using the **-load** flag; it will not hurt to specify package patterns that are not yet loaded.
If you have a package that is split across scripts and a binary file, then you should avoid the **-load** flag. The problem is that if you load a package before computing the index it masks any other files that provide part of the same package. If you must use **-load**, then you must specify the scripts first; otherwise the package loaded from the binary file may mask the package defined by the scripts.
See also
--------
**[package](package.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/pkgMkIndex.htm>
tcl_tk package package
=======
[NAME](package.htm#M2) package — Facilities for package loading and version control
[SYNOPSIS](package.htm#M3)
[DESCRIPTION](package.htm#M4)
[**package forget** ?*package package ...*?](package.htm#M5)
[**package ifneeded** *package version* ?*script*?](package.htm#M6)
[**package names**](package.htm#M7)
[**package present** ?**-exact**? *package* ?*requirement...*?](package.htm#M8)
[**package provide** *package* ?*version*?](package.htm#M9)
[**package require** *package* ?*requirement...*?](package.htm#M10)
[**package require -exact** *package version*](package.htm#M11)
[**package unknown** ?*command*?](package.htm#M12)
[**package vcompare** *version1 version2*](package.htm#M13)
[**package versions** *package*](package.htm#M14)
[**package vsatisfies** *version requirement...*](package.htm#M15)
[min](package.htm#M16)
[min-](package.htm#M17)
[min-max](package.htm#M18)
[**package prefer** ?**latest**|**stable**?](package.htm#M19)
[VERSION NUMBERS](package.htm#M20)
[PACKAGE INDICES](package.htm#M21)
[EXAMPLES](package.htm#M22)
[SEE ALSO](package.htm#M23)
[KEYWORDS](package.htm#M24)
Name
----
package — Facilities for package loading and version control Synopsis
--------
**package forget** ?*package package ...*?
**package ifneeded** *package version* ?*script*?
**package names**
**package present** *package* ?*requirement...*?
**package present -exact** *package version*
**package provide** *package* ?*version*?
**package require** *package* ?*requirement...*?
**package require -exact** *package version*
**package unknown** ?*command*?
**package vcompare** *version1 version2*
**package versions** *package*
**package vsatisfies** *version requirement...*
**package prefer** ?**latest**|**stable**?
Description
-----------
This command keeps a simple database of the packages available for use by the current interpreter and how to load them into the interpreter. It supports multiple versions of each package and arranges for the correct version of a package to be loaded based on what is needed by the application. This command also detects and reports version clashes. Typically, only the **package require** and **package provide** commands are invoked in normal Tcl scripts; the other commands are used primarily by system scripts that maintain the package database. The behavior of the **package** command is determined by its first argument. The following forms are permitted:
**package forget** ?*package package ...*?
Removes all information about each specified package from this interpreter, including information provided by both **package ifneeded** and **package provide**.
**package ifneeded** *package version* ?*script*?
This command typically appears only in system configuration scripts to set up the package database. It indicates that a particular version of a particular package is available if needed, and that the package can be added to the interpreter by executing *script*. The script is saved in a database for use by subsequent **package require** commands; typically, *script* sets up auto-loading for the commands in the package (or calls **[load](load.htm)** and/or **[source](source.htm)** directly), then invokes **package provide** to indicate that the package is present. There may be information in the database for several different versions of a single package. If the database already contains information for *package* and *version*, the new *script* replaces the existing one. If the *script* argument is omitted, the current script for version *version* of package *package* is returned, or an empty string if no **package ifneeded** command has been invoked for this *package* and *version*.
**package names**
Returns a list of the names of all packages in the interpreter for which a version has been provided (via **package provide**) or for which a **package ifneeded** script is available. The order of elements in the list is arbitrary.
**package present** ?**-exact**? *package* ?*requirement...*?
This command is equivalent to **package require** except that it does not try and load the package if it is not already loaded.
**package provide** *package* ?*version*?
This command is invoked to indicate that version *version* of package *package* is now present in the interpreter. It is typically invoked once as part of an **ifneeded** script, and again by the package itself when it is finally loaded. An error occurs if a different version of *package* has been provided by a previous **package provide** command. If the *version* argument is omitted, then the command returns the version number that is currently provided, or an empty string if no **package provide** command has been invoked for *package* in this interpreter.
**package require** *package* ?*requirement...*?
This command is typically invoked by Tcl code that wishes to use a particular version of a particular package. The arguments indicate which package is wanted, and the command ensures that a suitable version of the package is loaded into the interpreter. If the command succeeds, it returns the version number that is loaded; otherwise it generates an error. A suitable version of the package is any version which satisfies at least one of the requirements, per the rules of **package vsatisfies**. If multiple versions are suitable the implementation with the highest version is chosen. This last part is additionally influenced by the selection mode set with **package prefer**.
In the “stable” selection mode the command will select the highest stable version satisfying the requirements, if any. If no stable version satisfies the requirements, the highest unstable version satisfying the requirements will be selected. In the “latest” selection mode the command will accept the highest version satisfying all the requirements, regardless of its stableness.
If a version of *package* has already been provided (by invoking the **package provide** command), then its version number must satisfy the *requirement*s and the command returns immediately. Otherwise, the command searches the database of information provided by previous **package ifneeded** commands to see if an acceptable version of the package is available. If so, the script for the highest acceptable version number is evaluated in the global namespace; it must do whatever is necessary to load the package, including calling **package provide** for the package. If the **package ifneeded** database does not contain an acceptable version of the package and a **package unknown** command has been specified for the interpreter then that command is evaluated in the global namespace; when it completes, Tcl checks again to see if the package is now provided or if there is a **package ifneeded** script for it. If all of these steps fail to provide an acceptable version of the package, then the command returns an error.
**package require -exact** *package version*
This form of the command is used when only the given *version* of *package* is acceptable to the caller. This command is equivalent to **package require** *package version*-*version*.
**package unknown** ?*command*?
This command supplies a “last resort” command to invoke during **package require** if no suitable version of a package can be found in the **package ifneeded** database. If the *command* argument is supplied, it contains the first part of a command; when the command is invoked during a **package require** command, Tcl appends one or more additional arguments giving the desired package name and requirements. For example, if *command* is **foo bar** and later the command **package require test 2.4** is invoked, then Tcl will execute the command **foo bar test 2.4** to load the package. If no requirements are supplied to the **package require** command, then only the name will be added to invoked command. If the **package unknown** command is invoked without a *command* argument, then the current **package unknown** script is returned, or an empty string if there is none. If *command* is specified as an empty string, then the current **package unknown** script is removed, if there is one.
**package vcompare** *version1 version2*
Compares the two version numbers given by *version1* and *version2*. Returns -1 if *version1* is an earlier version than *version2*, 0 if they are equal, and 1 if *version1* is later than *version2*.
**package versions** *package*
Returns a list of all the version numbers of *package* for which information has been provided by **package ifneeded** commands.
**package vsatisfies** *version requirement...*
Returns 1 if the *version* satisfies at least one of the given requirements, and 0 otherwise. Each *requirement* is allowed to have any of the forms:
min
This form is called “min-bounded”.
min-
This form is called “min-unbound”.
min-max
This form is called “bounded”.
where “min” and “max” are valid version numbers. The legacy syntax is a special case of the extended syntax, keeping backward compatibility. Regarding satisfaction the rules are:
1. The *version* has to pass at least one of the listed *requirement*s to be satisfactory.
2. A version satisfies a “bounded” requirement when
1. For *min* equal to the *max* if, and only if the *version* is equal to the *min*.
2. Otherwise if, and only if the *version* is greater than or equal to the *min*, and less than the *max*, where both *min* and *max* have been padded internally with “a0”. Note that while the comparison to *min* is inclusive, the comparison to *max* is exclusive.
3. A “min-bounded” requirement is a “bounded” requirement in disguise, with the *max* part implicitly specified as the next higher major version number of the *min* part. A version satisfies it per the rules above.
4. A *version* satisfies a “min-unbound” requirement if, and only if it is greater than or equal to the *min*, where the *min* has been padded internally with “a0”. There is no constraint to a maximum.
**package prefer** ?**latest**|**stable**?
With no arguments, the commands returns either “latest” or “stable”, whichever describes the current mode of selection logic used by **package require**. When passed the argument “latest”, it sets the selection logic mode to “latest”.
When passed the argument “stable”, if the mode is already “stable”, that value is kept. If the mode is already “latest”, then the attempt to set it back to “stable” is ineffective and the mode value remains “latest”.
When passed any other value as an argument, raise an invalid argument error.
When an interpreter is created, its initial selection mode value is set to “stable” unless the environment variable **TCL\_PKG\_PREFER\_LATEST** is set. If that environment variable is defined (with any value) then the initial (and permanent) selection mode value is set to “latest”.
Version numbers
---------------
Version numbers consist of one or more decimal numbers separated by dots, such as 2 or 1.162 or 3.1.13.1. The first number is called the major version number. Larger numbers correspond to later versions of a package, with leftmost numbers having greater significance. For example, version 2.1 is later than 1.3 and version 3.4.6 is later than 3.3.5. Missing fields are equivalent to zeroes: version 1.3 is the same as version 1.3.0 and 1.3.0.0, so it is earlier than 1.3.1 or 1.3.0.2. In addition, the letters “a” (alpha) and/or “b” (beta) may appear exactly once to replace a dot for separation. These letters semantically add a negative specifier into the version, where “a” is -2, and “b” is -1. Each may be specified only once, and “a” or “b” are mutually exclusive in a specifier. Thus 1.3a1 becomes (semantically) 1.3.-2.1, 1.3b1 is 1.3.-1.1. Negative numbers are not directly allowed in version specifiers. A version number not containing the letters “a” or “b” as specified above is called a **stable** version, whereas presence of the letters causes the version to be called is **unstable**. A later version number is assumed to be upwards compatible with an earlier version number as long as both versions have the same major version number. For example, Tcl scripts written for version 2.3 of a package should work unchanged under versions 2.3.2, 2.4, and 2.5.1. Changes in the major version number signify incompatible changes: if code is written to use version 2.1 of a package, it is not guaranteed to work unmodified with either version 1.7.3 or version 3.1. Package indices
---------------
The recommended way to use packages in Tcl is to invoke **package require** and **package provide** commands in scripts, and use the procedure **pkg\_mkIndex** to create package index files. Once you have done this, packages will be loaded automatically in response to **package require** commands. See the documentation for **pkg\_mkIndex** for details. Examples
--------
To state that a Tcl script requires the Tk and http packages, put this at the top of the script:
```
**package require** Tk
**package require** http
```
To test to see if the Snack package is available and load if it is (often useful for optional enhancements to programs where the loss of the functionality is not critical) do this:
```
if {[catch {**package require** Snack}]} {
# Error thrown - package not found.
# Set up a dummy interface to work around the absence
} else {
# We have the package, configure the app to use it
}
```
See also
--------
**[msgcat](msgcat.htm)**, **[packagens](packagens.htm)**, **pkgMkIndex**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/package.htm>
| programming_docs |
tcl_tk expr expr
====
[NAME](expr.htm#M2) expr — Evaluate an expression
[SYNOPSIS](expr.htm#M3)
[DESCRIPTION](expr.htm#M4)
[OPERANDS](expr.htm#M5)
[OPERATORS](expr.htm#M6)
[**- + ~ !**](expr.htm#M7)
[**\*\***](expr.htm#M8)
[**\* / %**](expr.htm#M9)
[**+ -**](expr.htm#M10)
[**<< >>**](expr.htm#M11)
[**< > <= >=**](expr.htm#M12)
[**== !=**](expr.htm#M13)
[**eq ne**](expr.htm#M14)
[**in ni**](expr.htm#M15)
[**&**](expr.htm#M16)
[**^**](expr.htm#M17)
[**|**](expr.htm#M18)
[**&&**](expr.htm#M19)
[**||**](expr.htm#M20)
[*x***?***y***:***z*](expr.htm#M21)
[MATH FUNCTIONS](expr.htm#M22)
[TYPES, OVERFLOW, AND PRECISION](expr.htm#M23)
[STRING OPERATIONS](expr.htm#M24)
[PERFORMANCE CONSIDERATIONS](expr.htm#M25)
[EXAMPLES](expr.htm#M26)
[SEE ALSO](expr.htm#M27)
[KEYWORDS](expr.htm#M28)
[COPYRIGHT](expr.htm#M29)
Name
----
expr — Evaluate an expression Synopsis
--------
**expr** *arg* ?*arg arg ...*?
Description
-----------
Concatenates *arg*s (adding separator spaces between them), evaluates the result as a Tcl expression, and returns the value. The operators permitted in Tcl expressions include a subset of the operators permitted in C expressions. For those operators common to both Tcl and C, Tcl applies the same meaning and precedence as the corresponding C operators. Expressions almost always yield numeric results (integer or floating-point values). For example, the expression
```
**expr** 8.2 + 6
```
evaluates to 14.2. Tcl expressions differ from C expressions in the way that operands are specified. Also, Tcl expressions support non-numeric operands and string comparisons, as well as some additional operators not found in C.
### Operands
A Tcl expression consists of a combination of operands, operators, parentheses and commas. White space may be used between the operands and operators and parentheses (or commas); it is ignored by the expression's instructions. Where possible, operands are interpreted as integer values. Integer values may be specified in decimal (the normal case), in binary (if the first two characters of the operand are **0b**), in octal (if the first two characters of the operand are **0o**), or in hexadecimal (if the first two characters of the operand are **0x**). For compatibility with older Tcl releases, an octal integer value is also indicated simply when the first character of the operand is **0**, whether or not the second character is also **o**. If an operand does not have one of the integer formats given above, then it is treated as a floating-point number if that is possible. Floating-point numbers may be specified in any of several common formats making use of the decimal digits, the decimal point **.**, the characters **e** or **E** indicating scientific notation, and the sign characters **+** or **-**. For example, all of the following are valid floating-point numbers: 2.1, 3., 6e4, 7.91e+16. Also recognized as floating point values are the strings **Inf** and **NaN** making use of any case for each character. If no numeric interpretation is possible (note that all literal operands that are not numeric or boolean must be quoted with either braces or with double quotes), then an operand is left as a string (and only a limited set of operators may be applied to it). Operands may be specified in any of the following ways:
1. As a numeric value, either integer or floating-point.
2. As a boolean value, using any form understood by **[string is](string.htm)** **boolean**.
3. As a Tcl variable, using standard **$** notation. The variable's value will be used as the operand.
4. As a string enclosed in double-quotes. The expression parser will perform backslash, variable, and command substitutions on the information between the quotes, and use the resulting value as the operand
5. As a string enclosed in braces. The characters between the open brace and matching close brace will be used as the operand without any substitutions.
6. As a Tcl command enclosed in brackets. The command will be executed and its result will be used as the operand.
7. As a mathematical function whose arguments have any of the above forms for operands, such as **sin($x)**. See **[MATH FUNCTIONS](#M22)** below for a discussion of how mathematical functions are handled.
Where the above substitutions occur (e.g. inside quoted strings), they are performed by the expression's instructions. However, the command parser may already have performed one round of substitution before the expression processor was called. As discussed below, it is usually best to enclose expressions in braces to prevent the command parser from performing substitutions on the contents.
For some examples of simple expressions, suppose the variable **a** has the value 3 and the variable **b** has the value 6. Then the command on the left side of each of the lines below will produce the value on the right side of the line:
```
**expr** 3.1 + $a *6.1*
**expr** 2 + "$a.$b" *5.6*
**expr** 4*[llength "6 2"] *8*
**expr** {{word one} < "word $a"} *0*
```
### Operators
The valid operators (most of which are also available as commands in the **tcl::mathop** namespace; see the **[mathop](mathop.htm)**(n) manual page for details) are listed below, grouped in decreasing order of precedence:
**- + ~ !**
Unary minus, unary plus, bit-wise NOT, logical NOT. None of these operators may be applied to string operands, and bit-wise NOT may be applied only to integers.
**\*\***
Exponentiation. Valid for any numeric operands.
**\* / %**
Multiply, divide, remainder. None of these operators may be applied to string operands, and remainder may be applied only to integers. The remainder will always have the same sign as the divisor and an absolute value smaller than the absolute value of the divisor. When applied to integers, the division and remainder operators can be considered to partition the number line into a sequence of equal-sized adjacent non-overlapping pieces where each piece is the size of the divisor; the division result identifies which piece the divisor lay within, and the remainder result identifies where within that piece the divisor lay. A consequence of this is that the result of “-57 **/** 10” is always -6, and the result of “-57 **%** 10” is always 3.
**+ -**
Add and subtract. Valid for any numeric operands.
**<< >>**
Left and right shift. Valid for integer operands only. A right shift always propagates the sign bit.
**< > <= >=**
Boolean less, greater, less than or equal, and greater than or equal. Each operator produces 1 if the condition is true, 0 otherwise. These operators may be applied to strings as well as numeric operands, in which case string comparison is used.
**== !=**
Boolean equal and not equal. Each operator produces a zero/one result. Valid for all operand types.
**eq ne**
Boolean string equal and string not equal. Each operator produces a zero/one result. The operand types are interpreted only as strings.
**in ni**
List containment and negated list containment. Each operator produces a zero/one result and treats its first argument as a string and its second argument as a Tcl list. The **in** operator indicates whether the first argument is a member of the second argument list; the **ni** operator inverts the sense of the result.
**&**
Bit-wise AND. Valid for integer operands only.
**^**
Bit-wise exclusive OR. Valid for integer operands only.
**|**
Bit-wise OR. Valid for integer operands only.
**&&**
Logical AND. Produces a 1 result if both operands are non-zero, 0 otherwise. Valid for boolean and numeric (integers or floating-point) operands only.
**||**
Logical OR. Produces a 0 result if both operands are zero, 1 otherwise. Valid for boolean and numeric (integers or floating-point) operands only.
*x***?***y***:***z*
If-then-else, as in C. If *x* evaluates to non-zero, then the result is the value of *y*. Otherwise the result is the value of *z*. The *x* operand must have a boolean or numeric value.
See the C manual for more details on the results produced by each operator. The exponentiation operator promotes types like the multiply and divide operators, and produces a result that is the same as the output of the **pow** function (after any type conversions.) All of the binary operators but exponentiation group left-to-right within the same precedence level; exponentiation groups right-to-left. For example, the command
```
**expr** {4*2 < 7}
```
returns 0, while
```
**expr** {2**3**2}
```
returns 512.
The **&&**, **||**, and **?:** operators have “lazy evaluation”, just as in C, which means that operands are not evaluated if they are not needed to determine the outcome. For example, in the command
```
**expr** {$v ? [a] : [b]}
```
only one of “**[a]**” or “**[b]**” will actually be evaluated, depending on the value of **$v**. Note, however, that this is only true if the entire expression is enclosed in braces; otherwise the Tcl parser will evaluate both “**[a]**” and “**[b]**” before invoking the **expr** command.
### Math functions
When the expression parser encounters a mathematical function such as **sin($x)**, it replaces it with a call to an ordinary Tcl function in the **tcl::mathfunc** namespace. The processing of an expression such as:
```
**expr** {sin($x+$y)}
```
is the same in every way as the processing of:
```
**expr** {[tcl::mathfunc::sin [**expr** {$x+$y}]]}
```
which in turn is the same as the processing of:
```
tcl::mathfunc::sin [**expr** {$x+$y}]
```
The executor will search for **tcl::mathfunc::sin** using the usual rules for resolving functions in namespaces. Either **::tcl::mathfunc::sin** or **[namespace current]::tcl::mathfunc::sin** will satisfy the request, and others may as well (depending on the current **[namespace path](namespace.htm)** setting).
Some mathematical functions have several arguments, separated by commas like in C. Thus:
```
**expr** {hypot($x,$y)}
```
ends up as
```
tcl::mathfunc::hypot $x $y
```
See the **[mathfunc](mathfunc.htm)**(n) manual page for the math functions that are available by default.
### Types, overflow, and precision
All internal computations involving integers are done calling on the LibTomMath multiple precision integer library as required so that all integer calculations are performed exactly. Note that in Tcl releases prior to 8.5, integer calculations were performed with one of the C types *long int* or *[Tcl\_WideInt](https://www.tcl.tk/man/tcl/TclLib/IntObj.htm)*, causing implicit range truncation in those calculations where values overflowed the range of those types. Any code that relied on these implicit truncations will need to explicitly add **[int()](mathfunc.htm)** or **[wide()](mathfunc.htm)** function calls to expressions at the points where such truncation is required to take place. All internal computations involving floating-point are done with the C type *double*. When converting a string to floating-point, exponent overflow is detected and results in the *double* value of **Inf** or **-Inf** as appropriate. Floating-point overflow and underflow are detected to the degree supported by the hardware, which is generally pretty reliable.
Conversion among internal representations for integer, floating-point, and string operands is done automatically as needed. For arithmetic computations, integers are used until some floating-point number is introduced, after which floating-point is used. For example,
```
**expr** {5 / 4}
```
returns 1, while
```
**expr** {5 / 4.0}
**expr** {5 / ( [string length "abcd"] + 0.0 )}
```
both return 1.25. Floating-point values are always returned with a “**.**” or an “**e**” so that they will not look like integer values. For example,
```
**expr** {20.0/5.0}
```
returns **4.0**, not **4**.
### String operations
String values may be used as operands of the comparison operators, although the expression evaluator tries to do comparisons as integer or floating-point when it can, i.e., when all arguments to the operator allow numeric interpretations, except in the case of the **eq** and **ne** operators. If one of the operands of a comparison is a string and the other has a numeric value, a canonical string representation of the numeric operand value is generated to compare with the string operand. Canonical string representation for integer values is a decimal string format. Canonical string representation for floating-point values is that produced by the **%g** format specifier of Tcl's **[format](format.htm)** command. For example, the commands
```
**expr** {"0x03" > "2"}
**expr** {"0y" > "0x12"}
```
both return 1. The first comparison is done using integer comparison, and the second is done using string comparison. Because of Tcl's tendency to treat values as numbers whenever possible, it is not generally a good idea to use operators like **==** when you really want string comparison and the values of the operands could be arbitrary; it is better in these cases to use the **eq** or **ne** operators, or the **[string](string.htm)** command instead.
Performance considerations
--------------------------
Enclose expressions in braces for the best speed and the smallest storage requirements. This allows the Tcl bytecode compiler to generate the best code. As mentioned above, expressions are substituted twice: once by the Tcl parser and once by the **expr** command. For example, the commands
```
set a 3
set b {$a + 2}
**expr** $b*4
```
return 11, not a multiple of 4. This is because the Tcl parser will first substitute **$a + 2** for the variable **b**, then the **expr** command will evaluate the expression **$a + 2\*4**.
Most expressions do not require a second round of substitutions. Either they are enclosed in braces or, if not, their variable and command substitutions yield numbers or strings that do not themselves require substitutions. However, because a few unbraced expressions need two rounds of substitutions, the bytecode compiler must emit additional instructions to handle this situation. The most expensive code is required for unbraced expressions that contain command substitutions. These expressions must be implemented by generating new code each time the expression is executed. When the expression is unbraced to allow the substitution of a function or operator, consider using the commands documented in the **[mathfunc](mathfunc.htm)**(n) or **[mathop](mathop.htm)**(n) manual pages directly instead.
Examples
--------
Define a procedure that computes an “interesting” mathematical function:
```
proc tcl::mathfunc::calc {x y} {
**expr** { ($x**2 - $y**2) / exp($x**2 + $y**2) }
}
```
Convert polar coordinates into cartesian coordinates:
```
# convert from ($radius,$angle)
set x [**expr** { $radius * cos($angle) }]
set y [**expr** { $radius * sin($angle) }]
```
Convert cartesian coordinates into polar coordinates:
```
# convert from ($x,$y)
set radius [**expr** { hypot($y, $x) }]
set angle [**expr** { atan2($y, $x) }]
```
Print a message describing the relationship of two string values to each other:
```
puts "a and b are [**expr** {$a eq $b ? {equal} : {different}}]"
```
Set a variable to whether an environment variable is both defined at all and also set to a true boolean value:
```
set isTrue [**expr** {
[info exists ::env(SOME_ENV_VAR)] &&
[string is true -strict $::env(SOME_ENV_VAR)]
}]
```
Generate a random integer in the range 0..99 inclusive:
```
set randNum [**expr** { int(100 * rand()) }]
```
See also
--------
**[array](array.htm)**, **[for](for.htm)**, **[if](if.htm)**, **[mathfunc](mathfunc.htm)**, **[mathop](mathop.htm)**, **[namespace](namespace.htm)**, **[proc](proc.htm)**, **[string](string.htm)**, **[Tcl](tcl.htm)**, **[while](while.htm)** Copyright
---------
Copyright (c) 1993 The Regents of the University of California.
Copyright (c) 1994-2000 Sun Microsystems Incorporated.
Copyright (c) 2005 by Kevin B. Kenny <[email protected]>. All rights reserved.
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/expr.htm>
tcl_tk scan scan
====
[NAME](scan.htm#M2) scan — Parse string using conversion specifiers in the style of sscanf
[SYNOPSIS](scan.htm#M3)
[INTRODUCTION](scan.htm#M4)
[DETAILS ON SCANNING](scan.htm#M5)
[OPTIONAL POSITIONAL SPECIFIER](scan.htm#M6)
[OPTIONAL SIZE MODIFIER](scan.htm#M7)
[MANDATORY CONVERSION CHARACTER](scan.htm#M8)
[**d**](scan.htm#M9)
[**o**](scan.htm#M10)
[**x** or **X**](scan.htm#M11)
[**b**](scan.htm#M12)
[**u**](scan.htm#M13)
[**i**](scan.htm#M14)
[**c**](scan.htm#M15)
[**s**](scan.htm#M16)
[**e** or **f** or **g** or **E** or **G**](scan.htm#M17)
[**[***chars***]**](scan.htm#M18)
[**[^***chars***]**](scan.htm#M19)
[**n**](scan.htm#M20)
[DIFFERENCES FROM ANSI SSCANF](scan.htm#M21)
[EXAMPLES](scan.htm#M22)
[SEE ALSO](scan.htm#M23)
[KEYWORDS](scan.htm#M24)
Name
----
scan — Parse string using conversion specifiers in the style of sscanf Synopsis
--------
**scan** *string format* ?*varName varName ...*?
Introduction
------------
This command parses substrings from an input string in a fashion similar to the ANSI C **sscanf** procedure and returns a count of the number of conversions performed, or -1 if the end of the input string is reached before any conversions have been performed. *String* gives the input to be parsed and *format* indicates how to parse it, using **%** conversion specifiers as in **sscanf**. Each *varName* gives the name of a variable; when a substring is scanned from *string* that matches a conversion specifier, the substring is assigned to the corresponding variable. If no *varName* variables are specified, then **scan** works in an inline manner, returning the data that would otherwise be stored in the variables as a list. In the inline case, an empty string is returned when the end of the input string is reached before any conversions have been performed. Details on scanning
-------------------
**Scan** operates by scanning *string* and *format* together. If the next character in *format* is a blank or tab then it matches any number of white space characters in *string* (including zero). Otherwise, if it is not a **%** character then it must match the next character of *string*. When a **%** is encountered in *format*, it indicates the start of a conversion specifier. A conversion specifier contains up to four fields after the **%**: a XPG3 position specifier (or a **\*** to indicate the converted value is to be discarded instead of assigned to any variable); a number indicating a maximum substring width; a size modifier; and a conversion character. All of these fields are optional except for the conversion character. The fields that are present must appear in the order given above. When **scan** finds a conversion specifier in *format*, it first skips any white-space characters in *string* (unless the conversion character is **[** or **c**). Then it converts the next input characters according to the conversion specifier and stores the result in the variable given by the next argument to **scan**.
### Optional positional specifier
If the **%** is followed by a decimal number and a **$**, as in “**%2$d**”, then the variable to use is not taken from the next sequential argument. Instead, it is taken from the argument indicated by the number, where 1 corresponds to the first *varName*. If there are any positional specifiers in *format* then all of the specifiers must be positional. Every *varName* on the argument list must correspond to exactly one conversion specifier or an error is generated, or in the inline case, any position can be specified at most once and the empty positions will be filled in with empty strings. ### Optional size modifier
The size modifier field is used only when scanning a substring into one of Tcl's integer values. The size modifier field dictates the integer range acceptable to be stored in a variable, or, for the inline case, in a position in the result list. The syntactically valid values for the size modifier are **h**, **L**, **l**, and **ll**. The **h** size modifier value is equivalent to the absence of a size modifier in the the conversion specifier. Either one indicates the integer range to be stored is limited to the same range produced by the **[int()](mathfunc.htm)** function of the **[expr](expr.htm)** command. The **L** size modifier is equivalent to the **l** size modifier. Either one indicates the integer range to be stored is limited to the same range produced by the **[wide()](mathfunc.htm)** function of the **[expr](expr.htm)** command. The **ll** size modifier indicates that the integer range to be stored is unlimited. ### Mandatory conversion character
The following conversion characters are supported:
**d**
The input substring must be a decimal integer. It is read in and the integer value is stored in the variable, truncated as required by the size modifier value.
**o**
The input substring must be an octal integer. It is read in and the integer value is stored in the variable, truncated as required by the size modifier value.
**x** or **X**
The input substring must be a hexadecimal integer. It is read in and the integer value is stored in the variable, truncated as required by the size modifier value.
**b**
The input substring must be a binary integer. It is read in and the integer value is stored in the variable, truncated as required by the size modifier value.
**u**
The input substring must be a decimal integer. The integer value is truncated as required by the size modifier value, and the corresponding unsigned value for that truncated range is computed and stored in the variable as a decimal string. The conversion makes no sense without reference to a truncation range, so the size modifier **ll** is not permitted in combination with conversion character **u**.
**i**
The input substring must be an integer. The base (i.e. decimal, binary, octal, or hexadecimal) is determined in the same fashion as described in **[expr](expr.htm)**. The integer value is stored in the variable, truncated as required by the size modifier value.
**c**
A single character is read in and its Unicode value is stored in the variable as an integer value. Initial white space is not skipped in this case, so the input substring may be a white-space character.
**s**
The input substring consists of all the characters up to the next white-space character; the characters are copied to the variable.
**e** or **f** or **g** or **E** or **G**
The input substring must be a floating-point number consisting of an optional sign, a string of decimal digits possibly containing a decimal point, and an optional exponent consisting of an **e** or **E** followed by an optional sign and a string of decimal digits. It is read in and stored in the variable as a floating-point value.
**[***chars***]**
The input substring consists of one or more characters in *chars*. The matching string is stored in the variable. If the first character between the brackets is a **]** then it is treated as part of *chars* rather than the closing bracket for the set. If *chars* contains a sequence of the form *a***-***b* then any character between *a* and *b* (inclusive) will match. If the first or last character between the brackets is a **-**, then it is treated as part of *chars* rather than indicating a range.
**[^***chars***]**
The input substring consists of one or more characters not in *chars*. The matching string is stored in the variable. If the character immediately following the **^** is a **]** then it is treated as part of the set rather than the closing bracket for the set. If *chars* contains a sequence of the form *a***-***b* then any character between *a* and *b* (inclusive) will be excluded from the set. If the first or last character between the brackets is a **-**, then it is treated as part of *chars* rather than indicating a range value.
**n**
No input is consumed from the input string. Instead, the total number of characters scanned from the input string so far is stored in the variable.
The number of characters read from the input for a conversion is the largest number that makes sense for that particular conversion (e.g. as many decimal digits as possible for **%d**, as many octal digits as possible for **%o**, and so on). The input substring for a given conversion terminates either when a white-space character is encountered or when the maximum substring width has been reached, whichever comes first. If a **\*** is present in the conversion specifier then no variable is assigned and the next scan argument is not consumed.
Differences from ansi sscanf
----------------------------
The behavior of the **scan** command is the same as the behavior of the ANSI C **sscanf** procedure except for the following differences:
1. **%p** conversion specifier is not supported.
2. For **%c** conversions a single character value is converted to a decimal string, which is then assigned to the corresponding *varName*; no substring width may be specified for this conversion.
3. The **h** modifier is always ignored and the **l** and **L** modifiers are ignored when converting real values (i.e. type **double** is used for the internal representation). The **ll** modifier has no **sscanf** counterpart.
4. If the end of the input string is reached before any conversions have been performed and no variables are given, an empty string is returned.
Examples
--------
Convert a UNICODE character to its numeric value:
```
set char "x"
set value [**scan** $char %c]
```
Parse a simple color specification of the form *#RRGGBB* using hexadecimal conversions with substring sizes:
```
set string "#08D03F"
**scan** $string "#%2x%2x%2x" r g b
```
Parse a *HH:MM* time string, noting that this avoids problems with octal numbers by forcing interpretation as decimals (if we did not care, we would use the **%i** conversion instead):
```
set string "08:08" ;# *Not* octal!
if {[**scan** $string "%d:%d" hours minutes] != 2} {
error "not a valid time string"
}
# We have to understand numeric ranges ourselves...
if {$minutes < 0 || $minutes > 59} {
error "invalid number of minutes"
}
```
Break a string up into sequences of non-whitespace characters (note the use of the **%n** conversion so that we get skipping over leading whitespace correct):
```
set string " a string {with braced words} + leading space "
set words {}
while {[**scan** $string %s%n word length] == 2} {
lappend words $word
set string [string range $string $length end]
}
```
Parse a simple coordinate string, checking that it is complete by looking for the terminating character explicitly:
```
set string "(5.2,-4e-2)"
# Note that the spaces before the literal parts of
# the scan pattern are significant, and that ")" is
# the Unicode character \u0029
if {
[**scan** $string " (%f ,%f %c" x y last] != 3
|| $last != 0x0029
} then {
error "invalid coordinate string"
}
puts "X=$x, Y=$y"
```
An interactive session demonstrating the truncation of integer values determined by size modifiers:
```
*%* set tcl_platform(wordSize)
4
*%* scan 20000000000000000000 %d
2147483647
*%* scan 20000000000000000000 %ld
9223372036854775807
*%* scan 20000000000000000000 %lld
20000000000000000000
```
See also
--------
**[format](format.htm)**, **sscanf**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/scan.htm>
| programming_docs |
tcl_tk pwd pwd
===
Name
----
pwd — Return the absolute path of the current working directory Synopsis
--------
**pwd**
Description
-----------
Returns the absolute path name of the current working directory. Example
-------
Sometimes it is useful to change to a known directory when running some external command using **[exec](exec.htm)**, but it is important to keep the application usually running in the directory that it was started in (unless the user specifies otherwise) since that minimizes user confusion. The way to do this is to save the current directory while the external command is being run:
```
set tarFile [file normalize somefile.tar]
set savedDir [**pwd**]
cd /tmp
exec tar -xf $tarFile
cd $savedDir
```
See also
--------
**[file](file.htm)**, **[cd](cd.htm)**, **[glob](glob.htm)**, **[filename](filename.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/pwd.htm>
tcl_tk re_syntax re\_syntax
==========
[NAME](re_syntax.htm#M2) re\_syntax — Syntax of Tcl regular expressions
[DESCRIPTION](re_syntax.htm#M3)
[DIFFERENT FLAVORS OF REs](re_syntax.htm#M4)
[REGULAR EXPRESSION SYNTAX](re_syntax.htm#M5)
[QUANTIFIERS](re_syntax.htm#M6)
[**\***](re_syntax.htm#M7)
[**+**](re_syntax.htm#M8)
[**?**](re_syntax.htm#M9)
[**{***m***}**](re_syntax.htm#M10)
[**{***m***,}**](re_syntax.htm#M11)
[**{***m***,***n***}**](re_syntax.htm#M12)
[**\*? +? ?? {***m***}? {***m***,}? {***m***,***n***}?**](re_syntax.htm#M13)
[ATOMS](re_syntax.htm#M14)
[**(***re***)**](re_syntax.htm#M15)
[**(?:***re***)**](re_syntax.htm#M16)
[**()**](re_syntax.htm#M17)
[**(?:)**](re_syntax.htm#M18)
[**[***chars***]**](re_syntax.htm#M19)
[**.**](re_syntax.htm#M20)
[**\***k*](re_syntax.htm#M21)
[**\***c*](re_syntax.htm#M22)
[**{**](re_syntax.htm#M23)
[*x*](re_syntax.htm#M24)
[CONSTRAINTS](re_syntax.htm#M25)
[**^**](re_syntax.htm#M26)
[**$**](re_syntax.htm#M27)
[**(?=***re***)**](re_syntax.htm#M28)
[**(?!***re***)**](re_syntax.htm#M29)
[BRACKET EXPRESSIONS](re_syntax.htm#M30)
[CHARACTER CLASSES](re_syntax.htm#M31)
[**alpha**](re_syntax.htm#M32)
[**upper**](re_syntax.htm#M33)
[**lower**](re_syntax.htm#M34)
[**digit**](re_syntax.htm#M35)
[**xdigit**](re_syntax.htm#M36)
[**alnum**](re_syntax.htm#M37)
[**print**](re_syntax.htm#M38)
[**blank**](re_syntax.htm#M39)
[**space**](re_syntax.htm#M40)
[**punct**](re_syntax.htm#M41)
[**graph**](re_syntax.htm#M42)
[**cntrl**](re_syntax.htm#M43)
[BRACKETED CONSTRAINTS](re_syntax.htm#M44)
[COLLATING ELEMENTS](re_syntax.htm#M45)
[EQUIVALENCE CLASSES](re_syntax.htm#M46)
[ESCAPES](re_syntax.htm#M47)
[CHARACTER-ENTRY ESCAPES](re_syntax.htm#M48)
[**\a**](re_syntax.htm#M49)
[**\b**](re_syntax.htm#M50)
[**\B**](re_syntax.htm#M51)
[**\c***X*](re_syntax.htm#M52)
[**\e**](re_syntax.htm#M53)
[**\f**](re_syntax.htm#M54)
[**\n**](re_syntax.htm#M55)
[**\r**](re_syntax.htm#M56)
[**\t**](re_syntax.htm#M57)
[**\u***wxyz*](re_syntax.htm#M58)
[**\U***stuvwxyz*](re_syntax.htm#M59)
[**\v**](re_syntax.htm#M60)
[**\x***hh*](re_syntax.htm#M61)
[**\0**](re_syntax.htm#M62)
[**\***xyz*](re_syntax.htm#M63)
[**\***xy*](re_syntax.htm#M64)
[CLASS-SHORTHAND ESCAPES](re_syntax.htm#M65)
[**\d**](re_syntax.htm#M66)
[**\s**](re_syntax.htm#M67)
[**\w**](re_syntax.htm#M68)
[**\D**](re_syntax.htm#M69)
[**\S**](re_syntax.htm#M70)
[**\W**](re_syntax.htm#M71)
[CONSTRAINT ESCAPES](re_syntax.htm#M72)
[**\A**](re_syntax.htm#M73)
[**\m**](re_syntax.htm#M74)
[**\M**](re_syntax.htm#M75)
[**\y**](re_syntax.htm#M76)
[**\Y**](re_syntax.htm#M77)
[**\Z**](re_syntax.htm#M78)
[**\***m*](re_syntax.htm#M79)
[**\***mnn*](re_syntax.htm#M80)
[BACK REFERENCES](re_syntax.htm#M81)
[METASYNTAX](re_syntax.htm#M82)
[**b**](re_syntax.htm#M83)
[**c**](re_syntax.htm#M84)
[**e**](re_syntax.htm#M85)
[**i**](re_syntax.htm#M86)
[**m**](re_syntax.htm#M87)
[**n**](re_syntax.htm#M88)
[**p**](re_syntax.htm#M89)
[**q**](re_syntax.htm#M90)
[**s**](re_syntax.htm#M91)
[**t**](re_syntax.htm#M92)
[**w**](re_syntax.htm#M93)
[**x**](re_syntax.htm#M94)
[MATCHING](re_syntax.htm#M95)
[LIMITS AND COMPATIBILITY](re_syntax.htm#M96)
[BASIC REGULAR EXPRESSIONS](re_syntax.htm#M97)
[SEE ALSO](re_syntax.htm#M98)
[KEYWORDS](re_syntax.htm#M99)
Name
----
re\_syntax — Syntax of Tcl regular expressions Description
-----------
A *regular expression* describes strings of characters. It's a pattern that matches certain strings and does not match others. Different flavors of res
------------------------
Regular expressions (“RE”s), as defined by POSIX, come in two flavors: *extended* REs (“ERE”s) and *basic* REs (“BRE”s). EREs are roughly those of the traditional *egrep*, while BREs are roughly those of the traditional *ed*. This implementation adds a third flavor, *advanced* REs (“ARE”s), basically EREs with some significant extensions. This manual page primarily describes AREs. BREs mostly exist for backward compatibility in some old programs; they will be discussed at the end. POSIX EREs are almost an exact subset of AREs. Features of AREs that are not present in EREs will be indicated.
Regular expression syntax
-------------------------
Tcl regular expressions are implemented using the package written by Henry Spencer, based on the 1003.2 spec and some (not quite all) of the Perl5 extensions (thanks, Henry!). Much of the description of regular expressions below is copied verbatim from his manual entry. An ARE is one or more *branches*, separated by “**|**”, matching anything that matches any of the branches.
A branch is zero or more *constraints* or *quantified atoms*, concatenated. It matches a match for the first, followed by a match for the second, etc; an empty branch matches the empty string.
### Quantifiers
A quantified atom is an *atom* possibly followed by a single *quantifier*. Without a quantifier, it matches a single match for the atom. The quantifiers, and what a so-quantified atom matches, are:
**\***
a sequence of 0 or more matches of the atom
**+**
a sequence of 1 or more matches of the atom
**?**
a sequence of 0 or 1 matches of the atom
**{***m***}**
a sequence of exactly *m* matches of the atom
**{***m***,}**
a sequence of *m* or more matches of the atom
**{***m***,***n***}**
a sequence of *m* through *n* (inclusive) matches of the atom; *m* may not exceed *n*
**\*? +? ?? {***m***}? {***m***,}? {***m***,***n***}?**
*non-greedy* quantifiers, which match the same possibilities, but prefer the smallest number rather than the largest number of matches (see **[MATCHING](#M95)**)
The forms using **{** and **}** are known as *bound*s. The numbers *m* and *n* are unsigned decimal integers with permissible values from 0 to 255 inclusive.
### Atoms
An atom is one of:
**(***re***)**
matches a match for *re* (*re* is any regular expression) with the match noted for possible reporting
**(?:***re***)**
as previous, but does no reporting (a “non-capturing” set of parentheses)
**()**
matches an empty string, noted for possible reporting
**(?:)**
matches an empty string, without reporting
**[***chars***]**
a *bracket expression*, matching any one of the *chars* (see **[BRACKET EXPRESSIONS](#M30)** for more detail)
**.**
matches any single character
**\***k*
matches the non-alphanumeric character *k* taken as an ordinary character, e.g. **\\** matches a backslash character
**\***c*
where *c* is alphanumeric (possibly followed by other characters), an *escape* (AREs only), see **[ESCAPES](#M47)** below
**{**
when followed by a character other than a digit, matches the left-brace character “**{**”; when followed by a digit, it is the beginning of a *bound* (see above)
*x*
where *x* is a single character with no other significance, matches that character.
### Constraints
A *constraint* matches an empty string when specific conditions are met. A constraint may not be followed by a quantifier. The simple constraints are as follows; some more constraints are described later, under **[ESCAPES](#M47)**.
**^**
matches at the beginning of a line
**$**
matches at the end of a line
**(?=***re***)**
*positive lookahead* (AREs only), matches at any point where a substring matching *re* begins
**(?!***re***)**
*negative lookahead* (AREs only), matches at any point where no substring matching *re* begins
The lookahead constraints may not contain back references (see later), and all parentheses within them are considered non-capturing.
An RE may not end with “**\**”.
Bracket expressions
-------------------
A *bracket expression* is a list of characters enclosed in “**[ ]**”. It normally matches any single character from the list (but see below). If the list begins with “**^**”, it matches any single character (but see below) *not* from the rest of the list. If two characters in the list are separated by “**-**”, this is shorthand for the full *range* of characters between those two (inclusive) in the collating sequence, e.g. “**[0-9]**” in Unicode matches any conventional decimal digit. Two ranges may not share an endpoint, so e.g. “**a-c-e**” is illegal. Ranges in Tcl always use the Unicode collating sequence, but other programs may use other collating sequences and this can be a source of incompatibility between programs.
To include a literal **]** or **-** in the list, the simplest method is to enclose it in **[.** and **.]** to make it a collating element (see below). Alternatively, make it the first character (following a possible “**^**”), or (AREs only) precede it with “**\**”. Alternatively, for “**-**”, make it the last character, or the second endpoint of a range. To use a literal **-** as the first endpoint of a range, make it a collating element or (AREs only) precede it with “**\**”. With the exception of these, some combinations using **[** (see next paragraphs), and escapes, all other special characters lose their special significance within a bracket expression.
### Character classes
Within a bracket expression, the name of a *character class* enclosed in **[:** and **:]** stands for the list of all characters (not all collating elements!) belonging to that class. Standard character classes are:
**alpha**
A letter.
**upper**
An upper-case letter.
**lower**
A lower-case letter.
**digit**
A decimal digit.
**xdigit**
A hexadecimal digit.
**alnum**
An alphanumeric (letter or digit).
**print**
A "printable" (same as graph, except also including space).
**blank**
A space or tab character.
**space**
A character producing white space in displayed text.
**punct**
A punctuation character.
**graph**
A character with a visible representation (includes both **alnum** and **punct**).
**cntrl**
A control character.
A locale may provide others. A character class may not be used as an endpoint of a range.
(*Note:* the current Tcl implementation has only one locale, the Unicode locale, which supports exactly the above classes.)
### Bracketed constraints
There are two special cases of bracket expressions: the bracket expressions “**[[:<:]]**” and “**[[:>:]]**” are constraints, matching empty strings at the beginning and end of a word respectively. A word is defined as a sequence of word characters that is neither preceded nor followed by word characters. A word character is an *alnum* character or an underscore (“**\_**”). These special bracket expressions are deprecated; users of AREs should use constraint escapes instead (see below). ### Collating elements
Within a bracket expression, a collating element (a character, a multi-character sequence that collates as if it were a single character, or a collating-sequence name for either) enclosed in **[.** and **.]** stands for the sequence of characters of that collating element. The sequence is a single element of the bracket expression's list. A bracket expression in a locale that has multi-character collating elements can thus match more than one character. So (insidiously), a bracket expression that starts with **^** can match multi-character collating elements even if none of them appear in the bracket expression! (*Note:* Tcl has no multi-character collating elements. This information is only for illustration.)
For example, assume the collating sequence includes a **ch** multi-character collating element. Then the RE “**[[.ch.]]\*c**” (zero or more “**ch**s” followed by “**c**”) matches the first five characters of “**chchcc**”. Also, the RE “**[^c]b**” matches all of “**chb**” (because “**[^c]**” matches the multi-character “**ch**”).
### Equivalence classes
Within a bracket expression, a collating element enclosed in **[=** and **=]** is an equivalence class, standing for the sequences of characters of all collating elements equivalent to that one, including itself. (If there are no other equivalent collating elements, the treatment is as if the enclosing delimiters were “**[.**” and “**.]**”.) For example, if **o** and **ô** are the members of an equivalence class, then “**[[=o=]]**”, “**[[=ô=]]**”, and “**[oô]**” are all synonymous. An equivalence class may not be an endpoint of a range. (*Note:* Tcl implements only the Unicode locale. It does not define any equivalence classes. The examples above are just illustrations.)
Escapes
-------
Escapes (AREs only), which begin with a **\** followed by an alphanumeric character, come in several varieties: character entry, class shorthands, constraint escapes, and back references. A **\** followed by an alphanumeric character but not constituting a valid escape is illegal in AREs. In EREs, there are no escapes: outside a bracket expression, a **\** followed by an alphanumeric character merely stands for that character as an ordinary character, and inside a bracket expression, **\** is an ordinary character. (The latter is the one actual incompatibility between EREs and AREs.) ### Character-entry escapes
Character-entry escapes (AREs only) exist to make it easier to specify non-printing and otherwise inconvenient characters in REs:
**\a**
alert (bell) character, as in C
**\b**
backspace, as in C
**\B**
synonym for **\** to help reduce backslash doubling in some applications where there are multiple levels of backslash processing
**\c***X*
(where *X* is any character) the character whose low-order 5 bits are the same as those of *X*, and whose other bits are all zero
**\e**
the character whose collating-sequence name is “**ESC**”, or failing that, the character with octal value 033
**\f**
formfeed, as in C
**\n**
newline, as in C
**\r**
carriage return, as in C
**\t**
horizontal tab, as in C
**\u***wxyz*
(where *wxyz* is one up to four hexadecimal digits) the Unicode character **U+***wxyz* in the local byte ordering
**\U***stuvwxyz*
(where *stuvwxyz* is one up to eight hexadecimal digits) reserved for a Unicode extension up to 21 bits. The digits are parsed until the first non-hexadecimal character is encountered, the maximun of eight hexadecimal digits are reached, or an overflow would occur in the maximum value of **U+***10ffff*.
**\v**
vertical tab, as in C are all available.
**\x***hh*
(where *hh* is one or two hexadecimal digits) the character whose hexadecimal value is **0x***hh*.
**\0**
the character whose value is **0**
**\***xyz*
(where *xyz* is exactly three octal digits, and is not a *back reference* (see below)) the character whose octal value is **0***xyz*. The first digit must be in the range 0-3, otherwise the two-digit form is assumed.
**\***xy*
(where *xy* is exactly two octal digits, and is not a *back reference* (see below)) the character whose octal value is **0***xy*
Hexadecimal digits are “**0**–**9**”, “**a**–**f**”, and “**A**–**F**”. Octal digits are “**0**–**7**”.
The character-entry escapes are always taken as ordinary characters. For example, **\135** is **]** in Unicode, but **\135** does not terminate a bracket expression. Beware, however, that some applications (e.g., C compilers and the Tcl interpreter if the regular expression is not quoted with braces) interpret such sequences themselves before the regular-expression package gets to see them, which may require doubling (quadrupling, etc.) the “**\**”.
### Class-shorthand escapes
Class-shorthand escapes (AREs only) provide shorthands for certain commonly-used character classes:
**\d**
**[[:digit:]]**
**\s**
**[[:space:]]**
**\w**
**[[:alnum:]\_]** (note underscore)
**\D**
**[^[:digit:]]**
**\S**
**[^[:space:]]**
**\W**
**[^[:alnum:]\_]** (note underscore)
Within bracket expressions, “**\d**”, “**\s**”, and “**\w**” lose their outer brackets, and “**\D**”, “**\S**”, and “**\W**” are illegal. (So, for example, “**[a-c\d]**” is equivalent to “**[a-c[:digit:]]**”. Also, “**[a-c\D]**”, which is equivalent to “**[a-c^[:digit:]]**”, is illegal.)
### Constraint escapes
A constraint escape (AREs only) is a constraint, matching the empty string if specific conditions are met, written as an escape:
**\A**
matches only at the beginning of the string (see **[MATCHING](#M95)**, below, for how this differs from “**^**”)
**\m**
matches only at the beginning of a word
**\M**
matches only at the end of a word
**\y**
matches only at the beginning or end of a word
**\Y**
matches only at a point that is not the beginning or end of a word
**\Z**
matches only at the end of the string (see **[MATCHING](#M95)**, below, for how this differs from “**$**”)
**\***m*
(where *m* is a nonzero digit) a *back reference*, see below
**\***mnn*
(where *m* is a nonzero digit, and *nn* is some more digits, and the decimal value *mnn* is not greater than the number of closing capturing parentheses seen so far) a *back reference*, see below
A word is defined as in the specification of “**[[:<:]]**” and “**[[:>:]]**” above. Constraint escapes are illegal within bracket expressions.
### Back references
A back reference (AREs only) matches the same string matched by the parenthesized subexpression specified by the number, so that (e.g.) “**([bc])\1**” matches “**bb**” or “**cc**” but not “**bc**”. The subexpression must entirely precede the back reference in the RE. Subexpressions are numbered in the order of their leading parentheses. Non-capturing parentheses do not define subexpressions. There is an inherent historical ambiguity between octal character-entry escapes and back references, which is resolved by heuristics, as hinted at above. A leading zero always indicates an octal escape. A single non-zero digit, not followed by another digit, is always taken as a back reference. A multi-digit sequence not starting with a zero is taken as a back reference if it comes after a suitable subexpression (i.e. the number is in the legal range for a back reference), and otherwise is taken as octal.
Metasyntax
----------
In addition to the main syntax described above, there are some special forms and miscellaneous syntactic facilities available. Normally the flavor of RE being used is specified by application-dependent means. However, this can be overridden by a *director*. If an RE of any flavor begins with “**\*\*\*:**”, the rest of the RE is an ARE. If an RE of any flavor begins with “**\*\*\*=**”, the rest of the RE is taken to be a literal string, with all characters considered ordinary characters.
An ARE may begin with *embedded options*: a sequence **(?***xyz***)** (where *xyz* is one or more alphabetic characters) specifies options affecting the rest of the RE. These supplement, and can override, any options specified by the application. The available option letters are:
**b**
rest of RE is a BRE
**c**
case-sensitive matching (usual default)
**e**
rest of RE is an ERE
**i**
case-insensitive matching (see **[MATCHING](#M95)**, below)
**m**
historical synonym for **n**
**n**
newline-sensitive matching (see **[MATCHING](#M95)**, below)
**p**
partial newline-sensitive matching (see **[MATCHING](#M95)**, below)
**q**
rest of RE is a literal (“quoted”) string, all ordinary characters
**s**
non-newline-sensitive matching (usual default)
**t**
tight syntax (usual default; see below)
**w**
inverse partial newline-sensitive (“weird”) matching (see **[MATCHING](#M95)**, below)
**x**
expanded syntax (see below)
Embedded options take effect at the **)** terminating the sequence. They are available only at the start of an ARE, and may not be used later within it.
In addition to the usual (*tight*) RE syntax, in which all characters are significant, there is an *expanded* syntax, available in all flavors of RE with the **-expanded** switch, or in AREs with the embedded x option. In the expanded syntax, white-space characters are ignored and all characters between a **#** and the following newline (or the end of the RE) are ignored, permitting paragraphing and commenting a complex RE. There are three exceptions to that basic rule:
* a white-space character or “**#**” preceded by “**\**” is retained
* white space or “**#**” within a bracket expression is retained
* white space and comments are illegal within multi-character symbols like the ARE “**(?:**” or the BRE “**\(**”
Expanded-syntax white-space characters are blank, tab, newline, and any character that belongs to the *space* character class.
Finally, in an ARE, outside bracket expressions, the sequence “**(?#***ttt***)**” (where *ttt* is any text not containing a “**)**”) is a comment, completely ignored. Again, this is not allowed between the characters of multi-character symbols like “**(?:**”. Such comments are more a historical artifact than a useful facility, and their use is deprecated; use the expanded syntax instead.
*None* of these metasyntax extensions is available if the application (or an initial “**\*\*\*=**” director) has specified that the user's input be treated as a literal string rather than as an RE.
Matching
--------
In the event that an RE could match more than one substring of a given string, the RE matches the one starting earliest in the string. If the RE could match more than one substring starting at that point, its choice is determined by its *preference*: either the longest substring, or the shortest. Most atoms, and all constraints, have no preference. A parenthesized RE has the same preference (possibly none) as the RE. A quantified atom with quantifier **{***m***}** or **{***m***}?** has the same preference (possibly none) as the atom itself. A quantified atom with other normal quantifiers (including **{***m***,***n***}** with *m* equal to *n*) prefers longest match. A quantified atom with other non-greedy quantifiers (including **{***m***,***n***}?** with *m* equal to *n*) prefers shortest match. A branch has the same preference as the first quantified atom in it which has a preference. An RE consisting of two or more branches connected by the **|** operator prefers longest match.
Subject to the constraints imposed by the rules for matching the whole RE, subexpressions also match the longest or shortest possible substrings, based on their preferences, with subexpressions starting earlier in the RE taking priority over ones starting later. Note that outer subexpressions thus take priority over their component subexpressions.
The quantifiers **{1,1}** and **{1,1}?** can be used to force longest and shortest preference, respectively, on a subexpression or a whole RE.
**NOTE:** This means that you can usually make a RE be non-greedy overall by putting **{1,1}?** after one of the first non-constraint atoms or parenthesized sub-expressions in it. *It pays to experiment* with the placing of this non-greediness override on a suitable range of input texts when you are writing a RE if you are using this level of complexity.
For example, this regular expression is non-greedy, and will match the shortest substring possible given that “**abc**” will be matched as early as possible (the quantifier does not change that):
```
ab{1,1}?c.*x.*cba
```
The atom “**a**” has no greediness preference, we explicitly give one for “**b**”, and the remaining quantifiers are overridden to be non-greedy by the preceding non-greedy quantifier.
Match lengths are measured in characters, not collating elements. An empty string is considered longer than no match at all. For example, “**bb\***” matches the three middle characters of “**abbbc**”, “**(week|wee)(night|knights)**” matches all ten characters of “**weeknights**”, when “**(.\*).\***” is matched against “**abc**” the parenthesized subexpression matches all three characters, and when “**(a\*)\***” is matched against “**bc**” both the whole RE and the parenthesized subexpression match an empty string.
If case-independent matching is specified, the effect is much as if all case distinctions had vanished from the alphabet. When an alphabetic that exists in multiple cases appears as an ordinary character outside a bracket expression, it is effectively transformed into a bracket expression containing both cases, so that **x** becomes “**[xX]**”. When it appears inside a bracket expression, all case counterparts of it are added to the bracket expression, so that “**[x]**” becomes “**[xX]**” and “**[^x]**” becomes “**[^xX]**”.
If newline-sensitive matching is specified, **.** and bracket expressions using **^** will never match the newline character (so that matches will never cross newlines unless the RE explicitly arranges it) and **^** and **$** will match the empty string after and before a newline respectively, in addition to matching at beginning and end of string respectively. ARE **\A** and **\Z** continue to match beginning or end of string *only*.
If partial newline-sensitive matching is specified, this affects **.** and bracket expressions as with newline-sensitive matching, but not **^** and **$**.
If inverse partial newline-sensitive matching is specified, this affects **^** and **$** as with newline-sensitive matching, but not **.** and bracket expressions. This is not very useful but is provided for symmetry.
Limits and compatibility
------------------------
No particular limit is imposed on the length of REs. Programs intended to be highly portable should not employ REs longer than 256 bytes, as a POSIX-compliant implementation can refuse to accept such REs. The only feature of AREs that is actually incompatible with POSIX EREs is that **\** does not lose its special significance inside bracket expressions. All other ARE features use syntax which is illegal or has undefined or unspecified effects in POSIX EREs; the **\*\*\*** syntax of directors likewise is outside the POSIX syntax for both BREs and EREs.
Many of the ARE extensions are borrowed from Perl, but some have been changed to clean them up, and a few Perl extensions are not present. Incompatibilities of note include “**\b**”, “**\B**”, the lack of special treatment for a trailing newline, the addition of complemented bracket expressions to the things affected by newline-sensitive matching, the restrictions on parentheses and back references in lookahead constraints, and the longest/shortest-match (rather than first-match) matching semantics.
The matching rules for REs containing both normal and non-greedy quantifiers have changed since early beta-test versions of this package. (The new rules are much simpler and cleaner, but do not work as hard at guessing the user's real intentions.)
Henry Spencer's original 1986 *regexp* package, still in widespread use (e.g., in pre-8.1 releases of Tcl), implemented an early version of today's EREs. There are four incompatibilities between *regexp*'s near-EREs (“RREs” for short) and AREs. In roughly increasing order of significance:
* In AREs, **\** followed by an alphanumeric character is either an escape or an error, while in RREs, it was just another way of writing the alphanumeric. This should not be a problem because there was no reason to write such a sequence in RREs.
* **{** followed by a digit in an ARE is the beginning of a bound, while in RREs, **{** was always an ordinary character. Such sequences should be rare, and will often result in an error because following characters will not look like a valid bound.
* In AREs, **\** remains a special character within “**[ ]**”, so a literal **\** within **[ ]** must be written “**\\**”. **\\** also gives a literal **\** within **[ ]** in RREs, but only truly paranoid programmers routinely doubled the backslash.
* AREs report the longest/shortest match for the RE, rather than the first found in a specified search order. This may affect some RREs which were written in the expectation that the first match would be reported. (The careful crafting of RREs to optimize the search order for fast matching is obsolete (AREs examine all possible matches in parallel, and their performance is largely insensitive to their complexity) but cases where the search order was exploited to deliberately find a match which was *not* the longest/shortest will need rewriting.)
Basic regular expressions
-------------------------
BREs differ from EREs in several respects. “**|**”, “**+**”, and **?** are ordinary characters and there is no equivalent for their functionality. The delimiters for bounds are **\{** and “**\}**”, with **{** and **}** by themselves ordinary characters. The parentheses for nested subexpressions are **\(** and “**\)**”, with **(** and **)** by themselves ordinary characters. **^** is an ordinary character except at the beginning of the RE or the beginning of a parenthesized subexpression, **$** is an ordinary character except at the end of the RE or the end of a parenthesized subexpression, and **\*** is an ordinary character if it appears at the beginning of the RE or the beginning of a parenthesized subexpression (after a possible leading “**^**”). Finally, single-digit back references are available, and **\<** and **\>** are synonyms for “**[[:<:]]**” and “**[[:>:]]**” respectively; no other escapes are available. See also
--------
**[RegExp](regexp.htm)**, **[regexp](regexp.htm)**, **[regsub](regsub.htm)**, **[lsearch](lsearch.htm)**, **[switch](switch.htm)**, **[text](../tkcmd/text.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/re_syntax.htm>
| programming_docs |
tcl_tk lappend lappend
=======
Name
----
lappend — Append list elements onto a variable Synopsis
--------
**lappend** *varName* ?*value value value ...*?
Description
-----------
This command treats the variable given by *varName* as a list and appends each of the *value* arguments to that list as a separate element, with spaces between elements. If *varName* does not exist, it is created as a list with elements given by the *value* arguments. **Lappend** is similar to **[append](append.htm)** except that the *value*s are appended as list elements rather than raw text. This command provides a relatively efficient way to build up large lists. For example, “**lappend a $b**” is much more efficient than “**set a [concat $a [list $b]]**” when **$a** is long. Example
-------
Using **lappend** to build up a list of numbers.
```
% set var 1
1
% **lappend** var 2
1 2
% **lappend** var 3 4 5
1 2 3 4 5
```
See also
--------
**[list](list.htm)**, **[lindex](lindex.htm)**, **[linsert](linsert.htm)**, **[llength](llength.htm)**, **[lset](lset.htm)**, **[lsort](lsort.htm)**, **[lrange](lrange.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/lappend.htm>
tcl_tk apply apply
=====
Name
----
apply — Apply an anonymous function Synopsis
--------
**apply** *func* ?*arg1 arg2 ...*?
Description
-----------
The command **apply** applies the function *func* to the arguments *arg1 arg2 ...* and returns the result. The function *func* is a two element list *{args body}* or a three element list *{args body namespace}* (as if the **[list](list.htm)** command had been used). The first element *args* specifies the formal arguments to *func*. The specification of the formal arguments *args* is shared with the **[proc](proc.htm)** command, and is described in detail in the corresponding manual page.
The contents of *body* are executed by the Tcl interpreter after the local variables corresponding to the formal arguments are given the values of the actual parameters *arg1 arg2 ...*. When *body* is being executed, variable names normally refer to local variables, which are created automatically when referenced and deleted when **apply** returns. One local variable is automatically created for each of the function's arguments. Global variables can only be accessed by invoking the **[global](global.htm)** command or the **[upvar](upvar.htm)** command. Namespace variables can only be accessed by invoking the **[variable](variable.htm)** command or the **[upvar](upvar.htm)** command.
The invocation of **apply** adds a call frame to Tcl's evaluation stack (the stack of frames accessed via **[uplevel](uplevel.htm)**). The execution of *body* proceeds in this call frame, in the namespace given by *namespace* or in the global namespace if none was specified. If given, *namespace* is interpreted relative to the global namespace even if its name does not start with “::”.
The semantics of **apply** can also be described by:
```
proc apply {fun args} {
set len [llength $fun]
if {($len < 2) || ($len > 3)} {
error "can't interpret \"$fun\" as anonymous function"
}
lassign $fun argList body ns
set name ::$ns::[getGloballyUniqueName]
set body0 {
rename [lindex [info level 0] 0] {}
}
proc $name $argList ${body0}$body
set code [catch {uplevel 1 $name $args} res opt]
return -options $opt $res
}
```
Examples
--------
This shows how to make a simple general command that applies a transformation to each element of a list.
```
proc map {lambda list} {
set result {}
foreach item $list {
lappend result [**apply** $lambda $item]
}
return $result
}
map {x {return [string length $x]:$x}} {a bb ccc dddd}
*→ 1:a 2:bb 3:ccc 4:dddd*
map {x {expr {$x**2 + 3*$x - 2}}} {-4 -3 -2 -1 0 1 2 3 4}
*→ 2 -2 -4 -4 -2 2 8 16 26*
```
The **apply** command is also useful for defining callbacks for use in the **[trace](trace.htm)** command:
```
set vbl "123abc"
trace add variable vbl write {**apply** {{v1 v2 op} {
upvar 1 $v1 v
puts "updated variable to \"$v\""
}}}
set vbl 123
set vbl abc
```
See also
--------
**[proc](proc.htm)**, **[uplevel](uplevel.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/apply.htm>
tcl_tk bgerror bgerror
=======
Name
----
bgerror — Command invoked to process background errors Synopsis
--------
**bgerror** *message*
Description
-----------
Release 8.5 of Tcl supports the **[interp bgerror](interp.htm)** command, which allows applications to register in an interpreter the command that will handle background errors in that interpreter. In older releases of Tcl, this level of control was not available, and applications could control the handling of background errors only by creating a command with the particular command name **bgerror** in the global namespace of an interpreter. The following documentation describes the interface requirements of the **bgerror** command an application might define to retain compatibility with pre-8.5 releases of Tcl. Applications intending to support only Tcl releases 8.5 and later should simply make use of **[interp bgerror](interp.htm)**. The **bgerror** command does not exist as built-in part of Tcl. Instead, individual applications or users can define a **bgerror** command (e.g. as a Tcl procedure) if they wish to handle background errors.
A background error is one that occurs in an event handler or some other command that did not originate with the application. For example, if an error occurs while executing a command specified with the **[after](after.htm)** command, then it is a background error. For a non-background error, the error can simply be returned up through nested Tcl command evaluations until it reaches the top-level code in the application; then the application can report the error in whatever way it wishes. When a background error occurs, the unwinding ends in the Tcl library and there is no obvious way for Tcl to report the error.
When Tcl detects a background error, it saves information about the error and invokes a handler command registered by **[interp bgerror](interp.htm)** later as an idle event handler. The default handler command in turn calls the **bgerror** command . Before invoking **bgerror**, Tcl restores the **[errorInfo](tclvars.htm)** and **[errorCode](tclvars.htm)** variables to their values at the time the error occurred, then it invokes **bgerror** with the error message as its only argument. Tcl assumes that the application has implemented the **bgerror** command, and that the command will report the error in a way that makes sense for the application. Tcl will ignore any result returned by the **bgerror** command as long as no error is generated.
If another Tcl error occurs within the **bgerror** command (for example, because no **bgerror** command has been defined) then Tcl reports the error itself by writing a message to stderr.
If several background errors accumulate before **bgerror** is invoked to process them, **bgerror** will be invoked once for each error, in the order they occurred. However, if **bgerror** returns with a break exception, then any remaining errors are skipped without calling **bgerror**.
If you are writing code that will be used by others as part of a package or other kind of library, consider avoiding **bgerror**. The reason for this is that the application programmer may also want to define a **bgerror**, or use other code that does and thus will have trouble integrating your code.
Example
-------
This **bgerror** procedure appends errors to a file, with a timestamp.
```
proc bgerror {message} {
set timestamp [clock format [clock seconds]]
set fl [open mylog.txt {WRONLY CREAT APPEND}]
puts $fl "$timestamp: bgerror in $::argv '$message'"
close $fl
}
```
See also
--------
**[after](after.htm)**, **[errorCode](tclvars.htm)**, **[errorInfo](tclvars.htm)**, **[interp](interp.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/bgerror.htm>
tcl_tk append append
======
Name
----
append — Append to variable Synopsis
--------
**append** *varName* ?*value value value ...*?
Description
-----------
Append all of the *value* arguments to the current value of variable *varName*. If *varName* does not exist, it is given a value equal to the concatenation of all the *value* arguments. The result of this command is the new value stored in variable *varName*. This command provides an efficient way to build up long variables incrementally. For example, “**append a $b**” is much more efficient than “**set a $a$b**” if **$a** is long. Example
-------
Building a string of comma-separated numbers piecemeal using a loop.
```
set var 0
for {set i 1} {$i<=10} {incr i} {
**append** var "," $i
}
puts $var
# Prints 0,1,2,3,4,5,6,7,8,9,10
```
See also
--------
**[concat](concat.htm)**, **[lappend](lappend.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/append.htm>
tcl_tk mathop mathop
======
[NAME](mathop.htm#M2) mathop — Mathematical operators as Tcl commands
[SYNOPSIS](mathop.htm#M3)
[DESCRIPTION](mathop.htm#M4)
[MATHEMATICAL OPERATORS](mathop.htm#M5)
[**!** *boolean*](mathop.htm#M6)
[**+** ?*number* ...?](mathop.htm#M7)
[**-** *number* ?*number* ...?](mathop.htm#M8)
[**\*** ?*number* ...?](mathop.htm#M9)
[**/** *number* ?*number* ...?](mathop.htm#M10)
[**%** *number number*](mathop.htm#M11)
[**\*\*** ?*number* ...?](mathop.htm#M12)
[COMPARISON OPERATORS](mathop.htm#M13)
[**==** ?*arg* ...?](mathop.htm#M14)
[**eq** ?*arg* ...?](mathop.htm#M15)
[**!=** *arg arg*](mathop.htm#M16)
[**ne** *arg arg*](mathop.htm#M17)
[**<** ?*arg* ...?](mathop.htm#M18)
[**<=** ?*arg* ...?](mathop.htm#M19)
[**>** ?*arg* ...?](mathop.htm#M20)
[**>=** ?*arg* ...?](mathop.htm#M21)
[BIT-WISE OPERATORS](mathop.htm#M22)
[**~** *number*](mathop.htm#M23)
[**&** ?*number* ...?](mathop.htm#M24)
[**|** ?*number* ...?](mathop.htm#M25)
[**^** ?*number* ...?](mathop.htm#M26)
[**<<** *number number*](mathop.htm#M27)
[**>>** *number number*](mathop.htm#M28)
[LIST OPERATORS](mathop.htm#M29)
[**in** *arg list*](mathop.htm#M30)
[**ni** *arg list*](mathop.htm#M31)
[EXAMPLES](mathop.htm#M32)
[SEE ALSO](mathop.htm#M33)
[KEYWORDS](mathop.htm#M34)
Name
----
mathop — Mathematical operators as Tcl commands Synopsis
--------
package require **Tcl 8.5**
**::tcl::mathop::!** *number*
**::tcl::mathop::~** *number*
**::tcl::mathop::+** ?*number* ...?
**::tcl::mathop::-** *number* ?*number* ...?
**::tcl::mathop::\*** ?*number* ...?
**::tcl::mathop::/** *number* ?*number* ...?
**::tcl::mathop::%** *number number*
**::tcl::mathop::\*\*** ?*number* ...?
**::tcl::mathop::&** ?*number* ...?
**::tcl::mathop::|** ?*number* ...?
**::tcl::mathop::^** ?*number* ...?
**::tcl::mathop::<<** *number number*
**::tcl::mathop::>>** *number number*
**::tcl::mathop::==** ?*arg* ...?
**::tcl::mathop::!=** *arg arg*
**::tcl::mathop::<** ?*arg* ...?
**::tcl::mathop::<=** ?*arg* ...?
**::tcl::mathop::>=** ?*arg* ...?
**::tcl::mathop::>** ?*arg* ...?
**::tcl::mathop::eq** ?*arg* ...?
**::tcl::mathop::ne** *arg arg*
**::tcl::mathop::in** *arg list*
**::tcl::mathop::ni** *arg list*
Description
-----------
The commands in the **::tcl::mathop** namespace implement the same set of operations as supported by the **[expr](expr.htm)** command. All are exported from the namespace, but are not imported into any other namespace by default. Note that renaming, reimplementing or deleting any of the commands in the namespace does *not* alter the way that the **[expr](expr.htm)** command behaves, and nor does defining any new commands in the **::tcl::mathop** namespace. The following operator commands are supported:
| | | | | |
| --- | --- | --- | --- | --- |
| **~** | **!** | **+** | **-** | **\*** |
| **/** | **%** | **\*\*** | **&** | **|** |
| **^** | **>>** | **<<** | **==** | **eq** |
| **!=** | **ne** | **<** | **<=** | **>** |
| **>=** | **in** | **ni** |
### Mathematical operators
The behaviors of the mathematical operator commands are as follows:
**!** *boolean*
Returns the boolean negation of *boolean*, where *boolean* may be any numeric value or any other form of boolean value (i.e. it returns truth if the argument is falsity or zero, and falsity if the argument is truth or non-zero).
**+** ?*number* ...?
Returns the sum of arbitrarily many arguments. Each *number* argument may be any numeric value. If no arguments are given, the result will be zero (the summation identity).
**-** *number* ?*number* ...?
If only a single *number* argument is given, returns the negation of that numeric value. Otherwise returns the number that results when all subsequent numeric values are subtracted from the first one. All *number* arguments must be numeric values. At least one argument must be given.
**\*** ?*number* ...?
Returns the product of arbitrarily many arguments. Each *number* may be any numeric value. If no arguments are given, the result will be one (the multiplicative identity).
**/** *number* ?*number* ...?
If only a single *number* argument is given, returns the reciprocal of that numeric value (i.e. the value obtained by dividing 1.0 by that value). Otherwise returns the number that results when the first numeric argument is divided by all subsequent numeric arguments. All *number* arguments must be numeric values. At least one argument must be given. Note that when the leading values in the list of arguments are integers, integer division will be used for those initial steps (i.e. the intermediate results will be as if the functions *floor* and *int* are applied to them, in that order). If all values in the operation are integers, the result will be an integer.
**%** *number number*
Returns the integral modulus (i.e., remainder) of the first argument with respect to the second. Each *number* must have an integral value. Also, the sign of the result will be the same as the sign of the second *number*, which must not be zero. Note that Tcl defines this operation exactly even for negative numbers, so that the following command returns a true value (omitting the namespace for clarity):
```
**==** [**\*** [**/** *x y*] *y*] [**-** *x* [**%** *x y*]]
```
**\*\*** ?*number* ...?
Returns the result of raising each value to the power of the result of recursively operating on the result of processing the following arguments, so “**\*\* 2 3 4**” is the same as “**\*\* 2 [\*\* 3 4]**”. Each *number* may be any numeric value, though the second number must not be fractional if the first is negative. If no arguments are given, the result will be one, and if only one argument is given, the result will be that argument. The result will have an integral value only when all arguments are integral values.
### Comparison operators
The behaviors of the comparison operator commands (most of which operate preferentially on numeric arguments) are as follows:
**==** ?*arg* ...?
Returns whether each argument is equal to the arguments on each side of it in the sense of the **[expr](expr.htm)** == operator (*i.e.*, numeric comparison if possible, exact string comparison otherwise). If fewer than two arguments are given, this operation always returns a true value.
**eq** ?*arg* ...?
Returns whether each argument is equal to the arguments on each side of it using exact string comparison. If fewer than two arguments are given, this operation always returns a true value.
**!=** *arg arg*
Returns whether the two arguments are not equal to each other, in the sense of the **[expr](expr.htm)** != operator (*i.e.*, numeric comparison if possible, exact string comparison otherwise).
**ne** *arg arg*
Returns whether the two arguments are not equal to each other using exact string comparison.
**<** ?*arg* ...?
Returns whether the arbitrarily-many arguments are ordered, with each argument after the first having to be strictly more than the one preceding it. Comparisons are performed preferentially on the numeric values, and are otherwise performed using UNICODE string comparison. If fewer than two arguments are present, this operation always returns a true value. When the arguments are numeric but should be compared as strings, the **string compare** command should be used instead.
**<=** ?*arg* ...?
Returns whether the arbitrarily-many arguments are ordered, with each argument after the first having to be equal to or more than the one preceding it. Comparisons are performed preferentially on the numeric values, and are otherwise performed using UNICODE string comparison. If fewer than two arguments are present, this operation always returns a true value. When the arguments are numeric but should be compared as strings, the **string compare** command should be used instead.
**>** ?*arg* ...?
Returns whether the arbitrarily-many arguments are ordered, with each argument after the first having to be strictly less than the one preceding it. Comparisons are performed preferentially on the numeric values, and are otherwise performed using UNICODE string comparison. If fewer than two arguments are present, this operation always returns a true value. When the arguments are numeric but should be compared as strings, the **string compare** command should be used instead.
**>=** ?*arg* ...?
Returns whether the arbitrarily-many arguments are ordered, with each argument after the first having to be equal to or less than the one preceding it. Comparisons are performed preferentially on the numeric values, and are otherwise performed using UNICODE string comparison. If fewer than two arguments are present, this operation always returns a true value. When the arguments are numeric but should be compared as strings, the **string compare** command should be used instead.
### Bit-wise operators
The behaviors of the bit-wise operator commands (all of which only operate on integral arguments) are as follows:
**~** *number*
Returns the bit-wise negation of *number*. *Number* may be an integer of any size. Note that the result of this operation will always have the opposite sign to the input *number*.
**&** ?*number* ...?
Returns the bit-wise AND of each of the arbitrarily many arguments. Each *number* must have an integral value. If no arguments are given, the result will be minus one.
**|** ?*number* ...?
Returns the bit-wise OR of each of the arbitrarily many arguments. Each *number* must have an integral value. If no arguments are given, the result will be zero.
**^** ?*number* ...?
Returns the bit-wise XOR of each of the arbitrarily many arguments. Each *number* must have an integral value. If no arguments are given, the result will be zero.
**<<** *number number*
Returns the result of bit-wise shifting the first argument left by the number of bits specified in the second argument. Each *number* must have an integral value.
**>>** *number number*
Returns the result of bit-wise shifting the first argument right by the number of bits specified in the second argument. Each *number* must have an integral value.
### List operators
The behaviors of the list-oriented operator commands are as follows:
**in** *arg list*
Returns whether the value *arg* is present in the list *list* (according to exact string comparison of elements).
**ni** *arg list*
Returns whether the value *arg* is not present in the list *list* (according to exact string comparison of elements).
Examples
--------
The simplest way to use the operators is often by using **[namespace path](namespace.htm)** to make the commands available. This has the advantage of not affecting the set of commands defined by the current namespace.
```
namespace path {**::tcl::mathop** ::tcl::mathfunc}
*# Compute the sum of some numbers*
set sum [**+** 1 2 3]
*# Compute the average of a list*
set list {1 2 3 4 5 6}
set mean [**/** [**+** {*}$list] [double [llength $list]]]
*# Test for list membership*
set gotIt [**in** 3 $list]
*# Test to see if a value is within some defined range*
set inRange [**<=** 1 $x 5]
*# Test to see if a list is sorted*
set sorted [**<=** {*}$list]
```
See also
--------
**[expr](expr.htm)**, **[mathfunc](mathfunc.htm)**, **[namespace](namespace.htm)**
| programming_docs |
tcl_tk namespace namespace
=========
[NAME](namespace.htm#M2) namespace — create and manipulate contexts for commands and variables
[SYNOPSIS](namespace.htm#M3)
[DESCRIPTION](namespace.htm#M4)
[**namespace children** ?*namespace*? ?*pattern*?](namespace.htm#M5)
[**namespace code** *script*](namespace.htm#M6)
[**namespace current**](namespace.htm#M7)
[**namespace delete** ?*namespace namespace ...*?](namespace.htm#M8)
[**namespace ensemble** *subcommand* ?*arg ...*?](namespace.htm#M9)
[**namespace eval** *namespace arg* ?*arg ...*?](namespace.htm#M10)
[**namespace exists** *namespace*](namespace.htm#M11)
[**namespace export** ?**-clear**? ?*pattern pattern ...*?](namespace.htm#M12)
[**namespace forget** ?*pattern pattern ...*?](namespace.htm#M13)
[**namespace import** ?**-force**? ?*pattern* *pattern ...*?](namespace.htm#M14)
[**namespace inscope** *namespace* *script* ?*arg ...*?](namespace.htm#M15)
[**namespace origin** *command*](namespace.htm#M16)
[**namespace parent** ?*namespace*?](namespace.htm#M17)
[**namespace path** ?*namespaceList*?](namespace.htm#M18)
[**namespace qualifiers** *string*](namespace.htm#M19)
[**namespace tail** *string*](namespace.htm#M20)
[**namespace upvar** *namespace* ?*otherVar myVar* ...?](namespace.htm#M21)
[**namespace unknown** ?*script*?](namespace.htm#M22)
[**namespace which** ?**-command**? ?**-variable**? *name*](namespace.htm#M23)
[WHAT IS A NAMESPACE?](namespace.htm#M24)
[QUALIFIED NAMES](namespace.htm#M25)
[NAME RESOLUTION](namespace.htm#M26)
[IMPORTING COMMANDS](namespace.htm#M27)
[EXPORTING COMMANDS](namespace.htm#M28)
[SCOPED SCRIPTS](namespace.htm#M29)
[ENSEMBLES](namespace.htm#M30)
[**namespace ensemble create** ?*option value ...*?](namespace.htm#M31)
[**namespace ensemble configure** *command* ?*option*? ?*value ...*?](namespace.htm#M32)
[**namespace ensemble exists** *command*](namespace.htm#M33)
[ENSEMBLE OPTIONS](namespace.htm#M34)
[**-map**](namespace.htm#M35)
[**-parameters**](namespace.htm#M36)
[**-prefixes**](namespace.htm#M37)
[**-subcommands**](namespace.htm#M38)
[**-unknown**](namespace.htm#M39)
[**-command**](namespace.htm#M40)
[**-namespace**](namespace.htm#M41)
[UNKNOWN HANDLER BEHAVIOUR](namespace.htm#M42)
[EXAMPLES](namespace.htm#M43)
[SEE ALSO](namespace.htm#M44)
[KEYWORDS](namespace.htm#M45)
Name
----
namespace — create and manipulate contexts for commands and variables Synopsis
--------
**namespace** ?*subcommand*? ?*arg ...*?
Description
-----------
The **namespace** command lets you create, access, and destroy separate contexts for commands and variables. See the section **[WHAT IS A NAMESPACE?](#M24)** below for a brief overview of namespaces. The legal values of *subcommand* are listed below. Note that you can abbreviate the *subcommand*s.
**namespace children** ?*namespace*? ?*pattern*?
Returns a list of all child namespaces that belong to the namespace *namespace*. If *namespace* is not specified, then the children are returned for the current namespace. This command returns fully-qualified names, which start with a double colon (**::**). If the optional *pattern* is given, then this command returns only the names that match the glob-style pattern. The actual pattern used is determined as follows: a pattern that starts with double colon (**::**) is used directly, otherwise the namespace *namespace* (or the fully-qualified name of the current namespace) is prepended onto the pattern.
**namespace code** *script*
Captures the current namespace context for later execution of the script *script*. It returns a new script in which *script* has been wrapped in a **namespace inscope** command. The new script has two important properties. First, it can be evaluated in any namespace and will cause *script* to be evaluated in the current namespace (the one where the **namespace code** command was invoked). Second, additional arguments can be appended to the resulting script and they will be passed to *script* as additional arguments. For example, suppose the command **set script [namespace code {foo bar}]** is invoked in namespace **::a::b**. Then **eval $script [list x y]** can be executed in any namespace (assuming the value of **script** has been passed in properly) and will have the same effect as the command **::namespace eval ::a::b {foo bar x y}**. This command is needed because extensions like Tk normally execute callback scripts in the global namespace. A scoped command captures a command together with its namespace context in a way that allows it to be executed properly later. See the section **[SCOPED SCRIPTS](#M29)** for some examples of how this is used to create callback scripts.
**namespace current**
Returns the fully-qualified name for the current namespace. The actual name of the global namespace is “” (i.e., an empty string), but this command returns **::** for the global namespace as a convenience to programmers.
**namespace delete** ?*namespace namespace ...*?
Each namespace *namespace* is deleted and all variables, procedures, and child namespaces contained in the namespace are deleted. If a procedure is currently executing inside the namespace, the namespace will be kept alive until the procedure returns; however, the namespace is marked to prevent other code from looking it up by name. If a namespace does not exist, this command returns an error. If no namespace names are given, this command does nothing.
**namespace ensemble** *subcommand* ?*arg ...*?
Creates and manipulates a command that is formed out of an ensemble of subcommands. See the section **[ENSEMBLES](#M30)** below for further details.
**namespace eval** *namespace arg* ?*arg ...*?
Activates a namespace called *namespace* and evaluates some code in that context. If the namespace does not already exist, it is created. If more than one *arg* argument is specified, the arguments are concatenated together with a space between each one in the same fashion as the **[eval](eval.htm)** command, and the result is evaluated. If *namespace* has leading namespace qualifiers and any leading namespaces do not exist, they are automatically created.
**namespace exists** *namespace*
Returns **1** if *namespace* is a valid namespace in the current context, returns **0** otherwise.
**namespace export** ?**-clear**? ?*pattern pattern ...*?
Specifies which commands are exported from a namespace. The exported commands are those that can be later imported into another namespace using a **namespace import** command. Both commands defined in a namespace and commands the namespace has previously imported can be exported by a namespace. The commands do not have to be defined at the time the **namespace export** command is executed. Each *pattern* may contain glob-style special characters, but it may not include any namespace qualifiers. That is, the pattern can only specify commands in the current (exporting) namespace. Each *pattern* is appended onto the namespace's list of export patterns. If the **-clear** flag is given, the namespace's export pattern list is reset to empty before any *pattern* arguments are appended. If no *pattern*s are given and the **-clear** flag is not given, this command returns the namespace's current export list.
**namespace forget** ?*pattern pattern ...*?
Removes previously imported commands from a namespace. Each *pattern* is a simple or qualified name such as **x**, **foo::x** or **a::b::p\***. Qualified names contain double colons (**::**) and qualify a name with the name of one or more namespaces. Each “qualified pattern” is qualified with the name of an exporting namespace and may have glob-style special characters in the command name at the end of the qualified name. Glob characters may not appear in a namespace name. For each “simple pattern” this command deletes the matching commands of the current namespace that were imported from a different namespace. For “qualified patterns”, this command first finds the matching exported commands. It then checks whether any of those commands were previously imported by the current namespace. If so, this command deletes the corresponding imported commands. In effect, this un-does the action of a **namespace import** command.
**namespace import** ?**-force**? ?*pattern* *pattern ...*?
Imports commands into a namespace, or queries the set of imported commands in a namespace. When no arguments are present, **namespace import** returns the list of commands in the current namespace that have been imported from other namespaces. The commands in the returned list are in the format of simple names, with no namespace qualifiers at all. This format is suitable for composition with **namespace forget** (see **[EXAMPLES](#M43)** below). When *pattern* arguments are present, each *pattern* is a qualified name like **foo::x** or **a::p\***. That is, it includes the name of an exporting namespace and may have glob-style special characters in the command name at the end of the qualified name. Glob characters may not appear in a namespace name. When the namespace name is not fully qualified (i.e., does not start with a namespace separator) it is resolved as a namespace name in the way described in the **[NAME RESOLUTION](#M26)** section; it is an error if no namespace with that name can be found.
All the commands that match a *pattern* string and which are currently exported from their namespace are added to the current namespace. This is done by creating a new command in the current namespace that points to the exported command in its original namespace; when the new imported command is called, it invokes the exported command. This command normally returns an error if an imported command conflicts with an existing command. However, if the **-force** option is given, imported commands will silently replace existing commands. The **namespace import** command has snapshot semantics: that is, only requested commands that are currently defined in the exporting namespace are imported. In other words, you can import only the commands that are in a namespace at the time when the **namespace import** command is executed. If another command is defined and exported in this namespace later on, it will not be imported.
**namespace inscope** *namespace* *script* ?*arg ...*?
Executes a script in the context of the specified *namespace*. This command is not expected to be used directly by programmers; calls to it are generated implicitly when applications use **namespace code** commands to create callback scripts that the applications then register with, e.g., Tk widgets. The **namespace inscope** command is much like the **namespace eval** command except that the *namespace* must already exist, and **namespace inscope** appends additional *arg*s as proper list elements.
```
**namespace inscope ::foo $script $x $y $z**
```
is equivalent to
```
**namespace eval ::foo [concat $script [list $x $y $z]]**
```
thus additional arguments will not undergo a second round of substitution, as is the case with **namespace eval**.
**namespace origin** *command*
Returns the fully-qualified name of the original command to which the imported command *command* refers. When a command is imported into a namespace, a new command is created in that namespace that points to the actual command in the exporting namespace. If a command is imported into a sequence of namespaces *a, b,...,n* where each successive namespace just imports the command from the previous namespace, this command returns the fully-qualified name of the original command in the first namespace, *a*. If *command* does not refer to an imported command, the command's own fully-qualified name is returned.
**namespace parent** ?*namespace*?
Returns the fully-qualified name of the parent namespace for namespace *namespace*. If *namespace* is not specified, the fully-qualified name of the current namespace's parent is returned.
**namespace path** ?*namespaceList*?
Returns the command resolution path of the current namespace. If *namespaceList* is specified as a list of named namespaces, the current namespace's command resolution path is set to those namespaces and returns the empty list. The default command resolution path is always empty. See the section **[NAME RESOLUTION](#M26)** below for an explanation of the rules regarding name resolution.
**namespace qualifiers** *string*
Returns any leading namespace qualifiers for *string*. Qualifiers are namespace names separated by double colons (**::**). For the *string* **::foo::bar::x**, this command returns **::foo::bar**, and for **::** it returns an empty string. This command is the complement of the **namespace tail** command. Note that it does not check whether the namespace names are, in fact, the names of currently defined namespaces.
**namespace tail** *string*
Returns the simple name at the end of a qualified string. Qualifiers are namespace names separated by double colons (**::**). For the *string* **::foo::bar::x**, this command returns **x**, and for **::** it returns an empty string. This command is the complement of the **namespace qualifiers** command. It does not check whether the namespace names are, in fact, the names of currently defined namespaces.
**namespace upvar** *namespace* ?*otherVar myVar* ...?
This command arranges for zero or more local variables in the current procedure to refer to variables in *namespace*. The namespace name is resolved as described in section **[NAME RESOLUTION](#M26)**. The command **namespace upvar $ns a b** has the same behaviour as **upvar 0 ${ns}::a b**, with the sole exception of the resolution rules used for qualified namespace or variable names. **namespace upvar** returns an empty string.
**namespace unknown** ?*script*?
Sets or returns the unknown command handler for the current namespace. The handler is invoked when a command called from within the namespace cannot be found in the current namespace, the namespace's path nor in the global namespace. The *script* argument, if given, should be a well formed list representing a command name and optional arguments. When the handler is invoked, the full invocation line will be appended to the script and the result evaluated in the context of the namespace. The default handler for all namespaces is **::unknown**. If no argument is given, it returns the handler for the current namespace.
**namespace which** ?**-command**? ?**-variable**? *name*
Looks up *name* as either a command or variable and returns its fully-qualified name. For example, if *name* does not exist in the current namespace but does exist in the global namespace, this command returns a fully-qualified name in the global namespace. If the command or variable does not exist, this command returns an empty string. If the variable has been created but not defined, such as with the **[variable](variable.htm)** command or through a **[trace](trace.htm)** on the variable, this command will return the fully-qualified name of the variable. If no flag is given, *name* is treated as a command name. See the section **[NAME RESOLUTION](#M26)** below for an explanation of the rules regarding name resolution.
What is a namespace?
--------------------
A namespace is a collection of commands and variables. It encapsulates the commands and variables to ensure that they will not interfere with the commands and variables of other namespaces. Tcl has always had one such collection, which we refer to as the *global namespace*. The global namespace holds all global variables and commands. The **namespace eval** command lets you create new namespaces. For example,
```
**namespace eval** Counter {
**namespace export** bump
variable num 0
proc bump {} {
variable num
incr num
}
}
```
creates a new namespace containing the variable **num** and the procedure **bump**. The commands and variables in this namespace are separate from other commands and variables in the same program. If there is a command named **bump** in the global namespace, for example, it will be different from the command **bump** in the **Counter** namespace.
Namespace variables resemble global variables in Tcl. They exist outside of the procedures in a namespace but can be accessed in a procedure via the **[variable](variable.htm)** command, as shown in the example above.
Namespaces are dynamic. You can add and delete commands and variables at any time, so you can build up the contents of a namespace over time using a series of **namespace eval** commands. For example, the following series of commands has the same effect as the namespace definition shown above:
```
**namespace eval** Counter {
variable num 0
proc bump {} {
variable num
return [incr num]
}
}
**namespace eval** Counter {
proc test {args} {
return $args
}
}
**namespace eval** Counter {
rename test ""
}
```
Note that the **test** procedure is added to the **Counter** namespace, and later removed via the **[rename](rename.htm)** command.
Namespaces can have other namespaces within them, so they nest hierarchically. A nested namespace is encapsulated inside its parent namespace and can not interfere with other namespaces.
Qualified names
---------------
Each namespace has a textual name such as **[history](history.htm)** or **::safe::interp**. Since namespaces may nest, qualified names are used to refer to commands, variables, and child namespaces contained inside namespaces. Qualified names are similar to the hierarchical path names for Unix files or Tk widgets, except that **::** is used as the separator instead of **/** or **.**. The topmost or global namespace has the name “” (i.e., an empty string), although **::** is a synonym. As an example, the name **::safe::interp::create** refers to the command **create** in the namespace **[interp](interp.htm)** that is a child of namespace **::safe**, which in turn is a child of the global namespace, **::**. If you want to access commands and variables from another namespace, you must use some extra syntax. Names must be qualified by the namespace that contains them. From the global namespace, we might access the **Counter** procedures like this:
```
Counter::bump 5
Counter::Reset
```
We could access the current count like this:
```
puts "count = $Counter::num"
```
When one namespace contains another, you may need more than one qualifier to reach its elements. If we had a namespace **Foo** that contained the namespace **Counter**, you could invoke its **bump** procedure from the global namespace like this:
```
Foo::Counter::bump 3
```
You can also use qualified names when you create and rename commands. For example, you could add a procedure to the **Foo** namespace like this:
```
proc Foo::Test {args} {return $args}
```
And you could move the same procedure to another namespace like this:
```
rename Foo::Test Bar::Test
```
There are a few remaining points about qualified names that we should cover. Namespaces have nonempty names except for the global namespace. **::** is disallowed in simple command, variable, and namespace names except as a namespace separator. Extra colons in any separator part of a qualified name are ignored; i.e. two or more colons are treated as a namespace separator. A trailing **::** in a qualified variable or command name refers to the variable or command named {}. However, a trailing **::** in a qualified namespace name is ignored.
Name resolution
---------------
In general, all Tcl commands that take variable and command names support qualified names. This means you can give qualified names to such commands as **[set](set.htm)**, **[proc](proc.htm)**, **[rename](rename.htm)**, and **[interp alias](interp.htm)**. If you provide a fully-qualified name that starts with a **::**, there is no question about what command, variable, or namespace you mean. However, if the name does not start with a **::** (i.e., is *relative*), Tcl follows basic rules for looking it up:
* **Variable names** are always resolved by looking first in the current namespace, and then in the global namespace.
* **Command names** are always resolved by looking in the current namespace first. If not found there, they are searched for in every namespace on the current namespace's command path (which is empty by default). If not found there, command names are looked up in the global namespace (or, failing that, are processed by the appropriate **namespace unknown** handler.)
* **Namespace names** are always resolved by looking in only the current namespace.
In the following example,
```
set traceLevel 0
**namespace eval** Debug {
printTrace $traceLevel
}
```
Tcl looks for **traceLevel** in the namespace **Debug** and then in the global namespace. It looks up the command **printTrace** in the same way. If a variable or command name is not found in either context, the name is undefined. To make this point absolutely clear, consider the following example:
```
set traceLevel 0
**namespace eval** Foo {
variable traceLevel 3
**namespace eval** Debug {
printTrace $traceLevel
}
}
```
Here Tcl looks for **traceLevel** first in the namespace **Foo::Debug**. Since it is not found there, Tcl then looks for it in the global namespace. The variable **Foo::traceLevel** is completely ignored during the name resolution process.
You can use the **namespace which** command to clear up any question about name resolution. For example, the command:
```
**namespace eval** Foo::Debug {**namespace which** -variable traceLevel}
```
returns **::traceLevel**. On the other hand, the command,
```
**namespace eval** Foo {**namespace which** -variable traceLevel}
```
returns **::Foo::traceLevel**.
As mentioned above, namespace names are looked up differently than the names of variables and commands. Namespace names are always resolved in the current namespace. This means, for example, that a **namespace eval** command that creates a new namespace always creates a child of the current namespace unless the new namespace name begins with **::**.
Tcl has no access control to limit what variables, commands, or namespaces you can reference. If you provide a qualified name that resolves to an element by the name resolution rule above, you can access the element.
You can access a namespace variable from a procedure in the same namespace by using the **[variable](variable.htm)** command. Much like the **[global](global.htm)** command, this creates a local link to the namespace variable. If necessary, it also creates the variable in the current namespace and initializes it. Note that the **[global](global.htm)** command only creates links to variables in the global namespace. It is not necessary to use a **[variable](variable.htm)** command if you always refer to the namespace variable using an appropriate qualified name.
Importing commands
------------------
Namespaces are often used to represent libraries. Some library commands are used so frequently that it is a nuisance to type their qualified names. For example, suppose that all of the commands in a package like BLT are contained in a namespace called **Blt**. Then you might access these commands like this:
```
Blt::graph .g -background red
Blt::table . .g 0,0
```
If you use the **graph** and **table** commands frequently, you may want to access them without the **Blt::** prefix. You can do this by importing the commands into the current namespace, like this:
```
**namespace import** Blt::*
```
This adds all exported commands from the **Blt** namespace into the current namespace context, so you can write code like this:
```
graph .g -background red
table . .g 0,0
```
The **namespace import** command only imports commands from a namespace that that namespace exported with a **namespace export** command.
Importing *every* command from a namespace is generally a bad idea since you do not know what you will get. It is better to import just the specific commands you need. For example, the command
```
**namespace import** Blt::graph Blt::table
```
imports only the **graph** and **table** commands into the current context.
If you try to import a command that already exists, you will get an error. This prevents you from importing the same command from two different packages. But from time to time (perhaps when debugging), you may want to get around this restriction. You may want to reissue the **namespace import** command to pick up new commands that have appeared in a namespace. In that case, you can use the **-force** option, and existing commands will be silently overwritten:
```
**namespace import** -force Blt::graph Blt::table
```
If for some reason, you want to stop using the imported commands, you can remove them with a **namespace forget** command, like this:
```
**namespace forget** Blt::*
```
This searches the current namespace for any commands imported from **Blt**. If it finds any, it removes them. Otherwise, it does nothing. After this, the **Blt** commands must be accessed with the **Blt::** prefix.
When you delete a command from the exporting namespace like this:
```
rename Blt::graph ""
```
the command is automatically removed from all namespaces that import it.
Exporting commands
------------------
You can export commands from a namespace like this:
```
**namespace eval** Counter {
**namespace export** bump reset
variable Num 0
variable Max 100
proc bump {{by 1}} {
variable Num
incr Num $by
Check
return $Num
}
proc reset {} {
variable Num
set Num 0
}
proc Check {} {
variable Num
variable Max
if {$Num > $Max} {
error "too high!"
}
}
}
```
The procedures **bump** and **reset** are exported, so they are included when you import from the **Counter** namespace, like this:
```
**namespace import** Counter::*
```
However, the **Check** procedure is not exported, so it is ignored by the import operation.
The **namespace import** command only imports commands that were declared as exported by their namespace. The **namespace export** command specifies what commands may be imported by other namespaces. If a **namespace import** command specifies a command that is not exported, the command is not imported.
Scoped scripts
--------------
The **namespace code** command is the means by which a script may be packaged for evaluation in a namespace other than the one in which it was created. It is used most often to create event handlers, Tk bindings, and traces for evaluation in the global context. For instance, the following code indicates how to direct a variable **[trace](trace.htm)** callback into the current namespace:
```
**namespace eval** a {
variable b
proc theTraceCallback { n1 n2 op } {
upvar 1 $n1 var
puts "the value of $n1 has changed to $var"
return
}
trace add variable b write [**namespace code** theTraceCallback]
}
set a::b c
```
When executed, it prints the message:
```
the value of a::b has changed to c
```
Ensembles
---------
The **namespace ensemble** is used to create and manipulate ensemble commands, which are commands formed by grouping subcommands together. The commands typically come from the current namespace when the ensemble was created, though this is configurable. Note that there may be any number of ensembles associated with any namespace (including none, which is true of all namespaces by default), though all the ensembles associated with a namespace are deleted when that namespace is deleted. The link between an ensemble command and its namespace is maintained however the ensemble is renamed. Three subcommands of the **namespace ensemble** command are defined:
**namespace ensemble create** ?*option value ...*?
Creates a new ensemble command linked to the current namespace, returning the fully qualified name of the command created. The arguments to **namespace ensemble create** allow the configuration of the command as if with the **namespace ensemble configure** command. If not overridden with the **-command** option, this command creates an ensemble with exactly the same name as the linked namespace. See the section **[ENSEMBLE OPTIONS](#M34)** below for a full list of options supported and their effects.
**namespace ensemble configure** *command* ?*option*? ?*value ...*?
Retrieves the value of an option associated with the ensemble command named *command*, or updates some options associated with that ensemble command. See the section **[ENSEMBLE OPTIONS](#M34)** below for a full list of options supported and their effects.
**namespace ensemble exists** *command*
Returns a boolean value that describes whether the command *command* exists and is an ensemble command. This command only ever returns an error if the number of arguments to the command is wrong.
When called, an ensemble command takes its first argument and looks it up (according to the rules described below) to discover a list of words to replace the ensemble command and subcommand with. The resulting list of words is then evaluated (with no further substitutions) as if that was what was typed originally (i.e. by passing the list of words through **[Tcl\_EvalObjv](https://www.tcl.tk/man/tcl/TclLib/Eval.htm)**) and returning the result of the command. Note that it is legal to make the target of an ensemble rewrite be another (or even the same) ensemble command. The ensemble command will not be visible through the use of the **[uplevel](uplevel.htm)** or **[info level](info.htm)** commands.
### Ensemble options
The following options, supported by the **namespace ensemble create** and **namespace ensemble configure** commands, control how an ensemble command behaves:
**-map**
When non-empty, this option supplies a dictionary that provides a mapping from subcommand names to a list of prefix words to substitute in place of the ensemble command and subcommand words (in a manner similar to an alias created with **[interp alias](interp.htm)**; the words are not reparsed after substitution); if the first word of any target is not fully qualified when set, it is assumed to be relative to the *current* namespace and changed to be exactly that (that is, it is always fully qualified when read). When this option is empty, the mapping will be from the local name of the subcommand to its fully-qualified name. Note that when this option is non-empty and the **-subcommands** option is empty, the ensemble subcommand names will be exactly those words that have mappings in the dictionary.
**-parameters**
This option gives a list of named arguments (the names being used during generation of error messages) that are passed by the caller of the ensemble between the name of the ensemble and the subcommand argument. By default, it is the empty list.
**-prefixes**
This option (which is enabled by default) controls whether the ensemble command recognizes unambiguous prefixes of its subcommands. When turned off, the ensemble command requires exact matching of subcommand names.
**-subcommands**
When non-empty, this option lists exactly what subcommands are in the ensemble. The mapping for each of those commands will be either whatever is defined in the **-map** option, or to the command with the same name in the namespace linked to the ensemble. If this option is empty, the subcommands of the namespace will either be the keys of the dictionary listed in the **-map** option or the exported commands of the linked namespace at the time of the invocation of the ensemble command.
**-unknown**
When non-empty, this option provides a partial command (to which all the words that are arguments to the ensemble command, including the fully-qualified name of the ensemble, are appended) to handle the case where an ensemble subcommand is not recognized and would otherwise generate an error. When empty (the default) an error (in the style of **[Tcl\_GetIndexFromObj](https://www.tcl.tk/man/tcl/TclLib/GetIndex.htm)**) is generated whenever the ensemble is unable to determine how to implement a particular subcommand. See **[UNKNOWN HANDLER BEHAVIOUR](#M42)** for more details.
The following extra option is allowed by **namespace ensemble create**:
**-command**
This write-only option allows the name of the ensemble created by **namespace ensemble create** to be anything in any existing namespace. The default value for this option is the fully-qualified name of the namespace in which the **namespace ensemble create** command is invoked.
The following extra option is allowed by **namespace ensemble configure**:
**-namespace**
This read-only option allows the retrieval of the fully-qualified name of the namespace which the ensemble was created within.
### Unknown handler behaviour
If an unknown handler is specified for an ensemble, that handler is called when the ensemble command would otherwise return an error due to it being unable to decide which subcommand to invoke. The exact conditions under which that occurs are controlled by the **-subcommands**, **-map** and **-prefixes** options as described above. To execute the unknown handler, the ensemble mechanism takes the specified **-unknown** option and appends each argument of the attempted ensemble command invocation (including the ensemble command itself, expressed as a fully qualified name). It invokes the resulting command in the scope of the attempted call. If the execution of the unknown handler terminates normally, the ensemble engine reparses the subcommand (as described below) and tries to dispatch it again, which is ideal for when the ensemble's configuration has been updated by the unknown subcommand handler. Any other kind of termination of the unknown handler is treated as an error.
The result of the unknown handler is expected to be a list (it is an error if it is not). If the list is an empty list, the ensemble command attempts to look up the original subcommand again and, if it is not found this time, an error will be generated just as if the **-unknown** handler was not there (i.e. for any particular invocation of an ensemble, its unknown handler will be called at most once.) This makes it easy for the unknown handler to update the ensemble or its backing namespace so as to provide an implementation of the desired subcommand and reparse.
When the result is a non-empty list, the words of that list are used to replace the ensemble command and subcommand, just as if they had been looked up in the **-map**. It is up to the unknown handler to supply all namespace qualifiers if the implementing subcommand is not in the namespace of the caller of the ensemble command. Also note that when ensemble commands are chained (e.g. if you make one of the commands that implement an ensemble subcommand into an ensemble, in a manner similar to the **[text](../tkcmd/text.htm)** widget's tag and mark subcommands) then the rewrite happens in the context of the caller of the outermost ensemble. That is to say that ensembles do not in themselves place any namespace contexts on the Tcl call stack.
Where an empty **-unknown** handler is given (the default), the ensemble command will generate an error message based on the list of commands that the ensemble has defined (formatted similarly to the error message from **[Tcl\_GetIndexFromObj](https://www.tcl.tk/man/tcl/TclLib/GetIndex.htm)**). This is the error that will be thrown when the subcommand is still not recognized during reparsing. It is also an error for an **-unknown** handler to delete its namespace.
Examples
--------
Create a namespace containing a variable and an exported command:
```
**namespace eval** foo {
variable bar 0
proc grill {} {
variable bar
puts "called [incr bar] times"
}
**namespace export** grill
}
```
Call the command defined in the previous example in various ways.
```
# Direct call
::foo::grill
# Use the command resolution path to find the name
**namespace eval** boo {
**namespace path** ::foo
grill
}
# Import into current namespace, then call local alias
**namespace import** foo::grill
grill
# Create two ensembles, one with the default name and one with a
# specified name. Then call through the ensembles.
**namespace eval** foo {
**namespace ensemble** create
**namespace ensemble** create -command ::foobar
}
foo grill
foobar grill
```
Look up where the command imported in the previous example came from:
```
puts "grill came from [**namespace origin** grill]"
```
Remove all imported commands from the current namespace:
```
namespace forget {*}[namespace import]
```
Create an ensemble for simple working with numbers, using the **-parameters** option to allow the operator to be put between the first and second arguments.
```
**namespace eval** do {
**namespace export** *
**namespace ensemble** create -parameters x
proc plus {x y} {expr { $x + $y }}
proc minus {x y} {expr { $x - $y }}
}
# In use, the ensemble works like this:
puts [do 1 plus [do 9 minus 7]]
```
See also
--------
**[interp](interp.htm)**, **[upvar](upvar.htm)**, **[variable](variable.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/namespace.htm>
| programming_docs |
tcl_tk catch catch
=====
Name
----
catch — Evaluate script and trap exceptional returns Synopsis
--------
**catch** *script* ?*resultVarName*? ?*optionsVarName*?
Description
-----------
The **catch** command may be used to prevent errors from aborting command interpretation. The **catch** command calls the Tcl interpreter recursively to execute *script*, and always returns without raising an error, regardless of any errors that might occur while executing *script*. If *script* raises an error, **catch** will return a non-zero integer value corresponding to the exceptional return code returned by evaluation of *script*. Tcl defines the normal return code from script evaluation to be zero (0), or **TCL\_OK**. Tcl also defines four exceptional return codes: 1 (**TCL\_ERROR**), 2 (**TCL\_RETURN**), 3 (**TCL\_BREAK**), and 4 (**TCL\_CONTINUE**). Errors during evaluation of a script are indicated by a return code of **TCL\_ERROR**. The other exceptional return codes are returned by the **[return](return.htm)**, **[break](break.htm)**, and **[continue](continue.htm)** commands and in other special situations as documented. Tcl packages can define new commands that return other integer values as return codes as well, and scripts that make use of the **return -code** command can also have return codes other than the five defined by Tcl.
If the *resultVarName* argument is given, then the variable it names is set to the result of the script evaluation. When the return code from the script is 1 (**TCL\_ERROR**), the value stored in *resultVarName* is an error message. When the return code from the script is 0 (**TCL\_OK**), the value stored in *resultVarName* is the value returned from *script*.
If the *optionsVarName* argument is given, then the variable it names is set to a dictionary of return options returned by evaluation of *script*. Tcl specifies two entries that are always defined in the dictionary: **-code** and **-level**. When the return code from evaluation of *script* is not **TCL\_RETURN**, the value of the **-level** entry will be 0, and the value of the **-code** entry will be the same as the return code. Only when the return code is **TCL\_RETURN** will the values of the **-level** and **-code** entries be something else, as further described in the documentation for the **[return](return.htm)** command.
When the return code from evaluation of *script* is **TCL\_ERROR**, four additional entries are defined in the dictionary of return options stored in *optionsVarName*: **-errorinfo**, **-errorcode**, **-errorline**, and **-errorstack**. The value of the **-errorinfo** entry is a formatted stack trace containing more information about the context in which the error happened. The formatted stack trace is meant to be read by a person. The value of the **-errorcode** entry is additional information about the error stored as a list. The **-errorcode** value is meant to be further processed by programs, and may not be particularly readable by people. The value of the **-errorline** entry is an integer indicating which line of *script* was being evaluated when the error occurred. The value of the **-errorstack** entry is an even-sized list made of token-parameter pairs accumulated while unwinding the stack. The token may be “**CALL**”, in which case the parameter is a list made of the proc name and arguments at the corresponding level; or it may be “**UP**”, in which case the parameter is the relative level (as in **[uplevel](uplevel.htm)**) of the previous **CALL**. The salient differences with respect to **-errorinfo** are that:
1. it is a machine-readable form that is amenable to processing with [**[foreach](foreach.htm)** {tok prm} ...],
2. it contains the true (substituted) values passed to the functions, instead of the static text of the calling sites, and
3. it is coarser-grained, with only one element per stack frame (like procs; no separate elements for **[foreach](foreach.htm)** constructs for example).
The values of the **-errorinfo** and **-errorcode** entries of the most recent error are also available as values of the global variables **::errorInfo** and **::errorCode** respectively. The value of the **-errorstack** entry surfaces as **[info errorstack](info.htm)**.
Tcl packages may provide commands that set other entries in the dictionary of return options, and the **[return](return.htm)** command may be used by scripts to set return options in addition to those defined above.
Examples
--------
The **catch** command may be used in an **[if](if.htm)** to branch based on the success of a script.
```
if { [**catch** {open $someFile w} fid] } {
puts stderr "Could not open $someFile for writing\n$fid"
exit 1
}
```
There are more complex examples of **catch** usage in the documentation for the **[return](return.htm)** command.
See also
--------
**[break](break.htm)**, **[continue](continue.htm)**, **[dict](dict.htm)**, **[error](error.htm)**, **[errorCode](tclvars.htm)**, **[errorInfo](tclvars.htm)**, **[info](info.htm)**, **[return](return.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/catch.htm>
tcl_tk list list
====
Name
----
list — Create a list Synopsis
--------
**list** ?*arg arg ...*?
Description
-----------
This command returns a list comprised of all the *arg*s, or an empty string if no *arg*s are specified. Braces and backslashes get added as necessary, so that the **[lindex](lindex.htm)** command may be used on the result to re-extract the original arguments, and also so that **[eval](eval.htm)** may be used to execute the resulting list, with *arg1* comprising the command's name and the other *arg*s comprising its arguments. **List** produces slightly different results than **[concat](concat.htm)**: **[concat](concat.htm)** removes one level of grouping before forming the list, while **list** works directly from the original arguments. Example
-------
The command
```
**list** a b "c d e " " f {g h}"
```
will return
```
**a b {c d e } { f {g h}}**
```
while **[concat](concat.htm)** with the same arguments will return
```
**a b c d e f {g h}**
```
See also
--------
**[lappend](lappend.htm)**, **[lindex](lindex.htm)**, **[linsert](linsert.htm)**, **[llength](llength.htm)**, **[lrange](lrange.htm)**, **[lrepeat](lrepeat.htm)**, **[lreplace](lreplace.htm)**, **[lsearch](lsearch.htm)**, **[lset](lset.htm)**, **[lsort](lsort.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/list.htm>
tcl_tk encoding encoding
========
[NAME](encoding.htm#M2) encoding — Manipulate encodings
[SYNOPSIS](encoding.htm#M3)
[INTRODUCTION](encoding.htm#M4)
[DESCRIPTION](encoding.htm#M5)
[**encoding convertfrom** ?*encoding*? *data*](encoding.htm#M6)
[**encoding convertto** ?*encoding*? *string*](encoding.htm#M7)
[**encoding dirs** ?*directoryList*?](encoding.htm#M8)
[**encoding names**](encoding.htm#M9)
[**encoding system** ?*encoding*?](encoding.htm#M10)
[EXAMPLE](encoding.htm#M11)
[SEE ALSO](encoding.htm#M12)
[KEYWORDS](encoding.htm#M13)
Name
----
encoding — Manipulate encodings Synopsis
--------
**encoding** *option* ?*arg arg ...*?
Introduction
------------
Strings in Tcl are logically a sequence of 16-bit Unicode characters. These strings are represented in memory as a sequence of bytes that may be in one of several encodings: modified UTF-8 (which uses 1 to 3 bytes per character), 16-bit “Unicode” (which uses 2 bytes per character, with an endianness that is dependent on the host architecture), and binary (which uses a single byte per character but only handles a restricted range of characters). Tcl does not guarantee to always use the same encoding for the same string. Different operating system interfaces or applications may generate strings in other encodings such as Shift-JIS. The **encoding** command helps to bridge the gap between Unicode and these other formats.
Description
-----------
Performs one of several encoding related operations, depending on *option*. The legal *option*s are:
**encoding convertfrom** ?*encoding*? *data*
Convert *data* to Unicode from the specified *encoding*. The characters in *data* are treated as binary data where the lower 8-bits of each character is taken as a single byte. The resulting sequence of bytes is treated as a string in the specified *encoding*. If *encoding* is not specified, the current system encoding is used.
**encoding convertto** ?*encoding*? *string*
Convert *string* from Unicode to the specified *encoding*. The result is a sequence of bytes that represents the converted string. Each byte is stored in the lower 8-bits of a Unicode character (indeed, the resulting string is a binary string as far as Tcl is concerned, at least initially). If *encoding* is not specified, the current system encoding is used.
**encoding dirs** ?*directoryList*?
Tcl can load encoding data files from the file system that describe additional encodings for it to work with. This command sets the search path for **\*.enc** encoding data files to the list of directories *directoryList*. If *directoryList* is omitted then the command returns the current list of directories that make up the search path. It is an error for *directoryList* to not be a valid list. If, when a search for an encoding data file is happening, an element in *directoryList* does not refer to a readable, searchable directory, that element is ignored.
**encoding names**
Returns a list containing the names of all of the encodings that are currently available. The encodings “utf-8” and “iso8859-1” are guaranteed to be present in the list.
**encoding system** ?*encoding*?
Set the system encoding to *encoding*. If *encoding* is omitted then the command returns the current system encoding. The system encoding is used whenever Tcl passes strings to system calls.
Example
-------
It is common practice to write script files using a text editor that produces output in the euc-jp encoding, which represents the ASCII characters as singe bytes and Japanese characters as two bytes. This makes it easy to embed literal strings that correspond to non-ASCII characters by simply typing the strings in place in the script. However, because the **[source](source.htm)** command always reads files using the current system encoding, Tcl will only source such files correctly when the encoding used to write the file is the same. This tends not to be true in an internationalized setting. For example, if such a file was sourced in North America (where the ISO8859-1 is normally used), each byte in the file would be treated as a separate character that maps to the 00 page in Unicode. The resulting Tcl strings will not contain the expected Japanese characters. Instead, they will contain a sequence of Latin-1 characters that correspond to the bytes of the original string. The **encoding** command can be used to convert this string to the expected Japanese Unicode characters. For example,
```
set s [**encoding convertfrom** euc-jp "\xA4\xCF"]
```
would return the Unicode string “\u306F”, which is the Hiragana letter HA.
See also
--------
**[Tcl\_GetEncoding](https://www.tcl.tk/man/tcl/TclLib/Encoding.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/encoding.htm>
tcl_tk try try
===
Name
----
try — Trap and process errors and exceptions Synopsis
--------
**try** *body* ?*handler...*? ?**finally** *script*?
Description
-----------
This command executes the script *body* and, depending on what the outcome of that script is (normal exit, error, or some other exceptional result), runs a handler script to deal with the case. Once that has all happened, if the **finally** clause is present, the *script* it includes will be run and the result of the handler (or the *body* if no handler matched) is allowed to continue to propagate. Note that the **finally** clause is processed even if an error occurs and irrespective of which, if any, *handler* is used. The *handler* clauses are each expressed as several words, and must have one of the following forms:
**on** *code variableList script*
This clause matches if the evaluation of *body* completed with the exception code *code*. The *code* may be expressed as an integer or one of the following literal words: **ok**, **[error](error.htm)**, **[return](return.htm)**, **[break](break.htm)**, or **[continue](continue.htm)**. Those literals correspond to the integers 0 through 4 respectively.
**trap** *pattern variableList script*
This clause matches if the evaluation of *body* resulted in an error and the prefix of the **-errorcode** from the interpreter's status dictionary is equal to the *pattern*. The number of prefix words taken from the **-errorcode** is equal to the list-length of *pattern*, and inter-word spaces are normalized in both the **-errorcode** and *pattern* before comparison.
The *variableList* word in each *handler* is always interpreted as a list of variable names. If the first word of the list is present and non-empty, it names a variable into which the result of the evaluation of *body* (from the main **try**) will be placed; this will contain the human-readable form of any errors. If the second word of the list is present and non-empty, it names a variable into which the options dictionary of the interpreter at the moment of completion of execution of *body* will be placed.
The *script* word of each *handler* is also always interpreted the same: as a Tcl script to evaluate if the clause is matched. If *script* is a literal “-” and the *handler* is not the last one, the *script* of the following *handler* is invoked instead (just like with the **[switch](switch.htm)** command).
Note that *handler* clauses are matched against in order, and that the first matching one is always selected. At most one *handler* clause will selected. As a consequence, an **on error** will mask any subsequent **trap** in the **try**. Also note that **on error** is equivalent to **trap {}**.
If an exception (i.e. any non-**ok** result) occurs during the evaluation of either the *handler* or the **finally** clause, the original exception's status dictionary will be added to the new exception's status dictionary under the **-during** key.
Examples
--------
Ensure that a file is closed no matter what:
```
set f [open /some/file/name a]
**try** {
puts $f "some message"
# ...
} **finally** {
close $f
}
```
Handle different reasons for a file to not be openable for reading:
```
**try** {
set f [open /some/file/name w]
} **trap** {POSIX EISDIR} {} {
puts "failed to open /some/file/name: it's a directory"
} **trap** {POSIX ENOENT} {} {
puts "failed to open /some/file/name: it doesn't exist"
}
```
See also
--------
**[catch](catch.htm)**, **[error](error.htm)**, **[return](return.htm)**, **[throw](throw.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/try.htm>
tcl_tk lsort lsort
=====
[NAME](lsort.htm#M2) lsort — Sort the elements of a list
[SYNOPSIS](lsort.htm#M3)
[DESCRIPTION](lsort.htm#M4)
[**-ascii**](lsort.htm#M5)
[**-dictionary**](lsort.htm#M6)
[**-integer**](lsort.htm#M7)
[**-real**](lsort.htm#M8)
[**-command** *command*](lsort.htm#M9)
[**-increasing**](lsort.htm#M10)
[**-decreasing**](lsort.htm#M11)
[**-indices**](lsort.htm#M12)
[**-index** *indexList*](lsort.htm#M13)
[**-stride** *strideLength*](lsort.htm#M14)
[**-nocase**](lsort.htm#M15)
[**-unique**](lsort.htm#M16)
[NOTES](lsort.htm#M17)
[EXAMPLES](lsort.htm#M18)
[SEE ALSO](lsort.htm#M19)
[KEYWORDS](lsort.htm#M20)
Name
----
lsort — Sort the elements of a list Synopsis
--------
**lsort** ?*options*? *list*
Description
-----------
This command sorts the elements of *list*, returning a new list in sorted order. The implementation of the **lsort** command uses the merge-sort algorithm which is a stable sort that has O(n log n) performance characteristics. By default ASCII sorting is used with the result returned in increasing order. However, any of the following options may be specified before *list* to control the sorting process (unique abbreviations are accepted):
**-ascii**
Use string comparison with Unicode code-point collation order (the name is for backward-compatibility reasons.) This is the default.
**-dictionary**
Use dictionary-style comparison. This is the same as **-ascii** except (a) case is ignored except as a tie-breaker and (b) if two strings contain embedded numbers, the numbers compare as integers, not characters. For example, in **-dictionary** mode, **bigBoy** sorts between **bigbang** and **bigboy**, and **x10y** sorts between **x9y** and **x11y**.
**-integer**
Convert list elements to integers and use integer comparison.
**-real**
Convert list elements to floating-point values and use floating comparison.
**-command** *command*
Use *command* as a comparison command. To compare two elements, evaluate a Tcl script consisting of *command* with the two elements appended as additional arguments. The script should return an integer less than, equal to, or greater than zero if the first element is to be considered less than, equal to, or greater than the second, respectively.
**-increasing**
Sort the list in increasing order (“smallest”items first). This is the default.
**-decreasing**
Sort the list in decreasing order (“largest”items first).
**-indices**
Return a list of indices into *list* in sorted order instead of the values themselves.
**-index** *indexList*
If this option is specified, each of the elements of *list* must itself be a proper Tcl sublist (unless **-stride** is used). Instead of sorting based on whole sublists, **lsort** will extract the *indexList*'th element from each sublist (as if the overall element and the *indexList* were passed to **[lindex](lindex.htm)**) and sort based on the given element. For example,
```
**lsort** -integer -index 1 \
{{First 24} {Second 18} {Third 30}}
```
returns **{Second 18} {First 24} {Third 30}**,
```
**lsort** -index end-1 \
{{a 1 e i} {b 2 3 f g} {c 4 5 6 d h}}
```
returns **{c 4 5 6 d h} {a 1 e i} {b 2 3 f g}**, and
```
**lsort** -index {0 1} {
{{b i g} 12345}
{{d e m o} 34512}
{{c o d e} 54321}
}
```
returns **{{d e m o} 34512} {{b i g} 12345} {{c o d e} 54321}** (because **e** sorts before **i** which sorts before **o**.) This option is much more efficient than using **-command** to achieve the same effect.
**-stride** *strideLength*
If this option is specified, the list is treated as consisting of groups of *strideLength* elements and the groups are sorted by either their first element or, if the **-index** option is used, by the element within each group given by the first index passed to **-index** (which is then ignored by **-index**). Elements always remain in the same position within their group. The list length must be an integer multiple of *strideLength*, which in turn must be at least 2.
For example,
```
**lsort** -stride 2 {carrot 10 apple 50 banana 25}
```
returns “apple 50 banana 25 carrot 10”, and
```
**lsort** -stride 2 -index 1 -integer {carrot 10 apple 50 banana 25}
```
returns “carrot 10 banana 25 apple 50”.
**-nocase**
Causes comparisons to be handled in a case-insensitive manner. Has no effect if combined with the **-dictionary**, **-integer**, or **-real** options.
**-unique**
If this option is specified, then only the last set of duplicate elements found in the list will be retained. Note that duplicates are determined relative to the comparison used in the sort. Thus if **-index 0** is used, **{1 a}** and **{1 b}** would be considered duplicates and only the second element, **{1 b}**, would be retained.
Notes
-----
The options to **lsort** only control what sort of comparison is used, and do not necessarily constrain what the values themselves actually are. This distinction is only noticeable when the list to be sorted has fewer than two elements. The **lsort** command is reentrant, meaning it is safe to use as part of the implementation of a command used in the **-command** option.
Examples
--------
Sorting a list using ASCII sorting:
```
*%* **lsort** {a10 B2 b1 a1 a2}
B2 a1 a10 a2 b1
```
Sorting a list using Dictionary sorting:
```
*%* **lsort** -dictionary {a10 B2 b1 a1 a2}
a1 a2 a10 b1 B2
```
Sorting lists of integers:
```
*%* **lsort** -integer {5 3 1 2 11 4}
1 2 3 4 5 11
*%* **lsort** -integer {1 2 0x5 7 0 4 -1}
-1 0 1 2 4 0x5 7
```
Sorting lists of floating-point numbers:
```
*%* **lsort** -real {5 3 1 2 11 4}
1 2 3 4 5 11
*%* **lsort** -real {.5 0.07e1 0.4 6e-1}
0.4 .5 6e-1 0.07e1
```
Sorting using indices:
```
*%* # Note the space character before the c
*%* **lsort** {{a 5} { c 3} {b 4} {e 1} {d 2}}
{ c 3} {a 5} {b 4} {d 2} {e 1}
*%* **lsort** -index 0 {{a 5} { c 3} {b 4} {e 1} {d 2}}
{a 5} {b 4} { c 3} {d 2} {e 1}
*%* **lsort** -index 1 {{a 5} { c 3} {b 4} {e 1} {d 2}}
{e 1} {d 2} { c 3} {b 4} {a 5}
```
Sorting a dictionary:
```
*%* set d [dict create c d a b h i f g c e]
c e a b h i f g
*%* **lsort** -stride 2 $d
a b c e f g h i
```
Sorting using striding and multiple indices:
```
*%* # Note the first index value is relative to the group
*%* **lsort** -stride 3 -index {0 1} \
{{Bob Smith} 25 Audi {Jane Doe} 40 Ford}
{{Jane Doe} 40 Ford {Bob Smith} 25 Audi}
```
Stripping duplicate values using sorting:
```
*%* **lsort** -unique {a b c a b c a b c}
a b c
```
More complex sorting using a comparison function:
```
*%* proc compare {a b} {
set a0 [lindex $a 0]
set b0 [lindex $b 0]
if {$a0 < $b0} {
return -1
} elseif {$a0 > $b0} {
return 1
}
return [string compare [lindex $a 1] [lindex $b 1]]
}
*%* **lsort** -command compare \
{{3 apple} {0x2 carrot} {1 dingo} {2 banana}}
{1 dingo} {2 banana} {0x2 carrot} {3 apple}
```
See also
--------
**[list](list.htm)**, **[lappend](lappend.htm)**, **[lindex](lindex.htm)**, **[linsert](linsert.htm)**, **[llength](llength.htm)**, **[lsearch](lsearch.htm)**, **[lset](lset.htm)**, **[lrange](lrange.htm)**, **[lreplace](lreplace.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/lsort.htm>
| programming_docs |
tcl_tk trace trace
=====
[NAME](trace.htm#M2) trace — Monitor variable accesses, command usages and command executions
[SYNOPSIS](trace.htm#M3)
[DESCRIPTION](trace.htm#M4)
[**trace add** *type name ops ?args?*](trace.htm#M5)
[**trace add command** *name ops commandPrefix*](trace.htm#M6)
[**rename**](trace.htm#M7)
[**delete**](trace.htm#M8)
[**trace add execution** *name ops commandPrefix*](trace.htm#M9)
[**enter**](trace.htm#M10)
[**leave**](trace.htm#M11)
[**enterstep**](trace.htm#M12)
[**leavestep**](trace.htm#M13)
[**trace add variable** *name ops commandPrefix*](trace.htm#M14)
[**array**](trace.htm#M15)
[**read**](trace.htm#M16)
[**write**](trace.htm#M17)
[**unset**](trace.htm#M18)
[**trace remove** *type name opList commandPrefix*](trace.htm#M19)
[**trace remove command** *name opList commandPrefix*](trace.htm#M20)
[**trace remove execution** *name opList commandPrefix*](trace.htm#M21)
[**trace remove variable** *name opList commandPrefix*](trace.htm#M22)
[**trace info** *type name*](trace.htm#M23)
[**trace info command** *name*](trace.htm#M24)
[**trace info execution** *name*](trace.htm#M25)
[**trace info variable** *name*](trace.htm#M26)
[**trace variable** *name ops command*](trace.htm#M27)
[**trace vdelete** *name ops command*](trace.htm#M28)
[**trace vinfo** *name*](trace.htm#M29)
[EXAMPLES](trace.htm#M30)
[SEE ALSO](trace.htm#M31)
[KEYWORDS](trace.htm#M32)
Name
----
trace — Monitor variable accesses, command usages and command executions Synopsis
--------
**trace** *option* ?*arg arg ...*?
Description
-----------
This command causes Tcl commands to be executed whenever certain operations are invoked. The legal *option*s (which may be abbreviated) are:
**trace add** *type name ops ?args?*
Where *type* is **command**, **execution**, or **[variable](variable.htm)**.
**trace add command** *name ops commandPrefix*
Arrange for *commandPrefix* to be executed (with additional arguments) whenever command *name* is modified in one of the ways given by the list *ops*. *Name* will be resolved using the usual namespace resolution rules used by commands. If the command does not exist, an error will be thrown. *Ops* indicates which operations are of interest, and is a list of one or more of the following items:
**rename**
Invoke *commandPrefix* whenever the traced command is renamed. Note that renaming to the empty string is considered deletion, and will not be traced with “**[rename](rename.htm)**”.
**delete**
Invoke *commandPrefix* when the traced command is deleted. Commands can be deleted explicitly by using the **[rename](rename.htm)** command to rename the command to an empty string. Commands are also deleted when the interpreter is deleted, but traces will not be invoked because there is no interpreter in which to execute them.
When the trace triggers, depending on the operations being traced, a number of arguments are appended to *commandPrefix* so that the actual command is as follows:
```
*commandPrefix oldName newName op*
```
*OldName* and *newName* give the traced command's current (old) name, and the name to which it is being renamed (the empty string if this is a “delete” operation). *Op* indicates what operation is being performed on the command, and is one of **[rename](rename.htm)** or **delete** as defined above. The trace operation cannot be used to stop a command from being deleted. Tcl will always remove the command once the trace is complete. Recursive renaming or deleting will not cause further traces of the same type to be evaluated, so a delete trace which itself deletes the command, or a rename trace which itself renames the command will not cause further trace evaluations to occur. Both *oldName* and *newName* are fully qualified with any namespace(s) in which they appear.
**trace add execution** *name ops commandPrefix*
Arrange for *commandPrefix* to be executed (with additional arguments) whenever command *name* is executed, with traces occurring at the points indicated by the list *ops*. *Name* will be resolved using the usual namespace resolution rules used by commands. If the command does not exist, an error will be thrown. *Ops* indicates which operations are of interest, and is a list of one or more of the following items:
**enter**
Invoke *commandPrefix* whenever the command *name* is executed, just before the actual execution takes place.
**leave**
Invoke *commandPrefix* whenever the command *name* is executed, just after the actual execution takes place.
**enterstep**
Invoke *commandPrefix* for every Tcl command which is executed from the start of the execution of the procedure *name* until that procedure finishes. *CommandPrefix* is invoked just before the actual execution of the Tcl command being reported takes place. For example if we have “proc foo {} { puts "hello" }”, then an *enterstep* trace would be invoked just before “*puts "hello"*” is executed. Setting an *enterstep* trace on a command *name* that does not refer to a procedure will not result in an error and is simply ignored.
**leavestep**
Invoke *commandPrefix* for every Tcl command which is executed from the start of the execution of the procedure *name* until that procedure finishes. *CommandPrefix* is invoked just after the actual execution of the Tcl command being reported takes place. Setting a *leavestep* trace on a command *name* that does not refer to a procedure will not result in an error and is simply ignored.
When the trace triggers, depending on the operations being traced, a number of arguments are appended to *commandPrefix* so that the actual command is as follows:
For **enter** and **enterstep** operations:
```
*commandPrefix command-string op*
```
*Command-string* gives the complete current command being executed (the traced command for a **enter** operation, an arbitrary command for a **enterstep** operation), including all arguments in their fully expanded form. *Op* indicates what operation is being performed on the command execution, and is one of **enter** or **enterstep** as defined above. The trace operation can be used to stop the command from executing, by deleting the command in question. Of course when the command is subsequently executed, an “invalid command” error will occur.
For **leave** and **leavestep** operations:
```
*commandPrefix command-string code result op*
```
*Command-string* gives the complete current command being executed (the traced command for a **enter** operation, an arbitrary command for a **enterstep** operation), including all arguments in their fully expanded form. *Code* gives the result code of that execution, and *result* the result string. *Op* indicates what operation is being performed on the command execution, and is one of **leave** or **leavestep** as defined above. Note that the creation of many **enterstep** or **leavestep** traces can lead to unintuitive results, since the invoked commands from one trace can themselves lead to further command invocations for other traces.
*CommandPrefix* executes in the same context as the code that invoked the traced operation: thus the *commandPrefix*, if invoked from a procedure, will have access to the same local variables as code in the procedure. This context may be different than the context in which the trace was created. If *commandPrefix* invokes a procedure (which it normally does) then the procedure will have to use **[upvar](upvar.htm)** or **[uplevel](uplevel.htm)** commands if it wishes to access the local variables of the code which invoked the trace operation.
While *commandPrefix* is executing during an execution trace, traces on *name* are temporarily disabled. This allows the *commandPrefix* to execute *name* in its body without invoking any other traces again. If an error occurs while executing the *commandPrefix*, then the command *name* as a whole will return that same error.
When multiple traces are set on *name*, then for *enter* and *enterstep* operations, the traced commands are invoked in the reverse order of how the traces were originally created; and for *leave* and *leavestep* operations, the traced commands are invoked in the original order of creation.
The behavior of execution traces is currently undefined for a command *name* imported into another namespace.
**trace add variable** *name ops commandPrefix*
Arrange for *commandPrefix* to be executed whenever variable *name* is accessed in one of the ways given by the list *ops*. *Name* may refer to a normal variable, an element of an array, or to an array as a whole (i.e. *name* may be just the name of an array, with no parenthesized index). If *name* refers to a whole array, then *commandPrefix* is invoked whenever any element of the array is manipulated. If the variable does not exist, it will be created but will not be given a value, so it will be visible to **[namespace which](namespace.htm)** queries, but not to **[info exists](info.htm)** queries. *Ops* indicates which operations are of interest, and is a list of one or more of the following items:
**array**
Invoke *commandPrefix* whenever the variable is accessed or modified via the **[array](array.htm)** command, provided that *name* is not a scalar variable at the time that the **[array](array.htm)** command is invoked. If *name* is a scalar variable, the access via the **[array](array.htm)** command will not trigger the trace.
**read**
Invoke *commandPrefix* whenever the variable is read.
**write**
Invoke *commandPrefix* whenever the variable is written.
**unset**
Invoke *commandPrefix* whenever the variable is unset. Variables can be unset explicitly with the **[unset](unset.htm)** command, or implicitly when procedures return (all of their local variables are unset). Variables are also unset when interpreters are deleted, but traces will not be invoked because there is no interpreter in which to execute them.
When the trace triggers, three arguments are appended to *commandPrefix* so that the actual command is as follows:
```
*commandPrefix name1 name2 op*
```
*Name1* and *name2* give the name(s) for the variable being accessed: if the variable is a scalar then *name1* gives the variable's name and *name2* is an empty string; if the variable is an array element then *name1* gives the name of the array and name2 gives the index into the array; if an entire array is being deleted and the trace was registered on the overall array, rather than a single element, then *name1* gives the array name and *name2* is an empty string. *Name1* and *name2* are not necessarily the same as the name used in the **trace variable** command: the **[upvar](upvar.htm)** command allows a procedure to reference a variable under a different name. *Op* indicates what operation is being performed on the variable, and is one of **[read](read.htm)**, **write**, or **[unset](unset.htm)** as defined above.
*CommandPrefix* executes in the same context as the code that invoked the traced operation: if the variable was accessed as part of a Tcl procedure, then *commandPrefix* will have access to the same local variables as code in the procedure. This context may be different than the context in which the trace was created. If *commandPrefix* invokes a procedure (which it normally does) then the procedure will have to use **[upvar](upvar.htm)** or **[uplevel](uplevel.htm)** if it wishes to access the traced variable. Note also that *name1* may not necessarily be the same as the name used to set the trace on the variable; differences can occur if the access is made through a variable defined with the **[upvar](upvar.htm)** command.
For read and write traces, *commandPrefix* can modify the variable to affect the result of the traced operation. If *commandPrefix* modifies the value of a variable during a read or write trace, then the new value will be returned as the result of the traced operation. The return value from *commandPrefix* is ignored except that if it returns an error of any sort then the traced operation also returns an error with the same error message returned by the trace command (this mechanism can be used to implement read-only variables, for example). For write traces, *commandPrefix* is invoked after the variable's value has been changed; it can write a new value into the variable to override the original value specified in the write operation. To implement read-only variables, *commandPrefix* will have to restore the old value of the variable.
While *commandPrefix* is executing during a read or write trace, traces on the variable are temporarily disabled. This means that reads and writes invoked by *commandPrefix* will occur directly, without invoking *commandPrefix* (or any other traces) again. However, if *commandPrefix* unsets the variable then unset traces will be invoked.
When an unset trace is invoked, the variable has already been deleted: it will appear to be undefined with no traces. If an unset occurs because of a procedure return, then the trace will be invoked in the variable context of the procedure being returned to: the stack frame of the returning procedure will no longer exist. Traces are not disabled during unset traces, so if an unset trace command creates a new trace and accesses the variable, the trace will be invoked. Any errors in unset traces are ignored.
If there are multiple traces on a variable they are invoked in order of creation, most-recent first. If one trace returns an error, then no further traces are invoked for the variable. If an array element has a trace set, and there is also a trace set on the array as a whole, the trace on the overall array is invoked before the one on the element.
Once created, the trace remains in effect either until the trace is removed with the **trace remove variable** command described below, until the variable is unset, or until the interpreter is deleted. Unsetting an element of array will remove any traces on that element, but will not remove traces on the overall array.
This command returns an empty string.
**trace remove** *type name opList commandPrefix*
Where *type* is either **command**, **execution** or **[variable](variable.htm)**.
**trace remove command** *name opList commandPrefix*
If there is a trace set on command *name* with the operations and command given by *opList* and *commandPrefix*, then the trace is removed, so that *commandPrefix* will never again be invoked. Returns an empty string. If *name* does not exist, the command will throw an error.
**trace remove execution** *name opList commandPrefix*
If there is a trace set on command *name* with the operations and command given by *opList* and *commandPrefix*, then the trace is removed, so that *commandPrefix* will never again be invoked. Returns an empty string. If *name* does not exist, the command will throw an error.
**trace remove variable** *name opList commandPrefix*
If there is a trace set on variable *name* with the operations and command given by *opList* and *commandPrefix*, then the trace is removed, so that *commandPrefix* will never again be invoked. Returns an empty string.
**trace info** *type name*
Where *type* is either **command**, **execution** or **[variable](variable.htm)**.
**trace info command** *name*
Returns a list containing one element for each trace currently set on command *name*. Each element of the list is itself a list containing two elements, which are the *opList* and *commandPrefix* associated with the trace. If *name* does not have any traces set, then the result of the command will be an empty string. If *name* does not exist, the command will throw an error.
**trace info execution** *name*
Returns a list containing one element for each trace currently set on command *name*. Each element of the list is itself a list containing two elements, which are the *opList* and *commandPrefix* associated with the trace. If *name* does not have any traces set, then the result of the command will be an empty string. If *name* does not exist, the command will throw an error.
**trace info variable** *name*
Returns a list containing one element for each trace currently set on variable *name*. Each element of the list is itself a list containing two elements, which are the *opList* and *commandPrefix* associated with the trace. If *name* does not exist or does not have any traces set, then the result of the command will be an empty string.
For backwards compatibility, three other subcommands are available:
**trace variable** *name ops command*
This is equivalent to **trace add variable** *name ops command*.
**trace vdelete** *name ops command*
This is equivalent to **trace remove variable** *name ops command*
**trace vinfo** *name*
This is equivalent to **trace info variable** *name*
These subcommands are deprecated and will likely be removed in a future version of Tcl. They use an older syntax in which **[array](array.htm)**, **[read](read.htm)**, **write**, **[unset](unset.htm)** are replaced by **a**, **r**, **w** and **u** respectively, and the *ops* argument is not a list, but simply a string concatenation of the operations, such as **rwua**.
Examples
--------
Print a message whenever either of the global variables **foo** and **bar** are updated, even if they have a different local name at the time (which can be done with the **[upvar](upvar.htm)** command):
```
proc tracer {varname args} {
upvar #0 $varname var
puts "$varname was updated to be \"$var\""
}
**trace add** variable foo write "tracer foo"
**trace add** variable bar write "tracer bar"
```
Ensure that the global variable **foobar** always contains the product of the global variables **foo** and **bar**:
```
proc doMult args {
global foo bar foobar
set foobar [expr {$foo * $bar}]
}
**trace add** variable foo write doMult
**trace add** variable bar write doMult
```
Print a trace of what commands are executed during the processing of a Tcl procedure:
```
proc x {} { y }
proc y {} { z }
proc z {} { puts hello }
proc report args {puts [info level 0]}
**trace add** execution x enterstep report
x
→ *report y enterstep*
*report z enterstep*
*report {puts hello} enterstep*
*hello*
```
See also
--------
**[set](set.htm)**, **[unset](unset.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/trace.htm>
tcl_tk clock clock
=====
[NAME](clock.htm#M2) clock — Obtain and manipulate dates and times
[SYNOPSIS](clock.htm#M3)
[DESCRIPTION](clock.htm#M4)
[**clock add** *timeVal* ?*count unit...*? ?*-option value*?](clock.htm#M5)
[**clock clicks** ?*-option*?](clock.htm#M6)
[**clock format** *timeVal* ?*-option value*...?](clock.htm#M7)
[**clock microseconds**](clock.htm#M8)
[**clock milliseconds**](clock.htm#M9)
[**clock scan** *inputString* ?*-option value*...?](clock.htm#M10)
[**clock seconds**](clock.htm#M11)
[PARAMETERS](clock.htm#M12)
[*count*](clock.htm#M13)
[*timeVal*](clock.htm#M14)
[*unit*](clock.htm#M15)
[OPTIONS](clock.htm#M16)
[**-base** time](clock.htm#M17)
[**-format** format](clock.htm#M18)
[**-gmt** boolean](clock.htm#M19)
[**-locale** localeName](clock.htm#M20)
[**-timezone** zoneName](clock.htm#M21)
[CLOCK ARITHMETIC](clock.htm#M22)
[HIGH RESOLUTION TIMERS](clock.htm#M23)
[FORMATTING TIMES](clock.htm#M24)
[SCANNING TIMES](clock.htm#M25)
[FORMAT GROUPS](clock.htm#M26)
[**%a**](clock.htm#M27)
[**%A**](clock.htm#M28)
[**%b**](clock.htm#M29)
[**%B**](clock.htm#M30)
[**%c**](clock.htm#M31)
[**%C**](clock.htm#M32)
[**%d**](clock.htm#M33)
[**%D**](clock.htm#M34)
[**%e**](clock.htm#M35)
[**%Ec**](clock.htm#M36)
[**%EC**](clock.htm#M37)
[**%EE**](clock.htm#M38)
[**%Ex**](clock.htm#M39)
[**%EX**](clock.htm#M40)
[**%Ey**](clock.htm#M41)
[**%EY**](clock.htm#M42)
[**%g**](clock.htm#M43)
[**%G**](clock.htm#M44)
[**%h**](clock.htm#M45)
[**%H**](clock.htm#M46)
[**%I**](clock.htm#M47)
[**%j**](clock.htm#M48)
[**%J**](clock.htm#M49)
[**%k**](clock.htm#M50)
[**%l**](clock.htm#M51)
[**%m**](clock.htm#M52)
[**%M**](clock.htm#M53)
[**%N**](clock.htm#M54)
[**%Od**, **%Oe**, **%OH**, **%OI**, **%Ok**, **%Ol**, **%Om**, **%OM**, **%OS**, **%Ou**, **%Ow**, **%Oy**](clock.htm#M55)
[**%p**](clock.htm#M56)
[**%P**](clock.htm#M57)
[**%Q**](clock.htm#M58)
[**%r**](clock.htm#M59)
[**%R**](clock.htm#M60)
[**%s**](clock.htm#M61)
[**%S**](clock.htm#M62)
[**%t**](clock.htm#M63)
[**%T**](clock.htm#M64)
[**%u**](clock.htm#M65)
[**%U**](clock.htm#M66)
[**%V**](clock.htm#M67)
[**%w**](clock.htm#M68)
[**%W**](clock.htm#M69)
[**%x**](clock.htm#M70)
[**%X**](clock.htm#M71)
[**%y**](clock.htm#M72)
[**%Y**](clock.htm#M73)
[**%z**](clock.htm#M74)
[**%Z**](clock.htm#M75)
[**%%**](clock.htm#M76)
[**%+**](clock.htm#M77)
[TIME ZONES](clock.htm#M78)
[LOCALIZATION](clock.htm#M79)
[FREE FORM SCAN](clock.htm#M80)
[*time*](clock.htm#M81)
[*date*](clock.htm#M82)
[*ISO 8601 point-in-time*](clock.htm#M83)
[*relative time*](clock.htm#M84)
[SEE ALSO](clock.htm#M85)
[KEYWORDS](clock.htm#M86)
[COPYRIGHT](clock.htm#M87)
Name
----
clock — Obtain and manipulate dates and times Synopsis
--------
package require **Tcl 8.5**
**clock add** *timeVal* ?*count unit...*? ?*-option value*?
**clock clicks** ?*-option*?
**clock format** *timeVal* ?*-option value*...?
**clock microseconds**
**clock milliseconds**
**clock scan** *inputString* ?*-option value*...?
**clock seconds**
Description
-----------
The **clock** command performs several operations that obtain and manipulate values that represent times. The command supports several subcommands that determine what action is carried out by the command.
**clock add** *timeVal* ?*count unit...*? ?*-option value*?
Adds a (possibly negative) offset to a time that is expressed as an integer number of seconds. See **[CLOCK ARITHMETIC](#M22)** for a full description.
**clock clicks** ?*-option*?
If no *-option* argument is supplied, returns a high-resolution time value as a system-dependent integer value. The unit of the value is system-dependent but should be the highest resolution clock available on the system such as a CPU cycle counter. See **[HIGH RESOLUTION TIMERS](#M23)** for a full description. If the *-option* argument is **-milliseconds**, then the command is synonymous with **clock milliseconds** (see below). This usage is obsolete, and **clock milliseconds** is to be considered the preferred way of obtaining a count of milliseconds.
If the *-option* argument is **-microseconds**, then the command is synonymous with **clock microseconds** (see below). This usage is obsolete, and **clock microseconds** is to be considered the preferred way of obtaining a count of microseconds.
**clock format** *timeVal* ?*-option value*...?
Formats a time that is expressed as an integer number of seconds into a format intended for consumption by users or external programs. See **[FORMATTING TIMES](#M24)** for a full description.
**clock microseconds**
Returns the current time as an integer number of microseconds. See **[HIGH RESOLUTION TIMERS](#M23)** for a full description.
**clock milliseconds**
Returns the current time as an integer number of milliseconds. See **[HIGH RESOLUTION TIMERS](#M23)** for a full description.
**clock scan** *inputString* ?*-option value*...?
Scans a time that is expressed as a character string and produces an integer number of seconds. See **[SCANNING TIMES](#M25)** for a full description.
**clock seconds**
Returns the current time as an integer number of seconds.
### Parameters
*count*
An integer representing a count of some unit of time. See **[CLOCK ARITHMETIC](#M22)** for the details.
*timeVal*
An integer value passed to the **clock** command that represents an absolute time as a number of seconds from the *epoch time* of 1 January 1970, 00:00 UTC. Note that the count of seconds does not include any leap seconds; seconds are counted as if each UTC day has exactly 86400 seconds. Tcl responds to leap seconds by speeding or slowing its clock by a tiny fraction for some minutes until it is back in sync with UTC; its data model does not represent minutes that have 59 or 61 seconds.
*unit*
One of the words, **seconds**, **minutes**, **hours**, **days**, **weeks**, **months**, or **years**, or any unique prefix of such a word. Used in conjunction with *count* to identify an interval of time, for example, *3 seconds* or *1 year*.
### Options
**-base** time
Specifies that any relative times present in a **clock scan** command are to be given relative to *time*. *time* must be expressed as a count of nominal seconds from the epoch time of 1 January 1970, 00:00 UTC.
**-format** format
Specifies the desired output format for **clock format** or the expected input format for **clock scan**. The *format* string consists of any number of characters other than the per-cent sign (“**%**”) interspersed with any number of *format groups*, which are two-character sequences beginning with the per-cent sign. The permissible format groups, and their interpretation, are described under **[FORMAT GROUPS](#M26)**. On **clock format**, the default format is
```
%a %b %d %H:%M:%S %Z %Y
```
On **clock scan**, the lack of a **-format** option indicates that a “free format scan” is requested; see **[FREE FORM SCAN](#M80)** for a description of what happens.
**-gmt** boolean
If *boolean* is true, specifies that a time specified to **clock add**, **clock format** or **clock scan** should be processed in UTC. If *boolean* is false, the processing defaults to the local time zone. This usage is obsolete; the correct current usage is to specify the UTC time zone with “**-timezone** *:UTC*” or any of the equivalent ways to specify it.
**-locale** localeName
Specifies that locale-dependent scanning and formatting (and date arithmetic for dates preceding the adoption of the Gregorian calendar) is to be done in the locale identified by *localeName*. The locale name may be any of the locales acceptable to the **[msgcat](msgcat.htm)** package, or it may be the special name *system*, which represents the current locale of the process, or the null string, which represents Tcl's default locale. The effect of locale on scanning and formatting is discussed in the descriptions of the individual format groups under **[FORMAT GROUPS](#M26)**. The effect of locale on clock arithmetic is discussed under **[CLOCK ARITHMETIC](#M22)**.
**-timezone** zoneName
Specifies that clock arithmetic, formatting, and scanning are to be done according to the rules for the time zone specified by *zoneName*. The permissible values, and their interpretation, are discussed under **[TIME ZONES](#M78)**. On subcommands that expect a **-timezone** argument, the default is to use the *current time zone*. The current time zone is determined, in order of preference, by:
1. the environment variable **TCL\_TZ**.
2. the environment variable **TZ**.
3. on Windows systems, the time zone settings from the Control Panel.
If none of these is present, the C **localtime** and **mktime** functions are used to attempt to convert times between local and Greenwich. On 32-bit systems, this approach is likely to have bugs, particularly for times that lie outside the window (approximately the years 1902 to 2037) that can be represented in a 32-bit integer.
Clock arithmetic
----------------
The **clock add** command performs clock arithmetic on a value (expressed as nominal seconds from the epoch time of 1 January 1970, 00:00 UTC) given as its first argument. The remaining arguments (other than the possible **-timezone**, **-locale** and **-gmt** options) are integers and keywords in alternation, where the keywords are chosen from **seconds**, **minutes**, **hours**, **days**, **weeks**, **months**, or **years**, or any unique prefix of such a word. Addition of seconds, minutes and hours is fairly straightforward; the given time increment (times sixty for minutes, or 3600 for hours) is simply added to the *timeVal* given to the **clock add** command. The result is interpreted as a nominal number of seconds from the Epoch.
Surprising results may be obtained when crossing a point at which a leap second is inserted or removed; the **clock add** command simply ignores leap seconds and therefore assumes that times come in sequence, 23:59:58, 23:59:59, 00:00:00. (This assumption is handled by the fact that Tcl's model of time reacts to leap seconds by speeding or slowing the clock by a minuscule amount until Tcl's time is back in step with the world.
The fact that adding and subtracting hours is defined in terms of absolute time means that it will add fixed amounts of time in time zones that observe summer time (Daylight Saving Time). For example, the following code sets the value of **x** to **04:00:00** because the clock has changed in the interval in question.
```
set s [**clock scan** {2004-10-30 05:00:00} \
-format {%Y-%m-%d %H:%M:%S} \
-timezone :America/New_York]
set a [**clock add** $s 24 hours -timezone :America/New_York]
set x [**clock format** $a \
-format {%H:%M:%S} -timezone :America/New_York]
```
Adding and subtracting days and weeks is accomplished by converting the given time to a calendar day and time of day in the appropriate time zone and locale. The requisite number of days (weeks are converted to days by multiplying by seven) is added to the calendar day, and the date and time are then converted back to a count of seconds from the epoch time.
Adding and subtracting a given number of days across the point that the time changes at the start or end of summer time (Daylight Saving Time) results in the *same local time* on the day in question. For instance, the following code sets the value of **x** to **05:00:00**.
```
set s [**clock scan** {2004-10-30 05:00:00} \
-format {%Y-%m-%d %H:%M:%S} \
-timezone :America/New_York]
set a [**clock add** $s 1 day -timezone :America/New_York]
set x [**clock format** $a \
-format {%H:%M:%S} -timezone :America/New_York]
```
In cases of ambiguity, where the same local time happens twice on the same day, the earlier time is used. In cases where the conversion yields an impossible time (for instance, 02:30 during the Spring Daylight Saving Time change using US rules), the time is converted as if the clock had not changed. Thus, the following code will set the value of **x** to **03:30:00**.
```
set s [**clock scan** {2004-04-03 02:30:00} \
-format {%Y-%m-%d %H:%M:%S} \
-timezone :America/New_York]
set a [**clock add** $s 1 day -timezone :America/New_York]
set x [**clock format** $a \
-format {%H:%M:%S} -timezone :America/New_York]
```
Adding a given number of days or weeks works correctly across the conversion between the Julian and Gregorian calendars; the omitted days are skipped. The following code sets **z** to **1752-09-14**.
```
set x [**clock scan** 1752-09-02 -format %Y-%m-%d -locale en_US]
set y [**clock add** $x 1 day -locale en_US]
set z [**clock format** $y -format %Y-%m-%d -locale en_US]
```
In the bizarre case that adding the given number of days yields a date that does not exist because it falls within the dropped days of the Julian-to-Gregorian conversion, the date is converted as if it was on the Julian calendar.
Adding a number of months, or a number of years, is similar; it converts the given time to a calendar date and time of day. It then adds the requisite number of months or years, and reconverts the resulting date and time of day to an absolute time.
If the resulting date is impossible because the month has too few days (for example, when adding 1 month to 31 January), the last day of the month is substituted. Thus, adding 1 month to 31 January will result in 28 February in a common year or 29 February in a leap year.
The rules for handling anomalies relating to summer time and to the Gregorian calendar are the same when adding/subtracting months and years as they are when adding/subtracting days and weeks.
If multiple *count unit* pairs are present on the command, they are evaluated consecutively, from left to right.
High resolution timers
----------------------
Most of the subcommands supported by the **clock** command deal with times represented as a count of seconds from the epoch time, and this is the representation that **clock seconds** returns. There are three exceptions, which are all intended for use where higher-resolution times are required. **clock milliseconds** returns the count of milliseconds from the epoch time, and **clock microseconds** returns the count of microseconds from the epoch time. In addition, there is a **clock clicks** command that returns a platform-dependent high-resolution timer. Unlike **clock seconds** and **clock milliseconds**, the value of **clock clicks** is not guaranteed to be tied to any fixed epoch; it is simply intended to be the most precise interval timer available, and is intended only for relative timing studies such as benchmarks. Formatting times
----------------
The **clock format** command produces times for display to a user or writing to an external medium. The command accepts times that are expressed in seconds from the epoch time of 1 January 1970, 00:00 UTC, as returned by **clock seconds**, **clock scan**, **clock add**, **[file atime](file.htm)** or **[file mtime](file.htm)**. If a **-format** option is present, the following argument is a string that specifies how the date and time are to be formatted. The string consists of any number of characters other than the per-cent sign (“**%**”) interspersed with any number of *format groups*, which are two-character sequences beginning with the per-cent sign. The permissible format groups, and their interpretation, are described under **[FORMAT GROUPS](#M26)**.
If a **-timezone** option is present, the following argument is a string that specifies the time zone in which the date and time are to be formatted. As an alternative to “**-timezone** *:UTC*”, the obsolete usage “**-gmt** *true*” may be used. See **[TIME ZONES](#M78)** for the permissible variants for the time zone.
If a **-locale** option is present, the following argument is a string that specifies the locale in which the time is to be formatted, in the same format that is used for the **[msgcat](msgcat.htm)** package. Note that the default, if **-locale** is not specified, is the root locale **{}** rather than the current locale. The current locale may be obtained by using **-locale** **current**. In addition, some platforms support a **system** locale that reflects the user's current choices. For instance, on Windows, the format that the user has selected from dates and times in the Control Panel can be obtained by using the **system** locale. On platforms that do not define a user selection of date and time formats separate from **LC\_TIME**, **-locale** **system** is synonymous with **-locale** **current**.
Scanning times
--------------
The **clock scan** command accepts times that are formatted as strings and converts them to counts of seconds from the epoch time of 1 January 1970, 00:00 UTC. It normally takes a **-format** option that is followed by a string describing the expected format of the input. (See **[FREE FORM SCAN](#M80)** for the effect of **clock scan** without such an argument.) The string consists of any number of characters other than the per-cent sign (“**%**”), interspersed with any number of *format groups*, which are two-character sequences beginning with the per-cent sign. The permissible format groups, and their interpretation, are described under **[FORMAT GROUPS](#M26)**. If a **-timezone** option is present, the following argument is a string that specifies the time zone in which the date and time are to be interpreted. As an alternative to **-timezone** *:UTC*, the obsolete usage **-gmt** *true* may be used. See **[TIME ZONES](#M78)** for the permissible variants for the time zone.
If a **-locale** option is present, the following argument is a string that specifies the locale in which the time is to be interpreted, in the same format that is used for the **[msgcat](msgcat.htm)** package. Note that the default, if **-locale** is not specified, is the root locale **{}** rather than the current locale. The current locale may be obtained by using **-locale** **current**. In addition, some platforms support a **system** locale that reflects the user's current choices. For instance, on Windows, the format that the user has selected from dates and times in the Control Panel can be obtained by using the **system** locale. On platforms that do not define a user selection of date and time formats separate from **LC\_TIME**, **-locale** **system** is synonymous with **-locale** **current**.
If a **-base** option is present, the following argument is a time (expressed in seconds from the epoch time) that is used as a *base time* for interpreting relative times. If no **-base** option is present, the base time is the current time.
Scanning of times in fixed format works by determining three things: the date, the time of day, and the time zone. These three are then combined into a point in time, which is returned as the number of seconds from the epoch.
Before scanning begins, the format string is preprocessed to replace **%c**, **%Ec**, **%x**, **%Ex**, **%X**. **%Ex**, **%r**, **%R**, **%T**, **%D**, **%EY** and **%+** format groups with counterparts that are appropriate to the current locale and contain none of the above groups. For instance, **%D** will (in the **en\_US** locale) be replaced with **%m/%d/%Y**.
The date is determined according to the fields that are present in the preprocessed format string. In order of preference:
1. If the string contains a **%s** format group, representing seconds from the epoch, that group is used to determine the date.
2. If the string contains a **%J** format group, representing the Julian Day Number, that group is used to determine the date.
3. If the string contains a complete set of format groups specifying century, year, month, and day of month; century, year, and day of year; or ISO8601 fiscal year, week of year, and day of week; those groups are combined and used to determine the date. If more than one complete set is present, the one at the rightmost position in the string is used.
4. If the string lacks a century but contains a set of format groups specifying year of century, month and day of month; year of century and day of year; or two-digit ISO8601 fiscal year, week of year, and day of week; those groups are combined and used to determine the date. If more than one complete set is present, the one at the rightmost position in the string is used. The year is presumed to lie in the range 1938 to 2037 inclusive.
5. If the string entirely lacks any specification for the year (or contains the year only on the locale's alternative calendar) and contains a set of format groups specifying month and day of month, day of year, or week of year and day of week, those groups are combined and used to determine the date. If more than one complete set is present, the one at the rightmost position in the string is used. The year is determined by interpreting the base time in the given time zone.
6. If the string contains none of the above sets, but has a day of the month or day of the week, the day of the month or day of the week are used to determine the date by interpreting the base time in the given time zone and returning the given day of the current week or month. (The week runs from Monday to Sunday, ISO8601-fashion.) If both day of month and day of week are present, the day of the month takes priority.
7. If none of the above rules results in a usable date, the date of the base time in the given time zone is used.
The time is also determined according to the fields that are present in the preprocessed format string. In order of preference:
1. If the string contains a **%s** format group, representing seconds from the epoch, that group determines the time of day.
2. If the string contains either an hour on the 24-hour clock or an hour on the 12-hour clock plus an AM/PM indicator, that hour determines the hour of the day. If the string further contains a group specifying the minute of the hour, that group combines with the hour. If the string further contains a group specifying the second of the minute, that group combines with the hour and minute.
3. If the string contains neither a **%s** format group nor a group specifying the hour of the day, then midnight (**00:00**, the start of the given date) is used. The time zone is determined by either the **-timezone** or **-gmt** options, or by using the current time zone.
If a format string lacks a **%z** or **%Z** format group, it is possible for the time to be ambiguous because it appears twice in the same day, once without and once with Daylight Saving Time. If this situation occurs, the first occurrence of the time is chosen. (For this reason, it is wise to have the input string contain the time zone when converting local times. This caveat does not apply to UTC times.)
Format groups
-------------
The following format groups are recognized by the **clock scan** and **clock format** commands.
**%a**
On output, receives an abbreviation (*e.g.,* **Mon**) for the day of the week in the given locale. On input, matches the name of the day of the week in the given locale (in either abbreviated or full form, or any unique prefix of either form).
**%A**
On output, receives the full name (*e.g.,* **Monday**) of the day of the week in the given locale. On input, matches the name of the day of the week in the given locale (in either abbreviated or full form, or any unique prefix of either form).
**%b**
On output, receives an abbreviation (*e.g.,* **Jan**) for the name of the month in the given locale. On input, matches the name of the month in the given locale (in either abbreviated or full form, or any unique prefix of either form).
**%B**
On output, receives the full name (*e.g.,* **January**) of the month in the given locale. On input, matches the name of the month in the given locale (in either abbreviated or full form, or any unique prefix of either form).
**%c**
On output, receives a localized representation of date and time of day; the localized representation is expected to use the Gregorian calendar. On input, matches whatever **%c** produces.
**%C**
On output, receives the number of the century in Indo-Arabic numerals. On input, matches one or two digits, possibly with leading whitespace, that are expected to be the number of the century.
**%d**
On output, produces the number of the day of the month, as two decimal digits. On input, matches one or two digits, possibly with leading whitespace, that are expected to be the number of the day of the month.
**%D**
This format group is synonymous with **%m/%d/%Y**. It should be used only in exchanging data within the **en\_US** locale, since other locales typically do not use this order for the fields of the date.
**%e**
On output, produces the number of the day of the month, as one or two decimal digits (with a leading blank for one-digit dates). On input, matches one or two digits, possibly with leading whitespace, that are expected to be the number of the day of the month.
**%Ec**
On output, produces a locale-dependent representation of the date and time of day in the locale's alternative calendar. On input, matches whatever **%Ec** produces. The locale's alternative calendar need not be the Gregorian calendar.
**%EC**
On output, produces a locale-dependent name of an era in the locale's alternative calendar. On input, matches the name of the era or any unique prefix.
**%EE**
On output, produces the string **B.C.E.** or **C.E.**, or a string of the same meaning in the locale, to indicate whether **%Y** refers to years before or after Year 1 of the Common Era. On input, accepts the string **B.C.E.**, **B.C.**, **C.E.**, **A.D.**, or the abbreviation appropriate to the current locale, and uses it to fix whether **%Y** refers to years before or after Year 1 of the Common Era.
**%Ex**
On output, produces a locale-dependent representation of the date in the locale's alternative calendar. On input, matches whatever **%Ex** produces. The locale's alternative calendar need not be the Gregorian calendar.
**%EX**
On output, produces a locale-dependent representation of the time of day in the locale's alternative numerals. On input, matches whatever **%EX** produces.
**%Ey**
On output, produces a locale-dependent number of the year of the era in the locale's alternative calendar and numerals. On input, matches such a number.
**%EY**
On output, produces a representation of the year in the locale's alternative calendar and numerals. On input, matches what **%EY** produces. Often synonymous with **%EC%Ey**.
**%g**
On output, produces a two-digit year number suitable for use with the week-based ISO8601 calendar; that is, the year number corresponds to the week number produced by **%V**. On input, accepts such a two-digit year number, possibly with leading whitespace.
**%G**
On output, produces a four-digit year number suitable for use with the week-based ISO8601 calendar; that is, the year number corresponds to the week number produced by **%V**. On input, accepts such a four-digit year number, possibly with leading whitespace.
**%h**
This format group is synonymous with **%b**.
**%H**
On output, produces a two-digit number giving the hour of the day (00-23) on a 24-hour clock. On input, accepts such a number.
**%I**
On output, produces a two-digit number giving the hour of the day (12-11) on a 12-hour clock. On input, accepts such a number.
**%j**
On output, produces a three-digit number giving the day of the year (001-366). On input, accepts such a number.
**%J**
On output, produces a string of digits giving the Julian Day Number. On input, accepts a string of digits and interprets it as a Julian Day Number. The Julian Day Number is a count of the number of calendar days that have elapsed since 1 January, 4713 BCE of the proleptic Julian calendar. The epoch time of 1 January 1970 corresponds to Julian Day Number 2440588.
**%k**
On output, produces a one- or two-digit number giving the hour of the day (0-23) on a 24-hour clock. On input, accepts such a number.
**%l**
On output, produces a one- or two-digit number giving the hour of the day (12-11) on a 12-hour clock. On input, accepts such a number.
**%m**
On output, produces the number of the month (01-12) with exactly two digits. On input, accepts two digits and interprets them as the number of the month.
**%M**
On output, produces the number of the minute of the hour (00-59) with exactly two digits. On input, accepts two digits and interprets them as the number of the minute of the hour.
**%N**
On output, produces the number of the month (1-12) with one or two digits, and a leading blank for one-digit dates. On input, accepts one or two digits, possibly with leading whitespace, and interprets them as the number of the month.
**%Od**, **%Oe**, **%OH**, **%OI**, **%Ok**, **%Ol**, **%Om**, **%OM**, **%OS**, **%Ou**, **%Ow**, **%Oy**
All of these format groups are synonymous with their counterparts without the “**O**”, except that the string is produced and parsed in the locale-dependent alternative numerals.
**%p**
On output, produces an indicator for the part of the day, **AM** or **PM**, appropriate to the given locale. If the script of the given locale supports multiple letterforms, lowercase is preferred. On input, matches the representation **AM** or **PM** in the given locale, in either case.
**%P**
On output, produces an indicator for the part of the day, **am** or **pm**, appropriate to the given locale. If the script of the given locale supports multiple letterforms, uppercase is preferred. On input, matches the representation **AM** or **PM** in the given locale, in either case.
**%Q**
This format group is reserved for internal use within the Tcl library.
**%r**
On output, produces a locale-dependent time of day representation on a 12-hour clock. On input, accepts whatever **%r** produces.
**%R**
On output, the time in 24-hour notation (%H:%M). For a version including the seconds, see **%T** below. On input, accepts whatever **%R** produces.
**%s**
On output, simply formats the *timeVal* argument as a decimal integer and inserts it into the output string. On input, accepts a decimal integer and uses is as the time value without any further processing. Since **%s** uniquely determines a point in time, it overrides all other input formats.
**%S**
On output, produces a two-digit number of the second of the minute (00-59). On input, accepts two digits and uses them as the second of the minute.
**%t**
On output, produces a TAB character. On input, matches a TAB character.
**%T**
Synonymous with **%H:%M:%S**.
**%u**
On output, produces the number of the day of the week (**1**→Monday, **7**→Sunday). On input, accepts a single digit and interprets it as the day of the week. Sunday may be either **0** or **7**.
**%U**
On output, produces the ordinal number of the week of the year (00-53). The first Sunday of the year is the first day of week 01. On input accepts two digits which are otherwise ignored. This format group is never used in determining an input date. This interpretation of the week of the year was once common in US banking but is now largely obsolete. See **%V** for the ISO8601 week number.
**%V**
On output, produces the number of the ISO8601 week as a two digit number (01-53). Week 01 is the week containing January 4; or the first week of the year containing at least 4 days; or the week containing the first Thursday of the year (the three statements are equivalent). Each week begins on a Monday. On input, accepts the ISO8601 week number.
**%w**
On output, produces the ordinal number of the day of the week (Sunday==0; Saturday==6). On input, accepts a single digit and interprets it as the day of the week; Sunday may be represented as either 0 or 7. Note that **%w** is not the ISO8601 weekday number, which is produced and accepted by **%u**.
**%W**
On output, produces a week number (00-53) within the year; week 01 begins on the first Monday of the year. On input, accepts two digits, which are otherwise ignored. This format group is never used in determining an input date. It is not the ISO8601 week number; that week is produced and accepted by **%V**.
**%x**
On output, produces the date in a locale-dependent representation. On input, accepts whatever **%x** produces and is used to determine calendar date.
**%X**
On output, produces the time of day in a locale-dependent representation. On input, accepts whatever **%X** produces and is used to determine time of day.
**%y**
On output, produces the two-digit year of the century. On input, accepts two digits, and is used to determine calendar date. The date is presumed to lie between 1938 and 2037 inclusive. Note that **%y** does not yield a year appropriate for use with the ISO8601 week number **%V**; programs should use **%g** for that purpose.
**%Y**
On output, produces the four-digit calendar year. On input, accepts four digits and may be used to determine calendar date. Note that **%Y** does not yield a year appropriate for use with the ISO8601 week number **%V**; programs should use **%G** for that purpose.
**%z**
On output, produces the current time zone, expressed in hours and minutes east (+hhmm) or west (-hhmm) of Greenwich. On input, accepts a time zone specifier (see **[TIME ZONES](#M78)** below) that will be used to determine the time zone.
**%Z**
On output, produces the current time zone's name, possibly translated to the given locale. On input, accepts a time zone specifier (see **[TIME ZONES](#M78)** below) that will be used to determine the time zone. This option should, in general, be used on input only when parsing RFC822 dates. Other uses are fraught with ambiguity; for instance, the string **BST** may represent British Summer Time or Brazilian Standard Time. It is recommended that date/time strings for use by computers use numeric time zones instead.
**%%**
On output, produces a literal “**%**” character. On input, matches a literal “**%**” character.
**%+**
Synonymous with “**%a %b %e %H:%M:%S %Z %Y**”.
Time zones
----------
When the **clock** command is processing a local time, it has several possible sources for the time zone to use. In order of preference, they are:
1. A time zone specified inside a string being parsed and matched by a **%z** or **%Z** format group.
2. A time zone specified with the **-timezone** option to the **clock** command (or, equivalently, by **-gmt** **1**).
3. A time zone specified in an environment variable **TCL\_TZ**.
4. A time zone specified in an environment variable **TZ**.
5. The local time zone from the Control Panel on Windows systems.
6. The C library's idea of the local time zone, as defined by the **mktime** and **localtime** functions.
In case [1] *only,* the string is tested to see if it is one of the strings:
```
gmt ut utc bst wet wat at
nft nst ndt ast adt est edt
cst cdt mst mdt pst pdt yst
ydt hst hdt cat ahst nt idlw
cet cest met mewt mest swt sst
eet eest bt it zp4 zp5 ist
zp6 wast wadt jt cct jst cast
cadt east eadt gst nzt nzst nzdt
idle
```
If it is a string in the above list, it designates a known time zone, and is interpreted as such.
For time zones in case [1] that do not match any of the above strings, and always for cases [2]-[6], the following rules apply.
If the time zone begins with a colon, it is one of a standardized list of names like **:America/New\_York** that give the rules for various locales. A complete list of the location names is too lengthy to be listed here. On most Tcl installations, the definitions of the locations are to be found in named files in the directory “*/no\_backup/tools/lib/tcl8.5/clock/tzdata*”. On some Unix systems, these files are omitted, and the definitions are instead obtained from system files in “*/usr/share/zoneinfo*”, “*/usr/share/lib/zoneinfo*” or “*/usr/local/etc/zoneinfo*”. As a special case, the name **:localtime** refers to the local time zone as defined by the C library.
A time zone string consisting of a plus or minus sign followed by four or six decimal digits is interpreted as an offset in hours, minutes, and seconds (if six digits are present) from UTC. The plus sign denotes a sign east of Greenwich; the minus sign one west of Greenwich.
A time zone string conforming to the Posix specification of the **TZ** environment variable will be recognized. The specification may be found at *<http://www.opengroup.org/onlinepubs/009695399/basedefs/xbd_chap08.html>*.
If the Posix time zone string contains a DST (Daylight Savings Time) part, but doesn't contain a rule stating when DST starts or ends, then default rules are used. For Timezones with an offset between 0 and +12, the current European/Russian rules are used, otherwise the current US rules are used. In Europe (offset +0 to +2) the switch to summertime is done each last Sunday in March at 1:00 GMT, and the switch back is each last Sunday in October at 2:00 GMT. In Russia (offset +3 to +12), the switch dates are the same, only the switch to summertime is at 2:00 local time, and the switch back is at 3:00 local time in all time zones. The US switch to summertime takes place each second Sunday in March at 2:00 local time, and the switch back is each first Sunday in November at 3:00 local time. These default rules mean that in all European, Russian and US (or compatible) time zones, DST calculations will be correct for dates in 2007 and later, unless in the future the rules change again.
Any other time zone string is processed by prefixing a colon and attempting to use it as a location name, as above.
Localization
------------
Developers wishing to localize the date and time formatting and parsing are referred to *<http://tip.tcl.tk/173>* for a specification. Free form scan
--------------
If the **clock scan** command is invoked without a **-format** option, then it requests a *free-form scan.* *This form of scan is deprecated.* The reason for the deprecation is that there are too many ambiguities. (Does the string “2000” represent a year, a time of day, or a quantity?) No set of rules for interpreting free-form dates and times has been found to give unsurprising results in all cases. If free-form scan is used, only the **-base** and **-gmt** options are accepted. The **-timezone** and **-locale** options will result in an error if **-format** is not supplied.
For the benefit of users who need to understand legacy code that uses free-form scan, the documentation for how free-form scan interprets a string is included here:
If only a time is specified, the current date is assumed. If the *inputString* does not contain a time zone mnemonic, the local time zone is assumed, unless the **-gmt** argument is true, in which case the clock value is calculated assuming that the specified time is relative to Greenwich Mean Time. **-gmt**, if specified, affects only the computed time value; it does not impact the interpretation of **-base**.
If the **-base** flag is specified, the next argument should contain an integer clock value. Only the date in this value is used, not the time. This is useful for determining the time on a specific day or doing other date-relative conversions.
The *inputString* argument consists of zero or more specifications of the following form:
*time*
A time of day, which is of the form: **hh?:mm?:ss?? ?meridian? ?zone?** or **hhmm ?meridian? ?zone?** If no meridian is specified, **hh** is interpreted on a 24-hour clock.
*date*
A specific month and day with optional year. The acceptable formats are “**mm/dd**?**/yy**?”, “**monthname dd**?**, yy**?”, “**day, dd monthname** ?**yy**?”, “**dd monthname yy**”, “?**CC**?**yymmdd**”, and “**dd-monthname-**?**CC**?**yy**”. The default year is the current year. If the year is less than 100, we treat the years 00-68 as 2000-2068 and the years 69-99 as 1969-1999. Not all platforms can represent the years 38-70, so an error may result if these years are used.
*ISO 8601 point-in-time*
An ISO 8601 point-in-time specification, such as “*CCyymmdd***T***hhmmss*,” where **T** is the literal “T”, “*CCyymmdd hhmmss*”, or “*CCyymmdd***T***hh:mm:ss*”. Note that only these three formats are accepted. The command does *not* accept the full range of point-in-time specifications specified in ISO8601. Other formats can be recognized by giving an explicit **-format** option to the **clock scan** command.
*relative time*
A specification relative to the current time. The format is **number unit**. Acceptable units are **year**, **fortnight**, **month**, **week**, **day**, **hour**, **minute** (or **min**), and **second** (or **sec**). The unit can be specified as a singular or plural, as in **3 weeks**. These modifiers may also be specified: **tomorrow**, **yesterday**, **today**, **now**, **last**, **this**, **next**, **ago**.
The actual date is calculated according to the following steps.
First, any absolute date and/or time is processed and converted. Using that time as the base, day-of-week specifications are added. Next, relative specifications are used. If a date or day is specified, and no absolute or relative time is given, midnight is used. Finally, a correction is applied so that the correct hour of the day is produced after allowing for daylight savings time differences and the correct date is given when going from the end of a long month to a short month.
See also
--------
**[msgcat](msgcat.htm)** Copyright
---------
Copyright (c) 2004 Kevin B. Kenny <[email protected]>. All rights reserved.
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/clock.htm>
| programming_docs |
tcl_tk regexp regexp
======
[NAME](regexp.htm#M2) regexp — Match a regular expression against a string
[SYNOPSIS](regexp.htm#M3)
[DESCRIPTION](regexp.htm#M4)
[**-about**](regexp.htm#M5)
[**-expanded**](regexp.htm#M6)
[**-indices**](regexp.htm#M7)
[**-line**](regexp.htm#M8)
[**-linestop**](regexp.htm#M9)
[**-lineanchor**](regexp.htm#M10)
[**-nocase**](regexp.htm#M11)
[**-all**](regexp.htm#M12)
[**-inline**](regexp.htm#M13)
[**-start** *index*](regexp.htm#M14)
[**--**](regexp.htm#M15)
[EXAMPLES](regexp.htm#M16)
[SEE ALSO](regexp.htm#M17)
[KEYWORDS](regexp.htm#M18)
Name
----
regexp — Match a regular expression against a string Synopsis
--------
**regexp** ?*switches*? *exp string* ?*matchVar*? ?*subMatchVar subMatchVar ...*?
Description
-----------
Determines whether the regular expression *exp* matches part or all of *string* and returns 1 if it does, 0 if it does not, unless **-inline** is specified (see below). (Regular expression matching is described in the **[re\_syntax](re_syntax.htm)** reference page.) If additional arguments are specified after *string* then they are treated as the names of variables in which to return information about which part(s) of *string* matched *exp*. *MatchVar* will be set to the range of *string* that matched all of *exp*. The first *subMatchVar* will contain the characters in *string* that matched the leftmost parenthesized subexpression within *exp*, the next *subMatchVar* will contain the characters that matched the next parenthesized subexpression to the right in *exp*, and so on.
If the initial arguments to **regexp** start with **-** then they are treated as switches. The following switches are currently supported:
**-about**
Instead of attempting to match the regular expression, returns a list containing information about the regular expression. The first element of the list is a subexpression count. The second element is a list of property names that describe various attributes of the regular expression. This switch is primarily intended for debugging purposes.
**-expanded**
Enables use of the expanded regular expression syntax where whitespace and comments are ignored. This is the same as specifying the **(?x)** embedded option (see the **[re\_syntax](re_syntax.htm)** manual page).
**-indices**
Changes what is stored in the *matchVar* and *subMatchVar*s. Instead of storing the matching characters from *string*, each variable will contain a list of two decimal strings giving the indices in *string* of the first and last characters in the matching range of characters.
**-line**
Enables newline-sensitive matching. By default, newline is a completely ordinary character with no special meaning. With this flag, “[^” bracket expressions and “.” never match newline, “^” matches an empty string after any newline in addition to its normal function, and “$” matches an empty string before any newline in addition to its normal function. This flag is equivalent to specifying both **-linestop** and **-lineanchor**, or the **(?n)** embedded option (see the **[re\_syntax](re_syntax.htm)** manual page).
**-linestop**
Changes the behavior of “[^” bracket expressions and “.” so that they stop at newlines. This is the same as specifying the **(?p)** embedded option (see the **[re\_syntax](re_syntax.htm)** manual page).
**-lineanchor**
Changes the behavior of “^” and “$” (the “anchors”) so they match the beginning and end of a line respectively. This is the same as specifying the **(?w)** embedded option (see the **[re\_syntax](re_syntax.htm)** manual page).
**-nocase**
Causes upper-case characters in *string* to be treated as lower case during the matching process.
**-all**
Causes the regular expression to be matched as many times as possible in the string, returning the total number of matches found. If this is specified with match variables, they will contain information for the last match only.
**-inline**
Causes the command to return, as a list, the data that would otherwise be placed in match variables. When using **-inline**, match variables may not be specified. If used with **-all**, the list will be concatenated at each iteration, such that a flat list is always returned. For each match iteration, the command will append the overall match data, plus one element for each subexpression in the regular expression. Examples are:
```
**regexp** -inline -- {\w(\w)} " inlined "
*→ in n*
**regexp** -all -inline -- {\w(\w)} " inlined "
*→ in n li i ne e*
```
**-start** *index*
Specifies a character index offset into the string to start matching the regular expression at. The *index* value is interpreted in the same manner as the *index* argument to **[string index](string.htm)**. When using this switch, “^” will not match the beginning of the line, and \A will still match the start of the string at *index*. If **-indices** is specified, the indices will be indexed starting from the absolute beginning of the input string. *index* will be constrained to the bounds of the input string.
**--**
Marks the end of switches. The argument following this one will be treated as *exp* even if it starts with a **-**.
If there are more *subMatchVar*s than parenthesized subexpressions within *exp*, or if a particular subexpression in *exp* does not match the string (e.g. because it was in a portion of the expression that was not matched), then the corresponding *subMatchVar* will be set to “**-1 -1**” if **-indices** has been specified or to an empty string otherwise.
Examples
--------
Find the first occurrence of a word starting with **foo** in a string that is not actually an instance of **foobar**, and get the letters following it up to the end of the word into a variable:
```
**regexp** {\mfoo(?!bar\M)(\w*)} $string -> restOfWord
```
Note that the whole matched substring has been placed in the variable “**->**”, which is a name chosen to look nice given that we are not actually interested in its contents.
Find the index of the word **badger** (in any case) within a string and store that in the variable **location**:
```
**regexp** -indices {(?i)\mbadger\M} $string location
```
This could also be written as a *basic* regular expression (as opposed to using the default syntax of *advanced* regular expressions) match by prefixing the expression with a suitable flag:
```
**regexp** -indices {(?ib)\<badger\>} $string location
```
This counts the number of octal digits in a string:
```
**regexp** -all {[0-7]} $string
```
This lists all words (consisting of all sequences of non-whitespace characters) in a string, and is useful as a more powerful version of the **[split](split.htm)** command:
```
**regexp** -all -inline {\S+} $string
```
See also
--------
**[re\_syntax](re_syntax.htm)**, **[regsub](regsub.htm)**, **[string](string.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/regexp.htm>
tcl_tk history history
=======
[NAME](history.htm#M2) history — Manipulate the history list
[SYNOPSIS](history.htm#M3)
[DESCRIPTION](history.htm#M4)
[**history**](history.htm#M5)
[**history add** *command* ?**exec**?](history.htm#M6)
[**history change** *newValue* ?*event*?](history.htm#M7)
[**history clear**](history.htm#M8)
[**history event** ?*event*?](history.htm#M9)
[**history info** ?*count*?](history.htm#M10)
[**history keep** ?*count*?](history.htm#M11)
[**history nextid**](history.htm#M12)
[**history redo** ?*event*?](history.htm#M13)
[HISTORY REVISION](history.htm#M14)
[KEYWORDS](history.htm#M15)
Name
----
history — Manipulate the history list Synopsis
--------
**history** ?*option*? ?*arg arg ...*?
Description
-----------
The **history** command performs one of several operations related to recently-executed commands recorded in a history list. Each of these recorded commands is referred to as an “event”. When specifying an event to the **history** command, the following forms may be used:
1. A number: if positive, it refers to the event with that number (all events are numbered starting at 1). If the number is negative, it selects an event relative to the current event (**-1** refers to the previous event, **-2** to the one before that, and so on). Event **0** refers to the current event.
2. A string: selects the most recent event that matches the string. An event is considered to match the string either if the string is the same as the first characters of the event, or if the string matches the event in the sense of the **[string match](string.htm)** command.
The **history** command can take any of the following forms:
**history**
Same as **history info**, described below.
**history add** *command* ?**exec**?
Adds the *command* argument to the history list as a new event. If **exec** is specified (or abbreviated) then the command is also executed and its result is returned. If **exec** is not specified then an empty string is returned as result.
**history change** *newValue* ?*event*?
Replaces the value recorded for an event with *newValue*. *Event* specifies the event to replace, and defaults to the *current* event (not event **-1**). This command is intended for use in commands that implement new forms of history substitution and wish to replace the current event (which invokes the substitution) with the command created through substitution. The return value is an empty string.
**history clear**
Erase the history list. The current keep limit is retained. The history event numbers are reset.
**history event** ?*event*?
Returns the value of the event given by *event*. *Event* defaults to **-1**.
**history info** ?*count*?
Returns a formatted string (intended for humans to read) giving the event number and contents for each of the events in the history list except the current event. If *count* is specified then only the most recent *count* events are returned.
**history keep** ?*count*?
This command may be used to change the size of the history list to *count* events. Initially, 20 events are retained in the history list. If *count* is not specified, the current keep limit is returned.
**history nextid**
Returns the number of the next event to be recorded in the history list. It is useful for things like printing the event number in command-line prompts.
**history redo** ?*event*?
Re-executes the command indicated by *event* and returns its result. *Event* defaults to **-1**. This command results in history revision: see below for details.
History revision
----------------
Pre-8.0 Tcl had a complex history revision mechanism. The current mechanism is more limited, and the old history operations **substitute** and **words** have been removed. (As a consolation, the **clear** operation was added.) The history option **redo** results in much simpler “history revision”. When this option is invoked then the most recent event is modified to eliminate the history command and replace it with the result of the history command. If you want to redo an event without modifying history, then use the **[event](../tkcmd/event.htm)** operation to retrieve some event, and the **add** operation to add it to history and execute it.
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/history.htm>
tcl_tk exec exec
====
[NAME](exec.htm#M2) exec — Invoke subprocesses
[SYNOPSIS](exec.htm#M3)
[DESCRIPTION](exec.htm#M4)
[**-ignorestderr**](exec.htm#M5)
[**-keepnewline**](exec.htm#M6)
[**--**](exec.htm#M7)
[**|**](exec.htm#M8)
[**|&**](exec.htm#M9)
[**<** *fileName*](exec.htm#M10)
[**<@** *fileId*](exec.htm#M11)
[**<<** *value*](exec.htm#M12)
[**>** *fileName*](exec.htm#M13)
[**2>** *fileName*](exec.htm#M14)
[**>&** *fileName*](exec.htm#M15)
[**>>** *fileName*](exec.htm#M16)
[**2>>** *fileName*](exec.htm#M17)
[**>>&** *fileName*](exec.htm#M18)
[**>@** *fileId*](exec.htm#M19)
[**2>@** *fileId*](exec.htm#M20)
[**2>@1**](exec.htm#M21)
[**>&@** *fileId*](exec.htm#M22)
[PORTABILITY ISSUES](exec.htm#M23)
[**Windows** (all versions)](exec.htm#M24)
[**Unix** (including Mac OS X)](exec.htm#M25)
[UNIX EXAMPLES](exec.htm#M26)
[WORKING WITH NON-ZERO RESULTS](exec.htm#M27)
[WORKING WITH QUOTED ARGUMENTS](exec.htm#M28)
[WORKING WITH GLOBBING](exec.htm#M29)
[WORKING WITH USER-SUPPLIED SHELL SCRIPT FRAGMENTS](exec.htm#M30)
[WINDOWS EXAMPLES](exec.htm#M31)
[WORKING WITH CONSOLE PROGRAMS](exec.htm#M32)
[WORKING WITH COMMAND BUILT-INS](exec.htm#M33)
[WORKING WITH NATIVE FILENAMES](exec.htm#M34)
[SEE ALSO](exec.htm#M35)
[KEYWORDS](exec.htm#M36)
Name
----
exec — Invoke subprocesses Synopsis
--------
**exec** ?*switches*? *arg* ?*arg ...*? ?**&**?
Description
-----------
This command treats its arguments as the specification of one or more subprocesses to execute. The arguments take the form of a standard shell pipeline where each *arg* becomes one word of a command, and each distinct command becomes a subprocess. If the initial arguments to **exec** start with **-** then they are treated as command-line switches and are not part of the pipeline specification. The following switches are currently supported:
**-ignorestderr**
Stops the **exec** command from treating the output of messages to the pipeline's standard error channel as an error case.
**-keepnewline**
Retains a trailing newline in the pipeline's output. Normally a trailing newline will be deleted.
**--**
Marks the end of switches. The argument following this one will be treated as the first *arg* even if it starts with a **-**.
If an *arg* (or pair of *arg*s) has one of the forms described below then it is used by **exec** to control the flow of input and output among the subprocess(es). Such arguments will not be passed to the subprocess(es). In forms such as “**<** *fileName*”, *fileName* may either be in a separate argument from “**<**” or in the same argument with no intervening space (i.e. “**<***fileName*”).
**|**
Separates distinct commands in the pipeline. The standard output of the preceding command will be piped into the standard input of the next command.
**|&**
Separates distinct commands in the pipeline. Both standard output and standard error of the preceding command will be piped into the standard input of the next command. This form of redirection overrides forms such as 2> and >&.
**<** *fileName*
The file named by *fileName* is opened and used as the standard input for the first command in the pipeline.
**<@** *fileId*
*FileId* must be the identifier for an open file, such as the return value from a previous call to **[open](open.htm)**. It is used as the standard input for the first command in the pipeline. *FileId* must have been opened for reading.
**<<** *value*
*Value* is passed to the first command as its standard input.
**>** *fileName*
Standard output from the last command is redirected to the file named *fileName*, overwriting its previous contents.
**2>** *fileName*
Standard error from all commands in the pipeline is redirected to the file named *fileName*, overwriting its previous contents.
**>&** *fileName*
Both standard output from the last command and standard error from all commands are redirected to the file named *fileName*, overwriting its previous contents.
**>>** *fileName*
Standard output from the last command is redirected to the file named *fileName*, appending to it rather than overwriting it.
**2>>** *fileName*
Standard error from all commands in the pipeline is redirected to the file named *fileName*, appending to it rather than overwriting it.
**>>&** *fileName*
Both standard output from the last command and standard error from all commands are redirected to the file named *fileName*, appending to it rather than overwriting it.
**>@** *fileId*
*FileId* must be the identifier for an open file, such as the return value from a previous call to **[open](open.htm)**. Standard output from the last command is redirected to *fileId*'s file, which must have been opened for writing.
**2>@** *fileId*
*FileId* must be the identifier for an open file, such as the return value from a previous call to **[open](open.htm)**. Standard error from all commands in the pipeline is redirected to *fileId*'s file. The file must have been opened for writing.
**2>@1**
Standard error from all commands in the pipeline is redirected to the command result. This operator is only valid at the end of the command pipeline.
**>&@** *fileId*
*FileId* must be the identifier for an open file, such as the return value from a previous call to **[open](open.htm)**. Both standard output from the last command and standard error from all commands are redirected to *fileId*'s file. The file must have been opened for writing.
If standard output has not been redirected then the **exec** command returns the standard output from the last command in the pipeline, unless “2>@1” was specified, in which case standard error is included as well. If any of the commands in the pipeline exit abnormally or are killed or suspended, then **exec** will return an error and the error message will include the pipeline's output followed by error messages describing the abnormal terminations; the **-errorcode** return option will contain additional information about the last abnormal termination encountered. If any of the commands writes to its standard error file and that standard error is not redirected and **-ignorestderr** is not specified, then **exec** will return an error; the error message will include the pipeline's standard output, followed by messages about abnormal terminations (if any), followed by the standard error output.
If the last character of the result or error message is a newline then that character is normally deleted from the result or error message. This is consistent with other Tcl return values, which do not normally end with newlines. However, if **-keepnewline** is specified then the trailing newline is retained.
If standard input is not redirected with “<”, “<<” or “<@” then the standard input for the first command in the pipeline is taken from the application's current standard input.
If the last *arg* is “&” then the pipeline will be executed in background. In this case the **exec** command will return a list whose elements are the process identifiers for all of the subprocesses in the pipeline. The standard output from the last command in the pipeline will go to the application's standard output if it has not been redirected, and error output from all of the commands in the pipeline will go to the application's standard error file unless redirected.
The first word in each command is taken as the command name; tilde-substitution is performed on it, and if the result contains no slashes then the directories in the PATH environment variable are searched for an executable by the given name. If the name contains a slash then it must refer to an executable reachable from the current directory. No “glob” expansion or other shell-like substitutions are performed on the arguments to commands.
Portability issues
------------------
**Windows** (all versions)
Reading from or writing to a socket, using the “**@** *fileId*” notation, does not work. When reading from a socket, a 16-bit DOS application will hang and a 32-bit application will return immediately with end-of-file. When either type of application writes to a socket, the information is instead sent to the console, if one is present, or is discarded. The Tk console text widget does not provide real standard IO capabilities. Under Tk, when redirecting from standard input, all applications will see an immediate end-of-file; information redirected to standard output or standard error will be discarded.
Either forward or backward slashes are accepted as path separators for arguments to Tcl commands. When executing an application, the path name specified for the application may also contain forward or backward slashes as path separators. Bear in mind, however, that most Windows applications accept arguments with forward slashes only as option delimiters and backslashes only in paths. Any arguments to an application that specify a path name with forward slashes will not automatically be converted to use the backslash character. If an argument contains forward slashes as the path separator, it may or may not be recognized as a path name, depending on the program.
Additionally, when calling a 16-bit DOS or Windows 3.X application, all path names must use the short, cryptic, path format (e.g., using “applba~1.def” instead of “applbakery.default”), which can be obtained with the “**[file attributes](file.htm)** *fileName* **-shortname**” command.
Two or more forward or backward slashes in a row in a path refer to a network path. For example, a simple concatenation of the root directory **c:/** with a subdirectory **/windows/system** will yield **c://windows/system** (two slashes together), which refers to the mount point called **system** on the machine called **windows** (and the **c:/** is ignored), and is not equivalent to **c:/windows/system**, which describes a directory on the current computer. The **[file join](file.htm)** command should be used to concatenate path components.
Note that there are two general types of Win32 console applications:
1. CLI — CommandLine Interface, simple stdio exchange. **netstat.exe** for example.
2. TUI — Textmode User Interface, any application that accesses the console API for doing such things as cursor movement, setting text color, detecting key presses and mouse movement, etc. An example would be **telnet.exe** from Windows 2000. These types of applications are not common in a windows environment, but do exist.
**exec** will not work well with TUI applications when a console is not present, as is done when launching applications under wish. It is desirable to have console applications hidden and detached. This is a designed-in limitation as **exec** wants to communicate over pipes. The Expect extension addresses this issue when communicating with a TUI application.
When attempting to execute an application, **exec** first searches for the name as it was specified. Then, in order, **.com**, **.exe**, **.bat** and **.cmd** are appended to the end of the specified name and it searches for the longer name. If a directory name was not specified as part of the application name, the following directories are automatically searched in order when attempting to locate the application:
* The directory from which the Tcl executable was loaded.
* The current directory.
* The Windows NT 32-bit system directory.
* The Windows NT 16-bit system directory.
* The Windows NT home directory.
* The directories listed in the path.
In order to execute shell built-in commands like **dir** and **copy**, the caller must prepend the desired command with “**cmd.exe /c** ” because built-in commands are not implemented using executables.
**Unix** (including Mac OS X)
The **exec** command is fully functional and works as described.
Unix examples
-------------
Here are some examples of the use of the **exec** command on Unix. To execute a simple program and get its result:
```
**exec** uname -a
```
### Working with non-zero results
To execute a program that can return a non-zero result, you should wrap the call to **exec** in **[catch](catch.htm)** and check the contents of the **-errorcode** return option if you have an error:
```
set status 0
if {[catch {**exec** grep foo bar.txt} results options]} {
set details [dict get $options -errorcode]
if {[lindex $details 0] eq "CHILDSTATUS"} {
set status [lindex $details 2]
} else {
# Some other error; regenerate it to let caller handle
return -options $options -level 0 $results
}
}
```
This is more easily written using the **[try](try.htm)** command, as that makes it simpler to trap specific types of errors. This is done using code like this:
```
try {
set results [**exec** grep foo bar.txt]
set status 0
} trap CHILDSTATUS {results options} {
set status [lindex [dict get $options -errorcode] 2]
}
```
### Working with quoted arguments
When translating a command from a Unix shell invocation, care should be taken over the fact that single quote characters have no special significance to Tcl. Thus:
```
awk '{sum += $1} END {print sum}' numbers.list
```
would be translated into something like:
```
**exec** awk {{sum += $1} END {print sum}} numbers.list
```
### Working with globbing
If you are converting invocations involving shell globbing, you should remember that Tcl does not handle globbing or expand things into multiple arguments by default. Instead you should write things like this:
```
**exec** ls -l {*}[glob *.tcl]
```
### Working with user-supplied shell script fragments
One useful technique can be to expose to users of a script the ability to specify a fragment of shell script to execute that will have some data passed in on standard input that was produced by the Tcl program. This is a common technique for using the *lpr* program for printing. By far the simplest way of doing this is to pass the user's script to the user's shell for processing, as this avoids a lot of complexity with parsing other languages.
```
set lprScript [*get from user...*]
set postscriptData [*generate somehow...*]
**exec** $env(SHELL) -c $lprScript << $postscriptData
```
Windows examples
----------------
Here are some examples of the use of the **exec** command on Windows. To start an instance of *notepad* editing a file without waiting for the user to finish editing the file:
```
**exec** notepad myfile.txt &
```
To print a text file using *notepad*:
```
**exec** notepad /p myfile.txt
```
### Working with console programs
If a program calls other programs, such as is common with compilers, then you may need to resort to batch files to hide the console windows that sometimes pop up:
```
**exec** cmp.bat somefile.c -o somefile
```
With the file *cmp.bat* looking something like:
```
@gcc %1 %2 %3 %4 %5 %6 %7 %8 %9
```
### Working with command built-ins
Sometimes you need to be careful, as different programs may have the same name and be in the path. It can then happen that typing a command at the DOS prompt finds *a different program* than the same command run via **exec**. This is because of the (documented) differences in behaviour between **exec** and DOS batch files. When in doubt, use the command **[auto\_execok](library.htm)**: it will return the complete path to the program as seen by the **exec** command. This applies especially when you want to run “internal” commands like *dir* from a Tcl script (if you just want to list filenames, use the **[glob](glob.htm)** command.) To do that, use this:
```
**exec** {*}[auto_execok dir] *.tcl
```
### Working with native filenames
Many programs on Windows require filename arguments to be passed in with backslashes as pathname separators. This is done with the help of the **[file nativename](file.htm)** command. For example, to make a directory (on NTFS) encrypted so that only the current user can access it requires use of the *CIPHER* command, like this:
```
set secureDir "~/Desktop/Secure Directory"
file mkdir $secureDir
**exec** CIPHER /e /s:[file nativename $secureDir]
```
See also
--------
**[error](error.htm)**, **[file](file.htm)**, **[open](open.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/exec.htm>
| programming_docs |
tcl_tk subst subst
=====
Name
----
subst — Perform backslash, command, and variable substitutions Synopsis
--------
**subst** ?**-nobackslashes**? ?**-nocommands**? ?**-novariables**? *string*
Description
-----------
This command performs variable substitutions, command substitutions, and backslash substitutions on its *string* argument and returns the fully-substituted result. The substitutions are performed in exactly the same way as for Tcl commands. As a result, the *string* argument is actually substituted twice, once by the Tcl parser in the usual fashion for Tcl commands, and again by the *subst* command. If any of the **-nobackslashes**, **-nocommands**, or **-novariables** are specified, then the corresponding substitutions are not performed. For example, if **-nocommands** is specified, command substitution is not performed: open and close brackets are treated as ordinary characters with no special interpretation.
Note that the substitution of one kind can include substitution of other kinds. For example, even when the **-novariables** option is specified, command substitution is performed without restriction. This means that any variable substitution necessary to complete the command substitution will still take place. Likewise, any command substitution necessary to complete a variable substitution will take place, even when **-nocommands** is specified. See the **[EXAMPLES](#M5)** below.
If an error occurs during substitution, then **subst** will return that error. If a break exception occurs during command or variable substitution, the result of the whole substitution will be the string (as substituted) up to the start of the substitution that raised the exception. If a continue exception occurs during the evaluation of a command or variable substitution, an empty string will be substituted for that entire command or variable substitution (as long as it is well-formed Tcl.) If a return exception occurs, or any other return code is returned during command or variable substitution, then the returned value is substituted for that substitution. See the **[EXAMPLES](#M5)** below. In this way, all exceptional return codes are “caught” by **subst**. The **subst** command itself will either return an error, or will complete successfully.
Examples
--------
When it performs its substitutions, *subst* does not give any special treatment to double quotes or curly braces (except within command substitutions) so the script
```
set a 44
**subst** {xyz {$a}}
```
returns “**xyz {44}**”, not “**xyz {$a}**” and the script
```
set a "p\} q \{r"
**subst** {xyz {$a}}
```
returns “**xyz {p} q {r}**”, not “**xyz {p\} q \{r}**”.
When command substitution is performed, it includes any variable substitution necessary to evaluate the script.
```
set a 44
**subst** -novariables {$a [format $a]}
```
returns “**$a 44**”, not “**$a $a**”. Similarly, when variable substitution is performed, it includes any command substitution necessary to retrieve the value of the variable.
```
proc b {} {return c}
array set a {c c [b] tricky}
**subst** -nocommands {[b] $a([b])}
```
returns “**[b] c**”, not “**[b] tricky**”.
The continue and break exceptions allow command substitutions to prevent substitution of the rest of the command substitution and the rest of *string* respectively, giving script authors more options when processing text using *subst*. For example, the script
```
**subst** {abc,[break],def}
```
returns “**abc,**”, not “**abc,,def**” and the script
```
**subst** {abc,[continue;expr {1+2}],def}
```
returns “**abc,,def**”, not “**abc,3,def**”.
Other exceptional return codes substitute the returned value
```
**subst** {abc,[return foo;expr {1+2}],def}
```
returns “**abc,foo,def**”, not “**abc,3,def**” and
```
**subst** {abc,[return -code 10 foo;expr {1+2}],def}
```
also returns “**abc,foo,def**”, not “**abc,3,def**”.
See also
--------
**[Tcl](tcl.htm)**, **[eval](eval.htm)**, **[break](break.htm)**, **[continue](continue.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/subst.htm>
tcl_tk zlib zlib
====
[NAME](zlib.htm#M2) zlib — compression and decompression operations
[SYNOPSIS](zlib.htm#M3)
[DESCRIPTION](zlib.htm#M4)
[COMPRESSION SUBCOMMANDS](zlib.htm#M5)
[**zlib compress** *string* ?*level*?](zlib.htm#M6)
[**zlib decompress** *string* ?*bufferSize*?](zlib.htm#M7)
[**zlib deflate** *string* ?*level*?](zlib.htm#M8)
[**zlib gunzip** *string* ?**-headerVar** *varName*?](zlib.htm#M9)
[**comment**](zlib.htm#M10)
[**crc**](zlib.htm#M11)
[**filename**](zlib.htm#M12)
[**os**](zlib.htm#M13)
[**size**](zlib.htm#M14)
[**time**](zlib.htm#M15)
[**type**](zlib.htm#M16)
[**zlib gzip** *string* ?**-level** *level*? ?**-header** *dict*?](zlib.htm#M17)
[**comment**](zlib.htm#M18)
[**crc**](zlib.htm#M19)
[**filename**](zlib.htm#M20)
[**os**](zlib.htm#M21)
[**time**](zlib.htm#M22)
[**type**](zlib.htm#M23)
[**zlib inflate** *string* ?*bufferSize*?](zlib.htm#M24)
[CHANNEL SUBCOMMAND](zlib.htm#M25)
[**zlib push** *mode channel* ?*options ...*?](zlib.htm#M26)
[**compress**](zlib.htm#M27)
[**decompress**](zlib.htm#M28)
[**deflate**](zlib.htm#M29)
[**gunzip**](zlib.htm#M30)
[**gzip**](zlib.htm#M31)
[**inflate**](zlib.htm#M32)
[**-dictionary** *binData*](zlib.htm#M33)
[**-header** *dictionary*](zlib.htm#M34)
[**-level** *compressionLevel*](zlib.htm#M35)
[**-limit** *readaheadLimit*](zlib.htm#M36)
[**-checksum** *checksum*](zlib.htm#M37)
[**-dictionary** *binData*](zlib.htm#M38)
[**-flush** *type*](zlib.htm#M39)
[**-header** *dictionary*](zlib.htm#M40)
[**-limit** *readaheadLimit*](zlib.htm#M41)
[STREAMING SUBCOMMAND](zlib.htm#M42)
[**zlib stream** *mode* ?*options*?](zlib.htm#M43)
[**zlib stream compress** ?**-dictionary** *bindata*? ?**-level** *level*?](zlib.htm#M44)
[**zlib stream decompress** ?**-dictionary** *bindata*?](zlib.htm#M45)
[**zlib stream deflate** ?**-dictionary** *bindata*? ?**-level** *level*?](zlib.htm#M46)
[**zlib stream gunzip**](zlib.htm#M47)
[**zlib stream gzip** ?**-header** *header*? ?**-level** *level*?](zlib.htm#M48)
[**zlib stream inflate** ?**-dictionary** *bindata*?](zlib.htm#M49)
[CHECKSUMMING SUBCOMMANDS](zlib.htm#M50)
[**zlib adler32** *string* ?*initValue*?](zlib.htm#M51)
[**zlib crc32** *string* ?*initValue*?](zlib.htm#M52)
[STREAMING INSTANCE COMMAND](zlib.htm#M53)
[*stream* **add** ?*option...*? *data*](zlib.htm#M54)
[*stream* **checksum**](zlib.htm#M55)
[*stream* **close**](zlib.htm#M56)
[*stream* **eof**](zlib.htm#M57)
[*stream* **finalize**](zlib.htm#M58)
[*stream* **flush**](zlib.htm#M59)
[*stream* **fullflush**](zlib.htm#M60)
[*stream* **get** ?*count*?](zlib.htm#M61)
[*stream* **put** ?*option...*? *data*](zlib.htm#M62)
[**-dictionary** *binData*](zlib.htm#M63)
[**-finalize**](zlib.htm#M64)
[**-flush**](zlib.htm#M65)
[**-fullflush**](zlib.htm#M66)
[*stream* **reset**](zlib.htm#M67)
[EXAMPLES](zlib.htm#M68)
[SEE ALSO](zlib.htm#M69)
[KEYWORDS](zlib.htm#M70)
Name
----
zlib — compression and decompression operations Synopsis
--------
**zlib** *subcommand arg ...*
Description
-----------
The **zlib** command provides access to the compression and check-summing facilities of the Zlib library by Jean-loup Gailly and Mark Adler. It has the following subcommands. ### Compression subcommands
**zlib compress** *string* ?*level*?
Returns the zlib-format compressed binary data of the binary string in *string*. If present, *level* gives the compression level to use (from 0, which is uncompressed, to 9, maximally compressed).
**zlib decompress** *string* ?*bufferSize*?
Returns the uncompressed version of the raw compressed binary data in *string*. If present, *bufferSize* is a hint as to what size of buffer is to be used to receive the data.
**zlib deflate** *string* ?*level*?
Returns the raw compressed binary data of the binary string in *string*. If present, *level* gives the compression level to use (from 0, which is uncompressed, to 9, maximally compressed).
**zlib gunzip** *string* ?**-headerVar** *varName*?
Return the uncompressed contents of binary string *string*, which must have been in gzip format. If **-headerVar** is given, store a dictionary describing the contents of the gzip header in the variable called *varName*. The keys of the dictionary that may be present are:
**comment**
The comment field from the header, if present.
**crc**
A boolean value describing whether a CRC of the header is computed.
**filename**
The filename field from the header, if present.
**os**
The operating system type code field from the header (if not the QW unknown value). See RFC 1952 for the meaning of these codes.
**size**
The size of the uncompressed data.
**time**
The time field from the header if non-zero, expected to be time that the file named by the **filename** field was modified. Suitable for use with **[clock format](clock.htm)**.
**type**
The type of the uncompressed data (**binary** or **text**) if known.
**zlib gzip** *string* ?**-level** *level*? ?**-header** *dict*?
Return the compressed contents of binary string *string* in gzip format. If **-level** is given, *level* gives the compression level to use (from 0, which is uncompressed, to 9, maximally compressed). If **-header** is given, *dict* is a dictionary containing values used for the gzip header. The following keys may be defined:
**comment**
Add the given comment to the header of the gzip-format data.
**crc**
A boolean saying whether to compute a CRC of the header. Note that if the data is to be interchanged with the **gzip** program, a header CRC should *not* be computed.
**filename**
The name of the file that the data to be compressed came from.
**os**
The operating system type code, which should be one of the values described in RFC 1952.
**time**
The time that the file named in the **filename** key was last modified. This will be in the same as is returned by **[clock seconds](clock.htm)** or **[file mtime](file.htm)**.
**type**
The type of the data being compressed, being **binary** or **text**.
**zlib inflate** *string* ?*bufferSize*?
Returns the uncompressed version of the raw compressed binary data in *string*. If present, *bufferSize* is a hint as to what size of buffer is to be used to receive the data.
### Channel subcommand
**zlib push** *mode channel* ?*options ...*?
Pushes a compressing or decompressing transformation onto the channel *channel*. The transformation can be removed again with **[chan pop](chan.htm)**. The *mode* argument determines what type of transformation is pushed; the following are supported:
**compress**
The transformation will be a compressing transformation that produces zlib-format data on *channel*, which must be writable.
**decompress**
The transformation will be a decompressing transformation that reads zlib-format data from *channel*, which must be readable.
**deflate**
The transformation will be a compressing transformation that produces raw compressed data on *channel*, which must be writable.
**gunzip**
The transformation will be a decompressing transformation that reads gzip-format data from *channel*, which must be readable.
**gzip**
The transformation will be a compressing transformation that produces gzip-format data on *channel*, which must be writable.
**inflate**
The transformation will be a decompressing transformation that reads raw compressed data from *channel*, which must be readable.
The following options may be set when creating a transformation via the “*options ...*” to the **zlib push** command:
**-dictionary** *binData*
Sets the compression dictionary to use when working with compressing or decompressing the data to be *binData*. Not valid for transformations that work with gzip-format data. The dictionary should consist of strings (byte sequences) that are likely to be encountered later in the data to be compressed, with the most commonly used strings preferably put towards the end of the dictionary. Tcl provides no mechanism for choosing a good such dictionary for a particular data sequence.
**-header** *dictionary*
Passes a description of the gzip header to create, in the same format that **zlib gzip** understands.
**-level** *compressionLevel*
How hard to compress the data. Must be an integer from 0 (uncompressed) to 9 (maximally compressed).
**-limit** *readaheadLimit*
The maximum number of bytes ahead to read when decompressing. This defaults to 1, which ensures that data is always decompressed correctly, but may be increased to improve performance. This is more useful when the channel is non-blocking.
Both compressing and decompressing channel transformations add extra configuration options that may be accessed through **[chan configure](chan.htm)**. The options are:
**-checksum** *checksum*
This read-only option gets the current checksum for the uncompressed data that the compression engine has seen so far. It is valid for both compressing and decompressing transforms, but not for the raw inflate and deflate formats. The compression algorithm depends on what format is being produced or consumed.
**-dictionary** *binData*
This read-write options gets or sets the initial compression dictionary to use when working with compressing or decompressing the data to be *binData*. It is not valid for transformations that work with gzip-format data, and should not normally be set on compressing transformations other than at the point where the transformation is stacked. Note that this cannot be used to get the current active compression dictionary mid-stream, as that information is not exposed by the underlying library.
**-flush** *type*
This write-only operation flushes the current state of the compressor to the underlying channel. It is only valid for compressing transformations. The *type* must be either **sync** or **full** for a normal flush or an expensive flush respectively. Flushing degrades the compression ratio, but makes it easier for a decompressor to recover more of the file in the case of data corruption.
**-header** *dictionary*
This read-only option, only valid for decompressing transforms that are processing gzip-format data, returns the dictionary describing the header read off the data stream.
**-limit** *readaheadLimit*
This read-write option is used by decompressing channels to control the maximum number of bytes ahead to read from the underlying data source. This defaults to 1, which ensures that data is always decompressed correctly, but may be increased to improve performance. This is more useful when the channel is non-blocking.
### Streaming subcommand
**zlib stream** *mode* ?*options*?
Creates a streaming compression or decompression command based on the *mode*, and return the name of the command. For a description of how that command works, see **[STREAMING INSTANCE COMMAND](#M53)** below. The following modes and *options* are supported:
**zlib stream compress** ?**-dictionary** *bindata*? ?**-level** *level*?
The stream will be a compressing stream that produces zlib-format output, using compression level *level* (if specified) which will be an integer from 0 to 9, and the compression dictionary *bindata* (if specified).
**zlib stream decompress** ?**-dictionary** *bindata*?
The stream will be a decompressing stream that takes zlib-format input and produces uncompressed output. If *bindata* is supplied, it is a compression dictionary to use if required.
**zlib stream deflate** ?**-dictionary** *bindata*? ?**-level** *level*?
The stream will be a compressing stream that produces raw output, using compression level *level* (if specified) which will be an integer from 0 to 9, and the compression dictionary *bindata* (if specified). Note that the raw compressed data includes no metadata about what compression dictionary was used, if any; that is a feature of the zlib-format data.
**zlib stream gunzip**
The stream will be a decompressing stream that takes gzip-format input and produces uncompressed output.
**zlib stream gzip** ?**-header** *header*? ?**-level** *level*?
The stream will be a compressing stream that produces gzip-format output, using compression level *level* (if specified) which will be an integer from 0 to 9, and the header descriptor dictionary *header* (if specified; for keys see **zlib gzip**).
**zlib stream inflate** ?**-dictionary** *bindata*?
The stream will be a decompressing stream that takes raw compressed input and produces uncompressed output. If *bindata* is supplied, it is a compression dictionary to use. Note that there are no checks in place to determine whether the compression dictionary is correct.
### Checksumming subcommands
**zlib adler32** *string* ?*initValue*?
Compute a checksum of binary string *string* using the Adler-32 algorithm. If given, *initValue* is used to initialize the checksum engine.
**zlib crc32** *string* ?*initValue*?
Compute a checksum of binary string *string* using the CRC-32 algorithm. If given, *initValue* is used to initialize the checksum engine.
Streaming instance command
--------------------------
Streaming compression instance commands are produced by the **zlib stream** command. They are used by calling their **put** subcommand one or more times to load data in, and their **get** subcommand one or more times to extract the transformed data. The full set of subcommands supported by a streaming instance command, *stream*, is as follows:
*stream* **add** ?*option...*? *data*
A short-cut for “*stream* **put** ?*option...*? *data*” followed by “*stream* **get**”.
*stream* **checksum**
Returns the checksum of the uncompressed data seen so far by this stream.
*stream* **close**
Deletes this stream and frees up all resources associated with it.
*stream* **eof**
Returns a boolean indicating whether the end of the stream (as determined by the compressed data itself) has been reached. Not all formats support detection of the end of the stream.
*stream* **finalize**
A short-cut for “*stream* **put -finalize {}**”.
*stream* **flush**
A short-cut for “*stream* **put -flush {}**”.
*stream* **fullflush**
A short-cut for “*stream* **put -fullflush {}**”.
*stream* **get** ?*count*?
Return up to *count* bytes from *stream*'s internal buffers with the transformation applied. If *count* is omitted, the entire contents of the buffers are returned. *stream* **header** Return the gzip header description dictionary extracted from the stream. Only supported for streams created with their *mode* parameter set to **gunzip**.
*stream* **put** ?*option...*? *data*
Append the contents of the binary string *data* to *stream*'s internal buffers while applying the transformation. The following *option*s are supported (or an unambiguous prefix of them), which are used to modify the way in which the transformation is applied:
**-dictionary** *binData*
Sets the compression dictionary to use when working with compressing or decompressing the data to be *binData*.
**-finalize**
Mark the stream as finished, ensuring that all bytes have been wholly compressed or decompressed. For gzip streams, this also ensures that the footer is written to the stream. The stream will need to be reset before having more data written to it after this, though data can still be read out of the stream with the **get** subcommand. This option is mutually exclusive with the **-flush** and **-fullflush** options.
**-flush**
Ensure that a decompressor consuming the bytes that the current (compressing) stream is producing will be able to produce all the bytes that have been compressed so far, at some performance penalty. This option is mutually exclusive with the **-finalize** and **-fullflush** options.
**-fullflush**
Ensure that not only can a decompressor handle all the bytes produced so far (as with **-flush** above) but also that it can restart from this point if it detects that the stream is partially corrupt. This incurs a substantial performance penalty. This option is mutually exclusive with the **-finalize** and **-flush** options.
*stream* **reset**
Puts any stream, including those that have been finalized or that have reached eof, back into a state where it can process more data. Throws away all internally buffered data.
Examples
--------
To compress a Tcl string, it should be first converted to a particular charset encoding since the **zlib** command always operates on binary strings.
```
set binData [encoding convertto utf-8 $string]
set compData [**zlib compress** $binData]
```
When converting back, it is also important to reverse the charset encoding:
```
set binData [**zlib decompress** $compData]
set string [encoding convertfrom utf-8 $binData]
```
The compression operation from above can also be done with streams, which is especially helpful when you want to accumulate the data by stages:
```
set strm [**zlib stream** compress]
$*strm* **put** [encoding convertto utf-8 $string]
# ...
$*strm* **finalize**
set compData [$*strm* **get**]
$*strm* **close**
```
See also
--------
**binary**, **[chan](chan.htm)**, **[encoding](encoding.htm)**, **[Tcl\_ZlibDeflate](https://www.tcl.tk/man/tcl/TclLib/TclZlib.htm)**, **RFC1950 - RFC1952**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/zlib.htm>
| programming_docs |
tcl_tk open open
====
[NAME](open.htm#M2) open — Open a file-based or command pipeline channel
[SYNOPSIS](open.htm#M3)
[DESCRIPTION](open.htm#M4)
[**r**](open.htm#M5)
[**r+**](open.htm#M6)
[**w**](open.htm#M7)
[**w+**](open.htm#M8)
[**a**](open.htm#M9)
[**a+**](open.htm#M10)
[**RDONLY**](open.htm#M11)
[**WRONLY**](open.htm#M12)
[**RDWR**](open.htm#M13)
[**APPEND**](open.htm#M14)
[**BINARY**](open.htm#M15)
[**CREAT**](open.htm#M16)
[**EXCL**](open.htm#M17)
[**NOCTTY**](open.htm#M18)
[**NONBLOCK**](open.htm#M19)
[**TRUNC**](open.htm#M20)
[COMMAND PIPELINES](open.htm#M21)
[SERIAL COMMUNICATIONS](open.htm#M22)
[**-mode** *baud***,***parity***,***data***,***stop*](open.htm#M23)
[**-handshake** *type*](open.htm#M24)
[**-queue**](open.htm#M25)
[**-timeout** *msec*](open.htm#M26)
[**-ttycontrol** *{signal boolean signal boolean ...}*](open.htm#M27)
[**-ttystatus**](open.htm#M28)
[**-xchar** *{xonChar xoffChar}*](open.htm#M29)
[**-pollinterval** *msec*](open.htm#M30)
[**-sysbuffer** *inSize*](open.htm#M31)
[**-sysbuffer** *{inSize outSize}*](open.htm#M32)
[**-lasterror**](open.htm#M33)
[SERIAL PORT SIGNALS](open.htm#M34)
[**TXD**(output)](open.htm#M35)
[**RXD**(input)](open.htm#M36)
[**RTS**(output)](open.htm#M37)
[**CTS**(input)](open.htm#M38)
[**DTR**(output)](open.htm#M39)
[**DSR**(input)](open.htm#M40)
[**DCD**(input)](open.htm#M41)
[**RI**(input)](open.htm#M42)
[**BREAK**](open.htm#M43)
[ERROR CODES (Windows only)](open.htm#M44)
[**RXOVER**](open.htm#M45)
[**TXFULL**](open.htm#M46)
[**OVERRUN**](open.htm#M47)
[**RXPARITY**](open.htm#M48)
[**FRAME**](open.htm#M49)
[**BREAK**](open.htm#M50)
[PORTABILITY ISSUES](open.htm#M51)
[**Windows**](open.htm#M52)
[**Unix**](open.htm#M53)
[EXAMPLE](open.htm#M54)
[SEE ALSO](open.htm#M55)
[KEYWORDS](open.htm#M56)
Name
----
open — Open a file-based or command pipeline channel Synopsis
--------
**open** *fileName*
**open** *fileName access*
**open** *fileName access permissions*
Description
-----------
This command opens a file, serial port, or command pipeline and returns a channel identifier that may be used in future invocations of commands like **[read](read.htm)**, **[puts](puts.htm)**, and **[close](close.htm)**. If the first character of *fileName* is not **|** then the command opens a file: *fileName* gives the name of the file to open, and it must conform to the conventions described in the **[filename](filename.htm)** manual entry. The *access* argument, if present, indicates the way in which the file (or command pipeline) is to be accessed. In the first form *access* may have any of the following values:
**r**
Open the file for reading only; the file must already exist. This is the default value if *access* is not specified.
**r+**
Open the file for both reading and writing; the file must already exist.
**w**
Open the file for writing only. Truncate it if it exists. If it does not exist, create a new file.
**w+**
Open the file for reading and writing. Truncate it if it exists. If it does not exist, create a new file.
**a**
Open the file for writing only. If the file does not exist, create a new empty file. Set the file pointer to the end of the file prior to each write.
**a+**
Open the file for reading and writing. If the file does not exist, create a new empty file. Set the initial access position to the end of the file.
All of the legal *access* values above may have the character **b** added as the second or third character in the value to indicate that the opened channel should be configured as if with the **[fconfigure](fconfigure.htm)** **-translation binary** option, making the channel suitable for reading or writing of binary data.
In the second form, *access* consists of a list of any of the following flags, all of which have the standard POSIX meanings. One of the flags must be either **RDONLY**, **WRONLY** or **RDWR**.
**RDONLY**
Open the file for reading only.
**WRONLY**
Open the file for writing only.
**RDWR**
Open the file for both reading and writing.
**APPEND**
Set the file pointer to the end of the file prior to each write.
**BINARY**
Configure the opened channel with the **-translation binary** option.
**CREAT**
Create the file if it does not already exist (without this flag it is an error for the file not to exist).
**EXCL**
If **CREAT** is also specified, an error is returned if the file already exists.
**NOCTTY**
If the file is a terminal device, this flag prevents the file from becoming the controlling terminal of the process.
**NONBLOCK**
Prevents the process from blocking while opening the file, and possibly in subsequent I/O operations. The exact behavior of this flag is system- and device-dependent; its use is discouraged (it is better to use the **[fconfigure](fconfigure.htm)** command to put a file in nonblocking mode). For details refer to your system documentation on the **open** system call's **O\_NONBLOCK** flag.
**TRUNC**
If the file exists it is truncated to zero length.
If a new file is created as part of opening it, *permissions* (an integer) is used to set the permissions for the new file in conjunction with the process's file mode creation mask. *Permissions* defaults to 0666.
Command pipelines
-----------------
If the first character of *fileName* is “**|**” then the remaining characters of *fileName* are treated as a list of arguments that describe a command pipeline to invoke, in the same style as the arguments for **[exec](exec.htm)**. In this case, the channel identifier returned by **open** may be used to write to the command's input pipe or read from its output pipe, depending on the value of *access*. If write-only access is used (e.g. *access* is “**w**”), then standard output for the pipeline is directed to the current standard output unless overridden by the command. If read-only access is used (e.g. *access* is “**r**”), standard input for the pipeline is taken from the current standard input unless overridden by the command. The id of the spawned process is accessible through the **[pid](pid.htm)** command, using the channel id returned by **open** as argument. If the command (or one of the commands) executed in the command pipeline returns an error (according to the definition in **[exec](exec.htm)**), a Tcl error is generated when **[close](close.htm)** is called on the channel unless the pipeline is in non-blocking mode then no exit status is returned (a silent **[close](close.htm)** with -blocking 0).
It is often useful to use the **[fileevent](fileevent.htm)** command with pipelines so other processing may happen at the same time as running the command in the background.
Serial communications
---------------------
If *fileName* refers to a serial port, then the specified serial port is opened and initialized in a platform-dependent manner. Acceptable values for the *fileName* to use to open a serial port are described in the PORTABILITY ISSUES section. The **[fconfigure](fconfigure.htm)** command can be used to query and set additional configuration options specific to serial ports (where supported):
**-mode** *baud***,***parity***,***data***,***stop*
This option is a set of 4 comma-separated values: the baud rate, parity, number of data bits, and number of stop bits for this serial port. The *baud* rate is a simple integer that specifies the connection speed. *Parity* is one of the following letters: **n**, **o**, **e**, **m**, **s**; respectively signifying the parity options of “none”, “odd”, “even”, “mark”, or “space”. *Data* is the number of data bits and should be an integer from 5 to 8, while *stop* is the number of stop bits and should be the integer 1 or 2.
**-handshake** *type*
(Windows and Unix). This option is used to setup automatic handshake control. Note that not all handshake types maybe supported by your operating system. The *type* parameter is case-independent. If *type* is **none** then any handshake is switched off. **rtscts** activates hardware handshake. Hardware handshake signals are described below. For software handshake **xonxoff** the handshake characters can be redefined with **-xchar**. An additional hardware handshake **dtrdsr** is available only under Windows. There is no default handshake configuration, the initial value depends on your operating system settings. The **-handshake** option cannot be queried.
**-queue**
(Windows and Unix). The **-queue** option can only be queried. It returns a list of two integers representing the current number of bytes in the input and output queue respectively.
**-timeout** *msec*
(Windows and Unix). This option is used to set the timeout for blocking read operations. It specifies the maximum interval between the reception of two bytes in milliseconds. For Unix systems the granularity is 100 milliseconds. The **-timeout** option does not affect write operations or nonblocking reads. This option cannot be queried.
**-ttycontrol** *{signal boolean signal boolean ...}*
(Windows and Unix). This option is used to setup the handshake output lines (see below) permanently or to send a BREAK over the serial line. The *signal* names are case-independent. **{RTS 1 DTR 0}** sets the RTS output to high and the DTR output to low. The BREAK condition (see below) is enabled and disabled with **{BREAK 1}** and **{BREAK 0}** respectively. It is not a good idea to change the **RTS** (or **DTR**) signal with active hardware handshake **rtscts** (or **dtrdsr**). The result is unpredictable. The **-ttycontrol** option cannot be queried.
**-ttystatus**
(Windows and Unix). The **-ttystatus** option can only be queried. It returns the current modem status and handshake input signals (see below). The result is a list of signal,value pairs with a fixed order, e.g. **{CTS 1 DSR 0 RING 1 DCD 0}**. The *signal* names are returned upper case.
**-xchar** *{xonChar xoffChar}*
(Windows and Unix). This option is used to query or change the software handshake characters. Normally the operating system default should be DC1 (0x11) and DC3 (0x13) representing the ASCII standard XON and XOFF characters.
**-pollinterval** *msec*
(Windows only). This option is used to set the maximum time between polling for fileevents. This affects the time interval between checking for events throughout the Tcl interpreter (the smallest value always wins). Use this option only if you want to poll the serial port more or less often than 10 msec (the default).
**-sysbuffer** *inSize*
**-sysbuffer** *{inSize outSize}*
(Windows only). This option is used to change the size of Windows system buffers for a serial channel. Especially at higher communication rates the default input buffer size of 4096 bytes can overrun for latent systems. The first form specifies the input buffer size, in the second form both input and output buffers are defined.
**-lasterror**
(Windows only). This option is query only. In case of a serial communication error, **[read](read.htm)** or **[puts](puts.htm)** returns a general Tcl file I/O error. **[fconfigure](fconfigure.htm)** **-lasterror** can be called to get a list of error details. See below for an explanation of the various error codes.
Serial port signals
-------------------
RS-232 is the most commonly used standard electrical interface for serial communications. A negative voltage (-3V..-12V) define a mark (on=1) bit and a positive voltage (+3..+12V) define a space (off=0) bit (RS-232C). The following signals are specified for incoming and outgoing data, status lines and handshaking. Here we are using the terms *workstation* for your computer and *modem* for the external device, because some signal names (DCD, RI) come from modems. Of course your external device may use these signal lines for other purposes.
**TXD**(output)
**Transmitted Data:** Outgoing serial data.
**RXD**(input)
**Received Data:**Incoming serial data.
**RTS**(output)
**Request To Send:** This hardware handshake line informs the modem that your workstation is ready to receive data. Your workstation may automatically reset this signal to indicate that the input buffer is full.
**CTS**(input)
**Clear To Send:** The complement to RTS. Indicates that the modem is ready to receive data.
**DTR**(output)
**Data Terminal Ready:** This signal tells the modem that the workstation is ready to establish a link. DTR is often enabled automatically whenever a serial port is opened.
**DSR**(input)
**Data Set Ready:** The complement to DTR. Tells the workstation that the modem is ready to establish a link.
**DCD**(input)
**Data Carrier Detect:** This line becomes active when a modem detects a “Carrier” signal.
**RI**(input)
**Ring Indicator:** Goes active when the modem detects an incoming call.
**BREAK**
A BREAK condition is not a hardware signal line, but a logical zero on the TXD or RXD lines for a long period of time, usually 250 to 500 milliseconds. Normally a receive or transmit data signal stays at the mark (on=1) voltage until the next character is transferred. A BREAK is sometimes used to reset the communications line or change the operating mode of communications hardware.
Error codes (windows only)
--------------------------
A lot of different errors may occur during serial read operations or during event polling in background. The external device may have been switched off, the data lines may be noisy, system buffers may overrun or your mode settings may be wrong. That is why a reliable software should always **[catch](catch.htm)** serial read operations. In cases of an error Tcl returns a general file I/O error. Then **[fconfigure](fconfigure.htm)** **-lasterror** may help to locate the problem. The following error codes may be returned.
**RXOVER**
Windows input buffer overrun. The data comes faster than your scripts reads it or your system is overloaded. Use **[fconfigure](fconfigure.htm)** **-sysbuffer** to avoid a temporary bottleneck and/or make your script faster.
**TXFULL**
Windows output buffer overrun. Complement to RXOVER. This error should practically not happen, because Tcl cares about the output buffer status.
**OVERRUN**
UART buffer overrun (hardware) with data lost. The data comes faster than the system driver receives it. Check your advanced serial port settings to enable the FIFO (16550) buffer and/or setup a lower(1) interrupt threshold value.
**RXPARITY**
A parity error has been detected by your UART. Wrong parity settings with **[fconfigure](fconfigure.htm)** **-mode** or a noisy data line (RXD) may cause this error.
**FRAME**
A stop-bit error has been detected by your UART. Wrong mode settings with **[fconfigure](fconfigure.htm)** **-mode** or a noisy data line (RXD) may cause this error.
**BREAK**
A BREAK condition has been detected by your UART (see above).
Portability issues
------------------
**Windows**
Valid values for *fileName* to open a serial port are of the form **com***X*, where *X* is a number, generally from 1 to 9. A legacy form accepted as well is **com***X***:**. This notation only works for serial ports from 1 to 9. An attempt to open a serial port that does not exist or has a number greater than 9 will fail. An alternate form of opening serial ports is to use the filename **//./comX**, where X is any number that corresponds to a serial port.
When running Tcl interactively, there may be some strange interactions between the real console, if one is present, and a command pipeline that uses standard input or output. If a command pipeline is opened for reading, some of the lines entered at the console will be sent to the command pipeline and some will be sent to the Tcl evaluator. If a command pipeline is opened for writing, keystrokes entered into the console are not visible until the pipe is closed. These problems only occur because both Tcl and the child application are competing for the console at the same time. If the command pipeline is started from a script, so that Tcl is not accessing the console, or if the command pipeline does not use standard input or output, but is redirected from or to a file, then the above problems do not occur.
**Unix**
Valid values for *fileName* to open a serial port are generally of the form **/dev/tty***X*, where *X* is **a** or **b**, but the name of any pseudo-file that maps to a serial port may be used. Advanced configuration options are only supported for serial ports when Tcl is built to use the POSIX serial interface. When running Tcl interactively, there may be some strange interactions between the console, if one is present, and a command pipeline that uses standard input. If a command pipeline is opened for reading, some of the lines entered at the console will be sent to the command pipeline and some will be sent to the Tcl evaluator. This problem only occurs because both Tcl and the child application are competing for the console at the same time. If the command pipeline is started from a script, so that Tcl is not accessing the console, or if the command pipeline does not use standard input, but is redirected from a file, then the above problem does not occur.
See the **[PORTABILITY ISSUES](#M51)** section of the **[exec](exec.htm)** command for additional information not specific to command pipelines about executing applications on the various platforms
Example
-------
Open a command pipeline and catch any errors:
```
set fl [**open** "| ls this_file_does_not_exist"]
set data [read $fl]
if {[catch {close $fl} err]} {
puts "ls command failed: $err"
}
```
See also
--------
**[file](file.htm)**, **[close](close.htm)**, **[filename](filename.htm)**, **[fconfigure](fconfigure.htm)**, **[gets](gets.htm)**, **[read](read.htm)**, **[puts](puts.htm)**, **[exec](exec.htm)**, **[pid](pid.htm)**, **fopen**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/open.htm>
tcl_tk unset unset
=====
Name
----
unset — Delete variables Synopsis
--------
**unset** ?**-nocomplain**? ?**--**? ?*name name name ...*?
Description
-----------
This command removes one or more variables. Each *name* is a variable name, specified in any of the ways acceptable to the **[set](set.htm)** command. If a *name* refers to an element of an array then that element is removed without affecting the rest of the array. If a *name* consists of an array name with no parenthesized index, then the entire array is deleted. The **unset** command returns an empty string as result. If **-nocomplain** is specified as the first argument, any possible errors are suppressed. The option may not be abbreviated, in order to disambiguate it from possible variable names. The option **--** indicates the end of the options, and should be used if you wish to remove a variable with the same name as any of the options. If an error occurs during variable deletion, any variables after the named one causing the error are not deleted. An error can occur when the named variable does not exist, or the name refers to an array element but the variable is a scalar, or the name refers to a variable in a non-existent namespace. Example
-------
Create an array containing a mapping from some numbers to their squares and remove the array elements for non-prime numbers:
```
array set squares {
1 1 6 36
2 4 7 49
3 9 8 64
4 16 9 81
5 25 10 100
}
puts "The squares are:"
parray squares
**unset** squares(1) squares(4) squares(6)
**unset** squares(8) squares(9) squares(10)
puts "The prime squares are:"
parray squares
```
See also
--------
**[set](set.htm)**, **[trace](trace.htm)**, **[upvar](upvar.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/unset.htm>
| programming_docs |
tcl_tk lmap lmap
====
Name
----
lmap — Iterate over all elements in one or more lists and collect results Synopsis
--------
**lmap** *varname list body*
**lmap** *varlist1 list1* ?*varlist2 list2 ...*? *body*
Description
-----------
The **lmap** command implements a loop where the loop variable(s) take on values from one or more lists, and the loop returns a list of results collected from each iteration. In the simplest case there is one loop variable, *varname*, and one list, *list*, that is a list of values to assign to *varname*. The *body* argument is a Tcl script. For each element of *list* (in order from first to last), **lmap** assigns the contents of the element to *varname* as if the **[lindex](lindex.htm)** command had been used to extract the element, then calls the Tcl interpreter to execute *body*. If execution of the body completes normally then the result of the body is appended to an accumulator list. **lmap** returns the accumulator list.
In the general case there can be more than one value list (e.g., *list1* and *list2*), and each value list can be associated with a list of loop variables (e.g., *varlist1* and *varlist2*). During each iteration of the loop the variables of each *varlist* are assigned consecutive values from the corresponding *list*. Values in each *list* are used in order from first to last, and each value is used exactly once. The total number of loop iterations is large enough to use up all the values from all the value lists. If a value list does not contain enough elements for each of its loop variables in each iteration, empty values are used for the missing elements.
The **[break](break.htm)** and **[continue](continue.htm)** statements may be invoked inside *body*, with the same effect as in the **[for](for.htm)** and **[foreach](foreach.htm)** commands. In these cases the body does not complete normally and the result is not appended to the accumulator list.
Examples
--------
Zip lists together:
```
set list1 {a b c d}
set list2 {1 2 3 4}
set zipped [**lmap** a $list1 b $list2 {list $a $b}]
# The value of zipped is "{a 1} {b 2} {c 3} {d 4}"
```
Filter a list to remove odd values:
```
set values {1 2 3 4 5 6 7 8}
proc isEven {n} {expr {($n % 2) == 0}}
set goodOnes [**lmap** x $values {expr {
[isEven $x] ? $x : [continue]
}}]
# The value of goodOnes is "2 4 6 8"
```
Take a prefix from a list based on the contents of the list:
```
set values {8 7 6 5 4 3 2 1}
proc isGood {counter} {expr {$n > 3}}
set prefix [**lmap** x $values {expr {
[isGood $x] ? $x : [break]
}}]
# The value of prefix is "8 7 6 5 4"
```
See also
--------
**[break](break.htm)**, **[continue](continue.htm)**, **[for](for.htm)**, **[foreach](foreach.htm)**, **[while](while.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/lmap.htm>
tcl_tk lindex lindex
======
Name
----
lindex — Retrieve an element from a list Synopsis
--------
**lindex** *list ?index ...?*
Description
-----------
The **lindex** command accepts a parameter, *list*, which it treats as a Tcl list. It also accepts zero or more *indices* into the list. The indices may be presented either consecutively on the command line, or grouped in a Tcl list and presented as a single argument. If no indices are presented, the command takes the form:
```
**lindex** *list*
```
or
```
**lindex** *list* {}
```
In this case, the return value of **lindex** is simply the value of the *list* parameter.
When presented with a single index, the **lindex** command treats *list* as a Tcl list and returns the *index*'th element from it (0 refers to the first element of the list). In extracting the element, **lindex** observes the same rules concerning braces and quotes and backslashes as the Tcl command interpreter; however, variable substitution and command substitution do not occur. If *index* is negative or greater than or equal to the number of elements in *value*, then an empty string is returned. The interpretation of each simple *index* value is the same as for the command **[string index](string.htm)**, supporting simple index arithmetic and indices relative to the end of the list.
If additional *index* arguments are supplied, then each argument is used in turn to select an element from the previous indexing operation, allowing the script to select elements from sublists. The command,
```
**lindex** $a 1 2 3
```
or
```
**lindex** $a {1 2 3}
```
is synonymous with
```
**lindex** [**lindex** [**lindex** $a 1] 2] 3
```
Examples
--------
Lists can be indexed into from either end:
```
**lindex** {a b c} 0
*→ a*
**lindex** {a b c} 2
*→ c*
**lindex** {a b c} end
*→ c*
**lindex** {a b c} end-1
*→ b*
```
Lists or sequences of indices allow selection into lists of lists:
```
**lindex** {a b c}
*→ a b c*
**lindex** {a b c} {}
*→ a b c*
**lindex** {{a b c} {d e f} {g h i}} 2 1
*→ h*
**lindex** {{a b c} {d e f} {g h i}} {2 1}
*→ h*
**lindex** {{{a b} {c d}} {{e f} {g h}}} 1 1 0
*→ g*
**lindex** {{{a b} {c d}} {{e f} {g h}}} {1 1 0}
*→ g*
```
List indices may also perform limited computation, adding or subtracting fixed amounts from other indices:
```
set idx 1
**lindex** {a b c d e f} $idx+2
*→ d*
set idx 3
**lindex** {a b c d e f} $idx+2
*→ f*
```
See also
--------
**[list](list.htm)**, **[lappend](lappend.htm)**, **[linsert](linsert.htm)**, **[llength](llength.htm)**, **[lsearch](lsearch.htm)**, **[lset](lset.htm)**, **[lsort](lsort.htm)**, **[lrange](lrange.htm)**, **[lreplace](lreplace.htm)**, **[string](string.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/lindex.htm>
tcl_tk throw throw
=====
Name
----
throw — Generate a machine-readable error Synopsis
--------
**throw** *type message*
Description
-----------
This command causes the current evaluation to be unwound with an error. The error created is described by the *type* and *message* arguments: *type* must contain a list of words describing the error in a form that is machine-readable (and which will form the error-code part of the result dictionary), and *message* should contain text that is intended for display to a human being. The stack will be unwound until the error is trapped by a suitable **[catch](catch.htm)** or **[try](try.htm)** command. If it reaches the event loop without being trapped, it will be reported through the **[bgerror](bgerror.htm)** mechanism. If it reaches the top level of script evaluation in **[tclsh](../usercmd/tclsh.htm)**, it will be printed on the console before, in the non-interactive case, causing an exit (the behavior in other programs will depend on the details of how Tcl is embedded and used).
By convention, the words in the *type* argument should go from most general to most specific.
Examples
--------
The following produces an error that is identical to that produced by **[expr](expr.htm)** when trying to divide a value by zero.
```
**throw** {ARITH DIVZERO {divide by zero}} {divide by zero}
```
See also
--------
**[catch](catch.htm)**, **[error](error.htm)**, **[errorCode](tclvars.htm)**, **[errorInfo](tclvars.htm)**, **[return](return.htm)**, **[try](try.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/throw.htm>
tcl_tk lrepeat lrepeat
=======
Name
----
lrepeat — Build a list by repeating elements Synopsis
--------
**lrepeat** *count* ?*element ...*?
Description
-----------
The **lrepeat** command creates a list of size *count \* number of elements* by repeating *count* times the sequence of elements *element ...*. *count* must be a non-negative integer, *element* can be any Tcl value. Note that **lrepeat 1 element ...** is identical to **list element ...**. Examples
--------
```
**lrepeat** 3 a
*→ a a a*
**lrepeat** 3 [**lrepeat** 3 0]
*→ {0 0 0} {0 0 0} {0 0 0}*
**lrepeat** 3 a b c
*→ a b c a b c a b c*
**lrepeat** 3 [**lrepeat** 2 a] b c
*→ {a a} b c {a a} b c {a a} b c*
```
See also
--------
**[list](list.htm)**, **[lappend](lappend.htm)**, **[linsert](linsert.htm)**, **[llength](llength.htm)**, **[lset](lset.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/lrepeat.htm>
tcl_tk flush flush
=====
Name
----
flush — Flush buffered output for a channel Synopsis
--------
**flush** *channelId*
Description
-----------
Flushes any output that has been buffered for *channelId*. *ChannelId* must be an identifier for an open channel such as a Tcl standard channel (**[stdout](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)** or **[stderr](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)**), the return value from an invocation of **[open](open.htm)** or **[socket](socket.htm)**, or the result of a channel creation command provided by a Tcl extension. The channel must have been opened for writing.
If the channel is in blocking mode the command does not return until all the buffered output has been flushed to the channel. If the channel is in nonblocking mode, the command may return before all buffered output has been flushed; the remainder will be flushed in the background as fast as the underlying file or device is able to absorb it.
Example
-------
Prompt for the user to type some information in on the console:
```
puts -nonewline "Please type your name: "
**flush** stdout
gets stdin name
puts "Hello there, $name!"
```
See also
--------
**[file](file.htm)**, **[open](open.htm)**, **[socket](socket.htm)**, **[Tcl\_StandardChannels](https://www.tcl.tk/man/tcl/TclLib/StdChannels.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/flush.htm>
tcl_tk object object
======
[NAME](object.htm#M2) oo::object — root class of the class hierarchy
[SYNOPSIS](object.htm#M3)
[CLASS HIERARCHY](object.htm#M4)
[DESCRIPTION](object.htm#M5)
[CONSTRUCTOR](object.htm#M6)
[DESTRUCTOR](object.htm#M7)
[EXPORTED METHODS](object.htm#M8)
[*obj* **destroy**](object.htm#M9)
[NON-EXPORTED METHODS](object.htm#M10)
[*obj* **eval** ?*arg ...*?](object.htm#M11)
[*obj* **unknown ?***methodName*? ?*arg ...*?](object.htm#M12)
[*obj* **variable** ?*varName ...*?](object.htm#M13)
[*obj* **varname** *varName*](object.htm#M14)
[*obj* **<cloned>** *sourceObjectName*](object.htm#M15)
[EXAMPLES](object.htm#M16)
[SEE ALSO](object.htm#M17)
[KEYWORDS](object.htm#M18)
Name
----
oo::object — root class of the class hierarchy Synopsis
--------
package require TclOO
**oo::object** *method* ?*arg ...*?
Class hierarchy
---------------
**oo::object**
Description
-----------
The **oo::object** class is the root class of the object hierarchy; every object is an instance of this class. Since classes are themselves objects, they are instances of this class too. Objects are always referred to by their name, and may be **[rename](rename.htm)**d while maintaining their identity. Instances of objects may be made with either the **create** or **new** methods of the **oo::object** object itself, or by invoking those methods on any of the subclass objects; see **[oo::class](class.htm)** for more details. The configuration of individual objects (i.e., instance-specific methods, mixed-in classes, etc.) may be controlled with the **[oo::objdefine](define.htm)** command.
Each object has a unique namespace associated with it, the instance namespace. This namespace holds all the instance variables of the object, and will be the current namespace whenever a method of the object is invoked (including a method of the class of the object). When the object is destroyed, its instance namespace is deleted. The instance namespace contains the object's **[my](my.htm)** command, which may be used to invoke non-exported methods of the object or to create a reference to the object for the purpose of invocation which persists across renamings of the object.
### Constructor
The **oo::object** class does not define an explicit constructor. ### Destructor
The **oo::object** class does not define an explicit destructor. ### Exported methods
The **oo::object** class supports the following exported methods:
*obj* **destroy**
This method destroys the object, *obj*, that it is invoked upon, invoking any destructors on the object's class in the process. It is equivalent to using **[rename](rename.htm)** to delete the object command. The result of this method is always the empty string.
### Non-exported methods
The **oo::object** class supports the following non-exported methods:
*obj* **eval** ?*arg ...*?
This method concatenates the arguments, *arg*, as if with **[concat](concat.htm)**, and then evaluates the resulting script in the namespace that is uniquely associated with *obj*, returning the result of the evaluation.
*obj* **unknown ?***methodName*? ?*arg ...*?
This method is called when an attempt to invoke the method *methodName* on object *obj* fails. The arguments that the user supplied to the method are given as *arg* arguments. If *methodName* is absent, the object was invoked with no method name at all (or any other arguments). The default implementation (i.e., the one defined by the **oo::object** class) generates a suitable error, detailing what methods the object supports given whether the object was invoked by its public name or through the **[my](my.htm)** command.
*obj* **variable** ?*varName ...*?
This method arranges for each variable called *varName* to be linked from the object *obj*'s unique namespace into the caller's context. Thus, if it is invoked from inside a procedure then the namespace variable in the object is linked to the local variable in the procedure. Each *varName* argument must not have any namespace separators in it. The result is the empty string.
*obj* **varname** *varName*
This method returns the globally qualified name of the variable *varName* in the unique namespace for the object *obj*.
*obj* **<cloned>** *sourceObjectName*
This method is used by the **oo::object** command to copy the state of one object to another. It is responsible for copying the procedures and variables of the namespace of the source object (*sourceObjectName*) to the current object. It does not copy any other types of commands or any traces on the variables; that can be added if desired by overriding this method in a subclass.
Examples
--------
This example demonstrates basic use of an object.
```
set obj [**oo::object** new]
$obj foo *→ error "unknown method foo"*
oo::objdefine $obj method foo {} {
my **[variable](variable.htm)** count
puts "bar[incr count]"
}
$obj foo *→ prints "bar1"*
$obj foo *→ prints "bar2"*
$obj variable count *→ error "unknown method variable"*
$obj **[destroy](../tkcmd/destroy.htm)**
$obj foo *→ error "unknown command obj"*
```
See also
--------
**[my](my.htm)**, **[oo::class](class.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/object.htm>
tcl_tk time time
====
Name
----
time — Time the execution of a script Synopsis
--------
**time** *script* ?*count*?
Description
-----------
This command will call the Tcl interpreter *count* times to evaluate *script* (or once if *count* is not specified). It will then return a string of the form
```
**503.2 microseconds per iteration**
```
which indicates the average amount of time required per iteration, in microseconds. Time is measured in elapsed time, not CPU time.
Example
-------
Estimate how long it takes for a simple Tcl **[for](for.htm)** loop to count to a thousand:
```
time {
for {set i 0} {$i<1000} {incr i} {
# empty body
}
}
```
See also
--------
**[clock](clock.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/time.htm>
tcl_tk concat concat
======
Name
----
concat — Join lists together Synopsis
--------
**concat**?*arg arg ...*?
Description
-----------
This command joins each of its arguments together with spaces after trimming leading and trailing white-space from each of them. If all of the arguments are lists, this has the same effect as concatenating them into a single list. It permits any number of arguments; if no *arg*s are supplied, the result is an empty string. Examples
--------
Although **concat** will concatenate lists, flattening them in the process (so giving the following interactive session):
```
*%* **concat** a b {c d e} {f {g h}}
*a b c d e f {g h}*
```
it will also concatenate things that are not lists, as can be seen from this session:
```
*%* **concat** " a b {c " d " e} f"
*a b {c d e} f*
```
Note also that the concatenation does not remove spaces from the middle of values, as can be seen here:
```
*%* **concat** "a b c" { d e f }
*a b c d e f*
```
(i.e., there are three spaces between each of the **a**, the **b** and the **c**).
See also
--------
**[append](append.htm)**, **[eval](eval.htm)**, **[join](join.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/concat.htm>
tcl_tk copy copy
====
Name
----
oo::copy — create copies of objects and classes Synopsis
--------
package require TclOO
**oo::copy** *sourceObject* ?*targetObject*?
Description
-----------
The **oo::copy** command creates a copy of an object or class. It takes the name of the object or class to be copied, *sourceObject*, and optionally the name of the object or class to create, *targetObject*, which will be resolved relative to the current namespace if not an absolute qualified name. If *targetObject* is omitted, a new name is chosen. The copied object will be of the same class as the source object, and will have all its per-object methods copied. If it is a class, it will also have all the class methods in the class copied, but it will not have any of its instances copied. After the *targetObject* has been created and all definitions of its configuration (e.g., methods, filters, mixins) copied, the **<cloned>** method of *targetObject* will be invoked, to allow for customization of the created object such as installing related variable traces. The only argument given will be *sourceObject*. The default implementation of this method (in **[oo::object](object.htm)**) just copies the procedures and variables in the namespace of *sourceObject* to the namespace of *targetObject*. If this method call does not return a result that is successful (i.e., an error or other kind of exception) then the *targetObject* will be deleted and an error returned.
The result of the **oo::copy** command will be the fully-qualified name of the new object or class.
Examples
--------
This example creates an object, copies it, modifies the source object, and then demonstrates that the copied object is indeed a copy.
```
oo::object create src
oo::objdefine src method msg {} {puts foo}
**oo::copy** src dst
oo::objdefine src method msg {} {puts bar}
src msg *→ prints "bar"*
dst msg *→ prints "foo"*
```
See also
--------
**[oo::class](class.htm)**, **[oo::define](define.htm)**, **[oo::object](object.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/copy.htm>
tcl_tk close close
=====
Name
----
close — Close an open channel Synopsis
--------
**close** *channelId* ?r(ead)|w(rite)?
Description
-----------
Closes or half-closes the channel given by *channelId*. *ChannelId* must be an identifier for an open channel such as a Tcl standard channel (**[stdin](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)**, **[stdout](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)**, or **[stderr](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)**), the return value from an invocation of **[open](open.htm)** or **[socket](socket.htm)**, or the result of a channel creation command provided by a Tcl extension.
The single-argument form is a simple “full-close”: all buffered output is flushed to the channel's output device, any buffered input is discarded, the underlying file or device is closed, and *channelId* becomes unavailable for use.
If the channel is blocking, the command does not return until all output is flushed. If the channel is nonblocking and there is unflushed output, the channel remains open and the command returns immediately; output will be flushed in the background and the channel will be closed when all the flushing is complete.
If *channelId* is a blocking channel for a command pipeline then **close** waits for the child processes to complete.
If the channel is shared between interpreters, then **close** makes *channelId* unavailable in the invoking interpreter but has no other effect until all of the sharing interpreters have closed the channel. When the last interpreter in which the channel is registered invokes **close**, the cleanup actions described above occur. See the **[interp](interp.htm)** command for a description of channel sharing.
Channels are automatically closed when an interpreter is destroyed and when the process exits. From 8.6 on (TIP#398), nonblocking channels are no longer switched to blocking mode when exiting; this guarantees a timely exit even when the peer or a communication channel is stalled. To ensure proper flushing of stalled nonblocking channels on exit, one must now either (a) actively switch them back to blocking or (b) use the environment variable TCL\_FLUSH\_NONBLOCKING\_ON\_EXIT, which when set and not equal to "0" restores the previous behavior.
The command returns an empty string, and may generate an error if an error occurs while flushing output. If a command in a command pipeline created with **[open](open.htm)** returns an error, **close** generates an error (similar to the **[exec](exec.htm)** command.)
The two-argument form is a “half-close”: given a bidirectional channel like a socket or command pipeline and a (possibly abbreviated) direction, it closes only the sub-stream going in that direction. This means a shutdown() on a socket, and a close() of one end of a pipe for a command pipeline. Then, the Tcl-level channel data structure is either kept or freed depending on whether the other direction is still open.
A single-argument close on an already half-closed bidirectional channel is defined to just “finish the job”. A half-close on an already closed half, or on a wrong-sided unidirectional channel, raises an error.
In the case of a command pipeline, the child-reaping duty falls upon the shoulders of the last close or half-close, which is thus allowed to report an abnormal exit error.
Currently only sockets and command pipelines support half-close. A future extension will allow reflected and stacked channels to do so.
Example
-------
This illustrates how you can use Tcl to ensure that files get closed even when errors happen by combining **[catch](catch.htm)**, **close** and **[return](return.htm)**:
```
proc withOpenFile {filename channelVar script} {
upvar 1 $channelVar chan
set chan [open $filename]
catch {
uplevel 1 $script
} result options
**close** $chan
return -options $options $result
}
```
See also
--------
**[file](file.htm)**, **[open](open.htm)**, **[socket](socket.htm)**, **[eof](eof.htm)**, **[Tcl\_StandardChannels](https://www.tcl.tk/man/tcl/TclLib/StdChannels.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/close.htm>
| programming_docs |
tcl_tk puts puts
====
Name
----
puts — Write to a channel Synopsis
--------
**puts** ?**-nonewline**? ?*channelId*? *string*
Description
-----------
Writes the characters given by *string* to the channel given by *channelId*. *ChannelId* must be an identifier for an open channel such as a Tcl standard channel (**[stdout](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)** or **[stderr](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)**), the return value from an invocation of **[open](open.htm)** or **[socket](socket.htm)**, or the result of a channel creation command provided by a Tcl extension. The channel must have been opened for output.
If no *channelId* is specified then it defaults to **[stdout](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)**. **Puts** normally outputs a newline character after *string*, but this feature may be suppressed by specifying the **-nonewline** switch.
Newline characters in the output are translated by **puts** to platform-specific end-of-line sequences according to the current value of the **-translation** option for the channel (for example, on PCs newlines are normally replaced with carriage-return-linefeed sequences. See the **[fconfigure](fconfigure.htm)** manual entry for a discussion on ways in which **[fconfigure](fconfigure.htm)** will alter output.
Tcl buffers output internally, so characters written with **puts** may not appear immediately on the output file or device; Tcl will normally delay output until the buffer is full or the channel is closed. You can force output to appear immediately with the **[flush](flush.htm)** command.
When the output buffer fills up, the **puts** command will normally block until all the buffered data has been accepted for output by the operating system. If *channelId* is in nonblocking mode then the **puts** command will not block even if the operating system cannot accept the data. Instead, Tcl continues to buffer the data and writes it in the background as fast as the underlying file or device can accept it. The application must use the Tcl event loop for nonblocking output to work; otherwise Tcl never finds out that the file or device is ready for more output data. It is possible for an arbitrarily large amount of data to be buffered for a channel in nonblocking mode, which could consume a large amount of memory. To avoid wasting memory, nonblocking I/O should normally be used in an event-driven fashion with the **[fileevent](fileevent.htm)** command (do not invoke **puts** unless you have recently been notified via a file event that the channel is ready for more output data).
Examples
--------
Write a short message to the console (or wherever **[stdout](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)** is directed):
```
**puts** "Hello, World!"
```
Print a message in several parts:
```
**puts** -nonewline "Hello, "
**puts** "World!"
```
Print a message to the standard error channel:
```
**puts** stderr "Hello, World!"
```
Append a log message to a file:
```
set chan [open my.log a]
set timestamp [clock format [clock seconds]]
**puts** $chan "$timestamp - Hello, World!"
close $chan
```
See also
--------
**[file](file.htm)**, **[fileevent](fileevent.htm)**, **[Tcl\_StandardChannels](https://www.tcl.tk/man/tcl/TclLib/StdChannels.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/puts.htm>
tcl_tk vwait vwait
=====
Name
----
vwait — Process events until a variable is written Synopsis
--------
**vwait** *varName*
Description
-----------
This command enters the Tcl event loop to process events, blocking the application if no events are ready. It continues processing events until some event handler sets the value of the global variable *varName*. Once *varName* has been set, the **vwait** command will return as soon as the event handler that modified *varName* completes. The *varName* argument is always interpreted as a variable name with respect to the global namespace, but can refer to any namespace's variables if the fully-qualified name is given. In some cases the **vwait** command may not return immediately after *varName* is set. This happens if the event handler that sets *varName* does not complete immediately. For example, if an event handler sets *varName* and then itself calls **vwait** to wait for a different variable, then it may not return for a long time. During this time the top-level **vwait** is blocked waiting for the event handler to complete, so it cannot return either. (See the **[NESTED VWAITS BY EXAMPLE](#M6)** below.)
To be clear, *multiple* **vwait** *calls will nest and will not happen in parallel*. The outermost call to **vwait** will not return until all the inner ones do. It is recommended that code should never nest **vwait** calls (by avoiding putting them in event callbacks) but when that is not possible, care should be taken to add interlock variables to the code to prevent all reentrant calls to **vwait** that are not *strictly* necessary. Be aware that the synchronous modes of operation of some Tcl packages (e.g., **[http](http.htm)**) use **vwait** internally; if using the event loop, it is best to use the asynchronous callback-based modes of operation of those packages where available.
Examples
--------
Run the event-loop continually until some event calls **[exit](exit.htm)**. (You can use any variable not mentioned elsewhere, but the name *forever* reminds you at a glance of the intent.)
```
**vwait** forever
```
Wait five seconds for a connection to a server socket, otherwise close the socket and continue running the script:
```
# Initialise the state
after 5000 set state timeout
set server [socket -server accept 12345]
proc accept {args} {
global state connectionInfo
set state accepted
set connectionInfo $args
}
# Wait for something to happen
**vwait** state
# Clean up events that could have happened
close $server
after cancel set state timeout
# Do something based on how the vwait finished...
switch $state {
timeout {
puts "no connection on port 12345"
}
accepted {
puts "connection: $connectionInfo"
puts [lindex $connectionInfo 0] "Hello there!"
}
}
```
A command that will wait for some time delay by waiting for a namespace variable to be set. Includes an interlock to prevent nested waits.
```
namespace eval example {
variable v done
proc wait {delay} {
variable v
if {$v ne "waiting"} {
set v waiting
after $delay [namespace code {set v done}]
**vwait** [namespace which -variable v]
}
return $v
}
}
```
When running inside a **[coroutine](coroutine.htm)**, an alternative to using **vwait** is to **[yield](coroutine.htm)** to an outer event loop and to get recommenced when the variable is set, or at an idle moment after that.
```
coroutine task apply {{} {
# simulate [after 1000]
after 1000 [info coroutine]
yield
# schedule the setting of a global variable, as normal
after 2000 {set var 1}
# simulate [**vwait** var]
proc updatedVar {task args} {
after idle $task
trace remove variable ::var write "updatedVar $task"
}
trace add variable ::var write "updatedVar [info coroutine]"
yield
}}
```
### Nested vwaits by example
This example demonstrates what can happen when the **vwait** command is nested. The script will never finish because the waiting for the *a* variable never finishes; that **vwait** command is still waiting for a script scheduled with **[after](after.htm)** to complete, which just happens to be running an inner **vwait** (for *b*) even though the event that the outer **vwait** was waiting for (the setting of *a*) has occurred.
```
after 500 {
puts "waiting for b"
**vwait** b
puts "b was set"
}
after 1000 {
puts "setting a"
set a 10
}
puts "waiting for a"
**vwait** a
puts "a was set"
puts "setting b"
set b 42
```
If you run the above code, you get this output:
```
waiting for a
waiting for b
setting a
```
The script will never print “a was set” until after it has printed “b was set” because of the nesting of **vwait** commands, and yet *b* will not be set until after the outer **vwait** returns, so the script has deadlocked. The only ways to avoid this are to either structure the overall program in continuation-passing style or to use **[coroutine](coroutine.htm)** to make the continuations implicit. The first of these options would be written as:
```
after 500 {
puts "waiting for b"
trace add variable b write {apply {args {
global a b
trace remove variable ::b write \
[lrange [info level 0] 0 1]
puts "b was set"
set ::done ok
}}}
}
after 1000 {
puts "setting a"
set a 10
}
puts "waiting for a"
trace add variable a write {apply {args {
global a b
trace remove variable a write [lrange [info level 0] 0 1]
puts "a was set"
puts "setting b"
set b 42
}}}
**vwait** done
```
The second option, with **[coroutine](coroutine.htm)** and some helper procedures, is done like this:
```
# A coroutine-based wait-for-variable command
proc waitvar globalVar {
trace add variable ::$globalVar write \
[list apply {{v c args} {
trace remove variable $v write \
[lrange [info level 0] 0 3]
after 0 $c
}} ::$globalVar [info coroutine]]
yield
}
# A coroutine-based wait-for-some-time command
proc waittime ms {
after $ms [info coroutine]
yield
}
coroutine task-1 eval {
puts "waiting for a"
waitvar a
puts "a was set"
puts "setting b"
set b 42
}
coroutine task-2 eval {
waittime 500
puts "waiting for b"
waitvar b
puts "b was set"
set done ok
}
coroutine task-3 eval {
waittime 1000
puts "setting a"
set a 10
}
**vwait** done
```
See also
--------
**[global](global.htm)**, **[update](update.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/vwait.htm>
tcl_tk split split
=====
Name
----
split — Split a string into a proper Tcl list Synopsis
--------
**split** *string* ?*splitChars*?
Description
-----------
Returns a list created by splitting *string* at each character that is in the *splitChars* argument. Each element of the result list will consist of the characters from *string* that lie between instances of the characters in *splitChars*. Empty list elements will be generated if *string* contains adjacent characters in *splitChars*, or if the first or last character of *string* is in *splitChars*. If *splitChars* is an empty string then each character of *string* becomes a separate element of the result list. *SplitChars* defaults to the standard white-space characters. Examples
--------
Divide up a USENET group name into its hierarchical components:
```
**split** "comp.lang.tcl" .
*→ comp lang tcl*
```
See how the **split** command splits on *every* character in *splitChars*, which can result in information loss if you are not careful:
```
**split** "alpha beta gamma" "temp"
*→ al {ha b} {} {a ga} {} a*
```
Extract the list words from a string that is not a well-formed list:
```
**split** "Example with {unbalanced brace character"
*→ Example with \{unbalanced brace character*
```
Split a string into its constituent characters
```
**split** "Hello world" {}
*→ H e l l o { } w o r l d*
```
### Parsing record-oriented files
Parse a Unix /etc/passwd file, which consists of one entry per line, with each line consisting of a colon-separated list of fields:
```
## Read the file
set fid [open /etc/passwd]
set content [read $fid]
close $fid
## Split into records on newlines
set records [**split** $content "\n"]
## Iterate over the records
foreach rec $records {
## Split into fields on colons
set fields [**split** $rec ":"]
## Assign fields to variables and print some out...
lassign $fields \
userName password uid grp longName homeDir shell
puts "$longName uses [file tail $shell] for a login shell"
}
```
See also
--------
**[join](join.htm)**, **[list](list.htm)**, **[string](string.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/split.htm>
tcl_tk load load
====
Name
----
load — Load machine code and initialize new commands Synopsis
--------
**load** ?**-global**? ?**-lazy**? ?**--**? *fileName*
**load** ?**-global**? ?**-lazy**? ?**--**? *fileName packageName*
**load** ?**-global**? ?**-lazy**? ?**--**? *fileName packageName interp*
Description
-----------
This command loads binary code from a file into the application's address space and calls an initialization procedure in the package to incorporate it into an interpreter. *fileName* is the name of the file containing the code; its exact form varies from system to system but on most systems it is a shared library, such as a **.so** file under Solaris or a DLL under Windows. *packageName* is the name of the package, and is used to compute the name of an initialization procedure. *interp* is the path name of the interpreter into which to load the package (see the **[interp](interp.htm)** manual entry for details); if *interp* is omitted, it defaults to the interpreter in which the **load** command was invoked. Once the file has been loaded into the application's address space, one of two initialization procedures will be invoked in the new code. Typically the initialization procedure will add new commands to a Tcl interpreter. The name of the initialization procedure is determined by *packageName* and whether or not the target interpreter is a safe one. For normal interpreters the name of the initialization procedure will have the form *pkg***\_Init**, where *pkg* is the same as *packageName* except that the first letter is converted to upper case and all other letters are converted to lower case. For example, if *packageName* is **foo** or **FOo**, the initialization procedure's name will be **Foo\_Init**.
If the target interpreter is a safe interpreter, then the name of the initialization procedure will be *pkg***\_SafeInit** instead of *pkg***\_Init**. The *pkg***\_SafeInit** function should be written carefully, so that it initializes the safe interpreter only with partial functionality provided by the package that is safe for use by untrusted code. For more information on Safe-Tcl, see the **[safe](safe.htm)** manual entry.
The initialization procedure must match the following prototype:
```
typedef int **Tcl\_PackageInitProc**(
[Tcl\_Interp](https://www.tcl.tk/man/tcl/TclLib/Interp.htm) **interp*);
```
The *interp* argument identifies the interpreter in which the package is to be loaded. The initialization procedure must return **[TCL\_OK](catch.htm)** or **[TCL\_ERROR](catch.htm)** to indicate whether or not it completed successfully; in the event of an error it should set the interpreter's result to point to an error message. The result of the **load** command will be the result returned by the initialization procedure.
The actual loading of a file will only be done once for each *fileName* in an application. If a given *fileName* is loaded into multiple interpreters, then the first **load** will load the code and call the initialization procedure; subsequent **load**s will call the initialization procedure without loading the code again. For Tcl versions lower than 8.5, it is not possible to unload or reload a package. From version 8.5 however, the **[unload](unload.htm)** command allows the unloading of libraries loaded with **load**, for libraries that are aware of the Tcl's unloading mechanism.
The **load** command also supports packages that are statically linked with the application, if those packages have been registered by calling the **[Tcl\_StaticPackage](https://www.tcl.tk/man/tcl/TclLib/StaticPkg.htm)** procedure. If *fileName* is an empty string, then *packageName* must be specified.
If *packageName* is omitted or specified as an empty string, Tcl tries to guess the name of the package. This may be done differently on different platforms. The default guess, which is used on most UNIX platforms, is to take the last element of *fileName*, strip off the first three characters if they are **lib**, and use any following alphabetic and underline characters as the module name. For example, the command **load libxyz4.2.so** uses the module name **xyz** and the command **load bin/last.so {}** uses the module name **last**.
If *fileName* is an empty string, then *packageName* must be specified. The **load** command first searches for a statically loaded package (one that has been registered by calling the **[Tcl\_StaticPackage](https://www.tcl.tk/man/tcl/TclLib/StaticPkg.htm)** procedure) by that name; if one is found, it is used. Otherwise, the **load** command searches for a dynamically loaded package by that name, and uses it if it is found. If several different files have been **load**ed with different versions of the package, Tcl picks the file that was loaded first.
If **-global** is specified preceding the filename, all symbols found in the shared library are exported for global use by other libraries. The option **-lazy** delays the actual loading of symbols until their first actual use. The options may be abbreviated. The option **--** indicates the end of the options, and should be used if you wish to use a filename which starts with **-** and you provide a packageName to the **load** command.
On platforms which do not support the **-global** or **-lazy** options, the options still exist but have no effect. Note that use of the **-global** or **-lazy** option may lead to crashes in your application later (in case of symbol conflicts resp. missing symbols), which cannot be detected during the **load**. So, only use this when you know what you are doing, you will not get a nice error message when something is wrong with the loaded library.
Portability issues
------------------
**Windows**
When a load fails with “library not found” error, it is also possible that a dependent library was not found. To see the dependent libraries, type “dumpbin -imports <dllname>” in a DOS console to see what the library must import. When loading a DLL in the current directory, Windows will ignore “./” as a path specifier and use a search heuristic to find the DLL instead. To avoid this, load the DLL with:
```
**load** [file join [pwd] mylib.DLL]
```
Bugs
----
If the same file is **load**ed by different *fileName*s, it will be loaded into the process's address space multiple times. The behavior of this varies from system to system (some systems may detect the redundant loads, others may not). Example
-------
The following is a minimal extension:
```
#include <tcl.h>
#include <stdio.h>
static int fooCmd(ClientData clientData,
[Tcl\_Interp](https://www.tcl.tk/man/tcl/TclLib/Interp.htm) *interp, int objc, [Tcl\_Obj](https://www.tcl.tk/man/tcl/TclLib/Object.htm) *const objv[]) {
printf("called with %d arguments\n", objc);
return TCL_OK;
}
int Foo_Init([Tcl\_Interp](https://www.tcl.tk/man/tcl/TclLib/Interp.htm) *interp) {
if ([Tcl\_InitStubs](https://www.tcl.tk/man/tcl/TclLib/InitStubs.htm)(interp, "8.1", 0) == NULL) {
return TCL_ERROR;
}
printf("creating foo command");
[Tcl\_CreateObjCommand](https://www.tcl.tk/man/tcl/TclLib/CrtObjCmd.htm)(interp, "foo", fooCmd, NULL, NULL);
return TCL_OK;
}
```
When built into a shared/dynamic library with a suitable name (e.g. **foo.dll** on Windows, **libfoo.so** on Solaris and Linux) it can then be loaded into Tcl with the following:
```
# Load the extension
switch $tcl_platform(platform) {
windows {
**load** [file join [pwd] foo.dll]
}
unix {
**load** [file join [pwd] libfoo[info sharedlibextension]]
}
}
# Now execute the command defined by the extension
foo
```
See also
--------
**[info sharedlibextension](info.htm)**, **[package](package.htm)**, **[Tcl\_StaticPackage](https://www.tcl.tk/man/tcl/TclLib/StaticPkg.htm)**, **[safe](safe.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/load.htm>
| programming_docs |
tcl_tk uplevel uplevel
=======
Name
----
uplevel — Execute a script in a different stack frame Synopsis
--------
**uplevel** ?*level*? *arg* ?*arg ...*?
Description
-----------
All of the *arg* arguments are concatenated as if they had been passed to **[concat](concat.htm)**; the result is then evaluated in the variable context indicated by *level*. **Uplevel** returns the result of that evaluation. If *level* is an integer then it gives a distance (up the procedure calling stack) to move before executing the command. If *level* consists of **#** followed by a number then the number gives an absolute level number. If *level* is omitted then it defaults to **1**. *Level* cannot be defaulted if the first *command* argument starts with a digit or **#**.
For example, suppose that procedure **a** was invoked from top-level, and that it called **b**, and that **b** called **c**. Suppose that **c** invokes the **uplevel** command. If *level* is **1** or **#2** or omitted, then the command will be executed in the variable context of **b**. If *level* is **2** or **#1** then the command will be executed in the variable context of **a**. If *level* is **3** or **#0** then the command will be executed at top-level (only global variables will be visible).
The **uplevel** command causes the invoking procedure to disappear from the procedure calling stack while the command is being executed. In the above example, suppose **c** invokes the command
```
**uplevel** 1 {set x 43; d}
```
where **d** is another Tcl procedure. The **[set](set.htm)** command will modify the variable **x** in **b**'s context, and **d** will execute at level 3, as if called from **b**. If it in turn executes the command
```
**uplevel** {set x 42}
```
then the **[set](set.htm)** command will modify the same variable **x** in **b**'s context: the procedure **c** does not appear to be on the call stack when **d** is executing. The **[info level](info.htm)** command may be used to obtain the level of the current procedure.
**Uplevel** makes it possible to implement new control constructs as Tcl procedures (for example, **uplevel** could be used to implement the **[while](while.htm)** construct as a Tcl procedure).
The **[namespace eval](namespace.htm)** and **[apply](apply.htm)** commands offer other ways (besides procedure calls) that the Tcl naming context can change. They add a call frame to the stack to represent the namespace context. This means each **[namespace eval](namespace.htm)** command counts as another call level for **uplevel** and **[upvar](upvar.htm)** commands. For example, **info level 1** will return a list describing a command that is either the outermost procedure call or the outermost **[namespace eval](namespace.htm)** command. Also, **uplevel #0** evaluates a script at top-level in the outermost namespace (the global namespace).
Example
-------
As stated above, the **uplevel** command is useful for creating new control constructs. This example shows how (without error handling) it can be used to create a **do** command that is the counterpart of **[while](while.htm)** except for always performing the test after running the loop body:
```
proc do {body while condition} {
if {$while ne "while"} {
error "required word missing"
}
set conditionCmd [list expr $condition]
while {1} {
**uplevel** 1 $body
if {![**uplevel** 1 $conditionCmd]} {
break
}
}
}
```
See also
--------
**[apply](apply.htm)**, **[namespace](namespace.htm)**, **[upvar](upvar.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/uplevel.htm>
tcl_tk seek seek
====
Name
----
seek — Change the access position for an open channel Synopsis
--------
**seek** *channelId offset* ?*origin*?
Description
-----------
Changes the current access position for *channelId*. *ChannelId* must be an identifier for an open channel such as a Tcl standard channel (**[stdin](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)**, **[stdout](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)**, or **[stderr](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)**), the return value from an invocation of **[open](open.htm)** or **[socket](socket.htm)**, or the result of a channel creation command provided by a Tcl extension.
The *offset* and *origin* arguments specify the position at which the next read or write will occur for *channelId*. *Offset* must be an integer (which may be negative) and *origin* must be one of the following:
**start**
The new access position will be *offset* bytes from the start of the underlying file or device.
**current**
The new access position will be *offset* bytes from the current access position; a negative *offset* moves the access position backwards in the underlying file or device.
**end**
The new access position will be *offset* bytes from the end of the file or device. A negative *offset* places the access position before the end of file, and a positive *offset* places the access position after the end of file.
The *origin* argument defaults to **start**.
The command flushes all buffered output for the channel before the command returns, even if the channel is in non-blocking mode. It also discards any buffered and unread input. This command returns an empty string. An error occurs if this command is applied to channels whose underlying file or device does not support seeking.
Note that *offset* values are byte offsets, not character offsets. Both **seek** and **[tell](tell.htm)** operate in terms of bytes, not characters, unlike **[read](read.htm)**.
Examples
--------
Read a file twice:
```
set f [open file.txt]
set data1 [read $f]
**seek** $f 0
set data2 [read $f]
close $f
# $data1 eq $data2 if the file wasn't updated
```
Read the last 10 bytes from a file:
```
set f [open file.data]
# This is guaranteed to work with binary data but
# may fail with other encodings...
fconfigure $f -translation binary
**seek** $f -10 end
set data [read $f 10]
close $f
```
See also
--------
**[file](file.htm)**, **[open](open.htm)**, **[close](close.htm)**, **[gets](gets.htm)**, **[tell](tell.htm)**, **[Tcl\_StandardChannels](https://www.tcl.tk/man/tcl/TclLib/StdChannels.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/seek.htm>
tcl_tk dict dict
====
[NAME](dict.htm#M2) dict — Manipulate dictionaries
[SYNOPSIS](dict.htm#M3)
[DESCRIPTION](dict.htm#M4)
[**dict append** *dictionaryVariable key* ?*string ...*?](dict.htm#M5)
[**dict create** ?*key value ...*?](dict.htm#M6)
[**dict exists** *dictionaryValue key* ?*key ...*?](dict.htm#M7)
[**dict filter** *dictionaryValue filterType arg* ?*arg ...*?](dict.htm#M8)
[**dict filter** *dictionaryValue* **key** ?*globPattern ...*?](dict.htm#M9)
[**dict filter** *dictionaryValue* **script {***keyVariable valueVariable***}** *script*](dict.htm#M10)
[**dict filter** *dictionaryValue* **value** ?*globPattern ...*?](dict.htm#M11)
[**dict for {***keyVariable valueVariable***}** *dictionaryValue body*](dict.htm#M12)
[**dict get** *dictionaryValue* ?*key ...*?](dict.htm#M13)
[**dict incr** *dictionaryVariable key* ?*increment*?](dict.htm#M14)
[**dict info** *dictionaryValue*](dict.htm#M15)
[**dict keys** *dictionaryValue* ?*globPattern*?](dict.htm#M16)
[**dict lappend** *dictionaryVariable key* ?*value ...*?](dict.htm#M17)
[**dict map** {*keyVariable valueVariable*} *dictionaryValue body*](dict.htm#M18)
[**dict merge** ?*dictionaryValue ...*?](dict.htm#M19)
[**dict remove** *dictionaryValue* ?*key ...*?](dict.htm#M20)
[**dict replace** *dictionaryValue* ?*key value ...*?](dict.htm#M21)
[**dict set** *dictionaryVariable key* ?*key ...*? *value*](dict.htm#M22)
[**dict size** *dictionaryValue*](dict.htm#M23)
[**dict unset** *dictionaryVariable key* ?*key ...*?](dict.htm#M24)
[**dict update** *dictionaryVariable key varName* ?*key varName ...*? *body*](dict.htm#M25)
[**dict values** *dictionaryValue* ?*globPattern*?](dict.htm#M26)
[**dict with** *dictionaryVariable* ?*key ...*? *body*](dict.htm#M27)
[DICTIONARY VALUES](dict.htm#M28)
[EXAMPLES](dict.htm#M29)
[SEE ALSO](dict.htm#M30)
[KEYWORDS](dict.htm#M31)
Name
----
dict — Manipulate dictionaries Synopsis
--------
**dict** *option arg* ?*arg ...*?
Description
-----------
Performs one of several operations on dictionary values or variables containing dictionary values (see the **[DICTIONARY VALUES](#M28)** section below for a description), depending on *option*. The legal *option*s (which may be abbreviated) are:
**dict append** *dictionaryVariable key* ?*string ...*?
This appends the given string (or strings) to the value that the given key maps to in the dictionary value contained in the given variable, writing the resulting dictionary value back to that variable. Non-existent keys are treated as if they map to an empty string. The updated dictionary value is returned.
**dict create** ?*key value ...*?
Return a new dictionary that contains each of the key/value mappings listed as arguments (keys and values alternating, with each key being followed by its associated value.)
**dict exists** *dictionaryValue key* ?*key ...*?
This returns a boolean value indicating whether the given key (or path of keys through a set of nested dictionaries) exists in the given dictionary value. This returns a true value exactly when **dict get** on that path will succeed.
**dict filter** *dictionaryValue filterType arg* ?*arg ...*?
This takes a dictionary value and returns a new dictionary that contains just those key/value pairs that match the specified filter type (which may be abbreviated.) Supported filter types are:
**dict filter** *dictionaryValue* **key** ?*globPattern ...*?
The key rule only matches those key/value pairs whose keys match any of the given patterns (in the style of **[string match](string.htm)**.)
**dict filter** *dictionaryValue* **script {***keyVariable valueVariable***}** *script*
The script rule tests for matching by assigning the key to the *keyVariable* and the value to the *valueVariable*, and then evaluating the given script which should return a boolean value (with the key/value pair only being included in the result of the **dict filter** when a true value is returned.) Note that the first argument after the rule selection word is a two-element list. If the *script* returns with a condition of **[TCL\_BREAK](catch.htm)**, no further key/value pairs are considered for inclusion in the resulting dictionary, and a condition of **[TCL\_CONTINUE](catch.htm)** is equivalent to a false result. The key/value pairs are tested in the order in which the keys were inserted into the dictionary.
**dict filter** *dictionaryValue* **value** ?*globPattern ...*?
The value rule only matches those key/value pairs whose values match any of the given patterns (in the style of **[string match](string.htm)**.)
**dict for {***keyVariable valueVariable***}** *dictionaryValue body*
This command takes three arguments, the first a two-element list of variable names (for the key and value respectively of each mapping in the dictionary), the second the dictionary value to iterate across, and the third a script to be evaluated for each mapping with the key and value variables set appropriately (in the manner of **[foreach](foreach.htm)**.) The result of the command is an empty string. If any evaluation of the body generates a **[TCL\_BREAK](catch.htm)** result, no further pairs from the dictionary will be iterated over and the **dict for** command will terminate successfully immediately. If any evaluation of the body generates a **[TCL\_CONTINUE](catch.htm)** result, this shall be treated exactly like a normal **[TCL\_OK](catch.htm)** result. The order of iteration is the order in which the keys were inserted into the dictionary.
**dict get** *dictionaryValue* ?*key ...*?
Given a dictionary value (first argument) and a key (second argument), this will retrieve the value for that key. Where several keys are supplied, the behaviour of the command shall be as if the result of **dict get $dictVal $key** was passed as the first argument to **dict get** with the remaining arguments as second (and possibly subsequent) arguments. This facilitates lookups in nested dictionaries. For example, the following two commands are equivalent:
```
dict get $dict foo bar spong
dict get [dict get [dict get $dict foo] bar] spong
```
If no keys are provided, **dict get** will return a list containing pairs of elements in a manner similar to **[array get](array.htm)**. That is, the first element of each pair would be the key and the second element would be the value for that key.
It is an error to attempt to retrieve a value for a key that is not present in the dictionary.
**dict incr** *dictionaryVariable key* ?*increment*?
This adds the given increment value (an integer that defaults to 1 if not specified) to the value that the given key maps to in the dictionary value contained in the given variable, writing the resulting dictionary value back to that variable. Non-existent keys are treated as if they map to 0. It is an error to increment a value for an existing key if that value is not an integer. The updated dictionary value is returned.
**dict info** *dictionaryValue*
This returns information (intended for display to people) about the given dictionary though the format of this data is dependent on the implementation of the dictionary. For dictionaries that are implemented by hash tables, it is expected that this will return the string produced by **[Tcl\_HashStats](https://www.tcl.tk/man/tcl/TclLib/Hash.htm)**, similar to **[array statistics](array.htm)**.
**dict keys** *dictionaryValue* ?*globPattern*?
Return a list of all keys in the given dictionary value. If a pattern is supplied, only those keys that match it (according to the rules of **[string match](string.htm)**) will be returned. The returned keys will be in the order that they were inserted into the dictionary.
**dict lappend** *dictionaryVariable key* ?*value ...*?
This appends the given items to the list value that the given key maps to in the dictionary value contained in the given variable, writing the resulting dictionary value back to that variable. Non-existent keys are treated as if they map to an empty list, and it is legal for there to be no items to append to the list. It is an error for the value that the key maps to to not be representable as a list. The updated dictionary value is returned.
**dict map** {*keyVariable valueVariable*} *dictionaryValue body*
This command applies a transformation to each element of a dictionary, returning a new dictionary. It takes three arguments: the first is a two-element list of variable names (for the key and value respectively of each mapping in the dictionary), the second the dictionary value to iterate across, and the third a script to be evaluated for each mapping with the key and value variables set appropriately (in the manner of **[lmap](lmap.htm)**). In an iteration where the evaluated script completes normally (**[TCL\_OK](catch.htm)**, as opposed to an **[error](error.htm)**, etc.) the result of the script is put into an accumulator dictionary using the key that is the current contents of the *keyVariable* variable at that point. The result of the **dict map** command is the accumulator dictionary after all keys have been iterated over. If the evaluation of the body for any particular step generates a **[break](break.htm)**, no further pairs from the dictionary will be iterated over and the **dict map** command will terminate successfully immediately. If the evaluation of the body for a particular step generates a **[continue](continue.htm)** result, the current iteration is aborted and the accumulator dictionary is not modified. The order of iteration is the natural order of the dictionary (typically the order in which the keys were added to the dictionary; the order is the same as that used in **dict for**).
**dict merge** ?*dictionaryValue ...*?
Return a dictionary that contains the contents of each of the *dictionaryValue* arguments. Where two (or more) dictionaries contain a mapping for the same key, the resulting dictionary maps that key to the value according to the last dictionary on the command line containing a mapping for that key.
**dict remove** *dictionaryValue* ?*key ...*?
Return a new dictionary that is a copy of an old one passed in as first argument except without mappings for each of the keys listed. It is legal for there to be no keys to remove, and it also legal for any of the keys to be removed to not be present in the input dictionary in the first place.
**dict replace** *dictionaryValue* ?*key value ...*?
Return a new dictionary that is a copy of an old one passed in as first argument except with some values different or some extra key/value pairs added. It is legal for this command to be called with no key/value pairs, but illegal for this command to be called with a key but no value.
**dict set** *dictionaryVariable key* ?*key ...*? *value*
This operation takes the name of a variable containing a dictionary value and places an updated dictionary value in that variable containing a mapping from the given key to the given value. When multiple keys are present, this operation creates or updates a chain of nested dictionaries. The updated dictionary value is returned.
**dict size** *dictionaryValue*
Return the number of key/value mappings in the given dictionary value.
**dict unset** *dictionaryVariable key* ?*key ...*?
This operation (the companion to **dict set**) takes the name of a variable containing a dictionary value and places an updated dictionary value in that variable that does not contain a mapping for the given key. Where multiple keys are present, this describes a path through nested dictionaries to the mapping to remove. At least one key must be specified, but the last key on the key-path need not exist. All other components on the path must exist. The updated dictionary value is returned.
**dict update** *dictionaryVariable key varName* ?*key varName ...*? *body*
Execute the Tcl script in *body* with the value for each *key* (as found by reading the dictionary value in *dictionaryVariable*) mapped to the variable *varName*. There may be multiple *key*/*varName* pairs. If a *key* does not have a mapping, that corresponds to an unset *varName*. When *body* terminates, any changes made to the *varName*s is reflected back to the dictionary within *dictionaryVariable* (unless *dictionaryVariable* itself becomes unreadable, when all updates are silently discarded), even if the result of *body* is an error or some other kind of exceptional exit. The result of **dict update** is (unless some kind of error occurs) the result of the evaluation of *body*. Each *varName* is mapped in the scope enclosing the **dict update**; it is recommended that this command only be used in a local scope (**[proc](proc.htm)**edure, lambda term for **[apply](apply.htm)**, or method). Because of this, the variables set by **dict update** will continue to exist after the command finishes (unless explicitly **[unset](unset.htm)**). Note that the mapping of values to variables does not use traces; changes to the *dictionaryVariable*'s contents only happen when *body* terminates.
**dict values** *dictionaryValue* ?*globPattern*?
Return a list of all values in the given dictionary value. If a pattern is supplied, only those values that match it (according to the rules of **[string match](string.htm)**) will be returned. The returned values will be in the order of that the keys associated with those values were inserted into the dictionary.
**dict with** *dictionaryVariable* ?*key ...*? *body*
Execute the Tcl script in *body* with the value for each key in *dictionaryVariable* mapped (in a manner similarly to **dict update**) to a variable with the same name. Where one or more *key*s are available, these indicate a chain of nested dictionaries, with the innermost dictionary being the one opened out for the execution of *body*. As with **dict update**, making *dictionaryVariable* unreadable will make the updates to the dictionary be discarded, and this also happens if the contents of *dictionaryVariable* are adjusted so that the chain of dictionaries no longer exists. The result of **dict with** is (unless some kind of error occurs) the result of the evaluation of *body*. The variables are mapped in the scope enclosing the **dict with**; it is recommended that this command only be used in a local scope (**[proc](proc.htm)**edure, lambda term for **[apply](apply.htm)**, or method). Because of this, the variables set by **dict with** will continue to exist after the command finishes (unless explicitly **[unset](unset.htm)**). Note that the mapping of values to variables does not use traces; changes to the *dictionaryVariable*'s contents only happen when *body* terminates.
If the *dictionaryVariable* contains a value that is not a dictionary at the point when the *body* terminates (which can easily happen if the name is the same as any of the keys in dictionary) then an error occurs at that point. This command is thus not recommended for use when the keys in the dictionary are expected to clash with the *dictionaryVariable* name itself. Where the contained key does map to a dictionary, the net effect is to combine that inner dictionary into the outer dictionary; see the **[EXAMPLES](#M29)** below for an illustration of this.
Dictionary values
-----------------
Dictionaries are values that contain an efficient, order-preserving mapping from arbitrary keys to arbitrary values. Each key in the dictionary maps to a single value. They have a textual format that is exactly that of any list with an even number of elements, with each mapping in the dictionary being represented as two items in the list. When a command takes a dictionary and produces a new dictionary based on it (either returning it or writing it back into the variable that the starting dictionary was read from) the new dictionary will have the same order of keys, modulo any deleted keys and with new keys added on to the end. When a string is interpreted as a dictionary and it would otherwise have duplicate keys, only the last value for a particular key is used; the others are ignored, meaning that, “apple banana” and “apple carrot apple banana” are equivalent dictionaries (with different string representations). Operations that derive a new dictionary from an old one (e.g., updates like **dict set** and **dict unset**) preserve the order of keys in the dictionary. The exceptions to this are for any new keys they add, which are appended to the sequence, and any keys that are removed, which are excised from the order.
Examples
--------
Basic dictionary usage:
```
# Make a dictionary to map extensions to descriptions
set filetypes [**dict create** .txt "Text File" .tcl "Tcl File"]
# Add/update the dictionary
**dict set** filetypes .tcl "Tcl Script"
**dict set** filetypes .tm "Tcl Module"
**dict set** filetypes .gif "GIF Image"
**dict set** filetypes .png "PNG Image"
# Simple read from the dictionary
set ext ".tcl"
set desc [**dict get** $filetypes $ext]
puts "$ext is for a $desc"
# Somewhat more complex, with existence test
foreach filename [glob *] {
set ext [file extension $filename]
if {[**dict exists** $filetypes $ext]} {
puts "$filename is a [**dict get** $filetypes $ext]"
}
}
```
Constructing and using nested dictionaries:
```
# Data for one employee
**dict set** employeeInfo 12345-A forenames "Joe"
**dict set** employeeInfo 12345-A surname "Schmoe"
**dict set** employeeInfo 12345-A street "147 Short Street"
**dict set** employeeInfo 12345-A city "Springfield"
**dict set** employeeInfo 12345-A phone "555-1234"
# Data for another employee
**dict set** employeeInfo 98372-J forenames "Anne"
**dict set** employeeInfo 98372-J surname "Other"
**dict set** employeeInfo 98372-J street "32995 Oakdale Way"
**dict set** employeeInfo 98372-J city "Springfield"
**dict set** employeeInfo 98372-J phone "555-8765"
# The above data probably ought to come from a database...
# Print out some employee info
set i 0
puts "There are [**dict size** $employeeInfo] employees"
**dict for** {id info} $employeeInfo {
puts "Employee #[incr i]: $id"
**dict with** info {
puts " Name: $forenames $surname"
puts " Address: $street, $city"
puts " Telephone: $phone"
}
}
# Another way to iterate and pick out names...
foreach id [**dict keys** $employeeInfo] {
puts "Hello, [**dict get** $employeeInfo $id forenames]!"
}
```
A localizable version of **[string toupper](string.htm)**:
```
# Set up the basic C locale
set capital [**dict create** C [**dict create**]]
foreach c [split {abcdefghijklmnopqrstuvwxyz} ""] {
**dict set** capital C $c [string toupper $c]
}
# English locales can luckily share the "C" locale
**dict set** capital en [**dict get** $capital C]
**dict set** capital en_US [**dict get** $capital C]
**dict set** capital en_GB [**dict get** $capital C]
# ... and so on for other supported languages ...
# Now get the mapping for the current locale and use it.
set upperCaseMap [**dict get** $capital $env(LANG)]
set upperCase [string map $upperCaseMap $string]
```
Showing the detail of **dict with**:
```
proc sumDictionary {varName} {
upvar 1 $varName vbl
foreach key [**dict keys** $vbl] {
# Manufacture an entry in the subdictionary
**dict set** vbl $key total 0
# Add the values and remove the old
**dict with** vbl $key {
set total [expr {$x + $y + $z}]
unset x y z
}
}
puts "last total was $total, for key $key"
}
set myDict {
a {x 1 y 2 z 3}
b {x 6 y 5 z 4}
}
sumDictionary myDict
# prints: *last total was 15, for key b*
puts "dictionary is now \"$myDict\""
# prints: *dictionary is now "a {total 6} b {total 15}"*
```
When **dict with** is used with a key that clashes with the name of the dictionary variable:
```
set foo {foo {a b} bar 2 baz 3}
**dict with** foo {}
puts $foo
# prints: *a b foo {a b} bar 2 baz 3*
```
See also
--------
**[append](append.htm)**, **[array](array.htm)**, **[foreach](foreach.htm)**, **mapeach**, **[incr](incr.htm)**, **[list](list.htm)**, **[lappend](lappend.htm)**, **[set](set.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/dict.htm>
| programming_docs |
tcl_tk if if
==
Name
----
if — Execute scripts conditionally Synopsis
--------
**if** *expr1* ?**then**? *body1* **elseif** *expr2* ?**then**? *body2* **elseif** ... ?**else**? ?*bodyN*?
Description
-----------
The *if* command evaluates *expr1* as an expression (in the same way that **[expr](expr.htm)** evaluates its argument). The value of the expression must be a boolean (a numeric value, where 0 is false and anything is true, or a string value such as **true** or **yes** for true and **false** or **no** for false); if it is true then *body1* is executed by passing it to the Tcl interpreter. Otherwise *expr2* is evaluated as an expression and if it is true then **body2** is executed, and so on. If none of the expressions evaluates to true then *bodyN* is executed. The **then** and **else** arguments are optional “noise words” to make the command easier to read. There may be any number of **elseif** clauses, including zero. *BodyN* may also be omitted as long as **else** is omitted too. The return value from the command is the result of the body script that was executed, or an empty string if none of the expressions was non-zero and there was no *bodyN*. Examples
--------
A simple conditional:
```
**if** {$vbl == 1} { puts "vbl is one" }
```
With an **else**-clause:
```
**if** {$vbl == 1} {
puts "vbl is one"
} **else** {
puts "vbl is not one"
}
```
With an **elseif**-clause too:
```
**if** {$vbl == 1} {
puts "vbl is one"
} **elseif** {$vbl == 2} {
puts "vbl is two"
} **else** {
puts "vbl is not one or two"
}
```
Remember, expressions can be multi-line, but in that case it can be a good idea to use the optional **then** keyword for clarity:
```
**if** {
$vbl == 1
|| $vbl == 2
|| $vbl == 3
} **then** {
puts "vbl is one, two or three"
}
```
See also
--------
**[expr](expr.htm)**, **[for](for.htm)**, **[foreach](foreach.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/if.htm>
tcl_tk next next
====
[NAME](next.htm#M2) next, nextto — invoke superclass method implementations
[SYNOPSIS](next.htm#M3)
[DESCRIPTION](next.htm#M4)
[THE METHOD CHAIN](next.htm#M5)
[METHOD SEARCH ORDER](next.htm#M6)
[FILTERS](next.htm#M7)
[EXAMPLES](next.htm#M8)
[SEE ALSO](next.htm#M9)
[KEYWORDS](next.htm#M10)
Name
----
next, nextto — invoke superclass method implementations Synopsis
--------
package require TclOO
**next** ?*arg ...*?
**nextto** *class* ?*arg ...*?
Description
-----------
The **next** command is used to call implementations of a method by a class, superclass or mixin that are overridden by the current method. It can only be used from within a method. It is also used within filters to indicate the point where a filter calls the actual implementation (the filter may decide to not go along the chain, and may process the results of going along the chain of methods as it chooses). The result of the **next** command is the result of the next method in the method chain; if there are no further methods in the method chain, the result of **next** will be an error. The arguments, *arg*, to **next** are the arguments to pass to the next method in the chain. The **nextto** command is the same as the **next** command, except that it takes an additional *class* argument that identifies a class whose implementation of the current method chain (see **[info object](info.htm)** **call**) should be used; the method implementation selected will be the one provided by the given class, and it must refer to an existing non-filter invocation that lies further along the chain than the current implementation.
The method chain
----------------
When a method of an object is invoked, things happen in several stages:
1. The structure of the object, its class, superclasses, filters, and mixins, are examined to build a *method chain*, which contains a list of method implementations to invoke.
2. The first method implementation on the chain is invoked.
3. If that method implementation invokes the **next** command, the next method implementation is invoked (with its arguments being those that were passed to **next**).
4. The result from the overall method call is the result from the outermost method implementation; inner method implementations return their results through **next**.
5. The method chain is cached for future use.
### Method search order
When constructing the method chain, method implementations are searched for in the following order:
1. In the classes mixed into the object, in class traversal order. The list of mixins is checked in natural order.
2. In the classes mixed into the classes of the object, with sources of mixing in being searched in class traversal order. Within each class, the list of mixins is processed in natural order.
3. In the object itself.
4. In the object's class.
5. In the superclasses of the class, following each superclass in a depth-first fashion in the natural order of the superclass list.
Any particular method implementation always comes as *late* in the resulting list of implementations as possible; this means that if some class, A, is both mixed into a class, B, and is also a superclass of B, the instances of B will always treat A as a superclass from the perspective of inheritance. This is true even when the multiple inheritance is processed indirectly.
### Filters
When an object has a list of filter names set upon it, or is an instance of a class (or has mixed in a class) that has a list of filter names set upon it, before every invocation of any method the filters are processed. Filter implementations are found in class traversal order, as are the lists of filter names (each of which is traversed in natural list order). Explicitly invoking a method used as a filter will cause that method to be invoked twice, once as a filter and once as a normal method. Each filter should decide for itself whether to permit the execution to go forward to the proper implementation of the method (which it does by invoking the **next** command as filters are inserted into the front of the method call chain) and is responsible for returning the result of **next**.
Filters are invoked when processing an invokation of the **unknown** method because of a failure to locate a method implementation, but *not* when invoking either constructors or destructors. (Note however that the **[destroy](../tkcmd/destroy.htm)** method is a conventional method, and filters are invoked as normal when it is called.)
Examples
--------
This example demonstrates how to use the **next** command to call the (super)class's implementation of a method. The script:
```
oo::class create theSuperclass {
method example {args} {
puts "in the superclass, args = $args"
}
}
oo::class create theSubclass {
superclass theSuperclass
method example {args} {
puts "before chaining from subclass, args = $args"
**next** a {*}$args b
**next** pureSynthesis
puts "after chaining from subclass"
}
}
theSubclass create obj
oo::objdefine obj method example args {
puts "per-object method, args = $args"
**next** x {*}$args y
**next**
}
obj example 1 2 3
```
prints the following:
```
per-object method, args = 1 2 3
before chaining from subclass, args = x 1 2 3 y
in the superclass, args = a x 1 2 3 y b
in the superclass, args = pureSynthesis
after chaining from subclass
before chaining from subclass, args =
in the superclass, args = a b
in the superclass, args = pureSynthesis
after chaining from subclass
```
This example demonstrates how to build a simple cache class that applies memoization to all the method calls of the objects it is mixed into, and shows how it can make a difference to computation times:
```
oo::class create cache {
filter Memoize
method Memoize args {
*# Do not filter the core method implementations*
if {[lindex [self target] 0] eq "::oo::object"} {
return [**next** {*}$args]
}
*# Check if the value is already in the cache*
my variable ValueCache
set key [self target],$args
if {[info exist ValueCache($key)]} {
return $ValueCache($key)
}
*# Compute value, insert into cache, and return it*
return [set ValueCache($key) [**next** {*}$args]]
}
method flushCache {} {
my variable ValueCache
unset ValueCache
*# Skip the caching*
return -level 2 ""
}
}
oo::object create demo
oo::objdefine demo {
mixin cache
method compute {a b c} {
after 3000 *;# Simulate deep thought*
return [expr {$a + $b * $c}]
}
method compute2 {a b c} {
after 3000 *;# Simulate deep thought*
return [expr {$a * $b + $c}]
}
}
puts [demo compute 1 2 3] *→ prints "7" after delay*
puts [demo compute2 4 5 6] *→ prints "26" after delay*
puts [demo compute 1 2 3] *→ prints "7" instantly*
puts [demo compute2 4 5 6] *→ prints "26" instantly*
puts [demo compute 4 5 6] *→ prints "34" after delay*
puts [demo compute 4 5 6] *→ prints "34" instantly*
puts [demo compute 1 2 3] *→ prints "7" instantly*
demo flushCache
puts [demo compute 1 2 3] *→ prints "7" after delay*
```
See also
--------
**[oo::class](class.htm)**, **[oo::define](define.htm)**, **[oo::object](object.htm)**, **[self](self.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/next.htm>
tcl_tk fileevent fileevent
=========
Name
----
fileevent — Execute a script when a channel becomes readable or writable Synopsis
--------
**fileevent** *channelId* **readable** ?*script*?
**fileevent** *channelId* **writable** ?*script*?
Description
-----------
This command is used to create *file event handlers*. A file event handler is a binding between a channel and a script, such that the script is evaluated whenever the channel becomes readable or writable. File event handlers are most commonly used to allow data to be received from another process on an event-driven basis, so that the receiver can continue to interact with the user while waiting for the data to arrive. If an application invokes **[gets](gets.htm)** or **[read](read.htm)** on a blocking channel when there is no input data available, the process will block; until the input data arrives, it will not be able to service other events, so it will appear to the user to “freeze up”. With **fileevent**, the process can tell when data is present and only invoke **[gets](gets.htm)** or **[read](read.htm)** when they will not block. The *channelId* argument to **fileevent** refers to an open channel such as a Tcl standard channel (**[stdin](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)**, **[stdout](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)**, or **[stderr](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)**), the return value from an invocation of **[open](open.htm)** or **[socket](socket.htm)**, or the result of a channel creation command provided by a Tcl extension.
If the *script* argument is specified, then **fileevent** creates a new event handler: *script* will be evaluated whenever the channel becomes readable or writable (depending on the second argument to **fileevent**). In this case **fileevent** returns an empty string. The **readable** and **writable** event handlers for a file are independent, and may be created and deleted separately. However, there may be at most one **readable** and one **writable** handler for a file at a given time in a given interpreter. If **fileevent** is called when the specified handler already exists in the invoking interpreter, the new script replaces the old one.
If the *script* argument is not specified, **fileevent** returns the current script for *channelId*, or an empty string if there is none. If the *script* argument is specified as an empty string then the event handler is deleted, so that no script will be invoked. A file event handler is also deleted automatically whenever its channel is closed or its interpreter is deleted.
A channel is considered to be readable if there is unread data available on the underlying device. A channel is also considered to be readable if there is unread data in an input buffer, except in the special case where the most recent attempt to read from the channel was a **[gets](gets.htm)** call that could not find a complete line in the input buffer. This feature allows a file to be read a line at a time in nonblocking mode using events. A channel is also considered to be readable if an end of file or error condition is present on the underlying file or device. It is important for *script* to check for these conditions and handle them appropriately; for example, if there is no special check for end of file, an infinite loop may occur where *script* reads no data, returns, and is immediately invoked again.
A channel is considered to be writable if at least one byte of data can be written to the underlying file or device without blocking, or if an error condition is present on the underlying file or device.
Event-driven I/O works best for channels that have been placed into nonblocking mode with the **[fconfigure](fconfigure.htm)** command. In blocking mode, a **[puts](puts.htm)** command may block if you give it more data than the underlying file or device can accept, and a **[gets](gets.htm)** or **[read](read.htm)** command will block if you attempt to read more data than is ready; a readable underlying file or device may not even guarantee that a blocking [read 1] will succeed (counter-examples being multi-byte encodings, compression or encryption transforms ). In all such cases, no events will be processed while the commands block.
In nonblocking mode **[puts](puts.htm)**, **[read](read.htm)**, and **[gets](gets.htm)** never block. See the documentation for the individual commands for information on how they handle blocking and nonblocking channels.
Testing for the end of file condition should be done after any attempts read the channel data. The eof flag is set once an attempt to read the end of data has occurred and testing before this read will require an additional event to be fired.
The script for a file event is executed at global level (outside the context of any Tcl procedure) in the interpreter in which the **fileevent** command was invoked. If an error occurs while executing the script then the command registered with **[interp bgerror](interp.htm)** is used to report the error. In addition, the file event handler is deleted if it ever returns an error; this is done in order to prevent infinite loops due to buggy handlers.
Example
-------
In this setup **GetData** will be called with the channel as an argument whenever $chan becomes readable. The **[read](read.htm)** call will read whatever binary data is currently available without blocking. Here the channel has the fileevent removed when an end of file occurs to avoid being continually called (see above). Alternatively the channel may be closed on this condition.
```
proc GetData {chan} {
set data [read $chan]
puts "[string length $data] $data"
if {[eof $chan]} {
fileevent $chan readable {}
}
}
fconfigure $chan -blocking 0 -encoding binary
**fileevent** $chan readable [list GetData $chan]
```
The next example demonstrates use of **[gets](gets.htm)** to read line-oriented data.
```
proc GetData {chan} {
if {[gets $chan line] >= 0} {
puts $line
}
if {[eof $chan]} {
close $chan
}
}
fconfigure $chan -blocking 0 -buffering line -translation crlf
**fileevent** $chan readable [list GetData $chan]
```
Credits
-------
**fileevent** is based on the **addinput** command created by Mark Diekhans. See also
--------
**[fconfigure](fconfigure.htm)**, **[gets](gets.htm)**, **[interp](interp.htm)**, **[puts](puts.htm)**, **[read](read.htm)**, **[Tcl\_StandardChannels](https://www.tcl.tk/man/tcl/TclLib/StdChannels.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/fileevent.htm>
tcl_tk lreplace lreplace
========
Name
----
lreplace — Replace elements in a list with new elements Synopsis
--------
**lreplace** *list first last* ?*element element ...*?
Description
-----------
**lreplace** returns a new list formed by replacing one or more elements of *list* with the *element* arguments. *first* and *last* are index values specifying the first and last elements of the range to replace. The index values *first* and *last* are interpreted the same as index values for the command **[string index](string.htm)**, supporting simple index arithmetic and indices relative to the end of the list. 0 refers to the first element of the list, and **end** refers to the last element of the list. If *list* is empty, then *first* and *last* are ignored. If *first* is less than zero, it is considered to refer to before the first element of the list. For non-empty lists, the element indicated by *first* must exist or *first* must indicate before the start of the list.
If *last* is less than *first*, then any specified elements will be inserted into the list before the point specified by *first* with no elements being deleted.
The *element* arguments specify zero or more new arguments to be added to the list in place of those that were deleted. Each *element* argument will become a separate element of the list. If no *element* arguments are specified, then the elements between *first* and *last* are simply deleted. If *list* is empty, any *element* arguments are added to the end of the list.
Examples
--------
Replacing an element of a list with another:
```
% **lreplace** {a b c d e} 1 1 foo
a foo c d e
```
Replacing two elements of a list with three:
```
% **lreplace** {a b c d e} 1 2 three more elements
a three more elements d e
```
Deleting the last element from a list in a variable:
```
% set var {a b c d e}
a b c d e
% set var [**lreplace** $var end end]
a b c d
```
A procedure to delete a given element from a list:
```
proc lremove {listVariable value} {
upvar 1 $listVariable var
set idx [lsearch -exact $var $value]
set var [**lreplace** $var $idx $idx]
}
```
See also
--------
**[list](list.htm)**, **[lappend](lappend.htm)**, **[lindex](lindex.htm)**, **[linsert](linsert.htm)**, **[llength](llength.htm)**, **[lsearch](lsearch.htm)**, **[lset](lset.htm)**, **[lrange](lrange.htm)**, **[lsort](lsort.htm)**, **[string](string.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/lreplace.htm>
tcl_tk format format
======
[NAME](format.htm#M2) format — Format a string in the style of sprintf
[SYNOPSIS](format.htm#M3)
[INTRODUCTION](format.htm#M4)
[DETAILS ON FORMATTING](format.htm#M5)
[OPTIONAL POSITIONAL SPECIFIER](format.htm#M6)
[OPTIONAL FLAGS](format.htm#M7)
[**-**](format.htm#M8)
[**+**](format.htm#M9)
[*space*](format.htm#M10)
[**0**](format.htm#M11)
[**#**](format.htm#M12)
[OPTIONAL FIELD WIDTH](format.htm#M13)
[OPTIONAL PRECISION/BOUND](format.htm#M14)
[OPTIONAL SIZE MODIFIER](format.htm#M15)
[MANDATORY CONVERSION TYPE](format.htm#M16)
[**d**](format.htm#M17)
[**u**](format.htm#M18)
[**i**](format.htm#M19)
[**o**](format.htm#M20)
[**x** or **X**](format.htm#M21)
[**b**](format.htm#M22)
[**c**](format.htm#M23)
[**s**](format.htm#M24)
[**f**](format.htm#M25)
[**e** or **E**](format.htm#M26)
[**g** or **G**](format.htm#M27)
[**%**](format.htm#M28)
[DIFFERENCES FROM ANSI SPRINTF](format.htm#M29)
[EXAMPLES](format.htm#M30)
[SEE ALSO](format.htm#M31)
[KEYWORDS](format.htm#M32)
Name
----
format — Format a string in the style of sprintf Synopsis
--------
**format** *formatString* ?*arg arg ...*?
Introduction
------------
This command generates a formatted string in a fashion similar to the ANSI C **sprintf** procedure. *FormatString* indicates how to format the result, using **%** conversion specifiers as in **sprintf**, and the additional arguments, if any, provide values to be substituted into the result. The return value from **format** is the formatted string. Details on formatting
---------------------
The command operates by scanning *formatString* from left to right. Each character from the format string is appended to the result string unless it is a percent sign. If the character is a **%** then it is not copied to the result string. Instead, the characters following the **%** character are treated as a conversion specifier. The conversion specifier controls the conversion of the next successive *arg* to a particular format and the result is appended to the result string in place of the conversion specifier. If there are multiple conversion specifiers in the format string, then each one controls the conversion of one additional *arg*. The **format** command must be given enough *arg*s to meet the needs of all of the conversion specifiers in *formatString*. Each conversion specifier may contain up to six different parts: an XPG3 position specifier, a set of flags, a minimum field width, a precision, a size modifier, and a conversion character. Any of these fields may be omitted except for the conversion character. The fields that are present must appear in the order given above. The paragraphs below discuss each of these fields in turn.
### Optional positional specifier
If the **%** is followed by a decimal number and a **$**, as in “**%2$d**”, then the value to convert is not taken from the next sequential argument. Instead, it is taken from the argument indicated by the number, where 1 corresponds to the first *arg*. If the conversion specifier requires multiple arguments because of **\*** characters in the specifier then successive arguments are used, starting with the argument given by the number. This follows the XPG3 conventions for positional specifiers. If there are any positional specifiers in *formatString* then all of the specifiers must be positional. ### Optional flags
The second portion of a conversion specifier may contain any of the following flag characters, in any order:
**-**
Specifies that the converted argument should be left-justified in its field (numbers are normally right-justified with leading spaces if needed).
**+**
Specifies that a number should always be printed with a sign, even if positive.
*space*
Specifies that a space should be added to the beginning of the number if the first character is not a sign.
**0**
Specifies that the number should be padded on the left with zeroes instead of spaces.
**#**
Requests an alternate output form. For **o** and **O** conversions it guarantees that the first digit is always **0**. For **x** or **X** conversions, **0x** or **0X** (respectively) will be added to the beginning of the result unless it is zero. For **b** conversions, **0b** will be added to the beginning of the result unless it is zero. For all floating-point conversions (**e**, **E**, **f**, **g**, and **G**) it guarantees that the result always has a decimal point. For **g** and **G** conversions it specifies that trailing zeroes should not be removed.
### Optional field width
The third portion of a conversion specifier is a decimal number giving a minimum field width for this conversion. It is typically used to make columns line up in tabular printouts. If the converted argument contains fewer characters than the minimum field width then it will be padded so that it is as wide as the minimum field width. Padding normally occurs by adding extra spaces on the left of the converted argument, but the **0** and **-** flags may be used to specify padding with zeroes on the left or with spaces on the right, respectively. If the minimum field width is specified as **\*** rather than a number, then the next argument to the **format** command determines the minimum field width; it must be an integer value. ### Optional precision/bound
The fourth portion of a conversion specifier is a precision, which consists of a period followed by a number. The number is used in different ways for different conversions. For **e**, **E**, and **f** conversions it specifies the number of digits to appear to the right of the decimal point. For **g** and **G** conversions it specifies the total number of digits to appear, including those on both sides of the decimal point (however, trailing zeroes after the decimal point will still be omitted unless the **#** flag has been specified). For integer conversions, it specifies a minimum number of digits to print (leading zeroes will be added if necessary). For **s** conversions it specifies the maximum number of characters to be printed; if the string is longer than this then the trailing characters will be dropped. If the precision is specified with **\*** rather than a number then the next argument to the **format** command determines the precision; it must be a numeric string. ### Optional size modifier
The fifth part of a conversion specifier is a size modifier, which must be **ll**, **h**, or **l**. If it is **ll** it specifies that an integer value is taken without truncation for conversion to a formatted substring. If it is **h** it specifies that an integer value is truncated to a 16-bit range before converting. This option is rarely useful. If it is **l** it specifies that the integer value is truncated to the same range as that produced by the **[wide()](mathfunc.htm)** function of the **[expr](expr.htm)** command (at least a 64-bit range). If neither **h** nor **l** are present, the integer value is truncated to the same range as that produced by the **[int()](mathfunc.htm)** function of the **[expr](expr.htm)** command (at least a 32-bit range, but determined by the value of the **wordSize** element of the **[tcl\_platform](tclvars.htm)** array). ### Mandatory conversion type
The last thing in a conversion specifier is an alphabetic character that determines what kind of conversion to perform. The following conversion characters are currently supported:
**d**
Convert integer to signed decimal string.
**u**
Convert integer to unsigned decimal string.
**i**
Convert integer to signed decimal string (equivalent to **d**).
**o**
Convert integer to unsigned octal string.
**x** or **X**
Convert integer to unsigned hexadecimal string, using digits “0123456789abcdef” for **x** and “0123456789ABCDEF” for **X**).
**b**
Convert integer to binary string, using digits 0 and 1.
**c**
Convert integer to the Unicode character it represents.
**s**
No conversion; just insert string.
**f**
Convert number to signed decimal string of the form *xx.yyy*, where the number of *y*'s is determined by the precision (default: 6). If the precision is 0 then no decimal point is output.
**e** or **E**
Convert number to scientific notation in the form *x.yyy***e±***zz*, where the number of *y*'s is determined by the precision (default: 6). If the precision is 0 then no decimal point is output. If the **E** form is used then **E** is printed instead of **e**.
**g** or **G**
If the exponent is less than -4 or greater than or equal to the precision, then convert number as for **%e** or **%E**. Otherwise convert as for **%f**. Trailing zeroes and a trailing decimal point are omitted.
**%**
No conversion: just insert **%**.
Differences from ansi sprintf
-----------------------------
The behavior of the format command is the same as the ANSI C **sprintf** procedure except for the following differences:
1. Tcl guarantees that it will be working with UNICODE characters.
2. **%p** and **%n** specifiers are not supported.
3. For **%c** conversions the argument must be an integer value, which will then be converted to the corresponding character value.
4. The size modifiers are ignored when formatting floating-point values. The **ll** modifier has no **sprintf** counterpart. The **b** specifier has no **sprintf** counterpart.
Examples
--------
Convert the numeric value of a UNICODE character to the character itself:
```
set value 120
set char [**format** %c $value]
```
Convert the output of **[time](time.htm)** into seconds to an accuracy of hundredths of a second:
```
set us [lindex [time $someTclCode] 0]
puts [**format** "%.2f seconds to execute" [expr {$us / 1e6}]]
```
Create a packed X11 literal color specification:
```
# Each color-component should be in range (0..255)
set color [**format** "#%02x%02x%02x" $r $g $b]
```
Use XPG3 format codes to allow reordering of fields (a technique that is often used in localized message catalogs; see **[msgcat](msgcat.htm)**) without reordering the data values passed to **format**:
```
set fmt1 "Today, %d shares in %s were bought at $%.2f each"
puts [**format** $fmt1 123 "Global BigCorp" 19.37]
set fmt2 "Bought %2\$s equity ($%3$.2f x %1\$d) today"
puts [**format** $fmt2 123 "Global BigCorp" 19.37]
```
Print a small table of powers of three:
```
# Set up the column widths
set w1 5
set w2 10
# Make a nice header (with separator) for the table first
set sep +-[string repeat - $w1]-+-[string repeat - $w2]-+
puts $sep
puts [**format** "| %-*s | %-*s |" $w1 "Index" $w2 "Power"]
puts $sep
# Print the contents of the table
set p 1
for {set i 0} {$i<=20} {incr i} {
puts [**format** "| %*d | %*ld |" $w1 $i $w2 $p]
set p [expr {wide($p) * 3}]
}
# Finish off by printing the separator again
puts $sep
```
See also
--------
**[scan](scan.htm)**, **sprintf**, **[string](string.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/format.htm>
| programming_docs |
tcl_tk lassign lassign
=======
Name
----
lassign — Assign list elements to variables Synopsis
--------
**lassign** *list* ?*varName ...*?
Description
-----------
This command treats the value *list* as a list and assigns successive elements from that list to the variables given by the *varName* arguments in order. If there are more variable names than list elements, the remaining variables are set to the empty string. If there are more list elements than variables, a list of unassigned elements is returned. Examples
--------
An illustration of how multiple assignment works, and what happens when there are either too few or too many elements.
```
**lassign** {a b c} x y z ;# Empty return
puts $x ;# Prints "a"
puts $y ;# Prints "b"
puts $z ;# Prints "c"
**lassign** {d e} x y z ;# Empty return
puts $x ;# Prints "d"
puts $y ;# Prints "e"
puts $z ;# Prints ""
**lassign** {f g h i} x y ;# Returns "h i"
puts $x ;# Prints "f"
puts $y ;# Prints "g"
```
The **lassign** command has other uses. It can be used to create the analogue of the “shift” command in many shell languages like this:
```
set ::argv [**lassign** $::argv argumentToReadOff]
```
See also
--------
**[lindex](lindex.htm)**, **[list](list.htm)**, **[lrange](lrange.htm)**, **[lset](lset.htm)**, **[set](set.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/lassign.htm>
tcl_tk linsert linsert
=======
Name
----
linsert — Insert elements into a list Synopsis
--------
**linsert** *list index* ?*element element ...*?
Description
-----------
This command produces a new list from *list* by inserting all of the *element* arguments just before the *index*'th element of *list*. Each *element* argument will become a separate element of the new list. If *index* is less than or equal to zero, then the new elements are inserted at the beginning of the list, and if *index* is greater or equal to the length of *list*, it is as if it was **end**. As with **[string index](string.htm)**, the *index* value supports both simple index arithmetic and end-relative indexing. Subject to the restrictions that indices must refer to locations inside the list and that the *element*s will always be inserted in order, insertions are done so that when *index* is start-relative, the first *element* will be at that index in the resulting list, and when *index* is end-relative, the last *element* will be at that index in the resulting list.
Example
-------
Putting some values into a list, first indexing from the start and then indexing from the end, and then chaining them together:
```
set oldList {the fox jumps over the dog}
set midList [**linsert** $oldList 1 quick]
set newList [**linsert** $midList end-1 lazy]
# The old lists still exist though...
set newerList [**linsert** [**linsert** $oldList end-1 quick] 1 lazy]
```
See also
--------
**[list](list.htm)**, **[lappend](lappend.htm)**, **[lindex](lindex.htm)**, **[llength](llength.htm)**, **[lsearch](lsearch.htm)**, **[lset](lset.htm)**, **[lsort](lsort.htm)**, **[lrange](lrange.htm)**, **[lreplace](lreplace.htm)**, **[string](string.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/linsert.htm>
tcl_tk fblocked fblocked
========
Name
----
fblocked — Test whether the last input operation exhausted all available input Synopsis
--------
**fblocked** *channelId*
Description
-----------
The **fblocked** command returns 1 if the most recent input operation on *channelId* returned less information than requested because all available input was exhausted. For example, if **[gets](gets.htm)** is invoked when there are only three characters available for input and no end-of-line sequence, **[gets](gets.htm)** returns an empty string and a subsequent call to **fblocked** will return 1. *ChannelId* must be an identifier for an open channel such as a Tcl standard channel (**[stdin](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)**, **[stdout](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)**, or **[stderr](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)**), the return value from an invocation of **[open](open.htm)** or **[socket](socket.htm)**, or the result of a channel creation command provided by a Tcl extension.
Example
-------
The **fblocked** command is particularly useful when writing network servers, as it allows you to write your code in a line-by-line style without preventing the servicing of other connections. This can be seen in this simple echo-service:
```
# This is called whenever a new client connects to the server
proc connect {chan host port} {
set clientName [format <%s:%d> $host $port]
puts "connection from $clientName"
fconfigure $chan -blocking 0 -buffering line
fileevent $chan readable [list echoLine $chan $clientName]
}
# This is called whenever either at least one byte of input
# data is available, or the channel was closed by the client.
proc echoLine {chan clientName} {
gets $chan line
if {[eof $chan]} {
puts "finishing connection from $clientName"
close $chan
} elseif {![**fblocked** $chan]} {
# Didn't block waiting for end-of-line
puts "$clientName - $line"
puts $chan $line
}
}
# Create the server socket and enter the event-loop to wait
# for incoming connections...
socket -server connect 12345
vwait forever
```
See also
--------
**[gets](gets.htm)**, **[open](open.htm)**, **[read](read.htm)**, **[socket](socket.htm)**, **[Tcl\_StandardChannels](https://www.tcl.tk/man/tcl/TclLib/StdChannels.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/fblocked.htm>
tcl_tk for for
===
Name
----
for — 'For' loop Synopsis
--------
**for** *start test next body*
Description
-----------
**For** is a looping command, similar in structure to the C **for** statement. The *start*, *next*, and *body* arguments must be Tcl command strings, and *test* is an expression string. The **for** command first invokes the Tcl interpreter to execute *start*. Then it repeatedly evaluates *test* as an expression; if the result is non-zero it invokes the Tcl interpreter on *body*, then invokes the Tcl interpreter on *next*, then repeats the loop. The command terminates when *test* evaluates to 0. If a **[continue](continue.htm)** command is invoked within *body* then any remaining commands in the current execution of *body* are skipped; processing continues by invoking the Tcl interpreter on *next*, then evaluating *test*, and so on. If a **[break](break.htm)** command is invoked within *body* or *next*, then the **for** command will return immediately. The operation of **[break](break.htm)** and **[continue](continue.htm)** are similar to the corresponding statements in C. **For** returns an empty string. Note: *test* should almost always be enclosed in braces. If not, variable substitutions will be made before the **for** command starts executing, which means that variable changes made by the loop body will not be considered in the expression. This is likely to result in an infinite loop. If *test* is enclosed in braces, variable substitutions are delayed until the expression is evaluated (before each loop iteration), so changes in the variables will be visible. See below for an example:
Examples
--------
Print a line for each of the integers from 0 to 9:
```
**for** {set x 0} {$x<10} {incr x} {
puts "x is $x"
}
```
Either loop infinitely or not at all because the expression being evaluated is actually the constant, or even generate an error! The actual behaviour will depend on whether the variable *x* exists before the **for** command is run and whether its value is a value that is less than or greater than/equal to ten, and this is because the expression will be substituted before the **for** command is executed.
```
**for** {set x 0} $x<10 {incr x} {
puts "x is $x"
}
```
Print out the powers of two from 1 to 1024:
```
**for** {set x 1} {$x<=1024} {set x [expr {$x * 2}]} {
puts "x is $x"
}
```
See also
--------
**[break](break.htm)**, **[continue](continue.htm)**, **[foreach](foreach.htm)**, **[while](while.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/for.htm>
tcl_tk class class
=====
[NAME](class.htm#M2) oo::class — class of all classes
[SYNOPSIS](class.htm#M3)
[CLASS HIERARCHY](class.htm#M4)
[DESCRIPTION](class.htm#M5)
[CONSTRUCTOR](class.htm#M6)
[DESTRUCTOR](class.htm#M7)
[EXPORTED METHODS](class.htm#M8)
[*cls* **create** *name* ?*arg ...*?](class.htm#M9)
[*cls* **new** ?*arg ...*?](class.htm#M10)
[NON-EXPORTED METHODS](class.htm#M11)
[*cls* **createWithNamespace** *name nsName* ?*arg ...*?](class.htm#M12)
[EXAMPLES](class.htm#M13)
[SEE ALSO](class.htm#M14)
[KEYWORDS](class.htm#M15)
Name
----
oo::class — class of all classes Synopsis
--------
package require TclOO
**oo::class** *method* ?*arg ...*?
Class hierarchy
---------------
**[oo::object](object.htm)**
→ **oo::class**
Description
-----------
Classes are objects that can manufacture other objects according to a pattern stored in the factory object (the class). An instance of the class is created by calling one of the class's factory methods, typically either **create** if an explicit name is being given, or **new** if an arbitrary unique name is to be automatically selected. The **oo::class** class is the class of all classes; every class is an instance of this class, which is consequently an instance of itself. This class is a subclass of **[oo::object](object.htm)**, so every class is also an object. Additional metaclasses (i.e., classes of classes) can be defined if necessary by subclassing **oo::class**. Note that the **oo::class** object hides the **new** method on itself, so new classes should always be made using the **create** method.
### Constructor
The constructor of the **oo::class** class takes an optional argument which, if present, is sent to the **[oo::define](define.htm)** command (along with the name of the newly-created class) to allow the class to be conveniently configured at creation time. ### Destructor
The **oo::class** class does not define an explicit destructor. However, when a class is destroyed, all its subclasses and instances are also destroyed, along with all objects that it has been mixed into. ### Exported methods
*cls* **create** *name* ?*arg ...*?
This creates a new instance of the class *cls* called *name* (which is resolved within the calling context's namespace if not fully qualified), passing the arguments, *arg ...*, to the constructor, and (if that returns a successful result) returning the fully qualified name of the created object (the result of the constructor is ignored). If the constructor fails (i.e. returns a non-OK result) then the object is destroyed and the error message is the result of this method call.
*cls* **new** ?*arg ...*?
This creates a new instance of the class *cls* with a new unique name, passing the arguments, *arg ...*, to the constructor, and (if that returns a successful result) returning the fully qualified name of the created object (the result of the constructor is ignored). If the constructor fails (i.e., returns a non-OK result) then the object is destroyed and the error message is the result of this method call. Note that this method is not exported by the **oo::class** object itself, so classes should not be created using this method.
### Non-exported methods
The **oo::class** class supports the following non-exported methods:
*cls* **createWithNamespace** *name nsName* ?*arg ...*?
This creates a new instance of the class *cls* called *name* (which is resolved within the calling context's namespace if not fully qualified), passing the arguments, *arg ...*, to the constructor, and (if that returns a successful result) returning the fully qualified name of the created object (the result of the constructor is ignored). The name of the instance's internal namespace will be *nsName* unless that namespace already exists (when an arbitrary name will be chosen instead). If the constructor fails (i.e., returns a non-OK result) then the object is destroyed and the error message is the result of this method call.
Examples
--------
This example defines a simple class hierarchy and creates a new instance of it. It then invokes a method of the object before destroying the hierarchy and showing that the destruction is transitive.
```
**oo::class create** fruit {
method eat {} {
puts "yummy!"
}
}
**oo::class create** banana {
superclass fruit
constructor {} {
my variable peeled
set peeled 0
}
method peel {} {
my variable peeled
set peeled 1
puts "skin now off"
}
method edible? {} {
my variable peeled
return $peeled
}
method eat {} {
if {![my edible?]} {
my peel
}
next
}
}
set b [banana **new**]
$b eat *→ prints "skin now off" and "yummy!"*
fruit destroy
$b eat *→ error "unknown command"*
```
See also
--------
**[oo::define](define.htm)**, **[oo::object](object.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/class.htm>
tcl_tk lset lset
====
Name
----
lset — Change an element in a list Synopsis
--------
**lset** *varName ?index ...? newValue*
Description
-----------
The **lset** command accepts a parameter, *varName*, which it interprets as the name of a variable containing a Tcl list. It also accepts zero or more *indices* into the list. The indices may be presented either consecutively on the command line, or grouped in a Tcl list and presented as a single argument. Finally, it accepts a new value for an element of *varName*. If no indices are presented, the command takes the form:
```
**lset** varName newValue
```
or
```
**lset** varName {} newValue
```
In this case, *newValue* replaces the old value of the variable *varName*.
When presented with a single index, the **lset** command treats the content of the *varName* variable as a Tcl list. It addresses the *index*'th element in it (0 refers to the first element of the list). When interpreting the list, **lset** observes the same rules concerning braces and quotes and backslashes as the Tcl command interpreter; however, variable substitution and command substitution do not occur. The command constructs a new list in which the designated element is replaced with *newValue*. This new list is stored in the variable *varName*, and is also the return value from the **lset** command.
If *index* is negative or greater than the number of elements in *$varName*, then an error occurs.
If *index* is equal to the number of elements in *$varName*, then the given element is appended to the list.
The interpretation of each simple *index* value is the same as for the command **[string index](string.htm)**, supporting simple index arithmetic and indices relative to the end of the list.
If additional *index* arguments are supplied, then each argument is used in turn to address an element within a sublist designated by the previous indexing operation, allowing the script to alter elements in sublists (or append elements to sublists). The command,
```
**lset** a 1 2 newValue
```
or
```
**lset** a {1 2} newValue
```
replaces element 2 of sublist 1 with *newValue*.
The integer appearing in each *index* argument must be greater than or equal to zero. The integer appearing in each *index* argument must be less than or equal to the length of the corresponding list. In other words, the **lset** command can change the size of a list only by appending an element (setting the one after the current end). If an index is outside the permitted range, an error is reported.
Examples
--------
In each of these examples, the initial value of *x* is:
```
set x [list [list a b c] [list d e f] [list g h i]]
*→ {a b c} {d e f} {g h i}*
```
The indicated return value also becomes the new value of *x* (except in the last case, which is an error which leaves the value of *x* unchanged.)
```
**lset** x {j k l}
*→ j k l*
**lset** x {} {j k l}
*→ j k l*
**lset** x 0 j
*→ j {d e f} {g h i}*
**lset** x 2 j
*→ {a b c} {d e f} j*
**lset** x end j
*→ {a b c} {d e f} j*
**lset** x end-1 j
*→ {a b c} j {g h i}*
**lset** x 2 1 j
*→ {a b c} {d e f} {g j i}*
**lset** x {2 1} j
*→ {a b c} {d e f} {g j i}*
**lset** x {2 3} j
*→ list index out of range*
```
In the following examples, the initial value of *x* is:
```
set x [list [list [list a b] [list c d]] \
[list [list e f] [list g h]]]
*→ {{a b} {c d}} {{e f} {g h}}*
```
The indicated return value also becomes the new value of *x*.
```
**lset** x 1 1 0 j
*→ {{a b} {c d}} {{e f} {j h}}*
**lset** x {1 1 0} j
*→ {{a b} {c d}} {{e f} {j h}}*
```
See also
--------
**[list](list.htm)**, **[lappend](lappend.htm)**, **[lindex](lindex.htm)**, **[linsert](linsert.htm)**, **[llength](llength.htm)**, **[lsearch](lsearch.htm)**, **[lsort](lsort.htm)**, **[lrange](lrange.htm)**, **[lreplace](lreplace.htm)**, **[string](string.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/lset.htm>
tcl_tk library library
=======
[NAME](library.htm#M2) auto\_execok, auto\_import, auto\_load, auto\_mkindex, auto\_qualify, auto\_reset, tcl\_findLibrary, parray, tcl\_endOfWord, tcl\_startOfNextWord, tcl\_startOfPreviousWord, tcl\_wordBreakAfter, tcl\_wordBreakBefore — standard library of Tcl procedures
[SYNOPSIS](library.htm#M3)
[INTRODUCTION](library.htm#M4)
[COMMAND PROCEDURES](library.htm#M5)
[**auto\_execok** *cmd*](library.htm#M6)
[**auto\_import** *pattern*](library.htm#M7)
[**auto\_load** *cmd*](library.htm#M8)
[**auto\_mkindex** *dir pattern pattern ...*](library.htm#M9)
[**auto\_reset**](library.htm#M10)
[**auto\_qualify** *command namespace*](library.htm#M11)
[**tcl\_findLibrary** *basename version patch initScript enVarName varName*](library.htm#M12)
[**parray** *arrayName* ?*pattern*?](library.htm#M13)
[**tcl\_endOfWord** *str start*](library.htm#M14)
[**tcl\_startOfNextWord** *str start*](library.htm#M15)
[**tcl\_startOfPreviousWord** *str start*](library.htm#M16)
[**tcl\_wordBreakAfter** *str start*](library.htm#M17)
[**tcl\_wordBreakBefore** *str start*](library.htm#M18)
[VARIABLES](library.htm#M19)
[AUTOLOADING AND PACKAGE MANAGEMENT VARIABLES](library.htm#M20)
[**auto\_execs**](library.htm#M21)
[**auto\_index**](library.htm#M22)
[**auto\_noexec**](library.htm#M23)
[**auto\_noload**](library.htm#M24)
[**auto\_path**](library.htm#M25)
[**env(TCL\_LIBRARY)**](library.htm#M26)
[**env(TCLLIBPATH)**](library.htm#M27)
[WORD BOUNDARY DETERMINATION VARIABLES](library.htm#M28)
[**tcl\_nonwordchars**](library.htm#M29)
[**tcl\_wordchars**](library.htm#M30)
[SEE ALSO](library.htm#M31)
[KEYWORDS](library.htm#M32)
Name
----
auto\_execok, auto\_import, auto\_load, auto\_mkindex, auto\_qualify, auto\_reset, tcl\_findLibrary, parray, tcl\_endOfWord, tcl\_startOfNextWord, tcl\_startOfPreviousWord, tcl\_wordBreakAfter, tcl\_wordBreakBefore — standard library of Tcl procedures Synopsis
--------
**auto\_execok** *cmd*
**auto\_import** *pattern*
**auto\_load** *cmd*
**auto\_mkindex** *dir pattern pattern ...*
**auto\_qualify** *command namespace*
**auto\_reset**
**tcl\_findLibrary** *basename version patch initScript enVarName varName*
**parray** *arrayName* ?*pattern*?
**tcl\_endOfWord** *str start*
**tcl\_startOfNextWord** *str start*
**tcl\_startOfPreviousWord** *str start*
**tcl\_wordBreakAfter** *str start*
**tcl\_wordBreakBefore** *str start*
Introduction
------------
Tcl includes a library of Tcl procedures for commonly-needed functions. The procedures defined in the Tcl library are generic ones suitable for use by many different applications. The location of the Tcl library is returned by the **[info library](info.htm)** command. In addition to the Tcl library, each application will normally have its own library of support procedures as well; the location of this library is normally given by the value of the **$***app***\_library** global variable, where *app* is the name of the application. For example, the location of the Tk library is kept in the variable **[tk\_library](../tkcmd/tkvars.htm)**. To access the procedures in the Tcl library, an application should source the file **init.tcl** in the library, for example with the Tcl command
```
**source [file join [info library] init.tcl]**
```
If the library procedure **[Tcl\_Init](https://www.tcl.tk/man/tcl/TclLib/Init.htm)** is invoked from an application's **[Tcl\_AppInit](https://www.tcl.tk/man/tcl/TclLib/AppInit.htm)** procedure, this happens automatically. The code in **init.tcl** will define the **[unknown](unknown.htm)** procedure and arrange for the other procedures to be loaded on-demand using the auto-load mechanism defined below.
Command procedures
------------------
The following procedures are provided in the Tcl library:
**auto\_execok** *cmd*
Determines whether there is an executable file or shell builtin by the name *cmd*. If so, it returns a list of arguments to be passed to **[exec](exec.htm)** to execute the executable file or shell builtin named by *cmd*. If not, it returns an empty string. This command examines the directories in the current search path (given by the PATH environment variable) in its search for an executable file named *cmd*. On Windows platforms, the search is expanded with the same directories and file extensions as used by **[exec](exec.htm)**. **Auto\_execok** remembers information about previous searches in an array named **auto\_execs**; this avoids the path search in future calls for the same *cmd*. The command **auto\_reset** may be used to force **auto\_execok** to forget its cached information.
**auto\_import** *pattern*
**Auto\_import** is invoked during **[namespace import](namespace.htm)** to see if the imported commands specified by *pattern* reside in an autoloaded library. If so, the commands are loaded so that they will be available to the interpreter for creating the import links. If the commands do not reside in an autoloaded library, **auto\_import** does nothing. The pattern matching is performed according to the matching rules of **[namespace import](namespace.htm)**.
**auto\_load** *cmd*
This command attempts to load the definition for a Tcl command named *cmd*. To do this, it searches an *auto-load path*, which is a list of one or more directories. The auto-load path is given by the global variable **[auto\_path](tclvars.htm)** if it exists. If there is no **[auto\_path](tclvars.htm)** variable, then the TCLLIBPATH environment variable is used, if it exists. Otherwise the auto-load path consists of just the Tcl library directory. Within each directory in the auto-load path there must be a file **tclIndex** that describes one or more commands defined in that directory and a script to evaluate to load each of the commands. The **tclIndex** file should be generated with the **auto\_mkindex** command. If *cmd* is found in an index file, then the appropriate script is evaluated to create the command. The **auto\_load** command returns 1 if *cmd* was successfully created. The command returns 0 if there was no index entry for *cmd* or if the script did not actually define *cmd* (e.g. because index information is out of date). If an error occurs while processing the script, then that error is returned. **Auto\_load** only reads the index information once and saves it in the array **auto\_index**; future calls to **auto\_load** check for *cmd* in the array rather than re-reading the index files. The cached index information may be deleted with the command **auto\_reset**. This will force the next **auto\_load** command to reload the index database from disk.
**auto\_mkindex** *dir pattern pattern ...*
Generates an index suitable for use by **auto\_load**. The command searches *dir* for all files whose names match any of the *pattern* arguments (matching is done with the **[glob](glob.htm)** command), generates an index of all the Tcl command procedures defined in all the matching files, and stores the index information in a file named **tclIndex** in *dir*. If no pattern is given a pattern of **\*.tcl** will be assumed. For example, the command
```
**auto\_mkindex foo \*.tcl**
```
will read all the **.tcl** files in subdirectory **foo** and generate a new index file **foo/tclIndex**.
**Auto\_mkindex** parses the Tcl scripts by sourcing them into a slave interpreter and monitoring the proc and namespace commands that are executed. Extensions can use the (undocumented) auto\_mkindex\_parser package to register other commands that can contribute to the auto\_load index. You will have to read through auto.tcl to see how this works.
**Auto\_mkindex\_old** (which has the same syntax as **auto\_mkindex**) parses the Tcl scripts in a relatively unsophisticated way: if any line contains the word “**[proc](proc.htm)**” as its first characters then it is assumed to be a procedure definition and the next word of the line is taken as the procedure's name. Procedure definitions that do not appear in this way (e.g. they have spaces before the **[proc](proc.htm)**) will not be indexed. If your script contains “dangerous” code, such as global initialization code or procedure names with special characters like **$**, **\***, **[** or **]**, you are safer using **auto\_mkindex\_old**.
**auto\_reset**
Destroys all the information cached by **auto\_execok** and **auto\_load**. This information will be re-read from disk the next time it is needed. **Auto\_reset** also deletes any procedures listed in the auto-load index, so that fresh copies of them will be loaded the next time that they are used.
**auto\_qualify** *command namespace*
Computes a list of fully qualified names for *command*. This list mirrors the path a standard Tcl interpreter follows for command lookups: first it looks for the command in the current namespace, and then in the global namespace. Accordingly, if *command* is relative and *namespace* is not **::**, the list returned has two elements: *command* scoped by *namespace*, as if it were a command in the *namespace* namespace; and *command* as if it were a command in the global namespace. Otherwise, if either *command* is absolute (it begins with **::**), or *namespace* is **::**, the list contains only *command* as if it were a command in the global namespace. **Auto\_qualify** is used by the auto-loading facilities in Tcl, both for producing auto-loading indexes such as *pkgIndex.tcl*, and for performing the actual auto-loading of functions at runtime.
**tcl\_findLibrary** *basename version patch initScript enVarName varName*
This is a standard search procedure for use by extensions during their initialization. They call this procedure to look for their script library in several standard directories. The last component of the name of the library directory is normally *basenameversion* (e.g., tk8.0), but it might be “library” when in the build hierarchies. The *initScript* file will be sourced into the interpreter once it is found. The directory in which this file is found is stored into the global variable *varName*. If this variable is already defined (e.g., by C code during application initialization) then no searching is done. Otherwise the search looks in these directories: the directory named by the environment variable *enVarName*; relative to the Tcl library directory; relative to the executable file in the standard installation bin or bin/*arch* directory; relative to the executable file in the current build tree; relative to the executable file in a parallel build tree.
**parray** *arrayName* ?*pattern*?
Prints on standard output the names and values of all the elements in the array *arrayName*, or just the names that match *pattern* (using the matching rules of **[string match](string.htm)**) and their values if *pattern* is given. *ArrayName* must be an array accessible to the caller of **parray**. It may be either local or global.
**tcl\_endOfWord** *str start*
Returns the index of the first end-of-word location that occurs after a starting index *start* in the string *str*. An end-of-word location is defined to be the first non-word character following the first word character after the starting point. Returns -1 if there are no more end-of-word locations after the starting point. See the description of **[tcl\_wordchars](tclvars.htm)** and **[tcl\_nonwordchars](tclvars.htm)** below for more details on how Tcl determines which characters are word characters.
**tcl\_startOfNextWord** *str start*
Returns the index of the first start-of-word location that occurs after a starting index *start* in the string *str*. A start-of-word location is defined to be the first word character following a non-word character. Returns -1 if there are no more start-of-word locations after the starting point.
**tcl\_startOfPreviousWord** *str start*
Returns the index of the first start-of-word location that occurs before a starting index *start* in the string *str*. Returns -1 if there are no more start-of-word locations before the starting point.
**tcl\_wordBreakAfter** *str start*
Returns the index of the first word boundary after the starting index *start* in the string *str*. Returns -1 if there are no more boundaries after the starting point in the given string. The index returned refers to the second character of the pair that comprises a boundary.
**tcl\_wordBreakBefore** *str start*
Returns the index of the first word boundary before the starting index *start* in the string *str*. Returns -1 if there are no more boundaries before the starting point in the given string. The index returned refers to the second character of the pair that comprises a boundary.
Variables
---------
The following global variables are defined or used by the procedures in the Tcl library. They fall into two broad classes, handling unknown commands and packages, and determining what are words. ### Autoloading and package management variables
**auto\_execs**
Used by **auto\_execok** to record information about whether particular commands exist as executable files.
**auto\_index**
Used by **auto\_load** to save the index information read from disk.
**auto\_noexec**
If set to any value, then **[unknown](unknown.htm)** will not attempt to auto-exec any commands.
**auto\_noload**
If set to any value, then **[unknown](unknown.htm)** will not attempt to auto-load any commands.
**auto\_path**
If set, then it must contain a valid Tcl list giving directories to search during auto-load operations (including for package index files when using the default **[package unknown](package.htm)** handler). This variable is initialized during startup to contain, in order: the directories listed in the **TCLLIBPATH** environment variable, the directory named by the **[tcl\_library](tclvars.htm)** global variable, the parent directory of **[tcl\_library](tclvars.htm)**, the directories listed in the **[tcl\_pkgPath](tclvars.htm)** variable. Additional locations to look for files and package indices should normally be added to this variable using **[lappend](lappend.htm)**.
**env(TCL\_LIBRARY)**
If set, then it specifies the location of the directory containing library scripts (the value of this variable will be assigned to the **[tcl\_library](tclvars.htm)** variable and therefore returned by the command **[info library](info.htm)**). If this variable is not set then a default value is used.
**env(TCLLIBPATH)**
If set, then it must contain a valid Tcl list giving directories to search during auto-load operations. Directories must be specified in Tcl format, using “/” as the path separator, regardless of platform. This variable is only used when initializing the **[auto\_path](tclvars.htm)** variable.
### Word boundary determination variables
These variables are only used in the **tcl\_endOfWord**, **tcl\_startOfNextWord**, **tcl\_startOfPreviousWord**, **tcl\_wordBreakAfter**, and **tcl\_wordBreakBefore** commands.
**tcl\_nonwordchars**
This variable contains a regular expression that is used by routines like **tcl\_endOfWord** to identify whether a character is part of a word or not. If the pattern matches a character, the character is considered to be a non-word character. On Windows platforms, spaces, tabs, and newlines are considered non-word characters. Under Unix, everything but numbers, letters and underscores are considered non-word characters.
**tcl\_wordchars**
This variable contains a regular expression that is used by routines like **tcl\_endOfWord** to identify whether a character is part of a word or not. If the pattern matches a character, the character is considered to be a word character. On Windows platforms, words are comprised of any character that is not a space, tab, or newline. Under Unix, words are comprised of numbers, letters or underscores.
See also
--------
**[env](tclvars.htm)**, **[info](info.htm)**, **[re\_syntax](re_syntax.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/library.htm>
| programming_docs |
tcl_tk while while
=====
Name
----
while — Execute script repeatedly as long as a condition is met Synopsis
--------
**while** *test body*
Description
-----------
The **while** command evaluates *test* as an expression (in the same way that **[expr](expr.htm)** evaluates its argument). The value of the expression must a proper boolean value; if it is a true value then *body* is executed by passing it to the Tcl interpreter. Once *body* has been executed then *test* is evaluated again, and the process repeats until eventually *test* evaluates to a false boolean value. **[Continue](continue.htm)** commands may be executed inside *body* to terminate the current iteration of the loop, and **[break](break.htm)** commands may be executed inside *body* to cause immediate termination of the **while** command. The **while** command always returns an empty string. Note: *test* should almost always be enclosed in braces. If not, variable substitutions will be made before the **while** command starts executing, which means that variable changes made by the loop body will not be considered in the expression. This is likely to result in an infinite loop. If *test* is enclosed in braces, variable substitutions are delayed until the expression is evaluated (before each loop iteration), so changes in the variables will be visible. For an example, try the following script with and without the braces around **$x<10**:
```
set x 0
**while** {$x<10} {
puts "x is $x"
incr x
}
```
Example
-------
Read lines from a channel until we get to the end of the stream, and print them out with a line-number prepended:
```
set lineCount 0
**while** {[gets $chan line] >= 0} {
puts "[incr lineCount]: $line"
}
```
See also
--------
**[break](break.htm)**, **[continue](continue.htm)**, **[for](for.htm)**, **[foreach](foreach.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/while.htm>
tcl_tk error error
=====
Name
----
error — Generate an error Synopsis
--------
**error** *message* ?*info*? ?*code*?
Description
-----------
Returns a **[TCL\_ERROR](catch.htm)** code, which causes command interpretation to be unwound. *Message* is a string that is returned to the application to indicate what went wrong. The **-errorinfo** return option of an interpreter is used to accumulate a stack trace of what was in progress when an error occurred; as nested commands unwind, the Tcl interpreter adds information to the **-errorinfo** return option. If the *info* argument is present, it is used to initialize the **-errorinfo** return options and the first increment of unwind information will not be added by the Tcl interpreter. In other words, the command containing the **error** command will not appear in the stack trace; in its place will be *info*. Historically, this feature had been most useful in conjunction with the **[catch](catch.htm)** command: if a caught error cannot be handled successfully, *info* can be used to return a stack trace reflecting the original point of occurrence of the error:
```
catch {...} errMsg
set savedInfo $::errorInfo
...
**error** $errMsg $savedInfo
```
When working with Tcl 8.5 or later, the following code should be used instead:
```
catch {...} errMsg options
...
return -options $options $errMsg
```
If the *code* argument is present, then its value is stored in the **-errorcode** return option. The **-errorcode** return option is intended to hold a machine-readable description of the error in cases where such information is available; see the **[return](return.htm)** manual page for information on the proper format for this option's value.
Example
-------
Generate an error if a basic mathematical operation fails:
```
if {1+2 != 3} {
**error** "something is very wrong with addition"
}
```
See also
--------
**[catch](catch.htm)**, **[return](return.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/error.htm>
tcl_tk refchan refchan
=======
[NAME](refchan.htm#M2) refchan — command handler API of reflected channels
[SYNOPSIS](refchan.htm#M3)
[DESCRIPTION](refchan.htm#M4)
[MANDATORY SUBCOMMANDS](refchan.htm#M5)
[*cmdPrefix* **initialize** *channelId mode*](refchan.htm#M6)
[*cmdPrefix* **finalize** *channelId*](refchan.htm#M7)
[*cmdPrefix* **watch** *channelId eventspec*](refchan.htm#M8)
[OPTIONAL SUBCOMMANDS](refchan.htm#M9)
[*cmdPrefix* **read** *channelId count*](refchan.htm#M10)
[*cmdPrefix* **write** *channelId data*](refchan.htm#M11)
[*cmdPrefix* **seek** *channelId offset base*](refchan.htm#M12)
[**start**](refchan.htm#M13)
[**current**](refchan.htm#M14)
[**end**](refchan.htm#M15)
[*cmdPrefix* **configure** *channelId option value*](refchan.htm#M16)
[*cmdPrefix* **cget** *channelId option*](refchan.htm#M17)
[*cmdPrefix* **cgetall** *channelId*](refchan.htm#M18)
[*cmdPrefix* **blocking** *channelId mode*](refchan.htm#M19)
[NOTES](refchan.htm#M20)
[EXAMPLE](refchan.htm#M21)
[SEE ALSO](refchan.htm#M22)
[KEYWORDS](refchan.htm#M23)
Name
----
refchan — command handler API of reflected channels Synopsis
--------
**cmdPrefix** *option* ?*arg arg ...*?
Description
-----------
The Tcl-level handler for a reflected channel has to be a command with subcommands (termed an *ensemble*, as it is a command such as that created by **[namespace ensemble](namespace.htm)** **create**, though the implementation of handlers for reflected channel *is not* tied to **namespace ensemble**s in any way; see **[EXAMPLE](#M21)** below for how to build an **[oo::class](class.htm)** that supports the API). Note that *cmdPrefix* is whatever was specified in the call to **[chan create](chan.htm)**, and may consist of multiple arguments; this will be expanded to multiple words in place of the prefix. Of all the possible subcommands, the handler *must* support **initialize**, **finalize**, and **watch**. Support for the other subcommands is optional.
### Mandatory subcommands
*cmdPrefix* **initialize** *channelId mode*
An invocation of this subcommand will be the first call the *cmdPrefix* will receive for the specified new *channelId*. It is the responsibility of this subcommand to set up any internal data structures required to keep track of the channel and its state. The return value of the method has to be a list containing the names of all subcommands supported by the *cmdPrefix*. This also tells the Tcl core which version of the API for reflected channels is used by this command handler.
Any error thrown by the method will abort the creation of the channel and no channel will be created. The thrown error will appear as error thrown by **[chan create](chan.htm)**. Any exception other than an **[error](error.htm)** (e.g., **[break](break.htm)**, etc.) is treated as (and converted to) an error.
**Note:** If the creation of the channel was aborted due to failures here, then the **finalize** subcommand will not be called.
The *mode* argument tells the handler whether the channel was opened for reading, writing, or both. It is a list containing any of the strings **[read](read.htm)** or **write**. The list will always contain at least one element.
The subcommand must throw an error if the chosen mode is not supported by the *cmdPrefix*.
*cmdPrefix* **finalize** *channelId*
An invocation of this subcommand will be the last call the *cmdPrefix* will receive for the specified *channelId*. It will be generated just before the destruction of the data structures of the channel held by the Tcl core. The command handler *must not* access the *channelId* anymore in no way. Upon this subcommand being called, any internal resources allocated to this channel must be cleaned up. The return value of this subcommand is ignored.
If the subcommand throws an error the command which caused its invocation (usually **[chan close](chan.htm)**) will appear to have thrown this error. Any exception beyond **[error](error.htm)** (e.g., **[break](break.htm)**, etc.) is treated as (and converted to) an error.
This subcommand is not invoked if the creation of the channel was aborted during **initialize** (See above).
*cmdPrefix* **watch** *channelId eventspec*
This subcommand notifies the *cmdPrefix* that the specified *channelId* is interested in the events listed in the *eventspec*. This argument is a list containing any of **[read](read.htm)** and **write**. The list may be empty, which signals that the channel does not wish to be notified of any events. In that situation, the handler should disable event generation completely. **Warning:** Any return value of the subcommand is ignored. This includes all errors thrown by the subcommand, **[break](break.htm)**, **[continue](continue.htm)**, and custom return codes.
This subcommand interacts with **[chan postevent](chan.htm)**. Trying to post an event which was not listed in the last call to **watch** will cause **[chan postevent](chan.htm)** to throw an error.
### Optional subcommands
*cmdPrefix* **read** *channelId count*
This *optional* subcommand is called when the user requests data from the channel *channelId*. *count* specifies how many *bytes* have been requested. If the subcommand is not supported then it is not possible to read from the channel handled by the command. The return value of this subcommand is taken as the requested data *bytes*. If the returned data contains more bytes than requested, an error will be signaled and later thrown by the command which performed the read (usually **[gets](gets.htm)** or **[read](read.htm)**). However, returning fewer bytes than requested is acceptable.
Note that returning nothing (0 bytes) is a signal to the higher layers that **[EOF](eof.htm)** has been reached on the channel. To signal that the channel is out of data right now, but has not yet reached **[EOF](eof.htm)**, it is necessary to throw the error "EAGAIN", i.e. to either
```
return -code error EAGAIN
```
or
```
error EAGAIN
```
For extensibility any error whose value is a negative integer number will cause the higher layers to set the C-level variable "**errno**" to the absolute value of this number, signaling a system error. However, note that the exact mapping between these error numbers and their meanings is operating system dependent.
For example, while on Linux both
```
return -code error -11
```
and
```
error -11
```
are equivalent to the examples above, using the more readable string "EAGAIN", this is not true for BSD, where the equivalent number is -35.
The symbolic string however is the same across systems, and internally translated to the correct number. No other error value has such a mapping to a symbolic string.
If the subcommand throws any other error, the command which caused its invocation (usually **[gets](gets.htm)**, or **[read](read.htm)**) will appear to have thrown this error. Any exception beyond **[error](error.htm)**, (e.g., **[break](break.htm)**, etc.) is treated as and converted to an error.
*cmdPrefix* **write** *channelId data*
This *optional* subcommand is called when the user writes data to the channel *channelId*. The *data* argument contains *bytes*, not characters. Any type of transformation (EOL, encoding) configured for the channel has already been applied at this point. If this subcommand is not supported then it is not possible to write to the channel handled by the command. The return value of the subcommand is taken as the number of bytes written by the channel. Anything non-numeric will cause an error to be signaled and later thrown by the command which performed the write. A negative value implies that the write failed. Returning a value greater than the number of bytes given to the handler, or zero, is forbidden and will cause the Tcl core to throw an error.
To signal that the channel is not able to accept data for writing right now, it is necessary to throw the error "EAGAIN", i.e. to either
```
return -code error EAGAIN
```
or
```
error EAGAIN
```
For extensibility any error whose value is a negative integer number will cause the higher layers to set the C-level variable "**errno**" to the absolute value of this number, signaling a system error. However, note that the exact mapping between these error numbers and their meanings is operating system dependent.
For example, while on Linux both
```
return -code error -11
```
and
```
error -11
```
are equivalent to the examples above, using the more readable string "EAGAIN", this is not true for BSD, where the equivalent number is -35.
The symbolic string however is the same across systems, and internally translated to the correct number. No other error value has such a mapping to a symbolic string.
If the subcommand throws any other error the command which caused its invocation (usually **[puts](puts.htm)**) will appear to have thrown this error. Any exception beyond **[error](error.htm)** (e.g., **[break](break.htm)**, etc.) is treated as and converted to an error.
*cmdPrefix* **seek** *channelId offset base*
This *optional* subcommand is responsible for the handling of **[chan seek](chan.htm)** and **[chan tell](chan.htm)** requests on the channel *channelId*. If it is not supported then seeking will not be possible for the channel. The *base* argument is the same as the equivalent argument of the builtin **[chan seek](chan.htm)**, namely:
**start**
Seeking is relative to the beginning of the channel.
**current**
Seeking is relative to the current seek position.
**end**
Seeking is relative to the end of the channel.
The *offset* is an integer number specifying the amount of **bytes** to seek forward or backward. A positive number should seek forward, and a negative number should seek backward. A channel may provide only limited seeking. For example sockets can seek forward, but not backward.
The return value of the subcommand is taken as the (new) location of the channel, counted from the start. This has to be an integer number greater than or equal to zero. If the subcommand throws an error the command which caused its invocation (usually **[chan seek](chan.htm)**, or **[chan tell](chan.htm)**) will appear to have thrown this error. Any exception beyond **[error](error.htm)** (e.g., **[break](break.htm)**, etc.) is treated as and converted to an error.
The offset/base combination of 0/**current** signals a **[chan tell](chan.htm)** request, i.e., seek nothing relative to the current location, making the new location identical to the current one, which is then returned.
*cmdPrefix* **configure** *channelId option value*
This *optional* subcommand is for setting the type-specific options of channel *channelId*. The *option* argument indicates the option to be written, and the *value* argument indicates the value to set the option to. This subcommand will never try to update more than one option at a time; that is behavior implemented in the Tcl channel core.
The return value of the subcommand is ignored.
If the subcommand throws an error the command which performed the (re)configuration or query (usually **[fconfigure](fconfigure.htm)** or **[chan configure](chan.htm)**) will appear to have thrown this error. Any exception beyond **[error](error.htm)** (e.g., **[break](break.htm)**, etc.) is treated as and converted to an error.
*cmdPrefix* **cget** *channelId option*
This *optional* subcommand is used when reading a single type-specific option of channel *channelId*. If this subcommand is supported then the subcommand **cgetall** must be supported as well. The subcommand should return the value of the specified *option*.
If the subcommand throws an error, the command which performed the (re)configuration or query (usually **[fconfigure](fconfigure.htm)** or **[chan configure](chan.htm)**) will appear to have thrown this error. Any exception beyond *error* (e.g., **[break](break.htm)**, etc.) is treated as and converted to an error.
*cmdPrefix* **cgetall** *channelId*
This *optional* subcommand is used for reading all type-specific options of channel *channelId*. If this subcommand is supported then the subcommand **cget** has to be supported as well. The subcommand should return a list of all options and their values. This list must have an even number of elements.
If the subcommand throws an error the command which performed the (re)configuration or query (usually **[fconfigure](fconfigure.htm)** or **[chan configure](chan.htm)**) will appear to have thrown this error. Any exception beyond **[error](error.htm)** (e.g., **[break](break.htm)**, etc.) is treated as and converted to an error.
*cmdPrefix* **blocking** *channelId mode*
This *optional* subcommand handles changes to the blocking mode of the channel *channelId*. The *mode* is a boolean flag. A true value means that the channel has to be set to blocking, and a false value means that the channel should be non-blocking. The return value of the subcommand is ignored.
If the subcommand throws an error the command which caused its invocation (usually **[fconfigure](fconfigure.htm)** or **[chan configure](chan.htm)**) will appear to have thrown this error. Any exception beyond **[error](error.htm)** (e.g., **[break](break.htm)**, etc.) is treated as and converted to an error.
Notes
-----
Some of the functions supported in channels defined in Tcl's C interface are not available to channels reflected to the Tcl level. The function **Tcl\_DriverGetHandleProc** is not supported; i.e., reflected channels do not have OS specific handles.
The function **Tcl\_DriverHandlerProc** is not supported. This driver function is relevant only for stacked channels, i.e., transformations. Reflected channels are always base channels, not transformations.
The function **Tcl\_DriverFlushProc** is not supported. This is because the current generic I/O layer of Tcl does not use this function anywhere at all. Therefore support at the Tcl level makes no sense either. This may be altered in the future (through extending the API defined here and changing its version number) should the function be used at some time in the future.
Example
-------
This demonstrates how to make a channel that reads from a string.
```
oo::class create stringchan {
variable data pos
constructor {string {encoding {}}} {
if {$encoding eq ""} {set encoding [encoding system]}
set data [encoding convertto $encoding $string]
set pos 0
}
method **initialize** {ch mode} {
return "initialize finalize watch read seek"
}
method **finalize** {ch} {
my destroy
}
method **watch** {ch events} {
# Must be present but we ignore it because we do not
# post any events
}
# Must be present on a readable channel
method **[read](read.htm)** {ch count} {
set d [string range $data $pos [expr {$pos+$count-1}]]
incr pos [string length $d]
return $d
}
# This method is optional, but useful for the example below
method **[seek](seek.htm)** {ch offset base} {
switch $base {
start {
set pos $offset
}
current {
incr pos $offset
}
end {
set pos [string length $data]
incr pos $offset
}
}
if {$pos < 0} {
set pos 0
} elseif {$pos > [string length $data]} {
set pos [string length $data]
}
return $pos
}
}
# Now we create an instance...
set string "The quick brown fox jumps over the lazy dog.\n"
set ch [**[chan create](chan.htm)** read [stringchan new $string]]
puts [gets $ch]; # Prints the whole string
seek $ch -5 end;
puts [read $ch]; # Prints just the last word
```
See also
--------
**[chan](chan.htm)**, **[transchan](transchan.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/refchan.htm>
| programming_docs |
tcl_tk upvar upvar
=====
Name
----
upvar — Create link to variable in a different stack frame Synopsis
--------
**upvar** ?*level*? *otherVar myVar* ?*otherVar myVar* ...?
Description
-----------
This command arranges for one or more local variables in the current procedure to refer to variables in an enclosing procedure call or to global variables. *Level* may have any of the forms permitted for the **[uplevel](uplevel.htm)** command, and may be omitted (it defaults to **1**). For each *otherVar* argument, **upvar** makes the variable by that name in the procedure frame given by *level* (or at global level, if *level* is **#0**) accessible in the current procedure by the name given in the corresponding *myVar* argument. The variable named by *otherVar* need not exist at the time of the call; it will be created the first time *myVar* is referenced, just like an ordinary variable. There must not exist a variable by the name *myVar* at the time **upvar** is invoked. *MyVar* is always treated as the name of a variable, not an array element. An error is returned if the name looks like an array element, such as **a(b)**. *OtherVar* may refer to a scalar variable, an array, or an array element. **Upvar** returns an empty string. The **upvar** command simplifies the implementation of call-by-name procedure calling and also makes it easier to build new control constructs as Tcl procedures. For example, consider the following procedure:
```
proc *add2* name {
**upvar** $name x
set x [expr {$x + 2}]
}
```
If *add2* is invoked with an argument giving the name of a variable, it adds two to the value of that variable. Although *add2* could have been implemented using **[uplevel](uplevel.htm)** instead of **upvar**, **upvar** makes it simpler for *add2* to access the variable in the caller's procedure frame.
**[namespace eval](namespace.htm)** is another way (besides procedure calls) that the Tcl naming context can change. It adds a call frame to the stack to represent the namespace context. This means each **[namespace eval](namespace.htm)** command counts as another call level for **[uplevel](uplevel.htm)** and **upvar** commands. For example, **[info level](info.htm)** **1** will return a list describing a command that is either the outermost procedure call or the outermost **[namespace eval](namespace.htm)** command. Also, **uplevel #0** evaluates a script at top-level in the outermost namespace (the global namespace).
If an upvar variable is unset (e.g. **x** in **add2** above), the **[unset](unset.htm)** operation affects the variable it is linked to, not the upvar variable. There is no way to unset an upvar variable except by exiting the procedure in which it is defined. However, it is possible to retarget an upvar variable by executing another **upvar** command.
Traces and upvar
----------------
Upvar interacts with traces in a straightforward but possibly unexpected manner. If a variable trace is defined on *otherVar*, that trace will be triggered by actions involving *myVar*. However, the trace procedure will be passed the name of *myVar*, rather than the name of *otherVar*. Thus, the output of the following code will be “*localVar*” rather than “*originalVar*”:
```
proc *traceproc* { name index op } {
puts $name
}
proc *setByUpvar* { name value } {
**upvar** $name localVar
set localVar $value
}
set originalVar 1
trace variable originalVar w *traceproc*
*setByUpvar* originalVar 2
```
If *otherVar* refers to an element of an array, then variable traces set for the entire array will not be invoked when *myVar* is accessed (but traces on the particular element will still be invoked). In particular, if the array is **[env](tclvars.htm)**, then changes made to *myVar* will not be passed to subprocesses correctly.
Example
-------
A **decr** command that works like **[incr](incr.htm)** except it subtracts the value from the variable instead of adding it:
```
proc decr {varName {decrement 1}} {
**upvar** 1 $varName var
incr var [expr {-$decrement}]
}
```
See also
--------
**[global](global.htm)**, **[namespace](namespace.htm)**, **[uplevel](uplevel.htm)**, **[variable](variable.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/upvar.htm>
tcl_tk registry registry
========
[NAME](registry.htm#M2) registry — Manipulate the Windows registry
[SYNOPSIS](registry.htm#M3)
[DESCRIPTION](registry.htm#M4)
[**registry broadcast** *keyName* ?**-timeout** *milliseconds*?](registry.htm#M5)
[**registry delete** *keyName* ?*valueName*?](registry.htm#M6)
[**registry get** *keyName valueName*](registry.htm#M7)
[**registry keys** *keyName* ?*pattern*?](registry.htm#M8)
[**registry set** *keyName* ?*valueName data* ?*type*??](registry.htm#M9)
[**registry type** *keyName valueName*](registry.htm#M10)
[**registry values** *keyName* ?*pattern*?](registry.htm#M11)
[SUPPORTED TYPES](registry.htm#M12)
[**binary**](registry.htm#M13)
[**none**](registry.htm#M14)
[**sz**](registry.htm#M15)
[**expand\_sz**](registry.htm#M16)
[**dword**](registry.htm#M17)
[**dword\_big\_endian**](registry.htm#M18)
[**link**](registry.htm#M19)
[**multi\_sz**](registry.htm#M20)
[**resource\_list**](registry.htm#M21)
[PORTABILITY ISSUES](registry.htm#M22)
[EXAMPLE](registry.htm#M23)
[KEYWORDS](registry.htm#M24)
Name
----
registry — Manipulate the Windows registry Synopsis
--------
**package require registry 1.3**
**registry** ?*-mode*? *option* *keyName* ?*arg arg ...*?
Description
-----------
The **registry** package provides a general set of operations for manipulating the Windows registry. The package implements the **registry** Tcl command. This command is only supported on the Windows platform. Warning: this command should be used with caution as a corrupted registry can leave your system in an unusable state. *KeyName* is the name of a registry key. Registry keys must be one of the following forms:
**\\***hostname***\***rootname***\***keypath*
*rootname***\***keypath*
*rootname*
*Hostname* specifies the name of any valid Windows host that exports its registry. The *rootname* component must be one of **HKEY\_LOCAL\_MACHINE**, **HKEY\_USERS**, **HKEY\_CLASSES\_ROOT**, **HKEY\_CURRENT\_USER**, **HKEY\_CURRENT\_CONFIG**, **HKEY\_PERFORMANCE\_DATA**, or **HKEY\_DYN\_DATA**. The *keypath* can be one or more registry key names separated by backslash (**\**) characters.
The optional *-mode* argument indicates which registry to work with; when it is **-32bit** the 32-bit registry will be used, and when it is **-64bit** the 64-bit registry will be used. If this argument is omitted, the system's default registry will be the subject of the requested operation.
*Option* indicates what to do with the registry key name. Any unique abbreviation for *option* is acceptable. The valid options are:
**registry broadcast** *keyName* ?**-timeout** *milliseconds*?
Sends a broadcast message to the system and running programs to notify them of certain updates. This is necessary to propagate changes to key registry keys like Environment. The timeout specifies the amount of time, in milliseconds, to wait for applications to respond to the broadcast message. It defaults to 3000. The following example demonstrates how to add a path to the global Environment and notify applications of the change without requiring a logoff/logon step (assumes admin privileges):
```
set regPath [join {
HKEY_LOCAL_MACHINE
SYSTEM
CurrentControlSet
Control
{Session Manager}
Environment
} "\\"]
set curPath [**registry get** $regPath "Path"]
**registry set** $regPath "Path" "$curPath;$addPath"
**registry broadcast** "Environment"
```
**registry delete** *keyName* ?*valueName*?
If the optional *valueName* argument is present, the specified value under *keyName* will be deleted from the registry. If the optional *valueName* is omitted, the specified key and any subkeys or values beneath it in the registry hierarchy will be deleted. If the key could not be deleted then an error is generated. If the key did not exist, the command has no effect.
**registry get** *keyName valueName*
Returns the data associated with the value *valueName* under the key *keyName*. If either the key or the value does not exist, then an error is generated. For more details on the format of the returned data, see **[SUPPORTED TYPES](#M12)**, below.
**registry keys** *keyName* ?*pattern*?
If *pattern* is not specified, returns a list of names of all the subkeys of *keyName*. If *pattern* is specified, only those names matching *pattern* are returned. Matching is determined using the same rules as for **[string match](string.htm)**. If the specified *keyName* does not exist, then an error is generated.
**registry set** *keyName* ?*valueName data* ?*type*??
If *valueName* is not specified, creates the key *keyName* if it does not already exist. If *valueName* is specified, creates the key *keyName* and value *valueName* if necessary. The contents of *valueName* are set to *data* with the type indicated by *type*. If *type* is not specified, the type **sz** is assumed. For more details on the data and type arguments, see **[SUPPORTED TYPES](#M12)** below.
**registry type** *keyName valueName*
Returns the type of the value *valueName* in the key *keyName*. For more information on the possible types, see **[SUPPORTED TYPES](#M12)**, below.
**registry values** *keyName* ?*pattern*?
If *pattern* is not specified, returns a list of names of all the values of *keyName*. If *pattern* is specified, only those names matching *pattern* are returned. Matching is determined using the same rules as for **[string match](string.htm)**.
Supported types
---------------
Each value under a key in the registry contains some data of a particular type in a type-specific representation. The **registry** command converts between this internal representation and one that can be manipulated by Tcl scripts. In most cases, the data is simply returned as a Tcl string. The type indicates the intended use for the data, but does not actually change the representation. For some types, the **registry** command returns the data in a different form to make it easier to manipulate. The following types are recognized by the registry command:
**binary**
The registry value contains arbitrary binary data. The data is represented exactly in Tcl, including any embedded nulls.
**none**
The registry value contains arbitrary binary data with no defined type. The data is represented exactly in Tcl, including any embedded nulls.
**sz**
The registry value contains a null-terminated string. The data is represented in Tcl as a string.
**expand\_sz**
The registry value contains a null-terminated string that contains unexpanded references to environment variables in the normal Windows style (for example, “%PATH%”). The data is represented in Tcl as a string.
**dword**
The registry value contains a little-endian 32-bit number. The data is represented in Tcl as a decimal string.
**dword\_big\_endian**
The registry value contains a big-endian 32-bit number. The data is represented in Tcl as a decimal string.
**link**
The registry value contains a symbolic link. The data is represented exactly in Tcl, including any embedded nulls.
**multi\_sz**
The registry value contains an array of null-terminated strings. The data is represented in Tcl as a list of strings.
**resource\_list**
The registry value contains a device-driver resource list. The data is represented exactly in Tcl, including any embedded nulls.
In addition to the symbolically named types listed above, unknown types are identified using a 32-bit integer that corresponds to the type code returned by the system interfaces. In this case, the data is represented exactly in Tcl, including any embedded nulls.
Portability issues
------------------
The registry command is only available on Windows. Example
-------
Print out how double-clicking on a Tcl script file will invoke a Tcl interpreter:
```
package require registry
set ext .tcl
# Read the type name
set type [**registry get** HKEY_CLASSES_ROOT\\$ext {}]
# Work out where to look for the command
set path HKEY_CLASSES_ROOT\\$type\\Shell\\Open\\command
# Read the command!
set command [**registry get** $path {}]
puts "$ext opens with $command"
```
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/registry.htm>
tcl_tk array array
=====
[NAME](array.htm#M2) array — Manipulate array variables
[SYNOPSIS](array.htm#M3)
[DESCRIPTION](array.htm#M4)
[**array anymore** *arrayName searchId*](array.htm#M5)
[**array donesearch** *arrayName searchId*](array.htm#M6)
[**array exists** *arrayName*](array.htm#M7)
[**array get** *arrayName* ?*pattern*?](array.htm#M8)
[**array names** *arrayName* ?*mode*? ?*pattern*?](array.htm#M9)
[**array nextelement** *arrayName searchId*](array.htm#M10)
[**array set** *arrayName list*](array.htm#M11)
[**array size** *arrayName*](array.htm#M12)
[**array startsearch** *arrayName*](array.htm#M13)
[**array statistics** *arrayName*](array.htm#M14)
[**array unset** *arrayName* ?*pattern*?](array.htm#M15)
[EXAMPLES](array.htm#M16)
[SEE ALSO](array.htm#M17)
[KEYWORDS](array.htm#M18)
Name
----
array — Manipulate array variables Synopsis
--------
**array** *option arrayName* ?*arg arg ...*?
Description
-----------
This command performs one of several operations on the variable given by *arrayName*. Unless otherwise specified for individual commands below, *arrayName* must be the name of an existing array variable. The *option* argument determines what action is carried out by the command. The legal *options* (which may be abbreviated) are:
**array anymore** *arrayName searchId*
Returns 1 if there are any more elements left to be processed in an array search, 0 if all elements have already been returned. *SearchId* indicates which search on *arrayName* to check, and must have been the return value from a previous invocation of **array startsearch**. This option is particularly useful if an array has an element with an empty name, since the return value from **array nextelement** will not indicate whether the search has been completed.
**array donesearch** *arrayName searchId*
This command terminates an array search and destroys all the state associated with that search. *SearchId* indicates which search on *arrayName* to destroy, and must have been the return value from a previous invocation of **array startsearch**. Returns an empty string.
**array exists** *arrayName*
Returns 1 if *arrayName* is an array variable, 0 if there is no variable by that name or if it is a scalar variable.
**array get** *arrayName* ?*pattern*?
Returns a list containing pairs of elements. The first element in each pair is the name of an element in *arrayName* and the second element of each pair is the value of the array element. The order of the pairs is undefined. If *pattern* is not specified, then all of the elements of the array are included in the result. If *pattern* is specified, then only those elements whose names match *pattern* (using the matching rules of **[string match](string.htm)**) are included. If *arrayName* is not the name of an array variable, or if the array contains no elements, then an empty list is returned. If traces on the array modify the list of elements, the elements returned are those that exist both before and after the call to **array get**.
**array names** *arrayName* ?*mode*? ?*pattern*?
Returns a list containing the names of all of the elements in the array that match *pattern*. *Mode* may be one of **-exact**, **-glob**, or **-regexp**. If specified, *mode* designates which matching rules to use to match *pattern* against the names of the elements in the array. If not specified, *mode* defaults to **-glob**. See the documentation for **[string match](string.htm)** for information on glob style matching, and the documentation for **[regexp](regexp.htm)** for information on regexp matching. If *pattern* is omitted then the command returns all of the element names in the array. If there are no (matching) elements in the array, or if *arrayName* is not the name of an array variable, then an empty string is returned.
**array nextelement** *arrayName searchId*
Returns the name of the next element in *arrayName*, or an empty string if all elements of *arrayName* have already been returned in this search. The *searchId* argument identifies the search, and must have been the return value of an **array startsearch** command. Warning: if elements are added to or deleted from the array, then all searches are automatically terminated just as if **array donesearch** had been invoked; this will cause **array nextelement** operations to fail for those searches.
**array set** *arrayName list*
Sets the values of one or more elements in *arrayName*. *list* must have a form like that returned by **array get**, consisting of an even number of elements. Each odd-numbered element in *list* is treated as an element name within *arrayName*, and the following element in *list* is used as a new value for that array element. If the variable *arrayName* does not already exist and *list* is empty, *arrayName* is created with an empty array value.
**array size** *arrayName*
Returns a decimal string giving the number of elements in the array. If *arrayName* is not the name of an array then 0 is returned.
**array startsearch** *arrayName*
This command initializes an element-by-element search through the array given by *arrayName*, such that invocations of the **array nextelement** command will return the names of the individual elements in the array. When the search has been completed, the **array donesearch** command should be invoked. The return value is a search identifier that must be used in **array nextelement** and **array donesearch** commands; it allows multiple searches to be underway simultaneously for the same array. It is currently more efficient and easier to use either the **array get** or **array names**, together with **[foreach](foreach.htm)**, to iterate over all but very large arrays. See the examples below for how to do this.
**array statistics** *arrayName*
Returns statistics about the distribution of data within the hashtable that represents the array. This information includes the number of entries in the table, the number of buckets, and the utilization of the buckets.
**array unset** *arrayName* ?*pattern*?
Unsets all of the elements in the array that match *pattern* (using the matching rules of **[string match](string.htm)**). If *arrayName* is not the name of an array variable or there are no matching elements in the array, no error will be raised. If *pattern* is omitted and *arrayName* is an array variable, then the command unsets the entire array. The command always returns an empty string.
Examples
--------
```
**array set** colorcount {
red 1
green 5
blue 4
white 9
}
foreach {color count} [**array get** colorcount] {
puts "Color: $color Count: $count"
}
**→** Color: blue Count: 4
Color: white Count: 9
Color: green Count: 5
Color: red Count: 1
foreach color [**array names** colorcount] {
puts "Color: $color Count: $colorcount($color)"
}
**→** Color: blue Count: 4
Color: white Count: 9
Color: green Count: 5
Color: red Count: 1
foreach color [lsort [**array names** colorcount]] {
puts "Color: $color Count: $colorcount($color)"
}
**→** Color: blue Count: 4
Color: green Count: 5
Color: red Count: 1
Color: white Count: 9
**array statistics** colorcount
**→** 4 entries in table, 4 buckets
number of buckets with 0 entries: 1
number of buckets with 1 entries: 2
number of buckets with 2 entries: 1
number of buckets with 3 entries: 0
number of buckets with 4 entries: 0
number of buckets with 5 entries: 0
number of buckets with 6 entries: 0
number of buckets with 7 entries: 0
number of buckets with 8 entries: 0
number of buckets with 9 entries: 0
number of buckets with 10 or more entries: 0
average search distance for entry: 1.2
```
See also
--------
**[list](list.htm)**, **[string](string.htm)**, **[variable](variable.htm)**, **[trace](trace.htm)**, **[foreach](foreach.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/array.htm>
| programming_docs |
tcl_tk source source
======
Name
----
source — Evaluate a file or resource as a Tcl script Synopsis
--------
**source** *fileName*
**source** **-encoding** *encodingName fileName*
Description
-----------
This command takes the contents of the specified file or resource and passes it to the Tcl interpreter as a text script. The return value from **source** is the return value of the last command executed in the script. If an error occurs in evaluating the contents of the script then the **source** command will return that error. If a **[return](return.htm)** command is invoked from within the script then the remainder of the file will be skipped and the **source** command will return normally with the result from the **[return](return.htm)** command. The end-of-file character for files is “\32” (^Z) for all platforms. The source command will read files up to this character. This restriction does not exist for the **[read](read.htm)** or **[gets](gets.htm)** commands, allowing for files containing code and data segments (scripted documents). If you require a “^Z” in code for string comparison, you can use “\032” or “\u001a”, which will be safely substituted by the Tcl interpreter into “^Z”.
A leading BOM (Byte order mark) contained in the file is ignored for unicode encodings (utf-8, unicode).
The **-encoding** option is used to specify the encoding of the data stored in *fileName*. When the **-encoding** option is omitted, the system encoding is assumed.
Example
-------
Run the script in the file **foo.tcl** and then the script in the file **bar.tcl**:
```
**source** foo.tcl
**source** bar.tcl
```
Alternatively:
```
foreach scriptFile {foo.tcl bar.tcl} {
**source** $scriptFile
}
```
See also
--------
**[file](file.htm)**, **[cd](cd.htm)**, **[encoding](encoding.htm)**, **[info](info.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/source.htm>
tcl_tk prefix prefix
======
[NAME](prefix.htm#M2) tcl::prefix — facilities for prefix matching
[SYNOPSIS](prefix.htm#M3)
[DESCRIPTION](prefix.htm#M4)
[**::tcl::prefix all** *table* *string*](prefix.htm#M5)
[**::tcl::prefix longest** *table* *string*](prefix.htm#M6)
[**::tcl::prefix match** ?*options*? *table* *string*](prefix.htm#M7)
[**-exact**](prefix.htm#M8)
[**-message** *string*](prefix.htm#M9)
[**-error** *options*](prefix.htm#M10)
[EXAMPLES](prefix.htm#M11)
[SEE ALSO](prefix.htm#M12)
[KEYWORDS](prefix.htm#M13)
Name
----
tcl::prefix — facilities for prefix matching Synopsis
--------
**::tcl::prefix all** *table* *string*
**::tcl::prefix longest** *table* *string*
**::tcl::prefix match** *?option ...?* *table* *string*
Description
-----------
This document describes commands looking up a prefix in a list of strings. The following commands are supported:
**::tcl::prefix all** *table* *string*
Returns a list of all elements in *table* that begin with the prefix *string*.
**::tcl::prefix longest** *table* *string*
Returns the longest common prefix of all elements in *table* that begin with the prefix *string*.
**::tcl::prefix match** ?*options*? *table* *string*
If *string* equals one element in *table* or is a prefix to exactly one element, the matched element is returned. If not, the result depends on the **-error** option. (It is recommended that the *table* be sorted before use with this subcommand, so that the list of matches presented in the error message also becomes sorted, though this is not strictly necessary for the operation of this subcommand itself.)
**-exact**
Accept only exact matches.
**-message** *string*
Use *string* in the error message at a mismatch. Default is “option”.
**-error** *options*
The *options* are used when no match is found. If *options* is empty, no error is generated and an empty string is returned. Otherwise the *options* are used as **[return](return.htm)** options when generating the error message. The default corresponds to setting “-level 0”. Example: If “**-error** {-errorcode MyError -level 1}” is used, an error would be generated as:
```
return -errorcode MyError -level 1 -code error \
"ambiguous option ..."
```
Examples
--------
Basic use:
```
namespace import ::tcl::prefix
**prefix match** {apa bepa cepa} apa
*→ apa*
**prefix match** {apa bepa cepa} a
*→ apa*
**prefix match** -exact {apa bepa cepa} a
*→ bad option "a": must be apa, bepa, or cepa*
**prefix match** -message "switch" {apa ada bepa cepa} a
*→ ambiguous switch "a": must be apa, ada, bepa, or cepa*
**prefix longest** {fblocked fconfigure fcopy file fileevent flush} fc
*→ fco*
**prefix all** {fblocked fconfigure fcopy file fileevent flush} fc
*→ fconfigure fcopy*
```
Simplifying option matching:
```
array set opts {-apa 1 -bepa "" -cepa 0}
foreach {arg val} $args {
set opts([**prefix match** {-apa -bepa -cepa} $arg]) $val
}
```
Creating a **[switch](switch.htm)** that supports prefixes:
```
switch [**prefix match** {apa bepa cepa} $arg] {
apa { }
bepa { }
cepa { }
}
```
See also
--------
**[lsearch](lsearch.htm)**, **[namespace](namespace.htm)**, **[string](string.htm)**, **[Tcl\_GetIndexFromObj](https://www.tcl.tk/man/tcl/TclLib/GetIndex.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/prefix.htm>
tcl_tk tell tell
====
Name
----
tell — Return current access position for an open channel Synopsis
--------
**tell** *channelId*
Description
-----------
Returns an integer string giving the current access position in *channelId*. This value returned is a byte offset that can be passed to **[seek](seek.htm)** in order to set the channel to a particular position. Note that this value is in terms of bytes, not characters like **[read](read.htm)**. The value returned is -1 for channels that do not support seeking. *ChannelId* must be an identifier for an open channel such as a Tcl standard channel (**[stdin](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)**, **[stdout](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)**, or **[stderr](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)**), the return value from an invocation of **[open](open.htm)** or **[socket](socket.htm)**, or the result of a channel creation command provided by a Tcl extension.
Example
-------
Read a line from a file channel only if it starts with **foobar**:
```
# Save the offset in case we need to undo the read...
set offset [**tell** $chan]
if {[read $chan 6] eq "foobar"} {
gets $chan line
} else {
set line {}
# Undo the read...
seek $chan $offset
}
```
See also
--------
**[file](file.htm)**, **[open](open.htm)**, **[close](close.htm)**, **[gets](gets.htm)**, **[seek](seek.htm)**, **[Tcl\_StandardChannels](https://www.tcl.tk/man/tcl/TclLib/StdChannels.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/tell.htm>
tcl_tk regsub regsub
======
[NAME](regsub.htm#M2) regsub — Perform substitutions based on regular expression pattern matching
[SYNOPSIS](regsub.htm#M3)
[DESCRIPTION](regsub.htm#M4)
[**-all**](regsub.htm#M5)
[**-expanded**](regsub.htm#M6)
[**-line**](regsub.htm#M7)
[**-linestop**](regsub.htm#M8)
[**-lineanchor**](regsub.htm#M9)
[**-nocase**](regsub.htm#M10)
[**-start** *index*](regsub.htm#M11)
[**--**](regsub.htm#M12)
[EXAMPLES](regsub.htm#M13)
[SEE ALSO](regsub.htm#M14)
[KEYWORDS](regsub.htm#M15)
Name
----
regsub — Perform substitutions based on regular expression pattern matching Synopsis
--------
**regsub** ?*switches*? *exp string subSpec* ?*varName*?
Description
-----------
This command matches the regular expression *exp* against *string*, and either copies *string* to the variable whose name is given by *varName* or returns *string* if *varName* is not present. (Regular expression matching is described in the **[re\_syntax](re_syntax.htm)** reference page.) If there is a match, then while copying *string* to *varName* (or to the result of this command if *varName* is not present) the portion of *string* that matched *exp* is replaced with *subSpec*. If *subSpec* contains a “&” or “\0”, then it is replaced in the substitution with the portion of *string* that matched *exp*. If *subSpec* contains a “\*n*”, where *n* is a digit between 1 and 9, then it is replaced in the substitution with the portion of *string* that matched the *n*'th parenthesized subexpression of *exp*. Additional backslashes may be used in *subSpec* to prevent special interpretation of “&”, “\0”, “\*n*” and backslashes. The use of backslashes in *subSpec* tends to interact badly with the Tcl parser's use of backslashes, so it is generally safest to enclose *subSpec* in braces if it includes backslashes. If the initial arguments to **regsub** start with **-** then they are treated as switches. The following switches are currently supported:
**-all**
All ranges in *string* that match *exp* are found and substitution is performed for each of these ranges. Without this switch only the first matching range is found and substituted. If **-all** is specified, then “&” and “\*n*” sequences are handled for each substitution using the information from the corresponding match.
**-expanded**
Enables use of the expanded regular expression syntax where whitespace and comments are ignored. This is the same as specifying the **(?x)** embedded option (see the **[re\_syntax](re_syntax.htm)** manual page).
**-line**
Enables newline-sensitive matching. By default, newline is a completely ordinary character with no special meaning. With this flag, “[^” bracket expressions and “.” never match newline, “^” matches an empty string after any newline in addition to its normal function, and “$” matches an empty string before any newline in addition to its normal function. This flag is equivalent to specifying both **-linestop** and **-lineanchor**, or the **(?n)** embedded option (see the **[re\_syntax](re_syntax.htm)** manual page).
**-linestop**
Changes the behavior of “[^” bracket expressions and “.” so that they stop at newlines. This is the same as specifying the **(?p)** embedded option (see the **[re\_syntax](re_syntax.htm)** manual page).
**-lineanchor**
Changes the behavior of “^” and “$” (the “anchors”) so they match the beginning and end of a line respectively. This is the same as specifying the **(?w)** embedded option (see the **[re\_syntax](re_syntax.htm)** manual page).
**-nocase**
Upper-case characters in *string* will be converted to lower-case before matching against *exp*; however, substitutions specified by *subSpec* use the original unconverted form of *string*.
**-start** *index*
Specifies a character index offset into the string to start matching the regular expression at. The *index* value is interpreted in the same manner as the *index* argument to **[string index](string.htm)**. When using this switch, “^” will not match the beginning of the line, and \A will still match the start of the string at *index*. *index* will be constrained to the bounds of the input string.
**--**
Marks the end of switches. The argument following this one will be treated as *exp* even if it starts with a **-**.
If *varName* is supplied, the command returns a count of the number of matching ranges that were found and replaced, otherwise the string after replacement is returned. See the manual entry for **[regexp](regexp.htm)** for details on the interpretation of regular expressions.
Examples
--------
Replace (in the string in variable *string*) every instance of **foo** which is a word by itself with **bar**:
```
**regsub** -all {\mfoo\M} $string bar string
```
or (using the “basic regular expression” syntax):
```
**regsub** -all {(?b)\<foo\>} $string bar string
```
Insert double-quotes around the first instance of the word **interesting**, however it is capitalized.
```
**regsub** -nocase {\yinteresting\y} $string {"&"} string
```
Convert all non-ASCII and Tcl-significant characters into \u escape sequences by using **regsub** and **[subst](subst.htm)** in combination:
```
# This RE is just a character class for almost everything "bad"
set RE {[][{};#\\\$ \r\t\u0080-\uffff]}
# We will substitute with a fragment of Tcl script in brackets
set substitution {[format \\\\u%04x [scan "\\&" %c]]}
# Now we apply the substitution to get a subst-string that
# will perform the computational parts of the conversion. Note
# that newline is handled specially through **[string map](string.htm)** since
# backslash-newline is a special sequence.
set quoted [subst [string map {\n {\\u000a}} \
[**regsub** -all $RE $string $substitution]]]
```
See also
--------
**[regexp](regexp.htm)**, **[re\_syntax](re_syntax.htm)**, **[subst](subst.htm)**, **[string](string.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/regsub.htm>
tcl_tk gets gets
====
Name
----
gets — Read a line from a channel Synopsis
--------
**gets** *channelId* ?*varName*?
Description
-----------
This command reads the next line from *channelId*, returns everything in the line up to (but not including) the end-of-line character(s), and discards the end-of-line character(s). *ChannelId* must be an identifier for an open channel such as the Tcl standard input channel (**[stdin](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)**), the return value from an invocation of **[open](open.htm)** or **[socket](socket.htm)**, or the result of a channel creation command provided by a Tcl extension. The channel must have been opened for input.
If *varName* is omitted the line is returned as the result of the command. If *varName* is specified then the line is placed in the variable by that name and the return value is a count of the number of characters returned.
If end of file occurs while scanning for an end of line, the command returns whatever input is available up to the end of file. If *channelId* is in non-blocking mode and there is not a full line of input available, the command returns an empty string and does not consume any input. If *varName* is specified and an empty string is returned in *varName* because of end-of-file or because of insufficient data in non-blocking mode, then the return count is -1. Note that if *varName* is not specified then the end-of-file and no-full-line-available cases can produce the same results as if there were an input line consisting only of the end-of-line character(s). The **[eof](eof.htm)** and **[fblocked](fblocked.htm)** commands can be used to distinguish these three cases.
Example
-------
This example reads a file one line at a time and prints it out with the current line number attached to the start of each line.
```
set chan [open "some.file.txt"]
set lineNumber 0
while {[**gets** $chan line] >= 0} {
puts "[incr lineNumber]: $line"
}
close $chan
```
See also
--------
**[file](file.htm)**, **[eof](eof.htm)**, **[fblocked](fblocked.htm)**, **[Tcl\_StandardChannels](https://www.tcl.tk/man/tcl/TclLib/StdChannels.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/gets.htm>
tcl_tk proc proc
====
Name
----
proc — Create a Tcl procedure Synopsis
--------
**proc** *name args body*
Description
-----------
The **proc** command creates a new Tcl procedure named *name*, replacing any existing command or procedure there may have been by that name. Whenever the new command is invoked, the contents of *body* will be executed by the Tcl interpreter. Normally, *name* is unqualified (does not include the names of any containing namespaces), and the new procedure is created in the current namespace. If *name* includes any namespace qualifiers, the procedure is created in the specified namespace. *Args* specifies the formal arguments to the procedure. It consists of a list, possibly empty, each of whose elements specifies one argument. Each argument specifier is also a list with either one or two fields. If there is only a single field in the specifier then it is the name of the argument; if there are two fields, then the first is the argument name and the second is its default value. Arguments with default values that are followed by non-defaulted arguments become required arguments; enough actual arguments must be supplied to allow all arguments up to and including the last required formal argument. When *name* is invoked a local variable will be created for each of the formal arguments to the procedure; its value will be the value of corresponding argument in the invoking command or the argument's default value. Actual arguments are assigned to formal arguments strictly in order. Arguments with default values need not be specified in a procedure invocation. However, there must be enough actual arguments for all the formal arguments that do not have defaults, and there must not be any extra actual arguments. Arguments with default values that are followed by non-defaulted arguments become de-facto required arguments, though this may change in a future version of Tcl; portable code should ensure that all optional arguments come after all required arguments.
There is one special case to permit procedures with variable numbers of arguments. If the last formal argument has the name “**args**”, then a call to the procedure may contain more actual arguments than the procedure has formal arguments. In this case, all of the actual arguments starting at the one that would be assigned to **args** are combined into a list (as if the **[list](list.htm)** command had been used); this combined value is assigned to the local variable **args**.
When *body* is being executed, variable names normally refer to local variables, which are created automatically when referenced and deleted when the procedure returns. One local variable is automatically created for each of the procedure's arguments. Other variables can only be accessed by invoking one of the **[global](global.htm)**, **[variable](variable.htm)**, **[upvar](upvar.htm)** or **[namespace upvar](namespace.htm)** commands. The current namespace when *body* is executed will be the namespace that the procedure's name exists in, which will be the namespace that it was created in unless it has been changed with **[rename](rename.htm)**.
The **proc** command returns an empty string. When a procedure is invoked, the procedure's return value is the value specified in a **[return](return.htm)** command. If the procedure does not execute an explicit **[return](return.htm)**, then its return value is the value of the last command executed in the procedure's body. If an error occurs while executing the procedure body, then the procedure-as-a-whole will return that same error.
Examples
--------
This is a procedure that takes two arguments and prints both their sum and their product. It also returns the string “OK” to the caller as an explicit result.
```
**proc** printSumProduct {x y} {
set sum [expr {$x + $y}]
set prod [expr {$x * $y}]
puts "sum is $sum, product is $prod"
return "OK"
}
```
This is a procedure that accepts arbitrarily many arguments and prints them out, one by one.
```
**proc** printArguments args {
foreach arg $args {
puts $arg
}
}
```
This procedure is a bit like the **[incr](incr.htm)** command, except it multiplies the contents of the named variable by the value, which defaults to **2**:
```
**proc** mult {varName {multiplier 2}} {
upvar 1 $varName var
set var [expr {$var * $multiplier}]
}
```
See also
--------
**[info](info.htm)**, **[unknown](unknown.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/proc.htm>
| programming_docs |
tcl_tk break break
=====
Name
----
break — Abort looping command Synopsis
--------
**break**
Description
-----------
This command is typically invoked inside the body of a looping command such as **[for](for.htm)** or **[foreach](foreach.htm)** or **[while](while.htm)**. It returns a 3 (**[TCL\_BREAK](catch.htm)**) result code, which causes a break exception to occur. The exception causes the current script to be aborted out to the innermost containing loop command, which then aborts its execution and returns normally. Break exceptions are also handled in a few other situations, such as the **[catch](catch.htm)** command, Tk event bindings, and the outermost scripts of procedure bodies. Example
-------
Print a line for each of the integers from 0 to 5:
```
for {set x 0} {$x<10} {incr x} {
if {$x > 5} {
**break**
}
puts "x is $x"
}
```
See also
--------
**[catch](catch.htm)**, **[continue](continue.htm)**, **[for](for.htm)**, **[foreach](foreach.htm)**, **[return](return.htm)**, **[while](while.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/break.htm>
tcl_tk filename filename
========
[NAME](filename.htm#M2) filename — File name conventions supported by Tcl commands
[INTRODUCTION](filename.htm#M3)
[PATH TYPES](filename.htm#M4)
[PATH SYNTAX](filename.htm#M5)
[**Unix**](filename.htm#M6)
[**/**](filename.htm#M7)
[**/etc/passwd**](filename.htm#M8)
[**.**](filename.htm#M9)
[**foo**](filename.htm#M10)
[**foo/bar**](filename.htm#M11)
[**../foo**](filename.htm#M12)
[**Windows**](filename.htm#M13)
[**\\Host\share/file**](filename.htm#M14)
[**c:foo**](filename.htm#M15)
[**c:/foo**](filename.htm#M16)
[**foo\bar**](filename.htm#M17)
[**\foo**](filename.htm#M18)
[**\\foo**](filename.htm#M19)
[TILDE SUBSTITUTION](filename.htm#M20)
[PORTABILITY ISSUES](filename.htm#M21)
[SEE ALSO](filename.htm#M22)
[KEYWORDS](filename.htm#M23)
Name
----
filename — File name conventions supported by Tcl commands Introduction
------------
All Tcl commands and C procedures that take file names as arguments expect the file names to be in one of three forms, depending on the current platform. On each platform, Tcl supports file names in the standard forms(s) for that platform. In addition, on all platforms, Tcl supports a Unix-like syntax intended to provide a convenient way of constructing simple file names. However, scripts that are intended to be portable should not assume a particular form for file names. Instead, portable scripts must use the **[file split](file.htm)** and **file join** commands to manipulate file names (see the **[file](file.htm)** manual entry for more details). Path types
----------
File names are grouped into three general types based on the starting point for the path used to specify the file: absolute, relative, and volume-relative. Absolute names are completely qualified, giving a path to the file relative to a particular volume and the root directory on that volume. Relative names are unqualified, giving a path to the file relative to the current working directory. Volume-relative names are partially qualified, either giving the path relative to the root directory on the current volume, or relative to the current directory of the specified volume. The **[file pathtype](file.htm)** command can be used to determine the type of a given path. Path syntax
-----------
The rules for native names depend on the value reported in the Tcl **[platform](platform.htm)** element of the **[tcl\_platform](tclvars.htm)** array:
**Unix**
On Unix and Apple MacOS X platforms, Tcl uses path names where the components are separated by slashes. Path names may be relative or absolute, and file names may contain any character other than slash. The file names **.** and **..** are special and refer to the current directory and the parent of the current directory respectively. Multiple adjacent slash characters are interpreted as a single separator. Any number of trailing slash characters at the end of a path are simply ignored, so the paths **foo**, **foo/** and **foo//** are all identical, and in particular **foo/** does not necessarily mean a directory is being referred. The following examples illustrate various forms of path names:
**/**
Absolute path to the root directory.
**/etc/passwd**
Absolute path to the file named **passwd** in the directory **etc** in the root directory.
**.**
Relative path to the current directory.
**foo**
Relative path to the file **foo** in the current directory.
**foo/bar**
Relative path to the file **bar** in the directory **foo** in the current directory.
**../foo**
Relative path to the file **foo** in the directory above the current directory.
**Windows**
On Microsoft Windows platforms, Tcl supports both drive-relative and UNC style names. Both **/** and **\** may be used as directory separators in either type of name. Drive-relative names consist of an optional drive specifier followed by an absolute or relative path. UNC paths follow the general form **\\servername\sharename\path\file**, but must at the very least contain the server and share components, i.e. **\\servername\sharename**. In both forms, the file names **.** and **..** are special and refer to the current directory and the parent of the current directory respectively. The following examples illustrate various forms of path names:
**\\Host\share/file**
Absolute UNC path to a file called **[file](file.htm)** in the root directory of the export point **share** on the host **Host**. Note that repeated use of **[file dirname](file.htm)** on this path will give **//Host/share**, and will never give just **//Host**.
**c:foo**
Volume-relative path to a file **foo** in the current directory on drive **c**.
**c:/foo**
Absolute path to a file **foo** in the root directory of drive **c**.
**foo\bar**
Relative path to a file **bar** in the **foo** directory in the current directory on the current volume.
**\foo**
Volume-relative path to a file **foo** in the root directory of the current volume.
**\\foo**
Volume-relative path to a file **foo** in the root directory of the current volume. This is not a valid UNC path, so the assumption is that the extra backslashes are superfluous.
Tilde substitution
------------------
In addition to the file name rules described above, Tcl also supports *csh*-style tilde substitution. If a file name starts with a tilde, then the file name will be interpreted as if the first element is replaced with the location of the home directory for the given user. If the tilde is followed immediately by a separator, then the **$HOME** environment variable is substituted. Otherwise the characters between the tilde and the next separator are taken as a user name, which is used to retrieve the user's home directory for substitution. This works on Unix, MacOS X and Windows (except very old releases). Old Windows platforms do not support tilde substitution when a user name follows the tilde. On these platforms, attempts to use a tilde followed by a user name will generate an error that the user does not exist when Tcl attempts to interpret that part of the path or otherwise access the file. The behaviour of these paths when not trying to interpret them is the same as on Unix. File names that have a tilde without a user name will be correctly substituted using the **$HOME** environment variable, just like for Unix.
Portability issues
------------------
Not all file systems are case sensitive, so scripts should avoid code that depends on the case of characters in a file name. In addition, the character sets allowed on different devices may differ, so scripts should choose file names that do not contain special characters like: **<>:?"/\|**. The safest approach is to use names consisting of alphanumeric characters only. Care should be taken with filenames which contain spaces (common on Windows systems) and filenames where the backslash is the directory separator (Windows native path names). Also Windows 3.1 only supports file names with a root of no more than 8 characters and an extension of no more than 3 characters. On Windows platforms there are file and path length restrictions. Complete paths or filenames longer than about 260 characters will lead to errors in most file operations.
Another Windows peculiarity is that any number of trailing dots “.” in filenames are totally ignored, so, for example, attempts to create a file or directory with a name “foo.” will result in the creation of a file/directory with name “foo”. This fact is reflected in the results of **[file normalize](file.htm)**. Furthermore, a file name consisting only of dots “.........” or dots with trailing characters “.....abc” is illegal.
See also
--------
**[file](file.htm)**, **[glob](glob.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/filename.htm>
tcl_tk chan chan
====
[NAME](chan.htm#M2) chan — Read, write and manipulate channels
[SYNOPSIS](chan.htm#M3)
[DESCRIPTION](chan.htm#M4)
[**chan blocked** *channelId*](chan.htm#M5)
[**chan close** *channelId* ?*direction*?](chan.htm#M6)
[**chan configure** *channelId* ?*optionName*? ?*value*? ?*optionName value*?...](chan.htm#M7)
[**-blocking** *boolean*](chan.htm#M8)
[**-buffering** *newValue*](chan.htm#M9)
[**-buffersize** *newSize*](chan.htm#M10)
[**-encoding** *name*](chan.htm#M11)
[**-eofchar** *char*](chan.htm#M12)
[**-eofchar** **{***inChar outChar***}**](chan.htm#M13)
[**-translation** *mode*](chan.htm#M14)
[**-translation** **{***inMode outMode***}**](chan.htm#M15)
[**auto**](chan.htm#M16)
[**binary**](chan.htm#M17)
[**cr**](chan.htm#M18)
[**crlf**](chan.htm#M19)
[**lf**](chan.htm#M20)
[**chan copy** *inputChan outputChan* ?**-size** *size*? ?**-command** *callback*?](chan.htm#M21)
[**chan create** *mode cmdPrefix*](chan.htm#M22)
[**chan eof** *channelId*](chan.htm#M23)
[**chan event** *channelId event* ?*script*?](chan.htm#M24)
[**chan flush** *channelId*](chan.htm#M25)
[**chan gets** *channelId* ?*varName*?](chan.htm#M26)
[**chan names** ?*pattern*?](chan.htm#M27)
[**chan pending** *mode channelId*](chan.htm#M28)
[**chan pipe**](chan.htm#M29)
[**chan pop** *channelId*](chan.htm#M30)
[**chan postevent** *channelId eventSpec*](chan.htm#M31)
[**chan push** *channelId cmdPrefix*](chan.htm#M32)
[**chan puts** ?**-nonewline**? ?*channelId*? *string*](chan.htm#M33)
[**chan read** *channelId* ?*numChars*?](chan.htm#M34)
[**chan read** ?**-nonewline**? *channelId*](chan.htm#M35)
[**chan read** *channelId numChars*](chan.htm#M36)
[**chan read** *channelId*](chan.htm#M37)
[**chan seek** *channelId offset* ?*origin*?](chan.htm#M38)
[**start**](chan.htm#M39)
[**current**](chan.htm#M40)
[**end**](chan.htm#M41)
[**chan tell** *channelId*](chan.htm#M42)
[**chan truncate** *channelId* ?*length*?](chan.htm#M43)
[EXAMPLES](chan.htm#M44)
[SEE ALSO](chan.htm#M45)
[KEYWORDS](chan.htm#M46)
Name
----
chan — Read, write and manipulate channels Synopsis
--------
**chan** *option* ?*arg arg ...*?
Description
-----------
This command provides several operations for reading from, writing to and otherwise manipulating open channels (such as have been created with the **[open](open.htm)** and **[socket](socket.htm)** commands, or the default named channels **[stdin](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)**, **[stdout](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)** or **[stderr](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)** which correspond to the process's standard input, output and error streams respectively). *Option* indicates what to do with the channel; any unique abbreviation for *option* is acceptable. Valid options are:
**chan blocked** *channelId*
This tests whether the last input operation on the channel called *channelId* failed because it would have otherwise caused the process to block, and returns 1 if that was the case. It returns 0 otherwise. Note that this only ever returns 1 when the channel has been configured to be non-blocking; all Tcl channels have blocking turned on by default.
**chan close** *channelId* ?*direction*?
Close and destroy the channel called *channelId*. Note that this deletes all existing file-events registered on the channel. If the *direction* argument (which must be **[read](read.htm)** or **write** or any unique abbreviation of them) is present, the channel will only be half-closed, so that it can go from being read-write to write-only or read-only respectively. If a read-only channel is closed for reading, it is the same as if the channel is fully closed, and respectively similar for write-only channels. Without the *direction* argument, the channel is closed for both reading and writing (but only if those directions are currently open). It is an error to close a read-only channel for writing, or a write-only channel for reading. As part of closing the channel, all buffered output is flushed to the channel's output device (only if the channel is ceasing to be writable), any buffered input is discarded (only if the channel is ceasing to be readable), the underlying operating system resource is closed and *channelId* becomes unavailable for future use (both only if the channel is being completely closed).
If the channel is blocking and the channel is ceasing to be writable, the command does not return until all output is flushed. If the channel is non-blocking and there is unflushed output, the channel remains open and the command returns immediately; output will be flushed in the background and the channel will be closed when all the flushing is complete.
If *channelId* is a blocking channel for a command pipeline then **chan close** waits for the child processes to complete.
If the channel is shared between interpreters, then **chan close** makes *channelId* unavailable in the invoking interpreter but has no other effect until all of the sharing interpreters have closed the channel. When the last interpreter in which the channel is registered invokes **chan close** (or **[close](close.htm)**), the cleanup actions described above occur. With half-closing, the half-close of the channel only applies to the current interpreter's view of the channel until all channels have closed it in that direction (or completely). See the **[interp](interp.htm)** command for a description of channel sharing.
Channels are automatically fully closed when an interpreter is destroyed and when the process exits. Channels are switched to blocking mode, to ensure that all output is correctly flushed before the process exits.
The command returns an empty string, and may generate an error if an error occurs while flushing output. If a command in a command pipeline created with **[open](open.htm)** returns an error, **chan close** generates an error (similar to the **[exec](exec.htm)** command.)
Note that half-closes of sockets and command pipelines can have important side effects because they result in a shutdown() or close() of the underlying system resource, which can change how other processes or systems respond to the Tcl program.
**chan configure** *channelId* ?*optionName*? ?*value*? ?*optionName value*?...
Query or set the configuration options of the channel named *channelId*. If no *optionName* or *value* arguments are supplied, the command returns a list containing alternating option names and values for the channel. If *optionName* is supplied but no *value* then the command returns the current value of the given option. If one or more pairs of *optionName* and *value* are supplied, the command sets each of the named options to the corresponding *value*; in this case the return value is an empty string.
The options described below are supported for all channels. In addition, each channel type may add options that only it supports. See the manual entry for the command that creates each type of channel for the options supported by that specific type of channel. For example, see the manual entry for the **[socket](socket.htm)** command for additional options for sockets, and the **[open](open.htm)** command for additional options for serial devices.
**-blocking** *boolean*
The **-blocking** option determines whether I/O operations on the channel can cause the process to block indefinitely. The value of the option must be a proper boolean value. Channels are normally in blocking mode; if a channel is placed into non-blocking mode it will affect the operation of the **chan gets**, **chan read**, **chan puts**, **chan flush**, and **chan close** commands; see the documentation for those commands for details. For non-blocking mode to work correctly, the application must be using the Tcl event loop (e.g. by calling **[Tcl\_DoOneEvent](https://www.tcl.tk/man/tcl/TclLib/DoOneEvent.htm)** or invoking the **[vwait](vwait.htm)** command).
**-buffering** *newValue*
If *newValue* is **full** then the I/O system will buffer output until its internal buffer is full or until the **chan flush** command is invoked. If *newValue* is **line**, then the I/O system will automatically flush output for the channel whenever a newline character is output. If *newValue* is **none**, the I/O system will flush automatically after every output operation. The default is for **-buffering** to be set to **full** except for channels that connect to terminal-like devices; for these channels the initial setting is **line**. Additionally, **[stdin](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)** and **[stdout](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)** are initially set to **line**, and **[stderr](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)** is set to **none**.
**-buffersize** *newSize*
*Newvalue* must be an integer; its value is used to set the size of buffers, in bytes, subsequently allocated for this channel to store input or output. *Newvalue* must be a number of no more than one million, allowing buffers of up to one million bytes in size.
**-encoding** *name*
This option is used to specify the encoding of the channel as one of the named encodings returned by **[encoding names](encoding.htm)** or the special value **[binary](binary.htm)**, so that the data can be converted to and from Unicode for use in Tcl. For instance, in order for Tcl to read characters from a Japanese file in **shiftjis** and properly process and display the contents, the encoding would be set to **shiftjis**. Thereafter, when reading from the channel, the bytes in the Japanese file would be converted to Unicode as they are read. Writing is also supported - as Tcl strings are written to the channel they will automatically be converted to the specified encoding on output. If a file contains pure binary data (for instance, a JPEG image), the encoding for the channel should be configured to be **[binary](binary.htm)**. Tcl will then assign no interpretation to the data in the file and simply read or write raw bytes. The Tcl **[binary](binary.htm)** command can be used to manipulate this byte-oriented data. It is usually better to set the **-translation** option to **[binary](binary.htm)** when you want to transfer binary data, as this turns off the other automatic interpretations of the bytes in the stream as well.
The default encoding for newly opened channels is the same platform- and locale-dependent system encoding used for interfacing with the operating system, as returned by **[encoding system](encoding.htm)**.
**-eofchar** *char*
**-eofchar** **{***inChar outChar***}**
This option supports DOS file systems that use Control-z (\x1a) as an end of file marker. If *char* is not an empty string, then this character signals end-of-file when it is encountered during input. For output, the end-of-file character is output when the channel is closed. If *char* is the empty string, then there is no special end of file character marker. For read-write channels, a two-element list specifies the end of file marker for input and output, respectively. As a convenience, when setting the end-of-file character for a read-write channel you can specify a single value that will apply to both reading and writing. When querying the end-of-file character of a read-write channel, a two-element list will always be returned. The default value for **-eofchar** is the empty string in all cases except for files under Windows. In that case the **-eofchar** is Control-z (\x1a) for reading and the empty string for writing. The acceptable range for **-eofchar** values is \x01 - \x7f; attempting to set **-eofchar** to a value outside of this range will generate an error.
**-translation** *mode*
**-translation** **{***inMode outMode***}**
In Tcl scripts the end of a line is always represented using a single newline character (\n). However, in actual files and devices the end of a line may be represented differently on different platforms, or even for different devices on the same platform. For example, under UNIX newlines are used in files, whereas carriage-return-linefeed sequences are normally used in network connections. On input (i.e., with **chan gets** and **chan read**) the Tcl I/O system automatically translates the external end-of-line representation into newline characters. Upon output (i.e., with **chan puts**), the I/O system translates newlines to the external end-of-line representation. The default translation mode, **auto**, handles all the common cases automatically, but the **-translation** option provides explicit control over the end of line translations. The value associated with **-translation** is a single item for read-only and write-only channels. The value is a two-element list for read-write channels; the read translation mode is the first element of the list, and the write translation mode is the second element. As a convenience, when setting the translation mode for a read-write channel you can specify a single value that will apply to both reading and writing. When querying the translation mode of a read-write channel, a two-element list will always be returned. The following values are currently supported:
**auto**
As the input translation mode, **auto** treats any of newline (**lf**), carriage return (**cr**), or carriage return followed by a newline (**crlf**) as the end of line representation. The end of line representation can even change from line-to-line, and all cases are translated to a newline. As the output translation mode, **auto** chooses a platform specific representation; for sockets on all platforms Tcl chooses **crlf**, for all Unix flavors, it chooses **lf**, and for the various flavors of Windows it chooses **crlf**. The default setting for **-translation** is **auto** for both input and output.
**binary**
No end-of-line translations are performed. This is nearly identical to **lf** mode, except that in addition **[binary](binary.htm)** mode also sets the end-of-file character to the empty string (which disables it) and sets the encoding to **[binary](binary.htm)** (which disables encoding filtering). See the description of **-eofchar** and **-encoding** for more information.
**cr**
The end of a line in the underlying file or device is represented by a single carriage return character. As the input translation mode, **cr** mode converts carriage returns to newline characters. As the output translation mode, **cr** mode translates newline characters to carriage returns.
**crlf**
The end of a line in the underlying file or device is represented by a carriage return character followed by a linefeed character. As the input translation mode, **crlf** mode converts carriage-return-linefeed sequences to newline characters. As the output translation mode, **crlf** mode translates newline characters to carriage-return-linefeed sequences. This mode is typically used on Windows platforms and for network connections.
**lf**
The end of a line in the underlying file or device is represented by a single newline (linefeed) character. In this mode no translations occur during either input or output. This mode is typically used on UNIX platforms.
**chan copy** *inputChan outputChan* ?**-size** *size*? ?**-command** *callback*?
Copy data from the channel *inputChan*, which must have been opened for reading, to the channel *outputChan*, which must have been opened for writing. The **chan copy** command leverages the buffering in the Tcl I/O system to avoid extra copies and to avoid buffering too much data in main memory when copying large files to slow destinations like network sockets. The **chan copy** command transfers data from *inputChan* until end of file or *size* bytes or characters have been transferred; *size* is in bytes if the two channels are using the same encoding, and is in characters otherwise. If no **-size** argument is given, then the copy goes until end of file. All the data read from *inputChan* is copied to *outputChan*. Without the **-command** option, **chan copy** blocks until the copy is complete and returns the number of bytes or characters (using the same rules as for the **-size** option) written to *outputChan*.
The **-command** argument makes **chan copy** work in the background. In this case it returns immediately and the *callback* is invoked later when the copy completes. The *callback* is called with one or two additional arguments that indicates how many bytes were written to *outputChan*. If an error occurred during the background copy, the second argument is the error string associated with the error. With a background copy, it is not necessary to put *inputChan* or *outputChan* into non-blocking mode; the **chan copy** command takes care of that automatically. However, it is necessary to enter the event loop by using the **[vwait](vwait.htm)** command or by using Tk.
You are not allowed to do other I/O operations with *inputChan* or *outputChan* during a background **chan copy**. If either *inputChan* or *outputChan* get closed while the copy is in progress, the current copy is stopped and the command callback is *not* made. If *inputChan* is closed, then all data already queued for *outputChan* is written out.
Note that *inputChan* can become readable during a background copy. You should turn off any **chan event** or **[fileevent](fileevent.htm)** handlers during a background copy so those handlers do not interfere with the copy. Any I/O attempted by a **chan event** or **[fileevent](fileevent.htm)** handler will get a “channel busy” error.
**Chan copy** translates end-of-line sequences in *inputChan* and *outputChan* according to the **-translation** option for these channels (see **chan configure** above). The translations mean that the number of bytes read from *inputChan* can be different than the number of bytes written to *outputChan*. Only the number of bytes written to *outputChan* is reported, either as the return value of a synchronous **chan copy** or as the argument to the callback for an asynchronous **chan copy**.
**Chan copy** obeys the encodings and character translations configured for the channels. This means that the incoming characters are converted internally first UTF-8 and then into the encoding of the channel **chan copy** writes to (see **chan configure** above for details on the **-encoding** and **-translation** options). No conversion is done if both channels are set to encoding **[binary](binary.htm)** and have matching translations. If only the output channel is set to encoding **[binary](binary.htm)** the system will write the internal UTF-8 representation of the incoming characters. If only the input channel is set to encoding **[binary](binary.htm)** the system will assume that the incoming bytes are valid UTF-8 characters and convert them according to the output encoding. The behaviour of the system for bytes which are not valid UTF-8 characters is undefined in this case.
**chan create** *mode cmdPrefix*
This subcommand creates a new script level channel using the command prefix *cmdPrefix* as its handler. Any such channel is called a **reflected** channel. The specified command prefix, **cmdPrefix**, must be a non-empty list, and should provide the API described in the **[refchan](refchan.htm)** manual page. The handle of the new channel is returned as the result of the **chan create** command, and the channel is open. Use either **[close](close.htm)** or **chan close** to remove the channel. The argument *mode* specifies if the new channel is opened for reading, writing, or both. It has to be a list containing any of the strings “**[read](read.htm)**” or “**write**”. The list must have at least one element, as a channel you can neither write to nor read from makes no sense. The handler command for the new channel must support the chosen mode, or an error is thrown.
The command prefix is executed in the global namespace, at the top of call stack, following the appending of arguments as described in the **[refchan](refchan.htm)** manual page. Command resolution happens at the time of the call. Renaming the command, or destroying it means that the next call of a handler method may fail, causing the channel command invoking the handler to fail as well. Depending on the subcommand being invoked, the error message may not be able to explain the reason for that failure.
Every channel created with this subcommand knows which interpreter it was created in, and only ever executes its handler command in that interpreter, even if the channel was shared with and/or was moved into a different interpreter. Each reflected channel also knows the thread it was created in, and executes its handler command only in that thread, even if the channel was moved into a different thread. To this end all invocations of the handler are forwarded to the original thread by posting special events to it. This means that the original thread (i.e. the thread that executed the **chan create** command) must have an active event loop, i.e. it must be able to process such events. Otherwise the thread sending them will *block indefinitely*. Deadlock may occur.
Note that this permits the creation of a channel whose two endpoints live in two different threads, providing a stream-oriented bridge between these threads. In other words, we can provide a way for regular stream communication between threads instead of having to send commands.
When a thread or interpreter is deleted, all channels created with this subcommand and using this thread/interpreter as their computing base are deleted as well, in all interpreters they have been shared with or moved into, and in whatever thread they have been transferred to. While this pulls the rug out under the other thread(s) and/or interpreter(s), this cannot be avoided. Trying to use such a channel will cause the generation of a regular error about unknown channel handles.
This subcommand is **[safe](safe.htm)** and made accessible to safe interpreters. While it arranges for the execution of arbitrary Tcl code the system also makes sure that the code is always executed within the safe interpreter.
**chan eof** *channelId*
Test whether the last input operation on the channel called *channelId* failed because the end of the data stream was reached, returning 1 if end-of-file was reached, and 0 otherwise.
**chan event** *channelId event* ?*script*?
Arrange for the Tcl script *script* to be installed as a *file event handler* to be called whenever the channel called *channelId* enters the state described by *event* (which must be either **readable** or **writable**); only one such handler may be installed per event per channel at a time. If *script* is the empty string, the current handler is deleted (this also happens if the channel is closed or the interpreter deleted). If *script* is omitted, the currently installed script is returned (or an empty string if no such handler is installed). The callback is only performed if the event loop is being serviced (e.g. via **[vwait](vwait.htm)** or **[update](update.htm)**). A file event handler is a binding between a channel and a script, such that the script is evaluated whenever the channel becomes readable or writable. File event handlers are most commonly used to allow data to be received from another process on an event-driven basis, so that the receiver can continue to interact with the user or with other channels while waiting for the data to arrive. If an application invokes **chan gets** or **chan read** on a blocking channel when there is no input data available, the process will block; until the input data arrives, it will not be able to service other events, so it will appear to the user to “freeze up”. With **chan event**, the process can tell when data is present and only invoke **chan gets** or **chan read** when they will not block.
A channel is considered to be readable if there is unread data available on the underlying device. A channel is also considered to be readable if there is unread data in an input buffer, except in the special case where the most recent attempt to read from the channel was a **chan gets** call that could not find a complete line in the input buffer. This feature allows a file to be read a line at a time in non-blocking mode using events. A channel is also considered to be readable if an end of file or error condition is present on the underlying file or device. It is important for *script* to check for these conditions and handle them appropriately; for example, if there is no special check for end of file, an infinite loop may occur where *script* reads no data, returns, and is immediately invoked again.
A channel is considered to be writable if at least one byte of data can be written to the underlying file or device without blocking, or if an error condition is present on the underlying file or device. Note that client sockets opened in asynchronous mode become writable when they become connected or if the connection fails.
Event-driven I/O works best for channels that have been placed into non-blocking mode with the **chan configure** command. In blocking mode, a **chan puts** command may block if you give it more data than the underlying file or device can accept, and a **chan gets** or **chan read** command will block if you attempt to read more data than is ready; no events will be processed while the commands block. In non-blocking mode **chan puts**, **chan read**, and **chan gets** never block.
The script for a file event is executed at global level (outside the context of any Tcl procedure) in the interpreter in which the **chan event** command was invoked. If an error occurs while executing the script then the command registered with **[interp bgerror](interp.htm)** is used to report the error. In addition, the file event handler is deleted if it ever returns an error; this is done in order to prevent infinite loops due to buggy handlers.
**chan flush** *channelId*
Ensures that all pending output for the channel called *channelId* is written. If the channel is in blocking mode the command does not return until all the buffered output has been flushed to the channel. If the channel is in non-blocking mode, the command may return before all buffered output has been flushed; the remainder will be flushed in the background as fast as the underlying file or device is able to absorb it.
**chan gets** *channelId* ?*varName*?
Reads the next line from the channel called *channelId*. If *varName* is not specified, the result of the command will be the line that has been read (without a trailing newline character) or an empty string upon end-of-file or, in non-blocking mode, if the data available is exhausted. If *varName* is specified, the line that has been read will be written to the variable called *varName* and result will be the number of characters that have been read or -1 if end-of-file was reached or, in non-blocking mode, if the data available is exhausted. If an end-of-file occurs while part way through reading a line, the partial line will be returned (or written into *varName*). When *varName* is not specified, the end-of-file case can be distinguished from an empty line using the **chan eof** command, and the partial-line-but-non-blocking case can be distinguished with the **chan blocked** command.
**chan names** ?*pattern*?
Produces a list of all channel names. If *pattern* is specified, only those channel names that match it (according to the rules of **[string match](string.htm)**) will be returned.
**chan pending** *mode channelId*
Depending on whether *mode* is **input** or **output**, returns the number of bytes of input or output (respectively) currently buffered internally for *channelId* (especially useful in a readable event callback to impose application-specific limits on input line lengths to avoid a potential denial-of-service attack where a hostile user crafts an extremely long line that exceeds the available memory to buffer it). Returns -1 if the channel was not opened for the mode in question.
**chan pipe**
Creates a standalone pipe whose read- and write-side channels are returned as a 2-element list, the first element being the read side and the second the write side. Can be useful e.g. to redirect separately **[stderr](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)** and **[stdout](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)** from a subprocess. To do this, spawn with "2>@" or ">@" redirection operators onto the write side of a pipe, and then immediately close it in the parent. This is necessary to get an EOF on the read side once the child has exited or otherwise closed its output. Note that the pipe buffering semantics can vary at the operating system level substantially; it is not safe to assume that a write performed on the output side of the pipe will appear instantly to the input side. This is a fundamental difference and Tcl cannot conceal it. The overall stream semantics *are* compatible, so blocking reads and writes will not see most of the differences, but the details of what exactly gets written when are not. This is most likely to show up when using pipelines for testing; care should be taken to ensure that deadlocks do not occur and that potential short reads are allowed for.
**chan pop** *channelId*
Removes the topmost transformation from the channel *channelId*, if there is any. If there are no transformations added to *channelId*, this is equivalent to **chan close** of that channel. The result is normally the empty string, but can be an error in some situations (i.e. where the underlying system stream is closed and that results in an error).
**chan postevent** *channelId eventSpec*
This subcommand is used by command handlers specified with **chan create**. It notifies the channel represented by the handle *channelId* that the event(s) listed in the *eventSpec* have occurred. The argument has to be a list containing any of the strings **[read](read.htm)** and **write**. The list must contain at least one element as it does not make sense to invoke the command if there are no events to post. Note that this subcommand can only be used with channel handles that were created/opened by **chan create**. All other channels will cause this subcommand to report an error.
As only the Tcl level of a channel, i.e. its command handler, should post events to it we also restrict the usage of this command to the interpreter that created the channel. In other words, posting events to a reflected channel from an interpreter that does not contain it's implementation is not allowed. Attempting to post an event from any other interpreter will cause this subcommand to report an error.
Another restriction is that it is not possible to post events that the I/O core has not registered an interest in. Trying to do so will cause the method to throw an error. See the command handler method **watch** described in **[refchan](refchan.htm)**, the document specifying the API of command handlers for reflected channels.
This command is **[safe](safe.htm)** and made accessible to safe interpreters. It can trigger the execution of **chan event** handlers, whether in the current interpreter or in other interpreters or other threads, even where the event is posted from a safe interpreter and listened for by a trusted interpreter. **Chan event** handlers are *always* executed in the interpreter that set them up.
**chan push** *channelId cmdPrefix*
Adds a new transformation on top of the channel *channelId*. The *cmdPrefix* argument describes a list of one or more words which represent a handler that will be used to implement the transformation. The command prefix must provide the API described in the **[transchan](transchan.htm)** manual page. The result of this subcommand is a handle to the transformation. Note that it is important to make sure that the transformation is capable of supporting the channel mode that it is used with or this can make the channel neither readable nor writable.
**chan puts** ?**-nonewline**? ?*channelId*? *string*
Writes *string* to the channel named *channelId* followed by a newline character. A trailing newline character is written unless the optional flag **-nonewline** is given. If *channelId* is omitted, the string is written to the standard output channel, **[stdout](https://www.tcl.tk/man/tcl/TclLib/GetStdChan.htm)**. Newline characters in the output are translated by **chan puts** to platform-specific end-of-line sequences according to the currently configured value of the **-translation** option for the channel (for example, on PCs newlines are normally replaced with carriage-return-linefeed sequences; see **chan configure** above for details).
Tcl buffers output internally, so characters written with **chan puts** may not appear immediately on the output file or device; Tcl will normally delay output until the buffer is full or the channel is closed. You can force output to appear immediately with the **chan flush** command.
When the output buffer fills up, the **chan puts** command will normally block until all the buffered data has been accepted for output by the operating system. If *channelId* is in non-blocking mode then the **chan puts** command will not block even if the operating system cannot accept the data. Instead, Tcl continues to buffer the data and writes it in the background as fast as the underlying file or device can accept it. The application must use the Tcl event loop for non-blocking output to work; otherwise Tcl never finds out that the file or device is ready for more output data. It is possible for an arbitrarily large amount of data to be buffered for a channel in non-blocking mode, which could consume a large amount of memory. To avoid wasting memory, non-blocking I/O should normally be used in an event-driven fashion with the **chan event** command (do not invoke **chan puts** unless you have recently been notified via a file event that the channel is ready for more output data).
**chan read** *channelId* ?*numChars*?
**chan read** ?**-nonewline**? *channelId*
In the first form, the result will be the next *numChars* characters read from the channel named *channelId*; if *numChars* is omitted, all characters up to the point when the channel would signal a failure (whether an end-of-file, blocked or other error condition) are read. In the second form (i.e. when *numChars* has been omitted) the flag **-nonewline** may be given to indicate that any trailing newline in the string that has been read should be trimmed. If *channelId* is in non-blocking mode, **chan read** may not read as many characters as requested: once all available input has been read, the command will return the data that is available rather than blocking for more input. If the channel is configured to use a multi-byte encoding, then there may actually be some bytes remaining in the internal buffers that do not form a complete character. These bytes will not be returned until a complete character is available or end-of-file is reached. The **-nonewline** switch is ignored if the command returns before reaching the end of the file.
**Chan read** translates end-of-line sequences in the input into newline characters according to the **-translation** option for the channel (see **chan configure** above for a discussion on the ways in which **chan configure** will alter input).
When reading from a serial port, most applications should configure the serial port channel to be non-blocking, like this:
```
**chan configure** *channelId* **-blocking** *0*.
```
Then **chan read** behaves much like described above. Note that most serial ports are comparatively slow; it is entirely possible to get a **readable** event for each character read from them. Care must be taken when using **chan read** on blocking serial ports:
**chan read** *channelId numChars*
In this form **chan read** blocks until *numChars* have been received from the serial port.
**chan read** *channelId*
In this form **chan read** blocks until the reception of the end-of-file character, see **chan configure -eofchar**. If there no end-of-file character has been configured for the channel, then **chan read** will block forever.
**chan seek** *channelId offset* ?*origin*?
Sets the current access position within the underlying data stream for the channel named *channelId* to be *offset* bytes relative to *origin*. *Offset* must be an integer (which may be negative) and *origin* must be one of the following:
**start**
The new access position will be *offset* bytes from the start of the underlying file or device.
**current**
The new access position will be *offset* bytes from the current access position; a negative *offset* moves the access position backwards in the underlying file or device.
**end**
The new access position will be *offset* bytes from the end of the file or device. A negative *offset* places the access position before the end of file, and a positive *offset* places the access position after the end of file.
The *origin* argument defaults to **start**.
**Chan seek** flushes all buffered output for the channel before the command returns, even if the channel is in non-blocking mode. It also discards any buffered and unread input. This command returns an empty string. An error occurs if this command is applied to channels whose underlying file or device does not support seeking.
Note that *offset* values are byte offsets, not character offsets. Both **chan seek** and **chan tell** operate in terms of bytes, not characters, unlike **chan read**.
**chan tell** *channelId*
Returns a number giving the current access position within the underlying data stream for the channel named *channelId*. This value returned is a byte offset that can be passed to **chan seek** in order to set the channel to a particular position. Note that this value is in terms of bytes, not characters like **chan read**. The value returned is -1 for channels that do not support seeking.
**chan truncate** *channelId* ?*length*?
Sets the byte length of the underlying data stream for the channel named *channelId* to be *length* (or to the current byte offset within the underlying data stream if *length* is omitted). The channel is flushed before truncation.
Examples
--------
This opens a file using a known encoding (CP1252, a very common encoding on Windows), searches for a string, rewrites that part, and truncates the file after a further two lines.
```
set f [open somefile.txt r+]
**chan configure** $f -encoding cp1252
set offset 0
*# Search for string "FOOBAR" in the file*
while {[**chan gets** $f line] >= 0} {
set idx [string first FOOBAR $line]
if {$idx > -1} {
*# Found it; rewrite line*
**chan seek** $f [expr {$offset + $idx}]
**chan puts** -nonewline $f BARFOO
*# Skip to end of following line, and truncate*
**chan gets** $f
**chan gets** $f
**chan truncate** $f
*# Stop searching the file now*
break
}
*# Save offset of start of next line for later*
set offset [**chan tell** $f]
}
**chan close** $f
```
A network server that does echoing of its input line-by-line without preventing servicing of other connections at the same time.
```
# This is a very simple logger...
proc log {message} {
**chan puts** stdout $message
}
# This is called whenever a new client connects to the server
proc connect {chan host port} {
set clientName [format <%s:%d> $host $port]
log "connection from $clientName"
**chan configure** $chan -blocking 0 -buffering line
**chan event** $chan readable [list echoLine $chan $clientName]
}
# This is called whenever either at least one byte of input
# data is available, or the channel was closed by the client.
proc echoLine {chan clientName} {
**chan gets** $chan line
if {[**chan eof** $chan]} {
log "finishing connection from $clientName"
**chan close** $chan
} elseif {![**chan blocked** $chan]} {
# Didn't block waiting for end-of-line
log "$clientName - $line"
**chan puts** $chan $line
}
}
# Create the server socket and enter the event-loop to wait
# for incoming connections...
socket -server connect 12345
vwait forever
```
See also
--------
**[close](close.htm)**, **[eof](eof.htm)**, **[fblocked](fblocked.htm)**, **[fconfigure](fconfigure.htm)**, **[fcopy](fcopy.htm)**, **[file](file.htm)**, **[fileevent](fileevent.htm)**, **[flush](flush.htm)**, **[gets](gets.htm)**, **[open](open.htm)**, **[puts](puts.htm)**, **[read](read.htm)**, **[seek](seek.htm)**, **[socket](socket.htm)**, **[tell](tell.htm)**, **[refchan](refchan.htm)**, **[transchan](transchan.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/chan.htm>
| programming_docs |
tcl_tk continue continue
========
Name
----
continue — Skip to the next iteration of a loop Synopsis
--------
**continue**
Description
-----------
This command is typically invoked inside the body of a looping command such as **[for](for.htm)** or **[foreach](foreach.htm)** or **[while](while.htm)**. It returns a 4 (**[TCL\_CONTINUE](catch.htm)**) result code, which causes a continue exception to occur. The exception causes the current script to be aborted out to the innermost containing loop command, which then continues with the next iteration of the loop. Catch exceptions are also handled in a few other situations, such as the **[catch](catch.htm)** command and the outermost scripts of procedure bodies. Example
-------
Print a line for each of the integers from 0 to 10 *except* 5:
```
for {set x 0} {$x<10} {incr x} {
if {$x == 5} {
**continue**
}
puts "x is $x"
}
```
See also
--------
**[break](break.htm)**, **[for](for.htm)**, **[foreach](foreach.htm)**, **[return](return.htm)**, **[while](while.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/continue.htm>
tcl_tk interp interp
======
[NAME](interp.htm#M2) interp — Create and manipulate Tcl interpreters
[SYNOPSIS](interp.htm#M3)
[DESCRIPTION](interp.htm#M4)
[THE INTERP COMMAND](interp.htm#M5)
[**interp** **alias** *srcPath* *srcToken*](interp.htm#M6)
[**interp** **alias** *srcPath* *srcToken* **{}**](interp.htm#M7)
[**interp** **alias** *srcPath* *srcCmd* *targetPath* *targetCmd* ?*arg arg ...*?](interp.htm#M8)
[**interp** **aliases** ?*path*?](interp.htm#M9)
[**interp bgerror** *path* ?*cmdPrefix*?](interp.htm#M10)
[**interp** **cancel** ?**-unwind**? ?**--**? ?*path*? ?*result*?](interp.htm#M11)
[**interp** **create** ?**-safe**? ?**--**? ?*path*?](interp.htm#M12)
[**interp** **debug** *path* ?**-frame** ?*bool*??](interp.htm#M13)
[**interp** **delete** ?*path ...?*](interp.htm#M14)
[**interp** **eval** *path arg* ?*arg ...*?](interp.htm#M15)
[**interp exists** *path*](interp.htm#M16)
[**interp expose** *path* *hiddenName* ?*exposedCmdName*?](interp.htm#M17)
[**interp** **hide** *path* *exposedCmdName* ?*hiddenCmdName*?](interp.htm#M18)
[**interp** **hidden** *path*](interp.htm#M19)
[**interp** **invokehidden** *path* ?*-option ...*? *hiddenCmdName* ?*arg ...*?](interp.htm#M20)
[**interp issafe** ?*path*?](interp.htm#M21)
[**interp** **limit** *path* *limitType* ?*-option*? ?*value* *...*?](interp.htm#M22)
[**interp marktrusted** *path*](interp.htm#M23)
[**interp** **recursionlimit** *path* ?*newlimit*?](interp.htm#M24)
[**interp** **share** *srcPath channelId destPath*](interp.htm#M25)
[**interp** **slaves** ?*path*?](interp.htm#M26)
[**interp** **target** *path alias*](interp.htm#M27)
[**interp** **transfer** *srcPath channelId destPath*](interp.htm#M28)
[SLAVE COMMAND](interp.htm#M29)
[*slave* **aliases**](interp.htm#M30)
[*slave* **alias** *srcToken*](interp.htm#M31)
[*slave* **alias** *srcToken* **{}**](interp.htm#M32)
[*slave* **alias** *srcCmd targetCmd* ?*arg ..*?](interp.htm#M33)
[*slave* **bgerror** ?*cmdPrefix*?](interp.htm#M34)
[*slave* **eval** *arg* ?*arg ..*?](interp.htm#M35)
[*slave* **expose** *hiddenName* ?*exposedCmdName*?](interp.htm#M36)
[*slave* **hide** *exposedCmdName* ?*hiddenCmdName*?](interp.htm#M37)
[*slave* **hidden**](interp.htm#M38)
[*slave* **invokehidden** ?*-option ...*? *hiddenName* ?*arg ..*?](interp.htm#M39)
[*slave* **issafe**](interp.htm#M40)
[*slave* **limit** *limitType* ?*-option*? ?*value* *...*?](interp.htm#M41)
[*slave* **marktrusted**](interp.htm#M42)
[*slave* **recursionlimit** ?*newlimit*?](interp.htm#M43)
[SAFE INTERPRETERS](interp.htm#M44)
[ALIAS INVOCATION](interp.htm#M45)
[HIDDEN COMMANDS](interp.htm#M46)
[RESOURCE LIMITS](interp.htm#M47)
[LIMIT OPTIONS](interp.htm#M48)
[**-command**](interp.htm#M49)
[**-granularity**](interp.htm#M50)
[**-milliseconds**](interp.htm#M51)
[**-seconds**](interp.htm#M52)
[**-value**](interp.htm#M53)
[BACKGROUND EXCEPTION HANDLING](interp.htm#M54)
[CREDITS](interp.htm#M55)
[EXAMPLES](interp.htm#M56)
[SEE ALSO](interp.htm#M57)
[KEYWORDS](interp.htm#M58)
Name
----
interp — Create and manipulate Tcl interpreters Synopsis
--------
**interp** *subcommand* ?*arg arg ...*?
Description
-----------
This command makes it possible to create one or more new Tcl interpreters that co-exist with the creating interpreter in the same application. The creating interpreter is called the *master* and the new interpreter is called a *slave*. A master can create any number of slaves, and each slave can itself create additional slaves for which it is master, resulting in a hierarchy of interpreters. Each interpreter is independent from the others: it has its own name space for commands, procedures, and global variables. A master interpreter may create connections between its slaves and itself using a mechanism called an *alias*. An *alias* is a command in a slave interpreter which, when invoked, causes a command to be invoked in its master interpreter or in another slave interpreter. The only other connections between interpreters are through environment variables (the **[env](tclvars.htm)** variable), which are normally shared among all interpreters in the application, and by resource limit exceeded callbacks. Note that the name space for files (such as the names returned by the **[open](open.htm)** command) is no longer shared between interpreters. Explicit commands are provided to share files and to transfer references to open files from one interpreter to another.
The **interp** command also provides support for *safe* interpreters. A safe interpreter is a slave whose functions have been greatly restricted, so that it is safe to execute untrusted scripts without fear of them damaging other interpreters or the application's environment. For example, all IO channel creation commands and subprocess creation commands are made inaccessible to safe interpreters. See **[SAFE INTERPRETERS](#M44)** below for more information on what features are present in a safe interpreter. The dangerous functionality is not removed from the safe interpreter; instead, it is *hidden*, so that only trusted interpreters can obtain access to it. For a detailed explanation of hidden commands, see **[HIDDEN COMMANDS](#M46)**, below. The alias mechanism can be used for protected communication (analogous to a kernel call) between a slave interpreter and its master. See **[ALIAS INVOCATION](#M45)**, below, for more details on how the alias mechanism works.
A qualified interpreter name is a proper Tcl lists containing a subset of its ancestors in the interpreter hierarchy, terminated by the string naming the interpreter in its immediate master. Interpreter names are relative to the interpreter in which they are used. For example, if “**a**” is a slave of the current interpreter and it has a slave “**a1**”, which in turn has a slave “**a11**”, the qualified name of “**a11**” in “**a**” is the list “**a1 a11**”.
The **interp** command, described below, accepts qualified interpreter names as arguments; the interpreter in which the command is being evaluated can always be referred to as **{}** (the empty list or string). Note that it is impossible to refer to a master (ancestor) interpreter by name in a slave interpreter except through aliases. Also, there is no global name by which one can refer to the first interpreter created in an application. Both restrictions are motivated by safety concerns.
The interp command
------------------
The **interp** command is used to create, delete, and manipulate slave interpreters, and to share or transfer channels between interpreters. It can have any of several forms, depending on the *subcommand* argument:
**interp** **alias** *srcPath* *srcToken*
Returns a Tcl list whose elements are the *targetCmd* and *arg*s associated with the alias represented by *srcToken* (this is the value returned when the alias was created; it is possible that the name of the source command in the slave is different from *srcToken*).
**interp** **alias** *srcPath* *srcToken* **{}**
Deletes the alias for *srcToken* in the slave interpreter identified by *srcPath*. *srcToken* refers to the value returned when the alias was created; if the source command has been renamed, the renamed command will be deleted.
**interp** **alias** *srcPath* *srcCmd* *targetPath* *targetCmd* ?*arg arg ...*?
This command creates an alias between one slave and another (see the **alias** slave command below for creating aliases between a slave and its master). In this command, either of the slave interpreters may be anywhere in the hierarchy of interpreters under the interpreter invoking the command. *SrcPath* and *srcCmd* identify the source of the alias. *SrcPath* is a Tcl list whose elements select a particular interpreter. For example, “**a b**” identifies an interpreter “**b**”, which is a slave of interpreter “**a**”, which is a slave of the invoking interpreter. An empty list specifies the interpreter invoking the command. *srcCmd* gives the name of a new command, which will be created in the source interpreter. *TargetPath* and *targetCmd* specify a target interpreter and command, and the *arg* arguments, if any, specify additional arguments to *targetCmd* which are prepended to any arguments specified in the invocation of *srcCmd*. *TargetCmd* may be undefined at the time of this call, or it may already exist; it is not created by this command. The alias arranges for the given target command to be invoked in the target interpreter whenever the given source command is invoked in the source interpreter. See **[ALIAS INVOCATION](#M45)** below for more details. The command returns a token that uniquely identifies the command created *srcCmd*, even if the command is renamed afterwards. The token may but does not have to be equal to *srcCmd*.
**interp** **aliases** ?*path*?
This command returns a Tcl list of the tokens of all the source commands for aliases defined in the interpreter identified by *path*. The tokens correspond to the values returned when the aliases were created (which may not be the same as the current names of the commands).
**interp bgerror** *path* ?*cmdPrefix*?
This command either gets or sets the current background exception handler for the interpreter identified by *path*. If *cmdPrefix* is absent, the current background exception handler is returned, and if it is present, it is a list of words (of minimum length one) that describes what to set the interpreter's background exception handler to. See the **[BACKGROUND EXCEPTION HANDLING](#M54)** section for more details.
**interp** **cancel** ?**-unwind**? ?**--**? ?*path*? ?*result*?
Cancels the script being evaluated in the interpreter identified by *path*. Without the **-unwind** switch the evaluation stack for the interpreter is unwound until an enclosing catch command is found or there are no further invocations of the interpreter left on the call stack. With the **-unwind** switch the evaluation stack for the interpreter is unwound without regard to any intervening catch command until there are no further invocations of the interpreter left on the call stack. The **--** switch can be used to mark the end of switches; it may be needed if *path* is an unusual value such as **-safe**. If *result* is present, it will be used as the error message string; otherwise, a default error message string will be used.
**interp** **create** ?**-safe**? ?**--**? ?*path*?
Creates a slave interpreter identified by *path* and a new command, called a *slave command*. The name of the slave command is the last component of *path*. The new slave interpreter and the slave command are created in the interpreter identified by the path obtained by removing the last component from *path*. For example, if *path* is **a b c** then a new slave interpreter and slave command named **c** are created in the interpreter identified by the path **a b**. The slave command may be used to manipulate the new interpreter as described below. If *path* is omitted, Tcl creates a unique name of the form **interp***x*, where *x* is an integer, and uses it for the interpreter and the slave command. If the **-safe** switch is specified (or if the master interpreter is a safe interpreter), the new slave interpreter will be created as a safe interpreter with limited functionality; otherwise the slave will include the full set of Tcl built-in commands and variables. The **--** switch can be used to mark the end of switches; it may be needed if *path* is an unusual value such as **-safe**. The result of the command is the name of the new interpreter. The name of a slave interpreter must be unique among all the slaves for its master; an error occurs if a slave interpreter by the given name already exists in this master. The initial recursion limit of the slave interpreter is set to the current recursion limit of its parent interpreter.
**interp** **debug** *path* ?**-frame** ?*bool*??
Controls whether frame-level stack information is captured in the slave interpreter identified by *path*. If no arguments are given, option and current setting are returned. If **-frame** is given, the debug setting is set to the given boolean if provided and the current setting is returned. This only effects the output of **[info frame](info.htm)**, in that exact frame-level information for command invocation at the bytecode level is only captured with this setting on. For example, with code like
```
**[proc](proc.htm)** mycontrol {... script} {
...
**[uplevel](uplevel.htm)** 1 $script
...
}
**[proc](proc.htm)** dosomething {...} {
...
mycontrol {
somecode
}
}
```
the standard setting will provide a relative line number for the command **somecode** and the relevant frame will be of type **[eval](eval.htm)**. With frame-debug active on the other hand the tracking extends so far that the system will be able to determine the file and absolute line number of this command, and return a frame of type **[source](source.htm)**. This more exact information is paid for with slower execution of all commands.
Note that once it is on, this flag cannot be switched back off: such attempts are silently ignored. This is needed to maintain the consistency of the underlying interpreter's state.
**interp** **delete** ?*path ...?*
Deletes zero or more interpreters given by the optional *path* arguments, and for each interpreter, it also deletes its slaves. The command also deletes the slave command for each interpreter deleted. For each *path* argument, if no interpreter by that name exists, the command raises an error.
**interp** **eval** *path arg* ?*arg ...*?
This command concatenates all of the *arg* arguments in the same fashion as the **[concat](concat.htm)** command, then evaluates the resulting string as a Tcl script in the slave interpreter identified by *path*. The result of this evaluation (including all **[return](return.htm)** options, such as **-errorinfo** and **-errorcode** information, if an error occurs) is returned to the invoking interpreter. Note that the script will be executed in the current context stack frame of the *path* interpreter; this is so that the implementations (in a master interpreter) of aliases in a slave interpreter can execute scripts in the slave that find out information about the slave's current state and stack frame.
**interp exists** *path*
Returns **1** if a slave interpreter by the specified *path* exists in this master, **0** otherwise. If *path* is omitted, the invoking interpreter is used.
**interp expose** *path* *hiddenName* ?*exposedCmdName*?
Makes the hidden command *hiddenName* exposed, eventually bringing it back under a new *exposedCmdName* name (this name is currently accepted only if it is a valid global name space name without any ::), in the interpreter denoted by *path*. If an exposed command with the targeted name already exists, this command fails. Hidden commands are explained in more detail in **[HIDDEN COMMANDS](#M46)**, below.
**interp** **hide** *path* *exposedCmdName* ?*hiddenCmdName*?
Makes the exposed command *exposedCmdName* hidden, renaming it to the hidden command *hiddenCmdName*, or keeping the same name if *hiddenCmdName* is not given, in the interpreter denoted by *path*. If a hidden command with the targeted name already exists, this command fails. Currently both *exposedCmdName* and *hiddenCmdName* can not contain namespace qualifiers, or an error is raised. Commands to be hidden by **interp hide** are looked up in the global namespace even if the current namespace is not the global one. This prevents slaves from fooling a master interpreter into hiding the wrong command, by making the current namespace be different from the global one. Hidden commands are explained in more detail in **[HIDDEN COMMANDS](#M46)**, below.
**interp** **hidden** *path*
Returns a list of the names of all hidden commands in the interpreter identified by *path*.
**interp** **invokehidden** *path* ?*-option ...*? *hiddenCmdName* ?*arg ...*?
Invokes the hidden command *hiddenCmdName* with the arguments supplied in the interpreter denoted by *path*. No substitutions or evaluation are applied to the arguments. Three *-option*s are supported, all of which start with **-**: **-namespace** (which takes a single argument afterwards, *nsName*), **-global**, and **--**. If the **-namespace** flag is present, the hidden command is invoked in the namespace called *nsName* in the target interpreter. If the **-global** flag is present, the hidden command is invoked at the global level in the target interpreter; otherwise it is invoked at the current call frame and can access local variables in that and outer call frames. The **--** flag allows the *hiddenCmdName* argument to start with a “-” character, and is otherwise unnecessary. If both the **-namespace** and **-global** flags are present, the **-namespace** flag is ignored. Note that the hidden command will be executed (by default) in the current context stack frame of the *path* interpreter. Hidden commands are explained in more detail in **[HIDDEN COMMANDS](#M46)**, below.
**interp issafe** ?*path*?
Returns **1** if the interpreter identified by the specified *path* is safe, **0** otherwise.
**interp** **limit** *path* *limitType* ?*-option*? ?*value* *...*?
Sets up, manipulates and queries the configuration of the resource limit *limitType* for the interpreter denoted by *path*. If no *-option* is specified, return the current configuration of the limit. If *-option* is the sole argument, return the value of that option. Otherwise, a list of *-option*/*value* argument pairs must supplied. See **[RESOURCE LIMITS](#M47)** below for a more detailed explanation of what limits and options are supported.
**interp marktrusted** *path*
Marks the interpreter identified by *path* as trusted. Does not expose the hidden commands. This command can only be invoked from a trusted interpreter. The command has no effect if the interpreter identified by *path* is already trusted.
**interp** **recursionlimit** *path* ?*newlimit*?
Returns the maximum allowable nesting depth for the interpreter specified by *path*. If *newlimit* is specified, the interpreter recursion limit will be set so that nesting of more than *newlimit* calls to **[Tcl\_Eval](https://www.tcl.tk/man/tcl/TclLib/Eval.htm)** and related procedures in that interpreter will return an error. The *newlimit* value is also returned. The *newlimit* value must be a positive integer between 1 and the maximum value of a non-long integer on the platform. The command sets the maximum size of the Tcl call stack only. It cannot by itself prevent stack overflows on the C stack being used by the application. If your machine has a limit on the size of the C stack, you may get stack overflows before reaching the limit set by the command. If this happens, see if there is a mechanism in your system for increasing the maximum size of the C stack.
**interp** **share** *srcPath channelId destPath*
Causes the IO channel identified by *channelId* to become shared between the interpreter identified by *srcPath* and the interpreter identified by *destPath*. Both interpreters have the same permissions on the IO channel. Both interpreters must close it to close the underlying IO channel; IO channels accessible in an interpreter are automatically closed when an interpreter is destroyed.
**interp** **slaves** ?*path*?
Returns a Tcl list of the names of all the slave interpreters associated with the interpreter identified by *path*. If *path* is omitted, the invoking interpreter is used.
**interp** **target** *path alias*
Returns a Tcl list describing the target interpreter for an alias. The alias is specified with an interpreter path and source command name, just as in **interp alias** above. The name of the target interpreter is returned as an interpreter path, relative to the invoking interpreter. If the target interpreter for the alias is the invoking interpreter then an empty list is returned. If the target interpreter for the alias is not the invoking interpreter or one of its descendants then an error is generated. The target command does not have to be defined at the time of this invocation.
**interp** **transfer** *srcPath channelId destPath*
Causes the IO channel identified by *channelId* to become available in the interpreter identified by *destPath* and unavailable in the interpreter identified by *srcPath*.
Slave command
-------------
For each slave interpreter created with the **interp** command, a new Tcl command is created in the master interpreter with the same name as the new interpreter. This command may be used to invoke various operations on the interpreter. It has the following general form:
```
*slave command* ?*arg arg ...*?
```
*Slave* is the name of the interpreter, and *command* and the *arg*s determine the exact behavior of the command. The valid forms of this command are:
*slave* **aliases**
Returns a Tcl list whose elements are the tokens of all the aliases in *slave*. The tokens correspond to the values returned when the aliases were created (which may not be the same as the current names of the commands).
*slave* **alias** *srcToken*
Returns a Tcl list whose elements are the *targetCmd* and *arg*s associated with the alias represented by *srcToken* (this is the value returned when the alias was created; it is possible that the actual source command in the slave is different from *srcToken*).
*slave* **alias** *srcToken* **{}**
Deletes the alias for *srcToken* in the slave interpreter. *srcToken* refers to the value returned when the alias was created; if the source command has been renamed, the renamed command will be deleted.
*slave* **alias** *srcCmd targetCmd* ?*arg ..*?
Creates an alias such that whenever *srcCmd* is invoked in *slave*, *targetCmd* is invoked in the master. The *arg* arguments will be passed to *targetCmd* as additional arguments, prepended before any arguments passed in the invocation of *srcCmd*. See **[ALIAS INVOCATION](#M45)** below for details. The command returns a token that uniquely identifies the command created *srcCmd*, even if the command is renamed afterwards. The token may but does not have to be equal to *srcCmd*.
*slave* **bgerror** ?*cmdPrefix*?
This command either gets or sets the current background exception handler for the *slave* interpreter. If *cmdPrefix* is absent, the current background exception handler is returned, and if it is present, it is a list of words (of minimum length one) that describes what to set the interpreter's background exception handler to. See the **[BACKGROUND EXCEPTION HANDLING](#M54)** section for more details.
*slave* **eval** *arg* ?*arg ..*?
This command concatenates all of the *arg* arguments in the same fashion as the **[concat](concat.htm)** command, then evaluates the resulting string as a Tcl script in *slave*. The result of this evaluation (including all **[return](return.htm)** options, such as **-errorinfo** and **-errorcode** information, if an error occurs) is returned to the invoking interpreter. Note that the script will be executed in the current context stack frame of *slave*; this is so that the implementations (in a master interpreter) of aliases in a slave interpreter can execute scripts in the slave that find out information about the slave's current state and stack frame.
*slave* **expose** *hiddenName* ?*exposedCmdName*?
This command exposes the hidden command *hiddenName*, eventually bringing it back under a new *exposedCmdName* name (this name is currently accepted only if it is a valid global name space name without any ::), in *slave*. If an exposed command with the targeted name already exists, this command fails. For more details on hidden commands, see **[HIDDEN COMMANDS](#M46)**, below.
*slave* **hide** *exposedCmdName* ?*hiddenCmdName*?
This command hides the exposed command *exposedCmdName*, renaming it to the hidden command *hiddenCmdName*, or keeping the same name if the argument is not given, in the *slave* interpreter. If a hidden command with the targeted name already exists, this command fails. Currently both *exposedCmdName* and *hiddenCmdName* can not contain namespace qualifiers, or an error is raised. Commands to be hidden are looked up in the global namespace even if the current namespace is not the global one. This prevents slaves from fooling a master interpreter into hiding the wrong command, by making the current namespace be different from the global one. For more details on hidden commands, see **[HIDDEN COMMANDS](#M46)**, below.
*slave* **hidden**
Returns a list of the names of all hidden commands in *slave*.
*slave* **invokehidden** ?*-option ...*? *hiddenName* ?*arg ..*?
This command invokes the hidden command *hiddenName* with the supplied arguments, in *slave*. No substitutions or evaluations are applied to the arguments. Three *-option*s are supported, all of which start with **-**: **-namespace** (which takes a single argument afterwards, *nsName*), **-global**, and **--**. If the **-namespace** flag is given, the hidden command is invoked in the specified namespace in the slave. If the **-global** flag is given, the command is invoked at the global level in the slave; otherwise it is invoked at the current call frame and can access local variables in that or outer call frames. The **--** flag allows the *hiddenCmdName* argument to start with a “-” character, and is otherwise unnecessary. If both the **-namespace** and **-global** flags are given, the **-namespace** flag is ignored. Note that the hidden command will be executed (by default) in the current context stack frame of *slave*. For more details on hidden commands, see **[HIDDEN COMMANDS](#M46)**, below.
*slave* **issafe**
Returns **1** if the slave interpreter is safe, **0** otherwise.
*slave* **limit** *limitType* ?*-option*? ?*value* *...*?
Sets up, manipulates and queries the configuration of the resource limit *limitType* for the slave interpreter. If no *-option* is specified, return the current configuration of the limit. If *-option* is the sole argument, return the value of that option. Otherwise, a list of *-option*/*value* argument pairs must supplied. See **[RESOURCE LIMITS](#M47)** below for a more detailed explanation of what limits and options are supported.
*slave* **marktrusted**
Marks the slave interpreter as trusted. Can only be invoked by a trusted interpreter. This command does not expose any hidden commands in the slave interpreter. The command has no effect if the slave is already trusted.
*slave* **recursionlimit** ?*newlimit*?
Returns the maximum allowable nesting depth for the *slave* interpreter. If *newlimit* is specified, the recursion limit in *slave* will be set so that nesting of more than *newlimit* calls to **[Tcl\_Eval()](https://www.tcl.tk/man/tcl/TclLib/Eval.htm)** and related procedures in *slave* will return an error. The *newlimit* value is also returned. The *newlimit* value must be a positive integer between 1 and the maximum value of a non-long integer on the platform. The command sets the maximum size of the Tcl call stack only. It cannot by itself prevent stack overflows on the C stack being used by the application. If your machine has a limit on the size of the C stack, you may get stack overflows before reaching the limit set by the command. If this happens, see if there is a mechanism in your system for increasing the maximum size of the C stack.
Safe interpreters
-----------------
A safe interpreter is one with restricted functionality, so that is safe to execute an arbitrary script from your worst enemy without fear of that script damaging the enclosing application or the rest of your computing environment. In order to make an interpreter safe, certain commands and variables are removed from the interpreter. For example, commands to create files on disk are removed, and the **[exec](exec.htm)** command is removed, since it could be used to cause damage through subprocesses. Limited access to these facilities can be provided, by creating aliases to the master interpreter which check their arguments carefully and provide restricted access to a safe subset of facilities. For example, file creation might be allowed in a particular subdirectory and subprocess invocation might be allowed for a carefully selected and fixed set of programs. A safe interpreter is created by specifying the **-safe** switch to the **interp create** command. Furthermore, any slave created by a safe interpreter will also be safe.
A safe interpreter is created with exactly the following set of built-in commands:
| | | | |
| --- | --- | --- | --- |
| **[after](after.htm)** | **[append](append.htm)** | **[apply](apply.htm)** | **[array](array.htm)** |
| **[binary](binary.htm)** | **[break](break.htm)** | **[catch](catch.htm)** | **[chan](chan.htm)** |
| **[clock](clock.htm)** | **[close](close.htm)** | **[concat](concat.htm)** | **[continue](continue.htm)** |
| **[dict](dict.htm)** | **[eof](eof.htm)** | **[error](error.htm)** | **[eval](eval.htm)** |
| **[expr](expr.htm)** | **[fblocked](fblocked.htm)** | **[fcopy](fcopy.htm)** | **[fileevent](fileevent.htm)** |
| **[flush](flush.htm)** | **[for](for.htm)** | **[foreach](foreach.htm)** | **[format](format.htm)** |
| **[gets](gets.htm)** | **[global](global.htm)** | **[if](if.htm)** | **[incr](incr.htm)** |
| **[info](info.htm)** | **interp** | **[join](join.htm)** | **[lappend](lappend.htm)** |
| **[lassign](lassign.htm)** | **[lindex](lindex.htm)** | **[linsert](linsert.htm)** | **[list](list.htm)** |
| **[llength](llength.htm)** | **[lrange](lrange.htm)** | **[lrepeat](lrepeat.htm)** | **[lreplace](lreplace.htm)** |
| **[lsearch](lsearch.htm)** | **[lset](lset.htm)** | **[lsort](lsort.htm)** | **[namespace](namespace.htm)** |
| **[package](package.htm)** | **[pid](pid.htm)** | **[proc](proc.htm)** | **[puts](puts.htm)** |
| **[read](read.htm)** | **[regexp](regexp.htm)** | **[regsub](regsub.htm)** | **[rename](rename.htm)** |
| **[return](return.htm)** | **[scan](scan.htm)** | **[seek](seek.htm)** | **[set](set.htm)** |
| **[split](split.htm)** | **[string](string.htm)** | **[subst](subst.htm)** | **[switch](switch.htm)** |
| **[tell](tell.htm)** | **time** | **[trace](trace.htm)** | **[unset](unset.htm)** |
| **[update](update.htm)** | **[uplevel](uplevel.htm)** | **[upvar](upvar.htm)** | **[variable](variable.htm)** |
| **[vwait](vwait.htm)** | **[while](while.htm)** |
The following commands are hidden by **interp create** when it creates a safe interpreter:
| | | | |
| --- | --- | --- | --- |
| **[cd](cd.htm)** | **[encoding](encoding.htm)** | **[exec](exec.htm)** | **[exit](exit.htm)** |
| **[fconfigure](fconfigure.htm)** | **[file](file.htm)** | **[glob](glob.htm)** | **[load](load.htm)** |
| **[open](open.htm)** | **[pwd](pwd.htm)** | **[socket](socket.htm)** | **[source](source.htm)** |
| **[unload](unload.htm)** |
These commands can be recreated later as Tcl procedures or aliases, or re-exposed by **interp expose**. The following commands from Tcl's library of support procedures are not present in a safe interpreter:
| | | |
| --- | --- | --- |
| **auto\_exec\_ok** | **[auto\_import](library.htm)** | **[auto\_load](library.htm)** |
| **auto\_load\_index** | **[auto\_qualify](library.htm)** | **[unknown](unknown.htm)** |
Note in particular that safe interpreters have no default **[unknown](unknown.htm)** command, so Tcl's default autoloading facilities are not available. Autoload access to Tcl's commands that are normally autoloaded:
| | |
| --- | --- |
| **[auto\_mkindex](library.htm)** | **auto\_mkindex\_old** |
| **[auto\_reset](library.htm)** | **[history](history.htm)** |
| **[parray](library.htm)** | **pkg\_mkIndex** |
| **::pkg::create** | **::safe::interpAddToAccessPath** |
| **::safe::interpCreate** | **::safe::interpConfigure** |
| **::safe::interpDelete** | **::safe::interpFindInAccessPath** |
| **::safe::interpInit** | **::safe::setLogCmd** |
| **tcl\_endOfWord** | **tcl\_findLibrary** |
| **tcl\_startOfNextWord** | **tcl\_startOfPreviousWord** |
| **tcl\_wordBreakAfter** | **tcl\_wordBreakBefore** |
can only be provided by explicit definition of an **[unknown](unknown.htm)** command in the safe interpreter. This will involve exposing the **[source](source.htm)** command. This is most easily accomplished by creating the safe interpreter with Tcl's **[Safe-Tcl](safe.htm)** mechanism. **[Safe-Tcl](safe.htm)** provides safe versions of **[source](source.htm)**, **[load](load.htm)**, and other Tcl commands needed to support autoloading of commands and the loading of packages. In addition, the **[env](tclvars.htm)** variable is not present in a safe interpreter, so it cannot share environment variables with other interpreters. The **[env](tclvars.htm)** variable poses a security risk, because users can store sensitive information in an environment variable. For example, the PGP manual recommends storing the PGP private key protection password in the environment variable *PGPPASS*. Making this variable available to untrusted code executing in a safe interpreter would incur a security risk.
If extensions are loaded into a safe interpreter, they may also restrict their own functionality to eliminate unsafe commands. For a discussion of management of extensions for safety see the manual entries for **[Safe-Tcl](safe.htm)** and the **[load](load.htm)** Tcl command.
A safe interpreter may not alter the recursion limit of any interpreter, including itself.
Alias invocation
----------------
The alias mechanism has been carefully designed so that it can be used safely when an untrusted script is executing in a safe slave and the target of the alias is a trusted master. The most important thing in guaranteeing safety is to ensure that information passed from the slave to the master is never evaluated or substituted in the master; if this were to occur, it would enable an evil script in the slave to invoke arbitrary functions in the master, which would compromise security. When the source for an alias is invoked in the slave interpreter, the usual Tcl substitutions are performed when parsing that command. These substitutions are carried out in the source interpreter just as they would be for any other command invoked in that interpreter. The command procedure for the source command takes its arguments and merges them with the *targetCmd* and *arg*s for the alias to create a new array of arguments. If the words of *srcCmd* were “*srcCmd arg1 arg2 ... argN*”, the new set of words will be “*targetCmd arg arg ... arg arg1 arg2 ... argN*”, where *targetCmd* and *arg*s are the values supplied when the alias was created. *TargetCmd* is then used to locate a command procedure in the target interpreter, and that command procedure is invoked with the new set of arguments. An error occurs if there is no command named *targetCmd* in the target interpreter. No additional substitutions are performed on the words: the target command procedure is invoked directly, without going through the normal Tcl evaluation mechanism. Substitutions are thus performed on each word exactly once: *targetCmd* and *args* were substituted when parsing the command that created the alias, and *arg1 - argN* are substituted when the alias's source command is parsed in the source interpreter.
When writing the *targetCmd*s for aliases in safe interpreters, it is very important that the arguments to that command never be evaluated or substituted, since this would provide an escape mechanism whereby the slave interpreter could execute arbitrary code in the master. This in turn would compromise the security of the system.
Hidden commands
---------------
Safe interpreters greatly restrict the functionality available to Tcl programs executing within them. Allowing the untrusted Tcl program to have direct access to this functionality is unsafe, because it can be used for a variety of attacks on the environment. However, there are times when there is a legitimate need to use the dangerous functionality in the context of the safe interpreter. For example, sometimes a program must be **[source](source.htm)**d into the interpreter. Another example is Tk, where windows are bound to the hierarchy of windows for a specific interpreter; some potentially dangerous functions, e.g. window management, must be performed on these windows within the interpreter context. The **interp** command provides a solution to this problem in the form of *hidden commands*. Instead of removing the dangerous commands entirely from a safe interpreter, these commands are hidden so they become unavailable to Tcl scripts executing in the interpreter. However, such hidden commands can be invoked by any trusted ancestor of the safe interpreter, in the context of the safe interpreter, using **interp invoke**. Hidden commands and exposed commands reside in separate name spaces. It is possible to define a hidden command and an exposed command by the same name within one interpreter.
Hidden commands in a slave interpreter can be invoked in the body of procedures called in the master during alias invocation. For example, an alias for **[source](source.htm)** could be created in a slave interpreter. When it is invoked in the slave interpreter, a procedure is called in the master interpreter to check that the operation is allowable (e.g. it asks to source a file that the slave interpreter is allowed to access). The procedure then it invokes the hidden **[source](source.htm)** command in the slave interpreter to actually source in the contents of the file. Note that two commands named **[source](source.htm)** exist in the slave interpreter: the alias, and the hidden command.
Because a master interpreter may invoke a hidden command as part of handling an alias invocation, great care must be taken to avoid evaluating any arguments passed in through the alias invocation. Otherwise, malicious slave interpreters could cause a trusted master interpreter to execute dangerous commands on their behalf. See the section on **[ALIAS INVOCATION](#M45)** for a more complete discussion of this topic. To help avoid this problem, no substitutions or evaluations are applied to arguments of **interp invokehidden**.
Safe interpreters are not allowed to invoke hidden commands in themselves or in their descendants. This prevents safe slaves from gaining access to hidden functionality in themselves or their descendants.
The set of hidden commands in an interpreter can be manipulated by a trusted interpreter using **interp expose** and **interp hide**. The **interp expose** command moves a hidden command to the set of exposed commands in the interpreter identified by *path*, potentially renaming the command in the process. If an exposed command by the targeted name already exists, the operation fails. Similarly, **interp hide** moves an exposed command to the set of hidden commands in that interpreter. Safe interpreters are not allowed to move commands between the set of hidden and exposed commands, in either themselves or their descendants.
Currently, the names of hidden commands cannot contain namespace qualifiers, and you must first rename a command in a namespace to the global namespace before you can hide it. Commands to be hidden by **interp hide** are looked up in the global namespace even if the current namespace is not the global one. This prevents slaves from fooling a master interpreter into hiding the wrong command, by making the current namespace be different from the global one.
Resource limits
---------------
Every interpreter has two kinds of resource limits that may be imposed by any master interpreter upon its slaves. Command limits (of type **command**) restrict the total number of Tcl commands that may be executed by an interpreter (as can be inspected via the **[info cmdcount](info.htm)** command), and time limits (of type **time**) place a limit by which execution within the interpreter must complete. Note that time limits are expressed as *absolute* times (as in **[clock seconds](clock.htm)**) and not relative times (as in **[after](after.htm)**) because they may be modified after creation. When a limit is exceeded for an interpreter, first any handler callbacks defined by master interpreters are called. If those callbacks increase or remove the limit, execution within the (previously) limited interpreter continues. If the limit is still in force, an error is generated at that point and normal processing of errors within the interpreter (by the **[catch](catch.htm)** command) is disabled, so the error propagates outwards (building a stack-trace as it goes) to the point where the limited interpreter was invoked (e.g. by **interp eval**) where it becomes the responsibility of the calling code to catch and handle.
### Limit options
Every limit has a number of options associated with it, some of which are common across all kinds of limits, and others of which are particular to the kind of limit.
**-command**
This option (common for all limit types) specifies (if non-empty) a Tcl script to be executed in the global namespace of the interpreter reading and writing the option when the particular limit in the limited interpreter is exceeded. The callback may modify the limit on the interpreter if it wishes the limited interpreter to continue executing. If the callback generates an exception, it is reported through the background exception mechanism (see **[BACKGROUND EXCEPTION HANDLING](#M54)**). Note that the callbacks defined by one interpreter are completely isolated from the callbacks defined by another, and that the order in which those callbacks are called is undefined.
**-granularity**
This option (common for all limit types) specifies how frequently (out of the points when the Tcl interpreter is in a consistent state where limit checking is possible) that the limit is actually checked. This allows the tuning of how frequently a limit is checked, and hence how often the limit-checking overhead (which may be substantial in the case of time limits) is incurred.
**-milliseconds**
This option specifies the number of milliseconds after the moment defined in the **-seconds** option that the time limit will fire. It should only ever be specified in conjunction with the **-seconds** option (whether it was set previously or is being set this invocation.)
**-seconds**
This option specifies the number of seconds after the epoch (see **clock seconds**) that the time limit for the interpreter will be triggered. The limit will be triggered at the start of the second unless specified at a sub-second level using the **-milliseconds** option. This option may be the empty string, which indicates that a time limit is not set for the interpreter.
**-value**
This option specifies the number of commands that the interpreter may execute before triggering the command limit. This option may be the empty string, which indicates that a command limit is not set for the interpreter.
Where an interpreter with a resource limit set on it creates a slave interpreter, that slave interpreter will have resource limits imposed on it that are at least as restrictive as the limits on the creating master interpreter. If the master interpreter of the limited master wishes to relax these conditions, it should hide the **interp** command in the child and then use aliases and the **interp invokehidden** subcommand to provide such access as it chooses to the **interp** command to the limited master as necessary.
Background exception handling
-----------------------------
When an exception happens in a situation where it cannot be reported directly up the stack (e.g. when processing events in an **[update](update.htm)** or **[vwait](vwait.htm)** call) the exception is instead reported through the background exception handling mechanism. Every interpreter has a background exception handler registered; the default exception handler arranges for the **[bgerror](bgerror.htm)** command in the interpreter's global namespace to be called, but other exception handlers may be installed and process background exceptions in substantially different ways. A background exception handler consists of a non-empty list of words to which will be appended two further words at invocation time. The first word will be the interpreter result at time of the exception, typically an error message, and the second will be the dictionary of return options at the time of the exception. These are the same values that **[catch](catch.htm)** can capture when it controls script evaluation in a non-background situation. The resulting list will then be executed in the interpreter's global namespace without further substitutions being performed.
Credits
-------
The safe interpreter mechanism is based on the Safe-Tcl prototype implemented by Nathaniel Borenstein and Marshall Rose. Examples
--------
Creating and using an alias for a command in the current interpreter:
```
**interp alias** {} getIndex {} lsearch {alpha beta gamma delta}
set idx [getIndex delta]
```
Executing an arbitrary command in a safe interpreter where every invocation of **[lappend](lappend.htm)** is logged:
```
set i [**interp create** -safe]
**interp hide** $i lappend
**interp alias** $i lappend {} loggedLappend $i
proc loggedLappend {i args} {
puts "logged invocation of lappend $args"
**interp invokehidden** $i lappend {*}$args
}
**interp eval** $i $someUntrustedScript
```
Setting a resource limit on an interpreter so that an infinite loop terminates.
```
set i [**interp create**]
**interp limit** $i command -value 1000
**interp eval** $i {
set x 0
while {1} {
puts "Counting up... [incr x]"
}
}
```
See also
--------
**[bgerror](bgerror.htm)**, **[load](load.htm)**, **[safe](safe.htm)**, **[Tcl\_CreateSlave](https://www.tcl.tk/man/tcl/TclLib/CrtSlave.htm)**, **[Tcl\_Eval](https://www.tcl.tk/man/tcl/TclLib/Eval.htm)**, **[Tcl\_BackgroundException](https://www.tcl.tk/man/tcl/TclLib/BackgdErr.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/interp.htm>
| programming_docs |
tcl_tk tailcall tailcall
========
Name
----
tailcall — Replace the current procedure with another command Synopsis
--------
**tailcall** *command* ?*arg ...*?
Description
-----------
The **tailcall** command replaces the currently executing procedure, lambda application, or method with another command. The *command*, which will have *arg ...* passed as arguments if they are supplied, will be looked up in the current namespace context, not in the caller's. Apart from that difference in resolution, it is equivalent to:
```
return [uplevel 1 [list *command* ?*arg ...*?]]
```
This command may not be invoked from within an **[uplevel](uplevel.htm)** into a procedure or inside a **[catch](catch.htm)** inside a procedure or lambda.
Example
-------
Compute the factorial of a number.
```
proc factorial {n {accum 1}} {
if {$n < 2} {
return $accum
}
**tailcall** factorial [expr {$n - 1}] [expr {$accum * $n}]
}
```
Print the elements of a list with alternating lines having different indentations.
```
proc printList {theList} {
if {[llength $theList]} {
puts "> [lindex $theList 0]"
**tailcall** printList2 [lrange $theList 1 end]
}
}
proc printList2 {theList} {
if {[llength $theList]} {
puts "< [lindex $theList 0]"
**tailcall** printList [lrange $theList 1 end]
}
}
```
See also
--------
**[apply](apply.htm)**, **[proc](proc.htm)**, **[uplevel](uplevel.htm)**
Licensed under [Tcl/Tk terms](http://tcl.tk/software/tcltk/license.html)
<https://www.tcl.tk/man/tcl/TclCmd/tailcall.htm>
reactivex ReactiveX ReactiveX
=========
ReactiveX is a library for composing asynchronous and event-based programs by using observable sequences.
It extends [the observer pattern](http://en.wikipedia.org/wiki/Observer_pattern) to support sequences of data and/or events and adds operators that allow you to compose sequences together declaratively while abstracting away concerns about things like low-level threading, synchronization, thread-safety, concurrent data structures, and non-blocking I/O.
| Observables fill the gap by being the ideal way to access asynchronous sequences of multiple items |
| --- |
| | single items | multiple items |
| --- | --- | --- |
| synchronous | `T getData()` | `Iterable<T> getData()` |
| asynchronous | `Future<T> getData()` | `Observable<T> getData()` |
It is sometimes called “functional reactive programming” but this is a misnomer. ReactiveX may be functional, and it may be reactive, but “functional reactive programming” is a different animal. One main point of difference is that functional reactive programming operates on values that change *continuously* over time, while ReactiveX operates on *discrete* values that are emitted over time. (See [Conal Elliott’s work for more-precise information on functional reactive programming](https://github.com/conal/essence-and-origins-of-frp).)
Why Use Observables?
--------------------
The ReactiveX Observable model allows you to treat streams of asynchronous events with the same sort of simple, composable operations that you use for collections of data items like arrays. It frees you from tangled webs of callbacks, and thereby makes your code more readable and less prone to bugs.
Observables Are Composable
--------------------------
Techniques like [Java Futures](http://docs.oracle.com/javase/7/docs/api/java/util/concurrent/Future.html) are straightforward to use for [a single level of asynchronous execution](https://gist.github.com/4670979) but they start to add [non-trivial complexity](https://gist.github.com/4671081) when they’re nested.
It is [difficult to use Futures to optimally compose conditional asynchronous execution flows](https://gist.github.com/4671081#file-futuresb-java-L163) (or impossible, since latencies of each request vary at runtime). This [can be done](http://www.amazon.com/gp/product/0321349601?ie=UTF8&tag=none0b69&linkCode=as2&camp=1789&creative=9325&creativeASIN=0321349601), of course, but it quickly becomes complicated (and thus error-prone) or it prematurely blocks on `Future.get()`, which eliminates the benefit of asynchronous execution.
ReactiveX Observables, on the other hand, are *intended* for [composing flows and sequences of asynchronous data](https://github.com/Netflix/RxJava/wiki/How-To-Use#composition).
Observables Are Flexible
------------------------
ReactiveX Observables support not just the emission of single scalar values (as Futures do), but also of sequences of values or even infinite streams. `Observable` is a single abstraction that can be used for any of these use cases. An Observable has all of the flexibility and elegance associated with its mirror-image cousin the Iterable.
| An Observable is the asynchronous/push [“dual”](http://en.wikipedia.org/wiki/Dual_(category_theory)) to the synchronous/pull Iterable |
| --- |
| event | Iterable (pull) | Observable (push) |
| retrieve data | `T next()` | `onNext(T)` |
| discover error | throws `Exception` | `onError(Exception)` |
| complete | `!hasNext()` | `onCompleted()` |
Observables Are Less Opinionated
--------------------------------
ReactiveX is not biased toward some particular source of concurrency or asynchronicity. Observables can be implemented using thread-pools, event loops, non-blocking I/O, actors (such as from Akka), or whatever implementation suits your needs, your style, or your expertise. Client code treats all of its interactions with Observables as asynchronous, whether your underlying implementation is blocking or non-blocking and however you choose to implement it.
| How is this Observable implemented? |
| --- |
| `public Observable<data> getData();` |
| From the Observer’s point of view, it doesn’t matter! |
| --- |
| * does it work synchronously on the same thread as the caller?
* does it work asynchronously on a distinct thread?
* does it divide its work over multiple threads that may return data to the caller in any order?
* does it use an Actor (or multiple Actors) instead of a thread pool?
* does it use NIO with an event-loop to do asynchronous network access?
* does it use an event-loop to separate the work thread from the callback thread?
|
And importantly: with ReactiveX you can later change your mind, and radically change the underlying nature of your Observable implementation, without breaking the consumers of your Observable.
Callbacks Have Their Own Problems
---------------------------------
Callbacks solve the problem of premature blocking on `Future.get()` by not allowing anything to block. They are naturally efficient because they execute when the response is ready.
But as with Futures, while callbacks are easy to use with a single level of asynchronous execution, [with nested composition they become unwieldy](https://gist.github.com/4677544).
ReactiveX Is a Polyglot Implementation
--------------------------------------
ReactiveX is currently implemented in a variety of languages, in ways that respect those languages’ idioms, and more languages are being added at a rapid clip.
Reactive Programming
--------------------
ReactiveX provides [a collection of operators](documentation/operators) with which you can filter, select, transform, combine, and compose Observables. This allows for efficient execution and composition.
You can think of the Observable class as a “push” equivalent to [Iterable](http://docs.oracle.com/javase/7/docs/api/java/lang/Iterable.html), which is a “pull.” With an Iterable, the consumer pulls values from the producer and the thread blocks until those values arrive. By contrast, with an Observable the producer pushes values to the consumer whenever values are available. This approach is more flexible, because values can arrive synchronously or asynchronously.
| Example code showing how similar high-order functions can be applied to an Iterable and an Observable |
| --- |
| `Iterable` | `Observable` |
|
```
getDataFromLocalMemory()
.skip(10)
.take(5)
.map({ s -> return s + " transformed" })
.forEach({ println "next => " + it })
```
|
```
getDataFromNetwork()
.skip(10)
.take(5)
.map({ s -> return s + " transformed" })
.subscribe({ println "onNext => " + it })
```
|
The Observable type adds two missing semantics to [the Gang of Four’s Observer pattern](http://en.wikipedia.org/wiki/Observer_pattern), to match those that are available in the Iterable type:
1. the ability for the producer to signal to the consumer that there is no more data available (a foreach loop on an Iterable completes and returns normally in such a case; an Observable calls its observer’s `onCompleted` method)
2. the ability for the producer to signal to the consumer that an error has occurred (an Iterable throws an exception if an error takes place during iteration; an Observable calls its observer’s `onError` method)
With these additions, ReactiveX harmonizes the Iterable and Observable types. The only difference between them is the direction in which the data flows. This is very important because now any operation you can perform on an Iterable, you can also perform on an Observable.
reactivex Single Single
======
RxJava (and its derivatives like RxGroovy & RxScala) has developed an [Observable](observable) variant called “Single.”
A Single is something like an Observable, but instead of emitting a series of values — anywhere from none at all to an infinite number — it always either emits one value or an error notification.
For this reason, instead of subscribing to a Single with the three methods you use to respond to notifications from an Observable (onNext, onError, and onCompleted), you only use two methods to subscribe:
onSuccess a Single passes this method the sole item that the Single emits onError a Single passes this method the Throwable that caused the Single to be unable to emit an item
A Single will call only one of these methods, and will only call it once. Upon calling either method, the Single terminates and the subscription to it ends.
Composition via Single Operators
--------------------------------
Like Observables, Singles can be manipulated by means of a variety of operators. Some operators also allow for an interface between the Observable world and the Single world so that you can mix the two varieties:
| operator | returns | description |
| --- | --- | --- |
| compose | Single | allows you create a custom operator |
| concat and concatWith | Observable | concatenates the items emitted by multiple Singles as Observable emissions |
| create | Single | create a Single from scratch by calling subscriber methods explicitly |
| delay | Single | move the emission of an item from a Single forward in time |
| doOnError | Single | returns a Single that also calls a method you specify when it calls onError |
| doOnSuccess | Single | returns a Single that also calls a method you specify when it calls onSuccess |
| error | Single | returns a Single that immediately notifies subscribers of an error |
| flatMap | Single | returns a Single that is the result of a function applied to an item emitted by a Single |
| flatMapObservable | Observable | returns an Observable that is the result of a function applied to an item emitted by a Single |
| from | Single | converts a Future into a Single |
| just | Single | returns a Single that emits a specified item |
| map | Single | returns a Single that emits the result of a function applied to the item emitted by the source Single |
| merge | Single | converts a Single that emits a second Single into a Single that emits the item emitted by the second Single |
| merge and mergeWith | Observable | merges the items emitted by multiple Singles as Observable emissions |
| observeOn | Single | instructs the Single to call the subscriber methods on a particular [Scheduler](scheduler) |
| onErrorReturn | Single | converts a Single that makes an error notification into a Single that emits a specified item |
| subscribeOn | Single | instructs the Single to operate on a particular [Scheduler](scheduler) |
| timeout | Single | returns a Single that makes an error notification if the source Single does not emit a value in a specified time period |
| toSingle | Single | converts an Observable that emits a single item into a Single that emits that item |
| toObservable | Observable | converts a Single into an Observable that emits the item emitted by the Single and then completes |
| zip and zipWith | Single | returns a Single that emits an item that is the result of a function applied to items emitted by two or more other Singles |
The following sections of this page will give marble diagrams that explain these operators schematically. This diagram explains how Singles are represented in marble diagrams:

compose
-------
concat and concatWith
---------------------
 There is also an instance version of this operator:
 create
------
 delay
-----
 There is also a version of this operator that allows you to perform the delay on a particular [Scheduler](scheduler):
 doOnError
---------
 doOnSuccess
-----------
 error
-----
 flatMap
-------
 flatMapObservable
-----------------
 from
----
 There is also a variety that takes a [Scheduler](scheduler) as an argument: 
just
----
 map
---
 merge and mergeWith
-------------------
One version of merge takes a Single that emits a second Single and converts it into a Single that emits the item emitted by that second Single:
 Another version takes two or more Singles and merges them into an Observable that emits the items emitted by the source Singles (in an arbitrary order):
 observeOn
---------
 onErrorReturn
-------------
 subscribeOn
-----------
 timeout
-------
Timeout will cause a Single to abort with an error notification if it does not emit an item in a specified period of time after it is subscribed to. One version allows you to set this time out by means of a number of specified time units:
 You can also specify a particular [Scheduler](scheduler) for the timer to operate on:
 A version of the timeout operator allows you to switch to a backup Single rather than sending an error notification if the timeout expires:
 This, too, has a [Scheduler](scheduler)-specific version:
 toObservable
------------
 zip and zipWith
---------------
reactivex The Observable Contract The Observable Contract
=======================
“The Observable Contract,” which you may see referenced in various places in source documentation and in the pages on this site, is an attempt at a formal definition of an Observable, based originally on the 2010 document [Rx Design Guidelines](https://go.microsoft.com/fwlink/?LinkID=205219) from Microsoft that described its Rx.NET implementation of ReactiveX.
This page summarizes The Observable Contract.
Notifications
-------------
An Observable communicates with its observers with the following *notifications*:
OnNext conveys an *item* that is *emitted* by the Observable to the observer OnCompleted indicates that the Observable has completed successfully and that it will be emitting no further items OnError indicates that the Observable has terminated with a specified error condition and that it will be emitting no further items OnSubscribe (optional) indicates that the Observable is ready to accept Request notifications from the observer (see *Backpressure* below) An observer communicates with its Observable by means of the following notifications:
Subscribe indicates that the observer is ready to receive notifications from the Observable Unsubscribe indicates that the observer no longer wants to receive notifications from the Observable Request (optional) indicates that the observer wants no more than a particular number of additional OnNext notifications from the Observable (see *Backpressure* below) The Contract Governing Notifications
------------------------------------
An Observable may make zero or more OnNext notifications, each representing a single emitted item, and it may then follow those emission notifications by either an OnCompleted or an OnError notification, but not both. Upon issuing an OnCompleted or OnError notification, it may not thereafter issue any further notifications.
An Observable may emit no items at all. An Observable may also never terminate with either an OnCompleted or an OnError notification. That is to say that it is proper for an Observable to issue no notifications, to issue only an OnCompleted or an OnError notification, or to issue only OnNext notifications.
Observables must issue notifications to observers serially (not in parallel). They may issue these notifications from different threads, but there must be a formal *happens-before* relationship between the notifications.
Observable Termination
----------------------
If an Observable has not issued an OnCompleted or OnError notification, an observer may consider it to be still active (even if it is not currently emitting items) and may issue it notifications (such as an Unsubscribe or Request notification). When an Observable does issue an OnCompleted or OnError notification, the Observable may release its resources and terminate, and its observers should not attempt to communicate with it any further.
An OnError notification must contain the cause of the error (that is to say, it is invalid to call OnError with a `null` value).
Before an Observable terminates it must first issue either an OnCompleted or OnError notification to all of the observers that are subscribed to it.
Subscribing and Unsubscribing
-----------------------------
An Observable may begin issuing notifications to an observer immediately after the Observable receives a Subscribe notification from the observer.
When an observer issues an Unsubscribe notification to an Observable, the Observable will attempt to stop issuing notifications to the observer. It is not guaranteed, however, that the Observable will issue *no* notifications to the observer after an observer issues it an Unsubscribe notification.
When an Observable issues an OnError or OnComplete notification to its observers, this ends the subscription. Observers do not need to issue an Unsubscribe notification to end subscriptions that are ended by the Observable in this way.
Multiple Observers
------------------
If a second observer subscribes to an Observable that is already emitting items to a first observer, it is up to the Observable whether it will thenceforth emit the same items to each observer, or whether it will replay the complete sequence of items from the beginning to the second observer, or whether it will emit a wholly different sequence of items to the second observer. There is no general guarantee that two observers of the same Observable will see the same sequence of items.
Backpressure
------------
Backpressure is optional; not all ReactiveX implementations include backpressure, and in those that do, not all Observables or operators honor backpressure. An Observable *may* implement backpressure if it detects that its observer implements *Request* notifications and understands *OnSubscribe* notifications.
If an Observable implements backpressure and its observer employs backpressure, the Observable will not begin to emit items to the observer immediately upon subscription. Instead, it will issue an OnSubscribe notification to the observer.
At any time after it receives an OnSubscribe notification, an observer may issue a Request notification to the Observable it has subscribed to. This notification requests a particular number of items. The Observable responds to such a Request by emitting no more items to the observer than the number of items the observer requests. However the Observable may, in addition, issue an OnCompleted or OnError notification, and it may even issue such a notification before the observer requests any items at all.
An Observable that does not implement backpressure should respond to a Request notification from an observer by issuing an OnError notification that indicates that backpressure is not supported.
Requests are cumulative. For example, if an observer issues three Request notifications to an Observable, for 3, 5, and 10 items respectively, that Observable may emit as many as 18 items to the observer, no matter when those Request notifications arrived relative to when the Observable emitted items in response.
If the Observable produces more items than the observer requests, it is up to the Observable whether it will discard the excess items, store them to emit at a later time, or use some other strategy to deal with the overflow.
See Also
--------
* [Rx Design Guidelines](https://go.microsoft.com/fwlink/?LinkID=205219)
* [RxJS Design Guidelines](http://xgrommx.github.io/rx-book/content/guidelines/index.html)
| programming_docs |
reactivex Subject Subject
=======
A Subject is a sort of bridge or proxy that is available in some implementations of ReactiveX that acts both as an observer and as an Observable. Because it is an observer, it can subscribe to one or more Observables, and because it is an Observable, it can pass through the items it observes by reemitting them, and it can also emit new items.
Because a Subject subscribes to an Observable, it will trigger that Observable to begin emitting items (if that Observable is “cold” — that is, if it waits for a subscription before it begins to emit items). This can have the effect of making the resulting Subject a “hot” Observable variant of the original “cold” Observable.
#### See Also
* [To Use or Not to Use Subject](http://davesexton.com/blog/post/To-Use-Subject-Or-Not-To-Use-Subject.aspx) from Dave Sexton’s blog
* [Introduction to Rx: Subject](http://www.introtorx.com/Content/v1.0.10621.0/02_KeyTypes.html#Subject)
* [101 Rx Samples: ISubject<T> and ISubject<T1,T2>](http://rxwiki.wikidot.com/101samples#toc44)
* [Advanced RxJava: Subject](http://akarnokd.blogspot.hu/2015/06/subjects-part-1.html) by Dávid Karnok
* [Using Subjects](http://xgrommx.github.io/rx-book/content/getting_started_with_rxjs/subjects.html) by Dennis Stoyanov
Varieties of Subject
--------------------
There are four varieties of `Subject` that are designed for particular use cases. Not all of these are available in all implementations, and some implementations use other naming conventions (for example, in RxScala, what is called a “PublishSubject” here is known simply as a “Subject”):
### AsyncSubject
 An `AsyncSubject` emits the last value (and only the last value) emitted by the source Observable, and only after that source Observable completes. (If the source Observable does not emit any values, the `AsyncSubject` also completes without emitting any values.)
 It will also emit this same final value to any subsequent observers. However, if the source Observable terminates with an error, the `AsyncSubject` will not emit any items, but will simply pass along the error notification from the source Observable.
#### See Also
* [Introduction to Rx: AsyncSubject](http://www.introtorx.com/Content/v1.0.10621.0/02_KeyTypes.html#AsyncSubject)
### BehaviorSubject
 When an observer subscribes to a `BehaviorSubject`, it begins by emitting the item most recently emitted by the source Observable (or a seed/default value if none has yet been emitted) and then continues to emit any other items emitted later by the source Observable(s).
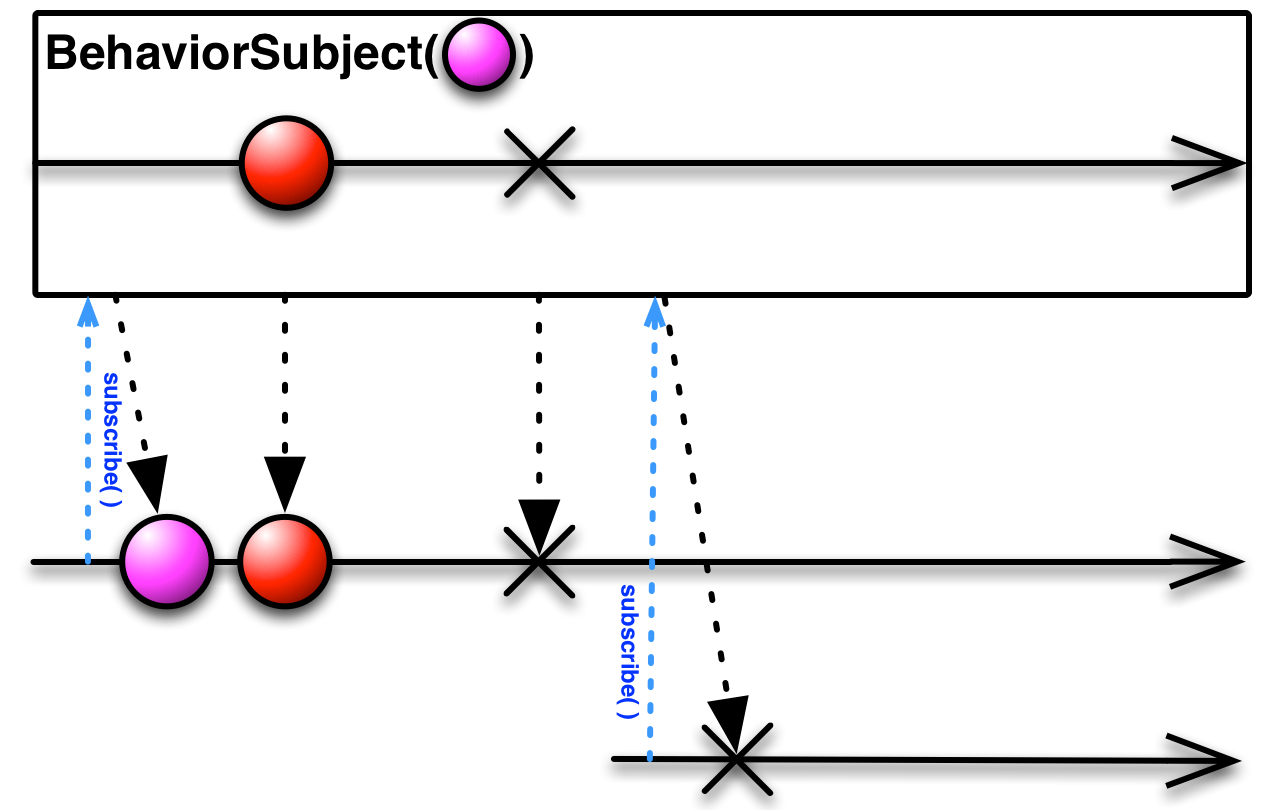 However, if the source Observable terminates with an error, the `BehaviorSubject` will not emit any items to subsequent observers, but will simply pass along the error notification from the source Observable.
#### See Also
* [Introduction to Rx: BehaviorSubject](http://www.introtorx.com/Content/v1.0.10621.0/02_KeyTypes.html#BehaviorSubject)
### PublishSubject
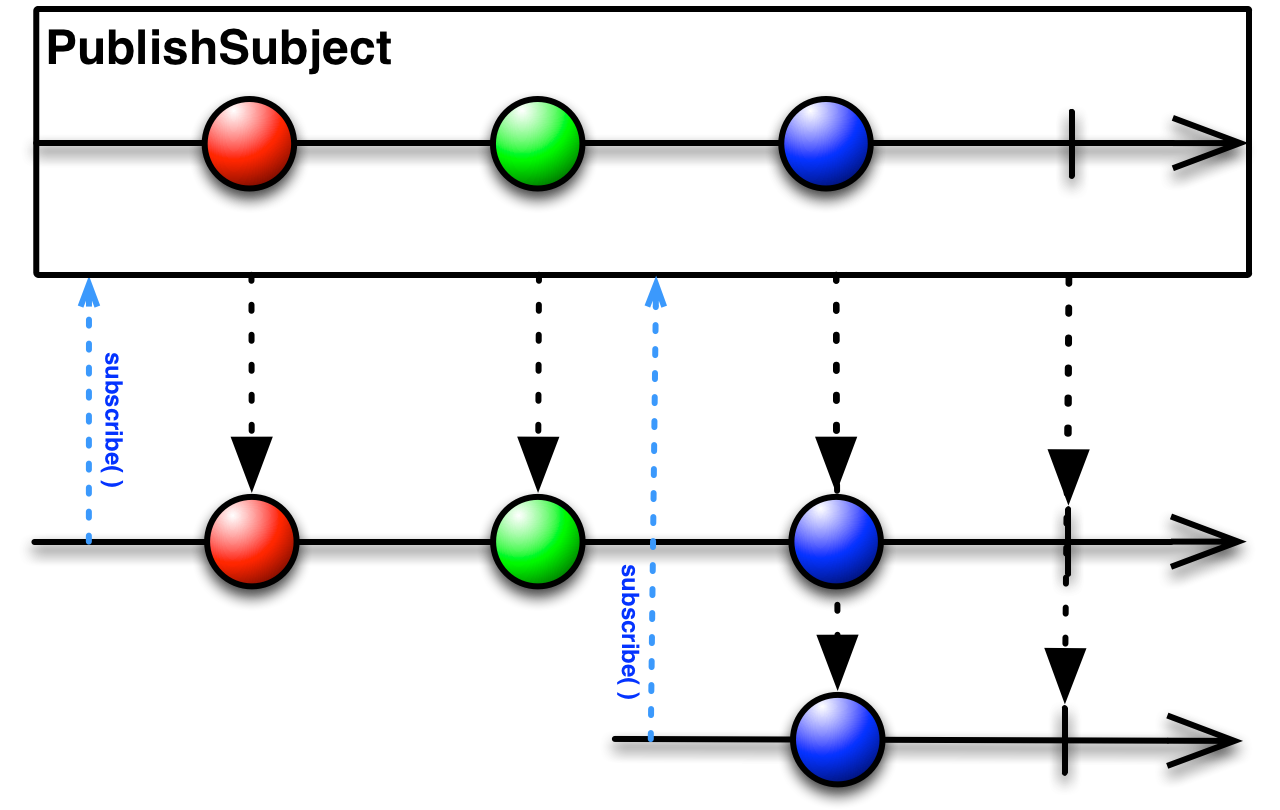 `PublishSubject` emits to an observer only those items that are emitted by the source Observable(s) subsequent to the time of the subscription.
Note that a `PublishSubject` may begin emitting items immediately upon creation (unless you have taken steps to prevent this), and so there is a risk that one or more items may be lost between the time the Subject is created and the observer subscribes to it. If you need to guarantee delivery of all items from the source Observable, you’ll need either to form that Observable with [`Create`](operators/create) so that you can manually reintroduce “cold” Observable behavior (checking to see that all observers have subscribed before beginning to emit items), or switch to using a `ReplaySubject` instead.
 If the source Observable terminates with an error, the `PublishSubject` will not emit any items to subsequent observers, but will simply pass along the error notification from the source Observable.
### ReplaySubject
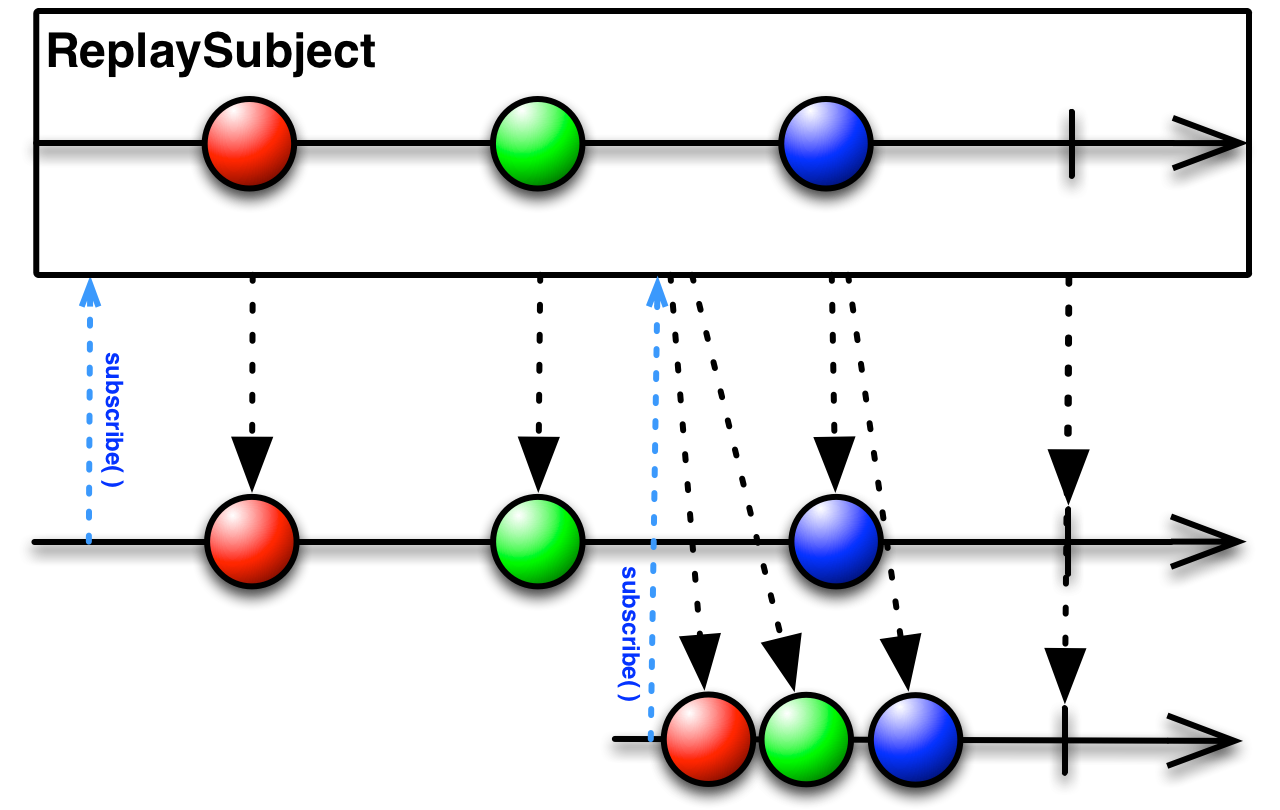 `ReplaySubject` emits to any observer all of the items that were emitted by the source Observable(s), regardless of when the observer subscribes.
There are also versions of `ReplaySubject` that will throw away old items once the replay buffer threatens to grow beyond a certain size, or when a specified timespan has passed since the items were originally emitted.
If you use a `ReplaySubject` as an observer, take care not to call its `onNext` method (or its other `on` methods) from multiple threads, as this could lead to coincident (non-sequential) calls, which violates [the Observable contract](contract) and creates an ambiguity in the resulting Subject as to which item or notification should be replayed first.
#### See Also
* [Introduction to Rx: ReplaySubject](http://www.introtorx.com/Content/v1.0.10621.0/02_KeyTypes.html#ReplaySubject)
Language-Specific Information
-----------------------------
### RxGroovy
If you have a `Subject` and you want to pass it along to some other agent without exposing its `Subscriber` interface, you can mask it by calling its `asObservable` method, which will return the Subject as a pure `Observable`.
#### See Also
* Javadoc: [`AsyncSubject`](http://reactivex.io/RxJava/javadoc/rx/subjects/AsyncSubject.html)
* Javadoc: [`BehaviorSubject`](http://reactivex.io/RxJava/javadoc/rx/subjects/BehaviorSubject.html)
* Javadoc: [`PublishSubject`](http://reactivex.io/RxJava/javadoc/rx/subjects/PublishSubject.html)
* Javadoc: [`ReplaySubject`](http://reactivex.io/RxJava/javadoc/rx/subjects/ReplaySubject.html)
### RxJava 1․x
If you have a `Subject` and you want to pass it along to some other agent without exposing its `Subscriber` interface, you can mask it by calling its `asObservable` method, which will return the Subject as a pure `Observable`.
#### See Also
* Javadoc: [`AsyncSubject`](http://reactivex.io/RxJava/javadoc/rx/subjects/AsyncSubject.html)
* Javadoc: [`BehaviorSubject`](http://reactivex.io/RxJava/javadoc/rx/subjects/BehaviorSubject.html)
* Javadoc: [`PublishSubject`](http://reactivex.io/RxJava/javadoc/rx/subjects/PublishSubject.html)
* Javadoc: [`ReplaySubject`](http://reactivex.io/RxJava/javadoc/rx/subjects/ReplaySubject.html)
reactivex Observable Observable
==========
In ReactiveX an observer subscribes to an Observable. Then that observer reacts to whatever item or sequence of items the Observable emits. This pattern facilitates concurrent operations because it does not need to block while waiting for the Observable to emit objects, but instead it creates a sentry in the form of an observer that stands ready to react appropriately at whatever future time the Observable does so.
This page explains what the reactive pattern is and what Observables and observers are (and how observers subscribe to Observables). Other pages show how you use [the variety of Observable operators](operators) to link Observables together and change their behaviors.
This documentation accompanies its explanations with “marble diagrams.” Here is how marble diagrams represent Observables and transformations of Observables:
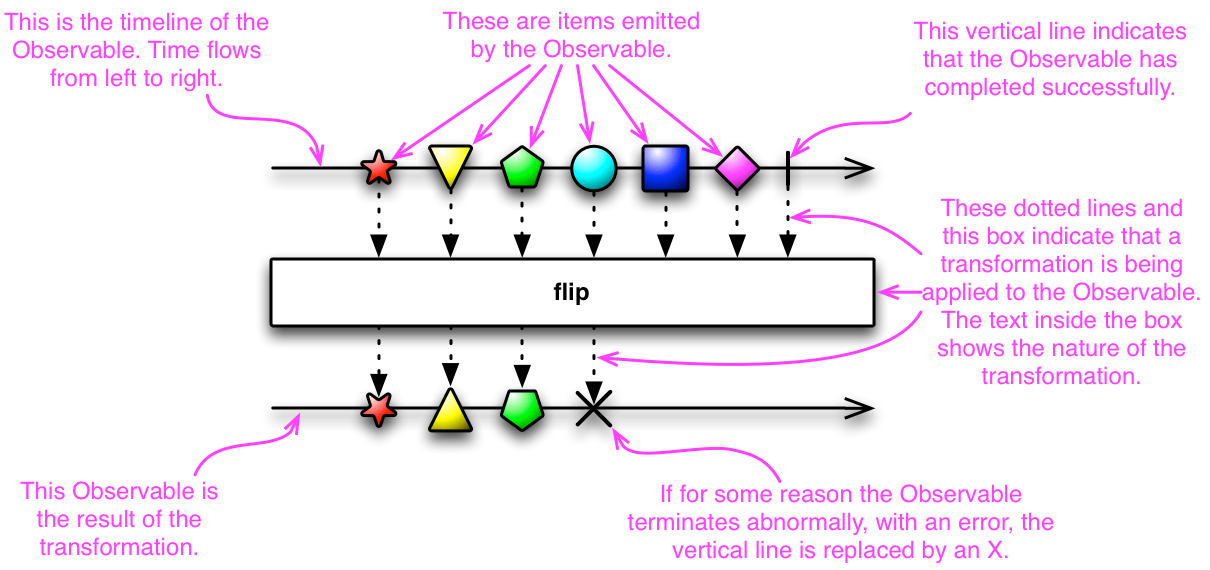 #### See Also
* [Single](single) — a specialized version of an Observable that emits only a single item
* [Rx Workshop: Introduction](http://channel9.msdn.com/Series/Rx-Workshop/Rx-Workshop-Introduction)
* [Introduction to Rx: IObservable](http://www.introtorx.com/Content/v1.0.10621.0/02_KeyTypes.html#IObservable)
* [Mastering observables](http://docs.couchbase.com/developer/java-2.0/observables.html) (from the Couchbase Server documentation)
* [2 minute introduction to Rx](https://medium.com/@andrestaltz/2-minute-introduction-to-rx-24c8ca793877) by Andre Staltz (“Think of an Observable as an asynchronous immutable array.”)
* [Introducing the Observable](https://egghead.io/lessons/javascript-introducing-the-observable) by Jafar Husain (JavaScript Video Tutorial)
* [Observable object](http://xgrommx.github.io/rx-book/content/observable/index.html) (RxJS) by Dennis Stoyanov
* [Turning a callback into an Rx Observable](https://afterecho.uk/blog/turning-a-callback-into-an-rx-observable.html) by @afterecho
Background
----------
In many software programming tasks, you more or less expect that the instructions you write will execute and complete incrementally, one-at-a-time, in order as you have written them. But in ReactiveX, many instructions may execute in parallel and their results are later captured, in arbitrary order, by “observers.” Rather than *calling* a method, you define a mechanism for retrieving and transforming the data, in the form of an “Observable,” and then *subscribe* an observer to it, at which point the previously-defined mechanism fires into action with the observer standing sentry to capture and respond to its emissions whenever they are ready.
An advantage of this approach is that when you have a bunch of tasks that are not dependent on each other, you can start them all at the same time rather than waiting for each one to finish before starting the next one — that way, your entire bundle of tasks only takes as long to complete as the longest task in the bundle.
There are many terms used to describe this model of asynchronous programming and design. This document will use the following terms: An observer subscribes to an Observable. An Observable emits items or sends notifications to its observers by calling the observers’ methods.
In other documents and other contexts, what we are calling an “observer” is sometimes called a “subscriber,” “watcher,” or “reactor.” This model in general is often referred to as the [“reactor pattern”](http://en.wikipedia.org/wiki/Reactor_pattern).
Establishing Observers
----------------------
This page uses Groovy-like pseudocode for its examples, but there are ReactiveX implementations in many languages.
In an ordinary method call — that is, *not* the sort of asynchronous, parallel calls typical in ReactiveX — the flow is something like this:
1. Call a method.
2. Store the return value from that method in a variable.
3. Use that variable and its new value to do something useful.
Or, something like this:
```
// make the call, assign its return value to `returnVal`
returnVal = someMethod(itsParameters);
// do something useful with returnVal
```
In the asynchronous model the flow goes more like this:
1. Define a method that does something useful with the return value from the asynchronous call; this method is part of the *observer*.
2. Define the asynchronous call itself as an *Observable*.
3. Attach the observer to that Observable by *subscribing* it (this also initiates the actions of the Observable).
4. Go on with your business; whenever the call returns, the observer’s method will begin to operate on its return value or values — the *items* emitted by the Observable.
Which looks something like this:
```
// defines, but does not invoke, the Subscriber's onNext handler
// (in this example, the observer is very simple and has only an onNext handler)
def myOnNext = { it -> do something useful with it };
// defines, but does not invoke, the Observable
def myObservable = someObservable(itsParameters);
// subscribes the Subscriber to the Observable, and invokes the Observable
myObservable.subscribe(myOnNext);
// go on about my business
```
onNext, onCompleted, and onError
--------------------------------
[The `Subscribe` method](operators/subscribe) is how you connect an observer to an Observable. Your observer implements some subset of the following methods:
`onNext` An Observable calls this method whenever the Observable emits an item. This method takes as a parameter the item emitted by the Observable. `onError` An Observable calls this method to indicate that it has failed to generate the expected data or has encountered some other error. It will not make further calls to `onNext` or `onCompleted`. The `onError` method takes as its parameter an indication of what caused the error. `onCompleted` An Observable calls this method after it has called `onNext` for the final time, if it has not encountered any errors. By the terms of [the Observable contract](contract), it may call `onNext` zero or more times, and then may follow those calls with a call to either `onCompleted` or `onError` but not both, which will be its last call. By convention, in this document, calls to `onNext` are usually called “emissions” of items, whereas calls to `onCompleted` or `onError` are called “notifications.”
A more complete `subscribe` call example looks like this:
```
def myOnNext = { item -> /* do something useful with item */ };
def myError = { throwable -> /* react sensibly to a failed call */ };
def myComplete = { /* clean up after the final response */ };
def myObservable = someMethod(itsParameters);
myObservable.subscribe(myOnNext, myError, myComplete);
// go on about my business
```
#### See Also
* [Introduction to Rx: IObserver](http://www.introtorx.com/Content/v1.0.10621.0/02_KeyTypes.html#IObserver)
Unsubscribing
-------------
In some ReactiveX implementations, there is a specialized observer interface, `Subscriber`, that implements an `unsubscribe` method. You can call this method to indicate that the Subscriber is no longer interested in any of the Observables it is currently subscribed to. Those Observables can then (if they have no other interested observers) choose to stop generating new items to emit.
The results of this unsubscription will cascade back through the chain of operators that applies to the Observable that the observer subscribed to, and this will cause each link in the chain to stop emitting items. This is not guaranteed to happen immediately, however, and it is possible for an Observable to generate and attempt to emit items for a while even after no observers remain to observe these emissions.
Some Notes on Naming Conventions
--------------------------------
Each language-specific implementation of ReactiveX has its own naming quirks. There is no canonical naming standard, though there are many commonalities between implementations.
Furthermore, some of these names have different implications in other contexts, or seem awkward in the idiom of a particular implementing language.
For example there is the `on*Event*` naming pattern (e.g. `onNext`, `onCompleted`, `onError`). In some contexts such names would indicate methods by means of which event handlers are *registered*. In ReactiveX, however, they name the event handlers themselves.
“Hot” and “Cold” Observables
----------------------------
When does an Observable begin emitting its sequence of items? It depends on the Observable. A “hot” Observable may begin emitting items as soon as it is created, and so any observer who later subscribes to that Observable may start observing the sequence somewhere in the middle. A “cold” Observable, on the other hand, waits until an observer subscribes to it before it begins to emit items, and so such an observer is guaranteed to see the whole sequence from the beginning.
In some implementations of ReactiveX, there is also something called a “Connectable” Observable. Such an Observable does not begin emitting items until its [Connect](operators/connect) method is called, whether or not any observers have subscribed to it.
Composition via Observable Operators
------------------------------------
Observables and observers are only the start of ReactiveX. By themselves they’d be nothing more than a slight extension of the standard observer pattern, better suited to handling a sequence of events rather than a single callback.
The real power comes with the “reactive extensions” (hence “ReactiveX”) — operators that allow you to transform, combine, manipulate, and work with the sequences of items emitted by Observables.
These Rx operators allow you to compose asynchronous sequences together in a declarative manner with all the efficiency benefits of callbacks but without the drawbacks of nesting callback handlers that are typically associated with asynchronous systems.
This documentation groups information about [the various operators](operators#alphabetical) and examples of their usage into the following pages:
[Creating Observables](operators#creating)
`Create`, `Defer`, `Empty`/`Never`/`Throw`, `From`, `Interval`, `Just`, `Range`, `Repeat`, `Start`, and `Timer`
[Transforming Observable Items](operators#transforming)
`Buffer`, `FlatMap`, `GroupBy`, `Map`, `Scan`, and `Window`
[Filtering Observables](operators#filtering)
`Debounce`, `Distinct`, `ElementAt`, `Filter`, `First`, `IgnoreElements`, `Last`, `Sample`, `Skip`, `SkipLast`, `Take`, and `TakeLast`
[Combining Observables](operators#combining)
`And`/`Then`/`When`, `CombineLatest`, `Join`, `Merge`, `StartWith`, `Switch`, and `Zip`
[Error Handling Operators](operators#error)
`Catch` and `Retry`
[Utility Operators](operators#utility)
`Delay`, `Do`, `Materialize`/`Dematerialize`, `ObserveOn`, `Serialize`, `Subscribe`, `SubscribeOn`, `TimeInterval`, `Timeout`, `Timestamp`, and `Using`
[Conditional and Boolean Operators](operators#conditional)
`All`, `Amb`, `Contains`, `DefaultIfEmpty`, `SequenceEqual`, `SkipUntil`, `SkipWhile`, `TakeUntil`, and `TakeWhile`
[Mathematical and Aggregate Operators](operators#mathematical)
`Average`, `Concat`, `Count`, `Max`, `Min`, `Reduce`, and `Sum`
[Converting Observables](operators#conversion) `To` [Connectable Observable Operators](operators#connectable)
`Connect`, `Publish`, `RefCount`, and `Replay`
[Backpressure Operators](operators/backpressure) a variety of operators that enforce particular flow-control policies These pages include information about some operators that are not part of the core of ReactiveX but are implemented in one or more of language-specific implementations and/or optional modules.
Chaining Operators
------------------
Most operators operate on an Observable and return an Observable. This allows you to apply these operators one after the other, in a chain. Each operator in the chain modifies the Observable that results from the operation of the previous operator.
There are other patterns, like the Builder Pattern, in which a variety of methods of a particular class operate on an item of that same class by modifying that object through the operation of the method. These patterns also allow you to chain the methods in a similar way. But while in the Builder Pattern, the order in which the methods appear in the chain does not usually matter, with the Observable operators *order matters*.
A chain of Observable operators do not operate independently on the original Observable that originates the chain, but they operate *in turn*, each one operating on the Observable generated by the operator immediately previous in the chain.
reactivex Scheduler Scheduler
=========
If you want to introduce multithreading into your cascade of Observable operators, you can do so by instructing those operators (or particular Observables) to operate on particular Schedulers.
Some ReactiveX Observable operators have variants that take a Scheduler as a parameter. These instruct the operator to do some or all of its work on a particular Scheduler.
By default, an Observable and the chain of operators that you apply to it will do its work, and will notify its observers, on the same thread on which its `Subscribe` method is called. The SubscribeOn operator changes this behavior by specifying a different Scheduler on which the Observable should operate. The ObserveOn operator specifies a different Scheduler that the Observable will use to send notifications to its observers.
As shown in this illustration, the SubscribeOn operator designates which thread the Observable will begin operating on, no matter at what point in the chain of operators that operator is called. ObserveOn, on the other hand, affects the thread that the Observable will use *below* where that operator appears. For this reason, you may call ObserveOn multiple times at various points during the chain of Observable operators in order to change on which threads certain of those operators operate.
 #### See Also
* [Introduction to Rx: Scheduling and Threading](http://www.introtorx.com/Content/v1.0.10621.0/15_SchedulingAndThreading.html)
* [Rx Workshop: Schedulers](http://channel9.msdn.com/Series/Rx-Workshop/Rx-Workshop-Schedulers)
* [Using Schedulers](http://xgrommx.github.io/rx-book/content/getting_started_with_rxjs/scheduling_and_concurrency.html) by Dennis Stoyanov
Language-Specific Information
-----------------------------
### RxGroovy
Varieties of Scheduler
----------------------
You obtain a Scheduler from the factory methods described in [the `Schedulers` class](http://reactivex.io/RxJava/javadoc/rx/schedulers/Schedulers.html). The following table shows the varieties of Scheduler that are available to you by means of these methods in RxGroovy:
| Scheduler | purpose |
| --- | --- |
| [`Schedulers.computation( )`](http://reactivex.io/RxJava/javadoc/rx/schedulers/Schedulers.html#computation()) | meant for computational work such as event-loops and callback processing; do not use this scheduler for I/O (use `Schedulers.io( )` instead); the number of threads, by default, is equal to the number of processors |
| [`Schedulers.from(executor)`](http://reactivex.io/RxJava/javadoc/rx/schedulers/Schedulers.html#from(java.util.concurrent.Executor)) | uses the specified `Executor` as a Scheduler |
| [`Schedulers.immediate( )`](http://reactivex.io/RxJava/javadoc/rx/schedulers/Schedulers.html#immediate()) | schedules work to begin immediately in the current thread |
| [`Schedulers.io( )`](http://reactivex.io/RxJava/javadoc/rx/schedulers/Schedulers.html#io()) | meant for I/O-bound work such as asynchronous performance of blocking I/O, this scheduler is backed by a thread-pool that will grow as needed; for ordinary computational work, switch to `Schedulers.computation( )`; `Schedulers.io( )` by default is a `CachedThreadScheduler`, which is something like a new thread scheduler with thread caching |
| [`Schedulers.newThread( )`](http://reactivex.io/RxJava/javadoc/rx/schedulers/Schedulers.html#newThread()) | creates a new thread for each unit of work |
| [`Schedulers.trampoline( )`](http://reactivex.io/RxJava/javadoc/rx/schedulers/Schedulers.html#trampoline()) | queues work to begin on the current thread after any already-queued work |
Default Schedulers for RxGroovy Observable Operators
----------------------------------------------------
Some Observable operators in RxGroovy have alternate forms that allow you to set which Scheduler the operator will use for (at least some part of) its operation. Others do not operate on any particular Scheduler, or operate on a particular default Scheduler. Those that have a particular default Scheduler include:
| operator | Scheduler |
| --- | --- |
| [`buffer(timespan)`](operators/buffer) | `computation` |
| [`buffer(timespan, count)`](operators/buffer) | `computation` |
| [`buffer(timespan, timeshift)`](operators/buffer) | `computation` |
| [`debounce(timeout, unit)`](operators/debounce) | `computation` |
| [`delay(delay, unit)`](operators/delay) | `computation` |
| [`delaySubscription(delay, unit)`](operators/delay) | `computation` |
| [`interval`](operators/interval) | `computation` |
| [`repeat`](operators/repeat) | `trampoline` |
| [`replay(time, unit)`](operators/replay) | `computation` |
| [`replay(buffersize, time, unit)`](operators/replay) | `computation` |
| [`replay(selector, time, unit)`](operators/replay) | `computation` |
| [`replay(selector, buffersize, time, unit)`](operators/replay) | `computation` |
| [`retry`](operators/retry) | `trampoline` |
| [`sample(period, unit)`](operators/sample) | `computation` |
| [`skip(time, unit)`](operators/skip) | `computation` |
| [`skipLast(time, unit)`](operators/skiplast) | `computation` |
| [`take(time, unit)`](operators/take) | `computation` |
| [`takeLast(time, unit)`](operators/takelast) | `computation` |
| [`takeLast(count, time, unit)`](operators/takelast) | `computation` |
| [`takeLastBuffer(time, unit)`](operators/takelast) | `computation` |
| [`takeLastBuffer(count, time, unit)`](operators/takelast) | `computation` |
| [`throttleFirst`](operators/sample) | `computation` |
| [`throttleLast`](operators/sample) | `computation` |
| [`throttleWithTimeout`](operators/debounce) | `computation` |
| [`timeInterval`](operators/timeinterval) | `immediate` |
| [`timeout(timeoutSelector)`](operators/timeout) | `immediate` |
| [`timeout(firstTimeoutSelector, timeoutSelector)`](operators/timeout) | `immediate` |
| [`timeout(timeoutSelector, other)`](operators/timeout) | `immediate` |
| [`timeout(timeout, timeUnit)`](operators/timeout) | `computation` |
| [`timeout(firstTimeoutSelector, timeoutSelector, other)`](operators/timeout) | `immediate` |
| [`timeout(timeout, timeUnit, other)`](operators/timeout) | `computation` |
| [`timer`](operators/timer) | `computation` |
| [`timestamp`](operators/timestamp) | `immediate` |
| [`window(timespan)`](operators/window) | `computation` |
| [`window(timespan, count)`](operators/window) | `computation` |
| [`window(timespan, timeshift)`](operators/window) | `computation` |
Test Scheduler
--------------
[The `TestScheduler`](http://reactivex.io/RxJava/javadoc/rx/schedulers/TestScheduler.html) allows you to exercise fine-tuned manual control over how the Scheduler’s clock behaves. This can be useful for testing interactions that depend on precise arrangements of actions in time. This Scheduler has three additional methods:
[`advanceTimeTo(time,unit)`](http://reactivex.io/RxJava/javadoc/rx/schedulers/TestScheduler.html#advanceTimeTo(long,%20java.util.concurrent.TimeUnit)) advances the Scheduler’s clock to a particular point in time [`advanceTimeBy(time,unit)`](http://reactivex.io/RxJava/javadoc/rx/schedulers/TestScheduler.html#advanceTimeBy(long,%20java.util.concurrent.TimeUnit)) advances the Scheduler’s clock forward by a particular amount of time [`triggerActions( )`](http://reactivex.io/RxJava/javadoc/rx/schedulers/TestScheduler.html#triggerActions()) start any unstarted actions that have been scheduled for a time equal to or earlier than the present time according to the Scheduler’s clock #### See Also
* [Testing Reactive Applications](https://speakerdeck.com/benjchristensen/applying-rxjava-to-existing-applications-at-philly-ete-2015) by Ben Christensen
* [RxJava Threading Examples](http://www.grahamlea.com/2014/07/rxjava-threading-examples/) by Graham Lea
* Advanced RxJava: Schedulers ([part 1](http://akarnokd.blogspot.hu/2015/05/schedulers-part-1.html)) ([part 2](http://akarnokd.blogspot.hu/2015/06/schedulers-part-2.html)) ([part 3](http://akarnokd.blogspot.hu/2015/06/schedulers-part-3.html)) ([part 4](http://akarnokd.blogspot.hu/2015/06/schedulers-part-4-final.html)) by Dávid Karnok
### RxJava 1․x
Varieties of Scheduler
----------------------
You obtain a Scheduler from the factory methods described in [the `Schedulers` class](http://reactivex.io/RxJava/javadoc/rx/schedulers/Schedulers.html). The following table shows the varieties of Scheduler that are available to you by means of these methods in RxJava:
| Scheduler | purpose |
| --- | --- |
| [`Schedulers.computation( )`](http://reactivex.io/RxJava/javadoc/rx/schedulers/Schedulers.html#computation()) | meant for computational work such as event-loops and callback processing; do not use this scheduler for I/O (use `Schedulers.io( )` instead); the number of threads, by default, is equal to the number of processors |
| [`Schedulers.from(executor)`](http://reactivex.io/RxJava/javadoc/rx/schedulers/Schedulers.html#from(java.util.concurrent.Executor)) | uses the specified `Executor` as a Scheduler |
| [`Schedulers.immediate( )`](http://reactivex.io/RxJava/javadoc/rx/schedulers/Schedulers.html#immediate()) | schedules work to begin immediately in the current thread |
| [`Schedulers.io( )`](http://reactivex.io/RxJava/javadoc/rx/schedulers/Schedulers.html#io()) | meant for I/O-bound work such as asynchronous performance of blocking I/O, this scheduler is backed by a thread-pool that will grow as needed; for ordinary computational work, switch to `Schedulers.computation( )`; `Schedulers.io( )` by default is a `CachedThreadScheduler`, which is something like a new thread scheduler with thread caching |
| [`Schedulers.newThread( )`](http://reactivex.io/RxJava/javadoc/rx/schedulers/Schedulers.html#newThread()) | creates a new thread for each unit of work |
| [`Schedulers.trampoline( )`](http://reactivex.io/RxJava/javadoc/rx/schedulers/Schedulers.html#trampoline()) | queues work to begin on the current thread after any already-queued work |
Default Schedulers for RxJava 1.x Observable Operators
------------------------------------------------------
Some Observable operators in RxJava have alternate forms that allow you to set which Scheduler the operator will use for (at least some part of) its operation. Others do not operate on any particular Scheduler, or operate on a particular default Scheduler. Those that have a particular default Scheduler include:
| operator | Scheduler |
| --- | --- |
| [`buffer(timespan)`](operators/buffer) | `computation` |
| [`buffer(timespan, count)`](operators/buffer) | `computation` |
| [`buffer(timespan, timeshift)`](operators/buffer) | `computation` |
| [`debounce(timeout, unit)`](operators/debounce) | `computation` |
| [`delay(delay, unit)`](operators/delay) | `computation` |
| [`delaySubscription(delay, unit)`](operators/delay) | `computation` |
| [`interval`](operators/interval) | `computation` |
| [`repeat`](operators/repeat) | `trampoline` |
| [`replay(time, unit)`](operators/replay) | `computation` |
| [`replay(buffersize, time, unit)`](operators/replay) | `computation` |
| [`replay(selector, time, unit)`](operators/replay) | `computation` |
| [`replay(selector, buffersize, time, unit)`](operators/replay) | `computation` |
| [`retry`](operators/retry) | `trampoline` |
| [`sample(period, unit)`](operators/sample) | `computation` |
| [`skip(time, unit)`](operators/skip) | `computation` |
| [`skipLast(time, unit)`](operators/skiplast) | `computation` |
| [`take(time, unit)`](operators/take) | `computation` |
| [`takeLast(time, unit)`](operators/takelast) | `computation` |
| [`takeLast(count, time, unit)`](operators/takelast) | `computation` |
| [`takeLastBuffer(time, unit)`](operators/takelast) | `computation` |
| [`takeLastBuffer(count, time, unit)`](operators/takelast) | `computation` |
| [`throttleFirst`](operators/sample) | `computation` |
| [`throttleLast`](operators/sample) | `computation` |
| [`throttleWithTimeout`](operators/debounce) | `computation` |
| [`timeInterval`](operators/timeinterval) | `immediate` |
| [`timeout(timeoutSelector)`](operators/timeout) | `immediate` |
| [`timeout(firstTimeoutSelector, timeoutSelector)`](operators/timeout) | `immediate` |
| [`timeout(timeoutSelector, other)`](operators/timeout) | `immediate` |
| [`timeout(timeout, timeUnit)`](operators/timeout) | `computation` |
| [`timeout(firstTimeoutSelector, timeoutSelector, other)`](operators/timeout) | `immediate` |
| [`timeout(timeout, timeUnit, other)`](operators/timeout) | `computation` |
| [`timer`](operators/timer) | `computation` |
| [`timestamp`](operators/timestamp) | `immediate` |
| [`window(timespan)`](operators/window) | `computation` |
| [`window(timespan, count)`](operators/window) | `computation` |
| [`window(timespan, timeshift)`](operators/window) | `computation` |
Using Schedulers
----------------
Aside from passing these Schedulers in to RxJava Observable operators, you can also use them to schedule your own work on Subscriptions. The following example uses [the `schedule` method](http://reactivex.io/RxJava/javadoc/rx/Scheduler.Worker.html#schedule(rx.functions.Action0)) of [the `Scheduler.Worker` class](http://reactivex.io/RxJava/javadoc/rx/Scheduler.Worker.html) to schedule work on the `newThread` Scheduler:
```
worker = Schedulers.newThread().createWorker();
worker.schedule(new Action0() {
@Override
public void call() {
yourWork();
}
});
// some time later...
worker.unsubscribe();
```
### Recursive Schedulers
To schedule recursive calls, you can use `schedule` and then `schedule(this)` on the Worker object:
```
worker = Schedulers.newThread().createWorker();
worker.schedule(new Action0() {
@Override
public void call() {
yourWork();
// recurse until unsubscribed (schedule will do nothing if unsubscribed)
worker.schedule(this);
}
});
// some time later...
worker.unsubscribe();
```
### Checking or Setting Unsubscribed Status
Objects of the `Worker` class implement [the `Subscription` interface](http://reactivex.io/RxJava/javadoc/rx/Subscription.html), with its [`isUnsubscribed`](http://reactivex.io/RxJava/javadoc/rx/Subscription.html#isUnsubscribed()) and [`unsubscribe`](http://reactivex.io/RxJava/javadoc/rx/Subscription.html#unsubscribe()) methods, so you can stop work when a subscription is cancelled, or you can cancel the subscription from within the scheduled task:
```
Worker worker = Schedulers.newThread().createWorker();
Subscription mySubscription = worker.schedule(new Action0() {
@Override
public void call() {
while(!worker.isUnsubscribed()) {
status = yourWork();
if(QUIT == status) { worker.unsubscribe(); }
}
}
});
```
The `Worker` is also a `Subscription` and so you can (and should, eventually) call its `unsubscribe` method to signal that it can halt work and release resources:
```
worker.unsubscribe();
```
### Delayed and Periodic Schedulers
You can also use [a version of `schedule`](http://reactivex.io/RxJava/javadoc/rx/Scheduler.Worker.html#schedule(rx.functions.Action0,%20long,%20java.util.concurrent.TimeUnit)) that delays your action on the given Scheduler until a certain timespan has passed. The following example schedules `someAction` to be performed on `someScheduler` after 500ms have passed according to that Scheduler’s clock:
```
someScheduler.schedule(someAction, 500, TimeUnit.MILLISECONDS);
```
[Another `Scheduler` method](http://reactivex.io/RxJava/javadoc/rx/Scheduler.Worker.html#schedulePeriodically(rx.functions.Action0,%20long,%20long,%20java.util.concurrent.TimeUnit)) allows you to schedule an action to take place at regular intervals. The following example schedules `someAction` to be performed on `someScheduler` after 500ms have passed, and then every 250ms thereafter:
```
someScheduler.schedulePeriodically(someAction, 500, 250, TimeUnit.MILLISECONDS);
```
Test Scheduler
--------------
[The `TestScheduler`](http://reactivex.io/RxJava/javadoc/rx/schedulers/TestScheduler.html) allows you to exercise fine-tuned manual control over how the Scheduler’s clock behaves. This can be useful for testing interactions that depend on precise arrangements of actions in time. This Scheduler has three additional methods:
[`advanceTimeTo(time,unit)`](http://reactivex.io/RxJava/javadoc/rx/schedulers/TestScheduler.html#advanceTimeTo(long,%20java.util.concurrent.TimeUnit)) advances the Scheduler’s clock to a particular point in time [`advanceTimeBy(time,unit)`](http://reactivex.io/RxJava/javadoc/rx/schedulers/TestScheduler.html#advanceTimeBy(long,%20java.util.concurrent.TimeUnit)) advances the Scheduler’s clock forward by a particular amount of time [`triggerActions( )`](http://reactivex.io/RxJava/javadoc/rx/schedulers/TestScheduler.html#triggerActions()) start any unstarted actions that have been scheduled for a time equal to or earlier than the present time according to the Scheduler’s clock #### See Also
* [RxJava Threading Examples](http://www.grahamlea.com/2014/07/rxjava-threading-examples/) by Graham Lea
* [Testing Reactive Applications](https://speakerdeck.com/benjchristensen/applying-rxjava-to-existing-applications-at-philly-ete-2015) by Ben Christensen
* Advanced RxJava: Schedulers ([part 1](http://akarnokd.blogspot.hu/2015/05/schedulers-part-1.html)) ([part 2](http://akarnokd.blogspot.hu/2015/06/schedulers-part-2.html)) ([part 3](http://akarnokd.blogspot.hu/2015/06/schedulers-part-3.html)) ([part 4](http://akarnokd.blogspot.hu/2015/06/schedulers-part-4-final.html)) by Dávid Karnok
### RxJS
In RxJS you obtain Schedulers from the `Rx.Scheduler` object or as independently-implemented objects. The following table shows the varieties of Scheduler that are available to you in RxJS:.
| Scheduler | purpose |
| --- | --- |
| `Rx.Scheduler.currentThread` | schedules work as soon as possible on the current thread |
| `Rx.HistoricalScheduler` | schedules work as though it were occurring at an arbitrary historical time |
| `Rx.Scheduler.immediate` | schedules work immediately on the current thread |
| `Rx.TestScheduler` | for unit testing; this allows you to manually manipulate the movement of time |
| `Rx.Scheduler.timeout` | schedules work by means of a timed callback |
#### See Also
* [StackOverflow: What is a “Scheduler” in RxJS](http://stackoverflow.com/questions/28145890/what-is-a-scheduler-in-rxjs)
* [Schedulers](http://xgrommx.github.io/rx-book/content/schedulers/index.html) by Dennis Stoyanov
* [RxJava Threading Examlpes](http://www.grahamlea.com/2014/07/rxjava-threading-examples/) by Graham Lea
| programming_docs |
reactivex Implementing Your Own Operators Implementing Your Own Operators
===============================
You can implement your own Observable operators. This page shows you how.
If your operator is designed to *originate* an Observable, rather than to transform or react to a source Observable, use the [`create( )`](operators/create) method rather than trying to implement `Observable` manually. Otherwise, follow the instructions below.
Chaining Your Custom Operators with Standard RxJava Operators
-------------------------------------------------------------
The following example shows how you can chain a custom operator (in this example: `myOperator`) along with standard RxJava operators by using the `lift( )` operator:
```
Observable foo = barObservable.ofType(Integer).map({it*2}).lift(new myOperator<T>()).map({"transformed by myOperator: " + it});
```
The following section will show how to form the scaffolding of your operator so that it will work correctly with `lift( )`.
Implementing Your Operator
--------------------------
Define your operator as a public class that implements the [`Operator`](http://reactivex.io/RxJava/javadoc/rx/Observable.Operator.html) interface, like so:
```
public class myOperator<T> implements Operator<T> {
public myOperator( /* any necessary params here */ ) {
/* any necessary initialization here */
}
@Override
public Subscriber<? super T> call(final Subscriber<? super T> s) {
return new Subscriber<t>(s) {
@Override
public void onCompleted() {
/* add your own onCompleted behavior here, or just pass the completed notification through: */
if(!s.isUnsubscribed()) {
s.onCompleted();
}
}
@Override
public void onError(Throwable t) {
/* add your own onError behavior here, or just pass the error notification through: */
if(!s.isUnsubscribed()) {
s.onError(t);
}
}
@Override
public void onNext(T item) {
/* this example performs some sort of simple transformation on each incoming item and then passes it along */
if(!s.isUnsubscribed()) {
transformedItem = myOperatorTransformOperation(item);
s.onNext(transformedItem);
}
}
};
}
}
```
Other Considerations
--------------------
* Your operator should check [its Subscriber's `isUnsubscribed( )` status](observable#unsubscribing) before it emits any item to (or sends any notification to) the Subscriber. Do not waste time generating items that no Subscriber is interested in seeing.
* Your operator should obey the core tenets of the Observable contract:
+ It may call a Subscriber's [`onNext( )`](observable#onnext-oncompleted-and-onerror) method any number of times, but these calls must be non-overlapping.
+ It may call either a Subscriber's [`onCompleted( )`](observable#onnext-oncompleted-and-onerror) or [`onError( )`](observable#onnext-oncompleted-and-onerror) method, but not both, exactly once, and it may not subsequently call a Subscriber's [`onNext( )`](observable#onnext-oncompleted-and-onerror) method.
+ If you are unable to guarantee that your operator conforms to the above two tenets, you can add the [`serialize( )`](observable-utility-operators#serialize) operator to it to force the correct behavior.
* Do not block within your operator.
* It is usually best that you compose new operators by combining existing ones, to the extent that this is possible, rather than reinventing the wheel. RxJava itself does this with some of its standard operators, for example:
+ [`first( )`](filtering-observables#wiki-first-and-takefirst) is defined as [`take(1)`](filtering-observables#wiki-take)`.`[`single( )`](observable-utility-operators#wiki-single-and-singleordefault)
+ [`ignoreElements( )`](filtering-observables#wiki-ignoreelements) is defined as [`filter(alwaysFalse( ))`](filtering-observables#wiki-filter)
+ [`reduce(a)`](mathematical-and-aggregate-operators#wiki-reduce) is defined as [`scan(a)`](transforming-observables#wiki-scan)`.`[`last( )`](filtering-observables#wiki-last)
* If your operator uses functions or lambdas that are passed in as parameters (predicates, for instance), note that these may be sources of exceptions, and be prepared to catch these and notify subscribers via `onError( )` calls.
* In general, notify subscribers of error conditions immediately, rather than making an effort to emit more items first.
* In some ReactiveX implementations, your operator may need to be sensitive to that implementation’s “backpressure” strategies. (See, for example: [Pitfalls of Operator Implementations (part 2)](http://akarnokd.blogspot.hu/2015/05/pitfalls-of-operator-implementations_14.html) by Dávid Karnok.)
See Also
--------
* [Pitfalls of Operator Implementations (part 1)](http://akarnokd.blogspot.hu/2015/05/pitfalls-of-operator-implementations.html) and [(part 2)](http://akarnokd.blogspot.hu/2015/05/pitfalls-of-operator-implementations_14.html) by Dávid Karnok.
* [Implementing Your Own Observable Operators](http://xgrommx.github.io/rx-book/content/getting_started_with_rxjs/implementing_your_own_operators.html) (in RxJS) by Dennis Stoyanov
reactivex Introduction Introduction
============
Each language-specific implementation of ReactiveX implements a set of operators. Although there is much overlap between implementations, there are also some operators that are only implemented in certain implementations. Also, each implementation tends to name its operators to resemble those of similar methods that are already familiar from other contexts in that language.
Chaining Operators
------------------
Most operators operate on an Observable and return an Observable. This allows you to apply these operators one after the other, in a chain. Each operator in the chain modifies the Observable that results from the operation of the previous operator.
There are other patterns, like the Builder Pattern, in which a variety of methods of a particular class operate on an item of that same class by modifying that object through the operation of the method. These patterns also allow you to chain the methods in a similar way. But while in the Builder Pattern, the order in which the methods appear in the chain does not usually matter, with the Observable operators *order matters*.
A chain of Observable operators do not operate independently on the original Observable that originates the chain, but they operate *in turn*, each one operating on the Observable generated by the operator immediately previous in the chain.
The Operators of ReactiveX
--------------------------
This page first lists what could be considered the “core” operators in ReactiveX, and links to pages that have more in-depth information on how these operators work and how particular language-specific ReactiveX versions have implemented these operators.
Next is a “decision tree” that may help you choose the operator that is most appropriate to your use case.
Finally, there is an alphabetical list of most of the operators available in the many language-specific implementations of ReactiveX. These link to the page that documents the core operator that most closely resembles the language-specific operator (so, for instance, the Rx.NET “SelectMany” operator links to the documentation of the FlatMap ReactiveX operator, of which “SelectMany” is the Rx.NET implementation).
If you want to implement your own operator, see [Implementing Your Own Operators](implement-operator).
#### Contents
1. [Operators By Category](#categorized)
2. [A Decision Tree of Observable Operators](#tree)
3. [An Alphabetical List of Observable Operators](#alphabetical)
Operators By Category
---------------------
Creating Observables
--------------------
Operators that originate new Observables.
* [`Create`](operators/create) — create an Observable from scratch by calling observer methods programmatically
* [`Defer`](operators/defer) — do not create the Observable until the observer subscribes, and create a fresh Observable for each observer
* [`Empty`/`Never`/`Throw`](operators/empty-never-throw) — create Observables that have very precise and limited behavior
* [`From`](operators/from) — convert some other object or data structure into an Observable
* [`Interval`](operators/interval) — create an Observable that emits a sequence of integers spaced by a particular time interval
* [`Just`](operators/just) — convert an object or a set of objects into an Observable that emits that or those objects
* [`Range`](operators/range) — create an Observable that emits a range of sequential integers
* [`Repeat`](operators/repeat) — create an Observable that emits a particular item or sequence of items repeatedly
* [`Start`](operators/start) — create an Observable that emits the return value of a function
* [`Timer`](operators/timer) — create an Observable that emits a single item after a given delay
Transforming Observables
------------------------
Operators that transform items that are emitted by an Observable.
* [`Buffer`](operators/buffer) — periodically gather items from an Observable into bundles and emit these bundles rather than emitting the items one at a time
* [`FlatMap`](operators/flatmap) — transform the items emitted by an Observable into Observables, then flatten the emissions from those into a single Observable
* [`GroupBy`](operators/groupby) — divide an Observable into a set of Observables that each emit a different group of items from the original Observable, organized by key
* [`Map`](operators/map) — transform the items emitted by an Observable by applying a function to each item
* [`Scan`](operators/scan) — apply a function to each item emitted by an Observable, sequentially, and emit each successive value
* [`Window`](operators/window) — periodically subdivide items from an Observable into Observable windows and emit these windows rather than emitting the items one at a time
Filtering Observables
---------------------
Operators that selectively emit items from a source Observable.
* [`Debounce`](operators/debounce) — only emit an item from an Observable if a particular timespan has passed without it emitting another item
* [`Distinct`](operators/distinct) — suppress duplicate items emitted by an Observable
* [`ElementAt`](operators/elementat) — emit only item *n* emitted by an Observable
* [`Filter`](operators/filter) — emit only those items from an Observable that pass a predicate test
* [`First`](operators/first) — emit only the first item, or the first item that meets a condition, from an Observable
* [`IgnoreElements`](operators/ignoreelements) — do not emit any items from an Observable but mirror its termination notification
* [`Last`](operators/last) — emit only the last item emitted by an Observable
* [`Sample`](operators/sample) — emit the most recent item emitted by an Observable within periodic time intervals
* [`Skip`](operators/skip) — suppress the first *n* items emitted by an Observable
* [`SkipLast`](operators/skiplast) — suppress the last *n* items emitted by an Observable
* [`Take`](operators/take) — emit only the first *n* items emitted by an Observable
* [`TakeLast`](operators/takelast) — emit only the last *n* items emitted by an Observable
Combining Observables
---------------------
Operators that work with multiple source Observables to create a single Observable
* [`And`/`Then`/`When`](operators/and-then-when) — combine sets of items emitted by two or more Observables by means of `Pattern` and `Plan` intermediaries
* [`CombineLatest`](operators/combinelatest) — when an item is emitted by either of two Observables, combine the latest item emitted by each Observable via a specified function and emit items based on the results of this function
* [`Join`](operators/join) — combine items emitted by two Observables whenever an item from one Observable is emitted during a time window defined according to an item emitted by the other Observable
* [`Merge`](operators/merge) — combine multiple Observables into one by merging their emissions
* [`StartWith`](operators/startwith) — emit a specified sequence of items before beginning to emit the items from the source Observable
* [`Switch`](operators/switch) — convert an Observable that emits Observables into a single Observable that emits the items emitted by the most-recently-emitted of those Observables
* [`Zip`](operators/zip) — combine the emissions of multiple Observables together via a specified function and emit single items for each combination based on the results of this function
Error Handling Operators
------------------------
Operators that help to recover from error notifications from an Observable
* [`Catch`](operators/catch) — recover from an `onError` notification by continuing the sequence without error
* [`Retry`](operators/retry) — if a source Observable sends an `onError` notification, resubscribe to it in the hopes that it will complete without error
Observable Utility Operators
----------------------------
A toolbox of useful Operators for working with Observables
* [`Delay`](operators/delay) — shift the emissions from an Observable forward in time by a particular amount
* [`Do`](operators/do) — register an action to take upon a variety of Observable lifecycle events
* [`Materialize`/`Dematerialize`](operators/materialize-dematerialize) — represent both the items emitted and the notifications sent as emitted items, or reverse this process
* [`ObserveOn`](operators/observeon) — specify the scheduler on which an observer will observe this Observable
* [`Serialize`](operators/serialize) — force an Observable to make serialized calls and to be well-behaved
* [`Subscribe`](operators/subscribe) — operate upon the emissions and notifications from an Observable
* [`SubscribeOn`](operators/subscribeon) — specify the scheduler an Observable should use when it is subscribed to
* [`TimeInterval`](operators/timeinterval) — convert an Observable that emits items into one that emits indications of the amount of time elapsed between those emissions
* [`Timeout`](operators/timeout) — mirror the source Observable, but issue an error notification if a particular period of time elapses without any emitted items
* [`Timestamp`](operators/timestamp) — attach a timestamp to each item emitted by an Observable
* [`Using`](operators/using) — create a disposable resource that has the same lifespan as the Observable
Conditional and Boolean Operators
---------------------------------
Operators that evaluate one or more Observables or items emitted by Observables
* [`All`](operators/all) — determine whether all items emitted by an Observable meet some criteria
* [`Amb`](operators/amb) — given two or more source Observables, emit all of the items from only the first of these Observables to emit an item
* [`Contains`](operators/contains) — determine whether an Observable emits a particular item or not
* [`DefaultIfEmpty`](operators/defaultifempty) — emit items from the source Observable, or a default item if the source Observable emits nothing
* [`SequenceEqual`](operators/sequenceequal) — determine whether two Observables emit the same sequence of items
* [`SkipUntil`](operators/skipuntil) — discard items emitted by an Observable until a second Observable emits an item
* [`SkipWhile`](operators/skipwhile) — discard items emitted by an Observable until a specified condition becomes false
* [`TakeUntil`](operators/takeuntil) — discard items emitted by an Observable after a second Observable emits an item or terminates
* [`TakeWhile`](operators/takewhile) — discard items emitted by an Observable after a specified condition becomes false
Mathematical and Aggregate Operators
------------------------------------
Operators that operate on the entire sequence of items emitted by an Observable
* [`Average`](operators/average) — calculates the average of numbers emitted by an Observable and emits this average
* [`Concat`](operators/concat) — emit the emissions from two or more Observables without interleaving them
* [`Count`](operators/count) — count the number of items emitted by the source Observable and emit only this value
* [`Max`](operators/max) — determine, and emit, the maximum-valued item emitted by an Observable
* [`Min`](operators/min) — determine, and emit, the minimum-valued item emitted by an Observable
* [`Reduce`](operators/reduce) — apply a function to each item emitted by an Observable, sequentially, and emit the final value
* [`Sum`](operators/sum) — calculate the sum of numbers emitted by an Observable and emit this sum
Backpressure Operators
----------------------
* [**backpressure operators**](operators/backpressure) — strategies for coping with Observables that produce items more rapidly than their observers consume them
Connectable Observable Operators
--------------------------------
Specialty Observables that have more precisely-controlled subscription dynamics
* [`Connect`](operators/connect) — instruct a connectable Observable to begin emitting items to its subscribers
* [`Publish`](operators/publish) — convert an ordinary Observable into a connectable Observable
* [`RefCount`](operators/refcount) — make a Connectable Observable behave like an ordinary Observable
* [`Replay`](operators/replay) — ensure that all observers see the same sequence of emitted items, even if they subscribe after the Observable has begun emitting items
Operators to Convert Observables
--------------------------------
* [`To`](operators/to) — convert an Observable into another object or data structure
A Decision Tree of Observable Operators
---------------------------------------
This tree can help you find the ReactiveX Observable operator you’re looking for.
I want to create a new Observable that emits a particular item [Just](operators/just) that was returned from a function called at subscribe-time [Start](operators/start) that was returned from an `Action`, `Callable`, `Runnable`, or something of that sort, called at subscribe-time [From](operators/from) after a specified delay [Timer](operators/timer) that pulls its emissions from a particular `Array`, `Iterable`, or something like that [From](operators/from) by retrieving it from a Future [Start](operators/start) that obtains its sequence from a Future [From](operators/from) that emits a sequence of items repeatedly [Repeat](operators/repeat) from scratch, with custom logic [Create](operators/create) for each observer that subscribes [Defer](operators/defer) that emits a sequence of integers [Range](operators/range) at particular intervals of time [Interval](operators/interval) after a specified delay [Timer](operators/timer) that completes without emitting items [Empty](operators/empty-never-throw) that does nothing at all [Never](operators/empty-never-throw) I want to create an Observable by combining other Observables and emitting all of the items from all of the Observables in whatever order they are received [Merge](operators/merge) and emitting all of the items from all of the Observables, one Observable at a time [Concat](operators/concat) by combining the items from two or more Observables sequentially to come up with new items to emit whenever *each* of the Observables has emitted a new item [Zip](operators/zip) whenever *any* of the Observables has emitted a new item [CombineLatest](operators/combinelatest) whenever an item is emitted by one Observable in a window defined by an item emitted by another [Join](operators/join) by means of `Pattern` and `Plan` intermediaries [And/Then/When](operators/and-then-when) and emitting the items from only the most-recently emitted of those Observables [Switch](operators/switch) I want to emit the items from an Observable after transforming them one at a time with a function [Map](operators/map) by emitting all of the items emitted by corresponding Observables [FlatMap](operators/flatmap) one Observable at a time, in the order they are emitted [ConcatMap](operators/flatmap) based on all of the items that preceded them [Scan](operators/scan) by attaching a timestamp to them [Timestamp](operators/timestamp) into an indicator of the amount of time that lapsed before the emission of the item [TimeInterval](operators/timeinterval) I want to shift the items emitted by an Observable forward in time before reemitting them [Delay](operators/delay) I want to transform items *and* notifications from an Observable into items and reemit them by wrapping them in `Notification` objects [Materialize](operators/materialize-dematerialize) which I can then unwrap again with [Dematerialize](operators/materialize-dematerialize) I want to ignore all items emitted by an Observable and only pass along its completed/error notification [IgnoreElements](operators/ignoreelements) I want to mirror an Observable but prefix items to its sequence [StartWith](operators/startwith) only if its sequence is empty [DefaultIfEmpty](operators/defaultifempty) I want to collect items from an Observable and reemit them as buffers of items [Buffer](operators/buffer) containing only the last items emitted [TakeLastBuffer](operators/takelast) I want to split one Observable into multiple Observables [Window](operators/window) so that similar items end up on the same Observable [GroupBy](operators/groupby) I want to retrieve a particular item emitted by an Observable: the last item emitted before it completed [Last](operators/last) the sole item it emitted [Single](operators/first) the first item it emitted [First](operators/first) I want to reemit only certain items from an Observable by filtering out those that do not match some predicate [Filter](operators/filter) that is, only the first item [First](operators/first) that is, only the first item*s*
[Take](operators/take) that is, only the last item [Last](operators/last) that is, only item *n*
[ElementAt](operators/elementat) that is, only those items after the first items that is, after the first *n* items [Skip](operators/skip) that is, until one of those items matches a predicate [SkipWhile](operators/skipwhile) that is, after an initial period of time [Skip](operators/skip) that is, after a second Observable emits an item [SkipUntil](operators/skipuntil) that is, those items except the last items that is, except the last *n* items [SkipLast](operators/skiplast) that is, until one of those items matches a predicate [TakeWhile](operators/takewhile) that is, except items emitted during a period of time before the source completes [SkipLast](operators/skiplast) that is, except items emitted after a second Observable emits an item [TakeUntil](operators/takeuntil) by sampling the Observable periodically [Sample](operators/sample) by only emitting items that are not followed by other items within some duration [Debounce](operators/debounce) by suppressing items that are duplicates of already-emitted items [Distinct](operators/distinct) if they immediately follow the item they are duplicates of [DistinctUntilChanged](operators/distinct) by delaying my subscription to it for some time after it begins emitting items [DelaySubscription](operators/delay) I want to reemit items from an Observable only on condition that it was the first of a collection of Observables to emit an item [Amb](operators/amb) I want to evaluate the entire sequence of items emitted by an Observable and emit a single boolean indicating if *all* of the items pass some test [All](operators/all) and emit a single boolean indicating if the Observable emitted *any* item (that passes some test) [Contains](operators/contains) and emit a single boolean indicating if the Observable emitted *no* items [IsEmpty](operators/contains) and emit a single boolean indicating if the sequence is identical to one emitted by a second Observable [SequenceEqual](operators/sequenceequal) and emit the average of all of their values [Average](operators/average) and emit the sum of all of their values [Sum](operators/sum) and emit a number indicating how many items were in the sequence [Count](operators/count) and emit the item with the maximum value [Max](operators/max) and emit the item with the minimum value [Min](operators/min) by applying an aggregation function to each item in turn and emitting the result [Scan](operators/scan) I want to convert the entire sequence of items emitted by an Observable into some other data structure [To](operators/to) I want an operator to operate on a particular [Scheduler](http://reactivex.io/scheduler.html)
[SubscribeOn](operators/subscribeon) when it notifies observers [ObserveOn](operators/observeon) I want an Observable to invoke a particular action when certain events occur [Do](operators/do) I want an Observable that will notify observers of an error [Throw](operators/empty-never-throw) if a specified period of time elapses without it emitting an item [Timeout](operators/timeout) I want an Observable to recover gracefully from a timeout by switching to a backup Observable [Timeout](operators/timeout) from an upstream error notification [Catch](operators/catch) by attempting to resubscribe to the upstream Observable [Retry](operators/retry) I want to create a resource that has the same lifespan as the Observable [Using](operators/using) I want to subscribe to an Observable and receive a `Future` that blocks until the Observable completes [Start](operators/start) I want an Observable that does not start emitting items to subscribers until asked [Publish](operators/publish) and then only emits the last item in its sequence [PublishLast](operators/publish) and then emits the complete sequence, even to those who subscribe after the sequence has begun [Replay](operators/replay) but I want it to go away once all of its subscribers unsubscribe [RefCount](operators/refcount) and then I want to ask it to start [Connect](operators/connect) #### See Also
* [Which Operator do I use?](http://xgrommx.github.io/rx-book/content/which_operator_do_i_use/index.html) by Dennis Stoyanov (a similar decision tree, specific to RxJS operators)
An Alphabetical List of Observable Operators
--------------------------------------------
Canonical, core operator names are in **boldface**. Other entries represent language-specific variants of these operators or specialty operators outside of the main ReactiveX core set of operators.
* [`Aggregate`](operators/reduce)
* [`All`](operators/all)
* [`Amb`](operators/amb)
* [`ambArray`](operators/amb)
* [`ambWith`](operators/amb)
* [`and_`](operators/and-then-when)
* [`And`](operators/and-then-when)
* [`Any`](operators/contains)
* [`apply`](operators/create)
* [`as_blocking`](operators/to)
* [`asObservable`](operators/from)
* [`AssertEqual`](operators/sequenceequal)
* [`asyncAction`](operators/start)
* [`asyncFunc`](operators/start)
* [`Average`](operators/average)
* [`averageDouble`](operators/average)
* [`averageFloat`](operators/average)
* [`averageInteger`](operators/average)
* [`averageLong`](operators/average)
* [`blocking`](operators/to)
* [`blockingFirst`](operators/first)
* [`blockingForEach`](operators/subscribe)
* [`blockingIterable`](operators/to)
* [`blockingLast`](operators/last)
* [`blockingLatest`](operators/to)
* [`blockingMostRecent`](operators/to)
* [`blockingNext`](operators/to)
* [`blockingSingle`](operators/first)
* [`blockingSubscribe`](operators/subscribe)
* [`Buffer`](operators/buffer)
* [`bufferWithCount`](operators/buffer)
* [`bufferWithTime`](operators/buffer)
* [`bufferWithTimeOrCount`](operators/buffer)
* [`byLine`](operators/map)
* [`cache`](operators/replay)
* [`cacheWithInitialCapacity`](operators/replay)
* [`case`](operators/defer)
* [`Cast`](operators/map)
* [`Catch`](operators/catch)
* [`catchError`](operators/catch)
* [`catchException`](operators/catch)
* [`collect`](operators/reduce)
* [`collect`](operators/filter) (RxScala version of **`Filter`**)
* [`collectInto`](operators/reduce)
* [`CombineLatest`](operators/combinelatest)
* [`combineLatestDelayError`](operators/combinelatest)
* [`combineLatestWith`](operators/combinelatest)
* [`Concat`](operators/concat)
* [`concat_all`](operators/flatmap)
* [`concatAll`](operators/concat)
* [`concatArray`](operators/concat)
* [`concatArrayDelayError`](operators/concat)
* [`concatArrayEager`](operators/concat)
* [`concatDelayError`](operators/concat)
* [`concatEager`](operators/concat)
* [`concatMap`](operators/flatmap)
* [`concatMapDelayError`](operators/flatmap)
* [`concatMapEager`](operators/flatmap)
* [`concatMapEagerDelayError`](operators/flatmap)
* [`concatMapIterable`](operators/flatmap)
* [`concatMapObserver`](operators/flatmap)
* [`concatMapTo`](operators/flatmap)
* [`concatWith`](operators/concat)
* [`Connect`](operators/connect)
* [`connect_forever`](operators/connect)
* [`cons`](operators/startwith)
* [`Contains`](operators/contains)
* [`controlled`](operators/backpressure)
* [`Count`](operators/count)
* [`countLong`](operators/count)
* [`Create`](operators/create)
* [`cycle`](operators/repeat)
* [`Debounce`](operators/debounce)
* [`decode`](operators/from)
* [`DefaultIfEmpty`](operators/defaultifempty)
* [`Defer`](operators/defer)
* [`deferFuture`](operators/start)
* [`Delay`](operators/delay)
* [`delaySubscription`](operators/delay)
* [`delayWithSelector`](operators/delay)
* [`Dematerialize`](operators/materialize-dematerialize)
* [`Distinct`](operators/distinct)
* [`distinctKey`](operators/distinct)
* [`distinctUntilChanged`](operators/distinct)
* [`distinctUntilKeyChanged`](operators/distinct)
* [`Do`](operators/do)
* [`doAction`](operators/do)
* [`doAfterTerminate`](operators/do)
* [`doOnComplete`](operators/do)
* [`doOnCompleted`](operators/do)
* [`doOnDispose`](operators/do)
* [`doOnEach`](operators/do)
* [`doOnError`](operators/do)
* [`doOnLifecycle`](operators/do)
* [`doOnNext`](operators/do)
* [`doOnRequest`](operators/do)
* [`doOnSubscribe`](operators/do)
* [`doOnTerminate`](operators/do)
* [`doOnUnsubscribe`](operators/do)
* [`doseq`](operators/subscribe)
* [`doWhile`](operators/repeat)
* [`drop`](operators/skip)
* [`dropRight`](operators/skiplast)
* [`dropUntil`](operators/skipuntil)
* [`dropWhile`](operators/skipwhile)
* [`ElementAt`](operators/elementat)
* [`ElementAtOrDefault`](operators/elementat)
* [`Empty`](operators/empty-never-throw)
* [`emptyObservable`](operators/empty-never-throw)
* [`empty?`](operators/contains)
* [`encode`](operators/map)
* [`ensures`](operators/do)
* [`error`](operators/empty-never-throw)
* [`every`](operators/all)
* [`exclusive`](operators/switch)
* [`exists`](operators/contains)
* [`expand`](operators/flatmap)
* [`failWith`](operators/empty-never-throw)
* [`Filter`](operators/filter)
* [`filterNot`](operators/filter)
* [`Finally`](operators/do)
* [`finallyAction`](operators/do)
* [`finallyDo`](operators/do)
* [`find`](operators/contains)
* [`findIndex`](operators/contains)
* [`First`](operators/first)
* [`firstElement`](operators/first)
* [`FirstOrDefault`](operators/first)
* [`firstOrElse`](operators/first)
* [`FlatMap`](operators/flatmap)
* [`flatMapFirst`](operators/flatmap)
* [`flatMapIterable`](operators/flatmap)
* [`flatMapIterableWith`](operators/flatmap)
* [`flatMapLatest`](operators/flatmap)
* [`flatMapObserver`](operators/flatmap)
* [`flatMapWith`](operators/flatmap)
* [`flatMapWithMaxConcurrent`](operators/flatmap)
* [`flat_map_with_index`](operators/flatmap)
* [`flatten`](operators/merge)
* [`flattenDelayError`](operators/merge)
* [`foldl`](operators/reduce)
* [`foldLeft`](operators/reduce)
* [`for`](operators/flatmap)
* [`forall`](operators/all)
* [`ForEach`](operators/subscribe)
* [`forEachFuture`](operators/start)
* [`forEachWhile`](operators/subscribe)
* [`forIn`](operators/flatmap)
* [`forkJoin`](operators/zip)
* [`From`](operators/from)
* [`fromAction`](operators/from)
* [`fromArray`](operators/from)
* [`FromAsyncPattern`](operators/from)
* [`fromCallable`](operators/from)
* [`fromCallback`](operators/from)
* [`FromEvent`](operators/from)
* [`FromEventPattern`](operators/from)
* [`fromFunc0`](operators/from)
* [`fromFuture`](operators/from)
* [`fromIterable`](operators/from)
* [`fromIterator`](operators/from)
* [`from_list`](operators/from)
* [`fromNodeCallback`](operators/from)
* [`fromPromise`](operators/from)
* [`fromPublisher`](operators/from)
* [`fromRunnable`](operators/from)
* [`Generate`](operators/create)
* [`generateWithAbsoluteTime`](operators/create)
* [`generateWithRelativeTime`](operators/create)
* [`generator`](operators/create)
* [`GetEnumerator`](operators/to)
* [`getIterator`](operators/to)
* [`GroupBy`](operators/groupby)
* [`GroupByUntil`](operators/groupby)
* [`GroupJoin`](operators/join)
* [`head`](operators/first)
* [`headOption`](operators/first)
* [`headOrElse`](operators/first)
* [`if`](operators/defer)
* [`ifThen`](operators/defer)
* [`IgnoreElements`](operators/ignoreelements)
* [`indexOf`](operators/contains)
* [`interleave`](operators/merge)
* [`interpose`](operators/to)
* [`Interval`](operators/interval)
* [`intervalRange`](operators/range)
* [`into`](operators/reduce)
* [`isEmpty`](operators/contains)
* [`items`](operators/just)
* [`Join`](operators/join)
* [`join`](operators/sum) (string)
* [`jortSort`](operators/all)
* [`jortSortUntil`](operators/all)
* [`Just`](operators/just)
* [`keep`](operators/map)
* [`keep-indexed`](operators/map)
* [`Last`](operators/last)
* [`lastElement`](operators/last)
* [`lastOption`](operators/last)
* [`LastOrDefault`](operators/last)
* [`lastOrElse`](operators/last)
* [`Latest`](operators/first)
* [`latest`](operators/switch) (Rx.rb version of **`Switch`**)
* [`length`](operators/count)
* [`let`](operators/publish)
* [`letBind`](operators/publish)
* [`lift`](implement-operator)
* [`limit`](operators/take)
* [`LongCount`](operators/count)
* [`ManySelect`](operators/flatmap)
* [`Map`](operators/map)
* [`map`](operators/zip) (RxClojure version of **`Zip`**)
* [`MapCat`](operators/flatmap)
* [`mapCat`](operators/zip) (RxClojure version of **`Zip`**)
* [`map-indexed`](operators/map)
* [`mapTo`](operators/map)
* [`mapWithIndex`](operators/map)
* [`Materialize`](operators/materialize-dematerialize)
* [`Max`](operators/max)
* [`MaxBy`](operators/max)
* [`Merge`](operators/merge)
* [`mergeAll`](operators/merge)
* [`mergeArray`](operators/merge)
* [`mergeArrayDelayError`](operators/merge)
* [`merge_concurrent`](operators/merge)
* [`mergeDelayError`](operators/merge)
* [`mergeObservable`](operators/merge)
* [`mergeWith`](operators/merge)
* [`Min`](operators/min)
* [`MinBy`](operators/min)
* [`MostRecent`](operators/first)
* [`Multicast`](operators/publish)
* [`multicastWithSelector`](operators/publish)
* [`nest`](operators/to)
* [`Never`](operators/empty-never-throw)
* [`Next`](operators/takelast)
* [`Next`](operators/first) (BlockingObservable version)
* [`none`](operators/contains)
* [`nonEmpty`](operators/contains)
* [`nth`](operators/elementat)
* [`ObserveOn`](operators/observeon)
* [`ObserveOnDispatcher`](operators/observeon)
* [`observeSingleOn`](operators/observeon)
* [`of`](operators/from)
* [`of_array`](operators/from)
* [`ofArrayChanges`](operators/from)
* [`of_enumerable`](operators/from)
* [`of_enumerator`](operators/from)
* [`ofObjectChanges`](operators/from)
* [`OfType`](operators/filter)
* [`ofWithScheduler`](operators/from)
* [`onBackpressureBlock`](operators/backpressure)
* [`onBackpressureBuffer`](operators/backpressure)
* [`onBackpressureDrop`](operators/backpressure)
* [`OnErrorResumeNext`](operators/catch)
* [`onErrorReturn`](operators/catch)
* [`onErrorReturnItem`](operators/catch)
* [`onExceptionResumeNext`](operators/catch)
* [`onTerminateDetach`](operators/do)
* [`orElse`](operators/defaultifempty)
* [`pairs`](operators/from)
* [`pairwise`](operators/buffer)
* [`partition`](operators/groupby)
* [`partition-all`](operators/window)
* [`pausable`](operators/backpressure)
* [`pausableBuffered`](operators/backpressure)
* [`pluck`](operators/map)
* [`product`](operators/sum)
* [`Publish`](operators/publish)
* [`PublishLast`](operators/publish)
* [`publish_synchronized`](operators/replay)
* [`publishValue`](operators/publish)
* [`raise_error`](operators/empty-never-throw)
* [`Range`](operators/range)
* [`Reduce`](operators/reduce)
* [`reduceWith`](operators/reduce)
* [`reductions`](operators/scan)
* [`RefCount`](operators/refcount)
* [`Repeat`](operators/repeat)
* [`repeat_infinitely`](operators/repeat)
* [`repeatUntil`](operators/repeat)
* [`repeatWhen`](operators/repeat)
* [`Replay`](operators/replay)
* [`rescue_error`](operators/catch)
* [`rest`](operators/first)
* [`Retry`](operators/retry)
* [`retry_infinitely`](operators/retry)
* [`retryUntil`](operators/retry)
* [`retryWhen`](operators/retry)
* [`Return`](operators/just)
* [`returnElement`](operators/just)
* [`returnValue`](operators/just)
* [`runAsync`](operators/from)
* [`safeSubscribe`](operators/subscribe)
* [`Sample`](operators/sample)
* [`Scan`](operators/scan)
* [`scanWith`](operators/scan)
* [`scope`](operators/using)
* [`Select`](operators/map) (alternate name of **`Map`**)
* [`select`](operators/filter) (alternate name of **`Filter`**)
* [`selectConcat`](operators/flatmap)
* [`selectConcatObserver`](operators/flatmap)
* [`SelectMany`](operators/flatmap)
* [`selectManyObserver`](operators/flatmap)
* [`select_switch`](operators/switch)
* [`selectSwitch`](operators/flatmap)
* [`selectSwitchFirst`](operators/flatmap)
* [`selectWithMaxConcurrent`](operators/flatmap)
* [`select_with_index`](operators/filter)
* [`seq`](operators/from)
* [`SequenceEqual`](operators/sequenceequal)
* [`sequence_eql?`](operators/sequenceequal)
* [`SequenceEqualWith`](operators/sequenceequal)
* [`Serialize`](operators/serialize)
* [`share`](operators/refcount)
* [`shareReplay`](operators/replay)
* [`shareValue`](operators/refcount)
* [`Single`](operators/first)
* [`singleElement`](operators/first)
* [`SingleOrDefault`](operators/first)
* [`singleOption`](operators/first)
* [`singleOrElse`](operators/first)
* [`size`](operators/count)
* [`Skip`](operators/skip)
* [`SkipLast`](operators/skiplast)
* [`skipLastWithTime`](operators/skiplast)
* [`SkipUntil`](operators/skipuntil)
* [`skipUntilWithTime`](operators/skipuntil)
* [`SkipWhile`](operators/skipwhile)
* [`skipWhileWithIndex`](operators/skipwhile)
* [`skip_with_time`](operators/skip)
* [`slice`](operators/filter)
* [`sliding`](operators/window)
* [`slidingBuffer`](operators/buffer)
* [`some`](operators/contains)
* [`sort`](operators/to)
* [`sorted`](operators/to)
* [`sort-by`](operators/to)
* [`sorted-list-by`](operators/to)
* [`split`](operators/flatmap)
* [`split-with`](operators/groupby)
* [`Start`](operators/start)
* [`startAsync`](operators/start)
* [`startFuture`](operators/start)
* [`StartWith`](operators/startwith)
* [`startWithArray`](operators/startwith)
* [`stringConcat`](operators/sum)
* [`stopAndWait`](operators/backpressure)
* [`subscribe`](operators/subscribe)
* [`subscribeActual`](operators/subscribe)
* [`SubscribeOn`](operators/subscribeon)
* [`SubscribeOnDispatcher`](operators/subscribeon)
* [`subscribeOnCompleted`](operators/subscribe)
* [`subscribeOnError`](operators/subscribe)
* [`subscribeOnNext`](operators/subscribe)
* [`subscribeWith`](operators/subscribe)
* [`Sum`](operators/sum)
* [`sumDouble`](operators/sum)
* [`sumFloat`](operators/sum)
* [`sumInteger`](operators/sum)
* [`sumLong`](operators/sum)
* [`Switch`](operators/switch)
* [`switchCase`](operators/defer)
* [`switchIfEmpty`](operators/defaultifempty)
* [`switchLatest`](operators/switch)
* [`switchMap`](operators/flatmap)
* [`switchMapDelayError`](operators/flatmap)
* [`switchOnNext`](operators/switch)
* [`switchOnNextDelayError`](operators/switch)
* [`Synchronize`](operators/serialize)
* [`Take`](operators/take)
* [`take_with_time`](operators/take)
* [`takeFirst`](operators/first)
* [`TakeLast`](operators/takelast)
* [`takeLastBuffer`](operators/takelast)
* [`takeLastBufferWithTime`](operators/takelast)
* [`takeLastWithTime`](operators/takelast)
* [`takeRight`](operators/last) (see also: [`TakeLast`](operators/takelast))
* [`TakeUntil`](operators/takeuntil)
* [`takeUntilWithTime`](operators/takeuntil)
* [`TakeWhile`](operators/takewhile)
* [`takeWhileWithIndex`](operators/takewhile)
* [`tail`](operators/takelast)
* [`tap`](operators/do)
* [`tapOnCompleted`](operators/do)
* [`tapOnError`](operators/do)
* [`tapOnNext`](operators/do)
* [`Then`](operators/and-then-when)
* [`thenDo`](operators/and-then-when)
* [`Throttle`](operators/debounce)
* [`throttleFirst`](operators/sample)
* [`throttleLast`](operators/sample)
* [`throttleWithSelector`](operators/debounce)
* [`throttleWithTimeout`](operators/debounce)
* [`Throw`](operators/empty-never-throw)
* [`throwError`](operators/empty-never-throw)
* [`throwException`](operators/empty-never-throw)
* [`TimeInterval`](operators/timeinterval)
* [`Timeout`](operators/timeout)
* [`timeoutWithSelector`](operators/timeout)
* [`Timer`](operators/timer)
* [`Timestamp`](operators/timestamp)
* [`To`](operators/to)
* [`to_a`](operators/to)
* [`ToArray`](operators/to)
* [`ToAsync`](operators/start)
* [`toBlocking`](operators/to)
* [`toBuffer`](operators/to)
* [`to_dict`](operators/to)
* [`ToDictionary`](operators/to)
* [`ToEnumerable`](operators/to)
* [`ToEvent`](operators/to)
* [`ToEventPattern`](operators/to)
* [`ToFlowable`](operators/to)
* [`ToFuture`](operators/to)
* [`to_h`](operators/to)
* [`toIndexedSeq`](operators/to)
* [`toIterable`](operators/to)
* [`toIterator`](operators/to)
* [`ToList`](operators/to)
* [`ToLookup`](operators/to)
* [`toMap`](operators/to)
* [`toMultiMap`](operators/to)
* [`ToObservable`](operators/from)
* [`toSet`](operators/to)
* [`toSortedList`](operators/to)
* [`toStream`](operators/to)
* [`ToTask`](operators/to)
* [`toTraversable`](operators/to)
* [`toVector`](operators/to)
* [`tumbling`](operators/window)
* [`tumblingBuffer`](operators/buffer)
* [`unsafeCreate`](operators/create)
* [`unsubscribeOn`](operators/subscribeon)
* [`Using`](operators/using)
* [`When`](operators/and-then-when)
* [`Where`](operators/filter)
* [`while`](operators/repeat)
* [`whileDo`](operators/repeat)
* [`Window`](operators/window)
* [`windowWithCount`](operators/window)
* [`windowWithTime`](operators/window)
* [`windowWithTimeOrCount`](operators/window)
* [`windowed`](operators/backpressure)
* [`withFilter`](operators/filter)
* [`withLatestFrom`](operators/combinelatest)
* [`Zip`](operators/zip)
* [`zipArray`](operators/zip)
* [`zipIterable`](operators/zip)
* [`zipWith`](operators/zip)
* [`zipWithIndex`](operators/zip)
* [`++`](operators/concat)
* [`+:`](operators/startwith)
* [`:+`](operators/just)
| programming_docs |
reactivex All All
===
> determine whether all items emitted by an Observable meet some criteria
[Open interactive diagram on rxmarbles.com](https://rxmarbles.com/#every) Pass a predicate function to the All operator that accepts an item emitted by the source Observable and returns a boolean value based on an evaluation of that item. All returns an Observable that emits a single boolean value: `true` if and only if the source Observable terminates normally and every item emitted by the source Observable evaluated as `true` according to this predicate; `false` if any item emitted by the source Observable evaluates as `false` according to this predicate.
#### See Also
* [Introduction to Rx: All](http://www.introtorx.com/Content/v1.0.10621.0/06_Inspection.html#All)
* [RxMarbles: `every`](http://rxmarbles.com/#every)
Language-Specific Information
-----------------------------
### RxGroovy `all`
 RxGroovy implements this operator as `all`. It does not by default operate on any particular [Scheduler](../scheduler). The following example shows how to use this operator:
#### Sample Code
```
numbers = Observable.from([1, 2, 3, 4, 5]);
println("all even?" )
numbers.all({ 0 == (it % 2) }).subscribe({ println(it); });
println("all positive?");
numbers.all({ 0 < it }).subscribe({ println(it); });
```
```
all even?
false
all positive?
true
```
* Javadoc: [`all(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#all(rx.functions.Func1))
### RxJava 1․x `all`
 RxJava 1.x implements this operator as `all`. It does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`all(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#all(rx.functions.Func1))
### RxJava 2․x `all`
 RxJava 2.x implements this operator as `all`. It does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`all(Predicate)`](http://reactivex.io/RxJava/2.x/javadoc/io/reactivex/Observable.html#all(io.reactivex.functions.Predicate))
### RxJS `every jortSort jortSortUntil`
 RxJS implements this operator as `every`. The following example shows how to use this operator:
#### Sample Code
```
var source = Rx.Observable.of(1,2,3,4,5)
.every(function (x) {
return x < 6;
});
var subscription = source.subscribe(
function (x) { console.log('Next: %s', x); },
function (err) { console.log('Error: %s', err); },
function () { console.log('Completed'); });
```
```
Next: true
Completed
```
`every` is found in the following distributions:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.aggregates.js`
It requires one of the following distributions:
* `rx.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
There is also a `jortSort` operator that performs a test on the entire sequence of items emitted by the source Observable. If those items are emitted in sorted order, upon the successful completion of the source Observable, the Observable returned from `jortSort` will emit `true` and then complete. If any of the items emitted by the source Observable is out of sort order, upon the successful completion of the source Observable, the Observable returned from `jortSort` will emit `false` and then complete.
There is also a `jortSortUntil` operator. It does not wait until the source Observable completes to evaluate its sequence for sortedness, as `jortSort` does, but waits until a second Observable emits an item to do so.
#### See also
* [jort.technology](http://jort.technology)
#### Sample Code
```
var source = Rx.Observable.of(1,2,3,4) // already sorted
.jortSort();
var subscription = source.subscribe(
function (x) { console.log('Next: %s', x); },
function (e) { console.log('Error: %s', e); },
function ( ) { console.log('Completed'); });
```
```
Next: true
Completed
```
```
var source = Rx.Observable.of(3,1,2,4) // not sorted
.jortSort();
var subscription = source.subscribe(
function (x) { console.log('Next: %s', x); },
function (e) { console.log('Error: %s', e); },
function ( ) { console.log('Completed'); });
```
```
Next: false
Completed
```
```
var just = Rx.helpers.just;
var source = Rx.Observable.of(1,2,3,4) // already sorted
.flatmap(function (x) {
return Rx.Observable.timer(1000).map(just(x));
}).jortSortUntil(Rx.Observable.timer(3000);
var subscription = source.subscribe(
function (x) { console.log('Next: %s', x); },
function (e) { console.log('Error: %s', e); },
function ( ) { console.log('Completed'); });
```
```
Next: true
Completed
```
```
var just = Rx.helpers.just;
var source = Rx.Observable.of(3,1,2,4) // not sorted
.flatmap(function (x) {
return Rx.Observable.timer(1000).map(just(x));
}).jortSortUntil(Rx.Observable.timer(3000);
var subscription = source.subscribe(
function (x) { console.log('Next: %s', x); },
function (e) { console.log('Error: %s', e); },
function ( ) { console.log('Completed'); });
```
```
Next: false
Completed
```
`jortSort` and `jortSortUntil` are found in the following distribution:
* `rx.sorting.js`
They require one of the following distributions:
* `rx.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
reactivex Join Join
====
> combine items emitted by two Observables whenever an item from one Observable is emitted during a time window defined according to an item emitted by the other Observable
 The `Join` operator combines the items emitted by two Observables, and selects which items to combine based on duration-windows that you define on a per-item basis. You implement these windows as Observables whose lifespans begin with each item emitted by either Observable. When such a window-defining Observable either emits an item or completes, the window for the item it is associated with closes. So long as an item’s window is open, it will combine with any item emitted by the other Observable. You define the function by which the items combine.
 Most ReactiveX implementations that have a `Join` operator also have a `GroupJoin` operator that is similar, except that the function you define to combine items emitted by the two Observables pairs individual items emitted by the source Observable not with an item from the second Observable, but with an Observable that emits items from the second Observable that fall in the same window.
#### See Also
* [CombineLatest](combinelatest)
* [Zip](zip)
* [Introduction to Rx: Join](http://www.introtorx.com/Content/v1.0.10621.0/17_SequencesOfCoincidence.html#Join)
* [Introduction to Rx: GroupJoin](http://www.introtorx.com/Content/v1.0.10621.0/17_SequencesOfCoincidence.html#GroupJoin)
* [101 Rx Samples: GroupJoin — Joins two streams by matching by one of their attributes](http://rxwiki.wikidot.com/101samples#toc39)
Language-Specific Information
-----------------------------
### RxGroovy `join groupJoin`
 The `join` operator takes four parameters:
1. the second Observable to combine with the source Observable
2. a function that accepts an item from the source Observable and returns an Observable whose lifespan governs the duration during which that item will combine with items from the second Observable
3. a function that accepts an item from the second Observable and returns an Observable whose lifespan governs the duration during which that item will combine with items from the first Observable
4. a function that accepts an item from the first Observable and an item from the second Observable and returns an item to be emitted by the Observable returned from `join`
`join` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`Join(Observable,Func1,Func1,Func2)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#join(rx.Observable,%20rx.functions.Func1,%20rx.functions.Func1,%20rx.functions.Func2))
 The `groupJoin` operator takes four parameters:
1. the second Observable to combine with the source Observable
2. a function that accepts an item from the source Observable and returns an Observable whose lifespan governs the duration during which that item will combine with items from the second Observable
3. a function that accepts an item from the second Observable and returns an Observable whose lifespan governs the duration during which that item will combine with items from the first Observable
4. a function that accepts an item from the first Observable and an Observable that emits items from the second Observable and returns an item to be emitted by the Observable returned from `groupJoin`
`groupJoin` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`groupJoin(Observable,Func1,Func1,Func2)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#groupJoin(rx.Observable,%20rx.functions.Func1,%20rx.functions.Func1,%20rx.functions.Func2))
 Note that there is also a `join` operator in the optional `StringObservable` class. It converts an Observable that emits a sequence of strings into an Observable that emits a single string that concatenates them all, separating them by a specified string delimiter.
### RxJava 1․x `join groupJoin`
 The `join` operator takes four parameters:
1. the second Observable to combine with the source Observable
2. a function that accepts an item from the source Observable and returns an Observable whose lifespan governs the duration during which that item will combine with items from the second Observable
3. a function that accepts an item from the second Observable and returns an Observable whose lifespan governs the duration during which that item will combine with items from the first Observable
4. a function that accepts an item from the first Observable and an item from the second Observable and returns an item to be emitted by the Observable returned from `join`
`join` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`Join(Observable,Func1,Func1,Func2)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#join(rx.Observable,%20rx.functions.Func1,%20rx.functions.Func1,%20rx.functions.Func2))
 The `groupJoin` operator takes four parameters:
1. the second Observable to combine with the source Observable
2. a function that accepts an item from the source Observable and returns an Observable whose lifespan governs the duration during which that item will combine with items from the second Observable
3. a function that accepts an item from the second Observable and returns an Observable whose lifespan governs the duration during which that item will combine with items from the first Observable
4. a function that accepts an item from the first Observable and an Observable that emits items from the second Observable and returns an item to be emitted by the Observable returned from `groupJoin`
`groupJoin` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`groupJoin(Observable,Func1,Func1,Func2)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#groupJoin(rx.Observable,%20rx.functions.Func1,%20rx.functions.Func1,%20rx.functions.Func2))
 Note that there is also a `join` operator in the optional `StringObservable` class. It converts an Observable that emits a sequence of strings into an Observable that emits a single string that concatenates them all, separating them by a specified string delimiter.
### RxJS `join groupJoin`
 The `join` operator takes four parameters:
1. the second Observable to combine with the source Observable
2. a function that accepts an item from the source Observable and returns an Observable whose lifespan governs the duration during which that item will combine with items from the second Observable
3. a function that accepts an item from the second Observable and returns an Observable whose lifespan governs the duration during which that item will combine with items from the first Observable
4. a function that accepts an item from the first Observable and an item from the second Observable and returns an item to be emitted by the Observable returned from `join`
#### Sample Code
```
var xs = Rx.Observable.interval(100)
.map(function (x) { return 'first' + x; });
var ys = Rx.Observable.interval(100)
.map(function (x) { return 'second' + x; });
var source = xs
.join(
ys,
function () { return Rx.Observable.timer(0); },
function () { return Rx.Observable.timer(0); },
function (x, y) { return x + y; }
)
.take(5);
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: first0second0
Next: first1second1
Next: first2second2
Next: first3second3
Next: first4second4
Completed
```
 The `groupJoin` operator takes four parameters:
1. the second Observable to combine with the source Observable
2. a function that accepts an item from the source Observable and returns an Observable whose lifespan governs the duration during which that item will combine with items from the second Observable
3. a function that accepts an item from the second Observable and returns an Observable whose lifespan governs the duration during which that item will combine with items from the first Observable
4. a function that accepts an item from the first Observable and an Observable that emits items from the second Observable and returns an item to be emitted by the Observable returned from `groupJoin`
#### Sample Code
```
ar xs = Rx.Observable.interval(100)
.map(function (x) { return 'first' + x; });
var ys = Rx.Observable.interval(100)
.map(function (x) { return 'second' + x; });
var source = xs.groupJoin(
ys,
function () { return Rx.Observable.timer(0); },
function () { return Rx.Observable.timer(0); },
function (x, yy) {
return yy.select(function (y) {
return x + y;
})
}).mergeAll().take(5);
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: first0second0
Next: first1second1
Next: first2second2
Next: first3second3
Next: first4second4
Completed
```
`join` and `groupJoin` are found in each of the following distributions:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.coincidence.js`
reactivex Contains Contains
========
> determine whether an Observable emits a particular item or not
[Open interactive diagram on rxmarbles.com](https://rxmarbles.com/#contains) Pass the Contains operator a particular item, and the Observable it returns will emit `true` if that item is emitted by the source Observable, or `false` if the source Observable terminates without emitting that item.
A related operator, IsEmpty returns an Observable that emits `true` if and only if the source Observable completes without emitting any items. It emits `false` if the source Observable emits an item.
#### See Also
* [All](all)
* [Introduction to Rx: Contains](http://www.introtorx.com/Content/v1.0.10621.0/06_Inspection.html#Contains)
* [RxMarbles: `contains`](http://rxmarbles.com/#contains)
* [RxMarbles: `some`](http://rxmarbles.com/#some)
Language-Specific Information
-----------------------------
### RxGroovy `contains exists isEmpty`
 RxGroovy implements this operator as `contains`. It does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`contains(Object)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#contains(java.lang.Object))
 RxGroovy also implements the `exists` operator. It is similar to `contains` but tests items emitted by the source Observable against a predicate function you supply, rather than testing them for identity with a particular object. The Observable returned from `exists` will return `true` if the source Observable emits an item that satisfies your predicate function, and `false` if it completes without emitting such an item.
It does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`exists(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#exists(rx.functions.Func1))
 RxGroovy also implements the `isEmpty` operator. The Observable returned from `isEmpty` will return `false` if the source Observable emits an item, and `true` if it completes without emitting an item.
It does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`isEmpty()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#isEmpty())
### RxJava 1․x `contains exists isEmpty`
 RxJava implements this operator as `contains`. It does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`contains(Object)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#contains(java.lang.Object))
 RxJava also implements the `exists` operator. It is similar to `contains` but tests items emitted by the source Observable against a predicate function you supply, rather than testing them for identity with a particular object. The Observable returned from `exists` will return `true` if the source Observable emits an item that satisfies your predicate function, and `false` if it completes without emitting such an item.
It does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`exists(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#exists(rx.functions.Func1))
 RxJava also implements the `isEmpty` operator. The Observable returned from `isEmpty` will return `false` if the source Observable emits an item, and `true` if it completes without emitting an item.
It does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`isEmpty()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#isEmpty())
### RxJava 2․x `any contains isEmpty`
### RxJS `contains findIndex indexOf isEmpty`
 The `contains` operator in RxJS takes an optional second parameter: a zero-based index into the source Observable’s sequence at which to start searching for the item.
#### Sample Code
```
/* Without an index */
var source = Rx.Observable.of(42)
.contains(42);
var subscription = source.subscribe(
function (x) { console.log('Next: %s', x); },
function (err) { console.log('Error: %s', err); },
function () { console.log('Completed'); });
```
```
Next: true
Completed
```
```
/* With an index */
var source = Rx.Observable.of(1,2,3)
.contains(2, 1);
var subscription = source.subscribe(
function (x) { console.log('Next: %s', x); },
function (err) { console.log('Error: %s', err); },
function () { console.log('Completed'); });
```
```
Next: true
Completed
```
`contains` is found in the following distributions:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.aggregates.js`
It requires one of the following distributions:
* `rx.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
 The `indexOf` operator in RxJS is similar to `contains` but rather than returning an Observable that emits `true` or `false` it returns an Observable that emits the index of the item in the source Observable sequence, or `−1` if no such item was emitted.
The `indexOf` operator takes an optional second parameter: a zero-based index into the source Observable’s sequence at which to start searching for the item. The index value that the resulting Observable emits will be relative to this start point, not to the beginning of the sequence.
#### Sample Code
```
/* Without an index */
var source = Rx.Observable.of(42)
.indexOf(42);
var subscription = source.subscribe(
function (x) { console.log('Next: %s', x); },
function (err) { console.log('Error: %s', err); },
function () { console.log('Completed'); });
```
```
Next: 0
Completed
```
```
/* With an index */
var source = Rx.Observable.of(1,2,3)
.indexOf(2, 1);
var subscription = source.subscribe(
function (x) { console.log('Next: %s', x); },
function (err) { console.log('Error: %s', err); },
function () { console.log('Completed'); });
```
```
Next: 0
Completed
```
`indexOf` is found in the following distributions:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.aggregates.js`
It requires one of the following distributions:
* `rx.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
 The `findIndex` operator in RxJS takes as its parameter a predicate function. It returns an Observable that emits either a single number — the zero-based index of the first item in the source Observable sequence that matches the predicate — or `−1` if no such item matches.
The predicate function takes three parameters:
* the item emitted by the source Observable
* the zero-based index of that item
* the source Observable itself
You can also pass an object to `findIndex` as an optional second parameter, and that object will be available to the predicate function as “`this`”.
#### Sample Code
```
/* Found an element */
var array = [1,2,3,4];
var source = Rx.Observable.fromArray(array)
.findIndex(function (x, i, obs) {
return x === 1;
});
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 0
Completed
```
```
/* Not found */
var array = [1,2,3,4];
var source = Rx.Observable.fromArray(array)
.findIndex(function (x, i, obs) {
return x === 5;
});
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: -1
Completed
```
`findIndex` is found in the following distributions:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.aggregates.js`
It requires one of the following distributions:
* `rx.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
 RxJS also implements the `isEmpty` operator. The Observable returned from `isEmpty` will return `false` if the source Observable emits an item, and `true` if it completes without emitting an item.
#### Sample Code
```
/* Not empty */
var source = Rx.Observable.range(0, 5)
.isEmpty()
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: false
Completed
```
```
/* Empty */
var source = Rx.Observable.empty()
.isEmpty()
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: true
Completed
```
`isEmpty` is found in the following distributions:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.aggregates.js`
It requires one of the following distributions:
* `rx.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
### RxPHP `isEmpty`
RxPHP implements this operator as `isEmpty`.
If the source Observable is empty it returns an Observable that emits true, otherwise it emits false.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/isEmpty/isEmpty.php
$source = \Rx\Observable::emptyObservable()
->isEmpty();
$source->subscribe($stdoutObserver);
```
```
Next value: 1
Complete!
```
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/isEmpty/isEmpty-false.php
$source = \Rx\Observable::just(1)
->isEmpty();
$source->subscribe($stdoutObserver);
```
```
Next value: 0
Complete!
```
| programming_docs |
reactivex Map Map
===
> transform the items emitted by an Observable by applying a function to each item
[Open interactive diagram on rxmarbles.com](https://rxmarbles.com/#map) The Map operator applies a function of your choosing to each item emitted by the source Observable, and returns an Observable that emits the results of these function applications.
#### See Also
* [FlatMap](flatmap)
* [Introduction to Rx: Select](http://www.introtorx.com/Content/v1.0.10621.0/08_Transformation.html#Select)
* [RxMarbles: `map`](http://rxmarbles.com/#map)
* [101 Rx Samples: Select — Indexed](http://rxwiki.wikidot.com/101samples#toc22)
* [Using the map method with Observable](https://egghead.io/lessons/javascript-using-the-map-method-with-observable) by Jafar Husain (JavaScript Video Tutorial)
Language-Specific Information
-----------------------------
### RxGroovy `byLine cast encode map`
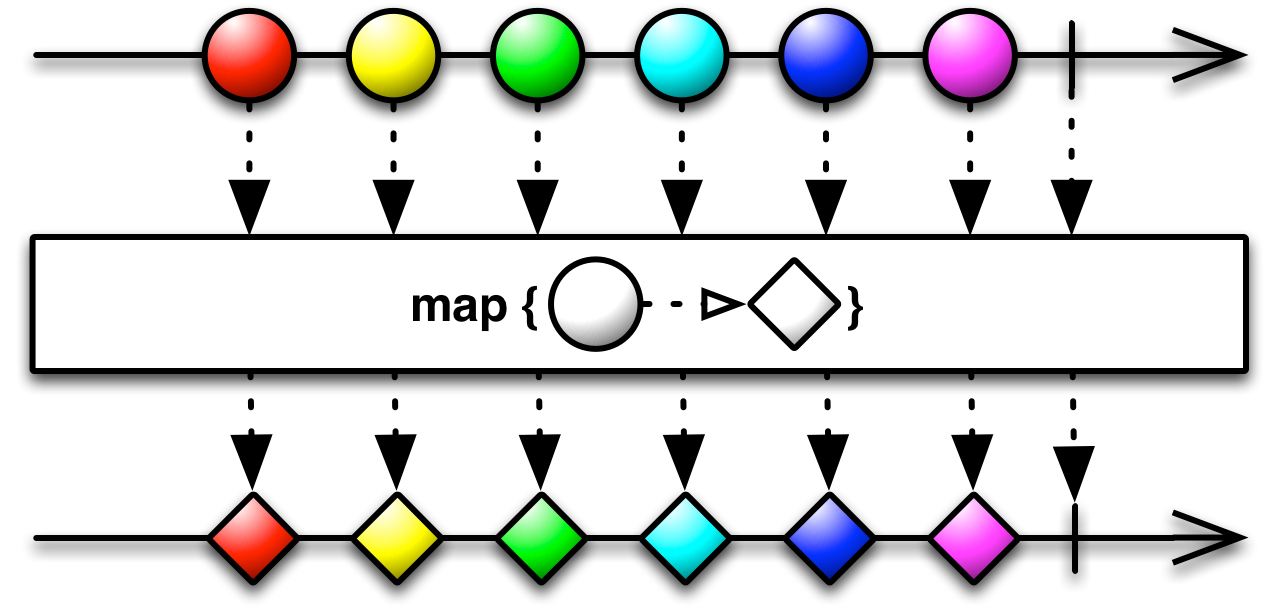 RxGroovy implements this operator as `map`. For example, the following code maps a function that squares the incoming value onto the values in `numbers`:
#### Sample Code
```
numbers = Observable.from([1, 2, 3, 4, 5]);
numbers.map({it * it}).subscribe(
{ println(it); }, // onNext
{ println("Error: " + it.getMessage()); }, // onError
{ println("Sequence complete"); } // onCompleted
);
```
```
1
4
9
16
25
Sequence complete
```
This operator does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`map(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#map(rx.functions.Func1))
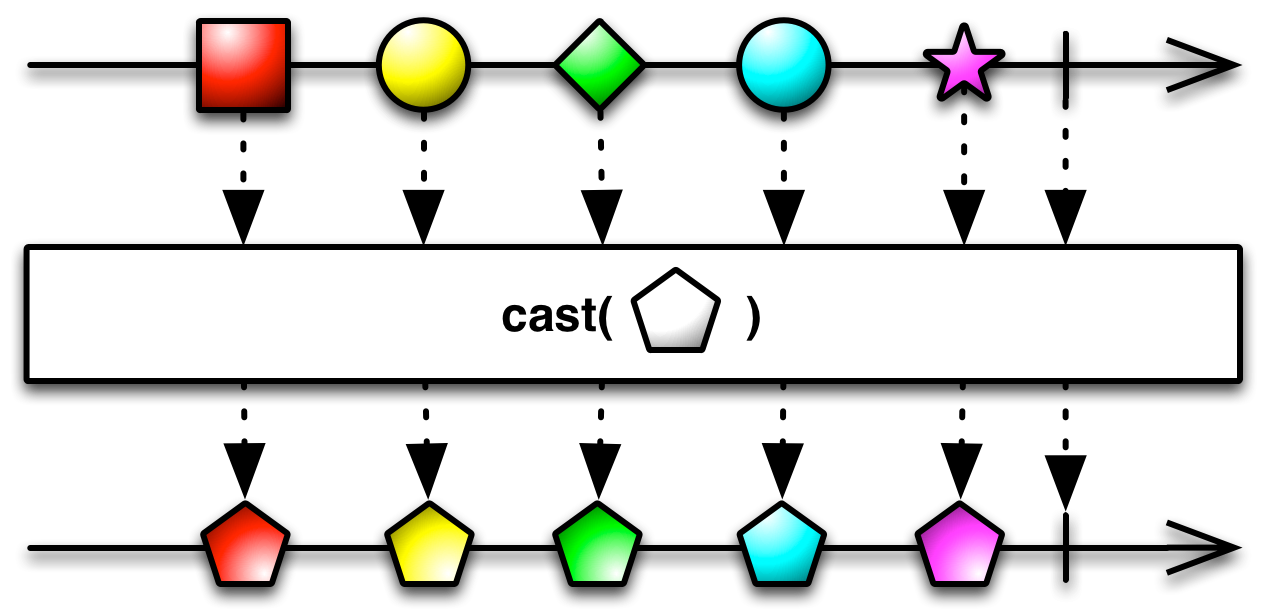 The `cast` operator is a specialized version of Map that transforms each item from the source Observable by casting it into a particular Class before reemitting it.
* Javadoc: [`cast(Class)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#cast(java.lang.Class))
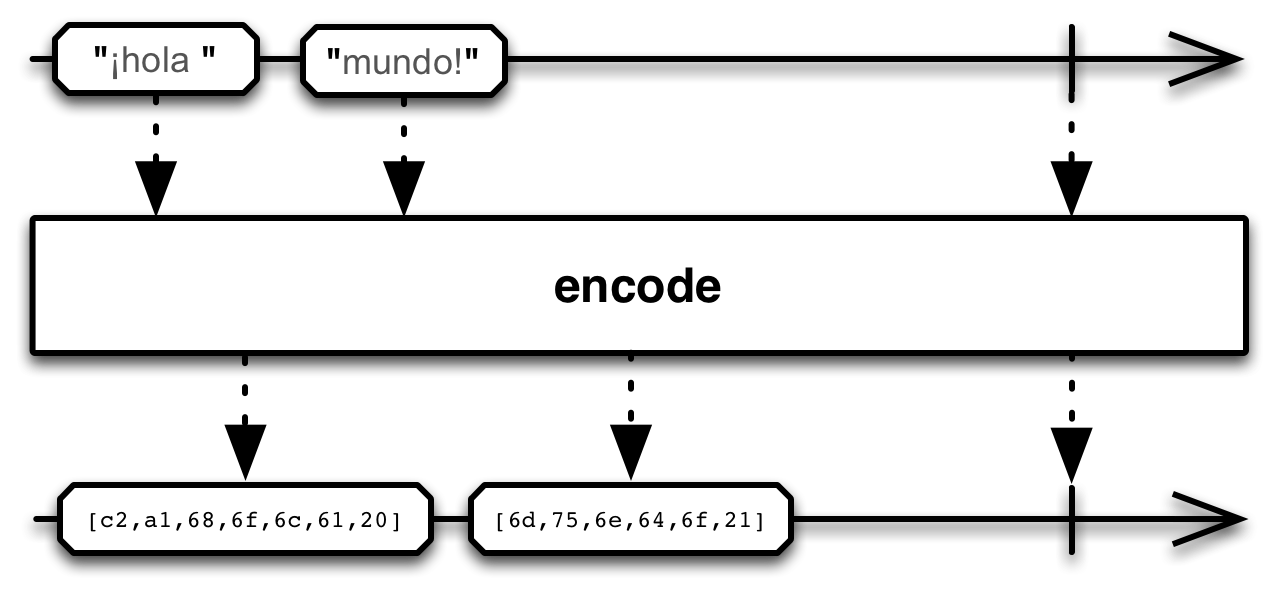 In the `StringObservable` class that is not part of the RxGroovy core there is also a specialty mapping operator, `encode`, that transforms an Observable that emits strings into an Observable that emits byte arrays that respect character boundaries of multibyte characters in the original strings.
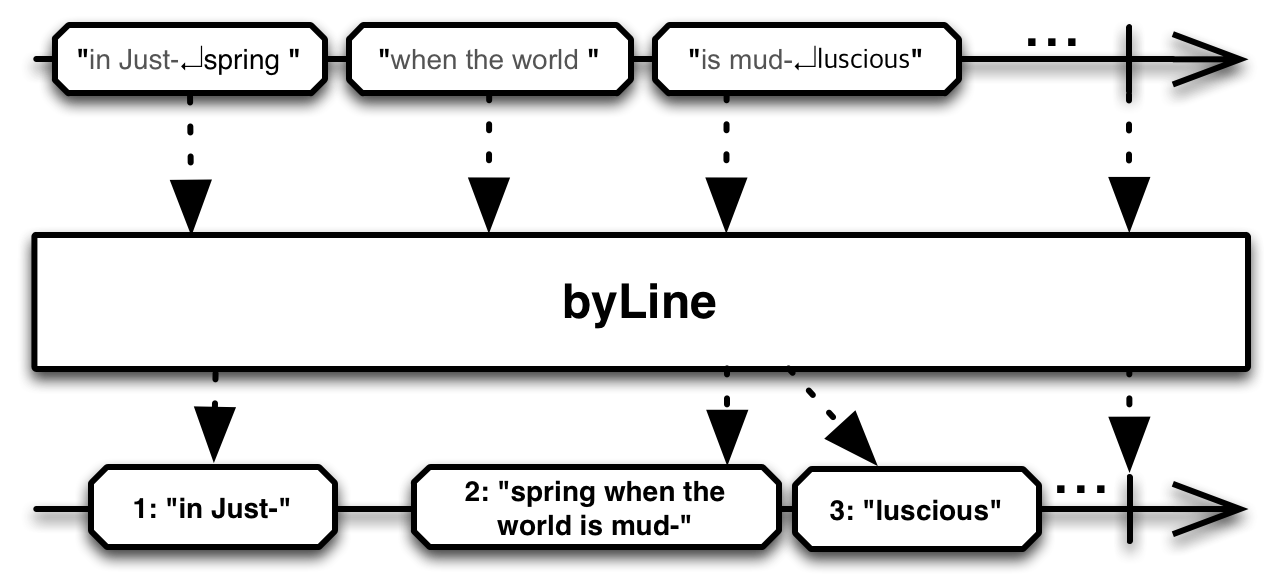 Also in the `StringObservable` class that is not part of the RxGroovy core there is a specialty mapping operator called `byLine`, that transforms an Observable that emits strings into an Observable that emits lines of text, by buffering the strings from the source Observable until a line-feed is found in one of them.
### RxJava 1․x `byLine cast encode map`
 RxJava implements this operator as `map`.
This operator does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`map(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#map(rx.functions.Func1))
 The `cast` operator is a specialized version of Map that transforms each item from the source Observable by casting it into a particular Class before reemitting it.
* Javadoc: [`cast(Class)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#cast(java.lang.Class))
 In the `StringObservable` class that is not part of the RxJava core there is also a specialty mapping operator, `encode`, that transforms an Observable that emits strings into an Observable that emits byte arrays that respect character boundaries of multibyte characters in the original strings.
 Also in the `StringObservable` class that is not part of the RxJava core there is a specialty mapping operator called `byLine`, that transforms an Observable that emits strings into an Observable that emits lines of text, by buffering the strings from the source Observable until a line-feed is found in one of them.
### RxJS `map pluck select`
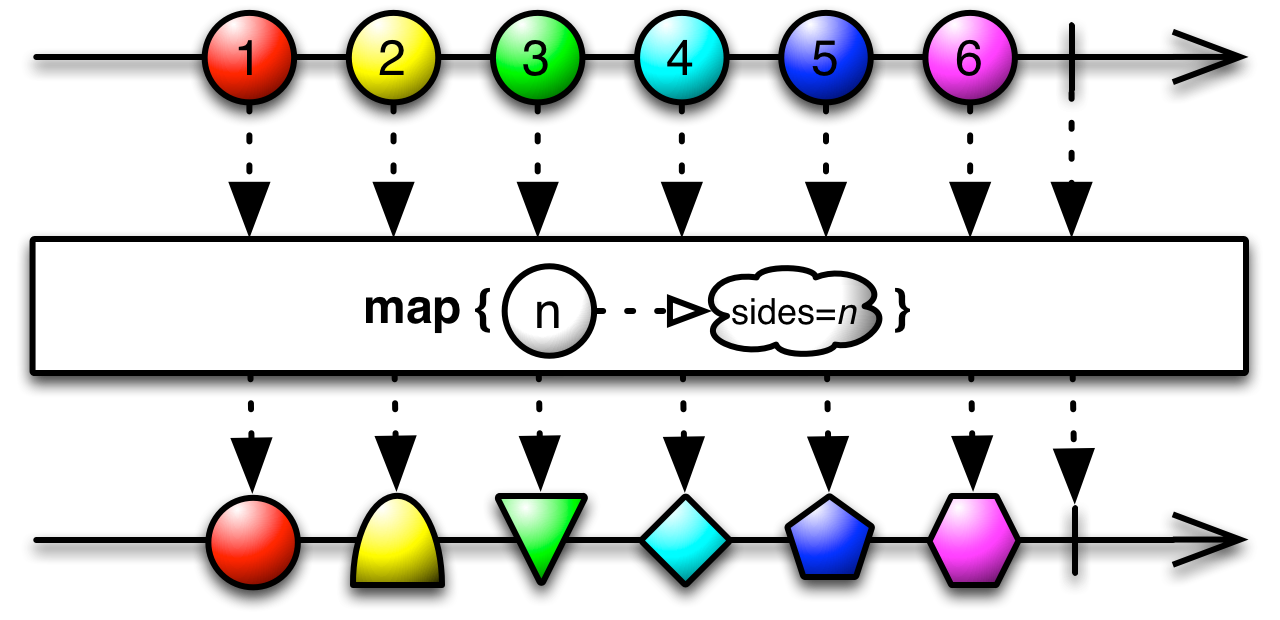 RxJS implements this operator as `map` or `select` (the two are synonymous). In addition to the transforming function, you may pass this operator an optional second parameter that will become the “`this`” context in which the transforming function will execute.
The transforming function gets three parameters:
1. the emitted item
2. the index of that item in the sequence of emitted items
3. the Observable from which that item was emitted
#### Sample Code
```
// Using a value
var md = Rx.Observable.fromEvent(document, 'mousedown').map(true);
var mu = Rx.Observable.fromEvent(document, 'mouseup').map(false);
// Using a function
var source = Rx.Observable.range(1, 3)
.select(function (x, idx, obs) {
return x * x;
});
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 1
Next: 4
Next: 9
Completed
```
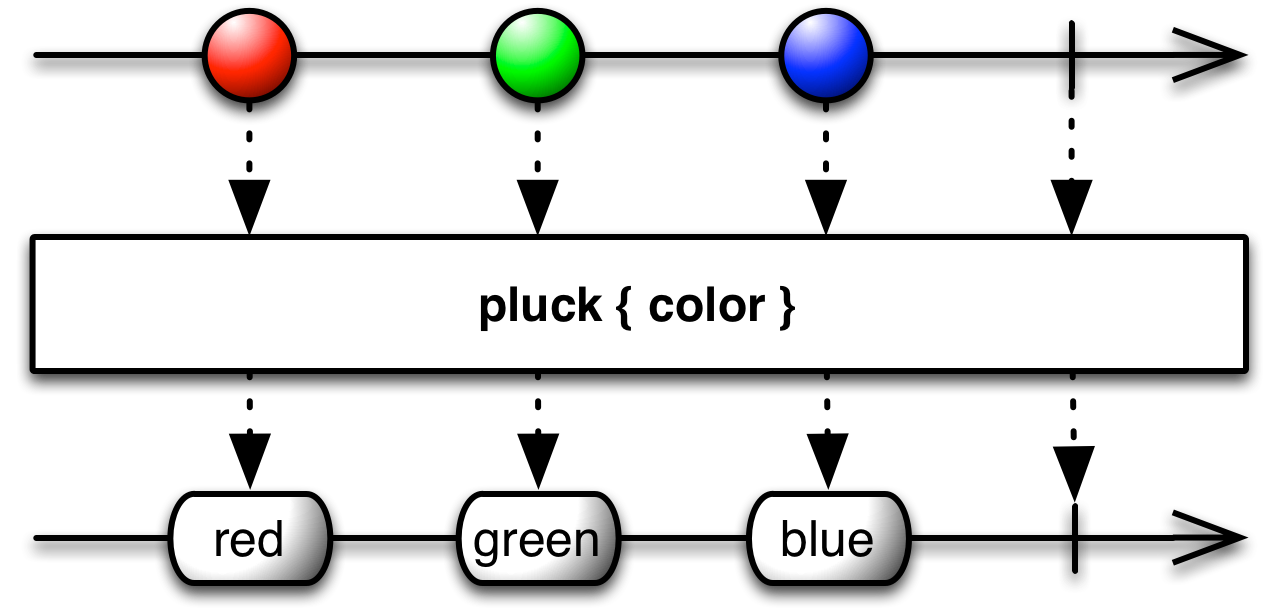 There is also an operator called `pluck` which is a simpler version of this operator. It transforms the elements emitted by the source Observable by extracting a single named property from those elements and emitting that property in their place.
#### Sample Code
```
var source = Rx.Observable
.fromArray([
{ value: 0 },
{ value: 1 },
{ value: 2 }
])
.pluck('value');
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 0
Next: 1
Next: 2
Completed
```
`map`/`select` and `pluck` are found in each of the following distributions:
* `rx.js`
* `rx.all.js`
* `rx.all.compat.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
#### See Also
* [`Rx.helpers.pluck(property)`](http://xgrommx.github.io/rx-book/content/helpers/pluck.html) from Dennis Stoyanov’s RxJS book
### RxPHP `map mapWithIndex mapTo select pluck`
RxPHP implements this operator as `map`.
Takes a transforming function that operates on each element.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/map/map.php
$observable = \Rx\Observable::fromArray([21, 42]);
$observable
->map(function ($elem) {
return $elem * 2;
})
->subscribe($stdoutObserver);
```
```
Next value: 42
Next value: 84
Complete!
```
RxPHP also has an operator `mapWithIndex`.
Maps operator variant that calls the map selector with the index and value
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/map/mapWithIndex.php
$subscriptions = Rx\Observable::fromArray([21, 42])
->mapWithIndex(function ($index, $elem) {
return $index + $elem;
})
->subscribe($stdoutObserver);
```
```
Next value: 21
Next value: 43
Complete!
```
RxPHP also has an operator `mapTo`.
Maps every value to the same value every time
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/map/mapTo.php
$subscription = Rx\Observable::fromArray([21, 42])
->mapTo(1)
->subscribe($stdoutObserver);
```
```
Next value: 1
Next value: 1
Complete!
```
RxPHP also has an operator `select`.
Alias for Map
RxPHP also has an operator `pluck`.
Returns an Observable containing the value of a specified array index (if array) or property (if object) from all elements in the Observable sequence. If a property can't be resolved the observable will error.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/pluck/pluck.php
$source = Rx\Observable::fromArray([
(object)['value' => 0],
(object)['value' => 1],
(object)['value' => 2]
])
->pluck('value');
$subscription = $source->subscribe($stdoutObserver);
```
```
Next value: 0
Next value: 1
Next value: 2
Complete!
```
reactivex Retry Retry
=====
> if a source Observable emits an error, resubscribe to it in the hopes that it will complete without error
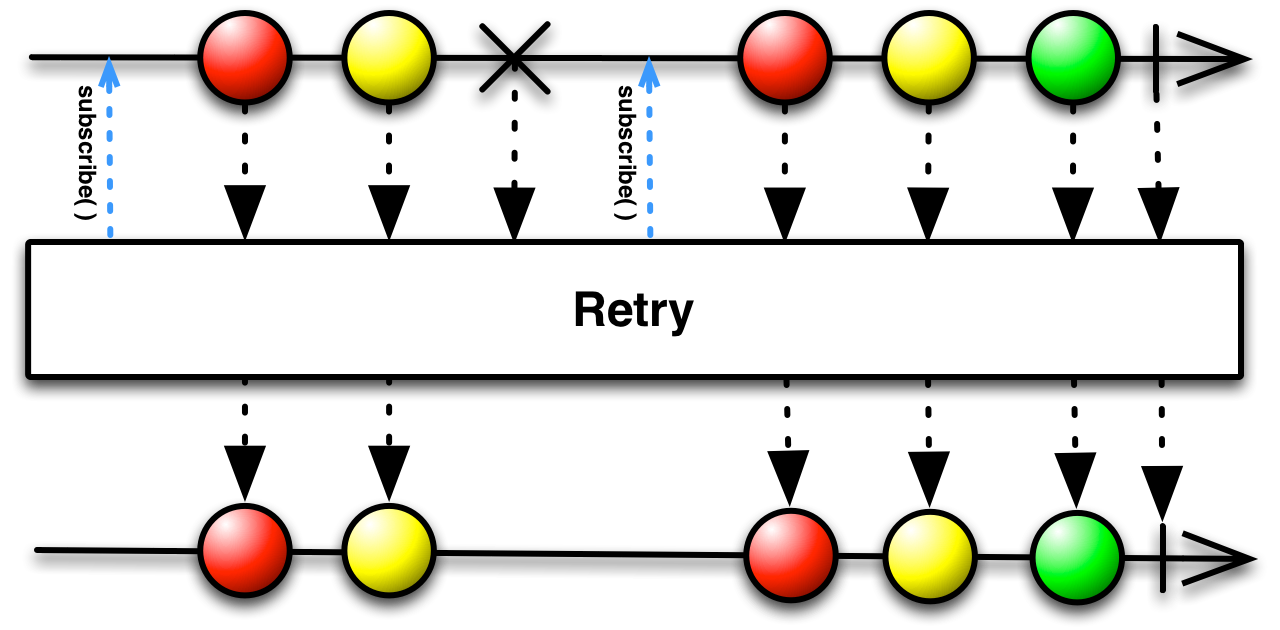 The Retry operator responds to an `onError` notification from the source Observable by not passing that call through to its observers, but instead by resubscribing to the source Observable and giving it another opportunity to complete its sequence without error. Retry always passes `onNext` notifications through to its observers, even from sequences that terminate with an error, so this can cause duplicate emissions (as shown in the diagram above).
#### See Also
* [Catch](catch)
* [Introduction to Rx: Retry](http://www.introtorx.com/Content/v1.0.10621.0/11_AdvancedErrorHandling.html#Retry)
Language-Specific Information
-----------------------------
### RxClojure
RxClojure does not implement the Retry operator.
### RxCpp `retry`
RxCpp implements this operator as `retry`:
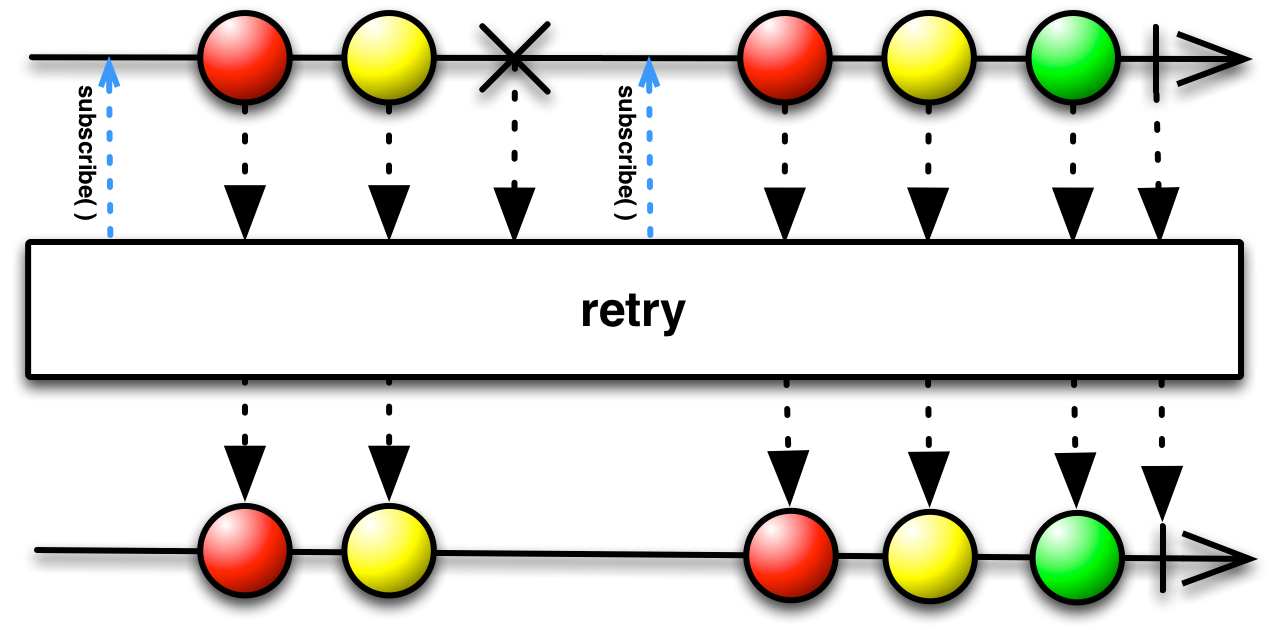 `retry` takes a single argument, a count of the number of times it should try resubscribing to the source Observable when it encounters errors. If this count is exceeded, `retry` will not attempt to resubscribe and will instead pass the `onError` notification to its observers.
### RxGroovy `retry retryWhen`
RxGroovy has two versions of this operator: `retry` and `retryWhen`.
 One variant of `retry` takes no parameters. It will continue to resubscribe to and mirror the source Observable no matter how many `onError` notifications it receives.
Another variant of `retry` takes a single parameter: a count of the number of times it should try to resubscribe to the source Observable when it encounters errors. If this count is exceeded, `retry` will not attempt to resubscribe again and will instead pass the latest `onError` notification to its observers.
A third variant of `retry` takes a predicate function as a parameter. You write this function to accept two arguments: an Integer count of how many retries have taken place thusfar, and a Throwable indicating the error that caused the `onError` notification. This function returns a Boolean to indicate whether or not `retry` should resubscribe to and mirror the source Observable. If it does not, then `retry` passes the latest `onError` notification to its observers.
`retry` by default operates on the `trampoline` [Scheduler](../scheduler).
* Javadoc: [`retry()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#retry())
* Javadoc: [`retry(long)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#retry(long))
* Javadoc: [`retry(Func2)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#retry(rx.functions.Func2))
 The `retryWhen` operator is similar to `retry` but decides whether or not to resubscribe to and mirror the source Observable by passing the Throwable from the `onError` notification to a function that generates a second Observable, and observes its result to determine what to do. If that result is an emitted item, `retryWhen` resubscribes to and mirrors the source and the process repeats; if that result is an `onError` notification, `retryWhen` passes this notification on to its observers and terminates.
`retryWhen` by default operates on the `trampoline` [Scheduler](../scheduler), and there is also a version that accepts a Scheduler as a parameter.
* Javadoc: [`retryWhen(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#retryWhen(rx.functions.Func1))
* Javadoc: [`retryWhen(Func1,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#retryWhen(rx.functions.Func1,%20rx.Scheduler))
### RxJava 1․x `retry retryWhen`
RxJava has two versions of this operator: `retry` and `retryWhen`.
 One variant of `retry` takes no parameters. It will continue to resubscribe to and mirror the source Observable no matter how many `onError` notifications it receives.
Another variant of `retry` takes a single parameter: a count of the number of times it should try to resubscribe to the source Observable when it encounters errors. If this count is exceeded, `retry` will not attempt to resubscribe again and will instead pass the latest `onError` notification to its observers.
A third variant of `retry` takes a predicate function as a parameter. You write this function to accept two arguments: an Integer count of how many retries have taken place thusfar, and a Throwable indicating the error that caused the `onError` notification. This function returns a Boolean to indicate whether or not `retry` should resubscribe to and mirror the source Observable. If it does not, then `retry` passes the latest `onError` notification to its observers.
`retry` by default operates on the `trampoline` [Scheduler](../scheduler).
* Javadoc: [`retry()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#retry())
* Javadoc: [`retry(long)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#retry(long))
* Javadoc: [`retry(Func2)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#retry(rx.functions.Func2))
 The `retryWhen` operator is similar to `retry` but decides whether or not to resubscribe to and mirror the source Observable by passing the Throwable from the `onError` notification to a function that generates a second Observable, and observes its result to determine what to do. If that result is an emitted item, `retryWhen` resubscribes to and mirrors the source and the process repeats; if that result is an `onError` notification, `retryWhen` passes this notification on to its observers and terminates.
`retryWhen` by default operates on the `trampoline` [Scheduler](../scheduler), and there is also a version that accepts a Scheduler as a parameter.
#### Sample Code
```
Observable.create((Subscriber<? super String> s) -> {
System.out.println("subscribing");
s.onError(new RuntimeException("always fails"));
}).retryWhen(attempts -> {
return attempts.zipWith(Observable.range(1, 3), (n, i) -> i).flatMap(i -> {
System.out.println("delay retry by " + i + " second(s)");
return Observable.timer(i, TimeUnit.SECONDS);
});
}).toBlocking().forEach(System.out::println);
```
```
subscribing
delay retry by 1 second(s)
subscribing
delay retry by 2 second(s)
subscribing
delay retry by 3 second(s)
subscribing
```
* Javadoc: [`retryWhen(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#retryWhen(rx.functions.Func1))
* Javadoc: [`retryWhen(Func1,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#retryWhen(rx.functions.Func1,%20rx.Scheduler))
### RxJS `retry`
RxJS implements this operator as `retry`.
 One variant of `retry` takes no parameters. It will continue to resubscribe to and mirror the source Observable no matter how many `onError` notifications it receives.
Another variant of `retry` takes a single parameter: a count of the number of `onError` notification it should be willing to accept before it too fails and passes the `onError` to its observers. For example, `retry(2)` means that `retry` will resubscribe to and mirror the source Observable the first time it receives an `onError` notification, but will terminate with an error the second time this happens.
`retry` is found in the following distributions:
* `rx.js`
* `rx.all.js`
* `rx.all.compat.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
### RxKotlin `retry retryWhen`
RxKotlin has two versions of this operator: `retry` and `retryWhen`.
 One variant of `retry` takes no parameters. It will continue to resubscribe to and mirror the source Observable no matter how many `onError` notifications it receives.
Another variant of `retry` takes a single parameter: a count of the number of times it should try to resubscribe to the source Observable when it encounters errors. If this count is exceeded, `retry` will not attempt to resubscribe again and will instead pass the latest `onError` notification to its observers.
A third variant of `retry` takes a predicate function as a parameter. You write this function to accept two arguments: an Integer count of how many retries have taken place thusfar, and a Throwable indicating the error that caused the `onError` notification. This function returns a Boolean to indicate whether or not `retry` should resubscribe to and mirror the source Observable. If it does not, then `retry` passes the latest `onError` notification to its observers.
 The `retryWhen` operator is similar to `retry` but decides whether or not to resubscribe to and mirror the source Observable by passing the Throwable from the `onError` notification to a function that generates a second Observable, and observes its result to determine what to do. If that result is an emitted item, `retryWhen` resubscribes to and mirrors the source and the process repeats; if that result is an `onError` notification, `retryWhen` passes this notification on to its observers and terminates.
### RxNET `Retry`
Rx.NET implements this operator as `Retry`.
 One variant of `Retry` takes no parameters. It will continue to resubscribe to and mirror the source Observable no matter how many `onError` notifications it receives.
Another variant of `Retry` takes a single parameter: a count of the number of `onError` notification it should be willing to accept before it too fails and passes the `onError` to its observers. For example, `Retry(2)` means that `Retry` will resubscribe to and mirror the source Observable the first time it receives an `onError` notification, but will terminate with an error the second time this happens.
### RxPHP `retry retryWhen`
RxPHP implements this operator as `retry`.
Repeats the source observable sequence the specified number of times or until it successfully terminates. If the retry count is not specified, it retries indefinitely. Note if you encounter an error and want it to retry once, then you must use ->retry(2).
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/retry/retry.php
$count = 0;
$observable = Rx\Observable::interval(1000)
->flatMap(function ($x) use (&$count) {
if (++$count < 2) {
return Rx\Observable::error(new \Exception('Something'));
}
return Rx\Observable::of(42);
})
->retry(3)
->take(1);
$observable->subscribe($stdoutObserver);
```
```
Next value: 42
Complete!
```
RxPHP also has an operator `retryWhen`.
Repeats the source observable sequence on error when the notifier emits a next value. If the source observable errors and the notifier completes, it will complete the source sequence.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/retry/retryWhen.php
$source = Rx\Observable::interval(1000)
->map(function ($n) {
if ($n === 2) {
throw new Exception();
}
return $n;
})
->retryWhen(function (\Rx\Observable $errors) {
return $errors->delay(200);
})
->take(6);
$subscription = $source->subscribe($createStdoutObserver());
```
```
Next value: 0
Next value: 1
Next value: 0
Next value: 1
Next value: 0
Next value: 1
Complete!
```
### RxPY `retry`
RxPY implements this operator as `retry`:
 `retry` takes a single optional parameter, a count of the number of times it should try resubscribing to and mirroring the source Observable when it encounters errors. If this count is exceeded, `retry` will not attempt to resubscribe and will instead pass the `onError` notification to its observers. If you omit this parameter, `retry` will attempt to resubscribe and mirror indefinitely, no matter how many `onError` notifications it receives.
### Rxrb `retry retry_infinitely`
Rx.rb has two versions of this operator: `retry` and `retry_infinitely`.
 `retry` takes a single optional parameter, a count of the number of times it should try resubscribing to and mirroring the source Observable when it encounters errors. If this count is exceeded, `retry` will not attempt to resubscribe and will instead pass the `onError` notification to its observers.
`retryInfinitely`, on the other hand, will attempt to resubscribe to and mirror the source Observable indefinitely, no matter how many `onError` notifications it receives.
### RxScala `retry retryWhen`
RxScala has two versions of this operator: `retry` and `retryWhen`.
 One variant of `retry` takes no parameters. It will continue to resubscribe to and mirror the source Observable no matter how many `onError` notifications it receives.
Another variant of `retry` takes a single parameter: a count of the number of times it should try to resubscribe to the source Observable when it encounters errors. If this count is exceeded, `retry` will not attempt to resubscribe again and will instead pass the latest `onError` notification to its observers.
A third variant of `retry` takes a predicate function as a parameter. You write this function to accept two arguments: an Int count of how many retries have taken place thusfar, and a Throwable indicating the error that caused the `onError` notification. This function returns a Boolean to indicate whether or not `retry` should resubscribe to and mirror the source Observable. If it does not, then `retry` passes the latest `onError` notification to its observers.
 The `retryWhen` operator is similar to `retry` but decides whether or not to resubscribe to and mirror the source Observable by passing the Throwable from the `onError` notification to a function that generates a second Observable, and observes its result to determine what to do. If that result is an emitted item, `retryWhen` resubscribes to and mirrors the source and the process repeats; if that result is an `onError` notification, `retryWhen` passes this notification on to its observers and terminates.
| programming_docs |
reactivex Backpressure Operators Backpressure Operators
======================
> strategies for coping with Observables that produce items more rapidly than their observers consume them
In ReactiveX it is not difficult to get into a situation in which an Observable is emitting items more rapidly than an operator or observer can consume them. This presents the problem of what to do with such a growing backlog of unconsumed items.
For example, imagine using the [Zip](zip) operator to zip together two infinite Observables, one of which emits items twice as frequently as the other. A naive implementation of the operator would have to maintain an ever-expanding buffer of items emitted by the faster Observable to eventually combine with items emitted by the slower one. This could cause ReactiveX to seize an unwieldy amount of system resources.
There are a variety of strategies with which you can exercise flow control and backpressure in ReactiveX in order to alleviate the problems caused when a quickly-producing Observable meets a slow-consuming observer, which include, in some ReactiveX implementations, reactive pull backpressure and some backpressure-specific operators.
A cold Observable emits a particular sequence of items, but can begin emitting this sequence when its observer finds it to be convenient, and at whatever rate the observer desires, without disrupting the integrity of the sequence. For example if you convert a static iterable into an Observable, that Observable will emit the same sequence of items no matter when it is later subscribed to or how frequently those items are observed. Examples of items emitted by a cold Observable might include the results of a database query, file retrieval, or web request.
A hot Observable begins generating items to emit immediately when it is created. Subscribers typically begin observing the sequence of items emitted by a hot Observable from somewhere in the middle of the sequence, beginning with the first item emitted by the Observable subsequent to the establishment of the subscription. Such an Observable emits items at its own pace, and it is up to its observers to keep up. Examples of items emitted by a hot Observable might include mouse & keyboard events, system events, or stock prices.
When a cold Observable is multicast (when it is converted into a connectable Observable and its [Connect](connect) method is called), it effectively becomes hot and for the purposes of backpressure and flow-control it should be treated as a hot Observable.
Cold Observables are ideal for the reactive pull model of backpressure implemented by some implementations of ReactiveX (which is described elsewhere). Hot Observables typically do not cope well with a reactive pull model, and are better candidates for other flow control strategies, such as the use of the operators described on this page, or operators like [Buffer](buffer), [Sample](sample), [Debounce](debounce), or [Window](window).
#### See Also
* [Buffer](buffer)
* [Sample](sample)
* [Debounce](debounce)
* [Window](window)
Language-Specific Information
-----------------------------
### RxGroovy `onBackpressureBuffer onBackpressureDrop onBackpressureLatest`
RxGroovy implements reactive pull backpressure, and many of its operators support that form of backpressure. It also has three operators that you can apply to Observables that have not been written to support backpressure:  `onBackpressureBuffer` maintains a buffer of all unobserved emissions from the source Observable and emits them to downstream observers according to the requests they generate.
A version of this operator that was introduced in RxGroovy 1.1 allows you to set the capacity of the buffer; applying this operator will cause the resulting Observable to terminate with an error if this buffer is overrun. A second version, introduced during the same release, allows you to set an `Action` that `onBackpressureBuffer` will call if the buffer is overrun.
* Javadoc: [`onBackpressureBuffer()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#onBackpressureBuffer())
* Javadoc: [`onBackpressureBuffer(long)` (RxGroovy 1.1)](http://reactivex.io/RxJava/javadoc/rx/Observable.html#onBackpressureBuffer(long))
* Javadoc: [`onBackpressureBuffer(long, Action0)` (RxGroovy 1.1)](http://reactivex.io/RxJava/javadoc/rx/Observable.html#onBackpressureBuffer(long,%20rx.functions.Action0))
 `onBackpressureDrop` drops emissions from the source Observable unless there is a pending request from a downstream observer, in which case it will emit enough items to fulfill the request.
A version of this operator that was introduced in the 1.1 release notifies you, by means of an `Action` you pass as a parameter, when an item has been dropped and which item was dropped.
* Javadoc: [`onBackpressureDrop()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#onBackpressureDrop())
* Javadoc: [onBackpressureDrop(Action1) (RxGroovy 1.1)](http://reactivex.io/RxJava/javadoc/rx/Observable.html#onBackpressureDrop(rx.functions.Action1))
 `onBackpressureLatest` (new in RxJava 1.1) holds on to the most-recently emitted item from the source Observable and immediately emits that item to its observer upon request. It drops any other items that it observes between requests from its observer.
* Javadoc: [`onBackpressureLatest()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#onBackpressureLatest())
### RxJava 1․x `onBackpressureBuffer onBackpressureDrop onBackpressureLatest`
RxJava implements reactive pull backpressure, and many of its operators support that form of backpressure. It also has three operators that you can apply to Observables that have not been written to support backpressure:  `onBackpressureBuffer` maintains a buffer of all unobserved emissions from the source Observable and emits them to downstream observers according to the requests they generate.
A version of this operator that was introduced in RxJava 1.1 allows you to set the capacity of the buffer; applying this operator will cause the resulting Observable to terminate with an error if this buffer is overrun. A second version, introduced during the same release, allows you to set an `Action` that `onBackpressureBuffer` will call if the buffer is overrun.
* Javadoc: [`onBackpressureBuffer()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#onBackpressureBuffer())
* Javadoc: [`onBackpressureBuffer(long)` (RxJava 1.1)](http://reactivex.io/RxJava/javadoc/rx/Observable.html#onBackpressureBuffer(long))
* Javadoc: [`onBackpressureBuffer(long, Action0)` (RxJava 1.1)](http://reactivex.io/RxJava/javadoc/rx/Observable.html#onBackpressureBuffer(long,%20rx.functions.Action0))
 `onBackpressureDrop` drops emissions from the source Observable unless there is a pending request from a downstream observer, in which case it will emit enough items to fulfill the request.
A version of this operator that was introduced in the 1.1 release notifies you, by means of an `Action` you pass as a parameter, when an item has been dropped and which item was dropped.
* Javadoc: [`onBackpressureDrop()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#onBackpressureDrop())
* Javadoc: [onBackpressureDrop(Action1) (RxJava 1.1)](http://reactivex.io/RxJava/javadoc/rx/Observable.html#onBackpressureDrop(rx.functions.Action1))
 `onBackpressureLatest` (new in RxJava 1.1) holds on to the most-recently emitted item from the source Observable and immediately emits that item to its observer upon request. It drops any other items that it observes between requests from its observer.
* Javadoc: [`onBackpressureLatest()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#onBackpressureLatest())
### RxJS `controlled pausable pausableBuffered stopAndWait windowed`
RxJS implements backpressure by transforming an ordinary Observable into a `ControlledObservable` with the `controlled` operator. This forces the Observable to respect pull `request`s from its observer rather than pushing items on its own initiative.
 As an alternative to using `request` to pull items from a `ControlledObservable`, you may apply the `stopAndWait` operator to it. This operator will request a new item from the Observable each time its observers’ `onNext` routine receives the latest item.
 A second possibility is to use the `windowed(`*n*`)`. This behaves similarly to `stopAndWait` but has an internal buffer of *n* items, which allows the `ControlledObservable` to run somewhat ahead of the observer from time to time. `windowed(1)` is equivalent to `stopAndWait`.
There are also two operators that convert an ordinary Observable into at `PausableObservable`.
 If you call the `pause` method of a `PausableObservable` created with the `pausable` operator, it will drop (ignore) any items emitted by the underlying source Observable until such time as you call its `resume` method, whereupon it will continue to pass along emitted items to its observers.
#### See Also
* [RxMarbles: `pausable`](http://rxmarbles.com/#pausable)
 If you call the `pause` method of a `PausableObservable` created with the `pausableBuffered` operator, it will buffer any items emitted by the underlying source Observable until such time as you call its `resume` method, whereupon it will emit those buffered items and then continue to pass along any additional emitted items to its observers.
#### See Also
* [RxMarbles: `pausableBuffered`](http://rxmarbles.com/#pausableBuffered)
reactivex Take Take
====
> emit only the first *n* items emitted by an Observable
[Open interactive diagram on rxmarbles.com](https://rxmarbles.com/#take) You can emit only the first *n* items emitted by an Observable and then complete while ignoring the remainder, by modifying the Observable with the Take operator.
#### See Also
* [First](first)
* [Skip](skip)
* [SkipLast](skiplast)
* [SkipUntil](skipuntil)
* [SkipWhile](skipwhile)
* [TakeLast](takelast)
* [TakeUntil](takeuntil)
* [TakeWhile](takewhile)
* [Introduction to Rx: Skip and Take](http://www.introtorx.com/Content/v1.0.10621.0/05_Filtering.html#SkipAndTake)
* [RxMarbles: `take`](http://rxmarbles.com/#take)
Language-Specific Information
-----------------------------
### RxGroovy `limit take`
 In RxGroovy, this operator is implemented as `take`.
If you use the `take(*n*)` operator (or its synonym, `limit(*n*)`) on an Observable, and that Observable emits fewer than *n* items before completing, the new, `take`-modified Observable will not throw an exception or invoke `onError`, but will merely emit this same fewer number of items before it completes.
#### Sample Code
```
numbers = Observable.from([1, 2, 3, 4, 5, 6, 7, 8]);
numbers.take(3).subscribe(
{ println(it); }, // onNext
{ println("Error: " + it.getMessage()); }, // onError
{ println("Sequence complete"); } // onCompleted
);
```
```
1
2
3
Sequence complete
```
This variant of `take` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`take(int)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#take(int))
 There is also a variant of `take` that takes a temporal duration rather than a quantity of items. It results in an Observable that emits only those items that are emitted during that initial duration of the source Observable’s lifespan. You set this duration by passing in a length of time and the time units this length is denominated in as parameters to `take`.
This variant of `take` by default operates on the `computation` [Scheduler](../scheduler), but you may also pass in a Scheduler of your choosing as an optional third parameter.
* Javadoc: [`take(long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#take(long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`take(long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#take(long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
### RxJava 1․x `limit take`
 In RxJava, this operator is implemented as `take`.
If you use the `take(*n*)` operator (or its synonym, `limit(*n*)`) on an Observable, and that Observable emits fewer than *n* items before completing, the new, `take`-modified Observable will not throw an exception or invoke `onError`, but will merely emit this same fewer number of items before it completes.
#### Sample Code
```
Observable.just(1, 2, 3, 4, 5, 6, 7, 8)
.take(4)
.subscribe(new Subscriber<Integer>() {
@Override
public void onNext(Integer item) {
System.out.println("Next: " + item);
}
@Override
public void onError(Throwable error) {
System.err.println("Error: " + error.getMessage());
}
@Override
public void onCompleted() {
System.out.println("Sequence complete.");
}
});
```
```
Next: 1
Next: 2
Next: 3
Next: 4
Sequence complete.
```
This variant of `take` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`take(int)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#take(int))
 There is also a variant of `take` that takes a temporal duration rather than a quantity of items. It results in an Observable that emits only those items that are emitted during that initial duration of the source Observable’s lifespan. You set this duration by passing in a length of time and the time units this length is denominated in as parameters to `take`.
This variant of `take` by default operates on the `computation` [Scheduler](../scheduler), but you may also pass in a Scheduler of your choosing as an optional third parameter.
* Javadoc: [`take(long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#take(long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`take(long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#take(long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
### RxJS `take takeUntilWithTime`
 RxJS implements the `take` operator.
#### Sample Code
```
var source = Rx.Observable.range(0, 5)
.take(3);
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 0
Next: 1
Next: 2
Completed
```
 For the special case of `take(0)` you can also pass as a second parameter a [Scheduler](../scheduler) that `take` will use to immediately schedule a call to `onCompleted`.
`take` is found in each of the following distributions:
* `rx.js`
* `rx.all.js`
* `rx.all.compat.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
 RxJS also implements a `takeUntilWithTime` operator, which is like `take` except that rather than taking a particular quantity of items, it takes all of the items that are emitted during an initial period of time. You establish this period of by passing in a parameter to `takeUntilWithTime`, in either of these formats:
a number mirrors items from the source Observable until this many milliseconds have passed since the Observable was subscribed to a `Date`
mirrors items from the source Observable until this absolute time You may also, optionally, pass in a [Scheduler](../scheduler) as a second parameter, and the timer will operate on that Scheduler (`takeUntilWithTime` uses the `timeout` Scheduler by default).
#### Sample Code
```
var source = Rx.Observable.timer(0, 1000)
.takeUntilWithTime(5000);
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 0
Next: 1
Next: 2
Next: 3
Next: 4
Completed
```
`takeUntilWithTime` is found in each of the following distributions:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.time.js` (requires `rx.js` or `rx.compat.js`)
* `rx.lite.js`
* `rx.lite.compat.js`
### RxPHP `take takeUntil`
RxPHP implements this operator as `take`.
Returns a specified number of contiguous elements from the start of an observable sequence
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/take/take.php
$observable = Rx\Observable::fromArray([21, 42, 63]);
$observable
->take(2)
->subscribe($stdoutObserver);
```
```
Next value: 21
Next value: 42
Complete!
```
RxPHP also has an operator `takeUntil`.
Returns the values from the source observable sequence until the other observable sequence produces a value.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/take/takeUntil.php
$source = \Rx\Observable::interval(105)
->takeUntil(\Rx\Observable::timer(1000));
$subscription = $source->subscribe($stdoutObserver);
```
```
Next value: 0
Next value: 1
Next value: 2
Next value: 3
Next value: 4
Next value: 5
Next value: 6
Next value: 7
Next value: 8
Complete!
```
reactivex Window Window
======
> periodically subdivide items from an Observable into Observable windows and emit these windows rather than emitting the items one at a time
 Window is similar to [Buffer](buffer), but rather than emitting packets of items from the source Observable, it emits Observables, each one of which emits a subset of items from the source Observable and then terminates with an `onCompleted` notification.
Like Buffer, Window has many varieties, each with its own way of subdividing the original Observable into the resulting Observable emissions, each one of which contains a “window” onto the original emitted items. In the terminology of the Window operator, when a window “opens,” this means that a new Observable is emitted and that Observable will begin emitting items emitted by the source Observable. When a window “closes,” this means that the emitted Observable stops emitting items from the source Observable and terminates with an `onCompleted` notification to its observers.
#### See Also
* [Buffer](buffer)
* [Introduction to Rx: Window](http://www.introtorx.com/Content/v1.0.10621.0/17_SequencesOfCoincidence.html#Window)
* [101 Rx Samples: Window](http://rxwiki.wikidot.com/101samples#toc38)
Language-Specific Information
-----------------------------
### RxClojure `partition-all`
RxClojure implements this operator as `partition-all`:
 `partition-all` opens its first window immediately. It opens a new window beginning with every `step` item from the source Observable (so, for example, if `step` is 3, then it opens a new window starting with every third item). It closes each window when that window has emitted `n` items or if it receives an `onCompleted` or `onError` notification from the source Observable. If `step = n` (which is the default if you omit the `step` parameter) then the window size is the same as the step size and there will be a one-to-one correspondence between the items emitted by the source Observable and the items emitted by the collection of window Observables. If `step < n` the windows will overlap by `n − step` items; if `step > n` the windows will drop `step − n` items from the source Observable between every window.
### RxCpp `window window_with_time window_with_time_or_count`
RxCpp implements this operator as two variants of `window`, two variants of `window_with_time`, and as `window_with_time_or_count`:
#### `window(count)`
 This variant of `window` opens its first window immediately. It closes the currently open window and immediately opens a new one whenever the current window has emitted `count` items. It will also close the currently open window if it receives an `onCompleted` or `onError` notification from the source Observable. This variant of `window` emits a series of non-overlapping windows whose collective emissions correspond one-to-one with those of the source Observable.
#### `window(count, skip)`
 This variant of `window` opens its first window immediately. It opens a new window beginning with every `skip` item from the source Observable (so, for example, if `skip` is 3, then it opens a new window starting with every third item). It closes each window when that window has emitted `count` items or if it receives an `onCompleted` or `onError` notification from the source Observable. If `skip = count` then this behaves the same as `window(source, count)`; if `skip < count` this will emit windows that overlap by `count − skip` items; if `skip > count` this will emit windows that drop `skip − count` items from the source Observable between every window.
####
`window_with_time(period`[`, coordination`]`)`
![window_with_time(period[,coordination])](http://reactivex.io/documentation/operators/images/window_with_time5.png) This variant of `window_with_time` opens its first window immediately. It closes the currently open window and opens another one every `period` of time (a Duration, optionally computed by a given Coordination). It will also close the currently open window if it receives an `onCompleted` or `onError` notification from the source Observable. This variant of `window_with_time` emits a series of non-overlapping windows whose collective emissions correspond one-to-one with those of the source Observable.
####
`window_with_time(period, skip`[`, coordination`]`)`
![window_with_time(period,skip[,coordination])](http://reactivex.io/documentation/operators/images/window_with_time7.png) This variant of `window_with_time` opens its first window immediately. It closes the currently open window after `period` amount of time has passed since it was opened, and opens a new window after `skip` amount of time has passed since the previous window was opened (both times are Durations, optionally computed by a given Coordination). It will also close the currently open window if it receives an `onCompleted` or `onError` notification from the source Observable. This variant of `window_with_time` may emit windows that overlap or that have gaps, depending on whether `skip` is less than or greater than `period`.
####
`window_with_time_or_count(period, count`[`, coordination`]`)`
![window_with_time_or_count(period,count[,coordination])](http://reactivex.io/documentation/operators/images/window_with_time_or_count.png) `window_with_time_or_count` opens its first window immediately. It closes the currently open window and opens another one every `period` of time (optionally computed by a given Coordination) or whenever the currently open window has emitted `count` items. It will also close the currently open window if it receives an `onCompleted` or `onError` notification from the source Observable. `window_with_time_or_count` emits a series of non-overlapping windows whose collective emissions correspond one-to-one with those of the source Observable.
### RxGroovy `window`
There are several varieties of Window in RxGroovy.
#### `window(closingSelector)`
 This variant of `window` opens its first window immediately. It closes the currently open window and immediately opens a new one each time it observes an object emitted by the Observable that is returned from `closingSelector`. In this way, this variant of `window` emits a series of non-overlapping windows whose collective emissions correspond one-to-one with those of the source Observable.
* Javadoc: [`window(Func0)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#window(rx.functions.Func0))
#### `window(windowOpenings, closingSelector)`
 This variant of `window` opens a window whenever it observes the `windowOpenings` Observable emit an `Opening` object and at the same time calls `closingSelector` to generate a closing Observable associated with that window. When that closing Observable emits an object, `window` closes that window. Since the closing of currently open windows and the opening of new windows are activities that are regulated by independent Observables, this variant of `window` may create windows that overlap (duplicating items from the source Observable) or that leave gaps (discarding items from the source Observable).
* Javadoc: [`window(Observable,Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#window(rx.Observable,%20rx.functions.Func1))
#### `window(count)`
 This variant of `window` opens its first window immediately. It closes the currently open window and immediately opens a new one whenever the current window has emitted `count` items. It will also close the currently open window if it receives an `onCompleted` or `onError` notification from the source Observable. This variant of `window` emits a series of non-overlapping windows whose collective emissions correspond one-to-one with those of the source Observable.
* Javadoc: [`window(int)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#window(int))
#### `window(count, skip)`
 This variant of `window` opens its first window immediately. It opens a new window beginning with every `skip` item from the source Observable (so, for example, if `skip` is 3, then it opens a new window starting with every third item). It closes each window when that window has emitted `count` items or if it receives an `onCompleted` or `onError` notification from the source Observable. If `skip = count` then this behaves the same as `window(source, count)`; if `skip < count` this will emit windows that overlap by `count − skip` items; if `skip > count` this will emit windows that drop `skip − count` items from the source Observable between every window.
* Javadoc: [`window(int,int)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#window(int,%20int))
####
`window(timespan, unit`[`, scheduler`]`)`
![window(timespan, unit[, scheduler])](http://reactivex.io/documentation/operators/images/window5.png) This variant of `window` opens its first window immediately. It closes the currently open window and opens another one every `timespan` period of time (measured in `unit`, and optionally on a particular [`Scheduler`](../scheduler)). It will also close the currently open window if it receives an `onCompleted` or `onError` notification from the source Observable. This variant of `window` emits a series of non-overlapping windows whose collective emissions correspond one-to-one with those of the source Observable.
If you do not specify a Scheduler, this variant of `window` uses the `computation` Scheduler for its timer by default.
* Javadoc: [`window(long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#window(long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`window(long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#window(long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
####
`window(timespan, unit, count`[`, scheduler`]`)`
![window(timespan, unit, count[, scheduler])](http://reactivex.io/documentation/operators/images/window6.png) This variant of `window` opens its first window immediately. It closes the currently open window and opens another one every `timespan` period of time (measured in `unit`, and optionally on a particular [`Scheduler`](../scheduler)) or whenever the currently open window has emitted `count` items. It will also close the currently open window if it receives an `onCompleted` or `onError` notification from the source Observable. This variant of `window` emits a series of non-overlapping windows whose collective emissions correspond one-to-one with those of the source Observable.
If you do not specify a Scheduler, this variant of `window` uses the `computation` Scheduler for its timer by default.
* Javadoc: [`window(long,TimeUnit,int)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#window(long,%20java.util.concurrent.TimeUnit,%20int))
* Javadoc: [`window(long,TimeUnit,int,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#window(long,%20java.util.concurrent.TimeUnit,%20int,%20rx.Scheduler))
####
`window(timespan, timeshift, unit`[`, scheduler`]`)`
![window(timespan, timeshift, unit[, scheduler])](http://reactivex.io/documentation/operators/images/window7.png) This variant of `window` opens its first window immediately, and thereafter opens a new window every `timeshift` period of time (measured in `unit`, and optionally on a particular [`Scheduler`](../scheduler)). It closes a currently open window after `timespan` period of time has passed since that window was opened. It will also close any currently open window if it receives an `onCompleted` or `onError` notification from the source Observable. Depending on how you set `timespan` and `timeshift` the windows that result from this operation may overlap or may have gaps.
If you do not specify a Scheduler, this variant of `window` uses the `computation` Scheduler for its timer by default.
* Javadoc: [`window(long,long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#window(long,%20long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`window(long,long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#window(long,%20long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
You can use the Window operator to implement backpressure (that is, to cope with an Observable that may produce items too quickly for its observer to consume).
 Window can reduce a sequence of many items to a sequence of fewer windows-of-items, making them more manageable. You could, for example, emit a window of items from a bursty Observable periodically, at a regular interval of time.
#### Sample Code
```
Observable<Observable<Integer>> burstyWindowed = bursty.window(500, TimeUnit.MILLISECONDS);
```
 Or you could choose to emit a new window of items for every *n* items emitted by the bursty Observable.
#### Sample Code
```
Observable<Observable<Integer>> burstyWindowed = bursty.window(5);
```
### RxJava 1․x `window`
There are several varieties of Window in RxJava.
#### `window(closingSelector)`
 This variant of `window` opens its first window immediately. It closes the currently open window and immediately opens a new one each time it observes an object emitted by the Observable that is returned from `closingSelector`. In this way, this variant of `window` emits a series of non-overlapping windows whose collective emissions correspond one-to-one with those of the source Observable.
* Javadoc: [`window(Func0)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#window(rx.functions.Func0))
#### `window(windowOpenings, closingSelector)`
 This variant of `window` opens a window whenever it observes the `windowOpenings` Observable emit an `Opening` object and at the same time calls `closingSelector` to generate a closing Observable associated with that window. When that closing Observable emits an object, `window` closes that window. Since the closing of currently open windows and the opening of new windows are activities that are regulated by independent Observables, this variant of `window` may create windows that overlap (duplicating items from the source Observable) or that leave gaps (discarding items from the source Observable).
* Javadoc: [`window(Observable,Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#window(rx.Observable,%20rx.functions.Func1))
#### `window(count)`
 This variant of `window` opens its first window immediately. It closes the currently open window and immediately opens a new one whenever the current window has emitted `count` items. It will also close the currently open window if it receives an `onCompleted` or `onError` notification from the source Observable. This variant of `window` emits a series of non-overlapping windows whose collective emissions correspond one-to-one with those of the source Observable.
* Javadoc: [`window(int)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#window(int))
#### `window(count, skip)`
 This variant of `window` opens its first window immediately. It opens a new window beginning with every `skip` item from the source Observable (so, for example, if `skip` is 3, then it opens a new window starting with every third item). It closes each window when that window has emitted `count` items or if it receives an `onCompleted` or `onError` notification from the source Observable. If `skip = count` then this behaves the same as `window(source, count)`; if `skip < count` this will emit windows that overlap by `count − skip` items; if `skip > count` this will emit windows that drop `skip − count` items from the source Observable between every window.
* Javadoc: [`window(int,int)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#window(int,%20int))
####
`window(timespan, unit`[`, scheduler`]`)`
![window(timespan, unit[, scheduler])](http://reactivex.io/documentation/operators/images/window5.png) This variant of `window` opens its first window immediately. It closes the currently open window and opens another one every `timespan` period of time (measured in `unit`, and optionally on a particular [`Scheduler`](../scheduler)). It will also close the currently open window if it receives an `onCompleted` or `onError` notification from the source Observable. This variant of `window` emits a series of non-overlapping windows whose collective emissions correspond one-to-one with those of the source Observable.
If you do not specify a Scheduler, this variant of `window` uses the `computation` Scheduler for its timer by default.
* Javadoc: [`window(long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#window(long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`window(long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#window(long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
####
`window(timespan, unit, count`[`, scheduler`]`)`
![window(timespan, unit, count[, scheduler])](http://reactivex.io/documentation/operators/images/window6.png) This variant of `window` opens its first window immediately. It closes the currently open window and opens another one every `timespan` period of time (measured in `unit`, and optionally on a particular [`Scheduler`](../scheduler)) or whenever the currently open window has emitted `count` items. It will also close the currently open window if it receives an `onCompleted` or `onError` notification from the source Observable. This variant of `window` emits a series of non-overlapping windows whose collective emissions correspond one-to-one with those of the source Observable.
If you do not specify a Scheduler, this variant of `window` uses the `computation` Scheduler for its timer by default.
* Javadoc: [`window(long,TimeUnit,int)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#window(long,%20java.util.concurrent.TimeUnit,%20int))
* Javadoc: [`window(long,TimeUnit,int,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#window(long,%20java.util.concurrent.TimeUnit,%20int,%20rx.Scheduler))
####
`window(timespan, timeshift, unit`[`, scheduler`]`)`
![window(timespan, timeshift, unit[, scheduler])](http://reactivex.io/documentation/operators/images/window7.png) This variant of `window` opens its first window immediately, and thereafter opens a new window every `timeshift` period of time (measured in `unit`, and optionally on a particular [`Scheduler`](../scheduler)). It closes a currently open window after `timespan` period of time has passed since that window was opened. It will also close any currently open window if it receives an `onCompleted` or `onError` notification from the source Observable. Depending on how you set `timespan` and `timeshift` the windows that result from this operation may overlap or may have gaps.
If you do not specify a Scheduler, this variant of `window` uses the `computation` Scheduler for its timer by default.
* Javadoc: [`window(long,long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#window(long,%20long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`window(long,long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#window(long,%20long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
You can use the Window operator to implement backpressure (that is, to cope with an Observable that may produce items too quickly for its observer to consume).
 Window can reduce a sequence of many items to a sequence of fewer windows-of-items, making them more manageable. You could, for example, emit a window of items from a bursty Observable periodically, at a regular interval of time.
#### Sample Code
```
Observable<Observable<Integer>> burstyWindowed = bursty.window(500, TimeUnit.MILLISECONDS);
```
 Or you could choose to emit a new window of items for every *n* items emitted by the bursty Observable.
#### Sample Code
```
Observable<Observable<Integer>> burstyWindowed = bursty.window(5);
```
### RxJS `window windowWithCount windowWithTime windowWithTimeOrCount`
#### `window(windowClosingSelector)`
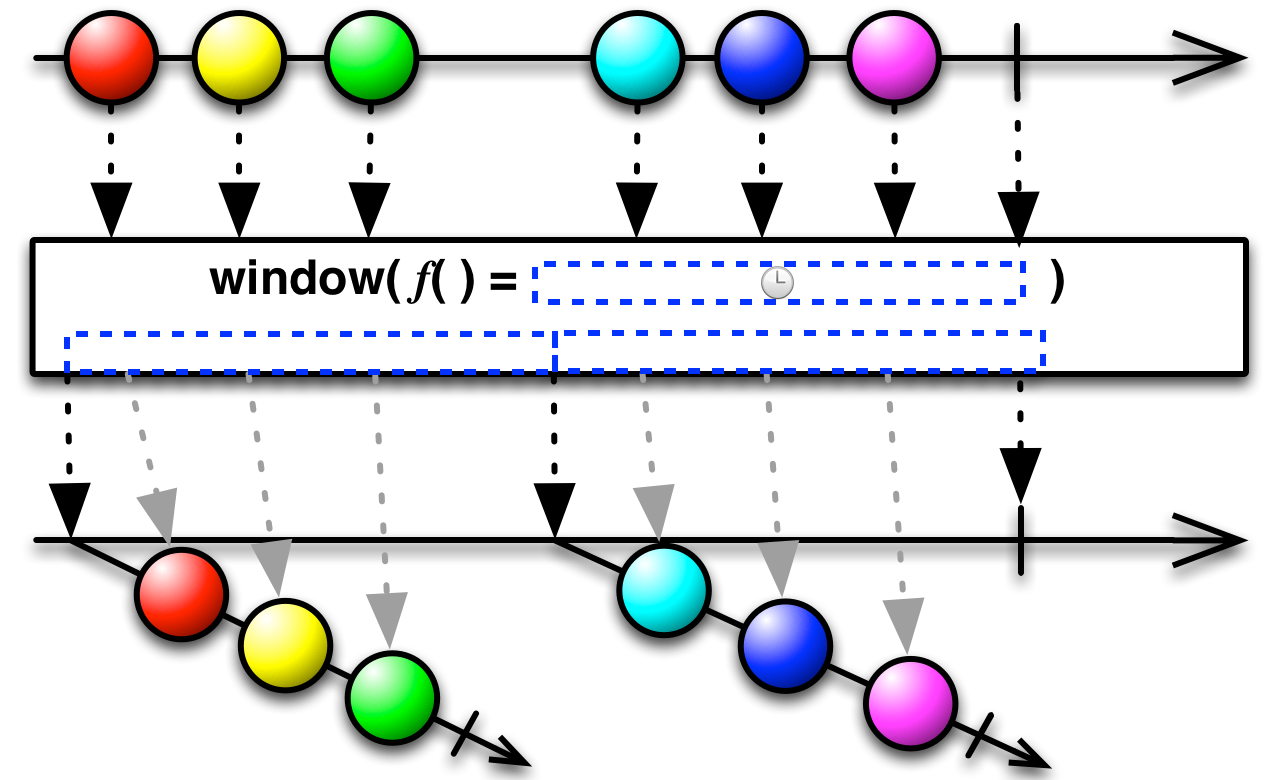 #### `window(windowOpenings, windowClosingSelector)`
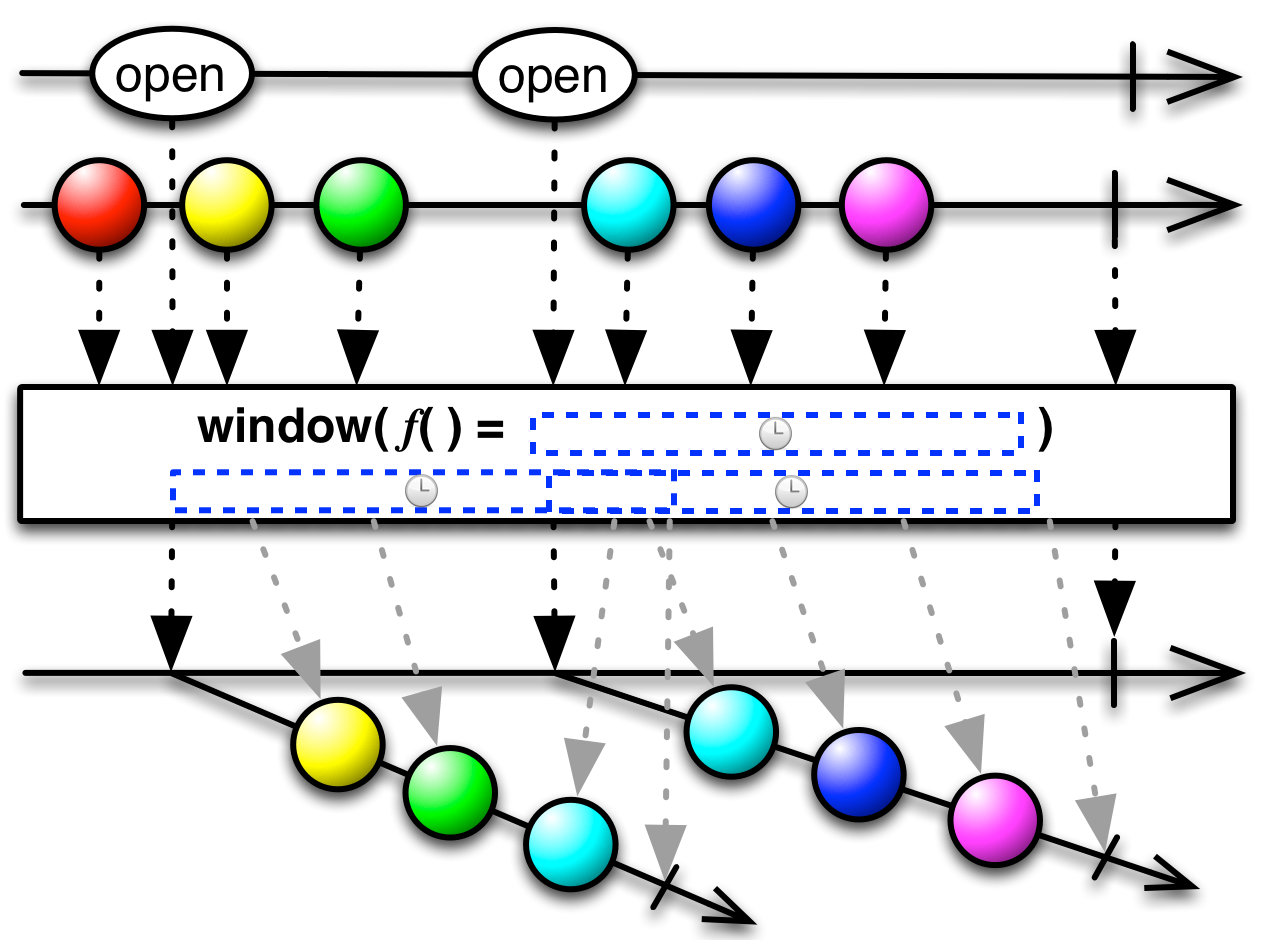 #### `window(windowBoundaries)`
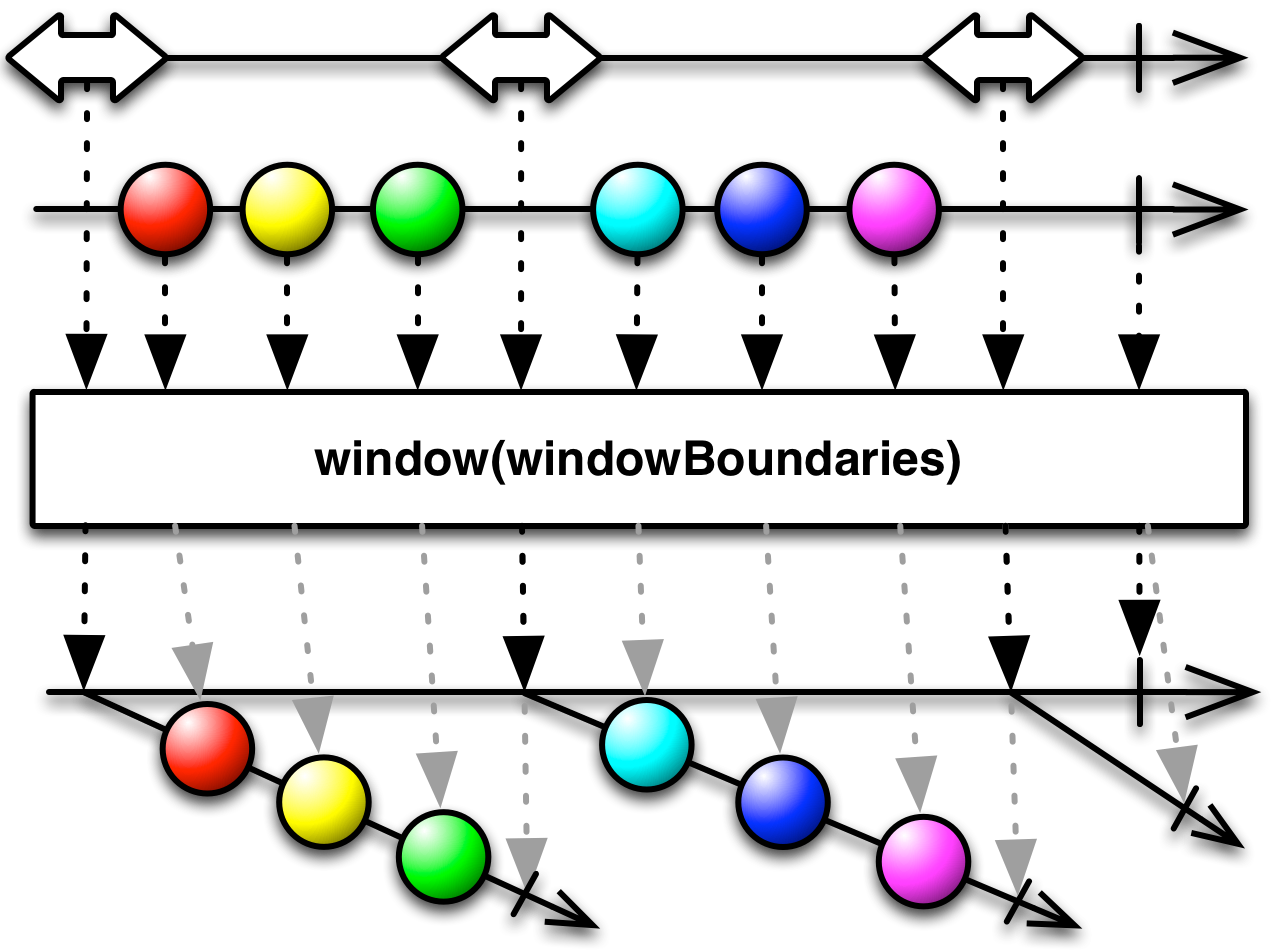 This variant of `window` takes a second Observable as a parameter. Whenever this second Observable emits an item, `window` closes the current Observable window (if any) and opens a new one.
#### `windowWithCount(count)`
 This variant of `windowWithCount` opens its first window immediately. It closes the currently open window and immediately opens a new one whenever the current window has emitted `count` items. It will also close the currently open window if it receives an `onCompleted` or `onError` notification from the source Observable. This variant of `windowWithCount` emits a series of non-overlapping windows whose collective emissions correspond one-to-one with those of the source Observable.
#### `windowWithCount(count, skip)`
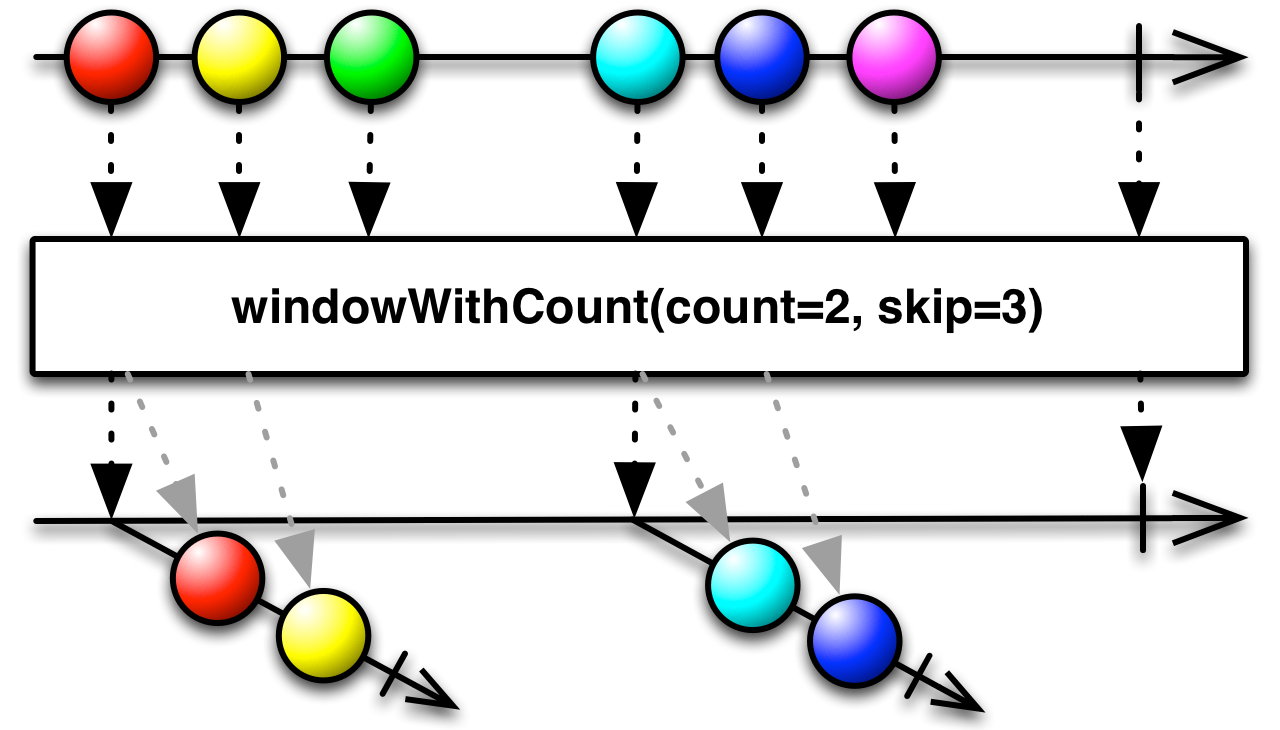 This variant of `windowWithCount` opens its first window immediately. It opens a new window beginning with every `skip` item from the source Observable (so, for example, if `skip` is 3, then it opens a new window starting with every third item). It closes each window when that window has emitted `count` items or if it receives an `onCompleted` or `onError` notification from the source Observable. If `skip = count` then this behaves the same as `windowWithCount(count)`; if `skip < count` this will emit windows that overlap by `count − skip` items; if `skip > count` this will emit windows that drop `skip − count` items from the source Observable between every window.
####
`windowWithTime(timeSpan`[`,scheduler`]`)`
 This variant of `windowWithTime` opens its first window immediately. It closes the currently open window and opens another one every `timespan` period of time (in milliseconds, optionally measured on a particular [Scheduler](../scheduler)). It will also close the currently open window if it receives an `onCompleted` or `onError` notification from the source Observable. This variant of `windowWithTime` emits a series of non-overlapping windows whose collective emissions correspond one-to-one with those of the source Observable.
If you do not specify a Scheduler, this variant of `windowWithTime` uses the `timeout` Scheduler for its timer by default.
####
`windowWithTime(timeSpan,timeShift`[`,scheduler`]`)`
 This variant of `windowWithTime` opens its first window immediately, and thereafter opens a new window every `timeshift` milliseconds (optionally measured on a particular [Scheduler](../scheduler)). It closes a currently open window after `timespan` milliseconds have passed since that window was opened. It will also close any currently open window if it receives an `onCompleted` or `onError` notification from the source Observable. Depending on how you set `timespan` and `timeshift` the windows that result from this operation may overlap or may have gaps.
If you do not specify a Scheduler, this variant of `windowWithTime` uses the `timeout` Scheduler for its timer by default.
####
`windowWithTimeOrCount(timeSpan,count`[`,scheduler`]`)`
 `windowWithTimeOrCount` opens its first window immediately. It closes the currently open window and opens another one every `timespan` milliseconds (optionally measured on a particular [Scheduler](../scheduler)) or whenever the currently open window has emitted `count` items. It will also close the currently open window if it receives an `onCompleted` or `onError` notification from the source Observable. `windowWithTimeOrCount` emits a series of non-overlapping windows whose collective emissions correspond one-to-one with those of the source Observable.
If you do not specify a Scheduler, this variant of `windowWithTimeOrCount` uses the `timeout` Scheduler for its timer by default.
### RxKotlin `window`
There are several varieties of Window in RxKotlin.
#### `window(closingSelector)`
 This variant of `window` opens its first window immediately. It closes the currently open window and immediately opens a new one each time it observes an object emitted by the Observable that is returned from `closingSelector`. In this way, this variant of `window` emits a series of non-overlapping windows whose collective emissions correspond one-to-one with those of the source Observable.
#### `window(windowOpenings, closingSelector)`
 This variant of `window` opens a window whenever it observes the `windowOpenings` Observable emit an `Opening` object and at the same time calls `closingSelector` to generate a closing Observable associated with that window. When that closing Observable emits an object, `window` closes that window. Since the closing of currently open windows and the opening of new windows are activities that are regulated by independent Observables, this variant of `window` may create windows that overlap (duplicating items from the source Observable) or that leave gaps (discarding items from the source Observable).
#### `window(count)`
 This variant of `window` opens its first window immediately. It closes the currently open window and immediately opens a new one whenever the current window has emitted `count` items. It will also close the currently open window if it receives an `onCompleted` or `onError` notification from the source Observable. This variant of `window` emits a series of non-overlapping windows whose collective emissions correspond one-to-one with those of the source Observable.
#### `window(count, skip)`
 This variant of `window` opens its first window immediately. It opens a new window beginning with every `skip` item from the source Observable (so, for example, if `skip` is 3, then it opens a new window starting with every third item). It closes each window when that window has emitted `count` items or if it receives an `onCompleted` or `onError` notification from the source Observable. If `skip = count` then this behaves the same as `window(source, count)`; if `skip < count` this will emit windows that overlap by `count − skip` items; if `skip > count` this will emit windows that drop `skip − count` items from the source Observable between every window.
####
`window(timespan, unit`[`, scheduler`]`)`
![window(timespan, unit[, scheduler])](http://reactivex.io/documentation/operators/images/window5.png) This variant of `window` opens its first window immediately. It closes the currently open window and opens another one every `timespan` period of time (measured in `unit`, and optionally on a particular [`Scheduler`](../scheduler)). It will also close the currently open window if it receives an `onCompleted` or `onError` notification from the source Observable. This variant of `window` emits a series of non-overlapping windows whose collective emissions correspond one-to-one with those of the source Observable.
If you do not specify a Scheduler, this variant of `window` uses the `computation` Scheduler for its timer by default.
####
`window(timespan, unit, count`[`, scheduler`]`)`
![window(timespan, unit, count[, scheduler])](http://reactivex.io/documentation/operators/images/window6.png) This variant of `window` opens its first window immediately. It closes the currently open window and opens another one every `timespan` period of time (measured in `unit`, and optionally on a particular [`Scheduler`](../scheduler)) or whenever the currently open window has emitted `count` items. It will also close the currently open window if it receives an `onCompleted` or `onError` notification from the source Observable. This variant of `window` emits a series of non-overlapping windows whose collective emissions correspond one-to-one with those of the source Observable.
If you do not specify a Scheduler, this variant of `window` uses the `computation` Scheduler for its timer by default.
####
`window(timespan, timeshift, unit`[`, scheduler`]`)`
![window(timespan, timeshift, unit[, scheduler])](http://reactivex.io/documentation/operators/images/window7.png) This variant of `window` opens its first window immediately, and thereafter opens a new window every `timeshift` period of time (measured in `unit`, and optionally on a particular [`Scheduler`](../scheduler)). It closes a currently open window after `timespan` period of time has passed since that window was opened. It will also close any currently open window if it receives an `onCompleted` or `onError` notification from the source Observable. Depending on how you set `timespan` and `timeshift` the windows that result from this operation may overlap or may have gaps.
If you do not specify a Scheduler, this variant of `window` uses the `computation` Scheduler for its timer by default.
### RxNET `Window`
There are several variants of the Window operator in Rx.NET.
#### `Window(windowClosingSelector)`
 This variant of `Window` opens its first window immediately and calls the `windowClosingSelector` function to obtain a second Observable. Whenever this second Observable emits a `TWindowClosing` object, `Window` closes the currently open window, and immediately opens a new one. It repeats this process until either Observable terminates. In this way, this variant of `Window` emits a series of non-overlapping windows whose collective emissions correspond one-to-one with those of the source Observable, until the closing selector observable terminates.
#### `Window(count)`
 This variant of `Window` opens its first window immediately. It closes the currently open window and immediately opens a new one whenever the current window has emitted `count` items. It will also close the currently open window if it receives an `onCompleted` or `onError` notification from the source Observable. This variant of `Window` emits a series of non-overlapping windows whose collective emissions correspond one-to-one with those of the source Observable.
####
`Window(timeSpan`[`,scheduler`]`)`
 This variant of `Window` opens its first window immediately. It closes the currently open window and opens another one every `timespan` period of time (in the form of a `TimeSpan` object, and optionally on a particular [`IScheduler`](../scheduler)). It will also close the currently open window if it receives an `onCompleted` or `onError` notification from the source Observable. This variant of `Window` emits a series of non-overlapping windows whose collective emissions correspond one-to-one with those of the source Observable.
#### `Window(count,skip)`
 This variant of `Window` opens its first window immediately. It opens a new window beginning with every `skip` item from the source Observable (so, for example, if `skip` is 3, then it opens a new window starting with every third item). It closes each window when that window has emitted `count` items or if it receives an `onCompleted` or `onError` notification from the source Observable. If `skip = count` then this behaves the same as `Window(source, count)`; if `skip < count` this will emit windows that overlap by `count − skip` items; if `skip > count` this will emit windows that drop `skip − count` items from the source Observable between every window.
#### `Window(windowOpenings,windowClosingSelector)`
 This variant of `Window` opens a window whenever it observes the `windowOpenings` Observable emit an `TWindowOpening` object and at the same time calls the `windowClosingSelector`, passing it that `TWindowOpening` object, to generate a closing Observable associated with that window. When that closing Observable emits a `TWindowClosing` object, `Window` closes the associated window. Since the closing of currently open windows and the opening of new windows are activities that are regulated by independent Observables, this variant of `Window` may create windows that overlap (duplicating items from the source Observable) or that leave gaps (discarding items from the source Observable).
####
`Window(timeSpan,count`[`,scheduler`]`)`
 This variant of `Window` opens its first window immediately. It closes the currently open window and opens another one every `timeSpan` period of time (in the form of a `TimeSpan` object, and optionally on a particular [`IScheduler`](../scheduler)) or whenever the currently open window has emitted `count` items. It will also close the currently open window if it receives an `onCompleted` or `onError` notification from the source Observable. This variant of `window` emits a series of non-overlapping windows whose collective emissions correspond one-to-one with those of the source Observable.
####
`Window(timeSpan,timeShift`[`,scheduler`]`)`
 This variant of `Window` opens its first window immediately, and thereafter opens a new window every `timeShift` period of time (in the form of a `TimeSpan` object, and optionally on a particular [`IScheduler`](../scheduler)). It closes a currently open window after `timeSpan` period of time has passed since that window was opened. It will also close any currently open window if it receives an `onCompleted` or `onError` notification from the source Observable. Depending on how you set `timeSpan` and `timeShift` the windows that result from this operation may overlap or may have gaps.
### RxPY `window window_with_count window_with_time window_with_time_or_count`
RxPY implements this operator with several variants of four different functions.
#### `window(window_closing_selector)`
 This variant of `window` opens its first window immediately and calls the `closing_selector` function to obtain a second Observable. When this second Observable emits an item, `window` closes the currently open window, immediately opens a new one, and again calls the `closing_selector` function to obtain a fresh Observable. It repeats this process until the source Observable terminates. In this way, this variant of `window` emits a series of non-overlapping windows whose collective emissions correspond one-to-one with those of the source Observable.
#### `window(window_openings,window_closing_selector)`
 This variant of `window` opens a window whenever it observes the `window_openings` Observable emit an item, and at the same time calls `closing_selector` to generate a closing Observable associated with that window. When that closing Observable emits an object, `window` closes that window. Since the closing of currently open windows and the opening of new windows are activities that are regulated by independent Observables, this variant of `window` may create windows that overlap (duplicating items from the source Observable) or that leave gaps (discarding items from the source Observable).
#### `window(window_openings)`
 This variant of `window` takes a second Observable as a parameter. Whenever this second Observable emits an item, `window` closes the current Observable window (if any) and opens a new one.
#### `window_with_count(count)`
 This variant of `window_with_count` opens its first window immediately. It closes the currently open window and immediately opens a new one whenever the current window has emitted `count` items. It will also close the currently open window if it receives an `onCompleted` or `onError` notification from the source Observable. This variant of `window_with_count` emits a series of non-overlapping windows whose collective emissions correspond one-to-one with those of the source Observable.
#### `window_with_count(count,skip)`
 This variant of `window_with_count` opens its first window immediately. It opens a new window beginning with every `skip` item from the source Observable (so, for example, if `skip` is 3, then it opens a new window starting with every third item). It closes each window when that window has emitted `count` items or if it receives an `onCompleted` or `onError` notification from the source Observable. If `skip = count` then this behaves the same as `window_with_count(count)`; if `skip < count` this will emit windows that overlap by `count − skip` items; if `skip > count` this will emit windows that drop `skip − count` items from the source Observable between every window.
####
`window_with_time(timespan`[`,scheduler`]`)`
 ####
`window_with_time(timespan,timeshift`[`,scheduler`]`)`
 This variant of `window_with_time` opens its first window immediately. It closes the currently open window and opens another one every `timespan` milliseconds (optionally measured on a particular [`Scheduler`](../scheduler)). It will also close the currently open window if it receives an `onCompleted` or `onError` notification from the source Observable. This variant of `window_with_time` emits a series of non-overlapping windows whose collective emissions correspond one-to-one with those of the source Observable.
If you do not specify a Scheduler, this variant of `window_with_time` uses the `timeout` Scheduler for its timer by default.
####
`window_with_time_or_count(timespan,count`[`,scheduler`]`)`
 `window_with_time_or_count` opens its first window immediately. It closes the currently open window and opens another one every `timespan` milliseconds (optionally measured on a particular [Scheduler](../scheduler)) or whenever the currently open window has emitted `count` items. It will also close the currently open window if it receives an `onCompleted` or `onError` notification from the source Observable. `window_with_time_or_count` emits a series of non-overlapping windows whose collective emissions correspond one-to-one with those of the source Observable.
If you do not specify a Scheduler, this variant of `window_with_time_or_count` uses the `timeout` Scheduler for its timer by default.
### Rxrb `window_with_count`
#### `window_with_count(count,skip)`
 Rx.rb implements this operator as `window_with_count`. It opens its first window immediately. It then opens a new window beginning with every `skip` item from the source Observable (so, for example, if `skip` is 3, then it opens a new window starting with every third item). It closes each window when that window has emitted `count` items or if it receives an `onCompleted` or `onError` notification from the source Observable. If `skip = count` then there is a one-to-one correspondence between the items emitted by the source Observable and those emitted by the window Observables; if `skip < count` the windows will overlap by `count − skip` items; if `skip > count` the windows will drop `skip − count` items from the source Observable between every window.
### RxScala `sliding tumbling`
RxScala implements this operator as `sliding` (creates windows that may overlap or have gaps) and `tumbling` (creates windows whose collective emissions match those of the source Observable one-to-one).
####
`sliding(timespan,timeshift,count`[`,scheduler`]`)`
 This variant of `sliding` opens its first window immediately, and thereafter opens a new window every `timeshift` period of time (in the form of a `Duration` object, and optionally on a particular [`Scheduler`](../scheduler)). It closes a currently open window after `timespan` period of time has passed since that window was opened or once `count` items have been emitted on that window. It will also close any currently open window if it receives an `onCompleted` or `onError` notification from the source Observable.
####
`sliding(timespan,timeshift`[`,scheduler`]`)`
 This variant of `sliding` opens its first window immediately, and thereafter opens a new window every `timeshift` period of time (in the form of a `Duration` object, and optionally on a particular [`Scheduler`](../scheduler)). It closes a currently open window after `timespan` period of time has passed since that window was opened. It will also close any currently open window if it receives an `onCompleted` or `onError` notification from the source Observable.
#### `sliding(count,skip)`
 This variant of `sliding` opens its first window immediately. It opens a new window beginning with every `skip` item from the source Observable (so, for example, if `skip` is 3, then it opens a new window starting with every third item). It closes each window when that window has emitted `count` items or if it receives an `onCompleted` or `onError` notification from the source Observable. If `skip = count` then this behaves the same as `tumbling(count)`; if `skip < count` this will emit windows that overlap by `count − skip` items; if `skip > count` this will emit windows that drop `skip − count` items from the source Observable between every window.
#### `sliding(openings,closings)`
 This variant of `sliding` opens a window whenever it observes the `openings` Observable emit an `Opening` object and at the same time calls `closings` to generate a closing Observable associated with that window. When that closing Observable emits an item, `sliding` closes that window.
####
`tumbling(timespan,count`[`,scheduler`]`)`
 This variant of `tumbling` opens its first window immediately. It closes the currently open window and opens another one every `timespan` period of time (a `Duration`, optionally measured on a particular [`Scheduler`](../scheduler)) or whenever the currently open window has emitted `count` items. It will also close the currently open window if it receives an `onCompleted` or `onError` notification from the source Observable.
####
`tumbling(timespan`[`,scheduler`]`)`
 This variant of `tumbling` opens its first window immediately. It closes the currently open window and opens another one every `timespan` period of time (a `Duration`, optionally measured on a particular [`scheduler`](../scheduler)). It will also close the currently open window if it receives an `onCompleted` or `onError` notification from the source Observable.
#### `tumbling(count)`
 This variant of `tumbling` opens its first window immediately. It closes the currently open window and immediately opens a new one whenever the current window has emitted `count` items. It will also close the currently open window if it receives an `onCompleted` or `onError` notification from the source Observable.
#### `tumbling(boundary)`
 This variant of `tumbling` takes a second Observable as a parameter. Whenever this second Observable emits an item, `tumbling` closes the current Observable window (if any) and opens a new one.
| programming_docs |
reactivex Last Last
====
> emit only the last item (or the last item that meets some condition) emitted by an Observable
[Open interactive diagram on rxmarbles.com](https://rxmarbles.com/#last) If you are only interested in the last item emitted by an Observable, or the last item that meets some criteria, you can filter the Observable with the Last operator.
In some implementations, `Last` is not implemented as a filtering operator that returns an Observable, but as a blocking function that returns a particular item when the source Observable terminates. In those implementations, if you instead want a filtering operator, you may have better luck with [`TakeLast(1)`](take).
#### See Also
* [ElementAt](elementat)
* [First](first)
* [Take](take)
* [TakeLast](takelast)
* [Introduction to Rx: Last](http://www.introtorx.com/Content/v1.0.10621.0/07_Aggregation.html#Last)
* [RxMarbles: `last`](http://rxmarbles.com/#last)
Language-Specific Information
-----------------------------
### RxGroovy `last lastOrDefault`
In RxGroovy, this filtering operator is implemented as `last` and `lastOrDefault`.
Somewhat confusingly, there are also `BlockingObservable` operators called `last` and `lastOrDefault` that block and then return items, rather than immediately returning Observables.
### The Filtering Operators
 To filter an Observable so that only its last emission is emitted, use the `last` operator with no parameters.
* Javadoc: [`last()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#last())
 You can also pass a predicate function to `last`, in which case it will produce an Observable that emits only the last item from the source Observable that the predicate evaluates as `true`.
* Javadoc: [`last(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#last(rx.functions.Func1))
 The `lastOrDefault` operator is similar to `last`, but you pass it a default item that it can emit if the source Observable fails to emit any items.
* Javadoc: [`lastOrDefault(T)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#lastOrDefault(T))
 `lastOrDefault` also has a variant to which you can pass a predicate function, so that its Observable will emit the last item from the source Observable that the predicate evaluates as `true`, or the default item if no items emitted by the source Observable pass the predicate.
* Javadoc: [`lastOrDefault(T)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#lastOrDefault(T))
`last` and `lastOrDefault` do not by default operate on any particular [Scheduler](../scheduler).
### The `BlockingObservable` Methods
The `BlockingObservable` methods do not transform an Observable into another, filtered Observable, but rather they break out of the Observable cascade, blocking until the Observable emits the desired item, and then return that item itself.
To turn an Observable into a `BlockingObservable` so that you can use these methods, you can use either the `Observable.toBlocking` or `BlockingObservable.from` methods.
* Javadoc: [`Observable.toBlocking()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#toBlocking())
* Javadoc: [`BlockingObservable.from(Observable)`](http://reactivex.io/RxJava/javadoc/rx/observables/BlockingObservable.html#from(rx.Observable))
 To retrieve the last emission from a `BlockingObservable`, use the `last` method with no parameters.
* Javadoc: [`BlockingObservable.last()`](http://reactivex.io/RxJava/javadoc/rx/observables/BlockingObservable.html#last())
 You can also pass a predicate function to the `last` method to retrieve the last emission from a `BlockingObservable` that satisfies the predicate.
* Javadoc: [`BlockingObservable.last(Func1)`](http://reactivex.io/RxJava/javadoc/rx/observables/BlockingObservable.html#last(rx.functions.Func1))
 As with the filtering operators, the `last` method of `BlockingObservable` will throw a `NoSuchElementException` if there is no last element in the source `BlockingObservable`. To return a default item instead in such cases, use the `lastOrDefault` method.
* Javadoc: [`BlockingObservable.lastOrDefault()`](http://reactivex.io/RxJava/javadoc/rx/observables/BlockingObservable.html#lastOrDefault(T))
 And, as with `last`, there is a `lastOrDefault` variant that takes a predicate function as an argument and retrieves the last item from the source `BlockingObservable` that satisfies that predicate, or a default item instead if no satisfying item was emitted.
* Javadoc: [`BlockingObservable.lastOrDefault(Func1)`](http://reactivex.io/RxJava/javadoc/rx/observables/BlockingObservable.html#lastOrDefault(T,%20rx.functions.Func1))
### RxJava 1․x `last lastOrDefault`
In RxJava, this filtering operator is implemented as `last` and `lastOrDefault`.
Somewhat confusingly, there are also `BlockingObservable` operators called `last` and `lastOrDefault` that block and then return items, rather than immediately returning Observables.
### The Filtering Operators
 To filter an Observable so that only its last emission is emitted, use the `last` operator with no parameters.
#### Sample Code
```
Observable.just(1, 2, 3)
.last()
.subscribe(new Subscriber<Integer>() {
@Override
public void onNext(Integer item) {
System.out.println("Next: " + item);
}
@Override
public void onError(Throwable error) {
System.err.println("Error: " + error.getMessage());
}
@Override
public void onCompleted() {
System.out.println("Sequence complete.");
}
});
```
```
Next: 3
Sequence complete.
```
* Javadoc: [`last()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#last())
 You can also pass a predicate function to `last`, in which case it will produce an Observable that emits only the last item from the source Observable that the predicate evaluates as `true`.
* Javadoc: [`last(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#last(rx.functions.Func1))
 The `lastOrDefault` operator is similar to `last`, but you pass it a default item that it can emit if the source Observable fails to emit any items.
* Javadoc: [`lastOrDefault(T)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#lastOrDefault(T))
 `lastOrDefault` also has a variant to which you can pass a predicate function, so that its Observable will emit the last item from the source Observable that the predicate evaluates as `true`, or the default item if no items emitted by the source Observable pass the predicate.
* Javadoc: [`lastOrDefault(T)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#lastOrDefault(T))
`last` and `lastOrDefault` do not by default operate on any particular [Scheduler](../scheduler).
### The `BlockingObservable` Methods
The `BlockingObservable` methods do not transform an Observable into another, filtered Observable, but rather they break out of the Observable cascade, blocking until the Observable emits the desired item, and then return that item itself.
To turn an Observable into a `BlockingObservable` so that you can use these methods, you can use either the `Observable.toBlocking` or `BlockingObservable.from` methods.
* Javadoc: [`Observable.toBlocking()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#toBlocking())
* Javadoc: [`BlockingObservable.from(Observable)`](http://reactivex.io/RxJava/javadoc/rx/observables/BlockingObservable.html#from(rx.Observable))
 To retrieve the last emission from a `BlockingObservable`, use the `last` method with no parameters.
* Javadoc: [`BlockingObservable.last()`](http://reactivex.io/RxJava/javadoc/rx/observables/BlockingObservable.html#last())
 You can also pass a predicate function to the `last` method to retrieve the last emission from a `BlockingObservable` that satisfies the predicate.
* Javadoc: [`BlockingObservable.last(Func1)`](http://reactivex.io/RxJava/javadoc/rx/observables/BlockingObservable.html#last(rx.functions.Func1))
 As with the filtering operators, the `last` method of `BlockingObservable` will throw a `NoSuchElementException` if there is no last element in the source `BlockingObservable`. To return a default item instead in such cases, use the `lastOrDefault` method.
* Javadoc: [`BlockingObservable.lastOrDefault()`](http://reactivex.io/RxJava/javadoc/rx/observables/BlockingObservable.html#lastOrDefault(T))
 And, as with `last`, there is a `lastOrDefault` variant that takes a predicate function as an argument and retrieves the last item from the source `BlockingObservable` that satisfies that predicate, or a default item instead if no satisfying item was emitted.
* Javadoc: [`BlockingObservable.lastOrDefault(Func1)`](http://reactivex.io/RxJava/javadoc/rx/observables/BlockingObservable.html#lastOrDefault(T,%20rx.functions.Func1))
### RxJS `last`
 RxJS implements the `last` operator. It optionally takes a predicate function as a parameter, in which case, rather than emitting the last item from the source Observable, the resulting Observable will emit the last item from the source Observable that satisfies the predicate.
The predicate function itself takes three arguments:
1. the item from the source Observable to be, or not be, filtered
2. the zero-based index of this item in the source Observable’s sequence
3. the source Observable object
#### Sample Code
```
var source = Rx.Observable.range(0, 10)
.last(function (x, idx, obs) { return x % 2 === 1; });
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 8
Completed
```
If the source Observable emits no items (or no items that match the predicate), `last` will terminate with a “`Sequence contains no elements.`” `onError` notification.
If instead you want the Observable to emit a default value in such a case, you can pass a second parameter (named `defaultValue`) to `last`:
#### Sample Code
```
var source = Rx.Observable.range(0, 10)
.last(function (x, idx, obs) { return x > 42; }, 88 );
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 88
Completed
```
`last` is found in each of the following distributions:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.aggregates.js`
It requires one of the following distributions:
* `rx.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
reactivex Merge Merge
=====
> combine multiple Observables into one by merging their emissions
[Open interactive diagram on rxmarbles.com](https://rxmarbles.com/#merge) You can combine the output of multiple Observables so that they act like a single Observable, by using the Merge operator.
Merge may interleave the items emitted by the merged Observables (a similar operator, [Concat](concat), does not interleave items, but emits all of each source Observable’s items in turn before beginning to emit items from the next source Observable).
As shown in the above diagram, an `onError` notification from any of the source Observables will immediately be passed through to observers and will terminate the merged Observable.
 In many ReactiveX implementations there is a second operator, MergeDelayError, that changes this behavior — reserving `onError` notifications until all of the merged Observables complete and only then passing it along to the observers:
#### See Also
* [Concat](concat)
* [Introduction to Rx: Merge](http://www.introtorx.com/Content/v1.0.10621.0/12_CombiningSequences.html#Merge)
* [RxMarbles: `merge`](http://rxmarbles.com/#merge)
* [101 Rx Samples: Merge](http://rxwiki.wikidot.com/101samples#toc47)
Language-Specific Information
-----------------------------
### RxClojure `interleave interleave* merge merge* merge-delay-error merge-delay-error*`
In RxClojure there are six operators of concern here:
 `merge` converts two or more Observables into a single Observable that emits all of the items emitted by all of those Observables.
 `merge*` converts an Observable that emits Observables into a single Observable that emits all of the items emitted by all of the emitted Observables.
 `merge-delay-error` is like `merge`, but will emit all items from all of the merged Observables even if one or more of those Observables terminates with an `onError` notification while emissions are still pending.
`merge-delay-error*` is a similarly-modified version of `merge*`.
 `interleave` is like `merge`, but more deliberate about how it interleaves the items from the source Observables: the resulting Observable emits the first item emitted by the first source Observable, then the first item emitted by the second source Observable, and so forth, and having reached the last source Observable, then emits the second item emitted by the first source Observable, the second item emitted by the second source Observable, and so forth, until all of the source Observables terminate.
`interleave*` is similar but operates on an Observable of Observables.
### RxCpp `merge`
RxCpp implements this operator as `merge`.
 ### RxGroovy `merge mergeDelayError mergeWith`
RxGroovy implements this operator as `merge`, `mergeWith`, and `mergeDelayError`.
 For example, the following code merges the `odds` and `evens` into a single Observable. (The `subscribeOn` operator makes `odds` operate on a different thread from `evens` so that the two Observables may both emit items at the same time, to demonstrate how Merge may interleave these items.)
#### Sample Code
```
odds = Observable.from([1, 3, 5, 7]).subscribeOn(someScheduler);
evens = Observable.from([2, 4, 6]);
Observable.merge(odds,evens).subscribe(
{ println(it); }, // onNext
{ println("Error: " + it.getMessage()); }, // onError
{ println("Sequence complete"); } // onCompleted
);
```
```
1
3
2
5
4
7
6
Sequence complete
```
Instead of passing multiple Observables (up to nine) into `merge`, you could also pass in a `List<>` (or other Iterable) of Observables, an Array of Observables, or even an Observable that emits Observables, and `merge` will merge their output into the output of a single Observable:
* Javadoc: [`merge(Iterable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#merge(java.lang.Iterable))
* Javadoc: [`merge(Iterable,int)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#merge(java.lang.Iterable,%20int))
* Javadoc: [`merge(Observable[])`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#merge(rx.Observable%5B%5D))
* Javadoc: [`merge(Observable[], int)` (RxGroovy 1.1)](http://reactivex.io/RxJava/javadoc/rx/Observable.html#merge(rx.Observable%5B%5D,%20int))
* Javadoc: [`merge(Observable, Observable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#merge(rx.Observable,%20rx.Observable)) (there are also versions that take up to nine Observables)
 If you pass in an Observable of Observables, you have the option of also passing in a value indicating to `merge` the maximum number of those Observables it should attempt to be subscribed to simultaneously. Once it reaches this maximum subscription count, it will refrain from subscribing to any other Observables emitted by the source Observable until such time as one of the already-subscribed-to Observables issues an `onCompleted` notification.
* Javadoc: [`merge(Observable<Observable>)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#merge(rx.Observable))
* Javadoc: [`merge(Observable<Observable>,int)` (RxGroovy 1.1)](http://reactivex.io/RxJava/javadoc/rx/Observable.html#merge(rx.Observable,%20int))
The instance version of `merge` is `mergeWith`, so, for example, in the code sample above, instead of writing `Observable.merge(odds,evens)` you could also write `odds.mergeWith(evens)`.
* Javadoc: [`mergeWith(Observable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#mergeWith(rx.Observable))
If any of the individual Observables passed into `merge` terminates with an `onError` notification, the Observable produced by `merge` itself will immediately terminate with an `onError` notification. If you would prefer a merge that continues emitting the results of the remaining, error-free Observables before reporting the error, use `mergeDelayError` instead.
 `mergeDelayError` behaves much like `merge`. The exception is when one of the Observables being merged terminates with an `onError` notification. If this happens with `merge`, the merged Observable will immediately issue an `onError` notification and terminate. `mergeDelayError`, on the other hand, will hold off on reporting the error until it has given any other non-error-producing Observables that it is merging a chance to finish emitting their items, and it will emit those itself, and will only terminate with an `onError` notification when all of the other merged Observables have finished.
Because it is possible that more than one of the merged Observables encountered an error, `mergeDelayError` may pass information about *multiple* errors in the `onError` notification (it will never invoke the observer’s `onError` method more than once). For this reason, if you want to know the nature of these errors, you should write your observers’ `onError` methods so that they accept a parameter of the class `CompositeException`.
`mergeDelayError` has fewer variants. You cannot pass it an Iterable or Array of Observables, but you can pass it an Observable that emits Observables or between one and nine individual Observables as parameters. There is not an instance method version of `mergeDelayError` as there is for `merge`.
* Javadoc: [`mergeDelayError(Observable<Observable>)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#mergeDelayError(rx.Observable))
* Javadoc: [`mergeDelayError(Observable,Observable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#mergeDelayError(rx.Observable,%20rx.Observable)) (there are also versions that take up to nine Observables)
### RxJava 1․x `merge mergeDelayError mergeWith`
RxJava implements this operator as `merge`, `mergeWith`, and `mergeDelayError`.
 #### Sample Code
```
Observable<Integer> odds = Observable.just(1, 3, 5).subscribeOn(someScheduler);
Observable<Integer> evens = Observable.just(2, 4, 6);
Observable.merge(odds, evens)
.subscribe(new Subscriber<Integer>() {
@Override
public void onNext(Integer item) {
System.out.println("Next: " + item);
}
@Override
public void onError(Throwable error) {
System.err.println("Error: " + error.getMessage());
}
@Override
public void onCompleted() {
System.out.println("Sequence complete.");
}
});
```
```
Next: 1
Next: 3
Next: 5
Next: 2
Next: 4
Next: 6
Sequence complete.
```
* Javadoc: [`merge(Iterable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#merge(java.lang.Iterable))
* Javadoc: [`merge(Iterable,int)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#merge(java.lang.Iterable,%20int))
* Javadoc: [`merge(Observable[])`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#merge(rx.Observable%5B%5D))
* Javadoc: [`merge(Observable[], int)` (RxJava 1.1)](http://reactivex.io/RxJava/javadoc/rx/Observable.html#merge(rx.Observable%5B%5D,%20int))
* Javadoc: [`merge(Observable, Observable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#merge(rx.Observable,%20rx.Observable)) (there are also versions that take up to nine Observables)
Instead of passing multiple Observables (up to nine) into `merge`, you could also pass in a `List<>` (or other Iterable) of Observables, an Array of Observables, or even an Observable that emits Observables, and `merge` will merge their output into the output of a single Observable:
 If you pass in an Observable of Observables, you have the option of also passing in a value indicating to `merge` the maximum number of those Observables it should attempt to be subscribed to simultaneously. Once it reaches this maximum subscription count, it will refrain from subscribing to any other Observables emitted by the source Observable until such time as one of the already-subscribed-to Observables issues an `onCompleted` notification.
* Javadoc: [`merge(Observable<Observable>)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#merge(rx.Observable))
* Javadoc: [`merge(Observable<Observable>, int)` (RxJava 1.1)](http://reactivex.io/RxJava/javadoc/rx/Observable.html#merge(rx.Observable,%20int))
The instance version of `merge` is `mergeWith`, so, for example, instead of writing `Observable.merge(odds,evens)` you could also write `odds.mergeWith(evens)`.
If any of the individual Observables passed into `merge` terminates with an `onError` notification, the Observable produced by `merge` itself will immediately terminate with an `onError` notification. If you would prefer a merge that continues emitting the results of the remaining, error-free Observables before reporting the error, use `mergeDelayError` instead.
 `mergeDelayError` behaves much like `merge`. The exception is when one of the Observables being merged terminates with an `onError` notification. If this happens with `merge`, the merged Observable will immediately issue an `onError` notification and terminate. `mergeDelayError`, on the other hand, will hold off on reporting the error until it has given any other non-error-producing Observables that it is merging a chance to finish emitting their items, and it will emit those itself, and will only terminate with an `onError` notification when all of the other merged Observables have finished.
Because it is possible that more than one of the merged Observables encountered an error, `mergeDelayError` may pass information about *multiple* errors in the `onError` notification (it will never invoke the observer’s `onError` method more than once). For this reason, if you want to know the nature of these errors, you should write your observers’ `onError` methods so that they accept a parameter of the class `CompositeException`.
`mergeDelayError` has fewer variants. You cannot pass it an Iterable or Array of Observables, but you can pass it an Observable that emits Observables or between one and nine individual Observables as parameters. There is not an instance method version of `mergeDelayError` as there is for `merge`.
* Javadoc: [`mergeDelayError(Observable<Observable>)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#mergeDelayError(rx.Observable))
* Javadoc: [`mergeDelayError(Observable,Observable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#mergeDelayError(rx.Observable,%20rx.Observable)) (there are also versions that take up to nine Observables)
### RxJS `merge mergeAll mergeDelayError`
 The first variant of `merge` is an instance operator that takes a variable number of Observables as parameters, merging each of these Observables with the source (instance) Observables to produce its single output Observable.
This first variant of `merge` is found in the following distributions:
* `rx.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
The second variant of `merge` is a prototype (class) operator that accepts two parameters. The second of these is an Observable that emits the Observables you want to merge. The first is a number that indicates the maximum number of these emitted Observables that you want `merge` to attempt to be subscribed to at any moment. Once it reaches this maximum subscription count, it will refrain from subscribing to any other Observables emitted by the source Observable until such time as one of the already-subscribed-to Observables issues an `onCompleted` notification.
This second variant of `merge` is found in the following distributions:
* `rx.js`
* `rx.all.js`
* `rx.all.compat.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
 `mergeAll` is like this second variant of `merge` except that it does not allow you to set this maximum subscription count. It only takes the single parameter of an Observable of Observables.
`mergeAll` is found in the following distributions:
* `rx.js`
* `rx.all.js`
* `rx.all.compat.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
 If any of the individual Observables passed into `merge` or `mergeAll` terminates with an `onError` notification, the resulting Observable will immediately terminate with an `onError` notification. If you would prefer a merge that continues emitting the results of the remaining, error-free Observables before reporting the error, use `mergeDelayError` instead.
#### Sample Code
```
var source1 = Rx.Observable.of(1,2,3);
var source2 = Rx.Observable.throwError(new Error('whoops!'));
var source3 = Rx.Observable.of(4,5,6);
var merged = Rx.Observable.mergeDelayError(source1, source2, source3);
var subscription = merged.subscribe(
function (x) { console.log('Next: %s', x); },
function (err) { console.log('Error: %s', err); }
function () { console.log('Completed' } );
```
```
1
2
3
4
5
6
Error: Error: whoops!
```
`mergeDelayError` is found in the following distributions:
* `rx.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
### RxKotlin `merge mergeDelayError mergeWith`
RxKotlin implements this operator as `merge`, `mergeWith`, and `mergeDelayError`.
 Instead of passing multiple Observables (up to nine) into `merge`, you could also pass in a `List<>` (or other Iterable) of Observables, an Array of Observables, or even an Observable that emits Observables, and `merge` will merge their output into the output of a single Observable:
 If you pass in an Observable of Observables, you have the option of also passing in a value indicating to `merge` the maximum number of those Observables it should attempt to be subscribed to simultaneously. Once it reaches this maximum subscription count, it will refrain from subscribing to any other Observables emitted by the source Observable until such time as one of the already-subscribed-to Observables issues an `onCompleted` notification.
The instance version of `merge` is `mergeWith`, so, for example, instead of writing `Observable.merge(odds,evens)` you could also write `odds.mergeWith(evens)`.
If any of the individual Observables passed into `merge` terminates with an `onError` notification, the Observable produced by `merge` itself will immediately terminate with an `onError` notification. If you would prefer a merge that continues emitting the results of the remaining, error-free Observables before reporting the error, use `mergeDelayError` instead.
 `mergeDelayError` behaves much like `merge`. The exception is when one of the Observables being merged terminates with an `onError` notification. If this happens with `merge`, the merged Observable will immediately issue an `onError` notification and terminate. `mergeDelayError`, on the other hand, will hold off on reporting the error until it has given any other non-error-producing Observables that it is merging a chance to finish emitting their items, and it will emit those itself, and will only terminate with an `onError` notification when all of the other merged Observables have finished.
Because it is possible that more than one of the merged Observables encountered an error, `mergeDelayError` may pass information about *multiple* errors in the `onError` notification (it will never invoke the observer’s `onError` method more than once). For this reason, if you want to know the nature of these errors, you should write your observers’ `onError` methods so that they accept a parameter of the class `CompositeException`.
`mergeDelayError` has fewer variants. You cannot pass it an Iterable or Array of Observables, but you can pass it an Observable that emits Observables or between one and nine individual Observables as parameters. There is not an instance method version of `mergeDelayError` as there is for `merge`.
### RxNET `Merge`
Rx.NET implements this operator as `Merge`.
 You can pass `Merge` an Array of Observables, an Enumerable of Observables, an Observable of Observables, or two individual Observables.
If you pass an Enumerable or Observable of Observables, you have the option of also passing in an integer indicating the maximum number of those Observables it should attempt to be subscribed to simultaneously. Once it reaches this maximum subscription count, it will refrain from subscribing to any other Observables emitted by the source Observable until such time as one of the already-subscribed-to Observables issues an `onCompleted` notification.
### RxPHP `merge mergeAll`
RxPHP implements this operator as `merge`.
Combine an Observable together with another Observable by merging their emissions into a single Observable.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/merge/merge.php
$observable = Rx\Observable::of(42)->repeat();
$otherObservable = Rx\Observable::of(21)->repeat();
$mergedObservable = $observable
->merge($otherObservable)
->take(10);
$disposable = $mergedObservable->subscribe($stdoutObserver);
```
```
Next value: 42
Next value: 21
Next value: 42
Next value: 21
Next value: 42
Next value: 21
Next value: 42
Next value: 21
Next value: 42
Next value: 21
Complete!
```
RxPHP also has an operator `mergeAll`.
Merges an observable sequence of observables into an observable sequence.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/merge/merge-all.php
$sources = Rx\Observable::range(0, 3)
->map(function ($x) {
return Rx\Observable::range($x, 3);
});
$merged = $sources->mergeAll();
$disposable = $merged->subscribe($stdoutObserver);
```
```
Next value: 0
Next value: 1
Next value: 1
Next value: 2
Next value: 2
Next value: 2
Next value: 3
Next value: 3
Next value: 4
Complete!
```
### RxPY `merge merge_all merge_observable`
RxPY implements this operator as `merge` and `merge_all`/`merge_observable`.
 You can either pass `merge` a set of Observables as individual parameters, or as a single parameter containing an array of those Observables.
 `merge_all` and its alias `merge_observable` take as their single parameter an Observable that emits Observables. They merge the emissions of all of these Observables to create their own Observable.
### Rxrb `merge merge_all merge_concurrent`
Rx.rb implements this operator as `merge`, `merge_concurrent`, and `merge_all`.
 `merge` merges a second Observable into the one it is operating on to create a new merged Observable.
`merge_concurrent` operates on an Observable that emits Observables, merging the emissions from each of these Observables into its own emissions. You can optionally pass it an integer parameter indicating how many of these emitted Observables `merge_concurrent` should try to subscribe to concurrently. Once it reaches this maximum subscription count, it will refrain from subscribing to any other Observables emitted by the source Observable until such time as one of the already-subscribed-to Observables issues an `onCompleted` notification. The default is 1, which makes it equivalent to `merge_all`.
 `merge_all` is like `merge_concurrent(1)`. It subscribes to each emitted Observable one at a time, mirroring its emissions as its own, and waiting to subscribe to the next Observable until the present one terminates with an `onCompleted` notification. In this respect it is more like a Concat variant.
### RxScala `flatten flattenDelayError merge mergeDelayError`
RxScala implements this operator as `flatten`, `flattenDelayError`, `merge`, and `mergeDelayError`.
 `merge` takes a second Observable as a parameter and merges that Observable with the one the `merge` operator is applied to in order to create a new output Observable.
 `mergeDelayError` is similar to `merge` except that it will always emit all items from both Observables even if one of the Observables terminates with an `onError` notification before the other Observable has finished emitting items.
 `flatten` takes as its parameter an Observable that emits Observables. It merges the items emitted by each of these Observables to create its own single Observable sequence. A variant of this operator allows you to pass in an `Int` indicating the maximum number of these emitted Observables you want `flatten` to try to be subscribed to at any time. It it hits this maximum subscription count, it will refrain from subscribing to any other Observables emitted by the source Observable until such time as one of the already-subscribed-to Observables issues an `onCompleted` notification.
`flattenDelayError` is similar to `flatten` except that it will always emit all items from all of the emitted Observables even if one or more of those Observables terminates with an `onError` notification before the other Observables have finished emitting items.
### RxSwift `merge`
RxSwift implements this operator as `merge`.
 `merge` takes as its parameter an Observable that emits Observables. It merges the items emitted by each of these Observables to create its own single Observable sequence.
A variant of this operator `merge(maxConcurrent:)` allows you to pass in an `Int` indicating the maximum number of these emitted Observables you want `merge` to try to be subscribed to at any time. If it hits this maximum subscription count, it will refrain from subscribing to any other Observables emitted by the source Observable until such time as one of the already-subscribed-to Observables issues an `onCompleted` notification.
#### Sample Code
```
let subject1 = PublishSubject()
let subject2 = PublishSubject()
Observable.of(subject1, subject2)
.merge()
.subscribe {
print($0)
}
subject1.on(.Next(10))
subject1.on(.Next(11))
subject1.on(.Next(12))
subject2.on(.Next(20))
subject2.on(.Next(21))
subject1.on(.Next(14))
subject1.on(.Completed)
subject2.on(.Next(22))
subject2.on(.Completed)
```
```
Next(10)
Next(11)
Next(12)
Next(20)
Next(21)
Next(14)
Next(22)
Completed
```
| programming_docs |
reactivex Scan Scan
====
> apply a function to each item emitted by an Observable, sequentially, and emit each successive value
[Open interactive diagram on rxmarbles.com](https://rxmarbles.com/#scan) The Scan operator applies a function to the first item emitted by the source Observable and then emits the result of that function as its own first emission. It also feeds the result of the function back into the function along with the second item emitted by the source Observable in order to generate its second emission. It continues to feed back its own subsequent emissions along with the subsequent emissions from the source Observable in order to create the rest of its sequence.
This sort of operator is sometimes called an “accumulator” in other contexts.
#### See Also
* [Reduce](reduce)
* [Introduction to Rx: Scan](http://www.introtorx.com/Content/v1.0.10621.0/07_Aggregation.html#Scan)
* [RxMarbles: `scan`](http://rxmarbles.com/#scan)
Language-Specific Information
-----------------------------
### RxGroovy `scan`
 RxGroovy implements this operator as `scan`. The following code, for example, takes an Observable that emits a consecutive sequence of *n* integers starting with `1` and converts it, via `scan`, into an Observable that emits the first *n* [triangular numbers](http://en.wikipedia.org/wiki/Triangular_number):
#### Sample Code
```
numbers = Observable.from([1, 2, 3, 4, 5]);
numbers.scan({ a, b -> a+b }).subscribe(
{ println(it); }, // onNext
{ println("Error: " + it.getMessage()); }, // onError
{ println("Sequence complete"); } // onCompleted
);
```
```
1
3
6
10
15
Sequence complete
```
* Javadoc: [`scan(Func2)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#scan(rx.functions.Func2))
 There is also a variant of `scan` to which you can pass a seed value to pass to the accumulator function the first time it is called (for the first emission from the source Observable) in place of the result from the missing prior call to the accumulator. Note that if you use this version, `scan` will emit this seed value as its own initial emission. Note also that passing a seed of `null` is *not* the same as passing no seed at all. A `null` seed is a valid variety of seed.
* Javadoc: [`scan(R,Func2)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#scan(R,%20rx.functions.Func2))
This operator does not by default operate on any particular [Scheduler](../scheduler).
### RxJava 1․x `scan`
 RxJava implements this operator as `scan`.
#### Sample Code
```
Observable.just(1, 2, 3, 4, 5)
.scan(new Func2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer sum, Integer item) {
return sum + item;
}
}).subscribe(new Subscriber<Integer>() {
@Override
public void onNext(Integer item) {
System.out.println("Next: " + item);
}
@Override
public void onError(Throwable error) {
System.err.println("Error: " + error.getMessage());
}
@Override
public void onCompleted() {
System.out.println("Sequence complete.");
}
});
```
```
Next: 1
Next: 3
Next: 6
Next: 10
Next: 15
Sequence complete.
```
* Javadoc: [`scan(Func2)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#scan(rx.functions.Func2))
 There is also a variant of `scan` to which you can pass a seed value to pass to the accumulator function the first time it is called (for the first emission from the source Observable) in place of the result from the missing prior call to the accumulator. Note that if you use this version, `scan` will emit this seed value as its own initial emission. Note also that passing a seed of `null` is *not* the same as passing no seed at all. A `null` seed is a valid variety of seed.
* Javadoc: [`scan(R,Func2)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#scan(R,%20rx.functions.Func2))
This operator does not by default operate on any particular [Scheduler](../scheduler).
### RxJS `expand scan`
 RxJS implements the `scan` operator.
#### Sample Code
```
var source = Rx.Observable.range(1, 3)
.scan(
function (acc, x) {
return acc + x;
});
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 1
Next: 3
Next: 6
Completed
```
 You can optionally pass `scan` a seed value as an additional parameter. `scan` will pass this seed value to the accumulator function the first time it is called (for the first emission from the source Observable) in place of the result from the missing prior call to the accumulator.
#### Sample Code
```
var source = Rx.Observable.range(1, 3)
.scan( function (acc, x) {
return acc * x;
}, 1 );
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 1
Next: 2
Next: 6
Completed
```
`scan` is found in each of the following distributions:
* `rx.js`
* `rx.all.js`
* `rx.all.compat.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
 RxJS also implements the `expand` operator, which is somewhat similar. Rather than applying the function to the previous return value of the function combined with the next item emitted from the source Observable, such that the number of items it emits is equal to the number emitted by the source Observable, `expand` simply feeds the return value from the function back into the function without regard to future emissions from the Observable, such that it will just continue to create new values at its own pace.
#### Sample Code
```
var source = Rx.Observable.return(42)
.expand(function (x) { return Rx.Observable.return(42 + x); })
.take(5);
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 42
Next: 84
Next: 126
Next: 168
Next: 210
Completed
```
`expand` is found in each of the following distributions:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.experimental.js`
`expand` requires one of the following distributions:
* `rx.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
### RxPHP `scan`
RxPHP implements this operator as `scan`.
Applies an accumulator function over an observable sequence and returns each intermediate result. The optional seed value is used as the initial accumulator value.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/scan/scan.php
//Without a seed
$source = Rx\Observable::range(1, 3);
$subscription = $source
->scan(function ($acc, $x) {
return $acc + $x;
})
->subscribe($createStdoutObserver());
```
```
Next value: 1
Next value: 3
Next value: 6
Complete!
```
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/scan/scan-with-seed.php
//With a seed
$source = Rx\Observable::range(1, 3);
$subscription = $source
->scan(function ($acc, $x) {
return $acc * $x;
}, 1)
->subscribe($createStdoutObserver());
```
```
Next value: 1
Next value: 2
Next value: 6
Complete!
```
reactivex Timestamp Timestamp
=========
> attach a timestamp to each item emitted by an Observable indicating when it was emitted
 The Timestamp operator attaches a timestamp to each item emitted by the source Observable before reemitting that item in its own sequence. The timestamp indicates at what time the item was emitted.
#### See Also
* [Timestamp](timestamp)
* [Introduction to Rx: Timestamp and TimeInterval](http://www.introtorx.com/Content/v1.0.10621.0/08_Transformation.html#TimeStampAndTimeInterval)
* [101 Rx Samples: Timestamp](http://rxwiki.wikidot.com/101samples#toc35)
Language-Specific Information
-----------------------------
### RxGroovy `timestamp`
 The `timestamp` method converts an Observable that emits items of type *T* into one that emits objects of type `Timestamped<*T*>`, where each such object is stamped with the time at which it was originally emitted.
```
def myObservable = Observable.range(1, 1000000).filter({ 0 == (it % 200000) });
myObservable.timestamp().subscribe(
{ println(it.toString()); }, // onNext
{ println("Error: " + it.getMessage()); }, // onError
{ println("Sequence complete"); } // onCompleted
);
```
```
Timestamped(timestampMillis = 1369252582698, value = 200000)
Timestamped(timestampMillis = 1369252582740, value = 400000)
Timestamped(timestampMillis = 1369252582782, value = 600000)
Timestamped(timestampMillis = 1369252582823, value = 800000)
Timestamped(timestampMillis = 1369252582864, value = 1000000)
Sequence complete
```
`timestamp` by default operates on the `immediate` [Scheduler](../scheduler) but also has a variant that allows you to choose the Scheduler by passing it in as a parameter.
* Javadoc: [`timestamp()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#timestamp())
* Javadoc: [`timestamp(Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#timestamp(rx.Scheduler))
### RxJava 1․x `timestamp`
 The `timestamp` method converts an Observable that emits items of type *T* into one that emits objects of type `Timestamped<*T*>`, where each such object is stamped with the time at which it was originally emitted.
`timestamp` by default operates on the `immediate` [Scheduler](../scheduler) but also has a variant that allows you to choose the Scheduler by passing it in as a parameter.
* Javadoc: [`timestamp()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#timestamp())
* Javadoc: [`timestamp(Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#timestamp(rx.Scheduler))
### RxJS `timestamp`
 The `timestamp` method attaches a timestamp to each item emitted by the source Observable before emitting that item as part of its own sequence. The timestamp indicates when the item was emitted by the source Observable.
#### Sample Code
```
var source = Rx.Observable.timer(0, 1000)
.timestamp()
.map(function (x) { return x.value + ':' + x.timestamp; })
.take(5);
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 0:1378690776351
Next: 1:1378690777313
Next: 2:1378690778316
Next: 3:1378690779317
Next: 4:1378690780319
Completed
```
`timestamp` by default operates on the `timeout` [Scheduler](../scheduler), but also has a variant that allows you to specify the Scheduler by passing it in as a parameter.
`timestamp` is found in each of the following distributions:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.time.js` (requires `rx.js` or `rx.compat.js`)
* `rx.lite.js`
* `rx.lite.compat.js`
### RxPHP `timestamp`
RxPHP implements this operator as `timestamp`.
Records the timestamp for each value in an observable sequence.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/timestamp/timestamp.php
$source = \Rx\Observable::interval(1000)
->timestamp()
->map(function (\Rx\Timestamped $x) {
return $x->getValue() . ':' . $x->getTimestampMillis();
})
->take(5);
$source->subscribe($createStdoutObserver());
// Next value: 0:1460781738354
// Next value: 1:1460781739358
// Next value: 2:1460781740359
// Next value: 3:1460781741362
// Next value: 4:1460781742367
// Complete!
```
```
Next value: 0:1489535638531
Next value: 1:1489535639534
Next value: 2:1489535640532
Next value: 3:1489535641528
Next value: 4:1489535642528
Complete!
```
reactivex Interval Interval
========
> create an Observable that emits a sequence of integers spaced by a given time interval
 The Interval operator returns an Observable that emits an infinite sequence of ascending integers, with a constant interval of time of your choosing between emissions.
#### See Also
* [Range](range)
* [Repeat](repeat)
* [Timer](timer)
* [Introduction to Rx: Interval](http://www.introtorx.com/Content/v1.0.10621.0/04_CreatingObservableSequences.html#ObservableInterval)
* [101 Rx Samples: Observing the Passing of Time](http://rxwiki.wikidot.com/101samples#toc15)
* [101 Rx Samples: Interval — Simple](http://rxwiki.wikidot.com/101samples#toc28)
* [ad-hockery: Simple Background Polling with RxJava](http://blog.freeside.co/2015/01/29/simple-background-polling-with-rxjava/)
Language-Specific Information
-----------------------------
### RxGroovy `interval`
 RxGroovy implements this operator as `interval`. It accepts as its parameters a span of time to wait between emissions and the `TimeUnit` in which this span is measured.
* Javadoc: [`interval(long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#interval(long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`interval(long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#interval(long,%20java.util.concurrent.TimeUnit%20rx.Scheduler))
 There is also a version of `interval` that returns an Observable that emits a single zero after a specified delay, and then emits incrementally increasing numbers periodically thereafter on a specified periodicity. This version of `interval` was called [`timer`](timer) in RxGroovy 1.0.0, but that method has since been deprecated in favor of the one named `interval` with the same behavior.
* Javadoc: [`interval(long,long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#interval(long,%20long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`interval(long,long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#interval(long,%20long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
`interval` operates by default on the `computation` [Scheduler](../scheduler). There are also variants that allow you to set the Scheduler by passing one in as a parameter.
### RxJava 1․x `interval`
 RxJava implements this operator as `interval`. It accepts as its parameters a span of time to wait between emissions and the `TimeUnit` in which this span is measured.
* Javadoc: [`interval(long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#interval(long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`interval(long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#interval(long,%20java.util.concurrent.TimeUnit%20rx.Scheduler))
 There is also a version of `interval` that returns an Observable that emits a single zero after a specified delay, and then emits incrementally increasing numbers periodically thereafter on a specified periodicity. This version of `interval` was called [`timer`](timer) in RxJava 1.0.0, but that method has since been deprecated in favor of the one named `interval` with the same behavior.
* Javadoc: [`interval(long,long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#interval(long,%20long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`interval(long,long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#interval(long,%20long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
`interval` operates by default on the `computation` [Scheduler](../scheduler). There are also variants that allow you to set the Scheduler by passing one in as a parameter.
### RxJS `interval`
 RxJS implements this operator as `interval`. It accepts as its parameter the number of milliseconds to wait between emissions.
`interval` operates by default on the `timeout` [Scheduler](../scheduler), or you can optionally pass in a different Scheduler as a second parameter, and `interval` will operate on that Scheduler instead.
#### Sample Code
```
var source = Rx.Observable
.interval(500 /* ms */)
.timeInterval()
.take(3);
var subscription = source.subscribe(
function (x) {
console.log('Next: ' + x);
},
function (err) {
console.log('Error: ' + err);
},
function () {
console.log('Completed');
});
```
```
Next: {value: 0, interval: 500}
Next: {value: 1, interval: 500}
Next: {value: 2, interval: 500}
Completed
```
`interval` is found in the following distributions:
* `rx.lite.js`
* `rx.lite.compat.js`
* `rx.timejs` (requires `rx.js` or `rx.compat.js`)
### RxPHP `interval`
RxPHP implements this operator as `interval`.
Returns an Observable that emits an infinite sequence of ascending integers starting at 0, with a constant interval of time of your choosing between emissions.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/interval/interval.php
\Rx\Observable::interval(1000)
->take(5)
->subscribe($createStdoutObserver());
```
```
Next value: 0
Next value: 1
Next value: 2
Next value: 3
Next value: 4
Complete!
```
reactivex DefaultIfEmpty DefaultIfEmpty
==============
> emit items from the source Observable, or a default item if the source Observable emits nothing
 The DefaultIfEmpty operator simply mirrors the source Observable exactly if the source Observable emits any items. If the source Observable terminates normally (with an `onComplete`) without emitting any items, the Observable returned from DefaultIfEmpty will instead emit a default item of your choosing before it too completes.
#### See Also
* [Introduction to Rx: DefaultIfEmpty](http://www.introtorx.com/Content/v1.0.10621.0/06_Inspection.html#DefaultIfEmpty)
Language-Specific Information
-----------------------------
### RxGroovy `defaultIfEmpty switchIfEmpty`
 RxGroovy implements this operator as `defaultIfEmpty`.
This operator does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`defaultIfEmpty(T)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#defaultIfEmpty(T))
There is also a new operator in RxGroovy 1.1 called `switchIfEmpty` that, rather than emitting a backup *value* if the source Observable terminates without having emitted any items, it emits the emissions from a backup *Observable*.
### RxJava 1․x `defaultIfEmpty switchIfEmpty`
 RxJava implements this operator as `defaultIfEmpty`.
This operator does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`defaultIfEmpty(T)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#defaultIfEmpty(T))
There is also a new operator in RxJava 1.1 called `switchIfEmpty` that, rather than emitting a backup *value* if the source Observable terminates without having emitted any items, it emits the emissions from a backup *Observable*.
#### Sample Code
```
Observable.empty().defaultIfEmpty(10).subscribe(
val -> System.out.println("next: " + val),
err -> System.err.println(err) ,
() -> System.out.println("completed")
);
```
```
next: 10
completed
```
### RxJava 2․x `defaultIfEmpty switchIfEmpty`
 RxJava implements this operator as `defaultIfEmpty`.
This operator does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`defaultIfEmpty(T)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#defaultIfEmpty(T))
#### Sample Code
```
Flowable.empty().defaultIfEmpty(10).subscribe(
val -> System.out.println("next: " + val),
err -> System.err.println(err) ,
() -> System.out.println("completed")
);
```
```
next: 10
completed
```
### RxJS `defaultIfEmpty`
 RxJS implements `defaultIfEmpty`, but the parameter that sets the default value is optional. If you do not pass this default value, `defaultIfEmpty` will emit a “`null`” if the source Observable completes without emitting anything. (Note that an emission of a “`null`” is *not* the same as no emission.)
#### Sample Code
```
/* Without a default value */
var source = Rx.Observable.empty().defaultIfEmpty();
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x.toString()); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: null
Completed
```
```
/* With a defaultValue */
var source = Rx.Observable.empty().defaultIfEmpty(false);
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x.toString()); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: false
Completed
```
`defaultIfEmpty` is found in each of the following distributions:
* `rx.js`
* `rx.all.js`
* `rx.all.compat.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
### RxPHP `defaultIfEmpty`
RxPHP implements this operator as `defaultIfEmpty`.
Returns the specified value of an observable if the sequence is empty.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/defaultIfEmpty/defaultIfEmpty.php
$source = \Rx\Observable::empty()->defaultIfEmpty(Rx\Observable::of('something'));
$subscription = $source->subscribe($stdoutObserver);
```
```
Next value: something
Complete!
```
| programming_docs |
reactivex Average Average
=======
> calculates the average of numbers emitted by an Observable and emits this average
[Open interactive diagram on rxmarbles.com](https://rxmarbles.com/#average) The Average operator operates on an Observable that emits numbers (or items that can be evaluated as numbers), and emits a single value: the average of all of the numbers emitted by the source Observable.
#### See Also
* [Sum](sum)
* [Introduction to Rx: Min, Max, Sum, and Average](http://www.introtorx.com/Content/v1.0.10621.0/07_Aggregation.html#MaxAndMin)
* [RxMarbles: `average`](http://rxmarbles.com/#average)
Language-Specific Information
-----------------------------
### RxGroovy `averageDouble averageFloat averageInteger averageLong`
In RxGroovy, this operator is not in the ReactiveX core, but is part of the distinct `rxjava-math` module, where it is implemented with four type-specific operators: `averageDouble`, `averageFloat`, `averageInteger`, and `averageLong`. The following example shows how these operators work:
#### Sample Code
```
def myObservable = Observable.create({ aSubscriber ->
if(false == aSubscriber.isUnsubscribed()) aSubscriber.onNext(4);
if(false == aSubscriber.isUnsubscribed()) aSubscriber.onNext(3);
if(false == aSubscriber.isUnsubscribed()) aSubscriber.onNext(2);
if(false == aSubscriber.isUnsubscribed()) aSubscriber.onNext(1);
if(false == aSubscriber.isUnsubscribed()) aSubscriber.onCompleted();
});
Observable.averageInteger(myObservable).subscribe(
{ println(it); }, // onNext
{ println("Error encountered"); }, // onError
{ println("Sequence complete"); } // onCompleted
);
```
```
2
Sequence complete
```
 You can also average not the items themselves but the results of a function applied to each item, as in the illustration above, which emits the average number of sides on the figures emitted by the source Observable.
This operator will fail with an `IllegalArgumentException` if the source Observable does not emit any items.
### RxJava 1․x `averageDouble averageFloat averageInteger averageLong`
This operator is not in the RxJava core, but is part of the distinct `rxjava-math` module, where it is implemented with four type-specific operators: `averageDouble`, `averageFloat`, `averageInteger`, and `averageLong`.
 You can also average not the items themselves but the results of a function applied to each item, as in the illustration above, which emits the average number of sides on the figures emitted by the source Observable.
This operator will fail with an `IllegalArgumentException` if the source Observable does not emit any items.
### RxJS `average`
 RxJS implements this operator as `average`. The following code sample shows how to use it:
#### Sample Code
```
var source = Rx.Observable.range(0, 9).average();
var subscription = source.subscribe(
function (x) {
console.log('Next: ' + x);
},
function (err) {
console.log('Error: ' + err);
},
function () {
console.log('Completed');
});
```
```
Next: 4
Completed
```
 You can also average not the items themselves but the results of a function applied to each item, as in the illustration above, which emits the average number of sides on the figures emitted by the source Observable.
#### Sample Code
```
var arr = [
{ value: 1 },
{ value: 2 },
{ value: 3 }
];
var source = Rx.Observable.fromArray(arr).average(function (x) {
return x.value;
});
var subscription = source.subscribe(
function (x) {
console.log('Next: ' + x);
},
function (err) {
console.log('Error: ' + err);
},
function () {
console.log('Completed');
});
```
```
Next: 2
Completed
```
`average` is found in the following distributions:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.aggregates.js`
It requires one of the following:
* `rx.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
### RxPHP `average`
RxPHP implements this operator as `average`.
Computes the average of an observable sequence of values.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/average/average.php
$source = Rx\Observable::range(0, 9)->average();
$subscription = $source->subscribe($stdoutObserver);
```
```
Next value: 4
Complete!
```
reactivex Publish Publish
=======
> convert an ordinary Observable into a connectable Observable
 A connectable Observable resembles an ordinary Observable, except that it does not begin emitting items when it is subscribed to, but only when the Connect operator is applied to it. In this way you can prompt an Observable to begin emitting items at a time of your choosing.
#### See Also
* [Connect](connect)
* [RefCount](refcount)
* [Replay](replay)
* [Introduction to Rx: Publish & Connect](http://www.introtorx.com/Content/v1.0.10621.0/14_HotAndColdObservables.html#PublishAndConnect)
* [101 Rx Samples: Publish — Sharing a subscription with multiple Observers](http://rxwiki.wikidot.com/101samples#toc48)
* [Wedding Party: Share, Publish, Refcount, and All That Jazz](http://blog.kaush.co/2015/01/21/rxjava-tip-for-the-day-share-publish-refcount-and-all-that-jazz/) by Kaushik Gopal
Language-Specific Information
-----------------------------
### RxGroovy `publish`
 RxGroovy implements this operator as `publish`.
* Javadoc: [`publish()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#publish())
 There is also a variant that takes a function as a parameter. This function takes an emitted item from the source Observable as a parameter and produces the item that will be emitted in its place by the resulting Observable.
* Javadoc: [`publish(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#publish(rx.functions.Func1))
### RxJava 1․x `publish`
 RxJava implements this operator as `publish`.
* Javadoc: [`publish()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#publish())
 There is also a variant that takes a function as a parameter. This function takes as a parameter the `ConnectableObservable` that shares a single subscription to the underlying Observable sequence. This function produces and returns a new Observable sequence.
* Javadoc: [`publish(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#publish(rx.functions.Func1))
### RxJS `let letBind multicast publish publishLast publishValue`
 In RxJS, the `publish` operator takes a function as a parameter. This function takes an emitted item from the source Observable as a parameter and produces the item that will be emitted in its place by the returned `ConnectableObservable`.
#### Sample Code
```
var interval = Rx.Observable.interval(1000);
var source = interval
.take(2)
.doAction(function (x) {
console.log('Side effect');
});
var published = source.publish();
published.subscribe(createObserver('SourceA'));
published.subscribe(createObserver('SourceB'));
var connection = published.connect();
function createObserver(tag) {
return Rx.Observer.create(
function (x) { console.log('Next: ' + tag + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
}
```
```
Side effect
Next: SourceA0
Next: SourceB0
Side effect
Next: SourceA1
Next: SourceB1
Completed
```
 The `publishValue` operator takes, in addition to the function described above, an initial item to be emitted by the resulting `ConnectableObservable` at connection time before emitting the items from the source Observable. It will not, however, emit this initial item to observers that subscribe after the time of connection.
#### Sample Code
```
var interval = Rx.Observable.interval(1000);
var source = interval
.take(2)
.doAction(function (x) {
console.log('Side effect');
});
var published = source.publishValue(42);
published.subscribe(createObserver('SourceA'));
published.subscribe(createObserver('SourceB'));
var connection = published.connect();
function createObserver(tag) {
return Rx.Observer.create(
function (x) { console.log('Next: ' + tag + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
}
```
```
Next: SourceA42
Next: SourceB42
Side effect
Next: SourceA0
Next: SourceB0
Side effect
Next: SourceA1
Next: SourceB1
Completed
Completed
```
 The `publishLast` operator is similar to `publish`, and takes a similarly-behaving function as its parameter. It differs from `publish` in that instead of applying that function to, and emitting an item for *every* item emitted by the source Observable subsequent to the connection, it only applies that function to and emits an item for the *last* item that was emitted by the source Observable, when that source Observable terminates normally.
#### Sample Code
```
var interval = Rx.Observable.interval(1000);
var source = interval
.take(2)
.doAction(function (x) {
console.log('Side effect');
});
var published = source.publishLast();
published.subscribe(createObserver('SourceA'));
published.subscribe(createObserver('SourceB'));
var connection = published.connect();
function createObserver(tag) {
return Rx.Observer.create(
function (x) { console.log('Next: ' + tag + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
}
```
```
Side effect
Side effect
Next: SourceA1
Completed
Next: SourceB1
Completed
```
The above operators are available in the following packages:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.binding.js` (requires either `rx.js` or `rx.compat.js`)
* `rx.lite.js`
* `rx.lite.compat.js`
RxJS also has a `multicast` operator which operates on an ordinary Observable, multicasts that Observable by means of a particular Subject that you specify, applies a transformative function to each emission, and then emits those transformed values as its own ordinary Observable sequence. Each subscription to this new Observable will trigger a new subscription to the underlying multicast Observable.
#### Sample Code
```
var subject = new Rx.Subject();
var source = Rx.Observable.range(0, 3)
.multicast(subject);
var observer = Rx.Observer.create(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); }
);
var subscription = source.subscribe(observer);
subject.subscribe(observer);
var connected = source.connect();
subscription.dispose();
```
```
Next: 0
Next: 0
Next: 1
Next: 1
Next: 2
Next: 2
Completed
```
The `multicast` operator is available in the following packages:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.binding.js` (requires either `rx.lite.js` or `rx.compat.js`)
* `rx.lite.js`
* `rx.lite.compat.js`
There is also a `let` operator (the alias `letBind` is available for browsers such as Internet Explorer before IE9 where “`let`” is forbidden). It is similar to `multicast` but does not multicast the underlying Observable through a Subject:
#### Sample Code
```
var obs = Rx.Observable.range(1, 3);
var source = obs.let(function (o) { return o.concat(o); });
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 1
Next: 2
Next: 3
Next: 1
Next: 2
Next: 3
Completed
```
The `let` (or `letBind`) operator is available in the following packages:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.experimental.js`
It requires one of the following packages:
* `rx.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
### RxPHP `multicast multicastWithSelector publish publishLast publishValue`
RxPHP implements this operator as `multicast`.
Multicasts the source sequence notifications through an instantiated subject into all uses of the sequence within a selector function. Each subscription to the resulting sequence causes a separate multicast invocation, exposing the sequence resulting from the selector function's invocation. For specializations with fixed subject types, see Publish, PublishLast, and Replay.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/multicast/multicast.php
$subject = new \Rx\Subject\Subject();
$source = \Rx\Observable::range(0, 3)->multicast($subject);
$subscription = $source->subscribe($stdoutObserver);
$subject->subscribe($stdoutObserver);
$connected = $source->connect();
```
```
Next value: 0
Next value: 0
Next value: 1
Next value: 1
Next value: 2
Next value: 2
Complete!
```
RxPHP also has an operator `multicastWithSelector`.
Multicasts the source sequence notifications through an instantiated subject from a subject selector factory, into all uses of the sequence within a selector function. Each subscription to the resulting sequence causes a separate multicast invocation, exposing the sequence resulting from the selector function's invocation. For specializations with fixed subject types, see Publish, PublishLast, and Replay.
RxPHP also has an operator `publish`.
Returns an observable sequence that is the result of invoking the selector on a connectable observable sequence that shares a single subscription to the underlying sequence. This operator is a specialization of Multicast using a regular Subject.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/publish/publish.php
/* With publish */
$interval = \Rx\Observable::range(0, 10);
$source = $interval
->take(2)
->doOnNext(function ($x) {
echo "Side effect\n";
});
$published = $source->publish();
$published->subscribe($createStdoutObserver('SourceC '));
$published->subscribe($createStdoutObserver('SourceD '));
$published->connect();
```
```
Side effect
SourceC Next value: 0
SourceD Next value: 0
Side effect
SourceC Next value: 1
SourceD Next value: 1
SourceC Complete!
SourceD Complete!
```
RxPHP also has an operator `publishLast`.
Returns an observable sequence that is the result of invoking the selector on a connectable observable sequence that shares a single subscription to the underlying sequence containing only the last notification. This operator is a specialization of Multicast using a AsyncSubject.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/publish/publishLast.php
$range = \Rx\Observable::fromArray(range(0, 1000));
$source = $range
->take(2)
->doOnNext(function ($x) {
echo "Side effect\n";
});
$published = $source->publishLast();
$published->subscribe($createStdoutObserver('SourceA'));
$published->subscribe($createStdoutObserver('SourceB'));
$connection = $published->connect();
```
```
Side effect
Side effect
SourceANext value: 1
SourceBNext value: 1
SourceAComplete!
SourceBComplete!
```
RxPHP also has an operator `publishValue`.
Returns an observable sequence that is the result of invoking the selector on a connectable observable sequence that shares a single subscription to the underlying sequence and starts with initialValue. This operator is a specialization of Multicast using a BehaviorSubject.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/publish/publishValue.php
$range = \Rx\Observable::fromArray(range(0, 1000));
$source = $range
->take(2)
->doOnNext(function ($x) {
echo "Side effect\n";
});
$published = $source->publishValue(42);
$published->subscribe($createStdoutObserver('SourceA'));
$published->subscribe($createStdoutObserver('SourceB'));
$connection = $published->connect();
```
```
SourceANext value: 42
SourceBNext value: 42
Side effect
SourceANext value: 0
SourceBNext value: 0
Side effect
SourceANext value: 1
SourceBNext value: 1
SourceAComplete!
SourceBComplete!
```
reactivex SubscribeOn SubscribeOn
===========
> specify the Scheduler on which an Observable will operate
 Many implementations of ReactiveX use [“`Scheduler`s”](../scheduler) to govern an Observable’s transitions between threads in a multi-threaded environment. You can instruct an Observable to do its work on a particular Scheduler by calling the Observable’s SubscribeOn operator.
The [ObserveOn](observeon) operator is similar, but more limited. It instructs the Observable to send notifications to observers on a specified Scheduler.
In some implementations there is also an UnsubscribeOn operator.
 By default, an Observable and the chain of operators that you apply to it will do its work, and will notify its observers, on the same thread on which its `Subscribe` method is called. The SubscribeOn operator changes this behavior by specifying a different Scheduler on which the Observable should operate. The ObserveOn operator specifies a different Scheduler that the Observable will use to send notifications to its observers.
As shown in this illustration, the SubscribeOn operator designates which thread the Observable will begin operating on, no matter at what point in the chain of operators that operator is called. ObserveOn, on the other hand, affects the thread that the Observable will use *below* where that operator appears. For this reason, you may call ObserveOn multiple times at various points during the chain of Observable operators in order to change on which threads certain of those operators operate.
#### See Also
* [`Scheduler`](../scheduler)
* [ObserveOn](observeon)
* [Rx Workshop: Schedulers](http://channel9.msdn.com/Series/Rx-Workshop/Rx-Workshop-Schedulers)
* [RxJava Threading Examples](http://www.grahamlea.com/2014/07/rxjava-threading-examples/) by Graham Lea
* [Introduction to Rx: SubscribeOn and ObserveOn](http://www.introtorx.com/Content/v1.0.10621.0/15_SchedulingAndThreading.html#SubscribeOnObserveOn)
* [Async Abstractions using rx-java](http://java.dzone.com/articles/async-abstractios-using-rx) by Biju Kunjummen, DZone
* [RxJava: Understanding observeOn() and subscribeOn()](http://tomstechnicalblog.blogspot.hu/2016/02/rxjava-understanding-observeon-and.html) by Thomas Nield
* [Advanced Reactive Java: SubscribeOn and ObserveOn](http://akarnokd.blogspot.hu/2016/03/subscribeon-and-observeon.html) by Dávid Karnok
Language-Specific Information
-----------------------------
### RxGroovy `subscribeOn unsubscribeOn`
 To specify on which Scheduler the Observable should operate, use the `subscribeOn` operator, passing it the appropriate `Scheduler`.
* Javadoc: [`subscribeOn(Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#subscribeOn(rx.Scheduler))
To specify which Scheduler observers will use to unsubscribe from an Observable, use the `unsubscribeOn` operator, passing it the appropriate `Scheduler`.
* Javadoc: [`unsubscribeOn(Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#unsubscribeOn(rx.Scheduler))
### RxJava 1․x `subscribeOn unsubscribeOn`
 To specify on which Scheduler the Observable should operate, use the `subscribeOn` operator, passing it the appropriate `Scheduler`.
* Javadoc: [`subscribeOn(Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#subscribeOn(rx.Scheduler))
To specify which Scheduler observers will use to unsubscribe from an Observable, use the `unsubscribeOn` operator, passing it the appropriate `Scheduler`.
* Javadoc: [`unsubscribeOn(Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#unsubscribeOn(rx.Scheduler))
### RxJS `subscribeOn`
 To specify on which Scheduler the Observable should operate, use the `subscribeOn` operator, passing it the appropriate `Scheduler`.
#### Sample Code
```
/* Change from immediate scheduler to timeout */
var source = Rx.Observable.return(42, Rx.Scheduler.immediate)
.subscribeOn(Rx.Scheduler.timeout);
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 42
Completed
```
`subscribeOn` is found in each of the following distributions:
* `rx.js`
* `rx.all.js`
* `rx.all.compat.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
| programming_docs |
reactivex Materialize/Dematerialize Materialize/Dematerialize
=========================
> represent both the items emitted and the notifications sent as emitted items, or reverse this process
 A well-formed, finite Observable will invoke its observer’s `onNext` method zero or more times, and then will invoke either the `onCompleted` or `onError` method exactly once. The Materialize operator converts this series of invocations — both the original `onNext` notifications and the terminal `onCompleted` or `onError` notification — into a series of *items* emitted by an Observable.
 The Dematerialize operator reverses this process. It operates on an Observable that has previously been transformed by Materialize and returns it to its original form.
#### See Also
* [Introduction to Rx: Materialize and Dematerialize](http://www.introtorx.com/Content/v1.0.10621.0/08_Transformation.html#MaterializeAndDematerialize)
Language-Specific Information
-----------------------------
### RxGroovy `dematerialize materialize`
 In RxGroovy, `materialize` transforms the notifications from the source Observable into `Notification` objects and emits them as the emissions from the Observable it returns. For example:
#### Sample Code
```
numbers = Observable.from([1, 2, 3]);
numbers.materialize().subscribe(
{ if(rx.Notification.Kind.OnNext == it.kind) { println("Next: " + it.value); }
else if(rx.Notification.Kind.OnCompleted == it.kind) { println("Completed"); }
else if(rx.Notification.Kind.OnError == it.kind) { println("Error: " + it.exception); } },
{ println("Error: " + it.getMessage()); }, // onError
{ println("Sequence complete"); } // onCompleted
);
```
```
Next: 1
Next: 2
Next: 3
Completed
Sequence complete
```
`materialize` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`materialize()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#materialize())
 `dematerialize` reverses this process: converting the emitted `Notification` objects from the source Observable into notifications from the resulting Observable. The following example dematerializes the materialized Observable from the previous section:
#### Sample Code
```
numbers = Observable.from([1, 2, 3]);
numbers.materialize().dematerialize().subscribe(
{ println(it); }, // onNext
{ println("Error: " + it.getMessage()); }, // onError
{ println("Sequence complete"); } // onCompleted
);
```
```
1
2
3
Sequence complete
```
`dematerialize` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`dematerialize()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#dematerialize())
### RxJava 1․x `dematerialize materialize`
 In RxJava, `materialize` transforms the notifications from the source Observable into `Notification` objects and emits them as the emissions from the Observable it returns.
`materialize` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`materialize()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#materialize())
 `dematerialize` reverses this process: converting the emitted `Notification` objects from the source Observable into notifications from the resulting Observable.
`dematerialize` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`dematerialize()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#dematerialize())
### RxJS `dematerialize`
 RxJS only implements the `dematerialize` operator. If you want a “materialized” Observable, you have to assemble it by hand by manually creating and emitting the `Notification` objects that represent Observable notification calls.
#### Sample Code
```
var source = Rx.Observable
.fromArray([
Rx.Notification.createOnNext(42),
Rx.Notification.createOnError(new Error('woops'))
])
.dematerialize();
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x.toString()); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 42
Error: Error: woops
```
`dematerialize` is found in each of the following distributions:
* `rx.js`
* `rx.all.js`
* `rx.all.compat.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
### RxPHP `materialize dematerialize`
RxPHP implements this operator as `materialize`.
Materializes the implicit notifications of an observable sequence as explicit notifications.
RxPHP also has an operator `dematerialize`.
Dematerializes the explicit notification values of an observable sequence as implicit notifications.
reactivex Delay Delay
=====
> shift the emissions from an Observable forward in time by a particular amount
[Open interactive diagram on rxmarbles.com](https://rxmarbles.com/#delay) The Delay operator modifies its source Observable by pausing for a particular increment of time (that you specify) before emitting each of the source Observable’s items. This has the effect of shifting the entire sequence of items emitted by the Observable forward in time by that specified increment.
#### See Also
* [Introduction to Rx: Delay](http://www.introtorx.com/Content/v1.0.10621.0/13_TimeShiftedSequences.html#Delay)
* [RxMarbles: `delay`](http://rxmarbles.com/#delay)
* [RxMarbles: `delayWithSelector`](http://rxmarbles.com/#delayWithSelector)
* [101 Rx Samples: Delay — Simple](http://rxwiki.wikidot.com/101samples#toc27)
Language-Specific Information
-----------------------------
### RxGroovy `delay delaySubscription`
RxGroovy implements this operator as variants of `delay` and `delaySubscription`.
 The first variant of `delay` accepts parameters that define a duration of time (a quantity of time, and a `TimeUnit` that this quantity is denominated in). Each time the source Observable emits an item, `delay` starts a timer, and when that timer reaches the given duration, the Observable returned from `delay` emits the same item.
Note that `delay` will not time-shift an `onError` notification in this fashion but it will forward such a notification immediately to its subscribers while dropping any pending `onNext` notifications. It will however time shift an `onCompleted` notification.
By default this variant of `delay` operates on the `computation` [Scheduler](../scheduler), but you can choose a different Scheduler by passing it in as an optional third parameter to `delay`
* Javadoc: [`delay(long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#delay(long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`delay()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#delay(long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
 Another variant of `delay` does not use a constant delay duration, but sets its delay duration on a per-item basis by passing each item from the source Observable into a function that returns an Observable and then monitoring those Observables. When any such Observable emits a item or completes, the Observable returned by `delay` emits the associated item.
This variant of `delay` does not by default run on any particular [Scheduler](../scheduler).
* Javadoc: [`delay(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#delay(rx.functions.Func1))
 The variant of `delay` that uses a per-item Observable to set the delay has a variant that allows you to pass in a function that returns an Observable that acts as a delay timer for the subscription to the source Observable (in the absence of this, `delay` subscribes to the source Observable as soon as an observer subscribes to the Observable returned by `delay`).
This variant of `delay` does not by default run on any particular [Scheduler](../scheduler).
* Javadoc: [`delay(Func0,Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#delay(rx.functions.Func0,%20rx.functions.Func1))
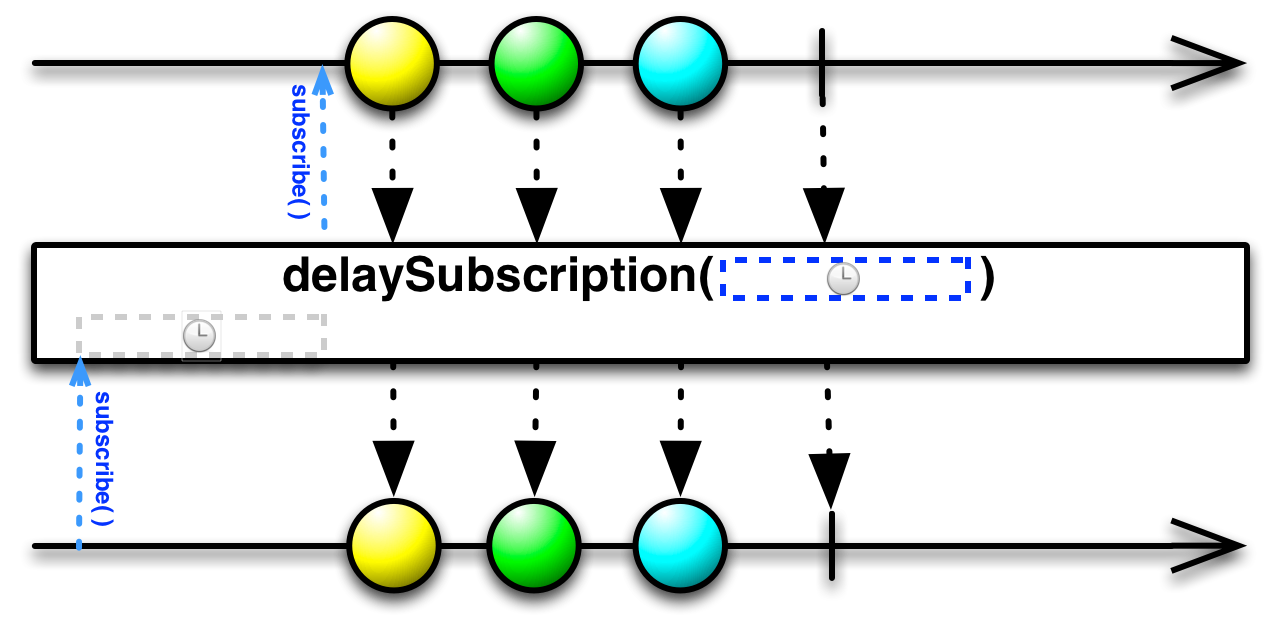 There is also an operator with which you can delay the subscription to the source Observable: `delaySubscription`. It accepts parameters that define the amount of time to delay (a quantity of time, and a `TimeUnit` that this quantity is denominated in).
This variant of `delay` by default runs on the `computation` [Scheduler](../scheduler), but you can choose a different Scheduler by passing it in as an optional third parameter to `delaySubscription`.
* Javadoc: [`delaySubscription(long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#delaySubscription(long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`delaySubscription(long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#delaySubscription(long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
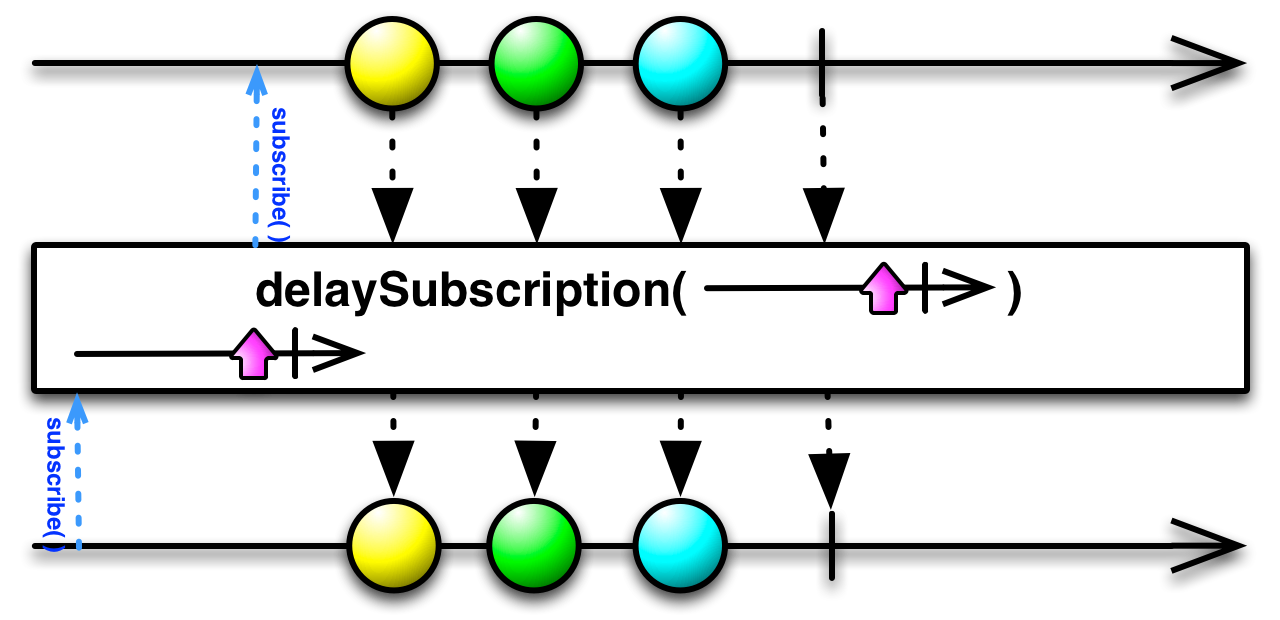 And there is a variant of `delaySubscription` that uses an Observable (returned by a function you supply) rather than a fixed duration in order to set the subscription delay.
This variant of `delaySubscription` does not by default run on any particular [Scheduler](../scheduler).
* Javadoc: [`delaySubscription(Func0)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#delaySubscription(rx.functions.Func0))
### RxJava 1․x `delay delaySubscription`
RxJava implements this operator as variants of `delay` and `delaySubscription`.
 The first variant of `delay` accepts parameters that define a duration of time (a quantity of time, and a `TimeUnit` that this quantity is denominated in). Each time the source Observable emits an item, `delay` starts a timer, and when that timer reaches the given duration, the Observable returned from `delay` emits the same item.
Note that `delay` will not time-shift an `onError` notification in this fashion but it will forward such a notification immediately to its subscribers while dropping any pending `onNext` notifications. It will however time shift an `onCompleted` notification.
By default this variant of `delay` operates on the `computation` [Scheduler](../scheduler), but you can choose a different Scheduler by passing it in as an optional third parameter to `delay`
* Javadoc: [`delay(long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#delay(long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`delay()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#delay(long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
 Another variant of `delay` does not use a constant delay duration, but sets its delay duration on a per-item basis by passing each item from the source Observable into a function that returns an Observable and then monitoring those Observables. When any such Observable emits an item or completes, the Observable returned by `delay` emits the associated item.
This variant of `delay` does not by default run on any particular [Scheduler](../scheduler).
* Javadoc: [`delay(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#delay(rx.functions.Func1))
 The variant of `delay` that uses a per-item Observable to set the delay has a variant that allows you to pass in a function that returns an Observable that acts as a delay timer for the subscription to the source Observable (in the absence of this, `delay` subscribes to the source Observable as soon as an observer subscribes to the Observable returned by `delay`).
This variant of `delay` does not by default run on any particular [Scheduler](../scheduler).
* Javadoc: [`delay(Func0,Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#delay(rx.functions.Func0,%20rx.functions.Func1))
 There is also an operator with which you can delay the subscription to the source Observable: `delaySubscription`. It accepts parameters that define the amount of time to delay (a quantity of time, and a `TimeUnit` that this quantity is denominated in).
This variant of `delay` by default runs on the `computation` [Scheduler](../scheduler), but you can choose a different Scheduler by passing it in as an optional third parameter to `delaySubscription`.
* Javadoc: [`delaySubscription(long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#delaySubscription(long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`delaySubscription(long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#delaySubscription(long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
 And there is a variant of `delaySubscription` that uses an Observable (returned by a function you supply) rather than a fixed duration in order to set the subscription delay.
This variant of `delaySubscription` does not by default run on any particular [Scheduler](../scheduler).
* Javadoc: [`delaySubscription(Func0)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#delaySubscription(rx.functions.Func0))
### RxJS `delay delaySubscription delayWithSelector`
 In RxJS you can set the per-item delay in two ways: by passing a number of milliseconds into the `delay` operator (which will delay each emission by that amount of time), or by passing in a `Date` object (which will delay the beginning of the sequence of emissions until that absolute point in time).
This operator operates by default on the `timeout` [Scheduler](../scheduler), but you can override this by passing in another Scheduler as an optional second parameter.
#### Sample Code
```
var source = Rx.Observable.range(0, 3)
.delay(new Date(Date.now() + 1000));
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x.toString()); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 0
Next: 1
Next: 2
Completed
```
```
var source = Rx.Observable.range(0, 3)
.delay(1000);
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x.toString()); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 0
Next: 1
Next: 2
Completed
```
 `delaySubscription` is similar to `delay` but rather than timeshifting the emissions from the source Observable, it timeshifts the moment of subscription to that Observable. You pass to this operator a time value (either a `Number`, in which case this sets the number of milliseconds of delay, or a `Date`, in which case this sets an absolute future time at which `delaySubscription` will trigger the subscription). You may optionally pass a [Scheduler](../scheduler) as a second parameter, which `delaySubscription` will use to govern the delay period or trigger time.
#### Sample Code
```
var start = Date.now();
var source = Rx.Observable.range(0, 3).delaySubscription(5000);
var subscription = source.subscribe(
function (x) { console.log('Next: %s, %s', x, Date.now() - start); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 0, 5001
Next: 1, 5002
Next: 2, 5003
Completed
```
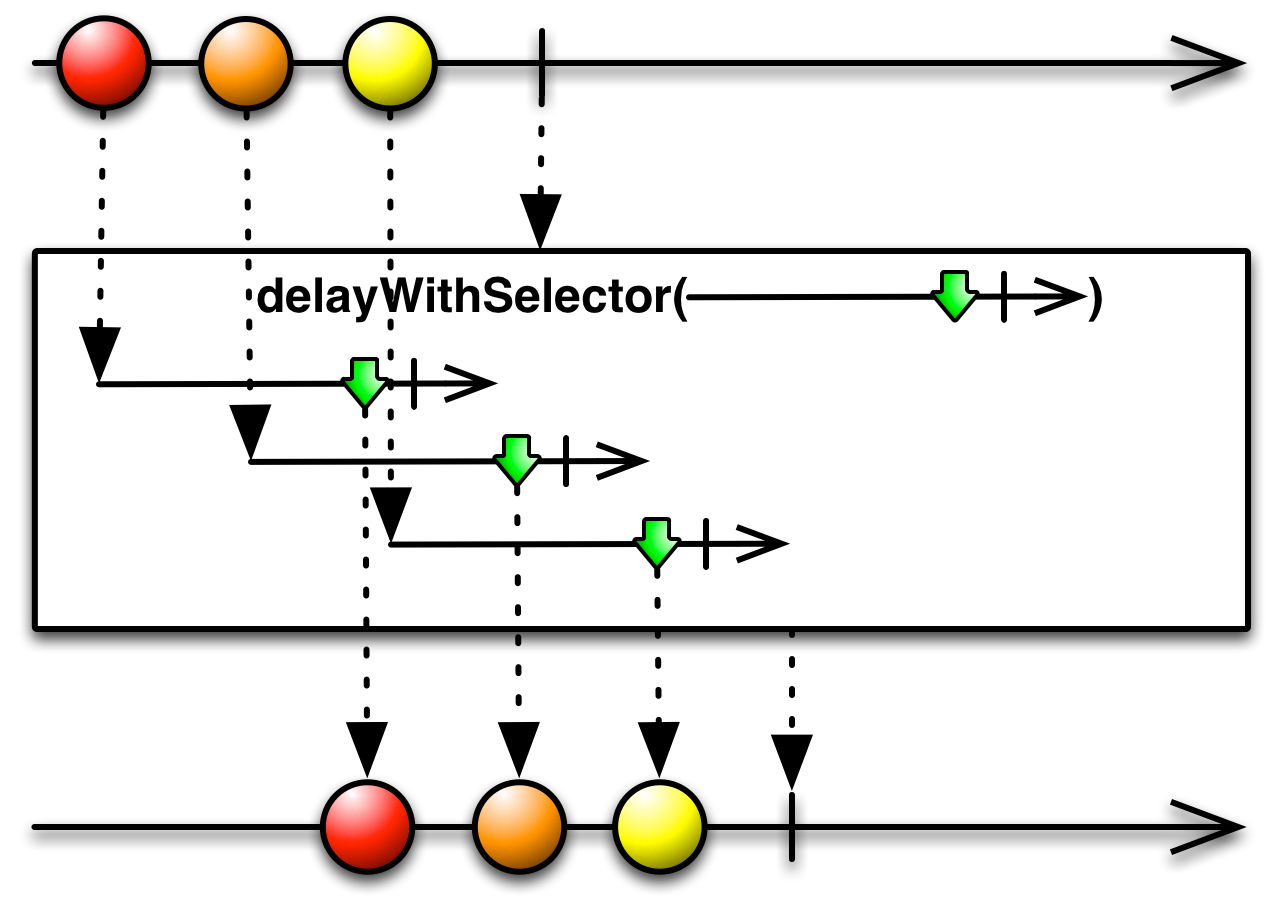 `delayWithSelector` is like `delay` but does not use a constant delay duration (or absolute time), but sets its delay duration on a per-item basis by passing each item from the source Observable into a function that returns an Observable and then monitoring those Observables. When any such Observable completes, the Observable returned by `delay` emits the associated item.
#### Sample Code
```
var source = Rx.Observable
.range(0, 3)
.delayWithSelector(
function (x) {
return Rx.Observable.timer(x * 400);
})
.timeInterval()
.map(function (x) { return x.value + ':' + x.interval; });
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 0:0
Next: 1:400
Next: 2:400
Completed
```
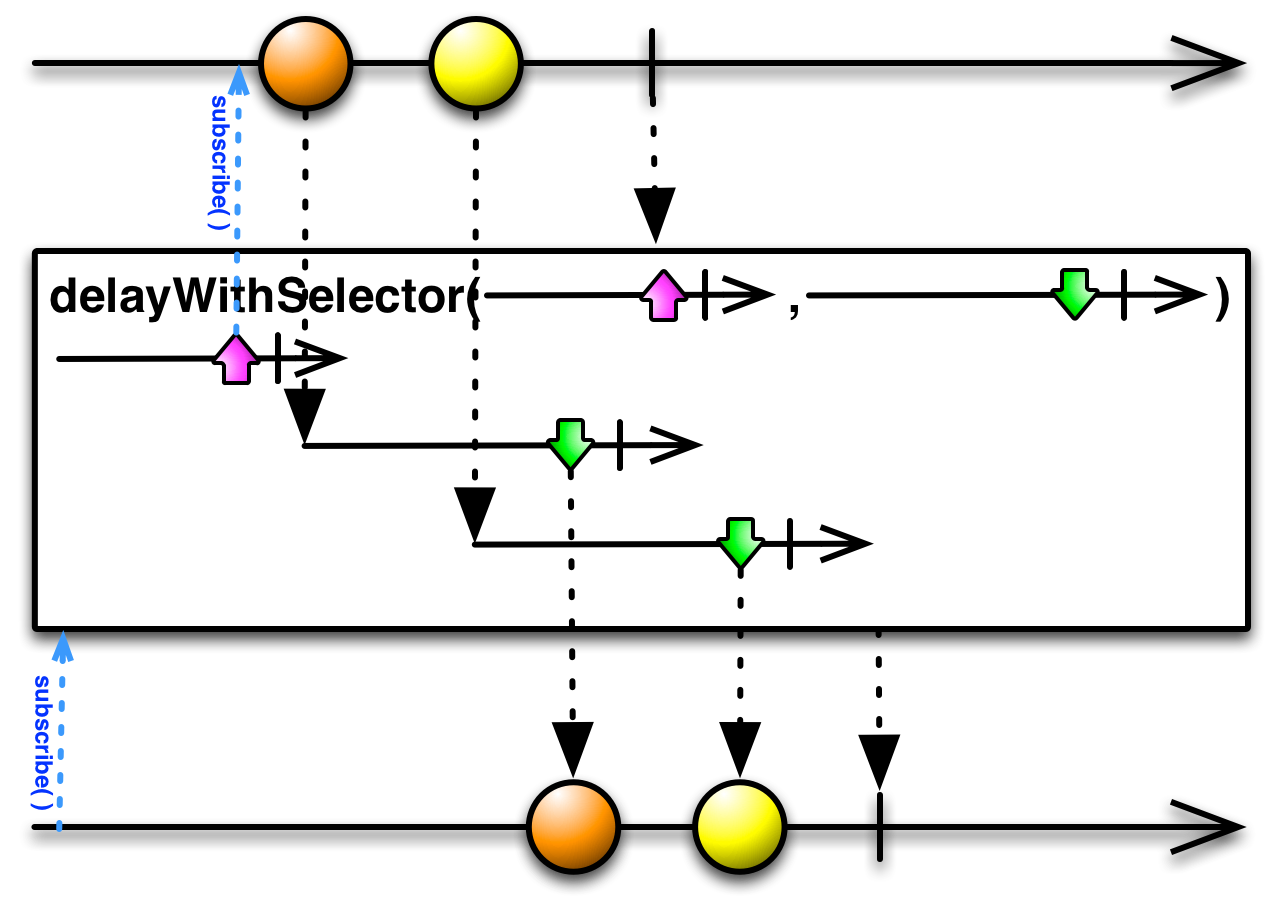 There is also a version of `delayWithSelector` that takes an additional (first) argument: an Observable that sets a delay before `delayWithSelector` subscribes to the source Observable after it itself is subscribed to.
#### Sample Code
```
var source = Rx.Observable
.range(0, 3)
.delayWithSelector(
Rx.Observable.timer(300),
function (x) {
return Rx.Observable.timer(x * 400);
}
)
.timeInterval()
.map(function (x) { return x.value + ':' + x.interval; });
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 0:300
Next: 1:400
Next: 2:400
Completed
```
`delay`, `delaySubscription`, and `delayWithSelector` require `rx.lite.js` or `rx.lite.compat.js` and are found in each of the following distributions:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.time.js` (requires `rx.js` or `rx.compat.js`)
### RxPHP `delay`
RxPHP implements this operator as `delay`.
Time shifts the observable sequence by dueTime. The relative time intervals between the values are preserved.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/delay/delay.php
\Rx\Observable::interval(1000)
->doOnNext(function ($x) {
echo 'Side effect: ' . $x . "\n";
})
->delay(500)
->take(5)
->subscribe($createStdoutObserver());
```
```
Side effect: 0
Next value: 0
Side effect: 1
Next value: 1
Side effect: 2
Next value: 2
Side effect: 3
Next value: 3
Side effect: 4
Next value: 4
Complete!
```
reactivex Repeat Repeat
======
> create an Observable that emits a particular item multiple times
 The Repeat operator emits an item repeatedly. Some implementations of this operator allow you to repeat a *sequence* of items, and some permit you to limit the number of repetitions.
#### See Also
* [Interval](interval)
* [Range](range)
* [Introduction to Rx: Repeat](http://www.introtorx.com/Content/v1.0.10621.0/12_CombiningSequences.html#Repeat)
Language-Specific Information
-----------------------------
### RxGroovy `doWhile repeat repeatWhen whileDo`
 RxGroovy implements this operator as `repeat`. It does not initiate an Observable, but operates on an Observable in such a way that it repeats the sequence emitted by the source Observable as its own sequence, either infinitely, or in the case of `repeat(*n*)`, *n* times.
`repeat` operates by default on the `trampoline` [Scheduler](../scheduler). There is also a variant that allows you to set the Scheduler by passing one in as a parameter.
* Javadoc: [`repeat()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#repeat())
* Javadoc: [`repeat(long)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#repeat(long))
* Javadoc: [`repeat(Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#repeat(rx.Scheduler))
* Javadoc: [`repeat(long,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#repeat(long,%20rx.Scheduler))
 There is also an operator called `repeatWhen`. Rather than buffering and replaying the sequence from the source Observable, it *resubscribes* to and mirrors the source Observable, but only conditionally.
It decides whether to resubscribe and remirror the source Observable by passing that Observable’s termination notifications (error or completed) to a notification handler as `void` emissions. This notification handler acts as an Observable operator, taking an Observable that emits these `void` notifications as input, and returning an Observable that emits `void` items (meaning, resubscribe and mirror the source Observable) or terminates (meaning, terminate the sequence emitted by `repeatWhen`).
`repeatWhen` operates by default on the `trampoline` [Scheduler](../scheduler). There is also a variant that allows you to set the Scheduler by passing one in as a parameter.
* Javadoc: [`repeatWhen(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#repeatWhen(rx.functions.Func1))
* Javadoc: [`repeatWhen(Func1,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#repeatWhen(rx.functions.Func1,%20rx.Scheduler))
 In RxGroovy, `doWhile` is not part of the standard set of operators, but is part of the optional `rxjava-computation-expressions` package. `doWhile` checks a condition after each repetition of the source sequence, and only repeats it if that condition is true.
 In RxGroovy, `whileDo` is not part of the standard set of operators, but is part of the optional `rxjava-computation-expressions` package. `whileDo` checks a condition before each repetition of the source sequence, and only repeats it if that condition is true.
### RxJava 1․x `doWhile repeat repeatWhen whileDo`
 RxJava implements this operator as `repeat`. It does not initiate an Observable, but operates on an Observable in such a way that it repeats the sequence emitted by the source Observable as its own sequence, either infinitely, or in the case of `repeat(*n*)`, *n* times.
`repeat` operates by default on the `trampoline` [Scheduler](../scheduler). There is also a variant that allows you to set the Scheduler by passing one in as a parameter.
* Javadoc: [`repeat()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#repeat())
* Javadoc: [`repeat(long)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#repeat(long))
* Javadoc: [`repeat(Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#repeat(rx.Scheduler))
* Javadoc: [`repeat(long,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#repeat(long,%20rx.Scheduler))
 There is also an operator called `repeatWhen`. Rather than buffering and replaying the sequence from the source Observable, it *resubscribes* to and mirrors the source Observable, but only conditionally.
It decides whether to resubscribe and remirror the source Observable by passing that Observable’s termination notifications (error or completed) to a notification handler as `void` emissions. This notification handler acts as an Observable operator, taking an Observable that emits these `void` notifications as input, and returning an Observable that emits `void` items (meaning, resubscribe and mirror the source Observable) or terminates (meaning, terminate the sequence emitted by `repeatWhen`).
`repeatWhen` operates by default on the `trampoline` [Scheduler](../scheduler). There is also a variant that allows you to set the Scheduler by passing one in as a parameter.
* Javadoc: [`repeatWhen(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#repeatWhen(rx.functions.Func1))
* Javadoc: [`repeatWhen(Func1,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#repeatWhen(rx.functions.Func1,%20rx.Scheduler))
 In RxJava, `doWhile` is not part of the standard set of operators, but is part of the optional `rxjava-computation-expressions` package. `doWhile` checks a condition after each repetition of the source sequence, and only repeats it if that condition is true.
 In RxJava, `whileDo` is not part of the standard set of operators, but is part of the optional `rxjava-computation-expressions` package. `whileDo` checks a condition before each repetition of the source sequence, and only repeats it if that condition is true.
### RxJS `doWhile repeat while`
 RxJS implements this operator as `repeat`. It accepts as its parameter the item to repeat, and optionally two other parameters: the number of times you want the item to repeat, and the [Scheduler](../scheduler) on which you want to perform this operation (it uses the `immediate` Scheduler by default).
#### Sample Code
```
var source = Rx.Observable.repeat(42, 3);
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 42
Next: 42
Next: 42
Completed
```
`repeat` is found in the following distributions:
* `rx.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
 RxJS also implements the `doWhile` operator. It repeats the source Observable’s sequence of emissions only so long as a condition you specify remains true.
```
var i = 0;
var source = Rx.Observable.return(42).doWhile(
function (x) { return ++i < 2; });
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 42
Next: 42
Completed
```
`doWhile` is found in each of the following distributions.
* `rx.all.js`
* `rx.all.compat.js`
* `rx.experimental.js`
It requires one of the following distributions:
* `rx.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
 RxJS also implements the `while` operator. It repeats the source Observable’s sequence of emissions only if a condition you specify is true.
```
var i = 0;
// Repeat until condition no longer holds
var source = Rx.Observable.while(
function () { return i++ < 3 },
Rx.Observable.return(42)
);
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 42
Next: 42
Next: 42
Completed
```
`while` is found in the `rx.experimental.js` distribution. It requires one of the following distributions:
* `rx.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
### RxPHP `repeat repeatWhen`
RxPHP implements this operator as `repeat`.
Generates an observable sequence that repeats the given element the specified number of times.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/repeat/repeat.php
$source = \Rx\Observable::range(1, 3)
->repeat(3);
$subscription = $source->subscribe($createStdoutObserver());
```
```
Next value: 1
Next value: 2
Next value: 3
Next value: 1
Next value: 2
Next value: 3
Next value: 1
Next value: 2
Next value: 3
Complete!
```
RxPHP also has an operator `repeatWhen`.
Returns an Observable that emits the same values as the source Observable with the exception of an onCompleted. An onCompleted notification from the source will result in the emission of a count item to the Observable provided as an argument to the notificationHandler function. If that Observable calls onComplete or onError then repeatWhen will call onCompleted or onError on the child subscription. Otherwise, this Observable will resubscribe to the source observable.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/repeat/repeatWhen.php
$source = Rx\Observable::of(42)
->repeatWhen(function (\Rx\Observable $notifications) {
return $notifications
->scan(function ($acc, $x) {
return $acc + $x;
}, 0)
->delay(1000)
->doOnNext(function () {
echo "1 second delay", PHP_EOL;
})
->takeWhile(function ($count) {
return $count < 2;
});
});
$subscription = $source->subscribe($createStdoutObserver());
```
```
Next value: 42
1 second delay
Next value: 42
1 second delay
Complete!
```
| programming_docs |
reactivex Sample Sample
======
> emit the most recent items emitted by an Observable within periodic time intervals
[Open interactive diagram on rxmarbles.com](https://rxmarbles.com/#sample) The Sample operator periodically looks at an Observable and emits whichever item it has most recently emitted since the previous sampling.
In some implementations, there is also a ThrottleFirst operator that is similar, but emits not the most-recently emitted item in the sample period, but the *first* item that was emitted during that period.
#### See Also
* [Backpressure-related Operators](backpressure)
* [Debounce](debounce)
* [Window](window)
* [Introduction to Rx: Sample](http://www.introtorx.com/Content/v1.0.10621.0/13_TimeShiftedSequences.html#Sample)
* [RxMarbles: `sample`](http://rxmarbles.com/#sample)
* [101 Rx Samples: Sample — Simple](http://rxwiki.wikidot.com/101samples#toc29)
Language-Specific Information
-----------------------------
### RxGroovy `sample throttleFirst throttleLast`
RxGroovy implements this operator as `sample` and `throttleLast`.
Note that if the source Observable has emitted no items since the last time it was sampled, the Observable that results from this operator will emit no item for that sampling period.
 One variant of `sample` (or its alias, `throttleLast`) samples at a periodic time interval that you choose by passing in a `TimeUnit` and a quantity of such units as parameters to `sample`.
The following code constructs an Observable that emits the numbers between one and a million, and then samples that Observable every ten milliseconds to see what number it is emitting at that moment.
#### Sample Code
```
def numbers = Observable.range( 1, 1000000 );
numbers.sample(10, java.util.concurrent.TimeUnit.MILLISECONDS).subscribe(
{ println(it); }, // onNext
{ println("Error: " + it.getMessage()); }, // onError
{ println("Sequence complete"); } // onCompleted
);
```
```
339707
547810
891282
Sequence complete
```
This variant of `sample` operates by default on the `computation` [Scheduler](../scheduler), but you can optionally pass in a Scheduler of your choosing as a third parameter.
* Javadoc: [`sample(long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#sample(long,%20java.util.concurrent.TimeUnit)) and [`throttleLast(long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#throttleLast(long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`sample(long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#sample(long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler)) and [`throttleLast(long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#throttleLast(long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
 There ia also a variant of `sample` (that does not have a `throttleLast` alias) that samples the source Observable each time a second Observable emits an item (or when it terminates). You pass in that second Observable as the parameter to `sample`.
This variant of `sample` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`sample(Observable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#sample(rx.Observable))
 There is also a `throttleFirst` operator, which differs from `throttleLast`/`sample` in that it emits the *first* item emitted by the source Observable in each sampling period rather than the *most recently emitted* item.
#### Sample Code
```
Scheduler s = new TestScheduler();
PublishSubject<Integer> o = PublishSubject.create();
o.throttleFirst(500, TimeUnit.MILLISECONDS, s).subscribe(
{ println(it); }, // onNext
{ println("Error: " + it.getMessage()); }, // onError
{ println("Sequence complete"); } // onCompleted
);
// send events with simulated time increments
s.advanceTimeTo(0, TimeUnit.MILLISECONDS);
o.onNext(1); // deliver
o.onNext(2); // skip
s.advanceTimeTo(501, TimeUnit.MILLISECONDS);
o.onNext(3); // deliver
s.advanceTimeTo(600, TimeUnit.MILLISECONDS);
o.onNext(4); // skip
s.advanceTimeTo(700, TimeUnit.MILLISECONDS);
o.onNext(5); // skip
o.onNext(6); // skip
s.advanceTimeTo(1001, TimeUnit.MILLISECONDS);
o.onNext(7); // deliver
s.advanceTimeTo(1501, TimeUnit.MILLISECONDS);
o.onCompleted();
```
```
1
3
7
Sequence complete
```
`throttleFirst` operates by default on the `computation` [Scheduler](../scheduler), but you can optionally pass in a Scheduler of your choosing as a third parameter.
* [`throttleFirst(long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#throttleFirst(long,%20java.util.concurrent.TimeUnit))
* [`throttleFirst(long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#throttleFirst(long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
### RxJava 1․x `sample throttleFirst throttleLast`
RxJava implements this operator as `sample` and `throttleLast`.
Note that if the source Observable has emitted no items since the last time it was sampled, the Observable that results from this operator will emit no item for that sampling period.
 One variant of `sample` (or its alias, `throttleLast`) samples at a periodic time interval that you choose by passing in a `TimeUnit` and a quantity of such units as parameters to `sample`.
This variant of `sample` operates by default on the `computation` [Scheduler](../scheduler), but you can optionally pass in a Scheduler of your choosing as a third parameter.
* Javadoc: [`sample(long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#sample(long,%20java.util.concurrent.TimeUnit)) and [`throttleLast(long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#throttleLast(long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`sample(long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#sample(long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler)) and [`throttleLast(long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#throttleLast(long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
 There ia also a variant of `sample` (that does not have a `throttleLast` alias) that samples the source Observable each time a second Observable emits an item (or when it terminates). You pass in that second Observable as the parameter to `sample`.
This variant of `sample` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`sample(Observable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#sample(rx.Observable))
 There is also a `throttleFirst` operator, which differs from `throttleLast`/`sample` in that it emits the *first* item emitted by the source Observable in each sampling period rather than the *most recently emitted* item.
`throttleFirst` operates by default on the `computation` [Scheduler](../scheduler), but you can optionally pass in a Scheduler of your choosing as a third parameter.
* [`throttleFirst(long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#throttleFirst(long,%20java.util.concurrent.TimeUnit))
* [`throttleFirst(long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#throttleFirst(long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
### RxJS `sample throttleFirst`
RxJS implements this operator with two variants of `sample`.
 The first variant accepts as its parameter a periodicity, defined as an integer number of milliseconds, and it samples the source Observable periodically at that frequency.
#### Sample Code
```
var source = Rx.Observable.interval(1000)
.sample(5000)
.take(2);
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 3
Next: 8
Completed
```
 The second variant accepts as its parameter an Observable, and it samples the source Observable whenever this second Observable emits an item.
#### Sample Code
```
var source = Rx.Observable.interval(1000)
.sample(Rx.Observable.interval(5000))
.take(2);
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 3
Next: 8
Completed
```
 There is also a `throttleFirst` operator, which differs from `sample` in that it emits the *first* item emitted by the source Observable in each sampling period rather than the *most recently emitted* item.
It does not have the variant that uses the emissions from a second Observable to regulate the sampling periodicity.
#### Sample Code
```
var times = [
{ value: 0, time: 100 },
{ value: 1, time: 600 },
{ value: 2, time: 400 },
{ value: 3, time: 900 },
{ value: 4, time: 200 }
];
// Delay each item by time and project value;
var source = Rx.Observable.from(times)
.flatMap(function (item) {
return Rx.Observable
.of(item.value)
.delay(item.time);
})
.throttleFirst(300 /* ms */);
var subscription = source.subscribe(
function (x) { console.log('Next: %s', x); },
function (err) { console.log('Error: %s', err); },
function () { console.log('Completed'); });
```
```
Next: 0
Next: 2
Next: 3
Completed
```
`sample` and `throttleFirst` operate by default on the `timeout` [Scheduler](../scheduler). They are found in each of the following distributions:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.time.js` (requires `rx.js` or `rx.compat.js`)
* `rx.lite.js`
* `rx.lite.compat.js`
reactivex CombineLatest CombineLatest
=============
> when an item is emitted by either of two Observables, combine the latest item emitted by each Observable via a specified function and emit items based on the results of this function
[Open interactive diagram on rxmarbles.com](https://rxmarbles.com/#combineLatest) The CombineLatest operator behaves in a similar way to Zip, but while Zip emits items only when *each* of the zipped source Observables have emitted a previously unzipped item, CombineLatest emits an item whenever *any* of the source Observables emits an item (so long as each of the source Observables has emitted at least one item). When any of the source Observables emits an item, CombineLatest combines the most recently emitted items from each of the other source Observables, using a function you provide, and emits the return value from that function.
#### See Also
* [Zip](zip)
* [Introduction to Rx: CombineLatest](http://www.introtorx.com/Content/v1.0.10621.0/12_CombiningSequences.html#CombineLatest)
* [RxMarbles: `combineLatest`](http://rxmarbles.com/#combineLatest)
* [RxMarbles: `withLatestFrom`](http://rxmarbles.com/#withLatestFrom)
* [101 Rx Samples: CombineLatest — Parallel Execution](http://rxwiki.wikidot.com/101samples#toc3)
* [101 Rx Samples: CombineLatest](http://rxwiki.wikidot.com/101samples#toc50)
Language-Specific Information
-----------------------------
### RxGroovy `combineLatest withLatestFrom`
 RxGroovy implements this operator as `combineLatest`. It may take between two and nine Observables (as well as the combining function) as parameters, or a single `List` of Observables (as well as the combining function). It does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`combineLatest(List,FuncN)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#combineLatest(java.util.List,%20rx.functions.FuncN))
* Javadoc: [`combineLatest(Observable,Observable,Func2)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#combineLatest(rx.Observable,%20rx.Observable,%20rx.functions.Func2)) (there are also versions that take up to nine Observables)
 Under development, but not part of the 1.0 release, is the `withLatestFrom` operator. It is similar to `combineLatest`, but only emits items when the single source Observable emits an item (not when *any* of the Observables that are passed to the operator do, as `combineLatest` does).
### RxJava 1․x `combineLatest withLatestFrom`
 RxJava implements this operator as `combineLatest`. It may take between two and nine Observables (as well as the combining function) as parameters, or a single `List` of Observables (as well as the combining function). It does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`combineLatest(List,FuncN)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#combineLatest(java.util.List,%20rx.functions.FuncN))
* Javadoc: [`combineLatest(Observable,Observable,Func2)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#combineLatest(rx.Observable,%20rx.Observable,%20rx.functions.Func2)) (there are also versions that take up to nine Observables)
 Under development, but not part of the 1.0 release, is the `withLatestFrom` operator. It is similar to `combineLatest`, but only emits items when the single source Observable emits an item (not when *any* of the Observables that are passed to the operator do, as `combineLatest` does).
### RxJS `combineLatest withLatestFrom`
 RxJS implements this operator as `combineLatest`. It may take a variable number of individual Observables (as well as the combining function) as parameters, or a single `Array` of Observables (as well as the combining function).
#### Sample Code
```
/* Have staggering intervals */
var source1 = Rx.Observable.interval(100)
.map(function (i) { return 'First: ' + i; });
var source2 = Rx.Observable.interval(150)
.map(function (i) { return 'Second: ' + i; });
// Combine latest of source1 and source2 whenever either gives a value
var source = source1.combineLatest(
source2,
function (s1, s2) { return s1 + ', ' + s2; }
).take(4);
var subscription = source.subscribe(
function (x) {
console.log('Next: ' + x.toString());
},
function (err) {
console.log('Error: ' + err);
},
function () {
console.log('Completed');
});
```
```
Next: First: 0, Second: 0
Next: First: 1, Second: 0
Next: First: 1, Second: 1
Next: First: 2, Second: 1
Completed
```
 RxJS also has a `withLatestFrom` operator. It is similar to `combineLatest`, but only emits items when the single source Observable emits an item (not when *any* of the Observables that are passed to the operator do, as `combineLatest` does).
#### Sample Code
```
/* Have staggering intervals */
var source1 = Rx.Observable.interval(140)
.map(function (i) { return 'First: ' + i; });
var source2 = Rx.Observable.interval(50)
.map(function (i) { return 'Second: ' + i; });
// When source1 emits a value, combine it with the latest emission from source2.
var source = source1.withLatestFrom(
source2,
function (s1, s2) { return s1 + ', ' + s2; }
).take(4);
var subscription = source.subscribe(
function (x) {
console.log('Next: ' + x.toString());
},
function (err) {
console.log('Error: ' + err);
},
function () {
console.log('Completed');
});
```
```
Next: First: 0, Second: 1
Next: First: 1, Second: 4
Next: First: 2, Second: 7
Next: First: 3, Second: 10
Completed
```
These two operators are both available in each of the following distributions:
* `rx.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
### RxPHP `combineLatest withLatestFrom`
RxPHP implements this operator as `combineLatest`.
Merges the specified observable sequences into one observable sequence by using the selector function whenever any of the observable sequences produces an element. Observables need to be an array. If the result selector is omitted, a list with the elements will be yielded.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/combineLatest/combineLatest.php
/* Have staggering intervals */
$source1 = \Rx\Observable::interval(100);
$source2 = \Rx\Observable::interval(120);
$source = $source1->combineLatest([$source2], function ($value1, $value2) {
return "First: {$value1}, Second: {$value2}";
})->take(4);
$subscription = $source->subscribe($stdoutObserver);
```
```
Next value: First: 0, Second: 0
Next value: First: 1, Second: 0
Next value: First: 1, Second: 1
Next value: First: 2, Second: 1
Complete!
```
RxPHP also has an operator `withLatestFrom`.
Merges the specified observable sequences into one observable sequence by using the selector function only when the (first) source observable sequence produces an element.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/withLatestFrom/withLatestFrom.php
/* Have staggering intervals */
$source1 = \Rx\Observable::interval(140)
->map(function ($i) {
return 'First: ' . $i;
});
$source2 = \Rx\Observable::interval(50)
->map(function ($i) {
return 'Second: ' . $i;
});
$source3 = \Rx\Observable::interval(100)
->map(function ($i) {
return 'Third: ' . $i;
});
$source = $source1->withLatestFrom([$source2, $source3], function ($value1, $value2, $value3) {
return $value1 . ', ' . $value2 . ', ' . $value3;
})->take(4);
$source->subscribe($stdoutObserver);
```
```
Next value: First: 0, Second: 1, Third: 0
Next value: First: 1, Second: 4, Third: 1
Next value: First: 2, Second: 7, Third: 3
Next value: First: 3, Second: 10, Third: 4
Complete!
```
reactivex Defer Defer
=====
> do not create the Observable until the observer subscribes, and create a fresh Observable for each observer
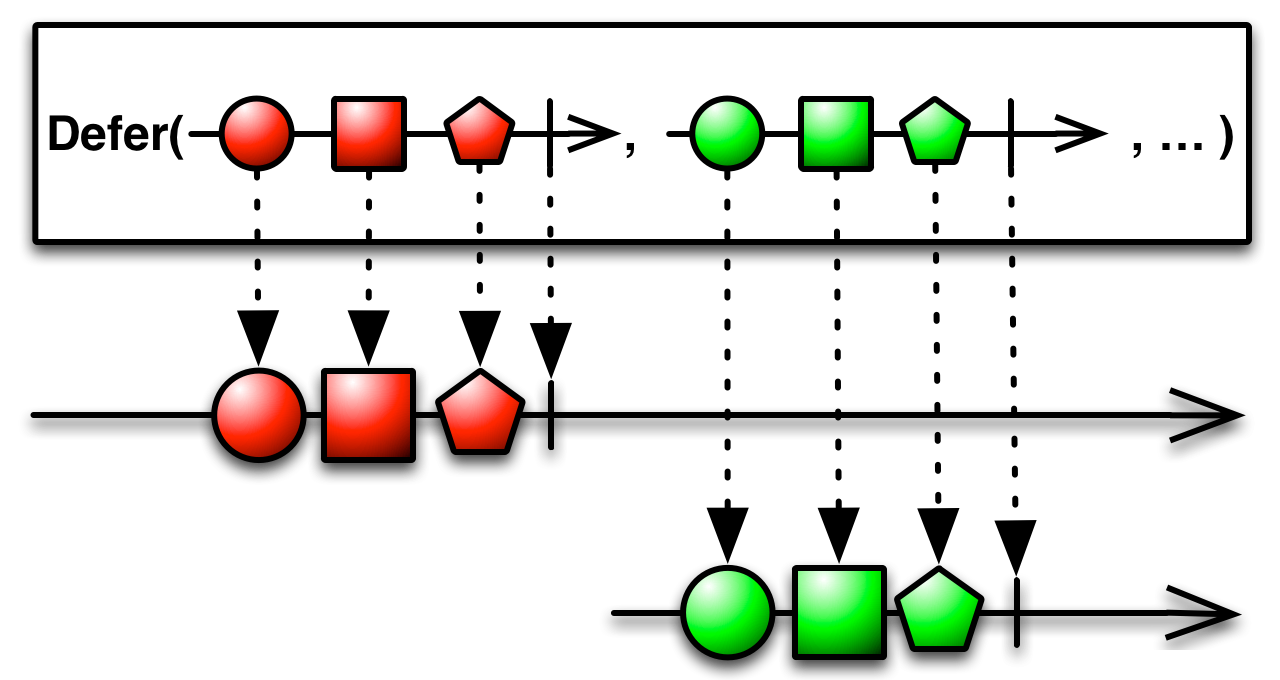 The Defer operator waits until an observer subscribes to it, and then it generates an Observable, typically with an Observable factory function. It does this afresh for each subscriber, so although each subscriber may think it is subscribing to the same Observable, in fact each subscriber gets its own individual sequence.
In some circumstances, waiting until the last minute (that is, until subscription time) to generate the Observable can ensure that this Observable contains the freshest data.
#### See Also:
* [Deferring Observable code until subscription in RxJava](http://blog.danlew.net/2015/07/23/deferring-observable-code-until-subscription-in-rxjava/) by Dan Lew
Language-Specific Information
-----------------------------
### RxGroovy `defer ifThen switchCase`
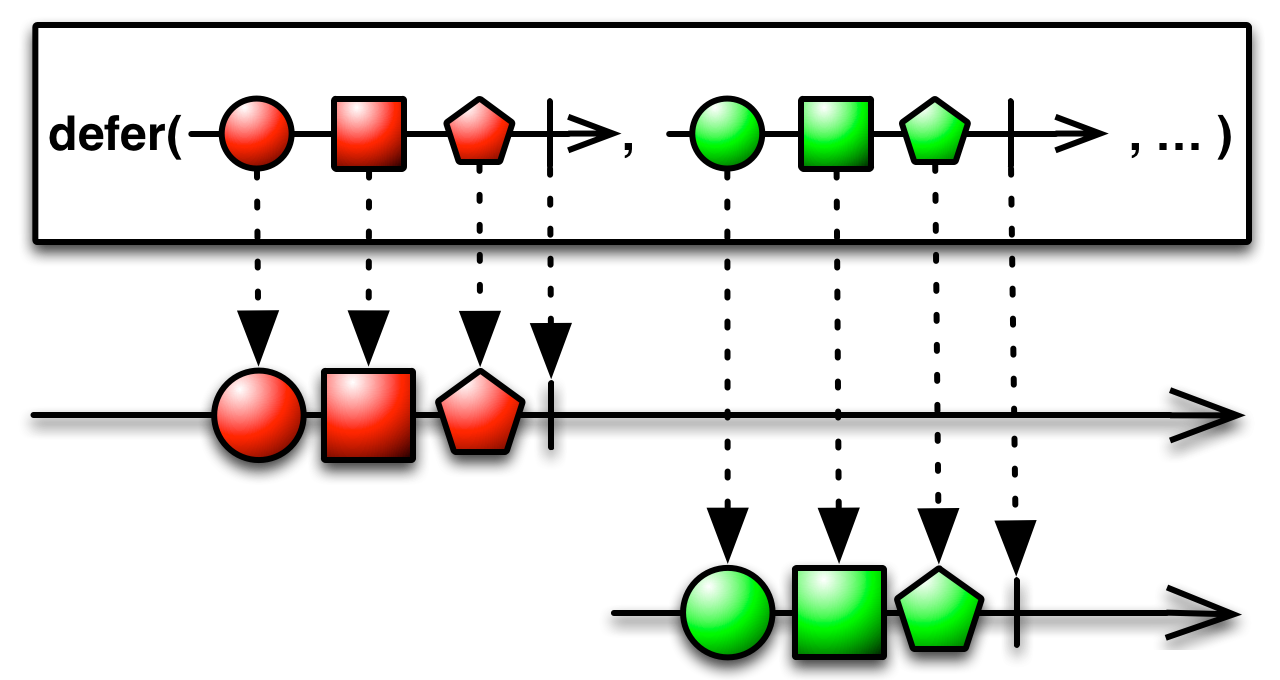 RxGroovy implements this operator as `defer`. This operator takes as its sole parameter an Observable factory function of your choosing. This function takes no parameters and returns an Observable.
`defer` does not by default operate on a particular [Scheduler](../scheduler).
* Javadoc: [`defer()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#defer(rx.functions.Func0))
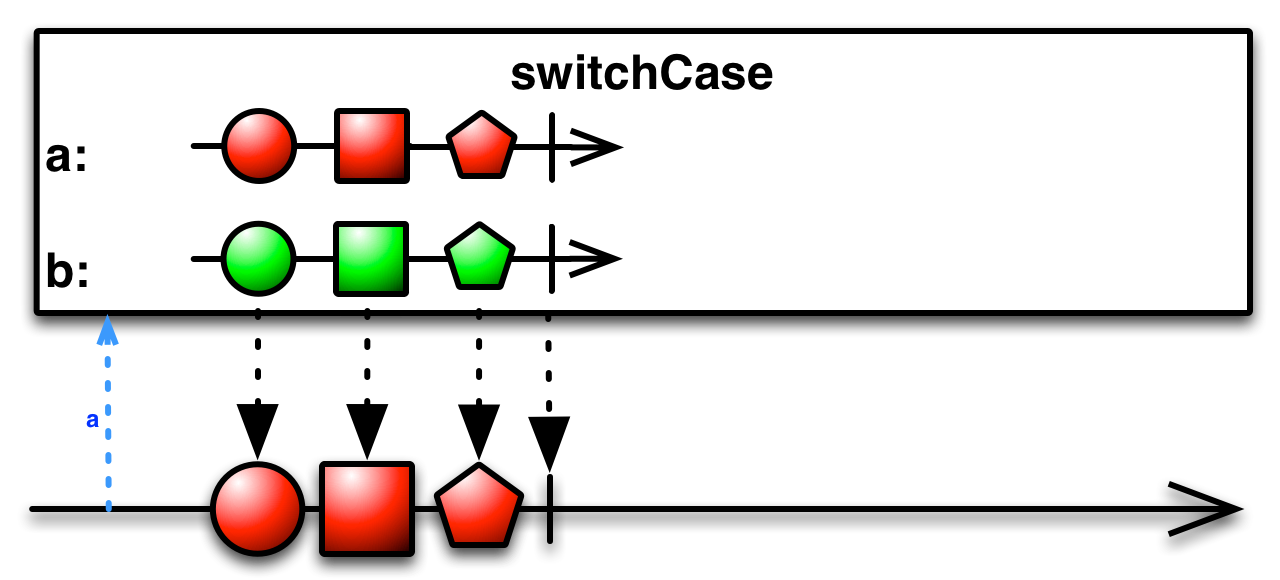 There is a somewhat similar operator in the optional `rxjava-computation-expressions` package (it is not part of the standard RxGroovy set of operators). The `switchCase` operator conditionally creates and returns one of a set of possible Observables.
 An even simpler operator in the optional `rxjava-computation-expressions` package (also not part of the standard RxGroovy set of operators) is `ifThen`. This operator checks a condition and then either mirrors the source Observable or an empty Observable depending on the result.
### RxJava 1․x `defer ifThen switchCase`
 RxJava implements this operator as `defer`. This operator takes as its sole parameter an Observable factory function of your choosing. This function takes no parameters and returns an Observable.
`defer` does not by default operate on a particular [Scheduler](../scheduler).
* Javadoc: [`defer()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#defer(rx.functions.Func0))
 There is a somewhat similar operator in the optional `rxjava-computation-expressions` package (it is not part of the standard RxJava set of operators). The `switchCase` operator conditionally creates and returns one of a set of possible Observables.
 An even simpler operator in the optional `rxjava-computation-expressions` package (also not part of the standard RxGroovy set of operators) is `ifThen`. This operator checks a condition and then either mirrors the source Observable or an empty Observable depending on the result.
### RxJS `case defer if switchCase`
 RxJS implements this operator as `defer`. This operator takes as its sole parameter an Observable factory function of your choosing. This function takes no parameters and returns an Observable or a Promise.
#### Sample Code
```
/* Using an observable sequence */
var source = Rx.Observable.defer(function () {
return Rx.Observable.return(42);
});
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); } );
```
```
Next: 42
Completed
```
```
var source = Rx.Observable.defer(function () {
return RSVP.Promise.resolve(42);
});
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); } );
```
```
Next: 42
Completed
```
`defer` is found in the following distributions:
* `rx.js`
* `rx.all.js`
* `rx.all.compat.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
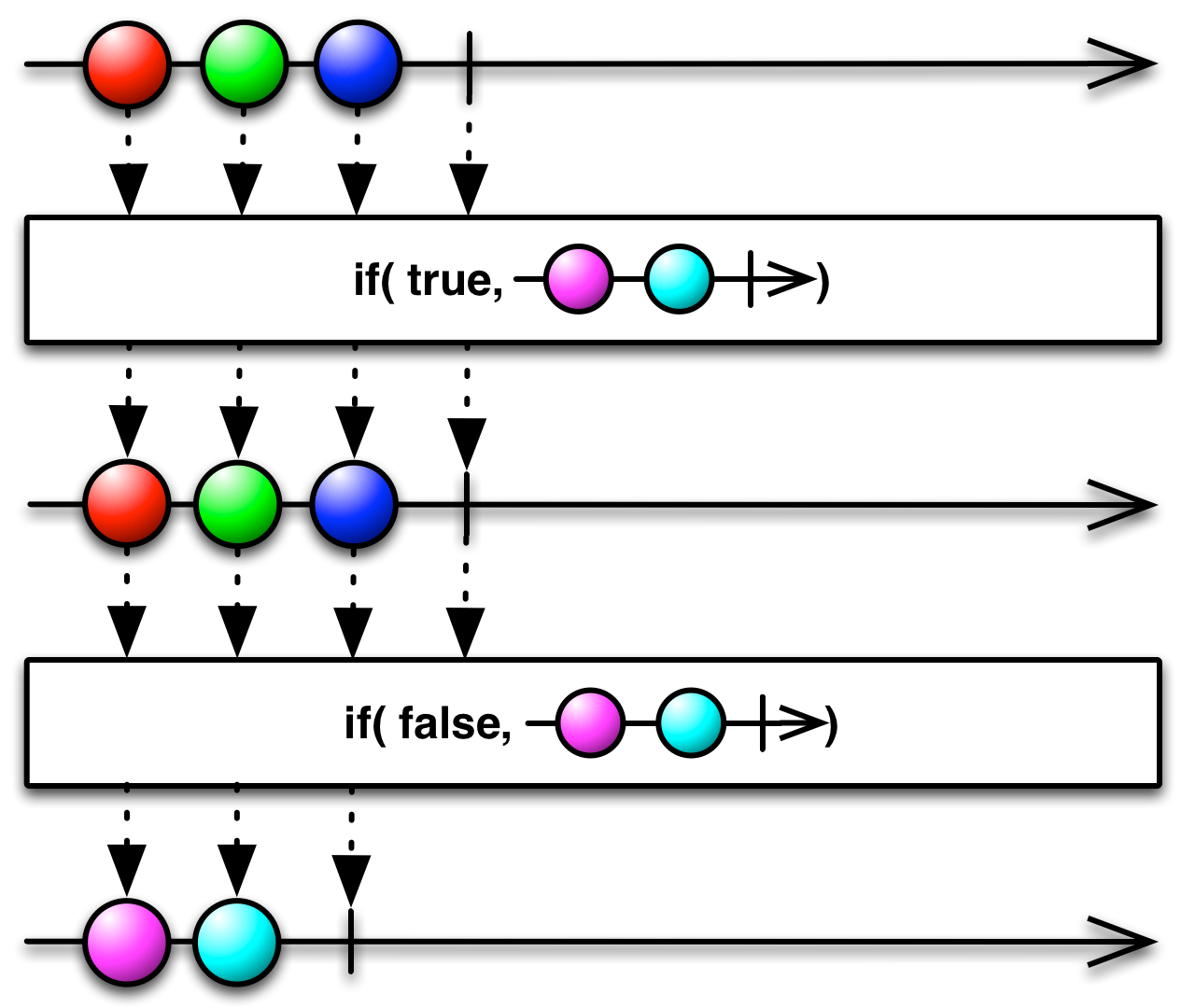 RxJS also implements the `if` operator. It takes as parameters a function that returns a boolean, an Observable to mirror if that function returns a true value, and optionally a second Observable to mirror if that function returns a false value (if you omit this parameter, `if` will mirror an empty Observable in such a case).
#### Sample Code
```
var shouldRun = false;
var source = Rx.Observable.if(
function () { return shouldRun; },
Rx.Observable.return(42),
Rx.Observable.return(56)
);
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 56
Completed
```
`if` is found in the following distributions:
* `rx.all.js`
* `rx.experimental.js` (requires `rx.js`, `rx.compat.js`, `rx.lite.js`, or `rx.lite.compat.js`)
 RxJS implements a somewhat similar operator called `case` (or “`switchCase`”). This operator conditionally creates and returns one of a set of possible Observables. It takes the following parameters:
1. a function that returns the key that determines which Observable to emit
2. an object that associates those keys with particular Observables
3. (optional) a [Scheduler](../scheduler) or an Observable: Scheduler the Scheduler you want this operator to use Observable the default Observable to emit if the key does not associate with any Observables
#### Sample Code
```
var sources = {
'foo': Rx.Observable.return(42),
'bar': Rx.Observable.return(56)
};
var defaultSource = Rx.Observable.empty();
var source = Rx.Observable.case(
function () {
return 'foo';
},
sources,
defaultSource);
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); } );
```
```
Next: 42
Completed
```
`case`/`switchCase` is found in the following distributions:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.experimental.js` (requires `rx.js`, `rx.compat.js`, `rx.lite.js`, or `rx.lite.compat.js`)
### RxPHP `defer`
RxPHP implements this operator as `defer`.
Returns an observable sequence that invokes the specified factory function whenever a new observer subscribes.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/defer/defer.php
$source = \Rx\Observable::defer(function () {
return \Rx\Observable::of(42);
});
$subscription = $source->subscribe($stdoutObserver);
```
```
Next value: 42
Complete!
```
| programming_docs |
reactivex ObserveOn ObserveOn
=========
> specify the Scheduler on which an observer will observe this Observable
 Many implementations of ReactiveX use [“`Scheduler`s”](../scheduler) to govern an Observable’s transitions between threads in a multi-threaded environment. You can instruct an Observable to send its notifications to observers on a particular Scheduler by means of the ObserveOn operator.
 Note that ObserveOn will forward an `onError` termination notification immediately if it receives one, and will not wait for a slow-consuming observer to receive any not-yet-emitted items that it is aware of first. This may mean that the `onError` notification jumps ahead of (and swallows) items emitted by the source Observable, as in the diagram above.
 The [SubscribeOn](subscribeon) operator is similar, but it instructs the Observable to *itself* operate on the specified Scheduler, as well as notifying its observers on that Scheduler.
By default, an Observable and the chain of operators that you apply to it will do its work, and will notify its observers, on the same thread on which its `Subscribe` method is called. The SubscribeOn operator changes this behavior by specifying a different Scheduler on which the Observable should operate. The ObserveOn operator specifies a different Scheduler that the Observable will use to send notifications to its observers.
As shown in this illustration, the SubscribeOn operator designates which thread the Observable will begin operating on, no matter at what point in the chain of operators that operator is called. ObserveOn, on the other hand, affects the thread that the Observable will use *below* where that operator appears. For this reason, you may call ObserveOn multiple times at various points during the chain of Observable operators in order to change on which threads certain of those operators operate.
#### See Also
* [`Scheduler`](../scheduler)
* [SubscribeOn](subscribeon)
* [Rx Workshop: Schedulers](http://channel9.msdn.com/Series/Rx-Workshop/Rx-Workshop-Schedulers)
* [RxJava Threading Examples by Graham Lea](http://www.grahamlea.com/2014/07/rxjava-threading-examples/)
* [Introduction to Rx: SubscribeOn and ObserveOn](http://www.introtorx.com/Content/v1.0.10621.0/15_SchedulingAndThreading.html#SubscribeOnObserveOn)
* [RxJava: Understanding observeOn() and subscribeOn()](http://tomstechnicalblog.blogspot.hu/2016/02/rxjava-understanding-observeon-and.html) by Thomas Nield
* [Advanced Reactive Java: SubscribeOn and ObserveOn](http://akarnokd.blogspot.hu/2016/03/subscribeon-and-observeon.html) by Dávid Karnok
Language-Specific Information
-----------------------------
### RxGroovy `observeOn`
 To specify on which Scheduler the Observable should invoke its observers’ `onNext`, `onCompleted`, and `onError` methods, use the `observeOn` operator, passing it the appropriate `Scheduler`.
* Javadoc: [`observeOn(Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#observeOn(rx.Scheduler))
### RxJava 1․x `observeOn`
 To specify on which Scheduler the Observable should invoke its observers’ `onNext`, `onCompleted`, and `onError` methods, use the `observeOn` operator, passing it the appropriate `Scheduler`.
* Javadoc: [`observeOn(Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#observeOn(rx.Scheduler))
### RxJS `observeOn`
 To specify on which Scheduler the Observable should invoke its observers’ `onNext`, `onCompleted`, and `onError` methods, use the `observeOn` operator, passing it the appropriate `Scheduler`.
#### Sample Code
```
/* Change from immediate scheduler to timeout */
var source = Rx.Observable.return(42, Rx.Scheduler.immediate)
.observeOn(Rx.Scheduler.timeout);
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 42
Completed
```
`observeOn` is found in each of the following distributions:
* `rx.js`
* `rx.all.js`
* `rx.all.compat.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
reactivex Subscribe Subscribe
=========
> operate upon the emissions and notifications from an Observable
The Subscribe operator is the glue that connects an observer to an Observable. In order for an observer to see the items being emitted by an Observable, or to receive error or completed notifications from the Observable, it must first subscribe to that Observable with this operator.
A typical implementation of the Subscribe operator may accept one to three methods (which then constitute the observer), or it may accept an object (sometimes called an `Observer` or `Subscriber`) that implements the interface which includes those three methods:
`onNext` An Observable calls this method whenever the Observable emits an item. This method takes as a parameter the item emitted by the Observable. `onError` An Observable calls this method to indicate that it has failed to generate the expected data or has encountered some other error. This stops the Observable and it will not make further calls to `onNext` or `onCompleted`. The `onError` method takes as its parameter an indication of what caused the error (sometimes an object like an Exception or Throwable, other times a simple string, depending on the implementation). `onCompleted` An Observable calls this method after it has called `onNext` for the final time, if it has not encountered any errors. An Observable is called a “cold” Observable if it does not begin to emit items until an observer has subscribed to it; an Observable is called a “hot” Observable if it may begin emitting items at any time, and a subscriber may begin observing the sequence of emitted items at some point after its commencement, missing out on any items emitted previously to the time of the subscription.
#### See Also
* [Do](do)
* [Introduction to Rx: IObserver](http://www.introtorx.com/Content/v1.0.10621.0/02_KeyTypes.html#IObserver)
Language-Specific Information
-----------------------------
### RxGroovy `BlockingObservable.forEach forEach subscribe`
RxGroovy implements several variants of `subscribe`.
If you pass it no parameters, it will trigger a subscription to the underlying Observable, but will ignore its emissions and notifications. This will activate a cold Observable.
You can also pass it between one and three functions; these will be interpreted as follows:
1. `onNext`
2. `onNext` and `onError`
3. `onNext`, `onError`, and `onCompleted`
Finally, you can pass it an object that implements either of the `Observer` or `Subscriber` interfaces. The `Observer` interface consists of the three previously-described “`on`” methods. The `Subscriber` interface implements these also, and adds a number of additional methods that facilitate reactive pull backpressure and that permit the Subscriber to unsubscribe to an Observable before it completes.
The call to `subscribe` returns an object that implements the `Subscription` interface. This interface includes the `unsubscribe` method that you can call at any time to sever the subscription that `subscribe` established between the Observable and the observer (or the methods that stand in for the observer).
* Javadoc: [`subscribe()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#subscribe())
* Javadoc: [`subscribe(Action1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#subscribe(rx.functions.Action1))
* Javadoc: [`subscribe(Action1,Action1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#subscribe(rx.functions.Action1,%20rx.functions.Action1))
* Javadoc: [`subscribe(Action1,Action1,Action0)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#subscribe(rx.functions.Action1,%20rx.functions.Action1,%20rx.functions.Action0))
* Javadoc: [`subscribe(Observer)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#subscribe(rx.Observer))
* Javadoc: [`subscribe(Subscriber)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#subscribe(rx.Subscriber))
The `forEach` operators are simpler versions of `subscribe`. You can pass them between one and three functions, which will be interpreted as follows:
1. `onNext`
2. `onNext` and `onError`
3. `onNext`, `onError`, and `onCompleted`
Unlike `subscribe`, `forEach` does not return an object with which you can cancel the subscription. Nor do you have the option of passing a parameter that has this capability. So you should only use this operator if you definitely need to operate on all of the emissions and notifications from the Observable.
* Javadoc: [`forEach(Action1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#forEach(rx.functions.Action1))
* Javadoc: [`forEach(Action1,Action1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#forEach(rx.functions.Action1,%20rx.functions.Action1))
* Javadoc: [`forEach(Action1,Action1,Action0)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#forEach(rx.functions.Action1,%20rx.functions.Action1,%20rx.functions.Action0))
 There is also a `BlockingObservable` method called `forEach` that is somewhat similar. In order to use it, you must first convert your source Observable into a `BlockingObservable` by means of either the `BlockingObservable.from` method or the `Observable.toBlocking` operator.
`BlockingObservable.forEach` takes a single function as its parameter, and this function behaves much like an `onNext` function in the subscription to an ordinary Observable. The `forEach` operator itself blocks until the `BlockingObservable` completes, and it is by unblocking, rather than by calling a callback function, that it indicates that it is complete. If it encounters an error it will throw a `RuntimeException` (rather than calling an analogue to the `onError` callback).
* Javadoc: [BlockingObservable.forEach(Action1)](http://reactivex.io/RxJava/javadoc/rx/observables/BlockingObservable.html#forEach(rx.functions.Action1))
### RxJava 1․x `BlockingObservable.forEach forEach subscribe`
RxJava implements several variants of `subscribe`.
If you pass it no parameters, it will trigger a subscription to the underlying Observable, but will ignore its emissions and notifications. This will activate a cold Observable.
You can also pass it between one and three functions; these will be interpreted as follows:
1. `onNext`
2. `onNext` and `onError`
3. `onNext`, `onError`, and `onCompleted`
Finally, you can pass it an object that implements either of the `Observer` or `Subscriber` interfaces. The `Observer` interface consists of the three previously-described “`on`” methods. The `Subscriber` interface implements these also, and adds a number of additional methods that facilitate reactive pull backpressure and that permit the Subscriber to unsubscribe to an Observable before it completes.
The call to `subscribe` returns an object that implements the `Subscription` interface. This interface includes the `unsubscribe` method that you can call at any time to sever the subscription that `subscribe` established between the Observable and the observer (or the methods that stand in for the observer).
* Javadoc: [`subscribe()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#subscribe())
* Javadoc: [`subscribe(Action1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#subscribe(rx.functions.Action1))
* Javadoc: [`subscribe(Action1,Action1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#subscribe(rx.functions.Action1,%20rx.functions.Action1))
* Javadoc: [`subscribe(Action1,Action1,Action0)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#subscribe(rx.functions.Action1,%20rx.functions.Action1,%20rx.functions.Action0))
* Javadoc: [`subscribe(Observer)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#subscribe(rx.Observer))
* Javadoc: [`subscribe(Subscriber)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#subscribe(rx.Subscriber))
The `forEach` operators are simpler versions of `subscribe`. You can pass them between one and three functions, which will be interpreted as follows:
1. `onNext`
2. `onNext` and `onError`
3. `onNext`, `onError`, and `onCompleted`
Unlike `subscribe`, `forEach` does not return an object with which you can cancel the subscription. Nor do you have the option of passing a parameter that has this capability. So you should only use this operator if you definitely need to operate on all of the emissions and notifications from the Observable.
* Javadoc: [`forEach(Action1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#forEach(rx.functions.Action1))
* Javadoc: [`forEach(Action1,Action1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#forEach(rx.functions.Action1,%20rx.functions.Action1))
* Javadoc: [`forEach(Action1,Action1,Action0)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#forEach(rx.functions.Action1,%20rx.functions.Action1,%20rx.functions.Action0))
 There is also a `BlockingObservable` method called `forEach` that is somewhat similar. In order to use it, you must first convert your source Observable into a `BlockingObservable` by means of either the `BlockingObservable.from` method or the `Observable.toBlocking` operator.
`BlockingObservable.forEach` takes a single function as its parameter, and this function behaves much like an `onNext` function in the subscription to an ordinary Observable. The `forEach` operator itself blocks until the `BlockingObservable` completes, and it is by unblocking, rather than by calling a callback function, that it indicates that it is complete. If it encounters an error it will throw a `RuntimeException` (rather than calling an analogue to the `onError` callback).
* Javadoc: [BlockingObservable.forEach(Action1)](http://reactivex.io/RxJava/javadoc/rx/observables/BlockingObservable.html#forEach(rx.functions.Action1))
### RxJS `forEach subscribe subscribeOnCompleted subscribeOnError subscribeOnNext`
In RxJS, you can subscribe to an Observable in two ways:
1. subscribe a single function to either the `onNext`, the `onCompleted`, or `onError` notifications from an Observable, with `subscribeOnNext`, `subscribeOnCompleted`, or `subscribeOnError` respectively
2. subscribe by passing zero to three individual functions, or an object that implements those three functions, into either the `subscribe` or `forEach` operator (those operators behave identically).
#### Sample Code
```
var source = Rx.Observable.range(0, 3)
var subscription = source.subscribeOnNext(
function (x) {
console.log('Next: %s', x);
});
```
```
Next: 0
Next: 1
Next: 2
```
```
var source = Rx.Observable.range(0, 3);
var subscription = source.subscribeOnCompleted(
function () {
console.log('Completed');
});
```
```
Completed
```
```
var source = Rx.Observable.throw(new Error());
var subscription = source.subscribeOnError(
function (err) {
console.log('Error: %s', err);
});
```
```
Error: Error
```
```
var observer = Rx.Observer.create(
function (x) { console.log('Next: %s', x); },
function (err) { console.log('Error: %s', err); },
function () { console.log('Completed'); });
var source = Rx.Observable.range(0, 3)
var subscription = source.subscribe(observer);
```
```
Next: 0
Next: 1
Next: 2
Completed
```
```
var source = Rx.Observable.range(0, 3)
var subscription = source.subscribe(
function (x) { console.log('Next: %s', x); },
function (err) { console.log('Error: %s', err); },
function () { console.log('Completed'); });
```
```
Next: 0
Next: 1
Next: 2
Completed
```
The functions described in this section are all found in each of the following distributions:
* `rx.js`
* `rx.all.js`
* `rx.all.compat.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
### RxPHP `subscribe`
RxPHP implements this operator as `subscribe`.
reactivex Create Create
======
> create an Observable from scratch by means of a function
 You can create an Observable from scratch by using the Create operator. You pass this operator a function that accepts the observer as its parameter. Write this function so that it behaves as an Observable — by calling the observer’s `onNext`, `onError`, and `onCompleted` methods appropriately.
A well-formed finite Observable must attempt to call either the observer’s `onCompleted` method exactly once or its `onError` method exactly once, and must not thereafter attempt to call any of the observer’s other methods.
#### See Also
* [Introduction to Rx: Create](http://www.introtorx.com/Content/v1.0.10621.0/04_CreatingObservableSequences.html#ObservableCreate)
* [Introduction to Rx: Generate](http://www.introtorx.com/Content/v1.0.10621.0/04_CreatingObservableSequences.html#ObservableGenerate)
* [101 Rx Samples: Generate](http://rxwiki.wikidot.com/101samples#toc42)
* [RxJava Tutorial 03: Observable from, just, & create methods](https://www.youtube.com/watch?v=sDqrlNprY24)
Language-Specific Information
-----------------------------
### RxGroovy `create`
 RxGroovy implements this operator as `create`.
#### Sample Code
```
def myObservable = Observable.create({ aSubscriber ->
try {
for (int i = 1; i < 1000000; i++) {
if (aSubscriber.isUnsubscribed()) {
return;
}
aSubscriber.onNext(i);
}
if (!aSubscriber.isUnsubscribed()) {
aSubscriber.onCompleted();
}
} catch(Throwable t) {
if (!aSubscriber.isUnsubscribed()) {
aSubscriber.onError(t);
}
}
})
```
It is good practice to check the observer’s `isUnsubscribed` state so that your Observable can stop emitting items or doing expensive calculations when there is no longer an interested observer.
`create` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`create(OnSubscribe)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#create(rx.Observable.OnSubscribe))
### RxJava 1․x `create`
 RxJava implements this operator as `create`.
It is good practice to check the observer’s `isUnsubscribed` state from within the function you pass to `create` so that your Observable can stop emitting items or doing expensive calculations when there is no longer an interested observer.
#### Sample Code
```
Observable.create(new Observable.OnSubscribe<Integer>() {
@Override
public void call(Subscriber<? super Integer> observer) {
try {
if (!observer.isUnsubscribed()) {
for (int i = 1; i < 5; i++) {
observer.onNext(i);
}
observer.onCompleted();
}
} catch (Exception e) {
observer.onError(e);
}
}
} ).subscribe(new Subscriber<Integer>() {
@Override
public void onNext(Integer item) {
System.out.println("Next: " + item);
}
@Override
public void onError(Throwable error) {
System.err.println("Error: " + error.getMessage());
}
@Override
public void onCompleted() {
System.out.println("Sequence complete.");
}
});
```
```
Next: 1
Next: 2
Next: 3
Next: 4
Sequence complete.
```
`create` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`create(OnSubscribe)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#create(rx.Observable.OnSubscribe))
### RxJS `create createWithDisposable generate generateWithAbsoluteTime generateWithRelativeTime`
 RxJS implements this operator as `create` (there is also an alternate name for the same operator: `createWithDisposable`).
#### Sample Code
```
/* Using a function */
var source = Rx.Observable.create(function (observer) {
observer.onNext(42);
observer.onCompleted();
// Note that this is optional, you do not have to return this if you require no cleanup
return function () { console.log('disposed'); };
});
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 42
Completed
```
```
/* Using a disposable */
var source = Rx.Observable.create(function (observer) {
observer.onNext(42);
observer.onCompleted();
// Note that this is optional, you do not have to return this if you require no cleanup
return Rx.Disposable.create(function () {
console.log('disposed');
});
});
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 42
Completed
```
`create` is found in the following distributions:
* `rx.js`
* `rx.all.js`
* `rx.all.compat.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
 You can use the `generate` operator to create simple Observables that can generate their next emissions, and can determine when to terminate, based on the value of the previous emission. The basic form of `generate` takes four parameters:
1. the first item to emit
2. a function to test an item to determine whether to emit it (`true`) or terminate the Observable (`false`)
3. a function to generate the next item to test and emit based on the value of the previous item
4. a function to transform items before emitting them
You can also pass in as an optional fifth parameter a [Scheduler](../scheduler) that `generate` will use to create and emit its sequence (it uses `currentThread` by default).
#### Sample Code
```
var source = Rx.Observable.generate(
0,
function (x) { return x < 3; },
function (x) { return x + 1; },
function (x) { return x; }
);
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 0
Next: 1
Next: 2
Completed
```
`generate` is found in the following distributions:
* `rx.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
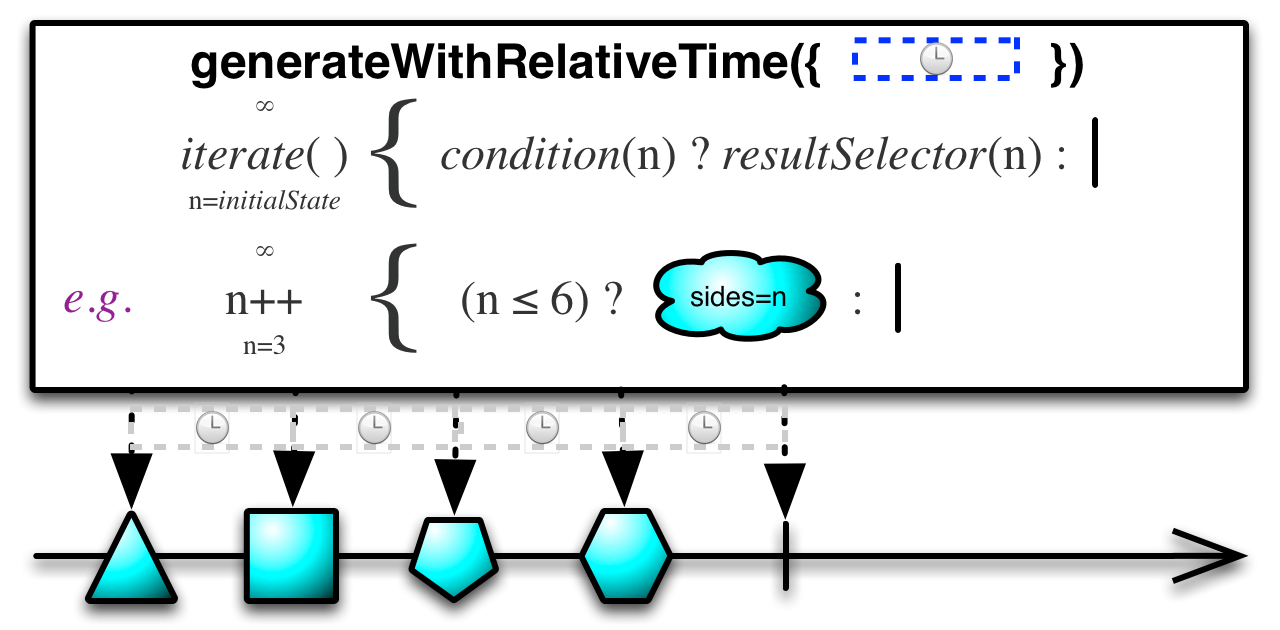 You can use the `generateWithRelativeTime` operator to create simple Observables that can generate their next emissions, and can determine when to terminate, based on the value of the previous emission. The basic form of `generateWithRelativeTime` takes five parameters:
1. the first item to emit
2. a function to test an item to determine whether to emit it (`true`) or terminate the Observable (`false`)
3. a function to generate the next item to test and emit based on the value of the previous item
4. a function to transform items before emitting them
5. a function to indicate how long, in milliseconds, the generator should wait after the emission of the previous item before emitting this item
You can also pass in as an optional sixth parameter a [Scheduler](../scheduler) that `generate` will use to create and emit its sequence (it uses `currentThread` by default).
#### Sample Code
```
var source = Rx.Observable.generateWithRelativeTime(
1,
function (x) { return x < 4; },
function (x) { return x + 1; },
function (x) { return x; },
function (x) { return 100 * x; }
).timeInterval();
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: {value: 1, interval: 100}
Next: {value: 2, interval: 200}
Next: {value: 3, interval: 300}
Completed
```
`generateWithRelativeTime` is found in the following distributions:
* `rx.lite.js`
* `rx.lite.compat.js`
* `rx.time.js` (requires `rx.js` or `rx.compat.js`)
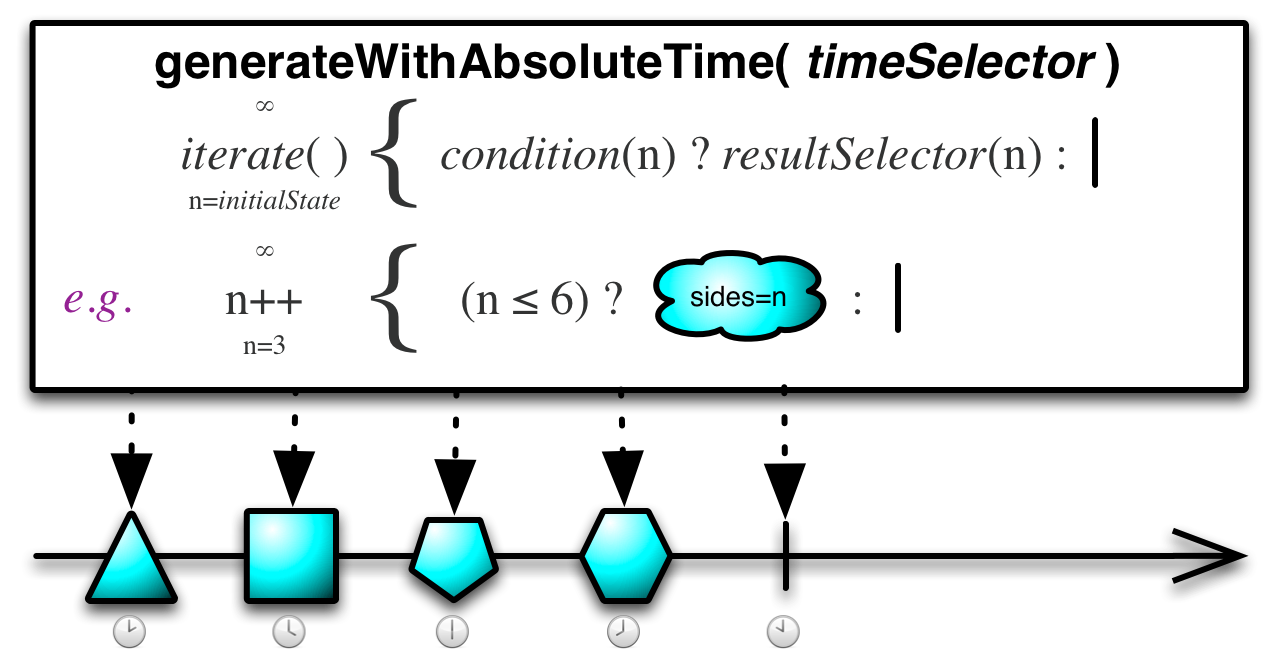 You can use the `generateWithAbsoluteTime` operator to create simple Observables that can generate their next emissions, and can determine when to terminate, based on the value of the previous emission. The basic form of `generateWithAbsoluteTime` takes five parameters:
1. the first item to emit
2. a function to test an item to determine whether to emit it (`true`) or terminate the Observable (`false`)
3. a function to generate the next item to test and emit based on the value of the previous item
4. a function to transform items before emitting them
5. a function to indicate at what time (expressed as a `Date`) the generator should emit the the new item
You can also pass in as an optional sixth parameter a [Scheduler](../scheduler) that `generate` will use to create and emit its sequence (it uses `currentThread` by default).
#### Sample Code
```
var source = Rx.Observable.generate(
1,
function (x) { return x < 4; },
function (x) { return x + 1; },
function (x) { return x; },
function (x) { return Date.now() + (100 * x); }
).timeInterval();
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: {value: 1, interval: 100}
Next: {value: 2, interval: 200}
Next: {value: 3, interval: 300}
Completed
```
`generateWithAbsoluteTime` is found in the following distribution:
* `rx.time.js` (requires `rx.js` or `rx.compat.js`)
### RxPHP `create`
RxPHP implements this operator as `create`.
Creates an observable sequence from a specified subscribeAction callable implementation.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/create/create.php
//With static method
$source = \Rx\Observable::create(function (\Rx\ObserverInterface $observer) {
$observer->onNext(42);
$observer->onCompleted();
return new CallbackDisposable(function () {
echo "Disposed\n";
});
});
$subscription = $source->subscribe($createStdoutObserver());
```
```
Next value: 42
Complete!
Disposed
```
### RxSwift `create generate`
 RxSwift implements this operator as `create`.
#### Sample Code
```
let source : Observable = Observable.create { observer in
for i in 1...5 {
observer.on(.next(i))
}
observer.on(.completed)
// Note that this is optional. If you require no cleanup you can return
// `Disposables.create()` (which returns the `NopDisposable` singleton)
return Disposables.create {
print("disposed")
}
}
source.subscribe {
print($0)
}
```
```
next(1)
next(2)
next(3)
next(4)
next(5)
completed
disposed
```
 You can use the `generate` operator to create simple Observables that can generate their next emissions, and can determine when to terminate, based on the value of the previous emission. The basic form of `generate` takes three parameters:
1. the first item to emit
2. a function to test an item to determine whether to emit it (`true`) or terminate the Observable (`false`)
3. a function to generate the next item to test and emit based on the value of the previous item
You can also pass in as an optional fourth parameter a [Scheduler](../scheduler) that `generate` will use to create and emit its sequence (it uses `CurrentThreadScheduler` by default).
#### Sample Code
```
let source = Observable.generate(
initialState: 0,
condition: { $0 < 3 },
iterate: { $0 + 1 }
)
source.subscribe {
print($0)
}
```
```
next(0)
next(1)
next(2)
completed
```
| programming_docs |
reactivex Count Count
=====
> count the number of items emitted by the source Observable and emit only this value
[Open interactive diagram on rxmarbles.com](https://rxmarbles.com/#count) The Count operator transforms an Observable that emits items into an Observable that emits a single value that represents the number of items emitted by the source Observable.
If the source Observable terminates with an error, Count will pass this error notification along without emitting an item first. If the source Observable does not terminate at all, Count will neither emit an item nor terminate.
#### See Also
* [Introduction to Rx: Count](http://www.introtorx.com/Content/v1.0.10621.0/07_Aggregation.html#Count)
* [RxMarbles: `count`](http://rxmarbles.com/#count)
Language-Specific Information
-----------------------------
### RxClojure `count longCount`
RxClojure has both `count` and `longCount` variants of this operator, but both of these in fact return long values.
### RxCpp `count`
RxCpp implements this operator as `count`.
### RxGroovy `count countLong`
In RxGroovy the operator is called `count` and the Observable it creates emits an Integer value. There is also a `countLong` whose Observable emits a Long value.
#### Sample Code
```
def myObservable = Observable.create({ aSubscriber ->
if(false == aSubscriber.isUnsubscribed()) aSubscriber.onNext('Three');
if(false == aSubscriber.isUnsubscribed()) aSubscriber.onNext('Two');
if(false == aSubscriber.isUnsubscribed()) aSubscriber.onNext('One');
if(false == aSubscriber.isUnsubscribed()) aSubscriber.onCompleted();
});
myObservable.count().subscribe(
{ println(it); }, // onNext
{ println("Error: " + it.getMessage()); }, // onError
{ println("Sequence complete"); } // onCompleted
);
```
```
3
Sequence complete
```
* Javadoc: [`count()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#count())
* Javadoc: [`countLong()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#countLong())
### RxJava 1․x `count countLong`
In RxJava the operator is called `count` and the Observable it creates emits an Integer value. There is also a `countLong` whose Observable emits a Long value.
#### Sample Code
```
String[] items = new String[] { "one", "two", "three" };
assertEquals( new Integer(3), Observable.from(items).count().toBlocking().single() );
```
* Javadoc: [`count()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#count())
* Javadoc: [`countLong()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#countLong())
### RxJS `count`
In RxJS the operator `count` counts the number of items in the source Observable that satisfy a specified predicate. That predicate takes the form of a function that takes three parameters:
1. the emitted item
2. the index of that item in the sequence of emitted items
3. the source Observable
If the predicate function returns `true`, `count` will increment the tally of items that it will report when the source Observable completes. If you want to count *all* of the items emitted by the source Observable, simply pass `count` a predicate that always returns `true`:
#### Sample Code
```
numberOfItems = someObservable.count(function() { return true; });
```
`count` is part of the following packages:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.aggregates.js`
`count` requires one of any of the following packages:
* `rx.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
### RxKotlin `count`
RxKotlin implements this operator as `count`.
#### Sample Code
```
val list = listOf(1, 2, 3, 4, 5)
assertEquals( 5, Observable.from(list)!!.count()!!.toBlocking()!!.single() )
```
### RxNET `Count LongCount`
In Rx.NET the Observable this operator creates emits an Integer value, but there is also a `LongCount` whose Observable emits a Long value. With both variants, you can either pass the source Observable in to the operator as a parameter or you can call the operator as an instance method of the source Observable (in which case you omit the parameter).
### RxPHP `count`
RxPHP implements this operator as `count`.
Returns an observable sequence containing a value that represents how many elements in the specified observable sequence satisfy a condition if provided, else the count of items.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/count/count.php
$source = \Rx\Observable::fromArray(range(1, 10));
$subscription = $source->count()->subscribe($stdoutObserver);
```
```
Next value: 10
Complete!
```
### RxPY `count`
In RxPY you have the option to pass `count` a predicate that takes an item emitted by the source Observable as a parameter. If you do so, `count` will emit a count only of those items from the source Observable that the predicate evaluates as `true`. Otherwise, it will emit a count of all items emitted by the source Observable.
#### Sample Code
```
numberOfItems = someObservable.count()
numberOfNegativeItems = someObservable.count(lambda x: x < 0)
```
### Rxrb `count`
In Rx.rb you have the option to pass `count` a predicate that takes an item emitted by the source Observable as a parameter. If you do so, `count` will emit a count only of those items from the source Observable that the predicate evaluates as `true`. Otherwise it will emit a count of all items emitted by the source Observable.
### RxScala `count length longCount size`
In RxScala the operator `count` counts the number of items in the source Observable that satisfy a specified predicate. That predicate accepts an emitted item as a parameter and returns a Boolean. `count` will emit a count of all items for which this predicate returned `true`.
Use `length` or `size` instead if you want to count *all* of the items emitted by the source Observable and emit this count as an Integer, or use `longCount` to emit it as a Long.
reactivex Catch Catch
=====
> recover from an onError notification by continuing the sequence without error
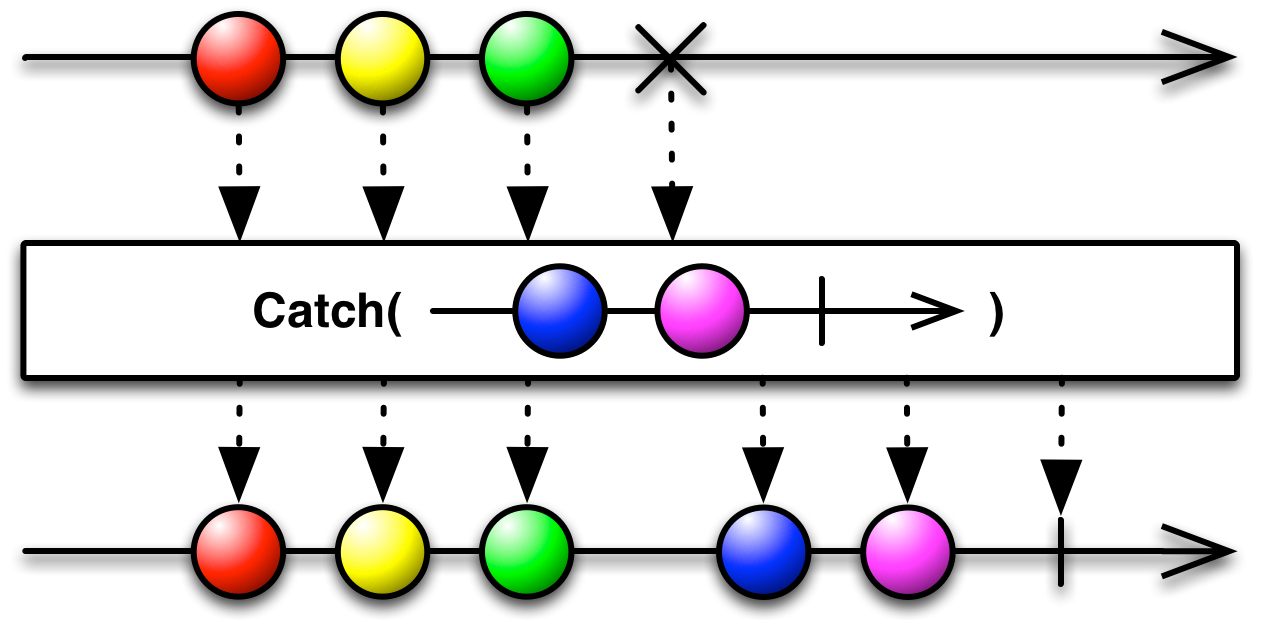 The Catch operator intercepts an `onError` notification from the source Observable and, instead of passing it through to any observers, replaces it with some other item or sequence of items, potentially allowing the resulting Observable to terminate normally or not to terminate at all.
There are several variants of the Catch operator, and a variety of names used by different ReactiveX implementations to describe this operation, as you can see in the sections below.
In some ReactiveX implementations, there is an operator called something like “OnErrorResumeNext” that behaves like a Catch variant: specifically reacting to an `onError` notification from the source Observable. In others, there is an operator with that name that behaves more like a Concat variant: performing the concatenation operation regardless of whether the source Observable terminates normally or with an error. This is unfortunate and confusing, but something we have to live with.
#### See Also
* [Concat](concat)
* [Retry](retry)
* [Introduction to Rx: Catch](http://www.introtorx.com/Content/v1.0.10621.0/11_AdvancedErrorHandling.html#Catch)
Language-Specific Information
-----------------------------
### RxClojure `catch*`
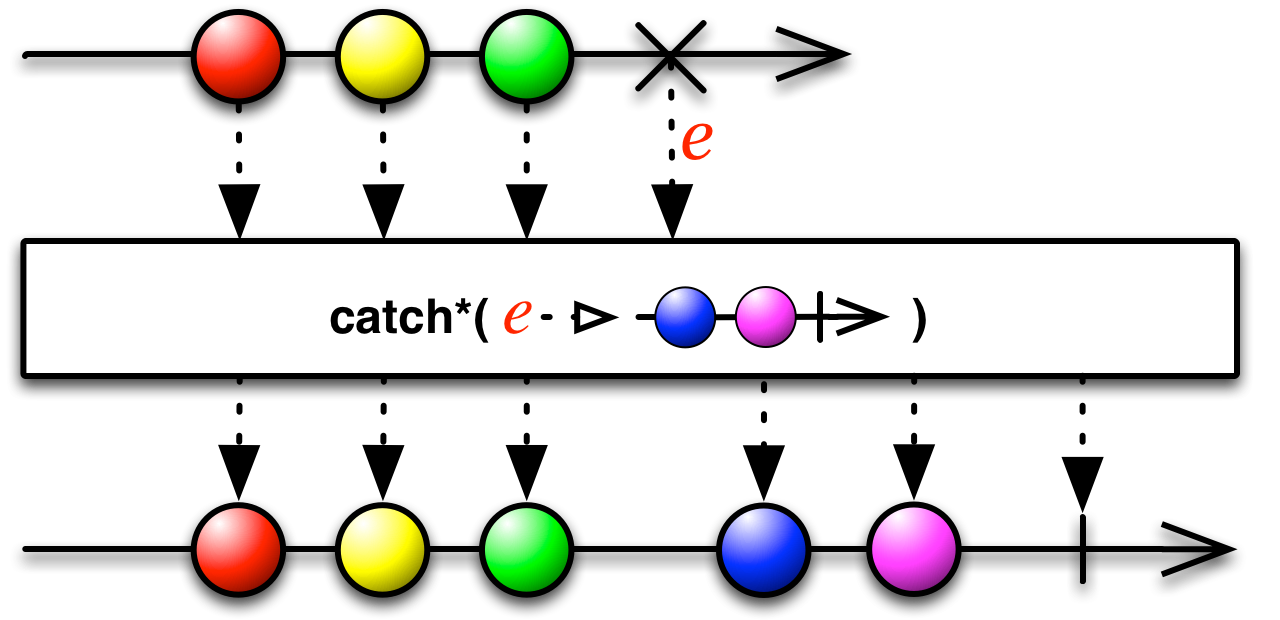 RxClojure implements this operator as `catch*`. This operator takes two arguments, both of which are functions of your choosing that take the exception raised by `onError` as their single parameters. The first function is a predicate. If it returns `false`, `catch*` passes the `onError` notification unchanged to its observers. If it returns `true`, however, `catch*` swallows the error, calls the second function (which returns an Observable), and passes along the emissions and notifications from this new Observable to its observers.
You may replace the first function parameter (the predicate that evaluates the exception) with a class object representing a variety of exception. If you do this, `catch*` will treat it as equivalent to predicate that performs an `instance?` check to see if the exception from the `onError` notification is an instance of the class object. In other words:
#### Sample Code
```
(->> my-observable
(catch* IllegalArgumentException
(fn [e] (rx/return 1)))
)
```
is equivalent to:
```
(->> my-observable
(catch* (fn [e] (-> instance? IllegalArgumentException e))
(fn [e] (rx/return 1)))
)
```
### RxCpp
RxCpp does not implement the Catch operator.
### RxGroovy `onErrorResumeNext onErrorReturn onExceptionResumeNext`
RxGroovy implements the Catch operator in the same way as does RxJava. There are three distinct operators that provide this functionality:
`onErrorReturn` instructs an Observable to emit a particular item when it encounters an error, and then terminate normally `onErrorResumeNext` instructs an Observable to begin emitting a second Observable sequence if it encounters an error `onExceptionResumeNext` instructs an Observable to continue emitting items after it encounters an exception (but not another variety of throwable) #### `onErrorReturn`
 The `onErrorReturn` method returns an Observable that mirrors the behavior of the source Observable, unless that Observable invokes `onError` in which case, rather than propagating that error to the observer, `onErrorReturn` will instead emit a specified item and invoke the observer’s `onCompleted` method, as shown in the following sample code:
#### Sample Code
```
def myObservable = Observable.create({ aSubscriber ->
if(false == aSubscriber.isUnsubscribed()) aSubscriber.onNext('Four');
if(false == aSubscriber.isUnsubscribed()) aSubscriber.onNext('Three');
if(false == aSubscriber.isUnsubscribed()) aSubscriber.onNext('Two');
if(false == aSubscriber.isUnsubscribed()) aSubscriber.onNext('One');
if(false == aSubscriber.isUnsubscribed()) aSubscriber.onError();
});
myObservable.onErrorReturn({ return('Blastoff!'); }).subscribe(
{ println(it); }, // onNext
{ println("Error: " + it.getMessage()); }, // onError
{ println("Sequence complete"); } // onCompleted
);
```
```
Four
Three
Two
One
Blastoff!
Sequence complete
```
* Javadoc: [`onErrorReturn(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#onErrorReturn(rx.functions.Func1))
#### `onErrorResumeNext`
 The `onErrorResumeNext` method returns an Observable that mirrors the behavior of the source Observable, unless that Observable invokes `onError` in which case, rather than propagating that error to the observer, `onErrorResumeNext` will instead begin mirroring a second, backup Observable, as shown in the following sample code:
#### Sample Code
```
def myObservable = Observable.create({ aSubscriber ->
if(false == aSubscriber.isUnsubscribed()) aSubscriber.onNext('Three');
if(false == aSubscriber.isUnsubscribed()) aSubscriber.onNext('Two');
if(false == aSubscriber.isUnsubscribed()) aSubscriber.onNext('One');
if(false == aSubscriber.isUnsubscribed()) aSubscriber.onError();
});
def myFallback = Observable.create({ aSubscriber ->
if(false == aSubscriber.isUnsubscribed()) aSubscriber.onNext('0');
if(false == aSubscriber.isUnsubscribed()) aSubscriber.onNext('1');
if(false == aSubscriber.isUnsubscribed()) aSubscriber.onNext('2');
if(false == aSubscriber.isUnsubscribed()) aSubscriber.onCompleted();
});
myObservable.onErrorResumeNext(myFallback).subscribe(
{ println(it); }, // onNext
{ println("Error: " + it.getMessage()); }, // onError
{ println("Sequence complete"); } // onCompleted
);
```
```
Three
Two
One
0
1
2
Sequence complete
```
* Javadoc: [`onErrorResumeNext(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#onErrorResumeNext(rx.functions.Func1))
* Javadoc: [`onErrorResumeNext(Observable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#onErrorResumeNext(rx.Observable))
#### `onExceptionResumeNext`
 Much like `onErrorResumeNext` method, this returns an Observable that mirrors the behavior of the source Observable, unless that Observable invokes `onError` in which case, if the Throwable passed to `onError` is an Exception, rather than propagating that Exception to the observer, `onExceptionResumeNext` will instead begin mirroring a second, backup Observable. If the Throwable is not an Exception, the Observable returned by `onExceptionResumeNext` will propagate it to its observer’s `onError` method and will not invoke its backup Observable.
* Javadoc: [`onExceptionResumeNext(Observable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#onExceptionResumeNext(rx.Observable))
### RxJava 1․x `onErrorResumeNext onErrorReturn onExceptionResumeNext`
RxJava implements the Catch operator with three distinct operators:
`onErrorReturn` instructs an Observable to emit a particular item when it encounters an error, and then terminate normally `onErrorResumeNext` instructs an Observable to begin emitting a second Observable sequence if it encounters an error `onExceptionResumeNext` instructs an Observable to continue emitting items after it encounters an exception (but not another variety of throwable) #### `onErrorReturn`
 The `onErrorReturn` method returns an Observable that mirrors the behavior of the source Observable, unless that Observable invokes `onError` in which case, rather than propagating that error to the observer, `onErrorReturn` will instead emit a specified item and invoke the observer’s `onCompleted` method.
* Javadoc: [`onErrorReturn(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#onErrorReturn(rx.functions.Func1))
#### `onErrorResumeNext`
 The `onErrorResumeNext` method returns an Observable that mirrors the behavior of the source Observable, unless that Observable invokes `onError` in which case, rather than propagating that error to the observer, `onErrorResumeNext` will instead begin mirroring a second, backup Observable.
* Javadoc: [`onErrorResumeNext(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#onErrorResumeNext(rx.functions.Func1))
* Javadoc: [`onErrorResumeNext(Observable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#onErrorResumeNext(rx.Observable))
#### `onExceptionResumeNext`
 Much like `onErrorResumeNext` method, this returns an Observable that mirrors the behavior of the source Observable, unless that Observable invokes `onError` in which case, if the Throwable passed to `onError` is an Exception, rather than propagating that Exception to the observer, `onExceptionResumeNext` will instead begin mirroring a second, backup Observable. If the Throwable is not an Exception, the Observable returned by `onExceptionResumeNext` will propagate it to its observer’s `onError` method and will not invoke its backup Observable.
* Javadoc: [`onExceptionResumeNext(Observable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#onExceptionResumeNext(rx.Observable))
### RxJS `catch onErrorResumeNext`
RxJS implements the Catch operator with two distinct operators:
`catch` instructs an Observable to begin emitting a second Observable sequence if it encounters an error `onErrorResumeNext` instructs an Observable to begin emitting a second Observable sequence if it encounters an error or if the source Observable terminates normally #### `catch`
 `catch` is found in the following distributions:
* `rx.js`
* `rx.all.js`
* `rx.all.compat.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
#### `onErrorResumeNext`
 This implementation borrows the confusing nomenclature from Rx.NET, in which `onErrorResumeNext` switches to a back-up Observable both on an error *and* on a normal, error-free termination of the source Observable.
`onErrorResumeNext` is found in the following distributions:
* `rx.js`
* `rx.compat.js`
### RxKotlin `onErrorResumeNext onErrorReturn onExceptionResumeNext`
RxKotlin implements the Catch operator in the same way as does RxJava. There are three distinct operators that provide this functionality:
`onErrorReturn` instructs an Observable to emit a particular item when it encounters an error, and then terminate normally `onErrorResumeNext` instructs an Observable to begin emitting a second Observable sequence if it encounters an error `onExceptionResumeNext` instructs an Observable to continue emitting items after it encounters an exception (but not another variety of throwable) #### `onErrorReturn`
 The `onErrorReturn` method returns an Observable that mirrors the behavior of the source Observable, unless that Observable invokes `onError` in which case, rather than propagating that error to the observer, `onErrorReturn` will instead emit a specified item and invoke the observer’s `onCompleted` method.
#### `onErrorResumeNext`
 The `onErrorResumeNext` method returns an Observable that mirrors the behavior of the source Observable, unless that Observable invokes `onError` in which case, rather than propagating that error to the observer, `onErrorResumeNext` will instead begin mirroring a second, backup Observable.
#### `onExceptionResumeNext`
 Much like `onErrorResumeNext` method, this returns an Observable that mirrors the behavior of the source Observable, unless that Observable invokes `onError` in which case, if the Throwable passed to `onError` is an Exception, rather than propagating that Exception to the observer, `onExceptionResumeNext` will instead begin mirroring a second, backup Observable. If the Throwable is not an Exception, the Observable returned by `onExceptionResumeNext` will propagate it to its observer’s `onError` method and will not invoke its backup Observable.
### RxNET `Catch OnErrorResumeNext`
Rx.NET implements the Catch operator with two distinct operators:
`Catch` instructs an Observable to begin emitting a second Observable sequence if it encounters an error `OnErrorResumeNext` instructs an Observable to begin emitting a second Observable sequence if it encounters an error or if the source Observable terminates normally #### `Catch`
 The `Catch` operator has a variant that allows you to specify which sort of Exception you want to catch. If you use that variant of the operator, any other Exceptions will be passed through to the observer as if the `Catch` operator had not been applied.
#### `OnErrorResumeNext`
 This implementation introduces a confusing nomenclature, in which in spite of its name `OnErrorResumeNext` switches to a back-up Observable both on an error *and* on a normal, error-free termination of the source Observable. It is therefore more like a concatenation operator.
### RxPHP `catch`
RxPHP implements this operator as `catch`.
Continues an observable sequence that is terminated by an exception with the next observable sequence.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/catch/catch.php
$obs2 = Rx\Observable::of(42);
$source = \Rx\Observable::error(new Exception('Some error'))
->catch(function (Throwable $e, \Rx\Observable $sourceObs) use ($obs2) {
return $obs2;
});
$subscription = $source->subscribe($stdoutObserver);
```
```
Next value: 42
Complete!
```
### RxPY `catch_exception on_error_resume_next`
RxPY implements the Catch operator with two distinct operators:
`catch_exception` instructs an Observable, if it encounters an error, to begin emitting items from a set of other Observables, one Observable at a time, until one of those Observables terminates successfully `on_error_resume_next` instructs an Observable to concatenate items emitted by a set of other Observables, one Observable at a time, regardless of whether the source Observable or any subsequent Observable terminates with an error #### `catch_exception`
 You may pass `catch_exception` a set of back-up Observables either as individual function parameters or as a single array of Observables. If it encounters an `onError` notification from the source Observable, it will subscribe to and begin mirroring the first of these back-up Observables. If this back-up Observable itself issues an `onError` notification, `catch_exception` will swallow it and switch over to the next back-up Observable. If any of these Observables issues an `onCompleted` notification, `catch_exception` will pass this along and will stop.
#### `on_error_resume_next`
 You may pass `on_error_resume_next` a set of back-up Observables either as individual function parameters, as a single array of Observables, or as a factory function that generates Observables. When the source Observable terminates, whether normally or with an error, `on_error_resume_next` will subscribe to and begin mirroring the first of these back-up Observables, and then will recursively continue this concatenation process for each additional Observable until there are no more Observables to mirror, at which time it will pass on the `onError` or `onCompleted` notification from the last of these Observables.
### Rxrb `on_error_resume_next rescue_error`
Rx.rb implements the Catch operator with two distinct operators:
`rescue_error` instructs an Observable to begin emitting items from another Observable, or from an Observable returned from an action, if it encounters an error `on_error_resume_next` instructs an Observable to concatenate items emitted by another Observable to the sequence emitted by the source Observable, regardless of whether the source Observable terminates normally or with an error #### `rescue_error`
 You may pass `rescue_error` either an Observable or a factory action that generates an Observable.
#### `on_error_resume_next`
 In Rx.rb, `on_error_resume_next` inherits the misleading nomenclature from Rx.NET in that it concatenates the second Observable sequence to the source sequence whether that source sequence terminates normally or with an error.
### RxScala `onErrorFlatMap onErrorResumeNext onErrorReturn onExceptionResumeNext`
Rx.rb implements the Catch operator with four distinct operators:
`onErrorFlatMap` replaces all `onError` notifications from a misbehaving Observable into the emissions from a secondary Observable `onErrorResumeNext` instructs an Observable to begin emitting a second Observable sequence if it encounters an error `onErrorReturn` instructs an Observable to emit a particular item when it encounters an error, and then terminate normally `onExceptionResumeNext` instructs an Observable to continue emitting items after it encounters an exception (but not another variety of throwable) #### `onErrorFlatMap`
 `onErrorFlatMap` handles a special case: a source Observable that is noncompliant with [the Observable contract](../contract) in such a way that it may interleave `onError` notifications with its emissions without terminating. This operator allows you to replace those `onError` notifications with the emissions of an Observable of your choosing without unsubscribing from the source, so that any future items emitted from the source will be passed along to observers as though the sequence had not been interrupted with an `onError` notification.
Because `onErrorFlatMap` is designed to work with pathological source Observables that do not terminate after issuing an error, it is mostly useful in debugging/testing scenarios.
 Note that you should apply `onErrorFlatMap` directly to the pathological source Observable, and not to that Observable after it has been modified by additional operators, as such operators may effectively renormalize the source Observable by unsubscribing from it immediately after it issues an error. Above, for example, is an illustration showing how `onErrorFlatMap` will respond to two error-generating Observables that have been merged by the [Merge](merge) operator:
Note that `onErrorFlatMap` will not react to both errors generated by both Observables, but only to the single error passed along by `merge`.
#### `onErrorResumeNext`
 The `onErrorResumeNext` method returns an Observable that mirrors the behavior of the source Observable, unless that Observable invokes `onError` in which case, rather than propagating that error to the observer, `onErrorResumeNext` will instead begin mirroring a second, backup Observable.
#### `onErrorReturn`
 The `onErrorReturn` method returns an Observable that mirrors the behavior of the source Observable, unless that Observable invokes `onError` in which case, rather than propagating that error to the observer, `onErrorReturn` will instead emit a specified item and invoke the observer’s `onCompleted` method.
#### `onExceptionResumeNext`
 Much like `onErrorResumeNext` method, this returns an Observable that mirrors the behavior of the source Observable, unless that Observable invokes `onError` in which case, if the Throwable passed to `onError` is an Exception, rather than propagating that Exception to the observer, `onExceptionResumeNext` will instead begin mirroring a second, backup Observable. If the Throwable is not an Exception, the Observable returned by `onExceptionResumeNext` will propagate it to its observer’s `onError` method and will not invoke its backup Observable.
| programming_docs |
reactivex RefCount RefCount
========
> make a Connectable Observable behave like an ordinary Observable
 A connectable Observable resembles an ordinary Observable, except that it does not begin emitting items when it is subscribed to, but only when the Connect operator is applied to it. In this way you can prompt an Observable to begin emitting items at a time of your choosing.
The RefCount operator automates the process of connecting to and disconnecting from a connectable Observable. It operates on a connectable Observable and returns an ordinary Observable. When the first observer subscribes to this Observable, RefCount connects to the underlying connectable Observable. RefCount then keeps track of how many other observers subscribe to it and does not disconnect from the underlying connectable Observable until the last observer has done so.
#### See Also
* [Connect](connect)
* [Publish](publish)
* [Replay](replay)
* [Introduction to Rx: RefCount](http://www.introtorx.com/Content/v1.0.10621.0/14_HotAndColdObservables.html#RefCount)
* [Wedding Party: Share, Publish, Refcount, and All That Jazz](http://blog.kaush.co/2015/01/21/rxjava-tip-for-the-day-share-publish-refcount-and-all-that-jazz/) by Kaushik Gopal
Language-Specific Information
-----------------------------
### RxGroovy `refCount share`
 RxGroovy implements this operator as `refCount`.
* Javadoc: [`refCount()`](http://reactivex.io/RxJava/javadoc/rx/observables/ConnectableObservable.html#refCount())
There is also a `share` operator, which is the equivalent of applying both the `publish` and `refCount` operators to an Observable, in that order.
* Javadoc: [`share()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#share())
### RxJava 1․x `refCount share`
 RxJava implements this operator as `refCount`.
* Javadoc: [`refCount()`](http://reactivex.io/RxJava/javadoc/rx/observables/ConnectableObservable.html#refCount())
There is also a `share` operator, which is the equivalent of applying both the `publish` and `refCount` operators to an Observable, in that order.
* Javadoc: [`share()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#share())
### RxJS `refCount share shareValue`
 RxJava implements this operator as `refCount`.
#### Sample Code
```
var interval = Rx.Observable.interval(1000);
var source = interval
.take(2)
.doAction(function (x) { console.log('Side effect'); });
var published = source.publish().refCount();
published.subscribe(createObserver('SourceA'));
published.subscribe(createObserver('SourceB'));
function createObserver(tag) {
return Rx.Observer.create(
function (x) { console.log('Next: ' + tag + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
}
```
```
Side effect
Next: SourceA0
Next: SourceB0
Side effect
Next: SourceA1
Next: SourceB1
Completed
Completed
```
`refCount` is found in the following distributions:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.binding.js` (requires `rx.js`, `rx.compat.js`, `rx.lite.js`, or `rx.lite.compat.js`)
* `rx.lite.js`
* `rx.lite.compat.js`
There is also a `share` operator, which is the equivalent of applying both the `publish` and `refCount` operators to an Observable, in that order. A variant called `shareValue` takes as a parameter a single item that it will emit to any subscribers before beginning to emit items from the source Observable.
#### Sample Code
```
var interval = Rx.Observable.interval(1000);
var source = interval
.take(2)
.do(
function (x) { console.log('Side effect'); });
var published = source.share();
// When the number of observers subscribed to published observable goes from
// 0 to 1, we connect to the underlying observable sequence.
published.subscribe(createObserver('SourceA'));
// When the second subscriber is added, no additional subscriptions are added to the
// underlying observable sequence. As a result the operations that result in side
// effects are not repeated per subscriber.
published.subscribe(createObserver('SourceB'));
function createObserver(tag) {
return Rx.Observer.create(
function (x) { console.log('Next: ' + tag + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
}
```
```
Side effect
Next: SourceA0
Next: SourceB0
Side effect
Next: SourceA1
Next: SourceB1
Completed
```
`share` and `shareValue` are found in the following distributions:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.binding.js` (requires `rx.js` or `rx.compat.js`)
* `rx.lite.js`
* `rx.lite.compat.js`
### RxPHP `share singleInstance shareValue`
RxPHP implements this operator as `share`.
Returns an observable sequence that shares a single subscription to the underlying sequence. This operator is a specialization of publish which creates a subscription when the number of observers goes from zero to one, then shares that subscription with all subsequent observers until the number of observers returns to zero, at which point the subscription is disposed.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/share/share.php
//With Share
$source = \Rx\Observable::interval(1000)
->take(2)
->doOnNext(function ($x) {
echo "Side effect\n";
});
$published = $source->share();
$published->subscribe($createStdoutObserver('SourceA '));
$published->subscribe($createStdoutObserver('SourceB '));
```
```
Side effect
SourceA Next value: 0
SourceB Next value: 0
Side effect
SourceA Next value: 1
SourceB Next value: 1
SourceA Complete!
SourceB Complete!
```
RxPHP also has an operator `singleInstance`.
Returns an observable sequence that shares a single subscription to the underlying sequence. This observable sequence can be resubscribed to, even if all prior subscriptions have ended. This operator behaves like share() in RxJS 5
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/share/singleInstance.php
$interval = Rx\Observable::interval(1000);
$source = $interval
->take(2)
->do(function () {
echo 'Side effect', PHP_EOL;
});
$single = $source->singleInstance();
// two simultaneous subscriptions, lasting 2 seconds
$single->subscribe($createStdoutObserver('SourceA '));
$single->subscribe($createStdoutObserver('SourceB '));
\Rx\Observable::timer(5000)->subscribe(function () use ($single, &$createStdoutObserver) {
// resubscribe two times again, more than 5 seconds later,
// long after the original two subscriptions have ended
$single->subscribe($createStdoutObserver('SourceC '));
$single->subscribe($createStdoutObserver('SourceD '));
});
```
```
Side effect
SourceA Next value: 0
SourceB Next value: 0
Side effect
SourceA Next value: 1
SourceB Next value: 1
SourceA Complete!
SourceB Complete!
Side effect
SourceC Next value: 0
SourceD Next value: 0
Side effect
SourceC Next value: 1
SourceD Next value: 1
SourceC Complete!
SourceD Complete!
```
RxPHP also has an operator `shareValue`.
Returns an observable sequence that shares a single subscription to the underlying sequence and starts with an initialValue. This operator is a specialization of publishValue which creates a subscription when the number of observers goes from zero to one, then shares that subscription with all subsequent observers until the number of observers returns to zero, at which point the subscription is disposed.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/share/shareValue.php
$source = \Rx\Observable::interval(1000)
->take(2)
->doOnNext(function ($x) {
echo "Side effect\n";
});
$published = $source->shareValue(42);
$published->subscribe($createStdoutObserver('SourceA '));
$published->subscribe($createStdoutObserver('SourceB '));
```
```
SourceA Next value: 42
SourceB Next value: 42
Side effect
SourceA Next value: 0
SourceB Next value: 0
Side effect
SourceA Next value: 1
SourceB Next value: 1
SourceA Complete!
SourceB Complete!
```
reactivex IgnoreElements IgnoreElements
==============
> do not emit any items from an Observable but mirror its termination notification
 The IgnoreElements operator suppresses all of the items emitted by the source Observable, but allows its termination notification (either `onError` or `onCompleted`) to pass through unchanged.
If you do not care about the items being emitted by an Observable, but you do want to be notified when it completes or when it terminates with an error, you can apply the `ignoreElements` operator to the Observable, which will ensure that it will never call its observers’ `onNext` handlers.
#### See Also
* [Introduction to Rx: IgnoreElements](http://www.introtorx.com/Content/v1.0.10621.0/05_Filtering.html#IgnoreElements)
Language-Specific Information
-----------------------------
### RxGroovy `ignoreElements`
 RxGroovy implements this operator as `ignoreElements`.
* Javadoc: [`ignoreElements()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#ignoreElements())
`ignoreElements` does not by default operate on any particular [Scheduler](../scheduler).
### RxJava 1․x `ignoreElements`
 RxJava implements this operator as `ignoreElements`.
* Javadoc: [`ignoreElements()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#ignoreElements())
`ignoreElements` does not by default operate on any particular [Scheduler](../scheduler).
### RxJS `ignoreElements`
 RxJS implements this operator as `ignoreElements`.
#### Sample Code
```
var source = Rx.Observable.range(0, 10)
.ignoreElements();
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Completed
```
`ignoreElements` is found in each of the following distributions:
* `rx.js`
* `rx.all.js`
* `rx.all.compat.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
reactivex Start Start
=====
> create an Observable that emits the return value of a function-like directive
 There are a number of ways that programming languages have for obtaining values as the result of calculations, with names like functions, futures, actions, callables, runnables, and so forth. The operators grouped here under the Start operator category make these things behave like Observables so that they can be chained with other Observables in an Observable cascade
See Also
--------
* [From](from)
* [Just](just)
* [101 Rx Samples: Start — Run Code Asynchronously](http://rxwiki.wikidot.com/101samples#toc1)
Language-Specific Information
-----------------------------
### RxGroovy `asyncAction asyncFunc deferFuture forEachFuture fromAction fromCallable fromFunc0 fromRunnable start startFuture toAsync`
The various RxGroovy implementations of Start are found in the optional `rxjava-async` module.
 The `rxjava-async` module includes the `start` operator, which accepts a function as its parameter, calls that function to retrieve a value, and then returns an Observable that will emit that value to each subsequent observer.
Note that the function will only be executed once, even if more than one observer subscribes to the resulting Observable.
 The `rxjava-async` module also includes the `toAsync`, `asyncAction`, and `asyncFunc` operators. These accept a function or an Action as their parameter. In the case of a function, this variant of the operator calls that function to retrieve a value, and then returns an Observable that will emit that value to each subsequent observer (just as the `start` operator does).
In the case of Action, the process is similar, but there is no return value. In this case, the Observable created by this operator will emit a `null` before terminating.
Note that the function or Action will only be executed once, even if more than one observer subscribes to the resulting Observable.
 The `rxjava-async` module also includes the `startFuture` operator. You pass it a function that returns a `Future`. `startFuture` calls this function immediately to obtain the `Future`, and calls the `Future`’s `get` method to try to obtain its value. It returns an Observable to which it will emit this value to any subsequent observers.
 The `rxjava-async` module also includes the `deferFuture` operator. You pass it a function that returns a `Future` that returns an Observable. `deferFuture` returns an Observable, but does not call the function you provide until such time as an observer subscribes to the Observable it returns. When it does so, it immediately calls `get` on the resulting `Future`, and then mirrors the emissions from the Observable returned by the `Future` as its own emissions.
In this way you can include a `Future` that returns an Observable in a cascade of Observables as a peer to other Observables.
 The `rxjava-async` module also includes the `fromAction` operator. It accepts an `Action` as its parameter, and returns an Observable that emits the item you pass to `fromAction` upon termination of the `Action`
 The `rxjava-async` module also includes the `fromCallable` operator. It accepts a `Callable` as its parameter, and returns an Observable that emits the result of this callable as its sole emission.
 The `rxjava-async` module also includes the `fromRunnable` operator. It accepts a `Runnable` as its parameter, and returns an Observable that emits the item you pass to `fromRunnable` upon termination of the `Runnable`
 The `rxjava-async` module also includes the `forEachFuture` operator. It is not really a variant of the Start operator, but something all its own. You pass `forEachFuture` some subset of the typical observer methods (`onNext`, `onError`, and `onCompleted`) and the Observable will call these methods in the usual way. But `forEachFuture` itself returns a `Future` that blocks on `get` until the source Observable completes, then returns either the completion or error, depending on how the Observable completed.
You can use this if you need a function that blocks until the completion of an Observable.
The `rxjava-async` module also includes the `runAsync` operator. It is peculiar in that it creates a specialization of an Observable called a `StoppableObservable`.
Pass `runAsync` an `Action` and a [`Scheduler`](../scheduler), and it will return a `StoppableObservable` that uses the specified `Action` to generate items that it emits. The `Action` accepts an `Observer` and a `Subscription`. It uses the `Subscription` to check for the `unsubscribed` condition, upon which it will stop emitting items. You can also manually stop a `StoppableObservable` at any time by calling its `unsubscribe` method (which will also unsubscribe the `Subscription` you have associated with the `StoppableObservable`).
Because `runAsync` immediately invokes the `Action` and begins emitting the items (that is, it produces a *hot* Observable), it is possible that some items may be lost in the interval between when you establish the `StoppableObservable` with this operator and when your `Observer` is ready to receive items. If this is a problem, you can use the variant of `runAsync` that also accepts a `Subject` and pass a `ReplaySubject` with which you can retrieve the otherwise-missing items.
In RxGroovy there is also a version of the [From](from) operator that converts a `Future` into an Observable, and in this way resembles the Start operator.
### RxJava 1․x `asyncAction asyncFunc deferFuture forEachFuture fromAction fromCallable fromFunc0 fromRunnable start startFuture toAsync`
The various RxJava implementations of Start are found in the optional `rxjava-async` module.
 The `rxjava-async` module includes the `start` operator, which accepts a function as its parameter, calls that function to retrieve a value, and then returns an Observable that will emit that value to each subsequent observer.
Note that the function will only be executed once, even if more than one observer subscribes to the resulting Observable.
 The `rxjava-async` module also includes the `toAsync`, `asyncAction`, and `asyncFunc` operators. These accept a function or an Action as their parameter. In the case of a function, this variant of the operator calls that function to retrieve a value, and then returns an Observable that will emit that value to each subsequent observer (just as the `start` operator does).
In the case of Action, the process is similar, but there is no return value. In this case, the Observable created by this operator will emit a `null` before terminating.
Note that the function or Action will only be executed once, even if more than one observer subscribes to the resulting Observable.
 The `rxjava-async` module also includes the `startFuture` operator. You pass it a function that returns a `Future`. `startFuture` calls this function immediately to obtain the `Future`, and calls the `Future`’s `get` method to try to obtain its value. It returns an Observable to which it will emit this value to any subsequent observers.
 The `rxjava-async` module also includes the `deferFuture` operator. You pass it a function that returns a `Future` that returns an Observable. `deferFuture` returns an Observable, but does not call the function you provide until such time as an observer subscribes to the Observable it returns. When it does so, it immediately calls `get` on the resulting `Future`, and then mirrors the emissions from the Observable returned by the `Future` as its own emissions.
In this way you can include a `Future` that returns an Observable in a cascade of Observables as a peer to other Observables.
 The `rxjava-async` module also includes the `fromAction` operator. It accepts an `Action` as its parameter, and returns an Observable that emits the item you pass to `fromAction` upon termination of the `Action`
 The `rxjava-async` module also includes the `fromCallable` operator. It accepts a `Callable` as its parameter, and returns an Observable that emits the result of this callable as its sole emission.
 The `rxjava-async` module also includes the `fromRunnable` operator. It accepts a `Runnable` as its parameter, and returns an Observable that emits the item you pass to `fromRunnable` upon termination of the `Runnable`
 The `rxjava-async` module also includes the `forEachFuture` operator. It is not really a variant of the Start operator, but something all its own. You pass `forEachFuture` some subset of the typical observer methods (`onNext`, `onError`, and `onCompleted`) and the Observable will call these methods in the usual way. But `forEachFuture` itself returns a `Future` that blocks on `get` until the source Observable completes, then returns either the completion or error, depending on how the Observable completed.
You can use this if you need a function that blocks until the completion of an Observable.
The `rxjava-async` module also includes the `runAsync` operator. It is peculiar in that it creates a specialization of an Observable called a `StoppableObservable`.
Pass `runAsync` an `Action` and a [`Scheduler`](../scheduler), and it will return a `StoppableObservable` that uses the specified `Action` to generate items that it emits. The `Action` accepts an `Observer` and a `Subscription`. It uses the `Subscription` to check for the `unsubscribed` condition, upon which it will stop emitting items. You can also manually stop a `StoppableObservable` at any time by calling its `unsubscribe` method (which will also unsubscribe the `Subscription` you have associated with the `StoppableObservable`).
Because `runAsync` immediately invokes the `Action` and begins emitting the items (that is, it produces a *hot* Observable), it is possible that some items may be lost in the interval between when you establish the `StoppableObservable` with this operator and when your `Observer` is ready to receive items. If this is a problem, you can use the variant of `runAsync` that also accepts a `Subject` and pass a `ReplaySubject` with which you can retrieve the otherwise-missing items.
In RxJava there is also a version of the [From](from) operator that converts a `Future` into an Observable, and in this way resembles the Start operator.
### RxJS `start startAsync toAsync`
 RxJS implements the `start` operator. It takes as its parameters a function whose return value will be the emission from the resulting Observable, and, optionally, any additional parameter to that function and a [Scheduler](../scheduler) on which to run the function.
#### Sample Code
```
var context = { value: 42 };
var source = Rx.Observable.start(
function () {
return this.value;
},
context,
Rx.Scheduler.timeout
);
var subscription = source.subscribe(
function (x) {
console.log('Next: ' + x);
},
function (err) {
console.log('Error: ' + err);
},
function () {
console.log('Completed');
});
```
```
Next: 42
Completed
```
`start` is found in the following distributions:
* `rx.async.js` (requires `rx.binding.js` and either `rx.js` or `rx.compat.js`)
* `rx.async.compat.js` (requires `rx.binding.js` and either `rx.js` or `rx.compat.js`)
* `rx.lite.js`
* `rx.lite.compat.js`
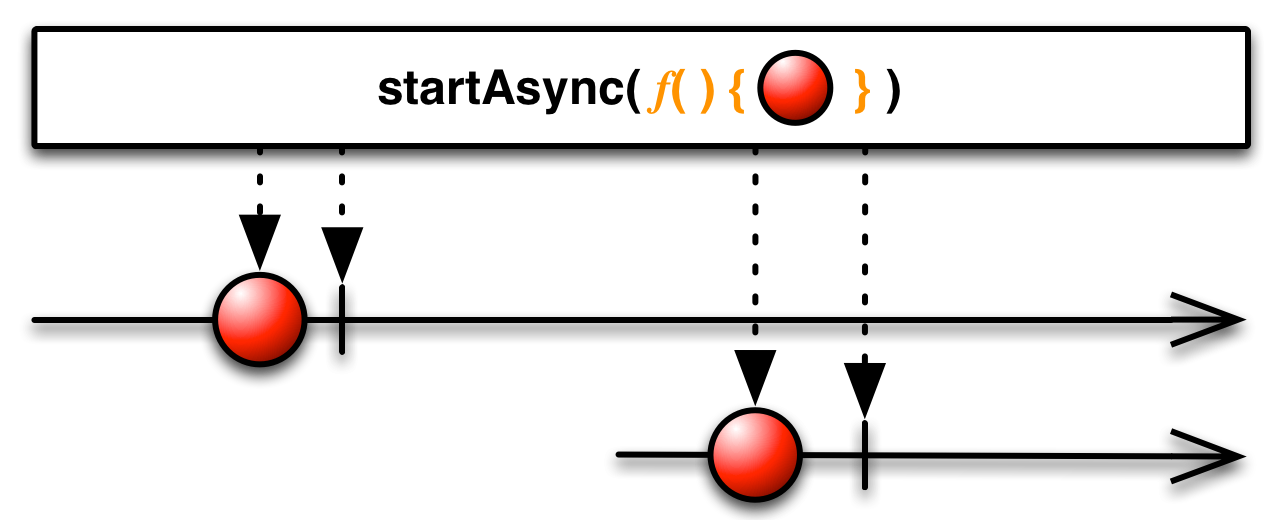 RxJS also implements the `startAsync` operator. It takes as its parameters an asynchronous function whose return value will be the emission from the resulting Observable.
You can convert a function into an asynchronous function with the `toAsync` method. It takes a function, function parameter, and [Scheduler](../scheduler) as parameters, and returns an asynchronous function that will be invoked on the specified Scheduler. The last two parameters are optional; if you do not specify a Scheduler, the `timeout` Scheduler will be used by default.
#### Sample Code
```
var source = Rx.Observable.startAsync(function () {
return RSVP.Promise.resolve(42);
});
var subscription = source.subscribe(
function (x) {
console.log('Next: ' + x);
},
function (err) {
console.log('Error: ' + err);
},
function () {
console.log('Completed');
});
```
```
Next: 42
Completed
```
`startAsync` is found in the following distributions:
* `rx.async.js` (requires `rx.binding.js` and either `rx.js` or `rx.compat.js`)
* `rx.async.compat.js` (requires `rx.binding.js` and either `rx.js` or `rx.compat.js`)
* `rx.lite.js`
* `rx.lite.compat.js`
`toAsync` is found in the following distributions:
* `rx.async.js` (requires `rx.binding.js` and either `rx.js` or `rx.compat.js`)
* `rx.async.compat.js` (requires `rx.binding.js` and either `rx.js` or `rx.compat.js`)
### RxPHP `start`
RxPHP implements this operator as `start`.
Invokes the specified function asynchronously on the specified scheduler, surfacing the result through an observable sequence.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/start/start.php
$source = Rx\Observable::start(function () {
return 42;
});
$source->subscribe($stdoutObserver);
```
```
Next value: 42
Complete!
```
| programming_docs |
reactivex Sum Sum
===
> calculates the sum of numbers emitted by an Observable and emits this sum
[Open interactive diagram on rxmarbles.com](https://rxmarbles.com/#sum) The Sum operator operates on an Observable that emits numbers (or items that can be evaluated as numbers), and emits a single value: the sum of all of the numbers emitted by the source Observable.
#### See Also
* [Average](average)
* [Introduction to Rx: Min, Max, Sum, and Average](http://www.introtorx.com/Content/v1.0.10621.0/07_Aggregation.html#MaxAndMin)
* [RxMarbles: `sum`](http://rxmarbles.com/#sum)
Language-Specific Information
-----------------------------
### RxGroovy `sumDouble sumFloat sumInteger sumLong StringObservable.join StringObservable.stringConcat`
In RxGroovy, this operator is not in the ReactiveX core, but is part of the distinct `rxjava-math` module, where it is implemented with four type-specific operators: `sumDouble`, `sumFloat`, `sumInteger`, and `sumLong`. The following example shows how these operators work:
#### Sample Code
```
def myObservable = Observable.create({ aSubscriber ->
if(false == aSubscriber.isUnsubscribed()) aSubscriber.onNext(4);
if(false == aSubscriber.isUnsubscribed()) aSubscriber.onNext(3);
if(false == aSubscriber.isUnsubscribed()) aSubscriber.onNext(2);
if(false == aSubscriber.isUnsubscribed()) aSubscriber.onNext(1);
if(false == aSubscriber.isUnsubscribed()) aSubscriber.onCompleted();
});
Observable.sumInteger(myObservable).subscribe(
{ println(it); }, // onNext
{ println("Error encountered"); }, // onError
{ println("Sequence complete"); } // onCompleted
);
```
```
10
Sequence complete
```
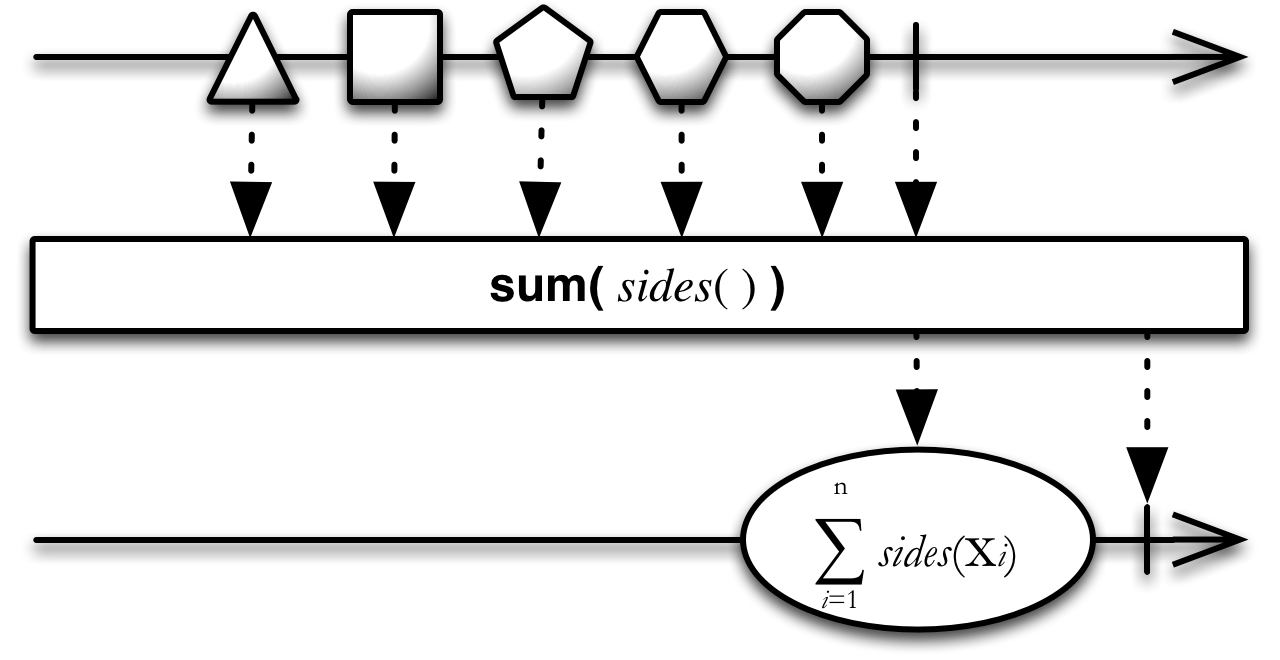 You can also sum not the items themselves but the results of a function applied to each item, as in the illustration above, which emits the sum of the number of sides on the figures emitted by the source Observable.
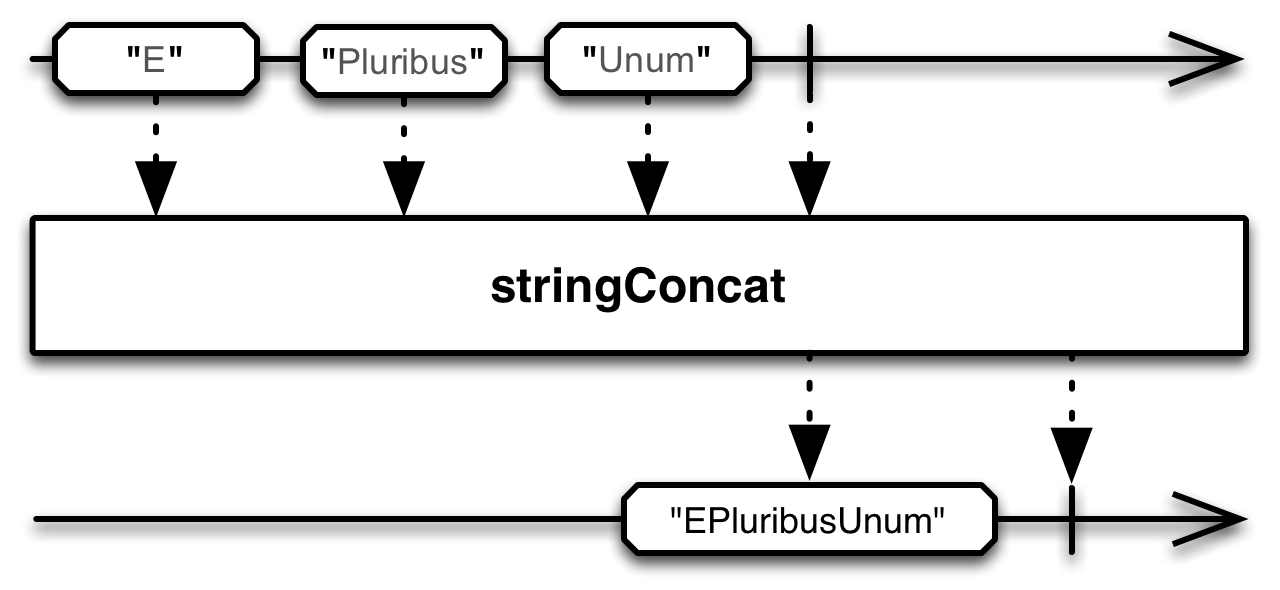 In the distinct `StringObservable` class (not part of RxGroovy by default) there is also a `stringConcat` operator that converts an Observable that emits a sequence of strings into an Observable that emits a single string that represents the concatenation of them all.
 In the distinct `StringObservable` class (not part of RxGroovy by default) there is also a `join` operator that converts an Observable that emits a sequence of strings into an Observable that emits a single string that represents the concatenation of each of them, delimited by a string of your choosing.
### RxJava 1․x `sumDouble sumFloat sumInteger sumLong StringObservable.join StringObservable.stringConcat`
This operator is not in the RxJava core, but is part of the distinct `rxjava-math` module, where it is implemented with four type-specific operators: `sumDouble`, `sumFloat`, `sumInteger`, and `sumLong`.
 You can also sum not the items themselves but the results of a function applied to each item, as in the illustration above, which emits the sum of the number of sides on the figures emitted by the source Observable.
 In the distinct `StringObservable` class (not part of RxJava by default) there is also a `stringConcat` operator that converts an Observable that emits a sequence of strings into an Observable that emits a single string that represents the concatenation of them all.
 In the distinct `StringObservable` class (not part of RxJava by default) there is also a `join` operator that converts an Observable that emits a sequence of strings into an Observable that emits a single string that represents the concatenation of each of them, delimited by a string of your choosing.
### RxJS `sum`
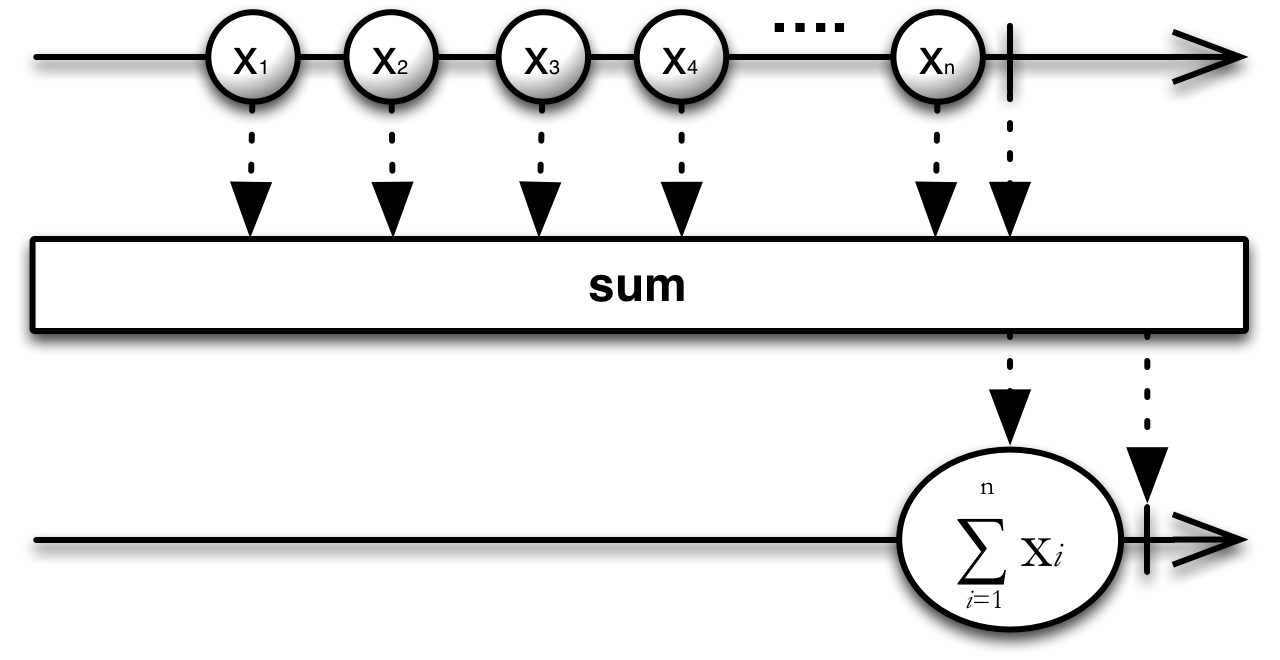 RxJS implements this operator as `sum`. The following code sample shows how to use it:
#### Sample Code
```
var source = Rx.Observable.range(0, 9).sum();
var subscription = source.subscribe(
function (x) {
console.log('Next: ' + x);
},
function (err) {
console.log('Error: ' + err);
},
function () {
console.log('Completed');
});
```
```
Next: 45
Completed
```
 You can also sum not the items themselves but the results of a function applied to each item, as in the illustration above, which emits the sum number of sides on the figures emitted by the source Observable.
#### Sample Code
```
var arr = [
{ value: 1 },
{ value: 2 },
{ value: 3 }
];
var source = Rx.Observable.fromArray(arr).sum(function (x) {
return x.value;
});
var subscription = source.subscribe(
function (x) {
console.log('Next: ' + x);
},
function (err) {
console.log('Error: ' + err);
},
function () {
console.log('Completed');
});
```
```
Next: 6
Completed
```
`sum` is found in the following distributions:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.aggregates.js`
It requires one of the following:
* `rx.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
### RxPHP `sum`
RxPHP implements this operator as `sum`.
Computes the sum of a sequence of values
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/sum/sum.php
$source = Rx\Observable::range(1, 10)
->sum();
$subscription = $source->subscribe($stdoutObserver);
```
```
Next value: 55
Complete!
```
reactivex Zip Zip
===
> combine the emissions of multiple Observables together via a specified function and emit single items for each combination based on the results of this function
[Open interactive diagram on rxmarbles.com](https://rxmarbles.com/#zip) The `Zip` method returns an Observable that applies a function of your choosing to the combination of items emitted, in sequence, by two (or more) other Observables, with the results of this function becoming the items emitted by the returned Observable. It applies this function in strict sequence, so the first item emitted by the new Observable will be the result of the function applied to the first item emitted by Observable #1 and the first item emitted by Observable #2; the second item emitted by the new zip-Observable will be the result of the function applied to the second item emitted by Observable #1 and the second item emitted by Observable #2; and so forth. It will only emit as many items as the number of items emitted by the source Observable that emits the fewest items.
#### See Also
* [And/Then/When](and-then-when)
* [CombineLatest](combinelatest)
* [Introduction to Rx: Zip](http://www.introtorx.com/Content/v1.0.10621.0/12_CombiningSequences.html#Zip)
* [RxMarbles: `zip`](http://rxmarbles.com/#zip)
* [101 Rx Samples: Zip](http://rxwiki.wikidot.com/101samples#toc49)
Language-Specific Information
-----------------------------
### RxGroovy `zip zipWith`
RxGroovy implements this operator as several variants of `zip` and also as `zipWith`, an instance function version of the operator.
 The last argument to `zip` is a function that accepts an item from each of the Observables being zipped and emits an item to be emitted in response by the Observable returned from `zip`. You can provide the Observables to be zipped together to `zip` either as between two and nine individual parameters, or as a single parameter: either an Iterable of Observables or an Observable that emits Observables (as in the illustration above).
#### Sample Code
```
odds = Observable.from([1, 3, 5, 7, 9]);
evens = Observable.from([2, 4, 6]);
Observable.zip(odds, evens, {o, e -> [o, e]}).subscribe(
{ println(it); }, // onNext
{ println("Error: " + it.getMessage()); }, // onError
{ println("Sequence complete"); } // onCompleted
);
```
```
[1, 2]
[3, 4]
[5, 6]
Sequence complete
```
Note that in this example, the resulting Observable completes normally after emitting three items, which is the number of items emitted by the shorter of the two component Observbles (`evens`, which emits three items).
* Javadoc: [`zip(Iterable<Observable>,FuncN)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#zip(java.lang.Iterable,%20rx.functions.FuncN))
* Javadoc: [`zip(Observable<Observable>,FuncN)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#zip(rx.Observable,%20rx.functions.FuncN))
* Javadoc: [`zip(Observable,Observable,Func2)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#zip(rx.Observable,%20rx.Observable,%20rx.functions.Func2)) (there are also versions that take up to nine Observables)
 The `zipWith` instance version of this operator always takes two parameters. The first parameter may be either a simple Observable, or an iterable (as in the illustration above).
* Javadoc: [`zipWith(Observable,Func2)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#zipWith(rx.Observable,%20rx.functions.Func2))
* Javadoc: [`zipWith(Iterable,Func2)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#zipWith(java.lang.Iterable,%20rx.functions.Func2))
`zip` and `zipWith` do not by default operate on any particular [Scheduler](../scheduler).
### RxJava 1․x `zip zipWith`
RxJava implements this operator as several variants of `zip` and also as `zipWith`, an instance function version of the operator.
 The last argument to `zip` is a function that accepts an item from each of the Observables being zipped and emits an item to be emitted in response by the Observable returned from `zip`. You can provide the Observables to be zipped together to `zip` either as between two and nine individual parameters, or as a single parameter: either an Iterable of Observables or an Observable that emits Observables (as in the illustration above).
* Javadoc: [`zip(Iterable<Observable>,FuncN)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#zip(java.lang.Iterable,%20rx.functions.FuncN))
* Javadoc: [`zip(Observable<Observable>,FuncN)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#zip(rx.Observable,%20rx.functions.FuncN))
* Javadoc: [`zip(Observable,Observable,Func2)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#zip(rx.Observable,%20rx.Observable,%20rx.functions.Func2)) (there are also versions that take up to nine Observables)
 The `zipWith` instance version of this operator always takes two parameters. The first parameter may be either a simple Observable, or an iterable (as in the illustration above).
* Javadoc: [`zipWith(Observable,Func2)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#zipWith(rx.Observable,%20rx.functions.Func2))
* Javadoc: [`zipWith(Iterable,Func2)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#zipWith(java.lang.Iterable,%20rx.functions.Func2))
`zip` and `zipWith` do not by default operate on any particular [Scheduler](../scheduler).
### RxJS `forkJoin zip zipArray`
RxJS implements this operator as `zip` and `zipArray`.
 `zip` accepts a variable number of Observables or Promises as parameters, followed by a function that accepts one item emitted by each of those Observables or resolved by those Promises as input and produces a single item to be emitted by the resulting Observable.
#### Sample Code
```
/* Using arguments */
var range = Rx.Observable.range(0, 5);
var source = Observable.zip(
range,
range.skip(1),
range.skip(2),
function (s1, s2, s3) {
return s1 + ':' + s2 + ':' + s3;
}
);
var subscription = source.subscribe(
function (x) {
console.log('Next: ' + x);
},
function (err) {
console.log('Error: ' + err);
},
function () {
console.log('Completed');
});
```
```
Next: 0:1:2
Next: 1:2:3
Next: 2:3:4
Completed
```
```
/* Using promises and Observables */
var range = Rx.Observable.range(0, 5);
var source = Observable.zip(
RSVP.Promise.resolve(0),
RSVP.Promise.resolve(1),
Rx.Observable.return(2)
function (s1, s2, s3) {
return s1 + ':' + s2 + ':' + s3;
}
);
var subscription = source.subscribe(
function (x) {
console.log('Next: ' + x);
},
function (err) {
console.log('Error: ' + err);
},
function () {
console.log('Completed');
});
```
```
Next: 0:1:2
Completed
```
 `zipArray` accepts a variable number of Observables as parameters and returns an Observable that emits arrays, each one containing the *n*th item from each source Observable.
#### Sample Code
```
var range = Rx.Observable.range(0, 5);
var source = Rx.Observable.zipArray(
range,
range.skip(1),
range.skip(2)
);
var subscription = source.subscribe(
function (x) {
console.log('Next: ' + x);
},
function (err) {
console.log('Error: ' + err);
},
function () {
console.log('Completed');
});
```
```
Next: [0,1,2]
Next: [1,2,3]
Next: [2,3,4]
Completed
```
 RxJS also implements a similar operator, `forkJoin`. There are two varieties of this operator. The first collects the last element emitted by each of the source Observables into an array and emits this array as its own sole emitted item. You can either pass a list of Observables to `forkJoin` as individual parameters or as an array of Observables.
```
var source = Rx.Observable.forkJoin(
Rx.Observable.return(42),
Rx.Observable.range(0, 10),
Rx.Observable.fromArray([1,2,3]),
RSVP.Promise.resolve(56)
);
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: [42, 9, 3, 56]
Completed
```
A second variant of `forkJoin` exists as a prototype function, and you call it on an instance of one source Observable, passing it another source Observable as a parameter. As a second parameter, you pass it a function that combines the final item emitted by the two source Observables into the sole item to be emitted by the resulting Observable.
```
var source1 = Rx.Observable.return(42);
var source2 = Rx.Observable.range(0, 3);
var source = source1.forkJoin(source2, function (s1, s2) {
return s1 + s2;
});
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 44
Completed
```
`forkJoin` is found in the following distributions:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.experimental.js` (requires `rx.js`, `rx.compat.js`, `rx.lite.js`, or `rx.lite.compat.js`)
### RxPHP `zip forkJoin`
RxPHP implements this operator as `zip`.
Merges the specified observable sequences into one observable sequence by using the selector function whenever all of the observable sequences have produced an element at a corresponding index. If the result selector function is omitted, a list with the elements of the observable sequences at corresponding indexes will be yielded.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/zip/zip.php
//Without a result selector
$range = \Rx\Observable::fromArray(range(0, 4));
$source = $range
->zip([
$range->skip(1),
$range->skip(2)
]);
$observer = $createStdoutObserver();
$subscription = $source
->subscribe(new CallbackObserver(
function ($array) use ($observer) {
$observer->onNext(json_encode($array));
},
[$observer, 'onError'],
[$observer, 'onCompleted']
));
```
```
Next value: [0,1,2]
Next value: [1,2,3]
Next value: [2,3,4]
Complete!
```
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/zip/zip-result-selector.php
//With a result selector
$range = \Rx\Observable::fromArray(range(0, 4));
$source = $range
->zip([
$range->skip(1),
$range->skip(2)
], function ($s1, $s2, $s3) {
return $s1 . ':' . $s2 . ':' . $s3;
});
$observer = $createStdoutObserver();
$subscription = $source->subscribe($createStdoutObserver());
```
```
Next value: 0:1:2
Next value: 1:2:3
Next value: 2:3:4
Complete!
```
RxPHP also has an operator `forkJoin`.
Runs all observable sequences in parallel and collect their last elements.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/forkJoin/forkJoin.php
use Rx\Observable;
$obs1 = Observable::range(1, 4);
$obs2 = Observable::range(3, 5);
$obs3 = Observable::fromArray(['a', 'b', 'c']);
$observable = Observable::forkJoin([$obs1, $obs2, $obs3], function($v1, $v2, $v3) {
return $v1 . $v2 . $v3;
});
$observable->subscribe($stdoutObserver);
```
```
Next value: 47c
Complete!
```
reactivex To To
==
> convert an Observable into another object or data structure
 The various language-specific implementations of ReactiveX have a variety of operators that you can use to convert an Observable, or a sequence of items emitted by an Observable, into another variety of object or data structure. Some of these block until the Observable terminates and then produce an equivalent object or data structure; others return an Observable that emits such an object or data structure.
In some implementations of ReactiveX, there is also an operator that converts an Observable into a “Blocking” Observable. A Blocking Observable extends the ordinary Observable by providing a set of methods, operating on the items emitted by the Observable, that block. Some of the To operators are in this Blocking Observable set of extended operations.
#### See Also
* [Introduction to Rx: Leaving the monad](http://www.introtorx.com/Content/v1.0.10621.0/10_LeavingTheMonad.html#LeavingTheMonad)
Language-Specific Information
-----------------------------
### RxGroovy `BlockingObservable.from BlockingObservable.getIterator nest toBlocking BlockingObservable.toFuture BlockingObservable.toIterable toList toMap toMultiMap toSortedList`
 The `getIterator` operator applies to the `BlockingObservable` subclass, so in order to use it, you must first convert your source Observable into a `BlockingObservable` by means of either the `BlockingObservable.from` method or the `Observable.toBlocking` operator.
This operator converts an Observable into an `Iterator` with which you can iterate over the set of items emitted by the source Observable.
* Javadoc: [`BlockingObservable.getIterator()`](http://reactivex.io/RxJava/javadoc/rx/observables/BlockingObservable.html#getIterator())
 The `toFuture` operator applies to the `BlockingObservable` subclass, so in order to use it, you must first convert your source Observable into a `BlockingObservable` by means of either the `BlockingObservable.from` method or the `Observable.toBlocking` operator.
This operator converts an Observable into an `Future` that will return the single item emitted by the source Observable. If the source Observable emits more than one item, the `Future` will receive an `IllegalArgumentException`; if it completes after emitting no items, the `Future` will receive a `NoSuchElementException`.
If you want to convert an Observable that may emit multiple items into a `Future`, try something like this: `myObservable.toList().toBlocking().toFuture()`.
* Javadoc: [`BlockingObservable.toFuture()`](http://reactivex.io/RxJava/javadoc/rx/observables/BlockingObservable.html#toFuture())
 The `toIterable` operator applies to the `BlockingObservable` subclass, so in order to use it, you must first convert your source Observable into a `BlockingObservable` by means of either the `BlockingObservable.from` method or the `Observable.toBlocking` operator.
This operator converts an Observable into an `Iterable` with which you can iterate over the set of items emitted by the source Observable.
* Javadoc: [`BlockingObservable.toIterable()`](http://reactivex.io/RxJava/javadoc/rx/observables/BlockingObservable.html#toIterable())
 Normally, an Observable that emits multiple items will do so by invoking its observer’s `onNext` method for each such item. You can change this behavior, instructing the Observable to compose a list of these multiple items and then to invoke the observer’s `onNext` method only once, passing it the entire list, by applying the `toList` operator to the Observable.
For example, the following rather pointless code takes a list of integers, converts it into an Observable, then converts that Observable into one that emits the original list as a single item:
#### Sample Code
```
numbers = Observable.from([1, 2, 3, 4, 5, 6, 7, 8, 9]);
numbers.toList().subscribe(
{ println(it); }, // onNext
{ println("Error: " + it.getMessage()); }, // onError
{ println("Sequence complete"); } // onCompleted
);
```
```
[1, 2, 3, 4, 5, 6, 7, 8, 9]
Sequence complete
```
If the source Observable invokes `onCompleted` before emitting any items, the Observable returned by `toList` will emit an empty list before invoking `onCompleted`. If the source Observable invokes `onError`, the Observable returned by `toList` will immediately invoke the `onError` methods of its observers.
`toList` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`toList()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#toList())
 The `toMap` operator collects the items emitted by the source Observable into a map (by default, a `HashMap`, but you can optionally supply a factory function that generates another `Map` variety) and then emits that map. You supply a function that generates the key for each emitted item. You may also optionally supply a function that converts an emitted item into the value to be stored in the map (by default, the item itself is this value).
`toMap` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`toMap(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#toMap(rx.functions.Func1))
* Javadoc: [`toMap(Func1,Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#toMap(rx.functions.Func1,%20rx.functions.Func1))
* Javadoc: [`toMap(Func1,Func1,Func0)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#toMap(rx.functions.Func1,%20rx.functions.Func1,%20rx.functions.Func0))
 The `toMultiMap` operator is similar to `toMap` except that the map it generates is also an `ArrayList` (by default; or you can pass an optional factory method as a fourth parameter by which you generate the variety of collection you prefer).
`toMultiMap` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`toMultiMap(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#toMultimap(rx.functions.Func1))
* Javadoc: [`toMultiMap(Func1,Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#toMultimap(rx.functions.Func1,%20rx.functions.Func1))
* Javadoc: [`toMultiMap(Func1,Func1,Func0)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#toMultimap(rx.functions.Func1,%20rx.functions.Func1,%20rx.functions.Func0))
* Javadoc: [`toMultiMap(Func1,Func1,Func0,Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#toMultimap(rx.functions.Func1,%20rx.functions.Func1,%20rx.functions.Func0,%20rx.functions.Func1))
 The `toSortedList` operator behaves much like `toList` except that it sorts the resulting list. By default it sorts the list naturally in ascending order by means of the `Comparable` interface. If any of the items emitted by the Observable does not support `Comparable` with respect to the type of every other item emitted by the Observable, `toSortedList` will throw an exception. However, you can change this default behavior by also passing in to `toSortedList` a function that takes as its parameters two items and returns a number; `toSortedList` will then use that function instead of `Comparable` to sort the items.
For example, the following code takes a list of unsorted integers, converts it into an Observable, then converts that Observable into one that emits the original list in sorted form as a single item:
#### Sample Code
```
numbers = Observable.from([8, 6, 4, 2, 1, 3, 5, 7, 9]);
numbers.toSortedList().subscribe(
{ println(it); }, // onNext
{ println("Error: " + it.getMessage()); }, // onError
{ println("Sequence complete"); } // onCompleted
);
```
```
[1, 2, 3, 4, 5, 6, 7, 8, 9]
Sequence complete
```
Here is an example that provides its own sorting function: in this case, one that sorts numbers according to how close they are to the number 5.
```
numbers = Observable.from([8, 6, 4, 2, 1, 3, 5, 7, 9]);
numbers.toSortedList({ n, m -> Math.abs(5-n) - Math.abs(5-m) }).subscribe(
{ println(it); }, // onNext
{ println("Error: " + it.getMessage()); }, // onError
{ println("Sequence complete"); } // onCompleted
);
```
```
[5, 6, 4, 3, 7, 8, 2, 1, 9]
Sequence complete
```
`toSortedList` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`toSortedList()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#toSortedList())
* Javadoc: [`toSortedList(Func2)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#toSortedList(rx.functions.Func2))
 RxGroovy also has a `nest` operator that has one particular purpose: it converts a source Observable into an Observable that emits that source Observable as its sole item.
### RxJava 1․x `BlockingObservable.from BlockingObservable.getIterator nest toBlocking BlockingObservable.toFuture BlockingObservable.toIterable toList toMap toMultiMap toSortedList`
 The `getIterator` operator applies to the `BlockingObservable` subclass, so in order to use it, you must first convert your source Observable into a `BlockingObservable` by means of either the `BlockingObservable.from` method or the `Observable.toBlocking` operator.
This operator converts an Observable into an `Iterator` with which you can iterate over the set of items emitted by the source Observable.
* Javadoc: [`BlockingObservable.getIterator()`](http://reactivex.io/RxJava/javadoc/rx/observables/BlockingObservable.html#getIterator())
 The `toFuture` operator applies to the `BlockingObservable` subclass, so in order to use it, you must first convert your source Observable into a `BlockingObservable` by means of either the `BlockingObservable.from` method or the `Observable.toBlocking` operator.
This operator converts an Observable into an `Future` that will return the single item emitted by the source Observable. If the source Observable emits more than one item, the `Future` will receive an `IllegalArgumentException`; if it completes after emitting no items, the `Future` will receive a `NoSuchElementException`.
If you want to convert an Observable that may emit multiple items into a `Future`, try something like this: `myObservable.toList().toBlocking().toFuture()`.
* Javadoc: [`BlockingObservable.toFuture()`](http://reactivex.io/RxJava/javadoc/rx/observables/BlockingObservable.html#toFuture())
 The `toIterable` operator applies to the `BlockingObservable` subclass, so in order to use it, you must first convert your source Observable into a `BlockingObservable` by means of either the `BlockingObservable.from` method or the `Observable.toBlocking` operator.
This operator converts an Observable into an `Iterable` with which you can iterate over the set of items emitted by the source Observable.
* Javadoc: [`BlockingObservable.toIterable()`](http://reactivex.io/RxJava/javadoc/rx/observables/BlockingObservable.html#toIterable())
 Normally, an Observable that emits multiple items will do so by invoking its observer’s `onNext` method for each such item. You can change this behavior, instructing the Observable to compose a list of these multiple items and then to invoke the observer’s `onNext` method only once, passing it the entire list, by applying the `toList` operator to the Observable.
If the source Observable invokes `onCompleted` before emitting any items, the Observable returned by `toList` will emit an empty list before invoking `onCompleted`. If the source Observable invokes `onError`, the Observable returned by `toList` will immediately invoke the `onError` methods of its observers.
`toList` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`toList()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#toList())
 The `toMap` operator collects the items emitted by the source Observable into a map (by default, a `HashMap`, but you can optionally supply a factory function that generates another `Map` variety) and then emits that map. You supply a function that generates the key for each emitted item. You may also optionally supply a function that converts an emitted item into the value to be stored in the map (by default, the item itself is this value).
`toMap` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`toMap(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#toMap(rx.functions.Func1))
* Javadoc: [`toMap(Func1,Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#toMap(rx.functions.Func1,%20rx.functions.Func1))
* Javadoc: [`toMap(Func1,Func1,Func0)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#toMap(rx.functions.Func1,%20rx.functions.Func1,%20rx.functions.Func0))
 The `toMultiMap` operator is similar to `toMap` except that the map it generates is also an `ArrayList` (by default; or you can pass an optional factory method as a fourth parameter by which you generate the variety of collection you prefer).
`toMultiMap` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`toMultiMap(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#toMultimap(rx.functions.Func1))
* Javadoc: [`toMultiMap(Func1,Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#toMultimap(rx.functions.Func1,%20rx.functions.Func1))
* Javadoc: [`toMultiMap(Func1,Func1,Func0)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#toMultimap(rx.functions.Func1,%20rx.functions.Func1,%20rx.functions.Func0))
* Javadoc: [`toMultiMap(Func1,Func1,Func0,Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#toMultimap(rx.functions.Func1,%20rx.functions.Func1,%20rx.functions.Func0,%20rx.functions.Func1))
 The `toSortedList` operator behaves much like `toList` except that it sorts the resulting list. By default it sorts the list naturally in ascending order by means of the `Comparable` interface. If any of the items emitted by the Observable does not support `Comparable` with respect to the type of every other item emitted by the Observable, `toSortedList` will throw an exception. However, you can change this default behavior by also passing in to `toSortedList` a function that takes as its parameters two items and returns a number; `toSortedList` will then use that function instead of `Comparable` to sort the items.
`toSortedList` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`toSortedList()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#toSortedList())
* Javadoc: [`toSortedList(Func2)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#toSortedList(rx.functions.Func2))
 RxJava also has a `nest` operator that has one particular purpose: it converts a source Observable into an Observable that emits that source Observable as its sole item.
### RxJS `toArray toMap toSet`
 Normally, an Observable that emits multiple items will do so by invoking its observer’s `onNext` method for each such item. You can change this behavior, instructing the Observable to compose an array of these multiple items and then to invoke the observer’s `onNext` method only once, passing it the entire array, by applying the `toArray` operator to the Observable.
#### Sample Code
```
var source = Rx.Observable.timer(0, 1000)
.take(5)
.toArray();
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: [0,1,2,3,4]
Completed
```
`toArray` is found in each of the following distributions:
* `rx.js`
* `rx.all.js`
* `rx.all.compat.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
 The `toMap` operator collects the items emitted by the source Observable into a `Map` and then emits that map. You supply a function that generates the key for each emitted item. You may also optionally supply a function that converts an emitted item into the value to be stored in the map (by default, the item itself is this value).
#### Sample Code
```
var source = Rx.Observable.timer(0, 1000)
.take(5)
.toMap(function (x) { return x * 2; }, function (x) { return x * 4; });
var subscription = source.subscribe(
function (x) {
var arr = [];
x.forEach(function (value, key) { arr.push(value, key); })
console.log('Next: ' + arr);
},
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: [0,0,2,4,4,8,6,12,8,16]
Completed
```
`toMap` is found in each of the following distributions:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.aggregates.js`
 Normally, an Observable that emits multiple items will do so by invoking its observer’s `onNext` method for each such item. You can change this behavior, instructing the Observable to compose a `Set` of these multiple items and then to invoke the observer’s `onNext` method only once, passing it the entire `Set`, by applying the `toSet` operator to the Observable.
Note that this only works in an ES6 environment or polyfilled.
```
var source = Rx.Observable.timer(0, 1000)
.take(5)
.toSet();
var subscription = source.subscribe(
function (x) {
var arr = [];
x.forEach(function (i) { arr.push(i); })
console.log('Next: ' + arr);
},
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: [0,1,2,3,4]
Completed
```
`toSet` is found in each of the following distributions:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.aggregates.js`
### RxPHP `toArray`
RxPHP implements this operator as `toArray`.
Creates an observable sequence containing a single element which is an array containing all the elements of the source sequence.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/toArray/toArray.php
$source = \Rx\Observable::fromArray([1, 2, 3, 4]);
$observer = $createStdoutObserver();
$subscription = $source->toArray()
->subscribe(new CallbackObserver(
function ($array) use ($observer) {
$observer->onNext(json_encode($array));
},
[$observer, "onError"],
[$observer, "onCompleted"]
));
```
```
Next value: [1,2,3,4]
Complete!
```
| programming_docs |
reactivex Timeout Timeout
=======
> mirror the source Observable, but issue an error notification if a particular period of time elapses without any emitted items
 The Timeout operator allows you to abort an Observable with an `onError` termination if that Observable fails to emit any items during a specified span of time.
#### See Also
* [Debounce](debounce)
* [Introduction to Rx: Timeout](http://www.introtorx.com/Content/v1.0.10621.0/13_TimeShiftedSequences.html#Timeout)
* [101 Rx Samples: Timeout — Simple](http://rxwiki.wikidot.com/101samples#toc33)
Language-Specific Information
-----------------------------
### RxGroovy `timeout`
RxGroovy implements this operator as `timeout`, but in several variants.
 The first variant accepts parameters that define a duration of time (a quantity of time, and a `TimeUnit` that this quantity is denominated in). Each time the source Observable emits an item, `timeout` starts a timer, and if that timer exceeds the duration before the source Observable emits another item, `timeout` terminates its Observable with an error (`TimeoutException`).
By default this variant of `timeout` operates on the `computation` [Scheduler](../scheduler), but you can choose a different Scheduler by passing it in as an optional third parameter to `timeout`
* Javadoc: [`timeout(long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#timeout(long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`timeout()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#timeout(long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
 A second variant of `timeout` differs from the first in that instead of issuing an error notification in case of a timeout condition, it instead immediately switches to a backup Observable that you specify.
By default this variant of `timeout` operates on the `computation` [Scheduler](../scheduler), but you can choose a different Scheduler by passing it in as an optional third parameter to `timeout`
* Javadoc: [`timeout(long,TimeUnit,Observable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#timeout(long,%20java.util.concurrent.TimeUnit,%20rx.Observable))
* Javadoc: [`timeout(long,TimeUnit,Observable,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#timeout(long,%20java.util.concurrent.TimeUnit,%20rx.Observable,%20rx.Scheduler))
 A third variant of `timeout` does not use a constant timeout duration, but sets its timeout duration on a per-item basis by passing each item from the source Observable into a function that returns an Observable and then monitoring those Observables. If any such Observable completes before the source Observable emits another item, this is considered a timeout condition, and triggers an `onError` notification (“`TimeoutException`”) from the Observable `timeout` returns.
This variant of `timeout` by default runs on the `immediate` [Scheduler](../scheduler).
* Javadoc: [`timeout(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#timeout(rx.functions.Func1))
 There is also a variant of `timeout` that both uses a per-item Observable to set the timeout duration and switches to a backup Observable in case of a timeout.
This variant of `timeout` by default runs on the `immediate` [Scheduler](../scheduler).
* Javadoc: [`timeout(Func1,Observable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#timeout(rx.functions.Func1,%20rx.Observable))
 The variant of `timeout` that uses a per-item Observable to set the timeout has a variant that allows you to pass in a function that returns an Observable that acts as a timeout timer for the very first item emitted by the source Observable (in the absence of this, there would be no timeout for the first item).
This variant of `timeout` by default runs on the `immediate` [Scheduler](../scheduler).
* Javadoc: [`timeout(Func0,Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#timeout(rx.functions.Func0,%20rx.functions.Func1))
 And that variant also has a cousin that will switch to a specified backup Observable rather than emitting an error upon hitting a timeout condition.
This variant of `timeout` by default runs on the `immediate` [Scheduler](../scheduler).
* Javadoc: [`timeout(Func0,Func1,Observable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#timeout(rx.functions.Func0,%20rx.functions.Func1,%20rx.Observable))
### RxJava 1․x `timeout`
RxJava implements this operator as `timeout`, but in several variants.
 The first variant accepts parameters that define a duration of time (a quantity of time, and a `TimeUnit` that this quantity is denominated in). Each time the source Observable emits an item, `timeout` starts a timer, and if that timer exceeds the duration before the source Observable emits another item, `timeout` terminates its Observable with an error (`TimeoutException`).
By default this variant of `timeout` operates on the `computation` [Scheduler](../scheduler), but you can choose a different Scheduler by passing it in as an optional third parameter to `timeout`
* Javadoc: [`timeout(long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#timeout(long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`timeout()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#timeout(long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
 A second variant of `timeout` differs from the first in that instead of issuing an error notification in case of a timeout condition, it instead immediately switches to a backup Observable that you specify.
By default this variant of `timeout` operates on the `computation` [Scheduler](../scheduler), but you can choose a different Scheduler by passing it in as an optional third parameter to `timeout`.
* Javadoc: [`timeout(long,TimeUnit,Observable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#timeout(long,%20java.util.concurrent.TimeUnit,%20rx.Observable))
* Javadoc: [`timeout(long,TimeUnit,Observable,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#timeout(long,%20java.util.concurrent.TimeUnit,%20rx.Observable,%20rx.Scheduler))
 A third variant of `timeout` does not use a constant timeout duration, but sets its timeout duration on a per-item basis by passing each item from the source Observable into a function that returns an Observable and then monitoring those Observables. If any such Observable completes before the source Observable emits another item, this is considered a timeout condition, and triggers an `onError` notification (“`TimeoutException`”) from the Observable `timeout` returns.
This variant of `timeout` by default runs on the `immediate` [Scheduler](../scheduler).
* Javadoc: [`timeout(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#timeout(rx.functions.Func1))
 There is also a variant of `timeout` that both uses a per-item Observable to set the timeout duration and switches to a backup Observable in case of a timeout.
This variant of `timeout` by default runs on the `immediate` [Scheduler](../scheduler).
* Javadoc: [`timeout(Func1,Observable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#timeout(rx.functions.Func1,%20rx.Observable))
 The variant of `timeout` that uses a per-item Observable to set the timeout has a variant that allows you to pass in a function that returns an Observable that acts as a timeout timer for the very first item emitted by the source Observable (in the absence of this, there would be no timeout for the first item).
This variant of `timeout` by default runs on the `immediate` [Scheduler](../scheduler).
* Javadoc: [`timeout(Func0,Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#timeout(rx.functions.Func0,%20rx.functions.Func1))
 And that variant also has a cousin that will switch to a specified backup Observable rather than emitting an error upon hitting a timeout condition.
This variant of `timeout` by default runs on the `immediate` [Scheduler](../scheduler).
* Javadoc: [`timeout(Func0,Func1,Observable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#timeout(rx.functions.Func0,%20rx.functions.Func1,%20rx.Observable))
### RxJS `timeout timeoutWithSelector`
RxJS implements this operator as `timeout` and `timeoutWithSelector`:
 One variant of `timeout` accepts a duration of time (in milliseconds). Each time the source Observable emits an item, `timeout` starts a timer, and if that timer exceeds the duration before the source Observable emits another item, `timeout` terminates its Observable with an error (“`Timeout`” or a string of your choice that you pass as an optional second parameter).
#### Sample Code
```
var source = Rx.Observable
.return(42)
.delay(5000)
.timeout(200, 'Timeout has occurred.');
var subscription = source.subscribe(
function (x) { console.log('Next: %s', x); },
function (err) { console.log('Error: %s', err); },
function () { console.log('Completed'); });
```
```
Error: Timeout has occurred.
```
 Another variant allows you to instruct `timeout` to switch to a backup Observable that you specify, rather than terminating with an error, if the timeout condition is triggered. To use this variant, pass the backup Observable (or `Promise`) as the second parameter to `timeout`.
#### Sample Code
```
var source = Rx.Observable
.return(42)
.delay(5000)
.timeout(200, Promise.resolve(42));
var subscription = source.subscribe(
function (x) { console.log('Next: %s', x); },
function (err) { console.log('Error: %s', err); },
function () { console.log('Completed'); });
```
```
Next: 42
Completed
```
 `timeoutWithSelector` does not use a constant timeout duration, but sets its timeout duration on a per-item basis by passing each item from the source Observable into a function that returns an Observable and then monitoring those Observables. If any such Observable completes before the source Observable emits another item, this is considered a timeout condition, and triggers an `onError` notification (“`Error: Timeout`”) from the Observable `timeoutWithSelector` returns.
#### Sample Code
```
var array = [
200,
300,
350,
400
];
var source = Rx.Observable
.for(array, function (x) {
return Rx.Observable.timer(x);
})
.map(function (x, i) { return i; })
.timeoutWithSelector(function (x) {
return Rx.Observable.timer(400);
});
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 0
Next: 1
Next: 2
Error: Error: Timeout
```
 There is also a variant of `timeoutWithSelector` that both uses a per-item Observable to set the timeout duration and switches to a backup Observable in case of a timeout.
#### Sample Code
```
var array = [
200,
300,
350,
400
];
var source = Rx.Observable
.for(array, function (x) {
return Rx.Observable.timer(x);
})
.map(function (x, i) { return i; })
.timeoutWithSelector(function (x) {
return Rx.Observable.timer(400);
}, Rx.Observable.return(42));
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 0
Next: 1
Next: 2
Next: 42
Completed
```
 The variant of `timeoutWithSelector` that uses a per-item Observable to set the timeout has a variant that allows you to pass in an Observable that acts as a timeout timer for the very first item emitted by the source Observable (in the absence of this, there would be no timeout for the first item; that is to say, the default Observable that governs this first timeout period is `Rx.Observable.never()`).
#### Sample Code
```
var array = [
200,
300,
350,
400
];
var source = Rx.Observable
.for(array, function (x) {
return Rx.Observable.timer(x);
})
.map(function (x, i) { return i; })
.timeoutWithSelector(Rx.Observable.timer(250), function (x) {
return Rx.Observable.timer(400);
});
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 0
Next: 1
Next: 2
Error: Error: Timeout
```
 And that variant also has a cousin that will switch to a specified backup Observable rather than emitting an error upon hitting a timeout condition.
#### Sample Code
```
var array = [
200,
300,
350,
400
];
var source = Rx.Observable
.for(array, function (x) {
return Rx.Observable.timer(x);
})
.map(function (x, i) { return i; })
.timeoutWithSelector(Rx.Observable.timer(250), function (x) {
return Rx.Observable.timer(400);
}, Rx.Observable.return(42));
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 0
Next: 1
Next: 2
Next: 42
Completed
```
`timeout` and `timeoutWithSelector` are found in each of the following distributions:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.time.js`
* `rx.lite.js`
* `rx.lite.compat.js`
They require one of the following distributions:
* `rx.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
### RxPHP `timeout`
RxPHP implements this operator as `timeout`.
Errors the observable sequence if no item is emitted in the specified time. When a timeout occurs, this operator errors with an instance of Rx\Exception\TimeoutException
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/timeout/timeout.php
Rx\Observable::interval(1000)
->timeout(500)
->subscribe($createStdoutObserver('One second - '));
Rx\Observable::interval(100)
->take(3)
->timeout(500)
->subscribe($createStdoutObserver('100 ms - '));
```
```
100 ms - Next value: 0
100 ms - Next value: 1
100 ms - Next value: 2
100 ms - Complete!
One second - Exception: timeout
```
reactivex SequenceEqual SequenceEqual
=============
> determine whether two Observables emit the same sequence of items
[Open interactive diagram on rxmarbles.com](https://rxmarbles.com/#sequenceEqual) Pass SequenceEqual two Observables, and it will compare the items emitted by each Observable, and the Observable it returns will emit `true` only if both sequences are the same (the same items, in the same order, with the same termination state).
#### See Also
* [Introduction to Rx: SequenceEqual](http://www.introtorx.com/Content/v1.0.10621.0/06_Inspection.html#SequenceEqual)
* [RxMarbles: `sequenceEqual`](http://rxmarbles.com/#sequenceEqual)
Language-Specific Information
-----------------------------
### RxGroovy `sequenceEqual`
 Pass `sequenceEqual` two Observables, and it will compare the items emitted by each Observable, and the Observable it returns will emit `true` only if both sequences terminate normally after emitting the same sequence of items in the same order; otherwise it will emit `false`. You can optionally pass a third parameter: a function that accepts two items and returns `true` if they are equal according to a standard of your choosing.
#### Sample Code
```
def firstfour = Observable.from([1, 2, 3, 4]);
def firstfouragain = Observable.from([1, 2, 3, 4]);
def firstfive = Observable.from([1, 2, 3, 4, 5]);
def firstfourscrambled = Observable.from([3, 2, 1, 4]);
println('firstfour == firstfive?');
Observable.sequenceEqual(firstfour, firstfive).subscribe({ println(it); });
println('firstfour == firstfouragain?');
Observable.sequenceEqual(firstfour, firstfouragain).subscribe({ println(it); });
println('firstfour == firstfourscrambled?');
Observable.sequenceEqual(firstfour, firstfourscrambled).subscribe({ println(it); });
```
```
firstfour == firstfive?
false
firstfour == firstfouragain?
true
firstfour == firstfourscrambled?
false
```
This operator does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`sequenceEqual(Observable,Observable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#sequenceEqual(rx.Observable,%20rx.Observable))
* Javadoc: [`sequenceEqual(Observable,Observable,Func2)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#sequenceEqual(rx.Observable,%20rx.Observable,%20rx.functions.Func2))
### RxJava 1․x `sequenceEqual`
 Pass `sequenceEqual` two Observables, and it will compare the items emitted by each Observable, and the Observable it returns will emit `true` only if both sequences terminate normally after emitting the same sequence of items in the same order; otherwise it will emit `false`. You can optionally pass a third parameter: a function that accepts two items and returns `true` if they are equal according to a standard of your choosing.
This operator does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`sequenceEqual(Observable,Observable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#sequenceEqual(rx.Observable,%20rx.Observable))
* Javadoc: [`sequenceEqual(Observable,Observable,Func2)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#sequenceEqual(rx.Observable,%20rx.Observable,%20rx.functions.Func2))
### RxJS `sequenceEqual`
 In RxJS, `sequenceEqual` is a method of a particular Observable instance, so you pass it exactly one other Observable to compare the instance to. You can optionally pass a second parameter: a function that accepts two items and returns `true` if they are equal according to a standard of your choosing. `sequenceEqual` returns an Observable that will emit a `true` if the two Observables emit the same set of items in the same order before completing, or a `false` otherwise.
#### Sample Code
```
var source1 = Rx.Observable.return(42);
var source2 = Rx.Observable.return(42);
var source = source1.sequenceEqual(source2);
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: true
Completed
```
`sequenceEqual` is found in each of the following distributions:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.aggregates.js`
`sequenceEqual` requires one of the following distributions:
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
| programming_docs |
reactivex Timer Timer
=====
> create an Observable that emits a particular item after a given delay
 The Timer operator creates an Observable that emits one particular item after a span of time that you specify.
#### See Also
* [From](from)
* [Interval](interval)
* [Just](just)
* [Introduction to Rx: Timer](http://www.introtorx.com/Content/v1.0.10621.0/04_CreatingObservableSequences.html#ObservableTimer)
* [101 Rx Samples: Timer — Simple](http://rxwiki.wikidot.com/101samples#toc34)
Language-Specific Information
-----------------------------
### RxGroovy `timer`
RxGroovy implements this operator as `timer`.
 `timer` returns an Observable that emits a single number zero after a delay period you specify.
`timer` by default operates on the `computation` [Scheduler](../scheduler), or you can override this by passing in a Scheduler as a final parameter.
* Javadoc: [`timer(long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#timer(long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`timer(long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#timer(long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
### RxJava 1․x `timer`
RxJava implements this operator as `timer`.
 `timer` returns an Observable that emits a single number zero after a delay period you specify.
`timer` by default operates on the `computation` [Scheduler](../scheduler), or you can override this by passing in a Scheduler as a final parameter.
* Javadoc: [`timer(long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#timer(long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`timer(long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#timer(long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
### RxJS `timer`
In RxJS there are two versions of the `timer` operator.
 The first version of `timer` returns an Observable that emits a single item after a delay period you specify. You can specify the delay either as a `Date` object (which means, delay until that absolute moment) or as an integer (which means, delay that many milliseconds).
 There is also a version of `timer` that returns an Observable that emits a single item after a specified delay, and then emits items periodically thereafter on a specified periodicity. In this way it behaves a bit more like the [Interval](interval) operator.
#### Sample Code
```
var source = Rx.Observable.timer(200, 100)
.timeInterval()
.pluck('interval')
.take(3);
var subscription = source.subscribe(
function (x) {
console.log('Next: ' + x);
},
function (err) {
console.log('Error: ' + err);
},
function () {
console.log('Completed');
});
```
```
Next: 200
Next: 100
Next: 100
Completed
```
`timer` by default operates on the `timeout` [Scheduler](../scheduler), or you can override this by passing in a Scheduler as a final parameter.
`timer` is found in each of the following distributions:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.time.js` (requires either `rx.js` or `rx.compat.js`)
* `rx.lite.js`
* `rx.lite.compat.js`
### RxPHP `timer`
RxPHP implements this operator as `timer`.
Returns an observable sequence that produces a value after dueTime has elapsed.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/timer/timer.php
$source = \Rx\Observable::timer(200);
$source->subscribe($createStdoutObserver());
```
```
Next value: 0
Complete!
```
reactivex FlatMap FlatMap
=======
> transform the items emitted by an Observable into Observables, then flatten the emissions from those into a single Observable
 The FlatMap operator transforms an Observable by applying a function that you specify to each item emitted by the source Observable, where that function returns an Observable that itself emits items. FlatMap then merges the emissions of these resulting Observables, emitting these merged results as its own sequence.
This method is useful, for example, when you have an Observable that emits a series of items that themselves have Observable members or are in other ways transformable into Observables, so that you can create a new Observable that emits the complete collection of items emitted by the sub-Observables of these items.
Note that FlatMap *merges* the emissions of these Observables, so that they may interleave.
In several of the language-specific implementations there is also an operator that does *not* interleave the emissions from the transformed Observables, but instead emits these emissions in strict order, often called ConcatMap or something similar.
#### See Also
* [Map](map)
* [Grokking RxJava: Operator, Operator](http://blog.danlew.net/2014/09/22/grokking-rxjava-part-2/) by Dan Lew
* [Introduction to Rx: SelectMany](http://www.introtorx.com/Content/v1.0.10621.0/08_Transformation.html#SelectMany)
* [Recursive Observables with RxJava](http://jschneider.io/2014/11/26/Recursive-Observables-with-Rx-Java.html) by Jon Schneider
* [RxJava Observable transformation: concatMap() vs. flatMap()](http://fernandocejas.com/2015/01/11/rxjava-observable-tranformation-concatmap-vs-flatmap/) by Fernando Cejas
Language-Specific Information
-----------------------------
### RxGroovy `concatMap flatMap flatMapIterable StringObservable.split switchMap`
 RxGroovy implements the `flatMap` operator.
#### Sample Code
```
// this closure is an Observable that emits three numbers
numbers = Observable.from([1, 2, 3]);
// this closure is an Observable that emits two numbers based on what number it is passed
multiples = { n -> Observable.from([ n*2, n*3 ]) };
numbers.flatMap(multiples).subscribe(
{ println(it); }, // onNext
{ println("Error: " + it.getMessage()); }, // onError
{ println("Sequence complete"); } // onCompleted
);
```
```
2
3
4
6
6
9
Sequence complete
```
Note that if any of the individual Observables mapped to the items from the source Observable by `flatMap` aborts by invoking `onError`, the Observable produced by `flatMap` will itself immediately abort and invoke `onError`.
A version of this variant of the operator (still in Beta as of this writing) takes an additional `int` parameter. This parameter sets the maximum number of concurrent subscriptions that `flatMap` will attempt to have to the Observables that the items emitted by the source Observable map to. When it reaches this maximum number, it will wait for one of those Observables to terminate before subscribing to another.
* Javadoc: [`flatMap(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#flatMap(rx.functions.Func1))
* Javadoc: [`flatMap(Func1,int)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#flatMap(rx.functions.Func1,%20int))
 Another version of `flatMap` creates (and flattens) a new Observable for each item *and notification* from the source Observable.
A version of this variant of the operator (still in Beta as of this writing) takes an additional `int` parameter. This parameter sets the maximum number of concurrent subscriptions that `flatMap` will attempt to have to the Observables that the items emitted by the source Observable map to. When it reaches this maximum number, it will wait for one of those Observables to terminate before subscribing to another.
* Javadoc: [`flatMap(Func1,Func1,Func0)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#flatMap(rx.functions.Func1,%20rx.functions.Func1,%20rx.functions.Func0))
* Javadoc: [`flatMap(Func1,Func1,Func0,int)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#flatMap(rx.functions.Func1,%20rx.functions.Func1,%20rx.functions.Func0,%20int))
 Another version combines items from the source Observable with the Observable triggered by those source items, and emits these combinations.
A version of this variant of the operator (still in Beta as of this writing) takes an additional `int` parameter. This parameter sets the maximum number of concurrent subscriptions that `flatMap` will attempt to have to the Observables that the items emitted by the source Observable map to. When it reaches this maximum number, it will wait for one of those Observables to terminate before subscribing to another.
* Javadoc: [`flatMap(Func1,Func2)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#flatMap(rx.functions.Func1,%20rx.functions.Func2))
* Javadoc: [`flatMap(Func1,Func2,int)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#flatMap(rx.functions.Func1,%20rx.functions.Func2,%20int))
 The `flatMapIterable` variants pair up source items and generated `Iterable`s rather than source items and generated Observables, but otherwise work in much the same way.
* Javadoc: [`flatMapIterable(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#flatMapIterable(rx.functions.Func1))
* Javadoc: [`flatMapIterable(Func1,Func2)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#flatMapIterable(rx.functions.Func1,%20rx.functions.Func2))
 There is also a `concatMap` operator, which is like the simpler version of the `flatMap` operator, but it concatenates rather than merges the resulting Observables in order to generate its own sequence.
* Javadoc: [`concatMap(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#concatMap(rx.functions.Func1))
 RxGroovy also implements the `switchMap` operator. It behaves much like `flatMap`, except that whenever a new item is emitted by the source Observable, it will unsubscribe to and stop mirroring the Observable that was generated from the previously-emitted item, and begin only mirroring the current one.
* Javadoc: [`switchMap(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#switchMap(rx.functions.Func1))
 In the distinct `StringObservable` class (not part of RxGroovy by default) there is also a `split` operator that converts an Observable of Strings into an Observable of Strings that treats the source sequence as a stream and splits it on a specified regex boundary, then merges the results of this split.
#### See Also
* [Aligning packets with JSON documents](http://www.nurkiewicz.com/2014/12/accessing-meetups-streaming-api-with.html) with the `split` operator
### RxJava 1․x `concatMap flatMap flatMapIterable StringObervable.split switchMap`
 RxJava implements the `flatMap` operator.
Note that if any of the individual Observables mapped to the items from the source Observable by `flatMap` aborts by invoking `onError`, the Observable produced by `flatMap` will itself immediately abort and invoke `onError`.
A version of this variant of the operator (still in Beta as of this writing) takes an additional `int` parameter. This parameter sets the maximum number of concurrent subscriptions that `flatMap` will attempt to have to the Observables that the items emitted by the source Observable map to. When it reaches this maximum number, it will wait for one of those Observables to terminate before subscribing to another.
* Javadoc: [`flatMap(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#flatMap(rx.functions.Func1))
* Javadoc: [`flatMap(Func1,int)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#flatMap(rx.functions.Func1,%20int))
 Another version of `flatMap` creates (and flattens) a new Observable for each item *and notification* from the source Observable.
A version of this variant of the operator (still in Beta as of this writing) takes an additional `int` parameter. This parameter sets the maximum number of concurrent subscriptions that `flatMap` will attempt to have to the Observables that the items emitted by the source Observable map to. When it reaches this maximum number, it will wait for one of those Observables to terminate before subscribing to another.
* Javadoc: [`flatMap(Func1,Func1,Func0)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#flatMap(rx.functions.Func1,%20rx.functions.Func1,%20rx.functions.Func0))
* Javadoc: [`flatMap(Func1,Func1,Func0,int)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#flatMap(rx.functions.Func1,%20rx.functions.Func1,%20rx.functions.Func0,%20int))
 Another version combines items from the source Observable with the Observable triggered by those source items, and emits these combinations.
A version of this variant of the operator (still in Beta as of this writing) takes an additional `int` parameter. This parameter sets the maximum number of concurrent subscriptions that `flatMap` will attempt to have to the Observables that the items emitted by the source Observable map to. When it reaches this maximum number, it will wait for one of those Observables to terminate before subscribing to another.
* Javadoc: [`flatMap(Func1,Func2)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#flatMap(rx.functions.Func1,%20rx.functions.Func2))
* Javadoc: [`flatMap(Func1,Func2,int)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#flatMap(rx.functions.Func1,%20rx.functions.Func2,%20int))
 The `flatMapIterable` variants pair up source items and generated `Iterable`s rather than source items and generated Observables, but otherwise work in much the same way.
* Javadoc: [`flatMapIterable(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#flatMapIterable(rx.functions.Func1))
* Javadoc: [`flatMapIterable(Func1,Func2)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#flatMapIterable(rx.functions.Func1,%20rx.functions.Func2))
 There is also a `concatMap` operator, which is like the simpler version of the `flatMap` operator, but it concatenates rather than merges the resulting Observables in order to generate its own sequence.
* Javadoc: [`concatMap(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#concatMap(rx.functions.Func1))
 RxJava also implements the `switchMap` operator. It behaves much like `flatMap`, except that whenever a new item is emitted by the source Observable, it will unsubscribe to and stop mirroring the Observable that was generated from the previously-emitted item, and begin only mirroring the current one.
* Javadoc: [`switchMap(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#switchMap(rx.functions.Func1))
 In the distinct `StringObservable` class (not part of RxJava by default) there is also a `split` operator that converts an Observable of Strings into an Observable of Strings that treats the source sequence as a stream and splits it on a specified regex boundary, then merges the results of this split.
### RxJS `concatMap concatMapObserver flatMap flatMapFirst flatMapLatest flatMapObserver flatMapWithMaxConcurrency for forIn manySelect selectConcat selectConcatObserver selectMany selectManyObserver selectSwitch selectSwitchFirst selectWithMatchConcurrent switchMap`
RxJS has a wealth of operators that perform FlatMap-like operations. In RxJS, the functions that transform items emitted by the source Observable into Observables typically take as parameters both the item and the index of the item in the Observable sequence.
 RxJS implements the basic `flatMap` operator. It has a variant that allows you to apply a transformative function (an optional second parameter to `flatMap`) to the items emitted by the Observables generated for each item in the source Observable, before merging and emitting those items.
`flatMap` works just as well if the function you provide transforms items from the source Observables into Observables, into Promises, or into arrays.
“`selectMany`” is an alias for `flatMap`.
#### Sample Code
```
var source = Rx.Observable
.range(1, 2)
.selectMany(function (x) {
return Rx.Observable.range(x, 2);
});
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 1
Next: 2
Next: 2
Next: 3
Completed
```
```
// Using a promise
var source = Rx.Observable.of(1,2,3,4)
.selectMany(function (x, i) {
return Promise.resolve(x + i);
});
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 1
Next: 3
Next: 5
Next: 7
Completed
```
```
// Using an array
Rx.Observable.of(1,2,3)
.flatMap(
function (x, i) { return [x,i]; },
function (x, y, ix, iy) { return x + y + ix + iy; }
);
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 2
Next: 2
Next: 5
Next: 5
Next: 8
Next: 8
Completed
```
`flatMap` is found in each of the following distributions:
* `rx.js`
* `rx.all.js`
* `rx.all.compat.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
 The `flatMapLatest` operator behaves much like the standard FlatMap operator, except that whenever a new item is emitted by the source Observable, it will unsubscribe to and stop mirroring the Observable that was generated from the previously-emitted item, and begin only mirroring the current one.
“`selectSwitch`” is an alias for `flatMapLatest`.
#### Sample Code
```
var source = Rx.Observable
.range(1, 2)
.flatMapLatest(function (x) {
return Rx.Observable.range(x, 2);
});
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 1
Next: 2
Next: 3
Completed
```
`flatMapLatest` is found in each of the following distributions:
* `rx.js`
* `rx.all.js`
* `rx.all.compat.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
 `flatMapObserver` creates (and flattens) a new Observable for each item *and notification* from the source Observable. It accepts a different transformation function to respond to `onNext`, `onError`, and `onCompleted` notifications and to return an Observable for each.
“`selectManyObserver`” is an alias for `flatMapObserver`.
#### Sample Code
```
var source = Rx.Observable.range(1, 3)
.flatMapObserver(
function (x, i) {
return Rx.Observable.repeat(x, i);
},
function (err) {
return Rx.Observable.return(42);
},
function () {
return Rx.Observable.empty();
});
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 2
Next: 3
Next: 3
Completed
```
`flatMapObserver` is found in each of the following distributions:
* `rx.js`
* `rx.all.js`
* `rx.all.compat.js`
* `rx.compat.js`
 There is also a `concatMap` operator, which is like the `flatMap` operator, but it concatenates rather than merges the resulting Observables in order to generate its own sequence.
As with `flatMap`, `concatMap` works just as well if the function you provide transforms items from the source Observables into Observables, into Promises, or into arrays.
“`selectConcat`” is an alias for `concatMap`.
`concatMap` is found in each of the following distributions:
* `rx.js`
* `rx.all.js`
* `rx.all.compat.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
 The `for` operator (and its alias, `forIn`) is very similar to `concatMap`, though it has a converse flexibility. While `concatMap` operates on an Observable source and can use Observable, Promise, or array intermediaries to generate its output sequence; `for` always uses Observables as its intermediaries, but can operate on a source that is either an Observable, a Promise, or an array.
`concatMap` is found in each of the following distributions:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.experimental.js` (requires either `rx.js`, `rx.compat.js`, `rx.lite.js`, or `rx.lite.compat.js`)
 There is also a `concatMapObserver` operator, which is like the `flatMapObserver` operator, in that it creates Observables to merge from both the emissions and terminal notifications of the source Observable, but it concatenates rather than merges these resulting Observables in order to generate its own sequence.
“`selectConcatObserver`” is an alias for `concatMapObserver`.
`concatMapObserver` is found in each of the following distributions:
* `rx.js`
* `rx.all.js`
* `rx.all.compat.js`
* `rx.compat.js`
 The `manySelect` operator is often described as a “comonadic bind.” If that clears things up for you, you’re welcome. Elsewise, here’s an explanation:
`manySelect` internally transforms each item emitted by the source Observable into an Observable that emits that item and all items subsequently emitted by the source Observable, in the same order. So, for example, it internally transforms an Observable that emits the numbers 1,2,3 into three Observables: one that emits 1,2,3, one that emits 2,3, and one that emits 3.
Then `manySelect` passes each of these Observables into a function that you provide, and emits, as the emissions from the Observable that `manySelect` returns, the return values from those function calls.
In this way, each item emitted by the resulting Observable is a function of the corresponding item in the source Observable and all of the items emitted by the source Observable after it.
`manySelect` is found in each of the following distributions:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.experimental.js`
`manySelect` requires one of the following distributions:
* `rx.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
#### See Also
* [Microsoft Developer Network: “What does the new ManySelect operator do?”](https://social.msdn.microsoft.com/Forums/en-US/e70fe8b6-6d9d-486a-a8d0-c1bc66551ded/what-does-the-new-manyselect-operator-do?forum=rx)
### RxPHP `flatMap flatMapTo selectMany flatMapLatest concatMap concatMapTo`
RxPHP implements this operator as `flatMap`.
Projects each element of an observable sequence to an observable sequence and merges the resulting observable sequences into one observable sequence.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/flatMap/flatMap.php
$observable = Rx\Observable::range(1, 2);
$selectManyObservable = $observable->flatMap(function ($value) {
return Rx\Observable::range($value, 2);
});
$selectManyObservable->subscribe($stdoutObserver);
```
```
Next value: 1
Next value: 2
Next value: 2
Next value: 3
Complete!
```
RxPHP also has an operator `flatMapTo`.
Projects each element of the source observable sequence to the other observable sequence and merges the resulting observable sequences into one observable sequence.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/concat/concatMapTo.php
$obs = \Rx\Observable::interval(100)
->take(3)
->mapWithIndex(function ($i) {
return $i;
});
$source = Rx\Observable::range(0, 5)
->concatMapTo($obs);
$subscription = $source->subscribe($stdoutObserver);
```
```
Next value: 0
Next value: 1
Next value: 2
Next value: 3
Next value: 4
Next value: 5
Next value: 6
Next value: 7
Next value: 8
Next value: 9
Next value: 10
Next value: 11
Next value: 12
Next value: 13
Next value: 14
Complete!
```
RxPHP also has an operator `selectMany`.
Alias for flatMap
RxPHP also has an operator `flatMapLatest`.
Bypasses a specified number of elements in an observable sequence and then returns the remaining elements. Transform the items emitted by an Observable into Observables, and mirror those items emitted by the most-recently transformed Observable. The flatMapLatest operator is similar to the flatMap and concatMap methods described above, however, rather than emitting all of the items emitted by all of the Observables that the operator generates by transforming items from the source Observable, flatMapLatest instead emits items from each such transformed Observable only until the next such Observable is emitted, then it ignores the previous one and begins emitting items emitted by the new one.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/flatMap/flatMapLatest.php
$source = \Rx\Observable::range(1, 3)
->flatMapLatest(function ($x) {
return \Rx\Observable::fromArray([$x . 'a', $x . 'b']);
});
$source->subscribe($stdoutObserver);
```
```
Next value: 1a
Next value: 2a
Next value: 3a
Next value: 3b
Complete!
```
RxPHP also has an operator `concatMap`.
Projects each element of an observable sequence to an observable sequence and concatenates the resulting observable sequences into one observable sequence.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/concat/concatMap.php
$source = Rx\Observable::range(0, 5)
->concatMap(function ($x, $i) {
return \Rx\Observable::interval(100)
->take($x)
->map(function () use ($i) {
return $i;
});
});
$subscription = $source->subscribe($stdoutObserver);
```
```
Next value: 1
Next value: 2
Next value: 2
Next value: 3
Next value: 3
Next value: 3
Next value: 4
Next value: 4
Next value: 4
Next value: 4
Complete!
```
RxPHP also has an operator `concatMapTo`.
Projects each element of the source observable sequence to the other observable sequence and merges the resulting observable sequences into one observable sequence.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/concat/concatMapTo.php
$obs = \Rx\Observable::interval(100)
->take(3)
->mapWithIndex(function ($i) {
return $i;
});
$source = Rx\Observable::range(0, 5)
->concatMapTo($obs);
$subscription = $source->subscribe($stdoutObserver);
```
```
Next value: 0
Next value: 1
Next value: 2
Next value: 3
Next value: 4
Next value: 5
Next value: 6
Next value: 7
Next value: 8
Next value: 9
Next value: 10
Next value: 11
Next value: 12
Next value: 13
Next value: 14
Complete!
```
| programming_docs |
reactivex Just Just
====
> create an Observable that emits a particular item
 The Just operator converts an item into an Observable that emits that item.
Just is similar to From, but note that From will dive into an array or an iterable or something of that sort to pull out items to emit, while Just will simply emit the array or iterable or what-have-you as it is, unchanged, as a single item.
Note that if you pass `null` to Just, it will return an Observable that *emits* `null` as an item. Do not make the mistake of assuming that this will return an empty Observable (one that emits no items at all). For that, you will need the [Empty](empty-never-throw) operator.
#### See Also
* [From](from)
* [Repeat](repeat)
* [Start](start)
* [Timer](timer)
* [Introduction to Rx: Return](http://www.introtorx.com/Content/v1.0.10621.0/04_CreatingObservableSequences.html#ObservableReturn)
* [RxJava Tutorial 03: Observable from, just, & create methods](https://www.youtube.com/watch?v=sDqrlNprY24)
Language-Specific Information
-----------------------------
### RxGroovy `just`
 RxGroovy implements this operator as `just`. It accepts between one and nine items as parameters, and returns an Observable that emits these items in the same order as they are given in the parameter list.
`just` does not by default operate on any particular [Scheduler](../scheduler).
#### Sample Code
```
// Observable emits "some string" as a single item
def observableThatEmitsAString = Observable.just("some string");
// Observable emits the list [1, 2, 3, 4, 5] as a single item
def observableThatEmitsAList = Observable.just([1, 2, 3, 4, 5]);
// Observable emits 1, 2, 3, 4, and 5 as distinct items
def observableThatEmitsSeveralNumbers = Observable.just( 1, 2, 3, 4, 5 );
```
* Javadoc: [`just(item)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#just(T)) (there are also versions that accept between two and nine items as parameters)
### RxJava 1․x `just`
 RxJava implements this operator as `just`. It accepts between one and nine items as parameters, and returns an Observable that emits these items in the same order as they are given in the parameter list.
`just` does not by default operate on any particular [Scheduler](../scheduler).
#### Sample Code
```
Observable.just(1, 2, 3)
.subscribe(new Subscriber<Integer>() {
@Override
public void onNext(Integer item) {
System.out.println("Next: " + item);
}
@Override
public void onError(Throwable error) {
System.err.println("Error: " + error.getMessage());
}
@Override
public void onCompleted() {
System.out.println("Sequence complete.");
}
});
```
```
Next: 1
Next: 2
Next: 3
Sequence complete.
```
* Javadoc: [`just(item)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#just(T)) (there are also versions that accept between two and nine items as parameters)
### RxJS `just return`
 RxJS implements this operator as `return` and as `just` (two names for the same operator with the same behavior). It accepts a single item as a parameter and returns an Observable that emits that single item as its sole emission.
`return`/`just` operates by default on the `immediate` [Scheduler](../scheduler), but you can also pass in a Scheduler of your choosing as an optional second parameter, in which case it will operate on that Scheduler instead.
#### Sample Code
```
var source = Rx.Observable.just(42);
var subscription = source.subscribe(
function (x) { console.log('Next: %s', x); },
function (err) { console.log('Error: %s', err); },
function () { console.log('Completed'); });
```
```
Next: 42
Completed
```
`return`/`just` is found in each of the following distributions:
* `rx.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
### RxPHP `of`
RxPHP implements this operator as `of`.
Returns an observable sequence that contains a single element.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/of/of.php
$source = \Rx\Observable::of(42);
$subscription = $source->subscribe($stdoutObserver);
```
```
Next value: 42
Complete!
```
### RxSwift `just sequenceOf`
In Swift, this is implemented using the `Observable.just` class method.
The parameter, whether a tuple (i.e. `(1, 2, 3)`) or an array (i.e. `[1,2,3]`) is produced as one emission.
#### Sample Code
```
let source = Observable.just(1, 2, 3)
source.subscribe {
print($0)
}
let source2 = Observable.just([1,2,3])
source2.subscribe {
print($0)
}
```
```
next((1, 2, 3))
completed
next([1, 2, 3])
completed
```
The difference between this and `Observable.from` is that the latter's parameter is an array or a sequence, and emits each of its element as one emission.
reactivex SkipLast SkipLast
========
> suppress the final *n* items emitted by an Observable
[Open interactive diagram on rxmarbles.com](https://rxmarbles.com/#skipLast) You can ignore the final *n* items emitted by an Observable and attend only to those items that come before them, by modifying the Observable with the SkipLast operator.
#### See Also
* [Last](last)
* [Skip](skip)
* [SkipUntil](skipuntil)
* [SkipWhile](skipwhile)
* [Take](take)
* [TakeLast](takelast)
* [TakeUntil](takeuntil)
* [TakeWhile](takewhile)
* [Introduction to Rx: SkipLast and TakeLast](http://www.introtorx.com/Content/v1.0.10621.0/05_Filtering.html#SkipLastTakeLast)
* [RxMarbles: `skipLast`](http://rxmarbles.com/#skipLast)
Language-Specific Information
-----------------------------
### RxGroovy `skipLast`
 You can ignore the final *n* items emitted by an Observable and attend only to those items that precede them, by modifying the Observable with the `skipLast(*n*)` operator. Note that the mechanism by which this is implemented will delay the emission of any item from the source Observable until *n* additional items have been emitted by that Observable.
This variant of `skipLast` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`skipLast(int)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#skipLast(int))
 There is also a variant of `skipLast` that takes a temporal duration rather than a quantity of items. It drops those items that are emitted during that final duration of the source Observable’s lifespan. You set this duration by passing in a length of time and the time units this length is denominated in as parameters to `skipLast`.
Note that the mechanism by which this is implemented will delay the emission of any item from the source Observable until the given duration passes since its emission.
This variant of `skipLast` by default operates on the `computation` [Scheduler](../scheduler), but you may also pass in a Scheduler of your choosing as an optional third parameter.
* Javadoc: [`skipLast(long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#skipLast(long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`skipLast(long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#skipLast(long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
### RxJava 1․x `skipLast`
 You can ignore the final *n* items emitted by an Observable and attend only to those items that precede them, by modifying the Observable with the `skipLast(*n*)` operator. Note that the mechanism by which this is implemented will delay the emission of any item from the source Observable until *n* additional items have been emitted by that Observable.
This variant of `skipLast` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`skipLast(int)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#skipLast(int))
 There is also a variant of `skipLast` that takes a temporal duration rather than a quantity of items. It drops those items that are emitted during that final duration of the source Observable’s lifespan. You set this duration by passing in a length of time and the time units this length is denominated in as parameters to `skipLast`.
Note that the mechanism by which this is implemented will delay the emission of any item from the source Observable until the given duration passes since its emission.
This variant of `skipLast` by default operates on the `computation` [Scheduler](../scheduler), but you may also pass in a Scheduler of your choosing as an optional third parameter.
* Javadoc: [`skipLast(long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#skipLast(long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`skipLast(long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#skipLast(long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
### RxJS `skipLast skipLastWithTime`
 You can ignore the final *n* items emitted by an Observable and attend only to those items that precede them, by modifying the Observable with the `skipLast(*n*)` operator. Note that the mechanism by which this is implemented will delay the emission of any item from the source Observable until *n* additional items have been emitted by that Observable.
#### Sample Code
```
var source = Rx.Observable.range(0, 5)
.skipLast(3);
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 0
Next: 1
Completed
```
`skipLast` is found in each of the following distributions:
* `rx.js`
* `rx.all.js`
* `rx.all.compat.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
 The `skipLastWithTime` operator takes a temporal duration rather than a quantity of items. It drops those items that are emitted during that final duration of the source Observable’s lifespan. You set this duration by passing in a number of milliseconds as a parameter to `skipLastWithTime`.
Note that the mechanism by which this is implemented will delay the emission of any item from the source Observable until the given duration passes since its emission.
`skipLastWithTime` by default operates on the `timeout` [Scheduler](../scheduler), but you may also pass in a Scheduler of your choosing as an optional second parameter.
#### Sample Code
```
var source = Rx.Observable.timer(0, 1000)
.take(10)
.skipLastWithTime(5000);
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 0
Next: 1
Next: 2
Next: 3
Next: 4
Completed
```
`skipLastWithTime` is found in each of the following distributions:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.time.js` (requires `rx.js` or `rx.compat.js`)
* `rx.lite.js`
* `rx.lite.compat.js`
### RxPHP `skipLast`
RxPHP implements this operator as `skipLast`.
Bypasses a specified number of elements at the end of an observable sequence. This operator accumulates a queue with a length enough to store the first `count` elements. As more elements are received, elements are taken from the front of the queue and produced on the result sequence. This causes elements to be delayed.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/skip/skipLast.php
$observable = Rx\Observable::range(0, 5)
->skipLast(3);
$observable->subscribe($stdoutObserver);
```
```
Next value: 0
Next value: 1
Complete!
```
reactivex TakeUntil TakeUntil
=========
> discard any items emitted by an Observable after a second Observable emits an item or terminates
[Open interactive diagram on rxmarbles.com](https://rxmarbles.com/#takeUntil) The TakeUntil subscribes and begins mirroring the source Observable. It also monitors a second Observable that you provide. If this second Observable emits an item or sends a termination notification, the Observable returned by TakeUntil stops mirroring the source Observable and terminates.
#### See Also
* [Skip](skip)
* [SkipLast](skiplast)
* [SkipUntil](skipuntil)
* [SkipWhile](skipwhile)
* [Take](take)
* [TakeLast](takelast)
* [TakeWhile](takewhile)
* [Introduction to Rx: SkipUntil and TakeUntil](http://www.introtorx.com/Content/v1.0.10621.0/05_Filtering.html#SkipUntilTakeUntil)
* [RxMarbles: `takeUntil`](http://rxmarbles.com/#takeUntil)
Language-Specific Information
-----------------------------
### RxGroovy `takeUntil`
 In RxGroovy, this operator is implemented as `takeUntil`. Note that the second Observable can cause `takeUntil` to quit emitting items either by emitting an item or by issuing an `onError` or `onCompleted` notification.
`takeUntil` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`takeUntil(Observable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#takeUntil(rx.Observable))
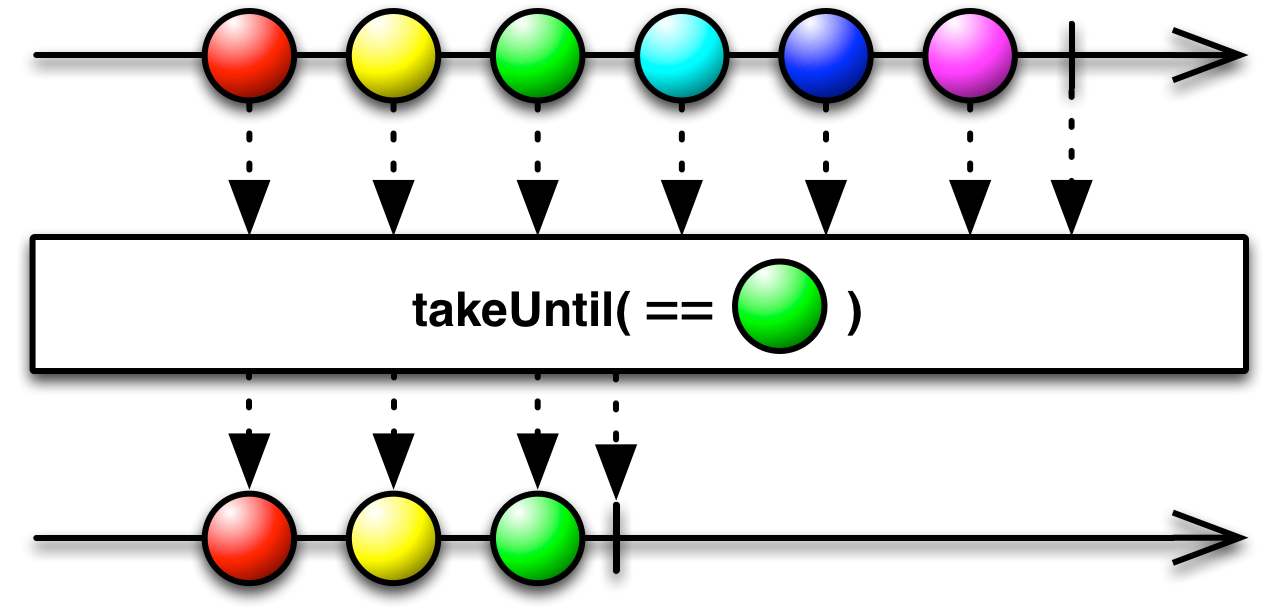 A second version of this operator was released in RxGroovy 1.1. It uses a predicate function that evaluates the items emitted by the source Observable, rather than a second Observable, to terminate the resulting Observable sequence. In this way, it behaves in a similar way to [TakeWhile](takewhile).
* Javadoc: [`takeUntil(Func1)` (RxGroovy 1.1)](http://reactivex.io/RxJava/javadoc/rx/Observable.html#takeUntil(rx.functions.Func1))
### RxJava 1․x `takeUntil`
 In RxJava, this operator is implemented as `takeUntil`. Note that the second Observable can cause `takeUntil` to quit emitting items either by emitting an item or by issuing an `onError` or `onCompleted` notification.
`takeUntil` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`takeUntil(Observable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#takeUntil(rx.Observable))
 A second version of this operator was released in RxJava 1.1. It uses a predicate function that evaluates the items emitted by the source Observable, rather than a second Observable, to terminate the resulting Observable sequence. In this way, it behaves in a similar way to [TakeWhile](takewhile).
* Javadoc: [`takeUntil(Func1)` (RxJava 1.1)](http://reactivex.io/RxJava/javadoc/rx/Observable.html#takeUntil(rx.functions.Func1))
### RxJS `takeUntil`
 RxJS implements the `takeUntil` operator. You can pass it either an Observable or a `Promise` that it will monitor for an item that triggers `takeUntil` to stop mirroring the source Observable.
#### Sample Code
```
var source = Rx.Observable.timer(0, 1000)
.takeUntil(Rx.Observable.timer(5000));
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 0
Next: 1
Next: 2
Next: 3
Next: 4
Completed
```
`takeUntil` is found in each of the following distributions:
* `rx.js`
* `rx.all.js`
* `rx.all.compat.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
There is also a `takeUntilWithTime` operator to which you can pass an absolute time or an initial duration, but this is described on the [Take](take) operator page.
### RxPHP `takeUntil`
RxPHP implements this operator as `takeUntil`.
Returns the values from the source observable sequence until the other observable sequence produces a value.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/take/take.php
$observable = Rx\Observable::fromArray([21, 42, 63]);
$observable
->take(2)
->subscribe($stdoutObserver);
```
```
Next value: 21
Next value: 42
Complete!
```
reactivex Amb Amb
===
> given two or more source Observables, emit all of the items from only the first of these Observables to emit an item or notification
[Open interactive diagram on rxmarbles.com](https://rxmarbles.com/#amb) When you pass a number of source Observables to Amb, it will pass through the emissions and notifications of exactly one of these Observables: the first one that sends a notification to Amb, either by emitting an item or sending an `onError` or `onCompleted` notification. Amb will ignore and discard the emissions and notifications of all of the other source Observables.
#### See Also
* [RxMarbles: `amb`](http://rxmarbles.com/#amb)
Language-Specific Information
-----------------------------
### RxGroovy `amb ambWith`
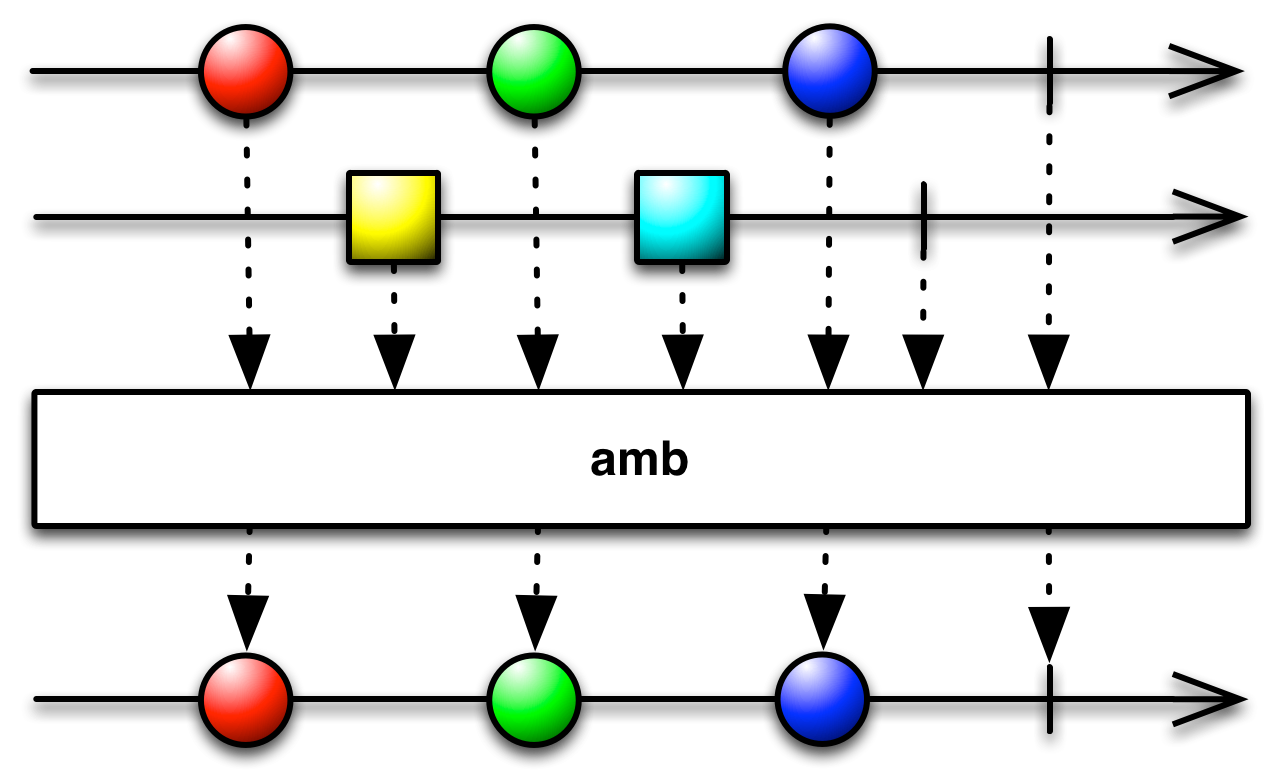 RxGroovy implements this operator as `amb`. It takes up to nine Observables as individual parameters, or a single Iterable of Observables. There is also an instance version of the operator, `ambWith`, so that, for example, instead of writing `Observable.amb(o1,o2)` you could also write `o1.ambWith(o2)` for the same effect.
This operator does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`amb(Iterable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#amb(java.lang.Iterable))
* Javadoc: [`amb(Observable,Observable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#amb(rx.Observable,%20rx.Observable)) (there are also versions that take up to nine Observable parameters)
* Javadoc: [`ambWith(Observable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#ambWith(rx.Observable))
### RxJava 1․x `amb ambWith`
 RxJava 1.x implements this operator as `amb`. It takes up to nine Observables as individual parameters, or a single Iterable of Observables. There is also an instance version of the operator, `ambWith`, so that, for example, instead of writing `Observable.amb(o1,o2)` you could also write `o1.ambWith(o2)` for the same effect.
This operator does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`amb(Iterable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#amb(java.lang.Iterable))
* Javadoc: [`amb(Observable,Observable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#amb(rx.Observable,%20rx.Observable)) (there are also versions that take up to nine Observable parameters)
* Javadoc: [`ambWith(Observable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#ambWith(rx.Observable))
### RxJava 2․x `amb ambArray ambWith`
 RxJava 2.x implements this operator as `amb`. It takes an Iterable of Observables as its parameter. You can also use `ambArray` to pass an array of Observables. There is also an instance version of the operator, `ambWith`, so that, for example, instead of writing `Observable.ambArray([o1,o2])` you could also write `o1.ambWith(o2)` for the same effect.
This operator does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`amb(Iterable)`](http://reactivex.io/RxJava/2.x/javadoc/io/reactivex/Observable.html#amb(java.lang.Iterable))
* Javadoc: [`ambArray(Iterable)`](#)
* Javadoc: [`ambWith(Observable)`](http://reactivex.io/RxJava/2.x/javadoc/io/reactivex/Observable.html#ambWith(io.reactivex.ObservableSource))
### RxJS `amb`
 RxJS implements this operator as `amb`. It takes a variable number of parameters, which may be either Observables or Promises (or combinations of the two).
#### Sample Code
```
/* Using Observable sequences */
var source = Rx.Observable.amb(
Rx.Observable.timer(500).select(function () { return 'foo'; }),
Rx.Observable.timer(200).select(function () { return 'bar'; })
);
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: bar
Completed
```
```
/* Using Promises and Observables */
var source = Rx.Observable.amb(
RSVP.Promise.resolve('foo')
Rx.Observable.timer(200).select(function () { return 'bar'; })
);
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: foo
Completed
```
### RxPHP `race`
RxPHP implements this operator as `race`.
Propagates the observable sequence that reacts first. Also known as 'amb'.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/race/race.php
$source = Rx\Observable::race(
[
Rx\Observable::timer(500)->map(function () {
return 'foo';
}),
Rx\Observable::timer(200)->map(function () {
return 'bar';
})
]
);
$source->subscribe($stdoutObserver);
```
```
Next value: bar
Complete!
```
| programming_docs |
reactivex Debounce Debounce
========
> only emit an item from an Observable if a particular timespan has passed without it emitting another item
[Open interactive diagram on rxmarbles.com](https://rxmarbles.com/#debounce) The Debounce operator filters out items emitted by the source Observable that are rapidly followed by another emitted item.
#### See Also
* [Backpressure-related Operators](backpressure)
* [Sample](sample)
* [Window](window)
* [Introduction to Rx: Throttle](http://www.introtorx.com/Content/v1.0.10621.0/13_TimeShiftedSequences.html#Throttle)
* [RxMarbles: `debounce`](http://rxmarbles.com/#debounce)
* [RxMarbles: `debounceWithSelector`](http://rxmarbles.com/#debounceWithSelector)
* [101 Rx Samples: Throttle — Simple](http://rxwiki.wikidot.com/101samples#toc30)
Language-Specific Information
-----------------------------
### RxGroovy `debounce throttleWithTimeout`
RxGroovy implements this operator as `throttleWithTimeout` and `debounce`.
Note that the last item emitted by the source Observable will be emitted in turn by this operator even if the source Observable’s `onCompleted` notification is issued within the time window you specify since that item’s emission. That is to say: an `onCompleted` notification will not trigger a throttle.
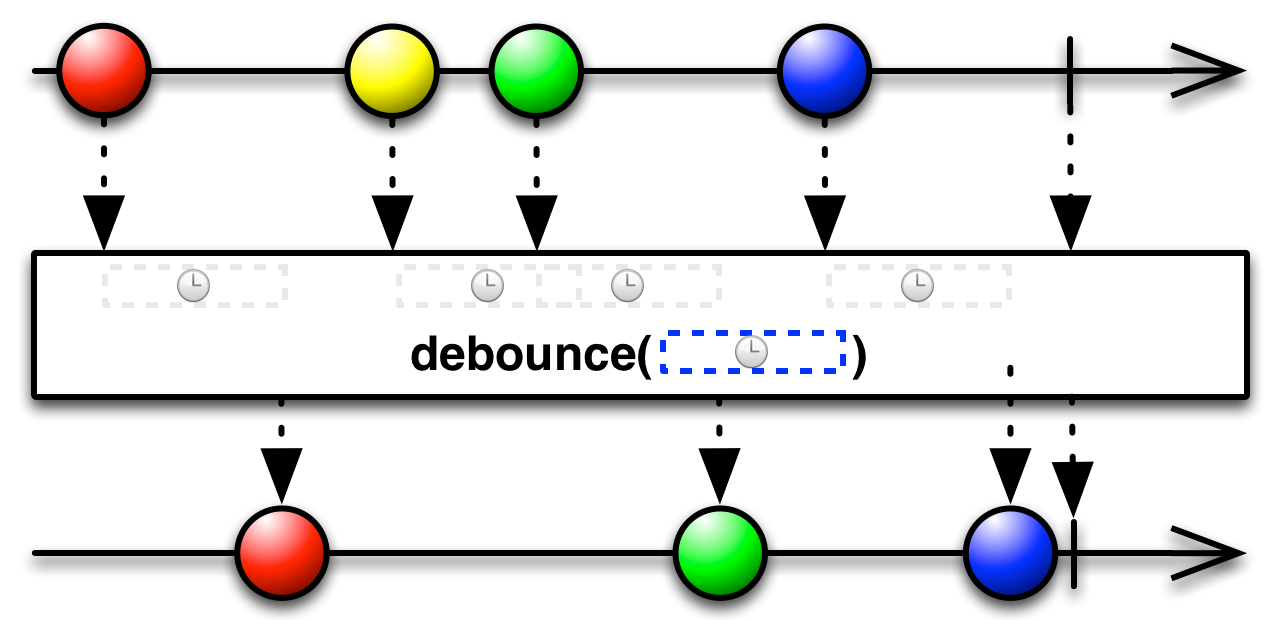 One variant of `throtleWithTimeout`/`debounce` (two names for the same operator variant) throttles at a periodic time interval that you choose by passing in a `TimeUnit` and a quantity of such units as parameters to the operator.
This variant operates by default on the `computation` [Scheduler](../scheduler), but you can optionally pass in a Scheduler of your choosing as a third parameter.
* Javadoc: [`throttleWithTimeout(long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#throttleWithTimeout(long,%20java.util.concurrent.TimeUnit)) and [`debounce(long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#debounce(long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`throttleWithTimeout(long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#throttleWithTimeout(long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler)) and [`debounce(long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#debounce(long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
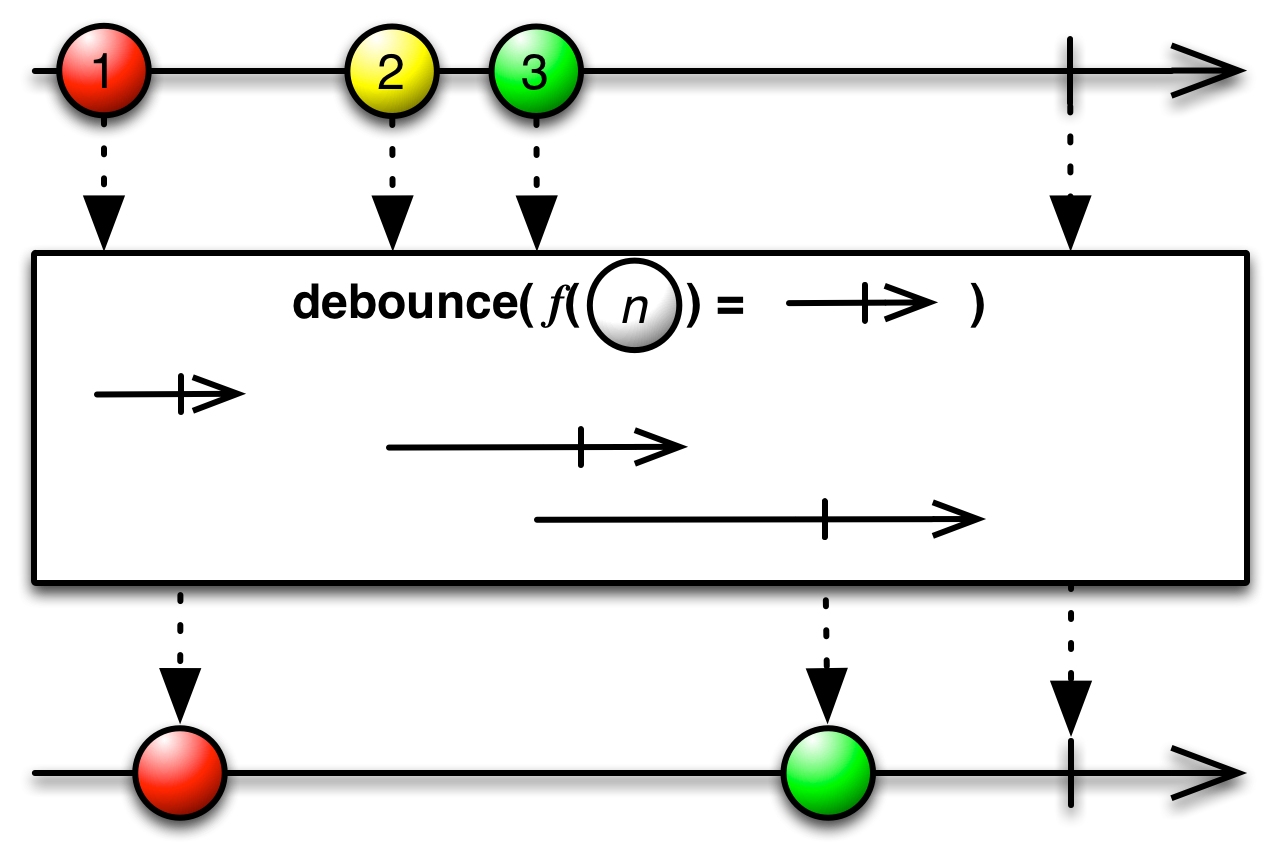 There ia also a variant of `debounce` (that does not have a `throttleWithTimeout` alias) that throttles the source Observable by applying a function to each item it emits, this function generating an Observable. If the source Observable emits another item before this newly-generated Observable terminates, `debounce` will suppress the item.
This variant of `debounce` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`debounce(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#debounce(rx.functions.Func1))
### RxJava 1․x `debounce throttleWithTimeout`
RxJava implements this operator as `throttleWithTimeout` and `debounce`.
Note that the last item emitted by the source Observable will be emitted in turn by this operator even if the source Observable’s `onCompleted` notification is issued within the time window you specify since that item’s emission. That is to say: an `onCompleted` notification will not trigger a throttle.
 One variant of `throtleWithTimeout`/`debounce` (two names for the same operator variant) throttles at a periodic time interval that you choose by passing in a `TimeUnit` and a quantity of such units as parameters to the operator.
This variant operates by default on the `computation` [Scheduler](../scheduler), but you can optionally pass in a Scheduler of your choosing as a third parameter.
* Javadoc: [`throttleWithTimeout(long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#throttleWithTimeout(long,%20java.util.concurrent.TimeUnit)) and [`debounce(long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#debounce(long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`throttleWithTimeout(long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#throttleWithTimeout(long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler)) and [`debounce(long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#debounce(long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
 There ia also a variant of `debounce` (that does not have a `throttleWithTimeout` alias) that throttles the source Observable by applying a function to each item it emits, this function generating an Observable. If the source Observable emits another item before this newly-generated Observable terminates, `debounce` will suppress the item.
This variant of `debounce` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`debounce(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#debounce(rx.functions.Func1))
### RxJS `debounce debounceWithSelector throttleWithTimeout`
 The first variant — called either `debounce` or `throttleWithTimeout` — accepts as its parameter a duration, defined as an integer number of milliseconds, and it suppresses any emitted items that are followed by other emitted items during that duration since the first item’s emission.
#### Sample Code
```
var times = [
{ value: 0, time: 100 },
{ value: 1, time: 600 },
{ value: 2, time: 400 },
{ value: 3, time: 700 },
{ value: 4, time: 200 }
];
// Delay each item by time and project value;
var source = Rx.Observable.from(times)
.flatMap(function (item) {
return Rx.Observable
.of(item.value)
.delay(item.time);
})
.debounce(500 /* ms */);
var subscription = source.subscribe(
function (x) {
console.log('Next: %s', x);
},
function (err) {
console.log('Error: %s', err);
},
function () {
console.log('Completed');
});
```
```
Next: 0
Next: 2
Next: 4
Completed
```
 The `debounceWithSelector` operator throttles the source Observable by applying a function to each item it emits, this function generating an Observable. If the source Observable emits another item before this newly-generated Observable terminates, `debounce` will suppress the item.
#### Sample Code
```
var array = [
800,
700,
600,
500
];
var source = Rx.Observable.for(
array,
function (x) {
return Rx.Observable.timer(x)
})
.map(function(x, i) { return i; })
.throttleWithSelector(function (x) {
return Rx.Observable.timer(700);
});
var subscription = source.subscribe(
function (x) {
console.log('Next: ' + x);
},
function (err) {
console.log('Error: ' + err);
},
function () {
console.log('Completed');
});
```
```
Next: 0
Next: 3
Completed
```
`debounce` and `debounceWithSelector` are found in each of the following distributions:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.time.js` (requires `rx.js` or `rx.compat.js`)
* `rx.lite.js`
* `rx.lite.compat.js`
### RxPHP `throttle`
RxPHP implements this operator as `throttle`.
Returns an Observable that emits only the first item emitted by the source Observable during sequential time windows of a specified duration. If items are emitted on the source observable prior to the expiration of the time period, the last item emitted on the source observable will be emitted.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/throttle/throttle.php
$times = [
['value' => 0, 'time' => 10],
['value' => 1, 'time' => 200],
['value' => 2, 'time' => 400],
['value' => 3, 'time' => 500],
['value' => 4, 'time' => 900]
];
// Delay each item by time and project value;
$source = Observable::fromArray($times)
->flatMap(function ($item) {
return Observable::of($item['value'])
->delay($item['time']);
})
->throttle(300 /* ms */);
$subscription = $source->subscribe($stdoutObserver);
```
```
Next value: 0
Next value: 1
Next value: 3
Next value: 4
Complete!
```
reactivex Reduce Reduce
======
> apply a function to each item emitted by an Observable, sequentially, and emit the final value
[Open interactive diagram on rxmarbles.com](https://rxmarbles.com/#reduce) The Reduce operator applies a function to the first item emitted by the source Observable and then feeds the result of the function back into the function along with the second item emitted by the source Observable, continuing this process until the source Observable emits its final item and completes, whereupon the Observable returned from Reduce emits the final value returned from the function.
This sort of operation is sometimes called “accumulate,” “aggregate,” “compress,” “fold,” or “inject” in other contexts.
#### See Also
* [Scan](scan)
* [Introduction to Rx: Aggregate](http://www.introtorx.com/Content/v1.0.10621.0/07_Aggregation.html#Aggregate)
* [RxMarbles: `reduce`](http://rxmarbles.com/#reduce)
* [Experimentation with RxJava](http://blog.joanzapata.com/experimentation-with-rx/) by Joan Zapata
Language-Specific Information
-----------------------------
### RxGroovy `collect reduce`
 The `reduce` operator returns an Observable that applies a function of your choosing to the first item emitted by a source Observable, then feeds the result of that function along with the second item emitted by the source Observable into the same function, then feeds the result of that function along with the third item into the same function, and so on until all items have been emitted by the source Observable. Then it emits the final result from the final call to your function as the sole output from the returned Observable.
Note that if the source Observable does not emit any items, `reduce` will fail with an `IllegalArgumentException`.
For example, the following code uses `reduce` to compute, and then emit as an Observable, the sum of the numbers emitted by the source Observable:
#### Sample Code
```
numbers = Observable.from([1, 2, 3, 4, 5]);
numbers.reduce({ a, b -> a+b }).subscribe(
{ println(it); }, // onNext
{ println("Error: " + it.getMessage()); }, // onError
{ println("Sequence complete"); } // onCompleted
);
```
```
15
Sequence complete
```
`reduce` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`reduce(Func2)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#reduce(rx.functions.Func2))
 There is also a version of `reduce` to which you can pass a seed item in addition to an accumulator function. Note that passing a `null` seed is not the same as not passing a seed. The behavior will be different. If you pass a seed of `null`, you will be seeding your reduction with the item `null`. Note also that if you do pass in a seed, and the source Observable emits no items, reduce will emit the seed and complete normally without error.
`reduce` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`reduce(R,Func2)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#reduce(R,%20rx.functions.Func2))
It is a bad idea to use `reduce` to collect emitted items into a mutable data structure. Instead, use `collect` for that purpose.
 The `collect` operator is similar to `reduce` but is specialized for the purpose of collecting the whole set of items emitted by the source Observable into a single mutable data structure to be emitted by the resulting Observable. Pass it two parameters:
1. a function that returns the mutable data structure
2. a function that, when given the data structure and an item emitted by the source Observable, modifies the data structure appropriately
`collect` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`collect(Func0,Action2)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#collect(rx.functions.Func0,%20rx.functions.Action2))
### RxJava 1․x `collect reduce`
 The `reduce` operator returns an Observable that applies a function of your choosing to the first item emitted by a source Observable, then feeds the result of that function along with the second item emitted by the source Observable into the same function, then feeds the result of that function along with the third item into the same function, and so on until all items have been emitted by the source Observable. Then it emits the final result from the final call to your function as the sole output from the returned Observable.
Note that if the source Observable does not emit any items, `reduce` will fail with an `IllegalArgumentException`.
`reduce` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`reduce(Func2)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#reduce(rx.functions.Func2))
 There is also a version of `reduce` to which you can pass a seed item in addition to an accumulator function. Note that passing a `null` seed is not the same as not passing a seed. The behavior will be different. If you pass a seed of `null`, you will be seeding your reduction with the item `null`. Note also that if you do pass in a seed, and the source Observable emits no items, reduce will emit the seed and complete normally without error.
`reduce` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`reduce(R,Func2)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#reduce(R,%20rx.functions.Func2))
It is a bad idea to use `reduce` to collect emitted items into a mutable data structure. Instead, use `collect` for that purpose.
 The `collect` operator is similar to `reduce` but is specialized for the purpose of collecting the whole set of items emitted by the source Observable into a single mutable data structure to be emitted by the resulting Observable. Pass it two parameters:
1. a function that returns the mutable data structure
2. a function that, when given the data structure and an item emitted by the source Observable, modifies the data structure appropriately
`collect` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`collect(Func0,Action2)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#collect(rx.functions.Func0,%20rx.functions.Action2))
### RxJS `reduce`
 RxJS implements the `reduce` operator. Pass it an accumulator function, and, optionally, a seed value to pass into the accumulator function with the first item emitted by the source Observable.
#### Sample Code
```
var source = Rx.Observable.range(1, 3)
.reduce(function (acc, x) {
return acc * x;
}, 1)
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 6
Completed
```
`reduce` is found in each of the following distributions:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.aggregates.js`
`reduce` requires one of the following distributions:
* `rx.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
### RxPHP `reduce`
RxPHP implements this operator as `reduce`.
Applies an accumulator function over an observable sequence, returning the result of the aggregation as a single element in the result sequence. The specified seed value is used as the initial accumulator value.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/reduce/reduce.php
//Without a seed
$source = \Rx\Observable::fromArray(range(1, 3));
$subscription = $source
->reduce(function ($acc, $x) {
return $acc + $x;
})
->subscribe($createStdoutObserver());
```
```
Next value: 6
Complete!
```
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/reduce/reduce-with-seed.php
//With a seed
$source = \Rx\Observable::fromArray(range(1, 3));
$subscription = $source
->reduce(function ($acc, $x) {
return $acc * $x;
}, 1)
->subscribe($createStdoutObserver());
```
```
Next value: 6
Complete!
```
reactivex Replay Replay
======
> ensure that all observers see the same sequence of emitted items, even if they subscribe after the Observable has begun emitting items
 A connectable Observable resembles an ordinary Observable, except that it does not begin emitting items when it is subscribed to, but only when the Connect operator is applied to it. In this way you can prompt an Observable to begin emitting items at a time of your choosing.
If you apply the Replay operator to an Observable before you convert it into a connectable Observable, the resulting connectable Observable will always emit the same complete sequence to any future observers, even those observers that subscribe after the connectable Observable has begun to emit items to other subscribed observers.
#### See Also
* [Connect](connect)
* [Publish](publish)
* [RefCount](refcount)
* [Introduction to Rx: Replay](http://www.introtorx.com/Content/v1.0.10621.0/14_HotAndColdObservables.html#Replay)
Language-Specific Information
-----------------------------
### RxGroovy `replay cache`
 In RxGroovy there is a variety of the `replay` operator that returns a connectable Observable. You must [Publish](publish) this connectable Observable before observers can subscribe to it, and then [Connect](connect) to it in order to observe its emissions.
Variants of this variety of the `replay` operator permit you to set a maximum buffer size to limit the number of items `replay` will buffer and replay to subsequent observers, and/or to establish a moving time window that defines when emitted items become too old to buffer and replay.
* Javadoc: [`replay()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#replay())
* Javadoc: [`replay(Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#replay(rx.Scheduler))
* Javadoc: [`replay(int)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#replay(int))
* Javadoc: [`replay(int,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#replay(int,%20rx.Scheduler))
* Javadoc: [`replay(long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#replay(long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`replay(long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#replay(long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
* Javadoc: [`replay(int,long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#replay(int,%20long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`replay(int,long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#replay(int,%20long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
 There is also a variety of `replay` that returns an ordinary Observable. These variants take as a parameter a transformative function; this function accepts an item emitted by the source Observable as its parameter, and returns an item to be emitted by the resulting Observable. So really, this operator does not replay the source Observable but instead replays the source Observable *as transformed* by this function.
Variants of this variety of the `replay` operator permit you to set a maximum buffer size to limit the number of items `replay` will buffer and replay to subsequent observers, and/or to establish a moving time window that defines when emitted items become too old to buffer and replay.
* Javadoc: [`replay(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#replay(rx.functions.Func1))
* Javadoc: [`replay(Func1,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#replay(rx.functions.Func1,%20rx.Scheduler))
* Javadoc: [`replay(Func1,int)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#replay(rx.functions.Func1,%20int))
* Javadoc: [`replay(Func1,int,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#replay(rx.functions.Func1,%20int,%20rx.Scheduler))
* Javadoc: [`replay(Func1,long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#replay(rx.functions.Func1,%20long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`replay(Func1,long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#replay(rx.functions.Func1,%20long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
* Javadoc: [`replay(Func1,int,long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#replay(rx.functions.Func1,%20int,%20long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`replay(Func1,int,long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#replay(rx.functions.Func1,%20int,%20long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
### RxJava 1․x `cache replay`
 In RxJava there is a variety of the `replay` operator that returns a connectable Observable. You must [Publish](publish) this connectable Observable before observers can subscribe to it, and then [Connect](connect) to it in order to observe its emissions.
Variants of this variety of the `replay` operator permit you to set a maximum buffer size to limit the number of items `replay` will buffer and replay to subsequent observers, and/or to establish a moving time window that defines when emitted items become too old to buffer and replay.
* Javadoc: [`replay()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#replay())
* Javadoc: [`replay(Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#replay(rx.Scheduler))
* Javadoc: [`replay(int)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#replay(int))
* Javadoc: [`replay(int,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#replay(int,%20rx.Scheduler))
* Javadoc: [`replay(long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#replay(long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`replay(long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#replay(long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
* Javadoc: [`replay(int,long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#replay(int,%20long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`replay(int,long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#replay(int,%20long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
 There is also a variety of `replay` that returns an ordinary Observable. These variants take as a parameter a transformative function; this function accepts an item emitted by the source Observable as its parameter, and returns an item to be emitted by the resulting Observable. So really, this operator does not replay the source Observable but instead replays the source Observable *as transformed* by this function.
Variants of this variety of the `replay` operator permit you to set a maximum buffer size to limit the number of items `replay` will buffer and replay to subsequent observers, and/or to establish a moving time window that defines when emitted items become too old to buffer and replay.
* Javadoc: [`replay(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#replay(rx.functions.Func1))
* Javadoc: [`replay(Func1,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#replay(rx.functions.Func1,%20rx.Scheduler))
* Javadoc: [`replay(Func1,int)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#replay(rx.functions.Func1,%20int))
* Javadoc: [`replay(Func1,int,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#replay(rx.functions.Func1,%20int,%20rx.Scheduler))
* Javadoc: [`replay(Func1,long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#replay(rx.functions.Func1,%20long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`replay(Func1,long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#replay(rx.functions.Func1,%20long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
* Javadoc: [`replay(Func1,int,long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#replay(rx.functions.Func1,%20int,%20long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`replay(Func1,int,long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#replay(rx.functions.Func1,%20int,%20long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
### RxJS `replay shareReplay`
 In RxJs the `replay` operator takes four optional parameters and returns an ordinary Observable:
`selector`
a transforming function that takes an item emitted by the source Observable as its parameter and returns an item to be emitted by the resulting Observable `bufferSize`
the maximum number of items to buffer and replay to subsequent observers `window`
the age, in milliseconds, at which items in this buffer may be discarded without being emitted to subsequent observers `scheduler`
the [Scheduler](../scheduler) on which this operator will operate #### Sample Code
```
var interval = Rx.Observable.interval(1000);
var source = interval
.take(2)
.do(function (x) {
console.log('Side effect');
});
var published = source
.replay(function (x) {
return x.take(2).repeat(2);
}, 3);
published.subscribe(createObserver('SourceA'));
published.subscribe(createObserver('SourceB'));
function createObserver(tag) {
return Rx.Observer.create(
function (x) { console.log('Next: ' + tag + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
}
```
```
Side effect
Next: SourceA0
Side effect
Next: SourceB0
Side effect
Next: SourceA1
Next: SourceA0
Next: SourceA1
Completed
Side effect
Next: SourceB1
Next: SourceB0
Next: SourceB1
Completed
```
There is also a `shareReplay` operator, which keeps track of the number of observers, and disconnects from the source Observable when that number drops to zero. `shareReplay` takes three optional parameters and returns an ordinary Observable:
`bufferSize`
the maximum number of items to buffer and replay to subsequent observers `window`
the age, in milliseconds, at which items in this buffer may be discarded without being emitted to subsequent observers `scheduler`
the [Scheduler](../scheduler) on which this operator will operate #### Sample Code
```
var interval = Rx.Observable.interval(1000);
var source = interval
.take(4)
.doAction(function (x) {
console.log('Side effect');
});
var published = source
.shareReplay(3);
published.subscribe(createObserver('SourceA'));
published.subscribe(createObserver('SourceB'));
// Creating a third subscription after the previous two subscriptions have
// completed. Notice that no side effects result from this subscription,
// because the notifications are cached and replayed.
Rx.Observable
.return(true)
.delay(6000)
.flatMap(published)
.subscribe(createObserver('SourceC'));
function createObserver(tag) {
return Rx.Observer.create(
function (x) { console.log('Next: ' + tag + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
}
```
```
Side effect
Next: SourceA0
Next: SourceB0
Side effect
Next: SourceA1
Next: SourceB1
Side effect
Next: SourceA2
Next: SourceB2
Side effect
Next: SourceA3
Next: SourceB3
Completed
Completed
Next: SourceC1
Next: SourceC2
Next: SourceC3
Completed
```
`replay` and `shareReplay` are found in the following distributions:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.binding.js` (requires `rx.js` or `rx.compat.js`)
* `rx.lite.js`
* `rx.lite.compat.js`
### RxPHP `replay shareReplay`
RxPHP implements this operator as `replay`.
Returns an observable sequence that is the result of invoking the selector on a connectable observable sequence that shares a single subscription to the underlying sequence replaying notifications subject to a maximum time length for the replay buffer. This operator is a specialization of Multicast using a ReplaySubject.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/replay/replay.php
$interval = \Rx\Observable::interval(1000);
$source = $interval
->take(2)
->doOnNext(function ($x) {
echo $x, ' something', PHP_EOL;
echo 'Side effect', PHP_EOL;
});
$published = $source
->replay(function (\Rx\Observable $x) {
return $x->take(2)->repeat(2);
}, 3);
$published->subscribe($createStdoutObserver('SourceA '));
$published->subscribe($createStdoutObserver('SourceB '));
```
```
0 something
Side effect
0 something
Side effect
SourceA Next value: 0
SourceB Next value: 0
SourceA Next value: 0
SourceB Next value: 0
SourceA Next value: 0
SourceB Next value: 0
SourceA Next value: 0
SourceA Complete!
SourceB Next value: 0
SourceB Complete!
1 something
Side effect
1 something
Side effect
```
RxPHP also has an operator `shareReplay`.
Returns an observable sequence that shares a single subscription to the underlying sequence replaying notifications subject to a maximum time length for the replay buffer. This operator is a specialization of replay which creates a subscription when the number of observers goes from zero to one, then shares that subscription with all subsequent observers until the number of observers returns to zero, at which point the subscription is disposed.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/share/shareReplay.php
$interval = Rx\Observable::interval(1000);
$source = $interval
->take(4)
->doOnNext(function ($x) {
echo 'Side effect', PHP_EOL;
});
$published = $source
->shareReplay(3);
$published->subscribe($createStdoutObserver('SourceA '));
$published->subscribe($createStdoutObserver('SourceB '));
Rx\Observable
::of(true)
->concatMapTo(\Rx\Observable::timer(6000))
->flatMap(function () use ($published) {
return $published;
})
->subscribe($createStdoutObserver('SourceC '));
```
```
Side effect
SourceA Next value: 0
SourceB Next value: 0
Side effect
SourceA Next value: 1
SourceB Next value: 1
Side effect
SourceA Next value: 2
SourceB Next value: 2
Side effect
SourceA Next value: 3
SourceB Next value: 3
SourceA Complete!
SourceB Complete!
SourceC Next value: 1
SourceC Next value: 2
SourceC Next value: 3
SourceC Complete!
```
| programming_docs |
reactivex Max Max
===
> emits the item from the source Observable that had the maximum value
[Open interactive diagram on rxmarbles.com](https://rxmarbles.com/#max) The Max operator operates on an Observable that emits numbers (or items that can be evaluated as numbers), and emits a single item: the item with the largest number.
#### See Also
* [Min](min)
* [Introduction to Rx: Min, Max, Sum, and Average](http://www.introtorx.com/Content/v1.0.10621.0/07_Aggregation.html#MaxAndMin)
* [RxMarbles: `max`](http://rxmarbles.com/#max)
Language-Specific Information
-----------------------------
### RxGroovy `max maxBy`
In RxGroovy, this operator is not in the ReactiveX core, but is part of the distinct `rxjava-math` module.
 RxGroovy implements a `max` operator. It takes an optional comparator that it will use instead of its default to compare the value of two items. If more than one item has the identical maximum value, `max` will emit the *last* such item emitted by the source Observable.
 The `maxBy` operator is similar to `max`, but instead of emitting the item with the maximum value, it emits the item with the maximum *key*, where that key is generated based on a function you provide to `maxBy`
### RxJava 1․x `max maxBy`
In RxJava, this operator is not in the ReactiveX core, but is part of the distinct `rxjava-math` module.
 RxJava implements a `max` operator. It takes an optional comparator that it will use instead of its default to compare the value of two items. If more than one item has the identical maximum value, `max` will emit the *last* such item emitted by the source Observable.
 The `maxBy` operator is similar to `max`, but instead of emitting the item with the maximum value, it emits the item with the maximum *key*, where that key is generated based on a function you provide to `maxBy`
### RxJS `max maxBy`
 RxJS implements the `max` operator. It takes an optional comparer function that it will use instead of its default to compare the value of two items.
#### Sample Code
```
var source = Rx.Observable.fromArray([1,3,5,7,9,2,4,6,8]).max();
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); } );
```
```
Next: 9
Completed
```
 The `maxBy` operator is similar to `max`, but instead of emitting the item with the maximum value, it emits the item with the maximum *key*, where that key is generated based on a function you provide to `maxBy`. `maxBy` also takes an optional second parameter: a comparer function that it will use instead of its default to compare the keys of the two items.
`maxBy` emits a list. If more than one item has the maximum key value, each such item will be represented in the list.
#### Sample Code
```
var source = Rx.Observable.fromArray([1,3,5,7,9,2,4,6,8,9])
.maxBy( function (x) { return x; } );
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); } );
```
```
Next: 9,9
Completed
```
`max` and `maxBy` are found in the following distributions:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.aggregates.js`
They requires one of the following:
* `rx.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
### RxPHP `max`
RxPHP implements this operator as `max`.
Returns the maximum value in an observable sequence according to the specified comparer.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/max/max.php
/* Without comparer */
$source = \Rx\Observable::fromArray([1, 3, 5, 7, 9, 2, 4, 6, 8])
->max();
$subscription = $source->subscribe($createStdoutObserver());
```
```
Next value: 9
Complete!
```
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/max/max-with-comparer.php
/* With a comparer */
$comparer = function ($x, $y) {
if ($x > $y) {
return 1;
} elseif ($x < $y) {
return -1;
}
return 0;
};
$source = \Rx\Observable::fromArray([1, 3, 5, 7, 9, 2, 4, 6, 8])
->max($comparer);
$subscription = $source->subscribe($createStdoutObserver());
```
```
Next value: 9
Complete!
```
reactivex SkipWhile SkipWhile
=========
> discard items emitted by an Observable until a specified condition becomes false
 The SkipWhile subscribes to the source Observable, but ignores its emissions until such time as some condition you specify becomes false, at which point SkipWhile begins to mirror the source Observable.
#### See Also
* [Skip](skip)
* [SkipLast](skiplast)
* [SkipUntil](skipuntil)
* [Take](take)
* [TakeLast](takelast)
* [TakeUntil](takeuntil)
* [TakeWhile](takewhile)
* [Introduction to Rx: SkipWhile and TakeWhile](http://www.introtorx.com/Content/v1.0.10621.0/05_Filtering.html#SkipWhileTakeWhile)
Language-Specific Information
-----------------------------
### RxGroovy `skipWhile`
 The `skipWhile` operator returns an Observable that discards items emitted by the source Observable until such time as a function, applied to an item emitted by that Observable, returns `false`, whereupon the new Observable emits that item and the remainder of the items emitted by the source Observable.
```
numbers = Observable.from( [1, 2, 3, 4, 5, 6, 7, 8, 9] );
numbers.skipWhile({ (5 != it) }).subscribe(
{ println(it); }, // onNext
{ println("Error: " + it.getMessage()); }, // onError
{ println("Sequence complete"); } // onCompleted
);
```
```
5
6
7
8
9
Sequence complete
```
`skipWhile` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`skipWhile(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#skipWhile(rx.functions.Func1))
### RxJava 1․x `skipWhile`
 The `skipWhile` operator returns an Observable that discards items emitted by the source Observable until such time as a function, applied to an item emitted by that Observable, returns `false`, whereupon the new Observable emits that item and the remainder of the items emitted by the source Observable.
`skipWhile` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`skipWhile(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#skipWhile(rx.functions.Func1))
### RxJS `skipWhile`
 RxJS implements the `skipWhile` operator. You pass it a function that governs the skipping process. `skipWhile` calls that function for each item emitted by the source Observable until such time as the function returns `false`, whereupon `skipWhile` begins mirroring the source Observable (starting with that item). The function takes three parameters:
1. the emitted item
2. the zero-based index of that item in the sequence of emissions
3. the source Observable
You may optionally pass a second parameter to `skipWhile`. If so, that item will also be available to your predicate function as “`this`”.
#### Sample Code
```
var source = Rx.Observable.range(1, 5)
.skipWhile(function (x) { return x < 3; });
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 3
Next: 4
Next: 5
Completed
```
`skipWhile` is found in each of the following distributions:
* `rx.js`
* `rx.all.js`
* `rx.all.compat.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
### RxPHP `skipWhile skipWhileWithIndex`
RxPHP implements this operator as `skipWhile`.
Bypasses elements in an observable sequence as long as a specified condition is true and then returns the remaining elements.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/skip/skipWhile.php
$observable = Rx\Observable::range(1, 5)
->skipWhile(function ($x) {
return $x < 3;
});
$observable->subscribe($stdoutObserver);
```
```
Next value: 3
Next value: 4
Next value: 5
Complete!
```
RxPHP also has an operator `skipWhileWithIndex`.
Bypasses elements in an observable sequence as long as a specified condition is true and then returns the remaining elements. The element's index is used in the logic of the predicate function.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/skip/skipWhileWithIndex.php
$observable = Rx\Observable::range(1, 5)
->skipWhileWithIndex(function ($i, $value) {
return $i < 3;
});
$observable->subscribe($stdoutObserver);
```
```
Next value: 4
Next value: 5
Complete!
```
reactivex ElementAt ElementAt
=========
> emit only item *n* emitted by an Observable
[Open interactive diagram on rxmarbles.com](https://rxmarbles.com/#elementAt) The `ElementAt` operator pulls an item located at a specified index location in the sequence of items emitted by the source Observable and emits that item as its own sole emission.
#### See Also
* [First](first)
* [Last](last)
* [Introduction to Rx: ElementAt and ElementAtUntilChanged](http://www.introtorx.com/Content/v1.0.10621.0/06_Inspection.html#ElementAt)
* [RxMarbles: `elementAt`](http://rxmarbles.com/#elementAt)
Language-Specific Information
-----------------------------
### RxGroovy `elementAt elementAtOrDefault`
 RxGroovy implements this operator as `elementAt`. Pass `elementAt` a zero-based index value and it will emit the solitary item from the source Observable’s sequence that matches that index value (for example, if you pass the index value 5, `elementAt` will emit the sixth item emitted by the source Observable).
If you pass in a negative index value, or if the source Observable emits fewer than `*index
value* + 1` items, `elementAt` will throw an `IndexOutOfBoundsException`.
* Javadoc: [`elementAt(int)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#elementAt(int))
 RxGroovy also implements the `elementAtOrDefault` operator. It differs from `elementAt` in that it will not throw an exception if the source Observable emits fewer than `*index value* + 1` items. Instead, it will emit a “default” item that you specify with an additional parameter to `elementAtOrDefault`.
If you pass in a negative index value, `elementAt` will throw an `IndexOutOfBoundsException`.
* Javadoc: [`elementAtOrDefault(int,T)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#elementAtOrDefault(int,%20T))
`elementAt` and `elementAtOrDefault` do not by default operate on any particular [Scheduler](../scheduler).
### RxJava 1․x `elementAt elementAtOrDefault`
 RxGroovy implements this operator as `elementAt`. Pass `elementAt` a zero-based index value and it will emit the solitary item from the source Observable’s sequence that matches that index value (for example, if you pass the index value 5, `elementAt` will emit the sixth item emitted by the source Observable).
If you pass in a negative index value, or if the source Observable emits fewer than `*index
value* + 1` items, `elementAt` will throw an `IndexOutOfBoundsException`.
* Javadoc: [`elementAt(int)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#elementAt(int))
 RxGroovy also implements the `elementAtOrDefault` operator. It differs from `elementAt` in that it will not throw an exception if the source Observable emits fewer than `*index value* + 1` items. Instead, it will emit a “default” item that you specify with an additional parameter to `elementAtOrDefault`.
If you pass in a negative index value, `elementAt` will throw an `IndexOutOfBoundsException`.
* Javadoc: [`elementAtOrDefault(int,T)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#elementAtOrDefault(int,%20T))
`elementAt` and `elementAtOrDefault` do not by default operate on any particular [Scheduler](../scheduler).
### RxJS `elementAt`
 RxJS implements this operator as `elementAt`. Pass `elementAt` a zero-based index value and it will emit the solitary item from the source Observable’s sequence that matches that index value (for example, if you pass the index value 5, `elementAt` will emit the sixth item emitted by the source Observable).
If there is no element in the source sequence with the index value you specify, `elementAt` will issue an `onError` notification: “`Argument out of range`”
#### Sample Code
```
var source = Rx.Observable.fromArray([1,2,3,4])
.elementAt(1);
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 2
Completed
```
You may optionally pass in a default value that `elementAt` will emit if the source Observable emits no values:
#### Sample Code
```
var source = Rx.Observable.fromArray([])
.element({defaultValue: 23});
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 23
Completed
```
`elementAt` is found in each of the following distributions:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.aggregates.js`
They require one of the following distributions:
* `rx.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
reactivex SkipUntil SkipUntil
=========
> discard items emitted by an Observable until a second Observable emits an item
[Open interactive diagram on rxmarbles.com](https://rxmarbles.com/#skipUntil) The SkipUntil subscribes to the source Observable, but ignores its emissions until such time as a second Observable emits an item, at which point SkipUntil begins to mirror the source Observable.
#### See Also
* [Skip](skip)
* [SkipLast](skiplast)
* [SkipWhile](skipwhile)
* [Take](take)
* [TakeLast](takelast)
* [TakeUntil](takeuntil)
* [TakeWhile](takewhile)
* [Introduction to Rx: SkipUntil and TakeUntil](http://www.introtorx.com/Content/v1.0.10621.0/05_Filtering.html#SkipUntilTakeUntil)
* [RxMarbles: `skipUntil`](http://rxmarbles.com/#skipUntil)
Language-Specific Information
-----------------------------
### RxGroovy `skipUntil`
 In RxGroovy, this operator is implemented as `skipUntil`.
`skipUntil` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`skipUntil(Observable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#skipUntil(rx.Observable))
### RxJava 1․x `skipUntil`
 In RxJava, this operator is implemented as `skipUntil`.
`skipUntil` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`skipUntil(Observable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#skipUntil(rx.Observable))
### RxJS `skipUntil`
 RxJS implements the `skipUntil` operator. You can pass it either an Observable or a `Promise` that it will monitor for an item that triggers `skipUntil` to begin mirroring the source Observable.
#### Sample Code
```
var source = Rx.Observable.timer(0, 1000)
.skipUntil(Rx.Observable.timer(5000));
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 6
Next: 7
Next: 8
Completed
```
`skipUntil` is found in each of the following distributions:
* `rx.js`
* `rx.all.js`
* `rx.all.compat.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
There is also a `skipUntilWithTime` operator to which you can pass an absolute time or an initial duration in place of an Observable, but this is described on the [Skip](skip) operator page.
### RxPHP `skipUntil`
RxPHP implements this operator as `skipUntil`.
Returns the values from the source observable sequence only after the other observable sequence produces a value.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/skip/skipUntil.php
$observable = Rx\Observable::interval(1000)
->skipUntil(\Rx\Observable::timer(5000))
->take(3);
$observable->subscribe($stdoutObserver);
```
```
Next value: 4
Next value: 5
Next value: 6
Complete!
```
reactivex Min Min
===
> emits the item from the source Observable that had the minimum value
[Open interactive diagram on rxmarbles.com](https://rxmarbles.com/#min) The Min operator operates on an Observable that emits numbers (or items that can be evaluated as numbers), and emits a single item: the item with the smallest number.
#### See Also
* [Min](min)
* [Introduction to Rx: Min, Max, Sum, and Average](http://www.introtorx.com/Content/v1.0.10621.0/07_Aggregation.html#MaxAndMin)
* [RxMarbles: `min`](http://rxmarbles.com/#min)
Language-Specific Information
-----------------------------
### RxGroovy `min minBy`
In RxGroovy, this operator is not in the ReactiveX core, but is part of the distinct `rxjava-math` module.
 RxGroovy implements a `min` operator. It takes an optional comparator that it will use instead of its default to compare the value of two items. If more than one item has the identical minimum value, `min` will emit the *last* such item emitted by the source Observable.
 The `minBy` operator is similar to `min`, but instead of emitting the item with the minimum value, it emits the item with the minimum *key*, where that key is generated based on a function you provide to `minBy`
### RxJava 1․x `min minBy`
In RxJava, this operator is not in the ReactiveX core, but is part of the distinct `rxjava-math` module.
 RxJava implements a `min` operator. It takes an optional comparator that it will use instead of its default to compare the value of two items. If more than one item has the identical minimum value, `min` will emit the *last* such item emitted by the source Observable.
 The `minBy` operator is similar to `min`, but instead of emitting the item with the minimum value, it emits the item with the minimum *key*, where that key is generated based on a function you provide to `minBy`
### RxJS `min minBy`
 RxJS implements the `min` operator. It takes an optional comparer function that it will use instead of its default to compare the value of two items.
#### Sample Code
```
var source = Rx.Observable.fromArray([1,3,5,7,9,2,4,6,8]).min();
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); } );
```
```
Next: 1
Completed
```
 The `minBy` operator is similar to `min`, but instead of emitting the item with the minimum value, it emits the item with the minimum *key*, where that key is generated based on a function you provide to `minBy`. `minBy` also takes an optional second parameter: a comparer function that it will use instead of its default to compare the keys of the two items.
`minBy` emits a list. If more than one item has the minimum key value, each such item will be represented in the list.
#### Sample Code
```
var source = Rx.Observable.fromArray([1,3,5,7,9,2,4,6,8,1])
.minBy( function (x) { return x; } );
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); } );
```
```
Next: 1,1
Completed
```
`min` and `minBy` are found in the following distributions:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.aggregates.js`
They requires one of the following:
* `rx.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
### RxPHP `min`
RxPHP implements this operator as `min`.
Returns the minimum value in an observable sequence according to the specified comparer.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/min/min.php
/* Without comparer */
$source = \Rx\Observable::fromArray([1, 3, 5, 7, 9, 2, 4, 6, 8])
->min();
$subscription = $source->subscribe($createStdoutObserver());
```
```
Next value: 1
Complete!
```
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/min/min-with-comparer.php
/* With a comparer */
$comparer = function ($x, $y) {
if ($x > $y) {
return 1;
} elseif ($x < $y) {
return -1;
}
return 0;
};
$source = \Rx\Observable::fromArray([1, 3, 5, 7, 9, 2, 4, 6, 8])
->min($comparer);
$subscription = $source->subscribe($createStdoutObserver());
```
```
Next value: 1
Complete!
```
| programming_docs |
reactivex TimeInterval TimeInterval
============
> convert an Observable that emits items into one that emits indications of the amount of time elapsed between those emissions
 The TimeInterval operator intercepts the items from the source Observable and emits in their place objects that indicate the amount of time that elapsed between pairs of emissions.
#### See Also
* [Timestamp](timestamp)
* [Introduction to Rx: Timestamp and TimeInterval](http://www.introtorx.com/Content/v1.0.10621.0/08_Transformation.html#TimeStampAndTimeInterval)
* [101 Rx Samples: Interval — With TimeInterval()](http://rxwiki.wikidot.com/101samples#toc31)
Language-Specific Information
-----------------------------
### RxGroovy `timeInterval`
 The timeInterval operator converts a source Observable into an Observable that emits indications of the amount of time lapsed between consecutive emissions of the source Observable. The first emission from this new Observable indicates the amount of time lapsed between the time when the observer subscribed to the Observable and the time when the source Observable emitted its first item. There is no corresponding emission marking the amount of time lapsed between the last emission of the source Observable and the subsequent call to `onCompleted`.
`timeInterval` by default operates on the `immediate` [Scheduler](../scheduler), but also has a variant that allows you to specify the Scheduler by passing it in as a parameter.
* Javadoc: [`timeInterval()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#timeInterval())
* Javadoc: [`timeInterval(Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#timeInterval(rx.Scheduler))
### RxJava 1․x `timeInterval`
 The timeInterval operator converts a source Observable into an Observable that emits indications of the amount of time lapsed between consecutive emissions of the source Observable. The first emission from this new Observable indicates the amount of time lapsed between the time when the observer subscribed to the Observable and the time when the source Observable emitted its first item. There is no corresponding emission marking the amount of time lapsed between the last emission of the source Observable and the subsequent call to `onCompleted`.
`timeInterval` by default operates on the `immediate` [Scheduler](../scheduler), but also has a variant that allows you to specify the Scheduler by passing it in as a parameter.
* Javadoc: [`timeInterval()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#timeInterval())
* Javadoc: [`timeInterval(Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#timeInterval(rx.Scheduler))
### RxJS `timeInterval`
 The `timeInterval` operator converts a source Observable into an Observable that emits indications of the amount of time lapsed between consecutive emissions of the source Observable. The first emission from this new Observable indicates the amount of time lapsed between the time when the observer subscribed to the Observable and the time when the source Observable emitted its first item. There is no corresponding emission marking the amount of time lapsed between the last emission of the source Observable and the subsequent call to `onCompleted`.
#### Sample Code
```
var source = Rx.Observable.timer(0, 1000)
.timeInterval()
.map(function (x) { return x.value + ':' + x.interval; })
.take(5);
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 0:0
Next: 1:1000
Next: 2:1000
Next: 3:1000
Next: 4:1000
Completed
```
`timeInterval` by default operates on the `timeout` [Scheduler](../scheduler), but also has a variant that allows you to specify the Scheduler by passing it in as a parameter.
`timeInterval` is found in each of the following distributions:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.time.js` (requires `rx.js` or `rx.compat.js`)
* `rx.lite.js`
* `rx.lite.compat.js`
reactivex StartWith StartWith
=========
> emit a specified sequence of items before beginning to emit the items from the source Observable
[Open interactive diagram on rxmarbles.com](https://rxmarbles.com/#startWith) If you want an Observable to emit a specific sequence of items before it begins emitting the items normally expected from it, apply the StartWith operator to it.
(If, on the other hand, you want to append a sequence of items to the end of those normally emitted by an Observable, you want the [Concat](concat) operator.)
#### See Also
* [Concat](concat)
* [Introduction to Rx: StartWith](http://www.introtorx.com/Content/v1.0.10621.0/12_CombiningSequences.html#StartWith)
* [RxMarbles: `startWith`](http://rxmarbles.com/#startWith)
Language-Specific Information
-----------------------------
### RxClojure `cons`
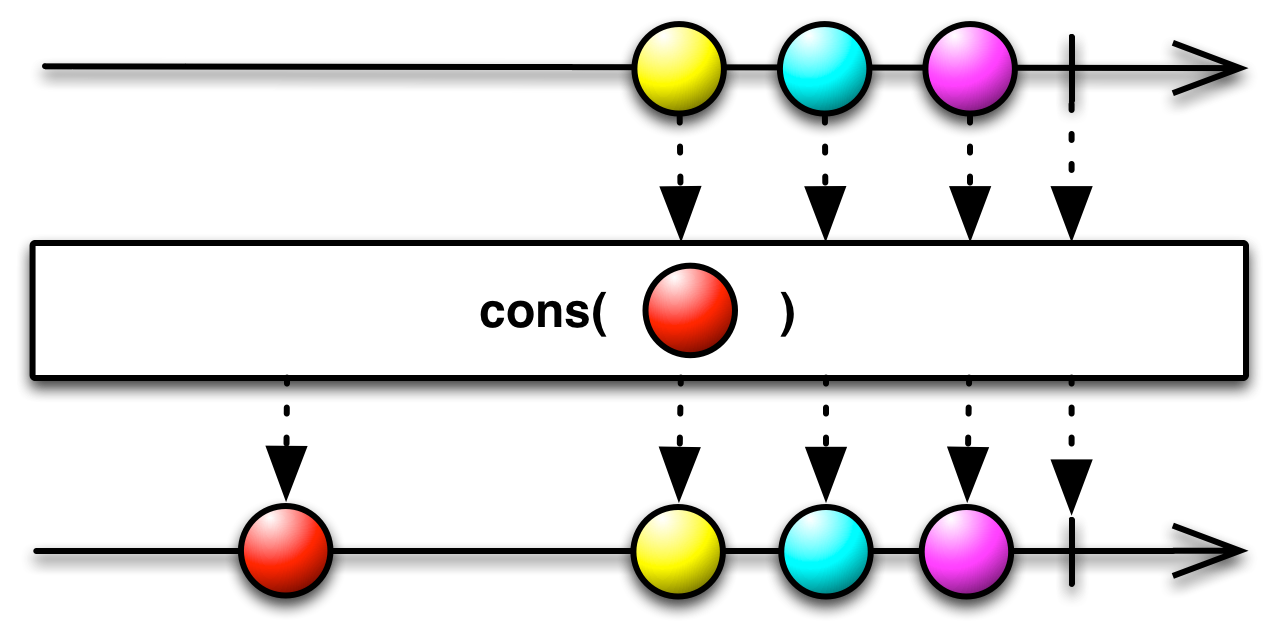 RxClojure implements this operator as `cons`. It takes an item and an Observable as parameters, and prepends the item to the items emitted by the Observable as its own Observable sequence.
### RxCpp `start_with`
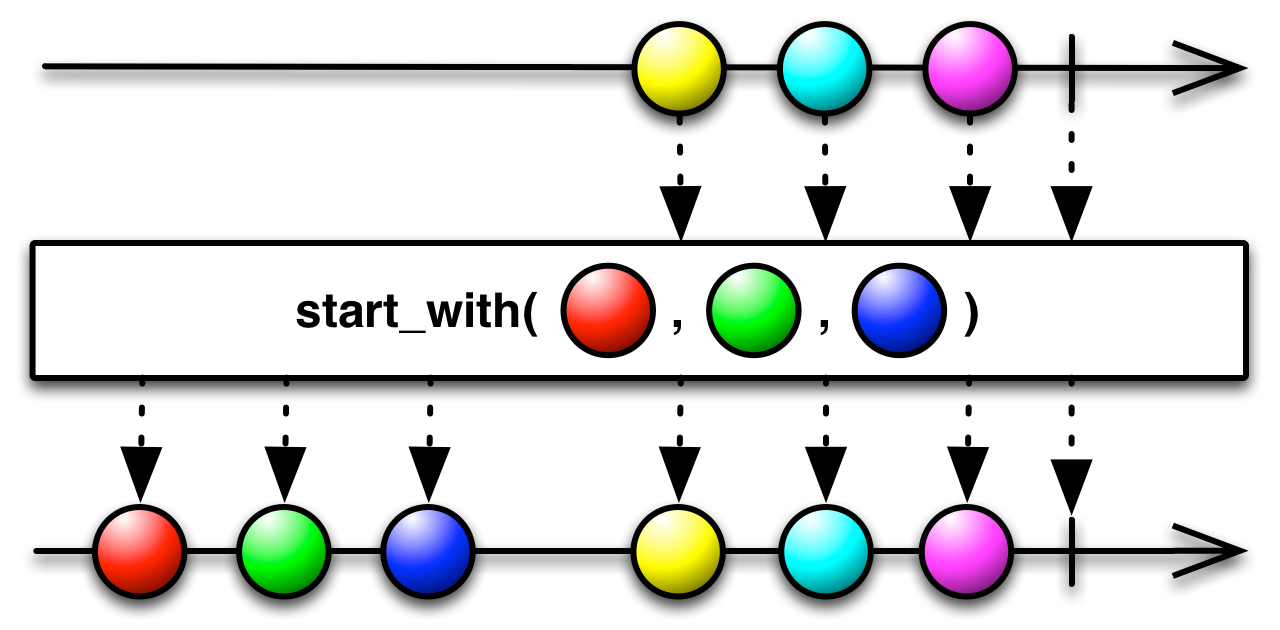 RxCpp implements this operator as `start_with`. It takes an Observable and one or more items as parameters, and prepends these items, in the order they are given in the parameter list, to the items emitted by the Observable as its own Observable sequence.
### RxGroovy `startWith`
RxGroovy implements this operator as `startWith`.
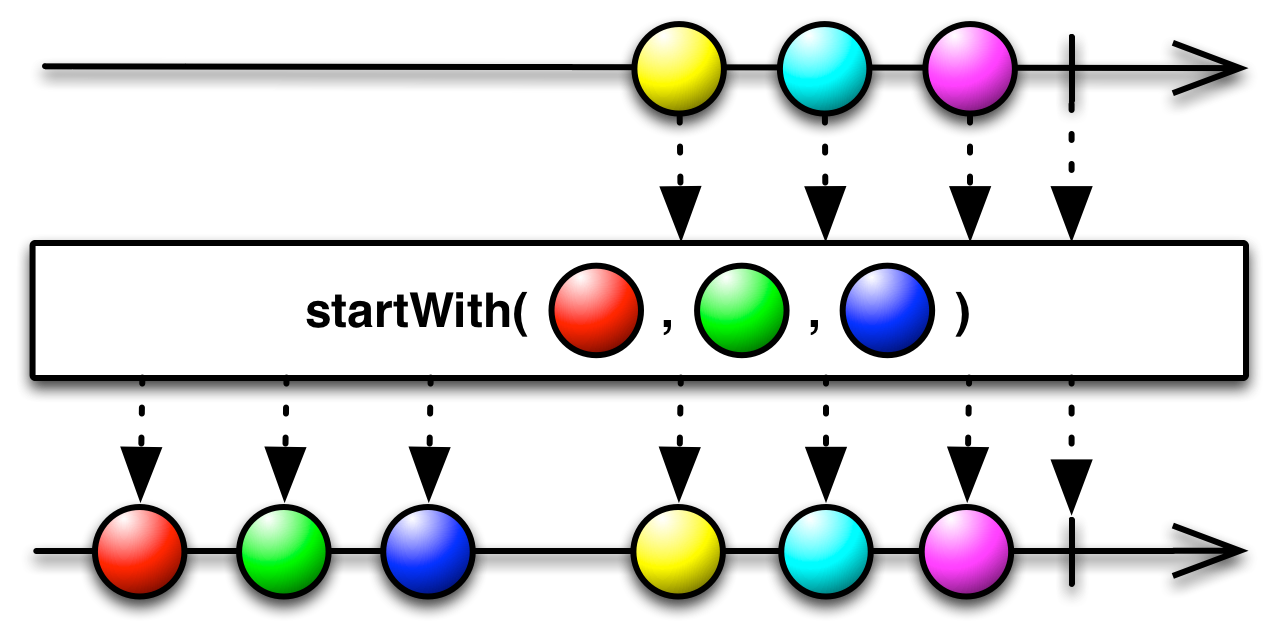 You can pass the values you want to prepend to the Observable sequence to `startWith` either in a single Iterable or as a series of one to nine function parameters.
#### Sample Code
```
def myObservable = Observable.from([1, 2, 3]);
myObservable.startWith(-3, -2, -1, 0).subscribe(
{ println(it); }, // onNext
{ println("Error: " + it.getMessage()); }, // onError
{ println("Sequence complete"); } // onCompleted
);
```
```
-3
-2
-1
0
1
2
3
```
* Javadoc: [`startWith(Iterable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#startWith(java.lang.Iterable))
* Javadoc: [`startWith(T)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#startWith(T)) (there are also versions that take up to nine individual items)
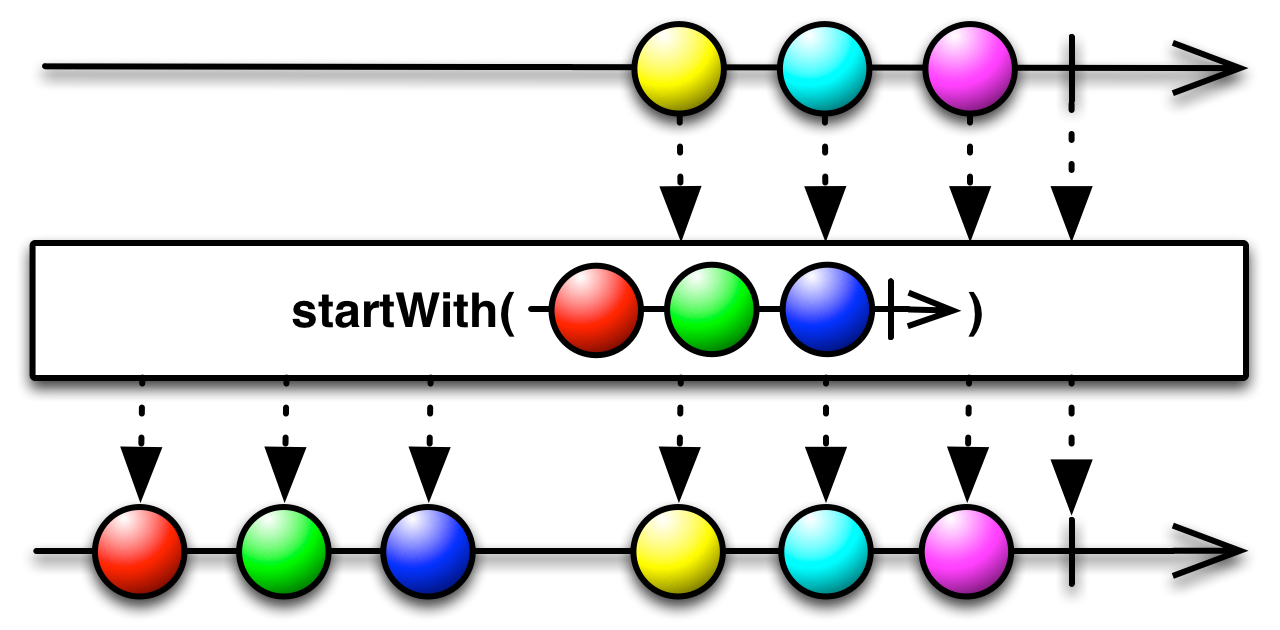 You can also pass `startWith` an Observable, and it will prepend the emissions from that Observable to those of the source Observable to make its own set of emissions. This is a sort of inverted Concat operation.
* Javadoc: [`startWith(Observable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#startWith(rx.Observable))
### RxJava 1․x `startWith`
RxJava implements this operator as `startWith`.
 You can pass the values you want to prepend to the Observable sequence to `startWith` either in a single Iterable or as a series of one to nine function parameters.
* Javadoc: [`startWith(Iterable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#startWith(java.lang.Iterable))
* Javadoc: [`startWith(T)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#startWith(T)) (there are also versions that take up to nine individual items)
 You can also pass `startWith` an Observable, and it will prepend the emissions from that Observable to those of the source Observable to make its own set of emissions. This is a sort of inverted Concat operation.
* Javadoc: [`startWith(Observable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#startWith(rx.Observable))
### RxJS `startWith`
 RxJS implements this operator as `startWith`. It accepts a variable number of function parameters and treats each one as an item that it will prepend to the resulting Observable sequence in the order they are given in the parameter list.
`startWith` is found in the following distributions:
* `rx.js`
* `rx.all.js`
* `rx.all.compat.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
### RxKotlin `startWith`
RxKotlin implements this operator as `startWith`.
 You can pass the values you want to prepend to the Observable sequence to `startWith` either in a single Iterable or as a series of one to nine function parameters.
 You can also pass `startWith` an Observable, and it will prepend the emissions from that Observable to those of the source Observable to make its own set of emissions. This is a sort of inverted Concat operation.
### RxNet `StartWith`
 Rx.NET implements this operator as `StartWith`. It accepts an array of items which it prepends to the resulting Observable sequence in the order they appear in the array before it emits the items from the source Observable.
### RxPHP `startWith startWithArray`
RxPHP implements this operator as `startWith`.
Prepends a value to an observable sequence with an argument of a signal value to prepend.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/startWith/startWith.php
$source = \Rx\Observable::of(2)
->startWith(1);
$subscription = $source->subscribe($stdoutObserver);
```
```
Next value: 1
Next value: 2
Complete!
```
RxPHP also has an operator `startWithArray`.
Prepends a sequence of values to an observable sequence with an argument of an array of values to prepend.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/startWith/startWithArray.php
$source = \Rx\Observable::of(4)
->startWithArray([1, 2, 3]);
$subscription = $source->subscribe($stdoutObserver);
```
```
Next value: 1
Next value: 2
Next value: 3
Next value: 4
Complete!
```
### RxPY `start_with`
 RxPY implements this operator as `start_with`. It accepts an array of items which it prepends to the resulting Observable sequence in the order they appear in the array before it emits the items from the source Observable.
### Rxrb `start_with`
 Rx.rb implements this operator as `start_with`. It accepts an array of items which it prepends to the resulting Observable sequence in the order they appear in the array before it emits the items from the source Observable.
### RxScala `+:`
 RxScala implements this operator with `+:` It takes an item and an Observable as parameters, and prepends the item to the items emitted by the Observable as its own Observable sequence.
reactivex And/Then/When And/Then/When
=============
> combine sets of items emitted by two or more Observables by means of Pattern and Plan intermediaries
 The combination of the And, Then, and When operators behave much like the Zip operator, but they do so by means of intermediate data structures. And accepts two or more Observables and combines the emissions from each, one set at a time, into `Pattern` objects. Then operates on such `Pattern` objects, transforming them in a `Plan`. When in turn transforms these various `Plan` objects into emissions from an Observable.
#### See Also
* [Zip](zip)
* [Introduction to Rx: And-Then-When](http://www.introtorx.com/content/v1.0.10621.0/12_CombiningSequences.html#AndThenWhen)
Language-Specific Information
-----------------------------
### RxGroovy `and then when`
 In RxGroovy, these are not part of the core ReactiveX implementation, but are found as `and`, `then`, and `when` in the `rxjava-joins` module.
### RxJava 1․x `and then when`
 These are not part of the core RxJava implementation, but are found as `and`, `then`, and `when` in the `rxjava-joins` module.
### RxJS `and thenDo when`
 RxJS implements these operators as `and`, `thenDo`, and `when`.
These are found in the following packages:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.joinpatterns.js`
They require one of the following packages:
* `rx.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
reactivex TakeWhile TakeWhile
=========
> mirror items emitted by an Observable until a specified condition becomes false
 The TakeWhile mirrors the source Observable until such time as some condition you specify becomes false, at which point TakeWhile stops mirroring the source Observable and terminates its own Observable.
#### See Also
* [Skip](skip)
* [SkipLast](skiplast)
* [SkipUntil](skipuntil)
* [SkipWhile](skipwhile)
* [Take](take)
* [TakeLast](takelast)
* [TakeUntil](takeuntil)
* [Introduction to Rx: SkipWhile and TakeWhile](http://www.introtorx.com/Content/v1.0.10621.0/05_Filtering.html#SkipWhileTakeWhile)
Language-Specific Information
-----------------------------
### RxGroovy `takeWhile`
 The `takeWhile` operator returns an Observable that mirrors the behavior of the source Observable until such time as a function, applied to an item emitted by that Observable, returns `false`, whereupon the new Observable terminates with an `onCompleted` notification.
```
numbers = Observable.from( [1, 2, 3, 4, 5, 6, 7, 8, 9] );
numbers.takeWhile({ ((it < 6) || (0 == (it % 2))) }).subscribe(
{ println(it); }, // onNext
{ println("Error: " + it.getMessage()); }, // onError
{ println("Sequence complete"); } // onCompleted
);
```
```
1
2
3
4
5
6
Sequence complete
```
`takeWhile` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`takeWhile(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#takeWhile(rx.functions.Func1))
### RxJava 1․x `takeWhile`
 The `takeWhile` operator returns an Observable that mirrors the behavior of the source Observable until such time as a function, applied to an item emitted by that Observable, returns `false`, whereupon the new Observable terminates with an `onCompleted` notification.
`takeWhile` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`takeWhile(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#takeWhile(rx.functions.Func1))
### RxJS `takeWhile`
 RxJS implements the `takeWhile` operator. You pass it a function that governs the takeping process. `takeWhile` calls that function for each item emitted by the source Observable until such time as the function returns `false`, whereupon `takeWhile` stops mirroring the source Observable (starting with that item) and issues an `onCompleted` notification. The function takes three parameters:
1. the emitted item
2. the zero-based index of that item in the sequence of emissions
3. the source Observable
You may optionally pass a second parameter to `takeWhile`. If so, that item will also be available to your predicate function as “`this`”.
#### Sample Code
```
var source = Rx.Observable.range(1, 5)
.takeWhile(function (x) { return x < 3; });
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 0
Next: 1
Next: 2
Completed
```
`takeWhile` is found in each of the following distributions:
* `rx.js`
* `rx.all.js`
* `rx.all.compat.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
### RxPHP `takeWhile takeWhileWithIndex`
RxPHP implements this operator as `takeWhile`.
Returns elements from an observable sequence as long as a specified condition is true. It takes as a parameter a a callback to test each source element for a condition. The callback predicate is called with the value of the element.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/take/takeWhile.php
$source = \Rx\Observable::range(1, 5)
->takeWhile(function ($x) {
return $x < 3;
});
$subscription = $source->subscribe($stdoutObserver);
```
```
Next value: 1
Next value: 2
Complete!
```
RxPHP also has an operator `takeWhileWithIndex`.
Returns elements from an observable sequence as long as a specified condition is true. It takes as a parameter a a callback to test each source element for a condition. The callback predicate is called with the index and the value of the element.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/take/takeWhileWithIndex.php
$source = \Rx\Observable::range(1, 5)
->takeWhileWithIndex(function ($i) {
return $i < 3;
});
$subscription = $source->subscribe($stdoutObserver);
```
```
Next value: 1
Next value: 2
Next value: 3
Complete!
```
reactivex TakeLast TakeLast
========
> emit only the final *n* items emitted by an Observable
[Open interactive diagram on rxmarbles.com](https://rxmarbles.com/#takeLast) You can emit only the final *n* items emitted by an Observable and ignore those items that come before them, by modifying the Observable with the TakeLast operator.
#### See Also
* [Last](last)
* [Skip](skip)
* [SkipLast](skiplast)
* [SkipUntil](skipuntil)
* [SkipWhile](skipwhile)
* [Take](take)
* [TakeUntil](takeuntil)
* [TakeWhile](takewhile)
* [Introduction to Rx: SkipLast and TakeLast](http://www.introtorx.com/Content/v1.0.10621.0/05_Filtering.html#SkipLastTakeLast)
* [RxMarbles: `takeLast`](http://rxmarbles.com/#takeLast)
Language-Specific Information
-----------------------------
### RxGroovy `takeLast takeLastBuffer`
 You can emit only the final *n* items emitted by an Observable and ignore those items that precede them, by modifying the Observable with the `takeLast(*n*)` operator. Note that this will delay the emission of any item from the source Observable until the source Observable completes.
#### Sample Code
```
numbers = Observable.from([1, 2, 3, 4, 5, 6, 7, 8, 9]);
numbers.takeLast(2).subscribe(
{ println(it); }, // onNext
{ println("Error: " + it.getMessage()); }, // onError
{ println("Sequence complete"); } // onCompleted
);
```
```
8
9
Sequence complete
```
This variant of `takeLast` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`takeLast(int)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#takeLast(int))
 There is also a variant of `takeLast` that takes a temporal duration rather than a quantity of items. It emits only those items that are emitted during that final duration of the source Observable’s lifespan. You set this duration by passing in a length of time and the time units this length is denominated in as parameters to `takeLast`.
Note that this will delay the emission of any item from the source Observable until the source Observable completes.
This variant of `takeLast` by default operates on the `computation` [Scheduler](../scheduler), but you may also pass in a Scheduler of your choosing as an optional third parameter.
* Javadoc: [`takeLast(long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#takeLast(long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`takeLast(long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#takeLast(long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
 There is also a variant that combines the two methods. It emits the minimum of the number of items emitted during a specified time window *or* a particular count of items.
This variant of `takeLast` by default operates on the `computation` [Scheduler](../scheduler), but you may also pass in a Scheduler of your choosing as an optional fourth parameter.
* Javadoc: [`takeLast(int,long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#takeLast(int,%20long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`takeLast(int,long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#takeLast(int,%20long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
 There is also an operator called `takeLastBuffer`. It exists in the same set of variants as described above for `takeLast`, and only differs in behavior by emitting its items not individually but collected into a single `List` of items that is emitted as a single item.
* Javadoc: [`takeLastBuffer(int)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#takeLastBuffer(int))
* Javadoc: [`takeLastBuffer(long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#takeLastBuffer(long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`takeLastBuffer(long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#takeLastBuffer(long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
* Javadoc: [`takeLastBuffer(int,long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#takeLastBuffer(int,%20long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`takeLastBuffer(int,long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#takeLastBuffer(int,%20long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
### RxJava 1․x `takeLast takeLastBuffer`
 You can emit only the final *n* items emitted by an Observable and ignore those items that precede them, by modifying the Observable with the `takeLast(*n*)` operator. Note that this will delay the emission of any item from the source Observable until the source Observable completes.
This variant of `takeLast` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`takeLast(int)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#takeLast(int))
 There is also a variant of `takeLast` that takes a temporal duration rather than a quantity of items. It emits only those items that are emitted during that final duration of the source Observable’s lifespan. You set this duration by passing in a length of time and the time units this length is denominated in as parameters to `takeLast`.
Note that this will delay the emission of any item from the source Observable until the source Observable completes.
This variant of `takeLast` by default operates on the `computation` [Scheduler](../scheduler), but you may also pass in a Scheduler of your choosing as an optional third parameter.
* Javadoc: [`takeLast(long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#takeLast(long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`takeLast(long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#takeLast(long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
 There is also a variant that combines the two methods. It emits the minimum of the number of items emitted during a specified time window *or* a particular count of items.
This variant of `takeLast` by default operates on the `computation` [Scheduler](../scheduler), but you may also pass in a Scheduler of your choosing as an optional fourth parameter.
* Javadoc: [`takeLast(int,long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#takeLast(int,%20long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`takeLast(int,long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#takeLast(int,%20long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
 There is also an operator called `takeLastBuffer`. It exists in the same set of variants as described above for `takeLast`, and only differs in behavior by emitting its items not individually but collected into a single `List` of items that is emitted as a single item.
* Javadoc: [`takeLastBuffer(int)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#takeLastBuffer(int))
* Javadoc: [`takeLastBuffer(long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#takeLastBuffer(long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`takeLastBuffer(long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#takeLastBuffer(long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
* Javadoc: [`takeLastBuffer(int,long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#takeLastBuffer(int,%20long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`takeLastBuffer(int,long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#takeLastBuffer(int,%20long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
### RxJS `takeLast takeLastBuffer takeLastBufferWithTime takeLastWithTime`
 You can emit only the final *n* items emitted by an Observable and ignore those items that precede them, by modifying the Observable with the `takeLast(*n*)` operator. Note that this will delay the emission of any item from the source Observable until that Observable completes.
#### Sample Code
```
var source = Rx.Observable.range(0, 5)
.takeLast(3);
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 2
Next: 3
Next: 4
Completed
```
`takeLast` is found in each of the following distributions:
* `rx.js`
* `rx.alljs`
* `rx.all.compatjs`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
 The `takeLastWithTime` operator takes a temporal duration rather than a quantity of items. It emits only those items that are emitted during that final duration of the source Observable’s lifespan. You set this duration by passing in a number of milliseconds as a parameter to `takeLastWithTime`.
Note that the mechanism by which this is implemented will delay the emission of any item from the source Observable until that Observable completes.
`takeLastWithTime` by default operates the timer on the `timeout` [Scheduler](../scheduler) and emits items on the `currentThread` Scheduler, but you may also pass in Schedulers of your choosing to override these, as an optional second and third parameters, respectively.
#### Sample Code
```
var source = Rx.Observable.timer(0, 1000)
.take(10)
.takeLastWithTime(5000);
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 5
Next: 6
Next: 7
Next: 8
Next: 9
Completed
```
`takeLastWithTime` is found in each of the following distributions:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.time.js` (requires `rx.js` or `rx.compat.js`)
* `rx.lite.js`
* `rx.lite.compat.js`
 There is also an operator called `takeLastBuffer`. It differs in behavior from `takeLast` by emitting its items not individually but collected into a single array of items that is emitted as a single item.
#### Sample Code
```
var source = Rx.Observable.range(0, 5)
.takeLastBuffer(3);
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 2,3,4
Completed
```
`takeLastBuffer` is found in each of the following distributions:
* `rx.js`
* `rx.all.js`
* `rx.all.compat.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
 `takeLastBuffer` also has its duration-based variant, `takeLastBufferWithTime`, which is similar to `takeLastWithTime` except that it emits its items not individually but collected into a single array of items that is emitted as a single item.
#### Sample Code
```
var source = Rx.Observable
.timer(0, 1000)
.take(10)
.takeLastBufferWithTime(5000);
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 5,6,7,8,9
Completed
```
`takeLastBufferWithTime` is found in each of the following distributions:
* `rx.js`
* `rx.all.js`
* `rx.all.compat.js`
* `rx.compat.js`
* `rx.time.js` (requires `rx.js` or `rx.compat.js`)
* `rx.lite.js`
* `rx.lite.compat.js`
### RxPHP `takeLast`
RxPHP implements this operator as `takeLast`.
Returns a specified number of contiguous elements from the end of an observable sequence.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/take/takeLast.php
$source = \Rx\Observable::range(0, 5)
->takeLast(3);
$source->subscribe($stdoutObserver);
```
```
Next value: 2
Next value: 3
Next value: 4
Complete!
```
| programming_docs |
reactivex Range Range
=====
> create an Observable that emits a particular range of sequential integers
 The Range operator emits a range of sequential integers, in order, where you select the start of the range and its length.
#### See Also
* [Interval](interval)
* [Introduction to Rx: Range](http://www.introtorx.com/Content/v1.0.10621.0/04_CreatingObservableSequences.html#ObservableRange)
* [101 Rx Samples: Range](http://rxwiki.wikidot.com/101samples#toc40)
Language-Specific Information
-----------------------------
### RxGroovy `range`
 RxGroovy implements this operator as `range`. It accepts as its parameters the start value of the range and the number of items in the range. If you set that number of items to zero, the resulting Observable will emit no values (if you set it to a negative number, `range` will cause an exception).
`range` does not by default operate on any particular [Scheduler](../scheduler), but there is a variant that allows you to set the Scheduler by passing one in as a parameter.
#### Sample Code
```
// myObservable emits the integers 5, 6, and 7 before completing:
def myObservable = Observable.range(5, 3);
```
* Javadoc: [`range(int,int)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#range(int,%20int))
* Javadoc: [`range(int,int,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#range(int,%20int%20rx.Scheduler))
### RxJava 1․x `range`
 RxJava implements this operator as `range`. It accepts as its parameters the start value of the range and the number of items in the range. If you set that number of items to zero, the resulting Observable will emit no values (if you set it to a negative number, `range` will cause an exception).
`range` does not by default operate on any particular [Scheduler](../scheduler), but there is a variant that allows you to set the Scheduler by passing one in as a parameter.
* Javadoc: [`range(int,int)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#range(int,%20int))
* Javadoc: [`range(int,int,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#range(int,%20int%20rx.Scheduler))
### RxJS `range`
 RxJS implements this operator as `range`. It accepts as its parameters the start value of the range and the number of items in the range.
`range` operates by default on the `currentThread` [Scheduler](../scheduler), but there is a variant that allows you to set the Scheduler by passing one in as the optional third parameter.
#### Sample Code
```
var source = Rx.Observable.range(0, 3);
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 0
Next: 1
Next: 2
Completed
```
`range` is found in each of the following distributions:
* `rx.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
### RxPHP `range`
RxPHP implements this operator as `range`.
Generates an observable sequence of integral numbers within a specified range, using the specified scheduler to send out observer messages.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/range/range.php
$observable = \Rx\Observable::range(0, 3);
$observable->subscribe($stdoutObserver);
```
```
Next value: 0
Next value: 1
Next value: 2
Complete!
```
reactivex Empty Empty
=====
> create an Observable that emits no items but terminates normally
 Never
-----
### create an Observable that emits no items and does not terminate
 Throw
-----
### create an Observable that emits no items and terminates with an error
 The Empty, Never, and Throw operators generate Observables with very specific and limited behavior. These are useful for testing purposes, and sometimes also for combining with other Observables or as parameters to operators that expect other Observables as parameters.
#### See Also
* [Introduction to Rx: Simple Factory Methods](http://www.introtorx.com/Content/v1.0.10621.0/04_CreatingObservableSequences.html#SimpleFactoryMethods)
Language-Specific Information
-----------------------------
### RxGroovy `empty never error`
RxGroovy implements these operators as `empty`, `never`, and `error`. The `error` operator takes as a parameter the `Throwable` with which you want the Observable to terminate.
These operators do not operate by default on any particular [Scheduler](../scheduler), but `empty` and `error` optionally take a Scheduler as a parameter, and if you pass them a Scheduler they will issue their termination notifications on that Scheduler.
#### Sample Code
```
println("*** empty() ***");
Observable.empty().subscribe(
{ println("empty: " + it); }, // onNext
{ println("empty: error - " + it.getMessage()); }, // onError
{ println("empty: Sequence complete"); } // onCompleted
);
println("*** error() ***");
Observable.error(new Throwable("badness")).subscribe(
{ println("error: " + it); }, // onNext
{ println("error: error - " + it.getMessage()); }, // onError
{ println("error: Sequence complete"); } // onCompleted
);
println("*** never() ***");
Observable.never().subscribe(
{ println("never: " + it); }, // onNext
{ println("never: error - " + it.getMessage()); }, // onError
{ println("never: Sequence complete"); } // onCompleted
);
println("*** END ***");
```
```
*** empty() ***
empty: Sequence complete
*** error() ***
error: error - badness
*** never() ***
*** END ***
```
* Javadoc: [`empty()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#empty())
* Javadoc: [`never()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#never())
* Javadoc: [`error(throwable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#error(java.lang.Throwable))
### RxJava 1․x `empty never error`
RxJava 1.x implements these operators as `empty`, `never`, and `error`. The `error` operator takes as a parameter the `Throwable` with which you want the Observable to terminate.
These operators do not operate by default on any particular [Scheduler](../scheduler), but `empty` and `error` optionally take a Scheduler as a parameter, and if you pass them a Scheduler they will issue their termination notifications on that Scheduler.
* Javadoc: [`empty()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#empty())
* Javadoc: [`never()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#never())
* Javadoc: [`error(throwable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#error(java.lang.Throwable))
### RxJava 2․x `empty never error`
RxJava 2.x implements these operators as `empty`, `never`, and `error`. The `error` operator takes as a parameter the `Throwable` with which you want the Observable to terminate, or a `Callable` that returns such a `Throwable`.
These operators do not operate by default on any particular [Scheduler](../scheduler).
* Javadoc: [`empty()`](http://reactivex.io/RxJava/2.x/javadoc/io/reactivex/Observable.html#empty())
* Javadoc: [`never()`](http://reactivex.io/RxJava/2.x/javadoc/io/reactivex/Observable.html#never())
* Javadoc: [`error(Callable)`](http://reactivex.io/RxJava/2.x/javadoc/io/reactivex/Observable.html#error(java.util.concurrent.Callable))
* Javadoc: [`error(Throwable)`](http://reactivex.io/RxJava/2.x/javadoc/io/reactivex/Observable.html#error(java.lang.Throwable))
### RxJS `empty never throw`
RxJS implements these operators as `empty`, `never`, and `throw`.
#### Sample Code
```
var source = Rx.Observable.empty();
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Completed
```
```
// This will never produce a value, hence never calling any of the callbacks
var source = Rx.Observable.never();
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
var source = Rx.Observable.return(42)
.selectMany(Rx.Observable.throw(new Error('error!')));
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Error: Error: error!
```
`empty` is found in the following distributions:
* `rx.js`
* `rx.all.js`
* `rx.all.compat.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
`never` is found in the following distributions:
* `rx.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
`throw` is found in the following distributions:
* `rx.js`
* `rx.all.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
### RxPHP `empty never error`
RxPHP implements this operator as `empty`.
Returns an empty observable sequence.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/empty/empty.php
$observable = \Rx\Observable::empty();
$observable->subscribe($stdoutObserver);
```
```
Complete!
```
RxPHP also has an operator `never`.
Returns a non-terminating observable sequence, which can be used to denote an infinite duration.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/never/never.php
$observable = \Rx\Observable::never();
$observable->subscribe($stdoutObserver);
```
RxPHP also has an operator `error`.
Returns an observable sequence that terminates with an exception.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/error-observable/error-observable.php
$observable = Rx\Observable::error(new Exception('Oops!'));
$observable->subscribe($stdoutObserver);
```
```
Exception: Oops!
```
reactivex From From
====
> convert various other objects and data types into Observables
 When you work with Observables, it can be more convenient if all of the data you mean to work with can be represented as Observables, rather than as a mixture of Observables and other types. This allows you to use a single set of operators to govern the entire lifespan of the data stream.
Iterables, for example, can be thought of as a sort of synchronous Observable; Futures, as a sort of Observable that always emits only a single item. By explicitly converting such objects to Observables, you allow them to interact as peers with other Observables.
For this reason, most ReactiveX implementations have methods that allow you to convert certain language-specific objects and data structures into Observables.
See Also
--------
* [Just](just)
* [Start](start)
* [101 Rx Samples: Observation Operators](http://rxwiki.wikidot.com/101samples#toc5)
* [RxJava Tutorial 03: Observable from, just, & create methods](https://www.youtube.com/watch?v=sDqrlNprY24)
Language-Specific Information
-----------------------------
### RxGroovy `decode from fromAction fromCallable fromFunc0 fromRunnable runAsync`
 In RxGroovy, the `from` operator can convert a Future, an Iterable, or an Array. In the case of an Iterable or an Array, the resulting Observable will emit each item contained in the Iterable or Array.
In the case of a Future, it will emit the single result of the `get` call. You may optionally pass the version of `from` that accepts a future two additional parameters indicating a timeout span and the units of time that span is denominated in. The resulting Observable will terminate with an error if that span of time passes before the Future responds with a value.
`from` does not by default operate on any particular [Scheduler](../scheduler), however you can pass the variant that converts a Future a Scheduler as an optional second parameter, and it will use that Scheduler to govern the Future.
* Javadoc: [`from(array)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#from(T%5B%5D))
* Javadoc: [`from(Iterable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#from(java.lang.Iterable))
* Javadoc: [`from(Future)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#from(java.util.concurrent.Future))
* Javadoc: [`from(Future,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#from(java.util.concurrent.Future,%20rx.Scheduler))
* Javadoc: [`from(Future,timout,timeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#from(java.util.concurrent.Future,%20long,%20java.util.concurrent.TimeUnit))
 In addition, in the `RxJavaAsyncUtil` package, you have available to you the following operators that convert actions, callables, functions, and runnables into Observables that emit the results of those things:
* `fromAction`
* `fromCallable`
* `fromFunc0`
* `fromRunnable`
See the [Start](start) operator for more information about those operators.
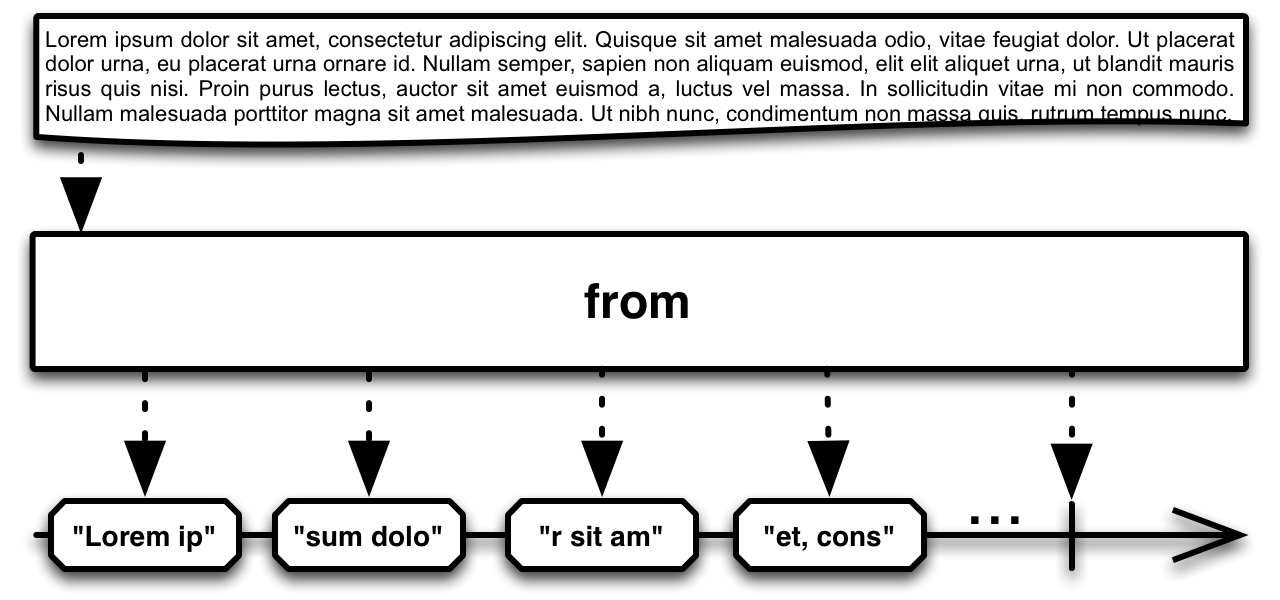 Note that there is also a `from` operator that is a method of the optional `StringObservable` class. It converts a stream of characters or a `Reader` into an Observable that emits byte arrays or Strings.
In the separate `RxJavaAsyncUtil` package, which is not included by default with RxGroovy, there is also a `runAsync` function. Pass `runAsync` an `Action` and a [`Scheduler`](../scheduler), and it will return a `StoppableObservable` that uses the specified `Action` to generate items that it emits.
The `Action` accepts an `Observer` and a `Subscription`. It uses the `Subscription` to check for the `isUnsubscribed` condition, upon which it will stop emitting items. You can also manually stop a `StoppableObservable` at any time by calling its `unsubscribe` method (which will also unsubscribe the `Subscription` you have associated with the `StoppableObservable`).
Because `runAsync` immediately invokes the `Action` and begins emitting the items, it is possible that some items may be lost in the interval between when you establish the `StoppableObservable` with this method and when your `Observer` is ready to receive items. If this is a problem, you can use the variant of `runAsync` that also accepts a [`Subject`](../subject) and pass a `ReplaySubject` with which you can retrieve the otherwise-missing items.
 The `StringObservable` class, which is not a default part of RxGroovy, also includes the `decode` operator which converts a stream of multibyte characters into an Observable that emits byte arrays that respect the character boundaries.
### RxJava 1․x `decode from fromAction fromCallable fromFunc0 fromRunnable runAsync`
 In RxJava, the `from` operator can convert a Future, an Iterable, or an Array. In the case of an Iterable or an Array, the resulting Observable will emit each item contained in the Iterable or Array.
#### Sample Code
```
Integer[] items = { 0, 1, 2, 3, 4, 5 };
Observable myObservable = Observable.from(items);
myObservable.subscribe(
new Action1<Integer>() {
@Override
public void call(Integer item) {
System.out.println(item);
}
},
new Action1<Throwable>() {
@Override
public void call(Throwable error) {
System.out.println("Error encountered: " + error.getMessage());
}
},
new Action0() {
@Override
public void call() {
System.out.println("Sequence complete");
}
}
);
```
```
0
1
2
3
4
5
Sequence complete
```
In the case of a Future, it will emit the single result of the `get` call. You may optionally pass the version of `from` that accepts a future two additional parameters indicating a timeout span and the units of time that span is denominated in. The resulting Observable will terminate with an error if that span of time passes before the Future responds with a value.
`from` does not by default operate on any particular [Scheduler](../scheduler), however you can pass the variant that converts a Future a Scheduler as an optional second parameter, and it will use that Scheduler to govern the Future.
* Javadoc: [`from(array)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#from(T%5B%5D))
* Javadoc: [`from(Iterable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#from(java.lang.Iterable))
* Javadoc: [`from(Future)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#from(java.util.concurrent.Future))
* Javadoc: [`from(Future,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#from(java.util.concurrent.Future,%20rx.Scheduler))
* Javadoc: [`from(Future,timout,timeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#from(java.util.concurrent.Future,%20long,%20java.util.concurrent.TimeUnit))
 In addition, in the `RxJavaAsyncUtil` package, you have available to you the following operators that convert actions, callables, functions, and runnables into Observables that emit the results of those things:
* `fromAction`
* `fromCallable`
* `fromFunc0`
* `fromRunnable`
See the [Start](start) operator for more information about those operators.
 Note that there is also a `from` operator that is a method of the optional `StringObservable` class. It converts a stream of characters or a `Reader` into an Observable that emits byte arrays or Strings.
In the separate `RxJavaAsyncUtil` package, which is not included by default with RxJava, there is also a `runAsync` function. Pass `runAsync` an `Action` and a [`Scheduler`](../scheduler), and it will return a `StoppableObservable` that uses the specified `Action` to generate items that it emits.
The `Action` accepts an `Observer` and a `Subscription`. It uses the `Subscription` to check for the `isUnsubscribed` condition, upon which it will stop emitting items. You can also manually stop a `StoppableObservable` at any time by calling its `unsubscribe` method (which will also unsubscribe the `Subscription` you have associated with the `StoppableObservable`).
Because `runAsync` immediately invokes the `Action` and begins emitting the items, it is possible that some items may be lost in the interval between when you establish the `StoppableObservable` with this method and when your `Observer` is ready to receive items. If this is a problem, you can use the variant of `runAsync` that also accepts a [`Subject`](../subject) and pass a `ReplaySubject` with which you can retrieve the otherwise-missing items.
 The `StringObservable` class, which is not a default part of RxGroovy, also includes the `decode` operator which converts a stream of multibyte characters into an Observable that emits byte arrays that respect the character boundaries.
### RxJS `from fromCallback fromEvent fromEventPattern fromNodeCallback fromPromise of ofArrayChanges ofObjectChanges ofWithScheduler pairs`
There are several, specialized From variants in RxJS:
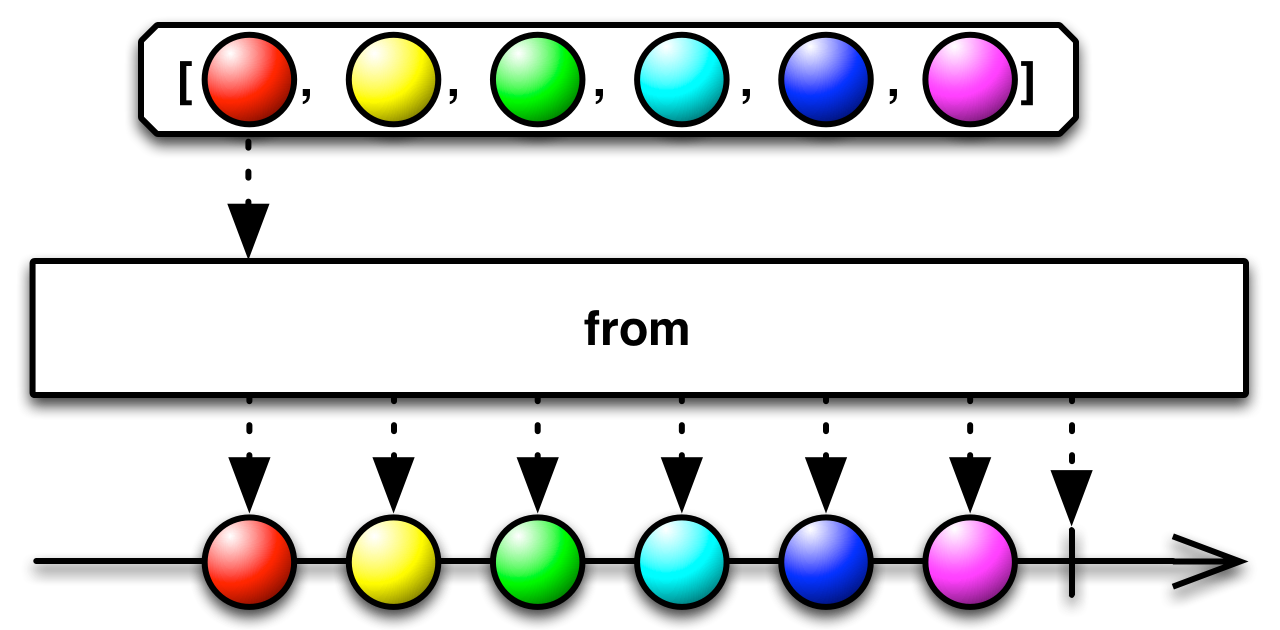 In RxJS, the `from` operator converts an array-like or iterable object into an Observable that emits the items in that array or iterable. A String, in this context, is treated as an array of characters.
This operator also takes three additional, optional parameters:
2. a transforming function that takes an item from the array or iterable as input and produces an item to be emitted by the resulting Observable as output
3. a second argument to pass into the transforming function as additional context information
4. a [Scheduler](../scheduler) on which this operator should operate
#### Sample Code
```
// Array-like object (arguments) to Observable
function f() {
return Rx.Observable.from(arguments);
}
f(1, 2, 3).subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 1
Next: 2
Next: 3
Completed
```
```
// Any iterable object...
// Set
var s = new Set(['foo', window]);
Rx.Observable.from(s).subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: foo
Next: window
Completed
```
```
// Map
var m = new Map([[1, 2], [2, 4], [4, 8]]);
Rx.Observable.from(m).subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: [1, 2]
Next: [2, 4]
Next: [4, 8]
Completed
```
```
// String
Rx.Observable.from("foo").subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: f
Next: o
Next: o
Completed
```
```
// Using an arrow function as the map function to manipulate the elements
Rx.Observable.from([1, 2, 3], function (x) { return x + x; }).subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 2
Next: 4
Next: 6
Completed
```
```
// Generate a sequence of numbers
Rx.Observable.from({length: 5}, function(v, k) { return k; }).subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 0
Next: 1
Next: 2
Next: 3
Next: 4
Completed
```
`from` is found in the following distributions:
* `rx.js`
* `rx.all.js`
* `rx.all.compat.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
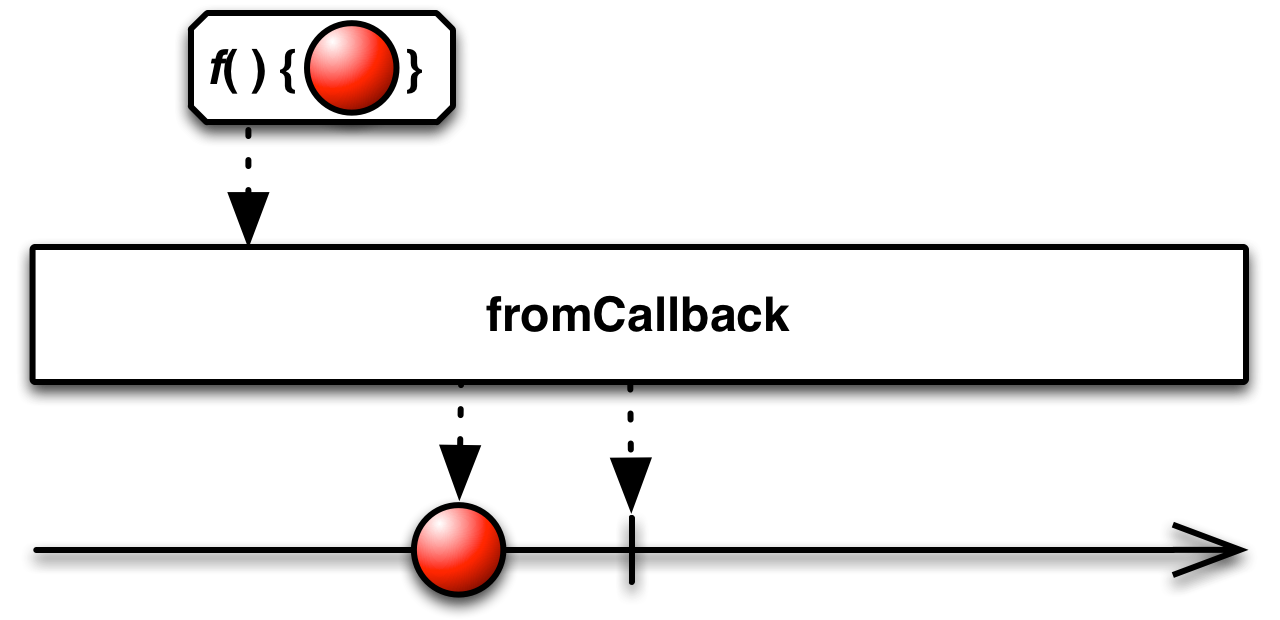 The `fromCallback` operator takes a function as a parameter, calls this function, and emits the value returned from it as its single emission.
This operator also takes two additional, optional parameters:
2. a parameter to pass to the callback function
3. a tranforming function that takes the return value of the callback function as input and returns an item to be emitted by the resulting Observable
#### Sample Code
```
var fs = require('fs'),
Rx = require('rx');
// Wrap fs.exists
var exists = Rx.Observable.fromCallback(fs.exists);
// Check if file.txt exists
var source = exists('file.txt');
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: true
Completed
```
`fromCallback` is found in the following distributions:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.async.js` (requires `rx.binding.js` and either `rx.js` or `rx.compat.js`)
* `rx.async.compat.js` (requires `rx.binding.js` and either `rx.js` or `rx.compat.js`)
* `rx.lite.js`
* `rx.lite.compat.js`
There is also a `fromNodeCallback` operator, which is specialized for the types of callback functions found in Node.js.
This operator takes three additional, optional parameters:
2. a [Scheduler](../scheduler) on which you want to run the Node.js callback
3. a parameter to give to the callback function
4. a tranforming function that takes the return value of the callback function as input and returns an item to be emitted by the resulting Observable
#### Sample Code
```
var fs = require('fs'),
Rx = require('rx');
// Wrap fs.exists
var rename = Rx.Observable.fromNodeCallback(fs.rename);
// Rename file which returns no parameters except an error
var source = rename('file1.txt', 'file2.txt');
var subscription = source.subscribe(
function () { console.log('Next: success!'); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: success!
Completed
```
`fromNodeCallback` is found in the following distributions:
* `rx.async.js` (requires `rx.binding.js` and either `rx.js` or `rx.compat.js`)
* `rx.async.compat.js` (requires `rx.binding.js` and either `rx.js` or `rx.compat.js`)
* `rx.lite.js`
* `rx.lite.compat.js`
 The `fromEvent` operator takes an “element” and an event name as parameters, and it then listens for events of that name taking place on that element. It returns an Observable that emits those events. An “element” may be a simple DOM element, or a NodeList, jQuery element, Zepto Element, Angular element, Ember.js element, or EventEmitter.
This operator also takes an optional third parameter: a function that accepts the arguments from the event handler as parameters and returns an item to be emitted by the resulting Observable in place of the event.
#### Sample Code
```
// using a jQuery element
var input = $('#input');
var source = Rx.Observable.fromEvent(input, 'click');
var subscription = source.subscribe(
function (x) { console.log('Next: Clicked!'); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
input.trigger('click');
```
```
Next: Clicked!
```
```
// using a Node.js EventEmitter and the optional third parameter
var EventEmitter = require('events').EventEmitter,
Rx = require('rx');
var eventEmitter = new EventEmitter();
var source = Rx.Observable.fromEvent(
eventEmitter,
'data',
function (first, second) {
return { foo: first, bar: second };
});
var subscription = source.subscribe(
function (x) {
console.log('Next: foo -' + x.foo + ', bar -' + x.bar);
},
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
eventEmitter.emit('data', 'baz', 'quux');
```
```
Next: foo - baz, bar - quux
```
`fromEvent` is found in the following distributions:
* `rx.async.js` (requires `rx.binding.js` and either `rx.js` or `rx.compat.js`)
* `rx.async.compat.js` (requires `rx.binding.js` and either `rx.js` or `rx.compat.js`)
* `rx.lite.js`
* `rx.lite.compat.js`
The `fromEventPattern` operator is similar, except that instead of taking an element and an event name as parameters, it takes two functions as parameters. The first function attaches an event listener to a variety of events on a variety of elements; the second function removes this set of listeners. In this way you can establish a single Observable that emits items representing a variety of events and a variety of target elements.
#### Sample Code
```
var input = $('#input');
var source = Rx.Observable.fromEventPattern(
function add (h) {
input.bind('click', h);
},
function remove (h) {
input.unbind('click', h);
}
);
var subscription = source.subscribe(
function (x) { console.log('Next: Clicked!'); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
input.trigger('click');
```
```
Next: Clicked!
```
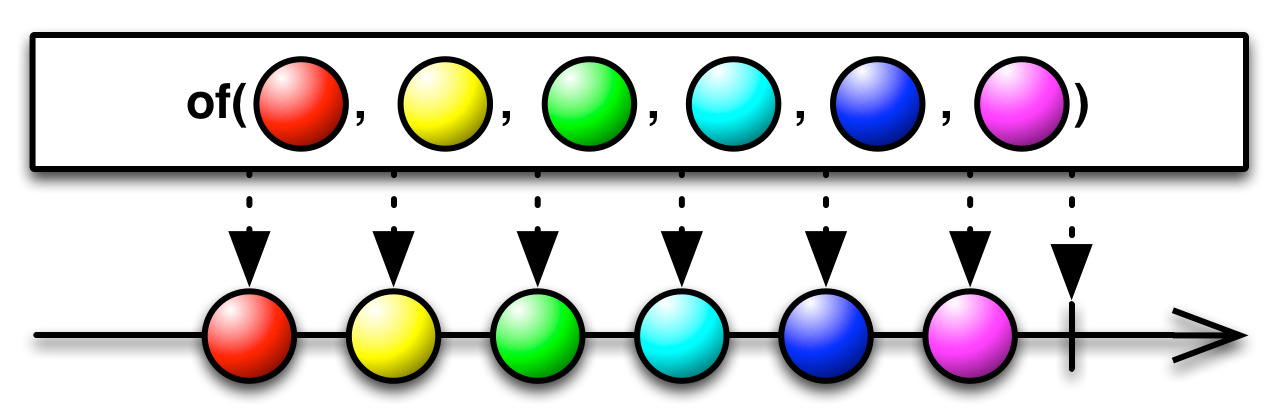 The `of` operator accepts a number of items as parameters, and returns an Observable that emits each of these parameters, in order, as its emitted sequence.
#### Sample Code
```
var source = Rx.Observable.of(1,2,3);
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 1
Next: 2
Next: 3
Completed
```
`of` is found in the following distributions:
* `rx.js`
* `rx.all.js`
* `rx.all.compat.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
A variant of this operator, called `ofWithScheduler` takes a [Scheduler](../scheduler) as its first parameter, and operates the resulting Observable on this Scheduler.
There is also a `fromPromise` operator that converts a Promise into an Observable, converting its `resolve` calls into `onNext` notifications, and its `reject` calls into `onError` notifications.
`fromPromise` is found in the following distributions:
* `rx.async.js` (requires `rx.binding.js` and either `rx.js` or `rx.compat.js`)
* `rx.async.compat.js` (requires `rx.binding.js` and either `rx.js` or `rx.compat.js`)
* `rx.lite.js`
* `rx.lite.compat.js`
#### Sample Code
```
var promise = new RSVP.Promise(function (resolve, reject) {
resolve(42);
});
var source = Rx.Observable.fromPromise(promise);
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (e) { console.log('Error: ' + e); },
function ( ) { console.log('Completed'); });
```
```
Next: 42:
Completed
```
```
var promise = new RSVP.Promise(function (resolve, reject) {
reject(new Error('reason'));
});
var source = Rx.Observable.fromPromise(promise);
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (e) { console.log('Error: ' + e); },
function ( ) { console.log('Completed'); });
```
```
Error: Error: reject
```
There is also an `ofArrayChanges` operator that monitors an Array with the `Array.observe` method, and returns an Observable that emits any changes that take place in the array. This operator is found only in the `rx.all.js` distribution.
#### Sample Code
```
var arr = [1,2,3];
var source = Rx.Observable.ofArrayChanges(arr);
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (e) { console.log('Error: ' + e); },
function ( ) { console.log('Completed'); });
arr.push(4)
```
```
Next: {type: "splice", object: Array[4], index: 3, removed: Array[0], addedCount: 1}
```
A similar operator is `ofObjectChanges`. It returns an Observable that emits any changes made to a particular object, as reported by its `Object.observe` method. It is also found only in the `rx.all.js` distribution.
#### Sample Code
```
var obj = {x: 1};
var source = Rx.Observable.ofObjectChanges(obj);
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (e) { console.log('Error: ' + e); },
function ( ) { console.log('Completed'); });
obj.x = 42;
```
```
Next: {type: "update", object: Object, name: "x", oldValue: 1}
```
There is also a `pairs` operator. This operator accepts an Object, and returns an Observable that emits, as key/value pairs, the attributes of that object.
#### Sample Code
```
var obj = {
foo: 42,
bar: 56,
baz: 78
};
var source = Rx.Observable.pairs(obj);
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (e) { console.log('Error: ' + e); },
function ( ) { console.log('Completed'); });
```
```
Next: ['foo', 42]
Next: ['bar', 56]
Next: ['baz', 78]
Completed
```
`pairs` is found in the following distributions:
* `rx.js`
* `rx.all.js`
* `rx.all.compat.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
### RxPHP `fromArray fromIterator asObservable fromPromise`
RxPHP implements this operator as `fromArray`.
Converts an array to an observable sequence
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/fromArray/fromArray.php
$source = \Rx\Observable::fromArray([1, 2, 3, 4]);
$subscription = $source->subscribe($stdoutObserver);
//Next value: 1
//Next value: 2
//Next value: 3
//Next value: 4
//Complete!
```
```
Next value: 1
Next value: 2
Next value: 3
Next value: 4
Complete!
```
RxPHP also has an operator `fromIterator`.
Converts an Iterator into an observable sequence
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/iterator/iterator.php
$generator = function () {
for ($i = 1; $i <= 3; $i++) {
yield $i;
}
return 4;
};
$source = Rx\Observable::fromIterator($generator());
$source->subscribe($stdoutObserver);
```
```
Next value: 1
Next value: 2
Next value: 3
Next value: 4
Complete!
```
RxPHP also has an operator `asObservable`.
Hides the identity of an observable sequence.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/asObservable/asObservable.php
// Create subject
$subject = new \Rx\Subject\AsyncSubject();
// Send a value
$subject->onNext(42);
$subject->onCompleted();
// Hide its type
$source = $subject->asObservable();
$source->subscribe($stdoutObserver);
```
```
Next value: 42
Complete!
```
RxPHP also has an operator `fromPromise`.
Converts a promise into an observable
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/promise/fromPromise.php
$promise = \React\Promise\resolve(42);
$source = \Rx\Observable::fromPromise($promise);
$subscription = $source->subscribe($stdoutObserver);
```
```
Next value: 42
Complete!
```
### RxSwift `from toObservable`
In Swift, this is implemented using the `Observable.from` class method.
Each element of the array is produced as an emission. The difference between this method and `Observable.just` is that the latter emits the whole array as one emission.
#### Sample Code
```
let numbers = [1,2,3,4,5]
let source = Observable.from(numbers)
source.subscribe {
print($0)
}
```
```
next(1)
next(2)
next(3)
next(4)
next(5)
completed
```
| programming_docs |
reactivex Buffer Buffer
======
> periodically gather items emitted by an Observable into bundles and emit these bundles rather than emitting the items one at a time
 The Buffer operator transforms an Observable that emits items into an Observable that emits buffered collections of those items. There are a number of variants in the various language-specific implementations of Buffer that differ in how they choose which items go in which buffers.
Note that if the source Observable issues an `onError` notification, Buffer will pass on this notification immediately without first emitting the buffer it is in the process of assembling, even if that buffer contains items that were emitted by the source Observable before it issued the error notification.
The [Window](window) operator is similar to Buffer but collects items into separate Observables rather than into data structures before reemitting them.
#### See Also
* [Window](window)
* [Introduction to Rx: Buffer](http://www.introtorx.com/Content/v1.0.10621.0/13_TimeShiftedSequences.html#Buffer)
* [Introduction to Rx: Buffer revisited](http://www.introtorx.com/Content/v1.0.10621.0/17_SequencesOfCoincidence.html#BufferRevisted)
* [101 Rx Samples: Buffer — Simple](http://rxwiki.wikidot.com/101samples#toc26)
Language-Specific Information
-----------------------------
### RxCpp `buffer pairwise`
RxCpp implements two variants of Buffer:
#### `buffer(count)`
 `buffer(count)` emits non-overlapping buffers in the form of `vector`s, each of which contains at most `count` items from the source Observable (the final emitted `vector` may have fewer than `count` items).
#### `buffer(count, skip)`
 `buffer(count, skip)` creates a new buffer starting with the first emitted item from the source Observable, and every `skip` items thereafter, and fills each buffer with `count` items: the initial item and `count-1` subsequent ones. It emits these buffers as `vector`s. Depending on the values of `count` and `skip` these buffers may overlap (multiple buffers may contain the same item), or they may have gaps (where items emitted by the source Observable are not represented in any buffer).
### RxGroovy `buffer`
In RxGroovy there are several variants of Buffer:
#### `buffer(count)`
 `buffer(count)` emits non-overlapping buffers in the form of `List`s, each of which contains at most `count` items from the source Observable (the final emitted `List` may have fewer than `count` items).
* Javadoc: [`buffer(int)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#buffer(int))
#### `buffer(count, skip)`
 `buffer(count, skip)` creates a new buffer starting with the first emitted item from the source Observable, and every `skip` items thereafter, and fills each buffer with `count` items: the initial item and `count-1` subsequent ones. It emits these buffers as `List`s. Depending on the values of `count` and `skip` these buffers may overlap (multiple buffers may contain the same item), or they may have gaps (where items emitted by the source Observable are not represented in any buffer).
* Javadoc: [`buffer(int,int)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#buffer(int,%20int))
#### `buffer(bufferClosingSelector)`
 When it subscribes to the source Observable, `buffer(bufferClosingSelector)` begins to collect its emissions into a `List`, and it also calls `bufferClosingSelector` to generate a second Observable. When this second Observable emits an `TClosing` object, `buffer` emits the current `List` and repeats this process: beginning a new `List` and calling `bufferClosingSelector` to create a new Observable to monitor. It will do this until the source Observable terminates.
* Javadoc: [`buffer(Func0)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#buffer(rx.functions.Func0))
####
`buffer(boundary`[`, initialCapacity`]`)`
 `buffer(boundary)` monitors an Observable, `boundary`. Each time that Observable emits an item, it creates a new `List` to begin collecting items emitted by the source Observable and emits the previous `List`.
* Javadoc: [`buffer(Observable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#buffer(rx.Observable))
* Javadoc: [`buffer(Observable,int)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#buffer(rx.Observable,%20int))
#### `buffer(bufferOpenings, bufferClosingSelector)`
 `buffer(bufferOpenings, bufferClosingSelector)` monitors an Observable, `bufferOpenings`, that emits `BufferOpening` objects. Each time it observes such an emitted item, it creates a new `List` to begin collecting items emitted by the source Observable and it passes the `bufferOpenings` Observable into the `closingSelector` function. That function returns an Observable. `buffer` monitors that Observable and when it detects an emitted item from it, it closes the `List` and emits it as its own emission.
* Javadoc: [`buffer(Observable,Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#buffer(rx.Observable,%20rx.functions.Func1))
####
`buffer(timespan, unit`[`, scheduler`]`)`
 `buffer(timespan, unit)` emits a new `List` of items periodically, every `timespan` amount of time, containing all items emitted by the source Observable since the previous bundle emission or, in the case of the first bundle, since the subscription to the source Observable. There is also a version of this variant of the operator that takes a [`Scheduler`](../scheduler) as a parameter and uses it to govern the timespan; by default this variant uses the `computation` Scheduler.
* Javadoc: [`buffer(long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#buffer(long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`buffer(long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#buffer(long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
####
`buffer(timespan, unit, count`[`, scheduler`]`)`
 `buffer(timespan, unit, count)` emits a new `List` of items for every `count` items emitted by the source Observable, or, if `timespan` has elapsed since its last bundle emission, it emits a bundle of however many items the source Observable has emitted in that span, even if this is fewer than `count`. There is also a version of this variant of the operator that takes a [`Scheduler`](../scheduler) as a parameter and uses it to govern the timespan; by default this variant uses the `computation` scheduler.
* Javadoc: [`buffer(long,TimeUnit,int)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#buffer(long,%20java.util.concurrent.TimeUnit,%20int))
* Javadoc: [`buffer(long,TimeUnit,int,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#buffer(long,%20java.util.concurrent.TimeUnit,%20int,%20rx.Scheduler))
####
`buffer(timespan, timeshift, unit`[`, scheduler`]`)`
 `buffer(timespan, timeshift, unit)` creates a new `List` of items every `timeshift` period of time, and fills this bundle with every item emitted by the source Observable from that time until `timespan` time has passed since the bundle’s creation, before emitting this `List` as its own emission. If `timespan` is longer than `timeshift`, the emitted bundles will represent time periods that overlap and so they may contain duplicate items. There is also a version of this variant of the operator that takes a [`Scheduler`](../scheduler) as a parameter and uses it to govern the timespan; by default this variant uses the `computation` scheduler.
* Javadoc: [`buffer(long,long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#buffer(long,%20long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`buffer(long,long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#buffer(long,%20long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
You can use the Buffer operator to implement backpressure (that is, to cope with an Observable that may produce items too quickly for its observer to consume).
 Buffer can reduce a sequence of many items to a sequence of fewer buffers-of-items, making them more manageable. You could, for example, close and emit a buffer of items from a bursty Observable periodically, at a regular interval of time.
#### Sample Code
```
Observable<List<Integer>> burstyBuffered = bursty.buffer(500, TimeUnit.MILLISECONDS);
```
 Or you could get fancy, and collect items in buffers during the bursty periods and emit them at the end of each burst, by using the [Debounce](debounce) operator to emit a buffer closing indicator to the buffer operator.
#### Sample Code
```
// we have to multicast the original bursty Observable so we can use it
// both as our source and as the source for our buffer closing selector:
Observable<Integer> burstyMulticast = bursty.publish().refCount();
// burstyDebounced will be our buffer closing selector:
Observable<Integer> burstyDebounced = burstyMulticast.debounce(10, TimeUnit.MILLISECONDS);
// and this, finally, is the Observable of buffers we're interested in:
Observable<List<Integer>> burstyBuffered = burstyMulticast.buffer(burstyDebounced);
```
### RxJava 1․x `buffer`
In RxJava there are several variants of Buffer:
#### `buffer(count)`
 `buffer(count)` emits non-overlapping buffers in the form of `List`s, each of which contains at most `count` items from the source Observable (the final emitted `List` may have fewer than `count` items).
* Javadoc: [`buffer(int)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#buffer(int))
#### `buffer(count, skip)`
 `buffer(count, skip)` creates a new buffer starting with the first emitted item from the source Observable, and every `skip` items thereafter, and fills each buffer with `count` items: the initial item and `count-1` subsequent ones. It emits these buffers as `List`s. Depending on the values of `count` and `skip` these buffers may overlap (multiple buffers may contain the same item), or they may have gaps (where items emitted by the source Observable are not represented in any buffer).
* Javadoc: [`buffer(int,int)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#buffer(int,%20int))
#### `buffer(bufferClosingSelector)`
 When it subscribes to the source Observable, `buffer(bufferClosingSelector)` begins to collect its emissions into a `List`, and it also calls `bufferClosingSelector` to generate a second Observable. When this second Observable emits an `TClosing` object, `buffer` emits the current `List` and repeats this process: beginning a new `List` and calling `bufferClosingSelector` to create a new Observable to monitor. It will do this until the source Observable terminates.
* Javadoc: [`buffer(Func0)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#buffer(rx.functions.Func0))
#### `buffer(boundary)`
 `buffer(boundary)` monitors an Observable, `boundary`. Each time that Observable emits an item, it creates a new `List` to begin collecting items emitted by the source Observable and emits the previous `List`.
* Javadoc: [`buffer(Observable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#buffer(rx.Observable))
* Javadoc: [`buffer(Observable,int)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#buffer(rx.Observable,%20int))
#### `buffer(bufferOpenings, bufferClosingSelector)`
 `buffer(bufferOpenings, bufferClosingSelector)` monitors an Observable, `bufferOpenings`, that emits `BufferOpening` objects. Each time it observes such an emitted item, it creates a new `List` to begin collecting items emitted by the source Observable and it passes the `bufferOpenings` Observable into the `closingSelector` function. That function returns an Observable. `buffer` monitors that Observable and when it detects an emitted item from it, it closes the `List` and emits it as its own emission.
* Javadoc: [`buffer(Observable,Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#buffer(rx.Observable,%20rx.functions.Func1))
####
`buffer(timespan, unit`[`, scheduler`]`)`
 `buffer(timespan, unit)` emits a new `List` of items periodically, every `timespan` amount of time, containing all items emitted by the source Observable since the previous bundle emission or, in the case of the first bundle, since the subscription to the source Observable. There is also a version of this variant of the operator that takes a [`Scheduler`](../scheduler) as a parameter and uses it to govern the timespan; by default this variant uses the `computation` scheduler.
* Javadoc: [`buffer(long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#buffer(long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`buffer(long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#buffer(long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
####
`buffer(timespan, unit, count`[`, scheduler`]`)`
 `buffer(timespan, unit, count)` emits a new `List` of items for every `count` items emitted by the source Observable, or, if `timespan` has elapsed since its last bundle emission, it emits a bundle of however many items the source Observable has emitted in that span, even if this is fewer than `count`. There is also a version of this variant of the operator that takes a [`Scheduler`](../scheduler) as a parameter and uses it to govern the timespan; by default this variant uses the `computation` scheduler.
* Javadoc: [`buffer(long,TimeUnit,int)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#buffer(long,%20java.util.concurrent.TimeUnit,%20int))
* Javadoc: [`buffer(long,TimeUnit,int,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#buffer(long,%20java.util.concurrent.TimeUnit,%20int,%20rx.Scheduler))
####
`buffer(timespan, timeshift, unit`[`, scheduler`]`)`
 `buffer(timespan, timeshift, unit)` creates a new `List` of items every `timeshift` period of time, and fills this bundle with every item emitted by the source Observable from that time until `timespan` time has passed since the bundle’s creation, before emitting this `List` as its own emission. If `timespan` is longer than `timeshift`, the emitted bundles will represent time periods that overlap and so they may contain duplicate items. There is also a version of this variant of the operator that takes a [`Scheduler`](../scheduler) as a parameter and uses it to govern the timespan; by default this variant uses the `computation` scheduler.
* Javadoc: [`buffer(long,long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#buffer(long,%20long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`buffer(long,long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#buffer(long,%20long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
You can use the Buffer operator to implement backpressure (that is, to cope with an Observable that may produce items too quickly for its observer to consume).
 Buffer can reduce a sequence of many items to a sequence of fewer buffers-of-items, making them more manageable. You could, for example, close and emit a buffer of items from a bursty Observable periodically, at a regular interval of time.
#### Sample Code
```
Observable<List<Integer>> burstyBuffered = bursty.buffer(500, TimeUnit.MILLISECONDS);
```
 Or you could get fancy, and collect items in buffers during the bursty periods and emit them at the end of each burst, by using the [Debounce](debounce) operator to emit a buffer closing indicator to the buffer operator.
#### Sample Code
```
// we have to multicast the original bursty Observable so we can use it
// both as our source and as the source for our buffer closing selector:
Observable<Integer> burstyMulticast = bursty.publish().refCount();
// burstyDebounced will be our buffer closing selector:
Observable<Integer> burstyDebounced = burstyMulticast.debounce(10, TimeUnit.MILLISECONDS);
// and this, finally, is the Observable of buffers we're interested in:
Observable<List<Integer>> burstyBuffered = burstyMulticast.buffer(burstyDebounced);
```
#### See Also
* [DebouncedBuffer With RxJava by Gopal Kaushik](http://blog.kaush.co/2015/01/05/debouncedbuffer-with-rxjava/)
* [DebounceBuffer: Use publish(), debounce() and buffer() together to capture bursts of events. by Ben Christensen](https://gist.github.com/benjchristensen/e4524a308456f3c21c0b#file-debouncebufferpublish-java)
### RxJS `buffer bufferWithCount bufferWithTime bufferWithTimeOrCount`
RxJS has four Buffer operators — `buffer`, `bufferWithCount`, `bufferWithTime`, and `bufferWithTimeOrCount` — each of which has variants that have different ways of governing which source Observable items are emitted as part of which buffers.
#### `buffer(bufferBoundaries)`
 `buffer(bufferBoundaries)` monitors an Observable, `bufferBoundaries`. Each time that Observable emits an item, it creates a new collection to begin collecting items emitted by the source Observable and emits the previous collection.
#### `buffer(bufferClosingSelector)`
 When it subscribes to the source Observable, `buffer(bufferClosingSelector)` begins to collect its emissions into a collection, and it also calls `bufferClosingSelector` to generate a second Observable. When this second Observable emits an item, `buffer` emits the current collection and repeats this process: beginning a new collection and calling `bufferClosingSelector` to create a new Observable to monitor. It will do this until the source Observable terminates.
#### `buffer(bufferOpenings,bufferClosingSelector)`
 `buffer(bufferOpenings, bufferClosingSelector)` monitors an Observable, `bufferOpenings`, that emits `BufferOpening` objects. Each time it observes such an emitted item, it creates a new collection to begin collecting items emitted by the source Observable and it passes the `bufferOpenings` Observable into the `bufferClosingSelector` function. That function returns an Observable. `buffer` monitors that Observable and when it detects an emitted item from it, it emits the current collection and begins a new one.
`buffer` is found in each of the following distributions:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.coincidence.js`
`buffer` requires one of the following distributions:
* `rx.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
#### `bufferWithCount(count)`
 `bufferWithCount(count)` emits non-overlapping buffers, each of which contains at most `count` items from the source Observable (the final emitted buffer may contain fewer than `count` items).
#### `bufferWithCount(count, skip)`
 `bufferWithCount(count, skip)` creates a new buffer starting with the first emitted item from the source Observable, and a new one for every `skip` items thereafter, and fills each buffer with `count` items: the initial item and `count-1` subsequent ones, emitting each buffer when it is complete. Depending on the values of `count` and `skip` these buffers may overlap (multiple buffers may contain the same item), or they may have gaps (where items emitted by the source Observable are not represented in any buffer).
`bufferWithCount` is found in each of the following distributions:
* `rx.js`
* `rx.compat.js`
* `rx.all.js`
* `rx.all.compat.js`
* `rx.lite.extras.js`
#### `bufferWithTime(timeSpan)`
 `bufferWithTime(timeSpan)` emits a new collection of items periodically, every `timeSpan` milliseconds, containing all items emitted by the source Observable since the previous bundle emission or, in the case of the first bundle, since the subscription to the source Observable. There is also a version of this variant of the operator that takes a [`Scheduler`](../scheduler) as a parameter and uses it to govern the timespan; by default this variant uses the `timeout` scheduler.
#### `bufferWithTime(timeSpan, timeShift)`
 `bufferWithTime(timeSpan, timeShift)` creates a new collection of items every `timeShift` milliseconds, and fills this bundle with every item emitted by the source Observable from that time until `timeSpan` milliseconds has passed since the collection’s creation, before emitting this collection as its own emission. If `timeSpan` is longer than `timeShift`, the emitted bundles will represent time periods that overlap and so they may contain duplicate items. There is also a version of this variant of the operator that takes a [`Scheduler`](../scheduler) as a parameter and uses it to govern the timespan; by default this variant uses the `timeout` scheduler.
#### `bufferWithTimeOrCount(timeSpan, count)`
 `bufferWithTimeOrCount(timeSpan, count)` emits a new collection of items for every `count` items emitted by the source Observable, or, if `timeSpan` milliseconds have elapsed since its last collection emission, it emits a collection of however many items the source Observable has emitted in that span, even if this is fewer than `count`. There is also a version of this variant of the operator that takes a [`Scheduler`](../scheduler) as a parameter and uses it to govern the timespan; by default this variant uses the `timeout` scheduler.
`bufferWithTime` and `bufferWithTimeOrCount` are found in each of the following distributions:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.time.js`
`bufferWithTime` and `bufferWithTimeOrCount` require one of the following distributions:
* `rx.time.js` requires `rx.js` or `rx.compat.js`
* otherwise: `rx.lite.js` or `rx.lite.compat.js`
### RxKotlin `buffer`
In RxKotlin there are several variants of Buffer:
#### `buffer(count)`
 `buffer(count)` emits non-overlapping buffers in the form of `List`s, each of which contains at most `count` items from the source Observable (the final emitted `List` may have fewer than `count` items).
#### `buffer(count, skip)`
 `buffer(count, skip)` creates a new buffer starting with the first emitted item from the source Observable, and every `skip` items thereafter, and fills each buffer with `count` items: the initial item and `count-1` subsequent ones. It emits these buffers as `List`s. Depending on the values of `count` and `skip` these buffers may overlap (multiple buffers may contain the same item), or they may have gaps (where items emitted by the source Observable are not represented in any buffer).
#### `buffer(bufferClosingSelector)`
 When it subscribes to the source Observable, `buffer(bufferClosingSelector)` begins to collect its emissions into a `List`, and it also calls `bufferClosingSelector` to generate a second Observable. When this second Observable emits an `TClosing` object, `buffer` emits the current `List` and repeats this process: beginning a new `List` and calling `bufferClosingSelector` to create a new Observable to monitor. It will do this until the source Observable terminates.
#### `buffer(boundary)`
 `buffer(boundary)` monitors an Observable, `boundary`. Each time that Observable emits an item, it creates a new `List` to begin collecting items emitted by the source Observable and emits the previous `List`.
#### `buffer(bufferOpenings, bufferClosingSelector)`
 `buffer(bufferOpenings, bufferClosingSelector)` monitors an Observable, `bufferOpenings`, that emits `BufferOpening` objects. Each time it observes such an emitted item, it creates a new `List` to begin collecting items emitted by the source Observable and it passes the `bufferOpenings` Observable into the `closingSelector` function. That function returns an Observable. `buffer` monitors that Observable and when it detects an emitted item from it, it closes the `List` and emits it as its own emission.
####
`buffer(timespan, unit`[`, scheduler`]`)`
 `buffer(timespan, unit)` emits a new `List` of items periodically, every `timespan` amount of time, containing all items emitted by the source Observable since the previous bundle emission or, in the case of the first bundle, since the subscription to the source Observable. There is also a version of this variant of the operator that takes a [`Scheduler`](../scheduler) as a parameter and uses it to govern the timespan; by default this variant uses the `computation` scheduler.
####
`buffer(timespan, unit, count`[`, scheduler`]`)`
 `buffer(timespan, unit, count)` emits a new `List` of items for every `count` items emitted by the source Observable, or, if `timespan` has elapsed since its last bundle emission, it emits a bundle of however many items the source Observable has emitted in that span, even if this is fewer than `count`. There is also a version of this variant of the operator that takes a [`Scheduler`](../scheduler) as a parameter and uses it to govern the timespan; by default this variant uses the `computation` scheduler.
####
`buffer(timespan, timeshift, unit`[`, scheduler`]`)`
 `buffer(timespan, timeshift, unit)` creates a new `List` of items every `timeshift` period of time, and fills this bundle with every item emitted by the source Observable from that time until `timespan` time has passed since the bundle’s creation, before emitting this `List` as its own emission. If `timespan` is longer than `timeshift`, the emitted bundles will represent time periods that overlap and so they may contain duplicate items. There is also a version of this variant of the operator that takes a [`Scheduler`](../scheduler) as a parameter and uses it to govern the timespan; by default this variant uses the `computation` scheduler.
### RxNET `Buffer`
In Rx.NET there are several variants of Buffer. For each variety you can either pass in the source Observable as the first parameter, or you can call it as an instance method of the source Observable (in which case you can omit that parameter):
#### `Buffer(count)`
 `Buffer(count)` emits non-overlapping buffers in the form of `IList`s, each of which contains at most `count` items from the source Observable (the final emitted `IList` may have fewer than `count` items).
#### `Buffer(count, skip)`
 `Buffer(count, skip)` creates a new buffer starting with the first emitted item from the source Observable, and every `skip` items thereafter, and fills each buffer with `count` items: the initial item and `count-1` subsequent ones. It emits these buffers as `IList`s. Depending on the values of `count` and `skip` these buffers may overlap (multiple buffers may contain the same item), or they may have gaps (where items emitted by the source Observable are not represented in any buffer).
#### `Buffer(bufferClosingSelector)`
 When it subscribes to the source Observable, `Buffer(bufferClosingSelector)` begins to collect its emissions into an `IList`, and it also calls `bufferClosingSelector` to generate a second Observable. When this second Observable emits an `TBufferClosing` object, `Buffer` emits the current `IList` and repeats this process: beginning a new `IList` and calling `bufferClosingSelector` to create a new Observable to monitor. It will do this until the source Observable terminates.
#### `Buffer(bufferOpenings,bufferClosingSelector)`
 `Buffer(bufferOpenings, bufferClosingSelector)` monitors an Observable, `BufferOpenings`, that emits `TBufferOpening` objects. Each time it observes such an emitted item, it creates a new `IList` to begin collecting items emitted by the source Observable and it passes the `TBufferOpening` object into the `bufferClosingSelector` function. That function returns an Observable. `Buffer` monitors that Observable and when it detects an emitted item from it, it closes the `IList` and emits it as its own emission.
#### `Buffer(timeSpan)`
 `Buffer(timeSpan)` emits a new `IList` of items periodically, every `timeSpan` amount of time, containing all items emitted by the source Observable since the previous bundle emission or, in the case of the first list, since the subscription to the source Observable. There is also a version of this variant of the operator that takes an [`IScheduler`](../scheduler) as a parameter and uses it to govern the timespan.
#### `Buffer(timeSpan, count)`
 `Buffer(timeSpan, count)` emits a new `IList` of items for every `count` items emitted by the source Observable, or, if `timeSpan` has elapsed since its last list emission, it emits a list of however many items the source Observable has emitted in that span, even if this is fewer than `count`. There is also a version of this variant of the operator that takes an [`IScheduler`](../scheduler) as a parameter and uses it to govern the timespan.
#### `Buffer(timeSpan, timeShift)`
 `Buffer(timeSpan, timeShift)` creates a new `IList` of items every `timeShift` period of time, and fills this list with every item emitted by the source Observable from that time until `timeSpan` time has passed since the list’s creation, before emitting this `IList` as its own emission. If `timeSpan` is longer than `timeShift`, the emitted lists will represent time periods that overlap and so they may contain duplicate items. There is also a version of this variant of the operator that takes an [`IScheduler`](../scheduler) as a parameter and uses it to govern the timespan.
### RxPHP `bufferWithCount`
RxPHP implements this operator as `bufferWithCount`.
Projects each element of an observable sequence into zero or more buffers which are produced based on element count information.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/bufferWithCount/bufferWithCount.php
$source = Rx\Observable::range(1, 6)
->bufferWithCount(2)
->subscribe($stdoutObserver);
```
```
Next value: [1,2]
Next value: [3,4]
Next value: [5,6]
Complete!
```
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/bufferWithCount/bufferWithCountAndSkip.php
$source = Rx\Observable::range(1, 6)
->bufferWithCount(2, 1)
->subscribe($stdoutObserver);
```
```
Next value: [1,2]
Next value: [2,3]
Next value: [3,4]
Next value: [4,5]
Next value: [5,6]
Next value: [6]
Complete!
```
### RxPY `buffer buffer_with_count buffer_with_time buffer_with_time_or_count pairwise`
RxPY has several Buffer variants: `buffer`, `buffer_with_count`, `buffer_with_time`, and `buffer_with_time_or_count`. For each of these variants there are optional parameters that change the behavior of the operator. As always in RxPY, when an operator may take more than one optional parameter, be sure to name the parameter in the parameter list when you call the operator so as to avoid ambiguity.
#### `buffer(buffer_openings)`
 `buffer(buffer_openings=boundaryObservable)` monitors an Observable, `buffer_openings`. Each time that Observable emits an item, it creates a new array to begin collecting items emitted by the source Observable and emits the previous array.
#### `buffer(closing_selector)`
 `buffer(closing_selector=closingSelector)` begins collecting items emitted by the source Observable immediately upon subscription, and also calls the `closing_selector` function to generate a second Observable. It monitors this new Observable and, when it completes or emits an item, it emits the current array, begins a new array to collect items from the source Observable, and calls `closing_selector` again to generate a new Observable to monitor in order to determine when to emit the new array. It repeats this process until the source Observable terminates, whereupon it emits the final array.
 `buffer(closing_selector=openingSelector, buffer_closing_selector=closingSelector)` begins by calling `closing_selector` to get an Observable. It monitors this Observable, and, whenever it emits an item, `buffer` creates a new array, begins to collect items subsequently emitted by the source Observable into this array, and calls `buffer_closing_selector` to get a new Observable to govern the closing of that array. When this new Observable emits an item or terminates, `buffer` closes and emits the array that the Observable governs.
#### `buffer_with_count(count)`
 `buffer_with_count(count)` emits non-overlapping buffers in the form of arrays, each of which contains at most `count` items from the source Observable (the final emitted array may have fewer than `count` items).
#### `buffer_with_count(count, skip)`
 `buffer_with_count(count, skip=skip)` creates a new buffer starting with the first emitted item from the source Observable, and every `skip` items thereafter, and fills each buffer with `count` items: the initial item and `count-1` subsequent ones. It emits these buffers as arrays. Depending on the values of `count` and `skip` these buffers may overlap (multiple buffers may contain the same item), or they may have gaps (where items emitted by the source Observable are not represented in any buffer).
#### `buffer_with_time(timespan)`
 `buffer_with_time(timespan)` emits a new array of items periodically, every `timespan` milliseconds, containing all items emitted by the source Observable since the previous bundle emission or, in the case of the first bundle, since the subscription to the source Observable. There is also a version of this variant of the operator that takes a `scheduler` parameter and uses it to govern the timespan; by default this variant uses the `timeout` scheduler.
#### `buffer_with_time(timespan, timeshift)`
 `buffer(timespan, timeshift=timeshift)` creates a new array of items every `timeshift` milliseconds, and fills this array with every item emitted by the source Observable from that time until `timespan` milliseconds have passed since the array’s creation, before emitting this array as its own emission. If `timespan` is longer than `timeshift`, the emitted arrays will represent time periods that overlap and so they may contain duplicate items. There is also a version of this variant of the operator that takes a `scheduler` parameter and uses it to govern the timespan; by default this variant uses the `timeout` scheduler.
#### `buffer_with_time_or_count(timespan, count)`
 `buffer_with_time_or_count(timespan, count)` emits a new array of items for every `count` items emitted by the source Observable, or, if `timespan` milliseconds have elapsed since its last bundle emission, it emits an array of however many items the source Observable has emitted in that span, even if this is fewer than `count`. There is also a version of this variant of the operator that takes a `scheduler` parameter and uses it to govern the timespan; by default this variant uses the `timeout` scheduler.
### Rxrb `buffer_with_count buffer_with_time`
Rx.rb has three variants of the Buffer operator:
#### `buffer_with_count(count)`
 `buffer_with_count(count)` emits non-overlapping buffers in the form of arrays, each of which contains at most `count` items from the source Observable (the final emitted array may have fewer than `count` items).
#### `buffer_with_count(count,skip)`
 `buffer_with_count(count, skip=skip)` creates a new buffer starting with the first emitted item from the source Observable, and every `skip` items thereafter, and fills each buffer with `count` items: the initial item and `count-1` subsequent ones. It emits these buffers as arrays. Depending on the values of `count` and `skip` these buffers may overlap (multiple buffers may contain the same item), or they may have gaps (where items emitted by the source Observable are not represented in any buffer).
#### `buffer_with_time(timespan)`
 `buffer_with_time(timespan)` emits a new array of items periodically, every `timespan` milliseconds, containing all items emitted by the source Observable since the previous bundle emission or, in the case of the first bundle, since the subscription to the source Observable.
### RxScala `slidingBuffer tumblingBuffer`
RxScala has two varieties of Buffer — `slidingBuffer` and `tumblingBuffer` — each of which has variants with different ways of assembling the buffers they emit:
#### `slidingBuffer(count, skip)`
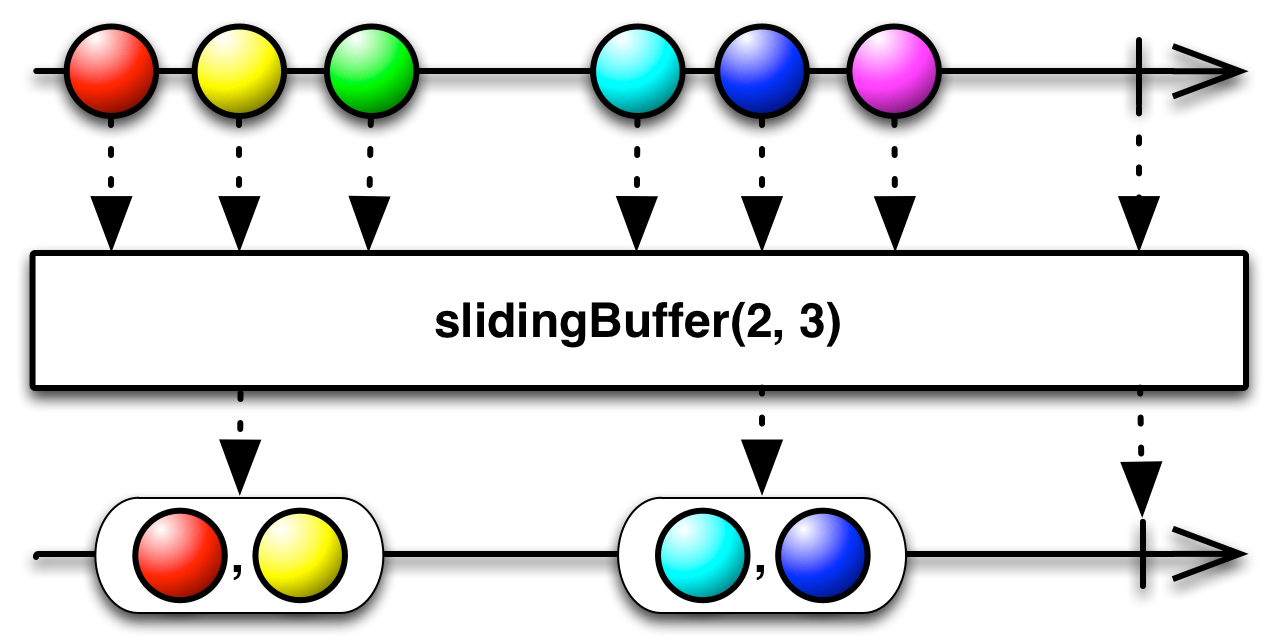 `slidingBuffer(count, skip)` creates a new buffer starting with the first emitted item from the source Observable, and every `skip` items thereafter, and fills each buffer with `count` items: the initial item and `count-1` subsequent ones. It emits these buffers as `Seq`s. Depending on the values of `count` and `skip` these buffers may overlap (multiple buffers may contain the same item), or they may have gaps (where items emitted by the source Observable are not represented in any buffer).
#### `slidingBuffer(timespan, timeshift)`
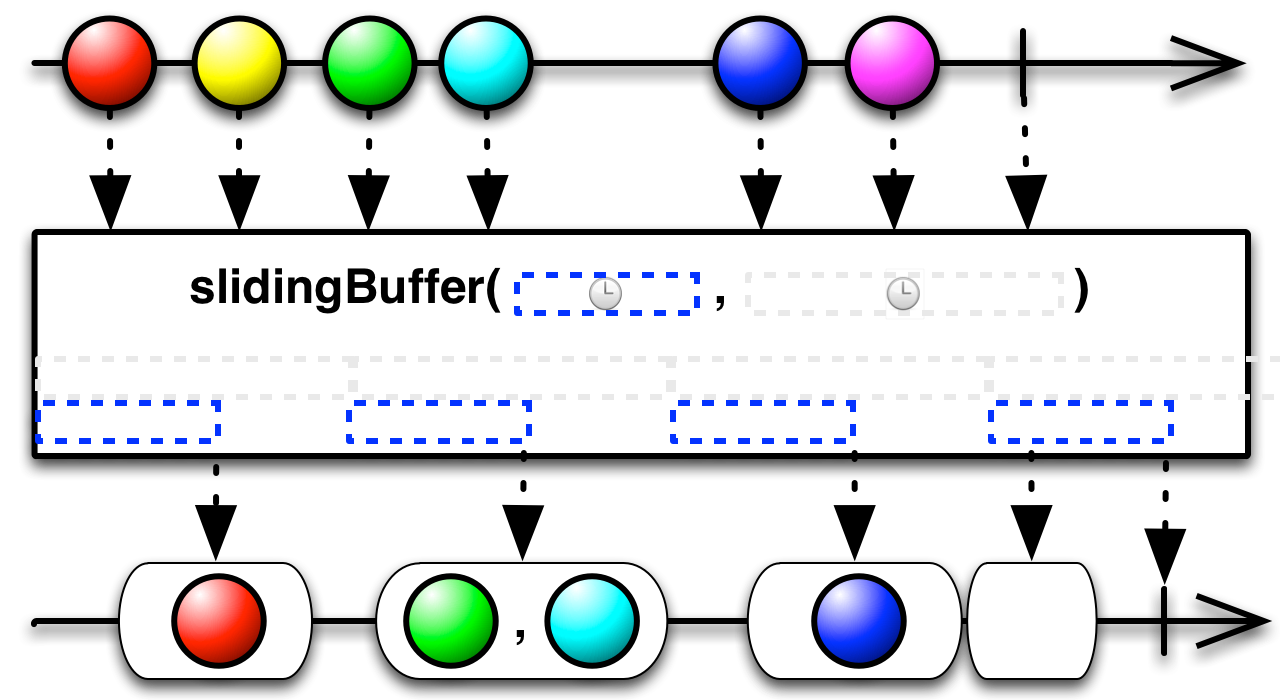 `slidingBuffer(timespan, timeshift)` creates a new `Seq` of items every `timeshift` (a `Duration`), and fills this buffer with every item emitted by the source Observable from that time until `timespan` (also a `Duration`) has passed since the buffer’s creation, before emitting this `Seq` as its own emission. If `timespan` is longer than `timeshift`, the emitted arrays will represent time periods that overlap and so they may contain duplicate items. There is also a version of this variant of the operator that takes a [`Scheduler`](../scheduler) as a parameter and uses it to govern the timespan.
#### `slidingBuffer(openings, closings)`
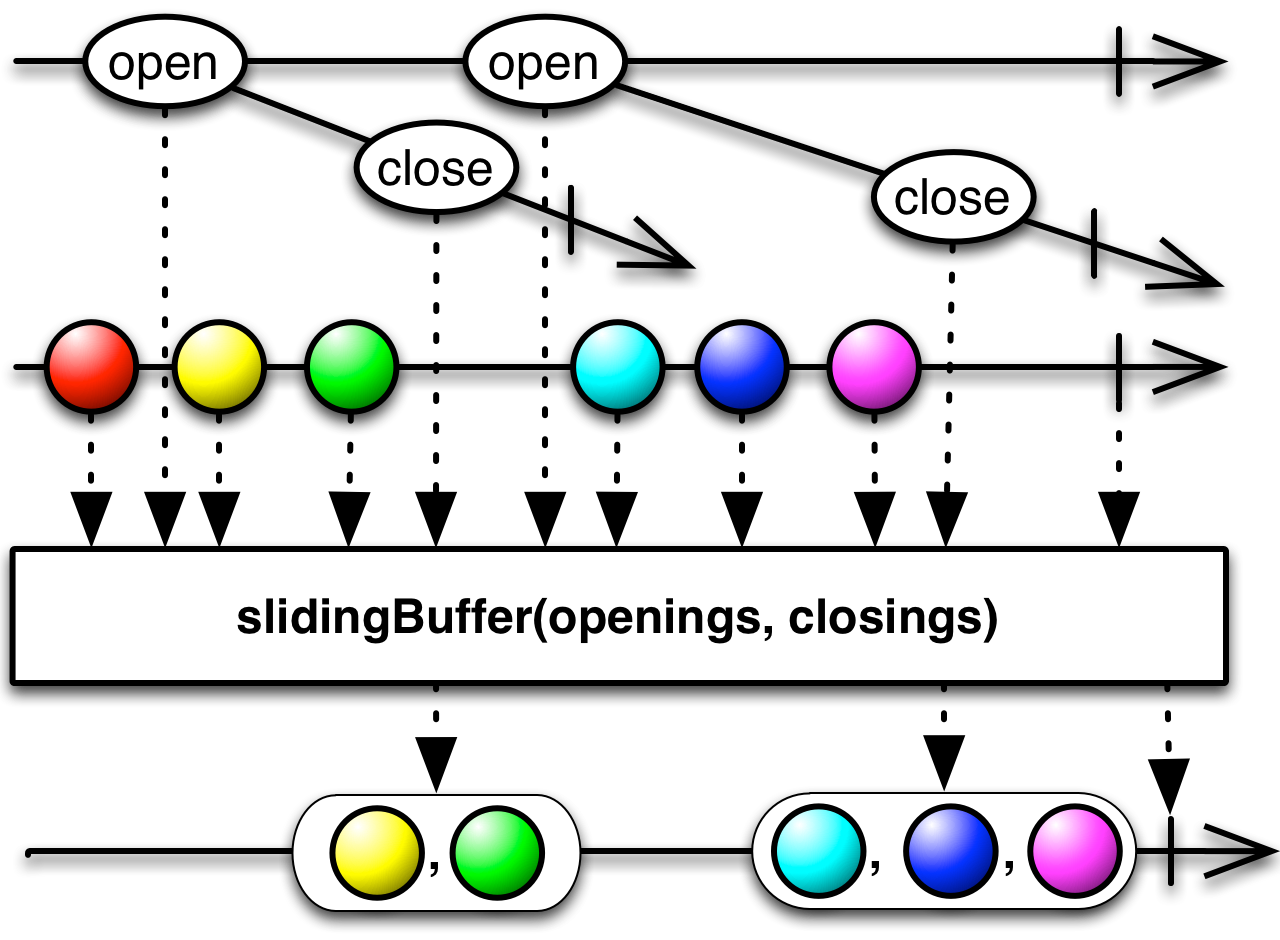 `slidingBuffer(openings,closings)` monitors the `openings` Observable, and, whenever it emits an `Opening` item, `slidingBuffer` creates a new `Seq`, begins to collect items subsequently emitted by the source Observable into this buffer, and calls `closings` to get a new Observable to govern the closing of that buffer. When this new Observable emits an item or terminates, `slidingBuffer` closes and emits the `Seq`that the Observable governs.
#### `tumblingBuffer(count)`
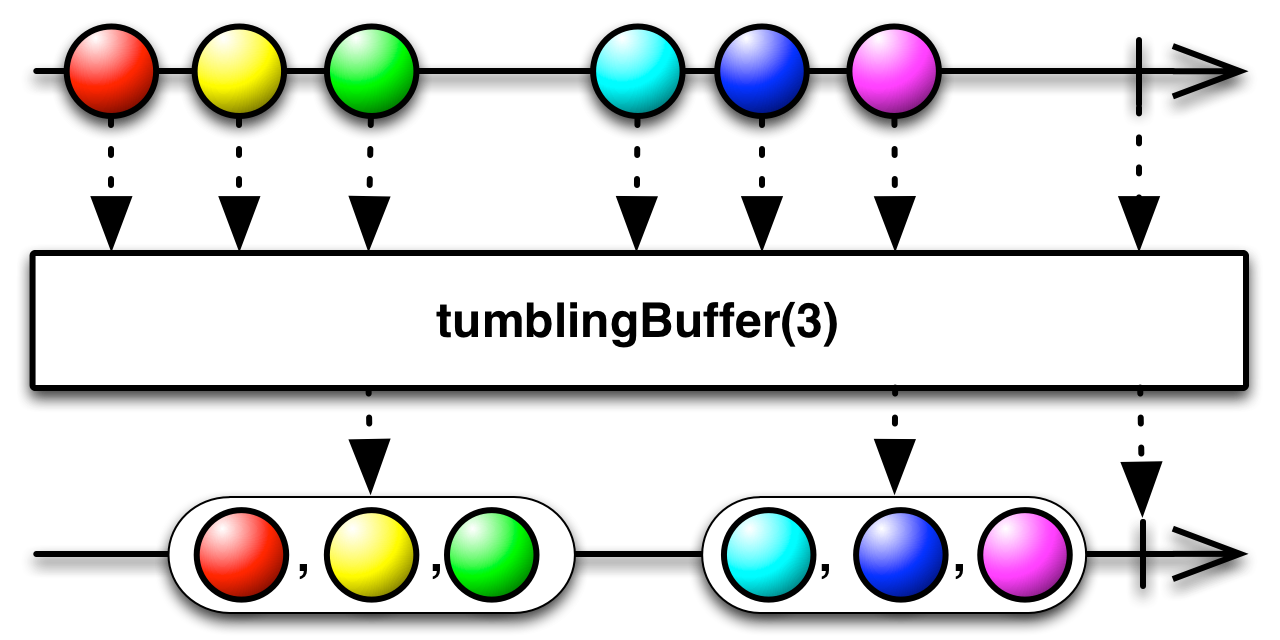 `tumblingBuffer(count)` emits non-overlapping buffers in the form of `Seq`s, each of which contains at most `count` items from the source Observable (the final emitted buffer may have fewer than `count` items).
#### `tumblingBuffer(boundary)`
 `tumblingBuffer(boundary)` monitors an Observable, `boundary`. Each time that Observable emits an item, it creates a new `Seq` to begin collecting items emitted by the source Observable and emits the previous `Seq`. This variant of the operator has an optional second parameter, `initialCapacity` with which you can indicate the expected size of these buffers so as to make memory allocation more efficient.
#### `tumblingBuffer(timespan)`
 `tumblingBuffer(timespan)` emits a new `Seq` of items periodically, every `timespan` (a `Duration`), containing all items emitted by the source Observable since the previous bundle emission or, in the case of the first bundle, since the subscription to the source Observable. This variant of the operator has an optional second parameter, `scheduler`, with which you can set the [`Scheduler`](../scheduler) that you want to govern the timespan calculation.
#### `tumblingBuffer(timespan, count)`
 `tumblingBuffer(timespan, count)` emits a new `Seq` of items for every `count` items emitted by the source Observable, or, if `timespan` (a `Duration`) has elapsed since its last bundle emission, it emits a `Seq` containing however many items the source Observable emitted in that span, even if this is fewer than `count`. This variant of the operator has an optional third parameter, `scheduler`, with which you can set the [`Scheduler`](../scheduler) that you want to govern the timespan calculation.
| programming_docs |
reactivex Using Using
=====
> create a disposable resource that has the same lifespan as the Observable
 The Using operator is a way you can instruct an Observable to create a resource that exists only during the lifespan of the Observable and is disposed of when the Observable terminates.
#### See Also
* [Introduction to Rx: Using](http://www.introtorx.com/Content/v1.0.10621.0/11_AdvancedErrorHandling.html#Using)
Language-Specific Information
-----------------------------
### RxGroovy `using`
 You pass the `using` operator three parameters:
1. a factory function that creates a disposable resource
2. a factory function that creates an Observable
3. a function that disposes of the resource
When an observer subscribes to the Observable returned from `using`, `using` will use the Observable factory function to create the Observable the observer will observe, while at the same time using the resource factory function to create whichever resource you have designed it to make. When the observer unsubscribes from the Observable, or when the Observable terminates (normally or with an error), `using` will call the third function to dispose of the resource it created.
`using` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`using(Func0,Func1,Action1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#using(rx.functions.Func0,%20rx.functions.Func1,%20rx.functions.Action1))
### RxJava 1․x `using`
 You pass the `using` operator three parameters:
1. a factory function that creates a disposable resource
2. a factory function that creates an Observable
3. a function that disposes of the resource
When an observer subscribes to the Observable returned from `using`, `using` will use the Observable factory function to create the Observable the observer will observe, while at the same time using the resource factory function to create whichever resource you have designed it to make. When the observer unsubscribes from the Observable, or when the Observable terminates (normally or with an error), `using` will call the third function to dispose of the resource it created.
`using` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`using(Func0,Func1,Action1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#using(rx.functions.Func0,%20rx.functions.Func1,%20rx.functions.Action1))
### RxJS `using`
 You pass the `using` operator two parameters:
1. a factory function that creates a disposable resource
2. a factory function that creates an Observable
When an observer subscribes to the Observable returned from `using`, `using` will use the Observable factory function to create the Observable the observer will observe, while at the same time using the resource factory function to create whichever resource you have designed it to make. To dispose of the resource, call the `dispose` method of the subscription that was returned from the `subscribe` call you used to subscribe an observer to the Observable that you modified with `using`.
#### Sample Code
```
/* Using an AsyncSubject as a resource which supports the .dispose method */
function DisposableResource(value) {
this.value = value;
this.disposed = false;
}
DisposableResource.prototype.getValue = function () {
if (this.disposed) {
throw new Error('Object is disposed');
}
return this.value;
};
DisposableResource.prototype.dispose = function () {
if (!this.disposed) {
this.disposed = true;
this.value = null;
}
console.log('Disposed');
};
var source = Rx.Observable.using(
function () { return new DisposableResource(42); },
function (resource) {
var subject = new Rx.AsyncSubject();
subject.onNext(resource.getValue());
subject.onCompleted();
return subject;
}
);
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 42
Completed
```
```
subscription.dispose();
```
```
Disposed
```
`using` is found in each of the following distributions:
* `rx.js`
* `rx.compat.js`
reactivex Concat Concat
======
> emit the emissions from two or more Observables without interleaving them
[Open interactive diagram on rxmarbles.com](https://rxmarbles.com/#concat) The Concat operator concatenates the output of multiple Observables so that they act like a single Observable, with all of the items emitted by the first Observable being emitted before any of the items emitted by the second Observable (and so forth, if there are more than two).
Concat waits to subscribe to each additional Observable that you pass to it until the previous Observable completes. Note that because of this, if you try to concatenate a “hot” Observable, that is, one that begins emitting items immediately and before it is subscribed to, Concat will not see, and therefore will not emit, any items that Observable emits before all previous Observables complete and Concat subscribes to the “hot” Observable.
In some ReactiveX implementations there is also a ConcatMap operator (a.k.a. `concat_all`, `concat_map`, `concatMapObserver`, `for`, `forIn`/`for_in`, `mapcat`, `selectConcat`, or `selectConcatObserver`) that transforms the items emitted by a source Observable into corresponding Observables and then concatenates the items emitted by each of these Observables in the order in which they are observed and transformed.
The [StartWith](startwith) operator is similar to Concat, but *prepends*, rather than appends, items or emissions of items to those emitted by a source Observable.
The [Merge](merge) operator is also similar. It combines the emissions of two or more Observables, but may interleave them, whereas Concat never interleaves the emissions from multiple Observables.
#### See Also
* [Catch](catch)
* [Merge](merge)
* [StartWith](startwith)
* [Introduction to Rx: Concat](http://www.introtorx.com/Content/v1.0.10621.0/12_CombiningSequences.html#Concat)
* [RxMarbles: `concat`](http://rxmarbles.com/#concat)
* [101 Rx Samples: Concat — cold observable](http://rxwiki.wikidot.com/101samples#toc51)
* [101 Rx Samples: Concat — hot observable](http://rxwiki.wikidot.com/101samples#toc52)
* [Loading data from multiple sources with RxJava](http://blog.danlew.net/2015/06/22/loading-data-from-multiple-sources-with-rxjava/) by Dan Lew (example using Concat and First)
Language-Specific Information
-----------------------------
### RxClojure `concat concat*`
 In RxClojure `concat` concatenates some number of individual Observables together in the order in which they are given.
 The `concat*` operator concatenates the Observables emitted by an Observable together, in the order in which they are emitted.
### RxCpp `concat`
RxCpp implements this operator as `concat`:
 ### RxGroovy `concat concatWith`
 RxGroovy implements this operator as `concat`. There are variants of this operator that take between two and nine Observables as parameters, and that concatenate them in the order they appear in the parameter list. There is also a variant that takes as a parameter an Observable of Observables, and concatenates each of these Observables in the order that they are emitted.
#### Sample Code
```
odds = Observable.from([1, 3, 5, 7]);
evens = Observable.from([2, 4, 6]);
Observable.concat(odds, evens).subscribe(
{ println(it); }, // onNext
{ println("Error: " + it.getMessage()); }, // onError
{ println("Sequence complete"); } // onCompleted
);
```
```
1
3
5
7
2
4
6
Sequence complete
```
* Javadoc: [`concat(Observable<Observable>)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#concat(rx.Observable))
* Javadoc: [`concat(Observable,Observable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#concat(rx.Observable,%20rx.Observable)) (there are also versions that take up to nine Observables)
There is also an instance method, `concatWith`, such that `Observable.concat(a,b)` is equivalent to `a.concatWith(b)`.
* Javadoc: [`concatWith(Observable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#concatWith(rx.Observable))
### RxJava 1․x `concat concatWith`
 RxJava implements this operator as `concat`. There are variants of this operator that take between two and nine Observables as parameters, and that concatenate them in the order they appear in the parameter list. There is also a variant that takes as a parameter an Observable of Observables, and concatenates each of these Observables in the order that they are emitted.
* Javadoc: [`concat(Observable<Observable>)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#concat(rx.Observable))
* Javadoc: [`concat(Observable,Observable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#concat(rx.Observable,%20rx.Observable)) (there are also versions that take up to nine Observables)
There is also an instance method, `concatWith`, such that `Observable.concat(a,b)` is equivalent to `a.concatWith(b)`.
* Javadoc: [`concatWith(Observable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#concatWith(rx.Observable))
### RxJS `concat concatAll`
RxJS implements this operator as `concat` and `concatAll`.
 `concat` takes a variable number of Observables (or Promises) as parameters (or a single array of Observables or Promises), and concatenates them in the order they appear in the parameter list (or array). It exists as both an Observable prototype method and as an instance method.
 `concatAll` is an instance method that operates on an Observable of Observables, concatinating each of these Observables in the order they are emitted.
`concat` and `concatAll` are found in each of the following distributions:
* `rx.js`
* `rx.all.js`
* `rx.all.compat.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
### RxKotlin `concat concatWith`
 RxKotlin implements this operator as `concat`. There are variants of this operator that take between two and nine Observables as parameters, and that concatenate them in the order they appear in the parameter list. There is also a variant that takes as a parameter an Observable of Observables, and concatenates each of these Observables in the order that they are emitted.
There is also an instance method, `concatWith`, such that `Observable.concat(a,b)` is equivalent to `a.concatWith(b)`.
### RxNET `Concat`
 Rx.NET implements this operator as `Concat`. It accepts either an enumerable of Observables, an Observable of Observables, or two Observables as parameters, and concatenates these in the order given.
### RxPHP `concat concatAll`
RxPHP implements this operator as `concat`.
Concatenate an observable sequence onto the end of the source observable.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/concat/concat.php
$source1 = \Rx\Observable::of(42);
$source2 = \Rx\Observable::of(56);
$source = \Rx\Observable::empty()->concat($source1)->concat($source2);
$subscription = $source->subscribe($stdoutObserver);
```
```
Next value: 42
Next value: 56
Complete!
```
RxPHP also has an operator `concatAll`.
Concatenates a sequence of observable sequences into a single observable sequence.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/concat/concatAll.php
$source = Rx\Observable::range(0, 3)
->map(function ($x) {
return \Rx\Observable::range($x, 3);
})
->concatAll();
$subscription = $source->subscribe($stdoutObserver);
```
```
Next value: 0
Next value: 1
Next value: 2
Next value: 1
Next value: 2
Next value: 3
Next value: 2
Next value: 3
Next value: 4
Complete!
```
### RxPY `concat concatAll`
 In RxPY `concat` takes a variable number of Observables as parameters (or an array of Observables), and concatenates them in the order they appear in the parameter list (or array).
 `concatAll` operates on an Observable of Observables, concatinating each of these Observables in the order they are emitted.
### Rxrb `concat merge_all`
 In Rx.rb, the `concat` operator operates on two Observables as an instance operator, or on an array of Observables as a class method.
 The `merge_all` operator, despite its name, really behaves like a Concat variant in Rx.rb. It accepts an Observable of Observables as its parameter, and concatenates the emissions from these Observables.
### RxScala `concat ++`
RxScala implements this operator in two ways. There is a `concat` operator that accepts an Observable of Observables as its parameter, and then concatenates each of these Observables in the order they are emitted. There is also a `++` operator that concatenates one Observable to another.
reactivex GroupBy GroupBy
=======
> divide an Observable into a set of Observables that each emit a different subset of items from the original Observable
 The GroupBy operator divides an Observable that emits items into an Observable that emits Observables, each one of which emits some subset of the items from the original source Observable. Which items end up on which Observable is typically decided by a discriminating function that evaluates each item and assigns it a key. All items with the same key are emitted by the same Observable.
#### See Also
* [Window](window)
* [Introduction to Rx: GroupBy](http://www.introtorx.com/Content/v1.0.10621.0/07_Aggregation.html#GroupBy)
* [Animations of Rx operators: GroupBy](http://blogs.microsoft.co.il/iblogger/2015/08/11/animations-of-rx-operators-groupby/) by Tamir Dresher
Language-Specific Information
-----------------------------
### RxGroovy `groupBy`
 RxGroovy implements the `groupBy` operator. The Observable it returns emits items of a particular subclass of Observable — the `GroupedObservable`. Objects that implement the `GroupedObservable` interface have an additional method — `getkey` — by which you can retrieve the key by which items were designated for this particular `GroupedObservable`.
The following sample code uses `groupBy` to transform a list of numbers into two lists, grouped by whether or not the numbers are even:
#### Sample Code
```
def numbers = Observable.from([1, 2, 3, 4, 5, 6, 7, 8, 9]);
def groupFunc = { return(0 == (it % 2)); };
numbers.groupBy(groupFunc).flatMap({ it.reduce([it.getKey()], {a, b -> a << b}) }).subscribe(
{ println(it); }, // onNext
{ println("Error: " + it.getMessage()); }, // onError
{ println("Sequence complete"); } // onCompleted
);
```
```
[false, 1, 3, 5, 7, 9]
[true, 2, 4, 6, 8]
Sequence complete
```
Another version of `groupBy` allows you to pass in a transformative function that changes the elements before they are emitted by the resulting `GroupedObservable`s.
Note that when `groupBy` splits up the source Observable into an Observable that emits `GroupedObservable`s, each of these `GroupedObservable`s begins to buffer the items that it will emit upon subscription. For this reason, if you ignore any of these `GroupedObservable`s (you neither subscribe to it or apply an operator to it that subscribes to it), this buffer will present a potential memory leak. For this reason, rather than ignoring a `GroupedObservable` that you have no interest in observing, you should instead apply an operator like [`take(0)`](take) to it as a way of signalling to it that it may discard its buffer.
If you unsubscribe from one of the `GroupedObservable`s, or if an operator like `take` that you apply to the `GroupedObservable` unsubscribes from it, that `GroupedObservable` will be terminated. If the source Observable later emits an item whose key matches the `GroupedObservable` that was terminated in this way, `groupBy` will create and emit a *new* `GroupedObservable` to match the key. In other words, unsubscribing from a `GroupedObservable` will *not* cause `groupBy` to swallow items from its group. For example, see the following code:
#### Sample Code
```
Observable.range(1,5)
.groupBy({ 0 })
.flatMap({ this.take(1) })
.subscribe(
{ println(it); }, // onNext
{ println("Error: " + it.getMessage()); }, // onError
{ println("Sequence complete"); } // onCompleted
);
```
```
1
2
3
4
5
```
In the above code, the source Observable emits the sequence `{ 1 2 3 4 5 }`. When it emits the first item in this sequence, the `groupBy` operator creates and emits a `GroupedObservable` with the key of `0`. The `flatMap` operator applies the `take(1)` operator to that `GroupedObservable`, which gives it the item (`1`) that it emits and that also unsubscribes from the `GroupedObservable`, which is terminated. When the source Observable emits the second item in its sequence, the `groupBy` operator creates and emits a *second* `GroupedObservable` with the same key (`0`) to replace the one that was terminated. `flatMap` again applies `take(1)` to this new `GroupedObservable` to retrieve the new item to emit (`2`) and to unsubscribe from and terminate the `GroupedObservable`, and this process repeats for the remaining items in the source sequence.
`groupBy` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`groupBy(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#groupBy(rx.functions.Func1))
* Javadoc: [`groupBy(Func1,Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#groupBy(rx.functions.Func1,%20rx.functions.Func1))
### RxJava 1․x `groupBy`
 RxJava implements the `groupBy` operator. The Observable it returns emits items of a particular subclass of Observable — the `GroupedObservable`. Objects that implement the `GroupedObservable` interface have an additional method — `getkey` — by which you can retrieve the key by which items were designated for this particular `GroupedObservable`.
Another version of `groupBy` allows you to pass in a transformative function that changes the elements before they are emitted by the resulting `GroupedObservable`s.
Note that when `groupBy` splits up the source Observable into an Observable that emits `GroupedObservable`s, each of these `GroupedObservable`s begins to buffer the items that it will emit upon subscription. For this reason, if you ignore any of these `GroupedObservable`s (you neither subscribe to it or apply an operator to it that subscribes to it), this buffer will present a potential memory leak. For this reason, rather than ignoring a `GroupedObservable` that you have no interest in observing, you should instead apply an operator like [`take(0)`](take) to it as a way of signalling to it that it may discard its buffer.
If you unsubscribe from one of the `GroupedObservable`s, that `GroupedObservable` will be terminated. If the source Observable later emits an item whose key matches the `GroupedObservable` that was terminated in this way, `groupBy` will create and emit a new `GroupedObservable` to match the key.
`groupBy` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`groupBy(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#groupBy(rx.functions.Func1))
* Javadoc: [`groupBy(Func1,Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#groupBy(rx.functions.Func1,%20rx.functions.Func1))
### RxJS `groupBy groupByUntil`
 RxJS implements `groupBy`. It takes one to three parameters:
1. (required) a function that accepts an item from the source Observable and returns its key
2. a function that accepts an item from the source Observable and returns an item to be emitted in its place by one of the resulting Observables
3. a function used to compare two keys for identity (that is, whether items with two keys should be emitted on the same Observable)
#### Sample Code
```
var codes = [
{ keyCode: 38}, // up
{ keyCode: 38}, // up
{ keyCode: 40}, // down
{ keyCode: 40}, // down
{ keyCode: 37}, // left
{ keyCode: 39}, // right
{ keyCode: 37}, // left
{ keyCode: 39}, // right
{ keyCode: 66}, // b
{ keyCode: 65} // a
];
var source = Rx.Observable.fromArray(codes)
.groupBy(
function (x) { return x.keyCode; },
function (x) { return x.keyCode; });
var subscription = source.subscribe(
function (obs) {
// Print the count
obs.count().subscribe(function (x) {
console.log('Count: ' + x);
});
},
function (err) {
console.log('Error: ' + err);
},
function () {
console.log('Completed');
});
```
```
Count: 2
Count: 2
Count: 2
Count: 2
Count: 1
Count: 1
Completed
```
`groupBy` is found in each of the following distributions:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.coincidence.js`
 RxJS also implements `groupByUntil`. It monitors an additional Observable, and whenever that Observable emits an item, it closes any of the keyed Observables it has opened (it will open new ones if additional items are emitted by the source Observable that match the key). `groupByUntil` takes from two to four parameters:
1. (required) a function that accepts an item from the source Observable and returns its key
2. a function that accepts an item from the source Observable and returns an item to be emitted in its place by one of the resulting Observables
3. (required) a function that returns an Observable, the emissions from which trigger the termination of any open Observables
4. a function used to compare two keys for identity (that is, whether items with two keys should be emitted on the same Observable)
#### Sample Code
```
var codes = [
{ keyCode: 38}, // up
{ keyCode: 38}, // up
{ keyCode: 40}, // down
{ keyCode: 40}, // down
{ keyCode: 37}, // left
{ keyCode: 39}, // right
{ keyCode: 37}, // left
{ keyCode: 39}, // right
{ keyCode: 66}, // b
{ keyCode: 65} // a
];
var source = Rx.Observable
.for(codes, function (x) { return Rx.Observable.return(x).delay(1000); })
.groupByUntil(
function (x) { return x.keyCode; },
function (x) { return x.keyCode; },
function (x) { return Rx.Observable.timer(2000); });
var subscription = source.subscribe(
function (obs) {
// Print the count
obs.count().subscribe(function (x) { console.log('Count: ' + x); });
},
function (err) {
console.log('Error: ' + err);
},
function () {
console.log('Completed');
});
```
```
Count: 2
Count: 2
Count: 1
Count: 1
Count: 1
Count: 1
Count: 1
Count: 1
Completed
```
`groupByUntil` is found in each of the following distributions:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.coincidence.js`
### RxPHP `groupBy groupByUntil partition`
RxPHP implements this operator as `groupBy`.
Groups the elements of an observable sequence according to a specified key selector function and comparer and selects the resulting elements by using a specified function.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/groupBy/groupBy.php
$observable = \Rx\Observable::fromArray([21, 42, 21, 42, 21, 42]);
$observable
->groupBy(
function ($elem) {
if ($elem === 42) {
return 0;
}
return 1;
},
null,
function ($key) {
return $key;
}
)
->subscribe(function ($groupedObserver) use ($createStdoutObserver) {
$groupedObserver->subscribe($createStdoutObserver($groupedObserver->getKey() . ": "));
});
```
```
1: Next value: 21
0: Next value: 42
1: Next value: 21
0: Next value: 42
1: Next value: 21
0: Next value: 42
1: Complete!
0: Complete!
```
RxPHP also has an operator `groupByUntil`.
Groups the elements of an observable sequence according to a specified key selector function and comparer and selects the resulting elements by using a specified function.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/groupBy/groupByUntil.php
$codes = [
['id' => 38],
['id' => 38],
['id' => 40],
['id' => 40],
['id' => 37],
['id' => 39],
['id' => 37],
['id' => 39],
['id' => 66],
['id' => 65]
];
$source = Rx\Observable
::fromArray($codes)
->concatMap(function ($x) {
return \Rx\Observable::timer(100)->mapTo($x);
})
->groupByUntil(
function ($x) {
return $x['id'];
},
function ($x) {
return $x['id'];
},
function ($x) {
return Rx\Observable::timer(200);
});
$subscription = $source->subscribe(new CallbackObserver(
function (\Rx\Observable $obs) {
// Print the count
$obs->count()->subscribe(new CallbackObserver(
function ($x) {
echo 'Count: ', $x, PHP_EOL;
}));
},
function (Throwable $err) {
echo 'Error', $err->getMessage(), PHP_EOL;
},
function () {
echo 'Completed', PHP_EOL;
}));
```
```
Count: 2
Count: 2
Count: 1
Count: 1
Count: 1
Count: 1
Count: 1
Count: 1
Completed
```
RxPHP also has an operator `partition`.
Returns two observables which partition the observations of the source by the given function. The first will trigger observations for those values for which the predicate returns true. The second will trigger observations for those values where the predicate returns false. The predicate is executed once for each subscribed observer. Both also propagate all error observations arising from the source and each completes when the source completes.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/partition/partition.php
list($evens, $odds) = \Rx\Observable::range(0, 10, \Rx\Scheduler::getImmediate())
->partition(function ($x) {
return $x % 2 === 0;
});
//Because we used the immediate scheduler with range, the subscriptions are not asynchronous.
$evens->subscribe($createStdoutObserver('Evens '));
$odds->subscribe($createStdoutObserver('Odds '));
```
```
Evens Next value: 0
Evens Next value: 2
Evens Next value: 4
Evens Next value: 6
Evens Next value: 8
Evens Complete!
Odds Next value: 1
Odds Next value: 3
Odds Next value: 5
Odds Next value: 7
Odds Next value: 9
Odds Complete!
```
| programming_docs |
reactivex Serialize Serialize
=========
> force an Observable to make serialized calls and to be well-behaved
 It is possible for an Observable to invoke its observers’ methods asynchronously, perhaps from different threads. This could make such an Observable violate [the Observable contract](../contract), in that it might try to send an `OnCompleted` or `OnError` notification before one of its `OnNext` notifications, or it might make an `OnNext` notification from two different threads concurrently. You can force such an Observable to be well-behaved and synchronous by applying the Serialize operator to it.
Language-Specific Information
-----------------------------
### RxGroovy `serialize`
 RxGroovy implements this operator as `serialize`. It does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`serialize()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#serialize())
### RxJava 1․x `serialize`
 RxJava implements this operator as `serialize`. It does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`serialize()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#serialize())
reactivex Connect Connect
=======
> instruct a connectable Observable to begin emitting items to its subscribers
 A connectable Observable resembles an ordinary Observable, except that it does not begin emitting items when it is subscribed to, but only when the Connect operator is applied to it. In this way you can wait for all intended observers to subscribe to the Observable before the Observable begins emitting items.
#### See Also
* [Publish](publish)
* [RefCount](refcount)
* [Replay](replay)
* [Introduction to Rx: Publish & Connect](http://www.introtorx.com/Content/v1.0.10621.0/14_HotAndColdObservables.html#PublishAndConnect)
Language-Specific Information
-----------------------------
### RxGroovy `connect`
 In RxGroovy, the `connect` operator is a method of the `ConnectableObservable` interface. You can use the `publish` operator to convert an ordinary Observable into a `ConnectableObservable`.
Call a `ConnectableObservable`’s `connect` method to instruct it to begin emitting the items from its underlying Observable to its Subscribers.
The `connect` method returns a `Subscription`. You can call that `Subscription` object’s `unsubscribe` method to instruct the Observable to stop emitting items to its Subscribers.
You can also use the `connect` method to instruct an Observable to begin emitting items (or, to begin generating items that would be emitted) even before any Subscriber has subscribed to it. In this way you can turn a cold Observable into a hot one.
* Javadoc: [`connect()`](http://reactivex.io/RxJava/javadoc/rx/observables/ConnectableObservable.html#connect())
* Javadoc: [`connect(Action1)`](http://reactivex.io/RxJava/javadoc/rx/observables/ConnectableObservable.html#connect(rx.functions.Action1))
### RxJava 1․x `connect`
 In RxJava, the `connect` operator is a method of the `ConnectableObservable` interface. You can use the `publish` operator to convert an ordinary Observable into a `ConnectableObservable`.
Call a `ConnectableObservable`’s `connect` method to instruct it to begin emitting the items from its underlying Observable to its Subscribers.
The `connect` method returns a `Subscription`. You can call that `Subscription` object’s `unsubscribe` method to instruct the Observable to stop emitting items to its Subscribers.
You can also use the `connect` method to instruct an Observable to begin emitting items (or, to begin generating items that would be emitted) even before any Subscriber has subscribed to it. In this way you can turn a cold Observable into a hot one.
* Javadoc: [`connect()`](http://reactivex.io/RxJava/javadoc/rx/observables/ConnectableObservable.html#connect())
* Javadoc: [`connect(Action1)`](http://reactivex.io/RxJava/javadoc/rx/observables/ConnectableObservable.html#connect(rx.functions.Action1))
### RxJS `connect`
 In RxJS, the `connect` operator is a method of the `ConnectableObservable` prototype. You can use the `publish` operator to convert an ordinary Observable into a `ConnectableObservable`.
Call a `ConnectableObservable`’s `connect` method to instruct it to begin emitting the items from its underlying Observable to its Subscribers.
The `connect` method returns a `Disposable`. You can call that `Disposable` object’s `dispose` method to instruct the Observable to stop emitting items to its Subscribers.
You can also use the `connect` method to instruct an Observable to begin emitting items (or, to begin generating items that would be emitted) even before any Subscriber has subscribed to it. In this way you can turn a cold Observable into a hot one.
#### Sample Code
```
var interval = Rx.Observable.interval(1000);
var source = interval
.take(2)
.do(function (x) { console.log('Side effect'); });
var published = source.publish();
published.subscribe(createObserver('SourceA'));
published.subscribe(createObserver('SourceB'));
// Connect the source
var connection = published.connect();
function createObserver(tag) {
return Rx.Observer.create(
function (x) { console.log('Next: ' + tag + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
}
```
```
Side effect
Next: SourceA0
Next: SourceB0
Side effect
Next: SourceA1
Next: SourceB1
Completed
Completed
```
`connect` is found in the following packages:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.all.binding.js`
`connect` requires one of the following packages:
* `rx.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
reactivex Skip Skip
====
> suppress the first *n* items emitted by an Observable
[Open interactive diagram on rxmarbles.com](https://rxmarbles.com/#skip) You can ignore the first *n* items emitted by an Observable and attend only to those items that come after, by modifying the Observable with the Skip operator.
#### See Also
* [Last](last)
* [SkipLast](skiplast)
* [SkipUntil](skipuntil)
* [SkipWhile](skipwhile)
* [Take](take)
* [TakeLast](takelast)
* [TakeUntil](takeuntil)
* [TakeWhile](takewhile)
* [Introduction to Rx: Skip and Take](http://www.introtorx.com/Content/v1.0.10621.0/05_Filtering.html#SkipAndTake)
* [RxMarbles: `skip`](http://rxmarbles.com/#skip)
Language-Specific Information
-----------------------------
### RxGroovy `skip`
 In RxGroovy, this operator is implemented as `skip`.
#### Sample Code
```
numbers = Observable.from([1, 2, 3, 4, 5, 6, 7, 8]);
numbers.skip(3).subscribe(
{ println(it); }, // onNext
{ println("Error: " + it.getMessage()); }, // onError
{ println("Sequence complete"); } // onCompleted
);
```
```
4
5
6
7
8
Sequence complete
```
This variant of `skip` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`skip(int)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#skip(int))
 There is also a variant of `skip` that takes a temporal duration rather than a quantity of items. It drops those items that are emitted during that initial duration of the source Observable’s lifespan. You set this duration by passing in a length of time and the time units this length is denominated in as parameters to `skip`.
This variant of `skip` by default operates on the `computation` [Scheduler](../scheduler), but you may also pass in a Scheduler of your choosing as an optional third parameter.
* Javadoc: [`skip(long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#skip(long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`skip(long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#skip(long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
### RxJava 1․x `skip`
 In RxJava, this operator is implemented as `skip`.
This variant of `skip` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`skip(int)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#skip(int))
 There is also a variant of `skip` that takes a temporal duration rather than a quantity of items. It drops those items that are emitted during that initial duration of the source Observable’s lifespan. You set this duration by passing in a length of time and the time units this length is denominated in as parameters to `skip`.
This variant of `skip` by default operates on the `computation` [Scheduler](../scheduler), but you may also pass in a Scheduler of your choosing as an optional third parameter.
* Javadoc: [`skip(long,TimeUnit)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#skip(long,%20java.util.concurrent.TimeUnit))
* Javadoc: [`skip(long,TimeUnit,Scheduler)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#skip(long,%20java.util.concurrent.TimeUnit,%20rx.Scheduler))
### RxJS `skip skipUntilWithTime`
 RxJS implements the `skip` operator.
#### Sample Code
```
var source = Rx.Observable.range(0, 5)
.skip(3);
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 3
Next: 4
Completed
```
`skip` is found in each of the following distributions:
* `rx.js`
* `rx.all.js`
* `rx.all.compat.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
 RxJS also implements a `skipUntilWithTime` operator that does not skip a particular quantity of items from the source Observable, but skips items based on chronology. You set this skip period by passing in a parameter to `skipUntilWithTime`, in either of these formats:
a number skips items from the source Observable until this many milliseconds have passed since the Observable was subscribed to a `Date`
skips items from the source Observable until this absolute time You may also, optionally, pass in a [Scheduler](../scheduler) as a second parameter, and the timer will operate on that Scheduler (`skipUntilWithTime` uses the `timeout` Scheduler by default).
#### Sample Code
```
var source = Rx.Observable.timer(0, 1000)
.skipUntilWithTime(5000);
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 6
Next: 7
Next: 8
Completed
```
`skipUntilWithTime` is found in each of the following distributions:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.time.js` (requires `rx.js` or `rx.compat.js`)
* `rx.lite.js`
* `rx.lite.compat.js`
### RxPHP `skip`
RxPHP implements this operator as `skip`.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/skip/skip.php
use Rx\Observable\ArrayObservable;
$observable = Rx\Observable::fromArray([1, 1, 2, 3, 5, 8, 13]);
$observable
->skip(3)
->subscribe($stdoutObserver);
```
```
Next value: 3
Next value: 5
Next value: 8
Next value: 13
Complete!
```
reactivex Switch Switch
======
> convert an Observable that emits Observables into a single Observable that emits the items emitted by the most-recently-emitted of those Observables
 Switch subscribes to an Observable that emits Observables. Each time it observes one of these emitted Observables, the Observable returned by Switch unsubscribes from the previously-emitted Observable begins emitting items from the latest Observable. Note that it will unsubscribe from the previously-emitted Observable when a new Observable is emitted from the source Observable, not when the new Observable emits an item. This means that items emitted by the previous Observable between the time the subsequent Observable is emitted and the time that subsequent Observable itself begins emitting items will be dropped (as with the yellow circle in the diagram above).
#### See Also
* [Amb](amb)
* [Concat](concat)
* [FlatMap](flatmap)
* [Introduction to Rx: Switch](http://www.introtorx.com/Content/v1.0.10621.0/12_CombiningSequences.html#Switch)
Language-Specific Information
-----------------------------
### RxGroovy `switchOnNext`
 RxGroovy implements this operator as `switchOnNext`. It does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`switchOnNext(Observable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#switchOnNext(rx.Observable))
### RxJava 1․x `switchOnNext`
 RxJava implements this operator as `switchOnNext`. It does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`switchOnNext(Observable)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#switchOnNext(rx.Observable))
### RxJS `switch`
 RxJS implements this operator as `switch`
#### Sample Code
```
var source = Rx.Observable.range(0, 3)
.select(function (x) { return Rx.Observable.range(x, 3); })
.switch();
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 0
Next: 1
Next: 2
Next: 3
Next: 4
Completed
```
`switch` is found in each of the following distributions:
* `rx.js`
* `rx.all.js`
* `rx.all.compat.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
### RxPHP `switch switchFirst`
RxPHP implements this operator as `switch`.
Transforms an observable sequence of observable sequences into an observable sequence producing values only from the most recent observable sequence.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/switch/switch.php
$source = Rx\Observable::range(0, 3)
->map(function ($x) {
return \Rx\Observable::range($x, 3);
})
->switch();
$subscription = $source->subscribe($stdoutObserver);
```
```
Next value: 0
Next value: 1
Next value: 2
Next value: 3
Next value: 4
Complete!
```
RxPHP also has an operator `switchFirst`.
Receives an Observable of Observables and propagates the first Observable exclusively until it completes before it begins subscribes to the next Observable. Observables that come before the current Observable completes will be dropped and will not propagate. This operator is similar to concatAll() except that it will not hold onto Observables that come in before the current one is finished completed.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/switch/switchFirst.php
$source = Rx\Observable::fromArray([
\Rx\Observable::interval(100)->mapTo('a'),
\Rx\Observable::interval(200)->mapTo('b'),
\Rx\Observable::interval(300)->mapTo('c'),
])
->switchFirst()
->take(3);
$subscription = $source->subscribe($stdoutObserver);
```
```
Next value: a
Next value: a
Next value: a
Complete!
```
reactivex Filter Filter
======
> emit only those items from an Observable that pass a predicate test
[Open interactive diagram on rxmarbles.com](https://rxmarbles.com/#filter) The Filter operator filters an Observable by only allowing items through that pass a test that you specify in the form of a predicate function.
#### See Also
* [Introduction to Rx: Where](http://www.introtorx.com/Content/v1.0.10621.0/05_Filtering.html#Where)
* [Introduction to Rx: Cast and OfType](http://www.introtorx.com/Content/v1.0.10621.0/08_Transformation.html#CastAndOfType)
* [RxMarbles: `filter`](http://rxmarbles.com/#filter)
Language-Specific Information
-----------------------------
### RxGroovy `filter ofType`
 RxGroovy implements this operator as `filter`. You can filter an Observable, discarding any items that do not meet some test, by passing a filtering function into the `filter` operator. For example, the following code filters a list of integers, emitting only those that are even (that is, where the remainder from dividing the number by two is zero):
#### Sample Code
```
numbers = Observable.from([1, 2, 3, 4, 5, 6, 7, 8, 9]);
numbers.filter({ 0 == (it % 2) }).subscribe(
{ println(it); }, // onNext
{ println("Error: " + it.getMessage()); }, // onError
{ println("Sequence complete"); } // onCompleted
);
```
```
2
4
6
8
Sequence complete
```
`filter` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`filter(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#filter(rx.functions.Func1))
 There is also a specialized form of the Filter operator in RxGroovy that filters an Observable so that it only emits items of a particular class.
`ofType` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`ofType(Class)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#ofType(java.lang.Class))
### RxJava 1․x `filter ofType`
 RxJava implements this operator as `filter`.
#### Sample Code
```
Observable.just(1, 2, 3, 4, 5)
.filter(new Func1<Integer, Boolean>() {
@Override
public Boolean call(Integer item) {
return( item < 4 );
}
}).subscribe(new Subscriber<Integer>() {
@Override
public void onNext(Integer item) {
System.out.println("Next: " + item);
}
@Override
public void onError(Throwable error) {
System.err.println("Error: " + error.getMessage());
}
@Override
public void onCompleted() {
System.out.println("Sequence complete.");
}
});
```
```
Next: 1
Next: 2
Next: 3
Sequence complete.
```
`filter` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`filter(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#filter(rx.functions.Func1))
 There is also a specialized form of the Filter operator in RxJava that filters an Observable so that it only emits items of a particular class.
`ofType` does not by default operate on any particular [Scheduler](../scheduler).
* Javadoc: [`ofType(Class)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#ofType(java.lang.Class))
### RxJS `filter where`
 RxJS implements this operator under two names, but with identical behavior: `filter` and `where`. This operator takes two parameters: the predicate function, and an optional object that will represent that function’s “`this`” context when it executes.
The predicate function itself takes three arguments:
1. the item from the source Observable to be, or not be, filtered
2. the zero-based index of this item in the source Observable’s sequence
3. the source Observable object
Write the predicate function so that it returns `true` for those items you want to pass through the filter to the next observer, and `false` for those items you want the filter to block and suppress.
#### Sample Code
```
var source = Rx.Observable.range(0, 5)
.filter(function (x, idx, obs) {
return x % 2 === 0;
});
var subscription = source.subscribe(
function (x) { console.log('Next: %s', x); },
function (err) { console.log('Error: %s', err); },
function () { console.log('Completed'); });
```
```
Next: 0
Next: 2
Next: 4
Completed
```
`filter` and `where` are found in each of the following distributions:
* `rx.js`
* `rx.all.js`
* `rx.all.compat.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
### RxPHP `filter where`
RxPHP implements this operator as `filter`.
Emit only those items from an Observable that pass a predicate test.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/filter/filter.php
$observable = Rx\Observable::fromArray([21, 42, 84]);
$observable
->filter(function ($elem) {
return $elem >= 42;
})
->subscribe($stdoutObserver);
```
```
Next value: 42
Next value: 84
Complete!
```
RxPHP also has an operator `where`.
Alias for filter
| programming_docs |
reactivex First First
=====
> emit only the first item (or the first item that meets some condition) emitted by an Observable
[Open interactive diagram on rxmarbles.com](https://rxmarbles.com/#first) If you are only interested in the first item emitted by an Observable, or the first item that meets some criteria, you can filter the Observable with the First operator.
In some implementations, `First` is not implemented as a filtering operator that returns an Observable, but as a blocking function that returns a particular item at such time as the source Observable emits that item. In those implementations, if you instead want a filtering operator, you may have better luck with [`Take(1)`](take) or [`ElementAt(0)`](elementat).
In some implementations there is also a Single operator. It behaves similarly to First except that it waits until the source Observable terminates in order to guarantee that it only emits a single item (otherwise, rather than emitting that item, it terminates with an error). You can use this to not only take the first item from the source Observable but to also guarantee that there was only one item.
#### See Also
* [ElementAt](elementat)
* [Last](last)
* [Take](take)
* [Introduction to Rx: First](http://www.introtorx.com/Content/v1.0.10621.0/07_Aggregation.html#First)
* [Introduction to Rx: Single](http://www.introtorx.com/Content/v1.0.10621.0/07_Aggregation.html#Single)
* [Loading data from multiple sources with RxJava](http://blog.danlew.net/2015/06/22/loading-data-from-multiple-sources-with-rxjava/) by Dan Lew (example using Concat and First)
* [RxMarbles: `find`](http://rxmarbles.com/#find)
* [RxMarbles: `findIndex`](http://rxmarbles.com/#findIndex)
* [RxMarbles: `first`](http://rxmarbles.com/#first)
Language-Specific Information
-----------------------------
### RxGroovy `first firstOrDefault latest mostRecent next single singleOrDefault takeFirst`
In RxGroovy, this filtering operator is implemented as `first`, `firstOrDefault`, and `takeFirst`.
Somewhat confusingly, there are also `BlockingObservable` operators called `first` and `firstOrDefault` that block and then return items, rather than immediately returning Observables.
There are also several other operators that perform similar functions.
### The Filtering Operators
 To filter an Observable so that only its first emission is emitted, use the `first` operator with no parameters.
* Javadoc: [`first()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#first())
 You can also pass a predicate function to `first`, in which case it will produce an Observable that emits only the first item from the source Observable that the predicate evaluates as `true`.
* Javadoc: [`first(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#first(rx.functions.Func1))
 The `firstOrDefault` operator is similar to `first`, but you pass it a default item that it can emit if the source Observable fails to emit any items
* Javadoc: [`firstOrDefault(T)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#firstOrDefault(T))
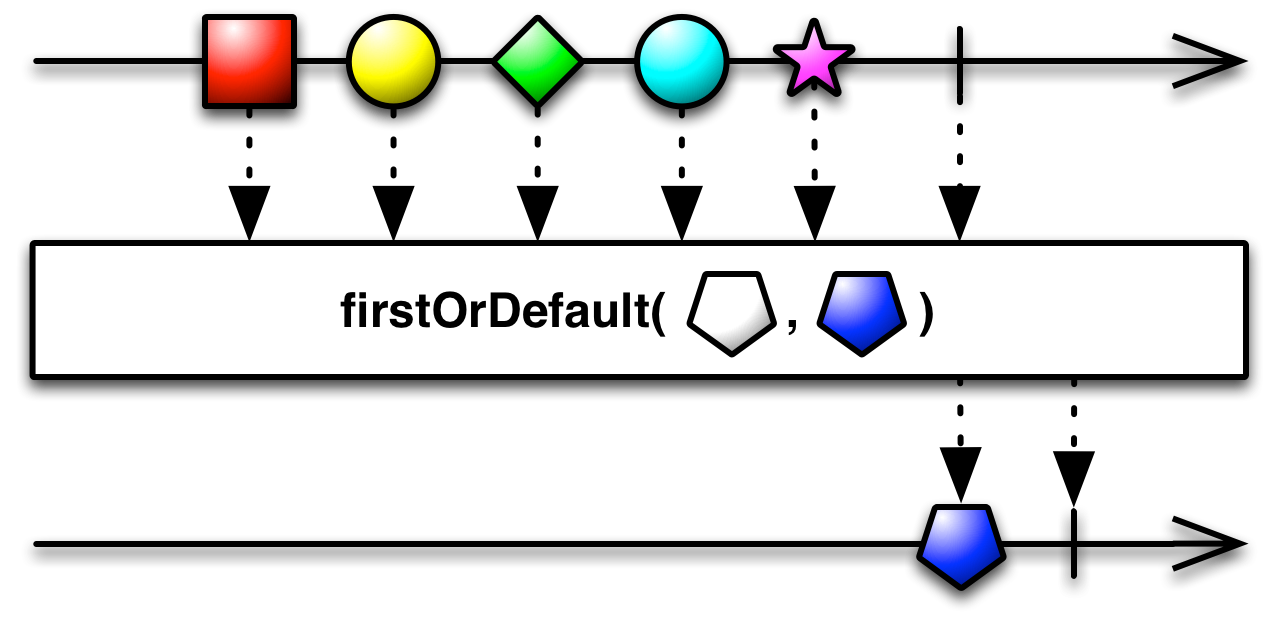 `firstOrDefault` also has a variant to which you can pass a predicate function, so that its Observable will emit the first item from the source Observable that the predicate evaluates as `true`, or the default item if no items emitted by the source Observable pass the predicate.
* Javadoc: [`firstOrDefault(T)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#firstOrDefault(T))
 The `takeFirst` operator behaves similarly to `first`, with the exception of how these operators behave wihen the source Observable emits no items that satisfy the predicate. In such a case, `first` will throw a `NoSuchElementException` while `takeFirst` will return an empty Observable (one that calls `onCompleted` but never calls `onNext`).
* Javadoc: [`takeFirst(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#takeFirst(rx.functions.Func1))
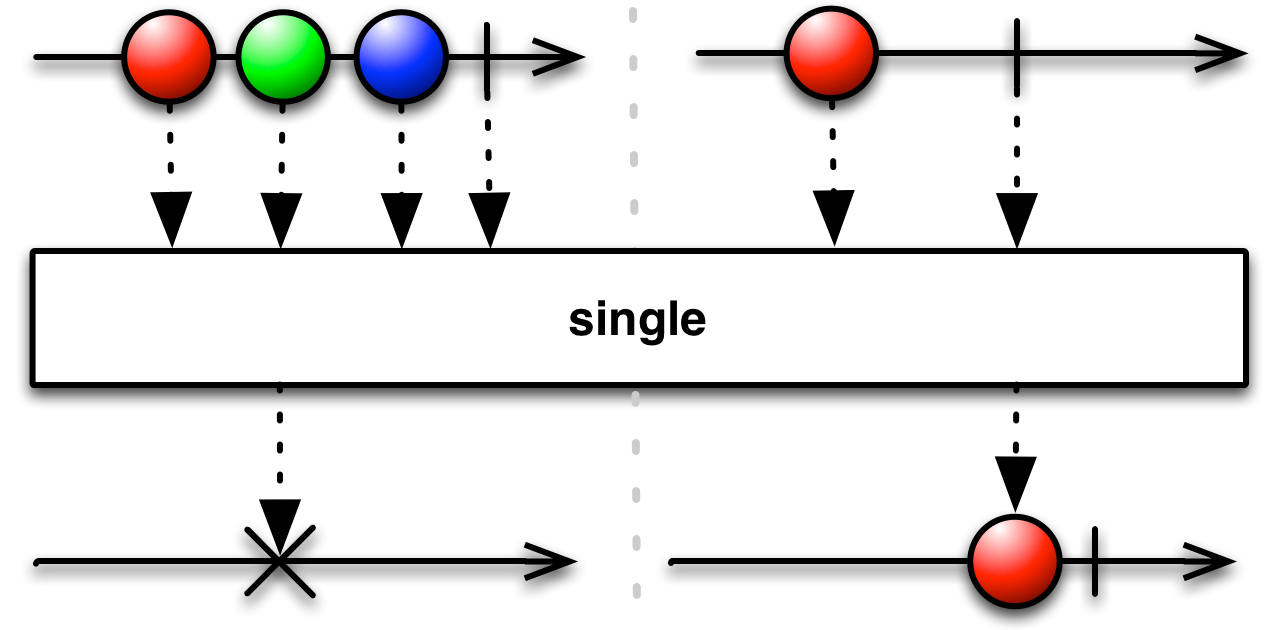 The `single` operator is similar to `first`, but throws a `NoSuchElementException` if the source Observable does not emit exactly one item before successfully completing.
* Javadoc: [`single()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#single())
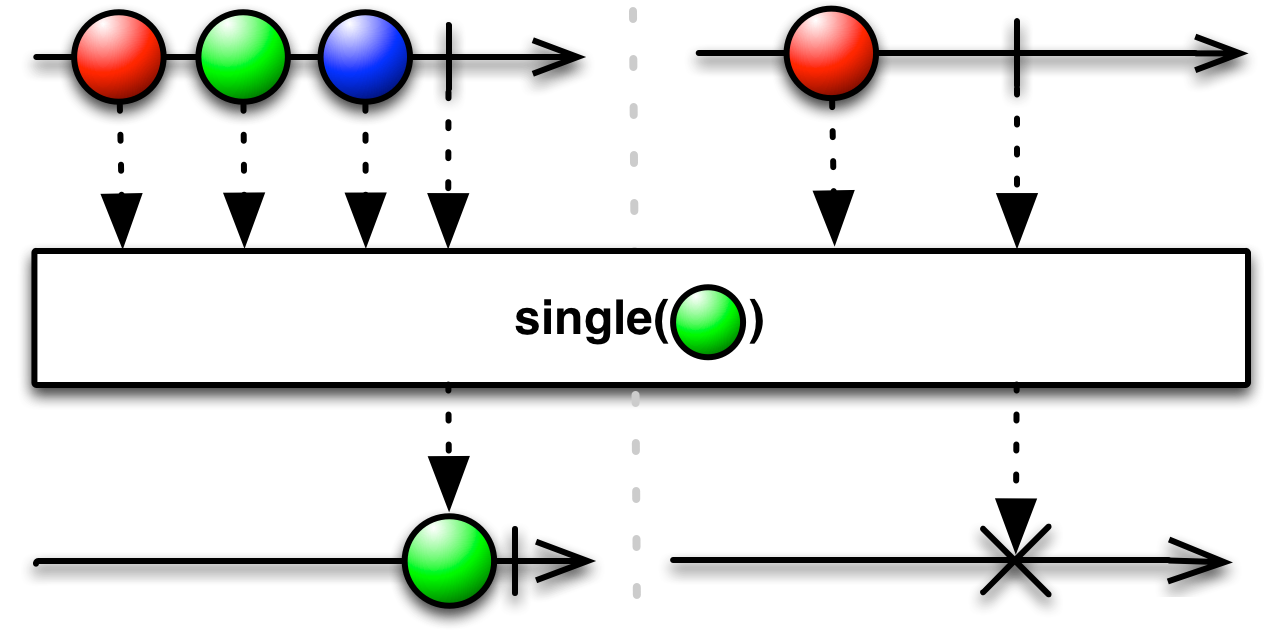 `single` also has a version that accepts a predicate, and emits the sole item emitted by the source Observable that matches that predicate, or notifies of an exception if exactly one such item does not match.
* Javadoc: [`single(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#single(rx.functions.Func1))
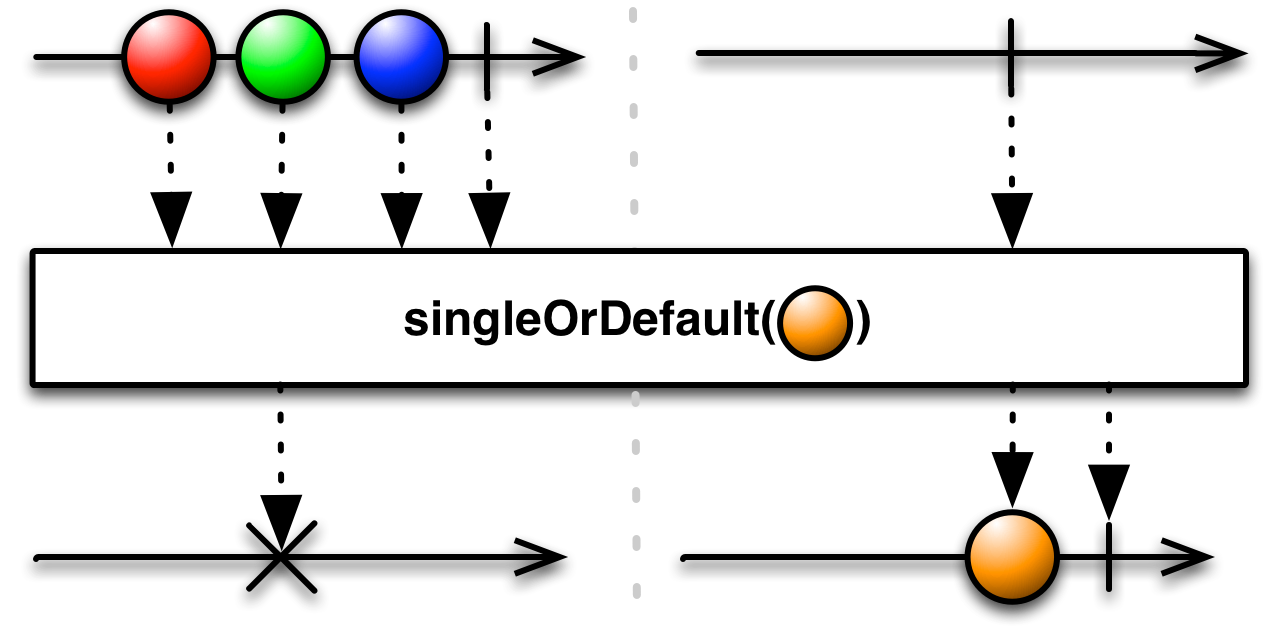 As with `firstOrDefault` there is also a `singleOrDefault` that emits a default item if the source Observable is empty, although it will still notify of an error if the source Observable emits more than one item.
* Javadoc: [`singleOrDefault(T)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#singleOrDefault(T))
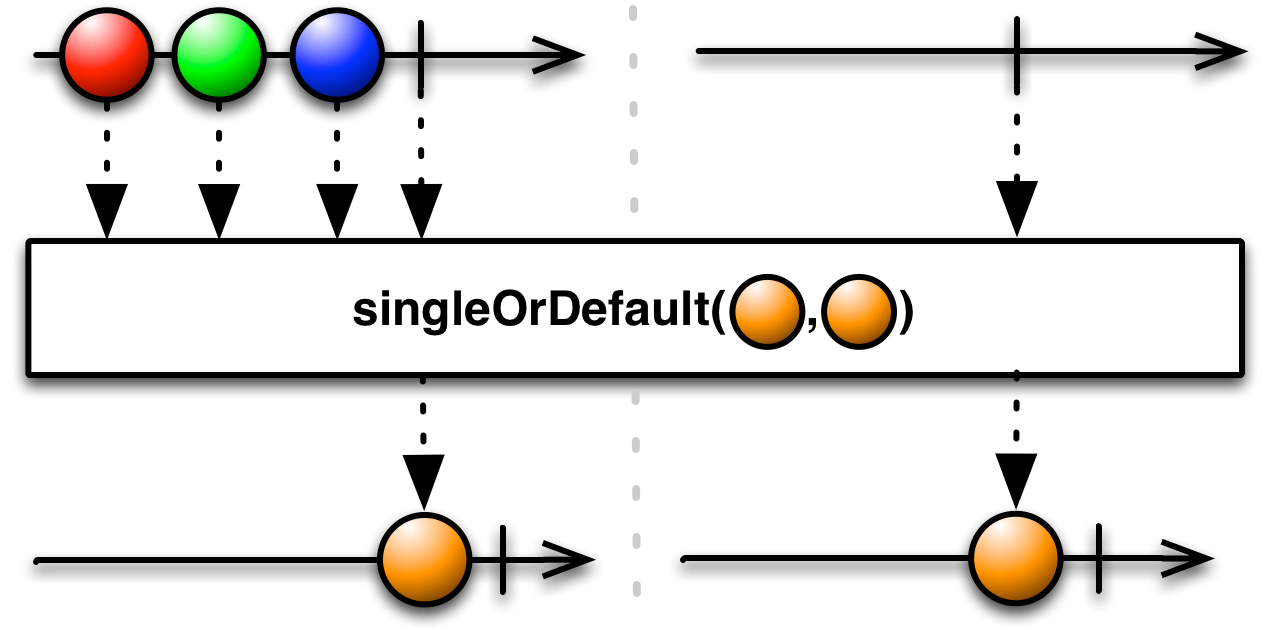 And there is also a verion of `singleOrDefault` that takes a predicate function and emits the sole item from the source Observable that matches that predicate, if any; the default item if no such items match; and makes an error notification if multiple items match.
* Javadoc: [`singleOrDefault(Func1,T)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#singleOrDefault(rx.functions.Func1,%20T))
`first`, `firstOrDefault`, `single`, `singleOrDefault`, and `takeFirst` do not by default operate on any particular [Scheduler](../scheduler).
### The `BlockingObservable` Methods
The `BlockingObservable` methods do not transform an Observable into another, filtered Observable, but rather they break out of the Observable cascade, blocking until the Observable emits the desired item, and then return that item itself.
To turn an Observable into a `BlockingObservable` so that you can use these methods, you can use either the `Observable.toBlocking` or `BlockingObservable.from` methods.
* Javadoc: [`Observable.toBlocking()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#toBlocking())
* Javadoc: [`BlockingObservable.from(Observable)`](http://reactivex.io/RxJava/javadoc/rx/observables/BlockingObservable.html#from(rx.Observable))
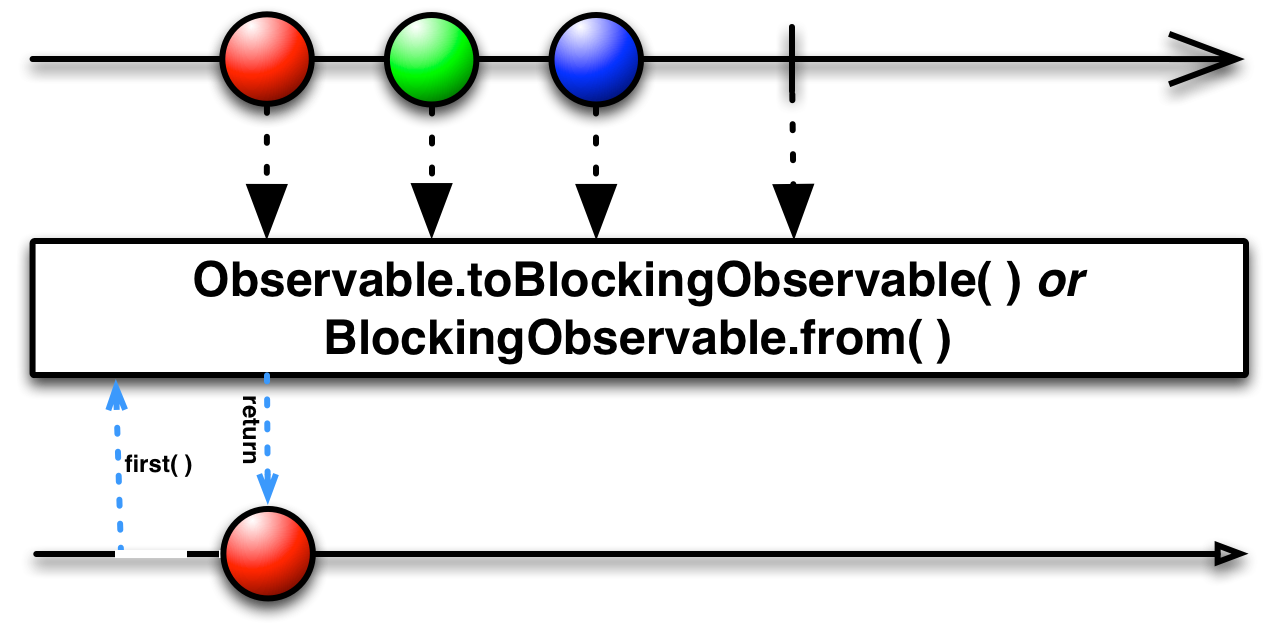 To retrieve the first emission from a `BlockingObservable`, use the `first` method with no parameters.
* Javadoc: [`BlockingObservable.first()`](http://reactivex.io/RxJava/javadoc/rx/observables/BlockingObservable.html#first())
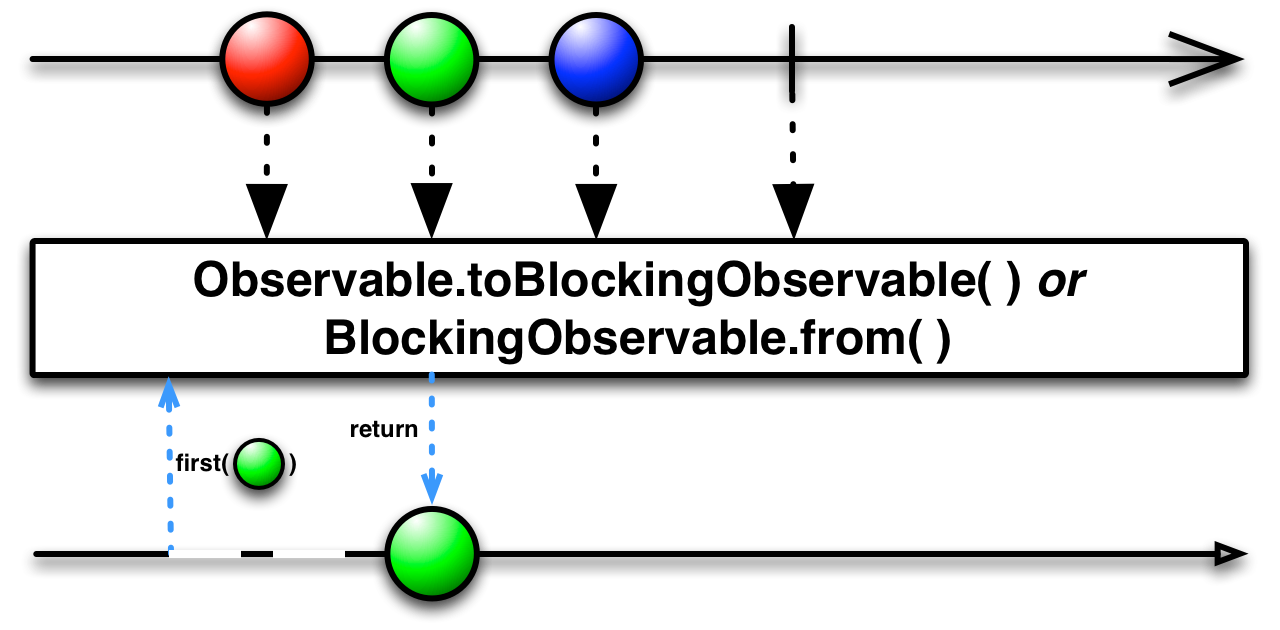 You can also pass a predicate function to the `first` method to retrieve the first emission from a `BlockingObservable` that satisfies the predicate.
* Javadoc: [`BlockingObservable.first(Func1)`](http://reactivex.io/RxJava/javadoc/rx/observables/BlockingObservable.html#first(rx.functions.Func1))
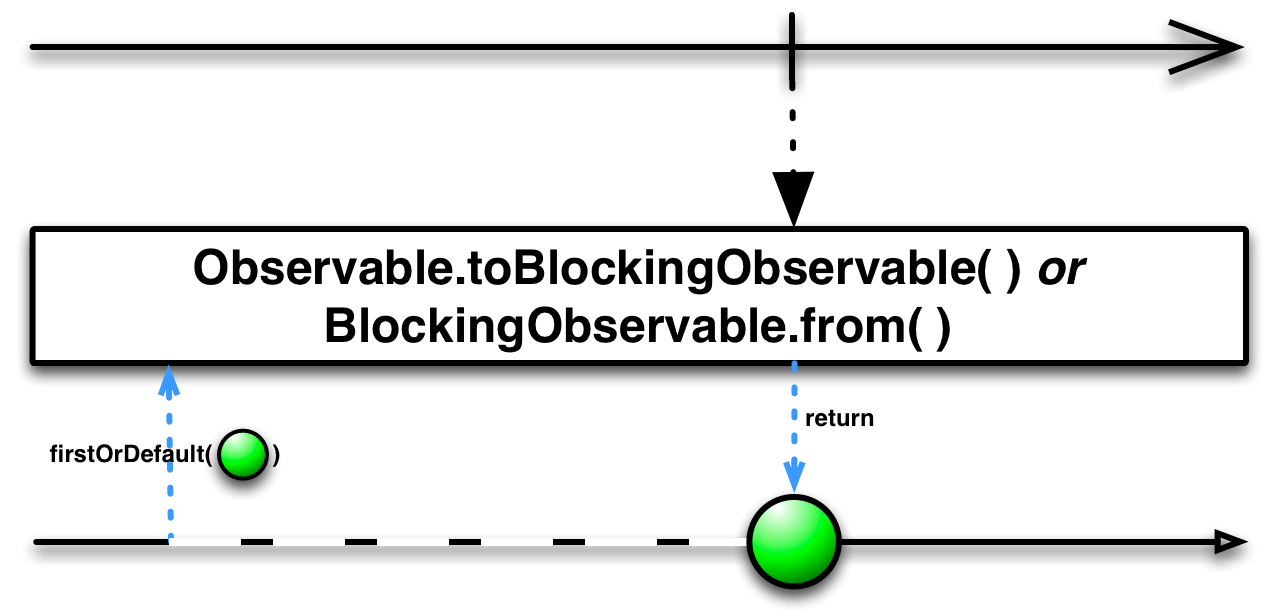 As with the filtering operators, the `first` method of `BlockingObservable` will throw a `NoSuchElementException` if there is no first element in the source `BlockingObservable`. To return a default item instead in such cases, use the `firstOrDefault` method.
* Javadoc: [`BlockingObservable.firstOrDefault()`](http://reactivex.io/RxJava/javadoc/rx/observables/BlockingObservable.html#firstOrDefault(T))
 And, as with `first`, there is a `firstOrDefault` variant that takes a predicate function as an argument and returns the first item from the source `BlockingObservable` that satisfies that predicate, or a default item instead if no satisfying item was emitted.
* Javadoc: [`BlockingObservable.firstOrDefault(Func1)`](http://reactivex.io/RxJava/javadoc/rx/observables/BlockingObservable.html#firstOrDefault(T,%20rx.functions.Func1))
 The `single` operator is similar to `first`, but throws a `NoSuchElementException` if the source Observable does not emit exactly one item before successfully completing.
* Javadoc: [`single()`](http://reactivex.io/RxJava/javadoc/rx/observables/BlockingObservable.html#single())
 `single` also has a version that accepts a predicate, and returns the sole item emitted by the source Observable that matches that predicate, or throws an exception if exactly one such item does not match.
* Javadoc: [`single(Func1)`](http://reactivex.io/RxJava/javadoc/rx/observables/BlockingObservable.html#single(rx.functions.Func1))
 As with `firstOrDefault` there is also a `singleOrDefault` that returns a default item if the source Observable is empty, although it will still throw an error if the source Observable emits more than one item.
* Javadoc: [`singleOrDefault(T)`](http://reactivex.io/RxJava/javadoc/rx/observables/BlockingObservable.html#singleOrDefault(T))
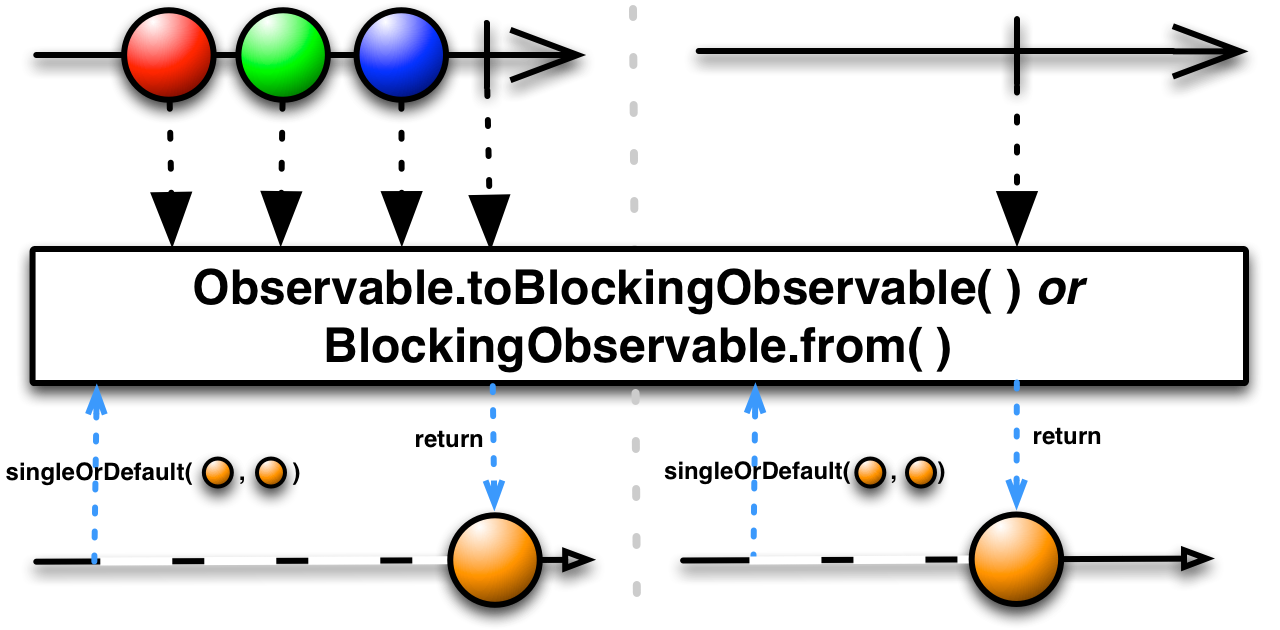 And there is also a verion of `singleOrDefault` that takes a predicate function and returns the sole item from the source Observable that matches that predicate, if any; the default item if no such items match; and throws an error if multiple items match.
* Javadoc: [`singleOrDefault(Func1,T)`](http://reactivex.io/RxJava/javadoc/rx/observables/BlockingObservable.html#singleOrDefault(rx.functions.Func1,%20T))
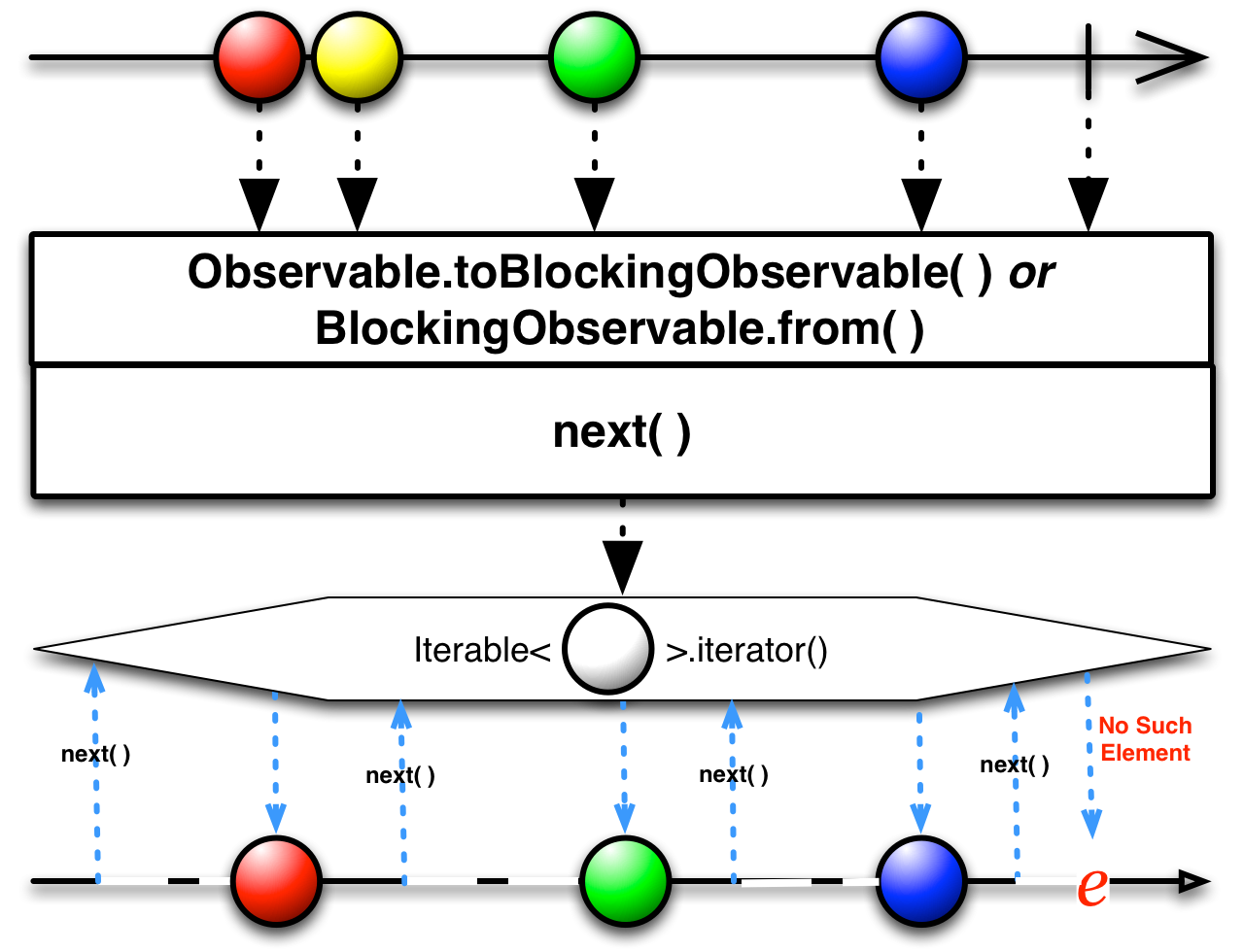 The `next` operator blocks until the `BlockingObservable` emits another item, and then returns that item. You can call this function repeatedly to get successive items from the `BlockingObservable`, effectively iterating over its emissions in a blocking fashion.
The `latest` operator is similar, but rather than blocking to wait for the next emitted item, it immediately returns the most-recently-emitted item, and only blocks if the Observable has not yet emitted anything.
* Javadoc: [`next()`](http://reactivex.io/RxJava/javadoc/rx/observables/BlockingObservable.html#next())
* Javadoc: [`latest()`](http://reactivex.io/RxJava/javadoc/rx/observables/BlockingObservable.html#latest())
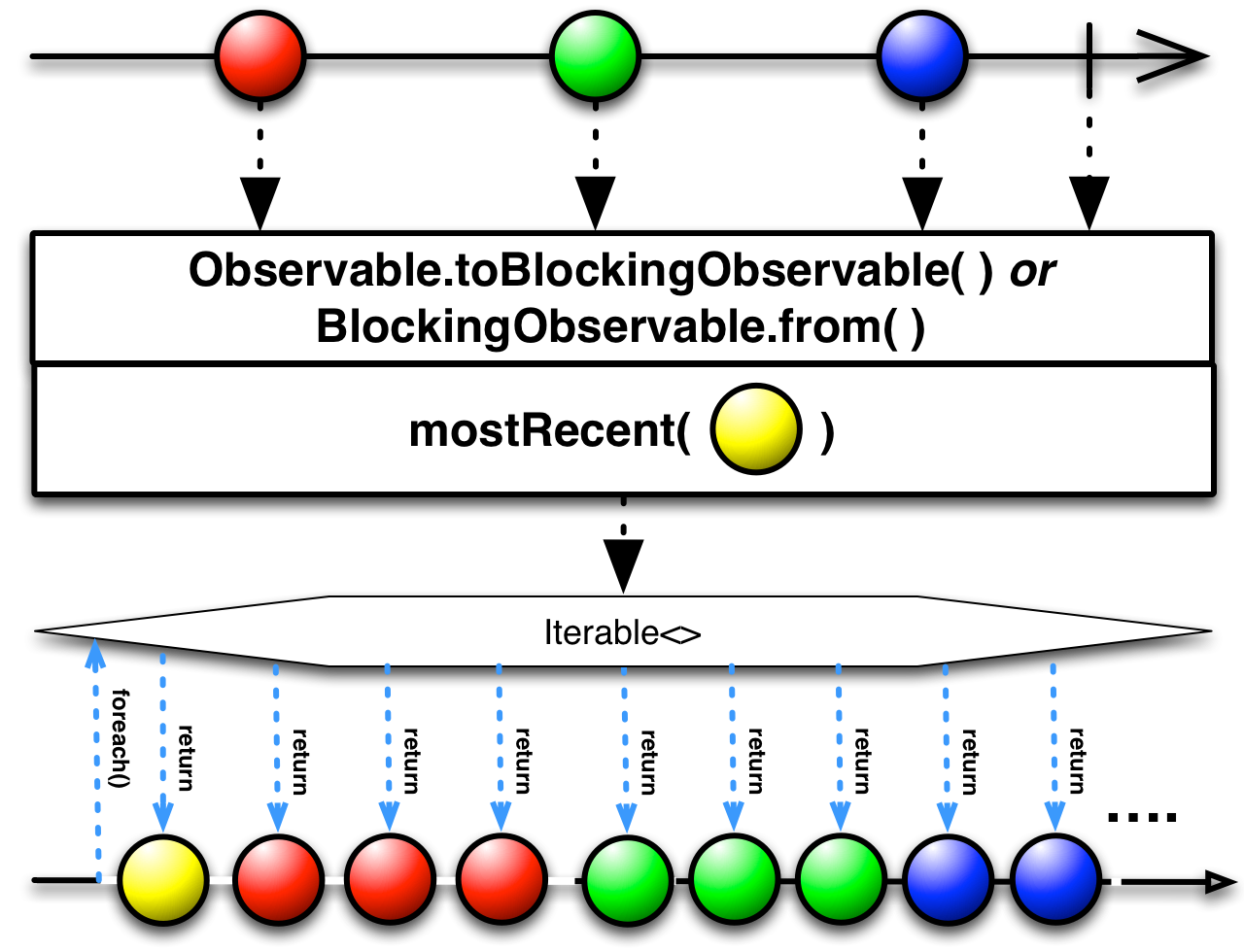 The `mostRecent` operator similarly allows you to iterate over the emissions of a `BlockingObservable`, but its Iterable always immediately returns a value: either a default item you provide (if the `BlockingObservable` has not yet emitted an item), or the latest item the `BlockingObservable` has emitted.
* Javadoc: [`mostRecent(T)`](http://reactivex.io/RxJava/javadoc/rx/observables/BlockingObservable.html#mostRecent(T))
### RxJava 1․x `first firstOrDefault latest mostRecent next single singleOrDefault takeFirst`
In RxJava, this filtering operator is implemented as `first`, `firstOrDefault`, and `takeFirst`.
Somewhat confusingly, there are also `BlockingObservable` operators called `first` and `firstOrDefault` that block and then return items, rather than immediately returning Observables.
There are also several other operators that perform similar functions.
### The Filtering Operators
 To filter an Observable so that only its first emission is emitted, use the `first` operator with no parameters.
#### Sample Code
```
Observable.just(1, 2, 3)
.first()
.subscribe(new Subscriber<Integer>() {
@Override
public void onNext(Integer item) {
System.out.println("Next: " + item);
}
@Override
public void onError(Throwable error) {
System.err.println("Error: " + error.getMessage());
}
@Override
public void onCompleted() {
System.out.println("Sequence complete.");
}
});
```
```
Next: 1
Sequence complete.
```
* Javadoc: [`first()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#first())
 You can also pass a predicate function to `first`, in which case it will produce an Observable that emits only the first item from the source Observable that the predicate evaluates as `true`.
* Javadoc: [`first(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#first(rx.functions.Func1))
 The `firstOrDefault` operator is similar to `first`, but you pass it a default item that it can emit if the source Observable fails to emit any items
* Javadoc: [`firstOrDefault(T)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#firstOrDefault(T))
 `firstOrDefault` also has a variant to which you can pass a predicate function, so that its Observable will emit the first item from the source Observable that the predicate evaluates as `true`, or the default item if no items emitted by the source Observable pass the predicate.
* Javadoc: [`firstOrDefault(T)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#firstOrDefault(T))
 The `takeFirst` operator behaves similarly to `first`, with the exception of how these operators behave wihen the source Observable emits no items that satisfy the predicate. In such a case, `first` will throw a `NoSuchElementException` while `takeFirst` will return an empty Observable (one that calls `onCompleted` but never calls `onNext`).
* Javadoc: [`takeFirst(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#takeFirst(rx.functions.Func1))
 The `single` operator is similar to `first`, but throws a `NoSuchElementException` if the source Observable does not emit exactly one item before successfully completing.
* Javadoc: [`single()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#single())
 `single` also has a version that accepts a predicate, and emits the sole item emitted by the source Observable that matches that predicate, or notifies of an exception if exactly one such item does not match.
* Javadoc: [`single(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#single(rx.functions.Func1))
 As with `firstOrDefault` there is also a `singleOrDefault` that emits a default item if the source Observable is empty, although it will still notify of an error if the source Observable emits more than one item.
* Javadoc: [`singleOrDefault(T)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#singleOrDefault(T))
 And there is also a verion of `singleOrDefault` that takes a predicate function and emits the sole item from the source Observable that matches that predicate, if any; the default item if no such items match; and makes an error notification if multiple items match.
* Javadoc: [`singleOrDefault(Func1,T)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#singleOrDefault(rx.functions.Func1,%20T))
`first`, `firstOrDefault`, `single`, `singleOrDefault`, and `takeFirst` do not by default operate on any particular [Scheduler](../scheduler).
### The `BlockingObservable` Methods
The `BlockingObservable` methods do not transform an Observable into another, filtered Observable, but rather they break out of the Observable cascade, blocking until the Observable emits the desired item, and then return that item itself.
To turn an Observable into a `BlockingObservable` so that you can use these methods, you can use either the `Observable.toBlocking` or `BlockingObservable.from` methods.
* Javadoc: [`Observable.toBlocking()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#toBlocking())
* Javadoc: [`BlockingObservable.from(Observable)`](http://reactivex.io/RxJava/javadoc/rx/observables/BlockingObservable.html#from(rx.Observable))
 To retrieve the first emission from a `BlockingObservable`, use the `first` method with no parameters.
* Javadoc: [`BlockingObservable.first()`](http://reactivex.io/RxJava/javadoc/rx/observables/BlockingObservable.html#first())
 You can also pass a predicate function to the `first` method to retrieve the first emission from a `BlockingObservable` that satisfies the predicate.
* Javadoc: [`BlockingObservable.first(Func1)`](http://reactivex.io/RxJava/javadoc/rx/observables/BlockingObservable.html#first(rx.functions.Func1))
 As with the filtering operators, the `first` method of `BlockingObservable` will throw a `NoSuchElementException` if there is no first element in the source `BlockingObservable`. To return a default item instead in such cases, use the `firstOrDefault` method.
* Javadoc: [`BlockingObservable.firstOrDefault()`](http://reactivex.io/RxJava/javadoc/rx/observables/BlockingObservable.html#firstOrDefault(T))
 And, as with `first`, there is a `firstOrDefault` variant that takes a predicate function as an argument and retrieves the first item from the source `BlockingObservable` that satisfies that predicate, or a default item instead if no satisfying item was emitted.
* Javadoc: [`BlockingObservable.firstOrDefault(Func1)`](http://reactivex.io/RxJava/javadoc/rx/observables/BlockingObservable.html#firstOrDefault(T,%20rx.functions.Func1))
 The `single` operator is similar to `first`, but throws a `NoSuchElementException` if the source Observable does not emit exactly one item before successfully completing.
* Javadoc: [`single()`](http://reactivex.io/RxJava/javadoc/rx/observables/BlockingObservable.html#single())
 `single` also has a version that accepts a predicate, and returns the sole item emitted by the source Observable that matches that predicate, or throws an exception if exactly one such item does not match.
* Javadoc: [`single(Func1)`](http://reactivex.io/RxJava/javadoc/rx/observables/BlockingObservable.html#single(rx.functions.Func1))
 As with `firstOrDefault` there is also a `singleOrDefault` that returns a default item if the source Observable is empty, although it will still throw an error if the source Observable emits more than one item.
* Javadoc: [`singleOrDefault(T)`](http://reactivex.io/RxJava/javadoc/rx/observables/BlockingObservable.html#singleOrDefault(T))
 And there is also a verion of `singleOrDefault` that takes a predicate function and returns the sole item from the source Observable that matches that predicate, if any; the default item if no such items match; and throws an error if multiple items match.
* Javadoc: [`singleOrDefault(Func1,T)`](http://reactivex.io/RxJava/javadoc/rx/observables/BlockingObservable.html#singleOrDefault(rx.functions.Func1,%20T))
 The `next` operator blocks until the `BlockingObservable` emits another item, and then returns that item. You can call this function repeatedly to get successive items from the `BlockingObservable`, effectively iterating over its emissions in a blocking fashion.
The `latest` operator is similar, but rather than blocking to wait for the next emitted item, it immediately returns the most-recently-emitted item, and only blocks if the Observable has not yet emitted anything.
* Javadoc: [`next()`](http://reactivex.io/RxJava/javadoc/rx/observables/BlockingObservable.html#next())
* Javadoc: [`latest()`](http://reactivex.io/RxJava/javadoc/rx/observables/BlockingObservable.html#latest())
 The `mostRecent` operator similarly allows you to iterate over the emissions of a `BlockingObservable`, but its Iterable always immediately returns a value: either a default item you provide (if the `BlockingObservable` has not yet emitted an item), or the latest item the `BlockingObservable` has emitted.
* Javadoc: [`mostRecent(T)`](http://reactivex.io/RxJava/javadoc/rx/observables/BlockingObservable.html#mostRecent(T))
### RxJS `find findIndex first single`
 RxJS implements the `first` operator. It optionally takes a predicate function as a parameter, in which case, rather than emitting the first item from the source Observable, the resulting Observable will emit the first item from the source Observable that satisfies the predicate.
The predicate function itself takes three arguments:
1. the item from the source Observable to be, or not be, filtered
2. the zero-based index of this item in the source Observable’s sequence
3. the source Observable object
An optional third parameter (named `defaultValue`) allows you to choose an item that `first` will emit if the source Observable does not emit any items (or if it does not emit the *n*th item that it expected.
#### Sample Code
```
var source = Rx.Observable.range(0, 10)
.first(function (x, idx, obs) { return x % 2 === 1; });
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 1
Completed
```
If the source Observable emits no items (or no items that match the predicate), `first` will terminate with a “`Sequence contains no elements.`” `onError` notification.
 The `single` operator is similar, except that it only emits its item once the source Observable successfully completes after emitting one item (or one item that matches the predicate). If it emits either no such items or more than one such item, `single` will terminate with an `onError` notitifcation (“`Sequence contains no elements.`”).
 The `find` operator is much like `first` except that the predicate argument is mandatory, and it behaves differently if no item from the source Observable matches the predicate. While `first` will send an `onError` notification in such a case, `find` will instead emit an `undefined` item.
#### Sample Code
```
var array = [1,2,3,4];
var source = Rx.Observable.fromArray(array)
.find(function (x, i, obs) {
return x === 5;
});
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: undefined
Completed
```

The `findIndex` operator is similar to `find`, except that instead of emitting the item that matches the predicate (or `undefined`), it emits the zero-based index of that item in the source Observable’s sequence (or `-1`).
#### Sample Code
```
var array = [1,2,3,4];
var source = Rx.Observable.fromArray(array)
.findIndex(function (x, i, obs) {
return x === 5;
});
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: -1
Completed
```
`find`, `findIndex`, and `first` are found in each of the following distributions:
* `rx.all.js`
* `rx.all.compat.js`
* `rx.aggregates.js`
They each require one of the following distributions:
* `rx.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
| programming_docs |
reactivex Do Do
==
> register an action to take upon a variety of Observable lifecycle events
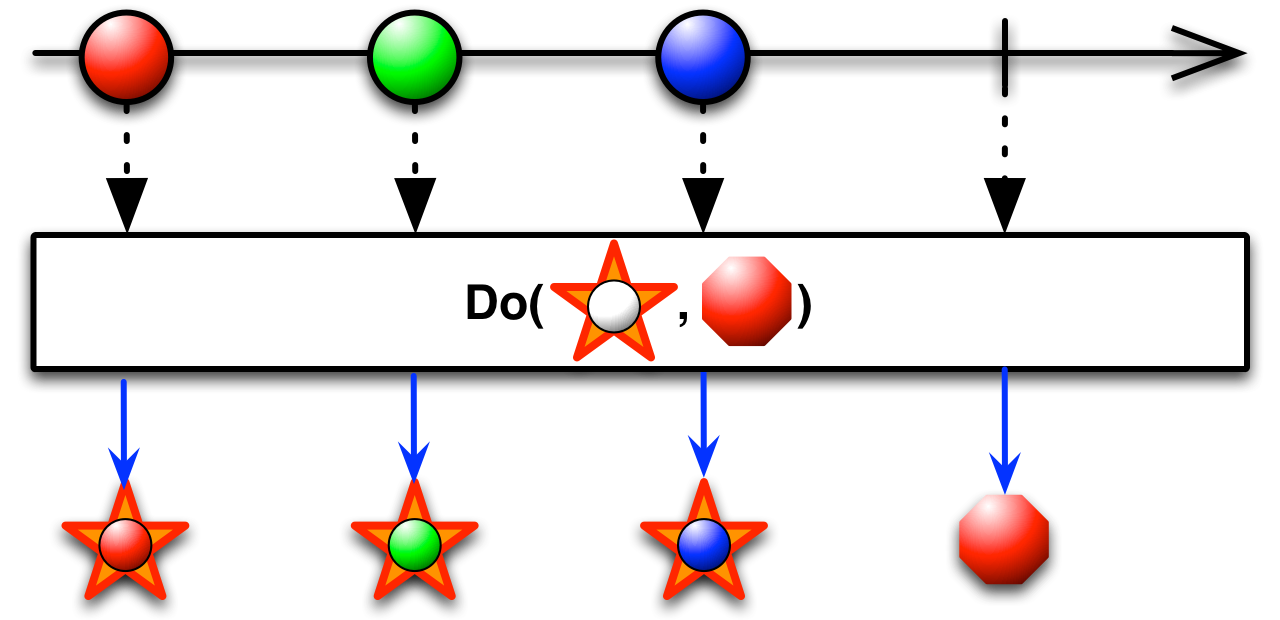 You can register callbacks that ReactiveX will call when certain events take place on an Observable, where those callbacks will be called independently from the normal set of notifications associated with an Observable cascade. There are a variety of operators that various ReactiveX implementations have designed to allow for this.
#### See Also
* [Subscribe](subscribe)
* [Introduction to Rx: Do](http://www.introtorx.com/Content/v1.0.10621.0/09_SideEffects.html#Do)
* [Introduction to Rx: Finally](http://www.introtorx.com/Content/v1.0.10621.0/11_AdvancedErrorHandling.html#Finally)
Language-Specific Information
-----------------------------
### RxGroovy `doOnCompleted doOnEach doOnError doOnNext doOnRequest doOnSubscribe doOnTerminate doOnUnsubscribe finallyDo`
RxGroovy has several Do variants.
 The `doOnEach` operator allows you to establish a callback that the resulting Observable will call each time it emits an item. You can pass this callback either in the form of an `Action` that takes an `onNext` variety of `Notification` as its sole parameter, or you can pass in an Observer whose `onNext` method will be called as if it had subscribed to the Observable.
* Javadoc: [`doOnEach(Action1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#doOnEach(rx.functions.Action1))
* Javadoc: [`doOnEach(Observer)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#doOnEach(rx.Observer))
 The `doOnNext` operator is much like `doOnEach(Action1)` except that the `Action` that you pass it as a parameter does not accept a `Notification` but instead simply accepts the emitted item.
* Javadoc: [`doOnNext(Action1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#doOnNext(rx.functions.Action1))
The `doOnRequest` operator (new in RxGroovy 1.1) registers an `Action` which will be called whenever an observer requests additional items from the resulting Observable. That `Action` receives as its parameter the number of items that the observer is requesting.
* Javadoc: [`doOnRequest(Action1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#doOnRequest(rx.functions.Action1))
 The `doOnSubscribe` operator registers an `Action` which will be called whenever an observer subscribes to the resulting Observable.
* Javadoc: [`doOnSubscribe(Action0)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#doOnSubscribe(rx.functions.Action0))
 The `doOnUnsubscribe` operator registers an `Action` which will be called whenever an observer unsubscribes from the resulting Observable.
* Javadoc: [`doOnUnsubscribe(Action0)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#doOnUnsubscribe(rx.functions.Action0))
 The `doOnCompleted` operator registers an `Action` which will be called if the resulting Observable terminates normally, calling `onCompleted`.
* Javadoc: [`doOnCompleted(Action0)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#doOnCompleted(rx.functions.Action0))
 The `doOnError` operator registers an `Action` which will be called if the resulting Observable terminates abnormally, calling `onError`. This `Action` will be passed the `Throwable` representing the error.
* Javadoc: [`doOnError(Action1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#doOnError(rx.functions.Action1))
 The `doOnTerminate` operator registers an `Action` which will be called just *before* the resulting Observable terminates, whether normally or with an error.
* Javadoc: [`doOnTerminate(Action0)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#doOnTerminate(rx.functions.Action0))
 The `finallyDo` operator registers an `Action` which will be called just *after* the resulting Observable terminates, whether normally or with an error.
#### Sample Code
```
def numbers = Observable.from([1, 2, 3, 4, 5]);
numbers.finallyDo({ println('Finally'); }).subscribe(
{ println(it); }, // onNext
{ println("Error: " + it.getMessage()); }, // onError
{ println("Sequence complete"); } // onCompleted
);
```
```
1
2
3
4
5
Sequence complete
Finally
```
* Javadoc: [`finallyDo(Action0)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#finallyDo(rx.functions.Action0))
### RxJava 1․x `doOnCompleted doOnEach doOnError doOnNext doOnRequest doOnSubscribe doOnTerminate doOnUnsubscribe finallyDo doAfterTerminate`
RxJava has several Do variants.
 The `doOnEach` operator allows you to establish a callback that the resulting Observable will call each time it emits an item. You can pass this callback either in the form of an `Action` that takes an `onNext` variety of `Notification` as its sole parameter, or you can pass in an Observer whose `onNext` method will be called as if it had subscribed to the Observable.
* Javadoc: [`doOnEach(Action1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#doOnEach(rx.functions.Action1))
* Javadoc: [`doOnEach(Observer)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#doOnEach(rx.Observer))
 The `doOnNext` operator is much like `doOnEach(Action1)` except that the `Action` that you pass it as a parameter does not accept a `Notification` but instead simply accepts the emitted item.
#### Sample Code
```
Observable.just(1, 2, 3)
.doOnNext(new Action1<Integer>() {
@Override
public void call(Integer item) {
if( item > 1 ) {
throw new RuntimeException( "Item exceeds maximum value" );
}
}
}).subscribe(new Subscriber<Integer>() {
@Override
public void onNext(Integer item) {
System.out.println("Next: " + item);
}
@Override
public void onError(Throwable error) {
System.err.println("Error: " + error.getMessage());
}
@Override
public void onCompleted() {
System.out.println("Sequence complete.");
}
});
```
```
Next: 1
Error: Item exceeds maximum value
```
* Javadoc: [`doOnNext(Action1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#doOnNext(rx.functions.Action1))
The `doOnRequest` operator (new in RxJava 1.1) registers an `Action` which will be called whenever an observer requests additional items from the resulting Observable. That `Action` receives as its parameter the number of items that the observer is requesting.
* Javadoc: [`doOnRequest(Action1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#doOnRequest(rx.functions.Action1))
 The `doOnSubscribe` operator registers an `Action` which will be called whenever an observer subscribes to the resulting Observable.
* Javadoc: [`doOnSubscribe(Action0)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#doOnSubscribe(rx.functions.Action0))
 The `doOnUnsubscribe` operator registers an `Action` which will be called whenever an observer unsubscribes from the resulting Observable.
* Javadoc: [`doOnUnsubscribe(Action0)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#doOnUnsubscribe(rx.functions.Action0))
 The `doOnCompleted` operator registers an `Action` which will be called if the resulting Observable terminates normally, calling `onCompleted`.
* Javadoc: [`doOnCompleted(Action0)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#doOnCompleted(rx.functions.Action0))
 The `doOnError` operator registers an `Action` which will be called if the resulting Observable terminates abnormally, calling `onError`. This `Action` will be passed the `Throwable` representing the error.
* Javadoc: [`doOnError(Action1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#doOnError(rx.functions.Action1))
 The `doOnTerminate` operator registers an `Action` which will be called just *before* the resulting Observable terminates, whether normally or with an error.
* Javadoc: [`doOnTerminate(Action0)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#doOnTerminate(rx.functions.Action0))
 `finallyDo` is deprecated since RxJava 1.1.1, in favor of `doAfterTerminate` with the same behavior.
The `finallyDo` operator registers an `Action` which will be called just *after* the resulting Observable terminates, whether normally or with an error.
* Javadoc: [`finallyDo(Action0)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#finallyDo(rx.functions.Action0))
 The `doAfterTerminate` operator registers an `Action` which will be called just *after* the resulting Observable terminates, whether normally or with an error.
* Javadoc: [`doAfterTerminate(Action0)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#doAfterTerminate(rx.functions.Action0))
### RxJS `do doOnCompleted doOnError doOnNext finally tap tapOnCompleted tapOnError tapOnNext`
 RxJS implements the basic Do operator as `do` or `tap` (two names for the same operator). You have two choices for how to use this operator:
1. You can pass it an Observer, in which case `do`/`tap` will call that Observer’s methods as though that Observer had subscribed to the resulting Observable.
2. You can pass in a set of 1–3 individual functions (`onNext`, `onError`, and `onCompleted`) that `do`/`tap` will call along with the similarly-named functions of any of its observers.
#### Sample Code
```
/* Using an observer */
var observer = Rx.Observer.create(
function (x) { console.log('Do Next: %s', x); },
function (err) { console.log('Do Error: %s', err); },
function () { console.log('Do Completed'); }
);
var source = Rx.Observable.range(0, 3)
.do(observer);
var subscription = source.subscribe(
function (x) { console.log('Next: %s', x); },
function (err) { console.log('Error: %s', err); },
function () { console.log('Completed'); });
```
```
Do Next: 0
Next: 0
Do Next: 1
Next: 1
Do Next: 2
Next: 2
Do Completed
Completed
```
```
/* Using a function */
var source = Rx.Observable.range(0, 3)
.do(
function (x) { console.log('Do Next:', x); },
function (err) { console.log('Do Error:', err); },
function () { console.log('Do Completed'); }
);
var subscription = source.subscribe(
function (x) { console.log('Next: %s', x); },
function (err) { console.log('Error: %s', err); },
function () { console.log('Completed'); });
```
```
Do Next: 0
Next: 0
Do Next: 1
Next: 1
Do Next: 2
Next: 2
Do Completed
Completed
```
 RxJS also implements `doOnNext` or `tapOnNext` (two names for the same operator). It is a specialized form of Do that responds only to the `onNext` case, by calling a callback function you provide as a parameter. You may also optionally pass a second parameter that will be the “`this`” object from the point of view of your callback function when it executes.
#### Sample Code
```
var source = Rx.Observable.range(0, 3)
.doOnNext(
function () { this.log('Do Next: %s', x); },
console
);
var subscription = source.subscribe(
function (x) { console.log('Next: %s', x); },
function (err) { console.log('Error: %s', err); },
function () { console.log('Completed'); });
```
```
Do Next: 0
Next: 0
Do Next: 1
Next: 1
Do Next: 2
Next: 2
Completed
```
 RxJS also implements `doOnError` or `tapOnError` (two names for the same operator). It is a specialized form of Do that responds only to the `onError` case, by calling a callback function you provide as a parameter. You may also optionally pass a second parameter that will be the “`this`” object from the point of view of your callback function when it executes.
#### Sample Code
```
var source = Rx.Observable.throw(new Error());
.doOnError(
function (err) { this.log('Do Error: %s', err); },
console
);
var subscription = source.subscribe(
function (x) { console.log('Next: %s', x); },
function (err) { console.log('Error: %s', err); },
function () { console.log('Completed'); });
```
```
Do Error: Error
Error: Error
```
 RxJS also implements `doOnCompleted` or `tapOnCompleted` (two names for the same operator). It is a specialized form of Do that responds only to the `onCompleted` case, by calling a callback function you provide as a parameter. You may also optionally pass a second parameter that will be the “`this`” object from the point of view of your callback function when it executes.
#### Sample Code
```
var source = Rx.Observable.range(0, 3)
.doOnCompleted(
function () { this.log('Do Completed'); },
console
);
var subscription = source.subscribe(
function (x) { console.log('Next: %s', x); },
function (err) { console.log('Error: %s', err); },
function () { console.log('Completed'); });
```
```
Next: 0
Next: 1
Next: 2
Do Completed
Completed
```
 RxJS also implements a `finally` operator. It takes a function that will be called after the resulting Observable terminates, whether normally (`onCompleted`) or abnormally (`onError`).
#### Sample Code
```
var source = Rx.Observable.throw(new Error())
.finally(function () {
console.log('Finally');
});
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Error: Error
Finally
```
`do`/`tap`, `doOnNext`/`tapOnNext`, `doOnError`/`tapOnError`, `doOnCompleted`/`tapOnCompleted`, and `finally` are found in each of the following distributions:
* `rx.js`
* `rx.all.js`
* `rx.all.compat.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
### RxPHP `do doOnError doOnCompleted finally`
RxPHP implements this operator as `do`.
Invokes an action for each element in the observable sequence and invokes an action upon graceful or exceptional termination of the observable sequence. This method can be used for debugging, logging, etc. of query behavior by intercepting the message stream to run arbitrary actions for messages on the pipeline. When using do, it is important to note that the Observer may receive additional events after a stream has completed or errored (such as when using a repeat or resubscribing). If you are using an Observable that extends the AbstractObservable, you will not receive these events. For this special case, use the DoObserver. doOnNext, doOnError, and doOnCompleted uses the DoObserver internally and will receive these additional events.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/do/do.php
$source = \Rx\Observable::range(0, 3)
->do(
function ($x) {
echo 'Do Next:', $x, PHP_EOL;
},
function (Throwable $err) {
echo 'Do Error:', $err->getMessage(), PHP_EOL;
},
function () {
echo 'Do Completed', PHP_EOL;
}
);
$subscription = $source->subscribe($stdoutObserver);
```
```
Do Next:0
Next value: 0
Do Next:1
Next value: 1
Do Next:2
Next value: 2
Do Completed
Complete!
```
RxPHP also has an operator `doOnError`.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/do/doOnError.php
$source = \Rx\Observable::error(new Exception('Oops'))
->doOnError(function (Throwable $err) {
echo 'Do Error:', $err->getMessage(), PHP_EOL;
});
$subscription = $source->subscribe($stdoutObserver);
```
```
Do Error:Oops
Exception: Oops
```
RxPHP also has an operator `doOnCompleted`.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/do/doOnCompleted.php
$source = \Rx\Observable::empty()
->doOnCompleted(function () {
echo 'Do Completed', PHP_EOL;
});
$subscription = $source->subscribe($stdoutObserver);
```
```
Do Completed
Complete!
```
RxPHP also has an operator `finally`.
Will call a specified function when the source terminates on complete or error.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/finally/finally.php
Rx\Observable::range(1, 3)
->finally(function() {
echo "Finally\n";
})
->subscribe($stdoutObserver);
```
```
Next value: 1
Next value: 2
Next value: 3
Complete!
Finally
```
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/finally/finally-error.php
Rx\Observable::range(1, 3)
->map(function($value) {
if ($value == 2) {
throw new \Exception('error');
}
return $value;
})
->finally(function() {
echo "Finally\n";
})
->subscribe($stdoutObserver);
```
```
Next value: 1
Exception: error
Finally
```
reactivex Distinct Distinct
========
> suppress duplicate items emitted by an Observable
[Open interactive diagram on rxmarbles.com](https://rxmarbles.com/#distinct) The Distinct operator filters an Observable by only allowing items through that have not already been emitted.
In some implementations there are variants that allow you to adjust the criteria by which two items are considered “distinct.” In some, there is a variant of the operator that only compares an item against its immediate predecessor for distinctness, thereby filtering only *consecutive* duplicate items from the sequence.
#### See Also
* [Filter](filter)
* [Introduction to Rx: Distinct and DistinctUntilChanged](http://www.introtorx.com/Content/v1.0.10621.0/05_Filtering.html#Distinct)
* [RxMarbles: `distinct`](http://rxmarbles.com/#distinct)
* [RxMarbles: `distinctUntilChanged`](http://rxmarbles.com/#distinctUntilChanged)
Language-Specific Information
-----------------------------
### RxGroovy `distinct distinctUntilChanged`
 RxGroovy implements this operator as `distinct`.
* Javadoc: [`distinct()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#distinct())
 There is also a variant of this operator that takes a function as a parameter. This function operates on items emitted by the source Observable to generate a “key.” It is these keys, then, and not the items themselves, that `distinct` will compare to determine whether or not two items are distinct.
* Javadoc: [`distinct(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#distinct(rx.functions.Func1))
 RxGroovy also implements the `distinctUntilChanged` operator. It only compares emitted items from the source Observable against their immediate predecessors in order to determine whether or not they are distinct.
* Javadoc: [`distinctUntilChanged()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#distinctUntilChanged())
 As with `distinct`, there is also a version of `distinctUntilChanged` that accepts a key selector function and that uses the resulting key to determine whether or not two adjacently-emitted items are distinct.
* Javadoc: [`distinctUntilChanged(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#distinctUntilChanged(rx.functions.Func1))
`distinct` and `distinctUntilChanged` do not by default operate on any particular [Scheduler](../scheduler).
### RxJava 1․x `distinct distinctUntilChanged`
 RxJava implements this operator as `distinct`.
#### Sample Code
```
Observable.just(1, 2, 1, 1, 2, 3)
.distinct()
.subscribe(new Subscriber<Integer>() {
@Override
public void onNext(Integer item) {
System.out.println("Next: " + item);
}
@Override
public void onError(Throwable error) {
System.err.println("Error: " + error.getMessage());
}
@Override
public void onCompleted() {
System.out.println("Sequence complete.");
}
});
```
```
Next: 1
Next: 2
Next: 3
Sequence complete.
```
* Javadoc: [`distinct()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#distinct())
 There is also a variant of this operator that takes a function as a parameter. This function operates on items emitted by the source Observable to generate a “key.” It is these keys, then, and not the items themselves, that `distinct` will compare to determine whether or not two items are distinct.
* Javadoc: [`distinct(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#distinct(rx.functions.Func1))
 RxJava also implements the `distinctUntilChanged` operator. It only compares emitted items from the source Observable against their immediate predecessors in order to determine whether or not they are distinct.
* Javadoc: [`distinctUntilChanged()`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#distinctUntilChanged())
 As with `distinct`, there is also a version of `distinctUntilChanged` that accepts a key selector function and that uses the resulting key to determine whether or not two adjacently-emitted items are distinct.
* Javadoc: [`distinctUntilChanged(Func1)`](http://reactivex.io/RxJava/javadoc/rx/Observable.html#distinctUntilChanged(rx.functions.Func1))
`distinct` and `distinctUntilChanged` do not by default operate on any particular [Scheduler](../scheduler).
### RxJS `distinct distinctUntilChanged`
 In RxJS, the `distinct` operator has two optional parameters:
1. a function that accepts an item emitted by the source Observable and returns a *key* which will be used instead of the item itself when comparing two items for distinctness
2. a function that accepts two items (or two keys) and compares them for distinctness, returning `false` if they are distinct (an equality function is the default if you do not supply your own function here)
#### Sample Code
```
/* Without key selector */
var source = Rx.Observable.fromArray([
42, 24, 42, 24
])
.distinct();
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x.toString()); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 42
Next: 24
Completed
```
```
/* With key selector */
var source = Rx.Observable.fromArray([
{value: 42}, {value: 24}, {value: 42}, {value: 24}
])
.distinct(function (x) { return x.value; });
var subscription = source.subscribe(
function (x) {
console.log('Next: ' + x.toString());
},
function (err) {
console.log('Error: ' + err);
},
function () {
console.log('Completed');
});
```
```
Next: { value: 42 }
Next: { value: 24 }
Completed
```
 RxJS also has a `distinctUntilChanged` operator. It only compares emitted items from the source Observable against their immediate predecessors in order to determine whether or not they are distinct. It takes the same two optional parameters as the `distinct` operator.
#### Sample Code
```
/* Without key selector */
var source = Rx.Observable.fromArray([
24, 42, 24, 24
])
.distinctUntilChanged();
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: 24
Next: 42
Next: 24
Completed
```
```
/* With key selector */
var source = Rx.Observable.fromArray([
{value: 24}, {value: 42}, {value: 42}, {value: 24}
])
.distinctUntilChanged(function (x) { return x.value; });
var subscription = source.subscribe(
function (x) { console.log('Next: ' + x.toString()); },
function (err) { console.log('Error: ' + err); },
function () { console.log('Completed'); });
```
```
Next: { value: 24 }
Next: { value: 42 }
Next: { value: 24 }
Completed
```
`distinct` and `distinctUntilChanged` are found in each of the following distributions:
* `rx.js`
* `rx.all.js`
* `rx.all.compat.js`
* `rx.compat.js`
* `rx.lite.js`
* `rx.lite.compat.js`
### RxPHP `distinct distinctKey distinctUntilChanged distinctUntilKeyChanged`
RxPHP implements this operator as `distinct`.
Returns an observable sequence that contains only distinct elements according to the keySelector and the comparer. Usage of this operator should be considered carefully due to the maintenance of an internal lookup structure which can grow large.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/distinct/distinct.php
$source = \Rx\Observable::fromArray([
42, 24, 42, 24
])->distinct();
$subscription = $source->subscribe($stdoutObserver);
```
```
Next value: 42
Next value: 24
Complete!
```
RxPHP also has an operator `distinctKey`.
Variant of distinct that takes a key selector
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/distinct/distinctKey.php
$source = \Rx\Observable::fromArray([
['id' => '42'],
['id' => '24'],
['id' => '42'],
['id' => '24']
])
->distinctKey(function ($x) {
return $x['id'];
})
->map(function ($x) {
return $x['id'];
});
$subscription = $source->subscribe($stdoutObserver);
```
```
Next value: 42
Next value: 24
Complete!
```
RxPHP also has an operator `distinctUntilChanged`.
A variant of distinct that only compares emitted items from the source Observable against their immediate predecessors in order to determine whether or not they are distinct.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/distinct/distinctUntilChanged.php
$source = \Rx\Observable::fromArray([
24, 42, 24, 24
])->distinctUntilChanged();
$subscription = $source->subscribe($stdoutObserver);
```
```
Next value: 24
Next value: 42
Next value: 24
Complete!
```
RxPHP also has an operator `distinctUntilKeyChanged`.
Variant of distinctUntilChanged that takes a key selector and the comparer.
#### Sample Code
```
//from https://github.com/ReactiveX/RxPHP/blob/master/demo/distinct/distinctUntilKeyChanged.php
$source = \Rx\Observable::fromArray([
['id' => '24'],
['id' => '42'],
['id' => '24'],
['id' => '24']
])
->distinctUntilKeyChanged(function ($x) {
return $x['id'];
})
->map(function ($x) {
return $x['id'];
});
$subscription = $source->subscribe($stdoutObserver);
```
```
Next value: 24
Next value: 42
Next value: 24
Complete!
```
| programming_docs |
git git-gui git-gui
=======
Name
----
git-gui - A portable graphical interface to Git
Synopsis
--------
```
git gui [<command>] [<arguments>]
```
Description
-----------
A Tcl/Tk based graphical user interface to Git. `git gui` focuses on allowing users to make changes to their repository by making new commits, amending existing ones, creating branches, performing local merges, and fetching/pushing to remote repositories.
Unlike `gitk`, `git gui` focuses on commit generation and single file annotation and does not show project history. It does however supply menu actions to start a `gitk` session from within `git gui`.
`git gui` is known to work on all popular UNIX systems, Mac OS X, and Windows (under both Cygwin and MSYS). To the extent possible OS specific user interface guidelines are followed, making `git gui` a fairly native interface for users.
Commands
--------
blame Start a blame viewer on the specified file on the given version (or working directory if not specified).
browser Start a tree browser showing all files in the specified commit. Files selected through the browser are opened in the blame viewer.
citool Start `git gui` and arrange to make exactly one commit before exiting and returning to the shell. The interface is limited to only commit actions, slightly reducing the application’s startup time and simplifying the menubar.
version Display the currently running version of `git gui`.
Examples
--------
`git gui blame Makefile` Show the contents of the file `Makefile` in the current working directory, and provide annotations for both the original author of each line, and who moved the line to its current location. The uncommitted file is annotated, and uncommitted changes (if any) are explicitly attributed to `Not Yet Committed`.
`git gui blame v0.99.8 Makefile` Show the contents of `Makefile` in revision `v0.99.8` and provide annotations for each line. Unlike the above example the file is read from the object database and not the working directory.
`git gui blame --line=100 Makefile` Loads annotations as described above and automatically scrolls the view to center on line `100`.
`git gui citool` Make one commit and return to the shell when it is complete. This command returns a non-zero exit code if the window was closed in any way other than by making a commit.
`git gui citool --amend` Automatically enter the `Amend Last Commit` mode of the interface.
`git gui citool --nocommit` Behave as normal citool, but instead of making a commit simply terminate with a zero exit code. It still checks that the index does not contain any unmerged entries, so you can use it as a GUI version of [git-mergetool[1]](git-mergetool)
`git citool` Same as `git gui citool` (above).
`git gui browser maint` Show a browser for the tree of the `maint` branch. Files selected in the browser can be viewed with the internal blame viewer.
See also
--------
[gitk[1]](gitk) The Git repository browser. Shows branches, commit history and file differences. gitk is the utility started by `git gui`'s Repository Visualize actions.
Other
-----
`git gui` is actually maintained as an independent project, but stable versions are distributed as part of the Git suite for the convenience of end users.
The official repository of the `git gui` project can be found at:
```
https://github.com/prati0100/git-gui.git/
```
git git-rm git-rm
======
Name
----
git-rm - Remove files from the working tree and from the index
Synopsis
--------
```
git rm [-f | --force] [-n] [-r] [--cached] [--ignore-unmatch]
[--quiet] [--pathspec-from-file=<file> [--pathspec-file-nul]]
[--] [<pathspec>…]
```
Description
-----------
Remove files matching pathspec from the index, or from the working tree and the index. `git rm` will not remove a file from just your working directory. (There is no option to remove a file only from the working tree and yet keep it in the index; use `/bin/rm` if you want to do that.) The files being removed have to be identical to the tip of the branch, and no updates to their contents can be staged in the index, though that default behavior can be overridden with the `-f` option. When `--cached` is given, the staged content has to match either the tip of the branch or the file on disk, allowing the file to be removed from just the index. When sparse-checkouts are in use (see [git-sparse-checkout[1]](git-sparse-checkout)), `git rm` will only remove paths within the sparse-checkout patterns.
Options
-------
<pathspec>… Files to remove. A leading directory name (e.g. `dir` to remove `dir/file1` and `dir/file2`) can be given to remove all files in the directory, and recursively all sub-directories, but this requires the `-r` option to be explicitly given.
The command removes only the paths that are known to Git.
File globbing matches across directory boundaries. Thus, given two directories `d` and `d2`, there is a difference between using `git rm 'd*'` and `git rm 'd/*'`, as the former will also remove all of directory `d2`.
For more details, see the `pathspec` entry in [gitglossary[7]](gitglossary).
-f --force Override the up-to-date check.
-n --dry-run Don’t actually remove any file(s). Instead, just show if they exist in the index and would otherwise be removed by the command.
-r Allow recursive removal when a leading directory name is given.
-- This option can be used to separate command-line options from the list of files, (useful when filenames might be mistaken for command-line options).
--cached Use this option to unstage and remove paths only from the index. Working tree files, whether modified or not, will be left alone.
--ignore-unmatch Exit with a zero status even if no files matched.
--sparse Allow updating index entries outside of the sparse-checkout cone. Normally, `git rm` refuses to update index entries whose paths do not fit within the sparse-checkout cone. See [git-sparse-checkout[1]](git-sparse-checkout) for more.
-q --quiet `git rm` normally outputs one line (in the form of an `rm` command) for each file removed. This option suppresses that output.
--pathspec-from-file=<file> Pathspec is passed in `<file>` instead of commandline args. If `<file>` is exactly `-` then standard input is used. Pathspec elements are separated by LF or CR/LF. Pathspec elements can be quoted as explained for the configuration variable `core.quotePath` (see [git-config[1]](git-config)). See also `--pathspec-file-nul` and global `--literal-pathspecs`.
--pathspec-file-nul Only meaningful with `--pathspec-from-file`. Pathspec elements are separated with NUL character and all other characters are taken literally (including newlines and quotes).
Removing files that have disappeared from the filesystem
--------------------------------------------------------
There is no option for `git rm` to remove from the index only the paths that have disappeared from the filesystem. However, depending on the use case, there are several ways that can be done.
###
Using “git commit -a”
If you intend that your next commit should record all modifications of tracked files in the working tree and record all removals of files that have been removed from the working tree with `rm` (as opposed to `git rm`), use `git commit -a`, as it will automatically notice and record all removals. You can also have a similar effect without committing by using `git add -u`.
###
Using “git add -A”
When accepting a new code drop for a vendor branch, you probably want to record both the removal of paths and additions of new paths as well as modifications of existing paths.
Typically you would first remove all tracked files from the working tree using this command:
```
git ls-files -z | xargs -0 rm -f
```
and then untar the new code in the working tree. Alternately you could `rsync` the changes into the working tree.
After that, the easiest way to record all removals, additions, and modifications in the working tree is:
```
git add -A
```
See [git-add[1]](git-add).
###
Other ways
If all you really want to do is to remove from the index the files that are no longer present in the working tree (perhaps because your working tree is dirty so that you cannot use `git commit -a`), use the following command:
```
git diff --name-only --diff-filter=D -z | xargs -0 git rm --cached
```
Submodules
----------
Only submodules using a gitfile (which means they were cloned with a Git version 1.7.8 or newer) will be removed from the work tree, as their repository lives inside the .git directory of the superproject. If a submodule (or one of those nested inside it) still uses a .git directory, `git rm` will move the submodules git directory into the superprojects git directory to protect the submodule’s history. If it exists the submodule.<name> section in the [gitmodules[5]](gitmodules) file will also be removed and that file will be staged (unless --cached or -n are used).
A submodule is considered up to date when the HEAD is the same as recorded in the index, no tracked files are modified and no untracked files that aren’t ignored are present in the submodules work tree. Ignored files are deemed expendable and won’t stop a submodule’s work tree from being removed.
If you only want to remove the local checkout of a submodule from your work tree without committing the removal, use [git-submodule[1]](git-submodule) `deinit` instead. Also see [gitsubmodules[7]](gitsubmodules) for details on submodule removal.
Examples
--------
`git rm Documentation/\*.txt` Removes all `*.txt` files from the index that are under the `Documentation` directory and any of its subdirectories.
Note that the asterisk `*` is quoted from the shell in this example; this lets Git, and not the shell, expand the pathnames of files and subdirectories under the `Documentation/` directory.
`git rm -f git-*.sh` Because this example lets the shell expand the asterisk (i.e. you are listing the files explicitly), it does not remove `subdir/git-foo.sh`.
Bugs
----
Each time a superproject update removes a populated submodule (e.g. when switching between commits before and after the removal) a stale submodule checkout will remain in the old location. Removing the old directory is only safe when it uses a gitfile, as otherwise the history of the submodule will be deleted too. This step will be obsolete when recursive submodule update has been implemented.
See also
--------
[git-add[1]](git-add)
git git-mergetool git-mergetool
=============
Name
----
git-mergetool - Run merge conflict resolution tools to resolve merge conflicts
Synopsis
--------
```
git mergetool [--tool=<tool>] [-y | --[no-]prompt] [<file>…]
```
Description
-----------
Use `git mergetool` to run one of several merge utilities to resolve merge conflicts. It is typically run after `git merge`.
If one or more <file> parameters are given, the merge tool program will be run to resolve differences on each file (skipping those without conflicts). Specifying a directory will include all unresolved files in that path. If no <file> names are specified, `git mergetool` will run the merge tool program on every file with merge conflicts.
Options
-------
-t <tool> --tool=<tool> Use the merge resolution program specified by <tool>. Valid values include emerge, gvimdiff, kdiff3, meld, vimdiff, and tortoisemerge. Run `git mergetool --tool-help` for the list of valid <tool> settings.
If a merge resolution program is not specified, `git mergetool` will use the configuration variable `merge.tool`. If the configuration variable `merge.tool` is not set, `git mergetool` will pick a suitable default.
You can explicitly provide a full path to the tool by setting the configuration variable `mergetool.<tool>.path`. For example, you can configure the absolute path to kdiff3 by setting `mergetool.kdiff3.path`. Otherwise, `git mergetool` assumes the tool is available in PATH.
Instead of running one of the known merge tool programs, `git mergetool` can be customized to run an alternative program by specifying the command line to invoke in a configuration variable `mergetool.<tool>.cmd`.
When `git mergetool` is invoked with this tool (either through the `-t` or `--tool` option or the `merge.tool` configuration variable) the configured command line will be invoked with `$BASE` set to the name of a temporary file containing the common base for the merge, if available; `$LOCAL` set to the name of a temporary file containing the contents of the file on the current branch; `$REMOTE` set to the name of a temporary file containing the contents of the file to be merged, and `$MERGED` set to the name of the file to which the merge tool should write the result of the merge resolution.
If the custom merge tool correctly indicates the success of a merge resolution with its exit code, then the configuration variable `mergetool.<tool>.trustExitCode` can be set to `true`. Otherwise, `git mergetool` will prompt the user to indicate the success of the resolution after the custom tool has exited.
--tool-help Print a list of merge tools that may be used with `--tool`.
-y --no-prompt Don’t prompt before each invocation of the merge resolution program. This is the default if the merge resolution program is explicitly specified with the `--tool` option or with the `merge.tool` configuration variable.
--prompt Prompt before each invocation of the merge resolution program to give the user a chance to skip the path.
-g --gui When `git-mergetool` is invoked with the `-g` or `--gui` option the default merge tool will be read from the configured `merge.guitool` variable instead of `merge.tool`. If `merge.guitool` is not set, we will fallback to the tool configured under `merge.tool`.
--no-gui This overrides a previous `-g` or `--gui` setting and reads the default merge tool will be read from the configured `merge.tool` variable.
-O<orderfile> Process files in the order specified in the <orderfile>, which has one shell glob pattern per line. This overrides the `diff.orderFile` configuration variable (see [git-config[1]](git-config)). To cancel `diff.orderFile`, use `-O/dev/null`.
Configuration
-------------
Everything below this line in this section is selectively included from the [git-config[1]](git-config) documentation. The content is the same as what’s found there:
mergetool.<tool>.path Override the path for the given tool. This is useful in case your tool is not in the PATH.
mergetool.<tool>.cmd Specify the command to invoke the specified merge tool. The specified command is evaluated in shell with the following variables available: `BASE` is the name of a temporary file containing the common base of the files to be merged, if available; `LOCAL` is the name of a temporary file containing the contents of the file on the current branch; `REMOTE` is the name of a temporary file containing the contents of the file from the branch being merged; `MERGED` contains the name of the file to which the merge tool should write the results of a successful merge.
mergetool.<tool>.hideResolved Allows the user to override the global `mergetool.hideResolved` value for a specific tool. See `mergetool.hideResolved` for the full description.
mergetool.<tool>.trustExitCode For a custom merge command, specify whether the exit code of the merge command can be used to determine whether the merge was successful. If this is not set to true then the merge target file timestamp is checked and the merge assumed to have been successful if the file has been updated, otherwise the user is prompted to indicate the success of the merge.
mergetool.meld.hasOutput Older versions of `meld` do not support the `--output` option. Git will attempt to detect whether `meld` supports `--output` by inspecting the output of `meld --help`. Configuring `mergetool.meld.hasOutput` will make Git skip these checks and use the configured value instead. Setting `mergetool.meld.hasOutput` to `true` tells Git to unconditionally use the `--output` option, and `false` avoids using `--output`.
mergetool.meld.useAutoMerge When the `--auto-merge` is given, meld will merge all non-conflicting parts automatically, highlight the conflicting parts and wait for user decision. Setting `mergetool.meld.useAutoMerge` to `true` tells Git to unconditionally use the `--auto-merge` option with `meld`. Setting this value to `auto` makes git detect whether `--auto-merge` is supported and will only use `--auto-merge` when available. A value of `false` avoids using `--auto-merge` altogether, and is the default value.
mergetool.vimdiff.layout The vimdiff backend uses this variable to control how its split windows look like. Applies even if you are using Neovim (`nvim`) or gVim (`gvim`) as the merge tool. See BACKEND SPECIFIC HINTS section for details.
mergetool.hideResolved During a merge Git will automatically resolve as many conflicts as possible and write the `MERGED` file containing conflict markers around any conflicts that it cannot resolve; `LOCAL` and `REMOTE` normally represent the versions of the file from before Git’s conflict resolution. This flag causes `LOCAL` and `REMOTE` to be overwritten so that only the unresolved conflicts are presented to the merge tool. Can be configured per-tool via the `mergetool.<tool>.hideResolved` configuration variable. Defaults to `false`.
mergetool.keepBackup After performing a merge, the original file with conflict markers can be saved as a file with a `.orig` extension. If this variable is set to `false` then this file is not preserved. Defaults to `true` (i.e. keep the backup files).
mergetool.keepTemporaries When invoking a custom merge tool, Git uses a set of temporary files to pass to the tool. If the tool returns an error and this variable is set to `true`, then these temporary files will be preserved, otherwise they will be removed after the tool has exited. Defaults to `false`.
mergetool.writeToTemp Git writes temporary `BASE`, `LOCAL`, and `REMOTE` versions of conflicting files in the worktree by default. Git will attempt to use a temporary directory for these files when set `true`. Defaults to `false`.
mergetool.prompt Prompt before each invocation of the merge resolution program.
Temporary files
---------------
`git mergetool` creates `*.orig` backup files while resolving merges. These are safe to remove once a file has been merged and its `git mergetool` session has completed.
Setting the `mergetool.keepBackup` configuration variable to `false` causes `git mergetool` to automatically remove the backup as files are successfully merged.
Backend specific hints
----------------------
###
vimdiff
####
Description
When specifying `--tool=vimdiff` in `git mergetool` Git will open Vim with a 4 windows layout distributed in the following way:
```
------------------------------------------
| | | |
| LOCAL | BASE | REMOTE |
| | | |
------------------------------------------
| |
| MERGED |
| |
------------------------------------------
```
`LOCAL`, `BASE` and `REMOTE` are read-only buffers showing the contents of the conflicting file in specific commits ("commit you are merging into", "common ancestor commit" and "commit you are merging from" respectively)
`MERGED` is a writable buffer where you have to resolve the conflicts (using the other read-only buffers as a reference). Once you are done, save and exit Vim as usual (`:wq`) or, if you want to abort, exit using `:cq`.
####
Layout configuration
You can change the windows layout used by Vim by setting configuration variable `mergetool.vimdiff.layout` which accepts a string where the following separators have special meaning:
* `+` is used to "open a new tab"
* `,` is used to "open a new vertical split"
* `/` is used to "open a new horizontal split"
* `@` is used to indicate which is the file containing the final version after solving the conflicts. If not present, `MERGED` will be used by default.
The precedence of the operators is this one (you can use parentheses to change it):
```
`@` > `+` > `/` > `,`
```
Let’s see some examples to understand how it works:
* `layout = "(LOCAL,BASE,REMOTE)/MERGED"`
This is exactly the same as the default layout we have already seen.
Note that `/` has precedence over `,` and thus the parenthesis are not needed in this case. The next layout definition is equivalent:
```
layout = "LOCAL,BASE,REMOTE / MERGED"
```
* `layout = "LOCAL,MERGED,REMOTE"`
If, for some reason, we are not interested in the `BASE` buffer.
```
------------------------------------------
| | | |
| | | |
| LOCAL | MERGED | REMOTE |
| | | |
| | | |
------------------------------------------
```
* `layout = "MERGED"`
Only the `MERGED` buffer will be shown. Note, however, that all the other ones are still loaded in vim, and you can access them with the "buffers" command.
```
------------------------------------------
| |
| |
| MERGED |
| |
| |
------------------------------------------
```
* `layout = "@LOCAL,REMOTE"`
When `MERGED` is not present in the layout, you must "mark" one of the buffers with an asterisk. That will become the buffer you need to edit and save after resolving the conflicts.
```
------------------------------------------
| | |
| | |
| | |
| LOCAL | REMOTE |
| | |
| | |
| | |
------------------------------------------
```
* `layout = "LOCAL,BASE,REMOTE / MERGED + BASE,LOCAL + BASE,REMOTE"`
Three tabs will open: the first one is a copy of the default layout, while the other two only show the differences between (`BASE` and `LOCAL`) and (`BASE` and `REMOTE`) respectively.
```
------------------------------------------
| <TAB #1> | TAB #2 | TAB #3 | |
------------------------------------------
| | | |
| LOCAL | BASE | REMOTE |
| | | |
------------------------------------------
| |
| MERGED |
| |
------------------------------------------
```
```
------------------------------------------
| TAB #1 | <TAB #2> | TAB #3 | |
------------------------------------------
| | |
| | |
| | |
| BASE | LOCAL |
| | |
| | |
| | |
------------------------------------------
```
```
------------------------------------------
| TAB #1 | TAB #2 | <TAB #3> | |
------------------------------------------
| | |
| | |
| | |
| BASE | REMOTE |
| | |
| | |
| | |
------------------------------------------
```
* `layout = "LOCAL,BASE,REMOTE / MERGED + BASE,LOCAL + BASE,REMOTE + (LOCAL/BASE/REMOTE),MERGED"`
Same as the previous example, but adds a fourth tab with the same information as the first tab, with a different layout.
```
---------------------------------------------
| TAB #1 | TAB #2 | TAB #3 | <TAB #4> |
---------------------------------------------
| LOCAL | |
|---------------------| |
| BASE | MERGED |
|---------------------| |
| REMOTE | |
---------------------------------------------
```
Note how in the third tab definition we need to use parenthesis to make `,` have precedence over `/`.
####
Variants
Instead of `--tool=vimdiff`, you can also use one of these other variants:
* `--tool=gvimdiff`, to open gVim instead of Vim.
* `--tool=nvimdiff`, to open Neovim instead of Vim.
When using these variants, in order to specify a custom layout you will have to set configuration variables `mergetool.gvimdiff.layout` and `mergetool.nvimdiff.layout` instead of `mergetool.vimdiff.layout`
In addition, for backwards compatibility with previous Git versions, you can also append `1`, `2` or `3` to either `vimdiff` or any of the variants (ex: `vimdiff3`, `nvimdiff1`, etc…) to use a predefined layout. In other words, using `--tool=[g,n,]vimdiffx` is the same as using `--tool=[g,n,]vimdiff` and setting configuration variable `mergetool.[g,n,]vimdiff.layout` to…
* `x=1`: `"@LOCAL, REMOTE"`
* `x=2`: `"LOCAL, MERGED, REMOTE"`
* `x=3`: `"MERGED"`
Example: using `--tool=gvimdiff2` will open `gvim` with three columns (LOCAL, MERGED and REMOTE).
| programming_docs |
git gitk gitk
====
Name
----
gitk - The Git repository browser
Synopsis
--------
```
gitk [<options>] [<revision range>] [--] [<path>…]
```
Description
-----------
Displays changes in a repository or a selected set of commits. This includes visualizing the commit graph, showing information related to each commit, and the files in the trees of each revision.
Options
-------
To control which revisions to show, gitk supports most options applicable to the `git rev-list` command. It also supports a few options applicable to the `git diff-*` commands to control how the changes each commit introduces are shown. Finally, it supports some gitk-specific options.
gitk generally only understands options with arguments in the `sticked` form (see [gitcli[7]](gitcli)) due to limitations in the command-line parser.
###
rev-list options and arguments
This manual page describes only the most frequently used options. See [git-rev-list[1]](git-rev-list) for a complete list.
--all Show all refs (branches, tags, etc.).
--branches[=<pattern>] --tags[=<pattern>] --remotes[=<pattern>] Pretend as if all the branches (tags, remote branches, resp.) are listed on the command line as `<commit>`. If `<pattern>` is given, limit refs to ones matching given shell glob. If pattern lacks `?`, `*`, or `[`, `/*` at the end is implied.
--since=<date> Show commits more recent than a specific date.
--until=<date> Show commits older than a specific date.
--date-order Sort commits by date when possible.
--merge After an attempt to merge stops with conflicts, show the commits on the history between two branches (i.e. the HEAD and the MERGE\_HEAD) that modify the conflicted files and do not exist on all the heads being merged.
--left-right Mark which side of a symmetric difference a commit is reachable from. Commits from the left side are prefixed with a `<` symbol and those from the right with a `>` symbol.
--full-history When filtering history with `<path>…`, does not prune some history. (See "History simplification" in [git-log[1]](git-log) for a more detailed explanation.)
--simplify-merges Additional option to `--full-history` to remove some needless merges from the resulting history, as there are no selected commits contributing to this merge. (See "History simplification" in [git-log[1]](git-log) for a more detailed explanation.)
--ancestry-path When given a range of commits to display (e.g. `commit1..commit2` or `commit2 ^commit1`), only display commits that exist directly on the ancestry chain between the `commit1` and `commit2`, i.e. commits that are both descendants of `commit1`, and ancestors of `commit2`. (See "History simplification" in [git-log[1]](git-log) for a more detailed explanation.)
-L<start>,<end>:<file> -L:<funcname>:<file> Trace the evolution of the line range given by `<start>,<end>`, or by the function name regex `<funcname>`, within the `<file>`. You may not give any pathspec limiters. This is currently limited to a walk starting from a single revision, i.e., you may only give zero or one positive revision arguments, and `<start>` and `<end>` (or `<funcname>`) must exist in the starting revision. You can specify this option more than once. Implies `--patch`. Patch output can be suppressed using `--no-patch`, but other diff formats (namely `--raw`, `--numstat`, `--shortstat`, `--dirstat`, `--summary`, `--name-only`, `--name-status`, `--check`) are not currently implemented.
`<start>` and `<end>` can take one of these forms:
* number
If `<start>` or `<end>` is a number, it specifies an absolute line number (lines count from 1).
* `/regex/`
This form will use the first line matching the given POSIX regex. If `<start>` is a regex, it will search from the end of the previous `-L` range, if any, otherwise from the start of file. If `<start>` is `^/regex/`, it will search from the start of file. If `<end>` is a regex, it will search starting at the line given by `<start>`.
* +offset or -offset
This is only valid for `<end>` and will specify a number of lines before or after the line given by `<start>`.
If `:<funcname>` is given in place of `<start>` and `<end>`, it is a regular expression that denotes the range from the first funcname line that matches `<funcname>`, up to the next funcname line. `:<funcname>` searches from the end of the previous `-L` range, if any, otherwise from the start of file. `^:<funcname>` searches from the start of file. The function names are determined in the same way as `git diff` works out patch hunk headers (see `Defining a custom hunk-header` in [gitattributes[5]](gitattributes)).
<revision range> Limit the revisions to show. This can be either a single revision meaning show from the given revision and back, or it can be a range in the form "`<from>`..`<to>`" to show all revisions between `<from>` and back to `<to>`. Note, more advanced revision selection can be applied. For a more complete list of ways to spell object names, see [gitrevisions[7]](gitrevisions).
<path>… Limit commits to the ones touching files in the given paths. Note, to avoid ambiguity with respect to revision names use "--" to separate the paths from any preceding options.
###
gitk-specific options
--argscmd=<command> Command to be run each time gitk has to determine the revision range to show. The command is expected to print on its standard output a list of additional revisions to be shown, one per line. Use this instead of explicitly specifying a `<revision range>` if the set of commits to show may vary between refreshes.
--select-commit=<ref> Select the specified commit after loading the graph. Default behavior is equivalent to specifying `--select-commit=HEAD`.
Examples
--------
gitk v2.6.12.. include/scsi drivers/scsi Show the changes since version `v2.6.12` that changed any file in the include/scsi or drivers/scsi subdirectories
gitk --since="2 weeks ago" -- gitk Show the changes during the last two weeks to the file `gitk`. The "--" is necessary to avoid confusion with the **branch** named `gitk`
gitk --max-count=100 --all -- Makefile Show at most 100 changes made to the file `Makefile`. Instead of only looking for changes in the current branch look in all branches.
Files
-----
User configuration and preferences are stored at:
* `$XDG_CONFIG_HOME/git/gitk` if it exists, otherwise
* `$HOME/.gitk` if it exists
If neither of the above exist then `$XDG_CONFIG_HOME/git/gitk` is created and used by default. If `$XDG_CONFIG_HOME` is not set it defaults to `$HOME/.config` in all cases.
History
-------
Gitk was the first graphical repository browser. It’s written in tcl/tk.
`gitk` is actually maintained as an independent project, but stable versions are distributed as part of the Git suite for the convenience of end users.
gitk-git/ comes from Paul Mackerras’s gitk project:
```
git://ozlabs.org/~paulus/gitk
```
See also
--------
*qgit(1)* A repository browser written in C++ using Qt.
*tig(1)* A minimal repository browser and Git tool output highlighter written in C using Ncurses.
git gittutorial gittutorial
===========
Name
----
gittutorial - A tutorial introduction to Git
Synopsis
--------
```
git *
```
Description
-----------
This tutorial explains how to import a new project into Git, make changes to it, and share changes with other developers.
If you are instead primarily interested in using Git to fetch a project, for example, to test the latest version, you may prefer to start with the first two chapters of [The Git User’s Manual](user-manual).
First, note that you can get documentation for a command such as `git log --graph` with:
```
$ man git-log
```
or:
```
$ git help log
```
With the latter, you can use the manual viewer of your choice; see [git-help[1]](git-help) for more information.
It is a good idea to introduce yourself to Git with your name and public email address before doing any operation. The easiest way to do so is:
```
$ git config --global user.name "Your Name Comes Here"
$ git config --global user.email [email protected]
```
Importing a new project
-----------------------
Assume you have a tarball project.tar.gz with your initial work. You can place it under Git revision control as follows.
```
$ tar xzf project.tar.gz
$ cd project
$ git init
```
Git will reply
```
Initialized empty Git repository in .git/
```
You’ve now initialized the working directory—you may notice a new directory created, named ".git".
Next, tell Git to take a snapshot of the contents of all files under the current directory (note the `.`), with `git add`:
```
$ git add .
```
This snapshot is now stored in a temporary staging area which Git calls the "index". You can permanently store the contents of the index in the repository with `git commit`:
```
$ git commit
```
This will prompt you for a commit message. You’ve now stored the first version of your project in Git.
Making changes
--------------
Modify some files, then add their updated contents to the index:
```
$ git add file1 file2 file3
```
You are now ready to commit. You can see what is about to be committed using `git diff` with the --cached option:
```
$ git diff --cached
```
(Without --cached, `git diff` will show you any changes that you’ve made but not yet added to the index.) You can also get a brief summary of the situation with `git status`:
```
$ git status
On branch master
Changes to be committed:
Your branch is up to date with 'origin/master'.
(use "git restore --staged <file>..." to unstage)
modified: file1
modified: file2
modified: file3
```
If you need to make any further adjustments, do so now, and then add any newly modified content to the index. Finally, commit your changes with:
```
$ git commit
```
This will again prompt you for a message describing the change, and then record a new version of the project.
Alternatively, instead of running `git add` beforehand, you can use
```
$ git commit -a
```
which will automatically notice any modified (but not new) files, add them to the index, and commit, all in one step.
A note on commit messages: Though not required, it’s a good idea to begin the commit message with a single short (less than 50 character) line summarizing the change, followed by a blank line and then a more thorough description. The text up to the first blank line in a commit message is treated as the commit title, and that title is used throughout Git. For example, [git-format-patch[1]](git-format-patch) turns a commit into email, and it uses the title on the Subject line and the rest of the commit in the body.
Git tracks content not files
----------------------------
Many revision control systems provide an `add` command that tells the system to start tracking changes to a new file. Git’s `add` command does something simpler and more powerful: `git add` is used both for new and newly modified files, and in both cases it takes a snapshot of the given files and stages that content in the index, ready for inclusion in the next commit.
Viewing project history
-----------------------
At any point you can view the history of your changes using
```
$ git log
```
If you also want to see complete diffs at each step, use
```
$ git log -p
```
Often the overview of the change is useful to get a feel of each step
```
$ git log --stat --summary
```
Managing branches
-----------------
A single Git repository can maintain multiple branches of development. To create a new branch named "experimental", use
```
$ git branch experimental
```
If you now run
```
$ git branch
```
you’ll get a list of all existing branches:
```
experimental
* master
```
The "experimental" branch is the one you just created, and the "master" branch is a default branch that was created for you automatically. The asterisk marks the branch you are currently on; type
```
$ git switch experimental
```
to switch to the experimental branch. Now edit a file, commit the change, and switch back to the master branch:
```
(edit file)
$ git commit -a
$ git switch master
```
Check that the change you made is no longer visible, since it was made on the experimental branch and you’re back on the master branch.
You can make a different change on the master branch:
```
(edit file)
$ git commit -a
```
at this point the two branches have diverged, with different changes made in each. To merge the changes made in experimental into master, run
```
$ git merge experimental
```
If the changes don’t conflict, you’re done. If there are conflicts, markers will be left in the problematic files showing the conflict;
```
$ git diff
```
will show this. Once you’ve edited the files to resolve the conflicts,
```
$ git commit -a
```
will commit the result of the merge. Finally,
```
$ gitk
```
will show a nice graphical representation of the resulting history.
At this point you could delete the experimental branch with
```
$ git branch -d experimental
```
This command ensures that the changes in the experimental branch are already in the current branch.
If you develop on a branch crazy-idea, then regret it, you can always delete the branch with
```
$ git branch -D crazy-idea
```
Branches are cheap and easy, so this is a good way to try something out.
Using git for collaboration
---------------------------
Suppose that Alice has started a new project with a Git repository in /home/alice/project, and that Bob, who has a home directory on the same machine, wants to contribute.
Bob begins with:
```
bob$ git clone /home/alice/project myrepo
```
This creates a new directory "myrepo" containing a clone of Alice’s repository. The clone is on an equal footing with the original project, possessing its own copy of the original project’s history.
Bob then makes some changes and commits them:
```
(edit files)
bob$ git commit -a
(repeat as necessary)
```
When he’s ready, he tells Alice to pull changes from the repository at /home/bob/myrepo. She does this with:
```
alice$ cd /home/alice/project
alice$ git pull /home/bob/myrepo master
```
This merges the changes from Bob’s "master" branch into Alice’s current branch. If Alice has made her own changes in the meantime, then she may need to manually fix any conflicts.
The "pull" command thus performs two operations: it fetches changes from a remote branch, then merges them into the current branch.
Note that in general, Alice would want her local changes committed before initiating this "pull". If Bob’s work conflicts with what Alice did since their histories forked, Alice will use her working tree and the index to resolve conflicts, and existing local changes will interfere with the conflict resolution process (Git will still perform the fetch but will refuse to merge — Alice will have to get rid of her local changes in some way and pull again when this happens).
Alice can peek at what Bob did without merging first, using the "fetch" command; this allows Alice to inspect what Bob did, using a special symbol "FETCH\_HEAD", in order to determine if he has anything worth pulling, like this:
```
alice$ git fetch /home/bob/myrepo master
alice$ git log -p HEAD..FETCH_HEAD
```
This operation is safe even if Alice has uncommitted local changes. The range notation "HEAD..FETCH\_HEAD" means "show everything that is reachable from the FETCH\_HEAD but exclude anything that is reachable from HEAD". Alice already knows everything that leads to her current state (HEAD), and reviews what Bob has in his state (FETCH\_HEAD) that she has not seen with this command.
If Alice wants to visualize what Bob did since their histories forked she can issue the following command:
```
$ gitk HEAD..FETCH_HEAD
```
This uses the same two-dot range notation we saw earlier with `git log`.
Alice may want to view what both of them did since they forked. She can use three-dot form instead of the two-dot form:
```
$ gitk HEAD...FETCH_HEAD
```
This means "show everything that is reachable from either one, but exclude anything that is reachable from both of them".
Please note that these range notation can be used with both gitk and "git log".
After inspecting what Bob did, if there is nothing urgent, Alice may decide to continue working without pulling from Bob. If Bob’s history does have something Alice would immediately need, Alice may choose to stash her work-in-progress first, do a "pull", and then finally unstash her work-in-progress on top of the resulting history.
When you are working in a small closely knit group, it is not unusual to interact with the same repository over and over again. By defining `remote` repository shorthand, you can make it easier:
```
alice$ git remote add bob /home/bob/myrepo
```
With this, Alice can perform the first part of the "pull" operation alone using the `git fetch` command without merging them with her own branch, using:
```
alice$ git fetch bob
```
Unlike the longhand form, when Alice fetches from Bob using a remote repository shorthand set up with `git remote`, what was fetched is stored in a remote-tracking branch, in this case `bob/master`. So after this:
```
alice$ git log -p master..bob/master
```
shows a list of all the changes that Bob made since he branched from Alice’s master branch.
After examining those changes, Alice could merge the changes into her master branch:
```
alice$ git merge bob/master
```
This `merge` can also be done by `pulling from her own remote-tracking branch`, like this:
```
alice$ git pull . remotes/bob/master
```
Note that git pull always merges into the current branch, regardless of what else is given on the command line.
Later, Bob can update his repo with Alice’s latest changes using
```
bob$ git pull
```
Note that he doesn’t need to give the path to Alice’s repository; when Bob cloned Alice’s repository, Git stored the location of her repository in the repository configuration, and that location is used for pulls:
```
bob$ git config --get remote.origin.url
/home/alice/project
```
(The complete configuration created by `git clone` is visible using `git config -l`, and the [git-config[1]](git-config) man page explains the meaning of each option.)
Git also keeps a pristine copy of Alice’s master branch under the name "origin/master":
```
bob$ git branch -r
origin/master
```
If Bob later decides to work from a different host, he can still perform clones and pulls using the ssh protocol:
```
bob$ git clone alice.org:/home/alice/project myrepo
```
Alternatively, Git has a native protocol, or can use http; see [git-pull[1]](git-pull) for details.
Git can also be used in a CVS-like mode, with a central repository that various users push changes to; see [git-push[1]](git-push) and [gitcvs-migration[7]](gitcvs-migration).
Exploring history
-----------------
Git history is represented as a series of interrelated commits. We have already seen that the `git log` command can list those commits. Note that first line of each git log entry also gives a name for the commit:
```
$ git log
commit c82a22c39cbc32576f64f5c6b3f24b99ea8149c7
Author: Junio C Hamano <[email protected]>
Date: Tue May 16 17:18:22 2006 -0700
merge-base: Clarify the comments on post processing.
```
We can give this name to `git show` to see the details about this commit.
```
$ git show c82a22c39cbc32576f64f5c6b3f24b99ea8149c7
```
But there are other ways to refer to commits. You can use any initial part of the name that is long enough to uniquely identify the commit:
```
$ git show c82a22c39c # the first few characters of the name are
# usually enough
$ git show HEAD # the tip of the current branch
$ git show experimental # the tip of the "experimental" branch
```
Every commit usually has one "parent" commit which points to the previous state of the project:
```
$ git show HEAD^ # to see the parent of HEAD
$ git show HEAD^^ # to see the grandparent of HEAD
$ git show HEAD~4 # to see the great-great grandparent of HEAD
```
Note that merge commits may have more than one parent:
```
$ git show HEAD^1 # show the first parent of HEAD (same as HEAD^)
$ git show HEAD^2 # show the second parent of HEAD
```
You can also give commits names of your own; after running
```
$ git tag v2.5 1b2e1d63ff
```
you can refer to 1b2e1d63ff by the name "v2.5". If you intend to share this name with other people (for example, to identify a release version), you should create a "tag" object, and perhaps sign it; see [git-tag[1]](git-tag) for details.
Any Git command that needs to know a commit can take any of these names. For example:
```
$ git diff v2.5 HEAD # compare the current HEAD to v2.5
$ git branch stable v2.5 # start a new branch named "stable" based
# at v2.5
$ git reset --hard HEAD^ # reset your current branch and working
# directory to its state at HEAD^
```
Be careful with that last command: in addition to losing any changes in the working directory, it will also remove all later commits from this branch. If this branch is the only branch containing those commits, they will be lost. Also, don’t use `git reset` on a publicly-visible branch that other developers pull from, as it will force needless merges on other developers to clean up the history. If you need to undo changes that you have pushed, use `git revert` instead.
The `git grep` command can search for strings in any version of your project, so
```
$ git grep "hello" v2.5
```
searches for all occurrences of "hello" in v2.5.
If you leave out the commit name, `git grep` will search any of the files it manages in your current directory. So
```
$ git grep "hello"
```
is a quick way to search just the files that are tracked by Git.
Many Git commands also take sets of commits, which can be specified in a number of ways. Here are some examples with `git log`:
```
$ git log v2.5..v2.6 # commits between v2.5 and v2.6
$ git log v2.5.. # commits since v2.5
$ git log --since="2 weeks ago" # commits from the last 2 weeks
$ git log v2.5.. Makefile # commits since v2.5 which modify
# Makefile
```
You can also give `git log` a "range" of commits where the first is not necessarily an ancestor of the second; for example, if the tips of the branches "stable" and "master" diverged from a common commit some time ago, then
```
$ git log stable..master
```
will list commits made in the master branch but not in the stable branch, while
```
$ git log master..stable
```
will show the list of commits made on the stable branch but not the master branch.
The `git log` command has a weakness: it must present commits in a list. When the history has lines of development that diverged and then merged back together, the order in which `git log` presents those commits is meaningless.
Most projects with multiple contributors (such as the Linux kernel, or Git itself) have frequent merges, and `gitk` does a better job of visualizing their history. For example,
```
$ gitk --since="2 weeks ago" drivers/
```
allows you to browse any commits from the last 2 weeks of commits that modified files under the "drivers" directory. (Note: you can adjust gitk’s fonts by holding down the control key while pressing "-" or "+".)
Finally, most commands that take filenames will optionally allow you to precede any filename by a commit, to specify a particular version of the file:
```
$ git diff v2.5:Makefile HEAD:Makefile.in
```
You can also use `git show` to see any such file:
```
$ git show v2.5:Makefile
```
Next steps
----------
This tutorial should be enough to perform basic distributed revision control for your projects. However, to fully understand the depth and power of Git you need to understand two simple ideas on which it is based:
* The object database is the rather elegant system used to store the history of your project—files, directories, and commits.
* The index file is a cache of the state of a directory tree, used to create commits, check out working directories, and hold the various trees involved in a merge.
Part two of this tutorial explains the object database, the index file, and a few other odds and ends that you’ll need to make the most of Git. You can find it at [gittutorial-2[7]](gittutorial-2).
If you don’t want to continue with that right away, a few other digressions that may be interesting at this point are:
* [git-format-patch[1]](git-format-patch), [git-am[1]](git-am): These convert series of git commits into emailed patches, and vice versa, useful for projects such as the Linux kernel which rely heavily on emailed patches.
* [git-bisect[1]](git-bisect): When there is a regression in your project, one way to track down the bug is by searching through the history to find the exact commit that’s to blame. Git bisect can help you perform a binary search for that commit. It is smart enough to perform a close-to-optimal search even in the case of complex non-linear history with lots of merged branches.
* [gitworkflows[7]](gitworkflows): Gives an overview of recommended workflows.
* [giteveryday[7]](giteveryday): Everyday Git with 20 Commands Or So.
* [gitcvs-migration[7]](gitcvs-migration): Git for CVS users.
See also
--------
[gittutorial-2[7]](gittutorial-2), [gitcvs-migration[7]](gitcvs-migration), [gitcore-tutorial[7]](gitcore-tutorial), [gitglossary[7]](gitglossary), [git-help[1]](git-help), [gitworkflows[7]](gitworkflows), [giteveryday[7]](giteveryday), [The Git User’s Manual](user-manual)
| programming_docs |
git git-revert git-revert
==========
Name
----
git-revert - Revert some existing commits
Synopsis
--------
```
git revert [--[no-]edit] [-n] [-m <parent-number>] [-s] [-S[<keyid>]] <commit>…
git revert (--continue | --skip | --abort | --quit)
```
Description
-----------
Given one or more existing commits, revert the changes that the related patches introduce, and record some new commits that record them. This requires your working tree to be clean (no modifications from the HEAD commit).
Note: `git revert` is used to record some new commits to reverse the effect of some earlier commits (often only a faulty one). If you want to throw away all uncommitted changes in your working directory, you should see [git-reset[1]](git-reset), particularly the `--hard` option. If you want to extract specific files as they were in another commit, you should see [git-restore[1]](git-restore), specifically the `--source` option. Take care with these alternatives as both will discard uncommitted changes in your working directory.
See "Reset, restore and revert" in [git[1]](git) for the differences between the three commands.
Options
-------
<commit>… Commits to revert. For a more complete list of ways to spell commit names, see [gitrevisions[7]](gitrevisions). Sets of commits can also be given but no traversal is done by default, see [git-rev-list[1]](git-rev-list) and its `--no-walk` option.
-e --edit With this option, `git revert` will let you edit the commit message prior to committing the revert. This is the default if you run the command from a terminal.
-m parent-number --mainline parent-number Usually you cannot revert a merge because you do not know which side of the merge should be considered the mainline. This option specifies the parent number (starting from 1) of the mainline and allows revert to reverse the change relative to the specified parent.
Reverting a merge commit declares that you will never want the tree changes brought in by the merge. As a result, later merges will only bring in tree changes introduced by commits that are not ancestors of the previously reverted merge. This may or may not be what you want.
See the [revert-a-faulty-merge How-To](https://git-scm.com/docs/howto/revert-a-faulty-merge) for more details.
--no-edit With this option, `git revert` will not start the commit message editor.
--cleanup=<mode> This option determines how the commit message will be cleaned up before being passed on to the commit machinery. See [git-commit[1]](git-commit) for more details. In particular, if the `<mode>` is given a value of `scissors`, scissors will be appended to `MERGE_MSG` before being passed on in the case of a conflict.
-n --no-commit Usually the command automatically creates some commits with commit log messages stating which commits were reverted. This flag applies the changes necessary to revert the named commits to your working tree and the index, but does not make the commits. In addition, when this option is used, your index does not have to match the HEAD commit. The revert is done against the beginning state of your index.
This is useful when reverting more than one commits' effect to your index in a row.
-S[<keyid>] --gpg-sign[=<keyid>] --no-gpg-sign GPG-sign commits. The `keyid` argument is optional and defaults to the committer identity; if specified, it must be stuck to the option without a space. `--no-gpg-sign` is useful to countermand both `commit.gpgSign` configuration variable, and earlier `--gpg-sign`.
-s --signoff Add a `Signed-off-by` trailer at the end of the commit message. See the signoff option in [git-commit[1]](git-commit) for more information.
--strategy=<strategy> Use the given merge strategy. Should only be used once. See the MERGE STRATEGIES section in [git-merge[1]](git-merge) for details.
-X<option> --strategy-option=<option> Pass the merge strategy-specific option through to the merge strategy. See [git-merge[1]](git-merge) for details.
--rerere-autoupdate --no-rerere-autoupdate After the rerere mechanism reuses a recorded resolution on the current conflict to update the files in the working tree, allow it to also update the index with the result of resolution. `--no-rerere-autoupdate` is a good way to double-check what `rerere` did and catch potential mismerges, before committing the result to the index with a separate `git add`.
--reference Instead of starting the body of the log message with "This reverts <full object name of the commit being reverted>.", refer to the commit using "--pretty=reference" format (cf. [git-log[1]](git-log)). The `revert.reference` configuration variable can be used to enable this option by default.
Sequencer subcommands
---------------------
--continue Continue the operation in progress using the information in `.git/sequencer`. Can be used to continue after resolving conflicts in a failed cherry-pick or revert.
--skip Skip the current commit and continue with the rest of the sequence.
--quit Forget about the current operation in progress. Can be used to clear the sequencer state after a failed cherry-pick or revert.
--abort Cancel the operation and return to the pre-sequence state.
Examples
--------
`git revert HEAD~3` Revert the changes specified by the fourth last commit in HEAD and create a new commit with the reverted changes.
`git revert -n master~5..master~2` Revert the changes done by commits from the fifth last commit in master (included) to the third last commit in master (included), but do not create any commit with the reverted changes. The revert only modifies the working tree and the index.
Configuration
-------------
Everything below this line in this section is selectively included from the [git-config[1]](git-config) documentation. The content is the same as what’s found there:
revert.reference Setting this variable to true makes `git revert` behave as if the `--reference` option is given.
See also
--------
[git-cherry-pick[1]](git-cherry-pick)
git scalar scalar
======
Name
----
scalar - A tool for managing large Git repositories
Synopsis
--------
```
scalar clone [--single-branch] [--branch <main-branch>] [--full-clone] <url> [<enlistment>]
scalar list
scalar register [<enlistment>]
scalar unregister [<enlistment>]
scalar run ( all | config | commit-graph | fetch | loose-objects | pack-files ) [<enlistment>]
scalar reconfigure [ --all | <enlistment> ]
scalar diagnose [<enlistment>]
scalar delete <enlistment>
```
Description
-----------
Scalar is a repository management tool that optimizes Git for use in large repositories. Scalar improves performance by configuring advanced Git settings, maintaining repositories in the background, and helping to reduce data sent across the network.
An important Scalar concept is the enlistment: this is the top-level directory of the project. It usually contains the subdirectory `src/` which is a Git worktree. This encourages the separation between tracked files (inside `src/`) and untracked files, such as build artifacts (outside `src/`). When registering an existing Git worktree with Scalar whose name is not `src`, the enlistment will be identical to the worktree.
The `scalar` command implements various subcommands, and different options depending on the subcommand. With the exception of `clone`, `list` and `reconfigure --all`, all subcommands expect to be run in an enlistment.
The following options can be specified `before` the subcommand:
-C <directory> Before running the subcommand, change the working directory. This option imitates the same option of [git[1]](git).
-c <key>=<value> For the duration of running the specified subcommand, configure this setting. This option imitates the same option of [git[1]](git).
Commands
--------
###
Clone
clone [<options>] <url> [<enlistment>] Clones the specified repository, similar to [git-clone[1]](git-clone). By default, only commit and tree objects are cloned. Once finished, the worktree is located at `<enlistment>/src`.
The sparse-checkout feature is enabled (except when run with `--full-clone`) and the only files present are those in the top-level directory. Use `git sparse-checkout set` to expand the set of directories you want to see, or `git sparse-checkout disable` to expand to all files (see [git-sparse-checkout[1]](git-sparse-checkout) for more details). You can explore the subdirectories outside your sparse-checkout by using `git ls-tree
HEAD[:<directory>]`.
-b <name> --branch <name> Instead of checking out the branch pointed to by the cloned repository’s HEAD, check out the `<name>` branch instead.
--[no-]single-branch Clone only the history leading to the tip of a single branch, either specified by the `--branch` option or the primary branch remote’s `HEAD` points at.
Further fetches into the resulting repository will only update the remote-tracking branch for the branch this option was used for the initial cloning. If the HEAD at the remote did not point at any branch when `--single-branch` clone was made, no remote-tracking branch is created.
--[no-]full-clone A sparse-checkout is initialized by default. This behavior can be turned off via `--full-clone`.
###
List
list List enlistments that are currently registered by Scalar. This subcommand does not need to be run inside an enlistment.
###
Register
register [<enlistment>] Adds the enlistment’s repository to the list of registered repositories and starts background maintenance. If `<enlistment>` is not provided, then the enlistment associated with the current working directory is registered.
Note: when this subcommand is called in a worktree that is called `src/`, its parent directory is considered to be the Scalar enlistment. If the worktree is `not` called `src/`, it itself will be considered to be the Scalar enlistment.
###
Unregister
unregister [<enlistment>] Remove the specified repository from the list of repositories registered with Scalar and stop the scheduled background maintenance.
###
Run
scalar run ( all | config | commit-graph | fetch | loose-objects | pack-files ) [<enlistment>] Run the given maintenance task (or all tasks, if `all` was specified). Except for `all` and `config`, this subcommand simply hands off to [git-maintenance[1]](git-maintenance) (mapping `fetch` to `prefetch` and `pack-files` to `incremental-repack`).
These tasks are run automatically as part of the scheduled maintenance, as soon as the repository is registered with Scalar. It should therefore not be necessary to run this subcommand manually.
The `config` task is specific to Scalar and configures all those opinionated default settings that make Git work more efficiently with large repositories. As this task is run as part of `scalar clone` automatically, explicit invocations of this task are rarely needed.
###
Reconfigure
After a Scalar upgrade, or when the configuration of a Scalar enlistment was somehow corrupted or changed by mistake, this subcommand allows to reconfigure the enlistment.
With the `--all` option, all enlistments currently registered with Scalar will be reconfigured. Use this option after each Scalar upgrade.
###
Diagnose
diagnose [<enlistment>] When reporting issues with Scalar, it is often helpful to provide the information gathered by this command, including logs and certain statistics describing the data shape of the current enlistment.
The output of this command is a `.zip` file that is written into a directory adjacent to the worktree in the `src` directory.
###
Delete
delete <enlistment> This subcommand lets you delete an existing Scalar enlistment from your local file system, unregistering the repository.
See also
--------
[git-clone[1]](git-clone), [git-maintenance[1]](git-maintenance).
git git-stash git-stash
=========
Name
----
git-stash - Stash the changes in a dirty working directory away
Synopsis
--------
```
git stash list [<log-options>]
git stash show [-u | --include-untracked | --only-untracked] [<diff-options>] [<stash>]
git stash drop [-q | --quiet] [<stash>]
git stash pop [--index] [-q | --quiet] [<stash>]
git stash apply [--index] [-q | --quiet] [<stash>]
git stash branch <branchname> [<stash>]
git stash [push [-p | --patch] [-S | --staged] [-k | --[no-]keep-index] [-q | --quiet]
[-u | --include-untracked] [-a | --all] [(-m | --message) <message>]
[--pathspec-from-file=<file> [--pathspec-file-nul]]
[--] [<pathspec>…]]
git stash save [-p | --patch] [-S | --staged] [-k | --[no-]keep-index] [-q | --quiet]
[-u | --include-untracked] [-a | --all] [<message>]
git stash clear
git stash create [<message>]
git stash store [(-m | --message) <message>] [-q | --quiet] <commit>
```
Description
-----------
Use `git stash` when you want to record the current state of the working directory and the index, but want to go back to a clean working directory. The command saves your local modifications away and reverts the working directory to match the `HEAD` commit.
The modifications stashed away by this command can be listed with `git stash list`, inspected with `git stash show`, and restored (potentially on top of a different commit) with `git stash apply`. Calling `git stash` without any arguments is equivalent to `git stash push`. A stash is by default listed as "WIP on `branchname` …", but you can give a more descriptive message on the command line when you create one.
The latest stash you created is stored in `refs/stash`; older stashes are found in the reflog of this reference and can be named using the usual reflog syntax (e.g. `stash@{0}` is the most recently created stash, `stash@{1}` is the one before it, `stash@{2.hours.ago}` is also possible). Stashes may also be referenced by specifying just the stash index (e.g. the integer `n` is equivalent to `stash@{n}`).
Commands
--------
push [-p|--patch] [-S|--staged] [-k|--[no-]keep-index] [-u|--include-untracked] [-a|--all] [-q|--quiet] [(-m|--message) <message>] [--pathspec-from-file=<file> [--pathspec-file-nul]] [--] [<pathspec>…] Save your local modifications to a new `stash entry` and roll them back to HEAD (in the working tree and in the index). The <message> part is optional and gives the description along with the stashed state.
For quickly making a snapshot, you can omit "push". In this mode, non-option arguments are not allowed to prevent a misspelled subcommand from making an unwanted stash entry. The two exceptions to this are `stash -p` which acts as alias for `stash push -p` and pathspec elements, which are allowed after a double hyphen `--` for disambiguation.
save [-p|--patch] [-S|--staged] [-k|--[no-]keep-index] [-u|--include-untracked] [-a|--all] [-q|--quiet] [<message>] This option is deprecated in favour of `git stash push`. It differs from "stash push" in that it cannot take pathspec. Instead, all non-option arguments are concatenated to form the stash message.
list [<log-options>] List the stash entries that you currently have. Each `stash entry` is listed with its name (e.g. `stash@{0}` is the latest entry, `stash@{1}` is the one before, etc.), the name of the branch that was current when the entry was made, and a short description of the commit the entry was based on.
```
stash@{0}: WIP on submit: 6ebd0e2... Update git-stash documentation
stash@{1}: On master: 9cc0589... Add git-stash
```
The command takes options applicable to the `git log` command to control what is shown and how. See [git-log[1]](git-log).
show [-u|--include-untracked|--only-untracked] [<diff-options>] [<stash>] Show the changes recorded in the stash entry as a diff between the stashed contents and the commit back when the stash entry was first created. By default, the command shows the diffstat, but it will accept any format known to `git diff` (e.g., `git stash show -p stash@{1}` to view the second most recent entry in patch form). If no `<diff-option>` is provided, the default behavior will be given by the `stash.showStat`, and `stash.showPatch` config variables. You can also use `stash.showIncludeUntracked` to set whether `--include-untracked` is enabled by default.
pop [--index] [-q|--quiet] [<stash>] Remove a single stashed state from the stash list and apply it on top of the current working tree state, i.e., do the inverse operation of `git stash push`. The working directory must match the index.
Applying the state can fail with conflicts; in this case, it is not removed from the stash list. You need to resolve the conflicts by hand and call `git stash drop` manually afterwards.
apply [--index] [-q|--quiet] [<stash>] Like `pop`, but do not remove the state from the stash list. Unlike `pop`, `<stash>` may be any commit that looks like a commit created by `stash push` or `stash create`.
branch <branchname> [<stash>] Creates and checks out a new branch named `<branchname>` starting from the commit at which the `<stash>` was originally created, applies the changes recorded in `<stash>` to the new working tree and index. If that succeeds, and `<stash>` is a reference of the form `stash@{<revision>}`, it then drops the `<stash>`.
This is useful if the branch on which you ran `git stash push` has changed enough that `git stash apply` fails due to conflicts. Since the stash entry is applied on top of the commit that was HEAD at the time `git stash` was run, it restores the originally stashed state with no conflicts.
clear Remove all the stash entries. Note that those entries will then be subject to pruning, and may be impossible to recover (see `Examples` below for a possible strategy).
drop [-q|--quiet] [<stash>] Remove a single stash entry from the list of stash entries.
create Create a stash entry (which is a regular commit object) and return its object name, without storing it anywhere in the ref namespace. This is intended to be useful for scripts. It is probably not the command you want to use; see "push" above.
store Store a given stash created via `git stash create` (which is a dangling merge commit) in the stash ref, updating the stash reflog. This is intended to be useful for scripts. It is probably not the command you want to use; see "push" above.
Options
-------
-a --all This option is only valid for `push` and `save` commands.
All ignored and untracked files are also stashed and then cleaned up with `git clean`.
-u --include-untracked --no-include-untracked When used with the `push` and `save` commands, all untracked files are also stashed and then cleaned up with `git clean`.
When used with the `show` command, show the untracked files in the stash entry as part of the diff.
--only-untracked This option is only valid for the `show` command.
Show only the untracked files in the stash entry as part of the diff.
--index This option is only valid for `pop` and `apply` commands.
Tries to reinstate not only the working tree’s changes, but also the index’s ones. However, this can fail, when you have conflicts (which are stored in the index, where you therefore can no longer apply the changes as they were originally).
-k --keep-index --no-keep-index This option is only valid for `push` and `save` commands.
All changes already added to the index are left intact.
-p --patch This option is only valid for `push` and `save` commands.
Interactively select hunks from the diff between HEAD and the working tree to be stashed. The stash entry is constructed such that its index state is the same as the index state of your repository, and its worktree contains only the changes you selected interactively. The selected changes are then rolled back from your worktree. See the “Interactive Mode” section of [git-add[1]](git-add) to learn how to operate the `--patch` mode.
The `--patch` option implies `--keep-index`. You can use `--no-keep-index` to override this.
-S --staged This option is only valid for `push` and `save` commands.
Stash only the changes that are currently staged. This is similar to basic `git commit` except the state is committed to the stash instead of current branch.
The `--patch` option has priority over this one.
--pathspec-from-file=<file> This option is only valid for `push` command.
Pathspec is passed in `<file>` instead of commandline args. If `<file>` is exactly `-` then standard input is used. Pathspec elements are separated by LF or CR/LF. Pathspec elements can be quoted as explained for the configuration variable `core.quotePath` (see [git-config[1]](git-config)). See also `--pathspec-file-nul` and global `--literal-pathspecs`.
--pathspec-file-nul This option is only valid for `push` command.
Only meaningful with `--pathspec-from-file`. Pathspec elements are separated with NUL character and all other characters are taken literally (including newlines and quotes).
-q --quiet This option is only valid for `apply`, `drop`, `pop`, `push`, `save`, `store` commands.
Quiet, suppress feedback messages.
-- This option is only valid for `push` command.
Separates pathspec from options for disambiguation purposes.
<pathspec>… This option is only valid for `push` command.
The new stash entry records the modified states only for the files that match the pathspec. The index entries and working tree files are then rolled back to the state in HEAD only for these files, too, leaving files that do not match the pathspec intact.
For more details, see the `pathspec` entry in [gitglossary[7]](gitglossary).
<stash> This option is only valid for `apply`, `branch`, `drop`, `pop`, `show` commands.
A reference of the form `stash@{<revision>}`. When no `<stash>` is given, the latest stash is assumed (that is, `stash@{0}`).
Discussion
----------
A stash entry is represented as a commit whose tree records the state of the working directory, and its first parent is the commit at `HEAD` when the entry was created. The tree of the second parent records the state of the index when the entry is made, and it is made a child of the `HEAD` commit. The ancestry graph looks like this:
```
.----W
/ /
-----H----I
```
where `H` is the `HEAD` commit, `I` is a commit that records the state of the index, and `W` is a commit that records the state of the working tree.
Examples
--------
Pulling into a dirty tree When you are in the middle of something, you learn that there are upstream changes that are possibly relevant to what you are doing. When your local changes do not conflict with the changes in the upstream, a simple `git pull` will let you move forward.
However, there are cases in which your local changes do conflict with the upstream changes, and `git pull` refuses to overwrite your changes. In such a case, you can stash your changes away, perform a pull, and then unstash, like this:
```
$ git pull
...
file foobar not up to date, cannot merge.
$ git stash
$ git pull
$ git stash pop
```
Interrupted workflow When you are in the middle of something, your boss comes in and demands that you fix something immediately. Traditionally, you would make a commit to a temporary branch to store your changes away, and return to your original branch to make the emergency fix, like this:
```
# ... hack hack hack ...
$ git switch -c my_wip
$ git commit -a -m "WIP"
$ git switch master
$ edit emergency fix
$ git commit -a -m "Fix in a hurry"
$ git switch my_wip
$ git reset --soft HEAD^
# ... continue hacking ...
```
You can use `git stash` to simplify the above, like this:
```
# ... hack hack hack ...
$ git stash
$ edit emergency fix
$ git commit -a -m "Fix in a hurry"
$ git stash pop
# ... continue hacking ...
```
Testing partial commits You can use `git stash push --keep-index` when you want to make two or more commits out of the changes in the work tree, and you want to test each change before committing:
```
# ... hack hack hack ...
$ git add --patch foo # add just first part to the index
$ git stash push --keep-index # save all other changes to the stash
$ edit/build/test first part
$ git commit -m 'First part' # commit fully tested change
$ git stash pop # prepare to work on all other changes
# ... repeat above five steps until one commit remains ...
$ edit/build/test remaining parts
$ git commit foo -m 'Remaining parts'
```
Saving unrelated changes for future use When you are in the middle of massive changes and you find some unrelated issue that you don’t want to forget to fix, you can do the change(s), stage them, and use `git stash push --staged` to stash them out for future use. This is similar to committing the staged changes, only the commit ends-up being in the stash and not on the current branch.
```
# ... hack hack hack ...
$ git add --patch foo # add unrelated changes to the index
$ git stash push --staged # save these changes to the stash
# ... hack hack hack, finish curent changes ...
$ git commit -m 'Massive' # commit fully tested changes
$ git switch fixup-branch # switch to another branch
$ git stash pop # to finish work on the saved changes
```
Recovering stash entries that were cleared/dropped erroneously If you mistakenly drop or clear stash entries, they cannot be recovered through the normal safety mechanisms. However, you can try the following incantation to get a list of stash entries that are still in your repository, but not reachable any more:
```
git fsck --unreachable |
grep commit | cut -d\ -f3 |
xargs git log --merges --no-walk --grep=WIP
```
Configuration
-------------
Everything below this line in this section is selectively included from the [git-config[1]](git-config) documentation. The content is the same as what’s found there:
stash.showIncludeUntracked If this is set to true, the `git stash show` command will show the untracked files of a stash entry. Defaults to false. See description of `show` command in [git-stash[1]](git-stash).
stash.showPatch If this is set to true, the `git stash show` command without an option will show the stash entry in patch form. Defaults to false. See description of `show` command in [git-stash[1]](git-stash).
stash.showStat If this is set to true, the `git stash show` command without an option will show diffstat of the stash entry. Defaults to true. See description of `show` command in [git-stash[1]](git-stash).
See also
--------
[git-checkout[1]](git-checkout), [git-commit[1]](git-commit), [git-reflog[1]](git-reflog), [git-reset[1]](git-reset), [git-switch[1]](git-switch)
| programming_docs |
git git-pack-redundant git-pack-redundant
==================
Name
----
git-pack-redundant - Find redundant pack files
Synopsis
--------
```
git pack-redundant [--verbose] [--alt-odb] (--all | <pack-filename>…)
```
Description
-----------
This program computes which packs in your repository are redundant. The output is suitable for piping to `xargs rm` if you are in the root of the repository.
`git pack-redundant` accepts a list of objects on standard input. Any objects given will be ignored when checking which packs are required. This makes the following command useful when wanting to remove packs which contain unreachable objects.
git fsck --full --unreachable | cut -d ' ' -f3 | \ git pack-redundant --all | xargs rm
Options
-------
--all Processes all packs. Any filenames on the command line are ignored.
--alt-odb Don’t require objects present in packs from alternate object database (odb) directories to be present in local packs.
--verbose Outputs some statistics to stderr. Has a small performance penalty.
See also
--------
[git-pack-objects[1]](git-pack-objects) [git-repack[1]](git-repack) [git-prune-packed[1]](git-prune-packed)
git git-http-fetch git-http-fetch
==============
Name
----
git-http-fetch - Download from a remote Git repository via HTTP
Synopsis
--------
```
git http-fetch [-c] [-t] [-a] [-d] [-v] [-w <filename>] [--recover] [--stdin | --packfile=<hash> | <commit>] <URL>
```
Description
-----------
Downloads a remote Git repository via HTTP.
This command always gets all objects. Historically, there were three options `-a`, `-c` and `-t` for choosing which objects to download. They are now silently ignored.
Options
-------
commit-id Either the hash or the filename under [URL]/refs/ to pull.
-a, -c, -t These options are ignored for historical reasons.
-v Report what is downloaded.
-w <filename> Writes the commit-id into the filename under $GIT\_DIR/refs/<filename> on the local end after the transfer is complete.
--stdin Instead of a commit id on the command line (which is not expected in this case), `git http-fetch` expects lines on stdin in the format
```
<commit-id>['\t'<filename-as-in--w>]
```
--packfile=<hash> For internal use only. Instead of a commit id on the command line (which is not expected in this case), `git http-fetch` fetches the packfile directly at the given URL and uses index-pack to generate corresponding .idx and .keep files. The hash is used to determine the name of the temporary file and is arbitrary. The output of index-pack is printed to stdout. Requires --index-pack-args.
--index-pack-args=<args> For internal use only. The command to run on the contents of the downloaded pack. Arguments are URL-encoded separated by spaces.
--recover Verify that everything reachable from target is fetched. Used after an earlier fetch is interrupted.
git git-remote-ext git-remote-ext
==============
Name
----
git-remote-ext - Bridge smart transport to external command.
Synopsis
--------
```
git remote add <nick> "ext::<command>[ <arguments>…]"
```
Description
-----------
This remote helper uses the specified `<command>` to connect to a remote Git server.
Data written to stdin of the specified `<command>` is assumed to be sent to a git:// server, git-upload-pack, git-receive-pack or git-upload-archive (depending on situation), and data read from stdout of <command> is assumed to be received from the same service.
Command and arguments are separated by an unescaped space.
The following sequences have a special meaning:
'% ' Literal space in command or argument.
*%%* Literal percent sign.
*%s* Replaced with name (receive-pack, upload-pack, or upload-archive) of the service Git wants to invoke.
*%S* Replaced with long name (git-receive-pack, git-upload-pack, or git-upload-archive) of the service Git wants to invoke.
*%G* (must be the first characters in an argument) This argument will not be passed to `<command>`. Instead, it will cause the helper to start by sending git:// service requests to the remote side with the service field set to an appropriate value and the repository field set to rest of the argument. Default is not to send such a request.
This is useful if remote side is git:// server accessed over some tunnel.
*%V* (must be first characters in argument) This argument will not be passed to `<command>`. Instead it sets the vhost field in the git:// service request (to rest of the argument). Default is not to send vhost in such request (if sent).
Environment variables
---------------------
GIT\_TRANSLOOP\_DEBUG If set, prints debugging information about various reads/writes.
Environment variables passed to command
---------------------------------------
GIT\_EXT\_SERVICE Set to long name (git-upload-pack, etc…) of service helper needs to invoke.
GIT\_EXT\_SERVICE\_NOPREFIX Set to long name (upload-pack, etc…) of service helper needs to invoke.
Examples
--------
This remote helper is transparently used by Git when you use commands such as "git fetch <URL>", "git clone <URL>", , "git push <URL>" or "git remote add <nick> <URL>", where <URL> begins with `ext::`. Examples:
"ext::ssh -i /home/foo/.ssh/somekey [email protected] %S *foo/repo*" Like host.example:foo/repo, but use /home/foo/.ssh/somekey as keypair and user as user on remote side. This avoids needing to edit .ssh/config.
"ext::socat -t3600 - ABSTRACT-CONNECT:/git-server %G/somerepo" Represents repository with path /somerepo accessible over git protocol at abstract namespace address /git-server.
"ext::git-server-alias foo %G/repo" Represents a repository with path /repo accessed using the helper program "git-server-alias foo". The path to the repository and type of request are not passed on the command line but as part of the protocol stream, as usual with git:// protocol.
"ext::git-server-alias foo %G/repo %Vfoo" Represents a repository with path /repo accessed using the helper program "git-server-alias foo". The hostname for the remote server passed in the protocol stream will be "foo" (this allows multiple virtual Git servers to share a link-level address).
"ext::git-server-alias foo %G/repo% with% spaces %Vfoo" Represents a repository with path `/repo with spaces` accessed using the helper program "git-server-alias foo". The hostname for the remote server passed in the protocol stream will be "foo" (this allows multiple virtual Git servers to share a link-level address).
"ext::git-ssl foo.example /bar" Represents a repository accessed using the helper program "git-ssl foo.example /bar". The type of request can be determined by the helper using environment variables (see above).
See also
--------
[gitremote-helpers[7]](gitremote-helpers)
git gitweb.conf gitweb.conf
===========
Name
----
gitweb.conf - Gitweb (Git web interface) configuration file
Synopsis
--------
/etc/gitweb.conf, /etc/gitweb-common.conf, $GITWEBDIR/gitweb\_config.perl
Description
-----------
The gitweb CGI script for viewing Git repositories over the web uses a perl script fragment as its configuration file. You can set variables using "`our $variable = value`"; text from a "#" character until the end of a line is ignored. See **perlsyn**(1) for details.
An example:
```
# gitweb configuration file for http://git.example.org
#
our $projectroot = "/srv/git"; # FHS recommendation
our $site_name = 'Example.org >> Repos';
```
The configuration file is used to override the default settings that were built into gitweb at the time the `gitweb.cgi` script was generated.
While one could just alter the configuration settings in the gitweb CGI itself, those changes would be lost upon upgrade. Configuration settings might also be placed into a file in the same directory as the CGI script with the default name `gitweb_config.perl` — allowing one to have multiple gitweb instances with different configurations by the use of symlinks.
Note that some configuration can be controlled on per-repository rather than gitweb-wide basis: see "Per-repository gitweb configuration" subsection on [gitweb[1]](gitweb) manpage.
Discussion
----------
Gitweb reads configuration data from the following sources in the following order:
* built-in values (some set during build stage),
* common system-wide configuration file (defaults to `/etc/gitweb-common.conf`),
* either per-instance configuration file (defaults to `gitweb_config.perl` in the same directory as the installed gitweb), or if it does not exists then fallback system-wide configuration file (defaults to `/etc/gitweb.conf`).
Values obtained in later configuration files override values obtained earlier in the above sequence.
Locations of the common system-wide configuration file, the fallback system-wide configuration file and the per-instance configuration file are defined at compile time using build-time Makefile configuration variables, respectively `GITWEB_CONFIG_COMMON`, `GITWEB_CONFIG_SYSTEM` and `GITWEB_CONFIG`.
You can also override locations of gitweb configuration files during runtime by setting the following environment variables: `GITWEB_CONFIG_COMMON`, `GITWEB_CONFIG_SYSTEM` and `GITWEB_CONFIG` to a non-empty value.
The syntax of the configuration files is that of Perl, since these files are handled by sourcing them as fragments of Perl code (the language that gitweb itself is written in). Variables are typically set using the `our` qualifier (as in "`our $variable = <value>;`") to avoid syntax errors if a new version of gitweb no longer uses a variable and therefore stops declaring it.
You can include other configuration file using read\_config\_file() subroutine. For example, one might want to put gitweb configuration related to access control for viewing repositories via Gitolite (one of Git repository management tools) in a separate file, e.g. in `/etc/gitweb-gitolite.conf`. To include it, put
```
read_config_file("/etc/gitweb-gitolite.conf");
```
somewhere in gitweb configuration file used, e.g. in per-installation gitweb configuration file. Note that read\_config\_file() checks itself that the file it reads exists, and does nothing if it is not found. It also handles errors in included file.
The default configuration with no configuration file at all may work perfectly well for some installations. Still, a configuration file is useful for customizing or tweaking the behavior of gitweb in many ways, and some optional features will not be present unless explicitly enabled using the configurable `%features` variable (see also "Configuring gitweb features" section below).
Configuration variables
-----------------------
Some configuration variables have their default values (embedded in the CGI script) set during building gitweb — if that is the case, this fact is put in their description. See gitweb’s `INSTALL` file for instructions on building and installing gitweb.
###
Location of repositories
The configuration variables described below control how gitweb finds Git repositories, and how repositories are displayed and accessed.
See also "Repositories" and later subsections in [gitweb[1]](gitweb) manpage.
$projectroot Absolute filesystem path which will be prepended to project path; the path to repository is `$projectroot/$project`. Set to `$GITWEB_PROJECTROOT` during installation. This variable has to be set correctly for gitweb to find repositories.
For example, if `$projectroot` is set to "/srv/git" by putting the following in gitweb config file:
```
our $projectroot = "/srv/git";
```
then
```
http://git.example.com/gitweb.cgi?p=foo/bar.git
```
and its path\_info based equivalent
```
http://git.example.com/gitweb.cgi/foo/bar.git
```
will map to the path `/srv/git/foo/bar.git` on the filesystem.
$projects\_list Name of a plain text file listing projects, or a name of directory to be scanned for projects.
Project list files should list one project per line, with each line having the following format
```
<URI-encoded filesystem path to repository> SP <URI-encoded repository owner>
```
The default value of this variable is determined by the `GITWEB_LIST` makefile variable at installation time. If this variable is empty, gitweb will fall back to scanning the `$projectroot` directory for repositories.
$project\_maxdepth If `$projects_list` variable is unset, gitweb will recursively scan filesystem for Git repositories. The `$project_maxdepth` is used to limit traversing depth, relative to `$projectroot` (starting point); it means that directories which are further from `$projectroot` than `$project_maxdepth` will be skipped.
It is purely performance optimization, originally intended for MacOS X, where recursive directory traversal is slow. Gitweb follows symbolic links, but it detects cycles, ignoring any duplicate files and directories.
The default value of this variable is determined by the build-time configuration variable `GITWEB_PROJECT_MAXDEPTH`, which defaults to 2007.
$export\_ok Show repository only if this file exists (in repository). Only effective if this variable evaluates to true. Can be set when building gitweb by setting `GITWEB_EXPORT_OK`. This path is relative to `GIT_DIR`. git-daemon[1] uses `git-daemon-export-ok`, unless started with `--export-all`. By default this variable is not set, which means that this feature is turned off.
$export\_auth\_hook Function used to determine which repositories should be shown. This subroutine should take one parameter, the full path to a project, and if it returns true, that project will be included in the projects list and can be accessed through gitweb as long as it fulfills the other requirements described by $export\_ok, $projects\_list, and $projects\_maxdepth. Example:
```
our $export_auth_hook = sub { return -e "$_[0]/git-daemon-export-ok"; };
```
though the above might be done by using `$export_ok` instead
```
our $export_ok = "git-daemon-export-ok";
```
If not set (default), it means that this feature is disabled.
See also more involved example in "Controlling access to Git repositories" subsection on [gitweb[1]](gitweb) manpage.
$strict\_export Only allow viewing of repositories also shown on the overview page. This for example makes `$export_ok` file decide if repository is available and not only if it is shown. If `$projects_list` points to file with list of project, only those repositories listed would be available for gitweb. Can be set during building gitweb via `GITWEB_STRICT_EXPORT`. By default this variable is not set, which means that you can directly access those repositories that are hidden from projects list page (e.g. the are not listed in the $projects\_list file).
###
Finding files
The following configuration variables tell gitweb where to find files. The values of these variables are paths on the filesystem.
$GIT Core git executable to use. By default set to `$GIT_BINDIR/git`, which in turn is by default set to `$(bindir)/git`. If you use Git installed from a binary package, you should usually set this to "/usr/bin/git". This can just be "git" if your web server has a sensible PATH; from security point of view it is better to use absolute path to git binary. If you have multiple Git versions installed it can be used to choose which one to use. Must be (correctly) set for gitweb to be able to work.
$mimetypes\_file File to use for (filename extension based) guessing of MIME types before trying `/etc/mime.types`. **NOTE** that this path, if relative, is taken as relative to the current Git repository, not to CGI script. If unset, only `/etc/mime.types` is used (if present on filesystem). If no mimetypes file is found, mimetype guessing based on extension of file is disabled. Unset by default.
$highlight\_bin Path to the highlight executable to use (it must be the one from <http://www.andre-simon.de> due to assumptions about parameters and output). By default set to `highlight`; set it to full path to highlight executable if it is not installed on your web server’s PATH. Note that `highlight` feature must be set for gitweb to actually use syntax highlighting.
**NOTE**: for a file to be highlighted, its syntax type must be detected and that syntax must be supported by "highlight". The default syntax detection is minimal, and there are many supported syntax types with no detection by default. There are three options for adding syntax detection. The first and second priority are `%highlight_basename` and `%highlight_ext`, which detect based on basename (the full filename, for example "Makefile") and extension (for example "sh"). The keys of these hashes are the basename and extension, respectively, and the value for a given key is the name of the syntax to be passed via `--syntax <syntax>` to "highlight". The last priority is the "highlight" configuration of `Shebang` regular expressions to detect the language based on the first line in the file, (for example, matching the line "#!/bin/bash"). See the highlight documentation and the default config at /etc/highlight/filetypes.conf for more details.
For example if repositories you are hosting use "phtml" extension for PHP files, and you want to have correct syntax-highlighting for those files, you can add the following to gitweb configuration:
```
our %highlight_ext;
$highlight_ext{'phtml'} = 'php';
```
###
Links and their targets
The configuration variables described below configure some of gitweb links: their target and their look (text or image), and where to find page prerequisites (stylesheet, favicon, images, scripts). Usually they are left at their default values, with the possible exception of `@stylesheets` variable.
@stylesheets List of URIs of stylesheets (relative to the base URI of a page). You might specify more than one stylesheet, for example to use "gitweb.css" as base with site specific modifications in a separate stylesheet to make it easier to upgrade gitweb. For example, you can add a `site` stylesheet by putting
```
push @stylesheets, "gitweb-site.css";
```
in the gitweb config file. Those values that are relative paths are relative to base URI of gitweb.
This list should contain the URI of gitweb’s standard stylesheet. The default URI of gitweb stylesheet can be set at build time using the `GITWEB_CSS` makefile variable. Its default value is `static/gitweb.css` (or `static/gitweb.min.css` if the `CSSMIN` variable is defined, i.e. if CSS minifier is used during build).
**Note**: there is also a legacy `$stylesheet` configuration variable, which was used by older gitweb. If `$stylesheet` variable is defined, only CSS stylesheet given by this variable is used by gitweb.
$logo Points to the location where you put `git-logo.png` on your web server, or to be more the generic URI of logo, 72x27 size). This image is displayed in the top right corner of each gitweb page and used as a logo for the Atom feed. Relative to the base URI of gitweb (as a path). Can be adjusted when building gitweb using `GITWEB_LOGO` variable By default set to `static/git-logo.png`.
$favicon Points to the location where you put `git-favicon.png` on your web server, or to be more the generic URI of favicon, which will be served as "image/png" type. Web browsers that support favicons (website icons) may display them in the browser’s URL bar and next to the site name in bookmarks. Relative to the base URI of gitweb. Can be adjusted at build time using `GITWEB_FAVICON` variable. By default set to `static/git-favicon.png`.
$javascript Points to the location where you put `gitweb.js` on your web server, or to be more generic the URI of JavaScript code used by gitweb. Relative to the base URI of gitweb. Can be set at build time using the `GITWEB_JS` build-time configuration variable.
The default value is either `static/gitweb.js`, or `static/gitweb.min.js` if the `JSMIN` build variable was defined, i.e. if JavaScript minifier was used at build time. **Note** that this single file is generated from multiple individual JavaScript "modules".
$home\_link Target of the home link on the top of all pages (the first part of view "breadcrumbs"). By default it is set to the absolute URI of a current page (to the value of `$my_uri` variable, or to "/" if `$my_uri` is undefined or is an empty string).
$home\_link\_str Label for the "home link" at the top of all pages, leading to `$home_link` (usually the main gitweb page, which contains the projects list). It is used as the first component of gitweb’s "breadcrumb trail": `<home link> / <project> / <action>`. Can be set at build time using the `GITWEB_HOME_LINK_STR` variable. By default it is set to "projects", as this link leads to the list of projects. Another popular choice is to set it to the name of site. Note that it is treated as raw HTML so it should not be set from untrusted sources.
@extra\_breadcrumbs Additional links to be added to the start of the breadcrumb trail before the home link, to pages that are logically "above" the gitweb projects list, such as the organization and department which host the gitweb server. Each element of the list is a reference to an array, in which element 0 is the link text (equivalent to `$home_link_str`) and element 1 is the target URL (equivalent to `$home_link`).
For example, the following setting produces a breadcrumb trail like "home / dev / projects / …" where "projects" is the home link.
```
our @extra_breadcrumbs = (
[ 'home' => 'https://www.example.org/' ],
[ 'dev' => 'https://dev.example.org/' ],
);
```
$logo\_url $logo\_label URI and label (title) for the Git logo link (or your site logo, if you chose to use different logo image). By default, these both refer to Git homepage, <https://git-scm.com>; in the past, they pointed to Git documentation at <https://www.kernel.org>.
###
Changing gitweb’s look
You can adjust how pages generated by gitweb look using the variables described below. You can change the site name, add common headers and footers for all pages, and add a description of this gitweb installation on its main page (which is the projects list page), etc.
$site\_name Name of your site or organization, to appear in page titles. Set it to something descriptive for clearer bookmarks etc. If this variable is not set or is, then gitweb uses the value of the `SERVER_NAME` `CGI` environment variable, setting site name to "$SERVER\_NAME Git", or "Untitled Git" if this variable is not set (e.g. if running gitweb as standalone script).
Can be set using the `GITWEB_SITENAME` at build time. Unset by default.
$site\_html\_head\_string HTML snippet to be included in the <head> section of each page. Can be set using `GITWEB_SITE_HTML_HEAD_STRING` at build time. No default value.
$site\_header Name of a file with HTML to be included at the top of each page. Relative to the directory containing the `gitweb.cgi` script. Can be set using `GITWEB_SITE_HEADER` at build time. No default value.
$site\_footer Name of a file with HTML to be included at the bottom of each page. Relative to the directory containing the `gitweb.cgi` script. Can be set using `GITWEB_SITE_FOOTER` at build time. No default value.
$home\_text Name of a HTML file which, if it exists, is included on the gitweb projects overview page ("projects\_list" view). Relative to the directory containing the gitweb.cgi script. Default value can be adjusted during build time using `GITWEB_HOMETEXT` variable. By default set to `indextext.html`.
$projects\_list\_description\_width The width (in characters) of the "Description" column of the projects list. Longer descriptions will be truncated (trying to cut at word boundary); the full description is available in the `title` attribute (usually shown on mouseover). The default is 25, which might be too small if you use long project descriptions.
$default\_projects\_order Default value of ordering of projects on projects list page, which means the ordering used if you don’t explicitly sort projects list (if there is no "o" CGI query parameter in the URL). Valid values are "none" (unsorted), "project" (projects are by project name, i.e. path to repository relative to `$projectroot`), "descr" (project description), "owner", and "age" (by date of most current commit).
Default value is "project". Unknown value means unsorted.
###
Changing gitweb’s behavior
These configuration variables control `internal` gitweb behavior.
$default\_blob\_plain\_mimetype Default mimetype for the blob\_plain (raw) view, if mimetype checking doesn’t result in some other type; by default "text/plain". Gitweb guesses mimetype of a file to display based on extension of its filename, using `$mimetypes_file` (if set and file exists) and `/etc/mime.types` files (see **mime.types**(5) manpage; only filename extension rules are supported by gitweb).
$default\_text\_plain\_charset Default charset for text files. If this is not set, the web server configuration will be used. Unset by default.
$fallback\_encoding Gitweb assumes this charset when a line contains non-UTF-8 characters. The fallback decoding is used without error checking, so it can be even "utf-8". The value must be a valid encoding; see the **Encoding::Supported**(3pm) man page for a list. The default is "latin1", aka. "iso-8859-1".
@diff\_opts Rename detection options for git-diff and git-diff-tree. The default is ('-M'); set it to ('-C') or ('-C', '-C') to also detect copies, or set it to () i.e. empty list if you don’t want to have renames detection.
**Note** that rename and especially copy detection can be quite CPU-intensive. Note also that non Git tools can have problems with patches generated with options mentioned above, especially when they involve file copies ('-C') or criss-cross renames ('-B').
###
Some optional features and policies
Most of features are configured via `%feature` hash; however some of extra gitweb features can be turned on and configured using variables described below. This list beside configuration variables that control how gitweb looks does contain variables configuring administrative side of gitweb (e.g. cross-site scripting prevention; admittedly this as side effect affects how "summary" pages look like, or load limiting).
@git\_base\_url\_list List of Git base URLs. These URLs are used to generate URLs describing from where to fetch a project, which are shown on project summary page. The full fetch URL is "`$git_base_url/$project`", for each element of this list. You can set up multiple base URLs (for example one for `git://` protocol, and one for `http://` protocol).
Note that per repository configuration can be set in `$GIT_DIR/cloneurl` file, or as values of multi-value `gitweb.url` configuration variable in project config. Per-repository configuration takes precedence over value composed from `@git_base_url_list` elements and project name.
You can setup one single value (single entry/item in this list) at build time by setting the `GITWEB_BASE_URL` build-time configuration variable. By default it is set to (), i.e. an empty list. This means that gitweb would not try to create project URL (to fetch) from project name.
$projects\_list\_group\_categories Whether to enable the grouping of projects by category on the project list page. The category of a project is determined by the `$GIT_DIR/category` file or the `gitweb.category` variable in each repository’s configuration. Disabled by default (set to 0).
$project\_list\_default\_category Default category for projects for which none is specified. If this is set to the empty string, such projects will remain uncategorized and listed at the top, above categorized projects. Used only if project categories are enabled, which means if `$projects_list_group_categories` is true. By default set to "" (empty string).
$prevent\_xss If true, some gitweb features are disabled to prevent content in repositories from launching cross-site scripting (XSS) attacks. Set this to true if you don’t trust the content of your repositories. False by default (set to 0).
$maxload Used to set the maximum load that we will still respond to gitweb queries. If the server load exceeds this value then gitweb will return "503 Service Unavailable" error. The server load is taken to be 0 if gitweb cannot determine its value. Currently it works only on Linux, where it uses `/proc/loadavg`; the load there is the number of active tasks on the system — processes that are actually running — averaged over the last minute.
Set `$maxload` to undefined value (`undef`) to turn this feature off. The default value is 300.
$omit\_age\_column If true, omit the column with date of the most current commit on the projects list page. It can save a bit of I/O and a fork per repository.
$omit\_owner If true prevents displaying information about repository owner.
$per\_request\_config If this is set to code reference, it will be run once for each request. You can set parts of configuration that change per session this way. For example, one might use the following code in a gitweb configuration file
```
our $per_request_config = sub {
$ENV{GL_USER} = $cgi->remote_user || "gitweb";
};
```
If `$per_request_config` is not a code reference, it is interpreted as boolean value. If it is true gitweb will process config files once per request, and if it is false gitweb will process config files only once, each time it is executed. True by default (set to 1).
**NOTE**: `$my_url`, `$my_uri`, and `$base_url` are overwritten with their default values before every request, so if you want to change them, be sure to set this variable to true or a code reference effecting the desired changes.
This variable matters only when using persistent web environments that serve multiple requests using single gitweb instance, like mod\_perl, FastCGI or Plackup.
###
Other variables
Usually you should not need to change (adjust) any of configuration variables described below; they should be automatically set by gitweb to correct value.
$version Gitweb version, set automatically when creating gitweb.cgi from gitweb.perl. You might want to modify it if you are running modified gitweb, for example
```
our $version .= " with caching";
```
if you run modified version of gitweb with caching support. This variable is purely informational, used e.g. in the "generator" meta header in HTML header.
$my\_url $my\_uri Full URL and absolute URL of the gitweb script; in earlier versions of gitweb you might have need to set those variables, but now there should be no need to do it. See `$per_request_config` if you need to set them still.
$base\_url Base URL for relative URLs in pages generated by gitweb, (e.g. `$logo`, `$favicon`, `@stylesheets` if they are relative URLs), needed and used `<base href="$base_url">` only for URLs with nonempty PATH\_INFO. Usually gitweb sets its value correctly, and there is no need to set this variable, e.g. to $my\_uri or "/". See `$per_request_config` if you need to override it anyway.
Configuring gitweb features
---------------------------
Many gitweb features can be enabled (or disabled) and configured using the `%feature` hash. Names of gitweb features are keys of this hash.
Each `%feature` hash element is a hash reference and has the following structure:
```
"<feature_name>" => {
"sub" => <feature-sub (subroutine)>,
"override" => <allow-override (boolean)>,
"default" => [ <options>... ]
},
```
Some features cannot be overridden per project. For those features the structure of appropriate `%feature` hash element has a simpler form:
```
"<feature_name>" => {
"override" => 0,
"default" => [ <options>... ]
},
```
As one can see it lacks the 'sub' element.
The meaning of each part of feature configuration is described below:
default List (array reference) of feature parameters (if there are any), used also to toggle (enable or disable) given feature.
Note that it is currently **always** an array reference, even if feature doesn’t accept any configuration parameters, and 'default' is used only to turn it on or off. In such case you turn feature on by setting this element to `[1]`, and torn it off by setting it to `[0]`. See also the passage about the "blame" feature in the "Examples" section.
To disable features that accept parameters (are configurable), you need to set this element to empty list i.e. `[]`.
override If this field has a true value then the given feature is overridable, which means that it can be configured (or enabled/disabled) on a per-repository basis.
Usually given "<feature>" is configurable via the `gitweb.<feature>` config variable in the per-repository Git configuration file.
**Note** that no feature is overridable by default.
sub Internal detail of implementation. What is important is that if this field is not present then per-repository override for given feature is not supported.
You wouldn’t need to ever change it in gitweb config file.
###
Features in `%feature`
The gitweb features that are configurable via `%feature` hash are listed below. This should be a complete list, but ultimately the authoritative and complete list is in gitweb.cgi source code, with features described in the comments.
blame Enable the "blame" and "blame\_incremental" blob views, showing for each line the last commit that modified it; see [git-blame[1]](git-blame). This can be very CPU-intensive and is therefore disabled by default.
This feature can be configured on a per-repository basis via repository’s `gitweb.blame` configuration variable (boolean).
snapshot Enable and configure the "snapshot" action, which allows user to download a compressed archive of any tree or commit, as produced by [git-archive[1]](git-archive) and possibly additionally compressed. This can potentially generate high traffic if you have large project.
The value of 'default' is a list of names of snapshot formats, defined in `%known_snapshot_formats` hash, that you wish to offer. Supported formats include "tgz", "tbz2", "txz" (gzip/bzip2/xz compressed tar archive) and "zip"; please consult gitweb sources for a definitive list. By default only "tgz" is offered.
This feature can be configured on a per-repository basis via repository’s `gitweb.snapshot` configuration variable, which contains a comma separated list of formats or "none" to disable snapshots. Unknown values are ignored.
grep Enable grep search, which lists the files in currently selected tree (directory) containing the given string; see [git-grep[1]](git-grep). This can be potentially CPU-intensive, of course. Enabled by default.
This feature can be configured on a per-repository basis via repository’s `gitweb.grep` configuration variable (boolean).
pickaxe Enable the so called pickaxe search, which will list the commits that introduced or removed a given string in a file. This can be practical and quite faster alternative to "blame" action, but it is still potentially CPU-intensive. Enabled by default.
The pickaxe search is described in [git-log[1]](git-log) (the description of `-S<string>` option, which refers to pickaxe entry in [gitdiffcore[7]](gitdiffcore) for more details).
This feature can be configured on a per-repository basis by setting repository’s `gitweb.pickaxe` configuration variable (boolean).
show-sizes Enable showing size of blobs (ordinary files) in a "tree" view, in a separate column, similar to what `ls -l` does; see description of `-l` option in [git-ls-tree[1]](git-ls-tree) manpage. This costs a bit of I/O. Enabled by default.
This feature can be configured on a per-repository basis via repository’s `gitweb.showSizes` configuration variable (boolean).
patches Enable and configure "patches" view, which displays list of commits in email (plain text) output format; see also [git-format-patch[1]](git-format-patch). The value is the maximum number of patches in a patchset generated in "patches" view. Set the `default` field to a list containing single item of or to an empty list to disable patch view, or to a list containing a single negative number to remove any limit. Default value is 16.
This feature can be configured on a per-repository basis via repository’s `gitweb.patches` configuration variable (integer).
avatar Avatar support. When this feature is enabled, views such as "shortlog" or "commit" will display an avatar associated with the email of each committer and author.
Currently available providers are **"gravatar"** and **"picon"**. Only one provider at a time can be selected (`default` is one element list). If an unknown provider is specified, the feature is disabled. **Note** that some providers might require extra Perl packages to be installed; see `gitweb/INSTALL` for more details.
This feature can be configured on a per-repository basis via repository’s `gitweb.avatar` configuration variable.
See also `%avatar_size` with pixel sizes for icons and avatars ("default" is used for one-line like "log" and "shortlog", "double" is used for two-line like "commit", "commitdiff" or "tag"). If the default font sizes or lineheights are changed (e.g. via adding extra CSS stylesheet in `@stylesheets`), it may be appropriate to change these values.
email-privacy Redact e-mail addresses from the generated HTML, etc. content. This obscures e-mail addresses retrieved from the author/committer and comment sections of the Git log. It is meant to hinder web crawlers that harvest and abuse addresses. Such crawlers may not respect robots.txt. Note that users and user tools also see the addresses as redacted. If Gitweb is not the final step in a workflow then subsequent steps may misbehave because of the redacted information they receive. Disabled by default.
highlight Server-side syntax highlight support in "blob" view. It requires `$highlight_bin` program to be available (see the description of this variable in the "Configuration variables" section above), and therefore is disabled by default.
This feature can be configured on a per-repository basis via repository’s `gitweb.highlight` configuration variable (boolean).
remote\_heads Enable displaying remote heads (remote-tracking branches) in the "heads" list. In most cases the list of remote-tracking branches is an unnecessary internal private detail, and this feature is therefore disabled by default. [git-instaweb[1]](git-instaweb), which is usually used to browse local repositories, enables and uses this feature.
This feature can be configured on a per-repository basis via repository’s `gitweb.remote_heads` configuration variable (boolean).
The remaining features cannot be overridden on a per project basis.
search Enable text search, which will list the commits which match author, committer or commit text to a given string; see the description of `--author`, `--committer` and `--grep` options in [git-log[1]](git-log) manpage. Enabled by default.
Project specific override is not supported.
forks If this feature is enabled, gitweb considers projects in subdirectories of project root (basename) to be forks of existing projects. For each project `$projname.git`, projects in the `$projname/` directory and its subdirectories will not be shown in the main projects list. Instead, a '+' mark is shown next to `$projname`, which links to a "forks" view that lists all the forks (all projects in `$projname/` subdirectory). Additionally a "forks" view for a project is linked from project summary page.
If the project list is taken from a file (`$projects_list` points to a file), forks are only recognized if they are listed after the main project in that file.
Project specific override is not supported.
actions Insert custom links to the action bar of all project pages. This allows you to link to third-party scripts integrating into gitweb.
The "default" value consists of a list of triplets in the form `("<label>", "<link>", "<position>")` where "position" is the label after which to insert the link, "link" is a format string where `%n` expands to the project name, `%f` to the project path within the filesystem (i.e. "$projectroot/$project"), `%h` to the current hash ('h' gitweb parameter) and `%b` to the current hash base ('hb' gitweb parameter); `%%` expands to '%'.
For example, at the time this page was written, the <http://repo.or.cz> Git hosting site set it to the following to enable graphical log (using the third party tool **git-browser**):
```
$feature{'actions'}{'default'} =
[ ('graphiclog', '/git-browser/by-commit.html?r=%n', 'summary')];
```
This adds a link titled "graphiclog" after the "summary" link, leading to `git-browser` script, passing `r=<project>` as a query parameter.
Project specific override is not supported.
timed Enable displaying how much time and how many Git commands it took to generate and display each page in the page footer (at the bottom of page). For example the footer might contain: "This page took 6.53325 seconds and 13 Git commands to generate." Disabled by default.
Project specific override is not supported.
javascript-timezone Enable and configure the ability to change a common time zone for dates in gitweb output via JavaScript. Dates in gitweb output include authordate and committerdate in "commit", "commitdiff" and "log" views, and taggerdate in "tag" view. Enabled by default.
The value is a list of three values: a default time zone (for if the client hasn’t selected some other time zone and saved it in a cookie), a name of cookie where to store selected time zone, and a CSS class used to mark up dates for manipulation. If you want to turn this feature off, set "default" to empty list: `[]`.
Typical gitweb config files will only change starting (default) time zone, and leave other elements at their default values:
```
$feature{'javascript-timezone'}{'default'}[0] = "utc";
```
The example configuration presented here is guaranteed to be backwards and forward compatible.
Time zone values can be "local" (for local time zone that browser uses), "utc" (what gitweb uses when JavaScript or this feature is disabled), or numerical time zones in the form of "+/-HHMM", such as "+0200".
Project specific override is not supported.
extra-branch-refs List of additional directories under "refs" which are going to be used as branch refs. For example if you have a gerrit setup where all branches under refs/heads/ are official, push-after-review ones and branches under refs/sandbox/, refs/wip and refs/other are user ones where permissions are much wider, then you might want to set this variable as follows:
```
$feature{'extra-branch-refs'}{'default'} =
['sandbox', 'wip', 'other'];
```
This feature can be configured on per-repository basis after setting $feature{`extra-branch-refs`}{`override`} to true, via repository’s `gitweb.extraBranchRefs` configuration variable, which contains a space separated list of refs. An example:
```
[gitweb]
extraBranchRefs = sandbox wip other
```
The gitweb.extraBranchRefs is actually a multi-valued configuration variable, so following example is also correct and the result is the same as of the snippet above:
```
[gitweb]
extraBranchRefs = sandbox
extraBranchRefs = wip other
```
It is an error to specify a ref that does not pass "git check-ref-format" scrutiny. Duplicated values are filtered.
Examples
--------
To enable blame, pickaxe search, and snapshot support (allowing "tar.gz" and "zip" snapshots), while allowing individual projects to turn them off, put the following in your GITWEB\_CONFIG file:
```
$feature{'blame'}{'default'} = [1];
$feature{'blame'}{'override'} = 1;
$feature{'pickaxe'}{'default'} = [1];
$feature{'pickaxe'}{'override'} = 1;
$feature{'snapshot'}{'default'} = ['zip', 'tgz'];
$feature{'snapshot'}{'override'} = 1;
```
If you allow overriding for the snapshot feature, you can specify which snapshot formats are globally disabled. You can also add any command-line options you want (such as setting the compression level). For instance, you can disable Zip compressed snapshots and set **gzip**(1) to run at level 6 by adding the following lines to your gitweb configuration file:
```
$known_snapshot_formats{'zip'}{'disabled'} = 1;
$known_snapshot_formats{'tgz'}{'compressor'} = ['gzip','-6'];
```
Bugs
----
Debugging would be easier if the fallback configuration file (`/etc/gitweb.conf`) and environment variable to override its location (`GITWEB_CONFIG_SYSTEM`) had names reflecting their "fallback" role. The current names are kept to avoid breaking working setups.
Environment
-----------
The location of per-instance and system-wide configuration files can be overridden using the following environment variables:
GITWEB\_CONFIG Sets location of per-instance configuration file.
GITWEB\_CONFIG\_SYSTEM Sets location of fallback system-wide configuration file. This file is read only if per-instance one does not exist.
GITWEB\_CONFIG\_COMMON Sets location of common system-wide configuration file.
Files
-----
gitweb\_config.perl This is default name of per-instance configuration file. The format of this file is described above.
/etc/gitweb.conf This is default name of fallback system-wide configuration file. This file is used only if per-instance configuration variable is not found.
/etc/gitweb-common.conf This is default name of common system-wide configuration file.
See also
--------
[gitweb[1]](gitweb), [git-instaweb[1]](git-instaweb)
`gitweb/README`, `gitweb/INSTALL`
| programming_docs |
git git-pack-objects git-pack-objects
================
Name
----
git-pack-objects - Create a packed archive of objects
Synopsis
--------
```
git pack-objects [-q | --progress | --all-progress] [--all-progress-implied]
[--no-reuse-delta] [--delta-base-offset] [--non-empty]
[--local] [--incremental] [--window=<n>] [--depth=<n>]
[--revs [--unpacked | --all]] [--keep-pack=<pack-name>]
[--cruft] [--cruft-expiration=<time>]
[--stdout [--filter=<filter-spec>] | <base-name>]
[--shallow] [--keep-true-parents] [--[no-]sparse] < <object-list>
```
Description
-----------
Reads list of objects from the standard input, and writes either one or more packed archives with the specified base-name to disk, or a packed archive to the standard output.
A packed archive is an efficient way to transfer a set of objects between two repositories as well as an access efficient archival format. In a packed archive, an object is either stored as a compressed whole or as a difference from some other object. The latter is often called a delta.
The packed archive format (.pack) is designed to be self-contained so that it can be unpacked without any further information. Therefore, each object that a delta depends upon must be present within the pack.
A pack index file (.idx) is generated for fast, random access to the objects in the pack. Placing both the index file (.idx) and the packed archive (.pack) in the pack/ subdirectory of $GIT\_OBJECT\_DIRECTORY (or any of the directories on $GIT\_ALTERNATE\_OBJECT\_DIRECTORIES) enables Git to read from the pack archive.
The `git unpack-objects` command can read the packed archive and expand the objects contained in the pack into "one-file one-object" format; this is typically done by the smart-pull commands when a pack is created on-the-fly for efficient network transport by their peers.
Options
-------
base-name Write into pairs of files (.pack and .idx), using <base-name> to determine the name of the created file. When this option is used, the two files in a pair are written in <base-name>-<SHA-1>.{pack,idx} files. <SHA-1> is a hash based on the pack content and is written to the standard output of the command.
--stdout Write the pack contents (what would have been written to .pack file) out to the standard output.
--revs Read the revision arguments from the standard input, instead of individual object names. The revision arguments are processed the same way as `git rev-list` with the `--objects` flag uses its `commit` arguments to build the list of objects it outputs. The objects on the resulting list are packed. Besides revisions, `--not` or `--shallow <SHA-1>` lines are also accepted.
--unpacked This implies `--revs`. When processing the list of revision arguments read from the standard input, limit the objects packed to those that are not already packed.
--all This implies `--revs`. In addition to the list of revision arguments read from the standard input, pretend as if all refs under `refs/` are specified to be included.
--include-tag Include unasked-for annotated tags if the object they reference was included in the resulting packfile. This can be useful to send new tags to native Git clients.
--stdin-packs Read the basenames of packfiles (e.g., `pack-1234abcd.pack`) from the standard input, instead of object names or revision arguments. The resulting pack contains all objects listed in the included packs (those not beginning with `^`), excluding any objects listed in the excluded packs (beginning with `^`).
Incompatible with `--revs`, or options that imply `--revs` (such as `--all`), with the exception of `--unpacked`, which is compatible.
--cruft Packs unreachable objects into a separate "cruft" pack, denoted by the existence of a `.mtimes` file. Typically used by `git
repack --cruft`. Callers provide a list of pack names and indicate which packs will remain in the repository, along with which packs will be deleted (indicated by the `-` prefix). The contents of the cruft pack are all objects not contained in the surviving packs which have not exceeded the grace period (see `--cruft-expiration` below), or which have exceeded the grace period, but are reachable from an other object which hasn’t.
When the input lists a pack containing all reachable objects (and lists all other packs as pending deletion), the corresponding cruft pack will contain all unreachable objects (with mtime newer than the `--cruft-expiration`) along with any unreachable objects whose mtime is older than the `--cruft-expiration`, but are reachable from an unreachable object whose mtime is newer than the `--cruft-expiration`).
Incompatible with `--unpack-unreachable`, `--keep-unreachable`, `--pack-loose-unreachable`, `--stdin-packs`, as well as any other options which imply `--revs`. Also incompatible with `--max-pack-size`; when this option is set, the maximum pack size is not inferred from `pack.packSizeLimit`.
--cruft-expiration=<approxidate> If specified, objects are eliminated from the cruft pack if they have an mtime older than `<approxidate>`. If unspecified (and given `--cruft`), then no objects are eliminated.
--window=<n> --depth=<n> These two options affect how the objects contained in the pack are stored using delta compression. The objects are first internally sorted by type, size and optionally names and compared against the other objects within --window to see if using delta compression saves space. --depth limits the maximum delta depth; making it too deep affects the performance on the unpacker side, because delta data needs to be applied that many times to get to the necessary object.
The default value for --window is 10 and --depth is 50. The maximum depth is 4095.
--window-memory=<n> This option provides an additional limit on top of `--window`; the window size will dynamically scale down so as to not take up more than `<n>` bytes in memory. This is useful in repositories with a mix of large and small objects to not run out of memory with a large window, but still be able to take advantage of the large window for the smaller objects. The size can be suffixed with "k", "m", or "g". `--window-memory=0` makes memory usage unlimited. The default is taken from the `pack.windowMemory` configuration variable.
--max-pack-size=<n> In unusual scenarios, you may not be able to create files larger than a certain size on your filesystem, and this option can be used to tell the command to split the output packfile into multiple independent packfiles, each not larger than the given size. The size can be suffixed with "k", "m", or "g". The minimum size allowed is limited to 1 MiB. The default is unlimited, unless the config variable `pack.packSizeLimit` is set. Note that this option may result in a larger and slower repository; see the discussion in `pack.packSizeLimit`.
--honor-pack-keep This flag causes an object already in a local pack that has a .keep file to be ignored, even if it would have otherwise been packed.
--keep-pack=<pack-name> This flag causes an object already in the given pack to be ignored, even if it would have otherwise been packed. `<pack-name>` is the pack file name without leading directory (e.g. `pack-123.pack`). The option could be specified multiple times to keep multiple packs.
--incremental This flag causes an object already in a pack to be ignored even if it would have otherwise been packed.
--local This flag causes an object that is borrowed from an alternate object store to be ignored even if it would have otherwise been packed.
--non-empty Only create a packed archive if it would contain at least one object.
--progress Progress status is reported on the standard error stream by default when it is attached to a terminal, unless -q is specified. This flag forces progress status even if the standard error stream is not directed to a terminal.
--all-progress When --stdout is specified then progress report is displayed during the object count and compression phases but inhibited during the write-out phase. The reason is that in some cases the output stream is directly linked to another command which may wish to display progress status of its own as it processes incoming pack data. This flag is like --progress except that it forces progress report for the write-out phase as well even if --stdout is used.
--all-progress-implied This is used to imply --all-progress whenever progress display is activated. Unlike --all-progress this flag doesn’t actually force any progress display by itself.
-q This flag makes the command not to report its progress on the standard error stream.
--no-reuse-delta When creating a packed archive in a repository that has existing packs, the command reuses existing deltas. This sometimes results in a slightly suboptimal pack. This flag tells the command not to reuse existing deltas but compute them from scratch.
--no-reuse-object This flag tells the command not to reuse existing object data at all, including non deltified object, forcing recompression of everything. This implies --no-reuse-delta. Useful only in the obscure case where wholesale enforcement of a different compression level on the packed data is desired.
--compression=<n> Specifies compression level for newly-compressed data in the generated pack. If not specified, pack compression level is determined first by pack.compression, then by core.compression, and defaults to -1, the zlib default, if neither is set. Add --no-reuse-object if you want to force a uniform compression level on all data no matter the source.
--[no-]sparse Toggle the "sparse" algorithm to determine which objects to include in the pack, when combined with the "--revs" option. This algorithm only walks trees that appear in paths that introduce new objects. This can have significant performance benefits when computing a pack to send a small change. However, it is possible that extra objects are added to the pack-file if the included commits contain certain types of direct renames. If this option is not included, it defaults to the value of `pack.useSparse`, which is true unless otherwise specified.
--thin Create a "thin" pack by omitting the common objects between a sender and a receiver in order to reduce network transfer. This option only makes sense in conjunction with --stdout.
Note: A thin pack violates the packed archive format by omitting required objects and is thus unusable by Git without making it self-contained. Use `git index-pack --fix-thin` (see [git-index-pack[1]](git-index-pack)) to restore the self-contained property.
--shallow Optimize a pack that will be provided to a client with a shallow repository. This option, combined with --thin, can result in a smaller pack at the cost of speed.
--delta-base-offset A packed archive can express the base object of a delta as either a 20-byte object name or as an offset in the stream, but ancient versions of Git don’t understand the latter. By default, `git pack-objects` only uses the former format for better compatibility. This option allows the command to use the latter format for compactness. Depending on the average delta chain length, this option typically shrinks the resulting packfile by 3-5 per-cent.
Note: Porcelain commands such as `git gc` (see [git-gc[1]](git-gc)), `git repack` (see [git-repack[1]](git-repack)) pass this option by default in modern Git when they put objects in your repository into pack files. So does `git bundle` (see [git-bundle[1]](git-bundle)) when it creates a bundle.
--threads=<n> Specifies the number of threads to spawn when searching for best delta matches. This requires that pack-objects be compiled with pthreads otherwise this option is ignored with a warning. This is meant to reduce packing time on multiprocessor machines. The required amount of memory for the delta search window is however multiplied by the number of threads. Specifying 0 will cause Git to auto-detect the number of CPU’s and set the number of threads accordingly.
--index-version=<version>[,<offset>] This is intended to be used by the test suite only. It allows to force the version for the generated pack index, and to force 64-bit index entries on objects located above the given offset.
--keep-true-parents With this option, parents that are hidden by grafts are packed nevertheless.
--filter=<filter-spec> Requires `--stdout`. Omits certain objects (usually blobs) from the resulting packfile. See [git-rev-list[1]](git-rev-list) for valid `<filter-spec>` forms.
--no-filter Turns off any previous `--filter=` argument.
--missing=<missing-action> A debug option to help with future "partial clone" development. This option specifies how missing objects are handled.
The form `--missing=error` requests that pack-objects stop with an error if a missing object is encountered. If the repository is a partial clone, an attempt to fetch missing objects will be made before declaring them missing. This is the default action.
The form `--missing=allow-any` will allow object traversal to continue if a missing object is encountered. No fetch of a missing object will occur. Missing objects will silently be omitted from the results.
The form `--missing=allow-promisor` is like `allow-any`, but will only allow object traversal to continue for EXPECTED promisor missing objects. No fetch of a missing object will occur. An unexpected missing object will raise an error.
--exclude-promisor-objects Omit objects that are known to be in the promisor remote. (This option has the purpose of operating only on locally created objects, so that when we repack, we still maintain a distinction between locally created objects [without .promisor] and objects from the promisor remote [with .promisor].) This is used with partial clone.
--keep-unreachable Objects unreachable from the refs in packs named with --unpacked= option are added to the resulting pack, in addition to the reachable objects that are not in packs marked with \*.keep files. This implies `--revs`.
--pack-loose-unreachable Pack unreachable loose objects (and their loose counterparts removed). This implies `--revs`.
--unpack-unreachable Keep unreachable objects in loose form. This implies `--revs`.
--delta-islands Restrict delta matches based on "islands". See DELTA ISLANDS below.
Delta islands
-------------
When possible, `pack-objects` tries to reuse existing on-disk deltas to avoid having to search for new ones on the fly. This is an important optimization for serving fetches, because it means the server can avoid inflating most objects at all and just send the bytes directly from disk. This optimization can’t work when an object is stored as a delta against a base which the receiver does not have (and which we are not already sending). In that case the server "breaks" the delta and has to find a new one, which has a high CPU cost. Therefore it’s important for performance that the set of objects in on-disk delta relationships match what a client would fetch.
In a normal repository, this tends to work automatically. The objects are mostly reachable from the branches and tags, and that’s what clients fetch. Any deltas we find on the server are likely to be between objects the client has or will have.
But in some repository setups, you may have several related but separate groups of ref tips, with clients tending to fetch those groups independently. For example, imagine that you are hosting several "forks" of a repository in a single shared object store, and letting clients view them as separate repositories through `GIT_NAMESPACE` or separate repos using the alternates mechanism. A naive repack may find that the optimal delta for an object is against a base that is only found in another fork. But when a client fetches, they will not have the base object, and we’ll have to find a new delta on the fly.
A similar situation may exist if you have many refs outside of `refs/heads/` and `refs/tags/` that point to related objects (e.g., `refs/pull` or `refs/changes` used by some hosting providers). By default, clients fetch only heads and tags, and deltas against objects found only in those other groups cannot be sent as-is.
Delta islands solve this problem by allowing you to group your refs into distinct "islands". Pack-objects computes which objects are reachable from which islands, and refuses to make a delta from an object `A` against a base which is not present in all of `A`'s islands. This results in slightly larger packs (because we miss some delta opportunities), but guarantees that a fetch of one island will not have to recompute deltas on the fly due to crossing island boundaries.
When repacking with delta islands the delta window tends to get clogged with candidates that are forbidden by the config. Repacking with a big --window helps (and doesn’t take as long as it otherwise might because we can reject some object pairs based on islands before doing any computation on the content).
Islands are configured via the `pack.island` option, which can be specified multiple times. Each value is a left-anchored regular expressions matching refnames. For example:
```
[pack]
island = refs/heads/
island = refs/tags/
```
puts heads and tags into an island (whose name is the empty string; see below for more on naming). Any refs which do not match those regular expressions (e.g., `refs/pull/123`) is not in any island. Any object which is reachable only from `refs/pull/` (but not heads or tags) is therefore not a candidate to be used as a base for `refs/heads/`.
Refs are grouped into islands based on their "names", and two regexes that produce the same name are considered to be in the same island. The names are computed from the regexes by concatenating any capture groups from the regex, with a `-` dash in between. (And if there are no capture groups, then the name is the empty string, as in the above example.) This allows you to create arbitrary numbers of islands. Only up to 14 such capture groups are supported though.
For example, imagine you store the refs for each fork in `refs/virtual/ID`, where `ID` is a numeric identifier. You might then configure:
```
[pack]
island = refs/virtual/([0-9]+)/heads/
island = refs/virtual/([0-9]+)/tags/
island = refs/virtual/([0-9]+)/(pull)/
```
That puts the heads and tags for each fork in their own island (named "1234" or similar), and the pull refs for each go into their own "1234-pull".
Note that we pick a single island for each regex to go into, using "last one wins" ordering (which allows repo-specific config to take precedence over user-wide config, and so forth).
Configuration
-------------
Various configuration variables affect packing, see [git-config[1]](git-config) (search for "pack" and "delta").
Notably, delta compression is not used on objects larger than the `core.bigFileThreshold` configuration variable and on files with the attribute `delta` set to false.
See also
--------
[git-rev-list[1]](git-rev-list) [git-repack[1]](git-repack) [git-prune-packed[1]](git-prune-packed)
git git-clone git-clone
=========
Name
----
git-clone - Clone a repository into a new directory
Synopsis
--------
```
git clone [--template=<template-directory>]
[-l] [-s] [--no-hardlinks] [-q] [-n] [--bare] [--mirror]
[-o <name>] [-b <name>] [-u <upload-pack>] [--reference <repository>]
[--dissociate] [--separate-git-dir <git-dir>]
[--depth <depth>] [--[no-]single-branch] [--no-tags]
[--recurse-submodules[=<pathspec>]] [--[no-]shallow-submodules]
[--[no-]remote-submodules] [--jobs <n>] [--sparse] [--[no-]reject-shallow]
[--filter=<filter> [--also-filter-submodules]] [--] <repository>
[<directory>]
```
Description
-----------
Clones a repository into a newly created directory, creates remote-tracking branches for each branch in the cloned repository (visible using `git branch --remotes`), and creates and checks out an initial branch that is forked from the cloned repository’s currently active branch.
After the clone, a plain `git fetch` without arguments will update all the remote-tracking branches, and a `git pull` without arguments will in addition merge the remote master branch into the current master branch, if any (this is untrue when "--single-branch" is given; see below).
This default configuration is achieved by creating references to the remote branch heads under `refs/remotes/origin` and by initializing `remote.origin.url` and `remote.origin.fetch` configuration variables.
Options
-------
-l --local When the repository to clone from is on a local machine, this flag bypasses the normal "Git aware" transport mechanism and clones the repository by making a copy of HEAD and everything under objects and refs directories. The files under `.git/objects/` directory are hardlinked to save space when possible.
If the repository is specified as a local path (e.g., `/path/to/repo`), this is the default, and --local is essentially a no-op. If the repository is specified as a URL, then this flag is ignored (and we never use the local optimizations). Specifying `--no-local` will override the default when `/path/to/repo` is given, using the regular Git transport instead.
**NOTE**: this operation can race with concurrent modification to the source repository, similar to running `cp -r src dst` while modifying `src`.
--no-hardlinks Force the cloning process from a repository on a local filesystem to copy the files under the `.git/objects` directory instead of using hardlinks. This may be desirable if you are trying to make a back-up of your repository.
-s --shared When the repository to clone is on the local machine, instead of using hard links, automatically setup `.git/objects/info/alternates` to share the objects with the source repository. The resulting repository starts out without any object of its own.
**NOTE**: this is a possibly dangerous operation; do **not** use it unless you understand what it does. If you clone your repository using this option and then delete branches (or use any other Git command that makes any existing commit unreferenced) in the source repository, some objects may become unreferenced (or dangling). These objects may be removed by normal Git operations (such as `git commit`) which automatically call `git maintenance run --auto`. (See [git-maintenance[1]](git-maintenance).) If these objects are removed and were referenced by the cloned repository, then the cloned repository will become corrupt.
Note that running `git repack` without the `--local` option in a repository cloned with `--shared` will copy objects from the source repository into a pack in the cloned repository, removing the disk space savings of `clone --shared`. It is safe, however, to run `git gc`, which uses the `--local` option by default.
If you want to break the dependency of a repository cloned with `--shared` on its source repository, you can simply run `git repack -a` to copy all objects from the source repository into a pack in the cloned repository.
--reference[-if-able] <repository> If the reference repository is on the local machine, automatically setup `.git/objects/info/alternates` to obtain objects from the reference repository. Using an already existing repository as an alternate will require fewer objects to be copied from the repository being cloned, reducing network and local storage costs. When using the `--reference-if-able`, a non existing directory is skipped with a warning instead of aborting the clone.
**NOTE**: see the NOTE for the `--shared` option, and also the `--dissociate` option.
--dissociate Borrow the objects from reference repositories specified with the `--reference` options only to reduce network transfer, and stop borrowing from them after a clone is made by making necessary local copies of borrowed objects. This option can also be used when cloning locally from a repository that already borrows objects from another repository—the new repository will borrow objects from the same repository, and this option can be used to stop the borrowing.
-q --quiet Operate quietly. Progress is not reported to the standard error stream.
-v --verbose Run verbosely. Does not affect the reporting of progress status to the standard error stream.
--progress Progress status is reported on the standard error stream by default when it is attached to a terminal, unless `--quiet` is specified. This flag forces progress status even if the standard error stream is not directed to a terminal.
--server-option=<option> Transmit the given string to the server when communicating using protocol version 2. The given string must not contain a NUL or LF character. The server’s handling of server options, including unknown ones, is server-specific. When multiple `--server-option=<option>` are given, they are all sent to the other side in the order listed on the command line.
-n --no-checkout No checkout of HEAD is performed after the clone is complete.
--[no-]reject-shallow Fail if the source repository is a shallow repository. The `clone.rejectShallow` configuration variable can be used to specify the default.
--bare Make a `bare` Git repository. That is, instead of creating `<directory>` and placing the administrative files in `<directory>/.git`, make the `<directory>` itself the `$GIT_DIR`. This obviously implies the `--no-checkout` because there is nowhere to check out the working tree. Also the branch heads at the remote are copied directly to corresponding local branch heads, without mapping them to `refs/remotes/origin/`. When this option is used, neither remote-tracking branches nor the related configuration variables are created.
--sparse Employ a sparse-checkout, with only files in the toplevel directory initially being present. The [git-sparse-checkout[1]](git-sparse-checkout) command can be used to grow the working directory as needed.
--filter=<filter-spec> Use the partial clone feature and request that the server sends a subset of reachable objects according to a given object filter. When using `--filter`, the supplied `<filter-spec>` is used for the partial clone filter. For example, `--filter=blob:none` will filter out all blobs (file contents) until needed by Git. Also, `--filter=blob:limit=<size>` will filter out all blobs of size at least `<size>`. For more details on filter specifications, see the `--filter` option in [git-rev-list[1]](git-rev-list).
--also-filter-submodules Also apply the partial clone filter to any submodules in the repository. Requires `--filter` and `--recurse-submodules`. This can be turned on by default by setting the `clone.filterSubmodules` config option.
--mirror Set up a mirror of the source repository. This implies `--bare`. Compared to `--bare`, `--mirror` not only maps local branches of the source to local branches of the target, it maps all refs (including remote-tracking branches, notes etc.) and sets up a refspec configuration such that all these refs are overwritten by a `git remote update` in the target repository.
-o <name> --origin <name> Instead of using the remote name `origin` to keep track of the upstream repository, use `<name>`. Overrides `clone.defaultRemoteName` from the config.
-b <name> --branch <name> Instead of pointing the newly created HEAD to the branch pointed to by the cloned repository’s HEAD, point to `<name>` branch instead. In a non-bare repository, this is the branch that will be checked out. `--branch` can also take tags and detaches the HEAD at that commit in the resulting repository.
-u <upload-pack> --upload-pack <upload-pack> When given, and the repository to clone from is accessed via ssh, this specifies a non-default path for the command run on the other end.
--template=<template-directory> Specify the directory from which templates will be used; (See the "TEMPLATE DIRECTORY" section of [git-init[1]](git-init).)
-c <key>=<value> --config <key>=<value> Set a configuration variable in the newly-created repository; this takes effect immediately after the repository is initialized, but before the remote history is fetched or any files checked out. The key is in the same format as expected by [git-config[1]](git-config) (e.g., `core.eol=true`). If multiple values are given for the same key, each value will be written to the config file. This makes it safe, for example, to add additional fetch refspecs to the origin remote.
Due to limitations of the current implementation, some configuration variables do not take effect until after the initial fetch and checkout. Configuration variables known to not take effect are: `remote.<name>.mirror` and `remote.<name>.tagOpt`. Use the corresponding `--mirror` and `--no-tags` options instead.
--depth <depth> Create a `shallow` clone with a history truncated to the specified number of commits. Implies `--single-branch` unless `--no-single-branch` is given to fetch the histories near the tips of all branches. If you want to clone submodules shallowly, also pass `--shallow-submodules`.
--shallow-since=<date> Create a shallow clone with a history after the specified time.
--shallow-exclude=<revision> Create a shallow clone with a history, excluding commits reachable from a specified remote branch or tag. This option can be specified multiple times.
--[no-]single-branch Clone only the history leading to the tip of a single branch, either specified by the `--branch` option or the primary branch remote’s `HEAD` points at. Further fetches into the resulting repository will only update the remote-tracking branch for the branch this option was used for the initial cloning. If the HEAD at the remote did not point at any branch when `--single-branch` clone was made, no remote-tracking branch is created.
--no-tags Don’t clone any tags, and set `remote.<remote>.tagOpt=--no-tags` in the config, ensuring that future `git pull` and `git fetch` operations won’t follow any tags. Subsequent explicit tag fetches will still work, (see [git-fetch[1]](git-fetch)).
Can be used in conjunction with `--single-branch` to clone and maintain a branch with no references other than a single cloned branch. This is useful e.g. to maintain minimal clones of the default branch of some repository for search indexing.
--recurse-submodules[=<pathspec>] After the clone is created, initialize and clone submodules within based on the provided pathspec. If no pathspec is provided, all submodules are initialized and cloned. This option can be given multiple times for pathspecs consisting of multiple entries. The resulting clone has `submodule.active` set to the provided pathspec, or "." (meaning all submodules) if no pathspec is provided.
Submodules are initialized and cloned using their default settings. This is equivalent to running `git submodule update --init --recursive <pathspec>` immediately after the clone is finished. This option is ignored if the cloned repository does not have a worktree/checkout (i.e. if any of `--no-checkout`/`-n`, `--bare`, or `--mirror` is given)
--[no-]shallow-submodules All submodules which are cloned will be shallow with a depth of 1.
--[no-]remote-submodules All submodules which are cloned will use the status of the submodule’s remote-tracking branch to update the submodule, rather than the superproject’s recorded SHA-1. Equivalent to passing `--remote` to `git submodule update`.
--separate-git-dir=<git-dir> Instead of placing the cloned repository where it is supposed to be, place the cloned repository at the specified directory, then make a filesystem-agnostic Git symbolic link to there. The result is Git repository can be separated from working tree.
-j <n> --jobs <n> The number of submodules fetched at the same time. Defaults to the `submodule.fetchJobs` option.
<repository> The (possibly remote) repository to clone from. See the [GIT URLS](#URLS) section below for more information on specifying repositories.
<directory> The name of a new directory to clone into. The "humanish" part of the source repository is used if no directory is explicitly given (`repo` for `/path/to/repo.git` and `foo` for `host.xz:foo/.git`). Cloning into an existing directory is only allowed if the directory is empty.
--bundle-uri=<uri> Before fetching from the remote, fetch a bundle from the given `<uri>` and unbundle the data into the local repository. The refs in the bundle will be stored under the hidden `refs/bundle/*` namespace. This option is incompatible with `--depth`, `--shallow-since`, and `--shallow-exclude`.
Git urls
--------
In general, URLs contain information about the transport protocol, the address of the remote server, and the path to the repository. Depending on the transport protocol, some of this information may be absent.
Git supports ssh, git, http, and https protocols (in addition, ftp, and ftps can be used for fetching, but this is inefficient and deprecated; do not use it).
The native transport (i.e. git:// URL) does no authentication and should be used with caution on unsecured networks.
The following syntaxes may be used with them:
* ssh://[user@]host.xz[:port]/path/to/repo.git/
* git://host.xz[:port]/path/to/repo.git/
* http[s]://host.xz[:port]/path/to/repo.git/
* ftp[s]://host.xz[:port]/path/to/repo.git/
An alternative scp-like syntax may also be used with the ssh protocol:
* [user@]host.xz:path/to/repo.git/
This syntax is only recognized if there are no slashes before the first colon. This helps differentiate a local path that contains a colon. For example the local path `foo:bar` could be specified as an absolute path or `./foo:bar` to avoid being misinterpreted as an ssh url.
The ssh and git protocols additionally support ~username expansion:
* ssh://[user@]host.xz[:port]/~[user]/path/to/repo.git/
* git://host.xz[:port]/~[user]/path/to/repo.git/
* [user@]host.xz:/~[user]/path/to/repo.git/
For local repositories, also supported by Git natively, the following syntaxes may be used:
* /path/to/repo.git/
* file:///path/to/repo.git/
These two syntaxes are mostly equivalent, except the former implies --local option.
`git clone`, `git fetch` and `git pull`, but not `git push`, will also accept a suitable bundle file. See [git-bundle[1]](git-bundle).
When Git doesn’t know how to handle a certain transport protocol, it attempts to use the `remote-<transport>` remote helper, if one exists. To explicitly request a remote helper, the following syntax may be used:
* <transport>::<address>
where <address> may be a path, a server and path, or an arbitrary URL-like string recognized by the specific remote helper being invoked. See [gitremote-helpers[7]](gitremote-helpers) for details.
If there are a large number of similarly-named remote repositories and you want to use a different format for them (such that the URLs you use will be rewritten into URLs that work), you can create a configuration section of the form:
```
[url "<actual url base>"]
insteadOf = <other url base>
```
For example, with this:
```
[url "git://git.host.xz/"]
insteadOf = host.xz:/path/to/
insteadOf = work:
```
a URL like "work:repo.git" or like "host.xz:/path/to/repo.git" will be rewritten in any context that takes a URL to be "git://git.host.xz/repo.git".
If you want to rewrite URLs for push only, you can create a configuration section of the form:
```
[url "<actual url base>"]
pushInsteadOf = <other url base>
```
For example, with this:
```
[url "ssh://example.org/"]
pushInsteadOf = git://example.org/
```
a URL like "git://example.org/path/to/repo.git" will be rewritten to "ssh://example.org/path/to/repo.git" for pushes, but pulls will still use the original URL.
Examples
--------
* Clone from upstream:
```
$ git clone git://git.kernel.org/pub/scm/.../linux.git my-linux
$ cd my-linux
$ make
```
* Make a local clone that borrows from the current directory, without checking things out:
```
$ git clone -l -s -n . ../copy
$ cd ../copy
$ git show-branch
```
* Clone from upstream while borrowing from an existing local directory:
```
$ git clone --reference /git/linux.git \
git://git.kernel.org/pub/scm/.../linux.git \
my-linux
$ cd my-linux
```
* Create a bare repository to publish your changes to the public:
```
$ git clone --bare -l /home/proj/.git /pub/scm/proj.git
```
Configuration
-------------
Everything below this line in this section is selectively included from the [git-config[1]](git-config) documentation. The content is the same as what’s found there:
init.templateDir Specify the directory from which templates will be copied. (See the "TEMPLATE DIRECTORY" section of [git-init[1]](git-init).)
init.defaultBranch Allows overriding the default branch name e.g. when initializing a new repository.
clone.defaultRemoteName The name of the remote to create when cloning a repository. Defaults to `origin`, and can be overridden by passing the `--origin` command-line option to [git-clone[1]](git-clone).
clone.rejectShallow Reject to clone a repository if it is a shallow one, can be overridden by passing option `--reject-shallow` in command line. See [git-clone[1]](git-clone)
clone.filterSubmodules If a partial clone filter is provided (see `--filter` in [git-rev-list[1]](git-rev-list)) and `--recurse-submodules` is used, also apply the filter to submodules.
| programming_docs |
git git-cvsexportcommit git-cvsexportcommit
===================
Name
----
git-cvsexportcommit - Export a single commit to a CVS checkout
Synopsis
--------
```
git cvsexportcommit [-h] [-u] [-v] [-c] [-P] [-p] [-a] [-d <cvsroot>]
[-w <cvs-workdir>] [-W] [-f] [-m <msgprefix>] [<parent-commit>] <commit-id>
```
Description
-----------
Exports a commit from Git to a CVS checkout, making it easier to merge patches from a Git repository into a CVS repository.
Specify the name of a CVS checkout using the -w switch or execute it from the root of the CVS working copy. In the latter case GIT\_DIR must be defined. See examples below.
It does its best to do the safe thing, it will check that the files are unchanged and up to date in the CVS checkout, and it will not autocommit by default.
Supports file additions, removals, and commits that affect binary files.
If the commit is a merge commit, you must tell `git cvsexportcommit` what parent the changeset should be done against.
Options
-------
-c Commit automatically if the patch applied cleanly. It will not commit if any hunks fail to apply or there were other problems.
-p Be pedantic (paranoid) when applying patches. Invokes patch with --fuzz=0
-a Add authorship information. Adds Author line, and Committer (if different from Author) to the message.
-d Set an alternative CVSROOT to use. This corresponds to the CVS -d parameter. Usually users will not want to set this, except if using CVS in an asymmetric fashion.
-f Force the merge even if the files are not up to date.
-P Force the parent commit, even if it is not a direct parent.
-m Prepend the commit message with the provided prefix. Useful for patch series and the like.
-u Update affected files from CVS repository before attempting export.
-k Reverse CVS keyword expansion (e.g. $Revision: 1.2.3.4$ becomes $Revision$) in working CVS checkout before applying patch.
-w Specify the location of the CVS checkout to use for the export. This option does not require GIT\_DIR to be set before execution if the current directory is within a Git repository. The default is the value of `cvsexportcommit.cvsdir`.
-W Tell cvsexportcommit that the current working directory is not only a Git checkout, but also the CVS checkout. Therefore, Git will reset the working directory to the parent commit before proceeding.
-v Verbose.
Configuration
-------------
cvsexportcommit.cvsdir The default location of the CVS checkout to use for the export.
Examples
--------
Merge one patch into CVS
```
$ export GIT_DIR=~/project/.git
$ cd ~/project_cvs_checkout
$ git cvsexportcommit -v <commit-sha1>
$ cvs commit -F .msg <files>
```
Merge one patch into CVS (-c and -w options). The working directory is within the Git Repo
```
$ git cvsexportcommit -v -c -w ~/project_cvs_checkout <commit-sha1>
```
Merge pending patches into CVS automatically — only if you really know what you are doing
```
$ export GIT_DIR=~/project/.git
$ cd ~/project_cvs_checkout
$ git cherry cvshead myhead | sed -n 's/^+ //p' | xargs -l1 git cvsexportcommit -c -p -v
```
git gitprotocol-common gitprotocol-common
==================
Name
----
gitprotocol-common - Things common to various protocols
Synopsis
--------
```
<over-the-wire-protocol>
```
Description
-----------
This document sets defines things common to various over-the-wire protocols and file formats used in Git.
Abnf notation
-------------
ABNF notation as described by RFC 5234 is used within the protocol documents, except the following replacement core rules are used:
```
HEXDIG = DIGIT / "a" / "b" / "c" / "d" / "e" / "f"
```
We also define the following common rules:
```
NUL = %x00
zero-id = 40*"0"
obj-id = 40*(HEXDIGIT)
refname = "HEAD"
refname /= "refs/" <see discussion below>
```
A refname is a hierarchical octet string beginning with "refs/" and not violating the `git-check-ref-format` command’s validation rules. More specifically, they:
1. They can include slash `/` for hierarchical (directory) grouping, but no slash-separated component can begin with a dot `.`.
2. They must contain at least one `/`. This enforces the presence of a category like `heads/`, `tags/` etc. but the actual names are not restricted.
3. They cannot have two consecutive dots `..` anywhere.
4. They cannot have ASCII control characters (i.e. bytes whose values are lower than \040, or \177 `DEL`), space, tilde `~`, caret `^`, colon `:`, question-mark `?`, asterisk `*`, or open bracket `[` anywhere.
5. They cannot end with a slash `/` or a dot `.`.
6. They cannot end with the sequence `.lock`.
7. They cannot contain a sequence `@{`.
8. They cannot contain a `\\`.
Pkt-line format
---------------
Much (but not all) of the payload is described around pkt-lines.
A pkt-line is a variable length binary string. The first four bytes of the line, the pkt-len, indicates the total length of the line, in hexadecimal. The pkt-len includes the 4 bytes used to contain the length’s hexadecimal representation.
A pkt-line MAY contain binary data, so implementors MUST ensure pkt-line parsing/formatting routines are 8-bit clean.
A non-binary line SHOULD BE terminated by an LF, which if present MUST be included in the total length. Receivers MUST treat pkt-lines with non-binary data the same whether or not they contain the trailing LF (stripping the LF if present, and not complaining when it is missing).
The maximum length of a pkt-line’s data component is 65516 bytes. Implementations MUST NOT send pkt-line whose length exceeds 65520 (65516 bytes of payload + 4 bytes of length data).
Implementations SHOULD NOT send an empty pkt-line ("0004").
A pkt-line with a length field of 0 ("0000"), called a flush-pkt, is a special case and MUST be handled differently than an empty pkt-line ("0004").
```
pkt-line = data-pkt / flush-pkt
data-pkt = pkt-len pkt-payload
pkt-len = 4*(HEXDIG)
pkt-payload = (pkt-len - 4)*(OCTET)
flush-pkt = "0000"
```
Examples (as C-style strings):
```
pkt-line actual value
---------------------------------
"0006a\n" "a\n"
"0005a" "a"
"000bfoobar\n" "foobar\n"
"0004" ""
```
git git-prune git-prune
=========
Name
----
git-prune - Prune all unreachable objects from the object database
Synopsis
--------
```
git prune [-n] [-v] [--progress] [--expire <time>] [--] [<head>…]
```
Description
-----------
| | |
| --- | --- |
| Note | In most cases, users should run *git gc*, which calls *git prune*. See the section "NOTES", below. |
This runs `git fsck --unreachable` using all the refs available in `refs/`, optionally with additional set of objects specified on the command line, and prunes all unpacked objects unreachable from any of these head objects from the object database. In addition, it prunes the unpacked objects that are also found in packs by running `git prune-packed`. It also removes entries from .git/shallow that are not reachable by any ref.
Note that unreachable, packed objects will remain. If this is not desired, see [git-repack[1]](git-repack).
Options
-------
-n --dry-run Do not remove anything; just report what it would remove.
-v --verbose Report all removed objects.
--progress Show progress.
--expire <time> Only expire loose objects older than <time>.
-- Do not interpret any more arguments as options.
<head>… In addition to objects reachable from any of our references, keep objects reachable from listed <head>s.
Examples
--------
To prune objects not used by your repository or another that borrows from your repository via its `.git/objects/info/alternates`:
```
$ git prune $(cd ../another && git rev-parse --all)
```
Notes
-----
In most cases, users will not need to call `git prune` directly, but should instead call `git gc`, which handles pruning along with many other housekeeping tasks.
For a description of which objects are considered for pruning, see `git fsck`'s --unreachable option.
See also
--------
[git-fsck[1]](git-fsck), [git-gc[1]](git-gc), [git-reflog[1]](git-reflog)
git git git
===
Name
----
git - the stupid content tracker
Synopsis
--------
```
git [-v | --version] [-h | --help] [-C <path>] [-c <name>=<value>]
[--exec-path[=<path>]] [--html-path] [--man-path] [--info-path]
[-p|--paginate|-P|--no-pager] [--no-replace-objects] [--bare]
[--git-dir=<path>] [--work-tree=<path>] [--namespace=<name>]
[--super-prefix=<path>] [--config-env=<name>=<envvar>]
<command> [<args>]
```
Description
-----------
Git is a fast, scalable, distributed revision control system with an unusually rich command set that provides both high-level operations and full access to internals.
See [gittutorial[7]](gittutorial) to get started, then see [giteveryday[7]](giteveryday) for a useful minimum set of commands. The [Git User’s Manual](user-manual) has a more in-depth introduction.
After you mastered the basic concepts, you can come back to this page to learn what commands Git offers. You can learn more about individual Git commands with "git help command". [gitcli[7]](gitcli) manual page gives you an overview of the command-line command syntax.
A formatted and hyperlinked copy of the latest Git documentation can be viewed at <https://git.github.io/htmldocs/git.html> or [https://git-scm.com/docs](index).
Options
-------
-v --version Prints the Git suite version that the `git` program came from.
This option is internally converted to `git version ...` and accepts the same options as the [git-version[1]](git-version) command. If `--help` is also given, it takes precedence over `--version`.
-h --help Prints the synopsis and a list of the most commonly used commands. If the option `--all` or `-a` is given then all available commands are printed. If a Git command is named this option will bring up the manual page for that command.
Other options are available to control how the manual page is displayed. See [git-help[1]](git-help) for more information, because `git --help ...` is converted internally into `git
help ...`.
-C <path> Run as if git was started in `<path>` instead of the current working directory. When multiple `-C` options are given, each subsequent non-absolute `-C <path>` is interpreted relative to the preceding `-C
<path>`. If `<path>` is present but empty, e.g. `-C ""`, then the current working directory is left unchanged.
This option affects options that expect path name like `--git-dir` and `--work-tree` in that their interpretations of the path names would be made relative to the working directory caused by the `-C` option. For example the following invocations are equivalent:
```
git --git-dir=a.git --work-tree=b -C c status
git --git-dir=c/a.git --work-tree=c/b status
```
-c <name>=<value> Pass a configuration parameter to the command. The value given will override values from configuration files. The <name> is expected in the same format as listed by `git config` (subkeys separated by dots).
Note that omitting the `=` in `git -c foo.bar ...` is allowed and sets `foo.bar` to the boolean true value (just like `[foo]bar` would in a config file). Including the equals but with an empty value (like `git -c
foo.bar= ...`) sets `foo.bar` to the empty string which `git config
--type=bool` will convert to `false`.
--config-env=<name>=<envvar> Like `-c <name>=<value>`, give configuration variable `<name>` a value, where <envvar> is the name of an environment variable from which to retrieve the value. Unlike `-c` there is no shortcut for directly setting the value to an empty string, instead the environment variable itself must be set to the empty string. It is an error if the `<envvar>` does not exist in the environment. `<envvar>` may not contain an equals sign to avoid ambiguity with `<name>` containing one.
This is useful for cases where you want to pass transitory configuration options to git, but are doing so on OS’s where other processes might be able to read your cmdline (e.g. `/proc/self/cmdline`), but not your environ (e.g. `/proc/self/environ`). That behavior is the default on Linux, but may not be on your system.
Note that this might add security for variables such as `http.extraHeader` where the sensitive information is part of the value, but not e.g. `url.<base>.insteadOf` where the sensitive information can be part of the key.
--exec-path[=<path>] Path to wherever your core Git programs are installed. This can also be controlled by setting the GIT\_EXEC\_PATH environment variable. If no path is given, `git` will print the current setting and then exit.
--html-path Print the path, without trailing slash, where Git’s HTML documentation is installed and exit.
--man-path Print the manpath (see `man(1)`) for the man pages for this version of Git and exit.
--info-path Print the path where the Info files documenting this version of Git are installed and exit.
-p --paginate Pipe all output into `less` (or if set, $PAGER) if standard output is a terminal. This overrides the `pager.<cmd>` configuration options (see the "Configuration Mechanism" section below).
-P --no-pager Do not pipe Git output into a pager.
--git-dir=<path> Set the path to the repository (".git" directory). This can also be controlled by setting the `GIT_DIR` environment variable. It can be an absolute path or relative path to current working directory.
Specifying the location of the ".git" directory using this option (or `GIT_DIR` environment variable) turns off the repository discovery that tries to find a directory with ".git" subdirectory (which is how the repository and the top-level of the working tree are discovered), and tells Git that you are at the top level of the working tree. If you are not at the top-level directory of the working tree, you should tell Git where the top-level of the working tree is, with the `--work-tree=<path>` option (or `GIT_WORK_TREE` environment variable)
If you just want to run git as if it was started in `<path>` then use `git -C <path>`.
--work-tree=<path> Set the path to the working tree. It can be an absolute path or a path relative to the current working directory. This can also be controlled by setting the GIT\_WORK\_TREE environment variable and the core.worktree configuration variable (see core.worktree in [git-config[1]](git-config) for a more detailed discussion).
--namespace=<path> Set the Git namespace. See [gitnamespaces[7]](gitnamespaces) for more details. Equivalent to setting the `GIT_NAMESPACE` environment variable.
--super-prefix=<path> Currently for internal use only. Set a prefix which gives a path from above a repository down to its root. One use is to give submodules context about the superproject that invoked it.
--bare Treat the repository as a bare repository. If GIT\_DIR environment is not set, it is set to the current working directory.
--no-replace-objects Do not use replacement refs to replace Git objects. See [git-replace[1]](git-replace) for more information.
--literal-pathspecs Treat pathspecs literally (i.e. no globbing, no pathspec magic). This is equivalent to setting the `GIT_LITERAL_PATHSPECS` environment variable to `1`.
--glob-pathspecs Add "glob" magic to all pathspec. This is equivalent to setting the `GIT_GLOB_PATHSPECS` environment variable to `1`. Disabling globbing on individual pathspecs can be done using pathspec magic ":(literal)"
--noglob-pathspecs Add "literal" magic to all pathspec. This is equivalent to setting the `GIT_NOGLOB_PATHSPECS` environment variable to `1`. Enabling globbing on individual pathspecs can be done using pathspec magic ":(glob)"
--icase-pathspecs Add "icase" magic to all pathspec. This is equivalent to setting the `GIT_ICASE_PATHSPECS` environment variable to `1`.
--no-optional-locks Do not perform optional operations that require locks. This is equivalent to setting the `GIT_OPTIONAL_LOCKS` to `0`.
--list-cmds=group[,group…] List commands by group. This is an internal/experimental option and may change or be removed in the future. Supported groups are: builtins, parseopt (builtin commands that use parse-options), main (all commands in libexec directory), others (all other commands in `$PATH` that have git- prefix), list-<category> (see categories in command-list.txt), nohelpers (exclude helper commands), alias and config (retrieve command list from config variable completion.commands)
Git commands
------------
We divide Git into high level ("porcelain") commands and low level ("plumbing") commands.
High-level commands (porcelain)
-------------------------------
We separate the porcelain commands into the main commands and some ancillary user utilities.
###
Main porcelain commands
[git-add[1]](git-add) Add file contents to the index
[git-am[1]](git-am) Apply a series of patches from a mailbox
[git-archive[1]](git-archive) Create an archive of files from a named tree
[git-bisect[1]](git-bisect) Use binary search to find the commit that introduced a bug
[git-branch[1]](git-branch) List, create, or delete branches
[git-bundle[1]](git-bundle) Move objects and refs by archive
[git-checkout[1]](git-checkout) Switch branches or restore working tree files
[git-cherry-pick[1]](git-cherry-pick) Apply the changes introduced by some existing commits
[git-citool[1]](git-citool) Graphical alternative to git-commit
[git-clean[1]](git-clean) Remove untracked files from the working tree
[git-clone[1]](git-clone) Clone a repository into a new directory
[git-commit[1]](git-commit) Record changes to the repository
[git-describe[1]](git-describe) Give an object a human readable name based on an available ref
[git-diff[1]](git-diff) Show changes between commits, commit and working tree, etc
[git-fetch[1]](git-fetch) Download objects and refs from another repository
[git-format-patch[1]](git-format-patch) Prepare patches for e-mail submission
[git-gc[1]](git-gc) Cleanup unnecessary files and optimize the local repository
[git-grep[1]](git-grep) Print lines matching a pattern
[git-gui[1]](git-gui) A portable graphical interface to Git
[git-init[1]](git-init) Create an empty Git repository or reinitialize an existing one
[git-log[1]](git-log) Show commit logs
[git-maintenance[1]](git-maintenance) Run tasks to optimize Git repository data
[git-merge[1]](git-merge) Join two or more development histories together
[git-mv[1]](git-mv) Move or rename a file, a directory, or a symlink
[git-notes[1]](git-notes) Add or inspect object notes
[git-pull[1]](git-pull) Fetch from and integrate with another repository or a local branch
[git-push[1]](git-push) Update remote refs along with associated objects
[git-range-diff[1]](git-range-diff) Compare two commit ranges (e.g. two versions of a branch)
[git-rebase[1]](git-rebase) Reapply commits on top of another base tip
[git-reset[1]](git-reset) Reset current HEAD to the specified state
[git-restore[1]](git-restore) Restore working tree files
[git-revert[1]](git-revert) Revert some existing commits
[git-rm[1]](git-rm) Remove files from the working tree and from the index
[git-shortlog[1]](git-shortlog) Summarize `git log` output
[git-show[1]](git-show) Show various types of objects
[git-sparse-checkout[1]](git-sparse-checkout) Reduce your working tree to a subset of tracked files
[git-stash[1]](git-stash) Stash the changes in a dirty working directory away
[git-status[1]](git-status) Show the working tree status
[git-submodule[1]](git-submodule) Initialize, update or inspect submodules
[git-switch[1]](git-switch) Switch branches
[git-tag[1]](git-tag) Create, list, delete or verify a tag object signed with GPG
[git-worktree[1]](git-worktree) Manage multiple working trees
[gitk[1]](gitk) The Git repository browser
[scalar[1]](scalar) A tool for managing large Git repositories
###
Ancillary Commands
Manipulators:
[git-config[1]](git-config) Get and set repository or global options
[git-fast-export[1]](git-fast-export) Git data exporter
[git-fast-import[1]](git-fast-import) Backend for fast Git data importers
[git-filter-branch[1]](git-filter-branch) Rewrite branches
[git-mergetool[1]](git-mergetool) Run merge conflict resolution tools to resolve merge conflicts
[git-pack-refs[1]](git-pack-refs) Pack heads and tags for efficient repository access
[git-prune[1]](git-prune) Prune all unreachable objects from the object database
[git-reflog[1]](git-reflog) Manage reflog information
[git-remote[1]](git-remote) Manage set of tracked repositories
[git-repack[1]](git-repack) Pack unpacked objects in a repository
[git-replace[1]](git-replace) Create, list, delete refs to replace objects
Interrogators:
[git-annotate[1]](git-annotate) Annotate file lines with commit information
[git-blame[1]](git-blame) Show what revision and author last modified each line of a file
[git-bugreport[1]](git-bugreport) Collect information for user to file a bug report
[git-count-objects[1]](git-count-objects) Count unpacked number of objects and their disk consumption
[git-diagnose[1]](git-diagnose) Generate a zip archive of diagnostic information
[git-difftool[1]](git-difftool) Show changes using common diff tools
[git-fsck[1]](git-fsck) Verifies the connectivity and validity of the objects in the database
[git-help[1]](git-help) Display help information about Git
[git-instaweb[1]](git-instaweb) Instantly browse your working repository in gitweb
[git-merge-tree[1]](git-merge-tree) Perform merge without touching index or working tree
[git-rerere[1]](git-rerere) Reuse recorded resolution of conflicted merges
[git-show-branch[1]](git-show-branch) Show branches and their commits
[git-verify-commit[1]](git-verify-commit) Check the GPG signature of commits
[git-verify-tag[1]](git-verify-tag) Check the GPG signature of tags
[git-version[1]](git-version) Display version information about Git
[git-whatchanged[1]](git-whatchanged) Show logs with difference each commit introduces
[gitweb[1]](gitweb) Git web interface (web frontend to Git repositories)
###
Interacting with Others
These commands are to interact with foreign SCM and with other people via patch over e-mail.
[git-archimport[1]](git-archimport) Import a GNU Arch repository into Git
[git-cvsexportcommit[1]](git-cvsexportcommit) Export a single commit to a CVS checkout
[git-cvsimport[1]](git-cvsimport) Salvage your data out of another SCM people love to hate
[git-cvsserver[1]](git-cvsserver) A CVS server emulator for Git
[git-imap-send[1]](git-imap-send) Send a collection of patches from stdin to an IMAP folder
[git-p4[1]](git-p4) Import from and submit to Perforce repositories
[git-quiltimport[1]](git-quiltimport) Applies a quilt patchset onto the current branch
[git-request-pull[1]](git-request-pull) Generates a summary of pending changes
[git-send-email[1]](git-send-email) Send a collection of patches as emails
[git-svn[1]](git-svn) Bidirectional operation between a Subversion repository and Git
###
Reset, restore and revert
There are three commands with similar names: `git reset`, `git restore` and `git revert`.
* [git-revert[1]](git-revert) is about making a new commit that reverts the changes made by other commits.
* [git-restore[1]](git-restore) is about restoring files in the working tree from either the index or another commit. This command does not update your branch. The command can also be used to restore files in the index from another commit.
* [git-reset[1]](git-reset) is about updating your branch, moving the tip in order to add or remove commits from the branch. This operation changes the commit history.
`git reset` can also be used to restore the index, overlapping with `git restore`.
Low-level commands (plumbing)
-----------------------------
Although Git includes its own porcelain layer, its low-level commands are sufficient to support development of alternative porcelains. Developers of such porcelains might start by reading about [git-update-index[1]](git-update-index) and [git-read-tree[1]](git-read-tree).
The interface (input, output, set of options and the semantics) to these low-level commands are meant to be a lot more stable than Porcelain level commands, because these commands are primarily for scripted use. The interface to Porcelain commands on the other hand are subject to change in order to improve the end user experience.
The following description divides the low-level commands into commands that manipulate objects (in the repository, index, and working tree), commands that interrogate and compare objects, and commands that move objects and references between repositories.
###
Manipulation commands
[git-apply[1]](git-apply) Apply a patch to files and/or to the index
[git-checkout-index[1]](git-checkout-index) Copy files from the index to the working tree
[git-commit-graph[1]](git-commit-graph) Write and verify Git commit-graph files
[git-commit-tree[1]](git-commit-tree) Create a new commit object
[git-hash-object[1]](git-hash-object) Compute object ID and optionally creates a blob from a file
[git-index-pack[1]](git-index-pack) Build pack index file for an existing packed archive
[git-merge-file[1]](git-merge-file) Run a three-way file merge
[git-merge-index[1]](git-merge-index) Run a merge for files needing merging
[git-mktag[1]](git-mktag) Creates a tag object with extra validation
[git-mktree[1]](git-mktree) Build a tree-object from ls-tree formatted text
[git-multi-pack-index[1]](git-multi-pack-index) Write and verify multi-pack-indexes
[git-pack-objects[1]](git-pack-objects) Create a packed archive of objects
[git-prune-packed[1]](git-prune-packed) Remove extra objects that are already in pack files
[git-read-tree[1]](git-read-tree) Reads tree information into the index
[git-symbolic-ref[1]](git-symbolic-ref) Read, modify and delete symbolic refs
[git-unpack-objects[1]](git-unpack-objects) Unpack objects from a packed archive
[git-update-index[1]](git-update-index) Register file contents in the working tree to the index
[git-update-ref[1]](git-update-ref) Update the object name stored in a ref safely
[git-write-tree[1]](git-write-tree) Create a tree object from the current index
###
Interrogation commands
[git-cat-file[1]](git-cat-file) Provide content or type and size information for repository objects
[git-cherry[1]](git-cherry) Find commits yet to be applied to upstream
[git-diff-files[1]](git-diff-files) Compares files in the working tree and the index
[git-diff-index[1]](git-diff-index) Compare a tree to the working tree or index
[git-diff-tree[1]](git-diff-tree) Compares the content and mode of blobs found via two tree objects
[git-for-each-ref[1]](git-for-each-ref) Output information on each ref
[git-for-each-repo[1]](git-for-each-repo) Run a Git command on a list of repositories
[git-get-tar-commit-id[1]](git-get-tar-commit-id) Extract commit ID from an archive created using git-archive
[git-ls-files[1]](git-ls-files) Show information about files in the index and the working tree
[git-ls-remote[1]](git-ls-remote) List references in a remote repository
[git-ls-tree[1]](git-ls-tree) List the contents of a tree object
[git-merge-base[1]](git-merge-base) Find as good common ancestors as possible for a merge
[git-name-rev[1]](git-name-rev) Find symbolic names for given revs
[git-pack-redundant[1]](git-pack-redundant) Find redundant pack files
[git-rev-list[1]](git-rev-list) Lists commit objects in reverse chronological order
[git-rev-parse[1]](git-rev-parse) Pick out and massage parameters
[git-show-index[1]](git-show-index) Show packed archive index
[git-show-ref[1]](git-show-ref) List references in a local repository
[git-unpack-file[1]](git-unpack-file) Creates a temporary file with a blob’s contents
[git-var[1]](git-var) Show a Git logical variable
[git-verify-pack[1]](git-verify-pack) Validate packed Git archive files
In general, the interrogate commands do not touch the files in the working tree.
###
Syncing repositories
[git-daemon[1]](git-daemon) A really simple server for Git repositories
[git-fetch-pack[1]](git-fetch-pack) Receive missing objects from another repository
[git-http-backend[1]](git-http-backend) Server side implementation of Git over HTTP
[git-send-pack[1]](git-send-pack) Push objects over Git protocol to another repository
[git-update-server-info[1]](git-update-server-info) Update auxiliary info file to help dumb servers
The following are helper commands used by the above; end users typically do not use them directly.
[git-http-fetch[1]](git-http-fetch) Download from a remote Git repository via HTTP
[git-http-push[1]](git-http-push) Push objects over HTTP/DAV to another repository
[git-receive-pack[1]](git-receive-pack) Receive what is pushed into the repository
[git-shell[1]](git-shell) Restricted login shell for Git-only SSH access
[git-upload-archive[1]](git-upload-archive) Send archive back to git-archive
[git-upload-pack[1]](git-upload-pack) Send objects packed back to git-fetch-pack
###
Internal helper commands
These are internal helper commands used by other commands; end users typically do not use them directly.
[git-check-attr[1]](git-check-attr) Display gitattributes information
[git-check-ignore[1]](git-check-ignore) Debug gitignore / exclude files
[git-check-mailmap[1]](git-check-mailmap) Show canonical names and email addresses of contacts
[git-check-ref-format[1]](git-check-ref-format) Ensures that a reference name is well formed
[git-column[1]](git-column) Display data in columns
[git-credential[1]](git-credential) Retrieve and store user credentials
[git-credential-cache[1]](git-credential-cache) Helper to temporarily store passwords in memory
[git-credential-store[1]](git-credential-store) Helper to store credentials on disk
[git-fmt-merge-msg[1]](git-fmt-merge-msg) Produce a merge commit message
[git-hook[1]](git-hook) Run git hooks
[git-interpret-trailers[1]](git-interpret-trailers) Add or parse structured information in commit messages
[git-mailinfo[1]](git-mailinfo) Extracts patch and authorship from a single e-mail message
[git-mailsplit[1]](git-mailsplit) Simple UNIX mbox splitter program
[git-merge-one-file[1]](git-merge-one-file) The standard helper program to use with git-merge-index
[git-patch-id[1]](git-patch-id) Compute unique ID for a patch
[git-sh-i18n[1]](git-sh-i18n) Git’s i18n setup code for shell scripts
[git-sh-setup[1]](git-sh-setup) Common Git shell script setup code
[git-stripspace[1]](git-stripspace) Remove unnecessary whitespace
Guides
------
The following documentation pages are guides about Git concepts.
[gitcore-tutorial[7]](gitcore-tutorial) A Git core tutorial for developers
[gitcredentials[7]](gitcredentials) Providing usernames and passwords to Git
[gitcvs-migration[7]](gitcvs-migration) Git for CVS users
[gitdiffcore[7]](gitdiffcore) Tweaking diff output
[giteveryday[7]](giteveryday) A useful minimum set of commands for Everyday Git
[gitfaq[7]](gitfaq) Frequently asked questions about using Git
[gitglossary[7]](gitglossary) A Git Glossary
[gitnamespaces[7]](gitnamespaces) Git namespaces
[gitremote-helpers[7]](gitremote-helpers) Helper programs to interact with remote repositories
[gitsubmodules[7]](gitsubmodules) Mounting one repository inside another
[gittutorial[7]](gittutorial) A tutorial introduction to Git
[gittutorial-2[7]](gittutorial-2) A tutorial introduction to Git: part two
[gitworkflows[7]](gitworkflows) An overview of recommended workflows with Git
Repository, command and file interfaces
---------------------------------------
This documentation discusses repository and command interfaces which users are expected to interact with directly. See `--user-formats` in [git-help[1]](git-help) for more details on the criteria.
[gitattributes[5]](gitattributes) Defining attributes per path
[gitcli[7]](gitcli) Git command-line interface and conventions
[githooks[5]](githooks) Hooks used by Git
[gitignore[5]](gitignore) Specifies intentionally untracked files to ignore
[gitmailmap[5]](gitmailmap) Map author/committer names and/or E-Mail addresses
[gitmodules[5]](gitmodules) Defining submodule properties
[gitrepository-layout[5]](gitrepository-layout) Git Repository Layout
[gitrevisions[7]](gitrevisions) Specifying revisions and ranges for Git
File formats, protocols and other developer interfaces
------------------------------------------------------
This documentation discusses file formats, over-the-wire protocols and other git developer interfaces. See `--developer-interfaces` in [git-help[1]](git-help).
[gitformat-bundle[5]](gitformat-bundle) The bundle file format
[gitformat-chunk[5]](gitformat-chunk) Chunk-based file formats
[gitformat-commit-graph[5]](gitformat-commit-graph) Git commit-graph format
[gitformat-index[5]](gitformat-index) Git index format
[gitformat-pack[5]](gitformat-pack) Git pack format
[gitformat-signature[5]](gitformat-signature) Git cryptographic signature formats
[gitprotocol-capabilities[5]](gitprotocol-capabilities) Protocol v0 and v1 capabilities
[gitprotocol-common[5]](gitprotocol-common) Things common to various protocols
[gitprotocol-http[5]](gitprotocol-http) Git HTTP-based protocols
[gitprotocol-pack[5]](gitprotocol-pack) How packs are transferred over-the-wire
[gitprotocol-v2[5]](gitprotocol-v2) Git Wire Protocol, Version 2
Configuration mechanism
-----------------------
Git uses a simple text format to store customizations that are per repository and are per user. Such a configuration file may look like this:
```
#
# A '#' or ';' character indicates a comment.
#
; core variables
[core]
; Don't trust file modes
filemode = false
; user identity
[user]
name = "Junio C Hamano"
email = "[email protected]"
```
Various commands read from the configuration file and adjust their operation accordingly. See [git-config[1]](git-config) for a list and more details about the configuration mechanism.
Identifier terminology
----------------------
<object> Indicates the object name for any type of object.
<blob> Indicates a blob object name.
<tree> Indicates a tree object name.
<commit> Indicates a commit object name.
<tree-ish> Indicates a tree, commit or tag object name. A command that takes a <tree-ish> argument ultimately wants to operate on a <tree> object but automatically dereferences <commit> and <tag> objects that point at a <tree>.
<commit-ish> Indicates a commit or tag object name. A command that takes a <commit-ish> argument ultimately wants to operate on a <commit> object but automatically dereferences <tag> objects that point at a <commit>.
<type> Indicates that an object type is required. Currently one of: `blob`, `tree`, `commit`, or `tag`.
<file> Indicates a filename - almost always relative to the root of the tree structure `GIT_INDEX_FILE` describes.
Symbolic identifiers
--------------------
Any Git command accepting any <object> can also use the following symbolic notation:
HEAD indicates the head of the current branch.
<tag> a valid tag `name` (i.e. a `refs/tags/<tag>` reference).
<head> a valid head `name` (i.e. a `refs/heads/<head>` reference).
For a more complete list of ways to spell object names, see "SPECIFYING REVISIONS" section in [gitrevisions[7]](gitrevisions).
File/directory structure
------------------------
Please see the [gitrepository-layout[5]](gitrepository-layout) document.
Read [githooks[5]](githooks) for more details about each hook.
Higher level SCMs may provide and manage additional information in the `$GIT_DIR`.
Terminology
-----------
Please see [gitglossary[7]](gitglossary).
Environment variables
---------------------
Various Git commands pay attention to environment variables and change their behavior. The environment variables marked as "Boolean" take their values the same way as Boolean valued configuration variables, e.g. "true", "yes", "on" and positive numbers are taken as "yes".
Here are the variables:
###
The Git Repository
These environment variables apply to `all` core Git commands. Nb: it is worth noting that they may be used/overridden by SCMS sitting above Git so take care if using a foreign front-end.
`GIT_INDEX_FILE` This environment variable specifies an alternate index file. If not specified, the default of `$GIT_DIR/index` is used.
`GIT_INDEX_VERSION` This environment variable specifies what index version is used when writing the index file out. It won’t affect existing index files. By default index file version 2 or 3 is used. See [git-update-index[1]](git-update-index) for more information.
`GIT_OBJECT_DIRECTORY` If the object storage directory is specified via this environment variable then the sha1 directories are created underneath - otherwise the default `$GIT_DIR/objects` directory is used.
`GIT_ALTERNATE_OBJECT_DIRECTORIES` Due to the immutable nature of Git objects, old objects can be archived into shared, read-only directories. This variable specifies a ":" separated (on Windows ";" separated) list of Git object directories which can be used to search for Git objects. New objects will not be written to these directories.
Entries that begin with `"` (double-quote) will be interpreted as C-style quoted paths, removing leading and trailing double-quotes and respecting backslash escapes. E.g., the value `"path-with-\"-and-:-in-it":vanilla-path` has two paths: `path-with-"-and-:-in-it` and `vanilla-path`.
`GIT_DIR` If the `GIT_DIR` environment variable is set then it specifies a path to use instead of the default `.git` for the base of the repository. The `--git-dir` command-line option also sets this value.
`GIT_WORK_TREE` Set the path to the root of the working tree. This can also be controlled by the `--work-tree` command-line option and the core.worktree configuration variable.
`GIT_NAMESPACE` Set the Git namespace; see [gitnamespaces[7]](gitnamespaces) for details. The `--namespace` command-line option also sets this value.
`GIT_CEILING_DIRECTORIES` This should be a colon-separated list of absolute paths. If set, it is a list of directories that Git should not chdir up into while looking for a repository directory (useful for excluding slow-loading network directories). It will not exclude the current working directory or a GIT\_DIR set on the command line or in the environment. Normally, Git has to read the entries in this list and resolve any symlink that might be present in order to compare them with the current directory. However, if even this access is slow, you can add an empty entry to the list to tell Git that the subsequent entries are not symlinks and needn’t be resolved; e.g., `GIT_CEILING_DIRECTORIES=/maybe/symlink::/very/slow/non/symlink`.
`GIT_DISCOVERY_ACROSS_FILESYSTEM` When run in a directory that does not have ".git" repository directory, Git tries to find such a directory in the parent directories to find the top of the working tree, but by default it does not cross filesystem boundaries. This Boolean environment variable can be set to true to tell Git not to stop at filesystem boundaries. Like `GIT_CEILING_DIRECTORIES`, this will not affect an explicit repository directory set via `GIT_DIR` or on the command line.
`GIT_COMMON_DIR` If this variable is set to a path, non-worktree files that are normally in $GIT\_DIR will be taken from this path instead. Worktree-specific files such as HEAD or index are taken from $GIT\_DIR. See [gitrepository-layout[5]](gitrepository-layout) and [git-worktree[1]](git-worktree) for details. This variable has lower precedence than other path variables such as GIT\_INDEX\_FILE, GIT\_OBJECT\_DIRECTORY…
`GIT_DEFAULT_HASH` If this variable is set, the default hash algorithm for new repositories will be set to this value. This value is currently ignored when cloning; the setting of the remote repository is used instead. The default is "sha1". THIS VARIABLE IS EXPERIMENTAL! See `--object-format` in [git-init[1]](git-init).
###
Git Commits
`GIT_AUTHOR_NAME` The human-readable name used in the author identity when creating commit or tag objects, or when writing reflogs. Overrides the `user.name` and `author.name` configuration settings.
`GIT_AUTHOR_EMAIL` The email address used in the author identity when creating commit or tag objects, or when writing reflogs. Overrides the `user.email` and `author.email` configuration settings.
`GIT_AUTHOR_DATE` The date used for the author identity when creating commit or tag objects, or when writing reflogs. See [git-commit[1]](git-commit) for valid formats.
`GIT_COMMITTER_NAME` The human-readable name used in the committer identity when creating commit or tag objects, or when writing reflogs. Overrides the `user.name` and `committer.name` configuration settings.
`GIT_COMMITTER_EMAIL` The email address used in the author identity when creating commit or tag objects, or when writing reflogs. Overrides the `user.email` and `committer.email` configuration settings.
`GIT_COMMITTER_DATE` The date used for the committer identity when creating commit or tag objects, or when writing reflogs. See [git-commit[1]](git-commit) for valid formats.
`EMAIL` The email address used in the author and committer identities if no other relevant environment variable or configuration setting has been set.
###
Git Diffs
`GIT_DIFF_OPTS` Only valid setting is "--unified=??" or "-u??" to set the number of context lines shown when a unified diff is created. This takes precedence over any "-U" or "--unified" option value passed on the Git diff command line.
`GIT_EXTERNAL_DIFF` When the environment variable `GIT_EXTERNAL_DIFF` is set, the program named by it is called to generate diffs, and Git does not use its builtin diff machinery. For a path that is added, removed, or modified, `GIT_EXTERNAL_DIFF` is called with 7 parameters:
```
path old-file old-hex old-mode new-file new-hex new-mode
```
where:
<old|new>-file are files GIT\_EXTERNAL\_DIFF can use to read the contents of <old|new>,
<old|new>-hex are the 40-hexdigit SHA-1 hashes,
<old|new>-mode are the octal representation of the file modes.
The file parameters can point at the user’s working file (e.g. `new-file` in "git-diff-files"), `/dev/null` (e.g. `old-file` when a new file is added), or a temporary file (e.g. `old-file` in the index). `GIT_EXTERNAL_DIFF` should not worry about unlinking the temporary file --- it is removed when `GIT_EXTERNAL_DIFF` exits.
For a path that is unmerged, `GIT_EXTERNAL_DIFF` is called with 1 parameter, <path>.
For each path `GIT_EXTERNAL_DIFF` is called, two environment variables, `GIT_DIFF_PATH_COUNTER` and `GIT_DIFF_PATH_TOTAL` are set.
`GIT_DIFF_PATH_COUNTER` A 1-based counter incremented by one for every path.
`GIT_DIFF_PATH_TOTAL` The total number of paths.
###
other
`GIT_MERGE_VERBOSITY` A number controlling the amount of output shown by the recursive merge strategy. Overrides merge.verbosity. See [git-merge[1]](git-merge)
`GIT_PAGER` This environment variable overrides `$PAGER`. If it is set to an empty string or to the value "cat", Git will not launch a pager. See also the `core.pager` option in [git-config[1]](git-config).
`GIT_PROGRESS_DELAY` A number controlling how many seconds to delay before showing optional progress indicators. Defaults to 2.
`GIT_EDITOR` This environment variable overrides `$EDITOR` and `$VISUAL`. It is used by several Git commands when, on interactive mode, an editor is to be launched. See also [git-var[1]](git-var) and the `core.editor` option in [git-config[1]](git-config).
`GIT_SEQUENCE_EDITOR` This environment variable overrides the configured Git editor when editing the todo list of an interactive rebase. See also [git-rebase[1]](git-rebase) and the `sequence.editor` option in [git-config[1]](git-config).
`GIT_SSH` `GIT_SSH_COMMAND` If either of these environment variables is set then `git fetch` and `git push` will use the specified command instead of `ssh` when they need to connect to a remote system. The command-line parameters passed to the configured command are determined by the ssh variant. See `ssh.variant` option in [git-config[1]](git-config) for details.
`$GIT_SSH_COMMAND` takes precedence over `$GIT_SSH`, and is interpreted by the shell, which allows additional arguments to be included. `$GIT_SSH` on the other hand must be just the path to a program (which can be a wrapper shell script, if additional arguments are needed).
Usually it is easier to configure any desired options through your personal `.ssh/config` file. Please consult your ssh documentation for further details.
`GIT_SSH_VARIANT` If this environment variable is set, it overrides Git’s autodetection whether `GIT_SSH`/`GIT_SSH_COMMAND`/`core.sshCommand` refer to OpenSSH, plink or tortoiseplink. This variable overrides the config setting `ssh.variant` that serves the same purpose.
`GIT_SSL_NO_VERIFY` Setting and exporting this environment variable to any value tells Git not to verify the SSL certificate when fetching or pushing over HTTPS.
`GIT_ASKPASS` If this environment variable is set, then Git commands which need to acquire passwords or passphrases (e.g. for HTTP or IMAP authentication) will call this program with a suitable prompt as command-line argument and read the password from its STDOUT. See also the `core.askPass` option in [git-config[1]](git-config).
`GIT_TERMINAL_PROMPT` If this Boolean environment variable is set to false, git will not prompt on the terminal (e.g., when asking for HTTP authentication).
`GIT_CONFIG_GLOBAL` `GIT_CONFIG_SYSTEM` Take the configuration from the given files instead from global or system-level configuration files. If `GIT_CONFIG_SYSTEM` is set, the system config file defined at build time (usually `/etc/gitconfig`) will not be read. Likewise, if `GIT_CONFIG_GLOBAL` is set, neither `$HOME/.gitconfig` nor `$XDG_CONFIG_HOME/git/config` will be read. Can be set to `/dev/null` to skip reading configuration files of the respective level.
`GIT_CONFIG_NOSYSTEM` Whether to skip reading settings from the system-wide `$(prefix)/etc/gitconfig` file. This Boolean environment variable can be used along with `$HOME` and `$XDG_CONFIG_HOME` to create a predictable environment for a picky script, or you can set it to true to temporarily avoid using a buggy `/etc/gitconfig` file while waiting for someone with sufficient permissions to fix it.
`GIT_FLUSH` If this environment variable is set to "1", then commands such as `git blame` (in incremental mode), `git rev-list`, `git log`, `git check-attr` and `git check-ignore` will force a flush of the output stream after each record have been flushed. If this variable is set to "0", the output of these commands will be done using completely buffered I/O. If this environment variable is not set, Git will choose buffered or record-oriented flushing based on whether stdout appears to be redirected to a file or not.
`GIT_TRACE` Enables general trace messages, e.g. alias expansion, built-in command execution and external command execution.
If this variable is set to "1", "2" or "true" (comparison is case insensitive), trace messages will be printed to stderr.
If the variable is set to an integer value greater than 2 and lower than 10 (strictly) then Git will interpret this value as an open file descriptor and will try to write the trace messages into this file descriptor.
Alternatively, if the variable is set to an absolute path (starting with a `/` character), Git will interpret this as a file path and will try to append the trace messages to it.
Unsetting the variable, or setting it to empty, "0" or "false" (case insensitive) disables trace messages.
`GIT_TRACE_FSMONITOR` Enables trace messages for the filesystem monitor extension. See `GIT_TRACE` for available trace output options.
`GIT_TRACE_PACK_ACCESS` Enables trace messages for all accesses to any packs. For each access, the pack file name and an offset in the pack is recorded. This may be helpful for troubleshooting some pack-related performance problems. See `GIT_TRACE` for available trace output options.
`GIT_TRACE_PACKET` Enables trace messages for all packets coming in or out of a given program. This can help with debugging object negotiation or other protocol issues. Tracing is turned off at a packet starting with "PACK" (but see `GIT_TRACE_PACKFILE` below). See `GIT_TRACE` for available trace output options.
`GIT_TRACE_PACKFILE` Enables tracing of packfiles sent or received by a given program. Unlike other trace output, this trace is verbatim: no headers, and no quoting of binary data. You almost certainly want to direct into a file (e.g., `GIT_TRACE_PACKFILE=/tmp/my.pack`) rather than displaying it on the terminal or mixing it with other trace output.
Note that this is currently only implemented for the client side of clones and fetches.
`GIT_TRACE_PERFORMANCE` Enables performance related trace messages, e.g. total execution time of each Git command. See `GIT_TRACE` for available trace output options.
`GIT_TRACE_REFS` Enables trace messages for operations on the ref database. See `GIT_TRACE` for available trace output options.
`GIT_TRACE_SETUP` Enables trace messages printing the .git, working tree and current working directory after Git has completed its setup phase. See `GIT_TRACE` for available trace output options.
`GIT_TRACE_SHALLOW` Enables trace messages that can help debugging fetching / cloning of shallow repositories. See `GIT_TRACE` for available trace output options.
`GIT_TRACE_CURL` Enables a curl full trace dump of all incoming and outgoing data, including descriptive information, of the git transport protocol. This is similar to doing curl `--trace-ascii` on the command line. See `GIT_TRACE` for available trace output options.
`GIT_TRACE_CURL_NO_DATA` When a curl trace is enabled (see `GIT_TRACE_CURL` above), do not dump data (that is, only dump info lines and headers).
`GIT_TRACE2` Enables more detailed trace messages from the "trace2" library. Output from `GIT_TRACE2` is a simple text-based format for human readability.
If this variable is set to "1", "2" or "true" (comparison is case insensitive), trace messages will be printed to stderr.
If the variable is set to an integer value greater than 2 and lower than 10 (strictly) then Git will interpret this value as an open file descriptor and will try to write the trace messages into this file descriptor.
Alternatively, if the variable is set to an absolute path (starting with a `/` character), Git will interpret this as a file path and will try to append the trace messages to it. If the path already exists and is a directory, the trace messages will be written to files (one per process) in that directory, named according to the last component of the SID and an optional counter (to avoid filename collisions).
In addition, if the variable is set to `af_unix:[<socket_type>:]<absolute-pathname>`, Git will try to open the path as a Unix Domain Socket. The socket type can be either `stream` or `dgram`.
Unsetting the variable, or setting it to empty, "0" or "false" (case insensitive) disables trace messages.
See [Trace2 documentation](api-trace2) for full details.
`GIT_TRACE2_EVENT` This setting writes a JSON-based format that is suited for machine interpretation. See `GIT_TRACE2` for available trace output options and [Trace2 documentation](api-trace2) for full details.
`GIT_TRACE2_PERF` In addition to the text-based messages available in `GIT_TRACE2`, this setting writes a column-based format for understanding nesting regions. See `GIT_TRACE2` for available trace output options and [Trace2 documentation](api-trace2) for full details.
`GIT_TRACE_REDACT` By default, when tracing is activated, Git redacts the values of cookies, the "Authorization:" header, the "Proxy-Authorization:" header and packfile URIs. Set this Boolean environment variable to false to prevent this redaction.
`GIT_LITERAL_PATHSPECS` Setting this Boolean environment variable to true will cause Git to treat all pathspecs literally, rather than as glob patterns. For example, running `GIT_LITERAL_PATHSPECS=1 git log -- '*.c'` will search for commits that touch the path `*.c`, not any paths that the glob `*.c` matches. You might want this if you are feeding literal paths to Git (e.g., paths previously given to you by `git ls-tree`, `--raw` diff output, etc).
`GIT_GLOB_PATHSPECS` Setting this Boolean environment variable to true will cause Git to treat all pathspecs as glob patterns (aka "glob" magic).
`GIT_NOGLOB_PATHSPECS` Setting this Boolean environment variable to true will cause Git to treat all pathspecs as literal (aka "literal" magic).
`GIT_ICASE_PATHSPECS` Setting this Boolean environment variable to true will cause Git to treat all pathspecs as case-insensitive.
`GIT_REFLOG_ACTION` When a ref is updated, reflog entries are created to keep track of the reason why the ref was updated (which is typically the name of the high-level command that updated the ref), in addition to the old and new values of the ref. A scripted Porcelain command can use set\_reflog\_action helper function in `git-sh-setup` to set its name to this variable when it is invoked as the top level command by the end user, to be recorded in the body of the reflog.
`GIT_REF_PARANOIA` If this Boolean environment variable is set to false, ignore broken or badly named refs when iterating over lists of refs. Normally Git will try to include any such refs, which may cause some operations to fail. This is usually preferable, as potentially destructive operations (e.g., [git-prune[1]](git-prune)) are better off aborting rather than ignoring broken refs (and thus considering the history they point to as not worth saving). The default value is `1` (i.e., be paranoid about detecting and aborting all operations). You should not normally need to set this to `0`, but it may be useful when trying to salvage data from a corrupted repository.
`GIT_ALLOW_PROTOCOL` If set to a colon-separated list of protocols, behave as if `protocol.allow` is set to `never`, and each of the listed protocols has `protocol.<name>.allow` set to `always` (overriding any existing configuration). See the description of `protocol.allow` in [git-config[1]](git-config) for more details.
`GIT_PROTOCOL_FROM_USER` Set this Boolean environment variable to false to prevent protocols used by fetch/push/clone which are configured to the `user` state. This is useful to restrict recursive submodule initialization from an untrusted repository or for programs which feed potentially-untrusted URLS to git commands. See [git-config[1]](git-config) for more details.
`GIT_PROTOCOL` For internal use only. Used in handshaking the wire protocol. Contains a colon `:` separated list of keys with optional values `key[=value]`. Presence of unknown keys and values must be ignored.
Note that servers may need to be configured to allow this variable to pass over some transports. It will be propagated automatically when accessing local repositories (i.e., `file://` or a filesystem path), as well as over the `git://` protocol. For git-over-http, it should work automatically in most configurations, but see the discussion in [git-http-backend[1]](git-http-backend). For git-over-ssh, the ssh server may need to be configured to allow clients to pass this variable (e.g., by using `AcceptEnv GIT_PROTOCOL` with OpenSSH).
This configuration is optional. If the variable is not propagated, then clients will fall back to the original "v0" protocol (but may miss out on some performance improvements or features). This variable currently only affects clones and fetches; it is not yet used for pushes (but may be in the future).
`GIT_OPTIONAL_LOCKS` If this Boolean environment variable is set to false, Git will complete any requested operation without performing any optional sub-operations that require taking a lock. For example, this will prevent `git status` from refreshing the index as a side effect. This is useful for processes running in the background which do not want to cause lock contention with other operations on the repository. Defaults to `1`.
`GIT_REDIRECT_STDIN` `GIT_REDIRECT_STDOUT` `GIT_REDIRECT_STDERR` Windows-only: allow redirecting the standard input/output/error handles to paths specified by the environment variables. This is particularly useful in multi-threaded applications where the canonical way to pass standard handles via `CreateProcess()` is not an option because it would require the handles to be marked inheritable (and consequently **every** spawned process would inherit them, possibly blocking regular Git operations). The primary intended use case is to use named pipes for communication (e.g. `\\.\pipe\my-git-stdin-123`).
Two special values are supported: `off` will simply close the corresponding standard handle, and if `GIT_REDIRECT_STDERR` is `2>&1`, standard error will be redirected to the same handle as standard output.
`GIT_PRINT_SHA1_ELLIPSIS` (deprecated) If set to `yes`, print an ellipsis following an (abbreviated) SHA-1 value. This affects indications of detached HEADs ([git-checkout[1]](git-checkout)) and the raw diff output ([git-diff[1]](git-diff)). Printing an ellipsis in the cases mentioned is no longer considered adequate and support for it is likely to be removed in the foreseeable future (along with the variable).
Discussion
----------
More detail on the following is available from the [Git concepts chapter of the user-manual](user-manual#git-concepts) and [gitcore-tutorial[7]](gitcore-tutorial).
A Git project normally consists of a working directory with a ".git" subdirectory at the top level. The .git directory contains, among other things, a compressed object database representing the complete history of the project, an "index" file which links that history to the current contents of the working tree, and named pointers into that history such as tags and branch heads.
The object database contains objects of three main types: blobs, which hold file data; trees, which point to blobs and other trees to build up directory hierarchies; and commits, which each reference a single tree and some number of parent commits.
The commit, equivalent to what other systems call a "changeset" or "version", represents a step in the project’s history, and each parent represents an immediately preceding step. Commits with more than one parent represent merges of independent lines of development.
All objects are named by the SHA-1 hash of their contents, normally written as a string of 40 hex digits. Such names are globally unique. The entire history leading up to a commit can be vouched for by signing just that commit. A fourth object type, the tag, is provided for this purpose.
When first created, objects are stored in individual files, but for efficiency may later be compressed together into "pack files".
Named pointers called refs mark interesting points in history. A ref may contain the SHA-1 name of an object or the name of another ref. Refs with names beginning `ref/head/` contain the SHA-1 name of the most recent commit (or "head") of a branch under development. SHA-1 names of tags of interest are stored under `ref/tags/`. A special ref named `HEAD` contains the name of the currently checked-out branch.
The index file is initialized with a list of all paths and, for each path, a blob object and a set of attributes. The blob object represents the contents of the file as of the head of the current branch. The attributes (last modified time, size, etc.) are taken from the corresponding file in the working tree. Subsequent changes to the working tree can be found by comparing these attributes. The index may be updated with new content, and new commits may be created from the content stored in the index.
The index is also capable of storing multiple entries (called "stages") for a given pathname. These stages are used to hold the various unmerged version of a file when a merge is in progress.
Further documentation
---------------------
See the references in the "description" section to get started using Git. The following is probably more detail than necessary for a first-time user.
The [Git concepts chapter of the user-manual](user-manual#git-concepts) and [gitcore-tutorial[7]](gitcore-tutorial) both provide introductions to the underlying Git architecture.
See [gitworkflows[7]](gitworkflows) for an overview of recommended workflows.
See also the [howto](howto-index) documents for some useful examples.
The internals are documented in the [Git API documentation](api-index).
Users migrating from CVS may also want to read [gitcvs-migration[7]](gitcvs-migration).
Authors
-------
Git was started by Linus Torvalds, and is currently maintained by Junio C Hamano. Numerous contributions have come from the Git mailing list <[[email protected]](mailto:[email protected])>. <http://www.openhub.net/p/git/contributors/summary> gives you a more complete list of contributors.
If you have a clone of git.git itself, the output of [git-shortlog[1]](git-shortlog) and [git-blame[1]](git-blame) can show you the authors for specific parts of the project.
Reporting bugs
--------------
Report bugs to the Git mailing list <[[email protected]](mailto:[email protected])> where the development and maintenance is primarily done. You do not have to be subscribed to the list to send a message there. See the list archive at <https://lore.kernel.org/git> for previous bug reports and other discussions.
Issues which are security relevant should be disclosed privately to the Git Security mailing list <[[email protected]](mailto:[email protected])>.
See also
--------
[gittutorial[7]](gittutorial), [gittutorial-2[7]](gittutorial-2), [giteveryday[7]](giteveryday), [gitcvs-migration[7]](gitcvs-migration), [gitglossary[7]](gitglossary), [gitcore-tutorial[7]](gitcore-tutorial), [gitcli[7]](gitcli), [The Git User’s Manual](user-manual), [gitworkflows[7]](gitworkflows)
| programming_docs |
git git-mktree git-mktree
==========
Name
----
git-mktree - Build a tree-object from ls-tree formatted text
Synopsis
--------
```
git mktree [-z] [--missing] [--batch]
```
Description
-----------
Reads standard input in non-recursive `ls-tree` output format, and creates a tree object. The order of the tree entries is normalized by mktree so pre-sorting the input is not required. The object name of the tree object built is written to the standard output.
Options
-------
-z Read the NUL-terminated `ls-tree -z` output instead.
--missing Allow missing objects. The default behaviour (without this option) is to verify that each tree entry’s sha1 identifies an existing object. This option has no effect on the treatment of gitlink entries (aka "submodules") which are always allowed to be missing.
--batch Allow building of more than one tree object before exiting. Each tree is separated by a single blank line. The final new-line is optional. Note - if the `-z` option is used, lines are terminated with NUL.
git git-hash-object git-hash-object
===============
Name
----
git-hash-object - Compute object ID and optionally creates a blob from a file
Synopsis
--------
```
git hash-object [-t <type>] [-w] [--path=<file> | --no-filters]
[--stdin [--literally]] [--] <file>…
git hash-object [-t <type>] [-w] --stdin-paths [--no-filters]
```
Description
-----------
Computes the object ID value for an object with specified type with the contents of the named file (which can be outside of the work tree), and optionally writes the resulting object into the object database. Reports its object ID to its standard output. When <type> is not specified, it defaults to "blob".
Options
-------
-t <type> Specify the type (default: "blob").
-w Actually write the object into the object database.
--stdin Read the object from standard input instead of from a file.
--stdin-paths Read file names from the standard input, one per line, instead of from the command-line.
--path Hash object as it were located at the given path. The location of file does not directly influence on the hash value, but path is used to determine what Git filters should be applied to the object before it can be placed to the object database, and, as result of applying filters, the actual blob put into the object database may differ from the given file. This option is mainly useful for hashing temporary files located outside of the working directory or files read from stdin.
--no-filters Hash the contents as is, ignoring any input filter that would have been chosen by the attributes mechanism, including the end-of-line conversion. If the file is read from standard input then this is always implied, unless the `--path` option is given.
--literally Allow `--stdin` to hash any garbage into a loose object which might not otherwise pass standard object parsing or git-fsck checks. Useful for stress-testing Git itself or reproducing characteristics of corrupt or bogus objects encountered in the wild.
git git-remote-fd git-remote-fd
=============
Name
----
git-remote-fd - Reflect smart transport stream back to caller
Synopsis
--------
"fd::<infd>[,<outfd>][/<anything>]" (as URL)
Description
-----------
This helper uses specified file descriptors to connect to a remote Git server. This is not meant for end users but for programs and scripts calling git fetch, push or archive.
If only <infd> is given, it is assumed to be a bidirectional socket connected to remote Git server (git-upload-pack, git-receive-pack or git-upload-archive). If both <infd> and <outfd> are given, they are assumed to be pipes connected to a remote Git server (<infd> being the inbound pipe and <outfd> being the outbound pipe.
It is assumed that any handshaking procedures have already been completed (such as sending service request for git://) before this helper is started.
<anything> can be any string. It is ignored. It is meant for providing information to user in the URL in case that URL is displayed in some context.
Environment variables
---------------------
GIT\_TRANSLOOP\_DEBUG If set, prints debugging information about various reads/writes.
Examples
--------
`git fetch fd::17 master` Fetch master, using file descriptor #17 to communicate with git-upload-pack.
`git fetch fd::17/foo master` Same as above.
`git push fd::7,8 master (as URL)` Push master, using file descriptor #7 to read data from git-receive-pack and file descriptor #8 to write data to same service.
`git push fd::7,8/bar master` Same as above.
See also
--------
[gitremote-helpers[7]](gitremote-helpers)
git git-daemon git-daemon
==========
Name
----
git-daemon - A really simple server for Git repositories
Synopsis
--------
```
git daemon [--verbose] [--syslog] [--export-all]
[--timeout=<n>] [--init-timeout=<n>] [--max-connections=<n>]
[--strict-paths] [--base-path=<path>] [--base-path-relaxed]
[--user-path | --user-path=<path>]
[--interpolated-path=<pathtemplate>]
[--reuseaddr] [--detach] [--pid-file=<file>]
[--enable=<service>] [--disable=<service>]
[--allow-override=<service>] [--forbid-override=<service>]
[--access-hook=<path>] [--[no-]informative-errors]
[--inetd |
[--listen=<host_or_ipaddr>] [--port=<n>]
[--user=<user> [--group=<group>]]]
[--log-destination=(stderr|syslog|none)]
[<directory>…]
```
Description
-----------
A really simple TCP Git daemon that normally listens on port "DEFAULT\_GIT\_PORT" aka 9418. It waits for a connection asking for a service, and will serve that service if it is enabled.
It verifies that the directory has the magic file "git-daemon-export-ok", and it will refuse to export any Git directory that hasn’t explicitly been marked for export this way (unless the `--export-all` parameter is specified). If you pass some directory paths as `git daemon` arguments, the offers are limited to repositories within those directories.
By default, only `upload-pack` service is enabled, which serves `git fetch-pack` and `git ls-remote` clients, which are invoked from `git fetch`, `git pull`, and `git clone`.
This is ideally suited for read-only updates, i.e., pulling from Git repositories.
An `upload-archive` also exists to serve `git archive`.
Options
-------
--strict-paths Match paths exactly (i.e. don’t allow "/foo/repo" when the real path is "/foo/repo.git" or "/foo/repo/.git") and don’t do user-relative paths. `git daemon` will refuse to start when this option is enabled and no directory arguments are provided.
--base-path=<path> Remap all the path requests as relative to the given path. This is sort of "Git root" - if you run `git daemon` with `--base-path=/srv/git` on example.com, then if you later try to pull `git://example.com/hello.git`, `git daemon` will interpret the path as `/srv/git/hello.git`.
--base-path-relaxed If --base-path is enabled and repo lookup fails, with this option `git daemon` will attempt to lookup without prefixing the base path. This is useful for switching to --base-path usage, while still allowing the old paths.
--interpolated-path=<pathtemplate> To support virtual hosting, an interpolated path template can be used to dynamically construct alternate paths. The template supports %H for the target hostname as supplied by the client but converted to all lowercase, %CH for the canonical hostname, %IP for the server’s IP address, %P for the port number, and %D for the absolute path of the named repository. After interpolation, the path is validated against the directory list.
--export-all Allow pulling from all directories that look like Git repositories (have the `objects` and `refs` subdirectories), even if they do not have the `git-daemon-export-ok` file.
--inetd Have the server run as an inetd service. Implies --syslog (may be overridden with `--log-destination=`). Incompatible with --detach, --port, --listen, --user and --group options.
--listen=<host\_or\_ipaddr> Listen on a specific IP address or hostname. IP addresses can be either an IPv4 address or an IPv6 address if supported. If IPv6 is not supported, then --listen=hostname is also not supported and --listen must be given an IPv4 address. Can be given more than once. Incompatible with `--inetd` option.
--port=<n> Listen on an alternative port. Incompatible with `--inetd` option.
--init-timeout=<n> Timeout (in seconds) between the moment the connection is established and the client request is received (typically a rather low value, since that should be basically immediate).
--timeout=<n> Timeout (in seconds) for specific client sub-requests. This includes the time it takes for the server to process the sub-request and the time spent waiting for the next client’s request.
--max-connections=<n> Maximum number of concurrent clients, defaults to 32. Set it to zero for no limit.
--syslog Short for `--log-destination=syslog`.
--log-destination=<destination> Send log messages to the specified destination. Note that this option does not imply --verbose, thus by default only error conditions will be logged. The <destination> must be one of:
stderr Write to standard error. Note that if `--detach` is specified, the process disconnects from the real standard error, making this destination effectively equivalent to `none`.
syslog Write to syslog, using the `git-daemon` identifier.
none Disable all logging.
The default destination is `syslog` if `--inetd` or `--detach` is specified, otherwise `stderr`.
--user-path --user-path=<path> Allow ~user notation to be used in requests. When specified with no parameter, requests to git://host/~alice/foo is taken as a request to access `foo` repository in the home directory of user `alice`. If `--user-path=path` is specified, the same request is taken as a request to access `path/foo` repository in the home directory of user `alice`.
--verbose Log details about the incoming connections and requested files.
--reuseaddr Use SO\_REUSEADDR when binding the listening socket. This allows the server to restart without waiting for old connections to time out.
--detach Detach from the shell. Implies --syslog.
--pid-file=<file> Save the process id in `file`. Ignored when the daemon is run under `--inetd`.
--user=<user> --group=<group> Change daemon’s uid and gid before entering the service loop. When only `--user` is given without `--group`, the primary group ID for the user is used. The values of the option are given to `getpwnam(3)` and `getgrnam(3)` and numeric IDs are not supported.
Giving these options is an error when used with `--inetd`; use the facility of inet daemon to achieve the same before spawning `git daemon` if needed.
Like many programs that switch user id, the daemon does not reset environment variables such as `$HOME` when it runs git programs, e.g. `upload-pack` and `receive-pack`. When using this option, you may also want to set and export `HOME` to point at the home directory of `<user>` before starting the daemon, and make sure any Git configuration files in that directory are readable by `<user>`.
--enable=<service> --disable=<service> Enable/disable the service site-wide per default. Note that a service disabled site-wide can still be enabled per repository if it is marked overridable and the repository enables the service with a configuration item.
--allow-override=<service> --forbid-override=<service> Allow/forbid overriding the site-wide default with per repository configuration. By default, all the services may be overridden.
--[no-]informative-errors When informative errors are turned on, git-daemon will report more verbose errors to the client, differentiating conditions like "no such repository" from "repository not exported". This is more convenient for clients, but may leak information about the existence of unexported repositories. When informative errors are not enabled, all errors report "access denied" to the client. The default is --no-informative-errors.
--access-hook=<path> Every time a client connects, first run an external command specified by the <path> with service name (e.g. "upload-pack"), path to the repository, hostname (%H), canonical hostname (%CH), IP address (%IP), and TCP port (%P) as its command-line arguments. The external command can decide to decline the service by exiting with a non-zero status (or to allow it by exiting with a zero status). It can also look at the $REMOTE\_ADDR and `$REMOTE_PORT` environment variables to learn about the requestor when making this decision.
The external command can optionally write a single line to its standard output to be sent to the requestor as an error message when it declines the service.
<directory> The remaining arguments provide a list of directories. If any directories are specified, then the `git-daemon` process will serve a requested directory only if it is contained in one of these directories. If `--strict-paths` is specified, then the requested directory must match one of these directories exactly.
Services
--------
These services can be globally enabled/disabled using the command-line options of this command. If finer-grained control is desired (e.g. to allow `git archive` to be run against only in a few selected repositories the daemon serves), the per-repository configuration file can be used to enable or disable them.
upload-pack This serves `git fetch-pack` and `git ls-remote` clients. It is enabled by default, but a repository can disable it by setting `daemon.uploadpack` configuration item to `false`.
upload-archive This serves `git archive --remote`. It is disabled by default, but a repository can enable it by setting `daemon.uploadarch` configuration item to `true`.
receive-pack This serves `git send-pack` clients, allowing anonymous push. It is disabled by default, as there is `no` authentication in the protocol (in other words, anybody can push anything into the repository, including removal of refs). This is solely meant for a closed LAN setting where everybody is friendly. This service can be enabled by setting `daemon.receivepack` configuration item to `true`.
Examples
--------
We assume the following in /etc/services
```
$ grep 9418 /etc/services
git 9418/tcp # Git Version Control System
```
*git daemon* as inetd server To set up `git daemon` as an inetd service that handles any repository within `/pub/foo` or `/pub/bar`, place an entry like the following into `/etc/inetd` all on one line:
```
git stream tcp nowait nobody /usr/bin/git
git daemon --inetd --verbose --export-all
/pub/foo /pub/bar
```
*git daemon* as inetd server for virtual hosts To set up `git daemon` as an inetd service that handles repositories for different virtual hosts, `www.example.com` and `www.example.org`, place an entry like the following into `/etc/inetd` all on one line:
```
git stream tcp nowait nobody /usr/bin/git
git daemon --inetd --verbose --export-all
--interpolated-path=/pub/%H%D
/pub/www.example.org/software
/pub/www.example.com/software
/software
```
In this example, the root-level directory `/pub` will contain a subdirectory for each virtual host name supported. Further, both hosts advertise repositories simply as `git://www.example.com/software/repo.git`. For pre-1.4.0 clients, a symlink from `/software` into the appropriate default repository could be made as well.
*git daemon* as regular daemon for virtual hosts To set up `git daemon` as a regular, non-inetd service that handles repositories for multiple virtual hosts based on their IP addresses, start the daemon like this:
```
git daemon --verbose --export-all
--interpolated-path=/pub/%IP/%D
/pub/192.168.1.200/software
/pub/10.10.220.23/software
```
In this example, the root-level directory `/pub` will contain a subdirectory for each virtual host IP address supported. Repositories can still be accessed by hostname though, assuming they correspond to these IP addresses.
selectively enable/disable services per repository To enable `git archive --remote` and disable `git fetch` against a repository, have the following in the configuration file in the repository (that is the file `config` next to `HEAD`, `refs` and `objects`).
```
[daemon]
uploadpack = false
uploadarch = true
```
Environment
-----------
`git daemon` will set REMOTE\_ADDR to the IP address of the client that connected to it, if the IP address is available. REMOTE\_ADDR will be available in the environment of hooks called when services are performed.
git git-show-index git-show-index
==============
Name
----
git-show-index - Show packed archive index
Synopsis
--------
```
git show-index [--object-format=<hash-algorithm>]
```
Description
-----------
Read the `.idx` file for a Git packfile (created with [git-pack-objects[1]](git-pack-objects) or [git-index-pack[1]](git-index-pack)) from the standard input, and dump its contents. The output consists of one object per line, with each line containing two or three space-separated columns:
* the first column is the offset in bytes of the object within the corresponding packfile
* the second column is the object id of the object
* if the index version is 2 or higher, the third column contains the CRC32 of the object data
The objects are output in the order in which they are found in the index file, which should be (in a correctly constructed file) sorted by object id.
Note that you can get more information on a packfile by calling [git-verify-pack[1]](git-verify-pack). However, as this command considers only the index file itself, it’s both faster and more flexible.
Options
-------
--object-format=<hash-algorithm> Specify the given object format (hash algorithm) for the index file. The valid values are `sha1` and (if enabled) `sha256`. The default is the algorithm for the current repository (set by `extensions.objectFormat`), or `sha1` if no value is set or outside a repository..
THIS OPTION IS EXPERIMENTAL! SHA-256 support is experimental and still in an early stage. A SHA-256 repository will in general not be able to share work with "regular" SHA-1 repositories. It should be assumed that, e.g., Git internal file formats in relation to SHA-256 repositories may change in backwards-incompatible ways. Only use `--object-format=sha256` for testing purposes.
git git-multi-pack-index git-multi-pack-index
====================
Name
----
git-multi-pack-index - Write and verify multi-pack-indexes
Synopsis
--------
```
git multi-pack-index [--object-dir=<dir>] [--[no-]bitmap] <sub-command>
```
Description
-----------
Write or verify a multi-pack-index (MIDX) file.
Options
-------
--object-dir=<dir> Use given directory for the location of Git objects. We check `<dir>/packs/multi-pack-index` for the current MIDX file, and `<dir>/packs` for the pack-files to index.
`<dir>` must be an alternate of the current repository.
--[no-]progress Turn progress on/off explicitly. If neither is specified, progress is shown if standard error is connected to a terminal. Supported by sub-commands `write`, `verify`, `expire`, and `repack.
The following subcommands are available:
write Write a new MIDX file. The following options are available for the `write` sub-command:
--preferred-pack=<pack> Optionally specify the tie-breaking pack used when multiple packs contain the same object. `<pack>` must contain at least one object. If not given, ties are broken in favor of the pack with the lowest mtime.
--[no-]bitmap Control whether or not a multi-pack bitmap is written.
--stdin-packs Write a multi-pack index containing only the set of line-delimited pack index basenames provided over stdin.
--refs-snapshot=<path> With `--bitmap`, optionally specify a file which contains a "refs snapshot" taken prior to repacking.
A reference snapshot is composed of line-delimited OIDs corresponding to the reference tips, usually taken by `git repack` prior to generating a new pack. A line may optionally start with a `+` character to indicate that the reference which corresponds to that OID is "preferred" (see [git-config[1]](git-config)'s `pack.preferBitmapTips`.)
The file given at `<path>` is expected to be readable, and can contain duplicates. (If a given OID is given more than once, it is marked as preferred if at least one instance of it begins with the special `+` marker).
verify Verify the contents of the MIDX file.
expire Delete the pack-files that are tracked by the MIDX file, but have no objects referenced by the MIDX (with the exception of `.keep` packs and cruft packs). Rewrite the MIDX file afterward to remove all references to these pack-files.
repack Create a new pack-file containing objects in small pack-files referenced by the multi-pack-index. If the size given by the `--batch-size=<size>` argument is zero, then create a pack containing all objects referenced by the multi-pack-index. For a non-zero batch size, Select the pack-files by examining packs from oldest-to-newest, computing the "expected size" by counting the number of objects in the pack referenced by the multi-pack-index, then divide by the total number of objects in the pack and multiply by the pack size. We select packs with expected size below the batch size until the set of packs have total expected size at least the batch size, or all pack-files are considered. If only one pack-file is selected, then do nothing. If a new pack-file is created, rewrite the multi-pack-index to reference the new pack-file. A later run of `git multi-pack-index expire` will delete the pack-files that were part of this batch.
If `repack.packKeptObjects` is `false`, then any pack-files with an associated `.keep` file will not be selected for the batch to repack.
Examples
--------
* Write a MIDX file for the packfiles in the current `.git` directory.
```
$ git multi-pack-index write
```
* Write a MIDX file for the packfiles in the current `.git` directory with a corresponding bitmap.
```
$ git multi-pack-index write --preferred-pack=<pack> --bitmap
```
* Write a MIDX file for the packfiles in an alternate object store.
```
$ git multi-pack-index --object-dir <alt> write
```
* Verify the MIDX file for the packfiles in the current `.git` directory.
```
$ git multi-pack-index verify
```
See also
--------
See [The Multi-Pack-Index Design Document](multi-pack-index) and [gitformat-pack[5]](gitformat-pack) for more information on the multi-pack-index feature and its file format.
| programming_docs |
git bundle-uri bundle-uri
==========
Git bundles are files that store a pack-file along with some extra metadata, including a set of refs and a (possibly empty) set of necessary commits. See [git-bundle[1]](git-bundle) and [gitformat-bundle[5]](gitformat-bundle) for more information.
Bundle URIs are locations where Git can download one or more bundles in order to bootstrap the object database in advance of fetching the remaining objects from a remote.
One goal is to speed up clones and fetches for users with poor network connectivity to the origin server. Another benefit is to allow heavy users, such as CI build farms, to use local resources for the majority of Git data and thereby reducing the load on the origin server.
To enable the bundle URI feature, users can specify a bundle URI using command-line options or the origin server can advertise one or more URIs via a protocol v2 capability.
Design goals
------------
The bundle URI standard aims to be flexible enough to satisfy multiple workloads. The bundle provider and the Git client have several choices in how they create and consume bundle URIs.
* Bundles can have whatever name the server desires. This name could refer to immutable data by using a hash of the bundle contents. However, this means that a new URI will be needed after every update of the content. This might be acceptable if the server is advertising the URI (and the server is aware of new bundles being generated) but would not be ergonomic for users using the command line option.
* The bundles could be organized specifically for bootstrapping full clones, but could also be organized with the intention of bootstrapping incremental fetches. The bundle provider must decide on one of several organization schemes to minimize client downloads during incremental fetches, but the Git client can also choose whether to use bundles for either of these operations.
* The bundle provider can choose to support full clones, partial clones, or both. The client can detect which bundles are appropriate for the repository’s partial clone filter, if any.
* The bundle provider can use a single bundle (for clones only), or a list of bundles. When using a list of bundles, the provider can specify whether or not the client needs `all` of the bundle URIs for a full clone, or if `any` one of the bundle URIs is sufficient. This allows the bundle provider to use different URIs for different geographies.
* The bundle provider can organize the bundles using heuristics, such as creation tokens, to help the client prevent downloading bundles it does not need. When the bundle provider does not provide these heuristics, the client can use optimizations to minimize how much of the data is downloaded.
* The bundle provider does not need to be associated with the Git server. The client can choose to use the bundle provider without it being advertised by the Git server.
* The client can choose to discover bundle providers that are advertised by the Git server. This could happen during `git clone`, during `git fetch`, both, or neither. The user can choose which combination works best for them.
* The client can choose to configure a bundle provider manually at any time. The client can also choose to specify a bundle provider manually as a command-line option to `git clone`.
Each repository is different and every Git server has different needs. Hopefully the bundle URI feature is flexible enough to satisfy all needs. If not, then the feature can be extended through its versioning mechanism.
Server requirements
-------------------
To provide a server-side implementation of bundle servers, no other parts of the Git protocol are required. This allows server maintainers to use static content solutions such as CDNs in order to serve the bundle files.
At the current scope of the bundle URI feature, all URIs are expected to be HTTP(S) URLs where content is downloaded to a local file using a `GET` request to that URL. The server could include authentication requirements to those requests with the aim of triggering the configured credential helper for secure access. (Future extensions could use "file://" URIs or SSH URIs.)
Assuming a `200 OK` response from the server, the content at the URL is inspected. First, Git attempts to parse the file as a bundle file of version 2 or higher. If the file is not a bundle, then the file is parsed as a plain-text file using Git’s config parser. The key-value pairs in that config file are expected to describe a list of bundle URIs. If neither of these parse attempts succeed, then Git will report an error to the user that the bundle URI provided erroneous data.
Any other data provided by the server is considered erroneous.
Bundle lists
------------
The Git server can advertise bundle URIs using a set of `key=value` pairs. A bundle URI can also serve a plain-text file in the Git config format containing these same `key=value` pairs. In both cases, we consider this to be a `bundle list`. The pairs specify information about the bundles that the client can use to make decisions for which bundles to download and which to ignore.
A few keys focus on properties of the list itself.
bundle.version (Required) This value provides a version number for the bundle list. If a future Git change enables a feature that needs the Git client to react to a new key in the bundle list file, then this version will increment. The only current version number is 1, and if any other value is specified then Git will fail to use this file.
bundle.mode (Required) This value has one of two values: `all` and `any`. When `all` is specified, then the client should expect to need all of the listed bundle URIs that match their repository’s requirements. When `any` is specified, then the client should expect that any one of the bundle URIs that match their repository’s requirements will suffice. Typically, the `any` option is used to list a number of different bundle servers located in different geographies.
bundle.heuristic If this string-valued key exists, then the bundle list is designed to work well with incremental `git fetch` commands. The heuristic signals that there are additional keys available for each bundle that help determine which subset of bundles the client should download. The only heuristic currently planned is `creationToken`.
The remaining keys include an `<id>` segment which is a server-designated name for each available bundle. The `<id>` must contain only alphanumeric and `-` characters.
bundle.<id>.uri (Required) This string value is the URI for downloading bundle `<id>`. If the URI begins with a protocol (`http://` or `https://`) then the URI is absolute. Otherwise, the URI is interpreted as relative to the URI used for the bundle list. If the URI begins with `/`, then that relative path is relative to the domain name used for the bundle list. (This use of relative paths is intended to make it easier to distribute a set of bundles across a large number of servers or CDNs with different domain names.)
bundle.<id>.filter This string value represents an object filter that should also appear in the header of this bundle. The server uses this value to differentiate different kinds of bundles from which the client can choose those that match their object filters.
bundle.<id>.creationToken This value is a nonnegative 64-bit integer used for sorting the bundles list. This is used to download a subset of bundles during a fetch when `bundle.heuristic=creationToken`.
bundle.<id>.location This string value advertises a real-world location from where the bundle URI is served. This can be used to present the user with an option for which bundle URI to use or simply as an informative indicator of which bundle URI was selected by Git. This is only valuable when `bundle.mode` is `any`.
Here is an example bundle list using the Git config format:
```
[bundle]
version = 1
mode = all
heuristic = creationToken
```
```
[bundle "2022-02-09-1644442601-daily"]
uri = https://bundles.example.com/git/git/2022-02-09-1644442601-daily.bundle
creationToken = 1644442601
```
```
[bundle "2022-02-02-1643842562"]
uri = https://bundles.example.com/git/git/2022-02-02-1643842562.bundle
creationToken = 1643842562
```
```
[bundle "2022-02-09-1644442631-daily-blobless"]
uri = 2022-02-09-1644442631-daily-blobless.bundle
creationToken = 1644442631
filter = blob:none
```
```
[bundle "2022-02-02-1643842568-blobless"]
uri = /git/git/2022-02-02-1643842568-blobless.bundle
creationToken = 1643842568
filter = blob:none
```
This example uses `bundle.mode=all` as well as the `bundle.<id>.creationToken` heuristic. It also uses the `bundle.<id>.filter` options to present two parallel sets of bundles: one for full clones and another for blobless partial clones.
Suppose that this bundle list was found at the URI `https://bundles.example.com/git/git/` and so the two blobless bundles have the following fully-expanded URIs:
* `https://bundles.example.com/git/git/2022-02-09-1644442631-daily-blobless.bundle`
* `https://bundles.example.com/git/git/2022-02-02-1643842568-blobless.bundle`
Advertising bundle uris
-----------------------
If a user knows a bundle URI for the repository they are cloning, then they can specify that URI manually through a command-line option. However, a Git host may want to advertise bundle URIs during the clone operation, helping users unaware of the feature.
The only thing required for this feature is that the server can advertise one or more bundle URIs. This advertisement takes the form of a new protocol v2 capability specifically for discovering bundle URIs.
The client could choose an arbitrary bundle URI as an option `or` select the URI with best performance by some exploratory checks. It is up to the bundle provider to decide if having multiple URIs is preferable to a single URI that is geodistributed through server-side infrastructure.
Cloning with bundle uris
------------------------
The primary need for bundle URIs is to speed up clones. The Git client will interact with bundle URIs according to the following flow:
1. The user specifies a bundle URI with the `--bundle-uri` command-line option `or` the client discovers a bundle list advertised by the Git server.
2. If the downloaded data from a bundle URI is a bundle, then the client inspects the bundle headers to check that the prerequisite commit OIDs are present in the client repository. If some are missing, then the client delays unbundling until other bundles have been unbundled, making those OIDs present. When all required OIDs are present, the client unbundles that data using a refspec. The default refspec is `+refs/heads/*:refs/bundles/*`, but this can be configured. These refs are stored so that later `git fetch` negotiations can communicate each bundled ref as a `have`, reducing the size of the fetch over the Git protocol. To allow pruning refs from this ref namespace, Git may introduce a numbered namespace (such as `refs/bundles/<i>/*`) such that stale bundle refs can be deleted.
3. If the file is instead a bundle list, then the client inspects the `bundle.mode` to see if the list is of the `all` or `any` form.
1. If `bundle.mode=all`, then the client considers all bundle URIs. The list is reduced based on the `bundle.<id>.filter` options matching the client repository’s partial clone filter. Then, all bundle URIs are requested. If the `bundle.<id>.creationToken` heuristic is provided, then the bundles are downloaded in decreasing order by the creation token, stopping when a bundle has all required OIDs. The bundles can then be unbundled in increasing creation token order. The client stores the latest creation token as a heuristic for avoiding future downloads if the bundle list does not advertise bundles with larger creation tokens.
2. If `bundle.mode=any`, then the client can choose any one of the bundle URIs to inspect. The client can use a variety of ways to choose among these URIs. The client can also fallback to another URI if the initial choice fails to return a result.
Note that during a clone we expect that all bundles will be required, and heuristics such as `bundle.<uri>.creationToken` can be used to download bundles in chronological order or in parallel.
If a given bundle URI is a bundle list with a `bundle.heuristic` value, then the client can choose to store that URI as its chosen bundle URI. The client can then navigate directly to that URI during later `git
fetch` calls.
When downloading bundle URIs, the client can choose to inspect the initial content before committing to downloading the entire content. This may provide enough information to determine if the URI is a bundle list or a bundle. In the case of a bundle, the client may inspect the bundle header to determine that all advertised tips are already in the client repository and cancel the remaining download.
Fetching with bundle uris
-------------------------
When the client fetches new data, it can decide to fetch from bundle servers before fetching from the origin remote. This could be done via a command-line option, but it is more likely useful to use a config value such as the one specified during the clone.
The fetch operation follows the same procedure to download bundles from a bundle list (although we do `not` want to use parallel downloads here). We expect that the process will end when all prerequisite commit OIDs in a thin bundle are already in the object database.
When using the `creationToken` heuristic, the client can avoid downloading any bundles if their creation tokens are not larger than the stored creation token. After fetching new bundles, Git updates this local creation token.
If the bundle provider does not provide a heuristic, then the client should attempt to inspect the bundle headers before downloading the full bundle data in case the bundle tips already exist in the client repository.
Error conditions
----------------
If the Git client discovers something unexpected while downloading information according to a bundle URI or the bundle list found at that location, then Git can ignore that data and continue as if it was not given a bundle URI. The remote Git server is the ultimate source of truth, not the bundle URI.
Here are a few example error conditions:
* The client fails to connect with a server at the given URI or a connection is lost without any chance to recover.
* The client receives a 400-level response (such as `404 Not Found` or `401 Not Authorized`). The client should use the credential helper to find and provide a credential for the URI, but match the semantics of Git’s other HTTP protocols in terms of handling specific 400-level errors.
* The server reports any other failure response.
* The client receives data that is not parsable as a bundle or bundle list.
* A bundle includes a filter that does not match expectations.
* The client cannot unbundle the bundles because the prerequisite commit OIDs are not in the object database and there are no more bundles to download.
There are also situations that could be seen as wasteful, but are not error conditions:
* The downloaded bundles contain more information than is requested by the clone or fetch request. A primary example is if the user requests a clone with `--single-branch` but downloads bundles that store every reachable commit from all `refs/heads/*` references. This might be initially wasteful, but perhaps these objects will become reachable by a later ref update that the client cares about.
* A bundle download during a `git fetch` contains objects already in the object database. This is probably unavoidable if we are using bundles for fetches, since the client will almost always be slightly ahead of the bundle servers after performing its "catch-up" fetch to the remote server. This extra work is most wasteful when the client is fetching much more frequently than the server is computing bundles, such as if the client is using hourly prefetches with background maintenance, but the server is computing bundles weekly. For this reason, the client should not use bundle URIs for fetch unless the server has explicitly recommended it through a `bundle.heuristic` value.
Example bundle provider organization
------------------------------------
The bundle URI feature is intentionally designed to be flexible to different ways a bundle provider wants to organize the object data. However, it can be helpful to have a complete organization model described here so providers can start from that base.
This example organization is a simplified model of what is used by the GVFS Cache Servers (see section near the end of this document) which have been beneficial in speeding up clones and fetches for very large repositories, although using extra software outside of Git.
The bundle provider deploys servers across multiple geographies. Each server manages its own bundle set. The server can track a number of Git repositories, but provides a bundle list for each based on a pattern. For example, when mirroring a repository at `https://<domain>/<org>/<repo>` the bundle server could have its bundle list available at `https://<server-url>/<domain>/<org>/<repo>`. The origin Git server can list all of these servers under the "any" mode:
```
[bundle]
version = 1
mode = any
```
```
[bundle "eastus"]
uri = https://eastus.example.com/<domain>/<org>/<repo>
```
```
[bundle "europe"]
uri = https://europe.example.com/<domain>/<org>/<repo>
```
```
[bundle "apac"]
uri = https://apac.example.com/<domain>/<org>/<repo>
```
This "list of lists" is static and only changes if a bundle server is added or removed.
Each bundle server manages its own set of bundles. The initial bundle list contains only a single bundle, containing all of the objects received from cloning the repository from the origin server. The list uses the `creationToken` heuristic and a `creationToken` is made for the bundle based on the server’s timestamp.
The bundle server runs regularly-scheduled updates for the bundle list, such as once a day. During this task, the server fetches the latest contents from the origin server and generates a bundle containing the objects reachable from the latest origin refs, but not contained in a previously-computed bundle. This bundle is added to the list, with care that the `creationToken` is strictly greater than the previous maximum `creationToken`.
When the bundle list grows too large, say more than 30 bundles, then the oldest "`N` minus 30" bundles are combined into a single bundle. This bundle’s `creationToken` is equal to the maximum `creationToken` among the merged bundles.
An example bundle list is provided here, although it only has two daily bundles and not a full list of 30:
```
[bundle]
version = 1
mode = all
heuristic = creationToken
```
```
[bundle "2022-02-13-1644770820-daily"]
uri = https://eastus.example.com/<domain>/<org>/<repo>/2022-02-09-1644770820-daily.bundle
creationToken = 1644770820
```
```
[bundle "2022-02-09-1644442601-daily"]
uri = https://eastus.example.com/<domain>/<org>/<repo>/2022-02-09-1644442601-daily.bundle
creationToken = 1644442601
```
```
[bundle "2022-02-02-1643842562"]
uri = https://eastus.example.com/<domain>/<org>/<repo>/2022-02-02-1643842562.bundle
creationToken = 1643842562
```
To avoid storing and serving object data in perpetuity despite becoming unreachable in the origin server, this bundle merge can be more careful. Instead of taking an absolute union of the old bundles, instead the bundle can be created by looking at the newer bundles and ensuring that their necessary commits are all available in this merged bundle (or in another one of the newer bundles). This allows "expiring" object data that is not being used by new commits in this window of time. That data could be reintroduced by a later push.
The intention of this data organization has two main goals. First, initial clones of the repository become faster by downloading precomputed object data from a closer source. Second, `git fetch` commands can be faster, especially if the client has not fetched for a few days. However, if a client does not fetch for 30 days, then the bundle list organization would cause redownloading a large amount of object data.
One way to make this organization more useful to users who fetch frequently is to have more frequent bundle creation. For example, bundles could be created every hour, and then once a day those "hourly" bundles could be merged into a "daily" bundle. The daily bundles are merged into the oldest bundle after 30 days.
It is recommended that this bundle strategy is repeated with the `blob:none` filter if clients of this repository are expecting to use blobless partial clones. This list of blobless bundles stays in the same list as the full bundles, but uses the `bundle.<id>.filter` key to separate the two groups. For very large repositories, the bundle provider may want to `only` provide blobless bundles.
Implementation plan
-------------------
This design document is being submitted on its own as an aspirational document, with the goal of implementing all of the mentioned client features over the course of several patch series. Here is a potential outline for submitting these features:
1. Integrate bundle URIs into `git clone` with a `--bundle-uri` option. This will include a new `git fetch --bundle-uri` mode for use as the implementation underneath `git clone`. The initial version here will expect a single bundle at the given URI.
2. Implement the ability to parse a bundle list from a bundle URI and update the `git fetch --bundle-uri` logic to properly distinguish between `bundle.mode` options. Specifically design the feature so that the config format parsing feeds a list of key-value pairs into the bundle list logic.
3. Create the `bundle-uri` protocol v2 command so Git servers can advertise bundle URIs using the key-value pairs. Plug into the existing key-value input to the bundle list logic. Allow `git clone` to discover these bundle URIs and bootstrap the client repository from the bundle data. (This choice is an opt-in via a config option and a command-line option.)
4. Allow the client to understand the `bundle.flag=forFetch` configuration and the `bundle.<id>.creationToken` heuristic. When `git clone` discovers a bundle URI with `bundle.flag=forFetch`, it configures the client repository to check that bundle URI during later `git fetch <remote>` commands.
5. Allow clients to discover bundle URIs during `git fetch` and configure a bundle URI for later fetches if `bundle.flag=forFetch`.
6. Implement the "inspect headers" heuristic to reduce data downloads when the `bundle.<id>.creationToken` heuristic is not available.
As these features are reviewed, this plan might be updated. We also expect that new designs will be discovered and implemented as this feature matures and becomes used in real-world scenarios.
Related work: packfile uris
---------------------------
The Git protocol already has a capability where the Git server can list a set of URLs along with the packfile response when serving a client request. The client is then expected to download the packfiles at those locations in order to have a complete understanding of the response.
This mechanism is used by the Gerrit server (implemented with JGit) and has been effective at reducing CPU load and improving user performance for clones.
A major downside to this mechanism is that the origin server needs to know `exactly` what is in those packfiles, and the packfiles need to be available to the user for some time after the server has responded. This coupling between the origin and the packfile data is difficult to manage.
Further, this implementation is extremely hard to make work with fetches.
Related work: gvfs cache servers
--------------------------------
The GVFS Protocol [2] is a set of HTTP endpoints designed independently of the Git project before Git’s partial clone was created. One feature of this protocol is the idea of a "cache server" which can be colocated with build machines or developer offices to transfer Git data without overloading the central server.
The endpoint that VFS for Git is famous for is the `GET /gvfs/objects/{oid}` endpoint, which allows downloading an object on-demand. This is a critical piece of the filesystem virtualization of that product.
However, a more subtle need is the `GET /gvfs/prefetch?lastPackTimestamp=<t>` endpoint. Given an optional timestamp, the cache server responds with a list of precomputed packfiles containing the commits and trees that were introduced in those time intervals.
The cache server computes these "prefetch" packfiles using the following strategy:
1. Every hour, an "hourly" pack is generated with a given timestamp.
2. Nightly, the previous 24 hourly packs are rolled up into a "daily" pack.
3. Nightly, all prefetch packs more than 30 days old are rolled up into one pack.
When a user runs `gvfs clone` or `scalar clone` against a repo with cache servers, the client requests all prefetch packfiles, which is at most `24 + 30 + 1` packfiles downloading only commits and trees. The client then follows with a request to the origin server for the references, and attempts to checkout that tip reference. (There is an extra endpoint that helps get all reachable trees from a given commit, in case that commit was not already in a prefetch packfile.)
During a `git fetch`, a hook requests the prefetch endpoint using the most-recent timestamp from a previously-downloaded prefetch packfile. Only the list of packfiles with later timestamps are downloaded. Most users fetch hourly, so they get at most one hourly prefetch pack. Users whose machines have been off or otherwise have not fetched in over 30 days might redownload all prefetch packfiles. This is rare.
It is important to note that the clients always contact the origin server for the refs advertisement, so the refs are frequently "ahead" of the prefetched pack data. The missing objects are downloaded on-demand using the `GET gvfs/objects/{oid}` requests, when needed by a command such as `git checkout` or `git log`. Some Git optimizations disable checks that would cause these on-demand downloads to be too aggressive.
See also
--------
[1] <https://lore.kernel.org/git/[email protected]/> An earlier RFC for a bundle URI feature.
[2] <https://github.com/microsoft/VFSForGit/blob/master/Protocol.md> The GVFS Protocol
| programming_docs |
git Reference Reference
=========
Quick reference guides: [GitHub Cheat Sheet](https://github.github.com/training-kit/) | [Visual Git Cheat Sheet](https://ndpsoftware.com/git-cheatsheet.html)
[Complete list of all commands](git#_git_commands) ### Setup and Config
* <git>
* [config](git-config)
* [help](git-help)
* [bugreport](git-bugreport)
### Getting and Creating Projects
* [init](git-init)
* [clone](git-clone)
### Basic Snapshotting
* [add](git-add)
* [status](git-status)
* [diff](git-diff)
* [commit](git-commit)
* [notes](git-notes)
* [restore](git-restore)
* [reset](git-reset)
* [rm](git-rm)
* [mv](git-mv)
### Branching and Merging
* [branch](git-branch)
* [checkout](git-checkout)
* [switch](git-switch)
* [merge](git-merge)
* [mergetool](git-mergetool)
* [log](git-log)
* [stash](git-stash)
* [tag](git-tag)
* [worktree](git-worktree)
### Sharing and Updating Projects
* [fetch](git-fetch)
* [pull](git-pull)
* [push](git-push)
* [remote](git-remote)
* [submodule](git-submodule)
### Inspection and Comparison
* [show](git-show)
* [log](git-log)
* [diff](git-diff)
* [difftool](git-difftool)
* [range-diff](git-range-diff)
* [shortlog](git-shortlog)
* [describe](git-describe)
### Patching
* [apply](git-apply)
* [cherry-pick](git-cherry-pick)
* [diff](git-diff)
* [rebase](git-rebase)
* [revert](git-revert)
### Debugging
* [bisect](git-bisect)
* [blame](git-blame)
* [grep](git-grep)
### Guides
* <gitattributes>
* [Command-line interface conventions](gitcli)
* [Everyday Git](giteveryday)
* [Frequently Asked Questions (FAQ)](gitfaq)
* [Glossary](gitglossary)
* [Hooks](githooks)
* <gitignore>
* <gitmodules>
* [Revisions](gitrevisions)
* [Submodules](gitsubmodules)
* [Tutorial](gittutorial)
* [Workflows](gitworkflows)
* [All guides...](git#_guides)
### Email
* [am](git-am)
* [apply](git-apply)
* [format-patch](git-format-patch)
* [send-email](git-send-email)
* [request-pull](git-request-pull)
### External Systems
* [svn](git-svn)
* [fast-import](git-fast-import)
### Administration
* [clean](git-clean)
* [gc](git-gc)
* [fsck](git-fsck)
* [reflog](git-reflog)
* [filter-branch](git-filter-branch)
* [instaweb](git-instaweb)
* [archive](git-archive)
* [bundle](git-bundle)
### Server Admin
* [daemon](git-daemon)
* [update-server-info](git-update-server-info)
### Plumbing Commands
* [cat-file](git-cat-file)
* [check-ignore](git-check-ignore)
* [checkout-index](git-checkout-index)
* [commit-tree](git-commit-tree)
* [count-objects](git-count-objects)
* [diff-index](git-diff-index)
* [for-each-ref](git-for-each-ref)
* [hash-object](git-hash-object)
* [ls-files](git-ls-files)
* [ls-tree](git-ls-tree)
* [merge-base](git-merge-base)
* [read-tree](git-read-tree)
* [rev-list](git-rev-list)
* [rev-parse](git-rev-parse)
* [show-ref](git-show-ref)
* [symbolic-ref](git-symbolic-ref)
* [update-index](git-update-index)
* [update-ref](git-update-ref)
* [verify-pack](git-verify-pack)
* [write-tree](git-write-tree)
git Git Git
===
Quick reference guides: [GitHub Cheat Sheet](https://github.github.com/training-kit/) | [Visual Git Cheat Sheet](https://ndpsoftware.com/git-cheatsheet.html)
[Complete list of all commands](git#_git_commands) ### Setup and Config
* <git>
* [config](git-config)
* [help](git-help)
* [bugreport](git-bugreport)
### Getting and Creating Projects
* [init](git-init)
* [clone](git-clone)
### Basic Snapshotting
* [add](git-add)
* [status](git-status)
* [diff](git-diff)
* [commit](git-commit)
* [notes](git-notes)
* [restore](git-restore)
* [reset](git-reset)
* [rm](git-rm)
* [mv](git-mv)
### Branching and Merging
* [branch](git-branch)
* [checkout](git-checkout)
* [switch](git-switch)
* [merge](git-merge)
* [mergetool](git-mergetool)
* [log](git-log)
* [stash](git-stash)
* [tag](git-tag)
* [worktree](git-worktree)
### Sharing and Updating Projects
* [fetch](git-fetch)
* [pull](git-pull)
* [push](git-push)
* [remote](git-remote)
* [submodule](git-submodule)
### Inspection and Comparison
* [show](git-show)
* [log](git-log)
* [diff](git-diff)
* [difftool](git-difftool)
* [range-diff](git-range-diff)
* [shortlog](git-shortlog)
* [describe](git-describe)
### Patching
* [apply](git-apply)
* [cherry-pick](git-cherry-pick)
* [diff](git-diff)
* [rebase](git-rebase)
* [revert](git-revert)
### Debugging
* [bisect](git-bisect)
* [blame](git-blame)
* [grep](git-grep)
### Guides
* <gitattributes>
* [Command-line interface conventions](gitcli)
* [Everyday Git](giteveryday)
* [Frequently Asked Questions (FAQ)](gitfaq)
* [Glossary](gitglossary)
* [Hooks](githooks)
* <gitignore>
* <gitmodules>
* [Revisions](gitrevisions)
* [Submodules](gitsubmodules)
* [Tutorial](gittutorial)
* [Workflows](gitworkflows)
* [All guides...](git#_guides)
### Email
* [am](git-am)
* [apply](git-apply)
* [format-patch](git-format-patch)
* [send-email](git-send-email)
* [request-pull](git-request-pull)
### External Systems
* [svn](git-svn)
* [fast-import](git-fast-import)
### Administration
* [clean](git-clean)
* [gc](git-gc)
* [fsck](git-fsck)
* [reflog](git-reflog)
* [filter-branch](git-filter-branch)
* [instaweb](git-instaweb)
* [archive](git-archive)
* [bundle](git-bundle)
### Server Admin
* [daemon](git-daemon)
* [update-server-info](git-update-server-info)
### Plumbing Commands
* [cat-file](git-cat-file)
* [check-ignore](git-check-ignore)
* [checkout-index](git-checkout-index)
* [commit-tree](git-commit-tree)
* [count-objects](git-count-objects)
* [diff-index](git-diff-index)
* [for-each-ref](git-for-each-ref)
* [hash-object](git-hash-object)
* [ls-files](git-ls-files)
* [ls-tree](git-ls-tree)
* [merge-base](git-merge-base)
* [read-tree](git-read-tree)
* [rev-list](git-rev-list)
* [rev-parse](git-rev-parse)
* [show-ref](git-show-ref)
* [symbolic-ref](git-symbolic-ref)
* [update-index](git-update-index)
* [update-ref](git-update-ref)
* [verify-pack](git-verify-pack)
* [write-tree](git-write-tree)
git git-bisect-lk2009 git-bisect-lk2009
=================
Abstract
--------
"git bisect" enables software users and developers to easily find the commit that introduced a regression. We show why it is important to have good tools to fight regressions. We describe how "git bisect" works from the outside and the algorithms it uses inside. Then we explain how to take advantage of "git bisect" to improve current practices. And we discuss how "git bisect" could improve in the future.
Introduction to "git bisect"
----------------------------
Git is a Distributed Version Control system (DVCS) created by Linus Torvalds and maintained by Junio Hamano.
In Git like in many other Version Control Systems (VCS), the different states of the data that is managed by the system are called commits. And, as VCS are mostly used to manage software source code, sometimes "interesting" changes of behavior in the software are introduced in some commits.
In fact people are specially interested in commits that introduce a "bad" behavior, called a bug or a regression. They are interested in these commits because a commit (hopefully) contains a very small set of source code changes. And it’s much easier to understand and properly fix a problem when you only need to check a very small set of changes, than when you don’t know where look in the first place.
So to help people find commits that introduce a "bad" behavior, the "git bisect" set of commands was invented. And it follows of course that in "git bisect" parlance, commits where the "interesting behavior" is present are called "bad" commits, while other commits are called "good" commits. And a commit that introduce the behavior we are interested in is called a "first bad commit". Note that there could be more than one "first bad commit" in the commit space we are searching.
So "git bisect" is designed to help find a "first bad commit". And to be as efficient as possible, it tries to perform a binary search.
Fighting regressions overview
-----------------------------
###
Regressions: a big problem
Regressions are a big problem in the software industry. But it’s difficult to put some real numbers behind that claim.
There are some numbers about bugs in general, like a NIST study in 2002 [[1]](#1) that said:
> Software bugs, or errors, are so prevalent and so detrimental that they cost the U.S. economy an estimated $59.5 billion annually, or about 0.6 percent of the gross domestic product, according to a newly released study commissioned by the Department of Commerce’s National Institute of Standards and Technology (NIST). At the national level, over half of the costs are borne by software users and the remainder by software developers/vendors. The study also found that, although all errors cannot be removed, more than a third of these costs, or an estimated $22.2 billion, could be eliminated by an improved testing infrastructure that enables earlier and more effective identification and removal of software defects. These are the savings associated with finding an increased percentage (but not 100 percent) of errors closer to the development stages in which they are introduced. Currently, over half of all errors are not found until "downstream" in the development process or during post-sale software use.
>
>
And then:
> Software developers already spend approximately 80 percent of development costs on identifying and correcting defects, and yet few products of any type other than software are shipped with such high levels of errors.
>
>
Eventually the conclusion started with:
> The path to higher software quality is significantly improved software testing.
>
>
There are other estimates saying that 80% of the cost related to software is about maintenance [[2]](#2).
Though, according to Wikipedia [[3]](#3):
> A common perception of maintenance is that it is merely fixing bugs. However, studies and surveys over the years have indicated that the majority, over 80%, of the maintenance effort is used for non-corrective actions (Pigosky 1997). This perception is perpetuated by users submitting problem reports that in reality are functionality enhancements to the system.
>
>
But we can guess that improving on existing software is very costly because you have to watch out for regressions. At least this would make the above studies consistent among themselves.
Of course some kind of software is developed, then used during some time without being improved on much, and then finally thrown away. In this case, of course, regressions may not be a big problem. But on the other hand, there is a lot of big software that is continually developed and maintained during years or even tens of years by a lot of people. And as there are often many people who depend (sometimes critically) on such software, regressions are a really big problem.
One such software is the Linux kernel. And if we look at the Linux kernel, we can see that a lot of time and effort is spent to fight regressions. The release cycle start with a 2 weeks long merge window. Then the first release candidate (rc) version is tagged. And after that about 7 or 8 more rc versions will appear with around one week between each of them, before the final release.
The time between the first rc release and the final release is supposed to be used to test rc versions and fight bugs and especially regressions. And this time is more than 80% of the release cycle time. But this is not the end of the fight yet, as of course it continues after the release.
And then this is what Ingo Molnar (a well known Linux kernel developer) says about his use of git bisect:
> I most actively use it during the merge window (when a lot of trees get merged upstream and when the influx of bugs is the highest) - and yes, there have been cases that i used it multiple times a day. My average is roughly once a day.
>
>
So regressions are fought all the time by developers, and indeed it is well known that bugs should be fixed as soon as possible, so as soon as they are found. That’s why it is interesting to have good tools for this purpose.
###
Other tools to fight regressions
So what are the tools used to fight regressions? They are nearly the same as those used to fight regular bugs. The only specific tools are test suites and tools similar as "git bisect".
Test suites are very nice. But when they are used alone, they are supposed to be used so that all the tests are checked after each commit. This means that they are not very efficient, because many tests are run for no interesting result, and they suffer from combinatorial explosion.
In fact the problem is that big software often has many different configuration options and that each test case should pass for each configuration after each commit. So if you have for each release: N configurations, M commits and T test cases, you should perform:
```
N * M * T tests
```
where N, M and T are all growing with the size your software.
So very soon it will not be possible to completely test everything.
And if some bugs slip through your test suite, then you can add a test to your test suite. But if you want to use your new improved test suite to find where the bug slipped in, then you will either have to emulate a bisection process or you will perhaps bluntly test each commit backward starting from the "bad" commit you have which may be very wasteful.
"git bisect" overview
---------------------
###
Starting a bisection
The first "git bisect" subcommand to use is "git bisect start" to start the search. Then bounds must be set to limit the commit space. This is done usually by giving one "bad" and at least one "good" commit. They can be passed in the initial call to "git bisect start" like this:
```
$ git bisect start [BAD [GOOD...]]
```
or they can be set using:
```
$ git bisect bad [COMMIT]
```
and:
```
$ git bisect good [COMMIT...]
```
where BAD, GOOD and COMMIT are all names that can be resolved to a commit.
Then "git bisect" will checkout a commit of its choosing and ask the user to test it, like this:
```
$ git bisect start v2.6.27 v2.6.25
Bisecting: 10928 revisions left to test after this (roughly 14 steps)
[2ec65f8b89ea003c27ff7723525a2ee335a2b393] x86: clean up using max_low_pfn on 32-bit
```
Note that the example that we will use is really a toy example, we will be looking for the first commit that has a version like "2.6.26-something", that is the commit that has a "SUBLEVEL = 26" line in the top level Makefile. This is a toy example because there are better ways to find this commit with Git than using "git bisect" (for example "git blame" or "git log -S<string>").
###
Driving a bisection manually
At this point there are basically 2 ways to drive the search. It can be driven manually by the user or it can be driven automatically by a script or a command.
If the user is driving it, then at each step of the search, the user will have to test the current commit and say if it is "good" or "bad" using the "git bisect good" or "git bisect bad" commands respectively that have been described above. For example:
```
$ git bisect bad
Bisecting: 5480 revisions left to test after this (roughly 13 steps)
[66c0b394f08fd89236515c1c84485ea712a157be] KVM: kill file->f_count abuse in kvm
```
And after a few more steps like that, "git bisect" will eventually find a first bad commit:
```
$ git bisect bad
2ddcca36c8bcfa251724fe342c8327451988be0d is the first bad commit
commit 2ddcca36c8bcfa251724fe342c8327451988be0d
Author: Linus Torvalds <[email protected]>
Date: Sat May 3 11:59:44 2008 -0700
Linux 2.6.26-rc1
:100644 100644 5cf82581... 4492984e... M Makefile
```
At this point we can see what the commit does, check it out (if it’s not already checked out) or tinker with it, for example:
```
$ git show HEAD
commit 2ddcca36c8bcfa251724fe342c8327451988be0d
Author: Linus Torvalds <[email protected]>
Date: Sat May 3 11:59:44 2008 -0700
Linux 2.6.26-rc1
diff --git a/Makefile b/Makefile
index 5cf8258..4492984 100644
--- a/Makefile
+++ b/Makefile
@@ -1,7 +1,7 @@
VERSION = 2
PATCHLEVEL = 6
-SUBLEVEL = 25
-EXTRAVERSION =
+SUBLEVEL = 26
+EXTRAVERSION = -rc1
NAME = Funky Weasel is Jiggy wit it
# *DOCUMENTATION*
```
And when we are finished we can use "git bisect reset" to go back to the branch we were in before we started bisecting:
```
$ git bisect reset
Checking out files: 100% (21549/21549), done.
Previous HEAD position was 2ddcca3... Linux 2.6.26-rc1
Switched to branch 'master'
```
###
Driving a bisection automatically
The other way to drive the bisection process is to tell "git bisect" to launch a script or command at each bisection step to know if the current commit is "good" or "bad". To do that, we use the "git bisect run" command. For example:
```
$ git bisect start v2.6.27 v2.6.25
Bisecting: 10928 revisions left to test after this (roughly 14 steps)
[2ec65f8b89ea003c27ff7723525a2ee335a2b393] x86: clean up using max_low_pfn on 32-bit
$
$ git bisect run grep '^SUBLEVEL = 25' Makefile
running grep ^SUBLEVEL = 25 Makefile
Bisecting: 5480 revisions left to test after this (roughly 13 steps)
[66c0b394f08fd89236515c1c84485ea712a157be] KVM: kill file->f_count abuse in kvm
running grep ^SUBLEVEL = 25 Makefile
SUBLEVEL = 25
Bisecting: 2740 revisions left to test after this (roughly 12 steps)
[671294719628f1671faefd4882764886f8ad08cb] V4L/DVB(7879): Adding cx18 Support for mxl5005s
...
...
running grep ^SUBLEVEL = 25 Makefile
Bisecting: 0 revisions left to test after this (roughly 0 steps)
[2ddcca36c8bcfa251724fe342c8327451988be0d] Linux 2.6.26-rc1
running grep ^SUBLEVEL = 25 Makefile
2ddcca36c8bcfa251724fe342c8327451988be0d is the first bad commit
commit 2ddcca36c8bcfa251724fe342c8327451988be0d
Author: Linus Torvalds <[email protected]>
Date: Sat May 3 11:59:44 2008 -0700
Linux 2.6.26-rc1
:100644 100644 5cf82581... 4492984e... M Makefile
bisect run success
```
In this example, we passed "grep `^SUBLEVEL = 25` Makefile" as parameter to "git bisect run". This means that at each step, the grep command we passed will be launched. And if it exits with code 0 (that means success) then git bisect will mark the current state as "good". If it exits with code 1 (or any code between 1 and 127 included, except the special code 125), then the current state will be marked as "bad".
Exit code between 128 and 255 are special to "git bisect run". They make it stop immediately the bisection process. This is useful for example if the command passed takes too long to complete, because you can kill it with a signal and it will stop the bisection process.
It can also be useful in scripts passed to "git bisect run" to "exit 255" if some very abnormal situation is detected.
###
Avoiding untestable commits
Sometimes it happens that the current state cannot be tested, for example if it does not compile because there was a bug preventing it at that time. This is what the special exit code 125 is for. It tells "git bisect run" that the current commit should be marked as untestable and that another one should be chosen and checked out.
If the bisection process is driven manually, you can use "git bisect skip" to do the same thing. (In fact the special exit code 125 makes "git bisect run" use "git bisect skip" in the background.)
Or if you want more control, you can inspect the current state using for example "git bisect visualize". It will launch gitk (or "git log" if the `DISPLAY` environment variable is not set) to help you find a better bisection point.
Either way, if you have a string of untestable commits, it might happen that the regression you are looking for has been introduced by one of these untestable commits. In this case it’s not possible to tell for sure which commit introduced the regression.
So if you used "git bisect skip" (or the run script exited with special code 125) you could get a result like this:
```
There are only 'skip'ped commits left to test.
The first bad commit could be any of:
15722f2fa328eaba97022898a305ffc8172db6b1
78e86cf3e850bd755bb71831f42e200626fbd1e0
e15b73ad3db9b48d7d1ade32f8cd23a751fe0ace
070eab2303024706f2924822bfec8b9847e4ac1b
We cannot bisect more!
```
###
Saving a log and replaying it
If you want to show other people your bisection process, you can get a log using for example:
```
$ git bisect log > bisect_log.txt
```
And it is possible to replay it using:
```
$ git bisect replay bisect_log.txt
```
"git bisect" details
--------------------
###
Bisection algorithm
As the Git commits form a directed acyclic graph (DAG), finding the best bisection commit to test at each step is not so simple. Anyway Linus found and implemented a "truly stupid" algorithm, later improved by Junio Hamano, that works quite well.
So the algorithm used by "git bisect" to find the best bisection commit when there are no skipped commits is the following:
1) keep only the commits that:
a) are ancestor of the "bad" commit (including the "bad" commit itself), b) are not ancestor of a "good" commit (excluding the "good" commits).
This means that we get rid of the uninteresting commits in the DAG.
For example if we start with a graph like this:
```
G-Y-G-W-W-W-X-X-X-X
\ /
W-W-B
/
Y---G-W---W
\ / \
Y-Y X-X-X-X
-> time goes this way ->
```
where B is the "bad" commit, "G" are "good" commits and W, X, and Y are other commits, we will get the following graph after this first step:
```
W-W-W
\
W-W-B
/
W---W
```
So only the W and B commits will be kept. Because commits X and Y will have been removed by rules a) and b) respectively, and because commits G are removed by rule b) too.
Note for Git users, that it is equivalent as keeping only the commit given by:
```
git rev-list BAD --not GOOD1 GOOD2...
```
Also note that we don’t require the commits that are kept to be descendants of a "good" commit. So in the following example, commits W and Z will be kept:
```
G-W-W-W-B
/
Z-Z
```
2) starting from the "good" ends of the graph, associate to each commit the number of ancestors it has plus one
For example with the following graph where H is the "bad" commit and A and D are some parents of some "good" commits:
```
A-B-C
\
F-G-H
/
D---E
```
this will give:
```
1 2 3
A-B-C
\6 7 8
F-G-H
1 2/
D---E
```
3) associate to each commit: min(X, N - X)
where X is the value associated to the commit in step 2) and N is the total number of commits in the graph.
In the above example we have N = 8, so this will give:
```
1 2 3
A-B-C
\2 1 0
F-G-H
1 2/
D---E
```
4) the best bisection point is the commit with the highest associated number
So in the above example the best bisection point is commit C.
5) note that some shortcuts are implemented to speed up the algorithm
As we know N from the beginning, we know that min(X, N - X) can’t be greater than N/2. So during steps 2) and 3), if we would associate N/2 to a commit, then we know this is the best bisection point. So in this case we can just stop processing any other commit and return the current commit.
###
Bisection algorithm debugging
For any commit graph, you can see the number associated with each commit using "git rev-list --bisect-all".
For example, for the above graph, a command like:
```
$ git rev-list --bisect-all BAD --not GOOD1 GOOD2
```
would output something like:
```
e15b73ad3db9b48d7d1ade32f8cd23a751fe0ace (dist=3)
15722f2fa328eaba97022898a305ffc8172db6b1 (dist=2)
78e86cf3e850bd755bb71831f42e200626fbd1e0 (dist=2)
a1939d9a142de972094af4dde9a544e577ddef0e (dist=2)
070eab2303024706f2924822bfec8b9847e4ac1b (dist=1)
a3864d4f32a3bf5ed177ddef598490a08760b70d (dist=1)
a41baa717dd74f1180abf55e9341bc7a0bb9d556 (dist=1)
9e622a6dad403b71c40979743bb9d5be17b16bd6 (dist=0)
```
###
Bisection algorithm discussed
First let’s define "best bisection point". We will say that a commit X is a best bisection point or a best bisection commit if knowing its state ("good" or "bad") gives as much information as possible whether the state of the commit happens to be "good" or "bad".
This means that the best bisection commits are the commits where the following function is maximum:
```
f(X) = min(information_if_good(X), information_if_bad(X))
```
where information\_if\_good(X) is the information we get if X is good and information\_if\_bad(X) is the information we get if X is bad.
Now we will suppose that there is only one "first bad commit". This means that all its descendants are "bad" and all the other commits are "good". And we will suppose that all commits have an equal probability of being good or bad, or of being the first bad commit, so knowing the state of c commits gives always the same amount of information wherever these c commits are on the graph and whatever c is. (So we suppose that these commits being for example on a branch or near a good or a bad commit does not give more or less information).
Let’s also suppose that we have a cleaned up graph like one after step 1) in the bisection algorithm above. This means that we can measure the information we get in terms of number of commit we can remove from the graph..
And let’s take a commit X in the graph.
If X is found to be "good", then we know that its ancestors are all "good", so we want to say that:
```
information_if_good(X) = number_of_ancestors(X) (TRUE)
```
And this is true because at step 1) b) we remove the ancestors of the "good" commits.
If X is found to be "bad", then we know that its descendants are all "bad", so we want to say that:
```
information_if_bad(X) = number_of_descendants(X) (WRONG)
```
But this is wrong because at step 1) a) we keep only the ancestors of the bad commit. So we get more information when a commit is marked as "bad", because we also know that the ancestors of the previous "bad" commit that are not ancestors of the new "bad" commit are not the first bad commit. We don’t know if they are good or bad, but we know that they are not the first bad commit because they are not ancestor of the new "bad" commit.
So when a commit is marked as "bad" we know we can remove all the commits in the graph except those that are ancestors of the new "bad" commit. This means that:
```
information_if_bad(X) = N - number_of_ancestors(X) (TRUE)
```
where N is the number of commits in the (cleaned up) graph.
So in the end this means that to find the best bisection commits we should maximize the function:
```
f(X) = min(number_of_ancestors(X), N - number_of_ancestors(X))
```
And this is nice because at step 2) we compute number\_of\_ancestors(X) and so at step 3) we compute f(X).
Let’s take the following graph as an example:
```
G-H-I-J
/ \
A-B-C-D-E-F O
\ /
K-L-M-N
```
If we compute the following non optimal function on it:
```
g(X) = min(number_of_ancestors(X), number_of_descendants(X))
```
we get:
```
4 3 2 1
G-H-I-J
1 2 3 4 5 6/ \0
A-B-C-D-E-F O
\ /
K-L-M-N
4 3 2 1
```
but with the algorithm used by git bisect we get:
```
7 7 6 5
G-H-I-J
1 2 3 4 5 6/ \0
A-B-C-D-E-F O
\ /
K-L-M-N
7 7 6 5
```
So we chose G, H, K or L as the best bisection point, which is better than F. Because if for example L is bad, then we will know not only that L, M and N are bad but also that G, H, I and J are not the first bad commit (since we suppose that there is only one first bad commit and it must be an ancestor of L).
So the current algorithm seems to be the best possible given what we initially supposed.
###
Skip algorithm
When some commits have been skipped (using "git bisect skip"), then the bisection algorithm is the same for step 1) to 3). But then we use roughly the following steps:
6) sort the commit by decreasing associated value
7) if the first commit has not been skipped, we can return it and stop here
8) otherwise filter out all the skipped commits in the sorted list
9) use a pseudo random number generator (PRNG) to generate a random number between 0 and 1
10) multiply this random number with its square root to bias it toward 0
11) multiply the result by the number of commits in the filtered list to get an index into this list
12) return the commit at the computed index
###
Skip algorithm discussed
After step 7) (in the skip algorithm), we could check if the second commit has been skipped and return it if it is not the case. And in fact that was the algorithm we used from when "git bisect skip" was developed in Git version 1.5.4 (released on February 1st 2008) until Git version 1.6.4 (released July 29th 2009).
But Ingo Molnar and H. Peter Anvin (another well known linux kernel developer) both complained that sometimes the best bisection points all happened to be in an area where all the commits are untestable. And in this case the user was asked to test many untestable commits, which could be very inefficient.
Indeed untestable commits are often untestable because a breakage was introduced at one time, and that breakage was fixed only after many other commits were introduced.
This breakage is of course most of the time unrelated to the breakage we are trying to locate in the commit graph. But it prevents us to know if the interesting "bad behavior" is present or not.
So it is a fact that commits near an untestable commit have a high probability of being untestable themselves. And the best bisection commits are often found together too (due to the bisection algorithm).
This is why it is a bad idea to just chose the next best unskipped bisection commit when the first one has been skipped.
We found that most commits on the graph may give quite a lot of information when they are tested. And the commits that will not on average give a lot of information are the one near the good and bad commits.
So using a PRNG with a bias to favor commits away from the good and bad commits looked like a good choice.
One obvious improvement to this algorithm would be to look for a commit that has an associated value near the one of the best bisection commit, and that is on another branch, before using the PRNG. Because if such a commit exists, then it is not very likely to be untestable too, so it will probably give more information than a nearly randomly chosen one.
###
Checking merge bases
There is another tweak in the bisection algorithm that has not been described in the "bisection algorithm" above.
We supposed in the previous examples that the "good" commits were ancestors of the "bad" commit. But this is not a requirement of "git bisect".
Of course the "bad" commit cannot be an ancestor of a "good" commit, because the ancestors of the good commits are supposed to be "good". And all the "good" commits must be related to the bad commit. They cannot be on a branch that has no link with the branch of the "bad" commit. But it is possible for a good commit to be related to a bad commit and yet not be neither one of its ancestor nor one of its descendants.
For example, there can be a "main" branch, and a "dev" branch that was forked of the main branch at a commit named "D" like this:
```
A-B-C-D-E-F-G <--main
\
H-I-J <--dev
```
The commit "D" is called a "merge base" for branch "main" and "dev" because it’s the best common ancestor for these branches for a merge.
Now let’s suppose that commit J is bad and commit G is good and that we apply the bisection algorithm like it has been previously described.
As described in step 1) b) of the bisection algorithm, we remove all the ancestors of the good commits because they are supposed to be good too.
So we would be left with only:
```
H-I-J
```
But what happens if the first bad commit is "B" and if it has been fixed in the "main" branch by commit "F"?
The result of such a bisection would be that we would find that H is the first bad commit, when in fact it’s B. So that would be wrong!
And yes it can happen in practice that people working on one branch are not aware that people working on another branch fixed a bug! It could also happen that F fixed more than one bug or that it is a revert of some big development effort that was not ready to be released.
In fact development teams often maintain both a development branch and a maintenance branch, and it would be quite easy for them if "git bisect" just worked when they want to bisect a regression on the development branch that is not on the maintenance branch. They should be able to start bisecting using:
```
$ git bisect start dev main
```
To enable that additional nice feature, when a bisection is started and when some good commits are not ancestors of the bad commit, we first compute the merge bases between the bad and the good commits and we chose these merge bases as the first commits that will be checked out and tested.
If it happens that one merge base is bad, then the bisection process is stopped with a message like:
```
The merge base BBBBBB is bad.
This means the bug has been fixed between BBBBBB and [GGGGGG,...].
```
where BBBBBB is the sha1 hash of the bad merge base and [GGGGGG,…] is a comma separated list of the sha1 of the good commits.
If some of the merge bases are skipped, then the bisection process continues, but the following message is printed for each skipped merge base:
```
Warning: the merge base between BBBBBB and [GGGGGG,...] must be skipped.
So we cannot be sure the first bad commit is between MMMMMM and BBBBBB.
We continue anyway.
```
where BBBBBB is the sha1 hash of the bad commit, MMMMMM is the sha1 hash of the merge base that is skipped and [GGGGGG,…] is a comma separated list of the sha1 of the good commits.
So if there is no bad merge base, the bisection process continues as usual after this step.
Best bisecting practices
------------------------
###
Using test suites and git bisect together
If you both have a test suite and use git bisect, then it becomes less important to check that all tests pass after each commit. Though of course it is probably a good idea to have some checks to avoid breaking too many things because it could make bisecting other bugs more difficult.
You can focus your efforts to check at a few points (for example rc and beta releases) that all the T test cases pass for all the N configurations. And when some tests don’t pass you can use "git bisect" (or better "git bisect run"). So you should perform roughly:
```
c * N * T + b * M * log2(M) tests
```
where c is the number of rounds of test (so a small constant) and b is the ratio of bug per commit (hopefully a small constant too).
So of course it’s much better as it’s O(N \* T) vs O(N \* T \* M) if you would test everything after each commit.
This means that test suites are good to prevent some bugs from being committed and they are also quite good to tell you that you have some bugs. But they are not so good to tell you where some bugs have been introduced. To tell you that efficiently, git bisect is needed.
The other nice thing with test suites, is that when you have one, you already know how to test for bad behavior. So you can use this knowledge to create a new test case for "git bisect" when it appears that there is a regression. So it will be easier to bisect the bug and fix it. And then you can add the test case you just created to your test suite.
So if you know how to create test cases and how to bisect, you will be subject to a virtuous circle:
more tests ⇒ easier to create tests ⇒ easier to bisect ⇒ more tests
So test suites and "git bisect" are complementary tools that are very powerful and efficient when used together.
###
Bisecting build failures
You can very easily automatically bisect broken builds using something like:
```
$ git bisect start BAD GOOD
$ git bisect run make
```
###
Passing sh -c "some commands" to "git bisect run"
For example:
```
$ git bisect run sh -c "make || exit 125; ./my_app | grep 'good output'"
```
On the other hand if you do this often, then it can be worth having scripts to avoid too much typing.
###
Finding performance regressions
Here is an example script that comes slightly modified from a real world script used by Junio Hamano [[4]](#4).
This script can be passed to "git bisect run" to find the commit that introduced a performance regression:
```
#!/bin/sh
# Build errors are not what I am interested in.
make my_app || exit 255
# We are checking if it stops in a reasonable amount of time, so
# let it run in the background...
./my_app >log 2>&1 &
# ... and grab its process ID.
pid=$!
# ... and then wait for sufficiently long.
sleep $NORMAL_TIME
# ... and then see if the process is still there.
if kill -0 $pid
then
# It is still running -- that is bad.
kill $pid; sleep 1; kill $pid;
exit 1
else
# It has already finished (the $pid process was no more),
# and we are happy.
exit 0
fi
```
###
Following general best practices
It is obviously a good idea not to have commits with changes that knowingly break things, even if some other commits later fix the breakage.
It is also a good idea when using any VCS to have only one small logical change in each commit.
The smaller the changes in your commit, the most effective "git bisect" will be. And you will probably need "git bisect" less in the first place, as small changes are easier to review even if they are only reviewed by the committer.
Another good idea is to have good commit messages. They can be very helpful to understand why some changes were made.
These general best practices are very helpful if you bisect often.
###
Avoiding bug prone merges
First merges by themselves can introduce some regressions even when the merge needs no source code conflict resolution. This is because a semantic change can happen in one branch while the other branch is not aware of it.
For example one branch can change the semantic of a function while the other branch add more calls to the same function.
This is made much worse if many files have to be fixed to resolve conflicts. That’s why such merges are called "evil merges". They can make regressions very difficult to track down. It can even be misleading to know the first bad commit if it happens to be such a merge, because people might think that the bug comes from bad conflict resolution when it comes from a semantic change in one branch.
Anyway "git rebase" can be used to linearize history. This can be used either to avoid merging in the first place. Or it can be used to bisect on a linear history instead of the non linear one, as this should give more information in case of a semantic change in one branch.
Merges can be also made simpler by using smaller branches or by using many topic branches instead of only long version related branches.
And testing can be done more often in special integration branches like linux-next for the linux kernel.
###
Adapting your work-flow
A special work-flow to process regressions can give great results.
Here is an example of a work-flow used by Andreas Ericsson:
* write, in the test suite, a test script that exposes the regression
* use "git bisect run" to find the commit that introduced it
* fix the bug that is often made obvious by the previous step
* commit both the fix and the test script (and if needed more tests)
And here is what Andreas said about this work-flow [[5]](#5):
> To give some hard figures, we used to have an average report-to-fix cycle of 142.6 hours (according to our somewhat weird bug-tracker which just measures wall-clock time). Since we moved to Git, we’ve lowered that to 16.2 hours. Primarily because we can stay on top of the bug fixing now, and because everyone’s jockeying to get to fix bugs (we’re quite proud of how lazy we are to let Git find the bugs for us). Each new release results in ~40% fewer bugs (almost certainly due to how we now feel about writing tests).
>
>
Clearly this work-flow uses the virtuous circle between test suites and "git bisect". In fact it makes it the standard procedure to deal with regression.
In other messages Andreas says that they also use the "best practices" described above: small logical commits, topic branches, no evil merge,… These practices all improve the bisectability of the commit graph, by making it easier and more useful to bisect.
So a good work-flow should be designed around the above points. That is making bisecting easier, more useful and standard.
###
Involving QA people and if possible end users
One nice about "git bisect" is that it is not only a developer tool. It can effectively be used by QA people or even end users (if they have access to the source code or if they can get access to all the builds).
There was a discussion at one point on the linux kernel mailing list of whether it was ok to always ask end user to bisect, and very good points were made to support the point of view that it is ok.
For example David Miller wrote [[6]](#6):
> What people don’t get is that this is a situation where the "end node principle" applies. When you have limited resources (here: developers) you don’t push the bulk of the burden upon them. Instead you push things out to the resource you have a lot of, the end nodes (here: users), so that the situation actually scales.
>
>
This means that it is often "cheaper" if QA people or end users can do it.
What is interesting too is that end users that are reporting bugs (or QA people that reproduced a bug) have access to the environment where the bug happens. So they can often more easily reproduce a regression. And if they can bisect, then more information will be extracted from the environment where the bug happens, which means that it will be easier to understand and then fix the bug.
For open source projects it can be a good way to get more useful contributions from end users, and to introduce them to QA and development activities.
###
Using complex scripts
In some cases like for kernel development it can be worth developing complex scripts to be able to fully automate bisecting.
Here is what Ingo Molnar says about that [[7]](#7):
> i have a fully automated bootup-hang bisection script. It is based on "git-bisect run". I run the script, it builds and boots kernels fully automatically, and when the bootup fails (the script notices that via the serial log, which it continuously watches - or via a timeout, if the system does not come up within 10 minutes it’s a "bad" kernel), the script raises my attention via a beep and i power cycle the test box. (yeah, i should make use of a managed power outlet to 100% automate it)
>
>
###
Combining test suites, git bisect and other systems together
We have seen that test suites and git bisect are very powerful when used together. It can be even more powerful if you can combine them with other systems.
For example some test suites could be run automatically at night with some unusual (or even random) configurations. And if a regression is found by a test suite, then "git bisect" can be automatically launched, and its result can be emailed to the author of the first bad commit found by "git bisect", and perhaps other people too. And a new entry in the bug tracking system could be automatically created too.
The future of bisecting
-----------------------
###
"git replace"
We saw earlier that "git bisect skip" is now using a PRNG to try to avoid areas in the commit graph where commits are untestable. The problem is that sometimes the first bad commit will be in an untestable area.
To simplify the discussion we will suppose that the untestable area is a simple string of commits and that it was created by a breakage introduced by one commit (let’s call it BBC for bisect breaking commit) and later fixed by another one (let’s call it BFC for bisect fixing commit).
For example:
```
...-Y-BBC-X1-X2-X3-X4-X5-X6-BFC-Z-...
```
where we know that Y is good and BFC is bad, and where BBC and X1 to X6 are untestable.
In this case if you are bisecting manually, what you can do is create a special branch that starts just before the BBC. The first commit in this branch should be the BBC with the BFC squashed into it. And the other commits in the branch should be the commits between BBC and BFC rebased on the first commit of the branch and then the commit after BFC also rebased on.
For example:
```
(BBC+BFC)-X1'-X2'-X3'-X4'-X5'-X6'-Z'
/
...-Y-BBC-X1-X2-X3-X4-X5-X6-BFC-Z-...
```
where commits quoted with ' have been rebased.
You can easily create such a branch with Git using interactive rebase.
For example using:
```
$ git rebase -i Y Z
```
and then moving BFC after BBC and squashing it.
After that you can start bisecting as usual in the new branch and you should eventually find the first bad commit.
For example:
```
$ git bisect start Z' Y
```
If you are using "git bisect run", you can use the same manual fix up as above, and then start another "git bisect run" in the special branch. Or as the "git bisect" man page says, the script passed to "git bisect run" can apply a patch before it compiles and test the software [[8]](#8). The patch should turn a current untestable commits into a testable one. So the testing will result in "good" or "bad" and "git bisect" will be able to find the first bad commit. And the script should not forget to remove the patch once the testing is done before exiting from the script.
(Note that instead of a patch you can use "git cherry-pick BFC" to apply the fix, and in this case you should use "git reset --hard HEAD^" to revert the cherry-pick after testing and before returning from the script.)
But the above ways to work around untestable areas are a little bit clunky. Using special branches is nice because these branches can be shared by developers like usual branches, but the risk is that people will get many such branches. And it disrupts the normal "git bisect" work-flow. So, if you want to use "git bisect run" completely automatically, you have to add special code in your script to restart bisection in the special branches.
Anyway one can notice in the above special branch example that the Z' and Z commits should point to the same source code state (the same "tree" in git parlance). That’s because Z' result from applying the same changes as Z just in a slightly different order.
So if we could just "replace" Z by Z' when we bisect, then we would not need to add anything to a script. It would just work for anyone in the project sharing the special branches and the replacements.
With the example above that would give:
```
(BBC+BFC)-X1'-X2'-X3'-X4'-X5'-X6'-Z'-...
/
...-Y-BBC-X1-X2-X3-X4-X5-X6-BFC-Z
```
That’s why the "git replace" command was created. Technically it stores replacements "refs" in the "refs/replace/" hierarchy. These "refs" are like branches (that are stored in "refs/heads/") or tags (that are stored in "refs/tags"), and that means that they can automatically be shared like branches or tags among developers.
"git replace" is a very powerful mechanism. It can be used to fix commits in already released history, for example to change the commit message or the author. And it can also be used instead of git "grafts" to link a repository with another old repository.
In fact it’s this last feature that "sold" it to the Git community, so it is now in the "master" branch of Git’s Git repository and it should be released in Git 1.6.5 in October or November 2009.
One problem with "git replace" is that currently it stores all the replacements refs in "refs/replace/", but it would be perhaps better if the replacement refs that are useful only for bisecting would be in "refs/replace/bisect/". This way the replacement refs could be used only for bisecting, while other refs directly in "refs/replace/" would be used nearly all the time.
###
Bisecting sporadic bugs
Another possible improvement to "git bisect" would be to optionally add some redundancy to the tests performed so that it would be more reliable when tracking sporadic bugs.
This has been requested by some kernel developers because some bugs called sporadic bugs do not appear in all the kernel builds because they are very dependent on the compiler output.
The idea is that every 3 test for example, "git bisect" could ask the user to test a commit that has already been found to be "good" or "bad" (because one of its descendants or one of its ancestors has been found to be "good" or "bad" respectively). If it happens that a commit has been previously incorrectly classified then the bisection can be aborted early, hopefully before too many mistakes have been made. Then the user will have to look at what happened and then restart the bisection using a fixed bisect log.
There is already a project called BBChop created by Ealdwulf Wuffinga on Github that does something like that using Bayesian Search Theory [[9]](#9):
> BBChop is like `git bisect` (or equivalent), but works when your bug is intermittent. That is, it works in the presence of false negatives (when a version happens to work this time even though it contains the bug). It assumes that there are no false positives (in principle, the same approach would work, but adding it may be non-trivial).
>
>
But BBChop is independent of any VCS and it would be easier for Git users to have something integrated in Git.
Conclusion
----------
We have seen that regressions are an important problem, and that "git bisect" has nice features that complement very well practices and other tools, especially test suites, that are generally used to fight regressions. But it might be needed to change some work-flows and (bad) habits to get the most out of it.
Some improvements to the algorithms inside "git bisect" are possible and some new features could help in some cases, but overall "git bisect" works already very well, is used a lot, and is already very useful. To back up that last claim, let’s give the final word to Ingo Molnar when he was asked by the author how much time does he think "git bisect" saves him when he uses it:
> a `lot`.
>
> About ten years ago did i do my first `bisection` of a Linux patch queue. That was prior the Git (and even prior the BitKeeper) days. I literally days spent sorting out patches, creating what in essence were standalone commits that i guessed to be related to that bug.
>
> It was a tool of absolute last resort. I’d rather spend days looking at printk output than do a manual `patch bisection`.
>
> With Git bisect it’s a breeze: in the best case i can get a ~15 step kernel bisection done in 20-30 minutes, in an automated way. Even with manual help or when bisecting multiple, overlapping bugs, it’s rarely more than an hour.
>
> In fact it’s invaluable because there are bugs i would never even `try` to debug if it wasn’t for git bisect. In the past there were bug patterns that were immediately hopeless for me to debug - at best i could send the crash/bug signature to lkml and hope that someone else can think of something.
>
> And even if a bisection fails today it tells us something valuable about the bug: that it’s non-deterministic - timing or kernel image layout dependent.
>
> So git bisect is unconditional goodness - and feel free to quote that ;-)
>
>
Acknowledgments
---------------
Many thanks to Junio Hamano for his help in reviewing this paper, for reviewing the patches I sent to the Git mailing list, for discussing some ideas and helping me improve them, for improving "git bisect" a lot and for his awesome work in maintaining and developing Git.
Many thanks to Ingo Molnar for giving me very useful information that appears in this paper, for commenting on this paper, for his suggestions to improve "git bisect" and for evangelizing "git bisect" on the linux kernel mailing lists.
Many thanks to Linus Torvalds for inventing, developing and evangelizing "git bisect", Git and Linux.
Many thanks to the many other great people who helped one way or another when I worked on Git, especially to Andreas Ericsson, Johannes Schindelin, H. Peter Anvin, Daniel Barkalow, Bill Lear, John Hawley, Shawn O. Pierce, Jeff King, Sam Vilain, Jon Seymour.
Many thanks to the Linux-Kongress program committee for choosing the author to given a talk and for publishing this paper.
References
----------
* [[[1]]] [*The Economic Impacts of Inadequate Infratructure for Software Testing*. Nist Planning Report 02-3](https://www.nist.gov/sites/default/files/documents/director/planning/report02-3.pdf), see Executive Summary and Chapter 8.
* [[[2]]] [*Code Conventions for the Java Programming Language*. Sun Microsystems.](http://www.oracle.com/technetwork/java/codeconvtoc-136057.html)
* [[[3]]] [*Software maintenance*. Wikipedia.](https://en.wikipedia.org/wiki/Software_maintenance)
* [[[4]]] [Junio C Hamano. *Automated bisect success story*.](https://lore.kernel.org/git/[email protected]/)
* [[[5]]] [Christian Couder. *Fully automated bisecting with "git bisect run"*. LWN.net.](https://lwn.net/Articles/317154/)
* [[[6]]] [Jonathan Corbet. *Bisection divides users and developers*. LWN.net.](https://lwn.net/Articles/277872/)
* [[[7]]] [Ingo Molnar. *Re: BUG 2.6.23-rc3 can’t see sd partitions on Alpha*. Linux-kernel mailing list.](https://lore.kernel.org/lkml/[email protected]/)
* [[[8]]] [Junio C Hamano and the git-list. *git-bisect(1) Manual Page*. Linux Kernel Archives.](https://www.kernel.org/pub/software/scm/git/docs/git-bisect.html)
* [[[9]]] [Ealdwulf. *bbchop*. GitHub.](https://github.com/Ealdwulf/bbchop)
| programming_docs |
git git-credential-store git-credential-store
====================
Name
----
git-credential-store - Helper to store credentials on disk
Synopsis
--------
```
git config credential.helper 'store [<options>]'
```
Description
-----------
| | |
| --- | --- |
| Note | Using this helper will store your passwords unencrypted on disk, protected only by filesystem permissions. If this is not an acceptable security tradeoff, try [git-credential-cache[1]](git-credential-cache), or find a helper that integrates with secure storage provided by your operating system. |
This command stores credentials indefinitely on disk for use by future Git programs.
You probably don’t want to invoke this command directly; it is meant to be used as a credential helper by other parts of git. See [gitcredentials[7]](gitcredentials) or `EXAMPLES` below.
Options
-------
--file=<path> Use `<path>` to lookup and store credentials. The file will have its filesystem permissions set to prevent other users on the system from reading it, but will not be encrypted or otherwise protected. If not specified, credentials will be searched for from `~/.git-credentials` and `$XDG_CONFIG_HOME/git/credentials`, and credentials will be written to `~/.git-credentials` if it exists, or `$XDG_CONFIG_HOME/git/credentials` if it exists and the former does not. See also [FILES](#FILES).
Files
-----
If not set explicitly with `--file`, there are two files where git-credential-store will search for credentials in order of precedence:
~/.git-credentials User-specific credentials file.
$XDG\_CONFIG\_HOME/git/credentials Second user-specific credentials file. If `$XDG_CONFIG_HOME` is not set or empty, `$HOME/.config/git/credentials` will be used. Any credentials stored in this file will not be used if `~/.git-credentials` has a matching credential as well. It is a good idea not to create this file if you sometimes use older versions of Git that do not support it.
For credential lookups, the files are read in the order given above, with the first matching credential found taking precedence over credentials found in files further down the list.
Credential storage will by default write to the first existing file in the list. If none of these files exist, `~/.git-credentials` will be created and written to.
When erasing credentials, matching credentials will be erased from all files.
Examples
--------
The point of this helper is to reduce the number of times you must type your username or password. For example:
```
$ git config credential.helper store
$ git push http://example.com/repo.git
Username: <type your username>
Password: <type your password>
[several days later]
$ git push http://example.com/repo.git
[your credentials are used automatically]
```
Storage format
--------------
The `.git-credentials` file is stored in plaintext. Each credential is stored on its own line as a URL like:
```
https://user:[email protected]
```
No other kinds of lines (e.g. empty lines or comment lines) are allowed in the file, even though some may be silently ignored. Do not view or edit the file with editors.
When Git needs authentication for a particular URL context, credential-store will consider that context a pattern to match against each entry in the credentials file. If the protocol, hostname, and username (if we already have one) match, then the password is returned to Git. See the discussion of configuration in [gitcredentials[7]](gitcredentials) for more information.
git git-request-pull git-request-pull
================
Name
----
git-request-pull - Generates a summary of pending changes
Synopsis
--------
```
git request-pull [-p] <start> <URL> [<end>]
```
Description
-----------
Generate a request asking your upstream project to pull changes into their tree. The request, printed to the standard output, begins with the branch description, summarizes the changes and indicates from where they can be pulled.
The upstream project is expected to have the commit named by `<start>` and the output asks it to integrate the changes you made since that commit, up to the commit named by `<end>`, by visiting the repository named by `<URL>`.
Options
-------
-p Include patch text in the output.
<start> Commit to start at. This names a commit that is already in the upstream history.
<URL> The repository URL to be pulled from.
<end> Commit to end at (defaults to HEAD). This names the commit at the tip of the history you are asking to be pulled.
When the repository named by `<URL>` has the commit at a tip of a ref that is different from the ref you have locally, you can use the `<local>:<remote>` syntax, to have its local name, a colon `:`, and its remote name.
Examples
--------
Imagine that you built your work on your `master` branch on top of the `v1.0` release, and want it to be integrated to the project. First you push that change to your public repository for others to see:
```
git push https://git.ko.xz/project master
```
Then, you run this command:
```
git request-pull v1.0 https://git.ko.xz/project master
```
which will produce a request to the upstream, summarizing the changes between the `v1.0` release and your `master`, to pull it from your public repository.
If you pushed your change to a branch whose name is different from the one you have locally, e.g.
```
git push https://git.ko.xz/project master:for-linus
```
then you can ask that to be pulled with
```
git request-pull v1.0 https://git.ko.xz/project master:for-linus
```
git gitprotocol-capabilities gitprotocol-capabilities
========================
Name
----
gitprotocol-capabilities - Protocol v0 and v1 capabilities
Synopsis
--------
```
<over-the-wire-protocol>
```
Description
-----------
| | |
| --- | --- |
| Note | this document describes capabilities for versions 0 and 1 of the pack protocol. For version 2, please refer to the [gitprotocol-v2[5]](gitprotocol-v2) doc. |
Servers SHOULD support all capabilities defined in this document.
On the very first line of the initial server response of either receive-pack and upload-pack the first reference is followed by a NUL byte and then a list of space delimited server capabilities. These allow the server to declare what it can and cannot support to the client.
Client will then send a space separated list of capabilities it wants to be in effect. The client MUST NOT ask for capabilities the server did not say it supports.
Server MUST diagnose and abort if capabilities it does not understand was sent. Server MUST NOT ignore capabilities that client requested and server advertised. As a consequence of these rules, server MUST NOT advertise capabilities it does not understand.
The `atomic`, `report-status`, `report-status-v2`, `delete-refs`, `quiet`, and `push-cert` capabilities are sent and recognized by the receive-pack (push to server) process.
The `ofs-delta` and `side-band-64k` capabilities are sent and recognized by both upload-pack and receive-pack protocols. The `agent` and `session-id` capabilities may optionally be sent in both protocols.
All other capabilities are only recognized by the upload-pack (fetch from server) process.
Multi\_ack
----------
The `multi_ack` capability allows the server to return "ACK obj-id continue" as soon as it finds a commit that it can use as a common base, between the client’s wants and the client’s have set.
By sending this early, the server can potentially head off the client from walking any further down that particular branch of the client’s repository history. The client may still need to walk down other branches, sending have lines for those, until the server has a complete cut across the DAG, or the client has said "done".
Without multi\_ack, a client sends have lines in --date-order until the server has found a common base. That means the client will send have lines that are already known by the server to be common, because they overlap in time with another branch that the server hasn’t found a common base on yet.
For example suppose the client has commits in caps that the server doesn’t and the server has commits in lower case that the client doesn’t, as in the following diagram:
```
+---- u ---------------------- x
/ +----- y
/ /
a -- b -- c -- d -- E -- F
\
+--- Q -- R -- S
```
If the client wants x,y and starts out by saying have F,S, the server doesn’t know what F,S is. Eventually the client says "have d" and the server sends "ACK d continue" to let the client know to stop walking down that line (so don’t send c-b-a), but it’s not done yet, it needs a base for x. The client keeps going with S-R-Q, until a gets reached, at which point the server has a clear base and it all ends.
Without multi\_ack the client would have sent that c-b-a chain anyway, interleaved with S-R-Q.
Multi\_ack\_detailed
--------------------
This is an extension of multi\_ack that permits client to better understand the server’s in-memory state. See [gitprotocol-pack[5]](gitprotocol-pack), section "Packfile Negotiation" for more information.
No-done
-------
This capability should only be used with the smart HTTP protocol. If multi\_ack\_detailed and no-done are both present, then the sender is free to immediately send a pack following its first "ACK obj-id ready" message.
Without no-done in the smart HTTP protocol, the server session would end and the client has to make another trip to send "done" before the server can send the pack. no-done removes the last round and thus slightly reduces latency.
Thin-pack
---------
A thin pack is one with deltas which reference base objects not contained within the pack (but are known to exist at the receiving end). This can reduce the network traffic significantly, but it requires the receiving end to know how to "thicken" these packs by adding the missing bases to the pack.
The upload-pack server advertises `thin-pack` when it can generate and send a thin pack. A client requests the `thin-pack` capability when it understands how to "thicken" it, notifying the server that it can receive such a pack. A client MUST NOT request the `thin-pack` capability if it cannot turn a thin pack into a self-contained pack.
Receive-pack, on the other hand, is assumed by default to be able to handle thin packs, but can ask the client not to use the feature by advertising the `no-thin` capability. A client MUST NOT send a thin pack if the server advertises the `no-thin` capability.
The reasons for this asymmetry are historical. The receive-pack program did not exist until after the invention of thin packs, so historically the reference implementation of receive-pack always understood thin packs. Adding `no-thin` later allowed receive-pack to disable the feature in a backwards-compatible manner.
Side-band, side-band-64k
------------------------
This capability means that server can send, and client understand multiplexed progress reports and error info interleaved with the packfile itself.
These two options are mutually exclusive. A modern client always favors `side-band-64k`.
Either mode indicates that the packfile data will be streamed broken up into packets of up to either 1000 bytes in the case of `side_band`, or 65520 bytes in the case of `side_band_64k`. Each packet is made up of a leading 4-byte pkt-line length of how much data is in the packet, followed by a 1-byte stream code, followed by the actual data.
The stream code can be one of:
```
1 - pack data
2 - progress messages
3 - fatal error message just before stream aborts
```
The "side-band-64k" capability came about as a way for newer clients that can handle much larger packets to request packets that are actually crammed nearly full, while maintaining backward compatibility for the older clients.
Further, with side-band and its up to 1000-byte messages, it’s actually 999 bytes of payload and 1 byte for the stream code. With side-band-64k, same deal, you have up to 65519 bytes of data and 1 byte for the stream code.
The client MUST send only maximum of one of "side-band" and "side- band-64k". Server MUST diagnose it as an error if client requests both.
Ofs-delta
---------
Server can send, and client understand PACKv2 with delta referring to its base by position in pack rather than by an obj-id. That is, they can send/read OBJ\_OFS\_DELTA (aka type 6) in a packfile.
Agent
-----
The server may optionally send a capability of the form `agent=X` to notify the client that the server is running version `X`. The client may optionally return its own agent string by responding with an `agent=Y` capability (but it MUST NOT do so if the server did not mention the agent capability). The `X` and `Y` strings may contain any printable ASCII characters except space (i.e., the byte range 32 < x < 127), and are typically of the form "package/version" (e.g., "git/1.8.3.1"). The agent strings are purely informative for statistics and debugging purposes, and MUST NOT be used to programmatically assume the presence or absence of particular features.
Object-format
-------------
This capability, which takes a hash algorithm as an argument, indicates that the server supports the given hash algorithms. It may be sent multiple times; if so, the first one given is the one used in the ref advertisement.
When provided by the client, this indicates that it intends to use the given hash algorithm to communicate. The algorithm provided must be one that the server supports.
If this capability is not provided, it is assumed that the only supported algorithm is SHA-1.
Symref
------
This parameterized capability is used to inform the receiver which symbolic ref points to which ref; for example, "symref=HEAD:refs/heads/master" tells the receiver that HEAD points to master. This capability can be repeated to represent multiple symrefs.
Servers SHOULD include this capability for the HEAD symref if it is one of the refs being sent.
Clients MAY use the parameters from this capability to select the proper initial branch when cloning a repository.
Shallow
-------
This capability adds "deepen", "shallow" and "unshallow" commands to the fetch-pack/upload-pack protocol so clients can request shallow clones.
Deepen-since
------------
This capability adds "deepen-since" command to fetch-pack/upload-pack protocol so the client can request shallow clones that are cut at a specific time, instead of depth. Internally it’s equivalent of doing "rev-list --max-age=<timestamp>" on the server side. "deepen-since" cannot be used with "deepen".
Deepen-not
----------
This capability adds "deepen-not" command to fetch-pack/upload-pack protocol so the client can request shallow clones that are cut at a specific revision, instead of depth. Internally it’s equivalent of doing "rev-list --not <rev>" on the server side. "deepen-not" cannot be used with "deepen", but can be used with "deepen-since".
Deepen-relative
---------------
If this capability is requested by the client, the semantics of "deepen" command is changed. The "depth" argument is the depth from the current shallow boundary, instead of the depth from remote refs.
No-progress
-----------
The client was started with "git clone -q" or something, and doesn’t want that side band 2. Basically the client just says "I do not wish to receive stream 2 on sideband, so do not send it to me, and if you did, I will drop it on the floor anyway". However, the sideband channel 3 is still used for error responses.
Include-tag
-----------
The `include-tag` capability is about sending annotated tags if we are sending objects they point to. If we pack an object to the client, and a tag object points exactly at that object, we pack the tag object too. In general this allows a client to get all new annotated tags when it fetches a branch, in a single network connection.
Clients MAY always send include-tag, hardcoding it into a request when the server advertises this capability. The decision for a client to request include-tag only has to do with the client’s desires for tag data, whether or not a server had advertised objects in the refs/tags/\* namespace.
Servers MUST pack the tags if their referrant is packed and the client has requested include-tags.
Clients MUST be prepared for the case where a server has ignored include-tag and has not actually sent tags in the pack. In such cases the client SHOULD issue a subsequent fetch to acquire the tags that include-tag would have otherwise given the client.
The server SHOULD send include-tag, if it supports it, regardless of whether or not there are tags available.
Report-status
-------------
The receive-pack process can receive a `report-status` capability, which tells it that the client wants a report of what happened after a packfile upload and reference update. If the pushing client requests this capability, after unpacking and updating references the server will respond with whether the packfile unpacked successfully and if each reference was updated successfully. If any of those were not successful, it will send back an error message. See [gitprotocol-pack[5]](gitprotocol-pack) for example messages.
Report-status-v2
----------------
Capability `report-status-v2` extends capability `report-status` by adding new "option" directives in order to support reference rewritten by the "proc-receive" hook. The "proc-receive" hook may handle a command for a pseudo-reference which may create or update a reference with different name, new-oid, and old-oid. While the capability `report-status` cannot report for such case. See [gitprotocol-pack[5]](gitprotocol-pack) for details.
Delete-refs
-----------
If the server sends back the `delete-refs` capability, it means that it is capable of accepting a zero-id value as the target value of a reference update. It is not sent back by the client, it simply informs the client that it can be sent zero-id values to delete references.
Quiet
-----
If the receive-pack server advertises the `quiet` capability, it is capable of silencing human-readable progress output which otherwise may be shown when processing the received pack. A send-pack client should respond with the `quiet` capability to suppress server-side progress reporting if the local progress reporting is also being suppressed (e.g., via `push -q`, or if stderr does not go to a tty).
Atomic
------
If the server sends the `atomic` capability it is capable of accepting atomic pushes. If the pushing client requests this capability, the server will update the refs in one atomic transaction. Either all refs are updated or none.
Push-options
------------
If the server sends the `push-options` capability it is able to accept push options after the update commands have been sent, but before the packfile is streamed. If the pushing client requests this capability, the server will pass the options to the pre- and post- receive hooks that process this push request.
Allow-tip-sha1-in-want
----------------------
If the upload-pack server advertises this capability, fetch-pack may send "want" lines with object names that exist at the server but are not advertised by upload-pack. For historical reasons, the name of this capability contains "sha1". Object names are always given using the object format negotiated through the `object-format` capability.
Allow-reachable-sha1-in-want
----------------------------
If the upload-pack server advertises this capability, fetch-pack may send "want" lines with object names that exist at the server but are not advertised by upload-pack. For historical reasons, the name of this capability contains "sha1". Object names are always given using the object format negotiated through the `object-format` capability.
Push-cert=<nonce>
-----------------
The receive-pack server that advertises this capability is willing to accept a signed push certificate, and asks the <nonce> to be included in the push certificate. A send-pack client MUST NOT send a push-cert packet unless the receive-pack server advertises this capability.
Filter
------
If the upload-pack server advertises the `filter` capability, fetch-pack may send "filter" commands to request a partial clone or partial fetch and request that the server omit various objects from the packfile.
Session-id=<session id>
-----------------------
The server may advertise a session ID that can be used to identify this process across multiple requests. The client may advertise its own session ID back to the server as well.
Session IDs should be unique to a given process. They must fit within a packet-line, and must not contain non-printable or whitespace characters. The current implementation uses trace2 session IDs (see <api-trace2> for details), but this may change and users of the session ID should not rely on this fact.
| programming_docs |
git git-svn git-svn
=======
Name
----
git-svn - Bidirectional operation between a Subversion repository and Git
Synopsis
--------
```
git svn <command> [<options>] [<arguments>]
```
Description
-----------
`git svn` is a simple conduit for changesets between Subversion and Git. It provides a bidirectional flow of changes between a Subversion and a Git repository.
`git svn` can track a standard Subversion repository, following the common "trunk/branches/tags" layout, with the --stdlayout option. It can also follow branches and tags in any layout with the -T/-t/-b options (see options to `init` below, and also the `clone` command).
Once tracking a Subversion repository (with any of the above methods), the Git repository can be updated from Subversion by the `fetch` command and Subversion updated from Git by the `dcommit` command.
Commands
--------
*init* Initializes an empty Git repository with additional metadata directories for `git svn`. The Subversion URL may be specified as a command-line argument, or as full URL arguments to -T/-t/-b. Optionally, the target directory to operate on can be specified as a second argument. Normally this command initializes the current directory.
-T<trunk\_subdir> --trunk=<trunk\_subdir> -t<tags\_subdir> --tags=<tags\_subdir> -b<branches\_subdir> --branches=<branches\_subdir> -s --stdlayout These are optional command-line options for init. Each of these flags can point to a relative repository path (--tags=project/tags) or a full url (--tags=https://foo.org/project/tags). You can specify more than one --tags and/or --branches options, in case your Subversion repository places tags or branches under multiple paths. The option --stdlayout is a shorthand way of setting trunk,tags,branches as the relative paths, which is the Subversion default. If any of the other options are given as well, they take precedence.
--no-metadata Set the `noMetadata` option in the [svn-remote] config. This option is not recommended, please read the `svn.noMetadata` section of this manpage before using this option.
--use-svm-props Set the `useSvmProps` option in the [svn-remote] config.
--use-svnsync-props Set the `useSvnsyncProps` option in the [svn-remote] config.
--rewrite-root=<URL> Set the `rewriteRoot` option in the [svn-remote] config.
--rewrite-uuid=<UUID> Set the `rewriteUUID` option in the [svn-remote] config.
--username=<user> For transports that SVN handles authentication for (http, https, and plain svn), specify the username. For other transports (e.g. `svn+ssh://`), you must include the username in the URL, e.g. `svn+ssh://[email protected]/project`
--prefix=<prefix> This allows one to specify a prefix which is prepended to the names of remotes if trunk/branches/tags are specified. The prefix does not automatically include a trailing slash, so be sure you include one in the argument if that is what you want. If --branches/-b is specified, the prefix must include a trailing slash. Setting a prefix (with a trailing slash) is strongly encouraged in any case, as your SVN-tracking refs will then be located at "refs/remotes/$prefix/**", which is compatible with Git’s own remote-tracking ref layout (refs/remotes/$remote/**). Setting a prefix is also useful if you wish to track multiple projects that share a common repository. By default, the prefix is set to `origin/`.
| | |
| --- | --- |
| Note | Before Git v2.0, the default prefix was "" (no prefix). This meant that SVN-tracking refs were put at "refs/remotes/\*", which is incompatible with how Git’s own remote-tracking refs are organized. If you still want the old default, you can get it by passing `--prefix ""` on the command line (`--prefix=""` may not work if your Perl’s Getopt::Long is < v2.37). |
--ignore-refs=<regex> When passed to `init` or `clone` this regular expression will be preserved as a config key. See `fetch` for a description of `--ignore-refs`.
--ignore-paths=<regex> When passed to `init` or `clone` this regular expression will be preserved as a config key. See `fetch` for a description of `--ignore-paths`.
--include-paths=<regex> When passed to `init` or `clone` this regular expression will be preserved as a config key. See `fetch` for a description of `--include-paths`.
--no-minimize-url When tracking multiple directories (using --stdlayout, --branches, or --tags options), git svn will attempt to connect to the root (or highest allowed level) of the Subversion repository. This default allows better tracking of history if entire projects are moved within a repository, but may cause issues on repositories where read access restrictions are in place. Passing `--no-minimize-url` will allow git svn to accept URLs as-is without attempting to connect to a higher level directory. This option is off by default when only one URL/branch is tracked (it would do little good).
*fetch* Fetch unfetched revisions from the Subversion remote we are tracking. The name of the [svn-remote "…"] section in the $GIT\_DIR/config file may be specified as an optional command-line argument.
This automatically updates the rev\_map if needed (see `$GIT_DIR/svn/**/.rev_map.*` in the FILES section below for details).
--localtime Store Git commit times in the local time zone instead of UTC. This makes `git log` (even without --date=local) show the same times that `svn log` would in the local time zone.
This doesn’t interfere with interoperating with the Subversion repository you cloned from, but if you wish for your local Git repository to be able to interoperate with someone else’s local Git repository, either don’t use this option or you should both use it in the same local time zone.
--parent Fetch only from the SVN parent of the current HEAD.
--ignore-refs=<regex> Ignore refs for branches or tags matching the Perl regular expression. A "negative look-ahead assertion" like `^refs/remotes/origin/(?!tags/wanted-tag|wanted-branch).*$` can be used to allow only certain refs.
```
config key: svn-remote.<name>.ignore-refs
```
If the ignore-refs configuration key is set, and the command-line option is also given, both regular expressions will be used.
--ignore-paths=<regex> This allows one to specify a Perl regular expression that will cause skipping of all matching paths from checkout from SVN. The `--ignore-paths` option should match for every `fetch` (including automatic fetches due to `clone`, `dcommit`, `rebase`, etc) on a given repository.
```
config key: svn-remote.<name>.ignore-paths
```
If the ignore-paths configuration key is set, and the command-line option is also given, both regular expressions will be used.
Examples:
Skip "doc\*" directory for every fetch
```
--ignore-paths="^doc"
```
Skip "branches" and "tags" of first level directories
```
--ignore-paths="^[^/]+/(?:branches|tags)"
```
--include-paths=<regex> This allows one to specify a Perl regular expression that will cause the inclusion of only matching paths from checkout from SVN. The `--include-paths` option should match for every `fetch` (including automatic fetches due to `clone`, `dcommit`, `rebase`, etc) on a given repository. `--ignore-paths` takes precedence over `--include-paths`.
```
config key: svn-remote.<name>.include-paths
```
--log-window-size=<n> Fetch <n> log entries per request when scanning Subversion history. The default is 100. For very large Subversion repositories, larger values may be needed for `clone`/`fetch` to complete in reasonable time. But overly large values may lead to higher memory usage and request timeouts.
*clone* Runs `init` and `fetch`. It will automatically create a directory based on the basename of the URL passed to it; or if a second argument is passed; it will create a directory and work within that. It accepts all arguments that the `init` and `fetch` commands accept; with the exception of `--fetch-all` and `--parent`. After a repository is cloned, the `fetch` command will be able to update revisions without affecting the working tree; and the `rebase` command will be able to update the working tree with the latest changes.
--preserve-empty-dirs Create a placeholder file in the local Git repository for each empty directory fetched from Subversion. This includes directories that become empty by removing all entries in the Subversion repository (but not the directory itself). The placeholder files are also tracked and removed when no longer necessary.
--placeholder-filename=<filename> Set the name of placeholder files created by --preserve-empty-dirs. Default: ".gitignore"
*rebase* This fetches revisions from the SVN parent of the current HEAD and rebases the current (uncommitted to SVN) work against it.
This works similarly to `svn update` or `git pull` except that it preserves linear history with `git rebase` instead of `git merge` for ease of dcommitting with `git svn`.
This accepts all options that `git svn fetch` and `git rebase` accept. However, `--fetch-all` only fetches from the current [svn-remote], and not all [svn-remote] definitions.
Like `git rebase`; this requires that the working tree be clean and have no uncommitted changes.
This automatically updates the rev\_map if needed (see `$GIT_DIR/svn/**/.rev_map.*` in the FILES section below for details).
-l --local Do not fetch remotely; only run `git rebase` against the last fetched commit from the upstream SVN.
*dcommit* Commit each diff from the current branch directly to the SVN repository, and then rebase or reset (depending on whether or not there is a diff between SVN and head). This will create a revision in SVN for each commit in Git.
When an optional Git branch name (or a Git commit object name) is specified as an argument, the subcommand works on the specified branch, not on the current branch.
Use of `dcommit` is preferred to `set-tree` (below).
--no-rebase After committing, do not rebase or reset.
--commit-url <URL> Commit to this SVN URL (the full path). This is intended to allow existing `git svn` repositories created with one transport method (e.g. `svn://` or `http://` for anonymous read) to be reused if a user is later given access to an alternate transport method (e.g. `svn+ssh://` or `https://`) for commit.
```
config key: svn-remote.<name>.commiturl
config key: svn.commiturl (overwrites all svn-remote.<name>.commiturl options)
```
Note that the SVN URL of the commiturl config key includes the SVN branch. If you rather want to set the commit URL for an entire SVN repository use svn-remote.<name>.pushurl instead.
Using this option for any other purpose (don’t ask) is very strongly discouraged.
--mergeinfo=<mergeinfo> Add the given merge information during the dcommit (e.g. `--mergeinfo="/branches/foo:1-10"`). All svn server versions can store this information (as a property), and svn clients starting from version 1.5 can make use of it. To specify merge information from multiple branches, use a single space character between the branches (`--mergeinfo="/branches/foo:1-10 /branches/bar:3,5-6,8"`)
```
config key: svn.pushmergeinfo
```
This option will cause git-svn to attempt to automatically populate the svn:mergeinfo property in the SVN repository when possible. Currently, this can only be done when dcommitting non-fast-forward merges where all parents but the first have already been pushed into SVN.
--interactive Ask the user to confirm that a patch set should actually be sent to SVN. For each patch, one may answer "yes" (accept this patch), "no" (discard this patch), "all" (accept all patches), or "quit".
`git svn dcommit` returns immediately if answer is "no" or "quit", without committing anything to SVN.
*branch* Create a branch in the SVN repository.
-m --message Allows to specify the commit message.
-t --tag Create a tag by using the tags\_subdir instead of the branches\_subdir specified during git svn init.
-d<path> --destination=<path> If more than one --branches (or --tags) option was given to the `init` or `clone` command, you must provide the location of the branch (or tag) you wish to create in the SVN repository. <path> specifies which path to use to create the branch or tag and should match the pattern on the left-hand side of one of the configured branches or tags refspecs. You can see these refspecs with the commands
```
git config --get-all svn-remote.<name>.branches
git config --get-all svn-remote.<name>.tags
```
where <name> is the name of the SVN repository as specified by the -R option to `init` (or "svn" by default).
--username Specify the SVN username to perform the commit as. This option overrides the `username` configuration property.
--commit-url Use the specified URL to connect to the destination Subversion repository. This is useful in cases where the source SVN repository is read-only. This option overrides configuration property `commiturl`.
```
git config --get-all svn-remote.<name>.commiturl
```
--parents Create parent folders. This parameter is equivalent to the parameter --parents on svn cp commands and is useful for non-standard repository layouts.
*tag* Create a tag in the SVN repository. This is a shorthand for `branch -t`.
*log* This should make it easy to look up svn log messages when svn users refer to -r/--revision numbers.
The following features from ‘svn log’ are supported:
-r <n>[:<n>] --revision=<n>[:<n>] is supported, non-numeric args are not: HEAD, NEXT, BASE, PREV, etc …
-v --verbose it’s not completely compatible with the --verbose output in svn log, but reasonably close.
--limit=<n> is NOT the same as --max-count, doesn’t count merged/excluded commits
--incremental supported
New features:
--show-commit shows the Git commit sha1, as well
--oneline our version of --pretty=oneline
| | |
| --- | --- |
| Note | SVN itself only stores times in UTC and nothing else. The regular svn client converts the UTC time to the local time (or based on the TZ= environment). This command has the same behaviour. |
Any other arguments are passed directly to `git log`
*blame* Show what revision and author last modified each line of a file. The output of this mode is format-compatible with the output of ‘svn blame’ by default. Like the SVN blame command, local uncommitted changes in the working tree are ignored; the version of the file in the HEAD revision is annotated. Unknown arguments are passed directly to `git blame`.
--git-format Produce output in the same format as `git blame`, but with SVN revision numbers instead of Git commit hashes. In this mode, changes that haven’t been committed to SVN (including local working-copy edits) are shown as revision 0.
*find-rev* When given an SVN revision number of the form `rN`, returns the corresponding Git commit hash (this can optionally be followed by a tree-ish to specify which branch should be searched). When given a tree-ish, returns the corresponding SVN revision number.
-B --before Don’t require an exact match if given an SVN revision, instead find the commit corresponding to the state of the SVN repository (on the current branch) at the specified revision.
-A --after Don’t require an exact match if given an SVN revision; if there is not an exact match return the closest match searching forward in the history.
*set-tree* You should consider using `dcommit` instead of this command. Commit specified commit or tree objects to SVN. This relies on your imported fetch data being up to date. This makes absolutely no attempts to do patching when committing to SVN, it simply overwrites files with those specified in the tree or commit. All merging is assumed to have taken place independently of `git svn` functions.
*create-ignore* Recursively finds the svn:ignore property on directories and creates matching .gitignore files. The resulting files are staged to be committed, but are not committed. Use -r/--revision to refer to a specific revision.
*show-ignore* Recursively finds and lists the svn:ignore property on directories. The output is suitable for appending to the $GIT\_DIR/info/exclude file.
*mkdirs* Attempts to recreate empty directories that core Git cannot track based on information in $GIT\_DIR/svn/<refname>/unhandled.log files. Empty directories are automatically recreated when using "git svn clone" and "git svn rebase", so "mkdirs" is intended for use after commands like "git checkout" or "git reset". (See the svn-remote.<name>.automkdirs config file option for more information.)
*commit-diff* Commits the diff of two tree-ish arguments from the command-line. This command does not rely on being inside a `git svn
init`-ed repository. This command takes three arguments, (a) the original tree to diff against, (b) the new tree result, (c) the URL of the target Subversion repository. The final argument (URL) may be omitted if you are working from a `git svn`-aware repository (that has been `init`-ed with `git svn`). The -r<revision> option is required for this.
The commit message is supplied either directly with the `-m` or `-F` option, or indirectly from the tag or commit when the second tree-ish denotes such an object, or it is requested by invoking an editor (see `--edit` option below).
-m <msg> --message=<msg> Use the given `msg` as the commit message. This option disables the `--edit` option.
-F <filename> --file=<filename> Take the commit message from the given file. This option disables the `--edit` option.
*info* Shows information about a file or directory similar to what ‘svn info’ provides. Does not currently support a -r/--revision argument. Use the --url option to output only the value of the `URL:` field.
*proplist* Lists the properties stored in the Subversion repository about a given file or directory. Use -r/--revision to refer to a specific Subversion revision.
*propget* Gets the Subversion property given as the first argument, for a file. A specific revision can be specified with -r/--revision.
*propset* Sets the Subversion property given as the first argument, to the value given as the second argument for the file given as the third argument.
Example:
```
git svn propset svn:keywords "FreeBSD=%H" devel/py-tipper/Makefile
```
This will set the property `svn:keywords` to `FreeBSD=%H` for the file `devel/py-tipper/Makefile`.
*show-externals* Shows the Subversion externals. Use -r/--revision to specify a specific revision.
*gc* Compress $GIT\_DIR/svn/<refname>/unhandled.log files and remove $GIT\_DIR/svn/<refname>/index files.
*reset* Undoes the effects of `fetch` back to the specified revision. This allows you to re-`fetch` an SVN revision. Normally the contents of an SVN revision should never change and `reset` should not be necessary. However, if SVN permissions change, or if you alter your --ignore-paths option, a `fetch` may fail with "not found in commit" (file not previously visible) or "checksum mismatch" (missed a modification). If the problem file cannot be ignored forever (with --ignore-paths) the only way to repair the repo is to use `reset`.
Only the rev\_map and refs/remotes/git-svn are changed (see `$GIT_DIR/svn/**/.rev_map.*` in the FILES section below for details). Follow `reset` with a `fetch` and then `git reset` or `git rebase` to move local branches onto the new tree.
-r <n> --revision=<n> Specify the most recent revision to keep. All later revisions are discarded.
-p --parent Discard the specified revision as well, keeping the nearest parent instead.
Example: Assume you have local changes in "master", but you need to refetch "r2".
```
r1---r2---r3 remotes/git-svn
\
A---B master
```
Fix the ignore-paths or SVN permissions problem that caused "r2" to be incomplete in the first place. Then:
```
git svn reset -r2 -p
git svn fetch
```
```
r1---r2'--r3' remotes/git-svn
\
r2---r3---A---B master
```
Then fixup "master" with `git rebase`. Do NOT use `git merge` or your history will not be compatible with a future `dcommit`!
```
git rebase --onto remotes/git-svn A^ master
```
```
r1---r2'--r3' remotes/git-svn
\
A'--B' master
```
Options
-------
--shared[=(false|true|umask|group|all|world|everybody)] --template=<template-directory> Only used with the `init` command. These are passed directly to `git init`.
-r <arg> --revision <arg> Used with the `fetch` command.
This allows revision ranges for partial/cauterized history to be supported. $NUMBER, $NUMBER1:$NUMBER2 (numeric ranges), $NUMBER:HEAD, and BASE:$NUMBER are all supported.
This can allow you to make partial mirrors when running fetch; but is generally not recommended because history will be skipped and lost.
- --stdin Only used with the `set-tree` command.
Read a list of commits from stdin and commit them in reverse order. Only the leading sha1 is read from each line, so `git rev-list --pretty=oneline` output can be used.
--rmdir Only used with the `dcommit`, `set-tree` and `commit-diff` commands.
Remove directories from the SVN tree if there are no files left behind. SVN can version empty directories, and they are not removed by default if there are no files left in them. Git cannot version empty directories. Enabling this flag will make the commit to SVN act like Git.
```
config key: svn.rmdir
```
-e --edit Only used with the `dcommit`, `set-tree` and `commit-diff` commands.
Edit the commit message before committing to SVN. This is off by default for objects that are commits, and forced on when committing tree objects.
```
config key: svn.edit
```
-l<num> --find-copies-harder Only used with the `dcommit`, `set-tree` and `commit-diff` commands.
They are both passed directly to `git diff-tree`; see [git-diff-tree[1]](git-diff-tree) for more information.
```
config key: svn.l
config key: svn.findcopiesharder
```
-A<filename> --authors-file=<filename> Syntax is compatible with the file used by `git cvsimport` but an empty email address can be supplied with `<>`:
```
loginname = Joe User <[email protected]>
```
If this option is specified and `git svn` encounters an SVN committer name that does not exist in the authors-file, `git svn` will abort operation. The user will then have to add the appropriate entry. Re-running the previous `git svn` command after the authors-file is modified should continue operation.
```
config key: svn.authorsfile
```
--authors-prog=<filename> If this option is specified, for each SVN committer name that does not exist in the authors file, the given file is executed with the committer name as the first argument. The program is expected to return a single line of the form "Name <email>" or "Name <>", which will be treated as if included in the authors file.
Due to historical reasons a relative `filename` is first searched relative to the current directory for `init` and `clone` and relative to the root of the working tree for `fetch`. If `filename` is not found, it is searched like any other command in `$PATH`.
```
config key: svn.authorsProg
```
-q --quiet Make `git svn` less verbose. Specify a second time to make it even less verbose.
-m --merge -s<strategy> --strategy=<strategy> -p --rebase-merges These are only used with the `dcommit` and `rebase` commands.
Passed directly to `git rebase` when using `dcommit` if a `git reset` cannot be used (see `dcommit`).
-n --dry-run This can be used with the `dcommit`, `rebase`, `branch` and `tag` commands.
For `dcommit`, print out the series of Git arguments that would show which diffs would be committed to SVN.
For `rebase`, display the local branch associated with the upstream svn repository associated with the current branch and the URL of svn repository that will be fetched from.
For `branch` and `tag`, display the urls that will be used for copying when creating the branch or tag.
--use-log-author When retrieving svn commits into Git (as part of `fetch`, `rebase`, or `dcommit` operations), look for the first `From:` line or `Signed-off-by` trailer in the log message and use that as the author string.
```
config key: svn.useLogAuthor
```
--add-author-from When committing to svn from Git (as part of `set-tree` or `dcommit` operations), if the existing log message doesn’t already have a `From:` or `Signed-off-by` trailer, append a `From:` line based on the Git commit’s author string. If you use this, then `--use-log-author` will retrieve a valid author string for all commits.
```
config key: svn.addAuthorFrom
```
Advanced options
----------------
-i<GIT\_SVN\_ID> --id <GIT\_SVN\_ID> This sets GIT\_SVN\_ID (instead of using the environment). This allows the user to override the default refname to fetch from when tracking a single URL. The `log` and `dcommit` commands no longer require this switch as an argument.
-R<remote name> --svn-remote <remote name> Specify the [svn-remote "<remote name>"] section to use, this allows SVN multiple repositories to be tracked. Default: "svn"
--follow-parent This option is only relevant if we are tracking branches (using one of the repository layout options --trunk, --tags, --branches, --stdlayout). For each tracked branch, try to find out where its revision was copied from, and set a suitable parent in the first Git commit for the branch. This is especially helpful when we’re tracking a directory that has been moved around within the repository. If this feature is disabled, the branches created by `git svn` will all be linear and not share any history, meaning that there will be no information on where branches were branched off or merged. However, following long/convoluted histories can take a long time, so disabling this feature may speed up the cloning process. This feature is enabled by default, use --no-follow-parent to disable it.
```
config key: svn.followparent
```
Config file-only options
------------------------
svn.noMetadata svn-remote.<name>.noMetadata This gets rid of the `git-svn-id:` lines at the end of every commit.
This option can only be used for one-shot imports as `git svn` will not be able to fetch again without metadata. Additionally, if you lose your `$GIT_DIR/svn/**/.rev_map.*` files, `git svn` will not be able to rebuild them.
The `git svn log` command will not work on repositories using this, either. Using this conflicts with the `useSvmProps` option for (hopefully) obvious reasons.
This option is NOT recommended as it makes it difficult to track down old references to SVN revision numbers in existing documentation, bug reports, and archives. If you plan to eventually migrate from SVN to Git and are certain about dropping SVN history, consider [git-filter-repo](https://github.com/newren/git-filter-repo) instead. filter-repo also allows reformatting of metadata for ease-of-reading and rewriting authorship info for non-"svn.authorsFile" users.
svn.useSvmProps svn-remote.<name>.useSvmProps This allows `git svn` to re-map repository URLs and UUIDs from mirrors created using SVN::Mirror (or svk) for metadata.
If an SVN revision has a property, "svm:headrev", it is likely that the revision was created by SVN::Mirror (also used by SVK). The property contains a repository UUID and a revision. We want to make it look like we are mirroring the original URL, so introduce a helper function that returns the original identity URL and UUID, and use it when generating metadata in commit messages.
svn.useSvnsyncProps svn-remote.<name>.useSvnsyncprops Similar to the useSvmProps option; this is for users of the svnsync(1) command distributed with SVN 1.4.x and later.
svn-remote.<name>.rewriteRoot This allows users to create repositories from alternate URLs. For example, an administrator could run `git svn` on the server locally (accessing via file://) but wish to distribute the repository with a public http:// or svn:// URL in the metadata so users of it will see the public URL.
svn-remote.<name>.rewriteUUID Similar to the useSvmProps option; this is for users who need to remap the UUID manually. This may be useful in situations where the original UUID is not available via either useSvmProps or useSvnsyncProps.
svn-remote.<name>.pushurl Similar to Git’s `remote.<name>.pushurl`, this key is designed to be used in cases where `url` points to an SVN repository via a read-only transport, to provide an alternate read/write transport. It is assumed that both keys point to the same repository. Unlike `commiturl`, `pushurl` is a base path. If either `commiturl` or `pushurl` could be used, `commiturl` takes precedence.
svn.brokenSymlinkWorkaround This disables potentially expensive checks to workaround broken symlinks checked into SVN by broken clients. Set this option to "false" if you track a SVN repository with many empty blobs that are not symlinks. This option may be changed while `git svn` is running and take effect on the next revision fetched. If unset, `git svn` assumes this option to be "true".
svn.pathnameencoding This instructs git svn to recode pathnames to a given encoding. It can be used by windows users and by those who work in non-utf8 locales to avoid corrupted file names with non-ASCII characters. Valid encodings are the ones supported by Perl’s Encode module.
svn-remote.<name>.automkdirs Normally, the "git svn clone" and "git svn rebase" commands attempt to recreate empty directories that are in the Subversion repository. If this option is set to "false", then empty directories will only be created if the "git svn mkdirs" command is run explicitly. If unset, `git svn` assumes this option to be "true".
Since the noMetadata, rewriteRoot, rewriteUUID, useSvnsyncProps and useSvmProps options all affect the metadata generated and used by `git svn`; they **must** be set in the configuration file before any history is imported and these settings should never be changed once they are set.
Additionally, only one of these options can be used per svn-remote section because they affect the `git-svn-id:` metadata line, except for rewriteRoot and rewriteUUID which can be used together.
Basic examples
--------------
Tracking and contributing to the trunk of a Subversion-managed project (ignoring tags and branches):
```
# Clone a repo (like git clone):
git svn clone http://svn.example.com/project/trunk
# Enter the newly cloned directory:
cd trunk
# You should be on master branch, double-check with 'git branch'
git branch
# Do some work and commit locally to Git:
git commit ...
# Something is committed to SVN, rebase your local changes against the
# latest changes in SVN:
git svn rebase
# Now commit your changes (that were committed previously using Git) to SVN,
# as well as automatically updating your working HEAD:
git svn dcommit
# Append svn:ignore settings to the default Git exclude file:
git svn show-ignore >> .git/info/exclude
```
Tracking and contributing to an entire Subversion-managed project (complete with a trunk, tags and branches):
```
# Clone a repo with standard SVN directory layout (like git clone):
git svn clone http://svn.example.com/project --stdlayout --prefix svn/
# Or, if the repo uses a non-standard directory layout:
git svn clone http://svn.example.com/project -T tr -b branch -t tag --prefix svn/
# View all branches and tags you have cloned:
git branch -r
# Create a new branch in SVN
git svn branch waldo
# Reset your master to trunk (or any other branch, replacing 'trunk'
# with the appropriate name):
git reset --hard svn/trunk
# You may only dcommit to one branch/tag/trunk at a time. The usage
# of dcommit/rebase/show-ignore should be the same as above.
```
The initial `git svn clone` can be quite time-consuming (especially for large Subversion repositories). If multiple people (or one person with multiple machines) want to use `git svn` to interact with the same Subversion repository, you can do the initial `git svn clone` to a repository on a server and have each person clone that repository with `git clone`:
```
# Do the initial import on a server
ssh server "cd /pub && git svn clone http://svn.example.com/project [options...]"
# Clone locally - make sure the refs/remotes/ space matches the server
mkdir project
cd project
git init
git remote add origin server:/pub/project
git config --replace-all remote.origin.fetch '+refs/remotes/*:refs/remotes/*'
git fetch
# Prevent fetch/pull from remote Git server in the future,
# we only want to use git svn for future updates
git config --remove-section remote.origin
# Create a local branch from one of the branches just fetched
git checkout -b master FETCH_HEAD
# Initialize 'git svn' locally (be sure to use the same URL and
# --stdlayout/-T/-b/-t/--prefix options as were used on server)
git svn init http://svn.example.com/project [options...]
# Pull the latest changes from Subversion
git svn rebase
```
Rebase vs. pull/merge
---------------------
Prefer to use `git svn rebase` or `git rebase`, rather than `git pull` or `git merge` to synchronize unintegrated commits with a `git svn` branch. Doing so will keep the history of unintegrated commits linear with respect to the upstream SVN repository and allow the use of the preferred `git svn dcommit` subcommand to push unintegrated commits back into SVN.
Originally, `git svn` recommended that developers pulled or merged from the `git svn` branch. This was because the author favored `git svn set-tree B` to commit a single head rather than the `git svn set-tree A..B` notation to commit multiple commits. Use of `git pull` or `git merge` with `git svn set-tree A..B` will cause non-linear history to be flattened when committing into SVN and this can lead to merge commits unexpectedly reversing previous commits in SVN.
Merge tracking
--------------
While `git svn` can track copy history (including branches and tags) for repositories adopting a standard layout, it cannot yet represent merge history that happened inside git back upstream to SVN users. Therefore it is advised that users keep history as linear as possible inside Git to ease compatibility with SVN (see the CAVEATS section below).
Handling of svn branches
------------------------
If `git svn` is configured to fetch branches (and --follow-branches is in effect), it sometimes creates multiple Git branches for one SVN branch, where the additional branches have names of the form `branchname@nnn` (with nnn an SVN revision number). These additional branches are created if `git svn` cannot find a parent commit for the first commit in an SVN branch, to connect the branch to the history of the other branches.
Normally, the first commit in an SVN branch consists of a copy operation. `git svn` will read this commit to get the SVN revision the branch was created from. It will then try to find the Git commit that corresponds to this SVN revision, and use that as the parent of the branch. However, it is possible that there is no suitable Git commit to serve as parent. This will happen, among other reasons, if the SVN branch is a copy of a revision that was not fetched by `git svn` (e.g. because it is an old revision that was skipped with `--revision`), or if in SVN a directory was copied that is not tracked by `git svn` (such as a branch that is not tracked at all, or a subdirectory of a tracked branch). In these cases, `git svn` will still create a Git branch, but instead of using an existing Git commit as the parent of the branch, it will read the SVN history of the directory the branch was copied from and create appropriate Git commits. This is indicated by the message "Initializing parent: <branchname>".
Additionally, it will create a special branch named `<branchname>@<SVN-Revision>`, where <SVN-Revision> is the SVN revision number the branch was copied from. This branch will point to the newly created parent commit of the branch. If in SVN the branch was deleted and later recreated from a different version, there will be multiple such branches with an `@`.
Note that this may mean that multiple Git commits are created for a single SVN revision.
An example: in an SVN repository with a standard trunk/tags/branches layout, a directory trunk/sub is created in r.100. In r.200, trunk/sub is branched by copying it to branches/. `git svn clone -s` will then create a branch `sub`. It will also create new Git commits for r.100 through r.199 and use these as the history of branch `sub`. Thus there will be two Git commits for each revision from r.100 to r.199 (one containing trunk/, one containing trunk/sub/). Finally, it will create a branch `sub@200` pointing to the new parent commit of branch `sub` (i.e. the commit for r.200 and trunk/sub/).
Caveats
-------
For the sake of simplicity and interoperating with Subversion, it is recommended that all `git svn` users clone, fetch and dcommit directly from the SVN server, and avoid all `git clone`/`pull`/`merge`/`push` operations between Git repositories and branches. The recommended method of exchanging code between Git branches and users is `git format-patch` and `git am`, or just 'dcommit’ing to the SVN repository.
Running `git merge` or `git pull` is NOT recommended on a branch you plan to `dcommit` from because Subversion users cannot see any merges you’ve made. Furthermore, if you merge or pull from a Git branch that is a mirror of an SVN branch, `dcommit` may commit to the wrong branch.
If you do merge, note the following rule: `git svn dcommit` will attempt to commit on top of the SVN commit named in
```
git log --grep=^git-svn-id: --first-parent -1
```
You `must` therefore ensure that the most recent commit of the branch you want to dcommit to is the `first` parent of the merge. Chaos will ensue otherwise, especially if the first parent is an older commit on the same SVN branch.
`git clone` does not clone branches under the refs/remotes/ hierarchy or any `git svn` metadata, or config. So repositories created and managed with using `git svn` should use `rsync` for cloning, if cloning is to be done at all.
Since `dcommit` uses rebase internally, any Git branches you `git push` to before `dcommit` on will require forcing an overwrite of the existing ref on the remote repository. This is generally considered bad practice, see the [git-push[1]](git-push) documentation for details.
Do not use the --amend option of [git-commit[1]](git-commit) on a change you’ve already dcommitted. It is considered bad practice to --amend commits you’ve already pushed to a remote repository for other users, and dcommit with SVN is analogous to that.
When cloning an SVN repository, if none of the options for describing the repository layout is used (--trunk, --tags, --branches, --stdlayout), `git svn clone` will create a Git repository with completely linear history, where branches and tags appear as separate directories in the working copy. While this is the easiest way to get a copy of a complete repository, for projects with many branches it will lead to a working copy many times larger than just the trunk. Thus for projects using the standard directory structure (trunk/branches/tags), it is recommended to clone with option `--stdlayout`. If the project uses a non-standard structure, and/or if branches and tags are not required, it is easiest to only clone one directory (typically trunk), without giving any repository layout options. If the full history with branches and tags is required, the options `--trunk` / `--branches` / `--tags` must be used.
When using multiple --branches or --tags, `git svn` does not automatically handle name collisions (for example, if two branches from different paths have the same name, or if a branch and a tag have the same name). In these cases, use `init` to set up your Git repository then, before your first `fetch`, edit the $GIT\_DIR/config file so that the branches and tags are associated with different name spaces. For example:
```
branches = stable/*:refs/remotes/svn/stable/*
branches = debug/*:refs/remotes/svn/debug/*
```
Configuration
-------------
`git svn` stores [svn-remote] configuration information in the repository $GIT\_DIR/config file. It is similar the core Git [remote] sections except `fetch` keys do not accept glob arguments; but they are instead handled by the `branches` and `tags` keys. Since some SVN repositories are oddly configured with multiple projects glob expansions such those listed below are allowed:
```
[svn-remote "project-a"]
url = http://server.org/svn
fetch = trunk/project-a:refs/remotes/project-a/trunk
branches = branches/*/project-a:refs/remotes/project-a/branches/*
branches = branches/release_*:refs/remotes/project-a/branches/release_*
branches = branches/re*se:refs/remotes/project-a/branches/*
tags = tags/*/project-a:refs/remotes/project-a/tags/*
```
Keep in mind that the `*` (asterisk) wildcard of the local ref (right of the `:`) **must** be the farthest right path component; however the remote wildcard may be anywhere as long as it’s an independent path component (surrounded by `/` or EOL). This type of configuration is not automatically created by `init` and should be manually entered with a text-editor or using `git config`.
Also note that only one asterisk is allowed per word. For example:
```
branches = branches/re*se:refs/remotes/project-a/branches/*
```
will match branches `release`, `rese`, `re123se`, however
```
branches = branches/re*s*e:refs/remotes/project-a/branches/*
```
will produce an error.
It is also possible to fetch a subset of branches or tags by using a comma-separated list of names within braces. For example:
```
[svn-remote "huge-project"]
url = http://server.org/svn
fetch = trunk/src:refs/remotes/trunk
branches = branches/{red,green}/src:refs/remotes/project-a/branches/*
tags = tags/{1.0,2.0}/src:refs/remotes/project-a/tags/*
```
Multiple fetch, branches, and tags keys are supported:
```
[svn-remote "messy-repo"]
url = http://server.org/svn
fetch = trunk/project-a:refs/remotes/project-a/trunk
fetch = branches/demos/june-project-a-demo:refs/remotes/project-a/demos/june-demo
branches = branches/server/*:refs/remotes/project-a/branches/*
branches = branches/demos/2011/*:refs/remotes/project-a/2011-demos/*
tags = tags/server/*:refs/remotes/project-a/tags/*
```
Creating a branch in such a configuration requires disambiguating which location to use using the -d or --destination flag:
```
$ git svn branch -d branches/server release-2-3-0
```
Note that git-svn keeps track of the highest revision in which a branch or tag has appeared. If the subset of branches or tags is changed after fetching, then $GIT\_DIR/svn/.metadata must be manually edited to remove (or reset) branches-maxRev and/or tags-maxRev as appropriate.
Files
-----
$GIT\_DIR/svn/\*\*/.rev\_map.\* Mapping between Subversion revision numbers and Git commit names. In a repository where the noMetadata option is not set, this can be rebuilt from the git-svn-id: lines that are at the end of every commit (see the `svn.noMetadata` section above for details).
`git svn fetch` and `git svn rebase` automatically update the rev\_map if it is missing or not up to date. `git svn reset` automatically rewinds it.
Bugs
----
We ignore all SVN properties except svn:executable. Any unhandled properties are logged to $GIT\_DIR/svn/<refname>/unhandled.log
Renamed and copied directories are not detected by Git and hence not tracked when committing to SVN. I do not plan on adding support for this as it’s quite difficult and time-consuming to get working for all the possible corner cases (Git doesn’t do it, either). Committing renamed and copied files is fully supported if they’re similar enough for Git to detect them.
In SVN, it is possible (though discouraged) to commit changes to a tag (because a tag is just a directory copy, thus technically the same as a branch). When cloning an SVN repository, `git svn` cannot know if such a commit to a tag will happen in the future. Thus it acts conservatively and imports all SVN tags as branches, prefixing the tag name with `tags/`.
See also
--------
[git-rebase[1]](git-rebase)
| programming_docs |
git gitdiffcore gitdiffcore
===========
Name
----
gitdiffcore - Tweaking diff output
Synopsis
--------
```
git diff *
```
Description
-----------
The diff commands `git diff-index`, `git diff-files`, and `git diff-tree` can be told to manipulate differences they find in unconventional ways before showing `diff` output. The manipulation is collectively called "diffcore transformation". This short note describes what they are and how to use them to produce `diff` output that is easier to understand than the conventional kind.
The chain of operation
----------------------
The `git diff-*` family works by first comparing two sets of files:
* `git diff-index` compares contents of a "tree" object and the working directory (when `--cached` flag is not used) or a "tree" object and the index file (when `--cached` flag is used);
* `git diff-files` compares contents of the index file and the working directory;
* `git diff-tree` compares contents of two "tree" objects;
In all of these cases, the commands themselves first optionally limit the two sets of files by any pathspecs given on their command-lines, and compare corresponding paths in the two resulting sets of files.
The pathspecs are used to limit the world diff operates in. They remove the filepairs outside the specified sets of pathnames. E.g. If the input set of filepairs included:
```
:100644 100644 bcd1234... 0123456... M junkfile
```
but the command invocation was `git diff-files myfile`, then the junkfile entry would be removed from the list because only "myfile" is under consideration.
The result of comparison is passed from these commands to what is internally called "diffcore", in a format similar to what is output when the -p option is not used. E.g.
```
in-place edit :100644 100644 bcd1234... 0123456... M file0
create :000000 100644 0000000... 1234567... A file4
delete :100644 000000 1234567... 0000000... D file5
unmerged :000000 000000 0000000... 0000000... U file6
```
The diffcore mechanism is fed a list of such comparison results (each of which is called "filepair", although at this point each of them talks about a single file), and transforms such a list into another list. There are currently 5 such transformations:
* diffcore-break
* diffcore-rename
* diffcore-merge-broken
* diffcore-pickaxe
* diffcore-order
* diffcore-rotate
These are applied in sequence. The set of filepairs `git diff-*` commands find are used as the input to diffcore-break, and the output from diffcore-break is used as the input to the next transformation. The final result is then passed to the output routine and generates either diff-raw format (see Output format sections of the manual for `git diff-*` commands) or diff-patch format.
Diffcore-break: for splitting up complete rewrites
--------------------------------------------------
The second transformation in the chain is diffcore-break, and is controlled by the -B option to the `git diff-*` commands. This is used to detect a filepair that represents "complete rewrite" and break such filepair into two filepairs that represent delete and create. E.g. If the input contained this filepair:
```
:100644 100644 bcd1234... 0123456... M file0
```
and if it detects that the file "file0" is completely rewritten, it changes it to:
```
:100644 000000 bcd1234... 0000000... D file0
:000000 100644 0000000... 0123456... A file0
```
For the purpose of breaking a filepair, diffcore-break examines the extent of changes between the contents of the files before and after modification (i.e. the contents that have "bcd1234…" and "0123456…" as their SHA-1 content ID, in the above example). The amount of deletion of original contents and insertion of new material are added together, and if it exceeds the "break score", the filepair is broken into two. The break score defaults to 50% of the size of the smaller of the original and the result (i.e. if the edit shrinks the file, the size of the result is used; if the edit lengthens the file, the size of the original is used), and can be customized by giving a number after "-B" option (e.g. "-B75" to tell it to use 75%).
Diffcore-rename: for detecting renames and copies
-------------------------------------------------
This transformation is used to detect renames and copies, and is controlled by the -M option (to detect renames) and the -C option (to detect copies as well) to the `git diff-*` commands. If the input contained these filepairs:
```
:100644 000000 0123456... 0000000... D fileX
:000000 100644 0000000... 0123456... A file0
```
and the contents of the deleted file fileX is similar enough to the contents of the created file file0, then rename detection merges these filepairs and creates:
```
:100644 100644 0123456... 0123456... R100 fileX file0
```
When the "-C" option is used, the original contents of modified files, and deleted files (and also unmodified files, if the "--find-copies-harder" option is used) are considered as candidates of the source files in rename/copy operation. If the input were like these filepairs, that talk about a modified file fileY and a newly created file file0:
```
:100644 100644 0123456... 1234567... M fileY
:000000 100644 0000000... bcd3456... A file0
```
the original contents of fileY and the resulting contents of file0 are compared, and if they are similar enough, they are changed to:
```
:100644 100644 0123456... 1234567... M fileY
:100644 100644 0123456... bcd3456... C100 fileY file0
```
In both rename and copy detection, the same "extent of changes" algorithm used in diffcore-break is used to determine if two files are "similar enough", and can be customized to use a similarity score different from the default of 50% by giving a number after the "-M" or "-C" option (e.g. "-M8" to tell it to use 8/10 = 80%).
Note that when rename detection is on but both copy and break detection are off, rename detection adds a preliminary step that first checks if files are moved across directories while keeping their filename the same. If there is a file added to a directory whose contents is sufficiently similar to a file with the same name that got deleted from a different directory, it will mark them as renames and exclude them from the later quadratic step (the one that pairwise compares all unmatched files to find the "best" matches, determined by the highest content similarity). So, for example, if a deleted docs/ext.txt and an added docs/config/ext.txt are similar enough, they will be marked as a rename and prevent an added docs/ext.md that may be even more similar to the deleted docs/ext.txt from being considered as the rename destination in the later step. For this reason, the preliminary "match same filename" step uses a bit higher threshold to mark a file pair as a rename and stop considering other candidates for better matches. At most, one comparison is done per file in this preliminary pass; so if there are several remaining ext.txt files throughout the directory hierarchy after exact rename detection, this preliminary step may be skipped for those files.
Note. When the "-C" option is used with `--find-copies-harder` option, `git diff-*` commands feed unmodified filepairs to diffcore mechanism as well as modified ones. This lets the copy detector consider unmodified files as copy source candidates at the expense of making it slower. Without `--find-copies-harder`, `git diff-*` commands can detect copies only if the file that was copied happened to have been modified in the same changeset.
Diffcore-merge-broken: for putting complete rewrites back together
------------------------------------------------------------------
This transformation is used to merge filepairs broken by diffcore-break, and not transformed into rename/copy by diffcore-rename, back into a single modification. This always runs when diffcore-break is used.
For the purpose of merging broken filepairs back, it uses a different "extent of changes" computation from the ones used by diffcore-break and diffcore-rename. It counts only the deletion from the original, and does not count insertion. If you removed only 10 lines from a 100-line document, even if you added 910 new lines to make a new 1000-line document, you did not do a complete rewrite. diffcore-break breaks such a case in order to help diffcore-rename to consider such filepairs as candidate of rename/copy detection, but if filepairs broken that way were not matched with other filepairs to create rename/copy, then this transformation merges them back into the original "modification".
The "extent of changes" parameter can be tweaked from the default 80% (that is, unless more than 80% of the original material is deleted, the broken pairs are merged back into a single modification) by giving a second number to -B option, like these:
* -B50/60 (give 50% "break score" to diffcore-break, use 60% for diffcore-merge-broken).
* -B/60 (the same as above, since diffcore-break defaults to 50%).
Note that earlier implementation left a broken pair as a separate creation and deletion patches. This was an unnecessary hack and the latest implementation always merges all the broken pairs back into modifications, but the resulting patch output is formatted differently for easier review in case of such a complete rewrite by showing the entire contents of old version prefixed with `-`, followed by the entire contents of new version prefixed with `+`.
Diffcore-pickaxe: for detecting addition/deletion of specified string
---------------------------------------------------------------------
This transformation limits the set of filepairs to those that change specified strings between the preimage and the postimage in a certain way. -S<block of text> and -G<regular expression> options are used to specify different ways these strings are sought.
"-S<block of text>" detects filepairs whose preimage and postimage have different number of occurrences of the specified block of text. By definition, it will not detect in-file moves. Also, when a changeset moves a file wholesale without affecting the interesting string, diffcore-rename kicks in as usual, and `-S` omits the filepair (since the number of occurrences of that string didn’t change in that rename-detected filepair). When used with `--pickaxe-regex`, treat the <block of text> as an extended POSIX regular expression to match, instead of a literal string.
"-G<regular expression>" (mnemonic: grep) detects filepairs whose textual diff has an added or a deleted line that matches the given regular expression. This means that it will detect in-file (or what rename-detection considers the same file) moves, which is noise. The implementation runs diff twice and greps, and this can be quite expensive. To speed things up binary files without textconv filters will be ignored.
When `-S` or `-G` are used without `--pickaxe-all`, only filepairs that match their respective criterion are kept in the output. When `--pickaxe-all` is used, if even one filepair matches their respective criterion in a changeset, the entire changeset is kept. This behavior is designed to make reviewing changes in the context of the whole changeset easier.
Diffcore-order: for sorting the output based on filenames
---------------------------------------------------------
This is used to reorder the filepairs according to the user’s (or project’s) taste, and is controlled by the -O option to the `git diff-*` commands.
This takes a text file each of whose lines is a shell glob pattern. Filepairs that match a glob pattern on an earlier line in the file are output before ones that match a later line, and filepairs that do not match any glob pattern are output last.
As an example, a typical orderfile for the core Git probably would look like this:
```
README
Makefile
Documentation
*.h
*.c
t
```
Diffcore-rotate: for changing at which path output starts
---------------------------------------------------------
This transformation takes one pathname, and rotates the set of filepairs so that the filepair for the given pathname comes first, optionally discarding the paths that come before it. This is used to implement the `--skip-to` and the `--rotate-to` options. It is an error when the specified pathname is not in the set of filepairs, but it is not useful to error out when used with "git log" family of commands, because it is unreasonable to expect that a given path would be modified by each and every commit shown by the "git log" command. For this reason, when used with "git log", the filepair that sorts the same as, or the first one that sorts after, the given pathname is where the output starts.
Use of this transformation combined with diffcore-order will produce unexpected results, as the input to this transformation is likely not sorted when diffcore-order is in effect.
See also
--------
[git-diff[1]](git-diff), [git-diff-files[1]](git-diff-files), [git-diff-index[1]](git-diff-index), [git-diff-tree[1]](git-diff-tree), [git-format-patch[1]](git-format-patch), [git-log[1]](git-log), [gitglossary[7]](gitglossary), [The Git User’s Manual](user-manual)
git git-get-tar-commit-id git-get-tar-commit-id
=====================
Name
----
git-get-tar-commit-id - Extract commit ID from an archive created using git-archive
Synopsis
--------
```
git get-tar-commit-id
```
Description
-----------
Read a tar archive created by `git archive` from the standard input and extract the commit ID stored in it. It reads only the first 1024 bytes of input, thus its runtime is not influenced by the size of the tar archive very much.
If no commit ID is found, `git get-tar-commit-id` quietly exists with a return code of 1. This can happen if the archive had not been created using `git archive` or if the first parameter of `git archive` had been a tree ID instead of a commit ID or tag.
git git-checkout-index git-checkout-index
==================
Name
----
git-checkout-index - Copy files from the index to the working tree
Synopsis
--------
```
git checkout-index [-u] [-q] [-a] [-f] [-n] [--prefix=<string>]
[--stage=<number>|all]
[--temp]
[--ignore-skip-worktree-bits]
[-z] [--stdin]
[--] [<file>…]
```
Description
-----------
Will copy all files listed from the index to the working directory (not overwriting existing files).
Options
-------
-u --index update stat information for the checked out entries in the index file.
-q --quiet be quiet if files exist or are not in the index
-f --force forces overwrite of existing files
-a --all checks out all files in the index except for those with the skip-worktree bit set (see `--ignore-skip-worktree-bits`). Cannot be used together with explicit filenames.
-n --no-create Don’t checkout new files, only refresh files already checked out.
--prefix=<string> When creating files, prepend <string> (usually a directory including a trailing /)
--stage=<number>|all Instead of checking out unmerged entries, copy out the files from named stage. <number> must be between 1 and 3. Note: --stage=all automatically implies --temp.
--temp Instead of copying the files to the working directory write the content to temporary files. The temporary name associations will be written to stdout.
--ignore-skip-worktree-bits Check out all files, including those with the skip-worktree bit set.
--stdin Instead of taking list of paths from the command line, read list of paths from the standard input. Paths are separated by LF (i.e. one path per line) by default.
-z Only meaningful with `--stdin`; paths are separated with NUL character instead of LF.
-- Do not interpret any more arguments as options.
The order of the flags used to matter, but not anymore.
Just doing `git checkout-index` does nothing. You probably meant `git checkout-index -a`. And if you want to force it, you want `git checkout-index -f -a`.
Intuitiveness is not the goal here. Repeatability is. The reason for the "no arguments means no work" behavior is that from scripts you are supposed to be able to do:
```
$ find . -name '*.h' -print0 | xargs -0 git checkout-index -f --
```
which will force all existing `*.h` files to be replaced with their cached copies. If an empty command line implied "all", then this would force-refresh everything in the index, which was not the point. But since `git checkout-index` accepts --stdin it would be faster to use:
```
$ find . -name '*.h' -print0 | git checkout-index -f -z --stdin
```
The `--` is just a good idea when you know the rest will be filenames; it will prevent problems with a filename of, for example, `-a`. Using `--` is probably a good policy in scripts.
Using --temp or --stage=all
---------------------------
When `--temp` is used (or implied by `--stage=all`) `git checkout-index` will create a temporary file for each index entry being checked out. The index will not be updated with stat information. These options can be useful if the caller needs all stages of all unmerged entries so that the unmerged files can be processed by an external merge tool.
A listing will be written to stdout providing the association of temporary file names to tracked path names. The listing format has two variations:
1. tempname TAB path RS
The first format is what gets used when `--stage` is omitted or is not `--stage=all`. The field tempname is the temporary file name holding the file content and path is the tracked path name in the index. Only the requested entries are output.
2. stage1temp SP stage2temp SP stage3tmp TAB path RS
The second format is what gets used when `--stage=all`. The three stage temporary fields (stage1temp, stage2temp, stage3temp) list the name of the temporary file if there is a stage entry in the index or `.` if there is no stage entry. Paths which only have a stage 0 entry will always be omitted from the output.
In both formats RS (the record separator) is newline by default but will be the null byte if -z was passed on the command line. The temporary file names are always safe strings; they will never contain directory separators or whitespace characters. The path field is always relative to the current directory and the temporary file names are always relative to the top level directory.
If the object being copied out to a temporary file is a symbolic link the content of the link will be written to a normal file. It is up to the end-user or the Porcelain to make use of this information.
Examples
--------
To update and refresh only the files already checked out
```
$ git checkout-index -n -f -a && git update-index --ignore-missing --refresh
```
Using *git checkout-index* to "export an entire tree" The prefix ability basically makes it trivial to use `git checkout-index` as an "export as tree" function. Just read the desired tree into the index, and do:
```
$ git checkout-index --prefix=git-export-dir/ -a
```
`git checkout-index` will "export" the index into the specified directory.
The final "/" is important. The exported name is literally just prefixed with the specified string. Contrast this with the following example.
Export files with a prefix
```
$ git checkout-index --prefix=.merged- Makefile
```
This will check out the currently cached copy of `Makefile` into the file `.merged-Makefile`.
git git-status git-status
==========
Name
----
git-status - Show the working tree status
Synopsis
--------
```
git status [<options>] [--] [<pathspec>…]
```
Description
-----------
Displays paths that have differences between the index file and the current HEAD commit, paths that have differences between the working tree and the index file, and paths in the working tree that are not tracked by Git (and are not ignored by [gitignore[5]](gitignore)). The first are what you `would` commit by running `git commit`; the second and third are what you `could` commit by running `git add` before running `git commit`.
Options
-------
-s --short Give the output in the short-format.
-b --branch Show the branch and tracking info even in short-format.
--show-stash Show the number of entries currently stashed away.
--porcelain[=<version>] Give the output in an easy-to-parse format for scripts. This is similar to the short output, but will remain stable across Git versions and regardless of user configuration. See below for details.
The version parameter is used to specify the format version. This is optional and defaults to the original version `v1` format.
--long Give the output in the long-format. This is the default.
-v --verbose In addition to the names of files that have been changed, also show the textual changes that are staged to be committed (i.e., like the output of `git diff --cached`). If `-v` is specified twice, then also show the changes in the working tree that have not yet been staged (i.e., like the output of `git diff`).
-u[<mode>] --untracked-files[=<mode>] Show untracked files.
The mode parameter is used to specify the handling of untracked files. It is optional: it defaults to `all`, and if specified, it must be stuck to the option (e.g. `-uno`, but not `-u no`).
The possible options are:
* `no` - Show no untracked files.
* `normal` - Shows untracked files and directories.
* `all` - Also shows individual files in untracked directories.
When `-u` option is not used, untracked files and directories are shown (i.e. the same as specifying `normal`), to help you avoid forgetting to add newly created files. Because it takes extra work to find untracked files in the filesystem, this mode may take some time in a large working tree. Consider enabling untracked cache and split index if supported (see `git update-index --untracked-cache` and `git update-index
--split-index`), Otherwise you can use `no` to have `git status` return more quickly without showing untracked files.
The default can be changed using the status.showUntrackedFiles configuration variable documented in [git-config[1]](git-config).
--ignore-submodules[=<when>] Ignore changes to submodules when looking for changes. <when> can be either "none", "untracked", "dirty" or "all", which is the default. Using "none" will consider the submodule modified when it either contains untracked or modified files or its HEAD differs from the commit recorded in the superproject and can be used to override any settings of the `ignore` option in [git-config[1]](git-config) or [gitmodules[5]](gitmodules). When "untracked" is used submodules are not considered dirty when they only contain untracked content (but they are still scanned for modified content). Using "dirty" ignores all changes to the work tree of submodules, only changes to the commits stored in the superproject are shown (this was the behavior before 1.7.0). Using "all" hides all changes to submodules (and suppresses the output of submodule summaries when the config option `status.submoduleSummary` is set).
--ignored[=<mode>] Show ignored files as well.
The mode parameter is used to specify the handling of ignored files. It is optional: it defaults to `traditional`.
The possible options are:
* `traditional` - Shows ignored files and directories, unless --untracked-files=all is specified, in which case individual files in ignored directories are displayed.
* `no` - Show no ignored files.
* `matching` - Shows ignored files and directories matching an ignore pattern.
When `matching` mode is specified, paths that explicitly match an ignored pattern are shown. If a directory matches an ignore pattern, then it is shown, but not paths contained in the ignored directory. If a directory does not match an ignore pattern, but all contents are ignored, then the directory is not shown, but all contents are shown.
-z Terminate entries with NUL, instead of LF. This implies the `--porcelain=v1` output format if no other format is given.
--column[=<options>] --no-column Display untracked files in columns. See configuration variable `column.status` for option syntax. `--column` and `--no-column` without options are equivalent to `always` and `never` respectively.
--ahead-behind --no-ahead-behind Display or do not display detailed ahead/behind counts for the branch relative to its upstream branch. Defaults to true.
--renames --no-renames Turn on/off rename detection regardless of user configuration. See also [git-diff[1]](git-diff) `--no-renames`.
--find-renames[=<n>] Turn on rename detection, optionally setting the similarity threshold. See also [git-diff[1]](git-diff) `--find-renames`.
<pathspec>… See the `pathspec` entry in [gitglossary[7]](gitglossary).
Output
------
The output from this command is designed to be used as a commit template comment. The default, long format, is designed to be human readable, verbose and descriptive. Its contents and format are subject to change at any time.
The paths mentioned in the output, unlike many other Git commands, are made relative to the current directory if you are working in a subdirectory (this is on purpose, to help cutting and pasting). See the status.relativePaths config option below.
###
Short Format
In the short-format, the status of each path is shown as one of these forms
```
XY PATH
XY ORIG_PATH -> PATH
```
where `ORIG_PATH` is where the renamed/copied contents came from. `ORIG_PATH` is only shown when the entry is renamed or copied. The `XY` is a two-letter status code.
The fields (including the `->`) are separated from each other by a single space. If a filename contains whitespace or other nonprintable characters, that field will be quoted in the manner of a C string literal: surrounded by ASCII double quote (34) characters, and with interior special characters backslash-escaped.
There are three different types of states that are shown using this format, and each one uses the `XY` syntax differently:
* When a merge is occurring and the merge was successful, or outside of a merge situation, `X` shows the status of the index and `Y` shows the status of the working tree.
* When a merge conflict has occurred and has not yet been resolved, `X` and `Y` show the state introduced by each head of the merge, relative to the common ancestor. These paths are said to be `unmerged`.
* When a path is untracked, `X` and `Y` are always the same, since they are unknown to the index. `??` is used for untracked paths. Ignored files are not listed unless `--ignored` is used; if it is, ignored files are indicated by `!!`.
Note that the term `merge` here also includes rebases using the default `--merge` strategy, cherry-picks, and anything else using the merge machinery.
In the following table, these three classes are shown in separate sections, and these characters are used for `X` and `Y` fields for the first two sections that show tracked paths:
* ' ' = unmodified
* `M` = modified
* `T` = file type changed (regular file, symbolic link or submodule)
* `A` = added
* `D` = deleted
* `R` = renamed
* `C` = copied (if config option status.renames is set to "copies")
* `U` = updated but unmerged
```
X Y Meaning
-------------------------------------------------
[AMD] not updated
M [ MTD] updated in index
T [ MTD] type changed in index
A [ MTD] added to index
D deleted from index
R [ MTD] renamed in index
C [ MTD] copied in index
[MTARC] index and work tree matches
[ MTARC] M work tree changed since index
[ MTARC] T type changed in work tree since index
[ MTARC] D deleted in work tree
R renamed in work tree
C copied in work tree
-------------------------------------------------
D D unmerged, both deleted
A U unmerged, added by us
U D unmerged, deleted by them
U A unmerged, added by them
D U unmerged, deleted by us
A A unmerged, both added
U U unmerged, both modified
-------------------------------------------------
? ? untracked
! ! ignored
-------------------------------------------------
```
Submodules have more state and instead report M the submodule has a different HEAD than recorded in the index m the submodule has modified content ? the submodule has untracked files since modified content or untracked files in a submodule cannot be added via `git add` in the superproject to prepare a commit.
`m` and `?` are applied recursively. For example if a nested submodule in a submodule contains an untracked file, this is reported as `?` as well.
If -b is used the short-format status is preceded by a line
```
## branchname tracking info
```
###
Porcelain Format Version 1
Version 1 porcelain format is similar to the short format, but is guaranteed not to change in a backwards-incompatible way between Git versions or based on user configuration. This makes it ideal for parsing by scripts. The description of the short format above also describes the porcelain format, with a few exceptions:
1. The user’s color.status configuration is not respected; color will always be off.
2. The user’s status.relativePaths configuration is not respected; paths shown will always be relative to the repository root.
There is also an alternate -z format recommended for machine parsing. In that format, the status field is the same, but some other things change. First, the `->` is omitted from rename entries and the field order is reversed (e.g `from -> to` becomes `to from`). Second, a NUL (ASCII 0) follows each filename, replacing space as a field separator and the terminating newline (but a space still separates the status field from the first filename). Third, filenames containing special characters are not specially formatted; no quoting or backslash-escaping is performed.
Any submodule changes are reported as modified `M` instead of `m` or single `?`.
###
Porcelain Format Version 2
Version 2 format adds more detailed information about the state of the worktree and changed items. Version 2 also defines an extensible set of easy to parse optional headers.
Header lines start with "#" and are added in response to specific command line arguments. Parsers should ignore headers they don’t recognize.
####
Branch Headers
If `--branch` is given, a series of header lines are printed with information about the current branch.
```
Line Notes
------------------------------------------------------------
# branch.oid <commit> | (initial) Current commit.
# branch.head <branch> | (detached) Current branch.
# branch.upstream <upstream_branch> If upstream is set.
# branch.ab +<ahead> -<behind> If upstream is set and
the commit is present.
------------------------------------------------------------
```
####
Stash Information
If `--show-stash` is given, one line is printed showing the number of stash entries if non-zero:
```
# stash <N>
```
####
Changed Tracked Entries
Following the headers, a series of lines are printed for tracked entries. One of three different line formats may be used to describe an entry depending on the type of change. Tracked entries are printed in an undefined order; parsers should allow for a mixture of the 3 line types in any order.
Ordinary changed entries have the following format:
```
1 <XY> <sub> <mH> <mI> <mW> <hH> <hI> <path>
```
Renamed or copied entries have the following format:
```
2 <XY> <sub> <mH> <mI> <mW> <hH> <hI> <X><score> <path><sep><origPath>
```
```
Field Meaning
--------------------------------------------------------
<XY> A 2 character field containing the staged and
unstaged XY values described in the short format,
with unchanged indicated by a "." rather than
a space.
<sub> A 4 character field describing the submodule state.
"N..." when the entry is not a submodule.
"S<c><m><u>" when the entry is a submodule.
<c> is "C" if the commit changed; otherwise ".".
<m> is "M" if it has tracked changes; otherwise ".".
<u> is "U" if there are untracked changes; otherwise ".".
<mH> The octal file mode in HEAD.
<mI> The octal file mode in the index.
<mW> The octal file mode in the worktree.
<hH> The object name in HEAD.
<hI> The object name in the index.
<X><score> The rename or copy score (denoting the percentage
of similarity between the source and target of the
move or copy). For example "R100" or "C75".
<path> The pathname. In a renamed/copied entry, this
is the target path.
<sep> When the `-z` option is used, the 2 pathnames are separated
with a NUL (ASCII 0x00) byte; otherwise, a tab (ASCII 0x09)
byte separates them.
<origPath> The pathname in the commit at HEAD or in the index.
This is only present in a renamed/copied entry, and
tells where the renamed/copied contents came from.
--------------------------------------------------------
```
Unmerged entries have the following format; the first character is a "u" to distinguish from ordinary changed entries.
```
u <XY> <sub> <m1> <m2> <m3> <mW> <h1> <h2> <h3> <path>
```
```
Field Meaning
--------------------------------------------------------
<XY> A 2 character field describing the conflict type
as described in the short format.
<sub> A 4 character field describing the submodule state
as described above.
<m1> The octal file mode in stage 1.
<m2> The octal file mode in stage 2.
<m3> The octal file mode in stage 3.
<mW> The octal file mode in the worktree.
<h1> The object name in stage 1.
<h2> The object name in stage 2.
<h3> The object name in stage 3.
<path> The pathname.
--------------------------------------------------------
```
####
Other Items
Following the tracked entries (and if requested), a series of lines will be printed for untracked and then ignored items found in the worktree.
Untracked items have the following format:
```
? <path>
```
Ignored items have the following format:
```
! <path>
```
####
Pathname Format Notes and -z
When the `-z` option is given, pathnames are printed as is and without any quoting and lines are terminated with a NUL (ASCII 0x00) byte.
Without the `-z` option, pathnames with "unusual" characters are quoted as explained for the configuration variable `core.quotePath` (see [git-config[1]](git-config)).
Configuration
-------------
The command honors `color.status` (or `status.color` — they mean the same thing and the latter is kept for backward compatibility) and `color.status.<slot>` configuration variables to colorize its output.
If the config variable `status.relativePaths` is set to false, then all paths shown are relative to the repository root, not to the current directory.
If `status.submoduleSummary` is set to a non zero number or true (identical to -1 or an unlimited number), the submodule summary will be enabled for the long format and a summary of commits for modified submodules will be shown (see --summary-limit option of [git-submodule[1]](git-submodule)). Please note that the summary output from the status command will be suppressed for all submodules when `diff.ignoreSubmodules` is set to `all` or only for those submodules where `submodule.<name>.ignore=all`. To also view the summary for ignored submodules you can either use the --ignore-submodules=dirty command line option or the `git submodule summary` command, which shows a similar output but does not honor these settings.
Background refresh
------------------
By default, `git status` will automatically refresh the index, updating the cached stat information from the working tree and writing out the result. Writing out the updated index is an optimization that isn’t strictly necessary (`status` computes the values for itself, but writing them out is just to save subsequent programs from repeating our computation). When `status` is run in the background, the lock held during the write may conflict with other simultaneous processes, causing them to fail. Scripts running `status` in the background should consider using `git --no-optional-locks status` (see [git[1]](git) for details).
See also
--------
[gitignore[5]](gitignore)
| programming_docs |
git git-http-backend git-http-backend
================
Name
----
git-http-backend - Server side implementation of Git over HTTP
Synopsis
--------
```
git http-backend
```
Description
-----------
A simple CGI program to serve the contents of a Git repository to Git clients accessing the repository over http:// and https:// protocols. The program supports clients fetching using both the smart HTTP protocol and the backwards-compatible dumb HTTP protocol, as well as clients pushing using the smart HTTP protocol. It also supports Git’s more-efficient "v2" protocol if properly configured; see the discussion of `GIT_PROTOCOL` in the ENVIRONMENT section below.
It verifies that the directory has the magic file "git-daemon-export-ok", and it will refuse to export any Git directory that hasn’t explicitly been marked for export this way (unless the `GIT_HTTP_EXPORT_ALL` environmental variable is set).
By default, only the `upload-pack` service is enabled, which serves `git fetch-pack` and `git ls-remote` clients, which are invoked from `git fetch`, `git pull`, and `git clone`. If the client is authenticated, the `receive-pack` service is enabled, which serves `git send-pack` clients, which is invoked from `git push`.
Services
--------
These services can be enabled/disabled using the per-repository configuration file:
http.getanyfile This serves Git clients older than version 1.6.6 that are unable to use the upload pack service. When enabled, clients are able to read any file within the repository, including objects that are no longer reachable from a branch but are still present. It is enabled by default, but a repository can disable it by setting this configuration item to `false`.
http.uploadpack This serves `git fetch-pack` and `git ls-remote` clients. It is enabled by default, but a repository can disable it by setting this configuration item to `false`.
http.receivepack This serves `git send-pack` clients, allowing push. It is disabled by default for anonymous users, and enabled by default for users authenticated by the web server. It can be disabled by setting this item to `false`, or enabled for all users, including anonymous users, by setting it to `true`.
Url translation
---------------
To determine the location of the repository on disk, `git http-backend` concatenates the environment variables PATH\_INFO, which is set automatically by the web server, and GIT\_PROJECT\_ROOT, which must be set manually in the web server configuration. If GIT\_PROJECT\_ROOT is not set, `git http-backend` reads PATH\_TRANSLATED, which is also set automatically by the web server.
Examples
--------
All of the following examples map `http://$hostname/git/foo/bar.git` to `/var/www/git/foo/bar.git`.
Apache 2.x Ensure mod\_cgi, mod\_alias, and mod\_env are enabled, set GIT\_PROJECT\_ROOT (or DocumentRoot) appropriately, and create a ScriptAlias to the CGI:
```
SetEnv GIT_PROJECT_ROOT /var/www/git
SetEnv GIT_HTTP_EXPORT_ALL
ScriptAlias /git/ /usr/libexec/git-core/git-http-backend/
# This is not strictly necessary using Apache and a modern version of
# git-http-backend, as the webserver will pass along the header in the
# environment as HTTP_GIT_PROTOCOL, and http-backend will copy that into
# GIT_PROTOCOL. But you may need this line (or something similar if you
# are using a different webserver), or if you want to support older Git
# versions that did not do that copying.
#
# Having the webserver set up GIT_PROTOCOL is perfectly fine even with
# modern versions (and will take precedence over HTTP_GIT_PROTOCOL,
# which means it can be used to override the client's request).
SetEnvIf Git-Protocol ".*" GIT_PROTOCOL=$0
```
To enable anonymous read access but authenticated write access, require authorization for both the initial ref advertisement (which we detect as a push via the service parameter in the query string), and the receive-pack invocation itself:
```
RewriteCond %{QUERY_STRING} service=git-receive-pack [OR]
RewriteCond %{REQUEST_URI} /git-receive-pack$
RewriteRule ^/git/ - [E=AUTHREQUIRED:yes]
<LocationMatch "^/git/">
Order Deny,Allow
Deny from env=AUTHREQUIRED
AuthType Basic
AuthName "Git Access"
Require group committers
Satisfy Any
...
</LocationMatch>
```
If you do not have `mod_rewrite` available to match against the query string, it is sufficient to just protect `git-receive-pack` itself, like:
```
<LocationMatch "^/git/.*/git-receive-pack$">
AuthType Basic
AuthName "Git Access"
Require group committers
...
</LocationMatch>
```
In this mode, the server will not request authentication until the client actually starts the object negotiation phase of the push, rather than during the initial contact. For this reason, you must also enable the `http.receivepack` config option in any repositories that should accept a push. The default behavior, if `http.receivepack` is not set, is to reject any pushes by unauthenticated users; the initial request will therefore report `403 Forbidden` to the client, without even giving an opportunity for authentication.
To require authentication for both reads and writes, use a Location directive around the repository, or one of its parent directories:
```
<Location /git/private>
AuthType Basic
AuthName "Private Git Access"
Require group committers
...
</Location>
```
To serve gitweb at the same url, use a ScriptAliasMatch to only those URLs that `git http-backend` can handle, and forward the rest to gitweb:
```
ScriptAliasMatch \
"(?x)^/git/(.*/(HEAD | \
info/refs | \
objects/(info/[^/]+ | \
[0-9a-f]{2}/[0-9a-f]{38} | \
pack/pack-[0-9a-f]{40}\.(pack|idx)) | \
git-(upload|receive)-pack))$" \
/usr/libexec/git-core/git-http-backend/$1
ScriptAlias /git/ /var/www/cgi-bin/gitweb.cgi/
```
To serve multiple repositories from different [gitnamespaces[7]](gitnamespaces) in a single repository:
```
SetEnvIf Request_URI "^/git/([^/]*)" GIT_NAMESPACE=$1
ScriptAliasMatch ^/git/[^/]*(.*) /usr/libexec/git-core/git-http-backend/storage.git$1
```
Accelerated static Apache 2.x Similar to the above, but Apache can be used to return static files that are stored on disk. On many systems this may be more efficient as Apache can ask the kernel to copy the file contents from the file system directly to the network:
```
SetEnv GIT_PROJECT_ROOT /var/www/git
AliasMatch ^/git/(.*/objects/[0-9a-f]{2}/[0-9a-f]{38})$ /var/www/git/$1
AliasMatch ^/git/(.*/objects/pack/pack-[0-9a-f]{40}.(pack|idx))$ /var/www/git/$1
ScriptAlias /git/ /usr/libexec/git-core/git-http-backend/
```
This can be combined with the gitweb configuration:
```
SetEnv GIT_PROJECT_ROOT /var/www/git
AliasMatch ^/git/(.*/objects/[0-9a-f]{2}/[0-9a-f]{38})$ /var/www/git/$1
AliasMatch ^/git/(.*/objects/pack/pack-[0-9a-f]{40}.(pack|idx))$ /var/www/git/$1
ScriptAliasMatch \
"(?x)^/git/(.*/(HEAD | \
info/refs | \
objects/info/[^/]+ | \
git-(upload|receive)-pack))$" \
/usr/libexec/git-core/git-http-backend/$1
ScriptAlias /git/ /var/www/cgi-bin/gitweb.cgi/
```
Lighttpd Ensure that `mod_cgi`, `mod_alias`, `mod_auth`, `mod_setenv` are loaded, then set `GIT_PROJECT_ROOT` appropriately and redirect all requests to the CGI:
```
alias.url += ( "/git" => "/usr/lib/git-core/git-http-backend" )
$HTTP["url"] =~ "^/git" {
cgi.assign = ("" => "")
setenv.add-environment = (
"GIT_PROJECT_ROOT" => "/var/www/git",
"GIT_HTTP_EXPORT_ALL" => ""
)
}
```
To enable anonymous read access but authenticated write access:
```
$HTTP["querystring"] =~ "service=git-receive-pack" {
include "git-auth.conf"
}
$HTTP["url"] =~ "^/git/.*/git-receive-pack$" {
include "git-auth.conf"
}
```
where `git-auth.conf` looks something like:
```
auth.require = (
"/" => (
"method" => "basic",
"realm" => "Git Access",
"require" => "valid-user"
)
)
# ...and set up auth.backend here
```
To require authentication for both reads and writes:
```
$HTTP["url"] =~ "^/git/private" {
include "git-auth.conf"
}
```
Environment
-----------
`git http-backend` relies upon the `CGI` environment variables set by the invoking web server, including:
* PATH\_INFO (if GIT\_PROJECT\_ROOT is set, otherwise PATH\_TRANSLATED)
* REMOTE\_USER
* REMOTE\_ADDR
* CONTENT\_TYPE
* QUERY\_STRING
* REQUEST\_METHOD
The `GIT_HTTP_EXPORT_ALL` environmental variable may be passed to `git-http-backend` to bypass the check for the "git-daemon-export-ok" file in each repository before allowing export of that repository.
The `GIT_HTTP_MAX_REQUEST_BUFFER` environment variable (or the `http.maxRequestBuffer` config variable) may be set to change the largest ref negotiation request that git will handle during a fetch; any fetch requiring a larger buffer will not succeed. This value should not normally need to be changed, but may be helpful if you are fetching from a repository with an extremely large number of refs. The value can be specified with a unit (e.g., `100M` for 100 megabytes). The default is 10 megabytes.
Clients may probe for optional protocol capabilities (like the v2 protocol) using the `Git-Protocol` HTTP header. In order to support these, the contents of that header must appear in the `GIT_PROTOCOL` environment variable. Most webservers will pass this header to the CGI via the `HTTP_GIT_PROTOCOL` variable, and `git-http-backend` will automatically copy that to `GIT_PROTOCOL`. However, some webservers may be more selective about which headers they’ll pass, in which case they need to be configured explicitly (see the mention of `Git-Protocol` in the Apache config from the earlier EXAMPLES section).
The backend process sets GIT\_COMMITTER\_NAME to `$REMOTE_USER` and GIT\_COMMITTER\_EMAIL to `${REMOTE_USER}@http.${REMOTE_ADDR}`, ensuring that any reflogs created by `git-receive-pack` contain some identifying information of the remote user who performed the push.
All `CGI` environment variables are available to each of the hooks invoked by the `git-receive-pack`.
git git-check-ignore git-check-ignore
================
Name
----
git-check-ignore - Debug gitignore / exclude files
Synopsis
--------
```
git check-ignore [<options>] <pathname>…
git check-ignore [<options>] --stdin
```
Description
-----------
For each pathname given via the command-line or from a file via `--stdin`, check whether the file is excluded by .gitignore (or other input files to the exclude mechanism) and output the path if it is excluded.
By default, tracked files are not shown at all since they are not subject to exclude rules; but see ‘--no-index’.
Options
-------
-q, --quiet Don’t output anything, just set exit status. This is only valid with a single pathname.
-v, --verbose Instead of printing the paths that are excluded, for each path that matches an exclude pattern, print the exclude pattern together with the path. (Matching an exclude pattern usually means the path is excluded, but if the pattern begins with "`!`" then it is a negated pattern and matching it means the path is NOT excluded.)
For precedence rules within and between exclude sources, see [gitignore[5]](gitignore).
--stdin Read pathnames from the standard input, one per line, instead of from the command-line.
-z The output format is modified to be machine-parsable (see below). If `--stdin` is also given, input paths are separated with a NUL character instead of a linefeed character.
-n, --non-matching Show given paths which don’t match any pattern. This only makes sense when `--verbose` is enabled, otherwise it would not be possible to distinguish between paths which match a pattern and those which don’t.
--no-index Don’t look in the index when undertaking the checks. This can be used to debug why a path became tracked by e.g. `git add .` and was not ignored by the rules as expected by the user or when developing patterns including negation to match a path previously added with `git add -f`.
Output
------
By default, any of the given pathnames which match an ignore pattern will be output, one per line. If no pattern matches a given path, nothing will be output for that path; this means that path will not be ignored.
If `--verbose` is specified, the output is a series of lines of the form:
<source> <COLON> <linenum> <COLON> <pattern> <HT> <pathname>
<pathname> is the path of a file being queried, <pattern> is the matching pattern, <source> is the pattern’s source file, and <linenum> is the line number of the pattern within that source. If the pattern contained a "`!`" prefix or "`/`" suffix, it will be preserved in the output. <source> will be an absolute path when referring to the file configured by `core.excludesFile`, or relative to the repository root when referring to `.git/info/exclude` or a per-directory exclude file.
If `-z` is specified, the pathnames in the output are delimited by the null character; if `--verbose` is also specified then null characters are also used instead of colons and hard tabs:
<source> <NULL> <linenum> <NULL> <pattern> <NULL> <pathname> <NULL>
If `-n` or `--non-matching` are specified, non-matching pathnames will also be output, in which case all fields in each output record except for <pathname> will be empty. This can be useful when running non-interactively, so that files can be incrementally streamed to STDIN of a long-running check-ignore process, and for each of these files, STDOUT will indicate whether that file matched a pattern or not. (Without this option, it would be impossible to tell whether the absence of output for a given file meant that it didn’t match any pattern, or that the output hadn’t been generated yet.)
Buffering happens as documented under the `GIT_FLUSH` option in [git[1]](git). The caller is responsible for avoiding deadlocks caused by overfilling an input buffer or reading from an empty output buffer.
Exit status
-----------
0 One or more of the provided paths is ignored.
1 None of the provided paths are ignored.
128 A fatal error was encountered.
See also
--------
[gitignore[5]](gitignore) [git-config[1]](git-config) [git-ls-files[1]](git-ls-files)
git multi-pack-index multi-pack-index
================
The Git object directory contains a `pack` directory containing packfiles (with suffix ".pack") and pack-indexes (with suffix ".idx"). The pack-indexes provide a way to lookup objects and navigate to their offset within the pack, but these must come in pairs with the packfiles. This pairing depends on the file names, as the pack-index differs only in suffix with its pack- file. While the pack-indexes provide fast lookup per packfile, this performance degrades as the number of packfiles increases, because abbreviations need to inspect every packfile and we are more likely to have a miss on our most-recently-used packfile. For some large repositories, repacking into a single packfile is not feasible due to storage space or excessive repack times.
The multi-pack-index (MIDX for short) stores a list of objects and their offsets into multiple packfiles. It contains:
* A list of packfile names.
* A sorted list of object IDs.
* A list of metadata for the ith object ID including:
+ A value j referring to the jth packfile.
+ An offset within the jth packfile for the object.
* If large offsets are required, we use another list of large offsets similar to version 2 pack-indexes.
+ An optional list of objects in pseudo-pack order (used with MIDX bitmaps).
Thus, we can provide O(log N) lookup time for any number of packfiles.
Design details
--------------
* The MIDX is stored in a file named `multi-pack-index` in the .git/objects/pack directory. This could be stored in the pack directory of an alternate. It refers only to packfiles in that same directory.
* The core.multiPackIndex config setting must be on (which is the default) to consume MIDX files. Setting it to `false` prevents Git from reading a MIDX file, even if one exists.
* The file format includes parameters for the object ID hash function, so a future change of hash algorithm does not require a change in format.
* The MIDX keeps only one record per object ID. If an object appears in multiple packfiles, then the MIDX selects the copy in the preferred packfile, otherwise selecting from the most-recently modified packfile.
* If there exist packfiles in the pack directory not registered in the MIDX, then those packfiles are loaded into the `packed_git` list and `packed_git_mru` cache.
* The pack-indexes (.idx files) remain in the pack directory so we can delete the MIDX file, set core.midx to false, or downgrade without any loss of information.
* The MIDX file format uses a chunk-based approach (similar to the commit-graph file) that allows optional data to be added.
Future work
-----------
* The multi-pack-index allows many packfiles, especially in a context where repacking is expensive (such as a very large repo), or unexpected maintenance time is unacceptable (such as a high-demand build machine). However, the multi-pack-index needs to be rewritten in full every time. We can extend the format to be incremental, so writes are fast. By storing a small "tip" multi-pack-index that points to large "base" MIDX files, we can keep writes fast while still reducing the number of binary searches required for object lookups.
* If the multi-pack-index is extended to store a "stable object order" (a function Order(hash) = integer that is constant for a given hash, even as the multi-pack-index is updated) then MIDX bitmaps could be updated independently of the MIDX.
* Packfiles can be marked as "special" using empty files that share the initial name but replace ".pack" with ".keep" or ".promisor". We can add an optional chunk of data to the multi-pack-index that records flags of information about the packfiles. This allows new states, such as `repacked` or `redeltified`, that can help with pack maintenance in a multi-pack environment. It may also be helpful to organize packfiles by object type (commit, tree, blob, etc.) and use this metadata to help that maintenance.
Related links
-------------
[0] <https://bugs.chromium.org/p/git/issues/detail?id=6> Chromium work item for: Multi-Pack Index (MIDX)
[1] <https://lore.kernel.org/git/[email protected]/> An earlier RFC for the multi-pack-index feature
[2] <https://lore.kernel.org/git/alpine.DEB.2.20.1803091557510.23109@alexmv-linux/> Git Merge 2018 Contributor’s summit notes (includes discussion of MIDX)
git git-gc git-gc
======
Name
----
git-gc - Cleanup unnecessary files and optimize the local repository
Synopsis
--------
```
git gc [--aggressive] [--auto] [--quiet] [--prune=<date> | --no-prune] [--force] [--keep-largest-pack]
```
Description
-----------
Runs a number of housekeeping tasks within the current repository, such as compressing file revisions (to reduce disk space and increase performance), removing unreachable objects which may have been created from prior invocations of `git add`, packing refs, pruning reflog, rerere metadata or stale working trees. May also update ancillary indexes such as the commit-graph.
When common porcelain operations that create objects are run, they will check whether the repository has grown substantially since the last maintenance, and if so run `git gc` automatically. See `gc.auto` below for how to disable this behavior.
Running `git gc` manually should only be needed when adding objects to a repository without regularly running such porcelain commands, to do a one-off repository optimization, or e.g. to clean up a suboptimal mass-import. See the "PACKFILE OPTIMIZATION" section in [git-fast-import[1]](git-fast-import) for more details on the import case.
Options
-------
--aggressive Usually `git gc` runs very quickly while providing good disk space utilization and performance. This option will cause `git gc` to more aggressively optimize the repository at the expense of taking much more time. The effects of this optimization are mostly persistent. See the "AGGRESSIVE" section below for details.
--auto With this option, `git gc` checks whether any housekeeping is required; if not, it exits without performing any work.
See the `gc.auto` option in the "CONFIGURATION" section below for how this heuristic works.
Once housekeeping is triggered by exceeding the limits of configuration options such as `gc.auto` and `gc.autoPackLimit`, all other housekeeping tasks (e.g. rerere, working trees, reflog…) will be performed as well.
--cruft When expiring unreachable objects, pack them separately into a cruft pack instead of storing them as loose objects.
--prune=<date> Prune loose objects older than date (default is 2 weeks ago, overridable by the config variable `gc.pruneExpire`). --prune=now prunes loose objects regardless of their age and increases the risk of corruption if another process is writing to the repository concurrently; see "NOTES" below. --prune is on by default.
--no-prune Do not prune any loose objects.
--quiet Suppress all progress reports.
--force Force `git gc` to run even if there may be another `git gc` instance running on this repository.
--keep-largest-pack All packs except the largest pack and those marked with a `.keep` files are consolidated into a single pack. When this option is used, `gc.bigPackThreshold` is ignored.
Aggressive
----------
When the `--aggressive` option is supplied, [git-repack[1]](git-repack) will be invoked with the `-f` flag, which in turn will pass `--no-reuse-delta` to [git-pack-objects[1]](git-pack-objects). This will throw away any existing deltas and re-compute them, at the expense of spending much more time on the repacking.
The effects of this are mostly persistent, e.g. when packs and loose objects are coalesced into one another pack the existing deltas in that pack might get re-used, but there are also various cases where we might pick a sub-optimal delta from a newer pack instead.
Furthermore, supplying `--aggressive` will tweak the `--depth` and `--window` options passed to [git-repack[1]](git-repack). See the `gc.aggressiveDepth` and `gc.aggressiveWindow` settings below. By using a larger window size we’re more likely to find more optimal deltas.
It’s probably not worth it to use this option on a given repository without running tailored performance benchmarks on it. It takes a lot more time, and the resulting space/delta optimization may or may not be worth it. Not using this at all is the right trade-off for most users and their repositories.
Configuration
-------------
Everything below this line in this section is selectively included from the [git-config[1]](git-config) documentation. The content is the same as what’s found there:
gc.aggressiveDepth The depth parameter used in the delta compression algorithm used by `git gc --aggressive`. This defaults to 50, which is the default for the `--depth` option when `--aggressive` isn’t in use.
See the documentation for the `--depth` option in [git-repack[1]](git-repack) for more details.
gc.aggressiveWindow The window size parameter used in the delta compression algorithm used by `git gc --aggressive`. This defaults to 250, which is a much more aggressive window size than the default `--window` of 10.
See the documentation for the `--window` option in [git-repack[1]](git-repack) for more details.
gc.auto When there are approximately more than this many loose objects in the repository, `git gc --auto` will pack them. Some Porcelain commands use this command to perform a light-weight garbage collection from time to time. The default value is 6700.
Setting this to 0 disables not only automatic packing based on the number of loose objects, but any other heuristic `git gc --auto` will otherwise use to determine if there’s work to do, such as `gc.autoPackLimit`.
gc.autoPackLimit When there are more than this many packs that are not marked with `*.keep` file in the repository, `git gc
--auto` consolidates them into one larger pack. The default value is 50. Setting this to 0 disables it. Setting `gc.auto` to 0 will also disable this.
See the `gc.bigPackThreshold` configuration variable below. When in use, it’ll affect how the auto pack limit works.
gc.autoDetach Make `git gc --auto` return immediately and run in background if the system supports it. Default is true.
gc.bigPackThreshold If non-zero, all packs larger than this limit are kept when `git gc` is run. This is very similar to `--keep-largest-pack` except that all packs that meet the threshold are kept, not just the largest pack. Defaults to zero. Common unit suffixes of `k`, `m`, or `g` are supported.
Note that if the number of kept packs is more than gc.autoPackLimit, this configuration variable is ignored, all packs except the base pack will be repacked. After this the number of packs should go below gc.autoPackLimit and gc.bigPackThreshold should be respected again.
If the amount of memory estimated for `git repack` to run smoothly is not available and `gc.bigPackThreshold` is not set, the largest pack will also be excluded (this is the equivalent of running `git gc` with `--keep-largest-pack`).
gc.writeCommitGraph If true, then gc will rewrite the commit-graph file when [git-gc[1]](git-gc) is run. When using `git gc --auto` the commit-graph will be updated if housekeeping is required. Default is true. See [git-commit-graph[1]](git-commit-graph) for details.
gc.logExpiry If the file gc.log exists, then `git gc --auto` will print its content and exit with status zero instead of running unless that file is more than `gc.logExpiry` old. Default is "1.day". See `gc.pruneExpire` for more ways to specify its value.
gc.packRefs Running `git pack-refs` in a repository renders it unclonable by Git versions prior to 1.5.1.2 over dumb transports such as HTTP. This variable determines whether `git gc` runs `git pack-refs`. This can be set to `notbare` to enable it within all non-bare repos or it can be set to a boolean value. The default is `true`.
gc.cruftPacks Store unreachable objects in a cruft pack (see [git-repack[1]](git-repack)) instead of as loose objects. The default is `false`.
gc.pruneExpire When `git gc` is run, it will call `prune --expire 2.weeks.ago` (and `repack --cruft --cruft-expiration 2.weeks.ago` if using cruft packs via `gc.cruftPacks` or `--cruft`). Override the grace period with this config variable. The value "now" may be used to disable this grace period and always prune unreachable objects immediately, or "never" may be used to suppress pruning. This feature helps prevent corruption when `git gc` runs concurrently with another process writing to the repository; see the "NOTES" section of [git-gc[1]](git-gc).
gc.worktreePruneExpire When `git gc` is run, it calls `git worktree prune --expire 3.months.ago`. This config variable can be used to set a different grace period. The value "now" may be used to disable the grace period and prune `$GIT_DIR/worktrees` immediately, or "never" may be used to suppress pruning.
gc.reflogExpire gc.<pattern>.reflogExpire `git reflog expire` removes reflog entries older than this time; defaults to 90 days. The value "now" expires all entries immediately, and "never" suppresses expiration altogether. With "<pattern>" (e.g. "refs/stash") in the middle the setting applies only to the refs that match the <pattern>.
gc.reflogExpireUnreachable gc.<pattern>.reflogExpireUnreachable `git reflog expire` removes reflog entries older than this time and are not reachable from the current tip; defaults to 30 days. The value "now" expires all entries immediately, and "never" suppresses expiration altogether. With "<pattern>" (e.g. "refs/stash") in the middle, the setting applies only to the refs that match the <pattern>.
These types of entries are generally created as a result of using `git
commit --amend` or `git rebase` and are the commits prior to the amend or rebase occurring. Since these changes are not part of the current project most users will want to expire them sooner, which is why the default is more aggressive than `gc.reflogExpire`.
gc.rerereResolved Records of conflicted merge you resolved earlier are kept for this many days when `git rerere gc` is run. You can also use more human-readable "1.month.ago", etc. The default is 60 days. See [git-rerere[1]](git-rerere).
gc.rerereUnresolved Records of conflicted merge you have not resolved are kept for this many days when `git rerere gc` is run. You can also use more human-readable "1.month.ago", etc. The default is 15 days. See [git-rerere[1]](git-rerere).
Notes
-----
`git gc` tries very hard not to delete objects that are referenced anywhere in your repository. In particular, it will keep not only objects referenced by your current set of branches and tags, but also objects referenced by the index, remote-tracking branches, reflogs (which may reference commits in branches that were later amended or rewound), and anything else in the refs/\* namespace. Note that a note (of the kind created by `git notes`) attached to an object does not contribute in keeping the object alive. If you are expecting some objects to be deleted and they aren’t, check all of those locations and decide whether it makes sense in your case to remove those references.
On the other hand, when `git gc` runs concurrently with another process, there is a risk of it deleting an object that the other process is using but hasn’t created a reference to. This may just cause the other process to fail or may corrupt the repository if the other process later adds a reference to the deleted object. Git has two features that significantly mitigate this problem:
1. Any object with modification time newer than the `--prune` date is kept, along with everything reachable from it.
2. Most operations that add an object to the database update the modification time of the object if it is already present so that #1 applies.
However, these features fall short of a complete solution, so users who run commands concurrently have to live with some risk of corruption (which seems to be low in practice).
Hooks
-----
The `git gc --auto` command will run the `pre-auto-gc` hook. See [githooks[5]](githooks) for more information.
See also
--------
[git-prune[1]](git-prune) [git-reflog[1]](git-reflog) [git-repack[1]](git-repack) [git-rerere[1]](git-rerere)
| programming_docs |
git git-patch-id git-patch-id
============
Name
----
git-patch-id - Compute unique ID for a patch
Synopsis
--------
```
git patch-id [--stable | --unstable | --verbatim]
```
Description
-----------
Read a patch from the standard input and compute the patch ID for it.
A "patch ID" is nothing but a sum of SHA-1 of the file diffs associated with a patch, with line numbers ignored. As such, it’s "reasonably stable", but at the same time also reasonably unique, i.e., two patches that have the same "patch ID" are almost guaranteed to be the same thing.
The main usecase for this command is to look for likely duplicate commits.
When dealing with `git diff-tree` output, it takes advantage of the fact that the patch is prefixed with the object name of the commit, and outputs two 40-byte hexadecimal strings. The first string is the patch ID, and the second string is the commit ID. This can be used to make a mapping from patch ID to commit ID.
Options
-------
--verbatim Calculate the patch-id of the input as it is given, do not strip any whitespace.
```
This is the default if patchid.verbatim is true.
```
--stable Use a "stable" sum of hashes as the patch ID. With this option:
* Reordering file diffs that make up a patch does not affect the ID. In particular, two patches produced by comparing the same two trees with two different settings for "-O<orderfile>" result in the same patch ID signature, thereby allowing the computed result to be used as a key to index some meta-information about the change between the two trees;
* Result is different from the value produced by git 1.9 and older or produced when an "unstable" hash (see --unstable below) is configured - even when used on a diff output taken without any use of "-O<orderfile>", thereby making existing databases storing such "unstable" or historical patch-ids unusable.
* All whitespace within the patch is ignored and does not affect the id.
```
This is the default if patchid.stable is set to true.
```
--unstable Use an "unstable" hash as the patch ID. With this option, the result produced is compatible with the patch-id value produced by git 1.9 and older and whitespace is ignored. Users with pre-existing databases storing patch-ids produced by git 1.9 and older (who do not deal with reordered patches) may want to use this option.
```
This is the default.
```
git gitformat-bundle gitformat-bundle
================
Name
----
gitformat-bundle - The bundle file format
Synopsis
--------
```
*.bundle
*.bdl
```
Description
-----------
The Git bundle format is a format that represents both refs and Git objects. A bundle is a header in a format similar to [git-show-ref[1]](git-show-ref) followed by a pack in \*.pack format.
The format is created and read by the [git-bundle[1]](git-bundle) command, and supported by e.g. [git-fetch[1]](git-fetch) and [git-clone[1]](git-clone).
Format
------
We will use ABNF notation to define the Git bundle format. See [gitprotocol-common[5]](gitprotocol-common) for the details.
A v2 bundle looks like this:
```
bundle = signature *prerequisite *reference LF pack
signature = "# v2 git bundle" LF
prerequisite = "-" obj-id SP comment LF
comment = *CHAR
reference = obj-id SP refname LF
pack = ... ; packfile
```
A v3 bundle looks like this:
```
bundle = signature *capability *prerequisite *reference LF pack
signature = "# v3 git bundle" LF
capability = "@" key ["=" value] LF
prerequisite = "-" obj-id SP comment LF
comment = *CHAR
reference = obj-id SP refname LF
key = 1*(ALPHA / DIGIT / "-")
value = *(%01-09 / %0b-FF)
pack = ... ; packfile
```
Semantics
---------
A Git bundle consists of several parts.
* "Capabilities", which are only in the v3 format, indicate functionality that the bundle requires to be read properly.
* "Prerequisites" lists the objects that are NOT included in the bundle and the reader of the bundle MUST already have, in order to use the data in the bundle. The objects stored in the bundle may refer to prerequisite objects and anything reachable from them (e.g. a tree object in the bundle can reference a blob that is reachable from a prerequisite) and/or expressed as a delta against prerequisite objects.
* "References" record the tips of the history graph, iow, what the reader of the bundle CAN "git fetch" from it.
* "Pack" is the pack data stream "git fetch" would send, if you fetch from a repository that has the references recorded in the "References" above into a repository that has references pointing at the objects listed in "Prerequisites" above.
In the bundle format, there can be a comment following a prerequisite obj-id. This is a comment and it has no specific meaning. The writer of the bundle MAY put any string here. The reader of the bundle MUST ignore the comment.
###
Note on the shallow clone and a Git bundle
Note that the prerequisites does not represent a shallow-clone boundary. The semantics of the prerequisites and the shallow-clone boundaries are different, and the Git bundle v2 format cannot represent a shallow clone repository.
Capabilities
------------
Because there is no opportunity for negotiation, unknown capabilities cause `git bundle` to abort.
* `object-format` specifies the hash algorithm in use, and can take the same values as the `extensions.objectFormat` configuration value.
* `filter` specifies an object filter as in the `--filter` option in [git-rev-list[1]](git-rev-list). The resulting pack-file must be marked as a `.promisor` pack-file after it is unbundled.
git git-init git-init
========
Name
----
git-init - Create an empty Git repository or reinitialize an existing one
Synopsis
--------
```
git init [-q | --quiet] [--bare] [--template=<template-directory>]
[--separate-git-dir <git-dir>] [--object-format=<format>]
[-b <branch-name> | --initial-branch=<branch-name>]
[--shared[=<permissions>]] [<directory>]
```
Description
-----------
This command creates an empty Git repository - basically a `.git` directory with subdirectories for `objects`, `refs/heads`, `refs/tags`, and template files. An initial branch without any commits will be created (see the `--initial-branch` option below for its name).
If the `$GIT_DIR` environment variable is set then it specifies a path to use instead of `./.git` for the base of the repository.
If the object storage directory is specified via the `$GIT_OBJECT_DIRECTORY` environment variable then the sha1 directories are created underneath - otherwise the default `$GIT_DIR/objects` directory is used.
Running `git init` in an existing repository is safe. It will not overwrite things that are already there. The primary reason for rerunning `git init` is to pick up newly added templates (or to move the repository to another place if --separate-git-dir is given).
Options
-------
-q --quiet Only print error and warning messages; all other output will be suppressed.
--bare Create a bare repository. If `GIT_DIR` environment is not set, it is set to the current working directory.
--object-format=<format> Specify the given object format (hash algorithm) for the repository. The valid values are `sha1` and (if enabled) `sha256`. `sha1` is the default.
THIS OPTION IS EXPERIMENTAL! SHA-256 support is experimental and still in an early stage. A SHA-256 repository will in general not be able to share work with "regular" SHA-1 repositories. It should be assumed that, e.g., Git internal file formats in relation to SHA-256 repositories may change in backwards-incompatible ways. Only use `--object-format=sha256` for testing purposes.
--template=<template-directory> Specify the directory from which templates will be used. (See the "TEMPLATE DIRECTORY" section below.)
--separate-git-dir=<git-dir> Instead of initializing the repository as a directory to either `$GIT_DIR` or `./.git/`, create a text file there containing the path to the actual repository. This file acts as filesystem-agnostic Git symbolic link to the repository.
If this is reinitialization, the repository will be moved to the specified path.
-b <branch-name> --initial-branch=<branch-name> Use the specified name for the initial branch in the newly created repository. If not specified, fall back to the default name (currently `master`, but this is subject to change in the future; the name can be customized via the `init.defaultBranch` configuration variable).
--shared[=(false|true|umask|group|all|world|everybody|<perm>)] Specify that the Git repository is to be shared amongst several users. This allows users belonging to the same group to push into that repository. When specified, the config variable "core.sharedRepository" is set so that files and directories under `$GIT_DIR` are created with the requested permissions. When not specified, Git will use permissions reported by umask(2).
The option can have the following values, defaulting to `group` if no value is given:
*umask* (or *false*) Use permissions reported by umask(2). The default, when `--shared` is not specified.
*group* (or *true*) Make the repository group-writable, (and g+sx, since the git group may be not the primary group of all users). This is used to loosen the permissions of an otherwise safe umask(2) value. Note that the umask still applies to the other permission bits (e.g. if umask is `0022`, using `group` will not remove read privileges from other (non-group) users). See `0xxx` for how to exactly specify the repository permissions.
*all* (or *world* or *everybody*) Same as `group`, but make the repository readable by all users.
*<perm>* `<perm>` is a 3-digit octal number prefixed with `0` and each file will have mode `<perm>`. `<perm>` will override users' umask(2) value (and not only loosen permissions as `group` and `all` does). `0640` will create a repository which is group-readable, but not group-writable or accessible to others. `0660` will create a repo that is readable and writable to the current user and group, but inaccessible to others (directories and executable files get their `x` bit from the `r` bit for corresponding classes of users).
By default, the configuration flag `receive.denyNonFastForwards` is enabled in shared repositories, so that you cannot force a non fast-forwarding push into it.
If you provide a `directory`, the command is run inside it. If this directory does not exist, it will be created.
Template directory
------------------
Files and directories in the template directory whose name do not start with a dot will be copied to the `$GIT_DIR` after it is created.
The template directory will be one of the following (in order):
* the argument given with the `--template` option;
* the contents of the `$GIT_TEMPLATE_DIR` environment variable;
* the `init.templateDir` configuration variable; or
* the default template directory: `/usr/share/git-core/templates`.
The default template directory includes some directory structure, suggested "exclude patterns" (see [gitignore[5]](gitignore)), and sample hook files.
The sample hooks are all disabled by default. To enable one of the sample hooks rename it by removing its `.sample` suffix.
See [githooks[5]](githooks) for more general info on hook execution.
Examples
--------
Start a new Git repository for an existing code base
```
$ cd /path/to/my/codebase
$ git init (1)
$ git add . (2)
$ git commit (3)
```
1. Create a /path/to/my/codebase/.git directory.
2. Add all existing files to the index.
3. Record the pristine state as the first commit in the history.
Configuration
-------------
Everything below this line in this section is selectively included from the [git-config[1]](git-config) documentation. The content is the same as what’s found there:
init.templateDir Specify the directory from which templates will be copied. (See the "TEMPLATE DIRECTORY" section of [git-init[1]](git-init).)
init.defaultBranch Allows overriding the default branch name e.g. when initializing a new repository.
git git-upload-archive git-upload-archive
==================
Name
----
git-upload-archive - Send archive back to git-archive
Synopsis
--------
```
git upload-archive <repository>
```
Description
-----------
Invoked by `git archive --remote` and sends a generated archive to the other end over the Git protocol.
This command is usually not invoked directly by the end user. The UI for the protocol is on the `git archive` side, and the program pair is meant to be used to get an archive from a remote repository.
Security
--------
In order to protect the privacy of objects that have been removed from history but may not yet have been pruned, `git-upload-archive` avoids serving archives for commits and trees that are not reachable from the repository’s refs. However, because calculating object reachability is computationally expensive, `git-upload-archive` implements a stricter but easier-to-check set of rules:
1. Clients may request a commit or tree that is pointed to directly by a ref. E.g., `git archive --remote=origin v1.0`.
2. Clients may request a sub-tree within a commit or tree using the `ref:path` syntax. E.g., `git archive --remote=origin v1.0:Documentation`.
3. Clients may `not` use other sha1 expressions, even if the end result is reachable. E.g., neither a relative commit like `master^` nor a literal sha1 like `abcd1234` is allowed, even if the result is reachable from the refs.
Note that rule 3 disallows many cases that do not have any privacy implications. These rules are subject to change in future versions of git, and the server accessed by `git archive --remote` may or may not follow these exact rules.
If the config option `uploadArchive.allowUnreachable` is true, these rules are ignored, and clients may use arbitrary sha1 expressions. This is useful if you do not care about the privacy of unreachable objects, or if your object database is already publicly available for access via non-smart-http.
Options
-------
<repository> The repository to get a tar archive from.
git git-log git-log
=======
Name
----
git-log - Show commit logs
Synopsis
--------
```
git log [<options>] [<revision-range>] [[--] <path>…]
```
Description
-----------
Shows the commit logs.
List commits that are reachable by following the `parent` links from the given commit(s), but exclude commits that are reachable from the one(s) given with a `^` in front of them. The output is given in reverse chronological order by default.
You can think of this as a set operation. Commits reachable from any of the commits given on the command line form a set, and then commits reachable from any of the ones given with `^` in front are subtracted from that set. The remaining commits are what comes out in the command’s output. Various other options and paths parameters can be used to further limit the result.
Thus, the following command:
```
$ git log foo bar ^baz
```
means "list all the commits which are reachable from `foo` or `bar`, but not from `baz`".
A special notation "`<commit1>`..`<commit2>`" can be used as a short-hand for "^`<commit1>` `<commit2>`". For example, either of the following may be used interchangeably:
```
$ git log origin..HEAD
$ git log HEAD ^origin
```
Another special notation is "`<commit1>`…`<commit2>`" which is useful for merges. The resulting set of commits is the symmetric difference between the two operands. The following two commands are equivalent:
```
$ git log A B --not $(git merge-base --all A B)
$ git log A...B
```
The command takes options applicable to the [git-rev-list[1]](git-rev-list) command to control what is shown and how, and options applicable to the [git-diff[1]](git-diff) command to control how the changes each commit introduces are shown.
Options
-------
--follow Continue listing the history of a file beyond renames (works only for a single file).
--no-decorate --decorate[=short|full|auto|no] Print out the ref names of any commits that are shown. If `short` is specified, the ref name prefixes `refs/heads/`, `refs/tags/` and `refs/remotes/` will not be printed. If `full` is specified, the full ref name (including prefix) will be printed. If `auto` is specified, then if the output is going to a terminal, the ref names are shown as if `short` were given, otherwise no ref names are shown. The option `--decorate` is short-hand for `--decorate=short`. Default to configuration value of `log.decorate` if configured, otherwise, `auto`.
--decorate-refs=<pattern> --decorate-refs-exclude=<pattern> For each candidate reference, do not use it for decoration if it matches any patterns given to `--decorate-refs-exclude` or if it doesn’t match any of the patterns given to `--decorate-refs`. The `log.excludeDecoration` config option allows excluding refs from the decorations, but an explicit `--decorate-refs` pattern will override a match in `log.excludeDecoration`.
If none of these options or config settings are given, then references are used as decoration if they match `HEAD`, `refs/heads/`, `refs/remotes/`, `refs/stash/`, or `refs/tags/`.
--clear-decorations When specified, this option clears all previous `--decorate-refs` or `--decorate-refs-exclude` options and relaxes the default decoration filter to include all references. This option is assumed if the config value `log.initialDecorationSet` is set to `all`.
--source Print out the ref name given on the command line by which each commit was reached.
--[no-]mailmap --[no-]use-mailmap Use mailmap file to map author and committer names and email addresses to canonical real names and email addresses. See [git-shortlog[1]](git-shortlog).
--full-diff Without this flag, `git log -p <path>...` shows commits that touch the specified paths, and diffs about the same specified paths. With this, the full diff is shown for commits that touch the specified paths; this means that "<path>…" limits only commits, and doesn’t limit diff for those commits.
Note that this affects all diff-based output types, e.g. those produced by `--stat`, etc.
--log-size Include a line “log size <number>” in the output for each commit, where <number> is the length of that commit’s message in bytes. Intended to speed up tools that read log messages from `git log` output by allowing them to allocate space in advance.
-L<start>,<end>:<file> -L:<funcname>:<file> Trace the evolution of the line range given by `<start>,<end>`, or by the function name regex `<funcname>`, within the `<file>`. You may not give any pathspec limiters. This is currently limited to a walk starting from a single revision, i.e., you may only give zero or one positive revision arguments, and `<start>` and `<end>` (or `<funcname>`) must exist in the starting revision. You can specify this option more than once. Implies `--patch`. Patch output can be suppressed using `--no-patch`, but other diff formats (namely `--raw`, `--numstat`, `--shortstat`, `--dirstat`, `--summary`, `--name-only`, `--name-status`, `--check`) are not currently implemented.
`<start>` and `<end>` can take one of these forms:
* number
If `<start>` or `<end>` is a number, it specifies an absolute line number (lines count from 1).
* `/regex/`
This form will use the first line matching the given POSIX regex. If `<start>` is a regex, it will search from the end of the previous `-L` range, if any, otherwise from the start of file. If `<start>` is `^/regex/`, it will search from the start of file. If `<end>` is a regex, it will search starting at the line given by `<start>`.
* +offset or -offset
This is only valid for `<end>` and will specify a number of lines before or after the line given by `<start>`.
If `:<funcname>` is given in place of `<start>` and `<end>`, it is a regular expression that denotes the range from the first funcname line that matches `<funcname>`, up to the next funcname line. `:<funcname>` searches from the end of the previous `-L` range, if any, otherwise from the start of file. `^:<funcname>` searches from the start of file. The function names are determined in the same way as `git diff` works out patch hunk headers (see `Defining a custom hunk-header` in [gitattributes[5]](gitattributes)).
<revision-range> Show only commits in the specified revision range. When no <revision-range> is specified, it defaults to `HEAD` (i.e. the whole history leading to the current commit). `origin..HEAD` specifies all the commits reachable from the current commit (i.e. `HEAD`), but not from `origin`. For a complete list of ways to spell <revision-range>, see the `Specifying Ranges` section of [gitrevisions[7]](gitrevisions).
[--] <path>… Show only commits that are enough to explain how the files that match the specified paths came to be. See `History Simplification` below for details and other simplification modes.
Paths may need to be prefixed with `--` to separate them from options or the revision range, when confusion arises.
###
Commit Limiting
Besides specifying a range of commits that should be listed using the special notations explained in the description, additional commit limiting may be applied.
Using more options generally further limits the output (e.g. `--since=<date1>` limits to commits newer than `<date1>`, and using it with `--grep=<pattern>` further limits to commits whose log message has a line that matches `<pattern>`), unless otherwise noted.
Note that these are applied before commit ordering and formatting options, such as `--reverse`.
-<number> -n <number> --max-count=<number> Limit the number of commits to output.
--skip=<number> Skip `number` commits before starting to show the commit output.
--since=<date> --after=<date> Show commits more recent than a specific date.
--since-as-filter=<date> Show all commits more recent than a specific date. This visits all commits in the range, rather than stopping at the first commit which is older than a specific date.
--until=<date> --before=<date> Show commits older than a specific date.
--author=<pattern> --committer=<pattern> Limit the commits output to ones with author/committer header lines that match the specified pattern (regular expression). With more than one `--author=<pattern>`, commits whose author matches any of the given patterns are chosen (similarly for multiple `--committer=<pattern>`).
--grep-reflog=<pattern> Limit the commits output to ones with reflog entries that match the specified pattern (regular expression). With more than one `--grep-reflog`, commits whose reflog message matches any of the given patterns are chosen. It is an error to use this option unless `--walk-reflogs` is in use.
--grep=<pattern> Limit the commits output to ones with log message that matches the specified pattern (regular expression). With more than one `--grep=<pattern>`, commits whose message matches any of the given patterns are chosen (but see `--all-match`).
When `--notes` is in effect, the message from the notes is matched as if it were part of the log message.
--all-match Limit the commits output to ones that match all given `--grep`, instead of ones that match at least one.
--invert-grep Limit the commits output to ones with log message that do not match the pattern specified with `--grep=<pattern>`.
-i --regexp-ignore-case Match the regular expression limiting patterns without regard to letter case.
--basic-regexp Consider the limiting patterns to be basic regular expressions; this is the default.
-E --extended-regexp Consider the limiting patterns to be extended regular expressions instead of the default basic regular expressions.
-F --fixed-strings Consider the limiting patterns to be fixed strings (don’t interpret pattern as a regular expression).
-P --perl-regexp Consider the limiting patterns to be Perl-compatible regular expressions.
Support for these types of regular expressions is an optional compile-time dependency. If Git wasn’t compiled with support for them providing this option will cause it to die.
--remove-empty Stop when a given path disappears from the tree.
--merges Print only merge commits. This is exactly the same as `--min-parents=2`.
--no-merges Do not print commits with more than one parent. This is exactly the same as `--max-parents=1`.
--min-parents=<number> --max-parents=<number> --no-min-parents --no-max-parents Show only commits which have at least (or at most) that many parent commits. In particular, `--max-parents=1` is the same as `--no-merges`, `--min-parents=2` is the same as `--merges`. `--max-parents=0` gives all root commits and `--min-parents=3` all octopus merges.
`--no-min-parents` and `--no-max-parents` reset these limits (to no limit) again. Equivalent forms are `--min-parents=0` (any commit has 0 or more parents) and `--max-parents=-1` (negative numbers denote no upper limit).
--first-parent When finding commits to include, follow only the first parent commit upon seeing a merge commit. This option can give a better overview when viewing the evolution of a particular topic branch, because merges into a topic branch tend to be only about adjusting to updated upstream from time to time, and this option allows you to ignore the individual commits brought in to your history by such a merge.
This option also changes default diff format for merge commits to `first-parent`, see `--diff-merges=first-parent` for details.
--exclude-first-parent-only When finding commits to exclude (with a `^`), follow only the first parent commit upon seeing a merge commit. This can be used to find the set of changes in a topic branch from the point where it diverged from the remote branch, given that arbitrary merges can be valid topic branch changes.
--not Reverses the meaning of the `^` prefix (or lack thereof) for all following revision specifiers, up to the next `--not`.
--all Pretend as if all the refs in `refs/`, along with `HEAD`, are listed on the command line as `<commit>`.
--branches[=<pattern>] Pretend as if all the refs in `refs/heads` are listed on the command line as `<commit>`. If `<pattern>` is given, limit branches to ones matching given shell glob. If pattern lacks `?`, `*`, or `[`, `/*` at the end is implied.
--tags[=<pattern>] Pretend as if all the refs in `refs/tags` are listed on the command line as `<commit>`. If `<pattern>` is given, limit tags to ones matching given shell glob. If pattern lacks `?`, `*`, or `[`, `/*` at the end is implied.
--remotes[=<pattern>] Pretend as if all the refs in `refs/remotes` are listed on the command line as `<commit>`. If `<pattern>` is given, limit remote-tracking branches to ones matching given shell glob. If pattern lacks `?`, `*`, or `[`, `/*` at the end is implied.
--glob=<glob-pattern> Pretend as if all the refs matching shell glob `<glob-pattern>` are listed on the command line as `<commit>`. Leading `refs/`, is automatically prepended if missing. If pattern lacks `?`, `*`, or `[`, `/*` at the end is implied.
--exclude=<glob-pattern> Do not include refs matching `<glob-pattern>` that the next `--all`, `--branches`, `--tags`, `--remotes`, or `--glob` would otherwise consider. Repetitions of this option accumulate exclusion patterns up to the next `--all`, `--branches`, `--tags`, `--remotes`, or `--glob` option (other options or arguments do not clear accumulated patterns).
The patterns given should not begin with `refs/heads`, `refs/tags`, or `refs/remotes` when applied to `--branches`, `--tags`, or `--remotes`, respectively, and they must begin with `refs/` when applied to `--glob` or `--all`. If a trailing `/*` is intended, it must be given explicitly.
--exclude-hidden=[receive|uploadpack] Do not include refs that would be hidden by `git-receive-pack` or `git-upload-pack` by consulting the appropriate `receive.hideRefs` or `uploadpack.hideRefs` configuration along with `transfer.hideRefs` (see [git-config[1]](git-config)). This option affects the next pseudo-ref option `--all` or `--glob` and is cleared after processing them.
--reflog Pretend as if all objects mentioned by reflogs are listed on the command line as `<commit>`.
--alternate-refs Pretend as if all objects mentioned as ref tips of alternate repositories were listed on the command line. An alternate repository is any repository whose object directory is specified in `objects/info/alternates`. The set of included objects may be modified by `core.alternateRefsCommand`, etc. See [git-config[1]](git-config).
--single-worktree By default, all working trees will be examined by the following options when there are more than one (see [git-worktree[1]](git-worktree)): `--all`, `--reflog` and `--indexed-objects`. This option forces them to examine the current working tree only.
--ignore-missing Upon seeing an invalid object name in the input, pretend as if the bad input was not given.
--bisect Pretend as if the bad bisection ref `refs/bisect/bad` was listed and as if it was followed by `--not` and the good bisection refs `refs/bisect/good-*` on the command line.
--stdin In addition to the `<commit>` listed on the command line, read them from the standard input. If a `--` separator is seen, stop reading commits and start reading paths to limit the result.
--cherry-mark Like `--cherry-pick` (see below) but mark equivalent commits with `=` rather than omitting them, and inequivalent ones with `+`.
--cherry-pick Omit any commit that introduces the same change as another commit on the “other side” when the set of commits are limited with symmetric difference.
For example, if you have two branches, `A` and `B`, a usual way to list all commits on only one side of them is with `--left-right` (see the example below in the description of the `--left-right` option). However, it shows the commits that were cherry-picked from the other branch (for example, “3rd on b” may be cherry-picked from branch A). With this option, such pairs of commits are excluded from the output.
--left-only --right-only List only commits on the respective side of a symmetric difference, i.e. only those which would be marked `<` resp. `>` by `--left-right`.
For example, `--cherry-pick --right-only A...B` omits those commits from `B` which are in `A` or are patch-equivalent to a commit in `A`. In other words, this lists the `+` commits from `git cherry A B`. More precisely, `--cherry-pick --right-only --no-merges` gives the exact list.
--cherry A synonym for `--right-only --cherry-mark --no-merges`; useful to limit the output to the commits on our side and mark those that have been applied to the other side of a forked history with `git log --cherry upstream...mybranch`, similar to `git cherry upstream mybranch`.
-g --walk-reflogs Instead of walking the commit ancestry chain, walk reflog entries from the most recent one to older ones. When this option is used you cannot specify commits to exclude (that is, `^commit`, `commit1..commit2`, and `commit1...commit2` notations cannot be used).
With `--pretty` format other than `oneline` and `reference` (for obvious reasons), this causes the output to have two extra lines of information taken from the reflog. The reflog designator in the output may be shown as `ref@{Nth}` (where `Nth` is the reverse-chronological index in the reflog) or as `ref@{timestamp}` (with the timestamp for that entry), depending on a few rules:
1. If the starting point is specified as `ref@{Nth}`, show the index format.
2. If the starting point was specified as `ref@{now}`, show the timestamp format.
3. If neither was used, but `--date` was given on the command line, show the timestamp in the format requested by `--date`.
4. Otherwise, show the index format.
Under `--pretty=oneline`, the commit message is prefixed with this information on the same line. This option cannot be combined with `--reverse`. See also [git-reflog[1]](git-reflog).
Under `--pretty=reference`, this information will not be shown at all.
--merge After a failed merge, show refs that touch files having a conflict and don’t exist on all heads to merge.
--boundary Output excluded boundary commits. Boundary commits are prefixed with `-`.
###
History Simplification
Sometimes you are only interested in parts of the history, for example the commits modifying a particular <path>. But there are two parts of `History Simplification`, one part is selecting the commits and the other is how to do it, as there are various strategies to simplify the history.
The following options select the commits to be shown:
<paths> Commits modifying the given <paths> are selected.
--simplify-by-decoration Commits that are referred by some branch or tag are selected.
Note that extra commits can be shown to give a meaningful history.
The following options affect the way the simplification is performed:
Default mode Simplifies the history to the simplest history explaining the final state of the tree. Simplest because it prunes some side branches if the end result is the same (i.e. merging branches with the same content)
--show-pulls Include all commits from the default mode, but also any merge commits that are not TREESAME to the first parent but are TREESAME to a later parent. This mode is helpful for showing the merge commits that "first introduced" a change to a branch.
--full-history Same as the default mode, but does not prune some history.
--dense Only the selected commits are shown, plus some to have a meaningful history.
--sparse All commits in the simplified history are shown.
--simplify-merges Additional option to `--full-history` to remove some needless merges from the resulting history, as there are no selected commits contributing to this merge.
--ancestry-path[=<commit>] When given a range of commits to display (e.g. `commit1..commit2` or `commit2 ^commit1`), only display commits in that range that are ancestors of <commit>, descendants of <commit>, or <commit> itself. If no commit is specified, use `commit1` (the excluded part of the range) as <commit>. Can be passed multiple times; if so, a commit is included if it is any of the commits given or if it is an ancestor or descendant of one of them.
A more detailed explanation follows.
Suppose you specified `foo` as the <paths>. We shall call commits that modify `foo` !TREESAME, and the rest TREESAME. (In a diff filtered for `foo`, they look different and equal, respectively.)
In the following, we will always refer to the same example history to illustrate the differences between simplification settings. We assume that you are filtering for a file `foo` in this commit graph:
```
.-A---M---N---O---P---Q
/ / / / / /
I B C D E Y
\ / / / / /
`-------------' X
```
The horizontal line of history A---Q is taken to be the first parent of each merge. The commits are:
* `I` is the initial commit, in which `foo` exists with contents “asdf”, and a file `quux` exists with contents “quux”. Initial commits are compared to an empty tree, so `I` is !TREESAME.
* In `A`, `foo` contains just “foo”.
* `B` contains the same change as `A`. Its merge `M` is trivial and hence TREESAME to all parents.
* `C` does not change `foo`, but its merge `N` changes it to “foobar”, so it is not TREESAME to any parent.
* `D` sets `foo` to “baz”. Its merge `O` combines the strings from `N` and `D` to “foobarbaz”; i.e., it is not TREESAME to any parent.
* `E` changes `quux` to “xyzzy”, and its merge `P` combines the strings to “quux xyzzy”. `P` is TREESAME to `O`, but not to `E`.
* `X` is an independent root commit that added a new file `side`, and `Y` modified it. `Y` is TREESAME to `X`. Its merge `Q` added `side` to `P`, and `Q` is TREESAME to `P`, but not to `Y`.
`rev-list` walks backwards through history, including or excluding commits based on whether `--full-history` and/or parent rewriting (via `--parents` or `--children`) are used. The following settings are available.
Default mode Commits are included if they are not TREESAME to any parent (though this can be changed, see `--sparse` below). If the commit was a merge, and it was TREESAME to one parent, follow only that parent. (Even if there are several TREESAME parents, follow only one of them.) Otherwise, follow all parents.
This results in:
```
.-A---N---O
/ / /
I---------D
```
Note how the rule to only follow the TREESAME parent, if one is available, removed `B` from consideration entirely. `C` was considered via `N`, but is TREESAME. Root commits are compared to an empty tree, so `I` is !TREESAME.
Parent/child relations are only visible with `--parents`, but that does not affect the commits selected in default mode, so we have shown the parent lines.
--full-history without parent rewriting This mode differs from the default in one point: always follow all parents of a merge, even if it is TREESAME to one of them. Even if more than one side of the merge has commits that are included, this does not imply that the merge itself is! In the example, we get
```
I A B N D O P Q
```
`M` was excluded because it is TREESAME to both parents. `E`, `C` and `B` were all walked, but only `B` was !TREESAME, so the others do not appear.
Note that without parent rewriting, it is not really possible to talk about the parent/child relationships between the commits, so we show them disconnected.
--full-history with parent rewriting Ordinary commits are only included if they are !TREESAME (though this can be changed, see `--sparse` below).
Merges are always included. However, their parent list is rewritten: Along each parent, prune away commits that are not included themselves. This results in
```
.-A---M---N---O---P---Q
/ / / / /
I B / D /
\ / / / /
`-------------'
```
Compare to `--full-history` without rewriting above. Note that `E` was pruned away because it is TREESAME, but the parent list of P was rewritten to contain `E`'s parent `I`. The same happened for `C` and `N`, and `X`, `Y` and `Q`.
In addition to the above settings, you can change whether TREESAME affects inclusion:
--dense Commits that are walked are included if they are not TREESAME to any parent.
--sparse All commits that are walked are included.
Note that without `--full-history`, this still simplifies merges: if one of the parents is TREESAME, we follow only that one, so the other sides of the merge are never walked.
--simplify-merges First, build a history graph in the same way that `--full-history` with parent rewriting does (see above).
Then simplify each commit `C` to its replacement `C'` in the final history according to the following rules:
* Set `C'` to `C`.
* Replace each parent `P` of `C'` with its simplification `P'`. In the process, drop parents that are ancestors of other parents or that are root commits TREESAME to an empty tree, and remove duplicates, but take care to never drop all parents that we are TREESAME to.
* If after this parent rewriting, `C'` is a root or merge commit (has zero or >1 parents), a boundary commit, or !TREESAME, it remains. Otherwise, it is replaced with its only parent.
The effect of this is best shown by way of comparing to `--full-history` with parent rewriting. The example turns into:
```
.-A---M---N---O
/ / /
I B D
\ / /
`---------'
```
Note the major differences in `N`, `P`, and `Q` over `--full-history`:
* `N`'s parent list had `I` removed, because it is an ancestor of the other parent `M`. Still, `N` remained because it is !TREESAME.
* `P`'s parent list similarly had `I` removed. `P` was then removed completely, because it had one parent and is TREESAME.
* `Q`'s parent list had `Y` simplified to `X`. `X` was then removed, because it was a TREESAME root. `Q` was then removed completely, because it had one parent and is TREESAME.
There is another simplification mode available:
--ancestry-path[=<commit>] Limit the displayed commits to those which are an ancestor of <commit>, or which are a descendant of <commit>, or are <commit> itself.
As an example use case, consider the following commit history:
```
D---E-------F
/ \ \
B---C---G---H---I---J
/ \
A-------K---------------L--M
```
A regular `D..M` computes the set of commits that are ancestors of `M`, but excludes the ones that are ancestors of `D`. This is useful to see what happened to the history leading to `M` since `D`, in the sense that “what does `M` have that did not exist in `D`”. The result in this example would be all the commits, except `A` and `B` (and `D` itself, of course).
When we want to find out what commits in `M` are contaminated with the bug introduced by `D` and need fixing, however, we might want to view only the subset of `D..M` that are actually descendants of `D`, i.e. excluding `C` and `K`. This is exactly what the `--ancestry-path` option does. Applied to the `D..M` range, it results in:
```
E-------F
\ \
G---H---I---J
\
L--M
```
We can also use `--ancestry-path=D` instead of `--ancestry-path` which means the same thing when applied to the `D..M` range but is just more explicit.
If we instead are interested in a given topic within this range, and all commits affected by that topic, we may only want to view the subset of `D..M` which contain that topic in their ancestry path. So, using `--ancestry-path=H D..M` for example would result in:
```
E
\
G---H---I---J
\
L--M
```
Whereas `--ancestry-path=K D..M` would result in
```
K---------------L--M
```
Before discussing another option, `--show-pulls`, we need to create a new example history.
A common problem users face when looking at simplified history is that a commit they know changed a file somehow does not appear in the file’s simplified history. Let’s demonstrate a new example and show how options such as `--full-history` and `--simplify-merges` works in that case:
```
.-A---M-----C--N---O---P
/ / \ \ \/ / /
I B \ R-'`-Z' /
\ / \/ /
\ / /\ /
`---X--' `---Y--'
```
For this example, suppose `I` created `file.txt` which was modified by `A`, `B`, and `X` in different ways. The single-parent commits `C`, `Z`, and `Y` do not change `file.txt`. The merge commit `M` was created by resolving the merge conflict to include both changes from `A` and `B` and hence is not TREESAME to either. The merge commit `R`, however, was created by ignoring the contents of `file.txt` at `M` and taking only the contents of `file.txt` at `X`. Hence, `R` is TREESAME to `X` but not `M`. Finally, the natural merge resolution to create `N` is to take the contents of `file.txt` at `R`, so `N` is TREESAME to `R` but not `C`. The merge commits `O` and `P` are TREESAME to their first parents, but not to their second parents, `Z` and `Y` respectively.
When using the default mode, `N` and `R` both have a TREESAME parent, so those edges are walked and the others are ignored. The resulting history graph is:
```
I---X
```
When using `--full-history`, Git walks every edge. This will discover the commits `A` and `B` and the merge `M`, but also will reveal the merge commits `O` and `P`. With parent rewriting, the resulting graph is:
```
.-A---M--------N---O---P
/ / \ \ \/ / /
I B \ R-'`--' /
\ / \/ /
\ / /\ /
`---X--' `------'
```
Here, the merge commits `O` and `P` contribute extra noise, as they did not actually contribute a change to `file.txt`. They only merged a topic that was based on an older version of `file.txt`. This is a common issue in repositories using a workflow where many contributors work in parallel and merge their topic branches along a single trunk: many unrelated merges appear in the `--full-history` results.
When using the `--simplify-merges` option, the commits `O` and `P` disappear from the results. This is because the rewritten second parents of `O` and `P` are reachable from their first parents. Those edges are removed and then the commits look like single-parent commits that are TREESAME to their parent. This also happens to the commit `N`, resulting in a history view as follows:
```
.-A---M--.
/ / \
I B R
\ / /
\ / /
`---X--'
```
In this view, we see all of the important single-parent changes from `A`, `B`, and `X`. We also see the carefully-resolved merge `M` and the not-so-carefully-resolved merge `R`. This is usually enough information to determine why the commits `A` and `B` "disappeared" from history in the default view. However, there are a few issues with this approach.
The first issue is performance. Unlike any previous option, the `--simplify-merges` option requires walking the entire commit history before returning a single result. This can make the option difficult to use for very large repositories.
The second issue is one of auditing. When many contributors are working on the same repository, it is important which merge commits introduced a change into an important branch. The problematic merge `R` above is not likely to be the merge commit that was used to merge into an important branch. Instead, the merge `N` was used to merge `R` and `X` into the important branch. This commit may have information about why the change `X` came to override the changes from `A` and `B` in its commit message.
--show-pulls In addition to the commits shown in the default history, show each merge commit that is not TREESAME to its first parent but is TREESAME to a later parent.
When a merge commit is included by `--show-pulls`, the merge is treated as if it "pulled" the change from another branch. When using `--show-pulls` on this example (and no other options) the resulting graph is:
```
I---X---R---N
```
Here, the merge commits `R` and `N` are included because they pulled the commits `X` and `R` into the base branch, respectively. These merges are the reason the commits `A` and `B` do not appear in the default history.
When `--show-pulls` is paired with `--simplify-merges`, the graph includes all of the necessary information:
```
.-A---M--. N
/ / \ /
I B R
\ / /
\ / /
`---X--'
```
Notice that since `M` is reachable from `R`, the edge from `N` to `M` was simplified away. However, `N` still appears in the history as an important commit because it "pulled" the change `R` into the main branch.
The `--simplify-by-decoration` option allows you to view only the big picture of the topology of the history, by omitting commits that are not referenced by tags. Commits are marked as !TREESAME (in other words, kept after history simplification rules described above) if (1) they are referenced by tags, or (2) they change the contents of the paths given on the command line. All other commits are marked as TREESAME (subject to be simplified away).
###
Commit Ordering
By default, the commits are shown in reverse chronological order.
--date-order Show no parents before all of its children are shown, but otherwise show commits in the commit timestamp order.
--author-date-order Show no parents before all of its children are shown, but otherwise show commits in the author timestamp order.
--topo-order Show no parents before all of its children are shown, and avoid showing commits on multiple lines of history intermixed.
For example, in a commit history like this:
```
---1----2----4----7
\ \
3----5----6----8---
```
where the numbers denote the order of commit timestamps, `git
rev-list` and friends with `--date-order` show the commits in the timestamp order: 8 7 6 5 4 3 2 1.
With `--topo-order`, they would show 8 6 5 3 7 4 2 1 (or 8 7 4 2 6 5 3 1); some older commits are shown before newer ones in order to avoid showing the commits from two parallel development track mixed together.
--reverse Output the commits chosen to be shown (see Commit Limiting section above) in reverse order. Cannot be combined with `--walk-reflogs`.
###
Object Traversal
These options are mostly targeted for packing of Git repositories.
--no-walk[=(sorted|unsorted)] Only show the given commits, but do not traverse their ancestors. This has no effect if a range is specified. If the argument `unsorted` is given, the commits are shown in the order they were given on the command line. Otherwise (if `sorted` or no argument was given), the commits are shown in reverse chronological order by commit time. Cannot be combined with `--graph`.
--do-walk Overrides a previous `--no-walk`.
###
Commit Formatting
--pretty[=<format>] --format=<format> Pretty-print the contents of the commit logs in a given format, where `<format>` can be one of `oneline`, `short`, `medium`, `full`, `fuller`, `reference`, `email`, `raw`, `format:<string>` and `tformat:<string>`. When `<format>` is none of the above, and has `%placeholder` in it, it acts as if `--pretty=tformat:<format>` were given.
See the "PRETTY FORMATS" section for some additional details for each format. When `=<format>` part is omitted, it defaults to `medium`.
Note: you can specify the default pretty format in the repository configuration (see [git-config[1]](git-config)).
--abbrev-commit Instead of showing the full 40-byte hexadecimal commit object name, show a prefix that names the object uniquely. "--abbrev=<n>" (which also modifies diff output, if it is displayed) option can be used to specify the minimum length of the prefix.
This should make "--pretty=oneline" a whole lot more readable for people using 80-column terminals.
--no-abbrev-commit Show the full 40-byte hexadecimal commit object name. This negates `--abbrev-commit`, either explicit or implied by other options such as "--oneline". It also overrides the `log.abbrevCommit` variable.
--oneline This is a shorthand for "--pretty=oneline --abbrev-commit" used together.
--encoding=<encoding> Commit objects record the character encoding used for the log message in their encoding header; this option can be used to tell the command to re-code the commit log message in the encoding preferred by the user. For non plumbing commands this defaults to UTF-8. Note that if an object claims to be encoded in `X` and we are outputting in `X`, we will output the object verbatim; this means that invalid sequences in the original commit may be copied to the output. Likewise, if iconv(3) fails to convert the commit, we will quietly output the original object verbatim.
--expand-tabs=<n> --expand-tabs --no-expand-tabs Perform a tab expansion (replace each tab with enough spaces to fill to the next display column that is multiple of `<n>`) in the log message before showing it in the output. `--expand-tabs` is a short-hand for `--expand-tabs=8`, and `--no-expand-tabs` is a short-hand for `--expand-tabs=0`, which disables tab expansion.
By default, tabs are expanded in pretty formats that indent the log message by 4 spaces (i.e. `medium`, which is the default, `full`, and `fuller`).
--notes[=<ref>] Show the notes (see [git-notes[1]](git-notes)) that annotate the commit, when showing the commit log message. This is the default for `git log`, `git show` and `git whatchanged` commands when there is no `--pretty`, `--format`, or `--oneline` option given on the command line.
By default, the notes shown are from the notes refs listed in the `core.notesRef` and `notes.displayRef` variables (or corresponding environment overrides). See [git-config[1]](git-config) for more details.
With an optional `<ref>` argument, use the ref to find the notes to display. The ref can specify the full refname when it begins with `refs/notes/`; when it begins with `notes/`, `refs/` and otherwise `refs/notes/` is prefixed to form a full name of the ref.
Multiple --notes options can be combined to control which notes are being displayed. Examples: "--notes=foo" will show only notes from "refs/notes/foo"; "--notes=foo --notes" will show both notes from "refs/notes/foo" and from the default notes ref(s).
--no-notes Do not show notes. This negates the above `--notes` option, by resetting the list of notes refs from which notes are shown. Options are parsed in the order given on the command line, so e.g. "--notes --notes=foo --no-notes --notes=bar" will only show notes from "refs/notes/bar".
--show-notes[=<ref>] --[no-]standard-notes These options are deprecated. Use the above --notes/--no-notes options instead.
--show-signature Check the validity of a signed commit object by passing the signature to `gpg --verify` and show the output.
--relative-date Synonym for `--date=relative`.
--date=<format> Only takes effect for dates shown in human-readable format, such as when using `--pretty`. `log.date` config variable sets a default value for the log command’s `--date` option. By default, dates are shown in the original time zone (either committer’s or author’s). If `-local` is appended to the format (e.g., `iso-local`), the user’s local time zone is used instead.
`--date=relative` shows dates relative to the current time, e.g. “2 hours ago”. The `-local` option has no effect for `--date=relative`.
`--date=local` is an alias for `--date=default-local`.
`--date=iso` (or `--date=iso8601`) shows timestamps in a ISO 8601-like format. The differences to the strict ISO 8601 format are:
* a space instead of the `T` date/time delimiter
* a space between time and time zone
* no colon between hours and minutes of the time zone
`--date=iso-strict` (or `--date=iso8601-strict`) shows timestamps in strict ISO 8601 format.
`--date=rfc` (or `--date=rfc2822`) shows timestamps in RFC 2822 format, often found in email messages.
`--date=short` shows only the date, but not the time, in `YYYY-MM-DD` format.
`--date=raw` shows the date as seconds since the epoch (1970-01-01 00:00:00 UTC), followed by a space, and then the timezone as an offset from UTC (a `+` or `-` with four digits; the first two are hours, and the second two are minutes). I.e., as if the timestamp were formatted with `strftime("%s %z")`). Note that the `-local` option does not affect the seconds-since-epoch value (which is always measured in UTC), but does switch the accompanying timezone value.
`--date=human` shows the timezone if the timezone does not match the current time-zone, and doesn’t print the whole date if that matches (ie skip printing year for dates that are "this year", but also skip the whole date itself if it’s in the last few days and we can just say what weekday it was). For older dates the hour and minute is also omitted.
`--date=unix` shows the date as a Unix epoch timestamp (seconds since 1970). As with `--raw`, this is always in UTC and therefore `-local` has no effect.
`--date=format:...` feeds the format `...` to your system `strftime`, except for %s, %z, and %Z, which are handled internally. Use `--date=format:%c` to show the date in your system locale’s preferred format. See the `strftime` manual for a complete list of format placeholders. When using `-local`, the correct syntax is `--date=format-local:...`.
`--date=default` is the default format, and is similar to `--date=rfc2822`, with a few exceptions:
* there is no comma after the day-of-week
* the time zone is omitted when the local time zone is used
--parents Print also the parents of the commit (in the form "commit parent…"). Also enables parent rewriting, see `History Simplification` above.
--children Print also the children of the commit (in the form "commit child…"). Also enables parent rewriting, see `History Simplification` above.
--left-right Mark which side of a symmetric difference a commit is reachable from. Commits from the left side are prefixed with `<` and those from the right with `>`. If combined with `--boundary`, those commits are prefixed with `-`.
For example, if you have this topology:
```
y---b---b branch B
/ \ /
/ .
/ / \
o---x---a---a branch A
```
you would get an output like this:
```
$ git rev-list --left-right --boundary --pretty=oneline A...B
>bbbbbbb... 3rd on b
>bbbbbbb... 2nd on b
<aaaaaaa... 3rd on a
<aaaaaaa... 2nd on a
-yyyyyyy... 1st on b
-xxxxxxx... 1st on a
```
--graph Draw a text-based graphical representation of the commit history on the left hand side of the output. This may cause extra lines to be printed in between commits, in order for the graph history to be drawn properly. Cannot be combined with `--no-walk`.
This enables parent rewriting, see `History Simplification` above.
This implies the `--topo-order` option by default, but the `--date-order` option may also be specified.
--show-linear-break[=<barrier>] When --graph is not used, all history branches are flattened which can make it hard to see that the two consecutive commits do not belong to a linear branch. This option puts a barrier in between them in that case. If `<barrier>` is specified, it is the string that will be shown instead of the default one.
Pretty formats
--------------
If the commit is a merge, and if the pretty-format is not `oneline`, `email` or `raw`, an additional line is inserted before the `Author:` line. This line begins with "Merge: " and the hashes of ancestral commits are printed, separated by spaces. Note that the listed commits may not necessarily be the list of the **direct** parent commits if you have limited your view of history: for example, if you are only interested in changes related to a certain directory or file.
There are several built-in formats, and you can define additional formats by setting a pretty.<name> config option to either another format name, or a `format:` string, as described below (see [git-config[1]](git-config)). Here are the details of the built-in formats:
* `oneline`
```
<hash> <title-line>
```
This is designed to be as compact as possible.
* `short`
```
commit <hash>
Author: <author>
```
```
<title-line>
```
* `medium`
```
commit <hash>
Author: <author>
Date: <author-date>
```
```
<title-line>
```
```
<full-commit-message>
```
* `full`
```
commit <hash>
Author: <author>
Commit: <committer>
```
```
<title-line>
```
```
<full-commit-message>
```
* `fuller`
```
commit <hash>
Author: <author>
AuthorDate: <author-date>
Commit: <committer>
CommitDate: <committer-date>
```
```
<title-line>
```
```
<full-commit-message>
```
* `reference`
```
<abbrev-hash> (<title-line>, <short-author-date>)
```
This format is used to refer to another commit in a commit message and is the same as `--pretty='format:%C(auto)%h (%s, %ad)'`. By default, the date is formatted with `--date=short` unless another `--date` option is explicitly specified. As with any `format:` with format placeholders, its output is not affected by other options like `--decorate` and `--walk-reflogs`.
* `email`
```
From <hash> <date>
From: <author>
Date: <author-date>
Subject: [PATCH] <title-line>
```
```
<full-commit-message>
```
* `mboxrd`
Like `email`, but lines in the commit message starting with "From " (preceded by zero or more ">") are quoted with ">" so they aren’t confused as starting a new commit.
* `raw`
The `raw` format shows the entire commit exactly as stored in the commit object. Notably, the hashes are displayed in full, regardless of whether --abbrev or --no-abbrev are used, and `parents` information show the true parent commits, without taking grafts or history simplification into account. Note that this format affects the way commits are displayed, but not the way the diff is shown e.g. with `git log --raw`. To get full object names in a raw diff format, use `--no-abbrev`.
* `format:<format-string>`
The `format:<format-string>` format allows you to specify which information you want to show. It works a little bit like printf format, with the notable exception that you get a newline with `%n` instead of `\n`.
E.g, `format:"The author of %h was %an, %ar%nThe title was >>%s<<%n"` would show something like this:
```
The author of fe6e0ee was Junio C Hamano, 23 hours ago
The title was >>t4119: test autocomputing -p<n> for traditional diff input.<<
```
The placeholders are:
+ Placeholders that expand to a single literal character:
*%n* newline
*%%* a raw `%`
*%x00* print a byte from a hex code
+ Placeholders that affect formatting of later placeholders:
*%Cred* switch color to red
*%Cgreen* switch color to green
*%Cblue* switch color to blue
*%Creset* reset color
*%C(…)* color specification, as described under Values in the "CONFIGURATION FILE" section of [git-config[1]](git-config). By default, colors are shown only when enabled for log output (by `color.diff`, `color.ui`, or `--color`, and respecting the `auto` settings of the former if we are going to a terminal). `%C(auto,...)` is accepted as a historical synonym for the default (e.g., `%C(auto,red)`). Specifying `%C(always,...)` will show the colors even when color is not otherwise enabled (though consider just using `--color=always` to enable color for the whole output, including this format and anything else git might color). `auto` alone (i.e. `%C(auto)`) will turn on auto coloring on the next placeholders until the color is switched again.
*%m* left (`<`), right (`>`) or boundary (`-`) mark
*%w([<w>[,<i1>[,<i2>]]])* switch line wrapping, like the -w option of [git-shortlog[1]](git-shortlog).
*%<(<N>[,trunc|ltrunc|mtrunc])* make the next placeholder take at least N columns, padding spaces on the right if necessary. Optionally truncate at the beginning (ltrunc), the middle (mtrunc) or the end (trunc) if the output is longer than N columns. Note that truncating only works correctly with N >= 2.
*%<|(<N>)* make the next placeholder take at least until Nth columns, padding spaces on the right if necessary
*%>(<N>)*, *%>|(<N>)* similar to `%<(<N>)`, `%<|(<N>)` respectively, but padding spaces on the left
*%>>(<N>)*, *%>>|(<N>)* similar to `%>(<N>)`, `%>|(<N>)` respectively, except that if the next placeholder takes more spaces than given and there are spaces on its left, use those spaces
*%><(<N>)*, *%><|(<N>)* similar to `%<(<N>)`, `%<|(<N>)` respectively, but padding both sides (i.e. the text is centered)
+ Placeholders that expand to information extracted from the commit:
*%H* commit hash
*%h* abbreviated commit hash
*%T* tree hash
*%t* abbreviated tree hash
*%P* parent hashes
*%p* abbreviated parent hashes
*%an* author name
*%aN* author name (respecting .mailmap, see [git-shortlog[1]](git-shortlog) or [git-blame[1]](git-blame))
*%ae* author email
*%aE* author email (respecting .mailmap, see [git-shortlog[1]](git-shortlog) or [git-blame[1]](git-blame))
*%al* author email local-part (the part before the `@` sign)
*%aL* author local-part (see `%al`) respecting .mailmap, see [git-shortlog[1]](git-shortlog) or [git-blame[1]](git-blame))
*%ad* author date (format respects --date= option)
*%aD* author date, RFC2822 style
*%ar* author date, relative
*%at* author date, UNIX timestamp
*%ai* author date, ISO 8601-like format
*%aI* author date, strict ISO 8601 format
*%as* author date, short format (`YYYY-MM-DD`)
*%ah* author date, human style (like the `--date=human` option of [git-rev-list[1]](git-rev-list))
*%cn* committer name
*%cN* committer name (respecting .mailmap, see [git-shortlog[1]](git-shortlog) or [git-blame[1]](git-blame))
*%ce* committer email
*%cE* committer email (respecting .mailmap, see [git-shortlog[1]](git-shortlog) or [git-blame[1]](git-blame))
*%cl* committer email local-part (the part before the `@` sign)
*%cL* committer local-part (see `%cl`) respecting .mailmap, see [git-shortlog[1]](git-shortlog) or [git-blame[1]](git-blame))
*%cd* committer date (format respects --date= option)
*%cD* committer date, RFC2822 style
*%cr* committer date, relative
*%ct* committer date, UNIX timestamp
*%ci* committer date, ISO 8601-like format
*%cI* committer date, strict ISO 8601 format
*%cs* committer date, short format (`YYYY-MM-DD`)
*%ch* committer date, human style (like the `--date=human` option of [git-rev-list[1]](git-rev-list))
*%d* ref names, like the --decorate option of [git-log[1]](git-log)
*%D* ref names without the " (", ")" wrapping.
*%(describe[:options])* human-readable name, like [git-describe[1]](git-describe); empty string for undescribable commits. The `describe` string may be followed by a colon and zero or more comma-separated options. Descriptions can be inconsistent when tags are added or removed at the same time.
- `tags[=<bool-value>]`: Instead of only considering annotated tags, consider lightweight tags as well.
- `abbrev=<number>`: Instead of using the default number of hexadecimal digits (which will vary according to the number of objects in the repository with a default of 7) of the abbreviated object name, use <number> digits, or as many digits as needed to form a unique object name.
- `match=<pattern>`: Only consider tags matching the given `glob(7)` pattern, excluding the "refs/tags/" prefix.
- `exclude=<pattern>`: Do not consider tags matching the given `glob(7)` pattern, excluding the "refs/tags/" prefix. *%S* ref name given on the command line by which the commit was reached (like `git log --source`), only works with `git log`
*%e* encoding
*%s* subject
*%f* sanitized subject line, suitable for a filename
*%b* body
*%B* raw body (unwrapped subject and body)
*%N* commit notes
*%GG* raw verification message from GPG for a signed commit
*%G?* show "G" for a good (valid) signature, "B" for a bad signature, "U" for a good signature with unknown validity, "X" for a good signature that has expired, "Y" for a good signature made by an expired key, "R" for a good signature made by a revoked key, "E" if the signature cannot be checked (e.g. missing key) and "N" for no signature
*%GS* show the name of the signer for a signed commit
*%GK* show the key used to sign a signed commit
*%GF* show the fingerprint of the key used to sign a signed commit
*%GP* show the fingerprint of the primary key whose subkey was used to sign a signed commit
*%GT* show the trust level for the key used to sign a signed commit
*%gD* reflog selector, e.g., `refs/stash@{1}` or `refs/stash@{2
minutes ago}`; the format follows the rules described for the `-g` option. The portion before the `@` is the refname as given on the command line (so `git log -g refs/heads/master` would yield `refs/heads/master@{0}`).
*%gd* shortened reflog selector; same as `%gD`, but the refname portion is shortened for human readability (so `refs/heads/master` becomes just `master`).
*%gn* reflog identity name
*%gN* reflog identity name (respecting .mailmap, see [git-shortlog[1]](git-shortlog) or [git-blame[1]](git-blame))
*%ge* reflog identity email
*%gE* reflog identity email (respecting .mailmap, see [git-shortlog[1]](git-shortlog) or [git-blame[1]](git-blame))
*%gs* reflog subject
*%(trailers[:options])* display the trailers of the body as interpreted by [git-interpret-trailers[1]](git-interpret-trailers). The `trailers` string may be followed by a colon and zero or more comma-separated options. If any option is provided multiple times the last occurrence wins.
- `key=<key>`: only show trailers with specified <key>. Matching is done case-insensitively and trailing colon is optional. If option is given multiple times trailer lines matching any of the keys are shown. This option automatically enables the `only` option so that non-trailer lines in the trailer block are hidden. If that is not desired it can be disabled with `only=false`. E.g., `%(trailers:key=Reviewed-by)` shows trailer lines with key `Reviewed-by`.
- `only[=<bool>]`: select whether non-trailer lines from the trailer block should be included.
- `separator=<sep>`: specify a separator inserted between trailer lines. When this option is not given each trailer line is terminated with a line feed character. The string <sep> may contain the literal formatting codes described above. To use comma as separator one must use `%x2C` as it would otherwise be parsed as next option. E.g., `%(trailers:key=Ticket,separator=%x2C )` shows all trailer lines whose key is "Ticket" separated by a comma and a space.
- `unfold[=<bool>]`: make it behave as if interpret-trailer’s `--unfold` option was given. E.g., `%(trailers:only,unfold=true)` unfolds and shows all trailer lines.
- `keyonly[=<bool>]`: only show the key part of the trailer.
- `valueonly[=<bool>]`: only show the value part of the trailer.
- `key_value_separator=<sep>`: specify a separator inserted between trailer lines. When this option is not given each trailer key-value pair is separated by ": ". Otherwise it shares the same semantics as `separator=<sep>` above.
| | |
| --- | --- |
| Note | Some placeholders may depend on other options given to the revision traversal engine. For example, the `%g*` reflog options will insert an empty string unless we are traversing reflog entries (e.g., by `git log -g`). The `%d` and `%D` placeholders will use the "short" decoration format if `--decorate` was not already provided on the command line. |
The boolean options accept an optional value `[=<bool-value>]`. The values `true`, `false`, `on`, `off` etc. are all accepted. See the "boolean" sub-section in "EXAMPLES" in [git-config[1]](git-config). If a boolean option is given with no value, it’s enabled.
If you add a `+` (plus sign) after `%` of a placeholder, a line-feed is inserted immediately before the expansion if and only if the placeholder expands to a non-empty string.
If you add a `-` (minus sign) after `%` of a placeholder, all consecutive line-feeds immediately preceding the expansion are deleted if and only if the placeholder expands to an empty string.
If you add a ` ` (space) after `%` of a placeholder, a space is inserted immediately before the expansion if and only if the placeholder expands to a non-empty string.
* `tformat:`
The `tformat:` format works exactly like `format:`, except that it provides "terminator" semantics instead of "separator" semantics. In other words, each commit has the message terminator character (usually a newline) appended, rather than a separator placed between entries. This means that the final entry of a single-line format will be properly terminated with a new line, just as the "oneline" format does. For example:
```
$ git log -2 --pretty=format:%h 4da45bef \
| perl -pe '$_ .= " -- NO NEWLINE\n" unless /\n/'
4da45be
7134973 -- NO NEWLINE
$ git log -2 --pretty=tformat:%h 4da45bef \
| perl -pe '$_ .= " -- NO NEWLINE\n" unless /\n/'
4da45be
7134973
```
In addition, any unrecognized string that has a `%` in it is interpreted as if it has `tformat:` in front of it. For example, these two are equivalent:
```
$ git log -2 --pretty=tformat:%h 4da45bef
$ git log -2 --pretty=%h 4da45bef
```
Diff formatting
---------------
By default, `git log` does not generate any diff output. The options below can be used to show the changes made by each commit.
Note that unless one of `--diff-merges` variants (including short `-m`, `-c`, and `--cc` options) is explicitly given, merge commits will not show a diff, even if a diff format like `--patch` is selected, nor will they match search options like `-S`. The exception is when `--first-parent` is in use, in which case `first-parent` is the default format.
-p -u --patch Generate patch (see section on generating patches).
-s --no-patch Suppress diff output. Useful for commands like `git show` that show the patch by default, or to cancel the effect of `--patch`.
--diff-merges=(off|none|on|first-parent|1|separate|m|combined|c|dense-combined|cc|remerge|r) --no-diff-merges Specify diff format to be used for merge commits. Default is `off` unless `--first-parent` is in use, in which case `first-parent` is the default.
--diff-merges=(off|none) --no-diff-merges Disable output of diffs for merge commits. Useful to override implied value.
--diff-merges=on --diff-merges=m -m This option makes diff output for merge commits to be shown in the default format. `-m` will produce the output only if `-p` is given as well. The default format could be changed using `log.diffMerges` configuration parameter, which default value is `separate`.
--diff-merges=first-parent --diff-merges=1 This option makes merge commits show the full diff with respect to the first parent only.
--diff-merges=separate This makes merge commits show the full diff with respect to each of the parents. Separate log entry and diff is generated for each parent.
--diff-merges=remerge --diff-merges=r --remerge-diff With this option, two-parent merge commits are remerged to create a temporary tree object — potentially containing files with conflict markers and such. A diff is then shown between that temporary tree and the actual merge commit.
The output emitted when this option is used is subject to change, and so is its interaction with other options (unless explicitly documented).
--diff-merges=combined --diff-merges=c -c With this option, diff output for a merge commit shows the differences from each of the parents to the merge result simultaneously instead of showing pairwise diff between a parent and the result one at a time. Furthermore, it lists only files which were modified from all parents. `-c` implies `-p`.
--diff-merges=dense-combined --diff-merges=cc --cc With this option the output produced by `--diff-merges=combined` is further compressed by omitting uninteresting hunks whose contents in the parents have only two variants and the merge result picks one of them without modification. `--cc` implies `-p`.
--combined-all-paths This flag causes combined diffs (used for merge commits) to list the name of the file from all parents. It thus only has effect when `--diff-merges=[dense-]combined` is in use, and is likely only useful if filename changes are detected (i.e. when either rename or copy detection have been requested).
-U<n> --unified=<n> Generate diffs with <n> lines of context instead of the usual three. Implies `--patch`.
--output=<file> Output to a specific file instead of stdout.
--output-indicator-new=<char> --output-indicator-old=<char> --output-indicator-context=<char> Specify the character used to indicate new, old or context lines in the generated patch. Normally they are `+`, `-` and ' ' respectively.
--raw For each commit, show a summary of changes using the raw diff format. See the "RAW OUTPUT FORMAT" section of [git-diff[1]](git-diff). This is different from showing the log itself in raw format, which you can achieve with `--format=raw`.
--patch-with-raw Synonym for `-p --raw`.
-t Show the tree objects in the diff output.
--indent-heuristic Enable the heuristic that shifts diff hunk boundaries to make patches easier to read. This is the default.
--no-indent-heuristic Disable the indent heuristic.
--minimal Spend extra time to make sure the smallest possible diff is produced.
--patience Generate a diff using the "patience diff" algorithm.
--histogram Generate a diff using the "histogram diff" algorithm.
--anchored=<text> Generate a diff using the "anchored diff" algorithm.
This option may be specified more than once.
If a line exists in both the source and destination, exists only once, and starts with this text, this algorithm attempts to prevent it from appearing as a deletion or addition in the output. It uses the "patience diff" algorithm internally.
--diff-algorithm={patience|minimal|histogram|myers} Choose a diff algorithm. The variants are as follows:
`default`, `myers` The basic greedy diff algorithm. Currently, this is the default.
`minimal` Spend extra time to make sure the smallest possible diff is produced.
`patience` Use "patience diff" algorithm when generating patches.
`histogram` This algorithm extends the patience algorithm to "support low-occurrence common elements".
For instance, if you configured the `diff.algorithm` variable to a non-default value and want to use the default one, then you have to use `--diff-algorithm=default` option.
--stat[=<width>[,<name-width>[,<count>]]] Generate a diffstat. By default, as much space as necessary will be used for the filename part, and the rest for the graph part. Maximum width defaults to terminal width, or 80 columns if not connected to a terminal, and can be overridden by `<width>`. The width of the filename part can be limited by giving another width `<name-width>` after a comma. The width of the graph part can be limited by using `--stat-graph-width=<width>` (affects all commands generating a stat graph) or by setting `diff.statGraphWidth=<width>` (does not affect `git format-patch`). By giving a third parameter `<count>`, you can limit the output to the first `<count>` lines, followed by `...` if there are more.
These parameters can also be set individually with `--stat-width=<width>`, `--stat-name-width=<name-width>` and `--stat-count=<count>`.
--compact-summary Output a condensed summary of extended header information such as file creations or deletions ("new" or "gone", optionally "+l" if it’s a symlink) and mode changes ("+x" or "-x" for adding or removing executable bit respectively) in diffstat. The information is put between the filename part and the graph part. Implies `--stat`.
--numstat Similar to `--stat`, but shows number of added and deleted lines in decimal notation and pathname without abbreviation, to make it more machine friendly. For binary files, outputs two `-` instead of saying `0 0`.
--shortstat Output only the last line of the `--stat` format containing total number of modified files, as well as number of added and deleted lines.
-X[<param1,param2,…>] --dirstat[=<param1,param2,…>] Output the distribution of relative amount of changes for each sub-directory. The behavior of `--dirstat` can be customized by passing it a comma separated list of parameters. The defaults are controlled by the `diff.dirstat` configuration variable (see [git-config[1]](git-config)). The following parameters are available:
`changes` Compute the dirstat numbers by counting the lines that have been removed from the source, or added to the destination. This ignores the amount of pure code movements within a file. In other words, rearranging lines in a file is not counted as much as other changes. This is the default behavior when no parameter is given.
`lines` Compute the dirstat numbers by doing the regular line-based diff analysis, and summing the removed/added line counts. (For binary files, count 64-byte chunks instead, since binary files have no natural concept of lines). This is a more expensive `--dirstat` behavior than the `changes` behavior, but it does count rearranged lines within a file as much as other changes. The resulting output is consistent with what you get from the other `--*stat` options.
`files` Compute the dirstat numbers by counting the number of files changed. Each changed file counts equally in the dirstat analysis. This is the computationally cheapest `--dirstat` behavior, since it does not have to look at the file contents at all.
`cumulative` Count changes in a child directory for the parent directory as well. Note that when using `cumulative`, the sum of the percentages reported may exceed 100%. The default (non-cumulative) behavior can be specified with the `noncumulative` parameter.
<limit> An integer parameter specifies a cut-off percent (3% by default). Directories contributing less than this percentage of the changes are not shown in the output.
Example: The following will count changed files, while ignoring directories with less than 10% of the total amount of changed files, and accumulating child directory counts in the parent directories: `--dirstat=files,10,cumulative`.
--cumulative Synonym for --dirstat=cumulative
--dirstat-by-file[=<param1,param2>…] Synonym for --dirstat=files,param1,param2…
--summary Output a condensed summary of extended header information such as creations, renames and mode changes.
--patch-with-stat Synonym for `-p --stat`.
-z Separate the commits with NULs instead of with new newlines.
Also, when `--raw` or `--numstat` has been given, do not munge pathnames and use NULs as output field terminators.
Without this option, pathnames with "unusual" characters are quoted as explained for the configuration variable `core.quotePath` (see [git-config[1]](git-config)).
--name-only Show only names of changed files. The file names are often encoded in UTF-8. For more information see the discussion about encoding in the [git-log[1]](git-log) manual page.
--name-status Show only names and status of changed files. See the description of the `--diff-filter` option on what the status letters mean. Just like `--name-only` the file names are often encoded in UTF-8.
--submodule[=<format>] Specify how differences in submodules are shown. When specifying `--submodule=short` the `short` format is used. This format just shows the names of the commits at the beginning and end of the range. When `--submodule` or `--submodule=log` is specified, the `log` format is used. This format lists the commits in the range like [git-submodule[1]](git-submodule) `summary` does. When `--submodule=diff` is specified, the `diff` format is used. This format shows an inline diff of the changes in the submodule contents between the commit range. Defaults to `diff.submodule` or the `short` format if the config option is unset.
--color[=<when>] Show colored diff. `--color` (i.e. without `=<when>`) is the same as `--color=always`. `<when>` can be one of `always`, `never`, or `auto`.
--no-color Turn off colored diff. It is the same as `--color=never`.
--color-moved[=<mode>] Moved lines of code are colored differently. The <mode> defaults to `no` if the option is not given and to `zebra` if the option with no mode is given. The mode must be one of:
no Moved lines are not highlighted.
default Is a synonym for `zebra`. This may change to a more sensible mode in the future.
plain Any line that is added in one location and was removed in another location will be colored with `color.diff.newMoved`. Similarly `color.diff.oldMoved` will be used for removed lines that are added somewhere else in the diff. This mode picks up any moved line, but it is not very useful in a review to determine if a block of code was moved without permutation.
blocks Blocks of moved text of at least 20 alphanumeric characters are detected greedily. The detected blocks are painted using either the `color.diff.{old,new}Moved` color. Adjacent blocks cannot be told apart.
zebra Blocks of moved text are detected as in `blocks` mode. The blocks are painted using either the `color.diff.{old,new}Moved` color or `color.diff.{old,new}MovedAlternative`. The change between the two colors indicates that a new block was detected.
dimmed-zebra Similar to `zebra`, but additional dimming of uninteresting parts of moved code is performed. The bordering lines of two adjacent blocks are considered interesting, the rest is uninteresting. `dimmed_zebra` is a deprecated synonym.
--no-color-moved Turn off move detection. This can be used to override configuration settings. It is the same as `--color-moved=no`.
--color-moved-ws=<modes> This configures how whitespace is ignored when performing the move detection for `--color-moved`. These modes can be given as a comma separated list:
no Do not ignore whitespace when performing move detection.
ignore-space-at-eol Ignore changes in whitespace at EOL.
ignore-space-change Ignore changes in amount of whitespace. This ignores whitespace at line end, and considers all other sequences of one or more whitespace characters to be equivalent.
ignore-all-space Ignore whitespace when comparing lines. This ignores differences even if one line has whitespace where the other line has none.
allow-indentation-change Initially ignore any whitespace in the move detection, then group the moved code blocks only into a block if the change in whitespace is the same per line. This is incompatible with the other modes.
--no-color-moved-ws Do not ignore whitespace when performing move detection. This can be used to override configuration settings. It is the same as `--color-moved-ws=no`.
--word-diff[=<mode>] Show a word diff, using the <mode> to delimit changed words. By default, words are delimited by whitespace; see `--word-diff-regex` below. The <mode> defaults to `plain`, and must be one of:
color Highlight changed words using only colors. Implies `--color`.
plain Show words as `[-removed-]` and `{+added+}`. Makes no attempts to escape the delimiters if they appear in the input, so the output may be ambiguous.
porcelain Use a special line-based format intended for script consumption. Added/removed/unchanged runs are printed in the usual unified diff format, starting with a `+`/`-`/` ` character at the beginning of the line and extending to the end of the line. Newlines in the input are represented by a tilde `~` on a line of its own.
none Disable word diff again.
Note that despite the name of the first mode, color is used to highlight the changed parts in all modes if enabled.
--word-diff-regex=<regex> Use <regex> to decide what a word is, instead of considering runs of non-whitespace to be a word. Also implies `--word-diff` unless it was already enabled.
Every non-overlapping match of the <regex> is considered a word. Anything between these matches is considered whitespace and ignored(!) for the purposes of finding differences. You may want to append `|[^[:space:]]` to your regular expression to make sure that it matches all non-whitespace characters. A match that contains a newline is silently truncated(!) at the newline.
For example, `--word-diff-regex=.` will treat each character as a word and, correspondingly, show differences character by character.
The regex can also be set via a diff driver or configuration option, see [gitattributes[5]](gitattributes) or [git-config[1]](git-config). Giving it explicitly overrides any diff driver or configuration setting. Diff drivers override configuration settings.
--color-words[=<regex>] Equivalent to `--word-diff=color` plus (if a regex was specified) `--word-diff-regex=<regex>`.
--no-renames Turn off rename detection, even when the configuration file gives the default to do so.
--[no-]rename-empty Whether to use empty blobs as rename source.
--check Warn if changes introduce conflict markers or whitespace errors. What are considered whitespace errors is controlled by `core.whitespace` configuration. By default, trailing whitespaces (including lines that consist solely of whitespaces) and a space character that is immediately followed by a tab character inside the initial indent of the line are considered whitespace errors. Exits with non-zero status if problems are found. Not compatible with --exit-code.
--ws-error-highlight=<kind> Highlight whitespace errors in the `context`, `old` or `new` lines of the diff. Multiple values are separated by comma, `none` resets previous values, `default` reset the list to `new` and `all` is a shorthand for `old,new,context`. When this option is not given, and the configuration variable `diff.wsErrorHighlight` is not set, only whitespace errors in `new` lines are highlighted. The whitespace errors are colored with `color.diff.whitespace`.
--full-index Instead of the first handful of characters, show the full pre- and post-image blob object names on the "index" line when generating patch format output.
--binary In addition to `--full-index`, output a binary diff that can be applied with `git-apply`. Implies `--patch`.
--abbrev[=<n>] Instead of showing the full 40-byte hexadecimal object name in diff-raw format output and diff-tree header lines, show the shortest prefix that is at least `<n>` hexdigits long that uniquely refers the object. In diff-patch output format, `--full-index` takes higher precedence, i.e. if `--full-index` is specified, full blob names will be shown regardless of `--abbrev`. Non default number of digits can be specified with `--abbrev=<n>`.
-B[<n>][/<m>] --break-rewrites[=[<n>][/<m>]] Break complete rewrite changes into pairs of delete and create. This serves two purposes:
It affects the way a change that amounts to a total rewrite of a file not as a series of deletion and insertion mixed together with a very few lines that happen to match textually as the context, but as a single deletion of everything old followed by a single insertion of everything new, and the number `m` controls this aspect of the -B option (defaults to 60%). `-B/70%` specifies that less than 30% of the original should remain in the result for Git to consider it a total rewrite (i.e. otherwise the resulting patch will be a series of deletion and insertion mixed together with context lines).
When used with -M, a totally-rewritten file is also considered as the source of a rename (usually -M only considers a file that disappeared as the source of a rename), and the number `n` controls this aspect of the -B option (defaults to 50%). `-B20%` specifies that a change with addition and deletion compared to 20% or more of the file’s size are eligible for being picked up as a possible source of a rename to another file.
-M[<n>] --find-renames[=<n>] If generating diffs, detect and report renames for each commit. For following files across renames while traversing history, see `--follow`. If `n` is specified, it is a threshold on the similarity index (i.e. amount of addition/deletions compared to the file’s size). For example, `-M90%` means Git should consider a delete/add pair to be a rename if more than 90% of the file hasn’t changed. Without a `%` sign, the number is to be read as a fraction, with a decimal point before it. I.e., `-M5` becomes 0.5, and is thus the same as `-M50%`. Similarly, `-M05` is the same as `-M5%`. To limit detection to exact renames, use `-M100%`. The default similarity index is 50%.
-C[<n>] --find-copies[=<n>] Detect copies as well as renames. See also `--find-copies-harder`. If `n` is specified, it has the same meaning as for `-M<n>`.
--find-copies-harder For performance reasons, by default, `-C` option finds copies only if the original file of the copy was modified in the same changeset. This flag makes the command inspect unmodified files as candidates for the source of copy. This is a very expensive operation for large projects, so use it with caution. Giving more than one `-C` option has the same effect.
-D --irreversible-delete Omit the preimage for deletes, i.e. print only the header but not the diff between the preimage and `/dev/null`. The resulting patch is not meant to be applied with `patch` or `git apply`; this is solely for people who want to just concentrate on reviewing the text after the change. In addition, the output obviously lacks enough information to apply such a patch in reverse, even manually, hence the name of the option.
When used together with `-B`, omit also the preimage in the deletion part of a delete/create pair.
-l<num> The `-M` and `-C` options involve some preliminary steps that can detect subsets of renames/copies cheaply, followed by an exhaustive fallback portion that compares all remaining unpaired destinations to all relevant sources. (For renames, only remaining unpaired sources are relevant; for copies, all original sources are relevant.) For N sources and destinations, this exhaustive check is O(N^2). This option prevents the exhaustive portion of rename/copy detection from running if the number of source/destination files involved exceeds the specified number. Defaults to diff.renameLimit. Note that a value of 0 is treated as unlimited.
--diff-filter=[(A|C|D|M|R|T|U|X|B)…[\*]] Select only files that are Added (`A`), Copied (`C`), Deleted (`D`), Modified (`M`), Renamed (`R`), have their type (i.e. regular file, symlink, submodule, …) changed (`T`), are Unmerged (`U`), are Unknown (`X`), or have had their pairing Broken (`B`). Any combination of the filter characters (including none) can be used. When `*` (All-or-none) is added to the combination, all paths are selected if there is any file that matches other criteria in the comparison; if there is no file that matches other criteria, nothing is selected.
Also, these upper-case letters can be downcased to exclude. E.g. `--diff-filter=ad` excludes added and deleted paths.
Note that not all diffs can feature all types. For instance, copied and renamed entries cannot appear if detection for those types is disabled.
-S<string> Look for differences that change the number of occurrences of the specified string (i.e. addition/deletion) in a file. Intended for the scripter’s use.
It is useful when you’re looking for an exact block of code (like a struct), and want to know the history of that block since it first came into being: use the feature iteratively to feed the interesting block in the preimage back into `-S`, and keep going until you get the very first version of the block.
Binary files are searched as well.
-G<regex> Look for differences whose patch text contains added/removed lines that match <regex>.
To illustrate the difference between `-S<regex> --pickaxe-regex` and `-G<regex>`, consider a commit with the following diff in the same file:
```
+ return frotz(nitfol, two->ptr, 1, 0);
...
- hit = frotz(nitfol, mf2.ptr, 1, 0);
```
While `git log -G"frotz\(nitfol"` will show this commit, `git log
-S"frotz\(nitfol" --pickaxe-regex` will not (because the number of occurrences of that string did not change).
Unless `--text` is supplied patches of binary files without a textconv filter will be ignored.
See the `pickaxe` entry in [gitdiffcore[7]](gitdiffcore) for more information.
--find-object=<object-id> Look for differences that change the number of occurrences of the specified object. Similar to `-S`, just the argument is different in that it doesn’t search for a specific string but for a specific object id.
The object can be a blob or a submodule commit. It implies the `-t` option in `git-log` to also find trees.
--pickaxe-all When `-S` or `-G` finds a change, show all the changes in that changeset, not just the files that contain the change in <string>.
--pickaxe-regex Treat the <string> given to `-S` as an extended POSIX regular expression to match.
-O<orderfile> Control the order in which files appear in the output. This overrides the `diff.orderFile` configuration variable (see [git-config[1]](git-config)). To cancel `diff.orderFile`, use `-O/dev/null`.
The output order is determined by the order of glob patterns in <orderfile>. All files with pathnames that match the first pattern are output first, all files with pathnames that match the second pattern (but not the first) are output next, and so on. All files with pathnames that do not match any pattern are output last, as if there was an implicit match-all pattern at the end of the file. If multiple pathnames have the same rank (they match the same pattern but no earlier patterns), their output order relative to each other is the normal order.
<orderfile> is parsed as follows:
* Blank lines are ignored, so they can be used as separators for readability.
* Lines starting with a hash ("`#`") are ignored, so they can be used for comments. Add a backslash ("`\`") to the beginning of the pattern if it starts with a hash.
* Each other line contains a single pattern.
Patterns have the same syntax and semantics as patterns used for fnmatch(3) without the FNM\_PATHNAME flag, except a pathname also matches a pattern if removing any number of the final pathname components matches the pattern. For example, the pattern "`foo*bar`" matches "`fooasdfbar`" and "`foo/bar/baz/asdf`" but not "`foobarx`".
--skip-to=<file> --rotate-to=<file> Discard the files before the named <file> from the output (i.e. `skip to`), or move them to the end of the output (i.e. `rotate to`). These were invented primarily for use of the `git difftool` command, and may not be very useful otherwise.
-R Swap two inputs; that is, show differences from index or on-disk file to tree contents.
--relative[=<path>] --no-relative When run from a subdirectory of the project, it can be told to exclude changes outside the directory and show pathnames relative to it with this option. When you are not in a subdirectory (e.g. in a bare repository), you can name which subdirectory to make the output relative to by giving a <path> as an argument. `--no-relative` can be used to countermand both `diff.relative` config option and previous `--relative`.
-a --text Treat all files as text.
--ignore-cr-at-eol Ignore carriage-return at the end of line when doing a comparison.
--ignore-space-at-eol Ignore changes in whitespace at EOL.
-b --ignore-space-change Ignore changes in amount of whitespace. This ignores whitespace at line end, and considers all other sequences of one or more whitespace characters to be equivalent.
-w --ignore-all-space Ignore whitespace when comparing lines. This ignores differences even if one line has whitespace where the other line has none.
--ignore-blank-lines Ignore changes whose lines are all blank.
-I<regex> --ignore-matching-lines=<regex> Ignore changes whose all lines match <regex>. This option may be specified more than once.
--inter-hunk-context=<lines> Show the context between diff hunks, up to the specified number of lines, thereby fusing hunks that are close to each other. Defaults to `diff.interHunkContext` or 0 if the config option is unset.
-W --function-context Show whole function as context lines for each change. The function names are determined in the same way as `git diff` works out patch hunk headers (see `Defining a custom hunk-header` in [gitattributes[5]](gitattributes)).
--ext-diff Allow an external diff helper to be executed. If you set an external diff driver with [gitattributes[5]](gitattributes), you need to use this option with [git-log[1]](git-log) and friends.
--no-ext-diff Disallow external diff drivers.
--textconv --no-textconv Allow (or disallow) external text conversion filters to be run when comparing binary files. See [gitattributes[5]](gitattributes) for details. Because textconv filters are typically a one-way conversion, the resulting diff is suitable for human consumption, but cannot be applied. For this reason, textconv filters are enabled by default only for [git-diff[1]](git-diff) and [git-log[1]](git-log), but not for [git-format-patch[1]](git-format-patch) or diff plumbing commands.
--ignore-submodules[=<when>] Ignore changes to submodules in the diff generation. <when> can be either "none", "untracked", "dirty" or "all", which is the default. Using "none" will consider the submodule modified when it either contains untracked or modified files or its HEAD differs from the commit recorded in the superproject and can be used to override any settings of the `ignore` option in [git-config[1]](git-config) or [gitmodules[5]](gitmodules). When "untracked" is used submodules are not considered dirty when they only contain untracked content (but they are still scanned for modified content). Using "dirty" ignores all changes to the work tree of submodules, only changes to the commits stored in the superproject are shown (this was the behavior until 1.7.0). Using "all" hides all changes to submodules.
--src-prefix=<prefix> Show the given source prefix instead of "a/".
--dst-prefix=<prefix> Show the given destination prefix instead of "b/".
--no-prefix Do not show any source or destination prefix.
--line-prefix=<prefix> Prepend an additional prefix to every line of output.
--ita-invisible-in-index By default entries added by "git add -N" appear as an existing empty file in "git diff" and a new file in "git diff --cached". This option makes the entry appear as a new file in "git diff" and non-existent in "git diff --cached". This option could be reverted with `--ita-visible-in-index`. Both options are experimental and could be removed in future.
For more detailed explanation on these common options, see also [gitdiffcore[7]](gitdiffcore).
Generating patch text with -p
-----------------------------
Running [git-diff[1]](git-diff), [git-log[1]](git-log), [git-show[1]](git-show), [git-diff-index[1]](git-diff-index), [git-diff-tree[1]](git-diff-tree), or [git-diff-files[1]](git-diff-files) with the `-p` option produces patch text. You can customize the creation of patch text via the `GIT_EXTERNAL_DIFF` and the `GIT_DIFF_OPTS` environment variables (see [git[1]](git)), and the `diff` attribute (see [gitattributes[5]](gitattributes)).
What the -p option produces is slightly different from the traditional diff format:
1. It is preceded with a "git diff" header that looks like this:
```
diff --git a/file1 b/file2
```
The `a/` and `b/` filenames are the same unless rename/copy is involved. Especially, even for a creation or a deletion, `/dev/null` is `not` used in place of the `a/` or `b/` filenames.
When rename/copy is involved, `file1` and `file2` show the name of the source file of the rename/copy and the name of the file that rename/copy produces, respectively.
2. It is followed by one or more extended header lines:
```
old mode <mode>
new mode <mode>
deleted file mode <mode>
new file mode <mode>
copy from <path>
copy to <path>
rename from <path>
rename to <path>
similarity index <number>
dissimilarity index <number>
index <hash>..<hash> <mode>
```
File modes are printed as 6-digit octal numbers including the file type and file permission bits.
Path names in extended headers do not include the `a/` and `b/` prefixes.
The similarity index is the percentage of unchanged lines, and the dissimilarity index is the percentage of changed lines. It is a rounded down integer, followed by a percent sign. The similarity index value of 100% is thus reserved for two equal files, while 100% dissimilarity means that no line from the old file made it into the new one.
The index line includes the blob object names before and after the change. The <mode> is included if the file mode does not change; otherwise, separate lines indicate the old and the new mode.
3. Pathnames with "unusual" characters are quoted as explained for the configuration variable `core.quotePath` (see [git-config[1]](git-config)).
4. All the `file1` files in the output refer to files before the commit, and all the `file2` files refer to files after the commit. It is incorrect to apply each change to each file sequentially. For example, this patch will swap a and b:
```
diff --git a/a b/b
rename from a
rename to b
diff --git a/b b/a
rename from b
rename to a
```
5. Hunk headers mention the name of the function to which the hunk applies. See "Defining a custom hunk-header" in [gitattributes[5]](gitattributes) for details of how to tailor to this to specific languages.
Combined diff format
--------------------
Any diff-generating command can take the `-c` or `--cc` option to produce a `combined diff` when showing a merge. This is the default format when showing merges with [git-diff[1]](git-diff) or [git-show[1]](git-show). Note also that you can give suitable `--diff-merges` option to any of these commands to force generation of diffs in specific format.
A "combined diff" format looks like this:
```
diff --combined describe.c
index fabadb8,cc95eb0..4866510
--- a/describe.c
+++ b/describe.c
@@@ -98,20 -98,12 +98,20 @@@
return (a_date > b_date) ? -1 : (a_date == b_date) ? 0 : 1;
}
- static void describe(char *arg)
-static void describe(struct commit *cmit, int last_one)
++static void describe(char *arg, int last_one)
{
+ unsigned char sha1[20];
+ struct commit *cmit;
struct commit_list *list;
static int initialized = 0;
struct commit_name *n;
+ if (get_sha1(arg, sha1) < 0)
+ usage(describe_usage);
+ cmit = lookup_commit_reference(sha1);
+ if (!cmit)
+ usage(describe_usage);
+
if (!initialized) {
initialized = 1;
for_each_ref(get_name);
```
1. It is preceded with a "git diff" header, that looks like this (when the `-c` option is used):
```
diff --combined file
```
or like this (when the `--cc` option is used):
```
diff --cc file
```
2. It is followed by one or more extended header lines (this example shows a merge with two parents):
```
index <hash>,<hash>..<hash>
mode <mode>,<mode>..<mode>
new file mode <mode>
deleted file mode <mode>,<mode>
```
The `mode <mode>,<mode>..<mode>` line appears only if at least one of the <mode> is different from the rest. Extended headers with information about detected contents movement (renames and copying detection) are designed to work with diff of two <tree-ish> and are not used by combined diff format.
3. It is followed by two-line from-file/to-file header
```
--- a/file
+++ b/file
```
Similar to two-line header for traditional `unified` diff format, `/dev/null` is used to signal created or deleted files.
However, if the --combined-all-paths option is provided, instead of a two-line from-file/to-file you get a N+1 line from-file/to-file header, where N is the number of parents in the merge commit
```
--- a/file
--- a/file
--- a/file
+++ b/file
```
This extended format can be useful if rename or copy detection is active, to allow you to see the original name of the file in different parents.
4. Chunk header format is modified to prevent people from accidentally feeding it to `patch -p1`. Combined diff format was created for review of merge commit changes, and was not meant to be applied. The change is similar to the change in the extended `index` header:
```
@@@ <from-file-range> <from-file-range> <to-file-range> @@@
```
There are (number of parents + 1) `@` characters in the chunk header for combined diff format.
Unlike the traditional `unified` diff format, which shows two files A and B with a single column that has `-` (minus — appears in A but removed in B), `+` (plus — missing in A but added to B), or `" "` (space — unchanged) prefix, this format compares two or more files file1, file2,… with one file X, and shows how X differs from each of fileN. One column for each of fileN is prepended to the output line to note how X’s line is different from it.
A `-` character in the column N means that the line appears in fileN but it does not appear in the result. A `+` character in the column N means that the line appears in the result, and fileN does not have that line (in other words, the line was added, from the point of view of that parent).
In the above example output, the function signature was changed from both files (hence two `-` removals from both file1 and file2, plus `++` to mean one line that was added does not appear in either file1 or file2). Also eight other lines are the same from file1 but do not appear in file2 (hence prefixed with `+`).
When shown by `git diff-tree -c`, it compares the parents of a merge commit with the merge result (i.e. file1..fileN are the parents). When shown by `git diff-files -c`, it compares the two unresolved merge parents with the working tree file (i.e. file1 is stage 2 aka "our version", file2 is stage 3 aka "their version").
Examples
--------
`git log --no-merges` Show the whole commit history, but skip any merges
`git log v2.6.12.. include/scsi drivers/scsi` Show all commits since version `v2.6.12` that changed any file in the `include/scsi` or `drivers/scsi` subdirectories
`git log --since="2 weeks ago" -- gitk` Show the changes during the last two weeks to the file `gitk`. The `--` is necessary to avoid confusion with the **branch** named `gitk`
`git log --name-status release..test` Show the commits that are in the "test" branch but not yet in the "release" branch, along with the list of paths each commit modifies.
`git log --follow builtin/rev-list.c` Shows the commits that changed `builtin/rev-list.c`, including those commits that occurred before the file was given its present name.
`git log --branches --not --remotes=origin` Shows all commits that are in any of local branches but not in any of remote-tracking branches for `origin` (what you have that origin doesn’t).
`git log master --not --remotes=*/master` Shows all commits that are in local master but not in any remote repository master branches.
`git log -p -m --first-parent` Shows the history including change diffs, but only from the “main branch” perspective, skipping commits that come from merged branches, and showing full diffs of changes introduced by the merges. This makes sense only when following a strict policy of merging all topic branches when staying on a single integration branch.
`git log -L '/int main/',/^}/:main.c` Shows how the function `main()` in the file `main.c` evolved over time.
`git log -3` Limits the number of commits to show to 3.
Discussion
----------
Git is to some extent character encoding agnostic.
* The contents of the blob objects are uninterpreted sequences of bytes. There is no encoding translation at the core level.
* Path names are encoded in UTF-8 normalization form C. This applies to tree objects, the index file, ref names, as well as path names in command line arguments, environment variables and config files (`.git/config` (see [git-config[1]](git-config)), [gitignore[5]](gitignore), [gitattributes[5]](gitattributes) and [gitmodules[5]](gitmodules)).
Note that Git at the core level treats path names simply as sequences of non-NUL bytes, there are no path name encoding conversions (except on Mac and Windows). Therefore, using non-ASCII path names will mostly work even on platforms and file systems that use legacy extended ASCII encodings. However, repositories created on such systems will not work properly on UTF-8-based systems (e.g. Linux, Mac, Windows) and vice versa. Additionally, many Git-based tools simply assume path names to be UTF-8 and will fail to display other encodings correctly.
* Commit log messages are typically encoded in UTF-8, but other extended ASCII encodings are also supported. This includes ISO-8859-x, CP125x and many others, but `not` UTF-16/32, EBCDIC and CJK multi-byte encodings (GBK, Shift-JIS, Big5, EUC-x, CP9xx etc.).
Although we encourage that the commit log messages are encoded in UTF-8, both the core and Git Porcelain are designed not to force UTF-8 on projects. If all participants of a particular project find it more convenient to use legacy encodings, Git does not forbid it. However, there are a few things to keep in mind.
1. `git commit` and `git commit-tree` issues a warning if the commit log message given to it does not look like a valid UTF-8 string, unless you explicitly say your project uses a legacy encoding. The way to say this is to have `i18n.commitEncoding` in `.git/config` file, like this:
```
[i18n]
commitEncoding = ISO-8859-1
```
Commit objects created with the above setting record the value of `i18n.commitEncoding` in its `encoding` header. This is to help other people who look at them later. Lack of this header implies that the commit log message is encoded in UTF-8.
2. `git log`, `git show`, `git blame` and friends look at the `encoding` header of a commit object, and try to re-code the log message into UTF-8 unless otherwise specified. You can specify the desired output encoding with `i18n.logOutputEncoding` in `.git/config` file, like this:
```
[i18n]
logOutputEncoding = ISO-8859-1
```
If you do not have this configuration variable, the value of `i18n.commitEncoding` is used instead.
Note that we deliberately chose not to re-code the commit log message when a commit is made to force UTF-8 at the commit object level, because re-coding to UTF-8 is not necessarily a reversible operation.
Configuration
-------------
See [git-config[1]](git-config) for core variables and [git-diff[1]](git-diff) for settings related to diff generation.
format.pretty Default for the `--format` option. (See `Pretty Formats` above.) Defaults to `medium`.
i18n.logOutputEncoding Encoding to use when displaying logs. (See `Discussion` above.) Defaults to the value of `i18n.commitEncoding` if set, and UTF-8 otherwise.
Everything above this line in this section isn’t included from the [git-config[1]](git-config) documentation. The content that follows is the same as what’s found there:
log.abbrevCommit If true, makes [git-log[1]](git-log), [git-show[1]](git-show), and [git-whatchanged[1]](git-whatchanged) assume `--abbrev-commit`. You may override this option with `--no-abbrev-commit`.
log.date Set the default date-time mode for the `log` command. Setting a value for log.date is similar to using `git log`'s `--date` option. See [git-log[1]](git-log) for details.
If the format is set to "auto:foo" and the pager is in use, format "foo" will be the used for the date format. Otherwise "default" will be used.
log.decorate Print out the ref names of any commits that are shown by the log command. If `short` is specified, the ref name prefixes `refs/heads/`, `refs/tags/` and `refs/remotes/` will not be printed. If `full` is specified, the full ref name (including prefix) will be printed. If `auto` is specified, then if the output is going to a terminal, the ref names are shown as if `short` were given, otherwise no ref names are shown. This is the same as the `--decorate` option of the `git log`.
log.initialDecorationSet By default, `git log` only shows decorations for certain known ref namespaces. If `all` is specified, then show all refs as decorations.
log.excludeDecoration Exclude the specified patterns from the log decorations. This is similar to the `--decorate-refs-exclude` command-line option, but the config option can be overridden by the `--decorate-refs` option.
log.diffMerges Set diff format to be used when `--diff-merges=on` is specified, see `--diff-merges` in [git-log[1]](git-log) for details. Defaults to `separate`.
log.follow If `true`, `git log` will act as if the `--follow` option was used when a single <path> is given. This has the same limitations as `--follow`, i.e. it cannot be used to follow multiple files and does not work well on non-linear history.
log.graphColors A list of colors, separated by commas, that can be used to draw history lines in `git log --graph`.
log.showRoot If true, the initial commit will be shown as a big creation event. This is equivalent to a diff against an empty tree. Tools like [git-log[1]](git-log) or [git-whatchanged[1]](git-whatchanged), which normally hide the root commit will now show it. True by default.
log.showSignature If true, makes [git-log[1]](git-log), [git-show[1]](git-show), and [git-whatchanged[1]](git-whatchanged) assume `--show-signature`.
log.mailmap If true, makes [git-log[1]](git-log), [git-show[1]](git-show), and [git-whatchanged[1]](git-whatchanged) assume `--use-mailmap`, otherwise assume `--no-use-mailmap`. True by default.
notes.mergeStrategy Which merge strategy to choose by default when resolving notes conflicts. Must be one of `manual`, `ours`, `theirs`, `union`, or `cat_sort_uniq`. Defaults to `manual`. See "NOTES MERGE STRATEGIES" section of [git-notes[1]](git-notes) for more information on each strategy.
This setting can be overridden by passing the `--strategy` option to [git-notes[1]](git-notes).
notes.<name>.mergeStrategy Which merge strategy to choose when doing a notes merge into refs/notes/<name>. This overrides the more general "notes.mergeStrategy". See the "NOTES MERGE STRATEGIES" section in [git-notes[1]](git-notes) for more information on the available strategies.
notes.displayRef Which ref (or refs, if a glob or specified more than once), in addition to the default set by `core.notesRef` or `GIT_NOTES_REF`, to read notes from when showing commit messages with the `git log` family of commands.
This setting can be overridden with the `GIT_NOTES_DISPLAY_REF` environment variable, which must be a colon separated list of refs or globs.
A warning will be issued for refs that do not exist, but a glob that does not match any refs is silently ignored.
This setting can be disabled by the `--no-notes` option to the `git log` family of commands, or by the `--notes=<ref>` option accepted by those commands.
The effective value of "core.notesRef" (possibly overridden by GIT\_NOTES\_REF) is also implicitly added to the list of refs to be displayed.
notes.rewrite.<command> When rewriting commits with <command> (currently `amend` or `rebase`), if this variable is `false`, git will not copy notes from the original to the rewritten commit. Defaults to `true`. See also "`notes.rewriteRef`" below.
This setting can be overridden with the `GIT_NOTES_REWRITE_REF` environment variable, which must be a colon separated list of refs or globs.
notes.rewriteMode When copying notes during a rewrite (see the "notes.rewrite.<command>" option), determines what to do if the target commit already has a note. Must be one of `overwrite`, `concatenate`, `cat_sort_uniq`, or `ignore`. Defaults to `concatenate`.
This setting can be overridden with the `GIT_NOTES_REWRITE_MODE` environment variable.
notes.rewriteRef When copying notes during a rewrite, specifies the (fully qualified) ref whose notes should be copied. May be a glob, in which case notes in all matching refs will be copied. You may also specify this configuration several times.
Does not have a default value; you must configure this variable to enable note rewriting. Set it to `refs/notes/commits` to enable rewriting for the default commit notes.
Can be overridden with the `GIT_NOTES_REWRITE_REF` environment variable. See `notes.rewrite.<command>` above for a further description of its format.
| programming_docs |
git git-describe git-describe
============
Name
----
git-describe - Give an object a human readable name based on an available ref
Synopsis
--------
```
git describe [--all] [--tags] [--contains] [--abbrev=<n>] [<commit-ish>…]
git describe [--all] [--tags] [--contains] [--abbrev=<n>] --dirty[=<mark>]
git describe <blob>
```
Description
-----------
The command finds the most recent tag that is reachable from a commit. If the tag points to the commit, then only the tag is shown. Otherwise, it suffixes the tag name with the number of additional commits on top of the tagged object and the abbreviated object name of the most recent commit. The result is a "human-readable" object name which can also be used to identify the commit to other git commands.
By default (without --all or --tags) `git describe` only shows annotated tags. For more information about creating annotated tags see the -a and -s options to [git-tag[1]](git-tag).
If the given object refers to a blob, it will be described as `<commit-ish>:<path>`, such that the blob can be found at `<path>` in the `<commit-ish>`, which itself describes the first commit in which this blob occurs in a reverse revision walk from HEAD.
Options
-------
<commit-ish>… Commit-ish object names to describe. Defaults to HEAD if omitted.
--dirty[=<mark>] --broken[=<mark>] Describe the state of the working tree. When the working tree matches HEAD, the output is the same as "git describe HEAD". If the working tree has local modification "-dirty" is appended to it. If a repository is corrupt and Git cannot determine if there is local modification, Git will error out, unless ‘--broken’ is given, which appends the suffix "-broken" instead.
--all Instead of using only the annotated tags, use any ref found in `refs/` namespace. This option enables matching any known branch, remote-tracking branch, or lightweight tag.
--tags Instead of using only the annotated tags, use any tag found in `refs/tags` namespace. This option enables matching a lightweight (non-annotated) tag.
--contains Instead of finding the tag that predates the commit, find the tag that comes after the commit, and thus contains it. Automatically implies --tags.
--abbrev=<n> Instead of using the default number of hexadecimal digits (which will vary according to the number of objects in the repository with a default of 7) of the abbreviated object name, use <n> digits, or as many digits as needed to form a unique object name. An <n> of 0 will suppress long format, only showing the closest tag.
--candidates=<n> Instead of considering only the 10 most recent tags as candidates to describe the input commit-ish consider up to <n> candidates. Increasing <n> above 10 will take slightly longer but may produce a more accurate result. An <n> of 0 will cause only exact matches to be output.
--exact-match Only output exact matches (a tag directly references the supplied commit). This is a synonym for --candidates=0.
--debug Verbosely display information about the searching strategy being employed to standard error. The tag name will still be printed to standard out.
--long Always output the long format (the tag, the number of commits and the abbreviated commit name) even when it matches a tag. This is useful when you want to see parts of the commit object name in "describe" output, even when the commit in question happens to be a tagged version. Instead of just emitting the tag name, it will describe such a commit as v1.2-0-gdeadbee (0th commit since tag v1.2 that points at object deadbee….).
--match <pattern> Only consider tags matching the given `glob(7)` pattern, excluding the "refs/tags/" prefix. If used with `--all`, it also considers local branches and remote-tracking references matching the pattern, excluding respectively "refs/heads/" and "refs/remotes/" prefix; references of other types are never considered. If given multiple times, a list of patterns will be accumulated, and tags matching any of the patterns will be considered. Use `--no-match` to clear and reset the list of patterns.
--exclude <pattern> Do not consider tags matching the given `glob(7)` pattern, excluding the "refs/tags/" prefix. If used with `--all`, it also does not consider local branches and remote-tracking references matching the pattern, excluding respectively "refs/heads/" and "refs/remotes/" prefix; references of other types are never considered. If given multiple times, a list of patterns will be accumulated and tags matching any of the patterns will be excluded. When combined with --match a tag will be considered when it matches at least one --match pattern and does not match any of the --exclude patterns. Use `--no-exclude` to clear and reset the list of patterns.
--always Show uniquely abbreviated commit object as fallback.
--first-parent Follow only the first parent commit upon seeing a merge commit. This is useful when you wish to not match tags on branches merged in the history of the target commit.
Examples
--------
With something like git.git current tree, I get:
```
[torvalds@g5 git]$ git describe parent
v1.0.4-14-g2414721
```
i.e. the current head of my "parent" branch is based on v1.0.4, but since it has a few commits on top of that, describe has added the number of additional commits ("14") and an abbreviated object name for the commit itself ("2414721") at the end.
The number of additional commits is the number of commits which would be displayed by "git log v1.0.4..parent". The hash suffix is "-g" + an unambigous abbreviation for the tip commit of parent (which was `2414721b194453f058079d897d13c4e377f92dc6`). The length of the abbreviation scales as the repository grows, using the approximate number of objects in the repository and a bit of math around the birthday paradox, and defaults to a minimum of 7. The "g" prefix stands for "git" and is used to allow describing the version of a software depending on the SCM the software is managed with. This is useful in an environment where people may use different SCMs.
Doing a `git describe` on a tag-name will just show the tag name:
```
[torvalds@g5 git]$ git describe v1.0.4
v1.0.4
```
With --all, the command can use branch heads as references, so the output shows the reference path as well:
```
[torvalds@g5 git]$ git describe --all --abbrev=4 v1.0.5^2
tags/v1.0.0-21-g975b
```
```
[torvalds@g5 git]$ git describe --all --abbrev=4 HEAD^
heads/lt/describe-7-g975b
```
With --abbrev set to 0, the command can be used to find the closest tagname without any suffix:
```
[torvalds@g5 git]$ git describe --abbrev=0 v1.0.5^2
tags/v1.0.0
```
Note that the suffix you get if you type these commands today may be longer than what Linus saw above when he ran these commands, as your Git repository may have new commits whose object names begin with 975b that did not exist back then, and "-g975b" suffix alone may not be sufficient to disambiguate these commits.
Search strategy
---------------
For each commit-ish supplied, `git describe` will first look for a tag which tags exactly that commit. Annotated tags will always be preferred over lightweight tags, and tags with newer dates will always be preferred over tags with older dates. If an exact match is found, its name will be output and searching will stop.
If an exact match was not found, `git describe` will walk back through the commit history to locate an ancestor commit which has been tagged. The ancestor’s tag will be output along with an abbreviation of the input commit-ish’s SHA-1. If `--first-parent` was specified then the walk will only consider the first parent of each commit.
If multiple tags were found during the walk then the tag which has the fewest commits different from the input commit-ish will be selected and output. Here fewest commits different is defined as the number of commits which would be shown by `git log tag..input` will be the smallest number of commits possible.
Bugs
----
Tree objects as well as tag objects not pointing at commits, cannot be described. When describing blobs, the lightweight tags pointing at blobs are ignored, but the blob is still described as <committ-ish>:<path> despite the lightweight tag being favorable.
git git-help git-help
========
Name
----
git-help - Display help information about Git
Synopsis
--------
```
git help [-a|--all] [--[no-]verbose] [--[no-]external-commands] [--[no-]aliases]
git help [[-i|--info] [-m|--man] [-w|--web]] [<command>|<doc>]
git help [-g|--guides]
git help [-c|--config]
git help [--user-interfaces]
git help [--developer-interfaces]
```
Description
-----------
With no options and no `<command>` or `<doc>` given, the synopsis of the `git` command and a list of the most commonly used Git commands are printed on the standard output.
If the option `--all` or `-a` is given, all available commands are printed on the standard output.
If the option `--guides` or `-g` is given, a list of the Git concept guides is also printed on the standard output.
If a command or other documentation is given, the relevant manual page will be brought up. The `man` program is used by default for this purpose, but this can be overridden by other options or configuration variables.
If an alias is given, git shows the definition of the alias on standard output. To get the manual page for the aliased command, use `git <command> --help`.
Note that `git --help ...` is identical to `git help ...` because the former is internally converted into the latter.
To display the [git[1]](git) man page, use `git help git`.
This page can be displayed with `git help help` or `git help --help`
Options
-------
-a --all Prints all the available commands on the standard output.
--no-external-commands When used with `--all`, exclude the listing of external "git-\*" commands found in the `$PATH`.
--no-aliases When used with `--all`, exclude the listing of configured aliases.
--verbose When used with `--all` print description for all recognized commands. This is the default.
-c --config List all available configuration variables. This is a short summary of the list in [git-config[1]](git-config).
-g --guides Prints a list of the Git concept guides on the standard output.
--user-interfaces Prints a list of the repository, command and file interfaces documentation on the standard output.
In-repository file interfaces such as `.git/info/exclude` are documented here (see [gitrepository-layout[5]](gitrepository-layout)), as well as in-tree configuration such as `.mailmap` (see [gitmailmap[5]](gitmailmap)).
This section of the documentation also covers general or widespread user-interface conventions (e.g. [gitcli[7]](gitcli)), and pseudo-configuration such as the file-based `.git/hooks/*` interface described in [githooks[5]](githooks).
--developer-interfaces Print list of file formats, protocols and other developer interfaces documentation on the standard output.
-i --info Display manual page for the command in the `info` format. The `info` program will be used for that purpose.
-m --man Display manual page for the command in the `man` format. This option may be used to override a value set in the `help.format` configuration variable.
By default the `man` program will be used to display the manual page, but the `man.viewer` configuration variable may be used to choose other display programs (see below).
-w --web Display manual page for the command in the `web` (HTML) format. A web browser will be used for that purpose.
The web browser can be specified using the configuration variable `help.browser`, or `web.browser` if the former is not set. If none of these config variables is set, the `git web--browse` helper script (called by `git help`) will pick a suitable default. See [git-web--browse[1]](git-web--browse) for more information about this.
Configuration variables
-----------------------
###
help.format
If no command-line option is passed, the `help.format` configuration variable will be checked. The following values are supported for this variable; they make `git help` behave as their corresponding command- line option:
* "man" corresponds to `-m|--man`,
* "info" corresponds to `-i|--info`,
* "web" or "html" correspond to `-w|--web`.
###
help.browser, web.browser and browser.<tool>.path
The `help.browser`, `web.browser` and `browser.<tool>.path` will also be checked if the `web` format is chosen (either by command-line option or configuration variable). See `-w|--web` in the OPTIONS section above and [git-web--browse[1]](git-web--browse).
###
man.viewer
The `man.viewer` configuration variable will be checked if the `man` format is chosen. The following values are currently supported:
* "man": use the `man` program as usual,
* "woman": use `emacsclient` to launch the "woman" mode in emacs (this only works starting with emacsclient versions 22),
* "konqueror": use `kfmclient` to open the man page in a new konqueror tab (see `Note about konqueror` below).
Values for other tools can be used if there is a corresponding `man.<tool>.cmd` configuration entry (see below).
Multiple values may be given to the `man.viewer` configuration variable. Their corresponding programs will be tried in the order listed in the configuration file.
For example, this configuration:
```
[man]
viewer = konqueror
viewer = woman
```
will try to use konqueror first. But this may fail (for example, if DISPLAY is not set) and in that case emacs' woman mode will be tried.
If everything fails, or if no viewer is configured, the viewer specified in the `GIT_MAN_VIEWER` environment variable will be tried. If that fails too, the `man` program will be tried anyway.
###
man.<tool>.path
You can explicitly provide a full path to your preferred man viewer by setting the configuration variable `man.<tool>.path`. For example, you can configure the absolute path to konqueror by setting `man.konqueror.path`. Otherwise, `git help` assumes the tool is available in PATH.
###
man.<tool>.cmd
When the man viewer, specified by the `man.viewer` configuration variables, is not among the supported ones, then the corresponding `man.<tool>.cmd` configuration variable will be looked up. If this variable exists then the specified tool will be treated as a custom command and a shell eval will be used to run the command with the man page passed as arguments.
###
Note about konqueror
When `konqueror` is specified in the `man.viewer` configuration variable, we launch `kfmclient` to try to open the man page on an already opened konqueror in a new tab if possible.
For consistency, we also try such a trick if `man.konqueror.path` is set to something like `A_PATH_TO/konqueror`. That means we will try to launch `A_PATH_TO/kfmclient` instead.
If you really want to use `konqueror`, then you can use something like the following:
```
[man]
viewer = konq
[man "konq"]
cmd = A_PATH_TO/konqueror
```
###
Note about git config --global
Note that all these configuration variables should probably be set using the `--global` flag, for example like this:
```
$ git config --global help.format web
$ git config --global web.browser firefox
```
as they are probably more user specific than repository specific. See [git-config[1]](git-config) for more information about this.
git gitformat-commit-graph gitformat-commit-graph
======================
Name
----
gitformat-commit-graph - Git commit-graph format
Synopsis
--------
```
$GIT_DIR/objects/info/commit-graph
$GIT_DIR/objects/info/commit-graphs/*
```
Description
-----------
The Git commit-graph stores a list of commit OIDs and some associated metadata, including:
* The generation number of the commit.
* The root tree OID.
* The commit date.
* The parents of the commit, stored using positional references within the graph file.
* The Bloom filter of the commit carrying the paths that were changed between the commit and its first parent, if requested.
These positional references are stored as unsigned 32-bit integers corresponding to the array position within the list of commit OIDs. Due to some special constants we use to track parents, we can store at most (1 << 30) + (1 << 29) + (1 << 28) - 1 (around 1.8 billion) commits.
Commit-graph files have the following format:
---------------------------------------------
In order to allow extensions that add extra data to the graph, we organize the body into "chunks" and provide a binary lookup table at the beginning of the body. The header includes certain values, such as number of chunks and hash type.
All multi-byte numbers are in network byte order.
###
HEADER:
```
4-byte signature:
The signature is: {'C', 'G', 'P', 'H'}
```
```
1-byte version number:
Currently, the only valid version is 1.
```
```
1-byte Hash Version
We infer the hash length (H) from this value:
1 => SHA-1
2 => SHA-256
If the hash type does not match the repository's hash algorithm, the
commit-graph file should be ignored with a warning presented to the
user.
```
```
1-byte number (C) of "chunks"
```
```
1-byte number (B) of base commit-graphs
We infer the length (H*B) of the Base Graphs chunk
from this value.
```
###
CHUNK LOOKUP:
```
(C + 1) * 12 bytes listing the table of contents for the chunks:
First 4 bytes describe the chunk id. Value 0 is a terminating label.
Other 8 bytes provide the byte-offset in current file for chunk to
start. (Chunks are ordered contiguously in the file, so you can infer
the length using the next chunk position if necessary.) Each chunk
ID appears at most once.
```
```
The CHUNK LOOKUP matches the table of contents from
the chunk-based file format, see gitformat-chunk[5]
```
```
The remaining data in the body is described one chunk at a time, and
these chunks may be given in any order. Chunks are required unless
otherwise specified.
```
###
CHUNK DATA:
####
OID Fanout (ID: {*O*, *I*, *D*, *F*}) (256 \* 4 bytes)
```
The ith entry, F[i], stores the number of OIDs with first
byte at most i. Thus F[255] stores the total
number of commits (N).
```
####
OID Lookup (ID: {*O*, *I*, *D*, *L*}) (N \* H bytes)
```
The OIDs for all commits in the graph, sorted in ascending order.
```
####
Commit Data (ID: {*C*, *D*, *A*, *T* }) (N \* (H + 16) bytes)
* The first H bytes are for the OID of the root tree.
* The next 8 bytes are for the positions of the first two parents of the ith commit. Stores value 0x70000000 if no parent in that position. If there are more than two parents, the second value has its most-significant bit on and the other bits store an array position into the Extra Edge List chunk.
* The next 8 bytes store the topological level (generation number v1) of the commit and the commit time in seconds since EPOCH. The generation number uses the higher 30 bits of the first 4 bytes, while the commit time uses the 32 bits of the second 4 bytes, along with the lowest 2 bits of the lowest byte, storing the 33rd and 34th bit of the commit time.
####
Generation Data (ID: {*G*, *D*, *A*, *2* }) (N \* 4 bytes) [Optional]
* This list of 4-byte values store corrected commit date offsets for the commits, arranged in the same order as commit data chunk.
* If the corrected commit date offset cannot be stored within 31 bits, the value has its most-significant bit on and the other bits store the position of corrected commit date into the Generation Data Overflow chunk.
* Generation Data chunk is present only when commit-graph file is written by compatible versions of Git and in case of split commit-graph chains, the topmost layer also has Generation Data chunk.
####
Generation Data Overflow (ID: {*G*, *D*, *O*, *2* }) [Optional]
* This list of 8-byte values stores the corrected commit date offsets for commits with corrected commit date offsets that cannot be stored within 31 bits.
* Generation Data Overflow chunk is present only when Generation Data chunk is present and atleast one corrected commit date offset cannot be stored within 31 bits.
####
Extra Edge List (ID: {*E*, *D*, *G*, *E*}) [Optional]
```
This list of 4-byte values store the second through nth parents for
all octopus merges. The second parent value in the commit data stores
an array position within this list along with the most-significant bit
on. Starting at that array position, iterate through this list of commit
positions for the parents until reaching a value with the most-significant
bit on. The other bits correspond to the position of the last parent.
```
####
Bloom Filter Index (ID: {*B*, *I*, *D*, *X*}) (N \* 4 bytes) [Optional]
* The ith entry, BIDX[i], stores the number of bytes in all Bloom filters from commit 0 to commit i (inclusive) in lexicographic order. The Bloom filter for the i-th commit spans from BIDX[i-1] to BIDX[i] (plus header length), where BIDX[-1] is 0.
* The BIDX chunk is ignored if the BDAT chunk is not present.
####
Bloom Filter Data (ID: {*B*, *D*, *A*, *T*}) [Optional]
* It starts with header consisting of three unsigned 32-bit integers:
+ Version of the hash algorithm being used. We currently only support value 1 which corresponds to the 32-bit version of the murmur3 hash implemented exactly as described in <https://en.wikipedia.org/wiki/MurmurHash#Algorithm> and the double hashing technique using seed values 0x293ae76f and 0x7e646e2 as described in <https://doi.org/10.1007/978-3-540-30494-4_26> "Bloom Filters in Probabilistic Verification"
+ The number of times a path is hashed and hence the number of bit positions that cumulatively determine whether a file is present in the commit.
+ The minimum number of bits `b` per entry in the Bloom filter. If the filter contains `n` entries, then the filter size is the minimum number of 64-bit words that contain n\*b bits.
* The rest of the chunk is the concatenation of all the computed Bloom filters for the commits in lexicographic order.
* Note: Commits with no changes or more than 512 changes have Bloom filters of length one, with either all bits set to zero or one respectively.
* The BDAT chunk is present if and only if BIDX is present.
####
Base Graphs List (ID: {*B*, *A*, *S*, *E*}) [Optional]
```
This list of H-byte hashes describe a set of B commit-graph files that
form a commit-graph chain. The graph position for the ith commit in this
file's OID Lookup chunk is equal to i plus the number of commits in all
base graphs. If B is non-zero, this chunk must exist.
```
###
TRAILER:
```
H-byte HASH-checksum of all of the above.
```
Historical notes:
-----------------
The Generation Data (GDA2) and Generation Data Overflow (GDO2) chunks have the number `2` in their chunk IDs because a previous version of Git wrote possibly erroneous data in these chunks with the IDs "GDAT" and "GDOV". By changing the IDs, newer versions of Git will silently ignore those older chunks and write the new information without trusting the incorrect data.
| programming_docs |
git git-pull git-pull
========
Name
----
git-pull - Fetch from and integrate with another repository or a local branch
Synopsis
--------
```
git pull [<options>] [<repository> [<refspec>…]]
```
Description
-----------
Incorporates changes from a remote repository into the current branch. If the current branch is behind the remote, then by default it will fast-forward the current branch to match the remote. If the current branch and the remote have diverged, the user needs to specify how to reconcile the divergent branches with `--rebase` or `--no-rebase` (or the corresponding configuration option in `pull.rebase`).
More precisely, `git pull` runs `git fetch` with the given parameters and then depending on configuration options or command line flags, will call either `git rebase` or `git merge` to reconcile diverging branches.
<repository> should be the name of a remote repository as passed to [git-fetch[1]](git-fetch). <refspec> can name an arbitrary remote ref (for example, the name of a tag) or even a collection of refs with corresponding remote-tracking branches (e.g., refs/heads/\*:refs/remotes/origin/\*), but usually it is the name of a branch in the remote repository.
Default values for <repository> and <branch> are read from the "remote" and "merge" configuration for the current branch as set by [git-branch[1]](git-branch) `--track`.
Assume the following history exists and the current branch is "`master`":
```
A---B---C master on origin
/
D---E---F---G master
^
origin/master in your repository
```
Then "`git pull`" will fetch and replay the changes from the remote `master` branch since it diverged from the local `master` (i.e., `E`) until its current commit (`C`) on top of `master` and record the result in a new commit along with the names of the two parent commits and a log message from the user describing the changes.
```
A---B---C origin/master
/ \
D---E---F---G---H master
```
See [git-merge[1]](git-merge) for details, including how conflicts are presented and handled.
In Git 1.7.0 or later, to cancel a conflicting merge, use `git reset --merge`. **Warning**: In older versions of Git, running `git pull` with uncommitted changes is discouraged: while possible, it leaves you in a state that may be hard to back out of in the case of a conflict.
If any of the remote changes overlap with local uncommitted changes, the merge will be automatically canceled and the work tree untouched. It is generally best to get any local changes in working order before pulling or stash them away with [git-stash[1]](git-stash).
Options
-------
-q --quiet This is passed to both underlying git-fetch to squelch reporting of during transfer, and underlying git-merge to squelch output during merging.
-v --verbose Pass --verbose to git-fetch and git-merge.
--[no-]recurse-submodules[=yes|on-demand|no] This option controls if new commits of populated submodules should be fetched, and if the working trees of active submodules should be updated, too (see [git-fetch[1]](git-fetch), [git-config[1]](git-config) and [gitmodules[5]](gitmodules)).
If the checkout is done via rebase, local submodule commits are rebased as well.
If the update is done via merge, the submodule conflicts are resolved and checked out.
###
Options related to merging
--commit --no-commit Perform the merge and commit the result. This option can be used to override --no-commit. Only useful when merging.
With --no-commit perform the merge and stop just before creating a merge commit, to give the user a chance to inspect and further tweak the merge result before committing.
Note that fast-forward updates do not create a merge commit and therefore there is no way to stop those merges with --no-commit. Thus, if you want to ensure your branch is not changed or updated by the merge command, use --no-ff with --no-commit.
--edit -e --no-edit Invoke an editor before committing successful mechanical merge to further edit the auto-generated merge message, so that the user can explain and justify the merge. The `--no-edit` option can be used to accept the auto-generated message (this is generally discouraged).
Older scripts may depend on the historical behaviour of not allowing the user to edit the merge log message. They will see an editor opened when they run `git merge`. To make it easier to adjust such scripts to the updated behaviour, the environment variable `GIT_MERGE_AUTOEDIT` can be set to `no` at the beginning of them.
--cleanup=<mode> This option determines how the merge message will be cleaned up before committing. See [git-commit[1]](git-commit) for more details. In addition, if the `<mode>` is given a value of `scissors`, scissors will be appended to `MERGE_MSG` before being passed on to the commit machinery in the case of a merge conflict.
--ff-only Only update to the new history if there is no divergent local history. This is the default when no method for reconciling divergent histories is provided (via the --rebase=\* flags).
--ff --no-ff When merging rather than rebasing, specifies how a merge is handled when the merged-in history is already a descendant of the current history. If merging is requested, `--ff` is the default unless merging an annotated (and possibly signed) tag that is not stored in its natural place in the `refs/tags/` hierarchy, in which case `--no-ff` is assumed.
With `--ff`, when possible resolve the merge as a fast-forward (only update the branch pointer to match the merged branch; do not create a merge commit). When not possible (when the merged-in history is not a descendant of the current history), create a merge commit.
With `--no-ff`, create a merge commit in all cases, even when the merge could instead be resolved as a fast-forward.
-S[<keyid>] --gpg-sign[=<keyid>] --no-gpg-sign GPG-sign the resulting merge commit. The `keyid` argument is optional and defaults to the committer identity; if specified, it must be stuck to the option without a space. `--no-gpg-sign` is useful to countermand both `commit.gpgSign` configuration variable, and earlier `--gpg-sign`.
--log[=<n>] --no-log In addition to branch names, populate the log message with one-line descriptions from at most <n> actual commits that are being merged. See also [git-fmt-merge-msg[1]](git-fmt-merge-msg). Only useful when merging.
With --no-log do not list one-line descriptions from the actual commits being merged.
--signoff --no-signoff Add a `Signed-off-by` trailer by the committer at the end of the commit log message. The meaning of a signoff depends on the project to which you’re committing. For example, it may certify that the committer has the rights to submit the work under the project’s license or agrees to some contributor representation, such as a Developer Certificate of Origin. (See <http://developercertificate.org> for the one used by the Linux kernel and Git projects.) Consult the documentation or leadership of the project to which you’re contributing to understand how the signoffs are used in that project.
The --no-signoff option can be used to countermand an earlier --signoff option on the command line.
--stat -n --no-stat Show a diffstat at the end of the merge. The diffstat is also controlled by the configuration option merge.stat.
With -n or --no-stat do not show a diffstat at the end of the merge.
--squash --no-squash Produce the working tree and index state as if a real merge happened (except for the merge information), but do not actually make a commit, move the `HEAD`, or record `$GIT_DIR/MERGE_HEAD` (to cause the next `git commit` command to create a merge commit). This allows you to create a single commit on top of the current branch whose effect is the same as merging another branch (or more in case of an octopus).
With --no-squash perform the merge and commit the result. This option can be used to override --squash.
With --squash, --commit is not allowed, and will fail.
Only useful when merging.
--[no-]verify By default, the pre-merge and commit-msg hooks are run. When `--no-verify` is given, these are bypassed. See also [githooks[5]](githooks). Only useful when merging.
-s <strategy> --strategy=<strategy> Use the given merge strategy; can be supplied more than once to specify them in the order they should be tried. If there is no `-s` option, a built-in list of strategies is used instead (`ort` when merging a single head, `octopus` otherwise).
-X <option> --strategy-option=<option> Pass merge strategy specific option through to the merge strategy.
--verify-signatures --no-verify-signatures Verify that the tip commit of the side branch being merged is signed with a valid key, i.e. a key that has a valid uid: in the default trust model, this means the signing key has been signed by a trusted key. If the tip commit of the side branch is not signed with a valid key, the merge is aborted.
Only useful when merging.
--summary --no-summary Synonyms to --stat and --no-stat; these are deprecated and will be removed in the future.
--autostash --no-autostash Automatically create a temporary stash entry before the operation begins, record it in the special ref `MERGE_AUTOSTASH` and apply it after the operation ends. This means that you can run the operation on a dirty worktree. However, use with care: the final stash application after a successful merge might result in non-trivial conflicts.
--allow-unrelated-histories By default, `git merge` command refuses to merge histories that do not share a common ancestor. This option can be used to override this safety when merging histories of two projects that started their lives independently. As that is a very rare occasion, no configuration variable to enable this by default exists and will not be added.
Only useful when merging.
-r --rebase[=false|true|merges|interactive] When true, rebase the current branch on top of the upstream branch after fetching. If there is a remote-tracking branch corresponding to the upstream branch and the upstream branch was rebased since last fetched, the rebase uses that information to avoid rebasing non-local changes.
When set to `merges`, rebase using `git rebase --rebase-merges` so that the local merge commits are included in the rebase (see [git-rebase[1]](git-rebase) for details).
When false, merge the upstream branch into the current branch.
When `interactive`, enable the interactive mode of rebase.
See `pull.rebase`, `branch.<name>.rebase` and `branch.autoSetupRebase` in [git-config[1]](git-config) if you want to make `git pull` always use `--rebase` instead of merging.
| | |
| --- | --- |
| Note | This is a potentially *dangerous* mode of operation. It rewrites history, which does not bode well when you published that history already. Do **not** use this option unless you have read [git-rebase[1]](git-rebase) carefully. |
--no-rebase This is shorthand for --rebase=false.
###
Options related to fetching
--all Fetch all remotes.
-a --append Append ref names and object names of fetched refs to the existing contents of `.git/FETCH_HEAD`. Without this option old data in `.git/FETCH_HEAD` will be overwritten.
--atomic Use an atomic transaction to update local refs. Either all refs are updated, or on error, no refs are updated.
--depth=<depth> Limit fetching to the specified number of commits from the tip of each remote branch history. If fetching to a `shallow` repository created by `git clone` with `--depth=<depth>` option (see [git-clone[1]](git-clone)), deepen or shorten the history to the specified number of commits. Tags for the deepened commits are not fetched.
--deepen=<depth> Similar to --depth, except it specifies the number of commits from the current shallow boundary instead of from the tip of each remote branch history.
--shallow-since=<date> Deepen or shorten the history of a shallow repository to include all reachable commits after <date>.
--shallow-exclude=<revision> Deepen or shorten the history of a shallow repository to exclude commits reachable from a specified remote branch or tag. This option can be specified multiple times.
--unshallow If the source repository is complete, convert a shallow repository to a complete one, removing all the limitations imposed by shallow repositories.
If the source repository is shallow, fetch as much as possible so that the current repository has the same history as the source repository.
--update-shallow By default when fetching from a shallow repository, `git fetch` refuses refs that require updating .git/shallow. This option updates .git/shallow and accept such refs.
--negotiation-tip=<commit|glob> By default, Git will report, to the server, commits reachable from all local refs to find common commits in an attempt to reduce the size of the to-be-received packfile. If specified, Git will only report commits reachable from the given tips. This is useful to speed up fetches when the user knows which local ref is likely to have commits in common with the upstream ref being fetched.
This option may be specified more than once; if so, Git will report commits reachable from any of the given commits.
The argument to this option may be a glob on ref names, a ref, or the (possibly abbreviated) SHA-1 of a commit. Specifying a glob is equivalent to specifying this option multiple times, one for each matching ref name.
See also the `fetch.negotiationAlgorithm` and `push.negotiate` configuration variables documented in [git-config[1]](git-config), and the `--negotiate-only` option below.
--negotiate-only Do not fetch anything from the server, and instead print the ancestors of the provided `--negotiation-tip=*` arguments, which we have in common with the server.
This is incompatible with `--recurse-submodules=[yes|on-demand]`. Internally this is used to implement the `push.negotiate` option, see [git-config[1]](git-config).
--dry-run Show what would be done, without making any changes.
-f --force When `git fetch` is used with `<src>:<dst>` refspec it may refuse to update the local branch as discussed in the `<refspec>` part of the [git-fetch[1]](git-fetch) documentation. This option overrides that check.
-k --keep Keep downloaded pack.
--prefetch Modify the configured refspec to place all refs into the `refs/prefetch/` namespace. See the `prefetch` task in [git-maintenance[1]](git-maintenance).
-p --prune Before fetching, remove any remote-tracking references that no longer exist on the remote. Tags are not subject to pruning if they are fetched only because of the default tag auto-following or due to a --tags option. However, if tags are fetched due to an explicit refspec (either on the command line or in the remote configuration, for example if the remote was cloned with the --mirror option), then they are also subject to pruning. Supplying `--prune-tags` is a shorthand for providing the tag refspec.
--no-tags By default, tags that point at objects that are downloaded from the remote repository are fetched and stored locally. This option disables this automatic tag following. The default behavior for a remote may be specified with the remote.<name>.tagOpt setting. See [git-config[1]](git-config).
--refmap=<refspec> When fetching refs listed on the command line, use the specified refspec (can be given more than once) to map the refs to remote-tracking branches, instead of the values of `remote.*.fetch` configuration variables for the remote repository. Providing an empty `<refspec>` to the `--refmap` option causes Git to ignore the configured refspecs and rely entirely on the refspecs supplied as command-line arguments. See section on "Configured Remote-tracking Branches" for details.
-t --tags Fetch all tags from the remote (i.e., fetch remote tags `refs/tags/*` into local tags with the same name), in addition to whatever else would otherwise be fetched. Using this option alone does not subject tags to pruning, even if --prune is used (though tags may be pruned anyway if they are also the destination of an explicit refspec; see `--prune`).
-j --jobs=<n> Number of parallel children to be used for all forms of fetching.
If the `--multiple` option was specified, the different remotes will be fetched in parallel. If multiple submodules are fetched, they will be fetched in parallel. To control them independently, use the config settings `fetch.parallel` and `submodule.fetchJobs` (see [git-config[1]](git-config)).
Typically, parallel recursive and multi-remote fetches will be faster. By default fetches are performed sequentially, not in parallel.
--set-upstream If the remote is fetched successfully, add upstream (tracking) reference, used by argument-less [git-pull[1]](git-pull) and other commands. For more information, see `branch.<name>.merge` and `branch.<name>.remote` in [git-config[1]](git-config).
--upload-pack <upload-pack> When given, and the repository to fetch from is handled by `git fetch-pack`, `--exec=<upload-pack>` is passed to the command to specify non-default path for the command run on the other end.
--progress Progress status is reported on the standard error stream by default when it is attached to a terminal, unless -q is specified. This flag forces progress status even if the standard error stream is not directed to a terminal.
-o <option> --server-option=<option> Transmit the given string to the server when communicating using protocol version 2. The given string must not contain a NUL or LF character. The server’s handling of server options, including unknown ones, is server-specific. When multiple `--server-option=<option>` are given, they are all sent to the other side in the order listed on the command line.
--show-forced-updates By default, git checks if a branch is force-updated during fetch. This can be disabled through fetch.showForcedUpdates, but the --show-forced-updates option guarantees this check occurs. See [git-config[1]](git-config).
--no-show-forced-updates By default, git checks if a branch is force-updated during fetch. Pass --no-show-forced-updates or set fetch.showForcedUpdates to false to skip this check for performance reasons. If used during `git-pull` the --ff-only option will still check for forced updates before attempting a fast-forward update. See [git-config[1]](git-config).
-4 --ipv4 Use IPv4 addresses only, ignoring IPv6 addresses.
-6 --ipv6 Use IPv6 addresses only, ignoring IPv4 addresses.
<repository> The "remote" repository that is the source of a fetch or pull operation. This parameter can be either a URL (see the section [GIT URLS](#URLS) below) or the name of a remote (see the section [REMOTES](#REMOTES) below).
<refspec> Specifies which refs to fetch and which local refs to update. When no <refspec>s appear on the command line, the refs to fetch are read from `remote.<repository>.fetch` variables instead (see the section "CONFIGURED REMOTE-TRACKING BRANCHES" in [git-fetch[1]](git-fetch)).
The format of a <refspec> parameter is an optional plus `+`, followed by the source <src>, followed by a colon `:`, followed by the destination ref <dst>. The colon can be omitted when <dst> is empty. <src> is typically a ref, but it can also be a fully spelled hex object name.
A <refspec> may contain a `*` in its <src> to indicate a simple pattern match. Such a refspec functions like a glob that matches any ref with the same prefix. A pattern <refspec> must have a `*` in both the <src> and <dst>. It will map refs to the destination by replacing the `*` with the contents matched from the source.
If a refspec is prefixed by `^`, it will be interpreted as a negative refspec. Rather than specifying which refs to fetch or which local refs to update, such a refspec will instead specify refs to exclude. A ref will be considered to match if it matches at least one positive refspec, and does not match any negative refspec. Negative refspecs can be useful to restrict the scope of a pattern refspec so that it will not include specific refs. Negative refspecs can themselves be pattern refspecs. However, they may only contain a <src> and do not specify a <dst>. Fully spelled out hex object names are also not supported.
`tag <tag>` means the same as `refs/tags/<tag>:refs/tags/<tag>`; it requests fetching everything up to the given tag.
The remote ref that matches <src> is fetched, and if <dst> is not an empty string, an attempt is made to update the local ref that matches it.
Whether that update is allowed without `--force` depends on the ref namespace it’s being fetched to, the type of object being fetched, and whether the update is considered to be a fast-forward. Generally, the same rules apply for fetching as when pushing, see the `<refspec>...` section of [git-push[1]](git-push) for what those are. Exceptions to those rules particular to `git fetch` are noted below.
Until Git version 2.20, and unlike when pushing with [git-push[1]](git-push), any updates to `refs/tags/*` would be accepted without `+` in the refspec (or `--force`). When fetching, we promiscuously considered all tag updates from a remote to be forced fetches. Since Git version 2.20, fetching to update `refs/tags/*` works the same way as when pushing. I.e. any updates will be rejected without `+` in the refspec (or `--force`).
Unlike when pushing with [git-push[1]](git-push), any updates outside of `refs/{tags,heads}/*` will be accepted without `+` in the refspec (or `--force`), whether that’s swapping e.g. a tree object for a blob, or a commit for another commit that’s doesn’t have the previous commit as an ancestor etc.
Unlike when pushing with [git-push[1]](git-push), there is no configuration which’ll amend these rules, and nothing like a `pre-fetch` hook analogous to the `pre-receive` hook.
As with pushing with [git-push[1]](git-push), all of the rules described above about what’s not allowed as an update can be overridden by adding an the optional leading `+` to a refspec (or using `--force` command line option). The only exception to this is that no amount of forcing will make the `refs/heads/*` namespace accept a non-commit object.
| | |
| --- | --- |
| Note | When the remote branch you want to fetch is known to be rewound and rebased regularly, it is expected that its new tip will not be descendant of its previous tip (as stored in your remote-tracking branch the last time you fetched). You would want to use the `+` sign to indicate non-fast-forward updates will be needed for such branches. There is no way to determine or declare that a branch will be made available in a repository with this behavior; the pulling user simply must know this is the expected usage pattern for a branch. |
| | |
| --- | --- |
| Note | There is a difference between listing multiple <refspec> directly on *git pull* command line and having multiple `remote.<repository>.fetch` entries in your configuration for a <repository> and running a *git pull* command without any explicit <refspec> parameters. <refspec>s listed explicitly on the command line are always merged into the current branch after fetching. In other words, if you list more than one remote ref, *git pull* will create an Octopus merge. On the other hand, if you do not list any explicit <refspec> parameter on the command line, *git pull* will fetch all the <refspec>s it finds in the `remote.<repository>.fetch` configuration and merge only the first <refspec> found into the current branch. This is because making an Octopus from remote refs is rarely done, while keeping track of multiple remote heads in one-go by fetching more than one is often useful. |
Git urls
--------
In general, URLs contain information about the transport protocol, the address of the remote server, and the path to the repository. Depending on the transport protocol, some of this information may be absent.
Git supports ssh, git, http, and https protocols (in addition, ftp, and ftps can be used for fetching, but this is inefficient and deprecated; do not use it).
The native transport (i.e. git:// URL) does no authentication and should be used with caution on unsecured networks.
The following syntaxes may be used with them:
* ssh://[user@]host.xz[:port]/path/to/repo.git/
* git://host.xz[:port]/path/to/repo.git/
* http[s]://host.xz[:port]/path/to/repo.git/
* ftp[s]://host.xz[:port]/path/to/repo.git/
An alternative scp-like syntax may also be used with the ssh protocol:
* [user@]host.xz:path/to/repo.git/
This syntax is only recognized if there are no slashes before the first colon. This helps differentiate a local path that contains a colon. For example the local path `foo:bar` could be specified as an absolute path or `./foo:bar` to avoid being misinterpreted as an ssh url.
The ssh and git protocols additionally support ~username expansion:
* ssh://[user@]host.xz[:port]/~[user]/path/to/repo.git/
* git://host.xz[:port]/~[user]/path/to/repo.git/
* [user@]host.xz:/~[user]/path/to/repo.git/
For local repositories, also supported by Git natively, the following syntaxes may be used:
* /path/to/repo.git/
* file:///path/to/repo.git/
These two syntaxes are mostly equivalent, except when cloning, when the former implies --local option. See [git-clone[1]](git-clone) for details.
`git clone`, `git fetch` and `git pull`, but not `git push`, will also accept a suitable bundle file. See [git-bundle[1]](git-bundle).
When Git doesn’t know how to handle a certain transport protocol, it attempts to use the `remote-<transport>` remote helper, if one exists. To explicitly request a remote helper, the following syntax may be used:
* <transport>::<address>
where <address> may be a path, a server and path, or an arbitrary URL-like string recognized by the specific remote helper being invoked. See [gitremote-helpers[7]](gitremote-helpers) for details.
If there are a large number of similarly-named remote repositories and you want to use a different format for them (such that the URLs you use will be rewritten into URLs that work), you can create a configuration section of the form:
```
[url "<actual url base>"]
insteadOf = <other url base>
```
For example, with this:
```
[url "git://git.host.xz/"]
insteadOf = host.xz:/path/to/
insteadOf = work:
```
a URL like "work:repo.git" or like "host.xz:/path/to/repo.git" will be rewritten in any context that takes a URL to be "git://git.host.xz/repo.git".
If you want to rewrite URLs for push only, you can create a configuration section of the form:
```
[url "<actual url base>"]
pushInsteadOf = <other url base>
```
For example, with this:
```
[url "ssh://example.org/"]
pushInsteadOf = git://example.org/
```
a URL like "git://example.org/path/to/repo.git" will be rewritten to "ssh://example.org/path/to/repo.git" for pushes, but pulls will still use the original URL.
Remotes
-------
The name of one of the following can be used instead of a URL as `<repository>` argument:
* a remote in the Git configuration file: `$GIT_DIR/config`,
* a file in the `$GIT_DIR/remotes` directory, or
* a file in the `$GIT_DIR/branches` directory.
All of these also allow you to omit the refspec from the command line because they each contain a refspec which git will use by default.
###
Named remote in configuration file
You can choose to provide the name of a remote which you had previously configured using [git-remote[1]](git-remote), [git-config[1]](git-config) or even by a manual edit to the `$GIT_DIR/config` file. The URL of this remote will be used to access the repository. The refspec of this remote will be used by default when you do not provide a refspec on the command line. The entry in the config file would appear like this:
```
[remote "<name>"]
url = <URL>
pushurl = <pushurl>
push = <refspec>
fetch = <refspec>
```
The `<pushurl>` is used for pushes only. It is optional and defaults to `<URL>`.
###
Named file in `$GIT_DIR/remotes`
You can choose to provide the name of a file in `$GIT_DIR/remotes`. The URL in this file will be used to access the repository. The refspec in this file will be used as default when you do not provide a refspec on the command line. This file should have the following format:
```
URL: one of the above URL format
Push: <refspec>
Pull: <refspec>
```
`Push:` lines are used by `git push` and `Pull:` lines are used by `git pull` and `git fetch`. Multiple `Push:` and `Pull:` lines may be specified for additional branch mappings.
###
Named file in `$GIT_DIR/branches`
You can choose to provide the name of a file in `$GIT_DIR/branches`. The URL in this file will be used to access the repository. This file should have the following format:
```
<URL>#<head>
```
`<URL>` is required; `#<head>` is optional.
Depending on the operation, git will use one of the following refspecs, if you don’t provide one on the command line. `<branch>` is the name of this file in `$GIT_DIR/branches` and `<head>` defaults to `master`.
git fetch uses:
```
refs/heads/<head>:refs/heads/<branch>
```
git push uses:
```
HEAD:refs/heads/<head>
```
Merge strategies
----------------
The merge mechanism (`git merge` and `git pull` commands) allows the backend `merge strategies` to be chosen with `-s` option. Some strategies can also take their own options, which can be passed by giving `-X<option>` arguments to `git merge` and/or `git pull`.
ort This is the default merge strategy when pulling or merging one branch. This strategy can only resolve two heads using a 3-way merge algorithm. When there is more than one common ancestor that can be used for 3-way merge, it creates a merged tree of the common ancestors and uses that as the reference tree for the 3-way merge. This has been reported to result in fewer merge conflicts without causing mismerges by tests done on actual merge commits taken from Linux 2.6 kernel development history. Additionally this strategy can detect and handle merges involving renames. It does not make use of detected copies. The name for this algorithm is an acronym ("Ostensibly Recursive’s Twin") and came from the fact that it was written as a replacement for the previous default algorithm, `recursive`.
The `ort` strategy can take the following options:
ours This option forces conflicting hunks to be auto-resolved cleanly by favoring `our` version. Changes from the other tree that do not conflict with our side are reflected in the merge result. For a binary file, the entire contents are taken from our side.
This should not be confused with the `ours` merge strategy, which does not even look at what the other tree contains at all. It discards everything the other tree did, declaring `our` history contains all that happened in it.
theirs This is the opposite of `ours`; note that, unlike `ours`, there is no `theirs` merge strategy to confuse this merge option with.
ignore-space-change ignore-all-space ignore-space-at-eol ignore-cr-at-eol Treats lines with the indicated type of whitespace change as unchanged for the sake of a three-way merge. Whitespace changes mixed with other changes to a line are not ignored. See also [git-diff[1]](git-diff) `-b`, `-w`, `--ignore-space-at-eol`, and `--ignore-cr-at-eol`.
* If `their` version only introduces whitespace changes to a line, `our` version is used;
* If `our` version introduces whitespace changes but `their` version includes a substantial change, `their` version is used;
* Otherwise, the merge proceeds in the usual way.
renormalize This runs a virtual check-out and check-in of all three stages of a file when resolving a three-way merge. This option is meant to be used when merging branches with different clean filters or end-of-line normalization rules. See "Merging branches with differing checkin/checkout attributes" in [gitattributes[5]](gitattributes) for details.
no-renormalize Disables the `renormalize` option. This overrides the `merge.renormalize` configuration variable.
find-renames[=<n>] Turn on rename detection, optionally setting the similarity threshold. This is the default. This overrides the `merge.renames` configuration variable. See also [git-diff[1]](git-diff) `--find-renames`.
rename-threshold=<n> Deprecated synonym for `find-renames=<n>`.
subtree[=<path>] This option is a more advanced form of `subtree` strategy, where the strategy makes a guess on how two trees must be shifted to match with each other when merging. Instead, the specified path is prefixed (or stripped from the beginning) to make the shape of two trees to match.
recursive This can only resolve two heads using a 3-way merge algorithm. When there is more than one common ancestor that can be used for 3-way merge, it creates a merged tree of the common ancestors and uses that as the reference tree for the 3-way merge. This has been reported to result in fewer merge conflicts without causing mismerges by tests done on actual merge commits taken from Linux 2.6 kernel development history. Additionally this can detect and handle merges involving renames. It does not make use of detected copies. This was the default strategy for resolving two heads from Git v0.99.9k until v2.33.0.
The `recursive` strategy takes the same options as `ort`. However, there are three additional options that `ort` ignores (not documented above) that are potentially useful with the `recursive` strategy:
patience Deprecated synonym for `diff-algorithm=patience`.
diff-algorithm=[patience|minimal|histogram|myers] Use a different diff algorithm while merging, which can help avoid mismerges that occur due to unimportant matching lines (such as braces from distinct functions). See also [git-diff[1]](git-diff) `--diff-algorithm`. Note that `ort` specifically uses `diff-algorithm=histogram`, while `recursive` defaults to the `diff.algorithm` config setting.
no-renames Turn off rename detection. This overrides the `merge.renames` configuration variable. See also [git-diff[1]](git-diff) `--no-renames`.
resolve This can only resolve two heads (i.e. the current branch and another branch you pulled from) using a 3-way merge algorithm. It tries to carefully detect criss-cross merge ambiguities. It does not handle renames.
octopus This resolves cases with more than two heads, but refuses to do a complex merge that needs manual resolution. It is primarily meant to be used for bundling topic branch heads together. This is the default merge strategy when pulling or merging more than one branch.
ours This resolves any number of heads, but the resulting tree of the merge is always that of the current branch head, effectively ignoring all changes from all other branches. It is meant to be used to supersede old development history of side branches. Note that this is different from the -Xours option to the `recursive` merge strategy.
subtree This is a modified `ort` strategy. When merging trees A and B, if B corresponds to a subtree of A, B is first adjusted to match the tree structure of A, instead of reading the trees at the same level. This adjustment is also done to the common ancestor tree.
With the strategies that use 3-way merge (including the default, `ort`), if a change is made on both branches, but later reverted on one of the branches, that change will be present in the merged result; some people find this behavior confusing. It occurs because only the heads and the merge base are considered when performing a merge, not the individual commits. The merge algorithm therefore considers the reverted change as no change at all, and substitutes the changed version instead.
Default behaviour
-----------------
Often people use `git pull` without giving any parameter. Traditionally, this has been equivalent to saying `git pull
origin`. However, when configuration `branch.<name>.remote` is present while on branch `<name>`, that value is used instead of `origin`.
In order to determine what URL to use to fetch from, the value of the configuration `remote.<origin>.url` is consulted and if there is not any such variable, the value on the `URL:` line in `$GIT_DIR/remotes/<origin>` is used.
In order to determine what remote branches to fetch (and optionally store in the remote-tracking branches) when the command is run without any refspec parameters on the command line, values of the configuration variable `remote.<origin>.fetch` are consulted, and if there aren’t any, `$GIT_DIR/remotes/<origin>` is consulted and its `Pull:` lines are used. In addition to the refspec formats described in the OPTIONS section, you can have a globbing refspec that looks like this:
```
refs/heads/*:refs/remotes/origin/*
```
A globbing refspec must have a non-empty RHS (i.e. must store what were fetched in remote-tracking branches), and its LHS and RHS must end with `/*`. The above specifies that all remote branches are tracked using remote-tracking branches in `refs/remotes/origin/` hierarchy under the same name.
The rule to determine which remote branch to merge after fetching is a bit involved, in order not to break backward compatibility.
If explicit refspecs were given on the command line of `git pull`, they are all merged.
When no refspec was given on the command line, then `git pull` uses the refspec from the configuration or `$GIT_DIR/remotes/<origin>`. In such cases, the following rules apply:
1. If `branch.<name>.merge` configuration for the current branch `<name>` exists, that is the name of the branch at the remote site that is merged.
2. If the refspec is a globbing one, nothing is merged.
3. Otherwise the remote branch of the first refspec is merged.
Examples
--------
* Update the remote-tracking branches for the repository you cloned from, then merge one of them into your current branch:
```
$ git pull
$ git pull origin
```
Normally the branch merged in is the HEAD of the remote repository, but the choice is determined by the branch.<name>.remote and branch.<name>.merge options; see [git-config[1]](git-config) for details.
* Merge into the current branch the remote branch `next`:
```
$ git pull origin next
```
This leaves a copy of `next` temporarily in FETCH\_HEAD, and updates the remote-tracking branch `origin/next`. The same can be done by invoking fetch and merge:
```
$ git fetch origin
$ git merge origin/next
```
If you tried a pull which resulted in complex conflicts and would want to start over, you can recover with `git reset`.
Security
--------
The fetch and push protocols are not designed to prevent one side from stealing data from the other repository that was not intended to be shared. If you have private data that you need to protect from a malicious peer, your best option is to store it in another repository. This applies to both clients and servers. In particular, namespaces on a server are not effective for read access control; you should only grant read access to a namespace to clients that you would trust with read access to the entire repository.
The known attack vectors are as follows:
1. The victim sends "have" lines advertising the IDs of objects it has that are not explicitly intended to be shared but can be used to optimize the transfer if the peer also has them. The attacker chooses an object ID X to steal and sends a ref to X, but isn’t required to send the content of X because the victim already has it. Now the victim believes that the attacker has X, and it sends the content of X back to the attacker later. (This attack is most straightforward for a client to perform on a server, by creating a ref to X in the namespace the client has access to and then fetching it. The most likely way for a server to perform it on a client is to "merge" X into a public branch and hope that the user does additional work on this branch and pushes it back to the server without noticing the merge.)
2. As in #1, the attacker chooses an object ID X to steal. The victim sends an object Y that the attacker already has, and the attacker falsely claims to have X and not Y, so the victim sends Y as a delta against X. The delta reveals regions of X that are similar to Y to the attacker.
Bugs
----
Using --recurse-submodules can only fetch new commits in already checked out submodules right now. When e.g. upstream added a new submodule in the just fetched commits of the superproject the submodule itself cannot be fetched, making it impossible to check out that submodule later without having to do a fetch again. This is expected to be fixed in a future Git version.
See also
--------
[git-fetch[1]](git-fetch), [git-merge[1]](git-merge), [git-config[1]](git-config)
| programming_docs |
git git-repack git-repack
==========
Name
----
git-repack - Pack unpacked objects in a repository
Synopsis
--------
```
git repack [-a] [-A] [-d] [-f] [-F] [-l] [-n] [-q] [-b] [-m] [--window=<n>] [--depth=<n>] [--threads=<n>] [--keep-pack=<pack-name>] [--write-midx]
```
Description
-----------
This command is used to combine all objects that do not currently reside in a "pack", into a pack. It can also be used to re-organize existing packs into a single, more efficient pack.
A pack is a collection of objects, individually compressed, with delta compression applied, stored in a single file, with an associated index file.
Packs are used to reduce the load on mirror systems, backup engines, disk storage, etc.
Options
-------
-a Instead of incrementally packing the unpacked objects, pack everything referenced into a single pack. Especially useful when packing a repository that is used for private development. Use with `-d`. This will clean up the objects that `git prune` leaves behind, but `git fsck --full --dangling` shows as dangling.
Note that users fetching over dumb protocols will have to fetch the whole new pack in order to get any contained object, no matter how many other objects in that pack they already have locally.
Promisor packfiles are repacked separately: if there are packfiles that have an associated ".promisor" file, these packfiles will be repacked into another separate pack, and an empty ".promisor" file corresponding to the new separate pack will be written.
-A Same as `-a`, unless `-d` is used. Then any unreachable objects in a previous pack become loose, unpacked objects, instead of being left in the old pack. Unreachable objects are never intentionally added to a pack, even when repacking. This option prevents unreachable objects from being immediately deleted by way of being left in the old pack and then removed. Instead, the loose unreachable objects will be pruned according to normal expiry rules with the next `git gc` invocation. See [git-gc[1]](git-gc).
-d After packing, if the newly created packs make some existing packs redundant, remove the redundant packs. Also run `git prune-packed` to remove redundant loose object files.
--cruft Same as `-a`, unless `-d` is used. Then any unreachable objects are packed into a separate cruft pack. Unreachable objects can be pruned using the normal expiry rules with the next `git gc` invocation (see [git-gc[1]](git-gc)). Incompatible with `-k`.
--cruft-expiration=<approxidate> Expire unreachable objects older than `<approxidate>` immediately instead of waiting for the next `git gc` invocation. Only useful with `--cruft -d`.
--expire-to=<dir> Write a cruft pack containing pruned objects (if any) to the directory `<dir>`. This option is useful for keeping a copy of any pruned objects in a separate directory as a backup. Only useful with `--cruft -d`.
-l Pass the `--local` option to `git pack-objects`. See [git-pack-objects[1]](git-pack-objects).
-f Pass the `--no-reuse-delta` option to `git-pack-objects`, see [git-pack-objects[1]](git-pack-objects).
-F Pass the `--no-reuse-object` option to `git-pack-objects`, see [git-pack-objects[1]](git-pack-objects).
-q --quiet Show no progress over the standard error stream and pass the `-q` option to `git pack-objects`. See [git-pack-objects[1]](git-pack-objects).
-n Do not update the server information with `git update-server-info`. This option skips updating local catalog files needed to publish this repository (or a direct copy of it) over HTTP or FTP. See [git-update-server-info[1]](git-update-server-info).
--window=<n> --depth=<n> These two options affect how the objects contained in the pack are stored using delta compression. The objects are first internally sorted by type, size and optionally names and compared against the other objects within `--window` to see if using delta compression saves space. `--depth` limits the maximum delta depth; making it too deep affects the performance on the unpacker side, because delta data needs to be applied that many times to get to the necessary object.
The default value for --window is 10 and --depth is 50. The maximum depth is 4095.
--threads=<n> This option is passed through to `git pack-objects`.
--window-memory=<n> This option provides an additional limit on top of `--window`; the window size will dynamically scale down so as to not take up more than `<n>` bytes in memory. This is useful in repositories with a mix of large and small objects to not run out of memory with a large window, but still be able to take advantage of the large window for the smaller objects. The size can be suffixed with "k", "m", or "g". `--window-memory=0` makes memory usage unlimited. The default is taken from the `pack.windowMemory` configuration variable. Note that the actual memory usage will be the limit multiplied by the number of threads used by [git-pack-objects[1]](git-pack-objects).
--max-pack-size=<n> Maximum size of each output pack file. The size can be suffixed with "k", "m", or "g". The minimum size allowed is limited to 1 MiB. If specified, multiple packfiles may be created, which also prevents the creation of a bitmap index. The default is unlimited, unless the config variable `pack.packSizeLimit` is set. Note that this option may result in a larger and slower repository; see the discussion in `pack.packSizeLimit`.
-b --write-bitmap-index Write a reachability bitmap index as part of the repack. This only makes sense when used with `-a`, `-A` or `-m`, as the bitmaps must be able to refer to all reachable objects. This option overrides the setting of `repack.writeBitmaps`. This option has no effect if multiple packfiles are created, unless writing a MIDX (in which case a multi-pack bitmap is created).
--pack-kept-objects Include objects in `.keep` files when repacking. Note that we still do not delete `.keep` packs after `pack-objects` finishes. This means that we may duplicate objects, but this makes the option safe to use when there are concurrent pushes or fetches. This option is generally only useful if you are writing bitmaps with `-b` or `repack.writeBitmaps`, as it ensures that the bitmapped packfile has the necessary objects.
--keep-pack=<pack-name> Exclude the given pack from repacking. This is the equivalent of having `.keep` file on the pack. `<pack-name>` is the pack file name without leading directory (e.g. `pack-123.pack`). The option could be specified multiple times to keep multiple packs.
--unpack-unreachable=<when> When loosening unreachable objects, do not bother loosening any objects older than `<when>`. This can be used to optimize out the write of any objects that would be immediately pruned by a follow-up `git prune`.
-k --keep-unreachable When used with `-ad`, any unreachable objects from existing packs will be appended to the end of the packfile instead of being removed. In addition, any unreachable loose objects will be packed (and their loose counterparts removed).
-i --delta-islands Pass the `--delta-islands` option to `git-pack-objects`, see [git-pack-objects[1]](git-pack-objects).
-g=<factor> --geometric=<factor> Arrange resulting pack structure so that each successive pack contains at least `<factor>` times the number of objects as the next-largest pack.
`git repack` ensures this by determining a "cut" of packfiles that need to be repacked into one in order to ensure a geometric progression. It picks the smallest set of packfiles such that as many of the larger packfiles (by count of objects contained in that pack) may be left intact.
Unlike other repack modes, the set of objects to pack is determined uniquely by the set of packs being "rolled-up"; in other words, the packs determined to need to be combined in order to restore a geometric progression.
When `--unpacked` is specified, loose objects are implicitly included in this "roll-up", without respect to their reachability. This is subject to change in the future. This option (implying a drastically different repack mode) is not guaranteed to work with all other combinations of option to `git repack`.
When writing a multi-pack bitmap, `git repack` selects the largest resulting pack as the preferred pack for object selection by the MIDX (see [git-multi-pack-index[1]](git-multi-pack-index)).
-m --write-midx Write a multi-pack index (see [git-multi-pack-index[1]](git-multi-pack-index)) containing the non-redundant packs.
Configuration
-------------
Various configuration variables affect packing, see [git-config[1]](git-config) (search for "pack" and "delta").
By default, the command passes `--delta-base-offset` option to `git pack-objects`; this typically results in slightly smaller packs, but the generated packs are incompatible with versions of Git older than version 1.4.4. If you need to share your repository with such ancient Git versions, either directly or via the dumb http protocol, then you need to set the configuration variable `repack.UseDeltaBaseOffset` to "false" and repack. Access from old Git versions over the native protocol is unaffected by this option as the conversion is performed on the fly as needed in that case.
Delta compression is not used on objects larger than the `core.bigFileThreshold` configuration variable and on files with the attribute `delta` set to false.
See also
--------
[git-pack-objects[1]](git-pack-objects) [git-prune-packed[1]](git-prune-packed)
git git-annotate git-annotate
============
Name
----
git-annotate - Annotate file lines with commit information
Synopsis
--------
```
git annotate [<options>] [<rev-opts>] [<rev>] [--] <file>
```
Description
-----------
Annotates each line in the given file with information from the commit which introduced the line. Optionally annotates from a given revision.
The only difference between this command and [git-blame[1]](git-blame) is that they use slightly different output formats, and this command exists only for backward compatibility to support existing scripts, and provide a more familiar command name for people coming from other SCM systems.
Options
-------
-b Show blank SHA-1 for boundary commits. This can also be controlled via the `blame.blankBoundary` config option.
--root Do not treat root commits as boundaries. This can also be controlled via the `blame.showRoot` config option.
--show-stats Include additional statistics at the end of blame output.
-L <start>,<end> -L :<funcname> Annotate only the line range given by `<start>,<end>`, or by the function name regex `<funcname>`. May be specified multiple times. Overlapping ranges are allowed.
`<start>` and `<end>` are optional. `-L <start>` or `-L <start>,` spans from `<start>` to end of file. `-L ,<end>` spans from start of file to `<end>`.
`<start>` and `<end>` can take one of these forms:
* number
If `<start>` or `<end>` is a number, it specifies an absolute line number (lines count from 1).
* `/regex/`
This form will use the first line matching the given POSIX regex. If `<start>` is a regex, it will search from the end of the previous `-L` range, if any, otherwise from the start of file. If `<start>` is `^/regex/`, it will search from the start of file. If `<end>` is a regex, it will search starting at the line given by `<start>`.
* +offset or -offset
This is only valid for `<end>` and will specify a number of lines before or after the line given by `<start>`.
If `:<funcname>` is given in place of `<start>` and `<end>`, it is a regular expression that denotes the range from the first funcname line that matches `<funcname>`, up to the next funcname line. `:<funcname>` searches from the end of the previous `-L` range, if any, otherwise from the start of file. `^:<funcname>` searches from the start of file. The function names are determined in the same way as `git diff` works out patch hunk headers (see `Defining a custom hunk-header` in [gitattributes[5]](gitattributes)).
-l Show long rev (Default: off).
-t Show raw timestamp (Default: off).
-S <revs-file> Use revisions from revs-file instead of calling [git-rev-list[1]](git-rev-list).
--reverse <rev>..<rev> Walk history forward instead of backward. Instead of showing the revision in which a line appeared, this shows the last revision in which a line has existed. This requires a range of revision like START..END where the path to blame exists in START. `git blame --reverse START` is taken as `git blame
--reverse START..HEAD` for convenience.
--first-parent Follow only the first parent commit upon seeing a merge commit. This option can be used to determine when a line was introduced to a particular integration branch, rather than when it was introduced to the history overall.
-p --porcelain Show in a format designed for machine consumption.
--line-porcelain Show the porcelain format, but output commit information for each line, not just the first time a commit is referenced. Implies --porcelain.
--incremental Show the result incrementally in a format designed for machine consumption.
--encoding=<encoding> Specifies the encoding used to output author names and commit summaries. Setting it to `none` makes blame output unconverted data. For more information see the discussion about encoding in the [git-log[1]](git-log) manual page.
--contents <file> When <rev> is not specified, the command annotates the changes starting backwards from the working tree copy. This flag makes the command pretend as if the working tree copy has the contents of the named file (specify `-` to make the command read from the standard input).
--date <format> Specifies the format used to output dates. If --date is not provided, the value of the blame.date config variable is used. If the blame.date config variable is also not set, the iso format is used. For supported values, see the discussion of the --date option at [git-log[1]](git-log).
--[no-]progress Progress status is reported on the standard error stream by default when it is attached to a terminal. This flag enables progress reporting even if not attached to a terminal. Can’t use `--progress` together with `--porcelain` or `--incremental`.
-M[<num>] Detect moved or copied lines within a file. When a commit moves or copies a block of lines (e.g. the original file has A and then B, and the commit changes it to B and then A), the traditional `blame` algorithm notices only half of the movement and typically blames the lines that were moved up (i.e. B) to the parent and assigns blame to the lines that were moved down (i.e. A) to the child commit. With this option, both groups of lines are blamed on the parent by running extra passes of inspection.
<num> is optional but it is the lower bound on the number of alphanumeric characters that Git must detect as moving/copying within a file for it to associate those lines with the parent commit. The default value is 20.
-C[<num>] In addition to `-M`, detect lines moved or copied from other files that were modified in the same commit. This is useful when you reorganize your program and move code around across files. When this option is given twice, the command additionally looks for copies from other files in the commit that creates the file. When this option is given three times, the command additionally looks for copies from other files in any commit.
<num> is optional but it is the lower bound on the number of alphanumeric characters that Git must detect as moving/copying between files for it to associate those lines with the parent commit. And the default value is 40. If there are more than one `-C` options given, the <num> argument of the last `-C` will take effect.
--ignore-rev <rev> Ignore changes made by the revision when assigning blame, as if the change never happened. Lines that were changed or added by an ignored commit will be blamed on the previous commit that changed that line or nearby lines. This option may be specified multiple times to ignore more than one revision. If the `blame.markIgnoredLines` config option is set, then lines that were changed by an ignored commit and attributed to another commit will be marked with a `?` in the blame output. If the `blame.markUnblamableLines` config option is set, then those lines touched by an ignored commit that we could not attribute to another revision are marked with a `*`.
--ignore-revs-file <file> Ignore revisions listed in `file`, which must be in the same format as an `fsck.skipList`. This option may be repeated, and these files will be processed after any files specified with the `blame.ignoreRevsFile` config option. An empty file name, `""`, will clear the list of revs from previously processed files.
--color-lines Color line annotations in the default format differently if they come from the same commit as the preceding line. This makes it easier to distinguish code blocks introduced by different commits. The color defaults to cyan and can be adjusted using the `color.blame.repeatedLines` config option.
--color-by-age Color line annotations depending on the age of the line in the default format. The `color.blame.highlightRecent` config option controls what color is used for each range of age.
-h Show help message.
See also
--------
[git-blame[1]](git-blame)
git git-sh-i18n--envsubst git-sh-i18n--envsubst
=====================
Name
----
git-sh-i18n—envsubst - Git’s own envsubst(1) for i18n fallbacks
Synopsis
--------
```
eval_gettext () {
printf "%s" "$1" | (
export PATH $(git sh-i18n--envsubst --variables "$1");
git sh-i18n--envsubst "$1"
)
}
```
Description
-----------
This is not a command the end user would want to run. Ever. This documentation is meant for people who are studying the plumbing scripts and/or are writing new ones.
`git sh-i18n--envsubst` is Git’s stripped-down copy of the GNU `envsubst(1)` program that comes with the GNU gettext package. It’s used internally by [git-sh-i18n[1]](git-sh-i18n) to interpolate the variables passed to the `eval_gettext` function.
No promises are made about the interface, or that this program won’t disappear without warning in the next version of Git. Don’t use it.
git git-update-ref git-update-ref
==============
Name
----
git-update-ref - Update the object name stored in a ref safely
Synopsis
--------
```
git update-ref [-m <reason>] [--no-deref] (-d <ref> [<oldvalue>] | [--create-reflog] <ref> <newvalue> [<oldvalue>] | --stdin [-z])
```
Description
-----------
Given two arguments, stores the <newvalue> in the <ref>, possibly dereferencing the symbolic refs. E.g. `git update-ref HEAD
<newvalue>` updates the current branch head to the new object.
Given three arguments, stores the <newvalue> in the <ref>, possibly dereferencing the symbolic refs, after verifying that the current value of the <ref> matches <oldvalue>. E.g. `git update-ref refs/heads/master <newvalue> <oldvalue>` updates the master branch head to <newvalue> only if its current value is <oldvalue>. You can specify 40 "0" or an empty string as <oldvalue> to make sure that the ref you are creating does not exist.
It also allows a "ref" file to be a symbolic pointer to another ref file by starting with the four-byte header sequence of "ref:".
More importantly, it allows the update of a ref file to follow these symbolic pointers, whether they are symlinks or these "regular file symbolic refs". It follows **real** symlinks only if they start with "refs/": otherwise it will just try to read them and update them as a regular file (i.e. it will allow the filesystem to follow them, but will overwrite such a symlink to somewhere else with a regular filename).
If --no-deref is given, <ref> itself is overwritten, rather than the result of following the symbolic pointers.
In general, using
```
git update-ref HEAD "$head"
```
should be a `lot` safer than doing
```
echo "$head" > "$GIT_DIR/HEAD"
```
both from a symlink following standpoint **and** an error checking standpoint. The "refs/" rule for symlinks means that symlinks that point to "outside" the tree are safe: they’ll be followed for reading but not for writing (so we’ll never write through a ref symlink to some other tree, if you have copied a whole archive by creating a symlink tree).
With `-d` flag, it deletes the named <ref> after verifying it still contains <oldvalue>.
With `--stdin`, update-ref reads instructions from standard input and performs all modifications together. Specify commands of the form:
```
update SP <ref> SP <newvalue> [SP <oldvalue>] LF
create SP <ref> SP <newvalue> LF
delete SP <ref> [SP <oldvalue>] LF
verify SP <ref> [SP <oldvalue>] LF
option SP <opt> LF
start LF
prepare LF
commit LF
abort LF
```
With `--create-reflog`, update-ref will create a reflog for each ref even if one would not ordinarily be created.
Quote fields containing whitespace as if they were strings in C source code; i.e., surrounded by double-quotes and with backslash escapes. Use 40 "0" characters or the empty string to specify a zero value. To specify a missing value, omit the value and its preceding SP entirely.
Alternatively, use `-z` to specify in NUL-terminated format, without quoting:
```
update SP <ref> NUL <newvalue> NUL [<oldvalue>] NUL
create SP <ref> NUL <newvalue> NUL
delete SP <ref> NUL [<oldvalue>] NUL
verify SP <ref> NUL [<oldvalue>] NUL
option SP <opt> NUL
start NUL
prepare NUL
commit NUL
abort NUL
```
In this format, use 40 "0" to specify a zero value, and use the empty string to specify a missing value.
In either format, values can be specified in any form that Git recognizes as an object name. Commands in any other format or a repeated <ref> produce an error. Command meanings are:
update Set <ref> to <newvalue> after verifying <oldvalue>, if given. Specify a zero <newvalue> to ensure the ref does not exist after the update and/or a zero <oldvalue> to make sure the ref does not exist before the update.
create Create <ref> with <newvalue> after verifying it does not exist. The given <newvalue> may not be zero.
delete Delete <ref> after verifying it exists with <oldvalue>, if given. If given, <oldvalue> may not be zero.
verify Verify <ref> against <oldvalue> but do not change it. If <oldvalue> is zero or missing, the ref must not exist.
option Modify behavior of the next command naming a <ref>. The only valid option is `no-deref` to avoid dereferencing a symbolic ref.
start Start a transaction. In contrast to a non-transactional session, a transaction will automatically abort if the session ends without an explicit commit. This command may create a new empty transaction when the current one has been committed or aborted already.
prepare Prepare to commit the transaction. This will create lock files for all queued reference updates. If one reference could not be locked, the transaction will be aborted.
commit Commit all reference updates queued for the transaction, ending the transaction.
abort Abort the transaction, releasing all locks if the transaction is in prepared state.
If all <ref>s can be locked with matching <oldvalue>s simultaneously, all modifications are performed. Otherwise, no modifications are performed. Note that while each individual <ref> is updated or deleted atomically, a concurrent reader may still see a subset of the modifications.
Logging updates
---------------
If config parameter "core.logAllRefUpdates" is true and the ref is one under "refs/heads/", "refs/remotes/", "refs/notes/", or a pseudoref like HEAD or ORIG\_HEAD; or the file "$GIT\_DIR/logs/<ref>" exists then `git update-ref` will append a line to the log file "$GIT\_DIR/logs/<ref>" (dereferencing all symbolic refs before creating the log name) describing the change in ref value. Log lines are formatted as:
```
oldsha1 SP newsha1 SP committer LF
```
Where "oldsha1" is the 40 character hexadecimal value previously stored in <ref>, "newsha1" is the 40 character hexadecimal value of <newvalue> and "committer" is the committer’s name, email address and date in the standard Git committer ident format.
Optionally with -m:
```
oldsha1 SP newsha1 SP committer TAB message LF
```
Where all fields are as described above and "message" is the value supplied to the -m option.
An update will fail (without changing <ref>) if the current user is unable to create a new log file, append to the existing log file or does not have committer information available.
| programming_docs |
git gitcore-tutorial gitcore-tutorial
================
Name
----
gitcore-tutorial - A Git core tutorial for developers
Synopsis
--------
git \*
Description
-----------
This tutorial explains how to use the "core" Git commands to set up and work with a Git repository.
If you just need to use Git as a revision control system you may prefer to start with "A Tutorial Introduction to Git" ([gittutorial[7]](gittutorial)) or [the Git User Manual](user-manual).
However, an understanding of these low-level tools can be helpful if you want to understand Git’s internals.
The core Git is often called "plumbing", with the prettier user interfaces on top of it called "porcelain". You may not want to use the plumbing directly very often, but it can be good to know what the plumbing does when the porcelain isn’t flushing.
Back when this document was originally written, many porcelain commands were shell scripts. For simplicity, it still uses them as examples to illustrate how plumbing is fit together to form the porcelain commands. The source tree includes some of these scripts in contrib/examples/ for reference. Although these are not implemented as shell scripts anymore, the description of what the plumbing layer commands do is still valid.
| | |
| --- | --- |
| Note | Deeper technical details are often marked as Notes, which you can skip on your first reading. |
Creating a git repository
-------------------------
Creating a new Git repository couldn’t be easier: all Git repositories start out empty, and the only thing you need to do is find yourself a subdirectory that you want to use as a working tree - either an empty one for a totally new project, or an existing working tree that you want to import into Git.
For our first example, we’re going to start a totally new repository from scratch, with no pre-existing files, and we’ll call it `git-tutorial`. To start up, create a subdirectory for it, change into that subdirectory, and initialize the Git infrastructure with `git init`:
```
$ mkdir git-tutorial
$ cd git-tutorial
$ git init
```
to which Git will reply
```
Initialized empty Git repository in .git/
```
which is just Git’s way of saying that you haven’t been doing anything strange, and that it will have created a local `.git` directory setup for your new project. You will now have a `.git` directory, and you can inspect that with `ls`. For your new empty project, it should show you three entries, among other things:
* a file called `HEAD`, that has `ref: refs/heads/master` in it. This is similar to a symbolic link and points at `refs/heads/master` relative to the `HEAD` file.
Don’t worry about the fact that the file that the `HEAD` link points to doesn’t even exist yet — you haven’t created the commit that will start your `HEAD` development branch yet.
* a subdirectory called `objects`, which will contain all the objects of your project. You should never have any real reason to look at the objects directly, but you might want to know that these objects are what contains all the real `data` in your repository.
* a subdirectory called `refs`, which contains references to objects.
In particular, the `refs` subdirectory will contain two other subdirectories, named `heads` and `tags` respectively. They do exactly what their names imply: they contain references to any number of different `heads` of development (aka `branches`), and to any `tags` that you have created to name specific versions in your repository.
One note: the special `master` head is the default branch, which is why the `.git/HEAD` file was created points to it even if it doesn’t yet exist. Basically, the `HEAD` link is supposed to always point to the branch you are working on right now, and you always start out expecting to work on the `master` branch.
However, this is only a convention, and you can name your branches anything you want, and don’t have to ever even `have` a `master` branch. A number of the Git tools will assume that `.git/HEAD` is valid, though.
| | |
| --- | --- |
| Note | An *object* is identified by its 160-bit SHA-1 hash, aka *object name*, and a reference to an object is always the 40-byte hex representation of that SHA-1 name. The files in the `refs` subdirectory are expected to contain these hex references (usually with a final `\n` at the end), and you should thus expect to see a number of 41-byte files containing these references in these `refs` subdirectories when you actually start populating your tree. |
| | |
| --- | --- |
| Note | An advanced user may want to take a look at [gitrepository-layout[5]](gitrepository-layout) after finishing this tutorial. |
You have now created your first Git repository. Of course, since it’s empty, that’s not very useful, so let’s start populating it with data.
Populating a git repository
---------------------------
We’ll keep this simple and stupid, so we’ll start off with populating a few trivial files just to get a feel for it.
Start off with just creating any random files that you want to maintain in your Git repository. We’ll start off with a few bad examples, just to get a feel for how this works:
```
$ echo "Hello World" >hello
$ echo "Silly example" >example
```
you have now created two files in your working tree (aka `working directory`), but to actually check in your hard work, you will have to go through two steps:
* fill in the `index` file (aka `cache`) with the information about your working tree state.
* commit that index file as an object.
The first step is trivial: when you want to tell Git about any changes to your working tree, you use the `git update-index` program. That program normally just takes a list of filenames you want to update, but to avoid trivial mistakes, it refuses to add new entries to the index (or remove existing ones) unless you explicitly tell it that you’re adding a new entry with the `--add` flag (or removing an entry with the `--remove`) flag.
So to populate the index with the two files you just created, you can do
```
$ git update-index --add hello example
```
and you have now told Git to track those two files.
In fact, as you did that, if you now look into your object directory, you’ll notice that Git will have added two new objects to the object database. If you did exactly the steps above, you should now be able to do
```
$ ls .git/objects/??/*
```
and see two files:
```
.git/objects/55/7db03de997c86a4a028e1ebd3a1ceb225be238
.git/objects/f2/4c74a2e500f5ee1332c86b94199f52b1d1d962
```
which correspond with the objects with names of `557db...` and `f24c7...` respectively.
If you want to, you can use `git cat-file` to look at those objects, but you’ll have to use the object name, not the filename of the object:
```
$ git cat-file -t 557db03de997c86a4a028e1ebd3a1ceb225be238
```
where the `-t` tells `git cat-file` to tell you what the "type" of the object is. Git will tell you that you have a "blob" object (i.e., just a regular file), and you can see the contents with
```
$ git cat-file blob 557db03
```
which will print out "Hello World". The object `557db03` is nothing more than the contents of your file `hello`.
| | |
| --- | --- |
| Note | Don’t confuse that object with the file `hello` itself. The object is literally just those specific **contents** of the file, and however much you later change the contents in file `hello`, the object we just looked at will never change. Objects are immutable. |
| | |
| --- | --- |
| Note | The second example demonstrates that you can abbreviate the object name to only the first several hexadecimal digits in most places. |
Anyway, as we mentioned previously, you normally never actually take a look at the objects themselves, and typing long 40-character hex names is not something you’d normally want to do. The above digression was just to show that `git update-index` did something magical, and actually saved away the contents of your files into the Git object database.
Updating the index did something else too: it created a `.git/index` file. This is the index that describes your current working tree, and something you should be very aware of. Again, you normally never worry about the index file itself, but you should be aware of the fact that you have not actually really "checked in" your files into Git so far, you’ve only **told** Git about them.
However, since Git knows about them, you can now start using some of the most basic Git commands to manipulate the files or look at their status.
In particular, let’s not even check in the two files into Git yet, we’ll start off by adding another line to `hello` first:
```
$ echo "It's a new day for git" >>hello
```
and you can now, since you told Git about the previous state of `hello`, ask Git what has changed in the tree compared to your old index, using the `git diff-files` command:
```
$ git diff-files
```
Oops. That wasn’t very readable. It just spit out its own internal version of a `diff`, but that internal version really just tells you that it has noticed that "hello" has been modified, and that the old object contents it had have been replaced with something else.
To make it readable, we can tell `git diff-files` to output the differences as a patch, using the `-p` flag:
```
$ git diff-files -p
diff --git a/hello b/hello
index 557db03..263414f 100644
--- a/hello
+++ b/hello
@@ -1 +1,2 @@
Hello World
+It's a new day for git
```
i.e. the diff of the change we caused by adding another line to `hello`.
In other words, `git diff-files` always shows us the difference between what is recorded in the index, and what is currently in the working tree. That’s very useful.
A common shorthand for `git diff-files -p` is to just write `git
diff`, which will do the same thing.
```
$ git diff
diff --git a/hello b/hello
index 557db03..263414f 100644
--- a/hello
+++ b/hello
@@ -1 +1,2 @@
Hello World
+It's a new day for git
```
Committing git state
--------------------
Now, we want to go to the next stage in Git, which is to take the files that Git knows about in the index, and commit them as a real tree. We do that in two phases: creating a `tree` object, and committing that `tree` object as a `commit` object together with an explanation of what the tree was all about, along with information of how we came to that state.
Creating a tree object is trivial, and is done with `git write-tree`. There are no options or other input: `git write-tree` will take the current index state, and write an object that describes that whole index. In other words, we’re now tying together all the different filenames with their contents (and their permissions), and we’re creating the equivalent of a Git "directory" object:
```
$ git write-tree
```
and this will just output the name of the resulting tree, in this case (if you have done exactly as I’ve described) it should be
```
8988da15d077d4829fc51d8544c097def6644dbb
```
which is another incomprehensible object name. Again, if you want to, you can use `git cat-file -t 8988d...` to see that this time the object is not a "blob" object, but a "tree" object (you can also use `git cat-file` to actually output the raw object contents, but you’ll see mainly a binary mess, so that’s less interesting).
However — normally you’d never use `git write-tree` on its own, because normally you always commit a tree into a commit object using the `git commit-tree` command. In fact, it’s easier to not actually use `git write-tree` on its own at all, but to just pass its result in as an argument to `git commit-tree`.
`git commit-tree` normally takes several arguments — it wants to know what the `parent` of a commit was, but since this is the first commit ever in this new repository, and it has no parents, we only need to pass in the object name of the tree. However, `git commit-tree` also wants to get a commit message on its standard input, and it will write out the resulting object name for the commit to its standard output.
And this is where we create the `.git/refs/heads/master` file which is pointed at by `HEAD`. This file is supposed to contain the reference to the top-of-tree of the master branch, and since that’s exactly what `git commit-tree` spits out, we can do this all with a sequence of simple shell commands:
```
$ tree=$(git write-tree)
$ commit=$(echo 'Initial commit' | git commit-tree $tree)
$ git update-ref HEAD $commit
```
In this case this creates a totally new commit that is not related to anything else. Normally you do this only **once** for a project ever, and all later commits will be parented on top of an earlier commit.
Again, normally you’d never actually do this by hand. There is a helpful script called `git commit` that will do all of this for you. So you could have just written `git commit` instead, and it would have done the above magic scripting for you.
Making a change
---------------
Remember how we did the `git update-index` on file `hello` and then we changed `hello` afterward, and could compare the new state of `hello` with the state we saved in the index file?
Further, remember how I said that `git write-tree` writes the contents of the **index** file to the tree, and thus what we just committed was in fact the **original** contents of the file `hello`, not the new ones. We did that on purpose, to show the difference between the index state, and the state in the working tree, and how they don’t have to match, even when we commit things.
As before, if we do `git diff-files -p` in our git-tutorial project, we’ll still see the same difference we saw last time: the index file hasn’t changed by the act of committing anything. However, now that we have committed something, we can also learn to use a new command: `git diff-index`.
Unlike `git diff-files`, which showed the difference between the index file and the working tree, `git diff-index` shows the differences between a committed **tree** and either the index file or the working tree. In other words, `git diff-index` wants a tree to be diffed against, and before we did the commit, we couldn’t do that, because we didn’t have anything to diff against.
But now we can do
```
$ git diff-index -p HEAD
```
(where `-p` has the same meaning as it did in `git diff-files`), and it will show us the same difference, but for a totally different reason. Now we’re comparing the working tree not against the index file, but against the tree we just wrote. It just so happens that those two are obviously the same, so we get the same result.
Again, because this is a common operation, you can also just shorthand it with
```
$ git diff HEAD
```
which ends up doing the above for you.
In other words, `git diff-index` normally compares a tree against the working tree, but when given the `--cached` flag, it is told to instead compare against just the index cache contents, and ignore the current working tree state entirely. Since we just wrote the index file to HEAD, doing `git diff-index --cached -p HEAD` should thus return an empty set of differences, and that’s exactly what it does.
| | |
| --- | --- |
| Note | `git diff-index` really always uses the index for its comparisons, and saying that it compares a tree against the working tree is thus not strictly accurate. In particular, the list of files to compare (the "meta-data") **always** comes from the index file, regardless of whether the `--cached` flag is used or not. The `--cached` flag really only determines whether the file **contents** to be compared come from the working tree or not. This is not hard to understand, as soon as you realize that Git simply never knows (or cares) about files that it is not told about explicitly. Git will never go **looking** for files to compare, it expects you to tell it what the files are, and that’s what the index is there for. |
However, our next step is to commit the **change** we did, and again, to understand what’s going on, keep in mind the difference between "working tree contents", "index file" and "committed tree". We have changes in the working tree that we want to commit, and we always have to work through the index file, so the first thing we need to do is to update the index cache:
```
$ git update-index hello
```
(note how we didn’t need the `--add` flag this time, since Git knew about the file already).
Note what happens to the different `git diff-*` versions here. After we’ve updated `hello` in the index, `git diff-files -p` now shows no differences, but `git diff-index -p HEAD` still **does** show that the current state is different from the state we committed. In fact, now `git diff-index` shows the same difference whether we use the `--cached` flag or not, since now the index is coherent with the working tree.
Now, since we’ve updated `hello` in the index, we can commit the new version. We could do it by writing the tree by hand again, and committing the tree (this time we’d have to use the `-p HEAD` flag to tell commit that the HEAD was the **parent** of the new commit, and that this wasn’t an initial commit any more), but you’ve done that once already, so let’s just use the helpful script this time:
```
$ git commit
```
which starts an editor for you to write the commit message and tells you a bit about what you have done.
Write whatever message you want, and all the lines that start with `#` will be pruned out, and the rest will be used as the commit message for the change. If you decide you don’t want to commit anything after all at this point (you can continue to edit things and update the index), you can just leave an empty message. Otherwise `git commit` will commit the change for you.
You’ve now made your first real Git commit. And if you’re interested in looking at what `git commit` really does, feel free to investigate: it’s a few very simple shell scripts to generate the helpful (?) commit message headers, and a few one-liners that actually do the commit itself (`git commit`).
Inspecting changes
------------------
While creating changes is useful, it’s even more useful if you can tell later what changed. The most useful command for this is another of the `diff` family, namely `git diff-tree`.
`git diff-tree` can be given two arbitrary trees, and it will tell you the differences between them. Perhaps even more commonly, though, you can give it just a single commit object, and it will figure out the parent of that commit itself, and show the difference directly. Thus, to get the same diff that we’ve already seen several times, we can now do
```
$ git diff-tree -p HEAD
```
(again, `-p` means to show the difference as a human-readable patch), and it will show what the last commit (in `HEAD`) actually changed.
| | |
| --- | --- |
| Note | Here is an ASCII art by Jon Loeliger that illustrates how various `diff-*` commands compare things.
```
diff-tree
+----+
| |
| |
V V
+-----------+
| Object DB |
| Backing |
| Store |
+-----------+
^ ^
| |
| | diff-index --cached
| |
diff-index | V
| +-----------+
| | Index |
| | "cache" |
| +-----------+
| ^
| |
| | diff-files
| |
V V
+-----------+
| Working |
| Directory |
+-----------+
```
|
More interestingly, you can also give `git diff-tree` the `--pretty` flag, which tells it to also show the commit message and author and date of the commit, and you can tell it to show a whole series of diffs. Alternatively, you can tell it to be "silent", and not show the diffs at all, but just show the actual commit message.
In fact, together with the `git rev-list` program (which generates a list of revisions), `git diff-tree` ends up being a veritable fount of changes. You can emulate `git log`, `git log -p`, etc. with a trivial script that pipes the output of `git rev-list` to `git diff-tree --stdin`, which was exactly how early versions of `git log` were implemented.
Tagging a version
-----------------
In Git, there are two kinds of tags, a "light" one, and an "annotated tag".
A "light" tag is technically nothing more than a branch, except we put it in the `.git/refs/tags/` subdirectory instead of calling it a `head`. So the simplest form of tag involves nothing more than
```
$ git tag my-first-tag
```
which just writes the current `HEAD` into the `.git/refs/tags/my-first-tag` file, after which point you can then use this symbolic name for that particular state. You can, for example, do
```
$ git diff my-first-tag
```
to diff your current state against that tag which at this point will obviously be an empty diff, but if you continue to develop and commit stuff, you can use your tag as an "anchor-point" to see what has changed since you tagged it.
An "annotated tag" is actually a real Git object, and contains not only a pointer to the state you want to tag, but also a small tag name and message, along with optionally a PGP signature that says that yes, you really did that tag. You create these annotated tags with either the `-a` or `-s` flag to `git tag`:
```
$ git tag -s <tagname>
```
which will sign the current `HEAD` (but you can also give it another argument that specifies the thing to tag, e.g., you could have tagged the current `mybranch` point by using `git tag <tagname> mybranch`).
You normally only do signed tags for major releases or things like that, while the light-weight tags are useful for any marking you want to do — any time you decide that you want to remember a certain point, just create a private tag for it, and you have a nice symbolic name for the state at that point.
Copying repositories
--------------------
Git repositories are normally totally self-sufficient and relocatable. Unlike CVS, for example, there is no separate notion of "repository" and "working tree". A Git repository normally **is** the working tree, with the local Git information hidden in the `.git` subdirectory. There is nothing else. What you see is what you got.
| | |
| --- | --- |
| Note | You can tell Git to split the Git internal information from the directory that it tracks, but we’ll ignore that for now: it’s not how normal projects work, and it’s really only meant for special uses. So the mental model of "the Git information is always tied directly to the working tree that it describes" may not be technically 100% accurate, but it’s a good model for all normal use. |
This has two implications:
* if you grow bored with the tutorial repository you created (or you’ve made a mistake and want to start all over), you can just do simple
```
$ rm -rf git-tutorial
```
and it will be gone. There’s no external repository, and there’s no history outside the project you created.
* if you want to move or duplicate a Git repository, you can do so. There is `git clone` command, but if all you want to do is just to create a copy of your repository (with all the full history that went along with it), you can do so with a regular `cp -a git-tutorial new-git-tutorial`.
Note that when you’ve moved or copied a Git repository, your Git index file (which caches various information, notably some of the "stat" information for the files involved) will likely need to be refreshed. So after you do a `cp -a` to create a new copy, you’ll want to do
```
$ git update-index --refresh
```
in the new repository to make sure that the index file is up to date.
Note that the second point is true even across machines. You can duplicate a remote Git repository with **any** regular copy mechanism, be it `scp`, `rsync` or `wget`.
When copying a remote repository, you’ll want to at a minimum update the index cache when you do this, and especially with other peoples' repositories you often want to make sure that the index cache is in some known state (you don’t know **what** they’ve done and not yet checked in), so usually you’ll precede the `git update-index` with a
```
$ git read-tree --reset HEAD
$ git update-index --refresh
```
which will force a total index re-build from the tree pointed to by `HEAD`. It resets the index contents to `HEAD`, and then the `git update-index` makes sure to match up all index entries with the checked-out files. If the original repository had uncommitted changes in its working tree, `git update-index --refresh` notices them and tells you they need to be updated.
The above can also be written as simply
```
$ git reset
```
and in fact a lot of the common Git command combinations can be scripted with the `git xyz` interfaces. You can learn things by just looking at what the various git scripts do. For example, `git reset` used to be the above two lines implemented in `git reset`, but some things like `git status` and `git commit` are slightly more complex scripts around the basic Git commands.
Many (most?) public remote repositories will not contain any of the checked out files or even an index file, and will **only** contain the actual core Git files. Such a repository usually doesn’t even have the `.git` subdirectory, but has all the Git files directly in the repository.
To create your own local live copy of such a "raw" Git repository, you’d first create your own subdirectory for the project, and then copy the raw repository contents into the `.git` directory. For example, to create your own copy of the Git repository, you’d do the following
```
$ mkdir my-git
$ cd my-git
$ rsync -rL rsync://rsync.kernel.org/pub/scm/git/git.git/ .git
```
followed by
```
$ git read-tree HEAD
```
to populate the index. However, now you have populated the index, and you have all the Git internal files, but you will notice that you don’t actually have any of the working tree files to work on. To get those, you’d check them out with
```
$ git checkout-index -u -a
```
where the `-u` flag means that you want the checkout to keep the index up to date (so that you don’t have to refresh it afterward), and the `-a` flag means "check out all files" (if you have a stale copy or an older version of a checked out tree you may also need to add the `-f` flag first, to tell `git checkout-index` to **force** overwriting of any old files).
Again, this can all be simplified with
```
$ git clone git://git.kernel.org/pub/scm/git/git.git/ my-git
$ cd my-git
$ git checkout
```
which will end up doing all of the above for you.
You have now successfully copied somebody else’s (mine) remote repository, and checked it out.
Creating a new branch
---------------------
Branches in Git are really nothing more than pointers into the Git object database from within the `.git/refs/` subdirectory, and as we already discussed, the `HEAD` branch is nothing but a symlink to one of these object pointers.
You can at any time create a new branch by just picking an arbitrary point in the project history, and just writing the SHA-1 name of that object into a file under `.git/refs/heads/`. You can use any filename you want (and indeed, subdirectories), but the convention is that the "normal" branch is called `master`. That’s just a convention, though, and nothing enforces it.
To show that as an example, let’s go back to the git-tutorial repository we used earlier, and create a branch in it. You do that by simply just saying that you want to check out a new branch:
```
$ git switch -c mybranch
```
will create a new branch based at the current `HEAD` position, and switch to it.
| | |
| --- | --- |
| Note | If you make the decision to start your new branch at some other point in the history than the current `HEAD`, you can do so by just telling `git switch` what the base of the checkout would be. In other words, if you have an earlier tag or branch, you’d just do
```
$ git switch -c mybranch earlier-commit
```
and it would create the new branch `mybranch` at the earlier commit, and check out the state at that time. |
You can always just jump back to your original `master` branch by doing
```
$ git switch master
```
(or any other branch-name, for that matter) and if you forget which branch you happen to be on, a simple
```
$ cat .git/HEAD
```
will tell you where it’s pointing. To get the list of branches you have, you can say
```
$ git branch
```
which used to be nothing more than a simple script around `ls .git/refs/heads`. There will be an asterisk in front of the branch you are currently on.
Sometimes you may wish to create a new branch `without` actually checking it out and switching to it. If so, just use the command
```
$ git branch <branchname> [startingpoint]
```
which will simply `create` the branch, but will not do anything further. You can then later — once you decide that you want to actually develop on that branch — switch to that branch with a regular `git switch` with the branchname as the argument.
Merging two branches
--------------------
One of the ideas of having a branch is that you do some (possibly experimental) work in it, and eventually merge it back to the main branch. So assuming you created the above `mybranch` that started out being the same as the original `master` branch, let’s make sure we’re in that branch, and do some work there.
```
$ git switch mybranch
$ echo "Work, work, work" >>hello
$ git commit -m "Some work." -i hello
```
Here, we just added another line to `hello`, and we used a shorthand for doing both `git update-index hello` and `git commit` by just giving the filename directly to `git commit`, with an `-i` flag (it tells Git to `include` that file in addition to what you have done to the index file so far when making the commit). The `-m` flag is to give the commit log message from the command line.
Now, to make it a bit more interesting, let’s assume that somebody else does some work in the original branch, and simulate that by going back to the master branch, and editing the same file differently there:
```
$ git switch master
```
Here, take a moment to look at the contents of `hello`, and notice how they don’t contain the work we just did in `mybranch` — because that work hasn’t happened in the `master` branch at all. Then do
```
$ echo "Play, play, play" >>hello
$ echo "Lots of fun" >>example
$ git commit -m "Some fun." -i hello example
```
since the master branch is obviously in a much better mood.
Now, you’ve got two branches, and you decide that you want to merge the work done. Before we do that, let’s introduce a cool graphical tool that helps you view what’s going on:
```
$ gitk --all
```
will show you graphically both of your branches (that’s what the `--all` means: normally it will just show you your current `HEAD`) and their histories. You can also see exactly how they came to be from a common source.
Anyway, let’s exit `gitk` (`^Q` or the File menu), and decide that we want to merge the work we did on the `mybranch` branch into the `master` branch (which is currently our `HEAD` too). To do that, there’s a nice script called `git merge`, which wants to know which branches you want to resolve and what the merge is all about:
```
$ git merge -m "Merge work in mybranch" mybranch
```
where the first argument is going to be used as the commit message if the merge can be resolved automatically.
Now, in this case we’ve intentionally created a situation where the merge will need to be fixed up by hand, though, so Git will do as much of it as it can automatically (which in this case is just merge the `example` file, which had no differences in the `mybranch` branch), and say:
```
Auto-merging hello
CONFLICT (content): Merge conflict in hello
Automatic merge failed; fix conflicts and then commit the result.
```
It tells you that it did an "Automatic merge", which failed due to conflicts in `hello`.
Not to worry. It left the (trivial) conflict in `hello` in the same form you should already be well used to if you’ve ever used CVS, so let’s just open `hello` in our editor (whatever that may be), and fix it up somehow. I’d suggest just making it so that `hello` contains all four lines:
```
Hello World
It's a new day for git
Play, play, play
Work, work, work
```
and once you’re happy with your manual merge, just do a
```
$ git commit -i hello
```
which will very loudly warn you that you’re now committing a merge (which is correct, so never mind), and you can write a small merge message about your adventures in `git merge`-land.
After you’re done, start up `gitk --all` to see graphically what the history looks like. Notice that `mybranch` still exists, and you can switch to it, and continue to work with it if you want to. The `mybranch` branch will not contain the merge, but next time you merge it from the `master` branch, Git will know how you merged it, so you’ll not have to do `that` merge again.
Another useful tool, especially if you do not always work in X-Window environment, is `git show-branch`.
```
$ git show-branch --topo-order --more=1 master mybranch
* [master] Merge work in mybranch
! [mybranch] Some work.
--
- [master] Merge work in mybranch
*+ [mybranch] Some work.
* [master^] Some fun.
```
The first two lines indicate that it is showing the two branches with the titles of their top-of-the-tree commits, you are currently on `master` branch (notice the asterisk `*` character), and the first column for the later output lines is used to show commits contained in the `master` branch, and the second column for the `mybranch` branch. Three commits are shown along with their titles. All of them have non blank characters in the first column (`*` shows an ordinary commit on the current branch, `-` is a merge commit), which means they are now part of the `master` branch. Only the "Some work" commit has the plus `+` character in the second column, because `mybranch` has not been merged to incorporate these commits from the master branch. The string inside brackets before the commit log message is a short name you can use to name the commit. In the above example, `master` and `mybranch` are branch heads. `master^` is the first parent of `master` branch head. Please see [gitrevisions[7]](gitrevisions) if you want to see more complex cases.
| | |
| --- | --- |
| Note | Without the *--more=1* option, *git show-branch* would not output the *[master^]* commit, as *[mybranch]* commit is a common ancestor of both *master* and *mybranch* tips. Please see [git-show-branch[1]](git-show-branch) for details. |
| | |
| --- | --- |
| Note | If there were more commits on the *master* branch after the merge, the merge commit itself would not be shown by *git show-branch* by default. You would need to provide `--sparse` option to make the merge commit visible in this case. |
Now, let’s pretend you are the one who did all the work in `mybranch`, and the fruit of your hard work has finally been merged to the `master` branch. Let’s go back to `mybranch`, and run `git merge` to get the "upstream changes" back to your branch.
```
$ git switch mybranch
$ git merge -m "Merge upstream changes." master
```
This outputs something like this (the actual commit object names would be different)
```
Updating from ae3a2da... to a80b4aa....
Fast-forward (no commit created; -m option ignored)
example | 1 +
hello | 1 +
2 files changed, 2 insertions(+)
```
Because your branch did not contain anything more than what had already been merged into the `master` branch, the merge operation did not actually do a merge. Instead, it just updated the top of the tree of your branch to that of the `master` branch. This is often called `fast-forward` merge.
You can run `gitk --all` again to see how the commit ancestry looks like, or run `show-branch`, which tells you this.
```
$ git show-branch master mybranch
! [master] Merge work in mybranch
* [mybranch] Merge work in mybranch
--
-- [master] Merge work in mybranch
```
Merging external work
---------------------
It’s usually much more common that you merge with somebody else than merging with your own branches, so it’s worth pointing out that Git makes that very easy too, and in fact, it’s not that different from doing a `git merge`. In fact, a remote merge ends up being nothing more than "fetch the work from a remote repository into a temporary tag" followed by a `git merge`.
Fetching from a remote repository is done by, unsurprisingly, `git fetch`:
```
$ git fetch <remote-repository>
```
One of the following transports can be used to name the repository to download from:
SSH `remote.machine:/path/to/repo.git/` or
`ssh://remote.machine/path/to/repo.git/`
This transport can be used for both uploading and downloading, and requires you to have a log-in privilege over `ssh` to the remote machine. It finds out the set of objects the other side lacks by exchanging the head commits both ends have and transfers (close to) minimum set of objects. It is by far the most efficient way to exchange Git objects between repositories.
Local directory `/path/to/repo.git/`
This transport is the same as SSH transport but uses `sh` to run both ends on the local machine instead of running other end on the remote machine via `ssh`.
Git Native `git://remote.machine/path/to/repo.git/`
This transport was designed for anonymous downloading. Like SSH transport, it finds out the set of objects the downstream side lacks and transfers (close to) minimum set of objects.
HTTP(S) `http://remote.machine/path/to/repo.git/`
Downloader from http and https URL first obtains the topmost commit object name from the remote site by looking at the specified refname under `repo.git/refs/` directory, and then tries to obtain the commit object by downloading from `repo.git/objects/xx/xxx...` using the object name of that commit object. Then it reads the commit object to find out its parent commits and the associate tree object; it repeats this process until it gets all the necessary objects. Because of this behavior, they are sometimes also called `commit walkers`.
The `commit walkers` are sometimes also called `dumb transports`, because they do not require any Git aware smart server like Git Native transport does. Any stock HTTP server that does not even support directory index would suffice. But you must prepare your repository with `git update-server-info` to help dumb transport downloaders.
Once you fetch from the remote repository, you `merge` that with your current branch.
However — it’s such a common thing to `fetch` and then immediately `merge`, that it’s called `git pull`, and you can simply do
```
$ git pull <remote-repository>
```
and optionally give a branch-name for the remote end as a second argument.
| | |
| --- | --- |
| Note | You could do without using any branches at all, by keeping as many local repositories as you would like to have branches, and merging between them with *git pull*, just like you merge between branches. The advantage of this approach is that it lets you keep a set of files for each `branch` checked out and you may find it easier to switch back and forth if you juggle multiple lines of development simultaneously. Of course, you will pay the price of more disk usage to hold multiple working trees, but disk space is cheap these days. |
It is likely that you will be pulling from the same remote repository from time to time. As a short hand, you can store the remote repository URL in the local repository’s config file like this:
```
$ git config remote.linus.url http://www.kernel.org/pub/scm/git/git.git/
```
and use the "linus" keyword with `git pull` instead of the full URL.
Examples.
1. `git pull linus`
2. `git pull linus tag v0.99.1`
the above are equivalent to:
1. `git pull http://www.kernel.org/pub/scm/git/git.git/ HEAD`
2. `git pull http://www.kernel.org/pub/scm/git/git.git/ tag v0.99.1`
How does the merge work?
------------------------
We said this tutorial shows what plumbing does to help you cope with the porcelain that isn’t flushing, but we so far did not talk about how the merge really works. If you are following this tutorial the first time, I’d suggest to skip to "Publishing your work" section and come back here later.
OK, still with me? To give us an example to look at, let’s go back to the earlier repository with "hello" and "example" file, and bring ourselves back to the pre-merge state:
```
$ git show-branch --more=2 master mybranch
! [master] Merge work in mybranch
* [mybranch] Merge work in mybranch
--
-- [master] Merge work in mybranch
+* [master^2] Some work.
+* [master^] Some fun.
```
Remember, before running `git merge`, our `master` head was at "Some fun." commit, while our `mybranch` head was at "Some work." commit.
```
$ git switch -C mybranch master^2
$ git switch master
$ git reset --hard master^
```
After rewinding, the commit structure should look like this:
```
$ git show-branch
* [master] Some fun.
! [mybranch] Some work.
--
* [master] Some fun.
+ [mybranch] Some work.
*+ [master^] Initial commit
```
Now we are ready to experiment with the merge by hand.
`git merge` command, when merging two branches, uses 3-way merge algorithm. First, it finds the common ancestor between them. The command it uses is `git merge-base`:
```
$ mb=$(git merge-base HEAD mybranch)
```
The command writes the commit object name of the common ancestor to the standard output, so we captured its output to a variable, because we will be using it in the next step. By the way, the common ancestor commit is the "Initial commit" commit in this case. You can tell it by:
```
$ git name-rev --name-only --tags $mb
my-first-tag
```
After finding out a common ancestor commit, the second step is this:
```
$ git read-tree -m -u $mb HEAD mybranch
```
This is the same `git read-tree` command we have already seen, but it takes three trees, unlike previous examples. This reads the contents of each tree into different `stage` in the index file (the first tree goes to stage 1, the second to stage 2, etc.). After reading three trees into three stages, the paths that are the same in all three stages are `collapsed` into stage 0. Also paths that are the same in two of three stages are collapsed into stage 0, taking the SHA-1 from either stage 2 or stage 3, whichever is different from stage 1 (i.e. only one side changed from the common ancestor).
After `collapsing` operation, paths that are different in three trees are left in non-zero stages. At this point, you can inspect the index file with this command:
```
$ git ls-files --stage
100644 7f8b141b65fdcee47321e399a2598a235a032422 0 example
100644 557db03de997c86a4a028e1ebd3a1ceb225be238 1 hello
100644 ba42a2a96e3027f3333e13ede4ccf4498c3ae942 2 hello
100644 cc44c73eb783565da5831b4d820c962954019b69 3 hello
```
In our example of only two files, we did not have unchanged files so only `example` resulted in collapsing. But in real-life large projects, when only a small number of files change in one commit, this `collapsing` tends to trivially merge most of the paths fairly quickly, leaving only a handful of real changes in non-zero stages.
To look at only non-zero stages, use `--unmerged` flag:
```
$ git ls-files --unmerged
100644 557db03de997c86a4a028e1ebd3a1ceb225be238 1 hello
100644 ba42a2a96e3027f3333e13ede4ccf4498c3ae942 2 hello
100644 cc44c73eb783565da5831b4d820c962954019b69 3 hello
```
The next step of merging is to merge these three versions of the file, using 3-way merge. This is done by giving `git merge-one-file` command as one of the arguments to `git merge-index` command:
```
$ git merge-index git-merge-one-file hello
Auto-merging hello
ERROR: Merge conflict in hello
fatal: merge program failed
```
`git merge-one-file` script is called with parameters to describe those three versions, and is responsible to leave the merge results in the working tree. It is a fairly straightforward shell script, and eventually calls `merge` program from RCS suite to perform a file-level 3-way merge. In this case, `merge` detects conflicts, and the merge result with conflict marks is left in the working tree.. This can be seen if you run `ls-files
--stage` again at this point:
```
$ git ls-files --stage
100644 7f8b141b65fdcee47321e399a2598a235a032422 0 example
100644 557db03de997c86a4a028e1ebd3a1ceb225be238 1 hello
100644 ba42a2a96e3027f3333e13ede4ccf4498c3ae942 2 hello
100644 cc44c73eb783565da5831b4d820c962954019b69 3 hello
```
This is the state of the index file and the working file after `git merge` returns control back to you, leaving the conflicting merge for you to resolve. Notice that the path `hello` is still unmerged, and what you see with `git diff` at this point is differences since stage 2 (i.e. your version).
Publishing your work
--------------------
So, we can use somebody else’s work from a remote repository, but how can **you** prepare a repository to let other people pull from it?
You do your real work in your working tree that has your primary repository hanging under it as its `.git` subdirectory. You **could** make that repository accessible remotely and ask people to pull from it, but in practice that is not the way things are usually done. A recommended way is to have a public repository, make it reachable by other people, and when the changes you made in your primary working tree are in good shape, update the public repository from it. This is often called `pushing`.
| | |
| --- | --- |
| Note | This public repository could further be mirrored, and that is how Git repositories at `kernel.org` are managed. |
Publishing the changes from your local (private) repository to your remote (public) repository requires a write privilege on the remote machine. You need to have an SSH account there to run a single command, `git-receive-pack`.
First, you need to create an empty repository on the remote machine that will house your public repository. This empty repository will be populated and be kept up to date by pushing into it later. Obviously, this repository creation needs to be done only once.
| | |
| --- | --- |
| Note | *git push* uses a pair of commands, *git send-pack* on your local machine, and *git-receive-pack* on the remote machine. The communication between the two over the network internally uses an SSH connection. |
Your private repository’s Git directory is usually `.git`, but your public repository is often named after the project name, i.e. `<project>.git`. Let’s create such a public repository for project `my-git`. After logging into the remote machine, create an empty directory:
```
$ mkdir my-git.git
```
Then, make that directory into a Git repository by running `git init`, but this time, since its name is not the usual `.git`, we do things slightly differently:
```
$ GIT_DIR=my-git.git git init
```
Make sure this directory is available for others you want your changes to be pulled via the transport of your choice. Also you need to make sure that you have the `git-receive-pack` program on the `$PATH`.
| | |
| --- | --- |
| Note | Many installations of sshd do not invoke your shell as the login shell when you directly run programs; what this means is that if your login shell is *bash*, only `.bashrc` is read and not `.bash_profile`. As a workaround, make sure `.bashrc` sets up `$PATH` so that you can run *git-receive-pack* program. |
| | |
| --- | --- |
| Note | If you plan to publish this repository to be accessed over http, you should do `mv my-git.git/hooks/post-update.sample
my-git.git/hooks/post-update` at this point. This makes sure that every time you push into this repository, `git update-server-info` is run. |
Your "public repository" is now ready to accept your changes. Come back to the machine you have your private repository. From there, run this command:
```
$ git push <public-host>:/path/to/my-git.git master
```
This synchronizes your public repository to match the named branch head (i.e. `master` in this case) and objects reachable from them in your current repository.
As a real example, this is how I update my public Git repository. Kernel.org mirror network takes care of the propagation to other publicly visible machines:
```
$ git push master.kernel.org:/pub/scm/git/git.git/
```
Packing your repository
-----------------------
Earlier, we saw that one file under `.git/objects/??/` directory is stored for each Git object you create. This representation is efficient to create atomically and safely, but not so convenient to transport over the network. Since Git objects are immutable once they are created, there is a way to optimize the storage by "packing them together". The command
```
$ git repack
```
will do it for you. If you followed the tutorial examples, you would have accumulated about 17 objects in `.git/objects/??/` directories by now. `git repack` tells you how many objects it packed, and stores the packed file in the `.git/objects/pack` directory.
| | |
| --- | --- |
| Note | You will see two files, `pack-*.pack` and `pack-*.idx`, in `.git/objects/pack` directory. They are closely related to each other, and if you ever copy them by hand to a different repository for whatever reason, you should make sure you copy them together. The former holds all the data from the objects in the pack, and the latter holds the index for random access. |
If you are paranoid, running `git verify-pack` command would detect if you have a corrupt pack, but do not worry too much. Our programs are always perfect ;-).
Once you have packed objects, you do not need to leave the unpacked objects that are contained in the pack file anymore.
```
$ git prune-packed
```
would remove them for you.
You can try running `find .git/objects -type f` before and after you run `git prune-packed` if you are curious. Also `git
count-objects` would tell you how many unpacked objects are in your repository and how much space they are consuming.
| | |
| --- | --- |
| Note | `git pull` is slightly cumbersome for HTTP transport, as a packed repository may contain relatively few objects in a relatively large pack. If you expect many HTTP pulls from your public repository you might want to repack & prune often, or never. |
If you run `git repack` again at this point, it will say "Nothing new to pack.". Once you continue your development and accumulate the changes, running `git repack` again will create a new pack, that contains objects created since you packed your repository the last time. We recommend that you pack your project soon after the initial import (unless you are starting your project from scratch), and then run `git repack` every once in a while, depending on how active your project is.
When a repository is synchronized via `git push` and `git pull` objects packed in the source repository are usually stored unpacked in the destination. While this allows you to use different packing strategies on both ends, it also means you may need to repack both repositories every once in a while.
Working with others
-------------------
Although Git is a truly distributed system, it is often convenient to organize your project with an informal hierarchy of developers. Linux kernel development is run this way. There is a nice illustration (page 17, "Merges to Mainline") in [Randy Dunlap’s presentation](https://web.archive.org/web/20120915203609/http://www.xenotime.net/linux/mentor/linux-mentoring-2006.pdf).
It should be stressed that this hierarchy is purely **informal**. There is nothing fundamental in Git that enforces the "chain of patch flow" this hierarchy implies. You do not have to pull from only one remote repository.
A recommended workflow for a "project lead" goes like this:
1. Prepare your primary repository on your local machine. Your work is done there.
2. Prepare a public repository accessible to others.
If other people are pulling from your repository over dumb transport protocols (HTTP), you need to keep this repository `dumb transport friendly`. After `git init`, `$GIT_DIR/hooks/post-update.sample` copied from the standard templates would contain a call to `git update-server-info` but you need to manually enable the hook with `mv post-update.sample post-update`. This makes sure `git update-server-info` keeps the necessary files up to date.
3. Push into the public repository from your primary repository.
4. `git repack` the public repository. This establishes a big pack that contains the initial set of objects as the baseline, and possibly `git prune` if the transport used for pulling from your repository supports packed repositories.
5. Keep working in your primary repository. Your changes include modifications of your own, patches you receive via e-mails, and merges resulting from pulling the "public" repositories of your "subsystem maintainers".
You can repack this private repository whenever you feel like.
6. Push your changes to the public repository, and announce it to the public.
7. Every once in a while, `git repack` the public repository. Go back to step 5. and continue working.
A recommended work cycle for a "subsystem maintainer" who works on that project and has an own "public repository" goes like this:
1. Prepare your work repository, by running `git clone` on the public repository of the "project lead". The URL used for the initial cloning is stored in the remote.origin.url configuration variable.
2. Prepare a public repository accessible to others, just like the "project lead" person does.
3. Copy over the packed files from "project lead" public repository to your public repository, unless the "project lead" repository lives on the same machine as yours. In the latter case, you can use `objects/info/alternates` file to point at the repository you are borrowing from.
4. Push into the public repository from your primary repository. Run `git repack`, and possibly `git prune` if the transport used for pulling from your repository supports packed repositories.
5. Keep working in your primary repository. Your changes include modifications of your own, patches you receive via e-mails, and merges resulting from pulling the "public" repositories of your "project lead" and possibly your "sub-subsystem maintainers".
You can repack this private repository whenever you feel like.
6. Push your changes to your public repository, and ask your "project lead" and possibly your "sub-subsystem maintainers" to pull from it.
7. Every once in a while, `git repack` the public repository. Go back to step 5. and continue working.
A recommended work cycle for an "individual developer" who does not have a "public" repository is somewhat different. It goes like this:
1. Prepare your work repository, by `git clone` the public repository of the "project lead" (or a "subsystem maintainer", if you work on a subsystem). The URL used for the initial cloning is stored in the remote.origin.url configuration variable.
2. Do your work in your repository on `master` branch.
3. Run `git fetch origin` from the public repository of your upstream every once in a while. This does only the first half of `git pull` but does not merge. The head of the public repository is stored in `.git/refs/remotes/origin/master`.
4. Use `git cherry origin` to see which ones of your patches were accepted, and/or use `git rebase origin` to port your unmerged changes forward to the updated upstream.
5. Use `git format-patch origin` to prepare patches for e-mail submission to your upstream and send it out. Go back to step 2. and continue.
Working with others, shared repository style
--------------------------------------------
If you are coming from a CVS background, the style of cooperation suggested in the previous section may be new to you. You do not have to worry. Git supports the "shared public repository" style of cooperation you are probably more familiar with as well.
See [gitcvs-migration[7]](gitcvs-migration) for the details.
Bundling your work together
---------------------------
It is likely that you will be working on more than one thing at a time. It is easy to manage those more-or-less independent tasks using branches with Git.
We have already seen how branches work previously, with "fun and work" example using two branches. The idea is the same if there are more than two branches. Let’s say you started out from "master" head, and have some new code in the "master" branch, and two independent fixes in the "commit-fix" and "diff-fix" branches:
```
$ git show-branch
! [commit-fix] Fix commit message normalization.
! [diff-fix] Fix rename detection.
* [master] Release candidate #1
---
+ [diff-fix] Fix rename detection.
+ [diff-fix~1] Better common substring algorithm.
+ [commit-fix] Fix commit message normalization.
* [master] Release candidate #1
++* [diff-fix~2] Pretty-print messages.
```
Both fixes are tested well, and at this point, you want to merge in both of them. You could merge in `diff-fix` first and then `commit-fix` next, like this:
```
$ git merge -m "Merge fix in diff-fix" diff-fix
$ git merge -m "Merge fix in commit-fix" commit-fix
```
Which would result in:
```
$ git show-branch
! [commit-fix] Fix commit message normalization.
! [diff-fix] Fix rename detection.
* [master] Merge fix in commit-fix
---
- [master] Merge fix in commit-fix
+ * [commit-fix] Fix commit message normalization.
- [master~1] Merge fix in diff-fix
+* [diff-fix] Fix rename detection.
+* [diff-fix~1] Better common substring algorithm.
* [master~2] Release candidate #1
++* [master~3] Pretty-print messages.
```
However, there is no particular reason to merge in one branch first and the other next, when what you have are a set of truly independent changes (if the order mattered, then they are not independent by definition). You could instead merge those two branches into the current branch at once. First let’s undo what we just did and start over. We would want to get the master branch before these two merges by resetting it to `master~2`:
```
$ git reset --hard master~2
```
You can make sure `git show-branch` matches the state before those two `git merge` you just did. Then, instead of running two `git merge` commands in a row, you would merge these two branch heads (this is known as `making an Octopus`):
```
$ git merge commit-fix diff-fix
$ git show-branch
! [commit-fix] Fix commit message normalization.
! [diff-fix] Fix rename detection.
* [master] Octopus merge of branches 'diff-fix' and 'commit-fix'
---
- [master] Octopus merge of branches 'diff-fix' and 'commit-fix'
+ * [commit-fix] Fix commit message normalization.
+* [diff-fix] Fix rename detection.
+* [diff-fix~1] Better common substring algorithm.
* [master~1] Release candidate #1
++* [master~2] Pretty-print messages.
```
Note that you should not do Octopus just because you can. An octopus is a valid thing to do and often makes it easier to view the commit history if you are merging more than two independent changes at the same time. However, if you have merge conflicts with any of the branches you are merging in and need to hand resolve, that is an indication that the development happened in those branches were not independent after all, and you should merge two at a time, documenting how you resolved the conflicts, and the reason why you preferred changes made in one side over the other. Otherwise it would make the project history harder to follow, not easier.
See also
--------
[gittutorial[7]](gittutorial), [gittutorial-2[7]](gittutorial-2), [gitcvs-migration[7]](gitcvs-migration), [git-help[1]](git-help), [giteveryday[7]](giteveryday), [The Git User’s Manual](user-manual)
| programming_docs |
git git-merge-base git-merge-base
==============
Name
----
git-merge-base - Find as good common ancestors as possible for a merge
Synopsis
--------
```
git merge-base [-a | --all] <commit> <commit>…
git merge-base [-a | --all] --octopus <commit>…
git merge-base --is-ancestor <commit> <commit>
git merge-base --independent <commit>…
git merge-base --fork-point <ref> [<commit>]
```
Description
-----------
`git merge-base` finds best common ancestor(s) between two commits to use in a three-way merge. One common ancestor is `better` than another common ancestor if the latter is an ancestor of the former. A common ancestor that does not have any better common ancestor is a `best common ancestor`, i.e. a `merge base`. Note that there can be more than one merge base for a pair of commits.
Operation modes
---------------
As the most common special case, specifying only two commits on the command line means computing the merge base between the given two commits.
More generally, among the two commits to compute the merge base from, one is specified by the first commit argument on the command line; the other commit is a (possibly hypothetical) commit that is a merge across all the remaining commits on the command line.
As a consequence, the `merge base` is not necessarily contained in each of the commit arguments if more than two commits are specified. This is different from [git-show-branch[1]](git-show-branch) when used with the `--merge-base` option.
--octopus Compute the best common ancestors of all supplied commits, in preparation for an n-way merge. This mimics the behavior of `git show-branch --merge-base`.
--independent Instead of printing merge bases, print a minimal subset of the supplied commits with the same ancestors. In other words, among the commits given, list those which cannot be reached from any other. This mimics the behavior of `git show-branch --independent`.
--is-ancestor Check if the first <commit> is an ancestor of the second <commit>, and exit with status 0 if true, or with status 1 if not. Errors are signaled by a non-zero status that is not 1.
--fork-point Find the point at which a branch (or any history that leads to <commit>) forked from another branch (or any reference) <ref>. This does not just look for the common ancestor of the two commits, but also takes into account the reflog of <ref> to see if the history leading to <commit> forked from an earlier incarnation of the branch <ref> (see discussion on this mode below).
Options
-------
-a --all Output all merge bases for the commits, instead of just one.
Discussion
----------
Given two commits `A` and `B`, `git merge-base A B` will output a commit which is reachable from both `A` and `B` through the parent relationship.
For example, with this topology:
```
o---o---o---B
/
---o---1---o---o---o---A
```
the merge base between `A` and `B` is `1`.
Given three commits `A`, `B` and `C`, `git merge-base A B C` will compute the merge base between `A` and a hypothetical commit `M`, which is a merge between `B` and `C`. For example, with this topology:
```
o---o---o---o---C
/
/ o---o---o---B
/ /
---2---1---o---o---o---A
```
the result of `git merge-base A B C` is `1`. This is because the equivalent topology with a merge commit `M` between `B` and `C` is:
```
o---o---o---o---o
/ \
/ o---o---o---o---M
/ /
---2---1---o---o---o---A
```
and the result of `git merge-base A M` is `1`. Commit `2` is also a common ancestor between `A` and `M`, but `1` is a better common ancestor, because `2` is an ancestor of `1`. Hence, `2` is not a merge base.
The result of `git merge-base --octopus A B C` is `2`, because `2` is the best common ancestor of all commits.
When the history involves criss-cross merges, there can be more than one `best` common ancestor for two commits. For example, with this topology:
```
---1---o---A
\ /
X
/ \
---2---o---o---B
```
both `1` and `2` are merge-bases of A and B. Neither one is better than the other (both are `best` merge bases). When the `--all` option is not given, it is unspecified which best one is output.
A common idiom to check "fast-forward-ness" between two commits A and B is (or at least used to be) to compute the merge base between A and B, and check if it is the same as A, in which case, A is an ancestor of B. You will see this idiom used often in older scripts.
```
A=$(git rev-parse --verify A)
if test "$A" = "$(git merge-base A B)"
then
... A is an ancestor of B ...
fi
```
In modern git, you can say this in a more direct way:
```
if git merge-base --is-ancestor A B
then
... A is an ancestor of B ...
fi
```
instead.
Discussion on fork-point mode
-----------------------------
After working on the `topic` branch created with `git switch -c
topic origin/master`, the history of remote-tracking branch `origin/master` may have been rewound and rebuilt, leading to a history of this shape:
```
o---B2
/
---o---o---B1--o---o---o---B (origin/master)
\
B0
\
D0---D1---D (topic)
```
where `origin/master` used to point at commits B0, B1, B2 and now it points at B, and your `topic` branch was started on top of it back when `origin/master` was at B0, and you built three commits, D0, D1, and D, on top of it. Imagine that you now want to rebase the work you did on the topic on top of the updated origin/master.
In such a case, `git merge-base origin/master topic` would return the parent of B0 in the above picture, but B0^..D is **not** the range of commits you would want to replay on top of B (it includes B0, which is not what you wrote; it is a commit the other side discarded when it moved its tip from B0 to B1).
`git merge-base --fork-point origin/master topic` is designed to help in such a case. It takes not only B but also B0, B1, and B2 (i.e. old tips of the remote-tracking branches your repository’s reflog knows about) into account to see on which commit your topic branch was built and finds B0, allowing you to replay only the commits on your topic, excluding the commits the other side later discarded.
Hence
```
$ fork_point=$(git merge-base --fork-point origin/master topic)
```
will find B0, and
```
$ git rebase --onto origin/master $fork_point topic
```
will replay D0, D1 and D on top of B to create a new history of this shape:
```
o---B2
/
---o---o---B1--o---o---o---B (origin/master)
\ \
B0 D0'--D1'--D' (topic - updated)
\
D0---D1---D (topic - old)
```
A caveat is that older reflog entries in your repository may be expired by `git gc`. If B0 no longer appears in the reflog of the remote-tracking branch `origin/master`, the `--fork-point` mode obviously cannot find it and fails, avoiding to give a random and useless result (such as the parent of B0, like the same command without the `--fork-point` option gives).
Also, the remote-tracking branch you use the `--fork-point` mode with must be the one your topic forked from its tip. If you forked from an older commit than the tip, this mode would not find the fork point (imagine in the above sample history B0 did not exist, origin/master started at B1, moved to B2 and then B, and you forked your topic at origin/master^ when origin/master was B1; the shape of the history would be the same as above, without B0, and the parent of B1 is what `git merge-base origin/master topic` correctly finds, but the `--fork-point` mode will not, because it is not one of the commits that used to be at the tip of origin/master).
See also
--------
[git-rev-list[1]](git-rev-list), [git-show-branch[1]](git-show-branch), [git-merge[1]](git-merge)
git git-fmt-merge-msg git-fmt-merge-msg
=================
Name
----
git-fmt-merge-msg - Produce a merge commit message
Synopsis
--------
```
git fmt-merge-msg [-m <message>] [--into-name <branch>] [--log[=<n>] | --no-log]
git fmt-merge-msg [-m <message>] [--log[=<n>] | --no-log] -F <file>
```
Description
-----------
Takes the list of merged objects on stdin and produces a suitable commit message to be used for the merge commit, usually to be passed as the `<merge-message>` argument of `git merge`.
This command is intended mostly for internal use by scripts automatically invoking `git merge`.
Options
-------
--log[=<n>] In addition to branch names, populate the log message with one-line descriptions from the actual commits that are being merged. At most <n> commits from each merge parent will be used (20 if <n> is omitted). This overrides the `merge.log` configuration variable.
--no-log Do not list one-line descriptions from the actual commits being merged.
--[no-]summary Synonyms to --log and --no-log; these are deprecated and will be removed in the future.
-m <message> --message <message> Use <message> instead of the branch names for the first line of the log message. For use with `--log`.
--into-name <branch> Prepare the merge message as if merging to the branch `<branch>`, instead of the name of the real branch to which the merge is made.
-F <file> --file <file> Take the list of merged objects from <file> instead of stdin.
Configuration
-------------
merge.branchdesc In addition to branch names, populate the log message with the branch description text associated with them. Defaults to false.
merge.log In addition to branch names, populate the log message with at most the specified number of one-line descriptions from the actual commits that are being merged. Defaults to false, and true is a synonym for 20.
merge.suppressDest By adding a glob that matches the names of integration branches to this multi-valued configuration variable, the default merge message computed for merges into these integration branches will omit "into <branch name>" from its title.
An element with an empty value can be used to clear the list of globs accumulated from previous configuration entries. When there is no `merge.suppressDest` variable defined, the default value of `master` is used for backward compatibility.
merge.summary Synonym to `merge.log`; this is deprecated and will be removed in the future.
Examples
--------
```
$ git fetch origin master
$ git fmt-merge-msg --log <$GIT_DIR/FETCH_HEAD
```
Print a log message describing a merge of the "master" branch from the "origin" remote.
See also
--------
[git-merge[1]](git-merge)
git git-range-diff git-range-diff
==============
Name
----
git-range-diff - Compare two commit ranges (e.g. two versions of a branch)
Synopsis
--------
```
git range-diff [--color=[<when>]] [--no-color] [<diff-options>]
[--no-dual-color] [--creation-factor=<factor>]
[--left-only | --right-only]
( <range1> <range2> | <rev1>…<rev2> | <base> <rev1> <rev2> )
[[--] <path>…]
```
Description
-----------
This command shows the differences between two versions of a patch series, or more generally, two commit ranges (ignoring merge commits).
In the presence of `<path>` arguments, these commit ranges are limited accordingly.
To that end, it first finds pairs of commits from both commit ranges that correspond with each other. Two commits are said to correspond when the diff between their patches (i.e. the author information, the commit message and the commit diff) is reasonably small compared to the patches' size. See ``Algorithm`` below for details.
Finally, the list of matching commits is shown in the order of the second commit range, with unmatched commits being inserted just after all of their ancestors have been shown.
There are three ways to specify the commit ranges:
* `<range1> <range2>`: Either commit range can be of the form `<base>..<rev>`, `<rev>^!` or `<rev>^-<n>`. See `SPECIFYING RANGES` in [gitrevisions[7]](gitrevisions) for more details.
* `<rev1>...<rev2>`. This is equivalent to `<rev2>..<rev1> <rev1>..<rev2>`.
* `<base> <rev1> <rev2>`: This is equivalent to `<base>..<rev1>
<base>..<rev2>`.
Options
-------
--no-dual-color When the commit diffs differ, `git range-diff` recreates the original diffs' coloring, and adds outer -/+ diff markers with the **background** being red/green to make it easier to see e.g. when there was a change in what exact lines were added.
Additionally, the commit diff lines that are only present in the first commit range are shown "dimmed" (this can be overridden using the `color.diff.<slot>` config setting where `<slot>` is one of `contextDimmed`, `oldDimmed` and `newDimmed`), and the commit diff lines that are only present in the second commit range are shown in bold (which can be overridden using the config settings `color.diff.<slot>` with `<slot>` being one of `contextBold`, `oldBold` or `newBold`).
This is known to `range-diff` as "dual coloring". Use `--no-dual-color` to revert to color all lines according to the outer diff markers (and completely ignore the inner diff when it comes to color).
--creation-factor=<percent> Set the creation/deletion cost fudge factor to `<percent>`. Defaults to 60. Try a larger value if `git range-diff` erroneously considers a large change a total rewrite (deletion of one commit and addition of another), and a smaller one in the reverse case. See the ``Algorithm`` section below for an explanation why this is needed.
--left-only Suppress commits that are missing from the first specified range (or the "left range" when using the `<rev1>...<rev2>` format).
--right-only Suppress commits that are missing from the second specified range (or the "right range" when using the `<rev1>...<rev2>` format).
--[no-]notes[=<ref>] This flag is passed to the `git log` program (see [git-log[1]](git-log)) that generates the patches.
<range1> <range2> Compare the commits specified by the two ranges, where `<range1>` is considered an older version of `<range2>`.
<rev1>…<rev2> Equivalent to passing `<rev2>..<rev1>` and `<rev1>..<rev2>`.
<base> <rev1> <rev2> Equivalent to passing `<base>..<rev1>` and `<base>..<rev2>`. Note that `<base>` does not need to be the exact branch point of the branches. Example: after rebasing a branch `my-topic`, `git range-diff my-topic@{u} my-topic@{1} my-topic` would show the differences introduced by the rebase.
`git range-diff` also accepts the regular diff options (see [git-diff[1]](git-diff)), most notably the `--color=[<when>]` and `--no-color` options. These options are used when generating the "diff between patches", i.e. to compare the author, commit message and diff of corresponding old/new commits. There is currently no means to tweak most of the diff options passed to `git log` when generating those patches.
Output stability
----------------
The output of the `range-diff` command is subject to change. It is intended to be human-readable porcelain output, not something that can be used across versions of Git to get a textually stable `range-diff` (as opposed to something like the `--stable` option to [git-patch-id[1]](git-patch-id)). There’s also no equivalent of [git-apply[1]](git-apply) for `range-diff`, the output is not intended to be machine-readable.
This is particularly true when passing in diff options. Currently some options like `--stat` can, as an emergent effect, produce output that’s quite useless in the context of `range-diff`. Future versions of `range-diff` may learn to interpret such options in a manner specific to `range-diff` (e.g. for `--stat` producing human-readable output which summarizes how the diffstat changed).
Configuration
-------------
This command uses the `diff.color.*` and `pager.range-diff` settings (the latter is on by default). See [git-config[1]](git-config).
Examples
--------
When a rebase required merge conflicts to be resolved, compare the changes introduced by the rebase directly afterwards using:
```
$ git range-diff @{u} @{1} @
```
A typical output of `git range-diff` would look like this:
```
-: ------- > 1: 0ddba11 Prepare for the inevitable!
1: c0debee = 2: cab005e Add a helpful message at the start
2: f00dbal ! 3: decafe1 Describe a bug
@@ -1,3 +1,3 @@
Author: A U Thor <[email protected]>
-TODO: Describe a bug
+Describe a bug
@@ -324,5 +324,6
This is expected.
-+What is unexpected is that it will also crash.
++Unexpectedly, it also crashes. This is a bug, and the jury is
++still out there how to fix it best. See ticket #314 for details.
Contact
3: bedead < -: ------- TO-UNDO
```
In this example, there are 3 old and 3 new commits, where the developer removed the 3rd, added a new one before the first two, and modified the commit message of the 2nd commit as well its diff.
When the output goes to a terminal, it is color-coded by default, just like regular `git diff`'s output. In addition, the first line (adding a commit) is green, the last line (deleting a commit) is red, the second line (with a perfect match) is yellow like the commit header of `git
show`'s output, and the third line colors the old commit red, the new one green and the rest like `git show`'s commit header.
A naive color-coded diff of diffs is actually a bit hard to read, though, as it colors the entire lines red or green. The line that added "What is unexpected" in the old commit, for example, is completely red, even if the intent of the old commit was to add something.
To help with that, `range` uses the `--dual-color` mode by default. In this mode, the diff of diffs will retain the original diff colors, and prefix the lines with -/+ markers that have their **background** red or green, to make it more obvious that they describe how the diff itself changed.
Algorithm
---------
The general idea is this: we generate a cost matrix between the commits in both commit ranges, then solve the least-cost assignment.
The cost matrix is populated thusly: for each pair of commits, both diffs are generated and the "diff of diffs" is generated, with 3 context lines, then the number of lines in that diff is used as cost.
To avoid false positives (e.g. when a patch has been removed, and an unrelated patch has been added between two iterations of the same patch series), the cost matrix is extended to allow for that, by adding fixed-cost entries for wholesale deletes/adds.
Example: Let commits `1--2` be the first iteration of a patch series and `A--C` the second iteration. Let’s assume that `A` is a cherry-pick of `2,` and `C` is a cherry-pick of `1` but with a small modification (say, a fixed typo). Visualize the commits as a bipartite graph:
```
1 A
2 B
C
```
We are looking for a "best" explanation of the new series in terms of the old one. We can represent an "explanation" as an edge in the graph:
```
1 A
/
2 --------' B
C
```
This explanation comes for "free" because there was no change. Similarly `C` could be explained using `1`, but that comes at some cost c>0 because of the modification:
```
1 ----. A
| /
2 ----+---' B
|
`----- C
c>0
```
In mathematical terms, what we are looking for is some sort of a minimum cost bipartite matching; `1` is matched to `C` at some cost, etc. The underlying graph is in fact a complete bipartite graph; the cost we associate with every edge is the size of the diff between the two commits' patches. To explain also new commits, we introduce dummy nodes on both sides:
```
1 ----. A
| /
2 ----+---' B
|
o `----- C
c>0
o o
o o
```
The cost of an edge `o--C` is the size of `C`'s diff, modified by a fudge factor that should be smaller than 100%. The cost of an edge `o--o` is free. The fudge factor is necessary because even if `1` and `C` have nothing in common, they may still share a few empty lines and such, possibly making the assignment `1--C`, `o--o` slightly cheaper than `1--o`, `o--C` even if `1` and `C` have nothing in common. With the fudge factor we require a much larger common part to consider patches as corresponding.
The overall time needed to compute this algorithm is the time needed to compute n+m commit diffs and then n\*m diffs of patches, plus the time needed to compute the least-cost assignment between n and m diffs. Git uses an implementation of the Jonker-Volgenant algorithm to solve the assignment problem, which has cubic runtime complexity. The matching found in this case will look like this:
```
1 ----. A
| /
2 ----+---' B
.--+-----'
o -' `----- C
c>0
o ---------- o
o ---------- o
```
See also
--------
[git-log[1]](git-log)
| programming_docs |
git git-commit git-commit
==========
Name
----
git-commit - Record changes to the repository
Synopsis
--------
```
git commit [-a | --interactive | --patch] [-s] [-v] [-u<mode>] [--amend]
[--dry-run] [(-c | -C | --squash) <commit> | --fixup [(amend|reword):]<commit>)]
[-F <file> | -m <msg>] [--reset-author] [--allow-empty]
[--allow-empty-message] [--no-verify] [-e] [--author=<author>]
[--date=<date>] [--cleanup=<mode>] [--[no-]status]
[-i | -o] [--pathspec-from-file=<file> [--pathspec-file-nul]]
[(--trailer <token>[(=|:)<value>])…] [-S[<keyid>]]
[--] [<pathspec>…]
```
Description
-----------
Create a new commit containing the current contents of the index and the given log message describing the changes. The new commit is a direct child of HEAD, usually the tip of the current branch, and the branch is updated to point to it (unless no branch is associated with the working tree, in which case HEAD is "detached" as described in [git-checkout[1]](git-checkout)).
The content to be committed can be specified in several ways:
1. by using [git-add[1]](git-add) to incrementally "add" changes to the index before using the `commit` command (Note: even modified files must be "added");
2. by using [git-rm[1]](git-rm) to remove files from the working tree and the index, again before using the `commit` command;
3. by listing files as arguments to the `commit` command (without --interactive or --patch switch), in which case the commit will ignore changes staged in the index, and instead record the current content of the listed files (which must already be known to Git);
4. by using the -a switch with the `commit` command to automatically "add" changes from all known files (i.e. all files that are already listed in the index) and to automatically "rm" files in the index that have been removed from the working tree, and then perform the actual commit;
5. by using the --interactive or --patch switches with the `commit` command to decide one by one which files or hunks should be part of the commit in addition to contents in the index, before finalizing the operation. See the “Interactive Mode” section of [git-add[1]](git-add) to learn how to operate these modes.
The `--dry-run` option can be used to obtain a summary of what is included by any of the above for the next commit by giving the same set of parameters (options and paths).
If you make a commit and then find a mistake immediately after that, you can recover from it with `git reset`.
Options
-------
-a --all Tell the command to automatically stage files that have been modified and deleted, but new files you have not told Git about are not affected.
-p --patch Use the interactive patch selection interface to choose which changes to commit. See [git-add[1]](git-add) for details.
-C <commit> --reuse-message=<commit> Take an existing commit object, and reuse the log message and the authorship information (including the timestamp) when creating the commit.
-c <commit> --reedit-message=<commit> Like `-C`, but with `-c` the editor is invoked, so that the user can further edit the commit message.
--fixup=[(amend|reword):]<commit> Create a new commit which "fixes up" `<commit>` when applied with `git rebase --autosquash`. Plain `--fixup=<commit>` creates a "fixup!" commit which changes the content of `<commit>` but leaves its log message untouched. `--fixup=amend:<commit>` is similar but creates an "amend!" commit which also replaces the log message of `<commit>` with the log message of the "amend!" commit. `--fixup=reword:<commit>` creates an "amend!" commit which replaces the log message of `<commit>` with its own log message but makes no changes to the content of `<commit>`.
The commit created by plain `--fixup=<commit>` has a subject composed of "fixup!" followed by the subject line from <commit>, and is recognized specially by `git rebase --autosquash`. The `-m` option may be used to supplement the log message of the created commit, but the additional commentary will be thrown away once the "fixup!" commit is squashed into `<commit>` by `git rebase --autosquash`.
The commit created by `--fixup=amend:<commit>` is similar but its subject is instead prefixed with "amend!". The log message of <commit> is copied into the log message of the "amend!" commit and opened in an editor so it can be refined. When `git rebase
--autosquash` squashes the "amend!" commit into `<commit>`, the log message of `<commit>` is replaced by the refined log message from the "amend!" commit. It is an error for the "amend!" commit’s log message to be empty unless `--allow-empty-message` is specified.
`--fixup=reword:<commit>` is shorthand for `--fixup=amend:<commit>
--only`. It creates an "amend!" commit with only a log message (ignoring any changes staged in the index). When squashed by `git
rebase --autosquash`, it replaces the log message of `<commit>` without making any other changes.
Neither "fixup!" nor "amend!" commits change authorship of `<commit>` when applied by `git rebase --autosquash`. See [git-rebase[1]](git-rebase) for details.
--squash=<commit> Construct a commit message for use with `rebase --autosquash`. The commit message subject line is taken from the specified commit with a prefix of "squash! ". Can be used with additional commit message options (`-m`/`-c`/`-C`/`-F`). See [git-rebase[1]](git-rebase) for details.
--reset-author When used with -C/-c/--amend options, or when committing after a conflicting cherry-pick, declare that the authorship of the resulting commit now belongs to the committer. This also renews the author timestamp.
--short When doing a dry-run, give the output in the short-format. See [git-status[1]](git-status) for details. Implies `--dry-run`.
--branch Show the branch and tracking info even in short-format.
--porcelain When doing a dry-run, give the output in a porcelain-ready format. See [git-status[1]](git-status) for details. Implies `--dry-run`.
--long When doing a dry-run, give the output in the long-format. Implies `--dry-run`.
-z --null When showing `short` or `porcelain` status output, print the filename verbatim and terminate the entries with NUL, instead of LF. If no format is given, implies the `--porcelain` output format. Without the `-z` option, filenames with "unusual" characters are quoted as explained for the configuration variable `core.quotePath` (see [git-config[1]](git-config)).
-F <file> --file=<file> Take the commit message from the given file. Use `-` to read the message from the standard input.
--author=<author> Override the commit author. Specify an explicit author using the standard `A U Thor <[email protected]>` format. Otherwise <author> is assumed to be a pattern and is used to search for an existing commit by that author (i.e. rev-list --all -i --author=<author>); the commit author is then copied from the first such commit found.
--date=<date> Override the author date used in the commit.
-m <msg> --message=<msg> Use the given <msg> as the commit message. If multiple `-m` options are given, their values are concatenated as separate paragraphs.
The `-m` option is mutually exclusive with `-c`, `-C`, and `-F`.
-t <file> --template=<file> When editing the commit message, start the editor with the contents in the given file. The `commit.template` configuration variable is often used to give this option implicitly to the command. This mechanism can be used by projects that want to guide participants with some hints on what to write in the message in what order. If the user exits the editor without editing the message, the commit is aborted. This has no effect when a message is given by other means, e.g. with the `-m` or `-F` options.
-s --signoff --no-signoff Add a `Signed-off-by` trailer by the committer at the end of the commit log message. The meaning of a signoff depends on the project to which you’re committing. For example, it may certify that the committer has the rights to submit the work under the project’s license or agrees to some contributor representation, such as a Developer Certificate of Origin. (See <http://developercertificate.org> for the one used by the Linux kernel and Git projects.) Consult the documentation or leadership of the project to which you’re contributing to understand how the signoffs are used in that project.
The --no-signoff option can be used to countermand an earlier --signoff option on the command line.
--trailer <token>[(=|:)<value>] Specify a (<token>, <value>) pair that should be applied as a trailer. (e.g. `git commit --trailer "Signed-off-by:C O Mitter \
<[email protected]>" --trailer "Helped-by:C O Mitter \
<[email protected]>"` will add the "Signed-off-by" trailer and the "Helped-by" trailer to the commit message.) The `trailer.*` configuration variables ([git-interpret-trailers[1]](git-interpret-trailers)) can be used to define if a duplicated trailer is omitted, where in the run of trailers each trailer would appear, and other details.
-n --[no-]verify By default, the pre-commit and commit-msg hooks are run. When any of `--no-verify` or `-n` is given, these are bypassed. See also [githooks[5]](githooks).
--allow-empty Usually recording a commit that has the exact same tree as its sole parent commit is a mistake, and the command prevents you from making such a commit. This option bypasses the safety, and is primarily for use by foreign SCM interface scripts.
--allow-empty-message Like --allow-empty this command is primarily for use by foreign SCM interface scripts. It allows you to create a commit with an empty commit message without using plumbing commands like [git-commit-tree[1]](git-commit-tree).
--cleanup=<mode> This option determines how the supplied commit message should be cleaned up before committing. The `<mode>` can be `strip`, `whitespace`, `verbatim`, `scissors` or `default`.
strip Strip leading and trailing empty lines, trailing whitespace, commentary and collapse consecutive empty lines.
whitespace Same as `strip` except #commentary is not removed.
verbatim Do not change the message at all.
scissors Same as `whitespace` except that everything from (and including) the line found below is truncated, if the message is to be edited. "`#`" can be customized with core.commentChar.
```
# ------------------------ >8 ------------------------
```
default Same as `strip` if the message is to be edited. Otherwise `whitespace`.
The default can be changed by the `commit.cleanup` configuration variable (see [git-config[1]](git-config)).
-e --edit The message taken from file with `-F`, command line with `-m`, and from commit object with `-C` are usually used as the commit log message unmodified. This option lets you further edit the message taken from these sources.
--no-edit Use the selected commit message without launching an editor. For example, `git commit --amend --no-edit` amends a commit without changing its commit message.
--amend Replace the tip of the current branch by creating a new commit. The recorded tree is prepared as usual (including the effect of the `-i` and `-o` options and explicit pathspec), and the message from the original commit is used as the starting point, instead of an empty message, when no other message is specified from the command line via options such as `-m`, `-F`, `-c`, etc. The new commit has the same parents and author as the current one (the `--reset-author` option can countermand this).
It is a rough equivalent for:
```
$ git reset --soft HEAD^
$ ... do something else to come up with the right tree ...
$ git commit -c ORIG_HEAD
```
but can be used to amend a merge commit.
You should understand the implications of rewriting history if you amend a commit that has already been published. (See the "RECOVERING FROM UPSTREAM REBASE" section in [git-rebase[1]](git-rebase).)
--no-post-rewrite Bypass the post-rewrite hook.
-i --include Before making a commit out of staged contents so far, stage the contents of paths given on the command line as well. This is usually not what you want unless you are concluding a conflicted merge.
-o --only Make a commit by taking the updated working tree contents of the paths specified on the command line, disregarding any contents that have been staged for other paths. This is the default mode of operation of `git commit` if any paths are given on the command line, in which case this option can be omitted. If this option is specified together with `--amend`, then no paths need to be specified, which can be used to amend the last commit without committing changes that have already been staged. If used together with `--allow-empty` paths are also not required, and an empty commit will be created.
--pathspec-from-file=<file> Pathspec is passed in `<file>` instead of commandline args. If `<file>` is exactly `-` then standard input is used. Pathspec elements are separated by LF or CR/LF. Pathspec elements can be quoted as explained for the configuration variable `core.quotePath` (see [git-config[1]](git-config)). See also `--pathspec-file-nul` and global `--literal-pathspecs`.
--pathspec-file-nul Only meaningful with `--pathspec-from-file`. Pathspec elements are separated with NUL character and all other characters are taken literally (including newlines and quotes).
-u[<mode>] --untracked-files[=<mode>] Show untracked files.
The mode parameter is optional (defaults to `all`), and is used to specify the handling of untracked files; when -u is not used, the default is `normal`, i.e. show untracked files and directories.
The possible options are:
* `no` - Show no untracked files
* `normal` - Shows untracked files and directories
* `all` - Also shows individual files in untracked directories.
The default can be changed using the status.showUntrackedFiles configuration variable documented in [git-config[1]](git-config).
-v --verbose Show unified diff between the HEAD commit and what would be committed at the bottom of the commit message template to help the user describe the commit by reminding what changes the commit has. Note that this diff output doesn’t have its lines prefixed with `#`. This diff will not be a part of the commit message. See the `commit.verbose` configuration variable in [git-config[1]](git-config).
If specified twice, show in addition the unified diff between what would be committed and the worktree files, i.e. the unstaged changes to tracked files.
-q --quiet Suppress commit summary message.
--dry-run Do not create a commit, but show a list of paths that are to be committed, paths with local changes that will be left uncommitted and paths that are untracked.
--status Include the output of [git-status[1]](git-status) in the commit message template when using an editor to prepare the commit message. Defaults to on, but can be used to override configuration variable commit.status.
--no-status Do not include the output of [git-status[1]](git-status) in the commit message template when using an editor to prepare the default commit message.
-S[<keyid>] --gpg-sign[=<keyid>] --no-gpg-sign GPG-sign commits. The `keyid` argument is optional and defaults to the committer identity; if specified, it must be stuck to the option without a space. `--no-gpg-sign` is useful to countermand both `commit.gpgSign` configuration variable, and earlier `--gpg-sign`.
-- Do not interpret any more arguments as options.
<pathspec>… When pathspec is given on the command line, commit the contents of the files that match the pathspec without recording the changes already added to the index. The contents of these files are also staged for the next commit on top of what have been staged before.
For more details, see the `pathspec` entry in [gitglossary[7]](gitglossary).
Examples
--------
When recording your own work, the contents of modified files in your working tree are temporarily stored to a staging area called the "index" with `git add`. A file can be reverted back, only in the index but not in the working tree, to that of the last commit with `git restore --staged <file>`, which effectively reverts `git add` and prevents the changes to this file from participating in the next commit. After building the state to be committed incrementally with these commands, `git commit` (without any pathname parameter) is used to record what has been staged so far. This is the most basic form of the command. An example:
```
$ edit hello.c
$ git rm goodbye.c
$ git add hello.c
$ git commit
```
Instead of staging files after each individual change, you can tell `git commit` to notice the changes to the files whose contents are tracked in your working tree and do corresponding `git add` and `git rm` for you. That is, this example does the same as the earlier example if there is no other change in your working tree:
```
$ edit hello.c
$ rm goodbye.c
$ git commit -a
```
The command `git commit -a` first looks at your working tree, notices that you have modified hello.c and removed goodbye.c, and performs necessary `git add` and `git rm` for you.
After staging changes to many files, you can alter the order the changes are recorded in, by giving pathnames to `git commit`. When pathnames are given, the command makes a commit that only records the changes made to the named paths:
```
$ edit hello.c hello.h
$ git add hello.c hello.h
$ edit Makefile
$ git commit Makefile
```
This makes a commit that records the modification to `Makefile`. The changes staged for `hello.c` and `hello.h` are not included in the resulting commit. However, their changes are not lost — they are still staged and merely held back. After the above sequence, if you do:
```
$ git commit
```
this second commit would record the changes to `hello.c` and `hello.h` as expected.
After a merge (initiated by `git merge` or `git pull`) stops because of conflicts, cleanly merged paths are already staged to be committed for you, and paths that conflicted are left in unmerged state. You would have to first check which paths are conflicting with `git status` and after fixing them manually in your working tree, you would stage the result as usual with `git add`:
```
$ git status | grep unmerged
unmerged: hello.c
$ edit hello.c
$ git add hello.c
```
After resolving conflicts and staging the result, `git ls-files -u` would stop mentioning the conflicted path. When you are done, run `git commit` to finally record the merge:
```
$ git commit
```
As with the case to record your own changes, you can use `-a` option to save typing. One difference is that during a merge resolution, you cannot use `git commit` with pathnames to alter the order the changes are committed, because the merge should be recorded as a single commit. In fact, the command refuses to run when given pathnames (but see `-i` option).
Commit information
------------------
Author and committer information is taken from the following environment variables, if set:
```
GIT_AUTHOR_NAME
GIT_AUTHOR_EMAIL
GIT_AUTHOR_DATE
GIT_COMMITTER_NAME
GIT_COMMITTER_EMAIL
GIT_COMMITTER_DATE
```
(nb "<", ">" and "\n"s are stripped)
The author and committer names are by convention some form of a personal name (that is, the name by which other humans refer to you), although Git does not enforce or require any particular form. Arbitrary Unicode may be used, subject to the constraints listed above. This name has no effect on authentication; for that, see the `credential.username` variable in [git-config[1]](git-config).
In case (some of) these environment variables are not set, the information is taken from the configuration items `user.name` and `user.email`, or, if not present, the environment variable EMAIL, or, if that is not set, system user name and the hostname used for outgoing mail (taken from `/etc/mailname` and falling back to the fully qualified hostname when that file does not exist).
The `author.name` and `committer.name` and their corresponding email options override `user.name` and `user.email` if set and are overridden themselves by the environment variables.
The typical usage is to set just the `user.name` and `user.email` variables; the other options are provided for more complex use cases.
Date formats
------------
The `GIT_AUTHOR_DATE` and `GIT_COMMITTER_DATE` environment variables support the following date formats:
Git internal format It is `<unix-timestamp> <time-zone-offset>`, where `<unix-timestamp>` is the number of seconds since the UNIX epoch. `<time-zone-offset>` is a positive or negative offset from UTC. For example CET (which is 1 hour ahead of UTC) is `+0100`.
RFC 2822 The standard email format as described by RFC 2822, for example `Thu, 07 Apr 2005 22:13:13 +0200`.
ISO 8601 Time and date specified by the ISO 8601 standard, for example `2005-04-07T22:13:13`. The parser accepts a space instead of the `T` character as well. Fractional parts of a second will be ignored, for example `2005-04-07T22:13:13.019` will be treated as `2005-04-07T22:13:13`.
| | |
| --- | --- |
| Note | In addition, the date part is accepted in the following formats: `YYYY.MM.DD`, `MM/DD/YYYY` and `DD.MM.YYYY`. |
In addition to recognizing all date formats above, the `--date` option will also try to make sense of other, more human-centric date formats, such as relative dates like "yesterday" or "last Friday at noon".
Discussion
----------
Though not required, it’s a good idea to begin the commit message with a single short (less than 50 character) line summarizing the change, followed by a blank line and then a more thorough description. The text up to the first blank line in a commit message is treated as the commit title, and that title is used throughout Git. For example, [git-format-patch[1]](git-format-patch) turns a commit into email, and it uses the title on the Subject line and the rest of the commit in the body.
Git is to some extent character encoding agnostic.
* The contents of the blob objects are uninterpreted sequences of bytes. There is no encoding translation at the core level.
* Path names are encoded in UTF-8 normalization form C. This applies to tree objects, the index file, ref names, as well as path names in command line arguments, environment variables and config files (`.git/config` (see [git-config[1]](git-config)), [gitignore[5]](gitignore), [gitattributes[5]](gitattributes) and [gitmodules[5]](gitmodules)).
Note that Git at the core level treats path names simply as sequences of non-NUL bytes, there are no path name encoding conversions (except on Mac and Windows). Therefore, using non-ASCII path names will mostly work even on platforms and file systems that use legacy extended ASCII encodings. However, repositories created on such systems will not work properly on UTF-8-based systems (e.g. Linux, Mac, Windows) and vice versa. Additionally, many Git-based tools simply assume path names to be UTF-8 and will fail to display other encodings correctly.
* Commit log messages are typically encoded in UTF-8, but other extended ASCII encodings are also supported. This includes ISO-8859-x, CP125x and many others, but `not` UTF-16/32, EBCDIC and CJK multi-byte encodings (GBK, Shift-JIS, Big5, EUC-x, CP9xx etc.).
Although we encourage that the commit log messages are encoded in UTF-8, both the core and Git Porcelain are designed not to force UTF-8 on projects. If all participants of a particular project find it more convenient to use legacy encodings, Git does not forbid it. However, there are a few things to keep in mind.
1. `git commit` and `git commit-tree` issues a warning if the commit log message given to it does not look like a valid UTF-8 string, unless you explicitly say your project uses a legacy encoding. The way to say this is to have `i18n.commitEncoding` in `.git/config` file, like this:
```
[i18n]
commitEncoding = ISO-8859-1
```
Commit objects created with the above setting record the value of `i18n.commitEncoding` in its `encoding` header. This is to help other people who look at them later. Lack of this header implies that the commit log message is encoded in UTF-8.
2. `git log`, `git show`, `git blame` and friends look at the `encoding` header of a commit object, and try to re-code the log message into UTF-8 unless otherwise specified. You can specify the desired output encoding with `i18n.logOutputEncoding` in `.git/config` file, like this:
```
[i18n]
logOutputEncoding = ISO-8859-1
```
If you do not have this configuration variable, the value of `i18n.commitEncoding` is used instead.
Note that we deliberately chose not to re-code the commit log message when a commit is made to force UTF-8 at the commit object level, because re-coding to UTF-8 is not necessarily a reversible operation.
Environment and configuration variables
---------------------------------------
The editor used to edit the commit log message will be chosen from the `GIT_EDITOR` environment variable, the core.editor configuration variable, the `VISUAL` environment variable, or the `EDITOR` environment variable (in that order). See [git-var[1]](git-var) for details.
Everything above this line in this section isn’t included from the [git-config[1]](git-config) documentation. The content that follows is the same as what’s found there:
commit.cleanup This setting overrides the default of the `--cleanup` option in `git commit`. See [git-commit[1]](git-commit) for details. Changing the default can be useful when you always want to keep lines that begin with comment character `#` in your log message, in which case you would do `git config commit.cleanup whitespace` (note that you will have to remove the help lines that begin with `#` in the commit log template yourself, if you do this).
commit.gpgSign A boolean to specify whether all commits should be GPG signed. Use of this option when doing operations such as rebase can result in a large number of commits being signed. It may be convenient to use an agent to avoid typing your GPG passphrase several times.
commit.status A boolean to enable/disable inclusion of status information in the commit message template when using an editor to prepare the commit message. Defaults to true.
commit.template Specify the pathname of a file to use as the template for new commit messages.
commit.verbose A boolean or int to specify the level of verbose with `git commit`. See [git-commit[1]](git-commit).
Hooks
-----
This command can run `commit-msg`, `prepare-commit-msg`, `pre-commit`, `post-commit` and `post-rewrite` hooks. See [githooks[5]](githooks) for more information.
Files
-----
`$GIT_DIR/COMMIT_EDITMSG` This file contains the commit message of a commit in progress. If `git commit` exits due to an error before creating a commit, any commit message that has been provided by the user (e.g., in an editor session) will be available in this file, but will be overwritten by the next invocation of `git commit`.
See also
--------
[git-add[1]](git-add), [git-rm[1]](git-rm), [git-mv[1]](git-mv), [git-merge[1]](git-merge), [git-commit-tree[1]](git-commit-tree)
| programming_docs |
git git-rev-parse git-rev-parse
=============
Name
----
git-rev-parse - Pick out and massage parameters
Synopsis
--------
```
git rev-parse [<options>] <args>…
```
Description
-----------
Many Git porcelainish commands take mixture of flags (i.e. parameters that begin with a dash `-`) and parameters meant for the underlying `git rev-list` command they use internally and flags and parameters for the other commands they use downstream of `git rev-list`. This command is used to distinguish between them.
Options
-------
###
Operation Modes
Each of these options must appear first on the command line.
--parseopt Use `git rev-parse` in option parsing mode (see PARSEOPT section below).
--sq-quote Use `git rev-parse` in shell quoting mode (see SQ-QUOTE section below). In contrast to the `--sq` option below, this mode does only quoting. Nothing else is done to command input.
###
Options for --parseopt
--keep-dashdash Only meaningful in `--parseopt` mode. Tells the option parser to echo out the first `--` met instead of skipping it.
--stop-at-non-option Only meaningful in `--parseopt` mode. Lets the option parser stop at the first non-option argument. This can be used to parse sub-commands that take options themselves.
--stuck-long Only meaningful in `--parseopt` mode. Output the options in their long form if available, and with their arguments stuck.
###
Options for Filtering
--revs-only Do not output flags and parameters not meant for `git rev-list` command.
--no-revs Do not output flags and parameters meant for `git rev-list` command.
--flags Do not output non-flag parameters.
--no-flags Do not output flag parameters.
###
Options for Output
--default <arg> If there is no parameter given by the user, use `<arg>` instead.
--prefix <arg> Behave as if `git rev-parse` was invoked from the `<arg>` subdirectory of the working tree. Any relative filenames are resolved as if they are prefixed by `<arg>` and will be printed in that form.
This can be used to convert arguments to a command run in a subdirectory so that they can still be used after moving to the top-level of the repository. For example:
```
prefix=$(git rev-parse --show-prefix)
cd "$(git rev-parse --show-toplevel)"
# rev-parse provides the -- needed for 'set'
eval "set $(git rev-parse --sq --prefix "$prefix" -- "$@")"
```
--verify Verify that exactly one parameter is provided, and that it can be turned into a raw 20-byte SHA-1 that can be used to access the object database. If so, emit it to the standard output; otherwise, error out.
If you want to make sure that the output actually names an object in your object database and/or can be used as a specific type of object you require, you can add the `^{type}` peeling operator to the parameter. For example, `git rev-parse "$VAR^{commit}"` will make sure `$VAR` names an existing object that is a commit-ish (i.e. a commit, or an annotated tag that points at a commit). To make sure that `$VAR` names an existing object of any type, `git rev-parse "$VAR^{object}"` can be used.
Note that if you are verifying a name from an untrusted source, it is wise to use `--end-of-options` so that the name argument is not mistaken for another option.
-q --quiet Only meaningful in `--verify` mode. Do not output an error message if the first argument is not a valid object name; instead exit with non-zero status silently. SHA-1s for valid object names are printed to stdout on success.
--sq Usually the output is made one line per flag and parameter. This option makes output a single line, properly quoted for consumption by shell. Useful when you expect your parameter to contain whitespaces and newlines (e.g. when using pickaxe `-S` with `git diff-*`). In contrast to the `--sq-quote` option, the command input is still interpreted as usual.
--short[=length] Same as `--verify` but shortens the object name to a unique prefix with at least `length` characters. The minimum length is 4, the default is the effective value of the `core.abbrev` configuration variable (see [git-config[1]](git-config)).
--not When showing object names, prefix them with `^` and strip `^` prefix from the object names that already have one.
--abbrev-ref[=(strict|loose)] A non-ambiguous short name of the objects name. The option core.warnAmbiguousRefs is used to select the strict abbreviation mode.
--symbolic Usually the object names are output in SHA-1 form (with possible `^` prefix); this option makes them output in a form as close to the original input as possible.
--symbolic-full-name This is similar to --symbolic, but it omits input that are not refs (i.e. branch or tag names; or more explicitly disambiguating "heads/master" form, when you want to name the "master" branch when there is an unfortunately named tag "master"), and show them as full refnames (e.g. "refs/heads/master").
###
Options for Objects
--all Show all refs found in `refs/`.
--branches[=pattern] --tags[=pattern] --remotes[=pattern] Show all branches, tags, or remote-tracking branches, respectively (i.e., refs found in `refs/heads`, `refs/tags`, or `refs/remotes`, respectively).
If a `pattern` is given, only refs matching the given shell glob are shown. If the pattern does not contain a globbing character (`?`, `*`, or `[`), it is turned into a prefix match by appending `/*`.
--glob=pattern Show all refs matching the shell glob pattern `pattern`. If the pattern does not start with `refs/`, this is automatically prepended. If the pattern does not contain a globbing character (`?`, `*`, or `[`), it is turned into a prefix match by appending `/*`.
--exclude=<glob-pattern> Do not include refs matching `<glob-pattern>` that the next `--all`, `--branches`, `--tags`, `--remotes`, or `--glob` would otherwise consider. Repetitions of this option accumulate exclusion patterns up to the next `--all`, `--branches`, `--tags`, `--remotes`, or `--glob` option (other options or arguments do not clear accumulated patterns).
The patterns given should not begin with `refs/heads`, `refs/tags`, or `refs/remotes` when applied to `--branches`, `--tags`, or `--remotes`, respectively, and they must begin with `refs/` when applied to `--glob` or `--all`. If a trailing `/*` is intended, it must be given explicitly.
--exclude-hidden=[receive|uploadpack] Do not include refs that would be hidden by `git-receive-pack` or `git-upload-pack` by consulting the appropriate `receive.hideRefs` or `uploadpack.hideRefs` configuration along with `transfer.hideRefs` (see [git-config[1]](git-config)). This option affects the next pseudo-ref option `--all` or `--glob` and is cleared after processing them.
--disambiguate=<prefix> Show every object whose name begins with the given prefix. The <prefix> must be at least 4 hexadecimal digits long to avoid listing each and every object in the repository by mistake.
###
Options for Files
--local-env-vars List the GIT\_\* environment variables that are local to the repository (e.g. GIT\_DIR or GIT\_WORK\_TREE, but not GIT\_EDITOR). Only the names of the variables are listed, not their value, even if they are set.
--path-format=(absolute|relative) Controls the behavior of certain other options. If specified as absolute, the paths printed by those options will be absolute and canonical. If specified as relative, the paths will be relative to the current working directory if that is possible. The default is option specific.
This option may be specified multiple times and affects only the arguments that follow it on the command line, either to the end of the command line or the next instance of this option.
The following options are modified by `--path-format`:
--git-dir Show `$GIT_DIR` if defined. Otherwise show the path to the .git directory. The path shown, when relative, is relative to the current working directory.
If `$GIT_DIR` is not defined and the current directory is not detected to lie in a Git repository or work tree print a message to stderr and exit with nonzero status.
--git-common-dir Show `$GIT_COMMON_DIR` if defined, else `$GIT_DIR`.
--resolve-git-dir <path> Check if <path> is a valid repository or a gitfile that points at a valid repository, and print the location of the repository. If <path> is a gitfile then the resolved path to the real repository is printed.
--git-path <path> Resolve "$GIT\_DIR/<path>" and takes other path relocation variables such as $GIT\_OBJECT\_DIRECTORY, $GIT\_INDEX\_FILE… into account. For example, if $GIT\_OBJECT\_DIRECTORY is set to /foo/bar then "git rev-parse --git-path objects/abc" returns /foo/bar/abc.
--show-toplevel Show the (by default, absolute) path of the top-level directory of the working tree. If there is no working tree, report an error.
--show-superproject-working-tree Show the absolute path of the root of the superproject’s working tree (if exists) that uses the current repository as its submodule. Outputs nothing if the current repository is not used as a submodule by any project.
--shared-index-path Show the path to the shared index file in split index mode, or empty if not in split-index mode.
The following options are unaffected by `--path-format`:
--absolute-git-dir Like `--git-dir`, but its output is always the canonicalized absolute path.
--is-inside-git-dir When the current working directory is below the repository directory print "true", otherwise "false".
--is-inside-work-tree When the current working directory is inside the work tree of the repository print "true", otherwise "false".
--is-bare-repository When the repository is bare print "true", otherwise "false".
--is-shallow-repository When the repository is shallow print "true", otherwise "false".
--show-cdup When the command is invoked from a subdirectory, show the path of the top-level directory relative to the current directory (typically a sequence of "../", or an empty string).
--show-prefix When the command is invoked from a subdirectory, show the path of the current directory relative to the top-level directory.
--show-object-format[=(storage|input|output)] Show the object format (hash algorithm) used for the repository for storage inside the `.git` directory, input, or output. For input, multiple algorithms may be printed, space-separated. If not specified, the default is "storage".
###
Other Options
--since=datestring --after=datestring Parse the date string, and output the corresponding --max-age= parameter for `git rev-list`.
--until=datestring --before=datestring Parse the date string, and output the corresponding --min-age= parameter for `git rev-list`.
<args>… Flags and parameters to be parsed.
Specifying revisions
--------------------
A revision parameter `<rev>` typically, but not necessarily, names a commit object. It uses what is called an `extended SHA-1` syntax. Here are various ways to spell object names. The ones listed near the end of this list name trees and blobs contained in a commit.
| | |
| --- | --- |
| Note | This document shows the "raw" syntax as seen by git. The shell and other UIs might require additional quoting to protect special characters and to avoid word splitting. |
*<sha1>*, e.g. *dae86e1950b1277e545cee180551750029cfe735*, *dae86e* The full SHA-1 object name (40-byte hexadecimal string), or a leading substring that is unique within the repository. E.g. dae86e1950b1277e545cee180551750029cfe735 and dae86e both name the same commit object if there is no other object in your repository whose object name starts with dae86e.
*<describeOutput>*, e.g. *v1.7.4.2-679-g3bee7fb* Output from `git describe`; i.e. a closest tag, optionally followed by a dash and a number of commits, followed by a dash, a `g`, and an abbreviated object name.
*<refname>*, e.g. *master*, *heads/master*, *refs/heads/master* A symbolic ref name. E.g. `master` typically means the commit object referenced by `refs/heads/master`. If you happen to have both `heads/master` and `tags/master`, you can explicitly say `heads/master` to tell Git which one you mean. When ambiguous, a `<refname>` is disambiguated by taking the first match in the following rules:
1. If `$GIT_DIR/<refname>` exists, that is what you mean (this is usually useful only for `HEAD`, `FETCH_HEAD`, `ORIG_HEAD`, `MERGE_HEAD` and `CHERRY_PICK_HEAD`);
2. otherwise, `refs/<refname>` if it exists;
3. otherwise, `refs/tags/<refname>` if it exists;
4. otherwise, `refs/heads/<refname>` if it exists;
5. otherwise, `refs/remotes/<refname>` if it exists;
6. otherwise, `refs/remotes/<refname>/HEAD` if it exists.
`HEAD` names the commit on which you based the changes in the working tree. `FETCH_HEAD` records the branch which you fetched from a remote repository with your last `git fetch` invocation. `ORIG_HEAD` is created by commands that move your `HEAD` in a drastic way, to record the position of the `HEAD` before their operation, so that you can easily change the tip of the branch back to the state before you ran them. `MERGE_HEAD` records the commit(s) which you are merging into your branch when you run `git merge`. `CHERRY_PICK_HEAD` records the commit which you are cherry-picking when you run `git cherry-pick`.
Note that any of the `refs/*` cases above may come either from the `$GIT_DIR/refs` directory or from the `$GIT_DIR/packed-refs` file. While the ref name encoding is unspecified, UTF-8 is preferred as some output processing may assume ref names in UTF-8.
*@* `@` alone is a shortcut for `HEAD`.
*[<refname>]@{<date>}*, e.g. *master@{yesterday}*, *HEAD@{5 minutes ago}* A ref followed by the suffix `@` with a date specification enclosed in a brace pair (e.g. `{yesterday}`, `{1 month 2 weeks 3 days 1 hour 1 second ago}` or `{1979-02-26 18:30:00}`) specifies the value of the ref at a prior point in time. This suffix may only be used immediately following a ref name and the ref must have an existing log (`$GIT_DIR/logs/<ref>`). Note that this looks up the state of your **local** ref at a given time; e.g., what was in your local `master` branch last week. If you want to look at commits made during certain times, see `--since` and `--until`.
*<refname>@{<n>}*, e.g. *master@{1}* A ref followed by the suffix `@` with an ordinal specification enclosed in a brace pair (e.g. `{1}`, `{15}`) specifies the n-th prior value of that ref. For example `master@{1}` is the immediate prior value of `master` while `master@{5}` is the 5th prior value of `master`. This suffix may only be used immediately following a ref name and the ref must have an existing log (`$GIT_DIR/logs/<refname>`).
*@{<n>}*, e.g. *@{1}* You can use the `@` construct with an empty ref part to get at a reflog entry of the current branch. For example, if you are on branch `blabla` then `@{1}` means the same as `blabla@{1}`.
*@{-<n>}*, e.g. *@{-1}* The construct `@{-<n>}` means the <n>th branch/commit checked out before the current one.
*[<branchname>]@{upstream}*, e.g. *master@{upstream}*, *@{u}* A branch B may be set up to build on top of a branch X (configured with `branch.<name>.merge`) at a remote R (configured with `branch.<name>.remote`). B@{u} refers to the remote-tracking branch for the branch X taken from remote R, typically found at `refs/remotes/R/X`.
*[<branchname>]@{push}*, e.g. *master@{push}*, *@{push}* The suffix `@{push}` reports the branch "where we would push to" if `git push` were run while `branchname` was checked out (or the current `HEAD` if no branchname is specified). Like for `@{upstream}`, we report the remote-tracking branch that corresponds to that branch at the remote.
Here’s an example to make it more clear:
```
$ git config push.default current
$ git config remote.pushdefault myfork
$ git switch -c mybranch origin/master
$ git rev-parse --symbolic-full-name @{upstream}
refs/remotes/origin/master
$ git rev-parse --symbolic-full-name @{push}
refs/remotes/myfork/mybranch
```
Note in the example that we set up a triangular workflow, where we pull from one location and push to another. In a non-triangular workflow, `@{push}` is the same as `@{upstream}`, and there is no need for it.
This suffix is also accepted when spelled in uppercase, and means the same thing no matter the case.
*<rev>^[<n>]*, e.g. *HEAD^, v1.5.1^0* A suffix `^` to a revision parameter means the first parent of that commit object. `^<n>` means the <n>th parent (i.e. `<rev>^` is equivalent to `<rev>^1`). As a special rule, `<rev>^0` means the commit itself and is used when `<rev>` is the object name of a tag object that refers to a commit object.
*<rev>~[<n>]*, e.g. *HEAD~, master~3* A suffix `~` to a revision parameter means the first parent of that commit object. A suffix `~<n>` to a revision parameter means the commit object that is the <n>th generation ancestor of the named commit object, following only the first parents. I.e. `<rev>~3` is equivalent to `<rev>^^^` which is equivalent to `<rev>^1^1^1`. See below for an illustration of the usage of this form.
*<rev>^{<type>}*, e.g. *v0.99.8^{commit}* A suffix `^` followed by an object type name enclosed in brace pair means dereference the object at `<rev>` recursively until an object of type `<type>` is found or the object cannot be dereferenced anymore (in which case, barf). For example, if `<rev>` is a commit-ish, `<rev>^{commit}` describes the corresponding commit object. Similarly, if `<rev>` is a tree-ish, `<rev>^{tree}` describes the corresponding tree object. `<rev>^0` is a short-hand for `<rev>^{commit}`.
`<rev>^{object}` can be used to make sure `<rev>` names an object that exists, without requiring `<rev>` to be a tag, and without dereferencing `<rev>`; because a tag is already an object, it does not have to be dereferenced even once to get to an object.
`<rev>^{tag}` can be used to ensure that `<rev>` identifies an existing tag object.
*<rev>^{}*, e.g. *v0.99.8^{}* A suffix `^` followed by an empty brace pair means the object could be a tag, and dereference the tag recursively until a non-tag object is found.
*<rev>^{/<text>}*, e.g. *HEAD^{/fix nasty bug}* A suffix `^` to a revision parameter, followed by a brace pair that contains a text led by a slash, is the same as the `:/fix nasty bug` syntax below except that it returns the youngest matching commit which is reachable from the `<rev>` before `^`.
*:/<text>*, e.g. *:/fix nasty bug* A colon, followed by a slash, followed by a text, names a commit whose commit message matches the specified regular expression. This name returns the youngest matching commit which is reachable from any ref, including HEAD. The regular expression can match any part of the commit message. To match messages starting with a string, one can use e.g. `:/^foo`. The special sequence `:/!` is reserved for modifiers to what is matched. `:/!-foo` performs a negative match, while `:/!!foo` matches a literal `!` character, followed by `foo`. Any other sequence beginning with `:/!` is reserved for now. Depending on the given text, the shell’s word splitting rules might require additional quoting.
*<rev>:<path>*, e.g. *HEAD:README*, *master:./README* A suffix `:` followed by a path names the blob or tree at the given path in the tree-ish object named by the part before the colon. A path starting with `./` or `../` is relative to the current working directory. The given path will be converted to be relative to the working tree’s root directory. This is most useful to address a blob or tree from a commit or tree that has the same tree structure as the working tree.
*:[<n>:]<path>*, e.g. *:0:README*, *:README* A colon, optionally followed by a stage number (0 to 3) and a colon, followed by a path, names a blob object in the index at the given path. A missing stage number (and the colon that follows it) names a stage 0 entry. During a merge, stage 1 is the common ancestor, stage 2 is the target branch’s version (typically the current branch), and stage 3 is the version from the branch which is being merged.
Here is an illustration, by Jon Loeliger. Both commit nodes B and C are parents of commit node A. Parent commits are ordered left-to-right.
```
G H I J
\ / \ /
D E F
\ | / \
\ | / |
\|/ |
B C
\ /
\ /
A
```
```
A = = A^0
B = A^ = A^1 = A~1
C = = A^2
D = A^^ = A^1^1 = A~2
E = B^2 = A^^2
F = B^3 = A^^3
G = A^^^ = A^1^1^1 = A~3
H = D^2 = B^^2 = A^^^2 = A~2^2
I = F^ = B^3^ = A^^3^
J = F^2 = B^3^2 = A^^3^2
```
Specifying ranges
-----------------
History traversing commands such as `git log` operate on a set of commits, not just a single commit.
For these commands, specifying a single revision, using the notation described in the previous section, means the set of commits `reachable` from the given commit.
Specifying several revisions means the set of commits reachable from any of the given commits.
A commit’s reachable set is the commit itself and the commits in its ancestry chain.
There are several notations to specify a set of connected commits (called a "revision range"), illustrated below.
###
Commit Exclusions
*^<rev>* (caret) Notation To exclude commits reachable from a commit, a prefix `^` notation is used. E.g. `^r1 r2` means commits reachable from `r2` but exclude the ones reachable from `r1` (i.e. `r1` and its ancestors).
###
Dotted Range Notations
The *..* (two-dot) Range Notation The `^r1 r2` set operation appears so often that there is a shorthand for it. When you have two commits `r1` and `r2` (named according to the syntax explained in SPECIFYING REVISIONS above), you can ask for commits that are reachable from r2 excluding those that are reachable from r1 by `^r1 r2` and it can be written as `r1..r2`.
The *...* (three-dot) Symmetric Difference Notation A similar notation `r1...r2` is called symmetric difference of `r1` and `r2` and is defined as `r1 r2 --not $(git merge-base --all r1 r2)`. It is the set of commits that are reachable from either one of `r1` (left side) or `r2` (right side) but not from both.
In these two shorthand notations, you can omit one end and let it default to HEAD. For example, `origin..` is a shorthand for `origin..HEAD` and asks "What did I do since I forked from the origin branch?" Similarly, `..origin` is a shorthand for `HEAD..origin` and asks "What did the origin do since I forked from them?" Note that `..` would mean `HEAD..HEAD` which is an empty range that is both reachable and unreachable from HEAD.
Commands that are specifically designed to take two distinct ranges (e.g. "git range-diff R1 R2" to compare two ranges) do exist, but they are exceptions. Unless otherwise noted, all "git" commands that operate on a set of commits work on a single revision range. In other words, writing two "two-dot range notation" next to each other, e.g.
```
$ git log A..B C..D
```
does **not** specify two revision ranges for most commands. Instead it will name a single connected set of commits, i.e. those that are reachable from either B or D but are reachable from neither A or C. In a linear history like this:
```
---A---B---o---o---C---D
```
because A and B are reachable from C, the revision range specified by these two dotted ranges is a single commit D.
###
Other <rev>^ Parent Shorthand Notations
Three other shorthands exist, particularly useful for merge commits, for naming a set that is formed by a commit and its parent commits.
The `r1^@` notation means all parents of `r1`.
The `r1^!` notation includes commit `r1` but excludes all of its parents. By itself, this notation denotes the single commit `r1`.
The `<rev>^-[<n>]` notation includes `<rev>` but excludes the <n>th parent (i.e. a shorthand for `<rev>^<n>..<rev>`), with `<n>` = 1 if not given. This is typically useful for merge commits where you can just pass `<commit>^-` to get all the commits in the branch that was merged in merge commit `<commit>` (including `<commit>` itself).
While `<rev>^<n>` was about specifying a single commit parent, these three notations also consider its parents. For example you can say `HEAD^2^@`, however you cannot say `HEAD^@^2`.
Revision range summary
----------------------
*<rev>* Include commits that are reachable from <rev> (i.e. <rev> and its ancestors).
*^<rev>* Exclude commits that are reachable from <rev> (i.e. <rev> and its ancestors).
*<rev1>..<rev2>* Include commits that are reachable from <rev2> but exclude those that are reachable from <rev1>. When either <rev1> or <rev2> is omitted, it defaults to `HEAD`.
*<rev1>...<rev2>* Include commits that are reachable from either <rev1> or <rev2> but exclude those that are reachable from both. When either <rev1> or <rev2> is omitted, it defaults to `HEAD`.
*<rev>^@*, e.g. *HEAD^@* A suffix `^` followed by an at sign is the same as listing all parents of `<rev>` (meaning, include anything reachable from its parents, but not the commit itself).
*<rev>^!*, e.g. *HEAD^!* A suffix `^` followed by an exclamation mark is the same as giving commit `<rev>` and all its parents prefixed with `^` to exclude them (and their ancestors).
*<rev>^-<n>*, e.g. *HEAD^-, HEAD^-2* Equivalent to `<rev>^<n>..<rev>`, with `<n>` = 1 if not given.
Here are a handful of examples using the Loeliger illustration above, with each step in the notation’s expansion and selection carefully spelt out:
```
Args Expanded arguments Selected commits
D G H D
D F G H I J D F
^G D H D
^D B E I J F B
^D B C E I J F B C
C I J F C
B..C = ^B C C
B...C = B ^F C G H D E B C
B^- = B^..B
= ^B^1 B E I J F B
C^@ = C^1
= F I J F
B^@ = B^1 B^2 B^3
= D E F D G H E F I J
C^! = C ^C^@
= C ^C^1
= C ^F C
B^! = B ^B^@
= B ^B^1 ^B^2 ^B^3
= B ^D ^E ^F B
F^! D = F ^I ^J D G H D F
```
Parseopt
--------
In `--parseopt` mode, `git rev-parse` helps massaging options to bring to shell scripts the same facilities C builtins have. It works as an option normalizer (e.g. splits single switches aggregate values), a bit like `getopt(1)` does.
It takes on the standard input the specification of the options to parse and understand, and echoes on the standard output a string suitable for `sh(1)` `eval` to replace the arguments with normalized ones. In case of error, it outputs usage on the standard error stream, and exits with code 129.
Note: Make sure you quote the result when passing it to `eval`. See below for an example.
###
Input Format
`git rev-parse --parseopt` input format is fully text based. It has two parts, separated by a line that contains only `--`. The lines before the separator (should be one or more) are used for the usage. The lines after the separator describe the options.
Each line of options has this format:
```
<opt-spec><flags>*<arg-hint>? SP+ help LF
```
`<opt-spec>` its format is the short option character, then the long option name separated by a comma. Both parts are not required, though at least one is necessary. May not contain any of the `<flags>` characters. `h,help`, `dry-run` and `f` are examples of correct `<opt-spec>`.
`<flags>` `<flags>` are of `*`, `=`, `?` or `!`.
* Use `=` if the option takes an argument.
* Use `?` to mean that the option takes an optional argument. You probably want to use the `--stuck-long` mode to be able to unambiguously parse the optional argument.
* Use `*` to mean that this option should not be listed in the usage generated for the `-h` argument. It’s shown for `--help-all` as documented in [gitcli[7]](gitcli).
* Use `!` to not make the corresponding negated long option available.
`<arg-hint>` `<arg-hint>`, if specified, is used as a name of the argument in the help output, for options that take arguments. `<arg-hint>` is terminated by the first whitespace. It is customary to use a dash to separate words in a multi-word argument hint.
The remainder of the line, after stripping the spaces, is used as the help associated to the option.
Blank lines are ignored, and lines that don’t match this specification are used as option group headers (start the line with a space to create such lines on purpose).
###
Example
```
OPTS_SPEC="\
some-command [<options>] <args>...
some-command does foo and bar!
--
h,help show the help
foo some nifty option --foo
bar= some cool option --bar with an argument
baz=arg another cool option --baz with a named argument
qux?path qux may take a path argument but has meaning by itself
An option group Header
C? option C with an optional argument"
eval "$(echo "$OPTS_SPEC" | git rev-parse --parseopt -- "$@" || echo exit $?)"
```
###
Usage text
When `"$@"` is `-h` or `--help` in the above example, the following usage text would be shown:
```
usage: some-command [<options>] <args>...
some-command does foo and bar!
-h, --help show the help
--foo some nifty option --foo
--bar ... some cool option --bar with an argument
--baz <arg> another cool option --baz with a named argument
--qux[=<path>] qux may take a path argument but has meaning by itself
An option group Header
-C[...] option C with an optional argument
```
Sq-quote
--------
In `--sq-quote` mode, `git rev-parse` echoes on the standard output a single line suitable for `sh(1)` `eval`. This line is made by normalizing the arguments following `--sq-quote`. Nothing other than quoting the arguments is done.
If you want command input to still be interpreted as usual by `git rev-parse` before the output is shell quoted, see the `--sq` option.
###
Example
```
$ cat >your-git-script.sh <<\EOF
#!/bin/sh
args=$(git rev-parse --sq-quote "$@") # quote user-supplied arguments
command="git frotz -n24 $args" # and use it inside a handcrafted
# command line
eval "$command"
EOF
$ sh your-git-script.sh "a b'c"
```
Examples
--------
* Print the object name of the current commit:
```
$ git rev-parse --verify HEAD
```
* Print the commit object name from the revision in the $REV shell variable:
```
$ git rev-parse --verify --end-of-options $REV^{commit}
```
This will error out if $REV is empty or not a valid revision.
* Similar to above:
```
$ git rev-parse --default master --verify --end-of-options $REV
```
but if $REV is empty, the commit object name from master will be printed.
| programming_docs |
git git-send-pack git-send-pack
=============
Name
----
git-send-pack - Push objects over Git protocol to another repository
Synopsis
--------
```
git send-pack [--mirror] [--dry-run] [--force]
[--receive-pack=<git-receive-pack>]
[--verbose] [--thin] [--atomic]
[--[no-]signed | --signed=(true|false|if-asked)]
[<host>:]<directory> (--all | <ref>…)
```
Description
-----------
Usually you would want to use `git push`, which is a higher-level wrapper of this command, instead. See [git-push[1]](git-push).
Invokes `git-receive-pack` on a possibly remote repository, and updates it from the current repository, sending named refs.
Options
-------
--receive-pack=<git-receive-pack> Path to the `git-receive-pack` program on the remote end. Sometimes useful when pushing to a remote repository over ssh, and you do not have the program in a directory on the default $PATH.
--exec=<git-receive-pack> Same as --receive-pack=<git-receive-pack>.
--all Instead of explicitly specifying which refs to update, update all heads that locally exist.
--stdin Take the list of refs from stdin, one per line. If there are refs specified on the command line in addition to this option, then the refs from stdin are processed after those on the command line.
If `--stateless-rpc` is specified together with this option then the list of refs must be in packet format (pkt-line). Each ref must be in a separate packet, and the list must end with a flush packet.
--dry-run Do everything except actually send the updates.
--force Usually, the command refuses to update a remote ref that is not an ancestor of the local ref used to overwrite it. This flag disables the check. What this means is that the remote repository can lose commits; use it with care.
--verbose Run verbosely.
--thin Send a "thin" pack, which records objects in deltified form based on objects not included in the pack to reduce network traffic.
--atomic Use an atomic transaction for updating the refs. If any of the refs fails to update then the entire push will fail without changing any refs.
--[no-]signed --signed=(true|false|if-asked) GPG-sign the push request to update refs on the receiving side, to allow it to be checked by the hooks and/or be logged. If `false` or `--no-signed`, no signing will be attempted. If `true` or `--signed`, the push will fail if the server does not support signed pushes. If set to `if-asked`, sign if and only if the server supports signed pushes. The push will also fail if the actual call to `gpg --sign` fails. See [git-receive-pack[1]](git-receive-pack) for the details on the receiving end.
--push-option=<string> Pass the specified string as a push option for consumption by hooks on the server side. If the server doesn’t support push options, error out. See [git-push[1]](git-push) and [githooks[5]](githooks) for details.
<host> A remote host to house the repository. When this part is specified, `git-receive-pack` is invoked via ssh.
<directory> The repository to update.
<ref>… The remote refs to update.
Specifying the refs
-------------------
There are three ways to specify which refs to update on the remote end.
With `--all` flag, all refs that exist locally are transferred to the remote side. You cannot specify any `<ref>` if you use this flag.
Without `--all` and without any `<ref>`, the heads that exist both on the local side and on the remote side are updated.
When one or more `<ref>` are specified explicitly (whether on the command line or via `--stdin`), it can be either a single pattern, or a pair of such pattern separated by a colon ":" (this means that a ref name cannot have a colon in it). A single pattern `<name>` is just a shorthand for `<name>:<name>`.
Each pattern pair consists of the source side (before the colon) and the destination side (after the colon). The ref to be pushed is determined by finding a match that matches the source side, and where it is pushed is determined by using the destination side. The rules used to match a ref are the same rules used by `git rev-parse` to resolve a symbolic ref name. See [git-rev-parse[1]](git-rev-parse).
* It is an error if <src> does not match exactly one of the local refs.
* It is an error if <dst> matches more than one remote refs.
* If <dst> does not match any remote ref, either
+ it has to start with "refs/"; <dst> is used as the destination literally in this case.
+ <src> == <dst> and the ref that matched the <src> must not exist in the set of remote refs; the ref matched <src> locally is used as the name of the destination.
Without `--force`, the <src> ref is stored at the remote only if <dst> does not exist, or <dst> is a proper subset (i.e. an ancestor) of <src>. This check, known as "fast-forward check", is performed in order to avoid accidentally overwriting the remote ref and lose other peoples' commits from there.
With `--force`, the fast-forward check is disabled for all refs.
Optionally, a <ref> parameter can be prefixed with a plus `+` sign to disable the fast-forward check only on that ref.
git git-rerere git-rerere
==========
Name
----
git-rerere - Reuse recorded resolution of conflicted merges
Synopsis
--------
```
git rerere [clear | forget <pathspec>… | diff | status | remaining | gc]
```
Description
-----------
In a workflow employing relatively long lived topic branches, the developer sometimes needs to resolve the same conflicts over and over again until the topic branches are done (either merged to the "release" branch, or sent out and accepted upstream).
This command assists the developer in this process by recording conflicted automerge results and corresponding hand resolve results on the initial manual merge, and applying previously recorded hand resolutions to their corresponding automerge results.
| | |
| --- | --- |
| Note | You need to set the configuration variable `rerere.enabled` in order to enable this command. |
Commands
--------
Normally, `git rerere` is run without arguments or user-intervention. However, it has several commands that allow it to interact with its working state.
*clear* Reset the metadata used by rerere if a merge resolution is to be aborted. Calling `git am [--skip|--abort]` or `git rebase [--skip|--abort]` will automatically invoke this command.
*forget* <pathspec> Reset the conflict resolutions which rerere has recorded for the current conflict in <pathspec>.
*diff* Display diffs for the current state of the resolution. It is useful for tracking what has changed while the user is resolving conflicts. Additional arguments are passed directly to the system `diff` command installed in PATH.
*status* Print paths with conflicts whose merge resolution rerere will record.
*remaining* Print paths with conflicts that have not been autoresolved by rerere. This includes paths whose resolutions cannot be tracked by rerere, such as conflicting submodules.
*gc* Prune records of conflicted merges that occurred a long time ago. By default, unresolved conflicts older than 15 days and resolved conflicts older than 60 days are pruned. These defaults are controlled via the `gc.rerereUnresolved` and `gc.rerereResolved` configuration variables respectively.
Discussion
----------
When your topic branch modifies an overlapping area that your master branch (or upstream) touched since your topic branch forked from it, you may want to test it with the latest master, even before your topic branch is ready to be pushed upstream:
```
o---*---o topic
/
o---o---o---*---o---o master
```
For such a test, you need to merge master and topic somehow. One way to do it is to pull master into the topic branch:
```
$ git switch topic
$ git merge master
o---*---o---+ topic
/ /
o---o---o---*---o---o master
```
The commits marked with `*` touch the same area in the same file; you need to resolve the conflicts when creating the commit marked with `+`. Then you can test the result to make sure your work-in-progress still works with what is in the latest master.
After this test merge, there are two ways to continue your work on the topic. The easiest is to build on top of the test merge commit `+`, and when your work in the topic branch is finally ready, pull the topic branch into master, and/or ask the upstream to pull from you. By that time, however, the master or the upstream might have been advanced since the test merge `+`, in which case the final commit graph would look like this:
```
$ git switch topic
$ git merge master
$ ... work on both topic and master branches
$ git switch master
$ git merge topic
o---*---o---+---o---o topic
/ / \
o---o---o---*---o---o---o---o---+ master
```
When your topic branch is long-lived, however, your topic branch would end up having many such "Merge from master" commits on it, which would unnecessarily clutter the development history. Readers of the Linux kernel mailing list may remember that Linus complained about such too frequent test merges when a subsystem maintainer asked to pull from a branch full of "useless merges".
As an alternative, to keep the topic branch clean of test merges, you could blow away the test merge, and keep building on top of the tip before the test merge:
```
$ git switch topic
$ git merge master
$ git reset --hard HEAD^ ;# rewind the test merge
$ ... work on both topic and master branches
$ git switch master
$ git merge topic
o---*---o-------o---o topic
/ \
o---o---o---*---o---o---o---o---+ master
```
This would leave only one merge commit when your topic branch is finally ready and merged into the master branch. This merge would require you to resolve the conflict, introduced by the commits marked with `*`. However, this conflict is often the same conflict you resolved when you created the test merge you blew away. `git rerere` helps you resolve this final conflicted merge using the information from your earlier hand resolve.
Running the `git rerere` command immediately after a conflicted automerge records the conflicted working tree files, with the usual conflict markers `<<<<<<<`, `=======`, and `>>>>>>>` in them. Later, after you are done resolving the conflicts, running `git rerere` again will record the resolved state of these files. Suppose you did this when you created the test merge of master into the topic branch.
Next time, after seeing the same conflicted automerge, running `git rerere` will perform a three-way merge between the earlier conflicted automerge, the earlier manual resolution, and the current conflicted automerge. If this three-way merge resolves cleanly, the result is written out to your working tree file, so you do not have to manually resolve it. Note that `git rerere` leaves the index file alone, so you still need to do the final sanity checks with `git diff` (or `git diff -c`) and `git add` when you are satisfied.
As a convenience measure, `git merge` automatically invokes `git rerere` upon exiting with a failed automerge and `git rerere` records the hand resolve when it is a new conflict, or reuses the earlier hand resolve when it is not. `git commit` also invokes `git rerere` when committing a merge result. What this means is that you do not have to do anything special yourself (besides enabling the rerere.enabled config variable).
In our example, when you do the test merge, the manual resolution is recorded, and it will be reused when you do the actual merge later with the updated master and topic branch, as long as the recorded resolution is still applicable.
The information `git rerere` records is also used when running `git rebase`. After blowing away the test merge and continuing development on the topic branch:
```
o---*---o-------o---o topic
/
o---o---o---*---o---o---o---o master
$ git rebase master topic
o---*---o-------o---o topic
/
o---o---o---*---o---o---o---o master
```
you could run `git rebase master topic`, to bring yourself up to date before your topic is ready to be sent upstream. This would result in falling back to a three-way merge, and it would conflict the same way as the test merge you resolved earlier. `git rerere` will be run by `git rebase` to help you resolve this conflict.
[NOTE] `git rerere` relies on the conflict markers in the file to detect the conflict. If the file already contains lines that look the same as lines with conflict markers, `git rerere` may fail to record a conflict resolution. To work around this, the `conflict-marker-size` setting in [gitattributes[5]](gitattributes) can be used.
git git-instaweb git-instaweb
============
Name
----
git-instaweb - Instantly browse your working repository in gitweb
Synopsis
--------
```
git instaweb [--local] [--httpd=<httpd>] [--port=<port>]
[--browser=<browser>]
git instaweb [--start] [--stop] [--restart]
```
Description
-----------
A simple script to set up `gitweb` and a web server for browsing the local repository.
Options
-------
-l --local Only bind the web server to the local IP (127.0.0.1).
-d --httpd The HTTP daemon command-line that will be executed. Command-line options may be specified here, and the configuration file will be added at the end of the command-line. Currently apache2, lighttpd, mongoose, plackup, python and webrick are supported. (Default: lighttpd)
-m --module-path The module path (only needed if httpd is Apache). (Default: /usr/lib/apache2/modules)
-p --port The port number to bind the httpd to. (Default: 1234)
-b --browser The web browser that should be used to view the gitweb page. This will be passed to the `git web--browse` helper script along with the URL of the gitweb instance. See [git-web--browse[1]](git-web--browse) for more information about this. If the script fails, the URL will be printed to stdout.
start --start Start the httpd instance and exit. Regenerate configuration files as necessary for spawning a new instance.
stop --stop Stop the httpd instance and exit. This does not generate any of the configuration files for spawning a new instance, nor does it close the browser.
restart --restart Restart the httpd instance and exit. Regenerate configuration files as necessary for spawning a new instance.
Configuration
-------------
You may specify configuration in your .git/config
```
[instaweb]
local = true
httpd = apache2 -f
port = 4321
browser = konqueror
modulePath = /usr/lib/apache2/modules
```
If the configuration variable `instaweb.browser` is not set, `web.browser` will be used instead if it is defined. See [git-web--browse[1]](git-web--browse) for more information about this.
See also
--------
[gitweb[1]](gitweb)
git git-merge-index git-merge-index
===============
Name
----
git-merge-index - Run a merge for files needing merging
Synopsis
--------
```
git merge-index [-o] [-q] <merge-program> (-a | ( [--] <file>…) )
```
Description
-----------
This looks up the <file>(s) in the index and, if there are any merge entries, passes the SHA-1 hash for those files as arguments 1, 2, 3 (empty argument if no file), and <file> as argument 4. File modes for the three files are passed as arguments 5, 6 and 7.
Options
-------
-- Do not interpret any more arguments as options.
-a Run merge against all files in the index that need merging.
-o Instead of stopping at the first failed merge, do all of them in one shot - continue with merging even when previous merges returned errors, and only return the error code after all the merges.
-q Do not complain about a failed merge program (a merge program failure usually indicates conflicts during the merge). This is for porcelains which might want to emit custom messages.
If `git merge-index` is called with multiple <file>s (or -a) then it processes them in turn only stopping if merge returns a non-zero exit code.
Typically this is run with a script calling Git’s imitation of the `merge` command from the RCS package.
A sample script called `git merge-one-file` is included in the distribution.
ALERT ALERT ALERT! The Git "merge object order" is different from the RCS `merge` program merge object order. In the above ordering, the original is first. But the argument order to the 3-way merge program `merge` is to have the original in the middle. Don’t ask me why.
Examples:
```
torvalds@ppc970:~/merge-test> git merge-index cat MM
This is MM from the original tree. # original
This is modified MM in the branch A. # merge1
This is modified MM in the branch B. # merge2
This is modified MM in the branch B. # current contents
```
or
```
torvalds@ppc970:~/merge-test> git merge-index cat AA MM
cat: : No such file or directory
This is added AA in the branch A.
This is added AA in the branch B.
This is added AA in the branch B.
fatal: merge program failed
```
where the latter example shows how `git merge-index` will stop trying to merge once anything has returned an error (i.e., `cat` returned an error for the AA file, because it didn’t exist in the original, and thus `git merge-index` didn’t even try to merge the MM thing).
git git-remote git-remote
==========
Name
----
git-remote - Manage set of tracked repositories
Synopsis
--------
```
git remote [-v | --verbose]
git remote add [-t <branch>] [-m <master>] [-f] [--[no-]tags] [--mirror=(fetch|push)] <name> <URL>
git remote rename [--[no-]progress] <old> <new>
git remote remove <name>
git remote set-head <name> (-a | --auto | -d | --delete | <branch>)
git remote set-branches [--add] <name> <branch>…
git remote get-url [--push] [--all] <name>
git remote set-url [--push] <name> <newurl> [<oldurl>]
git remote set-url --add [--push] <name> <newurl>
git remote set-url --delete [--push] <name> <URL>
git remote [-v | --verbose] show [-n] <name>…
git remote prune [-n | --dry-run] <name>…
git remote [-v | --verbose] update [-p | --prune] [(<group> | <remote>)…]
```
Description
-----------
Manage the set of repositories ("remotes") whose branches you track.
Options
-------
-v --verbose Be a little more verbose and show remote url after name. For promisor remotes, also show which filter (`blob:none` etc.) are configured. NOTE: This must be placed between `remote` and subcommand.
Commands
--------
With no arguments, shows a list of existing remotes. Several subcommands are available to perform operations on the remotes.
*add* Add a remote named <name> for the repository at <URL>. The command `git fetch <name>` can then be used to create and update remote-tracking branches <name>/<branch>.
With `-f` option, `git fetch <name>` is run immediately after the remote information is set up.
With `--tags` option, `git fetch <name>` imports every tag from the remote repository.
With `--no-tags` option, `git fetch <name>` does not import tags from the remote repository.
By default, only tags on fetched branches are imported (see [git-fetch[1]](git-fetch)).
With `-t <branch>` option, instead of the default glob refspec for the remote to track all branches under the `refs/remotes/<name>/` namespace, a refspec to track only `<branch>` is created. You can give more than one `-t <branch>` to track multiple branches without grabbing all branches.
With `-m <master>` option, a symbolic-ref `refs/remotes/<name>/HEAD` is set up to point at remote’s `<master>` branch. See also the set-head command.
When a fetch mirror is created with `--mirror=fetch`, the refs will not be stored in the `refs/remotes/` namespace, but rather everything in `refs/` on the remote will be directly mirrored into `refs/` in the local repository. This option only makes sense in bare repositories, because a fetch would overwrite any local commits.
When a push mirror is created with `--mirror=push`, then `git push` will always behave as if `--mirror` was passed.
*rename* Rename the remote named <old> to <new>. All remote-tracking branches and configuration settings for the remote are updated.
In case <old> and <new> are the same, and <old> is a file under `$GIT_DIR/remotes` or `$GIT_DIR/branches`, the remote is converted to the configuration file format.
*remove* *rm* Remove the remote named <name>. All remote-tracking branches and configuration settings for the remote are removed.
*set-head* Sets or deletes the default branch (i.e. the target of the symbolic-ref `refs/remotes/<name>/HEAD`) for the named remote. Having a default branch for a remote is not required, but allows the name of the remote to be specified in lieu of a specific branch. For example, if the default branch for `origin` is set to `master`, then `origin` may be specified wherever you would normally specify `origin/master`.
With `-d` or `--delete`, the symbolic ref `refs/remotes/<name>/HEAD` is deleted.
With `-a` or `--auto`, the remote is queried to determine its `HEAD`, then the symbolic-ref `refs/remotes/<name>/HEAD` is set to the same branch. e.g., if the remote `HEAD` is pointed at `next`, `git remote set-head origin -a` will set the symbolic-ref `refs/remotes/origin/HEAD` to `refs/remotes/origin/next`. This will only work if `refs/remotes/origin/next` already exists; if not it must be fetched first.
Use `<branch>` to set the symbolic-ref `refs/remotes/<name>/HEAD` explicitly. e.g., `git
remote set-head origin master` will set the symbolic-ref `refs/remotes/origin/HEAD` to `refs/remotes/origin/master`. This will only work if `refs/remotes/origin/master` already exists; if not it must be fetched first.
*set-branches* Changes the list of branches tracked by the named remote. This can be used to track a subset of the available remote branches after the initial setup for a remote.
The named branches will be interpreted as if specified with the `-t` option on the `git remote add` command line.
With `--add`, instead of replacing the list of currently tracked branches, adds to that list.
*get-url* Retrieves the URLs for a remote. Configurations for `insteadOf` and `pushInsteadOf` are expanded here. By default, only the first URL is listed.
With `--push`, push URLs are queried rather than fetch URLs.
With `--all`, all URLs for the remote will be listed.
*set-url* Changes URLs for the remote. Sets first URL for remote <name> that matches regex <oldurl> (first URL if no <oldurl> is given) to <newurl>. If <oldurl> doesn’t match any URL, an error occurs and nothing is changed.
With `--push`, push URLs are manipulated instead of fetch URLs.
With `--add`, instead of changing existing URLs, new URL is added.
With `--delete`, instead of changing existing URLs, all URLs matching regex <URL> are deleted for remote <name>. Trying to delete all non-push URLs is an error.
Note that the push URL and the fetch URL, even though they can be set differently, must still refer to the same place. What you pushed to the push URL should be what you would see if you immediately fetched from the fetch URL. If you are trying to fetch from one place (e.g. your upstream) and push to another (e.g. your publishing repository), use two separate remotes.
*show* Gives some information about the remote <name>.
With `-n` option, the remote heads are not queried first with `git ls-remote <name>`; cached information is used instead.
*prune* Deletes stale references associated with <name>. By default, stale remote-tracking branches under <name> are deleted, but depending on global configuration and the configuration of the remote we might even prune local tags that haven’t been pushed there. Equivalent to `git
fetch --prune <name>`, except that no new references will be fetched.
See the PRUNING section of [git-fetch[1]](git-fetch) for what it’ll prune depending on various configuration.
With `--dry-run` option, report what branches would be pruned, but do not actually prune them.
*update* Fetch updates for remotes or remote groups in the repository as defined by `remotes.<group>`. If neither group nor remote is specified on the command line, the configuration parameter remotes.default will be used; if remotes.default is not defined, all remotes which do not have the configuration parameter `remote.<name>.skipDefaultUpdate` set to true will be updated. (See [git-config[1]](git-config)).
With `--prune` option, run pruning against all the remotes that are updated.
Discussion
----------
The remote configuration is achieved using the `remote.origin.url` and `remote.origin.fetch` configuration variables. (See [git-config[1]](git-config)).
Exit status
-----------
On success, the exit status is `0`.
When subcommands such as `add`, `rename`, and `remove` can’t find the remote in question, the exit status is `2`. When the remote already exists, the exit status is `3`.
On any other error, the exit status may be any other non-zero value.
Examples
--------
* Add a new remote, fetch, and check out a branch from it
```
$ git remote
origin
$ git branch -r
origin/HEAD -> origin/master
origin/master
$ git remote add staging git://git.kernel.org/.../gregkh/staging.git
$ git remote
origin
staging
$ git fetch staging
...
From git://git.kernel.org/pub/scm/linux/kernel/git/gregkh/staging
* [new branch] master -> staging/master
* [new branch] staging-linus -> staging/staging-linus
* [new branch] staging-next -> staging/staging-next
$ git branch -r
origin/HEAD -> origin/master
origin/master
staging/master
staging/staging-linus
staging/staging-next
$ git switch -c staging staging/master
...
```
* Imitate `git clone` but track only selected branches
```
$ mkdir project.git
$ cd project.git
$ git init
$ git remote add -f -t master -m master origin git://example.com/git.git/
$ git merge origin
```
See also
--------
[git-fetch[1]](git-fetch) [git-branch[1]](git-branch) [git-config[1]](git-config)
| programming_docs |
git git-version git-version
===========
Name
----
git-version - Display version information about Git
Synopsis
--------
```
git version [--build-options]
```
Description
-----------
With no options given, the version of `git` is printed on the standard output.
Note that `git --version` is identical to `git version` because the former is internally converted into the latter.
Options
-------
--build-options Include additional information about how git was built for diagnostic purposes.
git git-imap-send git-imap-send
=============
Name
----
git-imap-send - Send a collection of patches from stdin to an IMAP folder
Synopsis
--------
```
git imap-send [-v] [-q] [--[no-]curl]
```
Description
-----------
This command uploads a mailbox generated with `git format-patch` into an IMAP drafts folder. This allows patches to be sent as other email is when using mail clients that cannot read mailbox files directly. The command also works with any general mailbox in which emails have the fields "From", "Date", and "Subject" in that order.
Typical usage is something like:
git format-patch --signoff --stdout --attach origin | git imap-send
Options
-------
-v --verbose Be verbose.
-q --quiet Be quiet.
--curl Use libcurl to communicate with the IMAP server, unless tunneling into it. Ignored if Git was built without the USE\_CURL\_FOR\_IMAP\_SEND option set.
--no-curl Talk to the IMAP server using git’s own IMAP routines instead of using libcurl. Ignored if Git was built with the NO\_OPENSSL option set.
Configuration
-------------
To use the tool, `imap.folder` and either `imap.tunnel` or `imap.host` must be set to appropriate values.
Everything above this line in this section isn’t included from the [git-config[1]](git-config) documentation. The content that follows is the same as what’s found there:
imap.folder The folder to drop the mails into, which is typically the Drafts folder. For example: "INBOX.Drafts", "INBOX/Drafts" or "[Gmail]/Drafts". Required.
imap.tunnel Command used to setup a tunnel to the IMAP server through which commands will be piped instead of using a direct network connection to the server. Required when imap.host is not set.
imap.host A URL identifying the server. Use an `imap://` prefix for non-secure connections and an `imaps://` prefix for secure connections. Ignored when imap.tunnel is set, but required otherwise.
imap.user The username to use when logging in to the server.
imap.pass The password to use when logging in to the server.
imap.port An integer port number to connect to on the server. Defaults to 143 for imap:// hosts and 993 for imaps:// hosts. Ignored when imap.tunnel is set.
imap.sslverify A boolean to enable/disable verification of the server certificate used by the SSL/TLS connection. Default is `true`. Ignored when imap.tunnel is set.
imap.preformattedHTML A boolean to enable/disable the use of html encoding when sending a patch. An html encoded patch will be bracketed with <pre> and have a content type of text/html. Ironically, enabling this option causes Thunderbird to send the patch as a plain/text, format=fixed email. Default is `false`.
imap.authMethod Specify authenticate method for authentication with IMAP server. If Git was built with the NO\_CURL option, or if your curl version is older than 7.34.0, or if you’re running git-imap-send with the `--no-curl` option, the only supported method is `CRAM-MD5`. If this is not set then `git imap-send` uses the basic IMAP plaintext LOGIN command.
Examples
--------
Using tunnel mode:
```
[imap]
folder = "INBOX.Drafts"
tunnel = "ssh -q -C [email protected] /usr/bin/imapd ./Maildir 2> /dev/null"
```
Using direct mode:
```
[imap]
folder = "INBOX.Drafts"
host = imap://imap.example.com
user = bob
pass = p4ssw0rd
```
Using direct mode with SSL:
```
[imap]
folder = "INBOX.Drafts"
host = imaps://imap.example.com
user = bob
pass = p4ssw0rd
port = 123
; sslVerify = false
```
| | |
| --- | --- |
| Note | You may want to use `sslVerify=false` while troubleshooting, if you suspect that the reason you are having trouble connecting is because the certificate you use at the private server `example.com` you are trying to set up (or have set up) may not be verified correctly. |
Using Gmail’s IMAP interface:
```
[imap]
folder = "[Gmail]/Drafts"
host = imaps://imap.gmail.com
user = [email protected]
port = 993
```
| | |
| --- | --- |
| Note | You might need to instead use: `folder = "[Google Mail]/Drafts"` if you get an error that the "Folder doesn’t exist". |
| | |
| --- | --- |
| Note | If your Gmail account is set to another language than English, the name of the "Drafts" folder will be localized. |
Once the commits are ready to be sent, run the following command:
```
$ git format-patch --cover-letter -M --stdout origin/master | git imap-send
```
Just make sure to disable line wrapping in the email client (Gmail’s web interface will wrap lines no matter what, so you need to use a real IMAP client).
Caution
-------
It is still your responsibility to make sure that the email message sent by your email program meets the standards of your project. Many projects do not like patches to be attached. Some mail agents will transform patches (e.g. wrap lines, send them as format=flowed) in ways that make them fail. You will get angry flames ridiculing you if you don’t check this.
Thunderbird in particular is known to be problematic. Thunderbird users may wish to visit this web page for more information: <http://kb.mozillazine.org/Plain_text_e-mail_-_Thunderbird#Completely_plain_email>
See also
--------
[git-format-patch[1]](git-format-patch), [git-send-email[1]](git-send-email), mbox(5)
git git-merge-tree git-merge-tree
==============
Name
----
git-merge-tree - Perform merge without touching index or working tree
Synopsis
--------
```
git merge-tree [--write-tree] [<options>] <branch1> <branch2>
git merge-tree [--trivial-merge] <base-tree> <branch1> <branch2> (deprecated)
```
Description
-----------
This command has a modern `--write-tree` mode and a deprecated `--trivial-merge` mode. With the exception of the [DEPRECATED DESCRIPTION](#DEPMERGE) section at the end, the rest of this documentation describes modern `--write-tree` mode.
Performs a merge, but does not make any new commits and does not read from or write to either the working tree or index.
The performed merge will use the same feature as the "real" [git-merge[1]](git-merge), including:
* three way content merges of individual files
* rename detection
* proper directory/file conflict handling
* recursive ancestor consolidation (i.e. when there is more than one merge base, creating a virtual merge base by merging the merge bases)
* etc.
After the merge completes, a new toplevel tree object is created. See `OUTPUT` below for details.
Options
-------
-z Do not quote filenames in the <Conflicted file info> section, and end each filename with a NUL character rather than newline. Also begin the messages section with a NUL character instead of a newline. See [OUTPUT](#OUTPUT) below for more information.
--name-only In the Conflicted file info section, instead of writing a list of (mode, oid, stage, path) tuples to output for conflicted files, just provide a list of filenames with conflicts (and do not list filenames multiple times if they have multiple conflicting stages).
--[no-]messages Write any informational messages such as "Auto-merging <path>" or CONFLICT notices to the end of stdout. If unspecified, the default is to include these messages if there are merge conflicts, and to omit them otherwise.
--allow-unrelated-histories merge-tree will by default error out if the two branches specified share no common history. This flag can be given to override that check and make the merge proceed anyway.
Output
------
For a successful merge, the output from git-merge-tree is simply one line:
```
<OID of toplevel tree>
```
Whereas for a conflicted merge, the output is by default of the form:
```
<OID of toplevel tree>
<Conflicted file info>
<Informational messages>
```
These are discussed individually below.
However, there is an exception. If `--stdin` is passed, then there is an extra section at the beginning, a NUL character at the end, and then all the sections repeat for each line of input. Thus, if the first merge is conflicted and the second is clean, the output would be of the form:
```
<Merge status>
<OID of toplevel tree>
<Conflicted file info>
<Informational messages>
NUL
<Merge status>
<OID of toplevel tree>
NUL
```
###
Merge status
This is an integer status followed by a NUL character. The integer status is:
```
0: merge had conflicts
1: merge was clean
<0: something prevented the merge from running (e.g. access to repository
objects denied by filesystem)
```
###
OID of toplevel tree
This is a tree object that represents what would be checked out in the working tree at the end of `git merge`. If there were conflicts, then files within this tree may have embedded conflict markers. This section is always followed by a newline (or NUL if `-z` is passed).
###
Conflicted file info
This is a sequence of lines with the format
```
<mode> <object> <stage> <filename>
```
The filename will be quoted as explained for the configuration variable `core.quotePath` (see [git-config[1]](git-config)). However, if the `--name-only` option is passed, the mode, object, and stage will be omitted. If `-z` is passed, the "lines" are terminated by a NUL character instead of a newline character.
###
Informational messages
This section provides informational messages, typically about conflicts. The format of the section varies significantly depending on whether `-z` is passed.
If `-z` is passed:
The output format is zero or more conflict informational records, each of the form:
```
<list-of-paths><conflict-type>NUL<conflict-message>NUL
```
where <list-of-paths> is of the form
```
<number-of-paths>NUL<path1>NUL<path2>NUL...<pathN>NUL
```
and includes paths (or branch names) affected by the conflict or informational message in <conflict-message>. Also, <conflict-type> is a stable string explaining the type of conflict, such as
* "Auto-merging"
* "CONFLICT (rename/delete)"
* "CONFLICT (submodule lacks merge base)"
* "CONFLICT (binary)"
and <conflict-message> is a more detailed message about the conflict which often (but not always) embeds the <stable-short-type-description> within it. These strings may change in future Git versions. Some examples:
* "Auto-merging <file>"
* "CONFLICT (rename/delete): <oldfile> renamed…but deleted in…"
* "Failed to merge submodule <submodule> (no merge base)"
* "Warning: cannot merge binary files: <filename>"
If `-z` is NOT passed:
This section starts with a blank line to separate it from the previous sections, and then only contains the <conflict-message> information from the previous section (separated by newlines). These are non-stable strings that should not be parsed by scripts, and are just meant for human consumption. Also, note that while <conflict-message> strings usually do not contain embedded newlines, they sometimes do. (However, the free-form messages will never have an embedded NUL character). So, the entire block of information is meant for human readers as an agglomeration of all conflict messages.
Exit status
-----------
For a successful, non-conflicted merge, the exit status is 0. When the merge has conflicts, the exit status is 1. If the merge is not able to complete (or start) due to some kind of error, the exit status is something other than 0 or 1 (and the output is unspecified). When --stdin is passed, the return status is 0 for both successful and conflicted merges, and something other than 0 or 1 if it cannot complete all the requested merges.
Usage notes
-----------
This command is intended as low-level plumbing, similar to [git-hash-object[1]](git-hash-object), [git-mktree[1]](git-mktree), [git-commit-tree[1]](git-commit-tree), [git-write-tree[1]](git-write-tree), [git-update-ref[1]](git-update-ref), and [git-mktag[1]](git-mktag). Thus, it can be used as a part of a series of steps such as:
```
NEWTREE=$(git merge-tree --write-tree $BRANCH1 $BRANCH2)
test $? -eq 0 || die "There were conflicts..."
NEWCOMMIT=$(git commit-tree $NEWTREE -p $BRANCH1 -p $BRANCH2)
git update-ref $BRANCH1 $NEWCOMMIT
```
Note that when the exit status is non-zero, `NEWTREE` in this sequence will contain a lot more output than just a tree.
For conflicts, the output includes the same information that you’d get with [git-merge[1]](git-merge):
* what would be written to the working tree (the [OID of toplevel tree](#OIDTLT))
* the higher order stages that would be written to the index (the [Conflicted file info](#CFI))
* any messages that would have been printed to stdout (the [Informational messages](#IM))
Mistakes to avoid
-----------------
Do NOT look through the resulting toplevel tree to try to find which files conflict; parse the [Conflicted file info](#CFI) section instead. Not only would parsing an entire tree be horrendously slow in large repositories, there are numerous types of conflicts not representable by conflict markers (modify/delete, mode conflict, binary file changed on both sides, file/directory conflicts, various rename conflict permutations, etc.)
Do NOT interpret an empty [Conflicted file info](#CFI) list as a clean merge; check the exit status. A merge can have conflicts without having individual files conflict (there are a few types of directory rename conflicts that fall into this category, and others might also be added in the future).
Do NOT attempt to guess or make the user guess the conflict types from the [Conflicted file info](#CFI) list. The information there is insufficient to do so. For example: Rename/rename(1to2) conflicts (both sides renamed the same file differently) will result in three different file having higher order stages (but each only has one higher order stage), with no way (short of the [Informational messages](#IM) section) to determine which three files are related. File/directory conflicts also result in a file with exactly one higher order stage. Possibly-involved-in-directory-rename conflicts (when "merge.directoryRenames" is unset or set to "conflicts") also result in a file with exactly one higher order stage. In all cases, the [Informational messages](#IM) section has the necessary info, though it is not designed to be machine parseable.
Do NOT assume that each paths from [Conflicted file info](#CFI), and the logical conflicts in the [Informational messages](#IM) have a one-to-one mapping, nor that there is a one-to-many mapping, nor a many-to-one mapping. Many-to-many mappings exist, meaning that each path can have many logical conflict types in a single merge, and each logical conflict type can affect many paths.
Do NOT assume all filenames listed in the [Informational messages](#IM) section had conflicts. Messages can be included for files that have no conflicts, such as "Auto-merging <file>".
AVOID taking the OIDS from the [Conflicted file info](#CFI) and re-merging them to present the conflicts to the user. This will lose information. Instead, look up the version of the file found within the [OID of toplevel tree](#OIDTLT) and show that instead. In particular, the latter will have conflict markers annotated with the original branch/commit being merged and, if renames were involved, the original filename. While you could include the original branch/commit in the conflict marker annotations when re-merging, the original filename is not available from the [Conflicted file info](#CFI) and thus you would be losing information that might help the user resolve the conflict.
Deprecated description
----------------------
Per the [DESCRIPTION](#NEWMERGE) and unlike the rest of this documentation, this section describes the deprecated `--trivial-merge` mode.
Other than the optional `--trivial-merge`, this mode accepts no options.
This mode reads three tree-ish, and outputs trivial merge results and conflicting stages to the standard output in a semi-diff format. Since this was designed for higher level scripts to consume and merge the results back into the index, it omits entries that match <branch1>. The result of this second form is similar to what three-way `git read-tree -m` does, but instead of storing the results in the index, the command outputs the entries to the standard output.
This form not only has limited applicability (a trivial merge cannot handle content merges of individual files, rename detection, proper directory/file conflict handling, etc.), the output format is also difficult to work with, and it will generally be less performant than the first form even on successful merges (especially if working in large repositories).
git git-sh-i18n git-sh-i18n
===========
Name
----
git-sh-i18n - Git’s i18n setup code for shell scripts
Synopsis
--------
```
. "$(git --exec-path)/git-sh-i18n"
```
Description
-----------
This is not a command the end user would want to run. Ever. This documentation is meant for people who are studying the Porcelain-ish scripts and/or are writing new ones.
The 'git sh-i18n scriptlet is designed to be sourced (using `.`) by Git’s porcelain programs implemented in shell script. It provides wrappers for the GNU `gettext` and `eval_gettext` functions accessible through the `gettext.sh` script, and provides pass-through fallbacks on systems without GNU gettext.
Functions
---------
gettext Currently a dummy fall-through function implemented as a wrapper around `printf(1)`. Will be replaced by a real gettext implementation in a later version.
eval\_gettext Currently a dummy fall-through function implemented as a wrapper around `printf(1)` with variables expanded by the [git-sh-i18n--envsubst[1]](git-sh-i18n--envsubst) helper. Will be replaced by a real gettext implementation in a later version.
git gitformat-index gitformat-index
===============
Name
----
gitformat-index - Git index format
Synopsis
--------
```
$GIT_DIR/index
```
Description
-----------
Git index format
The git index file has the following format
-------------------------------------------
```
All binary numbers are in network byte order.
In a repository using the traditional SHA-1, checksums and object IDs
(object names) mentioned below are all computed using SHA-1. Similarly,
in SHA-256 repositories, these values are computed using SHA-256.
Version 2 is described here unless stated otherwise.
```
* A 12-byte header consisting of
```
4-byte signature:
The signature is { 'D', 'I', 'R', 'C' } (stands for "dircache")
```
```
4-byte version number:
The current supported versions are 2, 3 and 4.
```
```
32-bit number of index entries.
```
* A number of sorted index entries (see below).
* Extensions
```
Extensions are identified by signature. Optional extensions can
be ignored if Git does not understand them.
```
```
4-byte extension signature. If the first byte is 'A'..'Z' the
extension is optional and can be ignored.
```
```
32-bit size of the extension
```
```
Extension data
```
* Hash checksum over the content of the index file before this checksum.
Index entry
-----------
```
Index entries are sorted in ascending order on the name field,
interpreted as a string of unsigned bytes (i.e. memcmp() order, no
localization, no special casing of directory separator '/'). Entries
with the same name are sorted by their stage field.
```
```
An index entry typically represents a file. However, if sparse-checkout
is enabled in cone mode (`core.sparseCheckoutCone` is enabled) and the
`extensions.sparseIndex` extension is enabled, then the index may
contain entries for directories outside of the sparse-checkout definition.
These entries have mode `040000`, include the `SKIP_WORKTREE` bit, and
the path ends in a directory separator.
```
```
32-bit ctime seconds, the last time a file's metadata changed
this is stat(2) data
```
```
32-bit ctime nanosecond fractions
this is stat(2) data
```
```
32-bit mtime seconds, the last time a file's data changed
this is stat(2) data
```
```
32-bit mtime nanosecond fractions
this is stat(2) data
```
```
32-bit dev
this is stat(2) data
```
```
32-bit ino
this is stat(2) data
```
```
32-bit mode, split into (high to low bits)
```
```
4-bit object type
valid values in binary are 1000 (regular file), 1010 (symbolic link)
and 1110 (gitlink)
```
```
3-bit unused
```
```
9-bit unix permission. Only 0755 and 0644 are valid for regular files.
Symbolic links and gitlinks have value 0 in this field.
```
```
32-bit uid
this is stat(2) data
```
```
32-bit gid
this is stat(2) data
```
```
32-bit file size
This is the on-disk size from stat(2), truncated to 32-bit.
```
```
Object name for the represented object
```
```
A 16-bit 'flags' field split into (high to low bits)
```
```
1-bit assume-valid flag
```
```
1-bit extended flag (must be zero in version 2)
```
```
2-bit stage (during merge)
```
```
12-bit name length if the length is less than 0xFFF; otherwise 0xFFF
is stored in this field.
```
```
(Version 3 or later) A 16-bit field, only applicable if the
"extended flag" above is 1, split into (high to low bits).
```
```
1-bit reserved for future
```
```
1-bit skip-worktree flag (used by sparse checkout)
```
```
1-bit intent-to-add flag (used by "git add -N")
```
```
13-bit unused, must be zero
```
```
Entry path name (variable length) relative to top level directory
(without leading slash). '/' is used as path separator. The special
path components ".", ".." and ".git" (without quotes) are disallowed.
Trailing slash is also disallowed.
```
```
The exact encoding is undefined, but the '.' and '/' characters
are encoded in 7-bit ASCII and the encoding cannot contain a NUL
byte (iow, this is a UNIX pathname).
```
```
(Version 4) In version 4, the entry path name is prefix-compressed
relative to the path name for the previous entry (the very first
entry is encoded as if the path name for the previous entry is an
empty string). At the beginning of an entry, an integer N in the
variable width encoding (the same encoding as the offset is encoded
for OFS_DELTA pack entries; see gitformat-pack[5]) is stored, followed
by a NUL-terminated string S. Removing N bytes from the end of the
path name for the previous entry, and replacing it with the string S
yields the path name for this entry.
```
```
1-8 nul bytes as necessary to pad the entry to a multiple of eight bytes
while keeping the name NUL-terminated.
```
```
(Version 4) In version 4, the padding after the pathname does not
exist.
```
```
Interpretation of index entries in split index mode is completely
different. See below for details.
```
Extensions
----------
###
Cache tree
```
Since the index does not record entries for directories, the cache
entries cannot describe tree objects that already exist in the object
database for regions of the index that are unchanged from an existing
commit. The cache tree extension stores a recursive tree structure that
describes the trees that already exist and completely match sections of
the cache entries. This speeds up tree object generation from the index
for a new commit by only computing the trees that are "new" to that
commit. It also assists when comparing the index to another tree, such
as `HEAD^{tree}`, since sections of the index can be skipped when a tree
comparison demonstrates equality.
```
```
The recursive tree structure uses nodes that store a number of cache
entries, a list of subnodes, and an object ID (OID). The OID references
the existing tree for that node, if it is known to exist. The subnodes
correspond to subdirectories that themselves have cache tree nodes. The
number of cache entries corresponds to the number of cache entries in
the index that describe paths within that tree's directory.
```
```
The extension tracks the full directory structure in the cache tree
extension, but this is generally smaller than the full cache entry list.
```
```
When a path is updated in index, Git invalidates all nodes of the
recursive cache tree corresponding to the parent directories of that
path. We store these tree nodes as being "invalid" by using "-1" as the
number of cache entries. Invalid nodes still store a span of index
entries, allowing Git to focus its efforts when reconstructing a full
cache tree.
```
```
The signature for this extension is { 'T', 'R', 'E', 'E' }.
```
```
A series of entries fill the entire extension; each of which
consists of:
```
* NUL-terminated path component (relative to its parent directory);
* ASCII decimal number of entries in the index that is covered by the tree this entry represents (entry\_count);
* A space (ASCII 32);
* ASCII decimal number that represents the number of subtrees this tree has;
* A newline (ASCII 10); and
* Object name for the object that would result from writing this span of index as a tree.
```
An entry can be in an invalidated state and is represented by having
a negative number in the entry_count field. In this case, there is no
object name and the next entry starts immediately after the newline.
When writing an invalid entry, -1 should always be used as entry_count.
```
```
The entries are written out in the top-down, depth-first order. The
first entry represents the root level of the repository, followed by the
first subtree--let's call this A--of the root level (with its name
relative to the root level), followed by the first subtree of A (with
its name relative to A), and so on. The specified number of subtrees
indicates when the current level of the recursive stack is complete.
```
###
Resolve undo
```
A conflict is represented in the index as a set of higher stage entries.
When a conflict is resolved (e.g. with "git add path"), these higher
stage entries will be removed and a stage-0 entry with proper resolution
is added.
```
```
When these higher stage entries are removed, they are saved in the
resolve undo extension, so that conflicts can be recreated (e.g. with
"git checkout -m"), in case users want to redo a conflict resolution
from scratch.
```
```
The signature for this extension is { 'R', 'E', 'U', 'C' }.
```
```
A series of entries fill the entire extension; each of which
consists of:
```
* NUL-terminated pathname the entry describes (relative to the root of the repository, i.e. full pathname);
* Three NUL-terminated ASCII octal numbers, entry mode of entries in stage 1 to 3 (a missing stage is represented by "0" in this field); and
* At most three object names of the entry in stages from 1 to 3 (nothing is written for a missing stage).
###
Split index
```
In split index mode, the majority of index entries could be stored
in a separate file. This extension records the changes to be made on
top of that to produce the final index.
```
```
The signature for this extension is { 'l', 'i', 'n', 'k' }.
```
```
The extension consists of:
```
* Hash of the shared index file. The shared index file path is $GIT\_DIR/sharedindex.<hash>. If all bits are zero, the index does not require a shared index file.
* An ewah-encoded delete bitmap, each bit represents an entry in the shared index. If a bit is set, its corresponding entry in the shared index will be removed from the final index. Note, because a delete operation changes index entry positions, but we do need original positions in replace phase, it’s best to just mark entries for removal, then do a mass deletion after replacement.
* An ewah-encoded replace bitmap, each bit represents an entry in the shared index. If a bit is set, its corresponding entry in the shared index will be replaced with an entry in this index file. All replaced entries are stored in sorted order in this index. The first "1" bit in the replace bitmap corresponds to the first index entry, the second "1" bit to the second entry and so on. Replaced entries may have empty path names to save space.
```
The remaining index entries after replaced ones will be added to the
final index. These added entries are also sorted by entry name then
stage.
```
Untracked cache
---------------
```
Untracked cache saves the untracked file list and necessary data to
verify the cache. The signature for this extension is { 'U', 'N',
'T', 'R' }.
```
```
The extension starts with
```
* A sequence of NUL-terminated strings, preceded by the size of the sequence in variable width encoding. Each string describes the environment where the cache can be used.
* Stat data of $GIT\_DIR/info/exclude. See "Index entry" section from ctime field until "file size".
* Stat data of core.excludesFile
* 32-bit dir\_flags (see struct dir\_struct)
* Hash of $GIT\_DIR/info/exclude. A null hash means the file does not exist.
* Hash of core.excludesFile. A null hash means the file does not exist.
* NUL-terminated string of per-dir exclude file name. This usually is ".gitignore".
* The number of following directory blocks, variable width encoding. If this number is zero, the extension ends here with a following NUL.
* A number of directory blocks in depth-first-search order, each consists of
* The number of untracked entries, variable width encoding.
* The number of sub-directory blocks, variable width encoding.
* The directory name terminated by NUL.
* A number of untracked file/dir names terminated by NUL.
The remaining data of each directory block is grouped by type:
* An ewah bitmap, the n-th bit marks whether the n-th directory has valid untracked cache entries.
* An ewah bitmap, the n-th bit records "check-only" bit of read\_directory\_recursive() for the n-th directory.
* An ewah bitmap, the n-th bit indicates whether hash and stat data is valid for the n-th directory and exists in the next data.
* An array of stat data. The n-th data corresponds with the n-th "one" bit in the previous ewah bitmap.
* An array of hashes. The n-th hash corresponds with the n-th "one" bit in the previous ewah bitmap.
* One NUL.
File system monitor cache
-------------------------
```
The file system monitor cache tracks files for which the core.fsmonitor
hook has told us about changes. The signature for this extension is
{ 'F', 'S', 'M', 'N' }.
```
```
The extension starts with
```
* 32-bit version number: the current supported versions are 1 and 2.
* (Version 1) 64-bit time: the extension data reflects all changes through the given time which is stored as the nanoseconds elapsed since midnight, January 1, 1970.
* (Version 2) A null terminated string: an opaque token defined by the file system monitor application. The extension data reflects all changes relative to that token.
* 32-bit bitmap size: the size of the CE\_FSMONITOR\_VALID bitmap.
* An ewah bitmap, the n-th bit indicates whether the n-th index entry is not CE\_FSMONITOR\_VALID.
End of index entry
------------------
```
The End of Index Entry (EOIE) is used to locate the end of the variable
length index entries and the beginning of the extensions. Code can take
advantage of this to quickly locate the index extensions without having
to parse through all of the index entries.
```
```
Because it must be able to be loaded before the variable length cache
entries and other index extensions, this extension must be written last.
The signature for this extension is { 'E', 'O', 'I', 'E' }.
```
```
The extension consists of:
```
* 32-bit offset to the end of the index entries
* Hash over the extension types and their sizes (but not their contents). E.g. if we have "TREE" extension that is N-bytes long, "REUC" extension that is M-bytes long, followed by "EOIE", then the hash would be:
```
Hash("TREE" + <binary representation of N> +
"REUC" + <binary representation of M>)
```
Index entry offset table
------------------------
```
The Index Entry Offset Table (IEOT) is used to help address the CPU
cost of loading the index by enabling multi-threading the process of
converting cache entries from the on-disk format to the in-memory format.
The signature for this extension is { 'I', 'E', 'O', 'T' }.
```
```
The extension consists of:
```
* 32-bit version (currently 1)
* A number of index offset entries each consisting of:
* 32-bit offset from the beginning of the file to the first cache entry in this block of entries.
* 32-bit count of cache entries in this block
Sparse directory entries
------------------------
```
When using sparse-checkout in cone mode, some entire directories within
the index can be summarized by pointing to a tree object instead of the
entire expanded list of paths within that tree. An index containing such
entries is a "sparse index". Index format versions 4 and less were not
implemented with such entries in mind. Thus, for these versions, an
index containing sparse directory entries will include this extension
with signature { 's', 'd', 'i', 'r' }. Like the split-index extension,
tools should avoid interacting with a sparse index unless they understand
this extension.
```
| programming_docs |
git gitremote-helpers gitremote-helpers
=================
Name
----
gitremote-helpers - Helper programs to interact with remote repositories
Synopsis
--------
```
git remote-<transport> <repository> [<URL>]
```
Description
-----------
Remote helper programs are normally not used directly by end users, but they are invoked by Git when it needs to interact with remote repositories Git does not support natively. A given helper will implement a subset of the capabilities documented here. When Git needs to interact with a repository using a remote helper, it spawns the helper as an independent process, sends commands to the helper’s standard input, and expects results from the helper’s standard output. Because a remote helper runs as an independent process from Git, there is no need to re-link Git to add a new helper, nor any need to link the helper with the implementation of Git.
Every helper must support the "capabilities" command, which Git uses to determine what other commands the helper will accept. Those other commands can be used to discover and update remote refs, transport objects between the object database and the remote repository, and update the local object store.
Git comes with a "curl" family of remote helpers, that handle various transport protocols, such as `git-remote-http`, `git-remote-https`, `git-remote-ftp` and `git-remote-ftps`. They implement the capabilities `fetch`, `option`, and `push`.
Invocation
----------
Remote helper programs are invoked with one or (optionally) two arguments. The first argument specifies a remote repository as in Git; it is either the name of a configured remote or a URL. The second argument specifies a URL; it is usually of the form `<transport>://<address>`, but any arbitrary string is possible. The `GIT_DIR` environment variable is set up for the remote helper and can be used to determine where to store additional data or from which directory to invoke auxiliary Git commands.
When Git encounters a URL of the form `<transport>://<address>`, where `<transport>` is a protocol that it cannot handle natively, it automatically invokes `git remote-<transport>` with the full URL as the second argument. If such a URL is encountered directly on the command line, the first argument is the same as the second, and if it is encountered in a configured remote, the first argument is the name of that remote.
A URL of the form `<transport>::<address>` explicitly instructs Git to invoke `git remote-<transport>` with `<address>` as the second argument. If such a URL is encountered directly on the command line, the first argument is `<address>`, and if it is encountered in a configured remote, the first argument is the name of that remote.
Additionally, when a configured remote has `remote.<name>.vcs` set to `<transport>`, Git explicitly invokes `git remote-<transport>` with `<name>` as the first argument. If set, the second argument is `remote.<name>.url`; otherwise, the second argument is omitted.
Input format
------------
Git sends the remote helper a list of commands on standard input, one per line. The first command is always the `capabilities` command, in response to which the remote helper must print a list of the capabilities it supports (see below) followed by a blank line. The response to the capabilities command determines what commands Git uses in the remainder of the command stream.
The command stream is terminated by a blank line. In some cases (indicated in the documentation of the relevant commands), this blank line is followed by a payload in some other protocol (e.g., the pack protocol), while in others it indicates the end of input.
###
Capabilities
Each remote helper is expected to support only a subset of commands. The operations a helper supports are declared to Git in the response to the `capabilities` command (see COMMANDS, below).
In the following, we list all defined capabilities and for each we list which commands a helper with that capability must provide.
####
Capabilities for Pushing
*connect* Can attempt to connect to `git receive-pack` (for pushing), `git upload-pack`, etc for communication using git’s native packfile protocol. This requires a bidirectional, full-duplex connection.
Supported commands: `connect`.
*stateless-connect* Experimental; for internal use only. Can attempt to connect to a remote server for communication using git’s wire-protocol version 2. See the documentation for the stateless-connect command for more information.
Supported commands: `stateless-connect`.
*push* Can discover remote refs and push local commits and the history leading up to them to new or existing remote refs.
Supported commands: `list for-push`, `push`.
*export* Can discover remote refs and push specified objects from a fast-import stream to remote refs.
Supported commands: `list for-push`, `export`.
If a helper advertises `connect`, Git will use it if possible and fall back to another capability if the helper requests so when connecting (see the `connect` command under COMMANDS). When choosing between `push` and `export`, Git prefers `push`. Other frontends may have some other order of preference.
*no-private-update* When using the `refspec` capability, git normally updates the private ref on successful push. This update is disabled when the remote-helper declares the capability `no-private-update`.
####
Capabilities for Fetching
*connect* Can try to connect to `git upload-pack` (for fetching), `git receive-pack`, etc for communication using the Git’s native packfile protocol. This requires a bidirectional, full-duplex connection.
Supported commands: `connect`.
*stateless-connect* Experimental; for internal use only. Can attempt to connect to a remote server for communication using git’s wire-protocol version 2. See the documentation for the stateless-connect command for more information.
Supported commands: `stateless-connect`.
*fetch* Can discover remote refs and transfer objects reachable from them to the local object store.
Supported commands: `list`, `fetch`.
*import* Can discover remote refs and output objects reachable from them as a stream in fast-import format.
Supported commands: `list`, `import`.
*check-connectivity* Can guarantee that when a clone is requested, the received pack is self contained and is connected.
*get* Can use the `get` command to download a file from a given URI.
If a helper advertises `connect`, Git will use it if possible and fall back to another capability if the helper requests so when connecting (see the `connect` command under COMMANDS). When choosing between `fetch` and `import`, Git prefers `fetch`. Other frontends may have some other order of preference.
####
Miscellaneous capabilities
*option* For specifying settings like `verbosity` (how much output to write to stderr) and `depth` (how much history is wanted in the case of a shallow clone) that affect how other commands are carried out.
*refspec* <refspec> For remote helpers that implement `import` or `export`, this capability allows the refs to be constrained to a private namespace, instead of writing to refs/heads or refs/remotes directly. It is recommended that all importers providing the `import` capability use this. It’s mandatory for `export`.
A helper advertising the capability `refspec refs/heads/*:refs/svn/origin/branches/*` is saying that, when it is asked to `import refs/heads/topic`, the stream it outputs will update the `refs/svn/origin/branches/topic` ref.
This capability can be advertised multiple times. The first applicable refspec takes precedence. The left-hand of refspecs advertised with this capability must cover all refs reported by the list command. If no `refspec` capability is advertised, there is an implied `refspec *:*`.
When writing remote-helpers for decentralized version control systems, it is advised to keep a local copy of the repository to interact with, and to let the private namespace refs point to this local repository, while the refs/remotes namespace is used to track the remote repository.
*bidi-import* This modifies the `import` capability. The fast-import commands `cat-blob` and `ls` can be used by remote-helpers to retrieve information about blobs and trees that already exist in fast-import’s memory. This requires a channel from fast-import to the remote-helper. If it is advertised in addition to "import", Git establishes a pipe from fast-import to the remote-helper’s stdin. It follows that Git and fast-import are both connected to the remote-helper’s stdin. Because Git can send multiple commands to the remote-helper it is required that helpers that use `bidi-import` buffer all `import` commands of a batch before sending data to fast-import. This is to prevent mixing commands and fast-import responses on the helper’s stdin.
*export-marks* <file> This modifies the `export` capability, instructing Git to dump the internal marks table to <file> when complete. For details, read up on `--export-marks=<file>` in [git-fast-export[1]](git-fast-export).
*import-marks* <file> This modifies the `export` capability, instructing Git to load the marks specified in <file> before processing any input. For details, read up on `--import-marks=<file>` in [git-fast-export[1]](git-fast-export).
*signed-tags* This modifies the `export` capability, instructing Git to pass `--signed-tags=verbatim` to [git-fast-export[1]](git-fast-export). In the absence of this capability, Git will use `--signed-tags=warn-strip`.
*object-format* This indicates that the helper is able to interact with the remote side using an explicit hash algorithm extension.
Commands
--------
Commands are given by the caller on the helper’s standard input, one per line.
*capabilities* Lists the capabilities of the helper, one per line, ending with a blank line. Each capability may be preceded with `*`, which marks them mandatory for Git versions using the remote helper to understand. Any unknown mandatory capability is a fatal error.
Support for this command is mandatory.
*list* Lists the refs, one per line, in the format "<value> <name> [<attr> …]". The value may be a hex sha1 hash, "@<dest>" for a symref, ":<keyword> <value>" for a key-value pair, or "?" to indicate that the helper could not get the value of the ref. A space-separated list of attributes follows the name; unrecognized attributes are ignored. The list ends with a blank line.
See REF LIST ATTRIBUTES for a list of currently defined attributes. See REF LIST KEYWORDS for a list of currently defined keywords.
Supported if the helper has the "fetch" or "import" capability.
*list for-push* Similar to `list`, except that it is used if and only if the caller wants to the resulting ref list to prepare push commands. A helper supporting both push and fetch can use this to distinguish for which operation the output of `list` is going to be used, possibly reducing the amount of work that needs to be performed.
Supported if the helper has the "push" or "export" capability.
*option* <name> <value> Sets the transport helper option <name> to <value>. Outputs a single line containing one of `ok` (option successfully set), `unsupported` (option not recognized) or `error <msg>` (option <name> is supported but <value> is not valid for it). Options should be set before other commands, and may influence the behavior of those commands.
See OPTIONS for a list of currently defined options.
Supported if the helper has the "option" capability.
*fetch* <sha1> <name> Fetches the given object, writing the necessary objects to the database. Fetch commands are sent in a batch, one per line, terminated with a blank line. Outputs a single blank line when all fetch commands in the same batch are complete. Only objects which were reported in the output of `list` with a sha1 may be fetched this way.
Optionally may output a `lock <file>` line indicating the full path of a file under `$GIT_DIR/objects/pack` which is keeping a pack until refs can be suitably updated. The path must end with `.keep`. This is a mechanism to name a <pack,idx,keep> tuple by giving only the keep component. The kept pack will not be deleted by a concurrent repack, even though its objects may not be referenced until the fetch completes. The `.keep` file will be deleted at the conclusion of the fetch.
If option `check-connectivity` is requested, the helper must output `connectivity-ok` if the clone is self-contained and connected.
Supported if the helper has the "fetch" capability.
*push* +<src>:<dst> Pushes the given local <src> commit or branch to the remote branch described by <dst>. A batch sequence of one or more `push` commands is terminated with a blank line (if there is only one reference to push, a single `push` command is followed by a blank line). For example, the following would be two batches of `push`, the first asking the remote-helper to push the local ref `master` to the remote ref `master` and the local `HEAD` to the remote `branch`, and the second asking to push ref `foo` to ref `bar` (forced update requested by the `+`).
```
push refs/heads/master:refs/heads/master
push HEAD:refs/heads/branch
\n
push +refs/heads/foo:refs/heads/bar
\n
```
Zero or more protocol options may be entered after the last `push` command, before the batch’s terminating blank line.
When the push is complete, outputs one or more `ok <dst>` or `error <dst> <why>?` lines to indicate success or failure of each pushed ref. The status report output is terminated by a blank line. The option field <why> may be quoted in a C style string if it contains an LF.
Supported if the helper has the "push" capability.
*import* <name> Produces a fast-import stream which imports the current value of the named ref. It may additionally import other refs as needed to construct the history efficiently. The script writes to a helper-specific private namespace. The value of the named ref should be written to a location in this namespace derived by applying the refspecs from the "refspec" capability to the name of the ref.
Especially useful for interoperability with a foreign versioning system.
Just like `push`, a batch sequence of one or more `import` is terminated with a blank line. For each batch of `import`, the remote helper should produce a fast-import stream terminated by a `done` command.
Note that if the `bidi-import` capability is used the complete batch sequence has to be buffered before starting to send data to fast-import to prevent mixing of commands and fast-import responses on the helper’s stdin.
Supported if the helper has the "import" capability.
*export* Instructs the remote helper that any subsequent input is part of a fast-import stream (generated by `git fast-export`) containing objects which should be pushed to the remote.
Especially useful for interoperability with a foreign versioning system.
The `export-marks` and `import-marks` capabilities, if specified, affect this command in so far as they are passed on to `git fast-export`, which then will load/store a table of marks for local objects. This can be used to implement for incremental operations.
Supported if the helper has the "export" capability.
*connect* <service> Connects to given service. Standard input and standard output of helper are connected to specified service (git prefix is included in service name so e.g. fetching uses `git-upload-pack` as service) on remote side. Valid replies to this command are empty line (connection established), `fallback` (no smart transport support, fall back to dumb transports) and just exiting with error message printed (can’t connect, don’t bother trying to fall back). After line feed terminating the positive (empty) response, the output of service starts. After the connection ends, the remote helper exits.
Supported if the helper has the "connect" capability.
*stateless-connect* <service> Experimental; for internal use only. Connects to the given remote service for communication using git’s wire-protocol version 2. Valid replies to this command are empty line (connection established), `fallback` (no smart transport support, fall back to dumb transports) and just exiting with error message printed (can’t connect, don’t bother trying to fall back). After line feed terminating the positive (empty) response, the output of the service starts. Messages (both request and response) must consist of zero or more PKT-LINEs, terminating in a flush packet. Response messages will then have a response end packet after the flush packet to indicate the end of a response. The client must not expect the server to store any state in between request-response pairs. After the connection ends, the remote helper exits.
Supported if the helper has the "stateless-connect" capability.
*get* <uri> <path> Downloads the file from the given `<uri>` to the given `<path>`. If `<path>.temp` exists, then Git assumes that the `.temp` file is a partial download from a previous attempt and will resume the download from that position.
If a fatal error occurs, the program writes the error message to stderr and exits. The caller should expect that a suitable error message has been printed if the child closes the connection without completing a valid response for the current command.
Additional commands may be supported, as may be determined from capabilities reported by the helper.
Ref list attributes
-------------------
The `list` command produces a list of refs in which each ref may be followed by a list of attributes. The following ref list attributes are defined.
*unchanged* This ref is unchanged since the last import or fetch, although the helper cannot necessarily determine what value that produced.
Ref list keywords
-----------------
The `list` command may produce a list of key-value pairs. The following keys are defined.
*object-format* The refs are using the given hash algorithm. This keyword is only used if the server and client both support the object-format extension.
Options
-------
The following options are defined and (under suitable circumstances) set by Git if the remote helper has the `option` capability.
*option verbosity* <n> Changes the verbosity of messages displayed by the helper. A value of 0 for <n> means that processes operate quietly, and the helper produces only error output. 1 is the default level of verbosity, and higher values of <n> correspond to the number of -v flags passed on the command line.
*option progress* {*true*|*false*} Enables (or disables) progress messages displayed by the transport helper during a command.
*option depth* <depth> Deepens the history of a shallow repository.
'option deepen-since <timestamp> Deepens the history of a shallow repository based on time.
'option deepen-not <ref> Deepens the history of a shallow repository excluding ref. Multiple options add up.
*option deepen-relative {'true*|*false*} Deepens the history of a shallow repository relative to current boundary. Only valid when used with "option depth".
*option followtags* {*true*|*false*} If enabled the helper should automatically fetch annotated tag objects if the object the tag points at was transferred during the fetch command. If the tag is not fetched by the helper a second fetch command will usually be sent to ask for the tag specifically. Some helpers may be able to use this option to avoid a second network connection.
`option dry-run` {`true`|`false`}: If true, pretend the operation completed successfully, but don’t actually change any repository data. For most helpers this only applies to the `push`, if supported.
*option servpath <c-style-quoted-path>* Sets service path (--upload-pack, --receive-pack etc.) for next connect. Remote helper may support this option, but must not rely on this option being set before connect request occurs.
*option check-connectivity* {*true*|*false*} Request the helper to check connectivity of a clone.
*option force* {*true*|*false*} Request the helper to perform a force update. Defaults to `false`.
*option cloning* {*true*|*false*} Notify the helper this is a clone request (i.e. the current repository is guaranteed empty).
*option update-shallow* {*true*|*false*} Allow to extend .git/shallow if the new refs require it.
*option pushcert* {*true*|*false*} GPG sign pushes.
'option push-option <string> Transmit <string> as a push option. As the push option must not contain LF or NUL characters, the string is not encoded.
*option from-promisor* {*true*|*false*} Indicate that these objects are being fetched from a promisor.
*option no-dependents* {*true*|*false*} Indicate that only the objects wanted need to be fetched, not their dependents.
*option atomic* {*true*|*false*} When pushing, request the remote server to update refs in a single atomic transaction. If successful, all refs will be updated, or none will. If the remote side does not support this capability, the push will fail.
*option object-format* {*true*|algorithm} If `true`, indicate that the caller wants hash algorithm information to be passed back from the remote. This mode is used when fetching refs.
If set to an algorithm, indicate that the caller wants to interact with the remote side using that algorithm.
See also
--------
[git-remote[1]](git-remote)
[git-remote-ext[1]](git-remote-ext)
[git-remote-fd[1]](git-remote-fd)
[git-fast-import[1]](git-fast-import)
| programming_docs |
git git-check-mailmap git-check-mailmap
=================
Name
----
git-check-mailmap - Show canonical names and email addresses of contacts
Synopsis
--------
```
git check-mailmap [<options>] <contact>…
```
Description
-----------
For each “Name <user@host>” or “<user@host>” from the command-line or standard input (when using `--stdin`), look up the person’s canonical name and email address (see "Mapping Authors" below). If found, print them; otherwise print the input as-is.
Options
-------
--stdin Read contacts, one per line, from the standard input after exhausting contacts provided on the command-line.
Output
------
For each contact, a single line is output, terminated by a newline. If the name is provided or known to the `mailmap`, “Name <user@host>” is printed; otherwise only “<user@host>” is printed.
Configuration
-------------
See `mailmap.file` and `mailmap.blob` in [git-config[1]](git-config) for how to specify a custom `.mailmap` target file or object.
Mapping authors
---------------
See [gitmailmap[5]](gitmailmap).
git git-ls-files git-ls-files
============
Name
----
git-ls-files - Show information about files in the index and the working tree
Synopsis
--------
```
git ls-files [-z] [-t] [-v] [-f]
[-c|--cached] [-d|--deleted] [-o|--others] [-i|--ignored]
[-s|--stage] [-u|--unmerged] [-k|--killed] [-m|--modified]
[--directory [--no-empty-directory]] [--eol]
[--deduplicate]
[-x <pattern>|--exclude=<pattern>]
[-X <file>|--exclude-from=<file>]
[--exclude-per-directory=<file>]
[--exclude-standard]
[--error-unmatch] [--with-tree=<tree-ish>]
[--full-name] [--recurse-submodules]
[--abbrev[=<n>]] [--format=<format>] [--] [<file>…]
```
Description
-----------
This merges the file listing in the index with the actual working directory list, and shows different combinations of the two.
One or more of the options below may be used to determine the files shown:
Options
-------
-c --cached Show cached files in the output (default)
-d --deleted Show deleted files in the output
-m --modified Show modified files in the output
-o --others Show other (i.e. untracked) files in the output
-i --ignored Show only ignored files in the output. When showing files in the index, print only those matched by an exclude pattern. When showing "other" files, show only those matched by an exclude pattern. Standard ignore rules are not automatically activated, therefore at least one of the `--exclude*` options is required.
-s --stage Show staged contents' mode bits, object name and stage number in the output.
--directory If a whole directory is classified as "other", show just its name (with a trailing slash) and not its whole contents.
--no-empty-directory Do not list empty directories. Has no effect without --directory.
-u --unmerged Show unmerged files in the output (forces --stage)
-k --killed Show files on the filesystem that need to be removed due to file/directory conflicts for checkout-index to succeed.
-z \0 line termination on output and do not quote filenames. See OUTPUT below for more information.
--deduplicate When only filenames are shown, suppress duplicates that may come from having multiple stages during a merge, or giving `--deleted` and `--modified` option at the same time. When any of the `-t`, `--unmerged`, or `--stage` option is in use, this option has no effect.
-x <pattern> --exclude=<pattern> Skip untracked files matching pattern. Note that pattern is a shell wildcard pattern. See EXCLUDE PATTERNS below for more information.
-X <file> --exclude-from=<file> Read exclude patterns from <file>; 1 per line.
--exclude-per-directory=<file> Read additional exclude patterns that apply only to the directory and its subdirectories in <file>.
--exclude-standard Add the standard Git exclusions: .git/info/exclude, .gitignore in each directory, and the user’s global exclusion file.
--error-unmatch If any <file> does not appear in the index, treat this as an error (return 1).
--with-tree=<tree-ish> When using --error-unmatch to expand the user supplied <file> (i.e. path pattern) arguments to paths, pretend that paths which were removed in the index since the named <tree-ish> are still present. Using this option with `-s` or `-u` options does not make any sense.
-t This feature is semi-deprecated. For scripting purpose, [git-status[1]](git-status) `--porcelain` and [git-diff-files[1]](git-diff-files) `--name-status` are almost always superior alternatives, and users should look at [git-status[1]](git-status) `--short` or [git-diff[1]](git-diff) `--name-status` for more user-friendly alternatives.
This option identifies the file status with the following tags (followed by a space) at the start of each line:
H cached
S skip-worktree
M unmerged
R removed/deleted
C modified/changed
K to be killed
? other
-v Similar to `-t`, but use lowercase letters for files that are marked as `assume unchanged` (see [git-update-index[1]](git-update-index)).
-f Similar to `-t`, but use lowercase letters for files that are marked as `fsmonitor valid` (see [git-update-index[1]](git-update-index)).
--full-name When run from a subdirectory, the command usually outputs paths relative to the current directory. This option forces paths to be output relative to the project top directory.
--recurse-submodules Recursively calls ls-files on each active submodule in the repository. Currently there is only support for the --cached and --stage modes.
--abbrev[=<n>] Instead of showing the full 40-byte hexadecimal object lines, show the shortest prefix that is at least `<n>` hexdigits long that uniquely refers the object. Non default number of digits can be specified with --abbrev=<n>.
--debug After each line that describes a file, add more data about its cache entry. This is intended to show as much information as possible for manual inspection; the exact format may change at any time.
--eol Show <eolinfo> and <eolattr> of files. <eolinfo> is the file content identification used by Git when the "text" attribute is "auto" (or not set and core.autocrlf is not false). <eolinfo> is either "-text", "none", "lf", "crlf", "mixed" or "".
"" means the file is not a regular file, it is not in the index or not accessible in the working tree.
<eolattr> is the attribute that is used when checking out or committing, it is either "", "-text", "text", "text=auto", "text eol=lf", "text eol=crlf". Since Git 2.10 "text=auto eol=lf" and "text=auto eol=crlf" are supported.
Both the <eolinfo> in the index ("i/<eolinfo>") and in the working tree ("w/<eolinfo>") are shown for regular files, followed by the ("attr/<eolattr>").
--sparse If the index is sparse, show the sparse directories without expanding to the contained files. Sparse directories will be shown with a trailing slash, such as "x/" for a sparse directory "x".
--format=<format> A string that interpolates `%(fieldname)` from the result being shown. It also interpolates `%%` to `%`, and `%xx` where `xx` are hex digits interpolates to character with hex code `xx`; for example `%00` interpolates to `\0` (NUL), `%09` to `\t` (TAB) and %0a to `\n` (LF). --format cannot be combined with `-s`, `-o`, `-k`, `-t`, `--resolve-undo` and `--eol`.
-- Do not interpret any more arguments as options.
<file> Files to show. If no files are given all files which match the other specified criteria are shown.
Output
------
`git ls-files` just outputs the filenames unless `--stage` is specified in which case it outputs:
```
[<tag> ]<mode> <object> <stage> <file>
```
`git ls-files --eol` will show i/<eolinfo><SPACES>w/<eolinfo><SPACES>attr/<eolattr><SPACE\*><TAB><file>
`git ls-files --unmerged` and `git ls-files --stage` can be used to examine detailed information on unmerged paths.
For an unmerged path, instead of recording a single mode/SHA-1 pair, the index records up to three such pairs; one from tree O in stage 1, A in stage 2, and B in stage 3. This information can be used by the user (or the porcelain) to see what should eventually be recorded at the path. (see [git-read-tree[1]](git-read-tree) for more information on state)
Without the `-z` option, pathnames with "unusual" characters are quoted as explained for the configuration variable `core.quotePath` (see [git-config[1]](git-config)). Using `-z` the filename is output verbatim and the line is terminated by a NUL byte.
It is possible to print in a custom format by using the `--format` option, which is able to interpolate different fields using a `%(fieldname)` notation. For example, if you only care about the "objectname" and "path" fields, you can execute with a specific "--format" like
```
git ls-files --format='%(objectname) %(path)'
```
Field names
-----------
The way each path is shown can be customized by using the `--format=<format>` option, where the %(fieldname) in the <format> string for various aspects of the index entry are interpolated. The following "fieldname" are understood:
objectmode The mode of the file which is recorded in the index.
objectname The name of the file which is recorded in the index.
stage The stage of the file which is recorded in the index.
eolinfo:index eolinfo:worktree The <eolinfo> (see the description of the `--eol` option) of the contents in the index or in the worktree for the path.
eolattr The <eolattr> (see the description of the `--eol` option) that applies to the path.
path The pathname of the file which is recorded in the index.
Exclude patterns
----------------
`git ls-files` can use a list of "exclude patterns" when traversing the directory tree and finding files to show when the flags --others or --ignored are specified. [gitignore[5]](gitignore) specifies the format of exclude patterns.
These exclude patterns come from these places, in order:
1. The command-line flag --exclude=<pattern> specifies a single pattern. Patterns are ordered in the same order they appear in the command line.
2. The command-line flag --exclude-from=<file> specifies a file containing a list of patterns. Patterns are ordered in the same order they appear in the file.
3. The command-line flag --exclude-per-directory=<name> specifies a name of the file in each directory `git ls-files` examines, normally `.gitignore`. Files in deeper directories take precedence. Patterns are ordered in the same order they appear in the files.
A pattern specified on the command line with --exclude or read from the file specified with --exclude-from is relative to the top of the directory tree. A pattern read from a file specified by --exclude-per-directory is relative to the directory that the pattern file appears in.
See also
--------
[git-read-tree[1]](git-read-tree), [gitignore[5]](gitignore)
git git-restore git-restore
===========
Name
----
git-restore - Restore working tree files
Synopsis
--------
```
git restore [<options>] [--source=<tree>] [--staged] [--worktree] [--] <pathspec>…
git restore [<options>] [--source=<tree>] [--staged] [--worktree] --pathspec-from-file=<file> [--pathspec-file-nul]
git restore (-p|--patch) [<options>] [--source=<tree>] [--staged] [--worktree] [--] [<pathspec>…]
```
Description
-----------
Restore specified paths in the working tree with some contents from a restore source. If a path is tracked but does not exist in the restore source, it will be removed to match the source.
The command can also be used to restore the content in the index with `--staged`, or restore both the working tree and the index with `--staged --worktree`.
By default, if `--staged` is given, the contents are restored from `HEAD`, otherwise from the index. Use `--source` to restore from a different commit.
See "Reset, restore and revert" in [git[1]](git) for the differences between the three commands.
THIS COMMAND IS EXPERIMENTAL. THE BEHAVIOR MAY CHANGE.
Options
-------
-s <tree> --source=<tree> Restore the working tree files with the content from the given tree. It is common to specify the source tree by naming a commit, branch or tag associated with it.
If not specified, the contents are restored from `HEAD` if `--staged` is given, otherwise from the index.
As a special case, you may use `"A...B"` as a shortcut for the merge base of `A` and `B` if there is exactly one merge base. You can leave out at most one of `A` and `B`, in which case it defaults to `HEAD`.
-p --patch Interactively select hunks in the difference between the restore source and the restore location. See the “Interactive Mode” section of [git-add[1]](git-add) to learn how to operate the `--patch` mode.
Note that `--patch` can accept no pathspec and will prompt to restore all modified paths.
-W --worktree -S --staged Specify the restore location. If neither option is specified, by default the working tree is restored. Specifying `--staged` will only restore the index. Specifying both restores both.
-q --quiet Quiet, suppress feedback messages. Implies `--no-progress`.
--progress --no-progress Progress status is reported on the standard error stream by default when it is attached to a terminal, unless `--quiet` is specified. This flag enables progress reporting even if not attached to a terminal, regardless of `--quiet`.
--ours --theirs When restoring files in the working tree from the index, use stage #2 (`ours`) or #3 (`theirs`) for unmerged paths.
Note that during `git rebase` and `git pull --rebase`, `ours` and `theirs` may appear swapped. See the explanation of the same options in [git-checkout[1]](git-checkout) for details.
-m --merge When restoring files on the working tree from the index, recreate the conflicted merge in the unmerged paths.
--conflict=<style> The same as `--merge` option above, but changes the way the conflicting hunks are presented, overriding the `merge.conflictStyle` configuration variable. Possible values are "merge" (default), "diff3", and "zdiff3".
--ignore-unmerged When restoring files on the working tree from the index, do not abort the operation if there are unmerged entries and neither `--ours`, `--theirs`, `--merge` or `--conflict` is specified. Unmerged paths on the working tree are left alone.
--ignore-skip-worktree-bits In sparse checkout mode, by default is to only update entries matched by `<pathspec>` and sparse patterns in $GIT\_DIR/info/sparse-checkout. This option ignores the sparse patterns and unconditionally restores any files in `<pathspec>`.
--recurse-submodules --no-recurse-submodules If `<pathspec>` names an active submodule and the restore location includes the working tree, the submodule will only be updated if this option is given, in which case its working tree will be restored to the commit recorded in the superproject, and any local modifications overwritten. If nothing (or `--no-recurse-submodules`) is used, submodules working trees will not be updated. Just like [git-checkout[1]](git-checkout), this will detach `HEAD` of the submodule.
--overlay --no-overlay In overlay mode, the command never removes files when restoring. In no-overlay mode, tracked files that do not appear in the `--source` tree are removed, to make them match `<tree>` exactly. The default is no-overlay mode.
--pathspec-from-file=<file> Pathspec is passed in `<file>` instead of commandline args. If `<file>` is exactly `-` then standard input is used. Pathspec elements are separated by LF or CR/LF. Pathspec elements can be quoted as explained for the configuration variable `core.quotePath` (see [git-config[1]](git-config)). See also `--pathspec-file-nul` and global `--literal-pathspecs`.
--pathspec-file-nul Only meaningful with `--pathspec-from-file`. Pathspec elements are separated with NUL character and all other characters are taken literally (including newlines and quotes).
-- Do not interpret any more arguments as options.
<pathspec>… Limits the paths affected by the operation.
For more details, see the `pathspec` entry in [gitglossary[7]](gitglossary).
Examples
--------
The following sequence switches to the `master` branch, reverts the `Makefile` to two revisions back, deletes hello.c by mistake, and gets it back from the index.
```
$ git switch master
$ git restore --source master~2 Makefile (1)
$ rm -f hello.c
$ git restore hello.c (2)
```
1. take a file out of another commit
2. restore hello.c from the index
If you want to restore `all` C source files to match the version in the index, you can say
```
$ git restore '*.c'
```
Note the quotes around `*.c`. The file `hello.c` will also be restored, even though it is no longer in the working tree, because the file globbing is used to match entries in the index (not in the working tree by the shell).
To restore all files in the current directory
```
$ git restore .
```
or to restore all working tree files with `top` pathspec magic (see [gitglossary[7]](gitglossary))
```
$ git restore :/
```
To restore a file in the index to match the version in `HEAD` (this is the same as using [git-reset[1]](git-reset))
```
$ git restore --staged hello.c
```
or you can restore both the index and the working tree (this the same as using [git-checkout[1]](git-checkout))
```
$ git restore --source=HEAD --staged --worktree hello.c
```
or the short form which is more practical but less readable:
```
$ git restore -s@ -SW hello.c
```
See also
--------
[git-checkout[1]](git-checkout), [git-reset[1]](git-reset)
git git-index-pack git-index-pack
==============
Name
----
git-index-pack - Build pack index file for an existing packed archive
Synopsis
--------
```
git index-pack [-v] [-o <index-file>] [--[no-]rev-index] <pack-file>
git index-pack --stdin [--fix-thin] [--keep] [-v] [-o <index-file>]
[--[no-]rev-index] [<pack-file>]
```
Description
-----------
Reads a packed archive (.pack) from the specified file, and builds a pack index file (.idx) for it. Optionally writes a reverse-index (.rev) for the specified pack. The packed archive together with the pack index can then be placed in the objects/pack/ directory of a Git repository.
Options
-------
-v Be verbose about what is going on, including progress status.
-o <index-file> Write the generated pack index into the specified file. Without this option the name of pack index file is constructed from the name of packed archive file by replacing .pack with .idx (and the program fails if the name of packed archive does not end with .pack).
--[no-]rev-index When this flag is provided, generate a reverse index (a `.rev` file) corresponding to the given pack. If `--verify` is given, ensure that the existing reverse index is correct. Takes precedence over `pack.writeReverseIndex`.
--stdin When this flag is provided, the pack is read from stdin instead and a copy is then written to <pack-file>. If <pack-file> is not specified, the pack is written to objects/pack/ directory of the current Git repository with a default name determined from the pack content. If <pack-file> is not specified consider using --keep to prevent a race condition between this process and `git repack`.
--fix-thin Fix a "thin" pack produced by `git pack-objects --thin` (see [git-pack-objects[1]](git-pack-objects) for details) by adding the excluded objects the deltified objects are based on to the pack. This option only makes sense in conjunction with --stdin.
--keep Before moving the index into its final destination create an empty .keep file for the associated pack file. This option is usually necessary with --stdin to prevent a simultaneous `git repack` process from deleting the newly constructed pack and index before refs can be updated to use objects contained in the pack.
--keep=<msg> Like --keep create a .keep file before moving the index into its final destination, but rather than creating an empty file place `<msg>` followed by an LF into the .keep file. The `<msg>` message can later be searched for within all .keep files to locate any which have outlived their usefulness.
--index-version=<version>[,<offset>] This is intended to be used by the test suite only. It allows to force the version for the generated pack index, and to force 64-bit index entries on objects located above the given offset.
--strict Die, if the pack contains broken objects or links.
--progress-title For internal use only.
Set the title of the progress bar. The title is "Receiving objects" by default and "Indexing objects" when `--stdin` is specified.
--check-self-contained-and-connected Die if the pack contains broken links. For internal use only.
--fsck-objects For internal use only.
Die if the pack contains broken objects. If the pack contains a tree pointing to a .gitmodules blob that does not exist, prints the hash of that blob (for the caller to check) after the hash that goes into the name of the pack/idx file (see "Notes").
--threads=<n> Specifies the number of threads to spawn when resolving deltas. This requires that index-pack be compiled with pthreads otherwise this option is ignored with a warning. This is meant to reduce packing time on multiprocessor machines. The required amount of memory for the delta search window is however multiplied by the number of threads. Specifying 0 will cause Git to auto-detect the number of CPU’s and use maximum 3 threads.
--max-input-size=<size> Die, if the pack is larger than <size>.
--object-format=<hash-algorithm> Specify the given object format (hash algorithm) for the pack. The valid values are `sha1` and (if enabled) `sha256`. The default is the algorithm for the current repository (set by `extensions.objectFormat`), or `sha1` if no value is set or outside a repository.
This option cannot be used with --stdin.
THIS OPTION IS EXPERIMENTAL! SHA-256 support is experimental and still in an early stage. A SHA-256 repository will in general not be able to share work with "regular" SHA-1 repositories. It should be assumed that, e.g., Git internal file formats in relation to SHA-256 repositories may change in backwards-incompatible ways. Only use `--object-format=sha256` for testing purposes.
--promisor[=<message>] Before committing the pack-index, create a .promisor file for this pack. Particularly helpful when writing a promisor pack with --fix-thin since the name of the pack is not final until the pack has been fully written. If a `<message>` is provided, then that content will be written to the .promisor file for future reference. See [partial clone](partial-clone) for more information.
Notes
-----
Once the index has been created, the hash that goes into the name of the pack/idx file is printed to stdout. If --stdin was also used then this is prefixed by either "pack\t", or "keep\t" if a new .keep file was successfully created. This is useful to remove a .keep file used as a lock to prevent the race with `git repack` mentioned above.
| programming_docs |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.